## What changes were proposed in this pull request?
Currently definitions of config entries in `core` module are in several files separately. We should move them into `internal/config` to be easy to manage.
## How was this patch tested?
Existing tests.
Closes#22928 from ueshin/issues/SPARK-25926/single_config_file.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
This avoids having two classes to deal with tokens; now the above
class is a one-stop shop for dealing with delegation tokens. The
YARN backend extends that class instead of doing composition like
before, resulting in a bit less code there too.
The renewer functionality is basically the same code that used to
be in YARN's AMCredentialRenewer. That is also the reason why the
public API of HadoopDelegationTokenManager is a little bit odd;
the YARN AM has some odd requirements for how this all should be
initialized, and the weirdness is needed currently to support that.
Tested:
- YARN with stress app for DT renewal
- Mesos and K8S with basic kerberos tests (both tgt and keytab)
Closes#22624 from vanzin/SPARK-23781.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
This patch is to bump the master branch version to 3.0.0-SNAPSHOT.
## How was this patch tested?
N/A
Closes#22606 from gatorsmile/bump3.0.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR adds a rule to force `.toLowerCase(Locale.ROOT)` or `toUpperCase(Locale.ROOT)`.
It produces an error as below:
```
[error] Are you sure that you want to use toUpperCase or toLowerCase without the root locale? In most cases, you
[error] should use toUpperCase(Locale.ROOT) or toLowerCase(Locale.ROOT) instead.
[error] If you must use toUpperCase or toLowerCase without the root locale, wrap the code block with
[error] // scalastyle:off caselocale
[error] .toUpperCase
[error] .toLowerCase
[error] // scalastyle:on caselocale
```
This PR excludes the cases above for SQL code path for external calls like table name, column name and etc.
For test suites, or when it's clear there's no locale problem like Turkish locale problem, it uses `Locale.ROOT`.
One minor problem is, `UTF8String` has both methods, `toLowerCase` and `toUpperCase`, and the new rule detects them as well. They are ignored.
## How was this patch tested?
Manually tested, and Jenkins tests.
Closes#22581 from HyukjinKwon/SPARK-25565.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Heartbeat shouldn't include accumulators for zero metrics.
Heartbeats sent from executors to the driver every 10 seconds contain metrics and are generally on the order of a few KBs. However, for large jobs with lots of tasks, heartbeats can be on the order of tens of MBs, causing tasks to die with heartbeat failures. We can mitigate this by not sending zero metrics to the driver.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22473 from mukulmurthy/25449-heartbeat.
Authored-by: Mukul Murthy <mukul.murthy@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
In the dev list, we can still discuss whether the next version is 2.5.0 or 3.0.0. Let us first bump the master branch version to `2.5.0-SNAPSHOT`.
## How was this patch tested?
N/A
Closes#22426 from gatorsmile/bumpVersionMaster.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Correct some comparisons between unrelated types to what they seem to… have been trying to do
## How was this patch tested?
Existing tests.
Closes#22384 from srowen/SPARK-25398.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The configuration parameter "spark.shuffle.service.enabled" has defined in `package.scala`, and it is also used in many place, so we can replace it with `SHUFFLE_SERVICE_ENABLED`.
and unified this configuration parameter "spark.shuffle.service.port" together.
## How was this patch tested?
N/A
Closes#22306 from 10110346/unifiedserviceenable.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
We shall check whether the barrier stage requires more slots (to be able to launch all tasks in the barrier stage together) than the total number of active slots currently, and fail fast if trying to submit a barrier stage that requires more slots than current total number.
This PR proposes to add a new method `getNumSlots()` to try to get the total number of currently active slots in `SchedulerBackend`, support of this new method has been added to all the first-class scheduler backends except `MesosFineGrainedSchedulerBackend`.
## How was this patch tested?
Added new test cases in `BarrierStageOnSubmittedSuite`.
Closes#22001 from jiangxb1987/SPARK-24819.
Lead-authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Co-authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
(a) disabled rest submission server by default in standalone mode
(b) fails the standalone master if rest server enabled & authentication secret set
(c) fails the mesos cluster dispatcher if authentication secret set
(d) doc updates
(e) when submitting a standalone app, only try the rest submission first if spark.master.rest.enabled=true
otherwise you'd see a 10 second pause like
18/08/09 08:13:22 INFO RestSubmissionClient: Submitting a request to launch an application in spark://...
18/08/09 08:13:33 WARN RestSubmissionClient: Unable to connect to server spark://...
I also made sure the mesos cluster dispatcher failed with the secret enabled, though I had to do that on slightly different code as I don't have mesos native libs around.
## How was this patch tested?
I ran the tests in the mesos module & in core for org.apache.spark.deploy.*
I ran a test on a cluster with standalone master to make sure I could still start with the right configs, and would fail the right way too.
Closes#22071 from squito/rest_doc_updates.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Fixing typos is sometimes very hard. It's not so easy to visually review them. Recently, I discovered a very useful tool for it, [misspell](https://github.com/client9/misspell).
This pull request fixes minor typos detected by [misspell](https://github.com/client9/misspell) except for the false positives. If you would like me to work on other files as well, let me know.
## How was this patch tested?
### before
```
$ misspell . | grep -v '.js'
R/pkg/R/SQLContext.R:354:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:424:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:445:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:495:43: "definiton" is a misspelling of "definition"
NOTICE-binary:454:16: "containd" is a misspelling of "contained"
R/pkg/R/context.R:46:43: "definiton" is a misspelling of "definition"
R/pkg/R/context.R:74:43: "definiton" is a misspelling of "definition"
R/pkg/R/DataFrame.R:591:48: "persistance" is a misspelling of "persistence"
R/pkg/R/streaming.R:166:44: "occured" is a misspelling of "occurred"
R/pkg/inst/worker/worker.R:65:22: "ouput" is a misspelling of "output"
R/pkg/tests/fulltests/test_utils.R:106:25: "environemnt" is a misspelling of "environment"
common/kvstore/src/test/java/org/apache/spark/util/kvstore/InMemoryStoreSuite.java:38:39: "existant" is a misspelling of "existent"
common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java:83:39: "existant" is a misspelling of "existent"
common/network-common/src/main/java/org/apache/spark/network/crypto/TransportCipher.java:243:46: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:234:19: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:238:63: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:244:46: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:276:39: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/util/AbstractFileRegion.java:27:20: "transfered" is a misspelling of "transferred"
common/unsafe/src/test/scala/org/apache/spark/unsafe/types/UTF8StringPropertyCheckSuite.scala:195:15: "orgin" is a misspelling of "origin"
core/src/main/scala/org/apache/spark/api/python/PythonRDD.scala:621:39: "gauranteed" is a misspelling of "guaranteed"
core/src/main/scala/org/apache/spark/status/storeTypes.scala:113:29: "ect" is a misspelling of "etc"
core/src/main/scala/org/apache/spark/storage/DiskStore.scala:282:18: "transfered" is a misspelling of "transferred"
core/src/main/scala/org/apache/spark/util/ListenerBus.scala:64:17: "overriden" is a misspelling of "overridden"
core/src/test/scala/org/apache/spark/ShuffleSuite.scala:211:7: "substracted" is a misspelling of "subtracted"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:1922:49: "agriculteur" is a misspelling of "agriculture"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:2468:84: "truely" is a misspelling of "truly"
core/src/test/scala/org/apache/spark/storage/FlatmapIteratorSuite.scala:25:18: "persistance" is a misspelling of "persistence"
core/src/test/scala/org/apache/spark/storage/FlatmapIteratorSuite.scala:26:69: "persistance" is a misspelling of "persistence"
data/streaming/AFINN-111.txt:1219:0: "humerous" is a misspelling of "humorous"
dev/run-pip-tests:55:28: "enviroments" is a misspelling of "environments"
dev/run-pip-tests:91:37: "virutal" is a misspelling of "virtual"
dev/merge_spark_pr.py:377:72: "accross" is a misspelling of "across"
dev/merge_spark_pr.py:378:66: "accross" is a misspelling of "across"
dev/run-pip-tests:126:25: "enviroments" is a misspelling of "environments"
docs/configuration.md:1830:82: "overriden" is a misspelling of "overridden"
docs/structured-streaming-programming-guide.md:525:45: "processs" is a misspelling of "processes"
docs/structured-streaming-programming-guide.md:1165:61: "BETWEN" is a misspelling of "BETWEEN"
docs/sql-programming-guide.md:1891:810: "behaivor" is a misspelling of "behavior"
examples/src/main/python/sql/arrow.py:98:8: "substract" is a misspelling of "subtract"
examples/src/main/python/sql/arrow.py:103:27: "substract" is a misspelling of "subtract"
