## What changes were proposed in this pull request?
In the `getBlockData`,`blockId.reduceId` is the `Int` type, when it is greater than 2^28, `blockId.reduceId*8` will overflow
In the `decompress0`, `len` and `unitSize` are Int type, so `len * unitSize` may lead to overflow
## How was this patch tested?
N/A
Author: liuxian <liu.xian3@zte.com.cn>
Closes#20581 from 10110346/overflow2.
## What changes were proposed in this pull request?
This is a regression in Spark 2.3.
In Spark 2.2, we have a fragile UI support for SQL data writing commands. We only track the input query plan of `FileFormatWriter` and display its metrics. This is not ideal because we don't know who triggered the writing(can be table insertion, CTAS, etc.), but it's still useful to see the metrics of the input query.
In Spark 2.3, we introduced a new mechanism: `DataWritigCommand`, to fix the UI issue entirely. Now these writing commands have real children, and we don't need to hack into the `FileFormatWriter` for the UI. This also helps with `explain`, now `explain` can show the physical plan of the input query, while in 2.2 the physical writing plan is simply `ExecutedCommandExec` and it has no child.
However there is a regression in CTAS. CTAS commands don't extend `DataWritigCommand`, and we don't have the UI hack in `FileFormatWriter` anymore, so the UI for CTAS is just an empty node. See https://issues.apache.org/jira/browse/SPARK-22977 for more information about this UI issue.
To fix it, we should apply the `DataWritigCommand` mechanism to CTAS commands.
TODO: In the future, we should refactor this part and create some physical layer code pieces for data writing, and reuse them in different writing commands. We should have different logical nodes for different operators, even some of them share some same logic, e.g. CTAS, CREATE TABLE, INSERT TABLE. Internally we can share the same physical logic.
## How was this patch tested?
manually tested.
For data source table
<img width="644" alt="1" src="https://user-images.githubusercontent.com/3182036/35874155-bdffab28-0ba6-11e8-94a8-e32e106ba069.png">
For hive table
<img width="666" alt="2" src="https://user-images.githubusercontent.com/3182036/35874161-c437e2a8-0ba6-11e8-98ed-7930f01432c5.png">
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20521 from cloud-fan/UI.
## What changes were proposed in this pull request?
Currently, we use SBT and MAVN to spark unit test, are affected by the parameters of `spark.testing`. However, when using the IDE test tool, `spark.testing` support is not very good, sometimes need to be manually added to the beforeEach. example: HiveSparkSubmitSuite RPackageUtilsSuite SparkSubmitSuite. The PR unified `spark.testing` parameter extraction to SparkFunSuite, support IDE test tool, and the test code is more compact.
## How was this patch tested?
the existed test cases.
Author: caoxuewen <cao.xuewen@zte.com.cn>
Closes#20582 from heary-cao/sparktesting.
## What changes were proposed in this pull request?
This PR targets to explicitly specify supported types in Pandas UDFs.
The main change here is to add a deduplicated and explicit type checking in `returnType` ahead with documenting this; however, it happened to fix multiple things.
1. Currently, we don't support `BinaryType` in Pandas UDFs, for example, see:
```python
from pyspark.sql.functions import pandas_udf
pudf = pandas_udf(lambda x: x, "binary")
df = spark.createDataFrame([[bytearray(1)]])
df.select(pudf("_1")).show()
```
```
...
TypeError: Unsupported type in conversion to Arrow: BinaryType
```
We can document this behaviour for its guide.
2. Also, the grouped aggregate Pandas UDF fails fast on `ArrayType` but seems we can support this case.
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
foo = pandas_udf(lambda v: v.mean(), 'array<double>', PandasUDFType.GROUPED_AGG)
df = spark.range(100).selectExpr("id", "array(id) as value")
df.groupBy("id").agg(foo("value")).show()
```
```
...
NotImplementedError: ArrayType, StructType and MapType are not supported with PandasUDFType.GROUPED_AGG
```
3. Since we can check the return type ahead, we can fail fast before actual execution.
```python
# we can fail fast at this stage because we know the schema ahead
pandas_udf(lambda x: x, BinaryType())
```
## How was this patch tested?
Manually tested and unit tests for `BinaryType` and `ArrayType(...)` were added.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20531 from HyukjinKwon/pudf-cleanup.
## What changes were proposed in this pull request?
This test only fails with sbt on Hadoop 2.7, I can't reproduce it locally, but here is my speculation by looking at the code:
1. FileSystem.delete doesn't delete the directory entirely, somehow we can still open the file as a 0-length empty file.(just speculation)
2. ORC intentionally allow empty files, and the reader fails during reading without closing the file stream.
This PR improves the test to make sure all files are deleted and can't be opened.
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20584 from cloud-fan/flaky-test.
## What changes were proposed in this pull request?
In #19340 some comments considered needed to use spherical KMeans when cosine distance measure is specified, as Matlab does; instead of the implementation based on the behavior of other tools/libraries like Rapidminer, nltk and ELKI, ie. the centroids are computed as the mean of all the points in the clusters.
The PR introduce the approach used in spherical KMeans. This behavior has the nice feature to minimize the within-cluster cosine distance.
