## What changes were proposed in this pull request?
Add Instrumentation to PrefixSpan
## How was this patch tested?
existing tests
Closes#22971 from zhengruifeng/log_PrefixSpan.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
Right now, we cancel pending allocate requests by its sending order. I thing we can take
locality preference into account when do this to perfom least impact on task locality preference.
## How was this patch tested?
N.A.
Closes#23344 from Ngone51/dev-cancel-pending-allocate-requests-by-taking-locality-preference-into-account.
Authored-by: Ngone51 <ngone_5451@163.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
`SQLConf` is supposed to be serializable. However, currently it is not serializable in `WithTestConf`. `WithTestConf` uses the method `overrideConfs` in closure, while the classes which implements it (`TestHiveSessionStateBuilder` and `TestSQLSessionStateBuilder`) are not serializable.
This PR is to use a local variable to fix it.
## How was this patch tested?
Add unit test.
Closes#23352 from gengliangwang/serializableSQLConf.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Added docs for running spark jobs with Mesos on SSL
Closes#23342 from jomach/master.
Lead-authored-by: Jorge Machado <jorge.w.machado@hotmail.com>
Co-authored-by: Jorge Machado <dxc.machado@extaccount.com>
Co-authored-by: Jorge Machado <jorge.machado.ext@kiwigrid.com>
Co-authored-by: Jorge Machado <JorgeWilson.Machado@ext.gfk.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
When NoClassDefFoundError thrown,it will cause job hang.
`Exception in thread "dag-scheduler-event-loop" java.lang.NoClassDefFoundError: Lcom/xxx/data/recommend/aggregator/queue/QueueName;
at java.lang.Class.getDeclaredFields0(Native Method)
at java.lang.Class.privateGetDeclaredFields(Class.java:2436)
at java.lang.Class.getDeclaredField(Class.java:1946)
at java.io.ObjectStreamClass.getDeclaredSUID(ObjectStreamClass.java:1659)
at java.io.ObjectStreamClass.access$700(ObjectStreamClass.java:72)
at java.io.ObjectStreamClass$2.run(ObjectStreamClass.java:480)
at java.io.ObjectStreamClass$2.run(ObjectStreamClass.java:468)
at java.security.AccessController.doPrivileged(Native Method)
at java.io.ObjectStreamClass.<init>(ObjectStreamClass.java:468)
at java.io.ObjectStreamClass.lookup(ObjectStreamClass.java:365)
at java.io.ObjectOutputStream.writeClass(ObjectOutputStream.java:1212)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1119)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.writeArray(ObjectOutputStream.java:1377)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1173)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.writeArray(ObjectOutputStream.java:1377)`
It is caused by NoClassDefFoundError will not catch up during task seriazation.
`var taskBinary: Broadcast[Array[Byte]] = null
try {
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
val taskBinaryBytes: Array[Byte] = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
// Abort execution
return
case NonFatal(e) =>
abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}`
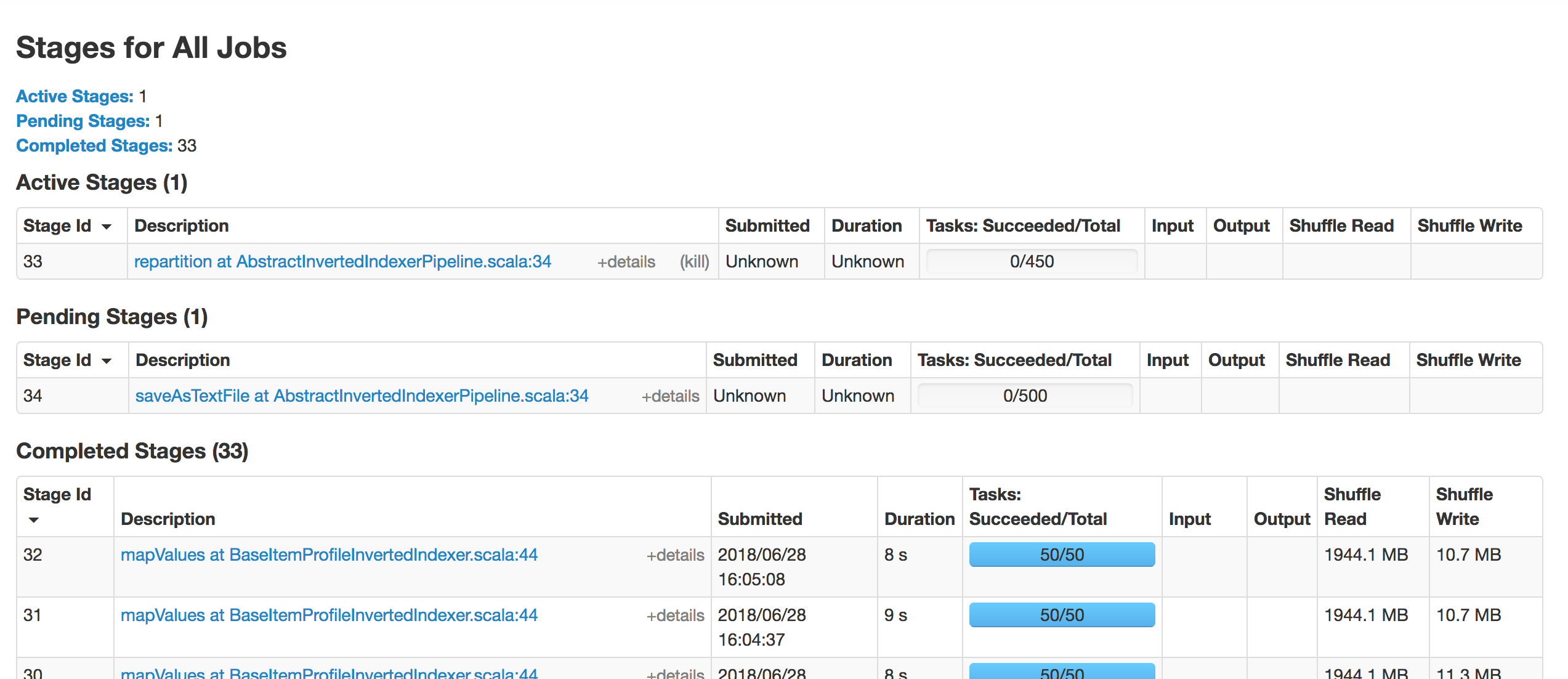
image below shows that stage 33 blocked and never be scheduled.
