### What changes were proposed in this pull request?
As discussed in https://github.com/apache/spark/pull/29491#discussion_r474451282 and in SPARK-32686, this PR un-deprecates Spark's ability to infer a DataFrame schema from a list of dictionaries. The ability is Pythonic and matches functionality offered by Pandas.
### Why are the changes needed?
This change clarifies to users that this behavior is supported and is not going away in the near future.
### Does this PR introduce _any_ user-facing change?
Yes. There used to be a `UserWarning` for this, but now there isn't.
### How was this patch tested?
I tested this manually.
Before:
```python
>>> spark.createDataFrame(spark.sparkContext.parallelize([{'a': 5}]))
/Users/nchamm/Documents/GitHub/nchammas/spark/python/pyspark/sql/session.py:388: UserWarning: Using RDD of dict to inferSchema is deprecated. Use pyspark.sql.Row instead
warnings.warn("Using RDD of dict to inferSchema is deprecated. "
DataFrame[a: bigint]
>>> spark.createDataFrame([{'a': 5}])
.../python/pyspark/sql/session.py:378: UserWarning: inferring schema from dict is deprecated,please use pyspark.sql.Row instead
warnings.warn("inferring schema from dict is deprecated,"
DataFrame[a: bigint]
```
After:
```python
>>> spark.createDataFrame(spark.sparkContext.parallelize([{'a': 5}]))
DataFrame[a: bigint]
>>> spark.createDataFrame([{'a': 5}])
DataFrame[a: bigint]
```
Closes#29510 from nchammas/SPARK-32686-df-dict-infer-schema.
Authored-by: Nicholas Chammas <nicholas.chammas@liveramp.com>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
### What changes were proposed in this pull request?
This PR proposes to make the behavior consistent for the `path` option when loading dataframes with a single path (e.g, `option("path", path).format("parquet").load(path)` vs. `option("path", path).parquet(path)`) by disallowing `path` option to coexist with `load`'s path parameters.
### Why are the changes needed?
The current behavior is inconsistent:
```scala
scala> Seq(1).toDF.write.mode("overwrite").parquet("/tmp/test")
scala> spark.read.option("path", "/tmp/test").format("parquet").load("/tmp/test").show
+-----+
|value|
+-----+
| 1|
+-----+
scala> spark.read.option("path", "/tmp/test").parquet("/tmp/test").show
+-----+
|value|
+-----+
| 1|
| 1|
+-----+
```
### Does this PR introduce _any_ user-facing change?
Yes, now if the `path` option is specified along with `load`'s path parameters, it would fail:
```scala
scala> Seq(1).toDF.write.mode("overwrite").parquet("/tmp/test")
scala> spark.read.option("path", "/tmp/test").format("parquet").load("/tmp/test").show
org.apache.spark.sql.AnalysisException: There is a path option set and load() is called with path parameters. Either remove the path option or move it into the load() parameters.;
at org.apache.spark.sql.DataFrameReader.verifyPathOptionDoesNotExist(DataFrameReader.scala:310)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:232)
... 47 elided
scala> spark.read.option("path", "/tmp/test").parquet("/tmp/test").show
org.apache.spark.sql.AnalysisException: There is a path option set and load() is called with path parameters. Either remove the path option or move it into the load() parameters.;
at org.apache.spark.sql.DataFrameReader.verifyPathOptionDoesNotExist(DataFrameReader.scala:310)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:250)
at org.apache.spark.sql.DataFrameReader.parquet(DataFrameReader.scala:778)
at org.apache.spark.sql.DataFrameReader.parquet(DataFrameReader.scala:756)
... 47 elided
```
The user can restore the previous behavior by setting `spark.sql.legacy.pathOptionBehavior.enabled` to `true`.
### How was this patch tested?
Added a test
Closes#29328 from imback82/dfw_option.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
In order to produce consistent results from SizeEstimator the tests
override some system properties that are used during SizeEstimator
initialization. However there were several places where either the
compressed references property wasn't set or the system properties
were set but the SizeEstimator not re-initialized.
This caused failures when running the tests with a large heap build
of OpenJ9 because it does not use compressed references unlike most
environments.
### What changes were proposed in this pull request?
Initialize SizeEstimator class explicitly in the tests where required to avoid relying on a particular environment.
### Why are the changes needed?
Test failures can be seen when compressed references are disabled (e.g. using an OpenJ9 large heap build or Hotspot with a large heap).
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Tests run on machine running OpenJ9 large heap build.
Closes#29407 from mundaym/fix-sizeestimator.
Authored-by: Michael Munday <mike.munday@ibm.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
For broadcast hash join and shuffled hash join, whenever the build side hashed relation turns out to be empty. We don't need to execute stream side plan at all, and can return an empty iterator (for inner join and left semi join), because we know for sure that none of stream side rows can be outputted as there's no match.
### Why are the changes needed?
A very minor optimization for rare use case, but in case build side turns out to be empty, we can leverage it to short-cut stream side to save CPU and IO.
