### What changes were proposed in this pull request?
This PR fixes SPARK-30904 by adding a null check.
### Why are the changes needed?
For HIVE_CLI_SERVICE_PROTOCOL_V5 and below, serialization fails on NULL-containing decimal columns, caused by a call to `value.toPlainString()`, where `value` might be null. This null check fixes it.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
A test was added for serialization of NULL decimals for all HIVE_CLI_SERVICE_PROTOCOL versions.
Closes#27654 from CJStuart/SPARK-30904.
Authored-by: Christian Stuart <christian.stuart@databricks.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
- Set `spark.sql.datetime.java8API.enabled` to `true` in `hiveResultString()`, and restore it back at the end of the call.
- Convert collected `java.time.Instant` & `java.time.LocalDate` to `java.sql.Timestamp` and `java.sql.Date` for correct formatting.
### Why are the changes needed?
Because of textual representation of timestamps/dates before 1582 year is incorrect:
```shell
$ export TZ="America/Los_Angeles"
$ ./bin/spark-sql -S
```
```sql
spark-sql> set spark.sql.session.timeZone=America/Los_Angeles;
spark.sql.session.timeZone America/Los_Angeles
spark-sql> SELECT DATE_TRUNC('MILLENNIUM', DATE '1970-03-20');
1001-01-01 00:07:02
```
It must be 1001-01-01 00:**00:00**.
### Does this PR introduce any user-facing change?
Yes. After the changes:
```shell
$ export TZ="America/Los_Angeles"
$ ./bin/spark-sql -S
```
```sql
spark-sql> set spark.sql.session.timeZone=America/Los_Angeles;
spark.sql.session.timeZone America/Los_Angeles
spark-sql> SELECT DATE_TRUNC('MILLENNIUM', DATE '1970-03-20');
1001-01-01 00:00:00
```
### How was this patch tested?
By running hive-thiftserver tests. In particular:
```
./build/sbt -Phadoop-2.7 -Phive-2.3 -Phive-thriftserver "hive-thriftserver/test:testOnly *SparkThriftServerProtocolVersionsSuite"
```
Closes#27552 from MaxGekk/hive-thriftserver-java8-time-api.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR scopes `SparkSession.active` to prevent problems with processing queries with possibly different spark sessions (and different configs). A new method, `withActive` is introduced on `SparkSession` that restores the previous spark session after the block of code is executed.
### Why are the changes needed?
`SparkSession.active` is a thread local variable that points to the current thread's spark session. It is important to note that the `SQLConf.get` method depends on `SparkSession.active`. In the current implementation it is possible that `SparkSession.active` points to a different session which causes various problems. Most of these problems arise because part of the query processing is done using the configurations of a different session. For example, when creating a data frame using a new session, i.e., `session.sql("...")`, part of the data frame is constructed using the currently active spark session, which can be a different session from the one used later for processing the query.
### Does this PR introduce any user-facing change?
The `withActive` method is introduced on `SparkSession`.
### How was this patch tested?
Unit tests (to be added)
Closes#27387 from dbaliafroozeh/UseWithActiveSessionInQueryExecution.
Authored-by: Ali Afroozeh <ali.afroozeh@databricks.com>
Signed-off-by: herman <herman@databricks.com>
### What changes were proposed in this pull request?
This PR adds two pages to Web UI for Structured Streaming:
- "/streamingquery": Streaming Query Page, providing some aggregate information for running/completed streaming queries.
- "/streamingquery/statistics": Streaming Query Statistics Page, providing detailed information for streaming query, including `Input Rate`, `Process Rate`, `Input Rows`, `Batch Duration` and `Operation Duration`


### Why are the changes needed?
It helps users to better monitor Structured Streaming query.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
- new added and existing UTs
- manual test
Closes#26201 from uncleGen/SPARK-29543.
Lead-authored-by: uncleGen <hustyugm@gmail.com>
Co-authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Co-authored-by: Genmao Yu <hustyugm@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
### What changes were proposed in this pull request?
This PR is to remove query index from the golden files of SQLQueryTestSuite
### Why are the changes needed?
Because the SQLQueryTestSuite's golden files have the query index for each query, removal of any query statement [except the last one] will generate many unneeded difference. This will make code review harder. The number of changed lines is misleading.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#27361 from gatorsmile/removeIndexNum.
Authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR propose to disallow negative `scale` of `Decimal` in Spark. And this PR brings two behavior changes:
1) for literals like `1.23E4BD` or `1.23E4`(with `spark.sql.legacy.exponentLiteralAsDecimal.enabled`=true, see [SPARK-29956](https://issues.apache.org/jira/browse/SPARK-29956)), we set its `(precision, scale)` to (5, 0) rather than (3, -2);
2) add negative `scale` check inside the decimal method if it exposes to set `scale` explicitly. If check fails, `AnalysisException` throws.
And user could still use `spark.sql.legacy.allowNegativeScaleOfDecimal.enabled` to restore the previous behavior.
### Why are the changes needed?
According to SQL standard,
> 4.4.2 Characteristics of numbers
An exact numeric type has a precision P and a scale S. P is a positive integer that determines the number of significant digits in a particular radix R, where R is either 2 or 10. S is a non-negative integer.
scale of Decimal should always be non-negative. And other mainstream databases, like Presto, PostgreSQL, also don't allow negative scale.
Presto:
```
presto:default> create table t (i decimal(2, -1));
Query 20191213_081238_00017_i448h failed: line 1:30: mismatched input '-'. Expecting: <integer>, <type>
create table t (i decimal(2, -1))
```
PostgrelSQL:
```
postgres=# create table t(i decimal(2, -1));
ERROR: NUMERIC scale -1 must be between 0 and precision 2
LINE 1: create table t(i decimal(2, -1));
^
```
And, actually, Spark itself already doesn't allow to create table with negative decimal types using SQL:
```
scala> spark.sql("create table t(i decimal(2, -1))");
org.apache.spark.sql.catalyst.parser.ParseException:
no viable alternative at input 'create table t(i decimal(2, -'(line 1, pos 28)
== SQL ==
create table t(i decimal(2, -1))
----------------------------^^^
at org.apache.spark.sql.catalyst.parser.ParseException.withCommand(ParseDriver.scala:263)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parse(ParseDriver.scala:130)
at org.apache.spark.sql.execution.SparkSqlParser.parse(SparkSqlParser.scala:48)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parsePlan(ParseDriver.scala:76)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:605)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:605)
... 35 elided
```
However, it is still possible to create such table or `DatFrame` using Spark SQL programming API:
```
scala> val tb =
CatalogTable(
TableIdentifier("test", None),
CatalogTableType.MANAGED,
CatalogStorageFormat.empty,
StructType(StructField("i", DecimalType(2, -1) ) :: Nil))
```
```
scala> spark.sql("SELECT 1.23E4BD")
res2: org.apache.spark.sql.DataFrame = [1.23E+4: decimal(3,-2)]
```
while, these two different behavior could make user confused.
On the other side, even if user creates such table or `DataFrame` with negative scale decimal type, it can't write data out if using format, like `parquet` or `orc`. Because these formats have their own check for negative scale and fail on it.
```
scala> spark.sql("SELECT 1.23E4BD").write.saveAsTable("parquet")
19/12/13 17:37:04 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)
java.lang.IllegalArgumentException: Invalid DECIMAL scale: -2
at org.apache.parquet.Preconditions.checkArgument(Preconditions.java:53)
at org.apache.parquet.schema.Types$BasePrimitiveBuilder.decimalMetadata(Types.java:495)
at org.apache.parquet.schema.Types$BasePrimitiveBuilder.build(Types.java:403)
at org.apache.parquet.schema.Types$BasePrimitiveBuilder.build(Types.java:309)
at org.apache.parquet.schema.Types$Builder.named(Types.java:290)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.convertField(ParquetSchemaConverter.scala:428)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.convertField(ParquetSchemaConverter.scala:334)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.$anonfun$convert$2(ParquetSchemaConverter.scala:326)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at org.apache.spark.sql.types.StructType.foreach(StructType.scala:99)
at scala.collection.TraversableLike.map(TraversableLike.scala:238)
at scala.collection.TraversableLike.map$(TraversableLike.scala:231)
at org.apache.spark.sql.types.StructType.map(StructType.scala:99)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.convert(ParquetSchemaConverter.scala:326)
at org.apache.spark.sql.execution.datasources.parquet.ParquetWriteSupport.init(ParquetWriteSupport.scala:97)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:388)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:349)
at org.apache.spark.sql.execution.datasources.parquet.ParquetOutputWriter.<init>(ParquetOutputWriter.scala:37)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$$anon$1.newInstance(ParquetFileFormat.scala:150)
at org.apache.spark.sql.execution.datasources.SingleDirectoryDataWriter.newOutputWriter(FileFormatDataWriter.scala:124)
at org.apache.spark.sql.execution.datasources.SingleDirectoryDataWriter.<init>(FileFormatDataWriter.scala:109)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeTask(FileFormatWriter.scala:264)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$write$15(FileFormatWriter.scala:205)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:127)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:441)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:444)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
So, I think it would be better to disallow negative scale totally and make behaviors above be consistent.
### Does this PR introduce any user-facing change?
Yes, if `spark.sql.legacy.allowNegativeScaleOfDecimal.enabled=false`, user couldn't create Decimal value with negative scale anymore.
### How was this patch tested?
Added new tests in `ExpressionParserSuite` and `DecimalSuite`;
Updated `SQLQueryTestSuite`.
Closes#26881 from Ngone51/nonnegative-scale.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Pick up the HTTP fix from https://issues.apache.org/jira/browse/HIVE-22708
### Why are the changes needed?
This is a small but important fix to digest handling we should pick up from Hive.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests
Closes#27273 from srowen/Hive22708.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
Avoid hive log initialisation as https://github.com/apache/hive/blob/rel/release-2.3.5/common/src/java/org/apache/hadoop/hive/common/LogUtils.java introduces dependency over `org.apache.logging.log4j.core.impl.Log4jContextFactory` which is missing in our spark installer classpath directly. I believe the `LogUtils.initHiveLog4j()` code is here as the HiveServer2 class is copied from Hive.
To make `start-thriftserver.sh --help` command success.
Currently, start-thriftserver.sh --help throws
```
...
Thrift server options:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/logging/log4j/spi/LoggerContextFactory
at org.apache.hive.service.server.HiveServer2.main(HiveServer2.java:167)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2$.main(HiveThriftServer2.scala:82)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.main(HiveThriftServer2.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.logging.log4j.spi.LoggerContextFactory
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 3 more
```
No
Checked Manually
Closes#27042 from ajithme/thrifthelp.
Authored-by: Ajith <ajith2489@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This patch fixes the intermittent test failure on ThriftServerQueryTestSuite/ThriftServerWithSparkContextSuite, getting ConnectException when querying to thrift server.
(https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/115646/testReport/)
The relevant unit test log messages are following:
```
19/12/23 13:33:01.875 pool-1-thread-1 INFO AbstractService: Service:ThriftBinaryCLIService is started.
19/12/23 13:33:01.875 pool-1-thread-1 INFO AbstractService: Service:HiveServer2 is started.
...
19/12/23 13:33:01.888 pool-1-thread-1 INFO ThriftServerWithSparkContextSuite: HiveThriftServer2 started successfully
...
19/12/23 13:33:01.909 pool-1-thread-1-ScalaTest-running-ThriftServerWithSparkContextSuite INFO ThriftServerWithSparkContextSuite:
===== TEST OUTPUT FOR o.a.s.sql.hive.thriftserver.ThriftServerWithSparkContextSuite: 'SPARK-29911: Uncache cached tables when session closed' =====
...
19/12/23 13:33:02.017 pool-1-thread-1-ScalaTest-running-ThriftServerWithSparkContextSuite INFO Utils: Supplied authorities: localhost:15441
19/12/23 13:33:02.018 pool-1-thread-1-ScalaTest-running-ThriftServerWithSparkContextSuite INFO Utils: Resolved authority: localhost:15441
19/12/23 13:33:02.078 HiveServer2-Background-Pool: Thread-213 INFO BaseSessionStateBuilder$$anon$2: Optimization rule 'org.apache.spark.sql.catalyst.optimizer.ConvertToLocalRelation' is excluded from the optimizer.
19/12/23 13:33:02.078 HiveServer2-Background-Pool: Thread-213 INFO BaseSessionStateBuilder$$anon$2: Optimization rule 'org.apache.spark.sql.catalyst.optimizer.ConvertToLocalRelation' is excluded from the optimizer.
19/12/23 13:33:02.121 pool-1-thread-1-ScalaTest-running-ThriftServerWithSparkContextSuite WARN HiveConnection: Failed to connect to localhost:15441
19/12/23 13:33:02.124 pool-1-thread-1-ScalaTest-running-ThriftServerWithSparkContextSuite INFO ThriftServerWithSparkContextSuite:
===== FINISHED o.a.s.sql.hive.thriftserver.ThriftServerWithSparkContextSuite: 'SPARK-29911: Uncache cached tables when session closed' =====
19/12/23 13:33:02.143 Thread-35 INFO ThriftCLIService: Starting ThriftBinaryCLIService on port 15441 with 5...500 worker threads
19/12/23 13:33:02.327 pool-1-thread-1 INFO HiveServer2: Shutting down HiveServer2
19/12/23 13:33:02.328 pool-1-thread-1 INFO ThriftCLIService: Thrift server has stopped
```
(Here the error is logged as `WARN HiveConnection: Failed to connect to localhost:15441` - the actual stack trace can be seen on Jenkins test summary.)
The reason of test failure: Thrift(Binary|Http)CLIService prepare and launch the service asynchronously (in new thread), which suites are not waiting for completion and just start running tests, ends up with race condition.
That can be easily reproduced, via adding artificial sleep in `ThriftBinaryCLIService.run()` here:
ba3f6330dd/sql/hive-thriftserver/v2.3/src/main/java/org/apache/hive/service/cli/thrift/ThriftBinaryCLIService.java (L49)
(Note that `sleep` should be added before initializing server socket. E.g. Line 57)
This patch changes the test initialization logic to try executing simple query to wait until the service is available. The patch also refactors the code to apply the change both ThriftServerQueryTestSuite and ThriftServerWithSparkContextSuite easily.
### Why are the changes needed?
This patch fixes the intermittent failure observed here:
https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/115646/testReport/
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Artificially made the test fail consistently (by the approach described above), and confirmed the patch fixed the test.
