### What changes were proposed in this pull request?
This PR makes window frame could support `YearMonthIntervalType` and `DayTimeIntervalType`.
### Why are the changes needed?
Extend the function of window frame
### Does this PR introduce _any_ user-facing change?
Yes. Users could use `YearMonthIntervalType` or `DayTimeIntervalType` as the sort expression for window frame.
### How was this patch tested?
New tests
Closes#32294 from beliefer/SPARK-35110.
Authored-by: beliefer <beliefer@163.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Use transformAllExpressions instead of transformExpressionsDown in CombineConcats. The latter only transforms the root plan node.
### Why are the changes needed?
It allows CombineConcats to cover more cases where `concat` are not in the root plan node.
### How was this patch tested?
Unit test. The updated tests would fail without the code change.
Closes#32290 from sigmod/concat.
Authored-by: Yingyi Bu <yingyi.bu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
PG and Oracle both support use CUBE/ROLLUP/GROUPING SETS in GROUPING SETS's grouping set as a sugar syntax.

In this PR, we support it in Spark SQL too
### Why are the changes needed?
Keep consistent with PG and oracle
### Does this PR introduce _any_ user-facing change?
User can write grouping analytics like
```
SELECT a, b, count(1) FROM testData GROUP BY a, GROUPING SETS(ROLLUP(a, b));
SELECT a, b, count(1) FROM testData GROUP BY a, GROUPING SETS((a, b), (a), ());
SELECT a, b, count(1) FROM testData GROUP BY a, GROUPING SETS(GROUPING SETS((a, b), (a), ()));
```
### How was this patch tested?
Added Test
Closes#32201 from AngersZhuuuu/SPARK-35026.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
IntervalUtils.fromYearMonthString should handle Int.MinValue months correctly.
In current logic, just use `Math.addExact(Math.multiplyExact(years, 12), months)` to calculate negative total months will overflow when actual total months is Int.MinValue, this pr fixes this bug.
### Why are the changes needed?
IntervalUtils.fromYearMonthString should handle Int.MinValue months correctly
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#32281 from AngersZhuuuu/SPARK-35177.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
It will remove `StructField` when [pruning nested columns](0f2c0b53e8/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/SchemaPruning.scala (L28-L42)). For example:
```scala
spark.sql(
"""
|CREATE TABLE t1 (
| _col0 INT,
| _col1 STRING,
| _col2 STRUCT<c1: STRING, c2: STRING, c3: STRING, c4: BIGINT>)
|USING ORC
|""".stripMargin)
spark.sql("INSERT INTO t1 values(1, '2', struct('a', 'b', 'c', 10L))")
spark.sql("SELECT _col0, _col2.c1 FROM t1").show
```
Before this pr. The returned schema is: ``` `_col0` INT,`_col2` STRUCT<`c1`: STRING> ``` add it will throw exception:
```
java.lang.AssertionError: assertion failed: The given data schema struct<_col0:int,_col2:struct<c1:string>> has less fields than the actual ORC physical schema, no idea which columns were dropped, fail to read.
at scala.Predef$.assert(Predef.scala:223)
at org.apache.spark.sql.execution.datasources.orc.OrcUtils$.requestedColumnIds(OrcUtils.scala:160)
```
After this pr. The returned schema is: ``` `_col0` INT,`_col1` STRING,`_col2` STRUCT<`c1`: STRING> ```.
The finally schema is ``` `_col0` INT,`_col2` STRUCT<`c1`: STRING> ``` after the complete column pruning:
7a5647a93a/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileSourceStrategy.scala (L208-L213)e64eb75aed/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/PushDownUtils.scala (L96-L97)
### Why are the changes needed?
Fix bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#31993 from wangyum/SPARK-34897.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
* Add `Not(In)` and `Not(InSet)` check in `NullPropagation` rule.
* Add more test for `In` and `Not(In)` in `Project` level.
### Why are the changes needed?
The semantics of `Not(In)` could be seen like `And(a != b, a != c)` that match the `NullIntolerant`.
As we already simplify the `NullIntolerant` expression to null if it's children have null. E.g. `a != null` => `null`. It's safe to do this with `Not(In)`/`Not(InSet)`.
Note that, we can only do the simplify in predicate which `ReplaceNullWithFalseInPredicate` rule do.
Let's say we have two sqls:
```
select 1 not in (2, null);
select 1 where 1 not in (2, null);
```
The first sql we cannot optimize since it would return `NULL` instead of `false`. The second is postive.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Add test.
Closes#31797 from ulysses-you/SPARK-34692.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
IntegralDivide should throw an exception on overflow in ANSI mode.
There is only one case that can cause that:
```
Long.MinValue div -1
```
### Why are the changes needed?
ANSI compliance
### Does this PR introduce _any_ user-facing change?
Yes, IntegralDivide throws an exception on overflow in ANSI mode
### How was this patch tested?
Unit test
Closes#32260 from gengliangwang/integralDiv.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
As a part of the SPARK-26837 pruning of nested fields from object serializers are supported. But it is missed to handle case insensitivity nature of spark
In this PR I have resolved the column names to be pruned based on `spark.sql.caseSensitive ` config
**Exception Before Fix**
```
Caused by: java.lang.ArrayIndexOutOfBoundsException: 0
at org.apache.spark.sql.types.StructType.apply(StructType.scala:414)
at org.apache.spark.sql.catalyst.optimizer.ObjectSerializerPruning$$anonfun$apply$4.$anonfun$applyOrElse$3(objects.scala:216)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
at scala.collection.immutable.List.foreach(List.scala:392)
at scala.collection.TraversableLike.map(TraversableLike.scala:238)
at scala.collection.TraversableLike.map$(TraversableLike.scala:231)
at scala.collection.immutable.List.map(List.scala:298)
at org.apache.spark.sql.catalyst.optimizer.ObjectSerializerPruning$$anonfun$apply$4.applyOrElse(objects.scala:215)
at org.apache.spark.sql.catalyst.optimizer.ObjectSerializerPruning$$anonfun$apply$4.applyOrElse(objects.scala:203)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDown$1(TreeNode.scala:309)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:72)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:309)
at
```
### Why are the changes needed?
After Upgrade to Spark 3 `foreachBatch` API throws` java.lang.ArrayIndexOutOfBoundsException`. This issue will be fixed using this PR
### Does this PR introduce _any_ user-facing change?
No, Infact fixes the regression
### How was this patch tested?
Added tests and also tested verified manually
Closes#32194 from sandeep-katta/SPARK-35096.
