### What changes were proposed in this pull request?
`OptimizeSkewedJoin `rule change the `outputPartitioning `after inserting `PartialShuffleReaderExec `or `SkewedPartitionReaderExec`. So it may need to introduce additional to ensure the right result. This PR disable `OptimizeSkewedJoin ` rule when introducing additional shuffle.
### Why are the changes needed?
bug fix
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Add new ut
Closes#27226 from JkSelf/followup-skewedoptimization.
Authored-by: jiake <ke.a.jia@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
TableCatalog reserves some properties, e,g `provider`, `location` for internal usage. Some of them are static once create, some of them need specific syntax to modify. Instead of using `OPTIONS (k='v')` or TBLPROPERTIES (k='v'), if k is a reserved TableCatalog property, we should use its specific syntax to add/modify/delete it. e.g. `provider` is a reserved property, we should use the `USING` clause to specify it, and should not allow `ALTER TABLE ... UNSET TBLPROPERTIES('provider')` to delete it. Also, there are two paths for v1/v2 catalog tables to resolve these properties, e.g. the v1 session catalog tables will only use the `USING` clause to decide `provider` but v2 tables will also lookup OPTION/TBLPROPERTIES(although there is a bug prohibit it).
Additionally, 'path' is not reserved but holds special meaning for `LOCATION` and it is used in `CREATE/REPLACE TABLE`'s `OPTIONS` sub-clause. Now for the session catalog tables, the `path` is case-insensitive, but for the non-session catalog tables, it is case-sensitive, we should make it both case insensitive for disambiguation.
### Why are the changes needed?
prevent reserved properties from being modified unexpectedly
unify the property resolution for v1/v2.
fix some bugs.
### Does this PR introduce any user-facing change?
yes
1 . `location` and `provider` (case sensitive) cannot be used in `CREATE/REPLACE TABLE ... OPTIONS/TBLPROPETIES` and `ALTER TABLE ... SET TBLPROPERTIES (...)`, if legacy on, they will be ignored to let the command success without having side effects
3. Once `path` in `CREATE/REPLACE TABLE ... OPTIONS` is case insensitive for v1 but sensitive for v2, but now we change it case insensitive for both kinds of tables, then v2 tables will also fail if `LOCATION` and `OPTIONS('PaTh' ='abc')` are both specified or will pick `PaTh`'s value as table location if `LOCATION` is missing.
4. Now we will detect if there are two different case `path` keys or more in `CREATE/REPLACE TABLE ... OPTIONS`, once it is a kind of unexpected last-win policy for v1, and v2 is case sensitive.
### How was this patch tested?
add ut
Closes#27197 from yaooqinn/SPARK-30507.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to use non-deprecated constructor of `ExpressionInfo` in `SparkSessionExtensionSuite`, and pass valid strings as `examples`, `note`, `since` and `deprecated` parameters.
### Why are the changes needed?
Using another constructor allows to eliminate the following deprecation warnings while compiling Spark:
```
Warning:(335, 5) constructor ExpressionInfo in class ExpressionInfo is deprecated: see corresponding Javadoc for more information.
new ExpressionInfo("noClass", "myDb", "myFunction", "usage", "extended usage"),
Warning:(732, 5) constructor ExpressionInfo in class ExpressionInfo is deprecated: see corresponding Javadoc for more information.
new ExpressionInfo("noClass", "myDb", "myFunction2", "usage", "extended usage"),
Warning:(751, 5) constructor ExpressionInfo in class ExpressionInfo is deprecated: see corresponding Javadoc for more information.
new ExpressionInfo("noClass", "myDb", "myFunction2", "usage", "extended usage"),
```
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By compiling and running `SparkSessionExtensionSuite`.
Closes#27221 from MaxGekk/eliminate-expr-info-warnings.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to support pushed down filters in CSV datasource. The reason of pushing a filter up to `UnivocityParser` is to apply the filter as soon as all its attributes become available i.e. converted from CSV fields to desired values according to the schema. This allows to skip conversions of other values if the filter returns `false`. This can improve performance when pushed filters are highly selective and conversion of CSV string fields to desired values are comparably expensive ( for example, conversion to `TIMESTAMP` values).
Here are details of the implementation:
- `UnivocityParser.convert()` converts parsed CSV tokens one-by-one sequentially starting from index 0 up to `parsedSchema.length - 1`. At current index `i`, it applies filters that refer to attributes at row fields indexes `0..i`. If any filter returns `false`, it skips conversions of other input tokens.
- Pushed filters are converted to expressions. The expressions are bound to row positions according to `requiredSchema`. The expressions are compiled to predicates via generating Java code.
- To be able to apply predicates to partially initialized rows, the predicates are grouped, and combined via the `And` expression. Final predicate at index `N` can refer to row fields at the positions `0..N`, and can be applied to a row even if other fields at the positions `N+1..requiredSchema.lenght-1` are not set.
### Why are the changes needed?
The changes improve performance on synthetic benchmarks more **than 9 times** (on JDK 8 & 11):
```
OpenJDK 64-Bit Server VM 11.0.5+10 on Mac OS X 10.15.2
Intel(R) Core(TM) i7-4850HQ CPU 2.30GHz
Filters pushdown: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
w/o filters 11889 11945 52 0.0 118893.1 1.0X
pushdown disabled 11790 11860 115 0.0 117902.3 1.0X
w/ filters 1240 1278 33 0.1 12400.8 9.6X
```
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
- Added new test suite `CSVFiltersSuite`
- Added tests to `CSVSuite` and `UnivocityParserSuite`
Closes#26973 from MaxGekk/csv-filters-pushdown.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Based on the [comment](https://github.com/apache/spark/pull/26956#discussion_r366680558), this patch changes the SQL config name from `spark.sql.truncateTable.ignorePermissionAcl` to `spark.sql.truncateTable.ignorePermissionAcl.enabled`.
### Why are the changes needed?
Make this config consistent other SQL configs.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#27210 from viirya/truncate-table-permission-followup.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
For decimal values between -1.0 and 1.0, it should has same precision and scale in `Decimal`, in order to make it be consistent with `DecimalType`.
### Why are the changes needed?
Currently, for values between -1.0 and 1.0, precision and scale is inconsistent between `Decimal` and `DecimalType`. For example, for numbers like 0.3, it will have (precision, scale) as (2, 1) in `Decimal`, but (1, 1) in `DecimalType`:
```
scala> Literal(new BigDecimal("0.3")).dataType.asInstanceOf[DecimalType].precision
res3: Int = 1
scala> Literal(new BigDecimal("0.3")).value.asInstanceOf[Decimal].precision
res4: Int = 2
```
We should make `Decimal` be consistent with `DecimalType`. And, here, we change it to only count precision digits after dot for values between -1.0 and 1.0 as other DBMS does, like hive:
```
hive> create table testrel as select 0.3;
hive> describe testrel;
OK
_c0 decimal(1,1)
```
This could bring larger scale for values between -1.0 and 1.0.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Updated existed tests.
Closes#27217 from Ngone51/set-decimal-from-javadecimal.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Use the new framework to resolve the DESCRIBE TABLE command.
The v1 DESCRIBE TABLE command supports both table and view. Checked with Hive and Presto, they don't have DESCRIBE TABLE syntax but only DESCRIBE, which supports both table and view:
1. https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-DescribeTable/View/MaterializedView/Column
2. https://prestodb.io/docs/current/sql/describe.html
We should make it clear that DESCRIBE support both table and view, by renaming the command to `DescribeRelation`.
This PR also tunes the framework a little bit to support the case that a command accepts both table and view.
### Why are the changes needed?
This is a part of effort to make the relation lookup behavior consistent: SPARK-29900.
