## What changes were proposed in this pull request?
This patch tries to keep consistency whenever UTF-8 charset is needed, as using `StandardCharsets.UTF_8` instead of using "UTF-8". If the String type is needed, `StandardCharsets.UTF_8.name()` is used.
This change also brings the benefit of getting rid of `UnsupportedEncodingException`, as we're providing `Charset` instead of `String` whenever possible.
This also changes some private Catalyst helper methods to operate on encodings as `Charset` objects rather than strings.
## How was this patch tested?
Existing unit tests.
Closes#25335 from HeartSaVioR/SPARK-28601.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR implements Spark's own GetFunctionsOperation which mitigates the differences between Spark SQL and Hive UDFs. But our implementation is different from Hive's implementation:
- Our implementation always returns results. Hive only returns results when [(null == catalogName || "".equals(catalogName)) && (null == schemaName || "".equals(schemaName))](https://github.com/apache/hive/blob/rel/release-3.1.1/service/src/java/org/apache/hive/service/cli/operation/GetFunctionsOperation.java#L101-L119).
- Our implementation pads the `REMARKS` field with the function usage - Hive returns an empty string.
- Our implementation does not support `FUNCTION_TYPE`, but Hive does.
## How was this patch tested?
unit tests
Closes#25252 from wangyum/SPARK-28510.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
How to reproduce this issue:
```shell
build/sbt clean package -Phive -Phive-thriftserver -Phadoop-3.2
export SPARK_PREPEND_CLASSES=true
sbin/start-thriftserver.sh
[rootspark-3267648 spark]# bin/beeline -u jdbc:hive2://localhost:10000/default -e "select cast(1 as decimal(38, 18));"
Connecting to jdbc:hive2://localhost:10000/default
Connected to: Spark SQL (version 3.0.0-SNAPSHOT)
Driver: Hive JDBC (version 2.3.5)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Error: java.lang.ClassCastException: java.math.BigDecimal incompatible with org.apache.hadoop.hive.common.type.HiveDecimal (state=,code=0)
Closing: 0: jdbc:hive2://localhost:10000/default
```
This pr fix this issue.
## How was this patch tested?
unit tests
Closes#25217 from wangyum/SPARK-28463.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
There are some hardcoded configs, using config entry to replace them.
## How was this patch tested?
Existing UT
Closes#25059 from WangGuangxin/ConfigEntry.
Authored-by: wangguangxin.cn <wangguangxin.cn@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr add support show global temporary view and local temporary view in database tool.
TODO: Database tools should support show temporary views because it's schema is null.
## How was this patch tested?
unit tests and manual tests:
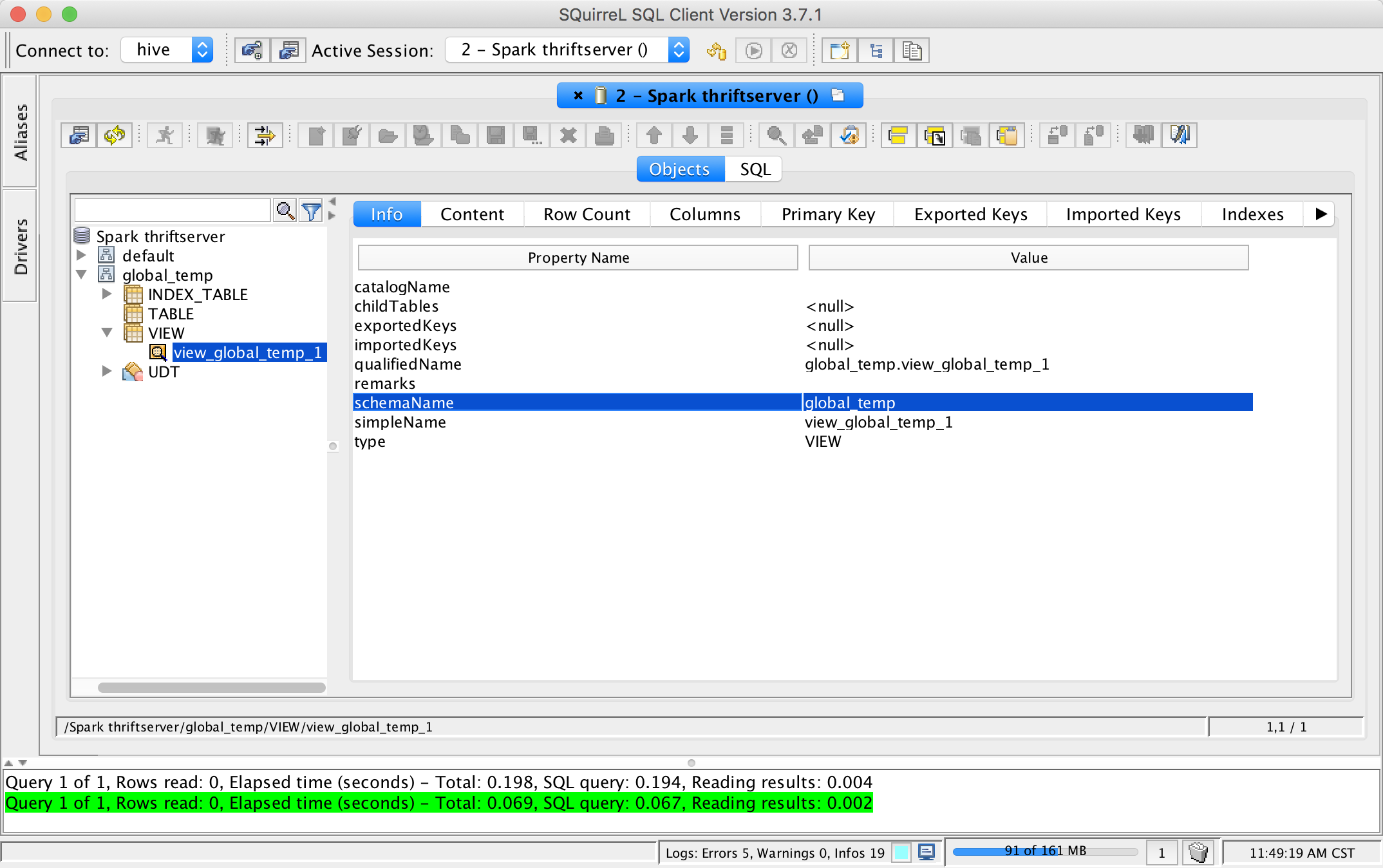
Closes#24972 from wangyum/SPARK-28167.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
To make the #24972 change smaller. This pr improves `SparkMetadataOperationSuite` to avoid creating new sessions when getSchemas/getTables/getColumns.
## How was this patch tested?
N/A
Closes#24985 from wangyum/SPARK-28184.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The new Spark ThriftServer SparkGetTablesOperation implemented in https://github.com/apache/spark/pull/22794 does a catalog.getTableMetadata request for every table. This can get very slow for large schemas (~50ms per table with an external Hive metastore).
Hive ThriftServer GetTablesOperation uses HiveMetastoreClient.getTableObjectsByName to get table information in bulk, but we don't expose that through our APIs that go through Hive -> HiveClientImpl (HiveClient) -> HiveExternalCatalog (ExternalCatalog) -> SessionCatalog.
If we added and exposed getTableObjectsByName through our catalog APIs, we could resolve that performance problem in SparkGetTablesOperation.
## How was this patch tested?
Add UT
Closes#24774 from LantaoJin/SPARK-27899.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This pr moves Hive test jars(`hive-contrib-0.13.1.jar`, `hive-hcatalog-core-0.13.1.jar`, `hive-contrib-2.3.5.jar` and `hive-hcatalog-core-2.3.5.jar`) to maven dependency.
## How was this patch tested?
Existing test
Please note that this pr need test with `maven` and `sbt`.
Closes#24751 from wangyum/SPARK-27831.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr moves Hive test jars(`hive-contrib-0.13.1.jar`, `hive-hcatalog-core-0.13.1.jar`, `hive-contrib-2.3.5.jar` and `hive-hcatalog-core-2.3.5.jar`) to maven dependency.
