### What changes were proposed in this pull request?
Task duration distribution is also very important for us to judge whether a stage's task is skew enough.
### Why are the changes needed?
Add important information in TaskMetricsDistribution
### Does this PR introduce _any_ user-facing change?
People can see duration distribution from TaskMetricsDistribution
### How was this patch tested?
Existed UT
Closes#31948 from AngersZhuuuu/SPARK-34848.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
for binary lr, performance centering by subtracting the mean, if possible;
### Why are the changes needed?
for a feature with small std (i.e. 0.03), the scaled feature may have a large value (i.e. >30),
underlying solvers (**OWLQN/LBFGS/LBFGSB**) can not handle a feature with large values;
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
added testsuite
Closes#31693 from zhengruifeng/blr_center.
Authored-by: Ruifeng Zheng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
1. Add new expression `DivideDTInterval` which multiplies a `DayTimeIntervalType` expression by a `NumericType` expression including ByteType, ShortType, IntegerType, LongType, FloatType, DoubleType, DecimalType.
2. Extend binary arithmetic rules to support `day-time interval / numeric`.
### Why are the changes needed?
To conform the ANSI SQL standard which requires such operation over day-time intervals:
<img width="656" alt="Screenshot 2021-03-25 at 18 44 58" src="https://user-images.githubusercontent.com/1580697/112501559-68f07080-8d9a-11eb-8781-66e6631bb7ef.png">
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *IntervalExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31972 from MaxGekk/div-dt-interval-by-num.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Add new expression `DivideYMInterval` which multiplies a `YearMonthIntervalType` expression by a `NumericType` expression including ByteType, ShortType, IntegerType, LongType, FloatType, DoubleType, DecimalType.
2. Extend binary arithmetic rules to support `year-month interval / numeric`.
### Why are the changes needed?
To conform the ANSI SQL standard which requires such operation over year-month intervals:
<img width="656" alt="Screenshot 2021-03-25 at 18 44 58" src="https://user-images.githubusercontent.com/1580697/112501559-68f07080-8d9a-11eb-8781-66e6631bb7ef.png">
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *IntervalExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31961 from MaxGekk/div-ym-interval-by-num.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This pr improve the cost model in `pruningHasBenefit` for filtering side can not build broadcast by join type:
1. The filtering side must be small enough to build broadcast by size.
2. The estimated size of the pruning side must be big enough: `estimatePruningSideSize * spark.sql.optimizer.dynamicPartitionPruning.pruningSideExtraFilterRatio > overhead`.
### Why are the changes needed?
Improve query performance for these cases.
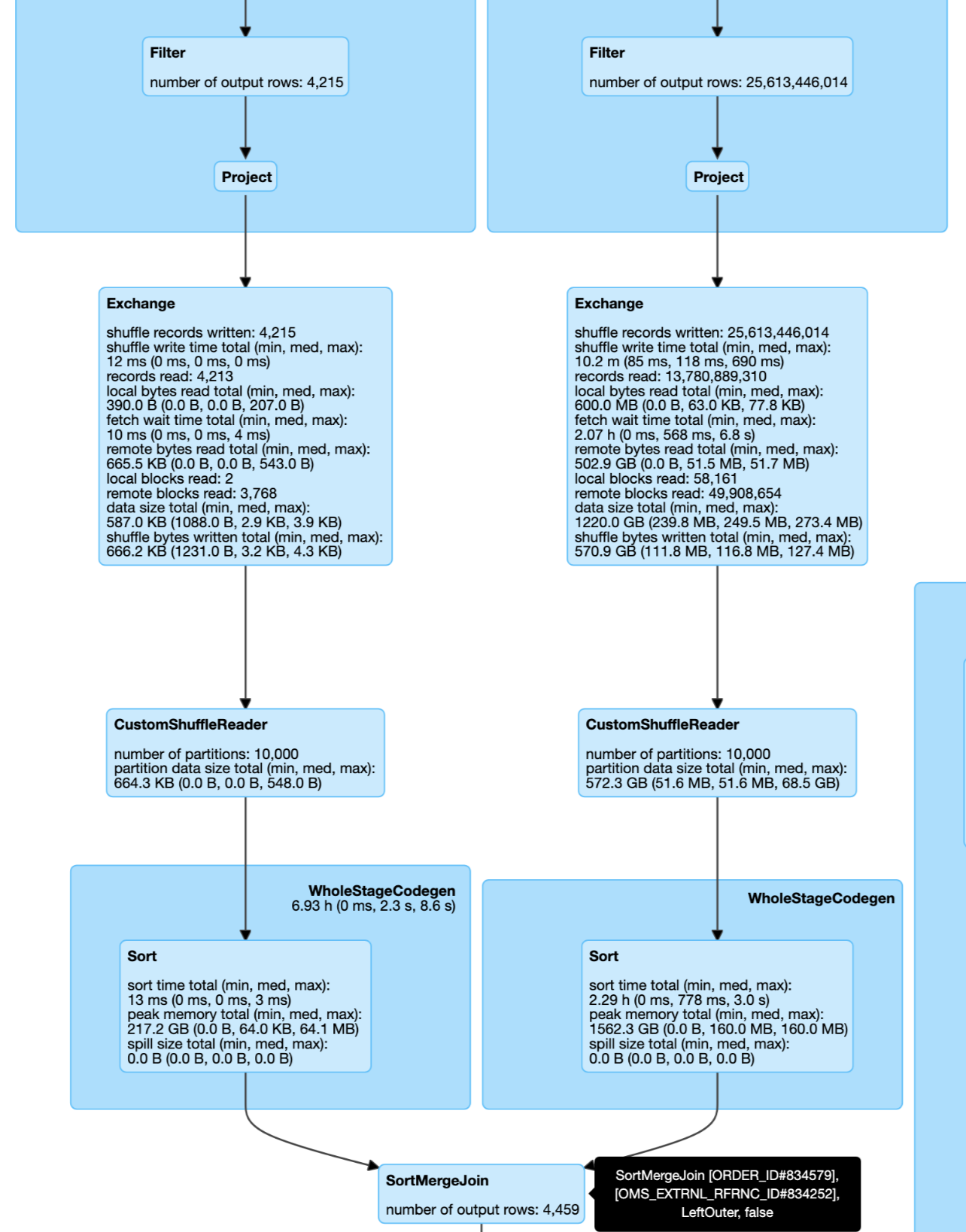
This a real case from cluster. Left join and left size very small and right side can build DPP:
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#29726 from wangyum/SPARK-32855.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
A companion PR for SPARK-34817, when we handle the unsigned int(<=32) logical types. In this PR, we map the unsigned int64 to decimal(20, 0) for better compatibility.
