### What changes were proposed in this pull request?
Update `ResolvedNamespace` to accept catalog as `CatalogPlugin` not `SupportsNamespaces`.
This is extracted from https://github.com/apache/spark/pull/27345
### Why are the changes needed?
not all commands that need to resolve namespaces require a namespace catalog. For example, `SHOW TABLE` is implemented by `TableCatalog.listTables`, and is nothing to do with `SupportsNamespace`.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
existing tests
Closes#27403 from cloud-fan/ns.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
override `Command.stats` to return a dummy statistics (Long.Max).
### Why are the changes needed?
Commands are eagerly executed. They will be converted to LocalRelation after the DataFrame is created. That said, the statistics of a command is useless. We should avoid unnecessary statistics calculation of command's children.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
new test
Closes#27344 from cloud-fan/command.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR is a follow-up of #25728. #25728 introduces additional arguments to determine sort order. Thus, this function does not sort only in ascending order. However, the description was not updated.
This PR updates the description to follow the latest feature.
### Why are the changes needed?
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing tests since this PR just updates description text.
Closes#27404 from kiszk/SPARK-29020-followup.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Fix following typos:
- tranformation -> transformation
- the boolean -> the Boolean
- signle -> single
### Why are the changes needed?
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Scala linter.
Closes#27382 from zero323/functions-typos.
Authored-by: zero323 <mszymkiewicz@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR adds two pages to Web UI for Structured Streaming:
- "/streamingquery": Streaming Query Page, providing some aggregate information for running/completed streaming queries.
- "/streamingquery/statistics": Streaming Query Statistics Page, providing detailed information for streaming query, including `Input Rate`, `Process Rate`, `Input Rows`, `Batch Duration` and `Operation Duration`


### Why are the changes needed?
It helps users to better monitor Structured Streaming query.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
- new added and existing UTs
- manual test
Closes#26201 from uncleGen/SPARK-29543.
Lead-authored-by: uncleGen <hustyugm@gmail.com>
Co-authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Co-authored-by: Genmao Yu <hustyugm@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
### What changes were proposed in this pull request?
This pr intends to rename `spark.sql.legacy.addDirectory.recursive` into `spark.sql.legacy.addDirectory.recursive.enabled`.
### Why are the changes needed?
For consistent option names.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#27372 from maropu/SPARK-30234-FOLLOWUP.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a follow-up for https://github.com/apache/spark/pull/24098 to refactor to build string once according to the [review comment](https://github.com/apache/spark/pull/24098#discussion_r369845234)
### Why are the changes needed?
Previously, we chose the minimal change way.
In this PR, we choose a more robust way than the previous post-step string processing.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
The test case is extended with more cases.
Closes#27353 from dongjoon-hyun/SPARK-27166-2.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose to transform the `Like` expression to `TernaryExpression`, and add third parameter `escape`. So, the `like` function will have feature parity with `LIKE ... ESCAPE` syntax supported by 187f3c1773.
### Why are the changes needed?
The `like` functions can be called with 2 or 3 parameters, and functionally equivalent to `LIKE` and `LIKE ... ESCAPE` SQL expressions.
### Does this PR introduce any user-facing change?
Yes, before `like` fails with the exception:
```sql
spark-sql> SELECT like('_Apache Spark_', '__%Spark__', '_');
Error in query: Invalid number of arguments for function like. Expected: 2; Found: 3; line 1 pos 7
```
After:
```sql
spark-sql> SELECT like('_Apache Spark_', '__%Spark__', '_');
true
```
### How was this patch tested?
- Add new example for the `like` function which is checked by `SQLQuerySuite`
- Run `RegexpExpressionsSuite` and `ExpressionParserSuite`.
Closes#27355 from MaxGekk/like-3-args.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Allow for using longs as seed for xxHash.
### Why are the changes needed?
Codegen fails when passing a seed to xxHash that is > 2^31.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests pass. Should more be added?
Closes#27354 from patrickcording/fix_xxhash_seed_bug.
Authored-by: Patrick Cording <patrick.cording@datarobot.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This patch converts CR/LF into LF in 3 source files, which most files are only using LF. This patch also add rules to enforce EOL as LF for all java, scala, xml, py, R files.
### Why are the changes needed?
The majority of source code files are using LF and only three files are CR/LF. While using IDE would let us don't bother with the difference, it still has a chance to make unnecessary diff if the file is modified with the editor which doesn't handle it automatically.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
```
grep -IUrl --color "^M" . | grep "\.java\|\.scala\|\.xml\|\.py\|\.R" | grep -v "/target/" | grep -v "/build/" | grep -v "/dist/" | grep -v "dependency-reduced-pom.xml" | grep -v ".pyc"
```
(Please note you'll need to type CTRL+V -> CTRL+M in bash shell to get `^M` because it's representing CR/LF, not a combination of `^` and `M`.)
Before the patch, the result is:
```
./sql/core/src/main/java/org/apache/spark/sql/execution/columnar/ColumnDictionary.java
./sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/complexTypesSuite.scala
./sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/ComplexTypes.scala
```
and after the patch, the result is None.
And git shows WARNING message if EOL of any of source files in given types are modified to CR/LF, like below:
```
warning: CRLF will be replaced by LF in sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala.
The file will have its original line endings in your working directory.
```
Closes#27365 from HeartSaVioR/MINOR-remove-CRLF-in-source-codes.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add identifier and catalog information in DataSourceV2Relation so it would be possible to do richer checks in checkAnalysis step.
### Why are the changes needed?
In data source v2, table implementations are all customized so we may not be able to get the resolved identifier from tables them selves. Therefore we encode the table and catalog information in DSV2Relation so no external changes are needed to make sure this information is available.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Unit tests in the following suites:
CatalogManagerSuite.scala
CatalogV2UtilSuite.scala
SupportsCatalogOptionsSuite.scala
PlanResolutionSuite.scala
Closes#26957 from yuchenhuo/SPARK-30314.
Authored-by: Yuchen Huo <yuchen.huo@databricks.com>
Signed-off-by: Burak Yavuz <brkyvz@gmail.com>
### What changes were proposed in this pull request?
This PR is to remove query index from the golden files of SQLQueryTestSuite
### Why are the changes needed?
Because the SQLQueryTestSuite's golden files have the query index for each query, removal of any query statement [except the last one] will generate many unneeded difference. This will make code review harder. The number of changed lines is misleading.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#27361 from gatorsmile/removeIndexNum.
Authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
This reverts commit 1d20d13149.
Closes#27351 from gatorsmile/revertSPARK25496.
Authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This patch proposes to prune unnecessary nested fields from Generate which has no Project on top of it.
### Why are the changes needed?
In Optimizer, we can prune nested columns from Project(projectList, Generate). However, unnecessary columns could still possibly be read in Generate, if no Project on top of it. We should prune it too.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Unit test.
Closes#26978 from viirya/SPARK-29721.
Lead-authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Co-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Disable all the V2 file sources in Spark 3.0 by default.
### Why are the changes needed?
There are still some missing parts in the file source V2 framework:
1. It doesn't support reporting file scan metrics such as "numOutputRows"/"numFiles"/"fileSize" like `FileSourceScanExec`. This requires another patch in the data source V2 framework. Tracked by [SPARK-30362](https://issues.apache.org/jira/browse/SPARK-30362)
2. It doesn't support partition pruning with subqueries(including dynamic partition pruning) for now. Tracked by [SPARK-30628](https://issues.apache.org/jira/browse/SPARK-30628)
As we are going to code freeze on Jan 31st, this PR proposes to disable all the V2 file sources in Spark 3.0 by default.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing tests.
Closes#27348 from gengliangwang/disableFileSourceV2.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR is a follow-up PR https://github.com/apache/spark/pull/25666 for adding the description and example for the Scala function API `filter`.
### Why are the changes needed?
It is hard to tell which parameter is the index column.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#27336 from gatorsmile/spark28962.
Authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR is to rename spark.sql.subquery.reuse to spark.sql.execution.subquery.reuse.enabled
### Why are the changes needed?
Make it consistent and clear.
### Does this PR introduce any user-facing change?
N/A. This is a [new conf added in Spark 3.0](https://github.com/apache/spark/pull/23998)
### How was this patch tested?
N/A
Closes#27346 from gatorsmile/spark27083.
Authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Currently, in the following scenario, bucket join is not utilized:
```scala
val df = (0 until 20).map(i => (i, i)).toDF("i", "j").as("df")
df.write.format("parquet").bucketBy(8, "i").saveAsTable("t")
sql("CREATE VIEW v AS SELECT * FROM t")
sql("SELECT * FROM t a JOIN v b ON a.i = b.i").explain
```
```
== Physical Plan ==
*(4) SortMergeJoin [i#13], [i#15], Inner
:- *(1) Sort [i#13 ASC NULLS FIRST], false, 0
: +- *(1) Project [i#13, j#14]
: +- *(1) Filter isnotnull(i#13)
: +- *(1) ColumnarToRow
: +- FileScan parquet default.t[i#13,j#14] Batched: true, DataFilters: [isnotnull(i#13)], Format: Parquet, Location: InMemoryFileIndex[file:..., PartitionFilters: [], PushedFilters: [IsNotNull(i)], ReadSchema: struct<i:int,j:int>, SelectedBucketsCount: 8 out of 8
+- *(3) Sort [i#15 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(i#15, 8), true, [id=#64] <----- Exchange node introduced
+- *(2) Project [i#13 AS i#15, j#14 AS j#16]
+- *(2) Filter isnotnull(i#13)
+- *(2) ColumnarToRow
+- FileScan parquet default.t[i#13,j#14] Batched: true, DataFilters: [isnotnull(i#13)], Format: Parquet, Location: InMemoryFileIndex[file:..., PartitionFilters: [], PushedFilters: [IsNotNull(i)], ReadSchema: struct<i:int,j:int>, SelectedBucketsCount: 8 out of 8
```
Notice that `Exchange` is present. This is because `Project` introduces aliases and `outputPartitioning` and `requiredChildDistribution` do not consider aliases while considering bucket join in `EnsureRequirements`. This PR addresses to allow this scenario.
### Why are the changes needed?
This allows bucket join to be utilized in the above example.
### Does this PR introduce any user-facing change?
Yes, now with the fix, the `explain` out is as follows:
```
== Physical Plan ==
*(3) SortMergeJoin [i#13], [i#15], Inner
:- *(1) Sort [i#13 ASC NULLS FIRST], false, 0
: +- *(1) Project [i#13, j#14]
: +- *(1) Filter isnotnull(i#13)
: +- *(1) ColumnarToRow
: +- FileScan parquet default.t[i#13,j#14] Batched: true, DataFilters: [isnotnull(i#13)], Format: Parquet, Location: InMemoryFileIndex[file:.., PartitionFilters: [], PushedFilters: [IsNotNull(i)], ReadSchema: struct<i:int,j:int>, SelectedBucketsCount: 8 out of 8
+- *(2) Sort [i#15 ASC NULLS FIRST], false, 0
+- *(2) Project [i#13 AS i#15, j#14 AS j#16]
+- *(2) Filter isnotnull(i#13)
+- *(2) ColumnarToRow
+- FileScan parquet default.t[i#13,j#14] Batched: true, DataFilters: [isnotnull(i#13)], Format: Parquet, Location: InMemoryFileIndex[file:.., PartitionFilters: [], PushedFilters: [IsNotNull(i)], ReadSchema: struct<i:int,j:int>, SelectedBucketsCount: 8 out of 8
```
Note that the `Exchange` is no longer present.
### How was this patch tested?
Closes#26943 from imback82/bucket_alias.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
In this PR, I propose to move the `RESERVED_PROPERTIES `s from `SupportsNamespaces` and `TableCatalog` to `CatalogV2Util`, which can keep `RESERVED_PROPERTIES ` safe for interval usages only.
### Why are the changes needed?
the `RESERVED_PROPERTIES` should not be changed by subclasses
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
existing uts
Closes#27318 from yaooqinn/SPARK-30603.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Fix a bug in https://github.com/apache/spark/pull/26589 , to make this feature work.
### Why are the changes needed?
This feature doesn't work actually.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
new test
Closes#27341 from cloud-fan/cache.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Expressions are very likely to be serialized and sent to executors, we should avoid unnecessary serialization overhead as much as we can.
This PR fixes `AggregateExpression`.
### Why are the changes needed?
small improvement
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
existing tests
Closes#27342 from cloud-fan/fix.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to remove sorting in the asserts of checking output of:
- expression examples,
- SQL tests in `SQLQueryTestSuite`.
### Why are the changes needed?
* Sorted `actual` and `expected` make assert output unusable. Instead of `"[true]" did not equal "[false]"`, it looks like `"[ertu]" did not equal "[aefls]"`.
* Output of expression examples should be always the same except nondeterministic expressions listed in the `ignoreSet` of the `check outputs of expression examples` test.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By running `SQLQuerySuite` via `./build/sbt "sql/test:testOnly org.apache.spark.sql.SQLQuerySuite"`.
Closes#27324 from MaxGekk/remove-sorting-in-examples-tests.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Move the `defaultNamespace` method from the interface `SupportsNamespace` to `CatalogPlugin`.
### Why are the changes needed?
While I'm implementing JDBC V2, I realize that the default namespace is very an important information. Even if you don't want to implement namespace manipulation functionalities like CREATE/DROP/ALTER namespace, you still need to report the default namespace.
The default namespace is not about functionality but a matter of correctness. If you don't know the default namespace of a catalog, it's wrong to assume it's `[]`. You may get table not found exception if you do so.
I think it's more reasonable to put the `defaultNamespace` method in the base class `CatalogPlugin`. It returns `[]` by default so won't bother implementation if they really don't have namespace concept.
### Does this PR introduce any user-facing change?
yes, but for an unreleased API.
### How was this patch tested?
existing tests
Closes#27319 from cloud-fan/ns.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR is to remove the conf
### Why are the changes needed?
This rule can be excluded using spark.sql.optimizer.excludedRules without an extra conf
### Does this PR introduce any user-facing change?
Yes
### How was this patch tested?
N/A
Closes#27334 from gatorsmile/spark27871.
Authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This reverts commit b5cb9abdd5.
### Why are the changes needed?
The merged commit (#27243) was too risky for several reasons:
1. It doesn't fix a bug
2. It makes the resolution of the table that's going to be altered a child. We had avoided this on purpose as having an arbitrary rule change the child of AlterTable seemed risky. This change alone is a big -1 for me for this change.
3. While the code may look cleaner, I think this approach makes certain things harder, e.g. differentiating between the Hive based Alter table CHANGE COLUMN and ALTER COLUMN syntax. Resolving and normalizing columns for ALTER COLUMN also becomes a bit harder, as we now have to check every single AlterTable command instead of just a single ALTER TABLE ALTER COLUMN statement
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing unit tests
This closes#27315Closes#27327 from brkyvz/revAlter.
Authored-by: Burak Yavuz <brkyvz@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Skip resolving the merge expressions if the target is a DSv2 table with ACCEPT_ANY_SCHEMA capability.
### Why are the changes needed?
Some DSv2 sources may want to customize the merge resolution logic. For example, a table that can accept any schema (TableCapability.ACCEPT_ANY_SCHEMA) may want to allow certain merge queries that are blocked (that is, throws AnalysisError) by the default resolution logic. So there should be a way to completely bypass the merge resolution logic in the Analyzer.
### Does this PR introduce any user-facing change?
No, since merge itself is an unreleased feature
### How was this patch tested?
added unit test to specifically test the skipping.
Closes#27326 from tdas/SPARK-30609.
Authored-by: Tathagata Das <tathagata.das1565@gmail.com>
Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com>
### What changes were proposed in this pull request?
In `org.apache.spark.sql.execution.SubqueryExec#relationFuture` make a copy of `org.apache.spark.SparkContext#localProperties` and pass it to the sub-execution thread in `org.apache.spark.sql.execution.SubqueryExec#executionContext`
### Why are the changes needed?
Local properties set via sparkContext are not available as TaskContext properties when executing jobs and threadpools have idle threads which are reused
Explanation:
When `SubqueryExec`, the relationFuture is evaluated via a separate thread. The threads inherit the `localProperties` from `sparkContext` as they are the child threads.
These threads are created in the `executionContext` (thread pools). Each Thread pool has a default keepAliveSeconds of 60 seconds for idle threads.
Scenarios where the thread pool has threads which are idle and reused for a subsequent new query, the thread local properties will not be inherited from spark context (thread properties are inherited only on thread creation) hence end up having old or no properties set. This will cause taskset properties to be missing when properties are transferred by child thread via `sparkContext.runJob/submitJob`
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Added UT
Closes#27267 from ajithme/subquerylocalprop.
Authored-by: Ajith <ajith2489@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
When you save a Spark UI SQL query page to disk and then display the html file with your browser, the query plan will be rendered a second time. This change avoids rendering the plan visualization when it exists already.
This is master:

And with the fix:

### Why are the changes needed?
The duplicate query plan is unexpected and redundant.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Manually tested. Testing this in a reproducible way requires a running browser or HTML rendering engine that executes the JavaScript.
Closes#27238 from EnricoMi/branch-sql-ui-duplicate-plan.
Authored-by: Enrico Minack <github@enrico.minack.dev>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
In the PR, I propose to add additional constructor in the `Like` expression. The constructor can be used on applying the `like` function with 2 parameters.
### Why are the changes needed?
`FunctionRegistry` cannot find a constructor if the `like` function is applied to 2 parameters.
