## What changes were proposed in this pull request?
This patch applies redaction to command line arguments before logging them. This applies to two resource managers: standalone cluster and YARN.
This patch only concerns about arguments starting with `-D` since Spark is likely passing the Spark configuration to command line arguments as `-Dspark.blabla=blabla`. More change is necessary if we also want to handle the case of `--conf spark.blabla=blabla`.
## How was this patch tested?
Added UT for redact logic. This patch only touches how to log so not easy to add UT regarding it.
Closes#23820 from HeartSaVioR/MINOR-redact-command-line-args-for-running-driver-executor.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
In the PR, I propose to refactor existing code related to date/time conversions, and replace constants like `1000` and `1000000` by `DateTimeUtils` constants and transformation functions from `java.util.concurrent.TimeUnit._`.
## How was this patch tested?
The changes are tested by existing test suites.
Closes#23878 from MaxGekk/magic-time-constants.
Lead-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
Since the yarn module is actually private to Spark, this interface was never
actually "public". Since it has no use inside of Spark, let's avoid adding
a yarn-specific extension that isn't public, and point any potential users
are more general solutions (like using a SparkListener).
Closes#23839 from vanzin/SPARK-26788.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
Before this PR the method `BlockManager#putBlockDataAsStream()` (which is used during block replication where the block data is received as a stream) was reading the whole block content into the memory even at DISK_ONLY storage level.
With this change the received block data (which was temporary stored in a file) is just simply moved into the right location backing the target block. This way a possible OOM error is avoided.
In this implementation to save code duplications the method `doPutBytes` is refactored into a template method called `BlockStoreUpdater` which has a separate implementation to handle byte buffer based and temporary file based block store updates.
With existing unit tests of `DistributedSuite` (the ones dealing with replications):
- caching on disk, replicated (encryption = off) (with replication as stream)
- caching on disk, replicated (encryption = on) (with replication as stream)
- caching in memory, serialized, replicated (encryption = on) (with replication as stream)
- caching in memory, serialized, replicated (encryption = off) (with replication as stream)
- etc.
And with new unit tests testing `putBlockDataAsStream` method directly:
- test putBlockDataAsStream with caching (encryption = off)
- test putBlockDataAsStream with caching (encryption = on)
- test putBlockDataAsStream with caching on disk (encryption = off)
- test putBlockDataAsStream with caching on disk (encryption = on)
Closes#23688 from attilapiros/SPARK-25035.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
In the PR, I propose to test the input showed at the end of the article: https://arxiv.org/pdf/1805.08612.pdf . The difference of the test and paper's test is type of array. This test allocates arrays of bytes instead of array of ints.
## How was this patch tested?
New test is added to `SorterSuite`.
Closes#23856 from MaxGekk/timsort-bug-fix.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR aims to remove references to "Shark", which is a precursor to Spark SQL. I searched the whole project for the text "Shark" (ignore case) and just found a single match. Note that occurrences like nickname or test data are irrelevant.
## How was this patch tested?
N/A. Change comments only.
Closes#23876 from seancxmao/remove-Shark.
Authored-by: seancxmao <seancxmao@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Don't use inaccessible fields in SizeEstimator, which comes up in Java 9+
## How was this patch tested?
Manually ran tests with Java 11; it causes these tests that failed before to pass.
This ought to pass on Java 8 as there's effectively no change for Java 8.
Closes#23866 from srowen/SPARK-26963.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR aims to fix some outdated comments about task schedulers.
1. Change "ClusterScheduler" to "YarnScheduler" in comments of `YarnClusterScheduler`
According to [SPARK-1140 Remove references to ClusterScheduler](https://issues.apache.org/jira/browse/SPARK-1140), ClusterScheduler is not used anymore.
I also searched "ClusterScheduler" within the whole project, no other occurrences are found in comments or test cases. Note classes like `YarnClusterSchedulerBackend` or `MesosClusterScheduler` are not relevant.
2. Update comments about `statusUpdate` from `TaskSetManager`
`statusUpdate` has been moved to `TaskSchedulerImpl`. StatusUpdate event handling is delegated to `handleSuccessfulTask`/`handleFailedTask`.
## How was this patch tested?
N/A. Fix comments only.
Closes#23844 from seancxmao/taskscheduler-comments.
Authored-by: seancxmao <seancxmao@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
`prepareSubmitEnvironment` performs globbing that will fail in the case where a proxy user (`--proxy-user`) doesn't have permission to the file. This is a bug also with 2.3, so we should backport, as currently you can't launch an application that for instance is passing a file under `--archives`, and that file is owned by the target user.
The solution is to call `prepareSubmitEnvironment` within a doAs context if proxying.
## How was this patch tested?
Manual tests running with `--proxy-user` and `--archives`, before and after, showing that the globbing is successful when the resource is owned by the target user.
I've looked at writing unit tests, but I am not sure I can do that cleanly (perhaps with a custom FileSystem). Open to ideas.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23806 from abellina/SPARK-26895_prepareSubmitEnvironment_from_doAs.
Lead-authored-by: Alessandro Bellina <abellina@gmail.com>
Co-authored-by: Alessandro Bellina <abellina@yahoo-inc.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Spark's TimSort deviates from JDK 11 TimSort in a couple places:
- `stackLen` was increased in jdk
- additional cases for break in `mergeCollapse`: `n < 0`
In the PR, I propose to align Spark TimSort to jdk implementation.
## How was this patch tested?
By existing test suites, in particular, `SorterSuite`.
Closes#23858 from MaxGekk/timsort-java-alignment.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently, RDD.saveAsTextFile may throw NullPointerException then null row is present.
```
scala> sc.parallelize(Seq(1,null),1).saveAsTextFile("/tmp/foobar.dat")
19/02/15 21:39:17 ERROR Utils: Aborting task
java.lang.NullPointerException
at org.apache.spark.rdd.RDD.$anonfun$saveAsTextFile$3(RDD.scala:1510)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:459)
at org.apache.spark.internal.io.SparkHadoopWriter$.$anonfun$executeTask$1(SparkHadoopWriter.scala:129)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1352)
at org.apache.spark.internal.io.SparkHadoopWriter$.executeTask(SparkHadoopWriter.scala:127)
at org.apache.spark.internal.io.SparkHadoopWriter$.$anonfun$write$1(SparkHadoopWriter.scala:83)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:121)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:425)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1318)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:428)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
This PR write "Null" for null row to avoid NPE and fix it.
## How was this patch tested?
NA
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23799 from liupc/Fix-saveAsTextFile-throws-NullPointerException-when-null-row-present.
Lead-authored-by: liupengcheng <liupengcheng@xiaomi.com>
Co-authored-by: Liupengcheng <liupengcheng@xiaomi.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR targets to support Arrow optimization for conversion from Spark DataFrame to R DataFrame.
Like PySpark side, it falls back to non-optimization code path when it's unable to use Arrow optimization.
This can be tested as below:
```bash
$ ./bin/sparkR --conf spark.sql.execution.arrow.enabled=true
```
```r
collect(createDataFrame(mtcars))
```
### Requirements
- R 3.5.x
- Arrow package 0.12+
```bash
Rscript -e 'remotes::install_github("apache/arrowapache-arrow-0.12.0", subdir = "r")'
```
**Note:** currently, Arrow R package is not in CRAN. Please take a look at ARROW-3204.
**Note:** currently, Arrow R package seems not supporting Windows. Please take a look at ARROW-3204.
### Benchmarks
**Shall**
```bash
sync && sudo purge
./bin/sparkR --conf spark.sql.execution.arrow.enabled=false --driver-memory 4g
```
```bash
sync && sudo purge
./bin/sparkR --conf spark.sql.execution.arrow.enabled=true --driver-memory 4g
```
**R code**
```r
df <- cache(createDataFrame(read.csv("500000.csv")))
count(df)
test <- function() {
options(digits.secs = 6) # milliseconds
start.time <- Sys.time()
collect(df)
end.time <- Sys.time()
time.taken <- end.time - start.time
print(time.taken)
}
test()
```
**Data (350 MB):**
```r
object.size(read.csv("500000.csv"))
350379504 bytes
```
"500000 Records" http://eforexcel.com/wp/downloads-16-sample-csv-files-data-sets-for-testing/
**Results**
```
Time difference of 221.32014 secs
```
```
Time difference of 15.51145 secs
```
The performance improvement was around **1426%**.
### Limitations:
- For now, Arrow optimization with R does not support when the data is `raw`, and when user explicitly gives float type in the schema. They produce corrupt values. In this case, we decide to fall back to non-optimization code path.