Authored-by: sandeep.katta <sandeep.katta2007@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Support ANSI interval in HashExpression and add UT
### Why are the changes needed?
Support ANSI interval in HashExpression
### Does this PR introduce _any_ user-facing change?
User can pass ANSI interval in HashExpression function
### How was this patch tested?
Added UT
Closes#32259 from AngersZhuuuu/SPARK-35113.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
dfs.replication is inconsistent from hadoop 2.x to 3.x, so in this PR we use `dfs.hosts` to verify per https://github.com/apache/spark/pull/32144#discussion_r616833099
```
== Results ==
!== Correct Answer - 1 == == Spark Answer - 1 ==
!struct<> struct<key:string,value:string>
![dfs.replication,<undefined>] [dfs.replication,3]
```
### Why are the changes needed?
fix Jenkins job with Hadoop 2.7
### Does this PR introduce _any_ user-facing change?
test only change
### How was this patch tested?
test only change
Closes#32263 from yaooqinn/SPARK-35044-F.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to override the `sql` and `toString` methods of the expressions that implement operators over ANSI intervals (`YearMonthIntervalType`/`DayTimeIntervalType`), and replace internal expression class names by operators like `*`, `/` and `-`.
### Why are the changes needed?
Proposed methods should make the textual representation of such operators more readable, and potentially parsable by Spark SQL parser.
### Does this PR introduce _any_ user-facing change?
Yes. This can influence on column names.
### How was this patch tested?
By running existing test suites for interval and datetime expressions, and re-generating the `*.sql` tests:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
```
Closes#32262 from MaxGekk/interval-operator-sql.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
`CurrentOrigin` is a thread-local variable to track the original SQL line position in plan/expression. Usually, we set `CurrentOrigin`, create `TreeNode` instances, and reset `CurrentOrigin`.
This PR updates the last step to set `CurrentOrigin` to its previous value, instead of resetting it. This is necessary when we invoke `CurrentOrigin` in a nested way, like with subqueries.
### Why are the changes needed?
To keep the original SQL line position in the error message in more cases.
### Does this PR introduce _any_ user-facing change?
No, only minor error message changes.
### How was this patch tested?
existing tests
Closes#32249 from cloud-fan/origin.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch proposes to leverage `CustomMetric`, `CustomTaskMetric` API to report custom metrics from DS v2 scan to Spark.
### Why are the changes needed?
This is related to #31398. In SPARK-34297, we want to add a couple of metrics when reading from Kafka in SS. We need some public API change in DS v2 to make it possible. This extracts only DS v2 change and make it general for DS v2 instead of micro-batch DS v2 API.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test.
Implement a simple test DS v2 class locally and run it:
```scala
scala> import org.apache.spark.sql.execution.datasources.v2._
import org.apache.spark.sql.execution.datasources.v2._
scala> classOf[CustomMetricDataSourceV2].getName
res0: String = org.apache.spark.sql.execution.datasources.v2.CustomMetricDataSourceV2
scala> val df = spark.read.format(res0).load()
df: org.apache.spark.sql.DataFrame = [i: int, j: int]
scala> df.collect
```
<img width="703" alt="Screen Shot 2021-03-30 at 11 07 13 PM" src="https://user-images.githubusercontent.com/68855/113098080-d8a49800-91ac-11eb-8681-be408a0f2e69.png">
Closes#31451 from viirya/dsv2-metrics.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Refactor ScriptTransformation to remove input parameter and replace it by child.output
### Why are the changes needed?
refactor code
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existed UT
Closes#32228 from AngersZhuuuu/SPARK-34035.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
After the PR https://github.com/apache/spark/pull/32209, this should be possible now.
We can add test case for ANSI intervals to HiveThriftBinaryServerSuite
### Why are the changes needed?
Add more test case
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#32250 from AngersZhuuuu/SPARK-35068.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR implements the decorrelation technique in the paper "Unnesting Arbitrary Queries" by T. Neumann; A. Kemper
(http://www.btw-2015.de/res/proceedings/Hauptband/Wiss/Neumann-Unnesting_Arbitrary_Querie.pdf). It currently supports Filter, Project, Aggregate, Join, and UnaryNode that passes CheckAnalysis.
This feature can be controlled by the config `spark.sql.optimizer.decorrelateInnerQuery.enabled` (default: true).
A few notes:
1. This PR does not relax any constraints in CheckAnalysis for correlated subqueries, even though some cases can be supported by this new framework, such as aggregate with correlated non-equality predicates. This PR focuses on adding the new framework and making sure all existing cases can be supported. Constraints can be relaxed gradually in the future via separate PRs.
2. The new framework is only enabled for correlated scalar subqueries, as the first step. EXISTS/IN subqueries can be supported in the future.
### Why are the changes needed?
Currently, Spark has limited support for correlated subqueries. It only allows `Filter` to reference outer query columns and does not support non-equality predicates when the subquery is aggregated. This new framework will allow more operators to host outer column references and support correlated non-equality predicates and more types of operators in correlated subqueries.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing unit and SQL query tests and new optimizer plan tests.
Closes#32072 from allisonwang-db/spark-34974-decorrelation.
Authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Add a test to check that Thrift server is able to collect year-month intervals and transfer them via thrift protocol.
2. Improve similar test for day-time intervals. After the changes, the test doesn't depend on the result of date subtractions. In the future, the type of date subtract can be changed. So, current PR should make the test tolerant to the changes.
