### What changes were proposed in this pull request?
Add toc tag on monitoring.md
### Why are the changes needed?
fix doc
### Does this PR introduce _any_ user-facing change?
yes, the table of content of the monitoring page will be shown on the official doc site.
### How was this patch tested?
pass GA doc build
Closes#32545 from yaooqinn/minor.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
Generally, we would expect that x = y => hash( x ) = hash( y ). However +-0 hash to different values for floating point types.
```
scala> spark.sql("select hash(cast('0.0' as double)), hash(cast('-0.0' as double))").show
+-------------------------+--------------------------+
|hash(CAST(0.0 AS DOUBLE))|hash(CAST(-0.0 AS DOUBLE))|
+-------------------------+--------------------------+
| -1670924195| -853646085|
+-------------------------+--------------------------+
scala> spark.sql("select cast('0.0' as double) == cast('-0.0' as double)").show
+--------------------------------------------+
|(CAST(0.0 AS DOUBLE) = CAST(-0.0 AS DOUBLE))|
+--------------------------------------------+
| true|
+--------------------------------------------+
```
Here is an extract from IEEE 754:
> The two zeros are distinguishable arithmetically only by either division-byzero ( producing appropriately signed infinities ) or else by the CopySign function recommended by IEEE 754 /854. Infinities, SNaNs, NaNs and Subnormal numbers necessitate four more special cases
From this, I deduce that the hash function must produce the same result for 0 and -0.
### Why are the changes needed?
It is a correctness issue
### Does this PR introduce _any_ user-facing change?
This changes only affect to the hash function applied to -0 value in float and double types
### How was this patch tested?
Unit testing and manual testing
Closes#32496 from planga82/feature/spark35207_hashnegativezero.
Authored-by: Pablo Langa <soypab@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In this PR I'm adding Structured Streaming Web UI state information documentation.
### Why are the changes needed?
Missing documentation.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
```
cd docs/
SKIP_API=1 bundle exec jekyll build
```
Manual webpage check.
Closes#32433 from gaborgsomogyi/SPARK-35311.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This proposes to document the available metrics for ExecutorAllocationManager in the Spark monitoring documentation.
### Why are the changes needed?
The ExecutorAllocationManager is instrumented with metrics using the Spark metrics system.
The relevant work is in SPARK-7007 and SPARK-33763
ExecutorAllocationManager metrics are currently undocumented.
### Does this PR introduce _any_ user-facing change?
This PR adds documentation only.
### How was this patch tested?
na
Closes#32500 from LucaCanali/followupMetricsDocSPARK33763.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR proposes to introduces three new configurations to limit the maximum number of jobs/stages/executors on the timeline view.
### Why are the changes needed?
If the number of items on the timeline view grows +1000, rendering can be significantly slow.
https://issues.apache.org/jira/browse/SPARK-35229
The maximum number of tasks on the timeline is already limited by `spark.ui.timeline.tasks.maximum` so l proposed to mitigate this issue with the same manner.
### Does this PR introduce _any_ user-facing change?
Yes. the maximum number of items shown on the timeline view is limited.
I proposed the default value 500 for jobs and stages, and 250 for executors.
A executor has at most 2 items (added and removed) 250 is chosen.
### How was this patch tested?
I manually confirm this change works with the following procedures.
```
# launch a cluster
$ bin/spark-shell --conf spark.ui.retainedDeadExecutors=300 --master "local-cluster[4, 1, 1024]"
// Confirm the maximum number of jobs
(1 to 1000).foreach { _ => sc.parallelize(List(1)).collect }
// Confirm the maximum number of stages
var df = sc.parallelize(1 to 2)
(1 to 1000).foreach { i => df = df.repartition(i % 5 + 1) }
df.collect
// Confirm the maximum number of executors
(1 to 300).foreach { _ => try sc.parallelize(List(1)).foreach { _ => System.exit(0) } catch { case e => }}
```
Screenshots here.



Closes#32381 from sarutak/mitigate-timeline-issue.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
1. Extend Spark SQL parser to support parsing of:
- `INTERVAL YEAR TO MONTH` to `YearMonthIntervalType`
- `INTERVAL DAY TO SECOND` to `DayTimeIntervalType`
2. Assign new names to the ANSI interval types according to the SQL standard to be able to parse the names back by Spark SQL parser. Override the `typeName()` name of `YearMonthIntervalType`/`DayTimeIntervalType`.
### Why are the changes needed?
To be able to use new ANSI interval types in SQL. The SQL standard requires the types to be defined according to the rules:
```
<interval type> ::= INTERVAL <interval qualifier>
<interval qualifier> ::= <start field> TO <end field> | <single datetime field>
<start field> ::= <non-second primary datetime field> [ <left paren> <interval leading field precision> <right paren> ]
<end field> ::= <non-second primary datetime field> | SECOND [ <left paren> <interval fractional seconds precision> <right paren> ]
<primary datetime field> ::= <non-second primary datetime field | SECOND
<non-second primary datetime field> ::= YEAR | MONTH | DAY | HOUR | MINUTE
<interval fractional seconds precision> ::= <unsigned integer>
<interval leading field precision> ::= <unsigned integer>
```
Currently, Spark SQL supports only `YEAR TO MONTH` and `DAY TO SECOND` as `<interval qualifier>`.
### Does this PR introduce _any_ user-facing change?
Should not since the types has not been released yet.
### How was this patch tested?
By running the affected tests such as:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "test:testOnly *ExpressionTypeCheckingSuite"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z windowFrameCoercion.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z literals.sql"
```
Closes#32409 from MaxGekk/parse-ansi-interval-types.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR extends `ADD FILE/JAR/ARCHIVE` commands to be able to take multiple path arguments like Hive.
### Why are the changes needed?
To make those commands more useful.
### Does this PR introduce _any_ user-facing change?
Yes. In the current implementation, those commands can take a path which contains whitespaces without enclose it by neither `'` nor `"` but after this change, users need to enclose such paths.
I've note this incompatibility in the migration guide.
### How was this patch tested?
New tests.
Closes#32205 from sarutak/add-multiple-files.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
This PR proposes to introduce a new JDBC option `refreshKrb5Config` which allows to reflect the change of `krb5.conf`.
### Why are the changes needed?
In the current master, JDBC datasources can't accept `refreshKrb5Config` which is defined in `Krb5LoginModule`.
So even if we change the `krb5.conf` after establishing a connection, the change will not be reflected.
The similar issue happens when we run multiple `*KrbIntegrationSuites` at the same time.
`MiniKDC` starts and stops every KerberosIntegrationSuite and different port number is recorded to `krb5.conf`.
Due to `SecureConnectionProvider.JDBCConfiguration` doesn't take `refreshKrb5Config`, KerberosIntegrationSuites except the first running one see the wrong port so those suites fail.
You can easily confirm with the following command.
```
build/sbt -Phive Phive-thriftserver -Pdocker-integration-tests "testOnly org.apache.spark.sql.jdbc.*KrbIntegrationSuite"
```
### Does this PR introduce _any_ user-facing change?
Yes. Users can set `refreshKrb5Config` to refresh krb5 relevant configuration.
### How was this patch tested?
New test.
Closes#32344 from sarutak/kerberos-refresh-issue.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
Add doc about `TRANSFORM` and related function.
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32257 from AngersZhuuuu/SPARK-33976-followup.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Add JindoFS SDK documents link in the cloud integration section of Spark's official document.
### Why are the changes needed?
If Spark users need to interact with Alibaba Cloud OSS, JindoFS SDK is the official solution provided by Alibaba Cloud.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
tested the url manually.
Closes#32360 from adrian-wang/jindodoc.
Authored-by: Daoyuan Wang <daoyuan.wdy@alibaba-inc.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Add note in migration guide about DayTimeIntervalType/YearMonthIntervalType show different between Hive SerDe and row format delimited
### Why are the changes needed?
Add note
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32343 from AngersZhuuuu/SPARK-35220-FOLLOWUP.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Extract common doc about hive format for `sql-ref-syntax-ddl-create-table-hiveformat.md` and `sql-ref-syntax-qry-select-transform.md` to refer.

### Why are the changes needed?
Improve doc
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32264 from AngersZhuuuu/SPARK-35159.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
PG and Oracle both support use CUBE/ROLLUP/GROUPING SETS in GROUPING SETS's grouping set as a sugar syntax.

In this PR, we support it in Spark SQL too
### Why are the changes needed?
Keep consistent with PG and oracle
### Does this PR introduce _any_ user-facing change?
User can write grouping analytics like
```
SELECT a, b, count(1) FROM testData GROUP BY a, GROUPING SETS(ROLLUP(a, b));
SELECT a, b, count(1) FROM testData GROUP BY a, GROUPING SETS((a, b), (a), ());
SELECT a, b, count(1) FROM testData GROUP BY a, GROUPING SETS(GROUPING SETS((a, b), (a), ()));
```
### How was this patch tested?
Added Test
Closes#32201 from AngersZhuuuu/SPARK-35026.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In YARN, ship the `spark.jars.ivySettings` file to the driver when using `cluster` deploy mode so that `addJar` is able to find it in order to resolve ivy paths.
### Why are the changes needed?
SPARK-33084 introduced support for Ivy paths in `sc.addJar` or Spark SQL `ADD JAR`. If we use a custom ivySettings file using `spark.jars.ivySettings`, it is loaded at b26e7b510b/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala (L1280). However, this file is only accessible on the client machine. In YARN cluster mode, this file is not available on the driver and so `addJar` fails to find it.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added unit tests to verify that the `ivySettings` file is localized by the YARN client and that a YARN cluster mode application is able to find to load the `ivySettings` file.
Closes#31591 from shardulm94/SPARK-34472.
Authored-by: Shardul Mahadik <smahadik@linkedin.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
Add doc about `TRANSFORM` and related function.

### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#31010 from AngersZhuuuu/SPARK-33976.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to support a new configuration, `spark.kubernetes.driver.service.deleteOnTermination`, to clean up `Driver Service` resource during app termination.
### Why are the changes needed?
The K8s service is one of the important resources and sometimes it's controlled by quota.
```
$ k describe quota
Name: service
Namespace: default
Resource Used Hard
-------- ---- ----
services 1 3
```
Apache Spark creates a service for driver whose lifecycle is the same with driver pod.
It means a new Spark job submission fails if the number of completed Spark jobs equals the number of service quota.
**BEFORE**
```
$ k get pod
NAME READY STATUS RESTARTS AGE
org-apache-spark-examples-sparkpi-a32c9278e7061b4d-driver 0/1 Completed 0 31m
org-apache-spark-examples-sparkpi-a9f1f578e721ef62-driver 0/1 Completed 0 78s
$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 80m
org-apache-spark-examples-sparkpi-a32c9278e7061b4d-driver-svc ClusterIP None <none> 7078/TCP,7079/TCP,4040/TCP 31m
org-apache-spark-examples-sparkpi-a9f1f578e721ef62-driver-svc ClusterIP None <none> 7078/TCP,7079/TCP,4040/TCP 80s
$ k describe quota
Name: service
Namespace: default
Resource Used Hard
-------- ---- ----
services 3 3
$ bin/spark-submit...
Exception in thread "main" io.fabric8.kubernetes.client.KubernetesClientException:
Failure executing: POST at: https://192.168.64.50:8443/api/v1/namespaces/default/services.
Message: Forbidden! User minikube doesn't have permission.
services "org-apache-spark-examples-sparkpi-843f6978e722819c-driver-svc" is forbidden:
exceeded quota: service, requested: services=1, used: services=3, limited: services=3.
```
**AFTER**
```
$ k get pod
NAME READY STATUS RESTARTS AGE
org-apache-spark-examples-sparkpi-23d5f278e77731a7-driver 0/1 Completed 0 26s
org-apache-spark-examples-sparkpi-d1292278e7768ed4-driver 0/1 Completed 0 67s
org-apache-spark-examples-sparkpi-e5bedf78e776ea9d-driver 0/1 Completed 0 44s
$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 172m
$ k describe quota
Name: service
Namespace: default
Resource Used Hard
-------- ---- ----
services 1 3
```
### Does this PR introduce _any_ user-facing change?
Yes, this PR adds a new configuration, `spark.kubernetes.driver.service.deleteOnTermination`, and enables it by default.
The change is documented at the migration guide.
### How was this patch tested?
Pass the CIs.
This is tested with K8s IT manually.
```
KubernetesSuite:
- Run SparkPi with no resources
- Run SparkPi with a very long application name.
- Use SparkLauncher.NO_RESOURCE
- Run SparkPi with a master URL without a scheme.
- Run SparkPi with an argument.
- Run SparkPi with custom labels, annotations, and environment variables.
- All pods have the same service account by default
- Run extraJVMOptions check on driver
- Run SparkRemoteFileTest using a remote data file
- Verify logging configuration is picked from the provided SPARK_CONF_DIR/log4j.properties
- Run SparkPi with env and mount secrets.
- Run PySpark on simple pi.py example
- Run PySpark to test a pyfiles example
- Run PySpark with memory customization
- Run in client mode.
- Start pod creation from template
- PVs with local storage
- Launcher client dependencies
- SPARK-33615: Launcher client archives
- SPARK-33748: Launcher python client respecting PYSPARK_PYTHON
- SPARK-33748: Launcher python client respecting spark.pyspark.python and spark.pyspark.driver.python
- Launcher python client dependencies using a zip file
- Test basic decommissioning
- Test basic decommissioning with shuffle cleanup
- Test decommissioning with dynamic allocation & shuffle cleanups
- Test decommissioning timeouts
- Run SparkR on simple dataframe.R example
Run completed in 19 minutes, 9 seconds.
Total number of tests run: 27
Suites: completed 2, aborted 0
Tests: succeeded 27, failed 0, canceled 0, ignored 0, pending 0
All tests passed.
```
Closes#32226 from dongjoon-hyun/SPARK-35131.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Parse the year-month interval literals like `INTERVAL '1-1' YEAR TO MONTH` to values of `YearMonthIntervalType`, and day-time interval literals to `DayTimeIntervalType` values. Currently, Spark SQL supports:
- DAY TO HOUR
- DAY TO MINUTE
- DAY TO SECOND
- HOUR TO MINUTE
- HOUR TO SECOND
- MINUTE TO SECOND
All such interval literals are converted to `DayTimeIntervalType`, and `YEAR TO MONTH` to `YearMonthIntervalType` while loosing info about `from` and `to` units.
**Note**: new behavior is under the SQL config `spark.sql.legacy.interval.enabled` which is `false` by default. When the config is set to `true`, the interval literals are parsed to `CaledarIntervalType` values.
Closes#32176
### Why are the changes needed?
To conform the ANSI SQL standard which assumes conversions of interval literals to year-month or day-time interval but not to mixed interval type like Catalyst's `CalendarIntervalType`.