Closes#27001 from HeartSaVioR/SPARK-30345.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Revert "Preparing development version 3.0.1-SNAPSHOT": 56dcd79
2. Revert "Preparing Spark release v3.0.0-preview2-rc2": c216ef1
### Why are the changes needed?
Shouldn't change master.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
manual test:
https://github.com/apache/spark/compare/5de5e46..wangyum:revert-masterCloses#26915 from wangyum/revert-master.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
Reprocess all PostgreSQL dialect related PRs, listing in order:
- #25158: PostgreSQL integral division support [revert]
- #25170: UT changes for the integral division support [revert]
- #25458: Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. [revert]
- #25697: Combine below 2 feature tags into "spark.sql.dialect" [revert]
- #26112: Date substraction support [keep the ANSI-compliant part]
- #26444: Rename config "spark.sql.ansi.enabled" to "spark.sql.dialect.spark.ansi.enabled" [revert]
- #26463: Cast to boolean support for PostgreSQL dialect [revert]
- #26584: Make the behavior of Postgre dialect independent of ansi mode config [keep the ANSI-compliant part]
### Why are the changes needed?
As the discussion in http://apache-spark-developers-list.1001551.n3.nabble.com/DISCUSS-PostgreSQL-dialect-td28417.html, we need to remove PostgreSQL dialect form code base for several reasons:
1. The current approach makes the codebase complicated and hard to maintain.
2. Fully migrating PostgreSQL workloads to Spark SQL is not our focus for now.
### Does this PR introduce any user-facing change?
Yes, the config `spark.sql.dialect` will be removed.
### How was this patch tested?
Existing UT.
Closes#26763 from xuanyuanking/SPARK-30125.
Lead-authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
improve the temporary functions test in SingleSessionSuite by verifying the result in a query
### Why are the changes needed?
### Does this PR introduce any user-facing change?
### How was this patch tested?
Closes#26812 from leoluan2009/SPARK-30179.
Authored-by: Luan <xuluan@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In this PR, we propose to use the value of `spark.sql.source.default` as the provider for `CREATE TABLE` syntax instead of `hive` in Spark 3.0.
And to help the migration, we introduce a legacy conf `spark.sql.legacy.respectHiveDefaultProvider.enabled` and set its default to `false`.
### Why are the changes needed?
1. Currently, `CREATE TABLE` syntax use hive provider to create table while `DataFrameWriter.saveAsTable` API using the value of `spark.sql.source.default` as a provider to create table. It would be better to make them consistent.
2. User may gets confused in some cases. For example:
```
CREATE TABLE t1 (c1 INT) USING PARQUET;
CREATE TABLE t2 (c1 INT);
```
In these two DDLs, use may think that `t2` should also use parquet as default provider since Spark always advertise parquet as the default format. However, it's hive in this case.
On the other hand, if we omit the USING clause in a CTAS statement, we do pick parquet by default if `spark.sql.hive.convertCATS=true`:
```
CREATE TABLE t3 USING PARQUET AS SELECT 1 AS VALUE;
CREATE TABLE t4 AS SELECT 1 AS VALUE;
```
And these two cases together can be really confusing.
3. Now, Spark SQL is very independent and popular. We do not need to be fully consistent with Hive's behavior.
### Does this PR introduce any user-facing change?
Yes, before this PR, using `CREATE TABLE` syntax will use hive provider. But now, it use the value of `spark.sql.source.default` as its provider.
### How was this patch tested?
Added tests in `DDLParserSuite` and `HiveDDlSuite`.
Closes#26736 from Ngone51/dev-create-table-using-parquet-by-default.
Lead-authored-by: wuyi <yi.wu@databricks.com>
Co-authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
[HIVE-12063](https://issues.apache.org/jira/browse/HIVE-12063) improved pad decimal numbers with trailing zeros to the scale of the column. The following description is copied from the description of HIVE-12063.
> HIVE-7373 was to address the problems of trimming tailing zeros by Hive, which caused many problems including treating 0.0, 0.00 and so on as 0, which has different precision/scale. Please refer to HIVE-7373 description. However, HIVE-7373 was reverted by HIVE-8745 while the underlying problems remained. HIVE-11835 was resolved recently to address one of the problems, where 0.0, 0.00, and so on cannot be read into decimal(1,1).
However, HIVE-11835 didn't address the problem of showing as 0 in query result for any decimal values such as 0.0, 0.00, etc. This causes confusion as 0 and 0.0 have different precision/scale than 0.
The proposal here is to pad zeros for query result to the type's scale. This not only removes the confusion described above, but also aligns with many other DBs. Internal decimal number representation doesn't change, however.
**Spark SQL**:
```sql
// bin/spark-sql
spark-sql> select cast(1 as decimal(38, 18));
1
spark-sql>
// bin/beeline
0: jdbc:hive2://localhost:10000/default> select cast(1 as decimal(38, 18));
+----------------------------+--+
| CAST(1 AS DECIMAL(38,18)) |
+----------------------------+--+
| 1.000000000000000000 |
+----------------------------+--+
// bin/spark-shell
scala> spark.sql("select cast(1 as decimal(38, 18))").show(false)
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
|1.000000000000000000 |
+-------------------------+
// bin/pyspark
>>> spark.sql("select cast(1 as decimal(38, 18))").show()
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
// bin/sparkR
> showDF(sql("SELECT cast(1 as decimal(38, 18))"))
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
```
**PostgreSQL**:
```sql
postgres=# select cast(1 as decimal(38, 18));
numeric
----------------------
1.000000000000000000
(1 row)
```
**Presto**:
```sql
presto> select cast(1 as decimal(38, 18));
_col0
----------------------
1.000000000000000000
(1 row)
```
## How was this patch tested?
unit tests and manual test:
```sql
spark-sql> select cast(1 as decimal(38, 18));
1.000000000000000000
```
Spark SQL Upgrading Guide:

Closes#26697 from wangyum/SPARK-28461.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Support JDBC/ODBC tab for HistoryServer WebUI. Currently from Historyserver we can't access the JDBC/ODBC tab for thrift server applications. In this PR, I am doing 2 main changes
1. Refactor existing thrift server listener to support kvstore
2. Add history server plugin for thrift server listener and tab.
### Why are the changes needed?
Users can access Thriftserver tab from History server for both running and finished applications,
### Does this PR introduce any user-facing change?
Support for JDBC/ODBC tab for the WEBUI from History server
### How was this patch tested?
Add UT and Manual tests
1. Start Thriftserver and Historyserver
```
sbin/stop-thriftserver.sh
sbin/stop-historyserver.sh
sbin/start-thriftserver.sh
sbin/start-historyserver.sh
```
2. Launch beeline
`bin/beeline -u jdbc:hive2://localhost:10000`
3. Run queries
Go to the JDBC/ODBC page of the WebUI from History server

Closes#26378 from shahidki31/ThriftKVStore.
Authored-by: shahid <shahidki31@gmail.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
## What changes were proposed in this pull request?
[HIVE-12063](https://issues.apache.org/jira/browse/HIVE-12063) improved pad decimal numbers with trailing zeros to the scale of the column. The following description is copied from the description of HIVE-12063.
> HIVE-7373 was to address the problems of trimming tailing zeros by Hive, which caused many problems including treating 0.0, 0.00 and so on as 0, which has different precision/scale. Please refer to HIVE-7373 description. However, HIVE-7373 was reverted by HIVE-8745 while the underlying problems remained. HIVE-11835 was resolved recently to address one of the problems, where 0.0, 0.00, and so on cannot be read into decimal(1,1).
However, HIVE-11835 didn't address the problem of showing as 0 in query result for any decimal values such as 0.0, 0.00, etc. This causes confusion as 0 and 0.0 have different precision/scale than 0.
The proposal here is to pad zeros for query result to the type's scale. This not only removes the confusion described above, but also aligns with many other DBs. Internal decimal number representation doesn't change, however.
**Spark SQL**:
```sql
// bin/spark-sql
spark-sql> select cast(1 as decimal(38, 18));
1
spark-sql>
// bin/beeline
0: jdbc:hive2://localhost:10000/default> select cast(1 as decimal(38, 18));
+----------------------------+--+
| CAST(1 AS DECIMAL(38,18)) |
+----------------------------+--+
| 1.000000000000000000 |
+----------------------------+--+
// bin/spark-shell
scala> spark.sql("select cast(1 as decimal(38, 18))").show(false)
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
|1.000000000000000000 |
+-------------------------+
// bin/pyspark
>>> spark.sql("select cast(1 as decimal(38, 18))").show()
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
// bin/sparkR
> showDF(sql("SELECT cast(1 as decimal(38, 18))"))
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
```
**PostgreSQL**:
```sql
postgres=# select cast(1 as decimal(38, 18));
numeric
----------------------
1.000000000000000000
(1 row)
```
**Presto**:
```sql
presto> select cast(1 as decimal(38, 18));
_col0
----------------------
1.000000000000000000
(1 row)
```
## How was this patch tested?
unit tests and manual test:
```sql
spark-sql> select cast(1 as decimal(38, 18));
1.000000000000000000
```
Spark SQL Upgrading Guide:

Closes#25214 from wangyum/SPARK-28461.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
add document to address https://github.com/apache/spark/pull/26612#discussion_r349844327
### Why are the changes needed?
help people understand how to use --CONFIG_DIM
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
N/A
Closes#26661 from cloud-fan/test.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This is a follow-up according to liancheng 's advice.
- https://github.com/apache/spark/pull/26619#discussion_r349326090
### Why are the changes needed?
Previously, we chose the full version to be carefully. As of today, it seems that `Apache Hive 2.3` branch seems to become stable.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Pass the compile combination on GitHub Action.
1. hadoop-2.7/hive-1.2/JDK8
2. hadoop-2.7/hive-2.3/JDK8
3. hadoop-3.2/hive-2.3/JDK8
4. hadoop-3.2/hive-2.3/JDK11
Also, pass the Jenkins with `hadoop-2.7` and `hadoop-3.2` for (1) and (4).
(2) and (3) is not ready in Jenkins.
Closes#26645 from dongjoon-hyun/SPARK-RENAME-HIVE-DIRECTORY.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is follow up of #26543
See https://github.com/apache/spark/pull/26543#discussion_r348934276
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Exist UT.
Closes#26628 from LantaoJin/SPARK-29911_FOLLOWUP.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
allow the sql test files to specify different dimensions of config sets during testing. For example,
```
--CONFIG_DIM1 a=1
--CONFIG_DIM1 b=2,c=3
--CONFIG_DIM2 x=1
--CONFIG_DIM2 y=1,z=2
```
This example defines 2 config dimensions, and each dimension defines 2 config sets. We will run the queries 4 times:
1. a=1, x=1
2. a=1, y=1, z=2
3. b=2, c=3, x=1
4. b=2, c=3, y=1, z=2
### Why are the changes needed?
Currently `SQLQueryTestSuite` takes a long time. This is because we run each test at least 3 times, to check with different codegen modes. This is not necessary for most of the tests, e.g. DESC TABLE. We should only check these codegen modes for certain tests.
With the --CONFIG_DIM directive, we can do things like: test different join operator(broadcast or shuffle join) X different codegen modes.
After reducing testing time, we should be able to run thrifter server SQL tests with config settings.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
test only
Closes#26612 from cloud-fan/test.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The local temporary view is session-scoped. Its lifetime is the lifetime of the session that created it. But now cache data is cross-session. Its lifetime is the lifetime of the Spark application. That's will cause the memory leak if cache a local temporary view in memory when the session closed.
In this PR, we uncache the cached data of local temporary view when session closed. This PR doesn't impact the cached data of global temp view and persisted view.
How to reproduce:
1. create a local temporary view v1
2. cache it in memory
3. close session without drop table v1.
The application will hold the memory forever. In a long running thrift server scenario. It's worse.
```shell
0: jdbc:hive2://localhost:10000> CACHE TABLE testCacheTable AS SELECT 1;
CACHE TABLE testCacheTable AS SELECT 1;
+---------+--+
| Result |
+---------+--+
+---------+--+
No rows selected (1.498 seconds)
0: jdbc:hive2://localhost:10000> !close
!close
Closing: 0: jdbc:hive2://localhost:10000
0: jdbc:hive2://localhost:10000 (closed)> !connect 'jdbc:hive2://localhost:10000'
!connect 'jdbc:hive2://localhost:10000'
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000:
lajin
Enter password for jdbc:hive2://localhost:10000:
***
Connected to: Spark SQL (version 3.0.0-SNAPSHOT)
Driver: Hive JDBC (version 1.2.1.spark2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
1: jdbc:hive2://localhost:10000> select * from testCacheTable;
select * from testCacheTable;
Error: Error running query: org.apache.spark.sql.AnalysisException: Table or view not found: testCacheTable; line 1 pos 14;
'Project [*]
+- 'UnresolvedRelation [testCacheTable] (state=,code=0)
```
<img width="1047" alt="Screen Shot 2019-11-15 at 2 03 49 PM" src="https://user-images.githubusercontent.com/1853780/68923527-7ca8c180-07b9-11ea-9cc7-74f276c46840.png">
### Why are the changes needed?
Resolve memory leak for thrift server
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manual test in UI storage tab
And add an UT
Closes#26543 from LantaoJin/SPARK-29911.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
This PR add guides for `ThriftServerQueryTestSuite`.
### Why are the changes needed?
Add guides
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#26587 from wangyum/SPARK-28527-FOLLOW-UP.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add 3 interval output types which are named as `SQL_STANDARD`, `ISO_8601`, `MULTI_UNITS`. And we add a new conf `spark.sql.dialect.intervalOutputStyle` for this. The `MULTI_UNITS` style displays the interval values in the former behavior and it is the default. The newly added `SQL_STANDARD`, `ISO_8601` styles can be found in the following table.
Style | conf | Year-Month Interval | Day-Time Interval | Mixed Interval
-- | -- | -- | -- | --
Format With Time Unit Designators | MULTI_UNITS | 1 year 2 mons | 1 days 2 hours 3 minutes 4.123456 seconds | interval 1 days 2 hours 3 minutes 4.123456 seconds
SQL STANDARD | SQL_STANDARD | 1-2 | 3 4:05:06 | -1-2 3 -4:05:06
ISO8601 Basic Format| ISO_8601| P1Y2M| P3DT4H5M6S|P-1Y-2M3D-4H-5M-6S
### Why are the changes needed?
for ANSI SQL support
### Does this PR introduce any user-facing change?
yes,interval out now has 3 output styles
### How was this patch tested?
add new unit tests
cc cloud-fan maropu MaxGekk HyukjinKwon thanks.
Closes#26418 from yaooqinn/SPARK-29783.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
What changes were proposed in this pull request?
Some of the columns of JDBC/ODBC tab Session info in Web UI are hard to understand.
Add tool tip for Start time, finish time , Duration and Total Execution

Why are the changes needed?
To improve the understanding of the WebUI
Does this PR introduce any user-facing change?
No
How was this patch tested?
manual test
Closes#26138 from PavithraRamachandran/JDBC_tooltip.
