### What changes were proposed in this pull request?
Add remote scheduler pool files support to the migration guide.
### Why are the changes needed?
To highlight this useful support.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass exiting tests.
Closes#33785 from Ngone51/SPARK-35083-follow-up.
Lead-authored-by: yi.wu <yi.wu@databricks.com>
Co-authored-by: wuyi <yi.wu@databricks.com>
Signed-off-by: Gengliang Wang <gengliang@apache.org>
(cherry picked from commit e3902d1975)
Signed-off-by: Gengliang Wang <gengliang@apache.org>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/30648
ANALYZE TABLE and TABLES are essentially the same command, it's weird to put them in 2 different doc pages. This PR proposes to merge them into one doc page.
### Why are the changes needed?
simplify the doc
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
N/A
Closes#33781 from cloud-fan/doc.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit 07d173a8b0)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Refine the SQL reference doc:
- remove useless subitems in the sidebar
- remove useless sub-menu-pages (e.g. `sql-ref-syntax-aux.md`)
- avoid using `#####` in `sql-ref-literals.md`
### Why are the changes needed?
The subitems in the sidebar are quite useless, as the menu page serves the same functionalities:
<img width="1040" alt="WX20210817-2358402x" src="https://user-images.githubusercontent.com/3182036/129765924-d7e69bc1-e351-4581-a6de-f2468022f372.png">
It's also extra work to keep the manu page and sidebar subitems in sync (The ANSI compliance page is already out of sync).
The sub-menu-pages are only referenced by the sidebar, and duplicates the content of the menu page. As a result, the `sql-ref-syntax-aux.md` is already outdated compared to the menu page. It's easier to just look at the menu page.
The `#####` is not rendered properly:
<img width="776" alt="WX20210818-0001192x" src="https://user-images.githubusercontent.com/3182036/129766760-6f385443-e597-44aa-888d-14d128d45f84.png">
It's better to avoid using it.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
N/A
Closes#33767 from cloud-fan/doc.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
(cherry picked from commit 4b015e8d7d)
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Revert [[SPARK-35028][SQL] ANSI mode: disallow group by aliases ](https://github.com/apache/spark/pull/32129)
### Why are the changes needed?
It turns out that many users are using the group by alias feature. Spark has its precedence rule when alias names conflict with column names in Group by clause: always use the table column. This should be reasonable and acceptable.
Also, external DBMS such as PostgreSQL and MySQL allow grouping by alias, too.
As we are going to announce ANSI mode GA in Spark 3.2, I suggest allowing the group by alias in ANSI mode.
### Does this PR introduce _any_ user-facing change?
No, the feature is not released yet.
### How was this patch tested?
Unit tests
Closes#33758 from gengliangwang/revertGroupByAlias.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Gengliang Wang <gengliang@apache.org>
(cherry picked from commit 8bfb4f1e72)
Signed-off-by: Gengliang Wang <gengliang@apache.org>
### What changes were proposed in this pull request?
Add the document for the new RocksDBStateStoreProvider.
### Why are the changes needed?
User guide for the new feature.
### Does this PR introduce _any_ user-facing change?
No, doc only.
### How was this patch tested?
Doc only.
Closes#33683 from xuanyuanking/SPARK-36041.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
(cherry picked from commit 3d57e00a7f)
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
Document the push-based shuffle feature with a high level overview of the feature and corresponding configuration options for both shuffle server side as well as client side. This is how the changes to the doc looks on the browser ([img](https://user-images.githubusercontent.com/8871522/129231582-ad86ee2f-246f-4b42-9528-4ccd693e86d2.png))
### Why are the changes needed?
Helps users understand the feature
### Does this PR introduce _any_ user-facing change?
Docs
### How was this patch tested?
N/A
Closes#33615 from venkata91/SPARK-36374.
Authored-by: Venkata krishnan Sowrirajan <vsowrirajan@linkedin.com>
Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com>
(cherry picked from commit 2270ecf32f)
Signed-off-by: Mridul Muralidharan <mridulatgmail.com>
### What changes were proposed in this pull request?
This patch supports dynamic gap duration in session window.
### Why are the changes needed?
The gap duration used in session window for now is a static value. To support more complex usage, it is better to support dynamic gap duration which determines the gap duration by looking at the current data. For example, in our usecase, we may have different gap by looking at the certain column in the input rows.
### Does this PR introduce _any_ user-facing change?
Yes, users can specify dynamic gap duration.
### How was this patch tested?
Modified existing tests and new test.
Closes#33691 from viirya/dynamic-session-window-gap.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
(cherry picked from commit 8b8d91cf64)
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This PR proposes to prohibit update mode in streaming aggregation with session window.
UnsupportedOperationChecker will check and prohibit the case. As a side effect, this PR also simplifies the code as we can remove the implementation of iterator to support outputs of update mode.
This PR also cleans up test code via deduplicating.
### Why are the changes needed?
The semantic of "update" mode for session window based streaming aggregation is quite unclear.
For normal streaming aggregation, Spark will provide the outputs which can be "upsert"ed based on the grouping key. This is based on the fact grouping key won't be changed.
This doesn't hold true for session window based streaming aggregation, as session range is changing.
