24847 commits
| Author | SHA1 | Message | Date | |
|---|---|---|---|---|
|
|
749b1d3a45 |
[SPARK-28178][SQL] DataSourceV2: DataFrameWriter.insertInfo
## What changes were proposed in this pull request?
Support multiple catalogs in the following InsertInto use cases:
- DataFrameWriter.insertInto("catalog.db.tbl")
Support matrix:
SaveMode|Partitioned Table|Partition Overwrite Mode|Action
--------|-----------------|------------------------|------
Append|*|*|AppendData
Overwrite|no|*|OverwriteByExpression(true)
Overwrite|yes|STATIC|OverwriteByExpression(true)
Overwrite|yes|DYNAMIC|OverwritePartitionsDynamic
## How was this patch tested?
New tests.
All existing catalyst and sql/core tests.
Closes #24980 from jzhuge/SPARK-28178-pr.
Authored-by: John Zhuge <jzhuge@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
|
||
|
|
df84bfe6fb |
[SPARK-28406][SQL][TEST] Port union.sql
## What changes were proposed in this pull request? This PR is to port union.sql from PostgreSQL regression tests. https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/sql/union.sql The expected results can be found in the link: https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/expected/union.out When porting the test cases, found four PostgreSQL specific features that do not exist in Spark SQL: [SPARK-28409](https://issues.apache.org/jira/browse/SPARK-28409): SELECT FROM syntax [SPARK-28298](https://issues.apache.org/jira/browse/SPARK-28298): Fully support char and varchar types [SPARK-28557](https://issues.apache.org/jira/browse/SPARK-28557): Support empty select list [SPARK-27767](https://issues.apache.org/jira/browse/SPARK-27767): Built-in function: generate_series ## How was this patch tested? N/A Closes #25163 from wangyum/SPARK-28406. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
d530d86ab8 |
[SPARK-28326][SQL][TEST] Port join.sql
## What changes were proposed in this pull request? This PR is to port join.sql from PostgreSQL regression tests. https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/sql/join.sql The expected results can be found in the link: https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/expected/join.out When porting the test cases, found nine PostgreSQL specific features that do not exist in Spark SQL: [SPARK-27877](https://issues.apache.org/jira/browse/SPARK-27877): ANSI SQL: LATERAL derived table(T491) [SPARK-20856](https://issues.apache.org/jira/browse/SPARK-20856): support statement using nested joins [SPARK-27987](https://issues.apache.org/jira/browse/SPARK-27987): Support POSIX Regular Expressions [SPARK-28382](https://issues.apache.org/jira/browse/SPARK-28382): Array Functions: unnest [SPARK-25411](https://issues.apache.org/jira/browse/SPARK-25411): Implement range partition in Spark [SPARK-28377](https://issues.apache.org/jira/browse/SPARK-28377): Fully support correlation names in the FROM clause [SPARK-28330](https://issues.apache.org/jira/browse/SPARK-28330): Enhance query limit [SPARK-28379](https://issues.apache.org/jira/browse/SPARK-28379): Correlated scalar subqueries must be aggregated [SPARK-16452](https://issues.apache.org/jira/browse/SPARK-16452): basic INFORMATION_SCHEMA support ## How was this patch tested? N/A Closes #25148 from wangyum/SPARK-28326. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
196a4d7117 |
[SPARK-28556][SQL] QueryExecutionListener should also notify Error
## What changes were proposed in this pull request? Right now `Error` is not sent to `QueryExecutionListener.onFailure`. If there is any `Error` (such as `AssertionError`) when running a query, `QueryExecutionListener.onFailure` cannot be triggered. This PR changes `onFailure` to accept a `Throwable` instead. ## How was this patch tested? Jenkins Closes #25292 from zsxwing/fix-QueryExecutionListener. Authored-by: Shixiong Zhu <zsxwing@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> |
||
|
|
caa23e3efd |
[SPARK-28459][SQL] Add make_timestamp function
## What changes were proposed in this pull request? New function `make_timestamp()` takes 6 columns `year`, `month`, `day`, `hour`, `min`, `sec` + optionally `timezone`, and makes new column of the `TIMESTAMP` type. If values in the input columns are `null` or out of valid ranges, the function returns `null`. Valid ranges are: - `year` - `[1, 9999]` - `month` - `[1, 12]` - `day` - `[1, 31]` - `hour` - `[0, 23]` - `min` - `[0, 59]` - `sec` - `[0, 60]`. If the `sec` argument equals to 60, the seconds field is set to 0 and 1 minute is added to the final timestamp. - `timezone` - an identifier of timezone. Actual database of timezones can be found there: https://www.iana.org/time-zones. Also constructed timestamp must be valid otherwise `make_timestamp` returns `null`. The function is implemented similarly to `make_timestamp` in PostgreSQL: https://www.postgresql.org/docs/11/functions-datetime.html to maintain feature parity with it. Here is an example: ```sql select make_timestamp(2014, 12, 28, 6, 30, 45.887); 2014-12-28 06:30:45.887 select make_timestamp(2014, 12, 28, 6, 30, 45.887, 'CET'); 2014-12-28 10:30:45.887 select make_timestamp(2019, 6, 30, 23, 59, 60) 2019-07-01 00:00:00 ``` Returned value has Spark Catalyst type `TIMESTAMP` which is similar to Oracle's `TIMESTAMP WITH LOCAL TIME ZONE` (see https://docs.oracle.com/cd/B28359_01/server.111/b28298/ch4datetime.htm#i1006169) where data is stored in the session time zone, and the time zone offset is not stored as part of the column data. When users retrieve the data, Spark returns it in the session time zone specified by the SQL config `spark.sql.session.timeZone`. ## How was this patch tested? Added new tests to `DateExpressionsSuite`, and uncommented a test for `make_timestamp` in `pgSQL/timestamp.sql`. Closes #25220 from MaxGekk/make_timestamp. Authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
946aef0535 |
[SPARK-28550][K8S][TESTS] Unset SPARK_HOME environment variable in K8S integration preparation
## What changes were proposed in this pull request? Currently, if we run the Kubernetes integration tests with `SPARK_HOME` already set, it refers the `SPARK_HOME` even when `--spark-tgz` is specified. This PR proposes to unset `SPARK_HOME` to let the docker-image-tool script detect `SPARK_HOME`. Otherwise, it cannot indicate the unpacked directory as its home. ## How was this patch tested? ```bash export SPARK_HOME=`pwd` dev/make-distribution.sh --pip --tgz -Phadoop-2.7 -Pkubernetes resource-managers/kubernetes/integration-tests/dev/dev-run-integration-tests.sh --deploy-mode docker-for-desktop --spark-tgz $PWD/spark-*.tgz ``` **Before:** ``` + /.../spark/resource-managers/kubernetes/integration-tests/target/spark-dist-unpacked/bin/docker-image-tool.sh -r docker.io/kubespark -t 650B51C8-BBED-47C9-AEAB-E66FC9A0E64E -p /.../spark/resource-managers/kubernetes/integration-tests/target/spark-dist-unpacked/kubernetes/dockerfiles/spark/bindings/python/Dockerfile build cp: resource-managers/kubernetes/docker/src/main/dockerfiles: No such file or directory cp: assembly/target/scala-2.12/jars: No such file or directory cp: resource-managers/kubernetes/integration-tests/tests: No such file or directory cp: examples/target/scala-2.12/jars/*: No such file or directory cp: resource-managers/kubernetes/docker/src/main/dockerfiles: No such file or directory cp: resource-managers/kubernetes/docker/src/main/dockerfiles: No such file or directory Cannot find docker image. This script must be run from a runnable distribution of Apache Spark. ... [INFO] Spark Project Kubernetes Integration Tests ......... FAILURE [ 4.870 s] [INFO] ------------------------------------------------------------------------ [INFO] BUILD FAILURE ``` **After:** ``` + /.../spark/resource-managers/kubernetes/integration-tests/target/spark-dist-unpacked/bin/docker-image-tool.sh -r docker.io/kubespark -t 2BA5883A-A0AC-4D2B-8D00-702D31B59B23 -p /.../spark/resource-managers/kubernetes/integration-tests/target/spark-dist-unpacked/kubernetes/dockerfiles/spark/bindings/python/Dockerfile build Sending build context to Docker daemon 250.2MB Step 1/15 : FROM openjdk:8-alpine ---> a3562aa0b991 ... Successfully built 8614fb5ac279 Successfully tagged kubespark/spark:2BA5883A-A0AC-4D2B-8D00-702D31B59B23 ``` Closes #25283 from HyukjinKwon/SPARK-28550. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
780d176136 |
[SPARK-28042][K8S] Support using volume mount as local storage
## What changes were proposed in this pull request? This pr is used to support using hostpath/PV volume mounts as local storage. In KubernetesExecutorBuilder.scala, the LocalDrisFeatureStep is built before MountVolumesFeatureStep which means we cannot use any volumes mount later. This pr adjust the order of feature building steps which moves localDirsFeature at last so that we can check if directories in SPARK_LOCAL_DIRS are set to volumes mounted such as hostPath, PV, or others. ## How was this patch tested? Unit tests Closes #24879 from chenjunjiedada/SPARK-28042. Lead-authored-by: Junjie Chen <jimmyjchen@tencent.com> Co-authored-by: Junjie Chen <cjjnjust@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> |
||
|
|
d98aa2a184 |
[MINOR] Trivial cleanups
These are what I found during working on #22282. - Remove unused value: `UnsafeArraySuite#defaultTz` - Remove redundant new modifier to the case class, `KafkaSourceRDDPartition` - Remove unused variables from `RDD.scala` - Remove trailing space from `structured-streaming-kafka-integration.md` - Remove redundant parameter from `ArrowConvertersSuite`: `nullable` is `true` by default. - Remove leading empty line: `UnsafeRow` - Remove trailing empty line: `KafkaTestUtils` - Remove unthrown exception type: `UnsafeMapData` - Replace unused declarations: `expressions` - Remove duplicated default parameter: `AnalysisErrorSuite` - `ObjectExpressionsSuite`: remove duplicated parameters, conversions and unused variable Closes #25251 from dongjinleekr/cleanup/201907. Authored-by: Lee Dongjin <dongjin@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> |
||
|
|
18156d5503 |
[SPARK-28086][SQL] Add a function alias random for Rand
## What changes were proposed in this pull request? This PR aims to add a SQL function alias `random` to the existing `rand` function. Please note that this adds the alias to SQL layer only because this is for PostgreSQL feature parity. - [PostgreSQL Random function](https://www.postgresql.org/docs/11/functions-math.html) - [SPARK-23160 Port window.sql](https://github.com/apache/spark/pull/24881/files#diff-14489bae6b27814d4cde0456a7ae75c8R702) - [SPARK-28406 Port union.sql](https://github.com/apache/spark/pull/25163/files#diff-23a3430e0e1ff88830cbb43701da1f2cR402) ## How was this patch tested? Manual. ```sql spark-sql> DESCRIBE FUNCTION random; Function: random Class: org.apache.spark.sql.catalyst.expressions.Rand Usage: random([seed]) - Returns a random value with independent and identically distributed (i.i.d.) uniformly distributed values in [0, 1). ``` Closes #25282 from dongjoon-hyun/SPARK-28086. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> |
||
