## What changes were proposed in this pull request?
This test only fails with sbt on Hadoop 2.7, I can't reproduce it locally, but here is my speculation by looking at the code:
1. FileSystem.delete doesn't delete the directory entirely, somehow we can still open the file as a 0-length empty file.(just speculation)
2. ORC intentionally allow empty files, and the reader fails during reading without closing the file stream.
This PR improves the test to make sure all files are deleted and can't be opened.
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20584 from cloud-fan/flaky-test.
## What changes were proposed in this pull request?
This is a long-standing bug in `UnsafeKVExternalSorter` and was reported in the dev list multiple times.
When creating `UnsafeKVExternalSorter` with `BytesToBytesMap`, we need to create a `UnsafeInMemorySorter` to sort the data in `BytesToBytesMap`. The data format of the sorter and the map is same, so no data movement is required. However, both the sorter and the map need a point array for some bookkeeping work.
There is an optimization in `UnsafeKVExternalSorter`: reuse the point array between the sorter and the map, to avoid an extra memory allocation. This sounds like a reasonable optimization, the length of the `BytesToBytesMap` point array is at least 4 times larger than the number of keys(to avoid hash collision, the hash table size should be at least 2 times larger than the number of keys, and each key occupies 2 slots). `UnsafeInMemorySorter` needs the pointer array size to be 4 times of the number of entries, so we are safe to reuse the point array.
However, the number of keys of the map doesn't equal to the number of entries in the map, because `BytesToBytesMap` supports duplicated keys. This breaks the assumption of the above optimization and we may run out of space when inserting data into the sorter, and hit error
```
java.lang.IllegalStateException: There is no space for new record
at org.apache.spark.util.collection.unsafe.sort.UnsafeInMemorySorter.insertRecord(UnsafeInMemorySorter.java:239)
at org.apache.spark.sql.execution.UnsafeKVExternalSorter.<init>(UnsafeKVExternalSorter.java:149)
...
```
This PR fixes this bug by creating a new point array if the existing one is not big enough.
## How was this patch tested?
a new test
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20561 from cloud-fan/bug.
## What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/20435.
While reorganizing the packages for streaming data source v2, the top level stream read/write support interfaces should not be in the reader/writer package, but should be in the `sources.v2` package, to follow the `ReadSupport`, `WriteSupport`, etc.
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20509 from cloud-fan/followup.
## What changes were proposed in this pull request?
For inserting/appending data to an existing table, Spark should adjust the data types of the input query according to the table schema, or fail fast if it's uncastable.
There are several ways to insert/append data: SQL API, `DataFrameWriter.insertInto`, `DataFrameWriter.saveAsTable`. The first 2 ways create `InsertIntoTable` plan, and the last way creates `CreateTable` plan. However, we only adjust input query data types for `InsertIntoTable`, and users may hit weird errors when appending data using `saveAsTable`. See the JIRA for the error case.
This PR fixes this bug by adjusting data types for `CreateTable` too.
## How was this patch tested?
new test.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20527 from cloud-fan/saveAsTable.
## What changes were proposed in this pull request?
This PR migrates the MemoryStream to DataSourceV2 APIs.
One additional change is in the reported keys in StreamingQueryProgress.durationMs. "getOffset" and "getBatch" replaced with "setOffsetRange" and "getEndOffset" as tracking these make more sense. Unit tests changed accordingly.
## How was this patch tested?
Existing unit tests, few updated unit tests.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Author: Burak Yavuz <brkyvz@gmail.com>
Closes#20445 from tdas/SPARK-23092.
## What changes were proposed in this pull request?
When `DebugFilesystem` closes opened stream, if any exception occurs, we still need to remove the open stream record from `DebugFilesystem`. Otherwise, it goes to report leaked filesystem connection.
## How was this patch tested?
Existing tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20524 from viirya/SPARK-23345.
## What changes were proposed in this pull request?
Replace `registerTempTable` by `createOrReplaceTempView`.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20523 from gatorsmile/updateExamples.
## What changes were proposed in this pull request?
Update the description and tests of three external API or functions `createFunction `, `length` and `repartitionByRange `
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20495 from gatorsmile/updateFunc.
## What changes were proposed in this pull request?
`DataSourceV2Relation` keeps a `fullOutput` and resolves the real output on demand by column name lookup. i.e.
```
lazy val output: Seq[Attribute] = reader.readSchema().map(_.name).map { name =>
fullOutput.find(_.name == name).get
}
```
This will be broken after we canonicalize the plan, because all attribute names become "None", see https://github.com/apache/spark/blob/v2.3.0-rc1/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Canonicalize.scala#L42
To fix this, `DataSourceV2Relation` should just keep `output`, and update the `output` when doing column pruning.
## How was this patch tested?
a new test case
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20485 from cloud-fan/canonicalize.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/20483 tried to provide a way to turn off the new columnar cache reader, to restore the behavior in 2.2. However even we turn off that config, the behavior is still different than 2.2.
If the output data are rows, we still enable whole stage codegen for the scan node, which is different with 2.2, we should also fix it.
## How was this patch tested?
existing tests.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20513 from cloud-fan/cache.
## What changes were proposed in this pull request?
Spark SQL executions page throws the following error and the page crashes:
```
HTTP ERROR 500
Problem accessing /SQL/. Reason:
Server Error
Caused by:
java.lang.NullPointerException
at scala.collection.immutable.StringOps$.length$extension(StringOps.scala:47)
at scala.collection.immutable.StringOps.length(StringOps.scala:47)
at scala.collection.IndexedSeqOptimized$class.isEmpty(IndexedSeqOptimized.scala:27)
at scala.collection.immutable.StringOps.isEmpty(StringOps.scala:29)
at scala.collection.TraversableOnce$class.nonEmpty(TraversableOnce.scala:111)
at scala.collection.immutable.StringOps.nonEmpty(StringOps.scala:29)
at org.apache.spark.sql.execution.ui.ExecutionTable.descriptionCell(AllExecutionsPage.scala:182)
at org.apache.spark.sql.execution.ui.ExecutionTable.row(AllExecutionsPage.scala:155)
at org.apache.spark.sql.execution.ui.ExecutionTable$$anonfun$8.apply(AllExecutionsPage.scala:204)
at org.apache.spark.sql.execution.ui.ExecutionTable$$anonfun$8.apply(AllExecutionsPage.scala:204)
at org.apache.spark.ui.UIUtils$$anonfun$listingTable$2.apply(UIUtils.scala:339)
at org.apache.spark.ui.UIUtils$$anonfun$listingTable$2.apply(UIUtils.scala:339)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.AbstractTraversable.map(Traversable.scala:104)
at org.apache.spark.ui.UIUtils$.listingTable(UIUtils.scala:339)
at org.apache.spark.sql.execution.ui.ExecutionTable.toNodeSeq(AllExecutionsPage.scala:203)
at org.apache.spark.sql.execution.ui.AllExecutionsPage.render(AllExecutionsPage.scala:67)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.JettyUtils$$anon$3.doGet(JettyUtils.scala:90)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:687)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:790)
at org.eclipse.jetty.servlet.ServletHolder.handle(ServletHolder.java:848)
at org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:584)
at org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1180)
at org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:512)
at org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1112)
at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:141)
at org.eclipse.jetty.server.handler.ContextHandlerCollection.handle(ContextHandlerCollection.java:213)
at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:134)
at org.eclipse.jetty.server.Server.handle(Server.java:534)
at org.eclipse.jetty.server.HttpChannel.handle(HttpChannel.java:320)
at org.eclipse.jetty.server.HttpConnection.onFillable(HttpConnection.java:251)
at org.eclipse.jetty.io.AbstractConnection$ReadCallback.succeeded(AbstractConnection.java:283)
at org.eclipse.jetty.io.FillInterest.fillable(FillInterest.java:108)
at org.eclipse.jetty.io.SelectChannelEndPoint$2.run(SelectChannelEndPoint.java:93)
at org.eclipse.jetty.util.thread.strategy.ExecuteProduceConsume.executeProduceConsume(ExecuteProduceConsume.java:303)
at org.eclipse.jetty.util.thread.strategy.ExecuteProduceConsume.produceConsume(ExecuteProduceConsume.java:148)
at org.eclipse.jetty.util.thread.strategy.ExecuteProduceConsume.run(ExecuteProduceConsume.java:136)
at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:671)
at org.eclipse.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:589)
at java.lang.Thread.run(Thread.java:748)
```
One of the possible reason that this page fails may be the `SparkListenerSQLExecutionStart` event get dropped before processed, so the execution description and details don't get updated.
This was not a issue in 2.2 because it would ignore any job start event that arrives before the corresponding execution start event, which doesn't sound like a good decision.
We shall try to handle the null values in the front page side, that is, try to give a default value when `execution.details` or `execution.description` is null.
Another possible approach is not to spill the `LiveExecutionData` in `SQLAppStatusListener.update(exec: LiveExecutionData)` if `exec.details` is null. This is not ideal because this way you will not see the execution if `SparkListenerSQLExecutionStart` event is lost, because `AllExecutionsPage` only read executions from KVStore.
## How was this patch tested?
After the change, the page shows the following:
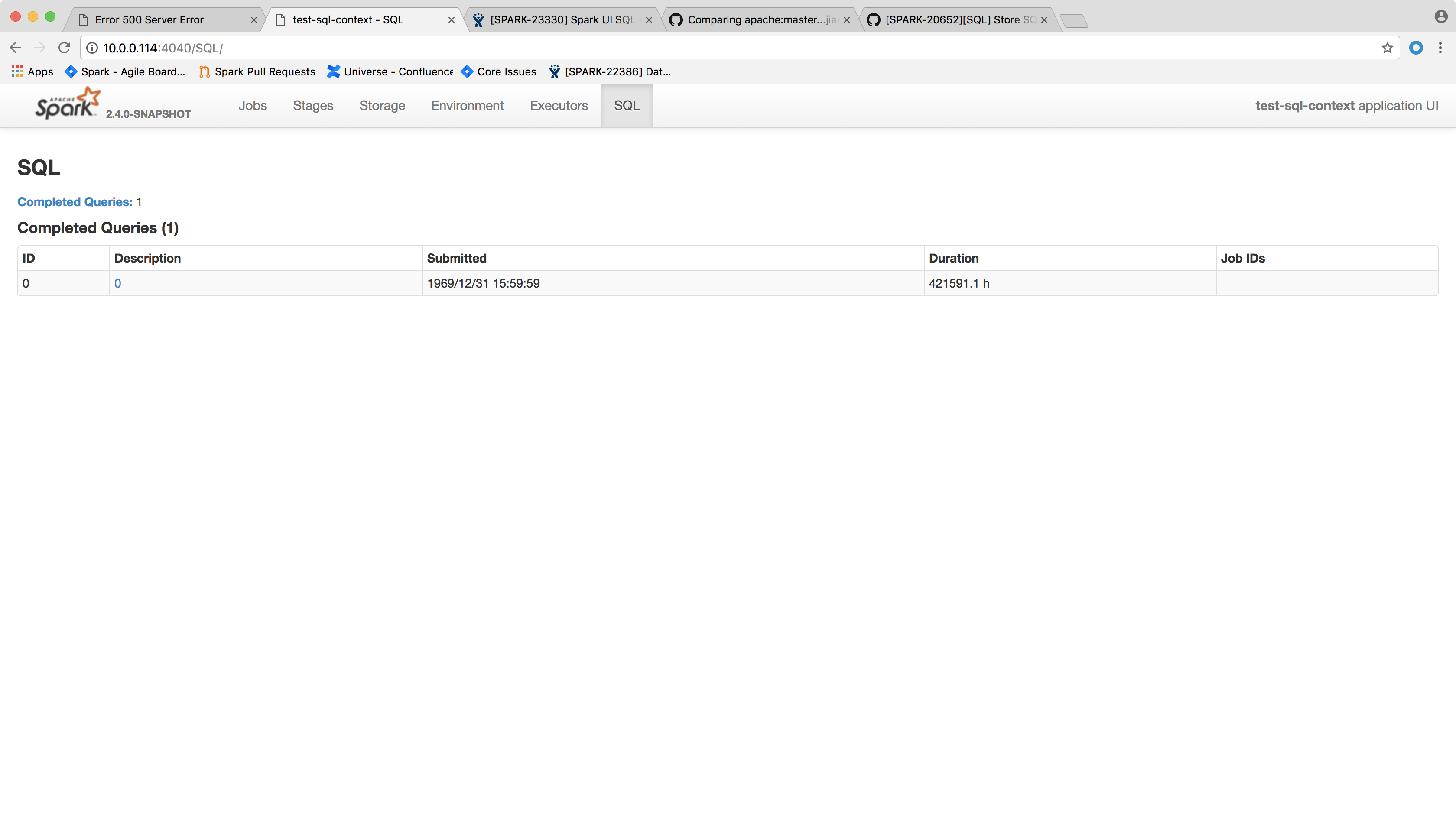
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#20502 from jiangxb1987/executionPage.
## What changes were proposed in this pull request?
Sort jobs/stages/tasks/queries with the completed timestamp before cleaning up them to make the behavior consistent with 2.2.
## How was this patch tested?
- Jenkins.
- Manually ran the following codes and checked the UI for jobs/stages/tasks/queries.
```
spark.ui.retainedJobs 10
spark.ui.retainedStages 10
spark.sql.ui.retainedExecutions 10
spark.ui.retainedTasks 10
```
```
new Thread() {
override def run() {
spark.range(1, 2).foreach { i =>
Thread.sleep(10000)
}
}
}.start()
Thread.sleep(5000)
for (_ <- 1 to 20) {
new Thread() {
override def run() {
spark.range(1, 2).foreach { i =>
}
}
}.start()
}
Thread.sleep(15000)
spark.range(1, 2).foreach { i =>
}
sc.makeRDD(1 to 100, 100).foreach { i =>
}
```
Author: Shixiong Zhu <zsxwing@gmail.com>
Closes#20481 from zsxwing/SPARK-23307.
## What changes were proposed in this pull request?
Fix decimalArithmeticOperations.sql test
## How was this patch tested?
N/A
Author: Yuming Wang <wgyumg@gmail.com>
Author: wangyum <wgyumg@gmail.com>
Author: Yuming Wang <yumwang@ebay.com>
Closes#20498 from wangyum/SPARK-22036.
## What changes were proposed in this pull request?
Like Parquet, all file-based data source handles `spark.sql.files.ignoreMissingFiles` correctly. We had better have a test coverage for feature parity and in order to prevent future accidental regression for all data sources.
## How was this patch tested?
Pass Jenkins with a newly added test case.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20479 from dongjoon-hyun/SPARK-23305.
## What changes were proposed in this pull request?
In the document of `ContinuousReader.setOffset`, we say this method is used to specify the start offset. We also have a `ContinuousReader.getStartOffset` to get the value back. I think it makes more sense to rename `ContinuousReader.setOffset` to `setStartOffset`.
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20486 from cloud-fan/rename.
## What changes were proposed in this pull request?
This patch adds a small example to the schema string definition of schema function. It isn't obvious how to use it, so an example would be useful.
## How was this patch tested?
N/A - doc only.
Author: Reynold Xin <rxin@databricks.com>
Closes#20491 from rxin/schema-doc.
## What changes were proposed in this pull request?
https://issues.apache.org/jira/browse/SPARK-23309 reported a performance regression about cached table in Spark 2.3. While the investigating is still going on, this PR adds a conf to turn off the vectorized cache reader, to unblock the 2.3 release.
## How was this patch tested?
a new test
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20483 from cloud-fan/cache.
## What changes were proposed in this pull request?
This PR fixes a mistake in the `PushDownOperatorsToDataSource` rule, the column pruning logic is incorrect about `Project`.
## How was this patch tested?
a new test case for column pruning with arbitrary expressions, and improve the existing tests to make sure the `PushDownOperatorsToDataSource` really works.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20476 from cloud-fan/push-down.
## What changes were proposed in this pull request?
For some ColumnVector get APIs such as getDecimal, getBinary, getStruct, getArray, getInterval, getUTF8String, we should clearly document their behaviors when accessing null slot. They should return null in this case. Then we can remove null checks from the places using above APIs.
For the APIs of primitive values like getInt, getInts, etc., this also documents their behaviors when accessing null slots. Their returning values are undefined and can be anything.
## How was this patch tested?
Added tests into `ColumnarBatchSuite`.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20455 from viirya/SPARK-23272-followup.
## What changes were proposed in this pull request?
`DataSourceV2Relation` should extend `MultiInstanceRelation`, to take care of self-join.
## How was this patch tested?
a new test
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20466 from cloud-fan/dsv2-selfjoin.
## What changes were proposed in this pull request?
The current DataSourceWriter API makes it hard to implement `onTaskCommit(taskCommit: TaskCommitMessage)` in `FileCommitProtocol`.
In general, on receiving commit message, driver can start processing messages(e.g. persist messages into files) before all the messages are collected.
The proposal to add a new API:
`add(WriterCommitMessage message)`: Handles a commit message on receiving from a successful data writer.
This should make the whole API of DataSourceWriter compatible with `FileCommitProtocol`, and more flexible.
There was another radical attempt in #20386. This one should be more reasonable.
## How was this patch tested?
Unit test
Author: Wang Gengliang <ltnwgl@gmail.com>
Closes#20454 from gengliangwang/write_api.
## What changes were proposed in this pull request?
This is a followup pr of #20450.
We should've enabled `MutableColumnarRow.getMap()` as well.
## How was this patch tested?
Existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20471 from ueshin/issues/SPARK-23280/fup2.
## What changes were proposed in this pull request?
This is a follow-up of #20450 which broke lint-java checks.
This pr fixes the lint-java issues.
```
[ERROR] src/main/java/org/apache/spark/sql/vectorized/ColumnVector.java:[20,8] (imports) UnusedImports: Unused import - org.apache.spark.sql.catalyst.util.MapData.
[ERROR] src/main/java/org/apache/spark/sql/vectorized/ColumnarArray.java:[21,8] (imports) UnusedImports: Unused import - org.apache.spark.sql.catalyst.util.MapData.
[ERROR] src/main/java/org/apache/spark/sql/vectorized/ColumnarRow.java:[22,8] (imports) UnusedImports: Unused import - org.apache.spark.sql.catalyst.util.MapData.
```
## How was this patch tested?
Checked manually in my local environment.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20468 from ueshin/issues/SPARK-23280/fup1.
## What changes were proposed in this pull request?
This PR include the following changes:
- Make the capacity of `VectorizedParquetRecordReader` configurable;
- Make the capacity of `OrcColumnarBatchReader` configurable;
- Update the error message when required capacity in writable columnar vector cannot be fulfilled.
## How was this patch tested?
N/A
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#20361 from jiangxb1987/vectorCapacity.
## What changes were proposed in this pull request?
1. create a new package for partitioning/distribution related classes.
As Spark will add new concrete implementations of `Distribution` in new releases, it is good to
have a new package for partitioning/distribution related classes.
2. move streaming related class to package `org.apache.spark.sql.sources.v2.reader/writer.streaming`, instead of `org.apache.spark.sql.sources.v2.streaming.reader/writer`.
So that the there won't be package reader/writer inside package streaming, which is quite confusing.
Before change:
```
v2
├── reader
├── streaming
│ ├── reader
│ └── writer
└── writer
```
After change:
```
v2
├── reader
│ └── streaming
└── writer
└── streaming
```
## How was this patch tested?
Unit test.
Author: Wang Gengliang <ltnwgl@gmail.com>
Closes#20435 from gengliangwang/new_pkg.
## What changes were proposed in this pull request?
Currently, we scan the execution plan of the data source, first the unsafe operation of each row of data, and then re traverse the data for the count of rows. In terms of performance, this is not necessary. this PR combines the two operations and makes statistics on the number of rows while performing the unsafe operation.
Before modified,
```
val unsafeRow = rdd.mapPartitionsWithIndexInternal { (index, iter) =>
val proj = UnsafeProjection.create(schema)
proj.initialize(index)
iter.map(proj)
}
val numOutputRows = longMetric("numOutputRows")
unsafeRow.map { r =>
numOutputRows += 1
r
}
```
After modified,
val numOutputRows = longMetric("numOutputRows")
rdd.mapPartitionsWithIndexInternal { (index, iter) =>
val proj = UnsafeProjection.create(schema)
proj.initialize(index)
iter.map( r => {
numOutputRows += 1
proj(r)
})
}
## How was this patch tested?
the existed test cases.
Author: caoxuewen <cao.xuewen@zte.com.cn>
Closes#20415 from heary-cao/DataSourceScanExec.
## What changes were proposed in this pull request?
Fill the last missing piece of `ColumnVector`: the map type support.
