### What changes were proposed in this pull request?
This is a follow-up on #29565, and addresses a few issues in the last PR:
- style issue pointed by [this comment](https://github.com/apache/spark/pull/29565#discussion_r487646749)
- skip optimization when `fromExp` is foldable (by [this comment](https://github.com/apache/spark/pull/29565#discussion_r487646973)) as there could be more efficient rule to apply for this case.
- pass timezone info to the generated cast on the literal value
- a bunch of cleanups and test improvements
Originally I plan to handle this when implementing [SPARK-32858](https://issues.apache.org/jira/browse/SPARK-32858) but now think it's better to isolate these changes from that.
### Why are the changes needed?
To fix a few left over issues in the above PR.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added a test for the foldable case. Otherwise relying on existing tests.
Closes#29775 from sunchao/SPARK-24994-followup.
Authored-by: Chao Sun <sunchao@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Write to static partition, check in advance that the partition field is empty.
### Why are the changes needed?
When writing to the current static partition, the partition field is empty, and an error will be reported when all tasks are completed.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
add ut
Closes#29316 from cxzl25/SPARK-32508.
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Credits to tdas who reported and described the fix to [SPARK-26425](https://issues.apache.org/jira/browse/SPARK-26425). I just followed the description of the issue.
This patch adds more checks on commit log as well as file streaming source so that multiple concurrent runs of streaming query don't mess up the status of query/checkpoint. This patch addresses two different spots which are having a bit different issues:
1. FileStreamSource.fetchMaxOffset()
In structured streaming, we don't allow multiple streaming queries to run with same checkpoint (including concurrent runs of same query), so query should fail if it fails to write the metadata of specific batch ID due to same batch ID being written by others.
2. commit log
As described in JIRA issue, assertion is already applied to the `offsetLog` for the same reason.
8167714cab/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala (L394-L402)
This patch applied the same for commit log.
### Why are the changes needed?
This prevents the inconsistent behavior on streaming query and lets query fail instead.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A, as the change is simple and obvious, and it's really hard to artificially reproduce the issue.
Closes#25965 from HeartSaVioR/SPARK-26425.
Lead-authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Co-authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This PR fixes a conflict between `RewriteDistinctAggregates` and `DecimalAggregates`.
In some cases, `DecimalAggregates` will wrap the decimal column to `UnscaledValue` using
different rules for different aggregates.
This means, same distinct column with different aggregates will change to different distinct columns
after `DecimalAggregates`. For example:
`avg(distinct decimal_col), sum(distinct decimal_col)` may change to
`avg(distinct UnscaledValue(decimal_col)), sum(distinct decimal_col)`
We assume after `RewriteDistinctAggregates`, there will be at most one distinct column in aggregates,
but `DecimalAggregates` breaks this assumption. To fix this, we have to switch the order of these two
rules.
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
added test cases
Closes#29673 from linhongliu-db/SPARK-32816.
Authored-by: Linhong Liu <linhong.liu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This proposes to enhance user document of the API for loading a Dataset of strings storing CSV rows. If the header option is set to true, the API will remove all lines same with the header.
### Why are the changes needed?
This behavior can confuse users. We should explicitly document it.
### Does this PR introduce _any_ user-facing change?
No. Only doc change.
### How was this patch tested?
Only doc change.
Closes#29765 from viirya/SPARK-32888.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR updates the `RemoveRedundantProjects` rule to make `GenerateExec` require column ordering.
### Why are the changes needed?
`GenerateExec` was originally considered as a node that does not require column ordering. However, `GenerateExec` binds its input rows directly with its `requiredChildOutput` without using the child's output schema.
In `doExecute()`:
```scala
val proj = UnsafeProjection.create(output, output)
```
In `doConsume()`:
```scala
val values = if (requiredChildOutput.nonEmpty) {
input
} else {
Seq.empty
}
```
In this case, changing input column ordering will result in `GenerateExec` binding the wrong schema to the input columns. For example, if we do not require child columns to be ordered, the `requiredChildOutput` [a, b, c] will directly bind to the schema of the input columns [c, b, a], which is incorrect:
```
GenerateExec explode(array(a, b, c)), [a, b, c], false, [d]
HashAggregate(keys=[a, b, c], functions=[], output=[c, b, a])
...
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes#29734 from allisonwang-db/generator.
Authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR only checks if there's any physical rule runs instead of a specific rule. This is rather just a trivial fix to make the tests more robust.
In fact, I faced a test failure from a in-house fork that applies a different physical rule that makes `CollapseCodegenStages` ineffective.
### Why are the changes needed?
To make the test more robust by unrelated changes.
### Does this PR introduce _any_ user-facing change?
No, test-only
### How was this patch tested?
Manually tested. Jenkins tests should pass.
Closes#29766 from HyukjinKwon/SPARK-32704.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR skips the test if trash directory cannot be created. It is possible that the trash directory cannot be created, for example, by permission. And the test fails below:
```
- SPARK-32481 Move data to trash on truncate table if enabled *** FAILED *** (154 milliseconds)
fs.exists(trashPath) was false (DDLSuite.scala:3184)
org.scalatest.exceptions.TestFailedException:
at org.scalatest.Assertions.newAssertionFailedException(Assertions.scala:530)
at org.scalatest.Assertions.newAssertionFailedException$(Assertions.scala:529)
at org.scalatest.FunSuite.newAssertionFailedException(FunSuite.scala:1560)
at org.scalatest.Assertions$AssertionsHelper.macroAssert(Assertions.scala:503)
```
### Why are the changes needed?
To make the tests pass independently.
### Does this PR introduce _any_ user-facing change?
No, test-only.
### How was this patch tested?
Manually tested.
Closes#29759 from HyukjinKwon/SPARK-32481.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add a new config `spark.sql.maxMetadataStringLength`. This config aims to limit metadata value length, e.g. file location.
### Why are the changes needed?
Some metadata have been abbreviated by `...` when I tried to add some test in `SQLQueryTestSuite`. We need to replace such value to `notIncludedMsg`. That caused we can't replace that like location value by `className` since the `className` has been abbreviated.
Here is a case:
```
CREATE table explain_temp1 (key int, val int) USING PARQUET;
EXPLAIN EXTENDED SELECT sum(distinct val) FROM explain_temp1;
-- ignore parsed,analyzed,optimized
-- The output like
== Physical Plan ==
*HashAggregate(keys=[], functions=[sum(distinct cast(val#x as bigint)#xL)], output=[sum(DISTINCT val)#xL])
+- Exchange SinglePartition, true, [id=#x]
+- *HashAggregate(keys=[], functions=[partial_sum(distinct cast(val#x as bigint)#xL)], output=[sum#xL])
+- *HashAggregate(keys=[cast(val#x as bigint)#xL], functions=[], output=[cast(val#x as bigint)#xL])
+- Exchange hashpartitioning(cast(val#x as bigint)#xL, 4), true, [id=#x]
+- *HashAggregate(keys=[cast(val#x as bigint) AS cast(val#x as bigint)#xL], functions=[], output=[cast(val#x as bigint)#xL])
+- *ColumnarToRow
+- FileScan parquet default.explain_temp1[val#x] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/home/runner/work/spark/spark/sql/core/spark-warehouse/org.apache.spark.sq...], PartitionFilters: ...
```
### Does this PR introduce _any_ user-facing change?
No, a new config.
### How was this patch tested?
new test.
Closes#29688 from ulysses-you/SPARK-32827.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR refactors the way we propagate the options from the `SparkSession.Builder` to the` SessionState`. This currently done via a mutable map inside the SparkSession. These setting settings are then applied **after** the Session. This is a bit confusing when you expect something to be set when constructing the `SessionState`. This PR passes the options as a constructor parameter to the `SessionStateBuilder` and this will set the options when the configuration is created.
### Why are the changes needed?
It makes it easier to reason about the configurations set in a SessionState than before. We recently had an incident where someone was using `SparkSessionExtensions` to create a planner rule that relied on a conf to be set. While this is in itself probably incorrect usage, it still illustrated this somewhat funky behavior.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests.
Closes#29752 from hvanhovell/SPARK-32879.
Authored-by: herman <herman@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to mark the following suite as `ExtendedSQLTest` to reduce GitHub Action test time.
- TPCDSQuerySuite
- TPCDSQueryANSISuite
- TPCDSQueryWithStatsSuite
### Why are the changes needed?
Currently, the longest GitHub Action task is `Build and test / Build modules: sql - other tests` with `1h 57m 10s` while `Build and test / Build modules: sql - slow tests` takes `42m 20s`. With this PR, we can move the workload from `other tests` to `slow tests` task and reduce the total waiting time about 7 ~ 8 minutes.
### Does this PR introduce _any_ user-facing change?
No. This is a test-only change.
### How was this patch tested?
Pass the GitHub Action with the reduced running time.
Closes#29755 from dongjoon-hyun/SPARK-SLOWTEST.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR appends `toMap` to `Map` instances with `filterKeys` if such maps is to be concatenated with another maps.
### Why are the changes needed?
As of Scala 2.13, Map#filterKeys return a MapView, not the original Map type.
This can cause compile error.
```
/sql/DataFrameReader.scala:279: type mismatch;
[error] found : Iterable[(String, String)]
[error] required: java.util.Map[String,String]
[error] Error occurred in an application involving default arguments.
[error] val dsOptions = new CaseInsensitiveStringMap(finalOptions.asJava)
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Compile passed with the following command.
`build/mvn -Pscala-2.13 -Phive -Phive-thriftserver -Pyarn -Pkubernetes -DskipTests test-compile`
Closes#29742 from sarutak/fix-filterKeys-issue.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Make `DataFrameReader.table` take the specified options for datasource v1.
### Why are the changes needed?
Keep the same behavior of v1/v2 datasource, the v2 fix has been done in SPARK-32592.
### Does this PR introduce _any_ user-facing change?
Yes. The DataFrameReader.table will take the specified options. Also, if there are the same key and value exists in specified options and table properties, an exception will be thrown.
### How was this patch tested?
New UT added.
Closes#29712 from xuanyuanking/SPARK-32844.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Several minor code and documentation improvement for stream-stream join. Specifically:
* Remove extending from `SparkPlan`, as extending from `BinaryExecNode` is enough.
* Return `left/right.outputPartitioning` for `Left/RightOuter` in `outputPartitioning`, as the `PartitioningCollection` wrapper is unnecessary (similar to batch joins `ShuffledHashJoinExec`, `SortMergeJoinExec`).
* Avoid per-row check for join type (https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamingSymmetricHashJoinExec.scala#L486-L492), by creating the method before the loop of reading rows (`generateFilteredJoinedRow` in `storeAndJoinWithOtherSide`). Similar optimization (i.e. create auxiliary method/variable per different join type before the iterator of input rows) has been done in batch join world (`SortMergeJoinExec`, `ShuffledHashJoinExec`).
* Minor fix for comment/indentation for better readability.
### Why are the changes needed?
Minor optimization to avoid per-row unnecessary work (this probably can be optimized away by compiler, but we can do a better join to avoid it at the first place). And other comment/indentation fix to have better code readability for future developers.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests in `StreamingJoinSuite.scala` as no new logic is introduced.
Closes#29724 from c21/streaming.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fix code which causes error when build with sbt and Scala 2.13 like as follows.
```
[error] [warn] /home/kou/work/oss/spark-scala-2.13/external/kafka-0-10/src/main/scala/org/apache/spark/streaming/kafka010/KafkaRDD.scala:251: method with a single empty parameter list overrides method without any parameter list
[error] [warn] override def hasNext(): Boolean = requestOffset < part.untilOffset
[error] [warn]
[error] [warn] /home/kou/work/oss/spark-scala-2.13/external/kafka-0-10/src/main/scala/org/apache/spark/streaming/kafka010/KafkaRDD.scala:294: method with a single empty parameter list overrides method without any parameter list
[error] [warn] override def hasNext(): Boolean = okNext
```
More specifically, what this PR fixes are
* Methods which has an empty parameter list and overrides an method which has no parameter list.
```
override def hasNext(): Boolean = okNext
```
* Methods which has no parameter list and overrides an method which has an empty parameter list.
```
override def next: (Int, Double) = {
```
* Infix operator expression that the operator wraps.
```
3L * math.min(k, numFeatures) * math.min(k, numFeatures)
3L * math.min(k, numFeatures) * math.min(k, numFeatures) +
+ math.max(math.max(k, numFeatures), 4L * math.min(k, numFeatures)
math.max(math.max(k, numFeatures), 4L * math.min(k, numFeatures) *
* math.min(k, numFeatures) + 4L * math.min(k, numFeatures))
```
### Why are the changes needed?
For building Spark with sbt and Scala 2.13.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
After this change and #29742 applied, compile passed with the following command.
```
build/sbt -Pscala-2.13 -Phive -Phive-thriftserver -Pyarn -Pkubernetes compile test:compile
```
Closes#29745 from sarutak/fix-code-for-sbt-and-spark-2.13.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Currently, in cases like the following:
```sql
SELECT * FROM t WHERE age < 40
```
where `age` is of short type, Spark won't be able to simplify this and can only generate filter `cast(age, int) < 40`. This won't get pushed down to datasources and therefore is not optimized.
