continuation to https://github.com/apache/spark/pull/24788
## What changes were proposed in this pull request?
Changes are related to BIG ENDIAN system
This changes are done to
identify s390x platform.
use byteorder to BIG_ENDIAN for big endian systems
changes for 2 are done in access functions putFloats() and putDouble()
## How was this patch tested?
Changes have been tested to build successfully on s390x as well x86 platform to make sure build is successful.
Closes#24861 from ketank-new/ketan_latest_v2.3.2.
Authored-by: ketank-new <ketan22584@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
After this PR, we can test Pandas and Python UDF as below **in Scala side**:
```scala
import IntegratedUDFTestUtils._
val pandasTestUDF = TestScalarPandasUDF("udf")
spark.range(10).select(pandasTestUDF($"id")).show()
```
## How was this patch tested?
Manually tested.
Closes#24945 from HyukjinKwon/SPARK-27893-followup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In #24068, IvanVergiliev fixes the issue that OrcFilters.createBuilder has exponential complexity in the height of the filter tree due to the way the check-and-build pattern is implemented.
Comparing to the approach in #24068, I propose a simple solution for the issue:
1. separate the logic of building a convertible filter tree and the actual SearchArgument builder, since the two procedures are different and their return types are different. Thus the new introduced class `ActionType`,`TrimUnconvertibleFilters` and `BuildSearchArgument` in #24068 can be dropped. The code is more readable.
2. For most of the leaf nodes, the convertible result is always Some(node), we can abstract it like this PR.
3. The code is actually small changes on the previous code. See https://github.com/apache/spark/pull/24783
## How was this patch tested?
Run the benchmark provided in #24068:
```
val schema = StructType.fromDDL("col INT")
(20 to 30).foreach { width =>
val whereFilter = (1 to width).map(i => EqualTo("col", i)).reduceLeft(Or)
val start = System.currentTimeMillis()
OrcFilters.createFilter(schema, Seq(whereFilter))
println(s"With $width filters, conversion takes ${System.currentTimeMillis() - start} ms")
}
```
Result:
```
With 20 filters, conversion takes 6 ms
With 21 filters, conversion takes 0 ms
With 22 filters, conversion takes 0 ms
With 23 filters, conversion takes 0 ms
With 24 filters, conversion takes 0 ms
With 25 filters, conversion takes 0 ms
With 26 filters, conversion takes 0 ms
With 27 filters, conversion takes 0 ms
With 28 filters, conversion takes 0 ms
With 29 filters, conversion takes 0 ms
With 30 filters, conversion takes 0 ms
```
Also verified with Unit tests.
Closes#24910 from gengliangwang/refactorOrcFilters.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
ShuffleMapTask's partition field is a FilePartition and FilePartition's 'files' field is a Stream$cons which is essentially a linked list. It is therefore serialized recursively.
If the number of files in each partition is, say, 10000 files, recursing into a linked list of length 10000 overflows the stack
The problem is only in Bucketed partitions. The corresponding implementation for non Bucketed partitions uses a StreamBuffer. The proposed change applies the same for Bucketed partitions.
## How was this patch tested?
Existing unit tests. Added new unit test. The unit test fails without the patch. Manual testing on dataset used to reproduce the problem.
Closes#24865 from parthchandra/SPARK-27100.
Lead-authored-by: Parth Chandra <parthc@apple.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
## What changes were proposed in this pull request?
[PostgreSQL](7c850320d8/src/test/regress/sql/strings.sql (L624)) support another trim pattern: `TRIM(trimStr FROM str)`:
Function | Return Type | Description | Example | Result
--- | --- | --- | --- | ---
trim([leading \| trailing \| both] [characters] from string) | text | Remove the longest string containing only characters from characters (a space by default) from the start, end, or both ends (both is the default) of string | trim(both 'xyz' from 'yxTomxx') | Tom
This pr add support this trim pattern. After this pr. We can support all standard syntax except `TRIM(FROM str)` because it conflicts with our Literals:
```sql
Literals of type 'FROM' are currently not supported.(line 1, pos 12)
== SQL ==
SELECT TRIM(FROM ' SPARK SQL ')
```
PostgreSQL, Vertica and MySQL support this pattern. Teradata, Oracle, DB2, SQL Server, Hive and Presto
**PostgreSQL**:
```
postgres=# SELECT substr(version(), 0, 16), trim('xyz' FROM 'yxTomxx');
substr | btrim
-----------------+-------
PostgreSQL 11.3 | Tom
(1 row)
```
**Vertica**:
```
dbadmin=> SELECT version(), trim('xyz' FROM 'yxTomxx');
version | btrim
------------------------------------+-------
Vertica Analytic Database v9.1.1-0 | Tom
(1 row)
```
**MySQL**:
```
mysql> SELECT version(), trim('xyz' FROM 'yxTomxx');
+-----------+----------------------------+
| version() | trim('xyz' FROM 'yxTomxx') |
+-----------+----------------------------+
| 5.7.26 | yxTomxx |
+-----------+----------------------------+
1 row in set (0.00 sec)
```
More details:
https://www.postgresql.org/docs/11/functions-string.html
## How was this patch tested?
unit tests
Closes#24924 from wangyum/SPARK-28075-2.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
When running FlatMapGroupsInPandasExec or AggregateInPandasExec the shuffle uses a default number of partitions of 200 in "spark.sql.shuffle.partitions". If the data is small, e.g. in testing, many of the partitions will be empty but are treated just the same.
This PR checks the `mapPartitionsInternal` iterator to be non-empty before calling `ArrowPythonRunner` to start computation on the iterator.
## How was this patch tested?
Existing tests. Ran the following benchmarks a simple example where most partitions are empty:
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql.types import *
df = spark.createDataFrame(
[(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
("id", "v"))
pandas_udf("id long, v double", PandasUDFType.GROUPED_MAP)
def normalize(pdf):
v = pdf.v
return pdf.assign(v=(v - v.mean()) / v.std())
df.groupby("id").apply(normalize).count()
```
**Before**
```
In [4]: %timeit df.groupby("id").apply(normalize).count()
1.58 s ± 62.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [5]: %timeit df.groupby("id").apply(normalize).count()
1.52 s ± 29.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [6]: %timeit df.groupby("id").apply(normalize).count()
1.52 s ± 37.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
```
**After this Change**
```
In [2]: %timeit df.groupby("id").apply(normalize).count()
646 ms ± 89.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [3]: %timeit df.groupby("id").apply(normalize).count()
408 ms ± 84.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [4]: %timeit df.groupby("id").apply(normalize).count()
381 ms ± 29.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
```
Closes#24926 from BryanCutler/pyspark-pandas_udf-map-agg-skip-empty-parts-SPARK-28128.
Authored-by: Bryan Cutler <cutlerb@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
File source V1 supports reading output of FileStreamSink as batch. https://github.com/apache/spark/pull/11897
We should support this in file source V2 as well. When reading with paths, we first check if there is metadata log of FileStreamSink. If yes, we use `MetadataLogFileIndex` for listing files; Otherwise, we use `InMemoryFileIndex`.
## How was this patch tested?
Unit test
Closes#24900 from gengliangwang/FileStreamV2.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Provide a way to recursively load data from datasource.
I add a "recursiveFileLookup" option.
When "recursiveFileLookup" option turn on, then partition inferring is turned off and all files from the directory will be loaded recursively.
If some datasource explicitly specify the partitionSpec, then if user turn on "recursive" option, then exception will be thrown.
## How was this patch tested?
Unit tests.
Please review https://spark.apache.org/contributing.html before opening a pull request.
Closes#24830 from WeichenXu123/recursive_ds.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
[SPARK-28093](https://issues.apache.org/jira/browse/SPARK-28093) fixed `TRIM/LTRIM/RTRIM('str', 'trimStr')` returns an incorrect value, but that fix introduced a new bug, `TRIM(type trimStr FROM str)` returns an incorrect value. This pr fix this issue.
## How was this patch tested?
unit tests and manual tests:
Before this PR:
```sql
spark-sql> SELECT trim('yxTomxx', 'xyz'), trim(BOTH 'xyz' FROM 'yxTomxx');
Tom z
spark-sql> SELECT trim('xxxbarxxx', 'x'), trim(BOTH 'x' FROM 'xxxbarxxx');
bar
spark-sql> SELECT ltrim('zzzytest', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytest');
test xyz
spark-sql> SELECT ltrim('zzzytestxyz', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytestxyz');
testxyz
spark-sql> SELECT ltrim('xyxXxyLAST WORD', 'xy'), trim(LEADING 'xy' FROM 'xyxXxyLAST WORD');
XxyLAST WORD
spark-sql> SELECT rtrim('testxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'testxxzx');
test xy
spark-sql> SELECT rtrim('xyztestxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'xyztestxxzx');
xyztest
spark-sql> SELECT rtrim('TURNERyxXxy', 'xy'), trim(TRAILING 'xy' FROM 'TURNERyxXxy');
TURNERyxX
```
After this PR:
```sql
spark-sql> SELECT trim('yxTomxx', 'xyz'), trim(BOTH 'xyz' FROM 'yxTomxx');
Tom Tom
spark-sql> SELECT trim('xxxbarxxx', 'x'), trim(BOTH 'x' FROM 'xxxbarxxx');
bar bar
spark-sql> SELECT ltrim('zzzytest', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytest');
test test
spark-sql> SELECT ltrim('zzzytestxyz', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytestxyz');
testxyz testxyz
spark-sql> SELECT ltrim('xyxXxyLAST WORD', 'xy'), trim(LEADING 'xy' FROM 'xyxXxyLAST WORD');
XxyLAST WORD XxyLAST WORD
spark-sql> SELECT rtrim('testxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'testxxzx');
test test
spark-sql> SELECT rtrim('xyztestxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'xyztestxxzx');
xyztest xyztest
spark-sql> SELECT rtrim('TURNERyxXxy', 'xy'), trim(TRAILING 'xy' FROM 'TURNERyxXxy');
TURNERyxX TURNERyxX
```
And PostgreSQL:
```sql
postgres=# SELECT trim('yxTomxx', 'xyz'), trim(BOTH 'xyz' FROM 'yxTomxx');
btrim | btrim
-------+-------
Tom | Tom
(1 row)
postgres=# SELECT trim('xxxbarxxx', 'x'), trim(BOTH 'x' FROM 'xxxbarxxx');
btrim | btrim
-------+-------
bar | bar
(1 row)
postgres=# SELECT ltrim('zzzytest', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytest');
ltrim | ltrim
-------+-------
test | test
(1 row)
postgres=# SELECT ltrim('zzzytestxyz', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytestxyz');
ltrim | ltrim
---------+---------
testxyz | testxyz
(1 row)
postgres=# SELECT ltrim('xyxXxyLAST WORD', 'xy'), trim(LEADING 'xy' FROM 'xyxXxyLAST WORD');
ltrim | ltrim
--------------+--------------
XxyLAST WORD | XxyLAST WORD
(1 row)
postgres=# SELECT rtrim('testxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'testxxzx');
rtrim | rtrim
-------+-------
test | test
(1 row)
postgres=# SELECT rtrim('xyztestxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'xyztestxxzx');
rtrim | rtrim
---------+---------
xyztest | xyztest
(1 row)
postgres=# SELECT rtrim('TURNERyxXxy', 'xy'), trim(TRAILING 'xy' FROM 'TURNERyxXxy');
rtrim | rtrim
-----------+-----------
TURNERyxX | TURNERyxX
(1 row)
```
Closes#24911 from wangyum/SPARK-28109.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Current SQL parser's error message for hyphen-connected identifiers without surrounding backquotes(e.g. hyphen-table) is confusing for end users. A possible approach to tackle this is to explicitly capture these wrong usages in the SQL parser. In this way, the end users can fix these errors more quickly.
