## What changes were proposed in this pull request?
By replacing loops with random possible value.
- `read partitioning bucketed tables with bucket pruning filters` reduce from 55s to 7s
- `read partitioning bucketed tables having composite filters` reduce from 54s to 8s
- total time: reduce from 288s to 192s
## How was this patch tested?
Unit test
Closes#22640 from gengliangwang/fastenBucketedReadSuite.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Current the CSV's infer schema code inlines `TypeCoercion.findTightestCommonType`. This is a minor refactor to make use of the common type coercion code when applicable. This way we can take advantage of any improvement to the base method.
Thanks to MaxGekk for finding this while reviewing another PR.
## How was this patch tested?
This is a minor refactor. Existing tests are used to verify the change.
Closes#22619 from dilipbiswal/csv_minor.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Adds support for the setting limit in the sql split function
## How was this patch tested?
1. Updated unit tests
2. Tested using Scala spark shell
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22227 from phegstrom/master.
Authored-by: Parker Hegstrom <phegstrom@palantir.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In this test case, we are verifying that the result of an UDF is cached when the underlying data frame is cached and that the udf is not evaluated again when the cached data frame is used.
To reduce the runtime we do :
1) Use a single partition dataframe, so the total execution time of UDF is more deterministic.
2) Cut down the size of the dataframe from 10 to 2.
3) Reduce the sleep time in the UDF from 5secs to 2secs.
4) Reduce the failafter condition from 3 to 2.
With the above change, it takes about 4 secs to cache the first dataframe. And subsequent check takes a few hundred milliseconds.
The new runtime for 5 consecutive runs of this test is as follows :
```
[info] - cache UDF result correctly (4 seconds, 906 milliseconds)
[info] - cache UDF result correctly (4 seconds, 281 milliseconds)
[info] - cache UDF result correctly (4 seconds, 288 milliseconds)
[info] - cache UDF result correctly (4 seconds, 355 milliseconds)
[info] - cache UDF result correctly (4 seconds, 280 milliseconds)
```
## How was this patch tested?
This is s test fix.
Closes#22638 from dilipbiswal/SPARK-25610.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Before ORC 1.5.3, `orc.dictionary.key.threshold` and `hive.exec.orc.dictionary.key.size.threshold` are applied for all columns. This has been a big huddle to enable dictionary encoding. From ORC 1.5.3, `orc.column.encoding.direct` is added to enforce direct encoding selectively in a column-wise manner. This PR aims to add that feature by upgrading ORC from 1.5.2 to 1.5.3.
The followings are the patches in ORC 1.5.3 and this feature is the only one related to Spark directly.
```
ORC-406: ORC: Char(n) and Varchar(n) writers truncate to n bytes & corrupts multi-byte data (gopalv)
ORC-403: [C++] Add checks to avoid invalid offsets in InputStream
ORC-405: Remove calcite as a dependency from the benchmarks.
ORC-375: Fix libhdfs on gcc7 by adding #include <functional> two places.
ORC-383: Parallel builds fails with ConcurrentModificationException
ORC-382: Apache rat exclusions + add rat check to travis
ORC-401: Fix incorrect quoting in specification.
ORC-385: Change RecordReader to extend Closeable.
ORC-384: [C++] fix memory leak when loading non-ORC files
ORC-391: [c++] parseType does not accept underscore in the field name
ORC-397: Allow selective disabling of dictionary encoding. Original patch was by Mithun Radhakrishnan.
ORC-389: Add ability to not decode Acid metadata columns
```
## How was this patch tested?
Pass the Jenkins with newly added test cases.
Closes#22622 from dongjoon-hyun/SPARK-25635.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The java `foreachBatch` API in `DataStreamWriter` should accept `java.lang.Long` rather `scala.Long`.
## How was this patch tested?
New java test.
Closes#22633 from zsxwing/fix-java-foreachbatch.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
When constructing a DataFrame from a Java bean, using nested beans throws an error despite [documentation](http://spark.apache.org/docs/latest/sql-programming-guide.html#inferring-the-schema-using-reflection) stating otherwise. This PR aims to add that support.
This PR does not yet add nested beans support in array or List fields. This can be added later or in another PR.
## How was this patch tested?
Nested bean was added to the appropriate unit test.
Also manually tested in Spark shell on code emulating the referenced JIRA:
```
scala> import scala.beans.BeanProperty
import scala.beans.BeanProperty
scala> class SubCategory(BeanProperty var id: String, BeanProperty var name: String) extends Serializable
defined class SubCategory
scala> class Category(BeanProperty var id: String, BeanProperty var subCategory: SubCategory) extends Serializable
defined class Category
scala> import scala.collection.JavaConverters._
import scala.collection.JavaConverters._
scala> spark.createDataFrame(Seq(new Category("s-111", new SubCategory("sc-111", "Sub-1"))).asJava, classOf[Category])
java.lang.IllegalArgumentException: The value (SubCategory65130cf2) of the type (SubCategory) cannot be converted to struct<id:string,name:string>
at org.apache.spark.sql.catalyst.CatalystTypeConverters$StructConverter.toCatalystImpl(CatalystTypeConverters.scala:262)
at org.apache.spark.sql.catalyst.CatalystTypeConverters$StructConverter.toCatalystImpl(CatalystTypeConverters.scala:238)
at org.apache.spark.sql.catalyst.CatalystTypeConverters$CatalystTypeConverter.toCatalyst(CatalystTypeConverters.scala:103)
at org.apache.spark.sql.catalyst.CatalystTypeConverters$$anonfun$createToCatalystConverter$2.apply(CatalystTypeConverters.scala:396)
at org.apache.spark.sql.SQLContext$$anonfun$beansToRows$1$$anonfun$apply$1.apply(SQLContext.scala:1108)
at org.apache.spark.sql.SQLContext$$anonfun$beansToRows$1$$anonfun$apply$1.apply(SQLContext.scala:1108)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.mutable.ArrayOps$ofRef.map(ArrayOps.scala:186)
at org.apache.spark.sql.SQLContext$$anonfun$beansToRows$1.apply(SQLContext.scala:1108)
at org.apache.spark.sql.SQLContext$$anonfun$beansToRows$1.apply(SQLContext.scala:1106)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$class.toStream(Iterator.scala:1320)
at scala.collection.AbstractIterator.toStream(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.toSeq(TraversableOnce.scala:298)
at scala.collection.AbstractIterator.toSeq(Iterator.scala:1334)
at org.apache.spark.sql.SparkSession.createDataFrame(SparkSession.scala:423)
... 51 elided
```
New behavior:
```
scala> spark.createDataFrame(Seq(new Category("s-111", new SubCategory("sc-111", "Sub-1"))).asJava, classOf[Category])
res0: org.apache.spark.sql.DataFrame = [id: string, subCategory: struct<id: string, name: string>]
scala> res0.show()
+-----+---------------+
| id| subCategory|
+-----+---------------+
|s-111|[sc-111, Sub-1]|
+-----+---------------+
```
Closes#22527 from michalsenkyr/SPARK-17952.
Authored-by: Michal Senkyr <mike.senkyr@gmail.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
Hi all,
Jackson is incompatible with upstream versions, therefore bump the Jackson version to a more recent one. I bumped into some issues with Azure CosmosDB that is using a more recent version of Jackson. This can be fixed by adding exclusions and then it works without any issues. So no breaking changes in the API's.
I would also consider bumping the version of Jackson in Spark. I would suggest to keep up to date with the dependencies, since in the future this issue will pop up more frequently.
## What changes were proposed in this pull request?
Bump Jackson to 2.9.6
## How was this patch tested?
Compiled and tested it locally to see if anything broke.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#21596 from Fokko/fd-bump-jackson.
Authored-by: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
``As part of insert command in FileFormatWriter, a job context is created for handling the write operation , While initializing the job context using setupJob() API
in HadoopMapReduceCommitProtocol , we set the jobid in the Jobcontext configuration.In FileFormatWriter since we are directly getting the jobId from the map reduce JobContext the job id will come as null while adding the log. As a solution we shall get the jobID from the configuration of the map reduce Jobcontext.``
## How was this patch tested?
Manually, verified the logs after the changes.

