### What changes were proposed in this pull request?
A small fix to the Maven build file under the `assembly` module by switch "dir" attribute to "file".
### Why are the changes needed?
To make the `<delete>` task properly delete an existing zip file.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Ran a build with the change and confirmed that a corrupted zip file was replaced with the correct one.
Closes#27171 from jeff303/SPARK-30489.
Authored-by: Jeff Evans <jeffrey.wayne.evans@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Removing the sorting of PySpark SQL Row fields that were previously sorted by name alphabetically for Python versions 3.6 and above. Field order will now match that as entered. Rows will be used like tuples and are applied to schema by position. For Python versions < 3.6, the order of kwargs is not guaranteed and therefore will be sorted automatically as in previous versions of Spark.
### Why are the changes needed?
This caused inconsistent behavior in that local Rows could be applied to a schema by matching names, but once serialized the Row could only be used by position and the fields were possibly in a different order.
### Does this PR introduce any user-facing change?
Yes, Row fields are no longer sorted alphabetically but will be in the order entered. For Python < 3.6 `kwargs` can not guarantee the order as entered, so `Row`s will be automatically sorted.
An environment variable "PYSPARK_ROW_FIELD_SORTING_ENABLED" can be set that will override construction of `Row` to maintain compatibility with Spark 2.x.
### How was this patch tested?
Existing tests are run with PYSPARK_ROW_FIELD_SORTING_ENABLED=true and added new test with unsorted fields for Python 3.6+
Closes#26496 from BryanCutler/pyspark-remove-Row-sorting-SPARK-29748.
Authored-by: Bryan Cutler <cutlerb@gmail.com>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
### What changes were proposed in this pull request?
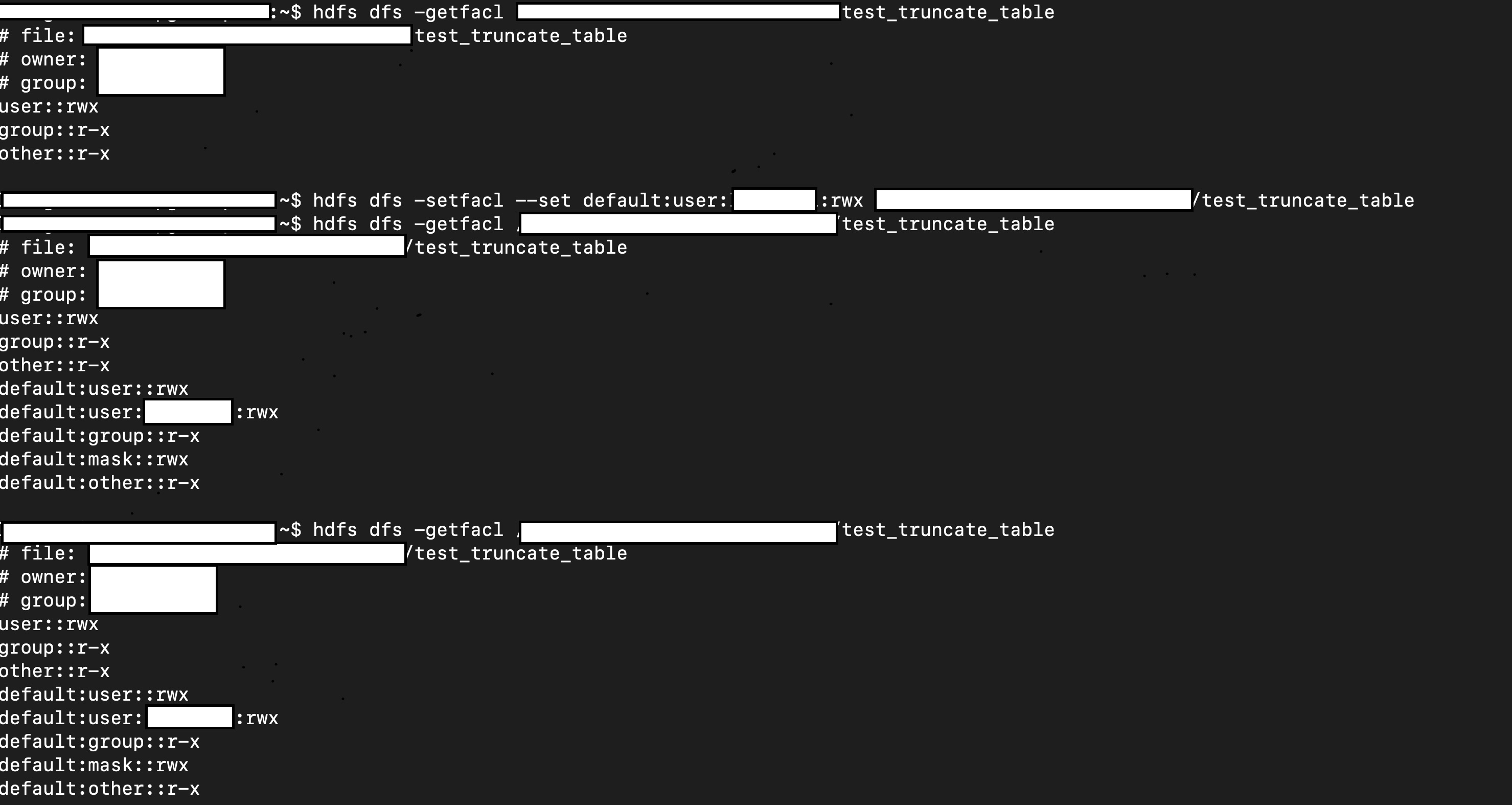
This patch proposes to preserve existing permission/acls of paths when truncate table/partition.
### Why are the changes needed?
When Spark SQL truncates table, it deletes the paths of table/partitions, then re-create new ones. If permission/acls were set on the paths, the existing permission/acls will be deleted.
We should preserve the permission/acls if possible.
### Does this PR introduce any user-facing change?
Yes. When truncate table/partition, Spark will keep permission/acls of paths.
### How was this patch tested?
Unit test.
Manual test:
1. Create a table.
2. Manually change it permission/acl
3. Truncate table
4. Check permission/acl
```scala
val df = Seq(1, 2, 3).toDF
df.write.mode("overwrite").saveAsTable("test.test_truncate_table")
val testTable = spark.table("test.test_truncate_table")
testTable.show()
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
+-----+
// hdfs dfs -setfacl ...
// hdfs dfs -getfacl ...
sql("truncate table test.test_truncate_table")
// hdfs dfs -getfacl ...
val testTable2 = spark.table("test.test_truncate_table")
testTable2.show()
+-----+
|value|
+-----+
+-----+
```
Closes#26956 from viirya/truncate-table-permission.
