## What changes were proposed in this pull request?
Remove Scala 2.11 support in build files and docs, and in various parts of code that accommodated 2.11. See some targeted comments below.
## How was this patch tested?
Existing tests.
Closes#23098 from srowen/SPARK-26132.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
LEGACY_DRIVER_IDENTIFIER and its reference are removed.
corresponding references test are updated.
## How was this patch tested?
tested UT test cases
Closes#24026 from shivusondur/newjira2.
Authored-by: shivusondur <shivusondur@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Use the sbt maven plugin option`antlr4TreatWarningsAsErrors` to make sure the warnings are treated as errors while generating the parser. In the absence of it, we may inadvertently introduce problems while making grammar changes. Please refer to PR-23897 to know more about the context. We made a change in [pr-23925](https://github.com/apache/spark/pull/23925) which handled only the maven build.
In this PR, we handle the sbt build. I had submitted [PR-23](https://github.com/ihji/sbt-antlr4/pull/23) to enhance the sbt-antlr plugin to make is possible to pass the error on warning option.
## How was this patch tested?
Force an warning in the grammar file to check if the build fails. Then remove the warning to verify the build succeeds.
Closes#24060 from dilipbiswal/sbt_build_antlr.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
`Saveable` interface introduces `formatVersion` which is protected and it is used nowhere. So the PR proposes to remove it.
## How was this patch tested?
existing tests
Closes#22830 from mgaido91/SPARK-25838.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The java version here means versions of javac source, javac target, scalac target. They could be consolidated as a single version (currently 1.8)
| |javac|scalac |
|------|-----|---------|
|source|1.8 |2.12/2.11|
|target|1.8 |1.8 |
The current issues are as follows
* Maven build defines a single property (`java.version`) to specify java version while SBT build defines different properties for javac (`javacJVMVersion`) and scalac (`scalacJVMVersion`). SBT build should use a single property as Maven build does.
* Furthermore, it's better for SBT build to refer to `java.version` defined by Maven build. This is possible since we've already been using sbt-pom-reader.
## How was this patch tested?
Tested locally.
```
build/mvn clean compile
build/sbt clean compile
```
Closes#23724 from seancxmao/specify-java-version-once.
Authored-by: seancxmao <seancxmao@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently ANTLR v4 versions used by Maven and SBT are slightly different. Maven uses `4.7.1` while SBT uses `4.7`.
* Maven(`pom.xml`): `<antlr4.version>4.7.1</antlr4.version>`
* SBT(`project/SparkBuild.scala`): `antlr4Version in Antlr4 := "4.7"`
We should make Maven and SBT use a single version. Furthermore we'd better specify antlr4 version in one place to avoid mismatch between Maven and SBT in the future.
This PR lets SBT use antlr4 version specified in Maven POM file, rather than specify its own antlr4 version. This is in the same as how `hadoop.version` is specified in `project/SparkBuild.scala`
## How was this patch tested?
Test locally.
After run `sbt compile`, Java files generated by ANTLR are located at:
```
sql/catalyst/target/scala-2.12/src_managed/main/antlr4/org/apache/spark/sql/catalyst/parser/*.java
```
These Java files have a comment at the head. We can see now SBT uses ANTLR `4.7.1`.
```
// Generated from .../spark/sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 by ANTLR 4.7.1
```
Closes#23713 from seancxmao/antlr4-version-consistent.
Authored-by: seancxmao <seancxmao@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This patch proposes adding a new configuration on SHS: custom executor log URL pattern. This will enable end users to replace executor logs to other than RM provide, like external log service, which enables to serve executor logs when NodeManager becomes unavailable in case of YARN.
End users can build their own of custom executor log URLs with pre-defined patterns which would be vary on each resource manager. This patch adds some patterns to YARN resource manager. (For others, there's even no executor log url available so cannot define patterns as well.)
Please refer the doc change as well as added UTs in this patch to see how to set up the feature.
## How was this patch tested?
Added UT, as well as manual test with YARN cluster
Closes#23260 from HeartSaVioR/SPARK-26311.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This takes over #19621 to add multi-column support to StringIndexer:
1. Supports encoding multiple columns.
2. Previously, when specifying `frequencyDesc` or `frequencyAsc` as `stringOrderType` param in `StringIndexer`, in case of equal frequency, the order of strings is undefined. After this change, the strings with equal frequency are further sorted alphabetically.
## How was this patch tested?
Added tests.
Closes#20146 from viirya/SPARK-11215.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
There are ugly provided dependencies inside core for the following:
* Hive
* Kafka
In this PR I've extracted them out. This PR contains the following:
* Token providers are now loaded with service loader
* Hive token provider moved to hive project
* Kafka token provider extracted into a new project
## How was this patch tested?
Existing + newly added unit tests.
Additionally tested on cluster.
Closes#23499 from gaborgsomogyi/SPARK-26254.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This change exposes the `df` (document frequency) as a public val along with the number of documents (`m`) as part of the IDF model.
* The document frequency is returned as an `Array[Long]`
* If the minimum document frequency is set, this is considered in the df calculation. If the count is less than minDocFreq, the df is 0 for such terms
* numDocs is not very required. But it can be useful, if we plan to provide a provision in future for user to give their own idf function, instead of using a default (log((1+m)/(1+df))). In such cases, the user can provide a function taking input of `m` and `df` and returning the idf value
* Pyspark changes
## How was this patch tested?
The existing test case was edited to also check for the document frequency values.
I am not very good with python or pyspark. I have committed and run tests based on my understanding. Kindly let me know if I have missed anything
Reviewer request: mengxr zjffdu yinxusen
Closes#23549 from purijatin/master.
Authored-by: Jatin Puri <purijatin@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
I know that yarn provided all hadoop configurations. But I guess it may be fine that the historyserver unify all configuration in it. It will be convenient for us to debug some problems.
## How was this patch tested?
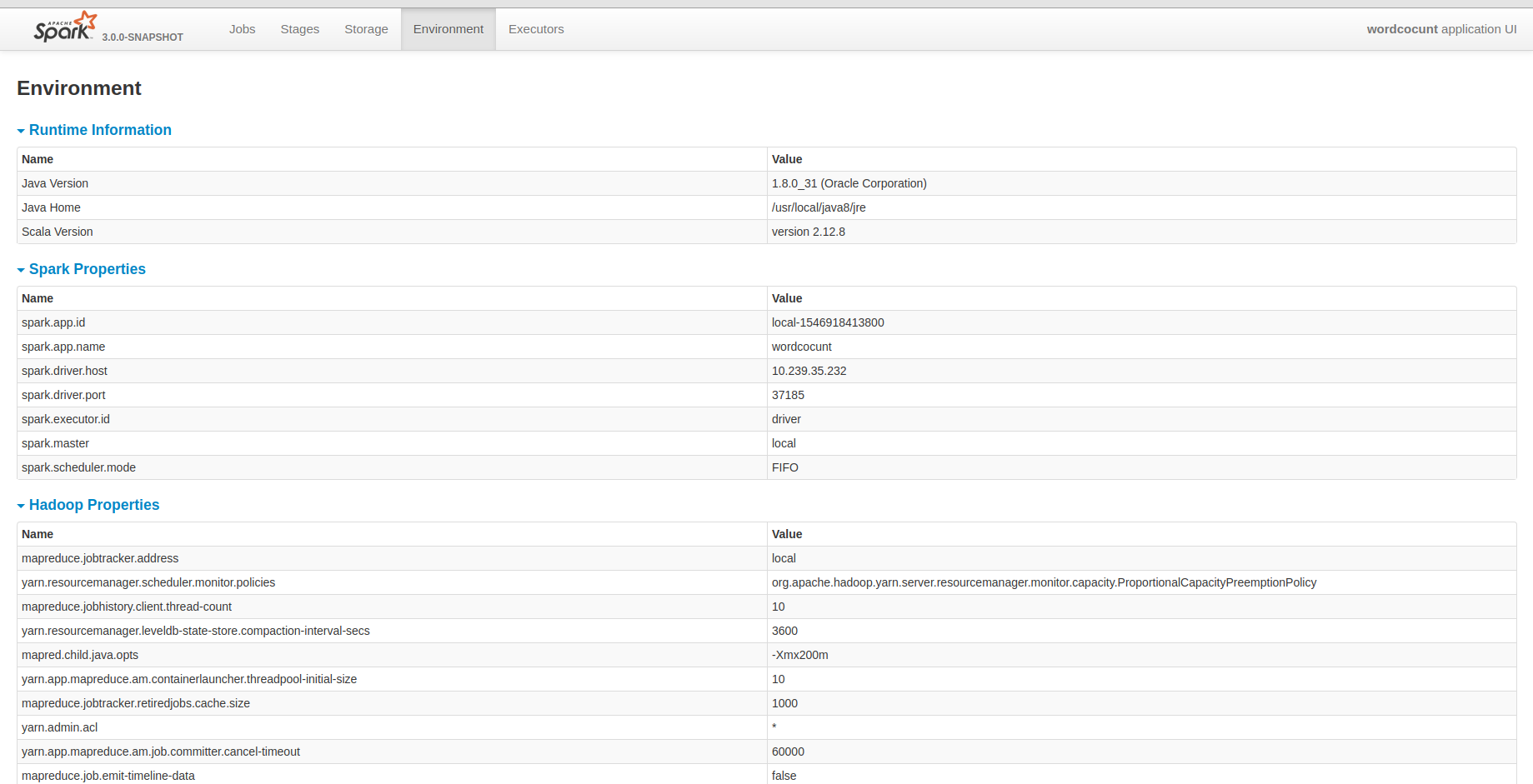
Closes#23486 from deshanxiao/spark-26457.
Lead-authored-by: xiaodeshan <xiaodeshan@xiaomi.com>
Co-authored-by: deshanxiao <42019462+deshanxiao@users.noreply.github.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Increase test memory to avoid OOM in TimSort-related tests.
## How was this patch tested?
Existing tests.
Closes#23425 from srowen/SPARK-26306.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The PR adds the `trainingCost` value to the `BisectingKMeansSummary`, in order to expose the information retrievable by running `computeCost` on the training dataset. This fills the gap with `KMeans` implementation.
## How was this patch tested?
improved UTs
Closes#22764 from mgaido91/SPARK-25765.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
A followup of https://github.com/apache/spark/pull/23178 , to keep binary compability by using abstract class.
## How was this patch tested?
Manual test. I created a simple app with Spark 2.4
```
object TryUDF {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("test").master("local[*]").getOrCreate()
import spark.implicits._
val f1 = udf((i: Int) => i + 1)
println(f1.deterministic)
spark.range(10).select(f1.asNonNullable().apply($"id")).show()
spark.stop()
}
}
```
When I run it with current master, it fails with
```
java.lang.IncompatibleClassChangeError: Found interface org.apache.spark.sql.expressions.UserDefinedFunction, but class was expected
```
When I run it with this PR, it works
Closes#23351 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Multiple SparkContexts are discouraged and it has been warning for last 4 years, see SPARK-4180. It could cause arbitrary and mysterious error cases, see SPARK-2243.
Honestly, I didn't even know Spark still allows it, which looks never officially supported, see SPARK-2243.
I believe It should be good timing now to remove this configuration.
## How was this patch tested?
Each doc was manually checked and manually tested:
```
$ ./bin/spark-shell --conf=spark.driver.allowMultipleContexts=true
...
scala> new SparkContext()
org.apache.spark.SparkException: Only one SparkContext should be running in this JVM (see SPARK-2243).The currently running SparkContext was created at:
org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:939)
...
org.apache.spark.SparkContext$.$anonfun$assertNoOtherContextIsRunning$2(SparkContext.scala:2435)
at scala.Option.foreach(Option.scala:274)
at org.apache.spark.SparkContext$.assertNoOtherContextIsRunning(SparkContext.scala:2432)
at org.apache.spark.SparkContext$.markPartiallyConstructed(SparkContext.scala:2509)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:80)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:112)
... 49 elided
```
Closes#23311 from HyukjinKwon/SPARK-26362.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The evaluators BinaryClassificationEvaluator, RegressionEvaluator, and MulticlassClassificationEvaluator and the corresponding metrics classes BinaryClassificationMetrics, RegressionMetrics and MulticlassMetrics should use sample weight data.
I've closed the PR: https://github.com/apache/spark/pull/16557
as recommended in favor of creating three pull requests, one for each of the evaluators (binary/regression/multiclass) to make it easier to review/update.
The updates to the regression metrics were based on (and updated with new changes based on comments):
https://issues.apache.org/jira/browse/SPARK-11520
("RegressionMetrics should support instance weights")
but the pull request was closed as the changes were never checked in.
## How was this patch tested?
I added tests to the metrics class.
Closes#17085 from imatiach-msft/ilmat/regression-evaluate.
Authored-by: Ilya Matiach <ilmat@microsoft.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
SBT 0.13.14 ~ 1.1.1 has a bug on accessing `java.util.Base64.getDecoder` with JDK9+. It's fixed at 1.1.2 and backported to [0.13.18 (released on Nov 28th)](https://github.com/sbt/sbt/releases/tag/v0.13.18). This PR aims to update SBT.
## How was this patch tested?
Pass the Jenkins with the building and existing tests.
Closes#23270 from dongjoon-hyun/SPARK-26317.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
1. Implement `SQLShuffleWriteMetricsReporter` on the SQL side as the customized `ShuffleWriteMetricsReporter`.
2. Add shuffle write metrics to `ShuffleExchangeExec`, and use these metrics to create corresponding `SQLShuffleWriteMetricsReporter` in shuffle dependency.
3. Rework on `ShuffleMapTask` to add new class named `ShuffleWriteProcessor` which control shuffle write process, we use sql shuffle write metrics by customizing a ShuffleWriteProcessor on SQL side.
## How was this patch tested?
Add UT in SQLMetricsSuite.
Manually test locally, update screen shot to document attached in JIRA.
Closes#23207 from xuanyuanking/SPARK-26193.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
Adds a new method to SparkAppHandle called getError which returns
the exception (if present) that caused the underlying Spark app to
fail.
New tests added to SparkLauncherSuite for the new method.
Closes#21849Closes#23221 from vanzin/SPARK-24243.
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
docker-image-tool.sh requires explicit argument to create the python
image now; do that from the sbt integration tests target too.
Closes#23172 from vanzin/SPARK-25957.followup.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
It's a bad idea to use case class as public API, as it has a very wide surface. For example, the `copy` method, its fields, the companion object, etc.
For a particular case, `UserDefinedFunction`. It has a private constructor, and I believe we only want users to access a few methods:`apply`, `nullable`, `asNonNullable`, etc.
However, all its fields, and `copy` method, and the companion object are public unexpectedly. As a result, we made many tricks to work around the binary compatibility issues.
This PR proposes to only make interfaces public, and hide implementations behind with a private class. Now `UserDefinedFunction` is a pure trait, and the concrete implementation is `SparkUserDefinedFunction`, which is private.
Changing class to interface is not binary compatible(but source compatible), so 3.0 is a good chance to do it.
This is the first PR to go with this direction. If it's accepted, I'll create a umbrella JIRA and fix all the public case classes.
## How was this patch tested?
existing tests.
Closes#23178 from cloud-fan/udf.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This is the first step of the data source v2 API refactor [proposal](https://docs.google.com/document/d/1uUmKCpWLdh9vHxP7AWJ9EgbwB_U6T3EJYNjhISGmiQg/edit?usp=sharing)
It adds the new API for batch read, without removing the old APIs, as they are still needed for streaming sources.
More concretely, it adds
1. `TableProvider`, works like an anonymous catalog
2. `Table`, represents a structured data set.
3. `ScanBuilder` and `Scan`, a logical represents of data source scan
4. `Batch`, a physical representation of data source batch scan.
## How was this patch tested?
existing tests
Closes#23086 from cloud-fan/refactor-batch.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
We have deprecated `OneHotEncoder` at Spark 2.3.0 and introduced `OneHotEncoderEstimator`. At 3.0.0, we remove deprecated `OneHotEncoder` and rename `OneHotEncoderEstimator` to `OneHotEncoder`.
TODO: According to ML migration guide, we need to keep `OneHotEncoderEstimator` as an alias after renaming. This is not done at this patch in order to facilitate review.
## How was this patch tested?
Existing tests.
Closes#23100 from viirya/remove_one_hot_encoder.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
The "build context" for a docker image - basically the whole contents of the
current directory where "docker" is invoked - can be huge in a dev build,
easily breaking a couple of gigs.
Doing that copy 3 times during the build of docker images severely slows
down the process.
This patch creates a smaller build context - basically mimicking what the
make-distribution.sh script does, so that when building the docker images,
only the necessary bits are in the current directory. For PySpark and R that
is optimized further, since those images are built based on the previously
built Spark main image.
In my current local clone, the dir size is about 2G, but with this script
the "context" sent to docker is about 250M for the main image, 1M for the
pyspark image and 8M for the R image. That speeds up the image builds
considerably.
I also snuck in a fix to the k8s integration test dependencies in the sbt
build, so that the examples are properly built (without having to do it
manually).
Closes#23019 from vanzin/SPARK-26025.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This is the write side counterpart to https://github.com/apache/spark/pull/23105
## How was this patch tested?
No behavior change expected, as it is a straightforward refactoring. Updated all existing test cases.