The idea is similar to the array type support. A map is basically 2 arrays: keys and values. We ask the implementations to provide a key array, a value array, and an offset and length to specify the range of this map in the key/value array.
In `WritableColumnVector`, we put the key array in first child vector, and value array in second child vector, and offsets and lengths in the current vector, which is very similar to how array type is implemented here.
## How was this patch tested?
a new test
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20450 from cloud-fan/map.
## What changes were proposed in this pull request?
Here is the test snippet.
``` SQL
scala> Seq[(Integer, Integer)](
| (1, 1),
| (1, 3),
| (2, 3),
| (3, 3),
| (4, null),
| (5, null)
| ).toDF("key", "value").createOrReplaceTempView("src")
scala> sql(
| """
| |SELECT MAX(value) as value, key as col2
| |FROM src
| |GROUP BY key
| |ORDER BY value desc, key
| """.stripMargin).show
+-----+----+
|value|col2|
+-----+----+
| 3| 3|
| 3| 2|
| 3| 1|
| null| 5|
| null| 4|
+-----+----+
```SQL
Here is the explain output :
```SQL
== Parsed Logical Plan ==
'Sort ['value DESC NULLS LAST, 'key ASC NULLS FIRST], true
+- 'Aggregate ['key], ['MAX('value) AS value#9, 'key AS col2#10]
+- 'UnresolvedRelation `src`
== Analyzed Logical Plan ==
value: int, col2: int
Project [value#9, col2#10]
+- Sort [value#9 DESC NULLS LAST, col2#10 DESC NULLS LAST], true
+- Aggregate [key#5], [max(value#6) AS value#9, key#5 AS col2#10]
+- SubqueryAlias src
+- Project [_1#2 AS key#5, _2#3 AS value#6]
+- LocalRelation [_1#2, _2#3]
``` SQL
The sort direction is being wrongly changed from ASC to DSC while resolving ```Sort``` in
resolveAggregateFunctions.
The above testcase models TPCDS-Q71 and thus we have the same issue in Q71 as well.
## How was this patch tested?
A few tests are added in SQLQuerySuite.
Author: Dilip Biswal <dbiswal@us.ibm.com>
Closes#20453 from dilipbiswal/local_spark.
## What changes were proposed in this pull request?
Change DataSourceScanExec so that when grouping blocks together into partitions, also checks the end of the sorted list of splits to more efficiently fill out partitions.
## How was this patch tested?
Updated old test to reflect the new logic, which causes the # of partitions to drop from 4 -> 3
Also, a current test exists to test large non-splittable files at c575977a59/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/FileSourceStrategySuite.scala (L346)
## Rationale
The current bin-packing method of next-fit descending for blocks into partitions is sub-optimal in a lot of cases and will result in extra partitions, un-even distribution of block-counts across partitions, and un-even distribution of partition sizes.
As an example, 128 files ranging from 1MB, 2MB,...127MB,128MB. will result in 82 partitions with the current algorithm, but only 64 using this algorithm. Also in this example, the max # of blocks per partition in NFD is 13, while in this algorithm is is 2.
More generally, running a simulation of 1000 runs using 128MB blocksize, between 1-1000 normally distributed file sizes between 1-500Mb, you can see an improvement of approx 5% reduction of partition counts, and a large reduction in standard deviation of blocks per partition.
This algorithm also runs in O(n) time as NFD does, and in every case is strictly better results than NFD.
Overall, the more even distribution of blocks across partitions and therefore reduced partition counts should result in a small but significant performance increase across the board
Author: Glen Takahashi <gtakahashi@palantir.com>
Closes#20372 from glentakahashi/feature/improved-block-merging.
## What changes were proposed in this pull request?
In https://github.com/apache/spark/pull/19980 , we thought `anyNullsSet` can be simply implemented by `numNulls() > 0`. This is logically true, but may have performance problems.
`OrcColumnVector` is an example. It doesn't have the `numNulls` property, only has a `noNulls` property. We will lose a lot of performance if we use `numNulls() > 0` to check null.
This PR simply revert #19980, with a renaming to call it `hasNull`. Better name suggestions are welcome, e.g. `nullable`?
## How was this patch tested?
existing test
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20452 from cloud-fan/null.
## What changes were proposed in this pull request?
`ColumnVector` is aimed to support all the data types, but `CalendarIntervalType` is missing. Actually we do support interval type for inner fields, e.g. `ColumnarRow`, `ColumnarArray` both support interval type. It's weird if we don't support interval type at the top level.
This PR adds the interval type support.
This PR also makes `ColumnVector.getChild` protect. We need it public because `MutableColumnaRow.getInterval` needs it. Now the interval implementation is in `ColumnVector.getInterval`.
## How was this patch tested?
a new test.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20438 from cloud-fan/interval.
## What changes were proposed in this pull request?
Console sink will redistribute collected local data and trigger a distributed job in each batch, this is not necessary, so here change to local job.
## How was this patch tested?
Existing UT and manual verification.
Author: jerryshao <sshao@hortonworks.com>
Closes#20447 from jerryshao/console-minor.
## What changes were proposed in this pull request?
This PR is to fix the `ReplaceExceptWithFilter` rule when the right's Filter contains the references that are not in the left output.
Before this PR, we got the error like
```
java.util.NoSuchElementException: key not found: a
at scala.collection.MapLike$class.default(MapLike.scala:228)
at scala.collection.AbstractMap.default(Map.scala:59)
at scala.collection.MapLike$class.apply(MapLike.scala:141)
at scala.collection.AbstractMap.apply(Map.scala:59)
```
After this PR, `ReplaceExceptWithFilter ` will not take an effect in this case.
## How was this patch tested?
Added tests
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20444 from gatorsmile/fixReplaceExceptWithFilter.
## What changes were proposed in this pull request?
Still saw the performance regression introduced by `spark.sql.codegen.hugeMethodLimit` in our internal workloads. There are two major issues in the current solution.
- The size of the complied byte code is not identical to the bytecode size of the method. The detection is still not accurate.
- The bytecode size of a single operator (e.g., `SerializeFromObject`) could still exceed 8K limit. We saw the performance regression in such scenario.
Since it is close to the release of 2.3, we decide to increase it to 64K for avoiding the perf regression.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20434 from gatorsmile/revertConf.
## What changes were proposed in this pull request?
It is reported that the test `Cancelling stage in a query with Range` in `DataFrameRangeSuite` fails a few times in unrelated PRs. I personally also saw it too in my PR.
This test is not very flaky actually but only fails occasionally. Based on how the test works, I guess that is because `range` finishes before the listener calls `cancelStage`.
I increase the range number from `1000000000L` to `100000000000L` and count the range in one partition. I also reduce the `interval` of checking stage id. Hopefully it can make the test not flaky anymore.
## How was this patch tested?
The modified tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20431 from viirya/SPARK-23222.
## What changes were proposed in this pull request?
Rename the public APIs and names of pandas udfs.
- `PANDAS SCALAR UDF` -> `SCALAR PANDAS UDF`
- `PANDAS GROUP MAP UDF` -> `GROUPED MAP PANDAS UDF`
- `PANDAS GROUP AGG UDF` -> `GROUPED AGG PANDAS UDF`
## How was this patch tested?
The existing tests
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20428 from gatorsmile/renamePandasUDFs.
## What changes were proposed in this pull request?
All other classes in the reader/writer package doesn't have `V2` in their names, and the streaming reader/writer don't have `V2` either. It's more consistent to remove `V2` from `DataSourceV2Reader` and `DataSourceVWriter`.
Also rename `DataSourceV2Option` to remote the `V2`, we should only have `V2` in the root interface: `DataSourceV2`.
This PR also fixes some places that the mix-in interface doesn't extend the interface it aimed to mix in.
## How was this patch tested?
existing tests.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20427 from cloud-fan/ds-v2.
## What changes were proposed in this pull request?
It's not obvious from the comments that any added column must be a
function of the dataset that we are adding it to. Add a comment to
that effect to Scala, Python and R Data* methods.
Author: Henry Robinson <henry@cloudera.com>
Closes#20429 from henryr/SPARK-23157.
## What changes were proposed in this pull request?
In `ShuffleExchangeExec`, we don't need to insert extra local sort before round-robin partitioning, if the new partitioning has only 1 partition, because under that case all output rows go to the same partition.
## How was this patch tested?
The existing test cases.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#20426 from jiangxb1987/repartition1.
## What changes were proposed in this pull request?
This PR is to update the description of the join algorithm changes.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20420 from gatorsmile/followUp22916.
## What changes were proposed in this pull request?
It is a common pattern to apply multiple transforms to a `Dataset` (using `Dataset.withColumn` for example. This is currently quite expensive because we run `CheckAnalysis` on the full plan and create an encoder for each intermediate `Dataset`.
This PR extends the usage of the `AnalysisBarrier` to include `CheckAnalysis`. By doing this we hide the already analyzed plan from `CheckAnalysis` because barrier is a `LeafNode`. The `AnalysisBarrier` is in the `FinishAnalysis` phase of the optimizer.
We also make binding the `Dataset` encoder lazy. The bound encoder is only needed when we materialize the dataset.
## How was this patch tested?
Existing test should cover this.
Author: Herman van Hovell <hvanhovell@databricks.com>
Closes#20402 from hvanhovell/SPARK-23223.
## What changes were proposed in this pull request?
Correct some improper with view related method usage
Only change test cases
like:
```
test("list global temp views") {
try {
sql("CREATE GLOBAL TEMP VIEW v1 AS SELECT 3, 4")
sql("CREATE TEMP VIEW v2 AS SELECT 1, 2")
checkAnswer(sql(s"SHOW TABLES IN $globalTempDB"),
Row(globalTempDB, "v1", true) ::
Row("", "v2", true) :: Nil)
assert(spark.catalog.listTables(globalTempDB).collect().toSeq.map(_.name) == Seq("v1", "v2"))
} finally {
spark.catalog.dropTempView("v1")
spark.catalog.dropGlobalTempView("v2")
}
}
```
other change please review the code.
## How was this patch tested?
See test case.
Author: xubo245 <601450868@qq.com>
Closes#20250 from xubo245/DropTempViewError.
## What changes were proposed in this pull request?
Currently we have `ReadTask` in data source v2 reader, while in writer we have `DataWriterFactory`.
To make the naming consistent and better, renaming `ReadTask` to `DataReaderFactory`.
## How was this patch tested?
Unit test
Author: Wang Gengliang <ltnwgl@gmail.com>
Closes#20397 from gengliangwang/rename.
## What changes were proposed in this pull request?
Replace streaming V2 sinks with a unified StreamWriteSupport interface, with a shim to use it with microbatch execution.
Add a new SQL config to use for disabling V2 sinks, falling back to the V1 sink implementation.
## How was this patch tested?
Existing tests, which in the case of Kafka (the only existing continuous V2 sink) now use V2 for microbatch.
Author: Jose Torres <jose@databricks.com>
Closes#20369 from jose-torres/streaming-sink.
## What changes were proposed in this pull request?
Fix typo in ScalaDoc for DataFrameWriter - originally stated "This is applicable for all file-based data sources (e.g. Parquet, JSON) staring Spark 2.1.0", should be "starting with Spark 2.1.0".
## How was this patch tested?
Check of correct spelling in ScalaDoc
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: CCInCharge <charles.l.chen.clc@gmail.com>
Closes#20417 from CCInCharge/master.
## What changes were proposed in this pull request?
`lastExecution.executedPlan` is lazy val so accessing it in StreamTest may need to acquire the lock of `lastExecution`. It may be waiting forever when the streaming thread is holding it and running a continuous Spark job.
This PR changes to check if `s.lastExecution` is null to avoid accessing `lastExecution.executedPlan`.
## How was this patch tested?
Jenkins
Author: Jose Torres <jose@databricks.com>
Closes#20413 from zsxwing/SPARK-23245.
## What changes were proposed in this pull request?
This PR fixes Scala/Java doc examples in `Trigger.java`.
## How was this patch tested?
N/A.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20401 from dongjoon-hyun/SPARK-TRIGGER.
## What changes were proposed in this pull request?
This is a regression introduced by https://github.com/apache/spark/pull/19864
When we lookup cache, we should not carry the hint info, as this cache entry might be added by a plan having hint info, while the input plan for this lookup may not have hint info, or have different hint info.
## How was this patch tested?
a new test.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20394 from cloud-fan/cache.
## What changes were proposed in this pull request?
Currently shuffle repartition uses RoundRobinPartitioning, the generated result is nondeterministic since the sequence of input rows are not determined.
The bug can be triggered when there is a repartition call following a shuffle (which would lead to non-deterministic row ordering), as the pattern shows below:
upstream stage -> repartition stage -> result stage
(-> indicate a shuffle)
When one of the executors process goes down, some tasks on the repartition stage will be retried and generate inconsistent ordering, and some tasks of the result stage will be retried generating different data.
The following code returns 931532, instead of 1000000:
```
import scala.sys.process._
import org.apache.spark.TaskContext
val res = spark.range(0, 1000 * 1000, 1).repartition(200).map { x =>
x
}.repartition(200).map { x =>
if (TaskContext.get.attemptNumber == 0 && TaskContext.get.partitionId < 2) {
throw new Exception("pkill -f java".!!)
}
x
}
res.distinct().count()
```
In this PR, we propose a most straight-forward way to fix this problem by performing a local sort before partitioning, after we make the input row ordering deterministic, the function from rows to partitions is fully deterministic too.
The downside of the approach is that with extra local sort inserted, the performance of repartition() will go down, so we add a new config named `spark.sql.execution.sortBeforeRepartition` to control whether this patch is applied. The patch is default enabled to be safe-by-default, but user may choose to manually turn it off to avoid performance regression.
This patch also changes the output rows ordering of repartition(), that leads to a bunch of test cases failure because they are comparing the results directly.
## How was this patch tested?
Add unit test in ExchangeSuite.
With this patch(and `spark.sql.execution.sortBeforeRepartition` set to true), the following query returns 1000000:
```
import scala.sys.process._
import org.apache.spark.TaskContext
spark.conf.set("spark.sql.execution.sortBeforeRepartition", "true")
val res = spark.range(0, 1000 * 1000, 1).repartition(200).map { x =>
x
}.repartition(200).map { x =>
if (TaskContext.get.attemptNumber == 0 && TaskContext.get.partitionId < 2) {
throw new Exception("pkill -f java".!!)
}
x
}
res.distinct().count()
res7: Long = 1000000
```
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#20393 from jiangxb1987/shuffle-repartition.
## What changes were proposed in this pull request?
`ColumnVector` is very flexible about how to implement array type. As a result `ColumnVector` has 3 abstract methods for array type: `arrayData`, `getArrayOffset`, `getArrayLength`. For example, in `WritableColumnVector` we use the first child vector as the array data vector, and store offsets and lengths in 2 arrays in the parent vector. `ArrowColumnVector` has a different implementation.
This PR simplifies `ColumnVector` by using only one abstract method for array type: `getArray`.
## How was this patch tested?
existing tests.
rerun `ColumnarBatchBenchmark`, there is no performance regression.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20395 from cloud-fan/vector.
## What changes were proposed in this pull request?
**Proposal**
Add a per-query ID to the codegen stages as represented by `WholeStageCodegenExec` operators. This ID will be used in
- the explain output of the physical plan, and in
- the generated class name.
Specifically, this ID will be stable within a query, counting up from 1 in depth-first post-order for all the `WholeStageCodegenExec` inserted into a plan.
The ID value 0 is reserved for "free-floating" `WholeStageCodegenExec` objects, which may have been created for one-off purposes, e.g. for fallback handling of codegen stages that failed to codegen the whole stage and wishes to codegen a subset of the children operators (as seen in `org.apache.spark.sql.execution.FileSourceScanExec#doExecute`).
Example: for the following query:
```scala
scala> spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1)
scala> val df1 = spark.range(10).select('id as 'x, 'id + 1 as 'y).orderBy('x).select('x + 1 as 'z, 'y)
df1: org.apache.spark.sql.DataFrame = [z: bigint, y: bigint]
scala> val df2 = spark.range(5)
df2: org.apache.spark.sql.Dataset[Long] = [id: bigint]
scala> val query = df1.join(df2, 'z === 'id)
query: org.apache.spark.sql.DataFrame = [z: bigint, y: bigint ... 1 more field]
```
The explain output before the change is:
```scala
scala> query.explain
== Physical Plan ==
*SortMergeJoin [z#9L], [id#13L], Inner
:- *Sort [z#9L ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(z#9L, 200)
: +- *Project [(x#3L + 1) AS z#9L, y#4L]
: +- *Sort [x#3L ASC NULLS FIRST], true, 0
: +- Exchange rangepartitioning(x#3L ASC NULLS FIRST, 200)
: +- *Project [id#0L AS x#3L, (id#0L + 1) AS y#4L]
: +- *Range (0, 10, step=1, splits=8)
+- *Sort [id#13L ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(id#13L, 200)
+- *Range (0, 5, step=1, splits=8)
```
Note how codegen'd operators are annotated with a prefix `"*"`. See how the `SortMergeJoin` operator and its direct children `Sort` operators are adjacent and all annotated with the `"*"`, so it's hard to tell they're actually in separate codegen stages.
and after this change it'll be:
```scala
scala> query.explain
== Physical Plan ==
*(6) SortMergeJoin [z#9L], [id#13L], Inner
:- *(3) Sort [z#9L ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(z#9L, 200)
: +- *(2) Project [(x#3L + 1) AS z#9L, y#4L]
: +- *(2) Sort [x#3L ASC NULLS FIRST], true, 0
: +- Exchange rangepartitioning(x#3L ASC NULLS FIRST, 200)
: +- *(1) Project [id#0L AS x#3L, (id#0L + 1) AS y#4L]
: +- *(1) Range (0, 10, step=1, splits=8)
+- *(5) Sort [id#13L ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(id#13L, 200)
+- *(4) Range (0, 5, step=1, splits=8)
```
Note that the annotated prefix becomes `"*(id) "`. See how the `SortMergeJoin` operator and its direct children `Sort` operators have different codegen stage IDs.
It'll also show up in the name of the generated class, as a suffix in the format of `GeneratedClass$GeneratedIterator$id`.
For example, note how `GeneratedClass$GeneratedIteratorForCodegenStage3` and `GeneratedClass$GeneratedIteratorForCodegenStage6` in the following stack trace corresponds to the IDs shown in the explain output above:
```
"Executor task launch worker for task 42412957" daemon prio=5 tid=0x58 nid=NA runnable
java.lang.Thread.State: RUNNABLE
at org.apache.spark.sql.execution.UnsafeExternalRowSorter.insertRow(UnsafeExternalRowSorter.java:109)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage3.sort_addToSorter$(generated.java:32)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage3.processNext(generated.java:41)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$9$$anon$1.hasNext(WholeStageCodegenExec.scala:494)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage6.findNextInnerJoinRows$(generated.java:42)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage6.processNext(generated.java:101)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$11$$anon$2.hasNext(WholeStageCodegenExec.scala:513)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:253)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:247)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:828)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:828)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
```
**Rationale**
Right now, the codegen from Spark SQL lacks the means to differentiate between a couple of things:
1. It's hard to tell which physical operators are in the same WholeStageCodegen stage. Note that this "stage" is a separate notion from Spark's RDD execution stages; this one is only to delineate codegen units.
There can be adjacent physical operators that are both codegen'd but are in separate codegen stages. Some of this is due to hacky implementation details, such as the case with `SortMergeJoin` and its `Sort` inputs -- they're hard coded to be split into separate stages although both are codegen'd.
When printing out the explain output of the physical plan, you'd only see the codegen'd physical operators annotated with a preceding star (`'*'`) but would have no way to figure out if they're in the same stage.
2. Performance/error diagnosis
The generated code has class/method names that are hard to differentiate between queries or even between codegen stages within the same query. If we use a Java-level profiler to collect profiles, or if we encounter a Java-level exception with a stack trace in it, it's really hard to tell which part of a query it's at.
By introducing a per-query codegen stage ID, we'd at least be able to know which codegen stage (and in turn, which group of physical operators) was a profile tick or an exception happened.
The reason why this proposal uses a per-query ID is because it's stable within a query, so that multiple runs of the same query will see the same resulting IDs. This both benefits understandability for users, and also it plays well with the codegen cache in Spark SQL which uses the generated source code as the key.
The downside to using per-query IDs as opposed to a per-session or globally incrementing ID is of course we can't tell apart different query runs with this ID alone. But for now I believe this is a good enough tradeoff.
## How was this patch tested?
Existing tests. This PR does not involve any runtime behavior changes other than some name changes.
The SQL query test suites that compares explain outputs have been updates to ignore the newly added `codegenStageId`.