- Due to ARROW-4512, it cannot send and receive batch by batch. It has to send all batches in Arrow stream format at once. It needs improvement later.
## How was this patch tested?
Existing tests related with Arrow optimization cover this change. Also, manually tested.
Closes#23760 from HyukjinKwon/SPARK-26762.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
`HadoopDelegationTokenProvider` has basically the same functionality just like `ServiceCredentialProvider` so the interfaces can be merged.
`YARNHadoopDelegationTokenManager` now loads `ServiceCredentialProvider`s in one step. The drawback of this if one provider fails all others are not loaded. `HadoopDelegationTokenManager` loads `HadoopDelegationTokenProvider`s independently so it provides more robust behaviour.
In this PR I've I've made the following changes:
* Deleted `YARNHadoopDelegationTokenManager` and `ServiceCredentialProvider`
* Made `HadoopDelegationTokenProvider` a `DeveloperApi`
## How was this patch tested?
Existing unit tests.
Closes#23686 from gaborgsomogyi/SPARK-26772.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This patch proposes to change the approach on extracting log urls as well as attributes from YARN executor:
- AS-IS: extract information from `Container` API and include them to container launch context
- TO-BE: let YARN executor self-extracting information
This approach leads us to populate more attributes like nodemanager's IPC port which can let us configure custom log url to JHS log url directly.
## How was this patch tested?
Existing unit tests.
Closes#23706 from HeartSaVioR/SPARK-26790.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
Make it a debug message so that it doesn't show up in the vast
majority of cases, where HBase classes are not available.
Closes#23776 from vanzin/SPARK-26650.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In the PR, I propose to use `System.nanoTime()` instead of `System.currentTimeMillis()` in measurements of time intervals.
`System.currentTimeMillis()` returns current wallclock time and will follow changes to the system clock. Thus, negative wallclock adjustments can cause timeouts to "hang" for a long time (until wallclock time has caught up to its previous value again). This can happen when ntpd does a "step" after the network has been disconnected for some time. The most canonical example is during system bootup when DHCP takes longer than usual. This can lead to failures that are really hard to understand/reproduce. `System.nanoTime()` is guaranteed to be monotonically increasing irrespective of wallclock changes.
## How was this patch tested?
By existing test suites.
Closes#23727 from MaxGekk/system-nanotime.
Lead-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR targets to add vectorized `gapply()` in R, Arrow optimization.
This can be tested as below:
```bash
$ ./bin/sparkR --conf spark.sql.execution.arrow.enabled=true
```
```r
df <- createDataFrame(mtcars)
collect(gapply(df,
"gear",
function(key, group) {
data.frame(gear = key[[1]], disp = mean(group$disp) > group$disp)
},
structType("gear double, disp boolean")))
```
### Requirements
- R 3.5.x
- Arrow package 0.12+
```bash
Rscript -e 'remotes::install_github("apache/arrowapache-arrow-0.12.0", subdir = "r")'
```
**Note:** currently, Arrow R package is not in CRAN. Please take a look at ARROW-3204.
**Note:** currently, Arrow R package seems not supporting Windows. Please take a look at ARROW-3204.
### Benchmarks
**Shall**
```bash
sync && sudo purge
./bin/sparkR --conf spark.sql.execution.arrow.enabled=false
```
```bash
sync && sudo purge
./bin/sparkR --conf spark.sql.execution.arrow.enabled=true
```
**R code**
```r
rdf <- read.csv("500000.csv")
rdf <- rdf[, c("Month.of.Joining", "Weight.in.Kgs.")] # We're only interested in the key and values to calculate.
df <- cache(createDataFrame(rdf))
count(df)
test <- function() {
options(digits.secs = 6) # milliseconds
start.time <- Sys.time()
count(gapply(df,
"Month_of_Joining",
function(key, group) {
data.frame(Month_of_Joining = key[[1]], Weight_in_Kgs_ = mean(group$Weight_in_Kgs_) > group$Weight_in_Kgs_)
},
structType("Month_of_Joining integer, Weight_in_Kgs_ boolean")))
end.time <- Sys.time()
time.taken <- end.time - start.time
print(time.taken)
}
test()
```
**Data (350 MB):**
```r
object.size(read.csv("500000.csv"))
350379504 bytes
```
"500000 Records" http://eforexcel.com/wp/downloads-16-sample-csv-files-data-sets-for-testing/
**Results**
```
Time difference of 35.67459 secs
```
```
Time difference of 4.301399 secs
```
The performance improvement was around **829%**.
**Note that** I am 100% sure this PR improves more then 829% because I gave up testing it with non-Arrow optimization because it took super super super long when the data size becomes bigger.
### Limitations
- For now, Arrow optimization with R does not support when the data is `raw`, and when user explicitly gives float type in the schema. They produce corrupt values.
- Due to ARROW-4512, it cannot send and receive batch by batch. It has to send all batches in Arrow stream format at once. It needs improvement later.
## How was this patch tested?
Unit tests were added
**TODOs:**
- [x] Draft codes
- [x] make the tests passed
- [x] make the CRAN check pass
- [x] Performance measurement
- [x] Supportability investigation (for instance types)
Closes#23746 from HyukjinKwon/SPARK-26759.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
- The benchmark of `XORShiftRandom.nextInt` vis-a-vis `java.util.Random.nextInt` is moved from the `XORShiftRandom` object to `XORShiftRandomBenchmark`.
- Added benchmarks for `nextLong`, `nextDouble` and `nextGaussian` that are used in Spark as well.
- Added a separate benchmark for `XORShiftRandom.hashSeed`.
Closes#23752 from MaxGekk/xorshiftrandom-benchmark.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Delegation token providers interface now has a parameter `fileSystems` but this is needed only for `HadoopFSDelegationTokenProvider`.
In this PR I've addressed this issue in the following way:
* Removed `fileSystems` parameter from `HadoopDelegationTokenProvider`
* Moved `YarnSparkHadoopUtil.hadoopFSsToAccess` into `HadoopFSDelegationTokenProvider`
* Moved `spark.yarn.stagingDir` into core
* Moved `spark.yarn.access.namenodes` into core and renamed to `spark.kerberos.access.namenodes`
* Moved `spark.yarn.access.hadoopFileSystems` into core and renamed to `spark.kerberos.access.hadoopFileSystems`
## How was this patch tested?
Existing unit tests.
Closes#23698 from gaborgsomogyi/SPARK-26766.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Recently, when I was reading some code of `BlockManager.getBlockData`, I found that there are useless code that would never reach. The related codes is as below:
```
override def getBlockData(blockId: BlockId): ManagedBuffer = {
if (blockId.isShuffle) {
shuffleManager.shuffleBlockResolver.getBlockData(blockId.asInstanceOf[ShuffleBlockId])
} else {
getLocalBytes(blockId) match {
case Some(blockData) =>
new BlockManagerManagedBuffer(blockInfoManager, blockId, blockData, true)
case None =>
// If this block manager receives a request for a block that it doesn't have then it's
// likely that the master has outdated block statuses for this block. Therefore, we send
// an RPC so that this block is marked as being unavailable from this block manager.
reportBlockStatus(blockId, BlockStatus.empty)
throw new BlockNotFoundException(blockId.toString)
}
}
}
```
```
def getLocalBytes(blockId: BlockId): Option[BlockData] = {
logDebug(s"Getting local block $blockId as bytes")
// As an optimization for map output fetches, if the block is for a shuffle, return it
// without acquiring a lock; the disk store never deletes (recent) items so this should work
if (blockId.isShuffle) {
val shuffleBlockResolver = shuffleManager.shuffleBlockResolver
// TODO: This should gracefully handle case where local block is not available. Currently
// downstream code will throw an exception.
val buf = new ChunkedByteBuffer(
shuffleBlockResolver.getBlockData(blockId.asInstanceOf[ShuffleBlockId]).nioByteBuffer())
Some(new ByteBufferBlockData(buf, true))
} else {
blockInfoManager.lockForReading(blockId).map { info => doGetLocalBytes(blockId, info) }
}
}
```
the `blockId.isShuffle` is checked twice, but however it seems that in the method calling hierarchy of `BlockManager.getLocalBytes`, the another callsite of the `BlockManager.getLocalBytes` is at `TorrentBroadcast.readBlocks` where the blockId can never be a `ShuffleBlockId`.
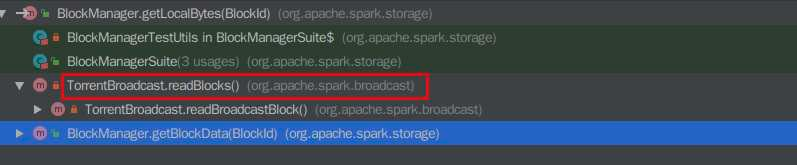
So I think we should remove these useless code for easy reading.