Closes#23106 from rxin/SPARK-26141.
Authored-by: Reynold Xin <rxin@databricks.com>
Signed-off-by: Reynold Xin <rxin@databricks.com>
## What changes were proposed in this pull request?
The PR removes the deprecated method `computeCost` of `KMeans`.
## How was this patch tested?
NA
Closes#22875 from mgaido91/SPARK-25867.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The setter methods are deprecated since 2.1 for the models of regression and classification using trees. The deprecation was stating that the method would have been removed in 3.0. Hence the PR removes the deprecated method.
## How was this patch tested?
NA
Closes#23093 from mgaido91/SPARK-26127.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Update many plugins we use to the latest version, especially MiMa, which entails excluding some new errors on old changes.
## How was this patch tested?
N/A
Closes#23087 from srowen/Plugins.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The build has a lot of deprecation warnings. Some are new in Scala 2.12 and Java 11. We've fixed some, but I wanted to take a pass at fixing lots of easy miscellaneous ones here.
They're too numerous and small to list here; see the pull request. Some highlights:
- `BeanInfo` is deprecated in 2.12, and BeanInfo classes are pretty ancient in Java. Instead, case classes can explicitly declare getters
- Eta expansion of zero-arg methods; foo() becomes () => foo() in many cases
- Floating-point Range is inexact and deprecated, like 0.0 to 100.0 by 1.0
- finalize() is finally deprecated (just needs to be suppressed)
- StageInfo.attempId was deprecated and easiest to remove here
I'm not now going to touch some chunks of deprecation warnings:
- Parquet deprecations
- Hive deprecations (particularly serde2 classes)
- Deprecations in generated code (mostly Thriftserver CLI)
- ProcessingTime deprecations (we may need to revive this class as internal)
- many MLlib deprecations because they concern methods that may be removed anyway
- a few Kinesis deprecations I couldn't figure out
- Mesos get/setRole, which I don't know well
- Kafka/ZK deprecations (e.g. poll())
- Kinesis
- a few other ones that will probably resolve by deleting a deprecated method
## How was this patch tested?
Existing tests, including manual testing with the 2.11 build and Java 11.
Closes#23065 from srowen/SPARK-26090.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Our `GBTClassifier` supports only `variance` impurity. But unfortunately, its `impurity` param by default contains the value `gini`: it is not even modifiable by the user and it differs from the actual impurity used, which is `variance`. This issue does not limit to a wrong value returned for it if the user queries by `getImpurity`, but it also affect the load of a saved model, as its `impurityStats` are created as `gini` (since this is the value stored for the model impurity) which leads to wrong `featureImportances` in model loaded from saved ones.
The PR changes the `impurity` param used to one which allows only the value `variance`.
## How was this patch tested?
modified UT
Closes#22986 from mgaido91/SPARK-25959.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR makes Spark's default Scala version as 2.12, and Scala 2.11 will be the alternative version. This implies that Scala 2.12 will be used by our CI builds including pull request builds.
We'll update the Jenkins to include a new compile-only jobs for Scala 2.11 to ensure the code can be still compiled with Scala 2.11.
## How was this patch tested?
existing tests
Closes#22967 from dbtsai/scala2.12.
Authored-by: DB Tsai <d_tsai@apple.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Since Spark 2.4.0 is already in maven repo, we can Bump previousSparkVersion in MimaBuild.scala to be 2.4.0.
Note that, seems we forgot to do it for branch 2.4, so this PR also updates MimaExcludes.scala
## How was this patch tested?
N/A
Closes#22977 from cloud-fan/mima.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Add `Locale.ROOT` to all internal calls to String `toLowerCase`, `toUpperCase`
## How was this patch tested?
existing tests
Closes#22975 from zhengruifeng/Tokenizer_Locale.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
- Remove some AccumulableInfo .apply() methods
- Remove non-label-specific multiclass precision/recall/fScore in favor of accuracy
- Remove toDegrees/toRadians in favor of degrees/radians (SparkR: only deprecated)
- Remove approxCountDistinct in favor of approx_count_distinct (SparkR: only deprecated)
- Remove unused Python StorageLevel constants
- Remove Dataset unionAll in favor of union
- Remove unused multiclass option in libsvm parsing
- Remove references to deprecated spark configs like spark.yarn.am.port
- Remove TaskContext.isRunningLocally
- Remove ShuffleMetrics.shuffle* methods
- Remove BaseReadWrite.context in favor of session
- Remove Column.!== in favor of =!=
- Remove Dataset.explode
- Remove Dataset.registerTempTable
- Remove SQLContext.getOrCreate, setActive, clearActive, constructors
Not touched yet
- everything else in MLLib
- HiveContext
- Anything deprecated more recently than 2.0.0, generally
## How was this patch tested?
Existing tests
Closes#22921 from srowen/SPARK-25908.
Lead-authored-by: Sean Owen <sean.owen@databricks.com>
Co-authored-by: hyukjinkwon <gurwls223@apache.org>
Co-authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
The integration tests can now be run in sbt if the right profile
is enabled, using the "test" task under the respective project.
This avoids having to fall back to maven to run the tests, which
invalidates all your compiled stuff when you go back to sbt, making
development way slower than it should.
There's also a task to run the tests directly without refreshing
the docker images, which is helpful if you just made a change to
the submission code which should not affect the code in the images.
The sbt tasks currently are not very customizable; there's some
very minor things you can set in the sbt shell itself, but otherwise
it's hardcoded to run on minikube.
I also had to make some slight adjustments to the IT code itself,
mostly to remove assumptions about the existing harness.
Tested on sbt and maven.
Closes#22909 from vanzin/SPARK-25897.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Remove JavaSparkContextVarargsWorkaround
## How was this patch tested?
Existing tests.
Closes#22729 from srowen/SPARK-25737.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove deprecated accumulator v1
## How was this patch tested?
Existing tests.
Closes#22730 from srowen/SPARK-16775.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The SQL execution listener framework was created from scratch(see https://github.com/apache/spark/pull/9078). It didn't leverage what we already have in the spark listener framework, and one major problem is, the listener runs on the spark execution thread, which means a bad listener can block spark's query processing.
This PR re-implements the SQL execution listener framework. Now `ExecutionListenerManager` is just a normal spark listener, which watches the `SparkListenerSQLExecutionEnd` events and post events to the
user-provided SQL execution listeners.
## How was this patch tested?
existing tests.
Closes#22674 from cloud-fan/listener.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Remove Kafka 0.8 integration
## How was this patch tested?
Existing tests, build scripts
Closes#22703 from srowen/SPARK-25705.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Fix old oversight in API: Java `flatMapValues` needs a `FlatMapFunction`
## How was this patch tested?
Existing tests.
Closes#22690 from srowen/SPARK-19287.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Removes all vestiges of Flume in the build, for Spark 3.
I don't think this needs Jenkins config changes.
## How was this patch tested?
Existing tests.
Closes#22692 from srowen/SPARK-25598.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove SnappyOutputStreamWrapper and other workaround now that new Snappy fixes these.
See also https://github.com/apache/spark/pull/21176 and comments it links to.
## How was this patch tested?
Existing tests
Closes#22691 from srowen/SPARK-24109.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This is the same as #22492 but for master branch. Revert SPARK-14681 to avoid API breaking changes.
cc: WeichenXu123
## How was this patch tested?
Existing unit tests.
Closes#22618 from mengxr/SPARK-25321.master.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This patch is to bump the master branch version to 3.0.0-SNAPSHOT.
## How was this patch tested?
N/A
Closes#22606 from gatorsmile/bump3.0.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In the dev list, we can still discuss whether the next version is 2.5.0 or 3.0.0. Let us first bump the master branch version to `2.5.0-SNAPSHOT`.
## How was this patch tested?
N/A
Closes#22426 from gatorsmile/bumpVersionMaster.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
Add new executor level memory metrics (JVM used memory, on/off heap execution memory, on/off heap storage memory, on/off heap unified memory, direct memory, and mapped memory), and expose via the executors REST API. This information will help provide insight into how executor and driver JVM memory is used, and for the different memory regions. It can be used to help determine good values for spark.executor.memory, spark.driver.memory, spark.memory.fraction, and spark.memory.storageFraction.
## What changes were proposed in this pull request?
An ExecutorMetrics class is added, with jvmUsedHeapMemory, jvmUsedNonHeapMemory, onHeapExecutionMemory, offHeapExecutionMemory, onHeapStorageMemory, and offHeapStorageMemory, onHeapUnifiedMemory, offHeapUnifiedMemory, directMemory and mappedMemory. The new ExecutorMetrics is sent by executors to the driver as part of the Heartbeat. A heartbeat is added for the driver as well, to collect these metrics for the driver.
The EventLoggingListener store information about the peak values for each metric, per active stage and executor. When a StageCompleted event is seen, a StageExecutorsMetrics event will be logged for each executor, with peak values for the stage.
The AppStatusListener records the peak values for each memory metric.
The new memory metrics are added to the executors REST API.
## How was this patch tested?
New unit tests have been added. This was also tested on our cluster.
Author: Edwina Lu <edlu@linkedin.com>
Author: Imran Rashid <irashid@cloudera.com>
Author: edwinalu <edwina.lu@gmail.com>
Closes#21221 from edwinalu/SPARK-23429.2.
## What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/22259 .
Scala case class has a wide surface: apply, unapply, accessors, copy, etc.
In https://github.com/apache/spark/pull/22259 , we change the type of `UserDefinedFunction.inputTypes` from `Option[Seq[DataType]]` to `Option[Seq[Schema]]`. This breaks backward compatibility.
This PR changes the type back, and use a `var` to keep the new nullable info.
## How was this patch tested?
N/A
Closes#22319 from cloud-fan/revert.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
I made one pass over barrier APIs added to Spark 2.4 and updates some scopes and docs. I will update Python docs once Scala doc was reviewed.
One major issue is that `BarrierTaskContext` implements `TaskContextImpl` that exposes some public methods. And internally there were several direct references to `TaskContextImpl` methods instead of `TaskContext`. This PR moved some methods from `TaskContextImpl` to `TaskContext`, remaining package private, and used delegate methods to avoid inheriting `TaskContextImp` and exposing unnecessary APIs.
TODOs:
- [x] scala doc
- [x] python doc (#22261 ).
Closes#22240 from mengxr/SPARK-25248.
Authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
Improve build for Scala 2.12. Current build for sbt fails on the subproject `repl`:
```
[info] Compiling 6 Scala sources to /Users/rendong/wdi/spark/repl/target/scala-2.12/classes...
[error] /Users/rendong/wdi/spark/repl/scala-2.11/src/main/scala/org/apache/spark/repl/SparkILoopInterpreter.scala:80: overriding lazy value importableSymbolsWithRenames in class ImportHandler of type List[(this.intp.global.Symbol, this.intp.global.Name)];
[error] lazy value importableSymbolsWithRenames needs `override' modifier
[error] lazy val importableSymbolsWithRenames: List[(Symbol, Name)] = {
[error] ^
[warn] /Users/rendong/wdi/spark/repl/src/main/scala/org/apache/spark/repl/SparkILoop.scala:53: variable addedClasspath in class ILoop is deprecated (since 2.11.0): use reset, replay or require to update class path
[warn] if (addedClasspath != "") {
[warn] ^
[warn] /Users/rendong/wdi/spark/repl/src/main/scala/org/apache/spark/repl/SparkILoop.scala:54: variable addedClasspath in class ILoop is deprecated (since 2.11.0): use reset, replay or require to update class path
[warn] settings.classpath append addedClasspath
[warn] ^
[warn] two warnings found
[error] one error found
[error] (repl/compile:compileIncremental) Compilation failed
[error] Total time: 93 s, completed 2018-9-3 10:07:26
```
## How was this patch tested?
```
./dev/change-scala-version.sh 2.12
## For Maven
./build/mvn -Pscala-2.12 [mvn commands]
## For SBT
sbt -Dscala.version=2.12.6
```
Closes#22310 from sadhen/SPARK-25298.
Authored-by: Darcy Shen <sadhen@zoho.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The PR adds the lift measure to Association rules.
## How was this patch tested?
existing and modified UTs
Closes#22236 from mgaido91/SPARK-10697.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Alternative take on https://github.com/apache/spark/pull/22063 that does not introduce udfInternal.
Resolve issue with inferring func types in 2.12 by instead using info captured when UDF is registered -- capturing which types are nullable (i.e. not primitive)
## How was this patch tested?
Existing tests.
Closes#22259 from srowen/SPARK-25044.2.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
When replicating large cached RDD blocks, it can be helpful to replicate
them as a stream, to avoid using large amounts of memory during the
transfer. This also allows blocks larger than 2GB to be replicated.
Added unit tests in DistributedSuite. Also ran tests on a cluster for
blocks > 2gb.
Closes#21451 from squito/clean_replication.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
When starting spark-shell from Mac terminal (MacOS High Sirra Version 10.13.6), Getting exception
[ERROR] Failed to construct terminal; falling back to unsupported
java.lang.NumberFormatException: For input string: "0x100"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Integer.parseInt(Integer.java:580)
at java.lang.Integer.valueOf(Integer.java:766)
at jline.internal.InfoCmp.parseInfoCmp(InfoCmp.java:59)
at jline.UnixTerminal.parseInfoCmp(UnixTerminal.java:242)
at jline.UnixTerminal.<init>(UnixTerminal.java:65)
at jline.UnixTerminal.<init>(UnixTerminal.java:50)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at java.lang.Class.newInstance(Class.java:442)
at jline.TerminalFactory.getFlavor(TerminalFactory.java:211)
This issue is due a jline defect : https://github.com/jline/jline2/issues/281, which is fixed in Jline 2.14.4, bumping up JLine version in spark to version >= Jline 2.14.4 will fix the issue
## How was this patch tested?
No new UT/automation test added, after upgrade to latest Jline version 2.14.6, manually tested spark shell features
Closes#22130 from vinodkc/br_UpgradeJLineVersion.
Authored-by: Vinod KC <vinod.kc.in@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In MultilayerPerceptronClassifier, we use RDD operation to encode labels for now. I think we should use ML's OneHotEncoderEstimator/Model to do the encoding.
## How was this patch tested?
Existing tests.
Closes#20232 from viirya/SPARK-23042.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
## What changes were proposed in this pull request?
Added the number of iterations in `ClusteringSummary`. This is an helpful information in evaluating how to eventually modify the parameters in order to get a better model.
## How was this patch tested?
modified existing UTs
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20701 from mgaido91/SPARK-23528.
## What changes were proposed in this pull request?
Apache Avro (https://avro.apache.org) is a popular data serialization format. It is widely used in the Spark and Hadoop ecosystem, especially for Kafka-based data pipelines. Using the external package https://github.com/databricks/spark-avro, Spark SQL can read and write the avro data. Making spark-Avro built-in can provide a better experience for first-time users of Spark SQL and structured streaming. We expect the built-in Avro data source can further improve the adoption of structured streaming.
The proposal is to inline code from spark-avro package (https://github.com/databricks/spark-avro). The target release is Spark 2.4.
[Built-in AVRO Data Source In Spark 2.4.pdf](https://github.com/apache/spark/files/2181511/Built-in.AVRO.Data.Source.In.Spark.2.4.pdf)
## How was this patch tested?
Unit test
Author: Gengliang Wang <gengliang.wang@databricks.com>
Closes#21742 from gengliangwang/export_avro.
## What changes were proposed in this pull request?
During SPARK-24418 (Upgrade Scala to 2.11.12 and 2.12.6), we upgrade `jline` version together. So, `mvn` works correctly. However, `sbt` brings old jline library and is hitting `NoSuchMethodError` in `master` branch, see https://github.com/apache/spark/pull/21495#issuecomment-401560826. This overrides jline version in SBT to make sbt build work.
## How was this patch tested?
Manually test.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#21692 from viirya/SPARK-24715.
These changes allow an RPCHandler to receive an upload as a stream of
data, without having to buffer the entire message in the FrameDecoder.
The primary use case is for replicating large blocks. By itself, this change is adding dead-code that is not being used -- it is a step towards SPARK-24296.
Added unit tests for handling streaming data, including successfully sending data, and failures in reading the stream with concurrent requests.
Summary of changes:
* Introduce a new UploadStream RPC which is sent to push a large payload as a stream (in contrast, the pre-existing StreamRequest and StreamResponse RPCs are used for pull-based streaming).
* Generalize RpcHandler.receive() to support requests which contain streams.
* Generalize StreamInterceptor to handle both request and response messages (previously it only handled responses).
* Introduce StdChannelListener to abstract away common logging logic in ChannelFuture listeners.
Author: Imran Rashid <irashid@cloudera.com>
Closes#21346 from squito/upload_stream.
## What changes were proposed in this pull request?
Fix java checkstyle failure of kubernetes-integration-tests
## How was this patch tested?
Checked manually on my local environment.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#21545 from jiangxb1987/k8s-checkstyle.
Apply the suggestion on the bug to fix source links. Tested with
the 2.3.1 release docs.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#21521 from vanzin/SPARK-23732.
## What changes were proposed in this pull request?
Upgrade SBT to 0.13.17 with Scala 2.10.7 for JDK9+
## How was this patch tested?
Existing tests
Author: DB Tsai <d_tsai@apple.com>
Closes#21458 from dbtsai/sbt.