Author: Kris Mok <kris.mok@databricks.com>
Closes#20224 from rednaxelafx/wsc-codegenstageid.
## What changes were proposed in this pull request?
Add colRegex API to PySpark
## How was this patch tested?
add a test in sql/tests.py
Author: Huaxin Gao <huaxing@us.ibm.com>
Closes#20390 from huaxingao/spark-23081.
## What changes were proposed in this pull request?
It has been observed in SPARK-21603 that whole-stage codegen suffers performance degradation, if the generated functions are too long to be optimized by JIT.
We basically produce a single function to incorporate generated codes from all physical operators in whole-stage. Thus, it is possibly to grow the size of generated function over a threshold that we can't have JIT optimization for it anymore.
This patch is trying to decouple the logic of consuming rows in physical operators to avoid a giant function processing rows.
## How was this patch tested?
Added tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#18931 from viirya/SPARK-21717.
…JSON / text
## What changes were proposed in this pull request?
Fix for JSON and CSV data sources when file names include characters
that would be changed by URL encoding.
## How was this patch tested?
New unit tests for JSON, CSV and text suites
Author: Henry Robinson <henry@cloudera.com>
Closes#20355 from henryr/spark-23148.
## What changes were proposed in this pull request?
We extract Python UDFs in logical aggregate which depends on aggregate expression or grouping key in ExtractPythonUDFFromAggregate rule. But Python UDFs which don't depend on above expressions should also be extracted to avoid the issue reported in the JIRA.
A small code snippet to reproduce that issue looks like:
```python
import pyspark.sql.functions as f
df = spark.createDataFrame([(1,2), (3,4)])
f_udf = f.udf(lambda: str("const_str"))
df2 = df.distinct().withColumn("a", f_udf())
df2.show()
```
Error exception is raised as:
```
: org.apache.spark.sql.catalyst.errors.package$TreeNodeException: Binding attribute, tree: pythonUDF0#50
at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:56)
at org.apache.spark.sql.catalyst.expressions.BindReferences$$anonfun$bindReference$1.applyOrElse(BoundAttribute.scala:91)
at org.apache.spark.sql.catalyst.expressions.BindReferences$$anonfun$bindReference$1.applyOrElse(BoundAttribute.scala:90)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$2.apply(TreeNode.scala:267)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$2.apply(TreeNode.scala:267)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:266)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformDown$1.apply(TreeNode.scala:272)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformDown$1.apply(TreeNode.scala:272)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$4.apply(TreeNode.scala:306)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:187)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:304)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:272)
at org.apache.spark.sql.catalyst.trees.TreeNode.transform(TreeNode.scala:256)
at org.apache.spark.sql.catalyst.expressions.BindReferences$.bindReference(BoundAttribute.scala:90)
at org.apache.spark.sql.execution.aggregate.HashAggregateExec$$anonfun$38.apply(HashAggregateExec.scala:514)
at org.apache.spark.sql.execution.aggregate.HashAggregateExec$$anonfun$38.apply(HashAggregateExec.scala:513)
```
This exception raises because `HashAggregateExec` tries to bind the aliased Python UDF expression (e.g., `pythonUDF0#50 AS a#44`) to grouping key.
## How was this patch tested?
Added test.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20360 from viirya/SPARK-23177.
## What changes were proposed in this pull request?
The broadcast hint of the cached plan is lost if we cache the plan. This PR is to correct it.
```Scala
val df1 = spark.createDataFrame(Seq((1, "4"), (2, "2"))).toDF("key", "value")
val df2 = spark.createDataFrame(Seq((1, "1"), (2, "2"))).toDF("key", "value")
broadcast(df2).cache()
df2.collect()
val df3 = df1.join(df2, Seq("key"), "inner")
```
## How was this patch tested?
Added a test.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20368 from gatorsmile/cachedBroadcastHint.
## What changes were proposed in this pull request?
The hint of the plan segment is lost, if the plan segment is replaced by the cached data.
```Scala
val df1 = spark.createDataFrame(Seq((1, "4"), (2, "2"))).toDF("key", "value")
val df2 = spark.createDataFrame(Seq((1, "1"), (2, "2"))).toDF("key", "value")
df2.cache()
val df3 = df1.join(broadcast(df2), Seq("key"), "inner")
```
This PR is to fix it.
## How was this patch tested?
Added a test
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20365 from gatorsmile/fixBroadcastHintloss.
## What changes were proposed in this pull request?
We need to override the prettyName for bit_length and octet_length for getting the expected auto-generated alias name.
## How was this patch tested?
The existing tests
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20358 from gatorsmile/test2.3More.
## What changes were proposed in this pull request?
Add support for using pandas UDFs with groupby().agg().
This PR introduces a new type of pandas UDF - group aggregate pandas UDF. This type of UDF defines a transformation of multiple pandas Series -> a scalar value. Group aggregate pandas UDFs can be used with groupby().agg(). Note group aggregate pandas UDF doesn't support partial aggregation, i.e., a full shuffle is required.
This PR doesn't support group aggregate pandas UDFs that return ArrayType, StructType or MapType. Support for these types is left for future PR.
## How was this patch tested?
GroupbyAggPandasUDFTests
Author: Li Jin <ice.xelloss@gmail.com>
Closes#19872 from icexelloss/SPARK-22274-groupby-agg.
## What changes were proposed in this pull request?
a new interface which allows data source to report partitioning and avoid shuffle at Spark side.
The design is pretty like the internal distribution/partitioing framework. Spark defines a `Distribution` interfaces and several concrete implementations, and ask the data source to report a `Partitioning`, the `Partitioning` should tell Spark if it can satisfy a `Distribution` or not.
## How was this patch tested?
new test
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20201 from cloud-fan/partition-reporting.
## What changes were proposed in this pull request?
Typo fixes
## How was this patch tested?
Local build / Doc-only changes
Author: Jacek Laskowski <jacek@japila.pl>
Closes#20344 from jaceklaskowski/typo-fixes.
## What changes were proposed in this pull request?
Several improvements:
* provide a default implementation for the batch get methods
* rename `getChildColumn` to `getChild`, which is more concise
* remove `getStruct(int, int)`, it's only used to simplify the codegen, which is an internal thing, we should not add a public API for this purpose.
## How was this patch tested?
existing tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20277 from cloud-fan/column-vector.
## What changes were proposed in this pull request?
Revert the unneeded test case changes we made in SPARK-23000
Also fixes the test suites that do not call `super.afterAll()` in the local `afterAll`. The `afterAll()` of `TestHiveSingleton` actually reset the environments.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20341 from gatorsmile/testRelated.
## What changes were proposed in this pull request?
This PR fixes the wrong comment on `org.apache.spark.sql.parquet.row.attributes`
which is useful for UDTs like Vector/Matrix. Please see [SPARK-22320](https://issues.apache.org/jira/browse/SPARK-22320) for the usage.
Originally, [SPARK-19411](bf493686eb (diff-ee26d4c4be21e92e92a02e9f16dbc285L314)) left this behind during removing optional column metadatas. In the same PR, the same comment was removed at line 310-311.
## How was this patch tested?
N/A (This is about comments).
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20346 from dongjoon-hyun/minor_comment_parquet.
## What changes were proposed in this pull request?
CheckCartesianProduct raises an AnalysisException also when the join condition is always false/null. In this case, we shouldn't raise it, since the result will not be a cartesian product.
## How was this patch tested?
added UT
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20333 from mgaido91/SPARK-23087.
[SPARK-21786][SQL] The 'spark.sql.parquet.compression.codec' and 'spark.sql.orc.compression.codec' configuration doesn't take effect on hive table writing
What changes were proposed in this pull request?
Pass ‘spark.sql.parquet.compression.codec’ value to ‘parquet.compression’.
Pass ‘spark.sql.orc.compression.codec’ value to ‘orc.compress’.
How was this patch tested?
Add test.
Note:
This is the same issue mentioned in #19218 . That branch was deleted mistakenly, so make a new pr instead.
gatorsmile maropu dongjoon-hyun discipleforteen
Author: fjh100456 <fu.jinhua6@zte.com.cn>
Author: Takeshi Yamamuro <yamamuro@apache.org>
Author: Wenchen Fan <wenchen@databricks.com>
Author: gatorsmile <gatorsmile@gmail.com>
Author: Yinan Li <liyinan926@gmail.com>
Author: Marcelo Vanzin <vanzin@cloudera.com>
Author: Juliusz Sompolski <julek@databricks.com>
Author: Felix Cheung <felixcheung_m@hotmail.com>
Author: jerryshao <sshao@hortonworks.com>
Author: Li Jin <ice.xelloss@gmail.com>
Author: Gera Shegalov <gera@apache.org>
Author: chetkhatri <ckhatrimanjal@gmail.com>
Author: Joseph K. Bradley <joseph@databricks.com>
Author: Bago Amirbekian <bago@databricks.com>
Author: Xianjin YE <advancedxy@gmail.com>
Author: Bruce Robbins <bersprockets@gmail.com>
Author: zuotingbing <zuo.tingbing9@zte.com.cn>
Author: Kent Yao <yaooqinn@hotmail.com>
Author: hyukjinkwon <gurwls223@gmail.com>
Author: Adrian Ionescu <adrian@databricks.com>
Closes#20087 from fjh100456/HiveTableWriting.
## What changes were proposed in this pull request?
Narrow bound on approx quantile test to epsilon from 2*epsilon to match paper
## How was this patch tested?
Existing tests.
Author: Sean Owen <sowen@cloudera.com>
Closes#20324 from srowen/SPARK-23091.
## What changes were proposed in this pull request?
Several cleanups in `ColumnarBatch`
* remove `schema`. The `ColumnVector`s inside `ColumnarBatch` already have the data type information, we don't need this `schema`.
* remove `capacity`. `ColumnarBatch` is just a wrapper of `ColumnVector`s, not builders, it doesn't need a capacity property.
* remove `DEFAULT_BATCH_SIZE`. As a wrapper, `ColumnarBatch` can't decide the batch size, it should be decided by the reader, e.g. parquet reader, orc reader, cached table reader. The default batch size should also be defined by the reader.
## How was this patch tested?
existing tests.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20316 from cloud-fan/columnar-batch.
## What changes were proposed in this pull request?
After session cloning in `TestHive`, the conf of the singleton SparkContext for derby DB location is changed to a new directory. The new directory is created in `HiveUtils.newTemporaryConfiguration(useInMemoryDerby = false)`.
This PR is to keep the conf value of `ConfVars.METASTORECONNECTURLKEY.varname` unchanged during the session clone.
## How was this patch tested?
The issue can be reproduced by the command:
> build/sbt -Phive "hive/test-only org.apache.spark.sql.hive.HiveSessionStateSuite org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite"
Also added a test case.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20328 from gatorsmile/fixTestFailure.
## What changes were proposed in this pull request?
This patch fixes a few recently introduced java style check errors in master and release branch.
As an aside, given that [java linting currently fails](https://github.com/apache/spark/pull/10763
) on machines with a clean maven cache, it'd be great to find another workaround to [re-enable the java style checks](3a07eff5af/dev/run-tests.py (L577)) as part of Spark PRB.
/cc zsxwing JoshRosen srowen for any suggestions
## How was this patch tested?
Manual Check
Author: Sameer Agarwal <sameerag@apache.org>
Closes#20323 from sameeragarwal/java.
## What changes were proposed in this pull request?
This is a follow-up of #20246.
If a UDT in Python doesn't have its corresponding Scala UDT, cast to string will be the raw string of the internal value, e.g. `"org.apache.spark.sql.catalyst.expressions.UnsafeArrayDataxxxxxxxx"` if the internal type is `ArrayType`.
This pr fixes it by using its `sqlType` casting.
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20306 from ueshin/issues/SPARK-23054/fup1.
## What changes were proposed in this pull request?
Refactored ConsoleWriter into ConsoleMicrobatchWriter and ConsoleContinuousWriter.
## How was this patch tested?
new unit test
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20311 from tdas/SPARK-23144.
## What changes were proposed in this pull request?
When there is an operation between Decimals and the result is a number which is not representable exactly with the result's precision and scale, Spark is returning `NULL`. This was done to reflect Hive's behavior, but it is against SQL ANSI 2011, which states that "If the result cannot be represented exactly in the result type, then whether it is rounded or truncated is implementation-defined". Moreover, Hive now changed its behavior in order to respect the standard, thanks to HIVE-15331.
Therefore, the PR propose to:
- update the rules to determine the result precision and scale according to the new Hive's ones introduces in HIVE-15331;
- round the result of the operations, when it is not representable exactly with the result's precision and scale, instead of returning `NULL`
- introduce a new config `spark.sql.decimalOperations.allowPrecisionLoss` which default to `true` (ie. the new behavior) in order to allow users to switch back to the previous one.
Hive behavior reflects SQLServer's one. The only difference is that the precision and scale are adjusted for all the arithmetic operations in Hive, while SQL Server is said to do so only for multiplications and divisions in the documentation. This PR follows Hive's behavior.
A more detailed explanation is available here: https://mail-archives.apache.org/mod_mbox/spark-dev/201712.mbox/%3CCAEorWNAJ4TxJR9NBcgSFMD_VxTg8qVxusjP%2BAJP-x%2BJV9zH-yA%40mail.gmail.com%3E.
## How was this patch tested?
modified and added UTs. Comparisons with results of Hive and SQLServer.
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20023 from mgaido91/SPARK-22036.
## What changes were proposed in this pull request?
Migrate ConsoleSink to data source V2 api.
Note that this includes a missing piece in DataStreamWriter required to specify a data source V2 writer.
Note also that I've removed the "Rerun batch" part of the sink, because as far as I can tell this would never have actually happened. A MicroBatchExecution object will only commit each batch once for its lifetime, and a new MicroBatchExecution object would have a new ConsoleSink object which doesn't know it's retrying a batch. So I think this represents an anti-feature rather than a weakness in the V2 API.
## How was this patch tested?
new unit test
Author: Jose Torres <jose@databricks.com>
Closes#20243 from jose-torres/console-sink.
## What changes were proposed in this pull request?
Structured streaming is now able to read files with space in file name (previously it would skip the file and output a warning)
## How was this patch tested?
Added new unit test.
Author: Xiayun Sun <xiayunsun@gmail.com>
Closes#19247 from xysun/SPARK-21996.
## What changes were proposed in this pull request?
- Added `InterfaceStability.Evolving` annotations
- Improved docs.
## How was this patch tested?
Existing tests.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20286 from tdas/SPARK-23119.
## What changes were proposed in this pull request?
This PR changes usage of `MapVector` in Spark codebase to use `NullableMapVector`.
`MapVector` is an internal Arrow class that is not supposed to be used directly. We should use `NullableMapVector` instead.
## How was this patch tested?
Existing test.
Author: Li Jin <ice.xelloss@gmail.com>
Closes#20239 from icexelloss/arrow-map-vector.
## What changes were proposed in this pull request?
Keep the run ID static, using a different ID for the epoch coordinator to avoid cross-execution message contamination.
## How was this patch tested?
new and existing unit tests
Author: Jose Torres <jose@databricks.com>
Closes#20282 from jose-torres/fix-runid.
## What changes were proposed in this pull request?
Continuous processing tasks will fail on any attempt number greater than 0. ContinuousExecution will catch these failures and restart globally from the last recorded checkpoints.
## How was this patch tested?
unit test
Author: Jose Torres <jose@databricks.com>
Closes#20225 from jose-torres/no-retry.
## What changes were proposed in this pull request?
Previously, PR #19201 fix the problem of non-converging constraints.
After that PR #19149 improve the loop and constraints is inferred only once.
So the problem of non-converging constraints is gone.
However, the case below will fail.
```
spark.range(5).write.saveAsTable("t")
val t = spark.read.table("t")
val left = t.withColumn("xid", $"id" + lit(1)).as("x")
val right = t.withColumnRenamed("id", "xid").as("y")
val df = left.join(right, "xid").filter("id = 3").toDF()
checkAnswer(df, Row(4, 3))
```
Because `aliasMap` replace all the aliased child. See the test case in PR for details.
This PR is to fix this bug by removing useless code for preventing non-converging constraints.
It can be also fixed with #20270, but this is much simpler and clean up the code.
## How was this patch tested?
Unit test
Author: Wang Gengliang <ltnwgl@gmail.com>
Closes#20278 from gengliangwang/FixConstraintSimple.
## What changes were proposed in this pull request?
ORC filter push-down is disabled by default from the beginning, [SPARK-2883](aa31e431fc (diff-41ef65b9ef5b518f77e2a03559893f4dR149)
).
Now, Apache Spark starts to depend on Apache ORC 1.4.1. For Apache Spark 2.3, this PR turns on ORC filter push-down by default like Parquet ([SPARK-9207](https://issues.apache.org/jira/browse/SPARK-21783)) as a part of [SPARK-20901](https://issues.apache.org/jira/browse/SPARK-20901), "Feature parity for ORC with Parquet".
## How was this patch tested?
Pass the existing tests.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20265 from dongjoon-hyun/SPARK-21783.
## What changes were proposed in this pull request?
Make the default behavior of EXCEPT (i.e. EXCEPT DISTINCT) more
explicit in the documentation, and call out the change in behavior
from 1.x.
Author: Henry Robinson <henry@cloudera.com>
Closes#20254 from henryr/spark-23062.
## What changes were proposed in this pull request?
The Kafka reader is now interruptible and can close itself.
## How was this patch tested?
I locally ran one of the ContinuousKafkaSourceSuite tests in a tight loop. Before the fix, my machine ran out of open file descriptors a few iterations in; now it works fine.
Author: Jose Torres <jose@databricks.com>
Closes#20253 from jose-torres/fix-data-reader.
## What changes were proposed in this pull request?
There are already quite a few integration tests using window frames, but the unit tests coverage is not ideal.
In this PR the already existing tests are reorganized, extended and where gaps found additional cases added.
## How was this patch tested?
Automated: Pass the Jenkins.
Author: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Closes#20019 from gaborgsomogyi/SPARK-22361.
## What changes were proposed in this pull request?
The following SQL involving scalar correlated query returns a map exception.
``` SQL
SELECT t1a
FROM t1
WHERE t1a = (SELECT count(*)
FROM t2
WHERE t2c = t1c
HAVING count(*) >= 1)
```
``` SQL
key not found: ExprId(278,786682bb-41f9-4bd5-a397-928272cc8e4e)
java.util.NoSuchElementException: key not found: ExprId(278,786682bb-41f9-4bd5-a397-928272cc8e4e)
at scala.collection.MapLike$class.default(MapLike.scala:228)
at scala.collection.AbstractMap.default(Map.scala:59)
at scala.collection.MapLike$class.apply(MapLike.scala:141)
at scala.collection.AbstractMap.apply(Map.scala:59)
at org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery$.org$apache$spark$sql$catalyst$optimizer$RewriteCorrelatedScalarSubquery$$evalSubqueryOnZeroTups(subquery.scala:378)
at org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery$$anonfun$org$apache$spark$sql$catalyst$optimizer$RewriteCorrelatedScalarSubquery$$constructLeftJoins$1.apply(subquery.scala:430)
at org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery$$anonfun$org$apache$spark$sql$catalyst$optimizer$RewriteCorrelatedScalarSubquery$$constructLeftJoins$1.apply(subquery.scala:426)
```
In this case, after evaluating the HAVING clause "count(*) > 1" statically
against the binding of aggregtation result on empty input, we determine
that this query will not have a the count bug. We should simply return
the evalSubqueryOnZeroTups with empty value.
(Please fill in changes proposed in this fix)
## How was this patch tested?
A new test was added in the Subquery bucket.
Author: Dilip Biswal <dbiswal@us.ibm.com>
Closes#20283 from dilipbiswal/scalar-count-defect.
## What changes were proposed in this pull request?
Lots of our tests don't properly shutdown everything they create, and end up leaking lots of threads. For example, `TaskSetManagerSuite` doesn't stop the extra `TaskScheduler` and `DAGScheduler` it creates. There are a couple more instances, eg. in `DAGSchedulerSuite`.
This PR adds the possibility to print out the not properly stopped thread list after a test suite executed. The format is the following:
```
===== FINISHED o.a.s.scheduler.DAGSchedulerSuite: 'task end event should have updated accumulators (SPARK-20342)' =====
...
===== Global thread whitelist loaded with name /thread_whitelist from classpath: rpc-client.*, rpc-server.*, shuffle-client.*, shuffle-server.*' =====
ScalaTest-run:
===== THREADS NOT STOPPED PROPERLY =====
ScalaTest-run: dag-scheduler-event-loop
ScalaTest-run: globalEventExecutor-2-5
ScalaTest-run:
===== END OF THREAD DUMP =====
ScalaTest-run:
===== EITHER PUT THREAD NAME INTO THE WHITELIST FILE OR SHUT IT DOWN PROPERLY =====
```
With the help of this leaking threads has been identified in TaskSetManagerSuite. My intention is to hunt down and fix such bugs in later PRs.
