### What changes were proposed in this pull request?
This PR intends to clean up the SQL documents in `doc/sql-ref*`.
Main changes are as follows;
- Fixes wrong syntaxes and capitalize sub-titles
- Adds some DDL queries in `Examples` so that users can run examples there
- Makes query output in `Examples` follows the `Dataset.showString` (right-aligned) format
- Adds/Removes spaces, Indents, or blank lines to follow the format below;
```
---
license...
---
### Description
Writes what's the syntax is.
### Syntax
{% highlight sql %}
SELECT...
WHERE... // 4 indents after the second line
...
{% endhighlight %}
### Parameters
<dl>
<dt><code><em>Param Name</em></code></dt>
<dd>
Param Description
</dd>
...
</dl>
### Examples
{% highlight sql %}
-- It is better that users are able to execute example queries here.
-- So, we prepare test data in the first section if possible.
CREATE TABLE t (key STRING, value DOUBLE);
INSERT INTO t VALUES
('a', 1.0), ('a', 2.0), ('b', 3.0), ('c', 4.0);
-- query output has 2 indents and it follows the `Dataset.showString`
-- format (right-aligned).
SELECT * FROM t;
+---+-----+
|key|value|
+---+-----+
| a| 1.0|
| a| 2.0|
| b| 3.0|
| c| 4.0|
+---+-----+
-- Query statements after the second line have 4 indents.
SELECT key, SUM(value)
FROM t
GROUP BY key;
+---+----------+
|key|sum(value)|
+---+----------+
| c| 4.0|
| b| 3.0|
| a| 3.0|
+---+----------+
...
{% endhighlight %}
### Related Statements
* [XXX](xxx.html)
* ...
```
### Why are the changes needed?
The most changes of this PR are pretty minor, but I think the consistent formats/rules to write documents are important for long-term maintenance in our community
### Does this PR introduce any user-facing change?
Yes.
### How was this patch tested?
Manually checked.
Closes#28151 from maropu/MakeRightAligned.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This pull request adds SparkR wrapper for `FMRegressor`:
- Supporting ` org.apache.spark.ml.r.FMRegressorWrapper`.
- `FMRegressionModel` S4 class.
- Corresponding `spark.fmRegressor`, `predict`, `summary` and `write.ml` generics.
- Corresponding docs and tests.
### Why are the changes needed?
Feature parity.
### Does this PR introduce any user-facing change?
No (new API).
### How was this patch tested?
New unit tests.
Closes#27571 from zero323/SPARK-30819.
Authored-by: zero323 <mszymkiewicz@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Document Spark integration with Hive UDFs/UDAFs/UDTFs
### Why are the changes needed?
To make SQL Reference complete
### Does this PR introduce any user-facing change?
Yes
<img width="1031" alt="Screen Shot 2020-04-02 at 2 22 42 PM" src="https://user-images.githubusercontent.com/13592258/78301971-cc7cf080-74ee-11ea-93c8-7d4c75213b47.png">
### How was this patch tested?
Manually build and check
Closes#28104 from huaxingao/hive-udfs.
Lead-authored-by: Huaxin Gao <huaxing@us.ibm.com>
Co-authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR explicitly mention that the requirement of Iterator of Series to Iterator of Series and Iterator of Multiple Series to Iterator of Series (previously Scalar Iterator pandas UDF).
The actual limitation of this UDF is the same length of the _entire input and output_, instead of each series's length. Namely you can do something as below:
```python
from typing import Iterator, Tuple
import pandas as pd
from pyspark.sql.functions import pandas_udf
pandas_udf("long")
def func(
iterator: Iterator[pd.Series]) -> Iterator[pd.Series]:
return iter([pd.concat(iterator)])
spark.range(100).select(func("id")).show()
```
This characteristic allows you to prefetch the data from the iterator to speed up, compared to the regular Scalar to Scalar (previously Scalar pandas UDF).
### Why are the changes needed?
To document the correct restriction and characteristics of a feature.
### Does this PR introduce any user-facing change?
Yes in the documentation but only in unreleased branches.
### How was this patch tested?
Github Actions should test the documentation build
Closes#28160 from HyukjinKwon/SPARK-30722-followup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This pull request adds SparkR wrapper for `LinearRegression`
- Supporting `org.apache.spark.ml.rLinearRegressionWrapper`.
- `LinearRegressionModel` S4 class.
- Corresponding `spark.lm` predict, summary and write.ml generics.
- Corresponding docs and tests.
### Why are the changes needed?
Feature parity.
### Does this PR introduce any user-facing change?
No (new API).
### How was this patch tested?
New unit tests.
Closes#27593 from zero323/SPARK-30818.
Authored-by: zero323 <mszymkiewicz@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
HyukjinKwon have ported back all the PR about version to branch-3.0.
I make a double check and found GraphX table lost version head.
This PR will fix the issue.
HyukjinKwon, please help me merge this PR to master and branch-3.0
### Why are the changes needed?
Add version head of GraphX table
### Does this PR introduce any user-facing change?
'No'.
### How was this patch tested?
Jenkins test.
Closes#28149 from beliefer/fix-head-of-graphx-table.
Authored-by: beliefer <beliefer@163.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Previously, user can issue `SHOW TABLES` to get info of both tables and views.
This PR (SPARK-31113) implements `SHOW VIEWS` SQL command similar to HIVE to get views only.(https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-ShowViews)
**Hive** -- Only show view names
```
hive> SHOW VIEWS;
OK
view_1
view_2
...
```
**Spark(Hive-Compatible)** -- Only show view names, used in tests and `SparkSQLDriver` for CLI applications
```
SHOW VIEWS IN showdb;
view_1
view_2
...
```
**Spark** -- Show more information database/viewName/isTemporary
```
spark-sql> SHOW VIEWS;
userdb view_1 false
userdb view_2 false
...
```
### Why are the changes needed?
`SHOW VIEWS` command provides better granularity to only get information of views.
### Does this PR introduce any user-facing change?
Add new `SHOW VIEWS` SQL command
### How was this patch tested?
Add new test `show-views.sql` and pass existing tests
Closes#27897 from Eric5553/ShowViews.
Authored-by: Eric Wu <492960551@qq.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This pull request adds SparkR wrapper for `FMClassifier`:
- Supporting ` org.apache.spark.ml.r.FMClassifierWrapper`.
- `FMClassificationModel` S4 class.
- Corresponding `spark.fmClassifier`, `predict`, `summary` and `write.ml` generics.
- Corresponding docs and tests.
### Why are the changes needed?
Feature parity.
### Does this PR introduce any user-facing change?
No (new API).
### How was this patch tested?
New unit tests.
Closes#27570 from zero323/SPARK-30820.
Authored-by: zero323 <mszymkiewicz@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Add migration guide for extracting second from datetimes
### Why are the changes needed?
doc the behavior change for extract expression
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A, just passing jenkins
Closes#28140 from yaooqinn/SPARK-29311.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR intends to improve the SQL document of `GROUP BY`; it added the description about FILTER clauses of aggregate functions.
### Why are the changes needed?
To improve the SQL documents
### Does this PR introduce any user-facing change?
Yes.
<img src="https://user-images.githubusercontent.com/692303/78558612-e2234a80-784d-11ea-9353-b3feac4d57a7.png" width="500">
### How was this patch tested?
Manually checked.
Closes#28134 from maropu/SPARK-31358.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR fixes the outdated requirement for `spark.dynamicAllocation.enabled=true`.
### Why are the changes needed?
This is found during 3.0.0 RC1 document review and testing. As described at `spark.dynamicAllocation.shuffleTracking.enabled` in the same table, we can enabled Dynamic Allocation without external shuffle service.
### Does this PR introduce any user-facing change?
Yes. (Doc.)
### How was this patch tested?
Manually generate the doc by `SKIP_API=1 jekyll build`
**BEFORE**

**AFTER**

Closes#28132 from dongjoon-hyun/SPARK-DA-DOC.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR intends to add a new SQL config for controlling a plan explain mode in the events of (e.g., `SparkListenerSQLExecutionStart` and `SparkListenerSQLAdaptiveExecutionUpdate`) SQL listeners. In the current master, the output of `QueryExecution.toString` (this is equivalent to the "extended" explain mode) is stored in these events. I think it is useful to control the content via `SQLConf`. For example, the query "Details" content (TPCDS q66 query) of a SQL tab in a Spark web UI will be changed as follows;
Before this PR:

After this PR:

### Why are the changes needed?
For better usability.
### Does this PR introduce any user-facing change?
Yes; since Spark 3.1, SQL UI data adopts the `formatted` mode for the query plan explain results. To restore the behavior before Spark 3.0, you can set `spark.sql.ui.explainMode` to `extended`.
### How was this patch tested?
Added unit tests.
Closes#28097 from maropu/SPARK-31325.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
For the stage level scheduling feature, add the ability to optionally merged resource profiles if they were specified on multiple RDD within a stage. There is a config to enable this feature, its off by default (spark.scheduler.resourceProfile.mergeConflicts). When the config is set to true, Spark will merge the profiles selecting the max value of each resource (cores, memory, gpu, etc). further documentation will be added with SPARK-30322.
This also added in the ability to check if an equivalent resource profile already exists. This is so that if a user is running stages and combining the same profiles over and over again we don't get an explosion in the number of profiles.
### Why are the changes needed?
To allow users to specify resource on multiple RDD and not worry as much about if they go into the same stage and fail.
### Does this PR introduce any user-facing change?
Yes, when the config is turned on it now merges the profiles instead of errorring out.
### How was this patch tested?
Unit tests
Closes#28053 from tgravescs/SPARK-29153.
Lead-authored-by: Thomas Graves <tgraves@apache.org>
Co-authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
This PR adds description for `Shuffle Write Time` to `web-ui.md`.
### Why are the changes needed?
#27837 added `Shuffle Write Time` metric to task metrics summary but it's not documented yet.
### Does this PR introduce any user-facing change?
Yes.
We can see the description for `Shuffle Write Time` in the new `web-ui.html`.
<img width="956" alt="shuffle-write-time-description" src="https://user-images.githubusercontent.com/4736016/78175342-a9722280-7495-11ea-9cc6-62c6f3619aa3.png">
### How was this patch tested?
Built docs by `SKIP_API=1 jekyll build` in `doc` directory and then confirmed `web-ui.html`.
Closes#28093 from sarutak/SPARK-31073-doc.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Add back the deprecated R APIs removed by https://github.com/apache/spark/pull/22843/ and https://github.com/apache/spark/pull/22815.
These APIs are
- `sparkR.init`
- `sparkRSQL.init`
- `sparkRHive.init`
- `registerTempTable`
- `createExternalTable`
- `dropTempTable`
No need to port the function such as
```r
createExternalTable <- function(x, ...) {
dispatchFunc("createExternalTable(tableName, path = NULL, source = NULL, ...)", x, ...)
}
```
because this was for the backward compatibility when SQLContext exists before assuming from https://github.com/apache/spark/pull/9192, but seems we don't need it anymore since SparkR replaced SQLContext with Spark Session at https://github.com/apache/spark/pull/13635.
### Why are the changes needed?
Amend Spark's Semantic Versioning Policy
### Does this PR introduce any user-facing change?
Yes
The removed R APIs are put back.
### How was this patch tested?
Add back the removed tests
Closes#28058 from huaxingao/r.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR (SPARK-30775) aims to improve the description of the executor metrics in the monitoring documentation.
### Why are the changes needed?
Improve and clarify monitoring documentation by:
- adding reference to the Prometheus end point, as implemented in [SPARK-29064]
- extending the list and descripion of executor metrics, following up from [SPARK-27157]
### Does this PR introduce any user-facing change?
Documentation update.
### How was this patch tested?
n.a.
Closes#27526 from LucaCanali/docPrometheusMetricsFollowupSpark29064.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR (SPARK-31293) fixes wrong command examples, parameter descriptions and help message format for Amazon Kinesis integration with Spark Streaming.
### Why are the changes needed?
To improve usability of those commands.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
I ran the fixed commands manually and confirmed they worked as expected.
Closes#28063 from sekikn/SPARK-31293.
Authored-by: Kengo Seki <sekikn@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Fix a broken link and make the relevant docs reference to the new doc
### Why are the changes needed?
### Does this PR introduce any user-facing change?
Yes, make CACHE TABLE, UNCACHE TABLE, CLEAR CACHE, REFRESH TABLE link to the new doc
### How was this patch tested?
Manually build and check
Closes#28065 from huaxingao/spark-30363-follow-up.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR adds "Pandas Function API" into the menu.
### Why are the changes needed?
To be consistent and to make easier to navigate.
### Does this PR introduce any user-facing change?
No, master only.