## How was this patch tested?
Existing test
Closes#24695 from wangyum/SPARK-27831.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
When we upgraded the built-in Hive to 2.3.4, the current `hive-thriftserver` module is not compatible, such as these Hive changes:
1. [HIVE-12442](https://issues.apache.org/jira/browse/HIVE-12442) HiveServer2: Refactor/repackage HiveServer2's Thrift code so that it can be used in the tasks
2. [HIVE-12237](https://issues.apache.org/jira/browse/HIVE-12237) Use slf4j as logging facade
3. [HIVE-13169](https://issues.apache.org/jira/browse/HIVE-13169) HiveServer2: Support delegation token based connection when using http transport
So this PR moves the incompatible code to `sql/hive-thriftserver/v1.2.1` and copies it to `sql/hive-thriftserver/v2.3.4` for the next code review.
## How was this patch tested?
manual tests:
```
diff -urNa sql/hive-thriftserver/v1.2.1 sql/hive-thriftserver/v2.3.4
```
Closes#24282 from wangyum/SPARK-27354.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Fix build warnings -- see some details below.
But mostly, remove use of postfix syntax where it causes warnings without the `scala.language.postfixOps` import. This is mostly in expressions like "120000 milliseconds". Which, I'd like to simplify to things like "2.minutes" anyway.
## How was this patch tested?
Existing tests.
Closes#24314 from srowen/SPARK-27404.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The user sets the value of spark.sql.thriftserver.scheduler.pool.
Spark thrift server saves this value in the LocalProperty of threadlocal type, but does not clean up after running, causing other sessions to run in the previously set pool name.
## How was this patch tested?
manual tests
Closes#23895 from cxzl25/thrift_server_scheduler_pool_pollute.
Lead-authored-by: cxzl25 <cxzl25@users.noreply.github.com>
Co-authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Use Single Abstract Method syntax where possible (and minor related cleanup). Comments below. No logic should change here.
## How was this patch tested?
Existing tests.
Closes#24241 from srowen/SPARK-27323.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
When using fair scheduler mode for thrift server, we may have unpredictable result.
```
val pool = sessionToActivePool.get(parentSession.getSessionHandle)
if (pool != null) {
sqlContext.sparkContext.setLocalProperty(SparkContext.SPARK_SCHEDULER_POOL, pool)
}
```
The cause is we use thread pool to execute queries for thriftserver, and when we call setLocalProperty we may have unpredictab behavior.
```
/**
* Set a local property that affects jobs submitted from this thread, such as the Spark fair
* scheduler pool. User-defined properties may also be set here. These properties are propagated
* through to worker tasks and can be accessed there via
* [[org.apache.spark.TaskContext#getLocalProperty]].
*
* These properties are inherited by child threads spawned from this thread. This
* may have unexpected consequences when working with thread pools. The standard java
* implementation of thread pools have worker threads spawn other worker threads.
* As a result, local properties may propagate unpredictably.
*/
def setLocalProperty(key: String, value: String) {
if (value == null) {
localProperties.get.remove(key)
} else {
localProperties.get.setProperty(key, value)
}
}
```
I post an example on https://jira.apache.org/jira/browse/SPARK-26914 .
## How was this patch tested?
UT
Closes#23826 from caneGuy/zhoukang/fix-scheduler-error.
Authored-by: zhoukang <zhoukang199191@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/12881 removed `HiveSessionHook`. But there are still some code related to `HiveSessionHook`.
This PR removes all `HiveSessionHook` related code.
## How was this patch tested?
manual tests
Closes#23957 from wangyum/SPARK-15095.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
In the PR, I propose to use `System.nanoTime()` instead of `System.currentTimeMillis()` in measurements of time intervals.
`System.currentTimeMillis()` returns current wallclock time and will follow changes to the system clock. Thus, negative wallclock adjustments can cause timeouts to "hang" for a long time (until wallclock time has caught up to its previous value again). This can happen when ntpd does a "step" after the network has been disconnected for some time. The most canonical example is during system bootup when DHCP takes longer than usual. This can lead to failures that are really hard to understand/reproduce. `System.nanoTime()` is guaranteed to be monotonically increasing irrespective of wallclock changes.
## How was this patch tested?
By existing test suites.
Closes#23727 from MaxGekk/system-nanotime.
Lead-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Delegation token providers interface now has a parameter `fileSystems` but this is needed only for `HadoopFSDelegationTokenProvider`.
In this PR I've addressed this issue in the following way:
* Removed `fileSystems` parameter from `HadoopDelegationTokenProvider`
* Moved `YarnSparkHadoopUtil.hadoopFSsToAccess` into `HadoopFSDelegationTokenProvider`
* Moved `spark.yarn.stagingDir` into core
* Moved `spark.yarn.access.namenodes` into core and renamed to `spark.kerberos.access.namenodes`
* Moved `spark.yarn.access.hadoopFileSystems` into core and renamed to `spark.kerberos.access.hadoopFileSystems`
## How was this patch tested?
Existing unit tests.
Closes#23698 from gaborgsomogyi/SPARK-26766.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
When we run in background and we get exception which is not HiveSQLException,
we may encounter memory leak since handleToOperation will not removed correctly.
The reason is below:
1. When calling operation.run() in HiveSessionImpl#executeStatementInternal we throw an exception which is not HiveSQLException
2. Then the opHandle generated by SparkSQLOperationManager will not be added into opHandleSet of HiveSessionImpl , and operationManager.closeOperation(opHandle) will not be called
3. When we close the session we will also call operationManager.closeOperation(opHandle),since we did not add this opHandle into the opHandleSet.
For the reasons above,the opHandled will always in SparkSQLOperationManager#handleToOperation,which will cause memory leak.
More details and a case has attached on https://issues.apache.org/jira/browse/SPARK-26751
This patch will always throw HiveSQLException when running in background
## How was this patch tested?
Exist UT
Closes#23673 from caneGuy/zhoukang/fix-hivesessionimpl-leak.
Authored-by: zhoukang <zhoukang199191@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
There are ugly provided dependencies inside core for the following:
* Hive
* Kafka
In this PR I've extracted them out. This PR contains the following:
* Token providers are now loaded with service loader
* Hive token provider moved to hive project
* Kafka token provider extracted into a new project
## How was this patch tested?
Existing + newly added unit tests.
Additionally tested on cluster.
Closes#23499 from gaborgsomogyi/SPARK-26254.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
The PR makes hardcoded `spark.dynamicAllocation`, `spark.scheduler`, `spark.rpc`, `spark.task`, `spark.speculation`, and `spark.cleaner` configs to use `ConfigEntry`.
## How was this patch tested?
Existing tests
Closes#23416 from kiszk/SPARK-26463.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The PR makes hardcoded configs below to use `ConfigEntry`.
* spark.ui
* spark.ssl
* spark.authenticate
* spark.master.rest
* spark.master.ui
* spark.metrics
* spark.admin
* spark.modify.acl
This patch doesn't change configs which are not relevant to SparkConf (e.g. system properties).
## How was this patch tested?
Existing tests.
Closes#23423 from HeartSaVioR/SPARK-26466.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
Currently there is code scattered in a bunch of places to do different
things related to HTTP security, such as access control, setting
security-related headers, and filtering out bad content. This makes it
really easy to miss these things when writing new UI code.
This change creates a new filter that does all of those things, and
makes sure that all servlet handlers that are attached to the UI get
the new filter and any user-defined filters consistently. The extent
of the actual features should be the same as before.
The new filter is added at the end of the filter chain, because authentication
is done by custom filters and thus needs to happen first. This means that
custom filters see unfiltered HTTP requests - which is actually the current
behavior anyway.
As a side-effect of some of the code refactoring, handlers added after
the initial set also get wrapped with a GzipHandler, which didn't happen
before.
Tested with added unit tests and in a history server with SPNEGO auth
configured.
Closes#23302 from vanzin/SPARK-24522.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
The `toHiveString()` and `toHiveStructString` methods were removed from `HiveUtils` because they have been already implemented in `HiveResult`. One related test was moved to `HiveResultSuite`.
## How was this patch tested?
By tests from `hive-thriftserver`.
