## What changes were proposed in this pull request?
remove the oldest checkpointed file only if next checkpoint exists.
I think this patch needs back-porting.
## How was this patch tested?
existing test
local check in spark-shell with following suite:
```
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.ml.classification.GBTClassifier
case class Row(features: org.apache.spark.ml.linalg.Vector, label: Int)
sc.setCheckpointDir("/checkpoints")
val trainingData = sc.parallelize(1 to 2426874, 256).map(x => Row(Vectors.dense(x, x + 1, x * 2 % 10), if (x % 5 == 0) 1 else 0)).toDF
val classifier = new GBTClassifier()
.setLabelCol("label")
.setFeaturesCol("features")
.setProbabilityCol("probability")
.setMaxIter(100)
.setMaxDepth(10)
.setCheckpointInterval(2)
classifier.fit(trainingData)
```
Closes#24870 from zhengruifeng/ck_update.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
Disabled negative dns caching for docker images
Improved logging on DNS resolution, convenient for slow k8s clusters
## What changes were proposed in this pull request?
Added retries when building the connection to the driver in K8s.
In some scenarios DNS reslution can take more than the timeout.
Also openjdk-8 by default has negative dns caching enabled, which means even retries may not help depending on the times.
## How was this patch tested?
This patch was tested agains an specific k8s cluster with slow response time in DNS to ensure it woks.
Closes#24702 from jlpedrosa/feature/kuberetries.
Authored-by: Jose Luis Pedrosa <jlpedrosa@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Event logs are different from the other data in terms of the lifetime. It would be great to have a new configuration for Spark event log compression like `spark.eventLog.compression.codec` .
This PR adds this new configuration as an optional configuration. So, if `spark.eventLog.compression.codec` is not given, `spark.io.compression.codec` will be used.
## How was this patch tested?
Pass the Jenkins with the newly added test case.
Closes#24921 from dongjoon-hyun/SPARK-28118.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
## What changes were proposed in this pull request?
The test `SparkContextSuite.test resource scheduling under local-cluster mode` has been flaky, because it expects the size of `sc.statusTracker.getExecutorInfos` be the same as the number of executors, while the returned list contains both the driver and executors.
## How was this patch tested?
Updated existing tests.
Closes#24917 from jiangxb1987/getExecutorInfos.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
In a nutshell, it looks like the absence of ML / MLlib classes on the classpath causes code in KryoSerializer to throw and catch ClassNotFoundExceptions whenever instantiating a new serializer in newInstance(). This isn't a performance problem in production (since MLlib is on the classpath there) but it's a huge issue in tests and appears to account for an enormous amount of test time
We can address this problem by reducing the total number of ClassNotFoundExceptions by performing the class existence checks once and storing the results in KryoSerializer instances rather than repeating the checks on each newInstance() call.
## How was this patch tested?
The existing tests.
Authored-by: Josh Rosen <joshrosendatabricks.com>
Closes#24916 from gatorsmile/kryoException.
Lead-authored-by: Josh Rosen <rosenville@gmail.com>
Co-authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Josh Rosen <rosenville@gmail.com>
## What changes were proposed in this pull request?
This PR fixes a performance problem in environments where `lz4-java`'s native JNI libraries fail to initialize.
Spark's uses `lz4-java` for LZ4 compression. Under the hood, the `LZ4BlockInputStream` and `LZ4BlockOutputStream` constructors call `LZ4Factory.fastestInstance()`, which attempts to load JNI libraries and falls back on Java implementations in case the JNI library cannot be loaded or initialized.
If the LZ4 JNI libraries are present on the library load path (`Native.isLoaded()`) but cannot be initialized (e.g. due to breakage caused by shading) then an exception will be thrown and caught, triggering fallback to `fastestJavaInstance()` (a non-JNI implementation).
Unfortunately, the LZ4 library does not cache the fact that the JNI library failed during initialization, so every call to `LZ4Factory.fastestInstance()` re-attempts (and fails) to initialize the native code. These initialization attempts are performed in a `static synchronized` method, so exceptions from failures are thrown while holding shared monitors and this causes monitor-contention performance issues. Here's an example stack trace showing the problem:
```java
java.lang.Throwable.fillInStackTrace(Native Method)
java.lang.Throwable.fillInStackTrace(Throwable.java:783) => holding Monitor(java.lang.NoClassDefFoundError441628568})
java.lang.Throwable.<init>(Throwable.java:265)
java.lang.Error.<init>(Error.java:70)
java.lang.LinkageError.<init>(LinkageError.java:55)
java.lang.NoClassDefFoundError.<init>(NoClassDefFoundError.java:59)
shaded.net.jpountz.lz4.LZ4JNICompressor.compress(LZ4JNICompressor.java:36)
shaded.net.jpountz.lz4.LZ4Factory.<init>(LZ4Factory.java:200)
shaded.net.jpountz.lz4.LZ4Factory.instance(LZ4Factory.java:51)
shaded.net.jpountz.lz4.LZ4Factory.nativeInstance(LZ4Factory.java:84) => holding Monitor(java.lang.Class1475983836})
shaded.net.jpountz.lz4.LZ4Factory.fastestInstance(LZ4Factory.java:157)
shaded.net.jpountz.lz4.LZ4BlockOutputStream.<init>(LZ4BlockOutputStream.java:135)
org.apache.spark.io.LZ4CompressionCodec.compressedOutputStream(CompressionCodec.scala:122)
org.apache.spark.serializer.SerializerManager.wrapForCompression(SerializerManager.scala:156)
org.apache.spark.serializer.SerializerManager.wrapStream(SerializerManager.scala:131)
org.apache.spark.storage.DiskBlockObjectWriter.open(DiskBlockObjectWriter.scala:120)
org.apache.spark.storage.DiskBlockObjectWriter.write(DiskBlockObjectWriter.scala:249)
org.apache.spark.shuffle.sort.ShuffleExternalSorter.writeSortedFile(ShuffleExternalSorter.java:211)
[...]
```
To avoid this problem, this PR modifies Spark's `LZ4CompressionCodec` to call `fastestInstance()` itself and cache the result (which is safe because these factories [are thread-safe](https://github.com/lz4/lz4-java/issues/82)).
## How was this patch tested?
Existing unit tests.
Closes#24905 from JoshRosen/lz4-factory-flags.
Lead-authored-by: Josh Rosen <rosenville@gmail.com>
Co-authored-by: Josh Rosen <joshrosen@stripe.com>
Signed-off-by: Josh Rosen <rosenville@gmail.com>
## What changes were proposed in this pull request?
Continue the work from https://github.com/apache/spark/pull/24821. Refactor resource handling code to make the code more readable. Major changes:
* Moved resource-related classes to `spark.resource` from `spark`.
* Added ResourceUtils and helper classes so we don't need to directly deal with Spark conf.