### How was this patch tested?
Manually verified by `SKIP_API=1 jekyll build`.
Closes#28054 from HyukjinKwon/followup-spark-30722.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Based on the discussion in the mailing list [[Proposal] Modification to Spark's Semantic Versioning Policy](http://apache-spark-developers-list.1001551.n3.nabble.com/Proposal-Modification-to-Spark-s-Semantic-Versioning-Policy-td28938.html) , this PR is to add back the following APIs whose maintenance cost are relatively small.
- HiveContext
- createExternalTable APIs
### Why are the changes needed?
Avoid breaking the APIs that are commonly used.
### Does this PR introduce any user-facing change?
Adding back the APIs that were removed in 3.0 branch does not introduce the user-facing changes, because Spark 3.0 has not been released.
### How was this patch tested?
add a new test suite for createExternalTable APIs.
Closes#27815 from gatorsmile/addAPIsBack.
Lead-authored-by: gatorsmile <gatorsmile@gmail.com>
Co-authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Skew join handling comes with an overhead: we need to read some data repeatedly. We should treat a partition as skewed if it's large enough so that it's beneficial to do so.
Currently the size threshold is the advisory partition size, which is 64 MB by default. This is not large enough for the skewed partition size threshold.
This PR adds a new config for the threshold and set default value as 256 MB.
### Why are the changes needed?
Avoid skew join handling that may introduce a perf regression.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
existing tests
Closes#27967 from cloud-fan/aqe.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Currently, ResetCommand clear all configurations, including sql configs, static sql configs and spark context level configs.
for example:
```sql
spark-sql> set xyz=abc;
xyz abc
spark-sql> set;
spark.app.id local-1585055396930
spark.app.name SparkSQL::10.242.189.214
spark.driver.host 10.242.189.214
spark.driver.port 65094
spark.executor.id driver
spark.jars
spark.master local[*]
spark.sql.catalogImplementation hive
spark.sql.hive.version 1.2.1
spark.submit.deployMode client
xyz abc
spark-sql> reset;
spark-sql> set;
spark-sql> set spark.sql.hive.version;
spark.sql.hive.version 1.2.1
spark-sql> set spark.app.id;
spark.app.id <undefined>
```
In this PR, we restore spark confs to RuntimeConfig after it is cleared
### Why are the changes needed?
reset command overkills configs which are static.
### Does this PR introduce any user-facing change?
yes, the ResetCommand do not change static configs now
### How was this patch tested?
add ut
Closes#28003 from yaooqinn/SPARK-31234.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Update ml-guide to include ```MulticlassClassificationEvaluator``` weight support in highlights
### Why are the changes needed?
```MulticlassClassificationEvaluator``` weight support is very important, so should include it in highlights
### Does this PR introduce any user-facing change?
Yes
after:

### How was this patch tested?
manually build and check
Closes#28031 from huaxingao/highlights-followup.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
Spark introduced CHAR type for hive compatibility but it only works for hive tables. CHAR type is never documented and is treated as STRING type for non-Hive tables.
However, this leads to confusing behaviors
**Apache Spark 3.0.0-preview2**
```
spark-sql> CREATE TABLE t(a CHAR(3));
spark-sql> INSERT INTO TABLE t SELECT 'a ';
spark-sql> SELECT a, length(a) FROM t;
a 2
```
**Apache Spark 2.4.5**
```
spark-sql> CREATE TABLE t(a CHAR(3));
spark-sql> INSERT INTO TABLE t SELECT 'a ';
spark-sql> SELECT a, length(a) FROM t;
a 3
```
According to the SQL standard, `CHAR(3)` should guarantee all the values are of length 3. Since `CHAR(3)` is treated as STRING so Spark doesn't guarantee it.
This PR forbids CHAR type in non-Hive tables as it's not supported correctly.
### Why are the changes needed?
avoid confusing/wrong behavior
### Does this PR introduce any user-facing change?
yes, now users can't create/alter non-Hive tables with CHAR type.
### How was this patch tested?
new tests
Closes#27902 from cloud-fan/char.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
https://github.com/apache/spark/pull/26412 introduced a behavior change that `date_add`/`date_sub` functions can't accept string and double values in the second parameter. This is reasonable as it's error-prone to cast string/double to int at runtime.
However, using string literals as function arguments is very common in SQL databases. To avoid breaking valid use cases that the string literal is indeed an integer, this PR proposes to add ansi_cast for string literal in date_add/date_sub functions. If the string value is not a valid integer, we fail at query compiling time because of constant folding.
### Why are the changes needed?
avoid breaking changes
### Does this PR introduce any user-facing change?
Yes, now 3.0 can run `date_add('2011-11-11', '1')` like 2.4
### How was this patch tested?
new tests.
Closes#27965 from cloud-fan/string.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
`INSERT OVERWRITE DIRECTORY` can only use file format (class implements `org.apache.spark.sql.execution.datasources.FileFormat`). This PR fixes it and other minor improvement.
### Why are the changes needed?
### Does this PR introduce any user-facing change?
### How was this patch tested?
Closes#27891 from cloud-fan/doc.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Change BLAS for part of level-1 routines(axpy, dot, scal(double, denseVector)) from java implementation to NativeBLAS when vector size>256
### Why are the changes needed?
In current ML BLAS.scala, all level-1 routines are fixed to use java
implementation. But NativeBLAS(intel MKL, OpenBLAS) can bring up to 11X
performance improvement based on performance test which apply direct
calls against these methods. We should provide a way to allow user take
advantage of NativeBLAS for level-1 routines. Here we do it through
switching to NativeBLAS for these methods from f2jBLAS.
### Does this PR introduce any user-facing change?
Yes, methods axpy, dot, scal in level-1 routines will switch to NativeBLAS when it has more than nativeL1Threshold(fixed value 256) elements and will fallback to f2jBLAS if native BLAS is not properly configured in system.
### How was this patch tested?
Perf test direct calls level-1 routines
Closes#27546 from yma11/SPARK-30773.
Lead-authored-by: yan ma <yan.ma@intel.com>
Co-authored-by: Ma Yan <yan.ma@intel.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Fix errors and missing parts for datetime pattern document
1. The pattern we use is similar to DateTimeFormatter and SimpleDateFormat but not identical. So we shouldn't use any of them in the API docs but use a link to the doc of our own.
2. Some pattern letters are missing
3. Some pattern letters are explicitly banned - Set('A', 'c', 'e', 'n', 'N')
4. the second fraction pattern different logic for parsing and formatting
### Why are the changes needed?
fix and improve doc
### Does this PR introduce any user-facing change?
yes, new and updated doc
### How was this patch tested?
pass Jenkins
viewed locally with `jekyll serve`

Closes#27956 from yaooqinn/SPARK-31189.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
A followup of https://github.com/apache/spark/pull/27936 to update document.
### Why are the changes needed?
correct document
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
N/A
Closes#27950 from cloud-fan/null.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
The meaning of 'u' was day number of the week in SimpleDateFormat, it was changed to year in DateTimeFormatter. Now we keep the old meaning of 'u' by substituting 'u' to 'e' internally and use DateTimeFormatter to parse the pattern string. In DateTimeFormatter, the 'e' and 'c' also represents day-of-week. e.g.
```sql
select date_format(timestamp '2019-10-06', 'yyyy-MM-dd uuuu');
select date_format(timestamp '2019-10-06', 'yyyy-MM-dd uuee');
select date_format(timestamp '2019-10-06', 'yyyy-MM-dd eeee');
```
Because of the substitution, they all goes to `.... eeee` silently. The users may congitive problems of their meanings, so we should mark them as illegal pattern characters to stay the same as before.
This pr move the method `convertIncompatiblePattern` from `DatetimeUtils` to `DateTimeFormatterHelper` object, since it is quite specific for `DateTimeFormatterHelper` class.
And 'e' and 'c' char checking in this method.
Besides,`convertIncompatiblePattern` has a bug that will lose the last `'` if it ends with it, this pr fixes this too. e.g.
```sql
spark-sql> select date_format(timestamp "2019-10-06", "yyyy-MM-dd'S'");
20/03/18 11:19:45 ERROR SparkSQLDriver: Failed in [select date_format(timestamp "2019-10-06", "yyyy-MM-dd'S'")]
java.lang.IllegalArgumentException: Pattern ends with an incomplete string literal: uuuu-MM-dd'S
spark-sql> select to_timestamp("2019-10-06S", "yyyy-MM-dd'S'");
NULL
```
### Why are the changes needed?
avoid vagueness
bug fix
### Does this PR introduce any user-facing change?
no, these are not exposed yet
### How was this patch tested?
add ut
Closes#27939 from yaooqinn/SPARK-31176.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR will add the user guide for AQE and the detailed configurations about the three mainly features in AQE.
### Why are the changes needed?
Add the detailed configurations.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
only add doc no need ut.
Closes#27616 from JkSelf/aqeuserguide.
Authored-by: jiake <ke.a.jia@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The current migration guide of SQL is too long for most readers to find the needed info. This PR is to group the items in the migration guide of Spark SQL based on the corresponding components.
Note. This PR does not change the contents of the migration guides. Attached figure is the screenshot after the change.

### Why are the changes needed?
The current migration guide of SQL is too long for most readers to find the needed info.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#27909 from gatorsmile/migrationGuideReorg.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Since we reverted the original change in https://github.com/apache/spark/pull/27540, this PR is to remove the corresponding migration guide made in the commit https://github.com/apache/spark/pull/24948
### Why are the changes needed?
N/A
### Does this PR introduce any user-facing change?
N/A
### How was this patch tested?
N/A
Closes#27896 from gatorsmile/SPARK-28093Followup.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
When loading DataFrames from JDBC datasource with Kerberos authentication, remote executors (yarn-client/cluster etc. modes) fail to establish a connection due to lack of Kerberos ticket or ability to generate it.
This is a real issue when trying to ingest data from kerberized data sources (SQL Server, Oracle) in enterprise environment where exposing simple authentication access is not an option due to IT policy issues.
In this PR I've added Postgres support (other supported databases will come in later PRs).
What this PR contains:
* Added `keytab` and `principal` JDBC options
* Added `ConnectionProvider` trait and it's impementations:
* `BasicConnectionProvider` => unsecure connection
* `PostgresConnectionProvider` => postgres secure connection
* Added `ConnectionProvider` tests
* Added `PostgresKrbIntegrationSuite` docker integration test
* Created `SecurityUtils` to concentrate re-usable security related functionalities
* Documentation
### Why are the changes needed?
Missing JDBC kerberos support.
### Does this PR introduce any user-facing change?
Yes, 2 additional JDBC options added:
* keytab
* principal
If both provided then Spark does kerberos authentication.
### How was this patch tested?
To demonstrate the functionality with a standalone application I've created this repository: https://github.com/gaborgsomogyi/docker-kerberos
* Additional + existing unit tests
* Additional docker integration test
* Test on cluster manually
* `SKIP_API=1 jekyll build`
Closes#27637 from gaborgsomogyi/SPARK-30874.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@apache.org>
### What changes were proposed in this pull request?
spark.sql.legacy.timeParser.enabled should be removed from SQLConf and the migration guide
spark.sql.legacy.timeParsePolicy is the right one
### Why are the changes needed?
fix doc
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
Pass the jenkins
Closes#27889 from yaooqinn/SPARK-31131.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
1.Add version information to the configuration of `Status`.
2.Update the docs of `Status`.
3.By the way supplementary documentation about https://github.com/apache/spark/pull/27847
I sorted out some information show below.
Item name | Since version | JIRA ID | Commit ID | Note
-- | -- | -- | -- | --
spark.appStateStore.asyncTracking.enable | 2.3.0 | SPARK-20653 | 772e4648d95bda3353723337723543c741ea8476#diff-9ab674b7af7b2097f7d28cb6f5fd1e8c |
spark.ui.liveUpdate.period | 2.3.0 | SPARK-20644 | c7f38e5adb88d43ef60662c5d6ff4e7a95bff580#diff-9ab674b7af7b2097f7d28cb6f5fd1e8c |
spark.ui.liveUpdate.minFlushPeriod | 2.4.2 | SPARK-27394 | a8a2ba11ac10051423e58920062b50f328b06421#diff-9ab674b7af7b2097f7d28cb6f5fd1e8c |
spark.ui.retainedJobs | 1.2.0 | SPARK-2321 | 9530316887612dca060a128fca34dd5a6ab2a9a9#diff-1f32bcb61f51133bd0959a4177a066a5 |
spark.ui.retainedStages | 0.9.0 | None | 112c0a1776bbc866a1026a9579c6f72f293414c4#diff-1f32bcb61f51133bd0959a4177a066a5 | 0.9.0-incubating-SNAPSHOT
spark.ui.retainedTasks | 2.0.1 | SPARK-15083 | 55db26245d69bb02b7d7d5f25029b1a1cd571644#diff-6bdad48cfc34314e89599655442ff210 |
spark.ui.retainedDeadExecutors | 2.0.0 | SPARK-7729 | 9f4263392e492b5bc0acecec2712438ff9a257b7#diff-a0ba36f9b1f9829bf3c4689b05ab6cf2 |
spark.ui.dagGraph.retainedRootRDDs | 2.1.0 | SPARK-17171 | cc87280fcd065b01667ca7a59a1a32c7ab757355#diff-3f492c527ea26679d4307041b28455b8 |
spark.metrics.appStatusSource.enabled | 3.0.0 | SPARK-30060 | 60f20e5ea2000ab8f4a593b5e4217fd5637c5e22#diff-9f796ae06b0272c1f0a012652a5b68d0 |
### Why are the changes needed?
Supplemental configuration version information.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Exists UT
Closes#27848 from beliefer/add-version-to-status-config.
Lead-authored-by: beliefer <beliefer@163.com>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
A few improvements to the sql ref SELECT doc:
1. correct the syntax of SELECT query
2. correct the default of null sort order
3. correct the GROUP BY syntax
4. several minor fixes
### Why are the changes needed?
refine document
### Does this PR introduce any user-facing change?
N/A
### How was this patch tested?
N/A
Closes#27866 from cloud-fan/doc.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR reverts https://github.com/apache/spark/pull/26051 and https://github.com/apache/spark/pull/26066
### Why are the changes needed?
There is no standard requiring that `size(null)` must return null, and returning -1 looks reasonable as well. This is kind of a cosmetic change and we should avoid it if it breaks existing queries. This is similar to reverting TRIM function parameter order change.
### Does this PR introduce any user-facing change?
Yes, change the behavior of `size(null)` back to be the same as 2.4.
### How was this patch tested?
N/A
Closes#27834 from cloud-fan/revert.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
In Spark version 2.4 and earlier, datetime parsing, formatting and conversion are performed by using the hybrid calendar (Julian + Gregorian).
Since the Proleptic Gregorian calendar is de-facto calendar worldwide, as well as the chosen one in ANSI SQL standard, Spark 3.0 switches to it by using Java 8 API classes (the java.time packages that are based on ISO chronology ). The switching job is completed in SPARK-26651.
But after the switching, there are some patterns not compatible between Java 8 and Java 7, Spark needs its own definition on the patterns rather than depends on Java API.
In this PR, we achieve this by writing the document and shadow the incompatible letters. See more details in [SPARK-31030](https://issues.apache.org/jira/browse/SPARK-31030)
### Why are the changes needed?
For backward compatibility.
### Does this PR introduce any user-facing change?
No.
After we define our own datetime parsing and formatting patterns, it's same to old Spark version.
### How was this patch tested?
Existing and new added UT.
Locally document test:

Closes#27830 from xuanyuanking/SPARK-31030.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR makes the following refinements to the workflow for building docs:
* Install Python and Ruby consistently using pyenv and rbenv across both the docs README and the release Dockerfile.
* Pin the Python and Ruby versions we use.
* Pin all direct Python and Ruby dependency versions.
* Eliminate any use of `sudo pip`, which the Python community discourages, or `sudo gem`.
### Why are the changes needed?
This PR should increase the consistency and reproducibility of the doc-building process by managing Python and Ruby in a more consistent way, and by eliminating unused or outdated code.
Here's a possible example of an issue building the docs that would be addressed by the changes in this PR: https://github.com/apache/spark/pull/27459#discussion_r376135719
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Manual tests:
* I was able to build the Docker image successfully, minus the final part about `RUN useradd`.
* I am unable to run `do-release-docker.sh` because I am not a committer and don't have the required GPG key.
* I built the docs locally and viewed them in the browser.
I think I need a committer to more fully test out these changes.
Closes#27534 from nchammas/SPARK-30731-building-docs.
Authored-by: Nicholas Chammas <nicholas.chammas@liveramp.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Updating ML docs for 3.0 changes
### Why are the changes needed?
I am auditing 3.0 ML changes, found some docs are missing or not updated. Need to update these.
### Does this PR introduce any user-facing change?
Yes, doc changes
### How was this patch tested?
Manually build and check
Closes#27762 from huaxingao/spark-doc.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This pr intends to support 32 or more grouping attributes for GROUPING_ID. In the current master, an integer overflow can occur to compute grouping IDs;
e75d9afb2f/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala (L613)
For example, the query below generates wrong grouping IDs in the master;
```
scala> val numCols = 32 // or, 31
scala> val cols = (0 until numCols).map { i => s"c$i" }
scala> sql(s"create table test_$numCols (${cols.map(c => s"$c int").mkString(",")}, v int) using parquet")
scala> val insertVals = (0 until numCols).map { _ => 1 }.mkString(",")
scala> sql(s"insert into test_$numCols values ($insertVals,3)")
scala> sql(s"select grouping_id(), sum(v) from test_$numCols group by grouping sets ((${cols.mkString(",")}), (${cols.init.mkString(",")}))").show(10, false)
scala> sql(s"drop table test_$numCols")
// numCols = 32
+-------------+------+
|grouping_id()|sum(v)|
+-------------+------+
|0 |3 |
|0 |3 | // Wrong Grouping ID
+-------------+------+
// numCols = 31
+-------------+------+
|grouping_id()|sum(v)|
+-------------+------+
|0 |3 |
|1 |3 |
+-------------+------+
```
To fix this issue, this pr change code to use long values for `GROUPING_ID` instead of int values.
### Why are the changes needed?
To support more cases in `GROUPING_ID`.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Added unit tests.
Closes#26918 from maropu/FixGroupingIdIssue.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR intends to fix typos and phrases in the `/docs` directory. To find them, I run the Intellij typo checker.
### Why are the changes needed?
For better documents.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#27819 from maropu/TypoFix-20200306.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
rename the config and make it non-internal.
### Why are the changes needed?
Now we fail the query if duplicated map keys are detected, and provide a legacy config to deduplicate it. However, we must provide a way to get users out of this situation, instead of just rejecting to run the query. This exit strategy should always be there, while legacy config indicates that it may be removed someday.
### Does this PR introduce any user-facing change?
no, just rename a config which was added in 3.0
### How was this patch tested?
add more tests for the fail behavior.
Closes#27772 from cloud-fan/map.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
-c is short for --conf, it was introduced since v1.1.0 but hidden from users until now
### Why are the changes needed?
### Does this PR introduce any user-facing change?
no
expose hidden feature
### How was this patch tested?
Nah
Closes#27802 from yaooqinn/conf.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Fix the migration guide document for `spark.sql.legacy.ctePrecedence.enabled`, which is introduced in #27579.
### Why are the changes needed?
The config value changed.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Document only.
Closes#27782 from xuanyuanking/SPARK-30829-follow.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
ForEachBatch Java example was incorrect
### Why are the changes needed?
Example did not compile
### Does this PR introduce any user-facing change?
Yes, to docs.
### How was this patch tested?
In IDE.
Closes#27740 from roland1982/foreachwriter_java_example_fix.
Authored-by: roland-ondeviceresearch <roland@ondeviceresearch.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Remove automatically resource coordination support from Standalone.
### Why are the changes needed?
Resource coordination is mainly designed for the scenario where multiple workers launched on the same host. However, it's, actually, a non-existed scenario for today's Spark. Because, Spark now can start multiple executors in a single Worker, while it only allow one executor per Worker at very beginning. So, now, it really help nothing for user to launch multiple workers on the same host. Thus, it's not worth for us to bring over complicated implementation and potential high maintain cost for such an impossible scenario.
### Does this PR introduce any user-facing change?
No, it's Spark 3.0 feature.
### How was this patch tested?
Pass Jenkins.
Closes#27722 from Ngone51/abandon_coordination.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
### What changes were proposed in this pull request?
1.Add version information to the configuration of `Kryo`.
2.Update the docs of `Kryo`.
I sorted out some information show below.
Item name | Since version | JIRA ID | Commit ID | Note
-- | -- | -- | -- | --
spark.kryo.registrationRequired | 1.1.0 | SPARK-2102 | efdaeb111917dd0314f1d00ee8524bed1e2e21ca#diff-1f81c62dad0e2dfc387a974bb08c497c |
spark.kryo.registrator | 0.5.0 | None | 91c07a33d90ab0357e8713507134ecef5c14e28a#diff-792ed56b3398163fa14e8578549d0d98 | This is not a release version, do we need to record it?
spark.kryo.classesToRegister | 1.2.0 | SPARK-1813 | 6bb56faea8d238ea22c2de33db93b1b39f492b3a#diff-529fc5c06b9731c1fbda6f3db60b16aa |
spark.kryo.unsafe | 2.1.0 | SPARK-928 | bc167a2a53f5a795d089e8a884569b1b3e2cd439#diff-1f81c62dad0e2dfc387a974bb08c497c |
spark.kryo.pool | 3.0.0 | SPARK-26466 | 38f030725c561979ca98b2a6cc7ca6c02a1f80ed#diff-a3c6b992784f9abeb9f3047d3dcf3ed9 |
spark.kryo.referenceTracking | 0.8.0 | None | 0a8cc309211c62f8824d76618705c817edcf2424#diff-1f81c62dad0e2dfc387a974bb08c497c |
spark.kryoserializer.buffer | 1.4.0 | SPARK-5932 | 2d222fb39dd978e5a33cde6ceb59307cbdf7b171#diff-1f81c62dad0e2dfc387a974bb08c497c |
spark.kryoserializer.buffer.max | 1.4.0 | SPARK-5932 | 2d222fb39dd978e5a33cde6ceb59307cbdf7b171#diff-1f81c62dad0e2dfc387a974bb08c497c |
### Why are the changes needed?
Supplemental configuration version information.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Exists UT
Closes#27734 from beliefer/add-version-to-kryo-config.
Authored-by: beliefer <beliefer@163.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Rename `spark.sql.legacy.addDirectory.recursive.enabled` to `spark.sql.legacy.addSingleFileInAddFile`
### Why are the changes needed?
To follow the naming convention
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing UTs.
Closes#27725 from iRakson/SPARK-30234_CONFIG.
Authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Renamed configuration from `spark.sql.legacy.useHashOnMapType` to `spark.sql.legacy.allowHashOnMapType`.
### Why are the changes needed?
Better readability of configuration.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing UTs.
Closes#27719 from iRakson/SPARK-27619_FOLLOWUP.
Authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR groups all hive upgrade related migration guides inside Spark 3.0 together.
Also add another behavior change of `ScriptTransform` in the new Hive section.
### Why are the changes needed?
Make the doc more clearly to user.
### Does this PR introduce any user-facing change?
No, new doc for Spark 3.0.
### How was this patch tested?
N/A.
Closes#27670 from Ngone51/hive_migration.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1.Add version information to the configuration of `Python`.
2.Update the docs of `Python`.
I sorted out some information show below.
Item name | Since version | JIRA ID | Commit ID | Note
-- | -- | -- | -- | --
spark.python.worker.reuse | 1.2.0 | SPARK-3030 | 2aea0da84c58a179917311290083456dfa043db7#diff-0a67bc4d171abe4df8eb305b0f4123a2 |
spark.python.task.killTimeout | 2.2.2 | SPARK-22535 | be68f86e11d64209d9e325ce807025318f383bea#diff-0a67bc4d171abe4df8eb305b0f4123a2 |
spark.python.use.daemon | 2.3.0 | SPARK-22554 | 57c5514de9dba1c14e296f85fb13fef23ce8c73f#diff-9008ad45db34a7eee2e265a50626841b |
spark.python.daemon.module | 2.4.0 | SPARK-22959 | afae8f2bc82597593595af68d1aa2d802210ea8b#diff-9008ad45db34a7eee2e265a50626841b |
spark.python.worker.module | 2.4.0 | SPARK-22959 | afae8f2bc82597593595af68d1aa2d802210ea8b#diff-9008ad45db34a7eee2e265a50626841b |
spark.executor.pyspark.memory | 2.4.0 | SPARK-25004 | 7ad18ee9f26e75dbe038c6034700f9cd4c0e2baa#diff-6bdad48cfc34314e89599655442ff210 |
### Why are the changes needed?
Supplemental configuration version information.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Exists UT
Closes#27704 from beliefer/add-version-to-python-config.
Authored-by: beliefer <beliefer@163.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1.Add version information to the configuration of `R`.
2.Update the docs of `R`.
I sorted out some information show below.
Item name | Since version | JIRA ID | Commit ID | Note
-- | -- | -- | -- | --
spark.r.backendConnectionTimeout | 2.1.0 | SPARK-17919 | 2881a2d1d1a650a91df2c6a01275eba14a43b42a#diff-025470e1b7094d7cf4a78ea353fb3981 |
spark.r.numRBackendThreads | 1.4.0 | SPARK-8282 | 28e8a6ea65fd08ab9cefc4d179d5c66ffefd3eb4#diff-697f7f2fc89808e0113efc71ed235db2 |
spark.r.heartBeatInterval | 2.1.0 | SPARK-17919 | 2881a2d1d1a650a91df2c6a01275eba14a43b42a#diff-fe903bf14db371aa320b7cc516f2463c |
spark.sparkr.r.command | 1.5.3 | SPARK-10971 | 9695f452e86a88bef3bcbd1f3c0b00ad9e9ac6e1#diff-025470e1b7094d7cf4a78ea353fb3981 |
spark.r.command | 1.5.3 | SPARK-10971 | 9695f452e86a88bef3bcbd1f3c0b00ad9e9ac6e1#diff-025470e1b7094d7cf4a78ea353fb3981 |
### Why are the changes needed?
Supplemental configuration version information.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Exists UT
Closes#27708 from beliefer/add-version-to-R-config.
Authored-by: beliefer <beliefer@163.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
`hash()` and `xxhash64()` cannot be used on elements of `Maptype`. A new configuration `spark.sql.legacy.useHashOnMapType` is introduced to allow users to restore the previous behaviour.
When `spark.sql.legacy.useHashOnMapType` is set to false:
```
scala> spark.sql("select hash(map())");
org.apache.spark.sql.AnalysisException: cannot resolve 'hash(map())' due to data type mismatch: input to function hash cannot contain elements of MapType; line 1 pos 7;
'Project [unresolvedalias(hash(map(), 42), None)]
+- OneRowRelation
```
when `spark.sql.legacy.useHashOnMapType` is set to true :
```
scala> spark.sql("set spark.sql.legacy.useHashOnMapType=true");
res3: org.apache.spark.sql.DataFrame = [key: string, value: string]
scala> spark.sql("select hash(map())").first()
res4: org.apache.spark.sql.Row = [42]
```
### Why are the changes needed?
As discussed in Jira, SparkSql's map hashcodes depends on their order of insertion which is not consistent with the normal scala behaviour which might confuse users.
Code snippet from JIRA :
```
val a = spark.createDataset(Map(1->1, 2->2) :: Nil)
val b = spark.createDataset(Map(2->2, 1->1) :: Nil)
// Demonstration of how Scala Map equality is unaffected by insertion order:
assert(Map(1->1, 2->2).hashCode() == Map(2->2, 1->1).hashCode())
assert(Map(1->1, 2->2) == Map(2->2, 1->1))
assert(a.first() == b.first())
// In contrast, this will print two different hashcodes:
println(Seq(a, b).map(_.selectExpr("hash(*)").first()))
```
Also `MapType` is prohibited for aggregation / joins / equality comparisons #7819 and set operations #17236.
### Does this PR introduce any user-facing change?
Yes. Now users cannot use hash functions on elements of `mapType`. To restore the previous behaviour set `spark.sql.legacy.useHashOnMapType` to true.
### How was this patch tested?
UT added.
Closes#27580 from iRakson/SPARK-27619.
Authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch is to bump the master branch version to 3.1.0-SNAPSHOT.
### Why are the changes needed?
N/A
### Does this PR introduce any user-facing change?
N/A
### How was this patch tested?
N/A
Closes#27698 from gatorsmile/updateVersion.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Rename config `spark.resources.discovery.plugin` to `spark.resources.discoveryPlugin`.
Also, as a side minor change: labeled `ResourceDiscoveryScriptPlugin` as `DeveloperApi` since it's not for end user.
### Why are the changes needed?
Discovery plugin doesn't need to reserve the "discovery" namespace here and it's more consistent with the interface name `ResourceDiscoveryPlugin` if we use `discoveryPlugin` instead.
### Does this PR introduce any user-facing change?
No, it's newly added in Spark3.0.
### How was this patch tested?
Pass Jenkins.
Closes#27689 from Ngone51/spark_30689_followup.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a FOLLOW-UP PR for review comment on #27208 : https://github.com/apache/spark/pull/27208#pullrequestreview-347451714
This PR documents a new feature `Eventlog Compaction` into the new section of `monitoring.md`, as it only has one configuration on the SHS side and it's hard to explain everything on the description on the single configuration.
### Why are the changes needed?
Event log compaction lacks the documentation for what it is and how it helps. This PR will explain it.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Built docs via jekyll.
> change on the new section
<img width="951" alt="Screen Shot 2020-02-16 at 2 23 18 PM" src="https://user-images.githubusercontent.com/1317309/74599587-eb9efa80-50c7-11ea-942c-f7744268e40b.png">
> change on the table
<img width="1126" alt="Screen Shot 2020-01-30 at 5 08 12 PM" src="https://user-images.githubusercontent.com/1317309/73431190-2e9c6680-4383-11ea-8ce0-815f10917ddd.png">
Closes#27398 from HeartSaVioR/SPARK-30481-FOLLOWUP-document-new-feature.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
1.Add version information to the configuration of `Deploy`.
2.Update the docs of `Deploy`.
I sorted out some information show below.
Item name | Since version | JIRA ID | Commit ID | Note
-- | -- | -- | -- | --
spark.deploy.recoveryMode | 0.8.1 | None | d66c01f2b6defb3db6c1be99523b734a4d960532#diff-29dffdccd5a7f4c8b496c293e87c8668 |
spark.deploy.recoveryMode.factory | 1.2.0 | SPARK-1830 | deefd9d7377a8091a1d184b99066febd0e9f6afd#diff-29dffdccd5a7f4c8b496c293e87c8668 | This configuration appears in branch-1.3, but the version number in the pom.xml file corresponding to the commit is 1.2.0-SNAPSHOT
spark.deploy.recoveryDirectory | 0.8.1 | None | d66c01f2b6defb3db6c1be99523b734a4d960532#diff-29dffdccd5a7f4c8b496c293e87c8668 |
spark.deploy.zookeeper.url | 0.8.1 | None | d66c01f2b6defb3db6c1be99523b734a4d960532#diff-4457313ca662a1cd60197122d924585c |
spark.deploy.zookeeper.dir | 0.8.1 | None | d66c01f2b6defb3db6c1be99523b734a4d960532#diff-a84228cb45c7d5bd93305a1f5bf720b6 |
spark.deploy.retainedApplications | 0.8.0 | None | 46eecd110a4017ea0c86cbb1010d0ccd6a5eb2ef#diff-29dffdccd5a7f4c8b496c293e87c8668 |
spark.deploy.retainedDrivers | 1.1.0 | None | 7446f5ff93142d2dd5c79c63fa947f47a1d4db8b#diff-29dffdccd5a7f4c8b496c293e87c8668 |
spark.dead.worker.persistence | 0.8.0 | None | 46eecd110a4017ea0c86cbb1010d0ccd6a5eb2ef#diff-29dffdccd5a7f4c8b496c293e87c8668 |
spark.deploy.maxExecutorRetries | 1.6.3 | SPARK-16956 | ace458f0330f22463ecf7cbee7c0465e10fba8a8#diff-29dffdccd5a7f4c8b496c293e87c8668 |
spark.deploy.spreadOut | 0.6.1 | None | bb2b9ff37cd2503cc6ea82c5dd395187b0910af0#diff-0e7ae91819fc8f7b47b0f97be7116325 |
spark.deploy.defaultCores | 0.9.0 | None | d8bcc8e9a095c1b20dd7a17b6535800d39bff80e#diff-29dffdccd5a7f4c8b496c293e87c8668 |
### Why are the changes needed?
Supplemental configuration version information.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Exists UT
Closes#27668 from beliefer/add-version-to-deploy-config.
Authored-by: beliefer <beliefer@163.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Previous exemple given for spark-streaming-kinesis was true for Apache Spark < 2.3.0. After that the method used in exemple became deprecated:
deprecated("use initialPosition(initialPosition: KinesisInitialPosition)", "2.3.0")
def initialPositionInStream(initialPosition: InitialPositionInStream)
This PR updates the doc on rewriting exemple in Scala/Java (remain unchanged in Python) to adapt Apache Spark 2.4.0 + releases.
### Why are the changes needed?
It introduces some confusion for developers to test their spark-streaming-kinesis exemple.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
In my opinion, the change is only about the documentation level, so I did not add any special test.
Closes#27652 from supaggregator/SPARK-30901.
Authored-by: XU Duo <Duo.XU@canal-plus.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Structured streaming documentation example fix
### Why are the changes needed?
Currently the java example uses incorrect syntax
### Does this PR introduce any user-facing change?
Yes
### How was this patch tested?
In IDE
Closes#27671 from roland1982/foreachwriter_java_example_fix.
Authored-by: roland-ondeviceresearch <roland@ondeviceresearch.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to throw exception by default when user use untyped UDF(a.k.a `org.apache.spark.sql.functions.udf(AnyRef, DataType)`).
And user could still use it by setting `spark.sql.legacy.useUnTypedUdf.enabled` to `true`.
### Why are the changes needed?
According to #23498, since Spark 3.0, the untyped UDF will return the default value of the Java type if the input value is null. For example, `val f = udf((x: Int) => x, IntegerType)`, `f($"x")` will return 0 in Spark 3.0 but null in Spark 2.4. And the behavior change is introduced due to Spark3.0 is built with Scala 2.12 by default.
As a result, this might change data silently and may cause correctness issue if user still expect `null` in some cases. Thus, we'd better to encourage user to use typed UDF to avoid this problem.
### Does this PR introduce any user-facing change?
Yeah. User will hit exception now when use untyped UDF.
### How was this patch tested?
Added test and updated some tests.
Closes#27488 from Ngone51/spark_26580_followup.
Lead-authored-by: yi.wu <yi.wu@databricks.com>
Co-authored-by: wuyi <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Revise the documentation of `spark.ui.retainedTasks` to make it clear that the configuration is for one stage.
### Why are the changes needed?
There are configurations for the limitation of UI data.
`spark.ui.retainedJobs`, `spark.ui.retainedStages` and `spark.worker.ui.retainedExecutors` are the total max number for one application, while the configuration `spark.ui.retainedTasks` is the max number for one stage.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
None, just doc.
Closes#27660 from gengliangwang/reviseRetainTask.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
mention the workaround if users do want to use map type as key, and add a test to demonstrate it.
### Why are the changes needed?
it's better to provide an alternative when we ban something.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
N/A
Closes#27621 from cloud-fan/map.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Improve the CREATE TABLE document:
1. mention that some clauses can come in as any order.
2. refine the description for some parameters.
3. mention how data source table interacts with data source
4. make the examples consistent between data source and hive serde tables.
### Why are the changes needed?
improve doc
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
N/A
Closes#27638 from cloud-fan/doc.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
fix kubernetes-client version doc
### Why are the changes needed?
correct doc
### Does this PR introduce any user-facing change?
nah
### How was this patch tested?
nah
Closes#27605 from yaooqinn/k8s-version-update.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
mention that `INT96` timestamp is still useful for interoperability.
### Why are the changes needed?
Give users more context of the behavior changes.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
N/A
Closes#27622 from cloud-fan/parquet.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
[HIVE-15167](https://issues.apache.org/jira/browse/HIVE-15167) removed the `SerDe` interface. This may break custom `SerDe` builds for Hive 1.2. This PR update the migration guide for this change.
### Why are the changes needed?
Otherwise:
```
2020-01-27 05:11:20.446 - stderr> 20/01/27 05:11:20 INFO DAGScheduler: ResultStage 2 (main at NativeMethodAccessorImpl.java:0) failed in 1.000 s due to Job aborted due to stage failure: Task 0 in stage 2.0 failed 4 times, most recent failure: Lost task 0.3 in stage 2.0 (TID 13, 10.110.21.210, executor 1): java.lang.NoClassDefFoundError: org/apache/hadoop/hive/serde2/SerDe
2020-01-27 05:11:20.446 - stderr> at java.lang.ClassLoader.defineClass1(Native Method)
2020-01-27 05:11:20.446 - stderr> at java.lang.ClassLoader.defineClass(ClassLoader.java:756)
2020-01-27 05:11:20.446 - stderr> at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
2020-01-27 05:11:20.446 - stderr> at java.net.URLClassLoader.defineClass(URLClassLoader.java:468)
2020-01-27 05:11:20.446 - stderr> at java.net.URLClassLoader.access$100(URLClassLoader.java:74)
2020-01-27 05:11:20.446 - stderr> at java.net.URLClassLoader$1.run(URLClassLoader.java:369)
2020-01-27 05:11:20.446 - stderr> at java.net.URLClassLoader$1.run(URLClassLoader.java:363)
2020-01-27 05:11:20.446 - stderr> at java.security.AccessController.doPrivileged(Native Method)
2020-01-27 05:11:20.446 - stderr> at java.net.URLClassLoader.findClass(URLClassLoader.java:362)
2020-01-27 05:11:20.446 - stderr> at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
2020-01-27 05:11:20.446 - stderr> at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
2020-01-27 05:11:20.446 - stderr> at java.lang.ClassLoader.loadClass(ClassLoader.java:405)
2020-01-27 05:11:20.446 - stderr> at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
2020-01-27 05:11:20.446 - stderr> at java.lang.Class.forName0(Native Method)
2020-01-27 05:11:20.446 - stderr> at java.lang.Class.forName(Class.java:348)
2020-01-27 05:11:20.446 - stderr> at org.apache.hadoop.hive.ql.plan.TableDesc.getDeserializerClass(TableDesc.java:76)
.....
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Manual test
Closes#27492 from wangyum/SPARK-30755.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a follow-up for #23124, add a new config `spark.sql.legacy.allowDuplicatedMapKeys` to control the behavior of removing duplicated map keys in build-in functions. With the default value `false`, Spark will throw a RuntimeException while duplicated keys are found.
### Why are the changes needed?
Prevent silent behavior changes.
### Does this PR introduce any user-facing change?
Yes, new config added and the default behavior for duplicated map keys changed to RuntimeException thrown.
### How was this patch tested?
Modify existing UT.
Closes#27478 from xuanyuanking/SPARK-25892-follow.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch addresses the post-hoc review comment linked here - https://github.com/apache/spark/pull/25670#discussion_r373304076
### Why are the changes needed?
We would like to explicitly document the direct relationship before we finish up structuring of configurations.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#27576 from HeartSaVioR/SPARK-28869-FOLLOWUP-doc.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
fix style issue in the k8s document, please go to http://spark.apache.org/docs/3.0.0-preview2/running-on-kubernetes.html and search the keyword`spark.kubernetes.file.upload.path` to jump to the error context
### Why are the changes needed?
doc correctness
### Does this PR introduce any user-facing change?
Nah
### How was this patch tested?
Nah
Closes#27582 from yaooqinn/k8s-doc.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add doc for recommended pandas and pyarrow versions.
### Why are the changes needed?
The recommended versions are those that have been thoroughly tested by Spark CI. Other versions may be used at the discretion of the user.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
NA
Closes#27587 from BryanCutler/python-doc-rec-pandas-pyarrow-SPARK-30834-3.0.
Lead-authored-by: Bryan Cutler <cutlerb@gmail.com>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/27489.
It declares the ANSI SQL compliance options as experimental in the documentation.
### Why are the changes needed?
The options are experimental. There can be new features/behaviors in future releases.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Generating doc
Closes#27590 from gengliangwang/ExperimentalAnsi.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Change the link to the Scala API document.
```
$ git grep "#org.apache.spark.package"
docs/_layouts/global.html: <li><a href="api/scala/index.html#org.apache.spark.package">Scala</a></li>
docs/index.md:* [Spark Scala API (Scaladoc)](api/scala/index.html#org.apache.spark.package)
docs/rdd-programming-guide.md:[Scala](api/scala/#org.apache.spark.package), [Java](api/java/), [Python](api/python/) and [R](api/R/).
```
### Why are the changes needed?
The home page link for Scala API document is incorrect after upgrade to 3.0
### Does this PR introduce any user-facing change?
Document UI change only.
### How was this patch tested?
Local test, attach screenshots below:
Before:

After:

Closes#27549 from xuanyuanking/scala-doc.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR address the comment at https://github.com/apache/spark/pull/26496#discussion_r379194091 and improves the migration guide to explicitly note that the legacy environment variable to set in both executor and driver.
### Why are the changes needed?
To clarify this env should be set both in driver and executors.
### Does this PR introduce any user-facing change?
Nope.
### How was this patch tested?
I checked it via md editor.
Closes#27573 from HyukjinKwon/SPARK-29748.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
### What changes were proposed in this pull request?
`spark.sql("select map()")` returns {}.
After these changes it will return map<null,null>
### Why are the changes needed?
After changes introduced due to #27521, it is important to maintain consistency while using map().
### Does this PR introduce any user-facing change?
Yes. Now map() will give map<null,null> instead of {}.
### How was this patch tested?
UT added. Migration guide updated as well
Closes#27542 from iRakson/SPARK-30790.
Authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This pr is a follow up of https://github.com/apache/spark/pull/26200.
In this PR, I modify the description of spark.sql.files.* in sql-performance-tuning.md to keep consistent with that in SQLConf.
### Why are the changes needed?
To keep consistent with the description in SQLConf.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existed UT.
Closes#27545 from turboFei/SPARK-29542-follow-up.
Authored-by: turbofei <fwang12@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR targets to document the Pandas UDF redesign with type hints introduced at SPARK-28264.
Mostly self-describing; however, there are few things to note for reviewers.
1. This PR replace the existing documentation of pandas UDFs to the newer redesign to promote the Python type hints. I added some words that Spark 3.0 still keeps the compatibility though.
2. This PR proposes to name non-pandas UDFs as "Pandas Function API"
3. SCALAR_ITER become two separate sections to reduce confusion:
- `Iterator[pd.Series]` -> `Iterator[pd.Series]`
- `Iterator[Tuple[pd.Series, ...]]` -> `Iterator[pd.Series]`
4. I removed some examples that look overkill to me.
5. I also removed some information in the doc, that seems duplicating or too much.
### Why are the changes needed?
To document new redesign in pandas UDF.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests should cover.
Closes#27466 from HyukjinKwon/SPARK-30722.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Document updated for `CACHE TABLE` & `UNCACHE TABLE`
### Why are the changes needed?
Cache table creates a temp view while caching data using `CACHE TABLE name AS query`. `UNCACHE TABLE` does not remove this temp view.
These things were not mentioned in the existing doc for `CACHE TABLE` & `UNCACHE TABLE`.
### Does this PR introduce any user-facing change?
Document updated for `CACHE TABLE` & `UNCACHE TABLE` command.
### How was this patch tested?
Manually
Closes#27090 from iRakson/SPARK-27545.
Lead-authored-by: root1 <raksonrakesh@gmail.com>
Co-authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This brings https://github.com/apache/spark/pull/26324 back. It was reverted basically because, firstly Hive compatibility, and the lack of investigations in other DBMSes and ANSI.
- In case of PostgreSQL seems coercing NULL literal to TEXT type.
- Presto seems coercing `array() + array(1)` -> array of int.
- Hive seems `array() + array(1)` -> array of strings
Given that, the design choices have been differently made for some reasons. If we pick one of both, seems coercing to array of int makes much more sense.
Another investigation was made offline internally. Seems ANSI SQL 2011, section 6.5 "<contextually typed value specification>" states:
> If ES is specified, then let ET be the element type determined by the context in which ES appears. The declared type DT of ES is Case:
>
> a) If ES simply contains ARRAY, then ET ARRAY[0].
>
> b) If ES simply contains MULTISET, then ET MULTISET.
>
> ES is effectively replaced by CAST ( ES AS DT )
From reading other related context, doing it to `NullType`. Given the investigation made, choosing to `null` seems correct, and we have a reference Presto now. Therefore, this PR proposes to bring it back.
### Why are the changes needed?
When empty array is created, it should be declared as array<null>.
### Does this PR introduce any user-facing change?
Yes, `array()` creates `array<null>`. Now `array(1) + array()` can correctly create `array(1)` instead of `array("1")`.
### How was this patch tested?
Tested manually
Closes#27521 from HyukjinKwon/SPARK-29462.
Lead-authored-by: HyukjinKwon <gurwls223@apache.org>
Co-authored-by: Aman Omer <amanomer1996@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a follow-up for #24938 to tweak error message and migration doc.
### Why are the changes needed?
Making user know workaround if SHOW CREATE TABLE doesn't work for some Hive tables.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing unit tests.
Closes#27505 from viirya/SPARK-27946-followup.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <liangchi@uber.com>
### What changes were proposed in this pull request?
Add the new tab `SQL` in the `Data Types` page.
### Why are the changes needed?
New type added in SPARK-29587.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Locally test by Jekyll.