## How was this patch tested?
Manual: TaskSetManagerSuite test executed and found out where are the leaking threads.
Automated: Pass the Jenkins.
Author: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Closes#19893 from gaborgsomogyi/SPARK-16139.
## What changes were proposed in this pull request?
a new Data Source V2 interface to allow the data source to return `ColumnarBatch` during the scan.
## How was this patch tested?
new tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20153 from cloud-fan/columnar-reader.
## What changes were proposed in this pull request?
This problem reported by yanlin-Lynn ivoson and LiangchangZ. Thanks!
When we union 2 streams from kafka or other sources, while one of them have no continues data coming and in the same time task restart, this will cause an `IllegalStateException`. This mainly cause because the code in [MicroBatchExecution](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala#L190) , while one stream has no continues data, its comittedOffset same with availableOffset during `populateStartOffsets`, and `currentPartitionOffsets` not properly handled in KafkaSource. Also, maybe we should also consider this scenario in other Source.
## How was this patch tested?
Add a UT in KafkaSourceSuite.scala
Author: Yuanjian Li <xyliyuanjian@gmail.com>
Closes#20150 from xuanyuanking/SPARK-22956.
## What changes were proposed in this pull request?
When a user puts the wrong number of parameters in a function, an AnalysisException is thrown. If the function is a UDF, he user is told how many parameters the function expected and how many he/she put. If the function, instead, is a built-in one, no information about the number of parameters expected and the actual one is provided. This can help in some cases, to debug the errors (eg. bad quotes escaping may lead to a different number of parameters than expected, etc. etc.)
The PR adds the information about the number of parameters passed and the expected one, analogously to what happens for UDF.
## How was this patch tested?
modified existing UT + manual test
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20271 from mgaido91/SPARK-23080.
## What changes were proposed in this pull request?
Problem: it throw TempTableAlreadyExistsException and output "Temporary table '$table' already exists" when we create temp view by using org.apache.spark.sql.catalyst.catalog.GlobalTempViewManager#create, it's improper.
So fix improper information about TempTableAlreadyExistsException when create temp view:
change "Temporary table" to "Temporary view"
## How was this patch tested?
test("rename temporary view - destination table already exists, with: CREATE TEMPORARY view")
test("rename temporary view - destination table with database name,with:CREATE TEMPORARY view")
Author: xubo245 <601450868@qq.com>
Closes#20227 from xubo245/fixDeprecated.
## What changes were proposed in this pull request?
The current `Datset.showString` prints rows thru `RowEncoder` deserializers like;
```
scala> Seq(Seq(Seq(1, 2), Seq(3), Seq(4, 5, 6))).toDF("a").show(false)
+------------------------------------------------------------+
|a |
+------------------------------------------------------------+
|[WrappedArray(1, 2), WrappedArray(3), WrappedArray(4, 5, 6)]|
+------------------------------------------------------------+
```
This result is incorrect because the correct one is;
```
scala> Seq(Seq(Seq(1, 2), Seq(3), Seq(4, 5, 6))).toDF("a").show(false)
+------------------------+
|a |
+------------------------+
|[[1, 2], [3], [4, 5, 6]]|
+------------------------+
```
So, this pr fixed code in `showString` to cast field data to strings before printing.
## How was this patch tested?
Added tests in `DataFrameSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#20214 from maropu/SPARK-23023.
## What changes were proposed in this pull request?
When `spark.sql.files.ignoreCorruptFiles=true`, we should ignore corrupted ORC files.
## How was this patch tested?
Pass the Jenkins with a newly added test case.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20240 from dongjoon-hyun/SPARK-23049.
## What changes were proposed in this pull request?
This pr fixed the issue when casting `UserDefinedType`s into strings;
```
>>> from pyspark.ml.classification import MultilayerPerceptronClassifier
>>> from pyspark.ml.linalg import Vectors
>>> df = spark.createDataFrame([(0.0, Vectors.dense([0.0, 0.0])), (1.0, Vectors.dense([0.0, 1.0]))], ["label", "features"])
>>> df.selectExpr("CAST(features AS STRING)").show(truncate = False)
+-------------------------------------------+
|features |
+-------------------------------------------+
|[6,1,0,0,2800000020,2,0,0,0] |
|[6,1,0,0,2800000020,2,0,0,3ff0000000000000]|
+-------------------------------------------+
```
The root cause is that `Cast` handles input data as `UserDefinedType.sqlType`(this is underlying storage type), so we should pass data into `UserDefinedType.deserialize` then `toString`.
This pr modified the result into;
```
+---------+
|features |
+---------+
|[0.0,0.0]|
|[0.0,1.0]|
+---------+
```
## How was this patch tested?
Added tests in `UserDefinedTypeSuite `.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#20246 from maropu/SPARK-23054.
## What changes were proposed in this pull request?
SHOW DATABASES (LIKE pattern = STRING)? Can be like the back increase?
When using this command, LIKE keyword can be removed.
You can refer to the SHOW TABLES command, SHOW TABLES 'test *' and SHOW TABELS like 'test *' can be used.
Similarly SHOW DATABASES 'test *' and SHOW DATABASES like 'test *' can be used.
## How was this patch tested?
unit tests manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: guoxiaolong <guo.xiaolong1@zte.com.cn>
Closes#20194 from guoxiaolongzte/SPARK-22999.
## What changes were proposed in this pull request?
This pr fixed code to compare values in `compareAndGetNewStats`.
The test below fails in the current master;
```
val oldStats2 = CatalogStatistics(sizeInBytes = BigInt(Long.MaxValue) * 2)
val newStats5 = CommandUtils.compareAndGetNewStats(
Some(oldStats2), newTotalSize = BigInt(Long.MaxValue) * 2, None)
assert(newStats5.isEmpty)
```
## How was this patch tested?
Added some tests in `CommandUtilsSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#20245 from maropu/SPARK-21213-FOLLOWUP.
## What changes were proposed in this pull request?
as per discussion in https://github.com/apache/spark/pull/19864#discussion_r156847927
the current HadoopFsRelation is purely based on the underlying file size which is not accurate and makes the execution vulnerable to errors like OOM
Users can enable CBO with the functionalities in https://github.com/apache/spark/pull/19864 to avoid this issue
This JIRA proposes to add a configurable factor to sizeInBytes method in HadoopFsRelation class so that users can mitigate this problem without CBO
## How was this patch tested?
Existing tests
Author: CodingCat <zhunansjtu@gmail.com>
Author: Nan Zhu <nanzhu@uber.com>
Closes#20072 from CodingCat/SPARK-22790.
## What changes were proposed in this pull request?
Add withGlobalTempView when create global temp view, like withTempView and withView.
And correct some improper usage.
Please see jira.
There are other similar place like that. I will fix it if community need. Please confirm it.
## How was this patch tested?
no new test.
Author: xubo245 <601450868@qq.com>
Closes#20228 from xubo245/DropTempView.
## What changes were proposed in this pull request?
`MetricsReporter ` assumes that there has been some progress for the query, ie. `lastProgress` is not null. If this is not true, as it might happen in particular conditions, a `NullPointerException` can be thrown.
The PR checks whether there is a `lastProgress` and if this is not true, it returns a default value for the metrics.
## How was this patch tested?
added UT
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20189 from mgaido91/SPARK-22975.
## What changes were proposed in this pull request?
This PR cleans up the java-lint errors (for v2.3.0-rc1 tag). Hopefully, this will be the final one.
```
$ dev/lint-java
Using `mvn` from path: /usr/local/bin/mvn
Checkstyle checks failed at following occurrences:
[ERROR] src/main/java/org/apache/spark/unsafe/memory/HeapMemoryAllocator.java:[85] (sizes) LineLength: Line is longer than 100 characters (found 101).
[ERROR] src/main/java/org/apache/spark/launcher/InProcessAppHandle.java:[20,8] (imports) UnusedImports: Unused import - java.io.IOException.
[ERROR] src/main/java/org/apache/spark/sql/execution/datasources/orc/OrcColumnVector.java:[41,9] (modifier) ModifierOrder: 'private' modifier out of order with the JLS suggestions.
[ERROR] src/test/java/test/org/apache/spark/sql/JavaDataFrameSuite.java:[464] (sizes) LineLength: Line is longer than 100 characters (found 102).
```
## How was this patch tested?
Manual.
```
$ dev/lint-java
Using `mvn` from path: /usr/local/bin/mvn
Checkstyle checks passed.
```
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20242 from dongjoon-hyun/fix_lint_java_2.3_rc1.
## What changes were proposed in this pull request?
Add support for `Null` type in the `schemaFor` method for Scala reflection.
## How was this patch tested?
Added UT
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20219 from mgaido91/SPARK-23025.
## What changes were proposed in this pull request?
Add kafka source and sink for continuous processing. This involves two small changes to the execution engine:
* Bring data reader close() into the normal data reader thread to avoid thread safety issues.
* Fix up the semantics of the RECONFIGURING StreamExecution state. State updates are now atomic, and we don't have to deal with swallowing an exception.
## How was this patch tested?
new unit tests
Author: Jose Torres <jose@databricks.com>
Closes#20096 from jose-torres/continuous-kafka.
## What changes were proposed in this pull request?
(courtesy of liancheng)
Spark SQL supports both global aggregation and grouping aggregation. Global aggregation always return a single row with the initial aggregation state as the output, even there are zero input rows. Spark implements this by simply checking the number of grouping keys and treats an aggregation as a global aggregation if it has zero grouping keys.
However, this simple principle drops the ball in the following case:
```scala
spark.emptyDataFrame.dropDuplicates().agg(count($"*") as "c").show()
// +---+
// | c |
// +---+
// | 1 |
// +---+
```
The reason is that:
1. `df.dropDuplicates()` is roughly translated into something equivalent to:
```scala
val allColumns = df.columns.map { col }
df.groupBy(allColumns: _*).agg(allColumns.head, allColumns.tail: _*)
```
This translation is implemented in the rule `ReplaceDeduplicateWithAggregate`.
2. `spark.emptyDataFrame` contains zero columns and zero rows.
Therefore, rule `ReplaceDeduplicateWithAggregate` makes a confusing transformation roughly equivalent to the following one:
```scala
spark.emptyDataFrame.dropDuplicates()
=> spark.emptyDataFrame.groupBy().agg(Map.empty[String, String])
```
The above transformation is confusing because the resulting aggregate operator contains no grouping keys (because `emptyDataFrame` contains no columns), and gets recognized as a global aggregation. As a result, Spark SQL allocates a single row filled by the initial aggregation state and uses it as the output, and returns a wrong result.
To fix this issue, this PR tweaks `ReplaceDeduplicateWithAggregate` by appending a literal `1` to the grouping key list of the resulting `Aggregate` operator when the input plan contains zero output columns. In this way, `spark.emptyDataFrame.dropDuplicates()` is now translated into a grouping aggregation, roughly depicted as:
```scala
spark.emptyDataFrame.dropDuplicates()
=> spark.emptyDataFrame.groupBy(lit(1)).agg(Map.empty[String, String])
```
Which is now properly treated as a grouping aggregation and returns the correct answer.
## How was this patch tested?
New unit tests added
Author: Feng Liu <fengliu@databricks.com>
Closes#20174 from liufengdb/fix-duplicate.
## What changes were proposed in this pull request?
This is mostly from https://github.com/apache/spark/pull/13775
The wrapper solution is pretty good for string/binary type, as the ORC column vector doesn't keep bytes in a continuous memory region, and has a significant overhead when copying the data to Spark columnar batch. For other cases, the wrapper solution is almost same with the current solution.
I think we can treat the wrapper solution as a baseline and keep improving the writing to Spark solution.
## How was this patch tested?
existing tests.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20205 from cloud-fan/orc.
## What changes were proposed in this pull request?
`BroadcastNestedLoopJoinExec` should be `BroadcastHashJoinExec`
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20202 from cloud-fan/typo.
## What changes were proposed in this pull request?
In current implementation of RDD.take, we overestimate the number of partitions we need to try by 50%:
`(1.5 * num * partsScanned / buf.size).toInt`
However, when the number is small, the result of `.toInt` is not what we want.
E.g, 2.9 will become 2, which should be 3.
Use Math.ceil to fix the problem.
Also clean up the code in RDD.scala.
## How was this patch tested?
Unit test
Author: Wang Gengliang <ltnwgl@gmail.com>
Closes#20200 from gengliangwang/Take.
## What changes were proposed in this pull request?
This PR adds an ORC columnar-batch reader to native `OrcFileFormat`. Since both Spark `ColumnarBatch` and ORC `RowBatch` are used together, it is faster than the current Spark implementation. This replaces the prior PR, #17924.
Also, this PR adds `OrcReadBenchmark` to show the performance improvement.
## How was this patch tested?
Pass the existing test cases.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19943 from dongjoon-hyun/SPARK-16060.
## What changes were proposed in this pull request?
Fix the warning: Couldn't find corresponding Hive SerDe for data source provider org.apache.spark.sql.hive.orc.
## How was this patch tested?
test("SPARK-22972: hive orc source")
assert(HiveSerDe.sourceToSerDe("org.apache.spark.sql.hive.orc")
.equals(HiveSerDe.sourceToSerDe("orc")))
Author: xubo245 <601450868@qq.com>
Closes#20165 from xubo245/HiveSerDe.
## What changes were proposed in this pull request?
Support for v2 data sources in microbatch streaming.
## How was this patch tested?
A very basic new unit test on the toy v2 implementation of rate source. Once we have a v1 source fully migrated to v2, we'll need to do more detailed compatibility testing.
Author: Jose Torres <jose@databricks.com>
Closes#20097 from jose-torres/v2-impl.
## What changes were proposed in this pull request?
1. Deprecate attemptId in StageInfo and add `def attemptNumber() = attemptId`
2. Replace usage of stageAttemptId with stageAttemptNumber
## How was this patch tested?
I manually checked the compiler warning info
Author: Xianjin YE <advancedxy@gmail.com>
Closes#20178 from advancedxy/SPARK-22952.
## What changes were proposed in this pull request?
**The current shuffle planning logic**
1. Each operator specifies the distribution requirements for its children, via the `Distribution` interface.
2. Each operator specifies its output partitioning, via the `Partitioning` interface.
3. `Partitioning.satisfy` determines whether a `Partitioning` can satisfy a `Distribution`.
4. For each operator, check each child of it, add a shuffle node above the child if the child partitioning can not satisfy the required distribution.
5. For each operator, check if its children's output partitionings are compatible with each other, via the `Partitioning.compatibleWith`.
6. If the check in 5 failed, add a shuffle above each child.
7. try to eliminate the shuffles added in 6, via `Partitioning.guarantees`.
This design has a major problem with the definition of "compatible".
`Partitioning.compatibleWith` is not well defined, ideally a `Partitioning` can't know if it's compatible with other `Partitioning`, without more information from the operator. For example, `t1 join t2 on t1.a = t2.b`, `HashPartitioning(a, 10)` should be compatible with `HashPartitioning(b, 10)` under this case, but the partitioning itself doesn't know it.
As a result, currently `Partitioning.compatibleWith` always return false except for literals, which make it almost useless. This also means, if an operator has distribution requirements for multiple children, Spark always add shuffle nodes to all the children(although some of them can be eliminated). However, there is no guarantee that the children's output partitionings are compatible with each other after adding these shuffles, we just assume that the operator will only specify `ClusteredDistribution` for multiple children.
I think it's very hard to guarantee children co-partition for all kinds of operators, and we can not even give a clear definition about co-partition between distributions like `ClusteredDistribution(a,b)` and `ClusteredDistribution(c)`.
I think we should drop the "compatible" concept in the distribution model, and let the operator achieve the co-partition requirement by special distribution requirements.
**Proposed shuffle planning logic after this PR**
(The first 4 are same as before)
1. Each operator specifies the distribution requirements for its children, via the `Distribution` interface.
2. Each operator specifies its output partitioning, via the `Partitioning` interface.
3. `Partitioning.satisfy` determines whether a `Partitioning` can satisfy a `Distribution`.
4. For each operator, check each child of it, add a shuffle node above the child if the child partitioning can not satisfy the required distribution.
5. For each operator, check if its children's output partitionings have the same number of partitions.
6. If the check in 5 failed, pick the max number of partitions from children's output partitionings, and add shuffle to child whose number of partitions doesn't equal to the max one.
The new distribution model is very simple, we only have one kind of relationship, which is `Partitioning.satisfy`. For multiple children, Spark only guarantees they have the same number of partitions, and it's the operator's responsibility to leverage this guarantee to achieve more complicated requirements. For example, non-broadcast joins can use the newly added `HashPartitionedDistribution` to achieve co-partition.
## How was this patch tested?
existing tests.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19080 from cloud-fan/exchange.
## What changes were proposed in this pull request?
The following SQL query should return zero rows, but in Spark it actually returns one row:
```
SELECT 1 from (
SELECT 1 AS z,
MIN(a.x)
FROM (select 1 as x) a
WHERE false
) b
where b.z != b.z
```
The problem stems from the `PushDownPredicate` rule: when this rule encounters a filter on top of an Aggregate operator, e.g. `Filter(Agg(...))`, it removes the original filter and adds a new filter onto Aggregate's child, e.g. `Agg(Filter(...))`. This is sometimes okay, but the case above is a counterexample: because there is no explicit `GROUP BY`, we are implicitly computing a global aggregate over the entire table so the original filter was not acting like a `HAVING` clause filtering the number of groups: if we push this filter then it fails to actually reduce the cardinality of the Aggregate output, leading to the wrong answer.
In 2016 I fixed a similar problem involving invalid pushdowns of data-independent filters (filters which reference no columns of the filtered relation). There was additional discussion after my fix was merged which pointed out that my patch was an incomplete fix (see #15289), but it looks I must have either misunderstood the comment or forgot to follow up on the additional points raised there.
This patch fixes the problem by choosing to never push down filters in cases where there are no grouping expressions. Since there are no grouping keys, the only columns are aggregate columns and we can't push filters defined over aggregate results, so this change won't cause us to miss out on any legitimate pushdown opportunities.
## How was this patch tested?
New regression tests in `SQLQueryTestSuite` and `FilterPushdownSuite`.
Author: Josh Rosen <joshrosen@databricks.com>
Closes#20180 from JoshRosen/SPARK-22983-dont-push-filters-beneath-aggs-with-empty-grouping-expressions.
## What changes were proposed in this pull request?
Seems we can avoid type dispatch for each value when Java objection (from Pyrolite) -> Spark's internal data format because we know the schema ahead.
I manually performed the benchmark as below:
```scala
test("EvaluatePython.fromJava / EvaluatePython.makeFromJava") {
val numRows = 1000 * 1000
val numFields = 30
val random = new Random(System.nanoTime())
val types = Array(
BooleanType, ByteType, FloatType, DoubleType, IntegerType, LongType, ShortType,
DecimalType.ShortDecimal, DecimalType.IntDecimal, DecimalType.ByteDecimal,
DecimalType.FloatDecimal, DecimalType.LongDecimal, new DecimalType(5, 2),
new DecimalType(12, 2), new DecimalType(30, 10), CalendarIntervalType)
val schema = RandomDataGenerator.randomSchema(random, numFields, types)
val rows = mutable.ArrayBuffer.empty[Array[Any]]
var i = 0
while (i < numRows) {
val row = RandomDataGenerator.randomRow(random, schema)
rows += row.toSeq.toArray
i += 1
}
val benchmark = new Benchmark("EvaluatePython.fromJava / EvaluatePython.makeFromJava", numRows)
benchmark.addCase("Before - EvaluatePython.fromJava", 3) { _ =>
var i = 0
while (i < numRows) {
EvaluatePython.fromJava(rows(i), schema)
i += 1
}
}
benchmark.addCase("After - EvaluatePython.makeFromJava", 3) { _ =>
val fromJava = EvaluatePython.makeFromJava(schema)
var i = 0
while (i < numRows) {
fromJava(rows(i))
i += 1
}
}
benchmark.run()
}
```
```
EvaluatePython.fromJava / EvaluatePython.makeFromJava: Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------
Before - EvaluatePython.fromJava 1265 / 1346 0.8 1264.8 1.0X
After - EvaluatePython.makeFromJava 571 / 649 1.8 570.8 2.2X
```
If the structure is nested, I think the advantage should be larger than this.
## How was this patch tested?
Existing tests should cover this. Also, I manually checked if the values from before / after are actually same via `assert` when performing the benchmarks.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20172 from HyukjinKwon/type-dispatch-python-eval.