### Why are the changes needed?
To improve test coverage.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running the modified test suite:
```
$ ./build/sbt -Phive -Phive-thriftserver "test:testOnly *SparkThriftServerProtocolVersionsSuite"
```
Closes#32240 from MaxGekk/year-month-interval-thrift-protocol.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
- Share a static ImmutableBitSet for `treePatternBits` in all object instances of AttributeReference.
- Share three static ImmutableBitSets for `treePatternBits` in three kinds of Literals.
- Add an ImmutableBitSet as a subclass of BitSet.
### Why are the changes needed?
Reduce the additional memory usage caused by `treePatternBits`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#32157 from sigmod/leaf.
Authored-by: Yingyi Bu <yingyi.bu@databricks.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
This PR updated the `foundNonEqualCorrelatedPred` logic for correlated subqueries in `CheckAnalysis` to only allow correlated equality predicates that guarantee one-to-one mapping between inner and outer attributes, instead of all equality predicates.
### Why are the changes needed?
To fix correctness bugs. Before this fix Spark can give wrong results for certain correlated subqueries that pass CheckAnalysis:
Example 1:
```sql
create or replace view t1(c) as values ('a'), ('b')
create or replace view t2(c) as values ('ab'), ('abc'), ('bc')
select c, (select count(*) from t2 where t1.c = substring(t2.c, 1, 1)) from t1
```
Correct results: [(a, 2), (b, 1)]
Spark results:
```
+---+-----------------+
|c |scalarsubquery(c)|
+---+-----------------+
|a |1 |
|a |1 |
|b |1 |
+---+-----------------+
```
Example 2:
```sql
create or replace view t1(a, b) as values (0, 6), (1, 5), (2, 4), (3, 3);
create or replace view t2(c) as values (6);
select c, (select count(*) from t1 where a + b = c) from t2;
```
Correct results: [(6, 4)]
Spark results:
```
+---+-----------------+
|c |scalarsubquery(c)|
+---+-----------------+
|6 |1 |
|6 |1 |
|6 |1 |
|6 |1 |
+---+-----------------+
```
### Does this PR introduce _any_ user-facing change?
Yes. Users will not be able to run queries that contain unsupported correlated equality predicates.
### How was this patch tested?
Added unit tests.
Closes#32179 from allisonwang-db/spark-35080-subquery-bug.
Lead-authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR fixes a couple of things in TypeCoercion rules:
- Only run the propagate types step if the children of a node have output attributes with changed dataTypes and/or nullability. This is implemented as custom tree transformation. The TypeCoercion rules now only implement a partial function.
- Combine multiple type coercion rules into a single rule. Multiple rules are applied in single tree traversal.
- Reduce calls to conf.get in DecimalPrecision. This now happens once per tree traversal, instead of once per matched expression.
- Reduce the use of withNewChildren.
This brings down the number of CPU cycles spend in analysis by ~28% (benchmark: 10 iterations of all TPC-DS queries on SF10).
## How was this patch tested?
Existing tests.
Closes#32208 from sigmod/coercion.
Authored-by: Yingyi Bu <yingyi.bu@databricks.com>
Signed-off-by: herman <herman@databricks.com>
### What changes were proposed in this pull request?
Remove Antlr 4.7 workaround.
### Why are the changes needed?
The https://github.com/antlr/antlr4/commit/ac9f7530 has been fixed in upstream, so remove the workaround to simplify code.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existed UTs.
Closes#32238 from pan3793/antlr-minor.
Authored-by: Cheng Pan <379377944@qq.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Firstly let's take a look at the definition and comment.
```
// A fake config which is only here for backward compatibility reasons. This config has no effect
// to Spark, just for reporting the builtin Hive version of Spark to existing applications that
// already rely on this config.
val FAKE_HIVE_VERSION = buildConf("spark.sql.hive.version")
.doc(s"deprecated, please use ${HIVE_METASTORE_VERSION.key} to get the Hive version in Spark.")
.version("1.1.1")
.fallbackConf(HIVE_METASTORE_VERSION)
```
It is used for reporting the built-in Hive version but the current status is unsatisfactory, as it is could be changed in many ways e.g. --conf/SET syntax.
It is marked as deprecated but kept a long way until now. I guess it is hard for us to remove it and not even necessary.
On second thought, it's actually good for us to keep it to work with the `spark.sql.hive.metastore.version`. As when `spark.sql.hive.metastore.version` is changed, it could be used to report the compiled hive version statically, it's useful when an error occurs in this case. So this parameter should be fixed to compiled hive version.
### Why are the changes needed?
`spark.sql.hive.version` is useful in certain cases and should be read-only
### Does this PR introduce _any_ user-facing change?
`spark.sql.hive.version` now is read-only
### How was this patch tested?
new test cases
Closes#32200 from yaooqinn/SPARK-35102.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Similarly to the test from the PR https://github.com/apache/spark/pull/31799, add tests:
1. Months -> Period -> Months
2. Period -> Months -> Period
3. Duration -> micros -> Duration
### Why are the changes needed?
Add round trip tests for period <-> month and duration <-> micros
### Does this PR introduce _any_ user-facing change?
'No'. Just test cases.
### How was this patch tested?
Jenkins test
Closes#32234 from beliefer/SPARK-34715.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Parse the year-month interval literals like `INTERVAL '1-1' YEAR TO MONTH` to values of `YearMonthIntervalType`, and day-time interval literals to `DayTimeIntervalType` values. Currently, Spark SQL supports:
- DAY TO HOUR
- DAY TO MINUTE
- DAY TO SECOND
- HOUR TO MINUTE
- HOUR TO SECOND
- MINUTE TO SECOND
All such interval literals are converted to `DayTimeIntervalType`, and `YEAR TO MONTH` to `YearMonthIntervalType` while loosing info about `from` and `to` units.