|
|
767802500c |
[SPARK-28534][K8S][TEST] Update node affinity for DockerForDesktop backend in PVTestsSuite
## What changes were proposed in this pull request? This PR aims to recover our K8s integration test suite by extending node affinity in order to pass `PVTestsSuite` in `DockerForDesktop` environment, too. Previously, `PVTestsSuite` fails at `--deploy-mode docker-for-desktop` option because the node affinity requires `minibase` node. For `Docker Desktop`, there are two node names like the following. Note that Spark testing needs K8s v1.13 and above. So, this PR should be verified with `Docker Desktop (Edge)` version. This PR adds both because next stable `Docker Desktop` will have K8s v1.14.3. **Docker Desktop (Stable, K8s v1.10.11)** ``` $ kubectl get node NAME STATUS ROLES AGE VERSION docker-for-desktop Ready master 52s v1.10.11 ``` **Docker Desktop 2.1.0.0 (Edge, K8s v1.14.3, Released 2019-07-26)** ``` $ kubectl get node NAME STATUS ROLES AGE VERSION docker-desktop Ready master 16h v1.14.3 ``` ## How was this patch tested? Pass the Jenkins K8s integration test (`minibase`) and install `Docker Desktop 2.1.0.0 (Edge)` and run the integration test in `DockerForDesktop`. Note that this fixes only `PVTestsSuite`. ``` $ dev/make-distribution.sh --pip --tgz -Phadoop-2.7 -Pkubernetes $ resource-managers/kubernetes/integration-tests/dev/dev-run-integration-tests.sh --deploy-mode docker-for-desktop --spark-tgz $PWD/spark-*.tgz ... KubernetesSuite: ... - PVs with local storage ... ``` Closes #25269 from dongjoon-hyun/SPARK-28534. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> |
||
|
|
a5a5da78cf |
[SPARK-28471][SQL] Replace yyyy by uuuu in date-timestamp patterns without era
## What changes were proposed in this pull request? In the PR, I propose to use `uuuu` for years instead of `yyyy` in date/timestamp patterns without the era pattern `G` (https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html). **Parsing/formatting of positive years (current era) will be the same.** The difference is in formatting negative years belong to previous era - BC (Before Christ). I replaced the `yyyy` pattern by `uuuu` everywhere except: 1. Test, Suite & Benchmark. Existing tests must work as is. 2. `SimpleDateFormat` because it doesn't support the `uuuu` pattern. 3. Comments and examples (except comments related to already replaced patterns). Before the changes, the year of common era `100` and the year of BC era `-99`, showed similarly as `100`. After the changes negative years will be formatted with the `-` sign. Before: ```Scala scala> Seq(java.time.LocalDate.of(-99, 1, 1)).toDF().show +----------+ | value| +----------+ |0100-01-01| +----------+ ``` After: ```Scala scala> Seq(java.time.LocalDate.of(-99, 1, 1)).toDF().show +-----------+ | value| +-----------+ |-0099-01-01| +-----------+ ``` ## How was this patch tested? By existing test suites, and added tests for negative years to `DateFormatterSuite` and `TimestampFormatterSuite`. Closes #25230 from MaxGekk/year-pattern-uuuu. Authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
a428f40669 |
[SPARK-28549][BUILD][CORE][SQL] Use text.StringEscapeUtils instead lang3.StringEscapeUtils
## What changes were proposed in this pull request? `org.apache.commons.lang3.StringEscapeUtils` was deprecated over two years ago at [LANG-1316](https://issues.apache.org/jira/browse/LANG-1316). There is no bug fixes after that. ```java /** * <p>Escapes and unescapes {code String}s for * Java, Java Script, HTML and XML.</p> * * <p>#ThreadSafe#</p> * since 2.0 * deprecated as of 3.6, use commons-text * <a href="https://commons.apache.org/proper/commons-text/javadocs/api-release/org/apache/commons/text/StringEscapeUtils.html"> * StringEscapeUtils</a> instead */ Deprecated public class StringEscapeUtils { ``` This PR aims to use the latest one from `commons-text` module which has more bug fixes like [TEXT-100](https://issues.apache.org/jira/browse/TEXT-100), [TEXT-118](https://issues.apache.org/jira/browse/TEXT-118) and [TEXT-120](https://issues.apache.org/jira/browse/TEXT-120) by the following replacement. ```scala -import org.apache.commons.lang3.StringEscapeUtils +import org.apache.commons.text.StringEscapeUtils ``` This will add a new dependency to `hadoop-2.7` profile distribution. In `hadoop-3.2` profile, we already have it. ``` +commons-text-1.6.jar ``` ## How was this patch tested? Pass the Jenkins with the existing tests. - [Hadoop 2.7](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/108281) - [Hadoop 3.2](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/108282) Closes #25281 from dongjoon-hyun/SPARK-28549. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> |
||
|
|
6bc5c6a4e7 |
[SPARK-28520][SQL] WholeStageCodegen does not work property for LocalTableScanExec
Code is not generated for LocalTableScanExec although proper situations.
If a LocalTableScanExec plan has the direct parent plan which supports WholeStageCodegen,
the LocalTableScanExec plan also should be within a WholeStageCodegen domain.
But code is not generated for LocalTableScanExec and InputAdapter is inserted for now.
```
val df1 = spark.createDataset(1 to 10).toDF
val df2 = spark.createDataset(1 to 10).toDF
val df3 = df1.join(df2, df1("value") === df2("value"))
df3.explain(true)
...
== Physical Plan ==
*(1) BroadcastHashJoin [value#1], [value#6], Inner, BuildRight
:- LocalTableScan [value#1] // LocalTableScanExec is not within a WholeStageCodegen domain
+- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint)))
+- LocalTableScan [value#6]
```
```
scala> df3.queryExecution.executedPlan.children.head.children.head.getClass
res4: Class[_ <: org.apache.spark.sql.execution.SparkPlan] = class org.apache.spark.sql.execution.InputAdapter
```
For the current implementation of LocalTableScanExec, codegen is enabled in case `parent` is not null
but `parent` is set in `consume`, which is called after `insertInputAdapter` so it doesn't work as intended.
After applying this cnahge, we can get following plan, which means LocalTableScanExec is within a WholeStageCodegen domain.
```
== Physical Plan ==
*(1) BroadcastHashJoin [value#63], [value#68], Inner, BuildRight
:- *(1) LocalTableScan [value#63]
+- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint)))
+- LocalTableScan [value#68]
## How was this patch tested?
New test cases are added into WholeStageCodegenSuite.
Closes #25260 from sarutak/localtablescan-improvement.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
|
||
|
|
3c5278748d |
[SPARK-28277][SQL][PYTHON][TESTS][FOLLOW-UP] Re-enable commented out test
## What changes were proposed in this pull request? Fix for ```SPARK-28441 (PythonUDF used in correlated scalar subquery causes UnsupportedOperationException)``` is in. Re-enable the commented out test for ```udf(max(udf(column))) ``` ## How was this patch tested? use existing test ```udf-except.sql``` Closes #25278 from huaxingao/spark-28277n. Authored-by: Huaxin Gao <huaxing@us.ibm.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
485ae6d181 |
[SPARK-25474][SQL] Support spark.sql.statistics.fallBackToHdfs in data source tables
In case of CatalogFileIndex datasource table, sizeInBytes is always coming as default size in bytes, which is 8.0EB (Even when the user give fallBackToHdfsForStatsEnabled=true) . So, the datasource table which has CatalogFileIndex, always prefer SortMergeJoin, instead of BroadcastJoin, even though the size is below broadcast join threshold. In this PR, In case of CatalogFileIndex table, if we enable "fallBackToHdfsForStatsEnabled=true", then the computeStatistics get the sizeInBytes from the hdfs and we get the actual size of the table. Hence, during join operation, when the table size is below broadcast threshold, it will prefer broadCastHashJoin instead of SortMergeJoin. Added UT Closes #22502 from shahidki31/SPARK-25474. Authored-by: shahid <shahidki31@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
70f82fd298 |
[SPARK-21481][ML] Add indexOf method in ml.feature.HashingTF
## What changes were proposed in this pull request? Add indexOf method for ml.feature.HashingTF. ## How was this patch tested? Add Unit test. Closes #25250 from huaxingao/spark-21481. Authored-by: Huaxin Gao <huaxing@us.ibm.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> |
||
|
|
d943ee0a88 |
[SPARK-28545][SQL] Add the hash map size to the directional log of ObjectAggregationIterator
## What changes were proposed in this pull request? `ObjectAggregationIterator` shows a directional info message to increase `spark.sql.objectHashAggregate.sortBased.fallbackThreshold` when the size of the in-memory hash map grows too large and it falls back to sort-based aggregation. However, we don't know how much we need to increase. This PR adds the size of the current in-memory hash map size to the log message. **BEFORE** ``` 15:21:41.669 Executor task launch worker for task 0 INFO ObjectAggregationIterator: Aggregation hash map reaches threshold capacity (2 entries), ... ``` **AFTER** ``` 15:20:05.742 Executor task launch worker for task 0 INFO ObjectAggregationIterator: Aggregation hash map size 2 reaches threshold capacity (2 entries), ... ``` ## How was this patch tested? Manual. For example, run `ObjectHashAggregateSuite.scala`'s `typed_count fallback to sort-based aggregation` and search the above message in `target/unit-tests.log`. Closes #25276 from dongjoon-hyun/SPARK-28545. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
33e6e4703d |
[SPARK-28544][BUILD] Update zstd-jni to 1.4.2-1
## What changes were proposed in this pull request? This PR aims to update `zstd-jni` library to bring the latest improvement and bug fixes in `1.4.1` and `1.4.2`. - https://github.com/facebook/zstd/releases/tag/v1.4.1 (4.5 ~ 11.8% performance improvement from v1.4.0 and bug fixes) - https://github.com/facebook/zstd/releases/tag/v1.4.2 (bug fixes) ## How was this patch tested? Pass the Jenkins. Closes #25275 from dongjoon-hyun/SPARK-28544. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
8255bd2937 |
[SPARK-28460][SQL][TEST][test-hadoop3.2] Port test from HIVE-11835
## What changes were proposed in this pull request? [HIVE-11835](https://issues.apache.org/jira/browse/HIVE-11835) fixed type `decimal(1,1)` reads 0.0, 0.00, etc from text file as NULL. We fixed this issue after upgrade the build-in Hive to 2.3.5. This PR port the test from [HIVE-11835](https://issues.apache.org/jira/browse/HIVE-11835). Hive test result: https://github.com/apache/hive/blob/release-2.3.5-rc0/ql/src/test/results/clientpositive/decimal_1_1.q.out#L67-L96 ## How was this patch tested? N/A Closes #25212 from wangyum/SPARK-28460. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