## What changes were proposed in this pull request?
This PR proposes to check Java lint via SBT for Jenkins. It uses the SBT wrapper for checkstyle.
I manually tested. If we build the codes once, running this script takes 2 mins at maximum in my local:
Test codes:
```
Checkstyle failed at following occurrences:
[error] Checkstyle error found in /.../spark/core/src/test/java/test/org/apache/spark/JavaAPISuite.java:82: Line is longer than 100 characters (found 103).
[error] 1 issue(s) found in Checkstyle report: /.../spark/core/target/checkstyle-test-report.xml
[error] Checkstyle error found in /.../spark/sql/hive/src/test/java/org/apache/spark/sql/hive/JavaDataFrameSuite.java:84: Line is longer than 100 characters (found 115).
[error] 1 issue(s) found in Checkstyle report: /.../spark/sql/hive/target/checkstyle-test-report.xml
...
```
Main codes:
```
Checkstyle failed at following occurrences:
[error] Checkstyle error found in /.../spark/sql/core/src/main/java/org/apache/spark/sql/sources/v2/reader/InputPartition.java:39: Line is longer than 100 characters (found 104).
[error] Checkstyle error found in /.../spark/sql/core/src/main/java/org/apache/spark/sql/sources/v2/reader/InputPartitionReader.java:26: Line is longer than 100 characters (found 110).
[error] Checkstyle error found in /.../spark/sql/core/src/main/java/org/apache/spark/sql/sources/v2/reader/InputPartitionReader.java:30: Line is longer than 100 characters (found 104).
...
```
## How was this patch tested?
Manually tested. Jenkins build should test this.
Author: hyukjinkwon <gurwls223@apache.org>
Closes#21399 from HyukjinKwon/SPARK-22269.
## What changes were proposed in this pull request?
The ultimate goal is for listeners to onTaskEnd to receive metrics when a task is killed intentionally, since the data is currently just thrown away. This is already done for ExceptionFailure, so this just copies the same approach.
## How was this patch tested?
Updated existing tests.
This is a rework of https://github.com/apache/spark/pull/17422, all credits should go to noodle-fb
Author: Xianjin YE <advancedxy@gmail.com>
Author: Charles Lewis <noodle@fb.com>
Closes#21165 from advancedxy/SPARK-20087.
## What changes were proposed in this pull request?
Add fit with validation set to spark.ml GBT
## How was this patch tested?
Will add later.
Author: WeichenXu <weichen.xu@databricks.com>
Closes#21129 from WeichenXu123/gbt_fit_validation.
## What changes were proposed in this pull request?
We save ML's user-supplied params and default params as one entity in metadata. During loading the saved models, we set all the loaded params into created ML model instances as user-supplied params.
It causes some problems, e.g., if we strictly disallow some params to be set at the same time, a default param can fail the param check because it is treated as user-supplied param after loading.
The loaded default params should not be set as user-supplied params. We should save ML default params separately in metadata.
For backward compatibility, when loading metadata, if it is a metadata file from previous Spark, we shouldn't raise error if we can't find the default param field.
## How was this patch tested?
Pass existing tests and added tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20633 from viirya/save-ml-default-params.
The current in-process launcher implementation just calls the SparkSubmit
object, which, in case of errors, will more often than not exit the JVM.
This is not desirable since this launcher is meant to be used inside other
applications, and that would kill the application.
The change turns SparkSubmit into a class, and abstracts aways some of
the functionality used to print error messages and abort the submission
process. The default implementation uses the logging system for messages,
and throws exceptions for errors. As part of that I also moved some code
that doesn't really belong in SparkSubmit to a better location.
The command line invocation of spark-submit now uses a special implementation
of the SparkSubmit class that overrides those behaviors to do what is expected
from the command line version (print to the terminal, exit the JVM, etc).
A lot of the changes are to replace calls to methods such as "printErrorAndExit"
with the new API.
As part of adding tests for this, I had to fix some small things in the
launcher option parser so that things like "--version" can work when
used in the launcher library.
There is still code that prints directly to the terminal, like all the
Ivy-related code in SparkSubmitUtils, and other areas where some re-factoring
would help, like the CommandLineUtils class, but I chose to leave those
alone to keep this change more focused.
Aside from existing and added unit tests, I ran command line tools with
a bunch of different arguments to make sure messages and errors behave
like before.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20925 from vanzin/SPARK-22941.
## What changes were proposed in this pull request?
The PR adds the option to specify a distance measure in BisectingKMeans. Moreover, it introduces the ability to use the cosine distance measure in it.
## How was this patch tested?
added UTs + existing UTs
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20600 from mgaido91/SPARK-23412.
## What changes were proposed in this pull request?
In this PR StorageStatus is made to private and simplified a bit moreover SparkContext.getExecutorStorageStatus method is removed. The reason of keeping StorageStatus is that it is usage from SparkContext.getRDDStorageInfo.
Instead of the method SparkContext.getExecutorStorageStatus executor infos are extended with additional memory metrics such as usedOnHeapStorageMemory, usedOffHeapStorageMemory, totalOnHeapStorageMemory, totalOffHeapStorageMemory.
## How was this patch tested?
By running existing unit tests.
Author: “attilapiros” <piros.attila.zsolt@gmail.com>
Author: Attila Zsolt Piros <2017933+attilapiros@users.noreply.github.com>
Closes#20546 from attilapiros/SPARK-20659.
## What changes were proposed in this pull request?
Bump previousSparkVersion in MimaBuild.scala to be 2.2.0 and add the missing exclusions to `v23excludes` in `MimaExcludes`. No item can be un-excluded in `v23excludes`.
## How was this patch tested?
The existing tests.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20264 from gatorsmile/bump22.
## What changes were proposed in this pull request?
This patch bumps the master branch version to `2.4.0-SNAPSHOT`.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20222 from gatorsmile/bump24.
## What changes were proposed in this pull request?
stageAttemptId added in TaskContext and corresponding construction modification
## How was this patch tested?
Added a new test in TaskContextSuite, two cases are tested:
1. Normal case without failure
2. Exception case with resubmitted stages
Link to [SPARK-22897](https://issues.apache.org/jira/browse/SPARK-22897)
Author: Xianjin YE <advancedxy@gmail.com>
Closes#20082 from advancedxy/SPARK-22897.
## What changes were proposed in this pull request?
Basic continuous execution, supporting map/flatMap/filter, with commits and advancement through RPC.
## How was this patch tested?
new unit-ish tests (exercising execution end to end)
Author: Jose Torres <jose@databricks.com>
Closes#19984 from jose-torres/continuous-impl.
Prevents Scala 2.12 scaladoc from blowing up attempting to parse java comments.
## What changes were proposed in this pull request?
Adds -no-java-comments to docs/scalacOptions under Scala 2.12. Also
moves scaladoc configs out of the TestSettings and into the standard sharedSettings
section in SparkBuild.scala.
## How was this patch tested?
SBT_OPTS=-Dscala-2.12 sbt
++2.12.4
tags/publishLocal
Author: Erik LaBianca <erik.labianca@gmail.com>
Closes#20042 from easel/scaladoc-212.
## What changes were proposed in this pull request?
Moves the -Xlint:unchecked flag in the sbt build configuration from Compile to (Compile, compile) scope, allowing publish and publishLocal commands to work.
## How was this patch tested?
Successfully published the spark-launcher subproject from within sbt successfully, where it fails without this patch.
Author: Erik LaBianca <erik.labianca@gmail.com>
Closes#20040 from easel/javadoc-xlint.
## What changes were proposed in this pull request?
MLlib ```LinearRegression``` supports _huber_ loss addition to _leastSquares_ loss. The huber loss objective function is:

Refer Eq.(6) and Eq.(8) in [A robust hybrid of lasso and ridge regression](http://statweb.stanford.edu/~owen/reports/hhu.pdf). This objective is jointly convex as a function of (w, σ) ∈ R × (0,∞), we can use L-BFGS-B to solve it.
The current implementation is a straight forward porting for Python scikit-learn [```HuberRegressor```](http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.HuberRegressor.html). There are some differences:
* We use mean loss (```lossSum/weightSum```), but sklearn uses total loss (```lossSum```).
* We multiply the loss function and L2 regularization by 1/2. It does not affect the result if we multiply the whole formula by a factor, we just keep consistent with _leastSquares_ loss.
So if fitting w/o regularization, MLlib and sklearn produce the same output. If fitting w/ regularization, MLlib should set ```regParam``` divide by the number of instances to match the output of sklearn.
## How was this patch tested?
Unit tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#19020 from yanboliang/spark-3181.
The main goal of this change is to allow multiple cluster-mode
submissions from the same JVM, without having them end up with
mixed configuration. That is done by extending the SparkApplication
trait, and doing so was reasonably trivial for standalone and
mesos modes.
For YARN mode, there was a complication. YARN used a "SPARK_YARN_MODE"
system property to control behavior indirectly in a whole bunch of
places, mainly in the SparkHadoopUtil / YarnSparkHadoopUtil classes.
Most of the changes here are removing that.
Since we removed support for Hadoop 1.x, some methods that lived in
YarnSparkHadoopUtil can now live in SparkHadoopUtil. The remaining
methods don't need to be part of the class, and can be called directly
from the YarnSparkHadoopUtil object, so now there's a single
implementation of SparkHadoopUtil.
There were two places in the code that relied on SPARK_YARN_MODE to
make decisions about YARN-specific functionality, and now explicitly check
the master from the configuration for that instead:
* fetching the external shuffle service port, which can come from the YARN
configuration.
* propagation of the authentication secret using Hadoop credentials. This also
was cleaned up a little to not need so many methods in `SparkHadoopUtil`.
With those out of the way, actually changing the YARN client
to extend SparkApplication was easy.
Tested with existing unit tests, and also by running YARN apps
with auth and kerberos both on and off in a real cluster.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#19631 from vanzin/SPARK-22372.
The only remaining use of this class was the SparkStatusTracker, which
was modified to use the new status store. The test code to wait for
executors was moved to TestUtils and now uses the SparkStatusTracker API.
Indirectly, ConsoleProgressBar also uses this data. Because it has
some lower latency requirements, a shortcut to efficiently get the
active stages from the active listener was added to the AppStateStore.
Now that all UI code goes through the status store to get its data,
the FsHistoryProvider can be cleaned up to only replay event logs
when needed - that is, when there is no pre-existing disk store for
the application.
As part of this change I also modified the streaming UI to read the needed
data from the store, which was missed in the previous patch that made
JobProgressListener redundant.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#19750 from vanzin/SPARK-20650.
## What changes were proposed in this pull request?
This is a stripped down version of the `KubernetesClusterSchedulerBackend` for Spark with the following components:
- Static Allocation of Executors
- Executor Pod Factory
- Executor Recovery Semantics
It's step 1 from the step-wise plan documented [here](https://github.com/apache-spark-on-k8s/spark/issues/441#issuecomment-330802935).
This addition is covered by the [SPIP vote](http://apache-spark-developers-list.1001551.n3.nabble.com/SPIP-Spark-on-Kubernetes-td22147.html) which passed on Aug 31 .
## How was this patch tested?
- The patch contains unit tests which are passing.
- Manual testing: `./build/mvn -Pkubernetes clean package` succeeded.
- It is a **subset** of the entire changelist hosted in http://github.com/apache-spark-on-k8s/spark which is in active use in several organizations.
- There is integration testing enabled in the fork currently [hosted by PepperData](spark-k8s-jenkins.pepperdata.org:8080) which is being moved over to RiseLAB CI.
- Detailed documentation on trying out the patch in its entirety is in: https://apache-spark-on-k8s.github.io/userdocs/running-on-kubernetes.html
cc rxin felixcheung mateiz (shepherd)
k8s-big-data SIG members & contributors: mccheah ash211 ssuchter varunkatta kimoonkim erikerlandson liyinan926 tnachen ifilonenko
Author: Yinan Li <liyinan926@gmail.com>
Author: foxish <ramanathana@google.com>
Author: mcheah <mcheah@palantir.com>
Closes#19468 from foxish/spark-kubernetes-3.
## What changes were proposed in this pull request?
Set `-ea` and `-Xss4m` consistently for tests, to fix in particular:
```
OrderingSuite:
...
- GenerateOrdering with ShortType
*** RUN ABORTED ***
java.lang.StackOverflowError:
at org.codehaus.janino.CodeContext.flowAnalysis(CodeContext.java:370)
at org.codehaus.janino.CodeContext.flowAnalysis(CodeContext.java:541)
at org.codehaus.janino.CodeContext.flowAnalysis(CodeContext.java:541)
at org.codehaus.janino.CodeContext.flowAnalysis(CodeContext.java:541)
at org.codehaus.janino.CodeContext.flowAnalysis(CodeContext.java:541)
at org.codehaus.janino.CodeContext.flowAnalysis(CodeContext.java:541)
at org.codehaus.janino.CodeContext.flowAnalysis(CodeContext.java:541)
at org.codehaus.janino.CodeContext.flowAnalysis(CodeContext.java:541)
...
```
## How was this patch tested?
Existing tests. Manually verified it resolves the StackOverflowError this intends to resolve.
Author: Sean Owen <sowen@cloudera.com>
Closes#19820 from srowen/SPARK-22607.
## What changes were proposed in this pull request?
We add a parameter whether to collect the full model list when CrossValidator/TrainValidationSplit training (Default is NOT), avoid the change cause OOM)
- Add a method in CrossValidatorModel/TrainValidationSplitModel, allow user to get the model list
- CrossValidatorModelWriter add a “option”, allow user to control whether to persist the model list to disk (will persist by default).
- Note: when persisting the model list, use indices as the sub-model path
## How was this patch tested?
Test cases added.
Author: WeichenXu <weichen.xu@databricks.com>
Closes#19208 from WeichenXu123/expose-model-list.
This change is a little larger because there's a whole lot of logic
behind these pages, all really tied to internal types and listeners,
and some of that logic had to be implemented in the new listener and
the needed data exposed through the API types.
- Added missing StageData and ExecutorStageSummary fields which are
used by the UI. Some json golden files needed to be updated to account
for new fields.
- Save RDD graph data in the store. This tries to re-use existing types as
much as possible, so that the code doesn't need to be re-written. So it's
probably not very optimal.
- Some old classes (e.g. JobProgressListener) still remain, since they're used
in other parts of the code; they're not used by the UI anymore, though, and
will be cleaned up in a separate change.
- Save information about active pools in the store. This data is not really used
in the SHS, but it's not a lot of data so it's still recorded when replaying
applications.
- Because the new store sorts things slightly differently from the previous
code, some json golden files had some elements within them shuffled around.
- The retention unit test in UISeleniumSuite was disabled because the code
to throw away old stages / tasks hasn't been added yet.
- The job description field in the API tries to follow the old behavior, which
makes it be empty most of the time, even though there's information to fill it
in. For stages, a new field was added to hold the description (which is basically
the job description), so that the UI can be rendered in the old way.
- A new stage status ("SKIPPED") was added to account for the fact that the API
couldn't represent that state before. Without this, the stage would show up as
"PENDING" in the UI, which is now based on API types.
- The API used to expose "executorRunTime" as the value of the task's duration,
which wasn't really correct (also because that value was easily available
from the metrics object); this change fixes that by storing the correct duration,
which also means a few expectation files needed to be updated to account for
the new durations and sorting differences due to the changed values.
- Added changes to implement SPARK-20713 and SPARK-21922 in the new code.
Tested with existing unit tests (and by using the UI a lot).
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#19698 from vanzin/SPARK-20648.
## What changes were proposed in this pull request?
`excludePackage` is deprecated like the [following](https://github.com/lightbend/migration-manager/blob/master/core/src/main/scala/com/typesafe/tools/mima/core/Filters.scala#L33-L36) and shows deprecation warnings now. This PR uses `exclude[Problem](packageName + ".*")` instead.
```scala
deprecated("Replace with ProblemFilters.exclude[Problem](\"my.package.*\")", "0.1.15")
def excludePackage(packageName: String): ProblemFilter = {
exclude[Problem](packageName + ".*")
}
```
## How was this patch tested?
Pass the Jenkins MiMa.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19710 from dongjoon-hyun/SPARK-22485.
This required adding information about StreamBlockId to the store,
which is not available yet via the API. So an internal type was added
until there's a need to expose that information in the API.
The UI only lists RDDs that have cached partitions, and that information
wasn't being correctly captured in the listener, so that's also fixed,
along with some minor (internal) API adjustments so that the UI can
get the correct data.
Because of the way partitions are cached, some optimizations w.r.t. how
often the data is flushed to the store could not be applied to this code;
because of that, some different ways to make the code more performant
were added to the data structures tracking RDD blocks, with the goal of
avoiding expensive copies when lots of blocks are being updated.
Tested with existing and updated unit tests.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#19679 from vanzin/SPARK-20647.
The executors page is built on top of the REST API, so the page itself
was easy to hook up to the new code.
Some other pages depend on the `ExecutorListener` class that is being
removed, though, so they needed to be modified to use data from the
new store. Fortunately, all they seemed to need is the map of executor
logs, so that was somewhat easy too.
The executor timeline graph required adding some properties to the
ExecutorSummary API type. Instead of following the previous code,
which stored all the listener events in memory, the timeline is
now created based on the data available from the API.
