## What changes were proposed in this pull request?
Remove surplus synchronized blocks.
## How was this patch tested?
Unit tests run OK.
Author: iurii.ant <sereneant@gmail.com>
Closes#18775 from SereneAnt/eliminate_unnecessary_synchronization_in_java-R_serialization.
## What changes were proposed in this pull request?
When BytesToBytesMap spills, its longArray should be released. Otherwise, it may not released until the task complete. This array may take a significant amount of memory, which cannot be used by later operator, such as UnsafeShuffleExternalSorter, resulting in more frequent spill in sorter. This patch release the array as destructive iterator will not use this array anymore.
## How was this patch tested?
Manual test in production
Author: Zhan Zhang <zhanzhang@fb.com>
Closes#17180 from zhzhan/memory.
## What changes were proposed in this pull request?
This PR proposes to fix few rather typos in `merge_spark_pr.py`.
- `# usage: ./apache-pr-merge.py (see config env vars below)`
-> `# usage: ./merge_spark_pr.py (see config env vars below)`
- `... have local a Spark ...` -> `... have a local Spark ...`
- `... to Apache.` -> `... to Apache Spark.`
I skimmed this file and these look all I could find.
## How was this patch tested?
pep8 check (`./dev/lint-python`).
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18776 from HyukjinKwon/minor-merge-script.
In programming guide, `numTasks` is used in several places as arguments of Transformations. However, in code, `numPartitions` is used. In this fix, I replace `numTasks` with `numPartitions` in programming guide for consistency.
Author: Cheng Wang <chengwang0511@gmail.com>
Closes#18774 from polarke/replace-numtasks-with-numpartitions-in-doc.
## What changes were proposed in this pull request?
The format of none should be consistent with other compression codec(\`snappy\`, \`lz4\`) as \`none\`.
## How was this patch tested?
This is a typo.
Author: GuoChenzhao <chenzhao.guo@intel.com>
Closes#18758 from gczsjdy/typo.
## What changes were proposed in this pull request?
This pr added parsing rules to support subquery column aliases in FROM clause.
This pr is a sub-task of #18079.
## How was this patch tested?
Added tests in `PlanParserSuite` and `SQLQueryTestSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#18185 from maropu/SPARK-20962.
## What changes were proposed in this pull request?
Long values can be passed to `rangeBetween` as range frame boundaries, but we silently convert it to Int values, this can cause wrong results and we should fix this.
Further more, we should accept any legal literal values as range frame boundaries. In this PR, we make it possible for Long values, and make accepting other DataTypes really easy to add.
This PR is mostly based on Herman's previous amazing work: 596f53c339
After this been merged, we can close#16818 .
## How was this patch tested?
Add new tests in `DataFrameWindowFunctionsSuite` and `TypeCoercionSuite`.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#18540 from jiangxb1987/rangeFrame.
## What changes were proposed in this pull request?
When there are aliases (these aliases were added for nested fields) as parameters in `RuntimeReplaceable`, as they are not in the children expression, those aliases can't be cleaned up in analyzer rule `CleanupAliases`.
An expression `nvl(foo.foo1, "value")` can be resolved to two semantically different expressions in a group by query because they contain different aliases.
Because those aliases are not children of `RuntimeReplaceable` which is an `UnaryExpression`. So we can't trim the aliases out by simple transforming the expressions in `CleanupAliases`.
If we want to replace the non-children aliases in `RuntimeReplaceable`, we need to add more codes to `RuntimeReplaceable` and modify all expressions of `RuntimeReplaceable`. It makes the interface ugly IMO.
Consider those aliases will be replaced later at optimization and so they're no harm, this patch chooses to simply override `canonicalized` of `RuntimeReplaceable`.
One concern is about `CleanupAliases`. Because it actually cannot clean up ALL aliases inside a plan. To make caller of this rule notice that, this patch adds a comment to `CleanupAliases`.
## How was this patch tested?
Added test.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#18761 from viirya/SPARK-21555.
