## What changes were proposed in this pull request?
This change exposes the `df` (document frequency) as a public val along with the number of documents (`m`) as part of the IDF model.
* The document frequency is returned as an `Array[Long]`
* If the minimum document frequency is set, this is considered in the df calculation. If the count is less than minDocFreq, the df is 0 for such terms
* numDocs is not very required. But it can be useful, if we plan to provide a provision in future for user to give their own idf function, instead of using a default (log((1+m)/(1+df))). In such cases, the user can provide a function taking input of `m` and `df` and returning the idf value
* Pyspark changes
## How was this patch tested?
The existing test case was edited to also check for the document frequency values.
I am not very good with python or pyspark. I have committed and run tests based on my understanding. Kindly let me know if I have missed anything
Reviewer request: mengxr zjffdu yinxusen
Closes#23549 from purijatin/master.
Authored-by: Jatin Puri <purijatin@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
I know that yarn provided all hadoop configurations. But I guess it may be fine that the historyserver unify all configuration in it. It will be convenient for us to debug some problems.
## How was this patch tested?
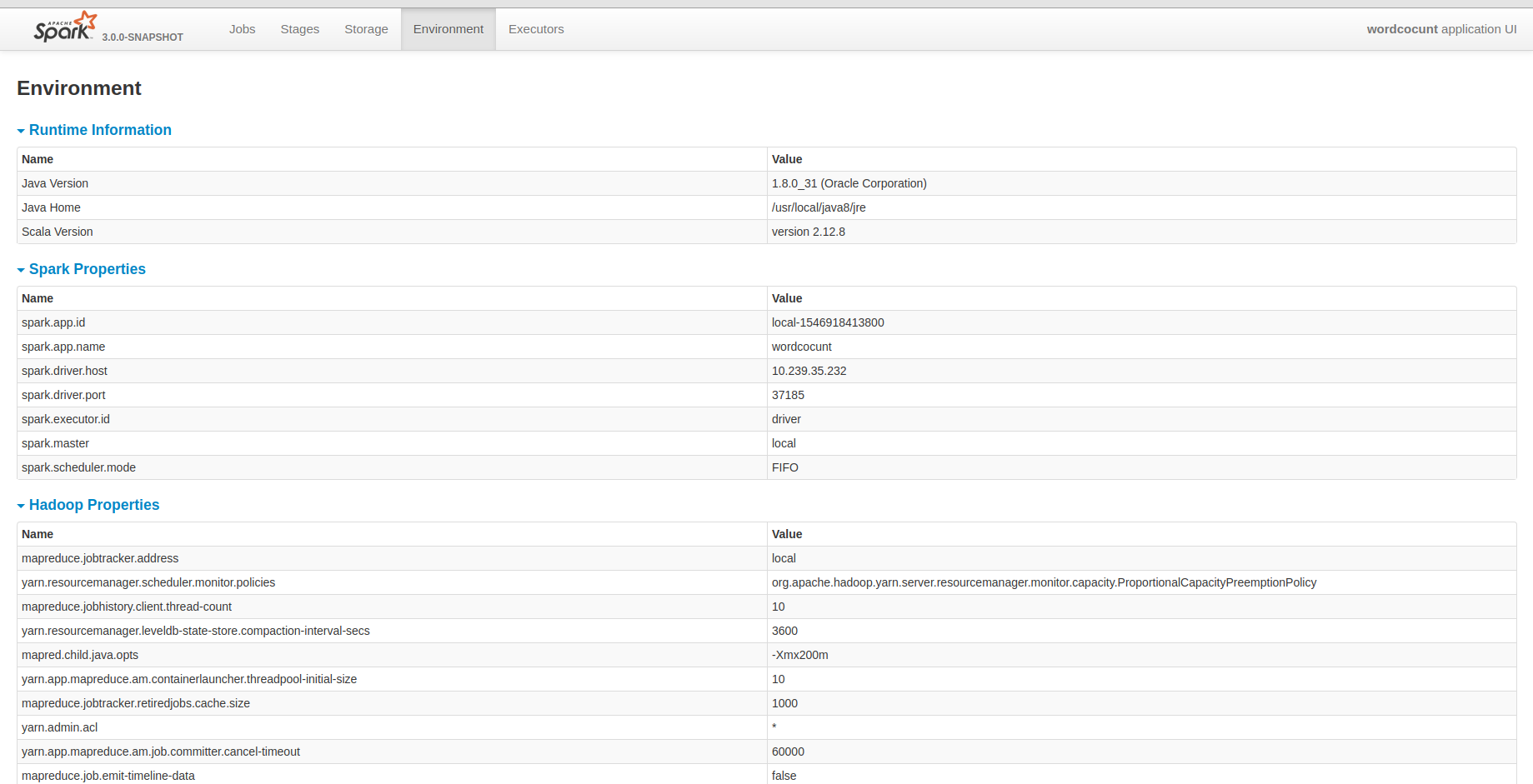
Closes#23486 from deshanxiao/spark-26457.