Note that I make a separate PR here instead of #26921, as I need to update the framework to support a new use case: accept both table and view.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
existing tests
Closes#27187 from cloud-fan/describe.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
This PR intends to improve partition pruning for nondeterministic expressions in Hive tables:
Before this PR:
```
scala> sql("""create table test(id int) partitioned by (dt string)""")
scala> sql("""select * from test where dt='20190101' and rand() < 0.5""").explain()
== Physical Plan ==
*(1) Filter ((isnotnull(dt#19) AND (dt#19 = 20190101)) AND (rand(6515336563966543616) < 0.5))
+- Scan hive default.test [id#18, dt#19], HiveTableRelation `default`.`test`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#18], [dt#19], Statistics(sizeInBytes=8.0 EiB)
```
After this PR:
```
== Physical Plan ==
*(1) Filter (rand(-9163956883277176328) < 0.5)
+- Scan hive default.test [id#0, dt#1], HiveTableRelation `default`.`test`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#0], [dt#1], Statistics(sizeInBytes=8.0 EiB), [isnotnull(dt#1), (dt#1 = 20190101)]
```
This PR is the rework of #24118.
### Why are the changes needed?
For better performance.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Unit tests added.
Closes#27219 from maropu/SPARK-26736.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This patch addresses adding event filter to handle SQL related events. This patch is next task of SPARK-29779 (#27085), please refer the description of PR #27085 to see overall rationalization of this patch.
Below functionalities will be addressed in later parts:
* integrate compaction into FsHistoryProvider
* documentation about new configuration
### Why are the changes needed?
One of major goal of SPARK-28594 is to prevent the event logs to become too huge, and SPARK-29779 achieves the goal. We've got another approach in prior, but the old approach required models in both KVStore and live entities to guarantee compatibility, while they're not designed to do so.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Added UTs.
Closes#27164 from HeartSaVioR/SPARK-30479.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
This pr intends to fix wrong aggregated values in `GROUPING SETS` when there are duplicated grouping sets in a query (e.g., `GROUPING SETS ((k1),(k1))`).
For example;
```
scala> spark.table("t").show()
+---+---+---+
| k1| k2| v|
+---+---+---+
| 0| 0| 3|
+---+---+---+
scala> sql("""select grouping_id(), k1, k2, sum(v) from t group by grouping sets ((k1),(k1,k2),(k2,k1),(k1,k2))""").show()
+-------------+---+----+------+
|grouping_id()| k1| k2|sum(v)|
+-------------+---+----+------+
| 0| 0| 0| 9| <---- wrong aggregate value and the correct answer is `3`
| 1| 0|null| 3|
+-------------+---+----+------+
// PostgreSQL case
postgres=# select k1, k2, sum(v) from t group by grouping sets ((k1),(k1,k2),(k2,k1),(k1,k2));
k1 | k2 | sum
----+------+-----
0 | 0 | 3
0 | 0 | 3
0 | 0 | 3
0 | NULL | 3
(4 rows)
// Hive case
hive> select GROUPING__ID, k1, k2, sum(v) from t group by k1, k2 grouping sets ((k1),(k1,k2),(k2,k1),(k1,k2));
1 0 NULL 3
0 0 0 3
```
[MS SQL Server has the same behaviour with PostgreSQL](https://github.com/apache/spark/pull/26961#issuecomment-573638442). This pr follows the behaviour of PostgreSQL/SQL server; it adds one more virtual attribute in `Expand` for avoiding wrongly grouping rows with the same grouping ID.
### Why are the changes needed?
To fix bugs.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
The existing tests.
Closes#26961 from maropu/SPARK-29708.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
The changes in the rule `SimplifyBinaryComparison` from https://github.com/apache/spark/pull/27008 could bring performance regression in the optimizer when there are a large set of filter conditions.
We need to improve the implementation and reduce the time complexity.
### Why are the changes needed?
Need to fix the potential performance regression in the optimizer.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing unit tests.
Also run a micor benchmark in `BinaryComparisonSimplificationSuite`
```
object Optimize extends RuleExecutor[LogicalPlan] {
val batches =
Batch("Constant Folding", FixedPoint(50),
SimplifyBinaryComparison) :: Nil
}
test("benchmark") {
val a = Symbol("a")
val condition = (1 to 500).map(i => EqualTo(a, a)).reduceLeft(And)
val finalCondition = And(condition, IsNotNull(a))
val plan = nullableRelation.where(finalCondition).analyze
val start = System.nanoTime()
Optimize.execute(plan)
println((System.nanoTime() - start) /1000000)
}
```
Before the changes: 2507ms
After the changes: 3ms
Closes#27212 from gengliangwang/SimplifyBinaryComparison.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Currently for Monitoring Spark application SQL information is not available from REST but only via UI. REST provides only applications,jobs,stages,environment. This Jira is targeted to provide a REST API so that SQL level information can be found
A single SQL query can result into multiple jobs. So for end user who is using STS or spark-sql, the intended highest level of probe is the SQL which he has executed. This information can be seen from SQL tab. Attaching a sample.

But same information he cannot access using the REST API exposed by spark and he always have to rely on jobs API which may be difficult. So i intend to expose the information seen in SQL tab in UI via REST API
Mainly:
Id : Long - execution id of the sql
status : String - possible values COMPLETED/RUNNING/FAILED
description : String - executed SQL string
planDescription : String - Plan representation
metrics : Seq[Metrics] - `Metrics` contain `metricName: String, metricValue: String`
submissionTime : String - formatted `Date` time of SQL submission
duration : Long - total run time in milliseconds
runningJobIds : Seq[Int] - sequence of running job ids
failedJobIds : Seq[Int] - sequence of failed job ids
successJobIds : Seq[Int] - sequence of success job ids
* To fetch sql executions: /sql?details=boolean&offset=integer&length=integer
* To fetch single execution: /sql/{executionID}?details=boolean
| parameter | type | remarks |
| ------------- |:-------------:| -----|
| details | boolean | Optional. Set true to get plan description and metrics information, defaults to false |
| offset | integer | Optional. offset to fetch the executions, defaults to 0 |
| length | integer | Optional. total number of executions to be fetched, defaults to 20 |
### Why are the changes needed?
To support users query SQL information via REST API
### Does this PR introduce any user-facing change?
Yes. It provides a new monitoring URL for SQL
### How was this patch tested?
Tested manually


Closes#24076 from ajithme/restapi.
Lead-authored-by: Ajith <ajith2489@gmail.com>
Co-authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
* Annotate UserDefinedAggregateFunction as deprecated by SPARK-27296
* Update user doc examples to reflect new ability to register typed Aggregator[IN, BUF, OUT] as an untyped aggregating UDF
### Why are the changes needed?
UserDefinedAggregateFunction is being deprecated
### Does this PR introduce any user-facing change?
Changes are to user documentation, and deprecation annotations.
### How was this patch tested?
Testing was via package build to verify doc generation, deprecation warnings, and successful example compilation.
Closes#27193 from erikerlandson/spark-30423.
Authored-by: Erik Erlandson <eerlands@redhat.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Skew Join is common and can severely downgrade performance of queries, especially those with joins. This PR aim to optimization the skew join based on the runtime Map output statistics by adding "OptimizeSkewedPartitions" rule. And The details design doc is [here](https://docs.google.com/document/d/1NkXN-ck8jUOS0COz3f8LUW5xzF8j9HFjoZXWGGX2HAg/edit). Currently we can support "Inner, Cross, LeftSemi, LeftAnti, LeftOuter, RightOuter" join type.
### Why are the changes needed?
To optimize the skewed partition in runtime based on AQE
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
UT
Closes#26434 from JkSelf/skewedPartitionBasedSize.
Lead-authored-by: jiake <ke.a.jia@intel.com>
Co-authored-by: Wenchen Fan <wenchen@databricks.com>
Co-authored-by: JiaKe <ke.a.jia@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
If spark.sql.ansi.enabled is set,
throw exception when cast to any numeric type do not follow the ANSI SQL standards.
### Why are the changes needed?
ANSI SQL standards do not allow invalid strings to get casted into numeric types and throw exception for that. Currently spark sql gives NULL in such cases.