I had to change some of the test golden files because the old code would
return executors in "random" order (since it used a mutable Map instead
of something that returns a sorted list), and the new code returns executors
in id order.
Tested with existing unit tests.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#19678 from vanzin/SPARK-20646.
This change modifies the status listener to collect the information
needed to render the envionment page, and populates that page and the
API with information collected by the listener.
Tested with existing and added unit tests.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#19677 from vanzin/SPARK-20645.
There are two somewhat unrelated things going on in this patch, but
both are meant to make integration of individual UI pages later on
much easier.
The first part is some tweaking of the code in the listener so that
it does less updates of the kvstore for data that changes fast; for
example, it avoids writing changes down to the store for every
task-related event, since those can arrive very quickly at times.
Instead, for these kinds of events, it chooses to only flush things
if a certain interval has passed. The interval is based on how often
the current spark-shell code updates the progress bar for jobs, so
that users can get reasonably accurate data.
The code also delays as much as possible hitting the underlying kvstore
when replaying apps in the history server. This is to avoid unnecessary
writes to disk.
The second set of changes prepare the history server and SparkUI for
integrating with the kvstore. A new class, AppStatusStore, is used
for translating between the stored data and the types used in the
UI / API. The SHS now populates a kvstore with data loaded from
event logs when an application UI is requested.
Because this store can hold references to disk-based resources, the
code was modified to retrieve data from the store under a read lock.
This allows the SHS to detect when the store is still being used, and
only update it (e.g. because an updated event log was detected) when
there is no other thread using the store.
This change ended up creating a lot of churn in the ApplicationCache
code, which was cleaned up a lot in the process. I also removed some
metrics which don't make too much sense with the new code.
Tested with existing and added unit tests, and by making sure the SHS
still works on a real cluster.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#19582 from vanzin/SPARK-20644.
## What changes were proposed in this pull request?
These are just some straightforward upgrades to use the latest versions of some sbt plugins that also support sbt 1.0.
The remaining sbt plugins that need upgrading will require bigger changes.
## How was this patch tested?
Tested sbt use manually.
Author: pj.fanning <pj.fanning@workday.com>
Closes#19609 from pjfanning/SPARK-21708.
The initial listener code is based on the existing JobProgressListener (and others),
and tries to mimic their behavior as much as possible. The change also includes
some minor code movement so that some types and methods from the initial history
server code code can be reused.
The code introduces a few mutable versions of public API types, used internally,
to make it easier to update information without ugly copy methods, and also to
make certain updates cheaper.
Note the code here is not 100% correct. This is meant as a building ground for
the UI integration in the next milestones. As different parts of the UI are
ported, fixes will be made to the different parts of this code to account
for the needed behavior.
I also added annotations to API types so that Jackson is able to correctly
deserialize options, sequences and maps that store primitive types.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#19383 from vanzin/SPARK-20643.
## What changes were proposed in this pull request?
Move flume behind a profile, take 2. See https://github.com/apache/spark/pull/19365 for most of the back-story.
This change should fix the problem by removing the examples module dependency and moving Flume examples to the module itself. It also adds deprecation messages, per a discussion on dev about deprecating for 2.3.0.
## How was this patch tested?
Existing tests, which still enable flume integration.
Author: Sean Owen <sowen@cloudera.com>
Closes#19412 from srowen/SPARK-22142.2.
## What changes were proposed in this pull request?
Add 'flume' profile to enable Flume-related integration modules
## How was this patch tested?
Existing tests; no functional change
Author: Sean Owen <sowen@cloudera.com>
Closes#19365 from srowen/SPARK-22142.
## What changes were proposed in this pull request?
Put Kafka 0.8 support behind a kafka-0-8 profile.
## How was this patch tested?
Existing tests, but, until PR builder and Jenkins configs are updated the effect here is to not build or test Kafka 0.8 support at all.
Author: Sean Owen <sowen@cloudera.com>
Closes#19134 from srowen/SPARK-21893.
## What changes were proposed in this pull request?
This PR proposes to match scalastyle version in POM and SparkBuild.scala
## How was this patch tested?
Manual builds.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19146 from HyukjinKwon/SPARK-21903-follow-up.
## What changes were proposed in this pull request?
1.0.0 fixes an issue with import order, explicit type for public methods, line length limitation and comment validation:
```
[error] .../spark/repl/scala-2.11/src/main/scala/org/apache/spark/repl/Main.scala:50:16: Are you sure you want to println? If yes, wrap the code block with
[error] // scalastyle:off println
[error] println(...)
[error] // scalastyle:on println
[error] .../spark/repl/scala-2.11/src/main/scala/org/apache/spark/repl/SparkILoop.scala:49: File line length exceeds 100 characters
[error] .../spark/repl/scala-2.11/src/main/scala/org/apache/spark/repl/SparkILoop.scala:22:21: Are you sure you want to println? If yes, wrap the code block with
[error] // scalastyle:off println
[error] println(...)
[error] // scalastyle:on println
[error] .../spark/streaming/src/test/java/org/apache/spark/streaming/JavaTestUtils.scala:35:6: Public method must have explicit type
[error] .../spark/streaming/src/test/java/org/apache/spark/streaming/JavaTestUtils.scala:51:6: Public method must have explicit type
[error] .../spark/streaming/src/test/java/org/apache/spark/streaming/JavaTestUtils.scala:93:15: Public method must have explicit type
[error] .../spark/streaming/src/test/java/org/apache/spark/streaming/JavaTestUtils.scala:98:15: Public method must have explicit type
[error] .../spark/streaming/src/test/java/org/apache/spark/streaming/JavaTestUtils.scala:47:2: Insert a space after the start of the comment
[error] .../spark/streaming/src/test/java/org/apache/spark/streaming/JavaTestUtils.scala:26:43: JavaDStream should come before JavaDStreamLike.
```
This PR also fixes the workaround added in SPARK-16877 for `org.scalastyle.scalariform.OverrideJavaChecker` feature, added from 0.9.0.
## How was this patch tested?
Manually tested.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19116 from HyukjinKwon/scalastyle-1.0.0.
…build; fix some things that will be warnings or errors in 2.12; restore Scala 2.12 profile infrastructure
## What changes were proposed in this pull request?
This change adds back the infrastructure for a Scala 2.12 build, but does not enable it in the release or Python test scripts.
In order to make that meaningful, it also resolves compile errors that the code hits in 2.12 only, in a way that still works with 2.11.
It also updates dependencies to the earliest minor release of dependencies whose current version does not yet support Scala 2.12. This is in a sense covered by other JIRAs under the main umbrella, but implemented here. The versions below still work with 2.11, and are the _latest_ maintenance release in the _earliest_ viable minor release.
- Scalatest 2.x -> 3.0.3
- Chill 0.8.0 -> 0.8.4
- Clapper 1.0.x -> 1.1.2
- json4s 3.2.x -> 3.4.2
- Jackson 2.6.x -> 2.7.9 (required by json4s)
This change does _not_ fully enable a Scala 2.12 build:
- It will also require dropping support for Kafka before 0.10. Easy enough, just didn't do it yet here
- It will require recreating `SparkILoop` and `Main` for REPL 2.12, which is SPARK-14650. Possible to do here too.
What it does do is make changes that resolve much of the remaining gap without affecting the current 2.11 build.
## How was this patch tested?
Existing tests and build. Manually tested with `./dev/change-scala-version.sh 2.12` to verify it compiles, modulo the exceptions above.
Author: Sean Owen <sowen@cloudera.com>
Closes#18645 from srowen/SPARK-14280.
## What changes were proposed in this pull request?
add an "asBinary" method to LogisticRegressionSummary for convenient casting to BinaryLogisticRegressionSummary.
## How was this patch tested?
Testcase updated.
Author: WeichenXu <weichen.xu@databricks.com>
Closes#19072 from WeichenXu123/mlor_summary_as_binary.
## What changes were proposed in this pull request?
Add 4 traits, using the following hierarchy:
LogisticRegressionSummary
LogisticRegressionTrainingSummary: LogisticRegressionSummary
BinaryLogisticRegressionSummary: LogisticRegressionSummary
BinaryLogisticRegressionTrainingSummary: LogisticRegressionTrainingSummary, BinaryLogisticRegressionSummary
and the public method such as `def summary` only return trait type listed above.
and then implement 4 concrete classes:
LogisticRegressionSummaryImpl (multiclass case)
LogisticRegressionTrainingSummaryImpl (multiclass case)
BinaryLogisticRegressionSummaryImpl (binary case).
BinaryLogisticRegressionTrainingSummaryImpl (binary case).
## How was this patch tested?
Existing tests & added tests.
Author: WeichenXu <WeichenXu123@outlook.com>
Closes#15435 from WeichenXu123/mlor_summary.
## What changes were proposed in this pull request?
This PR bumps the ANTLR version to 4.7, and fixes a number of small parser related issues uncovered by the bump.
The main reason for upgrading is that in some cases the current version of ANTLR (4.5) can exhibit exponential slowdowns if it needs to parse boolean predicates. For example the following query will take forever to parse:
```sql
SELECT *
FROM RANGE(1000)
WHERE
TRUE
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
AND NOT upper(DESCRIPTION) LIKE '%FOO%'
```
This is caused by a know bug in ANTLR (https://github.com/antlr/antlr4/issues/994), which was fixed in version 4.6.
## How was this patch tested?
Existing tests.
Author: Herman van Hovell <hvanhovell@databricks.com>
Closes#19042 from hvanhovell/SPARK-21830.
## What changes were proposed in this pull request?
When use Vector.compressed to change a Vector to SparseVector, the performance is very low comparing with Vector.toSparse.
This is because you have to scan the value three times using Vector.compressed, but you just need two times when use Vector.toSparse.
When the length of the vector is large, there is significant performance difference between this two method.
## How was this patch tested?
The existing UT
Author: Peng Meng <peng.meng@intel.com>
Closes#18899 from mpjlu/optVectorCompress.
This version fixes a few issues in the import order checker; it provides
better error messages, and detects more improper ordering (thus the need
to change a lot of files in this patch). The main fix is that it correctly
complains about the order of packages vs. classes.
As part of the above, I moved some "SparkSession" import in ML examples
inside the "$example on$" blocks; that didn't seem consistent across
different source files to start with, and avoids having to add more on/off blocks
around specific imports.
The new scalastyle also seems to have a better header detector, so a few
license headers had to be updated to match the expected indentation.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#18943 from vanzin/SPARK-21731.
## What changes were proposed in this pull request?
Update sbt version to 0.13.16. I think this is a useful stepping stone to getting to sbt 1.0.0.
## How was this patch tested?
Existing Build.
Author: pj.fanning <pj.fanning@workday.com>
Closes#18921 from pjfanning/SPARK-21709.
## What changes were proposed in this pull request?
This pr updated `lz4-java` to the latest (v1.4.0) and removed custom `LZ4BlockInputStream`. We currently use custom `LZ4BlockInputStream` to read concatenated byte stream in shuffle. But, this functionality has been implemented in the latest lz4-java (https://github.com/lz4/lz4-java/pull/105). So, we might update the latest to remove the custom `LZ4BlockInputStream`.
Major diffs between the latest release and v1.3.0 in the master are as follows (62f7547abb...6d4693f562);
- fixed NPE in XXHashFactory similarly
- Don't place resources in default package to support shading
- Fixes ByteBuffer methods failing to apply arrayOffset() for array-backed
- Try to load lz4-java from java.library.path, then fallback to bundled
- Add ppc64le binary
- Add s390x JNI binding
- Add basic LZ4 Frame v1.5.0 support
- enable aarch64 support for lz4-java
- Allow unsafeInstance() for ppc64le archiecture
- Add unsafeInstance support for AArch64
- Support 64-bit JNI build on Solaris
- Avoid over-allocating a buffer
- Allow EndMark to be incompressible for LZ4FrameInputStream.
- Concat byte stream
## How was this patch tested?
Existing tests.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#18883 from maropu/SPARK-21276.
This change adds an in-memory implementation of KVStore that can be
used by the live UI.
The implementation is not fully optimized, neither for speed nor
space, but should be fast enough for using in the listener bus.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#18395 from vanzin/SPARK-20655.
## What changes were proposed in this pull request?
Address scapegoat warnings for:
- BigDecimal double constructor
- Catching NPE
- Finalizer without super
- List.size is O(n)
- Prefer Seq.empty
- Prefer Set.empty
- reverse.map instead of reverseMap
- Type shadowing
- Unnecessary if condition.
- Use .log1p
- Var could be val
In some instances like Seq.empty, I avoided making the change even where valid in test code to keep the scope of the change smaller. Those issues are concerned with performance and it won't matter for tests.
## How was this patch tested?
Existing tests
Author: Sean Owen <sowen@cloudera.com>
Closes#18635 from srowen/Scapegoat1.
## What changes were proposed in this pull request?
- Remove Scala 2.10 build profiles and support
- Replace some 2.10 support in scripts with commented placeholders for 2.12 later
- Remove deprecated API calls from 2.10 support
- Remove usages of deprecated context bounds where possible
- Remove Scala 2.10 workarounds like ScalaReflectionLock
- Other minor Scala warning fixes
## How was this patch tested?
Existing tests
Author: Sean Owen <sowen@cloudera.com>
Closes#17150 from srowen/SPARK-19810.
In current code(https://github.com/apache/spark/pull/16989), big blocks are shuffled to disk.
This pr proposes to collect metrics for remote bytes fetched to disk.
Author: jinxing <jinxing6042@126.com>
Closes#18249 from jinxing64/SPARK-19937.
This change adds an abstraction and LevelDB implementation for a key-value
store that will be used to store UI and SHS data.
The interface is described in KVStore.java (see javadoc). Specifics
of the LevelDB implementation are discussed in the javadocs of both
LevelDB.java and LevelDBTypeInfo.java.
Included also are a few small benchmarks just to get some idea of
latency. Because they're too slow for regular unit test runs, they're
disabled by default.
Tested with the included unit tests, and also as part of the overall feature
implementation (including running SHS with hundreds of apps).
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#17902 from vanzin/shs-ng/M1.
## What changes were proposed in this pull request?
Spark Version for a specific application is not displayed on the history page now. It should be nice to switch the spark version on the UI when we click on the specific application.
Currently there seems to be way as SparkListenerLogStart records the application version. So, it should be trivial to listen to this event and provision this change on the UI.
For Example
<img width="1439" alt="screen shot 2017-04-06 at 3 23 41 pm" src="https://cloud.githubusercontent.com/assets/8295799/25092650/41f3970a-2354-11e7-9b0d-4646d0adeb61.png">
<img width="1399" alt="screen shot 2017-04-17 at 9 59 33 am" src="https://cloud.githubusercontent.com/assets/8295799/25092743/9f9e2f28-2354-11e7-9605-f2f1c63f21fe.png">
{"Event":"SparkListenerLogStart","Spark Version":"2.0.0"}
(Please fill in changes proposed in this fix)
Modified the SparkUI for History server to listen to SparkLogListenerStart event and extract the version and print it.
## How was this patch tested?
Manual testing of UI page. Attaching the UI screenshot changes here
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Sanket <schintap@untilservice-lm>
Closes#17658 from redsanket/SPARK-20355.
## What changes were proposed in this pull request?
Remove ML methods we deprecated in 2.1.
## How was this patch tested?
Existing tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17867 from yanboliang/spark-20606.
## What changes were proposed in this pull request?
Add a new `spark-hadoop-cloud` module and maven profile to pull in object store support from `hadoop-openstack`, `hadoop-aws` and `hadoop-azure` (Hadoop 2.7+) JARs, along with their dependencies, fixing up the dependencies so that everything works, in particular Jackson.
It restores `s3n://` access to S3, adds its `s3a://` replacement, OpenStack `swift://` and azure `wasb://`.
There's a documentation page, `cloud_integration.md`, which covers the basic details of using Spark with object stores, referring the reader to the supplier's own documentation, with specific warnings on security and the possible mismatch between a store's behavior and that of a filesystem. In particular, users are advised be very cautious when trying to use an object store as the destination of data, and to consult the documentation of the storage supplier and the connector.
(this is the successor to #12004; I can't re-open it)
## How was this patch tested?
Downstream tests exist in [https://github.com/steveloughran/spark-cloud-examples/tree/master/cloud-examples](https://github.com/steveloughran/spark-cloud-examples/tree/master/cloud-examples)
Those verify that the dependencies are sufficient to allow downstream applications to work with s3a, azure wasb and swift storage connectors, and perform basic IO & dataframe operations thereon. All seems well.
Manually clean build & verify that assembly contains the relevant aws-* hadoop-* artifacts on Hadoop 2.6; azure on a hadoop-2.7 profile.
SBT build: `build/sbt -Phadoop-cloud -Phadoop-2.7 package`
maven build `mvn install -Phadoop-cloud -Phadoop-2.7`
This PR *does not* update `dev/deps/spark-deps-hadoop-2.7` or `dev/deps/spark-deps-hadoop-2.6`, because unless the hadoop-cloud profile is enabled, no extra JARs show up in the dependency list. The dependency check in Jenkins isn't setting the property, so the new JARs aren't visible.
Author: Steve Loughran <stevel@apache.org>
Author: Steve Loughran <stevel@hortonworks.com>
Closes#17834 from steveloughran/cloud/SPARK-7481-current.