<img width="1273" alt="2018-06-28 4 28 42" src="https://user-images.githubusercontent.com/26762018/42621188-b87becca-85ef-11e8-9a0b-0ddf07504c96.png">
<img width="569" alt="2018-06-28 4 28 49" src="https://user-images.githubusercontent.com/26762018/42621191-b8b260e8-85ef-11e8-9d10-e97a5918baa6.png">
## How was this patch tested?
UT
Closes#21664 from caneGuy/zhoukang/fix-noclassdeferror.
Authored-by: zhoukang <zhoukang199191@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently, when we infer the schema for scala/java decimals, we return as data type the `SYSTEM_DEFAULT` implementation, ie. the decimal type with precision 38 and scale 18. But this is not right, as we know nothing about the right precision and scale and these values can be not enough to store the data. This problem arises in particular with UDF, where we cast all the input of type `DecimalType` to a `DecimalType(38, 18)`: in case this is not enough, null is returned as input for the UDF.
The PR defines a custom handling for casting to the expected data types for ScalaUDF: the decimal precision and scale is picked from the input, so no casting to different and maybe wrong percision and scale happens.
## How was this patch tested?
added UTs
Closes#23308 from mgaido91/SPARK-26308.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Deprecate Row.merge
## How was this patch tested?
N/A
Closes#23271 from KyleLi1985/master.
Authored-by: 李亮 <liang.li.work@outlook.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In Spark 2.3.0 and previous versions, Hive CTAS command will convert to use data source to write data into the table when the table is convertible. This behavior is controlled by the configs like HiveUtils.CONVERT_METASTORE_ORC and HiveUtils.CONVERT_METASTORE_PARQUET.
In 2.3.1, we drop this optimization by mistake in the PR [SPARK-22977](https://github.com/apache/spark/pull/20521/files#r217254430). Since that Hive CTAS command only uses Hive Serde to write data.
This patch adds this optimization back to Hive CTAS command. This patch adds OptimizedCreateHiveTableAsSelectCommand which uses data source to write data.
## How was this patch tested?
Added test.
Closes#22514 from viirya/SPARK-25271-2.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
For better test coverage, this pr proposed to use the 4 mixed config sets of `WHOLESTAGE_CODEGEN_ENABLED` and `CODEGEN_FACTORY_MODE` when running `SQLQueryTestSuite`:
1. WHOLESTAGE_CODEGEN_ENABLED=true, CODEGEN_FACTORY_MODE=CODEGEN_ONLY
2. WHOLESTAGE_CODEGEN_ENABLED=false, CODEGEN_FACTORY_MODE=CODEGEN_ONLY
3. WHOLESTAGE_CODEGEN_ENABLED=true, CODEGEN_FACTORY_MODE=NO_CODEGEN
4. WHOLESTAGE_CODEGEN_ENABLED=false, CODEGEN_FACTORY_MODE=NO_CODEGEN
This pr also moved some existing tests into `ExplainSuite` because explain output results are different between codegen and interpreter modes.
## How was this patch tested?
Existing tests.
Closes#23213 from maropu/InterpreterModeTest.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This is a small clean up.
By design catalyst rules should be orthogonal: each rule should have its own responsibility. However, the `ColumnPruning` rule does not only do column pruning, but also remove no-op project and window.