Before:
`select cast('str' as decimal) => NULL`
After :
`select cast('str' as decimal) => invalid input syntax for type numeric: str`
These results are after setting `spark.sql.ansi.enabled=true`
### Does this PR introduce any user-facing change?
Yes. Now when ansi mode is on users will get arithmetic exception for invalid strings.
### How was this patch tested?
Unit Tests Added.
Closes#26933 from iRakson/castDecimalANSI.
Lead-authored-by: root1 <raksonrakesh@gmail.com>
Co-authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to define a sub-class of `AppenderSkeleton` in `SparkFunSuite` and reuse it from other tests. The class stores incoming `LoggingEvent` in an array which is available to tests for future analysis of logged events.
### Why are the changes needed?
This eliminates code duplication in tests.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By existing test suites - `CSVSuite`, `OptimizerLoggingSuite`, `JoinHintSuite`, `CodeGenerationSuite` and `SQLConfSuite`.
Closes#27166 from MaxGekk/dedup-appender-skeleton.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to remove already deprecated SQL configs:
- `spark.sql.variable.substitute.depth` deprecated in Spark 2.1
- `spark.sql.parquet.int64AsTimestampMillis` deprecated in Spark 2.3
Also I moved `removedSQLConfigs` closer to `deprecatedSQLConfigs`. This will allow to have references to other config entries.
### Why are the changes needed?
To improve code maintainability.
### Does this PR introduce any user-facing change?
Yes.
### How was this patch tested?
By existing test suites `ParquetQuerySuite` and `SQLConfSuite`.
Closes#27169 from MaxGekk/remove-deprecated-conf-2.4.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Fix all the failed tests when enable AQE.
### Why are the changes needed?
Run more tests with AQE to catch bugs, and make it easier to enable AQE by default in the future.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing unit tests
Closes#26813 from JkSelf/enableAQEDefault.
Authored-by: jiake <ke.a.jia@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a follow-up for https://github.com/apache/spark/pull/25248 .
### Why are the changes needed?
The new behavior cannot access the existing table which is created by old behavior.
This PR provides a way to avoid new behavior for the existing users.
### Does this PR introduce any user-facing change?
Yes. This will fix the broken behavior on the existing tables.
### How was this patch tested?
Pass the Jenkins and manually run JDBC integration test.
```
build/mvn install -DskipTests
build/mvn -Pdocker-integration-tests -pl :spark-docker-integration-tests_2.12 test
```
Closes#27184 from dongjoon-hyun/SPARK-28152-CONF.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add cache for Like and RLike when pattern is not static
### Why are the changes needed?
When pattern is not static, we should avoid compile pattern every time if some pattern is same.
Here is perf numbers, include 3 test groups and use `range` to make it easy.
```
// ---------------------
// 10,000 rows and 10 partitions
val df1 = spark.range(0, 10000, 1, 10).withColumnRenamed("id", "id1")
val df2 = spark.range(0, 10000, 1, 10).withColumnRenamed("id", "id2")
val start = System.currentTimeMillis
df1.join(df2).where("id2 like id1").count()
// before 16939
// after 6352
println(System.currentTimeMillis - start)
// ---------------------
// 10,000 rows and 100 partitions
val df1 = spark.range(0, 10000, 1, 100).withColumnRenamed("id", "id1")
val df2 = spark.range(0, 10000, 1, 100).withColumnRenamed("id", "id2")
val start = System.currentTimeMillis
df1.join(df2).where("id2 like id1").count()
// before 11070
// after 4680
println(System.currentTimeMillis - start)
// ---------------------
// 20,000 rows and 10 partitions
val df1 = spark.range(0, 20000, 1, 10).withColumnRenamed("id", "id1")
val df2 = spark.range(0, 20000, 1, 10).withColumnRenamed("id", "id2")
val start = System.currentTimeMillis
df1.join(df2).where("id2 like id1").count()
// before 66962
// after 29934
println(System.currentTimeMillis - start)
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Closes#26875 from ulysses-you/SPARK-30245.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR removes a dangling test result, `JSONBenchmark-jdk11-results.txt`.
This causes a case-sensitive issue on Mac.
```
$ git clone https://gitbox.apache.org/repos/asf/spark.git spark-gitbox
Cloning into 'spark-gitbox'...
remote: Counting objects: 671717, done.
remote: Compressing objects: 100% (258021/258021), done.
remote: Total 671717 (delta 329181), reused 560390 (delta 228097)
Receiving objects: 100% (671717/671717), 149.69 MiB | 950.00 KiB/s, done.
Resolving deltas: 100% (329181/329181), done.
Updating files: 100% (16090/16090), done.
warning: the following paths have collided (e.g. case-sensitive paths
on a case-insensitive filesystem) and only one from the same
colliding group is in the working tree:
'sql/core/benchmarks/JSONBenchmark-jdk11-results.txt'
'sql/core/benchmarks/JsonBenchmark-jdk11-results.txt'
```
### Why are the changes needed?
Previously, since the file name didn't match with `object JSONBenchmark`, it made a confusion when we ran the benchmark. So, 4e0e4e51c4 renamed `JSONBenchmark` to `JsonBenchmark`. However, at the same time frame, https://github.com/apache/spark/pull/26003 regenerated this file.
Recently, https://github.com/apache/spark/pull/27078 regenerates the results with the correct file name, `JsonBenchmark-jdk11-results.txt`. So, we can remove the old one.
### Does this PR introduce any user-facing change?
No. This is a test result.
### How was this patch tested?
Manually check the following correctly generated files in the master. And, check this PR removes the dangling one.
- https://github.com/apache/spark/blob/master/sql/core/benchmarks/JsonBenchmark-results.txt
- https://github.com/apache/spark/blob/master/sql/core/benchmarks/JsonBenchmark-jdk11-results.txtCloses#27180 from dongjoon-hyun/SPARK-REMOVE.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose to replace `.collect()`, `.count()` and `.foreach(_ => ())` in SQL benchmarks and use the `NoOp` datasource. I added an implicit class to `SqlBasedBenchmark` with the `.noop()` method. It can be used in benchmark like: `ds.noop()`. The last one is unfolded to `ds.write.format("noop").mode(Overwrite).save()`.
### Why are the changes needed?
To avoid additional overhead that `collect()` (and other actions) has. For example, `.collect()` has to convert values according to external types and pull data to the driver. This can hide actual performance regressions or improvements of benchmarked operations.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Re-run all modified benchmarks using Amazon EC2.
| Item | Description |
| ---- | ----|
| Region | us-west-2 (Oregon) |
| Instance | r3.xlarge (spot instance) |
| AMI | ami-06f2f779464715dc5 (ubuntu/images/hvm-ssd/ubuntu-bionic-18.04-amd64-server-20190722.1) |
| Java | OpenJDK8/10 |
- Run `TPCDSQueryBenchmark` using instructions from the PR #26049
```
# `spark-tpcds-datagen` needs this. (JDK8)
$ git clone https://github.com/apache/spark.git -b branch-2.4 --depth 1 spark-2.4
$ export SPARK_HOME=$PWD
$ ./build/mvn clean package -DskipTests
# Generate data. (JDK8)
$ git clone gitgithub.com:maropu/spark-tpcds-datagen.git
$ cd spark-tpcds-datagen/
$ build/mvn clean package
$ mkdir -p /data/tpcds
$ ./bin/dsdgen --output-location /data/tpcds/s1 // This need `Spark 2.4`
```
- Other benchmarks ran by the script:
```
#!/usr/bin/env python3
import os
from sparktestsupport.shellutils import run_cmd
benchmarks = [
['sql/test', 'org.apache.spark.sql.execution.benchmark.AggregateBenchmark'],
['avro/test', 'org.apache.spark.sql.execution.benchmark.AvroReadBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.BloomFilterBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.DataSourceReadBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.DateTimeBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.ExtractBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.FilterPushdownBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.InExpressionBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.IntervalBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.JoinBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.MakeDateTimeBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.MiscBenchmark'],
['hive/test', 'org.apache.spark.sql.execution.benchmark.ObjectHashAggregateExecBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.OrcNestedSchemaPruningBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.OrcV2NestedSchemaPruningBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.ParquetNestedSchemaPruningBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.RangeBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.UDFBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.WideSchemaBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.WideTableBenchmark'],
['hive/test', 'org.apache.spark.sql.hive.orc.OrcReadBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.datasources.csv.CSVBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.datasources.json.JsonBenchmark']
]
print('Set SPARK_GENERATE_BENCHMARK_FILES=1')
os.environ['SPARK_GENERATE_BENCHMARK_FILES'] = '1'
for b in benchmarks:
print("Run benchmark: %s" % b[1])
run_cmd(['build/sbt', '%s:runMain %s' % (b[0], b[1])])
```
Closes#27078 from MaxGekk/noop-in-benchmarks.