### Does this PR introduce _any_ user-facing change?
Yes.
Before:
```sql
spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND;
1 days 1 hours 2 minutes 3.123 seconds
spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND);
interval
```
After:
```sql
spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND;
1 01:02:03.123000000
spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND);
day-time interval
```
### How was this patch tested?
1. By running the affected test suites:
```
$ ./build/sbt "test:testOnly *.ExpressionParserSuite"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z create_view.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql"
```
2. PostgresSQL tests are executed with `spark.sql.legacy.interval.enabled` is set to `true` to keep compatibility with PostgreSQL output:
```sql
> SELECT interval '999' second;
0 years 0 mons 0 days 0 hours 16 mins 39.00 secs
```
Closes#32209 from MaxGekk/parse-ansi-interval-literals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Support no-serde mode script transform use ArrayType/MapType/StructStpe data.
### Why are the changes needed?
Make user can process array/map/struct data
### Does this PR introduce _any_ user-facing change?
Yes, user can process array/map/struct data in script transform `no-serde` mode
### How was this patch tested?
Added UT
Closes#30957 from AngersZhuuuu/SPARK-31937.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Soften security warning and keep it in cluster management docs only, not in the main doc page, where it's not necessarily relevant.
### Why are the changes needed?
The statement is perhaps unnecessarily 'frightening' as the first section in the main docs page. It applies to clusters not local mode, anyhow.
### Does this PR introduce _any_ user-facing change?
Just a docs change.
### How was this patch tested?
N/A
Closes#32206 from srowen/SecurityStatement.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Use hadoop FileSystem instead of FileInputStream.
### Why are the changes needed?
Make `spark.scheduler.allocation.file` suport remote file. When using Spark as a server (e.g. SparkThriftServer), it's hard for user to specify a local path as the scheduler pool.
### Does this PR introduce _any_ user-facing change?
Yes, a minor feature.
### How was this patch tested?
Pass `core/src/test/scala/org/apache/spark/scheduler/PoolSuite.scala` and manul test
After add config `spark.scheduler.allocation.file=hdfs:///tmp/fairscheduler.xml`. We intrudoce the configed pool.

Closes#32184 from ulysses-you/SPARK-35083.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Normal function parameters should not support alias, hive not support too
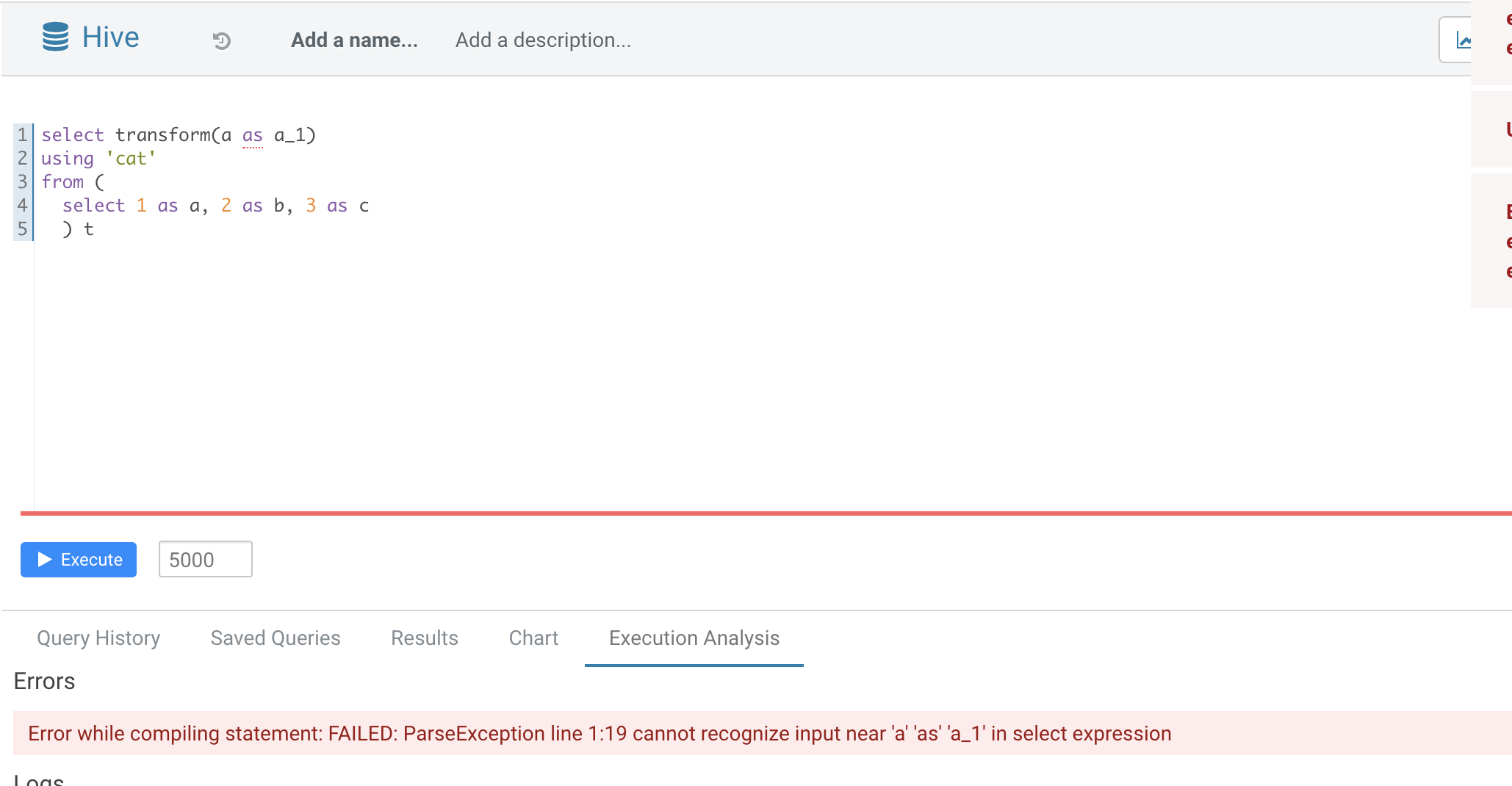
In this pr we forbid use alias in `TRANSFORM`'s inputs
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#32165 from AngersZhuuuu/SPARK-35070.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add change of `DESC NAMESPACE`'s schema to migration guide
### Why are the changes needed?
Update doc
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32155 from AngersZhuuuu/SPARK-34577-followup.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Deprecate Apache Mesos support for Spark 3.2.0 by adding documentation to this effect.
### Why are the changes needed?
Apache Mesos is ceasing development (https://lists.apache.org/thread.html/rab2a820507f7c846e54a847398ab20f47698ec5bce0c8e182bfe51ba%40%3Cdev.mesos.apache.org%3E) ; at some point we'll want to drop support, so, deprecate it now.
This doesn't mean it'll go away in 3.3.0.
### Does this PR introduce _any_ user-facing change?
No, docs only.
### How was this patch tested?
N/A
Closes#32150 from srowen/SPARK-35050.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Disallow group by aliases under ANSI mode.
### Why are the changes needed?
As per the ANSI SQL standard secion 7.12 <group by clause>:
>Each `grouping column reference` shall unambiguously reference a column of the table resulting from the `from clause`. A column referenced in a `group by clause` is a grouping column.
By forbidding it, we can avoid ambiguous SQL queries like:
```
SELECT col + 1 as col FROM t GROUP BY col
```
### Does this PR introduce _any_ user-facing change?
Yes, group by aliases is not allowed under ANSI mode.
### How was this patch tested?
Unit tests
Closes#32129 from gengliangwang/disallowGroupByAlias.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
This pr add test and document for Parquet Bloom filter push down.
### Why are the changes needed?
Improve document.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Generating docs:

Closes#32123 from wangyum/SPARK-34562.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Support GROUP BY use Separate columns and CUBE/ROLLUP
In postgres sql, it support
```
select a, b, c, count(1) from t group by a, b, cube (a, b, c);
select a, b, c, count(1) from t group by a, b, rollup(a, b, c);
select a, b, c, count(1) from t group by cube(a, b), rollup (a, b, c);
select a, b, c, count(1) from t group by a, b, grouping sets((a, b), (a), ());
```
In this pr, we have done two things as below:
1. Support partial grouping analytics such as `group by a, cube(a, b)`
2. Support mixed grouping analytics such as `group by cube(a, b), rollup(b,c)`
*Partial Groupings*
Partial Groupings means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
in GROUP BY clause. For example:
`GROUP BY warehouse, CUBE(product, location)` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse, location), (warehouse))`.
`GROUP BY warehouse, ROLLUP(product, location)` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse))`.
`GROUP BY warehouse, GROUPING SETS((product, location), (producet), ())` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, location), (warehouse))`.
*Concatenated Groupings*
Concatenated groupings offer a concise way to generate useful combinations of groupings. Groupings specified
with concatenated groupings yield the cross-product of groupings from each grouping set. The cross-product
operation enables even a small number of concatenated groupings to generate a large number of final groups.
The concatenated groupings are specified simply by listing multiple `GROUPING SETS`, `CUBES`, and `ROLLUP`,
and separating them with commas. For example:
`GROUP BY GROUPING SETS((warehouse), (producet)), GROUPING SETS((location), (size))` is equivalent to
`GROUP BY GROUPING SETS((warehouse, location), (warehouse, size), (product, location), (product, size))`.
`GROUP BY CUBE((warehouse), (producet)), ROLLUP((location), (size))` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product), (warehouse), (producet), ()), GROUPING SETS((location, size), (location), ())`
`GROUP BY GROUPING SETS(
(warehouse, product, location, size), (warehouse, product, location), (warehouse, product),
(warehouse, location, size), (warehouse, location), (warehouse),
(product, location, size), (product, location), (product),
(location, size), (location), ())`.
`GROUP BY order, CUBE((warehouse), (producet)), ROLLUP((location), (size))` is equivalent to
`GROUP BY order, GROUPING SETS((warehouse, product), (warehouse), (producet), ()), GROUPING SETS((location, size), (location), ())`
`GROUP BY GROUPING SETS(
(order, warehouse, product, location, size), (order, warehouse, product, location), (order, warehouse, product),
(order, warehouse, location, size), (order, warehouse, location), (order, warehouse),
(order, product, location, size), (order, product, location), (order, product),
(order, location, size), (order, location), (order))`.
### Why are the changes needed?
Support more flexible grouping analytics
### Does this PR introduce _any_ user-facing change?
User can use sql like
```
select a, b, c, agg_expr() from table group by a, cube(b, c)
```
### How was this patch tested?
Added UT
Closes#30144 from AngersZhuuuu/SPARK-33229.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch fixes wrong Python code sample for doc.
### Why are the changes needed?
Sample code is wrong.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Doc only.
Closes#32119 from Hisssy/ss-doc-typo-1.
Authored-by: hissy <aozora@live.cn>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR aims to add a documentation on how to read and write TEXT files through various APIs such as Scala, Python and JAVA in Spark to [Data Source documents](https://spark.apache.org/docs/latest/sql-data-sources.html#data-sources).
### Why are the changes needed?
Documentation on how Spark handles TEXT files is missing. It should be added to the document for user convenience.
### Does this PR introduce _any_ user-facing change?
Yes, this PR adds a new page to Data Sources documents.
### How was this patch tested?
Manually build documents and check the page on local as below.

Closes#32053 from itholic/SPARK-34491-TEXT.
Authored-by: itholic <haejoon.lee@databricks.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
CREATE TABLE LIKE should respect the reserved properties of tables and fail if specified, using `spark.sql.legacy.notReserveProperties` to restore.
### Why are the changes needed?
Make DDLs consistently treat reserved properties
### Does this PR introduce _any_ user-facing change?
YES, this is a breaking change as using `create table like` w/ reserved properties will fail.
### How was this patch tested?
new test
Closes#32025 from yaooqinn/SPARK-34935.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
GROUP BY ... GROUPING SETS (...) is a weird SQL syntax we copied from Hive. It's not in the SQL standard or any other mainstream databases. This syntax requires users to repeat the expressions inside `GROUPING SETS (...)` after `GROUP BY`, and has a weird null semantic if `GROUP BY` contains extra expressions than `GROUPING SETS (...)`.
This PR deprecates this syntax:
1. Do not promote it in the document and only mention it as a Hive compatible sytax.
2. Simplify the code to only keep it for Hive compatibility.
### Why are the changes needed?
Deprecate a weird grammar.
### Does this PR introduce _any_ user-facing change?
No breaking change, but it removes a check to simplify the code: `GROUP BY a GROUPING SETS(a, b)` fails before and forces users to also put `b` after `GROUP BY`. Now this works just as `GROUP BY GROUPING SETS(a, b)`.
### How was this patch tested?
existing tests
Closes#32022 from cloud-fan/followup.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Fix [SPARK-34492], add Scala examples to read/write CSV files.
### Why are the changes needed?
Fix [SPARK-34492].
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Build the document with "SKIP_API=1 bundle exec jekyll build", and everything looks fine.
Closes#31827 from twoentartian/master.
Authored-by: twoentartian <twoentartian@hotmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR removes the description that `||` and `&&` can be used as logical operators from the migration guide.
### Why are the changes needed?
At the `Compatibility with Apache Hive` section in the migration guide, it describes that `||` and `&&` can be used as logical operators.
But, in fact, they cannot be used as described.
AFAIK, Hive also doesn't support `&&` and `||` as logical operators.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
I confirmed that `&&` and `||` cannot be used as logical operators with both Hive's interactive shell and `spark-sql`.
I also built the modified document and confirmed that the modified document doesn't break layout.
Closes#32023 from sarutak/modify-hive-compatibility-doc.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Add more flexable parameters for stage end point
endpoint /application/{app-id}/stages. It can be:
/application/{app-id}/stages?details=[true|false]&status=[ACTIVE|COMPLETE|FAILED|PENDING|SKIPPED]&withSummaries=[true|false]$quantiles=[comma separated quantiles string]&taskStatus=[RUNNING|SUCCESS|FAILED|PENDING]
where
```
query parameter details=true is to show the detailed task information within each stage. The default value is details=false;
query parameter status can select those stages with the specified status. When status parameter is not specified, a list of all stages are generated.
query parameter withSummaries=true is to show both task summary information in percentile distribution and executor summary information in percentile distribution. The default value is withSummaries=false.
query parameter quantiles support user defined quantiles, default quantiles is `0.0,0.25,0.5,0.75,1.0`
query parameter taskStatus is to show only those tasks with the specified status within their corresponding stages. This parameter will be set when details=true (i.e. this parameter will be ignored when details=false).