If end users leverage their knowledge about streaming aggregation, they will consider the key as grouping key + session (since they'll specify these things in groupBy), and it's high likely possible that existing row is not updated (overwritten) and ended up with having different rows.
If end users consider the key as grouping key, there's a small chance for end users to upsert the session correctly, though only the last updated session will be stored so it won't work with event time processing which there could be multiple active sessions.
### Does this PR introduce _any_ user-facing change?
No, as we haven't released this feature.
### How was this patch tested?
Updated tests.
Closes#33689 from HeartSaVioR/SPARK-36463.
Authored-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
(cherry picked from commit ed60aaa9f1)
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
Add local-cluster mode option to submitting-applications.md
### Why are the changes needed?
Help users to find/use this option for unit tests.
### Does this PR introduce _any_ user-facing change?
Yes, docs changed.
### How was this patch tested?
`SKIP_API=1 bundle exec jekyll build`
<img width="460" alt="docchange" src="https://user-images.githubusercontent.com/87687356/127125380-6beb4601-7cf4-4876-b2c6-459454ce2a02.png">
Closes#33537 from yutoacts/SPARK-595.
Lead-authored-by: Yuto Akutsu <yuto.akutsu@jp.nttdata.com>
Co-authored-by: Yuto Akutsu <yuto.akutsu@nttdata.com>
Co-authored-by: Yuto Akutsu <87687356+yutoacts@users.noreply.github.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
(cherry picked from commit 41b011e416)
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
Add documentation for new functions try_cast/try_add/try_divide
### Why are the changes needed?
Better documentation. These new functions are useful when migrating to the ANSI dialect.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Build docs and preview:

Closes#33638 from gengliangwang/addDocForTry.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit 8a35243fa7)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add doc for the shuffle checksum configs in `configuration.md`.
### Why are the changes needed?
doc
### Does this PR introduce _any_ user-facing change?
No, since Spark 3.2 hasn't been released.
### How was this patch tested?
Pass existed tests.
Closes#33637 from Ngone51/SPARK-36384.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit 3b92c721b5)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR removes obsolete `contributing-to-spark.md` which is not referenced from anywhere.
### Why are the changes needed?
Just clean up.
### Does this PR introduce _any_ user-facing change?
No. Users can't have access to contributing-to-spark.html unless they directly point to the URL.
### How was this patch tested?
Built the document and confirmed that this change doesn't affect the result.
Closes#33619 from sarutak/remove-obsolete-contribution-doc.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit c31b653806)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is follow-up of https://github.com/apache/spark/pull/31522.
It adds docs for the new metrics of task/job commit time
### Why are the changes needed?
So that users can understand the metrics better and know that the new metrics are only for file table writes.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Build docs and preview:

Closes#33542 from gengliangwang/addDocForMetrics.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit c9a7ff3f36)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
update java doc, JDBC data source doc, address follow up comments
### Why are the changes needed?
update doc and address follow up comments
### Does this PR introduce _any_ user-facing change?
Yes, add the new JDBC option `pushDownAggregate` in JDBC data source doc.
### How was this patch tested?
manually checked
Closes#33526 from huaxingao/aggPD_followup.
Authored-by: Huaxin Gao <huaxin_gao@apple.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit c8dd97d456)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Update the tables at https://spark.apache.org/docs/latest/sql-ref-datatypes.html about mapping ANSI interval types to Java/Scala/SQL types.
2. Remove `CalendarIntervalType` from the table of mapping Catalyst types to SQL types.
<img width="1028" alt="Screenshot 2021-07-27 at 20 52 57" src="https://user-images.githubusercontent.com/1580697/127204790-7ccb9c64-daf2-427d-963e-b7367aaa3439.png">
<img width="1017" alt="Screenshot 2021-07-27 at 20 53 22" src="https://user-images.githubusercontent.com/1580697/127204806-a0a51950-3c2d-4198-8a22-0f6614bb1487.png">
### Why are the changes needed?
To inform users which types from language APIs should be used as ANSI interval types.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually checking by building the docs:
```
$ SKIP_RDOC=1 SKIP_API=1 SKIP_PYTHONDOC=1 bundle exec jekyll build
```
Closes#33543 from MaxGekk/doc-interval-type-lang-api.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
(cherry picked from commit 1614d00417)
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
In the PR, I propose to update the page https://spark.apache.org/docs/latest/sql-ref-datatypes.html and add information about the year-month and day-time interval types introduced by SPARK-27790.
<img width="932" alt="Screenshot 2021-07-27 at 10 38 23" src="https://user-images.githubusercontent.com/1580697/127115289-e633ca3a-2c18-49a0-a7c0-22421ae5c363.png">
### Why are the changes needed?
To inform users about new ANSI interval types, and improve UX with Spark SQL.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Should be tested by a GitHub action.
Authored-by: Max Gekk <max.gekkgmail.com>
Signed-off-by: Kousuke Saruta <sarutakoss.nttdata.com>
(cherry picked from commit f4837961a9)
Signed-off-by: Kousuke Saruta <sarutakoss.nttdata.com>
Closes#33539 from sarutak/backport-SPARK-34619-3.2.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Bugfix: link to correction location of Pyspark Dataframe documentation
### Why are the changes needed?
Current website returns "Not found"
### Does this PR introduce _any_ user-facing change?
Website fix
### How was this patch tested?
Documentation change
Closes#33420 from dominikgehl/feature/SPARK-36209.