Example broadcast hash join query similar to `JoinBenchmark` with empty hashed relation:
```
def broadcastHashJoinLongKey(): Unit = {
val N = 20 << 20
val M = 1 << 16
val dim = broadcast(spark.range(0).selectExpr("id as k", "cast(id as string) as v"))
codegenBenchmark("Join w long", N) {
val df = spark.range(N).join(dim, (col("id") % M) === col("k"))
assert(df.queryExecution.sparkPlan.find(_.isInstanceOf[BroadcastHashJoinExec]).isDefined)
df.noop()
}
}
```
Comparing wall clock time for enabling and disabling this PR (for non-codegen code path). Seeing like 8x improvement.
```
Java HotSpot(TM) 64-Bit Server VM 1.8.0_181-b13 on Mac OS X 10.15.4
Intel(R) Core(TM) i9-9980HK CPU 2.40GHz
Join w long: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
Join PR disabled 637 646 12 32.9 30.4 1.0X
Join PR enabled 77 78 2 271.8 3.7 8.3X
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit test in `JoinSuite`.
Closes#29484 from c21/empty-relation.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes a bug of #29406. #29406 partially pushes down data filter even if it mixed in partition filters. But in some cases partition columns might be in data columns too. It will possibly push down a predicate with partition column to datasource.
### Why are the changes needed?
The test "org.apache.spark.sql.hive.orc.HiveOrcHadoopFsRelationSuite.save()/load() - partitioned table - simple queries - partition columns in data" is currently failed with hive-1.2 profile in master branch.
```
[info] - save()/load() - partitioned table - simple queries - partition columns in data *** FAILED *** (1 second, 457 milliseconds)
[info] java.util.NoSuchElementException: key not found: p1
[info] at scala.collection.immutable.Map$Map2.apply(Map.scala:138)
[info] at org.apache.spark.sql.hive.orc.OrcFilters$.buildLeafSearchArgument(OrcFilters.scala:250)
[info] at org.apache.spark.sql.hive.orc.OrcFilters$.convertibleFiltersHelper$1(OrcFilters.scala:143)
[info] at org.apache.spark.sql.hive.orc.OrcFilters$.$anonfun$convertibleFilters$4(OrcFilters.scala:146)
[info] at scala.collection.TraversableLike.$anonfun$flatMap$1(TraversableLike.scala:245)
[info] at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
[info] at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
[info] at scala.collection.mutable.WrappedArray.foreach(WrappedArray.scala:38)
[info] at scala.collection.TraversableLike.flatMap(TraversableLike.scala:245)
[info] at scala.collection.TraversableLike.flatMap$(TraversableLike.scala:242)
[info] at scala.collection.AbstractTraversable.flatMap(Traversable.scala:108)
[info] at org.apache.spark.sql.hive.orc.OrcFilters$.convertibleFilters(OrcFilters.scala:145)
[info] at org.apache.spark.sql.hive.orc.OrcFilters$.createFilter(OrcFilters.scala:83)
[info] at org.apache.spark.sql.hive.orc.OrcFileFormat.buildReader(OrcFileFormat.scala:142)
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#29526 from viirya/SPARK-32352-followup.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Copy to master branch the unit test added for branch-2.4(https://github.com/apache/spark/pull/29430).
### Why are the changes needed?
The unit test will pass at master branch, indicating that issue reported in https://issues.apache.org/jira/browse/SPARK-32609 is already fixed at master branch. But adding this unit test for future possible failure catch.
### Does this PR introduce _any_ user-facing change?
no.
### How was this patch tested?
sbt test run
Closes#29435 from mingjialiu/master.
Authored-by: mingjial <mingjial@google.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
The PR checks for the emptiness of `--py-files` value and uses it only if it is not empty.
### Why are the changes needed?
There is a bug in Mesos cluster mode REST Submission API. It is using `--py-files` option without specifying any value for the conf `spark.submit.pyFiles` by the user.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
* Submitting an application to a Mesos cluster:
`curl -X POST http://localhost:7077/v1/submissions/create --header "Content-Type:application/json" --data '{
"action": "CreateSubmissionRequest",
"appResource": "file:///opt/spark-3.0.0-bin-3.2.0/examples/jars/spark-examples_2.12-3.0.0.jar",
"clientSparkVersion": "3.0.0",
"appArgs": ["30"],
"environmentVariables": {},
"mainClass": "org.apache.spark.examples.SparkPi",
"sparkProperties": {
"spark.jars": "file:///opt/spark-3.0.0-bin-3.2.0/examples/jars/spark-examples_2.12-3.0.0.jar",
"spark.driver.supervise": "false",
"spark.executor.memory": "512m",
"spark.driver.memory": "512m",
"spark.submit.deployMode": "cluster",
"spark.app.name": "SparkPi",
"spark.master": "mesos://localhost:5050"
}}'`
* It should be able to pick the correct class and run the job successfully.
Closes#29499 from farhan5900/SPARK-32675.
Authored-by: farhan5900 <farhan5900@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Removing unused DELETE_ACTION in FileStreamSinkLog.
### Why are the changes needed?
DELETE_ACTION is not used nowhere in the code.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Tests where not added, because code was removed.
Closes#29505 from michal-wieleba/SPARK-32648.
Authored-by: majsiel <majsiel@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Fix double caching in KMeans/BiKMeans:
1, let the callers of `runWithWeight` to pass whether `handlePersistence` is needed;
2, persist and unpersist inside of `runWithWeight`;
3, persist the `norms` if needed according to the comments;
### Why are the changes needed?
avoid double caching
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing testsuites
Closes#29501 from zhengruifeng/kmeans_handlePersistence.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Override `def get: Date` in `DaysWritable` use the `daysToMillis(int d)` from the parent class `DateWritable` instead of `long daysToMillis(int d, boolean doesTimeMatter)`.