Closes#23466 from MaxGekk/dedup-hive-result-string.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
In the PR, I propose to move `hiveResultString()` out of `QueryExecution` and put it to a separate object.
Closes#23409 from MaxGekk/hive-result-string.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Herman van Hovell <hvanhovell@databricks.com>
## What changes were proposed in this pull request?
The build has a lot of deprecation warnings. Some are new in Scala 2.12 and Java 11. We've fixed some, but I wanted to take a pass at fixing lots of easy miscellaneous ones here.
They're too numerous and small to list here; see the pull request. Some highlights:
- `BeanInfo` is deprecated in 2.12, and BeanInfo classes are pretty ancient in Java. Instead, case classes can explicitly declare getters
- Eta expansion of zero-arg methods; foo() becomes () => foo() in many cases
- Floating-point Range is inexact and deprecated, like 0.0 to 100.0 by 1.0
- finalize() is finally deprecated (just needs to be suppressed)
- StageInfo.attempId was deprecated and easiest to remove here
I'm not now going to touch some chunks of deprecation warnings:
- Parquet deprecations
- Hive deprecations (particularly serde2 classes)
- Deprecations in generated code (mostly Thriftserver CLI)
- ProcessingTime deprecations (we may need to revive this class as internal)
- many MLlib deprecations because they concern methods that may be removed anyway
- a few Kinesis deprecations I couldn't figure out
- Mesos get/setRole, which I don't know well
- Kafka/ZK deprecations (e.g. poll())
- Kinesis
- a few other ones that will probably resolve by deleting a deprecated method
## How was this patch tested?
Existing tests, including manual testing with the 2.11 build and Java 11.
Closes#23065 from srowen/SPARK-26090.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This restores scaladoc artifact generation, which got dropped with the Scala 2.12 update. The change looks large, but is almost all due to needing to make the InterfaceStability annotations top-level classes (i.e. `InterfaceStability.Stable` -> `Stable`), unfortunately. A few inner class references had to be qualified too.
Lots of scaladoc warnings now reappear. We can choose to disable generation by default and enable for releases, later.
## How was this patch tested?
N/A; build runs scaladoc now.
Closes#23069 from srowen/SPARK-26026.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
…. Other related changes to get JDK 11 working, to test
## What changes were proposed in this pull request?
- Access `sun.misc.Cleaner` (Java 8) and `jdk.internal.ref.Cleaner` (JDK 9+) by reflection (note: the latter only works if illegal reflective access is allowed)
- Access `sun.misc.Unsafe.invokeCleaner` in Java 9+ instead of `sun.misc.Cleaner` (Java 8)
In order to test anything on JDK 11, I also fixed a few small things, which I include here:
- Fix minor JDK 11 compile issues
- Update scala plugin, Jetty for JDK 11, to facilitate tests too
This doesn't mean JDK 11 tests all pass now, but lots do. Note also that the JDK 9+ solution for the Cleaner has a big caveat.
## How was this patch tested?
Existing tests. Manually tested JDK 11 build and tests, and tests covering this change appear to pass. All Java 8 tests should still pass, but this change alone does not achieve full JDK 11 compatibility.
Closes#22993 from srowen/SPARK-24421.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Deprecated in Java 11, replace Class.newInstance with Class.getConstructor.getInstance, and primtive wrapper class constructors with valueOf or equivalent
## How was this patch tested?
Existing tests.
Closes#22988 from srowen/SPARK-25984.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
'refreshInterval' is not used any where in the headerSparkPage method. So, we don't need to pass the parameter while calling the 'headerSparkPage' method.
## How was this patch tested?
Existing tests
Closes#22864 from shahidki31/unusedCode.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently if we run
```
sh start-thriftserver.sh -h
```
we get
```
...
Thrift server options:
2018-10-15 21:45:39 INFO HiveThriftServer2:54 - Starting SparkContext
2018-10-15 21:45:40 INFO SparkContext:54 - Running Spark version 2.3.2
2018-10-15 21:45:40 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2018-10-15 21:45:40 ERROR SparkContext:91 - Error initializing SparkContext.
org.apache.spark.SparkException: A master URL must be set in your configuration
at org.apache.spark.SparkContext.<init>(SparkContext.scala:367)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2493)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:934)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:925)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:925)
at org.apache.spark.sql.hive.thriftserver.SparkSQLEnv$.init(SparkSQLEnv.scala:48)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2$.main(HiveThriftServer2.scala:79)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.main(HiveThriftServer2.scala)
2018-10-15 21:45:40 ERROR Utils:91 - Uncaught exception in thread main
```
After fix, the usage output is clean:
```
...
Thrift server options:
--hiveconf <property=value> Use value for given property
```
Also exit with code 1, to follow other scripts(this is the behavior of parsing option `-h` for other linux commands as well).
## How was this patch tested?
Manual test.
Closes#22727 from gengliangwang/stsUsage.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
While working on another PR, I noticed that there is quite some legacy Java in there that can be beautified. For example the use og features from Java8, such as:
- Collection libraries
- Try-with-resource blocks
No code has been changed
What are your thoughts on this?
This makes code easier to read, and using try-with-resource makes is less likely to forget to close something.
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22399 from Fokko/SPARK-25408.
Authored-by: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR ensures to call `super.afterAll()` in `override afterAll()` method for test suites.
* Some suites did not call `super.afterAll()`
* Some suites may call `super.afterAll()` only under certain condition
* Others never call `super.afterAll()`.
This PR also ensures to call `super.beforeAll()` in `override beforeAll()` for test suites.
## How was this patch tested?
Existing UTs
Closes#22337 from kiszk/SPARK-25338.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Switch `org.apache.hive.service.server.HiveServer2` to register its shutdown callback with Spark's `ShutdownHookManager`, rather than direct with the Java Runtime callback.
This avoids race conditions in shutdown where the filesystem is shutdown before the flush/write/rename of the event log is completed, particularly on object stores where the write and rename can be slow.
## How was this patch tested?
There's no explicit unit for test this, which is consistent with every other shutdown hook in the codebase.
* There's an implicit test when the scalatest process is halted.
* More manual/integration testing is needed.
HADOOP-15679 has added the ability to explicitly execute the hadoop shutdown hook sequence which spark uses; that could be stabilized for testing if desired, after which all the spark hooks could be tested. Until then: external system tests only.
Author: Steve Loughran <stevel@hortonworks.com>
Closes#22186 from steveloughran/BUG/SPARK-25183-shutdown.
## What changes were proposed in this pull request?
A small change to print the master and appId from spark-sql as with logging turned down all the way (`log4j.logger.org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver=WARN`), we may not know this information easily. This adds the following string before the `spark-sql>` prompt shows on the screen.
`Spark master: yarn, Application Id: application_123456789_12345`
## How was this patch tested?
I ran spark-sql locally and saw the appId displayed as expected.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22025 from abellina/SPARK-25043_print_master_and_app_id_from_sparksql.
Lead-authored-by: Alessandro Bellina <abellina@gmail.com>
Co-authored-by: Alessandro Bellina <abellina@yahoo-inc.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
Fixing typos is sometimes very hard. It's not so easy to visually review them. Recently, I discovered a very useful tool for it, [misspell](https://github.com/client9/misspell).
This pull request fixes minor typos detected by [misspell](https://github.com/client9/misspell) except for the false positives. If you would like me to work on other files as well, let me know.
