### What changes were proposed in this pull request? The `explain()` method prints the arguments of tree nodes in logical/physical plans. The arguments could contain a map-type option that contains sensitive data. We should map-type options in the output of `explain()`. Otherwise, we will see sensitive data in explain output or Spark UI. 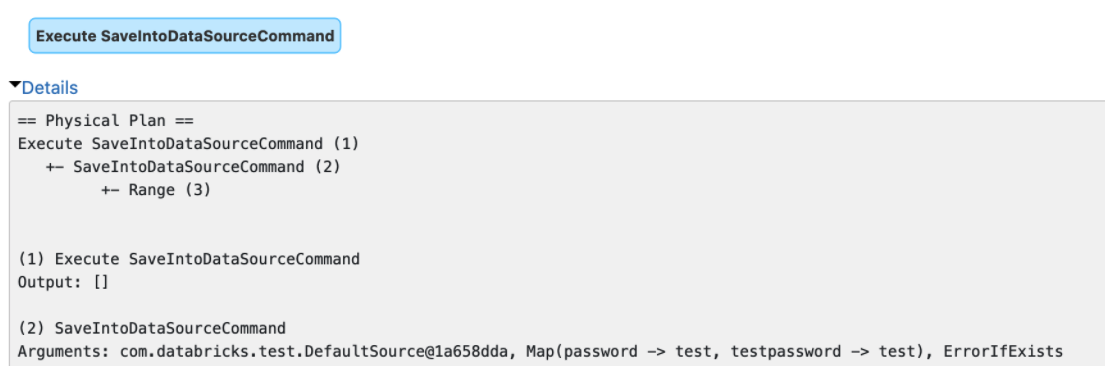 ### Why are the changes needed? Data security. ### Does this PR introduce _any_ user-facing change? Yes, redact the map-type options in the output of `explain()` ### How was this patch tested? Unit tests Closes #32066 from gengliangwang/redactOptions. Authored-by: Gengliang Wang <ltnwgl@gmail.com> Signed-off-by: Gengliang Wang <ltnwgl@gmail.com> |
||
|---|---|---|
| .github | ||
| assembly | ||
| bin | ||
| binder | ||
| build | ||
| common | ||
| conf | ||
| core | ||
| data | ||
| dev | ||
| docs | ||
| examples | ||
| external | ||
| graphx | ||
| hadoop-cloud | ||
| launcher | ||
| licenses | ||
| licenses-binary | ||
| mllib | ||
| mllib-local | ||
| project | ||
| python | ||
| R | ||
| repl | ||
| resource-managers | ||
| sbin | ||
| sql | ||
| streaming | ||
| tools | ||
| .asf.yaml | ||
| .gitattributes | ||
| .gitignore | ||
| appveyor.yml | ||
| CONTRIBUTING.md | ||
| LICENSE | ||
| LICENSE-binary | ||
| NOTICE | ||
| NOTICE-binary | ||
| pom.xml | ||
| README.md | ||
| scalastyle-config.xml | ||
{kind=link}
Apache Spark
Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an optimized engine that supports general computation graphs for data analysis. It also supports a rich set of higher-level tools including Spark SQL for SQL and DataFrames, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing.

![]()
Online Documentation
You can find the latest Spark documentation, including a programming guide, on the project web page. This README file only contains basic setup instructions.
Building Spark
Spark is built using Apache Maven. To build Spark and its example programs, run:
./build/mvn -DskipTests clean package
(You do not need to do this if you downloaded a pre-built package.)
More detailed documentation is available from the project site, at "Building Spark".
For general development tips, including info on developing Spark using an IDE, see "Useful Developer Tools".
Interactive Scala Shell
The easiest way to start using Spark is through the Scala shell:
./bin/spark-shell
Try the following command, which should return 1,000,000,000:
scala> spark.range(1000 * 1000 * 1000).count()
Interactive Python Shell
Alternatively, if you prefer Python, you can use the Python shell:
./bin/pyspark
And run the following command, which should also return 1,000,000,000:
>>> spark.range(1000 * 1000 * 1000).count()
Example Programs
Spark also comes with several sample programs in the examples directory.
To run one of them, use ./bin/run-example <class> [params]. For example:
./bin/run-example SparkPi
will run the Pi example locally.
You can set the MASTER environment variable when running examples to submit
examples to a cluster. This can be a mesos:// or spark:// URL,
"yarn" to run on YARN, and "local" to run
locally with one thread, or "local[N]" to run locally with N threads. You
can also use an abbreviated class name if the class is in the examples
package. For instance:
MASTER=spark://host:7077 ./bin/run-example SparkPi
Many of the example programs print usage help if no params are given.
Running Tests
Testing first requires building Spark. Once Spark is built, tests can be run using:
./dev/run-tests
Please see the guidance on how to run tests for a module, or individual tests.
There is also a Kubernetes integration test, see resource-managers/kubernetes/integration-tests/README.md
A Note About Hadoop Versions
Spark uses the Hadoop core library to talk to HDFS and other Hadoop-supported storage systems. Because the protocols have changed in different versions of Hadoop, you must build Spark against the same version that your cluster runs.
Please refer to the build documentation at "Specifying the Hadoop Version and Enabling YARN" for detailed guidance on building for a particular distribution of Hadoop, including building for particular Hive and Hive Thriftserver distributions.
Configuration
Please refer to the Configuration Guide in the online documentation for an overview on how to configure Spark.
Contributing
Please review the Contribution to Spark guide for information on how to get started contributing to the project.