## How was this patch tested?
existing/improved UTs
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20518 from mgaido91/SPARK-22119_followup.
## What changes were proposed in this pull request?
This is a long-standing bug in `UnsafeKVExternalSorter` and was reported in the dev list multiple times.
When creating `UnsafeKVExternalSorter` with `BytesToBytesMap`, we need to create a `UnsafeInMemorySorter` to sort the data in `BytesToBytesMap`. The data format of the sorter and the map is same, so no data movement is required. However, both the sorter and the map need a point array for some bookkeeping work.
There is an optimization in `UnsafeKVExternalSorter`: reuse the point array between the sorter and the map, to avoid an extra memory allocation. This sounds like a reasonable optimization, the length of the `BytesToBytesMap` point array is at least 4 times larger than the number of keys(to avoid hash collision, the hash table size should be at least 2 times larger than the number of keys, and each key occupies 2 slots). `UnsafeInMemorySorter` needs the pointer array size to be 4 times of the number of entries, so we are safe to reuse the point array.
However, the number of keys of the map doesn't equal to the number of entries in the map, because `BytesToBytesMap` supports duplicated keys. This breaks the assumption of the above optimization and we may run out of space when inserting data into the sorter, and hit error
```
java.lang.IllegalStateException: There is no space for new record
at org.apache.spark.util.collection.unsafe.sort.UnsafeInMemorySorter.insertRecord(UnsafeInMemorySorter.java:239)
at org.apache.spark.sql.execution.UnsafeKVExternalSorter.<init>(UnsafeKVExternalSorter.java:149)
...
```
This PR fixes this bug by creating a new point array if the existing one is not big enough.
## How was this patch tested?
a new test
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20561 from cloud-fan/bug.
## What changes were proposed in this pull request?
Expose range partitioning shuffle introduced by spark-22614
## How was this patch tested?
Unit test in dataframe.py
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: xubo245 <601450868@qq.com>
Closes#20456 from xubo245/SPARK22624_PysparkRangePartition.
## What changes were proposed in this pull request?
Added unboundedPreceding(), unboundedFollowing() and currentRow() to PySpark, also updated the rangeBetween API
## How was this patch tested?
did unit test on my local. Please let me know if I need to add unit test in tests.py
Author: Huaxin Gao <huaxing@us.ibm.com>
Closes#20400 from huaxingao/spark_23084.
## What changes were proposed in this pull request?
When tz_localize a tz-naive timetamp, pandas will throw exception if the timestamp is during daylight saving time period, e.g., `2015-11-01 01:30:00`. This PR fixes this issue by setting `ambiguous=False` when calling tz_localize, which is the same default behavior of pytz.
## How was this patch tested?
Add `test_timestamp_dst`
Author: Li Jin <ice.xelloss@gmail.com>
Closes#20537 from icexelloss/SPARK-23314.
## What changes were proposed in this pull request?
SPARK-22119 introduced a new parameter for KMeans, ie. `distanceMeasure`. The PR adds it also to the Python interface.
## How was this patch tested?
added UTs
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20520 from mgaido91/SPARK-23344.
## What changes were proposed in this pull request?
Currently we use `tzlocal()` to get Python local timezone, but it sometimes causes unexpected behavior.
I changed the way to get Python local timezone to use pytz if the timezone is specified in environment variable, or timezone file via dateutil .
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20559 from ueshin/issues/SPARK-23360/master.
## What changes were proposed in this pull request?
This is a follow up of https://github.com/apache/spark/pull/20441.
The two lines actually can trigger the hive metastore bug: https://issues.apache.org/jira/browse/HIVE-16844
The two configs are not in the default `ObjectStore` properties, so any run hive commands after these two lines will set the `propsChanged` flag in the `ObjectStore.setConf` and then cause thread leaks.
I don't think the two lines are very useful. They can be removed safely.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Feng Liu <fengliu@databricks.com>
Closes#20562 from liufengdb/fix-omm.
## What changes were proposed in this pull request?
Typo fixes (with expanding a Hive property)
## How was this patch tested?
local build. Awaiting Jenkins
Author: Jacek Laskowski <jacek@japila.pl>
Closes#20550 from jaceklaskowski/hiveutils-typos.
This commit modifies the Mesos submission client to allow the principal
and secret to be provided indirectly via files. The path to these files
can be specified either via Spark configuration or via environment
variable.
Assuming these files are appropriately protected by FS/OS permissions
this means we don't ever leak the actual values in process info like ps
Environment variable specification is useful because it allows you to
interpolate the location of this file when using per-user Mesos
credentials.
For some background as to why we have taken this approach I will briefly describe our set up. On our systems we provide each authorised user account with their own Mesos credentials to provide certain security and audit guarantees to our customers. These credentials are managed by a central Secret management service. In our `spark-env.sh` we determine the appropriate secret and principal files to use depending on the user who is invoking Spark hence the need to inject these via environment variables as well as by configuration properties. So we set these environment variables appropriately and our Spark read in the contents of those files to authenticate itself with Mesos.
This is functionality we have been using it in production across multiple customer sites for some time. This has been in the field for around 18 months with no reported issues. These changes have been sufficient to meet our customer security and audit requirements.