This PR proposes a optimizer rule to improve this when the following constraints are satisfied:
- input expression is binary comparisons when one side is a cast operation and another is a literal.
- both the cast child expression and literal are of integral type (i.e., byte, short, int or long)
When this is true, it tries to do several optimizations to either simplify the expression or move the cast to the literal side, so
result filter for the above case becomes `age < cast(40 as smallint)`. This is better since the cast can be optimized away later and the filter can be pushed down to data sources.
This PR follows a similar effort in Presto (https://prestosql.io/blog/2019/05/21/optimizing-the-casts-away.html). Here we only handles integral types but plan to extend to other types as follow-ups.
### Why are the changes needed?
As mentioned in the previous section, when cast is not optimized, it cannot be pushed down to data sources which can lead
to unnecessary IO and therefore longer job time and waste of resources. This helps to improve that.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit tests for both the optimizer rule and filter pushdown on datasource level for both Orc and Parquet.
Closes#29565 from sunchao/SPARK-24994.
Authored-by: Chao Sun <sunchao@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR intends to set `CODEGEN_ONLY` at `CODEGEN_FACTORY_MODE` in test spark context so that tests can fail if errors happen when generating expr code.
### Why are the changes needed?
I noticed that the code generation of `SafeProjection` failed in the existing test (https://issues.apache.org/jira/browse/SPARK-32828) but it passed because `FALLBACK` was set at `CODEGEN_FACTORY_MODE` (by default) in `SharedSparkSession`. To get aware of these failures quickly, I think its worth setting `CODEGEN_ONLY` at `CODEGEN_FACTORY_MODE`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#29721 from maropu/ExprCodegenTest.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR aims to add `sinkParameter` to check sink options robustly and independently in DataStreamReaderWriterSuite
### Why are the changes needed?
`LastOptions.parameters` is designed to catch three cases: `sourceSchema`, `createSource`, `createSink`. However, `StreamQuery.stop` invokes `queryExecutionThread.join`, `runStream`, `createSource` immediately and reset the stored options by `createSink`.
To catch `createSink` options, currently, the test suite is trying a workaround pattern. However, we observed a flakiness in this pattern sometimes. If we split `createSink` option separately, we don't need this workaround and can eliminate this flakiness.
```scala
val query = df.writeStream.
...
.start()
assert(LastOptions.paramters(..))
query.stop()
```
### Does this PR introduce _any_ user-facing change?
No. This is a test-only change.
### How was this patch tested?
Pass the newly updated test case.
Closes#29730 from dongjoon-hyun/SPARK-32845.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This is a follow-up to https://github.com/apache/spark/pull/29572.
LeftAnti SortMergeJoin should not buffer all matching right side rows when bound condition is empty, this is unnecessary and can lead to performance degradation especially when spilling happens.
### Why are the changes needed?
Performance improvement.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New UT.
Closes#29727 from peter-toth/SPARK-32730-improve-leftsemi-sortmergejoin-followup.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/29328
In https://github.com/apache/spark/pull/29328 , we forbid the use case that path option and path parameter are both specified. However, it breaks some use cases:
```
val dfr = spark.read.format(...).option(...)
dfr.load(path1).xxx
dfr.load(path2).xxx
```
The reason is that: `load` has side effects. It will set path option to the `DataFrameReader` instance. The next time you call `load`, Spark will fail because both path option and path parameter are specified.
This PR removes the side effect of `save`/`load`/`start` to not set the path option.
### Why are the changes needed?
recover some use cases
### Does this PR introduce _any_ user-facing change?
Yes, some use cases fail before this PR, and can run successfully after this PR.
### How was this patch tested?
new tests
Closes#29723 from cloud-fan/df.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
We made a mistake in https://github.com/apache/spark/pull/29502, as there is no code comment to explain why we can't load the UDF class when creating functions. This PR improves the code comment.
### Why are the changes needed?
To avoid making the same mistake.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
N/A
Closes#29713 from cloud-fan/comment.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR changes the behavior of RangeExec with WholeStageCodegen disabled or falled back to change the number of partitions to zero when a range is empty.
In the current master, if WholeStageCodegen effects, the number of partitions of an empty range will be changed to zero.
```
spark.range(1, 1, 1, 1000).rdd.getNumPartitions
res0: Int = 0
```
But it doesn't if WholeStageCodegen is disabled or falled back.
```
spark.conf.set("spark.sql.codegen.wholeStage", false)
spark.range(1, 1, 1, 1000).rdd.getNumPartitions
res2: Int = 1000
```
### Why are the changes needed?
To archive better performance even though WholeStageCodegen disabled or falled back.
### Does this PR introduce _any_ user-facing change?
Yes. the number of partitions gotten with `getNumPartitions` for an empty range will be changed when WholeStageCodegen is disabled.
### How was this patch tested?
New test.
Closes#29681 from sarutak/zero-size-range.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Spark SQL exists a bug show below:
```
spark.sql(
" SELECT COUNT(DISTINCT 2), COUNT(DISTINCT 2, 3)")
.show()
+-----------------+--------------------+
|count(DISTINCT 2)|count(DISTINCT 2, 3)|
+-----------------+--------------------+
| 1| 1|
+-----------------+--------------------+
spark.sql(
" SELECT COUNT(DISTINCT 2), COUNT(DISTINCT 3, 2)")
.show()
+-----------------+--------------------+
|count(DISTINCT 2)|count(DISTINCT 3, 2)|
+-----------------+--------------------+
| 1| 0|
+-----------------+--------------------+
```
The first query is correct, but the second query is not.
The root reason is the second query rewrited by `RewriteDistinctAggregates` who expand the output but lost the 2.
### Why are the changes needed?
Fix a bug.
`SELECT COUNT(DISTINCT 2), COUNT(DISTINCT 3, 2)` should return `1, 1`
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
New UT
Closes#29626 from beliefer/support-multiple-foldable-distinct-expressions.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: beliefer <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In this PR, we add a checker for STRING form interval value ahead for parsing multiple units intervals and fail directly if the interval value contains alphabets to prevent correctness issues like `interval '1 day 2' day`=`3 days`.
### Why are the changes needed?
fix correctness issue
### Does this PR introduce _any_ user-facing change?
yes, in spark 3.0.0 `interval '1 day 2' day`=`3 days` but now we fail with ParseException
### How was this patch tested?
add a test.
Closes#29708 from yaooqinn/SPARK-32840.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR intends to fix an existing bug below in `UserDefinedTypeSuite`;
```
[info] - SPARK-19311: UDFs disregard UDT type hierarchy (931 milliseconds)
16:22:35.936 WARN org.apache.spark.sql.catalyst.expressions.SafeProjection: Expr codegen error and falling back to interpreter mode
org.apache.spark.SparkException: Cannot cast org.apache.spark.sql.ExampleSubTypeUDT46b1771f to org.apache.spark.sql.ExampleBaseTypeUDT31e8d979.
at org.apache.spark.sql.catalyst.expressions.CastBase.nullSafeCastFunction(Cast.scala:891)
at org.apache.spark.sql.catalyst.expressions.CastBase.doGenCode(Cast.scala:852)
at org.apache.spark.sql.catalyst.expressions.Expression.$anonfun$genCode$3(Expression.scala:147)
...
```
### Why are the changes needed?
bugfix
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit tests.
Closes#29691 from maropu/FixUdtBug.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This patch proposes to update the doc (both SS guide doc and Dataset dropDuplicates method doc) to leave a note to check on using SQL statements with streaming Dataset.
Once end users create a temp view based on streaming Dataset, they won't bother with thinking about "streaming" and do whatever they do with batch query. In many cases it works, but not just smoothly for the case when streaming aggregation is involved. They still need to concern about maintaining state store.
### Why are the changes needed?
Although SPARK-32456 fixed the weird error message, as a side effect some operations are enabled on streaming workload via SQL statement, which is error-prone if end users don't indicate what they're doing.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Only doc change.
Closes#29461 from HeartSaVioR/SPARK-32456-FOLLOWUP-DOC.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to fix indeterministic behavior on DataStreamReader/Writer options like the following.
```scala
scala> spark.readStream.format("parquet").option("paTh", "1").option("PATH", "2").option("Path", "3").option("patH", "4").option("path", "5").load()
org.apache.spark.sql.AnalysisException: Path does not exist: 1;
```
### Why are the changes needed?
This will make the behavior deterministic.
### Does this PR introduce _any_ user-facing change?
Yes, but the previous behavior is indeterministic.
### How was this patch tested?
Pass the newly test cases.
Closes#29702 from dongjoon-hyun/SPARK-32832.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR renames `SupportsStreamingUpdate` to `SupportsStreamingUpdateAsAppend` as the new interface name represents the actual behavior clearer. This PR also removes the `update()` method (so the interface is more likely a marker), as the implementations of `SupportsStreamingUpdateAsAppend` should support append mode by default, hence no need to trigger some flag on it.
### Why are the changes needed?
SupportsStreamingUpdate was intended to revive the functionality of Streaming update output mode for internal data sources, but despite the name, that interface isn't really used to do actual update on sink; all sinks are implementing this interface to do append, so strictly saying, it's just to support update as append. Renaming the interface would make it clear.
### Does this PR introduce _any_ user-facing change?
No, as the class is only for internal data sources.
### How was this patch tested?
Jenkins test will follow.
Closes#29693 from HeartSaVioR/SPARK-32831.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This patch proposes to check `ignoreNullability` parameter recursively in `equalsStructurally` method.
### Why are the changes needed?
`equalsStructurally` is used to check type equality. We can optionally ask to ignore nullability check. But the parameter `ignoreNullability` is not passed recursively down to nested types. So it produces weird error like:
```
data type mismatch: argument 3 requires array<array<string>> type, however ... is of array<array<string>> type.
```
when running the query `select aggregate(split('abcdefgh',''), array(array('')), (acc, x) -> array(array( x ) ) )`.
### Does this PR introduce _any_ user-facing change?
Yes, fixed a bug when running user query.
### How was this patch tested?
Unit tests.
Closes#29698 from viirya/SPARK-32819.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to fix the test coverage at `DataStreamReaderWriterSuite`.
### Why are the changes needed?
Currently, the test case checks `DataStreamReader` options instead of `DataStreamWriter` options.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the revised test case.
Closes#29701 from dongjoon-hyun/SPARK-32836.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR is a follow up to https://github.com/apache/spark/pull/29543#discussion_r485409606, which correctly points out that the check for the empty string is not necessary.
### Why are the changes needed?
The unnecessary check actually could cause more confusion.
For example,
```scala
scala> Seq(1).toDF.write.option("path", "/tmp/path1").parquet("")
java.lang.IllegalArgumentException: Can not create a Path from an empty string
at org.apache.hadoop.fs.Path.checkPathArg(Path.java:168)
```
even when `path` option is available. This PR addresses to fix this confusion.
### Does this PR introduce _any_ user-facing change?
Yes, now the above example prints the consistent exception message whether the path parameter value is empty or not.
```scala
scala> Seq(1).toDF.write.option("path", "/tmp/path1").parquet("")
org.apache.spark.sql.AnalysisException: There is a 'path' option set and save() is called with a path parameter. Either remove the path option, or call save() without the parameter. To ignore this check, set 'spark.sql.legacy.pathOptionBehavior.enabled' to 'true'.;
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:290)
at org.apache.spark.sql.DataFrameWriter.parquet(DataFrameWriter.scala:856)
... 47 elided
```
### How was this patch tested?
Added unit tests.
Closes#29697 from imback82/SPARK-32516-followup.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Make MicroBatchExecution explicitly call `getBatch` when the start and end offsets are the same.
### Why are the changes needed?
Structured Streaming micro-batch engine has the contract with V1 data sources that, after a restart, it will call `source.getBatch()` on the last batch attempted before the restart. However, a very rare combination of sequences violates this contract. It occurs only when
- The streaming query has specific types of stateful operations with watermarks (e.g., aggregation in append, mapGroupsWithState with timeouts).
- These queries can execute a batch even without new data when the previous updates the watermark and the stateful ops are such that the new watermark can cause new output/cleanup. Such batches are called no-data-batches.
- The last batch before termination was an incomplete no-data-batch. Upon restart, the micro-batch engine fails to call `source.getBatch` when attempting to re-execute the incomplete no-data-batch.
This occurs because no-data-batches has the same and end offsets, and when a batch is executed, if the start and end offset is same then calling `source.getBatch` is skipped as it is assumed the generated plan will be empty. This only affects V1 data sources like Delta and Autoloader which rely on this invariant to detect in the source whether the query is being started from scratch or restarted.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
New unit test with a mock v1 source that fails without the fix.
Closes#29651 from tdas/SPARK-32794.