[SPARK-21786][SQL] When acquiring 'compressionCodecClassName' in 'ParquetOptions', `parquet.compression` needs to be considered.
## What changes were proposed in this pull request?
Since Hive 1.1, Hive allows users to set parquet compression codec via table-level properties parquet.compression. See the JIRA: https://issues.apache.org/jira/browse/HIVE-7858 . We do support orc.compression for ORC. Thus, for external users, it is more straightforward to support both. See the stackflow question: https://stackoverflow.com/questions/36941122/spark-sql-ignores-parquet-compression-propertie-specified-in-tblproperties
In Spark side, our table-level compression conf compression was added by #11464 since Spark 2.0.
We need to support both table-level conf. Users might also use session-level conf spark.sql.parquet.compression.codec. The priority rule will be like
If other compression codec configuration was found through hive or parquet, the precedence would be compression, parquet.compression, spark.sql.parquet.compression.codec. Acceptable values include: none, uncompressed, snappy, gzip, lzo.
The rule for Parquet is consistent with the ORC after the change.
Changes:
1.Increased acquiring 'compressionCodecClassName' from `parquet.compression`,and the precedence order is `compression`,`parquet.compression`,`spark.sql.parquet.compression.codec`, just like what we do in `OrcOptions`.
2.Change `spark.sql.parquet.compression.codec` to support "none".Actually in `ParquetOptions`,we do support "none" as equivalent to "uncompressed", but it does not allowed to configured to "none".
3.Change `compressionCode` to `compressionCodecClassName`.
## How was this patch tested?
Add test.
Author: fjh100456 <fu.jinhua6@zte.com.cn>
Closes#20076 from fjh100456/ParquetOptionIssue.
## What changes were proposed in this pull request?
This pr modified `elt` to output binary for binary inputs.
`elt` in the current master always output data as a string. But, in some databases (e.g., MySQL), if all inputs are binary, `elt` also outputs binary (Also, this might be a small surprise).
This pr is related to #19977.
## How was this patch tested?
Added tests in `SQLQueryTestSuite` and `TypeCoercionSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#20135 from maropu/SPARK-22937.
## What changes were proposed in this pull request?
This pr fixed the issue when casting arrays into strings;
```
scala> val df = spark.range(10).select('id.cast("integer")).agg(collect_list('id).as('ids))
scala> df.write.saveAsTable("t")
scala> sql("SELECT cast(ids as String) FROM t").show(false)
+------------------------------------------------------------------+
|ids |
+------------------------------------------------------------------+
|org.apache.spark.sql.catalyst.expressions.UnsafeArrayData8bc285df|
+------------------------------------------------------------------+
```
This pr modified the result into;
```
+------------------------------+
|ids |
+------------------------------+
|[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]|
+------------------------------+
```
## How was this patch tested?
Added tests in `CastSuite` and `SQLQuerySuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#20024 from maropu/SPARK-22825.
## What changes were proposed in this pull request?
32bit Int was used for row rank.
That overflowed in a dataframe with more than 2B rows.
## How was this patch tested?
Added test, but ignored, as it takes 4 minutes.
Author: Juliusz Sompolski <julek@databricks.com>
Closes#20152 from juliuszsompolski/SPARK-22957.
## What changes were proposed in this pull request?
Currently Scala users can use UDF like
```
val foo = udf((i: Int) => Math.random() + i).asNondeterministic
df.select(foo('a))
```
Python users can also do it with similar APIs. However Java users can't do it, we should add Java UDF APIs in the functions object.
## How was this patch tested?
new tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20141 from cloud-fan/udf.
## What changes were proposed in this pull request?
R Structured Streaming API for withWatermark, trigger, partitionBy
## How was this patch tested?
manual, unit tests
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#20129 from felixcheung/rwater.
## What changes were proposed in this pull request?
move `ColumnVector` and related classes to `org.apache.spark.sql.vectorized`, and improve the document.
## How was this patch tested?
existing tests.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20116 from cloud-fan/column-vector.
## What changes were proposed in this pull request?
When overwriting a partitioned table with dynamic partition columns, the behavior is different between data source and hive tables.
data source table: delete all partition directories that match the static partition values provided in the insert statement.
hive table: only delete partition directories which have data written into it
This PR adds a new config to make users be able to choose hive's behavior.
## How was this patch tested?
new tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#18714 from cloud-fan/overwrite-partition.
## What changes were proposed in this pull request?
Currently, our CREATE TABLE syntax require the EXACT order of clauses. It is pretty hard to remember the exact order. Thus, this PR is to make optional clauses order insensitive for `CREATE TABLE` SQL statement.
```
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name1 col_type1 [COMMENT col_comment1], ...)]
USING datasource
[OPTIONS (key1=val1, key2=val2, ...)]
[PARTITIONED BY (col_name1, col_name2, ...)]
[CLUSTERED BY (col_name3, col_name4, ...) INTO num_buckets BUCKETS]
[LOCATION path]
[COMMENT table_comment]
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
[AS select_statement]
```
The proposal is to make the following clauses order insensitive.
```
[OPTIONS (key1=val1, key2=val2, ...)]
[PARTITIONED BY (col_name1, col_name2, ...)]
[CLUSTERED BY (col_name3, col_name4, ...) INTO num_buckets BUCKETS]
[LOCATION path]
[COMMENT table_comment]
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
```
The same idea is also applicable to Create Hive Table.
```
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name1[:] col_type1 [COMMENT col_comment1], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name2[:] col_type2 [COMMENT col_comment2], ...)]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION path]
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
[AS select_statement]
```
The proposal is to make the following clauses order insensitive.
```
[COMMENT table_comment]
[PARTITIONED BY (col_name2[:] col_type2 [COMMENT col_comment2], ...)]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION path]
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
```
## How was this patch tested?
Added test cases
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20133 from gatorsmile/createDataSourceTableDDL.
## What changes were proposed in this pull request?
stageAttemptId added in TaskContext and corresponding construction modification
## How was this patch tested?
Added a new test in TaskContextSuite, two cases are tested:
1. Normal case without failure
2. Exception case with resubmitted stages
Link to [SPARK-22897](https://issues.apache.org/jira/browse/SPARK-22897)
Author: Xianjin YE <advancedxy@gmail.com>
Closes#20082 from advancedxy/SPARK-22897.
## What changes were proposed in this pull request?
This change adds `ArrayType` support for working with Arrow in pyspark when creating a DataFrame, calling `toPandas()`, and using vectorized `pandas_udf`.
## How was this patch tested?
Added new Python unit tests using Array data.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#20114 from BryanCutler/arrow-ArrayType-support-SPARK-22530.
## What changes were proposed in this pull request?
Currently, we do not guarantee an order evaluation of conjuncts in either Filter or Join operator. This is also true to the mainstream RDBMS vendors like DB2 and MS SQL Server. Thus, we should also push down the deterministic predicates that are after the first non-deterministic, if possible.
## How was this patch tested?
Updated the existing test cases.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20069 from gatorsmile/morePushDown.
## What changes were proposed in this pull request?
There is already test using window spilling, but the test coverage is not ideal.
In this PR the already existing test was fixed and additional cases added.
## How was this patch tested?
Automated: Pass the Jenkins.
Author: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Closes#20022 from gaborgsomogyi/SPARK-22363.
## What changes were proposed in this pull request?
This pr modified `concat` to concat binary inputs into a single binary output.
`concat` in the current master always output data as a string. But, in some databases (e.g., PostgreSQL), if all inputs are binary, `concat` also outputs binary.
## How was this patch tested?
Added tests in `SQLQueryTestSuite` and `TypeCoercionSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#19977 from maropu/SPARK-22771.
## What changes were proposed in this pull request?
ML regression package testsuite add StructuredStreaming test
In order to make testsuite easier to modify, new helper function added in `MLTest`:
```
def testTransformerByGlobalCheckFunc[A : Encoder](
dataframe: DataFrame,
transformer: Transformer,
firstResultCol: String,
otherResultCols: String*)
(globalCheckFunction: Seq[Row] => Unit): Unit
```
## How was this patch tested?
N/A
Author: WeichenXu <weichen.xu@databricks.com>
Author: Bago Amirbekian <bago@databricks.com>
Closes#19979 from WeichenXu123/ml_stream_test.
## What changes were proposed in this pull request?
The issue has been raised in two Jira tickets: [SPARK-21657](https://issues.apache.org/jira/browse/SPARK-21657), [SPARK-16998](https://issues.apache.org/jira/browse/SPARK-16998). Basically, what happens is that in collection generators like explode/inline we create many rows from each row. Currently each exploded row contains also the column on which it was created. This causes, for example, if we have a 10k array in one row that this array will get copy 10k times - to each of the row. this results a qudratic memory consumption. However, it is a common case that the original column gets projected out after the explode, so we can avoid duplicating it.
In this solution we propose to identify this situation in the optimizer and turn on a flag for omitting the original column in the generation process.
## How was this patch tested?
1. We added a benchmark test to MiscBenchmark that shows x16 improvement in runtimes.
2. We ran some of the other tests in MiscBenchmark and they show 15% improvements.
3. We ran this code on a specific case from our production data with rows containing arrays of size ~200k and it reduced the runtime from 6 hours to 3 mins.
Author: oraviv <oraviv@paypal.com>
Author: uzadude <ohad.raviv@gmail.com>
Author: uzadude <15645757+uzadude@users.noreply.github.com>
Closes#19683 from uzadude/optimize_explode.
## What changes were proposed in this pull request?
When there are no broadcast hints, the current spark strategies will prefer to building the right side, without considering the sizes of the two tables. This patch added the logic to consider the sizes of the two tables for the build side. To make the logic clear, the build side is determined by two steps:
1. If there are broadcast hints, the build side is determined by `broadcastSideByHints`;
2. If there are no broadcast hints, the build side is determined by `broadcastSideBySizes`;
3. If the broadcast is disabled by the config, it falls back to the next cases.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Feng Liu <fengliu@databricks.com>
Closes#20099 from liufengdb/fix-spark-strategies.
## What changes were proposed in this pull request?
With #19474, children of insertion commands are missing in UI.
To fix it:
1. Create a new physical plan `DataWritingCommandExec` to exec `DataWritingCommand` with children. So that the other commands won't be affected.
2. On creation of `DataWritingCommand`, a new field `allColumns` must be specified, which is the output of analyzed plan.
3. In `FileFormatWriter`, the output schema will use `allColumns` instead of the output of optimized plan.
Before code changes:

After code changes:

## How was this patch tested?
Unit test
Author: Wang Gengliang <ltnwgl@gmail.com>
Closes#20020 from gengliangwang/insert.
## What changes were proposed in this pull request?
Escape of escape should be considered when using the UniVocity csv encoding/decoding library.
Ref: https://github.com/uniVocity/univocity-parsers#escaping-quote-escape-characters
One option is added for reading and writing CSV: `escapeQuoteEscaping`
## How was this patch tested?
Unit test added.
Author: soonmok-kwon <soonmok.kwon@navercorp.com>
Closes#20004 from ep1804/SPARK-22818.
## What changes were proposed in this pull request?
Test Coverage for `DateTimeOperations`, this is a Sub-tasks for [SPARK-22722](https://issues.apache.org/jira/browse/SPARK-22722).
## How was this patch tested?
N/A
Author: Yuming Wang <wgyumg@gmail.com>
Closes#20061 from wangyum/SPARK-22890.
## What changes were proposed in this pull request?
This PR cleans up a few Java linter errors for Apache Spark 2.3 release.
## How was this patch tested?
```bash
$ dev/lint-java
Using `mvn` from path: /usr/local/bin/mvn
Checkstyle checks passed.
```
We can see the result from [Travis CI](https://travis-ci.org/dongjoon-hyun/spark/builds/322470787), too.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20101 from dongjoon-hyun/fix-java-lint.
## What changes were proposed in this pull request?
For empty/null column, the result of `ApproximatePercentile` is null. Then in `ApproxCountDistinctForIntervals`, a `MatchError` (for `endpoints`) will be thrown if we try to generate histogram for that column. Besides, there is no need to generate histogram for such column. In this patch, we exclude such column when generating histogram.
## How was this patch tested?
Enhanced test cases for empty/null columns.
Author: Zhenhua Wang <wangzhenhua@huawei.com>
Closes#20102 from wzhfy/no_record_hgm_bug.
## What changes were proposed in this pull request?
This PR addresses additional review comments in #19811
## How was this patch tested?
Existing test suites
Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Closes#20036 from kiszk/SPARK-18066-followup.
## What changes were proposed in this pull request?
Test coverage for arithmetic operations leading to:
1. Precision loss
2. Overflow
Moreover, tests for casting bad string to other input types and for using bad string as operators of some functions.
## How was this patch tested?
added tests
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20084 from mgaido91/SPARK-22904.
## What changes were proposed in this pull request?
`DateTimeOperations` accept [`StringType`](ae998ec2b5/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/TypeCoercion.scala (L669)), but:
```
spark-sql> SELECT '2017-12-24' + interval 2 months 2 seconds;
Error in query: cannot resolve '(CAST('2017-12-24' AS DOUBLE) + interval 2 months 2 seconds)' due to data type mismatch: differing types in '(CAST('2017-12-24' AS DOUBLE) + interval 2 months 2 seconds)' (double and calendarinterval).; line 1 pos 7;
'Project [unresolvedalias((cast(2017-12-24 as double) + interval 2 months 2 seconds), None)]
+- OneRowRelation
spark-sql>
```
After this PR:
```
spark-sql> SELECT '2017-12-24' + interval 2 months 2 seconds;
2018-02-24 00:00:02
Time taken: 0.2 seconds, Fetched 1 row(s)
```
## How was this patch tested?
unit tests
Author: Yuming Wang <wgyumg@gmail.com>
Closes#20067 from wangyum/SPARK-22894.
## What changes were proposed in this pull request?
In SPARK-20586 the flag `deterministic` was added to Scala UDF, but it is not available for python UDF. This flag is useful for cases when the UDF's code can return different result with the same input. Due to optimization, duplicate invocations may be eliminated or the function may even be invoked more times than it is present in the query. This can lead to unexpected behavior.
This PR adds the deterministic flag, via the `asNondeterministic` method, to let the user mark the function as non-deterministic and therefore avoid the optimizations which might lead to strange behaviors.
## How was this patch tested?
Manual tests:
```
>>> from pyspark.sql.functions import *
>>> from pyspark.sql.types import *
>>> df_br = spark.createDataFrame([{'name': 'hello'}])
>>> import random
>>> udf_random_col = udf(lambda: int(100*random.random()), IntegerType()).asNondeterministic()
>>> df_br = df_br.withColumn('RAND', udf_random_col())
>>> random.seed(1234)
>>> udf_add_ten = udf(lambda rand: rand + 10, IntegerType())
>>> df_br.withColumn('RAND_PLUS_TEN', udf_add_ten('RAND')).show()
+-----+----+-------------+
| name|RAND|RAND_PLUS_TEN|
+-----+----+-------------+
|hello| 3| 13|
+-----+----+-------------+
```
Author: Marco Gaido <marcogaido91@gmail.com>
Author: Marco Gaido <mgaido@hortonworks.com>
Closes#19929 from mgaido91/SPARK-22629.
## What changes were proposed in this pull request?
Decimal type is not yet supported in `ArrowWriter`.
This is adding the decimal type support.
## How was this patch tested?
Added a test to `ArrowConvertersSuite`.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#18754 from ueshin/issues/SPARK-21552.
## What changes were proposed in this pull request?
We should use `dataType.simpleString` to unified the data type mismatch message:
Before:
```
spark-sql> select cast(1 as binary);
Error in query: cannot resolve 'CAST(1 AS BINARY)' due to data type mismatch: cannot cast IntegerType to BinaryType; line 1 pos 7;
```
After:
```
park-sql> select cast(1 as binary);
Error in query: cannot resolve 'CAST(1 AS BINARY)' due to data type mismatch: cannot cast int to binary; line 1 pos 7;
```
## How was this patch tested?
Exist test.
Author: Yuming Wang <wgyumg@gmail.com>
Closes#20064 from wangyum/SPARK-22893.
## What changes were proposed in this pull request?
Basic continuous execution, supporting map/flatMap/filter, with commits and advancement through RPC.
## How was this patch tested?
new unit-ish tests (exercising execution end to end)
Author: Jose Torres <jose@databricks.com>
Closes#19984 from jose-torres/continuous-impl.
When one execution has multiple jobs, we need to append to the set of
stages, not replace them on every job.
Added unit test and ran existing tests on jenkins
Author: Imran Rashid <irashid@cloudera.com>
Closes#20047 from squito/SPARK-22861.
## What changes were proposed in this pull request?
This is a followup PR of https://github.com/apache/spark/pull/19257 where gatorsmile had left couple comments wrt code style.
## How was this patch tested?
Doesn't change any functionality. Will depend on build to see if no checkstyle rules are violated.
Author: Tejas Patil <tejasp@fb.com>
Closes#20041 from tejasapatil/followup_19257.
## What changes were proposed in this pull request?
Test Coverage for `WindowFrameCoercion` and `DecimalPrecision`, this is a Sub-tasks for [SPARK-22722](https://issues.apache.org/jira/browse/SPARK-22722).
## How was this patch tested?
N/A
Author: Yuming Wang <wgyumg@gmail.com>
Closes#20008 from wangyum/SPARK-22822.
## What changes were proposed in this pull request?
In https://github.com/apache/spark/pull/19681 we introduced a new interface called `AppStatusPlugin`, to register listeners and set up the UI for both live and history UI.
However I think it's an overkill for live UI. For example, we should not register `SQLListener` if users are not using SQL functions. Previously we register the `SQLListener` and set up SQL tab when `SparkSession` is firstly created, which indicates users are going to use SQL functions. But in #19681 , we register the SQL functions during `SparkContext` creation. The same thing should apply to streaming too.
I think we should keep the previous behavior, and only use this new interface for history server.
To reflect this change, I also rename the new interface to `SparkHistoryUIPlugin`
This PR also refines the tests for sql listener.
## How was this patch tested?
existing tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19981 from cloud-fan/listener.
## What changes were proposed in this pull request?
Upgrade Spark to Arrow 0.8.0 for Java and Python. Also includes an upgrade of Netty to 4.1.17 to resolve dependency requirements.
The highlights that pertain to Spark for the update from Arrow versoin 0.4.1 to 0.8.0 include:
* Java refactoring for more simple API
* Java reduced heap usage and streamlined hot code paths
* Type support for DecimalType, ArrayType
* Improved type casting support in Python
* Simplified type checking in Python
## How was this patch tested?
Existing tests
Author: Bryan Cutler <cutlerb@gmail.com>
Author: Shixiong Zhu <zsxwing@gmail.com>
Closes#19884 from BryanCutler/arrow-upgrade-080-SPARK-22324.
## What changes were proposed in this pull request?
Introduce a new interface `SessionConfigSupport` for `DataSourceV2`, it can help to propagate session configs with the specified key-prefix to all data source operations in this session.
## How was this patch tested?
Add new test suite `DataSourceV2UtilsSuite`.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#19861 from jiangxb1987/datasource-configs.
## What changes were proposed in this pull request?
Some users depend on source compatibility with the org.apache.spark.sql.execution.streaming.Offset class. Although this is not a stable interface, we can keep it in place for now to simplify upgrades to 2.3.
Author: Jose Torres <jose@databricks.com>
Closes#20012 from joseph-torres/binary-compat.
## What changes were proposed in this pull request?
Like `Parquet`, users can use `ORC` with Apache Spark structured streaming. This PR adds `orc()` to `DataStreamReader`(Scala/Python) in order to support creating streaming dataset with ORC file format more easily like the other file formats. Also, this adds a test coverage for ORC data source and updates the document.
**BEFORE**
```scala
scala> spark.readStream.schema("a int").orc("/tmp/orc_ss").writeStream.format("console").start()
<console>:24: error: value orc is not a member of org.apache.spark.sql.streaming.DataStreamReader
spark.readStream.schema("a int").orc("/tmp/orc_ss").writeStream.format("console").start()
```
**AFTER**
```scala
scala> spark.readStream.schema("a int").orc("/tmp/orc_ss").writeStream.format("console").start()
res0: org.apache.spark.sql.streaming.StreamingQuery = org.apache.spark.sql.execution.streaming.StreamingQueryWrapper678b3746
scala>
-------------------------------------------
Batch: 0
-------------------------------------------
+---+
| a|
+---+
| 1|
+---+
```
## How was this patch tested?
Pass the newly added test cases.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19975 from dongjoon-hyun/SPARK-22781.
## What changes were proposed in this pull request?
This change adds local checkpoint support to datasets and respective bind from Python Dataframe API.