Lead-authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Co-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This patch proposes to compact old event log files when end users enable rolling event log, and clean up these files after compaction.
Here the "compaction" really mean is filtering out listener events for finished/removed things - like jobs which take most of space for event log file except SQL related events. To achieve this, compactor does two phases reading: 1) tracking the live jobs (and more to add) 2) filtering events via leveraging the information about live things and rewriting to the "compacted" file.
This approach retains the ability of compatibility on event log file and adds the possibility of reducing the overall size of event logs. There's a downside here as well: executor metrics for tasks would be inaccurate, as compactor will filter out the task events which job is finished, but I don't feel it as a blocker.
Please note that SPARK-29779 leaves below functionalities for future JIRA issue as the patch for SPARK-29779 is too huge and we decided to break down:
* apply filter in SQL events
* integrate compaction into FsHistoryProvider
* documentation about new configuration
### Why are the changes needed?
One of major goal of SPARK-28594 is to prevent the event logs to become too huge, and SPARK-29779 achieves the goal. We've got another approach in prior, but the old approach required models in both KVStore and live entities to guarantee compatibility, while they're not designed to do so.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Added UTs.
Closes#27085 from HeartSaVioR/SPARK-29779-part1.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
Currently data columns are displayed in one line for show create table command, when the table has many columns (to make things even worse, columns may have long names or comments), the displayed result is really hard to read.
To improve readability, we print each column in a separate line. Note that other systems like Hive/MySQL also display in this way.
Also, for data columns, table properties and options, we put the right parenthesis to the end of the last column/property/option, instead of occupying a separate line.
### Why are the changes needed?
for better readability
### Does this PR introduce any user-facing change?
before the change:
```
spark-sql> show create table test_table;
CREATE TABLE `test_table` (`col1` INT COMMENT 'This is comment for column 1', `col2` STRING COMMENT 'This is comment for column 2', `col3` DOUBLE COMMENT 'This is comment for column 3')
USING parquet
OPTIONS (
`bar` '2',
`foo` '1'
)
TBLPROPERTIES (
'a' = 'x',
'b' = 'y'
)
```
after the change:
```
spark-sql> show create table test_table;
CREATE TABLE `test_table` (
`col1` INT COMMENT 'This is comment for column 1',
`col2` STRING COMMENT 'This is comment for column 2',
`col3` DOUBLE COMMENT 'This is comment for column 3')
USING parquet
OPTIONS (
`bar` '2',
`foo` '1')
TBLPROPERTIES (
'a' = 'x',
'b' = 'y')
```
### How was this patch tested?
modified existing tests
Closes#27147 from wzhfy/multi_line_columns.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This pr intends to skip the unnecessary checks that most aggregate quries don't need in RewriteDistinctAggregates.
### Why are the changes needed?
For minor optimization.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#26997 from maropu/OptDistinctAggRewrite.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR is to make sure cores is the limiting resource when using accelerator aware scheduling and fix a few issues with SparkContext.checkResourcesPerTask
For the first version of accelerator aware scheduling(SPARK-27495), the SPIP had a condition that we can support dynamic allocation because we were going to have a strict requirement that we don't waste any resources. This means that the number of slots each executor has could be calculated from the number of cores and task cpus just as is done today.
Somewhere along the line of development we relaxed that and only warn when we are wasting resources. This breaks the dynamic allocation logic if the limiting resource is no longer the cores because its using the cores and task cpus to calculate the number of executors it needs. This means we will request less executors then we really need to run everything. We have to enforce that cores is always the limiting resource so we should throw if its not.
The only issue with us enforcing this is on cluster managers (standalone and mesos coarse grained) where we don't know the executor cores up front by default. Meaning the spark.executor.cores config defaults to 1 but when the executor is started by default it gets all the cores of the Worker. So we have to add logic specifically to handle that and we can't enforce this requirements, we can just warn when dynamic allocation is enabled for those.
### Why are the changes needed?
Bug in dynamic allocation if cores is not limiting resource and warnings not correct.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
Unit test added and manually tested the confiditions on local mode, local cluster mode, standalone mode, and yarn.
Closes#27138 from tgravescs/SPARK-30446.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
Now users can add directories from sql CLI as well using ADD FILE command and setting spark.sql.addDirectory.recursive to true.
### Why are the changes needed?
In SPARK-4687, support was added for adding directories as resources. But sql users cannot use that feature from CLI.
`ADD FILE /path/to/folder` gives the following error:
`org.apache.spark.SparkException: Added file /path/to/folder is a directory and recursive is not turned on.`
Users need to turn on `recursive` for adding directories. Thus a configuration was required which will allow users to turn on `recursive`.
Also Hive allow users to add directories from their shell.
### Does this PR introduce any user-facing change?
Yes. Users can set recursive using `spark.sql.addDirectory.recursive`.
### How was this patch tested?
Manually.
Will add test cases soon.
SPARK SCREENSHOTS
When `spark.sql.addDirectory.recursive` is not turned on.
