### What changes were proposed in this pull request?
There is an issue when syncing to the Apache master branch, see also https://github.com/apache/spark/pull/32168:
```
From https://github.com/yaooqinn/spark
* branch SPARK-35044 -> FETCH_HEAD
fatal: Not possible to fast-forward, aborting.
Error: Process completed with exit code 128.
```
This is because we use `--ff-only` option so it assumes that the fork is always based on the latest master branch.
We should make it less strict.
This PR proposes to use the same command when we merge PRs:
c8f56eb7bb/dev/merge_spark_pr.py (L127)
### Why are the changes needed?
To unblock PR testing broken.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Locally tested
Co-authored-by: Kent Yao <yaooqinnhotmail.com>
Closes#32168Closes#32182 from Yikun/SPARK-rm-fast-forward.
Lead-authored-by: Yikun Jiang <yikunkero@gmail.com>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Now that we merged the Koalas main code into the PySpark code base (#32036), we should port the Koalas miscellaneous unit tests to PySpark.
### Why are the changes needed?
Currently, the pandas-on-Spark modules are not tested fully. We should enable miscellaneous unit tests.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Enable miscellaneous unit tests.
Closes#32152 from xinrong-databricks/port.misc_tests.
Lead-authored-by: xinrong-databricks <47337188+xinrong-databricks@users.noreply.github.com>
Co-authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This patch add `__version__` into pyspark.__init__.__all__ to make the `__version__` as exported explicitly, see more in https://github.com/apache/spark/pull/32110#issuecomment-817331896
### Why are the changes needed?
1. make the `__version__` as exported explicitly
2. cleanup `noqa: F401` on `__version`
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Python related CI passed
Closes#32125 from Yikun/SPARK-34629-Follow.
Authored-by: Yikun Jiang <yikunkero@gmail.com>
Signed-off-by: zero323 <mszymkiewicz@gmail.com>
### What changes were proposed in this pull request?
Currently, pure SQL users are short of ways to see the Hadoop configurations which may affect their jobs a lot, they are only able to get the Hadoop configs that exist in `SQLConf` while other defaults in `SharedState.hadoopConf` display wrongly and confusingly with `<undefined>`.
The pre-loaded ones from `core-site.xml, hive-site.xml` etc., will only stay in `sparkSession.sharedState.hadoopConf` or `sc._hadoopConfiguation` not `SQLConf`. Some of them that related the Hive Metastore connection(never change it spark runtime), e.g. `hive.metastore.uris`, are clearly global static and unchangeable but displayable I guess. Some of the ones that might be related to, for example, the output codec/compression, preset in Hadoop/hive config files like core-site.xml shall be still changeable from case to case, table to table, file to file, etc. It' meaningfully to show the defaults for users to change based on that.
In this PR, I propose to support get a Hadoop configuration by SET syntax, for example
```
SET mapreduce.map.output.compress.codec;
```
### Why are the changes needed?
better user experience for pure SQL users
### Does this PR introduce _any_ user-facing change?
yes, where retrieving a conf only existing in sessionState.hadoopConf, before is `undefined` and now you see it
### How was this patch tested?
new test
Closes#32144 from yaooqinn/SPARK-35044.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
There is a potential Netty memory leak in TransportResponseHandler.
### Why are the changes needed?
Fix a potential Netty memory leak in TransportResponseHandler.
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
NO
Closes#31942 from weixiuli/SPARK-34834.
Authored-by: weixiuli <weixiuli@jd.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This patch introduces a VectorizedBLAS class which implements such hardware-accelerated BLAS operations. This feature is hidden behind the "vectorized" profile that you can enable by passing "-Pvectorized" to sbt or maven.
The Vector API has been introduced in JDK 16. Following discussion on the mailing list, this API is introduced transparently and needs to be enabled explicitely.
### Why are the changes needed?
Whenever a native BLAS implementation isn't available on the system, Spark automatically falls back onto a Java implementation. With the recent release of the Vector API in the OpenJDK [1], we can use hardware acceleration for such operations.
This change was also discussed on the mailing list. [2]
### Does this PR introduce _any_ user-facing change?
It introduces a build-time profile called `vectorized`. You can pass it to sbt and mvn with `-Pvectorized`. There is no change to the end-user of Spark and it should only impact Spark developpers. It is also disabled by default.
### How was this patch tested?
It passes `build/sbt mllib-local/test` with and without `-Pvectorized` with JDK 16. This patch also introduces benchmarks for BLAS.
The benchmark results are as follows:
```
[info] daxpy: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 37 37 0 271.5 3.7 1.0X
[info] vector 24 25 4 416.1 2.4 1.5X
[info]
[info] ddot: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 70 70 0 143.2 7.0 1.0X
[info] vector 35 35 2 288.7 3.5 2.0X
[info]
[info] sdot: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 50 51 1 199.8 5.0 1.0X
[info] vector 15 15 0 648.7 1.5 3.2X
[info]
[info] dscal: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 34 34 0 295.6 3.4 1.0X
[info] vector 19 19 0 531.2 1.9 1.8X
[info]
[info] sscal: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 25 25 1 399.0 2.5 1.0X
[info] vector 8 9 1 1177.3 0.8 3.0X
[info]
[info] dgemv[N]: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 27 27 0 0.0 26651.5 1.0X
[info] vector 21 21 0 0.0 20646.3 1.3X
[info]
[info] dgemv[T]: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 36 36 0 0.0 35501.4 1.0X
[info] vector 22 22 0 0.0 21930.3 1.6X
[info]
[info] sgemv[N]: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 20 20 0 0.0 20283.3 1.0X
[info] vector 9 9 0 0.1 8657.7 2.3X
[info]
[info] sgemv[T]: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 30 30 0 0.0 29845.8 1.0X
[info] vector 10 10 1 0.1 9695.4 3.1X
[info]
[info] dgemm[N,N]: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 182 182 0 0.5 1820.0 1.0X
[info] vector 160 160 1 0.6 1597.6 1.1X
[info]
[info] dgemm[N,T]: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 211 211 1 0.5 2106.2 1.0X
[info] vector 156 157 0 0.6 1564.4 1.3X
[info]
[info] dgemm[T,N]: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 276 276 0 0.4 2757.8 1.0X
[info] vector 137 137 0 0.7 1365.1 2.0X
```
/cc srowen xkrogen
[1] https://openjdk.java.net/jeps/338
[2] https://mail-archives.apache.org/mod_mbox/spark-dev/202012.mbox/%3cDM5PR2101MB11106162BB3AF32AD29C6C79B0C69DM5PR2101MB1110.namprd21.prod.outlook.com%3eCloses#30810 from luhenry/master.