```
### Why are the changes needed?
More flexable restful API
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
UT
Closes#31204 from AngersZhuuuu/SPARK-26399-NEW.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Modify the `SubtractTimestamps` expression to return values of `DayTimeIntervalType` when `spark.sql.legacy.interval.enabled` is set to `false` (which is the default).
### Why are the changes needed?
To conform to the ANSI SQL standard which requires ANSI intervals as the result of timestamps subtraction, see
<img width="656" alt="Screenshot 2021-03-29 at 19 09 34" src="https://user-images.githubusercontent.com/1580697/112866455-7e2f0d00-90c2-11eb-96e6-3feb7eea7e09.png">
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateTimeUtilsSuite"
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
and some tests from `SQLQueryTestSuite`:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#32016 from MaxGekk/subtract-timestamps-to-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Add a new SQL function `try_cast`.
`try_cast` is identical to `AnsiCast` (or `Cast` when `spark.sql.ansi.enabled` is true), except it returns NULL instead of raising an error.
This expression has one major difference from `cast` with `spark.sql.ansi.enabled` as true: when the source value can't be stored in the target integral(Byte/Short/Int/Long) type, `try_cast` returns null instead of returning the low order bytes of the source value.
Note that the result of `try_cast` is not affected by the configuration `spark.sql.ansi.enabled`.
This is learned from Google BigQuery and Snowflake:
https://docs.snowflake.com/en/sql-reference/functions/try_cast.htmlhttps://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators#safe_casting
### Why are the changes needed?
This is an useful for the following scenarios:
1. When ANSI mode is on, users can choose `try_cast` an alternative way to run SQL without errors for certain operations.
2. When ANSI mode is off, users can use `try_cast` to get a more reasonable result for casting a value to an integral type: when an overflow error happens, `try_cast` returns null while `cast` returns the low order bytes of the source value.
### Does this PR introduce _any_ user-facing change?
Yes, adding a new function `try_cast`
### How was this patch tested?
Unit tests.
Closes#31982 from gengliangwang/tryCast.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
Fix code not close issue in monitoring.md
### Why are the changes needed?
Fix doc issue
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32008 from AngersZhuuuu/SPARK-34911.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
1. Add the SQL config `spark.sql.legacy.interval.enabled` which will control when Spark SQL should use `CalendarIntervalType` instead of ANSI intervals.
2. Modify the `SubtractDates` expression to return values of `DayTimeIntervalType` when `spark.sql.legacy.interval.enabled` is set to `false` (which is the default).
### Why are the changes needed?
To conform to the ANSI SQL standard which requires ANSI intervals as the result of dates subtraction, see
<img width="656" alt="Screenshot 2021-03-29 at 19 09 34" src="https://user-images.githubusercontent.com/1580697/112866455-7e2f0d00-90c2-11eb-96e6-3feb7eea7e09.png">
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
and some tests from `SQLQueryTestSuite`:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#31996 from MaxGekk/subtract-dates-to-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Add a new config, `spark.shuffle.service.name`, which allows for Spark applications to look for a YARN shuffle service which is defined at a name other than the default `spark_shuffle`.
Add a new config, `spark.yarn.shuffle.service.metrics.namespace`, which allows for configuring the namespace used when emitting metrics from the shuffle service into the NodeManager's `metrics2` system.
Add a new mechanism by which to override shuffle service configurations independently of the configurations in the NodeManager. When a resource `spark-shuffle-site.xml` is present on the classpath of the shuffle service, the configs present within it will be used to override the configs coming from `yarn-site.xml` (via the NodeManager).
### Why are the changes needed?
There are two use cases which can benefit from these changes.
One use case is to run multiple instances of the shuffle service side-by-side in the same NodeManager. This can be helpful, for example, when running a YARN cluster with a mixed workload of applications running multiple Spark versions, since a given version of the shuffle service is not always compatible with other versions of Spark (e.g. see SPARK-27780). With this PR, it is possible to run two shuffle services like `spark_shuffle` and `spark_shuffle_3.2.0`, one of which is "legacy" and one of which is for new applications. This is possible because YARN versions since 2.9.0 support the ability to run shuffle services within an isolated classloader (see YARN-4577), meaning multiple Spark versions can coexist.
Besides this, the separation of shuffle service configs into `spark-shuffle-site.xml` can be useful for administrators who want to change and/or deploy Spark shuffle service configurations independently of the configurations for the NodeManager (e.g., perhaps they are owned by two different teams).
### Does this PR introduce _any_ user-facing change?
Yes. There are two new configurations related to the external shuffle service, and a new mechanism which can optionally be used to configure the shuffle service. `docs/running-on-yarn.md` has been updated to provide user instructions; please see this guide for more details.
### How was this patch tested?
In addition to the new unit tests added, I have deployed this to a live YARN cluster and successfully deployed two Spark shuffle services simultaneously, one running a modified version of Spark 2.3.0 (which supports some of the newer shuffle protocols) and one running Spark 3.1.1. Spark applications of both versions are able to communicate with their respective shuffle services without issue.
Closes#31936 from xkrogen/xkrogen-SPARK-34828-shufflecompat-config-from-classpath.
Authored-by: Erik Krogen <xkrogen@apache.org>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
As discussed in
https://github.com/apache/spark/pull/30145#discussion_r514728642https://github.com/apache/spark/pull/30145#discussion_r514734648
We need to rewrite current Grouping Analytics grammar to support as flexible as Postgres SQL to support subsequent development.
In postgres sql, it support
```
select a, b, c, count(1) from t group by cube (a, b, c);
select a, b, c, count(1) from t group by cube(a, b, c);
select a, b, c, count(1) from t group by cube (a, b, c, (a, b), (a, b, c));
select a, b, c, count(1) from t group by rollup(a, b, c);
select a, b, c, count(1) from t group by rollup (a, b, c);
select a, b, c, count(1) from t group by rollup (a, b, c, (a, b), (a, b, c));
```
In this pr, we have done three things as below, and we will split it to different pr:
- Refactor CUBE/ROLLUP (regarding them as ANTLR tokens in a parser)
- Refactor GROUPING SETS (the logical node -> a new expr)
- Support new syntax for CUBE/ROLLUP (e.g., GROUP BY CUBE ((a, b), (a, c)))
### Why are the changes needed?
Rewrite current Grouping Analytics grammar to support as flexible as Postgres SQL to support subsequent development.
### Does this PR introduce _any_ user-facing change?
User can write Grouping Analytics grammar as flexible as Postgres SQL to support subsequent development.
### How was this patch tested?
Added UT
Closes#30212 from AngersZhuuuu/refact-grouping-analytics.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Co-authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, when a connection for TransportClient is marked as idled and closed, we suggest users adjust `spark.network.timeout` for all transport modules. As a lot of timeout configs will fallback to the `spark.network.timeout`, this could be a piece of overkill advice, we should give a more targeted one with `spark.${moduleName}.io.connectionTimeout`
### Why are the changes needed?
better advise for overloaded network traffic cases
### Does this PR introduce _any_ user-facing change?
yes, when a connection is zombied and closed by spark internally, users can use a more targeted config to tune their jobs
### How was this patch tested?
Just log and doc. Passing Jenkins and GA
Closes#31990 from yaooqinn/SPARK-34894.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
When we want to get stage's detail info with task information, it will return all tasks, the content is huge and always we just want to know some failed tasks/running tasks with whole stage info to judge is a task has some problem. This pr support
user to use
```
/application/[appid]/stages/[stage-id]?details=true&taskStatus=xxx
/application/[appid]/stages/[stage-id]/[stage-attempted-id]?details=true&taskStatus=xxx
```
to filter task details by task status
### Why are the changes needed?
More flexiable Restful API
### Does this PR introduce _any_ user-facing change?
User can use
```
/application/[appid]/stages/[stage-id]?details=true&taskStatus=xxx
/application/[appid]/stages/[stage-id]/[stage-attempted-id]?details=true&taskStatus=xxx
```
to filter task details by task status
### How was this patch tested?
Added
Closes#31165 from AngersZhuuuu/SPARK-34092.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Deprecating `spark.launcher.childConectionTimeout` in favor of `spark.launcher.childConnectionTimeout`
### Why are the changes needed?
srowen suggested it https://github.com/apache/spark/pull/30323#discussion_r521449342
### How was this patch tested?
No testing. Not even compiled
Closes#30679 from jsoref/spelling-connection.
Authored-by: Josh Soref <jsoref@users.noreply.github.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Allow casting complex types as string type in ANSI mode.
### Why are the changes needed?
Currently, complex types are not allowed to cast as string type. This breaks the DataFrame.show() API. E.g
```
scala> sql(“select array(1, 2, 2)“).show(false)
org.apache.spark.sql.AnalysisException: cannot resolve ‘CAST(`array(1, 2, 2)` AS STRING)’ due to data type mismatch:
cannot cast array<int> to string with ANSI mode on.
```
We should allow the conversion as the extension of the ANSI SQL standard, so that the DataFrame.show() still work in ANSI mode.
### Does this PR introduce _any_ user-facing change?
Yes, casting complex types as string type is now allowed in ANSI mode.
### How was this patch tested?
Unit tests.
Closes#31954 from gengliangwang/fixExplicitCast.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
For a specific stage, it is useful to show the task metrics in percentile distribution. This information can help users know whether or not there is a skew/bottleneck among tasks in a given stage. We list an example in taskMetricsDistributions.json
Similarly, it is useful to show the executor metrics in percentile distribution for a specific stage. This information can show whether or not there is a skewed load on some executors. We list an example in executorMetricsDistributions.json
We define `withSummaries` and `quantiles` query parameter in the REST API for a specific stage as:
applications/<application_id>/<application_attempt/stages/<stage_id>/<stage_attempt>?withSummaries=[true|false]& quantiles=0.05,0.25,0.5,0.75,0.95
1. withSummaries: default is false, define whether to show current stage's taskMetricsDistribution and executorMetricsDistribution
2. quantiles: default is `0.0,0.25,0.5,0.75,1.0` only effect when `withSummaries=true`, it define the quantiles we use when calculating metrics distributions.
When withSummaries=true, both task metrics in percentile distribution and executor metrics in percentile distribution are included in the REST API output. The default value of withSummaries is false, i.e. no metrics percentile distribution will be included in the REST API output.
### Why are the changes needed?
For a specific stage, it is useful to show the task metrics in percentile distribution. This information can help users know whether or not there is a skew/bottleneck among tasks in a given stage. We list an example in taskMetricsDistributions.json
### Does this PR introduce _any_ user-facing change?
User can use below restful API to get task metrics distribution and executor metrics distribution for indivial stage
```
applications/<application_id>/<application_attempt/stages/<stage_id>/<stage_attempt>?withSummaries=[true|false]
```
### How was this patch tested?
Added UT
Closes#31611 from AngersZhuuuu/SPARK-34488.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This patch adds a config `spark.yarn.kerberos.renewal.excludeHadoopFileSystems` which lists the filesystems to be excluded from delegation token renewal at YARN.
### Why are the changes needed?
MapReduce jobs can instruct YARN to skip renewal of tokens obtained from certain hosts by specifying the hosts with configuration mapreduce.job.hdfs-servers.token-renewal.exclude=<host1>,<host2>,..,<hostN>.
But seems Spark lacks of similar option. So the job submission fails if YARN fails to renew DelegationToken for any of the remote HDFS cluster. The failure in DT renewal can happen due to many reason like Remote HDFS does not trust Kerberos identity of YARN etc. We have a customer facing such issue.
### Does this PR introduce _any_ user-facing change?
No, if the config is not set. Yes, as users can use this config to instruct YARN not to renew delegation token from certain filesystems.
### How was this patch tested?
It is hard to do unit test for this. We did verify it work from the customer using this fix in the production environment.
Closes#31761 from viirya/SPARK-34295.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
the given example uses a non-standard syntax for CREATE TABLE, by defining the partitioning column with the other columns, instead of in PARTITION BY.
This works is this case, because the partitioning column happens to be the last column defined, but it will break if instead 'name' would be used for partitioning.
I suggest therefore to change the example to use a standard syntax, like in
https://spark.apache.org/docs/3.1.1/sql-ref-syntax-ddl-create-table-hiveformat.html
### Why are the changes needed?
To show the better documentation.
### Does this PR introduce _any_ user-facing change?
Yes, this fixes the user-facing docs.
### How was this patch tested?
CI should test it out.
Closes#31900 from robert4os/patch-1.
Authored-by: robert4os <robert4os@users.noreply.github.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Current link for `Azure Blob Storage and Azure Datalake Gen 2` leads to AWS information. Replacing the link to point to the right page.
### Why are the changes needed?
For users to access to the correct link.
### Does this PR introduce _any_ user-facing change?
Yes, it fixes the link correctly.
### How was this patch tested?
N/A
Closes#31938 from lenadroid/patch-1.
Authored-by: Lena <alehall@microsoft.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Update the Avro version to 1.10.2
### Why are the changes needed?
To stay up to date with upstream and catch compatibility issues with zstd
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests
Closes#31866 from iemejia/SPARK-27733-upgrade-avro-1.10.2.
Authored-by: Ismaël Mejía <iemejia@gmail.com>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request?
This PR aims to enable `spark.hadoopRDD.ignoreEmptySplits` by default for Apache Spark 3.2.0.
### Why are the changes needed?
Although this is a safe improvement, this hasn't been enabled by default to avoid the explicit behavior change. This PR aims to switch the default explicitly in Apache Spark 3.2.0.
### Does this PR introduce _any_ user-facing change?
Yes, the behavior change is documented.
### How was this patch tested?
Pass the existing CIs.
Closes#31909 from dongjoon-hyun/SPARK-34809.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Document `mode` as a supported Imputer strategy in Pyspark docs.
### Why are the changes needed?
Support was added in 3.1, and documented in Scala, but some Python docs were missed.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests.
Closes#31883 from srowen/ImputerModeDocs.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR aims to support remote driver/executor template files.
### Why are the changes needed?
Currently, `KubernetesUtils.loadPodFromTemplate` supports only local files.
With this PR, we can do the following.
```bash
bin/spark-submit \
...
-c spark.kubernetes.driver.podTemplateFile=s3a://dongjoon/driver.yml \
-c spark.kubernetes.executor.podTemplateFile=s3a://dongjoon/executor.yml \
...
```
### Does this PR introduce _any_ user-facing change?
Yes, this is an improvement.
### How was this patch tested?
Manual testing.
Closes#31877 from dongjoon-hyun/SPARK-34783-2.
Lead-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
For the following cases, ABS should throw exceptions since the results are out of the range of the result data types in ANSI mode.
```
SELECT abs(${Int.MinValue});
SELECT abs(${Long.MinValue});
```
### Why are the changes needed?
Better ANSI compliance
### Does this PR introduce _any_ user-facing change?
Yes, Abs throws an exception if input is out of range in ANSI mode
### How was this patch tested?
Unit test
Closes#31836 from gengliangwang/ansiAbs.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR adds `ADD ARCHIVE` and `LIST ARCHIVES` commands to SQL and updates relevant documents.