## What changes were proposed in this pull request?
```DStreams
class FileInputDStream
[line 162] protected[streaming] override def clearMetadata(time: Time) {
batchTimeToSelectedFiles.synchronized {
val oldFiles = batchTimeToSelectedFiles.filter(_._1 < (time - rememberDuration))
batchTimeToSelectedFiles --= oldFiles.keys
```
The above code does not remove the old generatedRDDs. "super.clearMetadata(time)" was added to the beginning of clearMetadata to remove the old generatedRDDs.
## How was this patch tested?
At the end of clearMetadata, the testing code (print the number of generatedRDDs) was added to check the old RDDS were removed manually.
Author: shaofei007 <1427357147@qq.com>
Author: Fei Shao <1427357147@qq.com>
Closes#18718 from shaofei007/master.
## What changes were proposed in this pull request?
This PR proposes `StructType.fieldNames` that returns a copy of a field name list rather than a (undocumented) `StructType.names`.
There are two points here:
- API consistency with Scala/Java
- Provide a safe way to get the field names. Manipulating these might cause unexpected behaviour as below:
```python
from pyspark.sql.types import *
struct = StructType([StructField("f1", StringType(), True)])
names = struct.names
del names[0]
spark.createDataFrame([{"f1": 1}], struct).show()
```
```
...
java.lang.IllegalStateException: Input row doesn't have expected number of values required by the schema. 1 fields are required while 0 values are provided.
at org.apache.spark.sql.execution.python.EvaluatePython$.fromJava(EvaluatePython.scala:138)
at org.apache.spark.sql.SparkSession$$anonfun$6.apply(SparkSession.scala:741)
at org.apache.spark.sql.SparkSession$$anonfun$6.apply(SparkSession.scala:741)
...
```
## How was this patch tested?
Added tests in `python/pyspark/sql/tests.py`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18618 from HyukjinKwon/SPARK-20090.
If you run a spark job without creating the SparkSession or SparkContext, the spark job logs says it succeeded but yarn says it fails and retries 3 times. Also, since, Application Master unregisters with Resource Manager and exits successfully, it deletes the spark staging directory, so when yarn makes subsequent retries, it fails to find the staging directory and thus, the retries fail.
Added a flag to check whether user has initialized SparkContext. If it is true, we let Application Master unregister with Resource Manager else, we do not let AM unregister with RM.
## How was this patch tested?
Manually tested the fix.
Before:
<img width="1253" alt="screen shot-before" src="https://user-images.githubusercontent.com/22228190/28647214-69bf81e2-722b-11e7-9ed0-d416d2bf23be.png">
After:
<img width="1319" alt="screen shot-after" src="https://user-images.githubusercontent.com/22228190/28647220-70f9eea2-722b-11e7-85c6-e56276b15614.png">
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: pgandhi <pgandhi@yahoo-inc.com>
Author: pgandhi999 <parthkgandhi9@gmail.com>
Closes#18741 from pgandhi999/SPARK-21541.
When I type spark-shell --help, I find that the default value description for the master parameter is missing. The user does not know what the default value is when the master parameter is not included, so we need to add the master parameter default description to the help information.
[https://issues.apache.org/jira/browse/SPARK-21553](https://issues.apache.org/jira/browse/SPARK-21553)
Author: davidxdh <xu.donghui@zte.com.cn>
Author: Donghui Xu <xu.donghui@zte.com.cn>
Closes#18755 from davidxdh/dev_0728.
## What changes were proposed in this pull request?
Fixes current failures in dev/lint-java
## How was this patch tested?
Existing linter, tests.
Author: Sean Owen <sowen@cloudera.com>
Closes#18757 from srowen/LintJava.
## What changes were proposed in this pull request?
add `setWeightCol` method for OneVsRest.
`weightCol` is ignored if classifier doesn't inherit HasWeightCol trait.
## How was this patch tested?
+ [x] add an unit test.
Author: Yan Facai (颜发才) <facai.yan@gmail.com>
Closes#18554 from facaiy/BUG/oneVsRest_missing_weightCol.