Lead-authored-by: Ludovic Henry <luhenry@microsoft.com>
Co-authored-by: Ludovic Henry <git@ludovic.dev>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Support `date +/- day-time interval`. In the PR, I propose to update the binary arithmetic rules, and cast an input date to a timestamp at the session time zone, and then add a day-time interval to it.
### Why are the changes needed?
1. To conform the ANSI SQL standard which requires to support such operation over dates and intervals:
<img width="811" alt="Screenshot 2021-03-12 at 11 36 14" src="https://user-images.githubusercontent.com/1580697/111081674-865d4900-8515-11eb-86c8-3538ecaf4804.png">
2. To fix the regression comparing to the recent Spark release 3.1 with default settings.
Before the changes:
```sql
spark-sql> select date'now' + (timestamp'now' - timestamp'yesterday');
Error in query: cannot resolve 'DATE '2021-04-14' + subtracttimestamps(TIMESTAMP '2021-04-14 18:14:56.497', TIMESTAMP '2021-04-13 00:00:00')' due to data type mismatch: argument 1 requires timestamp type, however, 'DATE '2021-04-14'' is of date type.; line 1 pos 7;
'Project [unresolvedalias(cast(2021-04-14 + subtracttimestamps(2021-04-14 18:14:56.497, 2021-04-13 00:00:00, false, Some(Europe/Moscow)) as date), None)]
+- OneRowRelation
```
Spark 3.1:
```sql
spark-sql> select date'now' + (timestamp'now' - timestamp'yesterday');
2021-04-15
```
Hive:
```sql
0: jdbc:hive2://localhost:10000/default> select date'2021-04-14' + (timestamp'2020-04-14 18:15:30' - timestamp'2020-04-13 00:00:00');
+------------------------+
| _c0 |
+------------------------+
| 2021-04-15 18:15:30.0 |
+------------------------+
```
### Does this PR introduce _any_ user-facing change?
Should not since new intervals have not been released yet.
After the changes:
```sql
spark-sql> select date'now' + (timestamp'now' - timestamp'yesterday');
2021-04-15 18:13:16.555
```
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#32170 from MaxGekk/date-add-day-time-interval.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR bumps up the version of pycodestyle from 2.6.0 to 2.7.0 released a month ago.
### Why are the changes needed?
2.7.0 includes three major fixes below (see https://readthedocs.org/projects/pycodestyle/downloads/pdf/latest/):
- Fix physical checks (such as W191) at end of file. PR #961.
- Add --indent-size option (defaulting to 4). PR #970.
- W605: fix escaped crlf false positive on windows. PR #976
The first and third ones could be useful for dev to detect the styles.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Manually tested locally.
Closes#32160 from HyukjinKwon/SPARK-35061.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
According to https://github.com/apache/spark/pull/29087#discussion_r612267050, add UT in `transform.sql`
It seems that distinct is not recognized as a reserved word here
```
-- !query
explain extended SELECT TRANSFORM(distinct b, a, c)
USING 'cat' AS (a, b, c)
FROM script_trans
WHERE a <= 4
-- !query schema
struct<plan:string>
-- !query output
== Parsed Logical Plan ==
'ScriptTransformation [*], cat, [a#x, b#x, c#x], ScriptInputOutputSchema(List(),List(),None,None,List(),List(),None,None,false)
+- 'Project ['distinct AS b#x, 'a, 'c]
+- 'Filter ('a <= 4)
+- 'UnresolvedRelation [script_trans], [], false
== Analyzed Logical Plan ==
org.apache.spark.sql.AnalysisException: cannot resolve 'distinct' given input columns: [script_trans.a, script_trans.b, script_trans.c]; line 1 pos 34;
'ScriptTransformation [*], cat, [a#x, b#x, c#x], ScriptInputOutputSchema(List(),List(),None,None,List(),List(),None,None,false)
+- 'Project ['distinct AS b#x, a#x, c#x]
+- Filter (a#x <= 4)
+- SubqueryAlias script_trans
+- View (`script_trans`, [a#x,b#x,c#x])
+- Project [cast(a#x as int) AS a#x, cast(b#x as int) AS b#x, cast(c#x as int) AS c#x]