**Note**: new behavior is under the SQL config `spark.sql.legacy.interval.enabled` which is `false` by default. When the config is set to `true`, the interval literals are parsed to `CaledarIntervalType` values.
Closes#32176
### Why are the changes needed?
To conform the ANSI SQL standard which assumes conversions of interval literals to year-month or day-time interval but not to mixed interval type like Catalyst's `CalendarIntervalType`.
### Does this PR introduce _any_ user-facing change?
Yes.
Before:
```sql
spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND;
1 days 1 hours 2 minutes 3.123 seconds
spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND);
interval
```
After:
```sql
spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND;
1 01:02:03.123000000
spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND);
day-time interval
```
### How was this patch tested?
1. By running the affected test suites:
```
$ ./build/sbt "test:testOnly *.ExpressionParserSuite"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z create_view.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql"
```
2. PostgresSQL tests are executed with `spark.sql.legacy.interval.enabled` is set to `true` to keep compatibility with PostgreSQL output:
```sql
> SELECT interval '999' second;
0 years 0 mons 0 days 0 hours 16 mins 39.00 secs
```
Closes#32209 from MaxGekk/parse-ansi-interval-literals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Extend the `Average` expression to support `DayTimeIntervalType` and `YearMonthIntervalType` added by #31614.
Note: the expressions can throw the overflow exception independently from the SQL config `spark.sql.ansi.enabled`. In this way, the modified expressions always behave in the ANSI mode for the intervals.
### Why are the changes needed?
Extend `org.apache.spark.sql.catalyst.expressions.aggregate.Average` to support `DayTimeIntervalType` and `YearMonthIntervalType`.
### Does this PR introduce _any_ user-facing change?
'No'.
Should not since new types have not been released yet.
### How was this patch tested?
Jenkins test
Closes#32229 from beliefer/SPARK-34837.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR makes the input buffer configurable (as an internal configuration). This is mainly to work around the regression in uniVocity/univocity-parsers#449.
This is particularly useful for SQL workloads that requires to rewrite the `CREATE TABLE` with options.
### Why are the changes needed?
To work around uniVocity/univocity-parsers#449.
### Does this PR introduce _any_ user-facing change?
No, it's only internal option.
### How was this patch tested?
Manually tested by modifying the unittest added in https://github.com/apache/spark/pull/31858 as below:
```diff
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
index fd25a79619d..705f38dbfbd 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
-2456,6 +2456,7 abstract class CSVSuite
test("SPARK-34768: counting a long record with ignoreTrailingWhiteSpace set to true") {
val bufSize = 128
val line = "X" * (bufSize - 1) + "| |"
+ spark.conf.set("spark.sql.csv.parser.inputBufferSize", 128)
withTempPath { path =>
Seq(line).toDF.write.text(path.getAbsolutePath)
assert(spark.read.format("csv")
```
Closes#32231 from HyukjinKwon/SPARK-35045-followup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Support no-serde mode script transform use ArrayType/MapType/StructStpe data.
### Why are the changes needed?
Make user can process array/map/struct data
### Does this PR introduce _any_ user-facing change?
Yes, user can process array/map/struct data in script transform `no-serde` mode
### How was this patch tested?
Added UT
Closes#30957 from AngersZhuuuu/SPARK-31937.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Now that `AnalysisOnlyCommand` in introduced in #32032, `CacheTable` and `UncacheTable` can extend `AnalysisOnlyCommand` to simplify the code base. For example, the logic to handle these commands such that the tables are only analyzed is scattered across different places.
### Why are the changes needed?
To simplify the code base to handle these two commands.
### Does this PR introduce _any_ user-facing change?
No, just internal refactoring.
### How was this patch tested?
The existing tests (e.g., `CachedTableSuite`) cover the changes in this PR. For example, if I make `CacheTable`/`UncacheTable` extend `LeafCommand`, there are few failures in `CachedTableSuite`.
Closes#32220 from imback82/cache_cmd_analysis_only.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR:
- Adds a new expression `GroupingExprRef` that can be used in aggregate expressions of `Aggregate` nodes to refer grouping expressions by index. These expressions capture the data type and nullability of the referred grouping expression.
- Adds a new rule `EnforceGroupingReferencesInAggregates` that inserts the references in the beginning of the optimization phase.
- Adds a new rule `UpdateGroupingExprRefNullability` to update nullability of `GroupingExprRef` expressions as nullability of referred grouping expression can change during optimization.
### Why are the changes needed?
If aggregate expressions (without aggregate functions) in an `Aggregate` node are complex then the `Optimizer` can optimize out grouping expressions from them and so making aggregate expressions invalid.
Here is a simple example:
```
SELECT not(t.id IS NULL) , count(*)
FROM t
GROUP BY t.id IS NULL
```
In this case the `BooleanSimplification` rule does this:
```
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.BooleanSimplification ===
!Aggregate [isnull(id#222)], [NOT isnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L]
+- Project [value#219 AS id#222] +- Project [value#219 AS id#222]
+- LocalRelation [value#219] +- LocalRelation [value#219]
```
where `NOT isnull(id#222)` is optimized to `isnotnull(id#222)` and so it no longer refers to any grouping expression.
Before this PR:
```
== Optimized Logical Plan ==
Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#234, count(1) AS c#232L]
+- Project [value#219 AS id#222]
+- LocalRelation [value#219]
```
and running the query throws an error:
```
Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L]
java.lang.IllegalStateException: Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L]
```
After this PR:
```
== Optimized Logical Plan ==
Aggregate [isnull(id#222)], [NOT groupingexprref(0) AS (NOT (id IS NULL))#234, count(1) AS c#232L]
+- Project [value#219 AS id#222]
+- LocalRelation [value#219]
```
and the query works.
### Does this PR introduce _any_ user-facing change?
Yes, the query works.
### How was this patch tested?
Added new UT.
