## What changes were proposed in this pull request?
``As part of insert command in FileFormatWriter, a job context is created for handling the write operation , While initializing the job context using setupJob() API
in HadoopMapReduceCommitProtocol , we set the jobid in the Jobcontext configuration.In FileFormatWriter since we are directly getting the jobId from the map reduce JobContext the job id will come as null while adding the log. As a solution we shall get the jobID from the configuration of the map reduce Jobcontext.``
## How was this patch tested?
Manually, verified the logs after the changes.

Closes#22572 from sujith71955/master_log_issue.
Authored-by: s71955 <sujithchacko.2010@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
While working on another PR, I noticed that there is quite some legacy Java in there that can be beautified. For example the use og features from Java8, such as:
- Collection libraries
- Try-with-resource blocks
No code has been changed
What are your thoughts on this?
This makes code easier to read, and using try-with-resource makes is less likely to forget to close something.
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22399 from Fokko/SPARK-25408.
Authored-by: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The test `cast string to timestamp` used to run for all time zones. So it run for more than 600 times. Running the tests for a significant subset of time zones is probably good enough and doing this in a randomized manner enforces anyway that we are going to test all time zones in different runs.
## How was this patch tested?
the test time reduces to 11 seconds from more than 2 minutes
Closes#22631 from mgaido91/SPARK-25605.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Reduce `DateExpressionsSuite.Hour` test time costs in Jenkins by reduce iteration times.
## How was this patch tested?
Manual tests on my local machine.
before:
```
- Hour (34 seconds, 54 milliseconds)
```
after:
```
- Hour (2 seconds, 697 milliseconds)
```
Closes#22632 from wangyum/SPARK-25606.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The PR changes the test introduced for SPARK-22226, so that we don't run analysis and optimization on the plan. The scope of the test is code generation and running the above mentioned operation is expensive and useless for the test.
The UT was also moved to the `CodeGenerationSuite` which is a better place given the scope of the test.
## How was this patch tested?
running the UT before SPARK-22226 fails, after it passes. The execution time is about 50% the original one. On my laptop this means that the test now runs in about 23 seconds (instead of 50 seconds).
Closes#22629 from mgaido91/SPARK-25609.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Original work by Steve Loughran.
Based on #17745.
This is a minimal patch of changes to FileInputDStream to reduce File status requests when querying files. Each call to file status is 3+ http calls to object store. This patch eliminates the need for it, by using FileStatus objects.
This is a minor optimisation when working with filesystems, but significant when working with object stores.
## How was this patch tested?
Tests included. Existing tests pass.
Closes#22339 from ScrapCodes/PR_17745.
Lead-authored-by: Prashant Sharma <prashant@apache.org>
Co-authored-by: Steve Loughran <stevel@hortonworks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Refactor `DatasetBenchmark` to use main method.
Generate benchmark result:
```sh
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.DatasetBenchmark"
```
## How was this patch tested?
manual tests
Closes#22488 from wangyum/SPARK-25479.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
In `SparkPlan.getByteArrayRdd`, we should only call `it.hasNext` when the limit is not hit, as `iter.hasNext` may produce one row and buffer it, and cause wrong metrics.
## How was this patch tested?
new tests
Closes#22621 from cloud-fan/range.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR proposes to register Grouped aggregate UDF Vectorized UDFs for SQL Statement, for instance:
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
pandas_udf("integer", PandasUDFType.GROUPED_AGG)
def sum_udf(v):
return v.sum()
spark.udf.register("sum_udf", sum_udf)
q = "SELECT v2, sum_udf(v1) FROM VALUES (3, 0), (2, 0), (1, 1) tbl(v1, v2) GROUP BY v2"
spark.sql(q).show()
```
```
+---+-----------+
| v2|sum_udf(v1)|
+---+-----------+
| 1| 1|
| 0| 5|
+---+-----------+
```
## How was this patch tested?
Manual test and unit test.
Closes#22620 from HyukjinKwon/SPARK-25601.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR proposes to register Grouped aggregate UDF Vectorized UDFs for SQL Statement, for instance:
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
pandas_udf("integer", PandasUDFType.GROUPED_AGG)
def sum_udf(v):
return v.sum()
spark.udf.register("sum_udf", sum_udf)
q = "SELECT v2, sum_udf(v1) FROM VALUES (3, 0), (2, 0), (1, 1) tbl(v1, v2) GROUP BY v2"
spark.sql(q).show()
```
```
+---+-----------+
| v2|sum_udf(v1)|
+---+-----------+
| 1| 1|
| 0| 5|
+---+-----------+
```
## How was this patch tested?
Manual test and unit test.