### Why are the changes needed?
Spark won't have unsigned types, but spark should be able to read existing parquet files written by other systems that support unsigned types for better compatibility.
### Does this PR introduce _any_ user-facing change?
yes, we can read parquet uint64 now
### How was this patch tested?
new unit tests
Closes#31960 from yaooqinn/SPARK-34786-2.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
Move the checkpoint location resolving into the rule ResolveWriteToStream, which is added in SPARK-34748.
### Why are the changes needed?
After SPARK-34748, we have a rule ResolveWriteToStream for the analysis logic for the resolving logic of stream write plans. Based on it, we can further move the checkpoint location resolving work in the rule. Then, all the checkpoint resolving logic was done in the analyzer.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing UT.
Closes#31963 from xuanyuanking/SPARK-34871.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/31940 . This PR generalizes the matching of attributes and outer references, so that outer references are handled everywhere.
Note that, currently correlated subquery has a lot of limitations in Spark, and the newly covered cases are not possible to happen. So this PR is a code refactor.
### Why are the changes needed?
code cleanup
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing tests
Closes#31959 from cloud-fan/follow.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR fixes bugs that causes corruption of push-merged blocks when a client terminates while pushing block. `RemoteBlockPushResolver` was introduced in #30062 (SPARK-32916).
There are 2 scenarios where the merged blocks get corrupted:
1. `StreamCallback.onFailure()` is called more than once. Initially we assumed that the onFailure callback will be called just once per stream. However, we observed that this is called twice when a client connection is reset. When the client connection is reset then there are 2 events that get triggered in this order.
- `exceptionCaught`. This event is propagated to `StreamInterceptor`. `StreamInterceptor.exceptionCaught()` invokes `callback.onFailure(streamId, cause)`. This is the first time StreamCallback.onFailure() will be invoked.
- `channelInactive`. Since the channel closes, the `channelInactive` event gets triggered which again is propagated to `StreamInterceptor`. `StreamInterceptor.channelInactive()` invokes `callback.onFailure(streamId, new ClosedChannelException())`. This is the second time StreamCallback.onFailure() will be invoked.
2. The flag `isWriting` is set prematurely to true. This introduces an edge case where a stream that is trying to merge a duplicate block (created because of a speculative task) may interfere with an active stream if the duplicate stream fails.
Also adding additional changes that improve the code.
1. Using positional writes all the time because this simplifies the code and with microbenchmarking haven't seen any performance impact.
2. Additional minor changes suggested by mridulm during an internal review.
### Why are the changes needed?
These are bug fixes and simplify the code.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added unit tests. I have also tested these changes in Linkedin's internal fork on a cluster.
Co-authored-by: Chandni Singh chsinghlinkedin.com
Co-authored-by: Min Shen mshenlinkedin.com
Closes#31934 from otterc/SPARK-32916-followup.
Lead-authored-by: Chandni Singh <singh.chandni@gmail.com>
Co-authored-by: Min Shen <mshen@linkedin.com>
Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com>
### What changes were proposed in this pull request?
Allow casting complex types as string type in ANSI mode.
### Why are the changes needed?
Currently, complex types are not allowed to cast as string type. This breaks the DataFrame.show() API. E.g
```
scala> sql(“select array(1, 2, 2)“).show(false)
org.apache.spark.sql.AnalysisException: cannot resolve ‘CAST(`array(1, 2, 2)` AS STRING)’ due to data type mismatch:
cannot cast array<int> to string with ANSI mode on.
```
We should allow the conversion as the extension of the ANSI SQL standard, so that the DataFrame.show() still work in ANSI mode.
### Does this PR introduce _any_ user-facing change?
Yes, casting complex types as string type is now allowed in ANSI mode.
### How was this patch tested?
Unit tests.
Closes#31954 from gengliangwang/fixExplicitCast.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
This PR groups exception messages in `execution/datasources/v2`.
### Why are the changes needed?
It will largely help with standardization of error messages and its maintenance.
### Does this PR introduce _any_ user-facing change?
No. Error messages remain unchanged.
### How was this patch tested?
No new tests - pass all original tests to make sure it doesn't break any existing behavior.
Closes#31619 from karenfeng/spark-33600.
Authored-by: Karen Feng <karen.feng@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Update the plan stability golden files even if only the `explain.txt` changes.
This is resubmition of #31927. The schema for one of the TPCDS tables was updated and that changed the `explain.txt` for the q17.