## What changes were proposed in this pull request?
This PR contains a tiny update that removes an attribute resolution inconsistency in the Dataset API. The following example is taken from the ticket description:
```
spark.range(1).withColumnRenamed("id", "x").sort(col("id")) // works
spark.range(1).withColumnRenamed("id", "x").sort($"id") // works
spark.range(1).withColumnRenamed("id", "x").sort('id) // works
spark.range(1).withColumnRenamed("id", "x").sort("id") // fails with:
org.apache.spark.sql.AnalysisException: Cannot resolve column name "id" among (x);
```
The above `AnalysisException` happens because the last case calls `Dataset.apply()` to convert strings into columns, which triggers attribute resolution. To make the API consistent between overloaded methods, this PR defers the resolution and constructs columns directly.
Author: aokolnychyi <anton.okolnychyi@sap.com>
Closes#18740 from aokolnychyi/spark-21538.
## What changes were proposed in this pull request?
`UnsafeExternalSorter.recordComparator` can be either `KVComparator` or `RowComparator`, and both of them will keep the reference to the input rows they compared last time.
After sorting, we return the sorted iterator to upstream operators. However, the upstream operators may take a while to consume up the sorted iterator, and `UnsafeExternalSorter` is registered to `TaskContext` at [here](https://github.com/apache/spark/blob/v2.2.0/core/src/main/java/org/apache/spark/util/collection/unsafe/sort/UnsafeExternalSorter.java#L159-L161), which means we will keep the `UnsafeExternalSorter` instance and keep the last compared input rows in memory until the sorted iterator is consumed up.
Things get worse if we sort within partitions of a dataset and coalesce all partitions into one, as we will keep a lot of input rows in memory and the time to consume up all the sorted iterators is long.
This PR takes over https://github.com/apache/spark/pull/18543 , the idea is that, we do not keep the record comparator instance in `UnsafeExternalSorter`, but a generator of record comparator.
close#18543
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#18679 from cloud-fan/memory-leak.
## What changes were proposed in this pull request?
Add R-like summary table to GLM summary, which includes feature name (if exist), parameter estimate, standard error, t-stat and p-value. This allows scala users to easily gather these commonly used inference results.
srowen yanboliang felixcheung
## How was this patch tested?
New tests. One for testing feature Name, and one for testing the summary Table.
Author: actuaryzhang <actuaryzhang10@gmail.com>
Author: Wayne Zhang <actuaryzhang10@gmail.com>
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#16630 from actuaryzhang/glmTable.
## What changes were proposed in this pull request?
This is a refactoring of `ArrowConverters` and related classes.
1. Refactor `ColumnWriter` as `ArrowWriter`.
2. Add `ArrayType` and `StructType` support.
3. Refactor `ArrowConverters` to skip intermediate `ArrowRecordBatch` creation.
## How was this patch tested?
Added some tests and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#18655 from ueshin/issues/SPARK-21440.
## What changes were proposed in this pull request?
This PR ensures that `Unsafe.sizeInBytes` must be a multiple of 8. It it is not satisfied. `Unsafe.hashCode` causes the assertion violation.
## How was this patch tested?
Will add test cases
Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Closes#18503 from kiszk/SPARK-21271.
## What changes were proposed in this pull request?
Update the description of `spark.shuffle.maxChunksBeingTransferred` to include that the new coming connections will be closed when the max is hit and client should have retry mechanism.
Author: jinxing <jinxing6042@126.com>
Closes#18735 from jinxing64/SPARK-21530.
## What changes were proposed in this pull request?
This generates a documentation for Spark SQL built-in functions.
One drawback is, this requires a proper build to generate built-in function list.
Once it is built, it only takes few seconds by `sql/create-docs.sh`.
Please see https://spark-test.github.io/sparksqldoc/ that I hosted to show the output documentation.
There are few more works to be done in order to make the documentation pretty, for example, separating `Arguments:` and `Examples:` but I guess this should be done within `ExpressionDescription` and `ExpressionInfo` rather than manually parsing it. I will fix these in a follow up.
This requires `pip install mkdocs` to generate HTMLs from markdown files.