+- Project [a#x, b#x, c#x]
+- SubqueryAlias script_trans
+- LocalRelation [a#x, b#x, c#x]
```
Hive's error
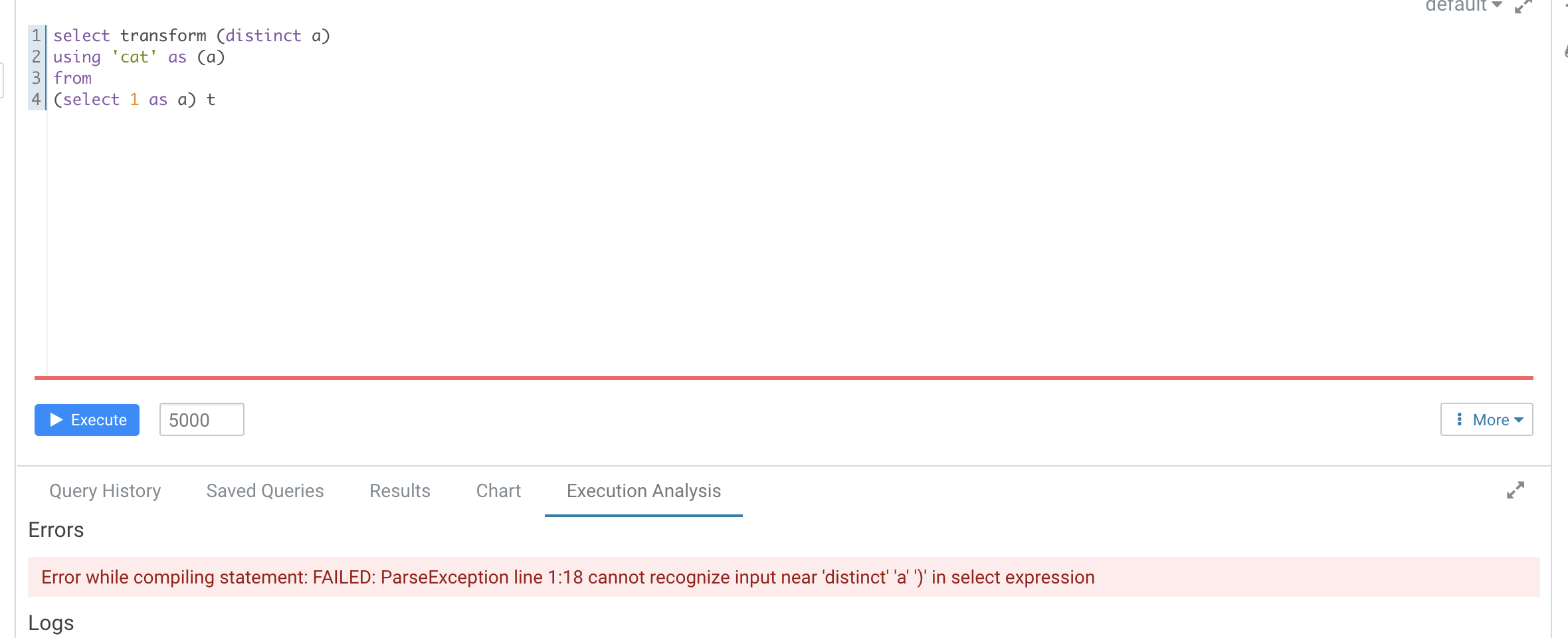
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added Ut
Closes#32149 from AngersZhuuuu/SPARK-28227-new-followup.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes two tests below:
https://github.com/apache/spark/runs/2320161984
```
[info] YarnShuffleIntegrationSuite:
[info] org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite *** ABORTED *** (228 milliseconds)
[info] org.apache.hadoop.yarn.exceptions.YarnRuntimeException: org.apache.hadoop.yarn.webapp.WebAppException: Error starting http server
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster.startResourceManager(MiniYARNCluster.java:373)
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster.access$300(MiniYARNCluster.java:128)
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster$ResourceManagerWrapper.serviceStart(MiniYARNCluster.java:503)
[info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
[info] at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:121)
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster.serviceStart(MiniYARNCluster.java:322)
[info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
[info] at org.apache.spark.deploy.yarn.BaseYarnClusterSuite.beforeAll(BaseYarnClusterSuite.scala:95)
...
[info] Cause: java.net.BindException: Port in use: fv-az186-831:0
[info] at org.apache.hadoop.http.HttpServer2.constructBindException(HttpServer2.java:1231)
[info] at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1253)
[info] at org.apache.hadoop.http.HttpServer2.openListeners(HttpServer2.java:1316)
[info] at org.apache.hadoop.http.HttpServer2.start(HttpServer2.java:1167)
[info] at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:449)
[info] at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.startWepApp(ResourceManager.java:1247)
[info] at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceStart(ResourceManager.java:1356)
[info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster.startResourceManager(MiniYARNCluster.java:365)
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster.access$300(MiniYARNCluster.java:128)
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster$ResourceManagerWrapper.serviceStart(MiniYARNCluster.java:503)
[info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
[info] at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:121)
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster.serviceStart(MiniYARNCluster.java:322)
[info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
[info] at org.apache.spark.deploy.yarn.BaseYarnClusterSuite.beforeAll(BaseYarnClusterSuite.scala:95)
[info] at org.scalatest.BeforeAndAfterAll.liftedTree1$1(BeforeAndAfterAll.scala:212)
[info] at org.scalatest.BeforeAndAfterAll.run(BeforeAndAfterAll.scala:210)
[info] at org.scalatest.BeforeAndAfterAll.run$(BeforeAndAfterAll.scala:208)
[info] at org.apache.spark.SparkFunSuite.run(SparkFunSuite.scala:61)
...
```
https://github.com/apache/spark/runs/2323342094
```
[info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadSecret started
[error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadSecret failed: java.lang.AssertionError: Connecting to /10.1.0.161:39895 timed out (120000 ms), took 120.081 sec
[error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadSecret(ExternalShuffleSecuritySuite.java:85)
[error] ...
[info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadAppId started
[error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadAppId failed: java.lang.AssertionError: Connecting to /10.1.0.198:44633 timed out (120000 ms), took 120.08 sec
[error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadAppId(ExternalShuffleSecuritySuite.java:76)
[error] ...
