Parquet may call the filter with a null value to check whether nulls are
accepted. While it seems Spark avoids that path in Parquet with 1.10, in
1.11 that causes Spark unit tests to fail.
Tested with Parquet 1.11 (and new unit test).
Closes#25140 from vanzin/SPARK-28371.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This patch fixes the flaky test "query without test harness" on ContinuousSuite, via adding some more gaps on waiting query to commit the epoch which writes output rows.
The observation of this issue is below (injected some debug logs to get them):
```
reader creation time 1562225320210
epoch 1 launched 1562225320593 (+380ms from reader creation time)
epoch 13 launched 1562225321702 (+1.5s from reader creation time)
partition reader creation time 1562225321715 (+1.5s from reader creation time)
next read time for first next call 1562225321210 (+1s from reader creation time)
first next called in partition reader 1562225321746 (immediately after creation of partition reader)
wait finished in next called in partition reader 1562225321746 (no wait)
second next called in partition reader 1562225321747 (immediately after first next())
epoch 0 commit started 1562225321861
writing rows (0, 1) (belong to epoch 13) 1562225321866 (+100ms after first next())
wait start in waitForRateSourceTriggers(2) 1562225322059
next read time for second next call 1562225322210 (+1s from previous "next read time")
wait finished in next called in partition reader 1562225322211 (+450ms wait)
writing rows (2, 3) (belong to epoch 13) 1562225322211 (immediately after next())
epoch 14 launched 1562225322246
desired wait time in waitForRateSourceTriggers(2) 1562225322510 (+2.3s from reader creation time)
epoch 12 committed 1562225323034
```
These rows were written within desired wait time, but the epoch 13 couldn't be committed within it. Interestingly, epoch 12 was lucky to be committed within a gap between finished waiting in waitForRateSourceTriggers and query.stop() - but even suppose the rows were written in epoch 12, it would be just in luck and epoch should be committed within desired wait time.
This patch modifies Rate continuous stream to track the highest committed value, so that test can wait until desired value is reported to the stream as committed.
This patch also modifies Rate continuous stream to track the timestamp at stream gets the first committed offset, and let `waitForRateSourceTriggers` use the timestamp. This also relies on waiting for specific period, but safer approach compared to current based on the observation above. Based on the change, this patch saves couple of seconds in test time.
## How was this patch tested?
10 sequential test runs succeeded locally.
Closes#25048 from HeartSaVioR/SPARK-28247.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
A code gen test in WholeStageCodeGenSuite was flaky because it used the codegen metrics class to test if the generated code for equivalent plans was identical under a particular flag. This patch switches the test to compare the generated code directly.
N/A
Closes#25131 from gatorsmile/WholeStageCodegenSuite.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds compatibility of handling a `WITH` clause within another `WITH` cause. Before this PR these queries retuned `1` while after this PR they return `2` as PostgreSQL does:
```
WITH
t AS (SELECT 1),
t2 AS (
WITH t AS (SELECT 2)
SELECT * FROM t
)
SELECT * FROM t2
```
```
WITH t AS (SELECT 1)
SELECT (
WITH t AS (SELECT 2)
SELECT * FROM t
)
```
As this is an incompatible change, the PR introduces the `spark.sql.legacy.cte.substitution.enabled` flag as an option to restore old behaviour.
## How was this patch tested?
Added new UTs.
Closes#25029 from peter-toth/SPARK-28228.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
There are some hardcoded configs, using config entry to replace them.
## How was this patch tested?
Existing UT
Closes#25059 from WangGuangxin/ConfigEntry.
Authored-by: wangguangxin.cn <wangguangxin.cn@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
0-args Java UDF alone calls the function even before making it as an expression.
It causes that the function always returns the same value and the function is called at driver side.
Seems like a mistake.
## How was this patch tested?
Unit test was added
Closes#25108 from HyukjinKwon/SPARK-28321.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Implement `ALTER TABLE` for v2 tables:
* Add `AlterTable` logical plan and `AlterTableExec` physical plan
* Convert `ALTER TABLE` parsed plans to `AlterTable` when a v2 catalog is responsible for an identifier
* Validate that columns to alter exist in analyzer checks
* Fix nested type handling in `CatalogV2Util`
## How was this patch tested?
* Add extensive tests in `DataSourceV2SQLSuite`
Closes#24937 from rdblue/SPARK-28139-add-v2-alter-table.
Lead-authored-by: Ryan Blue <blue@apache.org>
Co-authored-by: Ryan Blue <rdblue@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Cleaned up (removed) code duplication in `ObjectProducerExec` operators so they use the trait's methods.
## How was this patch tested?
Local build. Waiting for Jenkins.
Closes#25065 from jaceklaskowski/ObjectProducerExec-operators-cleanup.
Authored-by: Jacek Laskowski <jacek@japila.pl>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This is a second part of the https://issues.apache.org/jira/browse/SPARK-27396 and a follow on to #24795
## How was this patch tested?
I did some manual tests and ran/updated the automated tests
I did some simple performance tests on a single node to try to verify that there is no performance impact, and I was not able to measure anything beyond noise.
Closes#25008 from revans2/columnar-remove-batch-scan.
Authored-by: Robert (Bobby) Evans <bobby@apache.org>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
The tests added at https://github.com/apache/spark/pull/25069 seem flaky in some environments. See https://github.com/apache/spark/pull/25069#issuecomment-510338469
Python's string representation of floats can make the tests flaky. See https://docs.python.org/3/tutorial/floatingpoint.html.
I think it's just better to explicitly cast everywhere udf returns a float (or a double) to stay safe. (note that we're not targeting the Python <> Scala value conversions - there are inevitable differences between Python and Scala; therefore, other languages' UDFs cannot guarantee the same results between Python and Scala).
This PR proposes to cast cases to long, integer and decimal explicitly to make the test cases robust.
<details><summary>Diff comparing to 'pgSQL/aggregates_part1.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/pgSQL/aggregates_part1.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-aggregates_part1.sql.out
index 51ca1d55869..734634b7388 100644
--- a/sql/core/src/test/resources/sql-tests/results/pgSQL/aggregates_part1.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-aggregates_part1.sql.out
-3,23 +3,23
-- !query 0
-SELECT avg(four) AS avg_1 FROM onek
+SELECT CAST(avg(udf(four)) AS decimal(10,3)) AS avg_1 FROM onek
-- !query 0 schema
-struct<avg_1:double>
+struct<avg_1:decimal(10,3)>
-- !query 0 output
1.5
-- !query 1
-SELECT avg(a) AS avg_32 FROM aggtest WHERE a < 100
+SELECT CAST(udf(avg(a)) AS decimal(10,3)) AS avg_32 FROM aggtest WHERE a < 100
-- !query 1 schema
-struct<avg_32:double>
+struct<avg_32:decimal(10,3)>
-- !query 1 output
-32.666666666666664
+32.667
-- !query 2
-select CAST(avg(b) AS Decimal(10,3)) AS avg_107_943 FROM aggtest
+select CAST(avg(udf(b)) AS Decimal(10,3)) AS avg_107_943 FROM aggtest
-- !query 2 schema
struct<avg_107_943:decimal(10,3)>
-- !query 2 output
-27,39 +27,39 struct<avg_107_943:decimal(10,3)>
-- !query 3
-SELECT sum(four) AS sum_1500 FROM onek
+SELECT CAST(sum(udf(four)) AS int) AS sum_1500 FROM onek
-- !query 3 schema
-struct<sum_1500:bigint>
+struct<sum_1500:int>
-- !query 3 output
1500
-- !query 4
-SELECT sum(a) AS sum_198 FROM aggtest
+SELECT udf(sum(a)) AS sum_198 FROM aggtest
-- !query 4 schema
-struct<sum_198:bigint>
+struct<sum_198:string>
-- !query 4 output
198
-- !query 5
-SELECT sum(b) AS avg_431_773 FROM aggtest
+SELECT CAST(udf(udf(sum(b))) AS decimal(10,3)) AS avg_431_773 FROM aggtest
-- !query 5 schema
-struct<avg_431_773:double>
+struct<avg_431_773:decimal(10,3)>
-- !query 5 output
-431.77260909229517
+431.773
-- !query 6
-SELECT max(four) AS max_3 FROM onek
+SELECT udf(max(four)) AS max_3 FROM onek
-- !query 6 schema
-struct<max_3:int>
+struct<max_3:string>
-- !query 6 output
3
-- !query 7
-SELECT max(a) AS max_100 FROM aggtest
+SELECT max(CAST(udf(a) AS int)) AS max_100 FROM aggtest
-- !query 7 schema
struct<max_100:int>
-- !query 7 output
-67,245 +67,246 struct<max_100:int>
-- !query 8
-SELECT max(aggtest.b) AS max_324_78 FROM aggtest
+SELECT CAST(udf(udf(max(aggtest.b))) AS decimal(10,3)) AS max_324_78 FROM aggtest
-- !query 8 schema
-struct<max_324_78:float>
+struct<max_324_78:decimal(10,3)>
-- !query 8 output
324.78
-- !query 9
-SELECT stddev_pop(b) FROM aggtest
+SELECT CAST(stddev_pop(udf(b)) AS decimal(10,3)) FROM aggtest
-- !query 9 schema
-struct<stddev_pop(CAST(b AS DOUBLE)):double>
+struct<CAST(stddev_pop(CAST(udf(b) AS DOUBLE)) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 9 output
-131.10703231895047
+131.107
-- !query 10
-SELECT stddev_samp(b) FROM aggtest
+SELECT CAST(udf(stddev_samp(b)) AS decimal(10,3)) FROM aggtest
-- !query 10 schema
-struct<stddev_samp(CAST(b AS DOUBLE)):double>
+struct<CAST(udf(stddev_samp(cast(b as double))) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 10 output
-151.38936080399804
+151.389
-- !query 11
-SELECT var_pop(b) FROM aggtest
+SELECT CAST(var_pop(udf(b)) AS decimal(10,3)) FROM aggtest
-- !query 11 schema
-struct<var_pop(CAST(b AS DOUBLE)):double>
+struct<CAST(var_pop(CAST(udf(b) AS DOUBLE)) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 11 output
-17189.053923482323
+17189.054
-- !query 12
-SELECT var_samp(b) FROM aggtest
+SELECT CAST(udf(var_samp(b)) AS decimal(10,3)) FROM aggtest
-- !query 12 schema
-struct<var_samp(CAST(b AS DOUBLE)):double>