Authored-by: Pavithra Ramachandran <pavi.rams@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Rename config "spark.sql.ansi.enabled" to "spark.sql.dialect.spark.ansi.enabled"
### Why are the changes needed?
The relation between "spark.sql.ansi.enabled" and "spark.sql.dialect" is confusing, since the "PostgreSQL" dialect should contain the features of "spark.sql.ansi.enabled".
To make things clearer, we can rename the "spark.sql.ansi.enabled" to "spark.sql.dialect.spark.ansi.enabled", thus the option "spark.sql.dialect.spark.ansi.enabled" is only for Spark dialect.
For the casting and arithmetic operations, runtime exceptions should be thrown if "spark.sql.dialect" is "spark" and "spark.sql.dialect.spark.ansi.enabled" is true or "spark.sql.dialect" is PostgresSQL.
### Does this PR introduce any user-facing change?
Yes, the config name changed.
### How was this patch tested?
Existing UT.
Closes#26444 from xuanyuanking/SPARK-29807.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This pr is to support `--import` directive to load queries from another test case in SQLQueryTestSuite.
This fix comes from the cloud-fan suggestion in https://github.com/apache/spark/pull/26479#discussion_r345086978
### Why are the changes needed?
This functionality might reduce duplicate test code in `SQLQueryTestSuite`.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Run `SQLQueryTestSuite`.
Closes#26497 from maropu/ImportTests.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Provide Ellipses in Statement column , just like description in Jobs page .
### Why are the changes needed?
When a query is executed the whole query statement is displayed no matter how big it is. When bigger queries are executed, it covers a large portion of the page display, when we have multiple queries it is difficult to scroll down to view all.
### Does this PR introduce any user-facing change?
No
Before:

After:

### How was this patch tested?
Manual
Closes#26364 from PavithraRamachandran/ellipse_JDBC.
Authored-by: Pavithra Ramachandran <pavi.rams@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
remove the leading "interval" in `CalendarInterval.toString`.
### Why are the changes needed?
Although it's allowed to have "interval" prefix when casting string to int, it's not recommended.
This is also consistent with pgsql:
```
cloud0fan=# select interval '1' day;
interval
----------
1 day
(1 row)
```
### Does this PR introduce any user-facing change?
yes, when display a dataframe with interval type column, the result is different.
### How was this patch tested?
updated tests.
Closes#26401 from cloud-fan/interval.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Added UT for the classes `ThriftServerPage.scala` and `ThriftServerSessionPage.scala`
### Why are the changes needed?
Currently, there are no UTs for testing Thriftserver UI page
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
UT
Closes#26403 from shahidki31/ut.
Authored-by: shahid <shahidki31@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Current checkstyle checking folder can't cover all folder.
Since for support multi version hive, we have some divided hive folder.
We should check it too.
### Why are the changes needed?
Fix build bug
### Does this PR introduce any user-facing change?
NO
### How was this patch tested?
NO
Closes#26385 from AngersZhuuuu/SPARK-29742.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Currently, JDBC/ODBC tab in the WEBUI doesn't support hiding table. Other tabs in the web ui like, Jobs, stages, SQL etc supports hiding table (refer https://github.com/apache/spark/pull/22592).
In this PR, added the support for hide table in the jdbc/odbc tab also.
### Why are the changes needed?
Spark ui about the contents of the form need to have hidden and show features, when the table records very much. Because sometimes you do not care about the record of the table, you just want to see the contents of the next table, but you have to scroll the scroll bar for a long time to see the contents of the next table.
### Does this PR introduce any user-facing change?
No, except support of hide table
### How was this patch tested?
Manually tested


Closes#26353 from shahidki31/hideTable.
Authored-by: shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
To push the built jars to maven release repository, we need to remove the 'SNAPSHOT' tag from the version name.
Made the following changes in this PR:
* Update all the `3.0.0-SNAPSHOT` version name to `3.0.0-preview`
* Update the sparkR version number check logic to allow jvm version like `3.0.0-preview`
**Please note those changes were generated by the release script in the past, but this time since we manually add tags on master branch, we need to manually apply those changes too.**
We shall revert the changes after 3.0.0-preview release passed.
### Why are the changes needed?
To make the maven release repository to accept the built jars.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
### What changes were proposed in this pull request?
This patch fixes the issue that external listeners are not initialized properly when `spark.sql.hive.metastore.jars` is set to either "maven" or custom list of jar.
("builtin" is not a case here - all jars in Spark classloader are also available in separate classloader)
The culprit is lazy initialization (lazy val or passing builder function) & thread context classloader. HiveClient leverages IsolatedClientLoader to properly load Hive and relevant libraries without issue - to not mess up with Spark classpath it uses separate classloader with leveraging thread context classloader.
But there's a messed-up case - SessionState is being initialized while HiveClient changed the thread context classloader from Spark classloader to Hive isolated one, and streaming query listeners are loaded from changed classloader while initializing SessionState.
This patch forces initializing SessionState in SparkSQLEnv to avoid such case.
### Why are the changes needed?
ClassNotFoundException could occur in spark-sql with specific configuration, as explained above.
### Does this PR introduce any user-facing change?
No, as I don't think end users assume the classloader of external listeners is only containing jars for Hive client.
### How was this patch tested?
New UT added which fails on master branch and passes with the patch.
The error message with master branch when running UT:
```
java.lang.IllegalArgumentException: Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder':;
org.apache.spark.sql.AnalysisException: java.lang.IllegalArgumentException: Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder':;
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:109)
at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:221)
at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:147)
at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:137)
at org.apache.spark.sql.hive.thriftserver.SparkSQLEnv$.init(SparkSQLEnv.scala:59)
at org.apache.spark.sql.hive.thriftserver.SparkSQLEnvSuite.$anonfun$new$2(SparkSQLEnvSuite.scala:44)
at org.apache.spark.sql.hive.thriftserver.SparkSQLEnvSuite.withSystemProperties(SparkSQLEnvSuite.scala:61)
at org.apache.spark.sql.hive.thriftserver.SparkSQLEnvSuite.$anonfun$new$1(SparkSQLEnvSuite.scala:43)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85)
at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83)
at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104)
at org.scalatest.Transformer.apply(Transformer.scala:22)
at org.scalatest.Transformer.apply(Transformer.scala:20)
at org.scalatest.FunSuiteLike$$anon$1.apply(FunSuiteLike.scala:186)
at org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:149)
at org.scalatest.FunSuiteLike.invokeWithFixture$1(FunSuiteLike.scala:184)
at org.scalatest.FunSuiteLike.$anonfun$runTest$1(FunSuiteLike.scala:196)
at org.scalatest.SuperEngine.runTestImpl(Engine.scala:286)
at org.scalatest.FunSuiteLike.runTest(FunSuiteLike.scala:196)
at org.scalatest.FunSuiteLike.runTest$(FunSuiteLike.scala:178)
at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterEach$$super$runTest(SparkFunSuite.scala:56)
at org.scalatest.BeforeAndAfterEach.runTest(BeforeAndAfterEach.scala:221)
at org.scalatest.BeforeAndAfterEach.runTest$(BeforeAndAfterEach.scala:214)
at org.apache.spark.SparkFunSuite.runTest(SparkFunSuite.scala:56)
at org.scalatest.FunSuiteLike.$anonfun$runTests$1(FunSuiteLike.scala:229)
at org.scalatest.SuperEngine.$anonfun$runTestsInBranch$1(Engine.scala:393)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.scalatest.SuperEngine.traverseSubNodes$1(Engine.scala:381)
at org.scalatest.SuperEngine.runTestsInBranch(Engine.scala:376)
at org.scalatest.SuperEngine.runTestsImpl(Engine.scala:458)
at org.scalatest.FunSuiteLike.runTests(FunSuiteLike.scala:229)
at org.scalatest.FunSuiteLike.runTests$(FunSuiteLike.scala:228)
at org.scalatest.FunSuite.runTests(FunSuite.scala:1560)
at org.scalatest.Suite.run(Suite.scala:1124)
at org.scalatest.Suite.run$(Suite.scala:1106)
at org.scalatest.FunSuite.org$scalatest$FunSuiteLike$$super$run(FunSuite.scala:1560)
at org.scalatest.FunSuiteLike.$anonfun$run$1(FunSuiteLike.scala:233)
at org.scalatest.SuperEngine.runImpl(Engine.scala:518)
at org.scalatest.FunSuiteLike.run(FunSuiteLike.scala:233)
at org.scalatest.FunSuiteLike.run$(FunSuiteLike.scala:232)
at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterAll$$super$run(SparkFunSuite.scala:56)
at org.scalatest.BeforeAndAfterAll.liftedTree1$1(BeforeAndAfterAll.scala:213)
at org.scalatest.BeforeAndAfterAll.run(BeforeAndAfterAll.scala:210)
at org.scalatest.BeforeAndAfterAll.run$(BeforeAndAfterAll.scala:208)
at org.apache.spark.SparkFunSuite.run(SparkFunSuite.scala:56)
at org.scalatest.tools.SuiteRunner.run(SuiteRunner.scala:45)
at org.scalatest.tools.Runner$.$anonfun$doRunRunRunDaDoRunRun$13(Runner.scala:1349)
at org.scalatest.tools.Runner$.$anonfun$doRunRunRunDaDoRunRun$13$adapted(Runner.scala:1343)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.scalatest.tools.Runner$.doRunRunRunDaDoRunRun(Runner.scala:1343)
at org.scalatest.tools.Runner$.$anonfun$runOptionallyWithPassFailReporter$24(Runner.scala:1033)
at org.scalatest.tools.Runner$.$anonfun$runOptionallyWithPassFailReporter$24$adapted(Runner.scala:1011)
at org.scalatest.tools.Runner$.withClassLoaderAndDispatchReporter(Runner.scala:1509)
at org.scalatest.tools.Runner$.runOptionallyWithPassFailReporter(Runner.scala:1011)
at org.scalatest.tools.Runner$.run(Runner.scala:850)
at org.scalatest.tools.Runner.run(Runner.scala)
at org.jetbrains.plugins.scala.testingSupport.scalaTest.ScalaTestRunner.runScalaTest2(ScalaTestRunner.java:133)
at org.jetbrains.plugins.scala.testingSupport.scalaTest.ScalaTestRunner.main(ScalaTestRunner.java:27)
Caused by: java.lang.IllegalArgumentException: Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder':
at org.apache.spark.sql.SparkSession$.org$apache$spark$sql$SparkSession$$instantiateSessionState(SparkSession.scala:1054)
at org.apache.spark.sql.SparkSession.$anonfun$sessionState$2(SparkSession.scala:156)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.SparkSession.sessionState$lzycompute(SparkSession.scala:154)
at org.apache.spark.sql.SparkSession.sessionState(SparkSession.scala:151)
at org.apache.spark.sql.SparkSession.$anonfun$new$3(SparkSession.scala:105)
at scala.Option.map(Option.scala:230)
at org.apache.spark.sql.SparkSession.$anonfun$new$1(SparkSession.scala:105)
at org.apache.spark.sql.internal.SQLConf$.get(SQLConf.scala:164)
at org.apache.spark.sql.hive.client.HiveClientImpl.newState(HiveClientImpl.scala:183)
at org.apache.spark.sql.hive.client.HiveClientImpl.<init>(HiveClientImpl.scala:127)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.spark.sql.hive.client.IsolatedClientLoader.createClient(IsolatedClientLoader.scala:300)
at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:421)
at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:314)
at org.apache.spark.sql.hive.HiveExternalCatalog.client$lzycompute(HiveExternalCatalog.scala:68)
at org.apache.spark.sql.hive.HiveExternalCatalog.client(HiveExternalCatalog.scala:67)
at org.apache.spark.sql.hive.HiveExternalCatalog.$anonfun$databaseExists$1(HiveExternalCatalog.scala:221)
at scala.runtime.java8.JFunction0$mcZ$sp.apply(JFunction0$mcZ$sp.java:23)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:99)
... 58 more
Caused by: java.lang.ClassNotFoundException: test.custom.listener.DummyQueryExecutionListener
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.spark.util.Utils$.classForName(Utils.scala:206)
at org.apache.spark.util.Utils$.$anonfun$loadExtensions$1(Utils.scala:2746)
at scala.collection.TraversableLike.$anonfun$flatMap$1(TraversableLike.scala:245)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at scala.collection.TraversableLike.flatMap(TraversableLike.scala:245)
at scala.collection.TraversableLike.flatMap$(TraversableLike.scala:242)
at scala.collection.AbstractTraversable.flatMap(Traversable.scala:108)
at org.apache.spark.util.Utils$.loadExtensions(Utils.scala:2744)
at org.apache.spark.sql.util.ExecutionListenerManager.$anonfun$new$1(QueryExecutionListener.scala:83)
at org.apache.spark.sql.util.ExecutionListenerManager.$anonfun$new$1$adapted(QueryExecutionListener.scala:82)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.sql.util.ExecutionListenerManager.<init>(QueryExecutionListener.scala:82)
at org.apache.spark.sql.internal.BaseSessionStateBuilder.$anonfun$listenerManager$2(BaseSessionStateBuilder.scala:293)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.internal.BaseSessionStateBuilder.listenerManager(BaseSessionStateBuilder.scala:293)
at org.apache.spark.sql.internal.BaseSessionStateBuilder.build(BaseSessionStateBuilder.scala:320)
at org.apache.spark.sql.SparkSession$.org$apache$spark$sql$SparkSession$$instantiateSessionState(SparkSession.scala:1051)
... 80 more
```
Closes#26258 from HeartSaVioR/SPARK-29604.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
To push the built jars to maven release repository, we need to remove the 'SNAPSHOT' tag from the version name.
Made the following changes in this PR:
* Update all the `3.0.0-SNAPSHOT` version name to `3.0.0-preview`
* Update the PySpark version from `3.0.0.dev0` to `3.0.0`
**Please note those changes were generated by the release script in the past, but this time since we manually add tags on master branch, we need to manually apply those changes too.**
We shall revert the changes after 3.0.0-preview release passed.
### Why are the changes needed?
To make the maven release repository to accept the built jars.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#26243 from jiangxb1987/3.0.0-preview-prepare.
Lead-authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
### What changes were proposed in this pull request?
In this PR, extend the support of pagination to session table in `JDBC/PDBC` .
### Why are the changes needed?
Some times we may connect a lot client and there a many session info shown in session tab.
make it can be paged for better view.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manuel verify.
After pr:
<img width="1440" alt="Screen Shot 2019-10-25 at 4 19 27 PM" src="https://user-images.githubusercontent.com/46485123/67555133-50ae9900-f743-11e9-8724-9624a691f232.png">
<img width="1434" alt="Screen Shot 2019-10-25 at 4 19 38 PM" src="https://user-images.githubusercontent.com/46485123/67555165-5906d400-f743-11e9-819e-73f86a333dd3.png">
Closes#26253 from AngersZhuuuu/SPARK-29599.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
In the PR https://github.com/apache/spark/pull/26215, we supported pagination for sqlstats table in JDBC/ODBC server page. In this PR, we are extending the support of pagination to sqlstats session table by making use of existing pagination classes in https://github.com/apache/spark/pull/26215.
