## What changes were proposed in this pull request? The table type is from Hive now. This will have some issues. For example, we don't support `index_table`, different Hive supports different table types: Build with Hive 1.2.1: 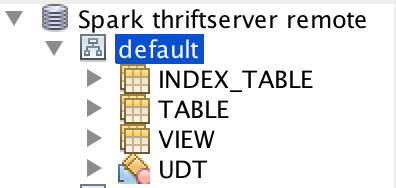 Build with Hive 2.3.5: 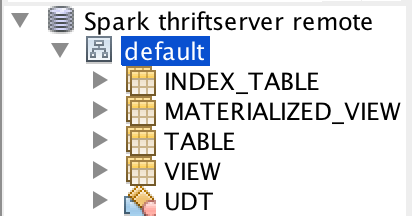 This pr implement Spark's own `GetTableTypesOperation`. ## How was this patch tested? unit tests and manual tests:  Closes #25073 from wangyum/SPARK-28293. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com> |
||
|---|---|---|
| .. | ||
| benchmarks | ||
| src | ||
| pom.xml | ||
{kind=link}
{kind=link}
{kind=link}