### What changes were proposed in this pull request? Now users can add directories from sql CLI as well using ADD FILE command and setting spark.sql.addDirectory.recursive to true. ### Why are the changes needed? In SPARK-4687, support was added for adding directories as resources. But sql users cannot use that feature from CLI. `ADD FILE /path/to/folder` gives the following error: `org.apache.spark.SparkException: Added file /path/to/folder is a directory and recursive is not turned on.` Users need to turn on `recursive` for adding directories. Thus a configuration was required which will allow users to turn on `recursive`. Also Hive allow users to add directories from their shell. ### Does this PR introduce any user-facing change? Yes. Users can set recursive using `spark.sql.addDirectory.recursive`. ### How was this patch tested? Manually. Will add test cases soon. SPARK SCREENSHOTS When `spark.sql.addDirectory.recursive` is not turned on. 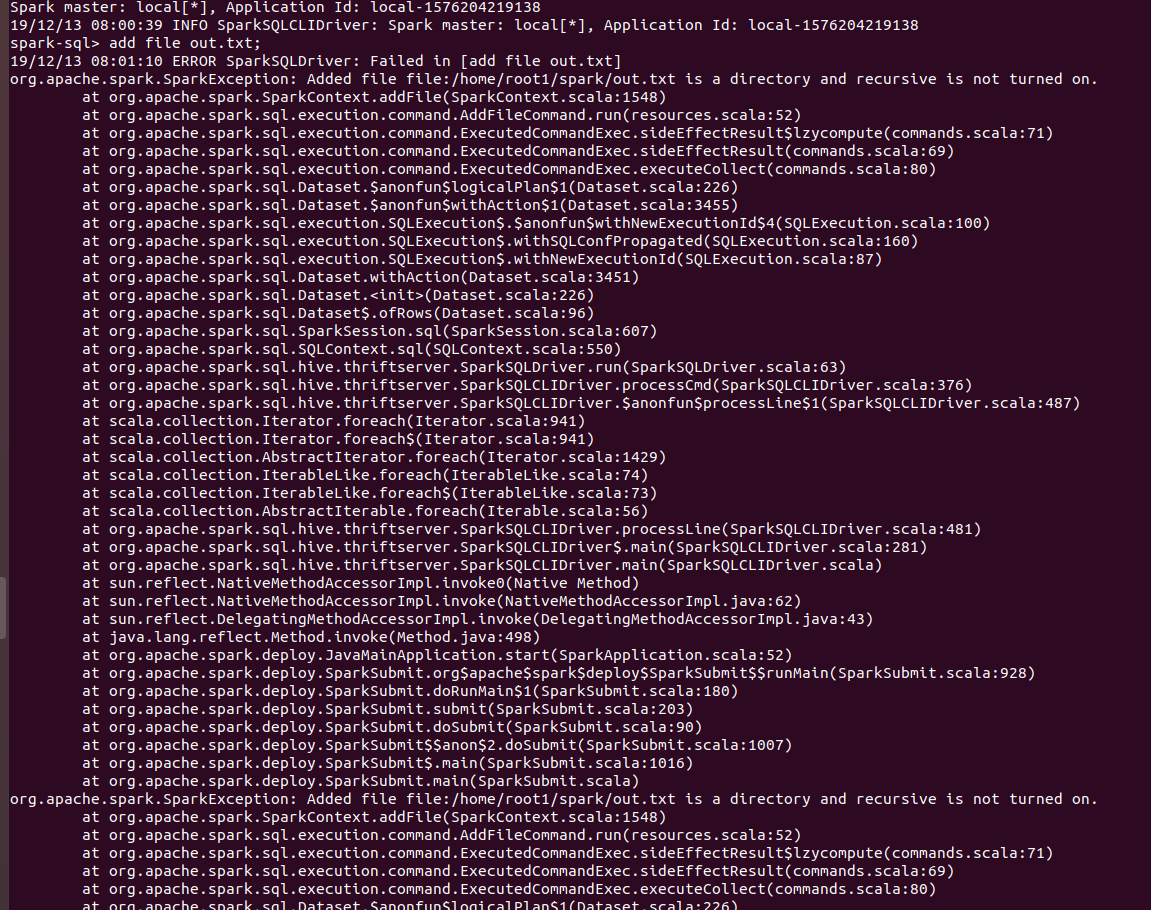 After setting `spark.sql.addDirectory.recursive` to true.  HIVE SCREENSHOT  `RELEASE_NOTES.txt` is text file while `dummy` is a directory. Closes #26863 from iRakson/SPARK-30234. Lead-authored-by: root1 <raksonrakesh@gmail.com> Co-authored-by: iRakson <raksonrakesh@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> |
||
|---|---|---|
| .. | ||
| _data | ||
| _includes | ||
| _layouts | ||
| _plugins | ||
| css | ||
| img | ||
| js | ||
| _config.yml | ||
| api.md | ||
| building-spark.md | ||
| cloud-integration.md | ||
| cluster-overview.md | ||
| configuration.md | ||
| contributing-to-spark.md | ||
| core-migration-guide.md | ||
| graphx-programming-guide.md | ||
| hadoop-provided.md | ||
| hardware-provisioning.md | ||
| index.md | ||
| job-scheduling.md | ||
| migration-guide.md | ||
| ml-advanced.md | ||
| ml-ann.md | ||
| ml-classification-regression.md | ||
| ml-clustering.md | ||
| ml-collaborative-filtering.md | ||
| ml-datasource.md | ||
| ml-decision-tree.md | ||
| ml-ensembles.md | ||
| ml-features.md | ||
| ml-frequent-pattern-mining.md | ||
| ml-guide.md | ||
| ml-linear-methods.md | ||
| ml-migration-guide.md | ||
| ml-pipeline.md | ||
| ml-statistics.md | ||
| ml-survival-regression.md | ||
| ml-tuning.md | ||
| mllib-classification-regression.md | ||
| mllib-clustering.md | ||
| mllib-collaborative-filtering.md | ||
| mllib-data-types.md | ||
| mllib-decision-tree.md | ||
| mllib-dimensionality-reduction.md | ||
| mllib-ensembles.md | ||
| mllib-evaluation-metrics.md | ||
| mllib-feature-extraction.md | ||