If reliability requirements can be lowered to favor performance, as in cases of further quick transformations followed by a reliable save, localCheckpoints() fit very well.
Furthermore, at the moment Reliable checkpoints still incur double computation (see #9428)
In general it makes the API more complete as well.
## How was this patch tested?
Python land quick use case:
```python
>>> from time import sleep
>>> from pyspark.sql import types as T
>>> from pyspark.sql import functions as F
>>> def f(x):
sleep(1)
return x*2
...:
>>> df1 = spark.range(30, numPartitions=6)
>>> df2 = df1.select(F.udf(f, T.LongType())("id"))
>>> %time _ = df2.collect()
CPU times: user 7.79 ms, sys: 5.84 ms, total: 13.6 ms
Wall time: 12.2 s
>>> %time df3 = df2.localCheckpoint()
CPU times: user 2.38 ms, sys: 2.3 ms, total: 4.68 ms
Wall time: 10.3 s
>>> %time _ = df3.collect()
CPU times: user 5.09 ms, sys: 410 µs, total: 5.5 ms
Wall time: 148 ms
>>> sc.setCheckpointDir(".")
>>> %time df3 = df2.checkpoint()
CPU times: user 4.04 ms, sys: 1.63 ms, total: 5.67 ms
Wall time: 20.3 s
```
Author: Fernando Pereira <fernando.pereira@epfl.ch>
Closes#19805 from ferdonline/feature_dataset_localCheckpoint.
## What changes were proposed in this pull request?
Currently, the task memory manager throws an OutofMemory error when there is an IO exception happens in spill() - https://github.com/apache/spark/blob/master/core/src/main/java/org/apache/spark/memory/TaskMemoryManager.java#L194. Similarly there any many other places in code when if a task is not able to acquire memory due to an exception we throw an OutofMemory error which kills the entire executor and hence failing all the tasks that are running on that executor instead of just failing one single task.
## How was this patch tested?
Unit tests
Author: Sital Kedia <skedia@fb.com>
Closes#20014 from sitalkedia/skedia/upstream_SPARK-22827.
## What changes were proposed in this pull request?
Test Coverage for `WidenSetOperationTypes`, `BooleanEquality`, `StackCoercion` and `Division`, this is a Sub-tasks for [SPARK-22722](https://issues.apache.org/jira/browse/SPARK-22722).
## How was this patch tested?
N/A
Author: Yuming Wang <wgyumg@gmail.com>
Closes#20006 from wangyum/SPARK-22821.
## What changes were proposed in this pull request?
This PR is follow-on of #19518. This PR tries to reduce the number of constant pool entries used for accessing mutable state.
There are two directions:
1. Primitive type variables should be allocated at the outer class due to better performance. Otherwise, this PR allocates an array.
2. The length of allocated array is up to 32768 due to avoiding usage of constant pool entry at access (e.g. `mutableStateArray[32767]`).
Here are some discussions to determine these directions.
1. [[1]](https://github.com/apache/spark/pull/19518#issuecomment-346690464), [[2]](https://github.com/apache/spark/pull/19518#issuecomment-346690642), [[3]](https://github.com/apache/spark/pull/19518#issuecomment-346828180), [[4]](https://github.com/apache/spark/pull/19518#issuecomment-346831544), [[5]](https://github.com/apache/spark/pull/19518#issuecomment-346857340)
2. [[6]](https://github.com/apache/spark/pull/19518#issuecomment-346729172), [[7]](https://github.com/apache/spark/pull/19518#issuecomment-346798358), [[8]](https://github.com/apache/spark/pull/19518#issuecomment-346870408)
This PR modifies `addMutableState` function in the `CodeGenerator` to check if the declared state can be easily initialized compacted into an array. We identify three types of states that cannot compacted:
- Primitive type state (ints, booleans, etc) if the number of them does not exceed threshold
- Multiple-dimensional array type
- `inline = true`
When `useFreshName = false`, the given name is used.
Many codes were ported from #19518. Many efforts were put here. I think this PR should credit to bdrillard
With this PR, the following code is generated:
```
/* 005 */ class SpecificMutableProjection extends org.apache.spark.sql.catalyst.expressions.codegen.BaseMutableProjection {
/* 006 */
/* 007 */ private Object[] references;
/* 008 */ private InternalRow mutableRow;
/* 009 */ private boolean isNull_0;
/* 010 */ private boolean isNull_1;
/* 011 */ private boolean isNull_2;
/* 012 */ private int value_2;
/* 013 */ private boolean isNull_3;
...
/* 10006 */ private int value_4999;
/* 10007 */ private boolean isNull_5000;
/* 10008 */ private int value_5000;
/* 10009 */ private InternalRow[] mutableStateArray = new InternalRow[2];
/* 10010 */ private boolean[] mutableStateArray1 = new boolean[7001];
/* 10011 */ private int[] mutableStateArray2 = new int[1001];
/* 10012 */ private UTF8String[] mutableStateArray3 = new UTF8String[6000];
/* 10013 */
...
/* 107956 */ private void init_176() {
/* 107957 */ isNull_4986 = true;
/* 107958 */ value_4986 = -1;
...
/* 108004 */ }
...
```
## How was this patch tested?
Added a new test case to `GeneratedProjectionSuite`
Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Closes#19811 from kiszk/SPARK-18016.
## What changes were proposed in this pull request?
When calling explain on a query, the output can contain sensitive information. We should provide an admin/user to redact such information.
Before this PR, the plan of SS is like this
```
== Physical Plan ==
*HashAggregate(keys=[value#6], functions=[count(1)], output=[value#6, count(1)#12L])
+- StateStoreSave [value#6], state info [ checkpoint = file:/private/var/folders/vx/j0ydl5rn0gd9mgrh1pljnw900000gn/T/temporary-91c6fac0-609f-4bc8-ad57-52c189f06797/state, runId = 05a4b3af-f02c-40f8-9ff9-a3e18bae496f, opId = 0, ver = 0, numPartitions = 5], Complete, 0
+- *HashAggregate(keys=[value#6], functions=[merge_count(1)], output=[value#6, count#18L])
+- StateStoreRestore [value#6], state info [ checkpoint = file:/private/var/folders/vx/j0ydl5rn0gd9mgrh1pljnw900000gn/T/temporary-91c6fac0-609f-4bc8-ad57-52c189f06797/state, runId = 05a4b3af-f02c-40f8-9ff9-a3e18bae496f, opId = 0, ver = 0, numPartitions = 5]
+- *HashAggregate(keys=[value#6], functions=[merge_count(1)], output=[value#6, count#18L])
+- Exchange hashpartitioning(value#6, 5)
+- *HashAggregate(keys=[value#6], functions=[partial_count(1)], output=[value#6, count#18L])
+- *SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0, java.lang.String, true], true, false) AS value#6]
+- *MapElements <function1>, obj#5: java.lang.String
+- *DeserializeToObject value#30.toString, obj#4: java.lang.String
+- LocalTableScan [value#30]
```
After this PR, we can get the following output if users set `spark.redaction.string.regex` to `file:/[\\w_]+`
```
== Physical Plan ==
*HashAggregate(keys=[value#6], functions=[count(1)], output=[value#6, count(1)#12L])
+- StateStoreSave [value#6], state info [ checkpoint = *********(redacted)/var/folders/vx/j0ydl5rn0gd9mgrh1pljnw900000gn/T/temporary-e7da9b7d-3ec0-474d-8b8c-927f7d12ed72/state, runId = 8a9c3761-93d5-4896-ab82-14c06240dcea, opId = 0, ver = 0, numPartitions = 5], Complete, 0
+- *HashAggregate(keys=[value#6], functions=[merge_count(1)], output=[value#6, count#32L])
+- StateStoreRestore [value#6], state info [ checkpoint = *********(redacted)/var/folders/vx/j0ydl5rn0gd9mgrh1pljnw900000gn/T/temporary-e7da9b7d-3ec0-474d-8b8c-927f7d12ed72/state, runId = 8a9c3761-93d5-4896-ab82-14c06240dcea, opId = 0, ver = 0, numPartitions = 5]
+- *HashAggregate(keys=[value#6], functions=[merge_count(1)], output=[value#6, count#32L])
+- Exchange hashpartitioning(value#6, 5)
+- *HashAggregate(keys=[value#6], functions=[partial_count(1)], output=[value#6, count#32L])
+- *SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0, java.lang.String, true], true, false) AS value#6]
+- *MapElements <function1>, obj#5: java.lang.String
+- *DeserializeToObject value#27.toString, obj#4: java.lang.String
+- LocalTableScan [value#27]
```
## How was this patch tested?
Added a test case
Author: gatorsmile <gatorsmile@gmail.com>
Closes#19985 from gatorsmile/redactPlan.
## What changes were proposed in this pull request?
The current implementation of InMemoryRelation always uses the most expensive execution plan when writing cache
With CBO enabled, we can actually have a more exact estimation of the underlying table size...
## How was this patch tested?
existing test
Author: CodingCat <zhunansjtu@gmail.com>
Author: Nan Zhu <CodingCat@users.noreply.github.com>
Author: Nan Zhu <nanzhu@uber.com>
Closes#19864 from CodingCat/SPARK-22673.
This change restores the functionality that keeps a limited number of
different types (jobs, stages, etc) depending on configuration, to avoid
the store growing indefinitely over time.
The feature is implemented by creating a new type (ElementTrackingStore)
that wraps a KVStore and allows triggers to be set up for when elements
of a certain type meet a certain threshold. Triggers don't need to
necessarily only delete elements, but the current API is set up in a way
that makes that use case easier.
The new store also has a trigger for the "close" call, which makes it
easier for listeners to register code for cleaning things up and flushing
partial state to the store.
The old configurations for cleaning up the stored elements from the core
and SQL UIs are now active again, and the old unit tests are re-enabled.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#19751 from vanzin/SPARK-20653.
## What changes were proposed in this pull request?
Test Coverage for `PromoteStrings` and `InConversion`, this is a Sub-tasks for [SPARK-22722](https://issues.apache.org/jira/browse/SPARK-22722).
## How was this patch tested?
N/A
Author: Yuming Wang <wgyumg@gmail.com>
Closes#20001 from wangyum/SPARK-22816.
## What changes were proposed in this pull request?
Basic tests for IfCoercion and CaseWhenCoercion
## How was this patch tested?
N/A
Author: Yuming Wang <wgyumg@gmail.com>
Closes#19949 from wangyum/SPARK-22762.
## What changes were proposed in this pull request?
Add a test suite to ensure all the [SSB (Star Schema Benchmark)](https://www.cs.umb.edu/~poneil/StarSchemaB.PDF) queries can be successfully analyzed, optimized and compiled without hitting the max iteration threshold.
## How was this patch tested?
Added `SSBQuerySuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#19990 from maropu/SPARK-22800.
## What changes were proposed in this pull request?
As the discussion in https://github.com/apache/spark/pull/16481 and https://github.com/apache/spark/pull/18975#discussion_r155454606
Currently the BaseRelation returned by `dataSource.writeAndRead` only used in `CreateDataSourceTableAsSelect`, planForWriting and writeAndRead has some common code paths.
In this patch I removed the writeAndRead function and added the getRelation function which only use in `CreateDataSourceTableAsSelectCommand` while saving data to non-existing table.
## How was this patch tested?
Existing UT
Author: Yuanjian Li <xyliyuanjian@gmail.com>
Closes#19941 from xuanyuanking/SPARK-22753.
## What changes were proposed in this pull request?
Add a test suite to ensure all the TPC-H queries can be successfully analyzed, optimized and compiled without hitting the max iteration threshold.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#19982 from gatorsmile/testTPCH.
## What changes were proposed in this pull request?
StreamExecution is now an abstract base class, which MicroBatchExecution (the current StreamExecution) inherits. When continuous processing is implemented, we'll have a new ContinuousExecution implementation of StreamExecution.
A few fields are also renamed to make them less microbatch-specific.
## How was this patch tested?
refactoring only
Author: Jose Torres <jose@databricks.com>
Closes#19926 from joseph-torres/continuous-refactor.
## What changes were proposed in this pull request?
In multiple text analysis problems, it is not often desirable for the rows to be split by "\n". There exists a wholeText reader for RDD API, and this JIRA just adds the same support for Dataset API.
## How was this patch tested?
Added relevant new tests for both scala and Java APIs
Author: Prashant Sharma <prashsh1@in.ibm.com>
Author: Prashant Sharma <prashant@apache.org>
Closes#14151 from ScrapCodes/SPARK-16496/wholetext.
## What changes were proposed in this pull request?
This PR adds check whether Java code generated by Catalyst can be compiled by `janino` correctly or not into `TPCDSQuerySuite`. Before this PR, this suite only checks whether analysis can be performed correctly or not.
This check will be able to avoid unexpected performance degrade by interpreter execution due to a Java compilation error.
## How was this patch tested?
Existing a test case, but updated it.
Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Closes#19971 from kiszk/SPARK-22774.
## What changes were proposed in this pull request?
`ColumnVector.anyNullsSet` is not called anywhere except tests, and we can easily replace it with `ColumnVector.numNulls > 0`
## How was this patch tested?
existing tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19980 from cloud-fan/minor.
## What changes were proposed in this pull request?
These dictionary related APIs are special to `WritableColumnVector` and should not be in `ColumnVector`, which will be public soon.
## How was this patch tested?
existing tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19970 from cloud-fan/final.
SQLConf allows some callers to define a custom default value for
configs, and that complicates a little bit the handling of fallback
config entries, since most of the default value resolution is
hidden by the config code.
This change peaks into the internals of these fallback configs
to figure out the correct default value, and also returns the
current human-readable default when showing the default value
(e.g. through "set -v").
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#19974 from vanzin/SPARK-22779.
## What changes were proposed in this pull request?
This PR provides DataSourceV2 API support for structured streaming, including new pieces needed to support continuous processing [SPARK-20928]. High level summary:
- DataSourceV2 includes new mixins to support micro-batch and continuous reads and writes. For reads, we accept an optional user specified schema rather than using the ReadSupportWithSchema model, because doing so would severely complicate the interface.
- DataSourceV2Reader includes new interfaces to read a specific microbatch or read continuously from a given offset. These follow the same setter pattern as the existing Supports* mixins so that they can work with SupportsScanUnsafeRow.
- DataReader (the per-partition reader) has a new subinterface ContinuousDataReader only for continuous processing. This reader has a special method to check progress, and next() blocks for new input rather than returning false.
- Offset, an abstract representation of position in a streaming query, is ported to the public API. (Each type of reader will define its own Offset implementation.)
- DataSourceV2Writer has a new subinterface ContinuousWriter only for continuous processing. Commits to this interface come tagged with an epoch number, as the execution engine will continue to produce new epoch commits as the task continues indefinitely.
Note that this PR does not propose to change the existing DataSourceV2 batch API, or deprecate the existing streaming source/sink internal APIs in spark.sql.execution.streaming.
## How was this patch tested?
Toy implementations of the new interfaces with unit tests.
Author: Jose Torres <jose@databricks.com>
Closes#19925 from joseph-torres/continuous-api.
## What changes were proposed in this pull request?
This pr fixed a compilation error of TPCDS `q75`/`q77` caused by #19813;
```
java.util.concurrent.ExecutionException: org.codehaus.commons.compiler.CompileException: File 'generated.java', Line 371, Column 16: failed to compile: org.codehaus.commons.compiler.CompileException: File 'generated.java', Line 371, Column 16: Expression "bhj_matched" is not an rvalue
at com.google.common.util.concurrent.AbstractFuture$Sync.getValue(AbstractFuture.java:306)
at com.google.common.util.concurrent.AbstractFuture$Sync.get(AbstractFuture.java:293)
at com.google.common.util.concurrent.AbstractFuture.get(AbstractFuture.java:116)
at com.google.common.util.concurrent.Uninterruptibles.getUninterruptibly(Uninterruptibles.java:135)
```
## How was this patch tested?
Manually checked `q75`/`q77` can be properly compiled
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#19969 from maropu/SPARK-22600-FOLLOWUP.
## What changes were proposed in this pull request?
See jira description for the bug : https://issues.apache.org/jira/browse/SPARK-22042
Fix done in this PR is: In `EnsureRequirements`, apply `ReorderJoinPredicates` over the input tree before doing its core logic. Since the tree is transformed bottom-up, we can assure that the children are resolved before doing `ReorderJoinPredicates`.
Theoretically this will guarantee to cover all such cases while keeping the code simple. My small grudge is for cosmetic reasons. This PR will look weird given that we don't call rules from other rules (not to my knowledge). I could have moved all the logic for `ReorderJoinPredicates` into `EnsureRequirements` but that will make it a but crowded. I am happy to discuss if there are better options.
## How was this patch tested?
Added a new test case
Author: Tejas Patil <tejasp@fb.com>
Closes#19257 from tejasapatil/SPARK-22042_ReorderJoinPredicates.
## What changes were proposed in this pull request?
We need to add some helper code to make testing ML transformers & models easier with streaming data. These tests might help us catch any remaining issues and we could encourage future PRs to use these tests to prevent new Models & Transformers from having issues.
I add a `MLTest` trait which extends `StreamTest` trait, and override `createSparkSession`. So ML testsuite can only extend `MLTest`, to use both ML & Stream test util functions.
I only modify one testcase in `LinearRegressionSuite`, for first pass review.
Link to #19746
## How was this patch tested?
`MLTestSuite` added.
Author: WeichenXu <weichen.xu@databricks.com>
Closes#19843 from WeichenXu123/ml_stream_test_helper.
## What changes were proposed in this pull request?
SPARK-22543 fixes the 64kb compile error for deeply nested expression for non-wholestage codegen. This PR extends it to support wholestage codegen.
This patch brings some util methods in to extract necessary parameters for an expression if it is split to a function.
The util methods are put in object `ExpressionCodegen` under `codegen`. The main entry is `getExpressionInputParams` which returns all necessary parameters to evaluate the given expression in a split function.
This util methods can be used to split expressions too. This is a TODO item later.
## How was this patch tested?
Added test.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#19813 from viirya/reduce-expr-code-for-wholestage.
## What changes were proposed in this pull request?
We have two methods to reference an object `addReferenceMinorObj` and `addReferenceObj `. The latter creates a new global variable, which means new entries in the constant pool.
The PR unifies the two method in a single `addReferenceObj` which returns the code to access the object in the `references` array and doesn't add new mutable states.
## How was this patch tested?
added UTs.
Author: Marco Gaido <mgaido@hortonworks.com>
Closes#19916 from mgaido91/SPARK-22716.
In order to enable truncate for PostgreSQL databases in Spark JDBC, a change is needed to the query used for truncating a PostgreSQL table. By default, PostgreSQL will automatically truncate any descendant tables if a TRUNCATE query is executed. As this may result in (unwanted) side-effects, the query used for the truncate should be specified separately for PostgreSQL, specifying only to TRUNCATE a single table.
## What changes were proposed in this pull request?
Add `getTruncateQuery` function to `JdbcDialect.scala`, with default query. Overridden this function for PostgreSQL to only truncate a single table. Also sets `isCascadingTruncateTable` to false, as this will allow truncates for PostgreSQL.
## How was this patch tested?
Existing tests all pass. Added test for `getTruncateQuery`
Author: Daniel van der Ende <daniel.vanderende@gmail.com>
Closes#19911 from danielvdende/SPARK-22717.
## What changes were proposed in this pull request?
In the previous PRs, https://github.com/apache/spark/pull/17832 and https://github.com/apache/spark/pull/17835 , we convert `TIMESTAMP WITH TIME ZONE` and `TIME WITH TIME ZONE` to `TIMESTAMP` for all the JDBC sources. However, this conversion could be risky since it does not respect our SQL configuration `spark.sql.session.timeZone`.
In addition, each vendor might have different semantics for these two types. For example, Postgres simply returns `TIMESTAMP` types for `TIMESTAMP WITH TIME ZONE`. For such supports, we should do it case by case. This PR reverts the general support of `TIMESTAMP WITH TIME ZONE` and `TIME WITH TIME ZONE` for JDBC sources, except ORACLE Dialect.
When supporting the ORACLE's `TIMESTAMP WITH TIME ZONE`, we only support it when the JVM default timezone is the same as the user-specified configuration `spark.sql.session.timeZone` (whose default is the JVM default timezone). Now, we still treat `TIMESTAMP WITH TIME ZONE` as `TIMESTAMP` when fetching the values via the Oracle JDBC connector, whose client converts the timestamp values with time zone to the timestamp values using the local JVM default timezone (a test case is added to `OracleIntegrationSuite.scala` in this PR for showing the behavior). Thus, to avoid any future behavior change, we will not support it if JVM default timezone is different from `spark.sql.session.timeZone`
No regression because the previous two PRs were just merged to be unreleased master branch.