licenses/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/hungarian.txt:170:0: "teh" is a misspelling of "the"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/portuguese.txt:53:0: "eles" is a misspelling of "eels"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:99:20: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:539:11: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/mllib/clustering/LDAOptimizer.scala:77:36: "Teh" is a misspelling of "The"
mllib/src/main/scala/org/apache/spark/mllib/clustering/StreamingKMeans.scala:230:24: "inital" is a misspelling of "initial"
mllib/src/main/scala/org/apache/spark/mllib/stat/MultivariateOnlineSummarizer.scala:276:9: "Euclidian" is a misspelling of "Euclidean"
mllib/src/test/scala/org/apache/spark/ml/clustering/KMeansSuite.scala:237:26: "descripiton" is a misspelling of "descriptions"
python/pyspark/find_spark_home.py:30:13: "enviroment" is a misspelling of "environment"
python/pyspark/context.py:937:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:938:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:939:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:940:12: "supress" is a misspelling of "suppress"
python/pyspark/heapq3.py:6:63: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:7:2: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:263:29: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:263:39: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:270:49: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:270:59: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:275:2: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:275:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:277:29: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:277:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:713:8: "probabilty" is a misspelling of "probability"
python/pyspark/ml/clustering.py:1038:8: "Currenlty" is a misspelling of "Currently"
python/pyspark/ml/stat.py:339:23: "Euclidian" is a misspelling of "Euclidean"
python/pyspark/ml/regression.py:1378:20: "paramter" is a misspelling of "parameter"
python/pyspark/mllib/stat/_statistics.py:262:8: "probabilty" is a misspelling of "probability"
python/pyspark/rdd.py:1363:32: "paramter" is a misspelling of "parameter"
python/pyspark/streaming/tests.py:825:42: "retuns" is a misspelling of "returns"
python/pyspark/sql/tests.py:768:29: "initalization" is a misspelling of "initialization"
python/pyspark/sql/tests.py:3616:31: "initalize" is a misspelling of "initialize"
resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosSchedulerBackendUtil.scala:120:39: "arbitary" is a misspelling of "arbitrary"
resource-managers/mesos/src/test/scala/org/apache/spark/deploy/mesos/MesosClusterDispatcherArgumentsSuite.scala:26:45: "sucessfully" is a misspelling of "successfully"
resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosSchedulerUtils.scala:358:27: "constaints" is a misspelling of "constraints"
resource-managers/yarn/src/test/scala/org/apache/spark/deploy/yarn/YarnClusterSuite.scala:111:24: "senstive" is a misspelling of "sensitive"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala:1063:5: "overwirte" is a misspelling of "overwrite"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala:1348:17: "compatability" is a misspelling of "compatibility"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala:77:36: "paramter" is a misspelling of "parameter"
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:1374:22: "precendence" is a misspelling of "precedence"
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/analysis/AnalysisSuite.scala:238:27: "unnecassary" is a misspelling of "unnecessary"
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/ConditionalExpressionSuite.scala:212:17: "whn" is a misspelling of "when"
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamingSymmetricHashJoinHelper.scala:147:60: "timestmap" is a misspelling of "timestamp"
sql/core/src/test/scala/org/apache/spark/sql/TPCDSQuerySuite.scala:150:45: "precentage" is a misspelling of "percentage"
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVInferSchemaSuite.scala:135:29: "infered" is a misspelling of "inferred"
sql/hive/src/test/resources/golden/udf_instr-1-2e76f819563dbaba4beb51e3a130b922:1:52: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_instr-2-32da357fc754badd6e3898dcc8989182:1:52: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_locate-1-6e41693c9c6dceea4d7fab4c02884e4e:1:63: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_locate-2-d9b5934457931447874d6bb7c13de478:1:63: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_translate-2-f7aa38a33ca0df73b7a1e6b6da4b7fe8:9:79: "occurence" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_translate-2-f7aa38a33ca0df73b7a1e6b6da4b7fe8:13:110: "occurence" is a misspelling of "occurrence"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/annotate_stats_join.q:46:105: "distint" is a misspelling of "distinct"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/auto_sortmerge_join_11.q:29:3: "Currenly" is a misspelling of "Currently"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/avro_partitioned.q:72:15: "existant" is a misspelling of "existent"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/decimal_udf.q:25:3: "substraction" is a misspelling of "subtraction"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/groupby2_map_multi_distinct.q:16:51: "funtion" is a misspelling of "function"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/groupby_sort_8.q:15:30: "issueing" is a misspelling of "issuing"
sql/hive/src/test/scala/org/apache/spark/sql/sources/HadoopFsRelationTest.scala:669:52: "wiht" is a misspelling of "with"
sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java:474:9: "Refering" is a misspelling of "Referring"
```
### after
```
$ misspell . | grep -v '.js'
common/network-common/src/main/java/org/apache/spark/network/util/AbstractFileRegion.java:27:20: "transfered" is a misspelling of "transferred"
core/src/main/scala/org/apache/spark/status/storeTypes.scala:113:29: "ect" is a misspelling of "etc"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:1922:49: "agriculteur" is a misspelling of "agriculture"
data/streaming/AFINN-111.txt:1219:0: "humerous" is a misspelling of "humorous"
licenses/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/hungarian.txt:170:0: "teh" is a misspelling of "the"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/portuguese.txt:53:0: "eles" is a misspelling of "eels"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:99:20: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:539:11: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/mllib/clustering/LDAOptimizer.scala:77:36: "Teh" is a misspelling of "The"
mllib/src/main/scala/org/apache/spark/mllib/stat/MultivariateOnlineSummarizer.scala:276:9: "Euclidian" is a misspelling of "Euclidean"
python/pyspark/heapq3.py:6:63: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:7:2: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:263:29: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:263:39: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:270:49: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:270:59: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:275:2: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:275:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:277:29: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:277:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/ml/stat.py:339:23: "Euclidian" is a misspelling of "Euclidean"
```
Closes#22070 from seratch/fix-typo.
Authored-by: Kazuhiro Sera <seratch@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
## What changes were proposed in this pull request?
Propose new APIs and modify job/task scheduling to support barrier execution mode, which requires all tasks in a same barrier stage start at the same time, and retry all tasks in case some tasks fail in the middle. The barrier execution mode is useful for some ML/DL workloads.
The proposed API changes include:
- `RDDBarrier` that marks an RDD as barrier (Spark must launch all the tasks together for the current stage).
- `BarrierTaskContext` that support global sync of all tasks in a barrier stage, and provide extra `BarrierTaskInfo`s.
In DAGScheduler, we retry all tasks of a barrier stage in case some tasks fail in the middle, this is achieved by unregistering map outputs for a shuffleId (for ShuffleMapStage) or clear the finished partitions in an active job (for ResultStage).
## How was this patch tested?
Add `RDDBarrierSuite` to ensure we convert RDDs correctly;
Add new test cases in `DAGSchedulerSuite` to ensure we do task scheduling correctly;
Add new test cases in `SparkContextSuite` to ensure the barrier execution mode actually works (both under local mode and local cluster mode).
Add new test cases in `TaskSchedulerImplSuite` to ensure we schedule tasks for barrier taskSet together.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#21758 from jiangxb1987/barrier-execution-mode.
This PR use spark.network.timeout in place of spark.storage.blockManagerSlaveTimeoutMs when it is not configured, as configuration doc said
manual test
Author: xueyu <278006819@qq.com>
Closes#21575 from xueyumusic/slaveTimeOutConfig.
## What changes were proposed in this pull request?
This change extends YARN resource allocation handling with blacklisting functionality.
This handles cases when node is messed up or misconfigured such that a container won't launch on it. Before this change backlisting only focused on task execution but this change introduces YarnAllocatorBlacklistTracker which tracks allocation failures per host (when enabled via "spark.yarn.blacklist.executor.launch.blacklisting.enabled").
## How was this patch tested?
### With unit tests
Including a new suite: YarnAllocatorBlacklistTrackerSuite.
#### Manually
It was tested on a cluster by deleting the Spark jars on one of the node.