+struct<CAST(udf(var_samp(cast(b as double))) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 12 output
-22918.738564643096
+22918.739
-- !query 13
-SELECT stddev_pop(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT CAST(udf(stddev_pop(CAST(b AS Decimal(38,0)))) AS decimal(10,3)) FROM aggtest
-- !query 13 schema
-struct<stddev_pop(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<CAST(udf(stddev_pop(cast(cast(b as decimal(38,0)) as double))) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 13 output
-131.18117242958306
+131.181
-- !query 14
-SELECT stddev_samp(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT CAST(stddev_samp(CAST(udf(b) AS Decimal(38,0))) AS decimal(10,3)) FROM aggtest
-- !query 14 schema
-struct<stddev_samp(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<CAST(stddev_samp(CAST(CAST(udf(b) AS DECIMAL(38,0)) AS DOUBLE)) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 14 output
-151.47497042966097
+151.475
-- !query 15
-SELECT var_pop(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT CAST(udf(var_pop(CAST(b AS Decimal(38,0)))) AS decimal(10,3)) FROM aggtest
-- !query 15 schema
-struct<var_pop(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<CAST(udf(var_pop(cast(cast(b as decimal(38,0)) as double))) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 15 output
17208.5
-- !query 16
-SELECT var_samp(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT CAST(var_samp(udf(CAST(b AS Decimal(38,0)))) AS decimal(10,3)) FROM aggtest
-- !query 16 schema
-struct<var_samp(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<CAST(var_samp(CAST(udf(cast(b as decimal(38,0))) AS DOUBLE)) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 16 output
-22944.666666666668
+22944.667
-- !query 17
-SELECT var_pop(1.0), var_samp(2.0)
+SELECT CAST(udf(var_pop(1.0)) AS int), var_samp(udf(2.0))
-- !query 17 schema
-struct<var_pop(CAST(1.0 AS DOUBLE)):double,var_samp(CAST(2.0 AS DOUBLE)):double>
+struct<CAST(udf(var_pop(cast(1.0 as double))) AS INT):int,var_samp(CAST(udf(2.0) AS DOUBLE)):double>
-- !query 17 output
-0.0 NaN
+0 NaN
-- !query 18
-SELECT stddev_pop(CAST(3.0 AS Decimal(38,0))), stddev_samp(CAST(4.0 AS Decimal(38,0)))
+SELECT CAST(stddev_pop(udf(CAST(3.0 AS Decimal(38,0)))) AS int), stddev_samp(CAST(udf(4.0) AS Decimal(38,0)))
-- !query 18 schema
-struct<stddev_pop(CAST(CAST(3.0 AS DECIMAL(38,0)) AS DOUBLE)):double,stddev_samp(CAST(CAST(4.0 AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<CAST(stddev_pop(CAST(udf(cast(3.0 as decimal(38,0))) AS DOUBLE)) AS INT):int,stddev_samp(CAST(CAST(udf(4.0) AS DECIMAL(38,0)) AS DOUBLE)):double>
-- !query 18 output
-0.0 NaN
+0 NaN
-- !query 19
-select sum(CAST(null AS int)) from range(1,4)
+select sum(udf(CAST(null AS int))) from range(1,4)
-- !query 19 schema
-struct<sum(CAST(NULL AS INT)):bigint>
+struct<sum(CAST(udf(cast(null as int)) AS DOUBLE)):double>
-- !query 19 output
NULL
-- !query 20
-select sum(CAST(null AS long)) from range(1,4)
+select sum(udf(CAST(null AS long))) from range(1,4)
-- !query 20 schema
-struct<sum(CAST(NULL AS BIGINT)):bigint>
+struct<sum(CAST(udf(cast(null as bigint)) AS DOUBLE)):double>
-- !query 20 output
NULL
-- !query 21
-select sum(CAST(null AS Decimal(38,0))) from range(1,4)
+select sum(udf(CAST(null AS Decimal(38,0)))) from range(1,4)
-- !query 21 schema
-struct<sum(CAST(NULL AS DECIMAL(38,0))):decimal(38,0)>
+struct<sum(CAST(udf(cast(null as decimal(38,0))) AS DOUBLE)):double>
-- !query 21 output
NULL
-- !query 22
-select sum(CAST(null AS DOUBLE)) from range(1,4)
+select sum(udf(CAST(null AS DOUBLE))) from range(1,4)
-- !query 22 schema
-struct<sum(CAST(NULL AS DOUBLE)):double>
+struct<sum(CAST(udf(cast(null as double)) AS DOUBLE)):double>
-- !query 22 output
NULL
-- !query 23
-select avg(CAST(null AS int)) from range(1,4)
+select avg(udf(CAST(null AS int))) from range(1,4)
-- !query 23 schema
-struct<avg(CAST(NULL AS INT)):double>
+struct<avg(CAST(udf(cast(null as int)) AS DOUBLE)):double>
-- !query 23 output
NULL
-- !query 24
-select avg(CAST(null AS long)) from range(1,4)
+select avg(udf(CAST(null AS long))) from range(1,4)
-- !query 24 schema
-struct<avg(CAST(NULL AS BIGINT)):double>
+struct<avg(CAST(udf(cast(null as bigint)) AS DOUBLE)):double>
-- !query 24 output
NULL
-- !query 25
-select avg(CAST(null AS Decimal(38,0))) from range(1,4)
+select avg(udf(CAST(null AS Decimal(38,0)))) from range(1,4)
-- !query 25 schema
-struct<avg(CAST(NULL AS DECIMAL(38,0))):decimal(38,4)>
+struct<avg(CAST(udf(cast(null as decimal(38,0))) AS DOUBLE)):double>
-- !query 25 output
NULL
-- !query 26
-select avg(CAST(null AS DOUBLE)) from range(1,4)
+select avg(udf(CAST(null AS DOUBLE))) from range(1,4)
-- !query 26 schema
-struct<avg(CAST(NULL AS DOUBLE)):double>
+struct<avg(CAST(udf(cast(null as double)) AS DOUBLE)):double>
-- !query 26 output
NULL
-- !query 27
-select sum(CAST('NaN' AS DOUBLE)) from range(1,4)
+select sum(CAST(udf('NaN') AS DOUBLE)) from range(1,4)
-- !query 27 schema
-struct<sum(CAST(NaN AS DOUBLE)):double>
+struct<sum(CAST(udf(NaN) AS DOUBLE)):double>
-- !query 27 output
NaN
-- !query 28
-select avg(CAST('NaN' AS DOUBLE)) from range(1,4)
+select avg(CAST(udf('NaN') AS DOUBLE)) from range(1,4)
-- !query 28 schema
-struct<avg(CAST(NaN AS DOUBLE)):double>
+struct<avg(CAST(udf(NaN) AS DOUBLE)):double>
-- !query 28 output
NaN
-- !query 30
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('Infinity'), ('1')) v(x)
-- !query 30 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(x) AS DOUBLE)):double,var_pop(CAST(udf(x) AS DOUBLE)):double>
-- !query 30 output
Infinity NaN
-- !query 31
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('Infinity'), ('Infinity')) v(x)
-- !query 31 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(x) AS DOUBLE)):double,var_pop(CAST(udf(x) AS DOUBLE)):double>
-- !query 31 output
Infinity NaN
-- !query 32
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('-Infinity'), ('Infinity')) v(x)
-- !query 32 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(x) AS DOUBLE)):double,var_pop(CAST(udf(x) AS DOUBLE)):double>
-- !query 32 output
NaN NaN
-- !query 33
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT CAST(avg(udf(CAST(x AS DOUBLE))) AS int), CAST(udf(var_pop(CAST(x AS DOUBLE))) AS decimal(10,3))
FROM (VALUES (100000003), (100000004), (100000006), (100000007)) v(x)
-- !query 33 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<CAST(avg(CAST(udf(cast(x as double)) AS DOUBLE)) AS INT):int,CAST(udf(var_pop(cast(x as double))) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 33 output
-1.00000005E8 2.5
+100000005 2.5
-- !query 34
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT CAST(avg(udf(CAST(x AS DOUBLE))) AS long), CAST(udf(var_pop(CAST(x AS DOUBLE))) AS decimal(10,3))
FROM (VALUES (7000000000005), (7000000000007)) v(x)
-- !query 34 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<CAST(avg(CAST(udf(cast(x as double)) AS DOUBLE)) AS BIGINT):bigint,CAST(udf(var_pop(cast(x as double))) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 34 output
-7.000000000006E12 1.0
+7000000000006 1
-- !query 35
-SELECT covar_pop(b, a), covar_samp(b, a) FROM aggtest
+SELECT CAST(udf(covar_pop(b, udf(a))) AS decimal(10,3)), CAST(covar_samp(udf(b), a) as decimal(10,3)) FROM aggtest
-- !query 35 schema
-struct<covar_pop(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double,covar_samp(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double>
+struct<CAST(udf(covar_pop(cast(b as double), cast(udf(a) as double))) AS DECIMAL(10,3)):decimal(10,3),CAST(covar_samp(CAST(udf(b) AS DOUBLE), CAST(a AS DOUBLE)) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 35 output
-653.6289553875104 871.5052738500139
+653.629 871.505
-- !query 36
-SELECT corr(b, a) FROM aggtest
+SELECT CAST(corr(b, udf(a)) AS decimal(10,3)) FROM aggtest
-- !query 36 schema
-struct<corr(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double>
+struct<CAST(corr(CAST(b AS DOUBLE), CAST(udf(a) AS DOUBLE)) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 36 output
-0.1396345165178734
+0.14
-- !query 37
-SELECT count(four) AS cnt_1000 FROM onek
+SELECT count(udf(four)) AS cnt_1000 FROM onek
-- !query 37 schema
struct<cnt_1000:bigint>
-- !query 37 output
-313,18 +314,18 struct<cnt_1000:bigint>
-- !query 38
-SELECT count(DISTINCT four) AS cnt_4 FROM onek
+SELECT udf(count(DISTINCT four)) AS cnt_4 FROM onek
-- !query 38 schema
-struct<cnt_4:bigint>
+struct<cnt_4:string>
-- !query 38 output
4
-- !query 39
-select ten, count(*), sum(four) from onek
+select ten, udf(count(*)), CAST(sum(udf(four)) AS int) from onek
group by ten order by ten
-- !query 39 schema
-struct<ten:int,count(1):bigint,sum(four):bigint>
+struct<ten:int,udf(count(1)):string,CAST(sum(CAST(udf(four) AS DOUBLE)) AS INT):int>
-- !query 39 output
0 100 100
1 100 200
-339,10 +340,10 struct<ten:int,count(1):bigint,sum(four):bigint>
-- !query 40
-select ten, count(four), sum(DISTINCT four) from onek
+select ten, count(udf(four)), udf(sum(DISTINCT four)) from onek
group by ten order by ten
-- !query 40 schema
-struct<ten:int,count(four):bigint,sum(DISTINCT four):bigint>
+struct<ten:int,count(udf(four)):bigint,udf(sum(distinct cast(four as bigint))):string>
-- !query 40 output
0 100 2
1 100 4
-357,11 +358,11 struct<ten:int,count(four):bigint,sum(DISTINCT four):bigint>
-- !query 41
-select ten, sum(distinct four) from onek a
+select ten, udf(sum(distinct four)) from onek a
group by ten
-having exists (select 1 from onek b where sum(distinct a.four) = b.four)
+having exists (select 1 from onek b where udf(sum(distinct a.four)) = b.four)
-- !query 41 schema
-struct<ten:int,sum(DISTINCT four):bigint>
+struct<ten:int,udf(sum(distinct cast(four as bigint))):string>
-- !query 41 output
0 2
2 2
-374,23 +375,23 struct<ten:int,sum(DISTINCT four):bigint>
select ten, sum(distinct four) from onek a
group by ten
having exists (select 1 from onek b
- where sum(distinct a.four + b.four) = b.four)
+ where sum(distinct a.four + b.four) = udf(b.four))
-- !query 42 schema
struct<>
-- !query 42 output
org.apache.spark.sql.AnalysisException
Aggregate/Window/Generate expressions are not valid in where clause of the query.