### Why are the changes needed?
It fixes failures of `HiveSerDeReadWriteSuite` with the profile `hive-1.2`. In that case, the parent class `DateWritable` has different implementation before the commit to Hive da3ed68eda. In particular, `get()` calls `new Date(daysToMillis(daysSinceEpoch))` instead of overrided `def get(doesTimeMatter: Boolean): Date` in the child class. The `get()` method returns wrong result `1970-01-01` because it uses not updated `daysSinceEpoch`.
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
By running the test suite `HiveSerDeReadWriteSuite`:
```
$ build/sbt -Phive-1.2 -Phadoop-2.7 "test:testOnly org.apache.spark.sql.hive.execution.HiveSerDeReadWriteSuite"
```
and
```
$ build/sbt -Phive-2.3 -Phadoop-2.7 "test:testOnly org.apache.spark.sql.hive.execution.HiveSerDeReadWriteSuite"
```
Closes#29523 from MaxGekk/insert-date-into-hive-table-1.2.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
As mentioned in https://github.com/apache/spark/pull/29428#issuecomment-678735163 by viirya ,
fix bug in UT, since in script transformation no-serde mode, output of decimal is same in both hive-1.2/hive-2.3
### Why are the changes needed?
FIX UT
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
EXISTED UT
Closes#29520 from AngersZhuuuu/SPARK-32608-FOLLOW.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
This reverts commit e277ef1a83.
### Why are the changes needed?
Because master and branch-3.0 both have few tests failed under hive-1.2 profile. And the PR #29457 missed a change in hive-1.2 code that causes compilation error. So it will make debugging the failed tests harder. I'd like revert #29457 first to unblock it.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes#29519 from viirya/revert-SPARK-32646.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
Some Code refine.
1. rename EmptyHashedRelationWithAllNullKeys to HashedRelationWithAllNullKeys.
2. simplify generated code for BHJ NAAJ.
### Why are the changes needed?
Refine code and naming to avoid confusing understanding.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing test.
Closes#29503 from leanken/leanken-SPARK-32678.
Authored-by: xuewei.linxuewei <xuewei.linxuewei@alibaba-inc.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
Simple typo
### What changes were proposed in this pull request?
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#29486 from Smith-Cruise/patch-1.
Authored-by: Smith Cruise <chendingchao1@126.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Changed the definitions of `CrossValidatorModel.copy()/_to_java()/_from_java()` so that exposed parameters (i.e. parameters with `get()` methods) are copied in these methods.
### Why are the changes needed?
Parameters are copied in the respective Scala interface for `CrossValidatorModel.copy()`.
It fits the semantics to persist parameters when calling `CrossValidatorModel.save()` and `CrossValidatorModel.load()` so that the user gets the same model by saving and loading it after. Not copying across `numFolds` also causes bugs like Array index out of bound and losing sub-models because this parameters will always default to 3 (as described in the JIRA ticket).
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Tests for `CrossValidatorModel.copy()` and `save()`/`load()` are updated so that they check parameters before and after function calls.
Closes#29445 from Louiszr/master.
Authored-by: Louiszr <zxhst14@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
The purpose of this pr is to resolve [SPARK-32526](https://issues.apache.org/jira/browse/SPARK-32526), all remaining failed cases are fixed.
The main change of this pr as follow:
- Change of `ExecutorAllocationManager.scala` for core module compilation in Scala 2.13, it's a blocking problem
- Change `Seq[_]` to `scala.collection.Seq[_]` refer to failed cases
- Added different expected plan of `Test 4: Star with several branches` of StarJoinCostBasedReorderSuite for Scala 2.13 because the candidates plans:
```
Join Inner, (d1_pk#5 = f1_fk1#0)
:- Join Inner, (f1_fk2#1 = d2_pk#8)
: :- Join Inner, (f1_fk3#2 = d3_pk#11)
```
and
```
Join Inner, (f1_fk2#1 = d2_pk#8)
:- Join Inner, (d1_pk#5 = f1_fk1#0)
: :- Join Inner, (f1_fk3#2 = d3_pk#11)
```
have same cost `Cost(200,9200)`, but `HashMap` is rewritten in scala 2.13 and The order of iterations leads to different results.
This pr fix test cases as follow:
- LiteralExpressionSuite (1 FAILED -> PASS)
- StarJoinCostBasedReorderSuite ( 1 FAILED-> PASS)
- ObjectExpressionsSuite( 2 FAILED-> PASS)
- ScalaReflectionSuite (1 FAILED-> PASS)
- RowEncoderSuite (10 FAILED-> PASS)
- ExpressionEncoderSuite (ABORTED-> PASS)
### Why are the changes needed?
We need to support a Scala 2.13 build.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
<!--
- Scala 2.12: Pass the Jenkins or GitHub Action
- Scala 2.13: Do the following:
```
dev/change-scala-version.sh 2.13
mvn clean install -DskipTests -pl sql/catalyst -Pscala-2.13 -am
mvn test -pl sql/catalyst -Pscala-2.13
```
**Before**
```
Tests: succeeded 4035, failed 17, canceled 0, ignored 6, pending 0
*** 1 SUITE ABORTED ***
*** 15 TESTS FAILED ***
```
**After**
```
Tests: succeeded 4338, failed 0, canceled 0, ignored 6, pending 0
All tests passed.