Closes#31913 from peter-toth/SPARK-34581-keep-grouping-expressions.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
It seems that we miss classifying one `SparkOutOfMemoryError` in `HashedRelation`. Add the error classification for it. In addition, clean up two errors definition of `HashJoin` as they are not used.
### Why are the changes needed?
Better error classification.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#32211 from c21/error-message.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Add checks for `YearMonthIntervalType` and `DayTimeIntervalType` to `MutableProjectionSuite`.
### Why are the changes needed?
To improve test coverage, and the same checks as for `CalendarIntervalType`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running the modified test suite:
```
$ build/sbt "test:testOnly *MutableProjectionSuite"
```
Closes#32225 from MaxGekk/test-ansi-intervals-in-MutableProjectionSuite.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Extend the `Sum` expression to to support `DayTimeIntervalType` and `YearMonthIntervalType` added by #31614.
Note: the expressions can throw the overflow exception independently from the SQL config `spark.sql.ansi.enabled`. In this way, the modified expressions always behave in the ANSI mode for the intervals.
### Why are the changes needed?
Extend `org.apache.spark.sql.catalyst.expressions.aggregate.Sum` to support `DayTimeIntervalType` and `YearMonthIntervalType`.
### Does this PR introduce _any_ user-facing change?
'No'.
Should not since new types have not been released yet.
### How was this patch tested?
Jenkins test
Closes#32107 from beliefer/SPARK-34716.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: beliefer <beliefer@163.com>
Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
In the PR, I propose to add additional checks for ANSI interval types `YearMonthIntervalType` and `DayTimeIntervalType` to `LiteralExpressionSuite`.
Also, I replaced some long literal values by `CalendarInterval` to check `CalendarIntervalType` that the tests were supposed to check.
### Why are the changes needed?
To improve test coverage and have the same checks for ANSI types as for `CalendarIntervalType`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running the modified test suite:
```
$ build/sbt "test:testOnly *LiteralExpressionSuite"
```
Closes#32213 from MaxGekk/interval-literal-tests.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
The precision of `java.time.Duration` is nanosecond, but when it is used as `DayTimeIntervalType` in Spark, it is microsecond.
At present, the `DayTimeIntervalType` data generated in the implementation of `RandomDataGenerator` is accurate to nanosecond, which will cause the `DayTimeIntervalType` to be converted to long, and then back to `DayTimeIntervalType` to lose the accuracy, which will cause the test to fail. For example: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137390/testReport/org.apache.spark.sql.hive.execution/HashAggregationQueryWithControlledFallbackSuite/udaf_with_all_data_types/
### Why are the changes needed?
Improve `RandomDataGenerator` so that the generated data fits the precision of DayTimeIntervalType in spark.
### Does this PR introduce _any_ user-facing change?
'No'. Just change the test class.
### How was this patch tested?
Jenkins test.
Closes#32212 from beliefer/SPARK-35116.
Authored-by: beliefer <beliefer@163.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This issue fixes an issue that indentation of multiple output JSON records in a single split file are broken except for the first record in the split when `pretty` option is `true`.
```
// Run in the Spark Shell.
// Set spark.sql.leafNodeDefaultParallelism to 1 for the current master.
// Or set spark.default.parallelism for the previous releases.
spark.conf.set("spark.sql.leafNodeDefaultParallelism", 1)
val df = Seq("a", "b", "c").toDF
df.write.option("pretty", "true").json("/path/to/output")
# Run in a Shell
$ cat /path/to/output/*.json
{
"value" : "a"
}
{
"value" : "b"
}
{
"value" : "c"
}
```
### Why are the changes needed?
It's not pretty even though `pretty` option is true.
### Does this PR introduce _any_ user-facing change?
I think "No". Indentation style is changed but JSON format is not changed.
### How was this patch tested?
New test.
Closes#32203 from sarutak/fix-ugly-indentation.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Handle `YearMonthIntervalType` and `DayTimeIntervalType` in the `sql()` and `toString()` method of `Literal`, and format the ANSI interval in the ANSI style.
### Why are the changes needed?
To improve readability and UX with Spark SQL. For example, a test output before the changes:
```
-- !query
select timestamp'2011-11-11 11:11:11' - interval '2' day
-- !query schema
struct<TIMESTAMP '2011-11-11 11:11:11' - 172800000000:timestamp>
-- !query output
2011-11-09 11:11:11
```
### Does this PR introduce _any_ user-facing change?
Should not since the new intervals haven't been released yet.