Closes#22620 from HyukjinKwon/SPARK-25601.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Cause: Recently test_glr_summary failed for PR of SPARK-25118, which enables
spark-shell to run with default log level. It failed because this logdebug was
called for GeneralizedLinearRegressionTrainingSummary which invoked its toString
method, which started a Spark Job and ended up running into an infinite loop.
Fix: Remove logDebug statement for outer objects as closures aren't implemented
with outerclasses in Scala 2.12 and this debug statement looses its purpose
## How was this patch tested?
Ran python pyspark-ml tests on top of PR for SPARK-25118 and ClosureCleaner unit
tests
Closes#22616 from ankuriitg/ankur/SPARK-25586.
Authored-by: ankurgupta <ankur.gupta@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
In #20850 when writing non-null decimals, instead of zero-ing all the 16 allocated bytes, we zero-out only the padding bytes. Since we always allocate 16 bytes, if the number of bytes needed for a decimal is lower than 9, then this means that the bytes between 8 and 16 are not zero-ed.
I see 2 solutions here:
- we can zero-out all the bytes in advance as it was done before #20850 (safer solution IMHO);
- we can allocate only the needed bytes (may be a bit more efficient in terms of memory used, but I have not investigated the feasibility of this option).
Hence I propose here the first solution in order to fix the correctness issue. We can eventually switch to the second if we think is more efficient later.
## How was this patch tested?
Running the test attached in the JIRA + added UT
Closes#22602 from mgaido91/SPARK-25582.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Refactor `UnsafeArrayDataBenchmark` to use main method.
Generate benchmark result:
```sh
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.UnsafeArrayDataBenchmark"
```
## How was this patch tested?
manual tests
Closes#22491 from wangyum/SPARK-25483.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This PR aims to add `BloomFilterBenchmark`. For ORC data source, Apache Spark has been supporting for a long time. For Parquet data source, it's expected to be added with next Parquet release update.
## How was this patch tested?
Manual.
```scala
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.BloomFilterBenchmark"
```
Closes#22605 from dongjoon-hyun/SPARK-25589.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
With flag `IGNORE_CORRUPT_FILES` enabled, schema inference should ignore corrupt Avro files, which is consistent with Parquet and Orc data source.
## How was this patch tested?
Unit test
Closes#22611 from gengliangwang/ignoreCorruptAvro.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
SPARK-24530 discovered a problem of generation python doc, and provided a fix: setting SPHINXPYTHON to python 3.
This PR makes this fix automatic in the release script using docker.
## How was this patch tested?
verified by the 2.4.0 rc2
Closes#22607 from cloud-fan/python.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Rename method `benchmark` in `BenchmarkBase` as `runBenchmarkSuite `. Also add comments.
Currently the method name `benchmark` is a bit confusing. Also the name is the same as instances of `Benchmark`:
f246813afb/sql/hive/src/test/scala/org/apache/spark/sql/hive/orc/OrcReadBenchmark.scala (L330-L339)
## How was this patch tested?
Unit test.
Closes#22599 from gengliangwang/renameBenchmarkSuite.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This patch is to bump the master branch version to 3.0.0-SNAPSHOT.
## How was this patch tested?
N/A
Closes#22606 from gatorsmile/bump3.0.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Update to Scala 2.12.7. See https://issues.apache.org/jira/browse/SPARK-25578 for why.
## How was this patch tested?
Existing tests.
Closes#22600 from srowen/SPARK-25578.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently, SQL tab in the WEBUI doesn't support hiding table. Other tabs in the web ui like, Jobs, stages etc supports hiding table (refer SPARK-23024 https://github.com/apache/spark/pull/20216).
In this PR, added the support for hide table in the sql tab also.
