### What changes were proposed in this pull request?
Now users can add directories from sql CLI as well using ADD FILE command and setting spark.sql.addDirectory.recursive to true.
### Why are the changes needed?
In SPARK-4687, support was added for adding directories as resources. But sql users cannot use that feature from CLI.
`ADD FILE /path/to/folder` gives the following error:
`org.apache.spark.SparkException: Added file /path/to/folder is a directory and recursive is not turned on.`
Users need to turn on `recursive` for adding directories. Thus a configuration was required which will allow users to turn on `recursive`.
Also Hive allow users to add directories from their shell.
### Does this PR introduce any user-facing change?
Yes. Users can set recursive using `spark.sql.addDirectory.recursive`.
### How was this patch tested?
Manually.
Will add test cases soon.
SPARK SCREENSHOTS
When `spark.sql.addDirectory.recursive` is not turned on.
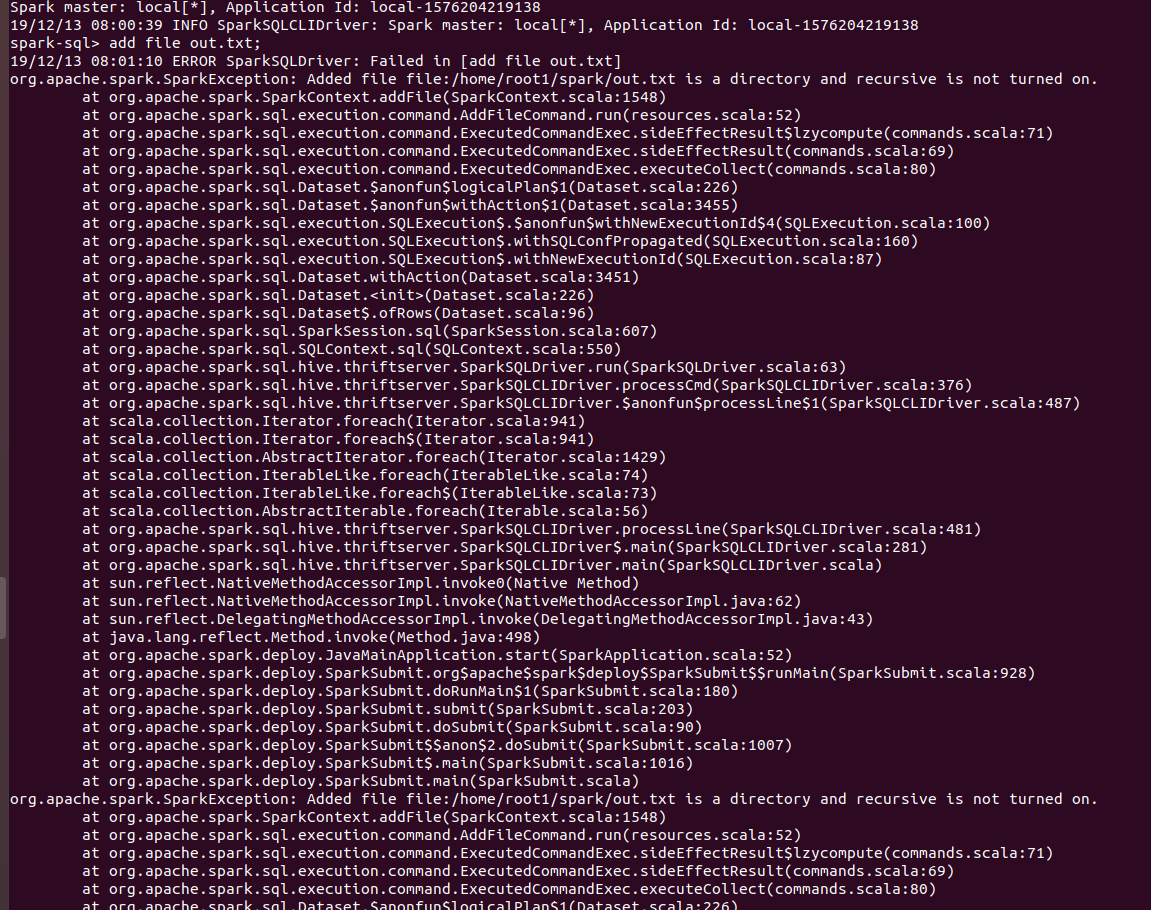
After setting `spark.sql.addDirectory.recursive` to true.

HIVE SCREENSHOT

`RELEASE_NOTES.txt` is text file while `dummy` is a directory.
Closes#26863 from iRakson/SPARK-30234.
Lead-authored-by: root1 <raksonrakesh@gmail.com>
Co-authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In this pull request, we are going to support `SET OWNER` syntax for databases and namespaces,
```sql
ALTER (DATABASE|SCHEME|NAMESPACE) database_name SET OWNER [USER|ROLE|GROUP] user_or_role_group;
```
Before this commit 332e252a14, we didn't care much about ownerships for the catalog objects. In 332e252a14, we determined to use properties to store ownership staff, and temporarily used `alter database ... set dbproperties ...` to support switch ownership of a database. This PR aims to use the formal syntax to replace it.
In hive, `ownerName/Type` are fields of the database objects, also they can be normal properties.
```
create schema test1 with dbproperties('ownerName'='yaooqinn')
```
The create/alter database syntax will not change the owner to `yaooqinn` but store it in parameters. e.g.
```
+----------+----------+---------------------------------------------------------------+-------------+-------------+-----------------------+--+
| db_name | comment | location | owner_name | owner_type | parameters |
+----------+----------+---------------------------------------------------------------+-------------+-------------+-----------------------+--+
| test1 | | hdfs://quickstart.cloudera:8020/user/hive/warehouse/test1.db | anonymous | USER | {ownerName=yaooqinn} |
+----------+----------+---------------------------------------------------------------+-------------+-------------+-----------------------+--+
```
In this pull request, because we let the `ownerName` become reversed, so it will neither change the owner nor store in dbproperties, just be omitted silently.
## Why are the changes needed?
Formal syntax support for changing database ownership
### Does this PR introduce any user-facing change?
yes, add a new syntax
### How was this patch tested?
add unit tests
Closes#26775 from yaooqinn/SPARK-30018.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, COMMENT and LOCATION are reserved properties for Datasource v2 namespaces. They can be set via specific clauses and via properties. And the ones specified in clauses take precede of properties. Since they are reserved, which means they are not able to visit directly. They should be used in COMMENT/LOCATION clauses ONLY.
### Why are the changes needed?
make reserved properties be reserved.
