## What changes were proposed in this pull request?
Before the patch, Spark could infer as Date a partition value which cannot be casted to Date (this can happen when there are extra characters after a valid date, like `2018-02-15AAA`).
When this happens and the input format has metadata which define the schema of the table, then `null` is returned as a value for the partition column, because the `cast` operator used in (`PartitioningAwareFileIndex.inferPartitioning`) is unable to convert the value.
The PR checks in the partition inference that values can be casted to Date and Timestamp, in order to infer that datatype to them.
## How was this patch tested?
added UT
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20621 from mgaido91/SPARK-23436.
## What changes were proposed in this pull request?
ParquetFileFormat leaks opened files in some cases. This PR prevents that by registering task completion listers first before initialization.
- [spark-branch-2.3-test-sbt-hadoop-2.7](https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-branch-2.3-test-sbt-hadoop-2.7/205/testReport/org.apache.spark.sql/FileBasedDataSourceSuite/_It_is_not_a_test_it_is_a_sbt_testing_SuiteSelector_/)
- [spark-master-test-sbt-hadoop-2.6](https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-2.6/4228/testReport/junit/org.apache.spark.sql.execution.datasources.parquet/ParquetQuerySuite/_It_is_not_a_test_it_is_a_sbt_testing_SuiteSelector_/)
```
Caused by: sbt.ForkMain$ForkError: java.lang.Throwable: null
at org.apache.spark.DebugFilesystem$.addOpenStream(DebugFilesystem.scala:36)
at org.apache.spark.DebugFilesystem.open(DebugFilesystem.scala:70)
at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:769)
at org.apache.parquet.hadoop.ParquetFileReader.<init>(ParquetFileReader.java:538)
at org.apache.spark.sql.execution.datasources.parquet.SpecificParquetRecordReaderBase.initialize(SpecificParquetRecordReaderBase.java:149)
at org.apache.spark.sql.execution.datasources.parquet.VectorizedParquetRecordReader.initialize(VectorizedParquetRecordReader.java:133)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$$anonfun$buildReaderWithPartitionValues$1.apply(ParquetFileFormat.scala:400)
at
```
## How was this patch tested?
Manual. The following test case generates the same leakage.
```scala
test("SPARK-23457 Register task completion listeners first in ParquetFileFormat") {
withSQLConf(SQLConf.PARQUET_VECTORIZED_READER_BATCH_SIZE.key -> s"${Int.MaxValue}") {
withTempDir { dir =>
val basePath = dir.getCanonicalPath
Seq(0).toDF("a").write.format("parquet").save(new Path(basePath, "first").toString)
Seq(1).toDF("a").write.format("parquet").save(new Path(basePath, "second").toString)
val df = spark.read.parquet(
new Path(basePath, "first").toString,
new Path(basePath, "second").toString)
val e = intercept[SparkException] {
df.collect()
}
assert(e.getCause.isInstanceOf[OutOfMemoryError])
}
}
}
```
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20619 from dongjoon-hyun/SPARK-23390.
## What changes were proposed in this pull request?
This PR updates Apache ORC dependencies to 1.4.3 released on February 9th. Apache ORC 1.4.2 release removes unnecessary dependencies and 1.4.3 has 5 more patches (https://s.apache.org/Fll8).
Especially, the following ORC-285 is fixed at 1.4.3.
```scala
scala> val df = Seq(Array.empty[Float]).toDF()
scala> df.write.format("orc").save("/tmp/floatarray")
scala> spark.read.orc("/tmp/floatarray")
res1: org.apache.spark.sql.DataFrame = [value: array<float>]
scala> spark.read.orc("/tmp/floatarray").show()
18/02/12 22:09:10 ERROR Executor: Exception in task 0.0 in stage 1.0 (TID 1)
java.io.IOException: Error reading file: file:/tmp/floatarray/part-00000-9c0b461b-4df1-4c23-aac1-3e4f349ac7d6-c000.snappy.orc
at org.apache.orc.impl.RecordReaderImpl.nextBatch(RecordReaderImpl.java:1191)
at org.apache.orc.mapreduce.OrcMapreduceRecordReader.ensureBatch(OrcMapreduceRecordReader.java:78)
...
Caused by: java.io.EOFException: Read past EOF for compressed stream Stream for column 2 kind DATA position: 0 length: 0 range: 0 offset: 0 limit: 0
```
## How was this patch tested?
Pass the Jenkins test.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20511 from dongjoon-hyun/SPARK-23340.
## What changes were proposed in this pull request?
Cleaned up the codegen templates for `Literal`s, to make sure that the `ExprCode` returned from `Literal.doGenCode()` has:
1. an empty `code` field;
2. an `isNull` field of either literal `true` or `false`;
3. a `value` field that is just a simple literal/constant.