-Expression in where clause: [(sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT)) = CAST(b.`four` AS BIGINT))]
+Expression in where clause: [(sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT)) = CAST(udf(four) AS BIGINT))]
Invalid expressions: [sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT))];
-- !query 43
select
- (select max((select i.unique2 from tenk1 i where i.unique1 = o.unique1)))
+ (select udf(max((select i.unique2 from tenk1 i where i.unique1 = o.unique1))))
from tenk1 o
-- !query 43 schema
struct<>
-- !query 43 output
org.apache.spark.sql.AnalysisException
-cannot resolve '`o.unique1`' given input columns: [i.even, i.fivethous, i.four, i.hundred, i.odd, i.string4, i.stringu1, i.stringu2, i.ten, i.tenthous, i.thousand, i.twenty, i.two, i.twothousand, i.unique1, i.unique2]; line 2 pos 63
+cannot resolve '`o.unique1`' given input columns: [i.even, i.fivethous, i.four, i.hundred, i.odd, i.string4, i.stringu1, i.stringu2, i.ten, i.tenthous, i.thousand, i.twenty, i.two, i.twothousand, i.unique1, i.unique2]; line 2 pos 67
```
</p>
</details>
## How was this patch tested?
Manually tested in local.
Also, with JDK 11:
```
Using /.../jdk-11.0.3.jdk/Contents/Home as default JAVA_HOME.
Note, this will be overridden by -java-home if it is set.
[info] Loading project definition from /.../spark/project
[info] Updating {file:/.../spark/project/}spark-build...
...
[info] SQLQueryTestSuite:
...
[info] - udf/pgSQL/udf-aggregates_part1.sql - Scala UDF (17 seconds, 228 milliseconds)
[info] - udf/pgSQL/udf-aggregates_part1.sql - Regular Python UDF (36 seconds, 170 milliseconds)
[info] - udf/pgSQL/udf-aggregates_part1.sql - Scalar Pandas UDF (41 seconds, 132 milliseconds)
...
```
Closes#25110 from HyukjinKwon/SPARK-28270-1.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
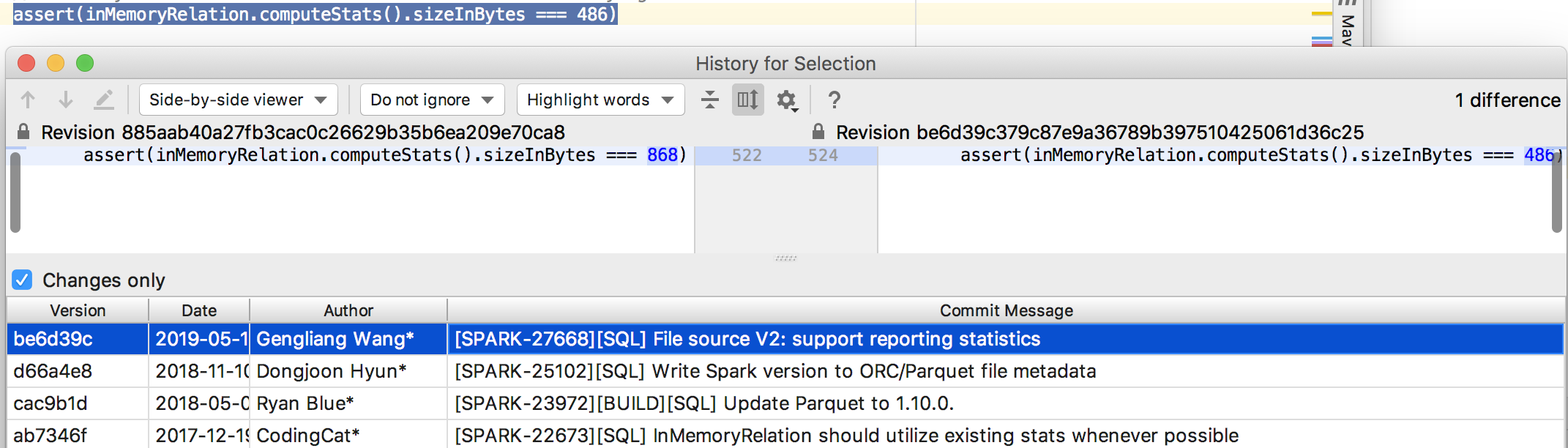
## What changes were proposed in this pull request?
This PR proposes to replace `REL_12_BETA1` to `REL_12_BETA2` which is latest.
## How was this patch tested?
Manually checked each link and checked via `git grep -r REL_12_BETA1` as well.
Closes#25105 from HyukjinKwon/SPARK-28342.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
The new adaptive execution framework introduced configuration `spark.sql.runtime.reoptimization.enabled`. We now rename it back to `spark.sql.adaptive.enabled` as the umbrella configuration for adaptive execution.
## How was this patch tested?
Existing tests.
Closes#25102 from carsonwang/renameAE.
Authored-by: Carson Wang <carson.wang@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR adds some tests converted from `pgSQL/aggregates_part1.sql'` to test UDFs. Please see contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
This PR also contains two minor fixes:
1. Change name of Scala UDF from `UDF:name(...)` to `name(...)` to be consistent with Python'
2. Fix Scala UDF at `IntegratedUDFTestUtils.scala ` to handle `null` in strings.
<details><summary>Diff comparing to 'pgSQL/aggregates_part1.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/pgSQL/aggregates_part1.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-aggregates_part1.sql.out
index 51ca1d55869..124fdd6416e 100644
--- a/sql/core/src/test/resources/sql-tests/results/pgSQL/aggregates_part1.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-aggregates_part1.sql.out
-3,7 +3,7
-- !query 0
-SELECT avg(four) AS avg_1 FROM onek
+SELECT avg(udf(four)) AS avg_1 FROM onek
-- !query 0 schema
struct<avg_1:double>
-- !query 0 output
-11,15 +11,15 struct<avg_1:double>
-- !query 1
-SELECT avg(a) AS avg_32 FROM aggtest WHERE a < 100
+SELECT udf(avg(a)) AS avg_32 FROM aggtest WHERE a < 100
-- !query 1 schema
-struct<avg_32:double>
+struct<avg_32:string>
-- !query 1 output
32.666666666666664
-- !query 2
-select CAST(avg(b) AS Decimal(10,3)) AS avg_107_943 FROM aggtest
+select CAST(avg(udf(b)) AS Decimal(10,3)) AS avg_107_943 FROM aggtest
-- !query 2 schema
struct<avg_107_943:decimal(10,3)>
-- !query 2 output
-27,285 +27,286 struct<avg_107_943:decimal(10,3)>
-- !query 3
-SELECT sum(four) AS sum_1500 FROM onek
+SELECT sum(udf(four)) AS sum_1500 FROM onek
-- !query 3 schema
-struct<sum_1500:bigint>
+struct<sum_1500:double>
-- !query 3 output
-1500
+1500.0
-- !query 4
-SELECT sum(a) AS sum_198 FROM aggtest
+SELECT udf(sum(a)) AS sum_198 FROM aggtest
-- !query 4 schema
-struct<sum_198:bigint>
+struct<sum_198:string>
-- !query 4 output
198
-- !query 5
-SELECT sum(b) AS avg_431_773 FROM aggtest
+SELECT udf(udf(sum(b))) AS avg_431_773 FROM aggtest
-- !query 5 schema
-struct<avg_431_773:double>
+struct<avg_431_773:string>
-- !query 5 output
431.77260909229517
-- !query 6
-SELECT max(four) AS max_3 FROM onek
+SELECT udf(max(four)) AS max_3 FROM onek
-- !query 6 schema
-struct<max_3:int>
+struct<max_3:string>
-- !query 6 output
3
-- !query 7
-SELECT max(a) AS max_100 FROM aggtest
+SELECT max(udf(a)) AS max_100 FROM aggtest
-- !query 7 schema
-struct<max_100:int>
+struct<max_100:string>
-- !query 7 output
-100
+56
-- !query 8
-SELECT max(aggtest.b) AS max_324_78 FROM aggtest
+SELECT CAST(udf(udf(max(aggtest.b))) AS int) AS max_324_78 FROM aggtest
-- !query 8 schema
-struct<max_324_78:float>
+struct<max_324_78:int>
-- !query 8 output
-324.78
+324
-- !query 9
-SELECT stddev_pop(b) FROM aggtest
+SELECT CAST(stddev_pop(udf(b)) AS int) FROM aggtest
-- !query 9 schema
-struct<stddev_pop(CAST(b AS DOUBLE)):double>
+struct<CAST(stddev_pop(CAST(udf(b) AS DOUBLE)) AS INT):int>
-- !query 9 output
-131.10703231895047
+131
-- !query 10
-SELECT stddev_samp(b) FROM aggtest
+SELECT udf(stddev_samp(b)) FROM aggtest
-- !query 10 schema
-struct<stddev_samp(CAST(b AS DOUBLE)):double>
+struct<udf(stddev_samp(cast(b as double))):string>
-- !query 10 output
151.38936080399804
-- !query 11
-SELECT var_pop(b) FROM aggtest
+SELECT CAST(var_pop(udf(b)) as int) FROM aggtest
-- !query 11 schema
-struct<var_pop(CAST(b AS DOUBLE)):double>
+struct<CAST(var_pop(CAST(udf(b) AS DOUBLE)) AS INT):int>
-- !query 11 output
-17189.053923482323
+17189
-- !query 12
-SELECT var_samp(b) FROM aggtest
+SELECT udf(var_samp(b)) FROM aggtest
-- !query 12 schema
-struct<var_samp(CAST(b AS DOUBLE)):double>
+struct<udf(var_samp(cast(b as double))):string>
-- !query 12 output
22918.738564643096
-- !query 13
-SELECT stddev_pop(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT udf(stddev_pop(CAST(b AS Decimal(38,0)))) FROM aggtest
-- !query 13 schema
-struct<stddev_pop(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<udf(stddev_pop(cast(cast(b as decimal(38,0)) as double))):string>
-- !query 13 output
131.18117242958306
-- !query 14
-SELECT stddev_samp(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT stddev_samp(CAST(udf(b) AS Decimal(38,0))) FROM aggtest
-- !query 14 schema
-struct<stddev_samp(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<stddev_samp(CAST(CAST(udf(b) AS DECIMAL(38,0)) AS DOUBLE)):double>
-- !query 14 output
151.47497042966097
-- !query 15
-SELECT var_pop(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT udf(var_pop(CAST(b AS Decimal(38,0)))) FROM aggtest
-- !query 15 schema
-struct<var_pop(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<udf(var_pop(cast(cast(b as decimal(38,0)) as double))):string>
-- !query 15 output
17208.5
-- !query 16
-SELECT var_samp(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT var_samp(udf(CAST(b AS Decimal(38,0)))) FROM aggtest
-- !query 16 schema
-struct<var_samp(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<var_samp(CAST(udf(cast(b as decimal(38,0))) AS DOUBLE)):double>
-- !query 16 output
22944.666666666668
-- !query 17
-SELECT var_pop(1.0), var_samp(2.0)
+SELECT udf(var_pop(1.0)), var_samp(udf(2.0))
-- !query 17 schema
-struct<var_pop(CAST(1.0 AS DOUBLE)):double,var_samp(CAST(2.0 AS DOUBLE)):double>
+struct<udf(var_pop(cast(1.0 as double))):string,var_samp(CAST(udf(2.0) AS DOUBLE)):double>
-- !query 17 output
0.0 NaN
-- !query 18
-SELECT stddev_pop(CAST(3.0 AS Decimal(38,0))), stddev_samp(CAST(4.0 AS Decimal(38,0)))
+SELECT stddev_pop(udf(CAST(3.0 AS Decimal(38,0)))), stddev_samp(CAST(udf(4.0) AS Decimal(38,0)))
-- !query 18 schema
-struct<stddev_pop(CAST(CAST(3.0 AS DECIMAL(38,0)) AS DOUBLE)):double,stddev_samp(CAST(CAST(4.0 AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<stddev_pop(CAST(udf(cast(3.0 as decimal(38,0))) AS DOUBLE)):double,stddev_samp(CAST(CAST(udf(4.0) AS DECIMAL(38,0)) AS DOUBLE)):double>
-- !query 18 output
0.0 NaN
-- !query 19
-select sum(CAST(null AS int)) from range(1,4)
+select sum(udf(CAST(null AS int))) from range(1,4)
-- !query 19 schema
-struct<sum(CAST(NULL AS INT)):bigint>
+struct<sum(CAST(udf(cast(null as int)) AS DOUBLE)):double>
-- !query 19 output
NULL
-- !query 20
-select sum(CAST(null AS long)) from range(1,4)
+select sum(udf(CAST(null AS long))) from range(1,4)
-- !query 20 schema
-struct<sum(CAST(NULL AS BIGINT)):bigint>
+struct<sum(CAST(udf(cast(null as bigint)) AS DOUBLE)):double>
-- !query 20 output
NULL
-- !query 21
-select sum(CAST(null AS Decimal(38,0))) from range(1,4)
+select sum(udf(CAST(null AS Decimal(38,0)))) from range(1,4)
-- !query 21 schema
-struct<sum(CAST(NULL AS DECIMAL(38,0))):decimal(38,0)>
+struct<sum(CAST(udf(cast(null as decimal(38,0))) AS DOUBLE)):double>
-- !query 21 output
NULL
-- !query 22
-select sum(CAST(null AS DOUBLE)) from range(1,4)
+select sum(udf(CAST(null AS DOUBLE))) from range(1,4)
-- !query 22 schema
-struct<sum(CAST(NULL AS DOUBLE)):double>
+struct<sum(CAST(udf(cast(null as double)) AS DOUBLE)):double>
-- !query 22 output
NULL
-- !query 23
-select avg(CAST(null AS int)) from range(1,4)
+select avg(udf(CAST(null AS int))) from range(1,4)
-- !query 23 schema
-struct<avg(CAST(NULL AS INT)):double>
+struct<avg(CAST(udf(cast(null as int)) AS DOUBLE)):double>
-- !query 23 output
NULL
-- !query 24
-select avg(CAST(null AS long)) from range(1,4)
+select avg(udf(CAST(null AS long))) from range(1,4)
-- !query 24 schema
-struct<avg(CAST(NULL AS BIGINT)):double>
+struct<avg(CAST(udf(cast(null as bigint)) AS DOUBLE)):double>
-- !query 24 output
NULL
-- !query 25
-select avg(CAST(null AS Decimal(38,0))) from range(1,4)
+select avg(udf(CAST(null AS Decimal(38,0)))) from range(1,4)
-- !query 25 schema
-struct<avg(CAST(NULL AS DECIMAL(38,0))):decimal(38,4)>
+struct<avg(CAST(udf(cast(null as decimal(38,0))) AS DOUBLE)):double>
-- !query 25 output
NULL
-- !query 26
-select avg(CAST(null AS DOUBLE)) from range(1,4)
+select avg(udf(CAST(null AS DOUBLE))) from range(1,4)
-- !query 26 schema
-struct<avg(CAST(NULL AS DOUBLE)):double>
+struct<avg(CAST(udf(cast(null as double)) AS DOUBLE)):double>
-- !query 26 output
NULL
-- !query 27
-select sum(CAST('NaN' AS DOUBLE)) from range(1,4)
+select sum(CAST(udf('NaN') AS DOUBLE)) from range(1,4)
-- !query 27 schema
-struct<sum(CAST(NaN AS DOUBLE)):double>
+struct<sum(CAST(udf(NaN) AS DOUBLE)):double>
-- !query 27 output
NaN
-- !query 28
-select avg(CAST('NaN' AS DOUBLE)) from range(1,4)
+select avg(CAST(udf('NaN') AS DOUBLE)) from range(1,4)
-- !query 28 schema
-struct<avg(CAST(NaN AS DOUBLE)):double>
+struct<avg(CAST(udf(NaN) AS DOUBLE)):double>
-- !query 28 output
NaN
-- !query 29
SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
-FROM (VALUES (CAST('1' AS DOUBLE)), (CAST('Infinity' AS DOUBLE))) v(x)
+FROM (VALUES (CAST(udf('1') AS DOUBLE)), (CAST(udf('Infinity') AS DOUBLE))) v(x)
-- !query 29 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<>
-- !query 29 output
-Infinity NaN
+org.apache.spark.sql.AnalysisException
+cannot evaluate expression CAST(udf(1) AS DOUBLE) in inline table definition; line 2 pos 14
-- !query 30
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('Infinity'), ('1')) v(x)
-- !query 30 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(x) AS DOUBLE)):double,var_pop(CAST(udf(x) AS DOUBLE)):double>
-- !query 30 output
Infinity NaN
-- !query 31
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('Infinity'), ('Infinity')) v(x)
-- !query 31 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(x) AS DOUBLE)):double,var_pop(CAST(udf(x) AS DOUBLE)):double>
-- !query 31 output
Infinity NaN
-- !query 32