Closes#27447 from xuanyuanking/SPARK-29587-follow.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a follow-up for #25029, in this PR we throw an AnalysisException when name conflict is detected in nested WITH clause. In this way, the config `spark.sql.legacy.ctePrecedence.enabled` should be set explicitly for the expected behavior.
### Why are the changes needed?
The original change might risky to end-users, it changes behavior silently.
### Does this PR introduce any user-facing change?
Yes, change the config `spark.sql.legacy.ctePrecedence.enabled` as optional.
### How was this patch tested?
New UT.
Closes#27454 from xuanyuanking/SPARK-28228-follow.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add new config `spark.network.maxRemoteBlockSizeFetchToMem` fallback to the old config `spark.maxRemoteBlockSizeFetchToMem`.
### Why are the changes needed?
For naming consistency.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#27463 from xuanyuanking/SPARK-26700-follow.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add migration note for removing `org.apache.spark.ml.image.ImageSchema.readImages`
### Why are the changes needed?
### Does this PR introduce any user-facing change?
### How was this patch tested?
Closes#27467 from WeichenXu123/SC-26286.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose to partially revert the commit 51a6ba0181, and provide a legacy parser based on `FastDateFormat` which is compatible to `SimpleDateFormat`.
To enable the legacy parser, set `spark.sql.legacy.timeParser.enabled` to `true`.
### Why are the changes needed?
To allow users to restore old behavior in parsing timestamps/dates using `SimpleDateFormat` patterns. The main reason for restoring is `DateTimeFormatter`'s patterns are not fully compatible to `SimpleDateFormat` patterns, see https://issues.apache.org/jira/browse/SPARK-30668
### Does this PR introduce any user-facing change?
Yes
### How was this patch tested?
- Added new test to `DateFunctionsSuite`
- Restored additional test cases in `JsonInferSchemaSuite`.
Closes#27441 from MaxGekk/support-simpledateformat.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This reverts commit b89c3de1a4.
### Why are the changes needed?
`FIRST_VALUE` is used only for window expression. Please see the discussion on https://github.com/apache/spark/pull/25082 .
### Does this PR introduce any user-facing change?
Yes.
### How was this patch tested?
Pass the Jenkins.
Closes#27458 from dongjoon-hyun/SPARK-28310.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a follow-up for #22787. In #22787 we disallowed empty strings for json parser except for string and binary types. This follow-up adds a legacy config for restoring previous behavior of allowing empty string.
### Why are the changes needed?
Adding a legacy config to make migration easy for Spark users.
### Does this PR introduce any user-facing change?
Yes. If set this legacy config to true, the users can restore previous behavior prior to Spark 3.0.0.
### How was this patch tested?
Unit test.
Closes#27456 from viirya/SPARK-25040-followup.
Lead-authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Co-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose to update the SQL migration guide, and clarify behavior change of typed `TIMESTAMP` and `DATE` literals for input strings without time zone information - local timestamp and date strings.
### Why are the changes needed?
To inform users that the typed literals may change their behavior in Spark 3.0 because of different sources of the default time zone - JVM system time zone in Spark 2.4 and earlier, and `spark.sql.session.timeZone` in Spark 3.0.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#27435 from MaxGekk/timestamp-lit-migration-guide.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
We have upgraded the built-in Hive from 1.2 to 2.3. This may need to set `spark.sql.hive.metastore.version` and `spark.sql.hive.metastore.jars` according to the version of your Hive metastore. Example:
```
--conf spark.sql.hive.metastore.version=1.2.1 --conf spark.sql.hive.metastore.jars=/root/hive-1.2.1-lib/*
```
Otherwise:
```
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: Unable to fetch table spark_27686. Invalid method name: 'get_table_req';
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:110)
at org.apache.spark.sql.hive.HiveExternalCatalog.tableExists(HiveExternalCatalog.scala:841)
at org.apache.spark.sql.catalyst.catalog.ExternalCatalogWithListener.tableExists(ExternalCatalogWithListener.scala:146)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.tableExists(SessionCatalog.scala:431)
at org.apache.spark.sql.execution.command.CreateDataSourceTableCommand.run(createDataSourceTables.scala:52)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:79)
at org.apache.spark.sql.Dataset.$anonfun$logicalPlan$1(Dataset.scala:226)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3487)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$4(SQLExecution.scala:100)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:160)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:87)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3485)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:226)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:96)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:607)
... 47 elided
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Unable to fetch table spark_27686. Invalid method name: 'get_table_req'
at org.apache.hadoop.hive.ql.metadata.Hive.getTable(Hive.java:1282)
at org.apache.spark.sql.hive.client.HiveClientImpl.getRawTableOption(HiveClientImpl.scala:422)
at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$tableExists$1(HiveClientImpl.scala:436)
at scala.runtime.java8.JFunction0$mcZ$sp.apply(JFunction0$mcZ$sp.java:23)
at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$withHiveState$1(HiveClientImpl.scala:322)
at org.apache.spark.sql.hive.client.HiveClientImpl.liftedTree1$1(HiveClientImpl.scala:256)
at org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:255)
at org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:305)
at org.apache.spark.sql.hive.client.HiveClientImpl.tableExists(HiveClientImpl.scala:436)
at org.apache.spark.sql.hive.HiveExternalCatalog.$anonfun$tableExists$1(HiveExternalCatalog.scala:841)
at scala.runtime.java8.JFunction0$mcZ$sp.apply(JFunction0$mcZ$sp.java:23)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:100)
... 63 more
Caused by: org.apache.thrift.TApplicationException: Invalid method name: 'get_table_req'
at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:79)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_get_table_req(ThriftHiveMetastore.java:1567)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.get_table_req(ThriftHiveMetastore.java:1554)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.getTable(HiveMetaStoreClient.java:1350)
at org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient.getTable(SessionHiveMetaStoreClient.java:127)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:173)
at com.sun.proxy.$Proxy38.getTable(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient$SynchronizedHandler.invoke(HiveMetaStoreClient.java:2336)
at com.sun.proxy.$Proxy38.getTable(Unknown Source)
at org.apache.hadoop.hive.ql.metadata.Hive.getTable(Hive.java:1274)
... 74 more
```
### Why are the changes needed?
Improve documentation.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
```SKIP_API=1 jekyll build```:

Closes#27161 from wangyum/SPARK-27686.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This change is to allow custom resource scheduler (GPUs,FPGAs,etc) resource discovery to be more flexible. Users are asking for it to work with hadoop 2.x versions that do not support resource scheduling in YARN and/or also they may not run in an isolated environment.
This change creates a plugin api that users can write their own resource discovery class that allows a lot more flexibility. The user can chain plugins for different resource types. The user specified plugins execute in the order specified and will fall back to use the discovery script plugin if they don't return information for a particular resource.
I had to open up a few of the classes to be public and change them to not be case classes and make them developer api in order for the the plugin to get enough information it needs.
I also relaxed the yarn side so that if yarn isn't configured for resource scheduling we just warn and go on. This helps users that have yarn 3.1 but haven't configured the resource scheduling side on their cluster yet, or aren't running in isolated environment.
The user would configured this like:
--conf spark.resources.discovery.plugin="org.apache.spark.resource.ResourceDiscoveryFPGAPlugin, org.apache.spark.resource.ResourceDiscoveryGPUPlugin"
Note the executor side had to be wrapped with a classloader to make sure we include the user classpath for jars they specified on submission.
Note this is more flexible because the discovery script has limitations such as spawning it in a separate process. This means if you are trying to allocate resources in that process they might be released when the script returns. Other things are the class makes it more flexible to be able to integrate with existing systems and solutions for assigning resources.
### Why are the changes needed?
to more easily use spark resource scheduling with older versions of hadoop or in non-isolated enivronments.
### Does this PR introduce any user-facing change?
Yes a plugin api
### How was this patch tested?
Unit tests added and manual testing done on yarn and standalone modes.
Closes#27410 from tgravescs/hadoop27spark3.
Lead-authored-by: Thomas Graves <tgraves@nvidia.com>
Co-authored-by: Thomas Graves <tgraves@apache.org>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
This patch adds a DDL command `SHOW CREATE TABLE AS SERDE`. It is used to generate Hive DDL for a Hive table.
For original `SHOW CREATE TABLE`, it now shows Spark DDL always. If given a Hive table, it tries to generate Spark DDL.
For Hive serde to data source conversion, this uses the existing mapping inside `HiveSerDe`. If can't find a mapping there, throws an analysis exception on unsupported serde configuration.
It is arguably that some Hive fileformat + row serde might be mapped to Spark data source, e.g., CSV. It is not included in this PR. To be conservative, it may not be supported.
For Hive serde properties, for now this doesn't save it to Spark DDL because it may not useful to keep Hive serde properties in Spark table.
## How was this patch tested?
Added test.
Closes#24938 from viirya/SPARK-27946.
Lead-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Co-authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Add a section to the Configuration page to document configurations for executor metrics.
At the same time, rename spark.eventLog.logStageExecutorProcessTreeMetrics.enabled to spark.executor.processTreeMetrics.enabled and make it independent of spark.eventLog.logStageExecutorMetrics.enabled.
### Why are the changes needed?
Executor metrics are new in Spark 3.0. They lack documentation.
Memory metrics as a whole are always collected, but the ones obtained from the process tree have to be optionally enabled. Making this depend on a single configuration makes for more intuitive behavior. Given this, the configuration property is renamed to better reflect its meaning.
### Does this PR introduce any user-facing change?
Yes, only in that the configurations are all new to 3.0.
### How was this patch tested?
Not necessary.
Closes#27329 from wypoon/SPARK-27324.
Authored-by: Wing Yew Poon <wypoon@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
### What changes were proposed in this pull request?
- Add `minPartitions` support for Kafka Streaming V1 source.
- Add `minPartitions` support for Kafka batch V1 and V2 source.
- There is lots of refactoring (moving codes to KafkaOffsetReader) to reuse codes.
### Why are the changes needed?
Right now, the "minPartitions" option only works in Kafka streaming source v2. It would be great that we can support it in batch and streaming source v1 (v1 is the fallback mode when a user hits a regression in v2) as well.
### Does this PR introduce any user-facing change?
Yep. The `minPartitions` options is supported in Kafka batch and streaming queries for both data source V1 and V2.
### How was this patch tested?
New unit tests are added to test "minPartitions".
Closes#27388 from zsxwing/kafka-min-partitions.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
### What changes were proposed in this pull request?
This PR removes any dependencies on pypandoc. It also makes related tweaks to the docs README to clarify the dependency on pandoc (not pypandoc).
### Why are the changes needed?
We are using pypandoc to convert the Spark README from Markdown to ReST for PyPI. PyPI now natively supports Markdown, so we don't need pypandoc anymore. The dependency on pypandoc also sometimes causes issues when installing Python packages that depend on PySpark, as described in #18981.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Manually:
```sh
python -m venv venv
source venv/bin/activate
pip install -U pip
cd python/
python setup.py sdist
pip install dist/pyspark-3.0.0.dev0.tar.gz
pyspark --version
```
I also built the PySpark and R API docs with `jekyll` and reviewed them locally.
It would be good if a maintainer could also test this by creating a PySpark distribution and uploading it to [Test PyPI](https://test.pypi.org) to confirm the README looks as it should.
Closes#27376 from nchammas/SPARK-30665-pypandoc.
Authored-by: Nicholas Chammas <nicholas.chammas@liveramp.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
add supported hive features
### Why are the changes needed?
update doc
### Does this PR introduce any user-facing change?
Before change UI info:

After this pr:


### How was this patch tested?
For PR about Spark Doc Web UI, we need to show UI format before and after pr.
We can build our local web server about spark docs with reference `$SPARK_PROJECT/docs/README.md`
You should install python and ruby in your env and also install plugin like below
```sh
$ sudo gem install jekyll jekyll-redirect-from rouge
# Following is needed only for generating API docs
$ sudo pip install sphinx pypandoc mkdocs
$ sudo Rscript -e 'install.packages(c("knitr", "devtools", "rmarkdown"), repos="https://cloud.r-project.org/")'
$ sudo Rscript -e 'devtools::install_version("roxygen2", version = "5.0.1", repos="https://cloud.r-project.org/")'
$ sudo Rscript -e 'devtools::install_version("testthat", version = "1.0.2", repos="https://cloud.r-project.org/")'
```
Then we call `jekyll serve --watch` after build we see below message
```
~/Documents/project/AngersZhu/spark/sql
Moving back into docs dir.
Making directory api/sql
cp -r ../sql/site/. api/sql
Source: /Users/angerszhu/Documents/project/AngersZhu/spark/docs
Destination: /Users/angerszhu/Documents/project/AngersZhu/spark/docs/_site
Incremental build: disabled. Enable with --incremental
Generating...
done in 24.717 seconds.
Auto-regeneration: enabled for '/Users/angerszhu/Documents/project/AngersZhu/spark/docs'
Server address: http://127.0.0.1:4000
Server running... press ctrl-c to stop.
```
Visit http://127.0.0.1:4000 to get your newest change in doc web.
Closes#27106 from AngersZhuuuu/SPARK-30435.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR adds `numpy` to the list of things that need to be installed in order to build the API docs. It doesn't add a new dependency; it just documents an existing dependency.
### Why are the changes needed?
You cannot build the PySpark API docs without numpy installed. Otherwise you get this series of errors:
```
$ SKIP_SCALADOC=1 SKIP_RDOC=1 SKIP_SQLDOC=1 jekyll serve
Configuration file: .../spark/docs/_config.yml
Moving to python/docs directory and building sphinx.
sphinx-build -b html -d _build/doctrees . _build/html
Running Sphinx v2.3.1
loading pickled environment... done
building [mo]: targets for 0 po files that are out of date
building [html]: targets for 0 source files that are out of date
updating environment: 0 added, 2 changed, 0 removed
reading sources... [100%] pyspark.mllib
WARNING: autodoc: failed to import module 'ml' from module 'pyspark'; the following exception was raised:
No module named 'numpy'
WARNING: autodoc: failed to import module 'ml.param' from module 'pyspark'; the following exception was raised:
No module named 'numpy'
...
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Manually, by building the API docs with and without numpy.
Closes#27390 from nchammas/SPARK-30672-numpy-pyspark-docs.
Authored-by: Nicholas Chammas <nicholas.chammas@liveramp.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
- Sets up links between related sections.
- Add "Related sections" for each section.
- Change to the left hand side menu to reflect the current status of the doc.
- Other minor cleanups.
### Why are the changes needed?
Currently Spark lacks documentation on the supported SQL constructs causing
confusion among users who sometimes have to look at the code to understand the
usage. This is aimed at addressing this issue.
### Does this PR introduce any user-facing change?
Yes.
### How was this patch tested?
Tested using jykyll build --serve
Closes#27371 from dilipbiswal/select_finalization.
Authored-by: Dilip Biswal <dkbiswal@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This pr intends to rename `spark.sql.legacy.addDirectory.recursive` into `spark.sql.legacy.addDirectory.recursive.enabled`.
### Why are the changes needed?
For consistent option names.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#27372 from maropu/SPARK-30234-FOLLOWUP.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
- Update `testthat` to >= 2.0.0
- Replace of `testthat:::run_tests` with `testthat:::test_package_dir`
- Add trivial assertions for tests, without any expectations, to avoid skipping.
- Update related docs.
### Why are the changes needed?
`testthat` version has been frozen by [SPARK-22817](https://issues.apache.org/jira/browse/SPARK-22817) / https://github.com/apache/spark/pull/20003, but 1.0.2 is pretty old, and we shouldn't keep things in this state forever.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
- Existing CI pipeline:
- Windows build on AppVeyor, R 3.6.2, testthtat 2.3.1
- Linux build on Jenkins, R 3.1.x, testthat 1.0.2
- Additional builds with thesthat 2.3.1 using [sparkr-build-sandbox](https://github.com/zero323/sparkr-build-sandbox) on c7ed64af9e697b3619779857dd820832176b3be3
R 3.4.4 (image digest ec9032f8cf98)
```
docker pull zero323/sparkr-build-sandbox:3.4.4
docker run zero323/sparkr-build-sandbox:3.4.4 zero323 --branch SPARK-23435 --commit c7ed64af9e697b3619779857dd820832176b3be3 --public-key https://keybase.io/zero323/pgp_keys.asc
```
3.5.3 (image digest 0b1759ee4d1d)
```
docker pull zero323/sparkr-build-sandbox:3.5.3
docker run zero323/sparkr-build-sandbox:3.5.3 zero323 --branch SPARK-23435 --commit
c7ed64af9e697b3619779857dd820832176b3be3 --public-key https://keybase.io/zero323/pgp_keys.asc
```
and 3.6.2 (image digest 6594c8ceb72f)
```
docker pull zero323/sparkr-build-sandbox:3.6.2
docker run zero323/sparkr-build-sandbox:3.6.2 zero323 --branch SPARK-23435 --commit c7ed64af9e697b3619779857dd820832176b3be3 --public-key https://keybase.io/zero323/pgp_keys.asc
````
Corresponding [asciicast](https://asciinema.org/) are available as 10.5281/zenodo.3629431
[](https://doi.org/10.5281/zenodo.3629431)
(a bit to large to burden asciinema.org, but can run locally via `asciinema play`).
----------------------------
Continued from #27328Closes#27359 from zero323/SPARK-23435.
Authored-by: zero323 <mszymkiewicz@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This patch addresses remaining functionality on event log compaction: integrate compaction into FsHistoryProvider.
This patch is next task of SPARK-30479 (#27164), please refer the description of PR #27085 to see overall rationalization of this patch.
### Why are the changes needed?
One of major goal of SPARK-28594 is to prevent the event logs to become too huge, and SPARK-29779 achieves the goal. We've got another approach in prior, but the old approach required models in both KVStore and live entities to guarantee compatibility, while they're not designed to do so.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Added UT.
Closes#27208 from HeartSaVioR/SPARK-30481.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@apache.org>
### What changes were proposed in this pull request?
Document CLUSTER BY clause of SELECT statement in SQL Reference Guide.
### Why are the changes needed?
Currently Spark lacks documentation on the supported SQL constructs causing
confusion among users who sometimes have to look at the code to understand the
usage. This is aimed at addressing this issue.
### Does this PR introduce any user-facing change?
Yes.
**Before:**
There was no documentation for this.
**After.**
<img width="972" alt="Screen Shot 2020-01-20 at 2 59 05 PM" src="https://user-images.githubusercontent.com/14225158/72762704-7528de80-3b95-11ea-9d34-8fa0ab63d4c0.png">
<img width="972" alt="Screen Shot 2020-01-20 at 2 59 19 PM" src="https://user-images.githubusercontent.com/14225158/72762710-78bc6580-3b95-11ea-8279-2848d3b9e619.png">
### How was this patch tested?
Tested using jykyll build --serve
Closes#27297 from dilipbiswal/sql-ref-select-clusterby.
Authored-by: Dilip Biswal <dkbiswal@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Document DISTRIBUTE BY clause of SELECT statement in SQL Reference Guide.
### Why are the changes needed?
Currently Spark lacks documentation on the supported SQL constructs causing
confusion among users who sometimes have to look at the code to understand the
usage. This is aimed at addressing this issue.
### Does this PR introduce any user-facing change?
Yes.
**Before:**
There was no documentation for this.
**After.**
<img width="972" alt="Screen Shot 2020-01-20 at 3 08 24 PM" src="https://user-images.githubusercontent.com/14225158/72763045-c08fbc80-3b96-11ea-8fb6-023cba5eb96a.png">
<img width="972" alt="Screen Shot 2020-01-20 at 3 08 34 PM" src="https://user-images.githubusercontent.com/14225158/72763047-c38aad00-3b96-11ea-80d8-cd3d2d4257c8.png">
### How was this patch tested?
Tested using jykyll build --serve
Closes#27298 from dilipbiswal/sql-ref-select-distributeby.
Authored-by: Dilip Biswal <dkbiswal@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Document CREATE TABLE statement in SQL Reference Guide.
### Why are the changes needed?
Adding documentation for SQL reference.
### Does this PR introduce any user-facing change?
yes
Before:
There was no documentation for this.
### How was this patch tested?
Used jekyll build and serve to verify.
Closes#26759 from PavithraRamachandran/create_doc.
Authored-by: Pavithra Ramachandran <pavi.rams@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Fix a few super nit problems
### Why are the changes needed?
To make doc look better
### Does this PR introduce any user-facing change?
Yes
### How was this patch tested?
Tested using jykyll build --serve
Closes#27332 from huaxingao/spark-30575-followup.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Document SELECT statement in SQL Reference Guide. In this PR includes the main
entry page for SELECT. I will open follow-up PRs for different clauses.
### Why are the changes needed?
Currently Spark lacks documentation on the supported SQL constructs causing
confusion among users who sometimes have to look at the code to understand the
usage. This is aimed at addressing this issue.
### Does this PR introduce any user-facing change?
Yes.
**Before:**
There was no documentation for this.
**After.**
<img width="972" alt="Screen Shot 2020-01-19 at 11 20 41 PM" src="https://user-images.githubusercontent.com/14225158/72706257-6c42f900-3b12-11ea-821a-171ff035443f.png">
<img width="972" alt="Screen Shot 2020-01-19 at 11 21 55 PM" src="https://user-images.githubusercontent.com/14225158/72706313-91d00280-3b12-11ea-90e4-be7174b4593d.png">
<img width="972" alt="Screen Shot 2020-01-19 at 11 22 16 PM" src="https://user-images.githubusercontent.com/14225158/72706323-97c5e380-3b12-11ea-99e5-e7aaa3b4df68.png">
### How was this patch tested?
Tested using jykyll build --serve
Closes#27216 from dilipbiswal/sql_ref_select_hook.
Authored-by: Dilip Biswal <dkbiswal@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Document LIMIT clause of SELECT statement in SQL Reference Guide.
### Why are the changes needed?
Currently Spark lacks documentation on the supported SQL constructs causing
confusion among users who sometimes have to look at the code to understand the
usage. This is aimed at addressing this issue.
### Does this PR introduce any user-facing change?
Yes.
**Before:**
There was no documentation for this.
**After.**
<img width="972" alt="Screen Shot 2020-01-20 at 1 37 28 AM" src="https://user-images.githubusercontent.com/14225158/72715533-7e7a6280-3b25-11ea-98fc-ed68b5d5024a.png">
<img width="972" alt="Screen Shot 2020-01-20 at 1 37 43 AM" src="https://user-images.githubusercontent.com/14225158/72715549-83d7ad00-3b25-11ea-98b3-610eca2628f6.png">
### How was this patch tested?
Tested using jykyll build --serve
Closes#27290 from dilipbiswal/sql-ref-select-limit.
Authored-by: Dilip Biswal <dkbiswal@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This pr removes the nonstandard `SET OWNER` syntax for namespaces and changes the owner reserved properties from `ownerName` and `ownerType` to `owner`.
### Why are the changes needed?
the `SET OWNER` syntax for namespaces is hive-specific and non-sql standard, we need a more future-proofing design before we implement user-facing changes for SQL security issues
### Does this PR introduce any user-facing change?
no, just revert an unpublic syntax
### How was this patch tested?
modified uts
Closes#27300 from yaooqinn/SPARK-30591.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR propose to disallow negative `scale` of `Decimal` in Spark. And this PR brings two behavior changes:
1) for literals like `1.23E4BD` or `1.23E4`(with `spark.sql.legacy.exponentLiteralAsDecimal.enabled`=true, see [SPARK-29956](https://issues.apache.org/jira/browse/SPARK-29956)), we set its `(precision, scale)` to (5, 0) rather than (3, -2);
2) add negative `scale` check inside the decimal method if it exposes to set `scale` explicitly. If check fails, `AnalysisException` throws.
And user could still use `spark.sql.legacy.allowNegativeScaleOfDecimal.enabled` to restore the previous behavior.
### Why are the changes needed?
According to SQL standard,
> 4.4.2 Characteristics of numbers
An exact numeric type has a precision P and a scale S. P is a positive integer that determines the number of significant digits in a particular radix R, where R is either 2 or 10. S is a non-negative integer.
scale of Decimal should always be non-negative. And other mainstream databases, like Presto, PostgreSQL, also don't allow negative scale.
Presto:
```
presto:default> create table t (i decimal(2, -1));
Query 20191213_081238_00017_i448h failed: line 1:30: mismatched input '-'. Expecting: <integer>, <type>
create table t (i decimal(2, -1))
```
PostgrelSQL:
```
postgres=# create table t(i decimal(2, -1));
ERROR: NUMERIC scale -1 must be between 0 and precision 2
LINE 1: create table t(i decimal(2, -1));
^
```
And, actually, Spark itself already doesn't allow to create table with negative decimal types using SQL:
```
scala> spark.sql("create table t(i decimal(2, -1))");
org.apache.spark.sql.catalyst.parser.ParseException:
no viable alternative at input 'create table t(i decimal(2, -'(line 1, pos 28)
== SQL ==
create table t(i decimal(2, -1))
----------------------------^^^
at org.apache.spark.sql.catalyst.parser.ParseException.withCommand(ParseDriver.scala:263)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parse(ParseDriver.scala:130)
at org.apache.spark.sql.execution.SparkSqlParser.parse(SparkSqlParser.scala:48)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parsePlan(ParseDriver.scala:76)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:605)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:605)
... 35 elided
```
However, it is still possible to create such table or `DatFrame` using Spark SQL programming API:
```
scala> val tb =
CatalogTable(
TableIdentifier("test", None),
CatalogTableType.MANAGED,
CatalogStorageFormat.empty,
StructType(StructField("i", DecimalType(2, -1) ) :: Nil))
```
```
scala> spark.sql("SELECT 1.23E4BD")
res2: org.apache.spark.sql.DataFrame = [1.23E+4: decimal(3,-2)]
```
while, these two different behavior could make user confused.
On the other side, even if user creates such table or `DataFrame` with negative scale decimal type, it can't write data out if using format, like `parquet` or `orc`. Because these formats have their own check for negative scale and fail on it.
```
scala> spark.sql("SELECT 1.23E4BD").write.saveAsTable("parquet")
19/12/13 17:37:04 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)
java.lang.IllegalArgumentException: Invalid DECIMAL scale: -2
at org.apache.parquet.Preconditions.checkArgument(Preconditions.java:53)
at org.apache.parquet.schema.Types$BasePrimitiveBuilder.decimalMetadata(Types.java:495)
at org.apache.parquet.schema.Types$BasePrimitiveBuilder.build(Types.java:403)
at org.apache.parquet.schema.Types$BasePrimitiveBuilder.build(Types.java:309)
at org.apache.parquet.schema.Types$Builder.named(Types.java:290)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.convertField(ParquetSchemaConverter.scala:428)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.convertField(ParquetSchemaConverter.scala:334)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.$anonfun$convert$2(ParquetSchemaConverter.scala:326)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at org.apache.spark.sql.types.StructType.foreach(StructType.scala:99)
at scala.collection.TraversableLike.map(TraversableLike.scala:238)
at scala.collection.TraversableLike.map$(TraversableLike.scala:231)
at org.apache.spark.sql.types.StructType.map(StructType.scala:99)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.convert(ParquetSchemaConverter.scala:326)
at org.apache.spark.sql.execution.datasources.parquet.ParquetWriteSupport.init(ParquetWriteSupport.scala:97)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:388)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:349)
at org.apache.spark.sql.execution.datasources.parquet.ParquetOutputWriter.<init>(ParquetOutputWriter.scala:37)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$$anon$1.newInstance(ParquetFileFormat.scala:150)
at org.apache.spark.sql.execution.datasources.SingleDirectoryDataWriter.newOutputWriter(FileFormatDataWriter.scala:124)
at org.apache.spark.sql.execution.datasources.SingleDirectoryDataWriter.<init>(FileFormatDataWriter.scala:109)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeTask(FileFormatWriter.scala:264)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$write$15(FileFormatWriter.scala:205)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:127)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:441)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:444)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
So, I think it would be better to disallow negative scale totally and make behaviors above be consistent.
### Does this PR introduce any user-facing change?
Yes, if `spark.sql.legacy.allowNegativeScaleOfDecimal.enabled=false`, user couldn't create Decimal value with negative scale anymore.
### How was this patch tested?
Added new tests in `ExpressionParserSuite` and `DecimalSuite`;
Updated `SQLQueryTestSuite`.
Closes#26881 from Ngone51/nonnegative-scale.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add `owner` property to v2 table, it is reversed by `TableCatalog`, indicates the table's owner.
### Why are the changes needed?
enhance ownership management of catalog API
### Does this PR introduce any user-facing change?
yes, add 1 reserved property - `owner` , and it is not allowed to use in OPTIONS/TBLPROPERTIES anymore, only if legacy on
### How was this patch tested?
add uts
Closes#27249 from yaooqinn/SPARK-30019.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR adds a migration guide for `SHOW TBLPROPERTIES` for Apache Spark 3.0.0.
### Why are the changes needed?
The behavior of `SHOW TBLPROPERTIES` changed when the table does not exist. The migration guide reflects this user facing change.
### Does this PR introduce any user-facing change?
Yes. This is a documentation change.
### How was this patch tested?
No tests were added because this is a doc change.
Closes#27276 from imback82/SPARK-30282-followup.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
make KUBERNETES_MASTER_INTERNAL_URL configurable
### Why are the changes needed?
we do not always use the default port number 443 to access our kube-apiserver, and even in some mulit-tenant cluster, people do not use the service `kubernetes.default.svc` to access the kube-apiserver, so make the internal master configurable is necessary。
### Does this PR introduce any user-facing change?
user can configure the internal master url by
```
--conf spark.kubernetes.internal.master=https://kubernetes.default.svc:6443
```
### How was this patch tested?
run in multi-cluster that do not use the https://kubernetes.default.svc to access the kube-apiserver
Closes#27029 from wackxu/internalmaster.
Authored-by: xushiwei 00425595 <xushiwei5@huawei.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR adds a migration guide for MsSQLServer JDBC dialect for Apache Spark 2.4.4 and 2.4.5.
### Why are the changes needed?
Apache Spark 2.4.4 updates the type mapping correctly according to MS SQL Server, but missed to mention that in the migration guide. In addition, 2.4.4 adds a configuration for the legacy behavior.
### Does this PR introduce any user-facing change?
Yes. This is a documentation change.

### How was this patch tested?
Manually generate and see the doc.
Closes#27270 from dongjoon-hyun/SPARK-28152-DOC.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/26956 to add a migration document for 2.4.5.
### Why are the changes needed?
New legacy configuration will restore the previous behavior safely.
### Does this PR introduce any user-facing change?
This PR updates the doc.
<img width="763" alt="screenshot" src="https://user-images.githubusercontent.com/9700541/72639939-9da5a400-391b-11ea-87b1-14bca15db5a6.png">
### How was this patch tested?
Build the document and see the change manually.
Closes#27269 from dongjoon-hyun/SPARK-30312.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
[SPARK-20568](https://issues.apache.org/jira/browse/SPARK-20568) added the possibility to clean up completed files in streaming query. Deleting/archiving uses the main thread which can slow down processing. In this PR I've created thread pool to handle file delete/archival. The number of threads can be configured with `spark.sql.streaming.fileSource.cleaner.numThreads`.
### Why are the changes needed?
Do file delete/archival in separate thread.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing unit tests.
Closes#26502 from gaborgsomogyi/SPARK-29876.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
The default value for backLog set back to -1, as any other value may break existing configuration by overriding Netty's default io.netty.util.NetUtil#SOMAXCONN. The documentation accordingly adjusted.
See discussion thread: https://github.com/apache/spark/pull/24732
### What changes were proposed in this pull request?
Partial rollback of https://github.com/apache/spark/pull/24732 (default for backLog set back to -1).
### Why are the changes needed?
Previous change introduces backward incompatibility by overriding default of Netty's `io.netty.util.NetUtil#SOMAXCONN`
Closes#27230 from xCASx/master.
Authored-by: Maxim Kolesnikov <swe.kolesnikov@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
SPARK-29894 provides information on the Codegen Stage Id in WEBUI for SQL Plan graphs. Similarly, this proposes to add Codegen Stage Id in the DAG visualization for Stage execution. DAGs for Stage execution are available in the WEBUI under the Jobs and Stages tabs.
### Why are the changes needed?
This is proposed as an aid for drill-down analysis of complex SQL statement execution, as it is not always easy to match parts of the SQL Plan graph with the corresponding Stage DAG execution graph. Adding Codegen Stage Id for WholeStageCodegen operations makes this task easier.
### Does this PR introduce any user-facing change?
Stage DAG visualization in the WEBUI will show codegen stage id for WholeStageCodegen operations, as in the example snippet from the WEBUI, Jobs tab (the query used in the example is TPCDS 2.4 q14a):

### How was this patch tested?
Manually tested, see also example snippet.
Closes#26675 from LucaCanali/addCodegenStageIdtoStageGraph.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Use the new framework to resolve the SHOW TBLPROPERTIES command. This PR along with #27243 should update all the existing V2 commands with `UnresolvedV2Relation`.
### Why are the changes needed?
This is a part of effort to make the relation lookup behavior consistent: [SPARK-2990](https://issues.apache.org/jira/browse/SPARK-29900).
### Does this PR introduce any user-facing change?
Yes `SHOW TBLPROPERTIES temp_view` now fails with `AnalysisException` will be thrown with a message `temp_view is a temp view not table`. Previously, it was returning empty row.
### How was this patch tested?
Existing tests
Closes#26921 from imback82/consistnet_v2command.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
TableCatalog reserves some properties, e,g `provider`, `location` for internal usage. Some of them are static once create, some of them need specific syntax to modify. Instead of using `OPTIONS (k='v')` or TBLPROPERTIES (k='v'), if k is a reserved TableCatalog property, we should use its specific syntax to add/modify/delete it. e.g. `provider` is a reserved property, we should use the `USING` clause to specify it, and should not allow `ALTER TABLE ... UNSET TBLPROPERTIES('provider')` to delete it. Also, there are two paths for v1/v2 catalog tables to resolve these properties, e.g. the v1 session catalog tables will only use the `USING` clause to decide `provider` but v2 tables will also lookup OPTION/TBLPROPERTIES(although there is a bug prohibit it).
Additionally, 'path' is not reserved but holds special meaning for `LOCATION` and it is used in `CREATE/REPLACE TABLE`'s `OPTIONS` sub-clause. Now for the session catalog tables, the `path` is case-insensitive, but for the non-session catalog tables, it is case-sensitive, we should make it both case insensitive for disambiguation.
### Why are the changes needed?
prevent reserved properties from being modified unexpectedly
unify the property resolution for v1/v2.
fix some bugs.
### Does this PR introduce any user-facing change?
yes
1 . `location` and `provider` (case sensitive) cannot be used in `CREATE/REPLACE TABLE ... OPTIONS/TBLPROPETIES` and `ALTER TABLE ... SET TBLPROPERTIES (...)`, if legacy on, they will be ignored to let the command success without having side effects
3. Once `path` in `CREATE/REPLACE TABLE ... OPTIONS` is case insensitive for v1 but sensitive for v2, but now we change it case insensitive for both kinds of tables, then v2 tables will also fail if `LOCATION` and `OPTIONS('PaTh' ='abc')` are both specified or will pick `PaTh`'s value as table location if `LOCATION` is missing.
4. Now we will detect if there are two different case `path` keys or more in `CREATE/REPLACE TABLE ... OPTIONS`, once it is a kind of unexpected last-win policy for v1, and v2 is case sensitive.
### How was this patch tested?
add ut
Closes#27197 from yaooqinn/SPARK-30507.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Updated `docs/sql-data-sources-avro.md`, and added a few sentences about already deprecated in code Avro option `ignoreExtension`.
<img width="968" alt="Screen Shot 2020-01-15 at 10 24 14" src="https://user-images.githubusercontent.com/1580697/72413684-64d1c780-3781-11ea-948a-d3cccf4c72df.png">
Closes#27174
### Why are the changes needed?
To make users doc consistent to the code where `ignoreExtension` has been already deprecated, see 3663dbe541/external/avro/src/main/scala/org/apache/spark/sql/avro/AvroUtils.scala (L46-L47)
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
by building docs
Closes#27194 from MaxGekk/avro-doc-deprecation-ignoreExtension.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
* Annotate UserDefinedAggregateFunction as deprecated by SPARK-27296
* Update user doc examples to reflect new ability to register typed Aggregator[IN, BUF, OUT] as an untyped aggregating UDF
### Why are the changes needed?
UserDefinedAggregateFunction is being deprecated
### Does this PR introduce any user-facing change?
Changes are to user documentation, and deprecation annotations.
### How was this patch tested?
Testing was via package build to verify doc generation, deprecation warnings, and successful example compilation.
Closes#27193 from erikerlandson/spark-30423.
Authored-by: Erik Erlandson <eerlands@redhat.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Updated the doc for ADD FILE and LIST FILE
### Why are the changes needed?
Due to changes made in #26863 , it is necessary to update ADD FILE and LIST FILE doc.
### Does this PR introduce any user-facing change?
Yeah. Document updated.
### How was this patch tested?
Manually
Closes#27188 from iRakson/SPARK-30234_FOLLOWUP.
Authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This patch documents the configuration for the Kafka producer pool, newly revised via SPARK-21869 (#26845)
### Why are the changes needed?
The explanation of new Kafka producer pool configuration is missing, whereas the doc has Kafka
consumer pool configuration.
### Does this PR introduce any user-facing change?
Yes. This is a documentation change.

### How was this patch tested?
N/A
Closes#27146 from HeartSaVioR/SPARK-21869-FOLLOWUP.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Removing the sorting of PySpark SQL Row fields that were previously sorted by name alphabetically for Python versions 3.6 and above. Field order will now match that as entered. Rows will be used like tuples and are applied to schema by position. For Python versions < 3.6, the order of kwargs is not guaranteed and therefore will be sorted automatically as in previous versions of Spark.
### Why are the changes needed?
This caused inconsistent behavior in that local Rows could be applied to a schema by matching names, but once serialized the Row could only be used by position and the fields were possibly in a different order.
### Does this PR introduce any user-facing change?
Yes, Row fields are no longer sorted alphabetically but will be in the order entered. For Python < 3.6 `kwargs` can not guarantee the order as entered, so `Row`s will be automatically sorted.
An environment variable "PYSPARK_ROW_FIELD_SORTING_ENABLED" can be set that will override construction of `Row` to maintain compatibility with Spark 2.x.
### How was this patch tested?
Existing tests are run with PYSPARK_ROW_FIELD_SORTING_ENABLED=true and added new test with unsorted fields for Python 3.6+
Closes#26496 from BryanCutler/pyspark-remove-Row-sorting-SPARK-29748.
Authored-by: Bryan Cutler <cutlerb@gmail.com>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
### What changes were proposed in this pull request?
Now users can add directories from sql CLI as well using ADD FILE command and setting spark.sql.addDirectory.recursive to true.
### Why are the changes needed?
In SPARK-4687, support was added for adding directories as resources. But sql users cannot use that feature from CLI.
`ADD FILE /path/to/folder` gives the following error:
`org.apache.spark.SparkException: Added file /path/to/folder is a directory and recursive is not turned on.`
Users need to turn on `recursive` for adding directories. Thus a configuration was required which will allow users to turn on `recursive`.
Also Hive allow users to add directories from their shell.
### Does this PR introduce any user-facing change?
Yes. Users can set recursive using `spark.sql.addDirectory.recursive`.
### How was this patch tested?
Manually.
Will add test cases soon.
SPARK SCREENSHOTS
When `spark.sql.addDirectory.recursive` is not turned on.
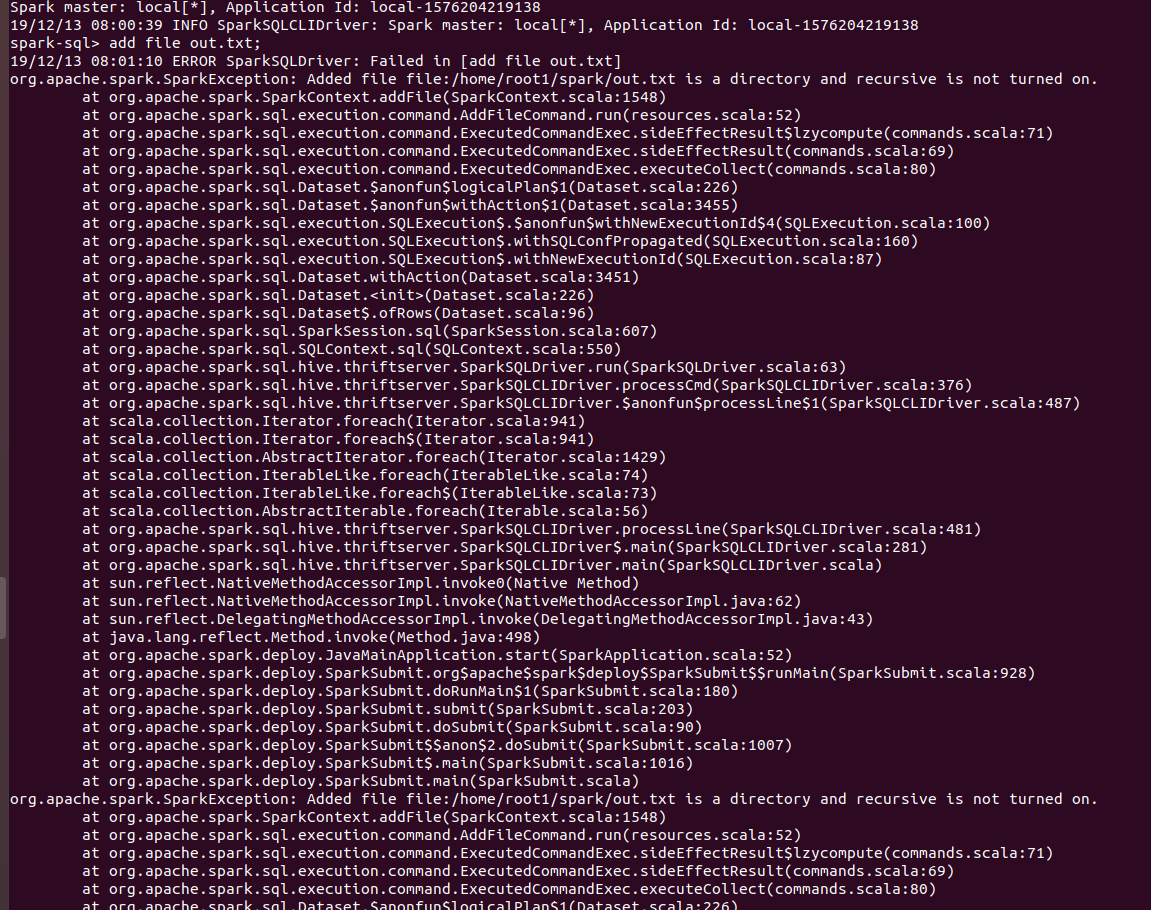
After setting `spark.sql.addDirectory.recursive` to true.

HIVE SCREENSHOT

`RELEASE_NOTES.txt` is text file while `dummy` is a directory.
Closes#26863 from iRakson/SPARK-30234.
Lead-authored-by: root1 <raksonrakesh@gmail.com>
Co-authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In this pull request, we are going to support `SET OWNER` syntax for databases and namespaces,
```sql
ALTER (DATABASE|SCHEME|NAMESPACE) database_name SET OWNER [USER|ROLE|GROUP] user_or_role_group;
```
Before this commit 332e252a14, we didn't care much about ownerships for the catalog objects. In 332e252a14, we determined to use properties to store ownership staff, and temporarily used `alter database ... set dbproperties ...` to support switch ownership of a database. This PR aims to use the formal syntax to replace it.
In hive, `ownerName/Type` are fields of the database objects, also they can be normal properties.
```
create schema test1 with dbproperties('ownerName'='yaooqinn')
```
The create/alter database syntax will not change the owner to `yaooqinn` but store it in parameters. e.g.
```
+----------+----------+---------------------------------------------------------------+-------------+-------------+-----------------------+--+
| db_name | comment | location | owner_name | owner_type | parameters |
+----------+----------+---------------------------------------------------------------+-------------+-------------+-----------------------+--+
| test1 | | hdfs://quickstart.cloudera:8020/user/hive/warehouse/test1.db | anonymous | USER | {ownerName=yaooqinn} |
+----------+----------+---------------------------------------------------------------+-------------+-------------+-----------------------+--+
```
In this pull request, because we let the `ownerName` become reversed, so it will neither change the owner nor store in dbproperties, just be omitted silently.
## Why are the changes needed?
Formal syntax support for changing database ownership
### Does this PR introduce any user-facing change?
yes, add a new syntax
### How was this patch tested?
add unit tests
Closes#26775 from yaooqinn/SPARK-30018.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, COMMENT and LOCATION are reserved properties for Datasource v2 namespaces. They can be set via specific clauses and via properties. And the ones specified in clauses take precede of properties. Since they are reserved, which means they are not able to visit directly. They should be used in COMMENT/LOCATION clauses ONLY.
### Why are the changes needed?
make reserved properties be reserved.
### Does this PR introduce any user-facing change?
yes, 'location', 'comment' are not allowed use in db properties
### How was this patch tested?
UNIT tests.
Closes#26806 from yaooqinn/SPARK-30183.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Previously in https://github.com/apache/spark/pull/26614/files#diff-bad3987c83bd22d46416d3dd9d208e76R90, we compare the number of tasks with `(conf.get(EXECUTOR_CORES) / sched.CPUS_PER_TASK)`. In standalone mode if the value is not explicitly set by default, the conf value would be 1 but the executor would actually use all the cores of the worker. So it is allowed to have `CPUS_PER_TASK` greater than `EXECUTOR_CORES`. To handle this case, we change the condition to be `numTasks <= Math.max(conf.get(EXECUTOR_CORES) / sched.CPUS_PER_TASK, 1)`
### Why are the changes needed?
For standalone mode if the user set the `spark.task.cpus` to be greater than 1 but didn't set the `spark.executor.cores`. Even though there is only 1 task in the stage it would not be speculative run.
### Does this PR introduce any user-facing change?
Solve the problem above by allowing speculative run when there is only 1 task in the stage.
### How was this patch tested?
Existing tests and one more test in TaskSetManagerSuite
Closes#27126 from yuchenhuo/SPARK-30417.
Authored-by: Yuchen Huo <yuchen.huo@databricks.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
### What changes were proposed in this pull request?
This patch renews the verification logic of archive path for FileStreamSource, as we found the logic doesn't take partitioned/recursive options into account.
Before the patch, it only requires the archive path to have depth more than 2 (two subdirectories from root), leveraging the fact FileStreamSource normally reads the files where the parent directory matches the pattern or the file itself matches the pattern. Given 'archive' operation moves the files to the base archive path with retaining the full path, archive path is tend to be safe if the depth is more than 2, meaning FileStreamSource doesn't re-read archived files as new source files.
WIth partitioned/recursive options, the fact is invalid, as FileStreamSource can read any files in any depth of subdirectories for source pattern. To deal with this correctly, we have to renew the verification logic, which may not intuitive and simple but works for all cases.
The new verification logic prevents both cases:
1) archive path matches with source pattern as "prefix" (the depth of archive path > the depth of source pattern)
e.g.
* source pattern: `/hello*/spar?`
* archive path: `/hello/spark/structured/streaming`
Any files in archive path will match with source pattern when recursive option is enabled.
2) source pattern matches with archive path as "prefix" (the depth of source pattern > the depth of archive path)
e.g.
* source pattern: `/hello*/spar?/structured/hello2*`
* archive path: `/hello/spark/structured`
Some archive files will not match with source pattern, e.g. file path: `/hello/spark/structured/hello2`, then final archived path: `/hello/spark/structured/hello/spark/structured/hello2`.
But some other archive files will still match with source pattern, e.g. file path: `/hello2/spark/structured/hello2`, then final archived path: `/hello/spark/structured/hello2/spark/structured/hello2` which matches with source pattern when recursive is enabled.
Implicitly it also prevents archive path matches with source pattern as full match (same depth).
We would want to prevent any source files to be archived and added to new source files again, so the patch takes most restrictive approach to prevent the possible cases.
### Why are the changes needed?
Without this patch, there's a chance archived files are included as new source files when partitioned/recursive option is enabled, as current condition doesn't take these options into account.
### Does this PR introduce any user-facing change?
Only for Spark 3.0.0-preview (only preview 1 for now, but possibly preview 2 as well) - end users are required to provide archive path with ensuring a bit complicated conditions, instead of simply higher than 2 depths.
### How was this patch tested?
New UT.
Closes#26920 from HeartSaVioR/SPARK-30281.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
Revert https://github.com/apache/spark/pull/20433 .
### Why are the changes needed?
According to the SQL standard, the INTERVAL prefix is required:
```
<interval literal> ::=
INTERVAL [ <sign> ] <interval string> <interval qualifier>
<interval string> ::=
<quote> <unquoted interval string> <quote>
```
### Does this PR introduce any user-facing change?
yes, but omitting the INTERVAL prefix is a new feature in 3.0
### How was this patch tested?
existing tests
Closes#27080 from cloud-fan/interval.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Change config name from `spark.sql.legacy.typeCoercion.datetimeToString` to `spark.sql.legacy.typeCoercion.datetimeToString.enabled`.
### Why are the changes needed?
To follow the other boolean conf naming convention.
### Does this PR introduce any user-facing change?
No, it's newly added in Spark 3.0.
### How was this patch tested?
Pass Jenkins
Closes#27065 from Ngone51/SPARK-27638-FOLLOWUP.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Documentation added for refresh resources command in spark-sql.
### Why are the changes needed?
Previously, only refresh table command was documented.
### Does this PR introduce any user-facing change?
Yes. Now users can access documentation for refresh resources command.
### How was this patch tested?
Manually.
Closes#27023 from iRakson/SPARK-30363.
Authored-by: root1 <raksonrakesh@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/26780
In https://github.com/apache/spark/pull/26780, a new Avro data source option `actualSchema` is introduced for setting the original Avro schema in function `from_avro`, while the expected schema is supposed to be set in the parameter `jsonFormatSchema` of `from_avro`.
However, there is another Avro data source option `avroSchema`. It is used for setting the expected schema in readiong and writing.
This PR is to use the option `avroSchema` option for reading Avro data with an evolved schema and remove the new one `actualSchema`
### Why are the changes needed?
Unify and simplify the Avro data source options.
### Does this PR introduce any user-facing change?
Yes.
To deserialize Avro data with an evolved schema, before changes:
```