### Why are the changes needed?
Support pagination for sqlsessionstats table in JDBC/ODBC server page in the WEBUI. It will easier for user to analyse the table and it may fix the potential issues like oom while loading the page, that may occur similar to the SQL page (refer #22645)
### Does this PR introduce any user-facing change?
There will be no change in the sqlsessionstats table in JDBC/ODBC server page execpt pagination support.
### How was this patch tested?
Manually verified.
Before:

After:

Closes#26246 from shahidki31/SPARK_29589.
Authored-by: shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Supports pagination for SQL Statisitcs table in the JDBC/ODBC tab using existing Spark pagination framework.
### Why are the changes needed?
It will easier for user to analyse the table and it may fix the potential issues like oom while loading the page, that may occur similar to the SQL page (refer https://github.com/apache/spark/pull/22645)
### Does this PR introduce any user-facing change?
There will be no change in the `SQLStatistics` table in JDBC/ODBC server page execpt pagination support.
### How was this patch tested?
Manually verified.
Before PR:

After PR:

Closes#26215 from shahidki31/jdbcPagination.
Authored-by: shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
This PR test `ThriftServerQueryTestSuite` in an asynchronous way.
### Why are the changes needed?
The default value of `spark.sql.hive.thriftServer.async` is `true`.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
```
build/sbt "hive-thriftserver/test-only *.ThriftServerQueryTestSuite" -Phive-thriftserver
build/mvn -Dtest=none -DwildcardSuites=org.apache.spark.sql.hive.thriftserver.ThriftServerQueryTestSuite test -Phive-thriftserver
```
Closes#26172 from wangyum/SPARK-29516.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
This pr refine the code in ThriftServerQueryTestSuite.blackList to reuse the black list of SQLQueryTestSuite instead of duplicating all test cases from SQLQueryTestSuite.blackList.
### Why are the changes needed?
To reduce code duplication.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#26188 from fuwhu/SPARK-TBD.
Authored-by: fuwhu <bestwwg@163.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
When adaptive execution is enabled, the Spark users who connected from JDBC always get adaptive execution error whatever the under root cause is. It's very confused. We have to check the driver log to find out why.
```shell
0: jdbc:hive2://localhost:10000> SELECT * FROM testData join testData2 ON key = v;
SELECT * FROM testData join testData2 ON key = v;
Error: Error running query: org.apache.spark.SparkException: Adaptive execution failed due to stage materialization failures. (state=,code=0)
0: jdbc:hive2://localhost:10000>
```
For example, a job queried from JDBC failed due to HDFS missing block. User still get the error message `Adaptive execution failed due to stage materialization failures`.
The easiest way to reproduce is changing the code of `AdaptiveSparkPlanExec`, to let it throws out an exception when it faces `StageSuccess`.
```scala
case class AdaptiveSparkPlanExec(
events.drainTo(rem)
(Seq(nextMsg) ++ rem.asScala).foreach {
case StageSuccess(stage, res) =>
// stage.resultOption = Some(res)
val ex = new SparkException("Wrapper Exception",
new IllegalArgumentException("Root cause is IllegalArgumentException for Test"))
errors.append(
new SparkException(s"Failed to materialize query stage: ${stage.treeString}", ex))
case StageFailure(stage, ex) =>
errors.append(
new SparkException(s"Failed to materialize query stage: ${stage.treeString}", ex))
```
### Why are the changes needed?
To make the error message more user-friend and more useful for query from JDBC.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Manually test query:
```shell
0: jdbc:hive2://localhost:10000> CREATE TEMPORARY VIEW testData (key, value) AS SELECT explode(array(1, 2, 3, 4)), cast(substring(rand(), 3, 4) as string);
CREATE TEMPORARY VIEW testData (key, value) AS SELECT explode(array(1, 2, 3, 4)), cast(substring(rand(), 3, 4) as string);
+---------+--+
| Result |
+---------+--+
+---------+--+
No rows selected (0.225 seconds)
0: jdbc:hive2://localhost:10000> CREATE TEMPORARY VIEW testData2 (k, v) AS SELECT explode(array(1, 1, 2, 2)), cast(substring(rand(), 3, 4) as int);
CREATE TEMPORARY VIEW testData2 (k, v) AS SELECT explode(array(1, 1, 2, 2)), cast(substring(rand(), 3, 4) as int);
+---------+--+
| Result |
+---------+--+
+---------+--+
No rows selected (0.043 seconds)
```
Before:
```shell
0: jdbc:hive2://localhost:10000> SELECT * FROM testData join testData2 ON key = v;
SELECT * FROM testData join testData2 ON key = v;
Error: Error running query: org.apache.spark.SparkException: Adaptive execution failed due to stage materialization failures. (state=,code=0)
0: jdbc:hive2://localhost:10000>
```
After:
```shell
0: jdbc:hive2://localhost:10000> SELECT * FROM testData join testData2 ON key = v;
SELECT * FROM testData join testData2 ON key = v;
Error: Error running query: java.lang.IllegalArgumentException: Root cause is IllegalArgumentException for Test (state=,code=0)
0: jdbc:hive2://localhost:10000>
```
Closes#25960 from LantaoJin/SPARK-29283.
Authored-by: lajin <lajin@ebay.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
Support FETCH_PRIOR fetching in Thriftserver, and report correct fetch start offset it TFetchResultsResp.results.startRowOffset
The semantics of FETCH_PRIOR are as follow: Assuming the previous fetch returned a block of rows from offsets [10, 20)
* calling FETCH_PRIOR(maxRows=5) will scroll back and return rows [5, 10)
* calling FETCH_PRIOR(maxRows=10) again, will scroll back, but can't go earlier than 0. It will nevertheless return 10 rows, returning rows [0, 10) (overlapping with the previous fetch)
* calling FETCH_PRIOR(maxRows=4) again will again return rows starting from offset 0 - [0, 4)
* calling FETCH_NEXT(maxRows=6) after that will move the cursor forward and return rows [4, 10)
##### Client/server backwards/forwards compatibility:
Old driver with new server:
* Drivers that don't support FETCH_PRIOR will not attempt to use it
* Field TFetchResultsResp.results.startRowOffset was not set, old drivers don't depend on it.
New driver with old server
* Using an older thriftserver with FETCH_PRIOR will make the thriftserver return unsupported operation error. The driver can then recognize that it's an old server.
* Older thriftserver will return TFetchResultsResp.results.startRowOffset=0. If the client driver receives 0, it can know that it can not rely on it as correct offset. If the client driver intentionally wants to fetch from 0, it can use FETCH_FIRST.
### Why are the changes needed?
It's intended to be used to recover after connection errors. If a client lost connection during fetching (e.g. of rows [10, 20)), and wants to reconnect and continue, it could not know whether the request got lost before reaching the server, or on the response back. When it issued another FETCH_NEXT(10) request after reconnecting, because TFetchResultsResp.results.startRowOffset was not set, it could not know if the server will return rows [10,20) (because the previous request didn't reach it) or rows [20, 30) (because it returned data from the previous request but the connection got broken on the way back). Now, with TFetchResultsResp.results.startRowOffset the client can know after reconnecting which rows it is getting, and use FETCH_PRIOR to scroll back if a fetch block was lost in transmission.
Driver should always use FETCH_PRIOR after a broken connection.
* If the Thriftserver returns unsuported operation error, the driver knows that it's an old server that doesn't support it. The driver then must error the query, as it will also not support returning the correct startRowOffset, so the driver cannot reliably guarantee if it hadn't lost any rows on the fetch cursor.
* If the driver gets a response to FETCH_PRIOR, it should also have a correctly set startRowOffset, which the driver can use to position itself back where it left off before the connection broke.
* If FETCH_NEXT was used after a broken connection on the first fetch, and returned with an startRowOffset=0, then the client driver can't know if it's 0 because it's the older server version, or if it's genuinely 0. Better to call FETCH_PRIOR, as scrolling back may anyway be possibly required after a broken connection.
This way it is implemented in a backwards/forwards compatible way, and doesn't require bumping the protocol version. FETCH_ABSOLUTE might have been better, but that would require a bigger protocol change, as there is currently no field to specify the requested absolute offset.
### Does this PR introduce any user-facing change?
ODBC/JDBC drivers connecting to Thriftserver may now implement using the FETCH_PRIOR fetch order to scroll back in query results, and check TFetchResultsResp.results.startRowOffset if their cursor position is consistent after connection errors.
### How was this patch tested?
Added tests to HiveThriftServer2Suites
Closes#26014 from juliuszsompolski/SPARK-29349.
Authored-by: Juliusz Sompolski <julek@databricks.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
When inserting a value into a column with the different data type, Spark performs type coercion. Currently, we support 3 policies for the store assignment rules: ANSI, legacy and strict, which can be set via the option "spark.sql.storeAssignmentPolicy":
1. ANSI: Spark performs the type coercion as per ANSI SQL. In practice, the behavior is mostly the same as PostgreSQL. It disallows certain unreasonable type conversions such as converting `string` to `int` and `double` to `boolean`. It will throw a runtime exception if the value is out-of-range(overflow).
2. Legacy: Spark allows the type coercion as long as it is a valid `Cast`, which is very loose. E.g., converting either `string` to `int` or `double` to `boolean` is allowed. It is the current behavior in Spark 2.x for compatibility with Hive. When inserting an out-of-range value to a integral field, the low-order bits of the value is inserted(the same as Java/Scala numeric type casting). For example, if 257 is inserted to a field of Byte type, the result is 1.
3. Strict: Spark doesn't allow any possible precision loss or data truncation in store assignment, e.g., converting either `double` to `int` or `decimal` to `double` is allowed. The rules are originally for Dataset encoder. As far as I know, no mainstream DBMS is using this policy by default.
Currently, the V1 data source uses "Legacy" policy by default, while V2 uses "Strict". This proposal is to use "ANSI" policy by default for both V1 and V2 in Spark 3.0.
### Why are the changes needed?
Following the ANSI SQL standard is most reasonable among the 3 policies.
### Does this PR introduce any user-facing change?
Yes.
The default store assignment policy is ANSI for both V1 and V2 data sources.
### How was this patch tested?
Unit test
Closes#26107 from gengliangwang/ansiPolicyAsDefault.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR adds 2 changes regarding exception handling in `SQLQueryTestSuite` and `ThriftServerQueryTestSuite`
- fixes an expected output sorting issue in `ThriftServerQueryTestSuite` as if there is an exception then there is no need for sort
- introduces common exception handling in those 2 suites with a new `handleExceptions` method
### Why are the changes needed?
Currently `ThriftServerQueryTestSuite` passes on master, but it fails on one of my PRs (https://github.com/apache/spark/pull/23531) with this error (https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111651/testReport/org.apache.spark.sql.hive.thriftserver/ThriftServerQueryTestSuite/sql_3/):
```
org.scalatest.exceptions.TestFailedException: Expected "
[Recursion level limit 100 reached but query has not exhausted, try increasing spark.sql.cte.recursion.level.limit
org.apache.spark.SparkException]
", but got "
[org.apache.spark.SparkException
Recursion level limit 100 reached but query has not exhausted, try increasing spark.sql.cte.recursion.level.limit]
" Result did not match for query #4 WITH RECURSIVE r(level) AS ( VALUES (0) UNION ALL SELECT level + 1 FROM r ) SELECT * FROM r
```
The unexpected reversed order of expected output (error message comes first, then the exception class) is due to this line: https://github.com/apache/spark/pull/26028/files#diff-b3ea3021602a88056e52bf83d8782de8L146. It should not sort the expected output if there was an error during execution.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing UTs.
Closes#26028 from peter-toth/SPARK-29359-better-exception-handling.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
For issue mentioned in [SPARK-29022](https://issues.apache.org/jira/browse/SPARK-29022)
Spark SQL CLI can't use class as serde class in jars add by SQL `ADD JAR`.
When we create table with `serde` class contains by jar added by SQL 'ADD JAR'.
We can create table with `serde` class construct success since we call `HiveClientImpl.createTable` under `withHiveState` method, it will add `clientLoader.classLoader` to `HiveClientImpl.state.getConf.classLoader`.
Jars added by SQL `ADD JAR` will be add to
1. `sparkSession.sharedState.jarClassLoader`.
2. 'HiveClientLoader.clientLoader.classLoader'
In Current spark-sql MODE, `HiveClientImpl.state` will use CliSessionState created when initialize
SparkSQLCliDriver, When we select data from table, it will check `serde` class, when call method `HiveTableScanExec#addColumnMetadataToConf()` to check for table desc serde class.
```
val deserializer = tableDesc.getDeserializerClass.getConstructor().newInstance()
deserializer.initialize(hiveConf, tableDesc.getProperties)
```
`getDeserializer` will use CliSessionState's hiveConf's classLoader in `Spark SQL CLI` mode.
But when we call `ADD JAR` in spark, the jar won't be added to `Classloader of CliSessionState' conf `, then `ClassNotFound` error happen.
So we reset `CliSessionState conf's classLoader ` to `sharedState.jarClassLoader` when `sharedState.jarClassLoader` has added jar passed by `HIVEAUXJARS`
Then when we use `ADD JAR ` to add jar, jar path will be added to CliSessionState's conf's ClassLoader
### Why are the changes needed?
Fix bug
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
ADD UT
Closes#25729 from AngersZhuuuu/SPARK-29015.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to remove `scalatest` deprecation warnings with the following changes.
- `org.scalatest.mockito.MockitoSugar` -> `org.scalatestplus.mockito.MockitoSugar`
- `org.scalatest.selenium.WebBrowser` -> `org.scalatestplus.selenium.WebBrowser`
- `org.scalatest.prop.Checkers` -> `org.scalatestplus.scalacheck.Checkers`
- `org.scalatest.prop.GeneratorDrivenPropertyChecks` -> `org.scalatestplus.scalacheck.ScalaCheckDrivenPropertyChecks`
### Why are the changes needed?
According to the Jenkins logs, there are 118 warnings about this.
```
grep "is deprecated" ~/consoleText | grep scalatest | wc -l
118
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
After Jenkins passes, we need to check the Jenkins log.
Closes#25982 from dongjoon-hyun/SPARK-29307.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Scala 2.13 emits a deprecation warning for procedure-like declarations:
```
def foo() {
...
```
This is equivalent to the following, so should be changed to avoid a warning:
```
def foo(): Unit = {
...
```
### Why are the changes needed?
It will avoid about a thousand compiler warnings when we start to support Scala 2.13. I wanted to make the change in 3.0 as there are less likely to be back-ports from 3.0 to 2.4 than 3.1 to 3.0, for example, minimizing that downside to touching so many files.
Unfortunately, that makes this quite a big change.