Authored-by: Tathagata Das <tathagata.das1565@gmail.com>
Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com>
### What changes were proposed in this pull request?
The purpose of this pr is to partial resolve [SPARK-32808](https://issues.apache.org/jira/browse/SPARK-32808), total of 26 failed test cases were fixed, the related suite as follow:
- `StreamingAggregationSuite` related test cases (2 FAILED -> Pass)
- `GeneratorFunctionSuite` related test cases (2 FAILED -> Pass)
- `UDFSuite` related test cases (2 FAILED -> Pass)
- `SQLQueryTestSuite` related test cases (5 FAILED -> Pass)
- `WholeStageCodegenSuite` related test cases (1 FAILED -> Pass)
- `DataFrameSuite` related test cases (3 FAILED -> Pass)
- `OrcV1QuerySuite\OrcV2QuerySuite` related test cases (4 FAILED -> Pass)
- `ExpressionsSchemaSuite` related test cases (1 FAILED -> Pass)
- `DataFrameStatSuite` related test cases (1 FAILED -> Pass)
- `JsonV1Suite\JsonV2Suite\JsonLegacyTimeParserSuite` related test cases (6 FAILED -> Pass)
The main change of this pr as following:
- Fix Scala 2.13 compilation problems in `ShuffleBlockFetcherIterator` and `Analyzer`
- Specified `Seq` to `scala.collection.Seq` in `objects.scala` and `GenericArrayData` because internal use `Seq` maybe `mutable.ArraySeq` and not easy to call `.toSeq`
- Should specified `Seq` to `scala.collection.Seq` when we call `Row.getAs[Seq]` and `Row.get(i).asInstanceOf[Seq]` because the data maybe `mutable.ArraySeq` but `Seq` is `immutable.Seq` in Scala 2.13
- Use a compatible way to let `+` and `-` method of `Decimal` having the same behavior in Scala 2.12 and Scala 2.13
- Call `toList` in `RelationalGroupedDataset.toDF` method when `groupingExprs` is `Stream` type because `Stream` can't serialize in Scala 2.13
- Add a manual sort to `classFunsMap` in `ExpressionsSchemaSuite` because `Iterable.groupBy` in Scala 2.13 has different result with `TraversableLike.groupBy` in Scala 2.12
### Why are the changes needed?
We need to support a Scala 2.13 build.
### Does this PR introduce _any_ user-facing change?
Should specified `Seq` to `scala.collection.Seq` when we call `Row.getAs[Seq]` and `Row.get(i).asInstanceOf[Seq]` because the data maybe `mutable.ArraySeq` but the `Seq` is `immutable.Seq` in Scala 2.13
### How was this patch tested?
- Scala 2.12: Pass the Jenkins or GitHub Action
- Scala 2.13: Do the following:
```
dev/change-scala-version.sh 2.13
mvn clean install -DskipTests -pl sql/core -Pscala-2.13 -am
mvn test -pl sql/core -Pscala-2.13
```
**Before**
```
Tests: succeeded 8166, failed 319, canceled 1, ignored 52, pending 0
*** 319 TESTS FAILED ***
```
**After**
```
Tests: succeeded 8204, failed 286, canceled 1, ignored 52, pending 0
*** 286 TESTS FAILED ***
```
Closes#29660 from LuciferYang/SPARK-32808.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
If no active SparkSession is available, let `FileSourceScanExec.needsUnsafeRowConversion` look at default SQL config of ParquetSource vectorized reader instead of failing the query execution.
### Why are the changes needed?
Fix a bug that if no active SparkSession is available, file-based data source scan for Parquet Source will throw exception.
### Does this PR introduce _any_ user-facing change?
Yes, this change fixes the bug.
### How was this patch tested?
Unit test.
Closes#29667 from viirya/SPARK-32813.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to move the test `SPARK-32810: CSV and JSON data sources should be able to read files with escaped glob metacharacter in the paths` from `DataFrameReaderWriterSuite` to `CSVSuite` and to `JsonSuite`. This will allow to run the same test in `CSVv1Suite`/`CSVv2Suite` and in `JsonV1Suite`/`JsonV2Suite`.
### Why are the changes needed?
To improve test coverage by checking JSON/CSV datasources v1 and v2.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running affected test suites:
```
$ build/sbt "sql/test:testOnly org.apache.spark.sql.execution.datasources.csv.*"
$ build/sbt "sql/test:testOnly org.apache.spark.sql.execution.datasources.json.*"
```
Closes#29684 from MaxGekk/globbing-paths-when-inferring-schema-dsv2.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Fix indentation and clean up view in the test added by https://github.com/apache/spark/pull/29593.
### Why are the changes needed?
Address review comments in https://github.com/apache/spark/pull/29665.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Updated test.
Closes#29682 from manuzhang/spark-32753-followup.
Authored-by: manuzhang <owenzhang1990@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In `SubqueryBroadcastExec.relationFuture`, if the `broadcastRelation` is an `EmptyHashedRelation`, then `broadcastRelation.keys()` will throw `UnsupportedOperationException`.
### Why are the changes needed?
To fix a bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added a new test.
Closes#29671 from wzhfy/dpp_empty_broadcast.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Before SPARK-31511 is fixed, `BytesToBytesMap` iterator() is not thread-safe and may cause data inaccuracy.
We need to add a unit test.
### Why are the changes needed?
Increase test coverage to ensure that iterator() is thread-safe.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
add ut
Closes#29669 from cxzl25/SPARK-31511-test.
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This reverts commit 04f7f6dac0 due to the discussion in [comment](https://github.com/apache/spark/pull/29589#discussion_r484657207).
### Why are the changes needed?
Based on the discussion in [comment](https://github.com/apache/spark/pull/29589#discussion_r484657207), propagation for thread local properties in `SubqueryBroadcastExec` is not necessary, since they will be propagated by broadcast exchange threads anyway.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Also revert the added test.
Closes#29674 from wzhfy/revert_dpp_thread_local.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This is a Spark 3.0 regression introduced by https://github.com/apache/spark/pull/26761. We missed a corner case that `java.lang.Double.compare` treats 0.0 and -0.0 as different, which breaks SQL semantic.
This PR adds back the `OrderingUtil`, to provide custom compare methods that take care of 0.0 vs -0.0
### Why are the changes needed?
Fix a correctness bug.
### Does this PR introduce _any_ user-facing change?
Yes, now `SELECT 0.0 > -0.0` returns false correctly as Spark 2.x.
### How was this patch tested?
new tests
Closes#29647 from cloud-fan/float.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to fix an issue with the CSV and JSON data sources in Spark SQL when both of the following are true:
* no user specified schema
* some file paths contain escaped glob metacharacters, such as `[``]`, `{``}`, `*` etc.
### Why are the changes needed?
To fix the issue when the follow two queries try to read from paths `[abc].csv` and `[abc].json`:
```scala
spark.read.csv("""/tmp/\[abc\].csv""").show
spark.read.json("""/tmp/\[abc\].json""").show
```
but would end up hitting an exception:
```
org.apache.spark.sql.AnalysisException: Path does not exist: file:/tmp/[abc].csv;
at org.apache.spark.sql.execution.datasources.DataSource$.$anonfun$checkAndGlobPathIfNecessary$1(DataSource.scala:722)
at scala.collection.TraversableLike.$anonfun$flatMap$1(TraversableLike.scala:244)
at scala.collection.immutable.List.foreach(List.scala:392)
```
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
Added new test cases in `DataFrameReaderWriterSuite`.
Closes#29659 from MaxGekk/globbing-paths-when-inferring-schema.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Only copy tags to node with no tags when transforming plans.
### Why are the changes needed?
cloud-fan [made a good point](https://github.com/apache/spark/pull/29593#discussion_r482013121) that it doesn't make sense to append tags to existing nodes when nodes are removed. That will cause such bugs as duplicate rows when deduplicating and repartitioning by the same column with AQE.
```
spark.range(10).union(spark.range(10)).createOrReplaceTempView("v1")
val df = spark.sql("select id from v1 group by id distribute by id")
println(df.collect().toArray.mkString(","))
println(df.queryExecution.executedPlan)
// With AQE
[4],[0],[3],[2],[1],[7],[6],[8],[5],[9],[4],[0],[3],[2],[1],[7],[6],[8],[5],[9]
AdaptiveSparkPlan(isFinalPlan=true)
+- CustomShuffleReader local
+- ShuffleQueryStage 0
+- Exchange hashpartitioning(id#183L, 10), true
+- *(3) HashAggregate(keys=[id#183L], functions=[], output=[id#183L])
+- Union
:- *(1) Range (0, 10, step=1, splits=2)
+- *(2) Range (0, 10, step=1, splits=2)
// Without AQE
[4],[7],[0],[6],[8],[3],[2],[5],[1],[9]
*(4) HashAggregate(keys=[id#206L], functions=[], output=[id#206L])
+- Exchange hashpartitioning(id#206L, 10), true
+- *(3) HashAggregate(keys=[id#206L], functions=[], output=[id#206L])
+- Union
:- *(1) Range (0, 10, step=1, splits=2)
+- *(2) Range (0, 10, step=1, splits=2)
```
It's too expensive to detect node removal so we make a compromise only to copy tags to node with no tags.
### Does this PR introduce _any_ user-facing change?
Yes. Fix a bug.
### How was this patch tested?
Add test.
Closes#29593 from manuzhang/spark-32753.
Authored-by: manuzhang <owenzhang1990@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Since [SPARK-22590](2854091d12), local property propagation is supported through `SQLExecution.withThreadLocalCaptured` in both `BroadcastExchangeExec` and `SubqueryExec` when computing `relationFuture`. This pr adds the support in `SubqueryBroadcastExec`.
### Why are the changes needed?
Local property propagation is missed in `SubqueryBroadcastExec`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Add a new test.
Closes#29589 from wzhfy/thread_local.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Change `CreateFunctionCommand` code that add class check before create function.
### Why are the changes needed?
We have different behavior between create permanent function and temporary function when function class is invaild. e.g.,
```
create function f as 'test.non.exists.udf';
-- Time taken: 0.104 seconds
create temporary function f as 'test.non.exists.udf'
-- Error in query: Can not load class 'test.non.exists.udf' when registering the function 'f', please make sure it is on the classpath;
```
And Hive also fails both of them.
### Does this PR introduce _any_ user-facing change?
Yes, user will get exception when create a invalid udf.
### How was this patch tested?
New test.
Closes#29502 from ulysses-you/function.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
bugfix for incomplete interval values, e.g. interval '1', interval '1 day 2', currently these cases will result null, but actually we should fail them with IllegalArgumentsException
### Why are the changes needed?
correctness
### Does this PR introduce _any_ user-facing change?
yes, incomplete intervals will throw exception now
#### before
```
bin/spark-sql -S -e "select interval '1', interval '+', interval '1 day -'"
NULL NULL NULL
```
#### after
```
-- !query
select interval '1'
-- !query schema
struct<>
-- !query output
org.apache.spark.sql.catalyst.parser.ParseException
Cannot parse the INTERVAL value: 1(line 1, pos 7)
== SQL ==
select interval '1'
```
### How was this patch tested?
unit tests added
Closes#29635 from yaooqinn/SPARK-32785.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, Spark Public Rest APIs support Application attemptId except SQL API. This causes `no such app: application_X` issue when the application has `attemptId` (e.g: YARN cluster mode).
Please find existing and supported Rest endpoints with attemptId.
```
// Existing Rest Endpoints
applications/{appId}/sql
applications/{appId}/sql/{executionId}
// Rest Endpoints required support
applications/{appId}/{attemptId}/sql
applications/{appId}/{attemptId}/sql/{executionId}
```
Also fixing following compile warning on `SqlResourceSuite`:
```
[WARNING] [Warn] ~/spark/sql/core/src/test/scala/org/apache/spark/status/api/v1/sql/SqlResourceSuite.scala:67: Reference to uninitialized value edges
```
### Why are the changes needed?
This causes `no such app: application_X` issue when the application has `attemptId`.
### Does this PR introduce _any_ user-facing change?
Not yet because SQL Rest API is being planned to release with `Spark 3.1`.
### How was this patch tested?
1. New Unit tests are added for existing Rest endpoints. `attemptId` seems not coming in `local-mode` and coming in `YARN cluster mode` so could not be added for `attemptId` case (Suggestions are welcome).
2. Also, patch has been tested manually through both Spark Core and History Server Rest APIs.
Closes#29364 from erenavsarogullari/SPARK-32548.
Authored-by: Eren Avsarogullari <erenavsarogullari@gmail.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
`sql-expression-schema.md` automatically generated by `ExpressionsSchemaSuite`, but only expressions entries are checked in `ExpressionsSchemaSuite`. So if we manually modify the contents of the file, `ExpressionsSchemaSuite` does not necessarily guarantee the correctness of the it some times. For example, [Spark-24884](https://github.com/apache/spark/pull/27507) added `regexp_extract_all` expression support, and manually modify the `sql-expression-schema.md` but not change the content of `Number of queries` cause file content inconsistency.
Some additional checks have been added to `ExpressionsSchemaSuite` to improve the correctness guarantee of `sql-expression-schema.md` as follow:
- `Number of queries` should equals size of `expressions entries` in `sql-expression-schema.md`
- `Number of expressions that missing example` should equals size of `Expressions missing examples` in `sql-expression-schema.md`
- `MissExamples` from case should same as `expectedMissingExamples` from `sql-expression-schema.md`
### Why are the changes needed?
Ensure the correctness of `sql-expression-schema.md` content.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Enhanced ExpressionsSchemaSuite
Closes#29608 from LuciferYang/sql-expression-schema.