Authored-by: Dominik Gehl <dog@open.ch>
Signed-off-by: Sean Owen <srowen@gmail.com>
(cherry picked from commit 3a1db2ddd4)
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Spark 3.2.0 will use parquet-mr.1.12.0 version (or higher), that contains the column encryption feature which can be called from Spark SQL. The aim of this PR is to document the use of Parquet encryption in Spark.
### Why are the changes needed?
- To provide information on how to use Parquet column encryption
### Does this PR introduce _any_ user-facing change?
Yes, documents a new feature.
### How was this patch tested?
bundle exec jekyll build
Closes#32895 from ggershinsky/parquet-encryption-doc.
Authored-by: Gidon Gershinsky <ggershinsky@apple.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Update trasform's doc to latest code.

### Why are the changes needed?
keep consistence
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
No
Closes#33362 from AngersZhuuuu/SPARK-36153.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR documents a new feature "native support of session window" into Structured Streaming guide doc.
Screenshots are following:


### Why are the changes needed?
This change is needed to explain a new feature to the end users.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Documentation changes.
Closes#33433 from HeartSaVioR/SPARK-36172.
Authored-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
(cherry picked from commit 0eb31a06d6)
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This PR documents about unicode literals added in SPARK-34051 (#31096) and a past PR in `sql-ref-literals.md`.
### Why are the changes needed?
Notice users about the literals.
### Does this PR introduce _any_ user-facing change?
Yes, but just add a sentence.
### How was this patch tested?
Built the document and confirmed the result.
```
SKIP_API=1 bundle exec jekyll build
```

Closes#33434 from sarutak/unicode-literal-doc.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit ba1294ea5a)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add reference to kubernetes-client's version
### Why are the changes needed?
Running Spark on Kubernetes potentially has upper limitation of Kubernetes version.
I think it is better for users to notice it because Kubernetes update speed is so fast that users tends to run Spark Jobs on unsupported version.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
SKIP_API=1 bundle exec jekyll build
Closes#33255 from yoda-mon/add-reference-kubernetes-client.
Authored-by: yoda-mon <yodal@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
(cherry picked from commit eea69c122f)
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR modifies comment for `UTF8String.trimAll` and`sql-migration-guide.mld`.
The comment for `UTF8String.trimAll` says like as follows.
```
Trims whitespaces ({literal <=} ASCII 32) from both ends of this string.
```
Similarly, `sql-migration-guide.md` mentions about the behavior of `cast` like as follows.
```
In Spark 3.0, when casting string value to integral types(tinyint, smallint, int and bigint),
datetime types(date, timestamp and interval) and boolean type,
the leading and trailing whitespaces (<= ASCII 32) will be trimmed before converted to these type values,
for example, `cast(' 1\t' as int)` results `1`, `cast(' 1\t' as boolean)` results `true`,
`cast('2019-10-10\t as date)` results the date value `2019-10-10`.
In Spark version 2.4 and below, when casting string to integrals and booleans,
it does not trim the whitespaces from both ends; the foregoing results is `null`,
while to datetimes, only the trailing spaces (= ASCII 32) are removed.
```
But SPARK-32559 (#29375) changed the behavior and only whitespace ASCII characters will be trimmed since Spark 3.0.1.
### Why are the changes needed?
To follow the previous change.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Confirmed the document built by the following command.
```
SKIP_API=1 bundle exec jekyll build
```
Closes#33287 from sarutak/fix-utf8string-trim-issue.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit 57a4f310df)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR allow the parser to parse unit list interval literals like `'3' day '10' hours '3' seconds` or `'8' years '3' months` as `YearMonthIntervalType` or `DayTimeIntervalType`.
### Why are the changes needed?
For ANSI compliance.
### Does this PR introduce _any_ user-facing change?
Yes. I noted the following things in the `sql-migration-guide.md`.
* Unit list interval literals are parsed as `YearMonthIntervaType` or `DayTimeIntervalType` instead of `CalendarIntervalType`.
* `WEEK`, `MILLISECONS`, `MICROSECOND` and `NANOSECOND` are not valid units for unit list interval literals.
* Units of year-month and day-time cannot be mixed like `1 YEAR 2 MINUTES`.
### How was this patch tested?
New tests and modified tests.
Closes#32949 from sarutak/day-time-multi-units.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit 8e92ef825a)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to update the SQL migration guide, in particular the section about the migration from Spark 2.4 to 3.0. New item informs users about the following issue:
**What**: Spark doesn't detect encoding (charset) in CSV files with BOM correctly. Such files can be read only in the multiLine mode when the CSV option encoding matches to the actual encoding of CSV files. For example, Spark cannot read UTF-16BE CSV files when encoding is set to UTF-8 which is the default mode. This is the case of the current ES ticket.
