## What changes were proposed in this pull request?
In `HeapMemoryAllocator`, when allocating memory from pool, and the key of pool is memory size.
Actually some size of memory ,such as 1025bytes,1026bytes,......1032bytes, we can think they are the same,because we allocate memory in multiples of 8 bytes.
In this case, we can improve memory reuse.
## How was this patch tested?
Existing tests and added unit tests
Author: liuxian <liu.xian3@zte.com.cn>
Closes#19077 from 10110346/headmemoptimize.
## What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/20435.
While reorganizing the packages for streaming data source v2, the top level stream read/write support interfaces should not be in the reader/writer package, but should be in the `sources.v2` package, to follow the `ReadSupport`, `WriteSupport`, etc.
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20509 from cloud-fan/followup.
## What changes were proposed in this pull request?
For inserting/appending data to an existing table, Spark should adjust the data types of the input query according to the table schema, or fail fast if it's uncastable.
There are several ways to insert/append data: SQL API, `DataFrameWriter.insertInto`, `DataFrameWriter.saveAsTable`. The first 2 ways create `InsertIntoTable` plan, and the last way creates `CreateTable` plan. However, we only adjust input query data types for `InsertIntoTable`, and users may hit weird errors when appending data using `saveAsTable`. See the JIRA for the error case.
This PR fixes this bug by adjusting data types for `CreateTable` too.
## How was this patch tested?
new test.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20527 from cloud-fan/saveAsTable.
## What changes were proposed in this pull request?
This is to revert the changes made in https://github.com/apache/spark/pull/19499 , because this causes a regression. We should not ignore the table-specific compression conf when the Hive serde tables are converted to the data source tables.
## How was this patch tested?
The existing tests.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20536 from gatorsmile/revert22279.
## What changes were proposed in this pull request?
This is a followup pr of #20487.
When importing module but it doesn't exists, the error message is slightly different between Python 2 and 3.
E.g., in Python 2:
```
No module named pandas
```
in Python 3:
```
No module named 'pandas'
```
So, one test to check an import error fails in Python 3 without pandas.
This pr fixes it.
## How was this patch tested?
Tested manually in my local environment.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20538 from ueshin/issues/SPARK-23319/fup1.
## What changes were proposed in this pull request?
This PR migrates the MemoryStream to DataSourceV2 APIs.
One additional change is in the reported keys in StreamingQueryProgress.durationMs. "getOffset" and "getBatch" replaced with "setOffsetRange" and "getEndOffset" as tracking these make more sense. Unit tests changed accordingly.
## How was this patch tested?
Existing unit tests, few updated unit tests.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Author: Burak Yavuz <brkyvz@gmail.com>
Closes#20445 from tdas/SPARK-23092.
## What changes were proposed in this pull request?
When `DebugFilesystem` closes opened stream, if any exception occurs, we still need to remove the open stream record from `DebugFilesystem`. Otherwise, it goes to report leaked filesystem connection.
## How was this patch tested?
Existing tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20524 from viirya/SPARK-23345.
## What changes were proposed in this pull request?
This PR proposes to explicitly specify Pandas and PyArrow versions in PySpark tests to skip or test.
We declared the extra dependencies:
b8bfce51ab/python/setup.py (L204)
In case of PyArrow:
Currently we only check if pyarrow is installed or not without checking the version. It already fails to run tests. For example, if PyArrow 0.7.0 is installed:
```
======================================================================
ERROR: test_vectorized_udf_wrong_return_type (pyspark.sql.tests.ScalarPandasUDF)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/.../spark/python/pyspark/sql/tests.py", line 4019, in test_vectorized_udf_wrong_return_type
f = pandas_udf(lambda x: x * 1.0, MapType(LongType(), LongType()))
File "/.../spark/python/pyspark/sql/functions.py", line 2309, in pandas_udf
return _create_udf(f=f, returnType=return_type, evalType=eval_type)
File "/.../spark/python/pyspark/sql/udf.py", line 47, in _create_udf
require_minimum_pyarrow_version()
File "/.../spark/python/pyspark/sql/utils.py", line 132, in require_minimum_pyarrow_version
"however, your version was %s." % pyarrow.__version__)
ImportError: pyarrow >= 0.8.0 must be installed on calling Python process; however, your version was 0.7.0.
----------------------------------------------------------------------
Ran 33 tests in 8.098s
FAILED (errors=33)
```
In case of Pandas:
There are few tests for old Pandas which were tested only when Pandas version was lower, and I rewrote them to be tested when both Pandas version is lower and missing.