Before this PR, there are a couple of paths that would return a non-trivial `code` and all of them are actually unnecessary. The `NaN` and `Infinity` constants for `double` and `float` can be accessed through constants directly available so there's no need to add a reference for them.
Also took the opportunity to add a new util method for ease of creating `ExprCode` for inline-able non-null values.
## How was this patch tested?
Existing tests.
Author: Kris Mok <kris.mok@databricks.com>
Closes#20626 from rednaxelafx/codegen-literal.
## What changes were proposed in this pull request?
Murmur3 hash generates a different value from the original and other implementations (like Scala standard library and Guava or so) when the length of a bytes array is not multiple of 4.
## How was this patch tested?
Added a unit test.
**Note: When we merge this PR, please give all the credits to Shintaro Murakami.**
Author: Shintaro Murakami <mrkm4ntrgmail.com>
Author: gatorsmile <gatorsmile@gmail.com>
Author: Shintaro Murakami <mrkm4ntr@gmail.com>
Closes#20630 from gatorsmile/pr-20568.
## What changes were proposed in this pull request?
Migrating KafkaSource (with data source v1) to KafkaMicroBatchReader (with data source v2).
Performance comparison:
In a unit test with in-process Kafka broker, I tested the read throughput of V1 and V2 using 20M records in a single partition. They were comparable.
## How was this patch tested?
Existing tests, few modified to be better tests than the existing ones.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20554 from tdas/SPARK-23362.
## What changes were proposed in this pull request?
This PR explicitly specifies and checks the types we supported in `toPandas`. This was a hole. For example, we haven't finished the binary type support in Python side yet but now it allows as below:
```python
spark.conf.set("spark.sql.execution.arrow.enabled", "false")
df = spark.createDataFrame([[bytearray("a")]])
df.toPandas()
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
df.toPandas()
```
```
_1
0 [97]
_1
0 a
```
This should be disallowed. I think the same things also apply to nested timestamps too.
I also added some nicer message about `spark.sql.execution.arrow.enabled` in the error message.
## How was this patch tested?
Manually tested and tests added in `python/pyspark/sql/tests.py`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20625 from HyukjinKwon/pandas_convertion_supported_type.
## What changes were proposed in this pull request?
Fixing exception got at sorting tasks by Host / Executor ID:
```
java.lang.IllegalArgumentException: Invalid sort column: Host
at org.apache.spark.ui.jobs.ApiHelper$.indexName(StagePage.scala:1017)
at org.apache.spark.ui.jobs.TaskDataSource.sliceData(StagePage.scala:694)
at org.apache.spark.ui.PagedDataSource.pageData(PagedTable.scala:61)
at org.apache.spark.ui.PagedTable$class.table(PagedTable.scala:96)
at org.apache.spark.ui.jobs.TaskPagedTable.table(StagePage.scala:708)
at org.apache.spark.ui.jobs.StagePage.liftedTree1$1(StagePage.scala:293)
at org.apache.spark.ui.jobs.StagePage.render(StagePage.scala:282)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.JettyUtils$$anon$3.doGet(JettyUtils.scala:90)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:687)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:790)
at org.spark_project.jetty.servlet.ServletHolder.handle(ServletHolder.java:848)
at org.spark_project.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:584)
```
Moreover some refactoring to avoid similar problems by introducing constants for each header name and reusing them at the identification of the corresponding sorting index.