**Why**: In previous Spark versions, encoding wasn't propagated to the underlying library that means the lib tried to detect file encoding automatically. It could success for some encodings that require BOM presents at the beginning of files. Starting from the versions 3.0, users can specify file encoding via the CSV option encoding which has UTF-8 as the default value. Spark propagates such default to the underlying library (uniVocity), and as a consequence this turned off encoding auto-detection.
**When**: Since Spark 3.0. In particular, the commit 2df34db586 causes the issue.
**Workaround**: Enabling the encoding auto-detection mechanism in uniVocity by passing null as the value of CSV option encoding. A more recommended approach is to set the encoding option explicitly.
### Why are the changes needed?
To improve user experience with Spark SQL. This should help to users in their migration from Spark 2.4.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Should be checked by building docs in GA/jenkins.
Closes#33300 from MaxGekk/csv-encoding-migration-guide.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit e788a3fa88)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Update AQE is `disabled` to `enabled` in sql-performance-tuning docs
### Why are the changes needed?
Make docs correct.
### Does this PR introduce _any_ user-facing change?
yes, docs changed.
### How was this patch tested?
Not need.
Closes#33295 from ulysses-you/enable-AQE.
Lead-authored-by: ulysses-you <ulyssesyou18@gmail.com>
Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit 286c231c1e)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add new configs in sql-performance-tuning docs.
* spark.sql.adaptive.coalescePartitions.parallelismFirst
* spark.sql.adaptive.coalescePartitions.minPartitionSize