For example, for a simple query such as `SELECT * FROM test-table`, the original error message is
```
Error in SQL statement: ParseException:
mismatched input '-' expecting <EOF>(line 1, pos 18)
```
which can be confusing in a large query.
After the fix, the error message is:
```
Error in query:
Possibly unquoted identifier test-table detected. Please consider quoting it with back-quotes as `test-table`(line 1, pos 14)
== SQL ==
SELECT * FROM test-table
--------------^^^
```
which is easier for end users to identify the issue and fix.
We safely augmented the current grammar rule to explicitly capture these error cases. The error handling logic is implemented in the SQL parsing listener `PostProcessor`.
However, note that for cases such as `a - my-func(b)`, the parser can't actually tell whether this should be ``a -`my-func`(b) `` or `a - my - func(b)`. Therefore for these cases, we leave the parser as is. Also, in this patch we only provide better error messages for character-only identifiers.
## How was this patch tested?
Adding new unit tests.
Closes#24749 from yeshengm/hyphen-ident.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The original `references` and `validConstraints` implementations in a few `QueryPlan` and `Expression` classes are methods, which means unnecessary re-computation can happen at times. This PR resolves this problem by making these method `lazy val`s.
As shown in the following chart, the planning time(without cost-based optimization) was dramatically reduced after this optimization.
- The average planning time of TPC-DS queries was reduced by 19.63%.
- The planning time of the most time-consuming TPC-DS query (q64) was reduced by 43.03%.
- The running time for rule-based reordering joins(not cost-based join reordering) optimization, which are common in real-world OLAP queries, was largely reduced.
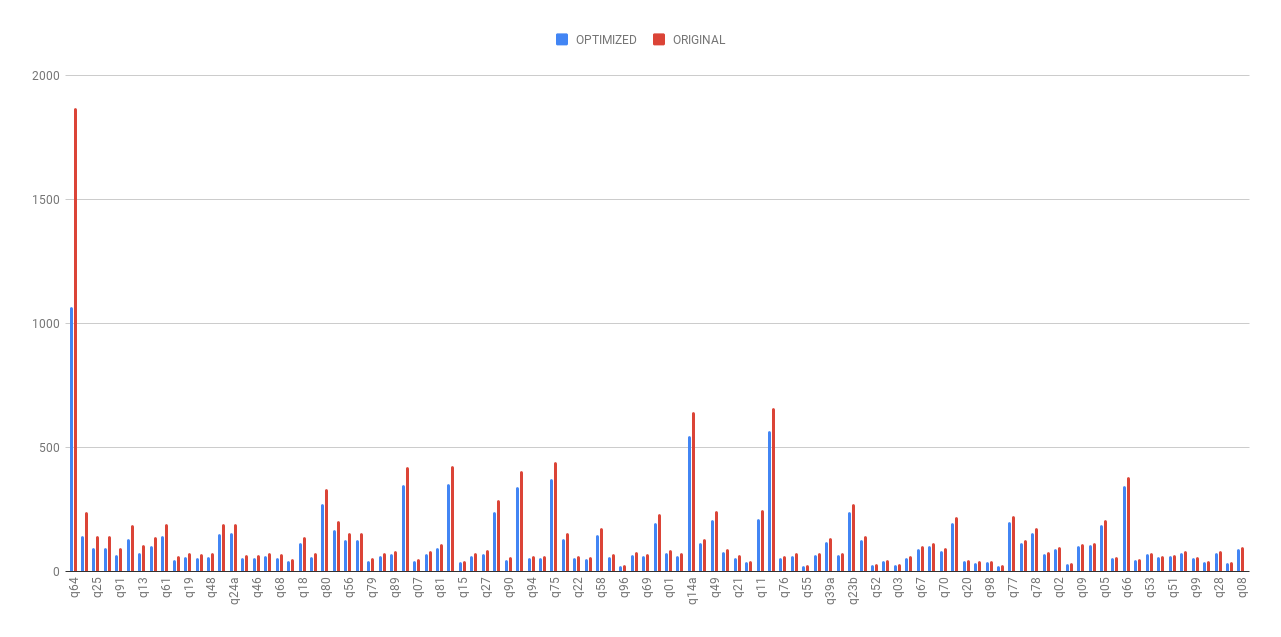
Detailed stats are listed in the following spreadsheet (we warmed up the queries 5 iterations and then took average of the next 5 iterations).
[Lazy val benchmark.xlsx](https://github.com/apache/spark/files/3303530/Lazy.val.benchmark.xlsx)
## How was this patch tested?
Existing UTs.
Closes#24866 from yeshengm/plannode-micro-opt.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
`OrcFilters.createBuilder` has exponential complexity in the height of the filter tree due to the way the check-and-build pattern is implemented. We've hit this in production by passing a `Column` filter to Spark directly, with a job taking multiple hours for a simple set of ~30 filters. This PR changes the checking logic so that the conversion has linear complexity in the size of the tree instead of exponential in its height.
Right now, due to the way ORC `SearchArgument` works, the code is forced to do two separate phases when converting a given Spark filter to an ORC filter:
1. Check if the filter is convertible.
2. Only if the check in 1. succeeds, perform the actual conversion into the resulting ORC filter.
However, there's one detail which is the culprit in the exponential complexity: phases 1. and 2. are both done using the exact same method. The resulting exponential complexity is easiest to see in the `NOT` case - consider the following code:
```
val f1 = col("id") === lit(5)
val f2 = !f1
val f3 = !f2
val f4 = !f3
val f5 = !f4
```
Now, when we run `createBuilder` on `f5`, we get the following behaviour:
1. call `createBuilder(f4)` to check if the child `f4` is convertible
2. call `createBuilder(f4)` to actually convert it
This seems fine when looking at a single level, but what actually ends up happening is:
- `createBuilder(f3)` will then recursively be called 4 times - 2 times in step 1., and two times in step 2.
- `createBuilder(f2)` will be called 8 times - 4 times in each top-level step, 2 times in each sub-step.
- `createBuilder(f1)` will be called 16 times.
As a result, having a tree of height > 30 leads to billions of calls to `createBuilder`, heap allocations, and so on and can take multiple hours.
The way this PR solves this problem is by separating the `check` and `convert` functionalities into separate functions. This way, the call to `createBuilder` on `f5` above would look like this:
1. call `isConvertible(f4)` to check if the child `f4` is convertible - amortized constant complexity
2. call `createBuilder(f4)` to actually convert it - linear complexity in the size of the subtree.
This way, we get an overall complexity that's linear in the size of the filter tree, allowing us to convert tree with 10s of thousands of nodes in milliseconds.
The reason this split (`check` and `build`) is possible is that the checking never actually depends on the actual building of the filter. The `check` part of `createBuilder` depends mainly on:
- `isSearchableType` for leaf nodes, and
- `check`-ing the child filters for composite nodes like NOT, AND and OR.
Situations like the `SearchArgumentBuilder` throwing an exception while building the resulting ORC filter are not handled right now - they just get thrown out of the class, and this change preserves this behaviour.
This PR extracts this part of the code to a separate class which allows the conversion to make very efficient checks to confirm that a given child is convertible before actually converting it.
Results:
Before:
- converting a skewed tree with a height of ~35 took about 6-7 hours.
- converting a skewed tree with hundreds or thousands of nodes would be completely impossible.
Now:
- filtering against a skewed tree with a height of 1500 in the benchmark suite finishes in less than 10 seconds.
## Steps to reproduce
```scala
val schema = StructType.fromDDL("col INT")
(20 to 30).foreach { width =>
val whereFilter = (1 to width).map(i => EqualTo("col", i)).reduceLeft(Or)
val start = System.currentTimeMillis()
OrcFilters.createFilter(schema, Seq(whereFilter))
println(s"With $width filters, conversion takes ${System.currentTimeMillis() - start} ms")
}
```
### Before this PR
```
With 20 filters, conversion takes 363 ms
With 21 filters, conversion takes 496 ms
With 22 filters, conversion takes 939 ms
With 23 filters, conversion takes 1871 ms
With 24 filters, conversion takes 3756 ms
With 25 filters, conversion takes 7452 ms
With 26 filters, conversion takes 14978 ms
With 27 filters, conversion takes 30519 ms
With 28 filters, conversion takes 60361 ms // 1 minute
With 29 filters, conversion takes 126575 ms // 2 minutes 6 seconds
With 30 filters, conversion takes 257369 ms // 4 minutes 17 seconds
```
### After this PR
```
With 20 filters, conversion takes 12 ms
With 21 filters, conversion takes 0 ms
With 22 filters, conversion takes 1 ms
With 23 filters, conversion takes 0 ms
With 24 filters, conversion takes 1 ms
With 25 filters, conversion takes 1 ms
With 26 filters, conversion takes 0 ms
With 27 filters, conversion takes 1 ms
With 28 filters, conversion takes 0 ms
With 29 filters, conversion takes 1 ms
With 30 filters, conversion takes 0 ms
```
## How was this patch tested?
There are no changes in behaviour, and the existing tests pass. Added new benchmarks that expose the problematic behaviour and they finish quickly with the changes applied.
Closes#24068 from IvanVergiliev/optimize-orc-filters.
Authored-by: Ivan Vergiliev <ivan.vergiliev@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Added an interface for handling hint errors, with a default implementation class that logs warnings in the callbacks.
## How was this patch tested?
Passed existing tests.
Closes#24653 from maryannxue/hint-handler.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
When using `DROPMALFORMED` mode, corrupted records aren't dropped if malformed columns aren't read. This behavior is due to CSV parser column pruning. Current doc of `DROPMALFORMED` doesn't mention the effect of column pruning. Users will be confused by the fact that `DROPMALFORMED` mode doesn't work as expected.
Column pruning also affects other modes. This is a doc improvement to add a note to doc of `mode` to explain it.
## How was this patch tested?
N/A. This is just doc change.
Closes#24894 from viirya/SPARK-28058.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Currently `ArrayExists` always returns boolean values (if the arguments are not `null`), but it should follow the three-valued boolean logic:
- `true` if the predicate holds at least one `true`
- otherwise, `null` if the predicate holds `null`
- otherwise, `false`
This behavior change is made to match Postgres' equivalent function `ANY/SOME (array)`'s behavior: https://www.postgresql.org/docs/9.6/functions-comparisons.html#AEN21174
## How was this patch tested?
Modified tests and existing tests.