SPARK-33530 added `addArchive` and `listArchives` to `SparkContext` but it's not supported yet to add/list archives with SQL.
### Why are the changes needed?
To complement features.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added new test and confirmed the generated HTML from the updated documents.
Closes#31721 from sarutak/sql-archive.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Use resolved attributes instead of data-frame fields for replacing values.
### Why are the changes needed?
dataframe.na.replace() does not work for column having a dot in the name
### Does this PR introduce _any_ user-facing change?
None
### How was this patch tested?
Added unit tests for the same
Closes#31769 from amandeep-sharma/master.
Authored-by: Amandeep Sharma <happyaman91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Fix the table of valid type coercion combinations. Binary type should be allowed casting to String type and disallowed casting to Numeric types.
2. Summary all the `CAST`s that can cause runtime exceptions.
### Why are the changes needed?
Fix a mistake in the docs.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Run `jekyll serve` and preview:

Closes#31781 from gengliangwang/reviseAnsiDoc2.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
1 add a sapce between words
2 unify the initials' case
### Why are the changes needed?
correct spelling issues for better user experience
### Does this PR introduce _any_ user-facing change?
yes.
### How was this patch tested?
manually
Closes#31748 from hopefulnick/doc_rectify.
Authored-by: nickhliu <nickhliu@tencent.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In ANSI mode, casting String to Boolean should throw an exception on parse error, instead of returning null
### Why are the changes needed?
For better ANSI compliance
### Does this PR introduce _any_ user-facing change?
Yes, in ANSI mode there will be an exception on parse failure of casting String value to Boolean type.
### How was this patch tested?
Unit tests.
Closes#31734 from gengliangwang/ansiCastToBoolean.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
Hive support type constructed value as partition spec value, spark should support too.
### Why are the changes needed?
Support TypeConstructed partition spec value keep same with hive
### Does this PR introduce _any_ user-facing change?
Yes, user can use TypeConstruct value as partition spec value such as
```
CREATE TABLE t1(name STRING) PARTITIONED BY (part DATE)
INSERT INTO t1 PARTITION(part = date'2019-01-02') VALUES('a')
CREATE TABLE t2(name STRING) PARTITIONED BY (part TIMESTAMP)
INSERT INTO t2 PARTITION(part = timestamp'2019-01-02 11:11:11') VALUES('a')
CREATE TABLE t4(name STRING) PARTITIONED BY (part BINARY)
INSERT INTO t4 PARTITION(part = X'537061726B2053514C') VALUES('a')
```
### How was this patch tested?
Added UT
Closes#30421 from AngersZhuuuu/SPARK-33474.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
spark.sql.adaptive.coalescePartitions.initialPartitionNum 200 -> (none)
spark.sql.adaptive.skewJoin.skewedPartitionFactor is 10 -> 5
### Why are the changes needed?
the wrong doc misguide people
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
passing doc
Closes#31717 from yaooqinn/minordoc0.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR is a follow-up of https://github.com/apache/spark/pull/31618 to document the available codecs for event log compression.
### Why are the changes needed?
Documentation.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual.
Closes#31695 from dongjoon-hyun/SPARK-34503-DOC.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Cleanup all Zinc standalone server code, and realated coniguration.
### Why are the changes needed?

- Zinc is the incremental compiler to speed up builds of compilation.
- The scala-maven-plugin is the mave plugin, which is used by Spark, one of the function is to integrate the Zinc to enable the incremental compiler.
- Since Spark v3.0.0 ([SPARK-28759](https://issues.apache.org/jira/browse/SPARK-28759)), the scala-maven-plugin is upgraded to v4.X, that means Zinc v0.3.13 standalone server is useless anymore.
However, we still download, install, start the standalone Zinc server. we should remove all zinc standalone server code, and all related configuration.
See more in [SPARK-34539](https://issues.apache.org/jira/projects/SPARK/issues/SPARK-34539) or the doc [Zinc standalone server is useless after scala-maven-plugin 4.x](https://docs.google.com/document/d/1u4kCHDx7KjVlHGerfmbcKSB0cZo6AD4cBdHSse-SBsM).
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Run any mvn build:
./build/mvn -DskipTests clean package -pl core
You could see the increamental compilation is still working, the stage of "scala-maven-plugin:4.3.0:compile (scala-compile-first)" with incremental compilation info, like:
```
[INFO] --- scala-maven-plugin:4.3.0:testCompile (scala-test-compile-first) spark-core_2.12 ---
[INFO] Using incremental compilation using Mixed compile order
[INFO] Compiler bridge file: /root/.sbt/1.0/zinc/org.scala-sbt/org.scala-sbt-compiler-bridge_2.12-1.3.1-bin_2.12.10__52.0-1.3.1_20191012T045515.jar
[INFO] compiler plugin: BasicArtifact(com.github.ghik,silencer-plugin_2.12.10,1.6.0,null)
[INFO] Compiling 303 Scala sources and 27 Java sources to /root/spark/core/target/scala-2.12/test-classes ...
```
Closes#31647 from Yikun/cleanup-zinc.
Authored-by: Yikun Jiang <yikunkero@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
SPARK-33084 added the ability to use ivy coordinates with `SparkContext.addJar`. PR #29966 claims to mimic Hive behavior although I found a few cases where it doesn't
1) The default value of the transitive parameter is false, both in case of parameter not being specified in coordinate or parameter value being invalid. The Hive behavior is that transitive is [true if not specified](cb2ac3dcc6/ql/src/java/org/apache/hadoop/hive/ql/util/DependencyResolver.java (L169)) in the coordinate and [false for invalid values](cb2ac3dcc6/ql/src/java/org/apache/hadoop/hive/ql/util/DependencyResolver.java (L124)). Also, regardless of Hive, I think a default of true for the transitive parameter also matches [ivy's own defaults](https://ant.apache.org/ivy/history/2.5.0/ivyfile/dependency.html#_attributes).
2) The parameter value for transitive parameter is regarded as case-sensitive [based on the understanding](https://github.com/apache/spark/pull/29966#discussion_r547752259) that Hive behavior is case-sensitive. However, this is not correct, Hive [treats the parameter value case-insensitively](cb2ac3dcc6/ql/src/java/org/apache/hadoop/hive/ql/util/DependencyResolver.java (L122)).
I propose that we be compatible with Hive for these behaviors
### Why are the changes needed?
To make `ADD JAR` with ivy coordinates compatible with Hive's transitive behavior
### Does this PR introduce _any_ user-facing change?
The user-facing changes here are within master as the feature introduced in SPARK-33084 has not been released yet
1. Previously an ivy coordinate without `transitive` parameter specified did not resolve transitive dependency, now it does.
2. Previously an `transitive` parameter value was treated case-sensitively. e.g. `transitive=TRUE` would be treated as false as it did not match exactly `true`. Now it will be treated case-insensitively.
### How was this patch tested?
Modified existing unit tests to test new behavior
Add new unit test to cover usage of `exclude` with unspecified `transitive`
Closes#31623 from shardulm94/spark-34506.
Authored-by: Shardul Mahadik <smahadik@linkedin.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Code in the PR generates random parameters for hyperparameter tuning. A discussion with Sean Owen can be found on the dev mailing list here:
http://apache-spark-developers-list.1001551.n3.nabble.com/Hyperparameter-Optimization-via-Randomization-td30629.html
All code is entirely my own work and I license the work to the project under the project’s open source license.
### Why are the changes needed?
Randomization can be a more effective techinique than a grid search since min/max points can fall between the grid and never be found. Randomisation is not so restricted although the probability of finding minima/maxima is dependent on the number of attempts.
Alice Zheng has an accessible description on how this technique works at https://www.oreilly.com/library/view/evaluating-machine-learning/9781492048756/ch04.html
Although there are Python libraries with more sophisticated techniques, not every Spark developer is using Python.
### Does this PR introduce _any_ user-facing change?
A new class (`ParamRandomBuilder.scala`) and its tests have been created but there is no change to existing code. This class offers an alternative to `ParamGridBuilder` and can be dropped into the code wherever `ParamGridBuilder` appears. Indeed, it extends `ParamGridBuilder` and is completely compatible with its interface. It merely adds one method that provides a range over which a hyperparameter will be randomly defined.
### How was this patch tested?
Tests `ParamRandomBuilderSuite.scala` and `RandomRangesSuite.scala` were added.
`ParamRandomBuilderSuite` is the analogue of the already existing `ParamGridBuilderSuite` which tests the user-facing interface.
`RandomRangesSuite` uses ScalaCheck to test the random ranges over which hyperparameters are distributed.
Closes#31535 from PhillHenry/ParamRandomBuilder.
Authored-by: Phillip Henry <PhillHenry@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
The endpoints of Prometheus metrics are properly marked and documented as an experimental (SPARK-31674). The class `PrometheusServlet` itself is not the part of an API so this PR proposes to remove it.
### Why are the changes needed?
To avoid marking a non-API as an API.
### Does this PR introduce _any_ user-facing change?
No, the class is already `private[spark]`.
### How was this patch tested?
Existing tests should cover.
Closes#31640 from HyukjinKwon/SPARK-34531.
Lead-authored-by: HyukjinKwon <gurwls223@apache.org>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Fix typo and highlight that `ADD PARTITIONS` is the default.
### Why are the changes needed?
Fix a typo which can mislead users.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
n/a
Closes#31633 from MaxGekk/repair-table-drop-partitions-followup.
Lead-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Co-authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR aims to update `Hadoop` dependency in K8S doc example.
### Why are the changes needed?
Apache Spark 3.2.0 is using Apache Hadoop 3.2.2 by default.
### Does this PR introduce _any_ user-facing change?
No. This is a doc-only change.
### How was this patch tested?
N/A
Closes#31628 from dongjoon-hyun/minor-doc.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Apache Spark 3.0 introduced `spark.eventLog.compression.codec` configuration.
For Apache Spark 3.2, this PR aims to set `zstd` as the default value for `spark.eventLog.compression.codec` configuration.
This only affects creating a new log file.
### Why are the changes needed?
The main purpose of event logs is archiving. Many logs are generated and occupy the storage, but most of them are never accessed by users.
**1. Save storage resources (and money)**
In general, ZSTD is much smaller than LZ4.
For example, in case of TPCDS (Scale 200) log, ZSTD generates about 3 times smaller log files than LZ4.
| CODEC | SIZE (bytes) |
|---------|-------------|
| LZ4 | 184001434|
| ZSTD | 64522396|
And, the plain file is 17.6 times bigger.
```
-rw-r--r-- 1 dongjoon staff 1135464691 Feb 21 22:31 spark-a1843ead29834f46b1125a03eca32679
-rw-r--r-- 1 dongjoon staff 64522396 Feb 21 22:31 spark-a1843ead29834f46b1125a03eca32679.zstd
```
**2. Better Usability**
We cannot decompress Spark-generated LZ4 event log files via CLI while we can for ZSTD event log files. Spark's LZ4 event log files are inconvenient to some users who want to uncompress and access them.
```
$ lz4 -d spark-d3deba027bd34435ba849e14fc2c42ef.lz4
Decoding file spark-d3deba027bd34435ba849e14fc2c42ef
Error 44 : Unrecognized header : file cannot be decoded
```
```
$ zstd -d spark-a1843ead29834f46b1125a03eca32679.zstd
spark-a1843ead29834f46b1125a03eca32679.zstd: 1135464691 bytes
```
**3. Speed**
The following results are collected by running [lzbench](https://github.com/inikep/lzbench) on the above Spark event log. Note that
- This is not a direct comparison of Spark compression/decompression codec.
- `lzbench` is an in-memory benchmark. So, it doesn't show the benefit of the reduced network traffic due to the small size of ZSTD.
Here,
- To get ZSTD 1.4.8-1 result, `lzbench` `master` branch is used because Spark is using ZSTD 1.4.8.
- To get LZ4 1.7.5 result, `lzbench` `v1.7` branch is used because Spark is using LZ4 1.7.1.
```
Compressor name Compress. Decompress. Compr. size Ratio Filename
memcpy 7393 MB/s 7166 MB/s 1135464691 100.00 spark-a1843ead29834f46b1125a03eca32679
zstd 1.4.8 -1 1344 MB/s 3351 MB/s 56665767 4.99 spark-a1843ead29834f46b1125a03eca32679
lz4 1.7.5 1385 MB/s 4782 MB/s 127662168 11.24 spark-a1843ead29834f46b1125a03eca32679
```
### Does this PR introduce _any_ user-facing change?
- No for the apps which doesn't use `spark.eventLog.compress` because `spark.eventLog.compress` is disabled by default.
- No for the apps using `spark.eventLog.compression.codec` explicitly because this is a change of the default value.
- Yes for the apps using `spark.eventLog.compress` without setting `spark.eventLog.compression.codec`. In this case, previously `spark.io.compression.codec` value was used whose default is `lz4`.
So this JIRA issue, SPARK-34503, is labeled with `releasenotes`.
### How was this patch tested?
Pass the updated UT.
Closes#31618 from dongjoon-hyun/SPARK-34503.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose to extend the `MSCK REPAIR TABLE` command, and support new options `{ADD|DROP|SYNC} PARTITIONS`. In particular:
1. Extend the logical node `RepairTable`, and add two new flags `enableAddPartitions` and `enableDropPartitions`.
2. Add similar flags to the v1 execution node `AlterTableRecoverPartitionsCommand`
3. Add new method `dropPartitions()` to `AlterTableRecoverPartitionsCommand` which drops partitions from the catalog if their locations in the file system don't exist.
4. Updated public docs about the `MSCK REPAIR TABLE` command:
<img width="1037" alt="Screenshot 2021-02-16 at 13 46 39" src="https://user-images.githubusercontent.com/1580697/108052607-7446d280-705d-11eb-8e25-7398254787a4.png">
Closes#31097
### Why are the changes needed?
- The changes allow to recover tables with removed partitions. The example below portraits the problem:
```sql
spark-sql> create table tbl2 (col int, part int) partitioned by (part);
spark-sql> insert into tbl2 partition (part=1) select 1;
spark-sql> insert into tbl2 partition (part=0) select 0;
spark-sql> show table extended like 'tbl2' partition (part = 0);
default tbl2 false Partition Values: [part=0]
Location: file:/Users/maximgekk/proj/apache-spark/spark-warehouse/tbl2/part=0
...