## How was this patch tested?
Manually tested by modifying the condition:
```
test_createDataFrame_column_name_encoding (pyspark.sql.tests.ArrowTests) ... skipped 'Pandas >= 1.19.2 must be installed; however, your version was 0.19.2.'
test_createDataFrame_does_not_modify_input (pyspark.sql.tests.ArrowTests) ... skipped 'Pandas >= 1.19.2 must be installed; however, your version was 0.19.2.'
test_createDataFrame_respect_session_timezone (pyspark.sql.tests.ArrowTests) ... skipped 'Pandas >= 1.19.2 must be installed; however, your version was 0.19.2.'
```
```
test_createDataFrame_column_name_encoding (pyspark.sql.tests.ArrowTests) ... skipped 'Pandas >= 0.19.2 must be installed; however, it was not found.'
test_createDataFrame_does_not_modify_input (pyspark.sql.tests.ArrowTests) ... skipped 'Pandas >= 0.19.2 must be installed; however, it was not found.'
test_createDataFrame_respect_session_timezone (pyspark.sql.tests.ArrowTests) ... skipped 'Pandas >= 0.19.2 must be installed; however, it was not found.'
```
```
test_createDataFrame_column_name_encoding (pyspark.sql.tests.ArrowTests) ... skipped 'PyArrow >= 1.8.0 must be installed; however, your version was 0.8.0.'
test_createDataFrame_does_not_modify_input (pyspark.sql.tests.ArrowTests) ... skipped 'PyArrow >= 1.8.0 must be installed; however, your version was 0.8.0.'
test_createDataFrame_respect_session_timezone (pyspark.sql.tests.ArrowTests) ... skipped 'PyArrow >= 1.8.0 must be installed; however, your version was 0.8.0.'
```
```
test_createDataFrame_column_name_encoding (pyspark.sql.tests.ArrowTests) ... skipped 'PyArrow >= 0.8.0 must be installed; however, it was not found.'
test_createDataFrame_does_not_modify_input (pyspark.sql.tests.ArrowTests) ... skipped 'PyArrow >= 0.8.0 must be installed; however, it was not found.'
test_createDataFrame_respect_session_timezone (pyspark.sql.tests.ArrowTests) ... skipped 'PyArrow >= 0.8.0 must be installed; however, it was not found.'
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20487 from HyukjinKwon/pyarrow-pandas-skip.
## What changes were proposed in this pull request?
Replace `registerTempTable` by `createOrReplaceTempView`.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20523 from gatorsmile/updateExamples.
## What changes were proposed in this pull request?
Update the description and tests of three external API or functions `createFunction `, `length` and `repartitionByRange `
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20495 from gatorsmile/updateFunc.
## What changes were proposed in this pull request?
`DataSourceV2Relation` keeps a `fullOutput` and resolves the real output on demand by column name lookup. i.e.
```
lazy val output: Seq[Attribute] = reader.readSchema().map(_.name).map { name =>
fullOutput.find(_.name == name).get
}
```
This will be broken after we canonicalize the plan, because all attribute names become "None", see https://github.com/apache/spark/blob/v2.3.0-rc1/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Canonicalize.scala#L42
To fix this, `DataSourceV2Relation` should just keep `output`, and update the `output` when doing column pruning.
## How was this patch tested?
a new test case
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20485 from cloud-fan/canonicalize.
## What changes were proposed in this pull request?
In b2ce17b4c9, I mistakenly renamed `VectorizedUDFTests` to `ScalarPandasUDF`. This PR fixes the mistake.
## How was this patch tested?
Existing tests.
Author: Li Jin <ice.xelloss@gmail.com>
Closes#20489 from icexelloss/fix-scalar-udf-tests.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/20483 tried to provide a way to turn off the new columnar cache reader, to restore the behavior in 2.2. However even we turn off that config, the behavior is still different than 2.2.
If the output data are rows, we still enable whole stage codegen for the scan node, which is different with 2.2, we should also fix it.
## How was this patch tested?
existing tests.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20513 from cloud-fan/cache.
## What changes were proposed in this pull request?
This is a follow-up of #20492 which broke lint-java checks.
This pr fixes the lint-java issues.
```
[ERROR] src/main/java/org/apache/spark/util/collection/unsafe/sort/UnsafeSorterSpillReader.java:[79] (sizes) LineLength: Line is longer than 100 characters (found 114).
```
## How was this patch tested?
Checked manually in my local environment.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20514 from ueshin/issues/SPARK-23310/fup1.
## What changes were proposed in this pull request?
In Python 2, when `pandas_udf` tries to return string type value created in the udf with `".."`, the execution fails. E.g.,
```python
from pyspark.sql.functions import pandas_udf, col
import pandas as pd
df = spark.range(10)
str_f = pandas_udf(lambda x: pd.Series(["%s" % i for i in x]), "string")
df.select(str_f(col('id'))).show()
```
raises the following exception:
```
...
java.lang.AssertionError: assertion failed: Invalid schema from pandas_udf: expected StringType, got BinaryType
at scala.Predef$.assert(Predef.scala:170)
at org.apache.spark.sql.execution.python.ArrowEvalPythonExec$$anon$2.<init>(ArrowEvalPythonExec.scala:93)
...