Closes#24873 from ueshin/issues/SPARK-28052/fix_exists.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Allow Pandas UDF to take an iterator of pd.Series or an iterator of tuple of pd.Series.
Note the UDF input args will be always one iterator:
* if the udf take only column as input, the iterator's element will be pd.Series (corresponding to the column values batch)
* if the udf take multiple columns as inputs, the iterator's element will be a tuple composed of multiple `pd.Series`s, each one corresponding to the multiple columns as inputs (keep the same order). For example:
```
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def the_udf(iterator):
for col1_batch, col2_batch in iterator:
yield col1_batch + col2_batch
df.select(the_udf("col1", "col2"))
```
The udf above will add col1 and col2.
I haven't add unit tests, but manually tests show it works fine. So it is ready for first pass review.
We can test several typical cases:
```
from pyspark.sql import SparkSession
from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql.functions import udf
from pyspark.taskcontext import TaskContext
df = spark.createDataFrame([(1, 20), (3, 40)], ["a", "b"])
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi1(it):
pid = TaskContext.get().partitionId()
print("DBG: fi1: do init stuff, partitionId=" + str(pid))
for batch in it:
yield batch + 100
print("DBG: fi1: do close stuff, partitionId=" + str(pid))
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi2(it):
pid = TaskContext.get().partitionId()
print("DBG: fi2: do init stuff, partitionId=" + str(pid))
for batch in it:
yield batch + 10000
print("DBG: fi2: do close stuff, partitionId=" + str(pid))
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi3(it):
pid = TaskContext.get().partitionId()
print("DBG: fi3: do init stuff, partitionId=" + str(pid))
for x, y in it:
yield x + y * 10 + 100000
print("DBG: fi3: do close stuff, partitionId=" + str(pid))
pandas_udf("int", PandasUDFType.SCALAR)
def fp1(x):
return x + 1000
udf("int")
def fu1(x):
return x + 10
# test select "pandas iter udf/pandas udf/sql udf" expressions at the same time.
# Note this case the `fi1("a"), fi2("b"), fi3("a", "b")` will generate only one plan,
# and `fu1("a")`, `fp1("a")` will generate another two separate plans.
df.select(fi1("a"), fi2("b"), fi3("a", "b"), fu1("a"), fp1("a")).show()
# test chain two pandas iter udf together
# Note this case `fi2(fi1("a"))` will generate only one plan
# Also note the init stuff/close stuff call order will be like:
# (debug output following)
# DBG: fi2: do init stuff, partitionId=0
# DBG: fi1: do init stuff, partitionId=0
# DBG: fi1: do close stuff, partitionId=0
# DBG: fi2: do close stuff, partitionId=0
df.select(fi2(fi1("a"))).show()
# test more complex chain
# Note this case `fi1("a"), fi2("a")` will generate one plan,
# and `fi3(fi1_output, fi2_output)` will generate another plan
df.select(fi3(fi1("a"), fi2("a"))).show()
```
## How was this patch tested?
To be added.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24643 from WeichenXu123/pandas_udf_iter.
Lead-authored-by: WeichenXu <weichen.xu@databricks.com>
Co-authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
Migrate Parquet to File Data Source V2
## How was this patch tested?
Unit test
Closes#24327 from gengliangwang/parquetV2.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Implemented a new SparkPlan that executes the query adaptively. It splits the query plan into independent stages and executes them in order according to their dependencies. The query stage materializes its output at the end. When one stage completes, the data statistics of the materialized output will be used to optimize the remainder of the query.
The adaptive mode is off by default, when turned on, user can see "AdaptiveSparkPlan" as the top node of a query or sub-query. The inner plan of "AdaptiveSparkPlan" is subject to change during query execution but becomes final once the execution is complete. Whether the inner plan is final is included in the EXPLAIN string. Below is an example of the EXPLAIN plan before and after execution:
Query:
```
SELECT * FROM testData JOIN testData2 ON key = a WHERE value = '1'
```
Before execution:
```
== Physical Plan ==
AdaptiveSparkPlan(isFinalPlan=false)
+- SortMergeJoin [key#13], [a#23], Inner
:- Sort [key#13 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(key#13, 5)
: +- Filter (isnotnull(value#14) AND (value#14 = 1))
: +- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).key AS key#13, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).value, true, false) AS value#14]
: +- Scan[obj#12]
+- Sort [a#23 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(a#23, 5)
+- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).a AS a#23, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).b AS b#24]
+- Scan[obj#22]
```
After execution:
```
== Physical Plan ==
AdaptiveSparkPlan(isFinalPlan=true)
+- *(1) BroadcastHashJoin [key#13], [a#23], Inner, BuildLeft
:- BroadcastQueryStage 2
: +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint)))
: +- ShuffleQueryStage 0
: +- Exchange hashpartitioning(key#13, 5)
: +- *(1) Filter (isnotnull(value#14) AND (value#14 = 1))
: +- *(1) SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).key AS key#13, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).value, true, false) AS value#14]
: +- Scan[obj#12]
+- ShuffleQueryStage 1
+- Exchange hashpartitioning(a#23, 5)
+- *(1) SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).a AS a#23, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).b AS b#24]
+- Scan[obj#22]
```
Credit also goes to carsonwang and cloud-fan
## How was this patch tested?
Added new UT.
Closes#24706 from maryannxue/aqe.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: herman <herman@databricks.com>
## What changes were proposed in this pull request?
This PR adds support of column aliasing in a CTE so this query becomes valid:
```
WITH t(x) AS (SELECT 1)
SELECT * FROM t WHERE x = 1
```
## How was this patch tested?
Added new UTs.
Closes#24842 from peter-toth/SPARK-28002.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This patch proposes making `purge` in `CompactibleFileStreamLog` to throw `UnsupportedOperationException` to prevent purging necessary batch files, as well as adding javadoc to document its behavior. Actually it would only break when latest compaction batch is requested to be purged, but caller wouldn't be aware of this so safer to just prevent it.
## How was this patch tested?
Added UT.
Closes#23850 from HeartSaVioR/SPARK-26949.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
I suspect that the doc of `rowsBetween` methods in Scala and PySpark looks wrong.
Because:
```scala
scala> val df = Seq((1, "a"), (2, "a"), (3, "a"), (4, "a"), (5, "a"), (6, "a")).toDF("id", "category")
df: org.apache.spark.sql.DataFrame = [id: int, category: string]
scala> val byCategoryOrderedById = Window.partitionBy('category).orderBy('id).rowsBetween(-1, 2)
byCategoryOrderedById: org.apache.spark.sql.expressions.WindowSpec = org.apache.spark.sql.expressions.WindowSpec7f04de97
scala> df.withColumn("sum", sum('id) over byCategoryOrderedById).show()
+---+--------+---+
| id|category|sum|
+---+--------+---+
| 1| a| 6| # sum from index 0 to (0 + 2): 1 + 2 + 3 = 6
| 2| a| 10| # sum from index (1 - 1) to (1 + 2): 1 + 2 + 3 + 4 = 10
| 3| a| 14|
| 4| a| 18|
| 5| a| 15|
| 6| a| 11|
+---+--------+---+
```
So the frame (-1, 2) for row with index 5, as described in the doc, should range from index 4 to index 7.
## How was this patch tested?
N/A, just doc change.
Closes#24864 from viirya/window-spec-doc.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Currently, SparkSQL can support interval format like this.
```sql
SELECT INTERVAL '0 23:59:59.155' DAY TO SECOND
```
Like Presto/Teradata, this PR aims to support grammar like below.
```sql
SELECT INTERVAL '23:59:59.155' HOUR TO SECOND
```
Although we can add a new function for this pattern, we had better extend the existing code to handle a missing day case. So, the following is also supported.
```sql
SELECT INTERVAL '23:59:59.155' DAY TO SECOND
SELECT INTERVAL '1 23:59:59.155' HOUR TO SECOND
```
Currently Vertica/Teradata/Postgresql/SQL Server have fully support of below interval functions.
- interval ... year to month
- interval ... day to hour
- interval ... day to minute
- interval ... day to second
- interval ... hour to minute
- interval ... hour to second
- interval ... minute to second
https://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/SQLReferenceManual/LanguageElements/Literals/interval-qualifier.htmdf1a699e5b/src/test/regress/sql/interval.sql (L180-L203)https://docs.teradata.com/reader/S0Fw2AVH8ff3MDA0wDOHlQ/KdCtT3pYFo~_enc8~kGKVwhttps://docs.microsoft.com/en-us/sql/odbc/reference/appendixes/interval-literals?view=sql-server-2017
## How was this patch tested?
Pass the Jenkins with the updated test cases.
Closes#24472 from lipzhu/SPARK-27578.
Lead-authored-by: Zhu, Lipeng <lipzhu@ebay.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Lipeng Zhu <lipzhu@icloud.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Support multi-catalog in the following SELECT code paths:
- SELECT * FROM catalog.db.tbl
- TABLE catalog.db.tbl
- JOIN or UNION tables from different catalogs
- SparkSession.table("catalog.db.tbl")
- CTE relation
- View text
## How was this patch tested?
New unit tests.
All existing unit tests in catalyst and sql core.
Closes#24741 from jzhuge/SPARK-27322-pr.
Authored-by: John Zhuge <jzhuge@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Convert `PartitionedFile.filePath` to URI first in binary file data source. Otherwise Spark will throw a FileNotFound exception because we create `Path` with URL encoded string, instead of wrapping it with URI.
## How was this patch tested?
Unit test.
Closes#24855 from mengxr/SPARK-28030.
Authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
`NestedColumnAliasing` rule covers `GetStructField` only, currently. It means that some nested field extraction expressions aren't pruned. For example, if only accessing a nested field in an array of struct (`GetArrayStructFields`), this column isn't pruned.
This patch extends the rule to cover general nested field cases, including `GetArrayStructFields`.
## How was this patch tested?
Added tests.
Closes#24599 from viirya/nested-pruning-extract-value.
Lead-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
Current Spark SQL parser can have pretty confusing error messages when parsing an incorrect SELECT SQL statement. The proposed fix has the following effect.
BEFORE:
```
spark-sql> SELECT * FROM test WHERE x NOT NULL;
Error in query:
mismatched input 'FROM' expecting {<EOF>, 'CLUSTER', 'DISTRIBUTE', 'EXCEPT', 'GROUP', 'HAVING', 'INTERSECT', 'LATERAL', 'LIMIT', 'ORDER', 'MINUS', 'SORT', 'UNION', 'WHERE', 'WINDOW'}(line 1, pos 9)
== SQL ==
SELECT * FROM test WHERE x NOT NULL
---------^^^
```
where in fact the error message should be hinted to be near `NOT NULL`.