* ResourceID: resource identifier and it provides conf keys
* ResourceRequest/Allocation: abstraction for requested and allocated resources
* Added `TestResourceIDs` to reference commonly used resource IDs in tests like `spark.executor.resource.gpu`.
cc: tgravescs jiangxb1987 Ngone51
## How was this patch tested?
Unit tests for added utils and existing unit tests.
Closes#24856 from mengxr/SPARK-27823.
Lead-authored-by: Xiangrui Meng <meng@databricks.com>
Co-authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
## What changes were proposed in this pull request?
PythonRunner uses an asynchronous way, which produces elements in WriteThread but consumes elements in another thread, to execute task. When child operator, like take()/first(), does not consume all elements produced by WriteThread, task would finish before WriteThread and releases all locks on blocks. However, WriteThread would continue to produce elements by pulling elements from parent operator until it exhausts all elements. And at the time WriteThread exhausts all elements, it will try to release the corresponding block but hit a AssertionError since task has already released that lock previously.
#24542 previously fix this by catching AssertionError, so that we won't fail our executor.
However, when not using PySpark, issue still exists when user implements a custom RDD or task, which spawn a separate child thread to consume iterator from a cached parent RDD. Below is a demo which could easily reproduce the issue.
```
val rdd0 = sc.parallelize(Range(0, 10), 1).cache()
rdd0.collect()
rdd0.mapPartitions { iter =>
val t = new Thread(new Runnable {
override def run(): Unit = {
while(iter.hasNext) {
println(iter.next())
Thread.sleep(1000)
}
}
})
t.setDaemon(false)
t.start()
Iterator(0)
}.collect()
Thread.sleep(100000)
```
So, if we could prevent the separate thread from releasing lock on block when TaskContext has already completed, we won't hit this issue again.
## How was this patch tested?
Added in new unit test in RDDSuite.
Closes#24699 from Ngone51/SPARK-27666.
Authored-by: wuyi <ngone_5451@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Allow Pandas UDF to take an iterator of pd.Series or an iterator of tuple of pd.Series.
Note the UDF input args will be always one iterator:
* if the udf take only column as input, the iterator's element will be pd.Series (corresponding to the column values batch)
* if the udf take multiple columns as inputs, the iterator's element will be a tuple composed of multiple `pd.Series`s, each one corresponding to the multiple columns as inputs (keep the same order). For example:
```
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def the_udf(iterator):
for col1_batch, col2_batch in iterator:
yield col1_batch + col2_batch
df.select(the_udf("col1", "col2"))
```
The udf above will add col1 and col2.
I haven't add unit tests, but manually tests show it works fine. So it is ready for first pass review.
We can test several typical cases:
```
from pyspark.sql import SparkSession
from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql.functions import udf
from pyspark.taskcontext import TaskContext
df = spark.createDataFrame([(1, 20), (3, 40)], ["a", "b"])
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi1(it):
pid = TaskContext.get().partitionId()
print("DBG: fi1: do init stuff, partitionId=" + str(pid))
for batch in it:
yield batch + 100
print("DBG: fi1: do close stuff, partitionId=" + str(pid))
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi2(it):
pid = TaskContext.get().partitionId()
print("DBG: fi2: do init stuff, partitionId=" + str(pid))
for batch in it:
yield batch + 10000
print("DBG: fi2: do close stuff, partitionId=" + str(pid))
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi3(it):
pid = TaskContext.get().partitionId()
print("DBG: fi3: do init stuff, partitionId=" + str(pid))
for x, y in it:
yield x + y * 10 + 100000
print("DBG: fi3: do close stuff, partitionId=" + str(pid))
pandas_udf("int", PandasUDFType.SCALAR)
def fp1(x):
return x + 1000
udf("int")
def fu1(x):
return x + 10
# test select "pandas iter udf/pandas udf/sql udf" expressions at the same time.
# Note this case the `fi1("a"), fi2("b"), fi3("a", "b")` will generate only one plan,
# and `fu1("a")`, `fp1("a")` will generate another two separate plans.
df.select(fi1("a"), fi2("b"), fi3("a", "b"), fu1("a"), fp1("a")).show()
# test chain two pandas iter udf together
# Note this case `fi2(fi1("a"))` will generate only one plan
# Also note the init stuff/close stuff call order will be like:
# (debug output following)
# DBG: fi2: do init stuff, partitionId=0
# DBG: fi1: do init stuff, partitionId=0
# DBG: fi1: do close stuff, partitionId=0
# DBG: fi2: do close stuff, partitionId=0
df.select(fi2(fi1("a"))).show()
# test more complex chain
# Note this case `fi1("a"), fi2("a")` will generate one plan,
# and `fi3(fi1_output, fi2_output)` will generate another plan
df.select(fi3(fi1("a"), fi2("a"))).show()
```
## How was this patch tested?
To be added.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24643 from WeichenXu123/pandas_udf_iter.
Lead-authored-by: WeichenXu <weichen.xu@databricks.com>
Co-authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
- Remove unused variables.
- Remove unused imports.
- Change var to val in few places.
## How was this patch tested?
Unit tests.
Closes#24857 from imback82/unused_variable.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
We're using an old-ish jQuery, 1.12.4, and should probably update for Spark 3 to keep up in general, but also to keep up with CVEs. In fact, we know of at least one resolved in only 3.4.0+ (https://nvd.nist.gov/vuln/detail/CVE-2019-11358). They may not affect Spark, but, if the update isn't painful, maybe worthwhile in order to make future 3.x updates easier.
jQuery 1 -> 2 doesn't sound like a breaking change, as 2.0 is supposed to maintain compatibility with 1.9+ (https://blog.jquery.com/2013/04/18/jquery-2-0-released/)
2 -> 3 has breaking changes: https://jquery.com/upgrade-guide/3.0/. It's hard to evaluate each one, but the most likely area for problems is in ajax(). However, our usage of jQuery (and plugins) is pretty simple.
Update jquery to 3.4.1; update jquery blockUI and mustache to latest
## How was this patch tested?
Manual testing of docs build (except R docs), worker/master UI, spark application UI.
Note: this really doesn't guarantee it works, as our tests can't test javascript, and this is merely anecdotal testing, although I clicked about every link I could find. There's a risk this breaks a minor part of the UI; it does seem to work fine in the main.
Closes#24843 from srowen/SPARK-28004.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
(Continuation of https://github.com/apache/spark/pull/19118 ; see for details)
## How was this patch tested?
Existing tests.
Closes#24863 from srowen/SPARK-21882.2.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Handle the case when ParsedStatement subclass has a Map field but not of type Map[String, String].
In ParsedStatement.productIterator, `case mapArg: Map[_, _]` can match any Map type due to type erasure, thus causing `asInstanceOf[Map[String, String]]` to throw ClassCastException.