### Does this PR introduce any user-facing change?
No behavior change at all.
### How was this patch tested?
Existing tests.
Closes#25968 from srowen/SPARK-29291.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Some of the columns of JDBC/ODBC server tab in Web UI are hard to understand.
We have documented it at SPARK-28373 but I think it is better to have some tooltips in the SQL statistics table to explain the columns

The columns with new tooltips are finish time, close time, execution time and duration

Improvements in UIUtils can be used in other tables in WebUI to add tooltips
### Why are the changes needed?
It is interesting to improve the undestanding of the WebUI
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Unit tests are added and manual test.
Closes#25723 from planga82/feature/SPARK-29019_tooltipjdbcServer.
Lead-authored-by: Unknown <soypab@gmail.com>
Co-authored-by: Pablo <soypab@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
This PR moves Hive test jars(`hive-contrib-*.jar` and `hive-hcatalog-core-*.jar`) from maven dependency to local file.
### Why are the changes needed?
`--jars` can't be tested since `hive-contrib-*.jar` and `hive-hcatalog-core-*.jar` are already in classpath.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
manual test
Closes#25690 from wangyum/SPARK-27831-revert.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
After https://github.com/apache/spark/pull/25158 and https://github.com/apache/spark/pull/25458, SQL features of PostgreSQL are introduced into Spark. AFAIK, both features are implementation-defined behaviors, which are not specified in ANSI SQL.
In such a case, this proposal is to add a configuration `spark.sql.dialect` for choosing a database dialect.
After this PR, Spark supports two database dialects, `Spark` and `PostgreSQL`. With `PostgreSQL` dialect, Spark will:
1. perform integral division with the / operator if both sides are integral types;
2. accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type.
### Why are the changes needed?
Unify the external database dialect with one configuration, instead of small flags.
### Does this PR introduce any user-facing change?
A new configuration `spark.sql.dialect` for choosing a database dialect.
### How was this patch tested?
Existing tests.
Closes#25697 from gengliangwang/dialect.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Rename the package pgSQL to postgreSQL
### Why are the changes needed?
To address the comment in https://github.com/apache/spark/pull/25697#discussion_r328431070 . The official full name seems more reasonable.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing unit tests.
Closes#25936 from gengliangwang/renamePGSQL.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
This PR enable `ThriftServerQueryTestSuite` and fix previously flaky test by:
1. Start thriftserver in `beforeAll()`.
2. Disable `spark.sql.hive.thriftServer.async`.
### Why are the changes needed?
Improve test coverage.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
```shell
build/sbt "hive-thriftserver/test-only *.ThriftServerQueryTestSuite " -Phive-thriftserver
build/mvn -Dtest=none -DwildcardSuites=org.apache.spark.sql.hive.thriftserver.ThriftServerQueryTestSuite test -Phive-thriftserver
```
Closes#25868 from wangyum/SPARK-28527-enable.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
Discuss in https://github.com/apache/spark/pull/25611
If cancel() and close() is called very quickly after the query is started, then they may both call cleanup() before Spark Jobs are started. Then sqlContext.sparkContext.cancelJobGroup(statementId) does nothing.
But then the execute thread can start the jobs, and only then get interrupted and exit through here. But then it will exit here, and no-one will cancel these jobs and they will keep running even though this execution has exited.
So when execute() was interrupted by `cancel()`, when get into catch block, we should call canJobGroup again to make sure the job was canceled.
### Why are the changes needed?
### Does this PR introduce any user-facing change?
NO
### How was this patch tested?
MT
Closes#25743 from AngersZhuuuu/SPARK-29036.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
This PR add support sorting `Execution Time` and `Duration` columns for `ThriftServerSessionPage`.
### Why are the changes needed?
Previously, it's not sorted correctly.
### Does this PR introduce any user-facing change?
Yes.
### How was this patch tested?
Manually do the following and test sorting on those columns in the Spark Thrift Server Session Page.
```
$ sbin/start-thriftserver.sh
$ bin/beeline -u jdbc:hive2://localhost:10000
0: jdbc:hive2://localhost:10000> create table t(a int);
+---------+--+
| Result |
+---------+--+
+---------+--+
No rows selected (0.521 seconds)
0: jdbc:hive2://localhost:10000> select * from t;
+----+--+
| a |
+----+--+
+----+--+
No rows selected (0.772 seconds)
0: jdbc:hive2://localhost:10000> show databases;
+---------------+--+
| databaseName |
+---------------+--+
| default |
+---------------+--+
1 row selected (0.249 seconds)
```
**Sorted by `Execution Time` column**:

**Sorted by `Duration` column**:

Closes#25892 from wangyum/SPARK-28599.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Currently, there are new configurations for compatibility with ANSI SQL:
* `spark.sql.parser.ansi.enabled`
* `spark.sql.decimalOperations.nullOnOverflow`
* `spark.sql.failOnIntegralTypeOverflow`
This PR is to add new configuration `spark.sql.ansi.enabled` and remove the 3 options above. When the configuration is true, Spark tries to conform to the ANSI SQL specification. It will be disabled by default.
### Why are the changes needed?
Make it simple and straightforward.
### Does this PR introduce any user-facing change?
The new features for ANSI compatibility will be set via one configuration `spark.sql.ansi.enabled`.
### How was this patch tested?
Existing unit tests.
Closes#25693 from gengliangwang/ansiEnabled.
Lead-authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
ThriftServerSessionPage displays timestamp 0 (1970/01/01) instead of nothing if query finish time and close time are not set.

Change it to display nothing, like ThriftServerPage.
### Why are the changes needed?
Obvious bug.
### Does this PR introduce any user-facing change?
Finish time and Close time will be displayed correctly on ThriftServerSessionPage in JDBC/ODBC Spark UI.
### How was this patch tested?
Manual test.
Closes#25762 from juliuszsompolski/SPARK-29056.
Authored-by: Juliusz Sompolski <julek@databricks.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
Current Spark Thrift Server return TypeInfo includes
1. INTERVAL_YEAR_MONTH
2. INTERVAL_DAY_TIME
3. UNION
4. USER_DEFINED
Spark doesn't support INTERVAL_YEAR_MONTH, INTERVAL_YEAR_MONTH, UNION
and won't return USER)DEFINED type.
This PR overwrite GetTypeInfoOperation with SparkGetTypeInfoOperation to exclude types which we don't need.
In hive-1.2.1 Type class is `org.apache.hive.service.cli.Type`
In hive-2.3.x Type class is `org.apache.hadoop.hive.serde2.thrift.Type`
Use ThrifrserverShimUtils to fit version problem and exclude types we don't need
### Why are the changes needed?
We should return type info of Spark's own type info
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manuel test & Added UT
Closes#25694 from AngersZhuuuu/SPARK-28982.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
The intent to use the --hiveconf/--hivevar parameter is just an initialization value, so setting it once in ```SparkSQLSessionManager#openSession``` is sufficient, and each time the ```SparkExecuteStatementOperation``` setting causes the variable to not be modified.
### Why are the changes needed?
It is wrong to set the --hivevar/--hiveconf variable in every ```SparkExecuteStatementOperation```, which prevents variable updates.
### Does this PR introduce any user-facing change?
```
cat <<EOF > test.sql
select '\${a}', '\${b}';
set b=bvalue_MOD_VALUE;
set b;
EOF
beeline -u jdbc:hive2://localhost:10000 --hiveconf a=avalue --hivevar b=bvalue -f test.sql
```
current result:
```
+-----------------+-----------------+--+
| avalue | bvalue |
+-----------------+-----------------+--+
| avalue | bvalue |
+-----------------+-----------------+--+
+-----------------+-----------------+--+
| key | value |
+-----------------+-----------------+--+
| b | bvalue |
+-----------------+-----------------+--+
1 row selected (0.022 seconds)
```
after modification:
```
+-----------------+-----------------+--+
| avalue | bvalue |
+-----------------+-----------------+--+
| avalue | bvalue |
+-----------------+-----------------+--+
+-----------------+-----------------+--+
| key | value |
+-----------------+-----------------+--+
| b | bvalue_MOD_VALUE|
+-----------------+-----------------+--+
1 row selected (0.022 seconds)
```
### How was this patch tested?
modified the existing unit test
Closes#25722 from cxzl25/fix_SPARK-26598.
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
## What changes were proposed in this pull request?
`bin/spark-shell` support query interval value:
```scala
scala> spark.sql("SELECT interval 3 months 1 hours AS i").show(false)
+-------------------------+
|i |
+-------------------------+
|interval 3 months 1 hours|
+-------------------------+
```
But `sbin/start-thriftserver.sh` can't support query interval value:
```sql
0: jdbc:hive2://localhost:10000/default> SELECT interval 3 months 1 hours AS i;
Error: java.lang.IllegalArgumentException: Unrecognized type name: interval (state=,code=0)
```
This PR maps `CalendarIntervalType` to `StringType` for `TableSchema` to make Thriftserver support query interval value because we do not support `INTERVAL_YEAR_MONTH` type and `INTERVAL_DAY_TIME`:
02c33694c8/sql/hive-thriftserver/v1.2.1/src/main/java/org/apache/hive/service/cli/Type.java (L73-L78)
[SPARK-27791](https://issues.apache.org/jira/browse/SPARK-27791): Support SQL year-month INTERVAL type
[SPARK-27793](https://issues.apache.org/jira/browse/SPARK-27793): Support SQL day-time INTERVAL type
## How was this patch tested?
unit tests
Closes#25277 from wangyum/Thriftserver-support-interval-type.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
This PR ignores Thrift server `ThriftServerQueryTestSuite`.
### Why are the changes needed?
This ThriftServerQueryTestSuite test case led to frequent Jenkins build failure.
### Does this PR introduce any user-facing change?
Yes.
### How was this patch tested?
N/A
Closes#25592 from wangyum/SPARK-28527-f1.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR implements `SparkGetCatalogsOperation` for Thrift Server metadata completeness.
### Why are the changes needed?
Thrift Server metadata completeness.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Unit test
Closes#25555 from wangyum/SPARK-28852.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
While processing the Rowdata in the server side ColumnValue BigDecimal type value processed by server has to converted to the HiveDecmal data type for successful processing of query using Hive ODBC client.As per current logic corresponding to the Decimal column datatype, the Spark server uses BigDecimal, and the ODBC client uses HiveDecimal. If the data type does not match, the client fail to parse
Since this handing was missing the query executed in Hive ODBC client wont return or provides result to the user even though the decimal type column value data present.
## How was this patch tested?
Manual test report and impact assessment is done using existing test-cases
Before fix

After Fix

Closes#23899 from sujith71955/master_decimalissue.
Authored-by: s71955 <sujithchacko.2010@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR port [HIVE-10646](https://issues.apache.org/jira/browse/HIVE-10646) to fix Hive 0.12's JDBC client can not handle `NULL_TYPE`:
```sql
Connected to: Hive (version 3.0.0-SNAPSHOT)
Driver: Hive (version 0.12.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 0.12.0 by Apache Hive
0: jdbc:hive2://localhost:10000> select null;
org.apache.thrift.transport.TTransportException
at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:132)
at org.apache.thrift.transport.TTransport.readAll(TTransport.java:84)
at org.apache.thrift.transport.TSaslTransport.readLength(TSaslTransport.java:346)
at org.apache.thrift.transport.TSaslTransport.readFrame(TSaslTransport.java:423)
at org.apache.thrift.transport.TSaslTransport.read(TSaslTransport.java:405)
```
Server log:
```
19/08/07 09:34:07 ERROR TThreadPoolServer: Error occurred during processing of message.
java.lang.NullPointerException
at org.apache.hive.service.cli.thrift.TRow$TRowStandardScheme.write(TRow.java:388)
at org.apache.hive.service.cli.thrift.TRow$TRowStandardScheme.write(TRow.java:338)
at org.apache.hive.service.cli.thrift.TRow.write(TRow.java:288)
at org.apache.hive.service.cli.thrift.TRowSet$TRowSetStandardScheme.write(TRowSet.java:605)
at org.apache.hive.service.cli.thrift.TRowSet$TRowSetStandardScheme.write(TRowSet.java:525)
at org.apache.hive.service.cli.thrift.TRowSet.write(TRowSet.java:455)
at org.apache.hive.service.cli.thrift.TFetchResultsResp$TFetchResultsRespStandardScheme.write(TFetchResultsResp.java:550)
at org.apache.hive.service.cli.thrift.TFetchResultsResp$TFetchResultsRespStandardScheme.write(TFetchResultsResp.java:486)
at org.apache.hive.service.cli.thrift.TFetchResultsResp.write(TFetchResultsResp.java:412)
at org.apache.hive.service.cli.thrift.TCLIService$FetchResults_result$FetchResults_resultStandardScheme.write(TCLIService.java:13192)
at org.apache.hive.service.cli.thrift.TCLIService$FetchResults_result$FetchResults_resultStandardScheme.write(TCLIService.java:13156)
at org.apache.hive.service.cli.thrift.TCLIService$FetchResults_result.write(TCLIService.java:13107)
at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:58)
at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39)
at org.apache.hive.service.auth.TSetIpAddressProcessor.process(TSetIpAddressProcessor.java:53)
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:310)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:819)
```
## How was this patch tested?
unit tests
Closes#25378 from wangyum/SPARK-28644.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR fix Hive 0.12 JDBC client can not handle binary type:
```sql
Connected to: Hive (version 3.0.0-SNAPSHOT)
Driver: Hive (version 0.12.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 0.12.0 by Apache Hive
0: jdbc:hive2://localhost:10000> SELECT cast('ABC' as binary);
Error: java.lang.ClassCastException: [B incompatible with java.lang.String (state=,code=0)
```
Server log:
```
19/08/07 10:10:04 WARN ThriftCLIService: Error fetching results:
java.lang.RuntimeException: java.lang.ClassCastException: [B incompatible with java.lang.String
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:83)
at org.apache.hive.service.cli.session.HiveSessionProxy.access$000(HiveSessionProxy.java:36)
at org.apache.hive.service.cli.session.HiveSessionProxy$1.run(HiveSessionProxy.java:63)
at java.security.AccessController.doPrivileged(AccessController.java:770)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1746)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:59)
at com.sun.proxy.$Proxy26.fetchResults(Unknown Source)
at org.apache.hive.service.cli.CLIService.fetchResults(CLIService.java:455)
at org.apache.hive.service.cli.thrift.ThriftCLIService.FetchResults(ThriftCLIService.java:621)
at org.apache.hive.service.cli.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1553)
at org.apache.hive.service.cli.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1538)
at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:38)
at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39)
at org.apache.hive.service.auth.TSetIpAddressProcessor.process(TSetIpAddressProcessor.java:53)
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:310)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:819)
Caused by: java.lang.ClassCastException: [B incompatible with java.lang.String
at org.apache.hive.service.cli.ColumnValue.toTColumnValue(ColumnValue.java:198)
at org.apache.hive.service.cli.RowBasedSet.addRow(RowBasedSet.java:60)
at org.apache.hive.service.cli.RowBasedSet.addRow(RowBasedSet.java:32)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.$anonfun$getNextRowSet$1(SparkExecuteStatementOperation.scala:151)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$Lambda$1923.000000009113BFE0.apply(Unknown Source)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.withSchedulerPool(SparkExecuteStatementOperation.scala:299)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.getNextRowSet(SparkExecuteStatementOperation.scala:113)
at org.apache.hive.service.cli.operation.OperationManager.getOperationNextRowSet(OperationManager.java:220)
at org.apache.hive.service.cli.session.HiveSessionImpl.fetchResults(HiveSessionImpl.java:785)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:78)
... 18 more
```
## How was this patch tested?
unit tests
Closes#25379 from wangyum/SPARK-28474.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This patch tries to keep consistency whenever UTF-8 charset is needed, as using `StandardCharsets.UTF_8` instead of using "UTF-8". If the String type is needed, `StandardCharsets.UTF_8.name()` is used.