| mllib-frequent-pattern-mining.md | ||
| mllib-guide.md | ||
| mllib-isotonic-regression.md | ||
| mllib-linear-methods.md | ||
| mllib-naive-bayes.md | ||
| mllib-optimization.md | ||
| mllib-pmml-model-export.md | ||
| mllib-statistics.md | ||
| monitoring.md | ||
| programming-guide.md | ||
| pyspark-migration-guide.md | ||
| quick-start.md | ||
| rdd-programming-guide.md | ||
| README.md | ||
| running-on-kubernetes.md | ||
| running-on-mesos.md | ||
| running-on-yarn.md | ||
| security.md | ||
| spark-standalone.md | ||
| sparkr-migration-guide.md | ||
| sparkr.md | ||
| sql-data-sources-avro.md | ||
| sql-data-sources-binaryFile.md | ||
| sql-data-sources-hive-tables.md | ||
| sql-data-sources-jdbc.md | ||
| sql-data-sources-json.md | ||
| sql-data-sources-load-save-functions.md | ||
| sql-data-sources-orc.md | ||
| sql-data-sources-parquet.md | ||
| sql-data-sources-troubleshooting.md | ||
| sql-data-sources.md | ||
| sql-distributed-sql-engine.md | ||
| sql-getting-started.md | ||
| sql-keywords.md | ||
| sql-migration-guide.md | ||
| sql-migration-old.md | ||
| sql-performance-tuning.md | ||
| sql-programming-guide.md | ||
| sql-pyspark-pandas-with-arrow.md | ||
| sql-ref-arithmetic-ops.md | ||
| sql-ref-datatypes.md | ||
| sql-ref-functions-builtin-aggregate.md | ||
| sql-ref-functions-builtin-scalar.md | ||
| sql-ref-functions-builtin.md | ||
| sql-ref-functions-udf-aggregate.md | ||
| sql-ref-functions-udf-scalar.md | ||
| sql-ref-functions-udf.md | ||
| sql-ref-functions.md | ||
| sql-ref-nan-semantics.md | ||
| sql-ref-null-semantics.md | ||
| sql-ref-syntax-aux-analyze-table.md | ||
| sql-ref-syntax-aux-analyze.md | ||
| sql-ref-syntax-aux-cache-cache-table.md | ||
| sql-ref-syntax-aux-cache-clear-cache.md | ||
| sql-ref-syntax-aux-cache-refresh.md | ||
| sql-ref-syntax-aux-cache-uncache-table.md | ||
| sql-ref-syntax-aux-cache.md | ||
| sql-ref-syntax-aux-conf-mgmt-reset.md | ||
| sql-ref-syntax-aux-conf-mgmt-set.md | ||
| sql-ref-syntax-aux-conf-mgmt.md | ||
| sql-ref-syntax-aux-describe-database.md | ||
| sql-ref-syntax-aux-describe-function.md | ||
| sql-ref-syntax-aux-describe-query.md | ||
| sql-ref-syntax-aux-describe-table.md | ||
| sql-ref-syntax-aux-describe.md | ||
| sql-ref-syntax-aux-refresh-table.md | ||
| sql-ref-syntax-aux-resource-mgmt-add-file.md | ||
| sql-ref-syntax-aux-resource-mgmt-add-jar.md | ||
| sql-ref-syntax-aux-resource-mgmt-list-file.md | ||
| sql-ref-syntax-aux-resource-mgmt-list-jar.md | ||
| sql-ref-syntax-aux-resource-mgmt.md | ||
| sql-ref-syntax-aux-show-columns.md | ||