## How was this patch tested?
NA
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23693 from liupc/Remove-useless-code-in-BlockManager.
Authored-by: Liupengcheng <liupengcheng@xiaomi.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
**updateAndSyncNumExecutorsTarget** API should be called after **initializing** flag is unset
## How was this patch tested?
Added UT and also manually tested
After Fix
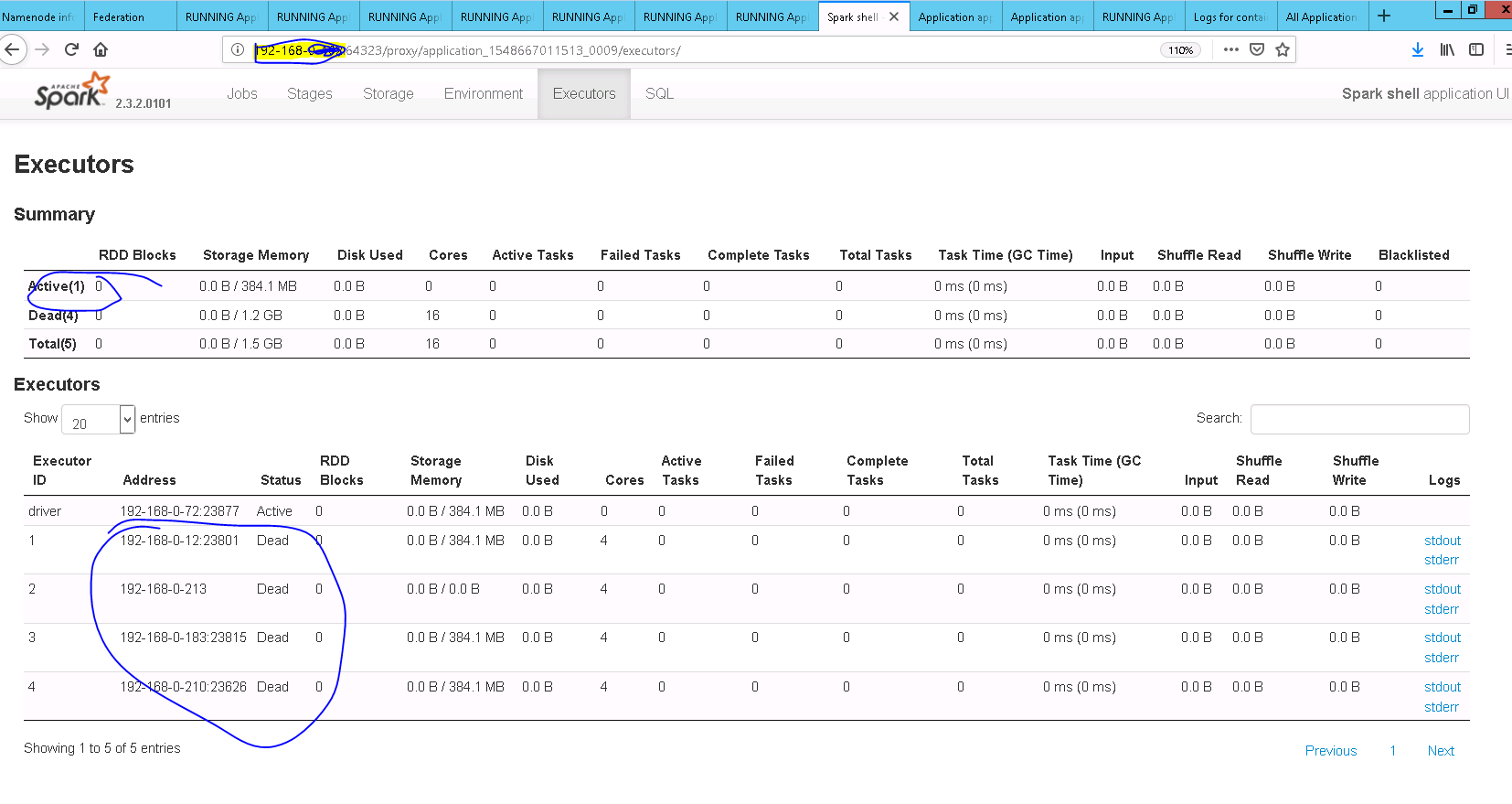
Closes#23697 from sandeep-katta/executorIssue.
Authored-by: sandeep-katta <sandeep.katta2007@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
When the job's partiton is zero, it will still get a jobid but not shown in ui. It's strange. This PR is to show this job in ui.
Example:
In bash:
mkdir -p /home/test/testdir
sc.textFile("/home/test/testdir")
Some logs:
```
19/01/24 17:26:19 INFO FileInputFormat: Total input paths to process : 0
19/01/24 17:26:19 INFO SparkContext: Starting job: collect at WordCount.scala:9
19/01/24 17:26:19 INFO DAGScheduler: Job 0 finished: collect at WordCount.scala:9, took 0.003735 s
```
## How was this patch tested?
UT
Closes#23637 from deshanxiao/spark-26714.
Authored-by: xiaodeshan <xiaodeshan@xiaomi.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Make .unpersist(), .destroy() non-blocking by default and adjust callers to request blocking only where important.
This also adds an optional blocking argument to Pyspark's RDD.unpersist(), which never had one.
## How was this patch tested?
Existing tests.
Closes#23685 from srowen/SPARK-26771.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently, spark would not release ShuffleBlockFetcherIterator until the whole task finished.In some conditions, it incurs memory leak.
An example is `rdd.repartition(m).coalesce(n, shuffle = false).save`, each `ShuffleBlockFetcherIterator` contains some metas about mapStatus(`blocksByAddress`) and each resultTask will keep n(max to shuffle partitions) shuffleBlockFetcherIterator and the memory would never released until the task completion, for they are referenced by the completion callbacks of TaskContext. In some case, it may take huge memory and incurs OOM.
Actually, We can release ShuffleBlockFetcherIterator as soon as it's consumed.
This PR is to resolve this problem.
## How was this patch tested?
unittest
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23438 from liupc/Fast-release-shuffleblockfetcheriterator.
Lead-authored-by: Liupengcheng <liupengcheng@xiaomi.com>
Co-authored-by: liupengcheng <liupengcheng@xiaomi.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…not synchronized to the UI display
## What changes were proposed in this pull request?
The amount of memory used by the broadcast variable is not synchronized to the UI display.
I added the case for BroadcastBlockId and updated the memory usage.
## How was this patch tested?
We can test this patch with unit tests.
Closes#23649 from httfighter/SPARK-26726.
Lead-authored-by: 韩田田00222924 <han.tiantian@zte.com.cn>
Co-authored-by: han.tiantian@zte.com.cn <han.tiantian@zte.com.cn>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This patch proposes adding a new configuration on SHS: custom executor log URL pattern. This will enable end users to replace executor logs to other than RM provide, like external log service, which enables to serve executor logs when NodeManager becomes unavailable in case of YARN.
End users can build their own of custom executor log URLs with pre-defined patterns which would be vary on each resource manager. This patch adds some patterns to YARN resource manager. (For others, there's even no executor log url available so cannot define patterns as well.)
Please refer the doc change as well as added UTs in this patch to see how to set up the feature.
## How was this patch tested?
Added UT, as well as manual test with YARN cluster
Closes#23260 from HeartSaVioR/SPARK-26311.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
This fix replaces the Threshold with a Filter for ConsoleAppender which checks
to ensure that either the logLevel is greater than thresholdLevel (shell log
level) or the log originated from a custom defined logger. In these cases, it
lets a log event go through, otherwise it doesn't.
1. Ensured that custom log level works when set by default (via log4j.properties)
2. Ensured that logs are not printed twice when log level is changed by setLogLevel
3. Ensured that custom logs are printed when log level is changed back by setLogLevel
Closes#23675 from ankuriitg/ankurgupta/SPARK-26753.
Authored-by: ankurgupta <ankur.gupta@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
This avoids trying to get delegation tokens when a TGT is not available, e.g.
when running in yarn-cluster mode without a keytab. That would result in an
error since that is not allowed.
Tested with some (internal) integration tests that started failing with the
patch for SPARK-25689.
Closes#23689 from vanzin/SPARK-25689.followup.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
Otherwise the RDD data may be out of date by the time the test tries to check it.
Tested with an artificial delay inserted in AppStatusListener.
