## What changes were proposed in this pull request?
Documentation about Mesos Reject Offer Configurations
## Related PR
https://github.com/apache/spark/pull/19510 for `spark.mem.max`
Author: Li, YanKit | Wilson | RIT <yankit.li@rakuten.com>
Closes#19555 from windkit/spark_22133.
## What changes were proposed in this pull request?
Add incompatible Hive UDF describe to DOC.
## How was this patch tested?
N/A
Author: Yuming Wang <wgyumg@gmail.com>
Closes#18833 from wangyum/SPARK-21625.
## What changes were proposed in this pull request?
Easy fix in the documentation, which is reporting that only numeric types and string are supported in type inference for partition columns, while Date and Timestamp are supported too since 2.1.0, thanks to SPARK-17388.
## How was this patch tested?
n/a
Author: Marco Gaido <mgaido@hortonworks.com>
Closes#19628 from mgaido91/SPARK-22398.
## What changes were proposed in this pull request?
Using zstd compression for Spark jobs spilling 100s of TBs of data, we could reduce the amount of data written to disk by as much as 50%. This translates to significant latency gain because of reduced disk io operations. There is a degradation CPU time by 2 - 5% because of zstd compression overhead, but for jobs which are bottlenecked by disk IO, this hit can be taken.
## Benchmark
Please note that this benchmark is using real world compute heavy production workload spilling TBs of data to disk
| | zstd performance as compred to LZ4 |
| ------------- | -----:|
| spill/shuffle bytes | -48% |
| cpu time | + 3% |
| cpu reservation time | -40%|
| latency | -40% |
## How was this patch tested?
Tested by running few jobs spilling large amount of data on the cluster and amount of intermediate data written to disk reduced by as much as 50%.
Author: Sital Kedia <skedia@fb.com>
Closes#18805 from sitalkedia/skedia/upstream_zstd.
## What changes were proposed in this pull request?
Update the url of reference paper.
## How was this patch tested?
It is comments, so nothing tested.
Author: bomeng <bmeng@us.ibm.com>
Closes#19614 from bomeng/22399.
Often times we want to impute custom values other than 'NaN'. My addition helps people locate this function without reading the API.
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: tengpeng <tengpeng@users.noreply.github.com>
Closes#19600 from tengpeng/patch-5.
## Background
In #18837 , ArtRand added Mesos secrets support to the dispatcher. **This PR is to add the same secrets support to the drivers.** This means if the secret configs are set, the driver will launch executors that have access to either env or file-based secrets.
One use case for this is to support TLS in the driver <=> executor communication.
## What changes were proposed in this pull request?
Most of the changes are a refactor of the dispatcher secrets support (#18837) - moving it to a common place that can be used by both the dispatcher and drivers. The same goes for the unit tests.
## How was this patch tested?
There are four config combinations: [env or file-based] x [value or reference secret]. For each combination:
- Added a unit test.
- Tested in DC/OS.
Author: Susan X. Huynh <xhuynh@mesosphere.com>
Closes#19437 from susanxhuynh/sh-mesos-driver-secret.
## What changes were proposed in this pull request?
Event Log Server has a total of five configuration parameters, and now the description of the other two configuration parameters on the doc, user-friendly access and use.
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: guoxiaolong <guo.xiaolong1@zte.com.cn>
Closes#19242 from guoxiaolongzte/addEventLogConf.
## What changes were proposed in this pull request?
The HTTP Strict-Transport-Security response header (often abbreviated as HSTS) is a security feature that lets a web site tell browsers that it should only be communicated with using HTTPS, instead of using HTTP.
Note: The Strict-Transport-Security header is ignored by the browser when your site is accessed using HTTP; this is because an attacker may intercept HTTP connections and inject the header or remove it. When your site is accessed over HTTPS with no certificate errors, the browser knows your site is HTTPS capable and will honor the Strict-Transport-Security header.
The HTTP X-XSS-Protection response header is a feature of Internet Explorer, Chrome and Safari that stops pages from loading when they detect reflected cross-site scripting (XSS) attacks.
The HTTP X-Content-Type-Options response header is used to protect against MIME sniffing vulnerabilities.
## How was this patch tested?
Checked on my system locally.
<img width="750" alt="screen shot 2017-10-03 at 6 49 20 pm" src="https://user-images.githubusercontent.com/6433184/31127234-eadf7c0c-a86b-11e7-8e5d-f6ea3f97b210.png">
Author: krishna-pandey <krish.pandey21@gmail.com>
Author: Krishna Pandey <krish.pandey21@gmail.com>
Closes#19419 from krishna-pandey/SPARK-22188.
Hive delegation tokens are only needed when the Spark driver has no access
to the kerberos TGT. That happens only in two situations:
- when using a proxy user
- when using cluster mode without a keytab
This change modifies the Hive provider so that it only generates delegation
tokens in those situations, and tweaks the YARN AM so that it makes the proper
user visible to the Hive code when running with keytabs, so that the TGT
can be used instead of a delegation token.
The effect of this change is that now it's possible to initialize multiple,
non-concurrent SparkContext instances in the same JVM. Before, the second
invocation would fail to fetch a new Hive delegation token, which then could
make the second (or third or...) application fail once the token expired.
With this change, the TGT will be used to authenticate to the HMS instead.
This change also avoids polluting the current logged in user's credentials
when launching applications. The credentials are copied only when running
applications as a proxy user. This makes it possible to implement SPARK-11035
later, where multiple threads might be launching applications, and each app
should have its own set of credentials.
Tested by verifying HDFS and Hive access in following scenarios:
- client and cluster mode
- client and cluster mode with proxy user
- client and cluster mode with principal / keytab
- long-running cluster app with principal / keytab
- pyspark app that creates (and stops) multiple SparkContext instances
through its lifetime
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#19509 from vanzin/SPARK-22290.
## What changes were proposed in this pull request?
I see that block updates are not logged to the event log.
This makes sense as a default for performance reasons.
However, I find it helpful when trying to get a better understanding of caching for a job to be able to log these updates.
This PR adds a configuration setting `spark.eventLog.blockUpdates` (defaulting to false) which allows block updates to be recorded in the log.
This contribution is original work which is licensed to the Apache Spark project.
## How was this patch tested?
Current and additional unit tests.
Author: Michael Mior <mmior@uwaterloo.ca>
Closes#19263 from michaelmior/log-block-updates.
## What changes were proposed in this pull request?
In the current BlockManager's `getRemoteBytes`, it will call `BlockTransferService#fetchBlockSync` to get remote block. In the `fetchBlockSync`, Spark will allocate a temporary `ByteBuffer` to store the whole fetched block. This will potentially lead to OOM if block size is too big or several blocks are fetched simultaneously in this executor.
So here leveraging the idea of shuffle fetch, to spill the large block to local disk before consumed by upstream code. The behavior is controlled by newly added configuration, if block size is smaller than the threshold, then this block will be persisted in memory; otherwise it will first spill to disk, and then read from disk file.
To achieve this feature, what I did is:
1. Rename `TempShuffleFileManager` to `TempFileManager`, since now it is not only used by shuffle.
2. Add a new `TempFileManager` to manage the files of fetched remote blocks, the files are tracked by weak reference, will be deleted when no use at all.
## How was this patch tested?
This was tested by adding UT, also manual verification in local test to perform GC to clean the files.
Author: jerryshao <sshao@hortonworks.com>
Closes#19476 from jerryshao/SPARK-22062.
## What changes were proposed in this pull request?
Adds links to the fork that provides integration with Nomad, in the same places the k8s integration is linked to.
## How was this patch tested?
I clicked on the links to make sure they're correct ;)
Author: Ben Barnard <barnardb@gmail.com>
Closes#19354 from barnardb/link-to-nomad-integration.
## What changes were proposed in this pull request?
Added documentation for loading csv files into Dataframes
## How was this patch tested?
/dev/run-tests
Author: Jorge Machado <jorge.w.machado@hotmail.com>
Closes#19429 from jomach/master.
## What changes were proposed in this pull request?
The number of cores assigned to each executor is configurable. When this is not explicitly set, multiple executors from the same application may be launched on the same worker too.
## How was this patch tested?
N/A
Author: liuxian <liu.xian3@zte.com.cn>
Closes#18711 from 10110346/executorcores.
## What changes were proposed in this pull request?
Move flume behind a profile, take 2. See https://github.com/apache/spark/pull/19365 for most of the back-story.
This change should fix the problem by removing the examples module dependency and moving Flume examples to the module itself. It also adds deprecation messages, per a discussion on dev about deprecating for 2.3.0.
## How was this patch tested?
Existing tests, which still enable flume integration.
Author: Sean Owen <sowen@cloudera.com>
Closes#19412 from srowen/SPARK-22142.2.
## What changes were proposed in this pull request?
Add 'flume' profile to enable Flume-related integration modules
## How was this patch tested?
Existing tests; no functional change
Author: Sean Owen <sowen@cloudera.com>
Closes#19365 from srowen/SPARK-22142.
The application listing is still generated from event logs, but is now stored
in a KVStore instance. By default an in-memory store is used, but a new config
allows setting a local disk path to store the data, in which case a LevelDB
store will be created.
The provider stores things internally using the public REST API types; I believe
this is better going forward since it will make it easier to get rid of the
internal history server API which is mostly redundant at this point.
I also added a finalizer to LevelDBIterator, to make sure that resources are
eventually released. This helps when code iterates but does not exhaust the
iterator, thus not triggering the auto-close code.
HistoryServerSuite was modified to not re-start the history server unnecessarily;
this makes the json validation tests run more quickly.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#18887 from vanzin/SPARK-20642.
## What changes were proposed in this pull request?
The `percentile_approx` function previously accepted numeric type input and output double type results.
But since all numeric types, date and timestamp types are represented as numerics internally, `percentile_approx` can support them easily.
After this PR, it supports date type, timestamp type and numeric types as input types. The result type is also changed to be the same as the input type, which is more reasonable for percentiles.
This change is also required when we generate equi-height histograms for these types.
## How was this patch tested?
Added a new test and modified some existing tests.
Author: Zhenhua Wang <wangzhenhua@huawei.com>
Closes#19321 from wzhfy/approx_percentile_support_types.
## What changes were proposed in this pull request?
Updated docs so that a line of python in the quick start guide executes. Closes#19283
## How was this patch tested?
Existing tests.
Author: John O'Leary <jgoleary@gmail.com>
Closes#19326 from jgoleary/issues/22107.
Change-Id: I88c272444ca734dc2cbc2592607c11287b90a383
## What changes were proposed in this pull request?
The documentation on File DStreams is enhanced to
1. Detail the exact timestamp logic for examining directories and files.
1. Detail how object stores different from filesystems, and so how using them as a source of data should be treated with caution, possibly publishing data to the store differently (direct PUTs as opposed to stage + rename)
## How was this patch tested?
n/a
Author: Steve Loughran <stevel@hortonworks.com>
Closes#17743 from steveloughran/cloud/SPARK-20448-document-dstream-blobstore.
## What changes were proposed in this pull request?
In the current Spark, when submitting application on YARN with remote resources `./bin/spark-shell --jars http://central.maven.org/maven2/com/github/swagger-akka-http/swagger-akka-http_2.11/0.10.1/swagger-akka-http_2.11-0.10.1.jar --master yarn-client -v`, Spark will be failed with:
```
java.io.IOException: No FileSystem for scheme: http
at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:2586)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2593)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:91)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2632)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2614)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:370)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:296)
at org.apache.spark.deploy.yarn.Client.copyFileToRemote(Client.scala:354)
at org.apache.spark.deploy.yarn.Client.org$apache$spark$deploy$yarn$Client$$distribute$1(Client.scala:478)
at org.apache.spark.deploy.yarn.Client$$anonfun$prepareLocalResources$11$$anonfun$apply$6.apply(Client.scala:600)
at org.apache.spark.deploy.yarn.Client$$anonfun$prepareLocalResources$11$$anonfun$apply$6.apply(Client.scala:599)
at scala.collection.mutable.ArraySeq.foreach(ArraySeq.scala:74)
at org.apache.spark.deploy.yarn.Client$$anonfun$prepareLocalResources$11.apply(Client.scala:599)
at org.apache.spark.deploy.yarn.Client$$anonfun$prepareLocalResources$11.apply(Client.scala:598)
at scala.collection.immutable.List.foreach(List.scala:381)
at org.apache.spark.deploy.yarn.Client.prepareLocalResources(Client.scala:598)
at org.apache.spark.deploy.yarn.Client.createContainerLaunchContext(Client.scala:848)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:173)
```
This is because `YARN#client` assumes resources are on the Hadoop compatible FS. To fix this problem, here propose to download remote http(s) resources to local and add this local downloaded resources to dist cache. This solution has one downside: remote resources are downloaded and uploaded again, but it only restricted to only remote http(s) resources, also the overhead is not so big. The advantages of this solution is that it is simple and the code changes restricts to only `SparkSubmit`.
## How was this patch tested?
Unit test added, also verified in local cluster.
Author: jerryshao <sshao@hortonworks.com>
Closes#19130 from jerryshao/SPARK-21917.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/18266 add a new feature to support read JDBC table use custom schema, but we must specify all the fields. For simplicity, this PR support specify partial fields.
## How was this patch tested?
unit tests
Author: Yuming Wang <wgyumg@gmail.com>
Closes#19231 from wangyum/SPARK-22002.
## What changes were proposed in this pull request?
Auto generated Oracle schema some times not we expect:
- `number(1)` auto mapped to BooleanType, some times it's not we expect, per [SPARK-20921](https://issues.apache.org/jira/browse/SPARK-20921).
- `number` auto mapped to Decimal(38,10), It can't read big data, per [SPARK-20427](https://issues.apache.org/jira/browse/SPARK-20427).
This PR fix this issue by custom schema as follows:
```scala
val props = new Properties()
props.put("customSchema", "ID decimal(38, 0), N1 int, N2 boolean")
val dfRead = spark.read.schema(schema).jdbc(jdbcUrl, "tableWithCustomSchema", props)
dfRead.show()
```
or
```sql
CREATE TEMPORARY VIEW tableWithCustomSchema
USING org.apache.spark.sql.jdbc
OPTIONS (url '$jdbcUrl', dbTable 'tableWithCustomSchema', customSchema'ID decimal(38, 0), N1 int, N2 boolean')
```
## How was this patch tested?
unit tests
Author: Yuming Wang <wgyumg@gmail.com>
Closes#18266 from wangyum/SPARK-20427.
## What changes were proposed in this pull request?
Put Kafka 0.8 support behind a kafka-0-8 profile.
## How was this patch tested?
Existing tests, but, until PR builder and Jenkins configs are updated the effect here is to not build or test Kafka 0.8 support at all.
Author: Sean Owen <sowen@cloudera.com>
Closes#19134 from srowen/SPARK-21893.
# What changes were proposed in this pull request?
Added tunable parallelism to the pyspark implementation of one vs. rest classification. Added a parallelism parameter to the Scala implementation of one vs. rest along with functionality for using the parameter to tune the level of parallelism.
I take this PR #18281 over because the original author is busy but we need merge this PR soon.
After this been merged, we can close#18281 .
## How was this patch tested?
Test suite added.
Author: Ajay Saini <ajays725@gmail.com>
Author: WeichenXu <weichen.xu@databricks.com>
Closes#19110 from WeichenXu123/spark-21027.
## What changes were proposed in this pull request?
Recently, I found two unreachable links in the document and fixed them.
Because of small changes related to the document, I don't file this issue in JIRA but please suggest I should do it if you think it's needed.
## How was this patch tested?
Tested manually.
Author: Kousuke Saruta <sarutak@oss.nttdata.co.jp>
Closes#19195 from sarutak/fix-unreachable-link.
## What changes were proposed in this pull request?
Fixed wrong documentation for Mean Absolute Error.
Even though the code is correct for the MAE:
```scala
Since("1.2.0")
def meanAbsoluteError: Double = {
summary.normL1(1) / summary.count
}
```
In the documentation the division by N is missing.
## How was this patch tested?
All of spark tests were run.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: FavioVazquez <favio.vazquezp@gmail.com>
Author: faviovazquez <favio.vazquezp@gmail.com>
Author: Favio André Vázquez <favio.vazquezp@gmail.com>
Closes#19190 from FavioVazquez/mae-fix.
## What changes were proposed in this pull request?
```
echo '{"field": 1}
{"field": 2}
{"field": "3"}' >/tmp/sample.json
```
```scala
import org.apache.spark.sql.types._
val schema = new StructType()
.add("field", ByteType)
.add("_corrupt_record", StringType)
val file = "/tmp/sample.json"
val dfFromFile = spark.read.schema(schema).json(file)
scala> dfFromFile.show(false)
+-----+---------------+
|field|_corrupt_record|
+-----+---------------+
|1 |null |
|2 |null |
|null |{"field": "3"} |
+-----+---------------+
scala> dfFromFile.filter($"_corrupt_record".isNotNull).count()
res1: Long = 0
scala> dfFromFile.filter($"_corrupt_record".isNull).count()
res2: Long = 3
```
When the `requiredSchema` only contains `_corrupt_record`, the derived `actualSchema` is empty and the `_corrupt_record` are all null for all rows. This PR captures above situation and raise an exception with a reasonable workaround messag so that users can know what happened and how to fix the query.
## How was this patch tested?
Added test case.
Author: Jen-Ming Chung <jenmingisme@gmail.com>
Closes#18865 from jmchung/SPARK-21610.
## What changes were proposed in this pull request?
Since [SPARK-15639](https://github.com/apache/spark/pull/13701), `spark.sql.parquet.cacheMetadata` and `PARQUET_CACHE_METADATA` is not used. This PR removes from SQLConf and docs.
