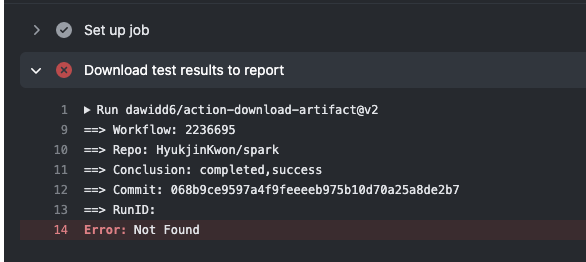
### What changes were proposed in this pull request?
This PR replaces 127.0.0.1 to `localhost`.
### Why are the changes needed?
- https://github.com/apache/spark/pull/32096#discussion_r610349269
- https://github.com/apache/spark/pull/32096#issuecomment-816442481
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
I didn't test it because it's CI specific issue. I will test it in Github Actions build in this PR.
Closes#32102 from HyukjinKwon/SPARK-35002.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request?
This PR tries to fix the `java.net.BindException` when testing with Github Action:
```
[info] org.apache.spark.sql.kafka010.producer.InternalKafkaProducerPoolSuite *** ABORTED *** (282 milliseconds)
[info] java.net.BindException: Cannot assign requested address: Service 'sparkDriver' failed after 100 retries (on a random free port)! Consider explicitly setting the appropriate binding address for the service 'sparkDriver' (for example spark.driver.bindAddress for SparkDriver) to the correct binding address.
[info] at sun.nio.ch.Net.bind0(Native Method)
[info] at sun.nio.ch.Net.bind(Net.java:461)
[info] at sun.nio.ch.Net.bind(Net.java:453)
```
https://github.com/apache/spark/pull/32090/checks?check_run_id=2295418529
### Why are the changes needed?
Fix test framework.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Test by Github Action.
Closes#32096 from wangyum/SPARK_LOCAL_IP=localhost.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Now that we merged the Koalas main code into PySpark code base (#32036), we should enable doctests on the Spark's infrastructure.
### Why are the changes needed?
Currently the pandas-on-Spark modules are not tested at all.
We should enable doctests first, and we will port other unit tests separately later.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Enabled the whole doctests.
Closes#32069 from ueshin/issues/SPARK-34972/pyspark-pandas_doctests.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to set the system encoding as UTF-8. For some reasons, it looks like GitHub Actions machines changed theirs to ASCII by default. This leads to default encoding/decoding to use ASCII in Python, e.g.) `"a".encode()`, and looks like Sphinx depends on that.
### Why are the changes needed?
To recover GItHub Actions build.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Tested in https://github.com/apache/spark/pull/32046Closes#32047 from HyukjinKwon/SPARK-34951.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to add a workflow that allows developers to run benchmarks and download the results files. After this PR, developers can run benchmarks in GitHub Actions in their fork.
### Why are the changes needed?
1. Very easy to use.
2. We can use the (almost) same environment to run the benchmarks. Given my few experiments and observation, the CPU, cores, and memory are same.
3. Does not burden ASF's resource at GitHub Actions.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Manually tested in https://github.com/HyukjinKwon/spark/pull/31.
Entire benchmarks are being run as below:
- [Run benchmarks: * (JDK 11)](https://github.com/HyukjinKwon/spark/actions/runs/713575465)
- [Run benchmarks: * (JDK 8)](https://github.com/HyukjinKwon/spark/actions/runs/713154337)
### How do developers use it in their fork?
1. **Go to Actions in your fork, and click "Run benchmarks"**

2. **Run the benchmarks with JDK 8 or 11 with benchmark classes to run. Glob pattern is supported just like `testOnly` in SBT**

3. **After finishing the jobs, the benchmark results are available on the top in the underlying workflow:**

4. **After downloading it, unzip and untar at Spark git root directory:**
```bash
cd .../spark
mv ~/Downloads/benchmark-results-8.zip .
unzip benchmark-results-8.zip
tar -xvf benchmark-results-8.tar
```
5. **Check the results:**
```bash
git status
```
```
...
modified: core/benchmarks/MapStatusesSerDeserBenchmark-results.txt
```
Closes#32015 from HyukjinKwon/SPARK-34821-pr.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR fixes the GA failure related to R linter which happens on some PRs (e.g. #32023, #32025).
The reason seems `Rscript -e "devtools::install_github('jimhester/lintrv2.0.0')"` fails to download `lintrv2.0.0`.
I don't know why but I confirmed we can download `v2.0.1`.
### Why are the changes needed?
To keep GA healthy.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
GA itself.
Closes#32028 from sarutak/hotfix-r.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR proposes to cache Maven, SBT and Scala in all jobs that use them. For simplicity, we use the same key `build-` and just cache all SBT, Maven and Scala. The cache is not very large.
### Why are the changes needed?
To speed up the build.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
It will be tested in this PR's GA jobs.
Closes#32011 from HyukjinKwon/SPARK-34915.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
This PR proposes to add a new job in GitHub Actions to check the output of TPC-DS queries.
NOTE: I've checked that the new job took 17m 35s in the GitHub Actions env.
### Why are the changes needed?
There are some cases where we noticed runtime-realted bugs after merging commits (e.g. .SPARK-33822). Therefore, I think it is worth adding a new job in GitHub Actions to check query output of TPC-DS (sf=1).
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
The new test added.