Closes#23654 from vanzin/SPARK-26732.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
This change addes a new mode for credential renewal that does not require
a keytab; it uses the local ticket cache instead, so it works while the
user keeps the cache valid.
This can be useful for, e.g., people running long spark-shell sessions where
their kerberos login is kept up-to-date.
The main change to enable this behavior is in HadoopDelegationTokenManager,
with a small change in the HDFS token provider. The other changes are to avoid
creating duplicate tokens when submitting the application to YARN; they allow
the tokens from the scheduler to be sent to the YARN AM, reducing the round trips
to HDFS.
For that, the scheduler initialization code was changed a little bit so that
the tokens are available when the YARN client is initialized. That basically
takes care of a long-standing TODO that was in the code to clean up configuration
propagation to the driver's RPC endpoint (in CoarseGrainedSchedulerBackend).
Tested with an app designed to stress this functionality, with both keytab and
cache-based logins. Some basic kerberos tests on k8s also.
Closes#23525 from vanzin/SPARK-26595.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
While obtaining token from hbase service , spark uses deprecated API of hbase ,
```public static Token<AuthenticationTokenIdentifier> obtainToken(Configuration conf)```
This deprecated API is already been removed from hbase 2.x version as part of the hbase 2.x major release. https://issues.apache.org/jira/browse/HBASE-14713_
there is one more stable API in
```public static Token<AuthenticationTokenIdentifier> obtainToken(Connection conn)``` in TokenUtil class
spark shall use this stable api for getting the delegation token.
To invoke this api first connection object has to be retrieved from ConnectionFactory and the same connection can be passed to obtainToken(Connection conn) for getting token.
eg: Call ```public static Connection createConnection(Configuration conf)```
, then call ```public static Token<AuthenticationTokenIdentifier> obtainToken( Connection conn)```.
## How was this patch tested?
Manual testing is been done.
Manual test result:
Before fix:

After fix:
1. Create 2 tables in hbase shell
>Launch hbase shell
>Enter commands to create tables and load data
create 'table1','cf'
put 'table1','row1','cf:cid','20'
create 'table2','cf'
put 'table2','row1','cf:cid','30'
>Show values command
get 'table1','row1','cf:cid' will diplay value as 20
get 'table2','row1','cf:cid' will diplay value as 30
2.Run SparkHbasetoHbase class in testSpark.jar using spark-submit
spark-submit --master yarn-cluster --class com.mrs.example.spark.SparkHbasetoHbase --conf "spark.yarn.security.credentials.hbase.enabled"="true" --conf "spark.security.credentials.hbase.enabled"="true" --keytab /opt/client/user.keytab --principal sen testSpark.jar
The SparkHbasetoHbase test class will update the value of table2 with sum of values of table1 & table2.
table2 = table1+table2
As we can see in the snapshot the spark job has been successfully able to interact with hbase service and able to update the row count.

Closes#23429 from sujith71955/master_hbase_service.
Authored-by: s71955 <sujithchacko.2010@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Manually release stdin writer and stderr reader thread when task is finished. This commit also marks
ShuffleBlockFetchIterator as fully consumed if isZombie is set.
## How was this patch tested?
Added new test
Closes#23638 from advancedxy/SPARK-26713.
Authored-by: Xianjin YE <advancedxy@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This is a followup of #16989
The fetch-big-block-to-disk feature is disabled by default, because it's not compatible with external shuffle service prior to Spark 2.2. The client sends stream request to fetch block chunks, and old shuffle service can't support it.
After 2 years, Spark 2.2 has EOL, and now it's safe to turn on this feature by default
## How was this patch tested?
existing tests
Closes#23625 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Adjust mem settings in UnifiedMemoryManager used in test suites to ha…ve execution memory > 0
Ref: https://github.com/apache/spark/pull/23457#issuecomment-457409976
## How was this patch tested?
Existing tests
Closes#23645 from srowen/SPARK-26725.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR makes hardcoded configs about spark memory and storage to use `ConfigEntry` and put them in the config package.
## How was this patch tested?
Existing unit tests.
Closes#23623 from SongYadong/configEntry_for_mem_storage.
Authored-by: SongYadong <song.yadong1@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
There are ugly provided dependencies inside core for the following:
* Hive
* Kafka
In this PR I've extracted them out. This PR contains the following:
* Token providers are now loaded with service loader
* Hive token provider moved to hive project
* Kafka token provider extracted into a new project
## How was this patch tested?
Existing + newly added unit tests.
Additionally tested on cluster.
Closes#23499 from gaborgsomogyi/SPARK-26254.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
SPARK-21568 made a change to ensure that progress bar is enabled for spark-shell
by default but not for other apps. Before that change, this was distinguished
using log-level which is not a good way to determine the same as users can change
the default log-level. That commit changed the way to determine whether current
app is running in spark-shell or not but it left the log-level part as it is,
which causes this regression. SPARK-25118 changed the default log level to INFO
for spark-shell because of which the progress bar is not enabled anymore.
This commit will remove the log-level check for enabling progress bar for
spark-shell as it is not necessary and seems to be a leftover from SPARK-21568
## How was this patch tested?
1. Ensured that progress bar is enabled with spark-shell by default
2. Ensured that progress bar is not enabled with spark-submit
Closes#23618 from ankuriitg/ankurgupta/SPARK-26694.
Authored-by: ankurgupta <ankur.gupta@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
To help debugging failed or slow tasks, its really useful to know the
size of the blocks getting fetched. Though that is available at the
debug level, debug logs aren't on in general -- but there is already an
info level log line that this augments a little.
## How was this patch tested?
Ran very basic local-cluster mode app, looked at logs. Example line:
```
INFO ShuffleBlockFetcherIterator: Getting 2 (194.0 B) non-empty blocks including 1 (97.0 B) local blocks and 1 (97.0 B) remote blocks
```
Full suite via jenkins.
Closes#23621 from squito/SPARK-26697.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Currently, heartbeat related arguments is not validated in spark, so if these args are inproperly specified, the Application may run for a while and not failed until the max executor failures reached(especially with spark.dynamicAllocation.enabled=true), thus may incurs resources waste.
This PR is to precheck these arguments in HeartbeatReceiver to fix this problem.
## How was this patch tested?
NA-just validation changes
Closes#23445 from liupc/validate-heartbeat-arguments-in-SparkSubmitArguments.
Authored-by: Liupengcheng <liupengcheng@xiaomi.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Currently, some ML library may generate large ml model, which may be referenced in the task closure, so driver will broadcasting large task binary, and executor may not able to deserialize it and result in OOM failures(for instance, executor's memory is not enough). This problem not only affects apps using ml library, some user specified closure or function which refers large data may also have this problem.
In order to facilitate the debuging of memory problem caused by large taskBinary broadcast, we can add same warning logs for it.
This PR will add some warning logs on the driver side when broadcasting a large task binary, and it also included some minor log changes in the reading of broadcast.
## How was this patch tested?
NA-Just log changes.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23580 from liupc/Add-warning-logs-for-large-taskBinary-size.
Authored-by: Liupengcheng <liupengcheng@xiaomi.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Followup of #20091. We could also use existing partitioner when defaultNumPartitions is equal to the maxPartitioner's numPartitions.
## How was this patch tested?
Existed.
Closes#23581 from Ngone51/dev-use-existing-partitioner-when-defaultNumPartitions-equalTo-MaxPartitioner#-numPartitions.
Authored-by: Ngone51 <ngone_5451@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
`ByteBuffer.allocate` may throw `OutOfMemoryError` when the block is large but no enough memory is available. However, when this happens, right now BlockTransferService.fetchBlockSync will just hang forever as its `BlockFetchingListener. onBlockFetchSuccess` doesn't complete `Promise`.
This PR catches `Throwable` and uses the error to complete `Promise`.
## How was this patch tested?
Added a unit test. Since I cannot make `ByteBuffer.allocate` throw `OutOfMemoryError`, I passed a negative size to make `ByteBuffer.allocate` fail. Although the error type is different, it should trigger the same code path.
Closes#23590 from zsxwing/SPARK-26665.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
The PR makes hardcoded `spark.dynamicAllocation`, `spark.scheduler`, `spark.rpc`, `spark.task`, `spark.speculation`, and `spark.cleaner` configs to use `ConfigEntry`.
## How was this patch tested?
Existing tests
Closes#23416 from kiszk/SPARK-26463.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR proposes to extend the spark-submit option --num-executors to be applicable to Spark on K8S too. It is motivated by convenience, for example when migrating jobs written for YARN to run on K8S.
## How was this patch tested?
Manually tested on a K8S cluster.
Author: Luca Canali <luca.canali@cern.ch>
Closes#23573 from LucaCanali/addNumExecutorsToK8s.