## How was this patch tested?
Pass the existing Jenkins.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19129 from dongjoon-hyun/SPARK-13656.
## What changes were proposed in this pull request?
Modified `CrossValidator` and `TrainValidationSplit` to be able to evaluate models in parallel for a given parameter grid. The level of parallelism is controlled by a parameter `numParallelEval` used to schedule a number of models to be trained/evaluated so that the jobs can be run concurrently. This is a naive approach that does not check the cluster for needed resources, so care must be taken by the user to tune the parameter appropriately. The default value is `1` which will train/evaluate in serial.
## How was this patch tested?
Added unit tests for CrossValidator and TrainValidationSplit to verify that model selection is the same when run in serial vs parallel. Manual testing to verify tasks run in parallel when param is > 1. Added parameter usage to relevant examples.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#16774 from BryanCutler/parallel-model-eval-SPARK-19357.
## What changes were proposed in this pull request?
Update the line "For example, the data (12:09, cat) is out of order and late, and it falls in windows 12:05 - 12:15 and 12:10 - 12:20." as follow "For example, the data (12:09, cat) is out of order and late, and it falls in windows 12:00 - 12:10 and 12:05 - 12:15." under the programming structured streaming programming guide.
Author: Riccardo Corbella <r.corbella@reply.it>
Closes#19137 from riccardocorbella/bugfix.
## What changes were proposed in this pull request?
All built-in data sources support `Partition Discovery`. We had better update the document to give the users more benefit clearly.
**AFTER**
<img width="906" alt="1" src="https://user-images.githubusercontent.com/9700541/30083628-14278908-9244-11e7-98dc-9ad45fe233a9.png">
## How was this patch tested?
```
SKIP_API=1 jekyll serve --watch
```
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19139 from dongjoon-hyun/partitiondiscovery.
Mesos has secrets primitives for environment and file-based secrets, this PR adds that functionality to the Spark dispatcher and the appropriate configuration flags.
Unit tested and manually tested against a DC/OS cluster with Mesos 1.4.
Author: ArtRand <arand@soe.ucsc.edu>
Closes#18837 from ArtRand/spark-20812-dispatcher-secrets-and-labels.
This patch adds statsd sink to the current metrics system in spark core.
Author: Xiaofeng Lin <xlin@twilio.com>
Closes#9518 from xflin/statsd.
Change-Id: Ib8720e86223d4a650df53f51ceb963cd95b49a44
## What changes were proposed in this pull request?
This PR adds ML examples for the FeatureHasher transform in Scala, Java, Python.
## How was this patch tested?
Manually ran examples and verified that output is consistent for different APIs
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#19024 from BryanCutler/ml-examples-FeatureHasher-SPARK-21810.
## What changes were proposed in this pull request?
Fair Scheduler can be built via one of the following options:
- By setting a `spark.scheduler.allocation.file` property,
- By setting `fairscheduler.xml` into classpath.
These options are checked **in order** and fair-scheduler is built via first found option. If invalid path is found, `FileNotFoundException` will be expected.
This PR aims unit test coverage of these use cases and a minor documentation change has been added for second option(`fairscheduler.xml` into classpath) to inform the users.
Also, this PR was related with #16813 and has been created separately to keep patch content as isolated and to help the reviewers.
## How was this patch tested?
Added new Unit Tests.
Author: erenavsarogullari <erenavsarogullari@gmail.com>
Closes#16992 from erenavsarogullari/SPARK-19662.
History Server Launch uses SparkClassCommandBuilder for launching the server. It is observed that SPARK_CLASSPATH has been removed and deprecated. For spark-submit this takes a different route and spark.driver.extraClasspath takes care of specifying additional jars in the classpath that were previously specified in the SPARK_CLASSPATH. Right now the only way specify the additional jars for launching daemons such as history server is using SPARK_DIST_CLASSPATH (https://spark.apache.org/docs/latest/hadoop-provided.html) but this I presume is a distribution classpath. It would be nice to have a similar config like spark.driver.extraClasspath for launching daemons similar to history server.
Added new environment variable SPARK_DAEMON_CLASSPATH to set classpath for launching daemons. Tested and verified for History Server and Standalone Mode.
## How was this patch tested?
Initially, history server start script would fail for the reason being that it could not find the required jars for launching the server in the java classpath. Same was true for running Master and Worker in standalone mode. By adding the environment variable SPARK_DAEMON_CLASSPATH to the java classpath, both the daemons(History Server, Standalone daemons) are starting up and running.
Author: pgandhi <pgandhi@yahoo-inc.com>
Author: pgandhi999 <parthkgandhi9@gmail.com>
Closes#19047 from pgandhi999/master.
## What changes were proposed in this pull request?
This PR proposes both:
- Add information about Javadoc, SQL docs and few more information in `docs/README.md` and a comment in `docs/_plugins/copy_api_dirs.rb` related with Javadoc.
- Adds some commands so that the script always runs the SQL docs build under `./sql` directory (for directly running `./sql/create-docs.sh` in the root directory).
## How was this patch tested?
Manual tests with `jekyll build` and `./sql/create-docs.sh` in the root directory.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19019 from HyukjinKwon/minor-doc-build.
JIRA ticket: https://issues.apache.org/jira/browse/SPARK-21694
## What changes were proposed in this pull request?
Spark already supports launching containers attached to a given CNI network by specifying it via the config `spark.mesos.network.name`.
This PR adds support to pass in network labels to CNI plugins via a new config option `spark.mesos.network.labels`. These network labels are key-value pairs that are set in the `NetworkInfo` of both the driver and executor tasks. More details in the related Mesos documentation: http://mesos.apache.org/documentation/latest/cni/#mesos-meta-data-to-cni-plugins
## How was this patch tested?
Unit tests, for both driver and executor tasks.
Manual integration test to submit a job with the `spark.mesos.network.labels` option, hit the mesos/state.json endpoint, and check that the labels are set in the driver and executor tasks.
ArtRand skonto
Author: Susan X. Huynh <xhuynh@mesosphere.com>
Closes#18910 from susanxhuynh/sh-mesos-cni-labels.
Right now the spark shuffle service has a cache for index files. It is based on a # of files cached (spark.shuffle.service.index.cache.entries). This can cause issues if people have a lot of reducers because the size of each entry can fluctuate based on the # of reducers.
We saw an issues with a job that had 170000 reducers and it caused NM with spark shuffle service to use 700-800MB or memory in NM by itself.
We should change this cache to be memory based and only allow a certain memory size used. When I say memory based I mean the cache should have a limit of say 100MB.
https://issues.apache.org/jira/browse/SPARK-21501
Manual Testing with 170000 reducers has been performed with cache loaded up to max 100MB default limit, with each shuffle index file of size 1.3MB. Eviction takes place as soon as the total cache size reaches the 100MB limit and the objects will be ready for garbage collection there by avoiding NM to crash. No notable difference in runtime has been observed.
Author: Sanket Chintapalli <schintap@yahoo-inc.com>
Closes#18940 from redsanket/SPARK-21501.
## What changes were proposed in this pull request?
This PR proposes to install `mkdocs` by `pip install` if missing in the path. Mainly to fix Jenkins's documentation build failure in `spark-master-docs`. See https://amplab.cs.berkeley.edu/jenkins/job/spark-master-docs/3580/console.
It also adds `mkdocs` as requirements in `docs/README.md`.
## How was this patch tested?
I manually ran `jekyll build` under `docs` directory after manually removing `mkdocs` via `pip uninstall mkdocs`.
Also, tested this in the same way but on CentOS Linux release 7.3.1611 (Core) where I built Spark few times but never built documentation before and `mkdocs` is not installed.
```
...
Moving back into docs dir.
Moving to SQL directory and building docs.
Missing mkdocs in your path, trying to install mkdocs for SQL documentation generation.
Collecting mkdocs
Downloading mkdocs-0.16.3-py2.py3-none-any.whl (1.2MB)
100% |████████████████████████████████| 1.2MB 574kB/s
Requirement already satisfied: PyYAML>=3.10 in /usr/lib64/python2.7/site-packages (from mkdocs)
Collecting livereload>=2.5.1 (from mkdocs)
Downloading livereload-2.5.1-py2-none-any.whl
Collecting tornado>=4.1 (from mkdocs)
Downloading tornado-4.5.1.tar.gz (483kB)
100% |████████████████████████████████| 491kB 1.4MB/s
Collecting Markdown>=2.3.1 (from mkdocs)
Downloading Markdown-2.6.9.tar.gz (271kB)
100% |████████████████████████████████| 276kB 2.4MB/s
Collecting click>=3.3 (from mkdocs)
Downloading click-6.7-py2.py3-none-any.whl (71kB)
100% |████████████████████████████████| 71kB 2.8MB/s
Requirement already satisfied: Jinja2>=2.7.1 in /usr/lib/python2.7/site-packages (from mkdocs)
Requirement already satisfied: six in /usr/lib/python2.7/site-packages (from livereload>=2.5.1->mkdocs)
Requirement already satisfied: backports.ssl_match_hostname in /usr/lib/python2.7/site-packages (from tornado>=4.1->mkdocs)
Collecting singledispatch (from tornado>=4.1->mkdocs)
Downloading singledispatch-3.4.0.3-py2.py3-none-any.whl
Collecting certifi (from tornado>=4.1->mkdocs)
Downloading certifi-2017.7.27.1-py2.py3-none-any.whl (349kB)
100% |████████████████████████████████| 358kB 2.1MB/s
Collecting backports_abc>=0.4 (from tornado>=4.1->mkdocs)
Downloading backports_abc-0.5-py2.py3-none-any.whl
Requirement already satisfied: MarkupSafe>=0.23 in /usr/lib/python2.7/site-packages (from Jinja2>=2.7.1->mkdocs)
Building wheels for collected packages: tornado, Markdown
Running setup.py bdist_wheel for tornado ... done
Stored in directory: /root/.cache/pip/wheels/84/83/cd/6a04602633457269d161344755e6766d24307189b7a67ff4b7
Running setup.py bdist_wheel for Markdown ... done
Stored in directory: /root/.cache/pip/wheels/bf/46/10/c93e17ae86ae3b3a919c7b39dad3b5ccf09aeb066419e5c1e5
Successfully built tornado Markdown
Installing collected packages: singledispatch, certifi, backports-abc, tornado, livereload, Markdown, click, mkdocs
Successfully installed Markdown-2.6.9 backports-abc-0.5 certifi-2017.7.27.1 click-6.7 livereload-2.5.1 mkdocs-0.16.3 singledispatch-3.4.0.3 tornado-4.5.1
Generating markdown files for SQL documentation.
Generating HTML files for SQL documentation.
INFO - Cleaning site directory
INFO - Building documentation to directory: .../spark/sql/site
Moving back into docs dir.
Making directory api/sql
cp -r ../sql/site/. api/sql
Source: .../spark/docs
Destination: .../spark/docs/_site
Generating...
done.
Auto-regeneration: disabled. Use --watch to enable.
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18984 from HyukjinKwon/sql-doc-mkdocs.
Add an option to the JDBC data source to initialize the environment of the remote database session
## What changes were proposed in this pull request?
This proposes an option to the JDBC datasource, tentatively called " sessionInitStatement" to implement the functionality of session initialization present for example in the Sqoop connector for Oracle (see https://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html#_oraoop_oracle_session_initialization_statements ) . After each database session is opened to the remote DB, and before starting to read data, this option executes a custom SQL statement (or a PL/SQL block in the case of Oracle).
See also https://issues.apache.org/jira/browse/SPARK-21519
## How was this patch tested?
Manually tested using Spark SQL data source and Oracle JDBC
Author: LucaCanali <luca.canali@cern.ch>
Closes#18724 from LucaCanali/JDBC_datasource_sessionInitStatement.
## What changes were proposed in this pull request?
This commit adds a new argument for IllegalArgumentException message. This recent commit added the argument:
[dcac1d57f0)
## How was this patch tested?
Unit test have been passed
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Marcos P. Sanchez <mpenate@stratio.com>
Closes#18862 from mpenate/feature/exception-errorifexists.
## What changes were proposed in this pull request?
Adds a sandbox link per driver in the dispatcher ui with minimal changes after a bug was fixed here:
https://issues.apache.org/jira/browse/MESOS-4992
The sandbox uri has the following format:
http://<proxy_uri>/#/slaves/\<agent-id\>/ frameworks/ \<scheduler-id\>/executors/\<driver-id\>/browse
For dc/os the proxy uri is <dc/os uri>/mesos. For the dc/os deployment scenario and to make things easier I introduced a new config property named `spark.mesos.proxy.baseURL` which should be passed to the dispatcher when launched using --conf. If no such configuration is detected then no sandbox uri is depicted, and there is an empty column with a header (this can be changed so nothing is shown).
Within dc/os the base url must be a property for the dispatcher that we should add in the future here:
9e7c909c3b/repo/packages/S/spark/26/config.json
It is not easy to detect in different environments what is that uri so user should pass it.
## How was this patch tested?
Tested with the mesos test suite here: https://github.com/typesafehub/mesos-spark-integration-tests.
Attached image shows the ui modification where the sandbox header is added.