### Does this PR introduce any user-facing change?
yes, 'location', 'comment' are not allowed use in db properties
### How was this patch tested?
UNIT tests.
Closes#26806 from yaooqinn/SPARK-30183.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Previously in https://github.com/apache/spark/pull/26614/files#diff-bad3987c83bd22d46416d3dd9d208e76R90, we compare the number of tasks with `(conf.get(EXECUTOR_CORES) / sched.CPUS_PER_TASK)`. In standalone mode if the value is not explicitly set by default, the conf value would be 1 but the executor would actually use all the cores of the worker. So it is allowed to have `CPUS_PER_TASK` greater than `EXECUTOR_CORES`. To handle this case, we change the condition to be `numTasks <= Math.max(conf.get(EXECUTOR_CORES) / sched.CPUS_PER_TASK, 1)`
### Why are the changes needed?
For standalone mode if the user set the `spark.task.cpus` to be greater than 1 but didn't set the `spark.executor.cores`. Even though there is only 1 task in the stage it would not be speculative run.
### Does this PR introduce any user-facing change?
Solve the problem above by allowing speculative run when there is only 1 task in the stage.
### How was this patch tested?
Existing tests and one more test in TaskSetManagerSuite
Closes#27126 from yuchenhuo/SPARK-30417.
Authored-by: Yuchen Huo <yuchen.huo@databricks.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
### What changes were proposed in this pull request?
This patch renews the verification logic of archive path for FileStreamSource, as we found the logic doesn't take partitioned/recursive options into account.
Before the patch, it only requires the archive path to have depth more than 2 (two subdirectories from root), leveraging the fact FileStreamSource normally reads the files where the parent directory matches the pattern or the file itself matches the pattern. Given 'archive' operation moves the files to the base archive path with retaining the full path, archive path is tend to be safe if the depth is more than 2, meaning FileStreamSource doesn't re-read archived files as new source files.
WIth partitioned/recursive options, the fact is invalid, as FileStreamSource can read any files in any depth of subdirectories for source pattern. To deal with this correctly, we have to renew the verification logic, which may not intuitive and simple but works for all cases.
The new verification logic prevents both cases:
1) archive path matches with source pattern as "prefix" (the depth of archive path > the depth of source pattern)
e.g.
* source pattern: `/hello*/spar?`
* archive path: `/hello/spark/structured/streaming`
Any files in archive path will match with source pattern when recursive option is enabled.
2) source pattern matches with archive path as "prefix" (the depth of source pattern > the depth of archive path)
e.g.
* source pattern: `/hello*/spar?/structured/hello2*`
* archive path: `/hello/spark/structured`
Some archive files will not match with source pattern, e.g. file path: `/hello/spark/structured/hello2`, then final archived path: `/hello/spark/structured/hello/spark/structured/hello2`.
But some other archive files will still match with source pattern, e.g. file path: `/hello2/spark/structured/hello2`, then final archived path: `/hello/spark/structured/hello2/spark/structured/hello2` which matches with source pattern when recursive is enabled.
Implicitly it also prevents archive path matches with source pattern as full match (same depth).
We would want to prevent any source files to be archived and added to new source files again, so the patch takes most restrictive approach to prevent the possible cases.
### Why are the changes needed?
Without this patch, there's a chance archived files are included as new source files when partitioned/recursive option is enabled, as current condition doesn't take these options into account.
### Does this PR introduce any user-facing change?
Only for Spark 3.0.0-preview (only preview 1 for now, but possibly preview 2 as well) - end users are required to provide archive path with ensuring a bit complicated conditions, instead of simply higher than 2 depths.
### How was this patch tested?
New UT.
Closes#26920 from HeartSaVioR/SPARK-30281.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
Revert https://github.com/apache/spark/pull/20433 .
### Why are the changes needed?
According to the SQL standard, the INTERVAL prefix is required:
```
<interval literal> ::=
INTERVAL [ <sign> ] <interval string> <interval qualifier>
<interval string> ::=
<quote> <unquoted interval string> <quote>
```
### Does this PR introduce any user-facing change?
yes, but omitting the INTERVAL prefix is a new feature in 3.0
### How was this patch tested?
existing tests
Closes#27080 from cloud-fan/interval.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Change config name from `spark.sql.legacy.typeCoercion.datetimeToString` to `spark.sql.legacy.typeCoercion.datetimeToString.enabled`.
### Why are the changes needed?
To follow the other boolean conf naming convention.
### Does this PR introduce any user-facing change?
No, it's newly added in Spark 3.0.
### How was this patch tested?
Pass Jenkins
Closes#27065 from Ngone51/SPARK-27638-FOLLOWUP.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Documentation added for refresh resources command in spark-sql.
### Why are the changes needed?
Previously, only refresh table command was documented.
### Does this PR introduce any user-facing change?
Yes. Now users can access documentation for refresh resources command.
### How was this patch tested?
Manually.
Closes#27023 from iRakson/SPARK-30363.
Authored-by: root1 <raksonrakesh@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/26780
In https://github.com/apache/spark/pull/26780, a new Avro data source option `actualSchema` is introduced for setting the original Avro schema in function `from_avro`, while the expected schema is supposed to be set in the parameter `jsonFormatSchema` of `from_avro`.
However, there is another Avro data source option `avroSchema`. It is used for setting the expected schema in readiong and writing.
This PR is to use the option `avroSchema` option for reading Avro data with an evolved schema and remove the new one `actualSchema`
### Why are the changes needed?
Unify and simplify the Avro data source options.
### Does this PR introduce any user-facing change?
Yes.
To deserialize Avro data with an evolved schema, before changes:
```
from_avro('col, expectedSchema, ("actualSchema" -> actualSchema))
```
After changes:
```
from_avro('col, actualSchema, ("avroSchema" -> expectedSchema))
```
The second parameter is always the actual Avro schema after changes.
### How was this patch tested?
Update the existing tests in https://github.com/apache/spark/pull/26780Closes#27045 from gengliangwang/renameAvroOption.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Updated the document for LIST FILE/JAR command.
### Why are the changes needed?
LIST FILE/JAR can take multiple filenames as argument and it returns the files which were added as resources.
### Does this PR introduce any user-facing change?
Yes. Documentation updated for LIST FILE/JAR command
### How was this patch tested?
Manually
Closes#26996 from iRakson/SPARK-30342.
Authored-by: root1 <raksonrakesh@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
## What changes were proposed in this pull request?
Create temporary or permanent function it should throw AnalysisException if the resource is not found. Need to keep behavior consistent across permanent and temporary functions.