* spark.sql.adaptive.autoBroadcastJoinThreshold
* spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold
### Why are the changes needed?
Help user to find them.
### Does this PR introduce _any_ user-facing change?
yes, docs changed.
### How was this patch tested?
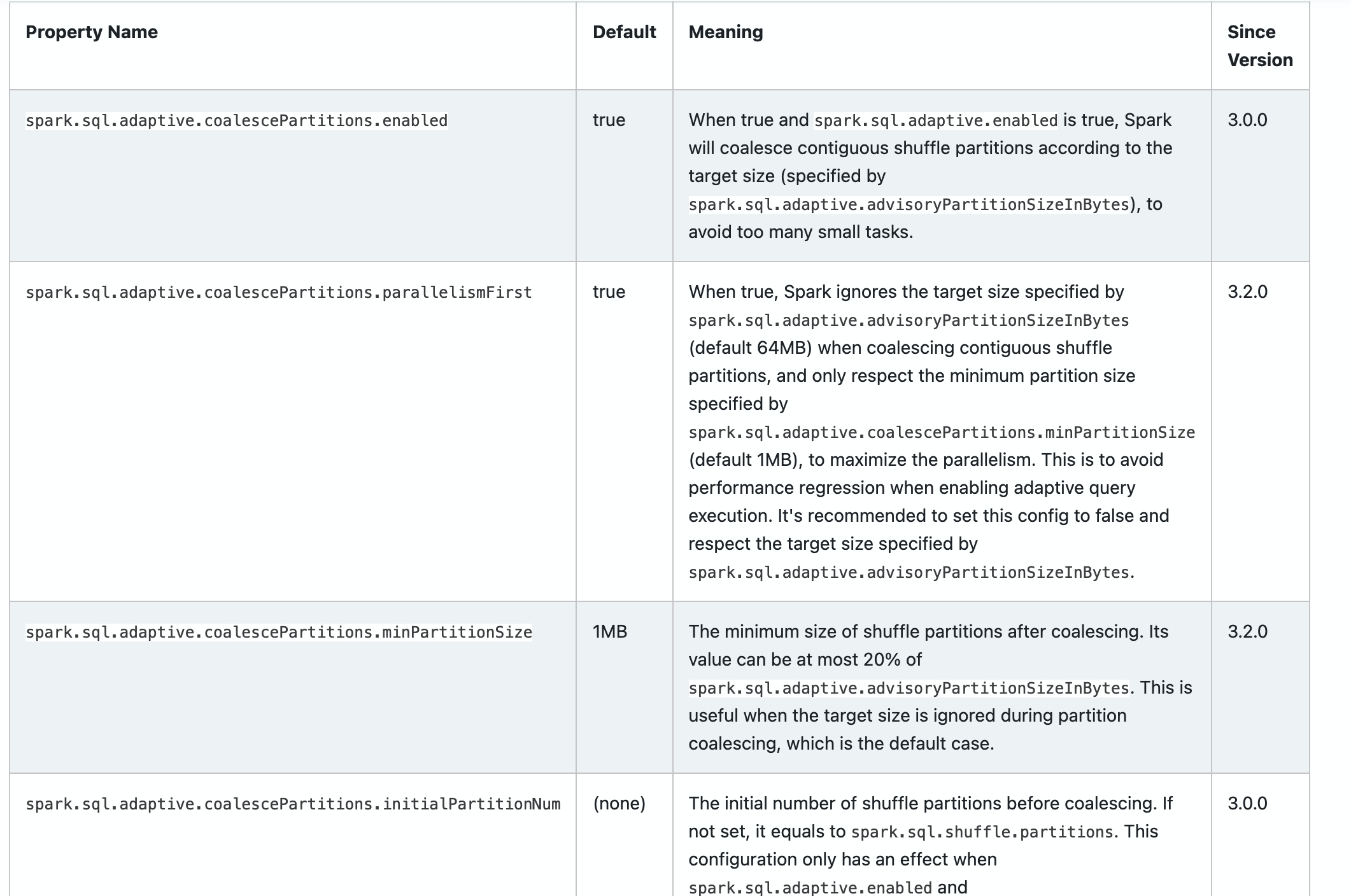
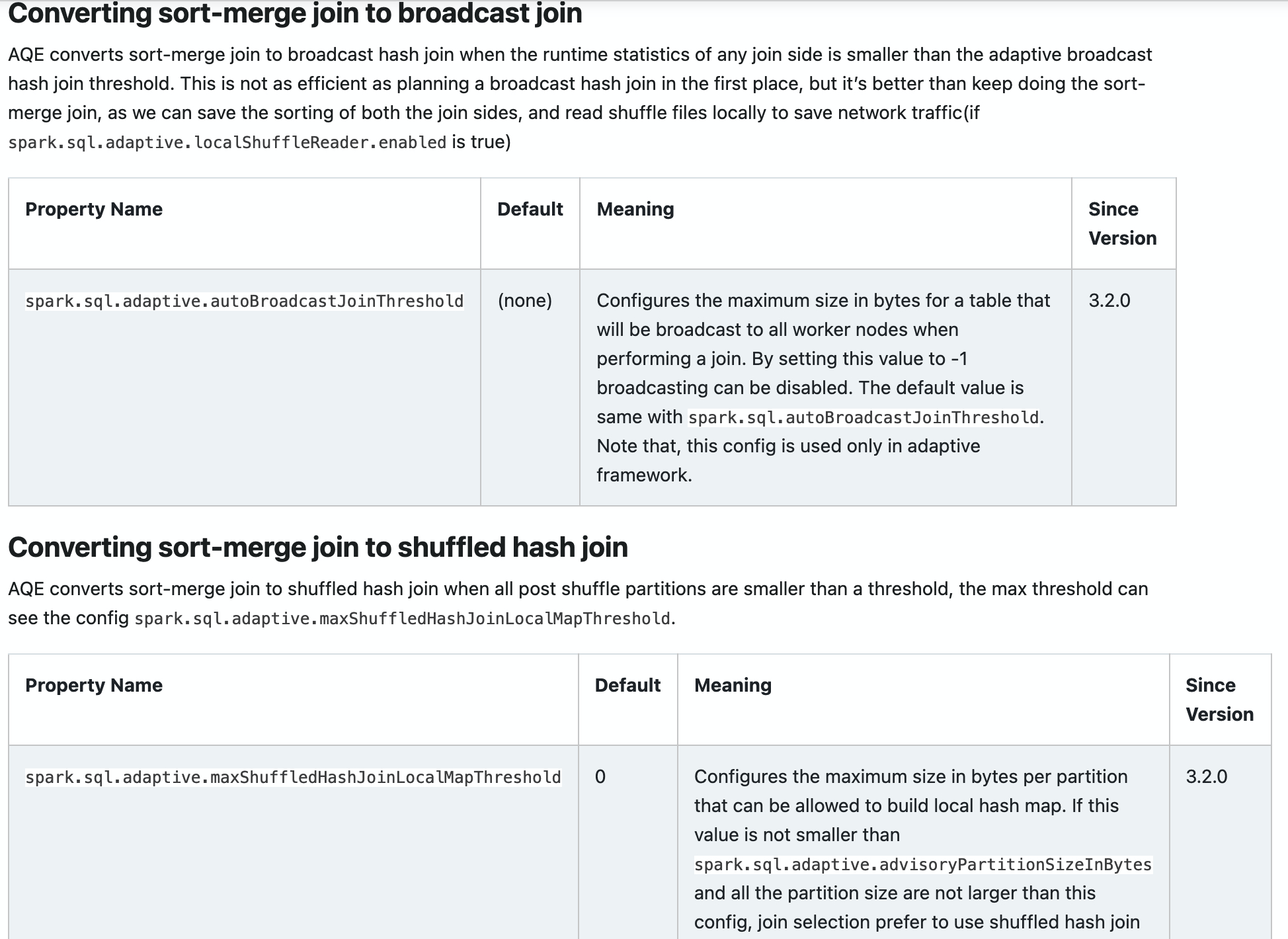
Closes#32960 from ulysses-you/SPARK-35813.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit 0e9786c712)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to remove the automatic build guides of documentation in `docs/README.md`.
### Why are the changes needed?
This doesn't work very well:
1. It doesn't detect the changes in RST files. But PySpark internally generates RST files so we can't just simply include it in the detection. Otherwise, it goes to an infinite loop
2. During PySpark documentation generation, it launches some jobs to generate plot images now. This is broken with `entr` command, and the job fails. Seems like it's related to how `entr` creates the process internally.
3. Minor issue but the documentation build directory was changed (`_build` -> `build` in `python/docs`)
I don't think it's worthwhile testing and fixing the docs to show an working example because dev people are already able to do it manually.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Manually tested.
Closes#33266 from HyukjinKwon/SPARK-36051.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit a1ce64904f)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
As described in #32831, Spark has compatible issues when querying a view created by an
older version. The root cause is that Spark changed the auto-generated alias name. To avoid
this in the future, we could ask the user to specify explicit column names when creating
a view.