Closes#31886 from maropu/TPCDSQueryTestSuite.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
1. This PR aims to ignore ORC encryption tests when ORC shim is loaded by old Hadoop library by some other tests. The test coverage is preserved by Jenkins SBT runs and GitHub Action jobs. This PR only aims to recover Maven Jenkins jobs.
2. In addition, this PR simplifies SBT testing by refactor the test config to `SparkBuild.scala/pom.xml` and remove `DedicatedJVMTest`. This will remove one GitHub Action job which was recently added for `DedicatedJVMTest` tag.
### Why are the changes needed?
Currently, Maven test fails when it runs in a batch mode because `HadoopShimsPre2_3$NullKeyProvider` is loaded.
**MVN COMMAND**
```
$ mvn test -pl sql/core --am -Dtest=none -DwildcardSuites=org.apache.spark.sql.execution.datasources.orc.OrcV1QuerySuite,org.apache.spark.sql.execution.datasources.orc.OrcEncryptionSuite
```
**BEFORE**
```
- Write and read an encrypted table *** FAILED ***
...
Cause: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 1.0 failed 1 times, most recent failure: Lost task 0.0 in stage 1.0 (TID 1) (localhost executor driver): java.lang.IllegalArgumentException: Unknown key pii
at org.apache.orc.impl.HadoopShimsPre2_3$NullKeyProvider.getCurrentKeyVersion(HadoopShimsPre2_3.java:71)
at org.apache.orc.impl.WriterImpl.getKey(WriterImpl.java:871)
```
**AFTER**
```
OrcV1QuerySuite
...
OrcEncryptionSuite:
- Write and read an encrypted file !!! CANCELED !!!
[] was empty org.apache.orc.impl.HadoopShimsPre2_3$NullKeyProvider1b705f65 doesn't has the test keys. ORC shim is created with old Hadoop libraries (OrcEncryptionSuite.scala:39)
- Write and read an encrypted table !!! CANCELED !!!
[] was empty org.apache.orc.impl.HadoopShimsPre2_3$NullKeyProvider22adeee1 doesn't has the test keys. ORC shim is created with old Hadoop libraries (OrcEncryptionSuite.scala:67)
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the Jenkins Maven tests.
For SBT command,
- the test suite required a dedicated JVM (Before)
- the test suite doesn't require a dedicated JVM (After)
```
$ build/sbt "sql/testOnly *.OrcV1QuerySuite *.OrcEncryptionSuite"
...
[info] OrcV1QuerySuite
...
[info] - SPARK-20728 Make ORCFileFormat configurable between sql/hive and sql/core (26 milliseconds)
[info] OrcEncryptionSuite:
[info] - Write and read an encrypted file (431 milliseconds)
[info] - Write and read an encrypted table (359 milliseconds)
[info] All tests passed.
[info] Passed: Total 35, Failed 0, Errors 0, Passed 35
```
Closes#31697 from dongjoon-hyun/SPARK-34578-TEST.
Lead-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Cleanup all Zinc standalone server code, and realated coniguration.
### Why are the changes needed?

- Zinc is the incremental compiler to speed up builds of compilation.
- The scala-maven-plugin is the mave plugin, which is used by Spark, one of the function is to integrate the Zinc to enable the incremental compiler.
- Since Spark v3.0.0 ([SPARK-28759](https://issues.apache.org/jira/browse/SPARK-28759)), the scala-maven-plugin is upgraded to v4.X, that means Zinc v0.3.13 standalone server is useless anymore.
However, we still download, install, start the standalone Zinc server. we should remove all zinc standalone server code, and all related configuration.
See more in [SPARK-34539](https://issues.apache.org/jira/projects/SPARK/issues/SPARK-34539) or the doc [Zinc standalone server is useless after scala-maven-plugin 4.x](https://docs.google.com/document/d/1u4kCHDx7KjVlHGerfmbcKSB0cZo6AD4cBdHSse-SBsM).
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Run any mvn build:
./build/mvn -DskipTests clean package -pl core
You could see the increamental compilation is still working, the stage of "scala-maven-plugin:4.3.0:compile (scala-compile-first)" with incremental compilation info, like:
```
[INFO] --- scala-maven-plugin:4.3.0:testCompile (scala-test-compile-first) spark-core_2.12 ---
[INFO] Using incremental compilation using Mixed compile order
[INFO] Compiler bridge file: /root/.sbt/1.0/zinc/org.scala-sbt/org.scala-sbt-compiler-bridge_2.12-1.3.1-bin_2.12.10__52.0-1.3.1_20191012T045515.jar
[INFO] compiler plugin: BasicArtifact(com.github.ghik,silencer-plugin_2.12.10,1.6.0,null)
[INFO] Compiling 303 Scala sources and 27 Java sources to /root/spark/core/target/scala-2.12/test-classes ...
```
Closes#31647 from Yikun/cleanup-zinc.
Authored-by: Yikun Jiang <yikunkero@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR aims to add a test tag, `DedicatedJVMTest`, and replace `SecurityTest` with this.
### Why are the changes needed?
To have a reusable general test tag.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the CIs.
Closes#31607 from dongjoon-hyun/SPARK-34495.
Lead-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a retry of #31065 . Last time, the newly add test cases passed in Jenkins and individually, but it's reverted because they fail when `GitHub Action` runs with `SERIAL_SBT_TESTS=1`.
In this PR, `SecurityTest` tag is used to isolate `KeyProvider`.
This PR aims to add a basis for columnar encryption test framework by add `OrcEncryptionSuite` and `FakeKeyProvider`.