```
Remove the partition (part = 0) from the filesystem:
```
$ rm -rf /Users/maximgekk/proj/apache-spark/spark-warehouse/tbl2/part=0
```
Even after recovering, we cannot query the table:
```sql
spark-sql> msck repair table tbl2;
spark-sql> select * from tbl2;
21/01/08 22:49:13 ERROR SparkSQLDriver: Failed in [select * from tbl2]
org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: file:/Users/maximgekk/proj/apache-spark/spark-warehouse/tbl2/part=0
```
- To have feature parity with Hive: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-RecoverPartitions(MSCKREPAIRTABLE)
### Does this PR introduce _any_ user-facing change?
Yes. After the changes, we can query recovered table:
```sql
spark-sql> msck repair table tbl2 sync partitions;
spark-sql> select * from tbl2;
1 1
spark-sql> show partitions tbl2;
part=1
```
### How was this patch tested?
- By running the modified test suite:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *MsckRepairTableParserSuite"
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *PlanResolutionSuite"
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableRecoverPartitionsSuite"
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableRecoverPartitionsParallelSuite"
```
- Added unified v1 and v2 tests for `MSCK REPAIR TABLE`:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *MsckRepairTableSuite"
```
Closes#31499 from MaxGekk/repair-table-drop-partitions.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR replaces all the occurrences of symbol literals (`'name`) with string interpolation (`$"name"`) in examples and documents.
### Why are the changes needed?
Symbol literals are used to represent columns in Spark SQL but the Scala community seems to remove `Symbol` completely.
As we discussed in #31569, first we should replacing symbol literals with `$"name"` in user facing examples and documents.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Build docs.
Closes#31615 from sarutak/replace-symbol-literals-in-doc-and-examples.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add `table_identifier` in sql-migration-guide for SHOW CREATE TABLE.
### Why are the changes needed?
To make document more readable.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing test suites.
Closes#31608 from Karl-WangSK/sqldoc.
Lead-authored-by: Karl-WangSK <shikai.wang@linkflowtech.com>
Co-authored-by: ShiKai Wang <wskqing@gmail.com>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request?
Update public docs of SQL commands about altering cached tables/views. For instance:
<img width="869" alt="Screenshot 2021-02-08 at 15 11 48" src="https://user-images.githubusercontent.com/1580697/107217940-fd3b8980-6a1f-11eb-98b9-9b2e3fe7f4ef.png">
### Why are the changes needed?
To inform users about commands behavior in altering cached tables or views.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running the command below and manually checking the docs:
```
$ SKIP_API=1 SKIP_SCALADOC=1 SKIP_PYTHONDOC=1 SKIP_RDOC=1 jekyll serve --watch
```
Closes#31524 from MaxGekk/doc-cmd-caching.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fix an issue that `java.sql.RowId` is mapped to `LongType` and prefer `StringType`.
In the current implementation, JDBC RowID type is mapped to `LongType` except for `OracleDialect`, but there is no guarantee to be able to convert RowID to long.
`java.sql.RowId` declares `toString` and the specification of `java.sql.RowId` says
> _all methods on the RowId interface must be fully implemented if the JDBC driver supports the data type_
(https://docs.oracle.com/javase/8/docs/api/java/sql/RowId.html)
So, we should prefer StringType to LongType.
### Why are the changes needed?
This seems to be a potential bug.
### Does this PR introduce _any_ user-facing change?
Yes. RowID is mapped to StringType rather than LongType.
### How was this patch tested?
New test and the existing test case `SPARK-32992: map Oracle's ROWID type to StringType` in `OracleIntegrationSuite` passes.
Closes#31491 from sarutak/rowid-type.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
This change is to document the newly added streaming table APIs in Structured Streaming Programming Guide.
### Why are the changes needed?
This will help our users when they try to use the new APIs.
### Does this PR introduce _any_ user-facing change?
Yes. Users will see the changes in the programming guide.
### How was this patch tested?
Built the HTML page and verified.
Attached is a screenshot of the section added:

Closes#31590 from bozhang2820/table-api-doc.
Lead-authored-by: Bo Zhang <bo.zhang@databricks.com>
Co-authored-by: Bo Zhang <bozhang2820@gmail.com>
Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
Explicitly highlight that the table rename command cannot move a table between databases.
### Why are the changes needed?
To inform users about actual behavior of the table rename command.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
```sql
spark-sql> CREATE DATABASE db1;
spark-sql> CREATE DATABASE db2;
spark-sql> CREATE TABLE db1.tbl1 (c0 INT);
spark-sql> ALTER TABLE db1.tbl1 RENAME TO db2.tbl1;
Error in query: RENAME TABLE source and destination databases do not match: 'db1' != 'db2';
spark-sql> ALTER TABLE db1.tbl1 RENAME TO db1.tbl2;
spark-sql> SHOW TABLES IN db1 LIKE '*';
db1 tbl2 false
```
Closes#31586 from MaxGekk/doc-rename-table.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
BasicWriteStatsTracker to probe for a custom Xattr if the size of
the generated file is 0 bytes; if found and parseable use that as
the declared length of the output.
The matching Hadoop patch in HADOOP-17414:
* Returns all S3 object headers as XAttr attributes prefixed "header."
* Sets the custom header x-hadoop-s3a-magic-data-length to the length of
the data in the marker file.
As a result, spark job tracking will correctly report the amount of data uploaded
and yet to materialize.
### Why are the changes needed?
Now that S3 is consistent, it's a lot easier to use the S3A "magic" committer
which redirects a file written to `dest/__magic/job_0011/task_1245/__base/year=2020/output.avro`
to its final destination `dest/year=2020/output.avro` , adding a zero byte marker file at
the end and a json file `dest/__magic/job_0011/task_1245/__base/year=2020/output.avro.pending`
containing all the information for the job committer to complete the upload.
But: the write tracker statictics don't show progress as they measure the length of the
created file, find the marker file and report 0 bytes.
By probing for a specific HTTP header in the marker file and parsing that if
retrieved, the real progress can be reported.
There's a matching change in Hadoop [https://github.com/apache/hadoop/pull/2530](https://github.com/apache/hadoop/pull/2530)
which adds getXAttr API support to the S3A connector and returns the headers; the magic
committer adds the relevant attributes.
If the FS being probed doesn't support the XAttr API, the header is missing
or the value not a positive long then the size of 0 is returned.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
New tests in BasicWriteTaskStatsTrackerSuite which use a filter FS to
implement getXAttr on top of LocalFS; this is used to explore the set of
options:
* no XAttr API implementation (existing tests; what callers would see with
most filesystems)
* no attribute found (HDFS, ABFS without the attribute)
* invalid data of different forms
All of these return Some(0) as file length.
The Hadoop PR verifies XAttr implementation in S3A and that
the commit protocol attaches the header to the files.
External downstream testing has done the full hadoop+spark end
to end operation, with manual review of logs to verify that the
data was successfully collected from the attribute.
Closes#30714 from steveloughran/cdpd/SPARK-33739-magic-commit-tracking-master.
Authored-by: Steve Loughran <stevel@cloudera.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to update the Spark SQL guide about the SQL configs that are related to datetime rebasing:
- spark.sql.parquet.int96RebaseModeInWrite
- spark.sql.parquet.datetimeRebaseModeInWrite
- spark.sql.parquet.int96RebaseModeInRead
- spark.sql.parquet.datetimeRebaseModeInRead
- spark.sql.avro.datetimeRebaseModeInWrite
- spark.sql.avro.datetimeRebaseModeInRead
Parquet options added by #31489:
- datetimeRebaseMode
- int96RebaseMode
and Avro options added by #31529:
- datetimeRebaseMode
<img width="998" alt="Screenshot 2021-02-17 at 21 42 09" src="https://user-images.githubusercontent.com/1580697/108252043-3afb8900-7169-11eb-8568-511e21fa7f78.png">
### Why are the changes needed?
To inform users about supported DS options and SQL configs.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By generating the doc and manually checking:
```
$ SKIP_API=1 SKIP_SCALADOC=1 SKIP_PYTHONDOC=1 SKIP_RDOC=1 jekyll serve --watch
```
Closes#31564 from MaxGekk/doc-rebase-options.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. Put the SQL config `spark.sql.legacy.replaceDatabricksSparkAvro.enabled` to the list of deprecated configs `deprecatedSQLConfigs`
2. Update docs for the Avro datasource
<img width="982" alt="Screenshot 2021-02-17 at 21 04 26" src="https://user-images.githubusercontent.com/1580697/108249890-abed7180-7166-11eb-8cb7-0c246d2a34fc.png">
### Why are the changes needed?
The config exists for enough time. We can deprecate it, and recommend users to use `.format("avro")` instead.
### Does this PR introduce _any_ user-facing change?
Should not except of the warning with the recommendation to use the `avro` format.
### How was this patch tested?
1. By generating docs via:
```
$ SKIP_API=1 SKIP_SCALADOC=1 SKIP_PYTHONDOC=1 SKIP_RDOC=1 jekyll serve --watch
```
2. Manually checking the warning:
```
scala> spark.conf.set("spark.sql.legacy.replaceDatabricksSparkAvro.enabled", false)
21/02/17 21:20:18 WARN SQLConf: The SQL config 'spark.sql.legacy.replaceDatabricksSparkAvro.enabled' has been deprecated in Spark v3.2 and may be removed in the future. Use `.format("avro")` in `DataFrameWriter` or `DataFrameReader` instead.
```
Closes#31578 from MaxGekk/deprecate-replaceDatabricksSparkAvro.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Improving the documentation and release process by pinning Jekyll version by Gemfile and Bundler.
Some files and their responsibilities within this PR:
- `docs/.bundle/config` is used to specify a directory "docs/.local_ruby_bundle" which will be used as destination to install the ruby packages into instead of the global one which requires root access
- `docs/Gemfile` is specifying the required Jekyll version and other top level gem versions
- `docs/Gemfile.lock` is generated by the "bundle install". This file contains the exact resolved versions of all the gems including the top level gems and all the direct and transitive dependencies of those gems. When this file is generated it contains a platform related section "PLATFORMS" (in my case after the generation it was "universal-darwin-19"). Still this file must be under version control as when the version of a gem does not fit to the one specified in `Gemfile` an error comes (i.e. if the `Gemfile.lock` was generated for Jekyll 4.1.0 and its version is updated in the `Gemfile` to 4.2.0 then it triggers the error: "The bundle currently has jekyll locked at 4.1.0."). This is solution is also suggested officially in [its documentation](https://bundler.io/rationale.html#checking-your-code-into-version-control). To get rid of the specific platform (like "universal-darwin-19") first we have to add "ruby" as platform [which means this should work on every platform where Ruby runs](https://guides.rubygems.org/what-is-a-gem/)) by running "bundle lock --add-platform ruby" then the specific platform can be removed by "bundle lock --remove-platform universal-darwin-19".
After this the correct process to update Jekyll version is the following:
1. update the version in `Gemfile`
2. run "bundle update" which updates the `Gemfile.lock`
3. commit both files
This process for version update is tested for details please check the testing section.
### Why are the changes needed?
Using different Jekyll versions can generate different output documents.
This PR standardize the process.
### Does this PR introduce _any_ user-facing change?
No, assuming the release was done via docker by using `do-release-docker.sh`.
In that case there should be no difference at all as the same Jekyll version is specified in the Gemfile.
### How was this patch tested?
#### Testing document generation
Doc generation step was triggered via the docker release:
```
$ ./do-release-docker.sh -d ~/working -n -s docs
...
========================
= Building documentation...
Command: /opt/spark-rm/release-build.sh docs
Log file: docs.log
Skipping publish step.
```
The docs.log contains the followings:
```
Building Spark docs
Fetching gem metadata from https://rubygems.org/.........
Using bundler 2.2.9
Fetching rb-fsevent 0.10.4
Fetching forwardable-extended 2.6.0
Fetching public_suffix 4.0.6
Fetching colorator 1.1.0
Fetching eventmachine 1.2.7
Fetching http_parser.rb 0.6.0
Fetching ffi 1.14.2
Fetching concurrent-ruby 1.1.8
Installing colorator 1.1.0
Installing forwardable-extended 2.6.0
Installing rb-fsevent 0.10.4
Installing public_suffix 4.0.6
Installing http_parser.rb 0.6.0 with native extensions
Installing eventmachine 1.2.7 with native extensions
Installing concurrent-ruby 1.1.8
Fetching rexml 3.2.4
Fetching liquid 4.0.3
Installing ffi 1.14.2 with native extensions
Installing rexml 3.2.4
Installing liquid 4.0.3
Fetching mercenary 0.4.0
Installing mercenary 0.4.0
Fetching rouge 3.26.0
Installing rouge 3.26.0
Fetching safe_yaml 1.0.5
Installing safe_yaml 1.0.5
Fetching unicode-display_width 1.7.0
Installing unicode-display_width 1.7.0
Fetching webrick 1.7.0
Installing webrick 1.7.0
Fetching pathutil 0.16.2
Fetching kramdown 2.3.0
Fetching terminal-table 2.0.0
Fetching addressable 2.7.0
Fetching i18n 1.8.9
Installing terminal-table 2.0.0
Installing pathutil 0.16.2
Installing i18n 1.8.9
Installing addressable 2.7.0
Installing kramdown 2.3.0
Fetching kramdown-parser-gfm 1.1.0
Installing kramdown-parser-gfm 1.1.0
Fetching rb-inotify 0.10.1
Fetching sassc 2.4.0
Fetching em-websocket 0.5.2
Installing rb-inotify 0.10.1
Installing em-websocket 0.5.2
Installing sassc 2.4.0 with native extensions
Fetching listen 3.4.1
Installing listen 3.4.1
Fetching jekyll-watch 2.2.1
Installing jekyll-watch 2.2.1
Fetching jekyll-sass-converter 2.1.0
Installing jekyll-sass-converter 2.1.0
Fetching jekyll 4.2.0
Installing jekyll 4.2.0
Fetching jekyll-redirect-from 0.16.0
Installing jekyll-redirect-from 0.16.0
Bundle complete! 4 Gemfile dependencies, 30 gems now installed.
Bundled gems are installed into `./.local_ruby_bundle`
```
#### Testing Jekyll (or other gem) update
First locally I reverted Jekyll to 4.1.0:
```
$ rm Gemfile.lock
$ rm -rf .local_ruby_bundle
# edited Gemfile to use version 4.1.0
$ cat Gemfile
source "https://rubygems.org"
gem "jekyll", "4.1.0"
gem "rouge", "3.26.0"
gem "jekyll-redirect-from", "0.16.0"
gem "webrick", "1.7"
$ bundle install
...
```
Testing Jekyll version before the update:
```
$ bundle exec jekyll --version
jekyll 4.1.0
```
Imitating Jekyll update coming from git by reverting my local changes:
```
$ git checkout Gemfile
Updated 1 path from the index
$ cat Gemfile
source "https://rubygems.org"
gem "jekyll", "4.2.0"
gem "rouge", "3.26.0"
gem "jekyll-redirect-from", "0.16.0"
gem "webrick", "1.7"
$ git checkout Gemfile.lock
Updated 1 path from the index
```
Run the install:
```
$ bundle install
...