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('-Infinity'), ('Infinity')) v(x)
-- !query 32 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(x) AS DOUBLE)):double,var_pop(CAST(udf(x) AS DOUBLE)):double>
-- !query 32 output
NaN NaN
-- !query 33
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(udf(CAST(x AS DOUBLE))), udf(var_pop(CAST(x AS DOUBLE)))
FROM (VALUES (100000003), (100000004), (100000006), (100000007)) v(x)
-- !query 33 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(cast(x as double)) AS DOUBLE)):double,udf(var_pop(cast(x as double))):string>
-- !query 33 output
1.00000005E8 2.5
-- !query 34
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(udf(CAST(x AS DOUBLE))), udf(var_pop(CAST(x AS DOUBLE)))
FROM (VALUES (7000000000005), (7000000000007)) v(x)
-- !query 34 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(cast(x as double)) AS DOUBLE)):double,udf(var_pop(cast(x as double))):string>
-- !query 34 output
7.000000000006E12 1.0
-- !query 35
-SELECT covar_pop(b, a), covar_samp(b, a) FROM aggtest
+SELECT CAST(udf(covar_pop(b, udf(a))) AS int), CAST(covar_samp(udf(b), a) as int) FROM aggtest
-- !query 35 schema
-struct<covar_pop(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double,covar_samp(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double>
+struct<CAST(udf(covar_pop(cast(b as double), cast(udf(a) as double))) AS INT):int,CAST(covar_samp(CAST(udf(b) AS DOUBLE), CAST(a AS DOUBLE)) AS INT):int>
-- !query 35 output
-653.6289553875104 871.5052738500139
+653 871
-- !query 36
-SELECT corr(b, a) FROM aggtest
+SELECT corr(b, udf(a)) FROM aggtest
-- !query 36 schema
-struct<corr(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double>
+struct<corr(CAST(b AS DOUBLE), CAST(udf(a) AS DOUBLE)):double>
-- !query 36 output
0.1396345165178734
-- !query 37
-SELECT count(four) AS cnt_1000 FROM onek
+SELECT count(udf(four)) AS cnt_1000 FROM onek
-- !query 37 schema
struct<cnt_1000:bigint>
-- !query 37 output
-313,36 +314,36 struct<cnt_1000:bigint>
-- !query 38
-SELECT count(DISTINCT four) AS cnt_4 FROM onek
+SELECT udf(count(DISTINCT four)) AS cnt_4 FROM onek
-- !query 38 schema
-struct<cnt_4:bigint>
+struct<cnt_4:string>
-- !query 38 output
4
-- !query 39
-select ten, count(*), sum(four) from onek
+select ten, udf(count(*)), sum(udf(four)) from onek
group by ten order by ten
-- !query 39 schema
-struct<ten:int,count(1):bigint,sum(four):bigint>
+struct<ten:int,udf(count(1)):string,sum(CAST(udf(four) AS DOUBLE)):double>
-- !query 39 output
-0 100 100
-1 100 200
-2 100 100
-3 100 200
-4 100 100
-5 100 200
-6 100 100
-7 100 200
-8 100 100
-9 100 200
+0 100 100.0
+1 100 200.0
+2 100 100.0
+3 100 200.0
+4 100 100.0
+5 100 200.0
+6 100 100.0
+7 100 200.0
+8 100 100.0
+9 100 200.0
-- !query 40
-select ten, count(four), sum(DISTINCT four) from onek
+select ten, count(udf(four)), udf(sum(DISTINCT four)) from onek
group by ten order by ten
-- !query 40 schema
-struct<ten:int,count(four):bigint,sum(DISTINCT four):bigint>
+struct<ten:int,count(udf(four)):bigint,udf(sum(distinct cast(four as bigint))):string>
-- !query 40 output
0 100 2
1 100 4
-357,11 +358,11 struct<ten:int,count(four):bigint,sum(DISTINCT four):bigint>
-- !query 41
-select ten, sum(distinct four) from onek a
+select ten, udf(sum(distinct four)) from onek a
group by ten
-having exists (select 1 from onek b where sum(distinct a.four) = b.four)
+having exists (select 1 from onek b where udf(sum(distinct a.four)) = b.four)
-- !query 41 schema
-struct<ten:int,sum(DISTINCT four):bigint>
+struct<ten:int,udf(sum(distinct cast(four as bigint))):string>
-- !query 41 output
0 2
2 2
-374,23 +375,23 struct<ten:int,sum(DISTINCT four):bigint>
select ten, sum(distinct four) from onek a
group by ten
having exists (select 1 from onek b
- where sum(distinct a.four + b.four) = b.four)
+ where sum(distinct a.four + b.four) = udf(b.four))
-- !query 42 schema
struct<>
-- !query 42 output
org.apache.spark.sql.AnalysisException
Aggregate/Window/Generate expressions are not valid in where clause of the query.
-Expression in where clause: [(sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT)) = CAST(b.`four` AS BIGINT))]
+Expression in where clause: [(sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT)) = CAST(udf(four) AS BIGINT))]
Invalid expressions: [sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT))];
-- !query 43
select
- (select max((select i.unique2 from tenk1 i where i.unique1 = o.unique1)))
+ (select udf(max((select i.unique2 from tenk1 i where i.unique1 = o.unique1))))
from tenk1 o
-- !query 43 schema
struct<>
-- !query 43 output
org.apache.spark.sql.AnalysisException
-cannot resolve '`o.unique1`' given input columns: [i.even, i.fivethous, i.four, i.hundred, i.odd, i.string4, i.stringu1, i.stringu2, i.ten, i.tenthous, i.thousand, i.twenty, i.two, i.twothousand, i.unique1, i.unique2]; line 2 pos 63
+cannot resolve '`o.unique1`' given input columns: [i.even, i.fivethous, i.four, i.hundred, i.odd, i.string4, i.stringu1, i.stringu2, i.ten, i.tenthous, i.thousand, i.twenty, i.two, i.twothousand, i.unique1, i.unique2]; line 2 pos 67
```
</p>
</details>
Note that, currently, `IntegratedUDFTestUtils.scala`'s UDFs only return strings. There are some differences between those UDFs (Scala, Pandas and Python):
- Python's string representation of floats can make the tests flaky. (See https://docs.python.org/3/tutorial/floatingpoint.html). To work around this, I had to `CAST(... as int)`.
- There are string representation differences between `Inf` `-Inf` <> `Infinity` `-Infinity` and `nan` <> `NaN`
- Maybe we should add other type versions of UDFs if this makes adding tests difficult.
Note that one issue found - [SPARK-28291](https://issues.apache.org/jira/browse/SPARK-28291). The test was commented for now.
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25069 from HyukjinKwon/SPARK-28270.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Fix `stringToDate()` for the formats `yyyy` and `yyyy-[m]m` that assumes there are no additional chars after the last components `yyyy` and `[m]m`. In the PR, I propose to check that entire input was consumed for the formats.
After the fix, the input `1999 08 01` will be invalid because it matches to the pattern `yyyy` but the strings contains additional chars ` 08 01`.
Since Spark 1.6.3 ~ 2.4.3, the behavior is the same.
```
spark-sql> SELECT CAST('1999 08 01' AS DATE);
1999-01-01
```
This PR makes it return NULL like Hive.
```
spark-sql> SELECT CAST('1999 08 01' AS DATE);
NULL
```
## How was this patch tested?
Added new checks to `DateTimeUtilsSuite` for the `1999 08 01` and `1999 08` inputs.
Closes#25097 from MaxGekk/spark-28015-invalid-date-format.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This fixes a problem where it is possible to create a v2 table using the default catalog that cannot be loaded with the session catalog. A session catalog should be used when the v1 catalog is responsible for tables with no catalog in the table identifier.
* Adds a v2 catalog implementation that delegates to the analyzer's SessionCatalog
* Uses the v2 session catalog for CTAS and CreateTable when the provider is a v2 provider and no v2 catalog is in the table identifier
* Updates catalog lookup to always provide the default if it is set for consistent behavior
## How was this patch tested?
* Adds a new test suite for the v2 session catalog that validates the TableCatalog API
* Adds test cases in PlanResolutionSuite to validate the v2 session catalog is used
* Adds test suite for LookupCatalog with a default catalog
Closes#24768 from rdblue/SPARK-27919-add-v2-session-catalog.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR adds some tests converted from having.sql to test UDFs following the combination guide in [SPARK-27921](url)
<details><summary>Diff comparing to 'having.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/having.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-having.sql.out
index d87ee52216..7cea2e5128 100644
--- a/sql/core/src/test/resources/sql-tests/results/having.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-having.sql.out
-16,34 +16,34 struct<>
-- !query 1
-SELECT k, sum(v) FROM hav GROUP BY k HAVING sum(v) > 2
+SELECT udf(k) AS k, udf(sum(v)) FROM hav GROUP BY k HAVING udf(sum(v)) > 2
-- !query 1 schema
-struct<k:string,sum(v):bigint>
+struct<k:string,udf(sum(cast(v as bigint))):string>
-- !query 1 output
one 6
three 3
-- !query 2
-SELECT count(k) FROM hav GROUP BY v + 1 HAVING v + 1 = 2
+SELECT udf(count(udf(k))) FROM hav GROUP BY v + 1 HAVING v + 1 = udf(2)
-- !query 2 schema
-struct<count(k):bigint>
+struct<udf(count(udf(k))):string>
-- !query 2 output
1
-- !query 3
-SELECT MIN(t.v) FROM (SELECT * FROM hav WHERE v > 0) t HAVING(COUNT(1) > 0)
+SELECT udf(MIN(t.v)) FROM (SELECT * FROM hav WHERE v > 0) t HAVING(udf(COUNT(udf(1))) > 0)
-- !query 3 schema
-struct<min(v):int>
+struct<udf(min(v)):string>
-- !query 3 output
1
-- !query 4
-SELECT a + b FROM VALUES (1L, 2), (3L, 4) AS T(a, b) GROUP BY a + b HAVING a + b > 1
+SELECT udf(a + b) FROM VALUES (1L, 2), (3L, 4) AS T(a, b) GROUP BY a + b HAVING a + b > udf(1)
-- !query 4 schema
-struct<(a + CAST(b AS BIGINT)):bigint>
+struct<udf((a + cast(b as bigint))):string>
-- !query 4 output
3
7
```
</p>
</details>
## How was this patch tested?
Tested as guided in SPARK-27921.