Lead-authored-by: xiaodeshan <xiaodeshan@xiaomi.com>
Co-authored-by: deshanxiao <42019462+deshanxiao@users.noreply.github.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Increase test memory to avoid OOM in TimSort-related tests.
## How was this patch tested?
Existing tests.
Closes#23425 from srowen/SPARK-26306.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The PR adds the `trainingCost` value to the `BisectingKMeansSummary`, in order to expose the information retrievable by running `computeCost` on the training dataset. This fills the gap with `KMeans` implementation.
## How was this patch tested?
improved UTs
Closes#22764 from mgaido91/SPARK-25765.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
A followup of https://github.com/apache/spark/pull/23178 , to keep binary compability by using abstract class.
## How was this patch tested?
Manual test. I created a simple app with Spark 2.4
```
object TryUDF {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("test").master("local[*]").getOrCreate()
import spark.implicits._
val f1 = udf((i: Int) => i + 1)
println(f1.deterministic)
spark.range(10).select(f1.asNonNullable().apply($"id")).show()
spark.stop()
}
}
```
When I run it with current master, it fails with
```
java.lang.IncompatibleClassChangeError: Found interface org.apache.spark.sql.expressions.UserDefinedFunction, but class was expected
```
When I run it with this PR, it works
Closes#23351 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Multiple SparkContexts are discouraged and it has been warning for last 4 years, see SPARK-4180. It could cause arbitrary and mysterious error cases, see SPARK-2243.
Honestly, I didn't even know Spark still allows it, which looks never officially supported, see SPARK-2243.
I believe It should be good timing now to remove this configuration.
## How was this patch tested?
Each doc was manually checked and manually tested:
```
$ ./bin/spark-shell --conf=spark.driver.allowMultipleContexts=true
...
scala> new SparkContext()
org.apache.spark.SparkException: Only one SparkContext should be running in this JVM (see SPARK-2243).The currently running SparkContext was created at:
org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:939)
...
org.apache.spark.SparkContext$.$anonfun$assertNoOtherContextIsRunning$2(SparkContext.scala:2435)
at scala.Option.foreach(Option.scala:274)
at org.apache.spark.SparkContext$.assertNoOtherContextIsRunning(SparkContext.scala:2432)
at org.apache.spark.SparkContext$.markPartiallyConstructed(SparkContext.scala:2509)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:80)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:112)
... 49 elided
```
Closes#23311 from HyukjinKwon/SPARK-26362.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The evaluators BinaryClassificationEvaluator, RegressionEvaluator, and MulticlassClassificationEvaluator and the corresponding metrics classes BinaryClassificationMetrics, RegressionMetrics and MulticlassMetrics should use sample weight data.
I've closed the PR: https://github.com/apache/spark/pull/16557
as recommended in favor of creating three pull requests, one for each of the evaluators (binary/regression/multiclass) to make it easier to review/update.
The updates to the regression metrics were based on (and updated with new changes based on comments):
https://issues.apache.org/jira/browse/SPARK-11520
("RegressionMetrics should support instance weights")
but the pull request was closed as the changes were never checked in.
## How was this patch tested?
I added tests to the metrics class.
Closes#17085 from imatiach-msft/ilmat/regression-evaluate.
Authored-by: Ilya Matiach <ilmat@microsoft.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
SBT 0.13.14 ~ 1.1.1 has a bug on accessing `java.util.Base64.getDecoder` with JDK9+. It's fixed at 1.1.2 and backported to [0.13.18 (released on Nov 28th)](https://github.com/sbt/sbt/releases/tag/v0.13.18). This PR aims to update SBT.