AFTER:
```
spark-sql> SELECT * FROM test WHERE x NOT NULL;
Error in query:
mismatched input 'NOT' expecting {<EOF>, 'AND', 'CLUSTER', 'DISTRIBUTE', 'EXCEPT', 'GROUP', 'HAVING', 'INTERSECT', 'LIMIT', 'OR', 'ORDER', 'MINUS', 'SORT', 'UNION', 'WINDOW'}(line 1, pos 27)
== SQL ==
SELECT * FROM test WHERE x NOT NULL
---------------------------^^^
```
In fact, this problem is brought by some problematic Spark SQL grammar. There are two kinds of SELECT statements that are supported by Hive (and thereby supported in SparkSQL):
* `FROM table SELECT blahblah SELECT blahblah`
* `SELECT blah FROM table`
*Reference* [HiveQL single-from stmt grammar](https://github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/parse/HiveParser.g)
It is fine when these two SELECT syntaxes are supported separately. However, since we are currently supporting these two kinds of syntaxes in a single ANTLR rule, this can be problematic and therefore leading to confusing parser errors. This is because when a SELECT clause was parsed, it can't tell whether the following FROM clause actually belongs to it or is just the beginning of a new `FROM table SELECT *` statement.
## What changes were proposed in this pull request?
1. Modify ANTLR grammar to fix the above-mentioned problem. This fix is important because the previous problematic grammar does affect a lot of real-world queries. Due to the previous problematic and messy grammar, we refactored the grammar related to `querySpecification`.
2. Modify `AstBuilder` to have separate visitors for `SELECT ... FROM ...` and `FROM ... SELECT ...` statements.
3. Drop the `FROM table` statement, which is supported by accident and is actually parsed in the wrong code path. Both Hive and Presto do not support this syntax.
## How was this patch tested?
Existing UTs and new UTs.
Closes#24809 from yeshengm/parser-refactor.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
## What changes were proposed in this pull request?
This PR is the same fix as https://github.com/apache/spark/pull/24816 but in vectorized `dapply` in SparkR.
## How was this patch tested?
Manually tested.
Closes#24818 from HyukjinKwon/SPARK-27971.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The newly added `Refresh` method in PR #24401 prevented the work of moving DataSourceV2Relation into catalyst. It calls `case table: FileTable => table.fileIndex.refresh()` while `FileTable` belongs to sql/core.
More importantly, Ryan Blue pointed out DataSourceV2Relation is immutable by design, it should not have refresh method.
## How was this patch tested?
Unit test
Closes#24815 from gengliangwang/removeRefreshTable.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Flush batch timely for pandas UDF.
This could improve performance when multiple pandas UDF plans are pipelined.
When batch being flushed in time, downstream pandas UDFs will get pipelined as soon as possible, and pipeline will help hide the donwstream UDFs computation time. For example:
When the first UDF start computing on batch-3, the second pipelined UDF can start computing on batch-2, and the third pipelined UDF can start computing on batch-1.
If we do not flush each batch in time, the donwstream UDF's pipeline will lag behind too much, which may increase the total processing time.
I add flush at two places:
* JVM process feed data into python worker. In jvm side, when write one batch, flush it
* VM process read data from python worker output, In python worker side, when write one batch, flush it
If no flush, the default buffer size for them are both 65536. Especially in the ML case, in order to make realtime prediction, we will make batch size very small. The buffer size is too large for the case, which cause downstream pandas UDF pipeline lag behind too much.
### Note
* This is only applied to pandas scalar UDF.
* Do not flush for each batch. The minimum interval between two flush is 0.1 second. This avoid too frequent flushing when batch size is small. It works like:
```
last_flush_time = time.time()
for batch in iterator:
writer.write_batch(batch)
flush_time = time.time()
if self.flush_timely and (flush_time - last_flush_time > 0.1):
stream.flush()
last_flush_time = flush_time
```
## How was this patch tested?
### Benchmark to make sure the flush do not cause performance regression
#### Test code:
```
numRows = ...
batchSize = ...
spark.conf.set('spark.sql.execution.arrow.maxRecordsPerBatch', str(batchSize))
df = spark.range(1, numRows + 1, numPartitions=1).select(col('id').alias('a'))
pandas_udf("int", PandasUDFType.SCALAR)
def fp1(x):
return x + 10
beg_time = time.time()
result = df.select(sum(fp1('a'))).head()
print("result: " + str(result[0]))
print("consume time: " + str(time.time() - beg_time))
```
#### Test Result:
params | Consume time (Before) | Consume time (After)
------------ | ----------------------- | ----------------------
numRows=100000000, batchSize=10000 | 23.43s | 24.64s
numRows=100000000, batchSize=1000 | 36.73s | 34.50s
numRows=10000000, batchSize=100 | 35.67s | 32.64s
numRows=1000000, batchSize=10 | 33.60s | 32.11s
numRows=100000, batchSize=1 | 33.36s | 31.82s
### Benchmark pipelined pandas UDF
#### Test code:
```
spark.conf.set('spark.sql.execution.arrow.maxRecordsPerBatch', '1')
df = spark.range(1, 31, numPartitions=1).select(col('id').alias('a'))
pandas_udf("int", PandasUDFType.SCALAR)
def fp1(x):
print("run fp1")
time.sleep(1)
return x + 100
pandas_udf("int", PandasUDFType.SCALAR)
def fp2(x, y):
print("run fp2")
time.sleep(1)
return x + y
beg_time = time.time()
result = df.select(sum(fp2(fp1('a'), col('a')))).head()
print("result: " + str(result[0]))
print("consume time: " + str(time.time() - beg_time))
```
#### Test Result:
**Before**: consume time: 63.57s
**After**: consume time: 32.43s
**So the PR improve performance by make downstream UDF get pipelined early.**
Please review https://spark.apache.org/contributing.html before opening a pull request.
Closes#24734 from WeichenXu123/improve_pandas_udf_pipeline.
Lead-authored-by: WeichenXu <weichen.xu@databricks.com>
Co-authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In PR https://github.com/apache/spark/pull/24365, we pass in the partitionBy columns as options in `DataFrameWriter`. To make this change less intrusive for a patch release, we added a feature flag `LEGACY_PASS_PARTITION_BY_AS_OPTIONS` with the default to be false.
For 3.0, we should just do the correct behavior for DSV1, i.e., always passing partitionBy as options, and remove this legacy feature flag.
## How was this patch tested?
Existing tests.
Closes#24784 from liwensun/SPARK-27453-default.
Authored-by: liwensun <liwen.sun@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Issued fixed in https://github.com/apache/spark/pull/24734 but that PR might takes longer to merge.
## How was this patch tested?
It should pass existing unit tests.
Closes#24816 from mengxr/SPARK-27968.
Authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
Move methods that implement v2 catalog operations to CatalogV2Util so they can be used in #24768.
## How was this patch tested?
Behavior is validated by existing tests.
Closes#24813 from rdblue/SPARK-27964-add-catalog-v2-util.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
I believe the log message: `Committer $committerClass is not a ParquetOutputCommitter and cannot create job summaries. Set Parquet option ${ParquetOutputFormat.JOB_SUMMARY_LEVEL} to NONE.` is at odds with the `if` statement that logs the warning. Despite the instructions in the warning, users still encounter the warning if `JOB_SUMMARY_LEVEL` is already set to `NONE`.
This pull request introduces a change to skip logging the warning if `JOB_SUMMARY_LEVEL` is set to `NONE`.
## How was this patch tested?
I built to make sure everything still compiled and I ran the existing test suite. I didn't feel it was worth the overhead to add a test to make sure a log message does not get logged, but if reviewers feel differently, I can add one.
Closes#24808 from jmsanders/master.
Authored-by: Jordan Sanders <jmsanders@users.noreply.github.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This moves parsing logic for `ALTER TABLE` into Catalyst and adds parsed logical plans for alter table changes that use multi-part identifiers. This PR is similar to SPARK-27108, PR #24029, that created parsed logical plans for create and CTAS.
* Create parsed logical plans
* Move parsing logic into Catalyst's AstBuilder
* Convert to DataSource plans in DataSourceResolution
* Parse `ALTER TABLE ... SET LOCATION ...` separately from the partition variant
* Parse `ALTER TABLE ... ALTER COLUMN ... [TYPE dataType] [COMMENT comment]` [as discussed on the dev list](http://apache-spark-developers-list.1001551.n3.nabble.com/DISCUSS-Syntax-for-table-DDL-td25197.html#a25270)
* Parse `ALTER TABLE ... RENAME COLUMN ... TO ...`
* Parse `ALTER TABLE ... DROP COLUMNS ...`
## How was this patch tested?
* Added new tests in Catalyst's `DDLParserSuite`
* Moved converted plan tests from SQL `DDLParserSuite` to `PlanResolutionSuite`
* Existing tests for regressions
Closes#24723 from rdblue/SPARK-27857-add-alter-table-statements-in-catalyst.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
Extracting the common purge "behaviour" to the parent StreamExecution.
## How was this patch tested?
No added behaviour so relying on existing tests.
Closes#24781 from jaceklaskowski/StreamExecution-purge.
Authored-by: Jacek Laskowski <jacek@japila.pl>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently we are in a strange status that, some data source v2 interfaces(catalog related) are in sql/catalyst, some data source v2 interfaces(Table, ScanBuilder, DataReader, etc.) are in sql/core.
I don't see a reason to keep data source v2 API in 2 modules. If we should pick one module, I think sql/catalyst is the one to go.
Catalyst module already has some user-facing stuff like DataType, Row, etc. And we have to update `Analyzer` and `SessionCatalog` to support the new catalog plugin, which needs to be in the catalyst module.
This PR can solve the problem we have in https://github.com/apache/spark/pull/24246
## How was this patch tested?
existing tests
Closes#24416 from cloud-fan/move.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Similar to https://github.com/apache/spark/pull/24070, we now propagate SparkExceptions that are encountered during the collect in the java process to the python process.
Fixes https://jira.apache.org/jira/browse/SPARK-27805
## How was this patch tested?
Added a new unit test
Closes#24677 from dvogelbacher/dv/betterErrorMsgWhenUsingArrow.
Authored-by: David Vogelbacher <dvogelbacher@palantir.com>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
## What changes were proposed in this pull request?
The current `SQLTestUtils` created many `withXXX` utility functions to clean up tables/views/caches created for testing purpose. Java's `try-with-resources` statement does something similar, but it does not mask exception throwing in the try block with any exception caught in the 'close()' statement. Exception caught in the 'close()' statement would add as a suppressed exception instead.
This PR standardizes those 'withXXX' function to use`Utils.tryWithSafeFinally` function, which does something similar to Java's try-with-resources statement. The purpose of this proposal is to help developers to identify what actually breaks their tests.
## How was this patch tested?
Existing testcases.
Closes#24747 from William1104/feature/SPARK-27772-2.
