## What changes were proposed in this pull request?
How to reproduce this issue:
```shell
build/sbt clean package -Phive -Phive-thriftserver -Phadoop-3.2
export SPARK_PREPEND_CLASSES=true
sbin/start-thriftserver.sh
[rootspark-3267648 spark]# bin/beeline -u jdbc:hive2://localhost:10000/default -e "select cast(1 as decimal(38, 18));"
Connecting to jdbc:hive2://localhost:10000/default
Connected to: Spark SQL (version 3.0.0-SNAPSHOT)
Driver: Hive JDBC (version 2.3.5)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Error: java.lang.ClassCastException: java.math.BigDecimal incompatible with org.apache.hadoop.hive.common.type.HiveDecimal (state=,code=0)
Closing: 0: jdbc:hive2://localhost:10000/default
```
This pr fix this issue.
## How was this patch tested?
unit tests
Closes#25217 from wangyum/SPARK-28463.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
For Thrift server, It's downward compatible. Such as if a PROTOCOL_VERSION_V7 client connect to a PROTOCOL_VERSION_V8 server, when OpenSession, server will change his response's protocol version to min of (client and server).
`TProtocolVersion protocol = getMinVersion(CLIService.SERVER_VERSION,`
` req.getClient_protocol());`
then set it to OpenSession's response.
But if OpenSession failed , it won't execute behavior of reset response's protocol_version.
Then it will return server's origin protocol version.
Finally client will get en error as below:
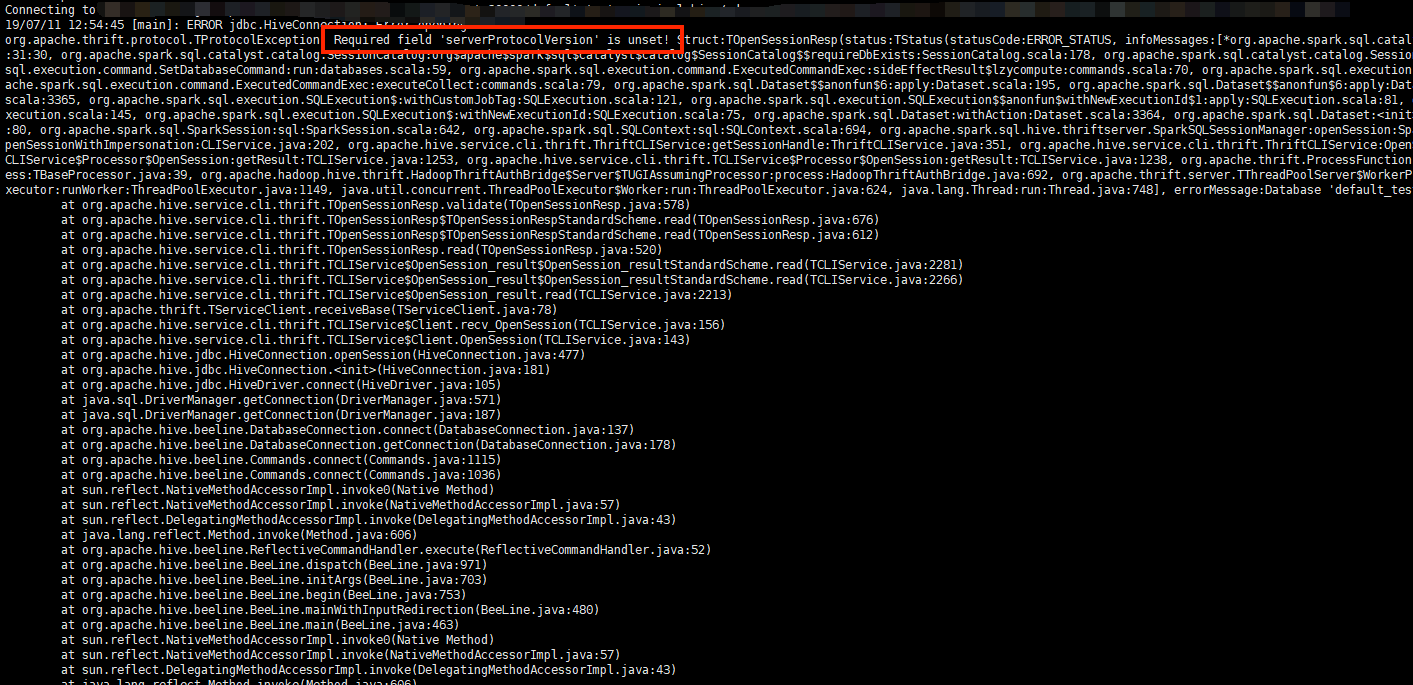
Since we write a wrong database,, OpenSession failed, right protocol version haven't been rest.