Closes#22572 from sujith71955/master_log_issue.
Authored-by: s71955 <sujithchacko.2010@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The PR changes the test introduced for SPARK-22226, so that we don't run analysis and optimization on the plan. The scope of the test is code generation and running the above mentioned operation is expensive and useless for the test.
The UT was also moved to the `CodeGenerationSuite` which is a better place given the scope of the test.
## How was this patch tested?
running the UT before SPARK-22226 fails, after it passes. The execution time is about 50% the original one. On my laptop this means that the test now runs in about 23 seconds (instead of 50 seconds).
Closes#22629 from mgaido91/SPARK-25609.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Refactor `DatasetBenchmark` to use main method.
Generate benchmark result:
```sh
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.DatasetBenchmark"
```
## How was this patch tested?
manual tests
Closes#22488 from wangyum/SPARK-25479.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
In `SparkPlan.getByteArrayRdd`, we should only call `it.hasNext` when the limit is not hit, as `iter.hasNext` may produce one row and buffer it, and cause wrong metrics.
## How was this patch tested?
new tests
Closes#22621 from cloud-fan/range.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Refactor `UnsafeArrayDataBenchmark` to use main method.
Generate benchmark result:
```sh
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.UnsafeArrayDataBenchmark"
```
## How was this patch tested?
manual tests
Closes#22491 from wangyum/SPARK-25483.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This PR aims to add `BloomFilterBenchmark`. For ORC data source, Apache Spark has been supporting for a long time. For Parquet data source, it's expected to be added with next Parquet release update.
## How was this patch tested?
Manual.
```scala
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.BloomFilterBenchmark"
```
Closes#22605 from dongjoon-hyun/SPARK-25589.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Rename method `benchmark` in `BenchmarkBase` as `runBenchmarkSuite `. Also add comments.
Currently the method name `benchmark` is a bit confusing. Also the name is the same as instances of `Benchmark`:
f246813afb/sql/hive/src/test/scala/org/apache/spark/sql/hive/orc/OrcReadBenchmark.scala (L330-L339)
## How was this patch tested?
Unit test.
Closes#22599 from gengliangwang/renameBenchmarkSuite.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This patch is to bump the master branch version to 3.0.0-SNAPSHOT.
## How was this patch tested?
N/A
Closes#22606 from gatorsmile/bump3.0.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Currently, SQL tab in the WEBUI doesn't support hiding table. Other tabs in the web ui like, Jobs, stages etc supports hiding table (refer SPARK-23024 https://github.com/apache/spark/pull/20216).
In this PR, added the support for hide table in the sql tab also.
## How was this patch tested?
bin/spark-shell
```
sql("create table a (id int)")
for(i <- 1 to 100) sql(s"insert into a values ($i)")
```
Open SQL tab in the web UI
**Before fix:**
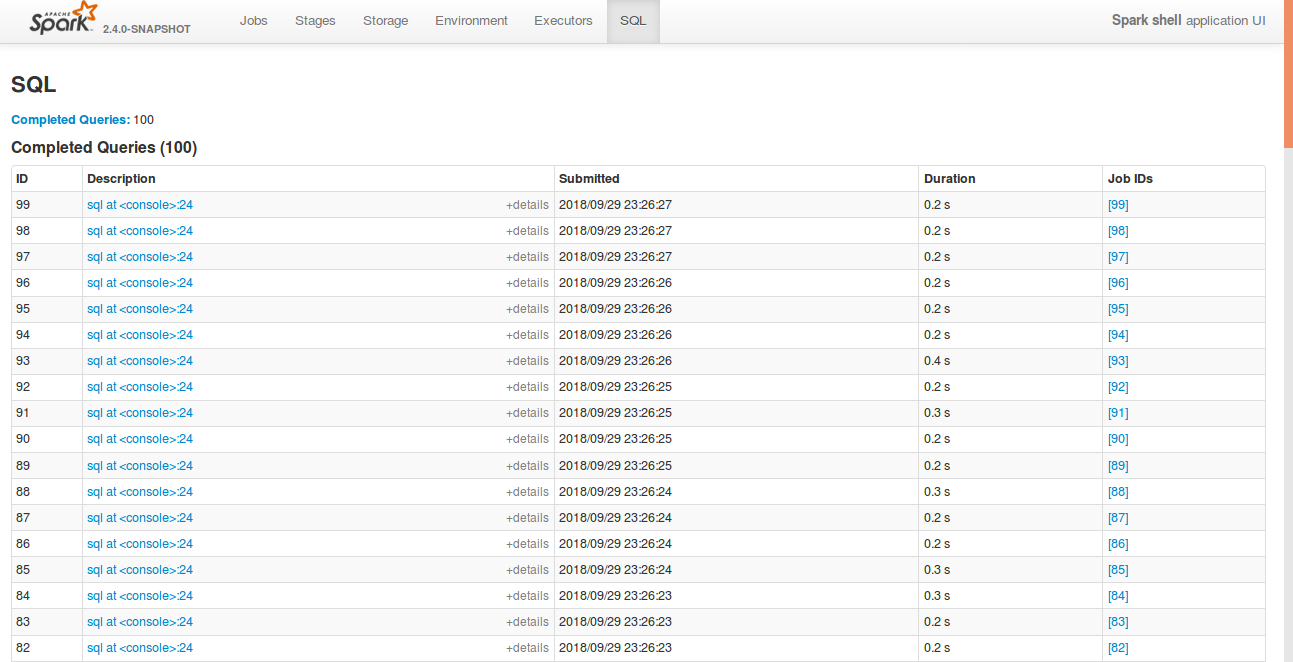
**After fix:** Consistent with the other tabs.

(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22592 from shahidki31/SPARK-25575.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR does 2 things:
1. Add a new trait(`SqlBasedBenchmark`) to better support Dataset and DataFrame API.
2. Refactor `AggregateBenchmark` to use main method. Generate benchmark result:
```
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.AggregateBenchmark"
```
## How was this patch tested?
manual tests
Closes#22484 from wangyum/SPARK-25476.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
#22519 introduced a bug when the attributes in the pivot clause are cosmetically different from the output ones (eg. different case). In particular, the problem is that the PR used a `Set[Attribute]` instead of an `AttributeSet`.
## How was this patch tested?
added UT
Closes#22582 from mgaido91/SPARK-25505_followup.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR adds a rule to force `.toLowerCase(Locale.ROOT)` or `toUpperCase(Locale.ROOT)`.
It produces an error as below:
```
[error] Are you sure that you want to use toUpperCase or toLowerCase without the root locale? In most cases, you
[error] should use toUpperCase(Locale.ROOT) or toLowerCase(Locale.ROOT) instead.
[error] If you must use toUpperCase or toLowerCase without the root locale, wrap the code block with
[error] // scalastyle:off caselocale
[error] .toUpperCase
[error] .toLowerCase
[error] // scalastyle:on caselocale
```
This PR excludes the cases above for SQL code path for external calls like table name, column name and etc.
For test suites, or when it's clear there's no locale problem like Turkish locale problem, it uses `Locale.ROOT`.
One minor problem is, `UTF8String` has both methods, `toLowerCase` and `toUpperCase`, and the new rule detects them as well. They are ignored.
## How was this patch tested?
Manually tested, and Jenkins tests.
Closes#22581 from HyukjinKwon/SPARK-25565.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In the PR, I propose to extend implementation of existing method:
```
def pivot(pivotColumn: Column, values: Seq[Any]): RelationalGroupedDataset
```
to support values of the struct type. This allows pivoting by multiple columns combined by `struct`:
```
trainingSales
.groupBy($"sales.year")
.pivot(
pivotColumn = struct(lower($"sales.course"), $"training"),
values = Seq(
struct(lit("dotnet"), lit("Experts")),
struct(lit("java"), lit("Dummies")))
).agg(sum($"sales.earnings"))
```
## How was this patch tested?
Added a test for values specified via `struct` in Java and Scala.