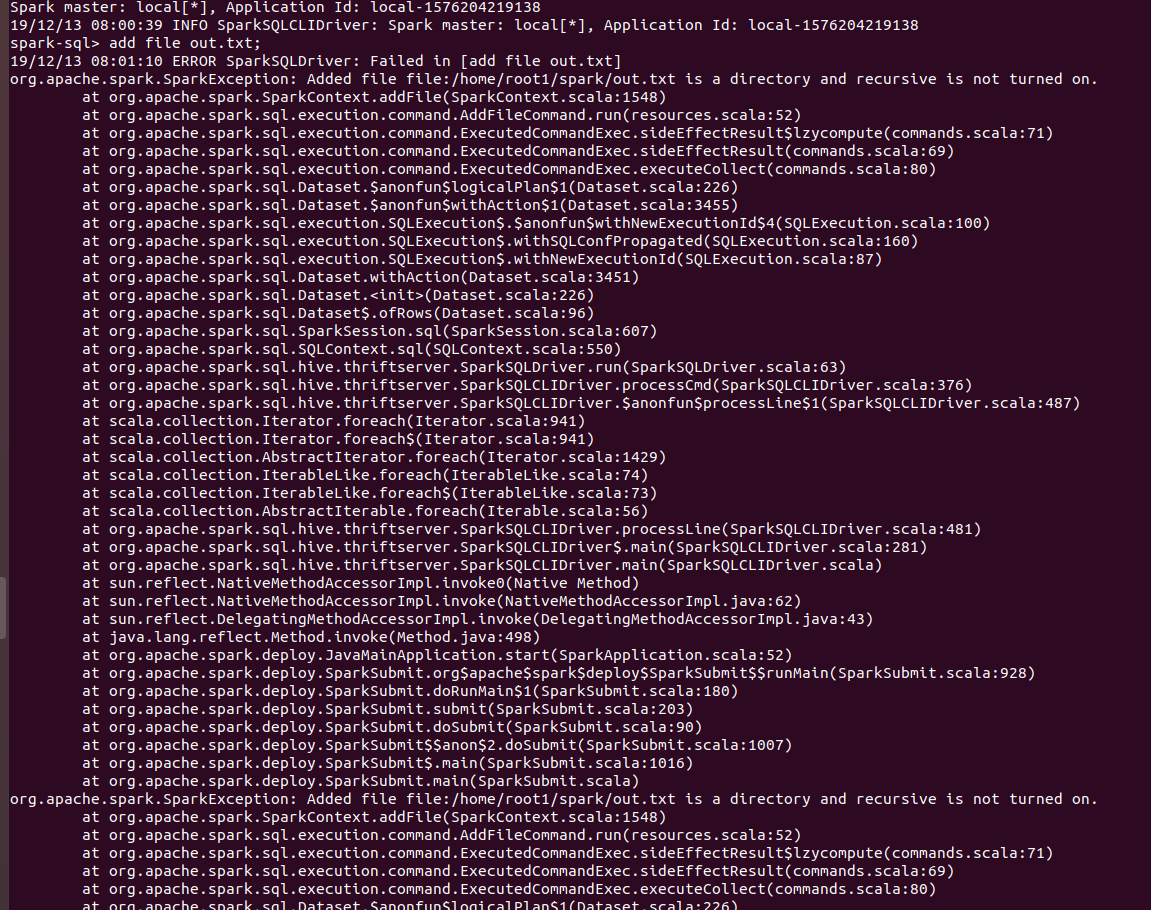
After setting `spark.sql.addDirectory.recursive` to true.

HIVE SCREENSHOT

`RELEASE_NOTES.txt` is text file while `dummy` is a directory.
Closes#26863 from iRakson/SPARK-30234.
Lead-authored-by: root1 <raksonrakesh@gmail.com>
Co-authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR fixes `ConstantPropagation` rule as the current implementation produce incorrect results in some cases. E.g.
```
SELECT * FROM t WHERE NOT(c = 1 AND c + 1 = 1)
```
returns those rows where `c` is null due to `1 + 1 = 1` propagation but it shouldn't.
## Why are the changes needed?
To fix a bug.
## Does this PR introduce any user-facing change?
Yes, fixes a bug.
## How was this patch tested?
New UTs.
Closes#27119 from peter-toth/SPARK-30447.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
In this pull request, we are going to support `SET OWNER` syntax for databases and namespaces,
```sql
ALTER (DATABASE|SCHEME|NAMESPACE) database_name SET OWNER [USER|ROLE|GROUP] user_or_role_group;
```
Before this commit 332e252a14, we didn't care much about ownerships for the catalog objects. In 332e252a14, we determined to use properties to store ownership staff, and temporarily used `alter database ... set dbproperties ...` to support switch ownership of a database. This PR aims to use the formal syntax to replace it.
In hive, `ownerName/Type` are fields of the database objects, also they can be normal properties.
```
create schema test1 with dbproperties('ownerName'='yaooqinn')
```
The create/alter database syntax will not change the owner to `yaooqinn` but store it in parameters. e.g.
```
+----------+----------+---------------------------------------------------------------+-------------+-------------+-----------------------+--+
| db_name | comment | location | owner_name | owner_type | parameters |
+----------+----------+---------------------------------------------------------------+-------------+-------------+-----------------------+--+
| test1 | | hdfs://quickstart.cloudera:8020/user/hive/warehouse/test1.db | anonymous | USER | {ownerName=yaooqinn} |
+----------+----------+---------------------------------------------------------------+-------------+-------------+-----------------------+--+
```
In this pull request, because we let the `ownerName` become reversed, so it will neither change the owner nor store in dbproperties, just be omitted silently.
## Why are the changes needed?
Formal syntax support for changing database ownership
### Does this PR introduce any user-facing change?
yes, add a new syntax
### How was this patch tested?
add unit tests
Closes#26775 from yaooqinn/SPARK-30018.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch increases the memory limit in the test 'test_memory_limit' from 1m to 8m.
Credit to srowen and HyukjinKwon to provide the idea of suspicion and guide how to fix.
### Why are the changes needed?
We observed consistent Pyspark test failures on multiple PRs (#26955, #26201, #27064) which block the PR builds whenever the test is included.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Jenkins builds passed in WIP PR (#27159)
Closes#27162 from HeartSaVioR/SPARK-30480.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Allow users to specify NOT NULL in CREATE TABLE and ADD COLUMN column definition, and add a new SQL syntax to alter column nullability: ALTER TABLE ... ALTER COLUMN SET/DROP NOT NULL. This is a SQL standard syntax:
```
<alter column definition> ::=
ALTER [ COLUMN ] <column name> <alter column action>
<alter column action> ::=
<set column default clause>
| <drop column default clause>
| <set column not null clause>
| <drop column not null clause>
| ...
<set column not null clause> ::=
SET NOT NULL
<drop column not null clause> ::=
DROP NOT NULL
```
### Why are the changes needed?
Previously we don't support it because the table schema in hive catalog are always nullable. Since we have catalog plugin now, it makes more sense to support NOT NULL at spark side, and let catalog implementations to decide if they support it or not.
### Does this PR introduce any user-facing change?
Yes, this is a new feature
### How was this patch tested?
new tests
Closes#27110 from cloud-fan/nullable.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. Put all deprecated SQL configs the map `SQLConf.deprecatedSQLConfigs` with extra info about when configs were deprecated and additional comments that explain why a config was deprecated, what an user can use instead of it. Here is the list of already deprecated configs:
- spark.sql.hive.verifyPartitionPath
- spark.sql.execution.pandas.respectSessionTimeZone
- spark.sql.legacy.execution.pandas.groupedMap.assignColumnsByName
- spark.sql.parquet.int64AsTimestampMillis
- spark.sql.variable.substitute.depth
- spark.sql.execution.arrow.enabled
- spark.sql.execution.arrow.fallback.enabled
2. Output warning in `set()` and `unset()` about deprecated SQL configs
### Why are the changes needed?
This should improve UX with Spark SQL and notify users about already deprecated SQL configs.