9eb541be22 |
[SPARK-28424][SQL] Support typed interval expression
## What changes were proposed in this pull request?
This PR add support typed `interval` expression:
```sql
spark-sql> select interval 'interval 3 year 1 hour';
interval 3 years 1 hours
spark-sql>
```
Please note that this pr did not add a cast alias for `interval` type like [other types](
|
||
|
|
fbaa177d2a |
[MINOR][PYTHON] Use _memory_limit to get worker memory conf in rdd.py
## What changes were proposed in this pull request? Replace duplicate code by function `_memory_limit` ## How was this patch tested? Existing UTs Closes #25273 from WangGuangxin/python_memory_limit. Authored-by: wangguangxin.cn <wangguangxin.cn@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
7f84104b39 |
[SPARK-28535][CORE][TEST] Slow down tasks to de-flake JobCancellationSuite
This test tries to detect correct behavior in racy code, where the event thread is racing with the executor thread that's trying to kill the running task. If the event that signals the stage end arrives first, any delay in the delivery of the message to kill the task causes the code to rapidly process elements, and may cause the test to assert. Adding a 10ms delay in LocalSchedulerBackend before the task kill makes the test run through ~1000 elements. A longer delay can easily cause the 10000 elements to be processed. Instead, by adding a small delay (10ms) in the test code that processes elements, there's a much lower probability that the kill event will not arrive before the end; that leaves a window of 100s for the event to be delivered to the executor. And because each element only sleeps for 10ms, the test is not really slowed down at all. Closes #25270 from vanzin/SPARK-28535. Authored-by: Marcelo Vanzin <vanzin@cloudera.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
8ce1ae52db |
[SPARK-28536][SQL][PYTHON][TESTS] Reduce shuffle partitions in Python UDF tests in SQLQueryTestSuite
## What changes were proposed in this pull request? In Python UDF tests, the number of shuffle partitions matters considerably in the testing time because it requires to fork and communicate between external processes. **Before:**  **After: (with 4)**  ## How was this patch tested? Manually tested in my local. **Before:** ``` [info] SQLQueryTestSuite: [info] - udf/udf-window.sql - Scala UDF (58 seconds, 558 milliseconds) [info] - udf/udf-window.sql - Regular Python UDF (58 seconds, 371 milliseconds) [info] - udf/udf-window.sql - Scalar Pandas UDF (1 minute, 8 seconds) ``` **After:** ``` [info] SQLQueryTestSuite: [info] - udf/udf-window.sql - Scala UDF (14 seconds, 690 milliseconds) [info] - udf/udf-window.sql - Regular Python UDF (10 seconds, 467 milliseconds) [info] - udf/udf-window.sql - Scalar Pandas UDF (10 seconds, 895 milliseconds) ``` Closes #25271 from HyukjinKwon/SPARK-28536. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
1856ee3b92 |
[SPARK-28441][SQL][TESTS][FOLLOW-UP] Skip Python tests if python executable and pyspark library are unavailable
## What changes were proposed in this pull request? We should add `assume(shouldTestPythonUDFs)`. Maybe it's not a biggie in general but it can matter in other venders' testing base. For instance, if somebody launches a test in a minimal docker image, it might make the tests failed suddenly. This skipping stuff isn't completely new in our test base. See `TestUtils.testCommandAvailable` for instance. ## How was this patch tested? Manually tested. Closes #25272 from HyukjinKwon/SPARK-28441. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> |
||
|
|
d4e246658a |
[SPARK-28530][SQL] Cost-based join reorder optimizer batch should be FixedPoint(1)
## What changes were proposed in this pull request? Since for AQP the cost for joins can change between multiple runs, there is no reason that we have an idempotence enforcement on this optimizer batch. We thus make it `FixedPoint(1)` instead of `Once`. ## How was this patch tested? Existing UTs. Closes #25266 from yeshengm/SPARK-28530. Lead-authored-by: Yesheng Ma <kimi.ysma@gmail.com> Co-authored-by: Xiao Li <gatorsmile@gmail.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com> |
||
|
|
e037a11494 |
[SPARK-28532][SQL] Make optimizer batch "subquery" FixedPoint(1)
## What changes were proposed in this pull request? In the Catalyst optimizer, the batch subquery actually calls the optimizer recursively. Therefore it makes no sense to enforce idempotence on it and we change this batch to `FixedPoint(1)`. ## How was this patch tested? Existing UTs. Closes #25267 from yeshengm/SPARK-28532. Authored-by: Yesheng Ma <kimi.ysma@gmail.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com> |
||
|
|
558dd23601 |
[SPARK-28441][SQL][PYTHON] Fix error when non-foldable expression is used in correlated scalar subquery
## What changes were proposed in this pull request?
In SPARK-15370, We checked the expression at the root of the correlated subquery, in order to fix count bug. If a `PythonUDF` in in the checking path, evaluating it causes the failure as we can't statically evaluate `PythonUDF`. The Python UDF test added at SPARK-28277 shows this issue.
If we can statically evaluate the expression, we intercept NULL values coming from the outer join and replace them with the value that the subquery's expression like before, if it is not, we replace them with the `PythonUDF` expression, with statically evaluated parameters.
After this, the last query in `udf-except.sql` which throws `java.lang.UnsupportedOperationException` can be run:
```
SELECT t1.k
FROM t1
WHERE t1.v <= (SELECT udf(max(udf(t2.v)))
FROM t2
WHERE udf(t2.k) = udf(t1.k))
MINUS
SELECT t1.k
FROM t1
WHERE udf(t1.v) >= (SELECT min(udf(t2.v))
FROM t2
WHERE t2.k = t1.k)
-- !query 2 schema
struct<k:string>
-- !query 2 output
two
```
Note that this issue is also for other non-foldable expressions, like rand. As like PythonUDF, we can't call `eval` on this kind of expressions in optimization. The evaluation needs to defer to query runtime.
## How was this patch tested?
Added tests.
Closes #25204 from viirya/SPARK-28441.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
|
||
|
|
836a8ff2b9 |
[SPARK-28518][SQL][TEST] Refer to ChecksumFileSystem#isChecksumFile to fix StatisticsCollectionTestBase#getDataSize
## What changes were proposed in this pull request?
This PR fix [StatisticsCollectionTestBase.getDataSize](
|
||
|
|
f2a2d980ed |
[SPARK-25285][CORE] Add startedTasks and finishedTasks to the metrics system in the executor instance
## What changes were proposed in this pull request? The motivation for these additional metrics is to help in troubleshooting and monitoring task execution workload when running on a cluster. Currently available metrics include executor threadpool metrics for task completed and for active tasks. The addition of threadpool taskStarted metric will allow for example to collect info on the (approximate) number of failed tasks by computing the difference thread started – (active threads + completed tasks and/or successfully finished tasks). The proposed metric finishedTasks is also intended for this type of troubleshooting. The difference between finshedTasks and threadpool.completeTasks, is that the latter is a (dropwizard library) gauge taken from the threadpool, while the former is a (dropwizard) counter computed in the [[Executor]] class, when a task successfully finishes, together with several other task metrics counters. Note, there are similarities with some of the metrics introduced in SPARK-24398, however there are key differences, coming from the fact that this PR concerns the executor source, therefore providing metric values per executor + metric values do not require to pass through the listerner bus in this case. ## How was this patch tested? Manually tested on a YARN cluster Closes #22290 from LucaCanali/AddMetricExecutorStartedTasks. Lead-authored-by: Luca Canali <luca.canali@cern.ch> Co-authored-by: LucaCanali <luca.canali@cern.ch> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> |
||
|
|
545c7ee00b |
[SPARK-28463][SQL] Thriftserver throws BigDecimal incompatible with HiveDecimal
## What changes were proposed in this pull request? How to reproduce this issue: ```shell build/sbt clean package -Phive -Phive-thriftserver -Phadoop-3.2 export SPARK_PREPEND_CLASSES=true sbin/start-thriftserver.sh [rootspark-3267648 spark]# bin/beeline -u jdbc:hive2://localhost:10000/default -e "select cast(1 as decimal(38, 18));" Connecting to jdbc:hive2://localhost:10000/default Connected to: Spark SQL (version 3.0.0-SNAPSHOT) Driver: Hive JDBC (version 2.3.5) Transaction isolation: TRANSACTION_REPEATABLE_READ Error: java.lang.ClassCastException: java.math.BigDecimal incompatible with org.apache.hadoop.hive.common.type.HiveDecimal (state=,code=0) Closing: 0: jdbc:hive2://localhost:10000/default ``` This pr fix this issue. ## How was this patch tested? unit tests Closes #25217 from wangyum/SPARK-28463. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com> |
||
|
|
3de4e1b9b4 |
[SPARK-28507][ML][PYSPARK] Remove deprecated API context(self, sqlContext) from pyspark/ml/util.py
## What changes were proposed in this pull request? remove deprecated ``` def context(self, sqlContext)``` from ```pyspark/ml/util.py``` ## How was this patch tested? test with existing ml PySpark test suites Closes #25246 from huaxingao/spark-28507. Authored-by: Huaxin Gao <huaxing@us.ibm.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> |
||
|
|
6807a82047 |
[SPARK-28524][SQL] Fix ThriftServerTab lost error message
## What changes were proposed in this pull request? The ThriftServerTab lost the error message since [SPARK-28260](https://issues.apache.org/jira/browse/SPARK-28260):   This pr fix this issue. ## How was this patch tested? manual tests   Closes #25263 from wangyum/SPARK-28524. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com> |
||
|
|
bf41070480 |
[SPARK-28499][ML] Optimize MinMaxScaler
## What changes were proposed in this pull request? 1, avoid calling param getter in udf; 2, for constant dims, precompute the transformed result; 3, for usual dims, precompute `scale / originalRange(i)` to skip a division; ## How was this patch tested? existing suites Closes #25244 from zhengruifeng/minmax_opt. Authored-by: zhengruifeng <ruifengz@foxmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> |
||
|
|
b9c2521de2 |
[SPARK-28489][SS] Fix a bug that KafkaOffsetRangeCalculator.getRanges may drop offsets
## What changes were proposed in this pull request? `KafkaOffsetRangeCalculator.getRanges` may drop offsets due to round off errors. The test added in this PR is one example. This PR rewrites the logic in `KafkaOffsetRangeCalculator.getRanges` to ensure it never drops offsets. ## How was this patch tested? The regression test. Closes #25237 from zsxwing/fix-range. Authored-by: Shixiong Zhu <zsxwing@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
c93d2dd183 |
[SPARK-28237][SQL] Enforce Idempotence for Once batches in RuleExecutor
## What changes were proposed in this pull request? In adaptive query processing (AQE), query plans are optimized on the fly during execution. However, a few `Once` rules can be problematic for such optimization since they can either generate wrong plan/unnecessary intermediate plan nodes. This PR enforces idempotence for "Once" batches that are supposed to run once. This is a key enabler for AQE re-optimization and can improve robustness for existing optimizer rules. Once batches that are currently not idempotent are marked in a blacklist. We will submit followup PRs to fix idempotence of these rules. ## How was this patch tested? Existing UTs. Failing Once rules are temporarily blacklisted. Closes #25249 from yeshengm/idempotence-checker. Authored-by: Yesheng Ma <kimi.ysma@gmail.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com> |
||
|
|
ded1a7495b |
[SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM
## What changes were proposed in this pull request?
Because the local default locale isn't in available locales at `Locale`, when I did some tests locally with python code, `StopWordsRemover` related python test hits some errors, like:
```
Traceback (most recent call last):
File "/spark-1/python/pyspark/ml/tests/test_feature.py", line 87, in test_stopwordsremover
stopWordRemover = StopWordsRemover(inputCol="input", outputCol="output")
File "/spark-1/python/pyspark/__init__.py", line 111, in wrapper
return func(self, **kwargs)
File "/spark-1/python/pyspark/ml/feature.py", line 2646, in __init__
self.uid)
File "/spark-1/python/pyspark/ml/wrapper.py", line 67, in _new_java_obj
return java_obj(*java_args)
File /spark-1/python/lib/py4j-0.10.8.1-src.zip/py4j/java_gateway.py", line 1554, in __call__
answer, self._gateway_client, None, self._fqn)
File "/spark-1/python/pyspark/sql/utils.py", line 93, in deco
raise converted
pyspark.sql.utils.IllegalArgumentException: 'StopWordsRemover_4598673ee802 parameter locale given invalid value en_TW.'
```
As per HyukjinKwon's advice, instead of setting up locale to pass test, it is better to have a workable locale if system default locale can't be found in available locales in JVM. Otherwise, users have to manually change system locale or accessing a private property _jvm in PySpark.
## How was this patch tested?
Added test and manual test.
```
scala> val remover = new StopWordsRemover().setInputCol("raw").setOutputCol("filtered")
19/07/14 19:20:03 WARN StopWordsRemover: Default locale set was [en_TW]; however, it was not found in available locales in JVM, falling back to en_US locale. Set param `locale` in order to respect another locale.