### Does this PR introduce any user-facing change?
Yes, before:
```sql
spark-sql> SELECT like('Spark', '_park');
Invalid arguments for function like; line 1 pos 7
org.apache.spark.sql.AnalysisException: Invalid arguments for function like; line 1 pos 7
at org.apache.spark.sql.catalyst.analysis.FunctionRegistry$.$anonfun$expression$7(FunctionRegistry.scala:618)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.catalyst.analysis.FunctionRegistry$.$anonfun$expression$4(FunctionRegistry.scala:602)
at org.apache.spark.sql.catalyst.analysis.SimpleFunctionRegistry.lookupFunction(FunctionRegistry.scala:121)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.lookupFunction(SessionCatalog.scala:1412)
```
After:
```sql
spark-sql> SELECT like('Spark', '_park');
true
```
### How was this patch tested?
By running `check outputs of expression examples` from `SQLQuerySuite`.
Closes#27323 from MaxGekk/fix-like-func.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In this PR, I'd propose to fully support interval for the CSV and JSON functions.
On one hand, CSV and JSON records consist of string values, in the cast logic, we can cast string from/to interval now, so we can make those functions support intervals easily.
Before this change we can only use this as a workaround.
```sql
SELECT cast(from_csv('1, 1 day', 'a INT, b string').b as interval)
struct<CAST(from_csv(1, 1 day).b AS INTERVAL):interval>
1 days
```
On the other hand, we ban reading or writing intervals from CSV and JSON files. To directly read and write with external json/csv storage, you still need explicit cast, e.g.
```scala
spark.read.schema("a string").json("a.json").selectExpr("cast(a as interval)").show
+------+
| a|
+------+
|1 days|
+------+
```
### Why are the changes needed?
for interval's future-proofing purpose
### Does this PR introduce any user-facing change?
yes, the `to_json`/`from_json` function can deal with intervals now. e.g.
for `from_json` there is no such use case because we do not support `a interval`
for `to_json`, we can use interval values now
#### before
```sql
SELECT to_json(map('a', interval 25 month 100 day 130 minute));
Error in query: cannot resolve 'to_json(map('a', INTERVAL '2 years 1 months 100 days 2 hours 10 minutes'))' due to data type mismatch: Unable to convert column a of type interval to JSON.; line 1 pos 7;
'Project [unresolvedalias(to_json(map(a, 2 years 1 months 100 days 2 hours 10 minutes), Some(Asia/Shanghai)), None)]
+- OneRowRelation
```
#### after
```sql
SELECT to_json(map('a', interval 25 month 100 day 130 minute))
{"a":"2 years 1 months 100 days 2 hours 10 minutes"}
```
### How was this patch tested?
add ut
Closes#27317 from yaooqinn/SPARK-30592.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
when resolving the `Assignment` of insert action in MERGE INTO, only resolve with the source table, to avoid ambiguous attribute failure if there is a same-name column in the target table.
### Why are the changes needed?
The insert action is used when NOT MATCHED, so it can't access the row from the target table anyway.
### Does this PR introduce any user-facing change?
on
### How was this patch tested?
new tests
Closes#27265 from cloud-fan/merge.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This pr removes the nonstandard `SET OWNER` syntax for namespaces and changes the owner reserved properties from `ownerName` and `ownerType` to `owner`.
### Why are the changes needed?
the `SET OWNER` syntax for namespaces is hive-specific and non-sql standard, we need a more future-proofing design before we implement user-facing changes for SQL security issues
### Does this PR introduce any user-facing change?
no, just revert an unpublic syntax
### How was this patch tested?
modified uts
Closes#27300 from yaooqinn/SPARK-30591.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add optimizer rule PruneHiveTablePartitions pruning hive table partitions based on filters on partition columns.
Doing so, the total size of pruned partitions may be small enough for broadcast join in JoinSelection strategy.
### Why are the changes needed?
In JoinSelection strategy, spark use the "plan.stats.sizeInBytes" to decide whether the plan is suitable for broadcast join.
Currently, "plan.stats.sizeInBytes" does not take "pruned partitions" into account, so it may miss some broadcast join and take sort-merge join instead, which will definitely impact join performance.
This PR aim at taking "pruned partitions" into account for hive table in "plan.stats.sizeInBytes" and then improve performance by using broadcast join if possible.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
Added unit tests.
This is based on #25919, credits should go to lianhuiwang and advancedxy.
Closes#26805 from fuwhu/SPARK-15616.
Authored-by: fuwhu <bestwwg@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR propose to disallow negative `scale` of `Decimal` in Spark. And this PR brings two behavior changes:
1) for literals like `1.23E4BD` or `1.23E4`(with `spark.sql.legacy.exponentLiteralAsDecimal.enabled`=true, see [SPARK-29956](https://issues.apache.org/jira/browse/SPARK-29956)), we set its `(precision, scale)` to (5, 0) rather than (3, -2);
2) add negative `scale` check inside the decimal method if it exposes to set `scale` explicitly. If check fails, `AnalysisException` throws.
And user could still use `spark.sql.legacy.allowNegativeScaleOfDecimal.enabled` to restore the previous behavior.
### Why are the changes needed?
According to SQL standard,
> 4.4.2 Characteristics of numbers
An exact numeric type has a precision P and a scale S. P is a positive integer that determines the number of significant digits in a particular radix R, where R is either 2 or 10. S is a non-negative integer.
scale of Decimal should always be non-negative. And other mainstream databases, like Presto, PostgreSQL, also don't allow negative scale.
Presto:
```
presto:default> create table t (i decimal(2, -1));
Query 20191213_081238_00017_i448h failed: line 1:30: mismatched input '-'. Expecting: <integer>, <type>
create table t (i decimal(2, -1))
```
PostgrelSQL:
```
postgres=# create table t(i decimal(2, -1));
ERROR: NUMERIC scale -1 must be between 0 and precision 2
LINE 1: create table t(i decimal(2, -1));
^
```
And, actually, Spark itself already doesn't allow to create table with negative decimal types using SQL:
```
scala> spark.sql("create table t(i decimal(2, -1))");
org.apache.spark.sql.catalyst.parser.ParseException:
no viable alternative at input 'create table t(i decimal(2, -'(line 1, pos 28)
== SQL ==
create table t(i decimal(2, -1))
----------------------------^^^
at org.apache.spark.sql.catalyst.parser.ParseException.withCommand(ParseDriver.scala:263)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parse(ParseDriver.scala:130)
at org.apache.spark.sql.execution.SparkSqlParser.parse(SparkSqlParser.scala:48)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parsePlan(ParseDriver.scala:76)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:605)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:605)
... 35 elided
```
However, it is still possible to create such table or `DatFrame` using Spark SQL programming API:
```
scala> val tb =
CatalogTable(
TableIdentifier("test", None),
CatalogTableType.MANAGED,
CatalogStorageFormat.empty,
StructType(StructField("i", DecimalType(2, -1) ) :: Nil))
```
```
scala> spark.sql("SELECT 1.23E4BD")
res2: org.apache.spark.sql.DataFrame = [1.23E+4: decimal(3,-2)]
```
while, these two different behavior could make user confused.
On the other side, even if user creates such table or `DataFrame` with negative scale decimal type, it can't write data out if using format, like `parquet` or `orc`. Because these formats have their own check for negative scale and fail on it.
```
scala> spark.sql("SELECT 1.23E4BD").write.saveAsTable("parquet")
19/12/13 17:37:04 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)
java.lang.IllegalArgumentException: Invalid DECIMAL scale: -2
at org.apache.parquet.Preconditions.checkArgument(Preconditions.java:53)
at org.apache.parquet.schema.Types$BasePrimitiveBuilder.decimalMetadata(Types.java:495)
at org.apache.parquet.schema.Types$BasePrimitiveBuilder.build(Types.java:403)
at org.apache.parquet.schema.Types$BasePrimitiveBuilder.build(Types.java:309)
at org.apache.parquet.schema.Types$Builder.named(Types.java:290)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.convertField(ParquetSchemaConverter.scala:428)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.convertField(ParquetSchemaConverter.scala:334)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.$anonfun$convert$2(ParquetSchemaConverter.scala:326)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at org.apache.spark.sql.types.StructType.foreach(StructType.scala:99)
at scala.collection.TraversableLike.map(TraversableLike.scala:238)
at scala.collection.TraversableLike.map$(TraversableLike.scala:231)
at org.apache.spark.sql.types.StructType.map(StructType.scala:99)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.convert(ParquetSchemaConverter.scala:326)
at org.apache.spark.sql.execution.datasources.parquet.ParquetWriteSupport.init(ParquetWriteSupport.scala:97)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:388)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:349)
at org.apache.spark.sql.execution.datasources.parquet.ParquetOutputWriter.<init>(ParquetOutputWriter.scala:37)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$$anon$1.newInstance(ParquetFileFormat.scala:150)
at org.apache.spark.sql.execution.datasources.SingleDirectoryDataWriter.newOutputWriter(FileFormatDataWriter.scala:124)
at org.apache.spark.sql.execution.datasources.SingleDirectoryDataWriter.<init>(FileFormatDataWriter.scala:109)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeTask(FileFormatWriter.scala:264)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$write$15(FileFormatWriter.scala:205)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:127)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:441)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:444)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
So, I think it would be better to disallow negative scale totally and make behaviors above be consistent.
### Does this PR introduce any user-facing change?
Yes, if `spark.sql.legacy.allowNegativeScaleOfDecimal.enabled=false`, user couldn't create Decimal value with negative scale anymore.
### How was this patch tested?
Added new tests in `ExpressionParserSuite` and `DecimalSuite`;
Updated `SQLQueryTestSuite`.
Closes#26881 from Ngone51/nonnegative-scale.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This revert https://github.com/apache/spark/pull/26418, file a new ticket under https://issues.apache.org/jira/browse/SPARK-30546 for better tracking interval behavior
### Why are the changes needed?
Revert interval ISO/ANSI SQL Standard output since we decide not to follow ANSI and there is no round trip
### Does this PR introduce any user-facing change?
no, not released yet
### How was this patch tested?
existing uts
Closes#27304 from yaooqinn/SPARK-30593.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For LogicalPlan(e.g. `MultiInstanceRelation`, `Project`, `Aggregate`, etc) whose output doesn't inherit directly from its children, we could just stop collect on it. Because we could always replace all the lower conflict attributes with the new attributes from the new plan.
Otherwise, we should recursively collect conflict plans, like `Generate`, `Window`.
### Why are the changes needed?
Performance improvement.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Pass existed tests.
Closes#27263 from Ngone51/spark_30433_followup.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Follow up on [SPARK-30428](https://github.com/apache/spark/pull/27112) which added support for partition pruning in File source V2.
This PR implements the necessary changes in order to pass the `dataFilters` to the `listFiles`. This enables having `FileIndex` implementations which use the `dataFilters` for further pruning the file listing (see the discussion [here](https://github.com/apache/spark/pull/27112#discussion_r364757217)).
### Why are the changes needed?
Datasources such as `csv` and `json` do not implement the `SupportsPushDownFilters` trait. In order to support data skipping uniformly for all file based data sources, one can override the `listFiles` method in a `FileIndex` implementation, which consults external metadata and prunes the list of files.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Modifying the unit tests for v2 file sources to verify the `dataFilters` are passed
Closes#27157 from guykhazma/PushdataFiltersInFileListing.
Authored-by: Guy Khazma <guykhag@gmail.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to make `JsonSuite` and `CSVSuite` abstract classes, and add sub-classes that check JSON/CSV datasource v1 and v2.
### Why are the changes needed?
To improve test coverage and test JSON/CSV v1 which is still supported, and can be enabled by users.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By running new test suites `JsonV1Suite` and `CSVv1Suite`.
Closes#27294 from MaxGekk/csv-json-v1-test-suites.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
After this commit d67b98ea01, we are able to create table or alter table with interval column types if the external catalog accepts which is varying the interval type's purpose for internal usage. With d67b98ea01 's original purpose it should only work from cast logic.
Instead of adding type checker for the interval type from commands to commands to work among catalogs, It much simpler to treat interval as an invalid data type but can be identified by cast only.
### Why are the changes needed?
enhance interval internal usage purpose.
### Does this PR introduce any user-facing change?
NO,
Additionally, this PR restores user behavior when using interval type to create/alter table schema, e.g. for hive catalog
for 2.4,
```java
Caused by: org.apache.spark.sql.catalyst.parser.ParseException:
DataType calendarinterval is not supported.(line 1, pos 0)
```
for master after d67b98ea01
```java
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.IllegalArgumentException: Error: type expected at the position 0 of 'interval' but 'interval' is found.
at org.apache.hadoop.hive.ql.metadata.Hive.createTable(Hive.java:862)
```
now with this pr, we restore the type checker in spark side.
### How was this patch tested?
add more ut
Closes#27277 from yaooqinn/SPARK-30568.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add `owner` property to v2 table, it is reversed by `TableCatalog`, indicates the table's owner.
### Why are the changes needed?
enhance ownership management of catalog API
### Does this PR introduce any user-facing change?
yes, add 1 reserved property - `owner` , and it is not allowed to use in OPTIONS/TBLPROPERTIES anymore, only if legacy on
### How was this patch tested?
add uts
Closes#27249 from yaooqinn/SPARK-30019.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to clean up `UnivocityParser`.
### Why are the changes needed?
It will slightly improve the performance since we don't do unnecessary computation for Array concatenations/creation.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Manually ran the existing tests.
Closes#27287 from HyukjinKwon/SPARK-30530-followup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to output additional msg from the tests where a log appender is added. The message is printed as a part of `IllegalStateException` in the case of reaching the limit of maximum number of logged events.
### Why are the changes needed?
If a log appender is not removed from the log4j appenders list. the caller message could help to investigate the problem and find the test which doesn't remove the log appender.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By running the modified test suites `AvroSuite`, `CSVSuite`, `ResolveHintsSuite` and etc.
Closes#27296 from MaxGekk/assign-name-to-log-appender.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Explicitly set conf to let orc use DSv2 in `OrcFilterSuite` in both v1.2 and v2.3.
### Why are the changes needed?
Tests should not rely on default conf when they're going to test something intentionally, which can be fail when conf changes.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Pass Jenkins.
Closes#27285 from Ngone51/fix-orcfilter-test.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Use the new framework to resolve the ALTER TABLE commands.
This PR also refactors ALTER TABLE logical plans such that they extend a base class `AlterTable`. Each plan now implements `def changes: Seq[TableChange]` for any table change operations.
Additionally, `UnresolvedV2Relation` and its usage is completely removed.
### Why are the changes needed?
This is a part of effort to make the relation lookup behavior consistent: [SPARK-29900](https://issues.apache.org/jira/browse/SPARK-29900).
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Updated existing tests
Closes#27243 from imback82/v2commands_newframework.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Changed signature of `rawParser` passed to `FailureSafeParser`. I propose to change return type from `Seq` to `Iterable`. I took `Iterable` to easier port the changes on Scala collections 2.13. Also, I replaced `Seq` by `Option` in CSV datasource - `UnivocityParser`, and in JSON parser exception one place in the case when specified schema is `StructType`, and JSON input is an array.
### Why are the changes needed?
`Seq` is unnecessary requirement for return type from rawParser which may not have multiple rows per input like CSV datasource.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By existing test suites `JsonSuite`, `UnivocityParserSuite`, `JsonFunctionsSuite`, `JsonExpressionsSuite`, `CsvSuite`, and `CsvFunctionsSuite`.
Closes#27264 from MaxGekk/failuresafe-parser-seq.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR implements a tiny performance optimization for a `GenericArrayData` constructor, avoiding an unnecessary roundtrip through `WrappedArray` when the provided value is already an array of objects.
It also fixes a related performance problem in `ParquetRowConverter`.
### Why are the changes needed?
`GenericArrayData` has a `this(seqOrArray: Any)` constructor, which was originally added in #13138 for use in `RowEncoder` (where we may not know concrete types until runtime) but is also called (perhaps unintentionally) in a few other code paths.
In this constructor's existing implementation, a call to `new WrappedArray(Array[Object](""))` is dispatched to the `this(seqOrArray: Any)` constructor, where we then call `this(array.toSeq)`: this wraps the provided array into a `WrappedArray`, which is subsequently unwrapped in a `this(seq.toArray)` call. For an interactive example, see https://scastie.scala-lang.org/7jOHydbNTaGSU677FWA8nA
This PR changes the `this(seqOrArray: Any)` constructor so that it calls the primary `this(array: Array[Any])` constructor, allowing us to save a `.toSeq.toArray` call; this comes at the cost of one additional `case` in the `match` statement (but I believe this has a negligible performance impact relative to the other savings).
As code cleanup, I also reverted the JVM 1.7 workaround from #14271.
I also fixed a related performance problem in `ParquetRowConverter`: previously, this code called `ArrayBasedMapData.apply` which, in turn, called the `this(Any)` constructor for `GenericArrayData`: this PR's micro-benchmarks show that this is _significantly_ slower than calling the `this(Array[Any])` constructor (and I also observed time spent here during other Parquet scan benchmarking work). To fix this performance problem, I replaced the call to the `ArrayBasedMapData.apply` method with direct calls to the `ArrayBasedMapData` and `GenericArrayData` constructors.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
I tested this by running code in a debugger and by running microbenchmarks (which I've added to a new `GenericArrayDataBenchmark` in this PR):
- With JDK8 benchmarks: this PR's changes more than double the performance of calls to the `this(Any)` constructor. Even after improvements, however, calls to the `this(Array[Any])` constructor are still ~60x faster than calls to `this(Any)` when passing a non-primitive array (thereby motivating this patch's other change in `ParquetRowConverter`).
- With JDK11 benchmarks: the changes more-or-less completely eliminate the performance penalty associated with the `this(Any)` constructor.
Closes#27088 from JoshRosen/joshrosen/GenericArrayData-optimization.