## What changes were proposed in this pull request?
Currently cacheTable API only supports MEMORY_AND_DISK. This PR adds additional API to take different storage levels.
## How was this patch tested?
unit tests
Author: madhu <phatak.dev@gmail.com>
Closes#17802 from phatak-dev/cacheTableAPI.
## What changes were proposed in this pull request?
This PR proposes two things as below:
- Avoid Unidoc build only if Hadoop 2.6 is explicitly set in SBT build
Due to a different dependency resolution in SBT & Unidoc by an unknown reason, the documentation build fails on a specific machine & environment in Jenkins but it was unable to reproduce.
So, this PR just checks an environment variable `AMPLAB_JENKINS_BUILD_PROFILE` that is set in Hadoop 2.6 SBT build against branches on Jenkins, and then disables Unidoc build. **Note that PR builder will still build it with Hadoop 2.6 & SBT.**
```
========================================================================
Building Unidoc API Documentation
========================================================================
[info] Building Spark unidoc (w/Hive 1.2.1) using SBT with these arguments: -Phadoop-2.6 -Pmesos -Pkinesis-asl -Pyarn -Phive-thriftserver -Phive unidoc
Using /usr/java/jdk1.8.0_60 as default JAVA_HOME.
...
```
I checked the environment variables from the logs (first bit) as below:
- **spark-master-test-sbt-hadoop-2.6** (this one is being failed) - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-2.6/lastBuild/consoleFull
```
JAVA_HOME=/usr/java/jdk1.8.0_60
JAVA_7_HOME=/usr/java/jdk1.7.0_79
SPARK_BRANCH=master
AMPLAB_JENKINS_BUILD_PROFILE=hadoop2.6 <- I use this variable
AMPLAB_JENKINS="true"
```
- spark-master-test-sbt-hadoop-2.7 - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-2.7/lastBuild/consoleFull
```
JAVA_HOME=/usr/java/jdk1.8.0_60
JAVA_7_HOME=/usr/java/jdk1.7.0_79
SPARK_BRANCH=master
AMPLAB_JENKINS_BUILD_PROFILE=hadoop2.7
AMPLAB_JENKINS="true"
```
- spark-master-test-maven-hadoop-2.6 - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.6/lastBuild/consoleFull
```
JAVA_HOME=/usr/java/jdk1.8.0_60
JAVA_7_HOME=/usr/java/jdk1.7.0_79
HADOOP_PROFILE=hadoop-2.6
HADOOP_VERSION=
SPARK_BRANCH=master
AMPLAB_JENKINS="true"
```
- spark-master-test-maven-hadoop-2.7 - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7/lastBuild/consoleFull
```
JAVA_HOME=/usr/java/jdk1.8.0_60
JAVA_7_HOME=/usr/java/jdk1.7.0_79
HADOOP_PROFILE=hadoop-2.7
HADOOP_VERSION=
SPARK_BRANCH=master
AMPLAB_JENKINS="true"
```
- PR builder - https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/75843/consoleFull
```
JENKINS_MASTER_HOSTNAME=amp-jenkins-master
JAVA_HOME=/usr/java/jdk1.8.0_60
JAVA_7_HOME=/usr/java/jdk1.7.0_79
```
Assuming from other logs in branch-2.1
- SBT & Hadoop 2.6 against branch-2.1 https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-branch-2.1-test-sbt-hadoop-2.6/lastBuild/consoleFull
```
JAVA_HOME=/usr/java/jdk1.8.0_60
JAVA_7_HOME=/usr/java/jdk1.7.0_79
SPARK_BRANCH=branch-2.1
AMPLAB_JENKINS_BUILD_PROFILE=hadoop2.6
AMPLAB_JENKINS="true"
```
- Maven & Hadoop 2.6 against branch-2.1 https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-branch-2.1-test-maven-hadoop-2.6/lastBuild/consoleFull
```
JAVA_HOME=/usr/java/jdk1.8.0_60
JAVA_7_HOME=/usr/java/jdk1.7.0_79
HADOOP_PROFILE=hadoop-2.6
HADOOP_VERSION=
SPARK_BRANCH=branch-2.1
AMPLAB_JENKINS="true"
```
We have been using the same convention for those variables. These are actually being used in `run-tests.py` script - here https://github.com/apache/spark/blob/master/dev/run-tests.py#L519-L520
- Revert the previous try
After https://github.com/apache/spark/pull/17651, it seems the build still fails on SBT Hadoop 2.6 master.
I am unable to reproduce this - https://github.com/apache/spark/pull/17477#issuecomment-294094092 and the reviewer was too. So, this got merged as it looks the only way to verify this is to merge it currently (as no one seems able to reproduce this).
## How was this patch tested?
I only checked `is_hadoop_version_2_6 = os.environ.get("AMPLAB_JENKINS_BUILD_PROFILE") == "hadoop2.6"` is working fine as expected as below:
```python
>>> import collections
>>> os = collections.namedtuple('os', 'environ')(environ={"AMPLAB_JENKINS_BUILD_PROFILE": "hadoop2.6"})
>>> print(not os.environ.get("AMPLAB_JENKINS_BUILD_PROFILE") == "hadoop2.6")
False
>>> os = collections.namedtuple('os', 'environ')(environ={"AMPLAB_JENKINS_BUILD_PROFILE": "hadoop2.7"})
>>> print(not os.environ.get("AMPLAB_JENKINS_BUILD_PROFILE") == "hadoop2.6")
True
>>> os = collections.namedtuple('os', 'environ')(environ={})
>>> print(not os.environ.get("AMPLAB_JENKINS_BUILD_PROFILE") == "hadoop2.6")
True
```
I tried many ways but I was unable to reproduce this in my local. Sean also tried the way I did but he was also unable to reproduce this.
Please refer the comments in https://github.com/apache/spark/pull/17477#issuecomment-294094092
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#17669 from HyukjinKwon/revert-SPARK-20343.
## What changes were proposed in this pull request?
This PR proposes to force Avro's version to 1.7.7 in core to resolve the build failure as below:
```
[error] /home/jenkins/workspace/spark-master-test-sbt-hadoop-2.6/core/src/main/scala/org/apache/spark/serializer/GenericAvroSerializer.scala:123: value createDatumWriter is not a member of org.apache.avro.generic.GenericData
[error] writerCache.getOrElseUpdate(schema, GenericData.get.createDatumWriter(schema))
[error]
```
https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-2.6/2770/consoleFull
Note that this is a hack and should be removed in the future.
## How was this patch tested?
I only tested this actually overrides the dependency.
I tried many ways but I was unable to reproduce this in my local. Sean also tried the way I did but he was also unable to reproduce this.
Please refer the comments in https://github.com/apache/spark/pull/17477#issuecomment-294094092
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#17651 from HyukjinKwon/SPARK-20343-sbt.
## What changes were proposed in this pull request?
With [SPARK-13992](https://issues.apache.org/jira/browse/SPARK-13992), Spark supports persisting data into off-heap memory, but the usage of on-heap and off-heap memory is not exposed currently, it is not so convenient for user to monitor and profile, so here propose to expose off-heap memory as well as on-heap memory usage in various places:
1. Spark UI's executor page will display both on-heap and off-heap memory usage.
2. REST request returns both on-heap and off-heap memory.
3. Also this can be gotten from MetricsSystem.
4. Last this usage can be obtained programmatically from SparkListener.
Attach the UI changes:

Backward compatibility is also considered for event-log and REST API. Old event log can still be replayed with off-heap usage displayed as 0. For REST API, only adds the new fields, so JSON backward compatibility can still be kept.
## How was this patch tested?
Unit test added and manual verification.
Author: jerryshao <sshao@hortonworks.com>
Closes#14617 from jerryshao/SPARK-17019.
## What changes were proposed in this pull request?
This patch adds a `compressed` method to ML `Matrix` class, which returns the minimal storage representation of the matrix - either sparse or dense. Because the space occupied by a sparse matrix is dependent upon its layout (i.e. column major or row major), this method must consider both cases. It may also be useful to force the layout to be column or row major beforehand, so an overload is added which takes in a `columnMajor: Boolean` parameter.
The compressed implementation relies upon two new abstract methods `toDense(columnMajor: Boolean)` and `toSparse(columnMajor: Boolean)`, similar to the compressed method implemented in the `Vector` class. These methods also allow the layout of the resulting matrix to be specified via the `columnMajor` parameter. More detail on the new methods is given below.
## How was this patch tested?
Added many new unit tests
## New methods (summary, not exhaustive list)
**Matrix trait**
- `private[ml] def toDenseMatrix(columnMajor: Boolean): DenseMatrix` (abstract) - converts the matrix (either sparse or dense) to dense format
- `private[ml] def toSparseMatrix(columnMajor: Boolean): SparseMatrix` (abstract) - converts the matrix (either sparse or dense) to sparse format
- `def toDense: DenseMatrix = toDense(true)` - converts the matrix (either sparse or dense) to dense format in column major layout
- `def toSparse: SparseMatrix = toSparse(true)` - converts the matrix (either sparse or dense) to sparse format in column major layout
- `def compressed: Matrix` - finds the minimum space representation of this matrix, considering both column and row major layouts, and converts it
- `def compressed(columnMajor: Boolean): Matrix` - finds the minimum space representation of this matrix considering only column OR row major, and converts it
**DenseMatrix class**
- `private[ml] def toDenseMatrix(columnMajor: Boolean): DenseMatrix` - converts the dense matrix to a dense matrix, optionally changing the layout (data is NOT duplicated if the layouts are the same)
- `private[ml] def toSparseMatrix(columnMajor: Boolean): SparseMatrix` - converts the dense matrix to sparse matrix, using the specified layout
**SparseMatrix class**
- `private[ml] def toDenseMatrix(columnMajor: Boolean): DenseMatrix` - converts the sparse matrix to a dense matrix, using the specified layout
- `private[ml] def toSparseMatrix(columnMajors: Boolean): SparseMatrix` - converts the sparse matrix to sparse matrix. If the sparse matrix contains any explicit zeros, they are removed. If the layout requested does not match the current layout, data is copied to a new representation. If the layouts match and no explicit zeros exist, the current matrix is returned.
Author: sethah <seth.hendrickson16@gmail.com>
Closes#15628 from sethah/matrix_compress.
This commit adds a killTaskAttempt method to SparkContext, to allow users to
kill tasks so that they can be re-scheduled elsewhere.
This also refactors the task kill path to allow specifying a reason for the task kill. The reason is propagated opaquely through events, and will show up in the UI automatically as `(N killed: $reason)` and `TaskKilled: $reason`. Without this change, there is no way to provide the user feedback through the UI.
Currently used reasons are "stage cancelled", "another attempt succeeded", and "killed via SparkContext.killTask". The user can also specify a custom reason through `SparkContext.killTask`.
cc rxin
In the stage overview UI the reasons are summarized:

Within the stage UI you can see individual task kill reasons:

Existing tests, tried killing some stages in the UI and verified the messages are as expected.
Author: Eric Liang <ekl@databricks.com>
Author: Eric Liang <ekl@google.com>
Closes#17166 from ericl/kill-reason.
## What changes were proposed in this pull request?
An additional trigger and trigger executor that will execute a single trigger only. One can use this OneTime trigger to have more control over the scheduling of triggers.
In addition, this patch requires an optimization to StreamExecution that logs a commit record at the end of successfully processing a batch. This new commit log will be used to determine the next batch (offsets) to process after a restart, instead of using the offset log itself to determine what batch to process next after restart; using the offset log to determine this would process the previously logged batch, always, thus not permitting a OneTime trigger feature.
## How was this patch tested?
A number of existing tests have been revised. These tests all assumed that when restarting a stream, the last batch in the offset log is to be re-processed. Given that we now have a commit log that will tell us if that last batch was processed successfully, the results/assumptions of those tests needed to be revised accordingly.
In addition, a OneTime trigger test was added to StreamingQuerySuite, which tests:
- The semantics of OneTime trigger (i.e., on start, execute a single batch, then stop).
- The case when the commit log was not able to successfully log the completion of a batch before restart, which would mean that we should fall back to what's in the offset log.
- A OneTime trigger execution that results in an exception being thrown.
marmbrus tdas zsxwing
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Tyson Condie <tcondie@gmail.com>
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#17219 from tcondie/stream-commit.
## What changes were proposed in this pull request?
The API docs should not include the "org.apache.spark.sql.internal" package because they are internal private APIs.
## How was this patch tested?
Jenkins
Author: Shixiong Zhu <shixiong@databricks.com>
Closes#17217 from zsxwing/SPARK-19874.
## What changes were proposed in this pull request?
This PR is an enhancement to ML StringIndexer.
Before this PR, String Indexer only supports "skip"/"error" options to deal with unseen records.
But those unseen records might still be useful and user would like to keep the unseen labels in
certain use cases, This PR enables StringIndexer to support keeping unseen labels as
indices [numLabels].
'''Before
StringIndexer().setHandleInvalid("skip")
StringIndexer().setHandleInvalid("error")
'''After
support the third option "keep"
StringIndexer().setHandleInvalid("keep")
## How was this patch tested?
Test added in StringIndexerSuite
Signed-off-by: VinceShieh <vincent.xieintel.com>
(Please fill in changes proposed in this fix)
Author: VinceShieh <vincent.xie@intel.com>
Closes#16883 from VinceShieh/spark-17498.
## What changes were proposed in this pull request?
Fault-tolerance in spark requires special handling of shuffle fetch
failures. The Executor would catch FetchFailedException and send a
special msg back to the driver.
However, intervening user code could intercept that exception, and wrap
it with something else. This even happens in SparkSQL. So rather than
checking the thrown exception only, we'll store the fetch failure directly
in the TaskContext, where users can't touch it.
## How was this patch tested?
Added a test case which failed before the fix. Full test suite via jenkins.
Author: Imran Rashid <irashid@cloudera.com>
Closes#16639 from squito/SPARK-19276.
The REST API has a security filter that performs auth checks
based on the UI root's security manager. That works fine when
the UI root is the app's UI, but not when it's the history server.
In the SHS case, all users would be allowed to see all applications
through the REST API, even if the UI itself wouldn't be available
to them.
This change adds auth checks for each app access through the API
too, so that only authorized users can see the app's data.
The change also modifies the existing security filter to use
`HttpServletRequest.getRemoteUser()`, which is used in other
places. That is not necessarily the same as the principal's
name; for example, when using Hadoop's SPNEGO auth filter,
the remote user strips the realm information, which then matches
the user name registered as the owner of the application.
I also renamed the UIRootFromServletContext trait to a more generic
name since I'm using it to store more context information now.
Tested manually with an authentication filter enabled.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#16978 from vanzin/SPARK-19652.
## What changes were proposed in this pull request?
Go back to selecting source/target 1.7 for Scala 2.10 builds, because the SBT-based build for 2.10 won't work otherwise.
## How was this patch tested?
Existing tests, but, we need to verify this vs what the SBT build would exactly run on Jenkins
Author: Sean Owen <sowen@cloudera.com>
Closes#16983 from srowen/SPARK-19550.3.
- Move external/java8-tests tests into core, streaming, sql and remove
- Remove MaxPermGen and related options
- Fix some reflection / TODOs around Java 8+ methods
- Update doc references to 1.7/1.8 differences
- Remove Java 7/8 related build profiles
- Update some plugins for better Java 8 compatibility
- Fix a few Java-related warnings
For the future:
- Update Java 8 examples to fully use Java 8
- Update Java tests to use lambdas for simplicity
- Update Java internal implementations to use lambdas
## How was this patch tested?
Existing tests
Author: Sean Owen <sowen@cloudera.com>
Closes#16871 from srowen/SPARK-19493.
## What changes were proposed in this pull request?
- Remove support for Hadoop 2.5 and earlier
- Remove reflection and code constructs only needed to support multiple versions at once
- Update docs to reflect newer versions
- Remove older versions' builds and profiles.
## How was this patch tested?
Existing tests
Author: Sean Owen <sowen@cloudera.com>
Closes#16810 from srowen/SPARK-19464.
## What changes were proposed in this pull request?
Adding convenience function to Python `JavaWrapper` so that it is easy to create a Py4J JavaArray that is compatible with current class constructors that have a Scala `Array` as input so that it is not necessary to have a Java/Python friendly constructor. The function takes a Java class as input that is used by Py4J to create the Java array of the given class. As an example, `OneVsRest` has been updated to use this and the alternate constructor is removed.
## How was this patch tested?
Added unit tests for the new convenience function and updated `OneVsRest` doctests which use this to persist the model.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#14725 from BryanCutler/pyspark-new_java_array-CountVectorizer-SPARK-17161.
## What changes were proposed in this pull request?
Although Spark history server UI shows task ‘status’ and ‘duration’ fields, it does not expose these fields in the REST API response. For the Spark history server API users, it is not possible to determine task status and duration. Spark history server has access to task status and duration from event log, but it is not exposing these in API. This patch is proposed to expose task ‘status’ and ‘duration’ fields in Spark history server REST API.
## How was this patch tested?
Modified existing test cases in org.apache.spark.deploy.history.HistoryServerSuite.
Author: Parag Chaudhari <paragpc@amazon.com>
Closes#16473 from paragpc/expose_task_status.