Please note that we will improve more in both Apache Spark and Apache ORC in Apache Spark 3.2.0 timeframe.
### Why are the changes needed?
Apache ORC 1.6 supports columnar encryption.
### Does this PR introduce _any_ user-facing change?
No. This is for a test case.
### How was this patch tested?
Pass the newly added test suite.
Closes#31603 from dongjoon-hyun/SPARK-34486-RETRY.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Improving the documentation and release process by pinning Jekyll version by Gemfile and Bundler.
Some files and their responsibilities within this PR:
- `docs/.bundle/config` is used to specify a directory "docs/.local_ruby_bundle" which will be used as destination to install the ruby packages into instead of the global one which requires root access
- `docs/Gemfile` is specifying the required Jekyll version and other top level gem versions
- `docs/Gemfile.lock` is generated by the "bundle install". This file contains the exact resolved versions of all the gems including the top level gems and all the direct and transitive dependencies of those gems. When this file is generated it contains a platform related section "PLATFORMS" (in my case after the generation it was "universal-darwin-19"). Still this file must be under version control as when the version of a gem does not fit to the one specified in `Gemfile` an error comes (i.e. if the `Gemfile.lock` was generated for Jekyll 4.1.0 and its version is updated in the `Gemfile` to 4.2.0 then it triggers the error: "The bundle currently has jekyll locked at 4.1.0."). This is solution is also suggested officially in [its documentation](https://bundler.io/rationale.html#checking-your-code-into-version-control). To get rid of the specific platform (like "universal-darwin-19") first we have to add "ruby" as platform [which means this should work on every platform where Ruby runs](https://guides.rubygems.org/what-is-a-gem/)) by running "bundle lock --add-platform ruby" then the specific platform can be removed by "bundle lock --remove-platform universal-darwin-19".
After this the correct process to update Jekyll version is the following:
1. update the version in `Gemfile`
2. run "bundle update" which updates the `Gemfile.lock`
3. commit both files
This process for version update is tested for details please check the testing section.
### Why are the changes needed?
Using different Jekyll versions can generate different output documents.
This PR standardize the process.
### Does this PR introduce _any_ user-facing change?
No, assuming the release was done via docker by using `do-release-docker.sh`.
In that case there should be no difference at all as the same Jekyll version is specified in the Gemfile.
### How was this patch tested?
#### Testing document generation
Doc generation step was triggered via the docker release:
```
$ ./do-release-docker.sh -d ~/working -n -s docs
...
========================
= Building documentation...
Command: /opt/spark-rm/release-build.sh docs
Log file: docs.log
Skipping publish step.
```
The docs.log contains the followings:
```
Building Spark docs
Fetching gem metadata from https://rubygems.org/.........
Using bundler 2.2.9
Fetching rb-fsevent 0.10.4
Fetching forwardable-extended 2.6.0
Fetching public_suffix 4.0.6
Fetching colorator 1.1.0
Fetching eventmachine 1.2.7
Fetching http_parser.rb 0.6.0
Fetching ffi 1.14.2
Fetching concurrent-ruby 1.1.8
Installing colorator 1.1.0
Installing forwardable-extended 2.6.0
Installing rb-fsevent 0.10.4
Installing public_suffix 4.0.6
Installing http_parser.rb 0.6.0 with native extensions
Installing eventmachine 1.2.7 with native extensions
Installing concurrent-ruby 1.1.8
Fetching rexml 3.2.4
Fetching liquid 4.0.3
Installing ffi 1.14.2 with native extensions
Installing rexml 3.2.4
Installing liquid 4.0.3
Fetching mercenary 0.4.0
Installing mercenary 0.4.0
Fetching rouge 3.26.0
Installing rouge 3.26.0
Fetching safe_yaml 1.0.5
Installing safe_yaml 1.0.5
Fetching unicode-display_width 1.7.0
Installing unicode-display_width 1.7.0
Fetching webrick 1.7.0
Installing webrick 1.7.0
Fetching pathutil 0.16.2
Fetching kramdown 2.3.0
Fetching terminal-table 2.0.0
Fetching addressable 2.7.0
Fetching i18n 1.8.9
Installing terminal-table 2.0.0
Installing pathutil 0.16.2
Installing i18n 1.8.9
Installing addressable 2.7.0
Installing kramdown 2.3.0
Fetching kramdown-parser-gfm 1.1.0
Installing kramdown-parser-gfm 1.1.0
Fetching rb-inotify 0.10.1
Fetching sassc 2.4.0
Fetching em-websocket 0.5.2
Installing rb-inotify 0.10.1
Installing em-websocket 0.5.2
Installing sassc 2.4.0 with native extensions
Fetching listen 3.4.1
Installing listen 3.4.1
Fetching jekyll-watch 2.2.1
Installing jekyll-watch 2.2.1
Fetching jekyll-sass-converter 2.1.0
Installing jekyll-sass-converter 2.1.0
Fetching jekyll 4.2.0
Installing jekyll 4.2.0
Fetching jekyll-redirect-from 0.16.0
Installing jekyll-redirect-from 0.16.0
Bundle complete! 4 Gemfile dependencies, 30 gems now installed.