The following test reproduces the issue:
```
case class TestStatement(p: Map[String, Int]) extends ParsedStatement {
override def output: Seq[Attribute] = Nil
override def children: Seq[LogicalPlan] = Nil
}
TestStatement(Map("abc" -> 1)).toString
```
Changing the code to `case mapArg: Map[String, String]` will not help due to type erasure. As a matter of fact, compiler gives this warning:
```
Warning:(41, 18) non-variable type argument String in type pattern
scala.collection.immutable.Map[String,String] (the underlying of Map[String,String])
is unchecked since it is eliminated by erasure
case mapArg: Map[String, String] =>
```
## How was this patch tested?
Add 2 unit tests.
Closes#24800 from jzhuge/SPARK-27947.
Authored-by: John Zhuge <jzhuge@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Hadoop `Configuration` has an internal `properties` map which is lazily initialized. Initialization of this field, done in the private `Configuration.getProps()` method, is rather expensive because it ends up parsing XML configuration files. When cloning a `Configuration`, this `properties` field is cloned if it has been initialized.
In some cases it's possible that `sc.hadoopConfiguration` never ends up computing this `properties` field, leading to performance problems when this configuration is cloned in `SessionState.newHadoopConf()` because each cloned `Configuration` needs to re-parse configuration XML files from disk.
To avoid this problem, we can call `Configuration.size()` to trigger a call to `getProps()`, ensuring that this expensive computation is cached and re-used when cloning configurations.
I discovered this problem while performance profiling the Spark ThriftServer while running a SQL fuzzing workload.
## How was this patch tested?
Examined YourKit profiles before and after my change.
Closes#24714 from JoshRosen/fuzzing-perf-improvements.
Authored-by: Josh Rosen <rosenville@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Change the resource config spark.{executor/driver}.resource.{resourceName}.count to .amount to allow future usage of containing both a count and a unit. Right now we only support counts - # of gpus for instance, but in the future we may want to support units for things like memory - 25G. I think making the user only have to specify a single config .amount is better then making them specify 2 separate configs of a .count and then a .unit. Change it now since its a user facing config.
Amount also matches how the spark on yarn configs are setup.
## How was this patch tested?
Unit tests and manually verified on yarn and local cluster mode
Closes#24810 from tgravescs/SPARK-27760-amount.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
This change refactors the portions of the ExecutorAllocationManager class that
track executor state into a new class, to achieve a few goals:
- make the code easier to understand
- better separate concerns (task backlog vs. executor state)
- less synchronization between event and allocation threads
- less coupling between the allocation code and executor state tracking
The executor tracking code was moved to a new class (ExecutorMonitor) that
encapsulates all the logic of tracking what happens to executors and when
they can be timed out. The logic to actually remove the executors remains
in the EAM, since it still requires information that is not tracked by the
new executor monitor code.
In the executor monitor itself, of interest, specifically, is a change in
how cached blocks are tracked; instead of polling the block manager, the
monitor now uses events to track which executors have cached blocks, and
is able to detect also unpersist events and adjust the time when the executor
should be removed accordingly. (That's the bug mentioned in the PR title.)
Because of the refactoring, a few tests in the old EAM test suite were removed,
since they're now covered by the newly added test suite. The EAM suite was
also changed a little bit to not instantiate a SparkContext every time. This
allowed some cleanup, and the tests also run faster.
Tested with new and updated unit tests, and with multiple TPC-DS workloads
running with dynamic allocation on; also some manual tests for the caching
behavior.
Closes#24704 from vanzin/SPARK-20286.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
Use objects in `ResourceName` to represent resource names.
## How was this patch tested?
Existing tests.
Closes#24799 from jiangxb1987/ResourceName.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds support to schedule tasks with extra resource requirements (eg. GPUs) on executors with available resources. It also introduce a new method `TaskContext.resources()` so tasks can access available resource addresses allocated to them.
## How was this patch tested?
* Added new end-to-end test cases in `SparkContextSuite`;
* Added new test case in `CoarseGrainedSchedulerBackendSuite`;
* Added new test case in `CoarseGrainedExecutorBackendSuite`;
* Added new test case in `TaskSchedulerImplSuite`;
* Added new test case in `TaskSetManagerSuite`;
* Updated existing tests.
Closes#24374 from jiangxb1987/gpu.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
This PR targets to deduplicate hardcoded `py4j-0.10.8.1-src.zip` in order to make py4j upgrade easier.
## How was this patch tested?
N/A
Closes#24770 from HyukjinKwon/minor-py4j-dedup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR targets to add an integrated test base for various UDF test cases so that Scalar UDF, Python UDF and Scalar Pandas UDFs can be tested in SBT & Maven tests.
### Problem
One of the problems we face is that: `ExtractPythonUDFs` (for Python UDF and Scalar Pandas UDF) has unevaluable expressions that always has to be wrapped with special plans. This special rule seems producing many issues, for instance, SPARK-27803, SPARK-26147, SPARK-26864, SPARK-26293, SPARK-25314 and SPARK-24721.
### Why do we have less test cases dedicated for SQL and plans with Python UDFs?
We have virtually no such SQL (or plan) dedicated tests in PySpark to catch such issues because:
- A developer should know all the analyzer, the optimizer, SQL, PySpark, Py4J and version differences in Python to write such good test cases
- To test plans, we should access to plans in JVM via Py4J which is tricky, messy and duplicates Scala test cases
- Usually we just add end-to-end test cases in PySpark therefore there are not so many dedicated examples to refer to write in PySpark
It is also a non-trivial overhead to switch test base and method (IMHO).
### How does this PR fix?
This PR adds Python UDF and Scalar Pandas UDF into our `*.sql` file based test base in runtime of SBT / Maven test cases. It generates Python-pickled instance (consisting of return type and Python native function) that is used in Python or Scalar Pandas UDF and directly brings into JVM.
After that, (we don't interact via Py4J) run the tests directly in JVM - we can just register and run Python UDF and Scalar Pandas UDF in JVM.
Currently, I only integrated this change into SQL file based testing. This is how works with test files under `udf` directory:
After the test files under 'inputs/udf' directory are detected, it creates three test cases:
- Scala UDF test case with a Scalar UDF registered named 'udf'.
- Python UDF test case with a Python UDF registered named 'udf' iff Python executable and pyspark are available.
- Scalar Pandas UDF test case with a Scalar Pandas UDF registered named 'udf' iff Python executable, pandas, pyspark and pyarrow are available.
Therefore, UDF test cases should have single input and output files but executed by three different types of UDFs.
For instance,
```sql
CREATE TEMPORARY VIEW ta AS
SELECT udf(a) AS a, udf('a') AS tag FROM t1
UNION ALL
SELECT udf(a) AS a, udf('b') AS tag FROM t2;
CREATE TEMPORARY VIEW tb AS
SELECT udf(a) AS a, udf('a') AS tag FROM t3
UNION ALL
SELECT udf(a) AS a, udf('b') AS tag FROM t4;
SELECT tb.* FROM ta INNER JOIN tb ON ta.a = tb.a AND ta.tag = tb.tag;
```
will be ran 3 times with Scalar UDF, Python UDF and Scalar Pandas UDF each.