Authored-by: Josh Rosen <rosenville@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose to fix the bug reported in SPARK-30530. CSV datasource returns invalid records in the case when `parsedSchema` is shorter than number of tokens returned by UniVocity parser. In the case `UnivocityParser.convert()` always throws `BadRecordException` independently from the result of applying filters.
For the described case, I propose to save the exception in `badRecordException` and continue value conversion according to `parsedSchema`. If a bad record doesn't pass filters, `convert()` returns empty Seq otherwise throws `badRecordException`.
### Why are the changes needed?
It fixes the bug reported in the JIRA ticket.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Added new test from the JIRA ticket.
Closes#27239 from MaxGekk/spark-30530-csv-filter-is-null.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
As we are not going to follow ANSI to implement year-month and day-time interval types, it is weird to compare the year-month part to the day-time part for our current implementation of interval type now.
Additionally, the current ordering logic comes from PostgreSQL where the implementation of the interval is messy. And we are not aiming PostgreSQL compliance at all.
THIS PR will revert https://github.com/apache/spark/pull/26681 and https://github.com/apache/spark/pull/26337
### Why are the changes needed?
make interval type more future-proofing
### Does this PR introduce any user-facing change?
there are new in 3.0, so no
### How was this patch tested?
existing uts shall work
Closes#27262 from yaooqinn/SPARK-30551.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Resolve the remaining comments in [PR#27226](https://github.com/apache/spark/pull/27226).
### Why are the changes needed?
Resolve the comments.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing unit tests.
Closes#27253 from JkSelf/followup-skewjoinoptimization2.
Authored-by: jiake <ke.a.jia@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Pick up the HTTP fix from https://issues.apache.org/jira/browse/HIVE-22708
### Why are the changes needed?
This is a small but important fix to digest handling we should pick up from Hive.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests
Closes#27273 from srowen/Hive22708.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
https://github.com/apache/spark/pull/26809 added `Dataset.tail` API. It should be good to have it in PySpark API as well.
### Why are the changes needed?
To support consistent APIs.
### Does this PR introduce any user-facing change?
No. It adds a new API.
### How was this patch tested?
Manually tested and doctest was added.
Closes#27251 from HyukjinKwon/SPARK-30539.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR aims to add these test cases for resolution of ORC table location reported by [SPARK-25993](https://issues.apache.org/jira/browse/SPARK-25993)
also add corresponding test cases for Parquet table.
### Why are the changes needed?
The current behavior is complex, this test case suites are designed to prevent the accidental behavior change. This pr is rebased on master, the original pr is [23108](https://github.com/apache/spark/pull/23108)
### Does this PR introduce any user-facing change?
No. This adds test cases only.
### How was this patch tested?
This is a new test case.
Closes#27130 from kevinyu98/spark-25993-2.
Authored-by: Kevin Yu <qyu@us.ibm.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
[SPARK-20568](https://issues.apache.org/jira/browse/SPARK-20568) added the possibility to clean up completed files in streaming query. Deleting/archiving uses the main thread which can slow down processing. In this PR I've created thread pool to handle file delete/archival. The number of threads can be configured with `spark.sql.streaming.fileSource.cleaner.numThreads`.
### Why are the changes needed?
Do file delete/archival in separate thread.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing unit tests.
Closes#26502 from gaborgsomogyi/SPARK-29876.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
SPARK-29894 provides information on the Codegen Stage Id in WEBUI for SQL Plan graphs. Similarly, this proposes to add Codegen Stage Id in the DAG visualization for Stage execution. DAGs for Stage execution are available in the WEBUI under the Jobs and Stages tabs.
### Why are the changes needed?
This is proposed as an aid for drill-down analysis of complex SQL statement execution, as it is not always easy to match parts of the SQL Plan graph with the corresponding Stage DAG execution graph. Adding Codegen Stage Id for WholeStageCodegen operations makes this task easier.
### Does this PR introduce any user-facing change?
Stage DAG visualization in the WEBUI will show codegen stage id for WholeStageCodegen operations, as in the example snippet from the WEBUI, Jobs tab (the query used in the example is TPCDS 2.4 q14a):

### How was this patch tested?
Manually tested, see also example snippet.
Closes#26675 from LucaCanali/addCodegenStageIdtoStageGraph.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Use the new framework to resolve the SHOW TBLPROPERTIES command. This PR along with #27243 should update all the existing V2 commands with `UnresolvedV2Relation`.
### Why are the changes needed?
This is a part of effort to make the relation lookup behavior consistent: [SPARK-2990](https://issues.apache.org/jira/browse/SPARK-29900).
### Does this PR introduce any user-facing change?
Yes `SHOW TBLPROPERTIES temp_view` now fails with `AnalysisException` will be thrown with a message `temp_view is a temp view not table`. Previously, it was returning empty row.
### How was this patch tested?
Existing tests
Closes#26921 from imback82/consistnet_v2command.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add a `V1Scan` interface, so that data source v1 implementations can migrate to DS v2 much easier.
### Why are the changes needed?
It's a lot of work to migrate v1 sources to DS v2. The new API added here can allow v1 sources to go through v2 code paths without implementing all the Batch, Stream, PartitionReaderFactory, ... stuff.
We already have a v1 write fallback API after https://github.com/apache/spark/pull/25348
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
new test suite
Closes#26231 from cloud-fan/v1-read-fallback.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to remove the SQL config `spark.sql.execution.pandas.respectSessionTimeZone` which has been deprecated since Spark 2.3.
### Why are the changes needed?
To improve code maintainability.
### Does this PR introduce any user-facing change?
Yes.
### How was this patch tested?
by running python tests, https://spark.apache.org/docs/latest/building-spark.html#pyspark-tests-with-maven-or-sbtCloses#27218 from MaxGekk/remove-respectSessionTimeZone.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
`OptimizeSkewedJoin `rule change the `outputPartitioning `after inserting `PartialShuffleReaderExec `or `SkewedPartitionReaderExec`. So it may need to introduce additional to ensure the right result. This PR disable `OptimizeSkewedJoin ` rule when introducing additional shuffle.
### Why are the changes needed?
bug fix
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Add new ut
Closes#27226 from JkSelf/followup-skewedoptimization.
Authored-by: jiake <ke.a.jia@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
TableCatalog reserves some properties, e,g `provider`, `location` for internal usage. Some of them are static once create, some of them need specific syntax to modify. Instead of using `OPTIONS (k='v')` or TBLPROPERTIES (k='v'), if k is a reserved TableCatalog property, we should use its specific syntax to add/modify/delete it. e.g. `provider` is a reserved property, we should use the `USING` clause to specify it, and should not allow `ALTER TABLE ... UNSET TBLPROPERTIES('provider')` to delete it. Also, there are two paths for v1/v2 catalog tables to resolve these properties, e.g. the v1 session catalog tables will only use the `USING` clause to decide `provider` but v2 tables will also lookup OPTION/TBLPROPERTIES(although there is a bug prohibit it).
Additionally, 'path' is not reserved but holds special meaning for `LOCATION` and it is used in `CREATE/REPLACE TABLE`'s `OPTIONS` sub-clause. Now for the session catalog tables, the `path` is case-insensitive, but for the non-session catalog tables, it is case-sensitive, we should make it both case insensitive for disambiguation.
### Why are the changes needed?
prevent reserved properties from being modified unexpectedly
unify the property resolution for v1/v2.
fix some bugs.
### Does this PR introduce any user-facing change?
yes
1 . `location` and `provider` (case sensitive) cannot be used in `CREATE/REPLACE TABLE ... OPTIONS/TBLPROPETIES` and `ALTER TABLE ... SET TBLPROPERTIES (...)`, if legacy on, they will be ignored to let the command success without having side effects
3. Once `path` in `CREATE/REPLACE TABLE ... OPTIONS` is case insensitive for v1 but sensitive for v2, but now we change it case insensitive for both kinds of tables, then v2 tables will also fail if `LOCATION` and `OPTIONS('PaTh' ='abc')` are both specified or will pick `PaTh`'s value as table location if `LOCATION` is missing.
4. Now we will detect if there are two different case `path` keys or more in `CREATE/REPLACE TABLE ... OPTIONS`, once it is a kind of unexpected last-win policy for v1, and v2 is case sensitive.
### How was this patch tested?
add ut
Closes#27197 from yaooqinn/SPARK-30507.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to use non-deprecated constructor of `ExpressionInfo` in `SparkSessionExtensionSuite`, and pass valid strings as `examples`, `note`, `since` and `deprecated` parameters.
### Why are the changes needed?
Using another constructor allows to eliminate the following deprecation warnings while compiling Spark:
```
Warning:(335, 5) constructor ExpressionInfo in class ExpressionInfo is deprecated: see corresponding Javadoc for more information.
new ExpressionInfo("noClass", "myDb", "myFunction", "usage", "extended usage"),
Warning:(732, 5) constructor ExpressionInfo in class ExpressionInfo is deprecated: see corresponding Javadoc for more information.
new ExpressionInfo("noClass", "myDb", "myFunction2", "usage", "extended usage"),
Warning:(751, 5) constructor ExpressionInfo in class ExpressionInfo is deprecated: see corresponding Javadoc for more information.
new ExpressionInfo("noClass", "myDb", "myFunction2", "usage", "extended usage"),
```
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By compiling and running `SparkSessionExtensionSuite`.
Closes#27221 from MaxGekk/eliminate-expr-info-warnings.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to support pushed down filters in CSV datasource. The reason of pushing a filter up to `UnivocityParser` is to apply the filter as soon as all its attributes become available i.e. converted from CSV fields to desired values according to the schema. This allows to skip conversions of other values if the filter returns `false`. This can improve performance when pushed filters are highly selective and conversion of CSV string fields to desired values are comparably expensive ( for example, conversion to `TIMESTAMP` values).
Here are details of the implementation:
- `UnivocityParser.convert()` converts parsed CSV tokens one-by-one sequentially starting from index 0 up to `parsedSchema.length - 1`. At current index `i`, it applies filters that refer to attributes at row fields indexes `0..i`. If any filter returns `false`, it skips conversions of other input tokens.
- Pushed filters are converted to expressions. The expressions are bound to row positions according to `requiredSchema`. The expressions are compiled to predicates via generating Java code.
- To be able to apply predicates to partially initialized rows, the predicates are grouped, and combined via the `And` expression. Final predicate at index `N` can refer to row fields at the positions `0..N`, and can be applied to a row even if other fields at the positions `N+1..requiredSchema.lenght-1` are not set.
### Why are the changes needed?
The changes improve performance on synthetic benchmarks more **than 9 times** (on JDK 8 & 11):
```
OpenJDK 64-Bit Server VM 11.0.5+10 on Mac OS X 10.15.2
Intel(R) Core(TM) i7-4850HQ CPU 2.30GHz
Filters pushdown: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
w/o filters 11889 11945 52 0.0 118893.1 1.0X
pushdown disabled 11790 11860 115 0.0 117902.3 1.0X
w/ filters 1240 1278 33 0.1 12400.8 9.6X
```
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
- Added new test suite `CSVFiltersSuite`
- Added tests to `CSVSuite` and `UnivocityParserSuite`
Closes#26973 from MaxGekk/csv-filters-pushdown.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Based on the [comment](https://github.com/apache/spark/pull/26956#discussion_r366680558), this patch changes the SQL config name from `spark.sql.truncateTable.ignorePermissionAcl` to `spark.sql.truncateTable.ignorePermissionAcl.enabled`.
### Why are the changes needed?
Make this config consistent other SQL configs.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#27210 from viirya/truncate-table-permission-followup.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
For decimal values between -1.0 and 1.0, it should has same precision and scale in `Decimal`, in order to make it be consistent with `DecimalType`.
### Why are the changes needed?
Currently, for values between -1.0 and 1.0, precision and scale is inconsistent between `Decimal` and `DecimalType`. For example, for numbers like 0.3, it will have (precision, scale) as (2, 1) in `Decimal`, but (1, 1) in `DecimalType`:
```
scala> Literal(new BigDecimal("0.3")).dataType.asInstanceOf[DecimalType].precision
res3: Int = 1
scala> Literal(new BigDecimal("0.3")).value.asInstanceOf[Decimal].precision
res4: Int = 2
```
We should make `Decimal` be consistent with `DecimalType`. And, here, we change it to only count precision digits after dot for values between -1.0 and 1.0 as other DBMS does, like hive:
```
hive> create table testrel as select 0.3;
hive> describe testrel;
OK
_c0 decimal(1,1)
```
This could bring larger scale for values between -1.0 and 1.0.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Updated existed tests.
Closes#27217 from Ngone51/set-decimal-from-javadecimal.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Use the new framework to resolve the DESCRIBE TABLE command.
The v1 DESCRIBE TABLE command supports both table and view. Checked with Hive and Presto, they don't have DESCRIBE TABLE syntax but only DESCRIBE, which supports both table and view:
1. https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-DescribeTable/View/MaterializedView/Column
2. https://prestodb.io/docs/current/sql/describe.html
We should make it clear that DESCRIBE support both table and view, by renaming the command to `DescribeRelation`.
This PR also tunes the framework a little bit to support the case that a command accepts both table and view.
### Why are the changes needed?
This is a part of effort to make the relation lookup behavior consistent: SPARK-29900.
Note that I make a separate PR here instead of #26921, as I need to update the framework to support a new use case: accept both table and view.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
existing tests
Closes#27187 from cloud-fan/describe.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
This PR intends to improve partition pruning for nondeterministic expressions in Hive tables:
Before this PR:
```
scala> sql("""create table test(id int) partitioned by (dt string)""")
scala> sql("""select * from test where dt='20190101' and rand() < 0.5""").explain()
== Physical Plan ==
*(1) Filter ((isnotnull(dt#19) AND (dt#19 = 20190101)) AND (rand(6515336563966543616) < 0.5))
+- Scan hive default.test [id#18, dt#19], HiveTableRelation `default`.`test`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#18], [dt#19], Statistics(sizeInBytes=8.0 EiB)
```
After this PR:
```
== Physical Plan ==
*(1) Filter (rand(-9163956883277176328) < 0.5)
+- Scan hive default.test [id#0, dt#1], HiveTableRelation `default`.`test`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#0], [dt#1], Statistics(sizeInBytes=8.0 EiB), [isnotnull(dt#1), (dt#1 = 20190101)]
```
This PR is the rework of #24118.
### Why are the changes needed?
For better performance.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Unit tests added.
Closes#27219 from maropu/SPARK-26736.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This patch addresses adding event filter to handle SQL related events. This patch is next task of SPARK-29779 (#27085), please refer the description of PR #27085 to see overall rationalization of this patch.
Below functionalities will be addressed in later parts:
* integrate compaction into FsHistoryProvider
* documentation about new configuration
### Why are the changes needed?
One of major goal of SPARK-28594 is to prevent the event logs to become too huge, and SPARK-29779 achieves the goal. We've got another approach in prior, but the old approach required models in both KVStore and live entities to guarantee compatibility, while they're not designed to do so.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Added UTs.
Closes#27164 from HeartSaVioR/SPARK-30479.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
This pr intends to fix wrong aggregated values in `GROUPING SETS` when there are duplicated grouping sets in a query (e.g., `GROUPING SETS ((k1),(k1))`).
For example;
```
scala> spark.table("t").show()
+---+---+---+
| k1| k2| v|
+---+---+---+
| 0| 0| 3|
+---+---+---+
scala> sql("""select grouping_id(), k1, k2, sum(v) from t group by grouping sets ((k1),(k1,k2),(k2,k1),(k1,k2))""").show()
+-------------+---+----+------+
|grouping_id()| k1| k2|sum(v)|
+-------------+---+----+------+
| 0| 0| 0| 9| <---- wrong aggregate value and the correct answer is `3`
| 1| 0|null| 3|
+-------------+---+----+------+
// PostgreSQL case
postgres=# select k1, k2, sum(v) from t group by grouping sets ((k1),(k1,k2),(k2,k1),(k1,k2));
k1 | k2 | sum
----+------+-----
0 | 0 | 3
0 | 0 | 3
0 | 0 | 3
0 | NULL | 3
(4 rows)
// Hive case
hive> select GROUPING__ID, k1, k2, sum(v) from t group by k1, k2 grouping sets ((k1),(k1,k2),(k2,k1),(k1,k2));
1 0 NULL 3
0 0 0 3
```
[MS SQL Server has the same behaviour with PostgreSQL](https://github.com/apache/spark/pull/26961#issuecomment-573638442). This pr follows the behaviour of PostgreSQL/SQL server; it adds one more virtual attribute in `Expand` for avoiding wrongly grouping rows with the same grouping ID.
### Why are the changes needed?
To fix bugs.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
The existing tests.
Closes#26961 from maropu/SPARK-29708.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
The changes in the rule `SimplifyBinaryComparison` from https://github.com/apache/spark/pull/27008 could bring performance regression in the optimizer when there are a large set of filter conditions.
We need to improve the implementation and reduce the time complexity.
### Why are the changes needed?
Need to fix the potential performance regression in the optimizer.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing unit tests.
Also run a micor benchmark in `BinaryComparisonSimplificationSuite`
```
object Optimize extends RuleExecutor[LogicalPlan] {
val batches =
Batch("Constant Folding", FixedPoint(50),
SimplifyBinaryComparison) :: Nil
}
test("benchmark") {
val a = Symbol("a")
val condition = (1 to 500).map(i => EqualTo(a, a)).reduceLeft(And)
val finalCondition = And(condition, IsNotNull(a))
val plan = nullableRelation.where(finalCondition).analyze
val start = System.nanoTime()
Optimize.execute(plan)
println((System.nanoTime() - start) /1000000)
}
```
Before the changes: 2507ms
After the changes: 3ms
Closes#27212 from gengliangwang/SimplifyBinaryComparison.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Currently for Monitoring Spark application SQL information is not available from REST but only via UI. REST provides only applications,jobs,stages,environment. This Jira is targeted to provide a REST API so that SQL level information can be found
A single SQL query can result into multiple jobs. So for end user who is using STS or spark-sql, the intended highest level of probe is the SQL which he has executed. This information can be seen from SQL tab. Attaching a sample.

