## What changes were proposed in this pull request?
This is the same as #22492 but for master branch. Revert SPARK-14681 to avoid API breaking changes.
cc: WeichenXu123
## How was this patch tested?
Existing unit tests.
Closes#22618 from mengxr/SPARK-25321.master.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Refactor `HashBenchmark` to use main method.
1. use `spark-submit`:
```console
bin/spark-submit --class org.apache.spark.sql.HashBenchmark --jars ./core/target/spark-core_2.11-3.0.0-SNAPSHOT-tests.jar ./sql/catalyst/target/spark-catalyst_2.11-3.0.0-SNAPSHOT-tests.jar
```
2. Generate benchmark result:
```console
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "catalyst/test:runMain org.apache.spark.sql.HashBenchmark"
```
## How was this patch tested?
manual tests
Closes#22651 from wangyum/SPARK-25657.
Lead-authored-by: Yuming Wang <wgyumg@gmail.com>
Co-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Refactor `HashByteArrayBenchmark` to use main method.
1. use `spark-submit`:
```console
bin/spark-submit --class org.apache.spark.sql.HashByteArrayBenchmark --jars ./core/target/spark-core_2.11-3.0.0-SNAPSHOT-tests.jar ./sql/catalyst/target/spark-catalyst_2.11-3.0.0-SNAPSHOT-tests.jar
```
2. Generate benchmark result:
```console
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "catalyst/test:runMain org.apache.spark.sql.HashByteArrayBenchmark"
```
## How was this patch tested?
manual tests
Closes#22652 from wangyum/SPARK-25658.
Lead-authored-by: Yuming Wang <wgyumg@gmail.com>
Co-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
For Pandas UDFs, we get arrow type from defined Catalyst return data type of UDFs. We use this arrow type to do serialization of data. If the defined return data type doesn't match with actual return type of Pandas.Series returned by Pandas UDFs, it has a risk to return incorrect data from Python side.
Currently we don't have reliable approach to check if the data conversion is safe or not. We leave some document to notify this to users for now. When there is next upgrade of PyArrow available we can use to check it, we should add the option to check it.
## How was this patch tested?
Only document change.
Closes#22610 from viirya/SPARK-25461.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR upgrade `lz4-java` to 1.5.0 get speed improvement.
**General speed improvements**
LZ4 decompression speed has always been a strong point. In v1.8.2, this gets even better, as it improves decompression speed by about 10%, thanks in a large part to suggestion from svpv .
For example, on a Mac OS-X laptop with an Intel Core i7-5557U CPU 3.10GHz,
running lz4 -bsilesia.tar compiled with default compiler llvm v9.1.0:
Version | v1.8.1 | v1.8.2 | Improvement
-- | -- | -- | --
Decompression speed | 2490 MB/s | 2770 MB/s | +11%
Compression speeds also receive a welcomed boost, though improvement is not evenly distributed, with higher levels benefiting quite a lot more.
Version | v1.8.1 | v1.8.2 | Improvement
-- | -- | -- | --
lz4 -1 | 504 MB/s | 516 MB/s | +2%
lz4 -9 | 23.2 MB/s | 25.6 MB/s | +10%
lz4 -12 | 3.5 Mb/s | 9.5 MB/s | +170%
More details:
https://github.com/lz4/lz4/releases/tag/v1.8.3
**Below is my benchmark result**
set `spark.sql.parquet.compression.codec` to `lz4` and disable orc benchmark, then run `FilterPushdownBenchmark`.
lz4-java 1.5.0:
```
[success] Total time: 5585 s, completed Sep 26, 2018 5:22:16 PM
```
lz4-java 1.4.0:
```
[success] Total time: 5591 s, completed Sep 26, 2018 5:22:24 PM
```
Some benchmark result:
```
lz4-java 1.5.0 Select 1 row with 500 filters: Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------
Parquet Vectorized 1953 / 1980 0.0 1952502908.0 1.0X
Parquet Vectorized (Pushdown) 2541 / 2585 0.0 2541019869.0 0.8X
lz4-java 1.4.0 Select 1 row with 500 filters: Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------
Parquet Vectorized 1979 / 2103 0.0 1979328144.0 1.0X
Parquet Vectorized (Pushdown) 2596 / 2909 0.0 2596222118.0 0.8X
```
Complete benchmark result:
https://issues.apache.org/jira/secure/attachment/12941360/FilterPushdownBenchmark-lz4-java-140-results.txthttps://issues.apache.org/jira/secure/attachment/12941361/FilterPushdownBenchmark-lz4-java-150-results.txt
## How was this patch tested?
manual tests
Closes#22551 from wangyum/SPARK-25539.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently, we do not build external/spark-ganglia-lgpl in Jenkins tests when the code is changed.