## How was this patch tested?
### before
```
$ misspell . | grep -v '.js'
R/pkg/R/SQLContext.R:354:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:424:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:445:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:495:43: "definiton" is a misspelling of "definition"
NOTICE-binary:454:16: "containd" is a misspelling of "contained"
R/pkg/R/context.R:46:43: "definiton" is a misspelling of "definition"
R/pkg/R/context.R:74:43: "definiton" is a misspelling of "definition"
R/pkg/R/DataFrame.R:591:48: "persistance" is a misspelling of "persistence"
R/pkg/R/streaming.R:166:44: "occured" is a misspelling of "occurred"
R/pkg/inst/worker/worker.R:65:22: "ouput" is a misspelling of "output"
R/pkg/tests/fulltests/test_utils.R:106:25: "environemnt" is a misspelling of "environment"
common/kvstore/src/test/java/org/apache/spark/util/kvstore/InMemoryStoreSuite.java:38:39: "existant" is a misspelling of "existent"
common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java:83:39: "existant" is a misspelling of "existent"
common/network-common/src/main/java/org/apache/spark/network/crypto/TransportCipher.java:243:46: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:234:19: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:238:63: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:244:46: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:276:39: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/util/AbstractFileRegion.java:27:20: "transfered" is a misspelling of "transferred"
common/unsafe/src/test/scala/org/apache/spark/unsafe/types/UTF8StringPropertyCheckSuite.scala:195:15: "orgin" is a misspelling of "origin"
core/src/main/scala/org/apache/spark/api/python/PythonRDD.scala:621:39: "gauranteed" is a misspelling of "guaranteed"
core/src/main/scala/org/apache/spark/status/storeTypes.scala:113:29: "ect" is a misspelling of "etc"
core/src/main/scala/org/apache/spark/storage/DiskStore.scala:282:18: "transfered" is a misspelling of "transferred"
core/src/main/scala/org/apache/spark/util/ListenerBus.scala:64:17: "overriden" is a misspelling of "overridden"
core/src/test/scala/org/apache/spark/ShuffleSuite.scala:211:7: "substracted" is a misspelling of "subtracted"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:1922:49: "agriculteur" is a misspelling of "agriculture"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:2468:84: "truely" is a misspelling of "truly"
core/src/test/scala/org/apache/spark/storage/FlatmapIteratorSuite.scala:25:18: "persistance" is a misspelling of "persistence"
core/src/test/scala/org/apache/spark/storage/FlatmapIteratorSuite.scala:26:69: "persistance" is a misspelling of "persistence"
data/streaming/AFINN-111.txt:1219:0: "humerous" is a misspelling of "humorous"
dev/run-pip-tests:55:28: "enviroments" is a misspelling of "environments"
dev/run-pip-tests:91:37: "virutal" is a misspelling of "virtual"
dev/merge_spark_pr.py:377:72: "accross" is a misspelling of "across"
dev/merge_spark_pr.py:378:66: "accross" is a misspelling of "across"
dev/run-pip-tests:126:25: "enviroments" is a misspelling of "environments"
docs/configuration.md:1830:82: "overriden" is a misspelling of "overridden"
docs/structured-streaming-programming-guide.md:525:45: "processs" is a misspelling of "processes"
docs/structured-streaming-programming-guide.md:1165:61: "BETWEN" is a misspelling of "BETWEEN"
docs/sql-programming-guide.md:1891:810: "behaivor" is a misspelling of "behavior"
examples/src/main/python/sql/arrow.py:98:8: "substract" is a misspelling of "subtract"
examples/src/main/python/sql/arrow.py:103:27: "substract" is a misspelling of "subtract"
licenses/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/hungarian.txt:170:0: "teh" is a misspelling of "the"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/portuguese.txt:53:0: "eles" is a misspelling of "eels"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:99:20: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:539:11: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/mllib/clustering/LDAOptimizer.scala:77:36: "Teh" is a misspelling of "The"
mllib/src/main/scala/org/apache/spark/mllib/clustering/StreamingKMeans.scala:230:24: "inital" is a misspelling of "initial"
mllib/src/main/scala/org/apache/spark/mllib/stat/MultivariateOnlineSummarizer.scala:276:9: "Euclidian" is a misspelling of "Euclidean"
mllib/src/test/scala/org/apache/spark/ml/clustering/KMeansSuite.scala:237:26: "descripiton" is a misspelling of "descriptions"
python/pyspark/find_spark_home.py:30:13: "enviroment" is a misspelling of "environment"
python/pyspark/context.py:937:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:938:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:939:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:940:12: "supress" is a misspelling of "suppress"
python/pyspark/heapq3.py:6:63: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:7:2: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:263:29: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:263:39: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:270:49: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:270:59: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:275:2: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:275:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:277:29: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:277:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:713:8: "probabilty" is a misspelling of "probability"
python/pyspark/ml/clustering.py:1038:8: "Currenlty" is a misspelling of "Currently"
python/pyspark/ml/stat.py:339:23: "Euclidian" is a misspelling of "Euclidean"
python/pyspark/ml/regression.py:1378:20: "paramter" is a misspelling of "parameter"
python/pyspark/mllib/stat/_statistics.py:262:8: "probabilty" is a misspelling of "probability"
python/pyspark/rdd.py:1363:32: "paramter" is a misspelling of "parameter"
python/pyspark/streaming/tests.py:825:42: "retuns" is a misspelling of "returns"
python/pyspark/sql/tests.py:768:29: "initalization" is a misspelling of "initialization"
python/pyspark/sql/tests.py:3616:31: "initalize" is a misspelling of "initialize"
resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosSchedulerBackendUtil.scala:120:39: "arbitary" is a misspelling of "arbitrary"
resource-managers/mesos/src/test/scala/org/apache/spark/deploy/mesos/MesosClusterDispatcherArgumentsSuite.scala:26:45: "sucessfully" is a misspelling of "successfully"
resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosSchedulerUtils.scala:358:27: "constaints" is a misspelling of "constraints"
resource-managers/yarn/src/test/scala/org/apache/spark/deploy/yarn/YarnClusterSuite.scala:111:24: "senstive" is a misspelling of "sensitive"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala:1063:5: "overwirte" is a misspelling of "overwrite"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala:1348:17: "compatability" is a misspelling of "compatibility"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala:77:36: "paramter" is a misspelling of "parameter"
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:1374:22: "precendence" is a misspelling of "precedence"
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/analysis/AnalysisSuite.scala:238:27: "unnecassary" is a misspelling of "unnecessary"
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/ConditionalExpressionSuite.scala:212:17: "whn" is a misspelling of "when"
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamingSymmetricHashJoinHelper.scala:147:60: "timestmap" is a misspelling of "timestamp"
sql/core/src/test/scala/org/apache/spark/sql/TPCDSQuerySuite.scala:150:45: "precentage" is a misspelling of "percentage"
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVInferSchemaSuite.scala:135:29: "infered" is a misspelling of "inferred"
sql/hive/src/test/resources/golden/udf_instr-1-2e76f819563dbaba4beb51e3a130b922:1:52: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_instr-2-32da357fc754badd6e3898dcc8989182:1:52: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_locate-1-6e41693c9c6dceea4d7fab4c02884e4e:1:63: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_locate-2-d9b5934457931447874d6bb7c13de478:1:63: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_translate-2-f7aa38a33ca0df73b7a1e6b6da4b7fe8:9:79: "occurence" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_translate-2-f7aa38a33ca0df73b7a1e6b6da4b7fe8:13:110: "occurence" is a misspelling of "occurrence"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/annotate_stats_join.q:46:105: "distint" is a misspelling of "distinct"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/auto_sortmerge_join_11.q:29:3: "Currenly" is a misspelling of "Currently"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/avro_partitioned.q:72:15: "existant" is a misspelling of "existent"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/decimal_udf.q:25:3: "substraction" is a misspelling of "subtraction"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/groupby2_map_multi_distinct.q:16:51: "funtion" is a misspelling of "function"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/groupby_sort_8.q:15:30: "issueing" is a misspelling of "issuing"
sql/hive/src/test/scala/org/apache/spark/sql/sources/HadoopFsRelationTest.scala:669:52: "wiht" is a misspelling of "with"
sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java:474:9: "Refering" is a misspelling of "Referring"
```
### after
```
$ misspell . | grep -v '.js'
common/network-common/src/main/java/org/apache/spark/network/util/AbstractFileRegion.java:27:20: "transfered" is a misspelling of "transferred"
core/src/main/scala/org/apache/spark/status/storeTypes.scala:113:29: "ect" is a misspelling of "etc"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:1922:49: "agriculteur" is a misspelling of "agriculture"
data/streaming/AFINN-111.txt:1219:0: "humerous" is a misspelling of "humorous"
licenses/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/hungarian.txt:170:0: "teh" is a misspelling of "the"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/portuguese.txt:53:0: "eles" is a misspelling of "eels"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:99:20: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:539:11: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/mllib/clustering/LDAOptimizer.scala:77:36: "Teh" is a misspelling of "The"
mllib/src/main/scala/org/apache/spark/mllib/stat/MultivariateOnlineSummarizer.scala:276:9: "Euclidian" is a misspelling of "Euclidean"
python/pyspark/heapq3.py:6:63: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:7:2: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:263:29: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:263:39: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:270:49: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:270:59: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:275:2: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:275:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:277:29: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:277:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/ml/stat.py:339:23: "Euclidian" is a misspelling of "Euclidean"
```
Closes#22070 from seratch/fix-typo.