Closes#25093 from huaxingao/spark-28281.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds some tests converted from `natural-join.sql` to test UDFs following the combination guide in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
<details><summary>Diff results comparing to `natural-join.sql`</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.
sql.out
index 43f2f9a..53ef177 100644
--- a/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out
-27,7 +27,7 struct<>
-- !query 2
-SELECT * FROM nt1 natural join nt2 where k = "one"
+SELECT * FROM nt1 natural join nt2 where udf(k) = "one"
-- !query 2 schema
struct<k:string,v1:int,v2:int>
-- !query 2 output
-36,7 +36,7 one 1 5
-- !query 3
-SELECT * FROM nt1 natural left join nt2 order by v1, v2
+SELECT * FROM nt1 natural left join nt2 where k <> udf("") order by v1, v2
-- !query 3 schema
diff --git a/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.
sql.out
index 43f2f9a..53ef177 100644
--- a/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out
-27,7 +27,7 struct<>
-- !query 2
-SELECT * FROM nt1 natural join nt2 where k = "one"
+SELECT * FROM nt1 natural join nt2 where udf(k) = "one"
-- !query 2 schema
struct<k:string,v1:int,v2:int>
-- !query 2 output
-36,7 +36,7 one 1 5
-- !query 3
-SELECT * FROM nt1 natural left join nt2 order by v1, v2
+SELECT * FROM nt1 natural left join nt2 where k <> udf("") order by v1, v2
-- !query 3 schema
struct<k:string,v1:int,v2:int>
```
</p>
</details>
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25088 from manuzhang/SPARK-27922.
Authored-by: manu.zhang <manu.zhang@vipshop.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
There is a bug in `ExtractPythonUDFs` that produces wrong result attributes. It causes a failure when using `PythonUDF`s among multiple child plans, e.g., join. An example is using `PythonUDF`s in join condition.
```python
>>> left = spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2, a1=2, a2=2)])
>>> right = spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=1, b1=3, b2=1)])
>>> f = udf(lambda a: a, IntegerType())
>>> df = left.join(right, [f("a") == f("b"), left.a1 == right.b1])
>>> df.collect()
19/07/10 12:20:49 ERROR Executor: Exception in task 5.0 in stage 0.0 (TID 5)
java.lang.ArrayIndexOutOfBoundsException: 1
at org.apache.spark.sql.catalyst.expressions.GenericInternalRow.genericGet(rows.scala:201)
at org.apache.spark.sql.catalyst.expressions.BaseGenericInternalRow.getAs(rows.scala:35)
at org.apache.spark.sql.catalyst.expressions.BaseGenericInternalRow.isNullAt(rows.scala:36)
at org.apache.spark.sql.catalyst.expressions.BaseGenericInternalRow.isNullAt$(rows.scala:36)
at org.apache.spark.sql.catalyst.expressions.GenericInternalRow.isNullAt(rows.scala:195)
at org.apache.spark.sql.catalyst.expressions.JoinedRow.isNullAt(JoinedRow.scala:70)
...
```
## How was this patch tested?
Added test.
Closes#25091 from viirya/SPARK-28323.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
## What changes were proposed in this pull request?
This is a followup of the discussion in https://github.com/apache/spark/pull/24675#discussion_r286786053
`QueryPlan#references` is an important property. The `ColumnPrunning` rule relies on it.
Some query plan nodes have `Seq[Attribute]` parameter, which is used as its output attributes. For example, leaf nodes, `Generate`, `MapPartitionsInPandas`, etc. These nodes override `producedAttributes` to make `missingInputs` correct.
However, these nodes also need to override `references` to make column pruning work. This PR proposes to exclude `producedAttributes` from the default implementation of `QueryPlan#references`, so that we don't need to override `references` in all these nodes.
Note that, technically we can remove `producedAttributes` and always ask query plan nodes to override `references`. But I do find the code can be simpler with `producedAttributes` in some places, where there is a base class for some specific query plan nodes.
## How was this patch tested?
existing tests
Closes#25052 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds some tests converted from `pgSQL/case.sql'` to test UDFs. Please see contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
This PR also contains two minor fixes:
1. Change name of Scala UDF from `UDF:name(...)` to `name(...)` to be consistent with Python'
2. Fix Scala UDF at `IntegratedUDFTestUtils.scala ` to handle `null` in strings.
<details><summary>Diff comparing to 'pgSQL/case.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/pgSQL/case.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-case.sql.out
index fa078d16d6d..55bef64338f 100644
--- a/sql/core/src/test/resources/sql-tests/results/pgSQL/case.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-case.sql.out
-115,7 +115,7 struct<>
-- !query 13
SELECT '3' AS `One`,
CASE
- WHEN 1 < 2 THEN 3
+ WHEN CAST(udf(1 < 2) AS boolean) THEN 3
END AS `Simple WHEN`
-- !query 13 schema
struct<One:string,Simple WHEN:int>
-126,10 +126,10 struct<One:string,Simple WHEN:int>
-- !query 14
SELECT '<NULL>' AS `One`,
CASE
- WHEN 1 > 2 THEN 3
+ WHEN 1 > 2 THEN udf(3)
END AS `Simple default`
-- !query 14 schema
-struct<One:string,Simple default:int>
+struct<One:string,Simple default:string>
-- !query 14 output
<NULL> NULL
-137,17 +137,17 struct<One:string,Simple default:int>
-- !query 15
SELECT '3' AS `One`,
CASE
- WHEN 1 < 2 THEN 3
- ELSE 4
+ WHEN udf(1) < 2 THEN udf(3)
+ ELSE udf(4)
END AS `Simple ELSE`
-- !query 15 schema
-struct<One:string,Simple ELSE:int>
+struct<One:string,Simple ELSE:string>
-- !query 15 output
3 3
-- !query 16
-SELECT '4' AS `One`,
+SELECT udf('4') AS `One`,
CASE
WHEN 1 > 2 THEN 3
ELSE 4
-159,10 +159,10 struct<One:string,ELSE default:int>
-- !query 17
-SELECT '6' AS `One`,
+SELECT udf('6') AS `One`,
CASE
- WHEN 1 > 2 THEN 3
- WHEN 4 < 5 THEN 6
+ WHEN CAST(udf(1 > 2) AS boolean) THEN 3
+ WHEN udf(4) < 5 THEN 6
ELSE 7
END AS `Two WHEN with default`
-- !query 17 schema
-173,7 +173,7 struct<One:string,Two WHEN with default:int>
-- !query 18
SELECT '7' AS `None`,
- CASE WHEN rand() < 0 THEN 1
+ CASE WHEN rand() < udf(0) THEN 1
END AS `NULL on no matches`
-- !query 18 schema
struct<None:string,NULL on no matches:int>
-182,36 +182,36 struct<None:string,NULL on no matches:int>
-- !query 19
-SELECT CASE WHEN 1=0 THEN 1/0 WHEN 1=1 THEN 1 ELSE 2/0 END
+SELECT CASE WHEN CAST(udf(1=0) AS boolean) THEN 1/0 WHEN 1=1 THEN 1 ELSE 2/0 END
-- !query 19 schema
-struct<CASE WHEN (1 = 0) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
+struct<CASE WHEN CAST(udf((1 = 0)) AS BOOLEAN) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
-- !query 19 output
1.0
-- !query 20
-SELECT CASE 1 WHEN 0 THEN 1/0 WHEN 1 THEN 1 ELSE 2/0 END
+SELECT CASE 1 WHEN 0 THEN 1/udf(0) WHEN 1 THEN 1 ELSE 2/0 END
-- !query 20 schema
-struct<CASE WHEN (1 = 0) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
+struct<CASE WHEN (1 = 0) THEN (CAST(1 AS DOUBLE) / CAST(CAST(udf(0) AS DOUBLE) AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
-- !query 20 output
1.0
-- !query 21
-SELECT CASE WHEN i > 100 THEN 1/0 ELSE 0 END FROM case_tbl
+SELECT CASE WHEN i > 100 THEN udf(1/0) ELSE udf(0) END FROM case_tbl
-- !query 21 schema
-struct<CASE WHEN (i > 100) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) ELSE CAST(0 AS DOUBLE) END:double>
+struct<CASE WHEN (i > 100) THEN udf((cast(1 as double) / cast(0 as double))) ELSE udf(0) END:string>
-- !query 21 output
-0.0
-0.0
-0.0
-0.0
+0
+0
+0
+0
-- !query 22
-SELECT CASE 'a' WHEN 'a' THEN 1 ELSE 2 END
+SELECT CASE 'a' WHEN 'a' THEN udf(1) ELSE udf(2) END
-- !query 22 schema
-struct<CASE WHEN (a = a) THEN 1 ELSE 2 END:int>
+struct<CASE WHEN (a = a) THEN udf(1) ELSE udf(2) END:string>
-- !query 22 output
1
-283,7 +283,7 big
-- !query 27
-SELECT * FROM CASE_TBL WHERE COALESCE(f,i) = 4
+SELECT * FROM CASE_TBL WHERE udf(COALESCE(f,i)) = 4
-- !query 27 schema
struct<i:int,f:double>
-- !query 27 output
-291,7 +291,7 struct<i:int,f:double>
-- !query 28
-SELECT * FROM CASE_TBL WHERE NULLIF(f,i) = 2
+SELECT * FROM CASE_TBL WHERE udf(NULLIF(f,i)) = 2
-- !query 28 schema
struct<i:int,f:double>
-- !query 28 output
-299,10 +299,10 struct<i:int,f:double>
-- !query 29
-SELECT COALESCE(a.f, b.i, b.j)
+SELECT udf(COALESCE(a.f, b.i, b.j))
FROM CASE_TBL a, CASE2_TBL b
-- !query 29 schema
-struct<coalesce(f, CAST(i AS DOUBLE), CAST(j AS DOUBLE)):double>
+struct<udf(coalesce(f, cast(i as double), cast(j as double))):string>
-- !query 29 output
-30.3
-30.3
-332,8 +332,8 struct<coalesce(f, CAST(i AS DOUBLE), CAST(j AS DOUBLE)):double>
-- !query 30
SELECT *
- FROM CASE_TBL a, CASE2_TBL b
- WHERE COALESCE(a.f, b.i, b.j) = 2
+ FROM CASE_TBL a, CASE2_TBL b
+ WHERE udf(COALESCE(a.f, b.i, b.j)) = 2
-- !query 30 schema
struct<i:int,f:double,i:int,j:int>
-- !query 30 output
-342,7 +342,7 struct<i:int,f:double,i:int,j:int>
-- !query 31
-SELECT '' AS Five, NULLIF(a.i,b.i) AS `NULLIF(a.i,b.i)`,
+SELECT udf('') AS Five, NULLIF(a.i,b.i) AS `NULLIF(a.i,b.i)`,
NULLIF(b.i, 4) AS `NULLIF(b.i,4)`
FROM CASE_TBL a, CASE2_TBL b
-- !query 31 schema
-377,7 +377,7 struct<Five:string,NULLIF(a.i,b.i):int,NULLIF(b.i,4):int>
-- !query 32
SELECT '' AS `Two`, *
FROM CASE_TBL a, CASE2_TBL b
- WHERE COALESCE(f,b.i) = 2
+ WHERE CAST(udf(COALESCE(f,b.i) = 2) AS boolean)
-- !query 32 schema
struct<Two:string,i:int,f:double,i:int,j:int>
-- !query 32 output
-388,15 +388,15 struct<Two:string,i:int,f:double,i:int,j:int>
-- !query 33
SELECT CASE
(CASE vol('bar')
- WHEN 'foo' THEN 'it was foo!'