## How was this patch tested?
N/A
Closes#22658 from gatorsmile/buildGanglia.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
After the PR, https://github.com/apache/spark/pull/22592, SQL tab supports collapsing table.
However, after refreshing the page, it doesn't store it previous state. This was due to a typo in the argument list in the collapseTablePageLoadCommand().
## How was this patch tested?
bin/spark-shell
```
sql("create table a (id int)")
for(i <- 1 to 100) sql(s"insert into a values ($i)")
```

Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22650 from shahidki31/SPARK-25575-followUp.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
`InMemoryFileIndex` contains a cache of `LocatedFileStatus` objects. Each `LocatedFileStatus` object can contain several `BlockLocation`s or some subclass of it. Filling up this cache by listing files happens recursively either on the driver or on the executors, depending on the parallel discovery threshold (`spark.sql.sources.parallelPartitionDiscovery.threshold`). If the listing happens on the executors block location objects are converted to simple `BlockLocation` objects to ensure serialization requirements. If it happens on the driver then there is no conversion and depending on the file system a `BlockLocation` object can be a subclass like `HdfsBlockLocation` and consume more memory. This PR adds the conversion to the latter case and decreases memory consumption.
## How was this patch tested?
Added unit test.
Closes#22603 from peter-toth/SPARK-25062.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This PR fixes the Scala-2.12 build error due to ambiguity in `foreachBatch` test cases.
- https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7-ubuntu-scala-2.12/428/console
```scala
[error] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7-ubuntu-scala-2.12/sql/core/src/test/scala/org/apache/spark/sql/execution/streaming/sources/ForeachBatchSinkSuite.scala:102: ambiguous reference to overloaded definition,
[error] both method foreachBatch in class DataStreamWriter of type (function: org.apache.spark.api.java.function.VoidFunction2[org.apache.spark.sql.Dataset[Int],Long])org.apache.spark.sql.streaming.DataStreamWriter[Int]
[error] and method foreachBatch in class DataStreamWriter of type (function: (org.apache.spark.sql.Dataset[Int], Long) => Unit)org.apache.spark.sql.streaming.DataStreamWriter[Int]
[error] match argument types ((org.apache.spark.sql.Dataset[Int], Any) => Unit)
[error] ds.writeStream.foreachBatch((_, _) => {}).trigger(Trigger.Continuous("1 second")).start()
[error] ^
[error] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7-ubuntu-scala-2.12/sql/core/src/test/scala/org/apache/spark/sql/execution/streaming/sources/ForeachBatchSinkSuite.scala:106: ambiguous reference to overloaded definition,
[error] both method foreachBatch in class DataStreamWriter of type (function: org.apache.spark.api.java.function.VoidFunction2[org.apache.spark.sql.Dataset[Int],Long])org.apache.spark.sql.streaming.DataStreamWriter[Int]
[error] and method foreachBatch in class DataStreamWriter of type (function: (org.apache.spark.sql.Dataset[Int], Long) => Unit)org.apache.spark.sql.streaming.DataStreamWriter[Int]
[error] match argument types ((org.apache.spark.sql.Dataset[Int], Any) => Unit)
[error] ds.writeStream.foreachBatch((_, _) => {}).partitionBy("value").start()
[error] ^
```
## How was this patch tested?
Manual.
Since this failure occurs in Scala-2.12 profile and test cases, Jenkins will not test this. We need to build with Scala-2.12 and run the tests.
Closes#22649 from dongjoon-hyun/SPARK-SCALA212.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Clean up the joinCriteria parsing in the parser by directly using identifierList
## How was this patch tested?
N/A
Closes#22648 from gatorsmile/cleanupJoinCriteria.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Refactor `MiscBenchmark ` to use main method.
Generate benchmark result:
```sh
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.MiscBenchmark"
```
## How was this patch tested?
manual tests
Closes#22500 from wangyum/SPARK-25488.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Yuming Wang <wgyumg@gmail.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
By replacing loops with random possible value.