Authored-by: yangjie <yangjie@MacintoshdeMacBook-Pro.local>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
The whole `DynamicPartitionPruningSuite` takes about 2 min on my laptop (either AE on or off). The slowest tests are `test("simple inner join triggers DPP with mock-up tables")` and `test("cleanup any DPP filter that isn't pushed down due to expression id clashes")`, which totally take about 1 min.
We can reuse existing test tables or use smaller tables to reduce the cost. After that, the two tests takes only about 1 sec in total, leading to 2x speedup for the suite.
### Why are the changes needed?
To speedup DPP test suites.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Modified two existing tests.
Closes#29636 from wzhfy/improve_dpp_test.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR fixes a bug `FileSourceStrategy`, which generates partition filters even if the table is not partitioned. This can confuse `FileSourceScanExec`, which mistakenly think the table is partitioned and tries to update the `numPartitions` metrics, and cause a failure. We should not generate partition filters for non-partitioned table.
### Why are the changes needed?
The bug was exposed by https://github.com/apache/spark/pull/29436.
### Does this PR introduce _any_ user-facing change?
Yes, fix a bug.
### How was this patch tested?
new test
Closes#29637 from cloud-fan/refactor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request?
This PR intends to fix a bug where references can be missing when adding aliases to widen data types in `WidenSetOperationTypes`. For example,
```
CREATE OR REPLACE TEMPORARY VIEW t3 AS VALUES (decimal(1)) tbl(v);
SELECT t.v FROM (
SELECT v FROM t3
UNION ALL
SELECT v + v AS v FROM t3
) t;
org.apache.spark.sql.AnalysisException: Resolved attribute(s) v#1 missing from v#3 in operator !Project [v#1]. Attribute(s) with the same name appear in the operation: v. Please check if the right attribute(s) are used.;;
!Project [v#1] <------ the reference got missing
+- SubqueryAlias t
+- Union
:- Project [cast(v#1 as decimal(11,0)) AS v#3]
: +- Project [v#1]
: +- SubqueryAlias t3
: +- SubqueryAlias tbl
: +- LocalRelation [v#1]
+- Project [v#2]
+- Project [CheckOverflow((promote_precision(cast(v#1 as decimal(11,0))) + promote_precision(cast(v#1 as decimal(11,0)))), DecimalType(11,0), true) AS v#2]
+- SubqueryAlias t3
+- SubqueryAlias tbl
+- LocalRelation [v#1]
```
In the case, `WidenSetOperationTypes` added the alias `cast(v#1 as decimal(11,0)) AS v#3`, then the reference in the top `Project` got missing. This PR correct the reference (`exprId` and widen `dataType`) after adding aliases in the rule.
### Why are the changes needed?
bugfixes
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added unit tests
Closes#29485 from maropu/SPARK-32638.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
LeftSemi and Existence SortMergeJoin should not buffer all matching right side rows when bound condition is empty, this is unnecessary and can lead to performance degradation especially when spilling happens.
### Why are the changes needed?
Performance improvement.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New UT and TPCDS benchmarks.
Closes#29572 from peter-toth/SPARK-32730-improve-leftsemi-sortmergejoin.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR changes `AttributeSet` and `ExpressionSet` to maintain the insertion order of the elements. More specifically, we:
- change the underlying data structure of `AttributeSet` from `HashSet` to `LinkedHashSet` to maintain the insertion order.
- `ExpressionSet` already uses a list to keep track of the expressions, however, since it is extending Scala's immutable.Set class, operations such as map and flatMap are delegated to the immutable.Set itself. This means that the result of these operations is not an instance of ExpressionSet anymore, rather it's a implementation picked up by the parent class. We also remove this inheritance from `immutable.Set `and implement the needed methods directly. ExpressionSet has a very specific semantics and it does not make sense to extend `immutable.Set` anyway.
- change the `PlanStabilitySuite` to not sort the attributes, to be able to catch changes in the order of expressions in different runs.
### Why are the changes needed?
Expressions identity is based on the `ExprId` which is an auto-incremented number. This means that the same query can yield a query plan with different expression ids in different runs. `AttributeSet` and `ExpressionSet` internally use a `HashSet` as the underlying data structure, and therefore cannot guarantee the a fixed order of operations in different runs. This can be problematic in cases we like to check for plan changes in different runs.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Passes `PlanStabilitySuite` after regenerating the golden files.
Closes#29598 from dbaliafroozeh/FixOrderOfExpressions.
Authored-by: Ali Afroozeh <ali.afroozeh@databricks.com>
Signed-off-by: herman <herman@databricks.com>
### What changes were proposed in this pull request?
Move StreamingRelationV2 to the catalyst module and bind with the Table interface.
### Why are the changes needed?
Currently, the StreamingRelationV2 is bind with TableProvider. Since the V2 relation is not bound with `DataSource`, to make it more flexible and have better expansibility, it should be moved to the catalyst module and bound with the Table interface. We did a similar thing for DataSourceV2Relation.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing UT.
Closes#29633 from xuanyuanking/SPARK-32782.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR fails the interval values parsing when they contain non-ASCII characters which are silently omitted right now.
e.g. the case below should be invalid
```
select interval 'interval中文 1 day'
```
### Why are the changes needed?
bugfix, intervals should fail when containing invalid characters
### Does this PR introduce _any_ user-facing change?
yes,
#### before
select interval 'interval中文 1 day' results 1 day, now it fails with
```
org.apache.spark.sql.catalyst.parser.ParseException
Cannot parse the INTERVAL value: interval中文 1 day
```
### How was this patch tested?
new tests
Closes#29632 from yaooqinn/SPARK-32781.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Struct field both in GROUP BY and Aggregate Expresison with CUBE/ROLLUP/GROUPING SET will failed when analysis.
```
test("SPARK-31670") {
withTable("t1") {
sql(
"""
|CREATE TEMPORARY VIEW t(a, b, c) AS
|SELECT * FROM VALUES
|('A', 1, NAMED_STRUCT('row_id', 1, 'json_string', '{"i": 1}')),
|('A', 2, NAMED_STRUCT('row_id', 2, 'json_string', '{"i": 1}')),
|('A', 2, NAMED_STRUCT('row_id', 2, 'json_string', '{"i": 2}')),
|('B', 1, NAMED_STRUCT('row_id', 3, 'json_string', '{"i": 1}')),
|('C', 3, NAMED_STRUCT('row_id', 4, 'json_string', '{"i": 1}'))
""".stripMargin)
checkAnswer(
sql(
"""
|SELECT a, c.json_string, SUM(b)
|FROM t
|GROUP BY a, c.json_string
|WITH CUBE
|""".stripMargin),
Row("A", "{\"i\": 1}", 3) :: Row("A", "{\"i\": 2}", 2) :: Row("A", null, 5) ::
Row("B", "{\"i\": 1}", 1) :: Row("B", null, 1) ::
Row("C", "{\"i\": 1}", 3) :: Row("C", null, 3) ::
Row(null, "{\"i\": 1}", 7) :: Row(null, "{\"i\": 2}", 2) :: Row(null, null, 9) :: Nil)
}
}
```
Error
```
[info] - SPARK-31670 *** FAILED *** (2 seconds, 857 milliseconds)
[info] Failed to analyze query: org.apache.spark.sql.AnalysisException: expression 't.`c`' is neither present in the group by, nor is it an aggregate function. Add to group by or wrap in first() (or first_value) if you don't care which value you get.;;
[info] Aggregate [a#247, json_string#248, spark_grouping_id#246L], [a#247, c#223.json_string AS json_string#241, sum(cast(b#222 as bigint)) AS sum(b)#243L]
[info] +- Expand [List(a#221, b#222, c#223, a#244, json_string#245, 0), List(a#221, b#222, c#223, a#244, null, 1), List(a#221, b#222, c#223, null, json_string#245, 2), List(a#221, b#222, c#223, null, null, 3)], [a#221, b#222, c#223, a#247, json_string#248, spark_grouping_id#246L]
[info] +- Project [a#221, b#222, c#223, a#221 AS a#244, c#223.json_string AS json_string#245]
[info] +- SubqueryAlias t
[info] +- Project [col1#218 AS a#221, col2#219 AS b#222, col3#220 AS c#223]
[info] +- Project [col1#218, col2#219, col3#220]
[info] +- LocalRelation [col1#218, col2#219, col3#220]
[info]
```
For Struct type Field, when we resolve it, it will construct with Alias. When struct field in GROUP BY with CUBE/ROLLUP etc, struct field in groupByExpression and aggregateExpression will be resolved with different exprId as below
```
'Aggregate [cube(a#221, c#223.json_string AS json_string#240)], [a#221, c#223.json_string AS json_string#241, sum(cast(b#222 as bigint)) AS sum(b)#243L]
+- SubqueryAlias t
+- Project [col1#218 AS a#221, col2#219 AS b#222, col3#220 AS c#223]
+- Project [col1#218, col2#219, col3#220]
+- LocalRelation [col1#218, col2#219, col3#220]
```
This makes `ResolveGroupingAnalytics.constructAggregateExprs()` failed to replace aggreagteExpression use expand groupByExpression attribute since there exprId is not same. then error happened.
### Why are the changes needed?
Fix analyze bug
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
Added UT
Closes#28490 from AngersZhuuuu/SPARK-31670.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently in DPP, left semi can only prune left, this pr makes it also support prune right.
### Why are the changes needed?
A minor improvement for DPP.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Add a test case.
Closes#29582 from wzhfy/dpp_support_leftsemi_pruneRight.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request?
This is a follow-up of #29160. This allows Spark SQL project to compile for Scala 2.13.
### Why are the changes needed?
It's needed for #28545
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
I compiled with Scala 2.13. It fails in `Spark REPL` project, which will be fixed by #28545Closes#29584 from karolchmist/SPARK-32364-scala-2.13.
Authored-by: Karol Chmist <info+github@chmist.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
#29401 move `test_script.py` from sql/hive module to sql/core module, cause HiveScripTransformationSuite load resource issue.
### Why are the changes needed?
This issue cause jenkins test failed in mvn
spark-master-test-maven-hadoop-2.7-hive-2.3-jdk-11: https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7-hive-2.3-jdk-11/
spark-master-test-maven-hadoop-3.2-hive-2.3-jdk-11:
https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-3.2-hive-2.3-jdk-11/
spark-master-test-maven-hadoop-3.2-hive-2.3:
https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-3.2-hive-2.3/


Error as below:
```
Exception thrown while executing Spark plan:
HiveScriptTransformation [a#349299, b#349300, c#349301, d#349302, e#349303], python /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7-hive-2.3-jdk-11/sql/hive/file:/home/jenkins/workspace/spark-master-test-maven-hadoop-2.7-hive-2.3-jdk-11/sql/core/target/spark-sql_2.12-3.1.0-SNAPSHOT-tests.jar!/test_script.py, [a#349309, b#349310, c#349311, d#349312, e#349313], ScriptTransformationIOSchema(List(),List(),Some(org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe),Some(org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe),List((field.delim, )),List((field.delim, )),Some(org.apache.hadoop.hive.ql.exec.TextRecordReader),Some(org.apache.hadoop.hive.ql.exec.TextRecordWriter),false)
+- Project [_1#349288 AS a#349299, _2#349289 AS b#349300, _3#349290 AS c#349301, _4#349291 AS d#349302, _5#349292 AS e#349303]
+- LocalTableScan [_1#349288, _2#349289, _3#349290, _4#349291, _5#349292]
== Exception ==
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 18021.0 failed 1 times, most recent failure: Lost task 0.0 in stage 18021.0 (TID 37324) (192.168.10.31 executor driver): org.apache.spark.SparkException: Subprocess exited with status 2. Error: python: can't open file '/home/jenkins/workspace/spark-master-test-maven-hadoop-2.7-hive-2.3-jdk-11/sql/hive/file:/home/jenkins/workspace/spark-master-test-maven-hadoop-2.7-hive-2.3-jdk-11/sql/core/target/spark-sql_2.12-3.1.0-SNAPSHOT-tests.jar!/test_script.py': [Errno 2] No such file or directory
at org.apache.spark.sql.execution.BaseScriptTransformationExec.checkFailureAndPropagate(BaseScriptTransformationExec.scala:180)
at org.apache.spark.sql.execution.BaseScriptTransformationExec.checkFailureAndPropagate$(BaseScriptTransformationExec.scala:157)
at org.apache.spark.sql.hive.execution.HiveScriptTransformationExec.checkFailureAndPropagate(HiveScriptTransformationExec.scala:49)
at org.apache.spark.sql.hive.execution.HiveScriptTransformationExec$$anon$1.hasNext(HiveScriptTransformationExec.scala:110)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:340)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:898)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:898)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:127)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:480)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1426)
at o
```
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
Existed UT
Closes#29588 from AngersZhuuuu/SPARK-32400-FOLLOWUP.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
PropagateEmptyRelation will not be applied to LIMIT operators in streaming queries.
### Why are the changes needed?
Right now, the limit operator in a streaming query may get optimized away when the relation is empty. This can be problematic for stateful streaming, as this empty batch will not write any state store files, and the next batch will fail when trying to read these state store files and throw a file not found error.
We should not let PropagateEmptyRelation optimize away the Limit operator for streaming queries.
This PR is intended as a small and safe fix for PropagateEmptyRelation. A fundamental fix that can prevent this from happening again in the future and in other optimizer rules is more desirable, but that's a much larger task.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
unit tests.