We have been building and deploying custom builds of Apache Spark with various minor tweaks like this which we are now looking to contribute back into the community in order that we can rely upon stock Apache Spark builds and stop maintaining our own internal fork.
Author: Rob Vesse <rvesse@dotnetrdf.org>
Closes#20167 from rvesse/SPARK-16501.
## What changes were proposed in this pull request?
#19077 introduced a Java style error (too long line). Quick fix.
## How was this patch tested?
running `./dev/lint-java`
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20558 from mgaido91/SPARK-21860.
## What changes were proposed in this pull request?
In the `checkIndexAndDataFile`,the `blocks` is the ` Int` type, when it is greater than 2^28, `blocks*8` will overflow, and this will result in an error result.
In fact, `blocks` is actually the number of partitions.
## How was this patch tested?
Manual test
Author: liuxian <liu.xian3@zte.com.cn>
Closes#20544 from 10110346/overflow.
## What changes were proposed in this pull request?
This PR proposes to disallow default value None when 'to_replace' is not a dictionary.
It seems weird we set the default value of `value` to `None` and we ended up allowing the case as below:
```python
>>> df.show()
```
```
+----+------+-----+
| age|height| name|
+----+------+-----+
| 10| 80|Alice|
...
```
```python
>>> df.na.replace('Alice').show()
```
```
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80|null|
...
```
**After**
This PR targets to disallow the case above:
```python
>>> df.na.replace('Alice').show()
```
```
...
TypeError: value is required when to_replace is not a dictionary.
```
while we still allow when `to_replace` is a dictionary:
```python
>>> df.na.replace({'Alice': None}).show()
```
```
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80|null|
...
```
## How was this patch tested?
Manually tested, tests were added in `python/pyspark/sql/tests.py` and doctests were fixed.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20499 from HyukjinKwon/SPARK-19454-followup.
## What changes were proposed in this pull request?
This PR upgrade snappy-java from 1.1.2.6 to 1.1.7.1.
1.1.7.1 release notes:
- Improved performance for big-endian architecture
- The other performance improvement in [snappy-1.1.5](https://github.com/google/snappy/releases/tag/1.1.5)
1.1.4 release notes:
- Fix a 1% performance regression when snappy is used in PIE executables.
- Improve compression performance by 5%.
- Improve decompression performance by 20%.
More details:
https://github.com/xerial/snappy-java/blob/master/Milestone.md
## How was this patch tested?
manual tests
Author: Yuming Wang <wgyumg@gmail.com>
Closes#20510 from wangyum/SPARK-23336.
## What changes were proposed in this pull request?
In `HeapMemoryAllocator`, when allocating memory from pool, and the key of pool is memory size.
Actually some size of memory ,such as 1025bytes,1026bytes,......1032bytes, we can think they are the same,because we allocate memory in multiples of 8 bytes.
In this case, we can improve memory reuse.
## How was this patch tested?
Existing tests and added unit tests
Author: liuxian <liu.xian3@zte.com.cn>
Closes#19077 from 10110346/headmemoptimize.
## What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/20435.
While reorganizing the packages for streaming data source v2, the top level stream read/write support interfaces should not be in the reader/writer package, but should be in the `sources.v2` package, to follow the `ReadSupport`, `WriteSupport`, etc.
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20509 from cloud-fan/followup.
## What changes were proposed in this pull request?
For inserting/appending data to an existing table, Spark should adjust the data types of the input query according to the table schema, or fail fast if it's uncastable.
There are several ways to insert/append data: SQL API, `DataFrameWriter.insertInto`, `DataFrameWriter.saveAsTable`. The first 2 ways create `InsertIntoTable` plan, and the last way creates `CreateTable` plan. However, we only adjust input query data types for `InsertIntoTable`, and users may hit weird errors when appending data using `saveAsTable`. See the JIRA for the error case.
This PR fixes this bug by adjusting data types for `CreateTable` too.
## How was this patch tested?
new test.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20527 from cloud-fan/saveAsTable.
## What changes were proposed in this pull request?
This is to revert the changes made in https://github.com/apache/spark/pull/19499 , because this causes a regression. We should not ignore the table-specific compression conf when the Hive serde tables are converted to the data source tables.
## How was this patch tested?
The existing tests.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20536 from gatorsmile/revert22279.
## What changes were proposed in this pull request?
This is a followup pr of #20487.
When importing module but it doesn't exists, the error message is slightly different between Python 2 and 3.
E.g., in Python 2:
```
No module named pandas
```
in Python 3:
```
No module named 'pandas'
```
So, one test to check an import error fails in Python 3 without pandas.
This pr fixes it.
## How was this patch tested?
Tested manually in my local environment.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20538 from ueshin/issues/SPARK-23319/fup1.
## What changes were proposed in this pull request?
This PR migrates the MemoryStream to DataSourceV2 APIs.
One additional change is in the reported keys in StreamingQueryProgress.durationMs. "getOffset" and "getBatch" replaced with "setOffsetRange" and "getEndOffset" as tracking these make more sense. Unit tests changed accordingly.