```
Closes #25133 from viirya/pytest-default-locale.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
|
||
|
|
6361467bde |
[SPARK-28289][SQL][PYTHON][TESTS] Convert and port 'union.sql' into UDF test base
## What changes were proposed in this pull request?
This PR adds some tests converted from 'union.sql' to test UDFs
<details><summary>Diff comparing to 'union.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/union.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-union.sql.out
index b023df825d..84b5e10dbe 100644
--- a/sql/core/src/test/resources/sql-tests/results/union.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-union.sql.out
-19,10 +19,10 struct<>
-- !query 2
-SELECT *
-FROM (SELECT * FROM t1
+SELECT udf(c1) as c1, udf(c2) as c2
+FROM (SELECT udf(c1) as c1, udf(c2) as c2 FROM t1
UNION ALL
- SELECT * FROM t1)
+ SELECT udf(c1) as c1, udf(c2) as c2 FROM t1)
-- !query 2 schema
struct<c1:int,c2:string>
-- !query 2 output
-33,12 +33,12 struct<c1:int,c2:string>
-- !query 3
-SELECT *
-FROM (SELECT * FROM t1
+SELECT udf(c1) as c1, udf(c2) as c2
+FROM (SELECT udf(c1) as c1, udf(c2) as c2 FROM t1
UNION ALL
- SELECT * FROM t2
+ SELECT udf(c1) as c1, udf(c2) as c2 FROM t2
UNION ALL
- SELECT * FROM t2)
+ SELECT udf(c1) as c1, udf(c2) as c2 FROM t2)
-- !query 3 schema
struct<c1:decimal(11,1),c2:string>
-- !query 3 output
-51,11 +51,11 struct<c1:decimal(11,1),c2:string>
-- !query 4
-SELECT a
-FROM (SELECT 0 a, 0 b
+SELECT udf(udf(a)) as a
+FROM (SELECT udf(0) a, udf(0) b
UNION ALL
- SELECT SUM(1) a, CAST(0 AS BIGINT) b
- UNION ALL SELECT 0 a, 0 b) T
+ SELECT udf(SUM(1)) a, udf(CAST(0 AS BIGINT)) b
+ UNION ALL SELECT udf(0) a, udf(0) b) T
-- !query 4 schema
struct<a:bigint>
-- !query 4 output
-89,13 +89,13 struct<>
-- !query 8
-SELECT 1 AS x,
- col
-FROM (SELECT col AS col
- FROM (SELECT p1.col AS col
+SELECT udf(1) AS x,
+ udf(col) as col
+FROM (SELECT udf(col) AS col
+ FROM (SELECT udf(p1.col) AS col
FROM p1 CROSS JOIN p2
UNION ALL
- SELECT col
+ SELECT udf(col)
FROM p3) T1) T2
-- !query 8 schema
struct<x:int,col:int>
-105,9 +105,9 struct<x:int,col:int>
-- !query 9
-SELECT map(1, 2), 'str'
+SELECT map(1, 2), udf('str') as str
UNION ALL
-SELECT map(1, 2, 3, NULL), 1
+SELECT map(1, 2, 3, NULL), udf(1)
-- !query 9 schema
struct<map(1, 2):map<int,int>,str:string>
-- !query 9 output
-116,9 +116,9 struct<map(1, 2):map<int,int>,str:string>
-- !query 10
-SELECT array(1, 2), 'str'
+SELECT array(1, 2), udf('str') as str
UNION ALL
-SELECT array(1, 2, 3, NULL), 1
+SELECT array(1, 2, 3, NULL), udf(1)
-- !query 10 schema
struct<array(1, 2):array<int>,str:string>
-- !query 10 output
```
</p>
</details>
## How was this patch tested?
Tested as guided in SPARK-27921.
Closes #25202 from yiheng/fix_28289.
Authored-by: Yiheng Wang <yihengw@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
|
||
|
|
cefce21acc |
[MINOR][SQL] Fix log messages of DataWritingSparkTask
## What changes were proposed in this pull request?
This PR fixes the log messages like `attempt 0stage 9.0` by adding a comma followed by space. These are all instances in `DataWritingSparkTask` which was introduced at
|
||
|
|
443904a140 |
[SPARK-27845][SQL] DataSourceV2: InsertTable
## What changes were proposed in this pull request? Support multiple catalogs in the following InsertTable use cases: - INSERT INTO [TABLE] catalog.db.tbl - INSERT OVERWRITE TABLE catalog.db.tbl Support matrix: Overwrite|Partitioned Table|Partition Clause |Partition Overwrite Mode|Action ---------|-----------------|-----------------|------------------------|----- false|*|*|*|AppendData true|no|(empty)|*|OverwriteByExpression(true) true|yes|p1,p2 or p1 or p2 or (empty)|STATIC|OverwriteByExpression(true) true|yes|p2,p2 or p1 or p2 or (empty)|DYNAMIC|OverwritePartitionsDynamic true|yes|p1=23,p2=3|*|OverwriteByExpression(p1=23 and p2=3) true|yes|p1=23,p2 or p1=23|STATIC|OverwriteByExpression(p1=23) true|yes|p1=23,p2 or p1=23|DYNAMIC|OverwritePartitionsDynamic Notes: - Assume the partitioned table has 2 partitions: p1 and p2. - `STATIC` is the default Partition Overwrite Mode for data source tables. - DSv2 tables currently do not support `IfPartitionNotExists`. ## How was this patch tested? New tests. All existing catalyst and sql/core tests. Closes #24832 from jzhuge/SPARK-27845-pr. Lead-authored-by: Ryan Blue <blue@apache.org> Co-authored-by: John Zhuge <jzhuge@apache.org> Signed-off-by: Burak Yavuz <brkyvz@gmail.com> |
||
|
|
dbd0a2aa37 |
[SPARK-28511][INFRA] Get REV from RELEASE_VERSION instead of VERSION
## What changes were proposed in this pull request? Unlike the other versions, `x.x.0-SNAPSHOT` causes `x.x.-1`. Although this will not happen in the tags (there is no `SNAPSHOT` postfix), we had better fix this. ``` $ dev/create-release/do-release-docker.sh -d /tmp/spark-3.0.0 -n Output directory already exists. Overwrite and continue? [y/n] y Branch [branch-2.4]: master Current branch version is 3.0.0-SNAPSHOT. Release [3.0.-1]: ``` Since we already have `RELEASE_VERSION` by removing `SNAPSHOT`. This PR uses `RELEASE_VERSION` instead of `VERSION`. ``` $ dev/create-release/do-release-docker.sh -d /tmp/spark-3.0.0 -n Branch [branch-2.4]: master Current branch version is 3.0.0-SNAPSHOT. Release [3.0.0]: ``` ## How was this patch tested? Manually do `dev/create-release/do-release-docker.sh -d /tmp/spark-3.0.0 -n` and see the default value of `Release`. Closes #25254 from dongjoon-hyun/SPARK-28511. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
89fd2b5efc |
[SPARK-28288][SQL][PYTHON][TESTS] Convert and port 'window.sql' into UDF test base
## What changes were proposed in this pull request? This PR adds some tests converted from window.sql to test UDFs. Please see the contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921). <details><summary>Diff comparing to 'xxx.sql'</summary> <p> ```diff diff --git a/sql/core/src/test/resources/sql-tests/results/window.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-window.sql.out index 367dc4f513..9354d5e311 100644 --- a/sql/core/src/test/resources/sql-tests/results/window.sql.out +++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-window.sql.out -21,10 +21,10 struct<> -- !query 1 -SELECT val, cate, count(val) OVER(PARTITION BY cate ORDER BY val ROWS CURRENT ROW) FROM testData -ORDER BY cate, val +SELECT udf(val), cate, count(val) OVER(PARTITION BY cate ORDER BY udf(val) ROWS CURRENT ROW) FROM testData +ORDER BY cate, udf(val) -- !query 1 schema -struct<val:int,cate:string,count(val) OVER (PARTITION BY cate ORDER BY val ASC NULLS FIRST ROWS BETWEEN CURRENT ROW AND CURRENT ROW):bigint> +struct<CAST(udf(cast(val as string)) AS INT):int,cate:string,count(val) OVER (PARTITION BY cate ORDER BY CAST(udf(cast(val as string)) AS INT) ASC NULLS FIRST ROWS BETWEEN CURRENT ROW AND CURRENT ROW):bigint> -- !query 1 output NULL NULL 0 3 NULL 1 -38,10 +38,10 NULL a 0 -- !query 2 -SELECT val, cate, sum(val) OVER(PARTITION BY cate ORDER BY val -ROWS BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING) FROM testData ORDER BY cate, val +SELECT udf(val), cate, sum(val) OVER(PARTITION BY cate ORDER BY udf(val) +ROWS BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING) FROM testData ORDER BY cate, udf(val) -- !query 2 schema -struct<val:int,cate:string,sum(val) OVER (PARTITION BY cate ORDER BY val ASC NULLS FIRST ROWS BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING):bigint> +struct<CAST(udf(cast(val as string)) AS INT):int,cate:string,sum(val) OVER (PARTITION BY cate ORDER BY CAST(udf(cast(val as string)) AS INT) ASC NULLS FIRST ROWS BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING):bigint> -- !query 2 output NULL NULL 3 3 NULL 3 -55,20 +55,20 NULL a 1 -- !query 3 -SELECT val_long, cate, sum(val_long) OVER(PARTITION BY cate ORDER BY val_long -ROWS BETWEEN CURRENT ROW AND 2147483648 FOLLOWING) FROM testData ORDER BY cate, val_long +SELECT val_long, udf(cate), sum(val_long) OVER(PARTITION BY cate ORDER BY udf(val_long) +ROWS BETWEEN CURRENT ROW AND 2147483648 FOLLOWING) FROM testData ORDER BY udf(cate), val_long -- !query 3 schema struct<> -- !query 3 output org.apache.spark.sql.AnalysisException -cannot resolve 'ROWS BETWEEN CURRENT ROW AND 2147483648L FOLLOWING' due to data type mismatch: The data type of the upper bound 'bigint' does not match the expected data type 'int'.; line 1 pos 41 +cannot resolve 'ROWS BETWEEN CURRENT ROW AND 2147483648L FOLLOWING' due to data type mismatch: The data type of the upper bound 'bigint' does not match the expected data type 'int'.; line 1 pos 46 -- !query 4 -SELECT val, cate, count(val) OVER(PARTITION BY cate ORDER BY val RANGE 1 PRECEDING) FROM testData -ORDER BY cate, val +SELECT udf(val), cate, count(val) OVER(PARTITION BY udf(cate) ORDER BY val RANGE 1 PRECEDING) FROM testData +ORDER BY cate, udf(val) -- !query 4 schema -struct<val:int,cate:string,count(val) OVER (PARTITION BY cate ORDER BY val ASC NULLS FIRST RANGE BETWEEN 1 PRECEDING AND CURRENT ROW):bigint> +struct<CAST(udf(cast(val as string)) AS INT):int,cate:string,count(val) OVER (PARTITION BY CAST(udf(cast(cate as string)) AS STRING) ORDER BY val ASC NULLS FIRST RANGE BETWEEN 1 PRECEDING AND CURRENT ROW):bigint> -- !query 4 output NULL NULL 0 3 NULL 1 -82,10 +82,10 NULL a 0 -- !query 5 -SELECT val, cate, sum(val) OVER(PARTITION BY cate ORDER BY val -RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING) FROM testData ORDER BY cate, val +SELECT val, udf(cate), sum(val) OVER(PARTITION BY udf(cate) ORDER BY val +RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING) FROM testData ORDER BY udf(cate), val -- !query 5 schema -struct<val:int,cate:string,sum(val) OVER (PARTITION BY cate ORDER BY val ASC NULLS FIRST RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING):bigint> +struct<val:int,CAST(udf(cast(cate as string)) AS STRING):string,sum(val) OVER (PARTITION BY CAST(udf(cast(cate as string)) AS STRING) ORDER BY val ASC NULLS FIRST RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING):bigint> -- !query 5 output NULL NULL NULL 3 NULL 3 -99,10 +99,10 NULL a NULL -- !query 6 -SELECT val_long, cate, sum(val_long) OVER(PARTITION BY cate ORDER BY val_long -RANGE BETWEEN CURRENT ROW AND 2147483648 FOLLOWING) FROM testData ORDER BY cate, val_long +SELECT val_long, udf(cate), sum(val_long) OVER(PARTITION BY udf(cate) ORDER BY val_long +RANGE BETWEEN CURRENT ROW AND 2147483648 FOLLOWING) FROM testData ORDER BY udf(cate), val_long -- !query 6 schema -struct<val_long:bigint,cate:string,sum(val_long) OVER (PARTITION BY cate ORDER BY val_long ASC NULLS FIRST RANGE BETWEEN CURRENT ROW AND 2147483648 FOLLOWING):bigint> +struct<val_long:bigint,CAST(udf(cast(cate as string)) AS STRING):string,sum(val_long) OVER (PARTITION BY CAST(udf(cast(cate as string)) AS STRING) ORDER BY val_long ASC NULLS FIRST RANGE BETWEEN CURRENT ROW AND 2147483648 FOLLOWING):bigint> -- !query 6 output NULL NULL NULL 1 NULL 1 -116,10 +116,10 NULL b NULL -- !query 7 -SELECT val_double, cate, sum(val_double) OVER(PARTITION BY cate ORDER BY val_double -RANGE BETWEEN CURRENT ROW AND 2.5 FOLLOWING) FROM testData ORDER BY cate, val_double +SELECT val_double, udf(cate), sum(val_double) OVER(PARTITION BY udf(cate) ORDER BY val_double +RANGE BETWEEN CURRENT ROW AND 2.5 FOLLOWING) FROM testData ORDER BY udf(cate), val_double -- !query 7 schema -struct<val_double:double,cate:string,sum(val_double) OVER (PARTITION BY cate ORDER BY val_double ASC NULLS FIRST RANGE BETWEEN CURRENT ROW AND CAST(2.5 AS DOUBLE) FOLLOWING):double> +struct<val_double:double,CAST(udf(cast(cate as string)) AS STRING):string,sum(val_double) OVER (PARTITION BY CAST(udf(cast(cate as string)) AS STRING) ORDER BY val_double ASC NULLS FIRST RANGE BETWEEN CURRENT ROW AND CAST(2.5 AS DOUBLE) FOLLOWING):double> -- !query 7 output NULL NULL NULL 1.0 NULL 1.0 -133,10 +133,10 NULL NULL NULL -- !query 8 -SELECT val_date, cate, max(val_date) OVER(PARTITION BY cate ORDER BY val_date -RANGE BETWEEN CURRENT ROW AND 2 FOLLOWING) FROM testData ORDER BY cate, val_date +SELECT val_date, udf(cate), max(val_date) OVER(PARTITION BY udf(cate) ORDER BY val_date +RANGE BETWEEN CURRENT ROW AND 2 FOLLOWING) FROM testData ORDER BY udf(cate), val_date -- !query 8 schema -struct<val_date:date,cate:string,max(val_date) OVER (PARTITION BY cate ORDER BY val_date ASC NULLS FIRST RANGE BETWEEN CURRENT ROW AND 2 FOLLOWING):date> +struct<val_date:date,CAST(udf(cast(cate as string)) AS STRING):string,max(val_date) OVER (PARTITION BY CAST(udf(cast(cate as string)) AS STRING) ORDER BY val_date ASC NULLS FIRST RANGE BETWEEN CURRENT ROW AND 2 FOLLOWING):date> -- !query 8 output NULL NULL NULL 2017-08-01 NULL 2017-08-01 -150,11 +150,11 NULL NULL NULL -- !query 9 -SELECT val_timestamp, cate, avg(val_timestamp) OVER(PARTITION BY cate ORDER BY val_timestamp +SELECT val_timestamp, udf(cate), avg(val_timestamp) OVER(PARTITION BY udf(cate) ORDER BY val_timestamp RANGE BETWEEN CURRENT ROW AND interval 23 days 4 hours FOLLOWING) FROM testData -ORDER BY cate, val_timestamp +ORDER BY udf(cate), val_timestamp -- !query 9 schema -struct<val_timestamp:timestamp,cate:string,avg(CAST(val_timestamp AS DOUBLE)) OVER (PARTITION BY cate ORDER BY val_timestamp ASC NULLS FIRST RANGE BETWEEN CURRENT ROW AND interval 3 weeks 2 days 4 hours FOLLOWING):double> +struct<val_timestamp:timestamp,CAST(udf(cast(cate as string)) AS STRING):string,avg(CAST(val_timestamp AS DOUBLE)) OVER (PARTITION BY CAST(udf(cast(cate as string)) AS STRING) ORDER BY val_timestamp ASC NULLS FIRST RANGE BETWEEN CURRENT ROW AND interval 3 weeks 2 days 4 hours FOLLOWING):double> -- !query 9 output NULL NULL NULL 2017-07-31 17:00:00 NULL 1.5015456E9 -168,10 +168,10 NULL NULL NULL -- !query 10 -SELECT val, cate, sum(val) OVER(PARTITION BY cate ORDER BY val DESC +SELECT val, udf(cate), sum(val) OVER(PARTITION BY cate ORDER BY val DESC RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING) FROM testData ORDER BY cate, val -- !query 10 schema -struct<val:int,cate:string,sum(val) OVER (PARTITION BY cate ORDER BY val DESC NULLS LAST RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING):bigint> +struct<val:int,CAST(udf(cast(cate as string)) AS STRING):string,sum(val) OVER (PARTITION BY cate ORDER BY val DESC NULLS LAST RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING):bigint> -- !query 10 output NULL NULL NULL 3 NULL 3 -185,58 +185,58 NULL a NULL -- !query 11 -SELECT val, cate, count(val) OVER(PARTITION BY cate -ROWS BETWEEN UNBOUNDED FOLLOWING AND 1 FOLLOWING) FROM testData ORDER BY cate, val +SELECT udf(val), cate, count(val) OVER(PARTITION BY udf(cate) +ROWS BETWEEN UNBOUNDED FOLLOWING AND 1 FOLLOWING) FROM testData ORDER BY cate, udf(val) -- !query 11 schema struct<> -- !query 11 output org.apache.spark.sql.AnalysisException -cannot resolve 'ROWS BETWEEN UNBOUNDED FOLLOWING AND 1 FOLLOWING' due to data type mismatch: Window frame upper bound '1' does not follow the lower bound 'unboundedfollowing$()'.; line 1 pos 33 +cannot resolve 'ROWS BETWEEN UNBOUNDED FOLLOWING AND 1 FOLLOWING' due to data type mismatch: Window frame upper bound '1' does not follow the lower bound 'unboundedfollowing$()'.; line 1 pos 38 -- !query 12 -SELECT val, cate, count(val) OVER(PARTITION BY cate -RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING) FROM testData ORDER BY cate, val +SELECT udf(val), cate, count(val) OVER(PARTITION BY udf(cate) +RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING) FROM testData ORDER BY cate, udf(val) -- !query 12 schema struct<> -- !query 12 output org.apache.spark.sql.AnalysisException -cannot resolve '(PARTITION BY testdata.`cate` RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING)' due to data type mismatch: A range window frame cannot be used in an unordered window specification.; line 1 pos 33 +cannot resolve '(PARTITION BY CAST(udf(cast(cate as string)) AS STRING) RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING)' due to data type mismatch: A range window frame cannot be used in an unordered window specification.; line 1 pos 38 -- !query 13 -SELECT val, cate, count(val) OVER(PARTITION BY cate ORDER BY val, cate -RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING) FROM testData ORDER BY cate, val +SELECT udf(val), cate, count(val) OVER(PARTITION BY udf(cate) ORDER BY udf(val), cate +RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING) FROM testData ORDER BY cate, udf(val) -- !query 13 schema struct<> -- !query 13 output org.apache.spark.sql.AnalysisException -cannot resolve '(PARTITION BY testdata.`cate` ORDER BY testdata.`val` ASC NULLS FIRST, testdata.`cate` ASC NULLS FIRST RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING)' due to data type mismatch: A range window frame with value boundaries cannot be used in a window specification with multiple order by expressions: val#x ASC NULLS FIRST,cate#x ASC NULLS FIRST; line 1 pos 33 +cannot resolve '(PARTITION BY CAST(udf(cast(cate as string)) AS STRING) ORDER BY CAST(udf(cast(val as string)) AS INT) ASC NULLS FIRST, testdata.`cate` ASC NULLS FIRST RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING)' due to data type mismatch: A range window frame with value boundaries cannot be used in a window specification with multiple order by expressions: cast(udf(cast(val#x as string)) as int) ASC NULLS FIRST,cate#x ASC NULLS FIRST; line 1 pos 38 -- !query 14 -SELECT val, cate, count(val) OVER(PARTITION BY cate ORDER BY current_timestamp -RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING) FROM testData ORDER BY cate, val +SELECT udf(val), cate, count(val) OVER(PARTITION BY udf(cate) ORDER BY current_timestamp +RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING) FROM testData ORDER BY cate, udf(val) -- !query 14 schema struct<> -- !query 14 output org.apache.spark.sql.AnalysisException -cannot resolve '(PARTITION BY testdata.`cate` ORDER BY current_timestamp() ASC NULLS FIRST RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING)' due to data type mismatch: The data type 'timestamp' used in the order specification does not match the data type 'int' which is used in the range frame.; line 1 pos 33 +cannot resolve '(PARTITION BY CAST(udf(cast(cate as string)) AS STRING) ORDER BY current_timestamp() ASC NULLS FIRST RANGE BETWEEN CURRENT ROW AND 1 FOLLOWING)' due to data type mismatch: The data type 'timestamp' used in the order specification does not match the data type 'int' which is used in the range frame.; line 1 pos 38 -- !query 15 -SELECT val, cate, count(val) OVER(PARTITION BY cate ORDER BY val -RANGE BETWEEN 1 FOLLOWING AND 1 PRECEDING) FROM testData ORDER BY cate, val +SELECT udf(val), cate, count(val) OVER(PARTITION BY udf(cate) ORDER BY val +RANGE BETWEEN 1 FOLLOWING AND 1 PRECEDING) FROM testData ORDER BY udf(cate), val -- !query 15 schema struct<> -- !query 15 output org.apache.spark.sql.AnalysisException -cannot resolve 'RANGE BETWEEN 1 FOLLOWING AND 1 PRECEDING' due to data type mismatch: The lower bound of a window frame must be less than or equal to the upper bound; line 1 pos 33 +cannot resolve 'RANGE BETWEEN 1 FOLLOWING AND 1 PRECEDING' due to data type mismatch: The lower bound of a window frame must be less than or equal to the upper bound; line 1 pos 38 -- !query 16 -SELECT val, cate, count(val) OVER(PARTITION BY cate ORDER BY val -RANGE BETWEEN CURRENT ROW AND current_date PRECEDING) FROM testData ORDER BY cate, val +SELECT udf(val), cate, count(val) OVER(PARTITION BY udf(cate) ORDER BY udf(val) +RANGE BETWEEN CURRENT ROW AND current_date PRECEDING) FROM testData ORDER BY cate, val(val) -- !query 16 schema struct<> -- !query 16 output -245,48 +245,48 org.apache.spark.sql.catalyst.parser.ParseException Frame bound value must be a literal.