### Why are the changes needed?
Currently only `simplified.txt` change is checked. There are some PRs, that update the `explain.txt`, that do not change the `simplified.txt`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
The updated golden files.
Closes#31957 from tanelk/SPARK-34822_update_plan_stability.
Lead-authored-by: Tanel Kiis <tanel.kiis@gmail.com>
Co-authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Removed the custom toString implementation of AtLeastNNoneNulls.
### Why are the changes needed?
It shows up wrong in the explain plan. The name of the function is wrong and the actual value of the first argument is not shown. Both of these would make it easier to understand the plan.
```
(12) Filter
Input [3]: [c1#2410L, c2#2419, c3#2422]
Condition : AtLeastNNulls(n, c1#2410L)
```
### Does this PR introduce _any_ user-facing change?
Only the explain plan changes if this function is used.
### How was this patch tested?
Added a simple unit test to make sure that the toString output is correct.
Closes#31956 from timarmstrong/atleastnnonnulls.
Authored-by: Tim Armstrong <tim.armstrong@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. Add new expression `MultiplyDTInterval` which multiplies a `DayTimeIntervalType` expression by a `NumericType` expression including ByteType, ShortType, IntegerType, LongType, FloatType, DoubleType, DecimalType.
2. Extend binary arithmetic rules to support `numeric * day-time interval` and `day-time interval * numeric`.
3. Invoke `DoubleMath.roundToInt` in `double/float * year-month interval`.
### Why are the changes needed?
To conform the ANSI SQL standard which requires such operation over day-time intervals:
<img width="667" alt="Screenshot 2021-03-22 at 16 33 16" src="https://user-images.githubusercontent.com/1580697/111997810-77d1eb80-8b2c-11eb-951d-e43911d9c5db.png">
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *IntervalExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31951 from MaxGekk/mul-day-time-interval.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Unsigned types may be used to produce smaller in-memory representations of the data. These types used by frameworks(e.g. hive, pig) using parquet. And parquet will map them to its base types.
see more https://github.com/apache/parquet-format/blob/master/LogicalTypes.mdhttps://github.com/apache/parquet-format/blob/master/src/main/thrift/parquet.thrift
```thrift
/**
* An unsigned integer value.
*
* The number describes the maximum number of meaningful data bits in
* the stored value. 8, 16 and 32 bit values are stored using the
* INT32 physical type. 64 bit values are stored using the INT64
* physical type.
*
*/
UINT_8 = 11;
UINT_16 = 12;
UINT_32 = 13;
UINT_64 = 14;
```
```
UInt8-[0:255]
UInt16-[0:65535]
UInt32-[0:4294967295]
UInt64-[0:18446744073709551615]
```
In this PR, we support read UINT_8 as ShortType, UINT_16 as IntegerType, UINT_32 as LongType to fit their range. Support for UINT_64 will be in another PR.
### Why are the changes needed?
better parquet support
### Does this PR introduce _any_ user-facing change?
yes, we can read unit[8/16/32] from parquet files
### How was this patch tested?
new tests
Closes#31921 from yaooqinn/SPARK-34817.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to remove re-analyzing the already analyzed plan for `CreateViewCommand` as discussed https://github.com/apache/spark/pull/31273/files#r581592786.
### Why are the changes needed?
No need to analyze the plan if it's already analyzed.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests should cover this.
Closes#31933 from imback82/remove_analyzed_from_create_temp_view.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Wrap Hive sessionStae `close` with `withHiveState`
### Why are the changes needed?
Some reason:
1. Shutdown hook is invoked using different thread
2. Hive may use metasotre client again during closing
Otherwise, we may get such expcetion with custom hive metastore version
```
21/03/24 13:26:18 INFO session.SessionState: Failed to remove classloaders from DataNucleus
java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1654)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:80)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:130)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:101)
at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:3367)
at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:3406)
at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:3386)
at org.apache.hadoop.hive.ql.session.SessionState.unCacheDataNucleusClassLoaders(SessionState.java:1546)
at org.apache.hadoop.hive.ql.session.SessionState.close(SessionState.java:1536)
at org.apache.spark.sql.hive.client.HiveClientImpl.closeState(HiveClientImpl.scala:172)
at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$new$1(HiveClientImpl.scala:175)
at org.apache.spark.util.SparkShutdownHook.run(ShutdownHookManager.scala:214)
at org.apache.spark.util.SparkShutdownHookManager.$anonfun$runAll$2(ShutdownHookManager.scala:188)
```
### Does this PR introduce _any_ user-facing change?
No, since this not released.
### How was this patch tested?
manual test.
Closes#31949 from ulysses-you/SPARK-34852.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
This PR intends to fix the bug that does not apply right-padding for char types inside correlated subquries.
For example, a query below returns nothing in master, but a correct result is `c`.
```
scala> sql(s"CREATE TABLE t1(v VARCHAR(3), c CHAR(5)) USING parquet")
scala> sql(s"CREATE TABLE t2(v VARCHAR(5), c CHAR(7)) USING parquet")
scala> sql("INSERT INTO t1 VALUES ('c', 'b')")
scala> sql("INSERT INTO t2 VALUES ('a', 'b')")
scala> val df = sql("""
|SELECT v FROM t1
|WHERE 'a' IN (SELECT v FROM t2 WHERE t2.c = t1.c )""".stripMargin)
scala> df.show()
+---+
| v|
+---+
+---+
```
This is because `ApplyCharTypePadding` does not handle the case above to apply right-padding into `'abc'`. This PR modifies the code in `ApplyCharTypePadding` for handling it correctly.