- `read partitioning bucketed tables with bucket pruning filters` reduce from 55s to 7s
- `read partitioning bucketed tables having composite filters` reduce from 54s to 8s
- total time: reduce from 288s to 192s
## How was this patch tested?
Unit test
Closes#22640 from gengliangwang/fastenBucketedReadSuite.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Current the CSV's infer schema code inlines `TypeCoercion.findTightestCommonType`. This is a minor refactor to make use of the common type coercion code when applicable. This way we can take advantage of any improvement to the base method.
Thanks to MaxGekk for finding this while reviewing another PR.
## How was this patch tested?
This is a minor refactor. Existing tests are used to verify the change.
Closes#22619 from dilipbiswal/csv_minor.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Adds support for the setting limit in the sql split function
## How was this patch tested?
1. Updated unit tests
2. Tested using Scala spark shell
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22227 from phegstrom/master.
Authored-by: Parker Hegstrom <phegstrom@palantir.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Our lint failed due to the following errors:
```
[INFO] --- scalastyle-maven-plugin:1.0.0:check (default) spark-ganglia-lgpl_2.11 ---
error file=/home/jenkins/workspace/spark-master-maven-snapshots/spark/external/spark-ganglia-lgpl/src/main/scala/org/apache/spark/metrics/sink/GangliaSink.scala message=
Are you sure that you want to use toUpperCase or toLowerCase without the root locale? In most cases, you
should use toUpperCase(Locale.ROOT) or toLowerCase(Locale.ROOT) instead.
If you must use toUpperCase or toLowerCase without the root locale, wrap the code block with
// scalastyle:off caselocale
.toUpperCase
.toLowerCase
// scalastyle:on caselocale
line=67 column=49
error file=/home/jenkins/workspace/spark-master-maven-snapshots/spark/external/spark-ganglia-lgpl/src/main/scala/org/apache/spark/metrics/sink/GangliaSink.scala message=
Are you sure that you want to use toUpperCase or toLowerCase without the root locale? In most cases, you
should use toUpperCase(Locale.ROOT) or toLowerCase(Locale.ROOT) instead.
If you must use toUpperCase or toLowerCase without the root locale, wrap the code block with
// scalastyle:off caselocale
.toUpperCase
.toLowerCase
// scalastyle:on caselocale
line=71 column=32
Saving to outputFile=/home/jenkins/workspace/spark-master-maven-snapshots/spark/external/spark-ganglia-lgpl/target/scalastyle-output.xml
```
See https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Compile/job/spark-master-lint/8890/
## How was this patch tested?
N/A
Closes#22647 from gatorsmile/fixLint.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
The docker file was referencing a path that only existed in the
distribution tarball; it needs to be parameterized so that the
right path can be used in a dev build.
Tested on local dev build.
Closes#22634 from vanzin/SPARK-25646.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
In this test case, we are verifying that the result of an UDF is cached when the underlying data frame is cached and that the udf is not evaluated again when the cached data frame is used.
To reduce the runtime we do :
1) Use a single partition dataframe, so the total execution time of UDF is more deterministic.
2) Cut down the size of the dataframe from 10 to 2.
3) Reduce the sleep time in the UDF from 5secs to 2secs.
4) Reduce the failafter condition from 3 to 2.
With the above change, it takes about 4 secs to cache the first dataframe. And subsequent check takes a few hundred milliseconds.
The new runtime for 5 consecutive runs of this test is as follows :
```
[info] - cache UDF result correctly (4 seconds, 906 milliseconds)
[info] - cache UDF result correctly (4 seconds, 281 milliseconds)
[info] - cache UDF result correctly (4 seconds, 288 milliseconds)
[info] - cache UDF result correctly (4 seconds, 355 milliseconds)
[info] - cache UDF result correctly (4 seconds, 280 milliseconds)
```
## How was this patch tested?
This is s test fix.
Closes#22638 from dilipbiswal/SPARK-25610.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The total run time of `HiveSparkSubmitSuite` is about 10 minutes.
While the related code is stable, add tag `ExtendedHiveTest` for it.
## How was this patch tested?
Unit test.
Closes#22642 from gengliangwang/addTagForHiveSparkSubmitSuite.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Before ORC 1.5.3, `orc.dictionary.key.threshold` and `hive.exec.orc.dictionary.key.size.threshold` are applied for all columns. This has been a big huddle to enable dictionary encoding. From ORC 1.5.3, `orc.column.encoding.direct` is added to enforce direct encoding selectively in a column-wise manner. This PR aims to add that feature by upgrading ORC from 1.5.2 to 1.5.3.