This PR updates the `RemoveRedundantProject` rule to remove no-op window as well, and clean up the `ColumnPruning` rule to only do column pruning.
## How was this patch tested?
existing tests
Closes#23343 from cloud-fan/column-pruning.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
In `ReplaceExceptWithFilter` we do not consider properly the case in which the condition returns NULL. Indeed, in that case, since negating NULL still returns NULL, so it is not true the assumption that negating the condition returns all the rows which didn't satisfy it, rows returning NULL may not be returned. This happens when constraints inferred by `InferFiltersFromConstraints` are not enough, as it happens with `OR` conditions.
The rule had also problems with non-deterministic conditions: in such a scenario, this rule would change the probability of the output.
The PR fixes these problem by:
- returning False for the condition when it is Null (in this way we do return all the rows which didn't satisfy it);
- avoiding any transformation when the condition is non-deterministic.
## How was this patch tested?
added UTs
Closes#23315 from mgaido91/SPARK-26366.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
This change hooks up the k8s backed to the updated HadoopDelegationTokenManager,
so that delegation tokens are also available in client mode, and keytab-based token
renewal is enabled.
The change re-works the k8s feature steps related to kerberos so
that the driver does all the credential management and provides all
the needed information to executors - so nothing needs to be added
to executor pods. This also makes cluster mode behave a lot more
similarly to client mode, since no driver-related config steps are run
in the latter case.
The main two things that don't need to happen in executors anymore are:
- adding the Hadoop config to the executor pods: this is not needed
since the Spark driver will serialize the Hadoop config and send
it to executors when running tasks.
- mounting the kerberos config file in the executor pods: this is
not needed once you remove the above. The Hadoop conf sent by
the driver with the tasks is already resolved (i.e. has all the
kerberos names properly defined), so executors do not need access
to the kerberos realm information anymore.
The change also avoids creating delegation tokens unnecessarily.
This means that they'll only be created if a secret with tokens
was not provided, and if a keytab is not provided. In either of
those cases, the driver code will handle delegation tokens: in
cluster mode by creating a secret and stashing them, in client
mode by using existing mechanisms to send DTs to executors.
One last feature: the change also allows defining a keytab with
a "local:" URI. This is supported in client mode (although that's
the same as not saying "local:"), and in k8s cluster mode. This
allows the keytab to be mounted onto the image from a pre-existing
secret, for example.
Finally, the new code always sets SPARK_USER in the driver and
executor pods. This is in line with how other resource managers
behave: the submitting user reflects which user will access
Hadoop services in the app. (With kerberos, that's overridden
by the logged in user.) That user is unrelated to the OS user
the app is running as inside the containers.
Tested:
- client and cluster mode with kinit
- cluster mode with keytab
- cluster mode with local: keytab
- YARN cluster with keytab (to make sure it isn't broken)
Closes#22911 from vanzin/SPARK-25815.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Change microseconds to milliseconds in annotation of Utils.timeStringAsMs.
Closes#23346 from stczwd/stczwd.
Authored-by: Jackey Lee <qcsd2011@163.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This is kind of a followup of https://github.com/apache/spark/pull/23239
The `UnsafeProject` will normalize special float/double values(NaN and -0.0), so the sorter doesn't have to handle it.
However, for consistency and future-proof, this PR proposes to normalize `-0.0` in the prefix comparator, so that it's same with the normal ordering. Note that prefix comparator handles NaN as well.
This is not a bug fix, but a safe guard.
## How was this patch tested?
existing tests
Closes#23334 from cloud-fan/sort.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Currently, SQL configs are not propagated to executors while schema inferring in CSV datasource. For example, changing of `spark.sql.legacy.timeParser.enabled` does not impact on inferring timestamp types. In the PR, I propose to fix the issue by wrapping schema inferring action using `SQLExecution.withSQLConfPropagated`.
## How was this patch tested?
Added logging to `TimestampFormatter`:
```patch
-object TimestampFormatter {
+object TimestampFormatter extends Logging {
def apply(format: String, timeZone: TimeZone, locale: Locale): TimestampFormatter = {
if (SQLConf.get.legacyTimeParserEnabled) {
+ logError("LegacyFallbackTimestampFormatter is being used")
new LegacyFallbackTimestampFormatter(format, timeZone, locale)
} else {
+ logError("Iso8601TimestampFormatter is being used")
new Iso8601TimestampFormatter(format, timeZone, locale)
}
}
```
and run the command in `spark-shell`:
```shell
$ ./bin/spark-shell --conf spark.sql.legacy.timeParser.enabled=true
```
```scala
scala> Seq("2010|10|10").toDF.repartition(1).write.mode("overwrite").text("/tmp/foo")
scala> spark.read.option("inferSchema", "true").option("header", "false").option("timestampFormat", "yyyy|MM|dd").csv("/tmp/foo").printSchema()
18/12/18 10:47:27 ERROR TimestampFormatter: LegacyFallbackTimestampFormatter is being used
root
|-- _c0: timestamp (nullable = true)
```
Closes#23345 from MaxGekk/csv-schema-infer-propagate-configs.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
spark.executorEnv.JAVA_HOME does not take effect when a Worker starting an Executor process in Standalone mode.