## How was this patch tested?
Added UT and also tested manually
**Before Fix**
If the UDF resource is not present then on creation of temporary function it throws AnalysisException where as for permanent function it does not throw. Permanent funtcion throws AnalysisException only after select operation is performed.
**After Fix**
For temporary and permanent function check for the resource, if the UDF resource is not found then throw AnalysisException

Closes#25399 from sandeep-katta/funcIssue.
Authored-by: sandeep katta <sandeep.katta2007@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Update the Spark SQL document menu and join strategy hints.
### Why are the changes needed?
- Several new changes in the Spark SQL document didn't change the menu-sql.yaml correspondingly.
- Update the demo code for join strategy hints.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Document change only.
Closes#26917 from xuanyuanking/SPARK-30278.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Implement Factorization Machines as a ml-pipeline component
1. loss function supports: logloss, mse
2. optimizer: GD, adamW
### Why are the changes needed?
Factorization Machines is widely used in advertising and recommendation system to estimate CTR(click-through rate).
Advertising and recommendation system usually has a lot of data, so we need Spark to estimate the CTR, and Factorization Machines are common ml model to estimate CTR.
References:
1. S. Rendle, “Factorization machines,” in Proceedings of IEEE International Conference on Data Mining (ICDM), pp. 995–1000, 2010.
https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
run unit tests
Closes#27000 from mob-ai/ml/fm.
Authored-by: zhanjf <zhanjf@mob.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
The filter predicate for aggregate expression is an `ANSI SQL`.
```
<aggregate function> ::=
COUNT <left paren> <asterisk> <right paren> [ <filter clause> ]
| <general set function> [ <filter clause> ]
| <binary set function> [ <filter clause> ]
| <ordered set function> [ <filter clause> ]
| <array aggregate function> [ <filter clause> ]
| <row pattern count function> [ <filter clause> ]
```
There are some mainstream database support this syntax.
**PostgreSQL:**
https://www.postgresql.org/docs/current/sql-expressions.html#SYNTAX-AGGREGATES
For example:
```
SELECT
year,
count(*) FILTER (WHERE gdp_per_capita >= 40000)
FROM
countries
GROUP BY
year
```
```
SELECT
year,
code,
gdp_per_capita,
count(*)
FILTER (WHERE gdp_per_capita >= 40000)
OVER (PARTITION BY year)
FROM
countries
```
**jOOQ:**
https://blog.jooq.org/2014/12/30/the-awesome-postgresql-9-4-sql2003-filter-clause-for-aggregate-functions/
**Notice:**
1.This PR only supports FILTER predicate without codegen. maropu will create another PR is related to SPARK-30027 to support codegen.
2.This PR only supports FILTER predicate without DISTINCT. I will create another PR is related to SPARK-30276 to support this.
3.This PR only supports FILTER predicate that can't reference the outer query. I created ticket SPARK-30219 to support it.
4.This PR only supports FILTER predicate that can't use IN/EXISTS predicate sub-queries. I created ticket SPARK-30220 to support it.
5.Spark SQL cannot supports a SQL with nested aggregate. I created ticket SPARK-30182 to support it.
There are some show of the PR on my production environment.
```
spark-sql> desc gja_test_partition;
key string NULL
value string NULL
other string NULL
col2 int NULL
# Partition Information
# col_name data_type comment
col2 int NULL
Time taken: 0.79 s
```
```
spark-sql> select * from gja_test_partition;
a A ao 1
b B bo 1
c C co 1
d D do 1
e E eo 2
g G go 2
h H ho 2
j J jo 2
f F fo 3
k K ko 3
l L lo 4
i I io 4
Time taken: 1.75 s
```
```
spark-sql> select count(key), sum(col2) from gja_test_partition;
12 26
Time taken: 1.848 s
```
```
spark-sql> select count(key) filter (where col2 > 1) from gja_test_partition;
8
Time taken: 2.926 s
```
```
spark-sql> select sum(col2) filter (where col2 > 2) from gja_test_partition;
14
Time taken: 2.087 s
```
```
spark-sql> select count(key) filter (where col2 > 1), sum(col2) filter (where col2 > 2) from gja_test_partition;
8 14
Time taken: 2.847 s
```
```
spark-sql> select count(key), count(key) filter (where col2 > 1), sum(col2), sum(col2) filter (where col2 > 2) from gja_test_partition;
12 8 26 14
Time taken: 1.787 s
```
```
spark-sql> desc student;
id int NULL
name string NULL
sex string NULL
class_id int NULL
Time taken: 0.206 s
```
```
spark-sql> select * from student;
1 张三 man 1
2 李四 man 1
3 王五 man 2
4 赵六 man 2
5 钱小花 woman 1
6 赵九红 woman 2
7 郭丽丽 woman 2
Time taken: 0.786 s
```
```
spark-sql> select class_id, count(id), sum(id) from student group by class_id;
1 3 8
2 4 20
Time taken: 18.783 s
```
```
spark-sql> select class_id, count(id) filter (where sex = 'man'), sum(id) filter (where sex = 'woman') from student group by class_id;
1 2 5
2 2 13
Time taken: 3.887 s
```
### Why are the changes needed?
Add new SQL feature.
### Does this PR introduce any user-facing change?
'No'.
### How was this patch tested?
Exists UT and new UT.
Closes#26656 from beliefer/support-aggregate-clause.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
accuracyExpression can accept Long which may cause overflow error.
accuracyExpression can accept fractions which are implicitly floored.
accuracyExpression can accept null which is implicitly changed to 0.
percentageExpression can accept null but cause MatchError.
percentageExpression can accept ArrayType(_, nullable=true) in which the nulls are implicitly changed to zeros.
##### cases
```sql
select percentile_approx(10.0, 0.5, 2147483648); -- overflow and fail
select percentile_approx(10.0, 0.5, 4294967297); -- overflow but success
select percentile_approx(10.0, 0.5, null); -- null cast to 0
select percentile_approx(10.0, 0.5, 1.2); -- 1.2 cast to 1
select percentile_approx(10.0, null, 1); -- scala.MatchError
select percentile_approx(10.0, array(0.2, 0.4, null), 1); -- null cast to zero.