## How was this patch tested?
Manually tested:
```
cd docs
jekyll build
```
,
```
cd docs
jekyll serve
```
and
```
cd sql
create-docs.sh
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18702 from HyukjinKwon/SPARK-21485.
## What changes were proposed in this pull request?
This change pulls the `LogisticAggregator` class out of LogisticRegression.scala and makes it extend `DifferentiableLossAggregator`. It also changes logistic regression to use the generic `RDDLossFunction` instead of having its own.
Other minor changes:
* L2Regularization accepts `Option[Int => Double]` for features standard deviation
* L2Regularization uses `Vector` type instead of Array
* Some tests added to LeastSquaresAggregator
## How was this patch tested?
Unit test suites are added.
Author: sethah <shendrickson@cloudera.com>
Closes#18305 from sethah/SPARK-20988.
## What changes were proposed in this pull request?
jira: https://issues.apache.org/jira/browse/SPARK-21524
ValidatorParamsSuiteHelpers.testFileMove() is generating temp dir in the wrong place and does not delete them.
ValidatorParamsSuiteHelpers.testFileMove() is invoked by TrainValidationSplitSuite and crossValidatorSuite. Currently it uses `tempDir` from `TempDirectory`, which unfortunately is never initialized since the `boforeAll()` of `ValidatorParamsSuiteHelpers` is never invoked.
In my system, it leaves some temp directories in the assembly folder each time I run the TrainValidationSplitSuite and crossValidatorSuite.
## How was this patch tested?
unit test fix
Author: Yuhao Yang <yuhao.yang@intel.com>
Closes#18728 from hhbyyh/tempDirFix.
## What changes were proposed in this pull request?
In our production cluster,oom happens when NettyBlockRpcServer receive OpenBlocks message.The reason we observed is below:
When BlockManagerManagedBuffer call ChunkedByteBuffer#toNetty, it will use Unpooled.wrappedBuffer(ByteBuffer... buffers) which use default maxNumComponents=16 in low-level CompositeByteBuf.When our component's number is bigger than 16, it will execute consolidateIfNeeded
int numComponents = this.components.size();
if(numComponents > this.maxNumComponents) {
int capacity = ((CompositeByteBuf.Component)this.components.get(numComponents - 1)).endOffset;
ByteBuf consolidated = this.allocBuffer(capacity);
for(int c = 0; c < numComponents; ++c) {
CompositeByteBuf.Component c1 = (CompositeByteBuf.Component)this.components.get(c);
ByteBuf b = c1.buf;
consolidated.writeBytes(b);
c1.freeIfNecessary();
}
CompositeByteBuf.Component var7 = new CompositeByteBuf.Component(consolidated);
var7.endOffset = var7.length;
this.components.clear();
this.components.add(var7);
}
in CompositeByteBuf which will consume some memory during buffer copy.
We can use another api Unpooled. wrappedBuffer(int maxNumComponents, ByteBuffer... buffers) to avoid this comsuming.
## How was this patch tested?
Test in production cluster.
Author: zhoukang <zhoukang@xiaomi.com>
Closes#18723 from caneGuy/zhoukang/fix-chunkbuffer.
There was some code based on the old SASL handler in the new auth client that
was incorrectly using the SASL user as the user to authenticate against the
external shuffle service. This caused the external service to not be able to
find the correct secret to authenticate the connection, failing the connection.
In the course of debugging, I found that some log messages from the YARN shuffle
service were a little noisy, so I silenced some of them, and also added a couple
of new ones that helped find this issue. On top of that, I found that a check
in the code that records app secrets was wrong, causing more log spam and also
using an O(n) operation instead of an O(1) call.
Also added a new integration suite for the YARN shuffle service with auth on,
and verified it failed before, and passes now.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#18706 from vanzin/SPARK-21494.
### What changes were proposed in this pull request?
Like [Hive UDFType](https://hive.apache.org/javadocs/r2.0.1/api/org/apache/hadoop/hive/ql/udf/UDFType.html), we should allow users to add the extra flags for ScalaUDF and JavaUDF too. _stateful_/_impliesOrder_ are not applicable to our Scala UDF. Thus, we only add the following two flags.