## How was this patch tested?
Existing unit tests, few updated unit tests.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Author: Burak Yavuz <brkyvz@gmail.com>
Closes#20445 from tdas/SPARK-23092.
## What changes were proposed in this pull request?
When `DebugFilesystem` closes opened stream, if any exception occurs, we still need to remove the open stream record from `DebugFilesystem`. Otherwise, it goes to report leaked filesystem connection.
## How was this patch tested?
Existing tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20524 from viirya/SPARK-23345.
## What changes were proposed in this pull request?
This PR proposes to explicitly specify Pandas and PyArrow versions in PySpark tests to skip or test.
We declared the extra dependencies:
b8bfce51ab/python/setup.py (L204)
In case of PyArrow:
Currently we only check if pyarrow is installed or not without checking the version. It already fails to run tests. For example, if PyArrow 0.7.0 is installed:
```
======================================================================
ERROR: test_vectorized_udf_wrong_return_type (pyspark.sql.tests.ScalarPandasUDF)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/.../spark/python/pyspark/sql/tests.py", line 4019, in test_vectorized_udf_wrong_return_type
f = pandas_udf(lambda x: x * 1.0, MapType(LongType(), LongType()))
File "/.../spark/python/pyspark/sql/functions.py", line 2309, in pandas_udf
return _create_udf(f=f, returnType=return_type, evalType=eval_type)
File "/.../spark/python/pyspark/sql/udf.py", line 47, in _create_udf
require_minimum_pyarrow_version()
File "/.../spark/python/pyspark/sql/utils.py", line 132, in require_minimum_pyarrow_version
"however, your version was %s." % pyarrow.__version__)
ImportError: pyarrow >= 0.8.0 must be installed on calling Python process; however, your version was 0.7.0.
----------------------------------------------------------------------
Ran 33 tests in 8.098s
FAILED (errors=33)
```
In case of Pandas:
There are few tests for old Pandas which were tested only when Pandas version was lower, and I rewrote them to be tested when both Pandas version is lower and missing.
## How was this patch tested?
Manually tested by modifying the condition:
```
test_createDataFrame_column_name_encoding (pyspark.sql.tests.ArrowTests) ... skipped 'Pandas >= 1.19.2 must be installed; however, your version was 0.19.2.'
test_createDataFrame_does_not_modify_input (pyspark.sql.tests.ArrowTests) ... skipped 'Pandas >= 1.19.2 must be installed; however, your version was 0.19.2.'
test_createDataFrame_respect_session_timezone (pyspark.sql.tests.ArrowTests) ... skipped 'Pandas >= 1.19.2 must be installed; however, your version was 0.19.2.'
```
```
test_createDataFrame_column_name_encoding (pyspark.sql.tests.ArrowTests) ... skipped 'Pandas >= 0.19.2 must be installed; however, it was not found.'
test_createDataFrame_does_not_modify_input (pyspark.sql.tests.ArrowTests) ... skipped 'Pandas >= 0.19.2 must be installed; however, it was not found.'
test_createDataFrame_respect_session_timezone (pyspark.sql.tests.ArrowTests) ... skipped 'Pandas >= 0.19.2 must be installed; however, it was not found.'
```
```
test_createDataFrame_column_name_encoding (pyspark.sql.tests.ArrowTests) ... skipped 'PyArrow >= 1.8.0 must be installed; however, your version was 0.8.0.'
test_createDataFrame_does_not_modify_input (pyspark.sql.tests.ArrowTests) ... skipped 'PyArrow >= 1.8.0 must be installed; however, your version was 0.8.0.'
test_createDataFrame_respect_session_timezone (pyspark.sql.tests.ArrowTests) ... skipped 'PyArrow >= 1.8.0 must be installed; however, your version was 0.8.0.'
```
```
test_createDataFrame_column_name_encoding (pyspark.sql.tests.ArrowTests) ... skipped 'PyArrow >= 0.8.0 must be installed; however, it was not found.'
test_createDataFrame_does_not_modify_input (pyspark.sql.tests.ArrowTests) ... skipped 'PyArrow >= 0.8.0 must be installed; however, it was not found.'
test_createDataFrame_respect_session_timezone (pyspark.sql.tests.ArrowTests) ... skipped 'PyArrow >= 0.8.0 must be installed; however, it was not found.'
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20487 from HyukjinKwon/pyarrow-pandas-skip.
## What changes were proposed in this pull request?
Replace `registerTempTable` by `createOrReplaceTempView`.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20523 from gatorsmile/updateExamples.
## What changes were proposed in this pull request?
Update the description and tests of three external API or functions `createFunction `, `length` and `repartitionByRange `
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20495 from gatorsmile/updateFunc.
## What changes were proposed in this pull request?
`DataSourceV2Relation` keeps a `fullOutput` and resolves the real output on demand by column name lookup. i.e.
```
lazy val output: Seq[Attribute] = reader.readSchema().map(_.name).map { name =>
fullOutput.find(_.name == name).get
}
```
This will be broken after we canonicalize the plan, because all attribute names become "None", see https://github.com/apache/spark/blob/v2.3.0-rc1/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Canonicalize.scala#L42
To fix this, `DataSourceV2Relation` should just keep `output`, and update the `output` when doing column pruning.