The followings are the patches in ORC 1.5.3 and this feature is the only one related to Spark directly.
```
ORC-406: ORC: Char(n) and Varchar(n) writers truncate to n bytes & corrupts multi-byte data (gopalv)
ORC-403: [C++] Add checks to avoid invalid offsets in InputStream
ORC-405: Remove calcite as a dependency from the benchmarks.
ORC-375: Fix libhdfs on gcc7 by adding #include <functional> two places.
ORC-383: Parallel builds fails with ConcurrentModificationException
ORC-382: Apache rat exclusions + add rat check to travis
ORC-401: Fix incorrect quoting in specification.
ORC-385: Change RecordReader to extend Closeable.
ORC-384: [C++] fix memory leak when loading non-ORC files
ORC-391: [c++] parseType does not accept underscore in the field name
ORC-397: Allow selective disabling of dictionary encoding. Original patch was by Mithun Radhakrishnan.
ORC-389: Add ability to not decode Acid metadata columns
```
## How was this patch tested?
Pass the Jenkins with newly added test cases.
Closes#22622 from dongjoon-hyun/SPARK-25635.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Improve the runtime by reducing the number of partitions created in the test. The number of partitions are reduced from 280 to 60.
Here are the test times for the `getPartitionsByFilter returns all partitions` test on my laptop.
```
[info] - 0.13: getPartitionsByFilter returns all partitions when hive.metastore.try.direct.sql=false (4 seconds, 230 milliseconds)
[info] - 0.14: getPartitionsByFilter returns all partitions when hive.metastore.try.direct.sql=false (3 seconds, 576 milliseconds)
[info] - 1.0: getPartitionsByFilter returns all partitions when hive.metastore.try.direct.sql=false (3 seconds, 495 milliseconds)
[info] - 1.1: getPartitionsByFilter returns all partitions when hive.metastore.try.direct.sql=false (6 seconds, 728 milliseconds)
[info] - 1.2: getPartitionsByFilter returns all partitions when hive.metastore.try.direct.sql=false (7 seconds, 260 milliseconds)
[info] - 2.0: getPartitionsByFilter returns all partitions when hive.metastore.try.direct.sql=false (8 seconds, 270 milliseconds)
[info] - 2.1: getPartitionsByFilter returns all partitions when hive.metastore.try.direct.sql=false (6 seconds, 856 milliseconds)
[info] - 2.2: getPartitionsByFilter returns all partitions when hive.metastore.try.direct.sql=false (7 seconds, 587 milliseconds)
[info] - 2.3: getPartitionsByFilter returns all partitions when hive.metastore.try.direct.sql=false (7 seconds, 230 milliseconds)
## How was this patch tested?
Test only.
Closes#22644 from dilipbiswal/SPARK-25626.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The java `foreachBatch` API in `DataStreamWriter` should accept `java.lang.Long` rather `scala.Long`.
## How was this patch tested?
New java test.
Closes#22633 from zsxwing/fix-java-foreachbatch.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
When constructing a DataFrame from a Java bean, using nested beans throws an error despite [documentation](http://spark.apache.org/docs/latest/sql-programming-guide.html#inferring-the-schema-using-reflection) stating otherwise. This PR aims to add that support.
This PR does not yet add nested beans support in array or List fields. This can be added later or in another PR.
## How was this patch tested?
Nested bean was added to the appropriate unit test.