#### Behaviour before these changes
Starting Spark as:
```
spark2-shell --master yarn --deploy-mode client --num-executors 4 --conf spark.executor.memory=4g --conf "spark.yarn.max.executor.failures=6"
```
Log is:
```
18/04/12 06:49:36 INFO yarn.ApplicationMaster: Final app status: FAILED, exitCode: 11, (reason: Max number of executor failures (6) reached)
18/04/12 06:49:39 INFO yarn.ApplicationMaster: Unregistering ApplicationMaster with FAILED (diag message: Max number of executor failures (6) reached)
18/04/12 06:49:39 INFO impl.AMRMClientImpl: Waiting for application to be successfully unregistered.
18/04/12 06:49:39 INFO yarn.ApplicationMaster: Deleting staging directory hdfs://apiros-1.gce.test.com:8020/user/systest/.sparkStaging/application_1523459048274_0016
18/04/12 06:49:39 INFO util.ShutdownHookManager: Shutdown hook called
```
#### Behaviour after these changes
Starting Spark as:
```
spark2-shell --master yarn --deploy-mode client --num-executors 4 --conf spark.executor.memory=4g --conf "spark.yarn.max.executor.failures=6" --conf "spark.yarn.blacklist.executor.launch.blacklisting.enabled=true"
```
And the log is:
```
18/04/13 05:37:43 INFO yarn.YarnAllocator: Will request 1 executor container(s), each with 1 core(s) and 4505 MB memory (including 409 MB of overhead)
18/04/13 05:37:43 INFO yarn.YarnAllocator: Submitted 1 unlocalized container requests.
18/04/13 05:37:43 INFO yarn.YarnAllocator: Launching container container_1523459048274_0025_01_000008 on host apiros-4.gce.test.com for executor with ID 6
18/04/13 05:37:43 INFO yarn.YarnAllocator: Received 1 containers from YARN, launching executors on 1 of them.
18/04/13 05:37:43 INFO yarn.YarnAllocator: Completed container container_1523459048274_0025_01_000007 on host: apiros-4.gce.test.com (state: COMPLETE, exit status: 1)
18/04/13 05:37:43 INFO yarn.YarnAllocatorBlacklistTracker: blacklisting host as YARN allocation failed: apiros-4.gce.test.com
18/04/13 05:37:43 INFO yarn.YarnAllocatorBlacklistTracker: adding nodes to YARN application master's blacklist: List(apiros-4.gce.test.com)
18/04/13 05:37:43 WARN yarn.YarnAllocator: Container marked as failed: container_1523459048274_0025_01_000007 on host: apiros-4.gce.test.com. Exit status: 1. Diagnostics: Exception from container-launch.
Container id: container_1523459048274_0025_01_000007
Exit code: 1
Stack trace: ExitCodeException exitCode=1:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:604)
at org.apache.hadoop.util.Shell.run(Shell.java:507)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:789)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:213)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
Where the most important part is:
```
18/04/13 05:37:43 INFO yarn.YarnAllocatorBlacklistTracker: blacklisting host as YARN allocation failed: apiros-4.gce.test.com
18/04/13 05:37:43 INFO yarn.YarnAllocatorBlacklistTracker: adding nodes to YARN application master's blacklist: List(apiros-4.gce.test.com)
```
And execution was continued (no shutdown called).
### Testing the backlisting of the whole cluster
Starting Spark with YARN blacklisting enabled then removing a the Spark core jar one by one from all the cluster nodes. Then executing a simple spark job which fails checking the yarn log the expected exit status is contained:
```
18/06/15 01:07:10 INFO yarn.ApplicationMaster: Final app status: FAILED, exitCode: 11, (reason: Due to executor failures all available nodes are blacklisted)
18/06/15 01:07:13 INFO util.ShutdownHookManager: Shutdown hook called
```
Author: “attilapiros” <piros.attila.zsolt@gmail.com>
Closes#21068 from attilapiros/SPARK-16630.
`WebUI` defines `addStaticHandler` that web UIs don't use (and simply introduce duplication). Let's clean them up and remove duplications.
Local build and waiting for Jenkins
Author: Jacek Laskowski <jacek@japila.pl>
Closes#21510 from jaceklaskowski/SPARK-24490-Use-WebUI.addStaticHandler.
## What changes were proposed in this pull request?
* Adds support for local:// scheme like in k8s case for image based deployments where the jar is already in the image. Affects cluster mode and the mesos dispatcher. Covers also file:// scheme. Keeps the default case where jar resolution happens on the host.
## How was this patch tested?
Dispatcher image with the patch, use it to start DC/OS Spark service:
skonto/spark-local-disp:test
Test image with my application jar located at the root folder:
skonto/spark-local:test
Dockerfile for that image.
From mesosphere/spark:2.3.0-2.2.1-2-hadoop-2.6
COPY spark-examples_2.11-2.2.1.jar /
WORKDIR /opt/spark/dist
Tests:
The following work as expected:
* local normal example
```
dcos spark run --submit-args="--conf spark.mesos.appJar.local.resolution.mode=container --conf spark.executor.memory=1g --conf spark.mesos.executor.docker.image=skonto/spark-local:test
--conf spark.executor.cores=2 --conf spark.cores.max=8
--class org.apache.spark.examples.SparkPi local:///spark-examples_2.11-2.2.1.jar"
```
* make sure the flag does not affect other uris
```
dcos spark run --submit-args="--conf spark.mesos.appJar.local.resolution.mode=container --conf spark.executor.memory=1g --conf spark.executor.cores=2 --conf spark.cores.max=8
--class org.apache.spark.examples.SparkPi https://s3-eu-west-1.amazonaws.com/fdp-stavros-test/spark-examples_2.11-2.1.1.jar"
```
* normal example no local
```
dcos spark run --submit-args="--conf spark.executor.memory=1g --conf spark.executor.cores=2 --conf spark.cores.max=8
--class org.apache.spark.examples.SparkPi https://s3-eu-west-1.amazonaws.com/fdp-stavros-test/spark-examples_2.11-2.1.1.jar"
```
The following fails
* uses local with no setting, default is host.
```
dcos spark run --submit-args="--conf spark.executor.memory=1g --conf spark.mesos.executor.docker.image=skonto/spark-local:test
--conf spark.executor.cores=2 --conf spark.cores.max=8
--class org.apache.spark.examples.SparkPi local:///spark-examples_2.11-2.2.1.jar"
```

Author: Stavros Kontopoulos <stavros.kontopoulos@lightbend.com>
Closes#21378 from skonto/local-upstream.
## What changes were proposed in this pull request?
This PR replaces `getTimeAsMs` with `getTimeAsSeconds` to fix the issue that reading "spark.network.timeout" using a wrong time unit when the user doesn't specify a time out.
## How was this patch tested?
Jenkins
Author: Shixiong Zhu <zsxwing@gmail.com>
Closes#21382 from zsxwing/fix-network-timeout-conf.
## What changes were proposed in this pull request?
The PR retrieves the proxyBase automatically from the header `X-Forwarded-Context` (if available). This is the header used by Knox to inform the proxied service about the base path.
This provides 0-configuration support for Knox gateway (instead of having to properly set `spark.ui.proxyBase`) and it allows to access directly SHS when it is proxied by Knox. In the previous scenario, indeed, after setting `spark.ui.proxyBase`, direct access to SHS was not working fine (due to bad link generated).
## How was this patch tested?
added UT + manual tests
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#21268 from mgaido91/SPARK-24209.
## What changes were proposed in this pull request?
Shell escaped the name passed to spark-submit and change how conf attributes are shell escaped.
## How was this patch tested?
This test has been tested manually with Hive-on-spark with mesos or with the use case described in the issue with the sparkPi application with a custom name which contains illegal shell characters.
With this PR, hive-on-spark on mesos works like a charm with hive 3.0.0-SNAPSHOT.
I state that this contribution is my original work and that I license the work to the project under the project’s open source license
Author: Bounkong Khamphousone <bounkong.khamphousone@ebiznext.com>
Closes#21014 from tiboun/fix/SPARK-23941.
## What changes were proposed in this pull request?
Added support to specify the 'spark.executor.extraJavaOptions' value in terms of the `{{APP_ID}}` and/or `{{EXECUTOR_ID}}`, `{{APP_ID}}` will be replaced by Application Id and `{{EXECUTOR_ID}}` will be replaced by Executor Id while starting the executor.
## How was this patch tested?
I have verified this by checking the executor process command and gc logs. I verified the same in different deployment modes(Standalone, YARN, Mesos) client and cluster modes.
Author: Devaraj K <devaraj@apache.org>
Closes#21088 from devaraj-kavali/SPARK-24003.
The current in-process launcher implementation just calls the SparkSubmit
object, which, in case of errors, will more often than not exit the JVM.