[info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testValid started
[error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testValid failed: java.io.IOException: Connecting to /10.1.0.119:43575 timed out (120000 ms), took 120.089 sec
[error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:285)
[error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:218)
[error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:230)
[error] at org.apache.spark.network.shuffle.ExternalBlockStoreClient.registerWithShuffleServer(ExternalBlockStoreClient.java:211)
[error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.validate(ExternalShuffleSecuritySuite.java:108)
[error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testValid(ExternalShuffleSecuritySuite.java:68)
[error] ...
[info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testEncryption started
[error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testEncryption failed: java.io.IOException: Connecting to /10.1.0.248:35271 timed out (120000 ms), took 120.014 sec
[error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:285)
[error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:218)
[error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:230)
[error] at org.apache.spark.network.shuffle.ExternalBlockStoreClient.registerWithShuffleServer(ExternalBlockStoreClient.java:211)
[error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.validate(ExternalShuffleSecuritySuite.java:108)
[error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testEncryption(ExternalShu
```
For Yarn cluster suites, its difficult to fix. This PR makes it skipped if it fails to bind.
For shuffle related suites, it uses local host
### Why are the changes needed?
To make the tests stable
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Its tested in GitHub Actions: https://github.com/HyukjinKwon/spark/runs/2340210765Closes#32126 from HyukjinKwon/SPARK-35002-followup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request?
This PR proposes to introduce the `AnalysisOnlyCommand` trait such that a command that extends this trait can have its children only analyzed, but not optimized. There is a corresponding analysis rule `HandleAnalysisOnlyCommand` that marks the command as analyzed after all other analysis rules are run.
This can be useful if a logical plan has children where they need to be only analyzed, but not optimized - e.g., `CREATE VIEW` or `CACHE TABLE AS`. This also addresses the issue found in #31933.
This PR also updates `CreateViewCommand`, `CacheTableAsSelect`, and `AlterViewAsCommand` to use the new trait / rule such that their children are only analyzed.
### Why are the changes needed?
To address the issue where the plan is unnecessarily re-analyzed in `CreateViewCommand`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests should cover the changes.
Closes#32032 from imback82/skip_transform.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Adds the duplicated common columns as hidden columns to the Projection used to rewrite NATURAL/USING JOINs.
### Why are the changes needed?
Allows users to resolve either side of the NATURAL/USING JOIN's common keys.
Previously, the user could only resolve the following columns:
| Join type | Left key columns | Right key columns |
| --- | --- | --- |
| Inner | Yes | No |
| Left | Yes | No |
| Right | No | Yes |
| Outer | No | No |
### Does this PR introduce _any_ user-facing change?
Yes. The user can now symmetrically resolve the common columns from a NATURAL/USING JOIN.
### How was this patch tested?
SQL-side tests. The behavior matches PostgreSQL and MySQL.
Closes#31666 from karenfeng/spark-34527.
Authored-by: Karen Feng <karen.feng@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add change of `DESC NAMESPACE`'s schema to migration guide
### Why are the changes needed?
Update doc
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32155 from AngersZhuuuu/SPARK-34577-followup.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Removes PySpark version dependent codes from `pyspark.pandas` main codes.
### Why are the changes needed?
There are several places to check the PySpark version and switch the logic, but now those are not necessary.
We should remove them.
We will do the same thing after we finish porting tests.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#32138 from ueshin/issues/SPARK-35039/pyspark_version.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Now that we merged the Koalas main code into the PySpark code base (#32036), we should port the Koalas internal implementation unit tests to PySpark.
### Why are the changes needed?
Currently, the pandas-on-Spark modules are not tested fully. We should enable the internal implementation unit tests.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Enable internal implementation unit tests.
Closes#32137 from xinrong-databricks/port.test_internal_impl.
Lead-authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Co-authored-by: xinrong-databricks <47337188+xinrong-databricks@users.noreply.github.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to leverage the GitHub Actions resources from the forked repositories instead of using the resources in ASF organisation at GitHub.
This is how it works:
1. "Build and test" (`build_and_test.yml`) triggers a build on any commit on any branch (except `branch-*.*`), which roughly means:
- The original repository will trigger the build on any commits in `master` branch
- The forked repository will trigger the build on any commit in any branch.
2. The build triggered in the forked repository will checkout the original repository's `master` branch locally, and merge the branch from the forked repository into the original repository's `master` branch locally.
Therefore, the tests in the forked repository will run after being sync'ed with the original repository's `master` branch.
3. In the original repository, it triggers a workflow that detects the workflow triggered in the forked repository, and add a comment, to the PR, pointing out the workflow in forked repository.
In short, please see this example HyukjinKwon#34
1. You create a PR and your repository triggers the workflow. Your PR uses the resources allocated to you for testing.
2. Apache Spark repository finds your workflow, and links it in a comment in your PR
**NOTE** that we will still run the tests in the original repository for each commit pushed to `master` branch. This distributes the workflows only in PRs.
### Why are the changes needed?
ASF shares the resources across all the ASF projects, which makes the development slow down.
Please see also:
- Discussion in the buildsa.o mailing list: https://lists.apache.org/x/thread.html/r48d079eeff292254db22705c8ef8618f87ff7adc68d56c4e5d0b4105%3Cbuilds.apache.org%3E
- Infra ticket: https://issues.apache.org/jira/browse/INFRA-21646
By distributing the workflows to use author's resources, we can get around this issue.
### Does this PR introduce _any_ user-facing change?
No, this is a dev-only change.
### How was this patch tested?
Manually tested at https://github.com/HyukjinKwon/spark/pull/34 and https://github.com/HyukjinKwon/spark/pull/33.
Closes#32092 from HyukjinKwon/poc-fork-resources.
Lead-authored-by: HyukjinKwon <gurwls223@apache.org>
Co-authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Now that we merged the Koalas main code into the PySpark code base (#32036), we should port the Koalas plot unit tests to PySpark.
### Why are the changes needed?
Currently, the pandas-on-Spark modules are not tested fully. We should enable the plot unit tests.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Enable plot unit tests.