This change also brings the benefit of getting rid of `UnsupportedEncodingException`, as we're providing `Charset` instead of `String` whenever possible.
This also changes some private Catalyst helper methods to operate on encodings as `Charset` objects rather than strings.
## How was this patch tested?
Existing unit tests.
Closes#25335 from HeartSaVioR/SPARK-28601.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR implements Spark's own GetFunctionsOperation which mitigates the differences between Spark SQL and Hive UDFs. But our implementation is different from Hive's implementation:
- Our implementation always returns results. Hive only returns results when [(null == catalogName || "".equals(catalogName)) && (null == schemaName || "".equals(schemaName))](https://github.com/apache/hive/blob/rel/release-3.1.1/service/src/java/org/apache/hive/service/cli/operation/GetFunctionsOperation.java#L101-L119).
- Our implementation pads the `REMARKS` field with the function usage - Hive returns an empty string.
- Our implementation does not support `FUNCTION_TYPE`, but Hive does.
## How was this patch tested?
unit tests
Closes#25252 from wangyum/SPARK-28510.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
How to reproduce this issue:
```shell
build/sbt clean package -Phive -Phive-thriftserver -Phadoop-3.2
export SPARK_PREPEND_CLASSES=true
sbin/start-thriftserver.sh
[rootspark-3267648 spark]# bin/beeline -u jdbc:hive2://localhost:10000/default -e "select cast(1 as decimal(38, 18));"
Connecting to jdbc:hive2://localhost:10000/default
Connected to: Spark SQL (version 3.0.0-SNAPSHOT)
Driver: Hive JDBC (version 2.3.5)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Error: java.lang.ClassCastException: java.math.BigDecimal incompatible with org.apache.hadoop.hive.common.type.HiveDecimal (state=,code=0)
Closing: 0: jdbc:hive2://localhost:10000/default
```
This pr fix this issue.
## How was this patch tested?
unit tests
Closes#25217 from wangyum/SPARK-28463.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
For Thrift server, It's downward compatible. Such as if a PROTOCOL_VERSION_V7 client connect to a PROTOCOL_VERSION_V8 server, when OpenSession, server will change his response's protocol version to min of (client and server).
`TProtocolVersion protocol = getMinVersion(CLIService.SERVER_VERSION,`
` req.getClient_protocol());`
then set it to OpenSession's response.
But if OpenSession failed , it won't execute behavior of reset response's protocol_version.
Then it will return server's origin protocol version.
Finally client will get en error as below:
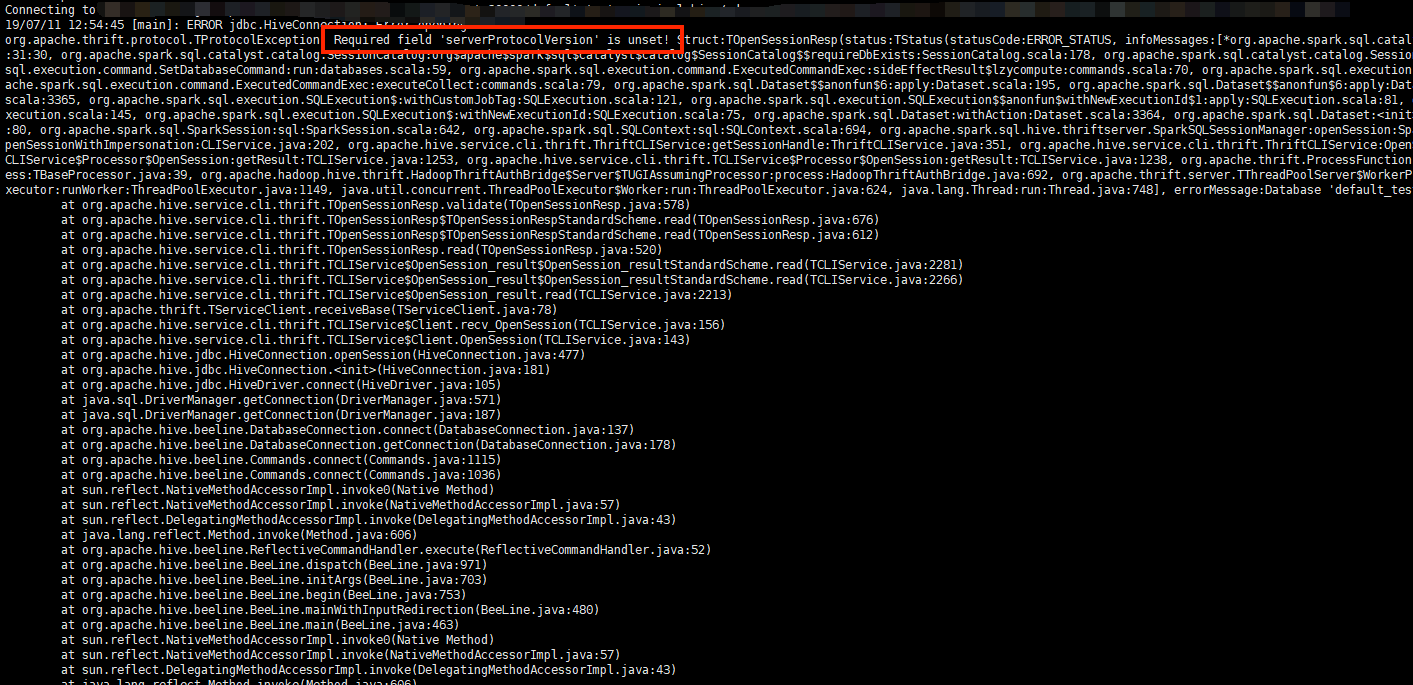
Since we write a wrong database,, OpenSession failed, right protocol version haven't been rest.
## How was this patch tested?
Since I really don't know how to write unit test about this, so I build a jar with this PR,and retry the error above, then it will return a reasonable Error of DB not found :

Closes#25083 from AngersZhuuuu/SPARK-28311.
Authored-by: 朱夷 <zhuyi01@corp.netease.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
There are some hardcoded configs, using config entry to replace them.
## How was this patch tested?
Existing UT
Closes#25059 from WangGuangxin/ConfigEntry.
Authored-by: wangguangxin.cn <wangguangxin.cn@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
`SslContextFactory` is deprecated at Jetty 9.4 and we are using `9.4.18.v20190429`. This PR aims to replace it with `SslContextFactory.Server`.
- https://www.eclipse.org/jetty/javadoc/9.4.19.v20190610/org/eclipse/jetty/util/ssl/SslContextFactory.html
- https://www.eclipse.org/jetty/javadoc/9.3.24.v20180605/org/eclipse/jetty/util/ssl/SslContextFactory.html
```
[WARNING] /Users/dhyun/APACHE/spark/core/src/main/scala/org/apache/spark/SSLOptions.scala:71:
constructor SslContextFactory in class SslContextFactory is deprecated:
see corresponding Javadoc for more information.
[WARNING] val sslContextFactory = new SslContextFactory()
[WARNING] ^
```
## How was this patch tested?
Pass the Jenkins with the existing tests.
Closes#25067 from dongjoon-hyun/SPARK-28290.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr add support show global temporary view and local temporary view in database tool.
TODO: Database tools should support show temporary views because it's schema is null.
## How was this patch tested?
unit tests and manual tests:
Closes#24972 from wangyum/SPARK-28167.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
To make the #24972 change smaller. This pr improves `SparkMetadataOperationSuite` to avoid creating new sessions when getSchemas/getTables/getColumns.
## How was this patch tested?
N/A
Closes#24985 from wangyum/SPARK-28184.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The new Spark ThriftServer SparkGetTablesOperation implemented in https://github.com/apache/spark/pull/22794 does a catalog.getTableMetadata request for every table. This can get very slow for large schemas (~50ms per table with an external Hive metastore).
Hive ThriftServer GetTablesOperation uses HiveMetastoreClient.getTableObjectsByName to get table information in bulk, but we don't expose that through our APIs that go through Hive -> HiveClientImpl (HiveClient) -> HiveExternalCatalog (ExternalCatalog) -> SessionCatalog.
If we added and exposed getTableObjectsByName through our catalog APIs, we could resolve that performance problem in SparkGetTablesOperation.
## How was this patch tested?
Add UT
Closes#24774 from LantaoJin/SPARK-27899.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This pr moves Hive test jars(`hive-contrib-0.13.1.jar`, `hive-hcatalog-core-0.13.1.jar`, `hive-contrib-2.3.5.jar` and `hive-hcatalog-core-2.3.5.jar`) to maven dependency.
## How was this patch tested?
Existing test
Please note that this pr need test with `maven` and `sbt`.
Closes#24751 from wangyum/SPARK-27831.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr moves `sql/hive-thriftserver/v2.3.4` to `sql/hive-thriftserver/v2.3.5` based on ([comment](https://github.com/apache/spark/pull/24628#issuecomment-496459258)).
## How was this patch tested?
N/A
Closes#24728 from wangyum/SPARK-27737-thriftserver.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr moves Hive test jars(`hive-contrib-0.13.1.jar`, `hive-hcatalog-core-0.13.1.jar`, `hive-contrib-2.3.5.jar` and `hive-hcatalog-core-2.3.5.jar`) to maven dependency.
## How was this patch tested?
Existing test
Closes#24695 from wangyum/SPARK-27831.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
When we upgraded the built-in Hive to 2.3.4, the current `hive-thriftserver` module is not compatible, such as these Hive changes:
1. [HIVE-12442](https://issues.apache.org/jira/browse/HIVE-12442) HiveServer2: Refactor/repackage HiveServer2's Thrift code so that it can be used in the tasks
2. [HIVE-12237](https://issues.apache.org/jira/browse/HIVE-12237) Use slf4j as logging facade
3. [HIVE-13169](https://issues.apache.org/jira/browse/HIVE-13169) HiveServer2: Support delegation token based connection when using http transport
So this PR moves the incompatible code to `sql/hive-thriftserver/v1.2.1` and copies it to `sql/hive-thriftserver/v2.3.4` for the next code review.
## How was this patch tested?
manual tests:
```
diff -urNa sql/hive-thriftserver/v1.2.1 sql/hive-thriftserver/v2.3.4
```
Closes#24282 from wangyum/SPARK-27354.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Fix build warnings -- see some details below.
But mostly, remove use of postfix syntax where it causes warnings without the `scala.language.postfixOps` import. This is mostly in expressions like "120000 milliseconds". Which, I'd like to simplify to things like "2.minutes" anyway.
## How was this patch tested?
Existing tests.
Closes#24314 from srowen/SPARK-27404.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The user sets the value of spark.sql.thriftserver.scheduler.pool.
Spark thrift server saves this value in the LocalProperty of threadlocal type, but does not clean up after running, causing other sessions to run in the previously set pool name.
## How was this patch tested?
manual tests
Closes#23895 from cxzl25/thrift_server_scheduler_pool_pollute.
Lead-authored-by: cxzl25 <cxzl25@users.noreply.github.com>
Co-authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Use Single Abstract Method syntax where possible (and minor related cleanup). Comments below. No logic should change here.
## How was this patch tested?
Existing tests.
Closes#24241 from srowen/SPARK-27323.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
When using fair scheduler mode for thrift server, we may have unpredictable result.
```
val pool = sessionToActivePool.get(parentSession.getSessionHandle)
if (pool != null) {
sqlContext.sparkContext.setLocalProperty(SparkContext.SPARK_SCHEDULER_POOL, pool)
}
```
The cause is we use thread pool to execute queries for thriftserver, and when we call setLocalProperty we may have unpredictab behavior.
```
/**
* Set a local property that affects jobs submitted from this thread, such as the Spark fair
* scheduler pool. User-defined properties may also be set here. These properties are propagated
* through to worker tasks and can be accessed there via
* [[org.apache.spark.TaskContext#getLocalProperty]].
*
* These properties are inherited by child threads spawned from this thread. This
* may have unexpected consequences when working with thread pools. The standard java
* implementation of thread pools have worker threads spawn other worker threads.
* As a result, local properties may propagate unpredictably.
*/
def setLocalProperty(key: String, value: String) {
if (value == null) {
localProperties.get.remove(key)
} else {
localProperties.get.setProperty(key, value)
}
}
```
I post an example on https://jira.apache.org/jira/browse/SPARK-26914 .
## How was this patch tested?
UT
Closes#23826 from caneGuy/zhoukang/fix-scheduler-error.
Authored-by: zhoukang <zhoukang199191@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/12881 removed `HiveSessionHook`. But there are still some code related to `HiveSessionHook`.
This PR removes all `HiveSessionHook` related code.
## How was this patch tested?
manual tests
Closes#23957 from wangyum/SPARK-15095.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
In the PR, I propose to use `System.nanoTime()` instead of `System.currentTimeMillis()` in measurements of time intervals.
`System.currentTimeMillis()` returns current wallclock time and will follow changes to the system clock. Thus, negative wallclock adjustments can cause timeouts to "hang" for a long time (until wallclock time has caught up to its previous value again). This can happen when ntpd does a "step" after the network has been disconnected for some time. The most canonical example is during system bootup when DHCP takes longer than usual. This can lead to failures that are really hard to understand/reproduce. `System.nanoTime()` is guaranteed to be monotonically increasing irrespective of wallclock changes.
## How was this patch tested?
By existing test suites.
Closes#23727 from MaxGekk/system-nanotime.
Lead-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Delegation token providers interface now has a parameter `fileSystems` but this is needed only for `HadoopFSDelegationTokenProvider`.