## How was this patch tested?
Pass the Jenkins with the building and existing tests.
Closes#23270 from dongjoon-hyun/SPARK-26317.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
1. Implement `SQLShuffleWriteMetricsReporter` on the SQL side as the customized `ShuffleWriteMetricsReporter`.
2. Add shuffle write metrics to `ShuffleExchangeExec`, and use these metrics to create corresponding `SQLShuffleWriteMetricsReporter` in shuffle dependency.
3. Rework on `ShuffleMapTask` to add new class named `ShuffleWriteProcessor` which control shuffle write process, we use sql shuffle write metrics by customizing a ShuffleWriteProcessor on SQL side.
## How was this patch tested?
Add UT in SQLMetricsSuite.
Manually test locally, update screen shot to document attached in JIRA.
Closes#23207 from xuanyuanking/SPARK-26193.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
Adds a new method to SparkAppHandle called getError which returns
the exception (if present) that caused the underlying Spark app to
fail.
New tests added to SparkLauncherSuite for the new method.
Closes#21849Closes#23221 from vanzin/SPARK-24243.
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
docker-image-tool.sh requires explicit argument to create the python
image now; do that from the sbt integration tests target too.
Closes#23172 from vanzin/SPARK-25957.followup.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
It's a bad idea to use case class as public API, as it has a very wide surface. For example, the `copy` method, its fields, the companion object, etc.
For a particular case, `UserDefinedFunction`. It has a private constructor, and I believe we only want users to access a few methods:`apply`, `nullable`, `asNonNullable`, etc.
However, all its fields, and `copy` method, and the companion object are public unexpectedly. As a result, we made many tricks to work around the binary compatibility issues.
This PR proposes to only make interfaces public, and hide implementations behind with a private class. Now `UserDefinedFunction` is a pure trait, and the concrete implementation is `SparkUserDefinedFunction`, which is private.
Changing class to interface is not binary compatible(but source compatible), so 3.0 is a good chance to do it.
This is the first PR to go with this direction. If it's accepted, I'll create a umbrella JIRA and fix all the public case classes.
## How was this patch tested?
existing tests.
Closes#23178 from cloud-fan/udf.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This is the first step of the data source v2 API refactor [proposal](https://docs.google.com/document/d/1uUmKCpWLdh9vHxP7AWJ9EgbwB_U6T3EJYNjhISGmiQg/edit?usp=sharing)
It adds the new API for batch read, without removing the old APIs, as they are still needed for streaming sources.
More concretely, it adds
1. `TableProvider`, works like an anonymous catalog
2. `Table`, represents a structured data set.
3. `ScanBuilder` and `Scan`, a logical represents of data source scan
4. `Batch`, a physical representation of data source batch scan.
## How was this patch tested?
existing tests
Closes#23086 from cloud-fan/refactor-batch.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
We have deprecated `OneHotEncoder` at Spark 2.3.0 and introduced `OneHotEncoderEstimator`. At 3.0.0, we remove deprecated `OneHotEncoder` and rename `OneHotEncoderEstimator` to `OneHotEncoder`.
TODO: According to ML migration guide, we need to keep `OneHotEncoderEstimator` as an alias after renaming. This is not done at this patch in order to facilitate review.
## How was this patch tested?
Existing tests.
Closes#23100 from viirya/remove_one_hot_encoder.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
The "build context" for a docker image - basically the whole contents of the
current directory where "docker" is invoked - can be huge in a dev build,
easily breaking a couple of gigs.
Doing that copy 3 times during the build of docker images severely slows
down the process.
This patch creates a smaller build context - basically mimicking what the
make-distribution.sh script does, so that when building the docker images,
only the necessary bits are in the current directory. For PySpark and R that
is optimized further, since those images are built based on the previously
built Spark main image.
In my current local clone, the dir size is about 2G, but with this script
the "context" sent to docker is about 250M for the main image, 1M for the
pyspark image and 8M for the R image. That speeds up the image builds
considerably.
I also snuck in a fix to the k8s integration test dependencies in the sbt
build, so that the examples are properly built (without having to do it
manually).
Closes#23019 from vanzin/SPARK-26025.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This is the write side counterpart to https://github.com/apache/spark/pull/23105
## How was this patch tested?
No behavior change expected, as it is a straightforward refactoring. Updated all existing test cases.