This PR fixed this.
## How was this patch tested?
Manual tests.
Closes#21663 from stanzhai/fix-executor-env-java-home.
Lead-authored-by: Stan Zhai <zhaishidan@haizhi.com>
Co-authored-by: Stan Zhai <mail@stanzhai.site>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR proposes to use foreach instead of misuse of map (for Unit). This could cause some weird errors potentially and it's not a good practice anyway. See also SPARK-16694
## How was this patch tested?
N/A
Closes#23341 from HyukjinKwon/followup-SPARK-26081.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The `JsonInferSchema` class is extended to support `TimestampType` inferring from string fields in JSON input:
- If the `prefersDecimal` option is set to `true`, it tries to infer decimal type from the string field.
- If decimal type inference fails or `prefersDecimal` is disabled, `JsonInferSchema` tries to infer `TimestampType`.
- If timestamp type inference fails, `StringType` is returned as the inferred type.
## How was this patch tested?
Added new test suite - `JsonInferSchemaSuite` to check date and timestamp types inferring from JSON using `JsonInferSchema` directly. A few tests were added `JsonSuite` to check type merging and roundtrip tests. This changes was tested by `JsonSuite`, `JsonExpressionsSuite` and `JsonFunctionsSuite` as well.
Closes#23201 from MaxGekk/json-infer-time.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR implements a new feature - window aggregation Pandas UDF for bounded window.
#### Doc:
https://docs.google.com/document/d/14EjeY5z4-NC27-SmIP9CsMPCANeTcvxN44a7SIJtZPc/edit#heading=h.c87w44wcj3wj
#### Example:
```
from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql.window import Window
df = spark.range(0, 10, 2).toDF('v')
w1 = Window.partitionBy().orderBy('v').rangeBetween(-2, 4)
w2 = Window.partitionBy().orderBy('v').rowsBetween(-2, 2)
pandas_udf('double', PandasUDFType.GROUPED_AGG)
def avg(v):
return v.mean()
df.withColumn('v_mean', avg(df['v']).over(w1)).show()
# +---+------+
# | v|v_mean|
# +---+------+
# | 0| 1.0|
# | 2| 2.0|
# | 4| 4.0|
# | 6| 6.0|
# | 8| 7.0|
# +---+------+
df.withColumn('v_mean', avg(df['v']).over(w2)).show()
# +---+------+
# | v|v_mean|
# +---+------+
# | 0| 2.0|
# | 2| 3.0|
# | 4| 4.0|
# | 6| 5.0|
# | 8| 6.0|
# +---+------+
```
#### High level changes:
This PR modifies the existing WindowInPandasExec physical node to deal with unbounded (growing, shrinking and sliding) windows.
* `WindowInPandasExec` now share the same base class as `WindowExec` and share utility functions. See `WindowExecBase`
* `WindowFunctionFrame` now has two new functions `currentLowerBound` and `currentUpperBound` - to return the lower and upper window bound for the current output row. It is also modified to allow `AggregateProcessor` == null. Null aggregator processor is used for `WindowInPandasExec` where we don't have an aggregator and only uses lower and upper bound functions from `WindowFunctionFrame`
* The biggest change is in `WindowInPandasExec`, where it is modified to take `currentLowerBound` and `currentUpperBound` and write those values together with the input data to the python process for rolling window aggregation. See `WindowInPandasExec` for more details.
#### Discussion
In benchmarking, I found numpy variant of the rolling window UDF is much faster than the pandas version:
Spark SQL window function: 20s
Pandas variant: ~80s
Numpy variant: 10s
Numpy variant with numba: 4s
Allowing numpy variant of the vectorized UDFs is something I want to discuss because of the performance improvement, but doesn't have to be in this PR.
## How was this patch tested?
New tests
Closes#22305 from icexelloss/SPARK-24561-bounded-window-udf.
Authored-by: Li Jin <ice.xelloss@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In K8S Cluster mode, the algorithm to generate spark-app-selector/spark.app.id of spark driver is different with spark executor.
This patch makes sure spark driver and executor to use the same spark-app-selector/spark.app.id if spark.app.id is set, otherwise it will use superclass applicationId.
In K8S Client mode, spark-app-selector/spark.app.id for executors will use superclass applicationId.
## How was this patch tested?
Manually run."
Closes#23322 from suxingfate/SPARK-25922.