```
Closes#29434 from LuciferYang/sql-catalyst-tests.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Rephrase the description for some operations to make it clearer.
### Why are the changes needed?
Add more detail in the document.
### Does this PR introduce _any_ user-facing change?
No, document only.
### How was this patch tested?
Document only.
Closes#29269 from xuanyuanking/SPARK-31792-follow.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
## What changes were proposed in this pull request?
This fixed SPARK-32672 a data corruption. Essentially the BooleanBitSet CompressionScheme would miss nulls at the end of a CompressedBatch. The values would then default to false.
### Why are the changes needed?
It fixes data corruption
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
I manually tested it against the original issue that was producing errors for me. I also added in a unit test.
Closes#29506 from revans2/SPARK-32672.
Authored-by: Robert (Bobby) Evans <bobby@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The strict requirement for the vocabulary to remain non-empty has been removed in this pull request.
Link to the discussion: http://apache-spark-user-list.1001560.n3.nabble.com/Ability-to-have-CountVectorizerModel-vocab-as-empty-td38396.html
### Why are the changes needed?
This soothens running it across the corner cases. Without this, the user has to manupulate the data in genuine case, which may be a perfectly fine valid use-case.
Question: Should we a log when empty vocabulary is found instead?
### Does this PR introduce _any_ user-facing change?
May be a slight change. If someone has put a try-catch to detect an empty vocab. Then that behavior would no longer stand still.
### How was this patch tested?
1. Added testcase to `fit` generating an empty vocabulary
2. Added testcase to `transform` with empty vocabulary
Request to review: srowen hhbyyh
Closes#29482 from purijatin/spark_32662.
Authored-by: Jatin Puri <purijatin@gmail.com>
Signed-off-by: Huaxin Gao <huaxing@us.ibm.com>
### What changes were proposed in this pull request?
Fix typo for docs, log messages and comments
### Why are the changes needed?
typo fix to increase readability
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
manual test has been performed to test the updated
Closes#29443 from brandonJY/spell-fix-doc.
Authored-by: Brandon Jiang <Brandon.jiang.a@outlook.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Add document to `ExpressionEvalHelper`, and ask people to explore all the cases that can lead to null results (including null in struct fields, array elements and map values).
This PR also fixes `ComplexTypeSuite.GetArrayStructFields` to explore all the null cases.
### Why are the changes needed?
It happened several times that we hit correctness bugs caused by wrong expression nullability. When writing unit tests, we usually don't test the nullability flag directly, and it's too late to add such tests for all expressions.
In https://github.com/apache/spark/pull/22375, we extended the expression test framework, which checks the nullability flag when the expected result/field/element is null.
This requires the test cases to explore all the cases that can lead to null results
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
I reverted 5d296ed39e locally, and `ComplexTypeSuite` can catch the bug.
Closes#29493 from cloud-fan/small.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR proposes to add a `workflow_dispatch` entry in the GitHub Action script (`build_and_test.yml`). This update can enable developers to run the Spark tests for a specific branch on their own local repository, so I think it might help to check if al the tests can pass before opening a new PR.
<img width="944" alt="Screen Shot 2020-08-21 at 16 28 41" src="https://user-images.githubusercontent.com/692303/90866249-96250c80-e3ce-11ea-8496-3dd6683e92ea.png">
### Why are the changes needed?
To reduce the pressure of GitHub Actions on the Spark repository.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually checked.
Closes#29504 from maropu/DispatchTest.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR proposes to fix ORC predicate pushdown under case-insensitive analysis case. The field names in pushed down predicates don't need to match in exact letter case with physical field names in ORC files, if we enable case-insensitive analysis.
### Why are the changes needed?
Currently ORC predicate pushdown doesn't work with case-insensitive analysis. A predicate "a < 0" cannot pushdown to ORC file with field name "A" under case-insensitive analysis.
But Parquet predicate pushdown works with this case. We should make ORC predicate pushdown work with case-insensitive analysis too.
### Does this PR introduce _any_ user-facing change?
Yes, after this PR, under case-insensitive analysis, ORC predicate pushdown will work.
### How was this patch tested?
Unit tests.
Closes#29457 from viirya/fix-orc-pushdown.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This adds some tuning guide for increasing parallelism of directory listing.
### Why are the changes needed?
Sometimes when job input has large number of directories, the listing can become a bottleneck. There are a few parameters to tune this. This adds some info to Spark tuning guide to make the knowledge better shared.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
N/A
Closes#29498 from sunchao/SPARK-32674.
Authored-by: Chao Sun <sunchao@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Hive no serde mode when column less then output specified column, it will pad null value to it, spark should do this also.