| sql-ref-syntax-aux-show-create-table.md | ||
| sql-ref-syntax-aux-show-databases.md | ||
| sql-ref-syntax-aux-show-functions.md | ||
| sql-ref-syntax-aux-show-partitions.md | ||
| sql-ref-syntax-aux-show-table.md | ||
| sql-ref-syntax-aux-show-tables.md | ||
| sql-ref-syntax-aux-show-tblproperties.md | ||
| sql-ref-syntax-aux-show.md | ||
| sql-ref-syntax-aux.md | ||
| sql-ref-syntax-ddl-alter-database.md | ||
| sql-ref-syntax-ddl-alter-table.md | ||
| sql-ref-syntax-ddl-alter-view.md | ||
| sql-ref-syntax-ddl-create-database.md | ||
| sql-ref-syntax-ddl-create-function.md | ||
| sql-ref-syntax-ddl-create-table.md | ||
| sql-ref-syntax-ddl-create-view.md | ||
| sql-ref-syntax-ddl-drop-database.md | ||
| sql-ref-syntax-ddl-drop-function.md | ||
| sql-ref-syntax-ddl-drop-table.md | ||
| sql-ref-syntax-ddl-drop-view.md | ||
| sql-ref-syntax-ddl-repair-table.md | ||
| sql-ref-syntax-ddl-truncate-table.md | ||
| sql-ref-syntax-ddl.md | ||
| sql-ref-syntax-dml-insert-into.md | ||
| sql-ref-syntax-dml-insert-overwrite-directory-hive.md | ||
| sql-ref-syntax-dml-insert-overwrite-directory.md | ||
| sql-ref-syntax-dml-insert-overwrite-table.md | ||
| sql-ref-syntax-dml-insert.md | ||
| sql-ref-syntax-dml-load.md | ||
| sql-ref-syntax-dml.md | ||
| sql-ref-syntax-qry-aggregation.md | ||
| sql-ref-syntax-qry-explain.md | ||
| sql-ref-syntax-qry-sampling.md | ||
| sql-ref-syntax-qry-select-cte.md | ||
| sql-ref-syntax-qry-select-distinct.md | ||
| sql-ref-syntax-qry-select-groupby.md | ||
| sql-ref-syntax-qry-select-having.md | ||
| sql-ref-syntax-qry-select-hints.md | ||
| sql-ref-syntax-qry-select-join.md | ||
| sql-ref-syntax-qry-select-limit.md | ||
| sql-ref-syntax-qry-select-orderby.md | ||
| sql-ref-syntax-qry-select-setops.md | ||
| sql-ref-syntax-qry-select-subqueries.md | ||
| sql-ref-syntax-qry-select-usedb.md | ||
| sql-ref-syntax-qry-select.md | ||
| sql-ref-syntax-qry-window.md | ||
| sql-ref-syntax-qry.md | ||
| sql-ref-syntax.md | ||
| sql-ref.md | ||
| ss-migration-guide.md | ||
| storage-openstack-swift.md | ||
| streaming-custom-receivers.md | ||
| streaming-kafka-0-10-integration.md | ||
| streaming-kafka-integration.md | ||
| streaming-kinesis-integration.md | ||
| streaming-programming-guide.md | ||
| structured-streaming-kafka-integration.md | ||
| structured-streaming-programming-guide.md | ||
| submitting-applications.md | ||
| tuning.md | ||
| web-ui.md | ||
{kind=link}
{kind=link}
{kind=link}
| license |
|---|
| Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. |
Welcome to the Spark documentation!