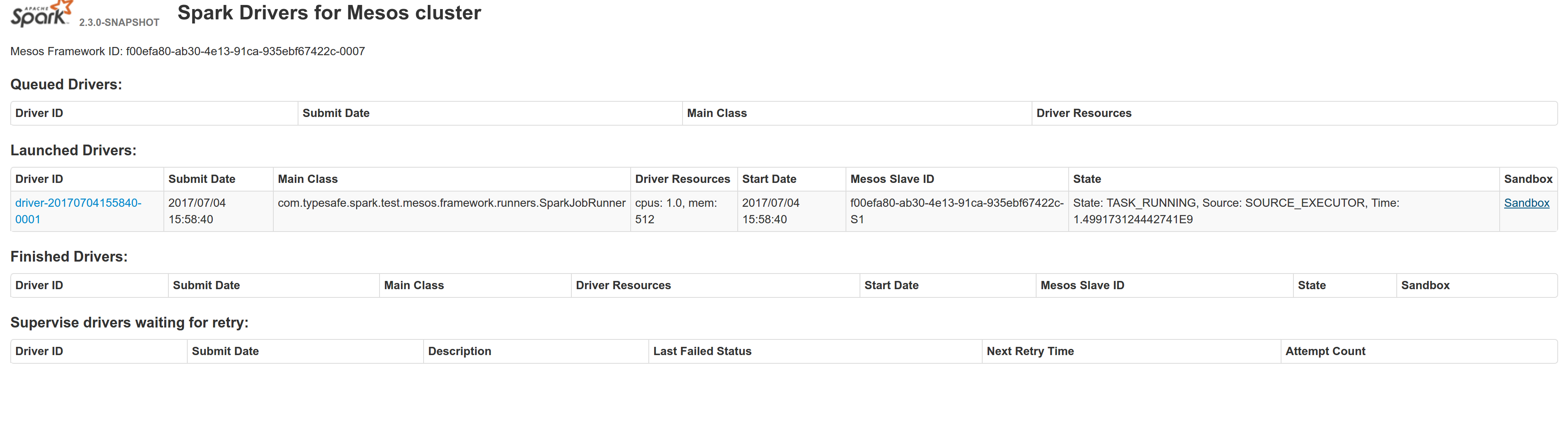
Tested the uri redirection the way it was suggested here:
https://issues.apache.org/jira/browse/MESOS-4992
Built mesos 1.4 from the master branch and started the mesos dispatcher with the command:
`./sbin/start-mesos-dispatcher.sh --conf spark.mesos.proxy.baseURL=http://localhost:5050 -m mesos://127.0.0.1:5050`
Run a spark example:
`./bin/spark-submit --class org.apache.spark.examples.SparkPi --master mesos://10.10.1.79:7078 --deploy-mode cluster --executor-memory 2G --total-executor-cores 2 http://<path>/spark-examples_2.11-2.1.1.jar 10`
Sandbox uri is shown at the bottom of the page:
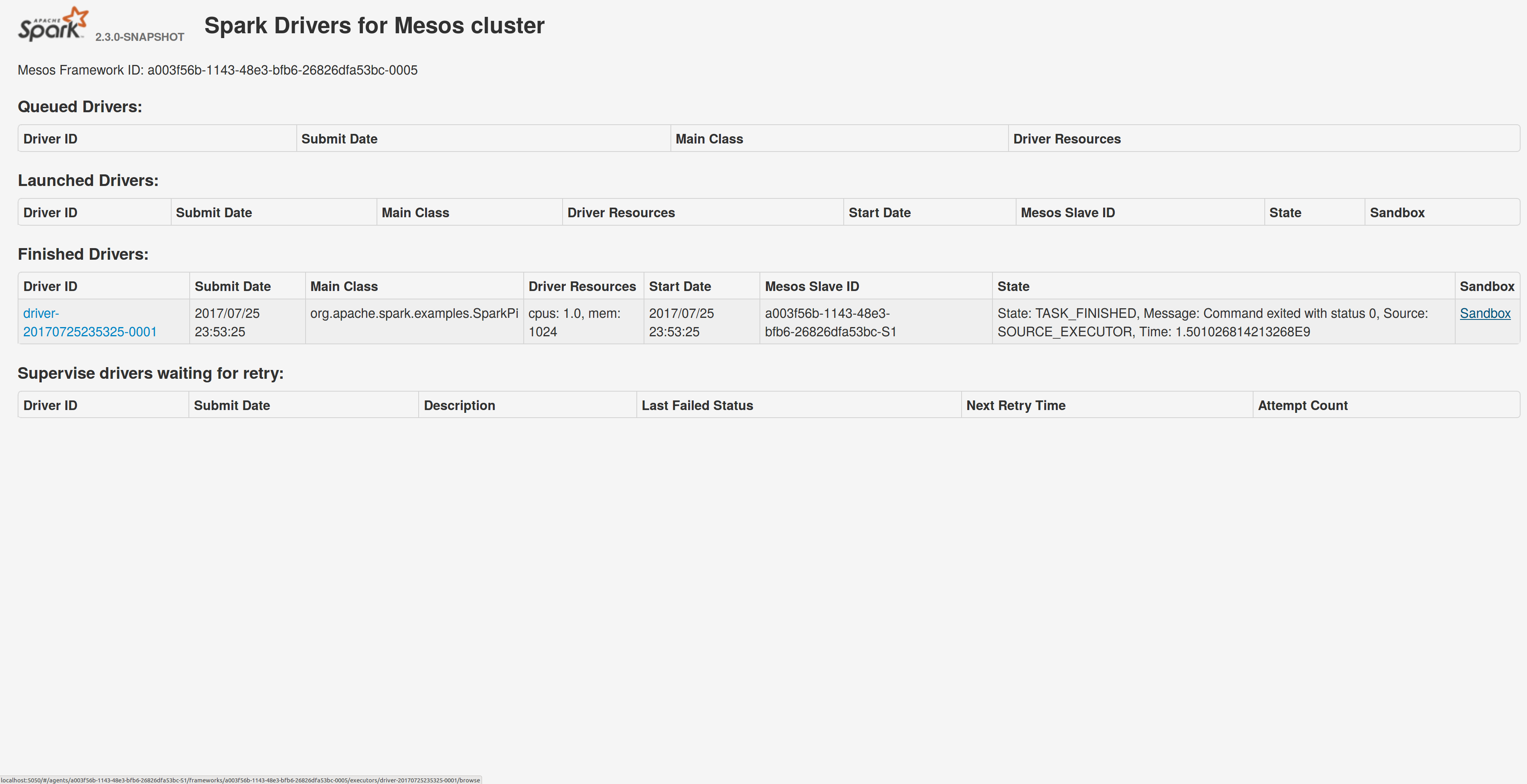
Redirection works as expected:
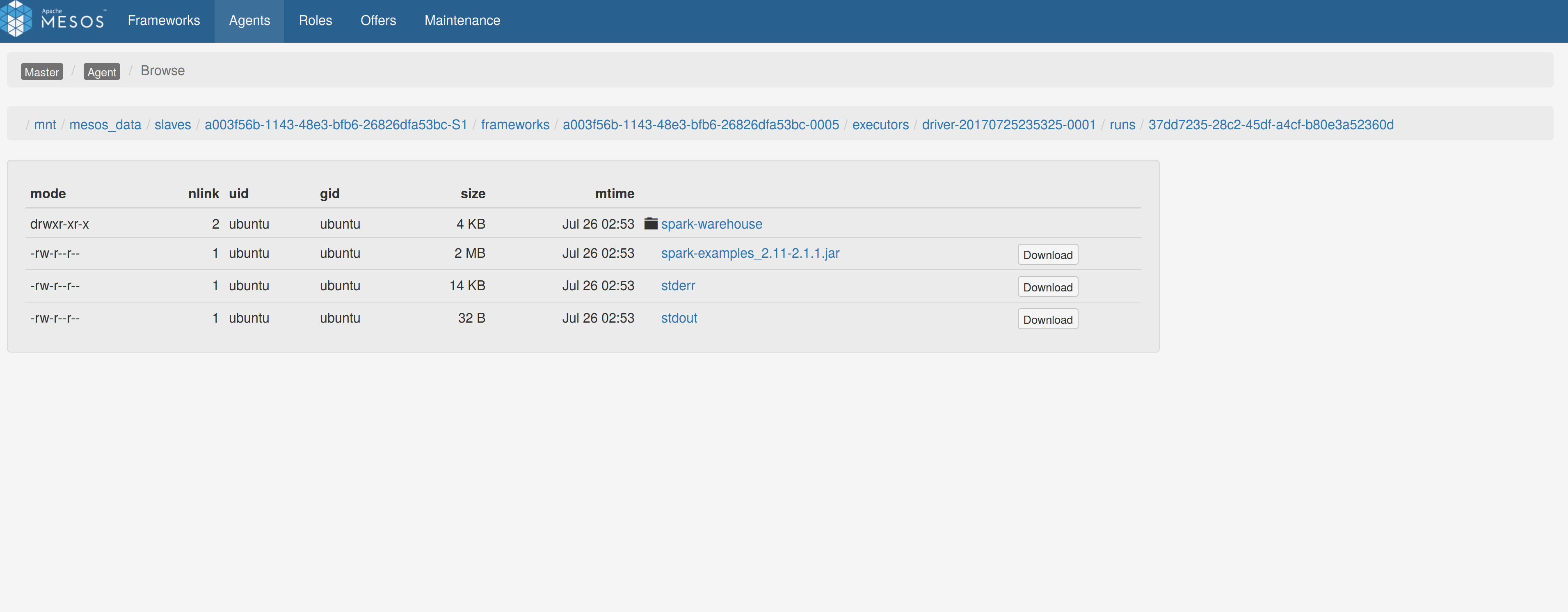
Author: Stavros Kontopoulos <st.kontopoulos@gmail.com>
Closes#18528 from skonto/adds_the_sandbox_uri.
## What changes were proposed in this pull request?
When we use `bin/spark-sql` command configuring `--conf spark.hadoop.foo=bar`, the `SparkSQLCliDriver` initializes an instance of hiveconf, it does not add `foo->bar` to it.
this pr gets `spark.hadoop.*` properties from sysProps to this hiveconf
## How was this patch tested?
UT
Author: hzyaoqin <hzyaoqin@corp.netease.com>
Author: Kent Yao <yaooqinn@hotmail.com>
Closes#18668 from yaooqinn/SPARK-21451.
## What changes were proposed in this pull request?
Add missing import and missing parentheses to invoke `SparkSession::text()`.
## How was this patch tested?
Built and the code for this application, ran jekyll locally per docs/README.md.
Author: Christiam Camacho <camacho@ncbi.nlm.nih.gov>
Closes#18795 from christiam/master.
## What changes were proposed in this pull request?
Fix 2 rendering errors on configuration doc page, due to SPARK-21243 and SPARK-15355.
## How was this patch tested?
Manually built and viewed docs with jekyll
Author: Sean Owen <sowen@cloudera.com>
Closes#18793 from srowen/SPARK-21593.
## What changes were proposed in this pull request?
This pr added documents about unsupported functions in Hive UDF/UDTF/UDAF.
This pr relates to #18768 and #18527.
## How was this patch tested?
N/A
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#18792 from maropu/HOTFIX-20170731.
In programming guide, `numTasks` is used in several places as arguments of Transformations. However, in code, `numPartitions` is used. In this fix, I replace `numTasks` with `numPartitions` in programming guide for consistency.
Author: Cheng Wang <chengwang0511@gmail.com>
Closes#18774 from polarke/replace-numtasks-with-numpartitions-in-doc.
## What changes were proposed in this pull request?
Update the description of `spark.shuffle.maxChunksBeingTransferred` to include that the new coming connections will be closed when the max is hit and client should have retry mechanism.
Author: jinxing <jinxing6042@126.com>
Closes#18735 from jinxing64/SPARK-21530.
## What changes were proposed in this pull request?
This generates a documentation for Spark SQL built-in functions.
One drawback is, this requires a proper build to generate built-in function list.
Once it is built, it only takes few seconds by `sql/create-docs.sh`.
Please see https://spark-test.github.io/sparksqldoc/ that I hosted to show the output documentation.
There are few more works to be done in order to make the documentation pretty, for example, separating `Arguments:` and `Examples:` but I guess this should be done within `ExpressionDescription` and `ExpressionInfo` rather than manually parsing it. I will fix these in a follow up.
This requires `pip install mkdocs` to generate HTMLs from markdown files.
## How was this patch tested?
Manually tested:
```
cd docs
jekyll build
```
,
```
cd docs
jekyll serve
```
and
```
cd sql
create-docs.sh
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18702 from HyukjinKwon/SPARK-21485.
## What changes were proposed in this pull request?
A shuffle service can serves blocks from multiple apps/tasks. Thus the shuffle service can suffers high memory usage when lots of shuffle-reads happen at the same time. In my cluster, OOM always happens on shuffle service. Analyzing heap dump, memory cost by Netty(ChannelOutboundBufferEntry) can be up to 2~3G. It might make sense to reject "open blocks" request when memory usage is high on shuffle service.
93dd0c518d and 85c6ce6193 tried to alleviate the memory pressure on shuffle service but cannot solve the root cause. This pr proposes to control currency of shuffle read.
## How was this patch tested?
Added unit test.
Author: jinxing <jinxing6042@126.com>
Closes#18388 from jinxing64/SPARK-21175.
I find a bug about 'quick start',and created a new issues,Sean Owen let
me to make a pull request, and I do
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Trueman <lizhaoch@users.noreply.github.com>
Author: lizhaoch <lizhaoc@163.com>
Closes#18722 from lizhaoch/master.
## What changes were proposed in this pull request?
The examples and docs for Spark-Kinesis integrations use the deprecated KinesisUtils. We should update the docs to use the KinesisInputDStream builder to create DStreams.
## How was this patch tested?
The patch primarily updates the documents. The patch will also need to make changes to the Spark-Kinesis examples. The examples need to be tested.
Author: Yash Sharma <ysharma@atlassian.com>
Closes#18071 from yssharma/ysharma/kinesis_docs.
## What changes were proposed in this pull request?
Update the Quickstart and RDD programming guides to mention pip.
## How was this patch tested?
Built docs locally.
Author: Holden Karau <holden@us.ibm.com>
Closes#18698 from holdenk/SPARK-21434-add-pyspark-pip-documentation.
## What changes were proposed in this pull request?
Minor change to kafka integration document for structured streaming.
## How was this patch tested?
N/A, doc change only.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#18550 from viirya/minor-ss-kafka-doc.
## What changes were proposed in this pull request?
After SPARK-12661, I guess we officially dropped Python 2.6 support. It looks there are few places missing this notes.
I grepped "Python 2.6" and "python 2.6" and the results were below:
```
./core/src/main/scala/org/apache/spark/api/python/SerDeUtil.scala: // Unpickle array.array generated by Python 2.6
./docs/index.md:Note that support for Java 7, Python 2.6 and old Hadoop versions before 2.6.5 were removed as of Spark 2.2.0.
./docs/rdd-programming-guide.md:Spark {{site.SPARK_VERSION}} works with Python 2.6+ or Python 3.4+. It can use the standard CPython interpreter,
./docs/rdd-programming-guide.md:Note that support for Python 2.6 is deprecated as of Spark 2.0.0, and may be removed in Spark 2.2.0.
./python/pyspark/context.py: warnings.warn("Support for Python 2.6 is deprecated as of Spark 2.0.0")
./python/pyspark/ml/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/mllib/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/serializers.py: # On Python 2.6, we can't write bytearrays to streams, so we need to convert them
./python/pyspark/sql/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/streaming/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/tests.py: # NOTE: dict is used instead of collections.Counter for Python 2.6
./python/pyspark/tests.py: # NOTE: dict is used instead of collections.Counter for Python 2.6
```
This PR only proposes to change visible changes as below:
```
./docs/rdd-programming-guide.md:Spark {{site.SPARK_VERSION}} works with Python 2.6+ or Python 3.4+. It can use the standard CPython interpreter,
./docs/rdd-programming-guide.md:Note that support for Python 2.6 is deprecated as of Spark 2.0.0, and may be removed in Spark 2.2.0.
./python/pyspark/context.py: warnings.warn("Support for Python 2.6 is deprecated as of Spark 2.0.0")
```
This one is already correct:
```
./docs/index.md:Note that support for Java 7, Python 2.6 and old Hadoop versions before 2.6.5 were removed as of Spark 2.2.0.
```
## How was this patch tested?
```bash
grep -r "Python 2.6" .
grep -r "python 2.6" .
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18682 from HyukjinKwon/minor-python.26.
## What changes were proposed in this pull request?
Current behavior: in Mesos cluster mode, the driver failover_timeout is set to zero. If the driver temporarily loses connectivity with the Mesos master, the framework will be torn down and all executors killed.
Proposed change: make the failover_timeout configurable via a new option, spark.mesos.driver.failoverTimeout. The default value is still zero.
Note: with non-zero failover_timeout, an explicit teardown is needed in some cases. This is captured in https://issues.apache.org/jira/browse/SPARK-21458
## How was this patch tested?
Added a unit test to make sure the config option is set while creating the scheduler driver.
Ran an integration test with mesosphere/spark showing that with a non-zero failover_timeout the Spark job finishes after a driver is disconnected from the master.
Author: Susan X. Huynh <xhuynh@mesosphere.com>
Closes#18674 from susanxhuynh/sh-mesos-failover-timeout.
## What changes were proposed in this pull request?
For configurations with external shuffle enabled, we have observed that if a very large no. of blocks are being fetched from a remote host, it puts the NM under extra pressure and can crash it. This change introduces a configuration `spark.reducer.maxBlocksInFlightPerAddress` , to limit the no. of map outputs being fetched from a given remote address. The changes applied here are applicable for both the scenarios - when external shuffle is enabled as well as disabled.
## How was this patch tested?
Ran the job with the default configuration which does not change the existing behavior and ran it with few configurations of lower values -10,20,50,100. The job ran fine and there is no change in the output. (I will update the metrics related to NM in some time.)
Author: Dhruve Ashar <dhruveashar@gmail.com>
Closes#18487 from dhruve/impr/SPARK-21243.
## What changes were proposed in this pull request?
Update internal references from programming-guide to rdd-programming-guide
See 5ddf243fd8 and https://github.com/apache/spark/pull/18485#issuecomment-314789751
Let's keep the redirector even if it's problematic to build, but not rely on it internally.
## How was this patch tested?
(Doc build)
Author: Sean Owen <sowen@cloudera.com>
Closes#18625 from srowen/SPARK-21267.2.
## What changes were proposed in this pull request?
- Remove Scala 2.10 build profiles and support
- Replace some 2.10 support in scripts with commented placeholders for 2.12 later
- Remove deprecated API calls from 2.10 support
- Remove usages of deprecated context bounds where possible
- Remove Scala 2.10 workarounds like ScalaReflectionLock
- Other minor Scala warning fixes
## How was this patch tested?
Existing tests
Author: Sean Owen <sowen@cloudera.com>
Closes#17150 from srowen/SPARK-19810.
## What changes were proposed in this pull request?
Since this document became obsolete, we had better remove this for Apache Spark 2.3.0. The original document is removed via SPARK-12735 on January 2016, and currently it's just redirection page. The only reference in Apache Spark website will go directly to the destination in https://github.com/apache/spark-website/pull/54.
## How was this patch tested?
N/A. This is a removal of documentation.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#18578 from dongjoon-hyun/SPARK-REMOVE-EC2.
## What changes were proposed in this pull request?
Spark provides several ways to set configurations, either from configuration file, or from `spark-submit` command line options, or programmatically through `SparkConf` class. It may confuses beginners why some configurations set through `SparkConf` cannot take affect. So here add some docs to address this problems and let beginners know how to correctly set configurations.
## How was this patch tested?
N/A
Author: jerryshao <sshao@hortonworks.com>
Closes#18552 from jerryshao/improve-doc.
## What changes were proposed in this pull request?
In current code, reducer can break the old shuffle service when `spark.reducer.maxReqSizeShuffleToMem` is enabled. Let's refine document.
Author: jinxing <jinxing6042@126.com>
Closes#18566 from jinxing64/SPARK-21343.
## What changes were proposed in this pull request?
Some link fixes for the documentation [Running Spark on Mesos](https://spark.apache.org/docs/latest/running-on-mesos.html):
* Updated Link to Mesos Frameworks (Projects built on top of Mesos)
* Update Link to Mesos binaries from Mesosphere (former link was redirected to dcos install page)
## How was this patch tested?
Documentation was built and changed page manually/visually inspected.
No code was changed, hence no dev tests.
Since these changes are rather trivial I did not open a new JIRA ticket.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Joachim Hereth <joachim.hereth@numberfour.eu>
Closes#18564 from daten-kieker/mesos_doc_fixes.
## What changes were proposed in this pull request?
SPARK-20979 added a new structured streaming source: Rate source. This patch adds the corresponding documentation to programming guide.
## How was this patch tested?
Tested by running jekyll locally.
Author: Prashant Sharma <prashant@apache.org>
Author: Prashant Sharma <prashsh1@in.ibm.com>
Closes#18562 from ScrapCodes/spark-21069/rate-source-docs.
## What changes were proposed in this pull request?
Few changes to the Structured Streaming documentation
- Clarify that the entire stream input table is not materialized
- Add information for Ganglia
- Add Kafka Sink to the main docs
- Removed a couple of leftover experimental tags
- Added more associated reading material and talk videos.
In addition, https://github.com/apache/spark/pull/16856 broke the link to the RDD programming guide in several places while renaming the page. This PR fixes those sameeragarwal cloud-fan.
- Added a redirection to avoid breaking internal and possible external links.
- Removed unnecessary redirection pages that were there since the separate scala, java, and python programming guides were merged together in 2013 or 2014.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#18485 from tdas/SPARK-21267.
Current "--jars (spark.jars)", "--files (spark.files)", "--py-files (spark.submit.pyFiles)" and "--archives (spark.yarn.dist.archives)" only support non-glob path. This is OK for most of the cases, but when user requires to add more jars, files into Spark, it is too verbose to list one by one. So here propose to add glob path support for resources.
Also improving the code of downloading resources.
## How was this patch tested?
UT added, also verified manually in local cluster.