Closes#23106 from rxin/SPARK-26141.
Authored-by: Reynold Xin <rxin@databricks.com>
Signed-off-by: Reynold Xin <rxin@databricks.com>
## What changes were proposed in this pull request?
The PR removes the deprecated method `computeCost` of `KMeans`.
## How was this patch tested?
NA
Closes#22875 from mgaido91/SPARK-25867.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The setter methods are deprecated since 2.1 for the models of regression and classification using trees. The deprecation was stating that the method would have been removed in 3.0. Hence the PR removes the deprecated method.
## How was this patch tested?
NA
Closes#23093 from mgaido91/SPARK-26127.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Update many plugins we use to the latest version, especially MiMa, which entails excluding some new errors on old changes.
## How was this patch tested?
N/A
Closes#23087 from srowen/Plugins.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The build has a lot of deprecation warnings. Some are new in Scala 2.12 and Java 11. We've fixed some, but I wanted to take a pass at fixing lots of easy miscellaneous ones here.
They're too numerous and small to list here; see the pull request. Some highlights:
- `BeanInfo` is deprecated in 2.12, and BeanInfo classes are pretty ancient in Java. Instead, case classes can explicitly declare getters
- Eta expansion of zero-arg methods; foo() becomes () => foo() in many cases
- Floating-point Range is inexact and deprecated, like 0.0 to 100.0 by 1.0
- finalize() is finally deprecated (just needs to be suppressed)
- StageInfo.attempId was deprecated and easiest to remove here
I'm not now going to touch some chunks of deprecation warnings:
- Parquet deprecations
- Hive deprecations (particularly serde2 classes)
- Deprecations in generated code (mostly Thriftserver CLI)
- ProcessingTime deprecations (we may need to revive this class as internal)
- many MLlib deprecations because they concern methods that may be removed anyway
- a few Kinesis deprecations I couldn't figure out
- Mesos get/setRole, which I don't know well
- Kafka/ZK deprecations (e.g. poll())
- Kinesis
- a few other ones that will probably resolve by deleting a deprecated method
## How was this patch tested?
Existing tests, including manual testing with the 2.11 build and Java 11.
Closes#23065 from srowen/SPARK-26090.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Our `GBTClassifier` supports only `variance` impurity. But unfortunately, its `impurity` param by default contains the value `gini`: it is not even modifiable by the user and it differs from the actual impurity used, which is `variance`. This issue does not limit to a wrong value returned for it if the user queries by `getImpurity`, but it also affect the load of a saved model, as its `impurityStats` are created as `gini` (since this is the value stored for the model impurity) which leads to wrong `featureImportances` in model loaded from saved ones.
The PR changes the `impurity` param used to one which allows only the value `variance`.
## How was this patch tested?
modified UT
Closes#22986 from mgaido91/SPARK-25959.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR makes Spark's default Scala version as 2.12, and Scala 2.11 will be the alternative version. This implies that Scala 2.12 will be used by our CI builds including pull request builds.
We'll update the Jenkins to include a new compile-only jobs for Scala 2.11 to ensure the code can be still compiled with Scala 2.11.
## How was this patch tested?
existing tests
Closes#22967 from dbtsai/scala2.12.
Authored-by: DB Tsai <d_tsai@apple.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Since Spark 2.4.0 is already in maven repo, we can Bump previousSparkVersion in MimaBuild.scala to be 2.4.0.
Note that, seems we forgot to do it for branch 2.4, so this PR also updates MimaExcludes.scala
## How was this patch tested?
N/A
Closes#22977 from cloud-fan/mima.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Add `Locale.ROOT` to all internal calls to String `toLowerCase`, `toUpperCase`
## How was this patch tested?
existing tests
Closes#22975 from zhengruifeng/Tokenizer_Locale.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
- Remove some AccumulableInfo .apply() methods
- Remove non-label-specific multiclass precision/recall/fScore in favor of accuracy
- Remove toDegrees/toRadians in favor of degrees/radians (SparkR: only deprecated)
- Remove approxCountDistinct in favor of approx_count_distinct (SparkR: only deprecated)
- Remove unused Python StorageLevel constants
- Remove Dataset unionAll in favor of union
- Remove unused multiclass option in libsvm parsing
- Remove references to deprecated spark configs like spark.yarn.am.port
- Remove TaskContext.isRunningLocally
- Remove ShuffleMetrics.shuffle* methods
- Remove BaseReadWrite.context in favor of session
- Remove Column.!== in favor of =!=
- Remove Dataset.explode
- Remove Dataset.registerTempTable
- Remove SQLContext.getOrCreate, setActive, clearActive, constructors
Not touched yet
- everything else in MLLib
- HiveContext
- Anything deprecated more recently than 2.0.0, generally
## How was this patch tested?
Existing tests
Closes#22921 from srowen/SPARK-25908.