## How was this patch tested?
bin/spark-shell
```
sql("create table a (id int)")
for(i <- 1 to 100) sql(s"insert into a values ($i)")
```
Open SQL tab in the web UI
**Before fix:**
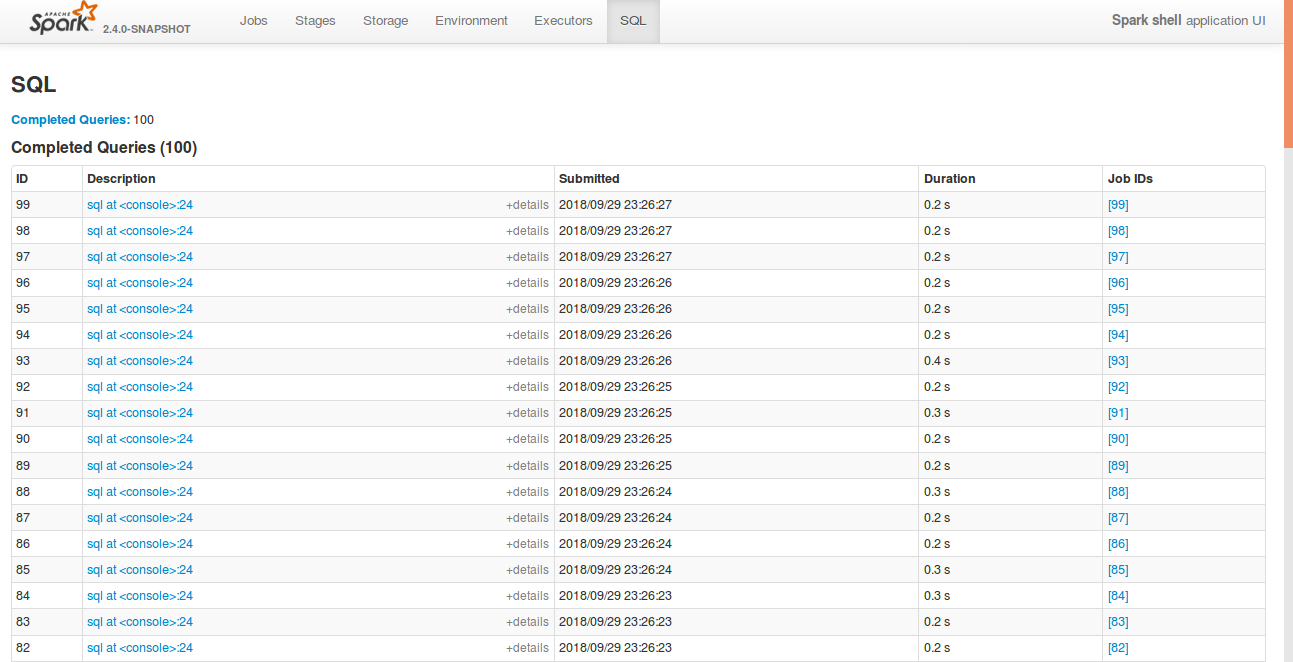
**After fix:** Consistent with the other tabs.

(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22592 from shahidki31/SPARK-25575.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR is follow-up of closed https://github.com/apache/spark/pull/17401 which only ended due to of inactivity, but its still nice feature to have.
Given review by jerryshao taken in consideration and edited:
- VisibleForTesting deleted because of dependency conflicts
- removed unnecessary reflection for `MetricsSystemImpl`
- added more available types for gauge
## How was this patch tested?
Manual deploy of new yarn-shuffle jar into a Node Manager and verifying that the metrics appear in the Node Manager-standard location. This is JMX with an query endpoint running on `hostname:port`
Resulting metrics look like this:
```
curl -sk -XGET hostname:port | grep -v '#' | grep 'shuffleService'
hadoop_nodemanager_openblockrequestlatencymillis_rate15{name="shuffleService",} 0.31428910657834713
hadoop_nodemanager_blocktransferratebytes_rate15{name="shuffleService",} 566144.9983653595
hadoop_nodemanager_blocktransferratebytes_ratemean{name="shuffleService",} 2464409.9678099006
hadoop_nodemanager_openblockrequestlatencymillis_rate1{name="shuffleService",} 1.2893844732240272
hadoop_nodemanager_registeredexecutorssize{name="shuffleService",} 2.0
hadoop_nodemanager_openblockrequestlatencymillis_ratemean{name="shuffleService",} 1.255574678369966
hadoop_nodemanager_openblockrequestlatencymillis_count{name="shuffleService",} 315.0
hadoop_nodemanager_openblockrequestlatencymillis_rate5{name="shuffleService",} 0.7661929192569739
hadoop_nodemanager_registerexecutorrequestlatencymillis_ratemean{name="shuffleService",} 0.0
hadoop_nodemanager_registerexecutorrequestlatencymillis_count{name="shuffleService",} 0.0
hadoop_nodemanager_registerexecutorrequestlatencymillis_rate1{name="shuffleService",} 0.0
hadoop_nodemanager_registerexecutorrequestlatencymillis_rate5{name="shuffleService",} 0.0
hadoop_nodemanager_blocktransferratebytes_count{name="shuffleService",} 6.18271213E8
hadoop_nodemanager_registerexecutorrequestlatencymillis_rate15{name="shuffleService",} 0.0
hadoop_nodemanager_blocktransferratebytes_rate5{name="shuffleService",} 1154114.4881816586
hadoop_nodemanager_blocktransferratebytes_rate1{name="shuffleService",} 574745.0749848988
```
Closes#22485 from mareksimunek/SPARK-18364.