### Does this PR introduce any user-facing change?
Yes, before:
```
spark-sql> set spark.sql.hive.verifyPartitionPath=true;
spark.sql.hive.verifyPartitionPath true
```
After:
```
spark-sql> set spark.sql.hive.verifyPartitionPath=true;
20/01/03 21:28:17 WARN RuntimeConfig: The SQL config 'spark.sql.hive.verifyPartitionPath' has been deprecated in Spark v3.0.0 and may be removed in the future. This config is replaced by spark.files.ignoreMissingFiles.
spark.sql.hive.verifyPartitionPath true
```
### How was this patch tested?
Add new test which registers new log appender and catches all logging to check that `set()` and `unset()` log any warning.
Closes#27092 from MaxGekk/group-deprecated-sql-configs.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
fixing a broken build:
https://amplab.cs.berkeley.edu/jenkins/job/spark-master-test-sbt-hadoop-2.7-hive-1.2/3/console
### Why are the changes needed?
the build is teh borked!
### Does this PR introduce any user-facing change?
newp
### How was this patch tested?
by the build system
Closes#27156 from shaneknapp/fix-scala-style.
Authored-by: shane knapp <incomplete@gmail.com>
Signed-off-by: shane knapp <incomplete@gmail.com>
### What changes were proposed in this pull request?
Fix ignoreMissingFiles/ignoreCorruptFiles in DSv2:
When `FilePartitionReader` finds a missing or corrupt file, it should just skip and continue to read next file rather than stop with current behavior.
### Why are the changes needed?
ignoreMissingFiles/ignoreCorruptFiles in DSv2 is wrong comparing to DSv1.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Updated existed test for `ignoreMissingFiles`. Note I didn't update tests for `ignoreCorruptFiles`, because there're various datasources has tests for `ignoreCorruptFiles`. So I'm not sure if it's worth to touch all those tests since the basic logic of `ignoreCorruptFiles` should be same with `ignoreMissingFiles`.
Closes#27136 from Ngone51/improve-missing-files.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
This PR introduces `SupportsCatalogOptions` as an interface for `TableProvider`. Through `SupportsCatalogOptions`, V2 DataSources can implement the two methods `extractIdentifier` and `extractCatalog` to support the creation, and existence check of tables without requiring a formal TableCatalog implementation.
We currently don't support all SaveModes for DataSourceV2 in DataFrameWriter.save. The idea here is that eventually File based tables can be written with `DataFrameWriter.save(path)` will create a PathIdentifier where the name is `path`, and the V2SessionCatalog will be able to perform FileSystem checks at `path` to support ErrorIfExists and Ignore SaveModes.
### Why are the changes needed?
To support all Save modes for V2 data sources with DataFrameWriter. Since we can now support table creation, we will be able to provide partitioning information when first creating the table as well.
### Does this PR introduce any user-facing change?
Introduces a new interface
### How was this patch tested?
Will add tests once interface is vetted.
Closes#26913 from brkyvz/catalogOptions.
Lead-authored-by: Burak Yavuz <brkyvz@gmail.com>
Co-authored-by: Burak Yavuz <burak@databricks.com>
Signed-off-by: Burak Yavuz <brkyvz@gmail.com>
### What changes were proposed in this pull request?
Add ```predict``` and ```numFeatures``` in Python ```IsotonicRegressionModel```
### Why are the changes needed?
```IsotonicRegressionModel``` doesn't extend ```JavaPredictionModel```, so it doesn't get ```predict``` and ```numFeatures``` from the super class.
### Does this PR introduce any user-facing change?
Yes. Python version of
```
IsotonicRegressionModel.predict
IsotonicRegressionModel.numFeatures
```
### How was this patch tested?
doctest
Closes#27122 from huaxingao/spark-30452.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
File source V2: support partition pruning.
Note: subquery predicates are not pushed down for partition pruning even after this PR, due to the limitation for the current data source V2 API and framework. The rule `PlanSubqueries` requires the subquery expression to be in the children or class parameters in `SparkPlan`, while the condition is not satisfied for `BatchScanExec`.
### Why are the changes needed?
It's important for reading performance.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
New unit tests for all the V2 file sources
Closes#27112 from gengliangwang/PartitionPruningInFileScan.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
https://github.com/apache/spark/pull/24997 missed to add `pyspark.sql.tests.test_pandas_udf_iter` to `modules.py`. This PR adds it.
### Why are the changes needed?
Currently, Jenkins does not run the test cases. We should run them.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Jenkins should test.
Closes#27141 from HyukjinKwon/SPARK-28198-followup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The regex is to exclude the .git folder for the python linter, but bash escaping caused only one forward slash to be included. This adds the necessary second slash.
### Why are the changes needed?
This is necessary to properly match the file separator character.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Manually.
Added File dev/something.git.py and ran `dev/lint-python`
```dev/lint-python
pycodestyle checks failed.
*** Error compiling './dev/something.git.py'...
File "./dev/something.git.py", line 1
mport asdf2
^
SyntaxError: invalid syntax```
Closes#27140 from ericfchang/master.
Authored-by: Eric Chang <eric.chang@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Currently, COMMENT and LOCATION are reserved properties for Datasource v2 namespaces. They can be set via specific clauses and via properties. And the ones specified in clauses take precede of properties. Since they are reserved, which means they are not able to visit directly. They should be used in COMMENT/LOCATION clauses ONLY.
### Why are the changes needed?
make reserved properties be reserved.
### Does this PR introduce any user-facing change?
yes, 'location', 'comment' are not allowed use in db properties
### How was this patch tested?
UNIT tests.
Closes#26806 from yaooqinn/SPARK-30183.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR adds a note that we're not adding "pandas compatible" aliases anymore.
### Why are the changes needed?
We added "pandas compatible" aliases as of https://github.com/apache/spark/pull/5544 and https://github.com/apache/spark/pull/6066 . There are too many differences and I don't think it makes sense to add such aliases anymore at this moment.
I was even considering deprecating them out but decided to take a more conservative approache by just documenting it.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests should cover.