```
##### behavior before
```sql
+select percentile_approx(10.0, 0.5, 2147483648)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, CAST(0.5BD AS DOUBLE), CAST(2147483648L AS INT))' due to data type mismatch: The accuracy provided must be a positive integer literal (current value = -2147483648); line 1 pos 7
+
+select percentile_approx(10.0, 0.5, 4294967297)
+10.0
+
+select percentile_approx(10.0, 0.5, null)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, CAST(0.5BD AS DOUBLE), CAST(NULL AS INT))' due to data type mismatch: The accuracy provided must be a positive integer literal (current value = 0); line 1 pos 7
+
+select percentile_approx(10.0, 0.5, 1.2)
+10.0
+
+select percentile_approx(10.0, null, 1)
+scala.MatchError
+null
+
+
+select percentile_approx(10.0, array(0.2, 0.4, null), 1)
+[10.0,10.0,10.0]
```
##### behavior after
```sql
+select percentile_approx(10.0, 0.5, 2147483648)
+10.0
+
+select percentile_approx(10.0, 0.5, 4294967297)
+10.0
+
+select percentile_approx(10.0, 0.5, null)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, 0.5BD, NULL)' due to data type mismatch: argument 3 requires integral type, however, 'NULL' is of null type.; line 1 pos 7
+
+select percentile_approx(10.0, 0.5, 1.2)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, 0.5BD, 1.2BD)' due to data type mismatch: argument 3 requires integral type, however, '1.2BD' is of decimal(2,1) type.; line 1 pos 7
+
+select percentile_approx(10.0, null, 1)
+java.lang.IllegalArgumentException
+The value of percentage must be be between 0.0 and 1.0, but got null
+
+select percentile_approx(10.0, array(0.2, 0.4, null), 1)
+java.lang.IllegalArgumentException
+Each value of the percentage array must be be between 0.0 and 1.0, but got [0.2,0.4,null]
```
### Why are the changes needed?
bug fix
### Does this PR introduce any user-facing change?
yes, fix some improper usages of percentile_approx as cases list above
### How was this patch tested?
add ut
Closes#26905 from yaooqinn/SPARK-30266.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Change config name from `spark.eventLog.allowErasureCoding` to `spark.eventLog.allowErasureCoding.enabled`.
### Why are the changes needed?
To follow the other boolean conf naming convention.
### Does this PR introduce any user-facing change?
No, it's newly added in Spark 3.0.
### How was this patch tested?
Tested manually and pass Jenkins.
Closes#26998 from Ngone51/SPARK-25855-FOLLOWUP.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to update the SQL migration guide and clarify semantic of string conversion to typed `TIMESTAMP` and `DATE` literals.
### Why are the changes needed?
This is a follow-up of the PR https://github.com/apache/spark/pull/23541 which changed the behavior of `TIMESTAMP`/`DATE` literals, and can impact on results of user's queries.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
It should be checked by jenkins build.
Closes#26985 from MaxGekk/timestamp-date-constructors-followup.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Implement Factorization Machines as a ml-pipeline component
1. loss function supports: logloss, mse
2. optimizer: GD, adamW
### Why are the changes needed?
Factorization Machines is widely used in advertising and recommendation system to estimate CTR(click-through rate).
Advertising and recommendation system usually has a lot of data, so we need Spark to estimate the CTR, and Factorization Machines are common ml model to estimate CTR.
References:
1. S. Rendle, “Factorization machines,” in Proceedings of IEEE International Conference on Data Mining (ICDM), pp. 995–1000, 2010.
https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
run unit tests
Closes#26124 from mob-ai/ml/fm.
Authored-by: zhanjf <zhanjf@mob.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Fixed typo in `docs` directory and in other directories
1. Find typo in `docs` and apply fixes to files in all directories
2. Fix `the the` -> `the`
### Why are the changes needed?
Better readability of documents
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
No test needed
Closes#26976 from kiszk/typo_20191221.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR update document for make Hive 2.3 dependency by default.
### Why are the changes needed?
The documentation is incorrect.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#26919 from wangyum/SPARK-30280.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
add a migration guide for date_add and date_sub to indicates their behavior change. It a followup for #26412
### Why are the changes needed?
add a migration guide
### Does this PR introduce any user-facing change?
yes, doc change
### How was this patch tested?
no
Closes#26932 from yaooqinn/SPARK-29774-f.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When `spark.shuffle.useOldFetchProtocol` is enabled then switching off the direct disk reading of host-local shuffle blocks and falling back to remote block fetching (and this way avoiding the `GetLocalDirsForExecutors` block transfer message which is introduced from Spark 3.0.0).
### Why are the changes needed?
In `[SPARK-27651][Core] Avoid the network when shuffle blocks are fetched from the same host` a new block transfer message is introduced, `GetLocalDirsForExecutors`. This new message could be sent to the external shuffle service and as it is not supported by the previous version of external shuffle service it should be avoided when `spark.shuffle.useOldFetchProtocol` is true.
In the migration guide I changed the exception type as `org.apache.spark.network.shuffle.protocol.BlockTransferMessage.Decoder#fromByteBuffer`
throws a IllegalArgumentException with the given text and uses the message type which is just a simple number (byte). I have checked and this is true for version 2.4.4 too.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
This specific case (considering one extra boolean to switch off host local disk reading feature) is not tested but existing tests were run.
Closes#26869 from attilapiros/SPARK-30235.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
1. Revert "Preparing development version 3.0.1-SNAPSHOT": 56dcd79
2. Revert "Preparing Spark release v3.0.0-preview2-rc2": c216ef1
### Why are the changes needed?
Shouldn't change master.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
manual test:
https://github.com/apache/spark/compare/5de5e46..wangyum:revert-masterCloses#26915 from wangyum/revert-master.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
Include `$SPARK_DIST_CLASSPATH` in class path when launching `CoarseGrainedExecutorBackend` on Kubernetes executors using the provided `entrypoint.sh`
### Why are the changes needed?
For user provided Hadoop, `$SPARK_DIST_CLASSPATH` contains the required jars.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
Kubernetes 1.14, Spark 2.4.4, Hadoop 3.2.1. Adding $SPARK_DIST_CLASSPATH to `-cp ` param of entrypoint.sh enables launching the executors correctly.
Closes#26493 from sshakeri/master.
Authored-by: Shahin Shakeri <shahin.shakeri@pwc.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
The PR adds a new config option to configure an address for the
proxy server, and a new handler that intercepts redirects and replaces
the URL with one pointing at the proxy server. This is needed on top
of the "proxy base path" support because redirects use full URLs, not
just absolute paths from the server's root.
### Why are the changes needed?
Spark's web UI has support for generating links to paths with a
prefix, to support a proxy server, but those do not apply when
the UI is responding with redirects. In that case, Spark is sending
its own URL back to the client, and if it's behind a dumb proxy
server that doesn't do rewriting (like when using stunnel for HTTPS
support) then the client will see the wrong URL and may fail.
### Does this PR introduce any user-facing change?
Yes. It's a new UI option.