Also manually tested in Spark shell on code emulating the referenced JIRA:
```
scala> import scala.beans.BeanProperty
import scala.beans.BeanProperty
scala> class SubCategory(BeanProperty var id: String, BeanProperty var name: String) extends Serializable
defined class SubCategory
scala> class Category(BeanProperty var id: String, BeanProperty var subCategory: SubCategory) extends Serializable
defined class Category
scala> import scala.collection.JavaConverters._
import scala.collection.JavaConverters._
scala> spark.createDataFrame(Seq(new Category("s-111", new SubCategory("sc-111", "Sub-1"))).asJava, classOf[Category])
java.lang.IllegalArgumentException: The value (SubCategory65130cf2) of the type (SubCategory) cannot be converted to struct<id:string,name:string>
at org.apache.spark.sql.catalyst.CatalystTypeConverters$StructConverter.toCatalystImpl(CatalystTypeConverters.scala:262)
at org.apache.spark.sql.catalyst.CatalystTypeConverters$StructConverter.toCatalystImpl(CatalystTypeConverters.scala:238)
at org.apache.spark.sql.catalyst.CatalystTypeConverters$CatalystTypeConverter.toCatalyst(CatalystTypeConverters.scala:103)
at org.apache.spark.sql.catalyst.CatalystTypeConverters$$anonfun$createToCatalystConverter$2.apply(CatalystTypeConverters.scala:396)
at org.apache.spark.sql.SQLContext$$anonfun$beansToRows$1$$anonfun$apply$1.apply(SQLContext.scala:1108)
at org.apache.spark.sql.SQLContext$$anonfun$beansToRows$1$$anonfun$apply$1.apply(SQLContext.scala:1108)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.mutable.ArrayOps$ofRef.map(ArrayOps.scala:186)
at org.apache.spark.sql.SQLContext$$anonfun$beansToRows$1.apply(SQLContext.scala:1108)
at org.apache.spark.sql.SQLContext$$anonfun$beansToRows$1.apply(SQLContext.scala:1106)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$class.toStream(Iterator.scala:1320)
at scala.collection.AbstractIterator.toStream(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.toSeq(TraversableOnce.scala:298)
at scala.collection.AbstractIterator.toSeq(Iterator.scala:1334)
at org.apache.spark.sql.SparkSession.createDataFrame(SparkSession.scala:423)
... 51 elided
```
New behavior:
```
scala> spark.createDataFrame(Seq(new Category("s-111", new SubCategory("sc-111", "Sub-1"))).asJava, classOf[Category])
res0: org.apache.spark.sql.DataFrame = [id: string, subCategory: struct<id: string, name: string>]
scala> res0.show()
+-----+---------------+
| id| subCategory|
+-----+---------------+
|s-111|[sc-111, Sub-1]|
+-----+---------------+
```
Closes#22527 from michalsenkyr/SPARK-17952.
Authored-by: Michal Senkyr <mike.senkyr@gmail.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
Hi all,
Jackson is incompatible with upstream versions, therefore bump the Jackson version to a more recent one. I bumped into some issues with Azure CosmosDB that is using a more recent version of Jackson. This can be fixed by adding exclusions and then it works without any issues. So no breaking changes in the API's.
I would also consider bumping the version of Jackson in Spark. I would suggest to keep up to date with the dependencies, since in the future this issue will pop up more frequently.
## What changes were proposed in this pull request?
Bump Jackson to 2.9.6
## How was this patch tested?
Compiled and tested it locally to see if anything broke.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#21596 from Fokko/fd-bump-jackson.
Authored-by: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
``As part of insert command in FileFormatWriter, a job context is created for handling the write operation , While initializing the job context using setupJob() API
in HadoopMapReduceCommitProtocol , we set the jobid in the Jobcontext configuration.In FileFormatWriter since we are directly getting the jobId from the map reduce JobContext the job id will come as null while adding the log. As a solution we shall get the jobID from the configuration of the map reduce Jobcontext.``
## How was this patch tested?
Manually, verified the logs after the changes.

Closes#22572 from sujith71955/master_log_issue.
Authored-by: s71955 <sujithchacko.2010@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
While working on another PR, I noticed that there is quite some legacy Java in there that can be beautified. For example the use og features from Java8, such as:
- Collection libraries
- Try-with-resource blocks
No code has been changed
What are your thoughts on this?
This makes code easier to read, and using try-with-resource makes is less likely to forget to close something.
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22399 from Fokko/SPARK-25408.
Authored-by: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The test `cast string to timestamp` used to run for all time zones. So it run for more than 600 times. Running the tests for a significant subset of time zones is probably good enough and doing this in a randomized manner enforces anyway that we are going to test all time zones in different runs.
## How was this patch tested?
the test time reduces to 11 seconds from more than 2 minutes
Closes#22631 from mgaido91/SPARK-25605.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Reduce `DateExpressionsSuite.Hour` test time costs in Jenkins by reduce iteration times.
## How was this patch tested?
Manual tests on my local machine.
before:
```
- Hour (34 seconds, 54 milliseconds)
```
after:
```
- Hour (2 seconds, 697 milliseconds)
```
Closes#22632 from wangyum/SPARK-25606.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The PR changes the test introduced for SPARK-22226, so that we don't run analysis and optimization on the plan. The scope of the test is code generation and running the above mentioned operation is expensive and useless for the test.
The UT was also moved to the `CodeGenerationSuite` which is a better place given the scope of the test.