Closes#29623 from liwensun/spark-32776.
Authored-by: liwensun <liwen.sun@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
For queries with multiple foldable distinct columns, since they will be eliminated during
execution, it's not mandatory to let `RewriteDistinctAggregates` handle this case. And
in the current code, `RewriteDistinctAggregates` *dose* miss some "aggregating with
multiple foldable distinct expressions" cases.
For example: `select count(distinct 2), count(distinct 2, 3)` will be missed.
But in the planner, this will trigger an error that "multiple distinct expressions" are not allowed.
As the foldable distinct columns can be eliminated finally, we can allow this in the aggregation
planner check.
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
added test case
Closes#29607 from linhongliu-db/SPARK-32761.
Authored-by: Linhong Liu <linhong.liu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/29601 , to fix a small mistake in `SubqueryBroadcastExec`. `SubqueryBroadcastExec.doCanonicalize` should canonicalize the build keys with the query output, not the `SubqueryBroadcastExec.output`.
### Why are the changes needed?
fix mistake
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing test
Closes#29610 from cloud-fan/follow.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add JDBCScan, JDBCScanBuilder, JDBCWriteBuilder in Datasource V2 JDBC
### Why are the changes needed?
Complete Datasource V2 JDBC implementation
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
new tests
Closes#29396 from huaxingao/v2jdbc.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
`InSubquery` can be either single-column mode, or multi-column mode, depending on the output length of the subquery. For multi-column mode, the length of input `values` must match the subquery output length.
However, `InSubqueryExec` doesn't follow it and always be executed under single column mode. It's OK as it's only used by DPP, which looks up one key in one `InSubqueryExec`, so the multi-column mode is not needed. But it's better to make the physical and logical node consistent.
This PR updates `InSubqueryExec` to support multi-column mode, and also fix `SubqueryBroadcastExec` to report output correctly.
### Why are the changes needed?
Fix a potential bug.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing tests
Closes#29601 from cloud-fan/follow.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Improve test for pruning DPP on non-atomic type:
- Avoid creating new partition tables. This may take 30 seconds..
- Add test `array` type.
### Why are the changes needed?
Improve test.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
N/A
Closes#29595 from wangyum/SPARK-32659-test.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
pass specified options in DataFrameReader.table to JDBCTableCatalog.loadTable
### Why are the changes needed?
Currently, `DataFrameReader.table` ignores the specified options. The options specified like the following are lost.
```
val df = spark.read
.option("partitionColumn", "id")
.option("lowerBound", "0")
.option("upperBound", "3")
.option("numPartitions", "2")
.table("h2.test.people")
```
We need to make `DataFrameReader.table` take the specified options.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually test for now. Will add a test after V2 JDBC read is implemented.
Closes#29535 from huaxingao/table_options.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For all three different aggregate physical operator: `HashAggregateExec`, `ObjectHashAggregateExec` and `SortAggregateExec`, they have same `outputPartitioning` and `requiredChildDistribution` logic. Refactor these same logic into their super class `BaseAggregateExec` to avoid code duplication and future bugs (similar to `HashJoin` and `ShuffledJoin`).
### Why are the changes needed?
Reduce duplicated code across classes and prevent future bugs if we only update one class but forget another. We already did similar refactoring for join (`HashJoin` and `ShuffledJoin`).
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing unit tests as this is pure refactoring and no new logic added.
Closes#29583 from c21/aggregate-refactor.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Instead of deleting the data, we can move the data to trash.
Based on the configuration provided by the user it will be deleted permanently from the trash.
### Why are the changes needed?
Instead of directly deleting the data, we can provide flexibility to move data to the trash and then delete it permanently.
### Does this PR introduce _any_ user-facing change?
Yes, After truncate table the data is not permanently deleted now.
It is first moved to the trash and then after the given time deleted permanently;
### How was this patch tested?
new UTs added
Closes#29552 from Udbhav30/truncate.
Authored-by: Udbhav30 <u.agrawal30@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This is followup from https://github.com/apache/spark/pull/29342, where to do two things:
* Per https://github.com/apache/spark/pull/29342#discussion_r470153323, change from java `HashSet` to spark in-house `OpenHashSet` to track matched rows for non-unique join keys. I checked `OpenHashSet` implementation which is built from a key index (`OpenHashSet._bitset` as `BitSet`) and key array (`OpenHashSet._data` as `Array`). Java `HashSet` is built from `HashMap`, which stores value in `Node` linked list and by theory should have taken more memory than `OpenHashSet`. Reran the same benchmark query used in https://github.com/apache/spark/pull/29342, and verified the query has similar performance here between `HashSet` and `OpenHashSet`.
* Track metrics of the extra data structure `BitSet`/`OpenHashSet` for full outer SHJ. This depends on above thing, because there seems no easy way to get java `HashSet` memory size.
### Why are the changes needed?
To better surface the memory usage for full outer SHJ more accurately.
This can help users/developers to debug/improve full outer SHJ.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unite test in `SQLMetricsSuite.scala` .
Closes#29566 from c21/add-metrics.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Remove the YEAR, MONTH, DAY, HOUR, MINUTE, SECOND keywords. They are not useful in the parser, as we need to support plural like YEARS, so the parser has to accept the general identifier as interval unit anyway.
### Why are the changes needed?
These keywords are reserved in ANSI. If Spark has these keywords, then they become reserved under ANSI mode. This makes Spark not able to run TPCDS queries as they use YEAR as alias name.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added `TPCDSQueryANSISuite`, to make sure Spark with ANSI mode can run TPCDS queries.
Closes#29560 from cloud-fan/keyword.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Remove the assertion in ParquetSchemaConverter that the parquet mapKey field must be PrimitiveType.
### Why are the changes needed?
There is a parquet file in the attachment of [SPARK-32639](https://issues.apache.org/jira/browse/SPARK-32639), and the MessageType recorded in the file is:
```
message parquet_schema {
optional group value (MAP) {
repeated group key_value {
required group key {
optional binary first (UTF8);
optional binary middle (UTF8);
optional binary last (UTF8);
}
optional binary value (UTF8);
}
}
}
```
Use `spark.read.parquet("000.snappy.parquet")` to read the file. Spark will throw an exception when converting Parquet MessageType to Spark SQL StructType:
> AssertionError(Map key type is expected to be a primitive type, but found...)
Use `spark.read.schema("value MAP<STRUCT<first:STRING, middle:STRING, last:STRING>, STRING>").parquet("000.snappy.parquet")` to read the file, spark returns the correct result .
According to the parquet project document (https://github.com/apache/parquet-format/blob/master/LogicalTypes.md#maps), the mapKey in the parquet format does not need to be a primitive type.
Note: This parquet file is not written by spark, because spark will write additional sparkSchema string information in the parquet file. When Spark reads, it will directly use the additional sparkSchema information in the file instead of converting Parquet MessageType to Spark SQL StructType.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added a unit test case
Closes#29451 from izchen/SPARK-32639.
Authored-by: Chen Zhang <izchen@126.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to add a specific `AQEOptimizer` for the `AdaptiveSparkPlanExec` instead of implementing an anonymous `RuleExecutor`. At the same time, this PR also adds the configuration `spark.sql.adaptive.optimizer.excludedRules`, which follows the same pattern of `Optimizer`, to make the `AQEOptimizer` more flexible for users and developers.
### Why are the changes needed?
Currently, `AdaptiveSparkPlanExec` has implemented an anonymous `RuleExecutor` to apply the AQE optimize rules on the plan. However, the anonymous class usually could be inconvenient to maintain and extend for the long term.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
It's a pure refactor so pass existing tests should be ok.
Closes#29559 from Ngone51/impro-aqe-optimizer.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This patch corrects the method doc of DataFrameWriterV2.replace() which explanation of exception is described oppositely.
### Why are the changes needed?
The method doc is incorrect.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Only doc change.
Closes#29568 from HeartSaVioR/SPARK-28612-FOLLOWUP-fix-doc-nit.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR changes key data types check in `HashJoin` to use `sameType`.
### Why are the changes needed?
Looks at the resolving condition of `SetOperation`, it requires only each left data types should be `sameType` as the right ones. Logically the `EqualTo` expression in equi-join, also requires only left data type `sameType` as right data type. Then `HashJoin` requires left keys data type exactly the same as right keys data type, looks not reasonable.
It makes inconsistent results when doing `except` between two dataframes.
If two dataframes don't have nested fields, even their field nullable property different, `HashJoin` passes the key type check because it checks field individually so field nullable property is ignored.
If two dataframes have nested fields like struct, `HashJoin` fails the key type check because now it compare two struct types and nullable property now affects.
### Does this PR introduce _any_ user-facing change?
Yes. Making consistent `except` operation between dataframes.
### How was this patch tested?
Unit test.
Closes#29555 from viirya/SPARK-32693.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Currently, EmptyHashedRelation and HashedRelationWithAllNullKeys is an object, and it will cause JavaDeserialization Exception as following
```
20/08/26 11:13:30 WARN [task-result-getter-2] TaskSetManager: Lost task 34.0 in stage 57.0 (TID 18076, emr-worker-5.cluster-183257, executor 18): java.io.InvalidClassException: org.apache.spark.sql.execution.joins.EmptyHashedRelation$; no valid constructor
at java.io.ObjectStreamClass$ExceptionInfo.newInvalidClassException(ObjectStreamClass.java:169)
at java.io.ObjectStreamClass.checkDeserialize(ObjectStreamClass.java:874)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2042)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1572)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:430)
at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:76)
at org.apache.spark.broadcast.TorrentBroadcast$.$anonfun$unBlockifyObject$4(TorrentBroadcast.scala:328)
```
This PR includes
* Using case object instead to fix serialization issue.
* Also change EmptyHashedRelation not to extend NullAwareHashedRelation since it's already being used in other non-NAAJ joins.
### Why are the changes needed?
It will cause BHJ failed when buildSide is Empty and BHJ(NAAJ) failed when buildSide with null partition keys.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
* Existing UT.
* Run entire TPCDS for E2E coverage.
Closes#29547 from leanken/leanken-SPARK-32705.
Authored-by: xuewei.linxuewei <xuewei.linxuewei@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a follow up PR to #29328 to apply the same constraint where `path` option cannot coexist with path parameter to `DataFrameWriter.save()`, `DataStreamReader.load()` and `DataStreamWriter.start()`.
### Why are the changes needed?
The current behavior silently overwrites the `path` option if path parameter is passed to `DataFrameWriter.save()`, `DataStreamReader.load()` and `DataStreamWriter.start()`.
For example,
```
Seq(1).toDF.write.option("path", "/tmp/path1").parquet("/tmp/path2")
```
will write the result to `/tmp/path2`.
### Does this PR introduce _any_ user-facing change?
Yes, if `path` option coexists with path parameter to any of the above methods, it will throw `AnalysisException`:
```
scala> Seq(1).toDF.write.option("path", "/tmp/path1").parquet("/tmp/path2")
org.apache.spark.sql.AnalysisException: There is a 'path' option set and save() is called with a path parameter. Either remove the path option, or call save() without the parameter. To ignore this check, set 'spark.sql.legacy.pathOptionBehavior.enabled' to 'true'.;
```
The user can restore the previous behavior by setting `spark.sql.legacy.pathOptionBehavior.enabled` to `true`.
### How was this patch tested?
Added new tests.
Closes#29543 from imback82/path_option.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Use `InSet` expression to fix data issue when pruning DPP on non-atomic type. for example:
```scala
spark.range(1000)
.select(col("id"), col("id").as("k"))
.write
.partitionBy("k")
.format("parquet")
.mode("overwrite")
.saveAsTable("df1");
spark.range(100)
.select(col("id"), col("id").as("k"))
.write
.partitionBy("k")
.format("parquet")
.mode("overwrite")
.saveAsTable("df2")
spark.sql("set spark.sql.optimizer.dynamicPartitionPruning.fallbackFilterRatio=2")
spark.sql("set spark.sql.optimizer.dynamicPartitionPruning.reuseBroadcastOnly=false")
spark.sql("SELECT df1.id, df2.k FROM df1 JOIN df2 ON struct(df1.k) = struct(df2.k) AND df2.id < 2").show
```
It should return two records, but it returns empty.
### Why are the changes needed?
Fix data issue
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Add new unit test.
Closes#29475 from wangyum/SPARK-32659.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Instead of deleting the data, we can move the data to trash.
Based on the configuration provided by the user it will be deleted permanently from the trash.
### Why are the changes needed?
Instead of directly deleting the data, we can provide flexibility to move data to the trash and then delete it permanently.
### Does this PR introduce _any_ user-facing change?
Yes, After truncate table the data is not permanently deleted now.
It is first moved to the trash and then after the given time deleted permanently;
### How was this patch tested?
new UTs added
Closes#29387 from Udbhav30/tuncateTrash.
Authored-by: Udbhav30 <u.agrawal30@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR regenerates the golden explain file based on the fix: https://github.com/apache/spark/pull/29537
### Why are the changes needed?
Eliminates the personal related information (e.g., local directories) in the explain plan.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Checked manually.