Lead-authored-by: marek.simunek <marek.simunek@firma.seznam.cz>
Co-authored-by: Andrew Ash <andrew@andrewash.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
This PR does 2 things:
1. Add a new trait(`SqlBasedBenchmark`) to better support Dataset and DataFrame API.
2. Refactor `AggregateBenchmark` to use main method. Generate benchmark result:
```
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.AggregateBenchmark"
```
## How was this patch tested?
manual tests
Closes#22484 from wangyum/SPARK-25476.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Add more data types for Pandas UDF Tests for PySpark SQL
## How was this patch tested?
manual tests
Closes#22568 from AlexanderKoryagin/new_types_for_pandas_udf_tests.
Lead-authored-by: Aleksandr Koriagin <aleksandr_koriagin@epam.com>
Co-authored-by: hyukjinkwon <gurwls223@apache.org>
Co-authored-by: Alexander Koryagin <AlexanderKoryagin@users.noreply.github.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR aims to fix the failed test of `OracleIntegrationSuite`.
## How was this patch tested?
Existing integration tests.
Closes#22461 from seancxmao/SPARK-25453.
Authored-by: seancxmao <seancxmao@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
#22519 introduced a bug when the attributes in the pivot clause are cosmetically different from the output ones (eg. different case). In particular, the problem is that the PR used a `Set[Attribute]` instead of an `AttributeSet`.
## How was this patch tested?
added UT
Closes#22582 from mgaido91/SPARK-25505_followup.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Spurious logs like /sec.
2018-09-26 09:33:57 DEBUG ExecutorPodsLifecycleManager:58 - Removed executors with ids from Spark that were either found to be deleted or non-existent in the cluster.
2018-09-26 09:33:58 DEBUG ExecutorPodsLifecycleManager:58 - Removed executors with ids from Spark that were either found to be deleted or non-existent in the cluster.
2018-09-26 09:33:59 DEBUG ExecutorPodsLifecycleManager:58 - Removed executors with ids from Spark that were either found to be deleted or non-existent in the cluster.
2018-09-26 09:34:00 DEBUG ExecutorPodsLifecycleManager:58 - Removed executors with ids from Spark that were either found to be deleted or non-existent in the cluster.
The fix is easy, first check if there are any removed executors, before producing the log message.
## How was this patch tested?
Tested by manually deploying to a minikube cluster.
Closes#22565 from ScrapCodes/spark-25543/k8s/debug-log-spurious-warning.
Authored-by: Prashant Sharma <prashsh1@in.ibm.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Fix an obvious error.
## How was this patch tested?
Existing tests.
Closes#22577 from sadhen/minor_fix.
Authored-by: Darcy Shen <sadhen@zoho.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR adds a rule to force `.toLowerCase(Locale.ROOT)` or `toUpperCase(Locale.ROOT)`.
It produces an error as below:
```
[error] Are you sure that you want to use toUpperCase or toLowerCase without the root locale? In most cases, you
[error] should use toUpperCase(Locale.ROOT) or toLowerCase(Locale.ROOT) instead.
[error] If you must use toUpperCase or toLowerCase without the root locale, wrap the code block with
[error] // scalastyle:off caselocale
[error] .toUpperCase
[error] .toLowerCase
[error] // scalastyle:on caselocale
```
This PR excludes the cases above for SQL code path for external calls like table name, column name and etc.
For test suites, or when it's clear there's no locale problem like Turkish locale problem, it uses `Locale.ROOT`.
One minor problem is, `UTF8String` has both methods, `toLowerCase` and `toUpperCase`, and the new rule detects them as well. They are ignored.
## How was this patch tested?
Manually tested, and Jenkins tests.
Closes#22581 from HyukjinKwon/SPARK-25565.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Since we don't fail a job when `AccumulatorV2.merge` fails, we should try to update the remaining accumulators so that they can still report correct values.
## How was this patch tested?
The new unit test.