### Why are the changes needed?
Avoid compatible issue when querying a view
### Does this PR introduce _any_ user-facing change?
Yes. User will get error when running query below after this change
```
CREATE OR REPLACE VIEW v AS SELECT CAST(t.a AS INT), to_date(t.b, 'yyyyMMdd') FROM t
```
### How was this patch tested?
not yet
Closes#32832 from linhongliu-db/SPARK-35686-no-auto-alias.
Authored-by: Linhong Liu <linhong.liu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In https://issues.apache.org/jira/browse/SPARK-34862, we added support for ORC nested column vectorized reader, and it is disabled by default for now. So we would like to add the user-facing documentation for it, and user can opt-in to use it if they want.
### Why are the changes needed?
To make user be aware of the feature, and let them know the instruction to use the feature.
### Does this PR introduce _any_ user-facing change?
Yes, the documentation itself.
### How was this patch tested?
Manually check generated documentation as below.
<img width="1153" alt="Screen Shot 2021-07-01 at 12 19 40 AM" src="https://user-images.githubusercontent.com/4629931/124083422-b0724280-da02-11eb-93aa-a25d118ba56e.png">
<img width="1147" alt="Screen Shot 2021-07-01 at 12 19 52 AM" src="https://user-images.githubusercontent.com/4629931/124083442-b5cf8d00-da02-11eb-899f-827d55b8558d.png">
Closes#33168 from c21/orc-doc.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR aims to deprecate old Java 8 versions prior to 8u201.
### Why are the changes needed?
This is a preparation of using G1GC during the migration among Java LTS versions (8/11/17).
8u162 has the following fix.
- JDK-8205376: JVM Crash during G1 GC
8u201 has the following fix.
- JDK-8208873: C1: G1 barriers don't preserve FP registers
### Does this PR introduce _any_ user-facing change?
No, Today's Java8 is usually 1.8.0_292 and this is just a deprecation in documentation.
### How was this patch tested?
N/A
Closes#33166 from dongjoon-hyun/SPARK-35962.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Deprecate Python 3.6 in Spark documentation
### Why are the changes needed?
According to https://endoflife.date/python, Python 3.6 will be EOL on 23 Dec, 2021.
We should prepare for the deprecation of Python 3.6 support in Spark in advance.
### Does this PR introduce _any_ user-facing change?
N/A.
### How was this patch tested?
Manual tests.
Closes#33141 from xinrong-databricks/deprecate3.6_doc.
Authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
There are two new Avro options `datetimeRebaseMode` and `positionalFieldMatching` after Spark 3.2.
We should document the since version so that users can know whether the option works in their Spark version.
### Why are the changes needed?
Better documentation.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manual preview on local setup.
<img width="828" alt="Screen Shot 2021-06-30 at 5 05 54 PM" src="https://user-images.githubusercontent.com/1097932/123934000-ba833b00-d947-11eb-9ca5-ce8ff8add74b.png">
<img width="711" alt="Screen Shot 2021-06-30 at 5 06 34 PM" src="https://user-images.githubusercontent.com/1097932/123934126-d4bd1900-d947-11eb-8d80-69df8f3d9900.png">
Closes#33153 from gengliangwang/version.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Gengliang Wang <gengliang@apache.org>
### What changes were proposed in this pull request?
Provide the (configurable) ability to perform Avro-to-Catalyst schema field matching using the position of the fields instead of their names. A new `option` is added for the Avro datasource, `positionalFieldMatching`, which instructs `AvroSerializer`/`AvroDeserializer` to perform positional field matching instead of matching by name.
### Why are the changes needed?
This by-name matching is somewhat recent; prior to PR #24635, at least on the write path, schemas were matched by positionally ("structural" comparison). While by-name is better behavior as a default, it will be better to make this configurable by a user. Even at the time that PR #24635 was handled, there was [interest in making this behavior configurable](https://github.com/apache/spark/pull/24635#issuecomment-494205251), but it appears it went unaddressed.
There is precedence for configurability of this behavior as seen in PR #29737, which added this support for ORC. Besides this precedence, the behavior of Hive is to perform matching positionally ([ref](https://cwiki.apache.org/confluence/display/Hive/AvroSerDe#AvroSerDe-WritingtablestoAvrofiles)), so this is behavior that Hadoop/Hive ecosystem users are familiar with.
### Does this PR introduce _any_ user-facing change?
Yes, a new option is provided for the Avro datasource, `positionalFieldMatching`, which provides compatibility with Hive and pre-3.0.0 Spark behavior.
### How was this patch tested?
New unit tests are added within `AvroSuite`, `AvroSchemaHelperSuite`, and `AvroSerdeSuite`; and most of the existing tests within `AvroSerdeSuite` are adapted to perform the same test using by-name and positional matching to ensure feature parity.
Closes#31490 from xkrogen/xkrogen-SPARK-34365-avro-positional-field-matching.
