6412 commits
| Author | SHA1 | Message | Date | |
|---|---|---|---|---|
|
|
ecb8b383af |
[SPARK-23365][CORE] Do not adjust num executors when killing idle executors.
The ExecutorAllocationManager should not adjust the target number of executors when killing idle executors, as it has already adjusted the target number down based on the task backlog. The name `replace` was misleading with DynamicAllocation on, as the target number of executors is changed outside of the call to `killExecutors`, so I adjusted that name. Also separated out the logic of `countFailures` as you don't always want that tied to `replace`. While I was there I made two changes that weren't directly related to this: 1) Fixed `countFailures` in a couple cases where it was getting an incorrect value since it used to be tied to `replace`, eg. when killing executors on a blacklisted node. 2) hard error if you call `sc.killExecutors` with dynamic allocation on, since that's another way the ExecutorAllocationManager and the CoarseGrainedSchedulerBackend would get out of sync. Added a unit test case which verifies that the calls to ExecutorAllocationClient do not adjust the number of executors. Author: Imran Rashid <irashid@cloudera.com> Closes #20604 from squito/SPARK-23365. |
||
|
|
c5abb3c2d1 |
[SPARK-23476][CORE] Generate secret in local mode when authentication on
## What changes were proposed in this pull request? If spark is run with "spark.authenticate=true", then it will fail to start in local mode. This PR generates secret in local mode when authentication on. ## How was this patch tested? Modified existing unit test. Manually started spark-shell. Author: Gabor Somogyi <gabor.g.somogyi@gmail.com> Closes #20652 from gaborgsomogyi/SPARK-23476. |
||
|
|
87293c746e |
[SPARK-23475][UI] Show also skipped stages
## What changes were proposed in this pull request? SPARK-20648 introduced the status `SKIPPED` for the stages. On the UI, previously, skipped stages were shown as `PENDING`; after this change, they are not shown on the UI. The PR introduce a new section in order to show also `SKIPPED` stages in a proper table. ## How was this patch tested? manual tests Author: Marco Gaido <marcogaido91@gmail.com> Closes #20651 from mgaido91/SPARK-23475. |
||
|
|
45cf714ee6 |
[SPARK-23475][WEBUI] Skipped stages should be evicted before completed stages
## What changes were proposed in this pull request? The root cause of missing completed stages is because `cleanupStages` will never remove skipped stages. This PR changes the logic to always remove skipped stage first. This is safe since the job itself contains enough information to render skipped stages in the UI. ## How was this patch tested? The new unit tests. Author: Shixiong Zhu <zsxwing@gmail.com> Closes #20656 from zsxwing/SPARK-23475. |
||
|
|
744d5af652 |
[SPARK-23481][WEBUI] lastStageAttempt should fail when a stage doesn't exist
## What changes were proposed in this pull request? The issue here is `AppStatusStore.lastStageAttempt` will return the next available stage in the store when a stage doesn't exist. This PR adds `last(stageId)` to ensure it returns a correct `StageData` ## How was this patch tested? The new unit test. Author: Shixiong Zhu <zsxwing@gmail.com> Closes #20654 from zsxwing/SPARK-23481. |
||
|
|
6d398c05cb |
[SPARK-23468][CORE] Stringify auth secret before storing it in credentials.
The secret is used as a string in many parts of the code, so it has to be turned into a hex string to avoid issues such as the random byte sequence not containing a valid UTF8 sequence. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20643 from vanzin/SPARK-23468. |
||
|
|
2ba77ed9e5 |
[SPARK-23470][UI] Use first attempt of last stage to define job description.
This is much faster than finding out what the last attempt is, and the data should be the same. There's room for improvement in this page (like only loading data for the jobs being shown, instead of loading all available jobs and sorting them), but this should bring performance on par with the 2.2 version. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20644 from vanzin/SPARK-23470. |
||
|
|
862fa697d8 |
[SPARK-23240][PYTHON] Better error message when extraneous data in pyspark.daemon's stdout
## What changes were proposed in this pull request? Print more helpful message when daemon module's stdout is empty or contains a bad port number. ## How was this patch tested? Manually recreated the environmental issues that caused the mysterious exceptions at one site. Tested that the expected messages are logged. Also, ran all scala unit tests. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Bruce Robbins <bersprockets@gmail.com> Closes #20424 from bersprockets/SPARK-23240_prop2. |
||
|
|
1dc2c1d5e8 |
[SPARK-23413][UI] Fix sorting tasks by Host / Executor ID at the Stage page
## What changes were proposed in this pull request?
Fixing exception got at sorting tasks by Host / Executor ID:
```
java.lang.IllegalArgumentException: Invalid sort column: Host
at org.apache.spark.ui.jobs.ApiHelper$.indexName(StagePage.scala:1017)
at org.apache.spark.ui.jobs.TaskDataSource.sliceData(StagePage.scala:694)
at org.apache.spark.ui.PagedDataSource.pageData(PagedTable.scala:61)
at org.apache.spark.ui.PagedTable$class.table(PagedTable.scala:96)
at org.apache.spark.ui.jobs.TaskPagedTable.table(StagePage.scala:708)
at org.apache.spark.ui.jobs.StagePage.liftedTree1$1(StagePage.scala:293)
at org.apache.spark.ui.jobs.StagePage.render(StagePage.scala:282)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.JettyUtils$$anon$3.doGet(JettyUtils.scala:90)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:687)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:790)
at org.spark_project.jetty.servlet.ServletHolder.handle(ServletHolder.java:848)
at org.spark_project.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:584)
```
Moreover some refactoring to avoid similar problems by introducing constants for each header name and reusing them at the identification of the corresponding sorting index.
## How was this patch tested?
Manually:
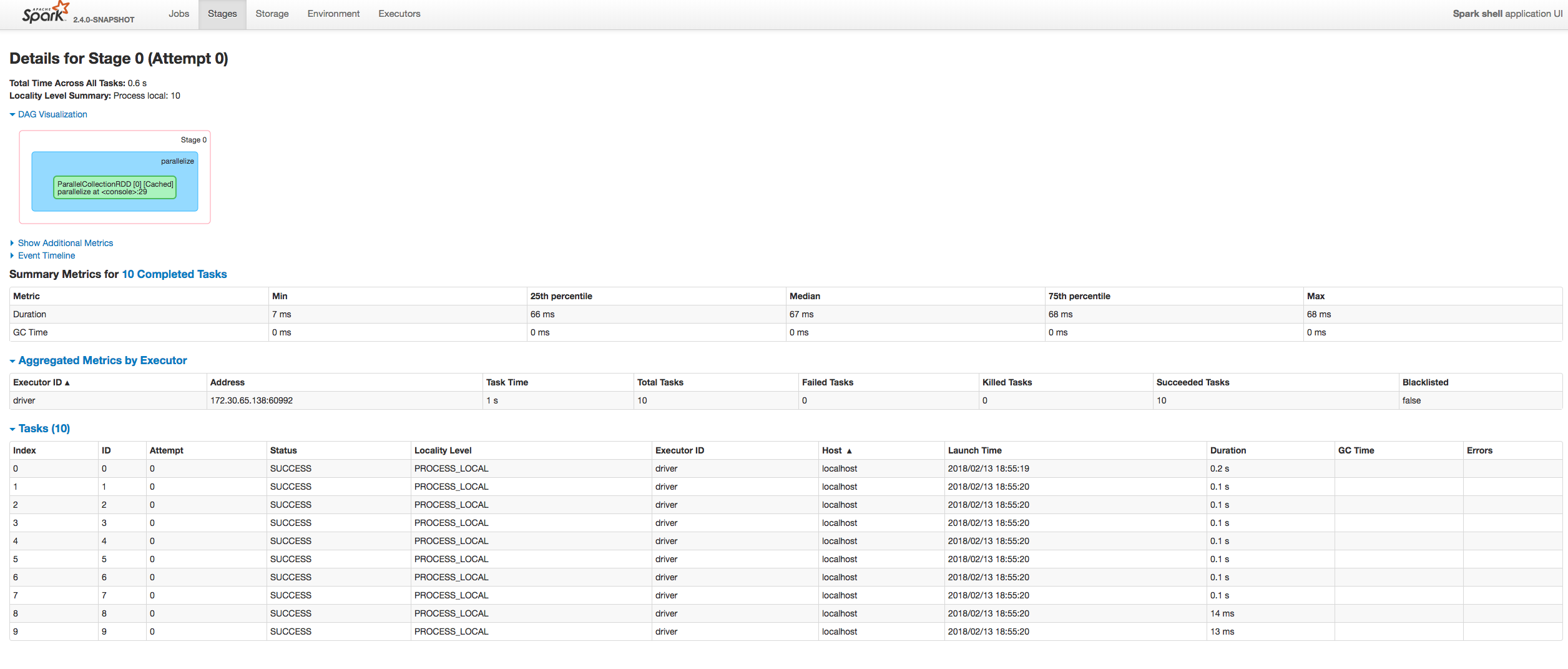
Author: “attilapiros” <piros.attila.zsolt@gmail.com>
Closes #20601 from attilapiros/SPARK-23413.