### How was this patch tested?
By running new tests:
```
$ ./build/sbt "test:testOnly *LiteralExpressionSuite"
```
Closes#32196 from MaxGekk/literal-ansi-interval-sql.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Normal function parameters should not support alias, hive not support too
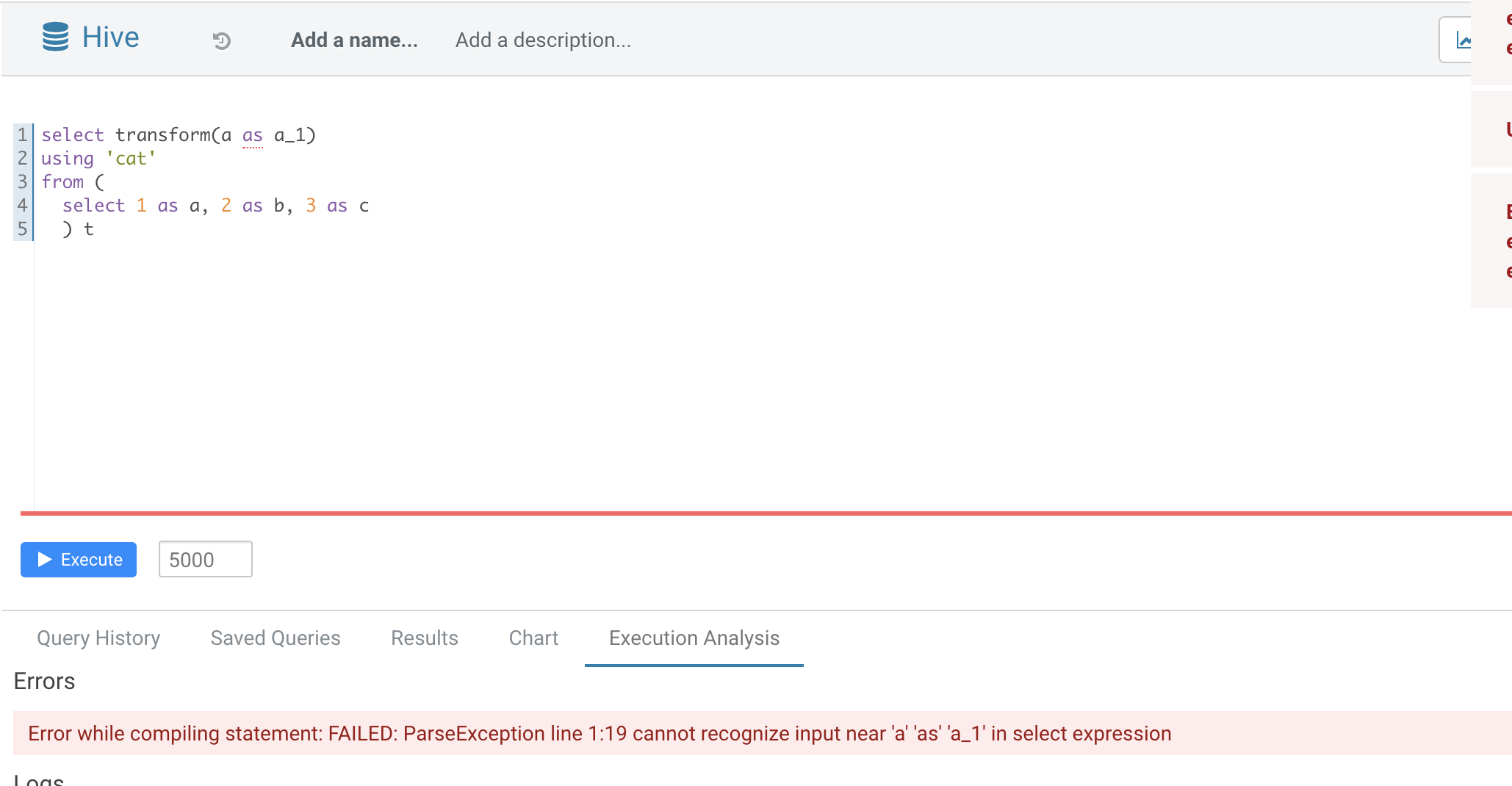
In this pr we forbid use alias in `TRANSFORM`'s inputs
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#32165 from AngersZhuuuu/SPARK-35070.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In current code, if we run spark sql with
```
./bin/spark-sql --verbose
```
It won't be passed to end SparkSQLCliDriver, then the SessionState won't call `setIsVerbose`
In the CLI option, it shows
```
CLI options:
-v,--verbose Verbose mode (echo executed SQL to the
console)
```
It's not consistent. This pr fix this issue
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
when user call `-v` when run spark sql, sql will be echoed to console.
### How was this patch tested?
Added UT
Closes#32163 from AngersZhuuuu/SPARK-35086.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request?
This PR refactors three parts of the comments in `HiveClientImpl.withHiveState`
One is about the following comment.
```
// The classloader in clientLoader could be changed after addJar, always use the latest
// classloader.
```
The comment was added in SPARK-10810 (#8909) because `IsolatedClientLoader.classLoader` was declared as `var`.
But the field is now `val` and cannot be changed after instanciation.
So, the comment can confuse developers.
One is about the following code and comment.
```
// classloader. We explicitly set the context class loader since "conf.setClassLoader" does
// not do that, and the Hive client libraries may need to load classes defined by the client's
// class loader.
Thread.currentThread().setContextClassLoader(clientLoader.classLoader)
```
It's not trivial why this part is necessary and it's difficult when we can remove this code in the future.
So, I revised the comment by adding the reference of the related JIRA.
And the last one is about the following code and comment.
```
// Replace conf in the thread local Hive with current conf
Hive.get(conf)
```
It's also not trivial why this part is necessary.
I revised the comment by adding the reference of the related discussion.
### Why are the changes needed?
To make code more readable.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
It's just a comment refactoring so I add no new test.
Closes#32162 from sarutak/refactor-HiveClientImpl.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Currently, pure SQL users are short of ways to see the Hadoop configurations which may affect their jobs a lot, they are only able to get the Hadoop configs that exist in `SQLConf` while other defaults in `SharedState.hadoopConf` display wrongly and confusingly with `<undefined>`.
The pre-loaded ones from `core-site.xml, hive-site.xml` etc., will only stay in `sparkSession.sharedState.hadoopConf` or `sc._hadoopConfiguation` not `SQLConf`. Some of them that related the Hive Metastore connection(never change it spark runtime), e.g. `hive.metastore.uris`, are clearly global static and unchangeable but displayable I guess. Some of the ones that might be related to, for example, the output codec/compression, preset in Hadoop/hive config files like core-site.xml shall be still changeable from case to case, table to table, file to file, etc. It' meaningfully to show the defaults for users to change based on that.
In this PR, I propose to support get a Hadoop configuration by SET syntax, for example
```
SET mapreduce.map.output.compress.codec;
```
### Why are the changes needed?
better user experience for pure SQL users
### Does this PR introduce _any_ user-facing change?
yes, where retrieving a conf only existing in sessionState.hadoopConf, before is `undefined` and now you see it
### How was this patch tested?
new test
Closes#32144 from yaooqinn/SPARK-35044.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
Support `date +/- day-time interval`. In the PR, I propose to update the binary arithmetic rules, and cast an input date to a timestamp at the session time zone, and then add a day-time interval to it.