```
hive> SELECT TRANSFORM(a, b)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '|'
> LINES TERMINATED BY '\n'
> NULL DEFINED AS 'NULL'
> USING 'cat' as (a string, b string, c string, d string)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '|'
> LINES TERMINATED BY '\n'
> NULL DEFINED AS 'NULL'
> FROM (
> select 1 as a, 2 as b
> ) tmp ;
OK
1 2 NULL NULL
Time taken: 24.626 seconds, Fetched: 1 row(s)
```
### Why are the changes needed?
Keep save behavior with hive data.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#29500 from AngersZhuuuu/SPARK-32667.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Removing the individual `close` method calls on the pooled `TransportClient` instances.
The pooled clients should be only closed via `TransportClientFactory#close()`.
### Why are the changes needed?
Reusing a closed `TransportClient` leads to the exception `java.nio.channels.ClosedChannelException`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
This is a trivial case which is not tested by specific test.
Closes#29492 from attilapiros/SPARK-32663.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com>
### What changes were proposed in this pull request?
This PR reverts https://github.com/apache/spark/pull/27860 to downgrade Janino, as the new version has a bug.
### Why are the changes needed?
The symptom is about NaN comparison. For code below
```
if (double_value <= 0.0) {
...
} else {
...
}
```
If `double_value` is NaN, `NaN <= 0.0` is false and we should go to the else branch. However, current Spark goes to the if branch and causes correctness issues like SPARK-32640.
One way to fix it is:
```
boolean cond = double_value <= 0.0;
if (cond) {
...
} else {
...
}
```
I'm not familiar with Janino so I don't know what's going on there.
### Does this PR introduce _any_ user-facing change?
Yes, fix correctness bugs.
### How was this patch tested?
a new test
Closes#29495 from cloud-fan/revert.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/29469
Instead of passing the physical plan to the fallbacked v1 source directly and skipping analysis, optimization, planning altogether, this PR proposes to pass the optimized plan.
### Why are the changes needed?
It's a bit risky to pass the physical plan directly. When the fallbacked v1 source applies more operations to the input DataFrame, it will re-apply the post-planning physical rules like `CollapseCodegenStages`, `InsertAdaptiveSparkPlan`, etc., which is very tricky.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existing test suite with some new tests
Closes#29489 from cloud-fan/follow.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In case that a last `SQLQueryTestSuite` test run is killed, it will fail in a next run because of a following reason:
```
[info] org.apache.spark.sql.SQLQueryTestSuite *** ABORTED *** (17 seconds, 483 milliseconds)
[info] org.apache.spark.sql.AnalysisException: Can not create the managed table('`testdata`'). The associated location('file:/Users/maropu/Repositories/spark/spark-master/sql/core/spark-warehouse/org.apache.spark.sql.SQLQueryTestSuite/testdata') already exists.;
[info] at org.apache.spark.sql.catalyst.catalog.SessionCatalog.validateTableLocation(SessionCatalog.scala:355)
[info] at org.apache.spark.sql.execution.command.CreateDataSourceTableAsSelectCommand.run(createDataSourceTables.scala:170)
[info] at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:108)
```
This PR intends to add code to deletes orphan directories under a warehouse dir in `SQLQueryTestSuite` before creating test tables.
### Why are the changes needed?
To improve test convenience
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually checked
Closes#29488 from maropu/DeleteDirs.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
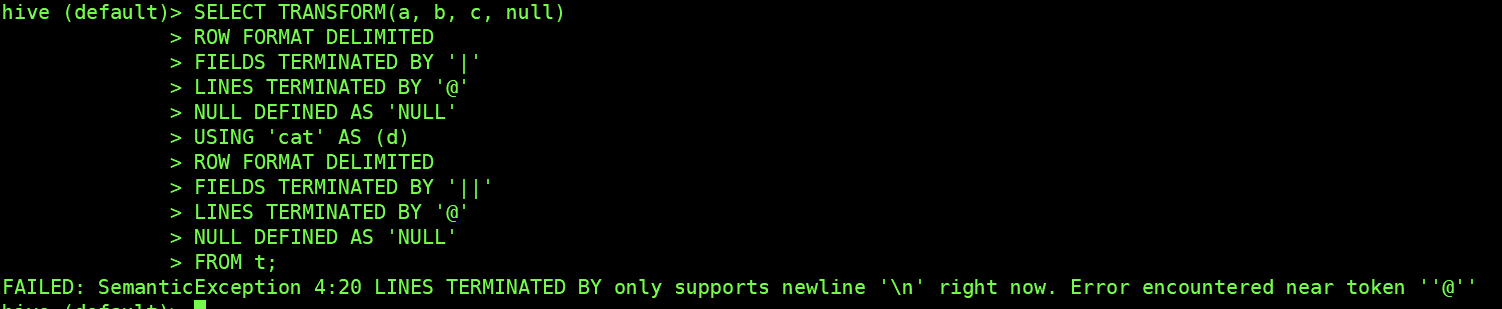
Scrip Transform no-serde (`ROW FORMAT DELIMITED`) mode `LINE TERMINNATED BY `
only support `\n`.