Closes#32151 from xinrong-databricks/port.plot_tests.
Authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Deprecate Apache Mesos support for Spark 3.2.0 by adding documentation to this effect.
### Why are the changes needed?
Apache Mesos is ceasing development (https://lists.apache.org/thread.html/rab2a820507f7c846e54a847398ab20f47698ec5bce0c8e182bfe51ba%40%3Cdev.mesos.apache.org%3E) ; at some point we'll want to drop support, so, deprecate it now.
This doesn't mean it'll go away in 3.3.0.
### Does this PR introduce _any_ user-facing change?
No, docs only.
### How was this patch tested?
N/A
Closes#32150 from srowen/SPARK-35050.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add a new line to the `lineSep` parameter so that the doc renders correctly.
### Why are the changes needed?
> <img width="608" alt="image" src="https://user-images.githubusercontent.com/8269566/114631408-5c608900-9c71-11eb-8ded-ae1e21ae48b2.png">
The first line of the description is part of the signature and is **bolded**.
### Does this PR introduce _any_ user-facing change?
Yes, it changes how the docs for `pyspark.sql.DataFrameWriter.json` are rendered.
### How was this patch tested?
I didn't test it; I don't have the doc rendering tool chain on my machine, but the change is obvious.
Closes#32153 from AlexMooney/patch-1.
Authored-by: Alex Mooney <alexmooney@fastmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR fixes an issue that `LIST FILES/JARS/ARCHIVES path1 path2 ...` cannot list all paths if at least one path is quoted.
An example here.
```
ADD FILE /tmp/test1;
ADD FILE /tmp/test2;
LIST FILES /tmp/test1 /tmp/test2;
file:/tmp/test1
file:/tmp/test2
LIST FILES /tmp/test1 "/tmp/test2";
file:/tmp/test2
```
In this example, the second `LIST FILES` doesn't show `file:/tmp/test1`.
To resolve this issue, I modified the syntax rule to be able to handle this case.
I also changed `SparkSQLParser` to be able to handle paths which contains white spaces.
### Why are the changes needed?
This is a bug.
I also have a plan which extends `ADD FILE/JAR/ARCHIVE` to take multiple paths like Hive and the syntax rule change is necessary for that.
### Does this PR introduce _any_ user-facing change?
Yes. Users can pass quoted paths when using `ADD FILE/JAR/ARCHIVE`.
### How was this patch tested?
New test.
Closes#32074 from sarutak/fix-list-files-bug.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
Now that we merged the Koalas main code into the PySpark code base (#32036), we should port the Koalas DataFrame-related unit tests to PySpark.
### Why are the changes needed?
Currently, the pandas-on-Spark modules are not fully tested. We should enable the DataFrame-related unit tests first.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Enable DataFrame-related unit tests.
Closes#32131 from xinrong-databricks/port.test_dataframe_related.
Lead-authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Co-authored-by: xinrong-databricks <47337188+xinrong-databricks@users.noreply.github.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
### What changes were proposed in this pull request?
Remove unused MapOutputTracker in BlockStoreShuffleReader
### Why are the changes needed?
Remove unused MapOutputTracker in BlockStoreShuffleReader
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32148 from AngersZhuuuu/SPARK-35049.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com>
### What changes were proposed in this pull request?
This PR group exception messages in `/core/src/main/scala/org/apache/spark/sql/execution`.
### Why are the changes needed?
It will largely help with standardization of error messages and its maintenance.
### Does this PR introduce _any_ user-facing change?
No. Error messages remain unchanged.
### How was this patch tested?
No new tests - pass all original tests to make sure it doesn't break any existing behavior.
Closes#31920 from beliefer/SPARK-33604.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Populate table catalog and identifier from `DataStreamWriter` to `WriteToMicroBatchDataSource` so that we can invalidate cache for tables that are updated by a streaming write.
This is somewhat related [SPARK-27484](https://issues.apache.org/jira/browse/SPARK-27484) and [SPARK-34183](https://issues.apache.org/jira/browse/SPARK-34183) (#31700), as ideally we may want to replace `WriteToMicroBatchDataSource` and `WriteToDataSourceV2` with logical write nodes and feed them to analyzer. That will potentially change the code path involved in this PR.
### Why are the changes needed?
Currently `WriteToDataSourceV2` doesn't have cache invalidation logic, and therefore, when the target table for a micro batch streaming job is cached, the cache entry won't be removed when the table is updated.
### Does this PR introduce _any_ user-facing change?
Yes now when a DSv2 table which supports streaming write is updated by a streaming job, its cache will also be invalidated.
### How was this patch tested?
Added a new UT.
Closes#32039 from sunchao/streaming-cache.
Authored-by: Chao Sun <sunchao@apple.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Remove duplicate code in `TreeNode.treePatternBits`
### Why are the changes needed?
Code clean up. Make it easier for maintainence.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests.
Closes#32143 from gengliangwang/getBits.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
This PR makes the input buffer configurable (as an internal option). This is mainly to work around uniVocity/univocity-parsers#449.
### Why are the changes needed?
To work around uniVocity/univocity-parsers#449.
### Does this PR introduce _any_ user-facing change?
No, it's only internal option.
### How was this patch tested?
Manually tested by modifying the unittest added in https://github.com/apache/spark/pull/31858 as below:
```diff
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
index fd25a79619d..b58f0bd3661 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
-2460,6 +2460,7 abstract class CSVSuite
Seq(line).toDF.write.text(path.getAbsolutePath)
assert(spark.read.format("csv")
.option("delimiter", "|")
+ .option("inputBufferSize", "128")
.option("ignoreTrailingWhiteSpace", "true").load(path.getAbsolutePath).count() == 1)
}
}
```
Closes#32145 from HyukjinKwon/SPARK-35045.