```
Seems like pyarrow ignores `type` parameter for `pa.Array.from_pandas()` and consider it as binary type when the type is string type and the string values are `str` instead of `unicode` in Python 2.
This pr adds a workaround for the case.
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20507 from ueshin/issues/SPARK-23334.
## What changes were proposed in this pull request?
This PR proposes to log if PyArrow and Pandas are installed or not so we can check if related tests are going to be skipped or not.
## How was this patch tested?
Manually tested:
I don't have PyArrow installed in PyPy.
```bash
$ ./run-tests --python-executables=python3
```
```
...
Will test against the following Python executables: ['python3']
Will test the following Python modules: ['pyspark-core', 'pyspark-ml', 'pyspark-mllib', 'pyspark-sql', 'pyspark-streaming']
Will test PyArrow related features against Python executable 'python3' in 'pyspark-sql' module.
Will test Pandas related features against Python executable 'python3' in 'pyspark-sql' module.
Starting test(python3): pyspark.mllib.tests
Starting test(python3): pyspark.sql.tests
Starting test(python3): pyspark.streaming.tests
Starting test(python3): pyspark.tests
```
```bash
$ ./run-tests --modules=pyspark-streaming
```
```
...
Will test against the following Python executables: ['python2.7', 'pypy']
Will test the following Python modules: ['pyspark-streaming']
Starting test(pypy): pyspark.streaming.tests
Starting test(pypy): pyspark.streaming.util
Starting test(python2.7): pyspark.streaming.tests
Starting test(python2.7): pyspark.streaming.util
```
```bash
$ ./run-tests
```
```
...
Will test against the following Python executables: ['python2.7', 'pypy']
Will test the following Python modules: ['pyspark-core', 'pyspark-ml', 'pyspark-mllib', 'pyspark-sql', 'pyspark-streaming']
Will test PyArrow related features against Python executable 'python2.7' in 'pyspark-sql' module.
Will test Pandas related features against Python executable 'python2.7' in 'pyspark-sql' module.
Will skip PyArrow related features against Python executable 'pypy' in 'pyspark-sql' module. PyArrow >= 0.8.0 is required; however, PyArrow was not found.
Will test Pandas related features against Python executable 'pypy' in 'pyspark-sql' module.
Starting test(pypy): pyspark.streaming.tests
Starting test(pypy): pyspark.sql.tests
Starting test(pypy): pyspark.tests
Starting test(python2.7): pyspark.mllib.tests
```
```bash
$ ./run-tests --modules=pyspark-sql --python-executables=pypy
```
```
...
Will test against the following Python executables: ['pypy']
Will test the following Python modules: ['pyspark-sql']
Will skip PyArrow related features against Python executable 'pypy' in 'pyspark-sql' module. PyArrow >= 0.8.0 is required; however, PyArrow was not found.
Will test Pandas related features against Python executable 'pypy' in 'pyspark-sql' module.
Starting test(pypy): pyspark.sql.tests
Starting test(pypy): pyspark.sql.catalog
Starting test(pypy): pyspark.sql.column
Starting test(pypy): pyspark.sql.conf
```
After some modification to produce other cases:
```bash
$ ./run-tests
```
```
...
Will test against the following Python executables: ['python2.7', 'pypy']
Will test the following Python modules: ['pyspark-core', 'pyspark-ml', 'pyspark-mllib', 'pyspark-sql', 'pyspark-streaming']
Will skip PyArrow related features against Python executable 'python2.7' in 'pyspark-sql' module. PyArrow >= 20.0.0 is required; however, PyArrow 0.8.0 was found.
Will skip Pandas related features against Python executable 'python2.7' in 'pyspark-sql' module. Pandas >= 20.0.0 is required; however, Pandas 0.20.2 was found.
Will skip PyArrow related features against Python executable 'pypy' in 'pyspark-sql' module. PyArrow >= 20.0.0 is required; however, PyArrow was not found.
Will skip Pandas related features against Python executable 'pypy' in 'pyspark-sql' module. Pandas >= 20.0.0 is required; however, Pandas 0.22.0 was found.
Starting test(pypy): pyspark.sql.tests
Starting test(pypy): pyspark.streaming.tests
Starting test(pypy): pyspark.tests
Starting test(python2.7): pyspark.mllib.tests
```
```bash
./run-tests-with-coverage
```
```
...
Will test against the following Python executables: ['python2.7', 'pypy']
Will test the following Python modules: ['pyspark-core', 'pyspark-ml', 'pyspark-mllib', 'pyspark-sql', 'pyspark-streaming']
Will test PyArrow related features against Python executable 'python2.7' in 'pyspark-sql' module.