Closes#22316 from MaxGekk/pivoting-by-multiple-columns2.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In the PR, I propose to extended the `schema_of_json()` function, and accept JSON options since they can impact on schema inferring. Purpose is to support the same options that `from_json` can use during schema inferring.
## How was this patch tested?
Added SQL, Python and Scala tests (`JsonExpressionsSuite` and `JsonFunctionsSuite`) that checks JSON options are used.
Closes#22442 from MaxGekk/schema_of_json-options.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Currently, in `ParquetFilters`, if one of the children predicates is not supported by Parquet, the entire predicates will be thrown away. In fact, if the unsupported predicate is in the top level `And` condition or in the child before hitting `Not` or `Or` condition, it can be safely removed.
## How was this patch tested?
Tests are added.
Closes#22574 from dbtsai/removeUnsupportedPredicatesInParquet.
Lead-authored-by: DB Tsai <d_tsai@apple.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Co-authored-by: DB Tsai <dbtsai@dbtsai.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Use `Set` instead of `Array` to improve `accumulatorIds.contains(acc.id)` performance.
This PR close https://github.com/apache/spark/pull/22420
## How was this patch tested?
manual tests.
Benchmark code:
```scala
def benchmark(func: () => Unit): Long = {
val start = System.currentTimeMillis()
func()
val end = System.currentTimeMillis()
end - start
}
val range = Range(1, 1000000)
val set = range.toSet
val array = range.toArray
for (i <- 0 until 5) {
val setExecutionTime =
benchmark(() => for (i <- 0 until 500) { set.contains(scala.util.Random.nextInt()) })
val arrayExecutionTime =
benchmark(() => for (i <- 0 until 500) { array.contains(scala.util.Random.nextInt()) })
println(s"set execution time: $setExecutionTime, array execution time: $arrayExecutionTime")
}
```
Benchmark result:
```
set execution time: 4, array execution time: 2760
set execution time: 1, array execution time: 1911
set execution time: 3, array execution time: 2043
set execution time: 12, array execution time: 2214
set execution time: 6, array execution time: 1770
```
Closes#22579 from wangyum/SPARK-25429.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
**Description from the JIRA :**
Currently, to collect the statistics of all the columns, users need to specify the names of all the columns when calling the command "ANALYZE TABLE ... FOR COLUMNS...". This is not user friendly. Instead, we can introduce the following SQL command to achieve it without specifying the column names.
```
ANALYZE TABLE [db_name.]tablename COMPUTE STATISTICS FOR ALL COLUMNS;
```
## How was this patch tested?
Added new tests in SparkSqlParserSuite and StatisticsSuite
Closes#22566 from dilipbiswal/SPARK-25458.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The grouping columns from a Pivot query are inferred as "input columns - pivot columns - pivot aggregate columns", where input columns are the output of the child relation of Pivot. The grouping columns will be the leading columns in the pivot output and they should preserve the same order as specified by the input. For example,
```
SELECT * FROM (
SELECT course, earnings, "a" as a, "z" as z, "b" as b, "y" as y, "c" as c, "x" as x, "d" as d, "w" as w
FROM courseSales
)
PIVOT (
sum(earnings)
FOR course IN ('dotNET', 'Java')
)
```
The output columns should be "a, z, b, y, c, x, d, w, ..." but now it is "a, b, c, d, w, x, y, z, ..."
The fix is to use the child plan's `output` instead of `outputSet` so that the order can be preserved.
## How was this patch tested?
Added UT.
Closes#22519 from maryannxue/spark-25505.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The `show create table` will show a lot of generated attributes for views that created by older Spark version. This PR will basically revert https://issues.apache.org/jira/browse/SPARK-19272 back, so when you `DESC [FORMATTED|EXTENDED] view` will show the original view DDL text.
## How was this patch tested?
Unit test.
Closes#22458 from zheyuan28/testbranch.
Lead-authored-by: Chris Zhao <chris.zhao@databricks.com>
Co-authored-by: Christopher Zhao <chris.zhao@databricks.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
There are 2 places we check for problematic `InSubquery`: the rule `ResolveSubquery` and `InSubquery.checkInputDataTypes`. We should unify them.
## How was this patch tested?
existing tests
Closes#22563 from cloud-fan/followup.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
As per the discussion in https://github.com/apache/spark/pull/22553#pullrequestreview-159192221,
override `filterKeys` violates the documented semantics.
This PR is to remove it and add documentation.
Also fix one potential non-serializable map in `FileStreamOptions`.
The only one call of `CaseInsensitiveMap`'s `filterKeys` left is
c3c45cbd76/sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/HiveOptions.scala (L88-L90)
But this one is OK.
## How was this patch tested?
Existing unit tests.
Closes#22562 from gengliangwang/SPARK-25541-FOLLOWUP.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The PR removes the `InSubquery` expression which was introduced a long time ago and its only usage was removed in 4ce970d714. Hence it is not used anymore.
## How was this patch tested?
existing UTs
Closes#22556 from mgaido91/minor_insubq.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In ElementAt, when first argument is MapType, we should coerce the key type and the second argument based on findTightestCommonType. This is not happening currently. We may produce wrong output as we will incorrectly downcast the right hand side double expression to int.
```SQL
spark-sql> select element_at(map(1,"one", 2, "two"), 2.2);
two
```
Also, when the first argument is ArrayType, the second argument should be an integer type or a smaller integral type that can be safely casted to an integer type. Currently we may do an unsafe cast. In the following case, we should fail with an error as 2.2 is not a integer index. But instead we down cast it to int currently and return a result instead.
```SQL
spark-sql> select element_at(array(1,2), 1.24D);
1
```
This PR also supports implicit cast between two MapTypes. I have followed similar logic that exists today to do implicit casts between two array types.
## How was this patch tested?
Added new tests in DataFrameFunctionSuite, TypeCoercionSuite.
Closes#22544 from dilipbiswal/SPARK-25522.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Refactor `ColumnarBatchBenchmark` to use main method.
Generate benchmark result:
```
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.vectorized.ColumnarBatchBenchmark"
```
## How was this patch tested?
manual tests
Closes#22490 from yucai/SPARK-25481.
Lead-authored-by: yucai <yyu1@ebay.com>
Co-authored-by: Yucai Yu <yucai.yu@foxmail.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/20023 proposed to allow precision lose during decimal operations, to reduce the possibilities of overflow. This is a behavior change and is protected by the DECIMAL_OPERATIONS_ALLOW_PREC_LOSS config. However, that PR introduced another behavior change: pick a minimum precision for integral literals, which is not protected by a config. This PR add a new config for it: `spark.sql.literal.pickMinimumPrecision`.
This can allow users to work around issue in SPARK-25454, which is caused by a long-standing bug of negative scale.
## How was this patch tested?
a new test
Closes#22494 from cloud-fan/decimal.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Currently, Spark has 7 `withTempPath` and 6 `withSQLConf` functions. This PR aims to remove duplicated and inconsistent code and reduce them to the following meaningful implementations.
**withTempPath**
- `SQLHelper.withTempPath`: The one which was used in `SQLTestUtils`.
**withSQLConf**
- `SQLHelper.withSQLConf`: The one which was used in `PlanTest`.
- `ExecutorSideSQLConfSuite.withSQLConf`: The one which doesn't throw `AnalysisException` on StaticConf changes.
- `SQLTestUtils.withSQLConf`: The one which overrides intentionally to change the active session.
```scala
protected override def withSQLConf(pairs: (String, String)*)(f: => Unit): Unit = {
SparkSession.setActiveSession(spark)
super.withSQLConf(pairs: _*)(f)
}
```
## How was this patch tested?
Pass the Jenkins with the existing tests.
Closes#22548 from dongjoon-hyun/SPARK-25534.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
The PR introduces new JSON option `pretty` which allows to turn on `DefaultPrettyPrinter` of `Jackson`'s Json generator. New option is useful in exploring of deep nested columns and in converting of JSON columns in more readable representation (look at the added test).
## How was this patch tested?
Added rount trip test which convert an JSON string to pretty representation via `from_json()` and `to_json()`.