(line 2, pos 30) == SQL == -SELECT val, cate, count(val) OVER(PARTITION BY cate ORDER BY val -RANGE BETWEEN CURRENT ROW AND current_date PRECEDING) FROM testData ORDER BY cate, val +SELECT udf(val), cate, count(val) OVER(PARTITION BY udf(cate) ORDER BY udf(val) +RANGE BETWEEN CURRENT ROW AND current_date PRECEDING) FROM testData ORDER BY cate, val(val) ------------------------------^^^ -- !query 17 -SELECT val, cate, -max(val) OVER w AS max, -min(val) OVER w AS min, -min(val) OVER w AS min, -count(val) OVER w AS count, -sum(val) OVER w AS sum, -avg(val) OVER w AS avg, -stddev(val) OVER w AS stddev, -first_value(val) OVER w AS first_value, -first_value(val, true) OVER w AS first_value_ignore_null, -first_value(val, false) OVER w AS first_value_contain_null, -last_value(val) OVER w AS last_value, -last_value(val, true) OVER w AS last_value_ignore_null, -last_value(val, false) OVER w AS last_value_contain_null, +SELECT udf(val), cate, +max(udf(val)) OVER w AS max, +min(udf(val)) OVER w AS min, +min(udf(val)) OVER w AS min, +count(udf(val)) OVER w AS count, +sum(udf(val)) OVER w AS sum, +avg(udf(val)) OVER w AS avg, +stddev(udf(val)) OVER w AS stddev, +first_value(udf(val)) OVER w AS first_value, +first_value(udf(val), true) OVER w AS first_value_ignore_null, +first_value(udf(val), false) OVER w AS first_value_contain_null, +last_value(udf(val)) OVER w AS last_value, +last_value(udf(val), true) OVER w AS last_value_ignore_null, +last_value(udf(val), false) OVER w AS last_value_contain_null, rank() OVER w AS rank, dense_rank() OVER w AS dense_rank, cume_dist() OVER w AS cume_dist, percent_rank() OVER w AS percent_rank, ntile(2) OVER w AS ntile, row_number() OVER w AS row_number, -var_pop(val) OVER w AS var_pop, -var_samp(val) OVER w AS var_samp, -approx_count_distinct(val) OVER w AS approx_count_distinct, -covar_pop(val, val_long) OVER w AS covar_pop, -corr(val, val_long) OVER w AS corr, -stddev_samp(val) OVER w AS stddev_samp, -stddev_pop(val) OVER w AS stddev_pop, -collect_list(val) OVER w AS collect_list, -collect_set(val) OVER w AS collect_set, -skewness(val_double) OVER w AS skewness, -kurtosis(val_double) OVER w AS kurtosis +var_pop(udf(val)) OVER w AS var_pop, +var_samp(udf(val)) OVER w AS var_samp, +approx_count_distinct(udf(val)) OVER w AS approx_count_distinct, +covar_pop(udf(val), udf(val_long)) OVER w AS covar_pop, +corr(udf(val), udf(val_long)) OVER w AS corr, +stddev_samp(udf(val)) OVER w AS stddev_samp, +stddev_pop(udf(val)) OVER w AS stddev_pop, +collect_list(udf(val)) OVER w AS collect_list, +collect_set(udf(val)) OVER w AS collect_set, +skewness(udf(val_double)) OVER w AS skewness, +kurtosis(udf(val_double)) OVER w AS kurtosis FROM testData -WINDOW w AS (PARTITION BY cate ORDER BY val) -ORDER BY cate, val +WINDOW w AS (PARTITION BY udf(cate) ORDER BY udf(val)) +ORDER BY cate, udf(val) -- !query 17 schema -struct<val:int,cate:string,max:int,min:int,min:int,count:bigint,sum:bigint,avg:double,stddev:double,first_value:int,first_value_ignore_null:int,first_value_contain_null:int,last_value:int,last_value_ignore_null:int,last_value_contain_null:int,rank:int,dense_rank:int,cume_dist:double,percent_rank:double,ntile:int,row_number:int,var_pop:double,var_samp:double,approx_count_distinct:bigint,covar_pop:double,corr:double,stddev_samp:double,stddev_pop:double,collect_list:array<int>,collect_set:array<int>,skewness:double,kurtosis:double> +struct<CAST(udf(cast(val as string)) AS INT):int,cate:string,max:int,min:int,min:int,count:bigint,sum:bigint,avg:double,stddev:double,first_value:int,first_value_ignore_null:int,first_value_contain_null:int,last_value:int,last_value_ignore_null:int,last_value_contain_null:int,rank:int,dense_rank:int,cume_dist:double,percent_rank:double,ntile:int,row_number:int,var_pop:double,var_samp:double,approx_count_distinct:bigint,covar_pop:double,corr:double,stddev_samp:double,stddev_pop:double,collect_list:array<int>,collect_set:array<int>,skewness:double,kurtosis:double> -- !query 17 output NULL NULL NULL NULL NULL 0 NULL NULL NULL NULL NULL NULL NULL NULL NULL 1 1 0.5 0.0 1 1 NULL NULL 0 NULL NULL NULL NULL [] [] NULL NULL 3 NULL 3 3 3 1 3 3.0 NaN NULL 3 NULL 3 3 3 2 2 1.0 1.0 2 2 0.0 NaN 1 0.0 NaN NaN 0.0 [3] [3] NaN NaN -300,9 +300,9 NULL a NULL NULL NULL 0 NULL NULL NULL NULL NULL NULL NULL NULL NULL 1 1 0.25 0. -- !query 18 -SELECT val, cate, avg(null) OVER(PARTITION BY cate ORDER BY val) FROM testData ORDER BY cate, val +SELECT udf(val), cate, avg(null) OVER(PARTITION BY cate ORDER BY val) FROM testData ORDER BY cate, val -- !query 18 schema -struct<val:int,cate:string,avg(CAST(NULL AS DOUBLE)) OVER (PARTITION BY cate ORDER BY val ASC NULLS FIRST RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW):double> +struct<CAST(udf(cast(val as string)) AS INT):int,cate:string,avg(CAST(NULL AS DOUBLE)) OVER (PARTITION BY cate ORDER BY val ASC NULLS FIRST RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW):double> -- !query 18 output NULL NULL NULL 3 NULL NULL -316,7 +316,7 NULL a NULL -- !query 19 -SELECT val, cate, row_number() OVER(PARTITION BY cate) FROM testData ORDER BY cate, val +SELECT udf(val), cate, row_number() OVER(PARTITION BY cate) FROM testData ORDER BY cate, udf(val) -- !query 19 schema struct<> -- !query 19 output -325,9 +325,9 Window function row_number() requires window to be ordered, please add ORDER BY -- !query 20 -SELECT val, cate, sum(val) OVER(), avg(val) OVER() FROM testData ORDER BY cate, val +SELECT udf(val), cate, sum(val) OVER(), avg(val) OVER() FROM testData ORDER BY cate, val -- !query 20 schema -struct<val:int,cate:string,sum(CAST(val AS BIGINT)) OVER (ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING):bigint,avg(CAST(val AS BIGINT)) OVER (ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING):double> +struct<CAST(udf(cast(val as string)) AS INT):int,cate:string,sum(CAST(val AS BIGINT)) OVER (ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING):bigint,avg(CAST(val AS BIGINT)) OVER (ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING):double> -- !query 20 output NULL NULL 13 1.8571428571428572 3 NULL 13 1.8571428571428572 -341,7 +341,7 NULL a 13 1.8571428571428572 -- !query 21 -SELECT val, cate, +SELECT udf(val), cate, first_value(false) OVER w AS first_value, first_value(true, true) OVER w AS first_value_ignore_null, first_value(false, false) OVER w AS first_value_contain_null, -352,7 +352,7 FROM testData WINDOW w AS () ORDER BY cate, val -- !query 21 schema -struct<val:int,cate:string,first_value:boolean,first_value_ignore_null:boolean,first_value_contain_null:boolean,last_value:boolean,last_value_ignore_null:boolean,last_value_contain_null:boolean> +struct<CAST(udf(cast(val as string)) AS INT):int,cate:string,first_value:boolean,first_value_ignore_null:boolean,first_value_contain_null:boolean,last_value:boolean,last_value_ignore_null:boolean,last_value_contain_null:boolean> -- !query 21 output NULL NULL false true false false true false 3 NULL false true false false true false -366,12 +366,12 NULL a false true false false true false -- !query 22 -SELECT cate, sum(val) OVER (w) +SELECT udf(cate), sum(val) OVER (w) FROM testData WHERE val is not null WINDOW w AS (PARTITION BY cate ORDER BY val) -- !query 22 schema -struct<cate:string,sum(CAST(val AS BIGINT)) OVER (PARTITION BY cate ORDER BY val ASC NULLS FIRST RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW):bigint> +struct<CAST(udf(cast(cate as string)) AS STRING):string,sum(CAST(val AS BIGINT)) OVER (PARTITION BY cate ORDER BY val ASC NULLS FIRST RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW):bigint> -- !query 22 output NULL 3 a 2 ``` </p> </details> ## How was this patch tested? Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921). Closes #25195 from younggyuchun/master. Authored-by: younggyu chun <younggyuchun@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> |
||
|
|
b367b323d2 |
[SPARK-28497][SQL] Disallow upcasting complex data types to string type
## What changes were proposed in this pull request? In the current implementation. complex types like Array/Map/StructType are allowed to upcast as StringType. This is not safe casting. We should disallow it. ## How was this patch tested? Update the existing test case Closes #25242 from gengliangwang/fixUpCastStringType. Authored-by: Gengliang Wang <gengliang.wang@databricks.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> |
||
|
|
7504eab42f |
[SPARK-28465][K8S] Fix integration tests which fail due to missing ceph-nano image
## What changes were proposed in this pull request? Fixes the tests. Follows instructions here: https://github.com/ceph/cn/issues/115#issuecomment-497384369 ## How was this patch tested? Manually by running the tests with minikube. Closes #25222 from skonto/fix-ceph. Authored-by: Stavros Kontopoulos <st.kontopoulos@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> |
||
|
|
cfca26e973 |
[SPARK-28496][INFRA] Use branch name instead of tag during dry-run
## What changes were proposed in this pull request? There are two cases when we use `dry run`. First, when the tag already exists, we can ask `confirmation` on the existing tag name. ``` $ dev/create-release/do-release-docker.sh -d /tmp/spark-2.4.4 -n -s docs Output directory already exists. Overwrite and continue? [y/n] y Branch [branch-2.4]: Current branch version is 2.4.4-SNAPSHOT. Release [2.4.4]: 2.4.3 RC # [1]: v2.4.3-rc1 already exists. Continue anyway [y/n]? y This is a dry run. Please confirm the ref that will be built for testing. Ref [v2.4.3-rc1]: ``` Second, when the tag doesn't exist, we had better ask `confirmation` on the branch name. If we do not change the default value, it will fail eventually. ``` $ dev/create-release/do-release-docker.sh -d /tmp/spark-2.4.4 -n -s docs Branch [branch-2.4]: Current branch version is 2.4.4-SNAPSHOT. Release [2.4.4]: RC # [1]: This is a dry run. Please confirm the ref that will be built for testing. Ref [v2.4.4-rc1]: ``` This PR improves the second case by providing the branch name instead. This helps the release testing before tagging. ## How was this patch tested? Manually do the following and check the default value of `Ref` field. ``` $ dev/create-release/do-release-docker.sh -d /tmp/spark-2.4.4 -n -s docs Branch [branch-2.4]: Current branch version is 2.4.4-SNAPSHOT. Release [2.4.4]: RC # [1]: This is a dry run. Please confirm the ref that will be built for testing. Ref [branch-2.4]: ... ``` Closes #25240 from dongjoon-hyun/SPARK-28496. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> |
||