### Why are the changes needed?
1. To conform the ANSI SQL standard which requires to support such operation over dates and intervals:
<img width="811" alt="Screenshot 2021-03-12 at 11 36 14" src="https://user-images.githubusercontent.com/1580697/111081674-865d4900-8515-11eb-86c8-3538ecaf4804.png">
2. To fix the regression comparing to the recent Spark release 3.1 with default settings.
Before the changes:
```sql
spark-sql> select date'now' + (timestamp'now' - timestamp'yesterday');
Error in query: cannot resolve 'DATE '2021-04-14' + subtracttimestamps(TIMESTAMP '2021-04-14 18:14:56.497', TIMESTAMP '2021-04-13 00:00:00')' due to data type mismatch: argument 1 requires timestamp type, however, 'DATE '2021-04-14'' is of date type.; line 1 pos 7;
'Project [unresolvedalias(cast(2021-04-14 + subtracttimestamps(2021-04-14 18:14:56.497, 2021-04-13 00:00:00, false, Some(Europe/Moscow)) as date), None)]
+- OneRowRelation
```
Spark 3.1:
```sql
spark-sql> select date'now' + (timestamp'now' - timestamp'yesterday');
2021-04-15
```
Hive:
```sql
0: jdbc:hive2://localhost:10000/default> select date'2021-04-14' + (timestamp'2020-04-14 18:15:30' - timestamp'2020-04-13 00:00:00');
+------------------------+
| _c0 |
+------------------------+
| 2021-04-15 18:15:30.0 |
+------------------------+
```
### Does this PR introduce _any_ user-facing change?
Should not since new intervals have not been released yet.
After the changes:
```sql
spark-sql> select date'now' + (timestamp'now' - timestamp'yesterday');
2021-04-15 18:13:16.555
```
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#32170 from MaxGekk/date-add-day-time-interval.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
According to https://github.com/apache/spark/pull/29087#discussion_r612267050, add UT in `transform.sql`
It seems that distinct is not recognized as a reserved word here
```
-- !query
explain extended SELECT TRANSFORM(distinct b, a, c)
USING 'cat' AS (a, b, c)
FROM script_trans
WHERE a <= 4
-- !query schema
struct<plan:string>
-- !query output
== Parsed Logical Plan ==
'ScriptTransformation [*], cat, [a#x, b#x, c#x], ScriptInputOutputSchema(List(),List(),None,None,List(),List(),None,None,false)
+- 'Project ['distinct AS b#x, 'a, 'c]
+- 'Filter ('a <= 4)
+- 'UnresolvedRelation [script_trans], [], false
== Analyzed Logical Plan ==
org.apache.spark.sql.AnalysisException: cannot resolve 'distinct' given input columns: [script_trans.a, script_trans.b, script_trans.c]; line 1 pos 34;
'ScriptTransformation [*], cat, [a#x, b#x, c#x], ScriptInputOutputSchema(List(),List(),None,None,List(),List(),None,None,false)
+- 'Project ['distinct AS b#x, a#x, c#x]
+- Filter (a#x <= 4)
+- SubqueryAlias script_trans
+- View (`script_trans`, [a#x,b#x,c#x])
+- Project [cast(a#x as int) AS a#x, cast(b#x as int) AS b#x, cast(c#x as int) AS c#x]
+- Project [a#x, b#x, c#x]
+- SubqueryAlias script_trans
+- LocalRelation [a#x, b#x, c#x]
```
Hive's error
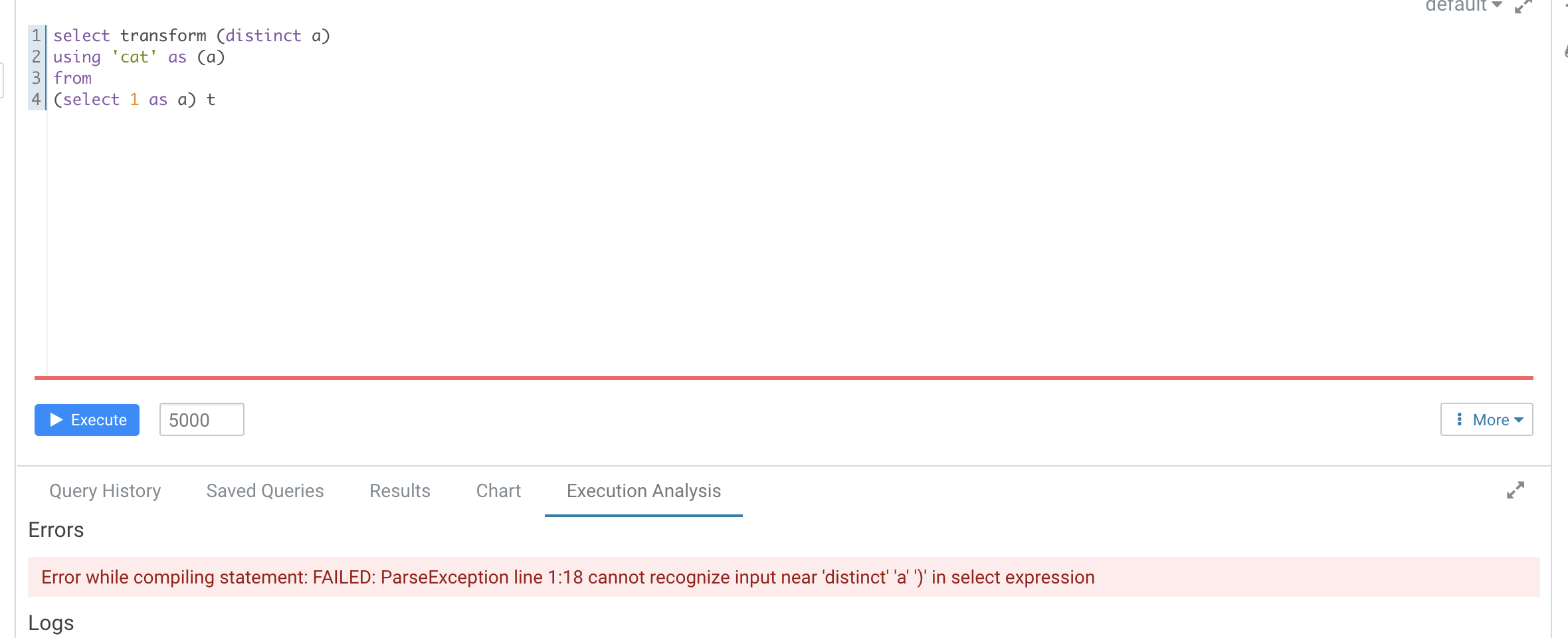
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added Ut
Closes#32149 from AngersZhuuuu/SPARK-28227-new-followup.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to introduce the `AnalysisOnlyCommand` trait such that a command that extends this trait can have its children only analyzed, but not optimized. There is a corresponding analysis rule `HandleAnalysisOnlyCommand` that marks the command as analyzed after all other analysis rules are run.
