## What changes were proposed in this pull request?
This PR fixes the migration note for SPARK-23291 since it's going to backport to 2.3.1. See the discussion in https://issues.apache.org/jira/browse/SPARK-23291
## How was this patch tested?
N/A
Author: hyukjinkwon <gurwls223@apache.org>
Closes#21249 from HyukjinKwon/SPARK-23291.
## What changes were proposed in this pull request?
`from_utc_timestamp` assumes its input is in UTC timezone and shifts it to the specified timezone. When the timestamp contains timezone(e.g. `2018-03-13T06:18:23+00:00`), Spark breaks the semantic and respect the timezone in the string. This is not what user expects and the result is different from Hive/Impala. `to_utc_timestamp` has the same problem.
More details please refer to the JIRA ticket.
This PR fixes this by returning null if the input timestamp contains timezone.
## How was this patch tested?
new tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#21169 from cloud-fan/from_utc_timezone.
## What changes were proposed in this pull request?
Added support to specify the 'spark.executor.extraJavaOptions' value in terms of the `{{APP_ID}}` and/or `{{EXECUTOR_ID}}`, `{{APP_ID}}` will be replaced by Application Id and `{{EXECUTOR_ID}}` will be replaced by Executor Id while starting the executor.
## How was this patch tested?
I have verified this by checking the executor process command and gc logs. I verified the same in different deployment modes(Standalone, YARN, Mesos) client and cluster modes.
Author: Devaraj K <devaraj@apache.org>
Closes#21088 from devaraj-kavali/SPARK-24003.
## What changes were proposed in this pull request?
By default, the dynamic allocation will request enough executors to maximize the
parallelism according to the number of tasks to process. While this minimizes the
latency of the job, with small tasks this setting can waste a lot of resources due to
executor allocation overhead, as some executor might not even do any work.
This setting allows to set a ratio that will be used to reduce the number of
target executors w.r.t. full parallelism.
The number of executors computed with this setting is still fenced by
`spark.dynamicAllocation.maxExecutors` and `spark.dynamicAllocation.minExecutors`
## How was this patch tested?
Units tests and runs on various actual workloads on a Yarn Cluster
Author: Julien Cuquemelle <j.cuquemelle@criteo.com>
Closes#19881 from jcuquemelle/AddTaskPerExecutorSlot.
## What changes were proposed in this pull request?
Currently we find the wider common type by comparing the two types from left to right, this can be a problem when you have two data types which don't have a common type but each can be promoted to StringType.
For instance, if you have a table with the schema:
[c1: date, c2: string, c3: int]
The following succeeds:
SELECT coalesce(c1, c2, c3) FROM table
While the following produces an exception:
SELECT coalesce(c1, c3, c2) FROM table
This is only a issue when the seq of dataTypes contains `StringType` and all the types can do string promotion.
close#19033
## How was this patch tested?
Add test in `TypeCoercionSuite`
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#21074 from jiangxb1987/typeCoercion.
## What changes were proposed in this pull request?
This PR proposes to fix `roxygen2` to `5.0.1` in `docs/README.md` for SparkR documentation generation.
If I use higher version and creates the doc, it shows the diff below. Not a big deal but it bothered me.
```diff
diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION
index 855eb5bf77f..159fca61e06 100644
--- a/R/pkg/DESCRIPTION
+++ b/R/pkg/DESCRIPTION
-57,6 +57,6 Collate:
'types.R'
'utils.R'
'window.R'
-RoxygenNote: 5.0.1
+RoxygenNote: 6.0.1
VignetteBuilder: knitr
NeedsCompilation: no
```
## How was this patch tested?
Manually tested. I met this every time I set the new environment for Spark dev but I have kept forgetting to fix it.
Author: hyukjinkwon <gurwls223@apache.org>
Closes#21020 from HyukjinKwon/minor-r-doc.
## What changes were proposed in this pull request?
Easy fix in the documentation.
## How was this patch tested?
N/A
Closes#20948
Author: Daniel Sakuma <dsakuma@gmail.com>
Closes#20928 from dsakuma/fix_typo_configuration_docs.