### Appendix
Plus, this PR adds `IntegratedUDFTestUtils` which enables to test and execute Python UDF and Scalar Pandas UDFs as below:
To register Python UDF in SQL:
```scala
IntegratedUDFTestUtils.registerTestUDF(TestPythonUDF(name = "udf"), spark)
```
To register Scalar Pandas UDF in SQL:
```scala
IntegratedUDFTestUtils.registerTestUDF(TestScalarPandasUDF(name = "udf"), spark)
```
To use it in Scala API:
```scala
spark.select(expr("udf(1)").show()
```
To use it in SQL:
```scala
sql("SELECT udf(1)").show()
```
This util could be used in the future for better coverage with Scala API combinations as well.
## How was this patch tested?
Tested via the command below:
```bash
build/sbt "sql/test-only *SQLQueryTestSuite -- -z udf/udf-inner-join.sql"
```
```
[info] SQLQueryTestSuite:
[info] - udf/udf-inner-join.sql - Scala UDF (5 seconds, 47 milliseconds)
[info] - udf/udf-inner-join.sql - Python UDF (4 seconds, 335 milliseconds)
[info] - udf/udf-inner-join.sql - Scalar Pandas UDF (5 seconds, 423 milliseconds)
```
[python] unavailable:
```
[info] SQLQueryTestSuite:
[info] - udf/udf-inner-join.sql - Scala UDF (4 seconds, 577 milliseconds)
[info] - udf/udf-inner-join.sql - Python UDF is skipped because [pyton] and/or pyspark were not available. !!! IGNORED !!!
[info] - udf/udf-inner-join.sql - Scalar Pandas UDF is skipped because pyspark,pandas and/or pyarrow were not available in [pyton]. !!! IGNORED !!!
```
pyspark unavailable:
```
[info] SQLQueryTestSuite:
[info] - udf/udf-inner-join.sql - Scala UDF (4 seconds, 991 milliseconds)
[info] - udf/udf-inner-join.sql - Python UDF is skipped because [python] and/or pyspark were not available. !!! IGNORED !!!
[info] - udf/udf-inner-join.sql - Scalar Pandas UDF is skipped because pyspark,pandas and/or pyarrow were not available in [python]. !!! IGNORED !!!
```
pandas and/or pyarrow unavailable:
```
[info] SQLQueryTestSuite:
[info] - udf/udf-inner-join.sql - Scala UDF (4 seconds, 713 milliseconds)
[info] - udf/udf-inner-join.sql - Python UDF (3 seconds, 89 milliseconds)
[info] - udf/udf-inner-join.sql - Scalar Pandas UDF is skipped because pandas and/or pyarrow were not available in [python]. !!! IGNORED !!!
```
Closes#24752 from HyukjinKwon/udf-tests.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
I found the docs of `spark.driver.memoryOverhead` and `spark.executor.memoryOverhead` exists a little ambiguity.
For example, the origin docs of `spark.driver.memoryOverhead` start with `The amount of off-heap memory to be allocated per driver in cluster mode`.
But `MemoryManager` also managed a memory area named off-heap used to allocate memory in tungsten mode.
So I think the description of `spark.driver.memoryOverhead` always make confused.
`spark.executor.memoryOverhead` has the same confused with `spark.driver.memoryOverhead`.
## How was this patch tested?
Exists UT.
Closes#24671 from beliefer/improve-docs-of-overhead.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Add ability to map the spark resource configs spark.{executor/driver}.resource.{resourceName} to kubernetes Container builder so that we request resources (gpu,s/fpgas/etc) from kubernetes.
Note that the spark configs will overwrite any resource configs users put into a pod template.
I added a generic vendor config which is only used by kubernetes right now. I intentionally didn't put it into the kubernetes config namespace just to avoid adding more config prefixes.
I will add more documentation for this under jira SPARK-27492. I think it will be easier to do all at once to get cohesive story.
## How was this patch tested?
Unit tests and manually testing on k8s cluster.
Closes#24703 from tgravescs/SPARK-27362.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
Move to json4s version 3.6.6
Add scala-xml 1.2.0
## How was this patch tested?
Pass the Jenkins
Closes#24736 from igreenfield/master.
Authored-by: Izek Greenfield <igreenfield@axiomsl.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Change the Driver resource discovery argument for standalone mode to be a file rather then separate address configs per resource. This makes it consistent with how the Executor is doing it and makes it more flexible in the future, and it makes for less configs if you have multiple resources.
## How was this patch tested?
Unit tests and basic manually testing to make sure files were parsed properly.
Closes#24730 from tgravescs/SPARK-27835-driver-resourcesFile.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
This pr wrap all `PrintWriter` with `Utils.tryWithResource` to prevent resource leak.
## How was this patch tested?
Existing test
Closes#24739 from wangyum/SPARK-27875.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
`A very little spelling mistake.`
## How was this patch tested?
No
Closes#24710 from LiShuMing/minor-spelling.
Authored-by: ShuMingLi <ming.moriarty@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently system properties are not redacted. This PR fixes that, so that any credentials passed as System properties are redacted as well.
## How was this patch tested?
Manual test. Run the following and see the UI.
```
bin/spark-shell --conf 'spark.driver.extraJavaOptions=-DMYSECRET=app'
```
Closes#24733 from aaruna/27869.
Authored-by: Aaruna <aaruna.godthi@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
### Standalone HA Background
In Spark Standalone HA mode, we'll have multiple masters running at the same time. But, there's only one master leader, which actively serving scheduling requests. Once this master leader crashes, other masters would compete for the leader and only one master is guaranteed to be elected as new master leader, which would reconstruct the state from the original master leader and continute to serve scheduling requests.
### Related Issues
#2828 firstly introduces the bug of *duplicate Worker registration*, and #3447 fixed it. But there're still corner cases(see SPARK-23191 for details) where #3447 can not cover it:
* CASE 1
(1) Initially, Worker registered with Master A.