Will test Pandas related features against Python executable 'python2.7' in 'pyspark-sql' module.
Coverage is not installed in Python executable 'pypy' but 'COVERAGE_PROCESS_START' environment variable is set, exiting.
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20473 from HyukjinKwon/SPARK-23300.
## What changes were proposed in this pull request?
When a task is still running, metrics like executorRunTime are not available. Then `schedulerDelay` will be almost the same as `duration` and that's confusing.
This PR makes `schedulerDelay` return 0 when the task is running which is the same behavior as 2.2.
## How was this patch tested?
`AppStatusUtilsSuite.schedulerDelay`
Author: Shixiong Zhu <zsxwing@gmail.com>
Closes#20493 from zsxwing/SPARK-23326.
## What changes were proposed in this pull request?
Spark SQL executions page throws the following error and the page crashes:
```
HTTP ERROR 500
Problem accessing /SQL/. Reason:
Server Error
Caused by:
java.lang.NullPointerException
at scala.collection.immutable.StringOps$.length$extension(StringOps.scala:47)
at scala.collection.immutable.StringOps.length(StringOps.scala:47)
at scala.collection.IndexedSeqOptimized$class.isEmpty(IndexedSeqOptimized.scala:27)
at scala.collection.immutable.StringOps.isEmpty(StringOps.scala:29)
at scala.collection.TraversableOnce$class.nonEmpty(TraversableOnce.scala:111)
at scala.collection.immutable.StringOps.nonEmpty(StringOps.scala:29)
at org.apache.spark.sql.execution.ui.ExecutionTable.descriptionCell(AllExecutionsPage.scala:182)
at org.apache.spark.sql.execution.ui.ExecutionTable.row(AllExecutionsPage.scala:155)
at org.apache.spark.sql.execution.ui.ExecutionTable$$anonfun$8.apply(AllExecutionsPage.scala:204)
at org.apache.spark.sql.execution.ui.ExecutionTable$$anonfun$8.apply(AllExecutionsPage.scala:204)
at org.apache.spark.ui.UIUtils$$anonfun$listingTable$2.apply(UIUtils.scala:339)
at org.apache.spark.ui.UIUtils$$anonfun$listingTable$2.apply(UIUtils.scala:339)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.AbstractTraversable.map(Traversable.scala:104)
at org.apache.spark.ui.UIUtils$.listingTable(UIUtils.scala:339)
at org.apache.spark.sql.execution.ui.ExecutionTable.toNodeSeq(AllExecutionsPage.scala:203)
at org.apache.spark.sql.execution.ui.AllExecutionsPage.render(AllExecutionsPage.scala:67)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.JettyUtils$$anon$3.doGet(JettyUtils.scala:90)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:687)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:790)
at org.eclipse.jetty.servlet.ServletHolder.handle(ServletHolder.java:848)
at org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:584)
at org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1180)
at org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:512)
at org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1112)
at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:141)
at org.eclipse.jetty.server.handler.ContextHandlerCollection.handle(ContextHandlerCollection.java:213)
at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:134)
at org.eclipse.jetty.server.Server.handle(Server.java:534)
at org.eclipse.jetty.server.HttpChannel.handle(HttpChannel.java:320)
at org.eclipse.jetty.server.HttpConnection.onFillable(HttpConnection.java:251)
at org.eclipse.jetty.io.AbstractConnection$ReadCallback.succeeded(AbstractConnection.java:283)
at org.eclipse.jetty.io.FillInterest.fillable(FillInterest.java:108)
at org.eclipse.jetty.io.SelectChannelEndPoint$2.run(SelectChannelEndPoint.java:93)
at org.eclipse.jetty.util.thread.strategy.ExecuteProduceConsume.executeProduceConsume(ExecuteProduceConsume.java:303)
at org.eclipse.jetty.util.thread.strategy.ExecuteProduceConsume.produceConsume(ExecuteProduceConsume.java:148)
at org.eclipse.jetty.util.thread.strategy.ExecuteProduceConsume.run(ExecuteProduceConsume.java:136)
at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:671)
at org.eclipse.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:589)
at java.lang.Thread.run(Thread.java:748)
```
One of the possible reason that this page fails may be the `SparkListenerSQLExecutionStart` event get dropped before processed, so the execution description and details don't get updated.
This was not a issue in 2.2 because it would ignore any job start event that arrives before the corresponding execution start event, which doesn't sound like a good decision.
We shall try to handle the null values in the front page side, that is, try to give a default value when `execution.details` or `execution.description` is null.
Another possible approach is not to spill the `LiveExecutionData` in `SQLAppStatusListener.update(exec: LiveExecutionData)` if `exec.details` is null. This is not ideal because this way you will not see the execution if `SparkListenerSQLExecutionStart` event is lost, because `AllExecutionsPage` only read executions from KVStore.