```
// Before this PR:
scala> df.explain(true)
== Analyzed Logical Plan ==
v: string
Project [v#13]
+- Filter a IN (list#12 [c#14])
: +- Project [v#15]
: +- Filter (c#16 = outer(c#14))
: +- SubqueryAlias spark_catalog.default.t2
: +- Relation default.t2[v#15,c#16] parquet
+- SubqueryAlias spark_catalog.default.t1
+- Relation default.t1[v#13,c#14] parquet
scala> df.show()
+---+
| v|
+---+
+---+
// After this PR:
scala> df.explain(true)
== Analyzed Logical Plan ==
v: string
Project [v#43]
+- Filter a IN (list#42 [c#44])
: +- Project [v#45]
: +- Filter (c#46 = rpad(outer(c#44), 7, ))
: +- SubqueryAlias spark_catalog.default.t2
: +- Relation default.t2[v#45,c#46] parquet
+- SubqueryAlias spark_catalog.default.t1
+- Relation default.t1[v#43,c#44] parquet
scala> df.show()
+---+
| v|
+---+
| c|
+---+
```
This fix is lated to TPCDS q17; the query returns nothing because of this bug: https://github.com/apache/spark/pull/31886/files#r599333799
### Why are the changes needed?
Bugfix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit tests added.
Closes#31940 from maropu/FixCharPadding.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
1, add `BinaryLogisticBlockAggregator` and `MultinomialLogisticBlockAggregator` and related testsuites;
2, impl `virtual centering` in standardization;
3, remove old `LogisticAggregator`
### Why are the changes needed?
previous [pr](https://github.com/apache/spark/pull/31693) and related works is too large, we need to split it into 3 prs:
1, this one, impl new agg supporting `virtual centering`, remove old `LogisticAggregator`;
2, adopt new blor-agg in lor, add new test suite for small var features;
3, adopt new mlor-agg in lor, add new test suite for small var features, remove `BlockLogisticAggregator`;
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
added testsuites
Closes#31889 from zhengruifeng/blor_mlor_agg.
Authored-by: Ruifeng Zheng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Currently, when implicit casting a data type to a `TypeCollection`, Spark returns the first convertible data type among `TypeCollection`.
In ANSI mode, we can make the behavior more reasonable by returning the closet convertible data type in `TypeCollection`.
In details, we first try to find the all the expected types we can implicitly cast:
1. if there is no convertible data types, return None;
2. if there is only one convertible data type, cast input as it;
3. otherwise if there are multiple convertible data types, find the closet data
type among them. If there is no such closet data type, return None.
Note that if the closet type is Float type and the convertible types contains Double type, simply return Double type as the closet type to avoid potential
precision loss on converting the Integral type as Float type.
### Why are the changes needed?
Make the type coercion rule for TypeCollection more reasonable and ANSI compatible.
E.g. returning Long instead of Double for`implicast(int, TypeCollect(Double, Long))`.
From ANSI SQL Spec section 4.33 "SQL-invoked routines"

Section 9.6 "Subject routine determination"

Section 10.4 "routine invocation"

### Does this PR introduce _any_ user-facing change?
Yes, in ANSI mode, implicit casting to a `TypeCollection` returns the narrowest convertible data type instead of the first convertible one.
### How was this patch tested?
Unit tests.
Closes#31859 from gengliangwang/implicitCastTypeCollection.
Lead-authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Co-authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Update the plan stability golden files even if only the `explain.txt` changes.
### Why are the changes needed?
Currently only `simplified.txt` change is checked. There are some PRs, that update the `explain.txt`, that do not change the `simplified.txt`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
The updated golden files.
Closes#31927 from tanelk/SPARK-34822_update_plan_stability.
Lead-authored-by: Tanel Kiis <tanel.kiis@gmail.com>
Co-authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR implements the missing typehints as per SPARK-34630.
### Why are the changes needed?
To satisfy the aforementioned Jira ticket
### Does this PR introduce _any_ user-facing change?
No, just adding a missing typehint for Project Zen
### How was this patch tested?
No tests needed (just adding a typehint)
Closes#31823 from dannymeijer/feature/SPARK-34630.
Authored-by: Danny Meijer <danny.meijer@nike.com>
Signed-off-by: zero323 <mszymkiewicz@gmail.com>
### What changes were proposed in this pull request?
Both local limit and global limit define the output partitioning and output ordering in the same way and this is duplicated (https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/limit.scala#L159-L175 ). We can move the output partitioning and ordering into their parent trait - `BaseLimitExec`. This is doable as `BaseLimitExec` has no more other child class. This is a minor code refactoring.
### Why are the changes needed?
Clean up the code a little bit. Better readability.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pure refactoring. Rely on existing unit tests.
Closes#31950 from c21/limit-cleanup.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
For a specific stage, it is useful to show the task metrics in percentile distribution. This information can help users know whether or not there is a skew/bottleneck among tasks in a given stage. We list an example in taskMetricsDistributions.json
Similarly, it is useful to show the executor metrics in percentile distribution for a specific stage. This information can show whether or not there is a skewed load on some executors. We list an example in executorMetricsDistributions.json
We define `withSummaries` and `quantiles` query parameter in the REST API for a specific stage as:
applications/<application_id>/<application_attempt/stages/<stage_id>/<stage_attempt>?withSummaries=[true|false]& quantiles=0.05,0.25,0.5,0.75,0.95
1. withSummaries: default is false, define whether to show current stage's taskMetricsDistribution and executorMetricsDistribution
2. quantiles: default is `0.0,0.25,0.5,0.75,1.0` only effect when `withSummaries=true`, it define the quantiles we use when calculating metrics distributions.