Authored-by: Kazuhiro Sera <seratch@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
## What changes were proposed in this pull request?
Updated URL/href links to include a '/' before '?id' to make links consistent and avoid http 302 redirect errors within UI port 4040 tabs.
## How was this patch tested?
Built a runnable distribution and executed jobs. Validated that http 302 redirects are no longer encountered when clicking on links within UI port 4040 tabs.
Author: Steven Kallman <SJKallmangmail.com>
Author: Kallman, Steven <Steven.Kallman@CapitalOne.com>
Closes#21600 from SJKallman/{Spark-24553}{WEB-UI}-redirect-href-fixes.
## What changes were proposed in this pull request?
`spark-sql` silent mode will broken if`SPARK_HOME/jars` missing `kubernetes-model-2.0.0.jar`.
This pr use `sc.setLogLevel (<logLevel>)` to implement silent mode.
## How was this patch tested?
manual tests
```
build/sbt -Phive -Phive-thriftserver package
export SPARK_PREPEND_CLASSES=true
./bin/spark-sql -S
```
Author: Yuming Wang <yumwang@ebay.com>
Closes#20274 from wangyum/SPARK-20120-FOLLOW-UP.
## What changes were proposed in this pull request?
The PR retrieves the proxyBase automatically from the header `X-Forwarded-Context` (if available). This is the header used by Knox to inform the proxied service about the base path.
This provides 0-configuration support for Knox gateway (instead of having to properly set `spark.ui.proxyBase`) and it allows to access directly SHS when it is proxied by Knox. In the previous scenario, indeed, after setting `spark.ui.proxyBase`, direct access to SHS was not working fine (due to bad link generated).
## How was this patch tested?
added UT + manual tests
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#21268 from mgaido91/SPARK-24209.
## What changes were proposed in this pull request?
This refactors the external catalog to be an interface. It can be easier for the future work in the catalog federation. After the refactoring, `ExternalCatalog` is much cleaner without mixing the listener event generation logic.
## How was this patch tested?
The existing tests
Author: gatorsmile <gatorsmile@gmail.com>
Closes#21122 from gatorsmile/refactorExternalCatalog.
## What changes were proposed in this pull request?
Spark ThriftServer will call UGI.loginUserFromKeytab twice in initialization. This is unnecessary and will cause various potential problems, like Hadoop IPC failure after 7 days, or RM failover issue and so on.
So here we need to remove all the unnecessary login logics and make sure UGI in the context never be created again.
Note this is actually a HS2 issue, If later on we upgrade supported Hive version, the issue may already be fixed in Hive side.
## How was this patch tested?
Local verification in secure cluster.
Author: jerryshao <sshao@hortonworks.com>
Closes#21178 from jerryshao/SPARK-24110.
## What changes were proposed in this pull request?
In SparkSQLCLI, SessionState generates before SparkContext instantiating. When we use --proxy-user to impersonate, it's unable to initializing a metastore client to talk to the secured metastore for no kerberos ticket.
This PR use real user ugi to obtain token for owner before talking to kerberized metastore.
## How was this patch tested?
Manually verified with kerberized hive metasotre / hdfs.
Author: Kent Yao <yaooqinn@hotmail.com>
Closes#20784 from yaooqinn/SPARK-23639.
A few different things going on:
- Remove unused methods.
- Move JSON methods to the only class that uses them.
- Move test-only methods to TestUtils.
- Make getMaxResultSize() a config constant.
- Reuse functionality from existing libraries (JRE or JavaUtils) where possible.
The change also includes changes to a few tests to call `Utils.createTempFile` correctly,
so that temp dirs are created under the designated top-level temp dir instead of
potentially polluting git index.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20706 from vanzin/SPARK-23550.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/18944 added one patch, which allowed a spark session to be created when the hive metastore server is down. However, it did not allow running any commands with the spark session. This brings troubles to the user who only wants to read / write data frames without metastore setup.
## How was this patch tested?
Added some unit tests to read and write data frames based on the original HiveMetastoreLazyInitializationSuite.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Feng Liu <fengliu@databricks.com>
Closes#20681 from liufengdb/completely-lazy.
## What changes were proposed in this pull request?
`--hiveconf` and `--hivevar` variables no longer work since Spark 2.0. The `spark-sql` client has fixed by [SPARK-15730](https://issues.apache.org/jira/browse/SPARK-15730) and [SPARK-18086](https://issues.apache.org/jira/browse/SPARK-18086). but `beeline`/[`Spark SQL HiveThriftServer2`](https://github.com/apache/spark/blob/v2.1.1/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/HiveThriftServer2.scala) is still broken. This pull request fix it.
This pull request works for both `JDBC client` and `beeline`.
## How was this patch tested?
unit tests for `JDBC client`
manual tests for `beeline`:
```
git checkout origin/pr/17886
dev/make-distribution.sh --mvn mvn --tgz -Phive -Phive-thriftserver -Phadoop-2.6 -DskipTests
tar -zxf spark-2.3.0-SNAPSHOT-bin-2.6.5.tgz && cd spark-2.3.0-SNAPSHOT-bin-2.6.5
sbin/start-thriftserver.sh
```
```
cat <<EOF > test.sql
select '\${a}', '\${b}';
EOF
beeline -u jdbc:hive2://localhost:10000 --hiveconf a=avalue --hivevar b=bvalue -f test.sql
```
Author: Yuming Wang <wgyumg@gmail.com>
Closes#17886 from wangyum/SPARK-13983-dev.
Signed-off-by: Atallah Hezbor <atallahhezborgmail.com>
## What changes were proposed in this pull request?
This PR proposes modifying the match statement that gets the columns of a row in HiveThriftServer. There was previously no case for `UserDefinedType`, so querying a table that contained them would throw a match error. The changes catch that case and return the string representation.
## How was this patch tested?
While I would have liked to add a unit test, I couldn't easily incorporate UDTs into the ``HiveThriftServer2Suites`` pipeline. With some guidance I would be happy to push a commit with tests.
Instead I did a manual test by loading a `DataFrame` with Point UDT in a spark shell with a HiveThriftServer. Then in beeline, connecting to the server and querying that table.
Here is the result before the change
```
0: jdbc:hive2://localhost:10000> select * from chicago;
Error: scala.MatchError: org.apache.spark.sql.PointUDT2d980dc3 (of class org.apache.spark.sql.PointUDT) (state=,code=0)
```
And after the change:
```
0: jdbc:hive2://localhost:10000> select * from chicago;
+---------------------------------------+--------------+------------------------+---------------------+--+
| __fid__ | case_number | dtg | geom |
+---------------------------------------+--------------+------------------------+---------------------+--+
| 109602f9-54f8-414b-8c6f-42b1a337643e | 2 | 2016-01-01 19:00:00.0 | POINT (-77 38) |
| 709602f9-fcff-4429-8027-55649b6fd7ed | 1 | 2015-12-31 19:00:00.0 | POINT (-76.5 38.5) |
| 009602f9-fcb5-45b1-a867-eb8ba10cab40 | 3 | 2016-01-02 19:00:00.0 | POINT (-78 39) |
+---------------------------------------+--------------+------------------------+---------------------+--+
```
Author: Atallah Hezbor <atallahhezbor@gmail.com>
Closes#20385 from atallahhezbor/udts_over_hive.