## How was this patch tested?
After the change, the page shows the following:
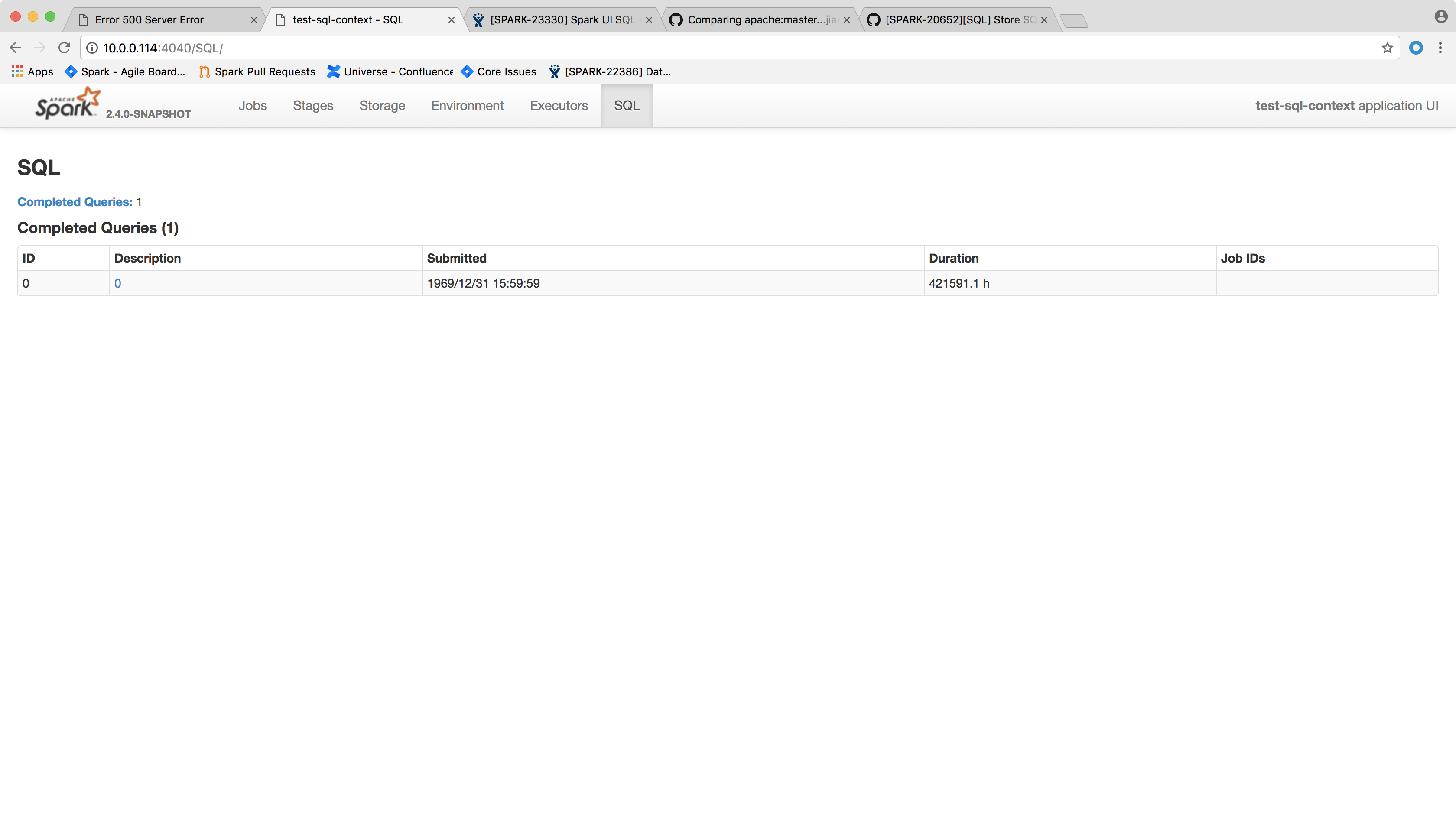
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#20502 from jiangxb1987/executionPage.
## What changes were proposed in this pull request?
Sort jobs/stages/tasks/queries with the completed timestamp before cleaning up them to make the behavior consistent with 2.2.
## How was this patch tested?
- Jenkins.
- Manually ran the following codes and checked the UI for jobs/stages/tasks/queries.
```
spark.ui.retainedJobs 10
spark.ui.retainedStages 10
spark.sql.ui.retainedExecutions 10
spark.ui.retainedTasks 10
```
```
new Thread() {
override def run() {
spark.range(1, 2).foreach { i =>
Thread.sleep(10000)
}
}
}.start()
Thread.sleep(5000)
for (_ <- 1 to 20) {
new Thread() {
override def run() {
spark.range(1, 2).foreach { i =>
}
}
}.start()
}
Thread.sleep(15000)
spark.range(1, 2).foreach { i =>
}
sc.makeRDD(1 to 100, 100).foreach { i =>
}
```
Author: Shixiong Zhu <zsxwing@gmail.com>
Closes#20481 from zsxwing/SPARK-23307.