## How was this patch tested?
Since I really don't know how to write unit test about this, so I build a jar with this PR,and retry the error above, then it will return a reasonable Error of DB not found :

Closes#25083 from AngersZhuuuu/SPARK-28311.
Authored-by: 朱夷 <zhuyi01@corp.netease.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
There are some hardcoded configs, using config entry to replace them.
## How was this patch tested?
Existing UT
Closes#25059 from WangGuangxin/ConfigEntry.
Authored-by: wangguangxin.cn <wangguangxin.cn@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
`SslContextFactory` is deprecated at Jetty 9.4 and we are using `9.4.18.v20190429`. This PR aims to replace it with `SslContextFactory.Server`.
- https://www.eclipse.org/jetty/javadoc/9.4.19.v20190610/org/eclipse/jetty/util/ssl/SslContextFactory.html
- https://www.eclipse.org/jetty/javadoc/9.3.24.v20180605/org/eclipse/jetty/util/ssl/SslContextFactory.html
```
[WARNING] /Users/dhyun/APACHE/spark/core/src/main/scala/org/apache/spark/SSLOptions.scala:71:
constructor SslContextFactory in class SslContextFactory is deprecated:
see corresponding Javadoc for more information.
[WARNING] val sslContextFactory = new SslContextFactory()
[WARNING] ^
```
## How was this patch tested?
Pass the Jenkins with the existing tests.
Closes#25067 from dongjoon-hyun/SPARK-28290.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr add support show global temporary view and local temporary view in database tool.
TODO: Database tools should support show temporary views because it's schema is null.
## How was this patch tested?
unit tests and manual tests:
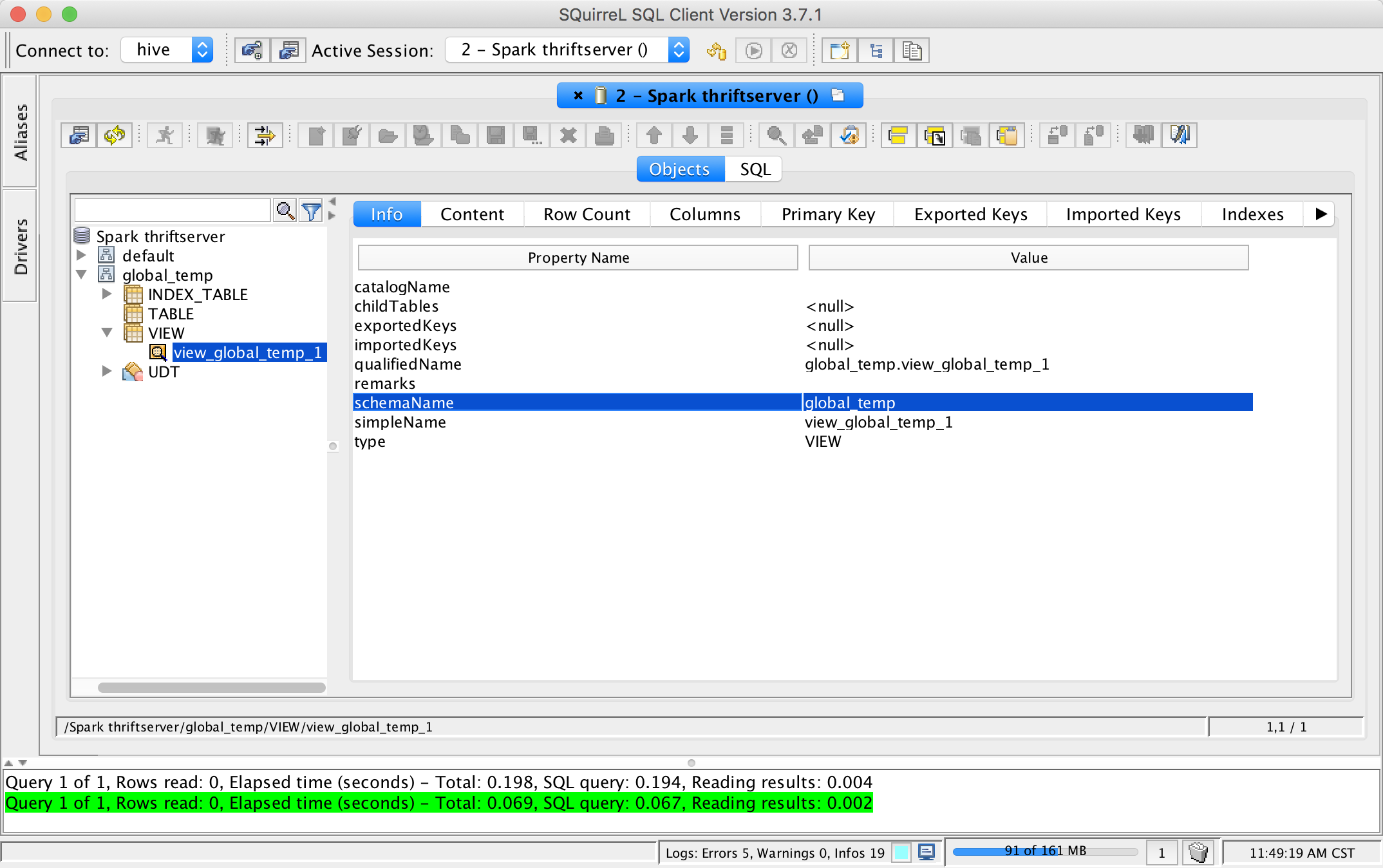
Closes#24972 from wangyum/SPARK-28167.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
To make the #24972 change smaller. This pr improves `SparkMetadataOperationSuite` to avoid creating new sessions when getSchemas/getTables/getColumns.
## How was this patch tested?
N/A
Closes#24985 from wangyum/SPARK-28184.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The new Spark ThriftServer SparkGetTablesOperation implemented in https://github.com/apache/spark/pull/22794 does a catalog.getTableMetadata request for every table. This can get very slow for large schemas (~50ms per table with an external Hive metastore).
Hive ThriftServer GetTablesOperation uses HiveMetastoreClient.getTableObjectsByName to get table information in bulk, but we don't expose that through our APIs that go through Hive -> HiveClientImpl (HiveClient) -> HiveExternalCatalog (ExternalCatalog) -> SessionCatalog.