When withSummaries=true, both task metrics in percentile distribution and executor metrics in percentile distribution are included in the REST API output. The default value of withSummaries is false, i.e. no metrics percentile distribution will be included in the REST API output.
### Why are the changes needed?
For a specific stage, it is useful to show the task metrics in percentile distribution. This information can help users know whether or not there is a skew/bottleneck among tasks in a given stage. We list an example in taskMetricsDistributions.json
### Does this PR introduce _any_ user-facing change?
User can use below restful API to get task metrics distribution and executor metrics distribution for indivial stage
```
applications/<application_id>/<application_attempt/stages/<stage_id>/<stage_attempt>?withSummaries=[true|false]
```
### How was this patch tested?
Added UT
Closes#31611 from AngersZhuuuu/SPARK-34488.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This patch adds a config `spark.yarn.kerberos.renewal.excludeHadoopFileSystems` which lists the filesystems to be excluded from delegation token renewal at YARN.
### Why are the changes needed?
MapReduce jobs can instruct YARN to skip renewal of tokens obtained from certain hosts by specifying the hosts with configuration mapreduce.job.hdfs-servers.token-renewal.exclude=<host1>,<host2>,..,<hostN>.
But seems Spark lacks of similar option. So the job submission fails if YARN fails to renew DelegationToken for any of the remote HDFS cluster. The failure in DT renewal can happen due to many reason like Remote HDFS does not trust Kerberos identity of YARN etc. We have a customer facing such issue.
### Does this PR introduce _any_ user-facing change?
No, if the config is not set. Yes, as users can use this config to instruct YARN not to renew delegation token from certain filesystems.
### How was this patch tested?
It is hard to do unit test for this. We did verify it work from the customer using this fix in the production environment.
Closes#31761 from viirya/SPARK-34295.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
1) Modify `GenericAvroSerializer` to support serialization of any `GenericContainer`
2) Register `KryoSerializer`s for `GenericData.{Array, EnumSymbol, Fixed}` using the modified `GenericAvroSerializer`
### Why are the changes needed?
Without this change, Kryo throws NPEs when trying to serialize `GenericData.{Array, EnumSymbol, Fixed}`. More details in SPARK-34477 Jira
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added unit tests for testing roundtrip serialization and deserialization of `GenericData.{Array, EnumSymbol, Fixed}` using `GenericAvroSerializer` directly and also indirectly through `KryoSerializer`
Closes#31597 from shardulm94/avro-array-serializer.
Authored-by: Shardul Mahadik <smahadik@linkedin.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
SPARK-32160 add a config(`EXECUTOR_ALLOW_SPARK_CONTEXT`) to switch allow/disallow to create `SparkContext` in executors and the default value of the config is `false`
`ExternalAppendOnlyUnsafeRowArrayBenchmark` will run fail when `EXECUTOR_ALLOW_SPARK_CONTEXT` use the default value because the `ExternalAppendOnlyUnsafeRowArrayBenchmark#withFakeTaskContext` method try to create a `SparkContext` manually in Executor Side.
So the main change of this pr is set `EXECUTOR_ALLOW_SPARK_CONTEXT` to `true` to ensure `ExternalAppendOnlyUnsafeRowArrayBenchmark` run successfully.
### Why are the changes needed?
Bug fix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual test:
```
bin/spark-submit --class org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark --jars spark-core_2.12-3.2.0-SNAPSHOT-tests.jar spark-sql_2.12-3.2.0-SNAPSHOT-tests.jar
```
**Before**
```
Exception in thread "main" java.lang.IllegalStateException: SparkContext should only be created and accessed on the driver.
at org.apache.spark.SparkContext$.org$apache$spark$SparkContext$$assertOnDriver(SparkContext.scala:2679)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:89)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:137)
at org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark$.withFakeTaskContext(ExternalAppendOnlyUnsafeRowArrayBenchmark.scala:52)
at org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark$.testAgainstRawArrayBuffer(ExternalAppendOnlyUnsafeRowArrayBenchmark.scala:119)
at org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark$.$anonfun$runBenchmarkSuite$1(ExternalAppendOnlyUnsafeRowArrayBenchmark.scala:189)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.benchmark.BenchmarkBase.runBenchmark(BenchmarkBase.scala:40)
at org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark$.runBenchmarkSuite(ExternalAppendOnlyUnsafeRowArrayBenchmark.scala:186)
at org.apache.spark.benchmark.BenchmarkBase.main(BenchmarkBase.scala:58)
at org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark.main(ExternalAppendOnlyUnsafeRowArrayBenchmark.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:951)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1030)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1039)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
```
**After**
`ExternalAppendOnlyUnsafeRowArrayBenchmark` run successfully.
Closes#31939 from LuciferYang/SPARK-34832.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR fixes an issue that `col()`, `$"<name>"` and `df("name")` don't handle quoted column names like ``` `a``b.c` ```properly.
For example, if we have a following DataFrame.
```
val df1 = spark.sql("SELECT 'col1' AS `a``b.c`")
```
For the DataFrame, this query is successfully executed.
```
scala> df1.selectExpr("`a``b.c`").show
+-----+
|a`b.c|
+-----+
| col1|
+-----+
```
But the following query will fail because ``` df1("`a``b.c`") ``` throws an exception.