Author: jerryshao <sshao@hortonworks.com>
Closes#18235 from jerryshao/SPARK-21012.
## What changes were proposed in this pull request?
This change adds a new configuration option `spark.scheduler.listenerbus.eventqueue.size` to the configuration docs to specify the capacity of the spark listener bus event queue. Default value is 10000.
This is doc PR for [SPARK-15703](https://issues.apache.org/jira/browse/SPARK-15703).
I added option to the `Scheduling` section, however it might be more related to `Spark UI` section.
## How was this patch tested?
Manually verified correct rendering of configuration option.
Author: sadikovi <ivan.sadikov@lincolnuni.ac.nz>
Author: Ivan Sadikov <ivan.sadikov@team.telstra.com>
Closes#18476 from sadikovi/SPARK-20858.
## What changes were proposed in this pull request?
Disable spark.reducer.maxReqSizeShuffleToMem because it breaks the old shuffle service.
Credits to wangyum
Closes#18466
## How was this patch tested?
Jenkins
Author: Shixiong Zhu <shixiong@databricks.com>
Author: Yuming Wang <wgyumg@gmail.com>
Closes#18467 from zsxwing/SPARK-21253.
## What changes were proposed in this pull request?
Currently we are running into an issue with Yarn work preserving enabled + external shuffle service.
In the work preserving enabled scenario, the failure of NM will not lead to the exit of executors, so executors can still accept and run the tasks. The problem here is when NM is failed, external shuffle service is actually inaccessible, so reduce tasks will always complain about the “Fetch failure”, and the failure of reduce stage will make the parent stage (map stage) rerun. The tricky thing here is Spark scheduler is not aware of the unavailability of external shuffle service, and will reschedule the map tasks on the executor where NM is failed, and again reduce stage will be failed with “Fetch failure”, and after 4 retries, the job is failed. This could also apply to other cluster manager with external shuffle service.
So here the main problem is that we should avoid assigning tasks to those bad executors (where shuffle service is unavailable). Current Spark's blacklist mechanism could blacklist executors/nodes by failure tasks, but it doesn't handle this specific fetch failure scenario. So here propose to improve the current application blacklist mechanism to handle fetch failure issue (especially with external shuffle service unavailable issue), to blacklist the executors/nodes where shuffle fetch is unavailable.
## How was this patch tested?
Unit test and small cluster verification.
Author: jerryshao <sshao@hortonworks.com>
Closes#17113 from jerryshao/SPARK-13669.
## What changes were proposed in this pull request?
Add lost `<tr>` tag for `configuration.md`.
## How was this patch tested?
N/A
Author: Yuming Wang <wgyumg@gmail.com>
Closes#18372 from wangyum/docs-missing-tr.
## What changes were proposed in this pull request?
Currently the shuffle service registration timeout and retry has been hardcoded. This works well for small workloads but under heavy workload when the shuffle service is busy transferring large amount of data we see significant delay in responding to the registration request, as a result we often see the executors fail to register with the shuffle service, eventually failing the job. We need to make these two parameters configurable.
## How was this patch tested?
* Updated `BlockManagerSuite` to test registration timeout and max attempts configuration actually works.
cc sitalkedia
Author: Li Yichao <lyc@zhihu.com>
Closes#18092 from liyichao/SPARK-20640.
## What changes were proposed in this pull request?
The description for several options of File Source for structured streaming appeared in the File Sink description instead.
This pull request has two commits: The first includes changes to the version as it appeared in spark 2.1 and the second handled an additional option added for spark 2.2
## How was this patch tested?
Built the documentation by SKIP_API=1 jekyll build and visually inspected the structured streaming programming guide.
The original documentation was written by tdas and lw-lin
Author: assafmendelson <assaf.mendelson@gmail.com>
Closes#18342 from assafmendelson/spark-21123.
## What changes were proposed in this pull request?
Update Running R Tests dependence packages to:
```bash
R -e "install.packages(c('knitr', 'rmarkdown', 'testthat', 'e1071', 'survival'), repos='http://cran.us.r-project.org')"
```
## How was this patch tested?
manual tests
Author: Yuming Wang <wgyumg@gmail.com>
Closes#18271 from wangyum/building-spark.
## What changes were proposed in this pull request?
Move Hadoop delegation token code from `spark-yarn` to `spark-core`, so that other schedulers (such as Mesos), may use it. In order to avoid exposing Hadoop interfaces in spark-core, the new Hadoop delegation token classes are kept private. In order to provider backward compatiblity, and to allow YARN users to continue to load their own delegation token providers via Java service loading, the old YARN interfaces, as well as the client code that uses them, have been retained.
Summary:
- Move registered `yarn.security.ServiceCredentialProvider` classes from `spark-yarn` to `spark-core`. Moved them into a new, private hierarchy under `HadoopDelegationTokenProvider`. Client code in `HadoopDelegationTokenManager` now loads credentials from a whitelist of three providers (`HadoopFSDelegationTokenProvider`, `HiveDelegationTokenProvider`, `HBaseDelegationTokenProvider`), instead of service loading, which means that users are not able to implement their own delegation token providers, as they are in the `spark-yarn` module.
- The `yarn.security.ServiceCredentialProvider` interface has been kept for backwards compatibility, and to continue to allow YARN users to implement their own delegation token provider implementations. Client code in YARN now fetches tokens via the new `YARNHadoopDelegationTokenManager` class, which fetches tokens from the core providers through `HadoopDelegationTokenManager`, as well as service loads them from `yarn.security.ServiceCredentialProvider`.
Old Hierarchy:
```
yarn.security.ServiceCredentialProvider (service loaded)
HadoopFSCredentialProvider
HiveCredentialProvider
HBaseCredentialProvider
yarn.security.ConfigurableCredentialManager
```
New Hierarchy:
```
HadoopDelegationTokenManager
HadoopDelegationTokenProvider (not service loaded)
HadoopFSDelegationTokenProvider
HiveDelegationTokenProvider
HBaseDelegationTokenProvider
yarn.security.ServiceCredentialProvider (service loaded)
yarn.security.YARNHadoopDelegationTokenManager
```
## How was this patch tested?
unit tests
Author: Michael Gummelt <mgummelt@mesosphere.io>
Author: Dr. Stefan Schimanski <sttts@mesosphere.io>
Closes#17723 from mgummelt/SPARK-20434-refactor-kerberos.
## What changes were proposed in this pull request?
doc only change
## How was this patch tested?
manually
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#18312 from felixcheung/sqljsonwholefiledoc.
## What changes were proposed in this pull request?
`df.groupBy.count()` should be `df.groupBy().count()` , otherwise there is an error :
ambiguous reference to overloaded definition, both method groupBy in class Dataset of type (col1: String, cols: String*) and method groupBy in class Dataset of type (cols: org.apache.spark.sql.Column*)
## How was this patch tested?
```scala
val df = spark.readStream.schema(...).json(...)
val dfCounts = df.groupBy().count()
```
Author: Ziyue Huang <zyhuang94@gmail.com>
Closes#18272 from ZiyueHuang/master.
## What changes were proposed in this pull request?
Add Mesos labels support to the Spark Dispatcher
## How was this patch tested?
unit tests
Author: Michael Gummelt <mgummelt@mesosphere.io>
Closes#18220 from mgummelt/SPARK-21000-dispatcher-labels.
## What changes were proposed in this pull request?
Add a new property `spark.streaming.kafka.consumer.cache.enabled` that allows users to enable or disable the cache for Kafka consumers. This property can be especially handy in cases where issues like SPARK-19185 get hit, for which there isn't a solution committed yet. By default, the cache is still on, so this change doesn't change any out-of-box behavior.
## How was this patch tested?
Running unit tests
Author: Mark Grover <mark@apache.org>
Author: Mark Grover <grover.markgrover@gmail.com>
Closes#18234 from markgrover/spark-19185.
## What changes were proposed in this pull request?
In our use case of launching Spark applications via REST APIs (Livy), there's no way for user to specify command line arguments, all Spark configurations are set through configurations map. For "--repositories" because there's no equivalent Spark configuration, so we cannot specify the custom repository through configuration.
So here propose to add "--repositories" equivalent configuration in Spark.
## How was this patch tested?
New UT added.
Author: jerryshao <sshao@hortonworks.com>
Closes#18201 from jerryshao/SPARK-20981.
## What changes were proposed in this pull request?
- Add Scala, Python and Java examples for `partitionBy`, `sortBy` and `bucketBy`.
- Add _Bucketing, Sorting and Partitioning_ section to SQL Programming Guide
- Remove bucketing from Unsupported Hive Functionalities.
## How was this patch tested?
Manual tests, docs build.
Author: zero323 <zero323@users.noreply.github.com>
Closes#17938 from zero323/DOCS-BUCKETING-AND-PARTITIONING.
Now that Structured Streaming has been out for several Spark release and has large production use cases, the `Experimental` label is no longer appropriate. I've left `InterfaceStability.Evolving` however, as I think we may make a few changes to the pluggable Source & Sink API in Spark 2.3.
Author: Michael Armbrust <michael@databricks.com>
Closes#18065 from marmbrus/streamingGA.
## What changes were proposed in this pull request?
1, add an example for sparkr `decisionTree`
2, document it in user guide
## How was this patch tested?
local submit
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#18067 from zhengruifeng/dt_example.
(Link to Jira: https://issues.apache.org/jira/browse/SPARK-20888)
## What changes were proposed in this pull request?
Document change of default setting of spark.sql.hive.caseSensitiveInferenceMode configuration key from NEVER_INFO to INFER_AND_SAVE in the Spark SQL 2.1 to 2.2 migration notes.
Author: Michael Allman <michael@videoamp.com>
Closes#18112 from mallman/spark-20888-document_infer_and_save.
## What changes were proposed in this pull request?
Currently the whole block is fetched into memory(off heap by default) when shuffle-read. A block is defined by (shuffleId, mapId, reduceId). Thus it can be large when skew situations. If OOM happens during shuffle read, job will be killed and users will be notified to "Consider boosting spark.yarn.executor.memoryOverhead". Adjusting parameter and allocating more memory can resolve the OOM. However the approach is not perfectly suitable for production environment, especially for data warehouse.
Using Spark SQL as data engine in warehouse, users hope to have a unified parameter(e.g. memory) but less resource wasted(resource is allocated but not used). The hope is strong especially when migrating data engine to Spark from another one(e.g. Hive). Tuning the parameter for thousands of SQLs one by one is very time consuming.
It's not always easy to predict skew situations, when happen, it make sense to fetch remote blocks to disk for shuffle-read, rather than kill the job because of OOM.
In this pr, I propose to fetch big blocks to disk(which is also mentioned in SPARK-3019):
1. Track average size and also the outliers(which are larger than 2*avgSize) in MapStatus;
2. Request memory from `MemoryManager` before fetch blocks and release the memory to `MemoryManager` when `ManagedBuffer` is released.
3. Fetch remote blocks to disk when failing acquiring memory from `MemoryManager`, otherwise fetch to memory.
This is an improvement for memory control when shuffle blocks and help to avoid OOM in scenarios like below:
1. Single huge block;
2. Sizes of many blocks are underestimated in `MapStatus` and the actual footprint of blocks is much larger than the estimated.
## How was this patch tested?
Added unit test in `MapStatusSuite` and `ShuffleBlockFetcherIteratorSuite`.
Author: jinxing <jinxing6042@126.com>
Closes#16989 from jinxing64/SPARK-19659.
## What changes were proposed in this pull request?
Currently, when number of reduces is above 2000, HighlyCompressedMapStatus is used to store size of blocks. in HighlyCompressedMapStatus, only average size is stored for non empty blocks. Which is not good for memory control when we shuffle blocks. It makes sense to store the accurate size of block when it's above threshold.
## How was this patch tested?
Added test in MapStatusSuite.
Author: jinxing <jinxing6042@126.com>
Closes#18031 from jinxing64/SPARK-20801.
Quick follow up to #17996 - forgot to add the HTML links to the relevant sections of the guide in the highlights list.
## How was this patch tested?
Built docs locally and tested links.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#18043 from MLnick/SPARK-20506-2.2-migration-guide-2.
Update ML guide for migration `2.1` -> `2.2` and the previous version migration guide section.
## How was this patch tested?
Build doc locally.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#17996 from MLnick/SPARK-20506-2.2-migration-guide.
## What changes were proposed in this pull request?
The changes were merged as part of - https://github.com/apache/spark/pull/17467.
The documentation was missed somewhere in the review iterations. Adding the documentation where it belongs.
## How was this patch tested?
Docs. Not tested.
cc budde , brkyvz
Author: Yash Sharma <ysharma@atlassian.com>
Closes#18028 from yssharma/ysharma/kinesis_retry_docs.
## What changes were proposed in this pull request?
Add docs and examples for ```ml.stat.Correlation``` and ```ml.stat.ChiSquareTest```.
## How was this patch tested?
Generate docs and run examples manually, successfully.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17994 from yanboliang/spark-20505.
## What changes were proposed in this pull request?
SPARK-13973 incorrectly removed the required PYSPARK_DRIVER_PYTHON_OPTS=notebook from documentation to use pyspark with Jupyter notebook. This patch corrects the documentation error.
## How was this patch tested?
Tested invocation locally with
```bash
PYSPARK_DRIVER_PYTHON=jupyter PYSPARK_DRIVER_PYTHON_OPTS=notebook ./bin/pyspark
```
Author: Andrew Ray <ray.andrew@gmail.com>
Closes#18001 from aray/patch-1.
## What changes were proposed in this pull request?
Any Dataset/DataFrame batch query with the operation `withWatermark` does not execute because the batch planner does not have any rule to explicitly handle the EventTimeWatermark logical plan.
The right solution is to simply remove the plan node, as the watermark should not affect any batch query in any way.
Changes:
- In this PR, we add a new rule `EliminateEventTimeWatermark` to check if we need to ignore the event time watermark. We will ignore watermark in any batch query.
Depends upon:
- [SPARK-20672](https://issues.apache.org/jira/browse/SPARK-20672). We can not add this rule into analyzer directly, because streaming query will be copied to `triggerLogicalPlan ` in every trigger, and the rule will be applied to `triggerLogicalPlan` mistakenly.
Others:
- A typo fix in example.
## How was this patch tested?
add new unit test.
Author: uncleGen <hustyugm@gmail.com>
Closes#17896 from uncleGen/SPARK-20373.
## What changes were proposed in this pull request?
After SPARK-10997, client mode Netty RpcEnv doesn't require to start server, so port configurations are not used any more, here propose to remove these two configurations: "spark.executor.port" and "spark.am.port".
## How was this patch tested?
Existing UTs.
Author: jerryshao <sshao@hortonworks.com>
Closes#17866 from jerryshao/SPARK-20605.
## What changes were proposed in this pull request?
Add a new `spark-hadoop-cloud` module and maven profile to pull in object store support from `hadoop-openstack`, `hadoop-aws` and `hadoop-azure` (Hadoop 2.7+) JARs, along with their dependencies, fixing up the dependencies so that everything works, in particular Jackson.
It restores `s3n://` access to S3, adds its `s3a://` replacement, OpenStack `swift://` and azure `wasb://`.
There's a documentation page, `cloud_integration.md`, which covers the basic details of using Spark with object stores, referring the reader to the supplier's own documentation, with specific warnings on security and the possible mismatch between a store's behavior and that of a filesystem. In particular, users are advised be very cautious when trying to use an object store as the destination of data, and to consult the documentation of the storage supplier and the connector.
(this is the successor to #12004; I can't re-open it)
## How was this patch tested?
Downstream tests exist in [https://github.com/steveloughran/spark-cloud-examples/tree/master/cloud-examples](https://github.com/steveloughran/spark-cloud-examples/tree/master/cloud-examples)
Those verify that the dependencies are sufficient to allow downstream applications to work with s3a, azure wasb and swift storage connectors, and perform basic IO & dataframe operations thereon. All seems well.
Manually clean build & verify that assembly contains the relevant aws-* hadoop-* artifacts on Hadoop 2.6; azure on a hadoop-2.7 profile.
SBT build: `build/sbt -Phadoop-cloud -Phadoop-2.7 package`
maven build `mvn install -Phadoop-cloud -Phadoop-2.7`
This PR *does not* update `dev/deps/spark-deps-hadoop-2.7` or `dev/deps/spark-deps-hadoop-2.6`, because unless the hadoop-cloud profile is enabled, no extra JARs show up in the dependency list. The dependency check in Jenkins isn't setting the property, so the new JARs aren't visible.
Author: Steve Loughran <stevel@apache.org>
Author: Steve Loughran <stevel@hortonworks.com>
Closes#17834 from steveloughran/cloud/SPARK-7481-current.
## What changes were proposed in this pull request?
Add
- R vignettes
- R programming guide
- SS programming guide
- R example
Also disable spark.als in vignettes for now since it's failing (SPARK-20402)
## How was this patch tested?
manually
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#17814 from felixcheung/rdocss.
Add PCA and SVD to PySpark's wrappers for `RowMatrix` and `IndexedRowMatrix` (SVD only).
Based on #7963, updated.
## How was this patch tested?
New doc tests and unit tests. Ran all examples locally.
Author: MechCoder <manojkumarsivaraj334@gmail.com>
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#17621 from MLnick/SPARK-6227-pyspark-svd-pca.
## What changes were proposed in this pull request?
Updating R Programming Guide
## How was this patch tested?
manually
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#17816 from felixcheung/r22relnote.
## What changes were proposed in this pull request?
Currently, our project needs to be set to clean up the worker directory cleanup cycle is three days.
When I follow http://spark.apache.org/docs/latest/spark-standalone.html, configure the 'spark.worker.cleanup.appDataTtl' parameter, I configured to 3 * 24 * 3600.