Bundled gems are installed into `./.local_ruby_bundle`
```
#### Testing Jekyll (or other gem) update
First locally I reverted Jekyll to 4.1.0:
```
$ rm Gemfile.lock
$ rm -rf .local_ruby_bundle
# edited Gemfile to use version 4.1.0
$ cat Gemfile
source "https://rubygems.org"
gem "jekyll", "4.1.0"
gem "rouge", "3.26.0"
gem "jekyll-redirect-from", "0.16.0"
gem "webrick", "1.7"
$ bundle install
...
```
Testing Jekyll version before the update:
```
$ bundle exec jekyll --version
jekyll 4.1.0
```
Imitating Jekyll update coming from git by reverting my local changes:
```
$ git checkout Gemfile
Updated 1 path from the index
$ cat Gemfile
source "https://rubygems.org"
gem "jekyll", "4.2.0"
gem "rouge", "3.26.0"
gem "jekyll-redirect-from", "0.16.0"
gem "webrick", "1.7"
$ git checkout Gemfile.lock
Updated 1 path from the index
```
Run the install:
```
$ bundle install
...
```
Checking the updated Jekyll version:
```
$ bundle exec jekyll --version
jekyll 4.2.0
```
Closes#31559 from attilapiros/pin-jekyll-version.
Lead-authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com>
Co-authored-by: Attila Zsolt Piros <2017933+attilapiros@users.noreply.github.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
Changes the configuration of the cancel workflow action to skip schedule/push events from canceling. This has the effect that duplicates of all direct pushes (master merges or direct pushes to the spark repository are not cancelled)
### What changes were proposed in this pull request?
Update to CI cancel policy to skip direct pushes. Duplicates will only be cancelled for Pull Requests.
### Why are the changes needed?
[Apparenlty](https://github.com/apache/spark/pull/31104#issuecomment-758318463) the aggressive behavior of the cancel action which also cancels duplicate master builds is too agressive for spark community. This change spares merges to master and scheduled builds from duplicate checking (as a result all merges to master will be always build to completion).
The previous behavior of the action was that in case of subsequent merges to master, only the latest one was guaranteed to complete. Other changes could be cancelled before they complete to save job queue.
### Does this PR introduce _any_ user-facing change?
No, except if the master builds were somehow facing the users (but it's unlikely taking into account the ASF release policy).
There was a potential that some changes that could be detected by specific master merge failing could be detected later (in one of the subsequent builds) which could make investigation of the root cause of failure a bit more difficult, because it could have been introduced in one of the commits between two completed builds merges. But this is at most impacting the timeline of release close to release itself, not the release itself.
### How was this patch tested?
This configuration parameter has been tested earlier in Airflow. We used it initially, but since our master builds are heavy and we have extensive tests in the PRs and investigation for failed builds is not as difficult we found that limiting the strain on Github Action and cancelling master builds was more important for the health of the whole ASF community and we removed that configuration.
Tested in https://github.com/potiuk/spark/runs/1688506527?check_suite_focus=true#step:2:46 where the action found other master builds in progress but did not add them as candidates to cancel.
Closes#31153 from potiuk/skip-schedule-push-branches.
Authored-by: Jarek Potiuk <potiuk@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is kind of a followup of https://github.com/apache/spark/pull/31104 but I decided to track it separately with a separate JIRA.
Currently the jobs are being canceled in main repo branches. If a commit is merged, for example, to master branch before the test finishes, it cancels the previous builds. This is a problem because we cannot, for example, detect logical conflict properly. We should only cancel the jobs in PRs:

This PR proposes to don't do this in the main repo branch commits but only do it in PRs.
### Why are the changes needed?
- To keep the test coverage
- To run the test in the synced master branch instead of relying on the builds made in each PR with an outdated master branch
- To detect test failures from logical conflicts from merging two conflicting PRs at the same time.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
I manually tested in
- https://github.com/HyukjinKwon/spark/pull/27
- https://github.com/HyukjinKwon/spark/pull/28
I added Yi Wu as a co-author since he helped verifying the current fix in the PR above.
I checked that it does not cancel in the main repo branch:

I checked it cancels in PRs:

Closes#31121 from HyukjinKwon/SPARK-34065.
Lead-authored-by: hyukjinkwon <gurwls223@apache.org>
Co-authored-by: yi.wu <yi.wu@databricks.com>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
Similar to: https://github.com/apache/spark/pull/31098https://github.com/apache/calcite/pull/2318 (solution suggestted by vlsi - https://github.com/apache/pulsar/issues/9154#issuecomment-756984731)
I used the action, which was maintained by potiuk instead of the original author, for two reasons:
- the original action was abandoned and is not supported (Proof: https://github.com/n1hility/cancel-previous-runs/issues/7)
- this action works with forks. The original action only worked when the contribution was run in the same repository and the action had a token with full accesses.
> If you use forks, you should create a separate "Cancelling" workflow_run triggered workflow. The workflow_run should be responsible for all canceling actions. The examples below show the possible ways the action can be utilized.
### What changes were proposed in this pull request?
This PR aims to reduce the GitHub Action usage by cancelling the previous build.
### Why are the changes needed?
In most case, the last commit is meaningful.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Due to the nature of the change, testing of this change is difficult.
> Note: This event will only trigger a workflow run if the workflow file is on the default branch.
https://docs.github.com/en/free-pro-teamlatest/actions/reference/events-that-trigger-workflows#workflow_run
However, you can see on my fork that this action is triggered.
https://github.com/mik-laj/spark/actions?query=workflow%3A%22Cancelling+Duplicates%22
I also asked the author of this action to review this change - potiuk (PMC of Apache Airflow) and I have a positive review.