Closes#22534 from MaxGekk/pretty-json.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Add the legacy prefix for spark.sql.execution.pandas.groupedMap.assignColumnsByPosition and rename it to spark.sql.legacy.execution.pandas.groupedMap.assignColumnsByName
## How was this patch tested?
The existing tests.
Closes#22540 from gatorsmile/renameAssignColumnsByPosition.
Lead-authored-by: gatorsmile <gatorsmile@gmail.com>
Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Refactor SortBenchmark to use main method.
Generate benchmark result:
```
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.SortBenchmark"
```
## How was this patch tested?
manual tests
Closes#22495 from yucai/SPARK-25486.
Authored-by: yucai <yyu1@ebay.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This patch reverts entirely all the regr_* functions added in SPARK-23907. These were added by mgaido91 (and proposed by gatorsmile) to improve compatibility with other database systems, without any actual use cases. However, they are very rarely used, and in Spark there are much better ways to compute these functions, due to Spark's flexibility in exposing real programming APIs.
I'm going through all the APIs added in Spark 2.4 and I think we should revert these. If there are strong enough demands and more use cases, we can add them back in the future pretty easily.
## How was this patch tested?
Reverted test cases also.
Closes#22541 from rxin/SPARK-23907.
Authored-by: Reynold Xin <rxin@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In ArrayRemove, we currently cast the right hand side expression to match the element type of the left hand side Array. This may result in down casting and may return wrong result or questionable result.
Example :
```SQL
spark-sql> select array_remove(array(1,2,3), 1.23D);
[2,3]
```
```SQL
spark-sql> select array_remove(array(1,2,3), 'foo');
NULL
```
We should safely coerce both left and right hand side expressions.
## How was this patch tested?
Added tests in DataFrameFunctionsSuite
Closes#22542 from dilipbiswal/SPARK-25519.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In ArrayPosition, we currently cast the right hand side expression to match the element type of the left hand side Array. This may result in down casting and may return wrong result or questionable result.
Example :
```SQL
spark-sql> select array_position(array(1), 1.34);
1
```
```SQL
spark-sql> select array_position(array(1), 'foo');
null
```
We should safely coerce both left and right hand side expressions.
## How was this patch tested?
Added tests in DataFrameFunctionsSuite
Closes#22407 from dilipbiswal/SPARK-25416.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Refactor `CompressionSchemeBenchmark` to use main method.
Generate benchmark result:
```sh
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.columnar.compression.CompressionSchemeBenchmark"
```
## How was this patch tested?
manual tests
Closes#22486 from wangyum/SPARK-25478.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Currently there are two classes with the same naming BenchmarkBase:
1. `org.apache.spark.util.BenchmarkBase`
2. `org.apache.spark.sql.execution.benchmark.BenchmarkBase`
This is very confusing. And the benchmark object `org.apache.spark.sql.execution.benchmark.FilterPushdownBenchmark` is using the one in `org.apache.spark.util.BenchmarkBase`, while there is another class `BenchmarkBase` in the same package of it...
Here I propose:
1. the package `org.apache.spark.util.BenchmarkBase` should be in test package of core module. Move it to package `org.apache.spark.benchmark` .
2. Move `org.apache.spark.util.Benchmark` to test package of core module. Move it to package `org.apache.spark.benchmark` .
3. Rename the class `org.apache.spark.sql.execution.benchmark.BenchmarkBase` as `BenchmarkWithCodegen`
## How was this patch tested?
Unit test
Closes#22513 from gengliangwang/refactorBenchmarkBase.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Refactor PrimitiveArrayBenchmark to use main method and print the output as a separate file.
Run blow command to generate benchmark results:
```
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.PrimitiveArrayBenchmark"
```
## How was this patch tested?
Manual tests.
Closes#22497 from seancxmao/SPARK-25487.
Authored-by: seancxmao <seancxmao@gmail.com>
Signed-off-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
## What changes were proposed in this pull request?
This reverts commit 417ad92502.
We decided to keep the current behaviors unchanged and will consider whether we will deprecate the these functions in 3.0. For more details, see the discussion in https://issues.apache.org/jira/browse/SPARK-23715
## How was this patch tested?
The existing tests.
Closes#22505 from gatorsmile/revertSpark-23715.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Refactor `DataSourceWriteBenchmark` and add write benchmark for AVRO.
## How was this patch tested?
Build and run the benchmark.
Closes#22451 from gengliangwang/avroWriteBenchmark.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Legitimate stops of streams may actually cause an exception to be captured by stream execution, because the job throws a SparkException regarding job cancellation during a stop. This PR makes the stop more graceful by swallowing this cancellation error.
## How was this patch tested?
This is pretty hard to test. The existing tests should make sure that we're not swallowing other specific SparkExceptions. I've also run the `KafkaSourceStressForDontFailOnDataLossSuite`100 times, and it didn't fail, whereas it used to be flaky.
Closes#22478 from brkyvz/SPARK-25472.
Authored-by: Burak Yavuz <brkyvz@gmail.com>
Signed-off-by: Burak Yavuz <brkyvz@gmail.com>
## What changes were proposed in this pull request?
In the PR, I propose to add an overloaded method for `sampleBy` which accepts the first argument of the `Column` type. This will allow to sample by any complex columns as well as sampling by multiple columns. For example:
```Scala
spark.createDataFrame(Seq(("Bob", 17), ("Alice", 10), ("Nico", 8), ("Bob", 17),
("Alice", 10))).toDF("name", "age")
.stat
.sampleBy(struct($"name", $"age"), Map(Row("Alice", 10) -> 0.3, Row("Nico", 8) -> 1.0), 36L)
.show()
+-----+---+
| name|age|
+-----+---+
| Nico| 8|
|Alice| 10|
+-----+---+
```
## How was this patch tested?
Added new test for sampling by multiple columns for Scala and test for Java, Python to check that `sampleBy` is able to sample by `Column` type argument.
Closes#22365 from MaxGekk/sample-by-column.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In ArrayContains, we currently cast the right hand side expression to match the element type of the left hand side Array. This may result in down casting and may return wrong result or questionable result.
Example :
```SQL
spark-sql> select array_contains(array(1), 1.34);
true
```
```SQL
spark-sql> select array_contains(array(1), 'foo');
null
```
We should safely coerce both left and right hand side expressions.
## How was this patch tested?
Added tests in DataFrameFunctionsSuite
Closes#22408 from dilipbiswal/SPARK-25417.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR proposes to respect `SessionConfigSupport` in SS datasources as well. Currently these are only respected in batch sources:
e06da95cd9/sql/core/src/main/scala/org/apache/spark/sql/DataFrameReader.scala (L198-L203)e06da95cd9/sql/core/src/main/scala/org/apache/spark/sql/DataFrameWriter.scala (L244-L249)
If a developer makes a datasource V2 that supports both structured streaming and batch jobs, batch jobs respect a specific configuration, let's say, URL to connect and fetch data (which end users might not be aware of); however, structured streaming ends up with not supporting this (and should explicitly be set into options).
## How was this patch tested?
Unit tests were added.
Closes#22462 from HyukjinKwon/SPARK-25460.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This goes to revert sequential PRs based on some discussion and comments at https://github.com/apache/spark/pull/16677#issuecomment-422650759.
#22344#22330#22239#16677
## How was this patch tested?
Existing tests.
Closes#22481 from viirya/revert-SPARK-19355-1.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Refactor `FilterPushdownBenchmark` use `main` method. we can use 3 ways to run this test now:
1. bin/spark-submit --class org.apache.spark.sql.execution.benchmark.FilterPushdownBenchmark spark-sql_2.11-2.5.0-SNAPSHOT-tests.jar
2. build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.FilterPushdownBenchmark"
3. SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.FilterPushdownBenchmark"
The method 2 and the method 3 do not need to compile the `spark-sql_*-tests.jar` package. So these two methods are mainly for developers to quickly do benchmark.