When I start the spark service, the startup fails, and the worker log displays the error log as follows:
2017-04-28 15:02:03,306 INFO Utils: Successfully started service 'sparkWorker' on port 48728.
Exception in thread "main" java.lang.NumberFormatException: For input string: "3 * 24 * 3600"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Long.parseLong(Long.java:430)
at java.lang.Long.parseLong(Long.java:483)
at scala.collection.immutable.StringLike$class.toLong(StringLike.scala:276)
at scala.collection.immutable.StringOps.toLong(StringOps.scala:29)
at org.apache.spark.SparkConf$$anonfun$getLong$2.apply(SparkConf.scala:380)
at org.apache.spark.SparkConf$$anonfun$getLong$2.apply(SparkConf.scala:380)
at scala.Option.map(Option.scala:146)
at org.apache.spark.SparkConf.getLong(SparkConf.scala:380)
at org.apache.spark.deploy.worker.Worker.<init>(Worker.scala:100)
at org.apache.spark.deploy.worker.Worker$.startRpcEnvAndEndpoint(Worker.scala:730)
at org.apache.spark.deploy.worker.Worker$.main(Worker.scala:709)
at org.apache.spark.deploy.worker.Worker.main(Worker.scala)
**Because we put 7 * 24 * 3600 as a string, forced to convert to the dragon type, will lead to problems in the program.**
**So I think the default value of the current configuration should be a specific long value, rather than 7 * 24 * 3600,should be 604800. Because it would mislead users for similar configurations, resulting in spark start failure.**
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: 郭小龙 10207633 <guo.xiaolong1@zte.com.cn>
Author: guoxiaolong <guo.xiaolong1@zte.com.cn>
Author: guoxiaolongzte <guo.xiaolong1@zte.com.cn>
Closes#17798 from guoxiaolongzte/SPARK-20521.
## What changes were proposed in this pull request?
Add a new section for fpm
Add Example for FPGrowth in scala and Java
updated: Rewrite transform to be more compact.
## How was this patch tested?
local doc generation.
Author: Yuhao Yang <yuhao.yang@intel.com>
Closes#17130 from hhbyyh/fpmdoc.
## What changes were proposed in this pull request?
Add hyper link in the SparkR programming guide.
## How was this patch tested?
Build doc and manually check the doc link.
Author: wangmiao1981 <wm624@hotmail.com>
Closes#17805 from wangmiao1981/doc.
## What changes were proposed in this pull request?
add link to svmLinear in the SparkR programming document.
## How was this patch tested?
Build doc manually and click the link to the document. It looks good.
Author: wangmiao1981 <wm624@hotmail.com>
Closes#17797 from wangmiao1981/doc.
## What changes were proposed in this pull request?
Add `spark.fpGrowth` to SparkR programming guide.
## How was this patch tested?
Manual tests.
Author: zero323 <zero323@users.noreply.github.com>
Closes#17775 from zero323/SPARK-20208-FOLLOW-UP.
This change does a more thorough redaction of sensitive information from logs and UI
Add unit tests that ensure that no regressions happen that leak sensitive information to the logs.
The motivation for this change was appearance of password like so in `SparkListenerEnvironmentUpdate` in event logs under some JVM configurations:
`"sun.java.command":"org.apache.spark.deploy.SparkSubmit ... --conf spark.executorEnv.HADOOP_CREDSTORE_PASSWORD=secret_password ..."
`
Previously redaction logic was only checking if the key matched the secret regex pattern, it'd redact it's value. That worked for most cases. However, in the above case, the key (sun.java.command) doesn't tell much, so the value needs to be searched. This PR expands the check to check for values as well.
## How was this patch tested?
New unit tests added that ensure that no sensitive information is present in the event logs or the yarn logs. Old unit test in UtilsSuite was modified because the test was asserting that a non-sensitive property's value won't be redacted. However, the non-sensitive value had the literal "secret" in it which was causing it to redact. Simply updating the non-sensitive property's value to another arbitrary value (that didn't have "secret" in it) fixed it.
Author: Mark Grover <mark@apache.org>
Closes#17725 from markgrover/spark-20435.
## What changes were proposed in this pull request?
Simple documentation change to remove explicit vendor references.
## How was this patch tested?
NA
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: anabranch <bill@databricks.com>
Closes#17695 from anabranch/remove-vendor.
## What changes were proposed in this pull request?
- Add `rollup` and `cube` methods and corresponding generics.
- Add short description to the vignette.
## How was this patch tested?
- Existing unit tests.
- Additional unit tests covering new features.
- `check-cran.sh`.
Author: zero323 <zero323@users.noreply.github.com>
Closes#17728 from zero323/SPARK-20437.
## What changes were proposed in this pull request?
Pregel-based iterative algorithms with more than ~50 iterations begin to slow down and eventually fail with a StackOverflowError due to Spark's lack of support for long lineage chains.
This PR causes Pregel to checkpoint the graph periodically if the checkpoint directory is set.
This PR moves PeriodicGraphCheckpointer.scala from mllib to graphx, moves PeriodicRDDCheckpointer.scala, PeriodicCheckpointer.scala from mllib to core
## How was this patch tested?
unit tests, manual tests
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Author: ding <ding@localhost.localdomain>
Author: dding3 <ding.ding@intel.com>
Author: Michael Allman <michael@videoamp.com>
Closes#15125 from dding3/cp2_pregel.
## What changes were proposed in this pull request?
Just added the Maven `test`goal.
## How was this patch tested?
No test needed, just a trivial documentation fix.
Author: Armin Braun <me@obrown.io>
Closes#17756 from original-brownbear/SPARK-20455.
## What changes were proposed in this pull request?
Use the REST interface submits the spark job.
e.g.
curl -X POST http://10.43.183.120:6066/v1/submissions/create --header "Content-Type:application/json;charset=UTF-8" --data'{
"action": "CreateSubmissionRequest",
"appArgs": [
"myAppArgument"
],
"appResource": "/home/mr/gxl/test.jar",
"clientSparkVersion": "2.2.0",
"environmentVariables": {
"SPARK_ENV_LOADED": "1"
},
"mainClass": "cn.zte.HdfsTest",
"sparkProperties": {
"spark.jars": "/home/mr/gxl/test.jar",
**"spark.driver.supervise": "true",**
"spark.app.name": "HdfsTest",
"spark.eventLog.enabled": "false",
"spark.submit.deployMode": "cluster",
"spark.master": "spark://10.43.183.120:6066"
}
}'
**I hope that make sure that the driver is automatically restarted if it fails with non-zero exit code.
But I can not find the 'spark.driver.supervise' configuration parameter specification and default values from the spark official document.**
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: 郭小龙 10207633 <guo.xiaolong1@zte.com.cn>
Author: guoxiaolong <guo.xiaolong1@zte.com.cn>
Author: guoxiaolongzte <guo.xiaolong1@zte.com.cn>
Closes#17696 from guoxiaolongzte/SPARK-20401.
Hello
PR #10991 removed the built-in history view from Spark Standalone, so the history server is no longer useful to Yarn or Mesos only.
Author: Hervé <dud225@users.noreply.github.com>
Closes#17709 from dud225/patch-1.
## What changes were proposed in this pull request?
Typos at a couple of place in the docs.
## How was this patch tested?
build including docs
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: ymahajan <ymahajan@snappydata.io>
Closes#17690 from ymahajan/master.
## What changes were proposed in this pull request?
Note that you shouldn't manually add dependencies on org.apache.kafka artifacts
## How was this patch tested?
Doc only change, did jekyll build and looked at the page.
Author: cody koeninger <cody@koeninger.org>
Closes#17675 from koeninger/SPARK-20036.
## What changes were proposed in this pull request?
Allow passing in arbitrary parameters into docker when launching spark executors on mesos with docker containerizer tnachen
## How was this patch tested?
Manually built and tested with passed in parameter
Author: Ji Yan <jiyan@Jis-MacBook-Air.local>
Closes#17109 from yanji84/ji/allow_set_docker_user.
## What changes were proposed in this pull request?
This PR proposes corrections related to JSON APIs as below:
- Rendering links in Python documentation
- Replacing `RDD` to `Dataset` in programing guide
- Adding missing description about JSON Lines consistently in `DataFrameReader.json` in Python API
- De-duplicating little bit of `DataFrameReader.json` in Scala/Java API
## How was this patch tested?
Manually build the documentation via `jekyll build`. Corresponding snapstops will be left on the codes.
Note that currently there are Javadoc8 breaks in several places. These are proposed to be handled in https://github.com/apache/spark/pull/17477. So, this PR does not fix those.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#17602 from HyukjinKwon/minor-json-documentation.
## What changes were proposed in this pull request?
1. Omitted space between the sentences: `... on static data.The Spark SQL engine will ...` -> `... on static data. The Spark SQL engine will ...`
2. Omitted colon in Output Model section.
## How was this patch tested?
None.
Author: Lee Dongjin <dongjin@apache.org>
Closes#17564 from dongjinleekr/feature/fix-programming-guide.
## What changes were proposed in this pull request?
Since SPARK-18112 and SPARK-13446, Apache Spark starts to support reading Hive metastore 2.0 ~ 2.1.1. This updates the docs.
## How was this patch tested?
N/A
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#17612 from dongjoon-hyun/metastore.
## What changes were proposed in this pull request?
Add documentation for adding master url in multi host, port format for standalone cluster with high availability with zookeeper.
Referring documentation [Standby Masters with ZooKeeper](http://spark.apache.org/docs/latest/spark-standalone.html#standby-masters-with-zookeeper)
## How was this patch tested?
Documenting the functionality already present.
Author: MirrorZ <chandrika3437@gmail.com>
Closes#17584 from MirrorZ/master.
## What changes were proposed in this pull request?
1. '/applications/[app-id]/stages' in rest api.status should add description '?status=[active|complete|pending|failed] list only stages in the state.'
Now the lack of this description, resulting in the use of this api do not know the use of the status through the brush stage list.
2.'/applications/[app-id]/stages/[stage-id]' in REST API,remove redundant description ‘?status=[active|complete|pending|failed] list only stages in the state.’.
Because only one stage is determined based on stage-id.
code:
GET
def stageList(QueryParam("status") statuses: JList[StageStatus]): Seq[StageData] = {
val listener = ui.jobProgressListener
val stageAndStatus = AllStagesResource.stagesAndStatus(ui)
val adjStatuses = {
if (statuses.isEmpty()) {
Arrays.asList(StageStatus.values(): _*)
} else {
statuses
}
};
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: 郭小龙 10207633 <guo.xiaolong1@zte.com.cn>
Closes#17534 from guoxiaolongzte/SPARK-20218.
## What changes were proposed in this pull request?
Add spark.mesos.task.labels configuration option to add mesos key:value labels to the executor.
"k1:v1,k2:v2" as the format, colons separating key-value and commas to list out more than one.
Discussion of labels with mgummelt at #17404
## How was this patch tested?
Added unit tests to verify labels were added correctly, with incorrect labels being ignored and added a test to test the name of the executor.
Tested with: `./build/sbt -Pmesos mesos/test`
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Kalvin Chau <kalvin.chau@viasat.com>
Closes#17413 from kalvinnchau/mesos-labels.
## What changes were proposed in this pull request?
- Fixed bug in Java API not passing timeout conf to scala API
- Updated markdown docs
- Updated scala docs
- Added scala and Java example
## How was this patch tested?
Manually ran examples.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#17539 from tdas/SPARK-20224.
## What changes were proposed in this pull request?
Adding documentation to point to Kubernetes cluster scheduler being developed out-of-repo in https://github.com/apache-spark-on-k8s/spark
cc rxin srowen tnachen ash211 mccheah erikerlandson
## How was this patch tested?
Docs only change
Author: Anirudh Ramanathan <foxish@users.noreply.github.com>
Author: foxish <ramanathana@google.com>
Closes#17522 from foxish/upstream-doc.
…ucceeded|failed|unknown]
## What changes were proposed in this pull request?
'/applications/[app-id]/jobs' in rest api.status should be'[running|succeeded|failed|unknown]'.
now status is '[complete|succeeded|failed]'.
but '/applications/[app-id]/jobs?status=complete' the server return 'HTTP ERROR 404'.
Added '?status=running' and '?status=unknown'.
code :
public enum JobExecutionStatus {
RUNNING,
SUCCEEDED,
FAILED,
UNKNOWN;
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: guoxiaolongzte <guo.xiaolong1@zte.com.cn>
Closes#17507 from guoxiaolongzte/SPARK-20190.
## What changes were proposed in this pull request?
Add docs and examples for spark.ml.feature.Imputer. Currently scala and Java examples are included. Python example will be added after https://github.com/apache/spark/pull/17316
## How was this patch tested?
local doc generation and example execution
Author: Yuhao Yang <yuhao.yang@intel.com>
Closes#17324 from hhbyyh/imputerdoc.
# What changes were proposed in this pull request?
It seems there are several non-breaking spaces were inserted into several `.md`s and they look breaking rendering markdown files.
These are different. For example, this can be checked via `python` as below:
```python
>>> " "
'\xc2\xa0'
>>> " "
' '
```
_Note that it seems this PR description automatically replaces non-breaking spaces into normal spaces. Please open a `vi` and copy and paste it into `python` to verify this (do not copy the characters here)._
I checked the output below in Sapari and Chrome on Mac OS and, Internal Explorer on Windows 10.
**Before**


**After**


## How was this patch tested?
Manually checking.
These instances were found via
```
grep --include=*.scala --include=*.python --include=*.java --include=*.r --include=*.R --include=*.md --include=*.r -r -I " " .
```
in Mac OS.
It seems there are several instances more as below:
```
./docs/sql-programming-guide.md: │ ├── ...
./docs/sql-programming-guide.md: │ │
./docs/sql-programming-guide.md: │ ├── country=US
./docs/sql-programming-guide.md: │ │ └── data.parquet
./docs/sql-programming-guide.md: │ ├── country=CN
./docs/sql-programming-guide.md: │ │ └── data.parquet
./docs/sql-programming-guide.md: │ └── ...
./docs/sql-programming-guide.md: ├── ...
./docs/sql-programming-guide.md: │
./docs/sql-programming-guide.md: ├── country=US
./docs/sql-programming-guide.md: │ └── data.parquet
./docs/sql-programming-guide.md: ├── country=CN
./docs/sql-programming-guide.md: │ └── data.parquet
./docs/sql-programming-guide.md: └── ...
./sql/core/src/test/README.md:│ ├── *.avdl # Testing Avro IDL(s)
./sql/core/src/test/README.md:│ └── *.avpr # !! NO TOUCH !! Protocol files generated from Avro IDL(s)
./sql/core/src/test/README.md:│ ├── gen-avro.sh # Script used to generate Java code for Avro
./sql/core/src/test/README.md:│ └── gen-thrift.sh # Script used to generate Java code for Thrift
```
These seems generated via `tree` command which inserts non-breaking spaces. They do not look causing any problem for rendering within code blocks and I did not fix it to reduce the overhead to manually replace it when it is overwritten via `tree` command in the future.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#17517 from HyukjinKwon/non-breaking-space.
…anges.
## What changes were proposed in this pull request?
Document compression way little detail changes.
1.spark.eventLog.compress add 'Compression will use spark.io.compression.codec.'
2.spark.broadcast.compress add 'Compression will use spark.io.compression.codec.'
3,spark.rdd.compress add 'Compression will use spark.io.compression.codec.'
4.spark.io.compression.codec add 'event log describe'.
eg
Through the documents, I don't know what is compression mode about 'event log'.
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: 郭小龙 10207633 <guo.xiaolong1@zte.com.cn>
Closes#17498 from guoxiaolongzte/SPARK-20177.
Fixed a few typos.
There is one more I'm not sure of:
```
Append mode uses watermark to drop old aggregation state. But the output of a
windowed aggregation is delayed the late threshold specified in `withWatermark()` as by
the modes semantics, rows can be added to the Result Table only once after they are
```
Not sure how to change `is delayed the late threshold`.
Author: Seigneurin, Alexis (CONT) <Alexis.Seigneurin@capitalone.com>
Closes#17443 from aseigneurin/typos.
## What changes were proposed in this pull request?
Currently JDBC data source creates tables in the target database using the default type mapping, and the JDBC dialect mechanism. If users want to specify different database data type for only some of columns, there is no option available. In scenarios where default mapping does not work, users are forced to create tables on the target database before writing. This workaround is probably not acceptable from a usability point of view. This PR is to provide a user-defined type mapping for specific columns.
The solution is to allow users to specify database column data type for the create table as JDBC datasource option(createTableColumnTypes) on write. Data type information can be specified in the same format as table schema DDL format (e.g: `name CHAR(64), comments VARCHAR(1024)`).
All supported target database types can not be specified , the data types has to be valid spark sql data types also. For example user can not specify target database CLOB data type. This will be supported in the follow-up PR.
Example:
```Scala
df.write
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)")
.jdbc(url, "TEST.DBCOLTYPETEST", properties)
```
## How was this patch tested?
Added new test cases to the JDBCWriteSuite
Author: sureshthalamati <suresh.thalamati@gmail.com>
Closes#16209 from sureshthalamati/jdbc_custom_dbtype_option_json-spark-10849.
## What changes were proposed in this pull request?
Add backslash for line continuation in python code.
## How was this patch tested?
Jenkins.
Author: uncleGen <hustyugm@gmail.com>
Author: dylon <hustyugm@gmail.com>
Closes#17352 from uncleGen/python-example-doc.
## What changes were proposed in this pull request?
API documentation and collaborative filtering documentation page changes to clarify inconsistent description of ALS rank parameter.
- [DOCS] was previously: "rank is the number of latent factors in the model."