## How was this patch tested?
a new test case
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20485 from cloud-fan/canonicalize.
## What changes were proposed in this pull request?
In b2ce17b4c9, I mistakenly renamed `VectorizedUDFTests` to `ScalarPandasUDF`. This PR fixes the mistake.
## How was this patch tested?
Existing tests.
Author: Li Jin <ice.xelloss@gmail.com>
Closes#20489 from icexelloss/fix-scalar-udf-tests.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/20483 tried to provide a way to turn off the new columnar cache reader, to restore the behavior in 2.2. However even we turn off that config, the behavior is still different than 2.2.
If the output data are rows, we still enable whole stage codegen for the scan node, which is different with 2.2, we should also fix it.
## How was this patch tested?
existing tests.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20513 from cloud-fan/cache.
## What changes were proposed in this pull request?
This is a follow-up of #20492 which broke lint-java checks.
This pr fixes the lint-java issues.
```
[ERROR] src/main/java/org/apache/spark/util/collection/unsafe/sort/UnsafeSorterSpillReader.java:[79] (sizes) LineLength: Line is longer than 100 characters (found 114).
```
## How was this patch tested?
Checked manually in my local environment.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20514 from ueshin/issues/SPARK-23310/fup1.
## What changes were proposed in this pull request?
In Python 2, when `pandas_udf` tries to return string type value created in the udf with `".."`, the execution fails. E.g.,
```python
from pyspark.sql.functions import pandas_udf, col
import pandas as pd
df = spark.range(10)
str_f = pandas_udf(lambda x: pd.Series(["%s" % i for i in x]), "string")
df.select(str_f(col('id'))).show()
```
raises the following exception:
```
...
java.lang.AssertionError: assertion failed: Invalid schema from pandas_udf: expected StringType, got BinaryType
at scala.Predef$.assert(Predef.scala:170)
at org.apache.spark.sql.execution.python.ArrowEvalPythonExec$$anon$2.<init>(ArrowEvalPythonExec.scala:93)
...
```
Seems like pyarrow ignores `type` parameter for `pa.Array.from_pandas()` and consider it as binary type when the type is string type and the string values are `str` instead of `unicode` in Python 2.
This pr adds a workaround for the case.
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20507 from ueshin/issues/SPARK-23334.
## What changes were proposed in this pull request?
This PR proposes to log if PyArrow and Pandas are installed or not so we can check if related tests are going to be skipped or not.
## How was this patch tested?
Manually tested:
I don't have PyArrow installed in PyPy.
```bash
$ ./run-tests --python-executables=python3
```
```
...
Will test against the following Python executables: ['python3']
Will test the following Python modules: ['pyspark-core', 'pyspark-ml', 'pyspark-mllib', 'pyspark-sql', 'pyspark-streaming']
Will test PyArrow related features against Python executable 'python3' in 'pyspark-sql' module.
Will test Pandas related features against Python executable 'python3' in 'pyspark-sql' module.
Starting test(python3): pyspark.mllib.tests
Starting test(python3): pyspark.sql.tests
Starting test(python3): pyspark.streaming.tests
Starting test(python3): pyspark.tests
```
```bash
$ ./run-tests --modules=pyspark-streaming
```
```
...
Will test against the following Python executables: ['python2.7', 'pypy']
Will test the following Python modules: ['pyspark-streaming']
Starting test(pypy): pyspark.streaming.tests
Starting test(pypy): pyspark.streaming.util
Starting test(python2.7): pyspark.streaming.tests
Starting test(python2.7): pyspark.streaming.util
```
```bash
$ ./run-tests
```
```
...
Will test against the following Python executables: ['python2.7', 'pypy']
Will test the following Python modules: ['pyspark-core', 'pyspark-ml', 'pyspark-mllib', 'pyspark-sql', 'pyspark-streaming']
Will test PyArrow related features against Python executable 'python2.7' in 'pyspark-sql' module.
Will test Pandas related features against Python executable 'python2.7' in 'pyspark-sql' module.
Will skip PyArrow related features against Python executable 'pypy' in 'pyspark-sql' module. PyArrow >= 0.8.0 is required; however, PyArrow was not found.
Will test Pandas related features against Python executable 'pypy' in 'pyspark-sql' module.
Starting test(pypy): pyspark.streaming.tests
Starting test(pypy): pyspark.sql.tests
Starting test(pypy): pyspark.tests
Starting test(python2.7): pyspark.mllib.tests
```
```bash
$ ./run-tests --modules=pyspark-sql --python-executables=pypy
```
```
...
Will test against the following Python executables: ['pypy']
Will test the following Python modules: ['pyspark-sql']
Will skip PyArrow related features against Python executable 'pypy' in 'pyspark-sql' module. PyArrow >= 0.8.0 is required; however, PyArrow was not found.
Will test Pandas related features against Python executable 'pypy' in 'pyspark-sql' module.
Starting test(pypy): pyspark.sql.tests
Starting test(pypy): pyspark.sql.catalog
Starting test(pypy): pyspark.sql.column
Starting test(pypy): pyspark.sql.conf
```
After some modification to produce other cases:
```bash
$ ./run-tests
```
```
...