## What changes were proposed in this pull request?
This PR is to finish https://github.com/apache/spark/pull/17272
This JIRA is a follow up work after SPARK-19583
As we discussed in that PR
The following DDL for a managed table with an existed default location should throw an exception:
CREATE TABLE ... (PARTITIONED BY ...) AS SELECT ...
CREATE TABLE ... (PARTITIONED BY ...)
Currently there are some situations which are not consist with above logic:
CREATE TABLE ... (PARTITIONED BY ...) succeed with an existed default location
situation: for both hive/datasource(with HiveExternalCatalog/InMemoryCatalog)
CREATE TABLE ... (PARTITIONED BY ...) AS SELECT ...
situation: hive table succeed with an existed default location
This PR is going to make above two situations consist with the logic that it should throw an exception
with an existed default location.
## How was this patch tested?
unit test added
Author: Gengliang Wang <gengliang.wang@databricks.com>
Closes#20886 from gengliangwang/pr-17272.
## What changes were proposed in this pull request?
Easy fix in the markdown.
## How was this patch tested?
jekyII build test manually.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: lemonjing <932191671@qq.com>
Closes#20897 from Lemonjing/master.
## What changes were proposed in this pull request?
As mentioned in SPARK-23285, this PR introduces a new configuration property `spark.kubernetes.executor.cores` for specifying the physical CPU cores requested for each executor pod. This is to avoid changing the semantics of `spark.executor.cores` and `spark.task.cpus` and their role in task scheduling, task parallelism, dynamic resource allocation, etc. The new configuration property only determines the physical CPU cores available to an executor. An executor can still run multiple tasks simultaneously by using appropriate values for `spark.executor.cores` and `spark.task.cpus`.
## How was this patch tested?
Unit tests.
felixcheung srowen jiangxb1987 jerryshao mccheah foxish
Author: Yinan Li <ynli@google.com>
Author: Yinan Li <liyinan926@gmail.com>
Closes#20553 from liyinan926/master.
This change basically rewrites the security documentation so that it's
up to date with new features, more correct, and more complete.
Because security is such an important feature, I chose to move all the
relevant configuration documentation to the security page, instead of
having them peppered all over the place in the configuration page. This
allows an almost one-stop shop for security configuration in Spark. The
only exceptions are some YARN-specific minor features which I left in
the YARN page.
I also re-organized the page's topics, since they didn't make a lot of
sense. You had kerberos features described inside paragraphs talking
about UI access control, and other oddities. It should be easier now
to find information about specific Spark security features. I also
enabled TOCs for both the Security and YARN pages, since that makes it
easier to see what is covered.
I removed most of the comments from the SecurityManager javadoc since
they just replicated information in the security doc, with different
levels of out-of-dateness.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20742 from vanzin/SPARK-23572.
## What changes were proposed in this pull request?
This PR fixes an incorrect comparison in SQL between timestamp and date. This is because both of them are casted to `string` and then are compared lexicographically. This implementation shows `false` regarding this query `spark.sql("select cast('2017-03-01 00:00:00' as timestamp) between cast('2017-02-28' as date) and cast('2017-03-01' as date)").show`.
This PR shows `true` for this query by casting `date("2017-03-01")` to `timestamp("2017-03-01 00:00:00")`.
(Please fill in changes proposed in this fix)
## How was this patch tested?
Added new UTs to `TypeCoercionSuite`.
Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Closes#20774 from kiszk/SPARK-23549.
## What changes were proposed in this pull request?
Currently we allow writing data frames with empty schema into a file based datasource for certain file formats such as JSON, ORC etc. For formats such as Parquet and Text, we raise error at different times of execution. For text format, we return error from the driver early on in processing where as for format such as parquet, the error is raised from executor.
**Example**
spark.emptyDataFrame.write.format("parquet").mode("overwrite").save(path)
**Results in**
``` SQL
org.apache.parquet.schema.InvalidSchemaException: Cannot write a schema with an empty group: message spark_schema {
}
at org.apache.parquet.schema.TypeUtil$1.visit(TypeUtil.java:27)
at org.apache.parquet.schema.TypeUtil$1.visit(TypeUtil.java:37)
at org.apache.parquet.schema.MessageType.accept(MessageType.java:58)
at org.apache.parquet.schema.TypeUtil.checkValidWriteSchema(TypeUtil.java:23)
at org.apache.parquet.hadoop.ParquetFileWriter.<init>(ParquetFileWriter.java:225)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:342)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:302)
at org.apache.spark.sql.execution.datasources.parquet.ParquetOutputWriter.<init>(ParquetOutputWriter.scala:37)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$$anon$1.newInstance(ParquetFileFormat.scala:151)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$SingleDirectoryWriteTask.newOutputWriter(FileFormatWriter.scala:376)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$SingleDirectoryWriteTask.execute(FileFormatWriter.scala:387)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:278)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:276)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1411)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:281)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:206)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:205)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.