Closes#29546 from Ngone51/follow-up-gen-golden-file.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Spark's CSV source can optionally ignore lines starting with a comment char. Some code paths check to see if it's set before applying comment logic (i.e. not set to default of `\0`), but many do not, including the one that passes the option to Univocity. This means that rows beginning with a null char were being treated as comments even when 'disabled'.
### Why are the changes needed?
To avoid dropping rows that start with a null char when this is not requested or intended. See JIRA for an example.
### Does this PR introduce _any_ user-facing change?
Nothing beyond the effect of the bug fix.
### How was this patch tested?
Existing tests plus new test case.
Closes#29516 from srowen/SPARK-32614.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. Extract `SQLQueryTestSuite.replaceNotIncludedMsg` to `PlanTest`.
2. Reuse `replaceNotIncludedMsg` to normalize the explain plan that generated in `PlanStabilitySuite`.
### Why are the changes needed?
This's a follow-up of https://github.com/apache/spark/pull/29270.
Eliminates the personal related information (e.g., local directories) in the explain plan.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Updated test.
Closes#29537 from Ngone51/follow-up-plan-stablity.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
There is a bug in the way the optimizer rule in `SimplifyExtractValueOps` is currently written in master branch which yields incorrect results in scenarios like the following:
```
sql("SELECT CAST(NULL AS struct<a:int,b:int>) struct_col")
.select($"struct_col".withField("d", lit(4)).getField("d").as("d"))
// currently returns this:
+---+
|d |
+---+
|4 |
+---+
// when in fact it should return this:
+----+
|d |
+----+
|null|
+----+
```
The changes in this PR will fix this bug.
### Why are the changes needed?
To fix the aforementioned bug. Optimizer rules should improve the performance of the query but yield exactly the same results.
### Does this PR introduce _any_ user-facing change?
Yes, this bug will no longer occur.
That said, this isn't something to be concerned about as this bug was introduced in Spark 3.1 and Spark 3.1 has yet to be released.
### How was this patch tested?
Unit tests were added. Jenkins must pass them.
Closes#29522 from fqaiser94/SPARK-32641.
Authored-by: fqaiser94@gmail.com <fqaiser94@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to fix ORC predicate pushdown under case-insensitive analysis case. The field names in pushed down predicates don't need to match in exact letter case with physical field names in ORC files, if we enable case-insensitive analysis.
This is re-submitted for #29457. Because #29457 has a hive-1.2 error and there were some tests failed with hive-1.2 profile at the same time, #29457 was reverted to unblock others.
### Why are the changes needed?
Currently ORC predicate pushdown doesn't work with case-insensitive analysis. A predicate "a < 0" cannot pushdown to ORC file with field name "A" under case-insensitive analysis.
But Parquet predicate pushdown works with this case. We should make ORC predicate pushdown work with case-insensitive analysis too.
### Does this PR introduce _any_ user-facing change?
Yes, after this PR, under case-insensitive analysis, ORC predicate pushdown will work.
### How was this patch tested?
Unit tests.
Closes#29530 from viirya/fix-orc-pushdown.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR enhances `Catalog.createTable()` to allow users to set the table's description. This corresponds to the following SQL syntax:
```sql
CREATE TABLE ...
COMMENT 'this is a fancy table';
```
### Why are the changes needed?
This brings the Scala/Python catalog APIs a bit closer to what's already possible via SQL.
### Does this PR introduce any user-facing change?
Yes, it adds a new parameter to `Catalog.createTable()`.
### How was this patch tested?
Existing unit tests:
```sh
./python/run-tests \
--python-executables python3.7 \
--testnames 'pyspark.sql.tests.test_catalog,pyspark.sql.tests.test_context'
```
```
$ ./build/sbt
testOnly org.apache.spark.sql.internal.CatalogSuite org.apache.spark.sql.CachedTableSuite org.apache.spark.sql.hive.MetastoreDataSourcesSuite org.apache.spark.sql.hive.execution.HiveDDLSuite
```
Closes#27908 from nchammas/SPARK-31000-table-description.
Authored-by: Nicholas Chammas <nicholas.chammas@liveramp.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to make the behavior consistent for the `path` option when loading dataframes with a single path (e.g, `option("path", path).format("parquet").load(path)` vs. `option("path", path).parquet(path)`) by disallowing `path` option to coexist with `load`'s path parameters.
### Why are the changes needed?
The current behavior is inconsistent:
```scala
scala> Seq(1).toDF.write.mode("overwrite").parquet("/tmp/test")
scala> spark.read.option("path", "/tmp/test").format("parquet").load("/tmp/test").show
+-----+
|value|
+-----+
| 1|
+-----+
scala> spark.read.option("path", "/tmp/test").parquet("/tmp/test").show
+-----+
|value|
+-----+
| 1|
| 1|
+-----+
```
### Does this PR introduce _any_ user-facing change?
Yes, now if the `path` option is specified along with `load`'s path parameters, it would fail:
```scala
scala> Seq(1).toDF.write.mode("overwrite").parquet("/tmp/test")
scala> spark.read.option("path", "/tmp/test").format("parquet").load("/tmp/test").show
org.apache.spark.sql.AnalysisException: There is a path option set and load() is called with path parameters. Either remove the path option or move it into the load() parameters.;
at org.apache.spark.sql.DataFrameReader.verifyPathOptionDoesNotExist(DataFrameReader.scala:310)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:232)
... 47 elided
scala> spark.read.option("path", "/tmp/test").parquet("/tmp/test").show
org.apache.spark.sql.AnalysisException: There is a path option set and load() is called with path parameters. Either remove the path option or move it into the load() parameters.;
at org.apache.spark.sql.DataFrameReader.verifyPathOptionDoesNotExist(DataFrameReader.scala:310)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:250)
at org.apache.spark.sql.DataFrameReader.parquet(DataFrameReader.scala:778)
at org.apache.spark.sql.DataFrameReader.parquet(DataFrameReader.scala:756)
... 47 elided
```
The user can restore the previous behavior by setting `spark.sql.legacy.pathOptionBehavior.enabled` to `true`.
### How was this patch tested?
Added a test
Closes#29328 from imback82/dfw_option.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For broadcast hash join and shuffled hash join, whenever the build side hashed relation turns out to be empty. We don't need to execute stream side plan at all, and can return an empty iterator (for inner join and left semi join), because we know for sure that none of stream side rows can be outputted as there's no match.
### Why are the changes needed?
A very minor optimization for rare use case, but in case build side turns out to be empty, we can leverage it to short-cut stream side to save CPU and IO.
Example broadcast hash join query similar to `JoinBenchmark` with empty hashed relation:
```
def broadcastHashJoinLongKey(): Unit = {
val N = 20 << 20
val M = 1 << 16
val dim = broadcast(spark.range(0).selectExpr("id as k", "cast(id as string) as v"))
codegenBenchmark("Join w long", N) {
val df = spark.range(N).join(dim, (col("id") % M) === col("k"))
assert(df.queryExecution.sparkPlan.find(_.isInstanceOf[BroadcastHashJoinExec]).isDefined)
df.noop()
}
}
```
Comparing wall clock time for enabling and disabling this PR (for non-codegen code path). Seeing like 8x improvement.
```
Java HotSpot(TM) 64-Bit Server VM 1.8.0_181-b13 on Mac OS X 10.15.4
Intel(R) Core(TM) i9-9980HK CPU 2.40GHz
Join w long: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
Join PR disabled 637 646 12 32.9 30.4 1.0X
Join PR enabled 77 78 2 271.8 3.7 8.3X
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit test in `JoinSuite`.
Closes#29484 from c21/empty-relation.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes a bug of #29406. #29406 partially pushes down data filter even if it mixed in partition filters. But in some cases partition columns might be in data columns too. It will possibly push down a predicate with partition column to datasource.
### Why are the changes needed?
The test "org.apache.spark.sql.hive.orc.HiveOrcHadoopFsRelationSuite.save()/load() - partitioned table - simple queries - partition columns in data" is currently failed with hive-1.2 profile in master branch.
```
[info] - save()/load() - partitioned table - simple queries - partition columns in data *** FAILED *** (1 second, 457 milliseconds)
[info] java.util.NoSuchElementException: key not found: p1
[info] at scala.collection.immutable.Map$Map2.apply(Map.scala:138)
[info] at org.apache.spark.sql.hive.orc.OrcFilters$.buildLeafSearchArgument(OrcFilters.scala:250)
[info] at org.apache.spark.sql.hive.orc.OrcFilters$.convertibleFiltersHelper$1(OrcFilters.scala:143)
[info] at org.apache.spark.sql.hive.orc.OrcFilters$.$anonfun$convertibleFilters$4(OrcFilters.scala:146)
[info] at scala.collection.TraversableLike.$anonfun$flatMap$1(TraversableLike.scala:245)
[info] at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
[info] at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
[info] at scala.collection.mutable.WrappedArray.foreach(WrappedArray.scala:38)
[info] at scala.collection.TraversableLike.flatMap(TraversableLike.scala:245)
[info] at scala.collection.TraversableLike.flatMap$(TraversableLike.scala:242)
[info] at scala.collection.AbstractTraversable.flatMap(Traversable.scala:108)
[info] at org.apache.spark.sql.hive.orc.OrcFilters$.convertibleFilters(OrcFilters.scala:145)
[info] at org.apache.spark.sql.hive.orc.OrcFilters$.createFilter(OrcFilters.scala:83)
[info] at org.apache.spark.sql.hive.orc.OrcFileFormat.buildReader(OrcFileFormat.scala:142)
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#29526 from viirya/SPARK-32352-followup.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Copy to master branch the unit test added for branch-2.4(https://github.com/apache/spark/pull/29430).
### Why are the changes needed?
The unit test will pass at master branch, indicating that issue reported in https://issues.apache.org/jira/browse/SPARK-32609 is already fixed at master branch. But adding this unit test for future possible failure catch.
### Does this PR introduce _any_ user-facing change?
no.
### How was this patch tested?
sbt test run
Closes#29435 from mingjialiu/master.
Authored-by: mingjial <mingjial@google.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Removing unused DELETE_ACTION in FileStreamSinkLog.
### Why are the changes needed?
DELETE_ACTION is not used nowhere in the code.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Tests where not added, because code was removed.
Closes#29505 from michal-wieleba/SPARK-32648.
Authored-by: majsiel <majsiel@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Override `def get: Date` in `DaysWritable` use the `daysToMillis(int d)` from the parent class `DateWritable` instead of `long daysToMillis(int d, boolean doesTimeMatter)`.
### Why are the changes needed?
It fixes failures of `HiveSerDeReadWriteSuite` with the profile `hive-1.2`. In that case, the parent class `DateWritable` has different implementation before the commit to Hive da3ed68eda. In particular, `get()` calls `new Date(daysToMillis(daysSinceEpoch))` instead of overrided `def get(doesTimeMatter: Boolean): Date` in the child class. The `get()` method returns wrong result `1970-01-01` because it uses not updated `daysSinceEpoch`.
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
By running the test suite `HiveSerDeReadWriteSuite`:
```
$ build/sbt -Phive-1.2 -Phadoop-2.7 "test:testOnly org.apache.spark.sql.hive.execution.HiveSerDeReadWriteSuite"
```
and
```
$ build/sbt -Phive-2.3 -Phadoop-2.7 "test:testOnly org.apache.spark.sql.hive.execution.HiveSerDeReadWriteSuite"
```
Closes#29523 from MaxGekk/insert-date-into-hive-table-1.2.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
As mentioned in https://github.com/apache/spark/pull/29428#issuecomment-678735163 by viirya ,
fix bug in UT, since in script transformation no-serde mode, output of decimal is same in both hive-1.2/hive-2.3
### Why are the changes needed?
FIX UT
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
EXISTED UT
Closes#29520 from AngersZhuuuu/SPARK-32608-FOLLOW.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
This reverts commit e277ef1a83.
### Why are the changes needed?
Because master and branch-3.0 both have few tests failed under hive-1.2 profile. And the PR #29457 missed a change in hive-1.2 code that causes compilation error. So it will make debugging the failed tests harder. I'd like revert #29457 first to unblock it.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes#29519 from viirya/revert-SPARK-32646.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
Some Code refine.
1. rename EmptyHashedRelationWithAllNullKeys to HashedRelationWithAllNullKeys.
2. simplify generated code for BHJ NAAJ.
### Why are the changes needed?
Refine code and naming to avoid confusing understanding.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing test.
Closes#29503 from leanken/leanken-SPARK-32678.
Authored-by: xuewei.linxuewei <xuewei.linxuewei@alibaba-inc.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
Rephrase the description for some operations to make it clearer.
### Why are the changes needed?
Add more detail in the document.
### Does this PR introduce _any_ user-facing change?
No, document only.
### How was this patch tested?
Document only.
Closes#29269 from xuanyuanking/SPARK-31792-follow.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
## What changes were proposed in this pull request?
This fixed SPARK-32672 a data corruption. Essentially the BooleanBitSet CompressionScheme would miss nulls at the end of a CompressedBatch. The values would then default to false.
### Why are the changes needed?
It fixes data corruption
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
I manually tested it against the original issue that was producing errors for me. I also added in a unit test.
Closes#29506 from revans2/SPARK-32672.