Lead-authored-by: Sean Owen <sean.owen@databricks.com>
Co-authored-by: hyukjinkwon <gurwls223@apache.org>
Co-authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
The integration tests can now be run in sbt if the right profile
is enabled, using the "test" task under the respective project.
This avoids having to fall back to maven to run the tests, which
invalidates all your compiled stuff when you go back to sbt, making
development way slower than it should.
There's also a task to run the tests directly without refreshing
the docker images, which is helpful if you just made a change to
the submission code which should not affect the code in the images.
The sbt tasks currently are not very customizable; there's some
very minor things you can set in the sbt shell itself, but otherwise
it's hardcoded to run on minikube.
I also had to make some slight adjustments to the IT code itself,
mostly to remove assumptions about the existing harness.
Tested on sbt and maven.
Closes#22909 from vanzin/SPARK-25897.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Remove JavaSparkContextVarargsWorkaround
## How was this patch tested?
Existing tests.
Closes#22729 from srowen/SPARK-25737.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove deprecated accumulator v1
## How was this patch tested?
Existing tests.
Closes#22730 from srowen/SPARK-16775.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The SQL execution listener framework was created from scratch(see https://github.com/apache/spark/pull/9078). It didn't leverage what we already have in the spark listener framework, and one major problem is, the listener runs on the spark execution thread, which means a bad listener can block spark's query processing.
This PR re-implements the SQL execution listener framework. Now `ExecutionListenerManager` is just a normal spark listener, which watches the `SparkListenerSQLExecutionEnd` events and post events to the
user-provided SQL execution listeners.
## How was this patch tested?
existing tests.
Closes#22674 from cloud-fan/listener.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Remove Kafka 0.8 integration
## How was this patch tested?
Existing tests, build scripts
Closes#22703 from srowen/SPARK-25705.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Fix old oversight in API: Java `flatMapValues` needs a `FlatMapFunction`
## How was this patch tested?
Existing tests.
Closes#22690 from srowen/SPARK-19287.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Removes all vestiges of Flume in the build, for Spark 3.
I don't think this needs Jenkins config changes.
## How was this patch tested?
Existing tests.
Closes#22692 from srowen/SPARK-25598.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove SnappyOutputStreamWrapper and other workaround now that new Snappy fixes these.
See also https://github.com/apache/spark/pull/21176 and comments it links to.
## How was this patch tested?
Existing tests
Closes#22691 from srowen/SPARK-24109.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This is the same as #22492 but for master branch. Revert SPARK-14681 to avoid API breaking changes.
cc: WeichenXu123
## How was this patch tested?
Existing unit tests.
Closes#22618 from mengxr/SPARK-25321.master.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This patch is to bump the master branch version to 3.0.0-SNAPSHOT.
## How was this patch tested?
N/A
Closes#22606 from gatorsmile/bump3.0.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In the dev list, we can still discuss whether the next version is 2.5.0 or 3.0.0. Let us first bump the master branch version to `2.5.0-SNAPSHOT`.
## How was this patch tested?
N/A
Closes#22426 from gatorsmile/bumpVersionMaster.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
Add new executor level memory metrics (JVM used memory, on/off heap execution memory, on/off heap storage memory, on/off heap unified memory, direct memory, and mapped memory), and expose via the executors REST API. This information will help provide insight into how executor and driver JVM memory is used, and for the different memory regions. It can be used to help determine good values for spark.executor.memory, spark.driver.memory, spark.memory.fraction, and spark.memory.storageFraction.