### How was this patch tested?
Tested with added unit test, with Spark behind stunnel, and in a
more complicated app using a different HTTPS proxy.
Closes#26873 from vanzin/SPARK-30240.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
- Reverts commit 1f94bf4 and d6be46e
- Switches python to python3 in Docker release image.
### Why are the changes needed?
`dev/make-distribution.sh` and `python/setup.py` are use python3.
https://github.com/apache/spark/pull/26844/files#diff-ba2c046d92a1d2b5b417788bfb5cb5f8L236https://github.com/apache/spark/pull/26330/files#diff-8cf6167d58ce775a08acafcfe6f40966
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
manual test:
```
yumwangubuntu-3513086:~/spark$ dev/create-release/do-release-docker.sh -n -d /home/yumwang/spark-release
Output directory already exists. Overwrite and continue? [y/n] y
Branch [branch-2.4]: master
Current branch version is 3.0.0-SNAPSHOT.
Release [3.0.0]: 3.0.0-preview2
RC # [1]:
This is a dry run. Please confirm the ref that will be built for testing.
Ref [master]:
ASF user [yumwang]:
Full name [Yuming Wang]:
GPG key [yumwangapache.org]: DBD447010C1B4F7DAD3F7DFD6E1B4122F6A3A338
================
Release details:
BRANCH: master
VERSION: 3.0.0-preview2
TAG: v3.0.0-preview2-rc1
NEXT: 3.0.1-SNAPSHOT
ASF USER: yumwang
GPG KEY: DBD447010C1B4F7DAD3F7DFD6E1B4122F6A3A338
FULL NAME: Yuming Wang
E-MAIL: yumwangapache.org
================
Is this info correct [y/n]? y
GPG passphrase:
========================
= Building spark-rm image with tag latest...
Command: docker build -t spark-rm:latest --build-arg UID=110302528 /home/yumwang/spark/dev/create-release/spark-rm
Log file: docker-build.log
Building v3.0.0-preview2-rc1; output will be at /home/yumwang/spark-release/output
gpg: directory '/home/spark-rm/.gnupg' created
gpg: keybox '/home/spark-rm/.gnupg/pubring.kbx' created
gpg: /home/spark-rm/.gnupg/trustdb.gpg: trustdb created
gpg: key 6E1B4122F6A3A338: public key "Yuming Wang <yumwangapache.org>" imported
gpg: key 6E1B4122F6A3A338: secret key imported
gpg: Total number processed: 1
gpg: imported: 1
gpg: secret keys read: 1
gpg: secret keys imported: 1
========================
= Creating release tag v3.0.0-preview2-rc1...
Command: /opt/spark-rm/release-tag.sh
Log file: tag.log
It may take some time for the tag to be synchronized to github.
Press enter when you've verified that the new tag (v3.0.0-preview2-rc1) is available.
========================
= Building Spark...
Command: /opt/spark-rm/release-build.sh package
Log file: build.log
========================
= Building documentation...
Command: /opt/spark-rm/release-build.sh docs
Log file: docs.log
========================
= Publishing release
Command: /opt/spark-rm/release-build.sh publish-release
Log file: publish.log
```
Generated doc:

Closes#26848 from wangyum/SPARK-30216.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This patch fixes the availability of `minPartitions` option for Kafka source, as it is only supported by micro-batch for now. There's a WIP PR for batch (#25436) as well but there's no progress on the PR so far, so safer to fix the doc first, and let it be added later when we address it with batch case as well.
### Why are the changes needed?
The doc is wrong and misleading.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Just a doc change.
Closes#26849 from HeartSaVioR/MINOR-FIX-minPartition-availability-doc.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose new implementation of `fromDayTimeString` which strictly parses strings in day-time formats to intervals. New implementation accepts only strings that match to a pattern defined by the `from` and `to`. Here is the mapping of user's bounds and patterns:
- `[+|-]D+ H[H]:m[m]:s[s][.SSSSSSSSS]` for **DAY TO SECOND**
- `[+|-]D+ H[H]:m[m]` for **DAY TO MINUTE**
- `[+|-]D+ H[H]` for **DAY TO HOUR**
- `[+|-]H[H]:m[m]s[s][.SSSSSSSSS]` for **HOUR TO SECOND**
- `[+|-]H[H]:m[m]` for **HOUR TO MINUTE**
- `[+|-]m[m]:s[s][.SSSSSSSSS]` for **MINUTE TO SECOND**
Closes#26327Closes#26358
### Why are the changes needed?
- Improve user experience with Spark SQL, and respect to the bound specified by users.
- Behave the same as other broadly used DBMS - Oracle and MySQL.
### Does this PR introduce any user-facing change?
Yes, before:
```sql
spark-sql> SELECT INTERVAL '10 11:12:13.123' HOUR TO MINUTE;
interval 1 weeks 3 days 11 hours 12 minutes
```
After:
```sql
spark-sql> SELECT INTERVAL '10 11:12:13.123' HOUR TO MINUTE;
Error in query:
requirement failed: Interval string must match day-time format of '^(?<sign>[+|-])?(?<hour>\d{1,2}):(?<minute>\d{1,2})$': 10 11:12:13.123(line 1, pos 16)
== SQL ==
SELECT INTERVAL '10 11:12:13.123' HOUR TO MINUTE
----------------^^^
```
### How was this patch tested?
- Added tests to `IntervalUtilsSuite`
- By `ExpressionParserSuite`
- Updated `literals.sql`
Closes#26473 from MaxGekk/strict-from-daytime-string.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Enhancement of the SQL NULL Semantics document: sql-ref-null-semantics.html.
### Why are the changes needed?
Clarify the behavior of `UNKNOWN` for both `EXIST` and `IN` operation.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Doc changes only.
Closes#26837 from xuanyuanking/SPARK-30207.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
Follow up of https://github.com/apache/spark/pull/24405
### What changes were proposed in this pull request?
The current implementation of _from_avro_ and _AvroDataToCatalyst_ doesn't allow doing schema evolution since it requires the deserialization of an Avro record with the exact same schema with which it was serialized.
The proposed change is to add a new option `actualSchema` to allow passing the schema used to serialize the records. This allows using a different compatible schema for reading by passing both schemas to _GenericDatumReader_. If no writer's schema is provided, nothing changes from before.
### Why are the changes needed?
Consider the following example.