Lead-authored-by: suxingfate <suxingfate@163.com>
Co-authored-by: xinglwang <xinglwang@ebay.com>
Signed-off-by: Yinan Li <ynli@google.com>
## What changes were proposed in this pull request?
SinkProgress should report similar properties like SourceProgress as long as they are available for given Sink. Count of written rows is metric availble for all Sinks. Since relevant progress information is with respect to commited rows, ideal object to carry this info is WriterCommitMessage. For brevity the implementation will focus only on Sinks with API V2 and on Micro Batch mode. Implemention for Continuous mode will be provided at later date.
### Before
```
{"description":"org.apache.spark.sql.kafka010.KafkaSourceProvider3c0bd317"}
```
### After
```
{"description":"org.apache.spark.sql.kafka010.KafkaSourceProvider3c0bd317","numOutputRows":5000}
```
### This PR is related to:
- https://issues.apache.org/jira/browse/SPARK-24647
- https://issues.apache.org/jira/browse/SPARK-21313
## How was this patch tested?
Existing and new unit tests.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#21919 from vackosar/feature/SPARK-24933-numOutputRows.
Lead-authored-by: Vaclav Kosar <admin@vaclavkosar.com>
Co-authored-by: Kosar, Vaclav: Functions Transformation <Vaclav.Kosar@barclayscapital.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
As Kafka delegation token added logic into ConfigUpdater it would be good to test it.
This PR contains the following changes:
* ConfigUpdater extracted to a separate file and renamed to KafkaConfigUpdater
* mockito-core dependency added to kafka-0-10-sql
* Unit tests added
## How was this patch tested?
Existing + new unit tests + on cluster.
Closes#23321 from gaborgsomogyi/SPARK-26371.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
User specified filters are not applied to SQL tab in yarn mode, as it is overridden by the yarn AmIp filter.
So we need to append user provided filters (spark.ui.filters) with yarn filter.
## How was this patch tested?
【Test step】:
1) Launch spark sql with authentication filter as below:
2) spark-sql --master yarn --conf spark.ui.filters=org.apache.hadoop.security.authentication.server.AuthenticationFilter --conf spark.org.apache.hadoop.security.authentication.server.AuthenticationFilter.params="type=simple"
3) Go to Yarn application list UI link
4) Launch the application master for the Spark-SQL app ID and access all the tabs by appending tab name.
5) It will display an error for all tabs including SQL tab.(before able to access SQL tab,as Authentication filter is not applied for SQL tab)
6) Also can be verified with info logs,that Authentication filter applied to SQL tab.(before it is not applied).
I have attached the behaviour below in following order..
1) Command used
2) Before fix (logs and UI)
3) After fix (logs and UI)
**1) COMMAND USED**:
launching spark-sql with authentication filter.

**2) BEFORE FIX:**
**UI result:**
able to access SQL tab.

**logs**:
authentication filter not applied to SQL tab.

**3) AFTER FIX:**
**UI result**:
Not able to access SQL tab.

**in logs**:
Both yarn filter and Authentication filter applied to SQL tab.

Closes#23312 from chakravarthiT/SPARK-26255_ui.
Authored-by: chakravarthi <tcchakra@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Add a trait HasTrainingSummary to avoid code duplicate related to training summary.
Currently all the training summary use the similar pattern which can be generalized,
```
private[ml] final var trainingSummary: Option[T] = None
def hasSummary: Boolean = trainingSummary.isDefined
def summary: T = trainingSummary.getOrElse...
private[ml] def setSummary(summary: Option[T]): ...
```
Classes with the trait need to override `setSummry`. And for Java compatibility, they will also have to override `summary` method, otherwise the java code will regard all the summary class as Object due to a known issue with Scala.
## How was this patch tested?
existing Java and Scala unit tests
Closes#17654 from hhbyyh/hassummary.
Authored-by: Yuhao Yang <yuhao.yang@intel.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
1. rename `FormatterUtils` to `DateTimeFormatterHelper`, and move it to a separated file
2. move `DateFormatter` and its implementation to a separated file
3. mark some methods as private
4. add `override` to some methods
## How was this patch tested?
existing tests
Closes#23329 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR is a follow-up of the PR https://github.com/apache/spark/pull/17899. It is to add the rule TransposeWindow the optimizer batch.
## How was this patch tested?
The existing tests.
Closes#23222 from gatorsmile/followupSPARK-20636.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
- The original comment about `updateDriverMetrics` is not right.
- Refactor the code to ensure `selectedPartitions ` has been set before sending the driver-side metrics.
- Restore the original name, which is more general and extendable.
## How was this patch tested?
The existing tests.
Closes#23328 from gatorsmile/followupSpark-26142.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The optimizer rule `org.apache.spark.sql.catalyst.optimizer.ReorderJoin` performs join reordering on inner joins. This was introduced from SPARK-12032 (https://github.com/apache/spark/pull/10073) in 2015-12.
After it had reordered the joins, though, it didn't check whether or not the output attribute order is still the same as before. Thus, it's possible to have a mismatch between the reordered output attributes order vs the schema that a DataFrame thinks it has.