Lead-authored-by: williamwong <william1104@gmail.com>
Co-authored-by: William Wong <william1104@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
In the previous work of csv/json migration, CSVFileFormat/JsonFileFormat is removed in the table provider whitelist of `AlterTableAddColumnsCommand.verifyAlterTableAddColumn`:
https://github.com/apache/spark/pull/24005https://github.com/apache/spark/pull/24058
This is regression. If a table is created with Provider `org.apache.spark.sql.execution.datasources.csv.CSVFileFormat` or `org.apache.spark.sql.execution.datasources.json.JsonFileFormat`, Spark should allow the "alter table add column" operation.
## How was this patch tested?
Unit test
Closes#24776 from gengliangwang/v1Table.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR targets to deduplicate hardcoded `py4j-0.10.8.1-src.zip` in order to make py4j upgrade easier.
## How was this patch tested?
N/A
Closes#24770 from HyukjinKwon/minor-py4j-dedup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR aims to add `interceptParseException` test utility function to `AnalysisTest` to reduce the duplications of `intercept` functions.
## How was this patch tested?
Pass the Jenkins with the updated test suites.
Closes#24769 from dongjoon-hyun/SPARK-27920.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
If we want to keep corrupt record when reading CSV, we provide a new column into the schema, that is `columnNameOfCorruptRecord`. But this new column isn't actually a column in CSV header. So if `enforceSchema` is disabled, `CSVHeaderChecker` throws a exception complaining that number of column in CSV header isn't equal to that in the schema.
## How was this patch tested?
Added test.
Closes#24757 from viirya/SPARK-27873.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR targets to add an integrated test base for various UDF test cases so that Scalar UDF, Python UDF and Scalar Pandas UDFs can be tested in SBT & Maven tests.
### Problem
One of the problems we face is that: `ExtractPythonUDFs` (for Python UDF and Scalar Pandas UDF) has unevaluable expressions that always has to be wrapped with special plans. This special rule seems producing many issues, for instance, SPARK-27803, SPARK-26147, SPARK-26864, SPARK-26293, SPARK-25314 and SPARK-24721.
### Why do we have less test cases dedicated for SQL and plans with Python UDFs?
We have virtually no such SQL (or plan) dedicated tests in PySpark to catch such issues because:
- A developer should know all the analyzer, the optimizer, SQL, PySpark, Py4J and version differences in Python to write such good test cases
- To test plans, we should access to plans in JVM via Py4J which is tricky, messy and duplicates Scala test cases
- Usually we just add end-to-end test cases in PySpark therefore there are not so many dedicated examples to refer to write in PySpark
It is also a non-trivial overhead to switch test base and method (IMHO).
### How does this PR fix?
This PR adds Python UDF and Scalar Pandas UDF into our `*.sql` file based test base in runtime of SBT / Maven test cases. It generates Python-pickled instance (consisting of return type and Python native function) that is used in Python or Scalar Pandas UDF and directly brings into JVM.
After that, (we don't interact via Py4J) run the tests directly in JVM - we can just register and run Python UDF and Scalar Pandas UDF in JVM.
Currently, I only integrated this change into SQL file based testing. This is how works with test files under `udf` directory:
After the test files under 'inputs/udf' directory are detected, it creates three test cases:
- Scala UDF test case with a Scalar UDF registered named 'udf'.
- Python UDF test case with a Python UDF registered named 'udf' iff Python executable and pyspark are available.
- Scalar Pandas UDF test case with a Scalar Pandas UDF registered named 'udf' iff Python executable, pandas, pyspark and pyarrow are available.
Therefore, UDF test cases should have single input and output files but executed by three different types of UDFs.
For instance,
```sql
CREATE TEMPORARY VIEW ta AS
SELECT udf(a) AS a, udf('a') AS tag FROM t1
UNION ALL
SELECT udf(a) AS a, udf('b') AS tag FROM t2;
CREATE TEMPORARY VIEW tb AS
SELECT udf(a) AS a, udf('a') AS tag FROM t3
UNION ALL
SELECT udf(a) AS a, udf('b') AS tag FROM t4;
SELECT tb.* FROM ta INNER JOIN tb ON ta.a = tb.a AND ta.tag = tb.tag;
```
will be ran 3 times with Scalar UDF, Python UDF and Scalar Pandas UDF each.
### Appendix
Plus, this PR adds `IntegratedUDFTestUtils` which enables to test and execute Python UDF and Scalar Pandas UDFs as below:
To register Python UDF in SQL:
```scala
IntegratedUDFTestUtils.registerTestUDF(TestPythonUDF(name = "udf"), spark)
```
To register Scalar Pandas UDF in SQL:
```scala
IntegratedUDFTestUtils.registerTestUDF(TestScalarPandasUDF(name = "udf"), spark)
```
To use it in Scala API:
```scala
spark.select(expr("udf(1)").show()
```
To use it in SQL:
```scala
sql("SELECT udf(1)").show()
```
This util could be used in the future for better coverage with Scala API combinations as well.
## How was this patch tested?
Tested via the command below:
```bash
build/sbt "sql/test-only *SQLQueryTestSuite -- -z udf/udf-inner-join.sql"
```
```
[info] SQLQueryTestSuite:
[info] - udf/udf-inner-join.sql - Scala UDF (5 seconds, 47 milliseconds)
[info] - udf/udf-inner-join.sql - Python UDF (4 seconds, 335 milliseconds)
[info] - udf/udf-inner-join.sql - Scalar Pandas UDF (5 seconds, 423 milliseconds)
```
[python] unavailable:
```
[info] SQLQueryTestSuite:
[info] - udf/udf-inner-join.sql - Scala UDF (4 seconds, 577 milliseconds)
[info] - udf/udf-inner-join.sql - Python UDF is skipped because [pyton] and/or pyspark were not available. !!! IGNORED !!!
[info] - udf/udf-inner-join.sql - Scalar Pandas UDF is skipped because pyspark,pandas and/or pyarrow were not available in [pyton]. !!! IGNORED !!!
```
pyspark unavailable:
```
[info] SQLQueryTestSuite:
[info] - udf/udf-inner-join.sql - Scala UDF (4 seconds, 991 milliseconds)
[info] - udf/udf-inner-join.sql - Python UDF is skipped because [python] and/or pyspark were not available. !!! IGNORED !!!
[info] - udf/udf-inner-join.sql - Scalar Pandas UDF is skipped because pyspark,pandas and/or pyarrow were not available in [python]. !!! IGNORED !!!
```
pandas and/or pyarrow unavailable:
```
[info] SQLQueryTestSuite:
[info] - udf/udf-inner-join.sql - Scala UDF (4 seconds, 713 milliseconds)
[info] - udf/udf-inner-join.sql - Python UDF (3 seconds, 89 milliseconds)
[info] - udf/udf-inner-join.sql - Scalar Pandas UDF is skipped because pandas and/or pyarrow were not available in [python]. !!! IGNORED !!!
```
Closes#24752 from HyukjinKwon/udf-tests.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
As outlined in the JIRA by JoshRosen, our conversion mechanism from catalyst types to scala ones is pretty inefficient for primitive data types. Indeed, in these cases, most of the times we are adding useless calls to `identity` function or anyway to functions which return the same value. Using the information we have when we generate the code, we can avoid most of these overheads.
## How was this patch tested?
Here is a simple test which shows the benefit that this PR can bring:
```
test("SPARK-27684: perf evaluation") {
val intLongUdf = ScalaUDF(
(a: Int, b: Long) => a + b, LongType,
Literal(1) :: Literal(1L) :: Nil,
true :: true :: Nil,
nullable = false)
val plan = generateProject(
MutableProjection.create(Alias(intLongUdf, s"udf")() :: Nil),
intLongUdf)
plan.initialize(0)
var i = 0
val N = 100000000
val t0 = System.nanoTime()
while(i < N) {
plan(EmptyRow).get(0, intLongUdf.dataType)
plan(EmptyRow).get(0, intLongUdf.dataType)
plan(EmptyRow).get(0, intLongUdf.dataType)
plan(EmptyRow).get(0, intLongUdf.dataType)
plan(EmptyRow).get(0, intLongUdf.dataType)
plan(EmptyRow).get(0, intLongUdf.dataType)
plan(EmptyRow).get(0, intLongUdf.dataType)
plan(EmptyRow).get(0, intLongUdf.dataType)
plan(EmptyRow).get(0, intLongUdf.dataType)
plan(EmptyRow).get(0, intLongUdf.dataType)
i += 1
}
val t1 = System.nanoTime()
println(s"Avg time: ${(t1 - t0).toDouble / N} ns")
}
```
The output before the patch is:
```
Avg time: 51.27083294 ns
```
after, we get:
```
Avg time: 11.85874227 ns
```
which is ~5X faster.
Moreover a benchmark has been added for Scala UDF. The output after the patch can be seen in this PR, before the patch, the output was:
```
================================================================================================
UDF with mixed input types
================================================================================================
Java HotSpot(TM) 64-Bit Server VM 1.8.0_152-b16 on Mac OS X 10.13.6
Intel(R) Core(TM) i7-4558U CPU 2.80GHz
long/nullable int/string to string: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
long/nullable int/string to string wholestage off 257 287 42 0,4 2569,5 1,0X
long/nullable int/string to string wholestage on 158 172 18 0,6 1579,0 1,6X
Java HotSpot(TM) 64-Bit Server VM 1.8.0_152-b16 on Mac OS X 10.13.6
Intel(R) Core(TM) i7-4558U CPU 2.80GHz
long/nullable int/string to option: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
long/nullable int/string to option wholestage off 104 107 5 1,0 1037,9 1,0X
long/nullable int/string to option wholestage on 80 92 12 1,2 804,0 1,3X
Java HotSpot(TM) 64-Bit Server VM 1.8.0_152-b16 on Mac OS X 10.13.6
Intel(R) Core(TM) i7-4558U CPU 2.80GHz
long/nullable int to primitive: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
long/nullable int to primitive wholestage off 71 76 7 1,4 712,1 1,0X
long/nullable int to primitive wholestage on 64 71 6 1,6 636,2 1,1X
================================================================================================
UDF with primitive types
================================================================================================
Java HotSpot(TM) 64-Bit Server VM 1.8.0_152-b16 on Mac OS X 10.13.6
Intel(R) Core(TM) i7-4558U CPU 2.80GHz
long/nullable int to string: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
long/nullable int to string wholestage off 60 60 0 1,7 600,3 1,0X
long/nullable int to string wholestage on 55 64 8 1,8 551,2 1,1X
Java HotSpot(TM) 64-Bit Server VM 1.8.0_152-b16 on Mac OS X 10.13.6
Intel(R) Core(TM) i7-4558U CPU 2.80GHz
long/nullable int to option: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
long/nullable int to option wholestage off 66 73 9 1,5 663,0 1,0X
long/nullable int to option wholestage on 30 32 2 3,3 300,7 2,2X
Java HotSpot(TM) 64-Bit Server VM 1.8.0_152-b16 on Mac OS X 10.13.6
Intel(R) Core(TM) i7-4558U CPU 2.80GHz
long/nullable int/string to primitive: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
long/nullable int/string to primitive wholestage off 32 35 5 3,2 316,7 1,0X
long/nullable int/string to primitive wholestage on 41 68 17 2,4 414,0 0,8X
```
The improvements are particularly visible in the second case, ie. when only primitive types are used as inputs.