```
scala> df1.select(df1("`a``b.c`")).show
org.apache.spark.sql.AnalysisException: syntax error in attribute name: `a``b.c`;
at org.apache.spark.sql.catalyst.analysis.UnresolvedAttribute$.e$1(unresolved.scala:152)
at org.apache.spark.sql.catalyst.analysis.UnresolvedAttribute$.parseAttributeName(unresolved.scala:162)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveQuoted(LogicalPlan.scala:121)
at org.apache.spark.sql.Dataset.resolve(Dataset.scala:221)
at org.apache.spark.sql.Dataset.col(Dataset.scala:1274)
at org.apache.spark.sql.Dataset.apply(Dataset.scala:1241)
... 49 elided
```
### Why are the changes needed?
It's a bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New tests.
Closes#31854 from sarutak/fix-parseAttributeName.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Support submit to k8s only with token.
### Why are the changes needed?
Now, sumbit to k8s always need oauth files.
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Before, submit job out of k8s cluster without correct ca.crt, we may get this exception:
```
Caused by: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at sun.security.validator.PKIXValidator.doBuild(PKIXValidator.java:439)
at sun.security.validator.PKIXValidator.engineValidate(PKIXValidator.java:306)
at sun.security.validator.Validator.validate(Validator.java:271)
at sun.security.ssl.X509TrustManagerImpl.validate(X509TrustManagerImpl.java:312)
```
When set spark.kubernetes.trust.certificates = true, we can submit only with correct token, no need to config ca.crt in local env.
Submit as:
```
bin/spark-submit \
--master $master \
--name pi \
--deploy-mode cluster \
--conf spark.kubernetes.container.image=$image \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \
--conf spark.kubernetes.authenticate.submission.oauthToken=$clusterToken \
--conf spark.kubernetes.trust.certificates=true \
local:///opt/spark/examples/src/main/python/pi.py 200
```
Closes#30684 from hddong/trust-certs.
Authored-by: hongdongdong <hongdongdong@cmss.chinamobile.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
SPARK-34842 (#31012) has a typo in the type of `date_dim.d_quarter_name` in the TPCDS schema (`TPCDSBase`). This PR replace `CHAR(1)` with `CHAR(6)`. This fix comes from p28 in [the TPCDS official doc](http://www.tpc.org/tpc_documents_current_versions/pdf/tpc-ds_v2.9.0.pdf).
### Why are the changes needed?
Bugfix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
N/A
Closes#31943 from maropu/SPARK-34083-FOLLOWUP.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
1. Add new expression `MultiplyYMInterval` which multiplies a `YearMonthIntervalType` expression by a `NumericType` expression including ByteType, ShortType, IntegerType, LongType, FloatType, DoubleType, DecimalType.
2. Extend binary arithmetic rules to support `numeric * year-month interval` and `year-month interval * numeric`.
### Why are the changes needed?
To conform the ANSI SQL standard which requires such operation over year-month intervals:
<img width="667" alt="Screenshot 2021-03-22 at 16 33 16" src="https://user-images.githubusercontent.com/1580697/111997810-77d1eb80-8b2c-11eb-951d-e43911d9c5db.png">
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *IntervalExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31929 from MaxGekk/interval-mul-div.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
the given example uses a non-standard syntax for CREATE TABLE, by defining the partitioning column with the other columns, instead of in PARTITION BY.
This works is this case, because the partitioning column happens to be the last column defined, but it will break if instead 'name' would be used for partitioning.
I suggest therefore to change the example to use a standard syntax, like in
https://spark.apache.org/docs/3.1.1/sql-ref-syntax-ddl-create-table-hiveformat.html
### Why are the changes needed?
To show the better documentation.
### Does this PR introduce _any_ user-facing change?
Yes, this fixes the user-facing docs.
### How was this patch tested?
CI should test it out.
Closes#31900 from robert4os/patch-1.
Authored-by: robert4os <robert4os@users.noreply.github.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
forward-port https://github.com/apache/spark/pull/31811 to master
### What changes were proposed in this pull request?
For permanent views (and the new SQL temp view in Spark 3.1), we store the view SQL text and re-parse/analyze the view SQL text when reading the view. In the case of `SELECT * FROM ...`, we want to avoid view schema change (e.g. the referenced table changes its schema) and will record the view query output column names when creating the view, so that when reading the view we can add a `SELECT recorded_column_names FROM ...` to retain the original view query schema.
In Spark 3.1 and before, the final SELECT is added after the analysis phase: https://github.com/apache/spark/blob/branch-3.1/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/view.scala#L67
If the view query has duplicated output column names, we always pick the first column when reading a view. A simple repro:
```
scala> sql("create view c(x, y) as select 1 a, 2 a")
res0: org.apache.spark.sql.DataFrame = []
scala> sql("select * from c").show
+---+---+
| x| y|
+---+---+
| 1| 1|
+---+---+
```
In the master branch, we will fail at the view reading time due to b891862fb6 , which adds the final SELECT during analysis, so that the query fails with `Reference 'a' is ambiguous`
This PR proposes to resolve the view query output column names from the matching attributes by ordinal.
For example, `create view c(x, y) as select 1 a, 2 a`, the view query output column names are `[a, a]`. When we reading the view, there are 2 matching attributes (e.g.`[a#1, a#2]`) and we can simply match them by ordinal.
A negative example is
```
create table t(a int)
create view v as select *, 1 as col from t
replace table t(a int, col int)
```
When reading the view, the view query output column names are `[a, col]`, and there are two matching attributes of `col`, and we should fail the query. See the tests for details.