If we added and exposed getTableObjectsByName through our catalog APIs, we could resolve that performance problem in SparkGetTablesOperation.
## How was this patch tested?
Add UT
Closes#24774 from LantaoJin/SPARK-27899.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This pr moves Hive test jars(`hive-contrib-0.13.1.jar`, `hive-hcatalog-core-0.13.1.jar`, `hive-contrib-2.3.5.jar` and `hive-hcatalog-core-2.3.5.jar`) to maven dependency.
## How was this patch tested?
Existing test
Please note that this pr need test with `maven` and `sbt`.
Closes#24751 from wangyum/SPARK-27831.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr moves `sql/hive-thriftserver/v2.3.4` to `sql/hive-thriftserver/v2.3.5` based on ([comment](https://github.com/apache/spark/pull/24628#issuecomment-496459258)).
## How was this patch tested?
N/A
Closes#24728 from wangyum/SPARK-27737-thriftserver.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr moves Hive test jars(`hive-contrib-0.13.1.jar`, `hive-hcatalog-core-0.13.1.jar`, `hive-contrib-2.3.5.jar` and `hive-hcatalog-core-2.3.5.jar`) to maven dependency.
## How was this patch tested?
Existing test
Closes#24695 from wangyum/SPARK-27831.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
When we upgraded the built-in Hive to 2.3.4, the current `hive-thriftserver` module is not compatible, such as these Hive changes:
1. [HIVE-12442](https://issues.apache.org/jira/browse/HIVE-12442) HiveServer2: Refactor/repackage HiveServer2's Thrift code so that it can be used in the tasks
2. [HIVE-12237](https://issues.apache.org/jira/browse/HIVE-12237) Use slf4j as logging facade
3. [HIVE-13169](https://issues.apache.org/jira/browse/HIVE-13169) HiveServer2: Support delegation token based connection when using http transport
So this PR moves the incompatible code to `sql/hive-thriftserver/v1.2.1` and copies it to `sql/hive-thriftserver/v2.3.4` for the next code review.
## How was this patch tested?
manual tests:
```
diff -urNa sql/hive-thriftserver/v1.2.1 sql/hive-thriftserver/v2.3.4
```
Closes#24282 from wangyum/SPARK-27354.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Fix build warnings -- see some details below.
But mostly, remove use of postfix syntax where it causes warnings without the `scala.language.postfixOps` import. This is mostly in expressions like "120000 milliseconds". Which, I'd like to simplify to things like "2.minutes" anyway.