## How was this patch tested?
manual tests
Closes#22443 from wangyum/SPARK-25339.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The PR proposes to return the data type of the operands as a result for the `div` operator. Before the PR, `bigint` is always returned. It introduces also a `spark.sql.legacy.integralDivide.returnBigint` config in order to let the users restore the legacy behavior.
## How was this patch tested?
added UTs
Closes#22465 from mgaido91/SPARK-25457.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
For self-join/self-union, Spark will produce a physical plan which has multiple `DataSourceV2ScanExec` instances referring to the same `ReadSupport` instance. In this case, the streaming source is indeed scanned multiple times, and the `numInputRows` metrics should be counted for each scan.
Actually we already have 2 test cases to verify the behavior:
1. `StreamingQuerySuite.input row calculation with same V2 source used twice in self-join`
2. `KafkaMicroBatchSourceSuiteBase.ensure stream-stream self-join generates only one offset in log and correct metrics`.
However, in these 2 tests, the expected result is different, which is super confusing. It turns out that, the first test doesn't trigger exchange reuse, so the source is scanned twice. The second test triggers exchange reuse, and the source is scanned only once.
This PR proposes to improve these 2 tests, to test with/without exchange reuse.
## How was this patch tested?
test only change
Closes#22402 from cloud-fan/bug.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In SPARK-23711, `UnsafeProjection` supports fallback to an interpreted mode. Therefore, this pr fixed code to support the same fallback mode in `MutableProjection` based on `CodeGeneratorWithInterpretedFallback`.
## How was this patch tested?
Added tests in `CodeGeneratorWithInterpretedFallbackSuite`.
Closes#22355 from maropu/SPARK-25358.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
PythonForeachWriterSuite was failing because RowQueue now needs to have a handle on a SparkEnv with a SerializerManager, so added a mock env with a serializer manager.
Also fixed a typo in the `finally` that was hiding the real exception.
Tested PythonForeachWriterSuite locally, full tests via jenkins.
Closes#22452 from squito/SPARK-25456.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
The PR takes over #14036 and it introduces a new expression `IntegralDivide` in order to avoid the several unneded cast added previously.
In order to prove the performance gain, the following benchmark has been run:
```
test("Benchmark IntegralDivide") {
val r = new scala.util.Random(91)
val nData = 1000000
val testDataInt = (1 to nData).map(_ => (r.nextInt(), r.nextInt()))
val testDataLong = (1 to nData).map(_ => (r.nextLong(), r.nextLong()))
val testDataShort = (1 to nData).map(_ => (r.nextInt().toShort, r.nextInt().toShort))
// old code
val oldExprsInt = testDataInt.map(x =>
Cast(Divide(Cast(Literal(x._1), DoubleType), Cast(Literal(x._2), DoubleType)), LongType))
val oldExprsLong = testDataLong.map(x =>
Cast(Divide(Cast(Literal(x._1), DoubleType), Cast(Literal(x._2), DoubleType)), LongType))
val oldExprsShort = testDataShort.map(x =>
Cast(Divide(Cast(Literal(x._1), DoubleType), Cast(Literal(x._2), DoubleType)), LongType))
// new code
val newExprsInt = testDataInt.map(x => IntegralDivide(x._1, x._2))
val newExprsLong = testDataLong.map(x => IntegralDivide(x._1, x._2))
val newExprsShort = testDataShort.map(x => IntegralDivide(x._1, x._2))
Seq(("Long", "old", oldExprsLong),
("Long", "new", newExprsLong),
("Int", "old", oldExprsInt),
("Int", "new", newExprsShort),
("Short", "old", oldExprsShort),
("Short", "new", oldExprsShort)).foreach { case (dt, t, ds) =>
val start = System.nanoTime()
ds.foreach(e => e.eval(EmptyRow))
val endNoCodegen = System.nanoTime()
println(s"Running $nData op with $t code on $dt (no-codegen): ${(endNoCodegen - start) / 1000000} ms")
}
}
```
The results on my laptop are:
```
Running 1000000 op with old code on Long (no-codegen): 600 ms
Running 1000000 op with new code on Long (no-codegen): 112 ms
Running 1000000 op with old code on Int (no-codegen): 560 ms
Running 1000000 op with new code on Int (no-codegen): 135 ms
Running 1000000 op with old code on Short (no-codegen): 317 ms
Running 1000000 op with new code on Short (no-codegen): 153 ms
```
Showing a 2-5X improvement. The benchmark doesn't include code generation as it is pretty hard to test the performance there as for such simple operations the most of the time is spent in the code generation/compilation process.
## How was this patch tested?
added UTs
Closes#22395 from mgaido91/SPARK-16323.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Output `dataFilters` in `DataSourceScanExec.metadata`.
## How was this patch tested?
unit tests
Closes#22435 from wangyum/SPARK-25423.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Spark supports BloomFilter creation for ORC files. This PR aims to add test coverages to prevent accidental regressions like [SPARK-12417](https://issues.apache.org/jira/browse/SPARK-12417).
## How was this patch tested?
Pass the Jenkins with newly added test cases.
Closes#22418 from dongjoon-hyun/SPARK-25427.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Fixes TPCH DDL datatype of `customer.c_nationkey` from `STRING` to `BIGINT` according to spec and `nation.nationkey` in `TPCHQuerySuite.scala`. The rest of the keys are OK.
Note, this will lead to **non-comparable previous results** to new runs involving the customer table.
## How was this patch tested?
Manual tests
Author: npoggi <npmnpm@gmail.com>
Closes#22430 from npoggi/SPARK-25439_Fix-TPCH-customer-c_nationkey.
## What changes were proposed in this pull request?
This PR aims to fix three things in `FilterPushdownBenchmark`.
**1. Use the same memory assumption.**
The following configurations are used in ORC and Parquet.
- Memory buffer for writing
- parquet.block.size (default: 128MB)
- orc.stripe.size (default: 64MB)
- Compression chunk size
- parquet.page.size (default: 1MB)
- orc.compress.size (default: 256KB)
SPARK-24692 used 1MB, the default value of `parquet.page.size`, for `parquet.block.size` and `orc.stripe.size`. But, it missed to match `orc.compress.size`. So, the current benchmark shows the result from ORC with 256KB memory for compression and Parquet with 1MB. To compare correctly, we need to be consistent.
**2. Dictionary encoding should not be enforced for all cases.**
SPARK-24206 enforced dictionary encoding for all test cases. This PR recovers the default behavior in general and enforces dictionary encoding only in case of `prepareStringDictTable`.
**3. Generate test result on AWS r3.xlarge**
SPARK-24206 generated the result on AWS in order to reproduce and compare easily. This PR also aims to update the result on the same machine again in the same reason. Specifically, AWS r3.xlarge with Instance Store is used.
## How was this patch tested?
Manual. Enable the test cases and run `FilterPushdownBenchmark` on `AWS r3.xlarge`. It takes about 4 hours 15 minutes.
Closes#22427 from dongjoon-hyun/SPARK-25438.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
In the PR, I propose overriding session options by extra options in DataSource V2. Extra options are more specific and set via `.option()`, and should overwrite more generic session options. Entries from seconds map overwrites entries with the same key from the first map, for example:
```Scala
scala> Map("option" -> false) ++ Map("option" -> true)
res0: scala.collection.immutable.Map[String,Boolean] = Map(option -> true)
```
## How was this patch tested?
Added a test for checking which option is propagated to a data source in `load()`.
Closes#22413 from MaxGekk/session-options.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
In the dev list, we can still discuss whether the next version is 2.5.0 or 3.0.0. Let us first bump the master branch version to `2.5.0-SNAPSHOT`.
## How was this patch tested?
N/A
Closes#22426 from gatorsmile/bumpVersionMaster.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This pr removed the duplicate fallback logic in `UnsafeProjection`.
This pr comes from #22355.
## How was this patch tested?
Added tests in `CodeGeneratorWithInterpretedFallbackSuite`.
Closes#22417 from maropu/SPARK-25426.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR ensures to call `super.afterAll()` in `override afterAll()` method for test suites.
* Some suites did not call `super.afterAll()`
* Some suites may call `super.afterAll()` only under certain condition
* Others never call `super.afterAll()`.