This can be useful if a logical plan has children where they need to be only analyzed, but not optimized - e.g., `CREATE VIEW` or `CACHE TABLE AS`. This also addresses the issue found in #31933.
This PR also updates `CreateViewCommand`, `CacheTableAsSelect`, and `AlterViewAsCommand` to use the new trait / rule such that their children are only analyzed.
### Why are the changes needed?
To address the issue where the plan is unnecessarily re-analyzed in `CreateViewCommand`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests should cover the changes.
Closes#32032 from imback82/skip_transform.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Adds the duplicated common columns as hidden columns to the Projection used to rewrite NATURAL/USING JOINs.
### Why are the changes needed?
Allows users to resolve either side of the NATURAL/USING JOIN's common keys.
Previously, the user could only resolve the following columns:
| Join type | Left key columns | Right key columns |
| --- | --- | --- |
| Inner | Yes | No |
| Left | Yes | No |
| Right | No | Yes |
| Outer | No | No |
### Does this PR introduce _any_ user-facing change?
Yes. The user can now symmetrically resolve the common columns from a NATURAL/USING JOIN.
### How was this patch tested?
SQL-side tests. The behavior matches PostgreSQL and MySQL.
Closes#31666 from karenfeng/spark-34527.
Authored-by: Karen Feng <karen.feng@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes an issue that `LIST FILES/JARS/ARCHIVES path1 path2 ...` cannot list all paths if at least one path is quoted.
An example here.
```
ADD FILE /tmp/test1;
ADD FILE /tmp/test2;
LIST FILES /tmp/test1 /tmp/test2;
file:/tmp/test1
file:/tmp/test2
LIST FILES /tmp/test1 "/tmp/test2";
file:/tmp/test2
```
In this example, the second `LIST FILES` doesn't show `file:/tmp/test1`.
To resolve this issue, I modified the syntax rule to be able to handle this case.
I also changed `SparkSQLParser` to be able to handle paths which contains white spaces.
### Why are the changes needed?
This is a bug.
I also have a plan which extends `ADD FILE/JAR/ARCHIVE` to take multiple paths like Hive and the syntax rule change is necessary for that.
### Does this PR introduce _any_ user-facing change?
Yes. Users can pass quoted paths when using `ADD FILE/JAR/ARCHIVE`.
### How was this patch tested?
New test.
Closes#32074 from sarutak/fix-list-files-bug.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
This PR group exception messages in `/core/src/main/scala/org/apache/spark/sql/execution`.
### Why are the changes needed?
It will largely help with standardization of error messages and its maintenance.
### Does this PR introduce _any_ user-facing change?
No. Error messages remain unchanged.
### How was this patch tested?
No new tests - pass all original tests to make sure it doesn't break any existing behavior.
Closes#31920 from beliefer/SPARK-33604.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Populate table catalog and identifier from `DataStreamWriter` to `WriteToMicroBatchDataSource` so that we can invalidate cache for tables that are updated by a streaming write.
This is somewhat related [SPARK-27484](https://issues.apache.org/jira/browse/SPARK-27484) and [SPARK-34183](https://issues.apache.org/jira/browse/SPARK-34183) (#31700), as ideally we may want to replace `WriteToMicroBatchDataSource` and `WriteToDataSourceV2` with logical write nodes and feed them to analyzer. That will potentially change the code path involved in this PR.
### Why are the changes needed?
Currently `WriteToDataSourceV2` doesn't have cache invalidation logic, and therefore, when the target table for a micro batch streaming job is cached, the cache entry won't be removed when the table is updated.
### Does this PR introduce _any_ user-facing change?
Yes now when a DSv2 table which supports streaming write is updated by a streaming job, its cache will also be invalidated.
### How was this patch tested?
Added a new UT.
Closes#32039 from sunchao/streaming-cache.
Authored-by: Chao Sun <sunchao@apple.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Remove duplicate code in `TreeNode.treePatternBits`
### Why are the changes needed?
Code clean up. Make it easier for maintainence.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests.
Closes#32143 from gengliangwang/getBits.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
This PR makes the input buffer configurable (as an internal option). This is mainly to work around uniVocity/univocity-parsers#449.
### Why are the changes needed?
To work around uniVocity/univocity-parsers#449.
### Does this PR introduce _any_ user-facing change?
No, it's only internal option.
### How was this patch tested?
Manually tested by modifying the unittest added in https://github.com/apache/spark/pull/31858 as below:
```diff
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
index fd25a79619d..b58f0bd3661 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
-2460,6 +2460,7 abstract class CSVSuite
Seq(line).toDF.write.text(path.getAbsolutePath)
assert(spark.read.format("csv")
.option("delimiter", "|")
+ .option("inputBufferSize", "128")
.option("ignoreTrailingWhiteSpace", "true").load(path.getAbsolutePath).count() == 1)
}
}
```
Closes#32145 from HyukjinKwon/SPARK-35045.
Lead-authored-by: Hyukjin Kwon <gurwls223@apache.org>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}