|
|
045191e610 |
[SPARK-28293][SQL] Implement Spark's own GetTableTypesOperation
## What changes were proposed in this pull request? The table type is from Hive now. This will have some issues. For example, we don't support `index_table`, different Hive supports different table types: Build with Hive 1.2.1: 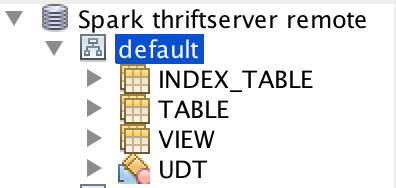 Build with Hive 2.3.5: 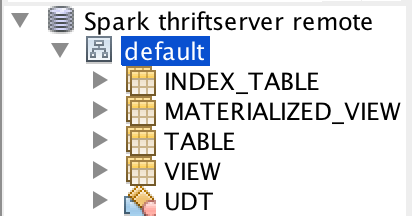 This pr implement Spark's own `GetTableTypesOperation`. ## How was this patch tested? unit tests and manual tests:  Closes #25073 from wangyum/SPARK-28293. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com> |
||
|
|
167fa0402d |
[SPARK-28390][SQL][PYTHON][TESTS] Convert and port 'pgSQL/select_having.sql' into UDF test base
## What changes were proposed in this pull request? changed the test according to steps mentioned in SPARK-27921 <details> <summary>difference comparing to select_having.sql</summary> <p> ```diff diff --git a/sql/core/src/test/resources/sql-tests/results/pgSQL/select_having.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-select_having.sql.out index 02536eb..f731d11 100644 --- a/sql/core/src/test/resources/sql-tests/results/pgSQL/select_having.sql.out +++ b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-select_having.sql.out -91,54 +91,54 struct<> -- !query 11 -SELECT b, c FROM test_having - GROUP BY b, c HAVING count(*) = 1 ORDER BY b, c +SELECT udf(b), udf(c) FROM test_having + GROUP BY b, c HAVING udf(count(*)) = 1 ORDER BY udf(b), udf(c) -- !query 11 schema -struct<b:int,c:string> +struct<CAST(udf(cast(b as string)) AS INT):int,CAST(udf(cast(c as string)) AS STRING):string> -- !query 11 output 1 XXXX 3 bbbb -- !query 12 -SELECT b, c FROM test_having - GROUP BY b, c HAVING b = 3 ORDER BY b, c +SELECT udf(b), udf(c) FROM test_having + GROUP BY b, c HAVING udf(b) = 3 ORDER BY udf(b), udf(c) -- !query 12 schema -struct<b:int,c:string> +struct<CAST(udf(cast(b as string)) AS INT):int,CAST(udf(cast(c as string)) AS STRING):string> -- !query 12 output 3 BBBB 3 bbbb -- !query 13 -SELECT c, max(a) FROM test_having - GROUP BY c HAVING count(*) > 2 OR min(a) = max(a) +SELECT udf(c), max(udf(a)) FROM test_having + GROUP BY c HAVING udf(count(*)) > 2 OR udf(min(a)) = udf(max(a)) ORDER BY c -- !query 13 schema -struct<c:string,max(a):int> +struct<CAST(udf(cast(c as string)) AS STRING):string,max(CAST(udf(cast(a as string)) AS INT)):int> -- !query 13 output XXXX 0 bbbb 5 -- !query 14 -SELECT min(a), max(a) FROM test_having HAVING min(a) = max(a) +SELECT udf(udf(min(udf(a)))), udf(udf(max(udf(a)))) FROM test_having HAVING udf(udf(min(udf(a)))) = udf(udf(max(udf(a)))) -- !query 14 schema -struct<min(a):int,max(a):int> +struct<CAST(udf(cast(cast(udf(cast(min(cast(udf(cast(a as string)) as int)) as string)) as int) as string)) AS INT):int,CAST(udf(cast(cast(udf(cast(max(cast(udf(cast(a as string)) as int)) as string)) as int) as string)) AS INT):int> -- !query 14 output -- !query 15 -SELECT min(a), max(a) FROM test_having HAVING min(a) < max(a) +SELECT udf(min(udf(a))), udf(udf(max(a))) FROM test_having HAVING udf(min(a)) < udf(max(udf(a))) -- !query 15 schema -struct<min(a):int,max(a):int> +struct<CAST(udf(cast(min(cast(udf(cast(a as string)) as int)) as string)) AS INT):int,CAST(udf(cast(cast(udf(cast(max(a) as string)) as int) as string)) AS INT):int> -- !query 15 output 0 9 -- !query 16 -SELECT a FROM test_having HAVING min(a) < max(a) +SELECT udf(a) FROM test_having HAVING udf(min(a)) < udf(max(a)) -- !query 16 schema struct<> -- !query 16 output -147,16 +147,16 grouping expressions sequence is empty, and 'default.test_having.`a`' is not an -- !query 17 -SELECT 1 AS one FROM test_having HAVING a > 1 +SELECT 1 AS one FROM test_having HAVING udf(a) > 1 -- !query 17 schema struct<> -- !query 17 output org.apache.spark.sql.AnalysisException -cannot resolve '`a`' given input columns: [one]; line 1 pos 40 +cannot resolve '`a`' given input columns: [one]; line 1 pos 44 -- !query 18 -SELECT 1 AS one FROM test_having HAVING 1 > 2 +SELECT 1 AS one FROM test_having HAVING udf(udf(1) > udf(2)) -- !query 18 schema struct<one:int> -- !query 18 output -164,7 +164,7 struct<one:int> -- !query 19 -SELECT 1 AS one FROM test_having HAVING 1 < 2 +SELECT 1 AS one FROM test_having HAVING udf(udf(1) < udf(2)) -- !query 19 schema struct<one:int> -- !query 19 output -172,7 +172,7 struct<one:int> -- !query 20 -SELECT 1 AS one FROM test_having WHERE 1/a = 1 HAVING 1 < 2 +SELECT 1 AS one FROM test_having WHERE 1/udf(a) = 1 HAVING 1 < 2 -- !query 20 schema struct<one:int> -- !query 20 output ``` </p> </details> ## How was this patch tested? by: ```bash sudo SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/test-only *SQLQueryTestSuite -- -z udf/pgSQL/udf-select_having.sql" ``` Closes #25161 from shivusondur/jira28390. Authored-by: shivusondur <shivusondur@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> |
||
|
|
d67b98ea01 |
[SPARK-28435][SQL] Support accepting the interval keyword in the schema string
## What changes were proposed in this pull request? https://github.com/apache/spark/pull/7355 add support casting between IntervalType and StringType for scala interface: ```scala import org.apache.spark.sql.types._ import org.apache.spark.sql.catalyst.expressions._ Cast(Literal("interval 3 month 1 hours"), CalendarIntervalType).eval() res0: Any = interval 3 months 1 hours ``` But SQL interface does not support it: ```sql scala> spark.sql("SELECT CAST('interval 3 month 1 hour' AS interval)").show org.apache.spark.sql.catalyst.parser.ParseException: DataType interval is not supported.(line 1, pos 41) == SQL == SELECT CAST('interval 3 month 1 hour' AS interval) -----------------------------------------^^^ at org.apache.spark.sql.catalyst.parser.AstBuilder.$anonfun$visitPrimitiveDataType$1(AstBuilder.scala:1931) at org.apache.spark.sql.catalyst.parser.ParserUtils$.withOrigin(ParserUtils.scala:108) at org.apache.spark.sql.catalyst.parser.AstBuilder.visitPrimitiveDataType(AstBuilder.scala:1909) at org.apache.spark.sql.catalyst.parser.AstBuilder.visitPrimitiveDataType(AstBuilder.scala:52) ... ``` This PR add supports accepting the `interval` keyword in the schema string. So that SQL interface can support this feature. ## How was this patch tested? unit tests Closes #25189 from wangyum/SPARK-28435. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> |
||
|
|
a3bbc371cb |
[SPARK-28421][ML] SparseVector.apply performance optimization
## What changes were proposed in this pull request?
optimize the `SparseVector.apply` by avoiding internal conversion
Since the speed up is significant (2.5X ~ 5X), and this method is widely used in ml, I suggest back porting.
| size| nnz | apply(old) | apply2(new impl) | apply3(new impl with extra range check)|
|------|----------|------------|----------|----------|
|10000000|100|75294|12208|18682|
|10000000|10000|75616|23132|32932|
|10000000|1000000|92949|42529|48821|
## How was this patch tested?
existing tests
using following code to test performance (here the new impl is named `apply2`, and another impl with extra range check is named `apply3`):
```
import scala.util.Random
import org.apache.spark.ml.linalg._
val size = 10000000
for (nnz <- Seq(100, 10000, 1000000)) {
val rng = new Random(123)
val indices = Array.fill(nnz + nnz)(rng.nextInt.abs % size).distinct.take(nnz).sorted
val values = Array.fill(nnz)(rng.nextDouble)
val vec = Vectors.sparse(size, indices, values).toSparse
val tic1 = System.currentTimeMillis;
(0 until 100).foreach{ round => var i = 0; var sum = 0.0; while(i < size) {sum+=vec(i); i+=1} };
val toc1 = System.currentTimeMillis;
val tic2 = System.currentTimeMillis;
(0 until 100).foreach{ round => var i = 0; var sum = 0.0; while(i < size) {sum+=vec.apply2(i); i+=1} };
val toc2 = System.currentTimeMillis;
val tic3 = System.currentTimeMillis;
(0 until 100).foreach{ round => var i = 0; var sum = 0.0; while(i < size) {sum+=vec.apply3(i); i+=1} };
val toc3 = System.currentTimeMillis;
println((size, nnz, toc1 - tic1, toc2 - tic2, toc3 - tic3))
}
```
Closes #25178 from zhengruifeng/sparse_vec_apply.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
|
||
|
|
b83b7927b3 |
[SPARK-27234][SS][PYTHON] Use InheritableThreadLocal for current epoch in EpochTracker (to support Python UDFs)
## What changes were proposed in this pull request? This PR proposes to use `InheritableThreadLocal` instead of `ThreadLocal` for current epoch in `EpochTracker`. Python UDF needs threads to write out to and read it from Python processes and when there are new threads, previously set epoch is lost. After this PR, Python UDFs can be used at Structured Streaming with the continuous mode. ## How was this patch tested? The test cases were written on the top of https://github.com/apache/spark/pull/24945. Unit tests were added. Manual tests. Closes #24946 from HyukjinKwon/SPARK-27234. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> |
||
|
|
86dad404bd |
[SPARK-28391][SQL][PYTHON][TESTS] Convert and port 'pgSQL/select_implicit.sql' into UDF test base