The same problem exists in the CBO version of join reordering (`CostBasedJoinReorder`) too.
This can be demonstrated with the example:
```scala
spark.sql("create table table_a (x int, y int) using parquet")
spark.sql("create table table_b (i int, j int) using parquet")
spark.sql("create table table_c (a int, b int) using parquet")
val df = spark.sql("""
with df1 as (select * from table_a cross join table_b)
select * from df1 join table_c on a = x and b = i
""")
```
here's what the DataFrame thinks:
```
scala> df.printSchema
root
|-- x: integer (nullable = true)
|-- y: integer (nullable = true)
|-- i: integer (nullable = true)
|-- j: integer (nullable = true)
|-- a: integer (nullable = true)
|-- b: integer (nullable = true)
```
here's what the optimized plan thinks, after join reordering:
```
scala> df.queryExecution.optimizedPlan.output.foreach(a => println(s"|-- ${a.name}: ${a.dataType.typeName}"))
|-- x: integer
|-- y: integer
|-- a: integer
|-- b: integer
|-- i: integer
|-- j: integer
```
If we exclude the `ReorderJoin` rule (using Spark 2.4's optimizer rule exclusion feature), it's back to normal:
```
scala> spark.conf.set("spark.sql.optimizer.excludedRules", "org.apache.spark.sql.catalyst.optimizer.ReorderJoin")
scala> val df = spark.sql("with df1 as (select * from table_a cross join table_b) select * from df1 join table_c on a = x and b = i")
df: org.apache.spark.sql.DataFrame = [x: int, y: int ... 4 more fields]
scala> df.queryExecution.optimizedPlan.output.foreach(a => println(s"|-- ${a.name}: ${a.dataType.typeName}"))
|-- x: integer
|-- y: integer
|-- i: integer
|-- j: integer
|-- a: integer
|-- b: integer
```
Note that this output attribute ordering problem leads to data corruption, and can manifest itself in various symptoms:
* Silently corrupting data, if the reordered columns happen to either have matching types or have sufficiently-compatible types (e.g. all fixed length primitive types are considered as "sufficiently compatible" in an `UnsafeRow`), then only the resulting data is going to be wrong but it might not trigger any alarms immediately. Or
* Weird Java-level exceptions like `java.lang.NegativeArraySizeException`, or even SIGSEGVs.
## How was this patch tested?
Added new unit test in `JoinReorderSuite` and new end-to-end test in `JoinSuite`.
Also made `JoinReorderSuite` and `StarJoinReorderSuite` assert more strongly on maintaining output attribute order.
Closes#23303 from rednaxelafx/fix-join-reorder.
Authored-by: Kris Mok <rednaxelafx@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Print `import org.apache.spark.sql.Row` of `SparkSQLExample.scala` on the `programmatic_schema` example to fix the `not found: value Row` error on it.
```
scala> val rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim))
<console>:28: error: not found: value Row
val rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim))
```
## How was this patch tested?
NA
Closes#23326 from kjmrknsn/fix-sql-getting-started.
Authored-by: Keiji Yoshida <kjmrknsn@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
The `CSVInferSchema` class is extended to support inferring of `DateType` from CSV input. The attempt to infer `DateType` is performed after inferring `TimestampType`.
## How was this patch tested?
Added new test for inferring date types from CSV . It was also tested by existing suites like `CSVInferSchemaSuite`, `CsvExpressionsSuite`, `CsvFunctionsSuite` and `CsvSuite`.
Closes#23202 from MaxGekk/csv-date-inferring.
Lead-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
CSV parsing accidentally uses the previous good value for a bad input field. See example in Jira.
This PR ensures that the associated column is set to null when an input field cannot be converted.
## How was this patch tested?
Added new test.
Ran all SQL unit tests (testOnly org.apache.spark.sql.*).
Ran pyspark tests for pyspark-sql
Closes#23323 from bersprockets/csv-bad-field.
Authored-by: Bruce Robbins <bersprockets@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
When there is a self-join as result of a IN subquery, the join condition may be invalid, resulting in trivially true predicates and return wrong results.
The PR deduplicates the subquery output in order to avoid the issue.
## How was this patch tested?
added UT
Closes#23057 from mgaido91/SPARK-26078.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In the PR, I propose to switch on **java.time API** for parsing timestamps and dates from JSON inputs with microseconds precision. The SQL config `spark.sql.legacy.timeParser.enabled` allow to switch back to previous behavior with using `java.text.SimpleDateFormat`/`FastDateFormat` for parsing/generating timestamps/dates.
## How was this patch tested?
It was tested by `JsonExpressionsSuite`, `JsonFunctionsSuite` and `JsonSuite`.
Closes#23196 from MaxGekk/json-time-parser.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
If the input parameter 'threshold' to the function approxSimilarityJoin is not a float, we would get an exception. The fix is to convert the 'threshold' into a float before calling the java implementation method.
