### What changes were proposed in this pull request? This pr improve the cost model in `pruningHasBenefit` for filtering side can not build broadcast by join type: 1. The filtering side must be small enough to build broadcast by size. 2. The estimated size of the pruning side must be big enough: `estimatePruningSideSize * spark.sql.optimizer.dynamicPartitionPruning.pruningSideExtraFilterRatio > overhead`. ### Why are the changes needed? Improve query performance for these cases. This a real case from cluster. Left join and left size very small and right side can build DPP: 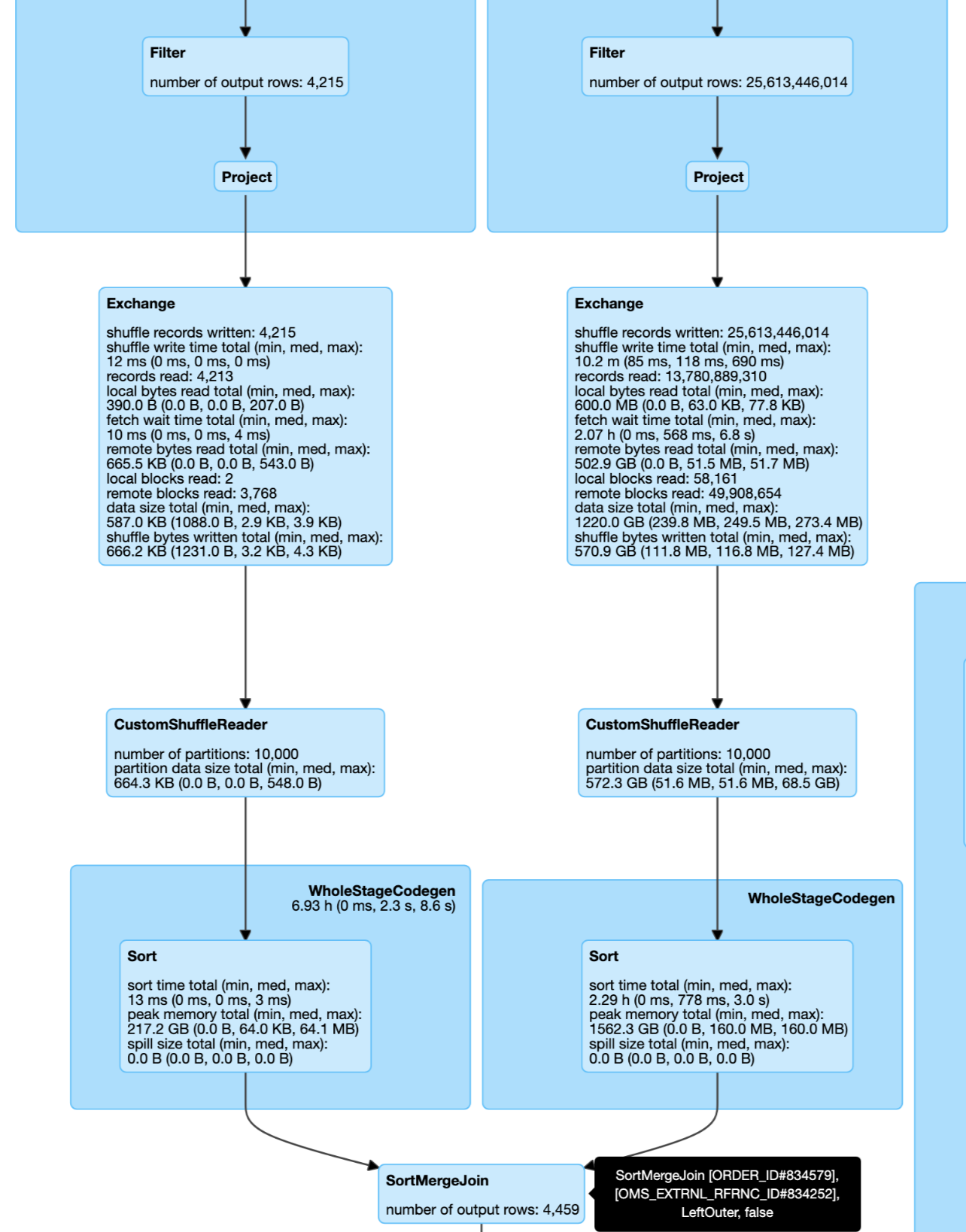 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Unit test. Closes #29726 from wangyum/SPARK-32855. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> |
||
|---|---|---|
| .. | ||
| benchmarks | ||
| src | ||
| pom.xml | ||
{kind=link}