- deterministic: Certain optimizations should not be applied if UDF is not deterministic. Deterministic UDF returns same result each time it is invoked with a particular input. This determinism just needs to hold within the context of a query.
When the deterministic flag is not correctly set, the results could be wrong.
For ScalaUDF in Dataset APIs, users can call the following extra APIs for `UserDefinedFunction` to make the corresponding changes.
- `nonDeterministic`: Updates UserDefinedFunction to non-deterministic.
Also fixed the Java UDF name loss issue.
Will submit a separate PR for `distinctLike` for UDAF
### How was this patch tested?
Added test cases for both ScalaUDF
Author: gatorsmile <gatorsmile@gmail.com>
Author: Wenchen Fan <cloud0fan@gmail.com>
Closes#17848 from gatorsmile/udfRegister.
## What changes were proposed in this pull request?
`Traversable.toMap` changed to 'collections.breakOut', that eliminates intermediate tuple collection creation, see [Stack Overflow article](https://stackoverflow.com/questions/1715681/scala-2-8-breakout).
## How was this patch tested?
Unit tests run.
No performance tests performed yet.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: iurii.ant <sereneant@gmail.com>
Closes#18693 from SereneAnt/performance_toMap-breakOut.
inprogress history file in some cases.
Add failure handling for EOFException that can be thrown during
decompression of an inprogress spark history file, treat same as case
where can't parse the last line.
## What changes were proposed in this pull request?
Failure handling for case of EOFException thrown within the ReplayListenerBus.replay method to handle the case analogous to json parse fail case. This path can arise in compressed inprogress history files since an incomplete compression block could be read (not flushed by writer on a block boundary). See the stack trace of this occurrence in the jira ticket (https://issues.apache.org/jira/browse/SPARK-21447)
## How was this patch tested?
Added a unit test that specifically targets validating the failure handling path appropriately when maybeTruncated is true and false.
Author: Eric Vandenberg <ericvandenberg@fb.com>
Closes#18673 from ericvandenbergfb/fix_inprogress_compr_history_file.
When NodeManagers launching Executors,
the `missing` value will exceed the
real value when the launch is slow, this can lead to YARN allocates more resource.
We add the `numExecutorsRunning` when calculate the `missing` to avoid this.
Test by experiment.
Author: DjvuLee <lihu@bytedance.com>
Closes#18651 from djvulee/YarnAllocate.
## What changes were proposed in this pull request?
A shuffle service can serves blocks from multiple apps/tasks. Thus the shuffle service can suffers high memory usage when lots of shuffle-reads happen at the same time. In my cluster, OOM always happens on shuffle service. Analyzing heap dump, memory cost by Netty(ChannelOutboundBufferEntry) can be up to 2~3G. It might make sense to reject "open blocks" request when memory usage is high on shuffle service.
93dd0c518d and 85c6ce6193 tried to alleviate the memory pressure on shuffle service but cannot solve the root cause. This pr proposes to control currency of shuffle read.
## How was this patch tested?
Added unit test.
Author: jinxing <jinxing6042@126.com>
Closes#18388 from jinxing64/SPARK-21175.
I find a bug about 'quick start',and created a new issues,Sean Owen let
me to make a pull request, and I do
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Trueman <lizhaoch@users.noreply.github.com>
Author: lizhaoch <lizhaoc@163.com>
Closes#18722 from lizhaoch/master.
## What changes were proposed in this pull request?
The examples and docs for Spark-Kinesis integrations use the deprecated KinesisUtils. We should update the docs to use the KinesisInputDStream builder to create DStreams.
## How was this patch tested?
The patch primarily updates the documents. The patch will also need to make changes to the Spark-Kinesis examples. The examples need to be tested.
Author: Yash Sharma <ysharma@atlassian.com>
Closes#18071 from yssharma/ysharma/kinesis_docs.