This is not desirable since this launcher is meant to be used inside other
applications, and that would kill the application.
The change turns SparkSubmit into a class, and abstracts aways some of
the functionality used to print error messages and abort the submission
process. The default implementation uses the logging system for messages,
and throws exceptions for errors. As part of that I also moved some code
that doesn't really belong in SparkSubmit to a better location.
The command line invocation of spark-submit now uses a special implementation
of the SparkSubmit class that overrides those behaviors to do what is expected
from the command line version (print to the terminal, exit the JVM, etc).
A lot of the changes are to replace calls to methods such as "printErrorAndExit"
with the new API.
As part of adding tests for this, I had to fix some small things in the
launcher option parser so that things like "--version" can work when
used in the launcher library.
There is still code that prints directly to the terminal, like all the
Ivy-related code in SparkSubmitUtils, and other areas where some re-factoring
would help, like the CommandLineUtils class, but I chose to leave those
alone to keep this change more focused.
Aside from existing and added unit tests, I ran command line tools with
a bunch of different arguments to make sure messages and errors behave
like before.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20925 from vanzin/SPARK-22941.
Currently, the Spark AM relies on the initial set of tokens created by
the submission client to be able to talk to HDFS and other services that
require delegation tokens. This means that after those tokens expire, a
new AM will fail to start (e.g. when there is an application failure and
re-attempts are enabled).
This PR makes it so that the first thing the AM does when the user provides
a principal and keytab is to create new delegation tokens for use. This
makes sure that the AM can be started irrespective of how old the original
token set is. It also allows all of the token management to be done by the
AM - there is no need for the submission client to set configuration values
to tell the AM when to renew tokens.
Note that even though in this case the AM will not be using the delegation
tokens created by the submission client, those tokens still need to be provided
to YARN, since they are used to do log aggregation.
To be able to re-use the code in the AMCredentialRenewal for the above
purposes, I refactored that class a bit so that it can fetch tokens into
a pre-defined UGI, insted of always logging in.
Another issue with re-attempts is that, after the fix that allows the AM
to restart correctly, new executors would get confused about when to
update credentials, because the credential updater used the update time
initially set up by the submission code. This could make the executor
fail to update credentials in time, since that value would be very out
of date in the situation described in the bug.
To fix that, I changed the YARN code to use the new RPC-based mechanism
for distributing tokens to executors. This allowed the old credential
updater code to be removed, and a lot of code in the renewer to be
simplified.
I also made two currently hardcoded values (the renewal time ratio, and
the retry wait) configurable; while this probably never needs to be set
by anyone in a production environment, it helps with testing; that's also
why they're not documented.
Tested on real cluster with a specially crafted application to test this
functionality: checked proper access to HDFS, Hive and HBase in cluster
mode with token renewal on and AM restarts. Tested things still work in
client mode too.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20657 from vanzin/SPARK-23361.
This commit modifies the Mesos submission client to allow the principal
and secret to be provided indirectly via files. The path to these files
can be specified either via Spark configuration or via environment
variable.
Assuming these files are appropriately protected by FS/OS permissions
this means we don't ever leak the actual values in process info like ps
Environment variable specification is useful because it allows you to
interpolate the location of this file when using per-user Mesos
credentials.
For some background as to why we have taken this approach I will briefly describe our set up. On our systems we provide each authorised user account with their own Mesos credentials to provide certain security and audit guarantees to our customers. These credentials are managed by a central Secret management service. In our `spark-env.sh` we determine the appropriate secret and principal files to use depending on the user who is invoking Spark hence the need to inject these via environment variables as well as by configuration properties. So we set these environment variables appropriately and our Spark read in the contents of those files to authenticate itself with Mesos.
This is functionality we have been using it in production across multiple customer sites for some time. This has been in the field for around 18 months with no reported issues. These changes have been sufficient to meet our customer security and audit requirements.
We have been building and deploying custom builds of Apache Spark with various minor tweaks like this which we are now looking to contribute back into the community in order that we can rely upon stock Apache Spark builds and stop maintaining our own internal fork.
Author: Rob Vesse <rvesse@dotnetrdf.org>
Closes#20167 from rvesse/SPARK-16501.
## What changes were proposed in this pull request?
This patch bumps the master branch version to `2.4.0-SNAPSHOT`.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20222 from gatorsmile/bump24.
This change adds a new launcher that allows applications to be run
in a separate thread in the same process as the calling code. To
achieve that, some code from the child process implementation was
moved to abstract classes that implement the common functionality,
and the new launcher inherits from those.
The new launcher was added as a new class, instead of implemented
as a new option to the existing SparkLauncher, to avoid ambigous
APIs. For example, SparkLauncher has ways to set the child app's
environment, modify SPARK_HOME, or control the logging of the
child process, none of which apply to in-process apps.
The in-process launcher has limitations: it needs Spark in the
context class loader of the calling thread, and it's bound by
Spark's current limitation of a single client-mode application
per JVM. It also relies on the recently added SparkApplication
trait to make sure different apps don't mess up each other's
configuration, so config isolation is currently limited to cluster mode.
I also chose to keep the same socket-based communication for in-process
apps, even though it might be possible to avoid it for in-process
mode. That helps both implementations share more code.
Tested with new and existing unit tests, and with a simple app that
uses the launcher; also made sure the app ran fine with older launcher
jar to check binary compatibility.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#19591 from vanzin/SPARK-11035.
## What changes were proposed in this pull request?
PR closed with all the comments -> https://github.com/apache/spark/pull/19793
It solves the problem when submitting a wrong CreateSubmissionRequest to Spark Dispatcher was causing a bad state of Dispatcher and making it inactive as a Mesos framework.
https://issues.apache.org/jira/browse/SPARK-22574
## How was this patch tested?
All spark test passed successfully.
It was tested sending a wrong request (without appArgs) before and after the change. The point is easy, check if the value is null before being accessed.
This was before the change, leaving the dispatcher inactive:
```
Exception in thread "Thread-22" java.lang.NullPointerException
at org.apache.spark.scheduler.cluster.mesos.MesosClusterScheduler.getDriverCommandValue(MesosClusterScheduler.scala:444)
at org.apache.spark.scheduler.cluster.mesos.MesosClusterScheduler.buildDriverCommand(MesosClusterScheduler.scala:451)
at org.apache.spark.scheduler.cluster.mesos.MesosClusterScheduler.org$apache$spark$scheduler$cluster$mesos$MesosClusterScheduler$$createTaskInfo(MesosClusterScheduler.scala:538)
at org.apache.spark.scheduler.cluster.mesos.MesosClusterScheduler$$anonfun$scheduleTasks$1.apply(MesosClusterScheduler.scala:570)
at org.apache.spark.scheduler.cluster.mesos.MesosClusterScheduler$$anonfun$scheduleTasks$1.apply(MesosClusterScheduler.scala:555)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.cluster.mesos.MesosClusterScheduler.scheduleTasks(MesosClusterScheduler.scala:555)
at org.apache.spark.scheduler.cluster.mesos.MesosClusterScheduler.resourceOffers(MesosClusterScheduler.scala:621)
```
And after:
```
"message" : "Malformed request: org.apache.spark.deploy.rest.SubmitRestProtocolException: Validation of message CreateSubmissionRequest failed!\n\torg.apache.spark.deploy.rest.SubmitRestProtocolMessage.validate(SubmitRestProtocolMessage.scala:70)\n\torg.apache.spark.deploy.rest.SubmitRequestServlet.doPost(RestSubmissionServer.scala:272)\n\tjavax.servlet.http.HttpServlet.service(HttpServlet.java:707)\n\tjavax.servlet.http.HttpServlet.service(HttpServlet.java:790)\n\torg.spark_project.jetty.servlet.ServletHolder.handle(ServletHolder.java:845)\n\torg.spark_project.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:583)\n\torg.spark_project.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1180)\n\torg.spark_project.jetty.servlet.ServletHandler.doScope(ServletHandler.java:511)\n\torg.spark_project.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1112)\n\torg.spark_project.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:141)\n\torg.spark_project.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:134)\n\torg.spark_project.jetty.server.Server.handle(Server.java:524)\n\torg.spark_project.jetty.server.HttpChannel.handle(HttpChannel.java:319)\n\torg.spark_project.jetty.server.HttpConnection.onFillable(HttpConnection.java:253)\n\torg.spark_project.jetty.io.AbstractConnection$ReadCallback.succeeded(AbstractConnection.java:273)\n\torg.spark_project.jetty.io.FillInterest.fillable(FillInterest.java:95)\n\torg.spark_project.jetty.io.SelectChannelEndPoint$2.run(SelectChannelEndPoint.java:93)\n\torg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.executeProduceConsume(ExecuteProduceConsume.java:303)\n\torg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.produceConsume(ExecuteProduceConsume.java:148)\n\torg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.run(ExecuteProduceConsume.java:136)\n\torg.spark_project.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:671)\n\torg.spark_project.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:589)\n\tjava.lang.Thread.run(Thread.java:745)"
```
Author: German Schiavon <germanschiavon@gmail.com>
Closes#19966 from Gschiavon/fix-submission-request.