from_avro('col, expectedSchema, ("actualSchema" -> actualSchema))
```
After changes:
```
from_avro('col, actualSchema, ("avroSchema" -> expectedSchema))
```
The second parameter is always the actual Avro schema after changes.
### How was this patch tested?
Update the existing tests in https://github.com/apache/spark/pull/26780Closes#27045 from gengliangwang/renameAvroOption.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Updated the document for LIST FILE/JAR command.
### Why are the changes needed?
LIST FILE/JAR can take multiple filenames as argument and it returns the files which were added as resources.
### Does this PR introduce any user-facing change?
Yes. Documentation updated for LIST FILE/JAR command
### How was this patch tested?
Manually
Closes#26996 from iRakson/SPARK-30342.
Authored-by: root1 <raksonrakesh@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
## What changes were proposed in this pull request?
Create temporary or permanent function it should throw AnalysisException if the resource is not found. Need to keep behavior consistent across permanent and temporary functions.
## How was this patch tested?
Added UT and also tested manually
**Before Fix**
If the UDF resource is not present then on creation of temporary function it throws AnalysisException where as for permanent function it does not throw. Permanent funtcion throws AnalysisException only after select operation is performed.
**After Fix**
For temporary and permanent function check for the resource, if the UDF resource is not found then throw AnalysisException

Closes#25399 from sandeep-katta/funcIssue.
Authored-by: sandeep katta <sandeep.katta2007@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Update the Spark SQL document menu and join strategy hints.
### Why are the changes needed?
- Several new changes in the Spark SQL document didn't change the menu-sql.yaml correspondingly.
- Update the demo code for join strategy hints.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Document change only.
Closes#26917 from xuanyuanking/SPARK-30278.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Implement Factorization Machines as a ml-pipeline component
1. loss function supports: logloss, mse
2. optimizer: GD, adamW
### Why are the changes needed?
Factorization Machines is widely used in advertising and recommendation system to estimate CTR(click-through rate).
Advertising and recommendation system usually has a lot of data, so we need Spark to estimate the CTR, and Factorization Machines are common ml model to estimate CTR.
References:
1. S. Rendle, “Factorization machines,” in Proceedings of IEEE International Conference on Data Mining (ICDM), pp. 995–1000, 2010.
https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
run unit tests
Closes#27000 from mob-ai/ml/fm.
Authored-by: zhanjf <zhanjf@mob.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
The filter predicate for aggregate expression is an `ANSI SQL`.
```
<aggregate function> ::=
COUNT <left paren> <asterisk> <right paren> [ <filter clause> ]
| <general set function> [ <filter clause> ]
| <binary set function> [ <filter clause> ]
| <ordered set function> [ <filter clause> ]
| <array aggregate function> [ <filter clause> ]
| <row pattern count function> [ <filter clause> ]
```
There are some mainstream database support this syntax.
**PostgreSQL:**
https://www.postgresql.org/docs/current/sql-expressions.html#SYNTAX-AGGREGATES
For example:
```
SELECT
year,
count(*) FILTER (WHERE gdp_per_capita >= 40000)
FROM
countries
GROUP BY
year
```
```
SELECT
year,
code,
gdp_per_capita,
count(*)
FILTER (WHERE gdp_per_capita >= 40000)
OVER (PARTITION BY year)
FROM
countries
```
**jOOQ:**
https://blog.jooq.org/2014/12/30/the-awesome-postgresql-9-4-sql2003-filter-clause-for-aggregate-functions/
**Notice:**
1.This PR only supports FILTER predicate without codegen. maropu will create another PR is related to SPARK-30027 to support codegen.
2.This PR only supports FILTER predicate without DISTINCT. I will create another PR is related to SPARK-30276 to support this.
3.This PR only supports FILTER predicate that can't reference the outer query. I created ticket SPARK-30219 to support it.
4.This PR only supports FILTER predicate that can't use IN/EXISTS predicate sub-queries. I created ticket SPARK-30220 to support it.
5.Spark SQL cannot supports a SQL with nested aggregate. I created ticket SPARK-30182 to support it.
There are some show of the PR on my production environment.
```
spark-sql> desc gja_test_partition;
key string NULL
value string NULL
other string NULL
col2 int NULL
# Partition Information
# col_name data_type comment
col2 int NULL
Time taken: 0.79 s
```
```
spark-sql> select * from gja_test_partition;
a A ao 1
b B bo 1
c C co 1
d D do 1
e E eo 2
g G go 2
h H ho 2
j J jo 2
f F fo 3
k K ko 3
l L lo 4
i I io 4
Time taken: 1.75 s
```
```
spark-sql> select count(key), sum(col2) from gja_test_partition;
12 26
Time taken: 1.848 s
```
```
spark-sql> select count(key) filter (where col2 > 1) from gja_test_partition;
8
Time taken: 2.926 s
```
```
spark-sql> select sum(col2) filter (where col2 > 2) from gja_test_partition;
14
Time taken: 2.087 s
```
```
spark-sql> select count(key) filter (where col2 > 1), sum(col2) filter (where col2 > 2) from gja_test_partition;
8 14
Time taken: 2.847 s
```
```
spark-sql> select count(key), count(key) filter (where col2 > 1), sum(col2), sum(col2) filter (where col2 > 2) from gja_test_partition;
12 8 26 14
Time taken: 1.787 s
```
```
spark-sql> desc student;
id int NULL
name string NULL
sex string NULL
class_id int NULL
Time taken: 0.206 s
```
```
spark-sql> select * from student;
1 张三 man 1
2 李四 man 1
3 王五 man 2
4 赵六 man 2
5 钱小花 woman 1
6 赵九红 woman 2
7 郭丽丽 woman 2
Time taken: 0.786 s
```
```
spark-sql> select class_id, count(id), sum(id) from student group by class_id;
1 3 8
2 4 20
Time taken: 18.783 s
```
```
spark-sql> select class_id, count(id) filter (where sex = 'man'), sum(id) filter (where sex = 'woman') from student group by class_id;
1 2 5
2 2 13
Time taken: 3.887 s
```
### Why are the changes needed?
Add new SQL feature.
### Does this PR introduce any user-facing change?
'No'.
### How was this patch tested?
Exists UT and new UT.
Closes#26656 from beliefer/support-aggregate-clause.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
accuracyExpression can accept Long which may cause overflow error.
accuracyExpression can accept fractions which are implicitly floored.
accuracyExpression can accept null which is implicitly changed to 0.
percentageExpression can accept null but cause MatchError.
percentageExpression can accept ArrayType(_, nullable=true) in which the nulls are implicitly changed to zeros.
##### cases
```sql
select percentile_approx(10.0, 0.5, 2147483648); -- overflow and fail
select percentile_approx(10.0, 0.5, 4294967297); -- overflow but success
select percentile_approx(10.0, 0.5, null); -- null cast to 0
select percentile_approx(10.0, 0.5, 1.2); -- 1.2 cast to 1
select percentile_approx(10.0, null, 1); -- scala.MatchError
select percentile_approx(10.0, array(0.2, 0.4, null), 1); -- null cast to zero.
```
##### behavior before
```sql
+select percentile_approx(10.0, 0.5, 2147483648)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, CAST(0.5BD AS DOUBLE), CAST(2147483648L AS INT))' due to data type mismatch: The accuracy provided must be a positive integer literal (current value = -2147483648); line 1 pos 7
+
+select percentile_approx(10.0, 0.5, 4294967297)
+10.0
+
+select percentile_approx(10.0, 0.5, null)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, CAST(0.5BD AS DOUBLE), CAST(NULL AS INT))' due to data type mismatch: The accuracy provided must be a positive integer literal (current value = 0); line 1 pos 7
+
+select percentile_approx(10.0, 0.5, 1.2)
+10.0
+
+select percentile_approx(10.0, null, 1)
+scala.MatchError
+null
+
+
+select percentile_approx(10.0, array(0.2, 0.4, null), 1)
+[10.0,10.0,10.0]
```
##### behavior after
```sql
+select percentile_approx(10.0, 0.5, 2147483648)
+10.0
+
+select percentile_approx(10.0, 0.5, 4294967297)
+10.0
+
+select percentile_approx(10.0, 0.5, null)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, 0.5BD, NULL)' due to data type mismatch: argument 3 requires integral type, however, 'NULL' is of null type.; line 1 pos 7
+
+select percentile_approx(10.0, 0.5, 1.2)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, 0.5BD, 1.2BD)' due to data type mismatch: argument 3 requires integral type, however, '1.2BD' is of decimal(2,1) type.; line 1 pos 7
+
+select percentile_approx(10.0, null, 1)
+java.lang.IllegalArgumentException
+The value of percentage must be be between 0.0 and 1.0, but got null
+
+select percentile_approx(10.0, array(0.2, 0.4, null), 1)
+java.lang.IllegalArgumentException
+Each value of the percentage array must be be between 0.0 and 1.0, but got [0.2,0.4,null]
```
### Why are the changes needed?
bug fix
### Does this PR introduce any user-facing change?
yes, fix some improper usages of percentile_approx as cases list above
### How was this patch tested?
add ut
Closes#26905 from yaooqinn/SPARK-30266.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Change config name from `spark.eventLog.allowErasureCoding` to `spark.eventLog.allowErasureCoding.enabled`.
### Why are the changes needed?
To follow the other boolean conf naming convention.
### Does this PR introduce any user-facing change?
No, it's newly added in Spark 3.0.
### How was this patch tested?
Tested manually and pass Jenkins.
Closes#26998 from Ngone51/SPARK-25855-FOLLOWUP.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to update the SQL migration guide and clarify semantic of string conversion to typed `TIMESTAMP` and `DATE` literals.
### Why are the changes needed?
This is a follow-up of the PR https://github.com/apache/spark/pull/23541 which changed the behavior of `TIMESTAMP`/`DATE` literals, and can impact on results of user's queries.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
It should be checked by jenkins build.
Closes#26985 from MaxGekk/timestamp-date-constructors-followup.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Implement Factorization Machines as a ml-pipeline component
1. loss function supports: logloss, mse
2. optimizer: GD, adamW
### Why are the changes needed?
Factorization Machines is widely used in advertising and recommendation system to estimate CTR(click-through rate).
Advertising and recommendation system usually has a lot of data, so we need Spark to estimate the CTR, and Factorization Machines are common ml model to estimate CTR.
References:
1. S. Rendle, “Factorization machines,” in Proceedings of IEEE International Conference on Data Mining (ICDM), pp. 995–1000, 2010.
https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
run unit tests
Closes#26124 from mob-ai/ml/fm.
Authored-by: zhanjf <zhanjf@mob.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Fixed typo in `docs` directory and in other directories
1. Find typo in `docs` and apply fixes to files in all directories
2. Fix `the the` -> `the`
### Why are the changes needed?
Better readability of documents
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
No test needed
Closes#26976 from kiszk/typo_20191221.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR update document for make Hive 2.3 dependency by default.
### Why are the changes needed?
The documentation is incorrect.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#26919 from wangyum/SPARK-30280.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
add a migration guide for date_add and date_sub to indicates their behavior change. It a followup for #26412
### Why are the changes needed?
add a migration guide
### Does this PR introduce any user-facing change?
yes, doc change
### How was this patch tested?
no
Closes#26932 from yaooqinn/SPARK-29774-f.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When `spark.shuffle.useOldFetchProtocol` is enabled then switching off the direct disk reading of host-local shuffle blocks and falling back to remote block fetching (and this way avoiding the `GetLocalDirsForExecutors` block transfer message which is introduced from Spark 3.0.0).
### Why are the changes needed?
In `[SPARK-27651][Core] Avoid the network when shuffle blocks are fetched from the same host` a new block transfer message is introduced, `GetLocalDirsForExecutors`. This new message could be sent to the external shuffle service and as it is not supported by the previous version of external shuffle service it should be avoided when `spark.shuffle.useOldFetchProtocol` is true.
In the migration guide I changed the exception type as `org.apache.spark.network.shuffle.protocol.BlockTransferMessage.Decoder#fromByteBuffer`
throws a IllegalArgumentException with the given text and uses the message type which is just a simple number (byte). I have checked and this is true for version 2.4.4 too.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
This specific case (considering one extra boolean to switch off host local disk reading feature) is not tested but existing tests were run.
Closes#26869 from attilapiros/SPARK-30235.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
1. Revert "Preparing development version 3.0.1-SNAPSHOT": 56dcd79
2. Revert "Preparing Spark release v3.0.0-preview2-rc2": c216ef1
### Why are the changes needed?
Shouldn't change master.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
manual test:
https://github.com/apache/spark/compare/5de5e46..wangyum:revert-masterCloses#26915 from wangyum/revert-master.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
Include `$SPARK_DIST_CLASSPATH` in class path when launching `CoarseGrainedExecutorBackend` on Kubernetes executors using the provided `entrypoint.sh`
### Why are the changes needed?
For user provided Hadoop, `$SPARK_DIST_CLASSPATH` contains the required jars.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
Kubernetes 1.14, Spark 2.4.4, Hadoop 3.2.1. Adding $SPARK_DIST_CLASSPATH to `-cp ` param of entrypoint.sh enables launching the executors correctly.
Closes#26493 from sshakeri/master.
Authored-by: Shahin Shakeri <shahin.shakeri@pwc.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
The PR adds a new config option to configure an address for the
proxy server, and a new handler that intercepts redirects and replaces
the URL with one pointing at the proxy server. This is needed on top
of the "proxy base path" support because redirects use full URLs, not
just absolute paths from the server's root.
### Why are the changes needed?
Spark's web UI has support for generating links to paths with a
prefix, to support a proxy server, but those do not apply when
the UI is responding with redirects. In that case, Spark is sending
its own URL back to the client, and if it's behind a dumb proxy
server that doesn't do rewriting (like when using stunnel for HTTPS
support) then the client will see the wrong URL and may fail.
### Does this PR introduce any user-facing change?
Yes. It's a new UI option.
### How was this patch tested?
Tested with added unit test, with Spark behind stunnel, and in a
more complicated app using a different HTTPS proxy.
Closes#26873 from vanzin/SPARK-30240.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
- Reverts commit 1f94bf4 and d6be46e
- Switches python to python3 in Docker release image.
### Why are the changes needed?
`dev/make-distribution.sh` and `python/setup.py` are use python3.
https://github.com/apache/spark/pull/26844/files#diff-ba2c046d92a1d2b5b417788bfb5cb5f8L236https://github.com/apache/spark/pull/26330/files#diff-8cf6167d58ce775a08acafcfe6f40966
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
manual test:
```
yumwangubuntu-3513086:~/spark$ dev/create-release/do-release-docker.sh -n -d /home/yumwang/spark-release
Output directory already exists. Overwrite and continue? [y/n] y
Branch [branch-2.4]: master
Current branch version is 3.0.0-SNAPSHOT.
Release [3.0.0]: 3.0.0-preview2
RC # [1]:
This is a dry run. Please confirm the ref that will be built for testing.
Ref [master]:
ASF user [yumwang]:
Full name [Yuming Wang]:
GPG key [yumwangapache.org]: DBD447010C1B4F7DAD3F7DFD6E1B4122F6A3A338
================
Release details:
BRANCH: master
VERSION: 3.0.0-preview2
TAG: v3.0.0-preview2-rc1
NEXT: 3.0.1-SNAPSHOT
ASF USER: yumwang
GPG KEY: DBD447010C1B4F7DAD3F7DFD6E1B4122F6A3A338
FULL NAME: Yuming Wang
E-MAIL: yumwangapache.org
================
Is this info correct [y/n]? y
GPG passphrase:
========================
= Building spark-rm image with tag latest...
Command: docker build -t spark-rm:latest --build-arg UID=110302528 /home/yumwang/spark/dev/create-release/spark-rm
Log file: docker-build.log
Building v3.0.0-preview2-rc1; output will be at /home/yumwang/spark-release/output
gpg: directory '/home/spark-rm/.gnupg' created
gpg: keybox '/home/spark-rm/.gnupg/pubring.kbx' created
gpg: /home/spark-rm/.gnupg/trustdb.gpg: trustdb created
gpg: key 6E1B4122F6A3A338: public key "Yuming Wang <yumwangapache.org>" imported
gpg: key 6E1B4122F6A3A338: secret key imported
gpg: Total number processed: 1
gpg: imported: 1
gpg: secret keys read: 1
gpg: secret keys imported: 1
========================
= Creating release tag v3.0.0-preview2-rc1...
Command: /opt/spark-rm/release-tag.sh
Log file: tag.log
It may take some time for the tag to be synchronized to github.
Press enter when you've verified that the new tag (v3.0.0-preview2-rc1) is available.
========================
= Building Spark...
Command: /opt/spark-rm/release-build.sh package
Log file: build.log
========================
= Building documentation...
Command: /opt/spark-rm/release-build.sh docs
Log file: docs.log
========================
= Publishing release
Command: /opt/spark-rm/release-build.sh publish-release
Log file: publish.log
```
Generated doc:

Closes#26848 from wangyum/SPARK-30216.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This patch fixes the availability of `minPartitions` option for Kafka source, as it is only supported by micro-batch for now. There's a WIP PR for batch (#25436) as well but there's no progress on the PR so far, so safer to fix the doc first, and let it be added later when we address it with batch case as well.
### Why are the changes needed?
The doc is wrong and misleading.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Just a doc change.
Closes#26849 from HeartSaVioR/MINOR-FIX-minPartition-availability-doc.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose new implementation of `fromDayTimeString` which strictly parses strings in day-time formats to intervals. New implementation accepts only strings that match to a pattern defined by the `from` and `to`. Here is the mapping of user's bounds and patterns:
- `[+|-]D+ H[H]:m[m]:s[s][.SSSSSSSSS]` for **DAY TO SECOND**
- `[+|-]D+ H[H]:m[m]` for **DAY TO MINUTE**
- `[+|-]D+ H[H]` for **DAY TO HOUR**
- `[+|-]H[H]:m[m]s[s][.SSSSSSSSS]` for **HOUR TO SECOND**
- `[+|-]H[H]:m[m]` for **HOUR TO MINUTE**
- `[+|-]m[m]:s[s][.SSSSSSSSS]` for **MINUTE TO SECOND**
Closes#26327Closes#26358
### Why are the changes needed?
- Improve user experience with Spark SQL, and respect to the bound specified by users.
- Behave the same as other broadly used DBMS - Oracle and MySQL.
### Does this PR introduce any user-facing change?
Yes, before:
```sql
spark-sql> SELECT INTERVAL '10 11:12:13.123' HOUR TO MINUTE;
interval 1 weeks 3 days 11 hours 12 minutes
```
After:
```sql
spark-sql> SELECT INTERVAL '10 11:12:13.123' HOUR TO MINUTE;
Error in query:
requirement failed: Interval string must match day-time format of '^(?<sign>[+|-])?(?<hour>\d{1,2}):(?<minute>\d{1,2})$': 10 11:12:13.123(line 1, pos 16)
== SQL ==
SELECT INTERVAL '10 11:12:13.123' HOUR TO MINUTE
----------------^^^
```
### How was this patch tested?
- Added tests to `IntervalUtilsSuite`
- By `ExpressionParserSuite`
- Updated `literals.sql`
Closes#26473 from MaxGekk/strict-from-daytime-string.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Enhancement of the SQL NULL Semantics document: sql-ref-null-semantics.html.
### Why are the changes needed?
Clarify the behavior of `UNKNOWN` for both `EXIST` and `IN` operation.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Doc changes only.
Closes#26837 from xuanyuanking/SPARK-30207.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
Follow up of https://github.com/apache/spark/pull/24405
### What changes were proposed in this pull request?
The current implementation of _from_avro_ and _AvroDataToCatalyst_ doesn't allow doing schema evolution since it requires the deserialization of an Avro record with the exact same schema with which it was serialized.
The proposed change is to add a new option `actualSchema` to allow passing the schema used to serialize the records. This allows using a different compatible schema for reading by passing both schemas to _GenericDatumReader_. If no writer's schema is provided, nothing changes from before.
### Why are the changes needed?
Consider the following example.
```
// schema ID: 1
val schema1 = """
{
"type": "record",
"name": "MySchema",
"fields": [
{"name": "col1", "type": "int"},
{"name": "col2", "type": "string"}
]
}
"""
// schema ID: 2
val schema2 = """
{
"type": "record",
"name": "MySchema",
"fields": [
{"name": "col1", "type": "int"},
{"name": "col2", "type": "string"},
{"name": "col3", "type": "string", "default": ""}
]
}
"""
```
The two schemas are compatible - i.e. you can use `schema2` to deserialize events serialized with `schema1`, in which case there will be the field `col3` with the default value.
Now imagine that you have two dataframes (read from batch or streaming), one with Avro events from schema1 and the other with events from schema2. **We want to combine them into one dataframe** for storing or further processing.
With the current `from_avro` function we can only decode each of them with the corresponding schema:
```
scalaval df1 = ... // Avro events created with schema1
df1: org.apache.spark.sql.DataFrame = [eventBytes: binary]
scalaval decodedDf1 = df1.select(from_avro('eventBytes, schema1) as "decoded")
decodedDf1: org.apache.spark.sql.DataFrame = [decoded: struct<col1: int, col2: string>]
scalaval df2= ... // Avro events created with schema2
df2: org.apache.spark.sql.DataFrame = [eventBytes: binary]
scalaval decodedDf2 = df2.select(from_avro('eventBytes, schema2) as "decoded")
decodedDf2: org.apache.spark.sql.DataFrame = [decoded: struct<col1: int, col2: string, col3: string>]
```
but then `decodedDf1` and `decodedDf2` have different Spark schemas and we can't union them. Instead, with the proposed change we can decode `df1` in the following way:
```
scalaimport scala.collection.JavaConverters._
scalaval decodedDf1 = df1.select(from_avro(data = 'eventBytes, jsonFormatSchema = schema2, options = Map("actualSchema" -> schema1).asJava) as "decoded")
decodedDf1: org.apache.spark.sql.DataFrame = [decoded: struct<col1: int, col2: string, col3: string>]
```
so that both dataframes have the same schemas and can be merged.
### Does this PR introduce any user-facing change?
This PR allows users to pass a new configuration but it doesn't affect current code.
### How was this patch tested?
A new unit test was added.
Closes#26780 from Fokko/SPARK-27506.
Lead-authored-by: Fokko Driesprong <fokko@apache.org>
Co-authored-by: Gianluca Amori <gianluca.amori@gmail.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
This PR switches python to python3 in `make-distribution.sh`.
### Why are the changes needed?
SPARK-29672 changed this
- https://github.com/apache/spark/pull/26330/files#diff-8cf6167d58ce775a08acafcfe6f40966
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#26844 from wangyum/SPARK-30211.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR add an optional spark conf for speculation to allow speculative runs for stages where there are only a few tasks.
```
spark.speculation.task.duration.threshold
```
If provided, tasks would be speculatively run if the TaskSet contains less tasks than the number of slots on a single executor and the task is taking longer time than the threshold.
### Why are the changes needed?
This change helps avoid scenarios where there is single executor that could hang forever due to disk issue and we unfortunately assigned the single task in a TaskSet to that executor and cause the whole job to hang forever.
### Does this PR introduce any user-facing change?
yes. If the new config `spark.speculation.task.duration.threshold` is provided and the TaskSet contains less tasks than the number of slots on a single executor and the task is taking longer time than the threshold, then speculative tasks would be submitted for the running tasks in the TaskSet.
### How was this patch tested?
Unit tests are added to TaskSetManagerSuite.
Closes#26614 from yuchenhuo/SPARK-29976.
Authored-by: Yuchen Huo <yuchen.huo@databricks.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
Reprocess all PostgreSQL dialect related PRs, listing in order:
- #25158: PostgreSQL integral division support [revert]
- #25170: UT changes for the integral division support [revert]
- #25458: Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. [revert]
- #25697: Combine below 2 feature tags into "spark.sql.dialect" [revert]
- #26112: Date substraction support [keep the ANSI-compliant part]
- #26444: Rename config "spark.sql.ansi.enabled" to "spark.sql.dialect.spark.ansi.enabled" [revert]
- #26463: Cast to boolean support for PostgreSQL dialect [revert]
- #26584: Make the behavior of Postgre dialect independent of ansi mode config [keep the ANSI-compliant part]
### Why are the changes needed?
As the discussion in http://apache-spark-developers-list.1001551.n3.nabble.com/DISCUSS-PostgreSQL-dialect-td28417.html, we need to remove PostgreSQL dialect form code base for several reasons:
1. The current approach makes the codebase complicated and hard to maintain.
2. Fully migrating PostgreSQL workloads to Spark SQL is not our focus for now.
### Does this PR introduce any user-facing change?
Yes, the config `spark.sql.dialect` will be removed.
### How was this patch tested?
Existing UT.
Closes#26763 from xuanyuanking/SPARK-30125.
Lead-authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR proposes to add instrumentation of memory usage via the Spark Dropwizard/Codahale metrics system. Memory usage metrics are available via the Executor metrics, recently implemented as detailed in https://issues.apache.org/jira/browse/SPARK-23206.
Additional notes: This takes advantage of the metrics poller introduced in #23767.
## Why are the changes needed?
Executor metrics bring have many useful insights on memory usage, in particular on the usage of storage memory and executor memory. This is useful for troubleshooting. Having the information in the metrics systems allows to add those metrics to Spark performance dashboards and study memory usage as a function of time, as in the example graph https://issues.apache.org/jira/secure/attachment/12962810/Example_dashboard_Spark_Memory_Metrics.PNG
## Does this PR introduce any user-facing change?
Adds `ExecutorMetrics` source to publish executor metrics via the Dropwizard metrics system. Details of the available metrics in docs/monitoring.md
Adds configuration parameter `spark.metrics.executormetrics.source.enabled`
## How was this patch tested?
Tested on YARN cluster and with an existing setup for a Spark dashboard based on InfluxDB and Grafana.
Closes#24132 from LucaCanali/memoryMetricsSource.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
### What changes were proposed in this pull request?
Now, we trim the string when casting string value to those `canCast` types values, e.g. int, double, decimal, interval, date, timestamps, except for boolean.
This behavior makes type cast and coercion inconsistency in Spark.
Not fitting ANSI SQL standard either.
```
If TD is boolean, then
Case:
a) If SD is character string, then SV is replaced by
TRIM ( BOTH ' ' FROM VE )
Case:
i) If the rules for literal in Subclause 5.3, “literal”, can be applied to SV to determine a valid
value of the data type TD, then let TV be that value.
ii) Otherwise, an exception condition is raised: data exception — invalid character value for cast.
b) If SD is boolean, then TV is SV
```
In this pull request, we trim all the whitespaces from both ends of the string before converting it to a bool value. This behavior is as same as others, but a bit different from sql standard, which trim only spaces.
### Why are the changes needed?
Type cast/coercion consistency
### Does this PR introduce any user-facing change?
yes, string with whitespaces in both ends will be trimmed before converted to booleans.
e.g. `select cast('\t true' as boolean)` results `true` now, before this pr it's `null`
### How was this patch tested?
add unit tests
Closes#26776 from yaooqinn/SPARK-30147.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
In this PR, we propose to use the value of `spark.sql.source.default` as the provider for `CREATE TABLE` syntax instead of `hive` in Spark 3.0.
And to help the migration, we introduce a legacy conf `spark.sql.legacy.respectHiveDefaultProvider.enabled` and set its default to `false`.
### Why are the changes needed?
1. Currently, `CREATE TABLE` syntax use hive provider to create table while `DataFrameWriter.saveAsTable` API using the value of `spark.sql.source.default` as a provider to create table. It would be better to make them consistent.
2. User may gets confused in some cases. For example:
```
CREATE TABLE t1 (c1 INT) USING PARQUET;
CREATE TABLE t2 (c1 INT);
```
In these two DDLs, use may think that `t2` should also use parquet as default provider since Spark always advertise parquet as the default format. However, it's hive in this case.
On the other hand, if we omit the USING clause in a CTAS statement, we do pick parquet by default if `spark.sql.hive.convertCATS=true`:
```
CREATE TABLE t3 USING PARQUET AS SELECT 1 AS VALUE;
CREATE TABLE t4 AS SELECT 1 AS VALUE;
```
And these two cases together can be really confusing.
3. Now, Spark SQL is very independent and popular. We do not need to be fully consistent with Hive's behavior.
### Does this PR introduce any user-facing change?
Yes, before this PR, using `CREATE TABLE` syntax will use hive provider. But now, it use the value of `spark.sql.source.default` as its provider.
### How was this patch tested?
Added tests in `DDLParserSuite` and `HiveDDlSuite`.
Closes#26736 from Ngone51/dev-create-table-using-parquet-by-default.
Lead-authored-by: wuyi <yi.wu@databricks.com>
Co-authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to upgrade Maven from 3.6.2 to 3.6.3.
### Why are the changes needed?
This will bring bug fixes like the following.
- MNG-6759 Maven fails to use <repositories> section from dependency when resolving transitive dependencies in some cases
- MNG-6760 ExclusionArtifactFilter result invalid when wildcard exclusion is followed by other exclusions
The following is the full release note.
- https://maven.apache.org/docs/3.6.3/release-notes.html
### Does this PR introduce any user-facing change?
No. (This is a dev-environment change.)
### How was this patch tested?
Pass the Jenkins with both SBT and Maven.
Closes#26770 from dongjoon-hyun/SPARK-30142.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The syntax 'LIKE predicate: ESCAPE clause' is a ANSI SQL.
For example:
```
select 'abcSpark_13sd' LIKE '%Spark\\_%'; //true
select 'abcSpark_13sd' LIKE '%Spark/_%'; //false
select 'abcSpark_13sd' LIKE '%Spark"_%'; //false
select 'abcSpark_13sd' LIKE '%Spark/_%' ESCAPE '/'; //true
select 'abcSpark_13sd' LIKE '%Spark"_%' ESCAPE '"'; //true
select 'abcSpark%13sd' LIKE '%Spark\\%%'; //true
select 'abcSpark%13sd' LIKE '%Spark/%%'; //false
select 'abcSpark%13sd' LIKE '%Spark"%%'; //false
select 'abcSpark%13sd' LIKE '%Spark/%%' ESCAPE '/'; //true
select 'abcSpark%13sd' LIKE '%Spark"%%' ESCAPE '"'; //true
select 'abcSpark\\13sd' LIKE '%Spark\\\\_%'; //true
select 'abcSpark/13sd' LIKE '%Spark//_%'; //false
select 'abcSpark"13sd' LIKE '%Spark""_%'; //false
select 'abcSpark/13sd' LIKE '%Spark//_%' ESCAPE '/'; //true
select 'abcSpark"13sd' LIKE '%Spark""_%' ESCAPE '"'; //true
```
But Spark SQL only supports 'LIKE predicate'.
Note: If the input string or pattern string is null, then the result is null too.
There are some mainstream database support the syntax.
**PostgreSQL:**
https://www.postgresql.org/docs/11/functions-matching.html
**Vertica:**
https://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/SQLReferenceManual/LanguageElements/Predicates/LIKE-predicate.htm?zoom_highlight=like%20escape
**MySQL:**
https://dev.mysql.com/doc/refman/5.6/en/string-comparison-functions.html
**Oracle:**
https://docs.oracle.com/en/database/oracle/oracle-database/19/jjdbc/JDBC-reference-information.html#GUID-5D371A5B-D7F6-42EB-8C0D-D317F3C53708https://docs.oracle.com/en/database/oracle/oracle-database/19/sqlrf/Pattern-matching-Conditions.html#GUID-0779657B-06A8-441F-90C5-044B47862A0A
## How was this patch tested?
Exists UT and new UT.
This PR merged to my production environment and runs above sql:
```
spark-sql> select 'abcSpark_13sd' LIKE '%Spark\\_%';
true
Time taken: 0.119 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark_13sd' LIKE '%Spark/_%';
false
Time taken: 0.103 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark_13sd' LIKE '%Spark"_%';
false
Time taken: 0.096 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark_13sd' LIKE '%Spark/_%' ESCAPE '/';
true
Time taken: 0.096 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark_13sd' LIKE '%Spark"_%' ESCAPE '"';
true
Time taken: 0.092 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark%13sd' LIKE '%Spark\\%%';
true
Time taken: 0.109 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark%13sd' LIKE '%Spark/%%';
false
Time taken: 0.1 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark%13sd' LIKE '%Spark"%%';
false
Time taken: 0.081 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark%13sd' LIKE '%Spark/%%' ESCAPE '/';
true
Time taken: 0.095 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark%13sd' LIKE '%Spark"%%' ESCAPE '"';
true
Time taken: 0.113 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark\\13sd' LIKE '%Spark\\\\_%';
true
Time taken: 0.078 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark/13sd' LIKE '%Spark//_%';
false
Time taken: 0.067 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark"13sd' LIKE '%Spark""_%';
false
Time taken: 0.084 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark/13sd' LIKE '%Spark//_%' ESCAPE '/';
true
Time taken: 0.091 seconds, Fetched 1 row(s)
spark-sql> select 'abcSpark"13sd' LIKE '%Spark""_%' ESCAPE '"';
true
Time taken: 0.091 seconds, Fetched 1 row(s)
```
I create a table and its schema is:
```
spark-sql> desc formatted gja_test;
key string NULL
value string NULL
other string NULL
# Detailed Table Information
Database test
Table gja_test
Owner test
Created Time Wed Apr 10 11:06:15 CST 2019
Last Access Thu Jan 01 08:00:00 CST 1970
Created By Spark 2.4.1-SNAPSHOT
Type MANAGED
Provider hive
Table Properties [transient_lastDdlTime=1563443838]
Statistics 26 bytes
Location hdfs://namenode.xxx:9000/home/test/hive/warehouse/test.db/gja_test
Serde Library org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat org.apache.hadoop.mapred.TextInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Storage Properties [field.delim= , serialization.format= ]
Partition Provider Catalog
Time taken: 0.642 seconds, Fetched 21 row(s)
```
Table `gja_test` exists three rows of data.
```
spark-sql> select * from gja_test;
a A ao
b B bo
"__ """__ "
Time taken: 0.665 seconds, Fetched 3 row(s)
```
At finally, I test this function:
```
spark-sql> select * from gja_test where key like value escape '"';
"__ """__ "
Time taken: 0.687 seconds, Fetched 1 row(s)
```
Closes#25001 from beliefer/ansi-sql-like.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
This patch prevents the cleanup operation in FileStreamSource if the source files belong to the FileStreamSink. This is needed because the output of FileStreamSink can be read with multiple Spark queries and queries will read the files based on the metadata log, which won't reflect the cleanup.
To simplify the logic, the patch only takes care of the case of when the source path without glob pattern refers to the output directory of FileStreamSink, via checking FileStreamSource to see whether it leverages metadata directory or not to list the source files.
### Why are the changes needed?
Without this patch, if end users turn on cleanup option with the path which is the output of FileStreamSink, there may be out of sync between metadata and available files which may break other queries reading the path.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Added UT.
Closes#26590 from HeartSaVioR/SPARK-29953.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
### What changes were proposed in this pull request?
This PR adds a note to the docs README showing how to get Jekyll to automatically pick up changes to the Python API docs.
### Why are the changes needed?
`jekyll serve --watch` doesn't watch for changes to the API docs. Without the technique documented in this note, or something equivalent, developers have to manually retrigger a Jekyll build any time they update the Python API docs.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
I tested this PR manually by making changes to Python docstrings and confirming that Jekyll automatically picks them up and serves them locally.
Closes#26719 from nchammas/SPARK-30084-watch-api-docs.
Authored-by: Nicholas Chammas <nicholas.chammas@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
This proposes to introduce a naming convention for Spark metrics configuration parameters used to enable/disable metrics source reporting using the Dropwizard metrics library: `spark.metrics.sourceNameCamelCase.enabled` and update 2 parameters to use this naming convention.
### Why are the changes needed?
Currently Spark has a few parameters to enable/disable metrics reporting. Their naming pattern is not uniform and this can create confusion. Currently we have:
`spark.metrics.static.sources.enabled`
`spark.app.status.metrics.enabled`
`spark.sql.streaming.metricsEnabled`
### Does this PR introduce any user-facing change?
Update parameters for enabling/disabling metrics reporting new in Spark 3.0: `spark.metrics.static.sources.enabled` -> `spark.metrics.staticSources.enabled`, `spark.app.status.metrics.enabled` -> `spark.metrics.appStatusSource.enabled`.
Note: `spark.sql.streaming.metricsEnabled` is left unchanged as it is already in use in Spark 2.x.
### How was this patch tested?
Manually tested
Closes#26692 from LucaCanali/uniformNamingMetricsEnableParameters.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
`UnaryPositive` only accepts numeric and interval as we defined, but what we do for this in `AstBuider.visitArithmeticUnary` is just bypassing it.
This should not be omitted for the type checking requirement.
### Why are the changes needed?
bug fix, you can find a pre-discussion here https://github.com/apache/spark/pull/26578#discussion_r347350398
### Does this PR introduce any user-facing change?
yes, +non-numeric-or-interval is now invalid.
```
-- !query 14
select +date '1900-01-01'
-- !query 14 schema
struct<DATE '1900-01-01':date>
-- !query 14 output
1900-01-01
-- !query 15
select +timestamp '1900-01-01'
-- !query 15 schema
struct<TIMESTAMP '1900-01-01 00:00:00':timestamp>
-- !query 15 output
1900-01-01 00:00:00
-- !query 16
select +map(1, 2)
-- !query 16 schema
struct<map(1, 2):map<int,int>>
-- !query 16 output
{1:2}
-- !query 17
select +array(1,2)
-- !query 17 schema
struct<array(1, 2):array<int>>
-- !query 17 output
[1,2]
-- !query 18
select -'1'
-- !query 18 schema
struct<(- CAST(1 AS DOUBLE)):double>
-- !query 18 output
-1.0
-- !query 19
select -X'1'
-- !query 19 schema
struct<>
-- !query 19 output
org.apache.spark.sql.AnalysisException
cannot resolve '(- X'01')' due to data type mismatch: argument 1 requires (numeric or interval) type, however, 'X'01'' is of binary type.; line 1 pos 7
-- !query 20
select +X'1'
-- !query 20 schema
struct<X'01':binary>
-- !query 20 output
```
### How was this patch tested?
add ut check
Closes#26716 from yaooqinn/SPARK-30083.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Standardize sql reference
### Why are the changes needed?
To have consistent docs
### Does this PR introduce any user-facing change?
Yes
### How was this patch tested?
Tested using jykyll build --serve
Closes#26721 from huaxingao/spark-30085.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
add `.enabled` postfix to `spark.sql.analyzer.failAmbiguousSelfJoin`.
### Why are the changes needed?
to follow the existing naming style
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
not needed
Closes#26694 from cloud-fan/conf.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In SPARK-29421 (#26097) , we can specify a different table provider for `CREATE TABLE LIKE` via `USING provider`.
Hive support `STORED AS` new file format syntax:
```sql
CREATE TABLE tbl(a int) STORED AS TEXTFILE;
CREATE TABLE tbl2 LIKE tbl STORED AS PARQUET;
```
For Hive compatibility, we should also support `STORED AS` in `CREATE TABLE LIKE`.
### Why are the changes needed?
See https://github.com/apache/spark/pull/26097#issue-327424759
### Does this PR introduce any user-facing change?
Add a new syntax based on current CTL:
CREATE TABLE tbl2 LIKE tbl [STORED AS hiveFormat];
### How was this patch tested?
Add UTs.
Closes#26466 from LantaoJin/SPARK-29839.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Summarizer support more metrics: sum, std
### Why are the changes needed?
Those metrics are widely used, it will be convenient to directly obtain them other than a conversion.
in `NaiveBayes`: we want the sum of vectors, mean & weightSum need to computed then multiplied
in `StandardScaler`,`AFTSurvivalRegression`,`LinearRegression`,`LinearSVC`,`LogisticRegression`: we need to obtain `variance` and then sqrt it to get std
### Does this PR introduce any user-facing change?
yes, new metrics are exposed to end users
### How was this patch tested?
added testsuites
Closes#26596 from zhengruifeng/summarizer_add_metrics.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
For a literal number with an exponent(e.g. 1e-45, 1E2), we'd parse it to Double by default rather than Decimal. And user could still use `spark.sql.legacy.exponentLiteralToDecimal.enabled=true` to fall back to previous behavior.
### Why are the changes needed?
According to ANSI standard of SQL, we see that the (part of) definition of `literal` :
```
<approximate numeric literal> ::=
<mantissa> E <exponent>
```
which indicates that a literal number with an exponent should be approximate numeric(e.g. Double) rather than exact numeric(e.g. Decimal).
And when we test Presto, we found that Presto also conforms to this standard:
```
presto:default> select typeof(1E2);
_col0
--------
double
(1 row)
```
```
presto:default> select typeof(1.2);
_col0
--------------
decimal(2,1)
(1 row)
```
We also find that, actually, literals like `1E2` are parsed as Double before Spark2.1, but changed to Decimal after #14828 due to *The difference between the two confuses most users* as it said. But we also see support(from DB2 test) of original behavior at #14828 (comment).
Although, we also see that PostgreSQL has its own implementation:
```
postgres=# select pg_typeof(1E2);
pg_typeof
-----------
numeric
(1 row)
postgres=# select pg_typeof(1.2);
pg_typeof
-----------
numeric
(1 row)
```
We still think that Spark should also conform to this standard while considering SQL standard and Spark own history and majority DBMS and also user experience.
### Does this PR introduce any user-facing change?
Yes.
For `1E2`, before this PR:
```
scala> spark.sql("select 1E2")
res0: org.apache.spark.sql.DataFrame = [1E+2: decimal(1,-2)]
```
After this PR:
```
scala> spark.sql("select 1E2")
res0: org.apache.spark.sql.DataFrame = [100.0: double]
```
And for `1E-45`, before this PR:
```
org.apache.spark.sql.catalyst.parser.ParseException:
decimal can only support precision up to 38
== SQL ==
select 1E-45
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parse(ParseDriver.scala:131)
at org.apache.spark.sql.execution.SparkSqlParser.parse(SparkSqlParser.scala:48)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parsePlan(ParseDriver.scala:76)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:605)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:605)
... 47 elided
```
after this PR:
```
scala> spark.sql("select 1E-45");
res1: org.apache.spark.sql.DataFrame = [1.0E-45: double]
```
And before this PR, user may feel super weird to see that `select 1e40` works but `select 1e-40 fails`. And now, both of them work well.
### How was this patch tested?
updated `literals.sql.out` and `ansi/literals.sql.out`
Closes#26595 from Ngone51/SPARK-29956.
Authored-by: wuyi <ngone_5451@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
[HIVE-12063](https://issues.apache.org/jira/browse/HIVE-12063) improved pad decimal numbers with trailing zeros to the scale of the column. The following description is copied from the description of HIVE-12063.
> HIVE-7373 was to address the problems of trimming tailing zeros by Hive, which caused many problems including treating 0.0, 0.00 and so on as 0, which has different precision/scale. Please refer to HIVE-7373 description. However, HIVE-7373 was reverted by HIVE-8745 while the underlying problems remained. HIVE-11835 was resolved recently to address one of the problems, where 0.0, 0.00, and so on cannot be read into decimal(1,1).
However, HIVE-11835 didn't address the problem of showing as 0 in query result for any decimal values such as 0.0, 0.00, etc. This causes confusion as 0 and 0.0 have different precision/scale than 0.
The proposal here is to pad zeros for query result to the type's scale. This not only removes the confusion described above, but also aligns with many other DBs. Internal decimal number representation doesn't change, however.
**Spark SQL**:
```sql
// bin/spark-sql
spark-sql> select cast(1 as decimal(38, 18));
1
spark-sql>
// bin/beeline
0: jdbc:hive2://localhost:10000/default> select cast(1 as decimal(38, 18));
+----------------------------+--+
| CAST(1 AS DECIMAL(38,18)) |
+----------------------------+--+
| 1.000000000000000000 |
+----------------------------+--+
// bin/spark-shell
scala> spark.sql("select cast(1 as decimal(38, 18))").show(false)
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
|1.000000000000000000 |
+-------------------------+
// bin/pyspark
>>> spark.sql("select cast(1 as decimal(38, 18))").show()
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
// bin/sparkR
> showDF(sql("SELECT cast(1 as decimal(38, 18))"))
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
```
**PostgreSQL**:
```sql
postgres=# select cast(1 as decimal(38, 18));
numeric
----------------------
1.000000000000000000
(1 row)
```
**Presto**:
```sql
presto> select cast(1 as decimal(38, 18));
_col0
----------------------
1.000000000000000000
(1 row)
```
## How was this patch tested?
unit tests and manual test:
```sql
spark-sql> select cast(1 as decimal(38, 18));
1.000000000000000000
```
Spark SQL Upgrading Guide:

Closes#26697 from wangyum/SPARK-28461.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
Closes#26690 from huangtianhua/add-note-spark-runs-on-arm64.
Authored-by: huangtianhua <huangtianhua@huawei.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
[HIVE-12063](https://issues.apache.org/jira/browse/HIVE-12063) improved pad decimal numbers with trailing zeros to the scale of the column. The following description is copied from the description of HIVE-12063.
> HIVE-7373 was to address the problems of trimming tailing zeros by Hive, which caused many problems including treating 0.0, 0.00 and so on as 0, which has different precision/scale. Please refer to HIVE-7373 description. However, HIVE-7373 was reverted by HIVE-8745 while the underlying problems remained. HIVE-11835 was resolved recently to address one of the problems, where 0.0, 0.00, and so on cannot be read into decimal(1,1).
However, HIVE-11835 didn't address the problem of showing as 0 in query result for any decimal values such as 0.0, 0.00, etc. This causes confusion as 0 and 0.0 have different precision/scale than 0.
The proposal here is to pad zeros for query result to the type's scale. This not only removes the confusion described above, but also aligns with many other DBs. Internal decimal number representation doesn't change, however.
**Spark SQL**:
```sql
// bin/spark-sql
spark-sql> select cast(1 as decimal(38, 18));
1
spark-sql>
// bin/beeline
0: jdbc:hive2://localhost:10000/default> select cast(1 as decimal(38, 18));
+----------------------------+--+
| CAST(1 AS DECIMAL(38,18)) |
+----------------------------+--+
| 1.000000000000000000 |
+----------------------------+--+
// bin/spark-shell
scala> spark.sql("select cast(1 as decimal(38, 18))").show(false)
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
|1.000000000000000000 |
+-------------------------+
// bin/pyspark
>>> spark.sql("select cast(1 as decimal(38, 18))").show()
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
// bin/sparkR
> showDF(sql("SELECT cast(1 as decimal(38, 18))"))
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
```
**PostgreSQL**:
```sql
postgres=# select cast(1 as decimal(38, 18));
numeric
----------------------
1.000000000000000000
(1 row)
```
**Presto**:
```sql
presto> select cast(1 as decimal(38, 18));
_col0
----------------------
1.000000000000000000
(1 row)
```
## How was this patch tested?
unit tests and manual test:
```sql
spark-sql> select cast(1 as decimal(38, 18));
1.000000000000000000
```
Spark SQL Upgrading Guide:

Closes#25214 from wangyum/SPARK-28461.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
* Replace hard-coded conf `spark.scheduler.listenerbus.eventqueue` with a constant variable(`LISTENER_BUS_EVENT_QUEUE_PREFIX `) defined in `config/package.scala`.
* Update documentation for `spark.scheduler.listenerbus.eventqueue.capacity` in both `config/package.scala` and `docs/configuration.md`.
### Why are the changes needed?
* Better code maintainability
* Better user guidance of the conf
### Does this PR introduce any user-facing change?
No behavior changes but user will see the updated document.
### How was this patch tested?
Pass Jenkins.
Closes#26676 from Ngone51/SPARK-28574-followup.
Authored-by: wuyi <ngone_5451@163.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
A java like string trim method trims all whitespaces that less or equal than 0x20. currently, our UTF8String handle the space =0x20 ONLY. This is not suitable for many cases in Spark, like trim for interval strings, date, timestamps, PostgreSQL like cast string to boolean.
### Why are the changes needed?
improve the white spaces handling in UTF8String, also with some bugs fixed
### Does this PR introduce any user-facing change?
yes,
string with `control character` at either end can be convert to date/timestamp and interval now
### How was this patch tested?
add ut
Closes#26626 from yaooqinn/SPARK-29986.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Modify `UTF8String.toInt/toLong` to support trim spaces for both sides before converting it to byte/short/int/long.
With this kind of "cheap" trim can help improve performance for casting string to integrals. The idea is from https://github.com/apache/spark/pull/24872#issuecomment-556917834
### Why are the changes needed?
make the behavior consistent.
### Does this PR introduce any user-facing change?
yes, cast string to an integral type, and binary comparison between string and integrals will trim spaces first. their behavior will be consistent with float and double.
### How was this patch tested?
1. add ut.
2. benchmark tests
the benchmark is modified based on https://github.com/apache/spark/pull/24872#issuecomment-503827016
```scala
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql.execution.benchmark
import org.apache.spark.benchmark.Benchmark
/**
* Benchmark trim the string when casting string type to Boolean/Numeric types.
* To run this benchmark:
* {{{
* 1. without sbt:
* bin/spark-submit --class <this class> --jars <spark core test jar> <spark sql test jar>
* 2. build/sbt "sql/test:runMain <this class>"
* 3. generate result: SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain <this class>"
* Results will be written to "benchmarks/CastBenchmark-results.txt".
* }}}
*/
object CastBenchmark extends SqlBasedBenchmark {
This conversation was marked as resolved by yaooqinn
override def runBenchmarkSuite(mainArgs: Array[String]): Unit = {
val title = "Cast String to Integral"
runBenchmark(title) {
withTempPath { dir =>
val N = 500L << 14
val df = spark.range(N)
val types = Seq("int", "long")
(1 to 5).by(2).foreach { i =>
df.selectExpr(s"concat(id, '${" " * i}') as str")
.write.mode("overwrite").parquet(dir + i.toString)
}
val benchmark = new Benchmark(title, N, minNumIters = 5, output = output)
Seq(true, false).foreach { trim =>
types.foreach { t =>
val str = if (trim) "trim(str)" else "str"
val expr = s"cast($str as $t) as c_$t"
(1 to 5).by(2).foreach { i =>
benchmark.addCase(expr + s" - with $i spaces") { _ =>
spark.read.parquet(dir + i.toString).selectExpr(expr).collect()
}
}
}
}
benchmark.run()
}
}
}
}
```
#### benchmark result.
normal trim v.s. trim in toInt/toLong
```java
================================================================================================
Cast String to Integral