Lead-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Defines a new subclass of UDF: `UserDefinedAggregator`. Also allows `Aggregator` to be registered as a udf. Under the hood, the implementation is based on the internal `TypedImperativeAggregate` class that spark's predefined aggregators make use of. The effect is that custom user defined aggregators are now serialized only on partition boundaries instead of being serialized and deserialized at each input row.
The two new modes of using `Aggregator` are as follows:
```scala
val agg: Aggregator[IN, BUF, OUT] = // typed aggregator
val udaf1 = UserDefinedAggregator(agg)
val udaf2 = spark.udf.register("agg", agg)
```
## How was this patch tested?
Unit testing has been added that corresponds to the testing suites for `UserDefinedAggregateFunction`. Additionally, unit tests explicitly count the number of aggregator ser/de cycles to ensure that it is governed only by the number of data partitions.
To evaluate the performance impact, I did two comparisons.
The code and REPL results are recorded on [this gist](https://gist.github.com/erikerlandson/b0e106a4dbaf7f80b4f4f3a21f05f892)
To characterize its behavior I benchmarked both a relatively simple aggregator and then an aggregator with a complex structure (a t-digest).
### performance
The following compares the new `Aggregator` based aggregation against UDAF. In this scenario, the new aggregation is about 100x faster. The difference in performance impact depends on the complexity of the aggregator. For very simple aggregators (e.g. implementing 'sum', etc), the performance impact is more like 25-30%.
```scala
scala> import scala.util.Random._, org.apache.spark.sql.Row, org.apache.spark.tdigest._
import scala.util.Random._
import org.apache.spark.sql.Row
import org.apache.spark.tdigest._
scala> val data = sc.parallelize(Vector.fill(50000){(nextInt(2), nextGaussian, nextGaussian.toFloat)}, 5).toDF("cat", "x1", "x2")
data: org.apache.spark.sql.DataFrame = [cat: int, x1: double ... 1 more field]
scala> val udaf = TDigestUDAF(0.5, 0)
udaf: org.apache.spark.tdigest.TDigestUDAF = TDigestUDAF(0.5,0)
scala> val bs = Benchmark.sample(10) { data.agg(udaf($"x1"), udaf($"x2")).first }
bs: Array[(Double, org.apache.spark.sql.Row)] = Array((16.523,[TDigestSQL(TDigest(0.5,0,130,TDigestMap(-4.9171836327285225 -> (1.0, 1.0), -3.9615949140987685 -> (1.0, 2.0), -3.792874086327091 -> (0.7500781537109753, 2.7500781537109753), -3.720534874164185 -> (1.796754196108008, 4.546832349818983), -3.702105588052377 -> (0.4531676501810167, 5.0), -3.665883591332569 -> (2.3434687534153142, 7.343468753415314), -3.649982231368131 -> (0.6565312465846858, 8.0), -3.5914188829817744 -> (4.0, 12.0), -3.530472305581248 -> (4.0, 16.0), -3.4060489584449467 -> (2.9372251939818383, 18.93722519398184), -3.3000694035428486 -> (8.12412890252889, 27.061354096510726), -3.2250016655261877 -> (8.30564453211017, 35.3669986286209), -3.180537395623448 -> (6.001782561137285, 41.3687811...
scala> bs.map(_._1)
res0: Array[Double] = Array(16.523, 17.138, 17.863, 17.801, 17.769, 17.786, 17.744, 17.8, 17.939, 17.854)
scala> val agg = TDigestAggregator(0.5, 0)
agg: org.apache.spark.tdigest.TDigestAggregator = TDigestAggregator(0.5,0)
scala> val udaa = spark.udf.register("tdigest", agg)
udaa: org.apache.spark.sql.expressions.UserDefinedAggregator[Double,org.apache.spark.tdigest.TDigestSQL,org.apache.spark.tdigest.TDigestSQL] = UserDefinedAggregator(TDigestAggregator(0.5,0),None,true,true)
scala> val bs = Benchmark.sample(10) { data.agg(udaa($"x1"), udaa($"x2")).first }
bs: Array[(Double, org.apache.spark.sql.Row)] = Array((0.313,[TDigestSQL(TDigest(0.5,0,130,TDigestMap(-4.9171836327285225 -> (1.0, 1.0), -3.9615949140987685 -> (1.0, 2.0), -3.792874086327091 -> (0.7500781537109753, 2.7500781537109753), -3.720534874164185 -> (1.796754196108008, 4.546832349818983), -3.702105588052377 -> (0.4531676501810167, 5.0), -3.665883591332569 -> (2.3434687534153142, 7.343468753415314), -3.649982231368131 -> (0.6565312465846858, 8.0), -3.5914188829817744 -> (4.0, 12.0), -3.530472305581248 -> (4.0, 16.0), -3.4060489584449467 -> (2.9372251939818383, 18.93722519398184), -3.3000694035428486 -> (8.12412890252889, 27.061354096510726), -3.2250016655261877 -> (8.30564453211017, 35.3669986286209), -3.180537395623448 -> (6.001782561137285, 41.36878118...
scala> bs.map(_._1)
res1: Array[Double] = Array(0.313, 0.193, 0.175, 0.185, 0.174, 0.176, 0.16, 0.186, 0.171, 0.179)
scala>
```
Closes#25024 from erikerlandson/spark-27296.
Authored-by: Erik Erlandson <eerlands@redhat.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Now Spark can propagate constraint during sql optimization when `spark.sql.constraintPropagation.enabled` is true, then `where c = 1` will convert to `where c = 1 and c is not null`. We also can use constraint in `SimplifyBinaryComparison`.
`SimplifyBinaryComparison` will simplify expression which is not nullable and semanticEquals. And we also can simplify if one expression is infered `IsNotNull`.
### Why are the changes needed?
Simplify SQL.
```
create table test (c1 string);
explain extended select c1 from test where c1 = c1 limit 10;
-- before
GlobalLimit 10
+- LocalLimit 10
+- Filter (isnotnull(c1#20) AND (c1#20 = c1#20))
+- Relation[c1#20]
-- after
GlobalLimit 10
+- LocalLimit 10
+- Filter (isnotnull(c1#20)
+- Relation[c1#20]
explain extended select c1 from test where c1 > c1 limit 10;
-- before
GlobalLimit 10
+- LocalLimit 10
+- Filter (isnotnull(c1#20) && (c1#20 > c1#20))
+- Relation[c1#20]
-- after
LocalRelation <empty>, [c1#20]
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Add UT.
Closes#27008 from ulysses-you/SPARK-30353.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch proposes to preserve existing permission/acls of paths when truncate table/partition.
### Why are the changes needed?
When Spark SQL truncates table, it deletes the paths of table/partitions, then re-create new ones. If permission/acls were set on the paths, the existing permission/acls will be deleted.
We should preserve the permission/acls if possible.
### Does this PR introduce any user-facing change?
Yes. When truncate table/partition, Spark will keep permission/acls of paths.
### How was this patch tested?
Unit test.
Manual test:
1. Create a table.
2. Manually change it permission/acl
3. Truncate table
4. Check permission/acl
```scala
val df = Seq(1, 2, 3).toDF
df.write.mode("overwrite").saveAsTable("test.test_truncate_table")
val testTable = spark.table("test.test_truncate_table")
testTable.show()
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
+-----+
// hdfs dfs -setfacl ...