## How was this patch tested?
Existing tests.
Closes#24314 from srowen/SPARK-27404.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The user sets the value of spark.sql.thriftserver.scheduler.pool.
Spark thrift server saves this value in the LocalProperty of threadlocal type, but does not clean up after running, causing other sessions to run in the previously set pool name.
## How was this patch tested?
manual tests
Closes#23895 from cxzl25/thrift_server_scheduler_pool_pollute.
Lead-authored-by: cxzl25 <cxzl25@users.noreply.github.com>
Co-authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Use Single Abstract Method syntax where possible (and minor related cleanup). Comments below. No logic should change here.
## How was this patch tested?
Existing tests.
Closes#24241 from srowen/SPARK-27323.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
When using fair scheduler mode for thrift server, we may have unpredictable result.
```
val pool = sessionToActivePool.get(parentSession.getSessionHandle)
if (pool != null) {
sqlContext.sparkContext.setLocalProperty(SparkContext.SPARK_SCHEDULER_POOL, pool)
}
```
The cause is we use thread pool to execute queries for thriftserver, and when we call setLocalProperty we may have unpredictab behavior.
```
/**
* Set a local property that affects jobs submitted from this thread, such as the Spark fair
* scheduler pool. User-defined properties may also be set here. These properties are propagated
* through to worker tasks and can be accessed there via
* [[org.apache.spark.TaskContext#getLocalProperty]].
*
* These properties are inherited by child threads spawned from this thread. This
* may have unexpected consequences when working with thread pools. The standard java
* implementation of thread pools have worker threads spawn other worker threads.
* As a result, local properties may propagate unpredictably.
*/
def setLocalProperty(key: String, value: String) {
if (value == null) {
localProperties.get.remove(key)
} else {
localProperties.get.setProperty(key, value)
}
}
```
I post an example on https://jira.apache.org/jira/browse/SPARK-26914 .
## How was this patch tested?
UT
Closes#23826 from caneGuy/zhoukang/fix-scheduler-error.
Authored-by: zhoukang <zhoukang199191@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/12881 removed `HiveSessionHook`. But there are still some code related to `HiveSessionHook`.
This PR removes all `HiveSessionHook` related code.
## How was this patch tested?
manual tests
Closes#23957 from wangyum/SPARK-15095.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
In the PR, I propose to use `System.nanoTime()` instead of `System.currentTimeMillis()` in measurements of time intervals.
`System.currentTimeMillis()` returns current wallclock time and will follow changes to the system clock. Thus, negative wallclock adjustments can cause timeouts to "hang" for a long time (until wallclock time has caught up to its previous value again). This can happen when ntpd does a "step" after the network has been disconnected for some time. The most canonical example is during system bootup when DHCP takes longer than usual. This can lead to failures that are really hard to understand/reproduce. `System.nanoTime()` is guaranteed to be monotonically increasing irrespective of wallclock changes.
## How was this patch tested?
By existing test suites.
Closes#23727 from MaxGekk/system-nanotime.
Lead-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Delegation token providers interface now has a parameter `fileSystems` but this is needed only for `HadoopFSDelegationTokenProvider`.
In this PR I've addressed this issue in the following way:
* Removed `fileSystems` parameter from `HadoopDelegationTokenProvider`
* Moved `YarnSparkHadoopUtil.hadoopFSsToAccess` into `HadoopFSDelegationTokenProvider`
* Moved `spark.yarn.stagingDir` into core
* Moved `spark.yarn.access.namenodes` into core and renamed to `spark.kerberos.access.namenodes`
* Moved `spark.yarn.access.hadoopFileSystems` into core and renamed to `spark.kerberos.access.hadoopFileSystems`
## How was this patch tested?
Existing unit tests.
Closes#23698 from gaborgsomogyi/SPARK-26766.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
When we run in background and we get exception which is not HiveSQLException,
we may encounter memory leak since handleToOperation will not removed correctly.
The reason is below:
1. When calling operation.run() in HiveSessionImpl#executeStatementInternal we throw an exception which is not HiveSQLException
2. Then the opHandle generated by SparkSQLOperationManager will not be added into opHandleSet of HiveSessionImpl , and operationManager.closeOperation(opHandle) will not be called
3. When we close the session we will also call operationManager.closeOperation(opHandle),since we did not add this opHandle into the opHandleSet.
For the reasons above,the opHandled will always in SparkSQLOperationManager#handleToOperation,which will cause memory leak.