Will test against the following Python executables: ['python2.7', 'pypy']
Will test the following Python modules: ['pyspark-core', 'pyspark-ml', 'pyspark-mllib', 'pyspark-sql', 'pyspark-streaming']
Will skip PyArrow related features against Python executable 'python2.7' in 'pyspark-sql' module. PyArrow >= 20.0.0 is required; however, PyArrow 0.8.0 was found.
Will skip Pandas related features against Python executable 'python2.7' in 'pyspark-sql' module. Pandas >= 20.0.0 is required; however, Pandas 0.20.2 was found.
Will skip PyArrow related features against Python executable 'pypy' in 'pyspark-sql' module. PyArrow >= 20.0.0 is required; however, PyArrow was not found.
Will skip Pandas related features against Python executable 'pypy' in 'pyspark-sql' module. Pandas >= 20.0.0 is required; however, Pandas 0.22.0 was found.
Starting test(pypy): pyspark.sql.tests
Starting test(pypy): pyspark.streaming.tests
Starting test(pypy): pyspark.tests
Starting test(python2.7): pyspark.mllib.tests
```
```bash
./run-tests-with-coverage
```
```
...
Will test against the following Python executables: ['python2.7', 'pypy']
Will test the following Python modules: ['pyspark-core', 'pyspark-ml', 'pyspark-mllib', 'pyspark-sql', 'pyspark-streaming']
Will test PyArrow related features against Python executable 'python2.7' in 'pyspark-sql' module.
Will test Pandas related features against Python executable 'python2.7' in 'pyspark-sql' module.
Coverage is not installed in Python executable 'pypy' but 'COVERAGE_PROCESS_START' environment variable is set, exiting.
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20473 from HyukjinKwon/SPARK-23300.
## What changes were proposed in this pull request?
When a task is still running, metrics like executorRunTime are not available. Then `schedulerDelay` will be almost the same as `duration` and that's confusing.
This PR makes `schedulerDelay` return 0 when the task is running which is the same behavior as 2.2.
## How was this patch tested?
`AppStatusUtilsSuite.schedulerDelay`
Author: Shixiong Zhu <zsxwing@gmail.com>
Closes#20493 from zsxwing/SPARK-23326.
## What changes were proposed in this pull request?
Spark SQL executions page throws the following error and the page crashes:
```
HTTP ERROR 500
Problem accessing /SQL/. Reason:
Server Error
Caused by:
java.lang.NullPointerException
at scala.collection.immutable.StringOps$.length$extension(StringOps.scala:47)
at scala.collection.immutable.StringOps.length(StringOps.scala:47)
at scala.collection.IndexedSeqOptimized$class.isEmpty(IndexedSeqOptimized.scala:27)
at scala.collection.immutable.StringOps.isEmpty(StringOps.scala:29)
at scala.collection.TraversableOnce$class.nonEmpty(TraversableOnce.scala:111)
at scala.collection.immutable.StringOps.nonEmpty(StringOps.scala:29)
at org.apache.spark.sql.execution.ui.ExecutionTable.descriptionCell(AllExecutionsPage.scala:182)
at org.apache.spark.sql.execution.ui.ExecutionTable.row(AllExecutionsPage.scala:155)
at org.apache.spark.sql.execution.ui.ExecutionTable$$anonfun$8.apply(AllExecutionsPage.scala:204)
at org.apache.spark.sql.execution.ui.ExecutionTable$$anonfun$8.apply(AllExecutionsPage.scala:204)
at org.apache.spark.ui.UIUtils$$anonfun$listingTable$2.apply(UIUtils.scala:339)
at org.apache.spark.ui.UIUtils$$anonfun$listingTable$2.apply(UIUtils.scala:339)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.AbstractTraversable.map(Traversable.scala:104)
at org.apache.spark.ui.UIUtils$.listingTable(UIUtils.scala:339)
at org.apache.spark.sql.execution.ui.ExecutionTable.toNodeSeq(AllExecutionsPage.scala:203)
at org.apache.spark.sql.execution.ui.AllExecutionsPage.render(AllExecutionsPage.scala:67)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.JettyUtils$$anon$3.doGet(JettyUtils.scala:90)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:687)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:790)
at org.eclipse.jetty.servlet.ServletHolder.handle(ServletHolder.java:848)
at org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:584)
at org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1180)
at org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:512)
at org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1112)
at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:141)
at org.eclipse.jetty.server.handler.ContextHandlerCollection.handle(ContextHandlerCollection.java:213)
at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:134)
at org.eclipse.jetty.server.Server.handle(Server.java:534)
at org.eclipse.jetty.server.HttpChannel.handle(HttpChannel.java:320)
at org.eclipse.jetty.server.HttpConnection.onFillable(HttpConnection.java:251)
at org.eclipse.jetty.io.AbstractConnection$ReadCallback.succeeded(AbstractConnection.java:283)
at org.eclipse.jetty.io.FillInterest.fillable(FillInterest.java:108)
at org.eclipse.jetty.io.SelectChannelEndPoint$2.run(SelectChannelEndPoint.java:93)
at org.eclipse.jetty.util.thread.strategy.ExecuteProduceConsume.executeProduceConsume(ExecuteProduceConsume.java:303)
at org.eclipse.jetty.util.thread.strategy.ExecuteProduceConsume.produceConsume(ExecuteProduceConsume.java:148)
at org.eclipse.jetty.util.thread.strategy.ExecuteProduceConsume.run(ExecuteProduceConsume.java:136)
at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:671)
at org.eclipse.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:589)
at java.lang.Thread.run(Thread.java:748)
```
One of the possible reason that this page fails may be the `SparkListenerSQLExecutionStart` event get dropped before processed, so the execution description and details don't get updated.