|
||
|
|
44e20c4225 |
[SPARK-23422][CORE] YarnShuffleIntegrationSuite fix when SPARK_PREPEN…
…D_CLASSES set to 1 ## What changes were proposed in this pull request? YarnShuffleIntegrationSuite fails when SPARK_PREPEND_CLASSES set to 1. Normally mllib built before yarn module. When SPARK_PREPEND_CLASSES used mllib classes are on yarn test classpath. Before 2.3 that did not cause issues. But 2.3 has SPARK-22450, which registered some mllib classes with the kryo serializer. Now it dies with the following error: ` 18/02/13 07:33:29 INFO SparkContext: Starting job: collect at YarnShuffleIntegrationSuite.scala:143 Exception in thread "dag-scheduler-event-loop" java.lang.NoClassDefFoundError: breeze/linalg/DenseMatrix ` In this PR NoClassDefFoundError caught only in case of testing and then do nothing. ## How was this patch tested? Automated: Pass the Jenkins. Author: Gabor Somogyi <gabor.g.somogyi@gmail.com> Closes #20608 from gaborgsomogyi/SPARK-23422. |
||
|
|
7539ae59d6 |
[SPARK-23366] Improve hot reading path in ReadAheadInputStream
## What changes were proposed in this pull request? `ReadAheadInputStream` was introduced in https://github.com/apache/spark/pull/18317/ to optimize reading spill files from disk. However, from the profiles it seems that the hot path of reading small amounts of data (like readInt) is inefficient - it involves taking locks, and multiple checks. Optimize locking: Lock is not needed when simply accessing the active buffer. Only lock when needing to swap buffers or trigger async reading, or get information about the async state. Optimize short-path single byte reads, that are used e.g. by Java library DataInputStream.readInt. The asyncReader used to call "read" only once on the underlying stream, that never filled the underlying buffer when it was wrapping an LZ4BlockInputStream. If the buffer was returned unfilled, that would trigger the async reader to be triggered to fill the read ahead buffer on each call, because the reader would see that the active buffer is below the refill threshold all the time. However, filling the full buffer all the time could introduce increased latency, so also add an `AtomicBoolean` flag for the async reader to return earlier if there is a reader waiting for data. Remove `readAheadThresholdInBytes` and instead immediately trigger async read when switching the buffers. It allows to simplify code paths, especially the hot one that then only has to check if there is available data in the active buffer, without worrying if it needs to retrigger async read. It seems to have positive effect on perf. ## How was this patch tested? It was noticed as a regression in some workloads after upgrading to Spark 2.3. It was particularly visible on TPCDS Q95 running on instances with fast disk (i3 AWS instances). Running with profiling: * Spark 2.2 - 5.2-5.3 minutes 9.5% in LZ4BlockInputStream.read * Spark 2.3 - 6.4-6.6 minutes 31.1% in ReadAheadInputStream.read * Spark 2.3 + fix - 5.3-5.4 minutes 13.3% in ReadAheadInputStream.read - very slightly slower, practically within noise. We didn't see other regressions, and many workloads in general seem to be faster with Spark 2.3 (not investigated if thanks to async readed, or unrelated). Author: Juliusz Sompolski <julek@databricks.com> Closes #20555 from juliuszsompolski/SPARK-23366. |
||
|
|
140f87533a |
[SPARK-23394][UI] In RDD storage page show the executor addresses instead of the IDs
## What changes were proposed in this pull request? Extending RDD storage page to show executor addresses in the block table. ## How was this patch tested? Manually:  Author: “attilapiros” <piros.attila.zsolt@gmail.com> Closes #20589 from attilapiros/SPARK-23394. |
||
|
|
a5a4b83501 |
[SPARK-23235][CORE] Add executor Threaddump to api
## What changes were proposed in this pull request? Extending api with the executor thread dump data. For this new REST URL is introduced: - GET http://localhost:4040/api/v1/applications/{applicationId}/executors/{executorId}/threads <details> <summary>Example response:</summary> ``` javascript [ { "threadId" : 52, "threadName" : "context-cleaner-periodic-gc", "threadState" : "TIMED_WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078)\njava.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1093)\njava.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)\njava.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1385411893})", "holdingLocks" : [ ] }, { "threadId" : 48, "threadName" : "dag-scheduler-event-loop", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingDeque.takeFirst(LinkedBlockingDeque.java:492)\njava.util.concurrent.LinkedBlockingDeque.take(LinkedBlockingDeque.java:680)\norg.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:46)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1138053349})", "holdingLocks" : [ ] }, { "threadId" : 17, "threadName" : "dispatcher-event-loop-0", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:215)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1764626380})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker832743930})" ] }, { "threadId" : 18, "threadName" : "dispatcher-event-loop-1", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:215)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1764626380})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker834153999})" ] }, { "threadId" : 19, "threadName" : "dispatcher-event-loop-2", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:215)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1764626380})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker664836465})" ] }, { "threadId" : 20, "threadName" : "dispatcher-event-loop-3", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:215)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1764626380})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker1645557354})" ] }, { "threadId" : 21, "threadName" : "dispatcher-event-loop-4", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:215)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1764626380})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker1188871851})" ] }, { "threadId" : 22, "threadName" : "dispatcher-event-loop-5", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:215)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1764626380})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker920926249})" ] }, { "threadId" : 23, "threadName" : "dispatcher-event-loop-6", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:215)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1764626380})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker355222677})" ] }, { "threadId" : 24, "threadName" : "dispatcher-event-loop-7", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:215)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1764626380})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker1589745212})" ] }, { "threadId" : 49, "threadName" : "driver-heartbeater", "threadState" : "TIMED_WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078)\njava.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1093)\njava.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)\njava.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1602885835})", "holdingLocks" : [ ] }, { "threadId" : 53, "threadName" : "element-tracking-store-worker", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\njava.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1439439099})", "holdingLocks" : [ ] }, { "threadId" : 3, "threadName" : "Finalizer", "threadState" : "WAITING", "stackTrace" : "java.lang.Object.wait(Native Method)\njava.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:143)\njava.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:164)\njava.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:209)", "blockedByLock" : "Lock(java.lang.ref.ReferenceQueue$Lock1213098236})", "holdingLocks" : [ ] }, { "threadId" : 15, "threadName" : "ForkJoinPool-1-worker-13", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\nscala.concurrent.forkjoin.ForkJoinPool.scan(ForkJoinPool.java:2075)\nscala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)\nscala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)", "blockedByLock" : "Lock(scala.concurrent.forkjoin.ForkJoinPool380286413})", "holdingLocks" : [ ] }, { "threadId" : 45, "threadName" : "heartbeat-receiver-event-loop-thread", "threadState" : "TIMED_WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078)\njava.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1093)\njava.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)\njava.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject715135812})", "holdingLocks" : [ ] }, { "threadId" : 1, "threadName" : "main", "threadState" : "RUNNABLE", "stackTrace" : "java.io.FileInputStream.read0(Native Method)\njava.io.FileInputStream.read(FileInputStream.java:207)\nscala.tools.jline_embedded.internal.NonBlockingInputStream.read(NonBlockingInputStream.java:169) => holding Monitor(scala.tools.jline_embedded.internal.NonBlockingInputStream46248392})\nscala.tools.jline_embedded.internal.NonBlockingInputStream.read(NonBlockingInputStream.java:137)\nscala.tools.jline_embedded.internal.NonBlockingInputStream.read(NonBlockingInputStream.java:246)\nscala.tools.jline_embedded.internal.InputStreamReader.read(InputStreamReader.java:261) => holding Monitor(scala.tools.jline_embedded.internal.NonBlockingInputStream46248392})\nscala.tools.jline_embedded.internal.InputStreamReader.read(InputStreamReader.java:198) => holding Monitor(scala.tools.jline_embedded.internal.NonBlockingInputStream46248392})\nscala.tools.jline_embedded.console.ConsoleReader.readCharacter(ConsoleReader.java:2145)\nscala.tools.jline_embedded.console.ConsoleReader.readLine(ConsoleReader.java:2349)\nscala.tools.jline_embedded.console.ConsoleReader.readLine(ConsoleReader.java:2269)\nscala.tools.nsc.interpreter.jline_embedded.InteractiveReader.readOneLine(JLineReader.scala:57)\nscala.tools.nsc.interpreter.InteractiveReader$$anonfun$readLine$2.apply(InteractiveReader.scala:37)\nscala.tools.nsc.interpreter.InteractiveReader$$anonfun$readLine$2.apply(InteractiveReader.scala:37)\nscala.tools.nsc.interpreter.InteractiveReader$.restartSysCalls(InteractiveReader.scala:44)\nscala.tools.nsc.interpreter.InteractiveReader$class.readLine(InteractiveReader.scala:37)\nscala.tools.nsc.interpreter.jline_embedded.InteractiveReader.readLine(JLineReader.scala:28)\nscala.tools.nsc.interpreter.ILoop.readOneLine(ILoop.scala:404)\nscala.tools.nsc.interpreter.ILoop.loop(ILoop.scala:413)\nscala.tools.nsc.interpreter.ILoop$$anonfun$process$1.apply$mcZ$sp(ILoop.scala:923)\nscala.tools.nsc.interpreter.ILoop$$anonfun$process$1.apply(ILoop.scala:909)\nscala.tools.nsc.interpreter.ILoop$$anonfun$process$1.apply(ILoop.scala:909)\nscala.reflect.internal.util.ScalaClassLoader$.savingContextLoader(ScalaClassLoader.scala:97)\nscala.tools.nsc.interpreter.ILoop.process(ILoop.scala:909)\norg.apache.spark.repl.Main$.doMain(Main.scala:76)\norg.apache.spark.repl.Main$.main(Main.scala:56)\norg.apache.spark.repl.Main.main(Main.scala)\nsun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)\nsun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)\nsun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\njava.lang.reflect.Method.invoke(Method.java:498)\norg.