(2) After a while, the connection channel between Master A and Worker becomes inactive(e.g. due to network drop), and Worker is notified about that by calling `onDisconnected` from NettyRpcEnv
(3) When Worker invokes `onDisconnected`, then, it will attempt to reconnect to all masters(including Master A)
(4) At the meanwhile, network between Worker and Master A recover, Worker successfully register to Master A again
(5) Master A response with `RegisterWorkerFailed("Duplicate worker ID")`
(6) Worker receives that msg, exit
* CASE 2
(1) Master A lost leadership(sends `RevokedLeadership` to itself). Master B takes over and recovery everything from master A(which would register workers for the first time in Master B) and sends `MasterChanged` to Worker
(2) Before Master A receives `RevokedLeadership`, it receives a late `HeartBeat` from Worker(which had been removed in Master A due to heartbeat timeout previously), so it sends `ReconnectWorker` to worker
(3) Worker receives `MasterChanged` before `ReconnectWorker` , changing masterRef to Master B
(4) Subsequently, Worker receives `ReconnectWorker` from Master A, then it reconnects to all masters
(5) Master B receives register request again from the Worker, response with `RegisterWorkerFailed("Duplicate worker ID")`
(6) Worker receives that msg, exit
In CASE 1, it is difficult for the Worker to know Master A's state. Normally, Worker thinks Master A has already died and is impossible that Master A would response with Worker's re-connect request.
In CASE 2, we can see race condition between `RevokedLeadership` and `HeartBeat`. Actually, Master A has already been revoked leadership while processing `HeartBeat` msg. That's means the state between Master and Zookeeper could be out of sync for a while.
### Solutions
In this PR, instead of exiting Worker process when *duplicate Worker registration* happens, we suggest to log warn about it. This would be fine since Master actually perform no-op when it receives duplicate registration from a Worker. In turn, Worker could continue living with that Master normally without any side effect.
## How was this patch tested?
Tested Manually.
I followed the steps as Neeraj Gupta suggested in JIRA SPARK-23191 to reproduce the case 1.
Before this pr, Worker would be DEAD from UI.
After this pr, Worker just warn the duplicate register behavior (as you can see the second last row in log snippet below), and still be ALIVE from UI.
```
19/05/09 20:58:32 ERROR Worker: Connection to master failed! Waiting for master to reconnect...
19/05/09 20:58:32 INFO Worker: wuyi.local:7077 Disassociated !
19/05/09 20:58:32 INFO Worker: Connecting to master wuyi.local:7077...
19/05/09 20:58:32 ERROR Worker: Connection to master failed! Waiting for master to reconnect...
19/05/09 20:58:32 INFO Worker: Not spawning another attempt to register with the master, since there is an attempt scheduled already.
19/05/09 20:58:37 WARN TransportClientFactory: DNS resolution for wuyi.local/127.0.0.1:7077 took 5005 ms
19/05/09 20:58:37 INFO TransportClientFactory: Found inactive connection to wuyi.local/127.0.0.1:7077, creating a new one.
19/05/09 20:58:37 INFO TransportClientFactory: Successfully created connection to wuyi.local/127.0.0.1:7077 after 3 ms (0 ms spent in bootstraps)
19/05/09 20:58:37 WARN Worker: Duplicate registration at master spark://wuyi.local:7077
19/05/09 20:58:37 INFO Worker: Successfully registered with master spark://wuyi.local:7077
```
Closes#24569 from Ngone51/fix-worker-dup-register-error.
Authored-by: wuyi <ngone_5451@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR exposes additional metrics in `status.api.v1.StageData`. These metrics were already computed for `LiveStage`, but they were never exposed to the user. This includes extra metrics about the JVM GC, executor (de)serialization times, shuffle reads and writes, and more.
## How was this patch tested?
Existing tests.
cc hvanhovell
Closes#24011 from tomvanbussel/SPARK-27071.
Authored-by: Tom van Bussel <tom.vanbussel@databricks.com>
Signed-off-by: herman <herman@databricks.com>
## What changes were proposed in this pull request?
As the current approach in OneForOneBlockFetcher, we reuse the OpenBlocks protocol to describe the fetch request for shuffle blocks, and it causes the extension work for shuffle fetching like #19788 and #24110 very awkward.
In this PR, we split the fetch request for shuffle blocks from OpenBlocks which named FetchShuffleBlocks. It's a loose bind with ShuffleBlockId and can easily extend by adding new fields in this protocol.
## How was this patch tested?
Existing and new added UT.
Closes#24565 from xuanyuanking/SPARK-27665.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
There are no unit test cases for this SortShuffleWriter,so add new test cases;
## How was this patch tested?
new test cases
Closes#24080 from wangjiaochun/UtestForSortShuffleWriter.
Authored-by: 10087686 <wang.jiaochun@zte.com.cn>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR aims to show Spark version at application lists of Spark History UI.
From the following, the first `Version` column is added. When the application has multiple attempts, this will show the first attempt's version number.
**COMPLETED APPLICATION LIST**
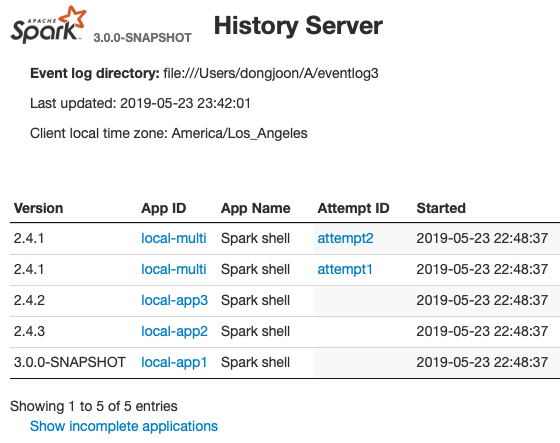
**INCOMPLETE APPLICATION LIST**
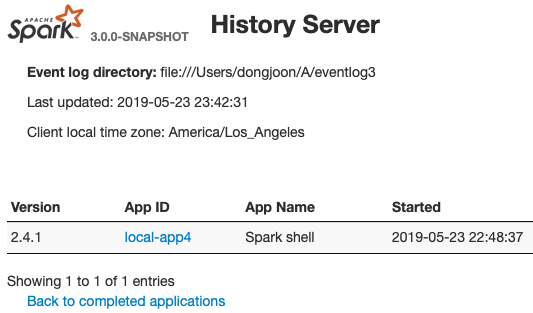
## How was this patch tested?
Manually launch Spark history server and see the UI. Please use *Private New Window (Safari)* or *New Incognito Window (Chrome)* to avoid browser caching.
```
sbin/start-history-server.sh
```
Closes#24694 from dongjoon-hyun/SPARK-27830.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
In the PR the config `spark.shuffle.service.fetch.rdd.enabled` default is changed to **false** to avoid breaking any compatibility with older external shuffle service installations. As external shuffle service is deployed separately and disk persisted RDD block fetching had even introduced new network messages (`RemoveBlocks` and `BlocksRemoved`) and changed the behaviour of the already existing fetching: extended it for RDD blocks.
## How was this patch tested?
With existing unit tests.
Closes#24697 from attilapiros/minor-ext-shuffle-fetch-disabled.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
# What changes were proposed in this pull request?
## Problem statement
An executor which has persisted blocks does not consider to be idle and this way ready to be released by dynamic allocation after the regular timeout `spark.dynamicAllocation.executorIdleTimeout` but there is separate configuration `spark.dynamicAllocation.cachedExecutorIdleTimeout` which defaults to `Integer.MAX_VALUE`. This is because releasing the executor also means losing the persisted blocks (as the metadata for individual blocks called `BlockInfo` are kept in memory) and when the RDD is referenced latter on this lost blocks will be recomputed.