Closes#27142 from HyukjinKwon/SPARK-30464.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to move pandas related functionalities into pandas package. Namely:
```bash
pyspark/sql/pandas
├── __init__.py
├── conversion.py # Conversion between pandas <> PySpark DataFrames
├── functions.py # pandas_udf
├── group_ops.py # Grouped UDF / Cogrouped UDF + groupby.apply, groupby.cogroup.apply
├── map_ops.py # Map Iter UDF + mapInPandas
├── serializers.py # pandas <> PyArrow serializers
├── types.py # Type utils between pandas <> PyArrow
└── utils.py # Version requirement checks
```
In order to separately locate `groupby.apply`, `groupby.cogroup.apply`, `mapInPandas`, `toPandas`, and `createDataFrame(pdf)` under `pandas` sub-package, I had to use a mix-in approach which Scala side uses often by `trait`, and also pandas itself uses this approach (see `IndexOpsMixin` as an example) to group related functionalities. Currently, you can think it's like Scala's self typed trait. See the structure below:
```python
class PandasMapOpsMixin(object):
def mapInPandas(self, ...):
...
return ...
# other Pandas <> PySpark APIs
```
```python
class DataFrame(PandasMapOpsMixin):
# other DataFrame APIs equivalent to Scala side.
```
Yes, This is a big PR but they are mostly just moving around except one case `createDataFrame` which I had to split the methods.
### Why are the changes needed?
There are pandas functionalities here and there and I myself gets lost where it was. Also, when you have to make a change commonly for all of pandas related features, it's almost impossible now.
Also, after this change, `DataFrame` and `SparkSession` become more consistent with Scala side since pandas is specific to Python, and this change separates pandas-specific APIs away from `DataFrame` or `SparkSession`.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests should cover. Also, I manually built the PySpark API documentation and checked.
Closes#27109 from HyukjinKwon/pandas-refactoring.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
There is a race condition in test case introduced in SPARK-30359 between reviveOffers in org.apache.spark.scheduler.TaskSchedulerImpl#submitTasks and org.apache.spark.scheduler.TaskSetManager#resourceOffer, in the testcase
No need to do resourceOffers as submitTask will revive offers from task set
### Why are the changes needed?
Fix flaky test
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Test case can pass after the change
Closes#27115 from ajithme/testflaky.
Authored-by: Ajith <ajith2489@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a minor code refactoring PR. It creates an adaptive execution context class to wrap objects shared across main query and sub-queries.
### Why are the changes needed?
This refactoring will improve code readability and reduce the number of parameters used to initialize `AdaptiveSparkPlanExec`.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Passed existing UTs.
Closes#26959 from maryannxue/aqe-context.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Previously in https://github.com/apache/spark/pull/26614/files#diff-bad3987c83bd22d46416d3dd9d208e76R90, we compare the number of tasks with `(conf.get(EXECUTOR_CORES) / sched.CPUS_PER_TASK)`. In standalone mode if the value is not explicitly set by default, the conf value would be 1 but the executor would actually use all the cores of the worker. So it is allowed to have `CPUS_PER_TASK` greater than `EXECUTOR_CORES`. To handle this case, we change the condition to be `numTasks <= Math.max(conf.get(EXECUTOR_CORES) / sched.CPUS_PER_TASK, 1)`
### Why are the changes needed?
For standalone mode if the user set the `spark.task.cpus` to be greater than 1 but didn't set the `spark.executor.cores`. Even though there is only 1 task in the stage it would not be speculative run.
### Does this PR introduce any user-facing change?
Solve the problem above by allowing speculative run when there is only 1 task in the stage.
### How was this patch tested?
Existing tests and one more test in TaskSetManagerSuite
Closes#27126 from yuchenhuo/SPARK-30417.
Authored-by: Yuchen Huo <yuchen.huo@databricks.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
### What changes were proposed in this pull request?
This patch renews the verification logic of archive path for FileStreamSource, as we found the logic doesn't take partitioned/recursive options into account.
Before the patch, it only requires the archive path to have depth more than 2 (two subdirectories from root), leveraging the fact FileStreamSource normally reads the files where the parent directory matches the pattern or the file itself matches the pattern. Given 'archive' operation moves the files to the base archive path with retaining the full path, archive path is tend to be safe if the depth is more than 2, meaning FileStreamSource doesn't re-read archived files as new source files.
WIth partitioned/recursive options, the fact is invalid, as FileStreamSource can read any files in any depth of subdirectories for source pattern. To deal with this correctly, we have to renew the verification logic, which may not intuitive and simple but works for all cases.
The new verification logic prevents both cases:
1) archive path matches with source pattern as "prefix" (the depth of archive path > the depth of source pattern)
e.g.
* source pattern: `/hello*/spar?`
* archive path: `/hello/spark/structured/streaming`
Any files in archive path will match with source pattern when recursive option is enabled.
2) source pattern matches with archive path as "prefix" (the depth of source pattern > the depth of archive path)
e.g.
* source pattern: `/hello*/spar?/structured/hello2*`
* archive path: `/hello/spark/structured`
Some archive files will not match with source pattern, e.g. file path: `/hello/spark/structured/hello2`, then final archived path: `/hello/spark/structured/hello/spark/structured/hello2`.
But some other archive files will still match with source pattern, e.g. file path: `/hello2/spark/structured/hello2`, then final archived path: `/hello/spark/structured/hello2/spark/structured/hello2` which matches with source pattern when recursive is enabled.
Implicitly it also prevents archive path matches with source pattern as full match (same depth).
We would want to prevent any source files to be archived and added to new source files again, so the patch takes most restrictive approach to prevent the possible cases.
### Why are the changes needed?
Without this patch, there's a chance archived files are included as new source files when partitioned/recursive option is enabled, as current condition doesn't take these options into account.
### Does this PR introduce any user-facing change?
Only for Spark 3.0.0-preview (only preview 1 for now, but possibly preview 2 as well) - end users are required to provide archive path with ensuring a bit complicated conditions, instead of simply higher than 2 depths.
### How was this patch tested?
New UT.
Closes#26920 from HeartSaVioR/SPARK-30281.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
Handle the accelerator aware configs being set to 0. This PR will just ignore the requests when the amount is 0.
### Why are the changes needed?
Better user experience
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
Unit tests added and manually tested on yarn, standalone, local, k8s.
Closes#27118 from tgravescs/SPARK-30445.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
1, for primitive types `Array.fill(n)(0)` -> `Array.ofDim(n)`;
2, for `AnyRef` types `Array.fill(n)(null)` -> `Array.ofDim(n)`;
3, for primitive types `Array.empty[XXX]` -> `Array.emptyXXXArray`
### Why are the changes needed?
`Array.ofDim` avoid assignments;
`Array.emptyXXXArray` avoid create new object;
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
existing testsuites
Closes#27133 from zhengruifeng/minor_fill_ofDim.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Use `println()` instead of `print()` to show process bar in console.