```
Checking the updated Jekyll version:
```
$ bundle exec jekyll --version
jekyll 4.2.0
```
Closes#31559 from attilapiros/pin-jekyll-version.
Lead-authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com>
Co-authored-by: Attila Zsolt Piros <2017933+attilapiros@users.noreply.github.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Per discussion in https://issues.apache.org/jira/browse/SPARK-32883?focusedCommentId=17285057&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-17285057, we should add documentation for added new features of full outer and left semi joins into SS programming guide.
* Reworded the section for "Outer Joins with Watermarking", to make it work for full outer join. Updated the code snippet to show up full outer and left semi join.
* Added one section for "Semi Joins with Watermarking", similar to "Outer Joins with Watermarking".
* Updated "Support matrix for joins in streaming queries" to reflect latest fact for full outer and left semi join.
### Why are the changes needed?
Good for users and developers to follow guide to try out these two new features.
### Does this PR introduce _any_ user-facing change?
Yes. They will see the corresponding updated guide.
### How was this patch tested?
No, just documentation change. Previewed the markdown file in browser.
Also attached here for the change to the "Support matrix for joins in streaming queries" table.
<img width="896" alt="Screen Shot 2021-02-16 at 8 12 07 PM" src="https://user-images.githubusercontent.com/4629931/108155275-73c92e80-7093-11eb-9f0b-c8b4bb7321e5.png">
Closes#31572 from c21/ss-doc.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This PR changes the type mapping for `money` and `money[]` types for PostgreSQL.
Currently, those types are tried to convert to `DoubleType` and `ArrayType` of `double` respectively.
But the JDBC driver seems not to be able to handle those types properly.
https://github.com/pgjdbc/pgjdbc/issues/100https://github.com/pgjdbc/pgjdbc/issues/1405
Due to these issue, we can get the error like as follows.
money type.
```
[info] org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0) (192.168.1.204 executor driver): org.postgresql.util.PSQLException: Bad value for type double : 1,000.00
[info] at org.postgresql.jdbc.PgResultSet.toDouble(PgResultSet.java:3104)
[info] at org.postgresql.jdbc.PgResultSet.getDouble(PgResultSet.java:2432)
[info] at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.$anonfun$makeGetter$5(JdbcUtils.scala:418)
```
money[] type.
```
[info] org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0) (192.168.1.204 executor driver): org.postgresql.util.PSQLException: Bad value for type double : $2,000.00
[info] at org.postgresql.jdbc.PgResultSet.toDouble(PgResultSet.java:3104)
[info] at org.postgresql.jdbc.ArrayDecoding$5.parseValue(ArrayDecoding.java:235)
[info] at org.postgresql.jdbc.ArrayDecoding$AbstractObjectStringArrayDecoder.populateFromString(ArrayDecoding.java:122)
[info] at org.postgresql.jdbc.ArrayDecoding.readStringArray(ArrayDecoding.java:764)
[info] at org.postgresql.jdbc.PgArray.buildArray(PgArray.java:310)
[info] at org.postgresql.jdbc.PgArray.getArrayImpl(PgArray.java:171)
[info] at org.postgresql.jdbc.PgArray.getArray(PgArray.java:111)
```
For money type, a known workaround is to treat it as string so this PR do it.
For money[], however, there is no reasonable workaround so this PR remove the support.
### Why are the changes needed?
This is a bug.
### Does this PR introduce _any_ user-facing change?
Yes. As of this PR merged, money type is mapped to `StringType` rather than `DoubleType` and the support for money[] is stopped.
For money type, if the value is less than one thousand, `$100.00` for instance, it works without this change so I also updated the migration guide because it's a behavior change for such small values.
On the other hand, money[] seems not to work with any value but mentioned in the migration guide just in case.
### How was this patch tested?
New test.
Closes#31442 from sarutak/fix-for-money-type.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
JDBC connection provider API and embedded connection providers already added to the code but no in-depth description about the internals. In this PR I've added both user and developer documentation and additionally added an example custom JDBC connection provider.
### Why are the changes needed?
No documentation and example custom JDBC provider.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
```
cd docs/
SKIP_API=1 jekyll build
```
<img width="793" alt="Screenshot 2021-02-02 at 16 35 43" src="https://user-images.githubusercontent.com/18561820/106623428-e48d2880-6574-11eb-8d14-e5c2aa7c37f1.png">
Closes#31384 from gaborgsomogyi/SPARK-31816.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Passing around the output attributes should have more benefits like keeping the exprID unchanged to avoid bugs when we apply more operators above the command output DataFrame.
This PR did 2 things :
1. After this pr, a `SHOW TBLPROPERTIES` clause's output shows `key` and `value` columns whether you specify the table property `key`. Before this pr, a `SHOW TBLPROPERTIES` clause's output only show a `value` column when you specify the table property `key`..
2. Keep `SHOW TBLPROPERTIES` command's output attribute exprId unchanged.
### Why are the changes needed?
1. Keep `SHOW TBLPROPERTIES`'s output schema consistence
2. Keep `SHOW TBLPROPERTIES` command's output attribute exprId unchanged.
### Does this PR introduce _any_ user-facing change?
After this pr, a `SHOW TBLPROPERTIES` clause's output shows `key` and `value` columns whether you specify the table property `key`. Before this pr, a `SHOW TBLPROPERTIES` clause's output only show a `value` column when you specify the table property `key`.
Before this PR:
```
sql > SHOW TBLPROPERTIES tabe_name('key')
value
value_of_key
```
After this PR
```
sql > SHOW TBLPROPERTIES tabe_name('key')
key value
key value_of_key
```
### How was this patch tested?
Added UT
Closes#31378 from AngersZhuuuu/SPARK-34240.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This follows up #31160 to update score function in the document.
### Why are the changes needed?
Currently we use `f_classif`, `ch2`, `f_regression`, which sound to me the sklearn's naming. It is good to have it but I think it is nice if we have formal score function name with sklearn's ones.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
No, only doc change.
Closes#31531 from viirya/SPARK-34080-minor.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Remove an unnecessary quote in the documentation.
Super trivial.
### Why are the changes needed?
Fix a mistake.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Just doc
Closes#31523 from gengliangwang/removeQuote.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The current implement of some DDL not unify the output and not pass the output properly to physical command.
Such as: The `ShowTables` output attributes `namespace`, but `ShowTablesCommand` output attributes `database`.
As the query plan, this PR pass the output attributes from `ShowTables` to `ShowTablesCommand`, `ShowTableExtended ` to `ShowTablesCommand`.
Take `show tables` and `show table extended like 'tbl'` as example.
The output before this PR:
`show tables`
|database|tableName|isTemporary|
-- | -- | --
| default| tbl| false|
If catalog is v2 session catalog, the output before this PR:
|namespace|tableName|
-- | --
| default| tbl
`show table extended like 'tbl'`
|database|tableName|isTemporary| information|
-- | -- | -- | --
| default| tbl| false|Database: default...|
The output after this PR:
`show tables`
|namespace|tableName|isTemporary|
-- | -- | --
| default| tbl| false|
`show table extended like 'tbl'`
|namespace|tableName|isTemporary| information|
-- | -- | -- | --
| default| tbl| false|Database: default...|
### Why are the changes needed?
This PR have benefits as follows:
First, Unify schema for the output of SHOW TABLES.
Second, pass the output attributes could keep the expr ID unchanged, so that avoid bugs when we apply more operators above the command output dataframe.
### Does this PR introduce _any_ user-facing change?
Yes.
The output schema of `SHOW TABLES` replace `database` by `namespace`.
### How was this patch tested?
Jenkins test.
Closes#31245 from beliefer/SPARK-34157.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: beliefer <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
docs/pyspark-migration-guide.md
### Why are the changes needed?
broken link
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually build and check
Closes#31514 from raphaelauv/patch-2.
Authored-by: raphaelauv <raphaelauv@users.noreply.github.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/26006
In #26006 , we merged the v1 and v2 SHOW DATABASES/NAMESPACES commands, but we missed a behavior change that the output schema of SHOW DATABASES becomes different.
This PR adds a legacy config to restore the old schema, with a migration guide item to mention this behavior change.
### Why are the changes needed?
Improve backward compatibility
### Does this PR introduce _any_ user-facing change?
No (the legacy config is false by default)
### How was this patch tested?
a new test
Closes#31474 from cloud-fan/command-schema.
Lead-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Co-authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Correct the version of SQL configuration `spark.sql.legacy.parseNullPartitionSpecAsStringLiteral` from 3.2.0 to 3.0.2.
Also, revise the documentation and test case.
### Why are the changes needed?
The release version in https://github.com/apache/spark/pull/31421 was wrong.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests
Closes#31434 from gengliangwang/reviseVersion.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In spark, the `count(table.*)` may cause very weird result, for example:
```
select count(*) from (select 1 as a, null as b) t;
output: 1
select count(t.*) from (select 1 as a, null as b) t;
output: 0
```
This is because spark expands `t.*` while converts `*` to count(1), this will confuse
users. After checking the ANSI standard, `count(*)` should always be `count(1)` while `count(t.*)`
is not allowed. What's more, this is also not allowed by common databases, e.g. MySQL, Oracle.
So, this PR proposes to block the ambiguous behavior and print a clear error message for users.
### Why are the changes needed?
to avoid ambiguous behavior and follow ANSI standard and other SQL engines
### Does this PR introduce _any_ user-facing change?
Yes, `count(table.*)` behavior will be blocked and output an error message.
### How was this patch tested?
newly added and existing tests
Closes#31286 from linhongliu-db/fix-table-star.
Authored-by: Linhong Liu <linhong.liu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a follow up for https://github.com/apache/spark/pull/30538.
It adds a legacy conf `spark.sql.legacy.parseNullPartitionSpecAsStringLiteral` in case users wants the legacy behavior.
It also adds document for the behavior change.
### Why are the changes needed?
In case users want the legacy behavior, they can set `spark.sql.legacy.parseNullPartitionSpecAsStringLiteral` as true.
### Does this PR introduce _any_ user-facing change?
Yes, adding a legacy configuration to restore the old behavior.
### How was this patch tested?
Unit test.
Closes#31421 from gengliangwang/legacyNullStringConstant.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR completes snake_case rule at functions APIs across the languages, see also SPARK-10621.
In more details, this PR:
- Adds `count_distinct` in Scala Python, and R, and document that `count_distinct` is encouraged. This was not deprecated because `countDistinct` is pretty commonly used. We could deprecate in the future releases.
- (Scala-specific) adds `typedlit` but doesn't deprecate `typedLit` which is arguably commonly used. Likewise, we could deprecate in the future releases.
- Deprecates and renames:
- `sumDistinct` -> `sum_distinct`
- `bitwiseNOT` -> `bitwise_not`
- `shiftLeft` -> `shiftleft` (matched with SQL name in `FunctionRegistry`)
- `shiftRight` -> `shiftright` (matched with SQL name in `FunctionRegistry`)
- `shiftRightUnsigned` -> `shiftrightunsigned` (matched with SQL name in `FunctionRegistry`)
- (Scala-specific) `callUDF` -> `call_udf`
### Why are the changes needed?
To keep the consistent naming in APIs.
### Does this PR introduce _any_ user-facing change?
Yes, it deprecates some APIs and add new renamed APIs as described above.
### How was this patch tested?
Unittests were added.
Closes#31408 from HyukjinKwon/SPARK-34306.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR aims to remove `internal()` from `spark.kubernetes.executor.podNamePrefix` in order to make it the configuration public.
### Why are the changes needed?
In line with K8s GA, this will allow some users control the full executor pod names officially.
This is useful when we want a custom executor pod name pattern independently from the app name.
### Does this PR introduce _any_ user-facing change?
No, this has been there since Apache Spark 2.3.0.
### How was this patch tested?
N/A.
Closes#31386 from dongjoon-hyun/SPARK-34281.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add document for the behavior change in SPARK-34052, in SQL migration guide.
### Why are the changes needed?
Document behavior change for Spark users.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
N/A
Closes#31351 from sunchao/SPARK-34052-followup.
Authored-by: Chao Sun <sunchao@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add notice about keep hive version consistence when config hive jars location
With PR #29881, if we don't keep hive version consistence. we will got below error.
```
Builtin jars can only be used when hive execution version == hive metastore version. Execution: 2.3.8 != Metastore: 1.2.1. Specify a valid path to the correct hive jars using spark.sql.hive.metastore.jars or change spark.sql.hive.metastore.version to 2.3.8.
```

### Why are the changes needed?
Make config doc detail
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#31317 from AngersZhuuuu/SPARK-32852-followup.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a follow up of the PRs https://github.com/apache/spark/pull/31066 and https://github.com/apache/spark/pull/31304 that changed behavior of some commands regarding to table cache refreshing. The PR updates the SQL migration guide, in particular, the item which describes new behavior.
### Why are the changes needed?
To inform users about command behavior changes.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
N/A
Closes#31309 from MaxGekk/refreshTable-sql-migration-guide.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR changes cache refreshing of v1 tables in v1 commands. In particular, v1 table dependents are not removed from the cache after this PR. Comparing to current implementation, we just clear cached data of all dependents and keep them in the cache. So, the next actions will fill in the cached data of the original v1 table and its dependents. In more details:
1. Modified the `CatalogImpl.refreshTable()` method to use `recacheByPlan()` instead of `lookupCachedData()`, `uncacheQuery()` and `cacheQuery()`. Users can call this method via public API like `spark.catalog.refreshTable()`.
2. Rewritten the part in `CatalogImpl.refreshTable()` which was responsible for table meta-data refreshing because this code stopped to work properly after removing of the second `sparkSession.table(tableIdent)`.
3. Added new private method `invalidateCachedTable()` to `SessionCatalog`. Comparing to the existing `SessionCatalog.refreshTable`, it invalidates the relation cache only. If we called `SessionCatalog.refreshTable` from `CatalogImpl.refreshTable()`, we would refresh temporary and global temporary views twice (that could lead to refreshing file index twice).
### Why are the changes needed?
1. This should improve user experience with table/view caching. For example, let's imagine that an user has cached v1 table and cached view based on the table. And the user passed the table to external library which drops/renames/adds partitions in the v1 table. Unfortunately, the user gets the view uncached after that even he/she hasn't uncached the view explicitly.