## What changes were proposed in this pull request?
This PR ensures to call `super.afterEach()` in overriding `afterEach()` method in `DatasetCacheSuite`. When we override `afterEach()` method in Testsuite, we have to call `super.afterEach()`.
This is a follow-up of #18719 and SPARK-21512.
## How was this patch tested?
Used the existing test suite
Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Closes#18721 from kiszk/SPARK-21516.
## What changes were proposed in this pull request?
With supervise enabled for a driver, re-launching it was failing because the driver had the same framework Id. This patch creates a new driver framework id every time we re-launch a driver, but we keep the driver submission id the same since that is the same with the task id the driver was launched with on mesos and retry state and other info within Dispatcher's data structures uses that as a key.
We append a "-retry-%4d" string as a suffix to the framework id passed by the dispatcher to the driver and the same value to the app_id created by each driver, except the first time where we dont need the retry suffix.
The previous format for the frameworkId was 'DispactherFId-DriverSubmissionId'.
We also detect the case where we have multiple spark contexts started from within the same driver and we do set proper names to their corresponding app-ids. The old practice was to unset the framework id passed from the dispatcher after the driver framework was started for the first time and let mesos decide the framework ID for subsequent spark contexts. The decided fId was passed as an appID.
This patch affects heavily the history server. Btw we dont have the issues of the standalone case where driver id must be different since the dispatcher will re-launch a driver(mesos task) only if it gets an update that it is dead and this is verified by mesos implicitly. We also dont fix the fine grained mode which is deprecated and of no use.
## How was this patch tested?
This task was manually tested on dc/os. Launched a driver, stoped its container and verified the expected behavior.
Initial retry of the driver, driver in pending state:

Driver re-launched:
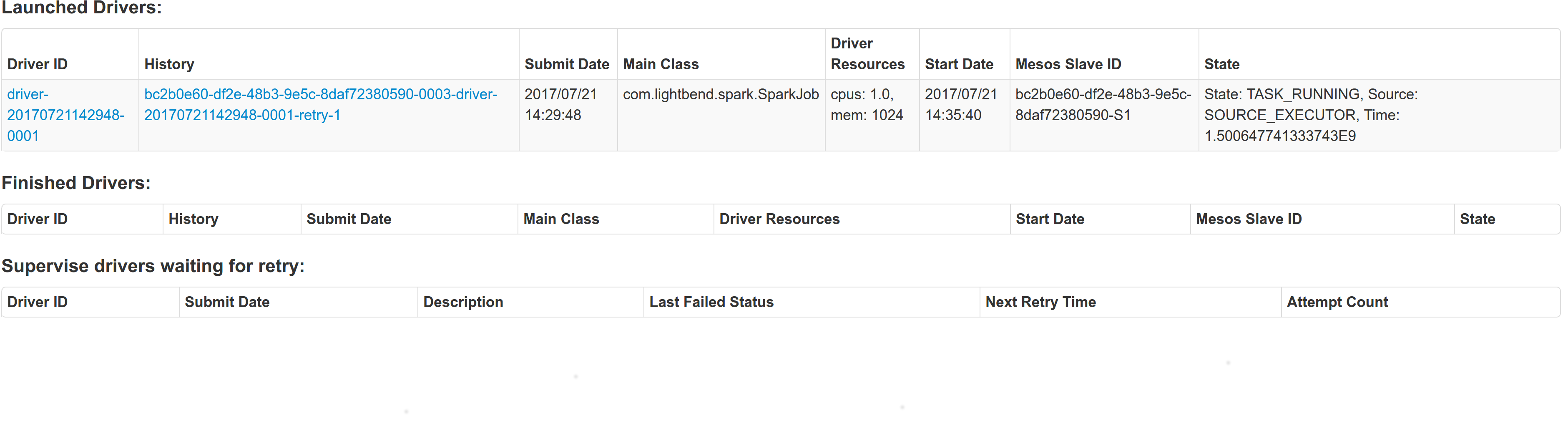
Another re-try:

The resulted entries in history server at the bottom:
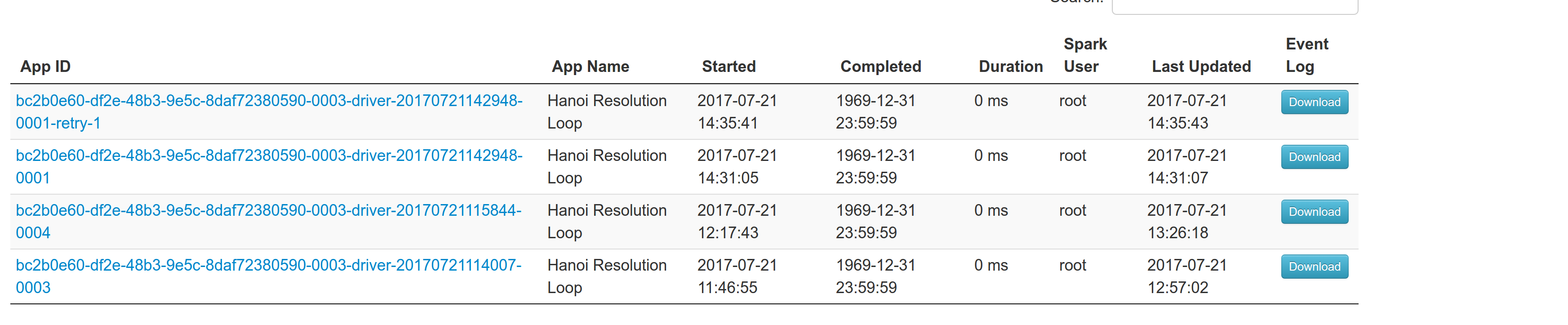
Regarding multiple spark contexts here is the end result regarding the spark history server, for the second spark context we add an increasing number as a suffix:

Author: Stavros Kontopoulos <st.kontopoulos@gmail.com>
Closes#18705 from skonto/fix_supervise_flag.