## What changes were proposed in this pull request?
Fix decimalArithmeticOperations.sql test
## How was this patch tested?
N/A
Author: Yuming Wang <wgyumg@gmail.com>
Author: wangyum <wgyumg@gmail.com>
Author: Yuming Wang <yumwang@ebay.com>
Closes#20498 from wangyum/SPARK-22036.
## What changes were proposed in this pull request?
This PR proposes to add `columnSchema` in Python side too.
```python
>>> from pyspark.ml.image import ImageSchema
>>> ImageSchema.columnSchema.simpleString()
'struct<origin:string,height:int,width:int,nChannels:int,mode:int,data:binary>'
```
## How was this patch tested?
Manually tested and unittest was added in `python/pyspark/ml/tests.py`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20475 from HyukjinKwon/SPARK-23256.
From [PEP 257](https://www.python.org/dev/peps/pep-0257/):
> For consistency, always use """triple double quotes""" around docstrings. Use r"""raw triple double quotes""" if you use any backslashes in your docstrings. For Unicode docstrings, use u"""Unicode triple-quoted strings""".
For example, this is what help (kafka_wordcount) shows:
```
DESCRIPTION
Counts words in UTF8 encoded, '
' delimited text received from the network every second.
Usage: kafka_wordcount.py <zk> <topic>
To run this on your local machine, you need to setup Kafka and create a producer first, see
http://kafka.apache.org/documentation.html#quickstart
and then run the example
`$ bin/spark-submit --jars external/kafka-assembly/target/scala-*/spark-streaming-kafka-assembly-*.jar examples/src/main/python/streaming/kafka_wordcount.py localhost:2181 test`
```
This is what it shows, after the fix:
```
DESCRIPTION
Counts words in UTF8 encoded, '\n' delimited text received from the network every second.
Usage: kafka_wordcount.py <zk> <topic>
To run this on your local machine, you need to setup Kafka and create a producer first, see
http://kafka.apache.org/documentation.html#quickstart
and then run the example
`$ bin/spark-submit --jars \
external/kafka-assembly/target/scala-*/spark-streaming-kafka-assembly-*.jar \
examples/src/main/python/streaming/kafka_wordcount.py \
localhost:2181 test`
```
The thing worth noticing is no linebreak here in the help.
## What changes were proposed in this pull request?
Change triple double quotes to raw triple double quotes when there are occurrences of backslashes in docstrings.
## How was this patch tested?
Manually as this is a doc fix.
Author: Shashwat Anand <me@shashwat.me>
Closes#20497 from ashashwat/docstring-fixes.
## What changes were proposed in this pull request?
Like Parquet, all file-based data source handles `spark.sql.files.ignoreMissingFiles` correctly. We had better have a test coverage for feature parity and in order to prevent future accidental regression for all data sources.
## How was this patch tested?
Pass Jenkins with a newly added test case.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20479 from dongjoon-hyun/SPARK-23305.
## What changes were proposed in this pull request?
In the current test case for CombineTypedFilters, we lack the test of FilterFunction, so let's add it.
In addition, in TypedFilterOptimizationSuite's existing test cases, Let's extract a common LocalRelation.
## How was this patch tested?
add new test cases.
Author: caoxuewen <cao.xuewen@zte.com.cn>
Closes#20482 from heary-cao/TypedFilterOptimizationSuite.
## What changes were proposed in this pull request?
In the document of `ContinuousReader.setOffset`, we say this method is used to specify the start offset. We also have a `ContinuousReader.getStartOffset` to get the value back. I think it makes more sense to rename `ContinuousReader.setOffset` to `setStartOffset`.
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20486 from cloud-fan/rename.
## What changes were proposed in this pull request?
This patch adds a small example to the schema string definition of schema function. It isn't obvious how to use it, so an example would be useful.
## How was this patch tested?
N/A - doc only.
Author: Reynold Xin <rxin@databricks.com>
Closes#20491 from rxin/schema-doc.
## What changes were proposed in this pull request?
Further clarification of caveats in using stream-stream outer joins.
## How was this patch tested?
N/A
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20494 from tdas/SPARK-23064-2.
## What changes were proposed in this pull request?
When we specified a wrong profile to make a spark distribution, such as `-Phadoop1000`, we will get an odd package named like `spark-[WARNING] The requested profile "hadoop1000" could not be activated because it does not exist.-bin-hadoop-2.7.tgz`, which actually should be `"spark-$VERSION-bin-$NAME.tgz"`
## How was this patch tested?
### before
```
build/mvn help:evaluate -Dexpression=scala.binary.version -Phadoop1000 2>/dev/null | grep -v "INFO" | tail -n 1
[WARNING] The requested profile "hadoop1000" could not be activated because it does not exist.