## How was this patch tested?
Added the test cases
Author: gatorsmile <gatorsmile@gmail.com>
Closes#19939 from gatorsmile/timezoneUpdate.
## What changes were proposed in this pull request?
Before we deliver the Hive compatibility mode, we plan to write a set of test cases that can be easily run in both Spark and Hive sides. We can easily compare whether they are the same or not. When new typeCoercion rules are added, we also can easily track the changes. These test cases can also be backported to the previous Spark versions for determining the changes we made.
This PR is the first attempt for improving the test coverage for type coercion compatibility. We generate these test cases for our binary comparison and ImplicitTypeCasts based on the Apache Derby test cases in https://github.com/apache/derby/blob/10.14/java/testing/org/apache/derbyTesting/functionTests/tests/lang/implicitConversions.sql
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#19918 from gatorsmile/typeCoercionTests.
## What changes were proposed in this pull request?
During https://github.com/apache/spark/pull/19882, `conf` is mistakenly used to switch ORC implementation between `native` and `hive`. To affect `OrcTest` correctly, `spark.conf` should be used.
## How was this patch tested?
Pass the tests.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19931 from dongjoon-hyun/SPARK-22672-2.
## What changes were proposed in this pull request?
Int96 data written by impala vs data written by hive & spark is stored slightly differently -- they use a different offset for the timezone. This adds an option "spark.sql.parquet.int96TimestampConversion" (false by default) to adjust timestamps if and only if the writer is impala (or more precisely, if the parquet file's "createdBy" metadata does not start with "parquet-mr"). This matches the existing behavior in hive from HIVE-9482.
## How was this patch tested?
Unit test added, existing tests run via jenkins.
Author: Imran Rashid <irashid@cloudera.com>
Author: Henry Robinson <henry@apache.org>
Closes#19769 from squito/SPARK-12297_skip_conversion.
## What changes were proposed in this pull request?
#19416 changed the format in which rows were encoded in the state store. However, this can break existing streaming queries with the old format in unpredictable ways (potentially crashing the JVM). Hence I am reverting this for now. This will be re-applied in the future after we start saving more metadata in checkpoints to signify which version of state row format the existing streaming query is running. Then we can decode old and new formats accordingly.
## How was this patch tested?
Existing tests.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#19924 from tdas/SPARK-22187-1.
## What changes were proposed in this pull request?
This PR support for pushing down filters for DateType in ORC
## How was this patch tested?
Pass the Jenkins with newly add and updated test cases.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#18995 from dongjoon-hyun/SPARK-21787.
…a-2.12 and JDK9
## What changes were proposed in this pull request?
Some compile error after upgrading to scala-2.12
```javascript
spark_source/core/src/main/scala/org/apache/spark/executor/Executor.scala:455: ambiguous reference to overloaded definition, method limit in class ByteBuffer of type (x$1: Int)java.nio.ByteBuffer
method limit in class Buffer of type ()Int
match expected type ?
val resultSize = serializedDirectResult.limit
error
```
The limit method was moved from ByteBuffer to the superclass Buffer and it can no longer be called without (). The same reason for position method.
```javascript
/home/zly/prj/oss/jdk9_HOS_SOURCE/spark_source/sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/ScriptTransformationExec.scala:427: ambiguous reference to overloaded definition, [error] both method putAll in class Properties of type (x$1: java.util.Map[_, _])Unit [error] and method putAll in class Hashtable of type (x$1: java.util.Map[_ <: Object, _ <: Object])Unit [error] match argument types (java.util.Map[String,String])
[error] props.putAll(outputSerdeProps.toMap.asJava)
[error] ^
```
This is because the key type is Object instead of String which is unsafe.
## How was this patch tested?
running tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: kellyzly <kellyzly@126.com>
Closes#19854 from kellyzly/SPARK-22660.
## What changes were proposed in this pull request?
To support vectorization in native OrcFileFormat later, we need to use `buildReaderWithPartitionValues` instead of `buildReader` like ParquetFileFormat. This PR replaces `buildReader` with `buildReaderWithPartitionValues`.
## How was this patch tested?
Pass the Jenkins with the existing test cases.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19907 from dongjoon-hyun/SPARK-ORC-BUILD-READER.
- Implemented methods getInt, getLong, getBoolean for DataSourceV2Options
- Added new unit tests to exercise these methods
Author: Sunitha Kambhampati <skambha@us.ibm.com>
Closes#19902 from skambha/spark22452.
## What changes were proposed in this pull request?
Similar to https://github.com/apache/spark/pull/19842 , we should also make `ColumnarRow` an immutable view, and move forward to make `ColumnVector` public.
## How was this patch tested?
Existing tests.
The performance concern should be same as https://github.com/apache/spark/pull/19842 .
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19898 from cloud-fan/row-id.
## What changes were proposed in this pull request?
Since SPARK-20682, we have two `OrcFileFormat`s. This PR refactors ORC tests with three principles (with a few exceptions)
1. Move test suite into `sql/core`.
2. Create `HiveXXX` test suite in `sql/hive` by reusing `sql/core` test suite.
3. `OrcTest` will provide common helper functions and `val orcImp: String`.
**Test Suites**
*Native OrcFileFormat*
- org.apache.spark.sql.hive.orc
- OrcFilterSuite
- OrcPartitionDiscoverySuite
- OrcQuerySuite
- OrcSourceSuite
- o.a.s.sql.hive.orc
- OrcHadoopFsRelationSuite
*Hive built-in OrcFileFormat*
- o.a.s.sql.hive.orc
- HiveOrcFilterSuite
- HiveOrcPartitionDiscoverySuite
- HiveOrcQuerySuite
- HiveOrcSourceSuite
- HiveOrcHadoopFsRelationSuite
**Hierarchy**
```
OrcTest
-> OrcSuite
-> OrcSourceSuite
-> OrcQueryTest
-> OrcQuerySuite
-> OrcPartitionDiscoveryTest
-> OrcPartitionDiscoverySuite
-> OrcFilterSuite
HadoopFsRelationTest
-> OrcHadoopFsRelationSuite
-> HiveOrcHadoopFsRelationSuite
```
Please note the followings.
- Unlike the other test suites, `OrcHadoopFsRelationSuite` doesn't inherit `OrcTest`. It is inside `sql/hive` like `ParquetHadoopFsRelationSuite` due to the dependencies and follows the existing convention to use `val dataSourceName: String`
- `OrcFilterSuite`s cannot reuse test cases due to the different function signatures using Hive 1.2.1 ORC classes and Apache ORC 1.4.1 classes.
## How was this patch tested?
Pass the Jenkins tests with reorganized test suites.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19882 from dongjoon-hyun/SPARK-22672.
## What changes were proposed in this pull request?
There was a bug in Univocity Parser that causes the issue in SPARK-22516. This was fixed by upgrading from 2.5.4 to 2.5.9 version of the library :
**Executing**
```
spark.read.option("header","true").option("inferSchema", "true").option("multiLine", "true").option("comment", "g").csv("test_file_without_eof_char.csv").show()
```
**Before**
```
ERROR Executor: Exception in task 0.0 in stage 6.0 (TID 6)
com.univocity.parsers.common.TextParsingException: java.lang.IllegalArgumentException - Unable to skip 1 lines from line 2. End of input reached
...
Internal state when error was thrown: line=3, column=0, record=2, charIndex=31
at com.univocity.parsers.common.AbstractParser.handleException(AbstractParser.java:339)
at com.univocity.parsers.common.AbstractParser.parseNext(AbstractParser.java:475)
at org.apache.spark.sql.execution.datasources.csv.UnivocityParser$$anon$1.next(UnivocityParser.scala:281)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:409)
```
**After**
```
+-------+-------+
|column1|column2|
+-------+-------+
| abc| def|
+-------+-------+
```
## How was this patch tested?
The already existing `CSVSuite.commented lines in CSV data` test was extended to parse the file also in multiline mode. The test input file was modified to also include a comment in the last line.
Author: smurakozi <smurakozi@gmail.com>
Closes#19906 from smurakozi/SPARK-22516.
## What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/19871 to improve an exception message.
## How was this patch tested?
Pass the Jenkins.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19903 from dongjoon-hyun/orc_exception.
## What changes were proposed in this pull request?
The SQL `Analyzer` goes through a whole query plan even most part of it is analyzed. This increases the time spent on query analysis for long pipelines in ML, especially.
This patch adds a logical node called `AnalysisBarrier` that wraps an analyzed logical plan to prevent it from analysis again. The barrier is applied to the analyzed logical plan in `Dataset`. It won't change the output of wrapped logical plan and just acts as a wrapper to hide it from analyzer. New operations on the dataset will be put on the barrier, so only the new nodes created will be analyzed.
This analysis barrier will be removed at the end of analysis stage.
## How was this patch tested?
Added tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#19873 from viirya/SPARK-20392-reopen.
## What changes were proposed in this pull request?
During [SPARK-22488](https://github.com/apache/spark/pull/19713) to fix view resolution issue, there occurs a regression at `2.2.1` and `master` branch like the following. This PR fixes that.
```scala
scala> spark.version
res2: String = 2.2.1
scala> sql("DROP TABLE IF EXISTS t").show
17/12/04 21:01:06 WARN DropTableCommand: org.apache.spark.sql.AnalysisException:
Table or view not found: t;
org.apache.spark.sql.AnalysisException: Table or view not found: t;
```
## How was this patch tested?
Manual.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19888 from dongjoon-hyun/SPARK-22686.
## What changes were proposed in this pull request?
This PR aims to provide a configuration to choose the default `OrcFileFormat` from legacy `sql/hive` module or new `sql/core` module.
For example, this configuration will affects the following operations.
```scala
spark.read.orc(...)
```
```sql
CREATE TABLE t
USING ORC
...
```
## How was this patch tested?
Pass the Jenkins with new test suites.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19871 from dongjoon-hyun/spark-sql-orc-enabled.
## What changes were proposed in this pull request?
PropagateTypes are called twice in TypeCoercion. We do not need to call it twice. Instead, we should call it after each change on the types.
## How was this patch tested?
The existing tests
Author: gatorsmile <gatorsmile@gmail.com>
Closes#19874 from gatorsmile/deduplicatePropagateTypes.
## What changes were proposed in this pull request?
The `HashAggregateExec` whole stage codegen path is a little messy and hard to understand, this code cleans it up a little bit, especially for the fast hash map part.
## How was this patch tested?
existing tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19869 from cloud-fan/hash-agg.
## What changes were proposed in this pull request?
Since [SPARK-2883](https://issues.apache.org/jira/browse/SPARK-2883), Apache Spark supports Apache ORC inside `sql/hive` module with Hive dependency. This PR aims to add a new ORC data source inside `sql/core` and to replace the old ORC data source eventually. This PR resolves the following three issues.
- [SPARK-20682](https://issues.apache.org/jira/browse/SPARK-20682): Add new ORCFileFormat based on Apache ORC 1.4.1
- [SPARK-15474](https://issues.apache.org/jira/browse/SPARK-15474): ORC data source fails to write and read back empty dataframe
- [SPARK-21791](https://issues.apache.org/jira/browse/SPARK-21791): ORC should support column names with dot
## How was this patch tested?
Pass the Jenkins with the existing all tests and new tests for SPARK-15474 and SPARK-21791.
Author: Dongjoon Hyun <dongjoon@apache.org>
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19651 from dongjoon-hyun/SPARK-20682.
## What changes were proposed in this pull request?
Use a separate Spark event queue for StreamingQueryListenerBus so that if there are many non-streaming events, streaming query listeners don't need to wait for other Spark listeners and can catch up.
## How was this patch tested?
Jenkins
Author: Shixiong Zhu <zsxwing@gmail.com>
Closes#19838 from zsxwing/SPARK-22638.
## What changes were proposed in this pull request?
When user tries to load data with a non existing hdfs file path system is not validating it and the load command operation is getting successful.
This is misleading to the user. already there is a validation in the scenario of none existing local file path. This PR has added validation in the scenario of nonexisting hdfs file path
## How was this patch tested?
UT has been added for verifying the issue, also snapshots has been added after the verification in a spark yarn cluster
Author: sujith71955 <sujithchacko.2010@gmail.com>
Closes#19823 from sujith71955/master_LoadComand_Issue.
## What changes were proposed in this pull request?
This PR introduces a way to explicitly range-partition a Dataset. So far, only round-robin and hash partitioning were possible via `df.repartition(...)`, but sometimes range partitioning might be desirable: e.g. when writing to disk, for better compression without the cost of global sort.
The current implementation piggybacks on the existing `RepartitionByExpression` `LogicalPlan` and simply adds the following logic: If its expressions are of type `SortOrder`, then it will do `RangePartitioning`; otherwise `HashPartitioning`. This was by far the least intrusive solution I could come up with.
## How was this patch tested?
Unit test for `RepartitionByExpression` changes, a test to ensure we're not changing the behavior of existing `.repartition()` and a few end-to-end tests in `DataFrameSuite`.
Author: Adrian Ionescu <adrian@databricks.com>
Closes#19828 from adrian-ionescu/repartitionByRange.
## What changes were proposed in this pull request?
How to reproduce:
```scala
import org.apache.spark.sql.execution.joins.BroadcastHashJoinExec
spark.createDataFrame(Seq((1, "4"), (2, "2"))).toDF("key", "value").createTempView("table1")
spark.createDataFrame(Seq((1, "1"), (2, "2"))).toDF("key", "value").createTempView("table2")
val bl = sql("SELECT /*+ MAPJOIN(t1) */ * FROM table1 t1 JOIN table2 t2 ON t1.key = t2.key").queryExecution.executedPlan
println(bl.children.head.asInstanceOf[BroadcastHashJoinExec].buildSide)
```
The result is `BuildRight`, but should be `BuildLeft`. This PR fix this issue.
## How was this patch tested?
unit tests
Author: Yuming Wang <wgyumg@gmail.com>
Closes#19714 from wangyum/SPARK-22489.
## What changes were proposed in this pull request?
To make `ColumnVector` public, `ColumnarArray` need to be public too, and we should not have mutable public fields in a public class. This PR proposes to make `ColumnarArray` an immutable view of the data, and always create a new instance of `ColumnarArray` in `ColumnVector#getArray`
## How was this patch tested?
new benchmark in `ColumnarBatchBenchmark`
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19842 from cloud-fan/column-vector.
## What changes were proposed in this pull request?
As a step to make `ColumnVector` public, the `ColumnarRow` returned by `ColumnVector#getStruct` should be immutable.
However we do need the mutability of `ColumnaRow` for the fast vectorized hashmap in hash aggregate. To solve this, this PR introduces a `MutableColumnarRow` for this use case.
## How was this patch tested?
existing test.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19847 from cloud-fan/mutable-row.
## What changes were proposed in this pull request?
Currently, in the optimize rule `PropagateEmptyRelation`, the following cases is not handled:
1. empty relation as right child in left outer join
2. empty relation as left child in right outer join
3. empty relation as right child in left semi join
4. empty relation as right child in left anti join
5. only one empty relation in full outer join
case 1 / 2 / 5 can be treated as **Cartesian product** and cause exception. See the new test cases.
## How was this patch tested?
Unit test
Author: Wang Gengliang <ltnwgl@gmail.com>
Closes#19825 from gengliangwang/SPARK-22615.
## What changes were proposed in this pull request?
For SQL write jobs, we only set metrics for the SQL listener and display them in the SQL plan UI. We should also set metrics for Spark task output metrics, which will be shown in spark job UI.
## How was this patch tested?
test it manually. For a simple write job
```
spark.range(1000).write.parquet("/tmp/p1")
```
now the spark job UI looks like

Author: Wenchen Fan <wenchen@databricks.com>
Closes#19833 from cloud-fan/ui.
## What changes were proposed in this pull request?
`CatalogImpl.refreshTable` uses `foreach(..)` to refresh all tables in a view. This traverses all nodes in the subtree and calls `LogicalPlan.refresh()` on these nodes. However `LogicalPlan.refresh()` is also refreshing its children, as a result refreshing a large view can be quite expensive.
This PR just calls `LogicalPlan.refresh()` on the top node.
## How was this patch tested?
Existing tests.
Author: Herman van Hovell <hvanhovell@databricks.com>
Closes#19837 from hvanhovell/SPARK-22637.
## What changes were proposed in this pull request?
* JIRA: [SPARK-22431](https://issues.apache.org/jira/browse/SPARK-22431) : Creating Permanent view with illegal type
**Description:**
- It is possible in Spark SQL to create a permanent view that uses an nested field with an illegal name.
- For example if we create the following view:
```create view x as select struct('a' as `$q`, 1 as b) q```
- A simple select fails with the following exception:
```
select * from x;
org.apache.spark.SparkException: Cannot recognize hive type string: struct<$q:string,b:int>
at org.apache.spark.sql.hive.client.HiveClientImpl$.fromHiveColumn(HiveClientImpl.scala:812)
at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$getTableOption$1$$anonfun$apply$11$$anonfun$7.apply(HiveClientImpl.scala:378)
at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$getTableOption$1$$anonfun$apply$11$$anonfun$7.apply(HiveClientImpl.scala:378)
...
```
**Issue/Analysis**: Right now, we can create a view with a schema that cannot be read back by Spark from the Hive metastore. For more details, please see the discussion about the analysis and proposed fix options in comment 1 and comment 2 in the [SPARK-22431](https://issues.apache.org/jira/browse/SPARK-22431)
**Proposed changes**:
- Fix the hive table/view codepath to check whether the schema datatype is parseable by Spark before persisting it in the metastore. This change is localized to HiveClientImpl to do the check similar to the check in FromHiveColumn. This is fail-fast and we will avoid the scenario where we write something to the metastore that we are unable to read it back.
- Added new unit tests
- Ran the sql related unit test suites ( hive/test, sql/test, catalyst/test) OK
With the fix:
```
create view x as select struct('a' as `$q`, 1 as b) q;
17/11/28 10:44:55 ERROR SparkSQLDriver: Failed in [create view x as select struct('a' as `$q`, 1 as b) q]
org.apache.spark.SparkException: Cannot recognize hive type string: struct<$q:string,b:int>
at org.apache.spark.sql.hive.client.HiveClientImpl$.org$apache$spark$sql$hive$client$HiveClientImpl$$getSparkSQLDataType(HiveClientImpl.scala:884)
at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$org$apache$spark$sql$hive$client$HiveClientImpl$$verifyColumnDataType$1.apply(HiveClientImpl.scala:906)
at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$org$apache$spark$sql$hive$client$HiveClientImpl$$verifyColumnDataType$1.apply(HiveClientImpl.scala:906)
at scala.collection.Iterator$class.foreach(Iterator.scala:893)
...
```
## How was this patch tested?
- New unit tests have been added.
hvanhovell, Please review and share your thoughts/comments. Thank you so much.
Author: Sunitha Kambhampati <skambha@us.ibm.com>
Closes#19747 from skambha/spark22431.
## What changes were proposed in this pull request?
Currently, relation size is computed as the sum of file size, which is error-prone because storage format like parquet may have a much smaller file size compared to in-memory size. When we choose broadcast join based on file size, there's a risk of OOM. But if the number of rows is available in statistics, we can get a better estimation by `numRows * rowSize`, which helps to alleviate this problem.
## How was this patch tested?
Added a new test case for data source table and hive table.
Author: Zhenhua Wang <wzh_zju@163.com>
Author: Zhenhua Wang <wangzhenhua@huawei.com>
Closes#19743 from wzhfy/better_leaf_size.
## What changes were proposed in this pull request?
When converting Pandas DataFrame/Series from/to Spark DataFrame using `toPandas()` or pandas udfs, timestamp values behave to respect Python system timezone instead of session timezone.
For example, let's say we use `"America/Los_Angeles"` as session timezone and have a timestamp value `"1970-01-01 00:00:01"` in the timezone. Btw, I'm in Japan so Python timezone would be `"Asia/Tokyo"`.
The timestamp value from current `toPandas()` will be the following:
```
>>> spark.conf.set("spark.sql.session.timeZone", "America/Los_Angeles")
>>> df = spark.createDataFrame([28801], "long").selectExpr("timestamp(value) as ts")
>>> df.show()
+-------------------+
| ts|
+-------------------+
|1970-01-01 00:00:01|
+-------------------+
>>> df.toPandas()
ts
0 1970-01-01 17:00:01
```
As you can see, the value becomes `"1970-01-01 17:00:01"` because it respects Python timezone.
As we discussed in #18664, we consider this behavior is a bug and the value should be `"1970-01-01 00:00:01"`.
## How was this patch tested?
Added tests and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#19607 from ueshin/issues/SPARK-22395.