Closes#24636 from mgaido91/SPARK-27684.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Josh Rosen <rosenville@gmail.com>
## What changes were proposed in this pull request?
Support DROP TABLE from V2 catalogs.
Move DROP TABLE into catalyst.
Move parsing tests for DROP TABLE/VIEW to PlanResolutionSuite to validate existing behavior.
Add new tests fo catalyst parser suite.
Separate DROP VIEW into different code path from DROP TABLE.
Move DROP VIEW into catalyst as a new operator.
Add a meaningful exception to indicate view is not currently supported in v2 catalog.
## How was this patch tested?
New unit tests.
Existing unit tests in catalyst and sql core.
Closes#24686 from jzhuge/SPARK-27813-pr.
Authored-by: John Zhuge <jzhuge@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This pr wrap all `PrintWriter` with `Utils.tryWithResource` to prevent resource leak.
## How was this patch tested?
Existing test
Closes#24739 from wangyum/SPARK-27875.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Require the lookup function with interface LookupCatalog. Rationale is in the review comments below.
Make `Analyzer` abstract. BaseSessionStateBuilder and HiveSessionStateBuilder implements lookupCatalog with a call to SparkSession.catalog().
Existing test cases and those that don't need catalog lookup will use a newly added `TestAnalyzer` with a default lookup function that throws` CatalogNotFoundException("No catalog lookup function")`.
Rewrote the unit test for LookupCatalog to demonstrate the interface can be used anywhere, not just Analyzer.
Removed Analyzer parameter `lookupCatalog` because we can override in the following manner:
```
new Analyzer() {
override def lookupCatalog(name: String): CatalogPlugin = ???
}
```
## How was this patch tested?
Existing unit tests.
Closes#24689 from jzhuge/SPARK-26946-follow.
Authored-by: John Zhuge <jzhuge@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
To follow https://github.com/apache/spark/pull/17397, the output of FileTable and DataSourceV2ScanExecBase can contain sensitive information (like Amazon keys). Such information should not end up in logs, or be exposed to non-privileged users.
This PR is to add a redaction facility for these outputs to resolve the issue. A user can enable this by setting a regex in the same spark.redaction.string.regex configuration as V1.
## How was this patch tested?
Unit test
Closes#24719 from gengliangwang/RedactionSuite.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
In order to support outer joins with null top-level objects, SPARK-15441 modified Dataset.joinWith to project both inputs into single-column structs prior to the join.
For inner joins, however, this step is unnecessary and actually harms performance: performing the nesting before the join increases the shuffled data size. As an optimization for inner joins only, we can move this nesting to occur after the join (effectively switching back to the pre-SPARK-15441 behavior; see #13425).
## How was this patch tested?
Existing tests, which I strengthened to also make assertions about the join result's nullability (since this guards against a bug I almost introduced during prototyping).
Here's a quick `spark-shell` experiment demonstrating the reduction in shuffle size:
```scala
// With --conf spark.shuffle.compress=false
sql("set spark.sql.autoBroadcastJoinThreshold=-1") // for easier shuffle measurements
case class Foo(a: Long, b: Long)
val left = spark.range(10000).map(x => Foo(x, x))
val right = spark.range(10000).map(x => Foo(x, x))
left.joinWith(right, left("a") === right("a"), "inner").rdd.count()
left.joinWith(right, left("a") === right("a"), "left").rdd.count()
```
With inner join (which benefits from this PR's optimization) we shuffle 546.9 KiB. With left outer join (whose plan hasn't changed, therefore being a representation of the state before this PR) we shuffle 859.4 KiB. Shuffle compression (which is enabled by default) narrows this gap a bit: with compression, outer joins shuffle about 12% more than inner joins.
Closes#24693 from JoshRosen/fast-join-with-for-inner-joins.
Lead-authored-by: Josh Rosen <rosenville@gmail.com>
Co-authored-by: Josh Rosen <joshrosen@stripe.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
I checked the code of
`org.apache.spark.sql.execution.datasources.DataSource`
, there exists duplicate Java reflection.
`sourceSchema`,`createSource`,`createSink`,`resolveRelation`,`writeAndRead`, all the methods call the `providingClass.getConstructor().newInstance()`.
The instance of `providingClass` is stateless, such as:
`KafkaSourceProvider`
`RateSourceProvider`
`TextSocketSourceProvider`
`JdbcRelationProvider`
`ConsoleSinkProvider`
AFAIK, Java reflection will result in significant performance issue.
The oracle website [https://docs.oracle.com/javase/tutorial/reflect/index.html](https://docs.oracle.com/javase/tutorial/reflect/index.html) contains some performance description about Java reflection:
```
Performance Overhead
Because reflection involves types that are dynamically resolved, certain Java virtual machine optimizations can not be performed. Consequently, reflective operations have slower performance than their non-reflective counterparts, and should be avoided in sections of code which are called frequently in performance-sensitive applications.
```
I have found some performance cost test of Java reflection as follows:
[https://blog.frankel.ch/performance-cost-of-reflection/](https://blog.frankel.ch/performance-cost-of-reflection/) contains performance cost test.
[https://stackoverflow.com/questions/435553/java-reflection-performance](https://stackoverflow.com/questions/435553/java-reflection-performance) has a discussion of java reflection.
So I think should avoid duplicate Java reflection and reuse the instance of `providingClass`.
## How was this patch tested?
Exists UT.
Closes#24647 from beliefer/optimize-DataSource.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
descending sort in HDFSMetadataLog.getLatest instead of two action of ascending sort and reverse
## How was this patch tested?
Jenkins
Closes#24711 from wenxuanguan/bug-fix-hdfsmetadatalog.
Authored-by: wenxuanguan <choose_home@126.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
In https://github.com/apache/spark/pull/22104 , we create the python-eval nodes at the end of the optimization phase, which causes a problem.
After the main optimization batch, Filter and Project nodes are usually pushed to the bottom, near the scan node. However, if we extract Python UDFs from Filter/Project, and create a python-eval node under Filter/Project, it will break column pruning/filter pushdown of the scan node.
There are some hacks in the `ExtractPythonUDFs` rule, to duplicate the column pruning and filter pushdown logic. However, it has some bugs as demonstrated in the new test case(only column pruning is broken). This PR removes the hacks and re-apply the column pruning and filter pushdown rules explicitly.
**Before:**
```
...
== Analyzed Logical Plan ==
a: bigint
Project [a#168L]
+- Filter dummyUDF(a#168L)
+- Relation[a#168L,b#169L] parquet
== Optimized Logical Plan ==
Project [a#168L]
+- Project [a#168L, b#169L]
+- Filter pythonUDF0#174: boolean
+- BatchEvalPython [dummyUDF(a#168L)], [a#168L, b#169L, pythonUDF0#174]
+- Relation[a#168L,b#169L] parquet
== Physical Plan ==
*(2) Project [a#168L]
+- *(2) Project [a#168L, b#169L]
+- *(2) Filter pythonUDF0#174: boolean
+- BatchEvalPython [dummyUDF(a#168L)], [a#168L, b#169L, pythonUDF0#174]
+- *(1) FileScan parquet [a#168L,b#169L] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/private/var/folders/_1/bzcp960d0hlb988k90654z2w0000gp/T/spark-798bae3c-a2..., PartitionFilters: [], PushedFilters: [], ReadSchema: struct<a:bigint,b:bigint>
```
**After:**
```
...
== Analyzed Logical Plan ==
a: bigint
Project [a#168L]
+- Filter dummyUDF(a#168L)
+- Relation[a#168L,b#169L] parquet
== Optimized Logical Plan ==
Project [a#168L]
+- Filter pythonUDF0#174: boolean
+- BatchEvalPython [dummyUDF(a#168L)], [pythonUDF0#174]
+- Project [a#168L]
+- Relation[a#168L,b#169L] parquet
== Physical Plan ==
*(2) Project [a#168L]
+- *(2) Filter pythonUDF0#174: boolean
+- BatchEvalPython [dummyUDF(a#168L)], [pythonUDF0#174]
+- *(1) FileScan parquet [a#168L] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/private/var/folders/_1/bzcp960d0hlb988k90654z2w0000gp/T/spark-9500cafb-78..., PartitionFilters: [], PushedFilters: [], ReadSchema: struct<a:bigint>
```
## How was this patch tested?
new test
Closes#24675 from cloud-fan/python.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This is a minor pr to use `#` as a marker for expression id that is embedded in the name field of SubqueryExec operator.
## How was this patch tested?
Added a small test in SubquerySuite.
Closes#24652 from dilipbiswal/subquery-name.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Avoid hard-coded config: `spark.rdd.parallelListingThreshold`.
## How was this patch tested?
N/A
Closes#24708 from wangyum/spark.rdd.parallelListingThreshold.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
InMemoryFileIndex.listLeafFiles should use listLocatedStatus for DistributedFileSystem. DistributedFileSystem overrides the listLocatedStatus method in order to do it with 1 single namenode call thus saving thousands of calls to getBlockLocations.
Currently in InMemoryFileIndex, all directory listings are done using FileSystem.listStatus following by individual calls to FileSystem.getFileBlockLocations. This is painstakingly slow for folders that have large numbers of files because this process happens serially and parallelism is only applied at the folder level, not the file level.
FileSystem also provides another API listLocatedStatus which returns the LocatedFileStatus objects that already have the block locations. In FileSystem main class this just delegates to listStatus and getFileBlockLocations similarly to the way Spark does it. However when HDFS specifically is the backing file system, DistributedFileSystem overrides this method and simply makes one single call to the namenode to retrieve the directory listing with the block locations. This avoids potentially thousands or more calls to namenode and also is more consistent because files will either exist with locations or not exist instead of having the FileNotFoundException exception case.
For our example directory with 6500 files, the load time of spark.read.parquet was reduced 96x from 76 seconds to .8 seconds. This savings only goes up with the number of files in the directory.
In the pull request instead of using this method always which could lead to a FileNotFoundException that could be tough to decipher in the default FileSystem implementation, this method is only used when the FileSystem is a DistributedFileSystem and otherwise the old logic still applies.
## How was this patch tested?
test suite ran
Closes#24672 from rrusso2007/master.
Authored-by: rrusso2007 <rrusso2007@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Each time, when I write a complex CREATE DATABASE/VIEW statements, I have to open the .g4 file to find the EXACT order of clauses in CREATE TABLE statement. When the order is not right, I will get A strange confusing error message generated from ANTLR4.
The original g4 grammar for CREATE VIEW is
```
CREATE [OR REPLACE] [[GLOBAL] TEMPORARY] VIEW [db_name.]view_name
[(col_name1 [COMMENT col_comment1], ...)]
[COMMENT table_comment]
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
AS select_statement
```
The proposal is to make the following clauses order insensitive.