## What changes were proposed in this pull request?
Currently we do not call the `super.init(hiveConf)` in `SparkSQLSessionManager.init`. So we do not load the config `HIVE_SERVER2_SESSION_CHECK_INTERVAL HIVE_SERVER2_IDLE_SESSION_TIMEOUT HIVE_SERVER2_IDLE_SESSION_CHECK_OPERATION` , which cause the session timeout checker does not work.
## How was this patch tested?
manual tests
Author: zuotingbing <zuo.tingbing9@zte.com.cn>
Closes#20025 from zuotingbing/SPARK-22837.
## What changes were proposed in this pull request?
Once a meta hive client is created, it generates its SessionState which creates a lot of session related directories, some deleteOnExit, some does not. if a hive client is useless we may not create it at the very start.
## How was this patch tested?
N/A
cc hvanhovell cloud-fan
Author: Kent Yao <11215016@zju.edu.cn>
Closes#18983 from yaooqinn/patch-1.
## What changes were proposed in this pull request?
When creating a session directory, Thrift should create the parent directory (i.e. /tmp/base_session_log_dir) if it is not present. It is common that many tools delete empty directories, so the directory may be deleted. This can cause the session log to be disabled.
This was fixed in HIVE-12262: this PR brings it in Spark too.
## How was this patch tested?
manual tests
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20281 from mgaido91/SPARK-23089.
## What changes were proposed in this pull request?
This PR cleans up a few Java linter errors for Apache Spark 2.3 release.
## How was this patch tested?
```bash
$ dev/lint-java
Using `mvn` from path: /usr/local/bin/mvn
Checkstyle checks passed.
```
We can see the result from [Travis CI](https://travis-ci.org/dongjoon-hyun/spark/builds/322470787), too.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20101 from dongjoon-hyun/fix-java-lint.
## What changes were proposed in this pull request?
since hive 2.0+ upgrades log4j to log4j2,a lot of [changes](https://issues.apache.org/jira/browse/HIVE-11304) are made working on it.
as spark is not to ready to update its inner hive version(1.2.1) , so I manage to make little changes.
the function registerCurrentOperationLog is moved from SQLOperstion to its parent class ExecuteStatementOperation so spark can use it.
## How was this patch tested?
manual test
Closes#19721 from ChenjunZou/operation-log.
Author: zouchenjun <zouchenjun@youzan.com>
Closes#19961 from ChenjunZou/spark-22496.
## What changes were proposed in this pull request?
since hive 2.0+ upgrades log4j to log4j2,a lot of [changes](https://issues.apache.org/jira/browse/HIVE-11304) are made working on it.
as spark is not to ready to update its inner hive version(1.2.1) , so I manage to make little changes.
the function registerCurrentOperationLog is moved from SQLOperstion to its parent class ExecuteStatementOperation so spark can use it.
## How was this patch tested?
manual test
Author: zouchenjun <zouchenjun@youzan.com>
Closes#19721 from ChenjunZou/operation-log.
## What changes were proposed in this pull request?
a followup of https://github.com/apache/spark/pull/19712 , adds back the `spark.sql.hive.version`, so that if users try to read this config, they can still get a default value instead of null.
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19719 from cloud-fan/minor.
## What changes were proposed in this pull request?
At the beginning https://github.com/apache/spark/pull/2843 added `spark.sql.hive.version` to reveal underlying hive version for jdbc connections. For some time afterwards, it was used as a version identifier for the execution hive client.
Actually there is no hive client for executions in spark now and there are no usages of HIVE_EXECUTION_VERSION found in whole spark project. HIVE_EXECUTION_VERSION is set by `spark.sql.hive.version`, which is still set internally in some places or by users, this may confuse developers and users with HIVE_METASTORE_VERSION(spark.sql.hive.metastore.version).
It might better to be removed.
## How was this patch tested?
modify some existing ut
cc cloud-fan gatorsmile
Author: Kent Yao <yaooqinn@hotmail.com>
Closes#19712 from yaooqinn/SPARK-22487.
## What changes were proposed in this pull request?
While running bin/spark-sql, we will reuse cliSessionState, but the Hive configurations generated here just points to a dummy meta store which actually should be the real one. And the warehouse is determined later in SharedState, HiveClient should respect this config changing in this case too.
## How was this patch tested?
existing ut
cc cloud-fan jiangxb1987
Author: Kent Yao <yaooqinn@hotmail.com>
Closes#19068 from yaooqinn/SPARK-21428-FOLLOWUP.
Spark ThriftServer doesn't support spnego auth for thrift/http protocol, this mainly used for knox+thriftserver scenario. Since in HiveServer2 CLIService there already has existing codes to support it. So here copy it to Spark ThriftServer to make it support.
Related Hive JIRA HIVE-6697.
Manual verification.
Author: jerryshao <sshao@hortonworks.com>
Closes#18628 from jerryshao/SPARK-21407.
Change-Id: I61ef0c09f6972bba982475084a6b0ae3a74e385e
## What changes were proposed in this pull request?
Set isolated to false while using builtin hive jars and `SessionState.get` returns a `CliSessionState` instance.
## How was this patch tested?
1 Unit Tests
2 Manually verified: `hive.exec.strachdir` was only created once because of reusing cliSessionState
```java
➜ spark git:(SPARK-21428) ✗ bin/spark-sql --conf spark.sql.hive.metastore.jars=builtin
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
17/07/16 23:59:27 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/16 23:59:27 INFO HiveMetaStore: 0: Opening raw store with implemenation class:org.apache.hadoop.hive.metastore.ObjectStore
17/07/16 23:59:27 INFO ObjectStore: ObjectStore, initialize called
17/07/16 23:59:28 INFO Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored
17/07/16 23:59:28 INFO Persistence: Property datanucleus.cache.level2 unknown - will be ignored
17/07/16 23:59:29 INFO ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order"
17/07/16 23:59:30 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
17/07/16 23:59:30 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
17/07/16 23:59:31 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
17/07/16 23:59:31 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
17/07/16 23:59:31 INFO MetaStoreDirectSql: Using direct SQL, underlying DB is DERBY
17/07/16 23:59:31 INFO ObjectStore: Initialized ObjectStore
17/07/16 23:59:31 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
17/07/16 23:59:31 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
17/07/16 23:59:32 INFO HiveMetaStore: Added admin role in metastore
17/07/16 23:59:32 INFO HiveMetaStore: Added public role in metastore
17/07/16 23:59:32 INFO HiveMetaStore: No user is added in admin role, since config is empty
17/07/16 23:59:32 INFO HiveMetaStore: 0: get_all_databases
17/07/16 23:59:32 INFO audit: ugi=Kent ip=unknown-ip-addr cmd=get_all_databases
17/07/16 23:59:32 INFO HiveMetaStore: 0: get_functions: db=default pat=*
17/07/16 23:59:32 INFO audit: ugi=Kent ip=unknown-ip-addr cmd=get_functions: db=default pat=*
17/07/16 23:59:32 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MResourceUri" is tagged as "embedded-only" so does not have its own datastore table.
17/07/16 23:59:32 INFO SessionState: Created local directory: /var/folders/k2/04p4k4ws73l6711h_mz2_tq00000gn/T/beea7261-221a-4711-89e8-8b12a9d37370_resources
17/07/16 23:59:32 INFO SessionState: Created HDFS directory: /tmp/hive/Kent/beea7261-221a-4711-89e8-8b12a9d37370
17/07/16 23:59:32 INFO SessionState: Created local directory: /var/folders/k2/04p4k4ws73l6711h_mz2_tq00000gn/T/Kent/beea7261-221a-4711-89e8-8b12a9d37370
17/07/16 23:59:32 INFO SessionState: Created HDFS directory: /tmp/hive/Kent/beea7261-221a-4711-89e8-8b12a9d37370/_tmp_space.db
17/07/16 23:59:32 INFO SparkContext: Running Spark version 2.3.0-SNAPSHOT
17/07/16 23:59:32 INFO SparkContext: Submitted application: SparkSQL::10.0.0.8
17/07/16 23:59:32 INFO SecurityManager: Changing view acls to: Kent
17/07/16 23:59:32 INFO SecurityManager: Changing modify acls to: Kent
17/07/16 23:59:32 INFO SecurityManager: Changing view acls groups to:
17/07/16 23:59:32 INFO SecurityManager: Changing modify acls groups to:
17/07/16 23:59:32 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Kent); groups with view permissions: Set(); users with modify permissions: Set(Kent); groups with modify permissions: Set()
17/07/16 23:59:33 INFO Utils: Successfully started service 'sparkDriver' on port 51889.