```
// schema ID: 1
val schema1 = """
{
"type": "record",
"name": "MySchema",
"fields": [
{"name": "col1", "type": "int"},
{"name": "col2", "type": "string"}
]
}
"""
// schema ID: 2
val schema2 = """
{
"type": "record",
"name": "MySchema",
"fields": [
{"name": "col1", "type": "int"},
{"name": "col2", "type": "string"},
{"name": "col3", "type": "string", "default": ""}
]
}
"""
```
The two schemas are compatible - i.e. you can use `schema2` to deserialize events serialized with `schema1`, in which case there will be the field `col3` with the default value.
Now imagine that you have two dataframes (read from batch or streaming), one with Avro events from schema1 and the other with events from schema2. **We want to combine them into one dataframe** for storing or further processing.
With the current `from_avro` function we can only decode each of them with the corresponding schema:
```
scalaval df1 = ... // Avro events created with schema1
df1: org.apache.spark.sql.DataFrame = [eventBytes: binary]
scalaval decodedDf1 = df1.select(from_avro('eventBytes, schema1) as "decoded")
decodedDf1: org.apache.spark.sql.DataFrame = [decoded: struct<col1: int, col2: string>]
scalaval df2= ... // Avro events created with schema2
df2: org.apache.spark.sql.DataFrame = [eventBytes: binary]
scalaval decodedDf2 = df2.select(from_avro('eventBytes, schema2) as "decoded")
decodedDf2: org.apache.spark.sql.DataFrame = [decoded: struct<col1: int, col2: string, col3: string>]
```
but then `decodedDf1` and `decodedDf2` have different Spark schemas and we can't union them. Instead, with the proposed change we can decode `df1` in the following way:
```
scalaimport scala.collection.JavaConverters._
scalaval decodedDf1 = df1.select(from_avro(data = 'eventBytes, jsonFormatSchema = schema2, options = Map("actualSchema" -> schema1).asJava) as "decoded")
decodedDf1: org.apache.spark.sql.DataFrame = [decoded: struct<col1: int, col2: string, col3: string>]
```
so that both dataframes have the same schemas and can be merged.
### Does this PR introduce any user-facing change?
This PR allows users to pass a new configuration but it doesn't affect current code.
### How was this patch tested?
A new unit test was added.
Closes#26780 from Fokko/SPARK-27506.
Lead-authored-by: Fokko Driesprong <fokko@apache.org>
Co-authored-by: Gianluca Amori <gianluca.amori@gmail.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
This PR switches python to python3 in `make-distribution.sh`.
### Why are the changes needed?
SPARK-29672 changed this
- https://github.com/apache/spark/pull/26330/files#diff-8cf6167d58ce775a08acafcfe6f40966
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#26844 from wangyum/SPARK-30211.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR add an optional spark conf for speculation to allow speculative runs for stages where there are only a few tasks.
```
spark.speculation.task.duration.threshold
```
If provided, tasks would be speculatively run if the TaskSet contains less tasks than the number of slots on a single executor and the task is taking longer time than the threshold.
### Why are the changes needed?
This change helps avoid scenarios where there is single executor that could hang forever due to disk issue and we unfortunately assigned the single task in a TaskSet to that executor and cause the whole job to hang forever.
### Does this PR introduce any user-facing change?
yes. If the new config `spark.speculation.task.duration.threshold` is provided and the TaskSet contains less tasks than the number of slots on a single executor and the task is taking longer time than the threshold, then speculative tasks would be submitted for the running tasks in the TaskSet.
### How was this patch tested?
Unit tests are added to TaskSetManagerSuite.
Closes#26614 from yuchenhuo/SPARK-29976.
Authored-by: Yuchen Huo <yuchen.huo@databricks.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
Reprocess all PostgreSQL dialect related PRs, listing in order:
- #25158: PostgreSQL integral division support [revert]
- #25170: UT changes for the integral division support [revert]
- #25458: Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. [revert]
- #25697: Combine below 2 feature tags into "spark.sql.dialect" [revert]
- #26112: Date substraction support [keep the ANSI-compliant part]
- #26444: Rename config "spark.sql.ansi.enabled" to "spark.sql.dialect.spark.ansi.enabled" [revert]
- #26463: Cast to boolean support for PostgreSQL dialect [revert]
- #26584: Make the behavior of Postgre dialect independent of ansi mode config [keep the ANSI-compliant part]
### Why are the changes needed?
As the discussion in http://apache-spark-developers-list.1001551.n3.nabble.com/DISCUSS-PostgreSQL-dialect-td28417.html, we need to remove PostgreSQL dialect form code base for several reasons:
1. The current approach makes the codebase complicated and hard to maintain.
2. Fully migrating PostgreSQL workloads to Spark SQL is not our focus for now.
### Does this PR introduce any user-facing change?
Yes, the config `spark.sql.dialect` will be removed.
### How was this patch tested?
Existing UT.
Closes#26763 from xuanyuanking/SPARK-30125.
Lead-authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR proposes to add instrumentation of memory usage via the Spark Dropwizard/Codahale metrics system. Memory usage metrics are available via the Executor metrics, recently implemented as detailed in https://issues.apache.org/jira/browse/SPARK-23206.
Additional notes: This takes advantage of the metrics poller introduced in #23767.
## Why are the changes needed?
Executor metrics bring have many useful insights on memory usage, in particular on the usage of storage memory and executor memory. This is useful for troubleshooting. Having the information in the metrics systems allows to add those metrics to Spark performance dashboards and study memory usage as a function of time, as in the example graph https://issues.apache.org/jira/secure/attachment/12962810/Example_dashboard_Spark_Memory_Metrics.PNG
## Does this PR introduce any user-facing change?
Adds `ExecutorMetrics` source to publish executor metrics via the Dropwizard metrics system. Details of the available metrics in docs/monitoring.md
Adds configuration parameter `spark.metrics.executormetrics.source.enabled`
## How was this patch tested?
Tested on YARN cluster and with an existing setup for a Spark dashboard based on InfluxDB and Grafana.
Closes#24132 from LucaCanali/memoryMetricsSource.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
### What changes were proposed in this pull request?
Now, we trim the string when casting string value to those `canCast` types values, e.g. int, double, decimal, interval, date, timestamps, except for boolean.
This behavior makes type cast and coercion inconsistency in Spark.
Not fitting ANSI SQL standard either.
```
If TD is boolean, then
Case:
a) If SD is character string, then SV is replaced by
TRIM ( BOTH ' ' FROM VE )
Case:
i) If the rules for literal in Subclause 5.3, “literal”, can be applied to SV to determine a valid
value of the data type TD, then let TV be that value.
ii) Otherwise, an exception condition is raised: data exception — invalid character value for cast.
b) If SD is boolean, then TV is SV
```
In this pull request, we trim all the whitespaces from both ends of the string before converting it to a bool value. This behavior is as same as others, but a bit different from sql standard, which trim only spaces.