## How was this patch tested?
Manually:
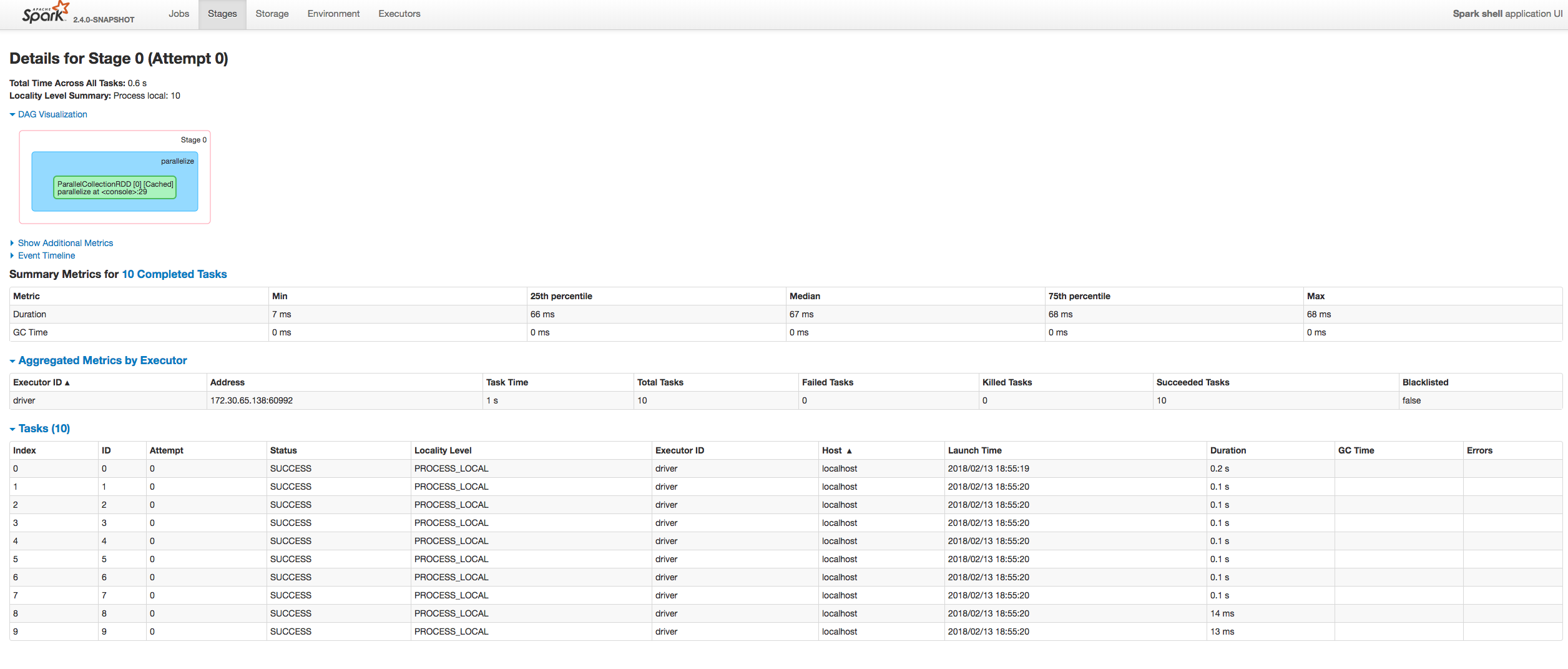
Author: “attilapiros” <piros.attila.zsolt@gmail.com>
Closes#20601 from attilapiros/SPARK-23413.
## What changes were proposed in this pull request?
#### Problem:
Since 2.3, `Bucketizer` supports multiple input/output columns. We will check if exclusive params are set during transformation. E.g., if `inputCols` and `outputCol` are both set, an error will be thrown.
However, when we write `Bucketizer`, looks like the default params and user-supplied params are merged during writing. All saved params are loaded back and set to created model instance. So the default `outputCol` param in `HasOutputCol` trait will be set in `paramMap` and become an user-supplied param. That makes the check of exclusive params failed.
#### Fix:
This changes the saving logic of Bucketizer to handle this case. This is a quick fix to catch the time of 2.3. We should consider modify the persistence mechanism later.
Please see the discussion in the JIRA.
Note: The multi-column `QuantileDiscretizer` also has the same issue.
## How was this patch tested?
Modified tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20594 from viirya/SPARK-23377-2.
## What changes were proposed in this pull request?
This replaces `Sparkcurrently` to `Spark currently` in the following error message.
```scala
scala> sql("insert into t2 select * from v1")
org.apache.spark.sql.AnalysisException: Output Hive table `default`.`t2`
is bucketed but Sparkcurrently does NOT populate bucketed ...
```
## How was this patch tested?
Manual.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20617 from dongjoon-hyun/SPARK-ERROR-MSG.
## What changes were proposed in this pull request?
To prevent any regressions, this PR changes ORC implementation to `hive` by default like Spark 2.2.X.
Users can enable `native` ORC. Also, ORC PPD is also restored to `false` like Spark 2.2.X.

## How was this patch tested?
Pass all test cases.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20610 from dongjoon-hyun/SPARK-ORC-DISABLE.
…D_CLASSES set to 1
## What changes were proposed in this pull request?
YarnShuffleIntegrationSuite fails when SPARK_PREPEND_CLASSES set to 1.
Normally mllib built before yarn module. When SPARK_PREPEND_CLASSES used mllib classes are on yarn test classpath.
Before 2.3 that did not cause issues. But 2.3 has SPARK-22450, which registered some mllib classes with the kryo serializer. Now it dies with the following error:
`
18/02/13 07:33:29 INFO SparkContext: Starting job: collect at YarnShuffleIntegrationSuite.scala:143
Exception in thread "dag-scheduler-event-loop" java.lang.NoClassDefFoundError: breeze/linalg/DenseMatrix
`
In this PR NoClassDefFoundError caught only in case of testing and then do nothing.
## How was this patch tested?
Automated: Pass the Jenkins.
Author: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Closes#20608 from gaborgsomogyi/SPARK-23422.