// hdfs dfs -getfacl ...
sql("truncate table test.test_truncate_table")
// hdfs dfs -getfacl ...
val testTable2 = spark.table("test.test_truncate_table")
testTable2.show()
+-----+
|value|
+-----+
+-----+
```
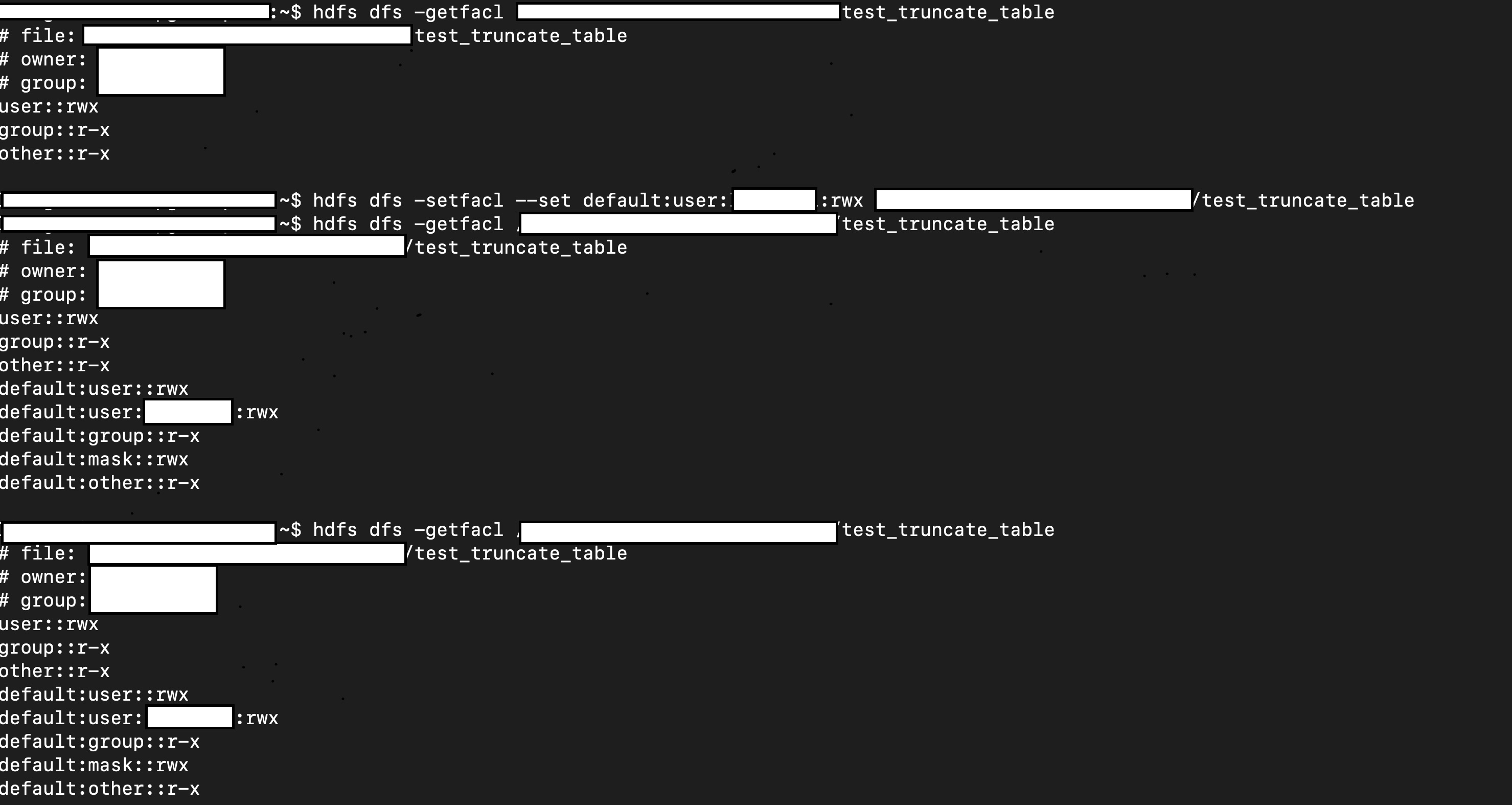
Closes#26956 from viirya/truncate-table-permission.
Lead-authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Co-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Currently data columns are displayed in one line for show create table command, when the table has many columns (to make things even worse, columns may have long names or comments), the displayed result is really hard to read.
To improve readability, we print each column in a separate line. Note that other systems like Hive/MySQL also display in this way.
Also, for data columns, table properties and options, we put the right parenthesis to the end of the last column/property/option, instead of occupying a separate line.
### Why are the changes needed?
for better readability
### Does this PR introduce any user-facing change?
before the change:
```
spark-sql> show create table test_table;
CREATE TABLE `test_table` (`col1` INT COMMENT 'This is comment for column 1', `col2` STRING COMMENT 'This is comment for column 2', `col3` DOUBLE COMMENT 'This is comment for column 3')
USING parquet
OPTIONS (
`bar` '2',
`foo` '1'
)
TBLPROPERTIES (
'a' = 'x',
'b' = 'y'
)
```
after the change:
```
spark-sql> show create table test_table;
CREATE TABLE `test_table` (
`col1` INT COMMENT 'This is comment for column 1',
`col2` STRING COMMENT 'This is comment for column 2',
`col3` DOUBLE COMMENT 'This is comment for column 3')
USING parquet
OPTIONS (
`bar` '2',
`foo` '1')
TBLPROPERTIES (
'a' = 'x',
'b' = 'y')
```
### How was this patch tested?
modified existing tests
Closes#27147 from wzhfy/multi_line_columns.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This pr intends to skip the unnecessary checks that most aggregate quries don't need in RewriteDistinctAggregates.
### Why are the changes needed?
For minor optimization.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#26997 from maropu/OptDistinctAggRewrite.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Now users can add directories from sql CLI as well using ADD FILE command and setting spark.sql.addDirectory.recursive to true.
### Why are the changes needed?
In SPARK-4687, support was added for adding directories as resources. But sql users cannot use that feature from CLI.
`ADD FILE /path/to/folder` gives the following error:
`org.apache.spark.SparkException: Added file /path/to/folder is a directory and recursive is not turned on.`
Users need to turn on `recursive` for adding directories. Thus a configuration was required which will allow users to turn on `recursive`.
Also Hive allow users to add directories from their shell.
### Does this PR introduce any user-facing change?
Yes. Users can set recursive using `spark.sql.addDirectory.recursive`.
### How was this patch tested?
Manually.
Will add test cases soon.
SPARK SCREENSHOTS
When `spark.sql.addDirectory.recursive` is not turned on.