Tested in hive :
Hive 1.1
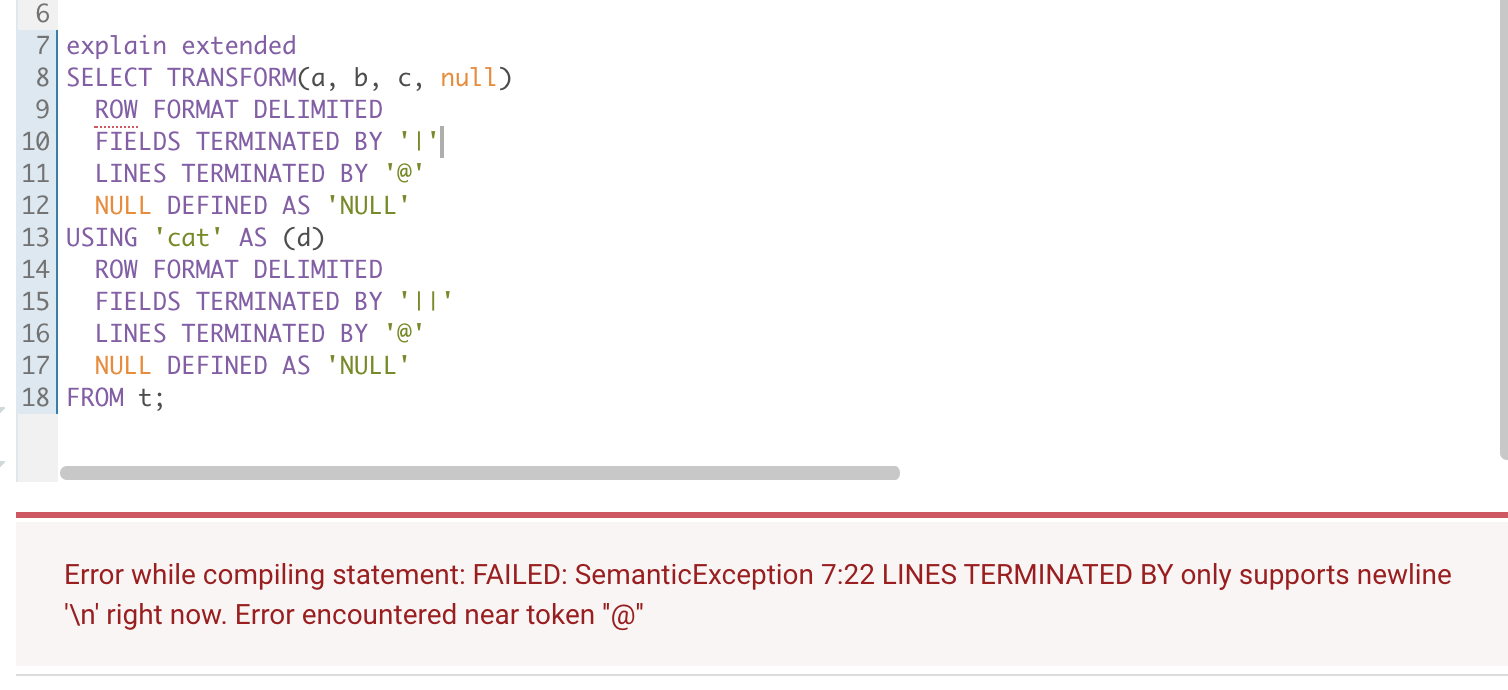
Hive 2.3.7
### Why are the changes needed?
Strictly limit the use method to ensure the accuracy of data
### Does this PR introduce _any_ user-facing change?
User use Scrip Transform no-serde (ROW FORMAT DELIMITED) mode with `LINE TERMINNATED BY `
not equal `'\n'`. will throw error
### How was this patch tested?
Added UT
Closes#29438 from AngersZhuuuu/SPARK-32607.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add decommissioning status checking for a host or executor while checking it's active or not. And a decommissioned host or executor should be considered as inactive.
### Why are the changes needed?
First of all, this PR is not a correctness bug fix but gives improvement indeed. And the main problem here we want to fix is that a decommissioned host or executor should be considered as inactive.
`TaskSetManager.computeValidLocalityLevels` depends on `TaskSchedulerImpl.isExecutorAlive/hasExecutorsAliveOnHost` to calculate the locality levels. Therefore, the `TaskSetManager` could also get corresponding locality levels of those decommissioned hosts or executors if they're not considered as inactive. However, on the other side, `CoarseGrainedSchedulerBackend` won't construct the `WorkerOffer` for those decommissioned executors. That also means `TaskSetManager` might never have a chance to launch tasks at certain locality levels but only suffers the unnecessary delay because of delay scheduling. So, this PR helps to reduce this kind of unnecessary delay by making decommissioned host/executor inactive in `TaskSchedulerImpl`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit tests
Closes#29468 from Ngone51/fix-decom-alive.
Lead-authored-by: yi.wu <yi.wu@databricks.com>
Co-authored-by: Devesh Agrawal <devesh.agrawal@gmail.com>
Co-authored-by: wuyi <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In many operations on CompactibleFileStreamLog reads a metadata log file and materializes all entries into memory. As the nature of the compact operation, CompactibleFileStreamLog may have a huge compact log file with bunch of entries included, and for now they're just monotonically increasing, which means the amount of memory to materialize also grows incrementally. This leads pressure on GC.
This patch proposes to streamline the logic on file stream source and sink whenever possible to avoid memory issue. To make this possible we have to break the existing behavior of excluding entries - now the `compactLogs` method is called with all entries, which forces us to materialize all entries into memory. This is hopefully no effect on end users, because only file stream sink has a condition to exclude entries, and the condition has been never true. (DELETE_ACTION has been never set.)