But same information he cannot access using the REST API exposed by spark and he always have to rely on jobs API which may be difficult. So i intend to expose the information seen in SQL tab in UI via REST API
Mainly:
Id : Long - execution id of the sql
status : String - possible values COMPLETED/RUNNING/FAILED
description : String - executed SQL string
planDescription : String - Plan representation
metrics : Seq[Metrics] - `Metrics` contain `metricName: String, metricValue: String`
submissionTime : String - formatted `Date` time of SQL submission
duration : Long - total run time in milliseconds
runningJobIds : Seq[Int] - sequence of running job ids
failedJobIds : Seq[Int] - sequence of failed job ids
successJobIds : Seq[Int] - sequence of success job ids
* To fetch sql executions: /sql?details=boolean&offset=integer&length=integer
* To fetch single execution: /sql/{executionID}?details=boolean
| parameter | type | remarks |
| ------------- |:-------------:| -----|
| details | boolean | Optional. Set true to get plan description and metrics information, defaults to false |
| offset | integer | Optional. offset to fetch the executions, defaults to 0 |
| length | integer | Optional. total number of executions to be fetched, defaults to 20 |
### Why are the changes needed?
To support users query SQL information via REST API
### Does this PR introduce any user-facing change?
Yes. It provides a new monitoring URL for SQL
### How was this patch tested?
Tested manually


Closes#24076 from ajithme/restapi.
Lead-authored-by: Ajith <ajith2489@gmail.com>
Co-authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
* Annotate UserDefinedAggregateFunction as deprecated by SPARK-27296
* Update user doc examples to reflect new ability to register typed Aggregator[IN, BUF, OUT] as an untyped aggregating UDF
### Why are the changes needed?
UserDefinedAggregateFunction is being deprecated
### Does this PR introduce any user-facing change?
Changes are to user documentation, and deprecation annotations.
### How was this patch tested?
Testing was via package build to verify doc generation, deprecation warnings, and successful example compilation.
Closes#27193 from erikerlandson/spark-30423.
Authored-by: Erik Erlandson <eerlands@redhat.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Skew Join is common and can severely downgrade performance of queries, especially those with joins. This PR aim to optimization the skew join based on the runtime Map output statistics by adding "OptimizeSkewedPartitions" rule. And The details design doc is [here](https://docs.google.com/document/d/1NkXN-ck8jUOS0COz3f8LUW5xzF8j9HFjoZXWGGX2HAg/edit). Currently we can support "Inner, Cross, LeftSemi, LeftAnti, LeftOuter, RightOuter" join type.
### Why are the changes needed?
To optimize the skewed partition in runtime based on AQE
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
UT
Closes#26434 from JkSelf/skewedPartitionBasedSize.
Lead-authored-by: jiake <ke.a.jia@intel.com>
Co-authored-by: Wenchen Fan <wenchen@databricks.com>
Co-authored-by: JiaKe <ke.a.jia@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
If spark.sql.ansi.enabled is set,
throw exception when cast to any numeric type do not follow the ANSI SQL standards.
### Why are the changes needed?
ANSI SQL standards do not allow invalid strings to get casted into numeric types and throw exception for that. Currently spark sql gives NULL in such cases.
Before:
`select cast('str' as decimal) => NULL`
After :
`select cast('str' as decimal) => invalid input syntax for type numeric: str`
These results are after setting `spark.sql.ansi.enabled=true`
### Does this PR introduce any user-facing change?
Yes. Now when ansi mode is on users will get arithmetic exception for invalid strings.
### How was this patch tested?
Unit Tests Added.
Closes#26933 from iRakson/castDecimalANSI.
Lead-authored-by: root1 <raksonrakesh@gmail.com>
Co-authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to define a sub-class of `AppenderSkeleton` in `SparkFunSuite` and reuse it from other tests. The class stores incoming `LoggingEvent` in an array which is available to tests for future analysis of logged events.
### Why are the changes needed?
This eliminates code duplication in tests.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By existing test suites - `CSVSuite`, `OptimizerLoggingSuite`, `JoinHintSuite`, `CodeGenerationSuite` and `SQLConfSuite`.
Closes#27166 from MaxGekk/dedup-appender-skeleton.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to remove already deprecated SQL configs:
- `spark.sql.variable.substitute.depth` deprecated in Spark 2.1
- `spark.sql.parquet.int64AsTimestampMillis` deprecated in Spark 2.3
Also I moved `removedSQLConfigs` closer to `deprecatedSQLConfigs`. This will allow to have references to other config entries.
### Why are the changes needed?
To improve code maintainability.
### Does this PR introduce any user-facing change?
Yes.
### How was this patch tested?
By existing test suites `ParquetQuerySuite` and `SQLConfSuite`.
Closes#27169 from MaxGekk/remove-deprecated-conf-2.4.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Fix all the failed tests when enable AQE.
### Why are the changes needed?
Run more tests with AQE to catch bugs, and make it easier to enable AQE by default in the future.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing unit tests
Closes#26813 from JkSelf/enableAQEDefault.
Authored-by: jiake <ke.a.jia@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a follow-up for https://github.com/apache/spark/pull/25248 .
### Why are the changes needed?
The new behavior cannot access the existing table which is created by old behavior.
This PR provides a way to avoid new behavior for the existing users.
### Does this PR introduce any user-facing change?
Yes. This will fix the broken behavior on the existing tables.
### How was this patch tested?
Pass the Jenkins and manually run JDBC integration test.
```
build/mvn install -DskipTests
build/mvn -Pdocker-integration-tests -pl :spark-docker-integration-tests_2.12 test
```
Closes#27184 from dongjoon-hyun/SPARK-28152-CONF.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add cache for Like and RLike when pattern is not static
### Why are the changes needed?
When pattern is not static, we should avoid compile pattern every time if some pattern is same.
Here is perf numbers, include 3 test groups and use `range` to make it easy.
```
// ---------------------
// 10,000 rows and 10 partitions
val df1 = spark.range(0, 10000, 1, 10).withColumnRenamed("id", "id1")
val df2 = spark.range(0, 10000, 1, 10).withColumnRenamed("id", "id2")
val start = System.currentTimeMillis
df1.join(df2).where("id2 like id1").count()
// before 16939
// after 6352
println(System.currentTimeMillis - start)
// ---------------------
// 10,000 rows and 100 partitions
val df1 = spark.range(0, 10000, 1, 100).withColumnRenamed("id", "id1")
val df2 = spark.range(0, 10000, 1, 100).withColumnRenamed("id", "id2")
val start = System.currentTimeMillis
df1.join(df2).where("id2 like id1").count()
// before 11070
// after 4680
println(System.currentTimeMillis - start)
// ---------------------
// 20,000 rows and 10 partitions
val df1 = spark.range(0, 20000, 1, 10).withColumnRenamed("id", "id1")
val df2 = spark.range(0, 20000, 1, 10).withColumnRenamed("id", "id2")
val start = System.currentTimeMillis
df1.join(df2).where("id2 like id1").count()
// before 66962
// after 29934
println(System.currentTimeMillis - start)
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Closes#26875 from ulysses-you/SPARK-30245.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR removes a dangling test result, `JSONBenchmark-jdk11-results.txt`.
This causes a case-sensitive issue on Mac.
```
$ git clone https://gitbox.apache.org/repos/asf/spark.git spark-gitbox
Cloning into 'spark-gitbox'...
remote: Counting objects: 671717, done.
remote: Compressing objects: 100% (258021/258021), done.
remote: Total 671717 (delta 329181), reused 560390 (delta 228097)
Receiving objects: 100% (671717/671717), 149.69 MiB | 950.00 KiB/s, done.
Resolving deltas: 100% (329181/329181), done.
Updating files: 100% (16090/16090), done.
warning: the following paths have collided (e.g. case-sensitive paths
on a case-insensitive filesystem) and only one from the same
colliding group is in the working tree:
'sql/core/benchmarks/JSONBenchmark-jdk11-results.txt'
'sql/core/benchmarks/JsonBenchmark-jdk11-results.txt'
```
### Why are the changes needed?
Previously, since the file name didn't match with `object JSONBenchmark`, it made a confusion when we ran the benchmark. So, 4e0e4e51c4 renamed `JSONBenchmark` to `JsonBenchmark`. However, at the same time frame, https://github.com/apache/spark/pull/26003 regenerated this file.
Recently, https://github.com/apache/spark/pull/27078 regenerates the results with the correct file name, `JsonBenchmark-jdk11-results.txt`. So, we can remove the old one.
### Does this PR introduce any user-facing change?
No. This is a test result.
### How was this patch tested?
Manually check the following correctly generated files in the master. And, check this PR removes the dangling one.
- https://github.com/apache/spark/blob/master/sql/core/benchmarks/JsonBenchmark-results.txt
- https://github.com/apache/spark/blob/master/sql/core/benchmarks/JsonBenchmark-jdk11-results.txtCloses#27180 from dongjoon-hyun/SPARK-REMOVE.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose to replace `.collect()`, `.count()` and `.foreach(_ => ())` in SQL benchmarks and use the `NoOp` datasource. I added an implicit class to `SqlBasedBenchmark` with the `.noop()` method. It can be used in benchmark like: `ds.noop()`. The last one is unfolded to `ds.write.format("noop").mode(Overwrite).save()`.
### Why are the changes needed?
To avoid additional overhead that `collect()` (and other actions) has. For example, `.collect()` has to convert values according to external types and pull data to the driver. This can hide actual performance regressions or improvements of benchmarked operations.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Re-run all modified benchmarks using Amazon EC2.
| Item | Description |
| ---- | ----|
| Region | us-west-2 (Oregon) |
| Instance | r3.xlarge (spot instance) |
| AMI | ami-06f2f779464715dc5 (ubuntu/images/hvm-ssd/ubuntu-bionic-18.04-amd64-server-20190722.1) |
| Java | OpenJDK8/10 |
- Run `TPCDSQueryBenchmark` using instructions from the PR #26049
```
# `spark-tpcds-datagen` needs this. (JDK8)
$ git clone https://github.com/apache/spark.git -b branch-2.4 --depth 1 spark-2.4
$ export SPARK_HOME=$PWD
$ ./build/mvn clean package -DskipTests
# Generate data. (JDK8)
$ git clone gitgithub.com:maropu/spark-tpcds-datagen.git
$ cd spark-tpcds-datagen/
$ build/mvn clean package
$ mkdir -p /data/tpcds
$ ./bin/dsdgen --output-location /data/tpcds/s1 // This need `Spark 2.4`
```
- Other benchmarks ran by the script:
```
#!/usr/bin/env python3
import os
from sparktestsupport.shellutils import run_cmd
benchmarks = [
['sql/test', 'org.apache.spark.sql.execution.benchmark.AggregateBenchmark'],
['avro/test', 'org.apache.spark.sql.execution.benchmark.AvroReadBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.BloomFilterBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.DataSourceReadBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.DateTimeBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.ExtractBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.FilterPushdownBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.InExpressionBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.IntervalBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.JoinBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.MakeDateTimeBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.MiscBenchmark'],
['hive/test', 'org.apache.spark.sql.execution.benchmark.ObjectHashAggregateExecBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.OrcNestedSchemaPruningBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.OrcV2NestedSchemaPruningBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.ParquetNestedSchemaPruningBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.RangeBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.UDFBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.WideSchemaBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.WideTableBenchmark'],
['hive/test', 'org.apache.spark.sql.hive.orc.OrcReadBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.datasources.csv.CSVBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.datasources.json.JsonBenchmark']
]
print('Set SPARK_GENERATE_BENCHMARK_FILES=1')
os.environ['SPARK_GENERATE_BENCHMARK_FILES'] = '1'
for b in benchmarks:
print("Run benchmark: %s" % b[1])
run_cmd(['build/sbt', '%s:runMain %s' % (b[0], b[1])])
```
Closes#27078 from MaxGekk/noop-in-benchmarks.
Lead-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Defines a new subclass of UDF: `UserDefinedAggregator`. Also allows `Aggregator` to be registered as a udf. Under the hood, the implementation is based on the internal `TypedImperativeAggregate` class that spark's predefined aggregators make use of. The effect is that custom user defined aggregators are now serialized only on partition boundaries instead of being serialized and deserialized at each input row.
The two new modes of using `Aggregator` are as follows:
```scala
val agg: Aggregator[IN, BUF, OUT] = // typed aggregator
val udaf1 = UserDefinedAggregator(agg)
val udaf2 = spark.udf.register("agg", agg)
```
## How was this patch tested?
Unit testing has been added that corresponds to the testing suites for `UserDefinedAggregateFunction`. Additionally, unit tests explicitly count the number of aggregator ser/de cycles to ensure that it is governed only by the number of data partitions.
To evaluate the performance impact, I did two comparisons.
The code and REPL results are recorded on [this gist](https://gist.github.com/erikerlandson/b0e106a4dbaf7f80b4f4f3a21f05f892)
To characterize its behavior I benchmarked both a relatively simple aggregator and then an aggregator with a complex structure (a t-digest).
### performance
The following compares the new `Aggregator` based aggregation against UDAF. In this scenario, the new aggregation is about 100x faster. The difference in performance impact depends on the complexity of the aggregator. For very simple aggregators (e.g. implementing 'sum', etc), the performance impact is more like 25-30%.
```scala
scala> import scala.util.Random._, org.apache.spark.sql.Row, org.apache.spark.tdigest._
import scala.util.Random._
import org.apache.spark.sql.Row
import org.apache.spark.tdigest._
scala> val data = sc.parallelize(Vector.fill(50000){(nextInt(2), nextGaussian, nextGaussian.toFloat)}, 5).toDF("cat", "x1", "x2")
data: org.apache.spark.sql.DataFrame = [cat: int, x1: double ... 1 more field]
scala> val udaf = TDigestUDAF(0.5, 0)
udaf: org.apache.spark.tdigest.TDigestUDAF = TDigestUDAF(0.5,0)
scala> val bs = Benchmark.sample(10) { data.agg(udaf($"x1"), udaf($"x2")).first }
bs: Array[(Double, org.apache.spark.sql.Row)] = Array((16.523,[TDigestSQL(TDigest(0.5,0,130,TDigestMap(-4.9171836327285225 -> (1.0, 1.0), -3.9615949140987685 -> (1.0, 2.0), -3.792874086327091 -> (0.7500781537109753, 2.7500781537109753), -3.720534874164185 -> (1.796754196108008, 4.546832349818983), -3.702105588052377 -> (0.4531676501810167, 5.0), -3.665883591332569 -> (2.3434687534153142, 7.343468753415314), -3.649982231368131 -> (0.6565312465846858, 8.0), -3.5914188829817744 -> (4.0, 12.0), -3.530472305581248 -> (4.0, 16.0), -3.4060489584449467 -> (2.9372251939818383, 18.93722519398184), -3.3000694035428486 -> (8.12412890252889, 27.061354096510726), -3.2250016655261877 -> (8.30564453211017, 35.3669986286209), -3.180537395623448 -> (6.001782561137285, 41.3687811...
scala> bs.map(_._1)
res0: Array[Double] = Array(16.523, 17.138, 17.863, 17.801, 17.769, 17.786, 17.744, 17.8, 17.939, 17.854)
scala> val agg = TDigestAggregator(0.5, 0)
agg: org.apache.spark.tdigest.TDigestAggregator = TDigestAggregator(0.5,0)
scala> val udaa = spark.udf.register("tdigest", agg)
udaa: org.apache.spark.sql.expressions.UserDefinedAggregator[Double,org.apache.spark.tdigest.TDigestSQL,org.apache.spark.tdigest.TDigestSQL] = UserDefinedAggregator(TDigestAggregator(0.5,0),None,true,true)
scala> val bs = Benchmark.sample(10) { data.agg(udaa($"x1"), udaa($"x2")).first }
bs: Array[(Double, org.apache.spark.sql.Row)] = Array((0.313,[TDigestSQL(TDigest(0.5,0,130,TDigestMap(-4.9171836327285225 -> (1.0, 1.0), -3.9615949140987685 -> (1.0, 2.0), -3.792874086327091 -> (0.7500781537109753, 2.7500781537109753), -3.720534874164185 -> (1.796754196108008, 4.546832349818983), -3.702105588052377 -> (0.4531676501810167, 5.0), -3.665883591332569 -> (2.3434687534153142, 7.343468753415314), -3.649982231368131 -> (0.6565312465846858, 8.0), -3.5914188829817744 -> (4.0, 12.0), -3.530472305581248 -> (4.0, 16.0), -3.4060489584449467 -> (2.9372251939818383, 18.93722519398184), -3.3000694035428486 -> (8.12412890252889, 27.061354096510726), -3.2250016655261877 -> (8.30564453211017, 35.3669986286209), -3.180537395623448 -> (6.001782561137285, 41.36878118...
scala> bs.map(_._1)
res1: Array[Double] = Array(0.313, 0.193, 0.175, 0.185, 0.174, 0.176, 0.16, 0.186, 0.171, 0.179)
scala>
```
Closes#25024 from erikerlandson/spark-27296.
Authored-by: Erik Erlandson <eerlands@redhat.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Now Spark can propagate constraint during sql optimization when `spark.sql.constraintPropagation.enabled` is true, then `where c = 1` will convert to `where c = 1 and c is not null`. We also can use constraint in `SimplifyBinaryComparison`.
`SimplifyBinaryComparison` will simplify expression which is not nullable and semanticEquals. And we also can simplify if one expression is infered `IsNotNull`.