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)\norg.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:879)\norg.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:197)\norg.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:227)\norg.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:136)\norg.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)", "blockedByLock" : "", "holdingLocks" : [ "Monitor(scala.tools.jline_embedded.internal.NonBlockingInputStream46248392})" ] }, { "threadId" : 26, "threadName" : "map-output-dispatcher-0", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.MapOutputTrackerMaster$MessageLoop.run(MapOutputTracker.scala:384)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject350285679})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker1791280119})" ] }, { "threadId" : 27, "threadName" : "map-output-dispatcher-1", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.MapOutputTrackerMaster$MessageLoop.run(MapOutputTracker.scala:384)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject350285679})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker1947378744})" ] }, { "threadId" : 28, "threadName" : "map-output-dispatcher-2", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.MapOutputTrackerMaster$MessageLoop.run(MapOutputTracker.scala:384)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject350285679})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker507507251})" ] }, { "threadId" : 29, "threadName" : "map-output-dispatcher-3", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.MapOutputTrackerMaster$MessageLoop.run(MapOutputTracker.scala:384)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject350285679})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker1016408627})" ] }, { "threadId" : 30, "threadName" : "map-output-dispatcher-4", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.MapOutputTrackerMaster$MessageLoop.run(MapOutputTracker.scala:384)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject350285679})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker1879219501})" ] }, { "threadId" : 31, "threadName" : "map-output-dispatcher-5", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.MapOutputTrackerMaster$MessageLoop.run(MapOutputTracker.scala:384)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject350285679})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker290509937})" ] }, { "threadId" : 32, "threadName" : "map-output-dispatcher-6", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.MapOutputTrackerMaster$MessageLoop.run(MapOutputTracker.scala:384)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject350285679})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker1889468930})" ] }, { "threadId" : 33, "threadName" : "map-output-dispatcher-7", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.MapOutputTrackerMaster$MessageLoop.run(MapOutputTracker.scala:384)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject350285679})", "holdingLocks" : [ "Lock(java.util.concurrent.ThreadPoolExecutor$Worker1699637904})" ] }, { "threadId" : 47, "threadName" : "netty-rpc-env-timeout", "threadState" : "TIMED_WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078)\njava.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1093)\njava.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)\njava.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject977194847})", "holdingLocks" : [ ] }, { "threadId" : 14, "threadName" : "NonBlockingInputStreamThread", "threadState" : "WAITING", "stackTrace" : "java.lang.Object.wait(Native Method)\nscala.tools.jline_embedded.internal.NonBlockingInputStream.run(NonBlockingInputStream.java:278)\njava.lang.Thread.run(Thread.java:748)", "blockedByThreadId" : 1, "blockedByLock" : "Lock(scala.tools.jline_embedded.internal.NonBlockingInputStream46248392})", "holdingLocks" : [ ] }, { "threadId" : 2, "threadName" : "Reference Handler", "threadState" : "WAITING", "stackTrace" : "java.lang.Object.wait(Native Method)\njava.lang.Object.wait(Object.java:502)\njava.lang.ref.Reference.tryHandlePending(Reference.java:191)\njava.lang.ref.Reference$ReferenceHandler.run(Reference.java:153)", "blockedByLock" : "Lock(java.lang.ref.Reference$Lock1359433302})", "holdingLocks" : [ ] }, { "threadId" : 35, "threadName" : "refresh progress", "threadState" : "TIMED_WAITING", "stackTrace" : "java.lang.Object.wait(Native Method)\njava.util.TimerThread.mainLoop(Timer.java:552)\njava.util.TimerThread.run(Timer.java:505)", "blockedByLock" : "Lock(java.util.TaskQueue44276328})", "holdingLocks" : [ ] }, { "threadId" : 34, "threadName" : "RemoteBlock-temp-file-clean-thread", "threadState" : "TIMED_WAITING", "stackTrace" : "java.lang.Object.wait(Native Method)\njava.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:143)\norg.apache.spark.storage.BlockManager$RemoteBlockTempFileManager.org$apache$spark$storage$BlockManager$RemoteBlockTempFileManager$$keepCleaning(BlockManager.scala:1630)\norg.apache.spark.storage.BlockManager$RemoteBlockTempFileManager$$anon$1.run(BlockManager.scala:1608)", "blockedByLock" : "Lock(java.lang.ref.ReferenceQueue$Lock391748181})", "holdingLocks" : [ ] }, { "threadId" : 25, "threadName" : "rpc-server-3-1", "threadState" : "RUNNABLE", "stackTrace" : "sun.nio.ch.KQueueArrayWrapper.kevent0(Native Method)\nsun.nio.ch.KQueueArrayWrapper.poll(KQueueArrayWrapper.java:198)\nsun.nio.ch.KQueueSelectorImpl.doSelect(KQueueSelectorImpl.java:117)\nsun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86) => holding Monitor(sun.nio.ch.KQueueSelectorImpl2057702496})\nsun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)\nio.netty.channel.nio.SelectedSelectionKeySetSelector.select(SelectedSelectionKeySetSelector.java:62)\nio.netty.channel.nio.NioEventLoop.select(NioEventLoop.java:753)\nio.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:409)\nio.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:858)\nio.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:138)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "", "holdingLocks" : [ "Monitor(io.netty.channel.nio.SelectedSelectionKeySet1066929256})", "Monitor(java.util.Collections$UnmodifiableSet561426729})", "Monitor(sun.nio.ch.KQueueSelectorImpl2057702496})" ] }, { "threadId" : 50, "threadName" : "shuffle-server-5-1", "threadState" : "RUNNABLE", "stackTrace" : "sun.nio.ch.KQueueArrayWrapper.kevent0(Native Method)\nsun.nio.ch.KQueueArrayWrapper.poll(KQueueArrayWrapper.java:198)\nsun.nio.ch.KQueueSelectorImpl.doSelect(KQueueSelectorImpl.java:117)\nsun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86) => holding Monitor(sun.nio.ch.KQueueSelectorImpl1401522546})\nsun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)\nio.netty.channel.nio.SelectedSelectionKeySetSelector.select(SelectedSelectionKeySetSelector.java:62)\nio.netty.channel.nio.NioEventLoop.select(NioEventLoop.java:753)\nio.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:409)\nio.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:858)\nio.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:138)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "", "holdingLocks" : [ "Monitor(io.netty.channel.nio.SelectedSelectionKeySet385972319})", "Monitor(java.util.Collections$UnmodifiableSet477937109})", "Monitor(sun.nio.ch.KQueueSelectorImpl1401522546})" ] }, { "threadId" : 4, "threadName" : "Signal Dispatcher", "threadState" : "RUNNABLE", "stackTrace" : "", "blockedByLock" : "", "holdingLocks" : [ ] }, { "threadId" : 51, "threadName" : "Spark Context Cleaner", "threadState" : "TIMED_WAITING", "stackTrace" : "java.lang.Object.wait(Native Method)\njava.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:143)\norg.apache.spark.ContextCleaner$$anonfun$org$apache$spark$ContextCleaner$$keepCleaning$1.apply$mcV$sp(ContextCleaner.scala:181)\norg.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1319)\norg.apache.spark.ContextCleaner.org$apache$spark$ContextCleaner$$keepCleaning(ContextCleaner.scala:178)\norg.apache.spark.ContextCleaner$$anon$1.run(ContextCleaner.scala:73)", "blockedByLock" : "Lock(java.lang.ref.ReferenceQueue$Lock1739420764})", "holdingLocks" : [ ] }, { "threadId" : 16, "threadName" : "spark-listener-group-appStatus", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.scheduler.AsyncEventQueue$$anonfun$org$apache$spark$scheduler$AsyncEventQueue$$dispatch$1.apply(AsyncEventQueue.scala:94)\nscala.util.DynamicVariable.withValue(DynamicVariable.scala:58)\norg.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:83)\norg.apache.spark.scheduler.AsyncEventQueue$$anon$1$$anonfun$run$1.apply$mcV$sp(AsyncEventQueue.scala:79)\norg.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1319)\norg.apache.spark.scheduler.AsyncEventQueue$$anon$1.run(AsyncEventQueue.scala:78)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1287190987})", "holdingLocks" : [ ] }, { "threadId" : 44, "threadName" : "spark-listener-group-executorManagement", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.scheduler.AsyncEventQueue$$anonfun$org$apache$spark$scheduler$AsyncEventQueue$$dispatch$1.apply(AsyncEventQueue.scala:94)\nscala.util.DynamicVariable.withValue(DynamicVariable.scala:58)\norg.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:83)\norg.apache.spark.scheduler.AsyncEventQueue$$anon$1$$anonfun$run$1.apply$mcV$sp(AsyncEventQueue.scala:79)\norg.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1319)\norg.apache.spark.scheduler.AsyncEventQueue$$anon$1.run(AsyncEventQueue.scala:78)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject943262890})", "holdingLocks" : [ ] }, { "threadId" : 54, "threadName" : "spark-listener-group-shared", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\norg.apache.spark.scheduler.AsyncEventQueue$$anonfun$org$apache$spark$scheduler$AsyncEventQueue$$dispatch$1.apply(AsyncEventQueue.scala:94)\nscala.util.DynamicVariable.withValue(DynamicVariable.scala:58)\norg.