Authored-by: Robert (Bobby) Evans <bobby@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Fix typo for docs, log messages and comments
### Why are the changes needed?
typo fix to increase readability
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
manual test has been performed to test the updated
Closes#29443 from brandonJY/spell-fix-doc.
Authored-by: Brandon Jiang <Brandon.jiang.a@outlook.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR proposes to fix ORC predicate pushdown under case-insensitive analysis case. The field names in pushed down predicates don't need to match in exact letter case with physical field names in ORC files, if we enable case-insensitive analysis.
### Why are the changes needed?
Currently ORC predicate pushdown doesn't work with case-insensitive analysis. A predicate "a < 0" cannot pushdown to ORC file with field name "A" under case-insensitive analysis.
But Parquet predicate pushdown works with this case. We should make ORC predicate pushdown work with case-insensitive analysis too.
### Does this PR introduce _any_ user-facing change?
Yes, after this PR, under case-insensitive analysis, ORC predicate pushdown will work.
### How was this patch tested?
Unit tests.
Closes#29457 from viirya/fix-orc-pushdown.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Hive no serde mode when column less then output specified column, it will pad null value to it, spark should do this also.
```
hive> SELECT TRANSFORM(a, b)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '|'
> LINES TERMINATED BY '\n'
> NULL DEFINED AS 'NULL'
> USING 'cat' as (a string, b string, c string, d string)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '|'
> LINES TERMINATED BY '\n'
> NULL DEFINED AS 'NULL'
> FROM (
> select 1 as a, 2 as b
> ) tmp ;
OK
1 2 NULL NULL
Time taken: 24.626 seconds, Fetched: 1 row(s)
```
### Why are the changes needed?
Keep save behavior with hive data.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#29500 from AngersZhuuuu/SPARK-32667.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR reverts https://github.com/apache/spark/pull/27860 to downgrade Janino, as the new version has a bug.
### Why are the changes needed?
The symptom is about NaN comparison. For code below
```
if (double_value <= 0.0) {
...
} else {
...
}
```
If `double_value` is NaN, `NaN <= 0.0` is false and we should go to the else branch. However, current Spark goes to the if branch and causes correctness issues like SPARK-32640.
One way to fix it is:
```
boolean cond = double_value <= 0.0;
if (cond) {
...
} else {
...
}
```
I'm not familiar with Janino so I don't know what's going on there.
### Does this PR introduce _any_ user-facing change?
Yes, fix correctness bugs.
### How was this patch tested?
a new test
Closes#29495 from cloud-fan/revert.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/29469
Instead of passing the physical plan to the fallbacked v1 source directly and skipping analysis, optimization, planning altogether, this PR proposes to pass the optimized plan.
### Why are the changes needed?
It's a bit risky to pass the physical plan directly. When the fallbacked v1 source applies more operations to the input DataFrame, it will re-apply the post-planning physical rules like `CollapseCodegenStages`, `InsertAdaptiveSparkPlan`, etc., which is very tricky.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existing test suite with some new tests
Closes#29489 from cloud-fan/follow.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In case that a last `SQLQueryTestSuite` test run is killed, it will fail in a next run because of a following reason:
```
[info] org.apache.spark.sql.SQLQueryTestSuite *** ABORTED *** (17 seconds, 483 milliseconds)
[info] org.apache.spark.sql.AnalysisException: Can not create the managed table('`testdata`'). The associated location('file:/Users/maropu/Repositories/spark/spark-master/sql/core/spark-warehouse/org.apache.spark.sql.SQLQueryTestSuite/testdata') already exists.;
[info] at org.apache.spark.sql.catalyst.catalog.SessionCatalog.validateTableLocation(SessionCatalog.scala:355)
[info] at org.apache.spark.sql.execution.command.CreateDataSourceTableAsSelectCommand.run(createDataSourceTables.scala:170)
[info] at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:108)
```
This PR intends to add code to deletes orphan directories under a warehouse dir in `SQLQueryTestSuite` before creating test tables.
### Why are the changes needed?
To improve test convenience
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually checked
Closes#29488 from maropu/DeleteDirs.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Scrip Transform no-serde (`ROW FORMAT DELIMITED`) mode `LINE TERMINNATED BY `
only support `\n`.
Tested in hive :
Hive 1.1
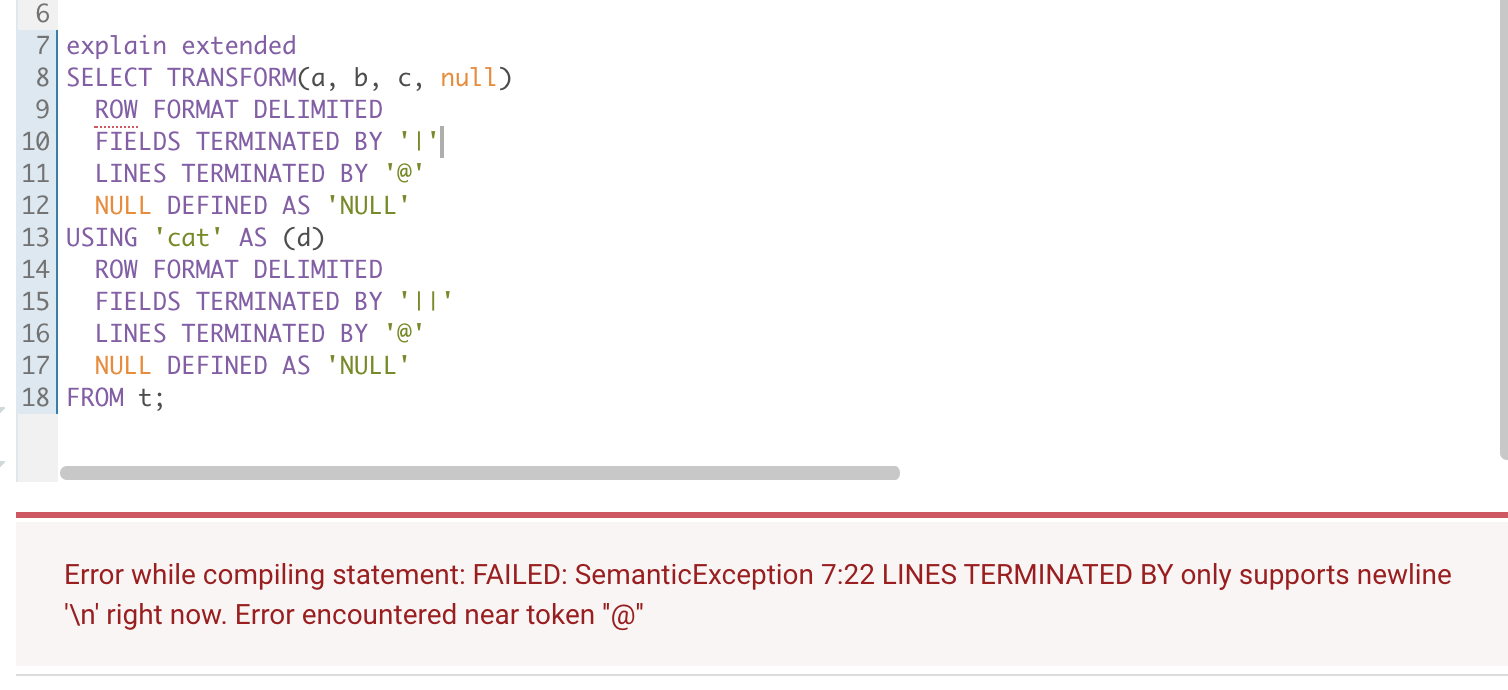
Hive 2.3.7
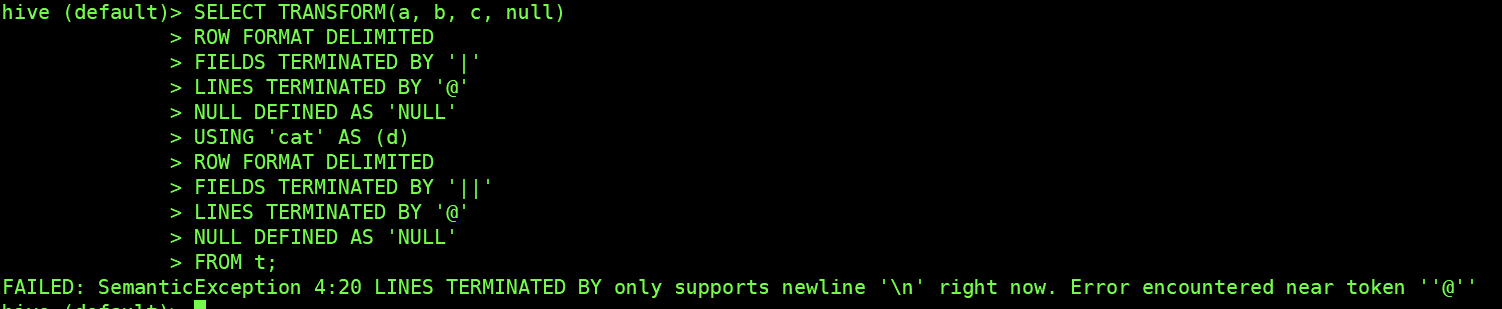
### Why are the changes needed?
Strictly limit the use method to ensure the accuracy of data
### Does this PR introduce _any_ user-facing change?
User use Scrip Transform no-serde (ROW FORMAT DELIMITED) mode with `LINE TERMINNATED BY `
not equal `'\n'`. will throw error
### How was this patch tested?
Added UT
Closes#29438 from AngersZhuuuu/SPARK-32607.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In many operations on CompactibleFileStreamLog reads a metadata log file and materializes all entries into memory. As the nature of the compact operation, CompactibleFileStreamLog may have a huge compact log file with bunch of entries included, and for now they're just monotonically increasing, which means the amount of memory to materialize also grows incrementally. This leads pressure on GC.
This patch proposes to streamline the logic on file stream source and sink whenever possible to avoid memory issue. To make this possible we have to break the existing behavior of excluding entries - now the `compactLogs` method is called with all entries, which forces us to materialize all entries into memory. This is hopefully no effect on end users, because only file stream sink has a condition to exclude entries, and the condition has been never true. (DELETE_ACTION has been never set.)
Based on the observation, this patch also changes the existing UT a bit which simulates the situation where "A" file is added, and another batch marks the "A" file as deleted. This situation simply doesn't work with the change, but as I mentioned earlier it hasn't been used. (I'm not sure the UT is from the actual run. I guess not.)
### Why are the changes needed?
The memory issue (OOME) is reported by both JIRA issue and user mailing list.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
* Existing UTs
* Manual test done
The manual test leverages the simple apps which continuously writes the file stream sink metadata log.
bea7680e4c
The test is configured to have a batch metadata log file at 1.9M (10,000 entries) whereas other Spark configuration is set to the default. (compact interval = 10) The app runs as driver, and the heap memory on driver is set to 3g.
> before the patch
<img width="1094" alt="Screen Shot 2020-06-23 at 3 37 44 PM" src="https://user-images.githubusercontent.com/1317309/85375841-d94f3480-b571-11ea-817b-c6b48b34888a.png">
It only ran for 40 mins, with the latest compact batch file size as 1.3G. The process struggled with GC, and after some struggling, it threw OOME.
> after the patch
<img width="1094" alt="Screen Shot 2020-06-23 at 3 53 29 PM" src="https://user-images.githubusercontent.com/1317309/85375901-eff58b80-b571-11ea-837e-30d107f677f9.png">
It sustained 2 hours run (manually stopped as it's expected to run more), with the latest compact batch file size as 2.2G. The actual memory usage didn't even go up to 1.2G, and be cleaned up soon without outstanding GC activity.
Closes#28904 from HeartSaVioR/SPARK-30462.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Address the [#comment](https://github.com/apache/spark/pull/28840#discussion_r471172006).
### Why are the changes needed?
Make code robust.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
ut.
Closes#29453 from ulysses-you/SPARK-31999-FOLLOWUP.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR introduces a LogicalNode AlreadyPlanned, and related physical plan and preparation rule.
With the DataSourceV2 write operations, we have a way to fallback to the V1 writer APIs using InsertableRelation. The gross part is that we're in physical land, but the InsertableRelation takes a logical plan, so we have to pass the logical plans to these physical nodes, and then potentially go through re-planning. This re-planning can cause issues for an already optimized plan.
A useful primitive could be specifying that a plan is ready for execution through a logical node AlreadyPlanned. This would wrap a physical plan, and then we can go straight to execution.
### Why are the changes needed?
To avoid having a physical plan that is disconnected from the physical plan that is being executed in V1WriteFallback execution. When a physical plan node executes a logical plan, the inner query is not connected to the running physical plan. The physical plan that actually runs is not visible through the Spark UI and its metrics are not exposed. In some cases, the EXPLAIN plan doesn't show it.
### Does this PR introduce _any_ user-facing change?
Nope
### How was this patch tested?
V1FallbackWriterSuite tests that writes still work
Closes#29469 from brkyvz/alreadyAnalyzed2.
Lead-authored-by: Burak Yavuz <brkyvz@gmail.com>
Co-authored-by: Burak Yavuz <burak@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When CSV/JSON datasources infer schema (e.g, `def inferSchema(files: Seq[FileStatus])`, they use the `files` along with the original options. `files` in `inferSchema` could have been deduced from the "path" option if the option was present, so this can cause issues (e.g., reading more data, listing the path again) since the "path" option is **added** to the `files`.