```
```
build/mvn help:evaluate -Dexpression=project.version -Phadoop1000 2>/dev/null | grep -v "INFO" | tail -n 1
[WARNING] The requested profile "hadoop1000" could not be activated because it does not exist.
```
### after
```
build/mvn help:evaluate -Dexpression=project.version -Phadoop1000 2>/dev/null | grep -v "INFO" | grep -v "WARNING" | tail -n 1
2.4.0-SNAPSHOT
```
```
build/mvn help:evaluate -Dexpression=scala.binary.version -Dscala.binary.version=2.11.1 2>/dev/null | grep -v "INFO" | grep -v "WARNING" | tail -n 1
2.11.1
```
cloud-fan srowen
Author: Kent Yao <yaooqinn@hotmail.com>
Closes#20469 from yaooqinn/dist-minor.
## What changes were proposed in this pull request?
Shuffle Index temporay file is used for atomic creating shuffle index file, it is not needed when the index file already exists after another attempts of same task had it done.
## How was this patch tested?
exitsting ut
cc squito
Author: Kent Yao <yaooqinn@hotmail.com>
Closes#20422 from yaooqinn/SPARK-23253.
## What changes were proposed in this pull request?
https://issues.apache.org/jira/browse/SPARK-23309 reported a performance regression about cached table in Spark 2.3. While the investigating is still going on, this PR adds a conf to turn off the vectorized cache reader, to unblock the 2.3 release.
## How was this patch tested?
a new test
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20483 from cloud-fan/cache.
## What changes were proposed in this pull request?
This PR fixes a mistake in the `PushDownOperatorsToDataSource` rule, the column pruning logic is incorrect about `Project`.
## How was this patch tested?
a new test case for column pruning with arbitrary expressions, and improve the existing tests to make sure the `PushDownOperatorsToDataSource` really works.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20476 from cloud-fan/push-down.
## What changes were proposed in this pull request?
here is race condition in TaskMemoryManger, which may cause OOM.
The memory released may be taken by another task because there is a gap between releaseMemory and acquireMemory, e.g., UnifiedMemoryManager, causing the OOM. if the current is the only one that can perform spill. It can happen to BytesToBytesMap, as it only spill required bytes.
Loop on current consumer if it still has memory to release.
## How was this patch tested?
The race contention is hard to reproduce, but the current logic seems causing the issue.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Zhan Zhang <zhanzhang@fb.com>
Closes#20480 from zhzhan/oom.
First the bad news: there's an unfixable race in the launcher code.
(By unfixable I mean it would take a lot more effort than this change
to fix it.) The good news is that it should only affect super short
lived applications, such as the one run by the flaky test, so it's
possible to work around it in our test.
The fix also uncovered an issue with the recently added "closeAndWait()"
method; closing the connection would still possibly cause data loss,
so this change waits a while for the connection to finish itself, and
closes the socket if that times out. The existing connection timeout
is reused so that if desired it's possible to control how long to wait.
As part of that I also restored the old behavior that disconnect() would
force a disconnection from the child app; the "wait for data to arrive"
approach is only taken when disposing of the handle.
I tested this by inserting a bunch of sleeps in the test and the socket
handling code in the launcher library; with those I was able to reproduce
the error from the jenkins jobs. With the changes, even with all the
sleeps still in place, all tests pass.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20462 from vanzin/SPARK-23020.
## What changes were proposed in this pull request?
For some ColumnVector get APIs such as getDecimal, getBinary, getStruct, getArray, getInterval, getUTF8String, we should clearly document their behaviors when accessing null slot. They should return null in this case. Then we can remove null checks from the places using above APIs.
For the APIs of primitive values like getInt, getInts, etc., this also documents their behaviors when accessing null slots. Their returning values are undefined and can be anything.
## How was this patch tested?
Added tests into `ColumnarBatchSuite`.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20455 from viirya/SPARK-23272-followup.
## What changes were proposed in this pull request?
Include stacktrace in the diagnostics message upon abnormal unregister from RM
## How was this patch tested?
Tested with a failing job, and confirmed a stacktrace in the client output and YARN webUI.
Author: Gera Shegalov <gera@apache.org>
Closes#20470 from gerashegalov/gera/stacktrace-diagnostics.
## What changes were proposed in this pull request?
`DataSourceV2Relation` should extend `MultiInstanceRelation`, to take care of self-join.
## How was this patch tested?
a new test
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20466 from cloud-fan/dsv2-selfjoin.