- [API] was previously: "rank - number of features to use"
This change describes rank in both places consistently as:
- "Number of features to use (also referred to as the number of latent factors)"
Author: Chris Snow <chris.snowuk.ibm.com>
Author: christopher snow <chsnow123@gmail.com>
Closes#17345 from snowch/SPARK-20011.
## What changes were proposed in this pull request?
Add documentation that describes how to write streaming and batch queries to Kafka.
zsxwing tdas
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Tyson Condie <tcondie@gmail.com>
Closes#17246 from tcondie/kafka-write-docs.
The previously hardcoded max 4 retries per stage is not suitable for all cluster configurations. Since spark retries a stage at the sign of the first fetch failure, you can easily end up with many stage retries to discover all the failures. In particular, two scenarios this value should change are (1) if there are more than 4 executors per node; in that case, it may take 4 retries to discover the problem with each executor on the node and (2) during cluster maintenance on large clusters, where multiple machines are serviced at once, but you also cannot afford total cluster downtime. By making this value configurable, cluster managers can tune this value to something more appropriate to their cluster configuration.
Unit tests
Author: Sital Kedia <skedia@fb.com>
Closes#17307 from sitalkedia/SPARK-13369.
## What changes were proposed in this pull request?
- SS python example: `TypeError: 'xxx' object is not callable`
- some other doc issue.
## How was this patch tested?
Jenkins.
Author: uncleGen <hustyugm@gmail.com>
Closes#17257 from uncleGen/docs-ss-python.
## What changes were proposed in this pull request?
Today, we compare the whole path when deciding if a file is new in the FileSource for structured streaming. However, this would cause false negatives in the case where the path has changed in a cosmetic way (i.e. changing `s3n` to `s3a`).
This patch adds an option `fileNameOnly` that causes the new file check to be based only on the filename (but still store the whole path in the log).
## Usage
```scala
spark
.readStream
.option("fileNameOnly", true)
.text("s3n://bucket/dir1/dir2")
.writeStream
...
```
## How was this patch tested?
Added a test case
Author: Liwei Lin <lwlin7@gmail.com>
Closes#17120 from lw-lin/filename-only.
## What changes were proposed in this pull request?
After Spark 2.0, `SparkSession` becomes the new entry point for Spark applications. We should update the public documents to reflect this.
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#16856 from cloud-fan/doc.
## What changes were proposed in this pull request?
This PR is an enhancement to ML StringIndexer.
Before this PR, String Indexer only supports "skip"/"error" options to deal with unseen records.
But those unseen records might still be useful and user would like to keep the unseen labels in
certain use cases, This PR enables StringIndexer to support keeping unseen labels as
indices [numLabels].
'''Before
StringIndexer().setHandleInvalid("skip")
StringIndexer().setHandleInvalid("error")
'''After
support the third option "keep"
StringIndexer().setHandleInvalid("keep")
## How was this patch tested?
Test added in StringIndexerSuite
Signed-off-by: VinceShieh <vincent.xieintel.com>
(Please fill in changes proposed in this fix)
Author: VinceShieh <vincent.xie@intel.com>
Closes#16883 from VinceShieh/spark-17498.
## What changes were proposed in this pull request?
Doc about enabling web UI https is not correct, "spark.ui.https.enabled" is not existed, actually enabling SSL is enough for https.
## How was this patch tested?
N/A
Author: jerryshao <sshao@hortonworks.com>
Closes#17147 from jerryshao/fix-doc-ssl.
## What changes were proposed in this pull request?
Description about pipeline in this paragraph is incorrect https://spark.apache.org/docs/latest/ml-pipeline.html#how-it-works
> If the Pipeline had more **stages**, it would call the LogisticRegressionModel’s transform() method on the DataFrame before passing the DataFrame to the next stage.
Reason: Transformer could also be a stage. But only another Estimator will invoke an transform call and pass the data to next stage. The description in the document misleads ML pipeline users.
## How was this patch tested?
This is a tiny modification of **docs/ml-pipelines.md**. I jekyll build the modification and check the compiled document.
Author: Zhe Sun <ymwdalex@gmail.com>
Closes#17137 from ymwdalex/SPARK-19797-ML-pipeline-document-correction.
[SPARK-14489](https://issues.apache.org/jira/browse/SPARK-14489) added the ability to skip `NaN` predictions during `ALSModel.transform`. This PR adds documentation for the `coldStartStrategy` param to the ALS user guide, and add code to the examples to illustrate usage.
## How was this patch tested?
Doc and example change only. Build HTML doc locally and verified example code builds, and runs in shell for Scala/Python.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#17102 from MLnick/SPARK-19345-coldstart-doc.
## What changes were proposed in this pull request?
Update doc for R, programming guide. Clarify default behavior for all languages.
## How was this patch tested?
manually
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#17128 from felixcheung/jsonwholefiledoc.
## What changes were proposed in this pull request?
This change addresses the renaming of the `simple.sbt` build file to
`build.sbt`. Newer versions of the sbt tool are not finding the older
named file and are looking for the `build.sbt`. The quickstart
instructions for self-contained applications is updated with this
change.
## How was this patch tested?
As this is a relatively minor change of a few words, the markdown was checked for syntax and spelling. Site was built with `SKIP_API=1 jekyll serve` for testing purposes.
Author: Michael McCune <msm@redhat.com>
Closes#17101 from elmiko/spark-19769.
Update GLM documentation to include the Tweedie distribution. #16344
jkbradley yanboliang
Author: actuaryzhang <actuaryzhang10@gmail.com>
Closes#17103 from actuaryzhang/doc.
## What changes were proposed in this pull request?
Removed duplicated lines in sql python example and found a typo.
## How was this patch tested?
Searched for other typo's in the page to minimize PR's.
Author: Boaz Mohar <boazmohar@gmail.com>
Closes#17066 from boazmohar/doc-fix.
## What changes were proposed in this pull request?
Minor typo in `even-time`, which is changed to `event-time` and a couple of grammatical errors fix.
## How was this patch tested?
N/A - since this is a doc fix. I did a jekyll build locally though.
Author: Ramkumar Venkataraman <rvenkataraman@paypal.com>
Closes#17037 from ramkumarvenkat/doc-fix.
## What changes were proposed in this pull request?
We are proposing addition of pro-active block replication in case of executor failures. BlockManagerMasterEndpoint does all the book-keeping to keep a track of all the executors and the blocks they hold. It also keeps a track of which executors are alive through heartbeats. When an executor is removed, all this book-keeping state is updated to reflect the lost executor. This step can be used to identify executors that are still in possession of a copy of the cached data and a message could be sent to them to use the existing "replicate" function to find and place new replicas on other suitable hosts. Blocks replicated this way will let the master know of their existence.
This can happen when an executor is lost, and would that way be pro-active as opposed be being done at query time.
## How was this patch tested?
This patch was tested with existing unit tests along with new unit tests added to test the functionality.
Author: Shubham Chopra <schopra31@bloomberg.net>
Closes#14412 from shubhamchopra/ProactiveBlockReplication.
## What changes were proposed in this pull request?
follow up pr of #16949.
## How was this patch tested?
jenkins
Author: uncleGen <hustyugm@gmail.com>
Closes#17033 from uncleGen/doc-restapi-environment.
This commit moves developer-specific information from the release-
specific documentation in this repo to the developer tools page on
the main Spark website. This commit relies on this PR on the
Spark website: https://github.com/apache/spark-website/pull/33.
srowen
Author: Kay Ousterhout <kayousterhout@gmail.com>
Closes#17018 from kayousterhout/SPARK-19684.
Allow an application to use the History Server URL as the tracking
URL in the YARN RM, so there's still a link to the web UI somewhere
in YARN even if the driver's UI is disabled. This is useful, for
example, if an admin wants to disable the driver UI by default for
applications, since it's harder to secure it (since it involves non
trivial ssl certificate and auth management that admins may not want
to expose to user apps).
This needs to be opt-in, because of the way the YARN proxy works, so
a new configuration was added to enable the option.
The YARN RM will proxy requests to live AMs instead of redirecting
the client, so pages in the SHS UI will not render correctly since
they'll reference invalid paths in the RM UI. The proxy base support
in the SHS cannot be used since that would prevent direct access to
the SHS.
So, to solve this problem, for the feature to work end-to-end, a new
YARN-specific filter was added that detects whether the requests come
from the proxy and redirects the client appropriatly. The SHS admin has
to add this filter manually if they want the feature to work.
Tested with new unit test, and by running with the documented configuration
set in a test cluster. Also verified the driver UI is used when it's
enabled.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#16946 from vanzin/SPARK-19554.
## What changes were proposed in this pull request?
Documentation and examples (Java, scala, python, R) for LinearSVC
## How was this patch tested?
local doc generation
Author: Yuhao Yang <yuhao.yang@intel.com>
Closes#16968 from hhbyyh/mlsvmdoc.
- Move external/java8-tests tests into core, streaming, sql and remove
- Remove MaxPermGen and related options
- Fix some reflection / TODOs around Java 8+ methods
- Update doc references to 1.7/1.8 differences
- Remove Java 7/8 related build profiles
- Update some plugins for better Java 8 compatibility
- Fix a few Java-related warnings
For the future:
- Update Java 8 examples to fully use Java 8
- Update Java tests to use lambdas for simplicity
- Update Java internal implementations to use lambdas
## How was this patch tested?
Existing tests
Author: Sean Owen <sowen@cloudera.com>
Closes#16871 from srowen/SPARK-19493.
## What changes were proposed in this pull request?
This pull request includes python API and examples for LSH. The API changes was based on yanboliang 's PR #15768 and resolved conflicts and API changes on the Scala API. The examples are consistent with Scala examples of MinHashLSH and BucketedRandomProjectionLSH.
## How was this patch tested?
API and examples are tested using spark-submit:
`bin/spark-submit examples/src/main/python/ml/min_hash_lsh.py`
`bin/spark-submit examples/src/main/python/ml/bucketed_random_projection_lsh.py`
User guide changes are generated and manually inspected:
`SKIP_API=1 jekyll build`
Author: Yun Ni <yunn@uber.com>
Author: Yanbo Liang <ybliang8@gmail.com>
Author: Yunni <Euler57721@gmail.com>
Closes#16715 from Yunni/spark-18080.
## What changes were proposed in this pull request?
Revision to structured-streaming-kafka-integration.md to reflect new Batch query specification and options.
zsxwing tdas
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Tyson Condie <tcondie@gmail.com>
Closes#16918 from tcondie/kafka-docs.
## What changes were proposed in this pull request?
https://spark.apache.org/docs/latest/sql-programming-guide.html#caching-data-in-memory
In the doc, the call spark.cacheTable(“tableName”) and spark.uncacheTable(“tableName”) actually needs to be spark.catalog.cacheTable and spark.catalog.uncacheTable
## How was this patch tested?
Built the docs and verified the change shows up fine.
Author: Sunitha Kambhampati <skambha@us.ibm.com>
Closes#16919 from skambha/docChange.
Spark's I/O encryption uses an ephemeral key for each driver instance.
So driver B cannot decrypt data written by driver A since it doesn't
have the correct key.
The write ahead log is used for recovery, thus needs to be readable by
a different driver. So it cannot be encrypted by Spark's I/O encryption
code.
The BlockManager APIs used by the WAL code to write the data automatically
encrypt data, so changes are needed so that callers can to opt out of
encryption.
Aside from that, the "putBytes" API in the BlockManager does not do
encryption, so a separate situation arised where the WAL would write
unencrypted data to the BM and, when those blocks were read, decryption
would fail. So the WAL code needs to ask the BM to encrypt that data
when encryption is enabled; this code is not optimal since it results
in a (temporary) second copy of the data block in memory, but should be
OK for now until a more performant solution is added. The non-encryption
case should not be affected.
Tested with new unit tests, and by running streaming apps that do
recovery using the WAL data with I/O encryption turned on.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#16862 from vanzin/SPARK-19520.
Hello
According to my understanding of commits 4b4e329e49 & 8b325b17ec, one may now encrypt shuffle files regardless of the cluster manager in use.
However I have limited understanding of the code, I'm not able to find out whether theses changes also comprise all "temporary local storage, such as shuffle files, cached data, and other application files".
Please feel free to amend or reject my PR if I'm wrong.
dud
Author: Hervé <dud225@users.noreply.github.com>
Closes#16885 from dud225/patch-1.
## What changes were proposed in this pull request?
Due to the newly added API in Hadoop 2.6.4+, Spark builds against Hadoop 2.6.0~2.6.3 will meet compile error. So here still reverting back to use reflection to handle this issue.
## How was this patch tested?
Manual verification.
Author: jerryshao <sshao@hortonworks.com>
Closes#16884 from jerryshao/SPARK-19545.
## What changes were proposed in this pull request?
In SPARK-8425, we introduced a mechanism for blacklisting executors and nodes (hosts). After a certain number of failures, these resources would be "blacklisted" and no further work would be assigned to them for some period of time.
In some scenarios, it is better to fail fast, and to simply kill these unreliable resources. This changes proposes to do so by having the BlacklistTracker kill unreliable resources when they would otherwise be "blacklisted".
In order to be thread safe, this code depends on the CoarseGrainedSchedulerBackend sending a message to the driver backend in order to do the actual killing. This also helps to prevent a race which would permit work to begin on a resource (executor or node), between the time the resource is marked for killing and the time at which it is finally killed.
## How was this patch tested?
./dev/run-tests
Ran https://github.com/jsoltren/jose-utils/blob/master/blacklist/test-blacklist.sh, and checked logs to see executors and nodes being killed.
Testing can likely be improved here; suggestions welcome.
Author: José Hiram Soltren <jose@cloudera.com>
Closes#16650 from jsoltren/SPARK-16554-submit.
Make the SSL port configuration explicit, instead of deriving it
from the non-SSL port, but retain the existing functionality in
case anyone depends on it.
The change starts the HTTPS and HTTP connectors separately, so
that it's possible to use independent ports for each. For that to
work, the initialization of the server needs to be shuffled around
a bit. The change also makes it so the initialization of both
connectors is similar, and end up using the same Scheduler - previously
only the HTTP connector would use the correct one.
Also fixed some outdated documentation about a couple of services
that were removed long ago.
Tested with unit tests and by running spark-shell with SSL configs.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#16625 from vanzin/SPARK-17874.
## What changes were proposed in this pull request?
- Remove support for Hadoop 2.5 and earlier
- Remove reflection and code constructs only needed to support multiple versions at once
- Update docs to reflect newer versions
- Remove older versions' builds and profiles.
## How was this patch tested?
Existing tests
Author: Sean Owen <sowen@cloudera.com>
Closes#16810 from srowen/SPARK-19464.
## What changes were proposed in this pull request?
Update programming guide, example and vignette with Bisecting k-means.
Author: krishnakalyan3 <krishnakalyan3@gmail.com>
Closes#16767 from krishnakalyan3/bisecting-kmeans.
## What changes were proposed in this pull request?
Fix brokens links in ml-pipeline and ml-tuning
`<div data-lang="scala">` -> `<div data-lang="scala" markdown="1">`
## How was this patch tested?
manual tests
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#16754 from zhengruifeng/doc_api_fix.
## What changes were proposed in this pull request?
This PR proposes three things as below:
- Support LaTex inline-formula, `\( ... \)` in Scala API documentation
It seems currently,
```
\( ... \)
```
are rendered as they are, for example,
<img width="345" alt="2017-01-30 10 01 13" src="https://cloud.githubusercontent.com/assets/6477701/22423960/ab37d54a-e737-11e6-9196-4f6229c0189c.png">
It seems mistakenly more backslashes were added.
- Fix warnings Scaladoc/Javadoc generation
This PR fixes t two types of warnings as below:
```
[warn] .../spark/sql/catalyst/src/main/scala/org/apache/spark/sql/Row.scala:335: Could not find any member to link for "UnsupportedOperationException".
[warn] /**
[warn] ^
```
```
[warn] .../spark/sql/core/src/main/scala/org/apache/spark/sql/internal/VariableSubstitution.scala:24: Variable var undefined in comment for class VariableSubstitution in class VariableSubstitution
[warn] * `${var}`, `${system:var}` and `${env:var}`.
[warn] ^
```
- Fix Javadoc8 break
```
[error] .../spark/mllib/target/java/org/apache/spark/ml/PredictionModel.java:7: error: reference not found
[error] * E.g., {link VectorUDT} for vector features.
[error] ^
[error] .../spark/mllib/target/java/org/apache/spark/ml/PredictorParams.java:12: error: reference not found
[error] * E.g., {link VectorUDT} for vector features.
[error] ^
[error] .../spark/mllib/target/java/org/apache/spark/ml/Predictor.java:10: error: reference not found
[error] * E.g., {link VectorUDT} for vector features.
[error] ^
[error] .../spark/sql/hive/target/java/org/apache/spark/sql/hive/HiveAnalysis.java:5: error: reference not found
[error] * Note that, this rule must be run after {link PreprocessTableInsertion}.
[error] ^
```
## How was this patch tested?
Manually via `sbt unidoc` and `jeykil build`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#16741 from HyukjinKwon/warn-and-break.
### What changes were proposed in this pull request?
The case are not sensitive in JDBC options, after the PR https://github.com/apache/spark/pull/15884 is merged to Spark 2.1.
### How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#16734 from gatorsmile/fixDocCaseInsensitive.
## What changes were proposed in this pull request?
- A separate subsection for Aggregations under “Getting Started” in the Spark SQL programming guide. It mentions which aggregate functions are predefined and how users can create their own.
- Examples of using the `UserDefinedAggregateFunction` abstract class for untyped aggregations in Java and Scala.
- Examples of using the `Aggregator` abstract class for type-safe aggregations in Java and Scala.
- Python is not covered.