```
[COMMENT table_comment]
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
```
–
The original g4 grammar for CREATE DATABASE is
```
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] db_name
[COMMENT comment_text]
[LOCATION path]
[WITH DBPROPERTIES (key1=val1, key2=val2, ...)]
```
The proposal is to make the following clauses order insensitive.
```
[COMMENT comment_text]
[LOCATION path]
[WITH DBPROPERTIES (key1=val1, key2=val2, ...)]
```
## How was this patch tested?
By adding new unit tests to test duplicate clauses and modifying some existing unit tests to test whether those clauses are actually order insensitive
Closes#24681 from yeshengm/create-view-parser.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This fix prevents the rule EliminateResolvedHint from being applied again if it's already applied.
## How was this patch tested?
Added new UT.
Closes#24692 from maryannxue/eliminatehint-bug.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In data source v1, save mode specified in `DataFrameWriter` is passed to data source implementation directly, and each data source can define its own behavior about save mode. This is confusing and we want to get rid of save mode in data source v2.
For data source v2, we expect data source to implement the `TableCatalog` API, and end-users use SQL(or the new write API described in [this doc](https://docs.google.com/document/d/1gYm5Ji2Mge3QBdOliFV5gSPTKlX4q1DCBXIkiyMv62A/edit?ts=5ace0718#heading=h.e9v1af12g5zo)) to acess data sources. The SQL API has very clear semantic and we don't need save mode at all.
However, for simple data sources that do not have table management (like a JIRA data source, a noop sink, etc.), it's not ideal to ask them to implement the `TableCatalog` API, and throw exception here and there.
`TableProvider` API is created for simple data sources. It can only get tables, without any other table management methods. This means, it can only deal with existing tables.
`TableProvider` fits well with `DataStreamReader` and `DataStreamWriter`, as they can only read/write existing tables. However, `TableProvider` doesn't fit `DataFrameWriter` well, as the save mode requires more than just get table. More specifically, `ErrorIfExists` mode needs to check if table exists, and create table. `Ignore` mode needs to check if table exists. When end-users specify `ErrorIfExists` or `Ignore` mode and write data to `TableProvider` via `DataFrameWriter`, Spark fails the query and asks users to use `Append` or `Overwrite` mode.
The file source is in the middle of `TableProvider` and `TableCatalog`: it's simple but it can check table(path) exists and create table(path). That said, file source supports all the save modes.
Currently file source implements `TableProvider`, and it's not working because `TableProvider` doesn't support `ErrorIfExists` and `Ignore` modes. Ideally we should create a new API for path-based data sources, but to unblock the work of file source v2 migration, this PR proposes to special-case file source v2 in `DataFrameWriter`, to make it work.
This PR also removes `SaveMode` from data source v2, as now only the internal file source v2 needs it.
## How was this patch tested?
existing tests
Closes#24233 from cloud-fan/file.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This adds a v2 implementation of create table:
* `CreateV2Table` is the logical plan, named using v2 to avoid conflicting with the existing plan
* `CreateTableExec` is the physical plan
## How was this patch tested?
Added resolution and v2 SQL tests.
Closes#24617 from rdblue/SPARK-27732-add-v2-create-table.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Add type parameter to `TreeNodeTag`.
## How was this patch tested?
existing tests
Closes#24687 from cloud-fan/tag.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
This PR is a follow up of https://github.com/apache/spark/pull/24669 to fix the wrong answers used in test cases.
Closes#24674 from dongjoon-hyun/SPARK-27800.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/22275 introduced a performance improvement where we send partitions out of order to python and then, as a last step, send the partition order as well.
However, if there are no partitions we will never send the partition order and we will get an "EofError" on the python side.
This PR fixes this by also sending the partition order if there are no partitions present.
## How was this patch tested?
New unit test added.
Closes#24650 from dvogelbacher/dv/fixNoPartitionArrowConversion.
Authored-by: David Vogelbacher <dvogelbacher@palantir.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
To return accurate pushed filters in Parquet file scan(https://github.com/apache/spark/pull/24327#pullrequestreview-234775673), we can process the original data source filters in the following way:
1. For "And" operators, split the conjunctive predicates and try converting each of them. After that
1.1 if partially predicate pushed down is allowed, return convertible results;
1.2 otherwise, return the whole predicate if convertible, or empty result if not convertible.
2. For "Or" operators, if both children can be pushed down, it is partially or totally convertible; otherwise, return empty result
3. For other operators, they are not able to be partially pushed down.
2.1 if the entire predicate is convertible, return itself
2.2 otherwise, return an empty result.
This PR also contains code refactoring. Currently `ParquetFilters. createFilter ` accepts parameter `schema: MessageType` and create field mapping for every input filter. We can make it a class member and avoid creating the `nameToParquetField` mapping for every input filter.
## How was this patch tested?
Unit test
Closes#24597 from gengliangwang/refactorParquetFilters.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
If we refresh a cached table, the table cache will be first uncached and then recache (lazily). Currently, the logic is embedded in CatalogImpl.refreshTable method.
The current implementation does not preserve the cache name and storage level. As a result, cache name and cache level could be changed after a REFERSH. IMHO, it is not what a user would expect.
I would like to fix this behavior by first save the cache name and storage level for recaching the table.
Two unit tests are added to make sure cache name is unchanged upon table refresh. Before applying this patch, the test created for qualified case would fail.
Closes#24221 from William1104/feature/SPARK-27248.
Lead-authored-by: williamwong <william1104@gmail.com>
Co-authored-by: William Wong <william1104@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Because a temporary view is resolved during analysis when we create a dataset, the content of the view is determined when the dataset is created, not when it is evaluated. Now the explain result of a dataset is not correctly consistent with the collected result of it, because we use pre-analyzed logical plan of the dataset in explain command. The explain command will analyzed the logical plan passed in. So if a view is changed after the dataset was created, the plans shown by explain command aren't the same with the plan of the dataset.
```scala
scala> spark.range(10).createOrReplaceTempView("test")
scala> spark.range(5).createOrReplaceTempView("test2")
scala> spark.sql("select * from test").createOrReplaceTempView("tmp001")
scala> val df = spark.sql("select * from tmp001")
scala> spark.sql("select * from test2").createOrReplaceTempView("tmp001")
scala> df.show
+---+
| id|
+---+
| 0|
| 1|
| 2|
| 3|
| 4|
| 5|
| 6|
| 7|
| 8|
| 9|
+---+
scala> df.explain(true)
```
Before:
```scala
== Parsed Logical Plan ==
'Project [*]
+- 'UnresolvedRelation `tmp001`
== Analyzed Logical Plan ==
id: bigint
Project [id#2L]
+- SubqueryAlias `tmp001`
+- Project [id#2L]
+- SubqueryAlias `test2`
+- Range (0, 5, step=1, splits=Some(12))
== Optimized Logical Plan ==
Range (0, 5, step=1, splits=Some(12))
== Physical Plan ==
*(1) Range (0, 5, step=1, splits=12)
```
After:
```scala
== Parsed Logical Plan ==
'Project [*]
+- 'UnresolvedRelation `tmp001`
== Analyzed Logical Plan ==
id: bigint
Project [id#0L]
+- SubqueryAlias `tmp001`
+- Project [id#0L]
+- SubqueryAlias `test`
+- Range (0, 10, step=1, splits=Some(12))
== Optimized Logical Plan ==
Range (0, 10, step=1, splits=Some(12))
== Physical Plan ==
*(1) Range (0, 10, step=1, splits=12)
```
Previous PR to this issue has a regression when to explain an explain statement, like `sql("explain select 1").explain(true)`. This new fix is following up with hvanhovell's advice at https://github.com/apache/spark/pull/24464#issuecomment-494165538.
Explain an explain:
```scala
scala> sql("explain select 1").explain(true)
== Parsed Logical Plan ==
ExplainCommand 'Project [unresolvedalias(1, None)], false, false, false
== Analyzed Logical Plan ==
plan: string
ExplainCommand 'Project [unresolvedalias(1, None)], false, false, false
== Optimized Logical Plan ==
ExplainCommand 'Project [unresolvedalias(1, None)], false, false, false
== Physical Plan ==
Execute ExplainCommand
+- ExplainCommand 'Project [unresolvedalias(1, None)], false, false, false
```
Btw, I found there is a regression after applying hvanhovell's advice:
```scala
spark.readStream
.format("org.apache.spark.sql.streaming.test")
.load()
.explain(true)
```
```scala
== Parsed Logical Plan ==
StreamingRelation DataSource(org.apache.spark.sql.test.TestSparkSession3e8c7175,org.apache.spark.sql.streaming.test,List(),None,List(),None,Map(),None
), dummySource, [a#559]
== Analyzed Logical Plan ==
a: int
StreamingRelation DataSource(org.apache.spark.sql.test.TestSparkSession3e8c7175,org.apache.spark.sql.streaming.test,List(),None,List(),None,Map(),Non$
), dummySource, [a#559]
== Optimized Logical Plan ==
org.apache.spark.sql.AnalysisException: Queries with streaming sources must be executed with writeStream.start();;
dummySource
== Physical Plan ==
org.apache.spark.sql.AnalysisException: Queries with streaming sources must be executed with writeStream.start();;
dummySource
```
So I did a change to that to fix it too.
## How was this patch tested?
Added test and manually test.
Closes#24654 from viirya/SPARK-27439-3.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Update the docs to reflect the changes made by https://github.com/apache/spark/pull/24129
## How was this patch tested?
N/A
Closes#24658 from cloud-fan/comment.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
It's pretty useful if we can convert a physical plan back to a logical plan, e.g., in https://github.com/apache/spark/pull/24389
This PR introduces a new feature to `TreeNode`, which allows `TreeNode` to carry some extra information via a mutable map, and keep the information when it's copied.
The planner leverages this feature to put the logical plan into the physical plan.
## How was this patch tested?
a test suite that runs all TPCDS queries and checks that some common physical plans contain the corresponding logical plans.
Closes#24626 from cloud-fan/link.
Lead-authored-by: Wenchen Fan <wenchen@databricks.com>
Co-authored-by: Peng Bo <bo.peng1019@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This pr makes it support collect statistics when CTAS(create a data source table using the result of a query).
## How was this patch tested?
unit tests and manual tests:
```sql
bin/spark-sql --conf spark.sql.statistics.size.autoUpdate.enabled=true -S
spark-sql> CREATE TABLE spark_27694 USING parquet AS SELECT 'a', 'b';
spark-sql> DESC FORMATTED spark_27694;
a string NULL
b string NULL
# Detailed Table Information
Database default
Table spark_27694
Owner root
Created Time Mon May 13 19:45:33 GMT-07:00 2019
Last Access Wed Dec 31 17:00:00 GMT-07:00 1969
Created By Spark 3.0.0-SNAPSHOT
Type MANAGED
Provider parquet
Statistics 561 bytes
Location file:/user/hive/warehouse/spark_27694
Serde Library org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
InputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
```
Closes#24596 from wangyum/SPARK-27694.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
Add a SQL config property for the default v2 catalog.
Existing tests for regressions.