## What changes were proposed in this pull request?
In #18483 , we fixed the data copy bug when saving into `InternalRow`, and removed all workarounds for this bug in the aggregate code path. However, the object hash aggregate was missed, this PR fixes it.
This patch is also a requirement for #17419 , which shows that DataFrame version is slower than RDD version because of this issue.
## How was this patch tested?
existing tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#18712 from cloud-fan/minor.
## What changes were proposed in this pull request?
This PR avoids to reuse unpersistent dataset among test cases by making dataset unpersistent at the end of each test case.
In `DatasetCacheSuite`, the test case `"get storage level"` does not make dataset unpersisit after make the dataset persisitent. The same dataset will be made persistent by the test case `"persist and then rebind right encoder when join 2 datasets"` Thus, we run these test cases, the second case does not perform to make dataset persistent. This is because in
When we run only the second case, it performs to make dataset persistent. It is not good to change behavior of the second test suite. The first test case should correctly make dataset unpersistent.
```
Testing started at 17:52 ...
01:52:15.053 WARN org.apache.hadoop.util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
01:52:48.595 WARN org.apache.spark.sql.execution.CacheManager: Asked to cache already cached data.
01:52:48.692 WARN org.apache.spark.sql.execution.CacheManager: Asked to cache already cached data.
01:52:50.864 WARN org.apache.spark.storage.RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.
01:52:50.864 WARN org.apache.spark.storage.RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.
01:52:50.868 WARN org.apache.spark.storage.BlockManager: Block rdd_8_1 replicated to only 0 peer(s) instead of 1 peers
01:52:50.868 WARN org.apache.spark.storage.BlockManager: Block rdd_8_0 replicated to only 0 peer(s) instead of 1 peers
```
After this PR, these messages do not appear
```
Testing started at 18:14 ...
02:15:05.329 WARN org.apache.hadoop.util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Process finished with exit code 0
```
## How was this patch tested?
Used the existing test
Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Closes#18719 from kiszk/SPARK-21512.
## What changes were proposed in this pull request?
This patch removes the `****` string from test names in FlatMapGroupsWithStateSuite. `***` is a common string developers grep for when using Scala test (because it immediately shows the failing test cases). The existence of the `****` in test names disrupts that workflow.