17/07/16 23:59:33 INFO SparkEnv: Registering MapOutputTracker
17/07/16 23:59:33 INFO SparkEnv: Registering BlockManagerMaster
17/07/16 23:59:33 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
17/07/16 23:59:33 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
17/07/16 23:59:33 INFO DiskBlockManager: Created local directory at /private/var/folders/k2/04p4k4ws73l6711h_mz2_tq00000gn/T/blockmgr-9cfae28a-01e9-4c73-a1f1-f76fa52fc7a5
17/07/16 23:59:33 INFO MemoryStore: MemoryStore started with capacity 366.3 MB
17/07/16 23:59:33 INFO SparkEnv: Registering OutputCommitCoordinator
17/07/16 23:59:33 INFO Utils: Successfully started service 'SparkUI' on port 4040.
17/07/16 23:59:33 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://10.0.0.8:4040
17/07/16 23:59:33 INFO Executor: Starting executor ID driver on host localhost
17/07/16 23:59:33 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 51890.
17/07/16 23:59:33 INFO NettyBlockTransferService: Server created on 10.0.0.8:51890
17/07/16 23:59:33 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
17/07/16 23:59:33 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 10.0.0.8, 51890, None)
17/07/16 23:59:33 INFO BlockManagerMasterEndpoint: Registering block manager 10.0.0.8:51890 with 366.3 MB RAM, BlockManagerId(driver, 10.0.0.8, 51890, None)
17/07/16 23:59:33 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 10.0.0.8, 51890, None)
17/07/16 23:59:33 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 10.0.0.8, 51890, None)
17/07/16 23:59:34 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('file:/Users/Kent/Documents/spark/spark-warehouse').
17/07/16 23:59:34 INFO SharedState: Warehouse path is 'file:/Users/Kent/Documents/spark/spark-warehouse'.
17/07/16 23:59:34 INFO HiveUtils: Initializing HiveMetastoreConnection version 1.2.1 using Spark classes.
17/07/16 23:59:34 INFO HiveClientImpl: Warehouse location for Hive client (version 1.2.2) is /user/hive/warehouse
17/07/16 23:59:34 INFO HiveMetaStore: 0: get_database: default
17/07/16 23:59:34 INFO audit: ugi=Kent ip=unknown-ip-addr cmd=get_database: default
17/07/16 23:59:34 INFO HiveClientImpl: Warehouse location for Hive client (version 1.2.2) is /user/hive/warehouse
17/07/16 23:59:34 INFO HiveMetaStore: 0: get_database: global_temp
17/07/16 23:59:34 INFO audit: ugi=Kent ip=unknown-ip-addr cmd=get_database: global_temp
17/07/16 23:59:34 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
17/07/16 23:59:34 INFO HiveClientImpl: Warehouse location for Hive client (version 1.2.2) is /user/hive/warehouse
17/07/16 23:59:34 INFO StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint
spark-sql>
```
cc cloud-fan gatorsmile
Author: Kent Yao <yaooqinn@hotmail.com>
Author: hzyaoqin <hzyaoqin@corp.netease.com>
Closes#18648 from yaooqinn/SPARK-21428.
## What changes were proposed in this pull request?
When a session is closed the Thriftserver doesn't cancel the jobs which may still be running. This is a huge waste of resources.
This PR address the problem canceling the pending jobs when a session is closed.
## How was this patch tested?
The patch was tested manually.
Author: Marco Gaido <mgaido@hortonworks.com>
Closes#18951 from mgaido91/SPARK-21738.
This version fixes a few issues in the import order checker; it provides
better error messages, and detects more improper ordering (thus the need
to change a lot of files in this patch). The main fix is that it correctly
complains about the order of packages vs. classes.
As part of the above, I moved some "SparkSession" import in ML examples
inside the "$example on$" blocks; that didn't seem consistent across
different source files to start with, and avoids having to add more on/off blocks
around specific imports.
The new scalastyle also seems to have a better header detector, so a few
license headers had to be updated to match the expected indentation.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#18943 from vanzin/SPARK-21731.
## What changes were proposed in this pull request?
This PR changes the codes to lazily init hive metastore client so that we can create SparkSession without talking to the hive metastore sever.
It's pretty helpful when you set a hive metastore server but it's down. You can still start the Spark shell to debug.
## How was this patch tested?
The new unit test.
Author: Shixiong Zhu <shixiong@databricks.com>
Closes#18944 from zsxwing/hive-lazy-init.
## What changes were proposed in this pull request?
When we use `bin/spark-sql` command configuring `--conf spark.hadoop.foo=bar`, the `SparkSQLCliDriver` initializes an instance of hiveconf, it does not add `foo->bar` to it.
this pr gets `spark.hadoop.*` properties from sysProps to this hiveconf
## How was this patch tested?
UT
Author: hzyaoqin <hzyaoqin@corp.netease.com>
Author: Kent Yao <yaooqinn@hotmail.com>
Closes#18668 from yaooqinn/SPARK-21451.
## What changes were proposed in this pull request?
Error class name for log in several classes. such as:
`2017-08-02 16:43:37,695 INFO CompositeService: Operation log root directory is created: /tmp/mr/operation_logs`
`Operation log root directory is created ... ` is in `SessionManager.java` actually.
## How was this patch tested?
manual tests
Author: zuotingbing <zuo.tingbing9@zte.com.cn>
Closes#18816 from zuotingbing/SPARK-21611.
## What changes were proposed in this pull request?
if the object extends Logging, i suggest to remove the var LOG which is useless.
## How was this patch tested?
Exist tests
Author: zuotingbing <zuo.tingbing9@zte.com.cn>
Closes#18811 from zuotingbing/SPARK-21604.
## What changes were proposed in this pull request?
[SPARK-5100](343d3bfafd) added Spark Thrift Server(STS) UI and the following logic to handle exceptions on case `Throwable`.
```scala
HiveThriftServer2.listener.onStatementError(
statementId, e.getMessage, SparkUtils.exceptionString(e))
```
However, there occurred a missed case after implementing [SPARK-6964](eb19d3f75c)'s `Support Cancellation in the Thrift Server` by adding case `HiveSQLException` before case `Throwable`.
```scala
case e: HiveSQLException =>
if (getStatus().getState() == OperationState.CANCELED) {
return
} else {
setState(OperationState.ERROR)
throw e
}
// Actually do need to catch Throwable as some failures don't inherit from Exception and
// HiveServer will silently swallow them.
case e: Throwable =>
val currentState = getStatus().getState()
logError(s"Error executing query, currentState $currentState, ", e)
setState(OperationState.ERROR)
HiveThriftServer2.listener.onStatementError(
statementId, e.getMessage, SparkUtils.exceptionString(e))
throw new HiveSQLException(e.toString)
```
Logically, we had better add `HiveThriftServer2.listener.onStatementError` on case `HiveSQLException`, too.
## How was this patch tested?
N/A
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#17643 from dongjoon-hyun/SPARK-20345.
## What changes were proposed in this pull request?
Currently the `DataFrameWriter` operations have several problems:
1. non-file-format data source writing action doesn't show up in the SQL tab in Spark UI
2. file-format data source writing action shows a scan node in the SQL tab, without saying anything about writing. (streaming also have this issue, but not fixed in this PR)
3. Spark SQL CLI actions don't show up in the SQL tab.
This PR fixes all of them, by refactoring the `ExecuteCommandExec` to make it have children.
close https://github.com/apache/spark/pull/17540
## How was this patch tested?
existing tests.