## How was this patch tested?
running the UT before SPARK-22226 fails, after it passes. The execution time is about 50% the original one. On my laptop this means that the test now runs in about 23 seconds (instead of 50 seconds).
Closes#22629 from mgaido91/SPARK-25609.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Original work by Steve Loughran.
Based on #17745.
This is a minimal patch of changes to FileInputDStream to reduce File status requests when querying files. Each call to file status is 3+ http calls to object store. This patch eliminates the need for it, by using FileStatus objects.
This is a minor optimisation when working with filesystems, but significant when working with object stores.
## How was this patch tested?
Tests included. Existing tests pass.
Closes#22339 from ScrapCodes/PR_17745.
Lead-authored-by: Prashant Sharma <prashant@apache.org>
Co-authored-by: Steve Loughran <stevel@hortonworks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Refactor `DatasetBenchmark` to use main method.
Generate benchmark result:
```sh
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.DatasetBenchmark"
```
## How was this patch tested?
manual tests
Closes#22488 from wangyum/SPARK-25479.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
In `SparkPlan.getByteArrayRdd`, we should only call `it.hasNext` when the limit is not hit, as `iter.hasNext` may produce one row and buffer it, and cause wrong metrics.
## How was this patch tested?
new tests
Closes#22621 from cloud-fan/range.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR proposes to register Grouped aggregate UDF Vectorized UDFs for SQL Statement, for instance:
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
pandas_udf("integer", PandasUDFType.GROUPED_AGG)
def sum_udf(v):
return v.sum()
spark.udf.register("sum_udf", sum_udf)
q = "SELECT v2, sum_udf(v1) FROM VALUES (3, 0), (2, 0), (1, 1) tbl(v1, v2) GROUP BY v2"
spark.sql(q).show()
```
```
+---+-----------+
| v2|sum_udf(v1)|
+---+-----------+
| 1| 1|
| 0| 5|
+---+-----------+
```
## How was this patch tested?
Manual test and unit test.
Closes#22620 from HyukjinKwon/SPARK-25601.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR proposes to register Grouped aggregate UDF Vectorized UDFs for SQL Statement, for instance:
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
pandas_udf("integer", PandasUDFType.GROUPED_AGG)
def sum_udf(v):
return v.sum()
spark.udf.register("sum_udf", sum_udf)
q = "SELECT v2, sum_udf(v1) FROM VALUES (3, 0), (2, 0), (1, 1) tbl(v1, v2) GROUP BY v2"
spark.sql(q).show()
```
```
+---+-----------+
| v2|sum_udf(v1)|
+---+-----------+
| 1| 1|
| 0| 5|
+---+-----------+
```
## How was this patch tested?
Manual test and unit test.
Closes#22620 from HyukjinKwon/SPARK-25601.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Cause: Recently test_glr_summary failed for PR of SPARK-25118, which enables
spark-shell to run with default log level. It failed because this logdebug was
called for GeneralizedLinearRegressionTrainingSummary which invoked its toString
method, which started a Spark Job and ended up running into an infinite loop.
Fix: Remove logDebug statement for outer objects as closures aren't implemented
with outerclasses in Scala 2.12 and this debug statement looses its purpose
## How was this patch tested?
Ran python pyspark-ml tests on top of PR for SPARK-25118 and ClosureCleaner unit
tests
Closes#22616 from ankuriitg/ankur/SPARK-25586.
Authored-by: ankurgupta <ankur.gupta@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
In #20850 when writing non-null decimals, instead of zero-ing all the 16 allocated bytes, we zero-out only the padding bytes. Since we always allocate 16 bytes, if the number of bytes needed for a decimal is lower than 9, then this means that the bytes between 8 and 16 are not zero-ed.
I see 2 solutions here:
- we can zero-out all the bytes in advance as it was done before #20850 (safer solution IMHO);
- we can allocate only the needed bytes (may be a bit more efficient in terms of memory used, but I have not investigated the feasibility of this option).
Hence I propose here the first solution in order to fix the correctness issue. We can eventually switch to the second if we think is more efficient later.
## How was this patch tested?
Running the test attached in the JIRA + added UT
Closes#22602 from mgaido91/SPARK-25582.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Refactor `UnsafeArrayDataBenchmark` to use main method.