================================================================================================
Java HotSpot(TM) 64-Bit Server VM 1.8.0_231-b11 on Mac OS X 10.15.1
Intel(R) Core(TM) i5-5287U CPU 2.90GHz
Cast String to Integral: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
cast(trim(str) as int) as c_int - with 1 spaces 10220 12994 1337 0.8 1247.5 1.0X
cast(trim(str) as int) as c_int - with 3 spaces 4763 8356 357 1.7 581.4 2.1X
cast(trim(str) as int) as c_int - with 5 spaces 4791 8042 NaN 1.7 584.9 2.1X
cast(trim(str) as long) as c_long - with 1 spaces 4014 6755 NaN 2.0 490.0 2.5X
cast(trim(str) as long) as c_long - with 3 spaces 4737 6938 NaN 1.7 578.2 2.2X
cast(trim(str) as long) as c_long - with 5 spaces 4478 6919 1404 1.8 546.6 2.3X
cast(str as int) as c_int - with 1 spaces 4443 6222 NaN 1.8 542.3 2.3X
cast(str as int) as c_int - with 3 spaces 3659 3842 170 2.2 446.7 2.8X
cast(str as int) as c_int - with 5 spaces 4372 7996 NaN 1.9 533.7 2.3X
cast(str as long) as c_long - with 1 spaces 3866 5838 NaN 2.1 471.9 2.6X
cast(str as long) as c_long - with 3 spaces 3793 5449 NaN 2.2 463.0 2.7X
cast(str as long) as c_long - with 5 spaces 4947 5961 1198 1.7 603.9 2.1X
```
Closes#26622 from yaooqinn/cheapstringtrim.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Impl Complement Naive Bayes Classifier as a `modelType` option in `NaiveBayes`
### Why are the changes needed?
1, it is a better choice for text classification: it is said in [scikit-learn](https://scikit-learn.org/stable/modules/naive_bayes.html#complement-naive-bayes) that 'CNB regularly outperforms MNB (often by a considerable margin) on text classification tasks.'
2, CNB is highly similar to existing MNB, only a small part of existing MNB need to be changed, so it is a easy win to support CNB.
### Does this PR introduce any user-facing change?
yes, a new `modelType` is supported
### How was this patch tested?
added testsuites
Closes#26575 from zhengruifeng/cnb.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
Fix the inconsistent behavior of build-in function SQL LEFT/RIGHT.
### Why are the changes needed?
As the comment in https://github.com/apache/spark/pull/26497#discussion_r345708065, Postgre dialect should not be affected by the ANSI mode config.
During reran the existing tests, only the LEFT/RIGHT build-in SQL function broke the assumption. We fix this by following https://www.postgresql.org/docs/12/sql-keywords-appendix.html: `LEFT/RIGHT reserved (can be function or type)`
### Does this PR introduce any user-facing change?
Yes, the Postgre dialect will not be affected by the ANSI mode config.
### How was this patch tested?
Existing UT.
Closes#26584 from xuanyuanking/SPARK-29951.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The Web UI SQL Tab provides information on the executed SQL using plan graphs and by reporting SQL execution plans. Both sources provide useful information. Physical execution plans report Codegen Stage Ids. This PR adds Codegen Stage Ids to the plan graphs.
### Why are the changes needed?
It is useful to have Codegen Stage Id information also reported in plan graphs, this allows to more easily match physical plans and graphs with metrics when troubleshooting SQL execution.
Example snippet to show the proposed change:

Example of the current state:

Physical plan:

### Does this PR introduce any user-facing change?
This PR adds Codegen Stage Id information to SQL plan graphs in the Web UI/SQL Tab.
### How was this patch tested?
Added a test + manually tested
Closes#26519 from LucaCanali/addCodegenStageIdtoWEBUIGraphs.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
support `modelType` `gaussian`
### Why are the changes needed?
current modelTypes do not support continuous data
### Does this PR introduce any user-facing change?
yes, add a `modelType` option
### How was this patch tested?
existing testsuites and added ones
Closes#26413 from zhengruifeng/gnb.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
Rename config "spark.sql.ansi.enabled" to "spark.sql.dialect.spark.ansi.enabled"
### Why are the changes needed?
The relation between "spark.sql.ansi.enabled" and "spark.sql.dialect" is confusing, since the "PostgreSQL" dialect should contain the features of "spark.sql.ansi.enabled".
To make things clearer, we can rename the "spark.sql.ansi.enabled" to "spark.sql.dialect.spark.ansi.enabled", thus the option "spark.sql.dialect.spark.ansi.enabled" is only for Spark dialect.
For the casting and arithmetic operations, runtime exceptions should be thrown if "spark.sql.dialect" is "spark" and "spark.sql.dialect.spark.ansi.enabled" is true or "spark.sql.dialect" is PostgresSQL.
### Does this PR introduce any user-facing change?
Yes, the config name changed.
### How was this patch tested?
Existing UT.
Closes#26444 from xuanyuanking/SPARK-29807.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add listener event queue capacity configuration to documentation
### Why are the changes needed?
We some time see many event drops happening in eventLog listener queue. So, instead of increasing all the queues size, using this config we just need to increase eventLog queue capacity.
```
scala> sc.parallelize(1 to 100000, 100000).count()
[Stage 0:=================================================>(98299 + 4) / 100000]19/11/14 20:56:35 ERROR AsyncEventQueue: Dropping event from queue eventLog. This likely means one of the listeners is too slow and cannot keep up with the rate at which tasks are being started by the scheduler.
19/11/14 20:56:35 WARN AsyncEventQueue: Dropped 1 events from eventLog since the application started.
```
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing tests
Closes#26529 from shahidki31/master1.
Authored-by: shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to switch `pygments.rb`, which only support Python 2 and seems inactive for the last few years (https://github.com/tmm1/pygments.rb), to Rouge which is pure Ruby code highlighter that is compatible with Pygments.
I thought it would be pretty difficult to change but thankfully Rouge does a great job as the alternative.
### Why are the changes needed?
We're moving to Python 3 and drop Python 2 completely.
### Does this PR introduce any user-facing change?
Maybe a little bit of different syntax style but should not have a notable change.
### How was this patch tested?
Manually tested the build and checked the documentation.
Closes#26521 from HyukjinKwon/SPARK-28752.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Fix broken links
### How was this patch tested?
Tested using jykyll build --serve
Closes#26528 from huaxingao/spark-29901.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add alter view link to drop view
### Why are the changes needed?
create view has links to drop view and alter view
alter view has links to create view and drop view
drop view currently doesn't have a link to alter view. I think it's better to link to alter view as well.
### Does this PR introduce any user-facing change?
Yes
### How was this patch tested?
Tested using jykyll build --serve
Closes#26495 from huaxingao/spark-28798.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Use html files for the links
### Why are the changes needed?
links not working
### Does this PR introduce any user-facing change?
Yes
### How was this patch tested?
Used jekyll build and serve to verify.
Closes#26494 from huaxingao/spark-28795.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
SPARK-29397 added new interfaces for creating driver and executor
plugins. These were added in a new, more isolated package that does
not pollute the main o.a.s package.
The old interface is now redundant. Since it's a DeveloperApi and
we're about to have a new major release, let's remove it instead of
carrying more baggage forward.
Closes#26390 from vanzin/SPARK-29399.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This patch fixes the edge case of streaming left/right outer join described below:
Suppose query is provided as
`select * from A join B on A.id = B.id AND (A.ts <= B.ts AND B.ts <= A.ts + interval 5 seconds)`
and there're two rows for L1 (from A) and R1 (from B) which ensures L1.id = R1.id and L1.ts = R1.ts.
(we can simply imagine it from self-join)
Then Spark processes L1 and R1 as below:
- row L1 and row R1 are joined at batch 1
- row R1 is evicted at batch 2 due to join and watermark condition, whereas row L1 is not evicted
- row L1 is evicted at batch 3 due to join and watermark condition
When determining outer rows to match with null, Spark applies some assumption commented in codebase, as below:
```
Checking whether the current row matches a key in the right side state, and that key
has any value which satisfies the filter function when joined. If it doesn't,
we know we can join with null, since there was never (including this batch) a match
within the watermark period. If it does, there must have been a match at some point, so
we know we can't join with null.
```
But as explained the edge-case earlier, the assumption is not correct. As we don't have any good assumption to optimize which doesn't have edge-case, we have to track whether such row is matched with others before, and match with null row only when the row is not matched.
To track the matching of row, the patch adds a new state to streaming join state manager, and mark whether the row is matched to others or not. We leverage the information when dealing with eviction of rows which would be candidates to match with null rows.
This approach introduces new state format which is not compatible with old state format - queries with old state format will be still running but they will still have the issue and be required to discard checkpoint and rerun to take this patch in effect.
### Why are the changes needed?
This patch fixes a correctness issue.
### Does this PR introduce any user-facing change?
No for compatibility viewpoint, but we'll encourage end users to discard the old checkpoint and rerun the query if they run stream-stream outer join query with old checkpoint, which might be "yes" for the question.
### How was this patch tested?
Added UT which fails on current Spark and passes with this patch. Also passed existing streaming join UTs.
Closes#26108 from HeartSaVioR/SPARK-26154-shorten-alternative.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
The Spark metrics system produces many different metrics and not all of them are used at the same time. This proposes to introduce a configuration parameter to allow disabling the registration of metrics in the "static sources" category.
### Why are the changes needed?
This allows to reduce the load and clutter on the sink, in the cases when the metrics in question are not needed. The metrics registerd as "static sources" are under the namespaces CodeGenerator and HiveExternalCatalog and can produce a significant amount of data, as they are registered for the driver and executors.
### Does this PR introduce any user-facing change?
It introduces a new configuration parameter `spark.metrics.register.static.sources.enabled`
### How was this patch tested?
Manually tested.
```
$ cat conf/metrics.properties
*.sink.prometheusServlet.class=org.apache.spark.metrics.sink.PrometheusServlet
*.sink.prometheusServlet.path=/metrics/prometheus
master.sink.prometheusServlet.path=/metrics/master/prometheus
applications.sink.prometheusServlet.path=/metrics/applications/prometheus
$ bin/spark-shell
$ curl -s http://localhost:4040/metrics/prometheus/ | grep Hive
metrics_local_1573330115306_driver_HiveExternalCatalog_fileCacheHits_Count 0
metrics_local_1573330115306_driver_HiveExternalCatalog_filesDiscovered_Count 0
metrics_local_1573330115306_driver_HiveExternalCatalog_hiveClientCalls_Count 0
metrics_local_1573330115306_driver_HiveExternalCatalog_parallelListingJobCount_Count 0
metrics_local_1573330115306_driver_HiveExternalCatalog_partitionsFetched_Count 0
$ bin/spark-shell --conf spark.metrics.static.sources.enabled=false
$ curl -s http://localhost:4040/metrics/prometheus/ | grep Hive
```
Closes#26320 from LucaCanali/addConfigRegisterStaticMetrics.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Fixing the typos in SQL reference document.
### Why are the changes needed?
For user readability
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Tested manually.
Closes#26424 from jobitmathew/typo.
Authored-by: Jobit Mathew <jobit.mathew@huawei.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
This PR supports MERGE INTO in the parser and add the corresponding logical plan. The SQL syntax likes,
```
MERGE INTO [ds_catalog.][multi_part_namespaces.]target_table [AS target_alias]
USING [ds_catalog.][multi_part_namespaces.]source_table | subquery [AS source_alias]
ON <merge_condition>
[ WHEN MATCHED [ AND <condition> ] THEN <matched_action> ]
[ WHEN MATCHED [ AND <condition> ] THEN <matched_action> ]
[ WHEN NOT MATCHED [ AND <condition> ] THEN <not_matched_action> ]
```
where
```
<matched_action> =
DELETE |
UPDATE SET * |
UPDATE SET column1 = value1 [, column2 = value2 ...]
<not_matched_action> =
INSERT * |
INSERT (column1 [, column2 ...]) VALUES (value1 [, value2 ...])
```
### Why are the changes needed?
This is a start work for introduce `MERGE INTO` support for the builtin datasource, and the design work for the `MERGE INTO` support in DSV2.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
New test cases.
Closes#26167 from xianyinxin/SPARK-28893.
Authored-by: xy_xin <xianyin.xxy@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
It adds a note about the required port of a master url in Kubernetes.
Currently a port needs to be specified for the Kubernetes API. Also in case the API is hosted on the HTTPS port. Else the driver might fail with https://medium.com/kidane.weldemariam_75349/thanks-james-on-issuing-spark-submit-i-run-into-this-error-cc507d4f8f0d
Yes, a change to the "Running on Kubernetes" guide.
None - Documentation change
Closes#26426 from Tapped/patch-1.
Authored-by: Emil Sandstø <emilalexer@hotmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This PR proposes to add **Single threading model design (pinned thread model)** mode which is an experimental mode to sync threads on PVM and JVM. See https://www.py4j.org/advanced_topics.html#using-single-threading-model-pinned-thread
### Multi threading model
Currently, PySpark uses this model. Threads on PVM and JVM are independent. For instance, in a different Python thread, callbacks are received and relevant Python codes are executed. JVM threads are reused when possible.
Py4J will create a new thread every time a command is received and there is no thread available. See the current model we're using - https://www.py4j.org/advanced_topics.html#the-multi-threading-model
One problem in this model is that we can't sync threads on PVM and JVM out of the box. This leads to some problems in particular at some codes related to threading in JVM side. See:
7056e004ee/core/src/main/scala/org/apache/spark/SparkContext.scala (L334)
Due to reusing JVM threads, seems the job groups in Python threads cannot be set in each thread as described in the JIRA.
### Single threading model design (pinned thread model)
This mode pins and syncs the threads on PVM and JVM to work around the problem above. For instance, in the same Python thread, callbacks are received and relevant Python codes are executed. See https://www.py4j.org/advanced_topics.html#the-single-threading-model
Even though this mode can sync threads on PVM and JVM for other thread related code paths,
this might cause another problem: seems unable to inherit properties as below (assuming multi-thread mode still creates new threads when existing threads are busy, I suspect this issue already exists when multiple jobs are submitted in multi-thread mode; however, it can be always seen in single threading mode):
```bash
$ PYSPARK_PIN_THREAD=true ./bin/pyspark
```
```python
import threading
spark.sparkContext.setLocalProperty("a", "hi")
def print_prop():
print(spark.sparkContext.getLocalProperty("a"))
threading.Thread(target=print_prop).start()
```
```
None
```
Unlike Scala side:
```scala
spark.sparkContext.setLocalProperty("a", "hi")
new Thread(new Runnable {
def run() = println(spark.sparkContext.getLocalProperty("a"))
}).start()
```
```
hi
```
This behaviour potentially could cause weird issues but this PR currently does not target this fix this for now since this mode is experimental.
### How does this PR fix?
Basically there are two types of Py4J servers `GatewayServer` and `ClientServer`. The former is for multi threading and the latter is for single threading. This PR adds a switch to use the latter.
In Scala side:
The logic to select a server is encapsulated in `Py4JServer` and use `Py4JServer` at `PythonRunner` for Spark summit and `PythonGatewayServer` for Spark shell. Each uses `ClientServer` when `PYSPARK_PIN_THREAD` is `true` and `GatewayServer` otherwise.
In Python side:
Simply do an if-else to switch the server to talk. It uses `ClientServer` when `PYSPARK_PIN_THREAD` is `true` and `GatewayServer` otherwise.
This is disabled by default for now.
## How was this patch tested?
Manually tested. This can be tested via:
```python
PYSPARK_PIN_THREAD=true ./bin/pyspark
```
and/or
```bash
cd python
./run-tests --python-executables=python --testnames "pyspark.tests.test_pin_thread"
```
Also, ran the Jenkins tests with `PYSPARK_PIN_THREAD` enabled.
Closes#24898 from HyukjinKwon/pinned-thread.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
remove the leading "interval" in `CalendarInterval.toString`.
### Why are the changes needed?
Although it's allowed to have "interval" prefix when casting string to int, it's not recommended.
This is also consistent with pgsql:
```
cloud0fan=# select interval '1' day;
interval
----------
1 day
(1 row)
```
### Does this PR introduce any user-facing change?
yes, when display a dataframe with interval type column, the result is different.
### How was this patch tested?
updated tests.
Closes#26401 from cloud-fan/interval.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Priority for YARN to define pending applications ordering policy, those with higher priority have a better opportunity to be activated. YARN CapacityScheduler only.
### Why are the changes needed?
Ordering pending spark apps
### Does this PR introduce any user-facing change?
add a conf
### How was this patch tested?
add ut
Closes#26255 from yaooqinn/SPARK-29603.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
During creation of array, if CreateArray does not gets any children to set data type for array, it will create an array of null type .
### Why are the changes needed?
When empty array is created, it should be declared as array<null>.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Tested manually
Closes#26324 from amanomer/29462.
Authored-by: Aman Omer <amanomer1996@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR adds the ability for tasks to request fractional resources, in order to be able to execute more than 1 task per resource. For example, if you have 1 GPU in the executor, and the task configuration is 0.5 GPU/task, the executor can schedule two tasks to run on that 1 GPU.
### Why are the changes needed?
Currently there is no good way to share a resource such that multiple tasks can run on a single unit. This allows multiple tasks to share an executor resource.
### Does this PR introduce any user-facing change?
Yes: There is a configuration change where `spark.task.resource.[resource type].amount` can now be fractional.
### How was this patch tested?
Unit tests and manually on standalone mode, and yarn.
Closes#26078 from abellina/SPARK-29151.
Authored-by: Alessandro Bellina <abellina@nvidia.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
This patch adds the option to clean up files which are completed in previous batch.
`cleanSource` -> "archive" / "delete" / "off"
The default value is "off", which Spark will do nothing.
If "delete" is specified, Spark will simply delete input files. If "archive" is specified, Spark will require additional config `sourceArchiveDir` which will be used to move input files to there. When archiving (via move) the path of input files are retained to the archived paths as sub-path.
Note that it is only applied to "micro-batch", since for batch all input files must be kept to get same result across multiple query executions.
## How was this patch tested?
Added UT. Manual test against local disk as well as HDFS.
Closes#22952 from HeartSaVioR/SPARK-20568.
Lead-authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Co-authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Co-authored-by: Jungtaek Lim <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
Spark 2.4 added the ability for executor plugins to be loaded into
Spark (see SPARK-24918). That feature intentionally skipped the
driver to keep changes small, and also because it is possible to
load code into the Spark driver using listeners + configuration.
But that is a bit awkward, because the listener interface does not
provide hooks into a lot of Spark functionality. This change reworks
the executor plugin interface to also extend to the driver.
- there's a "SparkPlugin" main interface that provides APIs to
load driver and executor components.
- custom metric support (added in SPARK-28091) can be used by
plugins to register metrics both in the driver process and in
executors.
- a communication channel now exists that allows the plugin's
executor components to send messages to the plugin's driver
component easily, using the existing Spark RPC system.
The latter was a feature intentionally left out of the original
plugin design (also because it didn't include a driver component).
To avoid polluting the "org.apache.spark" namespace, I added the new
interfaces to the "org.apache.spark.api" package, which seems like
a better place in any case. The actual implementation is kept in
an internal package.
The change includes unit tests for the new interface and features,
but I've also been running a custom plugin that extends the new
API in real applications.
Closes#26170 from vanzin/SPARK-29397.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
re-arrange the parser rules to make it clear that multiple unit TO unit statement like `SELECT INTERVAL '1-1' YEAR TO MONTH '2-2' YEAR TO MONTH` is not allowed.
### Why are the changes needed?
This is definitely an accident that we support such a weird syntax in the past. It's not supported by any other DBs and I can't think of any use case of it. Also no test covers this syntax in the current codebase.
### Does this PR introduce any user-facing change?
Yes, and a migration guide item is added.
### How was this patch tested?
new tests.
Closes#26285 from cloud-fan/syntax.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR changes the behavior of `Column.getItem` to call `Column.getItem` on Scala side instead of `Column.apply`.
### Why are the changes needed?
The current behavior is not consistent with that of Scala.
In PySpark:
```Python
df = spark.range(2)
map_col = create_map(lit(0), lit(100), lit(1), lit(200))
df.withColumn("mapped", map_col.getItem(col('id'))).show()
# +---+------+
# | id|mapped|
# +---+------+
# | 0| 100|
# | 1| 200|
# +---+------+
```
In Scala:
```Scala
val df = spark.range(2)
val map_col = map(lit(0), lit(100), lit(1), lit(200))
// The following getItem results in the following exception, which is the right behavior:
// java.lang.RuntimeException: Unsupported literal type class org.apache.spark.sql.Column id
// at org.apache.spark.sql.catalyst.expressions.Literal$.apply(literals.scala:78)
// at org.apache.spark.sql.Column.getItem(Column.scala:856)
// ... 49 elided
df.withColumn("mapped", map_col.getItem(col("id"))).show
```
### Does this PR introduce any user-facing change?
Yes. If the use wants to pass `Column` object to `getItem`, he/she now needs to use the indexing operator to achieve the previous behavior.
```Python
df = spark.range(2)
map_col = create_map(lit(0), lit(100), lit(1), lit(200))
df.withColumn("mapped", map_col[col('id'))].show()
# +---+------+
# | id|mapped|
# +---+------+
# | 0| 100|
# | 1| 200|
# +---+------+
```
### How was this patch tested?
Existing tests.
Closes#26351 from imback82/spark-29664.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
This PR adds some extra documentation for the new Cogrouped map Pandas udfs. Specifically:
- Updated the usage guide for the new `COGROUPED_MAP` Pandas udfs added in https://github.com/apache/spark/pull/24981
- Updated the docstring for pandas_udf to include the COGROUPED_MAP type as suggested by HyukjinKwon in https://github.com/apache/spark/pull/25939Closes#26110 from d80tb7/SPARK-29126-cogroup-udf-usage-guide.
Authored-by: Chris Martin <chris@cmartinit.co.uk>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
To push the built jars to maven release repository, we need to remove the 'SNAPSHOT' tag from the version name.
Made the following changes in this PR:
* Update all the `3.0.0-SNAPSHOT` version name to `3.0.0-preview`
* Update the sparkR version number check logic to allow jvm version like `3.0.0-preview`
**Please note those changes were generated by the release script in the past, but this time since we manually add tags on master branch, we need to manually apply those changes too.**
We shall revert the changes after 3.0.0-preview release passed.
### Why are the changes needed?
To make the maven release repository to accept the built jars.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
### What changes were proposed in this pull request?
This PR aims to deprecate `Python 3.4 ~ 3.5`, which is prior to version 3.6 additionally.
### Why are the changes needed?
Since `Python 3.8` is already out, we will focus on to support Python 3.6/3.7/3.8.
### Does this PR introduce any user-facing change?
Yes. It's highly recommended to use Python 3.6/3.7. We will verify Python 3.8 before Apache Spark 3.0.0 release.
### How was this patch tested?
NA (This is a doc-only change).
Closes#26326 from dongjoon-hyun/SPARK-29668.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR fix and use proper html tag in docs
### Why are the changes needed?
Fix documentation format error.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#26302 from uncleGen/minor-doc.
Authored-by: uncleGen <hustyugm@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
To push the built jars to maven release repository, we need to remove the 'SNAPSHOT' tag from the version name.
Made the following changes in this PR:
* Update all the `3.0.0-SNAPSHOT` version name to `3.0.0-preview`
* Update the PySpark version from `3.0.0.dev0` to `3.0.0`
**Please note those changes were generated by the release script in the past, but this time since we manually add tags on master branch, we need to manually apply those changes too.**
We shall revert the changes after 3.0.0-preview release passed.
### Why are the changes needed?
To make the maven release repository to accept the built jars.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#26243 from jiangxb1987/3.0.0-preview-prepare.
Lead-authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
### What changes were proposed in this pull request?
https://issues.apache.org/jira/browse/SPARK-29500
`KafkaRowWriter` now supports setting the Kafka partition by reading a "partition" column in the input dataframe.
Code changes in commit nr. 1.
Test changes in commit nr. 2.
Doc changes in commit nr. 3.
tcondie dongjinleekr srowen
### Why are the changes needed?
While it is possible to configure a custom Kafka Partitioner with
`.option("kafka.partitioner.class", "my.custom.Partitioner")`, this is not enough for certain use cases. See the Jira issue.
### Does this PR introduce any user-facing change?
No, as this behaviour is optional.
### How was this patch tested?
Two new UT were added and one was updated.
Closes#26153 from redsk/feature/SPARK-29500.
Authored-by: redsk <nicola.bova@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to deprecate old Java 8 versions prior to 8u92.
### Why are the changes needed?
This is a preparation to use JVM Option `ExitOnOutOfMemoryError`.
- https://www.oracle.com/technetwork/java/javase/8u92-relnotes-2949471.html
### Does this PR introduce any user-facing change?
Yes. It's highly recommended for users to use the latest JDK versions of Java 8/11.
### How was this patch tested?
NA (This is a doc change).
Closes#26249 from dongjoon-hyun/SPARK-29597.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR fixes our documentation build to copy minified jquery file instead.
The original file `jquery.js` seems missing as of Scala 2.12 upgrade. Scala 2.12 seems started to use minified `jquery.min.js` instead.
Since we dropped Scala 2.11, we won't have to take care about legacy `jquery.js` anymore.
Note that, there seem multiple weird stuff in the current ScalaDoc (e.g., some pages are weird, it starts from `scala.collection.*` or some pages are missing, or some docs are truncated, some badges look missing). It needs a separate double check and investigation.
This PR targets to make the documentation generation pass in order to unblock Spark 3.0 preview.
### Why are the changes needed?
To fix and make our official documentation build able to run.
### Does this PR introduce any user-facing change?
It will enable to build the documentation in our official way.
**Before:**
```
Making directory api/scala
cp -r ../target/scala-2.12/unidoc/. api/scala
Making directory api/java
cp -r ../target/javaunidoc/. api/java
Updating JavaDoc files for badge post-processing
Copying jquery.js from Scala API to Java API for page post-processing of badges
jekyll 3.8.6 | Error: No such file or directory rb_sysopen - ./api/scala/lib/jquery.js
```
**After:**
```
Making directory api/scala
cp -r ../target/scala-2.12/unidoc/. api/scala
Making directory api/java
cp -r ../target/javaunidoc/. api/java
Updating JavaDoc files for badge post-processing
Copying jquery.min.js from Scala API to Java API for page post-processing of badges
Copying api_javadocs.js to Java API for page post-processing of badges
Appending content of api-javadocs.css to JavaDoc stylesheet.css for badge styles
...
```
### How was this patch tested?
Manually tested via:
```
SKIP_PYTHONDOC=1 SKIP_RDOC=1 SKIP_SQLDOC=1 jekyll build
```
Closes#26228 from HyukjinKwon/SPARK-29569.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
### What changes were proposed in this pull request?
This PR adds `CREATE NAMESPACE` support for V2 catalogs.
### Why are the changes needed?
Currently, you cannot explicitly create namespaces for v2 catalogs.
### Does this PR introduce any user-facing change?
The user can now perform the following:
```SQL
CREATE NAMESPACE mycatalog.ns
```
to create a namespace `ns` inside `mycatalog` V2 catalog.
### How was this patch tested?
Added unit tests.
Closes#26166 from imback82/create_namespace.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR remove unnecessary orc version and hive version in doc.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A.
Closes#26146 from denglingang/SPARK-24576.
Lead-authored-by: denglingang <chitin1027@gmail.com>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR fixes the incorrect `EqualNullSafe` symbol in `sql-migration-guide.md`.
### Why are the changes needed?
Fix documentation error.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#26163 from wangyum/EqualNullSafe-symbol.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
This patch is a part of [SPARK-28594](https://issues.apache.org/jira/browse/SPARK-28594) and design doc for SPARK-28594 is linked here: https://docs.google.com/document/d/12bdCC4nA58uveRxpeo8k7kGOI2NRTXmXyBOweSi4YcY/edit?usp=sharing
This patch proposes adding new feature to event logging, rolling event log files via configured file size.
Previously event logging is done with single file and related codebase (`EventLoggingListener`/`FsHistoryProvider`) is tightly coupled with it. This patch adds layer on both reader (`EventLogFileReader`) and writer (`EventLogFileWriter`) to decouple implementation details between "handling events" and "how to read/write events from/to file".
This patch adds two properties, `spark.eventLog.rollLog` and `spark.eventLog.rollLog.maxFileSize` which provides configurable behavior of rolling log. The feature is disabled by default, as we only expect huge event log for huge/long-running application. For other cases single event log file would be sufficient and still simpler.
### Why are the changes needed?
This is a part of SPARK-28594 which addresses event log growing infinitely for long-running application.
This patch itself also provides some option for the situation where event log file gets huge and consume their storage. End users may give up replaying their events and want to delete the event log file, but given application is still running and writing the file, it's not safe to delete the file. End users will be able to delete some of old files after applying rolling over event log.
### Does this PR introduce any user-facing change?
No, as the new feature is turned off by default.
### How was this patch tested?
Added unit tests, as well as basic manual tests.
Basic manual tests - ran SHS, ran structured streaming query with roll event log enabled, verified split files are generated as well as SHS can load these files, with handling app status as incomplete/complete.
Closes#25670 from HeartSaVioR/SPARK-28869.
Lead-authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Co-authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
This PR proposes a few typos:
1. Sparks => Spark's
2. parallize => parallelize
3. doesnt => doesn't
Closes#26140 from plusplusjiajia/fix-typos.
Authored-by: Jiajia Li <jiajia.li@intel.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
When inserting a value into a column with the different data type, Spark performs type coercion. Currently, we support 3 policies for the store assignment rules: ANSI, legacy and strict, which can be set via the option "spark.sql.storeAssignmentPolicy":
1. ANSI: Spark performs the type coercion as per ANSI SQL. In practice, the behavior is mostly the same as PostgreSQL. It disallows certain unreasonable type conversions such as converting `string` to `int` and `double` to `boolean`. It will throw a runtime exception if the value is out-of-range(overflow).
2. Legacy: Spark allows the type coercion as long as it is a valid `Cast`, which is very loose. E.g., converting either `string` to `int` or `double` to `boolean` is allowed. It is the current behavior in Spark 2.x for compatibility with Hive. When inserting an out-of-range value to a integral field, the low-order bits of the value is inserted(the same as Java/Scala numeric type casting). For example, if 257 is inserted to a field of Byte type, the result is 1.
3. Strict: Spark doesn't allow any possible precision loss or data truncation in store assignment, e.g., converting either `double` to `int` or `decimal` to `double` is allowed. The rules are originally for Dataset encoder. As far as I know, no mainstream DBMS is using this policy by default.
Currently, the V1 data source uses "Legacy" policy by default, while V2 uses "Strict". This proposal is to use "ANSI" policy by default for both V1 and V2 in Spark 3.0.
### Why are the changes needed?
Following the ANSI SQL standard is most reasonable among the 3 policies.
### Does this PR introduce any user-facing change?
Yes.
The default store assignment policy is ANSI for both V1 and V2 data sources.
### How was this patch tested?
Unit test
Closes#26107 from gengliangwang/ansiPolicyAsDefault.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add documentation to SQL programming guide to use PyArrow >= 0.15.0 with current versions of Spark.
### Why are the changes needed?
Arrow 0.15.0 introduced a change in format which requires an environment variable to maintain compatibility.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Ran pandas_udfs tests using PyArrow 0.15.0 with environment variable set.
Closes#26045 from BryanCutler/arrow-document-legacy-IPC-fix-SPARK-29367.
Authored-by: Bryan Cutler <cutlerb@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
This adds an entry about PrometheusServlet to the documentation, following SPARK-29032
### Why are the changes needed?
The monitoring documentation lists all the available metrics sinks, this should be added to the list for completeness.
Closes#26081 from LucaCanali/FollowupSpark29032.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
This is just a followup on https://github.com/apache/spark/pull/26062 -- see it for more detail.
I think we will eventually find more cases of this. It's hard to get them all at once as there are many different types of compile errors in earlier modules. I'm trying to address them in as a big a chunk as possible.
Closes#26074 from srowen/SPARK-29401.2.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
The commit 4e6d31f570 changed default behavior of `size()` for the `NULL` input. In this PR, I propose to update the SQL migration guide.
### Why are the changes needed?
To inform users about new behavior of the `size()` function for the `NULL` input.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#26066 from MaxGekk/size-null-migration-guide.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Invocations like `sc.parallelize(Array((1,2)))` cause a compile error in 2.13, like:
```
[ERROR] [Error] /Users/seanowen/Documents/spark_2.13/core/src/test/scala/org/apache/spark/ShuffleSuite.scala:47: overloaded method value apply with alternatives:
(x: Unit,xs: Unit*)Array[Unit] <and>
(x: Double,xs: Double*)Array[Double] <and>
(x: Float,xs: Float*)Array[Float] <and>
(x: Long,xs: Long*)Array[Long] <and>
(x: Int,xs: Int*)Array[Int] <and>
(x: Char,xs: Char*)Array[Char] <and>
(x: Short,xs: Short*)Array[Short] <and>
(x: Byte,xs: Byte*)Array[Byte] <and>
(x: Boolean,xs: Boolean*)Array[Boolean]
cannot be applied to ((Int, Int), (Int, Int), (Int, Int), (Int, Int))
```
Using a `Seq` instead appears to resolve it, and is effectively equivalent.
### Why are the changes needed?
To better cross-build for 2.13.
### Does this PR introduce any user-facing change?
None.
### How was this patch tested?
Existing tests.
Closes#26062 from srowen/SPARK-29401.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Fix a config name typo from the resource scheduling user docs. In case users might get confused with the wrong config name, we'd better fix this typo.
### How was this patch tested?
Document change, no need to run test.
Closes#26047 from jiangxb1987/doc.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
### What changes were proposed in this pull request?
Document SHOW CREATE TABLE statement in SQL Reference
### Why are the changes needed?
To complete the SQL reference.
### Does this PR introduce any user-facing change?
Yes.
after the change:

### How was this patch tested?
Tested using jykyll build --serve
Closes#25885 from huaxingao/spark-28813.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes:
1. Use `is.data.frame` to check if it is a DataFrame.
2. to install Arrow and test Arrow optimization in AppVeyor build. We're currently not testing this in CI.
### Why are the changes needed?
1. To support SparkR with Arrow 0.14
2. To check if there's any regression and if it works correctly.
### Does this PR introduce any user-facing change?
```r
df <- createDataFrame(mtcars)
collect(dapply(df, function(rdf) { data.frame(rdf$gear + 1) }, structType("gear double")))
```
**Before:**
```
Error in readBin(con, raw(), as.integer(dataLen), endian = "big") :
invalid 'n' argument
```
**After:**
```
gear
1 5
2 5
3 5
4 4
5 4
6 4
7 4
8 5
9 5
...
```
### How was this patch tested?
AppVeyor
Closes#25993 from HyukjinKwon/arrow-r-appveyor.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR exposes USE CATALOG/USE SQL commands as described in this [SPIP](https://docs.google.com/document/d/1jEcvomPiTc5GtB9F7d2RTVVpMY64Qy7INCA_rFEd9HQ/edit#)
It also exposes `currentCatalog` in `CatalogManager`.
Finally, it changes `SHOW NAMESPACES` and `SHOW TABLES` to use the current catalog if no catalog is specified (instead of default catalog).
### Why are the changes needed?
There is currently no mechanism to change current catalog/namespace thru SQL commands.
### Does this PR introduce any user-facing change?
Yes, you can perform the following:
```scala
// Sets the current catalog to 'testcat'
spark.sql("USE CATALOG testcat")
// Sets the current catalog to 'testcat' and current namespace to 'ns1.ns2'.
spark.sql("USE ns1.ns2 IN testcat")
// Now, the following will use 'testcat' as the current catalog and 'ns1.ns2' as the current namespace.
spark.sql("SHOW NAMESPACES")
```
### How was this patch tested?
Added new unit tests.
Closes#25771 from imback82/use_namespace.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Please refer [the link on dev. mailing list](https://lists.apache.org/thread.html/cc6489a19316e7382661d305fabd8c21915e5faf6a928b4869ac2b4a%3Cdev.spark.apache.org%3E) to see rationalization of this patch.
This patch adds the functionality to detect the possible correct issue on multiple stateful operations in single streaming query and logs warning message to inform end users.
This patch also documents some notes to inform caveats when using multiple stateful operations in single query, and provide one known alternative.
## How was this patch tested?
Added new UTs in UnsupportedOperationsSuite to test various combination of stateful operators on streaming query.
Closes#24890 from HeartSaVioR/SPARK-28074.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Updated the SQL migration guide regarding to recently supported special date and timestamp values, see https://github.com/apache/spark/pull/25716 and https://github.com/apache/spark/pull/25708.
Closes#25834
### Why are the changes needed?
To let users know about new feature in Spark 3.0.
### Does this PR introduce any user-facing change?
No
Closes#25948 from MaxGekk/special-values-migration-guide.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Changed 'Phive-thriftserver' to ' -Phive-thriftserver'.
### Why are the changes needed?
Typo
### Does this PR introduce any user-facing change?
Yes.
### How was this patch tested?
Manually tested.
Closes#25937 from TomokoKomiyama/fix-build-doc.
Authored-by: Tomoko Komiyama <btkomiyamatm@oss.nttdata.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Copy any "spark.hive.foo=bar" spark properties into hadoop conf as "hive.foo=bar"
### Why are the changes needed?
Providing spark side config entry for hive configurations.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
UT.
Closes#25661 from WeichenXu123/add_hive_conf.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This patch introduces new options "startingOffsetsByTimestamp" and "endingOffsetsByTimestamp" to set specific timestamp per topic (since we're unlikely to set the different value per partition) to let source starts reading from offsets which have equal of greater timestamp, and ends reading until offsets which have equal of greater timestamp.
The new option would be optional of course, and take preference over existing offset options.
## How was this patch tested?
New unit tests added. Also manually tested basic functionality with Kafka 2.0.0 server.
Running query below
```
val df = spark.read.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "spark_26848_test_v1,spark_26848_test_2_v1")
.option("startingOffsetsByTimestamp", """{"spark_26848_test_v1": 1549669142193, "spark_26848_test_2_v1": 1549669240965}""")
.option("endingOffsetsByTimestamp", """{"spark_26848_test_v1": 1549669265676, "spark_26848_test_2_v1": 1549699265676}""")
.load().selectExpr("CAST(value AS STRING)")
df.show()
```
with below records (one string which number part remarks when they're put after such timestamp) in
topic `spark_26848_test_v1`
```
hello1 1549669142193
world1 1549669142193
hellow1 1549669240965
world1 1549669240965
hello1 1549669265676
world1 1549669265676
```
topic `spark_26848_test_2_v1`
```
hello2 1549669142193
world2 1549669142193
hello2 1549669240965
world2 1549669240965
hello2 1549669265676
world2 1549669265676
```
the result of `df.show()` follows:
```
+--------------------+
| value|
+--------------------+
|world1 1549669240965|
|world1 1549669142193|
|world2 1549669240965|
|hello2 1549669240965|
|hellow1 154966924...|
|hello2 1549669265676|
|hello1 1549669142193|
|world2 1549669265676|
+--------------------+
```
Note that endingOffsets (as well as endingOffsetsByTimestamp) are exclusive.
Closes#23747 from HeartSaVioR/SPARK-26848.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
This PR supports UPDATE in the parser and add the corresponding logical plan. The SQL syntax is a standard UPDATE statement:
```
UPDATE tableName tableAlias SET colName=value [, colName=value]+ WHERE predicate?
```
### Why are the changes needed?
With this change, we can start to implement UPDATE in builtin sources and think about how to design the update API in DS v2.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
New test cases added.
Closes#25626 from xianyinxin/SPARK-28892.
Authored-by: xy_xin <xianyin.xxy@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Credit to vanzin as he found and commented on this while reviewing #25670 - [comment](https://github.com/apache/spark/pull/25670#discussion_r325383512).
This patch proposes to specify UTF-8 explicitly while reading/writer event log file.
### Why are the changes needed?
The event log file is being read/written as default character set of JVM process which may open the chance to bring some problems on reading event log files from another machines. Spark's de facto standard character set is UTF-8, so it should be explicitly set to.
### Does this PR introduce any user-facing change?
Yes, if end users have been running Spark process with different default charset than "UTF-8", especially their driver JVM processes. No otherwise.
### How was this patch tested?
Existing UTs, as ReplayListenerSuite contains "end-to-end" event logging/reading tests (both uncompressed/compressed).
Closes#25845 from HeartSaVioR/SPARK-29160.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PRs add Java 11 version to the document.
### Why are the changes needed?
Apache Spark 3.0.0 starts to support JDK11 officially.
### Does this PR introduce any user-facing change?
Yes.

### How was this patch tested?
Manually. Doc generation.
Closes#25875 from dongjoon-hyun/SPARK-29196.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Added document reference for USE databse sql command
### Why are the changes needed?
For USE database command usage
### Does this PR introduce any user-facing change?
It is adding the USE database sql command refernce information in the doc
### How was this patch tested?
Attached the test snap

Closes#25572 from shivusondur/jiraUSEDaBa1.
Lead-authored-by: shivusondur <shivusondur@gmail.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
This PR aims to increase the JVM CodeCacheSize from 0.5G to 1G.
### Why are the changes needed?
After upgrading to `Scala 2.12.10`, the following is observed during building.
```
2019-09-18T20:49:23.5030586Z OpenJDK 64-Bit Server VM warning: CodeCache is full. Compiler has been disabled.
2019-09-18T20:49:23.5032920Z OpenJDK 64-Bit Server VM warning: Try increasing the code cache size using -XX:ReservedCodeCacheSize=
2019-09-18T20:49:23.5034959Z CodeCache: size=524288Kb used=521399Kb max_used=521423Kb free=2888Kb
2019-09-18T20:49:23.5035472Z bounds [0x00007fa62c000000, 0x00007fa64c000000, 0x00007fa64c000000]
2019-09-18T20:49:23.5035781Z total_blobs=156549 nmethods=155863 adapters=592
2019-09-18T20:49:23.5036090Z compilation: disabled (not enough contiguous free space left)
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Manually check the Jenkins or GitHub Action build log (which should not have the above).
Closes#25836 from dongjoon-hyun/SPARK-CODE-CACHE-1G.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Currently, there are new configurations for compatibility with ANSI SQL:
* `spark.sql.parser.ansi.enabled`
* `spark.sql.decimalOperations.nullOnOverflow`
* `spark.sql.failOnIntegralTypeOverflow`
This PR is to add new configuration `spark.sql.ansi.enabled` and remove the 3 options above. When the configuration is true, Spark tries to conform to the ANSI SQL specification. It will be disabled by default.
### Why are the changes needed?
Make it simple and straightforward.
### Does this PR introduce any user-facing change?
The new features for ANSI compatibility will be set via one configuration `spark.sql.ansi.enabled`.
### How was this patch tested?
Existing unit tests.
Closes#25693 from gengliangwang/ansiEnabled.
Lead-authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR upgrade Scala to **2.12.10**.
Release notes:
- Fix regression in large string interpolations with non-String typed splices
- Revert "Generate shallower ASTs in pattern translation"
- Fix regression in classpath when JARs have 'a.b' entries beside 'a/b'
- Faster compiler: 5–10% faster since 2.12.8
- Improved compatibility with JDK 11, 12, and 13
- Experimental support for build pipelining and outline type checking
More details:
https://github.com/scala/scala/releases/tag/v2.12.10https://github.com/scala/scala/releases/tag/v2.12.9
## How was this patch tested?
Existing tests
Closes#25404 from wangyum/SPARK-28683.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This proposes to improve Spark instrumentation by adding a hook for user-defined metrics, extending Spark’s Dropwizard/Codahale metrics system.
The original motivation of this work was to add instrumentation for S3 filesystem access metrics by Spark job. Currently, [[ExecutorSource]] instruments HDFS and local filesystem metrics. Rather than extending the code there, we proposes with this JIRA to add a metrics plugin system which is of more flexible and general use.
Context: The Spark metrics system provides a large variety of metrics, see also , useful to monitor and troubleshoot Spark workloads. A typical workflow is to sink the metrics to a storage system and build dashboards on top of that.
Highlights:
- The metric plugin system makes it easy to implement instrumentation for S3 access by Spark jobs.
- The metrics plugin system allows for easy extensions of how Spark collects HDFS-related workload metrics. This is currently done using the Hadoop Filesystem GetAllStatistics method, which is deprecated in recent versions of Hadoop. Recent versions of Hadoop Filesystem recommend using method GetGlobalStorageStatistics, which also provides several additional metrics. GetGlobalStorageStatistics is not available in Hadoop 2.7 (had been introduced in Hadoop 2.8). Using a metric plugin for Spark would allow an easy way to “opt in” using such new API calls for those deploying suitable Hadoop versions.
- We also have the use case of adding Hadoop filesystem monitoring for a custom Hadoop compliant filesystem in use in our organization (EOS using the XRootD protocol). The metrics plugin infrastructure makes this easy to do. Others may have similar use cases.
- More generally, this method makes it straightforward to plug in Filesystem and other metrics to the Spark monitoring system. Future work on plugin implementation can address extending monitoring to measure usage of external resources (OS, filesystem, network, accelerator cards, etc), that maybe would not normally be considered general enough for inclusion in Apache Spark code, but that can be nevertheless useful for specialized use cases, tests or troubleshooting.
Implementation:
The proposed implementation extends and modifies the work on Executor Plugin of SPARK-24918. Additionally, this is related to recent work on extending Spark executor metrics, such as SPARK-25228.
As discussed during the review, the implementaiton of this feature modifies the Developer API for Executor Plugins, such that the new version is incompatible with the original version in Spark 2.4.
## How was this patch tested?
This modifies existing tests for ExecutorPluginSuite to adapt them to the API changes. In addition, the new funtionality for registering pluginMetrics has been manually tested running Spark on YARN and K8S clusters, in particular for monitoring S3 and for extending HDFS instrumentation with the Hadoop Filesystem “GetGlobalStorageStatistics” metrics. Executor metric plugin example and code used for testing are available, for example at: https://github.com/cerndb/SparkExecutorPluginsCloses#24901 from LucaCanali/executorMetricsPlugin.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
HDFS doesn't update the file size reported by the NM if you just keep
writing to the file; this makes the SHS believe the file is inactive,
and so it may delete it after the configured max age for log files.
This change uses hsync to keep the log file as up to date as possible
when using HDFS. It also disables erasure coding by default for these
logs, since hsync (& friends) does not work with EC.
Tested with a SHS configured to aggressively clean up logs; verified
a spark-shell session kept updating the log, which was not deleted by
the SHS.
Closes#25819 from vanzin/SPARK-29105.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
Updating unit description in configurations, inorder to maintain consistency across configurations.
### Why are the changes needed?
the description does not mention about suffix that can be mentioned while configuring this value.
For better user understanding
### Does this PR introduce any user-facing change?
yes. Doc description
### How was this patch tested?
generated document and checked.