## What changes were proposed in this pull request? This PR adds some tests converted from 'pgSQL/select_implicit.sql' to test UDFs <details><summary>Diff comparing to 'pgSQL/select_implicit.sql'</summary> <p> ```diff ... diff --git a/sql/core/src/test/resources/sql-tests/results/pgSQL/select_implicit.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-select_implicit.sql.out index 0675820..e6a5995 100755 --- a/sql/core/src/test/resources/sql-tests/results/pgSQL/select_implicit.sql.out +++ b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-select_implicit.sql.out -91,9 +91,11 struct<> -- !query 11 -SELECT c, count(*) FROM test_missing_target GROUP BY test_missing_target.c ORDER BY c +SELECT udf(c), udf(count(*)) FROM test_missing_target GROUP BY +test_missing_target.c +ORDER BY udf(c) -- !query 11 schema -struct<c:string,count(1):bigint> +struct<CAST(udf(cast(c as string)) AS STRING):string,CAST(udf(cast(count(1) as string)) AS BIGINT):bigint> -- !query 11 output ABAB 2 BBBB 2 -104,9 +106,10 cccc 2 -- !query 12 -SELECT count(*) FROM test_missing_target GROUP BY test_missing_target.c ORDER BY c +SELECT udf(count(*)) FROM test_missing_target GROUP BY test_missing_target.c +ORDER BY udf(c) -- !query 12 schema -struct<count(1):bigint> +struct<CAST(udf(cast(count(1) as string)) AS BIGINT):bigint> -- !query 12 output 2 2 -117,18 +120,18 struct<count(1):bigint> -- !query 13 -SELECT count(*) FROM test_missing_target GROUP BY a ORDER BY b +SELECT udf(count(*)) FROM test_missing_target GROUP BY a ORDER BY udf(b) -- !query 13 schema struct<> -- !query 13 output org.apache.spark.sql.AnalysisException -cannot resolve '`b`' given input columns: [count(1)]; line 1 pos 61 +cannot resolve '`b`' given input columns: [CAST(udf(cast(count(1) as string)) AS BIGINT)]; line 1 pos 70 -- !query 14 -SELECT count(*) FROM test_missing_target GROUP BY b ORDER BY b +SELECT udf(count(*)) FROM test_missing_target GROUP BY b ORDER BY udf(b) -- !query 14 schema -struct<count(1):bigint> +struct<CAST(udf(cast(count(1) as string)) AS BIGINT):bigint> -- !query 14 output 1 2 -137,10 +140,10 struct<count(1):bigint> -- !query 15 -SELECT test_missing_target.b, count(*) - FROM test_missing_target GROUP BY b ORDER BY b +SELECT udf(test_missing_target.b), udf(count(*)) + FROM test_missing_target GROUP BY b ORDER BY udf(b) -- !query 15 schema -struct<b:int,count(1):bigint> +struct<CAST(udf(cast(b as string)) AS INT):int,CAST(udf(cast(count(1) as string)) AS BIGINT):bigint> -- !query 15 output 1 1 2 2 -149,9 +152,9 struct<b:int,count(1):bigint> -- !query 16 -SELECT c FROM test_missing_target ORDER BY a +SELECT udf(c) FROM test_missing_target ORDER BY udf(a) -- !query 16 schema -struct<c:string> +struct<CAST(udf(cast(c as string)) AS STRING):string> -- !query 16 output XXXX ABAB -166,9 +169,9 CCCC -- !query 17 -SELECT count(*) FROM test_missing_target GROUP BY b ORDER BY b desc +SELECT udf(count(*)) FROM test_missing_target GROUP BY b ORDER BY udf(b) desc -- !query 17 schema -struct<count(1):bigint> +struct<CAST(udf(cast(count(1) as string)) AS BIGINT):bigint> -- !query 17 output 4 3 -177,17 +180,17 struct<count(1):bigint> -- !query 18 -SELECT count(*) FROM test_missing_target ORDER BY 1 desc +SELECT udf(count(*)) FROM test_missing_target ORDER BY udf(1) desc -- !query 18 schema -struct<count(1):bigint> +struct<CAST(udf(cast(count(1) as string)) AS BIGINT):bigint> -- !query 18 output 10 -- !query 19 -SELECT c, count(*) FROM test_missing_target GROUP BY 1 ORDER BY 1 +SELECT udf(c), udf(count(*)) FROM test_missing_target GROUP BY 1 ORDER BY 1 -- !query 19 schema -struct<c:string,count(1):bigint> +struct<CAST(udf(cast(c as string)) AS STRING):string,CAST(udf(cast(count(1) as string)) AS BIGINT):bigint> -- !query 19 output ABAB 2 BBBB 2 -198,18 +201,18 cccc 2 -- !query 20 -SELECT c, count(*) FROM test_missing_target GROUP BY 3 +SELECT udf(c), udf(count(*)) FROM test_missing_target GROUP BY 3 -- !query 20 schema struct<> -- !query 20 output org.apache.spark.sql.AnalysisException -GROUP BY position 3 is not in select list (valid range is [1, 2]); line 1 pos 53 +GROUP BY position 3 is not in select list (valid range is [1, 2]); line 1 pos 63 -- !query 21 -SELECT count(*) FROM test_missing_target x, test_missing_target y - WHERE x.a = y.a - GROUP BY b ORDER BY b +SELECT udf(count(*)) FROM test_missing_target x, test_missing_target y + WHERE udf(x.a) = udf(y.a) + GROUP BY b ORDER BY udf(b) -- !query 21 schema struct<> -- !query 21 output -218,10 +221,10 Reference 'b' is ambiguous, could be: x.b, y.b.; line 3 pos 10 -- !query 22 -SELECT a, a FROM test_missing_target - ORDER BY a +SELECT udf(a), udf(a) FROM test_missing_target + ORDER BY udf(a) -- !query 22 schema -struct<a:int,a:int> +struct<CAST(udf(cast(a as string)) AS INT):int,CAST(udf(cast(a as string)) AS INT):int> -- !query 22 output 0 0 1 1 -236,10 +239,10 struct<a:int,a:int> -- !query 23 -SELECT a/2, a/2 FROM test_missing_target - ORDER BY a/2 +SELECT udf(udf(a)/2), udf(udf(a)/2) FROM test_missing_target + ORDER BY udf(udf(a)/2) -- !query 23 schema -struct<(a div 2):int,(a div 2):int> +struct<CAST(udf(cast((cast(udf(cast(a as string)) as int) div 2) as string)) AS INT):int,CAST(udf(cast((cast(udf(cast(a as string)) as int) div 2) as string)) AS INT):int> -- !query 23 output 0 0 0 0 -254,10 +257,10 struct<(a div 2):int,(a div 2):int> -- !query 24 -SELECT a/2, a/2 FROM test_missing_target - GROUP BY a/2 ORDER BY a/2 +SELECT udf(a/2), udf(a/2) FROM test_missing_target + GROUP BY a/2 ORDER BY udf(a/2) -- !query 24 schema -struct<(a div 2):int,(a div 2):int> +struct<CAST(udf(cast((a div 2) as string)) AS INT):int,CAST(udf(cast((a div 2) as string)) AS INT):int> -- !query 24 output 0 0 1 1 -267,11 +270,11 struct<(a div 2):int,(a div 2):int> -- !query 25 -SELECT x.b, count(*) FROM test_missing_target x, test_missing_target y - WHERE x.a = y.a - GROUP BY x.b ORDER BY x.b +SELECT udf(x.b), udf(count(*)) FROM test_missing_target x, test_missing_target y + WHERE udf(x.a) = udf(y.a) + GROUP BY x.b ORDER BY udf(x.b) -- !query 25 schema -struct<b:int,count(1):bigint> +struct<CAST(udf(cast(b as string)) AS INT):int,CAST(udf(cast(count(1) as string)) AS BIGINT):bigint> -- !query 25 output 1 1 2 2 -280,11 +283,11 struct<b:int,count(1):bigint> -- !query 26 -SELECT count(*) FROM test_missing_target x, test_missing_target y - WHERE x.a = y.a - GROUP BY x.b ORDER BY x.b +SELECT udf(count(*)) FROM test_missing_target x, test_missing_target y + WHERE udf(x.a) = udf(y.a) + GROUP BY x.b ORDER BY udf(x.b) -- !query 26 schema -struct<count(1):bigint> +struct<CAST(udf(cast(count(1) as string)) AS BIGINT):bigint> -- !query 26 output 1 2 -293,22 +296,22 struct<count(1):bigint> -- !query 27 -SELECT a%2, count(b) FROM test_missing_target +SELECT a%2, udf(count(udf(b))) FROM test_missing_target GROUP BY test_missing_target.a%2 -ORDER BY test_missing_target.a%2 +ORDER BY udf(test_missing_target.a%2) -- !query 27 schema -struct<(a % 2):int,count(b):bigint> +struct<(a % 2):int,CAST(udf(cast(count(cast(udf(cast(b as string)) as int)) as string)) AS BIGINT):bigint> -- !query 27 output 0 5 1 5 -- !query 28 -SELECT count(c) FROM test_missing_target +SELECT udf(count(c)) FROM test_missing_target GROUP BY lower(test_missing_target.c) -ORDER BY lower(test_missing_target.c) +ORDER BY udf(lower(test_missing_target.c)) -- !query 28 schema -struct<count(c):bigint> +struct<CAST(udf(cast(count(c) as string)) AS BIGINT):bigint> -- !query 28 output 2 3 -317,18 +320,18 struct<count(c):bigint> -- !query 29 -SELECT count(a) FROM test_missing_target GROUP BY a ORDER BY b +SELECT udf(count(udf(a))) FROM test_missing_target GROUP BY a ORDER BY udf(b) -- !query 29 schema struct<> -- !query 29 output org.apache.spark.sql.AnalysisException -cannot resolve '`b`' given input columns: [count(a)]; line 1 pos 61 +cannot resolve '`b`' given input columns: [CAST(udf(cast(count(cast(udf(cast(a as string)) as int)) as string)) AS BIGINT)]; line 1 pos 75 -- !query 30 -SELECT count(b) FROM test_missing_target GROUP BY b/2 ORDER BY b/2 +SELECT udf(count(b)) FROM test_missing_target GROUP BY b/2 ORDER BY udf(b/2) -- !query 30 schema -struct<count(b):bigint> +struct<CAST(udf(cast(count(b) as string)) AS BIGINT):bigint> -- !query 30 output 1 5 -336,10 +339,10 struct<count(b):bigint> -- !query 31 -SELECT lower(test_missing_target.c), count(c) - FROM test_missing_target GROUP BY lower(c) ORDER BY lower(c) +SELECT udf(lower(test_missing_target.c)), udf(count(udf(c))) + FROM test_missing_target GROUP BY lower(c) ORDER BY udf(lower(c)) -- !query 31 schema -struct<lower(c):string,count(c):bigint> +struct<CAST(udf(cast(lower(c) as string)) AS STRING):string,CAST(udf(cast(count(cast(udf(cast(c as string)) as string)) as string)) AS BIGINT):bigint> -- !query 31 output abab 2 bbbb 3 -348,9 +351,9 xxxx 1 -- !query 32 -SELECT a FROM test_missing_target ORDER BY upper(d) +SELECT udf(a) FROM test_missing_target ORDER BY udf(upper(udf(d))) -- !query 32 schema -struct<a:int> +struct<CAST(udf(cast(a as string)) AS INT):int> -- !query 32 output 0 1 -365,19 +368,19 struct<a:int> -- !query 33 -SELECT count(b) FROM test_missing_target - GROUP BY (b + 1) / 2 ORDER BY (b + 1) / 2 desc +SELECT udf(count(b)) FROM test_missing_target + GROUP BY (b + 1) / 2 ORDER BY udf((b + 1) / 2) desc -- !query 33 schema -struct<count(b):bigint> +struct<CAST(udf(cast(count(b) as string)) AS BIGINT):bigint> -- !query 33 output 7 3 -- !query 34 -SELECT count(x.a) FROM test_missing_target x, test_missing_target y - WHERE x.a = y.a - GROUP BY b/2 ORDER BY b/2 +SELECT udf(count(udf(x.a))) FROM test_missing_target x, test_missing_target y + WHERE udf(x.a) = udf(y.a) + GROUP BY b/2 ORDER BY udf(b/2) -- !query 34 schema struct<> -- !query 34 output -386,11 +389,12 Reference 'b' is ambiguous, could be: x.b, y.b.; line 3 pos 10 -- !query 35 -SELECT x.b/2, count(x.b) FROM test_missing_target x, test_missing_target y - WHERE x.a = y.a - GROUP BY x.b/2 ORDER BY x.b/2 +SELECT udf(x.b/2), udf(count(udf(x.b))) FROM test_missing_target x, +test_missing_target y + WHERE udf(x.a) = udf(y.a) + GROUP BY x.b/2 ORDER BY udf(x.b/2) -- !query 35 schema -struct<(b div 2):int,count(b):bigint> +struct<CAST(udf(cast((b div 2) as string)) AS INT):int,CAST(udf(cast(count(cast(udf(cast(b as string)) as int)) as string)) AS BIGINT):bigint> -- !query 35 output 0 1 1 5 -398,14 +402,14 struct<(b div 2):int,count(b):bigint> -- !query 36 -SELECT count(b) FROM test_missing_target x, test_missing_target y - WHERE x.a = y.a +SELECT udf(count(udf(b))) FROM test_missing_target x, test_missing_target y + WHERE udf(x.a) = udf(y.a) GROUP BY x.b/2 -- !query 36 schema struct<> -- !query 36 output org.apache.spark.sql.AnalysisException -Reference 'b' is ambiguous, could be: x.b, y.b.; line 1 pos 13 +Reference 'b' is ambiguous, could be: x.b, y.b.; line 1 pos 21 -- !query 37 ``` </p> </details> ## How was this patch tested? Tested as Guided in SPARK-27921 Closes #25233 from Udbhav30/master. Authored-by: Udbhav30 <u.agrawal30@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}