Generate benchmark result:
```sh
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.UnsafeArrayDataBenchmark"
```
## How was this patch tested?
manual tests
Closes#22491 from wangyum/SPARK-25483.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This PR aims to add `BloomFilterBenchmark`. For ORC data source, Apache Spark has been supporting for a long time. For Parquet data source, it's expected to be added with next Parquet release update.
## How was this patch tested?
Manual.
```scala
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.BloomFilterBenchmark"
```
Closes#22605 from dongjoon-hyun/SPARK-25589.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
With flag `IGNORE_CORRUPT_FILES` enabled, schema inference should ignore corrupt Avro files, which is consistent with Parquet and Orc data source.
## How was this patch tested?
Unit test
Closes#22611 from gengliangwang/ignoreCorruptAvro.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
SPARK-24530 discovered a problem of generation python doc, and provided a fix: setting SPHINXPYTHON to python 3.
This PR makes this fix automatic in the release script using docker.
## How was this patch tested?
verified by the 2.4.0 rc2
Closes#22607 from cloud-fan/python.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Rename method `benchmark` in `BenchmarkBase` as `runBenchmarkSuite `. Also add comments.
Currently the method name `benchmark` is a bit confusing. Also the name is the same as instances of `Benchmark`:
f246813afb/sql/hive/src/test/scala/org/apache/spark/sql/hive/orc/OrcReadBenchmark.scala (L330-L339)
## How was this patch tested?
Unit test.
Closes#22599 from gengliangwang/renameBenchmarkSuite.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This patch is to bump the master branch version to 3.0.0-SNAPSHOT.
## How was this patch tested?
N/A
Closes#22606 from gatorsmile/bump3.0.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Update to Scala 2.12.7. See https://issues.apache.org/jira/browse/SPARK-25578 for why.
## How was this patch tested?
Existing tests.
Closes#22600 from srowen/SPARK-25578.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently, SQL tab in the WEBUI doesn't support hiding table. Other tabs in the web ui like, Jobs, stages etc supports hiding table (refer SPARK-23024 https://github.com/apache/spark/pull/20216).
In this PR, added the support for hide table in the sql tab also.
## How was this patch tested?
bin/spark-shell
```
sql("create table a (id int)")
for(i <- 1 to 100) sql(s"insert into a values ($i)")