## What changes were proposed in this pull request?
It solves the problem when submitting a wrong CreateSubmissionRequest to Spark Dispatcher was causing a bad state of Dispatcher and making it inactive as a Mesos framework.
https://issues.apache.org/jira/browse/SPARK-22574
## How was this patch tested?
All spark test passed successfully.
It was tested sending a wrong request (without appArgs) before and after the change. The point is easy, check if the value is null before being accessed.
This was before the change, leaving the dispatcher inactive:
```
Exception in thread "Thread-22" java.lang.NullPointerException
at org.apache.spark.scheduler.cluster.mesos.MesosClusterScheduler.getDriverCommandValue(MesosClusterScheduler.scala:444)
at org.apache.spark.scheduler.cluster.mesos.MesosClusterScheduler.buildDriverCommand(MesosClusterScheduler.scala:451)
at org.apache.spark.scheduler.cluster.mesos.MesosClusterScheduler.org$apache$spark$scheduler$cluster$mesos$MesosClusterScheduler$$createTaskInfo(MesosClusterScheduler.scala:538)
at org.apache.spark.scheduler.cluster.mesos.MesosClusterScheduler$$anonfun$scheduleTasks$1.apply(MesosClusterScheduler.scala:570)
at org.apache.spark.scheduler.cluster.mesos.MesosClusterScheduler$$anonfun$scheduleTasks$1.apply(MesosClusterScheduler.scala:555)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.cluster.mesos.MesosClusterScheduler.scheduleTasks(MesosClusterScheduler.scala:555)
at org.apache.spark.scheduler.cluster.mesos.MesosClusterScheduler.resourceOffers(MesosClusterScheduler.scala:621)
```
And after:
```
"message" : "Malformed request: org.apache.spark.deploy.rest.SubmitRestProtocolException: Validation of message CreateSubmissionRequest failed!\n\torg.apache.spark.deploy.rest.SubmitRestProtocolMessage.validate(SubmitRestProtocolMessage.scala:70)\n\torg.apache.spark.deploy.rest.SubmitRequestServlet.doPost(RestSubmissionServer.scala:272)\n\tjavax.servlet.http.HttpServlet.service(HttpServlet.java:707)\n\tjavax.servlet.http.HttpServlet.service(HttpServlet.java:790)\n\torg.spark_project.jetty.servlet.ServletHolder.handle(ServletHolder.java:845)\n\torg.spark_project.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:583)\n\torg.spark_project.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1180)\n\torg.spark_project.jetty.servlet.ServletHandler.doScope(ServletHandler.java:511)\n\torg.spark_project.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1112)\n\torg.spark_project.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:141)\n\torg.spark_project.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:134)\n\torg.spark_project.jetty.server.Server.handle(Server.java:524)\n\torg.spark_project.jetty.server.HttpChannel.handle(HttpChannel.java:319)\n\torg.spark_project.jetty.server.HttpConnection.onFillable(HttpConnection.java:253)\n\torg.spark_project.jetty.io.AbstractConnection$ReadCallback.succeeded(AbstractConnection.java:273)\n\torg.spark_project.jetty.io.FillInterest.fillable(FillInterest.java:95)\n\torg.spark_project.jetty.io.SelectChannelEndPoint$2.run(SelectChannelEndPoint.java:93)\n\torg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.executeProduceConsume(ExecuteProduceConsume.java:303)\n\torg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.produceConsume(ExecuteProduceConsume.java:148)\n\torg.spark_project.jetty.util.thread.strategy.ExecuteProduceConsume.run(ExecuteProduceConsume.java:136)\n\torg.spark_project.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:671)\n\torg.spark_project.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:589)\n\tjava.lang.Thread.run(Thread.java:745)"
```
Author: German Schiavon <germanschiavon@gmail.com>
Closes#19793 from Gschiavon/fix-submission-request.
## What changes were proposed in this pull request?
- Solves the issue described in the ticket by preserving reservation and allocation info in all cases (port handling included).
- upgrades to 1.4
- Adds extra debug level logging to make debugging easier in the future, for example we add reservation info when applicable.
```
17/09/29 14:53:07 DEBUG MesosCoarseGrainedSchedulerBackend: Accepting offer: f20de49b-dee3-45dd-a3c1-73418b7de891-O32 with attributes: Map() allocation info: role: "spark-prive"
reservation info: name: "ports"
type: RANGES
ranges {
range {
begin: 31000
end: 32000
}
}
role: "spark-prive"
reservation {
principal: "test"
}
allocation_info {
role: "spark-prive"
}
```
- Some style cleanup.
## How was this patch tested?
Manually by running the example in the ticket with and without a principal. Specifically I tested it on a dc/os 1.10 cluster with 7 nodes and played with reservations. From the master node in order to reserve resources I executed:
```for i in 0 1 2 3 4 5 6
do
curl -i \
-d slaveId=90ec65ea-1f7b-479f-a824-35d2527d6d26-S$i \
-d resources='[
{
"name": "cpus",
"type": "SCALAR",
"scalar": { "value": 2 },
"role": "spark-role",
"reservation": {
"principal": ""
}
},
{
"name": "mem",
"type": "SCALAR",
"scalar": { "value": 8026 },
"role": "spark-role",
"reservation": {
"principal": ""
}
}
]' \
-X POST http://master.mesos:5050/master/reserve
done
```
Nodes had 4 cpus (m3.xlarge instances) and I reserved either 2 or 4 cpus (all for a role).
I verified it launches tasks on nodes with reserved resources under `spark-role` role only if
a) there are remaining resources for (*) default role and the spark driver has no role assigned to it.
b) the spark driver has a role assigned to it and it is the same role used in reservations.
I also tested this locally on my machine.
Author: Stavros Kontopoulos <st.kontopoulos@gmail.com>
Closes#19390 from skonto/fix_dynamic_reservation.
The first scheduled renewal time is is set to the exact expiration time,
and all subsequent renewal times are 75% of the renewal time. This makes
it so that the inital renewal time is also 75%.
## What changes were proposed in this pull request?
Set the initial renewal time to be 75% of renewal time.
## How was this patch tested?
Tested locally in a test HDFS cluster, checking various renewal times.
Author: Kalvin Chau <kalvin.chau@viasat.com>
Closes#19798 from kalvinnchau/fix-inital-renewal-time.
## What changes were proposed in this pull request?
tl;dr: Add a class, `MesosHadoopDelegationTokenManager` that updates delegation tokens on a schedule on the behalf of Spark Drivers. Broadcast renewed credentials to the executors.
## The problem
We recently added Kerberos support to Mesos-based Spark jobs as well as Secrets support to the Mesos Dispatcher (SPARK-16742, SPARK-20812, respectively). However the delegation tokens have a defined expiration. This poses a problem for long running Spark jobs (e.g. Spark Streaming applications). YARN has a solution for this where a thread is scheduled to renew the tokens they reach 75% of their way to expiration. It then writes the tokens to HDFS for the executors to find (uses a monotonically increasing suffix).
## This solution
We replace the current method in `CoarseGrainedSchedulerBackend` which used to discard the token renewal time with a protected method `fetchHadoopDelegationTokens`. Now the individual cluster backends are responsible for overriding this method to fetch and manage token renewal. The delegation tokens themselves, are still part of the `CoarseGrainedSchedulerBackend` as before.
In the case of Mesos renewed Credentials are broadcasted to the executors. This maintains all transfer of Credentials within Spark (as opposed to Spark-to-HDFS). It also does not require any writing of Credentials to disk. It also does not require any GC of old files.
## How was this patch tested?
Manually against a Kerberized HDFS cluster.
Thank you for the reviews.
Author: ArtRand <arand@soe.ucsc.edu>
Closes#19272 from ArtRand/spark-21842-450-kerberos-ticket-renewal.