More details and a case has attached on https://issues.apache.org/jira/browse/SPARK-26751
This patch will always throw HiveSQLException when running in background
## How was this patch tested?
Exist UT
Closes#23673 from caneGuy/zhoukang/fix-hivesessionimpl-leak.
Authored-by: zhoukang <zhoukang199191@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
There are ugly provided dependencies inside core for the following:
* Hive
* Kafka
In this PR I've extracted them out. This PR contains the following:
* Token providers are now loaded with service loader
* Hive token provider moved to hive project
* Kafka token provider extracted into a new project
## How was this patch tested?
Existing + newly added unit tests.
Additionally tested on cluster.
Closes#23499 from gaborgsomogyi/SPARK-26254.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
The PR makes hardcoded `spark.dynamicAllocation`, `spark.scheduler`, `spark.rpc`, `spark.task`, `spark.speculation`, and `spark.cleaner` configs to use `ConfigEntry`.
## How was this patch tested?
Existing tests
Closes#23416 from kiszk/SPARK-26463.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The PR makes hardcoded configs below to use `ConfigEntry`.
* spark.ui
* spark.ssl
* spark.authenticate
* spark.master.rest
* spark.master.ui
* spark.metrics
* spark.admin
* spark.modify.acl
This patch doesn't change configs which are not relevant to SparkConf (e.g. system properties).
## How was this patch tested?
Existing tests.
Closes#23423 from HeartSaVioR/SPARK-26466.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
Currently there is code scattered in a bunch of places to do different
things related to HTTP security, such as access control, setting
security-related headers, and filtering out bad content. This makes it
really easy to miss these things when writing new UI code.
This change creates a new filter that does all of those things, and
makes sure that all servlet handlers that are attached to the UI get
the new filter and any user-defined filters consistently. The extent
of the actual features should be the same as before.
The new filter is added at the end of the filter chain, because authentication
is done by custom filters and thus needs to happen first. This means that
custom filters see unfiltered HTTP requests - which is actually the current
behavior anyway.
As a side-effect of some of the code refactoring, handlers added after
the initial set also get wrapped with a GzipHandler, which didn't happen
before.
Tested with added unit tests and in a history server with SPNEGO auth
configured.
Closes#23302 from vanzin/SPARK-24522.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
The `toHiveString()` and `toHiveStructString` methods were removed from `HiveUtils` because they have been already implemented in `HiveResult`. One related test was moved to `HiveResultSuite`.
## How was this patch tested?
By tests from `hive-thriftserver`.
Closes#23466 from MaxGekk/dedup-hive-result-string.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
In the PR, I propose to move `hiveResultString()` out of `QueryExecution` and put it to a separate object.
Closes#23409 from MaxGekk/hive-result-string.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Herman van Hovell <hvanhovell@databricks.com>
## What changes were proposed in this pull request?
The build has a lot of deprecation warnings. Some are new in Scala 2.12 and Java 11. We've fixed some, but I wanted to take a pass at fixing lots of easy miscellaneous ones here.
They're too numerous and small to list here; see the pull request. Some highlights:
- `BeanInfo` is deprecated in 2.12, and BeanInfo classes are pretty ancient in Java. Instead, case classes can explicitly declare getters
- Eta expansion of zero-arg methods; foo() becomes () => foo() in many cases
- Floating-point Range is inexact and deprecated, like 0.0 to 100.0 by 1.0
- finalize() is finally deprecated (just needs to be suppressed)
- StageInfo.attempId was deprecated and easiest to remove here
I'm not now going to touch some chunks of deprecation warnings:
- Parquet deprecations
- Hive deprecations (particularly serde2 classes)
- Deprecations in generated code (mostly Thriftserver CLI)
- ProcessingTime deprecations (we may need to revive this class as internal)
- many MLlib deprecations because they concern methods that may be removed anyway
- a few Kinesis deprecations I couldn't figure out
- Mesos get/setRole, which I don't know well
- Kafka/ZK deprecations (e.g. poll())
- Kinesis
- a few other ones that will probably resolve by deleting a deprecated method
## How was this patch tested?
Existing tests, including manual testing with the 2.11 build and Java 11.
Closes#23065 from srowen/SPARK-26090.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This restores scaladoc artifact generation, which got dropped with the Scala 2.12 update. The change looks large, but is almost all due to needing to make the InterfaceStability annotations top-level classes (i.e. `InterfaceStability.Stable` -> `Stable`), unfortunately. A few inner class references had to be qualified too.