```
Open SQL tab in the web UI
**Before fix:**
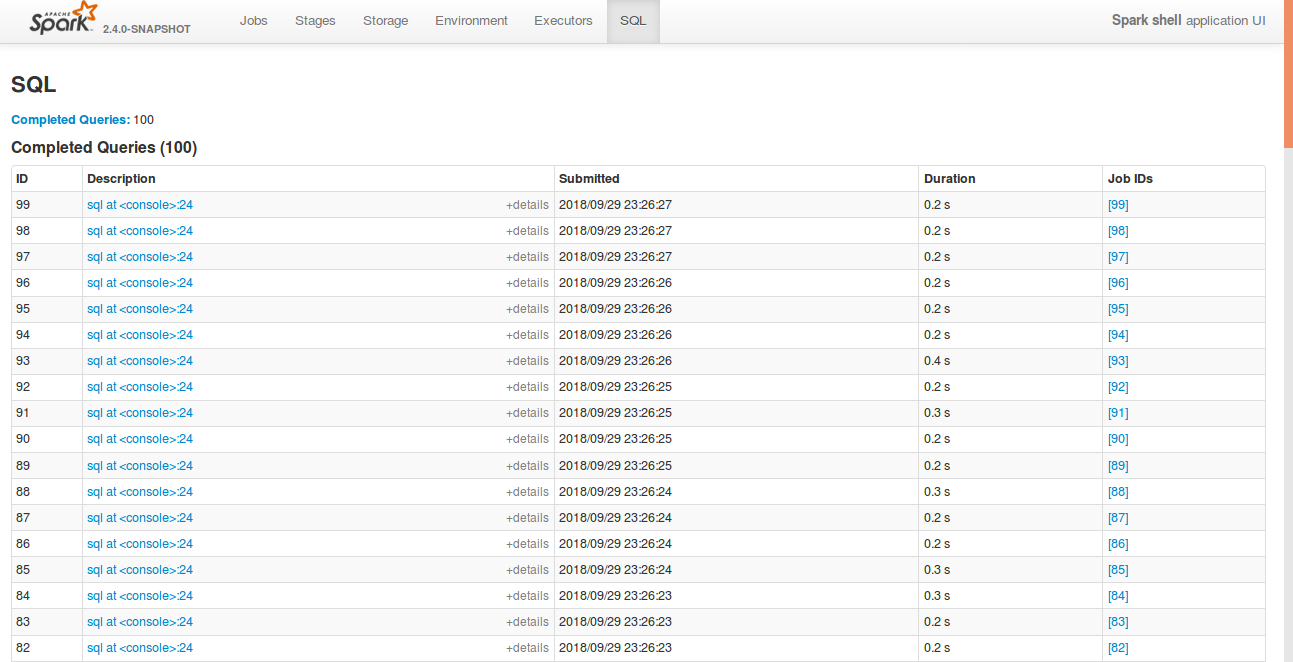
**After fix:** Consistent with the other tabs.

(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22592 from shahidki31/SPARK-25575.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR is follow-up of closed https://github.com/apache/spark/pull/17401 which only ended due to of inactivity, but its still nice feature to have.
Given review by jerryshao taken in consideration and edited:
- VisibleForTesting deleted because of dependency conflicts
- removed unnecessary reflection for `MetricsSystemImpl`
- added more available types for gauge
## How was this patch tested?
Manual deploy of new yarn-shuffle jar into a Node Manager and verifying that the metrics appear in the Node Manager-standard location. This is JMX with an query endpoint running on `hostname:port`
Resulting metrics look like this:
```
curl -sk -XGET hostname:port | grep -v '#' | grep 'shuffleService'
hadoop_nodemanager_openblockrequestlatencymillis_rate15{name="shuffleService",} 0.31428910657834713
hadoop_nodemanager_blocktransferratebytes_rate15{name="shuffleService",} 566144.9983653595
hadoop_nodemanager_blocktransferratebytes_ratemean{name="shuffleService",} 2464409.9678099006
hadoop_nodemanager_openblockrequestlatencymillis_rate1{name="shuffleService",} 1.2893844732240272
hadoop_nodemanager_registeredexecutorssize{name="shuffleService",} 2.0
hadoop_nodemanager_openblockrequestlatencymillis_ratemean{name="shuffleService",} 1.255574678369966
hadoop_nodemanager_openblockrequestlatencymillis_count{name="shuffleService",} 315.0
hadoop_nodemanager_openblockrequestlatencymillis_rate5{name="shuffleService",} 0.7661929192569739
hadoop_nodemanager_registerexecutorrequestlatencymillis_ratemean{name="shuffleService",} 0.0
hadoop_nodemanager_registerexecutorrequestlatencymillis_count{name="shuffleService",} 0.0
hadoop_nodemanager_registerexecutorrequestlatencymillis_rate1{name="shuffleService",} 0.0
hadoop_nodemanager_registerexecutorrequestlatencymillis_rate5{name="shuffleService",} 0.0
hadoop_nodemanager_blocktransferratebytes_count{name="shuffleService",} 6.18271213E8
hadoop_nodemanager_registerexecutorrequestlatencymillis_rate15{name="shuffleService",} 0.0
hadoop_nodemanager_blocktransferratebytes_rate5{name="shuffleService",} 1154114.4881816586
hadoop_nodemanager_blocktransferratebytes_rate1{name="shuffleService",} 574745.0749848988
```
Closes#22485 from mareksimunek/SPARK-18364.
Lead-authored-by: marek.simunek <marek.simunek@firma.seznam.cz>
Co-authored-by: Andrew Ash <andrew@andrewash.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
This PR does 2 things:
1. Add a new trait(`SqlBasedBenchmark`) to better support Dataset and DataFrame API.
2. Refactor `AggregateBenchmark` to use main method. Generate benchmark result:
```
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.AggregateBenchmark"
```
## How was this patch tested?
manual tests
Closes#22484 from wangyum/SPARK-25476.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Add more data types for Pandas UDF Tests for PySpark SQL
## How was this patch tested?
manual tests
Closes#22568 from AlexanderKoryagin/new_types_for_pandas_udf_tests.
Lead-authored-by: Aleksandr Koriagin <aleksandr_koriagin@epam.com>
Co-authored-by: hyukjinkwon <gurwls223@apache.org>
Co-authored-by: Alexander Koryagin <AlexanderKoryagin@users.noreply.github.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR aims to fix the failed test of `OracleIntegrationSuite`.
## How was this patch tested?
Existing integration tests.
Closes#22461 from seancxmao/SPARK-25453.
Authored-by: seancxmao <seancxmao@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}