## How was this patch tested?
N/A - test only change.
Author: Reynold Xin <rxin@databricks.com>
Closes#18715 from rxin/FlatMapGroupsWithStateStar.
## What changes were proposed in this pull request?
When the code that is generated is greater than 64k, then Janino compile will fail and CodeGenerator.scala will log the entire code at Error level.
SPARK-20871 suggests only logging the code at Debug level.
Since, the code is already logged at debug level, this Pull Request proposes not including the formatted code in the Error logging and exception message at all.
When an exception occurs, the code will be logged at Info level but truncated if it is more than 1000 lines long.
## How was this patch tested?
Existing tests were run.
An extra test test case was added to CodeFormatterSuite to test the new maxLines parameter,
Author: pj.fanning <pj.fanning@workday.com>
Closes#18658 from pjfanning/SPARK-20871.
Executors run a thread pool with daemon threads to run tasks. This means
that those threads remain active when the JVM is shutting down, meaning
those tasks are affected by code that runs in shutdown hooks.
So if a shutdown hook messes with something that the task is using (e.g.
an HDFS connection), the task will fail and will report that failure to
the driver. That will make the driver mark the task as failed regardless
of what caused the executor to shut down. So, for example, if YARN pre-empted
that executor, the driver would consider that task failed when it should
instead ignore the failure.
This change avoids reporting failures to the driver when shutdown hooks
are executing; this fixes the YARN preemption accounting, and doesn't really
change things much for other scenarios, other than reporting a more generic
error ("Executor lost") when the executor shuts down unexpectedly - which
is arguably more correct.
Tested with a hacky app running on spark-shell that tried to cause failures
only when shutdown hooks were running, verified that preemption didn't cause
the app to fail because of task failures exceeding the threshold.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#18594 from vanzin/SPARK-20904.
## What changes were proposed in this pull request?
It's a follow-up of https://github.com/apache/spark/pull/18689 , which forgot to remove a useless test.
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#18716 from cloud-fan/test.
## What changes were proposed in this pull request?
Update the Quickstart and RDD programming guides to mention pip.
## How was this patch tested?
Built docs locally.
Author: Holden Karau <holden@us.ibm.com>
Closes#18698 from holdenk/SPARK-21434-add-pyspark-pip-documentation.
## What changes were proposed in this pull request?
This is a follow-up of #18680.
In some environment, a compile error happens saying:
```
.../sql/core/src/main/java/org/apache/spark/sql/execution/vectorized/ArrowColumnVector.java:243:
error: not found: type Array
public void loadBytes(Array array) {
^
```
This pr fixes it.
## How was this patch tested?
Existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#18701 from ueshin/issues/SPARK-21472_fup1.
## What changes were proposed in this pull request?
Minor change to kafka integration document for structured streaming.
## How was this patch tested?
N/A, doc change only.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#18550 from viirya/minor-ss-kafka-doc.
## What changes were proposed in this pull request?
DirectParquetOutputCommitter was removed from Spark as it was deemed unsafe to use. We however still have some code to generate warning. This patch removes those code as well.
This is kind of a follow-up of https://github.com/apache/spark/pull/16796
## How was this patch tested?
existing tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#18689 from cloud-fan/minor.
## What changes were proposed in this pull request?
Currently spark-streaming-kafka-0-10 has a dependency on the full kafka distribution (but only uses and requires the kafka-clients library).
The PR fixes that (the library only depends on kafka-clients), and the tests depend on the full kafka.
## How was this patch tested?
All existing tests still pass.
Author: Tim Van Wassenhove <github@timvw.be>
Closes#18353 from timvw/master.
## What changes were proposed in this pull request?
During writing to the .inprogress file (stored on the HDFS) Hadoop doesn't update file length until close and therefor Spark's history server can't detect any changes. We have to send UPDATE_LENGTH manually.
Author: Oleg Danilov <oleg.danilov@wandisco.com>
Closes#16924 from dosoft/SPARK-19531.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}