Closes#24594 from rdblue/SPARK-27693-add-default-catalog-config.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Currently, in `ParquetFilters` and `OrcFilters`, if the child predicate of `Or` operator can't be entirely pushed down, the predicates will be thrown away.
In fact, the conjunctive predicates under `Or` operators can be partially pushed down.
For example, says `a` and `b` are convertible, while `c` can't be pushed down, the predicate
`a or (b and c)`
can be converted as
`(a or b) and (a or c)`
We can still push down `(a or b)`.
We can't push down disjunctive predicates only when one of its children is not partially convertible.
This PR also improve the filter pushing down logic in `DataSourceV2Strategy`. With partial filter push down in `Or` operator, the result of `pushedFilters()` might not exist in the mapping `translatedFilterToExpr`. To fix it, this PR changes the mapping `translatedFilterToExpr` as leaf filter expression to `sources.filter`, and later on rebuild the whole expression with the mapping.
## How was this patch tested?
Unit test
Closes#24598 from gengliangwang/pushdownDisjunctivePredicates.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Currently we have an analyzer rule, which resolves the output columns of data source v2 writing plans, to make sure the schema of input query is compatible with the table.
However, not all data sources need this check. For example, the `NoopDataSource` doesn't care about the schema of input query at all.
This PR introduces a new table capability: ACCEPT_ANY_SCHEMA. If a table reports this capability, we skip resolving output columns for it during write.
Note that, we already skip resolving output columns for `NoopDataSource` because it implements `SupportsSaveMode`. However, `SupportsSaveMode` is a hack and will be removed soon.
## How was this patch tested?
new test cases
Closes#24469 from cloud-fan/schema-check.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Some APIs in Structured Streaming requires the user to specify an interval. Right now these APIs don't accept upper-case strings.
This PR adds a new method `fromCaseInsensitiveString` to `CalendarInterval` to support paring upper-case strings, and fixes all APIs that need to parse an interval string.
## How was this patch tested?
The new unit test.
Closes#24619 from zsxwing/SPARK-27735.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
removed the unused "UnsafeKeyValueSorter.java" file
## How was this patch tested?
Ran Compilation and UT locally.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24622 from shivusondur/jira27722.
Authored-by: shivusondur <shivusondur@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/20365 .
#20365 fixed this problem when the hint node is a root node. This PR fixes this problem for all the cases.
## How was this patch tested?
a new test
Closes#24580 from cloud-fan/bug.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In the existing code, a broadcast execution timeout for the Future only causes a query failure, but the job running with the broadcast and the computation in the Future are not canceled. This wastes resources and slows down the other jobs. This PR tries to cancel both the running job and the running hashed relation construction thread.
## How was this patch tested?
Add new test suite `BroadcastExchangeExec`
Closes#24595 from jiangxb1987/SPARK-20774.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
`RecordBinaryComparator`, `UnsafeExternalRowSorter` and `UnsafeKeyValueSorter` now locates in catalyst, which should be moved to core, as they're used only in physical plan.
## How was this patch tested?
exist tests.
Closes#24607 from xianyinxin/SPARK-27713.
Authored-by: xy_xin <xianyin.xxy@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This adds a v2 implementation for CTAS queries
* Update the SQL parser to parse CREATE queries using multi-part identifiers
* Update `CheckAnalysis` to validate partitioning references with the CTAS query schema
* Add `CreateTableAsSelect` v2 logical plan and `CreateTableAsSelectExec` v2 physical plan
* Update create conversion from `CreateTableAsSelectStatement` to support the new v2 logical plan
* Update `DataSourceV2Strategy` to convert v2 CTAS logical plan to the new physical plan
* Add `findNestedField` to `StructType` to support reference validation
## How was this patch tested?
We have been running these changes in production for several months. Also:
* Add a test suite `CreateTablePartitioningValidationSuite` for new analysis checks
* Add a test suite for v2 SQL, `DataSourceV2SQLSuite`
* Update catalyst `DDLParserSuite` to use multi-part identifiers (`Seq[String]`)
* Add test cases to `PlanResolutionSuite` for v2 CTAS: known catalog and v2 source implementation
Closes#24570 from rdblue/SPARK-24923-add-v2-ctas.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The below example works with both Mysql and Hive, however not with spark.
```
mysql> select * from date_test where date_col >= '2000-1-1';
+------------+
| date_col |
+------------+
| 2000-01-01 |
+------------+
```
The reason is that Spark casts both sides to String type during date and string comparison for partial date support. Please find more details in https://issues.apache.org/jira/browse/SPARK-8420.
Based on some tests, the behavior of Date and String comparison in Hive and Mysql:
Hive: Cast to Date, partial date is not supported
Mysql: Cast to Date, certain "partial date" is supported by defining certain date string parse rules. Check out str_to_datetime in https://github.com/mysql/mysql-server/blob/5.5/sql-common/my_time.c
As below date patterns have been supported, the PR is to cast string to date when comparing string and date:
```
`yyyy`
`yyyy-[m]m`
`yyyy-[m]m-[d]d`
`yyyy-[m]m-[d]d `
`yyyy-[m]m-[d]d *`
`yyyy-[m]m-[d]dT*
```
## How was this patch tested?
UT has been added
Closes#24567 from pengbo/SPARK-27638.
Authored-by: mingbo.pb <mingbo.pb@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
When a null in a nested field in struct, casting from the struct throws error, currently.
```scala
scala> sql("select cast(struct(1, null) as struct<a:int,b:int>)").show
scala.MatchError: NullType (of class org.apache.spark.sql.types.NullType$)
at org.apache.spark.sql.catalyst.expressions.Cast.castToInt(Cast.scala:447)
at org.apache.spark.sql.catalyst.expressions.Cast.cast(Cast.scala:635)
at org.apache.spark.sql.catalyst.expressions.Cast.$anonfun$castStruct$1(Cast.scala:603)
```
Similarly, inline table, which casts null in nested field under the hood, also throws an error.
```scala
scala> sql("select * FROM VALUES (('a', (10, null))), (('b', (10, 50))), (('c', null)) AS tab(x, y)").show
org.apache.spark.sql.AnalysisException: failed to evaluate expression named_struct('col1', 10, 'col2', NULL): NullType (of class org.apache.spark.sql.t
ypes.NullType$); line 1 pos 14
at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:47)
at org.apache.spark.sql.catalyst.analysis.ResolveInlineTables.$anonfun$convert$6(ResolveInlineTables.scala:106)
```
This fixes the issue.
## How was this patch tested?
Added tests.
Closes#24576 from viirya/cast-null.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr fix hadoop-3.2 test issues(except the `hive-thriftserver` module):
1. Add `hive.metastore.schema.verification` and `datanucleus.schema.autoCreateAll` to HiveConf.
2. hadoop-3.2 support access the Hive metastore from 0.12 to 2.2
After [SPARK-27176](https://issues.apache.org/jira/browse/SPARK-27176) and this PR, we upgraded the built-in Hive to 2.3 when enabling the Hadoop 3.2+ profile. This upgrade fixes the following issues:
- [HIVE-6727](https://issues.apache.org/jira/browse/HIVE-6727): Table level stats for external tables are set incorrectly.
- [HIVE-15653](https://issues.apache.org/jira/browse/HIVE-15653): Some ALTER TABLE commands drop table stats.
- [SPARK-12014](https://issues.apache.org/jira/browse/SPARK-12014): Spark SQL query containing semicolon is broken in Beeline.
- [SPARK-25193](https://issues.apache.org/jira/browse/SPARK-25193): insert overwrite doesn't throw exception when drop old data fails.
- [SPARK-25919](https://issues.apache.org/jira/browse/SPARK-25919): Date value corrupts when tables are "ParquetHiveSerDe" formatted and target table is Partitioned.
- [SPARK-26332](https://issues.apache.org/jira/browse/SPARK-26332): Spark sql write orc table on viewFS throws exception.
- [SPARK-26437](https://issues.apache.org/jira/browse/SPARK-26437): Decimal data becomes bigint to query, unable to query.
## How was this patch tested?
This pr test Spark’s Hadoop 3.2 profile on jenkins and #24591 test Spark’s Hadoop 2.7 profile on jenkins
This PR close#24591Closes#24391 from wangyum/SPARK-27402.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR goes to add `max_by()` and `min_by()` SQL aggregate functions.
Quoting from the [Presto docs](https://prestodb.github.io/docs/current/functions/aggregate.html#max_by)
> max_by(x, y) → [same as x]
> Returns the value of x associated with the maximum value of y over all input values.
`min_by()` works similarly.
## How was this patch tested?
Added tests.
Closes#24557 from viirya/SPARK-27653.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Currently,thread number of broadcast-exchange thread pool is fixed and keepAliveSeconds is also fixed as 60s.
```
object BroadcastExchangeExec {
private[execution] val executionContext = ExecutionContext.fromExecutorService(
ThreadUtils.newDaemonCachedThreadPool("broadcast-exchange", 128))
}
/**
* Create a cached thread pool whose max number of threads is `maxThreadNumber`. Thread names
* are formatted as prefix-ID, where ID is a unique, sequentially assigned integer.
*/
def newDaemonCachedThreadPool(
prefix: String, maxThreadNumber: Int, keepAliveSeconds: Int = 60): ThreadPoolExecutor = {
val threadFactory = namedThreadFactory(prefix)
val threadPool = new ThreadPoolExecutor(
maxThreadNumber, // corePoolSize: the max number of threads to create before queuing the tasks
maxThreadNumber, // maximumPoolSize: because we use LinkedBlockingDeque, this one is not used
keepAliveSeconds,
TimeUnit.SECONDS,
new LinkedBlockingQueue[Runnable],
threadFactory)
threadPool.allowCoreThreadTimeOut(true)
threadPool
}
```
But some times, if the Thead object do not GC quickly it may caused server(driver) OOM. In such case,we need to make this thread pool configurable.
A case has described in https://issues.apache.org/jira/browse/SPARK-26601
## How was this patch tested?
UT
Closes#23670 from caneGuy/zhoukang/make-broadcat-config.
Authored-by: zhoukang <zhoukang199191@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In File source V1, the statistics of `HadoopFsRelation` is `compressionFactor * sizeInBytesOfAllFiles`.
To follow it, we can implement the interface SupportsReportStatistics in FileScan and report the same statistics.
## How was this patch tested?
Unit test
Closes#24571 from gengliangwang/stats.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
To move DS v2 API to the catalyst module, we can't refer to an internal class (`MutableColumnarRow`) in `ColumnarBatch`.
This PR creates a read-only version of `MutableColumnarRow`, and use it in `ColumnarBatch`.
close https://github.com/apache/spark/pull/24546
## How was this patch tested?
existing tests
Closes#24581 from cloud-fan/mutable-row.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
- the accumulator warning is too verbose
- when a test fails with schema mismatch, you never see the error message / exception
Closes#24549 from ericl/test-nits.
Lead-authored-by: Eric Liang <ekl@databricks.com>
Co-authored-by: Eric Liang <ekhliang@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}