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
yes
### How was this patch tested?
new test
Closes#31930 from cloud-fan/view2.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch proposes to add a few public API change to DS v2, to make DS v2 scan can report metrics to Spark.
Two public interfaces are added.
* `CustomMetric`: metric interface at the driver side. It basically defines how Spark aggregates task metrics with the same metric name.
* `CustomTaskMetric`: task metric reported at executors. It includes a name and long value. Spark will collect these metric values and update internal metrics.
There are two public methods added to existing public interfaces. They are optional to DS v2 implementations.
* `PartitionReader.currentMetricsValues()`: returns an array of CustomTaskMetric. Here is where the actual metrics values are collected. Empty array by default.
* `Scan.supportedCustomMetrics()`: returns an array of supported custom metrics `CustomMetric`. Empty array by default.
### Why are the changes needed?
In order to report custom metrics, we need some public API change in DS v2 to make it possible.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
This only adds interfaces. In follow-up PRs where adding implementation there will be tests added. See #31451 and #31398 for some details and manual test there.
Closes#31476 from viirya/SPARK-34366.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This bug was introduced by SPARK-30428 at Apache Spark 3.0.0.
This PR fixes `FileScan.equals()`.
### Why are the changes needed?
- Without this fix `FileScan.equals` doesn't take `fileIndex` and `readSchema` into account.
- Partition filters and data filters added to `FileScan` (in #27112 and #27157) caused that canonicalized form of some `BatchScanExec` nodes don't match and this prevents some reuse possibilities.
### Does this PR introduce _any_ user-facing change?
Yes, before this fix incorrect reuse of `FileScan` and so `BatchScanExec` could have happed causing correctness issues.
### How was this patch tested?
Added new UTs.
Closes#31848 from peter-toth/SPARK-34756-fix-filescan-equality-check.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Move `ExecutionListenerBus` register (both `ListenerBus` and `ContextCleaner` register) into itself.
Also with a minor change that put `registerSparkListenerForCleanup` to a better place.
### Why are the changes needed?
improve code
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass existing tests.
Closes#31919 from Ngone51/SPARK-34087-followup.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Current link for `Azure Blob Storage and Azure Datalake Gen 2` leads to AWS information. Replacing the link to point to the right page.
### Why are the changes needed?
For users to access to the correct link.
### Does this PR introduce _any_ user-facing change?
Yes, it fixes the link correctly.
### How was this patch tested?
N/A
Closes#31938 from lenadroid/patch-1.
Authored-by: Lena <alehall@microsoft.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This patch proposes to disable fetching shuffle blocks in batch when io encryption is enabled. Adaptive Query Execution fetch contiguous shuffle blocks for the same map task in batch to reduce IO and improve performance. However, we found that batch fetching is incompatible with io encryption.
### Why are the changes needed?
Before this patch, we set `spark.io.encryption.enabled` to true, then run some queries which coalesced partitions by AEQ, may got following error message:
```14:05:52.638 WARN org.apache.spark.scheduler.TaskSetManager: Lost task 1.0 in stage 2.0 (TID 3) (11.240.37.88 executor driver): FetchFailed(BlockManagerId(driver, 11.240.37.88, 63574, None), shuffleId=0, mapIndex=0, mapId=0, reduceId=2, message=
org.apache.spark.shuffle.FetchFailedException: Stream is corrupted
at org.apache.spark.storage.ShuffleBlockFetcherIterator.throwFetchFailedException(ShuffleBlockFetcherIterator.scala:772)
at org.apache.spark.storage.BufferReleasingInputStream.read(ShuffleBlockFetcherIterator.scala:845)
at java.io.BufferedInputStream.fill(BufferedInputStream.java:246)
at java.io.BufferedInputStream.read(BufferedInputStream.java:265)
at java.io.DataInputStream.readInt(DataInputStream.java:387)
at org.apache.spark.sql.execution.UnsafeRowSerializerInstance$$anon$2$$anon$3.readSize(UnsafeRowSerializer.scala:113)
at org.apache.spark.sql.execution.UnsafeRowSerializerInstance$$anon$2$$anon$3.next(UnsafeRowSerializer.scala:129)
at org.apache.spark.sql.execution.UnsafeRowSerializerInstance$$anon$2$$anon$3.next(UnsafeRowSerializer.scala:110)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:494)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:459)
at org.apache.spark.util.CompletionIterator.next(CompletionIterator.scala:29)
at org.apache.spark.InterruptibleIterator.next(InterruptibleIterator.scala:40)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:459)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:345)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:898)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:898)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:498)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1437)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:501)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.io.IOException: Stream is corrupted
at net.jpountz.lz4.LZ4BlockInputStream.refill(LZ4BlockInputStream.java:200)
at net.jpountz.lz4.LZ4BlockInputStream.refill(LZ4BlockInputStream.java:226)
at net.jpountz.lz4.LZ4BlockInputStream.read(LZ4BlockInputStream.java:157)
at org.apache.spark.storage.BufferReleasingInputStream.read(ShuffleBlockFetcherIterator.scala:841)
... 25 more
)
```
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
New tests.
Closes#31898 from hezuojiao/fetch_shuffle_in_batch.
Authored-by: hezuojiao <hezuojiao@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
We added the gnupg installation in https://github.com/apache/spark/pull/30130 , we should do apt update before gnupg isntallation, otherwise we will get a fetch error when package is updated.
See more in:
[1] http://apache-spark-developers-list.1001551.n3.nabble.com/K8s-Integration-test-is-unable-to-run-because-of-the-unavailable-libs-td30986.html
### Why are the changes needed?
add a apt-update cmd before gnupg installation to avoid invaild package cache list.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
K8s Integration test passed
Closes#31923 from Yikun/SPARK-34820.