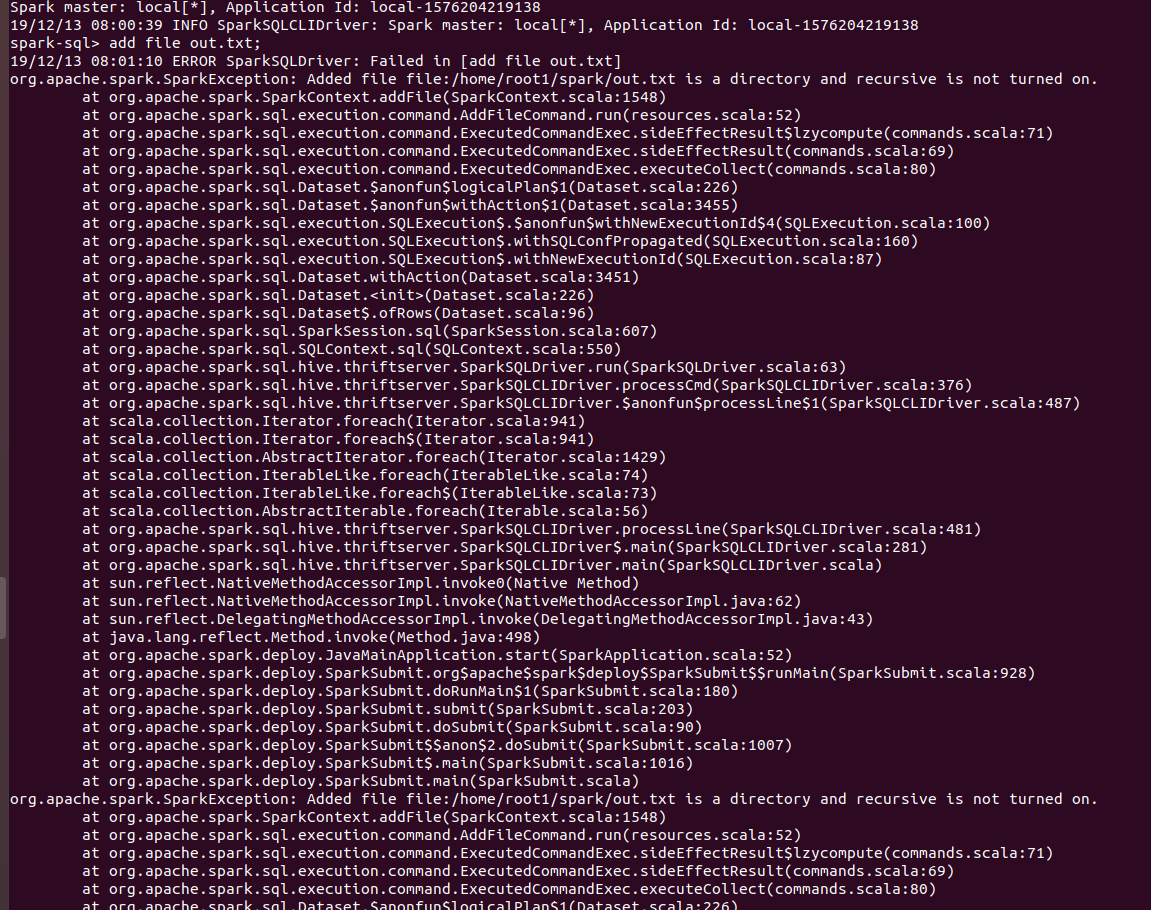
After setting `spark.sql.addDirectory.recursive` to true.

HIVE SCREENSHOT

`RELEASE_NOTES.txt` is text file while `dummy` is a directory.
Closes#26863 from iRakson/SPARK-30234.
Lead-authored-by: root1 <raksonrakesh@gmail.com>
Co-authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR fixes `ConstantPropagation` rule as the current implementation produce incorrect results in some cases. E.g.
```
SELECT * FROM t WHERE NOT(c = 1 AND c + 1 = 1)
```
returns those rows where `c` is null due to `1 + 1 = 1` propagation but it shouldn't.
## Why are the changes needed?
To fix a bug.
## Does this PR introduce any user-facing change?
Yes, fixes a bug.
## How was this patch tested?
New UTs.
Closes#27119 from peter-toth/SPARK-30447.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
In this pull request, we are going to support `SET OWNER` syntax for databases and namespaces,
```sql
ALTER (DATABASE|SCHEME|NAMESPACE) database_name SET OWNER [USER|ROLE|GROUP] user_or_role_group;
```
Before this commit 332e252a14, we didn't care much about ownerships for the catalog objects. In 332e252a14, we determined to use properties to store ownership staff, and temporarily used `alter database ... set dbproperties ...` to support switch ownership of a database. This PR aims to use the formal syntax to replace it.
In hive, `ownerName/Type` are fields of the database objects, also they can be normal properties.
```
create schema test1 with dbproperties('ownerName'='yaooqinn')
```
The create/alter database syntax will not change the owner to `yaooqinn` but store it in parameters. e.g.
```
+----------+----------+---------------------------------------------------------------+-------------+-------------+-----------------------+--+
| db_name | comment | location | owner_name | owner_type | parameters |
+----------+----------+---------------------------------------------------------------+-------------+-------------+-----------------------+--+
| test1 | | hdfs://quickstart.cloudera:8020/user/hive/warehouse/test1.db | anonymous | USER | {ownerName=yaooqinn} |
+----------+----------+---------------------------------------------------------------+-------------+-------------+-----------------------+--+
```
In this pull request, because we let the `ownerName` become reversed, so it will neither change the owner nor store in dbproperties, just be omitted silently.
## Why are the changes needed?
Formal syntax support for changing database ownership
### Does this PR introduce any user-facing change?
yes, add a new syntax
### How was this patch tested?
add unit tests
Closes#26775 from yaooqinn/SPARK-30018.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Allow users to specify NOT NULL in CREATE TABLE and ADD COLUMN column definition, and add a new SQL syntax to alter column nullability: ALTER TABLE ... ALTER COLUMN SET/DROP NOT NULL. This is a SQL standard syntax:
```
<alter column definition> ::=
ALTER [ COLUMN ] <column name> <alter column action>
<alter column action> ::=
<set column default clause>
| <drop column default clause>
| <set column not null clause>
| <drop column not null clause>
| ...
<set column not null clause> ::=
SET NOT NULL
<drop column not null clause> ::=
DROP NOT NULL
```
### Why are the changes needed?
Previously we don't support it because the table schema in hive catalog are always nullable. Since we have catalog plugin now, it makes more sense to support NOT NULL at spark side, and let catalog implementations to decide if they support it or not.
### Does this PR introduce any user-facing change?
Yes, this is a new feature
### How was this patch tested?
new tests
Closes#27110 from cloud-fan/nullable.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. Put all deprecated SQL configs the map `SQLConf.deprecatedSQLConfigs` with extra info about when configs were deprecated and additional comments that explain why a config was deprecated, what an user can use instead of it. Here is the list of already deprecated configs:
- spark.sql.hive.verifyPartitionPath
- spark.sql.execution.pandas.respectSessionTimeZone
- spark.sql.legacy.execution.pandas.groupedMap.assignColumnsByName
- spark.sql.parquet.int64AsTimestampMillis
- spark.sql.variable.substitute.depth
- spark.sql.execution.arrow.enabled
- spark.sql.execution.arrow.fallback.enabled
2. Output warning in `set()` and `unset()` about deprecated SQL configs
### Why are the changes needed?
This should improve UX with Spark SQL and notify users about already deprecated SQL configs.
### Does this PR introduce any user-facing change?
Yes, before:
```
spark-sql> set spark.sql.hive.verifyPartitionPath=true;
spark.sql.hive.verifyPartitionPath true
```
After:
```
spark-sql> set spark.sql.hive.verifyPartitionPath=true;
20/01/03 21:28:17 WARN RuntimeConfig: The SQL config 'spark.sql.hive.verifyPartitionPath' has been deprecated in Spark v3.0.0 and may be removed in the future. This config is replaced by spark.files.ignoreMissingFiles.
spark.sql.hive.verifyPartitionPath true
```
### How was this patch tested?
Add new test which registers new log appender and catches all logging to check that `set()` and `unset()` log any warning.
Closes#27092 from MaxGekk/group-deprecated-sql-configs.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
fixing a broken build:
https://amplab.cs.berkeley.edu/jenkins/job/spark-master-test-sbt-hadoop-2.7-hive-1.2/3/console
### Why are the changes needed?
the build is teh borked!
### Does this PR introduce any user-facing change?
newp
### How was this patch tested?
by the build system
Closes#27156 from shaneknapp/fix-scala-style.
Authored-by: shane knapp <incomplete@gmail.com>
Signed-off-by: shane knapp <incomplete@gmail.com>
### What changes were proposed in this pull request?
Fix ignoreMissingFiles/ignoreCorruptFiles in DSv2:
When `FilePartitionReader` finds a missing or corrupt file, it should just skip and continue to read next file rather than stop with current behavior.