## What changes were proposed in this pull request?
In PySpark API Document, DataFrame.write.csv() says that setting the quote parameter to an empty string should turn off quoting. Instead, it uses the [null character](https://en.wikipedia.org/wiki/Null_character) as the quote.
This PR fixes the doc.
## How was this patch tested?
Manual.
```
cd python/docs
make html
open _build/html/pyspark.sql.html
```
Author: gaborgsomogyi <gabor.g.somogyi@gmail.com>
Closes#19814 from gaborgsomogyi/SPARK-22484.
## What changes were proposed in this pull request?
Code generation is disabled for CaseWhen when the number of branches is higher than `spark.sql.codegen.maxCaseBranches` (which defaults to 20). This was done to prevent the well known 64KB method limit exception.
This PR proposes to support code generation also in those cases (without causing exceptions of course). As a side effect, we could get rid of the `spark.sql.codegen.maxCaseBranches` configuration.
## How was this patch tested?
existing UTs
Author: Marco Gaido <mgaido@hortonworks.com>
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#19752 from mgaido91/SPARK-22520.
## What changes were proposed in this pull request?
Currently, relation stats is the same whether cbo is enabled or not. While relation (`LogicalRelation` or `HiveTableRelation`) is a `LogicalPlan`, its behavior is inconsistent with other plans. This can cause confusion when user runs EXPLAIN COST commands. Besides, when CBO is disabled, we apply the size-only estimation strategy, so there's no need to propagate other catalog statistics to relation.
## How was this patch tested?
Enhanced existing tests case and added a test case.
Author: Zhenhua Wang <wangzhenhua@huawei.com>
Closes#19757 from wzhfy/catalog_stats_conversion.
## What changes were proposed in this pull request?
`ColumnVector#loadBytes` is only used as an optimization for reading UTF8String in `WritableColumnVector`, this PR moves this optimization to `WritableColumnVector` and simplified it.
## How was this patch tested?
existing test
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19815 from cloud-fan/load-bytes.
## What changes were proposed in this pull request?
`nullsNativeAddress` and `valuesNativeAddress` are only used in tests and benchmark, no need to be top class API.
## How was this patch tested?
existing tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19818 from cloud-fan/minor.
## What changes were proposed in this pull request?
`ctx.currentVars` means the input variables for the current operator, which is already decided in `CodegenSupport`, we can set it there instead of `doConsume`.
also add more comments to help people understand the codegen framework.
After this PR, we now have a principle about setting `ctx.currentVars` and `ctx.INPUT_ROW`:
1. for non-whole-stage-codegen path, never set them. (permit some special cases like generating ordering)
2. for whole-stage-codegen `produce` path, mostly we don't need to set them, but blocking operators may need to set them for expressions that produce data from data source, sort buffer, aggregate buffer, etc.
3. for whole-stage-codegen `consume` path, mostly we don't need to set them because `currentVars` is automatically set to child input variables and `INPUT_ROW` is mostly not used. A few plans need to tweak them as they may have different inputs, or they use the input row.
## How was this patch tested?
existing tests.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19803 from cloud-fan/codegen.
## What changes were proposed in this pull request?
A frequently reported issue of Spark is the Java 64kb compile error. This is because Spark generates a very big method and it's usually caused by 3 reasons:
1. a deep expression tree, e.g. a very complex filter condition
2. many individual expressions, e.g. expressions can have many children, operators can have many expressions.
3. a deep query plan tree (with whole stage codegen)
This PR focuses on 1. There are already several patches(#15620#18972#18641) trying to fix this issue and some of them are already merged. However this is an endless job as every non-leaf expression has this issue.
This PR proposes to fix this issue in `Expression.genCode`, to make sure the code for a single expression won't grow too big.
According to maropu 's benchmark, no regression is found with TPCDS (thanks maropu !): https://docs.google.com/spreadsheets/d/1K3_7lX05-ZgxDXi9X_GleNnDjcnJIfoSlSCDZcL4gdg/edit?usp=sharing
## How was this patch tested?
existing test
Author: Wenchen Fan <wenchen@databricks.com>
Author: Wenchen Fan <cloud0fan@gmail.com>
Closes#19767 from cloud-fan/codegen.
## What changes were proposed in this pull request?
Let’s say I have a nested AND expression shown below and p2 can not be pushed down,
(p1 AND p2) OR p3
In current Spark code, during data source filter translation, (p1 AND p2) is returned as p1 only and p2 is simply lost. This issue occurs with JDBC data source and is similar to [SPARK-12218](https://github.com/apache/spark/pull/10362) for Parquet. When we have AND nested below another expression, we should either push both legs or nothing.
Note that:
- The current Spark code will always split conjunctive predicate before it determines if a predicate can be pushed down or not
- If I have (p1 AND p2) AND p3, it will be split into p1, p2, p3. There won't be nested AND expression.
- The current Spark code logic for OR is OK. It either pushes both legs or nothing.
The same translation method is also called by Data Source V2.
## How was this patch tested?
Added new unit test cases to JDBCSuite
gatorsmile
Author: Jia Li <jiali@us.ibm.com>
Closes#19776 from jliwork/spark-22548.
## What changes were proposed in this pull request?
Added the histogram representation to the output of the `DESCRIBE EXTENDED table_name column_name` command.
## How was this patch tested?
Modified SQL UT and checked output
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Marco Gaido <mgaido@hortonworks.com>
Closes#19774 from mgaido91/SPARK-22475.
## What changes were proposed in this pull request?
This PR is to clean the usage of addMutableState and splitExpressions
1. replace hardcoded type string to ctx.JAVA_BOOLEAN etc.
2. create a default value of the initCode for ctx.addMutableStats
3. Use named arguments when calling `splitExpressions `
## How was this patch tested?
The existing test cases
Author: gatorsmile <gatorsmile@gmail.com>
Closes#19790 from gatorsmile/codeClean.
This PR enables to use ``OffHeapColumnVector`` when ``spark.sql.columnVector.offheap.enable`` is set to ``true``. While ``ColumnVector`` has two implementations ``OnHeapColumnVector`` and ``OffHeapColumnVector``, only ``OnHeapColumnVector`` is always used.
This PR implements the followings
- Pass ``OffHeapColumnVector`` to ``ColumnarBatch.allocate()`` when ``spark.sql.columnVector.offheap.enable`` is set to ``true``
- Free all of off-heap memory regions by ``OffHeapColumnVector.close()``
- Ensure to call ``OffHeapColumnVector.close()``
Use existing tests
Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Closes#17436 from kiszk/SPARK-20101.
## What changes were proposed in this pull request?
ScalaTest 3.0 uses an implicit `Signaler`. This PR makes it sure all Spark tests uses `ThreadSignaler` explicitly which has the same default behavior of interrupting a thread on the JVM like ScalaTest 2.2.x. This will reduce potential flakiness.
## How was this patch tested?
This is testsuite-only update. This should passes the Jenkins tests.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19784 from dongjoon-hyun/use_thread_signaler.
## What changes were proposed in this pull request?
Pass the FileSystem created using the correct Hadoop conf into `globPathIfNecessary` so that it can pick up user's hadoop configurations, such as credentials.
## How was this patch tested?
Jenkins
Author: Shixiong Zhu <zsxwing@gmail.com>
Closes#19771 from zsxwing/fix-file-stream-conf.
## What changes were proposed in this pull request?
* Add a "function type" argument to pandas_udf.
* Add a new public enum class `PandasUdfType` in pyspark.sql.functions
* Refactor udf related code from pyspark.sql.functions to pyspark.sql.udf
* Merge "PythonUdfType" and "PythonEvalType" into a single enum class "PythonEvalType"
Example:
```
from pyspark.sql.functions import pandas_udf, PandasUDFType
pandas_udf('double', PandasUDFType.SCALAR):
def plus_one(v):
return v + 1
```
## Design doc
https://docs.google.com/document/d/1KlLaa-xJ3oz28xlEJqXyCAHU3dwFYkFs_ixcUXrJNTc/edit
## How was this patch tested?
Added PandasUDFTests
## TODO:
* [x] Implement proper enum type for `PandasUDFType`
* [x] Update documentation
* [x] Add more tests in PandasUDFTests
Author: Li Jin <ice.xelloss@gmail.com>
Closes#19630 from icexelloss/spark-22409-pandas-udf-type.
## What changes were proposed in this pull request?
`ColumnarBatch` provides features to do fast filter and project in a columnar fashion, however this feature is never used by Spark, as Spark uses whole stage codegen and processes the data in a row fashion. This PR proposes to remove these unused features as we won't switch to columnar execution in the near future. Even we do, I think this part needs a proper redesign.
This is also a step to make `ColumnVector` public, as we don't wanna expose these features to users.
## How was this patch tested?
existing tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19766 from cloud-fan/vector.
## What changes were proposed in this pull request?
Do not include jdbc properties which may contain credentials in logging a logical plan with `SaveIntoDataSourceCommand` in it.
## How was this patch tested?
building locally and trying to reproduce (per the steps in https://issues.apache.org/jira/browse/SPARK-22479):
```
== Parsed Logical Plan ==
SaveIntoDataSourceCommand org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider570127fa, Map(dbtable -> test20, driver -> org.postgresql.Driver, url -> *********(redacted), password -> *********(redacted)), ErrorIfExists
+- Range (0, 100, step=1, splits=Some(8))
== Analyzed Logical Plan ==
SaveIntoDataSourceCommand org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider570127fa, Map(dbtable -> test20, driver -> org.postgresql.Driver, url -> *********(redacted), password -> *********(redacted)), ErrorIfExists
+- Range (0, 100, step=1, splits=Some(8))
== Optimized Logical Plan ==
SaveIntoDataSourceCommand org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider570127fa, Map(dbtable -> test20, driver -> org.postgresql.Driver, url -> *********(redacted), password -> *********(redacted)), ErrorIfExists
+- Range (0, 100, step=1, splits=Some(8))
== Physical Plan ==
Execute SaveIntoDataSourceCommand
+- SaveIntoDataSourceCommand org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider570127fa, Map(dbtable -> test20, driver -> org.postgresql.Driver, url -> *********(redacted), password -> *********(redacted)), ErrorIfExists
+- Range (0, 100, step=1, splits=Some(8))
```
Author: osatici <osatici@palantir.com>
Closes#19708 from onursatici/os/redact-jdbc-creds.
## What changes were proposed in this pull request?
This fixes a problem caused by #15880
`select '1.5' > 0.5; // Result is NULL in Spark but is true in Hive.
`
When compare string and numeric, cast them as double like Hive.
Author: liutang123 <liutang123@yeah.net>
Closes#19692 from liutang123/SPARK-22469.
## What changes were proposed in this pull request?
Logically the `Array` doesn't belong to `ColumnVector`, and `Row` doesn't belong to `ColumnarBatch`. e.g. `ColumnVector` needs to return `Array` for `getArray`, and `Row` for `getStruct`. `Array` and `Row` can return each other with the `getArray`/`getStruct` methods.
This is also a step to make `ColumnVector` public, it's cleaner to have `Array` and `Row` as top-level classes.
This PR is just code moving around, with 2 renaming: `Array` -> `VectorBasedArray`, `Row` -> `VectorBasedRow`.
## How was this patch tested?
existing tests.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19740 from cloud-fan/vector.
This change replaces the SQLListener with a new implementation that
saves the data to the same store used by the SparkContext's status
store. For that, the types used by the old SQLListener had to be
updated a bit so that they're more serialization-friendly.
The interface for getting data from the store was abstracted into
a new class, SQLAppStatusStore (following the convention used in
core).
Another change is the way that the SQL UI hooks up into the core
UI or the SHS. The old "SparkHistoryListenerFactory" was replaced
with a new "AppStatePlugin" that more explicitly differentiates
between the two use cases: processing events, and showing the UI.
Both live apps and the SHS use this new API (previously, it was
restricted to the SHS).
Note on the above: this causes a slight change of behavior for
live apps; the SQL tab will only show up after the first execution
is started.
The metrics gathering code was re-worked a bit so that the types
used are less memory hungry and more serialization-friendly. This
reduces memory usage when using in-memory stores, and reduces load
times when using disk stores.
Tested with existing and added unit tests. Note one unit test was
disabled because it depends on SPARK-20653, which isn't in yet.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#19681 from vanzin/SPARK-20652.
## What changes were proposed in this pull request?
Equi-height histogram is effective in cardinality estimation, and more accurate than basic column stats (min, max, ndv, etc) especially in skew distribution. So we need to support it.
For equi-height histogram, all buckets (intervals) have the same height (frequency).
In this PR, we use a two-step method to generate an equi-height histogram:
1. use `ApproximatePercentile` to get percentiles `p(0), p(1/n), p(2/n) ... p((n-1)/n), p(1)`;
2. construct range values of buckets, e.g. `[p(0), p(1/n)], [p(1/n), p(2/n)] ... [p((n-1)/n), p(1)]`, and use `ApproxCountDistinctForIntervals` to count ndv in each bucket. Each bucket is of the form: `(lowerBound, higherBound, ndv)`.
## How was this patch tested?
Added new test cases and modified some existing test cases.
Author: Zhenhua Wang <wangzhenhua@huawei.com>
Author: Zhenhua Wang <wzh_zju@163.com>
Closes#19479 from wzhfy/generate_histogram.
## What changes were proposed in this pull request?
There is a concern that Spark-side codegen row-by-row filtering might be faster than Parquet's one in general due to type-boxing and additional fuction calls which Spark's one tries to avoid.
So, this PR adds an option to disable/enable record-by-record filtering in Parquet side.
It sets the default to `false` to take the advantage of the improvement.
This was also discussed in https://github.com/apache/spark/pull/14671.
## How was this patch tested?
Manually benchmarks were performed. I generated a billion (1,000,000,000) records and tested equality comparison concatenated with `OR`. This filter combinations were made from 5 to 30.
It seem indeed Spark-filtering is faster in the test case and the gap increased as the filter tree becomes larger.
The details are as below:
**Code**
``` scala
test("Parquet-side filter vs Spark-side filter - record by record") {
withTempPath { path =>
val N = 1000 * 1000 * 1000
val df = spark.range(N).toDF("a")
df.write.parquet(path.getAbsolutePath)
val benchmark = new Benchmark("Parquet-side vs Spark-side", N)
Seq(5, 10, 20, 30).foreach { num =>
val filterExpr = (0 to num).map(i => s"a = $i").mkString(" OR ")
benchmark.addCase(s"Parquet-side filter - number of filters [$num]", 3) { _ =>
withSQLConf(SQLConf.PARQUET_VECTORIZED_READER_ENABLED.key -> false.toString,
SQLConf.PARQUET_RECORD_FILTER_ENABLED.key -> true.toString) {
// We should strip Spark-side filter to compare correctly.
stripSparkFilter(
spark.read.parquet(path.getAbsolutePath).filter(filterExpr)).count()
}
}
benchmark.addCase(s"Spark-side filter - number of filters [$num]", 3) { _ =>
withSQLConf(SQLConf.PARQUET_VECTORIZED_READER_ENABLED.key -> false.toString,
SQLConf.PARQUET_RECORD_FILTER_ENABLED.key -> false.toString) {
spark.read.parquet(path.getAbsolutePath).filter(filterExpr).count()
}
}
}
benchmark.run()
}
}
```
**Result**
```
Parquet-side vs Spark-side: Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------
Parquet-side filter - number of filters [5] 4268 / 4367 234.3 4.3 0.8X
Spark-side filter - number of filters [5] 3709 / 3741 269.6 3.7 0.9X
Parquet-side filter - number of filters [10] 5673 / 5727 176.3 5.7 0.6X
Spark-side filter - number of filters [10] 3588 / 3632 278.7 3.6 0.9X
Parquet-side filter - number of filters [20] 8024 / 8440 124.6 8.0 0.4X
Spark-side filter - number of filters [20] 3912 / 3946 255.6 3.9 0.8X
Parquet-side filter - number of filters [30] 11936 / 12041 83.8 11.9 0.3X
Spark-side filter - number of filters [30] 3929 / 3978 254.5 3.9 0.8X
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#15049 from HyukjinKwon/SPARK-17310.
## What changes were proposed in this pull request?
This change uses Arrow to optimize the creation of a Spark DataFrame from a Pandas DataFrame. The input df is sliced according to the default parallelism. The optimization is enabled with the existing conf "spark.sql.execution.arrow.enabled" and is disabled by default.
## How was this patch tested?
Added new unit test to create DataFrame with and without the optimization enabled, then compare results.
Author: Bryan Cutler <cutlerb@gmail.com>
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#19459 from BryanCutler/arrow-createDataFrame-from_pandas-SPARK-20791.
## What changes were proposed in this pull request?
This PR changes `AND` or `OR` code generation to place condition and then expressions' generated code into separated methods if these size could be large. When the method is newly generated, variables for `isNull` and `value` are declared as an instance variable to pass these values (e.g. `isNull1409` and `value1409`) to the callers of the generated method.
This PR resolved two cases:
* large code size of left expression
* large code size of right expression
## How was this patch tested?
Added a new test case into `CodeGenerationSuite`
Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Closes#18972 from kiszk/SPARK-21720.
## What changes were proposed in this pull request?
This PR makes Spark to be able to read Parquet TIMESTAMP_MICROS values, and add a new config to allow Spark to write timestamp values to parquet as TIMESTAMP_MICROS type.
## How was this patch tested?
new test
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19702 from cloud-fan/parquet.
## What changes were proposed in this pull request?
The current internal `table()` API of `SparkSession` bypasses the Analyzer and directly calls `sessionState.catalog.lookupRelation` API. This skips the view resolution logics in our Analyzer rule `ResolveRelations`. This internal API is widely used by various DDL commands, public and internal APIs.
Users might get the strange error caused by view resolution when the default database is different.
```
Table or view not found: t1; line 1 pos 14
org.apache.spark.sql.AnalysisException: Table or view not found: t1; line 1 pos 14
at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:42)
```
This PR is to fix it by enforcing it to use `ResolveRelations` to resolve the table.
## How was this patch tested?
Added a test case and modified the existing test cases
Author: gatorsmile <gatorsmile@gmail.com>
Closes#19713 from gatorsmile/viewResolution.
## What changes were proposed in this pull request?
For the few Dataset actions such as `foreach`, currently no SQL metrics are visible in the SQL tab of SparkUI. It is because it binds wrongly to Dataset's `QueryExecution`. As the actions directly evaluate on the RDD which has individual `QueryExecution`, to show correct SQL metrics on UI, we should bind to RDD's `QueryExecution`.
## How was this patch tested?
Manually test. Screenshot is attached in the PR.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#19689 from viirya/SPARK-22462.
## What changes were proposed in this pull request?
Fix to allow recovery on console , avoid checkpoint exception
## How was this patch tested?
existing tests
manual tests [ Replicating error and seeing no checkpoint error after fix]
Author: Rekha Joshi <rekhajoshm@gmail.com>
Author: rjoshi2 <rekhajoshm@gmail.com>
Closes#19407 from rekhajoshm/SPARK-21667.
## What changes were proposed in this pull request?
In `spark-sql` module tests there are deprecations warnings caused by the usage of deprecated methods of `java.sql.Date` and the usage of the deprecated `AsyncAssertions.Waiter` class.
This PR replace the deprecated methods of `java.sql.Date` with non-deprecated ones (using `Calendar` where needed). It replaces also the deprecated `org.scalatest.concurrent.AsyncAssertions.Waiter` with `org.scalatest.concurrent.Waiters._`.
## How was this patch tested?
existing UTs
Author: Marco Gaido <mgaido@hortonworks.com>
Closes#19696 from mgaido91/SPARK-22473.
## What changes were proposed in this pull request?
One powerful feature of `Dataset` is, we can easily map SQL rows to Scala/Java objects and do runtime null check automatically.
For example, let's say we have a parquet file with schema `<a: int, b: string>`, and we have a `case class Data(a: Int, b: String)`. Users can easily read this parquet file into `Data` objects, and Spark will throw NPE if column `a` has null values.
However the null checking is left behind for top-level primitive values. For example, let's say we have a parquet file with schema `<a: Int>`, and we read it into Scala `Int`. If column `a` has null values, we will get some weird results.
```
scala> val ds = spark.read.parquet(...).as[Int]
scala> ds.show()
+----+
|v |
+----+
|null|
|1 |
+----+
scala> ds.collect
res0: Array[Long] = Array(0, 1)
scala> ds.map(_ * 2).show
+-----+
|value|
+-----+
|-2 |
|2 |
+-----+
```
This is because internally Spark use some special default values for primitive types, but never expect users to see/operate these default value directly.
This PR adds null check for top-level primitive values
## How was this patch tested?
new test
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19707 from cloud-fan/bug.
{kind=link}
{kind=link}
{kind=link}
{kind=link}