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:83)\norg.apache.spark.scheduler.AsyncEventQueue$$anon$1$$anonfun$run$1.apply$mcV$sp(AsyncEventQueue.scala:79)\norg.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1319)\norg.apache.spark.scheduler.AsyncEventQueue$$anon$1.run(AsyncEventQueue.scala:78)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject334604425})", "holdingLocks" : [ ] }, { "threadId" : 37, "threadName" : "SparkUI-37", "threadState" : "TIMED_WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078)\norg.spark_project.jetty.util.BlockingArrayQueue.poll(BlockingArrayQueue.java:392)\norg.spark_project.jetty.util.thread.QueuedThreadPool.idleJobPoll(QueuedThreadPool.java:563)\norg.spark_project.jetty.util.thread.QueuedThreadPool.access$800(QueuedThreadPool.java:48)\norg.spark_project.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:626)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1503479572})", "holdingLocks" : [ ] }, { "threadId" : 38, "threadName" : "SparkUI-38", "threadState" : "RUNNABLE", "stackTrace" : "sun.nio.ch.KQueueArrayWrapper.kevent0(Native Method)\nsun.nio.ch.KQueueArrayWrapper.poll(KQueueArrayWrapper.java:198)\nsun.nio.ch.KQueueSelectorImpl.doSelect(KQueueSelectorImpl.java:117)\nsun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86) => holding Monitor(sun.nio.ch.KQueueSelectorImpl841741934})\nsun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)\nsun.nio.ch.SelectorImpl.select(SelectorImpl.java:101)\norg.spark_project.jetty.io.ManagedSelector$SelectorProducer.select(ManagedSelector.java:243)\norg.spark_project.jetty.io.ManagedSelector$SelectorProducer.produce(ManagedSelector.java:191)\norg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.executeProduceConsume(ExecuteProduceConsume.java:249)\norg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.produceConsume(ExecuteProduceConsume.java:148)\norg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.run(ExecuteProduceConsume.java:136)\norg.spark_project.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:671)\norg.spark_project.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:589)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "", "holdingLocks" : [ "Monitor(sun.nio.ch.Util$3873523986})", "Monitor(java.util.Collections$UnmodifiableSet1769333189})", "Monitor(sun.nio.ch.KQueueSelectorImpl841741934})" ] }, { "threadId" : 40, "threadName" : "SparkUI-40-acceptor-034929380-Spark3a557b62{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}", "threadState" : "RUNNABLE", "stackTrace" : "sun.nio.ch.ServerSocketChannelImpl.accept0(Native Method)\nsun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:422)\nsun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:250) => holding Monitor(java.lang.Object1134240909})\norg.spark_project.jetty.server.ServerConnector.accept(ServerConnector.java:371)\norg.spark_project.jetty.server.AbstractConnector$Acceptor.run(AbstractConnector.java:601)\norg.spark_project.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:671)\norg.spark_project.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:589)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "", "holdingLocks" : [ "Monitor(java.lang.Object1134240909})" ] }, { "threadId" : 43, "threadName" : "SparkUI-43", "threadState" : "RUNNABLE", "stackTrace" : "sun.management.ThreadImpl.dumpThreads0(Native Method)\nsun.management.ThreadImpl.dumpAllThreads(ThreadImpl.java:454)\norg.apache.spark.util.Utils$.getThreadDump(Utils.scala:2170)\norg.apache.spark.SparkContext.getExecutorThreadDump(SparkContext.scala:596)\norg.apache.spark.status.api.v1.AbstractApplicationResource$$anonfun$threadDump$1$$anonfun$apply$1.apply(OneApplicationResource.scala:66)\norg.apache.spark.status.api.v1.AbstractApplicationResource$$anonfun$threadDump$1$$anonfun$apply$1.apply(OneApplicationResource.scala:65)\nscala.Option.flatMap(Option.scala:171)\norg.apache.spark.status.api.v1.AbstractApplicationResource$$anonfun$threadDump$1.apply(OneApplicationResource.scala:65)\norg.apache.spark.status.api.v1.AbstractApplicationResource$$anonfun$threadDump$1.apply(OneApplicationResource.scala:58)\norg.apache.spark.status.api.v1.BaseAppResource$$anonfun$withUI$1.apply(ApiRootResource.scala:139)\norg.apache.spark.status.api.v1.BaseAppResource$$anonfun$withUI$1.apply(ApiRootResource.scala:134)\norg.apache.spark.ui.SparkUI.withSparkUI(SparkUI.scala:106)\norg.apache.spark.status.api.v1.BaseAppResource$class.withUI(ApiRootResource.scala:134)\norg.apache.spark.status.api.v1.AbstractApplicationResource.withUI(OneApplicationResource.scala:32)\norg.apache.spark.status.api.v1.AbstractApplicationResource.threadDump(OneApplicationResource.scala:58)\nsun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)\nsun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)\nsun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\njava.lang.reflect.Method.invoke(Method.java:498)\norg.glassfish.jersey.server.model.internal.ResourceMethodInvocationHandlerFactory$1.invoke(ResourceMethodInvocationHandlerFactory.java:81)\norg.glassfish.jersey.server.model.internal.AbstractJavaResourceMethodDispatcher$1.run(AbstractJavaResourceMethodDispatcher.java:144)\norg.glassfish.jersey.server.model.internal.AbstractJavaResourceMethodDispatcher.invoke(AbstractJavaResourceMethodDispatcher.java:161)\norg.glassfish.jersey.server.model.internal.JavaResourceMethodDispatcherProvider$TypeOutInvoker.doDispatch(JavaResourceMethodDispatcherProvider.java:205)\norg.glassfish.jersey.server.model.internal.AbstractJavaResourceMethodDispatcher.dispatch(AbstractJavaResourceMethodDispatcher.java:99)\norg.glassfish.jersey.server.model.ResourceMethodInvoker.invoke(ResourceMethodInvoker.java:389)\norg.glassfish.jersey.server.model.ResourceMethodInvoker.apply(ResourceMethodInvoker.java:347)\norg.glassfish.jersey.server.model.ResourceMethodInvoker.apply(ResourceMethodInvoker.java:102)\norg.glassfish.jersey.server.ServerRuntime$2.run(ServerRuntime.java:326)\norg.glassfish.jersey.internal.Errors$1.call(Errors.java:271)\norg.glassfish.jersey.internal.Errors$1.call(Errors.java:267)\norg.glassfish.jersey.internal.Errors.process(Errors.java:315)\norg.glassfish.jersey.internal.Errors.process(Errors.java:297)\norg.glassfish.jersey.internal.Errors.process(Errors.java:267)\norg.glassfish.jersey.process.internal.RequestScope.runInScope(RequestScope.java:317)\norg.glassfish.jersey.server.ServerRuntime.process(ServerRuntime.java:305)\norg.glassfish.jersey.server.ApplicationHandler.handle(ApplicationHandler.java:1154)\norg.glassfish.jersey.servlet.WebComponent.serviceImpl(WebComponent.java:473)\norg.glassfish.jersey.servlet.WebComponent.service(WebComponent.java:427)\norg.glassfish.jersey.servlet.ServletContainer.service(ServletContainer.java:388)\norg.glassfish.jersey.servlet.ServletContainer.service(ServletContainer.java:341)\norg.glassfish.jersey.servlet.ServletContainer.service(ServletContainer.java:228)\norg.spark_project.jetty.servlet.ServletHolder.handle(ServletHolder.java:848)\norg.spark_project.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:584)\norg.spark_project.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1180)\norg.spark_project.jetty.servlet.ServletHandler.doScope(ServletHandler.java:512)\norg.spark_project.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1112)\norg.spark_project.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:141)\norg.spark_project.jetty.server.handler.gzip.GzipHandler.handle(GzipHandler.java:493)\norg.spark_project.jetty.server.handler.ContextHandlerCollection.handle(ContextHandlerCollection.java:213)\norg.spark_project.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:134)\norg.spark_project.jetty.server.Server.handle(Server.java:534)\norg.spark_project.jetty.server.HttpChannel.handle(HttpChannel.java:320)\norg.spark_project.jetty.server.HttpConnection.onFillable(HttpConnection.java:251)\norg.spark_project.jetty.io.AbstractConnection$ReadCallback.succeeded(AbstractConnection.java:283)\norg.spark_project.jetty.io.FillInterest.fillable(FillInterest.java:108)\norg.spark_project.jetty.io.SelectChannelEndPoint$2.run(SelectChannelEndPoint.java:93)\norg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.executeProduceConsume(ExecuteProduceConsume.java:303)\norg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.produceConsume(ExecuteProduceConsume.java:148)\norg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.run(ExecuteProduceConsume.java:136)\norg.spark_project.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:671)\norg.spark_project.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:589)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "", "holdingLocks" : [ ] }, { "threadId" : 67, "threadName" : "SparkUI-67", "threadState" : "RUNNABLE", "stackTrace" : "sun.nio.ch.KQueueArrayWrapper.kevent0(Native Method)\nsun.nio.ch.KQueueArrayWrapper.poll(KQueueArrayWrapper.java:198)\nsun.nio.ch.KQueueSelectorImpl.doSelect(KQueueSelectorImpl.java:117)\nsun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86) => holding Monitor(sun.nio.ch.KQueueSelectorImpl1837806480})\nsun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)\nsun.nio.ch.SelectorImpl.select(SelectorImpl.java:101)\norg.spark_project.jetty.io.ManagedSelector$SelectorProducer.select(ManagedSelector.java:243)\norg.spark_project.jetty.io.ManagedSelector$SelectorProducer.produce(ManagedSelector.java:191)\norg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.executeProduceConsume(ExecuteProduceConsume.java:249)\norg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.produceConsume(ExecuteProduceConsume.java:148)\norg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.run(ExecuteProduceConsume.java:136)\norg.spark_project.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:671)\norg.spark_project.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:589)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "", "holdingLocks" : [ "Monitor(sun.nio.ch.Util$3881415814})", "Monitor(java.util.Collections$UnmodifiableSet62050480})", "Monitor(sun.nio.ch.KQueueSelectorImpl1837806480})" ] }, { "threadId" : 68, "threadName" : "SparkUI-68", "threadState" : "RUNNABLE", "stackTrace" : "sun.nio.ch.KQueueArrayWrapper.kevent0(Native Method)\nsun.nio.ch.KQueueArrayWrapper.poll(KQueueArrayWrapper.java:198)\nsun.nio.ch.KQueueSelectorImpl.doSelect(KQueueSelectorImpl.java:117)\nsun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86) => holding Monitor(sun.nio.ch.KQueueSelectorImpl223607814})\nsun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)\nsun.nio.ch.SelectorImpl.select(SelectorImpl.java:101)\norg.spark_project.jetty.io.ManagedSelector$SelectorProducer.select(ManagedSelector.java:243)\norg.spark_project.jetty.io.ManagedSelector$SelectorProducer.produce(ManagedSelector.java:191)\norg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.executeProduceConsume(ExecuteProduceConsume.java:249)\norg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.produceConsume(ExecuteProduceConsume.java:148)\norg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.run(ExecuteProduceConsume.java:136)\norg.spark_project.