Closes#25689 from PavithraRamachandran/heapsize_config.
Authored-by: Pavithra Ramachandran <pavi.rams@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Document CREATE DATABASE statement in SQL Reference Guide.
### Why are the changes needed?
Currently Spark lacks documentation on the supported SQL constructs causing
confusion among users who sometimes have to look at the code to understand the
usage. This is aimed at addressing this issue.
### Does this PR introduce any user-facing change?
Yes.
### Before:
There was no documentation for this.
### After:


### How was this patch tested?
Manual Review and Tested using jykyll build --serve
Closes#25595 from sharangk/createDbDoc.
Lead-authored-by: sharangk <sharan.gk@gmail.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Currently, there is no migration section for PySpark, SparkCore and Structured Streaming.
It is difficult for users to know what to do when they upgrade.
This PR proposes to create create a "Migration Guide" tap at Spark documentation.


This page will contain migration guides for Spark SQL, PySpark, SparkR, MLlib, Structured Streaming and Core. Basically it is a refactoring.
There are some new information added, which I will leave a comment inlined for easier review.
1. **MLlib**
Merge [ml-guide.html#migration-guide](https://spark.apache.org/docs/latest/ml-guide.html#migration-guide) and [ml-migration-guides.html](https://spark.apache.org/docs/latest/ml-migration-guides.html)
```
'docs/ml-guide.md'
↓ Merge new/old migration guides
'docs/ml-migration-guide.md'
```
2. **PySpark**
Extract PySpark specific items from https://spark.apache.org/docs/latest/sql-migration-guide-upgrade.html
```
'docs/sql-migration-guide-upgrade.md'
↓ Extract PySpark specific items
'docs/pyspark-migration-guide.md'
```
3. **SparkR**
Move [sparkr.html#migration-guide](https://spark.apache.org/docs/latest/sparkr.html#migration-guide) into a separate file, and extract from [sql-migration-guide-upgrade.html](https://spark.apache.org/docs/latest/sql-migration-guide-upgrade.html)
```
'docs/sparkr.md' 'docs/sql-migration-guide-upgrade.md'
Move migration guide section ↘ ↙ Extract SparkR specific items
docs/sparkr-migration-guide.md
```
4. **Core**
Newly created at `'docs/core-migration-guide.md'`. I skimmed resolved JIRAs at 3.0.0 and found some items to note.
5. **Structured Streaming**
Newly created at `'docs/ss-migration-guide.md'`. I skimmed resolved JIRAs at 3.0.0 and found some items to note.
6. **SQL**
Merged [sql-migration-guide-upgrade.html](https://spark.apache.org/docs/latest/sql-migration-guide-upgrade.html) and [sql-migration-guide-hive-compatibility.html](https://spark.apache.org/docs/latest/sql-migration-guide-hive-compatibility.html)
```
'docs/sql-migration-guide-hive-compatibility.md' 'docs/sql-migration-guide-upgrade.md'
Move Hive compatibility section ↘ ↙ Left over after filtering PySpark and SparkR items
'docs/sql-migration-guide.md'
```
### Why are the changes needed?
In order for users in production to effectively migrate to higher versions, and detect behaviour or breaking changes before upgrading and/or migrating.
### Does this PR introduce any user-facing change?
Yes, this changes Spark's documentation at https://spark.apache.org/docs/latest/index.html.
### How was this patch tested?
Manually build the doc. This can be verified as below:
```bash
cd docs
SKIP_API=1 jekyll build
open _site/index.html
```
Closes#25757 from HyukjinKwon/migration-doc.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This update adds support for Kafka Headers functionality in Structured Streaming.
## How was this patch tested?
With following unit tests:
- KafkaRelationSuite: "default starting and ending offsets with headers" (new)
- KafkaSinkSuite: "batch - write to kafka" (updated)
Closes#22282 from dongjinleekr/feature/SPARK-23539.
Lead-authored-by: Lee Dongjin <dongjin@apache.org>
Co-authored-by: Jungtaek Lim <kabhwan@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Added document for CREATE VIEW command.
### Why are the changes needed?
As a reference to syntax and examples of CREATE VIEW command.
### How was this patch tested?
Documentation update. Verified manually.
Closes#25543 from amanomer/spark-28795.
Lead-authored-by: aman_omer <amanomer1996@gmail.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Co-authored-by: Aman Omer <amanomer1996@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Document DROP DATABASE statement in SQL Reference
### Why are the changes needed?
Currently from spark there is no complete sql guide is present, so it is better to document all the sql commands, this jira is sub part of this task.
### Does this PR introduce any user-facing change?
Yes, Before there was no documentation about drop database syntax
After Fix