On the other hand keeping the executors too long without any task to work on is also a waste of resources (as executors are reserved for the application by the resource manager).
## Solution
This PR focuses on the first part of SPARK-25888: it extends the external shuffle service with the capability to serve RDD blocks which are persisted on the local disk store by the executors. Moreover when this feature is enabled by setting the `spark.shuffle.service.fetch.rdd.enabled` config to true and a block is reported to be persisted on to disk the external shuffle service instance running on the same host as the executor is also registered (along with the reporting block manager) as a possible location for fetching it.
## Some implementation detail
Some explanation about the decisions made during the development:
- the location list to fetch a block was randomized but the groups (same host, same rack, others) order was kept. In this PR the order of groups are kept and external shuffle service added to the end of the each group.
- `BlockManagerInfo` is not introduced for external shuffle service but only a lightweight solution is taken. A hash map from `BlockId` to `BlockStatus` is introduced. A type alias would make the source more readable but I know it is discouraged. On the other hand a new class wrapping this hash map would introduce unnecessary indirection.
- when this feature is on the cleanup triggered during removing of executors (which is handled in `ExternalShuffleBlockResolver`) is modified to keep the disk persisted RDD blocks. This cleanup is triggered in standalone mode when the `spark.storage.cleanupFilesAfterExecutorExit` config is set.
- the unpersisting of an RDD is extended to use the external shuffle service for disk persisted RDD blocks when the original executor which created the blocks are already released. New block transport messages are introduced to support this: `RemoveBlocks` and `BlocksRemoved`.
# How was this patch tested?
## Unit tests
### ExternalShuffleServiceSuite
Here the complete use case is tested by the "SPARK-25888: using external shuffle service fetching disk persisted blocks" with a tiny difference: here the executor is killed manually, this way the test is a bit faster than waiting for the idle timeout.
### ExternalShuffleBlockHandlerSuite
Tests the fetching of the RDD blocks via the external shuffle service.
### BlockManagerInfoSuite
This a new suite. As the `BlockManagerInfo` behaviour depends very much on whether the external shuffle service enabled or not all the tests are executed with and without it.
### BlockManagerSuite
Tests the sorting of the block locations.
## Manually on YARN
Spark App was:
~~~scala
package com.mycompany
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.storage.StorageLevel
object TestAppDiskOnlyLevel {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test-app")
println("Attila: START")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(0 until 100, 10)
.map { i =>
println(s"Attila: calculate first rdd i=$i")
Thread.sleep(1000)
i
}
rdd.persist(StorageLevel.DISK_ONLY)
rdd.count()
println("Attila: First RDD is processed, waiting for 60 sec")
Thread.sleep(60 * 1000)
println("Attila: Num executors must be 0 as executorIdleTimeout is way over")
val rdd2 = sc.parallelize(0 until 10, 1)
.map(i => (i, 1))
.persist(StorageLevel.DISK_ONLY)
rdd2.count()
println("Attila: Second RDD with one partition (only one executors must be alive)")
// reduce runs as user code to detect the empty seq (empty blocks)
println("Calling collect on the first RDD: " + rdd.collect().reduce(_ + _))
println("Attila: STOP")
}
}
~~~
I have submitted with the following configuration:
~~~bash
spark-submit --master yarn \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.dynamicAllocation.executorIdleTimeout=30 \
--conf spark.dynamicAllocation.cachedExecutorIdleTimeout=90 \
--class com.mycompany.TestAppDiskOnlyLevel dyn_alloc_demo-core_2.11-0.1.0-SNAPSHOT-jar-with-dependencies.jar
~~~
Checked the result by filtering for the side effect of the task calculations:
~~~bash
[userserver ~]$ yarn logs -applicationId application_1556299359453_0001 | grep "Attila: calculate" | wc -l
WARNING: YARN_OPTS has been replaced by HADOOP_OPTS. Using value of YARN_OPTS.
19/04/26 10:31:59 INFO client.RMProxy: Connecting to ResourceManager at apiros-1.gce.company.com/172.31.115.165:8032
100
~~~
So it is only 100 task execution and not 200 (which would be the case for re-computation).
Moreover from the submit/launcher log we can see executors really stopped in between (see the new total is 0 before the last line):
~~~
[userserver ~]$ grep "Attila: Num executors must be 0" -B 2 spark-submit.log
19/04/26 10:24:27 INFO cluster.YarnScheduler: Executor 9 on apiros-3.gce.company.com killed by driver.
19/04/26 10:24:27 INFO spark.ExecutorAllocationManager: Existing executor 9 has been removed (new total is 0)
Attila: Num executors must be 0 as executorIdleTimeout is way over
~~~
[Full spark submit log](https://github.com/attilapiros/spark/files/3122465/spark-submit.log)
I have done a test also after changing the `DISK_ONLY` storage level to `MEMORY_ONLY` for the first RDD. After this change during the 60sec waiting no executor was removed.
Closes#24499 from attilapiros/SPARK-25888-final.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Added the driver functionality to get the resources.
The user interface is: SparkContext.resources - I called it this to match the TaskContext.resources api proposed in the other PR. Originally it was going to be called SparkContext.getResources but changed to be consistent, if people have strong feelings I can change it.
There are 2 ways the driver can discover what resources it has.
1) user specifies a discoveryScript, this is similar to the executors and is meant for yarn and k8s where they don't tell you what you were allocated but you are running in isolated environment.
2) read the config spark.driver.resource.resourceName.addresses. The config is meant to be used with standalone mode where the Worker will have to assign what GPU addresses the Driver is allowed to use by setting that config.
When the user runs a spark application, if they want the driver to have GPU's they would specify the conf spark.driver.resource.gpu.count=X where x is the number they want. If they are running on yarn or k8s they will also have to specify the discoveryScript as specified above, if they are on standalone mode and cluster is setup properly they wouldn't have to specify anything else. We could potentially get rid of the spark.driver.resources.gpu.addresses config which is really meant to be an internal config for worker to set if the standalone mode Worker wanted to write a discoveryScript out and set that for the user. I'll wait for the jira that implements that to decide if we can remove.
- This PR also has changes to be consistent about using resourceName everywhere.
- change the config names from POSTFIX to SUFFIX to be more consistent with other areas in Spark
- Moved the config checks around a bit since now used by both executor and driver. Note those might overlap a bit with https://github.com/apache/spark/pull/24374 so we will have to figure out which one should go in first.
## How was this patch tested?
Unit tests and manually test the interface.