## What changes were proposed in this pull request?
This PR proposes to add an alias 'names' of 'fieldNames' in Scala. Please see the discussion in [SPARK-20090](https://issues.apache.org/jira/browse/SPARK-20090).
## How was this patch tested?
Unit tests added in `DataTypeSuite.scala`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20545 from HyukjinKwon/SPARK-23359.
## What changes were proposed in this pull request?
`ReadAheadInputStream` was introduced in https://github.com/apache/spark/pull/18317/ to optimize reading spill files from disk.
However, from the profiles it seems that the hot path of reading small amounts of data (like readInt) is inefficient - it involves taking locks, and multiple checks.
Optimize locking: Lock is not needed when simply accessing the active buffer. Only lock when needing to swap buffers or trigger async reading, or get information about the async state.
Optimize short-path single byte reads, that are used e.g. by Java library DataInputStream.readInt.
The asyncReader used to call "read" only once on the underlying stream, that never filled the underlying buffer when it was wrapping an LZ4BlockInputStream. If the buffer was returned unfilled, that would trigger the async reader to be triggered to fill the read ahead buffer on each call, because the reader would see that the active buffer is below the refill threshold all the time.
However, filling the full buffer all the time could introduce increased latency, so also add an `AtomicBoolean` flag for the async reader to return earlier if there is a reader waiting for data.
Remove `readAheadThresholdInBytes` and instead immediately trigger async read when switching the buffers. It allows to simplify code paths, especially the hot one that then only has to check if there is available data in the active buffer, without worrying if it needs to retrigger async read. It seems to have positive effect on perf.
## How was this patch tested?
It was noticed as a regression in some workloads after upgrading to Spark 2.3.
It was particularly visible on TPCDS Q95 running on instances with fast disk (i3 AWS instances).
Running with profiling:
* Spark 2.2 - 5.2-5.3 minutes 9.5% in LZ4BlockInputStream.read
* Spark 2.3 - 6.4-6.6 minutes 31.1% in ReadAheadInputStream.read
* Spark 2.3 + fix - 5.3-5.4 minutes 13.3% in ReadAheadInputStream.read - very slightly slower, practically within noise.
We didn't see other regressions, and many workloads in general seem to be faster with Spark 2.3 (not investigated if thanks to async readed, or unrelated).
Author: Juliusz Sompolski <julek@databricks.com>
Closes#20555 from juliuszsompolski/SPARK-23366.
## What changes were proposed in this pull request?
Streaming execution has a list of exceptions that means interruption, and handle them specially. `WriteToDataSourceV2Exec` should also respect this list and not wrap them with `SparkException`.
## How was this patch tested?
existing test.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20605 from cloud-fan/write.
## What changes were proposed in this pull request?
This PR is to revert the PR https://github.com/apache/spark/pull/20302, because it causes a regression.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20614 from gatorsmile/revertJsonFix.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/19579 introduces a behavior change. We need to document it in the migration guide.
## How was this patch tested?
Also update the HiveExternalCatalogVersionsSuite to verify it.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20606 from gatorsmile/addMigrationGuide.
## What changes were proposed in this pull request?
Solved two bugs to enable stream-stream self joins.
### Incorrect analysis due to missing MultiInstanceRelation trait
Streaming leaf nodes did not extend MultiInstanceRelation, which is necessary for the catalyst analyzer to convert the self-join logical plan DAG into a tree (by creating new instances of the leaf relations). This was causing the error `Failure when resolving conflicting references in Join:` (see JIRA for details).
### Incorrect attribute rewrite when splicing batch plans in MicroBatchExecution
When splicing the source's batch plan into the streaming plan (by replacing the StreamingExecutionPlan), we were rewriting the attribute reference in the streaming plan with the new attribute references from the batch plan. This was incorrectly handling the scenario when multiple StreamingExecutionRelation point to the same source, and therefore eventually point to the same batch plan returned by the source. Here is an example query, and its corresponding plan transformations.
```
val df = input.toDF
val join =
df.select('value % 5 as "key", 'value).join(
df.select('value % 5 as "key", 'value), "key")
```
Streaming logical plan before splicing the batch plan
```
Project [key#6, value#1, value#12]
+- Join Inner, (key#6 = key#9)
:- Project [(value#1 % 5) AS key#6, value#1]
: +- StreamingExecutionRelation Memory[#1], value#1
+- Project [(value#12 % 5) AS key#9, value#12]
+- StreamingExecutionRelation Memory[#1], value#12 // two different leaves pointing to same source
```
Batch logical plan after splicing the batch plan and before rewriting
```
Project [key#6, value#1, value#12]
+- Join Inner, (key#6 = key#9)
:- Project [(value#1 % 5) AS key#6, value#1]
: +- LocalRelation [value#66] // replaces StreamingExecutionRelation Memory[#1], value#1
+- Project [(value#12 % 5) AS key#9, value#12]
+- LocalRelation [value#66] // replaces StreamingExecutionRelation Memory[#1], value#12
```
Batch logical plan after rewriting the attributes. Specifically, for spliced, the new output attributes (value#66) replace the earlier output attributes (value#12, and value#1, one for each StreamingExecutionRelation).