Lead-authored-by: Hyukjin Kwon <gurwls223@apache.org>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Fix PhysicalAggregation to not transform a foldable expression.
### Why are the changes needed?
It can potentially break certain queries like the added unit test shows.
### Does this PR introduce _any_ user-facing change?
Yes, it fixes undesirable errors caused by a returned TypeCheckFailure from places like RegExpReplace.checkInputDataTypes.
Closes#32113 from sigmod/foldable.
Authored-by: Yingyi Bu <yingyi.bu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR contains:
- AnalysisHelper changes to allow the resolve function family to stop earlier without traversing the entire tree;
- Example changes in a few rules to support such pruning, e.g., ResolveRandomSeed, ResolveWindowFrame, ResolveWindowOrder, and ResolveNaturalAndUsingJoin.
### Why are the changes needed?
It's a framework-level change for reducing the query compilation time.
In particular, if we update existing analysis rules' call sites as per the examples in this PR, the analysis time can be reduced as described in the [doc](https://docs.google.com/document/d/1SEUhkbo8X-0cYAJFYFDQhxUnKJBz4lLn3u4xR2qfWqk).
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
It is tested by existing tests.
Closes#32135 from sigmod/resolver.
Authored-by: Yingyi Bu <yingyi.bu@databricks.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
Add overflow check before do `new byte[]`.
### Why are the changes needed?
Avoid overflow in extreme case.
### Does this PR introduce _any_ user-facing change?
Maybe yes, the error msg changed if overflow.
### How was this patch tested?
Pass CI.
Closes#32142 from ulysses-you/SPARK-35041.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This pr moves the added test from `SQLQuerySuite` to `ParquetQuerySuite`.
### Why are the changes needed?
1. It can be tested by `ParquetV1QuerySuite` and `ParquetV2QuerySuite`.
2. Reduce the testing time of `SQLQuerySuite`(SQLQuerySuite ~ 3 min 17 sec, ParquetV1QuerySuite ~ 27 sec).
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#32090 from wangyum/SPARK-34212.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Enhance the test instruction of ThriftServerQueryTestSuite:
1. how to run a single test case
2. how to regenerate golden file for a single test
### Why are the changes needed?
Better documentation.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
No, just enhance the comments.
Closes#32141 from gengliangwang/updateComment.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
This PR allows non-aggregated correlated scalar subquery if the max output row is less than 2. Correlated scalar subqueries need to be aggregated because they are going to be decorrelated and rewritten as LEFT OUTER joins. If the correlated scalar subquery produces more than one output row, the rewrite will yield wrong results.
But this constraint can be relaxed when the subquery plan's the max number of output rows is less than or equal to 1.
### Why are the changes needed?
To relax a constraint in CheckAnalysis for the correlated scalar subquery.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
Unit tests
Closes#32111 from allisonwang-db/spark-28379-aggregated.
Authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Supports cardinality estimation of union, sort and range operator.
1. **Union**: number of rows in output will be the sum of number of rows in the output for each child of union, min and max for each column in the output will be the min and max of that particular column coming from its children.
Example:
Table 1
a b
1 6
2 3
Table 2
a b
1 3
4 1
stats for table1 union table2 would be number of rows = 4, columnStats = (a: {min: 1, max: 4}, b: {min: 1, max: 6})
2. **Sort**: row and columns stats would be same as its children.
3. **Range**: number of output rows and distinct count will be equal to number of elements, min and max is calculated from start, end and step param.
### Why are the changes needed?
The change will enhance the feature https://issues.apache.org/jira/browse/SPARK-16026 and will help in other stats based optimizations.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
New unit tests added.
Closes#30334 from ayushi-agarwal/SPARK-33411.
Lead-authored-by: ayushi agarwal <ayaga@microsoft.com>
Co-authored-by: ayushi-agarwal <36420535+ayushi-agarwal@users.noreply.github.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
1. Extend SQL syntax rules to support a sign before the interval strings of ANSI year-month and day-time intervals.
2. Recognize `-` in `AstBuilder` and negate parsed intervals.
### Why are the changes needed?
To conform to the SQL standard which allows a sign before the string interval, see `"5.3 <literal>"`:
```
<interval literal> ::=
INTERVAL [ <sign> ] <interval string> <interval qualifier>
<interval string> ::=
<quote> <unquoted interval string> <quote>
<unquoted interval string> ::=
[ <sign> ] { <year-month literal> | <day-time literal> }
<sign> ::=
<plus sign>
| <minus sign>
```
### Does this PR introduce _any_ user-facing change?
Should not because it just extends supported intervals syntax.
### How was this patch tested?
By running new tests in `interval.sql`:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#32134 from MaxGekk/negative-parsed-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Now that we merged the Koalas main code into the PySpark code base (#32036), we should port the Koalas Series related unit tests to PySpark.
### Why are the changes needed?
Currently, the pandas-on-Spark modules are not fully tested. We should enable the Series related unit tests first.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Enable Series-related unit tests.
Closes#32117 from xinrong-databricks/port.test_series_related.
Lead-authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Co-authored-by: xinrong-databricks <47337188+xinrong-databricks@users.noreply.github.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The main change of this pr is extract a `private` method named `tryOrFetchFailedException` to eliminate duplicate code in `BufferReleasingInputStream`.