This PR also ensures to call `super.beforeAll()` in `override beforeAll()` for test suites.
## How was this patch tested?
Existing UTs
Closes#22337 from kiszk/SPARK-25338.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
(Link to Jira: https://issues.apache.org/jira/browse/SPARK-25406)
## What changes were proposed in this pull request?
The current use of `withSQLConf` in `ParquetSchemaPruningSuite.scala` is incorrect. The desired configuration settings are not being set when running the test cases.
This PR fixes that defective usage and addresses the test failures that were previously masked by that defect.
## How was this patch tested?
I added code to relevant test cases to print the expected SQL configuration settings and found that the settings were not being set as expected. When I changed the order of calls to `test` and `withSQLConf` I found that the configuration settings were being set as expected.
Closes#22394 from mallman/spark-25406-fix_broken_schema_pruning_tests.
Authored-by: Michael Allman <msa@allman.ms>
Signed-off-by: DB Tsai <d_tsai@apple.com>
## What changes were proposed in this pull request?
This follow-up patch addresses [the review comment](https://github.com/apache/spark/pull/22344/files#r217070658) by adding a helper method to simplify code and fixing style issue.
## How was this patch tested?
Existing unit tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#22409 from viirya/SPARK-25352-followup.
## What changes were proposed in this pull request?
Field metadata removed from SparkPlanInfo in #18600 . Corresponding, many meta data was also removed from event SparkListenerSQLExecutionStart in Spark event log. If we want to analyze event log to get all input paths, we couldn't get them. Instead, simpleString of SparkPlanInfo JSON only display 100 characters, it won't help.
Before 2.3, the fragment of SparkListenerSQLExecutionStart in event log looks like below (It contains the metadata field which has the intact information):
>{"Event":"org.apache.spark.sql.execution.ui.SparkListenerSQLExecutionStart", Location: InMemoryFileIndex[hdfs://cluster1/sys/edw/test1/test2/test3/test4..., "metadata": {"Location": "InMemoryFileIndex[hdfs://cluster1/sys/edw/test1/test2/test3/test4/test5/snapshot/dt=20180904]","ReadSchema":"struct<snpsht_start_dt:date,snpsht_end_dt:date,am_ntlogin_name:string,am_first_name:string,am_last_name:string,isg_name:string,CRE_DATE:date,CRE_USER:string,UPD_DATE:timestamp,UPD_USER:string>"}
After #18600, metadata field was removed.
>{"Event":"org.apache.spark.sql.execution.ui.SparkListenerSQLExecutionStart", Location: InMemoryFileIndex[hdfs://cluster1/sys/edw/test1/test2/test3/test4...,
So I add this field back to SparkPlanInfo class. Then it will log out the meta data to event log. Intact information in event log is very useful for offline job analysis.
## How was this patch tested?
Unit test
Closes#22353 from LantaoJin/SPARK-25357.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The PR fixes NPE in `UnivocityParser` caused by malformed CSV input. In some cases, `uniVocity` parser can return `null` for bad input. In the PR, I propose to check result of parsing and not propagate NPE to upper layers.
## How was this patch tested?
I added a test which reproduce the issue and tested by `CSVSuite`.
Closes#22374 from MaxGekk/npe-on-bad-csv.
Lead-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Schema pruning doesn't work if nested column is used in where clause.
For example,
```
sql("select name.first from contacts where name.first = 'David'")
== Physical Plan ==
*(1) Project [name#19.first AS first#40]
+- *(1) Filter (isnotnull(name#19) && (name#19.first = David))
+- *(1) FileScan parquet [name#19] Batched: false, Format: Parquet, PartitionFilters: [],
PushedFilters: [IsNotNull(name)], ReadSchema: struct<name:struct<first:string,middle:string,last:string>>
```
In above query plan, the scan node reads the entire schema of `name` column.
This issue is reported by:
https://github.com/apache/spark/pull/21320#issuecomment-419290197
The cause is that we infer a root field from expression `IsNotNull(name)`. However, for such expression, we don't really use the nested fields of this root field, so we can ignore the unnecessary nested fields.
## How was this patch tested?
Unit tests.
Closes#22357 from viirya/SPARK-25363.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
## What changes were proposed in this pull request?
We have optimization on global limit to evenly distribute limit rows across all partitions. This optimization doesn't work for ordered results.
For a query ending with sort + limit, in most cases it is performed by `TakeOrderedAndProjectExec`.
But if limit number is bigger than `SQLConf.TOP_K_SORT_FALLBACK_THRESHOLD`, global limit will be used. At this moment, we need to do ordered global limit.
## How was this patch tested?
Unit tests.
Closes#22344 from viirya/SPARK-25352.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR is to fix the null handling in BooleanSimplification. In the rule BooleanSimplification, there are two cases that do not properly handle null values. The optimization is not right if either side is null. This PR is to fix them.
## How was this patch tested?
Added test cases
Closes#22390 from gatorsmile/fixBooleanSimplification.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The leftover state from running a continuous processing streaming job should not affect later microbatch execution jobs. If a continuous processing job runs and the same thread gets reused for a microbatch execution job in the same environment, the microbatch job could get wrong answers because it can attempt to load the wrong version of the state.
## How was this patch tested?
New and existing unit tests
Closes#22386 from mukulmurthy/25399-streamthread.
Authored-by: Mukul Murthy <mukul.murthy@gmail.com>
Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com>
## What changes were proposed in this pull request?
Correct some comparisons between unrelated types to what they seem to… have been trying to do
## How was this patch tested?
Existing tests.
Closes#22384 from srowen/SPARK-25398.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
In the PR, I propose new CSV option `emptyValue` and an update in the SQL Migration Guide which describes how to revert previous behavior when empty strings were not written at all. Since Spark 2.4, empty strings are saved as `""` to distinguish them from saved `null`s.
Closes#22234Closes#22367
## How was this patch tested?
It was tested by `CSVSuite` and new tests added in the PR #22234Closes#22389 from MaxGekk/csv-empty-value-master.
Lead-authored-by: Mario Molina <mmolimar@gmail.com>
Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
It turns out it's a bug that a `DataSourceV2ScanExec` instance may be referred to in the execution plan multiple times. This bug is fixed by https://github.com/apache/spark/pull/22284 and now we have corrected SQL metrics for batch queries.
Thus we don't need the hack in `ProgressReporter` anymore, which fixes the same metrics problem for streaming queries.
## How was this patch tested?
existing tests
Closes#22380 from cloud-fan/followup.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
SPARK-21281 introduced a check for the inputs of `CreateStructLike` to be non-empty. This means that `struct()`, which was previously considered valid, now throws an Exception. This behavior change was introduced in 2.3.0. The change may break users' application on upgrade and it causes `VectorAssembler` to fail when an empty `inputCols` is defined.
The PR removes the added check making `struct()` valid again.
## How was this patch tested?
added UT
Closes#22373 from mgaido91/SPARK-25371.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In the Planner, we collect the placeholder which need to be substituted in the query execution plan and once we plan them, we substitute the placeholder with the effective plan.
In this second phase, we rely on the `==` comparison, ie. the `equals` method. This means that if two placeholder plans - which are different instances - have the same attributes (so that they are equal, according to the equal method) they are both substituted with their corresponding new physical plans. So, in such a situation, the first time we substitute both them with the first of the 2 new generated plan and the second time we substitute nothing.
This is usually of no harm for the execution of the query itself, as the 2 plans are identical. But since they are the same instance, now, the local variables are shared (which is unexpected). This causes issues for the metrics collected, as the same node is executed 2 times, so the metrics are accumulated 2 times, wrongly.
The PR proposes to use the `eq` method in checking which placeholder needs to be substituted,; thus in the previous situation, actually both the two different physical nodes which are created (one for each time the logical plan appears in the query plan) are used and the metrics are collected properly for each of them.
## How was this patch tested?
added UT
Closes#22284 from mgaido91/SPARK-25278.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR is to solve the CodeGen code generated by fast hash, and there is no need to apply for a block of memory for every new entry, because unsafeRow's memory can be reused.