```
Project [key#6, value#66, value#66] // both value#1 and value#12 replaces by value#66
+- Join Inner, (key#6 = key#9)
:- Project [(value#66 % 5) AS key#6, value#66]
: +- LocalRelation [value#66]
+- Project [(value#66 % 5) AS key#9, value#66]
+- LocalRelation [value#66]
```
This causes the optimizer to eliminate value#66 from one side of the join.
```
Project [key#6, value#66, value#66]
+- Join Inner, (key#6 = key#9)
:- Project [(value#66 % 5) AS key#6, value#66]
: +- LocalRelation [value#66]
+- Project [(value#66 % 5) AS key#9] // this does not generate value, incorrect join results
+- LocalRelation [value#66]
```
**Solution**: Instead of rewriting attributes, use a Project to introduce aliases between the output attribute references and the new reference generated by the spliced plans. The analyzer and optimizer will take care of the rest.
```
Project [key#6, value#1, value#12]
+- Join Inner, (key#6 = key#9)
:- Project [(value#1 % 5) AS key#6, value#1]
: +- Project [value#66 AS value#1] // solution: project with aliases
: +- LocalRelation [value#66]
+- Project [(value#12 % 5) AS key#9, value#12]
+- Project [value#66 AS value#12] // solution: project with aliases
+- LocalRelation [value#66]
```
## How was this patch tested?
New unit test
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20598 from tdas/SPARK-23406.
## What changes were proposed in this pull request?
This PR aims to resolve an open file leakage issue reported at [SPARK-23390](https://issues.apache.org/jira/browse/SPARK-23390) by moving the listener registration position. Currently, the sequence is like the following.
1. Create `batchReader`
2. `batchReader.initialize` opens a ORC file.
3. `batchReader.initBatch` may take a long time to alloc memory in some environment and cause errors.
4. `Option(TaskContext.get()).foreach(_.addTaskCompletionListener(_ => iter.close()))`
This PR moves 4 before 2 and 3. To sum up, the new sequence is 1 -> 4 -> 2 -> 3.
## How was this patch tested?
Manual. The following test case makes OOM intentionally to cause leaked filesystem connection in the current code base. With this patch, leakage doesn't occurs.
```scala
// This should be tested manually because it raises OOM intentionally
// in order to cause `Leaked filesystem connection`.
test("SPARK-23399 Register a task completion listener first for OrcColumnarBatchReader") {
withSQLConf(SQLConf.ORC_VECTORIZED_READER_BATCH_SIZE.key -> s"${Int.MaxValue}") {
withTempDir { dir =>
val basePath = dir.getCanonicalPath
Seq(0).toDF("a").write.format("orc").save(new Path(basePath, "first").toString)
Seq(1).toDF("a").write.format("orc").save(new Path(basePath, "second").toString)
val df = spark.read.orc(
new Path(basePath, "first").toString,
new Path(basePath, "second").toString)
val e = intercept[SparkException] {
df.collect()
}
assert(e.getCause.isInstanceOf[OutOfMemoryError])
}
}
}
```
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20590 from dongjoon-hyun/SPARK-23399.
## What changes were proposed in this pull request?
In this upcoming 2.3 release, we changed the interface of `ScalaUDF`. Unfortunately, some Spark packages (e.g., spark-deep-learning) are using our internal class `ScalaUDF`. In the release 2.3, we added new parameters into this class. The users hit the binary compatibility issues and got the exception:
```
> java.lang.NoSuchMethodError: org.apache.spark.sql.catalyst.expressions.ScalaUDF.<init>(Ljava/lang/Object;Lorg/apache/spark/sql/types/DataType;Lscala/collection/Seq;Lscala/collection/Seq;Lscala/Option;)V
```
This PR is to improve the backward compatibility. However, we definitely should not encourage the external packages to use our internal classes. This might make us hard to maintain/develop the codes in Spark.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20591 from gatorsmile/scalaUDF.
## What changes were proposed in this pull request?
Added documentation about what MLlib guarantees in terms of loading ML models and Pipelines from old Spark versions. Discussed & confirmed on linked JIRA.
Author: Joseph K. Bradley <joseph@databricks.com>
Closes#20592 from jkbradley/SPARK-23154-backwards-compat-doc.
## What changes were proposed in this pull request?
The PR provided an implementation of ClusteringEvaluator using the cosine distance measure.