### How was this patch tested?
tested with jenkyll build
Closes#25554 from sandeep-katta/dropDbDoc.
Authored-by: sandeep katta <sandeep.katta2007@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Document REFRESH TABLE statement in the SQL Reference Guide.
### Why are the changes needed?
Currently there is no documentation in the SPARK SQL to describe how to use this command, it is to address this issue.
### Does this PR introduce any user-facing change?
Yes.
#### Before:
There is no documentation for this.
#### After:
<img width="826" alt="Screen Shot 2019-09-12 at 11 39 21 AM" src="https://user-images.githubusercontent.com/7550280/64811385-01752600-d552-11e9-876d-91ebb005b851.png">
### How was this patch tested?
Using jykll build --serve
Closes#25549 from kevinyu98/spark-28828-refreshTable.
Authored-by: Kevin Yu <qyu@us.ibm.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
JIRA :https://issues.apache.org/jira/browse/SPARK-29050
'a hdfs' change into 'an hdfs'
'an unique' change into 'a unique'
'an url' change into 'a url'
'a error' change into 'an error'
Closes#25756 from dengziming/feature_fix_typos.
Authored-by: dengziming <dengziming@growingio.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Document the resource scheduling feature - https://issues.apache.org/jira/browse/SPARK-24615
Add general docs, yarn, kubernetes, and standalone cluster specific ones.
### Why are the changes needed?
Help users understand the feature
### Does this PR introduce any user-facing change?
docs
### How was this patch tested?
N/A
Closes#25698 from tgravescs/SPARK-27492-gpu-sched-docs.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
Add links to IBM Cloud Storage connector in cloud-integration.md
### Why are the changes needed?
This page mentions the connectors to cloud providers. Currently connector to
IBM cloud storage is not specified. This PR adds the necessary links for
completeness.
### Does this PR introduce any user-facing change?
Yes.
**Before:**
<img width="1234" alt="Screen Shot 2019-09-09 at 3 52 44 PM" src="https://user-images.githubusercontent.com/14225158/64571863-11a2c080-d31a-11e9-82e3-78c02675adb9.png">
**After.**
<img width="1234" alt="Screen Shot 2019-09-10 at 8 16 49 AM" src="https://user-images.githubusercontent.com/14225158/64626857-663e4e00-d3a3-11e9-8fa3-15ebf52ea832.png">
### How was this patch tested?
Tested using jykyll build --serve
Closes#25737 from dilipbiswal/ibm-cloud-storage.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Implement the SHOW DATABASES logical and physical plans for data source v2 tables.
### Why are the changes needed?
To support `SHOW DATABASES` SQL commands for v2 tables.
### Does this PR introduce any user-facing change?
`spark.sql("SHOW DATABASES")` will return namespaces if the default catalog is set:
```
+---------------+
| namespace|
+---------------+
| ns1|
| ns1.ns1_1|
|ns1.ns1_1.ns1_2|
+---------------+
```
### How was this patch tested?
Added unit tests to `DataSourceV2SQLSuite`.
Closes#25601 from imback82/show_databases.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
At the moment there are 3 places where communication protocol with Kafka cluster has to be set when delegation token used:
* On delegation token
* On source
* On sink
Most of the time users are using the same protocol on all these places (within one Kafka cluster). It would be better to declare it in one place (delegation token side) and Kafka sources/sinks can take this config over.
In this PR I've I've modified the code in a way that Kafka sources/sinks are taking over delegation token side `security.protocol` configuration when the token and the source/sink matches in `bootstrap.servers` configuration. This default configuration can be overwritten on each source/sink independently by using `kafka.security.protocol` configuration.
### Why are the changes needed?
The actual configuration's default behavior represents the minority of the use-cases and inconvenient.
### Does this PR introduce any user-facing change?
Yes, with this change users need to provide less configuration parameters by default.
### How was this patch tested?
Existing + additional unit tests.
Closes#25631 from gaborgsomogyi/SPARK-28928.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
Document CLEAR CACHE statement in SQL Reference
### Why are the changes needed?
To complete SQL Reference
### Does this PR introduce any user-facing change?
Yes
After change:

### How was this patch tested?
Tested using jykyll build --serve
Closes#25541 from huaxingao/spark-28831-n.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
- Remove SQLContext.createExternalTable and Catalog.createExternalTable, deprecated in favor of createTable since 2.2.0, plus tests of deprecated methods
- Remove HiveContext, deprecated in 2.0.0, in favor of `SparkSession.builder.enableHiveSupport`
- Remove deprecated KinesisUtils.createStream methods, plus tests of deprecated methods, deprecate in 2.2.0
- Remove deprecated MLlib (not Spark ML) linear method support, mostly utility constructors and 'train' methods, and associated docs. This includes methods in LinearRegression, LogisticRegression, Lasso, RidgeRegression. These have been deprecated since 2.0.0
- Remove deprecated Pyspark MLlib linear method support, including LogisticRegressionWithSGD, LinearRegressionWithSGD, LassoWithSGD
- Remove 'runs' argument in KMeans.train() method, which has been a no-op since 2.0.0
- Remove deprecated ChiSqSelector isSorted protected method
- Remove deprecated 'yarn-cluster' and 'yarn-client' master argument in favor of 'yarn' and deploy mode 'cluster', etc
Notes:
- I was not able to remove deprecated DataFrameReader.json(RDD) in favor of DataFrameReader.json(Dataset); the former was deprecated in 2.2.0, but, it is still needed to support Pyspark's .json() method, which can't use a Dataset.
- Looks like SQLContext.createExternalTable was not actually deprecated in Pyspark, but, almost certainly was meant to be? Catalog.createExternalTable was.
- I afterwards noted that the toDegrees, toRadians functions were almost removed fully in SPARK-25908, but Felix suggested keeping just the R version as they hadn't been technically deprecated. I'd like to revisit that. Do we really want the inconsistency? I'm not against reverting it again, but then that implies leaving SQLContext.createExternalTable just in Pyspark too, which seems weird.
- I *kept* LogisticRegressionWithSGD, LinearRegressionWithSGD, LassoWithSGD, RidgeRegressionWithSGD in Pyspark, though deprecated, as it is hard to remove them (still used by StreamingLogisticRegressionWithSGD?) and they are not fully removed in Scala. Maybe should not have been deprecated.
### Why are the changes needed?
Deprecated items are easiest to remove in a major release, so we should do so as much as possible for Spark 3. This does not target items deprecated 'recently' as of Spark 2.3, which is still 18 months old.
### Does this PR introduce any user-facing change?
Yes, in that deprecated items are removed from some public APIs.
### How was this patch tested?
Existing tests.
Closes#25684 from srowen/SPARK-28980.
Lead-authored-by: Sean Owen <sean.owen@databricks.com>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
KinesisInputDStream currently does not provide a way to disable
CloudWatch metrics push. Its default level is "DETAILED" which pushes
10s of metrics every 10 seconds. When dealing with multiple streaming
jobs this add up pretty quickly, leading to thousands of dollars in cost.
To address this problem, this PR adds interfaces for accessing
KinesisClientLibConfiguration's `withMetrics` and
`withMetricsEnabledDimensions` methods to KinesisInputDStream
so that users can configure KCL's metrics levels and dimensions.
## How was this patch tested?
By running updated unit tests in KinesisInputDStreamBuilderSuite.
In addition, I ran a Streaming job with MetricsLevel.NONE and confirmed:
* there's no data point for the "Operation", "Operation, ShardId" and "WorkerIdentifier" dimensions on the AWS management console
* there's no DEBUG level message from Amazon KCL, such as "Successfully published xx datums."
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24651 from sekikn/SPARK-27420.
Authored-by: Kengo Seki <sekikn@apache.org>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
This patch adds the description of common SQL metrics in web ui document.
### Why are the changes needed?
The current web ui document describes query plan but does not describe the meaning SQL metrics. For end users, they might not understand the meaning of the metrics.
### Does this PR introduce any user-facing change?
No. This is just documentation change.
### How was this patch tested?
Built the docs locally.

Closes#25658 from viirya/SPARK-28935.
Lead-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Document DESCRIBE DATABASE statement in SQL Reference
### Why are the changes needed?
To complete the SQL Reference
### Does this PR introduce any user-facing change?
Yes
#### Before
There is no documentation for this command in sql reference
#### After


### How was this patch tested?
Used jekyll build and serve to verify
Closes#25528 from kevinyu98/sql-ref-describe.
Lead-authored-by: Kevin Yu <qyu@us.ibm.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Document UNCACHE TABLE statement in SQL Reference
### Why are the changes needed?
To complete SQL Reference
### Does this PR introduce any user-facing change?
Yes.
After change:

### How was this patch tested?
Tested using jykyll build --serve
Closes#25540 from huaxingao/spark-28830.
Lead-authored-by: Huaxin Gao <huaxing@us.ibm.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Document SHOW TBLPROPERTIES statement in SQL Reference Guide.
### Why are the changes needed?
Currently Spark lacks documentation on the supported SQL constructs causing
confusion among users who sometimes have to look at the code to understand the
usage. This is aimed at addressing this issue.
### Does this PR introduce any user-facing change?
Yes.
**Before:**
There was no documentation for this.
**After.**