Closes#31104 from mik-laj/patch-1.
Lead-authored-by: Kamil Breguła <kamil.bregula@polidea.com>
Co-authored-by: Kamil Breguła <mik-laj@users.noreply.github.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR aims to recover GitHub Action `build_and_test` job.
### Why are the changes needed?
Currently, `build_and_test` job fails to start because of the following in master/branch-3.1 at least.
```
r-lib/actions/setup-rv1 is not allowed to be used in apache/spark.
Actions in this workflow must be: created by GitHub, verified in the GitHub Marketplace,
within a repository owned by apache or match the following:
adoptopenjdk/*, apache/*, gradle/wrapper-validation-action.
```
- https://github.com/apache/spark/actions/runs/449826457

### Does this PR introduce _any_ user-facing change?
No. This is a test infra.
### How was this patch tested?
To check GitHub Action `build_and_test` job on this PR.
Closes#30959 from dongjoon-hyun/SPARK-33931.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR adds `-Pspark-ganglia-lgpl` to the build definition with Scala 2.13 on GitHub Actions.
### Why are the changes needed?
Keep the code build-able with Scala 2.13.
With this change, all the sub-modules seems to be built-able with Scala 2.13.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
I confirmed Scala 2.13 build pass with the following command.
```
$ ./dev/change-scala-version.sh 2.13
$ build/sbt -Pspark-ganglia-lgpl -Pscala-2.13 compile test:compile
```
Closes#30834 from sarutak/ganglia-scala-2.13.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes a better solution for the R build failure on GitHub Actions.
The issue is solved in #30737 but I noticed the following two things.
* We can use the latest `usethis` if we install additional libraries on the GitHub Actions environment.
* For tests on AppVeyor, `usethis` is not necessary, so I partially revert the previous change.
### Why are the changes needed?
For more simple solution.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Confirmed on GitHub Actions and AppVeyor on my account.
Closes#30753 from sarutak/followup-SPARK-33757.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR fixes the R dependencies build error on GitHub Actions and AppVeyor.
The reason seems that `usethis` package is updated 2020/12/10.
https://cran.r-project.org/web/packages/usethis/index.html
### Why are the changes needed?
To keep the build clean.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Should be done by GitHub Actions.
Closes#30737 from sarutak/fix-r-dependencies-build-error.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR adds `kubernetes-integration-tests` to GitHub Actions for Scala 2.13 build.
### Why are the changes needed?
Now that the build pass with `kubernetes-integration-tests` and Scala 2.13, it's better to keep it build-able.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Should be done by GitHub Actions.
I also confirmed that the build passes with the following command.
```
$ build/sbt -Pscala-2.13 -Pkubernetes -Pkubernetes-integration-tests compile test:compile
```
Closes#30731 from sarutak/github-actions-k8s.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This aims to add `-Pdocker-integration-tests` at GitHub Action job for Scala 2.13 compilation.
### Why are the changes needed?
We fixed Scala 2.13 compilation of this module at https://github.com/apache/spark/pull/30660 . This PR will prevent accidental regression at that module.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GitHub Action Scala 2.13 job.
Closes#30661 from dongjoon-hyun/SPARK-DOCKER-IT.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
This PR removes `-Djava.version=11` from the build command for Scala 2.13 in the GitHub Actions' job.
In the GitHub Actions' job, the build command for Scala 2.13 is defined as follows.
```
./build/sbt -Pyarn -Pmesos -Pkubernetes -Phive -Phive-thriftserver -Phadoop-cloud -Pkinesis-asl -Djava.version=11 -Pscala-2.13 compile test:compile
```
Though, Scala 2.13 build uses Java 8 rather than 11 so let's remove `-Djava.version=11`.
### Why are the changes needed?
To build with consistent configuration.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Should be done by GitHub Actions' workflow.
Closes#30633 from sarutak/scala-213-java11.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Currently, GitHub Action is using two docker images.
```
$ git grep dongjoon/apache-spark-github-action-image
.github/workflows/build_and_test.yml: image: dongjoon/apache-spark-github-action-image:20201015
.github/workflows/build_and_test.yml: image: dongjoon/apache-spark-github-action-image:20201025
```
This PR aims to make it consistent by using the latest one.
```
- image: dongjoon/apache-spark-github-action-image:20201015
+ image: dongjoon/apache-spark-github-action-image:20201025
```
### Why are the changes needed?
This is for better maintainability. The image size is almost the same.
```
$ docker images | grep 202010
dongjoon/apache-spark-github-action-image 20201025 37adfa3d226a 5 weeks ago 2.18GB
dongjoon/apache-spark-github-action-image 20201015 ff6fee8dc36d 6 weeks ago 2.16GB
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the GitHub Action.
Closes#30578 from dongjoon-hyun/SPARK-MINOR.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes:
- Add `~/.sbt` directory into the build cache, see also https://github.com/sbt/sbt/issues/3681
- Move `hadoop-2` below to put up together with `java-11` and `scala-213`, see https://github.com/apache/spark/pull/30391#discussion_r524881430
- Remove unnecessary `.m2` cache if you run SBT tests only.
- Remove `rm ~/.m2/repository/org/apache/spark`. If you don't `sbt publishLocal` or `mvn install`, we don't need to care about it.
- Use Java 8 in Scala 2.13 build. We can switch the Java version to 11 used for release later.