This allows to evaluate clustering results created using the cosine distance, introduced in SPARK-22119.
In the corresponding JIRA, there is a design document for the algorithm implemented here.
## How was this patch tested?
Added UT which compares the result to the one provided by python sklearn.
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20396 from mgaido91/SPARK-23217.
## What changes were proposed in this pull request?
Added flag ignoreNullability to DataType.equalsStructurally.
The previous semantic is for ignoreNullability=false.
When ignoreNullability=true equalsStructurally ignores nullability of contained types (map key types, value types, array element types, structure field types).
In.checkInputTypes calls equalsStructurally to check if the children types match. They should match regardless of nullability (which is just a hint), so it is now called with ignoreNullability=true.
## How was this patch tested?
New test in SubquerySuite
Author: Bogdan Raducanu <bogdan@databricks.com>
Closes#20548 from bogdanrdc/SPARK-23316.
## What changes were proposed in this pull request?
Add some test cases for images feature
## How was this patch tested?
Add some test cases in ImageSchemaSuite
Author: xubo245 <601450868@qq.com>
Closes#20583 from xubo245/CARBONDATA23392_AddTestForImage.
## What changes were proposed in this pull request?
When we run concurrent jobs using the same rdd which is marked to do checkpoint. If one job has finished running the job, and start the process of RDD.doCheckpoint, while another job is submitted, then submitStage and submitMissingTasks will be called. In [submitMissingTasks](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L961), will serialize taskBinaryBytes and calculate task partitions which are both affected by the status of checkpoint, if the former is calculated before doCheckpoint finished, while the latter is calculated after doCheckpoint finished, when run task, rdd.compute will be called, for some rdds with particular partition type such as [UnionRDD](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/rdd/UnionRDD.scala) who will do partition type cast, will get a ClassCastException because the part params is actually a CheckpointRDDPartition.
This error occurs because rdd.doCheckpoint occurs in the same thread that called sc.runJob, while the task serialization occurs in the DAGSchedulers event loop.
## How was this patch tested?
the exist uts and also add a test case in DAGScheduerSuite to show the exception case.
Author: huangtengfei <huangtengfei@huangtengfeideMacBook-Pro.local>
Closes#20244 from ivoson/branch-taskpart-mistype.
## What changes were proposed in this pull request?
The purpose of this PR to reflect the stage level blacklisting on the executor tab for the currently active stages.
After this change in the executor tab at the Status column one of the following label will be:
- "Blacklisted" when the executor is blacklisted application level (old flag)
- "Dead" when the executor is not Blacklisted and not Active
- "Blacklisted in Stages: [...]" when the executor is Active but the there are active blacklisted stages for the executor. Within the [] coma separated active stageIDs are listed.
- "Active" when the executor is Active and there is no active blacklisted stages for the executor
## How was this patch tested?
Both with unit tests and manually.
#### Manual test
Spark was started as:
```bash
bin/spark-shell --master "local-cluster[2,1,1024]" --conf "spark.blacklist.enabled=true" --conf "spark.blacklist.stage.maxFailedTasksPerExecutor=1" --conf "spark.blacklist.application.maxFailedTasksPerExecutor=10"
```
And the job was:
```scala
import org.apache.spark.SparkEnv
val pairs = sc.parallelize(1 to 10000, 10).map { x =>
if (SparkEnv.get.executorId.toInt == 0) throw new RuntimeException("Bad executor")
else {
Thread.sleep(10)
(x % 10, x)
}
}
val all = pairs.cogroup(pairs)
all.collect()
```
UI screenshots about the running:
- One executor is blacklisted in the two stages:

- One stage completes the other one is still running:

- Both stages are completed:

### Unit tests
In AppStatusListenerSuite.scala both the node blacklisting for a stage and the executor blacklisting for stage are tested.
Author: “attilapiros” <piros.attila.zsolt@gmail.com>
Closes#20408 from attilapiros/SPARK-23189.
## What changes were proposed in this pull request?
In this PR StorageStatus is made to private and simplified a bit moreover SparkContext.getExecutorStorageStatus method is removed. The reason of keeping StorageStatus is that it is usage from SparkContext.getRDDStorageInfo.
Instead of the method SparkContext.getExecutorStorageStatus executor infos are extended with additional memory metrics such as usedOnHeapStorageMemory, usedOffHeapStorageMemory, totalOnHeapStorageMemory, totalOffHeapStorageMemory.
## How was this patch tested?
By running existing unit tests.
Author: “attilapiros” <piros.attila.zsolt@gmail.com>
Author: Attila Zsolt Piros <2017933+attilapiros@users.noreply.github.com>
Closes#20546 from attilapiros/SPARK-20659.