```
In this PR, we unify the error processing and raise error on attempt to write empty schema based dataframes into file based datasource (orc, parquet, text , csv, json etc) early on in the processing.
## How was this patch tested?
Unit tests added in FileBasedDatasourceSuite.
Author: Dilip Biswal <dbiswal@us.ibm.com>
Closes#20579 from dilipbiswal/spark-23372.
## What changes were proposed in this pull request?
To drop `exprId`s for `Alias` in user-facing info., this pr added an entry for `Alias` in `NonSQLExpression.sql`
## How was this patch tested?
Added tests in `UDFSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#20827 from maropu/SPARK-23666.
## What changes were proposed in this pull request?
Removal of the init-container for downloading remote dependencies. Built off of the work done by vanzin in an attempt to refactor driver/executor configuration elaborated in [this](https://issues.apache.org/jira/browse/SPARK-22839) ticket.
## How was this patch tested?
This patch was tested with unit and integration tests.
Author: Ilan Filonenko <if56@cornell.edu>
Closes#20669 from ifilonenko/remove-init-container.
## What changes were proposed in this pull request?
In the PR https://github.com/apache/spark/pull/20671, I forgot to update the doc about this new support.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20789 from gatorsmile/docUpdate.
## What changes were proposed in this pull request?
Below are the two cases.
``` SQL
case 1
scala> List.empty[String].toDF().rdd.partitions.length
res18: Int = 1
```
When we write the above data frame as parquet, we create a parquet file containing
just the schema of the data frame.
Case 2
``` SQL
scala> val anySchema = StructType(StructField("anyName", StringType, nullable = false) :: Nil)
anySchema: org.apache.spark.sql.types.StructType = StructType(StructField(anyName,StringType,false))
scala> spark.read.schema(anySchema).csv("/tmp/empty_folder").rdd.partitions.length
res22: Int = 0
```
For the 2nd case, since number of partitions = 0, we don't call the write task (the task has logic to create the empty metadata only parquet file)
The fix is to create a dummy single partition RDD and set up the write task based on it to ensure
the metadata-only file.
## How was this patch tested?
A new test is added to DataframeReaderWriterSuite.
Author: Dilip Biswal <dbiswal@us.ibm.com>
Closes#20525 from dilipbiswal/spark-23271.
## What changes were proposed in this pull request?
This PR adds a configuration to control the fallback of Arrow optimization for `toPandas` and `createDataFrame` with Pandas DataFrame.
## How was this patch tested?
Manually tested and unit tests added.
You can test this by:
**`createDataFrame`**
```python
spark.conf.set("spark.sql.execution.arrow.enabled", False)
pdf = spark.createDataFrame([[{'a': 1}]]).toPandas()
spark.conf.set("spark.sql.execution.arrow.enabled", True)
spark.conf.set("spark.sql.execution.arrow.fallback.enabled", True)
spark.createDataFrame(pdf, "a: map<string, int>")
```
```python
spark.conf.set("spark.sql.execution.arrow.enabled", False)
pdf = spark.createDataFrame([[{'a': 1}]]).toPandas()
spark.conf.set("spark.sql.execution.arrow.enabled", True)
spark.conf.set("spark.sql.execution.arrow.fallback.enabled", False)
spark.createDataFrame(pdf, "a: map<string, int>")
```
**`toPandas`**
```python
spark.conf.set("spark.sql.execution.arrow.enabled", True)
spark.conf.set("spark.sql.execution.arrow.fallback.enabled", True)
spark.createDataFrame([[{'a': 1}]]).toPandas()
```
```python
spark.conf.set("spark.sql.execution.arrow.enabled", True)
spark.conf.set("spark.sql.execution.arrow.fallback.enabled", False)
spark.createDataFrame([[{'a': 1}]]).toPandas()
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20678 from HyukjinKwon/SPARK-23380-conf.