## How was this patch tested?
the existed test cases.
Closes#21968 from heary-cao/updateNewMemory.
Authored-by: caoxuewen <cao.xuewen@zte.com.cn>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
How to reproduce:
```scala
spark.sql("CREATE TABLE tbl(id long)")
spark.sql("INSERT OVERWRITE TABLE tbl VALUES 4")
spark.sql("CREATE VIEW view1 AS SELECT id FROM tbl")
spark.sql(s"INSERT OVERWRITE LOCAL DIRECTORY '/tmp/spark/parquet' " +
"STORED AS PARQUET SELECT ID FROM view1")
spark.read.parquet("/tmp/spark/parquet").schema
scala> spark.read.parquet("/tmp/spark/parquet").schema
res10: org.apache.spark.sql.types.StructType = StructType(StructField(id,LongType,true))
```
The schema should be `StructType(StructField(ID,LongType,true))` as we `SELECT ID FROM view1`.
This pr fix this issue.
## How was this patch tested?
unit tests
Closes#22359 from wangyum/SPARK-25313-FOLLOW-UP.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Apache Spark doesn't create Hive table with duplicated fields in both case-sensitive and case-insensitive mode. However, if Spark creates ORC files in case-sensitive mode first and create Hive table on that location, where it's created. In this situation, field resolution should fail in case-insensitive mode. Otherwise, we don't know which columns will be returned or filtered. Previously, SPARK-25132 fixed the same issue in Parquet.
Here is a simple example:
```
val data = spark.range(5).selectExpr("id as a", "id * 2 as A")
spark.conf.set("spark.sql.caseSensitive", true)
data.write.format("orc").mode("overwrite").save("/user/hive/warehouse/orc_data")
sql("CREATE TABLE orc_data_source (A LONG) USING orc LOCATION '/user/hive/warehouse/orc_data'")
spark.conf.set("spark.sql.caseSensitive", false)
sql("select A from orc_data_source").show
+---+
| A|
+---+
| 3|
| 2|
| 4|
| 1|
| 0|
+---+
```
See #22148 for more details about parquet data source reader.
## How was this patch tested?
Unit tests added.
Closes#22262 from seancxmao/SPARK-25175.
Authored-by: seancxmao <seancxmao@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
How to reproduce:
```scala
val df1 = spark.createDataFrame(Seq(
(1, 1)
)).toDF("a", "b").withColumn("c", lit(null).cast("int"))
val df2 = df1.union(df1).withColumn("d", spark_partition_id).filter($"c".isNotNull)
df2.show
+---+---+----+---+
| a| b| c| d|
+---+---+----+---+
| 1| 1|null| 0|
| 1| 1|null| 1|
+---+---+----+---+
```
`filter($"c".isNotNull)` was transformed to `(null <=> c#10)` before https://github.com/apache/spark/pull/19201, but it is transformed to `(c#10 = null)` since https://github.com/apache/spark/pull/20155. This pr revert it to `(null <=> c#10)` to fix this issue.
## How was this patch tested?
unit tests
Closes#22368 from wangyum/SPARK-25368.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
When running TPC-DS benchmarks on 2.4 release, npoggi and winglungngai saw more than 10% performance regression on the following queries: q67, q24a and q24b. After we applying the PR https://github.com/apache/spark/pull/22338, the performance regression still exists. If we revert the changes in https://github.com/apache/spark/pull/19222, npoggi and winglungngai found the performance regression was resolved. Thus, this PR is to revert the related changes for unblocking the 2.4 release.
In the future release, we still can continue the investigation and find out the root cause of the regression.
## How was this patch tested?
The existing test cases
Closes#22361 from gatorsmile/revertMemoryBlock.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Add new optimization rule to eliminate unnecessary shuffling by flipping adjacent Window expressions.
## How was this patch tested?
Tested with unit tests, integration tests, and manual tests.
Closes#17899 from ptkool/adjacent_window_optimization.
Authored-by: ptkool <michael.styles@shopify.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In SharedSparkSession and TestHive, we need to disable the rule ConvertToLocalRelation for better test case coverage.
## How was this patch tested?
Identify the failures after excluding "ConvertToLocalRelation" rule.
Closes#22270 from dilipbiswal/SPARK-25267-final.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This pr removed the method `updateBytesReadWithFileSize` in `FileScanRDD` because it computes input metrics by file size supported in Hadoop 2.5 and earlier. The current Spark does not support the versions, so it causes wrong input metric numbers.
This is rework from #22232.
Closes#22232
## How was this patch tested?
Added tests in `FileBasedDataSourceSuite`.
Closes#22324 from maropu/pr22232-2.
Lead-authored-by: dujunling <dujunling@huawei.com>
Co-authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
This is not a perfect solution. It is designed to minimize complexity on the basis of solving problems.
It is effective for English, Chinese characters, Japanese, Korean and so on.
```scala
before:
+---+---------------------------+-------------+
|id |中国 |s2 |
+---+---------------------------+-------------+
|1 |ab |[a] |
|2 |null |[中国, abc] |
|3 |ab1 |[hello world]|
|4 |か行 きゃ(kya) きゅ(kyu) きょ(kyo) |[“中国] |
|5 |中国(你好)a |[“中(国), 312] |
|6 |中国山(东)服务区 |[“中(国)] |
|7 |中国山东服务区 |[中(国)] |
|8 | |[中国] |
+---+---------------------------+-------------+
after:
+---+-----------------------------------+----------------+
|id |中国 |s2 |
+---+-----------------------------------+----------------+
|1 |ab |[a] |
|2 |null |[中国, abc] |
|3 |ab1 |[hello world] |
|4 |か行 きゃ(kya) きゅ(kyu) きょ(kyo) |[“中国] |
|5 |中国(你好)a |[“中(国), 312]|
|6 |中国山(东)服务区 |[“中(国)] |
|7 |中国山东服务区 |[中(国)] |
|8 | |[中国] |
+---+-----------------------------------+----------------+
```
## What changes were proposed in this pull request?
When there are wide characters such as Chinese characters or Japanese characters in the data, the show method has a alignment problem.
Try to fix this problem.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)

Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22048 from xuejianbest/master.
Authored-by: xuejianbest <384329882@qq.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
In the PR, I propose to extended `to_json` and support any types as element types of input arrays. It should allow converting arrays of primitive types and arrays of arrays. For example:
```
select to_json(array('1','2','3'))
> ["1","2","3"]
select to_json(array(array(1,2,3),array(4)))
> [[1,2,3],[4]]
```
## How was this patch tested?
Added a couple sql tests for arrays of primitive type and of arrays. Also I added round trip test `from_json` -> `to_json`.
Closes#22226 from MaxGekk/to_json-array.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Let's see the follow example:
```
val location = "/tmp/t"
val df = spark.range(10).toDF("id")
df.write.format("parquet").saveAsTable("tbl")
spark.sql("CREATE VIEW view1 AS SELECT id FROM tbl")
spark.sql(s"CREATE TABLE tbl2(ID long) USING parquet location $location")
spark.sql("INSERT OVERWRITE TABLE tbl2 SELECT ID FROM view1")
println(spark.read.parquet(location).schema)
spark.table("tbl2").show()
```
The output column name in schema will be `id` instead of `ID`, thus the last query shows nothing from `tbl2`.
By enabling the debug message we can see that the output naming is changed from `ID` to `id`, and then the `outputColumns` in `InsertIntoHadoopFsRelationCommand` is changed in `RemoveRedundantAliases`.


**To guarantee correctness**, we should change the output columns from `Seq[Attribute]` to `Seq[String]` to avoid its names being replaced by optimizer.
I will fix project elimination related rules in https://github.com/apache/spark/pull/22311 after this one.
## How was this patch tested?
Unit test.
Closes#22320 from gengliangwang/fixOutputSchema.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
An alternative fix for https://github.com/apache/spark/pull/21698
When Spark rerun tasks for an RDD, there are 3 different behaviors:
1. determinate. Always return the same result with same order when rerun.
2. unordered. Returns same data set in random order when rerun.