The patterns of duplicate code as follows:
```
try {
block
} catch {
case e: IOException if detectCorruption =>
IOUtils.closeQuietly(this)
iterator.throwFetchFailedException(blockId, mapIndex, address, e)
}
```
### Why are the changes needed?
Eliminate duplicate code.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass the Jenkins or GitHub Action
Closes#32130 from LuciferYang/SPARK-35029.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
According to http://www.tpc.org/tpc_documents_current_versions/pdf/tpc-ds_v2.9.0.pdf
```
2.2.2 Datatype
2.2.2.1 Each column employs one of the following datatypes:
a) Identifier means that the column shall be able to hold any key value generated for that column.
b) Integer means that the column shall be able to exactly represent integer values (i.e., values in increments of
1) in the range of at least ( − 2n − 1) to (2n − 1 − 1), where n is 64.
c) Decimal(d, f) means that the column shall be able to represent decimal values up to and including d digits,
of which f shall occur to the right of the decimal place; the values can be either represented exactly or
interpreted to be in this range.
d) Char(N) means that the column shall be able to hold any string of characters of a fixed length of N.
Comment: If the string that a column of datatype char(N) holds is shorter than N characters, then trailing
spaces shall be stored in the database or the database shall automatically pad with spaces upon retrieval such
that a CHAR_LENGTH() function will return N.
e) Varchar(N) means that the column shall be able to hold any string of characters of a variable length with a
maximum length of N. Columns defined as "varchar(N)" may optionally be implemented as "char(N)".
f) Date means that the column shall be able to express any calendar day between January 1, 1900 and
December 31, 2199.
2.2.2.2 The datatypes do not correspond to any specific SQL-standard datatype. The definitions are provided to
highlight the properties that are required for a particular column. The benchmark implementer may employ any internal representation or SQL datatype that meets those requirements.
```
This PR proposes that we use int for identifiers instead of bigint to reach a compromise with TPC-DS Standard Specification.
After this PR, the field schemas are now consistent with those DDLs in the `tpcds.sql` from tpc-ds tool kit, see https://gist.github.com/yaooqinn/b9978a77bbf4f871a95d6a9103019907
### Why are the changes needed?
reach a compromise with TPC-DS Standard Specification
### Does this PR introduce _any_ user-facing change?
no test only
### How was this patch tested?
test only
Closes#32037 from yaooqinn/SPARK-34944.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
Disallow group by aliases under ANSI mode.
### Why are the changes needed?
As per the ANSI SQL standard secion 7.12 <group by clause>:
>Each `grouping column reference` shall unambiguously reference a column of the table resulting from the `from clause`. A column referenced in a `group by clause` is a grouping column.
By forbidding it, we can avoid ambiguous SQL queries like:
```
SELECT col + 1 as col FROM t GROUP BY col
```
### Does this PR introduce _any_ user-facing change?
Yes, group by aliases is not allowed under ANSI mode.
### How was this patch tested?
Unit tests
Closes#32129 from gengliangwang/disallowGroupByAlias.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
For Spark SQL, it can't support script transform SQL with aggregationClause/windowClause/LateralView.
This case we can't directly migration Hive SQL to Spark SQL.
In this PR, we treat all script transform statement's query part (exclude transform about part) as a separate query block and solve it as ScriptTransformation's child and pass a UnresolvedStart as ScriptTransform's input. Then in analyzer level, we pass child's output as ScriptTransform's input. Then we can support all kind of normal SELECT query combine with script transformation.
Such as transform with aggregation:
```
SELECT TRANSFORM ( d2, max(d1) as max_d1, sum(d3))
USING 'cat' AS (a,b,c)
FROM script_trans
WHERE d1 <= 100
GROUP BY d2
HAVING max_d1 > 0
```
When we build AST, we treat it as
```
SELECT TRANSFORM (*)
USING 'cat' AS (a,b,c)
FROM (
SELECT d2, max(d1) as max_d1, sum(d3)
FROM script_trans
WHERE d1 <= 100
GROUP BY d2
HAVING max_d1 > 0
) tmp
```
then in Analyzer's `ResolveReferences`, resolve `* (UnresolvedStar)`, then sql behavior like
```
SELECT TRANSFORM ( d2, max(d1) as max_d1, sum(d3))
USING 'cat' AS (a,b,c)
FROM script_trans
WHERE d1 <= 100
GROUP BY d2
HAVING max_d1 > 0
```
About UT, in this pr we add a lot of different SQL to check we can support all kind of such SQL and each kind of expressions can work well, such as alias, case when, binary compute etc...
### Why are the changes needed?
Support transform with aggregateClause/windowClause/LateralView etc , make sql migration more smoothly
### Does this PR introduce _any_ user-facing change?
User can write transform with aggregateClause/windowClause/LateralView.
### How was this patch tested?
Added UT
Closes#29087 from AngersZhuuuu/SPARK-28227-NEW.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Now that we merged the Koalas main code into the PySpark code base (#32036), we should port the Koalas operations on different frames unit tests to PySpark.
### Why are the changes needed?
Currently, the pandas-on-Spark modules are not tested fully. We should enable the operations on different frames unit tests.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Enable operations on different frames unit tests.
Closes#32133 from xinrong-databricks/port.test_ops_on_diff_frames.
Authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Fix type hints mismatches in pyspark.sql.*
### Why are the changes needed?
There were some mismatches in pyspark.sql.*
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
dev/lint-python passed.
Closes#32122 from Yikun/SPARK-35019.
Authored-by: Yikun Jiang <yikunkero@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/31708 . For full outer join, the final result RDD is created from
```
sparkContext.union(
matchedStreamRows,
sparkContext.makeRDD(notMatchedBroadcastRows)
)
```
It's incorrect to say that the final output partitioning is `UnknownPartitioning(left.outputPartitioning.numPartitions)`
### Why are the changes needed?
Fix a correctness bug
### Does this PR introduce _any_ user-facing change?
Yes, see the added test. Fortunately, this bug is not released yet.
### How was this patch tested?
new test
Closes#32132 from cloud-fan/bug.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
This pr add test and document for Parquet Bloom filter push down.
### Why are the changes needed?
Improve document.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Generating docs:

Closes#32123 from wangyum/SPARK-34562.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Add check if the byte length over `int`.