Also test the UI manually. For a simple command: `Seq(1 -> "a").toDF("i", "j").write.parquet("/tmp/qwe")`
before this PR:
<img width="266" alt="qq20170523-035840 2x" src="https://cloud.githubusercontent.com/assets/3182036/26326050/24e18ba2-3f6c-11e7-8817-6dd275bf6ac5.png">
after this PR:
<img width="287" alt="qq20170523-035708 2x" src="https://cloud.githubusercontent.com/assets/3182036/26326054/2ad7f460-3f6c-11e7-8053-d68325beb28f.png">
Author: Wenchen Fan <wenchen@databricks.com>
Closes#18064 from cloud-fan/execution.
## What changes were proposed in this pull request?
Add stripXSS and stripXSSMap to Spark Core's UIUtils. Calling these functions at any point that getParameter is called against a HttpServletRequest.
## How was this patch tested?
Unit tests, IBM Security AppScan Standard no longer showing vulnerabilities, manual verification of WebUI pages.
Author: NICHOLAS T. MARION <nmarion@us.ibm.com>
Closes#17686 from n-marion/xss-fix.
## What changes were proposed in this pull request?
val and var should strictly follow the Scala syntax
## How was this patch tested?
manual test and exisiting test cases
Author: ouyangxiaochen <ou.yangxiaochen@zte.com.cn>
Closes#17628 from ouyangxiaochen/spark-413.
## What changes were proposed in this pull request?
This PR proposes to run Spark unidoc to test Javadoc 8 build as Javadoc 8 is easily re-breakable.
There are several problems with it:
- It introduces little extra bit of time to run the tests. In my case, it took 1.5 mins more (`Elapsed :[94.8746569157]`). How it was tested is described in "How was this patch tested?".
- > One problem that I noticed was that Unidoc appeared to be processing test sources: if we can find a way to exclude those from being processed in the first place then that might significantly speed things up.
(see joshrosen's [comment](https://issues.apache.org/jira/browse/SPARK-18692?focusedCommentId=15947627&page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel#comment-15947627))
To complete this automated build, It also suggests to fix existing Javadoc breaks / ones introduced by test codes as described above.
There fixes are similar instances that previously fixed. Please refer https://github.com/apache/spark/pull/15999 and https://github.com/apache/spark/pull/16013
Note that this only fixes **errors** not **warnings**. Please see my observation https://github.com/apache/spark/pull/17389#issuecomment-288438704 for spurious errors by warnings.
## How was this patch tested?
Manually via `jekyll build` for building tests. Also, tested via running `./dev/run-tests`.
This was tested via manually adding `time.time()` as below:
```diff
profiles_and_goals = build_profiles + sbt_goals
print("[info] Building Spark unidoc (w/Hive 1.2.1) using SBT with these arguments: ",
" ".join(profiles_and_goals))
+ import time
+ st = time.time()
exec_sbt(profiles_and_goals)
+ print("Elapsed :[%s]" % str(time.time() - st))
```
produces
```
...
========================================================================
Building Unidoc API Documentation
========================================================================
...
[info] Main Java API documentation successful.
...
Elapsed :[94.8746569157]
...
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#17477 from HyukjinKwon/SPARK-18692.
## What changes were proposed in this pull request?
Add Locale.ROOT to internal calls to String `toLowerCase`, `toUpperCase`, to avoid inadvertent locale-sensitive variation in behavior (aka the "Turkish locale problem").
The change looks large but it is just adding `Locale.ROOT` (the locale with no country or language specified) to every call to these methods.
## How was this patch tested?
Existing tests.
Author: Sean Owen <sowen@cloudera.com>
Closes#17527 from srowen/SPARK-20156.
## What changes were proposed in this pull request?
If the shutdown hook called before the variable `uiTab` is set , it will throw a NullPointerException.
## How was this patch tested?
manual tests
Author: zuotingbing <zuo.tingbing9@zte.com.cn>
Closes#17496 from zuotingbing/SPARK-HiveThriftServer2.
## What changes were proposed in this pull request?
The column comment was missing while constructing the Hive TableSchema. This fix will preserve the original comment.
## How was this patch tested?
I have added a new test case to test the column with/without comment.
Author: bomeng <bmeng@us.ibm.com>
Closes#17470 from bomeng/SPARK-20146.
## What changes were proposed in this pull request?
Bugfix from [SPARK-19540.](https://github.com/apache/spark/pull/16826)
Cloning SessionState does not clone query execution listeners, so cloned session is unable to listen to events on queries.
## How was this patch tested?
- Unit test
Author: Kunal Khamar <kkhamar@outlook.com>
Closes#17379 from kunalkhamar/clone-bugfix.
## What changes were proposed in this pull request?
Commit ea361165e1 moved most of the logic from the SessionState classes into an accompanying builder. This makes the existence of the `HiveSessionState` redundant. This PR removes the `HiveSessionState`.
## How was this patch tested?
Existing tests.
Author: Herman van Hovell <hvanhovell@databricks.com>
Closes#17457 from hvanhovell/SPARK-20126.
## What changes were proposed in this pull request?
In spark 1.x ,the name of ThriftServer is SparkSQL:localHostName. While the ThriftServer default name is changed to the className of HiveThfift2 , which is not appropriate.
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: lvdongr <lv.dongdong@zte.com.cn>
Closes#17010 from lvdongr/ThriftserverName.
## What changes were proposed in this pull request?
To support `FETCH_FIRST`, SPARK-16563 used Scala `Iterator.duplicate`. However,
Scala `Iterator.duplicate` uses a **queue to buffer all items between both iterators**,
this causes GC and hangs for queries with large number of rows. We should not use this,
especially for `spark.sql.thriftServer.incrementalCollect`.
https://github.com/scala/scala/blob/2.12.x/src/library/scala/collection/Iterator.scala#L1262-L1300
## How was this patch tested?
Pass the existing tests.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#16440 from dongjoon-hyun/SPARK-18857.
## What changes were proposed in this pull request?
There are many locations in the Spark repo where the same word occurs consecutively. Sometimes they are appropriately placed, but many times they are not. This PR removes the inappropriately duplicated words.
## How was this patch tested?
N/A since only docs or comments were updated.
Author: Niranjan Padmanabhan <niranjan.padmanabhan@gmail.com>
Closes#16455 from neurons/np.structure_streaming_doc.
### What changes were proposed in this pull request?
Since `spark.sql.hive.thriftServer.singleSession` is a configuration of SQL component, this conf can be moved from `SparkConf` to `StaticSQLConf`.
When we introduced `spark.sql.hive.thriftServer.singleSession`, all the SQL configuration are session specific. They can be modified in different sessions.
In Spark 2.1, static SQL configuration is added. It is a perfect fit for `spark.sql.hive.thriftServer.singleSession`. Previously, we did the same move for `spark.sql.warehouse.dir` from `SparkConf` to `StaticSQLConf`
### How was this patch tested?
Added test cases in HiveThriftServer2Suites.scala
Author: gatorsmile <gatorsmile@gmail.com>
Closes#16392 from gatorsmile/hiveThriftServerSingleSession.
## What changes were proposed in this pull request?
This is a follow-up work of #15618.
Close file source;
For any newly created streaming context outside the withContext, explicitly close the context.
## How was this patch tested?
Existing unit tests.
Author: wm624@hotmail.com <wm624@hotmail.com>
Closes#15818 from wangmiao1981/rtest.
## What changes were proposed in this pull request?
This adds support for Hive variables:
* Makes values set via `spark-sql --hivevar name=value` accessible
* Adds `getHiveVar` and `setHiveVar` to the `HiveClient` interface
* Adds a SessionVariables trait for sessions like Hive that support variables (including Hive vars)
* Adds SessionVariables support to variable substitution
* Adds SessionVariables support to the SET command
## How was this patch tested?
* Adds a test to all supported Hive versions for accessing Hive variables
* Adds HiveVariableSubstitutionSuite
Author: Ryan Blue <blue@apache.org>
Closes#15738 from rdblue/SPARK-18086-add-hivevar-support.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
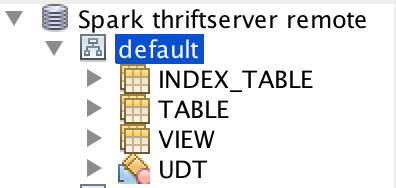{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}