### Why are the changes needed?
ignoreMissingFiles/ignoreCorruptFiles in DSv2 is wrong comparing to DSv1.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Updated existed test for `ignoreMissingFiles`. Note I didn't update tests for `ignoreCorruptFiles`, because there're various datasources has tests for `ignoreCorruptFiles`. So I'm not sure if it's worth to touch all those tests since the basic logic of `ignoreCorruptFiles` should be same with `ignoreMissingFiles`.
Closes#27136 from Ngone51/improve-missing-files.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
This PR introduces `SupportsCatalogOptions` as an interface for `TableProvider`. Through `SupportsCatalogOptions`, V2 DataSources can implement the two methods `extractIdentifier` and `extractCatalog` to support the creation, and existence check of tables without requiring a formal TableCatalog implementation.
We currently don't support all SaveModes for DataSourceV2 in DataFrameWriter.save. The idea here is that eventually File based tables can be written with `DataFrameWriter.save(path)` will create a PathIdentifier where the name is `path`, and the V2SessionCatalog will be able to perform FileSystem checks at `path` to support ErrorIfExists and Ignore SaveModes.
### Why are the changes needed?
To support all Save modes for V2 data sources with DataFrameWriter. Since we can now support table creation, we will be able to provide partitioning information when first creating the table as well.
### Does this PR introduce any user-facing change?
Introduces a new interface
### How was this patch tested?
Will add tests once interface is vetted.
Closes#26913 from brkyvz/catalogOptions.
Lead-authored-by: Burak Yavuz <brkyvz@gmail.com>
Co-authored-by: Burak Yavuz <burak@databricks.com>
Signed-off-by: Burak Yavuz <brkyvz@gmail.com>
### What changes were proposed in this pull request?
File source V2: support partition pruning.
Note: subquery predicates are not pushed down for partition pruning even after this PR, due to the limitation for the current data source V2 API and framework. The rule `PlanSubqueries` requires the subquery expression to be in the children or class parameters in `SparkPlan`, while the condition is not satisfied for `BatchScanExec`.
### Why are the changes needed?
It's important for reading performance.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
New unit tests for all the V2 file sources
Closes#27112 from gengliangwang/PartitionPruningInFileScan.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, COMMENT and LOCATION are reserved properties for Datasource v2 namespaces. They can be set via specific clauses and via properties. And the ones specified in clauses take precede of properties. Since they are reserved, which means they are not able to visit directly. They should be used in COMMENT/LOCATION clauses ONLY.
### Why are the changes needed?
make reserved properties be reserved.
### Does this PR introduce any user-facing change?
yes, 'location', 'comment' are not allowed use in db properties
### How was this patch tested?
UNIT tests.
Closes#26806 from yaooqinn/SPARK-30183.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to move pandas related functionalities into pandas package. Namely:
```bash
pyspark/sql/pandas
├── __init__.py
├── conversion.py # Conversion between pandas <> PySpark DataFrames
├── functions.py # pandas_udf
├── group_ops.py # Grouped UDF / Cogrouped UDF + groupby.apply, groupby.cogroup.apply
├── map_ops.py # Map Iter UDF + mapInPandas
├── serializers.py # pandas <> PyArrow serializers
├── types.py # Type utils between pandas <> PyArrow
└── utils.py # Version requirement checks
```
In order to separately locate `groupby.apply`, `groupby.cogroup.apply`, `mapInPandas`, `toPandas`, and `createDataFrame(pdf)` under `pandas` sub-package, I had to use a mix-in approach which Scala side uses often by `trait`, and also pandas itself uses this approach (see `IndexOpsMixin` as an example) to group related functionalities. Currently, you can think it's like Scala's self typed trait. See the structure below:
```python
class PandasMapOpsMixin(object):
def mapInPandas(self, ...):
...
return ...
# other Pandas <> PySpark APIs
```
```python
class DataFrame(PandasMapOpsMixin):
# other DataFrame APIs equivalent to Scala side.
```
Yes, This is a big PR but they are mostly just moving around except one case `createDataFrame` which I had to split the methods.
### Why are the changes needed?
There are pandas functionalities here and there and I myself gets lost where it was. Also, when you have to make a change commonly for all of pandas related features, it's almost impossible now.
Also, after this change, `DataFrame` and `SparkSession` become more consistent with Scala side since pandas is specific to Python, and this change separates pandas-specific APIs away from `DataFrame` or `SparkSession`.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests should cover. Also, I manually built the PySpark API documentation and checked.
Closes#27109 from HyukjinKwon/pandas-refactoring.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a minor code refactoring PR. It creates an adaptive execution context class to wrap objects shared across main query and sub-queries.
### Why are the changes needed?
This refactoring will improve code readability and reduce the number of parameters used to initialize `AdaptiveSparkPlanExec`.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Passed existing UTs.
Closes#26959 from maryannxue/aqe-context.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
This patch renews the verification logic of archive path for FileStreamSource, as we found the logic doesn't take partitioned/recursive options into account.
Before the patch, it only requires the archive path to have depth more than 2 (two subdirectories from root), leveraging the fact FileStreamSource normally reads the files where the parent directory matches the pattern or the file itself matches the pattern. Given 'archive' operation moves the files to the base archive path with retaining the full path, archive path is tend to be safe if the depth is more than 2, meaning FileStreamSource doesn't re-read archived files as new source files.
WIth partitioned/recursive options, the fact is invalid, as FileStreamSource can read any files in any depth of subdirectories for source pattern. To deal with this correctly, we have to renew the verification logic, which may not intuitive and simple but works for all cases.
The new verification logic prevents both cases:
1) archive path matches with source pattern as "prefix" (the depth of archive path > the depth of source pattern)
e.g.
* source pattern: `/hello*/spar?`
* archive path: `/hello/spark/structured/streaming`
Any files in archive path will match with source pattern when recursive option is enabled.
2) source pattern matches with archive path as "prefix" (the depth of source pattern > the depth of archive path)
e.g.
* source pattern: `/hello*/spar?/structured/hello2*`
* archive path: `/hello/spark/structured`
Some archive files will not match with source pattern, e.g. file path: `/hello/spark/structured/hello2`, then final archived path: `/hello/spark/structured/hello/spark/structured/hello2`.
But some other archive files will still match with source pattern, e.g. file path: `/hello2/spark/structured/hello2`, then final archived path: `/hello/spark/structured/hello2/spark/structured/hello2` which matches with source pattern when recursive is enabled.
Implicitly it also prevents archive path matches with source pattern as full match (same depth).
We would want to prevent any source files to be archived and added to new source files again, so the patch takes most restrictive approach to prevent the possible cases.
### Why are the changes needed?
Without this patch, there's a chance archived files are included as new source files when partitioned/recursive option is enabled, as current condition doesn't take these options into account.
### Does this PR introduce any user-facing change?
Only for Spark 3.0.0-preview (only preview 1 for now, but possibly preview 2 as well) - end users are required to provide archive path with ensuring a bit complicated conditions, instead of simply higher than 2 depths.
### How was this patch tested?
New UT.
Closes#26920 from HeartSaVioR/SPARK-30281.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
1, for primitive types `Array.fill(n)(0)` -> `Array.ofDim(n)`;
2, for `AnyRef` types `Array.fill(n)(null)` -> `Array.ofDim(n)`;
3, for primitive types `Array.empty[XXX]` -> `Array.emptyXXXArray`
### Why are the changes needed?
`Array.ofDim` avoid assignments;
`Array.emptyXXXArray` avoid create new object;
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
existing testsuites
Closes#27133 from zhengruifeng/minor_fill_ofDim.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
For a partitioned table, if the number of partitions are very large, e.g. tens of thousands or even larger, calculating its total size causes flooding logs.
The flooding happens in:
1. `calculateLocationSize` prints the starting and ending for calculating the location size, and it is called per partition;
2. `bulkListLeafFiles` prints all partition paths.
This pr is to simplify the logging when calculating the size of a partitioned table.