- WHEN vol(null) THEN 'null input'
+ WHEN udf('foo') THEN 'it was foo!'
+ WHEN udf(vol(null)) THEN 'null input'
WHEN 'bar' THEN 'it was bar!' END
)
- WHEN 'it was foo!' THEN 'foo recognized'
- WHEN 'it was bar!' THEN 'bar recognized'
- ELSE 'unrecognized' END
+ WHEN udf('it was foo!') THEN 'foo recognized'
+ WHEN 'it was bar!' THEN udf('bar recognized')
+ ELSE 'unrecognized' END AS col
-- !query 33 schema
-struct<CASE WHEN (CASE WHEN (UDF:vol(bar) = foo) THEN it was foo! WHEN (UDF:vol(bar) = UDF:vol(null)) THEN null input WHEN (UDF:vol(bar) = bar) THEN it was bar! END = it was foo!) THEN foo recognized WHEN (CASE WHEN (UDF:vol(bar) = foo) THEN it was foo! WHEN (UDF:vol(bar) = UDF:vol(null)) THEN null input WHEN (UDF:vol(bar) = bar) THEN it was bar! END = it was bar!) THEN bar recognized ELSE unrecognized END:string>
+struct<col:string>
-- !query 33 output
bar recognized
```
</p>
</details>
https://github.com/apache/spark/pull/25069 contains the same minor fixes as it's required to write the tests.
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25070 from HyukjinKwon/SPARK-28273.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In Dataset drop(col: Column) method, the `equals` comparison method was used instead of `semanticEquals`, which caused the problem of abnormal case-sensitivity behavior. When attributes of LogicalPlan are checked for equality, `semanticEquals` should be used instead.
A similar PR I referred to: https://github.com/apache/spark/pull/22713 created by mgaido91
## How was this patch tested?
- Added new unit test case in DataFrameSuite
- ./build/sbt "testOnly org.apache.spark.sql.*"
- The python code from ticket reporter at https://issues.apache.org/jira/browse/SPARK-28189Closes#25055 from Tonix517/SPARK-28189.
Authored-by: Tony Zhang <tony.zhang@uber.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds some more WITH test cases as a follow-up to https://github.com/apache/spark/pull/24842
## How was this patch tested?
Add new UTs.
Closes#24949 from peter-toth/SPARK-28002-follow-up.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR proposes to rename `mapPartitionsInPandas` to `mapInPandas` with a separate evaluation type .
Had an offline discussion with rxin, mengxr and cloud-fan
The reason is basically:
1. `SCALAR_ITER` doesn't make sense with `mapPartitionsInPandas`.
2. It cannot share the same Pandas UDF, for instance, at `select` and `mapPartitionsInPandas` unlike `GROUPED_AGG` because iterator's return type is different.
3. `mapPartitionsInPandas` -> `mapInPandas` - see https://github.com/apache/spark/pull/25044#issuecomment-508298552 and https://github.com/apache/spark/pull/25044#issuecomment-508299764
Renaming `SCALAR_ITER` as `MAP_ITER` is abandoned due to 2. reason.
For `XXX_ITER`, it might have to have a different interface in the future if we happen to add other versions of them. But this is an orthogonal topic with `mapPartitionsInPandas`.
## How was this patch tested?
Existing tests should cover.
Closes#25044 from HyukjinKwon/SPARK-28198.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds support of `WITH` clause within a subquery so this query becomes valid:
```
SELECT max(c) FROM (
WITH t AS (SELECT 1 AS c)
SELECT * FROM t
)
```
## How was this patch tested?
Added new UTs.
Closes#24831 from peter-toth/SPARK-19799-2.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This is to implement a ReduceNumShufflePartitions rule in the new adaptive execution framework introduced in #24706. This rule is used to adjust the post shuffle partitions based on the map output statistics.
## How was this patch tested?
Added ReduceNumShufflePartitionsSuite
Closes#24978 from carsonwang/reduceNumShufflePartitions.
Authored-by: Carson Wang <carson.wang@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This pr add calculate local directory size to `SQLTestUtils`.
We can avoid these changes after this pr:
## How was this patch tested?
Existing test
Closes#25014 from wangyum/SPARK-28216.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR makes the predicate pushdown logic in catalyst optimizer more efficient by unifying two existing rules `PushdownPredicates` and `PushPredicateThroughJoin`. Previously pushing down a predicate for queries such as `Filter(Join(Join(Join)))` requires n steps. This patch essentially reduces this to a single pass.
To make this actually work, we need to unify a few rules such as `CombineFilters`, `PushDownPredicate` and `PushDownPrdicateThroughJoin`. Otherwise cases such as `Filter(Join(Filter(Join)))` still requires several passes to fully push down predicates. This unification is done by composing several partial functions, which makes a minimal code change and can reuse existing UTs.
Results show that this optimization can improve the catalyst optimization time by 16.5%. For queries with more joins, the performance is even better. E.g., for TPC-DS q64, the performance boost is 49.2%.
## How was this patch tested?
Existing UTs + new a UT for the new rule.
Closes#24956 from yeshengm/fixed-point-opt.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In some cases, executeTake in SparkPlan could decode more than necessary.
For example, in case of below odd/even number partitioning, total row's count from partitions will be 100, although it is limited with 51. And 'executeTake' in SparkPlan decodes all of them, "49" rows of which are unnecessarily decoded.
```scala
spark.sparkContext.parallelize((0 until 100).map(i => (i, 1))).toDF()
.repartitionByRange(2, $"_1" % 2).limit(51).collect()
```
By using a iterator of the scalar collection, we can make ensure that at most n rows are decoded.
## How was this patch tested?
Existing unit tests that call limit function of DataFrame.
testOnly *SQLQuerySuite
testOnly *DataFrameSuite
Closes#22347 from Dooyoung-Hwang/refactor_execute_take.
Authored-by: Dooyoung Hwang <dooyoung.hwang@sk.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR proposes to add `mapPartitionsInPandas` API to DataFrame by using existing `SCALAR_ITER` as below:
1. Filtering via setting the column
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
df = spark.createDataFrame([(1, 21), (2, 30)], ("id", "age"))
pandas_udf(df.schema, PandasUDFType.SCALAR_ITER)
def filter_func(iterator):
for pdf in iterator:
yield pdf[pdf.id == 1]
df.mapPartitionsInPandas(filter_func).show()
```
```
+---+---+
| id|age|
+---+---+
| 1| 21|
+---+---+
```
2. `DataFrame.loc`
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
import pandas as pd
df = spark.createDataFrame([['aa'], ['bb'], ['cc'], ['aa'], ['aa'], ['aa']], ["value"])
pandas_udf(df.schema, PandasUDFType.SCALAR_ITER)
def filter_func(iterator):
for pdf in iterator:
yield pdf.loc[pdf.value.str.contains('^a'), :]
df.mapPartitionsInPandas(filter_func).show()
```
```
+-----+
|value|
+-----+
| aa|
| aa|
| aa|
| aa|
+-----+
```
3. `pandas.melt`
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
import pandas as pd
df = spark.createDataFrame(
pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},
'B': {0: 1, 1: 3, 2: 5},
'C': {0: 2, 1: 4, 2: 6}}))
pandas_udf("A string, variable string, value long", PandasUDFType.SCALAR_ITER)
def filter_func(iterator):
for pdf in iterator:
import pandas as pd
yield pd.melt(pdf, id_vars=['A'], value_vars=['B', 'C'])
df.mapPartitionsInPandas(filter_func).show()
```
```
+---+--------+-----+
| A|variable|value|
+---+--------+-----+
| a| B| 1|
| a| C| 2|
| b| B| 3|
| b| C| 4|
| c| B| 5|
| c| C| 6|
+---+--------+-----+
```
The current limitation of `SCALAR_ITER` is that it doesn't allow different length of result, which is pretty critical in practice - for instance, we cannot simply filter by using Pandas APIs but we merely just map N to N. This PR allows map N to M like flatMap.