## What changes were proposed in this pull request?
The PR makes hardcoded `spark.unsafe` configs to use ConfigEntry and put them in the `config` package.
## How was this patch tested?
Existing UTs
Closes#23412 from kiszk/SPARK-26477.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Misc code cleanup from lgtm.com analysis. See comments below for details.
## How was this patch tested?
Existing tests.
Closes#23571 from srowen/SPARK-26640.
Lead-authored-by: Sean Owen <sean.owen@databricks.com>
Co-authored-by: Hyukjin Kwon <gurwls223@apache.org>
Co-authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Try to make labels more obvious
"avg hash probe" avg hash probe bucket iterations
"partition pruning time (ms)" dynamic partition pruning time
"total number of files in the table" file count
"number of files that would be returned by partition pruning alone" file count after partition pruning
"total size of files in the table" file size
"size of files that would be returned by partition pruning alone" file size after partition pruning
"metadata time (ms)" metadata time
"aggregate time" time in aggregation build
"aggregate time" time in aggregation build
"time to construct rdd bc" time to build
"total time to remove rows" time to remove
"total time to update rows" time to update
Add proper metric type to some metrics:
"bytes of written output" written output - createSizeMetric
"metadata time" - createTimingMetric
"dataSize" - createSizeMetric
"collectTime" - createTimingMetric
"buildTime" - createTimingMetric
"broadcastTIme" - createTimingMetric
## How is this patch tested?
Existing tests.
Author: Stacy Kerkela <stacy.kerkeladatabricks.com>
Signed-off-by: Juliusz Sompolski <julekdatabricks.com>
Closes#23551 from juliuszsompolski/SPARK-26622.
Lead-authored-by: Juliusz Sompolski <julek@databricks.com>
Co-authored-by: Stacy Kerkela <stacy.kerkela@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The PR makes hardcoded `spark.shuffle` configs to use ConfigEntry and put them in the config package.
## How was this patch tested?
Existing unit tests
Closes#23550 from 10110346/ConfigEntry_shuffle.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
I know that yarn provided all hadoop configurations. But I guess it may be fine that the historyserver unify all configuration in it. It will be convenient for us to debug some problems.
## How was this patch tested?
Closes#23486 from deshanxiao/spark-26457.
Lead-authored-by: xiaodeshan <xiaodeshan@xiaomi.com>
Co-authored-by: deshanxiao <42019462+deshanxiao@users.noreply.github.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The PR makes hardcoded configs below to use `ConfigEntry`.
* spark.kryo
* spark.kryoserializer
* spark.serializer
* spark.jars
* spark.files
* spark.submit
* spark.deploy
* spark.worker
This patch doesn't change configs which are not relevant to SparkConf (e.g. system properties).
## How was this patch tested?
Existing tests.
Closes#23532 from HeartSaVioR/SPARK-26466-v2.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Spark-submit usage message should be put in sync with recent changes in particular regarding K8S support. These are the proposed changes to the usage message:
--executor-cores NUM -> can be useed for Spark on YARN and K8S
--principal PRINCIPAL and --keytab KEYTAB -> can be used for Spark on YARN and K8S
--total-executor-cores NUM> can be used for Spark standalone, YARN and K8S
In addition this PR proposes to remove certain implementation details from the --keytab argument description as the implementation details vary between YARN and K8S, for example.
## How was this patch tested?
Manually tested
Closes#23518 from LucaCanali/updateSparkSubmitArguments.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The regex (spark.redaction.regex) that is used to decide which config properties or environment settings are sensitive should also include oauthToken to match spark.kubernetes.authenticate.submission.oauthToken
## How was this patch tested?
Simple regex addition - happy to add a test if needed.
Author: Vinoo Ganesh <vganesh@palantir.com>
Closes#23555 from vinooganesh/vinooganesh/SPARK-26625.
## What changes were proposed in this pull request?
Fixing resource leaks where TransportClient/TransportServer instances are not closed properly.
In StandaloneSchedulerBackend the null check is added because during the SparkContextSchedulerCreationSuite #"local-cluster" test it turned out that client is not initialised as org.apache.spark.scheduler.cluster.StandaloneSchedulerBackend#start isn't called. It throw an NPE and some resource remained in open.
## How was this patch tested?
By executing the unittests and using some extra temporary logging for counting created and closed TransportClient/TransportServer instances.
Closes#23540 from attilapiros/leaks.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Now in `TransportRequestHandler.processStreamRequest`, when a stream request is processed, the stream id is not registered with the current channel in stream manager. It should do that so in case of that the channel gets terminated we can remove associated streams of stream requests too.
This also cleans up channel registration in `StreamManager`. Since `StreamManager` doesn't register channel but only `OneForOneStreamManager` does it, this removes `registerChannel` from `StreamManager`. When `OneForOneStreamManager` goes to register stream, it will also register channel for the stream.
## How was this patch tested?
Existing tests.
Closes#23521 from viirya/SPARK-26604.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Make the following hardcoded configs to use ConfigEntry.
spark.memory
spark.storage
spark.io
spark.buffer
spark.rdd
spark.locality
spark.broadcast
spark.reducer
## How was this patch tested?
Existing tests.
Closes#23447 from pralabhkumar/execution_categories.
Authored-by: Pralabh Kumar <pkumar2@linkedin.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Kafka is not yet support to obtain delegation token with proxy user. It has to be turned off until https://issues.apache.org/jira/browse/KAFKA-6945 implemented.
In this PR an exception will be thrown when this situation happens.
## How was this patch tested?
Additional unit test.
Closes#23511 from gaborgsomogyi/SPARK-26592.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Fix typos in comments by replacing "in-heap" with "on-heap".
## How was this patch tested?
Existing Tests.
Closes#23533 from SongYadong/typos_inheap_to_onheap.
Authored-by: SongYadong <song.yadong1@zte.com.cn>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
If users set equivalent values to spark.network.timeout and spark.executor.heartbeatInterval, they get the following message:
```
java.lang.IllegalArgumentException: requirement failed: The value of spark.network.timeout=120s must be no less than the value of spark.executor.heartbeatInterval=120s.
```
But it's misleading since it can be read as they could be equal. So this PR replaces "no less than" with "greater than". Also, it fixes similar inconsistencies found in MLlib and SQL components.
## How was this patch tested?
Ran Spark with equivalent values for them manually and confirmed that the revised message was displayed.
Closes#23488 from sekikn/SPARK-26564.
Authored-by: Kengo Seki <sekikn@apache.org>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The PR makes hardcoded configs below to use `ConfigEntry`.
* spark.ui
* spark.ssl
* spark.authenticate
* spark.master.rest
* spark.master.ui
* spark.metrics
* spark.admin
* spark.modify.acl
This patch doesn't change configs which are not relevant to SparkConf (e.g. system properties).
## How was this patch tested?
Existing tests.
Closes#23423 from HeartSaVioR/SPARK-26466.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Remove spark.memory.useLegacyMode and StaticMemoryManager. Update tests that used the StaticMemoryManager to equivalent use of UnifiedMemoryManager.
## How was this patch tested?
Existing tests, with modifications to make them work with a different mem manager.
Closes#23457 from srowen/SPARK-26539.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
With Scala-2.12 profile, Spark application fails while Spark is okay. For example, our documented `SimpleApp` Java example succeeds to compile but it fails at runtime because it doesn't use `paranamer 2.8` and hits [SPARK-22128](https://issues.apache.org/jira/browse/SPARK-22128). This PR aims to declare it explicitly for the Spark applications. Note that this doesn't introduce new dependency to Spark itself.
https://dist.apache.org/repos/dist/dev/spark/3.0.0-SNAPSHOT-2019_01_09_13_59-e853afb-docs/_site/quick-start.html
The following is the dependency tree from the Spark application.
**BEFORE**
```
$ mvn dependency:tree -Dincludes=com.thoughtworks.paranamer
[INFO] --- maven-dependency-plugin:2.8:tree (default-cli) simple ---
[INFO] my.test:simple:jar:1.0-SNAPSHOT
[INFO] \- org.apache.spark:spark-sql_2.12🫙3.0.0-SNAPSHOT:compile
[INFO] \- org.apache.spark:spark-core_2.12🫙3.0.0-SNAPSHOT:compile
[INFO] \- org.apache.avro:avro:jar:1.8.2:compile
[INFO] \- com.thoughtworks.paranamer:paranamer:jar:2.7:compile
```
**AFTER**
```
[INFO] --- maven-dependency-plugin:2.8:tree (default-cli) simple ---
[INFO] my.test:simple:jar:1.0-SNAPSHOT
[INFO] \- org.apache.spark:spark-sql_2.12🫙3.0.0-SNAPSHOT:compile
[INFO] \- org.apache.spark:spark-core_2.12🫙3.0.0-SNAPSHOT:compile
[INFO] \- com.thoughtworks.paranamer:paranamer:jar:2.8:compile
```
## How was this patch tested?
Pass the Jenkins. And manually test with the sample app is running.