## What changes were proposed in this pull request?
Cache the RDD of items in ml.FPGrowth before passing it to mllib.FPGrowth. Cache only when the user did not cache the input dataset of transactions. This fixes the warning about uncached data emerging from mllib.FPGrowth.
## How was this patch tested?
Manually:
1. Run ml.FPGrowthExample - warning is there
2. Apply the fix
3. Run ml.FPGrowthExample again - no warning anymore
Author: Arseniy Tashoyan <tashoyan@gmail.com>
Closes#20578 from tashoyan/SPARK-23318.
## What changes were proposed in this pull request?
Deprecating the field `name` in PySpark is not expected. This PR is to revert the change.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20595 from gatorsmile/removeDeprecate.
## What changes were proposed in this pull request?
If the target database name is as same as the current database, we should be able to skip one metastore access.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Feng Liu <fengliu@databricks.com>
Closes#20565 from liufengdb/remove-redundant.
## What changes were proposed in this pull request?
DataSourceV2 batch writes should use the output commit coordinator if it is required by the data source. This adds a new method, `DataWriterFactory#useCommitCoordinator`, that determines whether the coordinator will be used. If the write factory returns true, `WriteToDataSourceV2` will use the coordinator for batch writes.
## How was this patch tested?
This relies on existing write tests, which now use the commit coordinator.
Author: Ryan Blue <blue@apache.org>
Closes#20490 from rdblue/SPARK-23323-add-commit-coordinator.
When hive.default.fileformat is other kinds of file types, create textfile table cause a serde error.
We should take the default type of textfile and sequencefile both as org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe.
```
set hive.default.fileformat=orc;
create table tbl( i string ) stored as textfile;
desc formatted tbl;
Serde Library org.apache.hadoop.hive.ql.io.orc.OrcSerde
InputFormat org.apache.hadoop.mapred.TextInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
```
Author: sychen <sychen@ctrip.com>
Closes#20406 from cxzl25/default_serde.
## What changes were proposed in this pull request?
This removes the special case that `alterPartitions` call from `HiveExternalCatalog` can reset the current database in the hive client as a side effect.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Feng Liu <fengliu@databricks.com>
Closes#20564 from liufengdb/move.
## What changes were proposed in this pull request?
This is a follow-up pr of #19231 which modified the behavior to remove metadata from JDBC table schema.
This pr adds a test to check if the schema doesn't have metadata.
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20585 from ueshin/issues/SPARK-22002/fup1.
## What changes were proposed in this pull request?
Re-add support for parquet binary DecimalType in VectorizedColumnReader
## How was this patch tested?
Existing test suite
Author: James Thompson <jamesthomp@users.noreply.github.com>
Closes#20580 from jamesthomp/jt/add-back-binary-decimal.
## What changes were proposed in this pull request?
In the `getBlockData`,`blockId.reduceId` is the `Int` type, when it is greater than 2^28, `blockId.reduceId*8` will overflow
In the `decompress0`, `len` and `unitSize` are Int type, so `len * unitSize` may lead to overflow
## How was this patch tested?
N/A
Author: liuxian <liu.xian3@zte.com.cn>
Closes#20581 from 10110346/overflow2.
## What changes were proposed in this pull request?
This is a regression in Spark 2.3.
In Spark 2.2, we have a fragile UI support for SQL data writing commands. We only track the input query plan of `FileFormatWriter` and display its metrics. This is not ideal because we don't know who triggered the writing(can be table insertion, CTAS, etc.), but it's still useful to see the metrics of the input query.
In Spark 2.3, we introduced a new mechanism: `DataWritigCommand`, to fix the UI issue entirely. Now these writing commands have real children, and we don't need to hack into the `FileFormatWriter` for the UI. This also helps with `explain`, now `explain` can show the physical plan of the input query, while in 2.2 the physical writing plan is simply `ExecutedCommandExec` and it has no child.
However there is a regression in CTAS. CTAS commands don't extend `DataWritigCommand`, and we don't have the UI hack in `FileFormatWriter` anymore, so the UI for CTAS is just an empty node. See https://issues.apache.org/jira/browse/SPARK-22977 for more information about this UI issue.
To fix it, we should apply the `DataWritigCommand` mechanism to CTAS commands.
TODO: In the future, we should refactor this part and create some physical layer code pieces for data writing, and reuse them in different writing commands. We should have different logical nodes for different operators, even some of them share some same logic, e.g. CTAS, CREATE TABLE, INSERT TABLE. Internally we can share the same physical logic.
## How was this patch tested?
manually tested.
For data source table
<img width="644" alt="1" src="https://user-images.githubusercontent.com/3182036/35874155-bdffab28-0ba6-11e8-94a8-e32e106ba069.png">
For hive table
<img width="666" alt="2" src="https://user-images.githubusercontent.com/3182036/35874161-c437e2a8-0ba6-11e8-98ed-7930f01432c5.png">
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20521 from cloud-fan/UI.