Based on the observation, this patch also changes the existing UT a bit which simulates the situation where "A" file is added, and another batch marks the "A" file as deleted. This situation simply doesn't work with the change, but as I mentioned earlier it hasn't been used. (I'm not sure the UT is from the actual run. I guess not.)
### Why are the changes needed?
The memory issue (OOME) is reported by both JIRA issue and user mailing list.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
* Existing UTs
* Manual test done
The manual test leverages the simple apps which continuously writes the file stream sink metadata log.
bea7680e4c
The test is configured to have a batch metadata log file at 1.9M (10,000 entries) whereas other Spark configuration is set to the default. (compact interval = 10) The app runs as driver, and the heap memory on driver is set to 3g.
> before the patch
<img width="1094" alt="Screen Shot 2020-06-23 at 3 37 44 PM" src="https://user-images.githubusercontent.com/1317309/85375841-d94f3480-b571-11ea-817b-c6b48b34888a.png">
It only ran for 40 mins, with the latest compact batch file size as 1.3G. The process struggled with GC, and after some struggling, it threw OOME.
> after the patch
<img width="1094" alt="Screen Shot 2020-06-23 at 3 53 29 PM" src="https://user-images.githubusercontent.com/1317309/85375901-eff58b80-b571-11ea-837e-30d107f677f9.png">
It sustained 2 hours run (manually stopped as it's expected to run more), with the latest compact batch file size as 2.2G. The actual memory usage didn't even go up to 1.2G, and be cleaned up soon without outstanding GC activity.
Closes#28904 from HeartSaVioR/SPARK-30462.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
The `count` in `PartitionWriterStream` should be a long value, instead of int. The issue is introduced by apache/sparkabef84a . When the overflow happens, the shuffle index file would record wrong index of a reduceId, thus lead to `FetchFailedException: Stream is corrupted` error.
Besides the fix, I also added some debug logs, so in the future it's easier to debug similar issues.
### Why are the changes needed?
This is a regression and bug fix.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
A Spark user reported this issue when migrating their workload to 3.0. One of the jobs fail deterministically on Spark 3.0 without the patch, and the job succeed after applied the fix.
Closes#29474 from jiangxb1987/fixPartitionWriteStream.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Address the [#comment](https://github.com/apache/spark/pull/28840#discussion_r471172006).
### Why are the changes needed?
Make code robust.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
ut.
Closes#29453 from ulysses-you/SPARK-31999-FOLLOWUP.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Update the log strings to match the new log messages.
### Why are the changes needed?
Tests are failing
### Does this PR introduce _any_ user-facing change?
No, test only change.
### How was this patch tested?
WIP: Make sure the DecommissionSuite passes in Jenkins.
Closes#29479 from holdenk/SPARK-32657-Decommissioning-tests-update-log-string.
Authored-by: Holden Karau <hkarau@apple.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR introduces a LogicalNode AlreadyPlanned, and related physical plan and preparation rule.
With the DataSourceV2 write operations, we have a way to fallback to the V1 writer APIs using InsertableRelation. The gross part is that we're in physical land, but the InsertableRelation takes a logical plan, so we have to pass the logical plans to these physical nodes, and then potentially go through re-planning. This re-planning can cause issues for an already optimized plan.
A useful primitive could be specifying that a plan is ready for execution through a logical node AlreadyPlanned. This would wrap a physical plan, and then we can go straight to execution.
### Why are the changes needed?
To avoid having a physical plan that is disconnected from the physical plan that is being executed in V1WriteFallback execution. When a physical plan node executes a logical plan, the inner query is not connected to the running physical plan. The physical plan that actually runs is not visible through the Spark UI and its metrics are not exposed. In some cases, the EXPLAIN plan doesn't show it.
### Does this PR introduce _any_ user-facing change?
Nope
### How was this patch tested?
V1FallbackWriterSuite tests that writes still work
Closes#29469 from brkyvz/alreadyAnalyzed2.
Lead-authored-by: Burak Yavuz <brkyvz@gmail.com>
Co-authored-by: Burak Yavuz <burak@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When CSV/JSON datasources infer schema (e.g, `def inferSchema(files: Seq[FileStatus])`, they use the `files` along with the original options. `files` in `inferSchema` could have been deduced from the "path" option if the option was present, so this can cause issues (e.g., reading more data, listing the path again) since the "path" option is **added** to the `files`.
### Why are the changes needed?
The current behavior can cause the following issue:
```scala
class TestFileFilter extends PathFilter {
override def accept(path: Path): Boolean = path.getParent.getName != "p=2"
}
val path = "/tmp"
val df = spark.range(2)
df.write.json(path + "/p=1")
df.write.json(path + "/p=2")
val extraOptions = Map(
"mapred.input.pathFilter.class" -> classOf[TestFileFilter].getName,
"mapreduce.input.pathFilter.class" -> classOf[TestFileFilter].getName
)
// This works fine.
assert(spark.read.options(extraOptions).json(path).count == 2)
// The following with "path" option fails with the following:
// assertion failed: Conflicting directory structures detected. Suspicious paths
// file:/tmp
// file:/tmp/p=1
assert(spark.read.options(extraOptions).format("json").option("path", path).load.count() === 2)
```
### Does this PR introduce _any_ user-facing change?
Yes, the above failure doesn't happen and you get the consistent experience when you use `spark.read.csv(path)` or `spark.read.format("csv").option("path", path).load`.