## What changes were proposed in this pull request?
A discussed in SPARK-19606, the addition of a new config property named "spark.mesos.constraints.driver" for constraining drivers running on a Mesos cluster
## How was this patch tested?
Corresponding unit test added also tested locally on a Mesos cluster
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Paul Mackles <pmackles@adobe.com>
Closes#19543 from pmackles/SPARK-19606.
## Background
In #18837 , ArtRand added Mesos secrets support to the dispatcher. **This PR is to add the same secrets support to the drivers.** This means if the secret configs are set, the driver will launch executors that have access to either env or file-based secrets.
One use case for this is to support TLS in the driver <=> executor communication.
## What changes were proposed in this pull request?
Most of the changes are a refactor of the dispatcher secrets support (#18837) - moving it to a common place that can be used by both the dispatcher and drivers. The same goes for the unit tests.
## How was this patch tested?
There are four config combinations: [env or file-based] x [value or reference secret]. For each combination:
- Added a unit test.
- Tested in DC/OS.
Author: Susan X. Huynh <xhuynh@mesosphere.com>
Closes#19437 from susanxhuynh/sh-mesos-driver-secret.
## What changes were proposed in this pull request?
Added Launcher support for monitoring Mesos apps in Client mode. SPARK-11033 can handle the support for Mesos/Cluster mode since the Standalone/Cluster and Mesos/Cluster modes use the same code at client side.
## How was this patch tested?
I verified it manually by running launcher application, able to launch, stop and kill the mesos applications and also can invoke other launcher API's.
Author: Devaraj K <devaraj@apache.org>
Closes#19385 from devaraj-kavali/SPARK-11034.
## What changes were proposed in this pull request?
Improve the Spark-Mesos coarse-grained scheduler to consider the preferred locations when dynamic allocation is enabled.
## How was this patch tested?
Added a unittest, and performed manual testing on AWS.
Author: Gene Pang <gene.pang@gmail.com>
Closes#18098 from gpang/mesos_data_locality.
## What changes were proposed in this pull request?
Fix a trivial bug with how metrics are registered in the mesos dispatcher. Bug resulted in creating a new registry each time the metricRegistry() method was called.
## How was this patch tested?
Verified manually on local mesos setup
Author: Paul Mackles <pmackles@adobe.com>
Closes#19358 from pmackles/SPARK-22135.
…build; fix some things that will be warnings or errors in 2.12; restore Scala 2.12 profile infrastructure
## What changes were proposed in this pull request?
This change adds back the infrastructure for a Scala 2.12 build, but does not enable it in the release or Python test scripts.
In order to make that meaningful, it also resolves compile errors that the code hits in 2.12 only, in a way that still works with 2.11.
It also updates dependencies to the earliest minor release of dependencies whose current version does not yet support Scala 2.12. This is in a sense covered by other JIRAs under the main umbrella, but implemented here. The versions below still work with 2.11, and are the _latest_ maintenance release in the _earliest_ viable minor release.
- Scalatest 2.x -> 3.0.3
- Chill 0.8.0 -> 0.8.4
- Clapper 1.0.x -> 1.1.2
- json4s 3.2.x -> 3.4.2
- Jackson 2.6.x -> 2.7.9 (required by json4s)
This change does _not_ fully enable a Scala 2.12 build:
- It will also require dropping support for Kafka before 0.10. Easy enough, just didn't do it yet here
- It will require recreating `SparkILoop` and `Main` for REPL 2.12, which is SPARK-14650. Possible to do here too.
What it does do is make changes that resolve much of the remaining gap without affecting the current 2.11 build.
## How was this patch tested?
Existing tests and build. Manually tested with `./dev/change-scala-version.sh 2.12` to verify it compiles, modulo the exceptions above.
Author: Sean Owen <sowen@cloudera.com>
Closes#18645 from srowen/SPARK-14280.
Mesos has secrets primitives for environment and file-based secrets, this PR adds that functionality to the Spark dispatcher and the appropriate configuration flags.
Unit tested and manually tested against a DC/OS cluster with Mesos 1.4.
Author: ArtRand <arand@soe.ucsc.edu>
Closes#18837 from ArtRand/spark-20812-dispatcher-secrets-and-labels.
JIRA ticket: https://issues.apache.org/jira/browse/SPARK-21694
## What changes were proposed in this pull request?
Spark already supports launching containers attached to a given CNI network by specifying it via the config `spark.mesos.network.name`.
This PR adds support to pass in network labels to CNI plugins via a new config option `spark.mesos.network.labels`. These network labels are key-value pairs that are set in the `NetworkInfo` of both the driver and executor tasks. More details in the related Mesos documentation: http://mesos.apache.org/documentation/latest/cni/#mesos-meta-data-to-cni-plugins
## How was this patch tested?
Unit tests, for both driver and executor tasks.
Manual integration test to submit a job with the `spark.mesos.network.labels` option, hit the mesos/state.json endpoint, and check that the labels are set in the driver and executor tasks.
ArtRand skonto
Author: Susan X. Huynh <xhuynh@mesosphere.com>
Closes#18910 from susanxhuynh/sh-mesos-cni-labels.
## What changes were proposed in this pull request?
Add Kerberos Support to Mesos. This includes kinit and --keytab support, but does not include delegation token renewal.
## How was this patch tested?
Manually against a Secure DC/OS Apache HDFS cluster.
Author: ArtRand <arand@soe.ucsc.edu>
Author: Michael Gummelt <mgummelt@mesosphere.io>
Closes#18519 from mgummelt/SPARK-16742-kerberos.
This version fixes a few issues in the import order checker; it provides
better error messages, and detects more improper ordering (thus the need
to change a lot of files in this patch). The main fix is that it correctly
complains about the order of packages vs. classes.
As part of the above, I moved some "SparkSession" import in ML examples
inside the "$example on$" blocks; that didn't seem consistent across
different source files to start with, and avoids having to add more on/off blocks
around specific imports.
The new scalastyle also seems to have a better header detector, so a few
license headers had to be updated to match the expected indentation.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#18943 from vanzin/SPARK-21731.
## What changes were proposed in this pull request?
Adds a sandbox link per driver in the dispatcher ui with minimal changes after a bug was fixed here:
https://issues.apache.org/jira/browse/MESOS-4992
The sandbox uri has the following format:
http://<proxy_uri>/#/slaves/\<agent-id\>/ frameworks/ \<scheduler-id\>/executors/\<driver-id\>/browse
For dc/os the proxy uri is <dc/os uri>/mesos. For the dc/os deployment scenario and to make things easier I introduced a new config property named `spark.mesos.proxy.baseURL` which should be passed to the dispatcher when launched using --conf. If no such configuration is detected then no sandbox uri is depicted, and there is an empty column with a header (this can be changed so nothing is shown).
Within dc/os the base url must be a property for the dispatcher that we should add in the future here:
9e7c909c3b/repo/packages/S/spark/26/config.json
It is not easy to detect in different environments what is that uri so user should pass it.
## How was this patch tested?
Tested with the mesos test suite here: https://github.com/typesafehub/mesos-spark-integration-tests.
Attached image shows the ui modification where the sandbox header is added.