Authored-by: Erik Krogen <xkrogen@apache.org>
Signed-off-by: Gengliang Wang <gengliang@apache.org>
### What changes were proposed in this pull request?
This adds two new additional metrics to `ExternalBlockHandler`:
- `blockTransferRate` -- for indicating the rate of transferring blocks, vs. the data within them
- `blockTransferAvgSize_1min` -- a 1-minute trailing average of block sizes transferred by the ESS
Additionally, this enhances `YarnShuffleServiceMetrics` to expose the histogram/`Snapshot` information from `Timer` metrics within `ExternalBlockHandler`.
### Why are the changes needed?
Currently `ExternalBlockHandler` exposes some useful metrics, but is lacking around metrics for the rate of block transfers. We have `blockTransferRateBytes` to tell us the rate of _bytes_, but no metric to tell us the rate of _blocks_, which is especially relevant when running the ESS on HDDs that are sensitive to random reads. Many small block transfers can have a negative impact on performance, but won't show up as a spike in `blockTransferRateBytes` since the sizes are small. Thus the new metrics to show information around average block size and block transfer rate are very useful to monitor the health/performance of the ESS, especially when running on HDDs.
For the `YarnShuffleServiceMetrics`, currently the three `Timer` metrics exposed by `ExternalBlockHandler` are being underutilized in a YARN-based environment -- they are basically treated as a `Meter`, only exposing rate-based information, when the metrics themselves are collected detailed histograms of timing information. We should expose this information for better observability.
### Does this PR introduce _any_ user-facing change?
Yes, there are two entirely new metrics for the ESS, as documented in `monitoring.md`. Additionally in a YARN environment, `Timer` metrics exposed by the ESS will include more rich timing information.
### How was this patch tested?
New unit tests are added to verify that new metrics are showing up as expected.
We have been running this patch internally for approx. 1 year and have found it to be useful for monitoring the health of ESS and diagnosing performance issues.
Closes#32388 from xkrogen/xkrogen-SPARK-35258-ess-new-metrics.
Authored-by: Erik Krogen <xkrogen@apache.org>
Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com>
### What changes were proposed in this pull request?
The hyperlinks in Python code blocks in [Spark SQL Guide - Getting Started](https://spark.apache.org/docs/latest/sql-getting-started.html) currently point to invalid addresses and return 404. This pull request fixes that issue by pointing them to correct links in Python API docs.
### Why are the changes needed?
Error in documentation classifies as a bug and hence needs to be fixed.
### Does this PR introduce _any_ user-facing change?
Yes. This PR fixes documentation error in https://spark.apache.org/docs/latest/sql-getting-started.html
### How was this patch tested?
This patch was locally built after cloning the repo from scratch and then doing a clean build after fixing the required problems.
Closes#33107 from dhruvildave/sql-doc.
Authored-by: Dhruvil Dave <dhruvil.dave@outlook.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Update "Caching Data in Memory" section, add suggestion to call DataFrame `unpersist` method to make it consistent with previous suggestion of using `persist` method.
### Why are the changes needed?
Keep documentation consistent.
### Does this PR introduce _any_ user-facing change?
Yes, fixes the user-facing docs.
### How was this patch tested?
Manually.
Closes#33069 from Silverlight42/caching-data-doc.
Authored-by: Carlos Peña <Cdpm42@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR changes the unionByName with null filling logic to append new nested struct fields from the right side of the union to the schema versus sorting fields alphabetically. It removes the need to use UpdateField expressions, and just directly projects new nested structs from each side of the union with the correct schema. This changes the union'd schema from being alphabetically sorted previously to now "left dominant", where the fields from the left side of the union are included and then the missing ones from the right are added in the same order found originally.
### Why are the changes needed?
Certain nested structs would cause unionByName with null filling to error out due to part of the logic for rewriting the expression tree to sort the structs.
### Does this PR introduce _any_ user-facing change?
Yes, nested struct fields will be in a different order after unionByName with null filling than before, though shouldn't cause much effective difference.
### How was this patch tested?
Updated existing tests based on the new StructField ordering and added a new test for the case that was broken originally.
Closes#33040 from Kimahriman/union-by-name-struct-order.
Authored-by: Adam Binford <adamq43@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
* Add a new repartition operator `RebalanceRepartition`.
* Support a new hint `REBALANCE`
After this patch, user can run this query:
```sql
SELECT /*+ REBALANCE(c) */ * FROM t
```
### Why are the changes needed?
Add a new hint to distingush if we can optimize it safely.
This new hint can let AQE optimize with `CustomShuffleReaderExec` safely. Currently, AQE can only coalesce shuffle partitions but can not expand shuffle partitions due to the semantics of output partitioning.
Let's say we have a query:
```sql
SELECT /*+ REPARTITION(col) */ * FROM t
```
AQE can not expand the shuffle partitions even if `col` is skewed because expanding shuffle partitions will break the hashed output paritioning of `RepartitionByExpression`. But if the query is use`REPARTITION_BY_AQE`, AQE can optimize it without considering the semantics of output partitioning.
### Does this PR introduce _any_ user-facing change?
Yes, a new hint.
### How was this patch tested?
Add test.
Closes#32932 from ulysses-you/SPARK-35786.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This's a follow-up of https://github.com/apache/spark/pull/30710.