This readme will walk you through navigating and building the Spark documentation, which is included here with the Spark source code. You can also find documentation specific to release versions of Spark at https://spark.apache.org/documentation.html.
Read on to learn more about viewing documentation in plain text (i.e., markdown) or building the documentation yourself. Why build it yourself? So that you have the docs that correspond to whichever version of Spark you currently have checked out of revision control.
Prerequisites
The Spark documentation build uses a number of tools to build HTML docs and API docs in Scala, Java, Python, R and SQL.
You need to have Ruby and Python installed. Also install the following libraries:
$ sudo gem install jekyll jekyll-redirect-from rouge
# Following is needed only for generating API docs
$ sudo pip install sphinx pypandoc mkdocs
$ sudo Rscript -e 'install.packages(c("knitr", "devtools", "rmarkdown"), repos="https://cloud.r-project.org/")'
$ sudo Rscript -e 'devtools::install_version("roxygen2", version = "5.0.1", repos="https://cloud.r-project.org/")'
$ sudo Rscript -e 'devtools::install_version("testthat", version = "1.0.2", repos="https://cloud.r-project.org/")'
Note: If you are on a system with both Ruby 1.9 and Ruby 2.0 you may need to replace gem with gem2.0.
Note: Other versions of roxygen2 might work in SparkR documentation generation but RoxygenNote field in $SPARK_HOME/R/pkg/DESCRIPTION is 5.0.1, which is updated if the version is mismatched.
Generating the Documentation HTML
We include the Spark documentation as part of the source (as opposed to using a hosted wiki, such as the github wiki, as the definitive documentation) to enable the documentation to evolve along with the source code and be captured by revision control (currently git). This way the code automatically includes the version of the documentation that is relevant regardless of which version or release you have checked out or downloaded.
In this directory you will find text files formatted using Markdown, with an ".md" suffix. You can
read those text files directly if you want. Start with index.md.
Execute jekyll build from the docs/ directory to compile the site. Compiling the site with
Jekyll will create a directory called _site containing index.html as well as the rest of the
compiled files.
$ cd docs
$ jekyll build
You can modify the default Jekyll build as follows:
# Skip generating API docs (which takes a while)
$ SKIP_API=1 jekyll build
# Serve content locally on port 4000
$ jekyll serve --watch
# Build the site with extra features used on the live page
$ PRODUCTION=1 jekyll build
API Docs (Scaladoc, Javadoc, Sphinx, roxygen2, MkDocs)
You can build just the Spark scaladoc and javadoc by running ./build/sbt unidoc from the $SPARK_HOME directory.
Similarly, you can build just the PySpark docs by running make html from the
$SPARK_HOME/python/docs directory. Documentation is only generated for classes that are listed as
public in __init__.py. The SparkR docs can be built by running $SPARK_HOME/R/create-docs.sh, and
the SQL docs can be built by running $SPARK_HOME/sql/create-docs.sh
after building Spark first.
When you run jekyll build in the docs directory, it will also copy over the scaladoc and javadoc for the various
Spark subprojects into the docs directory (and then also into the _site directory). We use a
jekyll plugin to run ./build/sbt unidoc before building the site so if you haven't run it (recently) it
may take some time as it generates all of the scaladoc and javadoc using Unidoc.
The jekyll plugin also generates the PySpark docs using Sphinx, SparkR docs
using roxygen2 and SQL docs
using MkDocs.
NOTE: To skip the step of building and copying over the Scala, Java, Python, R and SQL API docs, run SKIP_API=1 jekyll build. In addition, SKIP_SCALADOC=1, SKIP_PYTHONDOC=1, SKIP_RDOC=1 and SKIP_SQLDOC=1 can be used
to skip a single step of the corresponding language. SKIP_SCALADOC indicates skipping both the Scala and Java docs.
Automatically Rebuilding API Docs
jekyll serve --watch will only watch what's in docs/, and it won't follow symlinks. That means it won't monitor your API docs under python/docs or elsewhere.
To work around this limitation for Python, install entr and run the following in a separate shell:
cd "$SPARK_HOME/python/docs"
find .. -type f -name '*.py' \
| entr -s 'make html && cp -r _build/html/. ../../docs/api/python'
Whenever there is a change to your Python code, entr will automatically rebuild the Python API docs and copy them to docs/, thus triggering a Jekyll update.