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:671)\norg.spark_project.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:589)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "", "holdingLocks" : [ "Monitor(sun.nio.ch.Util$3543145185})", "Monitor(java.util.Collections$UnmodifiableSet897441546})", "Monitor(sun.nio.ch.KQueueSelectorImpl223607814})" ] }, { "threadId" : 71, "threadName" : "SparkUI-71", "threadState" : "TIMED_WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078)\norg.spark_project.jetty.util.BlockingArrayQueue.poll(BlockingArrayQueue.java:392)\norg.spark_project.jetty.util.thread.QueuedThreadPool.idleJobPoll(QueuedThreadPool.java:563)\norg.spark_project.jetty.util.thread.QueuedThreadPool.access$800(QueuedThreadPool.java:48)\norg.spark_project.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:626)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1503479572})", "holdingLocks" : [ ] }, { "threadId" : 77, "threadName" : "SparkUI-77", "threadState" : "TIMED_WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078)\norg.spark_project.jetty.util.BlockingArrayQueue.poll(BlockingArrayQueue.java:392)\norg.spark_project.jetty.util.thread.QueuedThreadPool.idleJobPoll(QueuedThreadPool.java:563)\norg.spark_project.jetty.util.thread.QueuedThreadPool.access$800(QueuedThreadPool.java:48)\norg.spark_project.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:626)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1503479572})", "holdingLocks" : [ ] }, { "threadId" : 78, "threadName" : "SparkUI-78", "threadState" : "RUNNABLE", "stackTrace" : "sun.nio.ch.KQueueArrayWrapper.kevent0(Native Method)\nsun.nio.ch.KQueueArrayWrapper.poll(KQueueArrayWrapper.java:198)\nsun.nio.ch.KQueueSelectorImpl.doSelect(KQueueSelectorImpl.java:117)\nsun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86) => holding Monitor(sun.nio.ch.KQueueSelectorImpl403077801})\nsun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)\nsun.nio.ch.SelectorImpl.select(SelectorImpl.java:101)\norg.spark_project.jetty.io.ManagedSelector$SelectorProducer.select(ManagedSelector.java:243)\norg.spark_project.jetty.io.ManagedSelector$SelectorProducer.produce(ManagedSelector.java:191)\norg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.executeProduceConsume(ExecuteProduceConsume.java:249)\norg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.produceConsume(ExecuteProduceConsume.java:148)\norg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.run(ExecuteProduceConsume.java:136)\norg.spark_project.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:671)\norg.spark_project.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:589)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "", "holdingLocks" : [ "Monitor(sun.nio.ch.Util$3261312406})", "Monitor(java.util.Collections$UnmodifiableSet852901260})", "Monitor(sun.nio.ch.KQueueSelectorImpl403077801})" ] }, { "threadId" : 72, "threadName" : "SparkUI-JettyScheduler", "threadState" : "TIMED_WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078)\njava.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1093)\njava.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)\njava.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject1587346642})", "holdingLocks" : [ ] }, { "threadId" : 63, "threadName" : "task-result-getter-0", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\njava.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject537563105})", "holdingLocks" : [ ] }, { "threadId" : 64, "threadName" : "task-result-getter-1", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\njava.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject537563105})", "holdingLocks" : [ ] }, { "threadId" : 65, "threadName" : "task-result-getter-2", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\njava.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject537563105})", "holdingLocks" : [ ] }, { "threadId" : 66, "threadName" : "task-result-getter-3", "threadState" : "WAITING", "stackTrace" : "sun.misc.Unsafe.park(Native Method)\njava.util.concurrent.locks.LockSupport.park(LockSupport.java:175)\njava.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)\njava.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)\njava.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)\njava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)\njava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\njava.lang.Thread.run(Thread.java:748)", "blockedByLock" : "Lock(java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject537563105})", "holdingLocks" : [ ] }, { "threadId" : 46, "threadName" : "Timer-0", "threadState" : "WAITING", "stackTrace" : "java.lang.Object.wait(Native Method)\njava.lang.Object.wait(Object.java:502)\njava.util.TimerThread.mainLoop(Timer.java:526)\njava.util.TimerThread.run(Timer.java:505)", "blockedByLock" : "Lock(java.util.TaskQueue635634547})", "holdingLocks" : [ ] } ] ``` </details> ## How was this patch tested? It was tested manually. Old executor page with thread dumps: <img width="1632" alt="screen shot 2018-02-01 at 14 31 19" src="https://user-images.githubusercontent.com/2017933/35682124-e2ec5d96-075f-11e8-9713-a502e12d05c2.png"> New api: <img width="1669" alt="screen shot 2018-02-01 at 14 31 56" src="https://user-images.githubusercontent.com/2017933/35682149-f75b80d6-075f-11e8-95b0-c75d048f0b04.png"> Testing error cases. Initial state:  Dead executor: ```bash $ curl -o - -s -w "\n%{http_code}\n" http://localhost:4040/api/v1/applications/app-20180206122543-0000/executors/1/threads Executor is not active. 400 ``` Never existed (but well formatted: number) executor ID: ```bash $ curl -o - -s -w "\n%{http_code}\n" http://localhost:4040/api/v1/applications/app-20180206122543-0000/executors/42/threads Executor does not exist. 404 ``` Not available stacktrace (dead executor but UI has not registered as dead yet): ```bash $ kill -9 <PID of CoarseGrainedExecutorBackend for executor 2> ; curl -o - -s -w "\n%{http_code}\n" http://localhost:4040/api/v1/applications/app-20180206122543-0000/executors/2/threads No thread dump is available. 404 ``` Invalid executor ID format: ```bash $ curl -o - -s -w "\n%{http_code}\n" http://localhost:4040/api/v1/applications/app-20180206122543-0000/executors/something6/threads Invalid executorId: neither 'driver' nor number. 400 ``` Author: “attilapiros” <piros.attila.zsolt@gmail.com> Closes #20474 from attilapiros/SPARK-23235. |
||
|
|
bd24731722 |
[SPARK-23382][WEB-UI] Spark Streaming ui about the contents of the for need to have hidden and show features, when the table records very much.
## What changes were proposed in this pull request? Spark Streaming ui about the contents of the for need to have hidden and show features, when the table records very much. please refer to https://github.com/apache/spark/pull/20216 fix after:  ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: guoxiaolong <guo.xiaolong1@zte.com.cn> Closes #20570 from guoxiaolongzte/SPARK-23382. |
||
|
|
091a000d27 |
[SPARK-23053][CORE] taskBinarySerialization and task partitions calculate in DagScheduler.submitMissingTasks should keep the same RDD checkpoint status
## What changes were proposed in this pull request? When we run concurrent jobs using the same rdd which is marked to do checkpoint. If one job has finished running the job, and start the process of RDD.doCheckpoint, while another job is submitted, then submitStage and submitMissingTasks will be called. In [submitMissingTasks](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L961), will serialize taskBinaryBytes and calculate task partitions which are both affected by the status of checkpoint, if the former is calculated before doCheckpoint finished, while the latter is calculated after doCheckpoint finished, when run task, rdd.compute will be called, for some rdds with particular partition type such as [UnionRDD](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/rdd/UnionRDD.scala) who will do partition type cast, will get a ClassCastException because the part params is actually a CheckpointRDDPartition. This error occurs because rdd.doCheckpoint occurs in the same thread that called sc.runJob, while the task serialization occurs in the DAGSchedulers event loop. ## How was this patch tested? the exist uts and also add a test case in DAGScheduerSuite to show the exception case. Author: huangtengfei <huangtengfei@huangtengfeideMacBook-Pro.local> Closes #20244 from ivoson/branch-taskpart-mistype. |
||
|
|
d6e1958a24 |
[SPARK-23189][CORE][WEB UI] Reflect stage level blacklisting on executor tab
## What changes were proposed in this pull request?
The purpose of this PR to reflect the stage level blacklisting on the executor tab for the currently active stages.
After this change in the executor tab at the Status column one of the following label will be:
- "Blacklisted" when the executor is blacklisted application level (old flag)
- "Dead" when the executor is not Blacklisted and not Active
- "Blacklisted in Stages: [...]" when the executor is Active but the there are active blacklisted stages for the executor. Within the [] coma separated active stageIDs are listed.
- "Active" when the executor is Active and there is no active blacklisted stages for the executor
## How was this patch tested?
Both with unit tests and manually.
#### Manual test
Spark was started as:
```bash
bin/spark-shell --master "local-cluster[2,1,1024]" --conf "spark.blacklist.enabled=true" --conf "spark.blacklist.stage.maxFailedTasksPerExecutor=1" --conf "spark.blacklist.application.maxFailedTasksPerExecutor=10"
```
And the job was:
```scala
import org.apache.spark.SparkEnv
val pairs = sc.parallelize(1 to 10000, 10).map { x =>
if (SparkEnv.get.executorId.toInt == 0) throw new RuntimeException("Bad executor")
else {
Thread.sleep(10)
(x % 10, x)
}
}
val all = pairs.cogroup(pairs)
all.collect()
```
UI screenshots about the running:
- One executor is blacklisted in the two stages:

- One stage completes the other one is still running:

- Both stages are completed:

### Unit tests
In AppStatusListenerSuite.scala both the node blacklisting for a stage and the executor blacklisting for stage are tested.