### Why are the changes needed?
We encounter a very extreme case with expression `concat_ws`, and the error msg is
```
Caused by: java.lang.NegativeArraySizeException
at org.apache.spark.unsafe.types.UTF8String.concatWs
```
Seems the `UTF8String.concat` has already done the length check at [#21064](https://github.com/apache/spark/pull/21064), so it's better to add in `concatWs`.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
It's too heavy to add the test.
Closes#32106 from ulysses-you/SPARK-35005.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Remove `spark.sql.legacy.interval.enabled` settings from `SQLQueryTestSuite`/`ThriftServerQueryTestSuite` that enables new ANSI intervals by default.
### Why are the changes needed?
To use default settings for intervals, and test new ANSI intervals - year-month and day-time interval introduced by SPARK-27793.
### Does this PR introduce _any_ user-facing change?
Should not because this affects tests only.
### How was this patch tested?
By running the affected tests, for instance:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#32099 from MaxGekk/enable-ansi-intervals-sql-tests.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Support GROUP BY use Separate columns and CUBE/ROLLUP
In postgres sql, it support
```
select a, b, c, count(1) from t group by a, b, cube (a, b, c);
select a, b, c, count(1) from t group by a, b, rollup(a, b, c);
select a, b, c, count(1) from t group by cube(a, b), rollup (a, b, c);
select a, b, c, count(1) from t group by a, b, grouping sets((a, b), (a), ());
```
In this pr, we have done two things as below:
1. Support partial grouping analytics such as `group by a, cube(a, b)`
2. Support mixed grouping analytics such as `group by cube(a, b), rollup(b,c)`
*Partial Groupings*
Partial Groupings means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
in GROUP BY clause. For example:
`GROUP BY warehouse, CUBE(product, location)` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse, location), (warehouse))`.
`GROUP BY warehouse, ROLLUP(product, location)` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse))`.
`GROUP BY warehouse, GROUPING SETS((product, location), (producet), ())` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, location), (warehouse))`.
*Concatenated Groupings*
Concatenated groupings offer a concise way to generate useful combinations of groupings. Groupings specified
with concatenated groupings yield the cross-product of groupings from each grouping set. The cross-product
operation enables even a small number of concatenated groupings to generate a large number of final groups.
The concatenated groupings are specified simply by listing multiple `GROUPING SETS`, `CUBES`, and `ROLLUP`,
and separating them with commas. For example:
`GROUP BY GROUPING SETS((warehouse), (producet)), GROUPING SETS((location), (size))` is equivalent to
`GROUP BY GROUPING SETS((warehouse, location), (warehouse, size), (product, location), (product, size))`.
`GROUP BY CUBE((warehouse), (producet)), ROLLUP((location), (size))` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product), (warehouse), (producet), ()), GROUPING SETS((location, size), (location), ())`
`GROUP BY GROUPING SETS(
(warehouse, product, location, size), (warehouse, product, location), (warehouse, product),
(warehouse, location, size), (warehouse, location), (warehouse),
(product, location, size), (product, location), (product),
(location, size), (location), ())`.
`GROUP BY order, CUBE((warehouse), (producet)), ROLLUP((location), (size))` is equivalent to
`GROUP BY order, GROUPING SETS((warehouse, product), (warehouse), (producet), ()), GROUPING SETS((location, size), (location), ())`
`GROUP BY GROUPING SETS(
(order, warehouse, product, location, size), (order, warehouse, product, location), (order, warehouse, product),
(order, warehouse, location, size), (order, warehouse, location), (order, warehouse),
(order, product, location, size), (order, product, location), (order, product),
(order, location, size), (order, location), (order))`.
### Why are the changes needed?
Support more flexible grouping analytics
### Does this PR introduce _any_ user-facing change?
User can use sql like
```
select a, b, c, agg_expr() from table group by a, cube(b, c)
```
### How was this patch tested?
Added UT
Closes#30144 from AngersZhuuuu/SPARK-33229.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR contains:
- TreeNode, QueryPlan, AnalysisHelper changes to allow the transform function family to stop earlier without traversing the entire tree;
- Example changes in a few rules to support such pruning, e.g., ReorderJoin and OptimizeIn.
Here is a [design doc](https://docs.google.com/document/d/1SEUhkbo8X-0cYAJFYFDQhxUnKJBz4lLn3u4xR2qfWqk) that elaborates the ideas and benchmark numbers.
### Why are the changes needed?
It's a framework-level change for reducing the query compilation time.
In particular, if we update existing rules and transform call sites as per the examples in this PR, the analysis time and query optimization time can be reduced as described in this [doc](https://docs.google.com/document/d/1SEUhkbo8X-0cYAJFYFDQhxUnKJBz4lLn3u4xR2qfWqk) .
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
It is tested by existing tests.
Closes#32060 from sigmod/bits.
Authored-by: Yingyi Bu <yingyi.bu@databricks.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
SBT 1.5.0 deprecates `in` syntax from 0.13.x, so build file adjustment
is recommended.
See https://www.scala-sbt.org/1.x/docs/Migrating-from-sbt-013x.html#Migrating+to+slash+syntax
### Why are the changes needed?
Removes significant amount of deprecation warnings and prepares to syntax removal in next versions of SBT.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Build should pass on GH Actions.
Closes#32115 from gemelen/feature/sbt-1.5-fixes.
Authored-by: Denis Pyshev <git@gemelen.net>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
before when we use aggregate ordinal in group by expression and index position is a aggregate function, it will show error as
```
– !query
select a, b, sum(b) from data group by 3
– !query schema
struct<>
– !query output
org.apache.spark.sql.AnalysisException
aggregate functions are not allowed in GROUP BY, but found sum(data.b)
```
It't not clear enough refactor this error message in this pr
### Why are the changes needed?
refactor error message
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existed UT
Closes#32089 from AngersZhuuuu/SPARK-34986.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}