## What changes were proposed in this pull request?
An ExecutorMetrics class is added, with jvmUsedHeapMemory, jvmUsedNonHeapMemory, onHeapExecutionMemory, offHeapExecutionMemory, onHeapStorageMemory, and offHeapStorageMemory, onHeapUnifiedMemory, offHeapUnifiedMemory, directMemory and mappedMemory. The new ExecutorMetrics is sent by executors to the driver as part of the Heartbeat. A heartbeat is added for the driver as well, to collect these metrics for the driver.
The EventLoggingListener store information about the peak values for each metric, per active stage and executor. When a StageCompleted event is seen, a StageExecutorsMetrics event will be logged for each executor, with peak values for the stage.
The AppStatusListener records the peak values for each memory metric.
The new memory metrics are added to the executors REST API.
## How was this patch tested?
New unit tests have been added. This was also tested on our cluster.
Author: Edwina Lu <edlu@linkedin.com>
Author: Imran Rashid <irashid@cloudera.com>
Author: edwinalu <edwina.lu@gmail.com>
Closes#21221 from edwinalu/SPARK-23429.2.
## What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/22259 .
Scala case class has a wide surface: apply, unapply, accessors, copy, etc.
In https://github.com/apache/spark/pull/22259 , we change the type of `UserDefinedFunction.inputTypes` from `Option[Seq[DataType]]` to `Option[Seq[Schema]]`. This breaks backward compatibility.
This PR changes the type back, and use a `var` to keep the new nullable info.
## How was this patch tested?
N/A
Closes#22319 from cloud-fan/revert.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
I made one pass over barrier APIs added to Spark 2.4 and updates some scopes and docs. I will update Python docs once Scala doc was reviewed.
One major issue is that `BarrierTaskContext` implements `TaskContextImpl` that exposes some public methods. And internally there were several direct references to `TaskContextImpl` methods instead of `TaskContext`. This PR moved some methods from `TaskContextImpl` to `TaskContext`, remaining package private, and used delegate methods to avoid inheriting `TaskContextImp` and exposing unnecessary APIs.
TODOs:
- [x] scala doc
- [x] python doc (#22261 ).
Closes#22240 from mengxr/SPARK-25248.
Authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
Improve build for Scala 2.12. Current build for sbt fails on the subproject `repl`:
```
[info] Compiling 6 Scala sources to /Users/rendong/wdi/spark/repl/target/scala-2.12/classes...
[error] /Users/rendong/wdi/spark/repl/scala-2.11/src/main/scala/org/apache/spark/repl/SparkILoopInterpreter.scala:80: overriding lazy value importableSymbolsWithRenames in class ImportHandler of type List[(this.intp.global.Symbol, this.intp.global.Name)];
[error] lazy value importableSymbolsWithRenames needs `override' modifier
[error] lazy val importableSymbolsWithRenames: List[(Symbol, Name)] = {
[error] ^
[warn] /Users/rendong/wdi/spark/repl/src/main/scala/org/apache/spark/repl/SparkILoop.scala:53: variable addedClasspath in class ILoop is deprecated (since 2.11.0): use reset, replay or require to update class path
[warn] if (addedClasspath != "") {
[warn] ^
[warn] /Users/rendong/wdi/spark/repl/src/main/scala/org/apache/spark/repl/SparkILoop.scala:54: variable addedClasspath in class ILoop is deprecated (since 2.11.0): use reset, replay or require to update class path
[warn] settings.classpath append addedClasspath
[warn] ^
[warn] two warnings found
[error] one error found
[error] (repl/compile:compileIncremental) Compilation failed
[error] Total time: 93 s, completed 2018-9-3 10:07:26
```
## How was this patch tested?
```
./dev/change-scala-version.sh 2.12
## For Maven
./build/mvn -Pscala-2.12 [mvn commands]
## For SBT
sbt -Dscala.version=2.12.6
```
Closes#22310 from sadhen/SPARK-25298.
Authored-by: Darcy Shen <sadhen@zoho.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The PR adds the lift measure to Association rules.
## How was this patch tested?
existing and modified UTs
Closes#22236 from mgaido91/SPARK-10697.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Alternative take on https://github.com/apache/spark/pull/22063 that does not introduce udfInternal.
Resolve issue with inferring func types in 2.12 by instead using info captured when UDF is registered -- capturing which types are nullable (i.e. not primitive)
## How was this patch tested?
Existing tests.
Closes#22259 from srowen/SPARK-25044.2.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
When replicating large cached RDD blocks, it can be helpful to replicate
them as a stream, to avoid using large amounts of memory during the
transfer. This also allows blocks larger than 2GB to be replicated.