Closes#22586 from zsxwing/SPARK-25568.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
CRAN doesn't seem to respect the system requirements as running tests - we have seen cases where SparkR is run on Java 10, which unfortunately Spark does not start on. For 2.4, lets attempt skipping all tests
## How was this patch tested?
manual, jenkins, appveyor
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#22589 from felixcheung/ralltests.
## What changes were proposed in this pull request?
Refactor OrcReadBenchmark to use main method.
Generate benchmark result:
```
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "hive/test:runMain org.apache.spark.sql.hive.orc.OrcReadBenchmark"
```
## How was this patch tested?
manual tests
Closes#22580 from yucai/SPARK-25508.
Lead-authored-by: yucai <yyu1@ebay.com>
Co-authored-by: Yucai Yu <yucai.yu@foxmail.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
In the PR, I propose to extend implementation of existing method:
```
def pivot(pivotColumn: Column, values: Seq[Any]): RelationalGroupedDataset
```
to support values of the struct type. This allows pivoting by multiple columns combined by `struct`:
```
trainingSales
.groupBy($"sales.year")
.pivot(
pivotColumn = struct(lower($"sales.course"), $"training"),
values = Seq(
struct(lit("dotnet"), lit("Experts")),
struct(lit("java"), lit("Dummies")))
).agg(sum($"sales.earnings"))
```
## How was this patch tested?
Added a test for values specified via `struct` in Java and Scala.
Closes#22316 from MaxGekk/pivoting-by-multiple-columns2.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Markdown links are not working inside html table. We should use html link tag.
## How was this patch tested?
Verified in IntelliJ IDEA's markdown editor and online markdown editor.
Closes#22588 from viirya/SPARK-25262-followup.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In the PR, I propose to extended the `schema_of_json()` function, and accept JSON options since they can impact on schema inferring. Purpose is to support the same options that `from_json` can use during schema inferring.
## How was this patch tested?
Added SQL, Python and Scala tests (`JsonExpressionsSuite` and `JsonFunctionsSuite`) that checks JSON options are used.
Closes#22442 from MaxGekk/schema_of_json-options.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR aims to prevent test slowdowns at `HiveExternalCatalogVersionsSuite` by using the latest Apache Spark 2.3.2 link because the Apache mirrors will remove the old Spark 2.3.1 binaries eventually. `HiveExternalCatalogVersionsSuite` will not fail because [SPARK-24813](https://issues.apache.org/jira/browse/SPARK-24813) implements a fallback logic. However, it will cause many trials and fallbacks in all builds over `branch-2.3/branch-2.4/master`. We had better fix this issue.
## How was this patch tested?
Pass the Jenkins with the updated version.
Closes#22587 from dongjoon-hyun/SPARK-25570.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This adds a missing end markup tag. This should go `master` branch only.
## How was this patch tested?
This is a doc-only change. Manual via `SKIP_API=1 jekyll build`.
Closes#22584 from dongjoon-hyun/SPARK-25262.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Currently, in `ParquetFilters`, if one of the children predicates is not supported by Parquet, the entire predicates will be thrown away. In fact, if the unsupported predicate is in the top level `And` condition or in the child before hitting `Not` or `Or` condition, it can be safely removed.
## How was this patch tested?
Tests are added.
Closes#22574 from dbtsai/removeUnsupportedPredicatesInParquet.
Lead-authored-by: DB Tsai <d_tsai@apple.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Co-authored-by: DB Tsai <dbtsai@dbtsai.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Heartbeat shouldn't include accumulators for zero metrics.
Heartbeats sent from executors to the driver every 10 seconds contain metrics and are generally on the order of a few KBs. However, for large jobs with lots of tasks, heartbeats can be on the order of tens of MBs, causing tasks to die with heartbeat failures. We can mitigate this by not sending zero metrics to the driver.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22473 from mukulmurthy/25449-heartbeat.
Authored-by: Mukul Murthy <mukul.murthy@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
Use `Set` instead of `Array` to improve `accumulatorIds.contains(acc.id)` performance.
This PR close https://github.com/apache/spark/pull/22420
## How was this patch tested?
manual tests.