This API mimics the way of `mapPartitions` but keeps API shape of `SCALAR_ITER` by allowing different results.
### How does this PR implement?
This PR adds mimics both `dapply` with Arrow optimization and Grouped Map Pandas UDF. At Python execution side, it reuses existing `SCALAR_ITER` code path.
Therefore, externally, we don't introduce any new type of Pandas UDF but internally we use another evaluation type code `205` (`SQL_MAP_PANDAS_ITER_UDF`).
This approach is similar with Pandas' Windows function implementation with Grouped Aggregation Pandas UDF functions - internally we have `203` (`SQL_WINDOW_AGG_PANDAS_UDF`) but externally we just share the same `GROUPED_AGG`.
## How was this patch tested?
Manually tested and unittests were added.
Closes#24997 from HyukjinKwon/scalar-udf-iter.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Kafka batch data source is using v1 at the moment. In the PR I've migrated to v2. Majority of the change is moving code.
What this PR contains:
* useV1Sources usage fixed in `DataFrameReader` and `DataFrameWriter`
* `KafkaBatch` added to handle DSv2 batch reading
* `KafkaBatchWrite` added to handle DSv2 batch writing
* `KafkaBatchPartitionReader` extracted to share between batch and microbatch
* `KafkaDataWriter` extracted to share between batch, microbatch and continuous
* Batch related source/sink tests are now executing on v1 and v2 connectors
* Couple of classes hidden now, functions moved + couple of minor fixes
## How was this patch tested?
Existing + added unit tests.
Closes#24738 from gaborgsomogyi/SPARK-23098.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In the migration PR of Kafka V2: ac16c9a9ef (r298470645)
We find that the useV1SourceList configuration(spark.sql.sources.read.useV1SourceList and spark.sql.sources.write.useV1SourceList) should be for all data sources, instead of file source V2 only.
This PR is to fix it in DataFrameWriter/DataFrameReader.
## How was this patch tested?
Unit test
Closes#25004 from gengliangwang/reviseUseV1List.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Currently, ORC's `inferSchema` is implemented as randomly choosing one ORC file and reading its schema.
This PR follows the behavior of Parquet, it implements merge schemas logic by reading all ORC files in parallel through a spark job.
Users can enable merge schema by `spark.read.orc("xxx").option("mergeSchema", "true")` or by setting `spark.sql.orc.mergeSchema` to `true`, the prior one has higher priority.
## How was this patch tested?
tested by UT OrcUtilsSuite.scala
Closes#24043 from WangGuangxin/SPARK-11412.
Lead-authored-by: wangguangxin.cn <wangguangxin.cn@gmail.com>
Co-authored-by: wangguangxin.cn <wangguangxin.cn@bytedance.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
SPARK-27534 missed to address my own comments at https://github.com/WeichenXu123/spark/pull/8
It's better to push this in since the codes are already cleaned up.
## How was this patch tested?
Unittests fixed
Closes#25003 from HyukjinKwon/SPARK-27534.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This is the first part of [SPARK-27396](https://issues.apache.org/jira/browse/SPARK-27396). This is the minimum set of changes necessary to support a pluggable back end for columnar processing. Follow on JIRAs would cover removing some of the duplication between functionality in this patch and functionality currently covered by things like ColumnarBatchScan.
## How was this patch tested?
I added in a new unit test to cover new code not really covered in other places.
I also did manual testing by implementing two plugins/extensions that take advantage of the new APIs to allow for columnar processing for some simple queries. One version runs on the [CPU](https://gist.github.com/revans2/c3cad77075c4fa5d9d271308ee2f1b1d). The other version run on a GPU, but because it has unreleased dependencies I will not include a link to it yet.
The CPU version I would expect to add in as an example with other documentation in a follow on JIRA
This is contributed on behalf of NVIDIA Corporation.
Closes#24795 from revans2/columnar-basic.
Authored-by: Robert (Bobby) Evans <bobby@apache.org>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
The `OVERLAY` function is a `ANSI` `SQL`.
For example:
```
SELECT OVERLAY('abcdef' PLACING '45' FROM 4);
SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5);
SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5 FOR 0);
SELECT OVERLAY('babosa' PLACING 'ubb' FROM 2 FOR 4);
```
The results of the above four `SQL` are:
```
abc45f
yabadaba
yabadabadoo
bubba
```
Note: If the input string is null, then the result is null too.
There are some mainstream database support the syntax.
**PostgreSQL:**
https://www.postgresql.org/docs/11/functions-string.html
**Vertica:** https://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/SQLReferenceManual/Functions/String/OVERLAY.htm?zoom_highlight=overlay
**Oracle:**
https://docs.oracle.com/en/database/oracle/oracle-database/19/arpls/UTL_RAW.html#GUID-342E37E7-FE43-4CE1-A0E9-7DAABD000369
**DB2:**
https://www.ibm.com/support/knowledgecenter/SSGMCP_5.3.0/com.ibm.cics.rexx.doc/rexx/overlay.html
There are some show of the PR on my production environment.
```
spark-sql> SELECT OVERLAY('abcdef' PLACING '45' FROM 4);
abc45f
Time taken: 6.385 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5);
yabadaba
Time taken: 0.191 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5 FOR 0);
yabadabadoo
Time taken: 0.186 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY('babosa' PLACING 'ubb' FROM 2 FOR 4);
bubba
Time taken: 0.151 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING '45' FROM 4);
NULL
Time taken: 0.22 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING 'daba' FROM 5);
NULL
Time taken: 0.157 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING 'daba' FROM 5 FOR 0);
NULL
Time taken: 0.254 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING 'ubb' FROM 2 FOR 4);
NULL
Time taken: 0.159 seconds, Fetched 1 row(s)
```
## How was this patch tested?
Exists UT and new UT.
Closes#24918 from beliefer/ansi-sql-overlay.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
## What changes were proposed in this pull request?
Avoid hard-coded config: `spark.sql.globalTempDatabase`.
## How was this patch tested?
N/A
Closes#24979 from wangyum/SPARK-28179.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
For simplicity, all `LambdaVariable`s are globally unique, to avoid any potential conflicts. However, this causes a perf problem: we can never hit codegen cache for encoder expressions that deal with collections (which means they contain `LambdaVariable`).
To overcome this problem, `LambdaVariable` should have per-query unique IDs. This PR does 2 things:
1. refactor `LambdaVariable` to carry an ID, so that it's easier to change the ID.
2. add an optimizer rule to reassign `LambdaVariable` IDs, which are per-query unique.
## How was this patch tested?
new tests
Closes#24735 from cloud-fan/dataset.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
SQL ANSI 2011 states that in case of overflow during arithmetic operations, an exception should be thrown. This is what most of the SQL DBs do (eg. SQLServer, DB2). Hive currently returns NULL (as Spark does) but HIVE-18291 is open to be SQL compliant.
The PR introduce an option to decide which behavior Spark should follow, ie. returning NULL on overflow or throwing an exception.
## How was this patch tested?
added UTs
Closes#20350 from mgaido91/SPARK-23179.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Currently with `toLocalIterator()` and `toPandas()` with Arrow enabled, if the Spark job being run in the background serving thread errors, it will be caught and sent to Python through the PySpark serializer.
This is not the ideal solution because it is only catch a SparkException, it won't handle an error that occurs in the serializer, and each method has to have it's own special handling to propagate the error.
This PR instead returns the Python Server object along with the serving port and authentication info, so that it allows the Python caller to join with the serving thread. During the call to join, the serving thread Future is completed either successfully or with an exception. In the latter case, the exception will be propagated to Python through the Py4j call.
## How was this patch tested?
Existing tests
Closes#24834 from BryanCutler/pyspark-propagate-server-error-SPARK-27992.
Authored-by: Bryan Cutler <cutlerb@gmail.com>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
## What changes were proposed in this pull request?
Spark's `InMemoryFileIndex` contains two places where `FileNotFound` exceptions are caught and logged as warnings (during [directory listing](bcd3b61c4b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InMemoryFileIndex.scala (L274)) and [block location lookup](bcd3b61c4b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InMemoryFileIndex.scala (L333))). This logic was added in #15153 and #21408.
I think that this is a dangerous default behavior because it can mask bugs caused by race conditions (e.g. overwriting a table while it's being read) or S3 consistency issues (there's more discussion on this in the [JIRA ticket](https://issues.apache.org/jira/browse/SPARK-27676)). Failing fast when we detect missing files is not sufficient to make concurrent table reads/writes or S3 listing safe (there are other classes of eventual consistency issues to worry about), but I think it's still beneficial to throw exceptions and fail-fast on the subset of inconsistencies / races that we _can_ detect because that increases the likelihood that an end user will notice the problem and investigate further.
There may be some cases where users _do_ want to ignore missing files, but I think that should be an opt-in behavior via the existing `spark.sql.files.ignoreMissingFiles` flag (the current behavior is itself race-prone because a file might be be deleted between catalog listing and query execution time, triggering FileNotFoundExceptions on executors (which are handled in a way that _does_ respect `ignoreMissingFIles`)).
This PR updates `InMemoryFileIndex` to guard the log-and-ignore-FileNotFoundException behind the existing `spark.sql.files.ignoreMissingFiles` flag.
**Note**: this is a change of default behavior, so I think it needs to be mentioned in release notes.
## How was this patch tested?
New unit tests to simulate file-deletion race conditions, tested with both values of the `ignoreMissingFIles` flag.
Closes#24668 from JoshRosen/SPARK-27676.
Lead-authored-by: Josh Rosen <rosenville@gmail.com>
Co-authored-by: Josh Rosen <joshrosen@stripe.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}