Closes#23502 from dongjoon-hyun/SPARK-26583.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Introducing shared polled ByteBuf allocators.
This feature can be enabled via the "spark.network.sharedByteBufAllocators.enabled" configuration.
When it is on then only two pooled ByteBuf allocators are created:
- one for transport servers where caching is allowed and
- one for transport clients where caching is disabled
This way the cache allowance remains as before.
Both shareable pools are created with numCores parameter set to 0 (which defaults to the available processors) as conf.serverThreads() and conf.clientThreads() are module dependant and the lazy creation of this allocators would lead to unpredicted behaviour.
When "spark.network.sharedByteBufAllocators.enabled" is false then a new allocator is created for every transport client and server separately as was before this PR.
## How was this patch tested?
Existing unit tests.
Closes#23278 from attilapiros/SPARK-24920.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
Currently there is code scattered in a bunch of places to do different
things related to HTTP security, such as access control, setting
security-related headers, and filtering out bad content. This makes it
really easy to miss these things when writing new UI code.
This change creates a new filter that does all of those things, and
makes sure that all servlet handlers that are attached to the UI get
the new filter and any user-defined filters consistently. The extent
of the actual features should be the same as before.
The new filter is added at the end of the filter chain, because authentication
is done by custom filters and thus needs to happen first. This means that
custom filters see unfiltered HTTP requests - which is actually the current
behavior anyway.
As a side-effect of some of the code refactoring, handlers added after
the initial set also get wrapped with a GzipHandler, which didn't happen
before.
Tested with added unit tests and in a history server with SPNEGO auth
configured.
Closes#23302 from vanzin/SPARK-24522.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
The PR makes hardcoded `spark.test` and `spark.testing` configs to use `ConfigEntry` and put them in the config package.
## How was this patch tested?
existing UTs
Closes#23413 from mgaido91/SPARK-26491.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
This change modifies the behavior of the delegation token code when running
on YARN, so that the driver controls the renewal, in both client and cluster
mode. For that, a few different things were changed:
* The AM code only runs code that needs DTs when DTs are available.
In a way, this restores the AM behavior to what it was pre-SPARK-23361, but
keeping the fix added in that bug. Basically, all the AM code is run in a
"UGI.doAs()" block; but code that needs to talk to HDFS (basically the
distributed cache handling code) was delayed to the point where the driver
is up and running, and thus when valid delegation tokens are available.
* SparkSubmit / ApplicationMaster now handle user login, not the token manager.
The previous AM code was relying on the token manager to keep the user
logged in when keytabs are used. This required some odd APIs in the token
manager and the AM so that the right UGI was exposed and used in the right
places.
After this change, the logged in user is handled separately from the token
manager, so the API was cleaned up, and, as explained above, the whole AM
runs under the logged in user, which also helps with simplifying some more code.
* Distributed cache configs are sent separately to the AM.
Because of the delayed initialization of the cached resources in the AM, it
became easier to write the cache config to a separate properties file instead
of bundling it with the rest of the Spark config. This also avoids having
to modify the SparkConf to hide things from the UI.
* Finally, the AM doesn't manage the token manager anymore.
The above changes allow the token manager to be completely handled by the
driver's scheduler backend code also in YARN mode (whether client or cluster),
making it similar to other RMs. To maintain the fix added in SPARK-23361 also
in client mode, the AM now sends an extra message to the driver on initialization
to fetch delegation tokens; and although it might not really be needed, the
driver also keeps the running AM updated when new tokens are created.
Tested in a kerberized cluster with the same tests used to validate SPARK-23361,
in both client and cluster mode. Also tested with a non-kerberized cluster.
Closes#23338 from vanzin/SPARK-25689.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
When acquiring unroll memory from `StaticMemoryManager`, let it fail fast if required space exceeds memory limit, just like acquiring storage memory.
I think this may reduce some computation and memory evicting costs especially when required space(`numBytes`) is very big.
## How was this patch tested?
Existing unit tests.
Closes#23426 from SongYadong/acquireUnrollMemory_fail_fast.
Authored-by: SongYadong <song.yadong1@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR upgrades Mockito from 1.10.19 to 2.23.4. The following changes are required.
- Replace `org.mockito.Matchers` with `org.mockito.ArgumentMatchers`
- Replace `anyObject` with `any`
- Replace `getArgumentAt` with `getArgument` and add type annotation.
- Use `isNull` matcher in case of `null` is invoked.
```scala
saslHandler.channelInactive(null);
- verify(handler).channelInactive(any(TransportClient.class));
+ verify(handler).channelInactive(isNull());
```
- Make and use `doReturn` wrapper to avoid [SI-4775](https://issues.scala-lang.org/browse/SI-4775)
```scala
private def doReturn(value: Any) = org.mockito.Mockito.doReturn(value, Seq.empty: _*)
```
## How was this patch tested?
Pass the Jenkins with the existing tests.
Closes#23452 from dongjoon-hyun/SPARK-26536.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
The PR makes hardcoded spark.driver, spark.executor, and spark.cores.max configs to use `ConfigEntry`.
Note that some config keys are from `SparkLauncher` instead of defining in the config package object because the string is already defined in it and it does not depend on core module.
## How was this patch tested?
Existing tests.
Closes#23415 from ueshin/issues/SPARK-26445/hardcoded_driver_executor_configs.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The PR makes hardcoded configs below to use ConfigEntry.
* spark.pyspark
* spark.python
* spark.r
This patch doesn't change configs which are not relevant to SparkConf (e.g. system properties, python source code)
## How was this patch tested?
Existing tests.
Closes#23428 from HeartSaVioR/SPARK-26489.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
The overriden of SparkSubmit's exitFn at some previous tests in SparkSubmitSuite may cause the following tests pass even they failed when they were run separately. This PR is to fix this problem.
## How was this patch tested?
unittest
Closes#23404 from liupc/Fix-SparkSubmitSuite-exitFn.
Authored-by: Liupengcheng <liupengcheng@xiaomi.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This should make tests in core modules pass for Java 11.
## How was this patch tested?
Existing tests, with modifications.
Closes#23419 from srowen/Java11.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR addresses warning messages in Java files reported at [lgtm.com](https://lgtm.com).
[lgtm.com](https://lgtm.com) provides automated code review of Java/Python/JavaScript files for OSS projects. [Here](https://lgtm.com/projects/g/apache/spark/alerts/?mode=list&severity=warning) are warning messages regarding Apache Spark project.
This PR addresses the following warnings:
- Result of multiplication cast to wider type
- Implicit narrowing conversion in compound assignment
- Boxed variable is never null
- Useless null check
NOTE: `Potential input resource leak` looks false positive for now.
## How was this patch tested?
Existing UTs
Closes#23420 from kiszk/SPARK-26508.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
There's some inconsistency for log level while logging error messages in
delegation token providers. (DEBUG, INFO, WARNING)
Given that failing to obtain token would often crash the query, I guess
it would be nice to set higher log level for error log messages.
## How was this patch tested?
The patch just changed the log level.
Closes#23418 from HeartSaVioR/FIX-inconsistency-log-level-between-delegation-token-providers.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The PR makes hardcoded `spark.eventLog` configs to use `ConfigEntry` and put them in the `config` package.
## How was this patch tested?
existing tests
Closes#23395 from mgaido91/SPARK-26470.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
In the method `taskList`(since https://github.com/apache/spark/pull/21688), the executor log value is queried in KV store for every task(method `constructTaskData`).
This PR propose to use a hashmap for reducing duplicated KV store lookups in the method.

## How was this patch tested?
Manual check
Closes#23310 from gengliangwang/removeExecutorLog.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This pr makes hardcoded "spark.history" configs to use `ConfigEntry` and put them in `History` config object.
## How was this patch tested?
Existing tests.
Closes#23384 from ueshin/issues/SPARK-26443/hardcoded_history_configs.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Add docs to describe how remove policy act while considering the property `spark.dynamicAllocation.cachedExecutorIdleTimeout` in ExecutorAllocationManager
## How was this patch tested?
comment-only PR.
Closes#23386 from TopGunViper/SPARK-26446.