### Why are the changes needed?
Type cast/coercion consistency
### Does this PR introduce any user-facing change?
yes, string with whitespaces in both ends will be trimmed before converted to booleans.
e.g. `select cast('\t true' as boolean)` results `true` now, before this pr it's `null`
### How was this patch tested?
add unit tests
Closes#26776 from yaooqinn/SPARK-30147.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
In this PR, we propose to use the value of `spark.sql.source.default` as the provider for `CREATE TABLE` syntax instead of `hive` in Spark 3.0.
And to help the migration, we introduce a legacy conf `spark.sql.legacy.respectHiveDefaultProvider.enabled` and set its default to `false`.
### Why are the changes needed?
1. Currently, `CREATE TABLE` syntax use hive provider to create table while `DataFrameWriter.saveAsTable` API using the value of `spark.sql.source.default` as a provider to create table. It would be better to make them consistent.
2. User may gets confused in some cases. For example:
```
CREATE TABLE t1 (c1 INT) USING PARQUET;
CREATE TABLE t2 (c1 INT);
```
In these two DDLs, use may think that `t2` should also use parquet as default provider since Spark always advertise parquet as the default format. However, it's hive in this case.
On the other hand, if we omit the USING clause in a CTAS statement, we do pick parquet by default if `spark.sql.hive.convertCATS=true`:
```
CREATE TABLE t3 USING PARQUET AS SELECT 1 AS VALUE;
CREATE TABLE t4 AS SELECT 1 AS VALUE;
```
And these two cases together can be really confusing.
3. Now, Spark SQL is very independent and popular. We do not need to be fully consistent with Hive's behavior.
### Does this PR introduce any user-facing change?
Yes, before this PR, using `CREATE TABLE` syntax will use hive provider. But now, it use the value of `spark.sql.source.default` as its provider.
### How was this patch tested?
Added tests in `DDLParserSuite` and `HiveDDlSuite`.
Closes#26736 from Ngone51/dev-create-table-using-parquet-by-default.
Lead-authored-by: wuyi <yi.wu@databricks.com>
Co-authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to upgrade Maven from 3.6.2 to 3.6.3.
### Why are the changes needed?
This will bring bug fixes like the following.
- MNG-6759 Maven fails to use <repositories> section from dependency when resolving transitive dependencies in some cases
- MNG-6760 ExclusionArtifactFilter result invalid when wildcard exclusion is followed by other exclusions
The following is the full release note.
- https://maven.apache.org/docs/3.6.3/release-notes.html
### Does this PR introduce any user-facing change?
No. (This is a dev-environment change.)
### How was this patch tested?
Pass the Jenkins with both SBT and Maven.
Closes#26770 from dongjoon-hyun/SPARK-30142.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The syntax 'LIKE predicate: ESCAPE clause' is a ANSI SQL.
For example:
```
select 'abcSpark_13sd' LIKE '%Spark\\_%'; //true
select 'abcSpark_13sd' LIKE '%Spark/_%'; //false
select 'abcSpark_13sd' LIKE '%Spark"_%'; //false
select 'abcSpark_13sd' LIKE '%Spark/_%' ESCAPE '/'; //true
select 'abcSpark_13sd' LIKE '%Spark"_%' ESCAPE '"'; //true
select 'abcSpark%13sd' LIKE '%Spark\\%%'; //true
select 'abcSpark%13sd' LIKE '%Spark/%%'; //false
select 'abcSpark%13sd' LIKE '%Spark"%%'; //false
select 'abcSpark%13sd' LIKE '%Spark/%%' ESCAPE '/'; //true
select 'abcSpark%13sd' LIKE '%Spark"%%' ESCAPE '"'; //true
select 'abcSpark\\13sd' LIKE '%Spark\\\\_%'; //true
select 'abcSpark/13sd' LIKE '%Spark//_%'; //false
select 'abcSpark"13sd' LIKE '%Spark""_%'; //false
select 'abcSpark/13sd' LIKE '%Spark//_%' ESCAPE '/'; //true
select 'abcSpark"13sd' LIKE '%Spark""_%' ESCAPE '"'; //true
```
But Spark SQL only supports 'LIKE predicate'.
Note: If the input string or pattern string is null, then the result is null too.
There are some mainstream database support the syntax.
**PostgreSQL:**
https://www.postgresql.org/docs/11/functions-matching.html
**Vertica:**
https://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/SQLReferenceManual/LanguageElements/Predicates/LIKE-predicate.htm?zoom_highlight=like%20escape
**MySQL:**
https://dev.mysql.com/doc/refman/5.6/en/string-comparison-functions.html
**Oracle:**
https://docs.oracle.com/en/database/oracle/oracle-database/19/jjdbc/JDBC-reference-information.html#GUID-5D371A5B-D7F6-42EB-8C0D-D317F3C53708https://docs.oracle.com/en/database/oracle/oracle-database/19/sqlrf/Pattern-matching-Conditions.html#GUID-0779657B-06A8-441F-90C5-044B47862A0A
## How was this patch tested?
Exists UT and new UT.
This PR merged to my production environment and runs above sql:
```
spark-sql> select 'abcSpark_13sd' LIKE '%Spark\\_%';
true
Time taken: 0.119 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark_13sd' LIKE '%Spark/_%';
false
Time taken: 0.103 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark_13sd' LIKE '%Spark"_%';
false
Time taken: 0.096 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark_13sd' LIKE '%Spark/_%' ESCAPE '/';
true
Time taken: 0.096 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark_13sd' LIKE '%Spark"_%' ESCAPE '"';
true
Time taken: 0.092 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark%13sd' LIKE '%Spark\\%%';
true
Time taken: 0.109 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark%13sd' LIKE '%Spark/%%';
false
Time taken: 0.1 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark%13sd' LIKE '%Spark"%%';
false
Time taken: 0.081 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark%13sd' LIKE '%Spark/%%' ESCAPE '/';
true
Time taken: 0.095 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark%13sd' LIKE '%Spark"%%' ESCAPE '"';
true
Time taken: 0.113 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark\\13sd' LIKE '%Spark\\\\_%';
true
Time taken: 0.078 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark/13sd' LIKE '%Spark//_%';
false
Time taken: 0.067 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark"13sd' LIKE '%Spark""_%';
false
Time taken: 0.084 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark/13sd' LIKE '%Spark//_%' ESCAPE '/';
true
Time taken: 0.091 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark"13sd' LIKE '%Spark""_%' ESCAPE '"';
true
Time taken: 0.091 seconds, Fetched 1 row(s)
```
I create a table and its schema is:
```
spark-sql> desc formatted gja_test;
key string NULL
value string NULL
other string NULL
# Detailed Table Information
Database test
Table gja_test
Owner test
Created Time Wed Apr 10 11:06:15 CST 2019
Last Access Thu Jan 01 08:00:00 CST 1970
Created By Spark 2.4.1-SNAPSHOT
Type MANAGED
Provider hive
Table Properties [transient_lastDdlTime=1563443838]
Statistics 26 bytes
Location hdfs://namenode.xxx:9000/home/test/hive/warehouse/test.db/gja_test
Serde Library org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat org.apache.hadoop.mapred.TextInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Storage Properties [field.delim= , serialization.format= ]
Partition Provider Catalog
Time taken: 0.642 seconds, Fetched 21 row(s)
```
Table `gja_test` exists three rows of data.