- Add caches into linters. The linter scripts uses `sbt` in, for example, `./dev/lint-scala`, and uses `mvn` in, for example, `./dev/lint-java`. Also, it requires to `sbt package` in Jekyll build, see: https://github.com/apache/spark/blob/master/docs/_plugins/copy_api_dirs.rb#L160-L161. We need full caches here for SBT, Maven and build tools.
- Use the same syntax of Java version, 1.8 -> 8.
### Why are the changes needed?
- Remove unnecessary stuff
- Cache what we can in the build
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
It will be tested in GitHub Actions build at the current PR
Closes#30391 from HyukjinKwon/SPARK-33464.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR aims to protect `Hadoop 2.x` profile compilation in Apache Spark 3.1+.
### Why are the changes needed?
Since Apache Spark 3.1+ switch our default profile to Hadoop 3, we had better prevent at least compilation error with `Hadoop 2.x` profile at the PR review phase. Although this is an additional workload, it will finish quickly because it's compilation only.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the GitHub Action.
- This should be merged after https://github.com/apache/spark/pull/30375 .
Closes#30378 from dongjoon-hyun/SPARK-33454.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR aims to decrease the parallelism of `SQL` module like `Hive` module.
### Why are the changes needed?
GitHub Action `sql - slow tests` become flaky.
- https://github.com/apache/spark/runs/1393670291
- https://github.com/apache/spark/runs/1393088031
### Does this PR introduce _any_ user-facing change?
No. This is dev-only feature.
Although this will increase the running time, but it's better than flakiness.
### How was this patch tested?
Pass the GitHub Action stably.
Closes#30365 from dongjoon-hyun/SPARK-33439.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR change the behavior of GitHub Actions job that caches dependencies.
SPARK-33226 upgraded sbt to 1.4.1.
As of 1.3.0, sbt uses Coursier as the dependency resolver / fetcher.
So let's change the dependency cache configuration for the GitHub Actions job.
### Why are the changes needed?
To make build faster with Coursier for the GitHub Actions job.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Should be done by GitHub Actions itself.
Closes#30259 from sarutak/coursier-cache.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR removes the old Probot Autolabeler labeling configuration, as the probot autolabeler has been deprecated. I've updated the configs in Iceberg and in Avro, and we also need to update here. This PR adds in an additional workflow for labeling PRs and migrates the old probot config to the new format. Unfortunately, because certain features have not been released upstream, we will not get the _exact_ behavior as before. I have documented where that is and what changes are neeeded, and in the associated ticket I've also discussed other options and why I think this is the best way to go. Definitely a follow up ticket is needed to get the original behavior back in these few cases, but PRs have not been labeled for almost a month and so it's probably best to get it right 95% of the time and occasionally have some UI related PRs labeled as `CORE` while the issue is resolved upstream and/or further investigated.
### Why are the changes needed?
The probot autolabeler is dead and will not be maintained going forward. This has been confirmed with github user [at]mithro in an issue in their repository.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
To test this PR, I first merged the config into my local fork. I then edited it several times and ran tests on that.
Unfortunately, I've overwritten my fork with the apache repo in order to create a proper PR. However, I've also added the config for the same thing in the Iceberg repo as well as the Avro repo.
I have now merged this PR into my local repo and will be running some tests on edge cases there and for validating in general:
- [Check that the SQL label is applied for changes directly below repo root's sql directory](https://github.com/kbendick/spark/pull/16) ✅
- [Check that the structured streaming label is applied](https://github.com/kbendick/spark/pull/20) ✅
- [Check that a wildcard at the end of a pattern will match nested files](https://github.com/kbendick/spark/pull/19) ✅
- [Check that the rule **/*pom.xml will match the root pom.xml file](https://github.com/kbendick/spark/pull/25) ✅
I've also discovered that we're likely not killing github actions that run (like large tests etc) when users push to their PR. In most cases, I see that a user has to mark something as "OK to test", but it still seems like we might want to discuss whether or not we should add a cancellation step In order to save time / capacity on the runners. If so desired, we would add an action in each workflow that cancels old runs when a `push` action occurs on a PR. This will likely make waiting for test runners much faster iff tests are automatically rerun on push by anybody (such as PMCs, PRs that have been marked OK to test, etc). We could free a large number of resources potentially if a cancellation step was added to all of the workflows in the Apache account (as github action API limits are set at the account level).
Admittedly, the fact that the "old" workflow runs weren't cancelled could admittedly be because of the fact that I was working in a fork, but given that there are explicit actions to be added to the start of workflows to cancel old PR workflows and given that we don't have them configured indicates to me that likely this is the case in this repo (and in most `apache` repos as well), at least under certain circumstances (e.g. repos that don't have "Ok to test"-like webhooks as one example).
This is a separate issue though, which I can bring up on the mailing list once I'm done with this PR. Unfortunately I've been very busy the past two weeks, but if somebody else wanted to work on that I would be happy to support with any knowledge I have.
The last Apache repo to still have the probot autolabeler in it is Beam, at which point we can have Gavin from ASF Infra remove the permissions for the probot autolabeler entirely. See the associated JIRA ticket for the links to other tickets, like the one for ASF Infra to remove the dead probot autolabeler's read and write permissions to our PRs in the Apache organization.
Closes#30244 from kbendick/begin-migration-to-github-labeler-action.
Authored-by: Kyle Bendickson <kjbendickson@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to initiate the migration to NumPy documentation style (from reST style) in PySpark docstrings.
