### What changes were proposed in this pull request?
Push down limit through `Window` when the partitionSpec of all window functions is empty and the same order is used. This is a real case from production:

This pr support 2 cases:
1. All window functions have same orderSpec:
```sql
SELECT *, ROW_NUMBER() OVER(ORDER BY a) AS rn, RANK() OVER(ORDER BY a) AS rk FROM t1 LIMIT 5;
== Optimized Logical Plan ==
Window [row_number() windowspecdefinition(a#9L ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rn#4, rank(a#9L) windowspecdefinition(a#9L ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#5], [a#9L ASC NULLS FIRST]
+- GlobalLimit 5
+- LocalLimit 5
+- Sort [a#9L ASC NULLS FIRST], true
+- Relation default.t1[A#9L,B#10L,C#11L] parquet
```
2. There is a window function with a different orderSpec:
```sql
SELECT a, ROW_NUMBER() OVER(ORDER BY a) AS rn, RANK() OVER(ORDER BY b DESC) AS rk FROM t1 LIMIT 5;
== Optimized Logical Plan ==
Project [a#9L, rn#4, rk#5]
+- Window [rank(b#10L) windowspecdefinition(b#10L DESC NULLS LAST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#5], [b#10L DESC NULLS LAST]
+- GlobalLimit 5
+- LocalLimit 5
+- Sort [b#10L DESC NULLS LAST], true
+- Window [row_number() windowspecdefinition(a#9L ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rn#4], [a#9L ASC NULLS FIRST]
+- Project [a#9L, b#10L]
+- Relation default.t1[A#9L,B#10L,C#11L] parquet
```
### Why are the changes needed?
Improve query performance.
```scala
spark.range(500000000L).selectExpr("id AS a", "id AS b").write.saveAsTable("t1")
spark.sql("SELECT *, ROW_NUMBER() OVER(ORDER BY a) AS rowId FROM t1 LIMIT 5").show
```
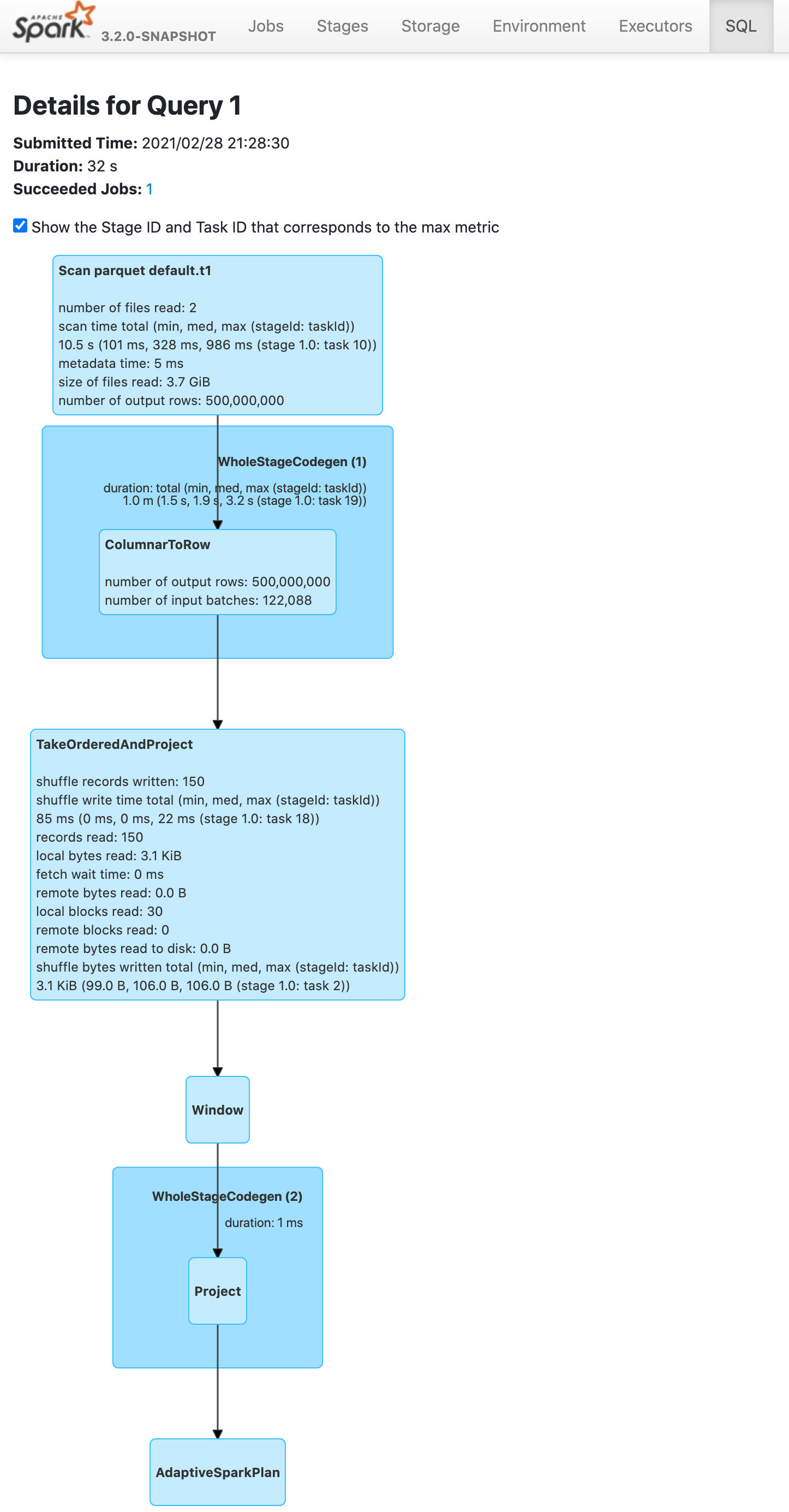
Before this pr | After this pr
-- | --
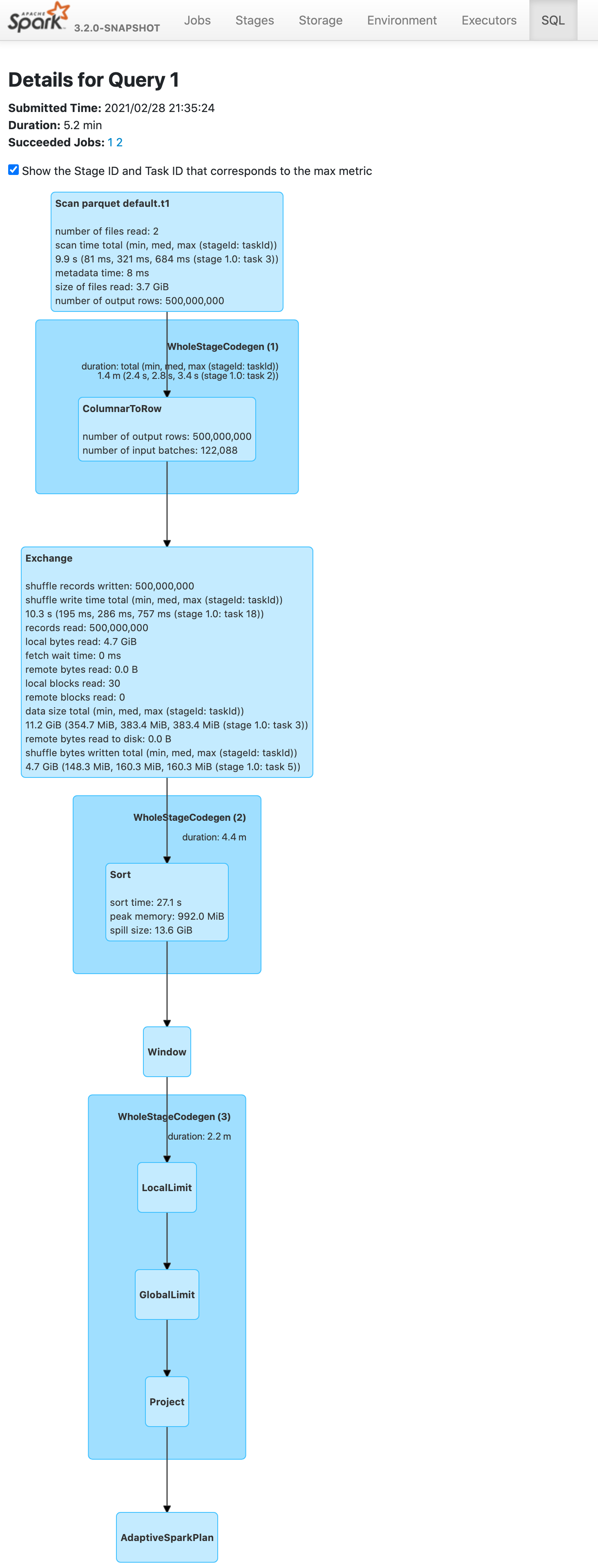 | 
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#31691 from wangyum/SPARK-34575.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}
{kind=link}