This was not a issue in 2.2 because it would ignore any job start event that arrives before the corresponding execution start event, which doesn't sound like a good decision.
We shall try to handle the null values in the front page side, that is, try to give a default value when `execution.details` or `execution.description` is null.
Another possible approach is not to spill the `LiveExecutionData` in `SQLAppStatusListener.update(exec: LiveExecutionData)` if `exec.details` is null. This is not ideal because this way you will not see the execution if `SparkListenerSQLExecutionStart` event is lost, because `AllExecutionsPage` only read executions from KVStore.
## How was this patch tested?
After the change, the page shows the following:
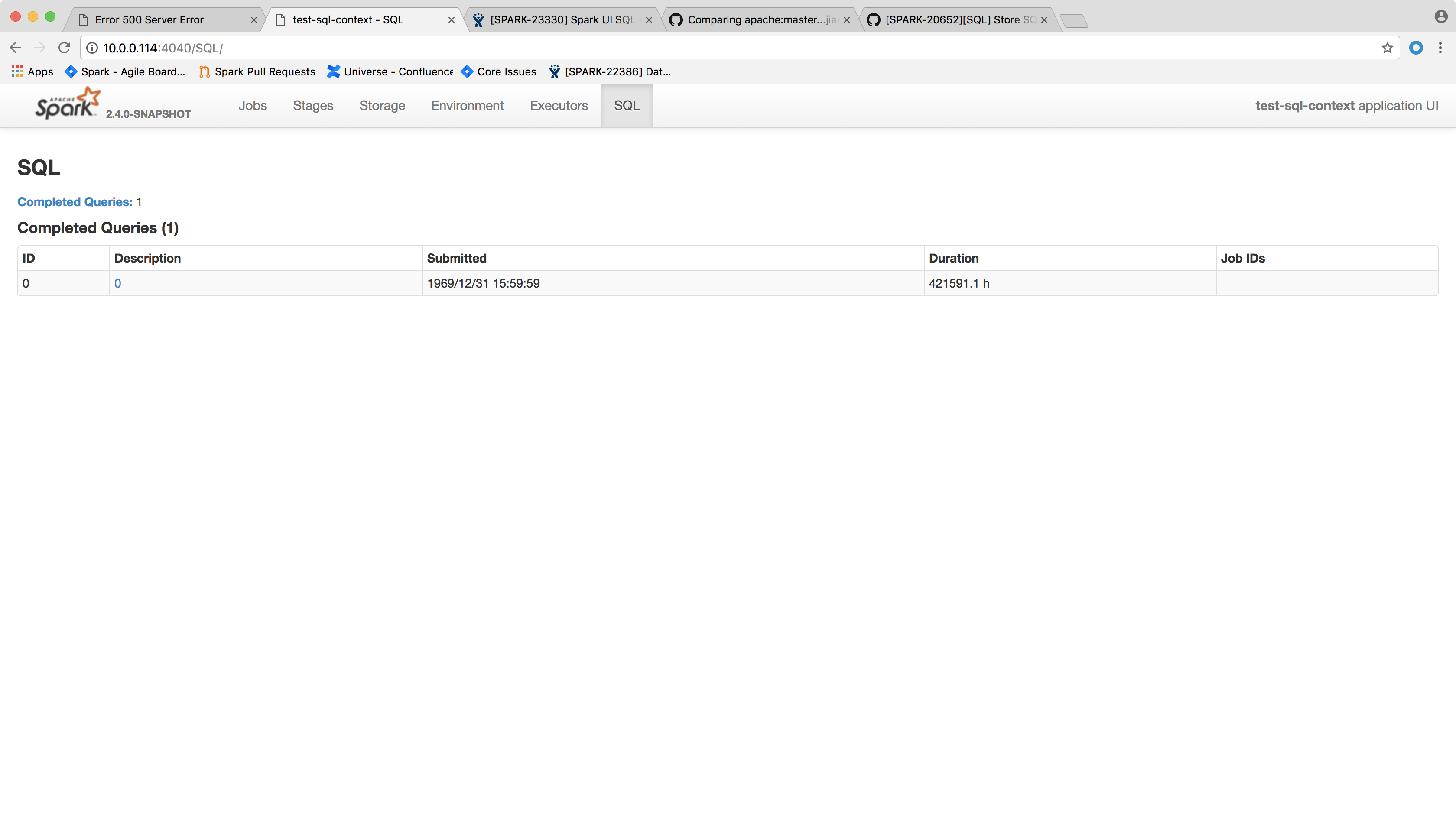
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#20502 from jiangxb1987/executionPage.