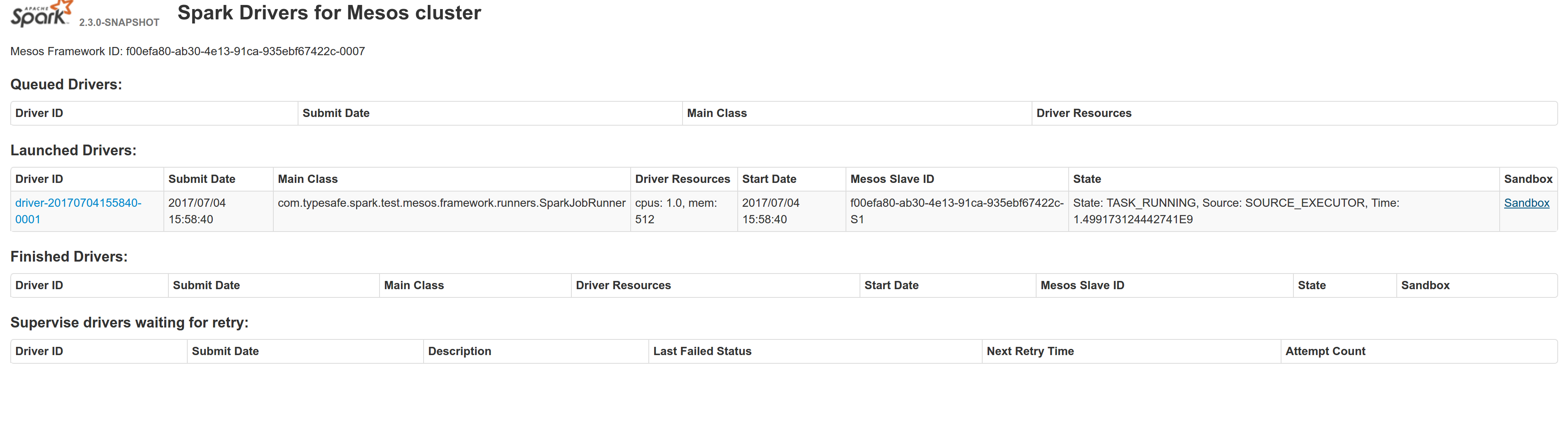
Tested the uri redirection the way it was suggested here:
https://issues.apache.org/jira/browse/MESOS-4992
Built mesos 1.4 from the master branch and started the mesos dispatcher with the command:
`./sbin/start-mesos-dispatcher.sh --conf spark.mesos.proxy.baseURL=http://localhost:5050 -m mesos://127.0.0.1:5050`
Run a spark example:
`./bin/spark-submit --class org.apache.spark.examples.SparkPi --master mesos://10.10.1.79:7078 --deploy-mode cluster --executor-memory 2G --total-executor-cores 2 http://<path>/spark-examples_2.11-2.1.1.jar 10`
Sandbox uri is shown at the bottom of the page:
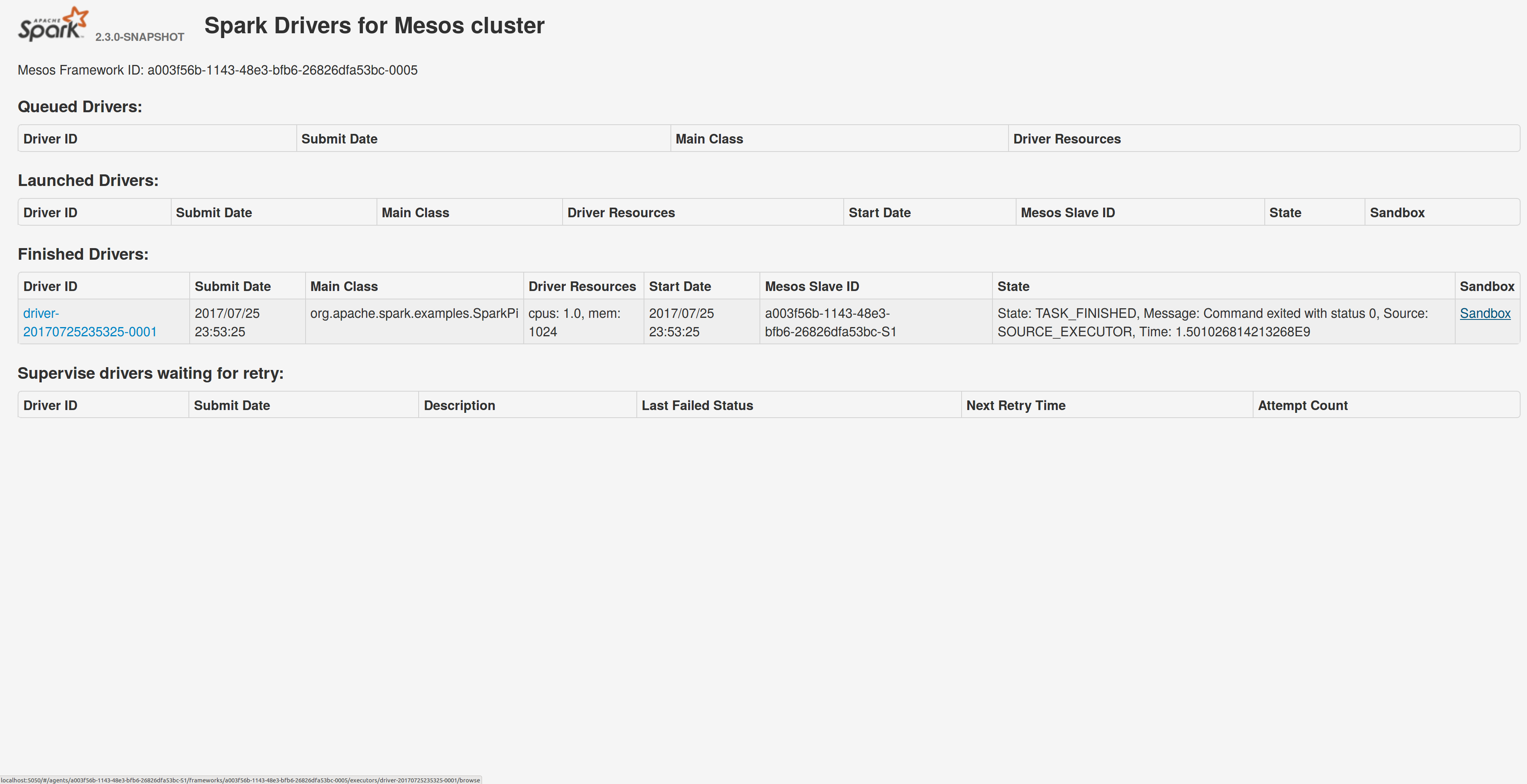
Redirection works as expected:
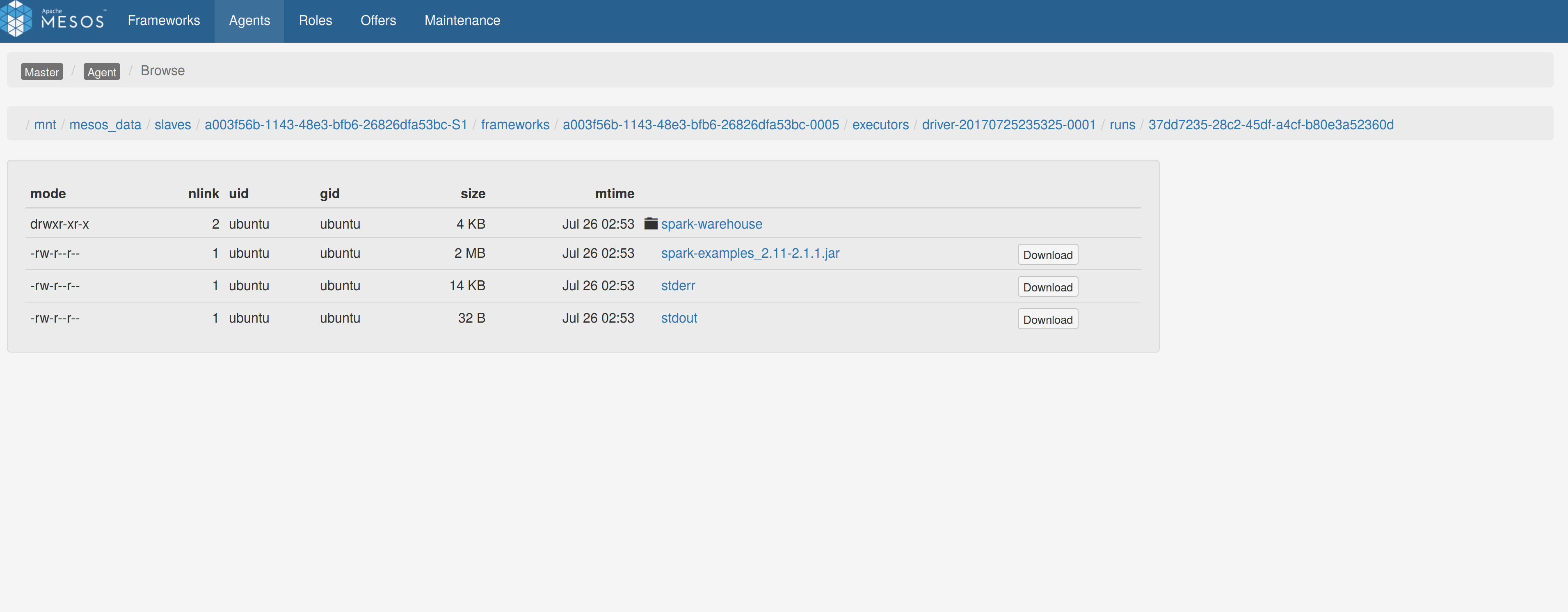
Author: Stavros Kontopoulos <st.kontopoulos@gmail.com>
Closes#18528 from skonto/adds_the_sandbox_uri.