## What changes were proposed in this pull request?
add loglikelihood in GMM.summary
## How was this patch tested?
added tests
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Author: Ruifeng Zheng <ruifengz@foxmail.com>
Closes#12064 from zhengruifeng/gmm_metric.
## What changes were proposed in this pull request?
In https://github.com/apache/spark/pull/16296 , we reached a consensus that we should hide the external/managed table concept to users and only expose custom table path.
This PR renames `Catalog.createExternalTable` to `createTable`(still keep the old versions for backward compatibility), and only set the table type to EXTERNAL if `path` is specified in options.
## How was this patch tested?
new tests in `CatalogSuite`
Author: Wenchen Fan <wenchen@databricks.com>
Closes#16528 from cloud-fan/create-table.
## What changes were proposed in this pull request?
This PR is an inheritance from #16000, and is a completion of #15904.
**Description**
- Augment the `org.apache.spark.status.api.v1` package for serving streaming information.
- Retrieve the streaming information through StreamingJobProgressListener.
> this api should cover exceptly the same amount of information as you can get from the web interface
> the implementation is base on the current REST implementation of spark-core
> and will be available for running applications only
>
> https://issues.apache.org/jira/browse/SPARK-18537
## How was this patch tested?
Local test.
Author: saturday_s <shi.indetail@gmail.com>
Author: Chan Chor Pang <ChorPang.Chan@access-company.com>
Author: peterCPChan <universknight@gmail.com>
Closes#16253 from saturday-shi/SPARK-18537.
### What changes were proposed in this pull request?
Currently, we only have a SQL interface for recovering all the partitions in the directory of a table and update the catalog. `MSCK REPAIR TABLE` or `ALTER TABLE table RECOVER PARTITIONS`. (Actually, very hard for me to remember `MSCK` and have no clue what it means)
After the new "Scalable Partition Handling", the table repair becomes much more important for making visible the data in the created data source partitioned table.
Thus, this PR is to add it into the Catalog interface. After this PR, users can repair the table by
```Scala
spark.catalog.recoverPartitions("testTable")
```
### How was this patch tested?
Modified the existing test cases.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#16356 from gatorsmile/repairTable.
## What changes were proposed in this pull request?
Currently, some tests are being failed and hanging on Windows due to this problem. For the reason in SPARK-18718, some tests using `local-cluster` mode were disabled on Windows due to the length limitation by paths given to classpaths.
The limitation seems roughly 32K (see the [blog in MS](https://blogs.msdn.microsoft.com/oldnewthing/20031210-00/?p=41553/) and [another reference](https://support.thoughtworks.com/hc/en-us/articles/213248526-Getting-around-maximum-command-line-length-is-32767-characters-on-Windows)) but in `local-cluster` mode, executors were being launched as processes with the command such as [here](https://gist.github.com/HyukjinKwon/5bc81061c250d4af5a180869b59d42ea) in (only) tests.
This length is roughly 40K due to the classpaths given to `java` command. However, it seems duplicates are almost half of them. So, if we deduplicate the paths, it seems reduced to roughly 20K with the command, [here](https://gist.github.com/HyukjinKwon/dad0c8db897e5e094684a2dc6a417790).
Maybe, we should consider as some more paths are added in the future but it seems better than disabling all the tests for now with minimised changes.
Therefore, this PR proposes to deduplicate the paths in classpaths in case of launching executors as processes in `local-cluster` mode.
## How was this patch tested?
Existing tests in `ShuffleSuite` and `BroadcastJoinSuite` manually via AppVeyor
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#16266 from HyukjinKwon/disable-local-cluster-tests.
## What changes were proposed in this pull request?
This PR is to upgrade sbt plugins. The following sbt plugins will be upgraded:
```
sbteclipse-plugin: 4.0.0 -> 5.0.1
sbt-mima-plugin: 0.1.11 -> 0.1.12
org.ow2.asm/asm: 5.0.3 -> 5.1
org.ow2.asm/asm-commons: 5.0.3 -> 5.1
```
## How was this patch tested?
Pass the Jenkins build.
Author: Weiqing Yang <yangweiqing001@gmail.com>
Closes#16223 from weiqingy/SPARK_18697.
Based on an informal survey, users find this option easier to understand / remember.
Author: Michael Armbrust <michael@databricks.com>
Closes#16182 from marmbrus/renameRecentProgress.
## What changes were proposed in this pull request?
This PR is to upgrade sbt plugins. The following sbt plugins will be upgraded:
```
sbt-assembly: 0.11.2 -> 0.14.3
sbteclipse-plugin: 4.0.0 -> 5.0.1
sbt-mima-plugin: 0.1.11 -> 0.1.12
org.ow2.asm/asm: 5.0.3 -> 5.1
org.ow2.asm/asm-commons: 5.0.3 -> 5.1
```
All other plugins are up-to-date.
## How was this patch tested?
Pass the Jenkins build.
Author: Weiqing Yang <yangweiqing001@gmail.com>
Closes#16159 from weiqingy/SPARK-18697.
## What changes were proposed in this pull request?
Here are the major changes in this PR.
- Added the ability to recover `StreamingQuery.id` from checkpoint location, by writing the id to `checkpointLoc/metadata`.
- Added `StreamingQuery.runId` which is unique for every query started and does not persist across restarts. This is to identify each restart of a query separately (same as earlier behavior of `id`).
- Removed auto-generation of `StreamingQuery.name`. The purpose of name was to have the ability to define an identifier across restarts, but since id is precisely that, there is no need for a auto-generated name. This means name becomes purely cosmetic, and is null by default.
- Added `runId` to `StreamingQueryListener` events and `StreamingQueryProgress`.
Implementation details
- Renamed existing `StreamExecutionMetadata` to `OffsetSeqMetadata`, and moved it to the file `OffsetSeq.scala`, because that is what this metadata is tied to. Also did some refactoring to make the code cleaner (got rid of a lot of `.json` and `.getOrElse("{}")`).
- Added the `id` as the new `StreamMetadata`.
- When a StreamingQuery is created it gets or writes the `StreamMetadata` from `checkpointLoc/metadata`.
- All internal logging in `StreamExecution` uses `(name, id, runId)` instead of just `name`
TODO
- [x] Test handling of name=null in json generation of StreamingQueryProgress
- [x] Test handling of name=null in json generation of StreamingQueryListener events
- [x] Test python API of runId
## How was this patch tested?
Updated unit tests and new unit tests
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#16113 from tdas/SPARK-18657.
## What changes were proposed in this pull request?
- Add StreamingQuery.explain and exception to Python.
- Fix StreamingQueryException to not expose `OffsetSeq`.
## How was this patch tested?
Jenkins
Author: Shixiong Zhu <shixiong@databricks.com>
Closes#16125 from zsxwing/py-streaming-explain.
## What changes were proposed in this pull request?
This PR is to upgrade:
```
sbt: 0.13.11 -> 0.13.13,
zinc: 0.3.9 -> 0.3.11,
maven-assembly-plugin: 2.6 -> 3.0.0
maven-compiler-plugin: 3.5.1 -> 3.6.
maven-jar-plugin: 2.6 -> 3.0.2
maven-javadoc-plugin: 2.10.3 -> 2.10.4
maven-source-plugin: 2.4 -> 3.0.1
org.codehaus.mojo:build-helper-maven-plugin: 1.10 -> 1.12
org.codehaus.mojo:exec-maven-plugin: 1.4.0 -> 1.5.0
```
The sbt release notes since the last version we used are: [v0.13.12](https://github.com/sbt/sbt/releases/tag/v0.13.12) and [v0.13.13 ](https://github.com/sbt/sbt/releases/tag/v0.13.13).
## How was this patch tested?
Pass build and the existing tests.
Author: Weiqing Yang <yangweiqing001@gmail.com>
Closes#16069 from weiqingy/SPARK-18638.
## What changes were proposed in this pull request?
This patch bumps master branch version to 2.2.0-SNAPSHOT.
## How was this patch tested?
N/A
Author: Reynold Xin <rxin@databricks.com>
Closes#16126 from rxin/SPARK-18695.
## What changes were proposed in this pull request?
SPARK-18429 introduced count-min sketch aggregate function for SQL, but the implementation and testing is more complicated than needed. This simplifies the test cases and removes support for data types that don't have clear equality semantics:
1. Removed support for floating point and decimal types.
2. Removed the heavy randomized tests. The underlying CountMinSketch implementation already had pretty good test coverage through randomized tests, and the SPARK-18429 implementation is just to add an aggregate function wrapper around CountMinSketch. There is no need for randomized tests at three different levels of the implementations.
## How was this patch tested?
A lot of the change is to simplify test cases.
Author: Reynold Xin <rxin@databricks.com>
Closes#16093 from rxin/SPARK-18663.
This PR separates the status of a `StreamingQuery` into two separate APIs:
- `status` - describes the status of a `StreamingQuery` at this moment, including what phase of processing is currently happening and if data is available.
- `recentProgress` - an array of statistics about the most recent microbatches that have executed.
A recent progress contains the following information:
```
{
"id" : "2be8670a-fce1-4859-a530-748f29553bb6",
"name" : "query-29",
"timestamp" : 1479705392724,
"inputRowsPerSecond" : 230.76923076923077,
"processedRowsPerSecond" : 10.869565217391303,
"durationMs" : {
"triggerExecution" : 276,
"queryPlanning" : 3,
"getBatch" : 5,
"getOffset" : 3,
"addBatch" : 234,
"walCommit" : 30
},
"currentWatermark" : 0,
"stateOperators" : [ ],
"sources" : [ {
"description" : "KafkaSource[Subscribe[topic-14]]",
"startOffset" : {
"topic-14" : {
"2" : 0,
"4" : 1,
"1" : 0,
"3" : 0,
"0" : 0
}
},
"endOffset" : {
"topic-14" : {
"2" : 1,
"4" : 2,
"1" : 0,
"3" : 0,
"0" : 1
}
},
"numRecords" : 3,
"inputRowsPerSecond" : 230.76923076923077,
"processedRowsPerSecond" : 10.869565217391303
} ]
}
```
Additionally, in order to make it possible to correlate progress updates across restarts, we change the `id` field from an integer that is unique with in the JVM to a `UUID` that is globally unique.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Author: Michael Armbrust <michael@databricks.com>
Closes#15954 from marmbrus/queryProgress.
## What changes were proposed in this pull request?
Remove deprecated methods for ML.
## How was this patch tested?
Existing tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#15913 from yanboliang/spark-18481.
## What changes were proposed in this pull request?
This PR only tries to fix things that looks pretty straightforward and were fixed in other previous PRs before.
This PR roughly fixes several things as below:
- Fix unrecognisable class and method links in javadoc by changing it from `[[..]]` to `` `...` ``
```
[error] .../spark/sql/core/target/java/org/apache/spark/sql/streaming/DataStreamReader.java:226: error: reference not found
[error] * Loads text files and returns a {link DataFrame} whose schema starts with a string column named
```
- Fix an exception annotation and remove code backticks in `throws` annotation
Currently, sbt unidoc with Java 8 complains as below:
```
[error] .../java/org/apache/spark/sql/streaming/StreamingQuery.java:72: error: unexpected text
[error] * throws StreamingQueryException, if <code>this</code> query has terminated with an exception.
```
`throws` should specify the correct class name from `StreamingQueryException,` to `StreamingQueryException` without backticks. (see [JDK-8007644](https://bugs.openjdk.java.net/browse/JDK-8007644)).
- Fix `[[http..]]` to `<a href="http..."></a>`.
```diff
- * [[https://blogs.oracle.com/java-platform-group/entry/diagnosing_tls_ssl_and_https Oracle
- * blog page]].
+ * <a href="https://blogs.oracle.com/java-platform-group/entry/diagnosing_tls_ssl_and_https">
+ * Oracle blog page</a>.
```
`[[http...]]` link markdown in scaladoc is unrecognisable in javadoc.
- It seems class can't have `return` annotation. So, two cases of this were removed.
```
[error] .../java/org/apache/spark/mllib/regression/IsotonicRegression.java:27: error: invalid use of return
[error] * return New instance of IsotonicRegression.
```
- Fix < to `<` and > to `>` according to HTML rules.
- Fix `</p>` complaint
- Exclude unrecognisable in javadoc, `constructor`, `todo` and `groupname`.
## How was this patch tested?
Manually tested by `jekyll build` with Java 7 and 8
```
java version "1.7.0_80"
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, mixed mode)
```
```
java version "1.8.0_45"
Java(TM) SE Runtime Environment (build 1.8.0_45-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
```
Note: this does not yet make sbt unidoc suceed with Java 8 yet but it reduces the number of errors with Java 8.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#15999 from HyukjinKwon/SPARK-3359-errors.
## What changes were proposed in this pull request?
This PR proposes/fixes two things.
- Remove many errors to generate javadoc with Java8 from unrecognisable tags, `tparam` and `group`.
```
[error] .../spark/mllib/target/java/org/apache/spark/ml/classification/Classifier.java:18: error: unknown tag: group
[error] /** group setParam */
[error] ^
[error] .../spark/mllib/target/java/org/apache/spark/ml/classification/Classifier.java:8: error: unknown tag: tparam
[error] * tparam FeaturesType Type of input features. E.g., <code>Vector</code>
[error] ^
...
```
It does not fully resolve the problem but remove many errors. It seems both `group` and `tparam` are unrecognisable in javadoc. It seems we can't print them pretty in javadoc in a way of `example` here because they appear differently (both examples can be found in http://spark.apache.org/docs/2.0.2/api/scala/index.html#org.apache.spark.ml.classification.Classifier).
- Print `example` in javadoc.
Currently, there are few `example` tag in several places.
```
./graphx/src/main/scala/org/apache/spark/graphx/Graph.scala: * example This operation might be used to evaluate a graph
./graphx/src/main/scala/org/apache/spark/graphx/Graph.scala: * example We might use this operation to change the vertex values
./graphx/src/main/scala/org/apache/spark/graphx/Graph.scala: * example This function might be used to initialize edge
./graphx/src/main/scala/org/apache/spark/graphx/Graph.scala: * example This function might be used to initialize edge
./graphx/src/main/scala/org/apache/spark/graphx/Graph.scala: * example This function might be used to initialize edge
./graphx/src/main/scala/org/apache/spark/graphx/Graph.scala: * example We can use this function to compute the in-degree of each
./graphx/src/main/scala/org/apache/spark/graphx/Graph.scala: * example This function is used to update the vertices with new values based on external data.
./graphx/src/main/scala/org/apache/spark/graphx/GraphLoader.scala: * example Loads a file in the following format:
./graphx/src/main/scala/org/apache/spark/graphx/GraphOps.scala: * example This function is used to update the vertices with new
./graphx/src/main/scala/org/apache/spark/graphx/GraphOps.scala: * example This function can be used to filter the graph based on some property, without
./graphx/src/main/scala/org/apache/spark/graphx/Pregel.scala: * example We can use the Pregel abstraction to implement PageRank:
./graphx/src/main/scala/org/apache/spark/graphx/VertexRDD.scala: * example Construct a `VertexRDD` from a plain RDD:
./repl/scala-2.10/src/main/scala/org/apache/spark/repl/SparkCommandLine.scala: * example new SparkCommandLine(Nil).settings
./repl/scala-2.10/src/main/scala/org/apache/spark/repl/SparkIMain.scala: * example addImports("org.apache.spark.SparkContext")
./sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/LiteralGenerator.scala: * example {{{
```
**Before**
<img width="505" alt="2016-11-20 2 43 23" src="https://cloud.githubusercontent.com/assets/6477701/20457285/26f07e1c-aecb-11e6-9ae9-d9dee66845f4.png">
**After**
<img width="499" alt="2016-11-20 1 27 17" src="https://cloud.githubusercontent.com/assets/6477701/20457240/409124e4-aeca-11e6-9a91-0ba514148b52.png">
## How was this patch tested?
Maunally tested by `jekyll build` with Java 7 and 8
```
java version "1.7.0_80"
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, mixed mode)
```
```
java version "1.8.0_45"
Java(TM) SE Runtime Environment (build 1.8.0_45-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
```
Note: this does not make sbt unidoc suceed with Java 8 yet but it reduces the number of errors with Java 8.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#15939 from HyukjinKwon/SPARK-3359-javadoc.
## What changes were proposed in this pull request?
When profiling heap dumps from the HistoryServer and live Spark web UIs, I found a large amount of memory being wasted on duplicated objects and strings. This patch's changes remove most of this duplication, resulting in over 40% memory savings for some benchmarks.
- **Task metrics** (6441f0624dfcda9c7193a64bfb416a145b5aabdf): previously, every `TaskUIData` object would have its own instances of `InputMetricsUIData`, `OutputMetricsUIData`, `ShuffleReadMetrics`, and `ShuffleWriteMetrics`, but for many tasks these metrics are irrelevant because they're all zero. This patch changes how we construct these metrics in order to re-use a single immutable "empty" value for the cases where these metrics are empty.
- **TaskInfo.accumulables** (ade86db901127bf13c0e0bdc3f09c933a093bb76): Previously, every `TaskInfo` object had its own empty `ListBuffer` for holding updates from named accumulators. Tasks which didn't use named accumulators still paid for the cost of allocating and storing this empty buffer. To avoid this overhead, I changed the `val` with a mutable buffer into a `var` which holds an immutable Scala list, allowing tasks which do not have named accumulator updates to share the same singleton `Nil` object.