2. To improve code maintenance.
3. To reduce the amount of calls to Hive external catalog.
4. Also this should speed up table recaching.
5. To have the same behavior as for v2 tables supported by https://github.com/apache/spark/pull/31172
### Does this PR introduce _any_ user-facing change?
From the view of the correctness of query results, there are no behavior changes but the changes might influence on consuming memory and query execution time. For example:
Before:
```scala
scala> sql("CREATE TABLE tbl (c int)")
scala> sql("CACHE TABLE tbl")
scala> sql("CREATE VIEW v AS SELECT * FROM tbl")
scala> sql("CACHE TABLE v")
scala> spark.catalog.isCached("v")
res6: Boolean = true
scala> spark.catalog.refreshTable("tbl")
scala> spark.catalog.isCached("v")
res8: Boolean = false
```
After:
```scala
scala> spark.catalog.refreshTable("tbl")
scala> spark.catalog.isCached("v")
res8: Boolean = true
```
### How was this patch tested?
1. Added new unit tests that create a view, a temporary view and a global temporary view on top of v1/v2 tables, and refresh the base table via `ALTER TABLE .. ADD/DROP/RENAME PARTITION`.
2. By running the unified test suites:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableAddPartitionSuite"
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableDropPartitionSuite"
# build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableRenamePartitionSuite"
```
Closes#31206 from MaxGekk/refreshTable-recache-by-plan.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When ruby version is 3.0, jekyll server will failed with
```
yi.zhu$ SKIP_API=1 jekyll serve --watch
Configuration file: /Users/yi.zhu/Documents/project/Angerszhuuuu/spark/docs/_config.yml
Source: /Users/yi.zhu/Documents/project/Angerszhuuuu/spark/docs
Destination: /Users/yi.zhu/Documents/project/Angerszhuuuu/spark/docs/_site
Incremental build: disabled. Enable with --incremental
Generating...
done in 5.085 seconds.
Auto-regeneration: enabled for '/Users/yi.zhu/Documents/project/Angerszhuuuu/spark/docs'
------------------------------------------------
Jekyll 4.2.0 Please append `--trace` to the `serve` command
for any additional information or backtrace.
------------------------------------------------
<internal:/usr/local/Cellar/ruby/3.0.0_1/lib/ruby/3.0.0/rubygems/core_ext/kernel_require.rb>:85:in `require': cannot load such file -- webrick (LoadError)
from <internal:/usr/local/Cellar/ruby/3.0.0_1/lib/ruby/3.0.0/rubygems/core_ext/kernel_require.rb>:85:in `require'
from /Users/yi.zhu/.gem/ruby/3.0.0/gems/jekyll-4.2.0/lib/jekyll/commands/serve/servlet.rb:3:in `<top (required)>'
from /Users/yi.zhu/.gem/ruby/3.0.0/gems/jekyll-4.2.0/lib/jekyll/commands/serve.rb:179:in `require_relative'
from /Users/yi.zhu/.gem/ruby/3.0.0/gems/jekyll-4.2.0/lib/jekyll/commands/serve.rb:179:in `setup'
from /Users/yi.zhu/.gem/ruby/3.0.0/gems/jekyll-4.2.0/lib/jekyll/commands/serve.rb💯in `process'
from /Users/yi.zhu/.gem/ruby/3.0.0/gems/jekyll-4.2.0/lib/jekyll/command.rb:91:in `block in process_with_graceful_fail'
from /Users/yi.zhu/.gem/ruby/3.0.0/gems/jekyll-4.2.0/lib/jekyll/command.rb:91:in `each'
from /Users/yi.zhu/.gem/ruby/3.0.0/gems/jekyll-4.2.0/lib/jekyll/command.rb:91:in `process_with_graceful_fail'
from /Users/yi.zhu/.gem/ruby/3.0.0/gems/jekyll-4.2.0/lib/jekyll/commands/serve.rb:86:in `block (2 levels) in init_with_program'
from /Users/yi.zhu/.gem/ruby/3.0.0/gems/mercenary-0.4.0/lib/mercenary/command.rb:221:in `block in execute'
from /Users/yi.zhu/.gem/ruby/3.0.0/gems/mercenary-0.4.0/lib/mercenary/command.rb:221:in `each'
from /Users/yi.zhu/.gem/ruby/3.0.0/gems/mercenary-0.4.0/lib/mercenary/command.rb:221:in `execute'
from /Users/yi.zhu/.gem/ruby/3.0.0/gems/mercenary-0.4.0/lib/mercenary/program.rb:44:in `go'
from /Users/yi.zhu/.gem/ruby/3.0.0/gems/mercenary-0.4.0/lib/mercenary.rb:21:in `program'
from /Users/yi.zhu/.gem/ruby/3.0.0/gems/jekyll-4.2.0/exe/jekyll:15:in `<top (required)>'
from /usr/local/bin/jekyll:23:in `load'
from /usr/local/bin/jekyll:23:in `<main>'
```
This issue is solved in https://github.com/jekyll/jekyll/issues/8523
### Why are the changes needed?
Fix build issue
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#31263 from AngersZhuuuu/SPARK-34181.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Update Avro dependency to version 1.10.1
### Why are the changes needed?
To catch up multiple improvements of Avro as well as fix security issues on transitive dependencies.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Since there were no API changes required we just run the tests
Closes#31232 from iemejia/SPARK-27733-avro-upgrade.
Authored-by: Ismaël Mejía <iemejia@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR aims to add a note for Apache Arrow project's `PyArrow` compatibility for Python 3.9.
### Why are the changes needed?
Although Apache Spark documentation claims `Spark runs on Java 8/11, Scala 2.12, Python 3.6+ and R 3.5+.`,
Apache Arrow's `PyArrow` is not compatible with Python 3.9.x yet. Without installing `PyArrow` library, PySpark UTs passed without any problem. So, it would be enough to add a note for this limitation and the compatibility link of Apache Arrow website.
- https://arrow.apache.org/docs/python/install.html#python-compatibility
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
**BEFORE**
<img width="804" alt="Screen Shot 2021-01-19 at 1 45 07 PM" src="https://user-images.githubusercontent.com/9700541/105096867-8fbdbe00-5a5c-11eb-88f7-8caae2427583.png">
**AFTER**
<img width="908" alt="Screen Shot 2021-01-19 at 7 06 41 PM" src="https://user-images.githubusercontent.com/9700541/105121661-85fe7f80-5a89-11eb-8af7-1b37e12c55c1.png">
Closes#31251 from dongjoon-hyun/SPARK-34162.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR is the 3rd try to upgrade Scala 2.12.x in order to see the feasibility.
- https://github.com/apache/spark/pull/27929 (Upgrade Scala to 2.12.11, wangyum )
- https://github.com/apache/spark/pull/30940 (Upgrade Scala to 2.12.12, viirya )
`silencer` library is updated accordingly. And, Kafka version upgrade is required because it fails like the following.
```
[info] KafkaDataConsumerSuite:
[info] org.apache.spark.streaming.kafka010.KafkaDataConsumerSuite *** ABORTED *** (1 second, 580 milliseconds)
[info] java.lang.NoClassDefFoundError: scala/math/Ordering$$anon$7
[info] at kafka.api.ApiVersion$.orderingByVersion(ApiVersion.scala:45)
```
### Why are the changes needed?
Apache Spark was stuck to 2.12.10 due to the regression in Scala 2.12.11 and 2.12.12. This will bring all the bug fixes.
- https://github.com/scala/scala/releases/tag/v2.12.13
- https://github.com/scala/scala/releases/tag/v2.12.12
- https://github.com/scala/scala/releases/tag/v2.12.11
### Does this PR introduce _any_ user-facing change?
Yes, but this is a bug-fixed version.
### How was this patch tested?
Pass the CIs.
Closes#31223 from dongjoon-hyun/SPARK-31168.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Hive 2.3.8 changes:
HIVE-19662: Upgrade Avro to 1.8.2
HIVE-24324: Remove deprecated API usage from Avro
HIVE-23980: Shade Guava from hive-exec in Hive 2.3
HIVE-24436: Fix Avro NULL_DEFAULT_VALUE compatibility issue
HIVE-24512: Exclude calcite in packaging.
HIVE-22708: Fix for HttpTransport to replace String.equals
HIVE-24551: Hive should include transitive dependencies from calcite after shading it
HIVE-24553: Exclude calcite from test-jar dependency of hive-exec
### Why are the changes needed?
Upgrade Avro and Parquet to latest version.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing test add test try to upgrade Parquet to 1.11.1 and Avro to 1.10.1: https://github.com/apache/spark/pull/30517Closes#30657 from wangyum/SPARK-33696.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR aims to update the Parquet website link from http://parquet.io to https://parquet.apache.orc
### Why are the changes needed?
The old website goes to the incubator site.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
N/A
Closes#31208 from williamhyun/minor-parquet.
Authored-by: William Hyun <williamhyun3@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add UnivariateFeatureSelector
### Why are the changes needed?
Have one UnivariateFeatureSelector, so we don't need to have three Feature Selectors.
### Does this PR introduce _any_ user-facing change?
Yes
```
selector = UnivariateFeatureSelector(featureCols=["x", "y", "z"], labelCol=["target"], featureType="categorical", labelType="continuous", selectorType="numTopFeatures", numTopFeatures=100)
```
Or
numTopFeatures
```
selector = UnivariateFeatureSelector(featureCols=["x", "y", "z"], labelCol=["target"], scoreFunction="f_classif", selectorType="numTopFeatures", numTopFeatures=100)
```
### How was this patch tested?
Add Unit test
Closes#31160 from huaxingao/UnivariateSelector.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Weichen Xu <weichen.xu@databricks.com>
### What changes were proposed in this pull request?
This PR aims to strip auto-generated cast. The main logic is:
1. Add tag if Cast is specified by user.
2. Wrap `PrettyAttribute` in usePrettyExpression.
### Why are the changes needed?
Make sql consistent with dsl. Here is an inconsistent example before this PR:
```
-- output field name: FLOOR(1)
spark.emptyDataFrame.select(floor(lit(1)))
-- output field name: FLOOR(CAST(1 AS DOUBLE))
spark.sql("select floor(1)")
```
Note that, we don't remove the `Cast` so the auto-generated `Cast` can still work. The only changed place is `usePrettyExpression`, we use `PrettyAttribute` replace `Cast` to give a better sql string.
### Does this PR introduce _any_ user-facing change?
Yes, the default field name may change.
### How was this patch tested?
Add test and pass exists test.
Closes#31034 from ulysses-you/SPARK-33989.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a followup PR for SPARK-33690 (#30647) .
In addition to the original PR, this PR intends to escape the following meta-characters in `Dataset#showString`.
* `\r` (carrige ret)
* `\f` (form feed)
* `\b` (backspace)
* `\u000B` (vertical tab)
* `\u0007` (bell)
### Why are the changes needed?
To avoid breaking the layout of `Dataset#showString`.
`\u0007` does not break the layout of `Dataset#showString` but it's noisy (beeps for each row) so it should be also escaped.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Modified the existing tests.
I also build the documents and check the generated html for `sql-migration-guide.md`.
Closes#31144 from sarutak/escape-metacharacters-in-getRows.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Add min threshold time speculation config
### Why are the changes needed?
When we turn on speculation with default configs we have the last 10% of the tasks subject to speculation. There are a lot of stages where the stage runs for few seconds to minutes. Also in general we don't want to speculate tasks that run within a minimum threshold. By setting a minimum threshold for speculation config gives us better control for speculative tasks
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes#30710 from redsanket/SPARK-33741.
Lead-authored-by: schintap <schintap@verizonmedia.com>
Co-authored-by: Sanket Chintapalli <chintapalli.sanketreddy@gmail.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
This patch adds a few description to SS doc about offset reset and data loss.
### Why are the changes needed?
During recent SS test, the behavior of gradual reducing input rows are confusing me. Comparing with Flink, I do not see a similar behavior. After looking into the code and doing some tests, I feel it is better to add some more description there in SS doc.
### Does this PR introduce _any_ user-facing change?
No, doc only.
### How was this patch tested?
Doc only.
Closes#31089 from viirya/ss-minor-5.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR tweaks the width of left-menu of Spark SQL Guide.
When I view the Spark SQL Guide with browsers on macOS, the title `Spark SQL Guide` looks prettily.
But I often use Pop!_OS, an Ubuntu variant, and the title is overlapped with browsers on it.

After this change, the title is no longer overlapped.

### Why are the changes needed?
For the pretty layout.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Built the document with `cd docs && SKIP_API=1 jekyll build` and confirmed the layout.
Closes#31091 from sarutak/modify-layout-sparksql-guide.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Kafka delegation token is obtained with `AdminClient` where security settings can be set. Keystore and trustrore type however can't be set. In this PR I've added these new configurations. This can be useful when the type is different. A good example is to make Spark FIPS compliant where the default JKS is not accepted.
### Why are the changes needed?
Missing configurations.
### Does this PR introduce _any_ user-facing change?
Yes, adding 2 additional config parameters.
### How was this patch tested?
Existing + modified unit tests + simple Kafka to Kafka app on cluster.
Closes#31070 from gaborgsomogyi/SPARK-34032.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This PR proposes to:
- Add a link of quick start in PySpark docs into "Programming Guides" in Spark main docs
- `ML` / `MLlib` -> `MLlib (DataFrame-based)` / `MLlib (RDD-based)` in API reference page
- Mention other user guides as well because the guide such as [ML](http://spark.apache.org/docs/latest/ml-guide.html) and [SQL](http://spark.apache.org/docs/latest/sql-programming-guide.html).
- Mention other migration guides as well because PySpark can get affected by it.
### Why are the changes needed?
For better documentation.
### Does this PR introduce _any_ user-facing change?
It fixes user-facing docs. However, it's not released out yet.
### How was this patch tested?
Manually tested by running:
```bash
cd docs
SKIP_SCALADOC=1 SKIP_RDOC=1 SKIP_SQLDOC=1 jekyll serve --watch
```
Closes#31082 from HyukjinKwon/SPARK-34041.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Update migration guide according to https://github.com/apache/spark/pull/30942#issuecomment-755054562
### Why are the changes needed?
update migration guide.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#31051 from AngersZhuuuu/SPARK-32685-FOLLOW-UP.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Instead of returning NULL, the next_day function throws runtime IllegalArgumentException when ansiMode is enable and receiving invalid input of the dayOfWeek parameter.
### Why are the changes needed?
For ansiMode.
### Does this PR introduce _any_ user-facing change?
Yes.
When spark.sql.ansi.enabled = true, the next_day function will throw IllegalArgumentException when receiving invalid input of the dayOfWeek parameter.
When spark.sql.ansi.enabled = false, same behaviour as before.
### How was this patch tested?
Ansi mode is tested with existing tests.
End-to-end tests have been added.
Closes#30807 from chongguang/SPARK-33794.