3. indeterminate. Returns different result when rerun.
Normally Spark doesn't need to care about it. Spark runs stages one by one, when a task is failed, just rerun it. Although the rerun task may return a different result, users will not be surprised.
However, Spark may rerun a finished stage when seeing fetch failures. When this happens, Spark needs to rerun all the tasks of all the succeeding stages if the RDD output is indeterminate, because the input of the succeeding stages has been changed.
If the RDD output is determinate, we only need to rerun the failed tasks of the succeeding stages, because the input doesn't change.
If the RDD output is unordered, it's same as determinate, because shuffle partitioner is always deterministic(round-robin partitioner is not a shuffle partitioner that extends `org.apache.spark.Partitioner`), so the reducers will still get the same input data set.
This PR fixed the failure handling for `repartition`, to avoid correctness issues.
For `repartition`, it applies a stateful map function to generate a round-robin id, which is order sensitive and makes the RDD's output indeterminate. When the stage contains `repartition` reruns, we must also rerun all the tasks of all the succeeding stages.
**future improvement:**
1. Currently we can't rollback and rerun a shuffle map stage, and just fail. We should fix it later. https://issues.apache.org/jira/browse/SPARK-25341
2. Currently we can't rollback and rerun a result stage, and just fail. We should fix it later. https://issues.apache.org/jira/browse/SPARK-25342
3. We should provide public API to allow users to tag the random level of the RDD's computing function.
## How is this pull request tested?
a new test case
Closes#22112 from cloud-fan/repartition.
Lead-authored-by: Wenchen Fan <wenchen@databricks.com>
Co-authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This is a follow-up of #22313 and aim to ignore the micro benchmark test which takes over 2 minutes in Jenkins.
- https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-2.6/4939/consoleFull
## How was this patch tested?
The test case should be ignored in Jenkins.
```
[info] FilterPushdownBenchmark:
...
[info] - Pushdown benchmark with many filters !!! IGNORED !!!
```
Closes#22336 from dongjoon-hyun/SPARK-25306-2.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/22259 .
Scala case class has a wide surface: apply, unapply, accessors, copy, etc.
In https://github.com/apache/spark/pull/22259 , we change the type of `UserDefinedFunction.inputTypes` from `Option[Seq[DataType]]` to `Option[Seq[Schema]]`. This breaks backward compatibility.
This PR changes the type back, and use a `var` to keep the new nullable info.
## How was this patch tested?
N/A
Closes#22319 from cloud-fan/revert.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Revert SPARK-24863 (#21819) and SPARK-24748 (#21721) as per discussion in #21721. We will revisit them when the data source v2 APIs are out.
## How was this patch tested?
Jenkins
Closes#22334 from zsxwing/revert-SPARK-24863-SPARK-24748.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In both ORC data sources, `createFilter` function has exponential time complexity due to its skewed filter tree generation. This PR aims to improve it by using new `buildTree` function.
**REPRODUCE**
```scala
// Create and read 1 row table with 1000 columns
sql("set spark.sql.orc.filterPushdown=true")
val selectExpr = (1 to 1000).map(i => s"id c$i")
spark.range(1).selectExpr(selectExpr: _*).write.mode("overwrite").orc("/tmp/orc")
print(s"With 0 filters, ")
spark.time(spark.read.orc("/tmp/orc").count)
// Increase the number of filters
(20 to 30).foreach { width =>
val whereExpr = (1 to width).map(i => s"c$i is not null").mkString(" and ")
print(s"With $width filters, ")
spark.time(spark.read.orc("/tmp/orc").where(whereExpr).count)
}
```
**RESULT**
```scala
With 0 filters, Time taken: 653 ms
With 20 filters, Time taken: 962 ms
With 21 filters, Time taken: 1282 ms
With 22 filters, Time taken: 1982 ms
With 23 filters, Time taken: 3855 ms
With 24 filters, Time taken: 6719 ms
With 25 filters, Time taken: 12669 ms
With 26 filters, Time taken: 25032 ms
With 27 filters, Time taken: 49585 ms
With 28 filters, Time taken: 98980 ms // over 1 min 38 seconds
With 29 filters, Time taken: 198368 ms // over 3 mins
With 30 filters, Time taken: 393744 ms // over 6 mins
```
**AFTER THIS PR**
```scala
With 0 filters, Time taken: 774 ms
With 20 filters, Time taken: 601 ms
With 21 filters, Time taken: 399 ms
With 22 filters, Time taken: 679 ms
With 23 filters, Time taken: 363 ms
With 24 filters, Time taken: 342 ms
With 25 filters, Time taken: 336 ms
With 26 filters, Time taken: 352 ms
With 27 filters, Time taken: 322 ms
With 28 filters, Time taken: 302 ms
With 29 filters, Time taken: 307 ms
With 30 filters, Time taken: 301 ms
```
## How was this patch tested?
Pass the Jenkins with newly added test cases.
Closes#22313 from dongjoon-hyun/SPARK-25306.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Previously in `TakeOrderedAndProjectSuite` the SparkSession will not get recycled when the test suite finishes.
## How was this patch tested?
N/A
Closes#22330 from jiangxb1987/SPARK-19355.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Move the output verification of Explain test cases to a new suite ExplainSuite.
## How was this patch tested?
N/A
Closes#22300 from gatorsmile/test3200.
Authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Currently, filter pushdown will not work if Parquet schema and Hive metastore schema are in different letter cases even spark.sql.caseSensitive is false.
Like the below case:
```scala
spark.sparkContext.hadoopConfiguration.setInt("parquet.block.size", 8 * 1024 * 1024)
spark.range(1, 40 * 1024 * 1024, 1, 1).sortWithinPartitions("id").write.parquet("/tmp/t")
sql("CREATE TABLE t (ID LONG) USING parquet LOCATION '/tmp/t'")
sql("select * from t where id < 100L").write.csv("/tmp/id")
```
Although filter "ID < 100L" is generated by Spark, it fails to pushdown into parquet actually, Spark still does the full table scan when reading.
This PR provides a case-insensitive field resolution to make it work.
Before - "ID < 100L" fail to pushedown:
<img width="273" alt="screen shot 2018-08-23 at 10 08 26 pm" src="https://user-images.githubusercontent.com/2989575/44530558-40ef8b00-a721-11e8-8abc-7f97671590d3.png">
After - "ID < 100L" pushedown sucessfully:
<img width="267" alt="screen shot 2018-08-23 at 10 08 40 pm" src="https://user-images.githubusercontent.com/2989575/44530567-44831200-a721-11e8-8634-e9f664b33d39.png">
## How was this patch tested?
Added UTs.
Closes#22197 from yucai/SPARK-25207.
Authored-by: yucai <yyu1@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
### For `SPARK-5775 read array from partitioned_parquet_with_key_and_complextypes`:
scala2.12
```
scala> (1 to 10).toString
res4: String = Range 1 to 10
```
scala2.11
```
scala> (1 to 10).toString
res2: String = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
```
And
```
def prepareAnswer(answer: Seq[Row], isSorted: Boolean): Seq[Row] = {
val converted: Seq[Row] = answer.map(prepareRow)
if (!isSorted) converted.sortBy(_.toString()) else converted
}
```
sortBy `_.toString` is not a good idea.
### Other failures are caused by
```
Array(Int.box(1)).toSeq == Array(Double.box(1.0)).toSeq
```
It is false in 2.12.2 + and is true in 2.11.x , 2.12.0, 2.12.1
## How was this patch tested?
This is a patch on a specific unit test.
Closes#22264 from sadhen/SPARK25256.
Authored-by: 忍冬 <rendong@wacai.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
`JavaColumnExpressionSuite.java` was added and `org.apache.spark.sql.ColumnExpressionSuite#test("isInCollection: Java Collection")` was removed.
It provides native Java tests for the method `org.apache.spark.sql.Column#isInCollection`.
Closes#22253 from aai95/isInCollectionJavaTest.
Authored-by: aai95 <aai95@yandex.ru>
Signed-off-by: DB Tsai <d_tsai@apple.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}