## What changes were proposed in this pull request?
With supervise enabled for a driver, re-launching it was failing because the driver had the same framework Id. This patch creates a new driver framework id every time we re-launch a driver, but we keep the driver submission id the same since that is the same with the task id the driver was launched with on mesos and retry state and other info within Dispatcher's data structures uses that as a key.
We append a "-retry-%4d" string as a suffix to the framework id passed by the dispatcher to the driver and the same value to the app_id created by each driver, except the first time where we dont need the retry suffix.
The previous format for the frameworkId was 'DispactherFId-DriverSubmissionId'.
We also detect the case where we have multiple spark contexts started from within the same driver and we do set proper names to their corresponding app-ids. The old practice was to unset the framework id passed from the dispatcher after the driver framework was started for the first time and let mesos decide the framework ID for subsequent spark contexts. The decided fId was passed as an appID.
This patch affects heavily the history server. Btw we dont have the issues of the standalone case where driver id must be different since the dispatcher will re-launch a driver(mesos task) only if it gets an update that it is dead and this is verified by mesos implicitly. We also dont fix the fine grained mode which is deprecated and of no use.
## How was this patch tested?
This task was manually tested on dc/os. Launched a driver, stoped its container and verified the expected behavior.
Initial retry of the driver, driver in pending state:

Driver re-launched:
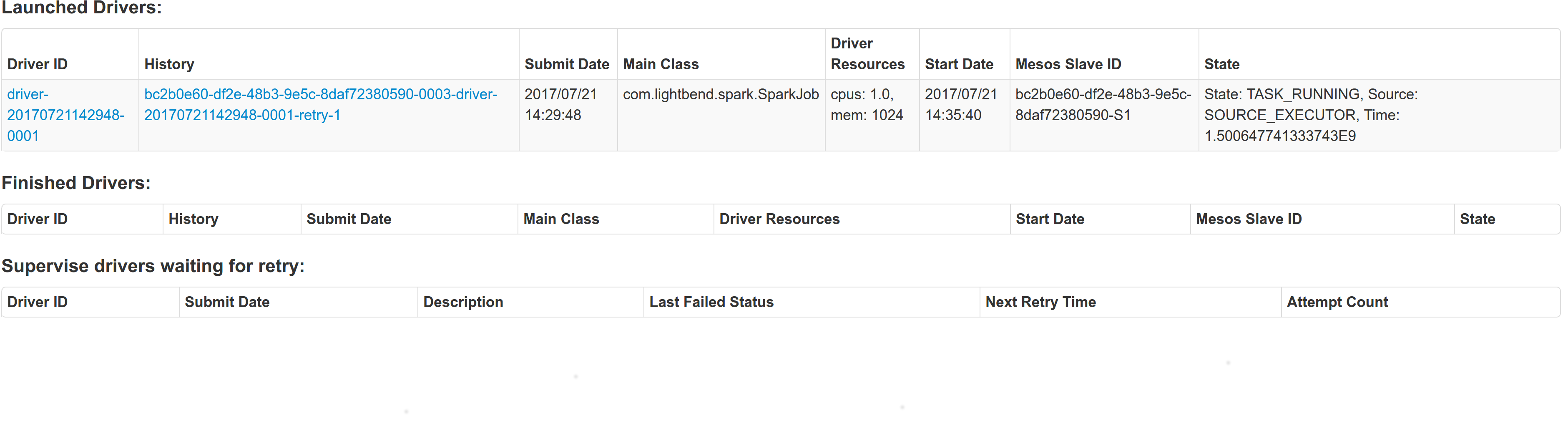
Another re-try:

The resulted entries in history server at the bottom:
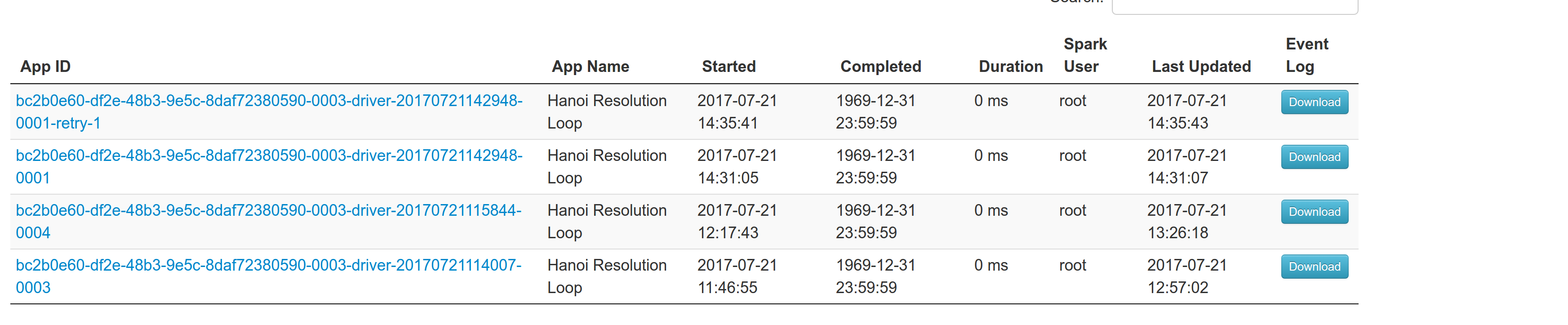
Regarding multiple spark contexts here is the end result regarding the spark history server, for the second spark context we add an increasing number as a suffix:

Author: Stavros Kontopoulos <st.kontopoulos@gmail.com>
Closes#18705 from skonto/fix_supervise_flag.
## What changes were proposed in this pull request?
Current behavior: in Mesos cluster mode, the driver failover_timeout is set to zero. If the driver temporarily loses connectivity with the Mesos master, the framework will be torn down and all executors killed.
Proposed change: make the failover_timeout configurable via a new option, spark.mesos.driver.failoverTimeout. The default value is still zero.
Note: with non-zero failover_timeout, an explicit teardown is needed in some cases. This is captured in https://issues.apache.org/jira/browse/SPARK-21458
## How was this patch tested?
Added a unit test to make sure the config option is set while creating the scheduler driver.
Ran an integration test with mesosphere/spark showing that with a non-zero failover_timeout the Spark job finishes after a driver is disconnected from the master.
Author: Susan X. Huynh <xhuynh@mesosphere.com>
Closes#18674 from susanxhuynh/sh-mesos-failover-timeout.
## What changes were proposed in this pull request?
Address scapegoat warnings for:
- BigDecimal double constructor
- Catching NPE
- Finalizer without super
- List.size is O(n)
- Prefer Seq.empty
- Prefer Set.empty
- reverse.map instead of reverseMap
- Type shadowing
- Unnecessary if condition.
- Use .log1p
- Var could be val
In some instances like Seq.empty, I avoided making the change even where valid in test code to keep the scope of the change smaller. Those issues are concerned with performance and it won't matter for tests.
## How was this patch tested?
Existing tests
Author: Sean Owen <sowen@cloudera.com>
Closes#18635 from srowen/Scapegoat1.
## What changes were proposed in this pull request?
Adding the default UncaughtExceptionHandler to the Worker.
## How was this patch tested?
I verified it manually, when any of the worker thread gets uncaught exceptions then the default UncaughtExceptionHandler will handle those exceptions.
Author: Devaraj K <devaraj@apache.org>
Closes#18357 from devaraj-kavali/SPARK-21146.
## What changes were proposed in this pull request?
Currently the shuffle service registration timeout and retry has been hardcoded. This works well for small workloads but under heavy workload when the shuffle service is busy transferring large amount of data we see significant delay in responding to the registration request, as a result we often see the executors fail to register with the shuffle service, eventually failing the job. We need to make these two parameters configurable.
## How was this patch tested?
* Updated `BlockManagerSuite` to test registration timeout and max attempts configuration actually works.
cc sitalkedia
Author: Li Yichao <lyc@zhihu.com>
Closes#18092 from liyichao/SPARK-20640.
## What changes were proposed in this pull request?
Add Mesos labels support to the Spark Dispatcher
## How was this patch tested?
unit tests
Author: Michael Gummelt <mgummelt@mesosphere.io>
Closes#18220 from mgummelt/SPARK-21000-dispatcher-labels.
Restore code that was removed as part of SPARK-17979, but instead of
using the deprecated env variable name to propagate the class path, use
a new one.
Verified by running "./bin/spark-class o.a.s.executor.CoarseGrainedExecutorBackend"
manually.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#18037 from vanzin/SPARK-20814.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}