### How was this patch tested?
Updated existing tests.
Closes#29437 from imback82/path_bug.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR replaces some arbitrary task names in logs with the widely used task name (e.g. "task 0.0 in stage 1.0 (TID 1)") among driver and executor. This will change the task name in `TaskDescription` by appending TID.
### Why are the changes needed?
Some logs are still using TID(a.k.a `taskId`) only as the task name, e.g.,
7f275ee597/core/src/main/scala/org/apache/spark/executor/Executor.scala (L786)7f275ee597/core/src/main/scala/org/apache/spark/executor/Executor.scala (L632-L635)
And the task thread name also only has the `taskId`:
7f275ee597/core/src/main/scala/org/apache/spark/executor/Executor.scala (L325)
As mentioned in https://github.com/apache/spark/pull/1259, TID itself does not capture stage or retries, making it harder to correlate with the application. It's inconvenient when debugging applications.
Actually, task name like "task name (e.g. "task 0.0 in stage 1.0 (TID 1)")" has already been used widely after https://github.com/apache/spark/pull/1259. We'd better follow the naming convention.
### Does this PR introduce _any_ user-facing change?
Yes. Users will see the more consistent task names in the log.
### How was this patch tested?
Manually checked.
Closes#29418 from Ngone51/unify-task-name.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For SQL
```
SELECT TRANSFORM(a, b, c)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
NULL DEFINED AS 'null'
USING 'cat' AS (a, b, c)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
NULL DEFINED AS 'NULL'
FROM testData
```
The correct
TOK_TABLEROWFORMATFIELD should be `, `nut actually ` ','`
TOK_TABLEROWFORMATLINES should be `\n` but actually` '\n'`
### Why are the changes needed?
Fix string value format
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#29428 from AngersZhuuuu/SPARK-32608.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Rename `spark.worker.decommission.enabled` to `spark.decommission.enabled` and move it from `org.apache.spark.internal.config.Worker` to `org.apache.spark.internal.config.package`.
### Why are the changes needed?
Decommission has been supported in Standalone and k8s yet and may be supported in Yarn(https://github.com/apache/spark/pull/27636) in the future. Therefore, the switch configuration should have the highest hierarchy rather than belongs to Standalone's Worker. In other words, it should be independent of the cluster managers.
### Does this PR introduce _any_ user-facing change?
No, as the decommission feature hasn't been released.
### How was this patch tested?
Pass existed tests.
Closes#29466 from Ngone51/fix-decom-conf.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Change maps in two constructors of SpecificInternalRow to while loops.
### Why are the changes needed?
This was originally noticed with https://github.com/apache/spark/pull/29353 and https://github.com/apache/spark/pull/29354 and will have impacts on performance of reading ORC and Avro files. Ran AvroReadBenchmarks with the new cases of nested and array'd structs in https://github.com/apache/spark/pull/29352. Haven't run benchmarks for ORC but can do that if needed.
**Before:**
```
Nested Struct Scan: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
Nested Struct 74674 75319 912 0.0 142429.1 1.0X
Array of Struct Scan: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
Array of Structs 34193 34339 206 0.0 65217.9 1.0X
```
**After:**
```
Nested Struct Scan: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
Nested Struct 48451 48619 237 0.0 92413.2 1.0X
Array of Struct Scan: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
Array of Structs 18518 18683 234 0.0 35319.6 1.0X
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Ran AvroReadBenchmarks with the new cases of nested and array'd structs in https://github.com/apache/spark/pull/29352.
Closes#29366 from msamirkhan/spark-32550.
Lead-authored-by: Samir Khan <muhammad.samir.khan@gmail.com>
Co-authored-by: skhan04 <samirkhan@verizonmedia.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The class `KMeansSummary` in pyspark is not included in `clustering.py`'s `__all__` declaration. It isn't included in the docs as a result.
`InheritableThread` and `KMeansSummary` should be into corresponding RST files for documentation.
### Why are the changes needed?
It seems like an oversight to not include this as all similar "summary" classes are.
`InheritableThread` should also be documented.
### Does this PR introduce _any_ user-facing change?
I don't believe there are functional changes. It should make this public class appear in docs.
### How was this patch tested?
Existing tests / N/A.
Closes#29470 from srowen/KMeansSummary.
Lead-authored-by: Sean Owen <srowen@gmail.com>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Update `ObjectSerializerPruning.alignNullTypeInIf`, to consider the isNull check generated in `RowEncoder`, which is `Invoke(inputObject, "isNullAt", BooleanType, Literal(index) :: Nil)`.
### Why are the changes needed?
Query fails if we don't fix this bug, due to type mismatch in `If`.
### Does this PR introduce _any_ user-facing change?
Yes, the failed query can run after this fix.
### How was this patch tested?
new tests
Closes#29467 from cloud-fan/bug.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Only calculate `executorKillTime` in `TaskSetManager.executorDecommission()` when speculation is enabled.
### Why are the changes needed?
Avoid unnecessary operations to save time/memory.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass existed tests.
Closes#29464 from Ngone51/followup-SPARK-21040.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}