In this PR I've addressed this issue in the following way:
* Removed `fileSystems` parameter from `HadoopDelegationTokenProvider`
* Moved `YarnSparkHadoopUtil.hadoopFSsToAccess` into `HadoopFSDelegationTokenProvider`
* Moved `spark.yarn.stagingDir` into core
* Moved `spark.yarn.access.namenodes` into core and renamed to `spark.kerberos.access.namenodes`
* Moved `spark.yarn.access.hadoopFileSystems` into core and renamed to `spark.kerberos.access.hadoopFileSystems`
## How was this patch tested?
Existing unit tests.
Closes#23698 from gaborgsomogyi/SPARK-26766.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
When we run in background and we get exception which is not HiveSQLException,
we may encounter memory leak since handleToOperation will not removed correctly.
The reason is below:
1. When calling operation.run() in HiveSessionImpl#executeStatementInternal we throw an exception which is not HiveSQLException
2. Then the opHandle generated by SparkSQLOperationManager will not be added into opHandleSet of HiveSessionImpl , and operationManager.closeOperation(opHandle) will not be called
3. When we close the session we will also call operationManager.closeOperation(opHandle),since we did not add this opHandle into the opHandleSet.
For the reasons above,the opHandled will always in SparkSQLOperationManager#handleToOperation,which will cause memory leak.
More details and a case has attached on https://issues.apache.org/jira/browse/SPARK-26751
This patch will always throw HiveSQLException when running in background
## How was this patch tested?
Exist UT
Closes#23673 from caneGuy/zhoukang/fix-hivesessionimpl-leak.
Authored-by: zhoukang <zhoukang199191@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
There are ugly provided dependencies inside core for the following:
* Hive
* Kafka
In this PR I've extracted them out. This PR contains the following:
* Token providers are now loaded with service loader
* Hive token provider moved to hive project
* Kafka token provider extracted into a new project
## How was this patch tested?
Existing + newly added unit tests.
Additionally tested on cluster.
Closes#23499 from gaborgsomogyi/SPARK-26254.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
The PR makes hardcoded `spark.dynamicAllocation`, `spark.scheduler`, `spark.rpc`, `spark.task`, `spark.speculation`, and `spark.cleaner` configs to use `ConfigEntry`.
## How was this patch tested?
Existing tests
Closes#23416 from kiszk/SPARK-26463.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The PR makes hardcoded configs below to use `ConfigEntry`.
* spark.ui
* spark.ssl
* spark.authenticate
* spark.master.rest
* spark.master.ui
* spark.metrics
* spark.admin
* spark.modify.acl
This patch doesn't change configs which are not relevant to SparkConf (e.g. system properties).
## How was this patch tested?
Existing tests.
Closes#23423 from HeartSaVioR/SPARK-26466.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
Currently there is code scattered in a bunch of places to do different
things related to HTTP security, such as access control, setting
security-related headers, and filtering out bad content. This makes it
really easy to miss these things when writing new UI code.
This change creates a new filter that does all of those things, and
makes sure that all servlet handlers that are attached to the UI get
the new filter and any user-defined filters consistently. The extent
of the actual features should be the same as before.
The new filter is added at the end of the filter chain, because authentication
is done by custom filters and thus needs to happen first. This means that
custom filters see unfiltered HTTP requests - which is actually the current
behavior anyway.
As a side-effect of some of the code refactoring, handlers added after
the initial set also get wrapped with a GzipHandler, which didn't happen
before.
Tested with added unit tests and in a history server with SPNEGO auth
configured.
Closes#23302 from vanzin/SPARK-24522.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
The `toHiveString()` and `toHiveStructString` methods were removed from `HiveUtils` because they have been already implemented in `HiveResult`. One related test was moved to `HiveResultSuite`.
## How was this patch tested?
By tests from `hive-thriftserver`.
Closes#23466 from MaxGekk/dedup-hive-result-string.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
In the PR, I propose to move `hiveResultString()` out of `QueryExecution` and put it to a separate object.
Closes#23409 from MaxGekk/hive-result-string.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Herman van Hovell <hvanhovell@databricks.com>
## What changes were proposed in this pull request?
The build has a lot of deprecation warnings. Some are new in Scala 2.12 and Java 11. We've fixed some, but I wanted to take a pass at fixing lots of easy miscellaneous ones here.
They're too numerous and small to list here; see the pull request. Some highlights:
- `BeanInfo` is deprecated in 2.12, and BeanInfo classes are pretty ancient in Java. Instead, case classes can explicitly declare getters
- Eta expansion of zero-arg methods; foo() becomes () => foo() in many cases
- Floating-point Range is inexact and deprecated, like 0.0 to 100.0 by 1.0
- finalize() is finally deprecated (just needs to be suppressed)
- StageInfo.attempId was deprecated and easiest to remove here
I'm not now going to touch some chunks of deprecation warnings:
- Parquet deprecations
- Hive deprecations (particularly serde2 classes)
- Deprecations in generated code (mostly Thriftserver CLI)
- ProcessingTime deprecations (we may need to revive this class as internal)
- many MLlib deprecations because they concern methods that may be removed anyway
- a few Kinesis deprecations I couldn't figure out
- Mesos get/setRole, which I don't know well
- Kafka/ZK deprecations (e.g. poll())
- Kinesis
- a few other ones that will probably resolve by deleting a deprecated method
## How was this patch tested?
Existing tests, including manual testing with the 2.11 build and Java 11.
Closes#23065 from srowen/SPARK-26090.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This restores scaladoc artifact generation, which got dropped with the Scala 2.12 update. The change looks large, but is almost all due to needing to make the InterfaceStability annotations top-level classes (i.e. `InterfaceStability.Stable` -> `Stable`), unfortunately. A few inner class references had to be qualified too.
Lots of scaladoc warnings now reappear. We can choose to disable generation by default and enable for releases, later.
## How was this patch tested?
N/A; build runs scaladoc now.
Closes#23069 from srowen/SPARK-26026.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR makes Spark's default Scala version as 2.12, and Scala 2.11 will be the alternative version. This implies that Scala 2.12 will be used by our CI builds including pull request builds.
We'll update the Jenkins to include a new compile-only jobs for Scala 2.11 to ensure the code can be still compiled with Scala 2.11.
## How was this patch tested?
existing tests
Closes#22967 from dbtsai/scala2.12.
Authored-by: DB Tsai <d_tsai@apple.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…. Other related changes to get JDK 11 working, to test
## What changes were proposed in this pull request?
- Access `sun.misc.Cleaner` (Java 8) and `jdk.internal.ref.Cleaner` (JDK 9+) by reflection (note: the latter only works if illegal reflective access is allowed)
- Access `sun.misc.Unsafe.invokeCleaner` in Java 9+ instead of `sun.misc.Cleaner` (Java 8)
In order to test anything on JDK 11, I also fixed a few small things, which I include here:
- Fix minor JDK 11 compile issues
- Update scala plugin, Jetty for JDK 11, to facilitate tests too
This doesn't mean JDK 11 tests all pass now, but lots do. Note also that the JDK 9+ solution for the Cleaner has a big caveat.
## How was this patch tested?
Existing tests. Manually tested JDK 11 build and tests, and tests covering this change appear to pass. All Java 8 tests should still pass, but this change alone does not achieve full JDK 11 compatibility.
Closes#22993 from srowen/SPARK-24421.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Deprecated in Java 11, replace Class.newInstance with Class.getConstructor.getInstance, and primtive wrapper class constructors with valueOf or equivalent
## How was this patch tested?
Existing tests.
Closes#22988 from srowen/SPARK-25984.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
'refreshInterval' is not used any where in the headerSparkPage method. So, we don't need to pass the parameter while calling the 'headerSparkPage' method.
## How was this patch tested?
Existing tests
Closes#22864 from shahidki31/unusedCode.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently if we run
```
sh start-thriftserver.sh -h
```
we get
```
...
Thrift server options:
2018-10-15 21:45:39 INFO HiveThriftServer2:54 - Starting SparkContext
2018-10-15 21:45:40 INFO SparkContext:54 - Running Spark version 2.3.2
2018-10-15 21:45:40 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2018-10-15 21:45:40 ERROR SparkContext:91 - Error initializing SparkContext.
org.apache.spark.SparkException: A master URL must be set in your configuration
at org.apache.spark.SparkContext.<init>(SparkContext.scala:367)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2493)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:934)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:925)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:925)
at org.apache.spark.sql.hive.thriftserver.SparkSQLEnv$.init(SparkSQLEnv.scala:48)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2$.main(HiveThriftServer2.scala:79)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.main(HiveThriftServer2.scala)
2018-10-15 21:45:40 ERROR Utils:91 - Uncaught exception in thread main
```
After fix, the usage output is clean:
```
...
Thrift server options:
--hiveconf <property=value> Use value for given property
```
Also exit with code 1, to follow other scripts(this is the behavior of parsing option `-h` for other linux commands as well).
## How was this patch tested?
Manual test.
Closes#22727 from gengliangwang/stsUsage.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
While working on another PR, I noticed that there is quite some legacy Java in there that can be beautified. For example the use og features from Java8, such as:
- Collection libraries
- Try-with-resource blocks
No code has been changed
What are your thoughts on this?
This makes code easier to read, and using try-with-resource makes is less likely to forget to close something.
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22399 from Fokko/SPARK-25408.
Authored-by: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This patch is to bump the master branch version to 3.0.0-SNAPSHOT.
## How was this patch tested?
N/A
Closes#22606 from gatorsmile/bump3.0.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In the dev list, we can still discuss whether the next version is 2.5.0 or 3.0.0. Let us first bump the master branch version to `2.5.0-SNAPSHOT`.
## How was this patch tested?
N/A
Closes#22426 from gatorsmile/bumpVersionMaster.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR ensures to call `super.afterAll()` in `override afterAll()` method for test suites.
* Some suites did not call `super.afterAll()`
* Some suites may call `super.afterAll()` only under certain condition
* Others never call `super.afterAll()`.
This PR also ensures to call `super.beforeAll()` in `override beforeAll()` for test suites.
## How was this patch tested?
Existing UTs
Closes#22337 from kiszk/SPARK-25338.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Switch `org.apache.hive.service.server.HiveServer2` to register its shutdown callback with Spark's `ShutdownHookManager`, rather than direct with the Java Runtime callback.
This avoids race conditions in shutdown where the filesystem is shutdown before the flush/write/rename of the event log is completed, particularly on object stores where the write and rename can be slow.
## How was this patch tested?
There's no explicit unit for test this, which is consistent with every other shutdown hook in the codebase.
* There's an implicit test when the scalatest process is halted.
* More manual/integration testing is needed.
HADOOP-15679 has added the ability to explicitly execute the hadoop shutdown hook sequence which spark uses; that could be stabilized for testing if desired, after which all the spark hooks could be tested. Until then: external system tests only.
Author: Steve Loughran <stevel@hortonworks.com>
Closes#22186 from steveloughran/BUG/SPARK-25183-shutdown.
## What changes were proposed in this pull request?
A small change to print the master and appId from spark-sql as with logging turned down all the way (`log4j.logger.org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver=WARN`), we may not know this information easily. This adds the following string before the `spark-sql>` prompt shows on the screen.
`Spark master: yarn, Application Id: application_123456789_12345`
## How was this patch tested?
I ran spark-sql locally and saw the appId displayed as expected.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22025 from abellina/SPARK-25043_print_master_and_app_id_from_sparksql.
Lead-authored-by: Alessandro Bellina <abellina@gmail.com>
Co-authored-by: Alessandro Bellina <abellina@yahoo-inc.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
Fixing typos is sometimes very hard. It's not so easy to visually review them. Recently, I discovered a very useful tool for it, [misspell](https://github.com/client9/misspell).
This pull request fixes minor typos detected by [misspell](https://github.com/client9/misspell) except for the false positives. If you would like me to work on other files as well, let me know.