- **String.intern() in JSONProtocol** (7e05630e9a78c455db8c8c499f0590c864624e05): in the HistoryServer, executor hostnames and ids are deserialized from JSON, leading to massive duplication of these string objects. By calling `String.intern()` on the deserialized values we can remove all of this duplication. Since Spark now requires Java 7+ we don't have to worry about string interning exhausting the permgen (see http://java-performance.info/string-intern-in-java-6-7-8/).
## How was this patch tested?
I ran
```
sc.parallelize(1 to 100000, 100000).count()
```
in `spark-shell` with event logging enabled, then loaded that event log in the HistoryServer, performed a full GC, and took a heap dump. According to YourKit, the changes in this patch reduced memory consumption by roughly 28 megabytes (or 770k Java objects):

Here's a table illustrating the drop in objects due to deduplication (the drop is <100k for some objects because some events were dropped from the listener bus; this is a separate, existing bug that I'll address separately after CPU-profiling):

Author: Josh Rosen <joshrosen@databricks.com>
Closes#15743 from JoshRosen/spark-ui-memory-usage.
## What changes were proposed in this pull request?
Don't need to build doc for KafkaSource because the user should use the data source APIs to use KafkaSource. All KafkaSource APIs are internal.
## How was this patch tested?
Verified manually.
Author: Shixiong Zhu <shixiong@databricks.com>
Closes#15630 from zsxwing/kafka-unidoc.
We should upgrade to the latest release of MiMa (0.1.11) in order to include a fix for a bug which led to flakiness in the MiMa checks (https://github.com/typesafehub/migration-manager/issues/115).
Author: Josh Rosen <joshrosen@databricks.com>
Closes#15571 from JoshRosen/SPARK-18034.
## What changes were proposed in this pull request?
As per rxin request, here are further API changes
- Changed `Stream(Started/Progress/Terminated)` events to `Stream*Event`
- Changed the fields in `StreamingQueryListener.on***` from `query*` to `event`
## How was this patch tested?
Existing unit tests.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#15530 from tdas/SPARK-17731-1.
## What changes were proposed in this pull request?
Metrics are needed for monitoring structured streaming apps. Here is the design doc for implementing the necessary metrics.
https://docs.google.com/document/d/1NIdcGuR1B3WIe8t7VxLrt58TJB4DtipWEbj5I_mzJys/edit?usp=sharing
Specifically, this PR adds the following public APIs changes.
### New APIs
- `StreamingQuery.status` returns a `StreamingQueryStatus` object (renamed from `StreamingQueryInfo`, see later)
- `StreamingQueryStatus` has the following important fields
- inputRate - Current rate (rows/sec) at which data is being generated by all the sources
- processingRate - Current rate (rows/sec) at which the query is processing data from
all the sources
- ~~outputRate~~ - *Does not work with wholestage codegen*
- latency - Current average latency between the data being available in source and the sink writing the corresponding output
- sourceStatuses: Array[SourceStatus] - Current statuses of the sources
- sinkStatus: SinkStatus - Current status of the sink
- triggerStatus - Low-level detailed status of the last completed/currently active trigger
- latencies - getOffset, getBatch, full trigger, wal writes
- timestamps - trigger start, finish, after getOffset, after getBatch
- numRows - input, output, state total/updated rows for aggregations
- `SourceStatus` has the following important fields
- inputRate - Current rate (rows/sec) at which data is being generated by the source
- processingRate - Current rate (rows/sec) at which the query is processing data from the source
- triggerStatus - Low-level detailed status of the last completed/currently active trigger
- Python API for `StreamingQuery.status()`
### Breaking changes to existing APIs
**Existing direct public facing APIs**
- Deprecated direct public-facing APIs `StreamingQuery.sourceStatuses` and `StreamingQuery.sinkStatus` in favour of `StreamingQuery.status.sourceStatuses/sinkStatus`.
- Branch 2.0 should have it deprecated, master should have it removed.
**Existing advanced listener APIs**
- `StreamingQueryInfo` renamed to `StreamingQueryStatus` for consistency with `SourceStatus`, `SinkStatus`
- Earlier StreamingQueryInfo was used only in the advanced listener API, but now it is used in direct public-facing API (StreamingQuery.status)
- Field `queryInfo` in listener events `QueryStarted`, `QueryProgress`, `QueryTerminated` changed have name `queryStatus` and return type `StreamingQueryStatus`.
- Field `offsetDesc` in `SourceStatus` was Option[String], converted it to `String`.
- For `SourceStatus` and `SinkStatus` made constructor private instead of private[sql] to make them more java-safe. Instead added `private[sql] object SourceStatus/SinkStatus.apply()` which are harder to accidentally use in Java.
## How was this patch tested?
Old and new unit tests.
- Rate calculation and other internal logic of StreamMetrics tested by StreamMetricsSuite.
- New info in statuses returned through StreamingQueryListener is tested in StreamingQueryListenerSuite.
- New and old info returned through StreamingQuery.status is tested in StreamingQuerySuite.
- Source-specific tests for making sure input rows are counted are is source-specific test suites.
- Additional tests to test minor additions in LocalTableScanExec, StateStore, etc.
Metrics also manually tested using Ganglia sink
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#15307 from tdas/SPARK-17731.
## What changes were proposed in this pull request?
address post hoc review comments for https://github.com/apache/spark/pull/14897
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#15424 from cloud-fan/global-temp-view.
## What changes were proposed in this pull request?
Global temporary view is a cross-session temporary view, which means it's shared among all sessions. Its lifetime is the lifetime of the Spark application, i.e. it will be automatically dropped when the application terminates. It's tied to a system preserved database `global_temp`(configurable via SparkConf), and we must use the qualified name to refer a global temp view, e.g. SELECT * FROM global_temp.view1.
changes for `SessionCatalog`:
1. add a new field `gloabalTempViews: GlobalTempViewManager`, to access the shared global temp views, and the global temp db name.
2. `createDatabase` will fail if users wanna create `global_temp`, which is system preserved.
3. `setCurrentDatabase` will fail if users wanna set `global_temp`, which is system preserved.
4. add `createGlobalTempView`, which is used in `CreateViewCommand` to create global temp views.
5. add `dropGlobalTempView`, which is used in `CatalogImpl` to drop global temp view.
6. add `alterTempViewDefinition`, which is used in `AlterViewAsCommand` to update the view definition for local/global temp views.
7. `renameTable`/`dropTable`/`isTemporaryTable`/`lookupRelation`/`getTempViewOrPermanentTableMetadata`/`refreshTable` will handle global temp views.
changes for SQL commands:
1. `CreateViewCommand`/`AlterViewAsCommand` is updated to support global temp views
2. `ShowTablesCommand` outputs a new column `database`, which is used to distinguish global and local temp views.
3. other commands can also handle global temp views if they call `SessionCatalog` APIs which accepts global temp views, e.g. `DropTableCommand`, `AlterTableRenameCommand`, `ShowColumnsCommand`, etc.
changes for other public API
1. add a new method `dropGlobalTempView` in `Catalog`
2. `Catalog.findTable` can find global temp view
3. add a new method `createGlobalTempView` in `Dataset`
## How was this patch tested?
new tests in `SQLViewSuite`
Author: Wenchen Fan <wenchen@databricks.com>
Closes#14897 from cloud-fan/global-temp-view.
## What changes were proposed in this pull request?
This PR adds a new project ` external/kafka-0-10-sql` for Structured Streaming Kafka source.
It's based on the design doc: https://docs.google.com/document/d/19t2rWe51x7tq2e5AOfrsM9qb8_m7BRuv9fel9i0PqR8/edit?usp=sharing
tdas did most of work and part of them was inspired by koeninger's work.
### Introduction
The Kafka source is a structured streaming data source to poll data from Kafka. The schema of reading data is as follows:
Column | Type
---- | ----
key | binary
value | binary
topic | string
partition | int
offset | long
timestamp | long
timestampType | int
The source can deal with deleting topics. However, the user should make sure there is no Spark job processing the data when deleting a topic.
### Configuration
The user can use `DataStreamReader.option` to set the following configurations.
Kafka Source's options | value | default | meaning
------ | ------- | ------ | -----
startingOffset | ["earliest", "latest"] | "latest" | The start point when a query is started, either "earliest" which is from the earliest offset, or "latest" which is just from the latest offset. Note: This only applies when a new Streaming query is started, and that resuming will always pick up from where the query left off.
failOnDataLost | [true, false] | true | Whether to fail the query when it's possible that data is lost (e.g., topics are deleted, or offsets are out of range). This may be a false alarm. You can disable it when it doesn't work as you expected.
subscribe | A comma-separated list of topics | (none) | The topic list to subscribe. Only one of "subscribe" and "subscribeParttern" options can be specified for Kafka source.
subscribePattern | Java regex string | (none) | The pattern used to subscribe the topic. Only one of "subscribe" and "subscribeParttern" options can be specified for Kafka source.
kafka.consumer.poll.timeoutMs | long | 512 | The timeout in milliseconds to poll data from Kafka in executors
fetchOffset.numRetries | int | 3 | Number of times to retry before giving up fatch Kafka latest offsets.
fetchOffset.retryIntervalMs | long | 10 | milliseconds to wait before retrying to fetch Kafka offsets
Kafka's own configurations can be set via `DataStreamReader.option` with `kafka.` prefix, e.g, `stream.option("kafka.bootstrap.servers", "host:port")`
### Usage
* Subscribe to 1 topic
```Scala
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host:port")
.option("subscribe", "topic1")
.load()
```
* Subscribe to multiple topics
```Scala
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host:port")
.option("subscribe", "topic1,topic2")
.load()
```
* Subscribe to a pattern
```Scala
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host:port")
.option("subscribePattern", "topic.*")
.load()
```
## How was this patch tested?
The new unit tests.
Author: Shixiong Zhu <shixiong@databricks.com>
Author: Tathagata Das <tathagata.das1565@gmail.com>
Author: Shixiong Zhu <zsxwing@gmail.com>
Author: cody koeninger <cody@koeninger.org>
Closes#15102 from zsxwing/kafka-source.
## What changes were proposed in this pull request?
Return Iterator of applications internally in history server, for consistency and performance. See https://github.com/apache/spark/pull/15248 for some back-story.
The code called by and calling HistoryServer.getApplicationList wants an Iterator, but this method materializes an Iterable, which potentially causes a performance problem. It's simpler too to make this internal method also pass through an Iterator.
## How was this patch tested?
Existing tests.
Author: Sean Owen <sowen@cloudera.com>
Closes#15321 from srowen/SPARK-17671.
## What changes were proposed in this pull request?
We added find and exists methods for Databases, Tables and Functions to the user facing Catalog in PR https://github.com/apache/spark/pull/15301. However, it was brought up that the semantics of the `find` methods are more in line a `get` method (get an object or else fail). So we rename these in this PR.
## How was this patch tested?
Existing tests.
Author: Herman van Hovell <hvanhovell@databricks.com>
Closes#15308 from hvanhovell/SPARK-17717-2.
## What changes were proposed in this pull request?
The current user facing catalog does not implement methods for checking object existence or finding objects. You could theoretically do this using the `list*` commands, but this is rather cumbersome and can actually be costly when there are many objects. This PR adds `exists*` and `find*` methods for Databases, Table and Functions.
## How was this patch tested?
Added tests to `org.apache.spark.sql.internal.CatalogSuite`
Author: Herman van Hovell <hvanhovell@databricks.com>
Closes#15301 from hvanhovell/SPARK-17717.
## What changes were proposed in this pull request?
Several performance improvement for ```ChiSqSelector```:
1, Keep ```selectedFeatures``` ordered ascendent.
```ChiSqSelectorModel.transform``` need ```selectedFeatures``` ordered to make prediction. We should sort it when training model rather than making prediction, since users usually train model once and use the model to do prediction multiple times.
2, When training ```fpr``` type ```ChiSqSelectorModel```, it's not necessary to sort the ChiSq test result by statistic.
## How was this patch tested?
Existing unit tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#15277 from yanboliang/spark-17704.
Currently task metrics don't support executor CPU time, so there's no way to calculate how much CPU time a stage/task took from History Server metrics. This PR enables reporting CPU time.
Author: jisookim <jisookim0513@gmail.com>
Closes#10212 from jisookim0513/add-cpu-time-metric.
This was missing, preventing code that uses javax.crypto to properly
compile in Spark.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#15204 from vanzin/SPARK-17639.
## What changes were proposed in this pull request?
Allow Spark 2.x to load instances of LDA, LocalLDAModel, and DistributedLDAModel saved from Spark 1.6.
## How was this patch tested?
I tested this manually, saving the 3 types from 1.6 and loading them into master (2.x). In the future, we can add generic tests for testing backwards compatibility across all ML models in SPARK-15573.
Author: Joseph K. Bradley <joseph@databricks.com>
Closes#15034 from jkbradley/lda-backwards.
## What changes were proposed in this pull request?
We are killing multiple executors together instead of iterating over expensive RPC calls to kill single executor.
## How was this patch tested?
Executed sample spark job to observe executors being killed/removed with dynamic allocation enabled.
Author: Dhruve Ashar <dashar@yahoo-inc.com>
Author: Dhruve Ashar <dhruveashar@gmail.com>
Closes#15152 from dhruve/impr/SPARK-17365.
## What changes were proposed in this pull request?
Univariate feature selection works by selecting the best features based on univariate statistical tests. False Positive Rate (FPR) is a popular univariate statistical test for feature selection. We add a chiSquare Selector based on False Positive Rate (FPR) test in this PR, like it is implemented in scikit-learn.
http://scikit-learn.org/stable/modules/feature_selection.html#univariate-feature-selection
## How was this patch tested?
Add Scala ut
Author: Peng, Meng <peng.meng@intel.com>
Closes#14597 from mpjlu/fprChiSquare.
## What changes were proposed in this pull request?
Merge `MultinomialLogisticRegression` into `LogisticRegression` and remove `MultinomialLogisticRegression`.
Marked as WIP because we should discuss the coefficients API in the model. See discussion below.
JIRA: [SPARK-17163](https://issues.apache.org/jira/browse/SPARK-17163)
## How was this patch tested?
Merged test suites and added some new unit tests.
## Design
### Switching between binomial and multinomial
We default to automatically detecting whether we should run binomial or multinomial lor. We expose a new parameter called `family` which defaults to auto. When "auto" is used, we run normal binomial lor with pivoting if there are 1 or 2 label classes. Otherwise, we run multinomial. If the user explicitly sets the family, then we abide by that setting. In the case where "binomial" is set but multiclass lor is detected, we throw an error.
### coefficients/intercept model API (TODO)
This is the biggest design point remaining, IMO. We need to decide how to store the coefficients and intercepts in the model, and in turn how to expose them via the API. Two important points:
* We must maintain compatibility with the old API, i.e. we must expose `def coefficients: Vector` and `def intercept: Double`
* There are two separate cases: binomial lr where we have a single set of coefficients and a single intercept and multinomial lr where we have `numClasses` sets of coefficients and `numClasses` intercepts.
Some options:
1. **Store the binomial coefficients as a `2 x numFeatures` matrix.** This means that we would center the model coefficients before storing them in the model. The BLOR algorithm gives `1 * numFeatures` coefficients, but we would convert them to `2 x numFeatures` coefficients before storing them, effectively doubling the storage in the model. This has the advantage that we can make the code cleaner (i.e. less `if (isMultinomial) ... else ...`) and we don't have to reason about the different cases as much. It has the disadvantage that we double the storage space and we could see small regressions at prediction time since there are 2x the number of operations in the prediction algorithms. Additionally, we still have to produce the uncentered coefficients/intercept via the API, so we will have to either ALSO store the uncentered version, or compute it in `def coefficients: Vector` every time.
2. **Store the binomial coefficients as a `1 x numFeatures` matrix.** We still store the coefficients as a matrix and the intercepts as a vector. When users call `coefficients` we return them a `Vector` that is backed by the same underlying array as the `coefficientMatrix`, so we don't duplicate any data. At prediction time, we use the old prediction methods that are specialized for binary LOR. The benefits here are that we don't store extra data, and we won't see any regressions in performance. The cost of this is that we have separate implementations for predict methods in the binary vs multiclass case. The duplicated code is really not very high, but it's still a bit messy.
If we do decide to store the 2x coefficients, we would likely want to see some performance tests to understand the potential regressions.
**Update:** We have chosen option 2
### Threshold/thresholds (TODO)
Currently, when `threshold` is set we clear whatever value is in `thresholds` and when `thresholds` is set we clear whatever value is in `threshold`. [SPARK-11543](https://issues.apache.org/jira/browse/SPARK-11543) was created to prefer thresholds over threshold. We should decide if we should implement this behavior now or if we want to do it in a separate JIRA.
**Update:** Let's leave it for a follow up PR
## Follow up
* Summary model for multiclass logistic regression [SPARK-17139](https://issues.apache.org/jira/browse/SPARK-17139)
* Thresholds vs threshold [SPARK-11543](https://issues.apache.org/jira/browse/SPARK-11543)
Author: sethah <seth.hendrickson16@gmail.com>
Closes#14834 from sethah/SPARK-17163.