Author: “attilapiros” <piros.attila.zsolt@gmail.com>
Closes #20408 from attilapiros/SPARK-23189.
|
||
|
|
116c581d26 |
[SPARK-20659][CORE] Removing sc.getExecutorStorageStatus and making StorageStatus private
## What changes were proposed in this pull request? In this PR StorageStatus is made to private and simplified a bit moreover SparkContext.getExecutorStorageStatus method is removed. The reason of keeping StorageStatus is that it is usage from SparkContext.getRDDStorageInfo. Instead of the method SparkContext.getExecutorStorageStatus executor infos are extended with additional memory metrics such as usedOnHeapStorageMemory, usedOffHeapStorageMemory, totalOnHeapStorageMemory, totalOffHeapStorageMemory. ## How was this patch tested? By running existing unit tests. Author: “attilapiros” <piros.attila.zsolt@gmail.com> Author: Attila Zsolt Piros <2017933+attilapiros@users.noreply.github.com> Closes #20546 from attilapiros/SPARK-20659. |
||
|
|
300c40f50a |
[SPARK-23384][WEB-UI] When it has no incomplete(completed) applications found, the last updated time is not formatted and client local time zone is not show in history server web ui.
## What changes were proposed in this pull request? When it has no incomplete(completed) applications found, the last updated time is not formatted and client local time zone is not show in history server web ui. It is a bug. fix before:  fix after:  ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: guoxiaolong <guo.xiaolong1@zte.com.cn> Closes #20573 from guoxiaolongzte/SPARK-23384. |
||
|
|
4a4dd4f36f |
[SPARK-23391][CORE] It may lead to overflow for some integer multiplication
## What changes were proposed in this pull request? In the `getBlockData`,`blockId.reduceId` is the `Int` type, when it is greater than 2^28, `blockId.reduceId*8` will overflow In the `decompress0`, `len` and `unitSize` are Int type, so `len * unitSize` may lead to overflow ## How was this patch tested? N/A Author: liuxian <liu.xian3@zte.com.cn> Closes #20581 from 10110346/overflow2. |
||
|
|
caeb108e25 |
[MINOR][TEST] spark.testing` No effect on the SparkFunSuite unit test
## What changes were proposed in this pull request? Currently, we use SBT and MAVN to spark unit test, are affected by the parameters of `spark.testing`. However, when using the IDE test tool, `spark.testing` support is not very good, sometimes need to be manually added to the beforeEach. example: HiveSparkSubmitSuite RPackageUtilsSuite SparkSubmitSuite. The PR unified `spark.testing` parameter extraction to SparkFunSuite, support IDE test tool, and the test code is more compact. ## How was this patch tested? the existed test cases. Author: caoxuewen <cao.xuewen@zte.com.cn> Closes #20582 from heary-cao/sparktesting. |
||
|
|
f77270b881 |
[SPARK-23358][CORE] When the number of partitions is greater than 2^28, it will result in an error result
## What changes were proposed in this pull request? In the `checkIndexAndDataFile`,the `blocks` is the ` Int` type, when it is greater than 2^28, `blocks*8` will overflow, and this will result in an error result. In fact, `blocks` is actually the number of partitions. ## How was this patch tested? Manual test Author: liuxian <liu.xian3@zte.com.cn> Closes #20544 from 10110346/overflow. |
||
|
|
9841ae0313 |
[SPARK-23345][SQL] Remove open stream record even closing it fails
## What changes were proposed in this pull request? When `DebugFilesystem` closes opened stream, if any exception occurs, we still need to remove the open stream record from `DebugFilesystem`. Otherwise, it goes to report leaked filesystem connection. ## How was this patch tested? Existing tests. Author: Liang-Chi Hsieh <viirya@gmail.com> Closes #20524 from viirya/SPARK-23345. |
||
|
|
7db9979bab |
[SPARK-23310][CORE][FOLLOWUP] Fix Java style check issues.
## What changes were proposed in this pull request? This is a follow-up of #20492 which broke lint-java checks. This pr fixes the lint-java issues. ``` [ERROR] src/main/java/org/apache/spark/util/collection/unsafe/sort/UnsafeSorterSpillReader.java:[79] (sizes) LineLength: Line is longer than 100 characters (found 114). ``` ## How was this patch tested? Checked manually in my local environment. Author: Takuya UESHIN <ueshin@databricks.com> Closes #20514 from ueshin/issues/SPARK-23310/fup1. |
||
|
|
f3f1e14bb7 |
[SPARK-23326][WEBUI] schedulerDelay should return 0 when the task is running
## What changes were proposed in this pull request? When a task is still running, metrics like executorRunTime are not available. Then `schedulerDelay` will be almost the same as `duration` and that's confusing. This PR makes `schedulerDelay` return 0 when the task is running which is the same behavior as 2.2. ## How was this patch tested? `AppStatusUtilsSuite.schedulerDelay` Author: Shixiong Zhu <zsxwing@gmail.com> Closes #20493 from zsxwing/SPARK-23326. |
||
|
|
03b7e120dd |
[SPARK-23310][CORE] Turn off read ahead input stream for unshafe shuffle reader
To fix regression for TPC-DS queries Author: Sital Kedia <skedia@fb.com> Closes #20492 from sitalkedia/turn_off_async_inputstream. |
||
|
|
a6bf3db207 |
[SPARK-23307][WEBUI] Sort jobs/stages/tasks/queries with the completed timestamp before cleaning up them
## What changes were proposed in this pull request?
Sort jobs/stages/tasks/queries with the completed timestamp before cleaning up them to make the behavior consistent with 2.2.
## How was this patch tested?
- Jenkins.
- Manually ran the following codes and checked the UI for jobs/stages/tasks/queries.
```
spark.ui.retainedJobs 10
spark.ui.retainedStages 10
spark.sql.ui.retainedExecutions 10
spark.ui.retainedTasks 10
```
```
new Thread() {
override def run() {
spark.range(1, 2).foreach { i =>
Thread.sleep(10000)
}
}
}.start()
Thread.sleep(5000)
for (_ <- 1 to 20) {
new Thread() {
override def run() {
spark.range(1, 2).foreach { i =>
}
}
}.start()
}
Thread.sleep(15000)
spark.range(1, 2).foreach { i =>
}
sc.makeRDD(1 to 100, 100).foreach { i =>
}
```
Author: Shixiong Zhu <zsxwing@gmail.com>
Closes #20481 from zsxwing/SPARK-23307.
|
||
|
|
dd52681bf5 |
[SPARK-23253][CORE][SHUFFLE] Only write shuffle temporary index file when there is not an existing one
## What changes were proposed in this pull request? Shuffle Index temporay file is used for atomic creating shuffle index file, it is not needed when the index file already exists after another attempts of same task had it done. ## How was this patch tested? exitsting ut cc squito Author: Kent Yao <yaooqinn@hotmail.com> Closes #20422 from yaooqinn/SPARK-23253. |
||
|
|
b3a04283f4 |
[SPARK-23306] Fix the oom caused by contention
## What changes were proposed in this pull request? here is race condition in TaskMemoryManger, which may cause OOM. The memory released may be taken by another task because there is a gap between releaseMemory and acquireMemory, e.g., UnifiedMemoryManager, causing the OOM. if the current is the only one that can perform spill. It can happen to BytesToBytesMap, as it only spill required bytes. Loop on current consumer if it still has memory to release. ## How was this patch tested? The race contention is hard to reproduce, but the current logic seems causing the issue. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Zhan Zhang <zhanzhang@fb.com> Closes #20480 from zhzhan/oom. |
||
|
|
969eda4a02 |
[SPARK-23020][CORE] Fix another race in the in-process launcher test.
First the bad news: there's an unfixable race in the launcher code. (By unfixable I mean it would take a lot more effort than this change to fix it.) The good news is that it should only affect super short lived applications, such as the one run by the flaky test, so it's possible to work around it in our test. The fix also uncovered an issue with the recently added "closeAndWait()" method; closing the connection would still possibly cause data loss, so this change waits a while for the connection to finish itself, and closes the socket if that times out. The existing connection timeout is reused so that if desired it's possible to control how long to wait. As part of that I also restored the old behavior that disconnect() would force a disconnection from the child app; the "wait for data to arrive" approach is only taken when disposing of the handle. I tested this by inserting a bunch of sleeps in the test and the socket handling code in the launcher library; with those I was able to reproduce the error from the jenkins jobs. With the changes, even with all the sleeps still in place, all tests pass. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20462 from vanzin/SPARK-23020. |
||
|
|
ec63e2d074 |
[SPARK-23289][CORE] OneForOneBlockFetcher.DownloadCallback.onData should write the buffer fully
## What changes were proposed in this pull request? `channel.write(buf)` may not write the whole buffer since the underlying channel is a FileChannel, we should retry until the whole buffer is written. ## How was this patch tested? Jenkins Author: Shixiong Zhu <zsxwing@gmail.com> Closes #20461 from zsxwing/SPARK-23289. |
||
|
|
7a2ada223e |
[SPARK-23261][PYSPARK] Rename Pandas UDFs
## What changes were proposed in this pull request? Rename the public APIs and names of pandas udfs. - `PANDAS SCALAR UDF` -> `SCALAR PANDAS UDF` - `PANDAS GROUP MAP UDF` -> `GROUPED MAP PANDAS UDF` - `PANDAS GROUP AGG UDF` -> `GROUPED AGG PANDAS UDF` ## How was this patch tested? The existing tests Author: gatorsmile <gatorsmile@gmail.com> Closes #20428 from gatorsmile/renamePandasUDFs. |
||
|
|
31bd1dab13 |
[SPARK-23088][CORE] History server not showing incomplete/running applications
## What changes were proposed in this pull request? History server not showing incomplete/running applications when spark.history.ui.maxApplications property is set to a value that is smaller than the total number of applications. ## How was this patch tested? Verified manually against master and 2.2.2 branch. Author: Paul Mackles <pmackles@adobe.com> Closes #20335 from pmackles/SPARK-23088. |
||
|
|
b834446ec1 |
[SPARK-23209][core] Allow credential manager to work when Hive not available.