### Why are the changes needed?
Simplify SQL.
```
create table test (c1 string);
explain extended select c1 from test where c1 = c1 limit 10;
-- before
GlobalLimit 10
+- LocalLimit 10
+- Filter (isnotnull(c1#20) AND (c1#20 = c1#20))
+- Relation[c1#20]
-- after
GlobalLimit 10
+- LocalLimit 10
+- Filter (isnotnull(c1#20)
+- Relation[c1#20]
explain extended select c1 from test where c1 > c1 limit 10;
-- before
GlobalLimit 10
+- LocalLimit 10
+- Filter (isnotnull(c1#20) && (c1#20 > c1#20))
+- Relation[c1#20]
-- after
LocalRelation <empty>, [c1#20]
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Add UT.
Closes#27008 from ulysses-you/SPARK-30353.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch proposes to preserve existing permission/acls of paths when truncate table/partition.
### Why are the changes needed?
When Spark SQL truncates table, it deletes the paths of table/partitions, then re-create new ones. If permission/acls were set on the paths, the existing permission/acls will be deleted.
We should preserve the permission/acls if possible.
### Does this PR introduce any user-facing change?
Yes. When truncate table/partition, Spark will keep permission/acls of paths.
### How was this patch tested?
Unit test.
Manual test:
1. Create a table.
2. Manually change it permission/acl
3. Truncate table
4. Check permission/acl
```scala
val df = Seq(1, 2, 3).toDF
df.write.mode("overwrite").saveAsTable("test.test_truncate_table")
val testTable = spark.table("test.test_truncate_table")
testTable.show()
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
+-----+
// hdfs dfs -setfacl ...
// hdfs dfs -getfacl ...
sql("truncate table test.test_truncate_table")
// hdfs dfs -getfacl ...
val testTable2 = spark.table("test.test_truncate_table")
testTable2.show()
+-----+
|value|
+-----+
+-----+
```
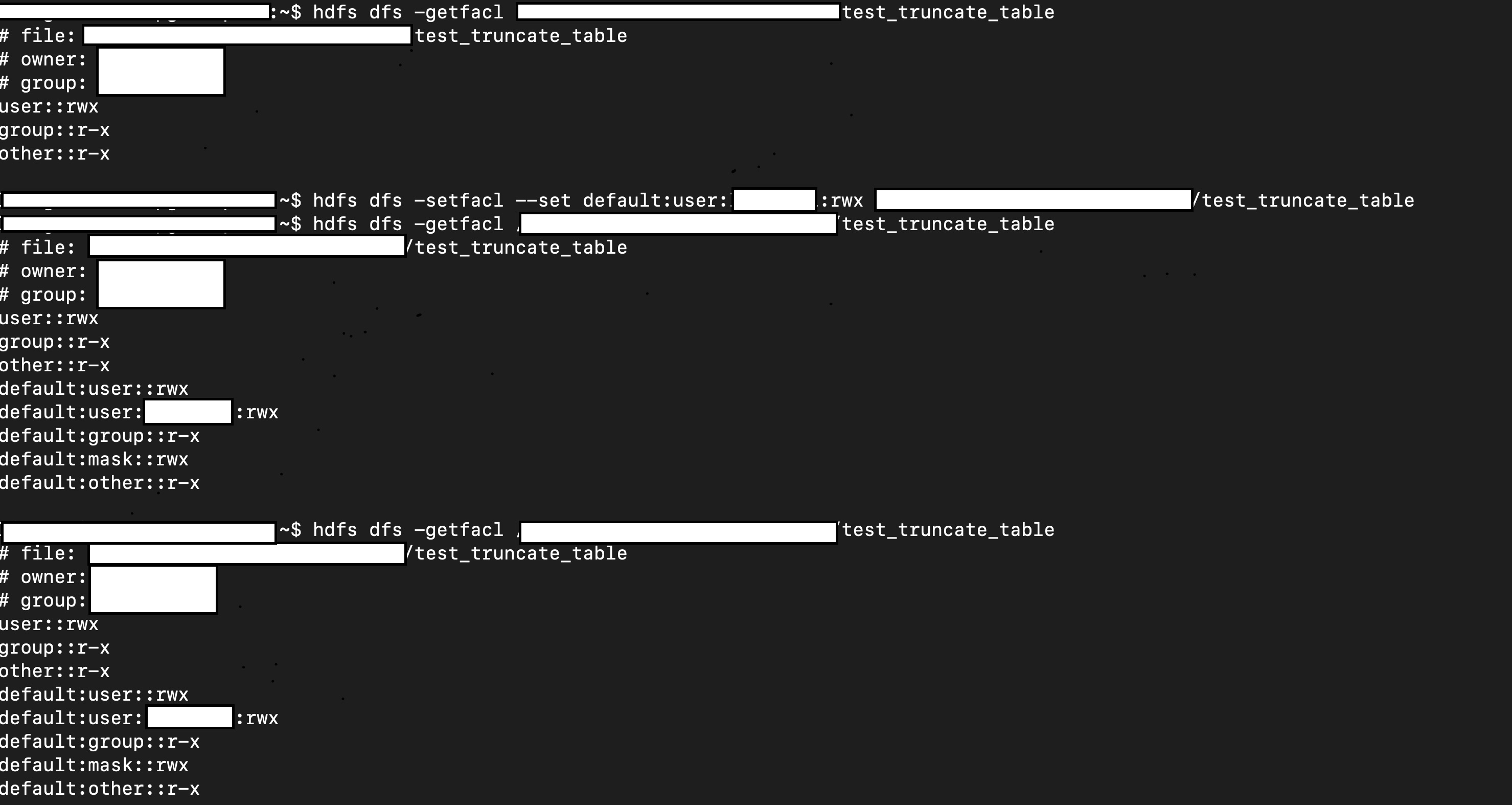
Closes#26956 from viirya/truncate-table-permission.
Lead-authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Co-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Currently data columns are displayed in one line for show create table command, when the table has many columns (to make things even worse, columns may have long names or comments), the displayed result is really hard to read.
To improve readability, we print each column in a separate line. Note that other systems like Hive/MySQL also display in this way.
Also, for data columns, table properties and options, we put the right parenthesis to the end of the last column/property/option, instead of occupying a separate line.
### Why are the changes needed?
for better readability
### Does this PR introduce any user-facing change?
before the change:
```
spark-sql> show create table test_table;
CREATE TABLE `test_table` (`col1` INT COMMENT 'This is comment for column 1', `col2` STRING COMMENT 'This is comment for column 2', `col3` DOUBLE COMMENT 'This is comment for column 3')
USING parquet
OPTIONS (
`bar` '2',
`foo` '1'
)
TBLPROPERTIES (
'a' = 'x',
'b' = 'y'
)
```
after the change:
```
spark-sql> show create table test_table;
CREATE TABLE `test_table` (
`col1` INT COMMENT 'This is comment for column 1',
`col2` STRING COMMENT 'This is comment for column 2',
`col3` DOUBLE COMMENT 'This is comment for column 3')
USING parquet
OPTIONS (
`bar` '2',
`foo` '1')
TBLPROPERTIES (
'a' = 'x',
'b' = 'y')
```
### How was this patch tested?
modified existing tests
Closes#27147 from wzhfy/multi_line_columns.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This pr intends to skip the unnecessary checks that most aggregate quries don't need in RewriteDistinctAggregates.
### Why are the changes needed?
For minor optimization.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#26997 from maropu/OptDistinctAggRewrite.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Now users can add directories from sql CLI as well using ADD FILE command and setting spark.sql.addDirectory.recursive to true.
### Why are the changes needed?
In SPARK-4687, support was added for adding directories as resources. But sql users cannot use that feature from CLI.
`ADD FILE /path/to/folder` gives the following error:
`org.apache.spark.SparkException: Added file /path/to/folder is a directory and recursive is not turned on.`
Users need to turn on `recursive` for adding directories. Thus a configuration was required which will allow users to turn on `recursive`.
Also Hive allow users to add directories from their shell.
### Does this PR introduce any user-facing change?
Yes. Users can set recursive using `spark.sql.addDirectory.recursive`.
### How was this patch tested?
Manually.
Will add test cases soon.
SPARK SCREENSHOTS
When `spark.sql.addDirectory.recursive` is not turned on.
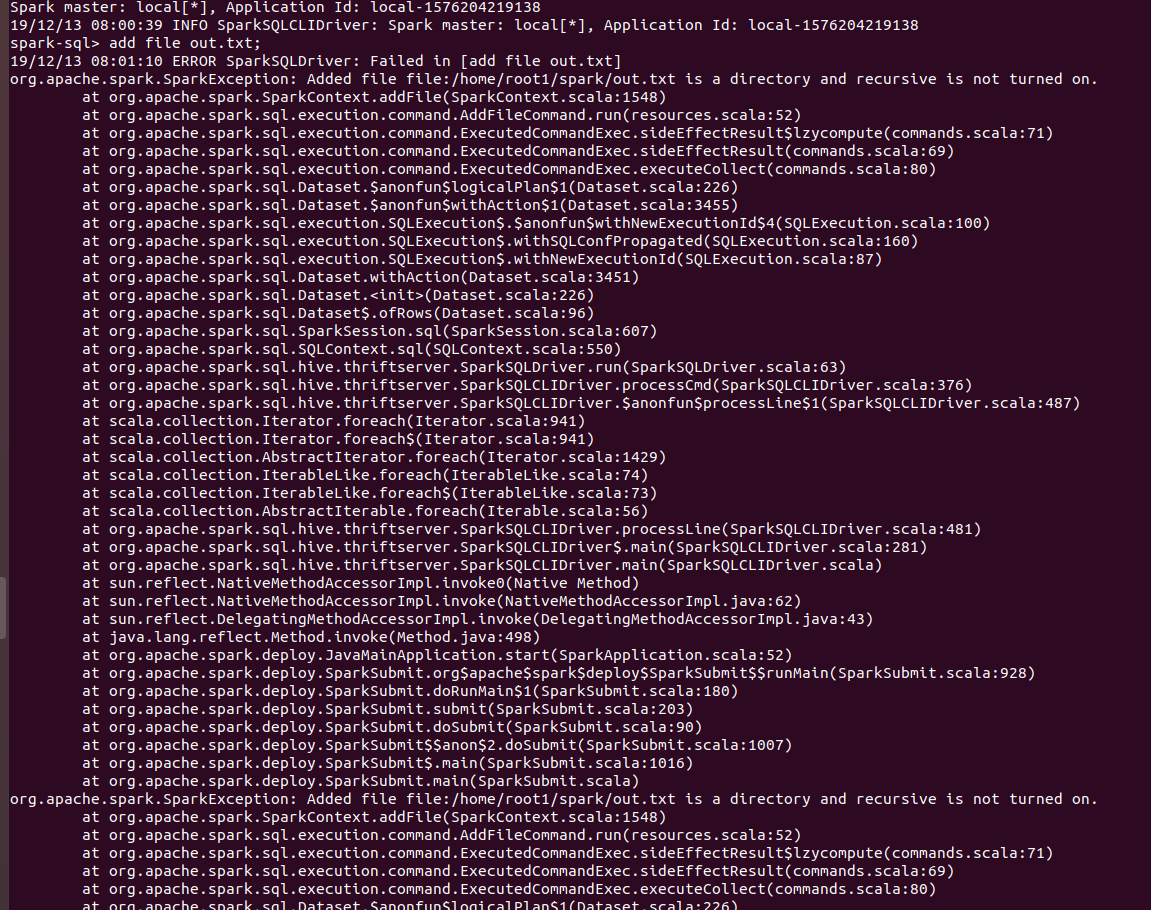
After setting `spark.sql.addDirectory.recursive` to true.

HIVE SCREENSHOT

`RELEASE_NOTES.txt` is text file while `dummy` is a directory.
Closes#26863 from iRakson/SPARK-30234.
Lead-authored-by: root1 <raksonrakesh@gmail.com>
Co-authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR fixes `ConstantPropagation` rule as the current implementation produce incorrect results in some cases. E.g.
```
SELECT * FROM t WHERE NOT(c = 1 AND c + 1 = 1)
```
returns those rows where `c` is null due to `1 + 1 = 1` propagation but it shouldn't.
## Why are the changes needed?
To fix a bug.
## Does this PR introduce any user-facing change?
Yes, fixes a bug.
## How was this patch tested?
New UTs.
Closes#27119 from peter-toth/SPARK-30447.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
In this pull request, we are going to support `SET OWNER` syntax for databases and namespaces,
```sql
ALTER (DATABASE|SCHEME|NAMESPACE) database_name SET OWNER [USER|ROLE|GROUP] user_or_role_group;
```
Before this commit 332e252a14, we didn't care much about ownerships for the catalog objects. In 332e252a14, we determined to use properties to store ownership staff, and temporarily used `alter database ... set dbproperties ...` to support switch ownership of a database. This PR aims to use the formal syntax to replace it.
In hive, `ownerName/Type` are fields of the database objects, also they can be normal properties.
```
create schema test1 with dbproperties('ownerName'='yaooqinn')
```
The create/alter database syntax will not change the owner to `yaooqinn` but store it in parameters. e.g.
```
+----------+----------+---------------------------------------------------------------+-------------+-------------+-----------------------+--+
| db_name | comment | location | owner_name | owner_type | parameters |
+----------+----------+---------------------------------------------------------------+-------------+-------------+-----------------------+--+
| test1 | | hdfs://quickstart.cloudera:8020/user/hive/warehouse/test1.db | anonymous | USER | {ownerName=yaooqinn} |
+----------+----------+---------------------------------------------------------------+-------------+-------------+-----------------------+--+
```
In this pull request, because we let the `ownerName` become reversed, so it will neither change the owner nor store in dbproperties, just be omitted silently.
## Why are the changes needed?
Formal syntax support for changing database ownership
### Does this PR introduce any user-facing change?
yes, add a new syntax
### How was this patch tested?
add unit tests
Closes#26775 from yaooqinn/SPARK-30018.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Allow users to specify NOT NULL in CREATE TABLE and ADD COLUMN column definition, and add a new SQL syntax to alter column nullability: ALTER TABLE ... ALTER COLUMN SET/DROP NOT NULL. This is a SQL standard syntax:
```
<alter column definition> ::=
ALTER [ COLUMN ] <column name> <alter column action>
<alter column action> ::=
<set column default clause>
| <drop column default clause>
| <set column not null clause>
| <drop column not null clause>
| ...
<set column not null clause> ::=
SET NOT NULL
<drop column not null clause> ::=
DROP NOT NULL
```
### Why are the changes needed?
Previously we don't support it because the table schema in hive catalog are always nullable. Since we have catalog plugin now, it makes more sense to support NOT NULL at spark side, and let catalog implementations to decide if they support it or not.
### Does this PR introduce any user-facing change?
Yes, this is a new feature
### How was this patch tested?
new tests
Closes#27110 from cloud-fan/nullable.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. Put all deprecated SQL configs the map `SQLConf.deprecatedSQLConfigs` with extra info about when configs were deprecated and additional comments that explain why a config was deprecated, what an user can use instead of it. Here is the list of already deprecated configs:
- spark.sql.hive.verifyPartitionPath
- spark.sql.execution.pandas.respectSessionTimeZone
- spark.sql.legacy.execution.pandas.groupedMap.assignColumnsByName
- spark.sql.parquet.int64AsTimestampMillis
- spark.sql.variable.substitute.depth
- spark.sql.execution.arrow.enabled
- spark.sql.execution.arrow.fallback.enabled
2. Output warning in `set()` and `unset()` about deprecated SQL configs
### Why are the changes needed?
This should improve UX with Spark SQL and notify users about already deprecated SQL configs.
### Does this PR introduce any user-facing change?
Yes, before:
```
spark-sql> set spark.sql.hive.verifyPartitionPath=true;
spark.sql.hive.verifyPartitionPath true
```
After:
```
spark-sql> set spark.sql.hive.verifyPartitionPath=true;
20/01/03 21:28:17 WARN RuntimeConfig: The SQL config 'spark.sql.hive.verifyPartitionPath' has been deprecated in Spark v3.0.0 and may be removed in the future. This config is replaced by spark.files.ignoreMissingFiles.
spark.sql.hive.verifyPartitionPath true
```
### How was this patch tested?
Add new test which registers new log appender and catches all logging to check that `set()` and `unset()` log any warning.
Closes#27092 from MaxGekk/group-deprecated-sql-configs.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
fixing a broken build:
https://amplab.cs.berkeley.edu/jenkins/job/spark-master-test-sbt-hadoop-2.7-hive-1.2/3/console
### Why are the changes needed?
the build is teh borked!
### Does this PR introduce any user-facing change?
newp
### How was this patch tested?
by the build system
Closes#27156 from shaneknapp/fix-scala-style.
Authored-by: shane knapp <incomplete@gmail.com>
Signed-off-by: shane knapp <incomplete@gmail.com>
### What changes were proposed in this pull request?
Fix ignoreMissingFiles/ignoreCorruptFiles in DSv2:
When `FilePartitionReader` finds a missing or corrupt file, it should just skip and continue to read next file rather than stop with current behavior.
### Why are the changes needed?
ignoreMissingFiles/ignoreCorruptFiles in DSv2 is wrong comparing to DSv1.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Updated existed test for `ignoreMissingFiles`. Note I didn't update tests for `ignoreCorruptFiles`, because there're various datasources has tests for `ignoreCorruptFiles`. So I'm not sure if it's worth to touch all those tests since the basic logic of `ignoreCorruptFiles` should be same with `ignoreMissingFiles`.
Closes#27136 from Ngone51/improve-missing-files.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
This PR introduces `SupportsCatalogOptions` as an interface for `TableProvider`. Through `SupportsCatalogOptions`, V2 DataSources can implement the two methods `extractIdentifier` and `extractCatalog` to support the creation, and existence check of tables without requiring a formal TableCatalog implementation.