Authored-by: Chongguang LIU <chongguang.liu@laposte.fr>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Removed the **hiveClientCalls.count** in CodeGenerator metrics in Component instance = Executor
### Why are the changes needed?
Wrong information regarding metrics was being displayed on Monitoring Documentation. I had added referred documentation for adding metrics logging in Graphite. This metric was not being reported. I had to check if the issue was at my application end or spark code or documentation. Documentation had the wrong info.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual, checked it on my forked repository feature branch [SPARK-33942](https://github.com/coderbond007/spark/blob/SPARK-33942/docs/monitoring.md)
Closes#30976 from coderbond007/SPARK-33942.
Authored-by: Pradyumn Agrawal (pradyumn.ag) <pradyumn.ag@media.net>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
For same SQL
```
SELECT TRANSFORM(a, b, c, null)
ROW FORMAT DELIMITED
USING 'cat'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '&'
FROM (select 1 as a, 2 as b, 3 as c) t
```
In hive:
```
hive> SELECT TRANSFORM(a, b, c, null)
> ROW FORMAT DELIMITED
> USING 'cat'
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '&'
> FROM (select 1 as a, 2 as b, 3 as c) t;
OK
123\N NULL
Time taken: 14.519 seconds, Fetched: 1 row(s)
hive> packet_write_wait: Connection to 10.191.58.100 port 32200: Broken pipe
```
In Spark
```
Spark master: local[*], Application Id: local-1609225830376
spark-sql> SELECT TRANSFORM(a, b, c, null)
> ROW FORMAT DELIMITED
> USING 'cat'
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '&'
> FROM (select 1 as a, 2 as b, 3 as c) t;
1 2 3 null NULL
Time taken: 4.297 seconds, Fetched 1 row(s)
spark-sql>
```
We should keep same. Change default ROW FORMAT FIELD DELIMIT to `\u0001`
In hive default value is '1' to char is '\u0001'
```
bucket_count -1
column.name.delimiter ,
columns
columns.comments
columns.types
file.inputformat org.apache.hadoop.hive.ql.io.NullRowsInputFormat
```
### Why are the changes needed?
Keep same behavior with hive
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#30958 from AngersZhuuuu/SPARK-33930.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Update the SQL migration guide about the changes made by:
- https://github.com/apache/spark/pull/30778
- https://github.com/apache/spark/pull/30711
- https://github.com/apache/spark/pull/30866
### Why are the changes needed?
To inform users about the recent changes in the upcoming releases.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
N/A
Closes#30925 from MaxGekk/sql-migr-guide-hiveclientimpl.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Support add jar with ivy path
### Why are the changes needed?
Since submit app can support ivy, add jar we can also support ivy now.
### Does this PR introduce _any_ user-facing change?
User can add jar with sql like
```
add jar ivy:://group:artifict:version?exclude=xxx,xxx&transitive=true
add jar ivy:://group:artifict:version?exclude=xxx,xxx&transitive=false
```
core api
```
sparkContext.addJar("ivy:://group:artifict:version?exclude=xxx,xxx&transitive=true")
sparkContext.addJar("ivy:://group:artifict:version?exclude=xxx,xxx&transitive=false")
```
#### Doc Update snapshot

### How was this patch tested?
Added UT
Closes#29966 from AngersZhuuuu/support-add-jar-ivy.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
followup of a3dd8dacee via suggestion https://github.com/apache/spark/pull/30888#discussion_r547822642
### Why are the changes needed?
doc improvement
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
passing GA doc
Closes#30909 from yaooqinn/SPARK-33877-F.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR is a followup of https://github.com/apache/spark/pull/28788, and proposes to update migration guide.
### Why are the changes needed?
To tell users about the behaviour change.
### Does this PR introduce _any_ user-facing change?
Yes, it updates migration guides for users.
### How was this patch tested?
GitHub Actions' documentation build should test it.
Closes#30903 from HyukjinKwon/SPARK-31960-followup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR aims to enable `spark.storage.replication.proactive` by default for Apache Spark 3.2.0.
### Why are the changes needed?
`spark.storage.replication.proactive` is added by SPARK-15355 at Apache Spark 2.2.0 and has been helpful when the block manager loss occurs frequently like K8s environment.
### Does this PR introduce _any_ user-facing change?
Yes, this will make the Spark jobs more robust.
### How was this patch tested?
Pass the existing UTs.
Closes#30876 from dongjoon-hyun/SPARK-33870.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add `spark.sql.files.minPartitionNum` and it's description to sql-performence-tuning.md.
### Why are the changes needed?
Help user to find it.
### Does this PR introduce _any_ user-facing change?
Yes, it's the doc.
### How was this patch tested?
Pass CI.
Closes#30838 from ulysses-you/SPARK-33840.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This updates SS documentation to document about State Store and task locality.
### Why are the changes needed?
During running some tests for structured streaming, I found state store locality becomes an issue sometimes and it is not very straightforward for end-users. It'd be great if we can document it.
### Does this PR introduce _any_ user-facing change?
No, only doc change.
### How was this patch tested?
No, only doc change.
Closes#30789 from viirya/ss-statestore-doc.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This is a simple change to support allocating a specified amount of overhead memory for the driver's mesos container. This is already supported for executors.
### Why are the changes needed?
This is needed to keep the driver process from exceeding memory limits and being killed off when running on mesos.
### Does this PR introduce _any_ user-facing change?
Yes, it adds a `spark.mesos.driver.memoryOverhead` configuration option. Documentation changes for this option are included in the PR.
### How was this patch tested?
Test cases covering allocation of driver memory overhead are included in the changes.
### Other notes
This is a second attempt to get this change reviewed, accepted and merged. The original pull request was closed as stale back in January: https://github.com/apache/spark/pull/21006.
For this pull request, I took the original change by pmackles, rebased it onto the current master branch, and added a test case that was requested in the original code review.
I'm happy to make any further edits or do anything needed so that this can be included in a future spark release. I keep having to build custom spark distributions so that we can use spark within our mesos clusters.
Closes#30739 from dmcwhorter/dmcwhorter-SPARK-22256.
Lead-authored-by: David McWhorter <david_mcwhorter@premierinc.com>
Co-authored-by: Paul Mackles <pmackles@adobe.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR proposes:
- Respect `PYSPARK_PYTHON` and `PYSPARK_DRIVER_PYTHON` environment variables, or `spark.pyspark.python` and `spark.pyspark.driver.python` configurations in Kubernates just like other cluster types in Spark.
- Depreate `spark.kubernetes.pyspark.pythonVersion` and guide users to set the environment variables and configurations for Python executables.
NOTE that `spark.kubernetes.pyspark.pythonVersion` is already a no-op configuration without this PR. Default is `3` and other values are disallowed.
- In order for Python executable settings to be consistently used, fix `spark.archives` option to unpack into the current working directory in the driver of Kubernates' cluster mode. This behaviour is identical with Yarn's cluster mode. By doing this, users can leverage Conda or virtuenenv in cluster mode as below:
```python
conda create -y -n pyspark_conda_env -c conda-forge pyarrow pandas conda-pack
conda activate pyspark_conda_env
conda pack -f -o pyspark_conda_env.tar.gz
PYSPARK_PYTHON=./environment/bin/python spark-submit --archives pyspark_conda_env.tar.gz#environment app.py
```
- Removed several unused or useless codes such as `extractS3Key` and `renameResourcesToLocalFS`
### Why are the changes needed?
- To provide a consistent support of PySpark by using `PYSPARK_PYTHON` and `PYSPARK_DRIVER_PYTHON` environment variables, or `spark.pyspark.python` and `spark.pyspark.driver.python` configurations.
- To provide Conda and virtualenv support via `spark.archives` options.
### Does this PR introduce _any_ user-facing change?
Yes:
- `spark.kubernetes.pyspark.pythonVersion` is deprecated.
- `PYSPARK_PYTHON` and `PYSPARK_DRIVER_PYTHON` environment variables, and `spark.pyspark.python` and `spark.pyspark.driver.python` configurations are respected.
### How was this patch tested?
Manually tested via:
```bash
minikube delete
minikube start --cpus 12 --memory 16384
kubectl create namespace spark-integration-test
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ServiceAccount
metadata:
name: spark
namespace: spark-integration-test
EOF
kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=spark-integration-test:spark --namespace=spark-integration-test
dev/make-distribution.sh --pip --tgz -Pkubernetes
resource-managers/kubernetes/integration-tests/dev/dev-run-integration-tests.sh --spark-tgz `pwd`/spark-3.2.0-SNAPSHOT-bin-3.2.0.tgz --service-account spark --namespace spark-integration-test
```
Unittests were also added.
Closes#30735 from HyukjinKwon/SPARK-33748.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Addressed comments in PR #30567, including:
1. add test case for SPARK-33647 and SPARK-33142
2. add migration guide
3. add `getRawTempView` and `getRawGlobalTempView` to return the raw view info (i.e. TemporaryViewRelation)
4. other minor code clean
### Why are the changes needed?
Code clean and more test cases
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing and newly added test cases
Closes#30666 from linhongliu-db/SPARK-33142-followup.
Lead-authored-by: Linhong Liu <linhong.liu@databricks.com>
Co-authored-by: Linhong Liu <67896261+linhongliu-db@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, when casting a string as timestamp type in ANSI mode, Spark throws a runtime exception on parsing error.
However, the result for casting a string to date is always null. We should throw an exception on parsing error as well.
### Why are the changes needed?
Add missing feature for ANSI mode
### Does this PR introduce _any_ user-facing change?
Yes for ANSI mode, Casting string to date will throw an exception on parsing error
### How was this patch tested?
Unit test
Closes#30687 from gengliangwang/castDate.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR intends to escape meta-characters (e.g., \n and \t) in `Dataset.showString`.
Before this PR:
```
scala> Seq("aaa\nbbb\t\tccccc").toDF("value").show()
+--------------+
| value|
+--------------+
|aaa
bbb ccccc|
+--------------+
```
After this PR:
```
+-----------------+
| value|
+-----------------+
|aaa\nbbb\t\tccccc|
+-----------------+
```
### Why are the changes needed?
For better output.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added a unit test.
Closes#30647 from maropu/EscapeMetaInShow.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Add make_date/make_timestamp/make_interval into the doc of ANSI Compliance
### Why are the changes needed?
Users can know that these functions throw runtime exceptions under ANSI mode if the result is not valid.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Build doc and check it in browser:

Closes#30683 from gengliangwang/improveDoc.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add migration guide for CHAR VARCHAR types
### Why are the changes needed?
for migration
### Does this PR introduce _any_ user-facing change?
doc change
### How was this patch tested?
passing ci
Closes#30654 from yaooqinn/SPARK-33641-F.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to enable `spark.sql.adaptive.enabled` by default for Apache Spark **3.2.0**.
### Why are the changes needed?
By switching the default for Apache Spark 3.2, the whole community can focus more on the stabilizing this feature in the various situation more seriously.
### Does this PR introduce _any_ user-facing change?
Yes, but this is an improvement and it's supposed to have no bugs.
### How was this patch tested?
Pass the CIs.
Closes#30628 from dongjoon-hyun/SPARK-33679.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR aims to update `master` branch version to 3.2.0-SNAPSHOT.
### Why are the changes needed?
Start to prepare Apache Spark 3.2.0.
### Does this PR introduce _any_ user-facing change?
N/A.
### How was this patch tested?
Pass the CIs.
Closes#30606 from dongjoon-hyun/SPARK-3.2.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Update kafka headers documentation, type is not longer a map but an array
[jira](https://issues.apache.org/jira/browse/SPARK-33660)
### Why are the changes needed?
To help users
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
It is only documentation
Closes#30605 from Gschiavon/SPARK-33660-fix-kafka-headers-documentation.
Authored-by: german <germanschiavon@gmail.com>
Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This PR proposes to make `spark.archives` configuration working in Kubernates.
It works without a problem in standalone cluster but there seems a bug in Kubernates.
It fails to fetch the file on the driver side as below:
```
20/12/03 13:33:53 INFO SparkContext: Added JAR file:/tmp/spark-75004286-c83a-4369-b624-14c5d2d2a748/spark-examples_2.12-3.1.0-SNAPSHOT.jar at spark://spark-test-app-48ae737628cee6f8-driver-svc.spark-integration-test.svc:7078/jars/spark-examples_2.12-3.1.0-SNAPSHOT.jar with timestamp 1607002432558
20/12/03 13:33:53 INFO SparkContext: Added archive file:///tmp/tmp4542734800151332666.txt.tar.gz#test_tar_gz at spark://spark-test-app-48ae737628cee6f8-driver-svc.spark-integration-test.svc:7078/files/tmp4542734800151332666.txt.tar.gz with timestamp 1607002432558
20/12/03 13:33:53 INFO TransportClientFactory: Successfully created connection to spark-test-app-48ae737628cee6f8-driver-svc.spark-integration-test.svc/172.17.0.4:7078 after 83 ms (47 ms spent in bootstraps)
20/12/03 13:33:53 INFO Utils: Fetching spark://spark-test-app-48ae737628cee6f8-driver-svc.spark-integration-test.svc:7078/files/tmp4542734800151332666.txt.tar.gz to /tmp/spark-66573e24-27a3-427c-99f4-36f06d9e9cd5/fetchFileTemp2665785666227461849.tmp
20/12/03 13:33:53 ERROR SparkContext: Error initializing SparkContext.
java.lang.RuntimeException: Stream '/files/tmp4542734800151332666.txt.tar.gz' was not found.
at org.apache.spark.network.client.TransportResponseHandler.handle(TransportResponseHandler.java:242)
at org.apache.spark.network.server.TransportChannelHandler.channelRead0(TransportChannelHandler.java:142)
at org.apache.spark.network.server.TransportChannelHandler.channelRead0(TransportChannelHandler.java:53)
```
This is because `spark.archives` was not actually added on the driver side correctly. The changes here fix it by adding and resolving URIs correctly.
### Why are the changes needed?
`spark.archives` feature can be leveraged for many things such as Conda support. We should make it working in Kubernates as well.
This is a bug fix too.
### Does this PR introduce _any_ user-facing change?
No, this feature is not out yet.
### How was this patch tested?
I manually tested with Minikube 1.15.1. For an environment issue (?), I had to use a custom namespace, service account and roles. `default` service account does not work for me and complains it doesn't have permissions to get/list pods, etc.
```bash
minikube delete
minikube start --cpus 12 --memory 16384
kubectl create namespace spark-integration-test
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ServiceAccount
metadata:
name: spark
namespace: spark-integration-test
EOF
kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=spark-integration-test:spark --namespace=spark-integration-test
dev/make-distribution.sh --pip --tgz -Pkubernetes
resource-managers/kubernetes/integration-tests/dev/dev-run-integration-tests.sh --spark-tgz `pwd`/spark-3.1.0-SNAPSHOT-bin-3.2.0.tgz --service-account spark --namespace spark-integration-test
```
Closes#30581 from HyukjinKwon/SPARK-33615.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}