The JVM seems to be doing early binding of classes that the Hive provider depends on, causing an error to be thrown before it was caught by the code in the class. The fix wraps the creation of the provider in a try..catch so that the provider can be ignored when dependencies are missing. Added a unit test (which fails without the fix), and also tested that getting tokens still works in a real cluster. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20399 from vanzin/SPARK-23209. |
||
|
|
94c67a76ec |
[SPARK-23207][SQL] Shuffle+Repartition on a DataFrame could lead to incorrect answers
## What changes were proposed in this pull request?
Currently shuffle repartition uses RoundRobinPartitioning, the generated result is nondeterministic since the sequence of input rows are not determined.
The bug can be triggered when there is a repartition call following a shuffle (which would lead to non-deterministic row ordering), as the pattern shows below:
upstream stage -> repartition stage -> result stage
(-> indicate a shuffle)
When one of the executors process goes down, some tasks on the repartition stage will be retried and generate inconsistent ordering, and some tasks of the result stage will be retried generating different data.
The following code returns 931532, instead of 1000000:
```
import scala.sys.process._
import org.apache.spark.TaskContext
val res = spark.range(0, 1000 * 1000, 1).repartition(200).map { x =>
x
}.repartition(200).map { x =>
if (TaskContext.get.attemptNumber == 0 && TaskContext.get.partitionId < 2) {
throw new Exception("pkill -f java".!!)
}
x
}
res.distinct().count()
```
In this PR, we propose a most straight-forward way to fix this problem by performing a local sort before partitioning, after we make the input row ordering deterministic, the function from rows to partitions is fully deterministic too.
The downside of the approach is that with extra local sort inserted, the performance of repartition() will go down, so we add a new config named `spark.sql.execution.sortBeforeRepartition` to control whether this patch is applied. The patch is default enabled to be safe-by-default, but user may choose to manually turn it off to avoid performance regression.
This patch also changes the output rows ordering of repartition(), that leads to a bunch of test cases failure because they are comparing the results directly.
## How was this patch tested?
Add unit test in ExchangeSuite.
With this patch(and `spark.sql.execution.sortBeforeRepartition` set to true), the following query returns 1000000:
```
import scala.sys.process._
import org.apache.spark.TaskContext
spark.conf.set("spark.sql.execution.sortBeforeRepartition", "true")
val res = spark.range(0, 1000 * 1000, 1).repartition(200).map { x =>
x
}.repartition(200).map { x =>
if (TaskContext.get.attemptNumber == 0 && TaskContext.get.partitionId < 2) {
throw new Exception("pkill -f java".!!)
}
x
}
res.distinct().count()
res7: Long = 1000000
```
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes #20393 from jiangxb1987/shuffle-repartition.
|
||
|
|
3e25251474 |
[SPARK-22068][CORE] Reduce the duplicate code between putIteratorAsValues and putIteratorAsBytes
## What changes were proposed in this pull request? The code logic between `MemoryStore.putIteratorAsValues` and `Memory.putIteratorAsBytes` are almost same, so we should reduce the duplicate code between them. ## How was this patch tested? Existing UT. Author: Xianyang Liu <xianyang.liu@intel.com> Closes #19285 from ConeyLiu/rmemorystore. |
||
|
|
45b4bbfddc |
[SPARK-23129][CORE] Make deserializeStream of DiskMapIterator init lazily
## What changes were proposed in this pull request? Currently,the deserializeStream in ExternalAppendOnlyMap#DiskMapIterator init when DiskMapIterator instance created.This will cause memory use overhead when ExternalAppendOnlyMap spill too much times. We can avoid this by making deserializeStream init when it is used the first time. This patch make deserializeStream init lazily. ## How was this patch tested? Exist tests Author: zhoukang <zhoukang199191@gmail.com> Closes #20292 from caneGuy/zhoukang/lay-diskmapiterator. |
||
|
|
0e178e1523 |
[SPARK-22297][CORE TESTS] Flaky test: BlockManagerSuite "Shuffle registration timeout and maxAttempts conf"
## What changes were proposed in this pull request? [Ticket](https://issues.apache.org/jira/browse/SPARK-22297) - one of the tests seems to produce unreliable results due to execution speed variability Since the original test was trying to connect to the test server with `40 ms` timeout, and the test server replied after `50 ms`, the error might be produced under the following conditions: - it might occur that the test server replies correctly after `50 ms` - but the client does only receive the timeout after `51 ms`s - this might happen if the executor has to schedule a big number of threads, and decides to delay the thread/actor that is responsible to watch the timeout, because of high CPU load - running an entire test suite usually produces high loads on the CPU executing the tests ## How was this patch tested? The test's check cases remain the same and the set-up emulates the previous version's. Author: Mark Petruska <petruska.mark@gmail.com> Closes #19671 from mpetruska/SPARK-22297. |
||
|
|
8c273b4162 |
[SPARK-23020][CORE][FOLLOWUP] Fix Java style check issues.
## What changes were proposed in this pull request? This is a follow-up of #20297 which broke lint-java checks. This pr fixes the lint-java issues. ``` [ERROR] src/test/java/org/apache/spark/launcher/BaseSuite.java:[21,8] (imports) UnusedImports: Unused import - java.util.concurrent.TimeUnit. [ERROR] src/test/java/org/apache/spark/launcher/SparkLauncherSuite.java:[27,8] (imports) UnusedImports: Unused import - java.util.concurrent.TimeUnit. ``` ## How was this patch tested? Checked manually in my local environment. Author: Takuya UESHIN <ueshin@databricks.com> Closes #20376 from ueshin/issues/SPARK-23020/fup1. |
||
|
|
0ec95bb7df |
[SPARK-22577][CORE] executor page blacklist status should update with TaskSet level blacklisting
## What changes were proposed in this pull request?
In this PR stage blacklisting is propagated to UI by introducing a new Spark listener event (SparkListenerExecutorBlacklistedForStage) which indicates the executor is blacklisted for a stage. Either because of the number of failures are exceeded a limit given for an executor (spark.blacklist.stage.maxFailedTasksPerExecutor) or because of the whole node is blacklisted for a stage (spark.blacklist.stage.maxFailedExecutorsPerNode). In case of the node is blacklisting all executors will listed as blacklisted for the stage.
Blacklisting state for a selected stage can be seen "Aggregated Metrics by Executor" table's blacklisting column, where after this change three possible labels could be found:
- "for application": when the executor is blacklisted for the application (see the configuration spark.blacklist.application.maxFailedTasksPerExecutor for details)
- "for stage": when the executor is **only** blacklisted for the stage
- "false" : when the executor is not blacklisted at all
## How was this patch tested?
It is tested both manually and with unit tests.
#### Unit tests
- HistoryServerSuite
- TaskSetBlacklistSuite
- AppStatusListenerSuite
#### Manual test for executor blacklisting
Running Spark as a local cluster:
```
$ bin/spark-shell --master "local-cluster[2,1,1024]" --conf "spark.blacklist.enabled=true" --conf "spark.blacklist.stage.maxFailedTasksPerExecutor=1" --conf "spark.blacklist.application.maxFailedTasksPerExecutor=10" --conf "spark.eventLog.enabled=true"
```
Executing:
``` scala
import org.apache.spark.SparkEnv
sc.parallelize(1 to 10, 10).map { x =>
if (SparkEnv.get.executorId == "0") throw new RuntimeException("Bad executor")
else (x % 3, x)
}.reduceByKey((a, b) => a + b).collect()
```
To see result check the "Aggregated Metrics by Executor" section at the bottom of picture:

#### Manual test for node blacklisting
Running Spark as on a cluster:
``` bash
./bin/spark-shell --master yarn --deploy-mode client --executor-memory=2G --num-executors=8 --conf "spark.blacklist.enabled=true" --conf "spark.blacklist.stage.maxFailedTasksPerExecutor=1" --conf "spark.blacklist.stage.maxFailedExecutorsPerNode=1" --conf "spark.blacklist.application.maxFailedTasksPerExecutor=10" --conf "spark.eventLog.enabled=true"
```
And the job was:
``` scala
import org.apache.spark.SparkEnv
sc.parallelize(1 to 10000, 10).map { x =>
if (SparkEnv.get.executorId.toInt >= 4) throw new RuntimeException("Bad executor")
else (x % 3, x)
}.reduceByKey((a, b) => a + b).collect()
```
The result is:

Here you can see apiros3.gce.test.com was node blacklisted for the stage because of failures on executor 4 and 5. As expected executor 3 is also blacklisted even it has no failures itself but sharing the node with 4 and 5.
Author: “attilapiros” <piros.attila.zsolt@gmail.com>
Author: Attila Zsolt Piros <2017933+attilapiros@users.noreply.github.com>
Closes #20203 from attilapiros/SPARK-22577.
|
||
|
|
bdebb8e48e |
[SPARK-20664][SPARK-23103][CORE] Follow-up: remove workaround for .
Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20353 from vanzin/SPARK-20664. |
||
|
|
96cb60bc33 |
[SPARK-22465][FOLLOWUP] Update the number of partitions of default partitioner when defaultParallelism is set
## What changes were proposed in this pull request? #20002 purposed a way to safe check the default partitioner, however, if `spark.default.parallelism` is set, the defaultParallelism still could be smaller than the proper number of partitions for upstreams RDDs. This PR tries to extend the approach to address the condition when `spark.default.parallelism` is set. The requirements where the PR helps with are : - Max partitioner is not eligible since it is atleast an order smaller, and - User has explicitly set 'spark.default.parallelism', and - Value of 'spark.default.parallelism' is lower than max partitioner - Since max partitioner was discarded due to being at least an order smaller, default parallelism is worse - even though user specified. Under the rest cases, the changes should be no-op. ## How was this patch tested? Add corresponding test cases in `PairRDDFunctionsSuite` and `PartitioningSuite`. Author: Xingbo Jiang <xingbo.jiang@databricks.com> Closes #20091 from jiangxb1987/partitioner. |
||
|
|
b2ce17b4c9 |
[SPARK-22274][PYTHON][SQL] User-defined aggregation functions with pandas udf (full shuffle)
## What changes were proposed in this pull request? Add support for using pandas UDFs with groupby().agg(). This PR introduces a new type of pandas UDF - group aggregate pandas UDF. This type of UDF defines a transformation of multiple pandas Series -> a scalar value. Group aggregate pandas UDFs can be used with groupby().agg(). Note group aggregate pandas UDF doesn't support partial aggregation, i.e., a full shuffle is required. This PR doesn't support group aggregate pandas UDFs that return ArrayType, StructType or MapType. Support for these types is left for future PR. ## How was this patch tested? GroupbyAggPandasUDFTests Author: Li Jin <ice.xelloss@gmail.com> Closes #19872 from icexelloss/SPARK-22274-groupby-agg. |
||
|
|
76b8b840dd |
[MINOR] Typo fixes
## What changes were proposed in this pull request? Typo fixes ## How was this patch tested? Local build / Doc-only changes Author: Jacek Laskowski <jacek@japila.pl> Closes #20344 from jaceklaskowski/typo-fixes. |
||
|
|
446948af1d |
[SPARK-23121][CORE] Fix for ui becoming unaccessible for long running streaming apps
## What changes were proposed in this pull request? The allJobs and the job pages attempt to use stage attempt and DAG visualization from the store, but for long running jobs they are not guaranteed to be retained, leading to exceptions when these pages are rendered. To fix it `store.lastStageAttempt(stageId)` and `store.operationGraphForJob(jobId)` are wrapped in `store.asOption` and default values are used if the info is missing. ## How was this patch tested? Manual testing of the UI, also using the test command reported in SPARK-23121: ./bin/spark-submit --class org.apache.spark.examples.streaming.HdfsWordCount ./examples/jars/spark-examples_2.11-2.4.0-SNAPSHOT.jar /spark Closes #20287 Author: Sandor Murakozi <smurakozi@gmail.com> Closes #20330 from smurakozi/SPARK-23121. |
||
|
|
4327ccf289 |
[SPARK-11630][CORE] ClosureCleaner moved from warning to debug
## What changes were proposed in this pull request? ClosureCleaner moved from warning to debug ## How was this patch tested? Existing tests Author: Rekha Joshi <rekhajoshm@gmail.com> Author: rjoshi2 <rekhajoshm@gmail.com> Closes #20337 from rekhajoshm/SPARK-11630-1. |
||
|
|
ec22897615 |
[SPARK-23020][CORE] Fix races in launcher code, test.
The race in the code is because the handle might update its state to the wrong state if the connection handling thread is still processing incoming data; so the handle needs to wait for the connection to finish up before checking the final state. The race in the test is because when waiting for a handle to reach a final state, the waitFor() method needs to wait until all handle state is updated (which also includes waiting for the connection thread above to finish). Otherwise, waitFor() may return too early, which would cause a bunch of different races (like the listener not being yet notified of the state change, or being in the middle of being notified, or the handle not being properly disposed and causing postChecks() to assert). On top of that I found, by code inspection, a couple of potential races that could make a handle end up in the wrong state when being killed. The original version of this fix introduced the flipped version of the first race described above; the connection closing might override the handle state before the handle might have a chance to do cleanup. The fix there is to only dispose of the handle from the connection when there is an error, and let the handle dispose itself in the normal case. The fix also caused a bug in YarnClusterSuite to be surfaced; the code was checking for a file in the classpath that was not expected to be there in client mode. Because of the above issues, the error was not propagating correctly and the (buggy) test was incorrectly passing. Tested by running the existing unit tests a lot (and not seeing the errors I was seeing before). Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20297 from vanzin/SPARK-23020. |
||
|
|
11daeb8332 |
[SPARK-22976][CORE] Cluster mode driver dir removed while running
## What changes were proposed in this pull request? The clean up logic on the worker perviously determined the liveness of a particular applicaiton based on whether or not it had running executors. This would fail in the case that a directory was made for a driver running in cluster mode if that driver had no running executors on the same machine. To preserve driver directories we consider both executors and running drivers when checking directory liveness. ## How was this patch tested? Manually started up two node cluster with a single core on each node. Turned on worker directory cleanup and set the interval to 1 second and liveness to one second. Without the patch the driver directory is removed immediately after the app is launched. With the patch it is not ### Without Patch ``` INFO 2018-01-05 23:48:24,693 Logging.scala:54 - Asked to launch driver driver-20180105234824-0000 INFO 2018-01-05 23:48:25,293 Logging.scala:54 - Changing view acls to: cassandra INFO 2018-01-05 23:48:25,293 Logging.scala:54 - Changing modify acls to: cassandra INFO 2018-01-05 23:48:25,294 Logging.scala:54 - Changing view acls groups to: INFO 2018-01-05 23:48:25,294 Logging.scala:54 - Changing modify acls groups to: INFO 2018-01-05 23:48:25,294 Logging.scala:54 - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(cassandra); groups with view permissions: Set(); users with modify permissions: Set(cassandra); groups with modify permissions: Set() INFO 2018-01-05 23:48:25,330 Logging.scala:54 - Copying user jar file:/home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180105234824-0000/writeRead-0.1.jar INFO 2018-01-05 23:48:25,332 Logging.scala:54 - Copying /home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180105234824-0000/writeRead-0.1.jar INFO 2018-01-05 23:48:25,361 Logging.scala:54 - Launch Command: "/usr/lib/jvm/jdk1.8.0_40//bin/java" .... **** INFO 2018-01-05 23:48:56,577 Logging.scala:54 - Removing directory: /var/lib/spark/worker/driver-20180105234824-0000 ### << Cleaned up **** -- One minute passes while app runs (app has 1 minute sleep built in) -- WARN 2018-01-05 23:49:58,080 ShuffleSecretManager.java:73 - Attempted to unregister application app-20180105234831-0000 when it is not registered INFO 2018-01-05 23:49:58,081 ExternalShuffleBlockResolver.java:163 - Application app-20180105234831-0000 removed, cleanupLocalDirs = false INFO 2018-01-05 23:49:58,081 ExternalShuffleBlockResolver.java:163 - Application app-20180105234831-0000 removed, cleanupLocalDirs = false INFO 2018-01-05 23:49:58,082 ExternalShuffleBlockResolver.java:163 - Application app-20180105234831-0000 removed, cleanupLocalDirs = true INFO 2018-01-05 23:50:00,999 Logging.scala:54 - Driver driver-20180105234824-0000 exited successfully ``` With Patch ``` INFO 2018-01-08 23:19:54,603 Logging.scala:54 - Asked to launch driver driver-20180108231954-0002 INFO 2018-01-08 23:19:54,975 Logging.scala:54 - Changing view acls to: automaton INFO 2018-01-08 23:19:54,976 Logging.scala:54 - Changing modify acls to: automaton INFO 2018-01-08 23:19:54,976 Logging.scala:54 - Changing view acls groups to: INFO 2018-01-08 23:19:54,976 Logging.scala:54 - Changing modify acls groups to: INFO 2018-01-08 23:19:54,976 Logging.scala:54 - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(automaton); groups with view permissions: Set(); users with modify permissions: Set(automaton); groups with modify permissions: Set() INFO 2018-01-08 23:19:55,029 Logging.scala:54 - Copying user jar file:/home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180108231954-0002/writeRead-0.1.jar INFO 2018-01-08 23:19:55,031 Logging.scala:54 - Copying /home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180108231954-0002/writeRead-0.1.jar INFO 2018-01-08 23:19:55,038 Logging.scala:54 - Launch Command: ...... INFO 2018-01-08 23:21:28,674 ShuffleSecretManager.java:69 - Unregistered shuffle secret for application app-20180108232000-0000 INFO 2018-01-08 23:21:28,675 ExternalShuffleBlockResolver.java:163 - Application app-20180108232000-0000 removed, cleanupLocalDirs = false INFO 2018-01-08 23:21:28,675 ExternalShuffleBlockResolver.java:163 - Application app-20180108232000-0000 removed, cleanupLocalDirs = false INFO 2018-01-08 23:21:28,681 ExternalShuffleBlockResolver.java:163 - Application app-20180108232000-0000 removed, cleanupLocalDirs = true INFO 2018-01-08 23:21:31,703 Logging.scala:54 - Driver driver-20180108231954-0002 exited successfully ***** INFO 2018-01-08 23:21:32,346 Logging.scala:54 - Removing directory: /var/lib/spark/worker/driver-20180108231954-0002 ### < Happening AFTER the Run completes rather than during it ***** ``` Author: Russell Spitzer <Russell.Spitzer@gmail.com> Closes #20298 from RussellSpitzer/SPARK-22976-master. |
||
|
|
f6da41b015 |
[SPARK-23135][UI] Fix rendering of accumulators in the stage page.
This follows the behavior of 2.2: only named accumulators with a value are rendered. Screenshot:  Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20299 from vanzin/SPARK-23135. |
||
|
|
aa3a1276f9 |
[SPARK-23103][CORE] Ensure correct sort order for negative values in LevelDB.
The code was sorting "0" as "less than" negative values, which is a little wrong. Fix is simple, most of the changes are the added test and related cleanup. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20284 from vanzin/SPARK-23103. |
||
|
|
fed2139f05 |
[SPARK-20664][CORE] Delete stale application data from SHS.
Detect the deletion of event log files from storage, and remove data about the related application attempt in the SHS. Also contains code to fix SPARK-21571 based on code by ericvandenbergfb. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20138 from vanzin/SPARK-20664. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}