```
spark-sql> select * from gja_test;
a A ao
b B bo
"__ """__ "
Time taken: 0.665 seconds, Fetched 3 row(s)
```
At finally, I test this function:
```
spark-sql> select * from gja_test where key like value escape '"';
"__ """__ "
Time taken: 0.687 seconds, Fetched 1 row(s)
```
Closes#25001 from beliefer/ansi-sql-like.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
This patch prevents the cleanup operation in FileStreamSource if the source files belong to the FileStreamSink. This is needed because the output of FileStreamSink can be read with multiple Spark queries and queries will read the files based on the metadata log, which won't reflect the cleanup.
To simplify the logic, the patch only takes care of the case of when the source path without glob pattern refers to the output directory of FileStreamSink, via checking FileStreamSource to see whether it leverages metadata directory or not to list the source files.
### Why are the changes needed?
Without this patch, if end users turn on cleanup option with the path which is the output of FileStreamSink, there may be out of sync between metadata and available files which may break other queries reading the path.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Added UT.
Closes#26590 from HeartSaVioR/SPARK-29953.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
### What changes were proposed in this pull request?
This PR adds a note to the docs README showing how to get Jekyll to automatically pick up changes to the Python API docs.
### Why are the changes needed?
`jekyll serve --watch` doesn't watch for changes to the API docs. Without the technique documented in this note, or something equivalent, developers have to manually retrigger a Jekyll build any time they update the Python API docs.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
I tested this PR manually by making changes to Python docstrings and confirming that Jekyll automatically picks them up and serves them locally.
Closes#26719 from nchammas/SPARK-30084-watch-api-docs.
Authored-by: Nicholas Chammas <nicholas.chammas@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
This proposes to introduce a naming convention for Spark metrics configuration parameters used to enable/disable metrics source reporting using the Dropwizard metrics library: `spark.metrics.sourceNameCamelCase.enabled` and update 2 parameters to use this naming convention.
### Why are the changes needed?
Currently Spark has a few parameters to enable/disable metrics reporting. Their naming pattern is not uniform and this can create confusion. Currently we have:
`spark.metrics.static.sources.enabled`
`spark.app.status.metrics.enabled`
`spark.sql.streaming.metricsEnabled`
### Does this PR introduce any user-facing change?
Update parameters for enabling/disabling metrics reporting new in Spark 3.0: `spark.metrics.static.sources.enabled` -> `spark.metrics.staticSources.enabled`, `spark.app.status.metrics.enabled` -> `spark.metrics.appStatusSource.enabled`.
Note: `spark.sql.streaming.metricsEnabled` is left unchanged as it is already in use in Spark 2.x.
### How was this patch tested?
Manually tested
Closes#26692 from LucaCanali/uniformNamingMetricsEnableParameters.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
`UnaryPositive` only accepts numeric and interval as we defined, but what we do for this in `AstBuider.visitArithmeticUnary` is just bypassing it.
This should not be omitted for the type checking requirement.
### Why are the changes needed?
bug fix, you can find a pre-discussion here https://github.com/apache/spark/pull/26578#discussion_r347350398
### Does this PR introduce any user-facing change?
yes, +non-numeric-or-interval is now invalid.
```
-- !query 14
select +date '1900-01-01'
-- !query 14 schema
struct<DATE '1900-01-01':date>
-- !query 14 output
1900-01-01
-- !query 15
select +timestamp '1900-01-01'
-- !query 15 schema
struct<TIMESTAMP '1900-01-01 00:00:00':timestamp>
-- !query 15 output
1900-01-01 00:00:00
-- !query 16
select +map(1, 2)
-- !query 16 schema
struct<map(1, 2):map<int,int>>
-- !query 16 output
{1:2}
-- !query 17
select +array(1,2)
-- !query 17 schema
struct<array(1, 2):array<int>>
-- !query 17 output
[1,2]
-- !query 18
select -'1'
-- !query 18 schema
struct<(- CAST(1 AS DOUBLE)):double>
-- !query 18 output
-1.0
-- !query 19
select -X'1'
-- !query 19 schema
struct<>
-- !query 19 output
org.apache.spark.sql.AnalysisException
cannot resolve '(- X'01')' due to data type mismatch: argument 1 requires (numeric or interval) type, however, 'X'01'' is of binary type.; line 1 pos 7
-- !query 20
select +X'1'
-- !query 20 schema
struct<X'01':binary>
-- !query 20 output
```
### How was this patch tested?
add ut check
Closes#26716 from yaooqinn/SPARK-30083.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Standardize sql reference
### Why are the changes needed?
To have consistent docs
### Does this PR introduce any user-facing change?
Yes
### How was this patch tested?
Tested using jykyll build --serve
Closes#26721 from huaxingao/spark-30085.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
add `.enabled` postfix to `spark.sql.analyzer.failAmbiguousSelfJoin`.
### Why are the changes needed?
to follow the existing naming style
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
not needed
Closes#26694 from cloud-fan/conf.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In SPARK-29421 (#26097) , we can specify a different table provider for `CREATE TABLE LIKE` via `USING provider`.
Hive support `STORED AS` new file format syntax:
```sql
CREATE TABLE tbl(a int) STORED AS TEXTFILE;
CREATE TABLE tbl2 LIKE tbl STORED AS PARQUET;
```
For Hive compatibility, we should also support `STORED AS` in `CREATE TABLE LIKE`.
### Why are the changes needed?
See https://github.com/apache/spark/pull/26097#issue-327424759
### Does this PR introduce any user-facing change?
Add a new syntax based on current CTL:
CREATE TABLE tbl2 LIKE tbl [STORED AS hiveFormat];
### How was this patch tested?
Add UTs.
Closes#26466 from LantaoJin/SPARK-29839.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}