## What changes were proposed in this pull request?
Seems R's substr API treats Scala substr API as zero based and so subtracts the given starting position by 1.
Because Scala's substr API also accepts zero-based starting position (treated as the first element), so the current R's substr test results are correct as they all use 1 as starting positions.
## How was this patch tested?
Modified tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20464 from viirya/SPARK-23291.
These options were used to configure the built-in JRE SSL libraries
when downloading files from HTTPS servers. But because they were also
used to set up the now (long) removed internal HTTPS file server,
their default configuration chose convenience over security by having
overly lenient settings.
This change removes the configuration options that affect the JRE SSL
libraries. The JRE trust store can still be configured via system
properties (or globally in the JRE security config). The only lost
functionality is not being able to disable the default hostname
verifier when using spark-submit, which should be fine since Spark
itself is not using https for any internal functionality anymore.
I also removed the HTTP-related code from the REPL class loader, since
we haven't had a HTTP server for REPL-generated classes for a while.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20723 from vanzin/SPARK-23538.
## What changes were proposed in this pull request?
If spark is run with "spark.authenticate=true", then it will fail to start in local mode.
This PR generates secret in local mode when authentication on.
## How was this patch tested?
Modified existing unit test.
Manually started spark-shell.
Author: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Closes#20652 from gaborgsomogyi/SPARK-23476.
## What changes were proposed in this pull request?
- Added clear information about triggers
- Made the semantics guarantees of watermarks more clear for streaming aggregations and stream-stream joins.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20631 from tdas/SPARK-23454.
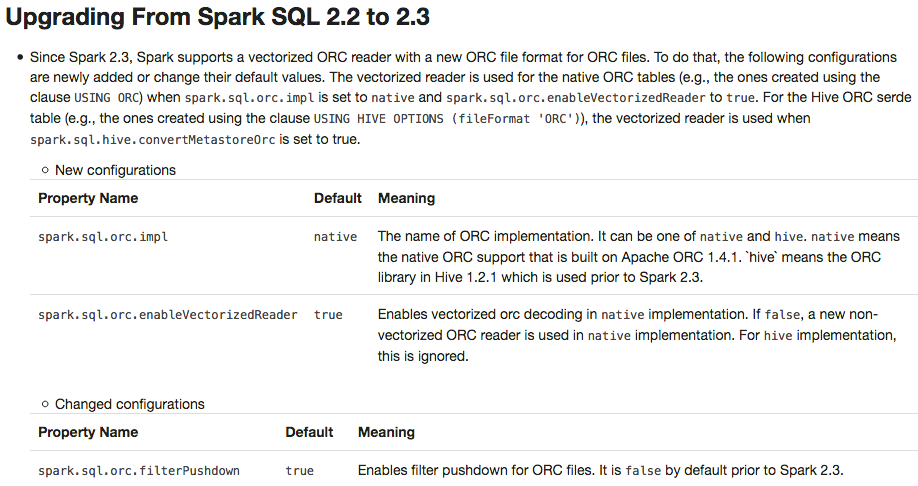
## What changes were proposed in this pull request?
Apache Spark 2.3 introduced `native` ORC supports with vectorization and many fixes. However, it's shipped as a not-default option. This PR enables `native` ORC implementation and predicate-pushdown by default for Apache Spark 2.4. We will improve and stabilize ORC data source before Apache Spark 2.4. And, eventually, Apache Spark will drop old Hive-based ORC code.
## How was this patch tested?
Pass the Jenkins with existing tests.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20634 from dongjoon-hyun/SPARK-23456.
## What changes were proposed in this pull request?
To prevent any regressions, this PR changes ORC implementation to `hive` by default like Spark 2.2.X.
Users can enable `native` ORC. Also, ORC PPD is also restored to `false` like Spark 2.2.X.

## How was this patch tested?
Pass all test cases.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20610 from dongjoon-hyun/SPARK-ORC-DISABLE.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/19579 introduces a behavior change. We need to document it in the migration guide.