We currently don't support all SaveModes for DataSourceV2 in DataFrameWriter.save. The idea here is that eventually File based tables can be written with `DataFrameWriter.save(path)` will create a PathIdentifier where the name is `path`, and the V2SessionCatalog will be able to perform FileSystem checks at `path` to support ErrorIfExists and Ignore SaveModes.
### Why are the changes needed?
To support all Save modes for V2 data sources with DataFrameWriter. Since we can now support table creation, we will be able to provide partitioning information when first creating the table as well.
### Does this PR introduce any user-facing change?
Introduces a new interface
### How was this patch tested?
Will add tests once interface is vetted.
Closes#26913 from brkyvz/catalogOptions.
Lead-authored-by: Burak Yavuz <brkyvz@gmail.com>
Co-authored-by: Burak Yavuz <burak@databricks.com>
Signed-off-by: Burak Yavuz <brkyvz@gmail.com>
### What changes were proposed in this pull request?
File source V2: support partition pruning.
Note: subquery predicates are not pushed down for partition pruning even after this PR, due to the limitation for the current data source V2 API and framework. The rule `PlanSubqueries` requires the subquery expression to be in the children or class parameters in `SparkPlan`, while the condition is not satisfied for `BatchScanExec`.
### Why are the changes needed?
It's important for reading performance.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
New unit tests for all the V2 file sources
Closes#27112 from gengliangwang/PartitionPruningInFileScan.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, COMMENT and LOCATION are reserved properties for Datasource v2 namespaces. They can be set via specific clauses and via properties. And the ones specified in clauses take precede of properties. Since they are reserved, which means they are not able to visit directly. They should be used in COMMENT/LOCATION clauses ONLY.
### Why are the changes needed?
make reserved properties be reserved.
### Does this PR introduce any user-facing change?
yes, 'location', 'comment' are not allowed use in db properties
### How was this patch tested?
UNIT tests.
Closes#26806 from yaooqinn/SPARK-30183.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to move pandas related functionalities into pandas package. Namely:
```bash
pyspark/sql/pandas
├── __init__.py
├── conversion.py # Conversion between pandas <> PySpark DataFrames
├── functions.py # pandas_udf
├── group_ops.py # Grouped UDF / Cogrouped UDF + groupby.apply, groupby.cogroup.apply
├── map_ops.py # Map Iter UDF + mapInPandas
├── serializers.py # pandas <> PyArrow serializers
├── types.py # Type utils between pandas <> PyArrow
└── utils.py # Version requirement checks
```
In order to separately locate `groupby.apply`, `groupby.cogroup.apply`, `mapInPandas`, `toPandas`, and `createDataFrame(pdf)` under `pandas` sub-package, I had to use a mix-in approach which Scala side uses often by `trait`, and also pandas itself uses this approach (see `IndexOpsMixin` as an example) to group related functionalities. Currently, you can think it's like Scala's self typed trait. See the structure below:
```python
class PandasMapOpsMixin(object):
def mapInPandas(self, ...):
...
return ...
# other Pandas <> PySpark APIs
```
```python
class DataFrame(PandasMapOpsMixin):
# other DataFrame APIs equivalent to Scala side.
```
Yes, This is a big PR but they are mostly just moving around except one case `createDataFrame` which I had to split the methods.
### Why are the changes needed?
There are pandas functionalities here and there and I myself gets lost where it was. Also, when you have to make a change commonly for all of pandas related features, it's almost impossible now.
Also, after this change, `DataFrame` and `SparkSession` become more consistent with Scala side since pandas is specific to Python, and this change separates pandas-specific APIs away from `DataFrame` or `SparkSession`.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests should cover. Also, I manually built the PySpark API documentation and checked.
Closes#27109 from HyukjinKwon/pandas-refactoring.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a minor code refactoring PR. It creates an adaptive execution context class to wrap objects shared across main query and sub-queries.
### Why are the changes needed?
This refactoring will improve code readability and reduce the number of parameters used to initialize `AdaptiveSparkPlanExec`.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Passed existing UTs.
Closes#26959 from maryannxue/aqe-context.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
This patch renews the verification logic of archive path for FileStreamSource, as we found the logic doesn't take partitioned/recursive options into account.
Before the patch, it only requires the archive path to have depth more than 2 (two subdirectories from root), leveraging the fact FileStreamSource normally reads the files where the parent directory matches the pattern or the file itself matches the pattern. Given 'archive' operation moves the files to the base archive path with retaining the full path, archive path is tend to be safe if the depth is more than 2, meaning FileStreamSource doesn't re-read archived files as new source files.
WIth partitioned/recursive options, the fact is invalid, as FileStreamSource can read any files in any depth of subdirectories for source pattern. To deal with this correctly, we have to renew the verification logic, which may not intuitive and simple but works for all cases.
The new verification logic prevents both cases:
1) archive path matches with source pattern as "prefix" (the depth of archive path > the depth of source pattern)
e.g.
* source pattern: `/hello*/spar?`
* archive path: `/hello/spark/structured/streaming`
Any files in archive path will match with source pattern when recursive option is enabled.
2) source pattern matches with archive path as "prefix" (the depth of source pattern > the depth of archive path)
e.g.
* source pattern: `/hello*/spar?/structured/hello2*`
* archive path: `/hello/spark/structured`
Some archive files will not match with source pattern, e.g. file path: `/hello/spark/structured/hello2`, then final archived path: `/hello/spark/structured/hello/spark/structured/hello2`.
But some other archive files will still match with source pattern, e.g. file path: `/hello2/spark/structured/hello2`, then final archived path: `/hello/spark/structured/hello2/spark/structured/hello2` which matches with source pattern when recursive is enabled.
Implicitly it also prevents archive path matches with source pattern as full match (same depth).
We would want to prevent any source files to be archived and added to new source files again, so the patch takes most restrictive approach to prevent the possible cases.
### Why are the changes needed?
Without this patch, there's a chance archived files are included as new source files when partitioned/recursive option is enabled, as current condition doesn't take these options into account.
### Does this PR introduce any user-facing change?
Only for Spark 3.0.0-preview (only preview 1 for now, but possibly preview 2 as well) - end users are required to provide archive path with ensuring a bit complicated conditions, instead of simply higher than 2 depths.
### How was this patch tested?
New UT.
Closes#26920 from HeartSaVioR/SPARK-30281.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
1, for primitive types `Array.fill(n)(0)` -> `Array.ofDim(n)`;
2, for `AnyRef` types `Array.fill(n)(null)` -> `Array.ofDim(n)`;
3, for primitive types `Array.empty[XXX]` -> `Array.emptyXXXArray`
### Why are the changes needed?
`Array.ofDim` avoid assignments;
`Array.emptyXXXArray` avoid create new object;
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
existing testsuites
Closes#27133 from zhengruifeng/minor_fill_ofDim.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
For a partitioned table, if the number of partitions are very large, e.g. tens of thousands or even larger, calculating its total size causes flooding logs.
The flooding happens in:
1. `calculateLocationSize` prints the starting and ending for calculating the location size, and it is called per partition;
2. `bulkListLeafFiles` prints all partition paths.
This pr is to simplify the logging when calculating the size of a partitioned table.
### How was this patch tested?
not related
Closes#27079 from wzhfy/improve_log.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Remove PrunedInMemoryFileIndex and merge its functionality into InMemoryFileIndex.
### Why are the changes needed?
PrunedInMemoryFileIndex is only used in CatalogFileIndex.filterPartitions, and its name is kind of confusing, we can completely merge its functionality into InMemoryFileIndex and remove the class.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing unit tests.
Closes#26850 from fuwhu/SPARK-30215.
Authored-by: fuwhu <bestwwg@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a follow-up to address the following comment: https://github.com/apache/spark/pull/27095#discussion_r363152180
Currently, a SQL command string is parsed to a "statement" logical plan, converted to a logical plan with catalog/namespace, then finally converted to a physical plan. With the new resolution framework, there is no need to create a "statement" logical plan; a logical plan can contain `UnresolvedNamespace` which will be resolved to a `ResolvedNamespace`. This should simply the code base and make it a bit easier to add a new command.
### Why are the changes needed?
Clean up codebase.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing tests should cover the changes.
Closes#27125 from imback82/SPARK-30214-followup.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch proposes:
1. Fix OOM at WideSchemaBenchmark: make `ValidateExternalType.errMsg` lazy variable, i.e. not to initiate it in the constructor
2. Truncate `errMsg`: Replacing `catalogString` with `simpleString` which is truncated
3. Optimizing `override def catalogString` in `StructType`: Make `catalogString` more efficient in string generation by using `StringConcat`
### Why are the changes needed?
In the JIRA, it is found that WideSchemaBenchmark fails with OOM, like:
```
[error] Exception in thread "main" org.apache.spark.sql.catalyst.errors.package$TreeNodeException: makeCopy, tree: validateexternaltype(getexternalrowfield(input[0, org.apac
he.spark.sql.Row, true], 0, a), StructField(b,StructType(StructField(c,StructType(StructField(value_1,LongType,true), StructField(value_10,LongType,true), StructField(value_
100,LongType,true), StructField(value_1000,LongType,true), StructField(value_1001,LongType,true), StructField(value_1002,LongType,true), StructField(value_1003,LongType,true
), StructField(value_1004,LongType,true), StructField(value_1005,LongType,true), StructField(value_1006,LongType,true), StructField(value_1007,LongType,true), StructField(va
lue_1008,LongType,true), StructField(value_1009,LongType,true), StructField(value_101,LongType,true), StructField(value_1010,LongType,true), StructField(value_1011,LongType,
...
ue), StructField(value_99,LongType,true), StructField(value_990,LongType,true), StructField(value_991,LongType,true), StructField(value_992,LongType,true), StructField(value
_993,LongType,true), StructField(value_994,LongType,true), StructField(value_995,LongType,true), StructField(value_996,LongType,true), StructField(value_997,LongType,true),
StructField(value_998,LongType,true), StructField(value_999,LongType,true)),true))
[error] at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:56)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.makeCopy(TreeNode.scala:435)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:408)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:327)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:307)
....
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$mapChildren$1(TreeNode.scala:404)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:214)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:374)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:327)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:307)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformUp$1(TreeNode.scala:307)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$mapChildren$1(TreeNode.scala:376)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:214)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:374)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:327)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:307)
[error] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoder.<init>(ExpressionEncoder.scala:198)
[error] at org.apache.spark.sql.catalyst.encoders.RowEncoder$.apply(RowEncoder.scala:71)
[error] at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:88)
[error] at org.apache.spark.sql.SparkSession.internalCreateDataFrame(SparkSession.scala:554)
[error] at org.apache.spark.sql.DataFrameReader.json(DataFrameReader.scala:476)
[error] at org.apache.spark.sql.execution.benchmark.WideSchemaBenchmark$.$anonfun$wideShallowlyNestedStructFieldReadAndWrite$1(WideSchemaBenchmark.scala:126)
...
[error] Caused by: java.lang.OutOfMemoryError: GC overhead limit exceeded
[error] at java.util.Arrays.copyOf(Arrays.java:3332)
[error] at java.lang.AbstractStringBuilder.ensureCapacityInternal(AbstractStringBuilder.java:124)
[error] at java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:448)
[error] at java.lang.StringBuilder.append(StringBuilder.java:136)
[error] at scala.collection.mutable.StringBuilder.append(StringBuilder.scala:213)
[error] at scala.collection.TraversableOnce.$anonfun$addString$1(TraversableOnce.scala:368)
[error] at scala.collection.TraversableOnce$$Lambda$67/667447085.apply(Unknown Source)
[error] at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
[error] at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
[error] at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:198)
[error] at scala.collection.TraversableOnce.addString(TraversableOnce.scala:362)
[error] at scala.collection.TraversableOnce.addString$(TraversableOnce.scala:358)
[error] at scala.collection.mutable.ArrayOps$ofRef.addString(ArrayOps.scala:198)
[error] at scala.collection.TraversableOnce.mkString(TraversableOnce.scala:328)
[error] at scala.collection.TraversableOnce.mkString$(TraversableOnce.scala:327)
[error] at scala.collection.mutable.ArrayOps$ofRef.mkString(ArrayOps.scala:198)
[error] at scala.collection.TraversableOnce.mkString(TraversableOnce.scala:330)
[error] at scala.collection.TraversableOnce.mkString$(TraversableOnce.scala:330)
[error] at scala.collection.mutable.ArrayOps$ofRef.mkString(ArrayOps.scala:198)
[error] at org.apache.spark.sql.types.StructType.catalogString(StructType.scala:411)
[error] at org.apache.spark.sql.catalyst.expressions.objects.ValidateExternalType.<init>(objects.scala:1695)
[error] at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
[error] at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
[error] at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
[error] at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$makeCopy$7(TreeNode.scala:468)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode$$Lambda$934/387827651.apply(Unknown Source)
[error] at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:72)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$makeCopy$1(TreeNode.scala:467)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode$$Lambda$929/449240381.apply(Unknown Source)
[error] at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:52)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.makeCopy(TreeNode.scala:435)
```
It is after cb5ea201df commit which refactors `ExpressionEncoder`.
The stacktrace shows it fails at `transformUp` on `objSerializer` in `ExpressionEncoder`. In particular, it fails at initializing `ValidateExternalType.errMsg`, that interpolates `catalogString` of given `expected` data type in a string. In WideSchemaBenchmark we have very deeply nested data type. When we transform on the serializer which contains `ValidateExternalType`, we create redundant big string `errMsg`. Because we just in transforming it and don't use it yet, it is useless and waste a lot of memory.
After make `ValidateExternalType.errMsg` as lazy variable, WideSchemaBenchmark works.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manual test with WideSchemaBenchmark.
Closes#27117 from viirya/SPARK-30429.
Lead-authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Co-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add table/column comments and table properties to the result of show create table of views.
### Does this PR introduce any user-facing change?
When show create table for views, after this patch, the result can contain table/column comments and table properties if they exist.
### How was this patch tested?
add new tests
Closes#26944 from wzhfy/complete_show_create_view.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
Avoid hive log initialisation as https://github.com/apache/hive/blob/rel/release-2.3.5/common/src/java/org/apache/hadoop/hive/common/LogUtils.java introduces dependency over `org.apache.logging.log4j.core.impl.Log4jContextFactory` which is missing in our spark installer classpath directly. I believe the `LogUtils.initHiveLog4j()` code is here as the HiveServer2 class is copied from Hive.
To make `start-thriftserver.sh --help` command success.
Currently, start-thriftserver.sh --help throws
```
...
Thrift server options:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/logging/log4j/spi/LoggerContextFactory
at org.apache.hive.service.server.HiveServer2.main(HiveServer2.java:167)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2$.main(HiveThriftServer2.scala:82)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.main(HiveThriftServer2.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.logging.log4j.spi.LoggerContextFactory
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 3 more
```
No
Checked Manually
Closes#27042 from ajithme/thrifthelp.
Authored-by: Ajith <ajith2489@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add CreateFunctionStatement and make CREATE FUNCTION go through the same catalog/table resolution framework of v2 commands.
### Why are the changes needed?
It's important to make all the commands have the same table resolution behavior, to avoid confusing
CREATE FUNCTION namespace.function
### Does this PR introduce any user-facing change?
Yes. When running CREATE FUNCTION namespace.function Spark fails the command if the current catalog is set to a v2 catalog.
### How was this patch tested?
Unit tests.
Closes#26890 from planga82/feature/SPARK-30039_CreateFunctionV2Command.
Authored-by: Pablo Langa <soypab@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In `SqlBase.g4`, the `comment` clause is used as `COMMENT comment=STRING` and `COMMENT STRING` in many places.
While the `location` clause often appears along with the `comment` clause with a pattern defined as
```sql
locationSpec
: LOCATION STRING
;
```
Then, we have to visit `locationSpec` as a `List` but comment as a single token.
We defined `commentSpec` for the comment clause to simplify and unify the grammar and the invocations.
### Why are the changes needed?
To simplify the grammar.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
existing tests
Closes#27102 from yaooqinn/SPARK-30431.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
#26847 introduced new framework for resolving catalog/namespaces. This PR proposes to integrate commands that need to resolve namespaces into the new framework.
### Why are the changes needed?
This is one of the work items for moving into the new resolution framework. Resolving v1/v2 tables with the new framework will be followed up in different PRs.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing tests should cover the changes.
Closes#27095 from imback82/unresolved_ns.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR adds a note first and last can be non-deterministic in SQL function docs as well.
This is already documented in `functions.scala`.
### Why are the changes needed?
Some people look reading SQL docs only.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Jenkins will test.
Closes#27099 from HyukjinKwon/SPARK-30335.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR implements multiple performance optimizations for `ParquetRowConverter`, achieving some modest constant-factor wins for all fields and larger wins for map and array fields:
- Add `private[this]` to several `val`s (90cebf080a5d3857ea8cf2a89e8e060b8b5a2fbf)
- Keep a `fieldUpdaters` array, saving two`.updater()` calls per field (7318785d350cc924198d7514e40973fd76d54ad5): I suspect that these are often megamorphic calls, so cutting these out seems like it could be a relatively large performance win.
- Only call `currentRow.numFields` once per `start()` call (e05de150813b639929c18af1df09ec718d2d16fc): previously we'd call it once per field and this had a significant enough cost that it was visible during profiling.
- Reuse buffers in array and map converters (c7d1534685fbad5d2280b082f37bed6d75848e76, 6d16f596ef6af9fd8946a062f79d0eeace9e1959): previously we would create a brand-new Scala `ArrayBuffer` for each field read, but this isn't actually necessary because the data is already copied into a fresh array when `end()` constructs a `GenericArrayData`.