- The PR might not resolve the ticket since I do not know what exactly was planned by the author.
In total, there are four new standalone examples that can be executed via `spark-submit` or `run-example`. The updated Spark SQL programming guide references to these examples and does not contain hard-coded snippets.
## How was this patch tested?
The patch was tested locally by building the docs. The examples were run as well.

Author: aokolnychyi <okolnychyyanton@gmail.com>
Closes#16329 from aokolnychyi/SPARK-16046.
This change introduces a new auth mechanism to the transport library,
to be used when users enable strong encryption. This auth mechanism
has better security than the currently used DIGEST-MD5.
The new protocol uses symmetric key encryption to mutually authenticate
the endpoints, and is very loosely based on ISO/IEC 9798.
The new protocol falls back to SASL when it thinks the remote end is old.
Because SASL does not support asking the server for multiple auth protocols,
which would mean we could re-use the existing SASL code by just adding a
new SASL provider, the protocol is implemented outside of the SASL API
to avoid the boilerplate of adding a new provider.
Details of the auth protocol are discussed in the included README.md
file.
This change partly undos the changes added in SPARK-13331; AES encryption
is now decoupled from SASL authentication. The encryption code itself,
though, has been re-used as part of this change.
## How was this patch tested?
- Unit tests
- Tested Spark 2.2 against Spark 1.6 shuffle service with SASL enabled
- Tested Spark 2.2 against Spark 2.2 shuffle service with SASL fallback disabled
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#16521 from vanzin/SPARK-19139.
## What changes were proposed in this pull request?
Currently, spark history server REST API provides functionality to query applications by application start time range based on minDate and maxDate query parameters, but it lacks support to query applications by their end time. In this pull request we are proposing optional minEndDate and maxEndDate query parameters and filtering capability based on these parameters to spark history server REST API. This functionality can be used for following queries,
1. Applications finished in last 'x' minutes
2. Applications finished before 'y' time
3. Applications finished between 'x' time to 'y' time
4. Applications started from 'x' time and finished before 'y' time.
For backward compatibility, we can keep existing minDate and maxDate query parameters as they are and they can continue support filtering based on start time range.
## How was this patch tested?
Existing unit tests and 4 new unit tests.
Author: Parag Chaudhari <paragpc@amazon.com>
Closes#11867 from paragpc/master-SHS-query-by-endtime_2.
## What changes were proposed in this pull request?
Fix typo in docs
## How was this patch tested?
Author: uncleGen <hustyugm@gmail.com>
Closes#16658 from uncleGen/typo-issue.
## What changes were proposed in this pull request?
Drop more elements when `stageData.taskData.size > retainedTasks` to reduce the number of times on call drop function.
## How was this patch tested?
Jenkins
Author: Yuming Wang <wgyumg@gmail.com>
Closes#16527 from wangyum/SPARK-19146.
## What changes were proposed in this pull request?
In docs/security.md, there is a description as follows.
```
steps to configure the key-stores and the trust-store for the standalone deployment mode is as
follows:
* Generate a keys pair for each node
* Export the public key of the key pair to a file on each node
* Import all exported public keys into a single trust-store
```
According to markdown format, the first item should follow a blank line.
## How was this patch tested?
Manually tested.
Following captures are rendered web page before and after fix.
* before

* after

Author: sarutak <sarutak@oss.nttdata.co.jp>
Closes#16653 from sarutak/SPARK-19302.
## What changes were proposed in this pull request?
`spark.yarn.access.namenodes` configuration cannot actually reflects the usage of it, inside the code it is the Hadoop filesystems we get tokens, not NNs. So here propose to update the name of this configuration, also change the related code and doc.
## How was this patch tested?
Local verification.
Author: jerryshao <sshao@hortonworks.com>
Closes#16560 from jerryshao/SPARK-19179.
## What changes were proposed in this pull request?
core/src/main/scala/org/apache/spark/SparkContext.scala contains LOCAL_N_FAILURES_REGEX master mode, but this was never documented, so do so.
## How was this patch tested?
By using the Github Markdown preview feature.
Author: Maurus Cuelenaere <mcuelenaere@gmail.com>
Closes#16562 from mcuelenaere/patch-1.
## What changes were proposed in this pull request?
Adding option in spark-submit to allow overriding the default IvySettings used to resolve artifacts as part of the Spark Packages functionality. This will allow all artifact resolution to go through a central managed repository, such as Nexus or Artifactory, where site admins can better approve and control what is used with Spark apps.
This change restructures the creation of the IvySettings object in two distinct ways. First, if the `spark.ivy.settings` option is not defined then `buildIvySettings` will create a default settings instance, as before, with defined repositories (Maven Central) included. Second, if the option is defined, the ivy settings file will be loaded from the given path and only repositories defined within will be used for artifact resolution.
## How was this patch tested?
Existing tests for default behaviour, Manual tests that load a ivysettings.xml file with local and Nexus repositories defined. Added new test to load a simple Ivy settings file with a local filesystem resolver.
Author: Bryan Cutler <cutlerb@gmail.com>
Author: Ian Hummel <ian@themodernlife.net>
Closes#15119 from BryanCutler/spark-custom-IvySettings.
Currently Spark can only get token renewal interval from security HDFS (hdfs://), if Spark runs with other security file systems like webHDFS (webhdfs://), wasb (wasb://), ADLS, it will ignore these tokens and not get token renewal intervals from these tokens. These will make Spark unable to work with these security clusters. So instead of only checking HDFS token, we should generalize to support different DelegationTokenIdentifier.
## How was this patch tested?
Manually verified in security cluster.
Author: jerryshao <sshao@hortonworks.com>
Closes#16432 from jerryshao/SPARK-19021.
## What changes were proposed in this pull request?
This PR allow update mode for non-aggregation streaming queries. It will be same as the append mode if a query has no aggregations.
## How was this patch tested?
Jenkins
Author: Shixiong Zhu <shixiong@databricks.com>
Closes#16520 from zsxwing/update-without-agg.
## What changes were proposed in this pull request?
Add FDR test case in ml/feature/ChiSqSelectorSuite.
Improve some comments in the code.
This is a follow-up pr for #15212.
## How was this patch tested?
ut
Author: Peng, Meng <peng.meng@intel.com>
Closes#16434 from mpjlu/fdr_fwe_update.
## What changes were proposed in this pull request?
This PR adds a new behavior change description on `CREATE TABLE ... LOCATION` at `sql-programming-guide.md` clearly under `Upgrading From Spark SQL 1.6 to 2.0`. This change is introduced at Apache Spark 2.0.0 as [SPARK-15276](https://issues.apache.org/jira/browse/SPARK-15276).
## How was this patch tested?
```
SKIP_API=1 jekyll build
```
**Newly Added Description**
<img width="913" alt="new" src="https://cloud.githubusercontent.com/assets/9700541/21743606/7efe2b12-d4ba-11e6-8a0d-551222718ea2.png">
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#16400 from dongjoon-hyun/SPARK-18941.
## What changes were proposed in this pull request?
configuration.html section headings were not specified correctly in markdown and weren't rendering, being recognized correctly. Removed extra p tags and pulled level 4 titles up to level 3, since level 3 had been skipped. This improves the TOC.
## How was this patch tested?
Doc build, manual check.
Author: Sean Owen <sowen@cloudera.com>
Closes#16490 from srowen/SPARK-19106.
## What changes were proposed in this pull request?
Current HistoryServer's ACLs is derived from application event-log, which means the newly changed ACLs cannot be applied to the old data, this will become a problem where newly added admin cannot access the old application history UI, only the new application can be affected.
So here propose to add admin ACLs for history server, any configured user/group could have the view access to all the applications, while the view ACLs derived from application run-time still take effect.
## How was this patch tested?
Unit test added.
Author: jerryshao <sshao@hortonworks.com>
Closes#16470 from jerryshao/SPARK-19033.
## What changes were proposed in this pull request?
Today we have different syntax to create data source or hive serde tables, we should unify them to not confuse users and step forward to make hive a data source.
Please read https://issues.apache.org/jira/secure/attachment/12843835/CREATE-TABLE.pdf for details.
TODO(for follow-up PRs):
1. TBLPROPERTIES is not added to the new syntax, we should decide if we wanna add it later.
2. `SHOW CREATE TABLE` should be updated to use the new syntax.
3. we should decide if we wanna change the behavior of `SET LOCATION`.
## How was this patch tested?
new tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#16296 from cloud-fan/create-table.
## What changes were proposed in this pull request?
add streaming rest api doc
related to pr #16253
cc saturday-shi srowen
## How was this patch tested?
Author: uncleGen <hustyugm@gmail.com>
Closes#16414 from uncleGen/SPARK-19009.
## What changes were proposed in this pull request?
There are many locations in the Spark repo where the same word occurs consecutively. Sometimes they are appropriately placed, but many times they are not. This PR removes the inappropriately duplicated words.
## How was this patch tested?
N/A since only docs or comments were updated.
Author: Niranjan Padmanabhan <niranjan.padmanabhan@gmail.com>
Closes#16455 from neurons/np.structure_streaming_doc.
## What changes were proposed in this pull request?
The configuration `spark.yarn.security.tokens.{service}.enabled` is deprecated. Now we should use `spark.yarn.security.credentials.{service}.enabled`. Some places in the doc is not updated yet.
## How was this patch tested?
N/A. Just doc change.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#16444 from viirya/minor-credential-provider-doc.
## What changes were proposed in this pull request?
Currently some code snippets in the programming guide just do not compile. We should fix them.
## How was this patch tested?
```
SKIP_API=1 jekyll build
```
## Screenshot from part of the change:

Author: Liwei Lin <lwlin7@gmail.com>
Closes#16442 from lw-lin/ss-pro-guide-.
## What changes were proposed in this pull request?
This PR documents the scalable partition handling feature in the body of the programming guide.
Before this PR, we only mention it in the migration guide. It's not super clear that external datasource tables require an extra `MSCK REPAIR TABLE` command is to have per-partition information persisted since 2.1.
## How was this patch tested?
N/A.
Author: Cheng Lian <lian@databricks.com>
Closes#16424 from liancheng/scalable-partition-handling-doc.
## What changes were proposed in this pull request?
Added missing Java example under section "Design Patterns for using foreachRDD". Now this section has examples in all 3 languages, improving consistency of documentation.
## How was this patch tested?
Manual.
Generated docs using command "SKIP_API=1 jekyll build" and verified generated HTML page manually.
The syntax of example has been tested for correctness using sample code on Java1.7 and Spark 2.2.0-SNAPSHOT.
Author: adesharatushar <tushar_adeshara@persistent.com>
Closes#16408 from adesharatushar/streaming-doc-fix.
## What changes were proposed in this pull request?
Univariate feature selection works by selecting the best features based on univariate statistical tests.
FDR and FWE are a popular univariate statistical test for feature selection.
In 2005, the Benjamini and Hochberg paper on FDR was identified as one of the 25 most-cited statistical papers. The FDR uses the Benjamini-Hochberg procedure in this PR. https://en.wikipedia.org/wiki/False_discovery_rate.
In statistics, FWE is the probability of making one or more false discoveries, or type I errors, among all the hypotheses when performing multiple hypotheses tests.
https://en.wikipedia.org/wiki/Family-wise_error_rate
We add FDR and FWE methods for ChiSqSelector in this PR, like it is implemented in scikit-learn.
http://scikit-learn.org/stable/modules/feature_selection.html#univariate-feature-selection
## How was this patch tested?
ut will be added soon
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Author: Peng <peng.meng@intel.com>
Author: Peng, Meng <peng.meng@intel.com>
Closes#15212 from mpjlu/fdr_fwe.
## What changes were proposed in this pull request?
add example with `--pip` and `--r` switch as it is actually done in create-release
## How was this patch tested?
Doc only
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#16364 from felixcheung/buildguide.
## What changes were proposed in this pull request?
On configuration doc page:https://spark.apache.org/docs/latest/configuration.html
We mentioned spark.kryoserializer.buffer.max : Maximum allowable size of Kryo serialization buffer. This must be larger than any object you attempt to serialize. Increase this if you get a "buffer limit exceeded" exception inside Kryo.
from source code, it has hard coded upper limit :
```
val maxBufferSizeMb = conf.getSizeAsMb("spark.kryoserializer.buffer.max", "64m").toInt
if (maxBufferSizeMb >= ByteUnit.GiB.toMiB(2))
{ throw new IllegalArgumentException("spark.kryoserializer.buffer.max must be less than " + s"2048 mb, got: + $maxBufferSizeMb mb.") }
```
We should mention "this value must be less than 2048 mb" on the configuration doc page as well.
## How was this patch tested?
None. Since it's minor doc change.
Author: Yuexin Zhang <yxzhang@cloudera.com>
Closes#16412 from cnZach/SPARK-19006.
## What changes were proposed in this pull request?
We can build Python API docs by `cd ./python/docs && make html for Python` and R API docs by `cd ./R && sh create-docs.sh for R` separately. However, `jekyll` fails in some environments.
This PR aims to support `SKIP_PYTHONDOC` and `SKIP_RDOC` for documentation build in `docs` folder. Currently, we can use `SKIP_SCALADOC` or `SKIP_API`. The reason providing additional options is that the Spark documentation build uses a number of tools to build HTML docs and API docs in Scala, Python and R. Specifically, for Python and R,
- Python API docs requires `sphinx`.
- R API docs requires `R` installation and `knitr` (and more others libraries).
In other words, we cannot generate Python API docs without R installation. Also, we cannot generate R API docs without Python `sphinx` installation. If Spark provides `SKIP_PYTHONDOC` and `SKIP_RDOC` like `SKIP_SCALADOC`, it would be more convenient.
## How was this patch tested?
Manual.
**Skipping Scala/Java/Python API Doc Build**
```bash
$ cd docs
$ SKIP_SCALADOC=1 SKIP_PYTHONDOC=1 jekyll build
$ ls api
DESCRIPTION R
```
**Skipping Scala/Java/R API Doc Build**
```bash
$ cd docs
$ SKIP_SCALADOC=1 SKIP_RDOC=1 jekyll build
$ ls api
python
```
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#16336 from dongjoon-hyun/SPARK-18923.
## What changes were proposed in this pull request?
Spark's current task cancellation / task killing mechanism is "best effort" because some tasks may not be interruptible or may not respond to their "killed" flags being set. If a significant fraction of a cluster's task slots are occupied by tasks that have been marked as killed but remain running then this can lead to a situation where new jobs and tasks are starved of resources that are being used by these zombie tasks.
This patch aims to address this problem by adding a "task reaper" mechanism to executors. At a high-level, task killing now launches a new thread which attempts to kill the task and then watches the task and periodically checks whether it has been killed. The TaskReaper will periodically re-attempt to call `TaskRunner.kill()` and will log warnings if the task keeps running. I modified TaskRunner to rename its thread at the start of the task, allowing TaskReaper to take a thread dump and filter it in order to log stacktraces from the exact task thread that we are waiting to finish. If the task has not stopped after a configurable timeout then the TaskReaper will throw an exception to trigger executor JVM death, thereby forcibly freeing any resources consumed by the zombie tasks.
This feature is flagged off by default and is controlled by four new configurations under the `spark.task.reaper.*` namespace. See the updated `configuration.md` doc for details.
## How was this patch tested?
Tested via a new test case in `JobCancellationSuite`, plus manual testing.
Author: Josh Rosen <joshrosen@databricks.com>
Closes#16189 from JoshRosen/cancellation.
## What changes were proposed in this pull request?
Add additional information to wholeTextFiles in the Programming Guide. Also explain partitioning policy difference in relation to textFile and its impact on performance.
Also added reference to the underlying CombineFileInputFormat
## How was this patch tested?
Manual build of documentation and inspection in browser
```
cd docs
jekyll serve --watch
```
Author: Michal Senkyr <mike.senkyr@gmail.com>
Closes#16157 from michalsenkyr/wholeTextFilesExpandedDocs.
## What changes were proposed in this pull request?
This builds upon the blacklisting introduced in SPARK-17675 to add blacklisting of executors and nodes for an entire Spark application. Resources are blacklisted based on tasks that fail, in tasksets that eventually complete successfully; they are automatically returned to the pool of active resources based on a timeout. Full details are available in a design doc attached to the jira.
## How was this patch tested?
Added unit tests, ran them via Jenkins, also ran a handful of them in a loop to check for flakiness.
The added tests include:
- verifying BlacklistTracker works correctly
- verifying TaskSchedulerImpl interacts with BlacklistTracker correctly (via a mock BlacklistTracker)
- an integration test for the entire scheduler with blacklisting in a few different scenarios
Author: Imran Rashid <irashid@cloudera.com>
Author: mwws <wei.mao@intel.com>
Closes#14079 from squito/blacklist-SPARK-8425.
## What changes were proposed in this pull request?
Since Apache Spark 1.4.0, R API document page has a broken link on `DESCRIPTION file` because Jekyll plugin script doesn't copy the file. This PR aims to fix that.
- Official Latest Website: http://spark.apache.org/docs/latest/api/R/index.html
- Apache Spark 2.1.0-rc2: http://people.apache.org/~pwendell/spark-releases/spark-2.1.0-rc2-docs/api/R/index.html
## How was this patch tested?
Manual.
```bash
cd docs
SKIP_SCALADOC=1 jekyll build
```
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#16292 from dongjoon-hyun/SPARK-18875.
This change moves the logic that translates Spark configuration to
commons-crypto configuration to the network-common module. It also
extends TransportConf and ConfigProvider to provide the necessary
interfaces for the translation to work.
As part of the change, I removed SystemPropertyConfigProvider, which
was mostly used as an "empty config" in unit tests, and adjusted the
very few tests that required a specific config.