## How was this patch tested?
Also update the HiveExternalCatalogVersionsSuite to verify it.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20606 from gatorsmile/addMigrationGuide.
## What changes were proposed in this pull request?
Added documentation about what MLlib guarantees in terms of loading ML models and Pipelines from old Spark versions. Discussed & confirmed on linked JIRA.
Author: Joseph K. Bradley <joseph@databricks.com>
Closes#20592 from jkbradley/SPARK-23154-backwards-compat-doc.
## What changes were proposed in this pull request?
This PR targets to explicitly specify supported types in Pandas UDFs.
The main change here is to add a deduplicated and explicit type checking in `returnType` ahead with documenting this; however, it happened to fix multiple things.
1. Currently, we don't support `BinaryType` in Pandas UDFs, for example, see:
```python
from pyspark.sql.functions import pandas_udf
pudf = pandas_udf(lambda x: x, "binary")
df = spark.createDataFrame([[bytearray(1)]])
df.select(pudf("_1")).show()
```
```
...
TypeError: Unsupported type in conversion to Arrow: BinaryType
```
We can document this behaviour for its guide.
2. Also, the grouped aggregate Pandas UDF fails fast on `ArrayType` but seems we can support this case.
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
foo = pandas_udf(lambda v: v.mean(), 'array<double>', PandasUDFType.GROUPED_AGG)
df = spark.range(100).selectExpr("id", "array(id) as value")
df.groupBy("id").agg(foo("value")).show()
```
```
...
NotImplementedError: ArrayType, StructType and MapType are not supported with PandasUDFType.GROUPED_AGG
```
3. Since we can check the return type ahead, we can fail fast before actual execution.
```python
# we can fail fast at this stage because we know the schema ahead
pandas_udf(lambda x: x, BinaryType())
```
## How was this patch tested?
Manually tested and unit tests for `BinaryType` and `ArrayType(...)` were added.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20531 from HyukjinKwon/pudf-cleanup.
This commit modifies the Mesos submission client to allow the principal
and secret to be provided indirectly via files. The path to these files
can be specified either via Spark configuration or via environment
variable.
Assuming these files are appropriately protected by FS/OS permissions
this means we don't ever leak the actual values in process info like ps
Environment variable specification is useful because it allows you to
interpolate the location of this file when using per-user Mesos
credentials.
For some background as to why we have taken this approach I will briefly describe our set up. On our systems we provide each authorised user account with their own Mesos credentials to provide certain security and audit guarantees to our customers. These credentials are managed by a central Secret management service. In our `spark-env.sh` we determine the appropriate secret and principal files to use depending on the user who is invoking Spark hence the need to inject these via environment variables as well as by configuration properties. So we set these environment variables appropriately and our Spark read in the contents of those files to authenticate itself with Mesos.
This is functionality we have been using it in production across multiple customer sites for some time. This has been in the field for around 18 months with no reported issues. These changes have been sufficient to meet our customer security and audit requirements.
We have been building and deploying custom builds of Apache Spark with various minor tweaks like this which we are now looking to contribute back into the community in order that we can rely upon stock Apache Spark builds and stop maintaining our own internal fork.
Author: Rob Vesse <rvesse@dotnetrdf.org>
Closes#20167 from rvesse/SPARK-16501.
## What changes were proposed in this pull request?
This PR proposes to disallow default value None when 'to_replace' is not a dictionary.
It seems weird we set the default value of `value` to `None` and we ended up allowing the case as below:
```python
>>> df.show()
```
```
+----+------+-----+
| age|height| name|
+----+------+-----+
| 10| 80|Alice|
...
```
```python
>>> df.na.replace('Alice').show()
```
```
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80|null|
...
```
**After**
This PR targets to disallow the case above:
```python
>>> df.na.replace('Alice').show()
```
```
...
TypeError: value is required when to_replace is not a dictionary.
```
while we still allow when `to_replace` is a dictionary:
```python
>>> df.na.replace({'Alice': None}).show()
```
```
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80|null|
...
```
## How was this patch tested?
Manually tested, tests were added in `python/pyspark/sql/tests.py` and doctests were fixed.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20499 from HyukjinKwon/SPARK-19454-followup.
## What changes were proposed in this pull request?
Further clarification of caveats in using stream-stream outer joins.