Added unit tests in DistributedSuite. Also ran tests on a cluster for
blocks > 2gb.
Closes#21451 from squito/clean_replication.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
When starting spark-shell from Mac terminal (MacOS High Sirra Version 10.13.6), Getting exception
[ERROR] Failed to construct terminal; falling back to unsupported
java.lang.NumberFormatException: For input string: "0x100"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Integer.parseInt(Integer.java:580)
at java.lang.Integer.valueOf(Integer.java:766)
at jline.internal.InfoCmp.parseInfoCmp(InfoCmp.java:59)
at jline.UnixTerminal.parseInfoCmp(UnixTerminal.java:242)
at jline.UnixTerminal.<init>(UnixTerminal.java:65)
at jline.UnixTerminal.<init>(UnixTerminal.java:50)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at java.lang.Class.newInstance(Class.java:442)
at jline.TerminalFactory.getFlavor(TerminalFactory.java:211)
This issue is due a jline defect : https://github.com/jline/jline2/issues/281, which is fixed in Jline 2.14.4, bumping up JLine version in spark to version >= Jline 2.14.4 will fix the issue
## How was this patch tested?
No new UT/automation test added, after upgrade to latest Jline version 2.14.6, manually tested spark shell features
Closes#22130 from vinodkc/br_UpgradeJLineVersion.
Authored-by: Vinod KC <vinod.kc.in@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In MultilayerPerceptronClassifier, we use RDD operation to encode labels for now. I think we should use ML's OneHotEncoderEstimator/Model to do the encoding.
## How was this patch tested?
Existing tests.
Closes#20232 from viirya/SPARK-23042.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
## What changes were proposed in this pull request?
Added the number of iterations in `ClusteringSummary`. This is an helpful information in evaluating how to eventually modify the parameters in order to get a better model.
## How was this patch tested?
modified existing UTs
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20701 from mgaido91/SPARK-23528.
## What changes were proposed in this pull request?
Apache Avro (https://avro.apache.org) is a popular data serialization format. It is widely used in the Spark and Hadoop ecosystem, especially for Kafka-based data pipelines. Using the external package https://github.com/databricks/spark-avro, Spark SQL can read and write the avro data. Making spark-Avro built-in can provide a better experience for first-time users of Spark SQL and structured streaming. We expect the built-in Avro data source can further improve the adoption of structured streaming.
The proposal is to inline code from spark-avro package (https://github.com/databricks/spark-avro). The target release is Spark 2.4.
[Built-in AVRO Data Source In Spark 2.4.pdf](https://github.com/apache/spark/files/2181511/Built-in.AVRO.Data.Source.In.Spark.2.4.pdf)
## How was this patch tested?
Unit test
Author: Gengliang Wang <gengliang.wang@databricks.com>
Closes#21742 from gengliangwang/export_avro.
## What changes were proposed in this pull request?
During SPARK-24418 (Upgrade Scala to 2.11.12 and 2.12.6), we upgrade `jline` version together. So, `mvn` works correctly. However, `sbt` brings old jline library and is hitting `NoSuchMethodError` in `master` branch, see https://github.com/apache/spark/pull/21495#issuecomment-401560826. This overrides jline version in SBT to make sbt build work.
## How was this patch tested?
Manually test.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#21692 from viirya/SPARK-24715.
These changes allow an RPCHandler to receive an upload as a stream of
data, without having to buffer the entire message in the FrameDecoder.
The primary use case is for replicating large blocks. By itself, this change is adding dead-code that is not being used -- it is a step towards SPARK-24296.
Added unit tests for handling streaming data, including successfully sending data, and failures in reading the stream with concurrent requests.
Summary of changes:
* Introduce a new UploadStream RPC which is sent to push a large payload as a stream (in contrast, the pre-existing StreamRequest and StreamResponse RPCs are used for pull-based streaming).
* Generalize RpcHandler.receive() to support requests which contain streams.
* Generalize StreamInterceptor to handle both request and response messages (previously it only handled responses).
* Introduce StdChannelListener to abstract away common logging logic in ChannelFuture listeners.
Author: Imran Rashid <irashid@cloudera.com>
Closes#21346 from squito/upload_stream.
{kind=link}