Authored-by: wuqingxin <wuqingxin@baidu.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…leAccumulator
## What changes were proposed in this pull request?
This PR implements metric sources for LongAccumulator and DoubleAccumulator, such that a user can register these accumulators easily and have their values be reported by the driver's metric namespace.
## How was this patch tested?
Unit tests, and manual tests.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23242 from abellina/SPARK-26285_accumulator_source.
Lead-authored-by: Alessandro Bellina <abellina@yahoo-inc.com>
Co-authored-by: Alessandro Bellina <abellina@oath.com>
Co-authored-by: Alessandro Bellina <abellina@gmail.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
Recently, the ability to expose the metrics for YARN Shuffle Service was added as part of [SPARK-18364](https://github.com/apache/spark/pull/22485). We need to add some metrics to be able to determine the number of active connections as well as open connections to the external shuffle service to benchmark network and connection issues on large cluster environments.
Added two more shuffle server metrics for Spark Yarn shuffle service: numRegisteredConnections which indicate the number of registered connections to the shuffle service and numActiveConnections which indicate the number of active connections to the shuffle service at any given point in time.
If these metrics are outputted to a file, we get something like this:
1533674653489 default.shuffleService: Hostname=server1.abc.com, openBlockRequestLatencyMillis_count=729, openBlockRequestLatencyMillis_rate15=0.7110833548897356, openBlockRequestLatencyMillis_rate5=1.657808981793011, openBlockRequestLatencyMillis_rate1=2.2404486061620474, openBlockRequestLatencyMillis_rateMean=0.9242558551196706,
numRegisteredConnections=35,
blockTransferRateBytes_count=2635880512, blockTransferRateBytes_rate15=2578547.6094160094, blockTransferRateBytes_rate5=6048721.726302424, blockTransferRateBytes_rate1=8548922.518223226, blockTransferRateBytes_rateMean=3341878.633637769, registeredExecutorsSize=5, registerExecutorRequestLatencyMillis_count=5, registerExecutorRequestLatencyMillis_rate15=0.0027973949328659836, registerExecutorRequestLatencyMillis_rate5=0.0021278007987206426, registerExecutorRequestLatencyMillis_rate1=2.8270296777387467E-6, registerExecutorRequestLatencyMillis_rateMean=0.006339206380043053, numActiveConnections=35
Closes#22498 from pgandhi999/SPARK-18364.
Authored-by: pgandhi <pgandhi@oath.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
When NoClassDefFoundError thrown,it will cause job hang.
`Exception in thread "dag-scheduler-event-loop" java.lang.NoClassDefFoundError: Lcom/xxx/data/recommend/aggregator/queue/QueueName;
at java.lang.Class.getDeclaredFields0(Native Method)
at java.lang.Class.privateGetDeclaredFields(Class.java:2436)
at java.lang.Class.getDeclaredField(Class.java:1946)
at java.io.ObjectStreamClass.getDeclaredSUID(ObjectStreamClass.java:1659)
at java.io.ObjectStreamClass.access$700(ObjectStreamClass.java:72)
at java.io.ObjectStreamClass$2.run(ObjectStreamClass.java:480)
at java.io.ObjectStreamClass$2.run(ObjectStreamClass.java:468)
at java.security.AccessController.doPrivileged(Native Method)
at java.io.ObjectStreamClass.<init>(ObjectStreamClass.java:468)
at java.io.ObjectStreamClass.lookup(ObjectStreamClass.java:365)
at java.io.ObjectOutputStream.writeClass(ObjectOutputStream.java:1212)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1119)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.writeArray(ObjectOutputStream.java:1377)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1173)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.writeArray(ObjectOutputStream.java:1377)`
It is caused by NoClassDefFoundError will not catch up during task seriazation.
`var taskBinary: Broadcast[Array[Byte]] = null
try {
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
val taskBinaryBytes: Array[Byte] = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
// Abort execution
return
case NonFatal(e) =>
abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}`
image below shows that stage 33 blocked and never be scheduled.
<img width="1273" alt="2018-06-28 4 28 42" src="https://user-images.githubusercontent.com/26762018/42621188-b87becca-85ef-11e8-9a0b-0ddf07504c96.png">
<img width="569" alt="2018-06-28 4 28 49" src="https://user-images.githubusercontent.com/26762018/42621191-b8b260e8-85ef-11e8-9d10-e97a5918baa6.png">
## How was this patch tested?
UT
Closes#21664 from caneGuy/zhoukang/fix-noclassdeferror.
Authored-by: zhoukang <zhoukang199191@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
This change hooks up the k8s backed to the updated HadoopDelegationTokenManager,
so that delegation tokens are also available in client mode, and keytab-based token
renewal is enabled.
The change re-works the k8s feature steps related to kerberos so
that the driver does all the credential management and provides all
the needed information to executors - so nothing needs to be added
to executor pods. This also makes cluster mode behave a lot more
similarly to client mode, since no driver-related config steps are run
in the latter case.
The main two things that don't need to happen in executors anymore are:
- adding the Hadoop config to the executor pods: this is not needed
since the Spark driver will serialize the Hadoop config and send
it to executors when running tasks.
- mounting the kerberos config file in the executor pods: this is
not needed once you remove the above. The Hadoop conf sent by
the driver with the tasks is already resolved (i.e. has all the
kerberos names properly defined), so executors do not need access
to the kerberos realm information anymore.
The change also avoids creating delegation tokens unnecessarily.
This means that they'll only be created if a secret with tokens
was not provided, and if a keytab is not provided. In either of
those cases, the driver code will handle delegation tokens: in
cluster mode by creating a secret and stashing them, in client
mode by using existing mechanisms to send DTs to executors.
One last feature: the change also allows defining a keytab with
a "local:" URI. This is supported in client mode (although that's
the same as not saying "local:"), and in k8s cluster mode. This
allows the keytab to be mounted onto the image from a pre-existing
secret, for example.
Finally, the new code always sets SPARK_USER in the driver and
executor pods. This is in line with how other resource managers
behave: the submitting user reflects which user will access
Hadoop services in the app. (With kerberos, that's overridden
by the logged in user.) That user is unrelated to the OS user
the app is running as inside the containers.
Tested:
- client and cluster mode with kinit
- cluster mode with keytab
- cluster mode with local: keytab
- YARN cluster with keytab (to make sure it isn't broken)
Closes#22911 from vanzin/SPARK-25815.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Change microseconds to milliseconds in annotation of Utils.timeStringAsMs.
Closes#23346 from stczwd/stczwd.
Authored-by: Jackey Lee <qcsd2011@163.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This is kind of a followup of https://github.com/apache/spark/pull/23239
The `UnsafeProject` will normalize special float/double values(NaN and -0.0), so the sorter doesn't have to handle it.
However, for consistency and future-proof, this PR proposes to normalize `-0.0` in the prefix comparator, so that it's same with the normal ordering. Note that prefix comparator handles NaN as well.
This is not a bug fix, but a safe guard.
## How was this patch tested?
existing tests
Closes#23334 from cloud-fan/sort.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Multiple SparkContexts are discouraged and it has been warning for last 4 years, see SPARK-4180. It could cause arbitrary and mysterious error cases, see SPARK-2243.
Honestly, I didn't even know Spark still allows it, which looks never officially supported, see SPARK-2243.
I believe It should be good timing now to remove this configuration.
## How was this patch tested?
Each doc was manually checked and manually tested:
```
$ ./bin/spark-shell --conf=spark.driver.allowMultipleContexts=true
...
scala> new SparkContext()
org.apache.spark.SparkException: Only one SparkContext should be running in this JVM (see SPARK-2243).The currently running SparkContext was created at:
org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:939)
...
org.apache.spark.SparkContext$.$anonfun$assertNoOtherContextIsRunning$2(SparkContext.scala:2435)
at scala.Option.foreach(Option.scala:274)
at org.apache.spark.SparkContext$.assertNoOtherContextIsRunning(SparkContext.scala:2432)
at org.apache.spark.SparkContext$.markPartiallyConstructed(SparkContext.scala:2509)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:80)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:112)
... 49 elided
```
Closes#23311 from HyukjinKwon/SPARK-26362.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Based on the [comment](https://github.com/apache/spark/pull/23272#discussion_r240735509), it seems to be better to put `freePage` into a `finally` block. This patch as a follow-up to do so.
## How was this patch tested?
Existing tests.
Closes#23294 from viirya/SPARK-26265-followup.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
Currently this check is only performed for dynamic allocation use case in
ExecutorAllocationManager.
## What changes were proposed in this pull request?
Checks that cpu per task is lower than number of cores per executor otherwise throw an exception
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23290 from ashangit/master.