### How was this patch tested?
not related
Closes#27079 from wzhfy/improve_log.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Remove PrunedInMemoryFileIndex and merge its functionality into InMemoryFileIndex.
### Why are the changes needed?
PrunedInMemoryFileIndex is only used in CatalogFileIndex.filterPartitions, and its name is kind of confusing, we can completely merge its functionality into InMemoryFileIndex and remove the class.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing unit tests.
Closes#26850 from fuwhu/SPARK-30215.
Authored-by: fuwhu <bestwwg@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a follow-up to address the following comment: https://github.com/apache/spark/pull/27095#discussion_r363152180
Currently, a SQL command string is parsed to a "statement" logical plan, converted to a logical plan with catalog/namespace, then finally converted to a physical plan. With the new resolution framework, there is no need to create a "statement" logical plan; a logical plan can contain `UnresolvedNamespace` which will be resolved to a `ResolvedNamespace`. This should simply the code base and make it a bit easier to add a new command.
### Why are the changes needed?
Clean up codebase.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing tests should cover the changes.
Closes#27125 from imback82/SPARK-30214-followup.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch proposes:
1. Fix OOM at WideSchemaBenchmark: make `ValidateExternalType.errMsg` lazy variable, i.e. not to initiate it in the constructor
2. Truncate `errMsg`: Replacing `catalogString` with `simpleString` which is truncated
3. Optimizing `override def catalogString` in `StructType`: Make `catalogString` more efficient in string generation by using `StringConcat`
### Why are the changes needed?
In the JIRA, it is found that WideSchemaBenchmark fails with OOM, like:
```
[error] Exception in thread "main" org.apache.spark.sql.catalyst.errors.package$TreeNodeException: makeCopy, tree: validateexternaltype(getexternalrowfield(input[0, org.apac
he.spark.sql.Row, true], 0, a), StructField(b,StructType(StructField(c,StructType(StructField(value_1,LongType,true), StructField(value_10,LongType,true), StructField(value_
100,LongType,true), StructField(value_1000,LongType,true), StructField(value_1001,LongType,true), StructField(value_1002,LongType,true), StructField(value_1003,LongType,true
), StructField(value_1004,LongType,true), StructField(value_1005,LongType,true), StructField(value_1006,LongType,true), StructField(value_1007,LongType,true), StructField(va
lue_1008,LongType,true), StructField(value_1009,LongType,true), StructField(value_101,LongType,true), StructField(value_1010,LongType,true), StructField(value_1011,LongType,
...
ue), StructField(value_99,LongType,true), StructField(value_990,LongType,true), StructField(value_991,LongType,true), StructField(value_992,LongType,true), StructField(value
_993,LongType,true), StructField(value_994,LongType,true), StructField(value_995,LongType,true), StructField(value_996,LongType,true), StructField(value_997,LongType,true),
StructField(value_998,LongType,true), StructField(value_999,LongType,true)),true))
[error] at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:56)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.makeCopy(TreeNode.scala:435)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:408)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:327)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:307)
....
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$mapChildren$1(TreeNode.scala:404)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:214)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:374)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:327)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:307)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformUp$1(TreeNode.scala:307)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$mapChildren$1(TreeNode.scala:376)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:214)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:374)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:327)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:307)
[error] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoder.<init>(ExpressionEncoder.scala:198)
[error] at org.apache.spark.sql.catalyst.encoders.RowEncoder$.apply(RowEncoder.scala:71)
[error] at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:88)
[error] at org.apache.spark.sql.SparkSession.internalCreateDataFrame(SparkSession.scala:554)
[error] at org.apache.spark.sql.DataFrameReader.json(DataFrameReader.scala:476)
[error] at org.apache.spark.sql.execution.benchmark.WideSchemaBenchmark$.$anonfun$wideShallowlyNestedStructFieldReadAndWrite$1(WideSchemaBenchmark.scala:126)
...
[error] Caused by: java.lang.OutOfMemoryError: GC overhead limit exceeded
[error] at java.util.Arrays.copyOf(Arrays.java:3332)
[error] at java.lang.AbstractStringBuilder.ensureCapacityInternal(AbstractStringBuilder.java:124)
[error] at java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:448)
[error] at java.lang.StringBuilder.append(StringBuilder.java:136)
[error] at scala.collection.mutable.StringBuilder.append(StringBuilder.scala:213)
[error] at scala.collection.TraversableOnce.$anonfun$addString$1(TraversableOnce.scala:368)
[error] at scala.collection.TraversableOnce$$Lambda$67/667447085.apply(Unknown Source)
[error] at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
[error] at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
[error] at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:198)
[error] at scala.collection.TraversableOnce.addString(TraversableOnce.scala:362)
[error] at scala.collection.TraversableOnce.addString$(TraversableOnce.scala:358)
[error] at scala.collection.mutable.ArrayOps$ofRef.addString(ArrayOps.scala:198)
[error] at scala.collection.TraversableOnce.mkString(TraversableOnce.scala:328)
[error] at scala.collection.TraversableOnce.mkString$(TraversableOnce.scala:327)
[error] at scala.collection.mutable.ArrayOps$ofRef.mkString(ArrayOps.scala:198)
[error] at scala.collection.TraversableOnce.mkString(TraversableOnce.scala:330)
[error] at scala.collection.TraversableOnce.mkString$(TraversableOnce.scala:330)
[error] at scala.collection.mutable.ArrayOps$ofRef.mkString(ArrayOps.scala:198)
[error] at org.apache.spark.sql.types.StructType.catalogString(StructType.scala:411)
[error] at org.apache.spark.sql.catalyst.expressions.objects.ValidateExternalType.<init>(objects.scala:1695)
[error] at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
[error] at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
[error] at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
[error] at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$makeCopy$7(TreeNode.scala:468)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode$$Lambda$934/387827651.apply(Unknown Source)
[error] at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:72)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$makeCopy$1(TreeNode.scala:467)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode$$Lambda$929/449240381.apply(Unknown Source)
[error] at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:52)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.makeCopy(TreeNode.scala:435)
```
It is after cb5ea201df commit which refactors `ExpressionEncoder`.
The stacktrace shows it fails at `transformUp` on `objSerializer` in `ExpressionEncoder`. In particular, it fails at initializing `ValidateExternalType.errMsg`, that interpolates `catalogString` of given `expected` data type in a string. In WideSchemaBenchmark we have very deeply nested data type. When we transform on the serializer which contains `ValidateExternalType`, we create redundant big string `errMsg`. Because we just in transforming it and don't use it yet, it is useless and waste a lot of memory.
After make `ValidateExternalType.errMsg` as lazy variable, WideSchemaBenchmark works.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manual test with WideSchemaBenchmark.
Closes#27117 from viirya/SPARK-30429.
Lead-authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Co-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add table/column comments and table properties to the result of show create table of views.
### Does this PR introduce any user-facing change?
When show create table for views, after this patch, the result can contain table/column comments and table properties if they exist.
### How was this patch tested?
add new tests
Closes#26944 from wzhfy/complete_show_create_view.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
Avoid hive log initialisation as https://github.com/apache/hive/blob/rel/release-2.3.5/common/src/java/org/apache/hadoop/hive/common/LogUtils.java introduces dependency over `org.apache.logging.log4j.core.impl.Log4jContextFactory` which is missing in our spark installer classpath directly. I believe the `LogUtils.initHiveLog4j()` code is here as the HiveServer2 class is copied from Hive.
To make `start-thriftserver.sh --help` command success.
Currently, start-thriftserver.sh --help throws
```
...
Thrift server options:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/logging/log4j/spi/LoggerContextFactory
at org.apache.hive.service.server.HiveServer2.main(HiveServer2.java:167)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2$.main(HiveThriftServer2.scala:82)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.main(HiveThriftServer2.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.logging.log4j.spi.LoggerContextFactory
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 3 more
```
No
Checked Manually
Closes#27042 from ajithme/thrifthelp.
Authored-by: Ajith <ajith2489@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}