## What changes were proposed in this pull request?
Currently, we use SBT and MAVN to spark unit test, are affected by the parameters of `spark.testing`. However, when using the IDE test tool, `spark.testing` support is not very good, sometimes need to be manually added to the beforeEach. example: HiveSparkSubmitSuite RPackageUtilsSuite SparkSubmitSuite. The PR unified `spark.testing` parameter extraction to SparkFunSuite, support IDE test tool, and the test code is more compact.
## How was this patch tested?
the existed test cases.
Author: caoxuewen <cao.xuewen@zte.com.cn>
Closes#20582 from heary-cao/sparktesting.
## What changes were proposed in this pull request?
This PR targets to explicitly specify supported types in Pandas UDFs.
The main change here is to add a deduplicated and explicit type checking in `returnType` ahead with documenting this; however, it happened to fix multiple things.
1. Currently, we don't support `BinaryType` in Pandas UDFs, for example, see:
```python
from pyspark.sql.functions import pandas_udf
pudf = pandas_udf(lambda x: x, "binary")
df = spark.createDataFrame([[bytearray(1)]])
df.select(pudf("_1")).show()
```
```
...
TypeError: Unsupported type in conversion to Arrow: BinaryType
```
We can document this behaviour for its guide.
2. Also, the grouped aggregate Pandas UDF fails fast on `ArrayType` but seems we can support this case.
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
foo = pandas_udf(lambda v: v.mean(), 'array<double>', PandasUDFType.GROUPED_AGG)
df = spark.range(100).selectExpr("id", "array(id) as value")
df.groupBy("id").agg(foo("value")).show()
```
```
...
NotImplementedError: ArrayType, StructType and MapType are not supported with PandasUDFType.GROUPED_AGG
```
3. Since we can check the return type ahead, we can fail fast before actual execution.
```python
# we can fail fast at this stage because we know the schema ahead
pandas_udf(lambda x: x, BinaryType())
```
## How was this patch tested?
Manually tested and unit tests for `BinaryType` and `ArrayType(...)` were added.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20531 from HyukjinKwon/pudf-cleanup.
## What changes were proposed in this pull request?
This test only fails with sbt on Hadoop 2.7, I can't reproduce it locally, but here is my speculation by looking at the code:
1. FileSystem.delete doesn't delete the directory entirely, somehow we can still open the file as a 0-length empty file.(just speculation)
2. ORC intentionally allow empty files, and the reader fails during reading without closing the file stream.
This PR improves the test to make sure all files are deleted and can't be opened.
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20584 from cloud-fan/flaky-test.
## What changes were proposed in this pull request?
In #19340 some comments considered needed to use spherical KMeans when cosine distance measure is specified, as Matlab does; instead of the implementation based on the behavior of other tools/libraries like Rapidminer, nltk and ELKI, ie. the centroids are computed as the mean of all the points in the clusters.
The PR introduce the approach used in spherical KMeans. This behavior has the nice feature to minimize the within-cluster cosine distance.
## How was this patch tested?
existing/improved UTs
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20518 from mgaido91/SPARK-22119_followup.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
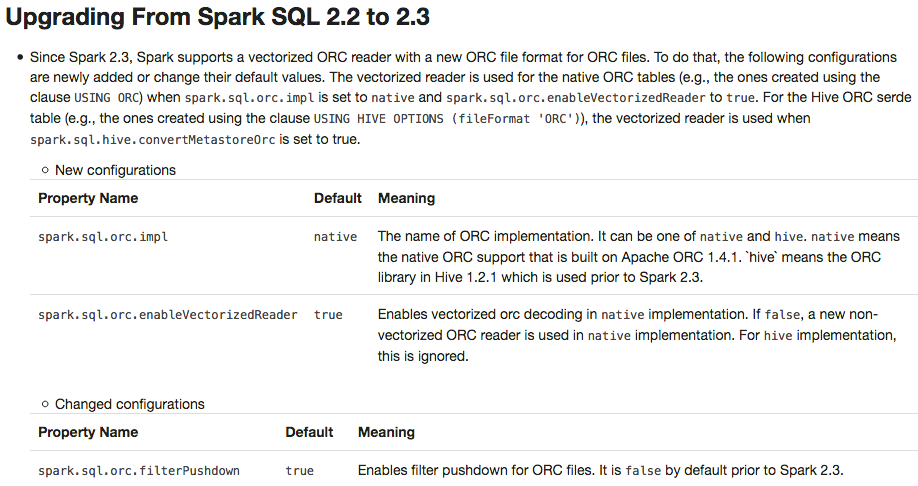{kind=link}
{kind=link}
{kind=link}