This PR also adds one migration example of `SparkContext`.
- **Before:**
...

...

...
- **After:**
...

...
See also https://numpydoc.readthedocs.io/en/latest/format.html
### Why are the changes needed?
There are many reasons for switching to NumPy documentation style.
1. Arguably reST style doesn't fit well when the docstring grows large because it provides (arguably) less structures and syntax.
2. NumPy documentation style provides a better human readable docstring format. For example, notebook users often just do `help(...)` by `pydoc`.
3. NumPy documentation style is pretty commonly used in data science libraries, for example, pandas, numpy, Dask, Koalas,
matplotlib, ... Using NumPy documentation style can give users a consistent documentation style.
### Does this PR introduce _any_ user-facing change?
The dependency itself doesn't change anything user-facing.
The documentation change in `SparkContext` does, as shown above.
### How was this patch tested?
Manually tested via running `cd python` and `make clean html`.
Closes#30149 from HyukjinKwon/SPARK-33243.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR aims to use a pre-built image for Github Action SparkR job.
### Why are the changes needed?
This will reduce the execution time and the flakiness.
**BEFORE (21 minutes 39 seconds)**

### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the GitHub Action `sparkr` job in this PR.
Closes#30066 from dongjoon-hyun/SPARKR.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add an environment variable `PYARROW_IGNORE_TIMEZONE` to pyspark tests in run-tests.py to use legacy nested timestamp behavior. This means that when converting arrow to pandas, nested timestamps with timezones will have the timezone localized during conversion.
### Why are the changes needed?
The default behavior was changed in PyArrow 2.0.0 to propagate timezone information. Using the environment variable enables testing with newer versions of pyarrow until the issue can be fixed in SPARK-32285.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests
Closes#30111 from BryanCutler/arrow-enable-legacy-nested-timestamps-SPARK-33189.
Authored-by: Bryan Cutler <cutlerb@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
PyArrow is uploaded into PyPI today (https://pypi.org/project/pyarrow/), and some tests fail with PyArrow 2.0.0+:
```
======================================================================
ERROR [0.774s]: test_grouped_over_window_with_key (pyspark.sql.tests.test_pandas_grouped_map.GroupedMapInPandasTests)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/__w/spark/spark/python/pyspark/sql/tests/test_pandas_grouped_map.py", line 595, in test_grouped_over_window_with_key
.select('id', 'result').collect()
File "/__w/spark/spark/python/pyspark/sql/dataframe.py", line 588, in collect
sock_info = self._jdf.collectToPython()
File "/__w/spark/spark/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py", line 1305, in __call__
answer, self.gateway_client, self.target_id, self.name)
File "/__w/spark/spark/python/pyspark/sql/utils.py", line 117, in deco
raise converted from None
pyspark.sql.utils.PythonException:
An exception was thrown from the Python worker. Please see the stack trace below.
Traceback (most recent call last):
File "/__w/spark/spark/python/lib/pyspark.zip/pyspark/worker.py", line 601, in main
process()
File "/__w/spark/spark/python/lib/pyspark.zip/pyspark/worker.py", line 593, in process
serializer.dump_stream(out_iter, outfile)
File "/__w/spark/spark/python/lib/pyspark.zip/pyspark/sql/pandas/serializers.py", line 255, in dump_stream
return ArrowStreamSerializer.dump_stream(self, init_stream_yield_batches(), stream)
File "/__w/spark/spark/python/lib/pyspark.zip/pyspark/sql/pandas/serializers.py", line 81, in dump_stream
for batch in iterator:
File "/__w/spark/spark/python/lib/pyspark.zip/pyspark/sql/pandas/serializers.py", line 248, in init_stream_yield_batches
for series in iterator:
File "/__w/spark/spark/python/lib/pyspark.zip/pyspark/worker.py", line 426, in mapper
return f(keys, vals)
File "/__w/spark/spark/python/lib/pyspark.zip/pyspark/worker.py", line 170, in <lambda>
return lambda k, v: [(wrapped(k, v), to_arrow_type(return_type))]
File "/__w/spark/spark/python/lib/pyspark.zip/pyspark/worker.py", line 158, in wrapped
result = f(key, pd.concat(value_series, axis=1))
File "/__w/spark/spark/python/lib/pyspark.zip/pyspark/util.py", line 68, in wrapper
return f(*args, **kwargs)
File "/__w/spark/spark/python/pyspark/sql/tests/test_pandas_grouped_map.py", line 590, in f
"{} != {}".format(expected_key[i][1], window_range)
AssertionError: {'start': datetime.datetime(2018, 3, 15, 0, 0), 'end': datetime.datetime(2018, 3, 20, 0, 0)} != {'start': datetime.datetime(2018, 3, 15, 0, 0, tzinfo=<StaticTzInfo 'Etc/UTC'>), 'end': datetime.datetime(2018, 3, 20, 0, 0, tzinfo=<StaticTzInfo 'Etc/UTC'>)}
```
https://github.com/apache/spark/runs/1278917457
This PR proposes to set the upper bound of PyArrow in GitHub Actions build. This should be removed when we properly support PyArrow 2.0.0+ (SPARK-33189).
### Why are the changes needed?
To make build pass.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
GitHub Actions in this build will test it out.
Closes#30098 from HyukjinKwon/hot-fix-test.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add MyPy to the CI. Once this is installed on the CI: https://issues.apache.org/jira/browse/SPARK-32797?jql=project%20%3D%20SPARK%20AND%20text%20~%20mypy this wil automatically check the types.