I also changed the config keys for AES encryption to live under the
"spark.network." namespace, which is more correct than their previous
names under "spark.authenticate.".
Tested via existing unit test.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#16200 from vanzin/SPARK-18773.
## What changes were proposed in this pull request?
This PR clarifies where accumulators will be displayed.
## How was this patch tested?
No testing.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Bill Chambers <bill@databricks.com>
Author: anabranch <wac.chambers@gmail.com>
Author: Bill Chambers <wchambers@ischool.berkeley.edu>
Closes#16180 from anabranch/improve-acc-docs.
## What changes were proposed in this pull request?
According to the notice of the following Wiki front page, we can remove the obsolete wiki pointer safely in `README.md` and `docs/index.md`, too. These two lines are the last occurrence of that links.
```
All current wiki content has been merged into pages at http://spark.apache.org as of November 2016.
Each page links to the new location of its information on the Spark web site.
Obsolete wiki content is still hosted here, but carries a notice that it is no longer current.
```
## How was this patch tested?
Manual.
- `README.md`: https://github.com/dongjoon-hyun/spark/tree/remove_wiki_from_readme
- `docs/index.md`:
```
cd docs
SKIP_API=1 jekyll build
```

Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#16239 from dongjoon-hyun/remove_wiki_from_readme.
## What changes were proposed in this pull request?
There has been some confusion around "Spark ML" vs. "MLlib". This PR adds some FAQ-like entries to the MLlib user guide to explain "Spark ML" and reduce the confusion.
I check the [Spark FAQ page](http://spark.apache.org/faq.html), which seems too high-level for the content here. So I added it to the MLlib user guide instead.
cc: mateiz
Author: Xiangrui Meng <meng@databricks.com>
Closes#16241 from mengxr/SPARK-18812.
## What changes were proposed in this pull request?
Typo fixes
## How was this patch tested?
Local build. Awaiting the official build.
Author: Jacek Laskowski <jacek@japila.pl>
Closes#16144 from jaceklaskowski/typo-fixes.
## What changes were proposed in this pull request?
* Add all R examples for ML wrappers which were added during 2.1 release cycle.
* Split the whole ```ml.R``` example file into individual example for each algorithm, which will be convenient for users to rerun them.
* Add corresponding examples to ML user guide.
* Update ML section of SparkR user guide.
Note: MLlib Scala/Java/Python examples will be consistent, however, SparkR examples may different from them, since R users may use the algorithms in a different way, for example, using R ```formula``` to specify ```featuresCol``` and ```labelCol```.
## How was this patch tested?
Run all examples manually.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#16148 from yanboliang/spark-18325.
## What changes were proposed in this pull request?
WeightedLeastSquares now supports L1 and elastic net penalties and has an additional solver option: QuasiNewton. The docs are updated to reflect this change.
## How was this patch tested?
Docs only. Generated documentation to make sure Latex looks ok.
Author: sethah <seth.hendrickson16@gmail.com>
Closes#16139 from sethah/SPARK-18705.
## What changes were proposed in this pull request?
Logistic Regression summary is added in Python API. We need to add example and document for summary.
The newly added example is consistent with Scala and Java examples.
## How was this patch tested?
Manually tests: Run the example with spark-submit; copy & paste code into pyspark; build document and check the document.
Author: wm624@hotmail.com <wm624@hotmail.com>
Closes#16064 from wangmiao1981/py.
## What changes were proposed in this pull request?
Although, currently, the saveAsTable does not provide an API to save the table as an external table from a DataFrame, we can achieve this functionality by using options on DataFrameWriter where the key for the map is the String: "path" and the value is another String which is the location of the external table itself. This can be provided before the call to saveAsTable is performed.
## How was this patch tested?
Documentation was reviewed for formatting and content after the push was performed on the branch.

Author: c-sahuja <sahuja@cloudera.com>
Closes#16185 from c-sahuja/createExternalTable.
This PR adds `spark.ui.showConsoleProgress` to the configuration docs.
I tested this PR by building the docs locally and confirming that this change shows up as expected.
Relates to #3029.
Author: Nicholas Chammas <nicholas.chammas@gmail.com>
Closes#16151 from nchammas/ui-progressbar-doc.
Looking at the distributions provided on spark.apache.org, I see that the Spark YARN shuffle jar is under `yarn/` and not `lib/`.
This change is so minor I'm not sure it needs a JIRA. But let me know if so and I'll create one.
Author: Nicholas Chammas <nicholas.chammas@gmail.com>
Closes#16130 from nchammas/yarn-doc-fix.
## What changes were proposed in this pull request?
Add R examples to ML programming guide for the following algorithms as POC:
* spark.glm
* spark.survreg
* spark.naiveBayes
* spark.kmeans
The four algorithms were added to SparkR since 2.0.0, more docs for algorithms added during 2.1 release cycle will be addressed in a separate follow-up PR.
## How was this patch tested?
This is the screenshots of generated ML programming guide for ```GeneralizedLinearRegression```:

Author: Yanbo Liang <ybliang8@gmail.com>
Closes#16136 from yanboliang/spark-18279.
## What changes were proposed in this pull request?
If SparkR is running as a package and it has previously downloaded Spark Jar it should be able to run as before without having to set SPARK_HOME. Basically with this bug the auto install Spark will only work in the first session.
This seems to be a regression on the earlier behavior.
Fix is to always try to install or check for the cached Spark if running in an interactive session.
As discussed before, we should probably only install Spark iff running in an interactive session (R shell, RStudio etc)
## How was this patch tested?
Manually
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#16077 from felixcheung/rsessioninteractive.
## What changes were proposed in this pull request?
The user guide for LSH is added to ml-features.md, with several scala/java examples in spark-examples.
## How was this patch tested?
Doc has been generated through Jekyll, and checked through manual inspection.
Author: Yunni <Euler57721@gmail.com>
Author: Yun Ni <yunn@uber.com>
Author: Joseph K. Bradley <joseph@databricks.com>
Author: Yun Ni <Euler57721@gmail.com>
Closes#15795 from Yunni/SPARK-18081-lsh-guide.
## What changes were proposed in this pull request?
This patch bumps master branch version to 2.2.0-SNAPSHOT.
## How was this patch tested?
N/A
Author: Reynold Xin <rxin@databricks.com>
Closes#16126 from rxin/SPARK-18695.
## What changes were proposed in this pull request?
Update ML programming and migration guide for 2.1 release.
## How was this patch tested?
Doc change, no test.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#16076 from yanboliang/spark-18324.
## What changes were proposed in this pull request?
API review for 2.1, except ```LSH``` related classes which are still under development.
## How was this patch tested?
Only doc changes, no new tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#16009 from yanboliang/spark-18318.
## What changes were proposed in this pull request?
Added missing semicolon in quick-start-guide java example code which wasn't compiling before.
## How was this patch tested?
Locally by running and generating site for docs. You can see the last line contains ";" in the below snapshot.

Author: manishAtGit <manish@knoldus.com>
Closes#16081 from manishatGit/fixed-quick-start-guide.
## What changes were proposed in this pull request?
This documents the partition handling changes for Spark 2.1 and how to migrate existing tables.
## How was this patch tested?
Built docs locally.
rxin
Author: Eric Liang <ekl@databricks.com>
Closes#16074 from ericl/spark-18145.
## What changes were proposed in this pull request?
This pull request contains updates to Scala and Java Accumulator code snippets in the programming guide.
- For Scala, the pull request fixes the signature of the 'add()' method in the custom Accumulator, which contained two params (as the old AccumulatorParam) instead of one (as in AccumulatorV2).
- The Java example was updated to use the AccumulatorV2 class since AccumulatorParam is marked as deprecated.
- Scala and Java examples are more consistent now.
## How was this patch tested?
This patch was tested manually by building the docs locally.

Author: aokolnychyi <okolnychyyanton@gmail.com>
Closes#16024 from aokolnychyi/fixed_accumulator_example.
This change modifies the method used to propagate encryption keys used during
shuffle. Instead of relying on YARN's UserGroupInformation credential propagation,
this change explicitly distributes the key using the messages exchanged between
driver and executor during registration. When RPC encryption is enabled, this means
key propagation is also secure.
This allows shuffle encryption to work in non-YARN mode, which means that it's
easier to write unit tests for areas of the code that are affected by the feature.
The key is stored in the SecurityManager; because there are many instances of
that class used in the code, the key is only guaranteed to exist in the instance
managed by the SparkEnv. This path was chosen to avoid storing the key in the
SparkConf, which would risk having the key being written to disk as part of the
configuration (as, for example, is done when starting YARN applications).
Tested by new and existing unit tests (which were moved from the YARN module to
core), and by running apps with shuffle encryption enabled.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#15981 from vanzin/SPARK-18547.
## What changes were proposed in this pull request?
This patch adds a new property called `spark.secret.redactionPattern` that
allows users to specify a scala regex to decide which Spark configuration
properties and environment variables in driver and executor environments
contain sensitive information. When this regex matches the property or
environment variable name, its value is redacted from the environment UI and
various logs like YARN and event logs.
This change uses this property to redact information from event logs and YARN
logs. It also, updates the UI code to adhere to this property instead of
hardcoding the logic to decipher which properties are sensitive.
Here's an image of the UI post-redaction:

Here's the text in the YARN logs, post-redaction:
``HADOOP_CREDSTORE_PASSWORD -> *********(redacted)``
Here's the text in the event logs, post-redaction:
``...,"spark.executorEnv.HADOOP_CREDSTORE_PASSWORD":"*********(redacted)","spark.yarn.appMasterEnv.HADOOP_CREDSTORE_PASSWORD":"*********(redacted)",...``
## How was this patch tested?
1. Unit tests are added to ensure that redaction works.
2. A YARN job reading data off of S3 with confidential information
(hadoop credential provider password) being provided in the environment
variables of driver and executor. And, afterwards, logs were grepped to make
sure that no mention of secret password was present. It was also ensure that
the job was able to read the data off of S3 correctly, thereby ensuring that
the sensitive information was being trickled down to the right places to read
the data.
3. The event logs were checked to make sure no mention of secret password was
present.
4. UI environment tab was checked to make sure there was no secret information
being displayed.
Author: Mark Grover <mark@apache.org>
Closes#15971 from markgrover/master_redaction.
## What changes were proposed in this pull request?
This PR is to fix incorrect `code` tag in `sql-programming-guide.md`
## How was this patch tested?
Manually.
Author: Weiqing Yang <yangweiqing001@gmail.com>
Closes#15941 from weiqingy/fixtag.
## What changes were proposed in this pull request?
This is a follow-up PR of #15868 to merge `maxConnections` option into `numPartitions` options.
## How was this patch tested?
Pass the existing tests.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#15966 from dongjoon-hyun/SPARK-18413-2.
## What changes were proposed in this pull request?
Updates links to the wiki to links to the new location of content on spark.apache.org.
## How was this patch tested?
Doc builds
Author: Sean Owen <sowen@cloudera.com>
Closes#15967 from srowen/SPARK-18073.1.
## What changes were proposed in this pull request?
This PR adds a new JDBCOption `maxConnections` which means the maximum number of simultaneous JDBC connections allowed. This option applies only to writing with coalesce operation if needed. It defaults to the number of partitions of RDD. Previously, SQL users cannot cannot control this while Scala/Java/Python users can use `coalesce` (or `repartition`) API.
**Reported Scenario**
For the following cases, the number of connections becomes 200 and database cannot handle all of them.
```sql
CREATE OR REPLACE TEMPORARY VIEW resultview
USING org.apache.spark.sql.jdbc
OPTIONS (
url "jdbc:oracle:thin:10.129.10.111:1521:BKDB",
dbtable "result",
user "HIVE",
password "HIVE"
);
-- set spark.sql.shuffle.partitions=200
INSERT OVERWRITE TABLE resultview SELECT g, count(1) AS COUNT FROM tnet.DT_LIVE_INFO GROUP BY g
```
## How was this patch tested?
Manual. Do the followings and see Spark UI.
**Step 1 (MySQL)**
```
CREATE TABLE t1 (a INT);
CREATE TABLE data (a INT);
INSERT INTO data VALUES (1);
INSERT INTO data VALUES (2);
INSERT INTO data VALUES (3);
```
**Step 2 (Spark)**
```scala
SPARK_HOME=$PWD bin/spark-shell --driver-memory 4G --driver-class-path mysql-connector-java-5.1.40-bin.jar
scala> sql("SET spark.sql.shuffle.partitions=3")
scala> sql("CREATE OR REPLACE TEMPORARY VIEW data USING org.apache.spark.sql.jdbc OPTIONS (url 'jdbc:mysql://localhost:3306/t', dbtable 'data', user 'root', password '')")
scala> sql("CREATE OR REPLACE TEMPORARY VIEW t1 USING org.apache.spark.sql.jdbc OPTIONS (url 'jdbc:mysql://localhost:3306/t', dbtable 't1', user 'root', password '', maxConnections '1')")
scala> sql("INSERT OVERWRITE TABLE t1 SELECT a FROM data GROUP BY a")
scala> sql("CREATE OR REPLACE TEMPORARY VIEW t1 USING org.apache.spark.sql.jdbc OPTIONS (url 'jdbc:mysql://localhost:3306/t', dbtable 't1', user 'root', password '', maxConnections '2')")
scala> sql("INSERT OVERWRITE TABLE t1 SELECT a FROM data GROUP BY a")
scala> sql("CREATE OR REPLACE TEMPORARY VIEW t1 USING org.apache.spark.sql.jdbc OPTIONS (url 'jdbc:mysql://localhost:3306/t', dbtable 't1', user 'root', password '', maxConnections '3')")
scala> sql("INSERT OVERWRITE TABLE t1 SELECT a FROM data GROUP BY a")
scala> sql("CREATE OR REPLACE TEMPORARY VIEW t1 USING org.apache.spark.sql.jdbc OPTIONS (url 'jdbc:mysql://localhost:3306/t', dbtable 't1', user 'root', password '', maxConnections '4')")
scala> sql("INSERT OVERWRITE TABLE t1 SELECT a FROM data GROUP BY a")
```

Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#15868 from dongjoon-hyun/SPARK-18413.
## What changes were proposed in this pull request?
Avoid hard-coding spark.rpc.askTimeout to non-default in Client; fix doc about spark.rpc.askTimeout default
## How was this patch tested?
Existing tests
Author: Sean Owen <sowen@cloudera.com>
Closes#15833 from srowen/SPARK-18353.
## What changes were proposed in this pull request?
1, There are two `[Graph.partitionBy]` in `graphx-programming-guide.md`, the first one had no effert.
2, `DataFrame`, `Transformer`, `Pipeline` and `Parameter` in `ml-pipeline.md` were linked to `ml-guide.html` by mistake.
3, `PythonMLLibAPI` in `mllib-linear-methods.md` was not accessable, because class `PythonMLLibAPI` is private.
4, Other link updates.
## How was this patch tested?
manual tests
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#15912 from zhengruifeng/md_fix.
## What changes were proposed in this pull request?
Remove `spark.driver.memory`, `spark.executor.memory`, `spark.driver.cores`, and `spark.executor.cores` from `running-on-yarn.md` as they are not Yarn-specific, and they are also defined in`configuration.md`.
## How was this patch tested?
Build passed & Manually check.
Author: Weiqing Yang <yangweiqing001@gmail.com>
Closes#15869 from weiqingy/yarnDoc.
## What changes were proposed in this pull request?
Suggest users to increase `NodeManager's` heap size if `External Shuffle Service` is enabled as
`NM` can spend a lot of time doing GC resulting in shuffle operations being a bottleneck due to `Shuffle Read blocked time` bumped up.
Also because of GC `NodeManager` can use an enormous amount of CPU and cluster performance will suffer.
I have seen NodeManager using 5-13G RAM and up to 2700% CPU with `spark_shuffle` service on.
## How was this patch tested?
#### Added step 5:

Author: Artur Sukhenko <artur.sukhenko@gmail.com>
Closes#15906 from Devian-ua/nmHeapSize.
## What changes were proposed in this pull request?
This PR aims to provide a pip installable PySpark package. This does a bunch of work to copy the jars over and package them with the Python code (to prevent challenges from trying to use different versions of the Python code with different versions of the JAR). It does not currently publish to PyPI but that is the natural follow up (SPARK-18129).
Done:
- pip installable on conda [manual tested]
- setup.py installed on a non-pip managed system (RHEL) with YARN [manual tested]
- Automated testing of this (virtualenv)
- packaging and signing with release-build*
Possible follow up work:
- release-build update to publish to PyPI (SPARK-18128)
- figure out who owns the pyspark package name on prod PyPI (is it someone with in the project or should we ask PyPI or should we choose a different name to publish with like ApachePySpark?)
- Windows support and or testing ( SPARK-18136 )
- investigate details of wheel caching and see if we can avoid cleaning the wheel cache during our test
- consider how we want to number our dev/snapshot versions
Explicitly out of scope:
- Using pip installed PySpark to start a standalone cluster
- Using pip installed PySpark for non-Python Spark programs
*I've done some work to test release-build locally but as a non-committer I've just done local testing.
## How was this patch tested?
Automated testing with virtualenv, manual testing with conda, a system wide install, and YARN integration.
release-build changes tested locally as a non-committer (no testing of upload artifacts to Apache staging websites)
Author: Holden Karau <holden@us.ibm.com>
Author: Juliet Hougland <juliet@cloudera.com>
Author: Juliet Hougland <not@myemail.com>
Closes#15659 from holdenk/SPARK-1267-pip-install-pyspark.
## What changes were proposed in this pull request?
Add links to API docs for ML algos
## How was this patch tested?
Manual checking for the API links
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#15890 from zhengruifeng/algo_link.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}