### Why are the changes needed?
To improve Parquet read performance; this is complementary to #26993's (orthogonal) improvements for nested struct read performance.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests, plus manual benchmarking with both synthetic and realistic schemas (similar to the ones in #26993). I've seen ~10%+ improvements in scan performance on certain real-world datasets.
Closes#27089 from JoshRosen/joshrosen/more-ParquetRowConverter-optimizations.
Lead-authored-by: Josh Rosen <rosenville@gmail.com>
Co-authored-by: Josh Rosen <joshrosen@stripe.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR modifies `ParquetRowConverter` to remove unnecessary `InternalRow.copy()` calls for structs that are directly nested in other structs.
### Why are the changes needed?
These changes can significantly improve performance when reading Parquet files that contain deeply-nested structs with many fields.
The `ParquetRowConverter` uses per-field `Converter`s for handling individual fields. Internally, these converters may have mutable state and may return mutable objects. In most cases, each `converter` is only invoked once per Parquet record (this is true for top-level fields, for example). However, arrays and maps may call their child element converters multiple times per Parquet record: in these cases we must be careful to copy any mutable outputs returned by child converters.
In the existing code, `InternalRow`s are copied whenever they are stored into _any_ parent container (not just maps and arrays). This copying can be especially expensive for deeply-nested fields, since a deep copy is performed at every level of nesting.
This PR modifies the code to avoid copies for structs that are directly nested in structs; see inline code comments for an argument for why this is safe.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
**Correctness**: I added new test cases to `ParquetIOSuite` to increase coverage of nested structs, including structs nested in arrays: previously this suite didn't test that case, so we used to lack mutation coverage of this `copy()` code (the suite's tests still passed if I incorrectly removed the `.copy()` in all cases). I also added a test for maps with struct keys and modified the existing "map with struct values" test case include maps with two elements (since the incorrect omission of a `copy()` can only be detected if the map has multiple elements).
**Performance**: I put together a simple local benchmark demonstrating the performance problems:
First, construct a nested schema:
```scala
case class Inner(
f1: Int,
f2: Long,
f3: String,
f4: Int,
f5: Long,
f6: String,
f7: Int,
f8: Long,
f9: String,
f10: Int
)
case class Wrapper1(inner: Inner)
case class Wrapper2(wrapper1: Wrapper1)
case class Wrapper3(wrapper2: Wrapper2)
```
`Wrapper3`'s schema looks like:
```
root
|-- wrapper2: struct (nullable = true)
| |-- wrapper1: struct (nullable = true)
| | |-- inner: struct (nullable = true)
| | | |-- f1: integer (nullable = true)
| | | |-- f2: long (nullable = true)
| | | |-- f3: string (nullable = true)
| | | |-- f4: integer (nullable = true)
| | | |-- f5: long (nullable = true)
| | | |-- f6: string (nullable = true)
| | | |-- f7: integer (nullable = true)
| | | |-- f8: long (nullable = true)
| | | |-- f9: string (nullable = true)
| | | |-- f10: integer (nullable = true)
```
Next, generate some fake data:
```scala
val data = spark.range(1, 1000 * 1000 * 25, 1, 1).map { i =>
Wrapper3(Wrapper2(Wrapper1(Inner(
i.toInt,
i * 2,
(i * 3).toString,
(i * 4).toInt,
i * 5,
(i * 6).toString,
(i * 7).toInt,
i * 8,
(i * 9).toString,
(i * 10).toInt
))))
}
data.write.mode("overwrite").parquet("/tmp/parquet-test")
```
I then ran a simple benchmark consisting of
```
spark.read.parquet("/tmp/parquet-test").selectExpr("hash(*)").rdd.count()
```
where the `hash(*)` is designed to force decoding of all Parquet fields but avoids `RowEncoder` costs in the `.rdd.count()` stage.
In the old code, expensive copying takes place at every level of nesting; this is apparent in the following flame graph:

After this PR's changes, the above toy benchmark runs ~30% faster.
Closes#26993 from JoshRosen/joshrosen/faster-parquet-nested-scan-by-avoiding-copies.
Lead-authored-by: Josh Rosen <rosenville@gmail.com>
Co-authored-by: Josh Rosen <joshrosen@stripe.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR tries to make conflict attributes resolution in `ResolveReferences` more scalable by doing resolution in batch way.
### Why are the changes needed?
Currently, `ResolveReferences` rule only resolves conflict attributes of one single conflict plan pair in one iteration, which can be inefficient when there're many conflicts.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Covered by existed tests.
Closes#27105 from Ngone51/resolve-conflict-columns-in-batch.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Adding a `LogicalWriteInfo` interface as suggested by cloud-fan in https://github.com/apache/spark/pull/25990#issuecomment-555132991
### Why are the changes needed?
It provides compile-time guarantees where we previously had none, which will make it harder to introduce bugs in the future.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Compiles and passes tests
Closes#26678 from edrevo/add-logical-write-info.
Lead-authored-by: Ximo Guanter <joaquin.guantergonzalbez@telefonica.com>
Co-authored-by: Ximo Guanter
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Current catalyst rewrite non-correlated exists subquery to BroadcastNestLoopJoin, it's performance is not good , now we rewrite non-correlated EXISTS subquery to ScalaSubquery to optimize the performance.
We rewrite
```
WHERE EXISTS (SELECT A FROM TABLE B WHERE COL1 > 10)
```
to
```
WHERE (SELECT 1 FROM (SELECT A FROM TABLE B WHERE COL1 > 10) LIMIT 1) IS NOT NULL
```
to avoid build join to solve EXISTS expression.
### Why are the changes needed?
Optimize EXISTS performance.
### Does this PR introduce any user-facing change?
NO
### How was this patch tested?
Manuel Tested
Closes#26437 from AngersZhuuuu/SPARK-29800.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
SQLCOnf Doc updated.
### Why are the changes needed?
Some doc comments were not written properly. Space was missing at many places. This patch updates the doc.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Documentation update.
Closes#27091 from iRakson/SQLConfDoc.
Authored-by: root1 <raksonrakesh@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Revert https://github.com/apache/spark/pull/20433 .
### Why are the changes needed?
According to the SQL standard, the INTERVAL prefix is required:
```
<interval literal> ::=
INTERVAL [ <sign> ] <interval string> <interval qualifier>
<interval string> ::=
<quote> <unquoted interval string> <quote>
```
### Does this PR introduce any user-facing change?
yes, but omitting the INTERVAL prefix is a new feature in 3.0
### How was this patch tested?
existing tests
Closes#27080 from cloud-fan/interval.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
1. For `ScanOperation`, if it collects more than one filters, then all filters must be deterministic. And filter can be non-deterministic iff there's only one collected filter.
2. `FileSourceStrategy` should filter out non-deterministic filter, as it will hit haven't initialized exception if it's a partition related filter.
### Why are the changes needed?
Strictly follow `CombineFilters`'s behavior which doesn't allow combine two filters where non-deterministic predicates exist. And avoid hitting exception for file source.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Test exists.
Closes#27073 from Ngone51/SPARK-29768-FOLLOWUP.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, we have a v2 adapter for v1 catalog (`V2SessionCatalog`), all the table/namespace commands can be implemented via v2 APIs.
Usually, a command needs to know which catalog it needs to operate, but different commands have different requirements about what to resolve. A few examples:
- `DROP NAMESPACE`: only need to know the name of the namespace.
- `DESC NAMESPACE`: need to lookup the namespace and get metadata, but is done during execution
- `DROP TABLE`: need to do lookup and make sure it's a table not (temp) view.
- `DESC TABLE`: need to lookup the table and get metadata.
For namespaces, the analyzer only needs to find the catalog and the namespace name. The command can do lookup during execution if needed.
For tables, mostly commands need the analyzer to do lookup.
Note that, table and namespace have a difference: `DESC NAMESPACE testcat` works and describes the root namespace under `testcat`, while `DESC TABLE testcat` fails if there is no table `testcat` under the current catalog. It's because namespaces can be named [], but tables can't. The commands should explicitly specify it needs to operate on namespace or table.
In this Pull Request, we introduce a new framework to resolve v2 commands:
1. parser creates logical plans or commands with `UnresolvedNamespace`/`UnresolvedTable`/`UnresolvedView`/`UnresolvedRelation`. (CREATE TABLE still keeps Seq[String], as it doesn't need to look up relations)
2. analyzer converts
2.1 `UnresolvedNamespace` to `ResolvesNamespace` (contains catalog and namespace identifier)
2.2 `UnresolvedTable` to `ResolvedTable` (contains catalog, identifier and `Table`)
2.3 `UnresolvedView` to `ResolvedView` (will be added later when we migrate view commands)
2.4 `UnresolvedRelation` to relation.
3. an extra analyzer rule to match commands with `V1Table` and converts them to corresponding v1 commands. This will be added later when we migrate existing commands
4. planner matches commands and converts them to the corresponding physical nodes.
We also introduce brand new v2 commands - the `comment` syntaxes to illustrate how to work with the newly added framework.
```sql
COMMENT ON (DATABASE|SCHEMA|NAMESPACE) ... IS ...
COMMENT ON TABLE ... IS ...
```
Details about the `comment` syntaxes:
As the new design of catalog v2, some properties become reserved, e.g. `location`, `comment`. We are going to disable setting reserved properties by dbproperties or tblproperites directly to avoid confliction with their related subClause or specific commands.
They are the best practices from PostgreSQL and presto.
https://www.postgresql.org/docs/12/sql-comment.htmlhttps://prestosql.io/docs/current/sql/comment.html
Mostly, the basic thoughts of the new framework came from the discussions bellow with cloud-fan, https://github.com/apache/spark/pull/26847#issuecomment-564510061,
### Why are the changes needed?
To make it easier to add new v2 commands, and easier to unify the table relation behavior.
### Does this PR introduce any user-facing change?
yes, add new syntax
### How was this patch tested?
add uts.
Closes#26847 from yaooqinn/SPARK-30214.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to add the `SuppressWarnings("deprecation")` annotation to Java tests for deprecated Spark SQL APIs.
### Why are the changes needed?
This eliminates the following warnings:
```
sql/core/src/test/java/test/org/apache/spark/sql/JavaDatasetAggregatorSuite.java
Warning:Warning:line (32)java: org.apache.spark.sql.expressions.javalang.typed in org.apache.spark.sql.expressions.javalang has been deprecated
Warning:Warning:line (91)java: org.apache.spark.sql.expressions.javalang.typed in org.apache.spark.sql.expressions.javalang has been deprecated
Warning:Warning:line (100)java: org.apache.spark.sql.expressions.javalang.typed in org.apache.spark.sql.expressions.javalang has been deprecated
Warning:Warning:line (109)java: org.apache.spark.sql.expressions.javalang.typed in org.apache.spark.sql.expressions.javalang has been deprecated
Warning:Warning:line (118)java: org.apache.spark.sql.expressions.javalang.typed in org.apache.spark.sql.expressions.javalang has been deprecated
sql/core/src/test/java/test/org/apache/spark/sql/Java8DatasetAggregatorSuite.java
Warning:Warning:line (28)java: org.apache.spark.sql.expressions.javalang.typed in org.apache.spark.sql.expressions.javalang has been deprecated
Warning:Warning:line (37)java: org.apache.spark.sql.expressions.javalang.typed in org.apache.spark.sql.expressions.javalang has been deprecated
Warning:Warning:line (46)java: org.apache.spark.sql.expressions.javalang.typed in org.apache.spark.sql.expressions.javalang has been deprecated
Warning:Warning:line (55)java: org.apache.spark.sql.expressions.javalang.typed in org.apache.spark.sql.expressions.javalang has been deprecated
Warning:Warning:line (64)java: org.apache.spark.sql.expressions.javalang.typed in org.apache.spark.sql.expressions.javalang has been deprecated
sql/core/src/test/java/test/org/apache/spark/sql/JavaDataFrameSuite.java
Warning:Warning:line (478)java: json(org.apache.spark.api.java.JavaRDD<java.lang.String>) in org.apache.spark.sql.DataFrameReader has been deprecated
```
and highlights warnings about real problems.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By existing test suites `Java8DatasetAggregatorSuite.java`, `JavaDataFrameSuite.java` and `JavaDatasetAggregatorSuite.java`.
Closes#27081 from MaxGekk/eliminate-warnings-part2.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to throw `AnalysisException` when a removed SQL config is set to non-default value. The following SQL configs removed by #26559 are marked as removed:
1. `spark.sql.fromJsonForceNullableSchema`
2. `spark.sql.legacy.compareDateTimestampInTimestamp`
3. `spark.sql.legacy.allowCreatingManagedTableUsingNonemptyLocation`
### Why are the changes needed?
To improve user experience with Spark SQL by notifying of removed SQL configs used by users.
### Does this PR introduce any user-facing change?
Yes, before the `set` command was silently ignored:
```sql
spark-sql> set spark.sql.fromJsonForceNullableSchema=false;
spark.sql.fromJsonForceNullableSchema false
```
after the exception should be raised:
```sql
spark-sql> set spark.sql.fromJsonForceNullableSchema=false;
Error in query: The SQL config 'spark.sql.fromJsonForceNullableSchema' was removed in the version 3.0.0. It was removed to prevent errors like SPARK-23173 for non-default value.;
```
### How was this patch tested?
Added new tests into `SQLConfSuite` for both cases when removed SQL configs are set to default and non-default values.
Closes#27057 from MaxGekk/remove-sql-configs-followup.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. For the interval arithmetic functions, e.g. `add`/`subtract`/`negative`/`multiply`/`divide`, enable overflow check when `ANSI` is on.
2. For `multiply`/`divide`, throw an exception when an overflow happens in spite of `ANSI` is on/off.
3. `add`/`subtract`/`negative` stay the same for backward compatibility.
4. `divide` by 0 throws ArithmeticException whether `ANSI` or not as same as numerics.
5. These behaviors fit the numeric type operations fully when ANSI is on.
6. These behaviors fit the numeric type operations fully when ANSI is off, except 2 and 4.
### Why are the changes needed?
1. bug fix
2. `ANSI` support
### Does this PR introduce any user-facing change?
When `ANSI` is on, interval `add`/`subtract`/`negative`/`multiply`/`divide` will overflow if any field overflows
### How was this patch tested?
add unit tests
Closes#26995 from yaooqinn/SPARK-30341.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Revert https://github.com/apache/spark/pull/26338 , as the syntax is actually the [hive style ALTER COLUMN](https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-ChangeColumnName/Type/Position/Comment).
This PR brings it back, and make it support multi-catalog:
1. renaming is not allowed as `AlterTableAlterColumnStatement` can't do renaming.
2. column name should be multi-part
### Why are the changes needed?
to not break hive compatibility.
### Does this PR introduce any user-facing change?
no, as the removal was merged in 3.0.
### How was this patch tested?
new parser tests
Closes#27076 from cloud-fan/alter.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Update CREATE VIEW command to store the current catalog and namespace instead of current database in view metadata. Also update analyzer to leverage the catalog and namespace in view metastore to resolve relations inside views.
Note that, this PR still keeps the way we resolve views, by recursively calling Analyzer. This is necessary because view text may contain CTE, window spec, etc. which needs rules outside of the main resolution batch (e.g. `CTESubstitution`)
### Why are the changes needed?
To resolve relations inside view correctly.
### Does this PR introduce any user-facing change?
Yes, fix a bug. Now tables referred by a view can be resolved correctly even if the current catalog/namespace has been updated.
### How was this patch tested?
a new test
Closes#26923 from cloud-fan/view.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aim to fix the NoSuchElementException exception when enable AQE with insubquery expression.
### Why are the changes needed?
Fix exception
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
added new ut
Closes#27068 from JkSelf/fixSubqueryIssue.
Authored-by: jiake <ke.a.jia@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch is based on #23921 but revised to be simpler, as well as adds UT to test the behavior.
(This patch contains the commit from #23921 to retain credit.)
Spark loads new JARs for `ADD JAR` and `CREATE FUNCTION ... USING JAR` into jar classloader in shared state, and changes current thread's context classloader to jar classloader as many parts of remaining codes rely on current thread's context classloader.
This would work if the further queries will run in same thread and there's no change on context classloader for the thread, but once the context classloader of current thread is switched back by various reason, Spark fails to create instance of class for the function.
This bug mostly affects spark-shell, as spark-shell will roll back current thread's context classloader at every prompt. But it may also affects the case of job-server, where the queries may be running in multiple threads.
This patch fixes the issue via switching the context classloader to the classloader which loads the class. Hopefully FunctionBuilder created by `makeFunctionBuilder` has the information of Class as a part of closure, hence the Class itself can be provided regardless of current thread's context classloader.
### Why are the changes needed?
Without this patch, end users cannot execute Hive UDF using JAR twice in spark-shell.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
New UT.
Closes#27025 from HeartSaVioR/SPARK-26560-revised.
Lead-authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Co-authored-by: nivo091 <nivedeeta.singh@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Change config name from `spark.sql.legacy.typeCoercion.datetimeToString` to `spark.sql.legacy.typeCoercion.datetimeToString.enabled`.
### Why are the changes needed?
To follow the other boolean conf naming convention.
### Does this PR introduce any user-facing change?
No, it's newly added in Spark 3.0.
### How was this patch tested?
Pass Jenkins
Closes#27065 from Ngone51/SPARK-27638-FOLLOWUP.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Change config name from `spark.sql.optimizer.reassignLambdaVariableID` to `spark.sql.optimizer.reassignLambdaVariableID.enabled`.
### Why are the changes needed?
To follow the other boolean conf naming convention.
### Does this PR introduce any user-facing change?
No, it's newly added in Spark 3.0.