## What changes were proposed in this pull request?
`--hiveconf` and `--hivevar` variables no longer work since Spark 2.0. The `spark-sql` client has fixed by [SPARK-15730](https://issues.apache.org/jira/browse/SPARK-15730) and [SPARK-18086](https://issues.apache.org/jira/browse/SPARK-18086). but `beeline`/[`Spark SQL HiveThriftServer2`](https://github.com/apache/spark/blob/v2.1.1/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/HiveThriftServer2.scala) is still broken. This pull request fix it.
This pull request works for both `JDBC client` and `beeline`.
## How was this patch tested?
unit tests for `JDBC client`
manual tests for `beeline`:
```
git checkout origin/pr/17886
dev/make-distribution.sh --mvn mvn --tgz -Phive -Phive-thriftserver -Phadoop-2.6 -DskipTests
tar -zxf spark-2.3.0-SNAPSHOT-bin-2.6.5.tgz && cd spark-2.3.0-SNAPSHOT-bin-2.6.5
sbin/start-thriftserver.sh
```
```
cat <<EOF > test.sql
select '\${a}', '\${b}';
EOF
beeline -u jdbc:hive2://localhost:10000 --hiveconf a=avalue --hivevar b=bvalue -f test.sql
```
Author: Yuming Wang <wgyumg@gmail.com>
Closes#17886 from wangyum/SPARK-13983-dev.
## What changes were proposed in this pull request?
`channel.write(buf)` may not write the whole buffer since the underlying channel is a FileChannel, we should retry until the whole buffer is written.
## How was this patch tested?
Jenkins
Author: Shixiong Zhu <zsxwing@gmail.com>
Closes#20461 from zsxwing/SPARK-23289.
## What changes were proposed in this pull request?
The current DataSourceWriter API makes it hard to implement `onTaskCommit(taskCommit: TaskCommitMessage)` in `FileCommitProtocol`.
In general, on receiving commit message, driver can start processing messages(e.g. persist messages into files) before all the messages are collected.
The proposal to add a new API:
`add(WriterCommitMessage message)`: Handles a commit message on receiving from a successful data writer.
This should make the whole API of DataSourceWriter compatible with `FileCommitProtocol`, and more flexible.
There was another radical attempt in #20386. This one should be more reasonable.
## How was this patch tested?
Unit test
Author: Wang Gengliang <ltnwgl@gmail.com>
Closes#20454 from gengliangwang/write_api.
## What changes were proposed in this pull request?
This is a followup pr of #20450.
We should've enabled `MutableColumnarRow.getMap()` as well.
## How was this patch tested?
Existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20471 from ueshin/issues/SPARK-23280/fup2.
## What changes were proposed in this pull request?
This is a follow-up of #20450 which broke lint-java checks.
This pr fixes the lint-java issues.
```
[ERROR] src/main/java/org/apache/spark/sql/vectorized/ColumnVector.java:[20,8] (imports) UnusedImports: Unused import - org.apache.spark.sql.catalyst.util.MapData.
[ERROR] src/main/java/org/apache/spark/sql/vectorized/ColumnarArray.java:[21,8] (imports) UnusedImports: Unused import - org.apache.spark.sql.catalyst.util.MapData.
[ERROR] src/main/java/org/apache/spark/sql/vectorized/ColumnarRow.java:[22,8] (imports) UnusedImports: Unused import - org.apache.spark.sql.catalyst.util.MapData.
```
## How was this patch tested?
Checked manually in my local environment.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20468 from ueshin/issues/SPARK-23280/fup1.
## What changes were proposed in this pull request?
Audit new APIs and docs in 2.3.0.
## How was this patch tested?
No test.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#20459 from yanboliang/SPARK-23107.
## What changes were proposed in this pull request?
This is a follow-up pr of #19872 which uses `assertRaisesRegex` but it doesn't exist in Python 2, so some tests fail when running tests in Python 2 environment.
Unfortunately, we missed it because currently Python 2 environment of the pr builder doesn't have proper versions of pandas or pyarrow, so the tests were skipped.
This pr modifies to use `assertRaisesRegexp` instead of `assertRaisesRegex`.
## How was this patch tested?
Tested manually in my local environment.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20467 from ueshin/issues/SPARK-22274/fup1.
## What changes were proposed in this pull request?
SpecifiedWindowFrame.defaultWindowFrame(hasOrderSpecification, acceptWindowFrame) was designed to handle the cases when some Window functions don't support setting a window frame (e.g. rank). However this param is never used.
We may inline the whole of this function to simplify the code.
## How was this patch tested?
Existing tests.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#20463 from jiangxb1987/defaultWindowFrame.
## What changes were proposed in this pull request?
This PR include the following changes:
- Make the capacity of `VectorizedParquetRecordReader` configurable;
- Make the capacity of `OrcColumnarBatchReader` configurable;
- Update the error message when required capacity in writable columnar vector cannot be fulfilled.
## How was this patch tested?
N/A
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#20361 from jiangxb1987/vectorCapacity.
{kind=link}