### Why are the changes needed?
Logs are polluted by process bar:

This is easy to reproduce:
1. start `./bin/spark-shell`
2. `sc.setLogLevel("INFO")`
3. run: `spark.range(100000000).coalesce(1).write.parquet("/tmp/result")`
### Does this PR introduce any user-facing change?
Yeah, more friendly format in console.
### How was this patch tested?
Tested manually.
Closes#27061 from Ngone51/fix-processbar.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
For a partitioned table, if the number of partitions are very large, e.g. tens of thousands or even larger, calculating its total size causes flooding logs.
The flooding happens in:
1. `calculateLocationSize` prints the starting and ending for calculating the location size, and it is called per partition;
2. `bulkListLeafFiles` prints all partition paths.
This pr is to simplify the logging when calculating the size of a partitioned table.
### How was this patch tested?
not related
Closes#27079 from wzhfy/improve_log.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Remove PrunedInMemoryFileIndex and merge its functionality into InMemoryFileIndex.
### Why are the changes needed?
PrunedInMemoryFileIndex is only used in CatalogFileIndex.filterPartitions, and its name is kind of confusing, we can completely merge its functionality into InMemoryFileIndex and remove the class.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing unit tests.
Closes#26850 from fuwhu/SPARK-30215.
Authored-by: fuwhu <bestwwg@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a follow-up to address the following comment: https://github.com/apache/spark/pull/27095#discussion_r363152180
Currently, a SQL command string is parsed to a "statement" logical plan, converted to a logical plan with catalog/namespace, then finally converted to a physical plan. With the new resolution framework, there is no need to create a "statement" logical plan; a logical plan can contain `UnresolvedNamespace` which will be resolved to a `ResolvedNamespace`. This should simply the code base and make it a bit easier to add a new command.
### Why are the changes needed?
Clean up codebase.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing tests should cover the changes.
Closes#27125 from imback82/SPARK-30214-followup.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/26907
It changes the for loop `for (element <- array.asScala)` to while loop
### Why are the changes needed?
As per https://github.com/databricks/scala-style-guide#traversal-and-zipwithindex, we should use while loop for the performance-sensitive code.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing tests.
Closes#27127 from gengliangwang/SPARK-30267-FollowUp.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
This patch proposes:
1. Fix OOM at WideSchemaBenchmark: make `ValidateExternalType.errMsg` lazy variable, i.e. not to initiate it in the constructor
2. Truncate `errMsg`: Replacing `catalogString` with `simpleString` which is truncated
3. Optimizing `override def catalogString` in `StructType`: Make `catalogString` more efficient in string generation by using `StringConcat`
### Why are the changes needed?
In the JIRA, it is found that WideSchemaBenchmark fails with OOM, like:
```
[error] Exception in thread "main" org.apache.spark.sql.catalyst.errors.package$TreeNodeException: makeCopy, tree: validateexternaltype(getexternalrowfield(input[0, org.apac
he.spark.sql.Row, true], 0, a), StructField(b,StructType(StructField(c,StructType(StructField(value_1,LongType,true), StructField(value_10,LongType,true), StructField(value_
100,LongType,true), StructField(value_1000,LongType,true), StructField(value_1001,LongType,true), StructField(value_1002,LongType,true), StructField(value_1003,LongType,true
), StructField(value_1004,LongType,true), StructField(value_1005,LongType,true), StructField(value_1006,LongType,true), StructField(value_1007,LongType,true), StructField(va
lue_1008,LongType,true), StructField(value_1009,LongType,true), StructField(value_101,LongType,true), StructField(value_1010,LongType,true), StructField(value_1011,LongType,
...
ue), StructField(value_99,LongType,true), StructField(value_990,LongType,true), StructField(value_991,LongType,true), StructField(value_992,LongType,true), StructField(value
_993,LongType,true), StructField(value_994,LongType,true), StructField(value_995,LongType,true), StructField(value_996,LongType,true), StructField(value_997,LongType,true),
StructField(value_998,LongType,true), StructField(value_999,LongType,true)),true))
[error] at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:56)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.makeCopy(TreeNode.scala:435)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:408)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:327)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:307)
....
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$mapChildren$1(TreeNode.scala:404)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:214)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:374)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:327)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:307)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformUp$1(TreeNode.scala:307)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$mapChildren$1(TreeNode.scala:376)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:214)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:374)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:327)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:307)
[error] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoder.<init>(ExpressionEncoder.scala:198)
[error] at org.apache.spark.sql.catalyst.encoders.RowEncoder$.apply(RowEncoder.scala:71)
[error] at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:88)
[error] at org.apache.spark.sql.SparkSession.internalCreateDataFrame(SparkSession.scala:554)
[error] at org.apache.spark.sql.DataFrameReader.json(DataFrameReader.scala:476)
[error] at org.apache.spark.sql.execution.benchmark.WideSchemaBenchmark$.$anonfun$wideShallowlyNestedStructFieldReadAndWrite$1(WideSchemaBenchmark.scala:126)
...
[error] Caused by: java.lang.OutOfMemoryError: GC overhead limit exceeded
[error] at java.util.Arrays.copyOf(Arrays.java:3332)
[error] at java.lang.AbstractStringBuilder.ensureCapacityInternal(AbstractStringBuilder.java:124)
[error] at java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:448)
[error] at java.lang.StringBuilder.append(StringBuilder.java:136)
[error] at scala.collection.mutable.StringBuilder.append(StringBuilder.scala:213)
[error] at scala.collection.TraversableOnce.$anonfun$addString$1(TraversableOnce.scala:368)
[error] at scala.collection.TraversableOnce$$Lambda$67/667447085.apply(Unknown Source)
[error] at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
[error] at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
[error] at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:198)
[error] at scala.collection.TraversableOnce.addString(TraversableOnce.scala:362)
[error] at scala.collection.TraversableOnce.addString$(TraversableOnce.scala:358)
[error] at scala.collection.mutable.ArrayOps$ofRef.addString(ArrayOps.scala:198)
[error] at scala.collection.TraversableOnce.mkString(TraversableOnce.scala:328)
[error] at scala.collection.TraversableOnce.mkString$(TraversableOnce.scala:327)
[error] at scala.collection.mutable.ArrayOps$ofRef.mkString(ArrayOps.scala:198)
[error] at scala.collection.TraversableOnce.mkString(TraversableOnce.scala:330)
[error] at scala.collection.TraversableOnce.mkString$(TraversableOnce.scala:330)
[error] at scala.collection.mutable.ArrayOps$ofRef.mkString(ArrayOps.scala:198)
[error] at org.apache.spark.sql.types.StructType.catalogString(StructType.scala:411)
[error] at org.apache.spark.sql.catalyst.expressions.objects.ValidateExternalType.<init>(objects.scala:1695)
[error] at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
[error] at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
[error] at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
[error] at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$makeCopy$7(TreeNode.scala:468)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode$$Lambda$934/387827651.apply(Unknown Source)
[error] at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:72)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$makeCopy$1(TreeNode.scala:467)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode$$Lambda$929/449240381.apply(Unknown Source)
[error] at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:52)
[error] at org.apache.spark.sql.catalyst.trees.TreeNode.makeCopy(TreeNode.scala:435)
```
It is after cb5ea201df commit which refactors `ExpressionEncoder`.