Lots of scaladoc warnings now reappear. We can choose to disable generation by default and enable for releases, later.
## How was this patch tested?
N/A; build runs scaladoc now.
Closes#23069 from srowen/SPARK-26026.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR makes Spark's default Scala version as 2.12, and Scala 2.11 will be the alternative version. This implies that Scala 2.12 will be used by our CI builds including pull request builds.
We'll update the Jenkins to include a new compile-only jobs for Scala 2.11 to ensure the code can be still compiled with Scala 2.11.
## How was this patch tested?
existing tests
Closes#22967 from dbtsai/scala2.12.
Authored-by: DB Tsai <d_tsai@apple.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…. Other related changes to get JDK 11 working, to test
## What changes were proposed in this pull request?
- Access `sun.misc.Cleaner` (Java 8) and `jdk.internal.ref.Cleaner` (JDK 9+) by reflection (note: the latter only works if illegal reflective access is allowed)
- Access `sun.misc.Unsafe.invokeCleaner` in Java 9+ instead of `sun.misc.Cleaner` (Java 8)
In order to test anything on JDK 11, I also fixed a few small things, which I include here:
- Fix minor JDK 11 compile issues
- Update scala plugin, Jetty for JDK 11, to facilitate tests too
This doesn't mean JDK 11 tests all pass now, but lots do. Note also that the JDK 9+ solution for the Cleaner has a big caveat.
## How was this patch tested?
Existing tests. Manually tested JDK 11 build and tests, and tests covering this change appear to pass. All Java 8 tests should still pass, but this change alone does not achieve full JDK 11 compatibility.
Closes#22993 from srowen/SPARK-24421.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Deprecated in Java 11, replace Class.newInstance with Class.getConstructor.getInstance, and primtive wrapper class constructors with valueOf or equivalent
## How was this patch tested?
Existing tests.
Closes#22988 from srowen/SPARK-25984.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
'refreshInterval' is not used any where in the headerSparkPage method. So, we don't need to pass the parameter while calling the 'headerSparkPage' method.
## How was this patch tested?
Existing tests
Closes#22864 from shahidki31/unusedCode.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently if we run
```
sh start-thriftserver.sh -h
```
we get
```
...
Thrift server options:
2018-10-15 21:45:39 INFO HiveThriftServer2:54 - Starting SparkContext
2018-10-15 21:45:40 INFO SparkContext:54 - Running Spark version 2.3.2
2018-10-15 21:45:40 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2018-10-15 21:45:40 ERROR SparkContext:91 - Error initializing SparkContext.
org.apache.spark.SparkException: A master URL must be set in your configuration
at org.apache.spark.SparkContext.<init>(SparkContext.scala:367)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2493)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:934)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:925)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:925)
at org.apache.spark.sql.hive.thriftserver.SparkSQLEnv$.init(SparkSQLEnv.scala:48)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2$.main(HiveThriftServer2.scala:79)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.main(HiveThriftServer2.scala)
2018-10-15 21:45:40 ERROR Utils:91 - Uncaught exception in thread main
```
After fix, the usage output is clean:
```
...
Thrift server options:
--hiveconf <property=value> Use value for given property
```
Also exit with code 1, to follow other scripts(this is the behavior of parsing option `-h` for other linux commands as well).
## How was this patch tested?
Manual test.
Closes#22727 from gengliangwang/stsUsage.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
While working on another PR, I noticed that there is quite some legacy Java in there that can be beautified. For example the use og features from Java8, such as:
- Collection libraries
- Try-with-resource blocks
No code has been changed
What are your thoughts on this?
This makes code easier to read, and using try-with-resource makes is less likely to forget to close something.
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22399 from Fokko/SPARK-25408.
Authored-by: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This patch is to bump the master branch version to 3.0.0-SNAPSHOT.
## How was this patch tested?
N/A
Closes#22606 from gatorsmile/bump3.0.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In the dev list, we can still discuss whether the next version is 2.5.0 or 3.0.0. Let us first bump the master branch version to `2.5.0-SNAPSHOT`.
## How was this patch tested?
N/A
Closes#22426 from gatorsmile/bumpVersionMaster.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR ensures to call `super.afterAll()` in `override afterAll()` method for test suites.
* Some suites did not call `super.afterAll()`
* Some suites may call `super.afterAll()` only under certain condition
* Others never call `super.afterAll()`.
This PR also ensures to call `super.beforeAll()` in `override beforeAll()` for test suites.
## How was this patch tested?
Existing UTs
Closes#22337 from kiszk/SPARK-25338.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}