Authored-by: Yikun Jiang <yikunkero@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Remove the unused variable 'secMgr' in SparkSubmit.scala and DriverWrapper.scala
In jira https://issues.apache.org/jira/browse/SPARK-33925, The last usage of SecurityManager in Utils.fetchFile was removed. We don't need the variable anymore
### Why are the changes needed?
For better readablity of codes
### Does this PR introduce _any_ user-facing change?
No,dev-only
### How was this patch tested?
Manually complied. Github Actions and Jenkins build should test it out as well.
Closes#31928 from Peng-Lei/rm_secMgr.
Authored-by: PengLei <18066542445@189.cn>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Marked `RowNumberLike` and `RankLike` as not-nullable.
### Why are the changes needed?
`RowNumberLike` and `RankLike` SQL expressions never return null value. Marking them as non-nullable can have some performance benefits, because some optimizer rules apply only to non-nullable expressions
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Did not find any existing tests on the nullability of aggregate functions.
Plan stability suite partially covers this.
Closes#31924 from tanelk/SPARK-34812_nullability.
Authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Pass the raised `ImportError` on failing to import pandas/pyarrow. This will help the user identify whether pandas/pyarrow are indeed not in the environment or if they threw a different `ImportError`.
### Why are the changes needed?
This can already happen in Pandas for example where it could throw an `ImportError` on its initialisation path if `dateutil` doesn't satisfy a certain version requirement https://github.com/pandas-dev/pandas/blob/0.24.x/pandas/compat/__init__.py#L438
### Does this PR introduce _any_ user-facing change?
Yes, it will now show the root cause of the exception when pandas or arrow is missing during import.
### How was this patch tested?
Manually tested.
```python
from pyspark.sql.functions import pandas_udf
spark.range(1).select(pandas_udf(lambda x: x))
```
Before:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/...//spark/python/pyspark/sql/pandas/functions.py", line 332, in pandas_udf
require_minimum_pyarrow_version()
File "/.../spark/python/pyspark/sql/pandas/utils.py", line 53, in require_minimum_pyarrow_version
raise ImportError("PyArrow >= %s must be installed; however, "
ImportError: PyArrow >= 1.0.0 must be installed; however, it was not found.
```
After:
```
Traceback (most recent call last):
File "/.../spark/python/pyspark/sql/pandas/utils.py", line 49, in require_minimum_pyarrow_version
import pyarrow
ModuleNotFoundError: No module named 'pyarrow'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/.../spark/python/pyspark/sql/pandas/functions.py", line 332, in pandas_udf
require_minimum_pyarrow_version()
File "/.../spark/python/pyspark/sql/pandas/utils.py", line 55, in require_minimum_pyarrow_version
raise ImportError("PyArrow >= %s must be installed; however, "
ImportError: PyArrow >= 1.0.0 must be installed; however, it was not found.
```
Closes#31902 from johnhany97/jayad/spark-34803.
Lead-authored-by: John Ayad <johnhany97@gmail.com>
Co-authored-by: John H. Ayad <johnhany97@gmail.com>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Update the Avro version to 1.10.2
### Why are the changes needed?
To stay up to date with upstream and catch compatibility issues with zstd
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests
Closes#31866 from iemejia/SPARK-27733-upgrade-avro-1.10.2.
Authored-by: Ismaël Mejía <iemejia@gmail.com>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request?
Use fine-grained lock in SessionCatalog.tableExists, in order to lock currentDB variable rather than lock `tableExists` method which will block inner external catalog's behaviour.
### Why are the changes needed?
We have modified the underlying hive meta store which a different hive database is placed in its own shard for performance. However, we found that the synchronized lock limits the concurrency.
### How was this patch tested?
Existing tests.
Closes#31891 from woyumen4597/SPARK-34800.
Authored-by: woyumen4597 <woyumen4597@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Now that all the temporary views are wrapped with `TemporaryViewRelation`(#31273, #31652, and #31825), this PR proposes to update `SessionCatalog`'s APIs for temporary views to take or return more concrete types.
APIs that will take `TemporaryViewRelation` instead of `LogicalPlan`:
```
createTempView, createGlobalTempView, alterTempViewDefinition
```
APIs that will return `TemporaryViewRelation` instead of `LogicalPlan`:
```
getRawTempView, getRawGlobalTempView
```
APIs that will return `View` instead of `LogicalPlan`:
```
getTempView, getGlobalTempView, lookupTempView
```
### Why are the changes needed?
Internal refactoring to work with more concrete types.
### Does this PR introduce _any_ user-facing change?
No, this is internal refactoring.
### How was this patch tested?
Updated existing tests affected by the refactoring.
Closes#31906 from imback82/use_temporary_view_relation.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes the `HybridRowQueue ` to respect the configured memory mode.
Besides, this PR also refactored the constructor of `MemoryConsumer` to accept the memory mode explicitly.
### Why are the changes needed?
`HybridRowQueue` supports both onHeap and offHeap manipulation. But it inherited the wrong `MemoryConsumer` constructor, which hard-coded the memory mode to `onHeap`.
### Does this PR introduce _any_ user-facing change?
No. (Maybe yes in some cases where users can't complete the job before could complete successfully after the fix because of `HybridRowQueue` is able to spill under offHeap mode now. )
### How was this patch tested?
Updated the existing test to make it test both offHeap and onHeap modes.
Closes#31152 from Ngone51/fix-MemoryConsumer-memorymode.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}