The stacktrace shows it fails at `transformUp` on `objSerializer` in `ExpressionEncoder`. In particular, it fails at initializing `ValidateExternalType.errMsg`, that interpolates `catalogString` of given `expected` data type in a string. In WideSchemaBenchmark we have very deeply nested data type. When we transform on the serializer which contains `ValidateExternalType`, we create redundant big string `errMsg`. Because we just in transforming it and don't use it yet, it is useless and waste a lot of memory.
After make `ValidateExternalType.errMsg` as lazy variable, WideSchemaBenchmark works.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manual test with WideSchemaBenchmark.
Closes#27117 from viirya/SPARK-30429.
Lead-authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Co-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
R version 3.6.2 (Dark and Stormy Night) was released on 2019-12-12. This PR targets to upgrade R installation for AppVeyor CI environment.
### Why are the changes needed?
To test the latest R versions before the release, and see if there are any regressions.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
AppVeyor will test.
Closes#27124 from HyukjinKwon/upgrade-r-version-appveyor.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add table/column comments and table properties to the result of show create table of views.
### Does this PR introduce any user-facing change?
When show create table for views, after this patch, the result can contain table/column comments and table properties if they exist.
### How was this patch tested?
add new tests
Closes#26944 from wzhfy/complete_show_create_view.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Make GBT reuse splits/treePoints for all trees:
1, reuse splits/treePoints for all trees:
existing impl will find feature splits and transform input vectors to treePoints for each tree; while other famous impls like XGBoost/lightGBM will build a global splits/binned features and reuse them for all trees;
Note: the sampling rate in existing impl to build `splits` is not the param `subsamplingRate` but the output of `RandomForest.samplesFractionForFindSplits` which depends on `maxBins` and `numExamples`.
Note II: Existing impl do not guarantee that splits among iteration are the same, so this may cause a little difference in convergence.
2, do not cache input vectors:
existing impl will cached the input twice: 1,`input: RDD[Instance]` is used to compute/update prediction and errors; 2, at each iteration, input is transformed to bagged points, the bagged points will be cached during this iteration;
In this PR,`input: RDD[Instance]` is no longer cached, since it is only used three times: 1, compute metadata; 2, find splits; 3, converted to treePoints;
Instead, the treePoints `RDD[TreePoint]` is cached, at each iter, it is convert to bagged points by attaching extra `labelWithCounts: RDD[(Double, Int)]` containing residuals/sampleCount information, this rdd is relative small (like cached `norms` in KMeans);
To compute/update prediction and errors, new prediction method based on binned features are added in `Node`
### Why are the changes needed?
for perfermance improvement:
1,40%~50% faster than existing impl
2,save 30%~50% RAM
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
existing testsuites & several manual tests in REPL
Closes#27103 from zhengruifeng/gbt_reuse_bagged.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
This excludes the .git folder when the python linter runs. We want to exclude because there may be files in .git from other branches that could cause the linter to fail.
### Why are the changes needed?
I ran into a case where there was a branch name that ended ".py" suffix so there were git refs files in .git folder in .git/logs/refs and .git/refs/remotes.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Manual.
```
$ git branch 3.py
$ git checkout 3.py
Switched to branch '3.py'
$ dev/lint-python
starting python compilation test...
Python compilation failed with the following errors:
*** Error compiling './.git/logs/refs/heads/3.py'...
File "./.git/logs/refs/heads/3.py", line 1
0000000000000000000000000000000000000000 895e572b73 Dongjoon Hyun <dhyunapple.com> 1578438255 -0800 branch: Created from master
^
SyntaxError: invalid syntax
*** Error compiling './.git/refs/heads/3.py'...
File "./.git/refs/heads/3.py", line 1
895e572b73
^
SyntaxError: invalid syntax
```
Closes#27120 from ericfchang/master.
Authored-by: Eric Chang <eric.chang@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
Avoid hive log initialisation as https://github.com/apache/hive/blob/rel/release-2.3.5/common/src/java/org/apache/hadoop/hive/common/LogUtils.java introduces dependency over `org.apache.logging.log4j.core.impl.Log4jContextFactory` which is missing in our spark installer classpath directly. I believe the `LogUtils.initHiveLog4j()` code is here as the HiveServer2 class is copied from Hive.
To make `start-thriftserver.sh --help` command success.
Currently, start-thriftserver.sh --help throws
```
...
Thrift server options:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/logging/log4j/spi/LoggerContextFactory
at org.apache.hive.service.server.HiveServer2.main(HiveServer2.java:167)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2$.main(HiveThriftServer2.scala:82)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.main(HiveThriftServer2.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.logging.log4j.spi.LoggerContextFactory
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 3 more
```
No
Checked Manually
Closes#27042 from ajithme/thrifthelp.
Authored-by: Ajith <ajith2489@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add CreateFunctionStatement and make CREATE FUNCTION go through the same catalog/table resolution framework of v2 commands.
### Why are the changes needed?
It's important to make all the commands have the same table resolution behavior, to avoid confusing
CREATE FUNCTION namespace.function
### Does this PR introduce any user-facing change?
Yes. When running CREATE FUNCTION namespace.function Spark fails the command if the current catalog is set to a v2 catalog.
### How was this patch tested?
Unit tests.
Closes#26890 from planga82/feature/SPARK-30039_CreateFunctionV2Command.
Authored-by: Pablo Langa <soypab@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
Follow-on to #26877.
### What changes were proposed in this pull request?
This PR tweaks the stale PR message to [clarify](https://github.com/apache/spark/pull/24457#issuecomment-571393900) the procedure for reopening a PR after it has been marked as stale.
### Why are the changes needed?
This change should clarify the reopening process for contributors.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#27114 from nchammas/SPARK-30173-stale-tweaks.
Authored-by: Nicholas Chammas <nicholas.chammas@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
In `SqlBase.g4`, the `comment` clause is used as `COMMENT comment=STRING` and `COMMENT STRING` in many places.