Authored-by: n.fraison <n.fraison@criteo.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
These three condition descriptions should be updated, follow #23228 :
<li>no Ordering is specified,</li>
<li>no Aggregator is specified, and</li>
<li>the number of partitions is less than
<code>spark.shuffle.sort.bypassMergeThreshold</code>.
</li>
1、If the shuffle dependency specifies aggregation, but it only aggregates at the reduce-side, BypassMergeSortShuffle can still be used.
2、If the number of output partitions is spark.shuffle.sort.bypassMergeThreshold(eg.200), we can use BypassMergeSortShuffle.
## How was this patch tested?
N/A
Closes#23281 from lcqzte10192193/wid-lcq-1211.
Authored-by: lichaoqun <li.chaoqun@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
When Kafka delegation token obtained, SCRAM `sasl.mechanism` has to be configured for authentication. This can be configured on the related source/sink which is inconvenient from user perspective. Such granularity is not required and this configuration can be implemented with one central parameter.
In this PR `spark.kafka.sasl.token.mechanism` added to configure this centrally (default: `SCRAM-SHA-512`).
## How was this patch tested?
Existing unit tests + on cluster.
Closes#23274 from gaborgsomogyi/SPARK-26322.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
YARN applicationMaster metrics registration introduced in SPARK-24594 causes further registration of static metrics (Codegenerator and HiveExternalCatalog) and of JVM metrics, which I believe do not belong in this context.
This looks like an unintended side effect of using the start method of [[MetricsSystem]].
A possible solution proposed here, is to introduce startNoRegisterSources to avoid these additional registrations of static sources and of JVM sources in the case of YARN applicationMaster metrics (this could be useful for other metrics that may be added in the future).
## How was this patch tested?
Manually tested on a YARN cluster,
Closes#22279 from LucaCanali/YarnMetricsRemoveExtraSourceRegistration.
Lead-authored-by: Luca Canali <luca.canali@cern.ch>
Co-authored-by: LucaCanali <luca.canali@cern.ch>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Follow up pr for #23207, include following changes:
- Rename `SQLShuffleMetricsReporter` to `SQLShuffleReadMetricsReporter` to make it match with write side naming.
- Display text changes for read side for naming consistent.
- Rename function in `ShuffleWriteProcessor`.
- Delete `private[spark]` in execution package.
## How was this patch tested?
Existing tests.
Closes#23286 from xuanyuanking/SPARK-26193-follow.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
This proposes an alternative way to load secret keys into a Spark application that is running on Kubernetes. Instead of automatically generating the secret, the secret key can reside in a file that is shared between both the driver and executor containers.
Unit tests.
Closes#23252 from mccheah/auth-secret-with-file.
Authored-by: mcheah <mcheah@palantir.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
In `BytesToBytesMap.MapIterator.advanceToNextPage`, We will first lock this `MapIterator` and then `TaskMemoryManager` when going to free a memory page by calling `freePage`. At the same time, it is possibly that another memory consumer first locks `TaskMemoryManager` and then this `MapIterator` when it acquires memory and causes spilling on this `MapIterator`.
So it ends with the `MapIterator` object holds lock to the `MapIterator` object and waits for lock on `TaskMemoryManager`, and the other consumer holds lock to `TaskMemoryManager` and waits for lock on the `MapIterator` object.
To avoid deadlock here, this patch proposes to keep reference to the page to free and free it after releasing the lock of `MapIterator`.
## How was this patch tested?
Added test and manually test by running the test 100 times to make sure there is no deadlock.
Closes#23272 from viirya/SPARK-26265.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
… incorrect.
## What changes were proposed in this pull request?
In the reported heartbeat information, the unit of the memory data is bytes, which is converted by the formatBytes() function in the utils.js file before being displayed in the interface. The cardinality of the unit conversion in the formatBytes function is 1000, which should be 1024.
Change the cardinality of the unit conversion in the formatBytes function to 1024.
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22683 from httfighter/SPARK-25696.
Lead-authored-by: 韩田田00222924 <han.tiantian@zte.com.cn>
Co-authored-by: han.tiantian@zte.com.cn <han.tiantian@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
This adds the entire memory used by spark’s executor (as measured by procfs) to the executor metrics. The memory usage is collected from the entire process tree under the executor. The metrics are subdivided into memory used by java, by python, and by other processes, to aid users in diagnosing the source of high memory usage.
The additional metrics are sent to the driver in heartbeats, using the mechanism introduced by SPARK-23429. This also slightly extends that approach to allow one ExecutorMetricType to collect multiple metrics.
Added unit tests and also tested on a live cluster.
Closes#22612 from rezasafi/ptreememory2.
Authored-by: Reza Safi <rezasafi@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
`1. The shuffle dependency specifies no aggregation or output ordering.`
If the shuffle dependency specifies aggregation, but it only aggregates at the reduce-side, serialized shuffle can still be used.
`3. The shuffle produces fewer than 16777216 output partitions.`
If the number of output partitions is 16777216 , we can use serialized shuffle.
We can see this mothod: `canUseSerializedShuffle`
## How was this patch tested?
N/A
Closes#23228 from 10110346/SerializedShuffle_doc.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
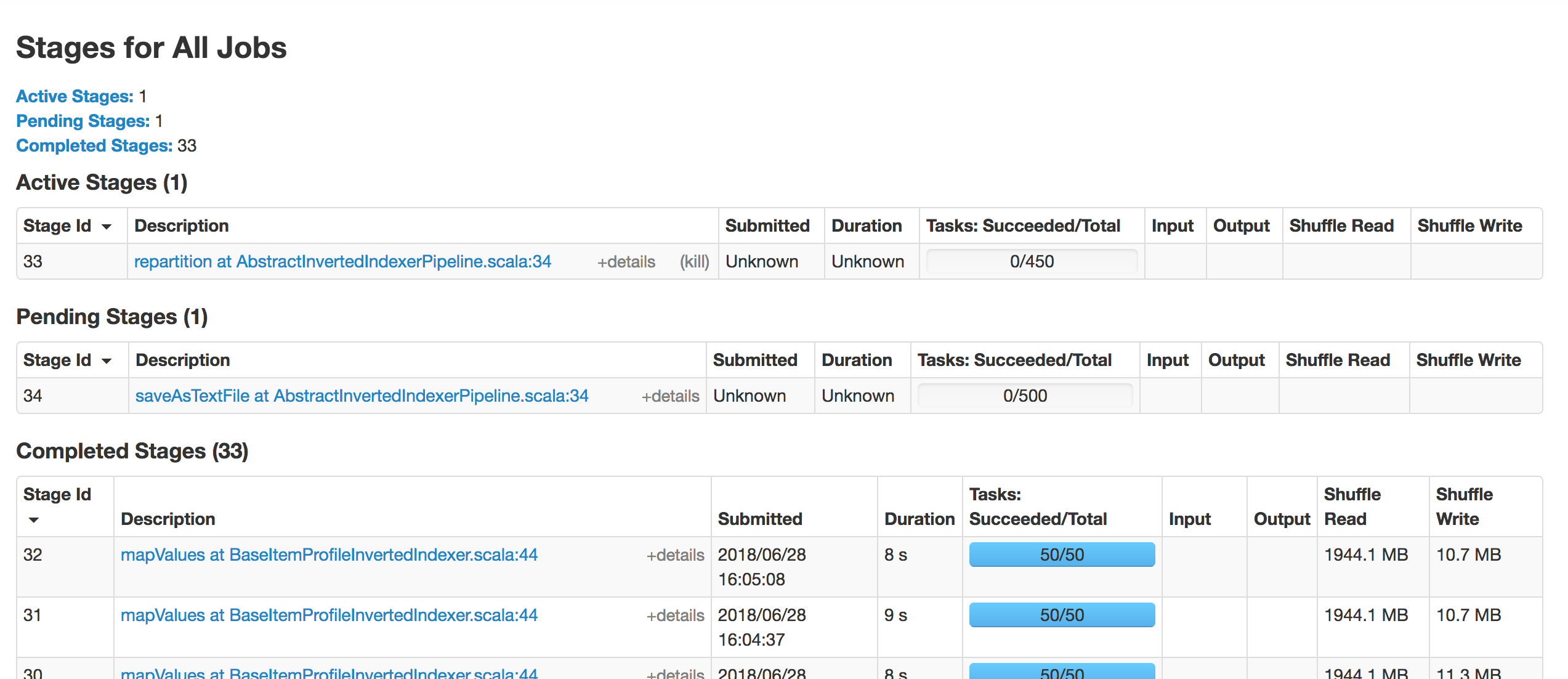{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}