## What changes were proposed in this pull request?
Following https://github.com/apache/spark/pull/14969 for some reason the MiMa excludes weren't complete, but still passed the PR builder. This adds 3 more excludes from https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-2.2/1749/consoleFull
It also moves the excludes to their own Seq in the build, as they probably should have been.
Even though this is merged to 2.1.x only / master, I left the exclude in for 2.0.x in case we back port. It's a private API so is always a false positive.
## How was this patch tested?
Jenkins build
Author: Sean Owen <sowen@cloudera.com>
Closes#15110 from srowen/SPARK-17406.2.
## What changes were proposed in this pull request?
The job page will be too slow to open when there are thousands of executor events(added or removed). I found that in ExecutorsTab file, executorIdToData will not remove elements, it will increase all the time.Before this pr, it looks like [timeline1.png](https://issues.apache.org/jira/secure/attachment/12827112/timeline1.png). After this pr, it looks like [timeline2.png](https://issues.apache.org/jira/secure/attachment/12827113/timeline2.png)(we can set how many executor events will be displayed)
Author: cenyuhai <cenyuhai@didichuxing.com>
Closes#14969 from cenyuhai/SPARK-17406.
This patch makes a handful of post-Spark-2.0 MiMa exclusion and build updates. It should be merged to master and a subset of it should be picked into branch-2.0 in order to test Spark 2.0.1-SNAPSHOT.
- Remove the ` sketch`, `mllibLocal`, and `streamingKafka010` from the list of excluded subprojects so that MiMa checks them.
- Remove now-unnecessary special-case handling of the Kafka 0.8 artifact in `mimaSettings`.
- Move the exclusion added in SPARK-14743 from `v20excludes` to `v21excludes`, since that patch was only merged into master and not branch-2.0.
- Add exclusions for an API change introduced by SPARK-17096 / #14675.
- Add missing exclusions for the `o.a.spark.internal` and `o.a.spark.sql.internal` packages.
Author: Josh Rosen <joshrosen@databricks.com>
Closes#15061 from JoshRosen/post-2.0-mima-changes.
## What changes were proposed in this pull request?
Improved the code quality of spark by replacing all pattern match on boolean value by if/else block.
## How was this patch tested?
By running the tests
Author: Shivansh <shiv4nsh@gmail.com>
Closes#14873 from shiv4nsh/SPARK-17308.
## What changes were proposed in this pull request?
Move Mesos code into a mvn module
## How was this patch tested?
unit tests
manually submitting a client mode and cluster mode job
spark/mesos integration test suite
Author: Michael Gummelt <mgummelt@mesosphere.io>
Closes#14637 from mgummelt/mesos-module.
## What changes were proposed in this pull request?
Add a configurable token manager for Spark on running on yarn.
### Current Problems ###
1. Supported token provider is hard-coded, currently only hdfs, hbase and hive are supported and it is impossible for user to add new token provider without code changes.
2. Also this problem exits in timely token renewer and updater.
### Changes In This Proposal ###
In this proposal, to address the problems mentioned above and make the current code more cleaner and easier to understand, mainly has 3 changes:
1. Abstract a `ServiceTokenProvider` as well as `ServiceTokenRenewable` interface for token provider. Each service wants to communicate with Spark through token way needs to implement this interface.
2. Provide a `ConfigurableTokenManager` to manage all the register token providers, also token renewer and updater. Also this class offers the API for other modules to obtain tokens, get renewal interval and so on.
3. Implement 3 built-in token providers `HDFSTokenProvider`, `HiveTokenProvider` and `HBaseTokenProvider` to keep the same semantics as supported today. Whether to load in these built-in token providers is controlled by configuration "spark.yarn.security.tokens.${service}.enabled", by default for all the built-in token providers are loaded.
### Behavior Changes ###
For the end user there's no behavior change, we still use the same configuration `spark.yarn.security.tokens.${service}.enabled` to decide which token provider is enabled (hbase or hive).
For user implemented token provider (assume the name of token provider is "test") needs to add into this class should have two configurations:
1. `spark.yarn.security.tokens.test.enabled` to true
2. `spark.yarn.security.tokens.test.class` to the full qualified class name.
So we still keep the same semantics as current code while add one new configuration.
### Current Status ###
- [x] token provider interface and management framework.
- [x] implement built-in token providers (hdfs, hbase, hive).
- [x] Coverage of unit test.
- [x] Integrated test with security cluster.
## How was this patch tested?
Unit test and integrated test.
Please suggest and review, any comment is greatly appreciated.
Author: jerryshao <sshao@hortonworks.com>
Closes#14065 from jerryshao/SPARK-16342.
## What changes were proposed in this pull request?
For DataSet typed select:
```
def select[U1: Encoder](c1: TypedColumn[T, U1]): Dataset[U1]
```
If type T is a case class or a tuple class that is not atomic, the resulting logical plan's schema will mismatch with `Dataset[T]` encoder's schema, which will cause encoder error and throw AnalysisException.
### Before change:
```
scala> case class A(a: Int, b: Int)
scala> Seq((0, A(1,2))).toDS.select($"_2".as[A])
org.apache.spark.sql.AnalysisException: cannot resolve '`a`' given input columns: [_2];
..
```
### After change:
```
scala> case class A(a: Int, b: Int)
scala> Seq((0, A(1,2))).toDS.select($"_2".as[A]).show
+---+---+
| a| b|
+---+---+
| 1| 2|
+---+---+
```
## How was this patch tested?
Unit test.
Author: Sean Zhong <seanzhong@databricks.com>
Closes#14474 from clockfly/SPARK-16853.
## What changes were proposed in this pull request?
It would be useful to support listing the columns that are referenced by a filter. This can help simplify data source planning, because with this we would be able to implement unhandledFilters method in HadoopFsRelation.
This is based on rxin's patch (#13901) and adds unit tests.
## How was this patch tested?
Added a new suite FiltersSuite.
Author: petermaxlee <petermaxlee@gmail.com>
Author: Reynold Xin <rxin@databricks.com>
Closes#14120 from petermaxlee/SPARK-16199.
## What changes were proposed in this pull request?
It is currently fairly difficult to have proper mima excludes when we cut a version branch. I'm proposing a small change to take the exclude list out of the exclude function, and put it in a variable so we can easily union excludes.
After this change, we can bump pom.xml version to 2.1.0-SNAPSHOT, without bumping the diff base version. Note that I also deleted all the exclude rules for version 1.x, to cut down the size of the file.
## How was this patch tested?
N/A - this is a build infra change.
Author: Reynold Xin <rxin@databricks.com>
Closes#14128 from rxin/SPARK-16476.
## What changes were proposed in this pull request?
This patches `MemoryAllocator` to fill clean and freed memory with known byte values, similar to https://github.com/jemalloc/jemalloc/wiki/Use-Case:-Find-a-memory-corruption-bug . Memory filling is flag-enabled in test only by default.
## How was this patch tested?
Unit test that it's on in test.
cc sameeragarwal
Author: Eric Liang <ekl@databricks.com>
Closes#13983 from ericl/spark-16021.
## What changes were proposed in this pull request?
during sbt unidoc task, skip the streamingKafka010 subproject and filter kafka 0.10 classes from the classpath, so that at least existing kafka 0.8 doc can be included in unidoc without error
## How was this patch tested?
sbt spark/scalaunidoc:doc | grep -i error
Author: cody koeninger <cody@koeninger.org>
Closes#14041 from koeninger/SPARK-16359.
Link to Jira issue: https://issues.apache.org/jira/browse/SPARK-16353
## What changes were proposed in this pull request?
The javadoc options for the java unidoc generation are ignored when generating the java unidoc. For example, the generated `index.html` has the wrong HTML page title. This can be seen at http://spark.apache.org/docs/latest/api/java/index.html.
I changed the relevant setting scope from `doc` to `(JavaUnidoc, unidoc)`.
## How was this patch tested?
I ran `docs/jekyll build` and verified that the java unidoc `index.html` has the correct HTML page title.
Author: Michael Allman <michael@videoamp.com>
Closes#14031 from mallman/spark-16353.
## What changes were proposed in this pull request?
New Kafka consumer api for the released 0.10 version of Kafka
## How was this patch tested?
Unit tests, manual tests
Author: cody koeninger <cody@koeninger.org>
Closes#11863 from koeninger/kafka-0.9.
## What changes were proposed in this pull request?
In 1.4 and earlier releases, we have package grouping in the generated Java API docs. See http://spark.apache.org/docs/1.4.0/api/java/index.html. However, this disappeared in 1.5.0: http://spark.apache.org/docs/1.5.0/api/java/index.html.
Rather than fixing it, I'd suggest removing grouping. Because it might take some time to fix and it is a manual process to update the grouping in `SparkBuild.scala`. I didn't find anyone complaining about missing groups since 1.5.0 on Google.
Manually checked the generated Java API docs and confirmed that they are the same as in master.
Author: Xiangrui Meng <meng@databricks.com>
Closes#13856 from mengxr/SPARK-16155.
## What changes were proposed in this pull request?
The way bash script `build/spark-build-info` is called from core/pom.xml prevents Spark building on Windows. Instead of calling the script directly we call bash and pass the script as an argument. This enables running it on Windows with bash installed which typically comes with Git.
This brings https://github.com/apache/spark/pull/13612 up-to-date and also addresses comments from the code review.
Closes#13612
## How was this patch tested?
I built manually (on a Mac) to verify it didn't break Mac compilation.
Author: Reynold Xin <rxin@databricks.com>
Author: avulanov <nashb@yandex.ru>
Closes#13691 from rxin/SPARK-15851.
## What changes were proposed in this pull request?
Revert partial changes in SPARK-12600, and add some deprecated method back to SQLContext for backward source code compatibility.
## How was this patch tested?
Manual test.
Author: Sean Zhong <seanzhong@databricks.com>
Closes#13637 from clockfly/SPARK-15914.
## What changes were proposed in this pull request?
These were not updated after performance improvements. To make updating them easier, I also moved the results from inline comments out into a file, which is auto-generated when the benchmark is re-run.
Author: Eric Liang <ekl@databricks.com>
Closes#13607 from ericl/sc-3538.
Spark's SBT build currently uses a fork of the sbt-pom-reader plugin but depends on that fork via a SBT subproject which is cloned from https://github.com/scrapcodes/sbt-pom-reader/tree/ignore_artifact_id. This unnecessarily slows down the initial build on fresh machines and is also risky because it risks a build breakage in case that GitHub repository ever changes or is deleted.
In order to address these issues, I have published a pre-built binary of our forked sbt-pom-reader plugin to Maven Central under the `org.spark-project` namespace and have updated Spark's build to use that artifact. This published artifact was built from https://github.com/JoshRosen/sbt-pom-reader/tree/v1.0.0-spark, which contains the contents of ScrapCodes's branch plus an additional patch to configure the build for artifact publication.
/cc srowen ScrapCodes for review.
Author: Josh Rosen <joshrosen@databricks.com>
Closes#13564 from JoshRosen/use-published-fork-of-pom-reader.
## What changes were proposed in this pull request?
Change the way spark picks up version information. Also embed the build information to better identify the spark version running.
More context can be found here : https://github.com/apache/spark/pull/12152
## How was this patch tested?
Ran the mvn and sbt builds to verify the version information was being displayed correctly on executing <code>spark-submit --version </code>

Author: Dhruve Ashar <dhruveashar@gmail.com>
Closes#13061 from dhruve/impr/SPARK-14279.
This helps with preventing jdk8-specific calls being checked in,
because PR builders are running the compiler with the wrong settings.
If the JAVA_7_HOME env variable is set, assume it points at
a jdk7 and use its rt.jar when invoking javac. For zinc, just run
it with jdk7, and disable it when building jdk8-specific code.
A big note for sbt usage: adding the bootstrap options forces sbt
to fork the compiler, and that disables incremental compilation.
That means that it's really not convenient to use for normal
development, but should be ok for automated builds.
Tested with JAVA_HOME=jdk8 and JAVA_7_HOME=jdk7:
- mvn + zinc
- mvn sans zinc
- sbt
Verified that in all cases, jdk8-specific library calls fail to
compile.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#13272 from vanzin/SPARK-15451.
## What changes were proposed in this pull request?
We're using `asML` to convert the mllib vector/matrix to ml vector/matrix now. Using `as` is more correct given that this conversion actually shares the same underline data structure. As a result, in this PR, `toBreeze` will be changed to `asBreeze`. This is a private API, as a result, it will not affect any user's application.
## How was this patch tested?
unit tests
Author: DB Tsai <dbt@netflix.com>
Closes#13198 from dbtsai/minor.
## What changes were proposed in this pull request?
This PR changes SQLContext/HiveContext's public constructor to use SparkSession.build.getOrCreate and removes isRootContext from SQLContext.
## How was this patch tested?
Existing tests.
Author: Yin Huai <yhuai@databricks.com>
Closes#13310 from yhuai/SPARK-15532.
## What changes were proposed in this pull request?
This patch renames various DefaultSources to make their names more self-describing. The choice of "DefaultSource" was from the days when we did not have a good way to specify short names.
They are now named:
- LibSVMFileFormat
- CSVFileFormat
- JdbcRelationProvider
- JsonFileFormat
- ParquetFileFormat
- TextFileFormat
Backward compatibility is maintained through aliasing.
## How was this patch tested?
Updated relevant test cases too.
Author: Reynold Xin <rxin@databricks.com>
Closes#13311 from rxin/SPARK-15543.
## What changes were proposed in this pull request?
The ANTLR4 SBT plugin has been moved from its own repo to one on bintray. The version was also changed from `0.7.10` to `0.7.11`. The latter actually broke our build (ihji has fixed this by also adding `0.7.10` and others to the bin-tray repo).
This PR upgrades the SBT-ANTLR4 plugin and ANTLR4 to their most recent versions (`0.7.11`/`4.5.3`). I have also removed a few obsolete build configurations.
## How was this patch tested?
Manually running SBT/Maven builds.
Author: Herman van Hovell <hvanhovell@questtec.nl>
Closes#13299 from hvanhovell/SPARK-15525.
## What changes were proposed in this pull request?
I initially asked to create a hivecontext-compatibility module to put the HiveContext there. But we are so close to Spark 2.0 release and there is only a single class in it. It seems overkill to have an entire package, which makes it more inconvenient, for a single class.
## How was this patch tested?
Tests were moved.
Author: Reynold Xin <rxin@databricks.com>
Closes#13207 from rxin/SPARK-15424.
## What changes were proposed in this pull request?
Since we support forced spilling for Spillable, which only works in OnHeap mode, different from other SQL operators (could be OnHeap or OffHeap), we should considering the mode of consumer before calling trigger forced spilling.
## How was this patch tested?
Add new test.
Author: Davies Liu <davies@databricks.com>
Closes#13151 from davies/fix_mode.
## What changes were proposed in this pull request?
Once SPARK-14487 and SPARK-14549 are merged, we will migrate to use the new vector and matrix type in the new ml pipeline based apis.
## How was this patch tested?
Unit tests
Author: DB Tsai <dbt@netflix.com>
Author: Liang-Chi Hsieh <simonh@tw.ibm.com>
Author: Xiangrui Meng <meng@databricks.com>
Closes#12627 from dbtsai/SPARK-14615-NewML.
## What changes were proposed in this pull request?
(See https://github.com/apache/spark/pull/12416 where most of this was already reviewed and committed; this is just the module structure and move part. This change does not move the annotations into test scope, which was the apparently problem last time.)
Rename `spark-test-tags` -> `spark-tags`; move common annotations like `Since` to `spark-tags`
## How was this patch tested?
Jenkins tests.
Author: Sean Owen <sowen@cloudera.com>
Closes#13074 from srowen/SPARK-15290.
## What changes were proposed in this pull request?
Renaming the streaming-kafka artifact to include kafka version, in anticipation of needing a different artifact for later kafka versions
## How was this patch tested?
Unit tests
Author: cody koeninger <cody@koeninger.org>
Closes#12946 from koeninger/SPARK-15085.
## What changes were proposed in this pull request?
This PR removes the old `json(path: String)` API which is covered by the new `json(paths: String*)`.
## How was this patch tested?
Jenkins tests (existing tests should cover this)
Author: hyukjinkwon <gurwls223@gmail.com>
Author: Hyukjin Kwon <gurwls223@gmail.com>
Closes#13040 from HyukjinKwon/SPARK-15250.
## What changes were proposed in this pull request?
Currently PipedRDD internally uses PrintWriter to write data to the stdin of the piped process, which by default uses a BufferedWriter of buffer size 8k. In our experiment, we have seen that 8k buffer size is too small and the job spends significant amount of CPU time in system calls to copy the data. We should have a way to configure the buffer size for the writer.
## How was this patch tested?
Ran PipedRDDSuite tests.
Author: Sital Kedia <skedia@fb.com>
Closes#12309 from sitalkedia/bufferedPipedRDD.
## What changes were proposed in this pull request?
Removed blockTransferService and sparkFilesDir from SparkEnv since they're rarely used and don't need to be in stored in the env. Edited their few usages to accommodate the change.
## How was this patch tested?
ran dev/run-tests locally
Author: Alex Bozarth <ajbozart@us.ibm.com>
Closes#12970 from ajbozarth/spark10653.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}