While the `location` clause often appears along with the `comment` clause with a pattern defined as
```sql
locationSpec
: LOCATION STRING
;
```
Then, we have to visit `locationSpec` as a `List` but comment as a single token.
We defined `commentSpec` for the comment clause to simplify and unify the grammar and the invocations.
### Why are the changes needed?
To simplify the grammar.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
existing tests
Closes#27102 from yaooqinn/SPARK-30431.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
#26847 introduced new framework for resolving catalog/namespaces. This PR proposes to integrate commands that need to resolve namespaces into the new framework.
### Why are the changes needed?
This is one of the work items for moving into the new resolution framework. Resolving v1/v2 tables with the new framework will be followed up in different PRs.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing tests should cover the changes.
Closes#27095 from imback82/unresolved_ns.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR adds a note first and last can be non-deterministic in SQL function docs as well.
This is already documented in `functions.scala`.
### Why are the changes needed?
Some people look reading SQL docs only.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Jenkins will test.
Closes#27099 from HyukjinKwon/SPARK-30335.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR implements multiple performance optimizations for `ParquetRowConverter`, achieving some modest constant-factor wins for all fields and larger wins for map and array fields:
- Add `private[this]` to several `val`s (90cebf080a5d3857ea8cf2a89e8e060b8b5a2fbf)
- Keep a `fieldUpdaters` array, saving two`.updater()` calls per field (7318785d350cc924198d7514e40973fd76d54ad5): I suspect that these are often megamorphic calls, so cutting these out seems like it could be a relatively large performance win.
- Only call `currentRow.numFields` once per `start()` call (e05de150813b639929c18af1df09ec718d2d16fc): previously we'd call it once per field and this had a significant enough cost that it was visible during profiling.
- Reuse buffers in array and map converters (c7d1534685fbad5d2280b082f37bed6d75848e76, 6d16f596ef6af9fd8946a062f79d0eeace9e1959): previously we would create a brand-new Scala `ArrayBuffer` for each field read, but this isn't actually necessary because the data is already copied into a fresh array when `end()` constructs a `GenericArrayData`.
### Why are the changes needed?
To improve Parquet read performance; this is complementary to #26993's (orthogonal) improvements for nested struct read performance.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests, plus manual benchmarking with both synthetic and realistic schemas (similar to the ones in #26993). I've seen ~10%+ improvements in scan performance on certain real-world datasets.
Closes#27089 from JoshRosen/joshrosen/more-ParquetRowConverter-optimizations.
Lead-authored-by: Josh Rosen <rosenville@gmail.com>
Co-authored-by: Josh Rosen <joshrosen@stripe.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR modifies `ParquetRowConverter` to remove unnecessary `InternalRow.copy()` calls for structs that are directly nested in other structs.
### Why are the changes needed?
These changes can significantly improve performance when reading Parquet files that contain deeply-nested structs with many fields.
The `ParquetRowConverter` uses per-field `Converter`s for handling individual fields. Internally, these converters may have mutable state and may return mutable objects. In most cases, each `converter` is only invoked once per Parquet record (this is true for top-level fields, for example). However, arrays and maps may call their child element converters multiple times per Parquet record: in these cases we must be careful to copy any mutable outputs returned by child converters.
In the existing code, `InternalRow`s are copied whenever they are stored into _any_ parent container (not just maps and arrays). This copying can be especially expensive for deeply-nested fields, since a deep copy is performed at every level of nesting.
This PR modifies the code to avoid copies for structs that are directly nested in structs; see inline code comments for an argument for why this is safe.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
**Correctness**: I added new test cases to `ParquetIOSuite` to increase coverage of nested structs, including structs nested in arrays: previously this suite didn't test that case, so we used to lack mutation coverage of this `copy()` code (the suite's tests still passed if I incorrectly removed the `.copy()` in all cases). I also added a test for maps with struct keys and modified the existing "map with struct values" test case include maps with two elements (since the incorrect omission of a `copy()` can only be detected if the map has multiple elements).
**Performance**: I put together a simple local benchmark demonstrating the performance problems:
First, construct a nested schema:
```scala
case class Inner(
f1: Int,
f2: Long,
f3: String,
f4: Int,
f5: Long,
f6: String,
f7: Int,
f8: Long,
f9: String,
f10: Int
)
case class Wrapper1(inner: Inner)
case class Wrapper2(wrapper1: Wrapper1)
case class Wrapper3(wrapper2: Wrapper2)
```
`Wrapper3`'s schema looks like:
```
root
|-- wrapper2: struct (nullable = true)
| |-- wrapper1: struct (nullable = true)
| | |-- inner: struct (nullable = true)
| | | |-- f1: integer (nullable = true)
| | | |-- f2: long (nullable = true)
| | | |-- f3: string (nullable = true)
| | | |-- f4: integer (nullable = true)
| | | |-- f5: long (nullable = true)
| | | |-- f6: string (nullable = true)
| | | |-- f7: integer (nullable = true)
| | | |-- f8: long (nullable = true)
| | | |-- f9: string (nullable = true)
| | | |-- f10: integer (nullable = true)
```
Next, generate some fake data:
```scala
val data = spark.range(1, 1000 * 1000 * 25, 1, 1).map { i =>
Wrapper3(Wrapper2(Wrapper1(Inner(
i.toInt,
i * 2,
(i * 3).toString,
(i * 4).toInt,
i * 5,
(i * 6).toString,
(i * 7).toInt,
i * 8,
(i * 9).toString,
(i * 10).toInt
))))
}
data.write.mode("overwrite").parquet("/tmp/parquet-test")
```
I then ran a simple benchmark consisting of
```
spark.read.parquet("/tmp/parquet-test").selectExpr("hash(*)").rdd.count()
```
where the `hash(*)` is designed to force decoding of all Parquet fields but avoids `RowEncoder` costs in the `.rdd.count()` stage.
In the old code, expensive copying takes place at every level of nesting; this is apparent in the following flame graph:

After this PR's changes, the above toy benchmark runs ~30% faster.
Closes#26993 from JoshRosen/joshrosen/faster-parquet-nested-scan-by-avoiding-copies.
Lead-authored-by: Josh Rosen <rosenville@gmail.com>
Co-authored-by: Josh Rosen <joshrosen@stripe.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR tries to make conflict attributes resolution in `ResolveReferences` more scalable by doing resolution in batch way.
### Why are the changes needed?
Currently, `ResolveReferences` rule only resolves conflict attributes of one single conflict plan pair in one iteration, which can be inefficient when there're many conflicts.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Covered by existed tests.
Closes#27105 from Ngone51/resolve-conflict-columns-in-batch.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}