## How was this patch tested?
Added a new test case. Without this fix, the test will throw an exception as reported in the JIRA. With the fix, the test passes.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23313 from jerryjch/SPARK-26315.
Authored-by: Jing Chen He <jinghe@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Multiple SparkContexts are discouraged and it has been warning for last 4 years, see SPARK-4180. It could cause arbitrary and mysterious error cases, see SPARK-2243.
Honestly, I didn't even know Spark still allows it, which looks never officially supported, see SPARK-2243.
I believe It should be good timing now to remove this configuration.
## How was this patch tested?
Each doc was manually checked and manually tested:
```
$ ./bin/spark-shell --conf=spark.driver.allowMultipleContexts=true
...
scala> new SparkContext()
org.apache.spark.SparkException: Only one SparkContext should be running in this JVM (see SPARK-2243).The currently running SparkContext was created at:
org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:939)
...
org.apache.spark.SparkContext$.$anonfun$assertNoOtherContextIsRunning$2(SparkContext.scala:2435)
at scala.Option.foreach(Option.scala:274)
at org.apache.spark.SparkContext$.assertNoOtherContextIsRunning(SparkContext.scala:2432)
at org.apache.spark.SparkContext$.markPartiallyConstructed(SparkContext.scala:2509)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:80)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:112)
... 49 elided
```
Closes#23311 from HyukjinKwon/SPARK-26362.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Based on the [comment](https://github.com/apache/spark/pull/23272#discussion_r240735509), it seems to be better to put `freePage` into a `finally` block. This patch as a follow-up to do so.
## How was this patch tested?
Existing tests.
Closes#23294 from viirya/SPARK-26265-followup.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
When using ordinals to access linked list, the time cost is O(n).
## How was this patch tested?
Existing tests.
Closes#23280 from CarolinePeng/update_Two.
Authored-by: CarolinPeng <00244106@zte.intra>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
When using a higher-order function with the same variable name as the existing columns in `Filter` or something which uses `Analyzer.resolveExpressionBottomUp` during the resolution, e.g.,:
```scala
val df = Seq(
(Seq(1, 9, 8, 7), 1, 2),
(Seq(5, 9, 7), 2, 2),
(Seq.empty, 3, 2),
(null, 4, 2)
).toDF("i", "x", "d")
checkAnswer(df.filter("exists(i, x -> x % d == 0)"),
Seq(Row(Seq(1, 9, 8, 7), 1, 2)))
checkAnswer(df.select("x").filter("exists(i, x -> x % d == 0)"),
Seq(Row(1)))
```
the following exception happens:
```
java.lang.ClassCastException: org.apache.spark.sql.catalyst.expressions.BoundReference cannot be cast to org.apache.spark.sql.catalyst.expressions.NamedExpression
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:237)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at scala.collection.TraversableLike.map(TraversableLike.scala:237)
at scala.collection.TraversableLike.map$(TraversableLike.scala:230)
at scala.collection.AbstractTraversable.map(Traversable.scala:108)
at org.apache.spark.sql.catalyst.expressions.HigherOrderFunction.$anonfun$functionsForEval$1(higherOrderFunctions.scala:147)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:237)
at scala.collection.immutable.List.foreach(List.scala:392)
at scala.collection.TraversableLike.map(TraversableLike.scala:237)
at scala.collection.TraversableLike.map$(TraversableLike.scala:230)
at scala.collection.immutable.List.map(List.scala:298)
at org.apache.spark.sql.catalyst.expressions.HigherOrderFunction.functionsForEval(higherOrderFunctions.scala:145)
at org.apache.spark.sql.catalyst.expressions.HigherOrderFunction.functionsForEval$(higherOrderFunctions.scala:145)
at org.apache.spark.sql.catalyst.expressions.ArrayExists.functionsForEval$lzycompute(higherOrderFunctions.scala:369)
at org.apache.spark.sql.catalyst.expressions.ArrayExists.functionsForEval(higherOrderFunctions.scala:369)
at org.apache.spark.sql.catalyst.expressions.SimpleHigherOrderFunction.functionForEval(higherOrderFunctions.scala:176)
at org.apache.spark.sql.catalyst.expressions.SimpleHigherOrderFunction.functionForEval$(higherOrderFunctions.scala:176)
at org.apache.spark.sql.catalyst.expressions.ArrayExists.functionForEval(higherOrderFunctions.scala:369)
at org.apache.spark.sql.catalyst.expressions.ArrayExists.nullSafeEval(higherOrderFunctions.scala:387)
at org.apache.spark.sql.catalyst.expressions.SimpleHigherOrderFunction.eval(higherOrderFunctions.scala:190)
at org.apache.spark.sql.catalyst.expressions.SimpleHigherOrderFunction.eval$(higherOrderFunctions.scala:185)
at org.apache.spark.sql.catalyst.expressions.ArrayExists.eval(higherOrderFunctions.scala:369)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificPredicate.eval(Unknown Source)
at org.apache.spark.sql.execution.FilterExec.$anonfun$doExecute$3(basicPhysicalOperators.scala:216)
at org.apache.spark.sql.execution.FilterExec.$anonfun$doExecute$3$adapted(basicPhysicalOperators.scala:215)
...