### Why are the changes needed?
We should check if the types are still correct on the CI.
```
MacBook-Pro-van-Fokko:spark fokkodriesprong$ ./dev/lint-python
starting python compilation test...
python compilation succeeded.
starting pycodestyle test...
pycodestyle checks passed.
starting flake8 test...
flake8 checks passed.
starting mypy test...
mypy checks passed.
The sphinx-build command was not found. Skipping Sphinx build for now.
all lint-python tests passed!
```
### Does this PR introduce _any_ user-facing change?
No :)
### How was this patch tested?
By running `./dev/lint-python` locally.
Closes#30088 from Fokko/SPARK-17333.
Authored-by: Fokko Driesprong <fokko@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR proposes to install `scipy` as well in PyPy. It will test several ML specific test cases in PyPy as well. For example, 31a16fbb40/python/pyspark/mllib/tests/test_linalg.py (L487)
It was not installed when GitHub Actions build was added because it failed to install for an unknown reason. Seems like it's fixed in the latest scipy.
### Why are the changes needed?
To improve test coverage.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
GitHub Actions build in this PR will test it out.
Closes#30054 from HyukjinKwon/SPARK-32247.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
SPARK-32926 added a build test to GitHub Action for Scala 2.13 but it's only with Maven.
As SPARK-32873 reported, some compilation error happens only with SBT so I think we need to add another build test to GitHub Action for SBT.
Unfortunately, we don't have abundant resources for GitHub Actions so instead of just adding the new SBT job, let's replace the existing Maven job with the new SBT job for Scala 2.13.
### Why are the changes needed?
To ensure build test passes even with SBT for Scala 2.13.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
GitHub Actions' job.
Closes#29958 from sarutak/add-sbt-job-for-scala-2.13.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR aims to upgrade `Github Action` runner image from `Ubuntu 18.04 (LTS)` to `Ubuntu 20.04 (LTS)`.
### Why are the changes needed?
`ubuntu-latest` in `GitHub Action` is still `Ubuntu 18.04 (LTS)`.
- https://github.com/actions/virtual-environments#available-environments
This upgrade will help Apache Spark 3.1+ preparation for vote and release on the latest OS.
This is tested here.
- https://github.com/dongjoon-hyun/spark/pull/36
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the `Github Action` in this PR.
Closes#30050 from dongjoon-hyun/ubuntu_20.04.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR proposes to skip test reporting ("Report test results") if there are no JUnit XML files are found.
Currently, we're running and skipping the tests dynamically. For example,
- if there are only changes in SparkR at the underlying commit, it only runs the SparkR tests, and skip the other tests and generate JUnit XML files for SparkR test cases.
- if there are only changes in `docs` at the underlying commit, the build skips all tests except linters and do not generate any JUnit XML files.
When test reporting ("Report test results") job is triggered after the main build ("Build and test
") is finished, and there are no JUnit XML files found, it reports the case as a failure. See https://github.com/apache/spark/runs/1196184007 as an example.
This PR works around it by simply skipping the testing report when there are no JUnit XML files are found.
Please see https://github.com/apache/spark/pull/29906#issuecomment-702525542 for more details.
### Why are the changes needed?
To avoid false alarm for test results.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Manually tested in my fork.
Positive case:
https://github.com/HyukjinKwon/spark/runs/1208624679?check_suite_focus=truehttps://github.com/HyukjinKwon/spark/actions/runs/288996327
Negative case:
https://github.com/HyukjinKwon/spark/runs/1208229838?check_suite_focus=truehttps://github.com/HyukjinKwon/spark/actions/runs/289000058Closes#29946 from HyukjinKwon/test-junit-files.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
At SPARK-32493, the R installation was switched to manual installation because setup-r was broken. This seems fixed in the upstream so we should better switch it back.
### Why are the changes needed?
To avoid maintaining the installation steps by ourselve.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
GitHub Actions build in this PR should test it.
Closes#29931 from HyukjinKwon/recover-r-build.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The PR aims to add Scala 2.13 build test coverage into GitHub Action for Apache Spark 3.1.0.
### Why are the changes needed?
The branch is ready for Scala 2.13 and this will prevent any regression.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass the GitHub Action.
Closes#29793 from dongjoon-hyun/SPARK-32926.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR proposes to explicitly cache and hash the files/directories under 'build' for SBT and Zinc at GitHub Actions. Otherwise, it can end up with overwriting `build` directory. See also https://github.com/apache/spark/pull/29286#issuecomment-679368436
Previously, other files like `build/mvn` and `build/sbt` are also cached and overwritten. So, when you have some changes there, they are ignored.
### Why are the changes needed?
To make GitHub Actions build stable.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
The builds in this PR test it out.
Closes#29536 from HyukjinKwon/SPARK-32695.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to add a `workflow_dispatch` entry in the GitHub Action script (`build_and_test.yml`). This update can enable developers to run the Spark tests for a specific branch on their own local repository, so I think it might help to check if al the tests can pass before opening a new PR.
<img width="944" alt="Screen Shot 2020-08-21 at 16 28 41" src="https://user-images.githubusercontent.com/692303/90866249-96250c80-e3ce-11ea-8496-3dd6683e92ea.png">
### Why are the changes needed?
To reduce the pressure of GitHub Actions on the Spark repository.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually checked.
Closes#29504 from maropu/DispatchTest.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}