Benchmark code:
```scala
def benchmark(func: () => Unit): Long = {
val start = System.currentTimeMillis()
func()
val end = System.currentTimeMillis()
end - start
}
val range = Range(1, 1000000)
val set = range.toSet
val array = range.toArray
for (i <- 0 until 5) {
val setExecutionTime =
benchmark(() => for (i <- 0 until 500) { set.contains(scala.util.Random.nextInt()) })
val arrayExecutionTime =
benchmark(() => for (i <- 0 until 500) { array.contains(scala.util.Random.nextInt()) })
println(s"set execution time: $setExecutionTime, array execution time: $arrayExecutionTime")
}
```
Benchmark result:
```
set execution time: 4, array execution time: 2760
set execution time: 1, array execution time: 1911
set execution time: 3, array execution time: 2043
set execution time: 12, array execution time: 2214
set execution time: 6, array execution time: 1770
```
Closes#22579 from wangyum/SPARK-25429.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
**Description from the JIRA :**
Currently, to collect the statistics of all the columns, users need to specify the names of all the columns when calling the command "ANALYZE TABLE ... FOR COLUMNS...". This is not user friendly. Instead, we can introduce the following SQL command to achieve it without specifying the column names.
```
ANALYZE TABLE [db_name.]tablename COMPUTE STATISTICS FOR ALL COLUMNS;
```
## How was this patch tested?
Added new tests in SparkSqlParserSuite and StatisticsSuite
Closes#22566 from dilipbiswal/SPARK-25458.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The specified test in OpenHashMapSuite to test large items is somehow flaky to throw OOM.
By considering the original work #6763 that added this test, the test can be against OpenHashSetSuite. And by doing this should be to save memory because OpenHashMap allocates two more arrays when growing the map/set.
## How was this patch tested?
Existing tests.
Closes#22569 from viirya/SPARK-25542.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This adds a missing markup tag. This should go to `master/branch-2.4`.
## How was this patch tested?
Manual via `SKIP_API=1 jekyll build`.
Closes#22585 from dongjoon-hyun/SPARK-23285.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
The grouping columns from a Pivot query are inferred as "input columns - pivot columns - pivot aggregate columns", where input columns are the output of the child relation of Pivot. The grouping columns will be the leading columns in the pivot output and they should preserve the same order as specified by the input. For example,
```
SELECT * FROM (
SELECT course, earnings, "a" as a, "z" as z, "b" as b, "y" as y, "c" as c, "x" as x, "d" as d, "w" as w
FROM courseSales
)
PIVOT (
sum(earnings)
FOR course IN ('dotNET', 'Java')
)
```
The output columns should be "a, z, b, y, c, x, d, w, ..." but now it is "a, b, c, d, w, x, y, z, ..."
The fix is to use the child plan's `output` instead of `outputSet` so that the order can be preserved.
## How was this patch tested?
Added UT.
Closes#22519 from maryannxue/spark-25505.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The `show create table` will show a lot of generated attributes for views that created by older Spark version. This PR will basically revert https://issues.apache.org/jira/browse/SPARK-19272 back, so when you `DESC [FORMATTED|EXTENDED] view` will show the original view DDL text.
## How was this patch tested?
Unit test.
Closes#22458 from zheyuan28/testbranch.
Lead-authored-by: Chris Zhao <chris.zhao@databricks.com>
Co-authored-by: Christopher Zhao <chris.zhao@databricks.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
Caching the value of that config means different instances of SparkEnv
will always use whatever was the first value to be read. It also breaks
tests that use RDDInfo outside of the scope of a SparkContext.
Since this is not a performance sensitive area, there's no advantage
in caching the config value.
Closes#22558 from vanzin/SPARK-25546.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
There are 2 places we check for problematic `InSubquery`: the rule `ResolveSubquery` and `InSubquery.checkInputDataTypes`. We should unify them.
## How was this patch tested?
existing tests
Closes#22563 from cloud-fan/followup.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Special case the situation where we know the partioner and the number of requested partions output is the same as the current partioner to avoid a shuffle and instead compute distinct inside of each partion.
## How was this patch tested?
New unit test that verifies partitioner does not change if the partitioner is known and distinct is called with the same target # of partition.
Closes#22010 from holdenk/SPARK-21436-take-advantage-of-known-partioner-for-distinct-on-rdds.
Authored-by: Holden Karau <holden@pigscanfly.ca>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
As per the discussion in https://github.com/apache/spark/pull/22553#pullrequestreview-159192221,
override `filterKeys` violates the documented semantics.
This PR is to remove it and add documentation.
Also fix one potential non-serializable map in `FileStreamOptions`.
The only one call of `CaseInsensitiveMap`'s `filterKeys` left is
c3c45cbd76/sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/HiveOptions.scala (L88-L90)
But this one is OK.
## How was this patch tested?
Existing unit tests.
Closes#22562 from gengliangwang/SPARK-25541-FOLLOWUP.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}