```
because the `UnresolvedAttribute`s in `LambdaFunction` are unexpectedly resolved by the rule.
This pr modified to use a placeholder `UnresolvedNamedLambdaVariable` to prevent unexpected resolution.
## How was this patch tested?
Added a test and modified some tests.
Closes#23320 from ueshin/issues/SPARK-26370/hof_resolution.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
I was looking at the code and it was a bit difficult to see the life cycle of InMemoryFileIndex passed into getOrInferFileFormatSchema, because once it is passed in, and another time it was created in getOrInferFileFormatSchema. It'd be easier to understand the life cycle if we move the creation of it out.
## How was this patch tested?
This is a simple code move and should be covered by existing tests.
Closes#23317 from rxin/SPARK-26368.
Authored-by: Reynold Xin <rxin@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Regarding the performance issue of SPARK-26155, it reports the issue on TPC-DS. I think it is better to add a benchmark for `LongToUnsafeRowMap` which is the root cause of performance regression.
It can be easier to show performance difference between different metric implementations in `LongToUnsafeRowMap`.
## How was this patch tested?
Manually run added benchmark.
Closes#23284 from viirya/SPARK-26337.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
remove a redundant `KafkaWriter.validateQuery` call in `KafkaSourceProvider `
## How was this patch tested?
Just removing duplicate codes, so I just build and run unit tests.
Closes#23309 from JasonWayne/SPARK-26360.
Authored-by: jasonwayne <wuwenjie0102@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Clean up unconditional import statements and move them to the top.
Conditional imports (pandas, numpy, pyarrow) are left as-is.
## How was this patch tested?
Exising tests.
Closes#23314 from icexelloss/clean-up-test-imports.
Authored-by: Li Jin <ice.xelloss@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Added query status updates to ContinuousExecution.
## How was this patch tested?
Existing unit tests + added ContinuousQueryStatusAndProgressSuite.
Closes#23095 from gaborgsomogyi/SPARK-23886.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
As discussed in https://github.com/apache/spark/pull/23208/files#r239684490 , we should put `newScanBuilder` in read related mix-in traits like `SupportsBatchRead`, to support write-only table.
In the `Append` operator, we should skip schema validation if not necessary. In the future we would introduce a capability API, so that data source can tell Spark that it doesn't want to do validation.
## How was this patch tested?
existing tests.
Closes#23266 from cloud-fan/ds-read.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
Currently this check is only performed for dynamic allocation use case in
ExecutorAllocationManager.
## What changes were proposed in this pull request?
Checks that cpu per task is lower than number of cores per executor otherwise throw an exception
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23290 from ashangit/master.
Authored-by: n.fraison <n.fraison@criteo.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
These three condition descriptions should be updated, follow #23228 :
<li>no Ordering is specified,</li>
<li>no Aggregator is specified, and</li>
<li>the number of partitions is less than
<code>spark.shuffle.sort.bypassMergeThreshold</code>.
</li>
1、If the shuffle dependency specifies aggregation, but it only aggregates at the reduce-side, BypassMergeSortShuffle can still be used.
2、If the number of output partitions is spark.shuffle.sort.bypassMergeThreshold(eg.200), we can use BypassMergeSortShuffle.
## How was this patch tested?
N/A
Closes#23281 from lcqzte10192193/wid-lcq-1211.
Authored-by: lichaoqun <li.chaoqun@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
There are some comments issues left when `ConvertToLocalRelation` rule was added (see #22205/[SPARK-25212](https://issues.apache.org/jira/browse/SPARK-25212)). This PR fixes those comments issues.
## How was this patch tested?
N/A
Closes#23273 from seancxmao/ConvertToLocalRelation-doc.
Authored-by: seancxmao <seancxmao@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
1. Removed empty space at the beginning of welcome message lines of sparkR to be consistent with welcome message of `pyspark` and `spark-shell`
2. Setting indent of logo message lines to 3 to be consistent with welcome message of `pyspark` and `spark-shell`
Output of `pyspark`:
```
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Python version 3.6.6 (default, Jun 28 2018 11:07:29)
SparkSession available as 'spark'.
```
Output of `spark-shell`:
```
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_161)
Type in expressions to have them evaluated.
Type :help for more information.
```
## How was this patch tested?
Before:
Output of `sparkR`:
```
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
SparkSession available as 'spark'.
```
After:
```
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
SparkSession available as 'spark'.
```
Closes#23293 from AzureQ/master.
Authored-by: Qi Shao <qi.shao.nyu@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}