### How was this patch tested?
Pass Jenkins.
Closes#27063 from Ngone51/SPARK-27871-FOLLOWUP.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Calls of `requireNonStaticConf()` are removed from the `set()` methods in RuntimeConfig because those methods invoke `def set(key: String, value: String): Unit` where `requireNonStaticConf()` is called as well.
### Why are the changes needed?
To avoid unnecessary calls of `requireNonStaticConf()`.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By existing tests from `SQLConfSuite`
Closes#27062 from MaxGekk/call-requireNonStaticConf-once.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Currently if function lookup fails, spark will give it a second change by casting decimal type to double type. But for cases where decimal type doesn't exist, it's meaningless to lookup again and causes extra cost like unnecessary metastore access. We should throw exceptions directly in these cases.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Covered by existing tests.
Closes#26994 from wzhfy/avoid_udf_fail_twice.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This patch fixes a small bug in the example of streaming query, as the type of observable metrics is Java Map instead of Scala Map, so to use foreach it should be converted first.
### Why are the changes needed?
Described above.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Ran below query via `spark-shell`:
**Streaming**
```scala
import scala.collection.JavaConverters._
import scala.util.Random
import org.apache.spark.sql.streaming.StreamingQueryListener
import org.apache.spark.sql.streaming.StreamingQueryListener._
spark.streams.addListener(new StreamingQueryListener() {
override def onQueryProgress(event: QueryProgressEvent): Unit = {
event.progress.observedMetrics.asScala.get("my_event").foreach { row =>
// Trigger if the number of errors exceeds 5 percent
val num_rows = row.getAs[Long]("rc")
val num_error_rows = row.getAs[Long]("erc")
val ratio = num_error_rows.toDouble / num_rows
if (ratio > 0.05) {
// Trigger alert
println(s"alert! error ratio: $ratio")
}
}
}
def onQueryStarted(event: QueryStartedEvent): Unit = {}
def onQueryTerminated(event: QueryTerminatedEvent): Unit = {}
})
val rates = spark
.readStream
.format("rate")
.option("rowsPerSecond", 10)
.load
val rand = new Random()
val df = rates.map { row => (row.getLong(1), if (row.getLong(1) % 2 == 0) "error" else null) }.toDF
val ds = df.selectExpr("_1 AS id", "_2 AS error")
// Observe row count (rc) and error row count (erc) in the batch Dataset
val observed_ds = ds.observe("my_event", count(lit(1)).as("rc"), count($"error").as("erc"))
observed_ds.writeStream.format("console").start()
```
Closes#27046 from HeartSaVioR/SPARK-29348-FOLLOWUP.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In `SqlBase.g4`, `database` is defined as
```
database : DATABASE | SCHEMA;
```
and it is being used as `(database | NAMESPACE)` in many places.
This PR proposes to define the following and use it as discussed in https://github.com/apache/spark/pull/26847/files#r359754778:
```
namespace : NAMESPACE | DATABASE | SCHEMA;
```
### Why are the changes needed?
To simplify the grammar.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
There is no change in the actual grammar, so the existing tests should be sufficient.
Closes#27027 from imback82/sqlbase_namespace.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
This reverts commit f926809a1f.
Closes#27032 from gatorsmile/revertSPARK-29390.
Authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Create temporary or permanent function it should throw AnalysisException if the resource is not found. Need to keep behavior consistent across permanent and temporary functions.
## How was this patch tested?
Added UT and also tested manually
**Before Fix**
If the UDF resource is not present then on creation of temporary function it throws AnalysisException where as for permanent function it does not throw. Permanent funtcion throws AnalysisException only after select operation is performed.
**After Fix**
For temporary and permanent function check for the resource, if the UDF resource is not found then throw AnalysisException

Closes#25399 from sandeep-katta/funcIssue.
Authored-by: sandeep katta <sandeep.katta2007@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This patch fixes the intermittent test failure on ThriftServerQueryTestSuite/ThriftServerWithSparkContextSuite, getting ConnectException when querying to thrift server.
(https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/115646/testReport/)
The relevant unit test log messages are following:
```
19/12/23 13:33:01.875 pool-1-thread-1 INFO AbstractService: Service:ThriftBinaryCLIService is started.
19/12/23 13:33:01.875 pool-1-thread-1 INFO AbstractService: Service:HiveServer2 is started.
...
19/12/23 13:33:01.888 pool-1-thread-1 INFO ThriftServerWithSparkContextSuite: HiveThriftServer2 started successfully
...
19/12/23 13:33:01.909 pool-1-thread-1-ScalaTest-running-ThriftServerWithSparkContextSuite INFO ThriftServerWithSparkContextSuite:
===== TEST OUTPUT FOR o.a.s.sql.hive.thriftserver.ThriftServerWithSparkContextSuite: 'SPARK-29911: Uncache cached tables when session closed' =====
...
19/12/23 13:33:02.017 pool-1-thread-1-ScalaTest-running-ThriftServerWithSparkContextSuite INFO Utils: Supplied authorities: localhost:15441
19/12/23 13:33:02.018 pool-1-thread-1-ScalaTest-running-ThriftServerWithSparkContextSuite INFO Utils: Resolved authority: localhost:15441
19/12/23 13:33:02.078 HiveServer2-Background-Pool: Thread-213 INFO BaseSessionStateBuilder$$anon$2: Optimization rule 'org.apache.spark.sql.catalyst.optimizer.ConvertToLocalRelation' is excluded from the optimizer.
19/12/23 13:33:02.078 HiveServer2-Background-Pool: Thread-213 INFO BaseSessionStateBuilder$$anon$2: Optimization rule 'org.apache.spark.sql.catalyst.optimizer.ConvertToLocalRelation' is excluded from the optimizer.
19/12/23 13:33:02.121 pool-1-thread-1-ScalaTest-running-ThriftServerWithSparkContextSuite WARN HiveConnection: Failed to connect to localhost:15441
19/12/23 13:33:02.124 pool-1-thread-1-ScalaTest-running-ThriftServerWithSparkContextSuite INFO ThriftServerWithSparkContextSuite:
===== FINISHED o.a.s.sql.hive.thriftserver.ThriftServerWithSparkContextSuite: 'SPARK-29911: Uncache cached tables when session closed' =====
19/12/23 13:33:02.143 Thread-35 INFO ThriftCLIService: Starting ThriftBinaryCLIService on port 15441 with 5...500 worker threads
19/12/23 13:33:02.327 pool-1-thread-1 INFO HiveServer2: Shutting down HiveServer2
19/12/23 13:33:02.328 pool-1-thread-1 INFO ThriftCLIService: Thrift server has stopped
```
(Here the error is logged as `WARN HiveConnection: Failed to connect to localhost:15441` - the actual stack trace can be seen on Jenkins test summary.)
The reason of test failure: Thrift(Binary|Http)CLIService prepare and launch the service asynchronously (in new thread), which suites are not waiting for completion and just start running tests, ends up with race condition.
That can be easily reproduced, via adding artificial sleep in `ThriftBinaryCLIService.run()` here:
ba3f6330dd/sql/hive-thriftserver/v2.3/src/main/java/org/apache/hive/service/cli/thrift/ThriftBinaryCLIService.java (L49)
(Note that `sleep` should be added before initializing server socket. E.g. Line 57)
This patch changes the test initialization logic to try executing simple query to wait until the service is available. The patch also refactors the code to apply the change both ThriftServerQueryTestSuite and ThriftServerWithSparkContextSuite easily.
### Why are the changes needed?
This patch fixes the intermittent failure observed here:
https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/115646/testReport/
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Artificially made the test fail consistently (by the approach described above), and confirmed the patch fixed the test.
Closes#27001 from HeartSaVioR/SPARK-30345.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### Why are the changes needed?
`EnsureRequirements` adds `ShuffleExchangeExec` (RangePartitioning) after Sort if `RoundRobinPartitioning` behinds it. This will cause 2 shuffles, and the number of partitions in the final stage is not the number specified by `RoundRobinPartitioning.
**Example SQL**
```
SELECT /*+ REPARTITION(5) */ * FROM test ORDER BY a
```
**BEFORE**
```
== Physical Plan ==
*(1) Sort [a#0 ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(a#0 ASC NULLS FIRST, 200), true, [id=#11]
+- Exchange RoundRobinPartitioning(5), false, [id=#9]
+- Scan hive default.test [a#0, b#1], HiveTableRelation `default`.`test`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [a#0, b#1]
```
**AFTER**
```
== Physical Plan ==
*(1) Sort [a#0 ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(a#0 ASC NULLS FIRST, 5), true, [id=#11]
+- Scan hive default.test [a#0, b#1], HiveTableRelation `default`.`test`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [a#0, b#1]
```
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Run suite Tests and add new test for this.
Closes#26946 from stczwd/RoundRobinPartitioning.
Lead-authored-by: lijunqing <lijunqing@baidu.com>
Co-authored-by: stczwd <qcsd2011@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes `ScalaReflection.arrayClassFor()` to use an empty array instead of a one-element array for getting its class object by reflection.
### Why are the changes needed?
Because it may reduce unnecessary memory allocation.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Ran the existing unit tests for sql/catalyst and confirmed that all of them succeeded.
Closes#27005 from sekikn/SPARK-30350.
Authored-by: Kengo Seki <sekikn@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
The filter predicate for aggregate expression is an `ANSI SQL`.
```
<aggregate function> ::=
COUNT <left paren> <asterisk> <right paren> [ <filter clause> ]
| <general set function> [ <filter clause> ]
| <binary set function> [ <filter clause> ]
| <ordered set function> [ <filter clause> ]
| <array aggregate function> [ <filter clause> ]
| <row pattern count function> [ <filter clause> ]
```
There are some mainstream database support this syntax.
**PostgreSQL:**
https://www.postgresql.org/docs/current/sql-expressions.html#SYNTAX-AGGREGATES
For example:
```
SELECT
year,
count(*) FILTER (WHERE gdp_per_capita >= 40000)
FROM
countries
GROUP BY
year
```
```
SELECT
year,
code,
gdp_per_capita,
count(*)
FILTER (WHERE gdp_per_capita >= 40000)
OVER (PARTITION BY year)
FROM
countries
```
**jOOQ:**
https://blog.jooq.org/2014/12/30/the-awesome-postgresql-9-4-sql2003-filter-clause-for-aggregate-functions/
**Notice:**
1.This PR only supports FILTER predicate without codegen. maropu will create another PR is related to SPARK-30027 to support codegen.
2.This PR only supports FILTER predicate without DISTINCT. I will create another PR is related to SPARK-30276 to support this.
3.This PR only supports FILTER predicate that can't reference the outer query. I created ticket SPARK-30219 to support it.
4.This PR only supports FILTER predicate that can't use IN/EXISTS predicate sub-queries. I created ticket SPARK-30220 to support it.
5.Spark SQL cannot supports a SQL with nested aggregate. I created ticket SPARK-30182 to support it.
There are some show of the PR on my production environment.
```
spark-sql> desc gja_test_partition;
key string NULL
value string NULL
other string NULL
col2 int NULL
# Partition Information
# col_name data_type comment
col2 int NULL
Time taken: 0.79 s
```
```
spark-sql> select * from gja_test_partition;
a A ao 1
b B bo 1
c C co 1
d D do 1
e E eo 2
g G go 2
h H ho 2
j J jo 2
f F fo 3
k K ko 3
l L lo 4
i I io 4
Time taken: 1.75 s
```
```
spark-sql> select count(key), sum(col2) from gja_test_partition;
12 26
Time taken: 1.848 s
```
```
spark-sql> select count(key) filter (where col2 > 1) from gja_test_partition;
8
Time taken: 2.926 s
```
```
spark-sql> select sum(col2) filter (where col2 > 2) from gja_test_partition;
14
Time taken: 2.087 s
```
```
spark-sql> select count(key) filter (where col2 > 1), sum(col2) filter (where col2 > 2) from gja_test_partition;
8 14
Time taken: 2.847 s
```
```
spark-sql> select count(key), count(key) filter (where col2 > 1), sum(col2), sum(col2) filter (where col2 > 2) from gja_test_partition;
12 8 26 14
Time taken: 1.787 s
```
```
spark-sql> desc student;
id int NULL
name string NULL
sex string NULL
class_id int NULL
Time taken: 0.206 s
```
```
spark-sql> select * from student;
1 张三 man 1
2 李四 man 1
3 王五 man 2
4 赵六 man 2
5 钱小花 woman 1
6 赵九红 woman 2
7 郭丽丽 woman 2
Time taken: 0.786 s
```
```
spark-sql> select class_id, count(id), sum(id) from student group by class_id;
1 3 8
2 4 20
Time taken: 18.783 s
```
```
spark-sql> select class_id, count(id) filter (where sex = 'man'), sum(id) filter (where sex = 'woman') from student group by class_id;
1 2 5
2 2 13
Time taken: 3.887 s
```
### Why are the changes needed?
Add new SQL feature.
### Does this PR introduce any user-facing change?
'No'.
### How was this patch tested?
Exists UT and new UT.
Closes#26656 from beliefer/support-aggregate-clause.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
I execute some query as` select get_json_object(ytag, '$.y1') AS y1 from t4`; SparkSQL return null but Hive return correct results.
In my production environment, ytag is a json wrapped by single quotes,as follows
```
{'y1': 'shuma', 'y2': 'shuma:shouji'}
{'y1': 'jiaoyu', 'y2': 'jiaoyu:gaokao'}
{'y1': 'yule', 'y2': 'yule:mingxing'}
```
Then l realized some functions including get_json_object and json_tuple does not support single quotes json parsing.
So l provide this PR to resolve the question.
### Why are the changes needed?
Enabled for Hive compatibility
### Does this PR introduce any user-facing change?
NO
### How was this patch tested?
NEW TESTS
Closes#26965 from wenfang6/enableSingleQuotesJsonForSparkSQL.
Authored-by: wenfang <wenfang@360.cn>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Rename `spark.sql.streaming.forceDeleteTempCheckpointLocation` to `spark.sql.streaming.forceDeleteTempCheckpointLocation.enabled`.
### Why are the changes needed?
To follow the other boolean conf naming convention.
### Does this PR introduce any user-facing change?
No, as this config is newly added in 3.0.
### How was this patch tested?
Pass Jenkins.
Closes#26981 from Ngone51/SPARK-26389-FOLLOWUP.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
accuracyExpression can accept Long which may cause overflow error.
accuracyExpression can accept fractions which are implicitly floored.
accuracyExpression can accept null which is implicitly changed to 0.
percentageExpression can accept null but cause MatchError.
percentageExpression can accept ArrayType(_, nullable=true) in which the nulls are implicitly changed to zeros.
##### cases
```sql
select percentile_approx(10.0, 0.5, 2147483648); -- overflow and fail
select percentile_approx(10.0, 0.5, 4294967297); -- overflow but success
select percentile_approx(10.0, 0.5, null); -- null cast to 0
select percentile_approx(10.0, 0.5, 1.2); -- 1.2 cast to 1
select percentile_approx(10.0, null, 1); -- scala.MatchError
select percentile_approx(10.0, array(0.2, 0.4, null), 1); -- null cast to zero.
```
##### behavior before
```sql
+select percentile_approx(10.0, 0.5, 2147483648)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, CAST(0.5BD AS DOUBLE), CAST(2147483648L AS INT))' due to data type mismatch: The accuracy provided must be a positive integer literal (current value = -2147483648); line 1 pos 7
+
+select percentile_approx(10.0, 0.5, 4294967297)
+10.0
+
+select percentile_approx(10.0, 0.5, null)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, CAST(0.5BD AS DOUBLE), CAST(NULL AS INT))' due to data type mismatch: The accuracy provided must be a positive integer literal (current value = 0); line 1 pos 7
+
+select percentile_approx(10.0, 0.5, 1.2)
+10.0
+
+select percentile_approx(10.0, null, 1)
+scala.MatchError
+null
+
+
+select percentile_approx(10.0, array(0.2, 0.4, null), 1)
+[10.0,10.0,10.0]
```
##### behavior after
```sql
+select percentile_approx(10.0, 0.5, 2147483648)
+10.0
+
+select percentile_approx(10.0, 0.5, 4294967297)
+10.0
+
+select percentile_approx(10.0, 0.5, null)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, 0.5BD, NULL)' due to data type mismatch: argument 3 requires integral type, however, 'NULL' is of null type.; line 1 pos 7
+
+select percentile_approx(10.0, 0.5, 1.2)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, 0.5BD, 1.2BD)' due to data type mismatch: argument 3 requires integral type, however, '1.2BD' is of decimal(2,1) type.; line 1 pos 7
+
+select percentile_approx(10.0, null, 1)
+java.lang.IllegalArgumentException
+The value of percentage must be be between 0.0 and 1.0, but got null
+
+select percentile_approx(10.0, array(0.2, 0.4, null), 1)
+java.lang.IllegalArgumentException
+Each value of the percentage array must be be between 0.0 and 1.0, but got [0.2,0.4,null]
```
### Why are the changes needed?
bug fix
### Does this PR introduce any user-facing change?
yes, fix some improper usages of percentile_approx as cases list above
### How was this patch tested?
add ut
Closes#26905 from yaooqinn/SPARK-30266.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Set `isFinalPlan=true` before posting the final AdaptiveSparkPlan event (`SparkListenerSQLAdaptiveExecutionUpdate`)
### Why are the changes needed?
Otherwise, any attempt to listen on the final event by pattern matching `isFinalPlan=true` would fail
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
All tests in `AdaptiveQueryExecSuite` are exteneded with a verification that a `SparkListenerSQLAdaptiveExecutionUpdate` event with `isFinalPlan=True` exists
Closes#26983 from manuzhang/spark-30331.
Authored-by: manuzhang <owenzhang1990@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}