Closes#24615 from tgravescs/SPARK-27488.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
Unset InputFileBlockHolder at the end of tasks to stop the file name from leaking over to other tasks in the same thread. This happens in particular in Pyspark because of its complex threading model.
## How was this patch tested?
new pyspark test
Closes#24605 from jose-torres/fix254.
Authored-by: Jose Torres <torres.joseph.f+github@gmail.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
## What changes were proposed in this pull request?
- solves the current issue with --packages in cluster mode (there is no ticket for it). Also note of some [issues](https://issues.apache.org/jira/browse/SPARK-22657) of the past here when hadoop libs are used at the spark submit side.
- supports spark.jars, spark.files, app jar.
It works as follows:
Spark submit uploads the deps to the HCFS. Then the driver serves the deps via the Spark file server.
No hcfs uris are propagated.
The related design document is [here](https://docs.google.com/document/d/1peg_qVhLaAl4weo5C51jQicPwLclApBsdR1To2fgc48/edit). the next option to add is the RSS but has to be improved given the discussion in the past about it (Spark 2.3).
## How was this patch tested?
- Run integration test suite.
- Run an example using S3:
```
./bin/spark-submit \
...
--packages com.amazonaws:aws-java-sdk:1.7.4,org.apache.hadoop:hadoop-aws:2.7.6 \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.memory=1G \
--conf spark.kubernetes.namespace=spark \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-sa \
--conf spark.driver.memory=1G \
--conf spark.executor.instances=2 \
--conf spark.sql.streaming.metricsEnabled=true \
--conf "spark.driver.extraJavaOptions=-Divy.cache.dir=/tmp -Divy.home=/tmp" \
--conf spark.kubernetes.container.image.pullPolicy=Always \
--conf spark.kubernetes.container.image=skonto/spark:k8s-3.0.0 \
--conf spark.kubernetes.file.upload.path=s3a://fdp-stavros-test \
--conf spark.hadoop.fs.s3a.access.key=... \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--conf spark.hadoop.fs.s3a.fast.upload=true \
--conf spark.kubernetes.executor.deleteOnTermination=false \
--conf spark.hadoop.fs.s3a.secret.key=... \
--conf spark.files=client:///...resolv.conf \
file:///my.jar **
```
Added integration tests based on [Ceph nano](https://github.com/ceph/cn). Looks very [active](http://www.sebastien-han.fr/blog/2019/02/24/Ceph-nano-is-getting-better-and-better/).
Unfortunately minio needs hadoop >= 2.8.
Closes#23546 from skonto/support-client-deps.
Authored-by: Stavros Kontopoulos <stavros.kontopoulos@lightbend.com>
Signed-off-by: Erik Erlandson <eerlands@redhat.com>
## What changes were proposed in this pull request?
avoid hardcoded configs in `SparkConf` and `SparkSubmit` and test
## How was this patch tested?
N/A
Closes#24631 from wenxuanguan/minor-fix.
Authored-by: wenxuanguan <choose_home@126.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
The details of the PR are explored in-depth in the sub-tasks of the umbrella jira SPARK-27726.
Briefly:
1. Stop issuing asynchronous requests to cleanup elements in the tracking store when a request is already pending
2. Fix a couple of thread-safety issues (mutable state and mis-ordered updates)
3. Move Summary deletion outside of Stage deletion loop like Tasks already are
4. Reimplement multi-delete in a removeAllKeys call which allows InMemoryStore to implement it in a performant manner.
5. Some generic typing and exception handling cleanup
We see about five orders of magnitude improvement in the deletion code, which for us is the difference between a server that needs restarting daily, and one that is stable over weeks.
Unit tests for the fire-once asynchronous code and the removeAll calls in both LevelDB and InMemoryStore are supplied. It was noted that the testing code for the LevelDB and InMemoryStore is highly repetitive, and should probably be merged, but we did not attempt that in this PR.
A version of this code was run in our production 2.3.3 and we were able to sustain higher throughput without going into GC overload (which was happening on a daily basis some weeks ago).
A version of this code was also put under a purpose-built Performance Suite of tests to verify performance under both types of Store implementations for both before and after code streams and for both total and partial delete cases (this code is not included in this PR).
Closes#24616 from davidnavas/PentaBugFix.
Authored-by: David Navas <davidn@clearstorydata.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
There are several kinds of shuffle client, blockTransferService and externalShuffleClient.
For the externalShuffleClient, there are relative external shuffle service, which guarantees the shuffle block data and regardless the state of executors.
For the blockTransferService, it is used to fetch broadcast block, and fetch the shuffle data when external shuffle service is not enabled.
When fetching data by using blockTransferService, the shuffle client would connect relative executor's blockManager, so if the relative executor is dead, it would never fetch successfully.
When spark.shuffle.service.enabled is true and spark.dynamicAllocation.enabled is true, the executor will be removed while it has been idle for more than idleTimeout.
If a blockTransferService create connection to relative executor successfully, but the relative executor is removed when beginning to fetch broadcast block, it would retry (see RetryingBlockFetcher), which is Ineffective.
If the spark.shuffle.io.retryWait and spark.shuffle.io.maxRetries is big, such as 30s and 10 times, it would waste 5 minutes.
In this PR, we check whether relative executor is alive before retry.
## How was this patch tested?
Unit test.
Closes#24533 from turboFei/SPARK-27637.
Authored-by: hustfeiwang <wangfei3@corp.netease.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Kafka related Spark parameters has to start with `spark.kafka.` and not with `spark.sql.`. Because of this I've renamed `spark.sql.kafkaConsumerCache.capacity`.
Since Kafka consumer caching is not documented I've added this also.
## How was this patch tested?
Existing + added unit test.
```
cd docs
SKIP_API=1 jekyll build
```
and manual webpage check.
Closes#24590 from gaborgsomogyi/SPARK-27687.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
This feature allows proxy servers to identify the actual request user
using a request parameter, and performs access control checks against
that user instead of the authenticated user. Impersonation is only
allowed if the authenticated user is configured as an admin.
The request parameter used ("doAs") matches the one currently used by
Knox, but it should be easy to change / customize if different proxy
servers use a different way of identifying the original user.
Tested with updated unit tests and also with a live server behind Knox.
Closes#24582 from vanzin/SPARK-27678.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This replaces use of collection classes like `MutableList` and `ArrayStack` with workalikes that are available in 2.12, as they will be removed in 2.13. It also removes use of `.to[Collection]` as its uses was superfluous anyway. Removing `collection.breakOut` will have to wait until 2.13
## How was this patch tested?
Existing tests
Closes#24586 from srowen/SPARK-27682.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This removes usage of `Traversable`, which is removed in Scala 2.13. This is mostly an internal change, except for the change in the `SparkConf.setAll` method. See additional comments below.
## How was this patch tested?
Existing tests.