### How was this patch tested?
Tested using jykyll build --serve
Closes#25571 from dilipbiswal/ref-show-tblproperties.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This patch does pooling for both kafka consumers as well as fetched data. The overall benefits of the patch are following:
* Both pools support eviction on idle objects, which will help closing invalid idle objects which topic or partition are no longer be assigned to any tasks.
* It also enables applying different policies on pool, which helps optimization of pooling for each pool.
* We concerned about multiple tasks pointing same topic partition as well as same group id, and existing code can't handle this hence excess seek and fetch could happen. This patch properly handles the case.
* It also makes the code always safe to leverage cache, hence no need to maintain reuseCache parameter.
Moreover, pooling kafka consumers is implemented based on Apache Commons Pool, which also gives couple of benefits:
* We can get rid of synchronization of KafkaDataConsumer object while acquiring and returning InternalKafkaConsumer.
* We can extract the feature of object pool to outside of the class, so that the behaviors of the pool can be tested easily.
* We can get various statistics for the object pool, and also be able to enable JMX for the pool.
FetchedData instances are pooled by custom implementation of pool instead of leveraging Apache Commons Pool, because they have CacheKey as first key and "desired offset" as second key which "desired offset" is changing - I haven't found any general pool implementations supporting this.
This patch brings additional dependency, Apache Commons Pool 2.6.0 into `spark-sql-kafka-0-10` module.
## How was this patch tested?
Existing unit tests as well as new tests for object pool.
Also did some experiment regarding proving concurrent access of consumers for same topic partition.
* Made change on both sides (master and patch) to log when creating Kafka consumer or fetching records from Kafka is happening.
* branches
* master: https://github.com/HeartSaVioR/spark/tree/SPARK-25151-master-ref-debugging
* patch: https://github.com/HeartSaVioR/spark/tree/SPARK-25151-debugging
* Test query (doing self-join)
* https://gist.github.com/HeartSaVioR/d831974c3f25c02846f4b15b8d232cc2
* Ran query from spark-shell, with using `local[*]` to maximize the chance to have concurrent access
* Collected the count of fetch requests on Kafka via command: `grep "creating new Kafka consumer" logfile | wc -l`
* Collected the count of creating Kafka consumers via command: `grep "fetching data from Kafka consumer" logfile | wc -l`
Topic and data distribution is follow:
```
truck_speed_events_stream_spark_25151_v1:0:99440
truck_speed_events_stream_spark_25151_v1:1:99489
truck_speed_events_stream_spark_25151_v1:2:397759
truck_speed_events_stream_spark_25151_v1:3:198917
truck_speed_events_stream_spark_25151_v1:4:99484
truck_speed_events_stream_spark_25151_v1:5:497320
truck_speed_events_stream_spark_25151_v1:6:99430
truck_speed_events_stream_spark_25151_v1:7:397887
truck_speed_events_stream_spark_25151_v1:8:397813
truck_speed_events_stream_spark_25151_v1:9:0
```
The experiment only used smallest 4 partitions (0, 1, 4, 6) from these partitions to finish the query earlier.
The result of experiment is below:
branch | create Kafka consumer | fetch request
-- | -- | --
master | 1986 | 2837
patch | 8 | 1706
Closes#22138 from HeartSaVioR/SPARK-25151.
Lead-authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Co-authored-by: Jungtaek Lim <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
If MEMORY_OFFHEAP_ENABLED is true, add MEMORY_OFFHEAP_SIZE to resource requested for executor to ensure instance has enough memory to use.
In this pr add a helper method `executorOffHeapMemorySizeAsMb` in `YarnSparkHadoopUtil`.
## How was this patch tested?
Add 3 new test suite to test `YarnSparkHadoopUtil#executorOffHeapMemorySizeAsMb`
Closes#25309 from LuciferYang/spark-28577.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
Document DESCRIBE FUNCTION statement in SQL Reference Guide.
### Why are the changes needed?
Currently Spark lacks documentation on the supported SQL constructs causing
confusion among users who sometimes have to look at the code to understand the
usage. This is aimed at addressing this issue.
### Does this PR introduce any user-facing change?
Yes.
**Before:**
There was no documentation for this.
**After.**
<img width="1234" alt="Screen Shot 2019-09-02 at 11 14 09 PM" src="https://user-images.githubusercontent.com/14225158/64148193-85534380-cdd7-11e9-9c07-5956b5e8276e.png">
<img width="1234" alt="Screen Shot 2019-09-02 at 11 14 29 PM" src="https://user-images.githubusercontent.com/14225158/64148201-8a17f780-cdd7-11e9-93d8-10ad9932977c.png">
<img width="1234" alt="Screen Shot 2019-09-02 at 11 14 42 PM" src="https://user-images.githubusercontent.com/14225158/64148208-8dab7e80-cdd7-11e9-97c5-3a4ce12cac7a.png">
### How was this patch tested?
Tested using jykyll build --serve
Closes#25530 from dilipbiswal/ref-doc-desc-function.
Lead-authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Document SHOW COLUMNS statement in SQL Reference Guide.
### Why are the changes needed?
Currently Spark lacks documentation on the supported SQL constructs causing
confusion among users who sometimes have to look at the code to understand the
usage. This is aimed at addressing this issue.
### Does this PR introduce any user-facing change?
Yes.
**Before:**
There was no documentation for this.
**After.**
<img width="1234" alt="Screen Shot 2019-09-02 at 11 07 48 PM" src="https://user-images.githubusercontent.com/14225158/64148033-0fe77300-cdd7-11e9-93ee-e5951c7ed33c.png">
<img width="1234" alt="Screen Shot 2019-09-02 at 11 08 08 PM" src="https://user-images.githubusercontent.com/14225158/64148039-137afa00-cdd7-11e9-8bec-634ea9d2594c.png">
<img width="1234" alt="Screen Shot 2019-09-02 at 11 11 45 PM" src="https://user-images.githubusercontent.com/14225158/64148046-17a71780-cdd7-11e9-91c3-95a9c97e7a77.png">
### How was this patch tested?
Tested using jykyll build --serve
Closes#25531 from dilipbiswal/ref-doc-show-columns.
Lead-authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Document DESCRIBE QUERY statement in SQL Reference Guide.
### Why are the changes needed?
Currently Spark lacks documentation on the supported SQL constructs causing
confusion among users who sometimes have to look at the code to understand the
usage. This is aimed at addressing this issue.
### Does this PR introduce any user-facing change?
Yes.
**Before:**
There was no documentation for this.
**After.**
<img width="1234" alt="Screen Shot 2019-08-29 at 5 47 51 PM" src="https://user-images.githubusercontent.com/14225158/63985609-43e43080-ca85-11e9-8a1a-c9c15d988e24.png">
<img width="1234" alt="Screen Shot 2019-08-29 at 5 48 06 PM" src="https://user-images.githubusercontent.com/14225158/63985610-46468a80-ca85-11e9-882a-7163784f72c6.png">
<img width="1234" alt="Screen Shot 2019-08-29 at 5 48 18 PM" src="https://user-images.githubusercontent.com/14225158/63985617-49da1180-ca85-11e9-9e77-a6d6c7042a85.png">
### How was this patch tested?
Tested using jykyll build --serve
Closes#25529 from dilipbiswal/ref-doc-desc-query.
Lead-authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Document ALTER DATABSE statement in SQL Reference Guide.
### Why are the changes needed?
Currently Spark lacks documentation on the supported SQL constructs causing
confusion among users who sometimes have to look at the code to understand the
usage. This is aimed at addressing this issue.
### Does this PR introduce any user-facing change?
Yes.
**Before:**
There was no documentation for this.
**After.**
<img width="1234" alt="Screen Shot 2019-08-28 at 1 51 13 PM" src="https://user-images.githubusercontent.com/14225158/63891854-fc817580-c99a-11e9-918e-6b305edf92e6.png">
<img width="1234" alt="Screen Shot 2019-08-28 at 1 51 27 PM" src="https://user-images.githubusercontent.com/14225158/63891869-0acf9180-c99b-11e9-91a4-04d870474a40.png">
### How was this patch tested?
Tested using jykyll build --serve
Closes#25523 from dilipbiswal/ref-doc-alterdb.
Lead-authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Hive 3.1.2 has been released. This PR upgrades the Hive Metastore Client to 3.1.2 for Hive 3.1.
Hive 3.1.2 release notes:
https://issues.apache.org/jira/secure/ReleaseNote.jspa?version=12344397&styleName=Html&projectId=12310843
### Why are the changes needed?
This is an improvement to support a newly release 3.1.2. Otherwise, it will throws `UnsupportedOperationException` if user `set spark.sql.hive.metastore.version=3.1.2`:
```scala
Exception in thread "main" java.lang.UnsupportedOperationException: Unsupported Hive Metastore version (3.1.2). Please set spark.sql.hive.metastore.version with a valid version.
at org.apache.spark.sql.hive.client.IsolatedClientLoader$.hiveVersion(IsolatedClientLoader.scala:109)
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing UT
Closes#25604 from wangyum/SPARK-28890.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
1, add a basic doc for executor page
2, btw, move the version number in the document of SQL page outside
### Why are the changes needed?
Spark web UIs are being used to monitor the status and resource consumption of your Spark applications and clusters. However, we do not have the corresponding document. It is hard for end users to use and understand them.
### Does this PR introduce any user-facing change?
yes, the doc is changed
### How was this patch tested?
locally build
<img width="468" alt="图片" src="https://user-images.githubusercontent.com/7322292/63758724-d2727980-c8ee-11e9-8380-cbae51453629.png">
Closes#25596 from zhengruifeng/doc_ui_exe.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Make `spark.sql.crossJoin.enabled` default value true
### Why are the changes needed?
For implicit cross join, we can set up a watchdog to cancel it if running for a long time.
When "spark.sql.crossJoin.enabled" is false, because `CheckCartesianProducts` is implemented in logical plan stage, it may generate some mismatching error which may confuse end user:
* it's done in logical phase, so we may fail queries that can be executed via broadcast join, which is very fast.
* if we move the check to the physical phase, then a query may success at the beginning, and begin to fail when the table size gets larger (other people insert data to the table). This can be quite confusing.
* the CROSS JOIN syntax doesn't work well if join reorder happens.
* some non-equi-join will generate plan using cartesian product, but `CheckCartesianProducts` do not detect it and raise error.
So that in order to address this in simpler way, we can turn off showing this cross-join error by default.
For reference, I list some cases raising mismatching error here:
Providing:
```
spark.range(2).createOrReplaceTempView("sm1") // can be broadcast
spark.range(50000000).createOrReplaceTempView("bg1") // cannot be broadcast
spark.range(60000000).createOrReplaceTempView("bg2") // cannot be broadcast
```
1) Some join could be convert to broadcast nested loop join, but CheckCartesianProducts raise error. e.g.
```
select sm1.id, bg1.id from bg1 join sm1 where sm1.id < bg1.id
```
2) Some join will run by CartesianJoin but CheckCartesianProducts DO NOT raise error. e.g.
```
select bg1.id, bg2.id from bg1 join bg2 where bg1.id < bg2.id
```
### Does this PR introduce any user-facing change?
### How was this patch tested?
Closes#25520 from WeichenXu123/SPARK-28621.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The code style in the 'Policy for handling multiple watermarks' in structured-streaming-programming-guide.md
### Why are the changes needed?
Making it look friendly to user.
### Does this PR introduce any user-facing change?
NO
### How was this patch tested?
cd docs
SKIP_API=1 jekyll build
Closes#25580 from cyq89051127/master.
Authored-by: cyq89051127 <chaiyq@asiainfo.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
add an example for storage tab
## How was this patch tested?
locally building
Closes#25445 from zhengruifeng/doc_ui_storage.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This change reverts the logic which was introduced as a part of SPARK-24149 and a subsequent followup PR.
With existing logic:
- Spark fails to launch with HDFS federation enabled while trying to get a path to a logical nameservice.
- It gets tokens for unrelated namespaces if they are used in HDFS Federation
- Automatic namespace discovery is supported only if these are on the same cluster.
Rationale for change:
- For accessing data from related namespaces, viewfs should handle getting tokens for spark
- For accessing data from unrelated namespaces(user explicitly specifies them using existing configs) as these could be on the same or different cluster.
(Please fill in changes proposed in this fix)
Revert the changes.
## How was this patch tested?
Ran few manual tests and unit test.
Closes#24785 from dhruve/bug/SPARK-27937.
Authored-by: Dhruve Ashar <dhruveashar@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
# What changes were proposed in this pull request?
This patch modifies the explanation of guarantee for ForeachWriter as it doesn't guarantee same output for `(partitionId, epochId)`. Refer the description of [SPARK-28650](https://issues.apache.org/jira/browse/SPARK-28650) for more details.
Spark itself still guarantees same output for same epochId (batch) if the preconditions are met, 1) source is always providing the same input records for same offset request. 2) the query is idempotent in overall (indeterministic calculation like now(), random() can break this).
Assuming breaking preconditions as an exceptional case (the preconditions are implicitly required even before), we still can describe the guarantee with `epochId`, though it will be harder to leverage the guarantee: 1) ForeachWriter should implement a feature to track whether all the partitions are written successfully for given `epochId` 2) There's pretty less chance to leverage the fact, as the chance for Spark to successfully write all partitions and fail to checkpoint the batch is small.
Credit to zsxwing on discovering the broken guarantee.
## How was this patch tested?
This is just a documentation change, both on javadoc and guide doc.
Closes#25407 from HeartSaVioR/SPARK-28650.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
This is a initial PR that creates the table of content for SQL reference guide. The left side bar will displays additional menu items corresponding to supported SQL constructs. One this PR is merged, we will fill in the content incrementally. Additionally this PR contains a minor change to make the left sidebar scrollable. Currently it is not possible to scroll in the left hand side window.
## How was this patch tested?
Used jekyll build and serve to verify.
Closes#25459 from dilipbiswal/ref-doc.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR aims to fix CTAS fails after we closed a session of ThriftServer.
- sql-distributed-sql-engine.md

It seems the simplest way to fix [[SPARK-21067]](https://issues.apache.org/jira/browse/SPARK-21067).
For example :
If we use HDFS, we can set the following property in hive-site.xml.
`<property>`
` <name>fs.hdfs.impl.disable.cache</name>`
` <value>true</value>`
`</property>`
## How was this patch tested
Manual.
Closes#25364 from Deegue/fix_add_doc_file_system.
Authored-by: Yizhong Zhang <zyzzxycj@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
After Apache Spark 3.0.0 supports JDK11 officially, people will try JDK11 on old Spark releases (especially 2.4.4/2.3.4) in the same way because our document says `Java 8+`. We had better avoid that misleading situation.
This PR aims to remove `+` from `Java 8+` in the documentation (master/2.4/2.3). Especially, 2.4.4 release and 2.3.4 release (cc kiszk )
On master branch, we will add JDK11 after [SPARK-24417.](https://issues.apache.org/jira/browse/SPARK-24417)
## How was this patch tested?
This is a documentation only change.
<img width="923" alt="java8" src="https://user-images.githubusercontent.com/9700541/63116589-e1504800-bf4e-11e9-8904-b160ec7a42c0.png">
Closes#25466 from dongjoon-hyun/SPARK-DOC-JDK8.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
This patch adds the binding classes to enable spark to switch dataframe output to using the S3A zero-rename committers shipping in Hadoop 3.1+. It adds a source tree into the hadoop-cloud-storage module which only compiles with the hadoop-3.2 profile, and contains a binding for normal output and a specific bridge class for Parquet (as the parquet output format requires a subclass of `ParquetOutputCommitter`.
Commit algorithms are a critical topic. There's no formal proof of correctness, but the algorithms are documented an analysed in [A Zero Rename Committer](https://github.com/steveloughran/zero-rename-committer/releases). This also reviews the classic v1 and v2 algorithms, IBM's swift committer and the one from EMRFS which they admit was based on the concepts implemented here.
Test-wise
* There's a public set of scala test suites [on github](https://github.com/hortonworks-spark/cloud-integration)
* We have run integration tests against Spark on Yarn clusters.
* This code has been shipping for ~12 months in HDP-3.x.
Closes#24970 from steveloughran/cloud/SPARK-23977-s3a-committer.
Authored-by: Steve Loughran <stevel@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Here is the problem description from the JIRA.
```
When the inputs contain the constant 'infinity', Spark SQL does not generate the expected results.
SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
FROM (VALUES ('1'), (CAST('infinity' AS DOUBLE))) v(x);
SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
FROM (VALUES ('infinity'), ('1')) v(x);
SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
FROM (VALUES ('infinity'), ('infinity')) v(x);
SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
FROM (VALUES ('-infinity'), ('infinity')) v(x);
The root cause: Spark SQL does not recognize the special constants in a case insensitive way. In PostgreSQL, they are recognized in a case insensitive way.
Link: https://www.postgresql.org/docs/9.3/datatype-numeric.html
```
In this PR, the casting code is enhanced to handle these `special` string literals in case insensitive manner.
## How was this patch tested?
Added tests in CastSuite and modified existing test suites.
Closes#25331 from dilipbiswal/double_infinity.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
SPARK-24817 and SPARK-24819 introduced new 3 non-internal properties for barrier-execution mode but they are not documented.
So I've added a section into configuration.md for barrier-mode execution.
## How was this patch tested?
Built using jekyll and confirm the layout by browser.
Closes#25370 from sarutak/barrier-exec-mode-conf-doc.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
In this PR, we implements a complete process of GPU-aware resources scheduling
in Standalone. The whole process looks like: Worker sets up isolated resources
when it starts up and registers to master along with its resources. And, Master
picks up usable workers according to driver/executor's resource requirements to
launch driver/executor on them. Then, Worker launches the driver/executor after
preparing resources file, which is created under driver/executor's working directory,
with specified resource addresses(told by master). When driver/executor finished,
their resources could be recycled to worker. Finally, if a worker stops, it
should always release its resources firstly.
For the case of Workers and Drivers in **client** mode run on the same host, we introduce
a config option named `spark.resources.coordinate.enable`(default true) to indicate
whether Spark should coordinate resources for user. If `spark.resources.coordinate.enable=false`, user should be responsible for configuring different resources for Workers and Drivers when use resourcesFile or discovery script. If true, Spark would help user to assign different resources for Workers and Drivers.
The solution for Spark to coordinate resources among Workers and Drivers is:
Generally, use a shared file named *____allocated_resources____.json* to sync allocated
resources info among Workers and Drivers on the same host.
After a Worker or Driver found all resources using the configured resourcesFile and/or
discovery script during launching, it should filter out available resources by excluding resources already allocated in *____allocated_resources____.json* and acquire resources from available resources according to its own requirement. After that, it should write its allocated resources along with its process id (pid) into *____allocated_resources____.json*. Pid (proposed by tgravescs) here used to check whether the allocated resources are still valid in case of Worker or Driver crashes and doesn't release resources properly. And when a Worker or Driver finished, normally, it would always clean up its own allocated resources in *____allocated_resources____.json*.
Note that we'll always get a file lock before any access to file *____allocated_resources____.json*
and release the lock finally.
Futhermore, we appended resources info in `WorkerSchedulerStateResponse` to work
around master change behaviour in HA mode.
## How was this patch tested?
Added unit tests in WorkerSuite, MasterSuite, SparkContextSuite.
Manually tested with client/cluster mode (e.g. multiple workers) in a single node Standalone.
Closes#25047 from Ngone51/SPARK-27371.
Authored-by: wuyi <ngone_5451@163.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
This is an alternative solution of https://github.com/apache/spark/pull/24442 . It fails the query if ambiguous self join is detected, instead of trying to disambiguate it. The problem is that, it's hard to come up with a reasonable rule to disambiguate, the rule proposed by #24442 is mostly a heuristic.
### background of the self-join problem:
This is a long-standing bug and I've seen many people complaining about it in JIRA/dev list.
A typical example:
```
val df1 = …
val df2 = df1.filter(...)
df1.join(df2, df1("a") > df2("a")) // returns empty result
```
The root cause is, `Dataset.apply` is so powerful that users think it returns a column reference which can point to the column of the Dataset at anywhere. This is not true in many cases. `Dataset.apply` returns an `AttributeReference` . Different Datasets may share the same `AttributeReference`. In the example above, `df2` adds a Filter operator above the logical plan of `df1`, and the Filter operator reserves the output `AttributeReference` of its child. This means, `df1("a")` is exactly the same as `df2("a")`, and `df1("a") > df2("a")` always evaluates to false.
### The rule to detect ambiguous column reference caused by self join:
We can reuse the infra in #24442 :
1. each Dataset has a globally unique id.
2. the `AttributeReference` returned by `Dataset.apply` carries the ID and column position(e.g. 3rd column of the Dataset) via metadata.
3. the logical plan of a `Dataset` carries the ID via `TreeNodeTag`
When self-join happens, the analyzer asks the right side plan of join to re-generate output attributes with new exprIds. Based on it, a simple rule to detect ambiguous self join is:
1. find all column references (i.e. `AttributeReference`s with Dataset ID and col position) in the root node of a query plan.
2. for each column reference, traverse the query plan tree, find a sub-plan that carries Dataset ID and the ID is the same as the one in the column reference.
3. get the corresponding output attribute of the sub-plan by the col position in the column reference.
4. if the corresponding output attribute has a different exprID than the column reference, then it means this sub-plan is on the right side of a self-join and has regenerated its output attributes. This is an ambiguous self join because the column reference points to a table being self-joined.
## How was this patch tested?
existing tests and new test cases
Closes#25107 from cloud-fan/new-self-join.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
`minPartitions` has been used as a hint and relevant method (KafkaOffsetRangeCalculator.getRanges) doesn't guarantee the behavior that partitions will be equal or more than given value.
d67b98ea01/external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaOffsetRangeCalculator.scala (L32-L46)
This patch makes clear the configuration is a hint, and actual partitions could be less or more.
## How was this patch tested?
Just a documentation change.
Closes#25332 from HeartSaVioR/MINOR-correct-kafka-structured-streaming-doc-minpartition.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
See discussion on the JIRA (and dev). At heart, we find that math.log and math.pow can actually return slightly different results across platforms because of hardware optimizations. For the actual SQL log and pow functions, I propose that we should use StrictMath instead to ensure the answers are already the same. (This should have the benefit of helping tests pass on aarch64.)
Further, the atanh function (which is not part of java.lang.Math) can be implemented in a slightly different and more accurate way.
## How was this patch tested?
Existing tests (which will need to be changed).
Some manual testing locally to understand the numeric issues.
Closes#25279 from srowen/SPARK-28519.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Today all registered metric sources are reported to GraphiteSink with no filtering mechanism, although the codahale project does support it.
GraphiteReporter (ScheduledReporter) from the codahale project requires you implement and supply the MetricFilter interface (there is only a single implementation by default in the codahale project, MetricFilter.ALL).
Propose to add an additional regex config to match and filter metrics to the GraphiteSink
## How was this patch tested?
Included a GraphiteSinkSuite that tests:
1. Absence of regex filter (existing default behavior maintained)
2. Presence of `regex=<regexexpr>` correctly filters metric keys
Closes#25232 from nkarpov/graphite_regex.
Authored-by: Nick Karpov <nick@nickkarpov.com>
Signed-off-by: jerryshao <jerryshao@tencent.com>
## What changes were proposed in this pull request?
This PR aims to support ANSI SQL `Boolean-Predicate` syntax.
```sql
expression IS [NOT] TRUE
expression IS [NOT] FALSE
expression IS [NOT] UNKNOWN
```
There are some mainstream database support this syntax.
- **PostgreSQL:** https://www.postgresql.org/docs/9.1/functions-comparison.html
- **Hive:** https://issues.apache.org/jira/browse/HIVE-13583
- **Redshift:** https://docs.aws.amazon.com/redshift/latest/dg/r_Boolean_type.html
- **Vertica:** https://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/SQLReferenceManual/LanguageElements/Predicates/Boolean-predicate.htm
For example:
```sql
spark-sql> select null is true, null is not true;
false true
spark-sql> select false is true, false is not true;
false true
spark-sql> select true is true, true is not true;
true false
spark-sql> select null is false, null is not false;
false true
spark-sql> select false is false, false is not false;
true false
spark-sql> select true is false, true is not false;
false true
spark-sql> select null is unknown, null is not unknown;
true false
spark-sql> select false is unknown, false is not unknown;
false true
spark-sql> select true is unknown, true is not unknown;
false true
```
**Note**: A null input is treated as the logical value "unknown".
## How was this patch tested?
Pass the Jenkins with the newly added test cases.
Closes#25074 from beliefer/ansi-sql-boolean-test.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
The latest docs http://spark.apache.org/docs/latest/configuration.html contains some description as below:
spark.ui.showConsoleProgress | true | Show the progress bar in the console. The progress bar shows the progress of stages that run for longer than 500ms. If multiple stages run at the same time, multiple progress bars will be displayed on the same line.
-- | -- | --
But the class `org.apache.spark.internal.config.UI` define the config `spark.ui.showConsoleProgress` as below:
```
val UI_SHOW_CONSOLE_PROGRESS = ConfigBuilder("spark.ui.showConsoleProgress")
.doc("When true, show the progress bar in the console.")
.booleanConf
.createWithDefault(false)
```
So I think there are exists some little mistake and lead to confuse reader.
## How was this patch tested?
No need UT.
Closes#25297 from beliefer/inconsistent-desc-showConsoleProgress.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Implement `RobustScaler`
Since the transformation is quite similar to `StandardScaler`, I refactor the transform function so that it can be reused in both scalers.
## How was this patch tested?
existing and added tests
Closes#25160 from zhengruifeng/robust_scaler.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This pr is used to support using hostpath/PV volume mounts as local storage. In KubernetesExecutorBuilder.scala, the LocalDrisFeatureStep is built before MountVolumesFeatureStep which means we cannot use any volumes mount later. This pr adjust the order of feature building steps which moves localDirsFeature at last so that we can check if directories in SPARK_LOCAL_DIRS are set to volumes mounted such as hostPath, PV, or others.
## How was this patch tested?
Unit tests
Closes#24879 from chenjunjiedada/SPARK-28042.
Lead-authored-by: Junjie Chen <jimmyjchen@tencent.com>
Co-authored-by: Junjie Chen <cjjnjust@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
These are what I found during working on #22282.
- Remove unused value: `UnsafeArraySuite#defaultTz`
- Remove redundant new modifier to the case class, `KafkaSourceRDDPartition`
- Remove unused variables from `RDD.scala`
- Remove trailing space from `structured-streaming-kafka-integration.md`
- Remove redundant parameter from `ArrowConvertersSuite`: `nullable` is `true` by default.
- Remove leading empty line: `UnsafeRow`
- Remove trailing empty line: `KafkaTestUtils`
- Remove unthrown exception type: `UnsafeMapData`
- Replace unused declarations: `expressions`
- Remove duplicated default parameter: `AnalysisErrorSuite`
- `ObjectExpressionsSuite`: remove duplicated parameters, conversions and unused variable
Closes#25251 from dongjinleekr/cleanup/201907.
Authored-by: Lee Dongjin <dongjin@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The motivation for these additional metrics is to help in troubleshooting and monitoring task execution workload when running on a cluster. Currently available metrics include executor threadpool metrics for task completed and for active tasks. The addition of threadpool taskStarted metric will allow for example to collect info on the (approximate) number of failed tasks by computing the difference thread started – (active threads + completed tasks and/or successfully finished tasks).
The proposed metric finishedTasks is also intended for this type of troubleshooting. The difference between finshedTasks and threadpool.completeTasks, is that the latter is a (dropwizard library) gauge taken from the threadpool, while the former is a (dropwizard) counter computed in the [[Executor]] class, when a task successfully finishes, together with several other task metrics counters.
Note, there are similarities with some of the metrics introduced in SPARK-24398, however there are key differences, coming from the fact that this PR concerns the executor source, therefore providing metric values per executor + metric values do not require to pass through the listerner bus in this case.
## How was this patch tested?
Manually tested on a YARN cluster
Closes#22290 from LucaCanali/AddMetricExecutorStartedTasks.
Lead-authored-by: Luca Canali <luca.canali@cern.ch>
Co-authored-by: LucaCanali <luca.canali@cern.ch>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Change the format of the build command in the README to start with a `./` prefix
./build/mvn -DskipTests clean package
This increases stylistic consistency across the README- all the other commands have a `./` prefix. Having a visible `./` prefix also makes it clear to the user that the shell command requires the current working directory to be at the repository root.
## How was this patch tested?
README.md was reviewed both in raw markdown and in the Github rendered landing page for stylistic consistency.
Closes#25231 from Mister-Meeseeks/master.
Lead-authored-by: Douglas R Colkitt <douglas.colkitt@gmail.com>
Co-authored-by: Mister-Meeseeks <douglas.colkitt@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR proposes to add a note in the migration guide. See https://github.com/apache/spark/pull/25108#issuecomment-513526585
## How was this patch tested?
N/A
Closes#25224 from HyukjinKwon/SPARK-28321-doc.
Lead-authored-by: HyukjinKwon <gurwls223@apache.org>
Co-authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR is a follow-up PR to recover three links from [the previous commit](https://github.com/apache/spark/pull/22703/files#diff-21245da8f8dbfef6401c5500f559f0bc).
Currently, those three are broken.
```
$ git grep structured-streaming-kafka-0-10-integration
structured-streaming-programming-guide.md: - **Kafka source** - Reads data from Kafka. It's compatible with Kafka broker versions 0.10.0 or higher. See the [Kafka Integration Guide](structured-streaming-kafka-0-10-integration.html) for more details.
structured-streaming-programming-guide.md: See the <a href="structured-streaming-kafka-0-10-integration.html">Kafka Integration Guide</a>.
structured-streaming-programming-guide.md: <td>See the <a href="structured-streaming-kafka-0-10-integration.html">Kafka Integration Guide</a></td>
```
It's because we have `structured-streaming-kafka-integration.html` instead of `structured-streaming-kafka-0-10-integration.html`.
```
$ find . -name structured-streaming-kafka-0-10-integration.md
$ find . -name structured-streaming-kafka-integration.md
./structured-streaming-kafka-integration.md
```
## How was this patch tested?
Manual.
Closes#25221 from dongjoon-hyun/SPARK-25705.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR proposes to add one example to describe 'add_months' behaviour change by https://github.com/apache/spark/pull/25153.
**Spark 2.4:**
```sql
select add_months(DATE'2019-02-28', 1)
```
```
+--------------------------------+
|add_months(DATE '2019-02-28', 1)|
+--------------------------------+
| 2019-03-31|
+--------------------------------+
```
**Current master:**
```sql
select add_months(DATE'2019-02-28', 1)
```
```
+--------------------------------+
|add_months(DATE '2019-02-28', 1)|
+--------------------------------+
| 2019-03-28|
+--------------------------------+
```
## How was this patch tested?
Manually tested on Spark 2.4.1 and the current master.
Closes#25199 from HyukjinKwon/SPARK-28389.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
This change adds a new option that enables dynamic allocation without
the need for a shuffle service. This mode works by tracking which stages
generate shuffle files, and keeping executors that generate data for those
shuffles alive while the jobs that use them are active.
A separate timeout is also added for shuffle data; so that executors that
hold shuffle data can use a separate timeout before being removed because
of being idle. This allows the shuffle data to be kept around in case it
is needed by some new job, or allow users to be more aggressive in timing
out executors that don't have shuffle data in active use.
The code also hooks up to the context cleaner so that shuffles that are
garbage collected are detected, and the respective executors not held
unnecessarily.
Testing done with added unit tests, and also with TPC-DS workloads on
YARN without a shuffle service.
Closes#24817 from vanzin/SPARK-27963.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
we are adding in generic resource support into spark where we have suffix for the amount of the resource so that we could support other configs.
Spark on yarn already had added configs to request resources via the configs spark.yarn.{executor/driver/am}.resource=<some amount>, where the <some amount> is value and unit together. We should change those configs to have a `.amount` suffix on them to match the spark configs and to allow future configs to be more easily added. YARN itself already supports tags and attributes so if we want the user to be able to pass those from spark at some point having a suffix makes sense. it would allow for a spark.yarn.{executor/driver/am}.resource.{resource}.tag= type config.
## How was this patch tested?
Tested via unit tests and manually on a yarn 3.x cluster with GPU resources configured on.
Closes#24989 from tgravescs/SPARK-27959-yarn-resourceconfigs.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
In the PR, I propose to use the `plusMonths()` method of `LocalDate` to add months to a date. This method adds the specified amount to the months field of `LocalDate` in three steps:
1. Add the input months to the month-of-year field
2. Check if the resulting date would be invalid
3. Adjust the day-of-month to the last valid day if necessary
The difference between current behavior and propose one is in handling the last day of month in the original date. For example, adding 1 month to `2019-02-28` will produce `2019-03-28` comparing to the current implementation where the result is `2019-03-31`.
The proposed behavior is implemented in MySQL and PostgreSQL.
## How was this patch tested?
By existing test suites `DateExpressionsSuite`, `DateFunctionsSuite` and `DateTimeUtilsSuite`.
Closes#25153 from MaxGekk/add-months.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR adds compatibility of handling a `WITH` clause within another `WITH` cause. Before this PR these queries retuned `1` while after this PR they return `2` as PostgreSQL does:
```
WITH
t AS (SELECT 1),
t2 AS (
WITH t AS (SELECT 2)
SELECT * FROM t
)
SELECT * FROM t2
```
```
WITH t AS (SELECT 1)
SELECT (
WITH t AS (SELECT 2)
SELECT * FROM t
)
```
As this is an incompatible change, the PR introduces the `spark.sql.legacy.cte.substitution.enabled` flag as an option to restore old behaviour.
## How was this patch tested?
Added new UTs.
Closes#25029 from peter-toth/SPARK-28228.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds two new config properties: `spark.driver.defaultJavaOptions` and `spark.executor.defaultJavaOptions`. These are intended to be set by administrators in a file of defaults for options like JVM garbage collection algorithm. Users will still set `extraJavaOptions` properties, and both sets of JVM options will be added to start a JVM (default options are prepended to extra options).
## How was this patch tested?
Existing + additional unit tests.
```
cd docs/
SKIP_API=1 jekyll build
```
Manual webpage check.
Closes#24804 from gaborgsomogyi/SPARK-23472.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
At the moment Kafka delegation tokens are fetched through `AdminClient` but there is no possibility to add custom configuration parameters. In [options](https://spark.apache.org/docs/2.4.3/structured-streaming-kafka-integration.html#kafka-specific-configurations) there is already a possibility to add custom configurations.
In this PR I've added similar this possibility to `AdminClient`.
## How was this patch tested?
Existing + added unit tests.
```
cd docs/
SKIP_API=1 jekyll build
```
Manual webpage check.
Closes#24875 from gaborgsomogyi/SPARK-28055.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Up to now, Apache Spark maintains the given event log directory by **time** policy, `spark.history.fs.cleaner.maxAge`. However, there are two issues.
1. Some file system has a limitation on the maximum number of files in a single directory. For example, HDFS `dfs.namenode.fs-limits.max-directory-items` is 1024 * 1024 by default.
https://hadoop.apache.org/docs/r3.2.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
2. Spark is sometimes unable to to clean up some old log files due to permission issues (mainly, security policy).
To handle both (1) and (2), this PR aims to support an additional policy configuration for the maximum number of files in the event log directory, `spark.history.fs.cleaner.maxNum`. Spark will try to keep the number of files in the event log directory according to this policy.
## How was this patch tested?
Pass the Jenkins with a newly added test case.
Closes#25072 from dongjoon-hyun/SPARK-28294.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
We changed our non-standard syntax for `trim` function in #24902 from `TRIM(trimStr, str)` to `TRIM(str, trimStr)` to be compatible with other databases. This pr update the migration guide.
I checked various databases(PostgreSQL, Teradata, Vertica, Oracle, DB2, SQL Server 2019, MySQL, Hive, Presto) and it seems that only PostgreSQL and Presto support this non-standard syntax.
**PostgreSQL**:
```sql
postgres=# select substr(version(), 0, 16), trim('yxTomxx', 'x');
substr | btrim
-----------------+-------
PostgreSQL 11.3 | yxTom
(1 row)
```
**Presto**:
```sql
presto> select trim('yxTomxx', 'x');
_col0
-------
yxTom
(1 row)
```
## How was this patch tested?
manual tests
Closes#24948 from wangyum/SPARK-28093-FOLLOW-UP-DOCS.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
link doc & example of Interaction
## How was this patch tested?
existing tests
Closes#25027 from zhengruifeng/py_doc_interaction.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The `OVERLAY` function is a `ANSI` `SQL`.
For example:
```
SELECT OVERLAY('abcdef' PLACING '45' FROM 4);
SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5);
SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5 FOR 0);
SELECT OVERLAY('babosa' PLACING 'ubb' FROM 2 FOR 4);
```
The results of the above four `SQL` are:
```
abc45f
yabadaba
yabadabadoo
bubba
```
Note: If the input string is null, then the result is null too.
There are some mainstream database support the syntax.
**PostgreSQL:**
https://www.postgresql.org/docs/11/functions-string.html
**Vertica:** https://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/SQLReferenceManual/Functions/String/OVERLAY.htm?zoom_highlight=overlay
**Oracle:**
https://docs.oracle.com/en/database/oracle/oracle-database/19/arpls/UTL_RAW.html#GUID-342E37E7-FE43-4CE1-A0E9-7DAABD000369
**DB2:**
https://www.ibm.com/support/knowledgecenter/SSGMCP_5.3.0/com.ibm.cics.rexx.doc/rexx/overlay.html
There are some show of the PR on my production environment.
```
spark-sql> SELECT OVERLAY('abcdef' PLACING '45' FROM 4);
abc45f
Time taken: 6.385 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5);
yabadaba
Time taken: 0.191 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5 FOR 0);
yabadabadoo
Time taken: 0.186 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY('babosa' PLACING 'ubb' FROM 2 FOR 4);
bubba
Time taken: 0.151 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING '45' FROM 4);
NULL
Time taken: 0.22 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING 'daba' FROM 5);
NULL
Time taken: 0.157 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING 'daba' FROM 5 FOR 0);
NULL
Time taken: 0.254 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING 'ubb' FROM 2 FOR 4);
NULL
Time taken: 0.159 seconds, Fetched 1 row(s)
```
## How was this patch tested?
Exists UT and new UT.
Closes#24918 from beliefer/ansi-sql-overlay.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
## What changes were proposed in this pull request?
Spark's `InMemoryFileIndex` contains two places where `FileNotFound` exceptions are caught and logged as warnings (during [directory listing](bcd3b61c4b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InMemoryFileIndex.scala (L274)) and [block location lookup](bcd3b61c4b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InMemoryFileIndex.scala (L333))). This logic was added in #15153 and #21408.
I think that this is a dangerous default behavior because it can mask bugs caused by race conditions (e.g. overwriting a table while it's being read) or S3 consistency issues (there's more discussion on this in the [JIRA ticket](https://issues.apache.org/jira/browse/SPARK-27676)). Failing fast when we detect missing files is not sufficient to make concurrent table reads/writes or S3 listing safe (there are other classes of eventual consistency issues to worry about), but I think it's still beneficial to throw exceptions and fail-fast on the subset of inconsistencies / races that we _can_ detect because that increases the likelihood that an end user will notice the problem and investigate further.
There may be some cases where users _do_ want to ignore missing files, but I think that should be an opt-in behavior via the existing `spark.sql.files.ignoreMissingFiles` flag (the current behavior is itself race-prone because a file might be be deleted between catalog listing and query execution time, triggering FileNotFoundExceptions on executors (which are handled in a way that _does_ respect `ignoreMissingFIles`)).
This PR updates `InMemoryFileIndex` to guard the log-and-ignore-FileNotFoundException behind the existing `spark.sql.files.ignoreMissingFiles` flag.
**Note**: this is a change of default behavior, so I think it needs to be mentioned in release notes.
## How was this patch tested?
New unit tests to simulate file-deletion race conditions, tested with both values of the `ignoreMissingFIles` flag.
Closes#24668 from JoshRosen/SPARK-27676.
Lead-authored-by: Josh Rosen <rosenville@gmail.com>
Co-authored-by: Josh Rosen <joshrosen@stripe.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Event logs are different from the other data in terms of the lifetime. It would be great to have a new configuration for Spark event log compression like `spark.eventLog.compression.codec` .
This PR adds this new configuration as an optional configuration. So, if `spark.eventLog.compression.codec` is not given, `spark.io.compression.codec` will be used.
## How was this patch tested?
Pass the Jenkins with the newly added test case.
Closes#24921 from dongjoon-hyun/SPARK-28118.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}