## How was this patch tested?
### before
```
$ misspell . | grep -v '.js'
R/pkg/R/SQLContext.R:354:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:424:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:445:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:495:43: "definiton" is a misspelling of "definition"
NOTICE-binary:454:16: "containd" is a misspelling of "contained"
R/pkg/R/context.R:46:43: "definiton" is a misspelling of "definition"
R/pkg/R/context.R:74:43: "definiton" is a misspelling of "definition"
R/pkg/R/DataFrame.R:591:48: "persistance" is a misspelling of "persistence"
R/pkg/R/streaming.R:166:44: "occured" is a misspelling of "occurred"
R/pkg/inst/worker/worker.R:65:22: "ouput" is a misspelling of "output"
R/pkg/tests/fulltests/test_utils.R:106:25: "environemnt" is a misspelling of "environment"
common/kvstore/src/test/java/org/apache/spark/util/kvstore/InMemoryStoreSuite.java:38:39: "existant" is a misspelling of "existent"
common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java:83:39: "existant" is a misspelling of "existent"
common/network-common/src/main/java/org/apache/spark/network/crypto/TransportCipher.java:243:46: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:234:19: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:238:63: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:244:46: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:276:39: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/util/AbstractFileRegion.java:27:20: "transfered" is a misspelling of "transferred"
common/unsafe/src/test/scala/org/apache/spark/unsafe/types/UTF8StringPropertyCheckSuite.scala:195:15: "orgin" is a misspelling of "origin"
core/src/main/scala/org/apache/spark/api/python/PythonRDD.scala:621:39: "gauranteed" is a misspelling of "guaranteed"
core/src/main/scala/org/apache/spark/status/storeTypes.scala:113:29: "ect" is a misspelling of "etc"
core/src/main/scala/org/apache/spark/storage/DiskStore.scala:282:18: "transfered" is a misspelling of "transferred"
core/src/main/scala/org/apache/spark/util/ListenerBus.scala:64:17: "overriden" is a misspelling of "overridden"
core/src/test/scala/org/apache/spark/ShuffleSuite.scala:211:7: "substracted" is a misspelling of "subtracted"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:1922:49: "agriculteur" is a misspelling of "agriculture"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:2468:84: "truely" is a misspelling of "truly"
core/src/test/scala/org/apache/spark/storage/FlatmapIteratorSuite.scala:25:18: "persistance" is a misspelling of "persistence"
core/src/test/scala/org/apache/spark/storage/FlatmapIteratorSuite.scala:26:69: "persistance" is a misspelling of "persistence"
data/streaming/AFINN-111.txt:1219:0: "humerous" is a misspelling of "humorous"
dev/run-pip-tests:55:28: "enviroments" is a misspelling of "environments"
dev/run-pip-tests:91:37: "virutal" is a misspelling of "virtual"
dev/merge_spark_pr.py:377:72: "accross" is a misspelling of "across"
dev/merge_spark_pr.py:378:66: "accross" is a misspelling of "across"
dev/run-pip-tests:126:25: "enviroments" is a misspelling of "environments"
docs/configuration.md:1830:82: "overriden" is a misspelling of "overridden"
docs/structured-streaming-programming-guide.md:525:45: "processs" is a misspelling of "processes"
docs/structured-streaming-programming-guide.md:1165:61: "BETWEN" is a misspelling of "BETWEEN"
docs/sql-programming-guide.md:1891:810: "behaivor" is a misspelling of "behavior"
examples/src/main/python/sql/arrow.py:98:8: "substract" is a misspelling of "subtract"
examples/src/main/python/sql/arrow.py:103:27: "substract" is a misspelling of "subtract"
licenses/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/hungarian.txt:170:0: "teh" is a misspelling of "the"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/portuguese.txt:53:0: "eles" is a misspelling of "eels"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:99:20: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:539:11: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/mllib/clustering/LDAOptimizer.scala:77:36: "Teh" is a misspelling of "The"
mllib/src/main/scala/org/apache/spark/mllib/clustering/StreamingKMeans.scala:230:24: "inital" is a misspelling of "initial"
mllib/src/main/scala/org/apache/spark/mllib/stat/MultivariateOnlineSummarizer.scala:276:9: "Euclidian" is a misspelling of "Euclidean"
mllib/src/test/scala/org/apache/spark/ml/clustering/KMeansSuite.scala:237:26: "descripiton" is a misspelling of "descriptions"
python/pyspark/find_spark_home.py:30:13: "enviroment" is a misspelling of "environment"
python/pyspark/context.py:937:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:938:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:939:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:940:12: "supress" is a misspelling of "suppress"
python/pyspark/heapq3.py:6:63: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:7:2: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:263:29: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:263:39: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:270:49: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:270:59: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:275:2: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:275:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:277:29: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:277:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:713:8: "probabilty" is a misspelling of "probability"
python/pyspark/ml/clustering.py:1038:8: "Currenlty" is a misspelling of "Currently"
python/pyspark/ml/stat.py:339:23: "Euclidian" is a misspelling of "Euclidean"
python/pyspark/ml/regression.py:1378:20: "paramter" is a misspelling of "parameter"
python/pyspark/mllib/stat/_statistics.py:262:8: "probabilty" is a misspelling of "probability"
python/pyspark/rdd.py:1363:32: "paramter" is a misspelling of "parameter"
python/pyspark/streaming/tests.py:825:42: "retuns" is a misspelling of "returns"
python/pyspark/sql/tests.py:768:29: "initalization" is a misspelling of "initialization"
python/pyspark/sql/tests.py:3616:31: "initalize" is a misspelling of "initialize"
resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosSchedulerBackendUtil.scala:120:39: "arbitary" is a misspelling of "arbitrary"
resource-managers/mesos/src/test/scala/org/apache/spark/deploy/mesos/MesosClusterDispatcherArgumentsSuite.scala:26:45: "sucessfully" is a misspelling of "successfully"
resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosSchedulerUtils.scala:358:27: "constaints" is a misspelling of "constraints"
resource-managers/yarn/src/test/scala/org/apache/spark/deploy/yarn/YarnClusterSuite.scala:111:24: "senstive" is a misspelling of "sensitive"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala:1063:5: "overwirte" is a misspelling of "overwrite"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala:1348:17: "compatability" is a misspelling of "compatibility"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala:77:36: "paramter" is a misspelling of "parameter"
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:1374:22: "precendence" is a misspelling of "precedence"
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/analysis/AnalysisSuite.scala:238:27: "unnecassary" is a misspelling of "unnecessary"
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/ConditionalExpressionSuite.scala:212:17: "whn" is a misspelling of "when"
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamingSymmetricHashJoinHelper.scala:147:60: "timestmap" is a misspelling of "timestamp"
sql/core/src/test/scala/org/apache/spark/sql/TPCDSQuerySuite.scala:150:45: "precentage" is a misspelling of "percentage"
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVInferSchemaSuite.scala:135:29: "infered" is a misspelling of "inferred"
sql/hive/src/test/resources/golden/udf_instr-1-2e76f819563dbaba4beb51e3a130b922:1:52: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_instr-2-32da357fc754badd6e3898dcc8989182:1:52: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_locate-1-6e41693c9c6dceea4d7fab4c02884e4e:1:63: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_locate-2-d9b5934457931447874d6bb7c13de478:1:63: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_translate-2-f7aa38a33ca0df73b7a1e6b6da4b7fe8:9:79: "occurence" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_translate-2-f7aa38a33ca0df73b7a1e6b6da4b7fe8:13:110: "occurence" is a misspelling of "occurrence"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/annotate_stats_join.q:46:105: "distint" is a misspelling of "distinct"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/auto_sortmerge_join_11.q:29:3: "Currenly" is a misspelling of "Currently"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/avro_partitioned.q:72:15: "existant" is a misspelling of "existent"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/decimal_udf.q:25:3: "substraction" is a misspelling of "subtraction"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/groupby2_map_multi_distinct.q:16:51: "funtion" is a misspelling of "function"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/groupby_sort_8.q:15:30: "issueing" is a misspelling of "issuing"
sql/hive/src/test/scala/org/apache/spark/sql/sources/HadoopFsRelationTest.scala:669:52: "wiht" is a misspelling of "with"
sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java:474:9: "Refering" is a misspelling of "Referring"
```
### after
```
$ misspell . | grep -v '.js'
common/network-common/src/main/java/org/apache/spark/network/util/AbstractFileRegion.java:27:20: "transfered" is a misspelling of "transferred"
core/src/main/scala/org/apache/spark/status/storeTypes.scala:113:29: "ect" is a misspelling of "etc"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:1922:49: "agriculteur" is a misspelling of "agriculture"
data/streaming/AFINN-111.txt:1219:0: "humerous" is a misspelling of "humorous"
licenses/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/hungarian.txt:170:0: "teh" is a misspelling of "the"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/portuguese.txt:53:0: "eles" is a misspelling of "eels"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:99:20: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:539:11: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/mllib/clustering/LDAOptimizer.scala:77:36: "Teh" is a misspelling of "The"
mllib/src/main/scala/org/apache/spark/mllib/stat/MultivariateOnlineSummarizer.scala:276:9: "Euclidian" is a misspelling of "Euclidean"
python/pyspark/heapq3.py:6:63: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:7:2: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:263:29: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:263:39: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:270:49: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:270:59: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:275:2: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:275:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:277:29: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:277:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/ml/stat.py:339:23: "Euclidian" is a misspelling of "Euclidean"
```
Closes#22070 from seratch/fix-typo.
Authored-by: Kazuhiro Sera <seratch@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
## What changes were proposed in this pull request?
Updated URL/href links to include a '/' before '?id' to make links consistent and avoid http 302 redirect errors within UI port 4040 tabs.
## How was this patch tested?
Built a runnable distribution and executed jobs. Validated that http 302 redirects are no longer encountered when clicking on links within UI port 4040 tabs.
Author: Steven Kallman <SJKallmangmail.com>
Author: Kallman, Steven <Steven.Kallman@CapitalOne.com>
Closes#21600 from SJKallman/{Spark-24553}{WEB-UI}-redirect-href-fixes.
## What changes were proposed in this pull request?
`spark-sql` silent mode will broken if`SPARK_HOME/jars` missing `kubernetes-model-2.0.0.jar`.
This pr use `sc.setLogLevel (<logLevel>)` to implement silent mode.
## How was this patch tested?
manual tests
```
build/sbt -Phive -Phive-thriftserver package
export SPARK_PREPEND_CLASSES=true
./bin/spark-sql -S
```
Author: Yuming Wang <yumwang@ebay.com>
Closes#20274 from wangyum/SPARK-20120-FOLLOW-UP.
## What changes were proposed in this pull request?
The PR retrieves the proxyBase automatically from the header `X-Forwarded-Context` (if available). This is the header used by Knox to inform the proxied service about the base path.
This provides 0-configuration support for Knox gateway (instead of having to properly set `spark.ui.proxyBase`) and it allows to access directly SHS when it is proxied by Knox. In the previous scenario, indeed, after setting `spark.ui.proxyBase`, direct access to SHS was not working fine (due to bad link generated).
## How was this patch tested?
added UT + manual tests
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#21268 from mgaido91/SPARK-24209.
## What changes were proposed in this pull request?
This refactors the external catalog to be an interface. It can be easier for the future work in the catalog federation. After the refactoring, `ExternalCatalog` is much cleaner without mixing the listener event generation logic.
## How was this patch tested?
The existing tests
Author: gatorsmile <gatorsmile@gmail.com>
Closes#21122 from gatorsmile/refactorExternalCatalog.
## What changes were proposed in this pull request?
Spark ThriftServer will call UGI.loginUserFromKeytab twice in initialization. This is unnecessary and will cause various potential problems, like Hadoop IPC failure after 7 days, or RM failover issue and so on.
So here we need to remove all the unnecessary login logics and make sure UGI in the context never be created again.
Note this is actually a HS2 issue, If later on we upgrade supported Hive version, the issue may already be fixed in Hive side.
## How was this patch tested?
Local verification in secure cluster.
Author: jerryshao <sshao@hortonworks.com>
Closes#21178 from jerryshao/SPARK-24110.
## What changes were proposed in this pull request?
In SparkSQLCLI, SessionState generates before SparkContext instantiating. When we use --proxy-user to impersonate, it's unable to initializing a metastore client to talk to the secured metastore for no kerberos ticket.
This PR use real user ugi to obtain token for owner before talking to kerberized metastore.
## How was this patch tested?
Manually verified with kerberized hive metasotre / hdfs.
Author: Kent Yao <yaooqinn@hotmail.com>
Closes#20784 from yaooqinn/SPARK-23639.
A few different things going on:
- Remove unused methods.
- Move JSON methods to the only class that uses them.
- Move test-only methods to TestUtils.
- Make getMaxResultSize() a config constant.
- Reuse functionality from existing libraries (JRE or JavaUtils) where possible.
The change also includes changes to a few tests to call `Utils.createTempFile` correctly,
so that temp dirs are created under the designated top-level temp dir instead of
potentially polluting git index.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20706 from vanzin/SPARK-23550.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/18944 added one patch, which allowed a spark session to be created when the hive metastore server is down. However, it did not allow running any commands with the spark session. This brings troubles to the user who only wants to read / write data frames without metastore setup.
## How was this patch tested?
Added some unit tests to read and write data frames based on the original HiveMetastoreLazyInitializationSuite.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Feng Liu <fengliu@databricks.com>
Closes#20681 from liufengdb/completely-lazy.
## What changes were proposed in this pull request?
`--hiveconf` and `--hivevar` variables no longer work since Spark 2.0. The `spark-sql` client has fixed by [SPARK-15730](https://issues.apache.org/jira/browse/SPARK-15730) and [SPARK-18086](https://issues.apache.org/jira/browse/SPARK-18086). but `beeline`/[`Spark SQL HiveThriftServer2`](https://github.com/apache/spark/blob/v2.1.1/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/HiveThriftServer2.scala) is still broken. This pull request fix it.
This pull request works for both `JDBC client` and `beeline`.
## How was this patch tested?
unit tests for `JDBC client`
manual tests for `beeline`:
```
git checkout origin/pr/17886
dev/make-distribution.sh --mvn mvn --tgz -Phive -Phive-thriftserver -Phadoop-2.6 -DskipTests
tar -zxf spark-2.3.0-SNAPSHOT-bin-2.6.5.tgz && cd spark-2.3.0-SNAPSHOT-bin-2.6.5
sbin/start-thriftserver.sh
```
```
cat <<EOF > test.sql
select '\${a}', '\${b}';
EOF
beeline -u jdbc:hive2://localhost:10000 --hiveconf a=avalue --hivevar b=bvalue -f test.sql
```
Author: Yuming Wang <wgyumg@gmail.com>
Closes#17886 from wangyum/SPARK-13983-dev.
Signed-off-by: Atallah Hezbor <atallahhezborgmail.com>
## What changes were proposed in this pull request?
This PR proposes modifying the match statement that gets the columns of a row in HiveThriftServer. There was previously no case for `UserDefinedType`, so querying a table that contained them would throw a match error. The changes catch that case and return the string representation.
## How was this patch tested?
While I would have liked to add a unit test, I couldn't easily incorporate UDTs into the ``HiveThriftServer2Suites`` pipeline. With some guidance I would be happy to push a commit with tests.
Instead I did a manual test by loading a `DataFrame` with Point UDT in a spark shell with a HiveThriftServer. Then in beeline, connecting to the server and querying that table.
Here is the result before the change
```
0: jdbc:hive2://localhost:10000> select * from chicago;
Error: scala.MatchError: org.apache.spark.sql.PointUDT2d980dc3 (of class org.apache.spark.sql.PointUDT) (state=,code=0)
```
And after the change:
```
0: jdbc:hive2://localhost:10000> select * from chicago;
+---------------------------------------+--------------+------------------------+---------------------+--+
| __fid__ | case_number | dtg | geom |
+---------------------------------------+--------------+------------------------+---------------------+--+
| 109602f9-54f8-414b-8c6f-42b1a337643e | 2 | 2016-01-01 19:00:00.0 | POINT (-77 38) |
| 709602f9-fcff-4429-8027-55649b6fd7ed | 1 | 2015-12-31 19:00:00.0 | POINT (-76.5 38.5) |
| 009602f9-fcb5-45b1-a867-eb8ba10cab40 | 3 | 2016-01-02 19:00:00.0 | POINT (-78 39) |
+---------------------------------------+--------------+------------------------+---------------------+--+
```
Author: Atallah Hezbor <atallahhezbor@gmail.com>
Closes#20385 from atallahhezbor/udts_over_hive.
## What changes were proposed in this pull request?
Currently we do not call the `super.init(hiveConf)` in `SparkSQLSessionManager.init`. So we do not load the config `HIVE_SERVER2_SESSION_CHECK_INTERVAL HIVE_SERVER2_IDLE_SESSION_TIMEOUT HIVE_SERVER2_IDLE_SESSION_CHECK_OPERATION` , which cause the session timeout checker does not work.
## How was this patch tested?
manual tests
Author: zuotingbing <zuo.tingbing9@zte.com.cn>
Closes#20025 from zuotingbing/SPARK-22837.
## What changes were proposed in this pull request?
Once a meta hive client is created, it generates its SessionState which creates a lot of session related directories, some deleteOnExit, some does not. if a hive client is useless we may not create it at the very start.
## How was this patch tested?
N/A
cc hvanhovell cloud-fan
Author: Kent Yao <11215016@zju.edu.cn>
Closes#18983 from yaooqinn/patch-1.
## What changes were proposed in this pull request?
When creating a session directory, Thrift should create the parent directory (i.e. /tmp/base_session_log_dir) if it is not present. It is common that many tools delete empty directories, so the directory may be deleted. This can cause the session log to be disabled.
This was fixed in HIVE-12262: this PR brings it in Spark too.
## How was this patch tested?
manual tests
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20281 from mgaido91/SPARK-23089.
## What changes were proposed in this pull request?
This patch bumps the master branch version to `2.4.0-SNAPSHOT`.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20222 from gatorsmile/bump24.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}