Closes#24584 from srowen/SPARK-27680.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
The Pull Request to add datatables to stage page SPARK-21809 got merged. The search functionality in those datatables being a great improvement for searching through a large number of tasks, also performs search over the raw data rather than the formatted data displayed in the tables. It would be great if the search can happen for the formatted data as well.
## What changes were proposed in this pull request?
Added code to enable searching over displayed data in tables e.g. searching on "165.7 MiB" or "0.3 ms" will now return the search results. Also, earlier we were missing search for two columns in the task table "Shuffle Read Bytes" as well as "Shuffle Remote Reads", which I have added here.
## How was this patch tested?
Manual Tests
Closes#24419 from pgandhi999/SPARK-25719.
Authored-by: pgandhi <pgandhi@verizonmedia.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Add in GPU and generic resource type allocation to the executors.
Note this is part of a bigger feature for gpu-aware scheduling and is just how the executor find the resources. The general flow :
- users ask for a certain set of resources, for instance number of gpus - each cluster manager has a specific way to do this.
- cluster manager allocates a container or set of resources (standalone mode)
- When spark launches the executor in that container, the executor either has to be told what resources it has or it has to auto discover them.
- Executor has to register with Driver and tell the driver the set of resources it has so the scheduler can use that to schedule tasks that requires a certain amount of each of those resources
In this pr I added configs and arguments to the executor to be able discover resources. The argument to the executor is intended to be used by standalone mode or other cluster managers that don't have isolation so that it can assign specific resources to specific executors in case there are multiple executors on a node. The argument is a file contains JSON Array of ResourceInformation objects.
The discovery script is meant to be used in an isolated environment where the executor only sees the resources it should use.
Note that there will be follow on PRs to add other parts like the scheduler part. See the epic high level jira: https://issues.apache.org/jira/browse/SPARK-24615
## How was this patch tested?
Added unit tests and manually tested.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24406 from tgravescs/gpu-sched-executor-clean.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
For the below three thread configuration items applied to both driver and executor,
spark.rpc.io.serverThreads
spark.rpc.io.clientThreads
spark.rpc.netty.dispatcher.numThreads,
we separate them to driver specifics and executor specifics.
spark.driver.rpc.io.serverThreads < - > spark.executor.rpc.io.serverThreads
spark.driver.rpc.io.clientThreads < - > spark.executor.rpc.io.clientThreads
spark.driver.rpc.netty.dispatcher.numThreads < - > spark.executor.rpc.netty.dispatcher.numThreads
Spark reads these specifics first and fall back to the common configurations.
## How was this patch tested?
We ran the SimpleMap app without shuffle for benchmark purpose to test Spark's scalability in HPC with omini-path NIC which has higher bandwidth than normal ethernet NIC.
Spark's base version is 2.4.0.
Spark ran in the Standalone mode. Driver was in a standalone node.
After the separation, the performance is improved a lot in 256 nodes and 512 nodes. see below test results of SimpleMapTask before and after the enhancement. You can view the tables in the [JIRA](https://issues.apache.org/jira/browse/SPARK-26632) too.
ds: spark.driver.rpc.io.serverThreads
dc: spark.driver.rpc.io.clientThreads
dd: spark.driver.rpc.netty.dispatcher.numThreads
ed: spark.executor.rpc.netty.dispatcher.numThreads
time: Overall Time (s)
old time: Overall Time without Separation (s)
**Before:**
nodes | ds | dc | dd | ed | time
-- |-- | -- | -- | -- | --
128 nodes | 8 | 8 | 8 | 8 | 108
256 nodes | 8 | 8 | 8 | 8 | 196
512 nodes | 8 | 8 | 8 | 8 | 377
**After:**
nodes | ds | dc | dd | ed | time | improvement
-- | -- | -- | -- | -- | -- | --
128 nodes | 15 | 15 | 10 | 30 | 107 | 0.9%
256 nodes | 12 | 15 | 10 | 30 | 159 | 18.8%
512 nodes | 12 | 15 | 10 | 30 | 283 | 24.9%
Closes#23560 from zjf2012/thread_conf_separation.
Authored-by: jiafu.zhang@intel.com <jiafu.zhang@intel.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Python uses a prefetch approach to read the result from upstream and serve them in another thread, thus it's possible that if the children operator doesn't consume all the data then the Task cleanup may happen before Python side read process finishes, this in turn create a race condition that the block read locks are freed during Task cleanup and then the reader try to release the read lock it holds and find it has been released, in this case we shall hit a AssertionError.
We shall catch the AssertionError in PythonRunner and prevent this kill the Executor.
## How was this patch tested?
Hard to write a unit test case for this case, manually verified with failed job.
Closes#24542 from jiangxb1987/pyError.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This fixes an error when a PySpark local iterator, for both RDD and DataFrames, goes out of scope and the connection is closed before fully consuming the iterator. The error occurs on the JVM in the serving thread, when Python closes the local socket while the JVM is writing to it. This usually happens when there is enough data to fill the socket read buffer, causing the write call to block.
Additionally, this fixes a problem when an error occurs in the Python worker and the collect job is cancelled with an exception. Previously, the Python driver was never notified of the error so the user could get a partial result (iteration until the error) and the application will continue. With this change, an error in the worker is sent to the Python iterator and is then raised.
The change here introduces a protocol for PySpark local iterators that work as follows:
1) The local socket connection is made when the iterator is created
2) When iterating, Python first sends a request for partition data as a non-zero integer
3) While the JVM local iterator over partitions has next, it triggers a job to collect the next partition
4) The JVM sends a nonzero response to indicate it has the next partition to send
5) The next partition is sent to Python and read by the PySpark deserializer
6) After sending the entire partition, an `END_OF_DATA_SECTION` is sent to Python which stops the deserializer and allows to make another request
7) When the JVM gets a request from Python but has already consumed it's local iterator, it will send a zero response to Python and both will close the socket cleanly
8) If an error occurs in the worker, a negative response is sent to Python followed by the error message. Python will then raise a RuntimeError with the message, stopping iteration.
9) When the PySpark local iterator is garbage-collected, it will read any remaining data from the current partition (this is data that has already been collected) and send a request of zero to tell the JVM to stop collection jobs and close the connection.
Steps 1, 3, 5, 6 are the same as before. Step 8 was completely missing before because errors in the worker were never communicated back to Python. The other steps add synchronization to allow for a clean closing of the socket, with a small trade-off in performance for each partition. This is mainly because the JVM does not start collecting partition data until it receives a request to do so, where before it would eagerly write all data until the socket receive buffer is full.
## How was this patch tested?
Added new unit tests for DataFrame and RDD `toLocalIterator` and tested not fully consuming the iterator. Manual tests with Python 2.7 and 3.6.
Closes#24070 from BryanCutler/pyspark-toLocalIterator-clean-stop-SPARK-23961.
Authored-by: Bryan Cutler <cutlerb@gmail.com>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
{kind=link}
{kind=link}