## What changes were proposed in this pull request?
Sort jobs/stages/tasks/queries with the completed timestamp before cleaning up them to make the behavior consistent with 2.2.
## How was this patch tested?
- Jenkins.
- Manually ran the following codes and checked the UI for jobs/stages/tasks/queries.
```
spark.ui.retainedJobs 10
spark.ui.retainedStages 10
spark.sql.ui.retainedExecutions 10
spark.ui.retainedTasks 10
```
```
new Thread() {
override def run() {
spark.range(1, 2).foreach { i =>
Thread.sleep(10000)
}
}
}.start()
Thread.sleep(5000)
for (_ <- 1 to 20) {
new Thread() {
override def run() {
spark.range(1, 2).foreach { i =>
}
}
}.start()
}
Thread.sleep(15000)
spark.range(1, 2).foreach { i =>
}
sc.makeRDD(1 to 100, 100).foreach { i =>
}
```
Author: Shixiong Zhu <zsxwing@gmail.com>
Closes#20481 from zsxwing/SPARK-23307.
## What changes were proposed in this pull request?
Fix decimalArithmeticOperations.sql test
## How was this patch tested?
N/A
Author: Yuming Wang <wgyumg@gmail.com>
Author: wangyum <wgyumg@gmail.com>
Author: Yuming Wang <yumwang@ebay.com>
Closes#20498 from wangyum/SPARK-22036.
## What changes were proposed in this pull request?
This PR proposes to add `columnSchema` in Python side too.
```python
>>> from pyspark.ml.image import ImageSchema
>>> ImageSchema.columnSchema.simpleString()
'struct<origin:string,height:int,width:int,nChannels:int,mode:int,data:binary>'
```
## How was this patch tested?
Manually tested and unittest was added in `python/pyspark/ml/tests.py`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20475 from HyukjinKwon/SPARK-23256.
From [PEP 257](https://www.python.org/dev/peps/pep-0257/):
> For consistency, always use """triple double quotes""" around docstrings. Use r"""raw triple double quotes""" if you use any backslashes in your docstrings. For Unicode docstrings, use u"""Unicode triple-quoted strings""".
For example, this is what help (kafka_wordcount) shows:
```
DESCRIPTION
Counts words in UTF8 encoded, '
' delimited text received from the network every second.
Usage: kafka_wordcount.py <zk> <topic>
To run this on your local machine, you need to setup Kafka and create a producer first, see
http://kafka.apache.org/documentation.html#quickstart
and then run the example
`$ bin/spark-submit --jars external/kafka-assembly/target/scala-*/spark-streaming-kafka-assembly-*.jar examples/src/main/python/streaming/kafka_wordcount.py localhost:2181 test`
```
This is what it shows, after the fix:
```
DESCRIPTION
Counts words in UTF8 encoded, '\n' delimited text received from the network every second.
Usage: kafka_wordcount.py <zk> <topic>
To run this on your local machine, you need to setup Kafka and create a producer first, see
http://kafka.apache.org/documentation.html#quickstart
and then run the example
`$ bin/spark-submit --jars \
external/kafka-assembly/target/scala-*/spark-streaming-kafka-assembly-*.jar \
examples/src/main/python/streaming/kafka_wordcount.py \
localhost:2181 test`
```
The thing worth noticing is no linebreak here in the help.
## What changes were proposed in this pull request?
Change triple double quotes to raw triple double quotes when there are occurrences of backslashes in docstrings.
## How was this patch tested?
Manually as this is a doc fix.
Author: Shashwat Anand <me@shashwat.me>
Closes#20497 from ashashwat/docstring-fixes.
## What changes were proposed in this pull request?
Like Parquet, all file-based data source handles `spark.sql.files.ignoreMissingFiles` correctly. We had better have a test coverage for feature parity and in order to prevent future accidental regression for all data sources.
## How was this patch tested?
Pass Jenkins with a newly added test case.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20479 from dongjoon-hyun/SPARK-23305.
## What changes were proposed in this pull request?
In the current test case for CombineTypedFilters, we lack the test of FilterFunction, so let's add it.
In addition, in TypedFilterOptimizationSuite's existing test cases, Let's extract a common LocalRelation.
## How was this patch tested?
add new test cases.
Author: caoxuewen <cao.xuewen@zte.com.cn>
Closes#20482 from heary-cao/TypedFilterOptimizationSuite.
## What changes were proposed in this pull request?
In the document of `ContinuousReader.setOffset`, we say this method is used to specify the start offset. We also have a `ContinuousReader.getStartOffset` to get the value back. I think it makes more sense to rename `ContinuousReader.setOffset` to `setStartOffset`.
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20486 from cloud-fan/rename.
## What changes were proposed in this pull request?
This patch adds a small example to the schema string definition of schema function. It isn't obvious how to use it, so an example would be useful.
## How was this patch tested?
N/A - doc only.
Author: Reynold Xin <rxin@databricks.com>
Closes#20491 from rxin/schema-doc.
## What changes were proposed in this pull request?
Further clarification of caveats in using stream-stream outer joins.
## How was this patch tested?
N/A
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20494 from tdas/SPARK-23064-2.
{kind=link}
{kind=link}
{kind=link}