## How was this patch tested?
N/A
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20494 from tdas/SPARK-23064-2.
Add breaking changes, as well as update behavior changes, to `2.3` ML migration guide.
## How was this patch tested?
Doc only
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#20421 from MLnick/SPARK-23112-ml-guide.
## What changes were proposed in this pull request?
Rename the public APIs and names of pandas udfs.
- `PANDAS SCALAR UDF` -> `SCALAR PANDAS UDF`
- `PANDAS GROUP MAP UDF` -> `GROUPED MAP PANDAS UDF`
- `PANDAS GROUP AGG UDF` -> `GROUPED AGG PANDAS UDF`
## How was this patch tested?
The existing tests
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20428 from gatorsmile/renamePandasUDFs.
## What changes were proposed in this pull request?
User guide and examples are updated to reflect multiclass logistic regression summary which was added in [SPARK-17139](https://issues.apache.org/jira/browse/SPARK-17139).
I did not make a separate summary example, but added the summary code to the multiclass example that already existed. I don't see the need for a separate example for the summary.
## How was this patch tested?
Docs and examples only. Ran all examples locally using spark-submit.
Author: sethah <shendrickson@cloudera.com>
Closes#20332 from sethah/multiclass_summary_example.
## What changes were proposed in this pull request?
Adding user facing documentation for working with Arrow in Spark
Author: Bryan Cutler <cutlerb@gmail.com>
Author: Li Jin <ice.xelloss@gmail.com>
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19575 from BryanCutler/arrow-user-docs-SPARK-2221.
Update ML user guide with highlights and migration guide for `2.3`.
## How was this patch tested?
Doc only.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#20363 from MLnick/SPARK-23112-ml-guide.
## What changes were proposed in this pull request?
Added documentation for new transformer.
Author: Bago Amirbekian <bago@databricks.com>
Closes#20285 from MrBago/sizeHintDocs.
## What changes were proposed in this pull request?
The example jar file is now in ./examples/jars directory of Spark distribution.
Author: Arseniy Tashoyan <tashoyan@users.noreply.github.com>
Closes#20349 from tashoyan/patch-1.
## What changes were proposed in this pull request?
streaming programming guide changes
## How was this patch tested?
manually
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#20340 from felixcheung/rstreamdoc.
## What changes were proposed in this pull request?
Fix spelling in quick-start doc.
## How was this patch tested?
Doc only.
Author: Shashwat Anand <me@shashwat.me>
Closes#20336 from ashashwat/SPARK-23165.
## What changes were proposed in this pull request?
Docs changes:
- Adding a warning that the backend is experimental.
- Removing a defunct internal-only option from documentation
- Clarifying that node selectors can be used right away, and other minor cosmetic changes
## How was this patch tested?
Docs only change
Author: foxish <ramanathana@google.com>
Closes#20314 from foxish/ambiguous-docs.
## What changes were proposed in this pull request?
We have `OneHotEncoderEstimator` now and `OneHotEncoder` will be deprecated since 2.3.0. We should add `OneHotEncoderEstimator` into mllib document.
We also need to provide corresponding examples for `OneHotEncoderEstimator` which are used in the document too.
## How was this patch tested?
Existing tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20257 from viirya/SPARK-23048.
Update user guide entry for `FeatureHasher` to match the Scala / Python doc, to describe the `categoricalCols` parameter.
## How was this patch tested?
Doc only
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#20293 from MLnick/SPARK-23127-catCol-userguide.
## What changes were proposed in this pull request?
In latest structured-streaming-kafka-integration document, Java code example for Kafka integration is using `DataFrame<Row>`, shouldn't it be changed to `DataSet<Row>`?
## How was this patch tested?
manual test has been performed to test the updated example Java code in Spark 2.2.1 with Kafka 1.0
Author: brandonJY <brandonJY@users.noreply.github.com>
Closes#20312 from brandonJY/patch-2.
## What changes were proposed in this pull request?
In the Kubernetes mode, fails fast in the submission process if any submission client local dependencies are used as the use case is not supported yet.
## How was this patch tested?
Unit tests, integration tests, and manual tests.
vanzin foxish
Author: Yinan Li <liyinan926@gmail.com>
Closes#20320 from liyinan926/master.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}