Rename the conf from `spark.speculation.min.threshold` to `spark.speculation.minTaskRuntime`.
### Why are the changes needed?
To follow the [config naming policy](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/internal/config/ConfigEntry.scala#L21).
### Does this PR introduce _any_ user-facing change?
No (since Spark 3.2 hasn't been released).
### How was this patch tested?
Pass existing tests.
Closes#33037 from Ngone51/spark-33741-followup.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to introduce the strategy on mismatched offset for start offset timestamp on Kafka data source.
Please read the section `Why are the changes needed?` to understand the rationalization of the functionality.
This would be pretty much helpful for the case where there's a skew between partitions and some partitions have older records.
* AS-IS: Spark simply fails the query and end users have to deal with workarounds requiring manual steps.
* TO-BE: Spark will assign the latest offset for these partitions, so that Spark can read newer records from these partitions in further micro-batches.
To retain the existing behavior and also give some help for the proposed "TO-BE" behavior, we'd like to introduce the strategy on mismatched offset for start offset timestamp to let end users choose from them.
The strategy will be added as source option, to ensure end users set the behavior explicitly (otherwise simply "known" default value).
* New source option to be added: startingOffsetsByTimestampStrategy
* Available values: `error` (fail the query as referred as AS-IS), `latest` (set the offset to the latest as referred as TO-BE)
Doc changes are following:


### Why are the changes needed?
We encountered a real-world case Spark fails the query if some of the partitions don't have matching offset by timestamp.
This is intended behavior to avoid bring unintended output for some cases like:
* timestamp 2 is presented as timestamp-offset, but the some of partitions don't have the record yet
* record with timestamp 1 comes "later" in the following micro-batch
which is possible since Kafka allows to specify the timestamp in record.
Here the unintended output we talked about was the risk of reading record with timestamp 1 in the next micro-batch despite the option specifying timestamp 2.
But for many cases end users just suppose timestamp is increasing monotonically with wall clocks are all in sync, and current behavior blocks these cases to make progress.
### Does this PR introduce _any_ user-facing change?
Yes, but not a breaking change. It's up to end users to choose the behavior which the default value is "error" (current behavior). And it's a source option (not config) so they need to explicitly set the behavior to let the functionality takes effect.
### How was this patch tested?
New UTs.
Closes#32747 from HeartSaVioR/SPARK-35611.
Authored-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
PySpark added pinned thread mode at https://github.com/apache/spark/pull/24898 to sync Python thread to JVM thread. Previously, one JVM thread could be reused which ends up with messed inheritance hierarchy such as thread local especially when multiple jobs run in parallel. To completely fix this, we should enable this mode by default.
### Why are the changes needed?
To correctly support parallel job submission and management.
### Does this PR introduce _any_ user-facing change?
Yes, now Python thread is mapped to JVM thread one to one.
### How was this patch tested?
Existing tests should cover it.
Closes#32429 from HyukjinKwon/SPARK-35303.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/32513
It's hard to keep the command execution name for `DataFrameWriter`, as the command logical plan is a bit messy (DS v1, file source and hive and different command logical plans) and sometimes it's hard to distinguish "insert" and "save".
However, `DataFrameWriterV2` only produce v2 commands which are pretty clean. It's easy to keep the command execution name for them.
### Why are the changes needed?
less breaking changes.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
N/A
Closes#32919 from cloud-fan/follow.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR updates the document about building Spark with Hadoop for Hadoop 3.x and Hadoop 3.2.
### Why are the changes needed?
The document says about how to build like as follows:
```
./build/mvn -Pyarn -Dhadoop.version=2.8.5 -DskipTests clean package
```
But this command fails because the default build settings are for Hadoop 3.x.
So, we need to modify the command example.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
I confirmed both of these commands successfully finished.
```
./build/mvn -Pyarn -Dhadoop.version=3.3.0 -DskipTests package
./build/mvn -Phadoop-2.7 -Pyarn -Dhadoop.version=2.8.5 -DskipTests package
```
I also built the document and confirmed the result.
This is before:

And this is after:

Closes#32917 from sarutak/fix-build-doc-with-hadoop.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR adda a feature which allow the parser parse any day-time interval types in SQL.
### Why are the changes needed?
To comply with ANSI standard, we additionally need to support the following types.
* INTERVAL DAY
* INTERVAL DAY TO HOUR
* INTERVAL DAY TO MINUTE
* INTERVAL HOUR
* INTERVAL HOUR TO MINUTE
* INTERVAL HOUR TO SECOND
* INTERVAL MINUTE
* INTERVAL MINUTE TO SECOND
* INTERVAL SECOND
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New tests.
Closes#32893 from sarutak/parse-any-day-time.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
The STRUCT type syntax is defined like this:
STRUCT(fieldNmae: fileType [NOT NULL][COMMENT stringLiteral][,.....])
So the field list is nearly the same as a column list
if we could make ':' optional it would be so much cleaner an less proprietary
### Why are the changes needed?
ease of use
### Does this PR introduce _any_ user-facing change?
Yes, you can use Struct type list is nearly the same as a column list
### How was this patch tested?
unit tests
Closes#32858 from jerqi/master.
Authored-by: RoryQi <1242949407@qq.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}