### Why are the changes needed?
The current behavior can cause the following issue:
```scala
class TestFileFilter extends PathFilter {
override def accept(path: Path): Boolean = path.getParent.getName != "p=2"
}
val path = "/tmp"
val df = spark.range(2)
df.write.json(path + "/p=1")
df.write.json(path + "/p=2")
val extraOptions = Map(
"mapred.input.pathFilter.class" -> classOf[TestFileFilter].getName,
"mapreduce.input.pathFilter.class" -> classOf[TestFileFilter].getName
)
// This works fine.
assert(spark.read.options(extraOptions).json(path).count == 2)
// The following with "path" option fails with the following:
// assertion failed: Conflicting directory structures detected. Suspicious paths
// file:/tmp
// file:/tmp/p=1
assert(spark.read.options(extraOptions).format("json").option("path", path).load.count() === 2)
```
### Does this PR introduce _any_ user-facing change?
Yes, the above failure doesn't happen and you get the consistent experience when you use `spark.read.csv(path)` or `spark.read.format("csv").option("path", path).load`.
### How was this patch tested?
Updated existing tests.
Closes#29437 from imback82/path_bug.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For SQL
```
SELECT TRANSFORM(a, b, c)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
NULL DEFINED AS 'null'
USING 'cat' AS (a, b, c)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
NULL DEFINED AS 'NULL'
FROM testData
```
The correct
TOK_TABLEROWFORMATFIELD should be `, `nut actually ` ','`
TOK_TABLEROWFORMATLINES should be `\n` but actually` '\n'`
### Why are the changes needed?
Fix string value format
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#29428 from AngersZhuuuu/SPARK-32608.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Update `ObjectSerializerPruning.alignNullTypeInIf`, to consider the isNull check generated in `RowEncoder`, which is `Invoke(inputObject, "isNullAt", BooleanType, Literal(index) :: Nil)`.
### Why are the changes needed?
Query fails if we don't fix this bug, due to type mismatch in `If`.
### Does this PR introduce _any_ user-facing change?
Yes, the failed query can run after this fix.
### How was this patch tested?
new tests
Closes#29467 from cloud-fan/bug.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
During working on SPARK-25557, we found that ORC predicate pushdown doesn't have case-sensitivity test. This PR proposes to add case-sensitivity test for ORC predicate pushdown.
### Why are the changes needed?
Increasing test coverage for ORC predicate pushdown.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass Jenkins tests.
Closes#29427 from viirya/SPARK-25557-followup3.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Found java.util.NoSuchElementException in UT log of AdaptiveQueryExecSuite. During AQE, when sub-plan changed, LiveExecutionData is using the new sub-plan SQLMetrics to override the old ones, But in the final aggregateMetrics, since the plan was updated, the old metrics will throw NoSuchElementException when it try to match with the new metricTypes. To sum up, we need to filter out those outdated metrics to avoid throwing java.util.NoSuchElementException, which cause SparkUI SQL Tab abnormally rendered.
### Why are the changes needed?
SQL Metrics is not correct for some AQE cases, and it break SparkUI SQL Tab when it comes to NAAJ rewritten to LocalRelation case.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
* Added case in SQLAppStatusListenerSuite.
* Run AdaptiveQueryExecSuite with no "java.util.NoSuchElementException".
* Validation on Spark Web UI
Closes#29431 from leanken/leanken-SPARK-32615.
Authored-by: xuewei.linxuewei <xuewei.linxuewei@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to detect possible regression inside `SparkPlan`. To achieve this goal, this PR added a base test suite called `PlanStabilitySuite`. The basic workflow of this test suite is similar to `SQLQueryTestSuite`. It also uses `SPARK_GENERATE_GOLDEN_FILES` to decide whether it should regenerate the golden files or compare to the golden result for each input query. The difference is, `PlanStabilitySuite` uses the serialized explain result(.txt format) of the `SparkPlan` as the output of a query, instead of the data result.
And since `SparkPlan` is non-deterministic for various reasons, e.g., expressions ids changes, expression order changes, we'd reduce the plan to a simplified version that only contains node names and references. And we only identify those important nodes, e.g., `Exchange`, `SubqueryExec`, in the simplified plan.
And we'd reuse TPC-DS queries(v1.4, v2.7, modified) to test plans' stability. Currently, one TPC-DS query can only have one corresponding simplified golden plan.
This PR also did a few refactor, which extracts `TPCDSBase` from `TPCDSQuerySuite`. So, `PlanStabilitySuite` can use the TPC-DS queries as well.
### Why are the changes needed?
Nowadays, Spark is getting more and more complex. Any changes might cause regression unintentionally. Spark already has some benchmark to catch the performance regression. But, yet, it doesn't have a way to detect the regression inside `SparkPlan`. It would be good if we could detect the possible regression early during the compile phase before the runtime phase.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added `PlanStabilitySuite` and it's subclasses.
Closes#29270 from Ngone51/plan-stable.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add support for full outer join inside shuffled hash join. Currently if the query is a full outer join, we only use sort merge join as the physical operator. However it can be CPU and IO intensive in case input table is large for sort merge join. Shuffled hash join on the other hand saves the sort CPU and IO compared to sort merge join, especially when table is large.
This PR implements the full outer join as followed:
* Process rows from stream side by looking up hash relation, and mark the matched rows from build side by:
* for joining with unique key, a `BitSet` is used to record matched rows from build side (`key index` to represent each row)
* for joining with non-unique key, a `HashSet[Long]` is used to record matched rows from build side (`key index` + `value index` to represent each row).
`key index` is defined as the index into key addressing array `longArray` in `BytesToBytesMap`.
`value index` is defined as the iterator index of values for same key.
* Process rows from build side by iterating hash relation, and filter out rows from build side being looked up already (done in `ShuffledHashJoinExec.fullOuterJoin`)
For context, this PR was originally implemented as followed (up to commit e3322766d4):
1. Construct hash relation from build side, with extra boolean value at the end of row to track look up information (done in `ShuffledHashJoinExec.buildHashedRelation` and `UnsafeHashedRelation.apply`).
2. Process rows from stream side by looking up hash relation, and mark the matched rows from build side be looked up (done in `ShuffledHashJoinExec.fullOuterJoin`).
3. Process rows from build side by iterating hash relation, and filter out rows from build side being looked up already (done in `ShuffledHashJoinExec.fullOuterJoin`).
See discussion of pros and cons between these two approaches [here](https://github.com/apache/spark/pull/29342#issuecomment-672275450), [here](https://github.com/apache/spark/pull/29342#issuecomment-672288194) and [here](https://github.com/apache/spark/pull/29342#issuecomment-672640531).
TODO: codegen for full outer shuffled hash join can be implemented in another followup PR.
### Why are the changes needed?
As implementation in this PR, full outer shuffled hash join will have overhead to iterate build side twice (once for building hash map, and another for outputting non-matching rows), and iterate stream side once. However, full outer sort merge join needs to iterate both sides twice, and sort the large table can be more CPU and IO intensive. So full outer shuffled hash join can be more efficient than sort merge join when stream side is much more larger than build side.
For example query below, full outer SHJ saved 30% wall clock time compared to full outer SMJ.
```
def shuffleHashJoin(): Unit = {
val N: Long = 4 << 22
withSQLConf(
SQLConf.SHUFFLE_PARTITIONS.key -> "2",
SQLConf.AUTO_BROADCASTJOIN_THRESHOLD.key -> "20000000") {
codegenBenchmark("shuffle hash join", N) {
val df1 = spark.range(N).selectExpr(s"cast(id as string) as k1")
val df2 = spark.range(N / 10).selectExpr(s"cast(id * 10 as string) as k2")
val df = df1.join(df2, col("k1") === col("k2"), "full_outer")
df.noop()
}
}
}
```
```
Running benchmark: shuffle hash join
Running case: shuffle hash join off
Stopped after 2 iterations, 16602 ms
Running case: shuffle hash join on
Stopped after 5 iterations, 31911 ms
Java HotSpot(TM) 64-Bit Server VM 1.8.0_181-b13 on Mac OS X 10.15.4
Intel(R) Core(TM) i9-9980HK CPU 2.40GHz
shuffle hash join: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
shuffle hash join off 7900 8301 567 2.1 470.9 1.0X
shuffle hash join on 6250 6382 95 2.7 372.5 1.3X
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit test in `JoinSuite.scala`, `AbstractBytesToBytesMapSuite.java` and `HashedRelationSuite.scala`.
Closes#29342 from c21/full-outer-shj.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
In the docs concerning the approx_count_distinct I have changed the description of the rsd parameter from **_maximum estimation error allowed_** to _**maximum relative standard deviation allowed**_
### Why are the changes needed?
Maximum estimation error allowed can be misleading. You can set the target relative standard deviation, which affects the estimation error, but on given runs the estimation error can still be above the rsd parameter.
### Does this PR introduce _any_ user-facing change?
This PR should make it easier for users reading the docs to understand that the rsd parameter in approx_count_distinct doesn't cap the estimation error, but just sets the target deviation instead,
### How was this patch tested?
No tests, as no code changes were made.
Closes#29424 from Comonut/fix-approx_count_distinct-rsd-param-description.
Authored-by: alexander-daskalov <alexander.daskalov@adevinta.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Remove `fullOutput` from `RowDataSourceScanExec`
### Why are the changes needed?
`RowDataSourceScanExec` requires the full output instead of the scan output after column pruning. However, in v2 code path, we don't have the full output anymore so we just pass the pruned output. `RowDataSourceScanExec.fullOutput` is actually meaningless so we should remove it.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existing tests
Closes#29415 from huaxingao/rm_full_output.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Discussion with [comment](https://github.com/apache/spark/pull/29244#issuecomment-671746329).
Add `HiveVoidType` class in `HiveClientImpl` then we can replace `NullType` to `HiveVoidType` before we call hive client.
### Why are the changes needed?
Better compatible with hive.
More details in [#29244](https://github.com/apache/spark/pull/29244).
### Does this PR introduce _any_ user-facing change?
Yes, user can create view with null type in Hive.
### How was this patch tested?
New test.
Closes#29423 from ulysses-you/add-HiveVoidType.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Added a new `dropFields` method to the `Column` class.
This method should allow users to drop a `StructField` in a `StructType` column (with similar semantics to the `drop` method on `Dataset`).
### Why are the changes needed?
Often Spark users have to work with deeply nested data e.g. to fix a data quality issue with an existing `StructField`. To do this with the existing Spark APIs, users have to rebuild the entire struct column.
For example, let's say you have the following deeply nested data structure which has a data quality issue (`5` is missing):
```
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
val data = spark.createDataFrame(sc.parallelize(
Seq(Row(Row(Row(1, 2, 3), Row(Row(4, null, 6), Row(7, 8, 9), Row(10, 11, 12)), Row(13, 14, 15))))),
StructType(Seq(
StructField("a", StructType(Seq(
StructField("a", StructType(Seq(
StructField("a", IntegerType),
StructField("b", IntegerType),
StructField("c", IntegerType)))),
StructField("b", StructType(Seq(
StructField("a", StructType(Seq(
StructField("a", IntegerType),
StructField("b", IntegerType),
StructField("c", IntegerType)))),
StructField("b", StructType(Seq(
StructField("a", IntegerType),
StructField("b", IntegerType),
StructField("c", IntegerType)))),
StructField("c", StructType(Seq(
StructField("a", IntegerType),
StructField("b", IntegerType),
StructField("c", IntegerType))))
))),
StructField("c", StructType(Seq(
StructField("a", IntegerType),
StructField("b", IntegerType),
StructField("c", IntegerType))))
)))))).cache
data.show(false)
+---------------------------------+
|a |
+---------------------------------+
|[[1, 2, 3], [[4,, 6], [7, 8, 9]]]|
+---------------------------------+
```
Currently, to drop the missing value users would have to do something like this:
```
val result = data.withColumn("a",
struct(
$"a.a",
struct(
struct(
$"a.b.a.a",
$"a.b.a.c"
).as("a"),
$"a.b.b",
$"a.b.c"
).as("b"),
$"a.c"
))
result.show(false)
+---------------------------------------------------------------+
|a |
+---------------------------------------------------------------+
|[[1, 2, 3], [[4, 6], [7, 8, 9], [10, 11, 12]], [13, 14, 15]]|
+---------------------------------------------------------------+
```
As you can see above, with the existing methods users must call the `struct` function and list all fields, including fields they don't want to change. This is not ideal as:
>this leads to complex, fragile code that cannot survive schema evolution.
[SPARK-16483](https://issues.apache.org/jira/browse/SPARK-16483)
In contrast, with the method added in this PR, a user could simply do something like this to get the same result:
```
val result = data.withColumn("a", 'a.dropFields("b.a.b"))
result.show(false)
+---------------------------------------------------------------+
|a |
+---------------------------------------------------------------+
|[[1, 2, 3], [[4, 6], [7, 8, 9], [10, 11, 12]], [13, 14, 15]]|
+---------------------------------------------------------------+
```
This is the second of maybe 3 methods that could be added to the `Column` class to make it easier to manipulate nested data.
Other methods under discussion in [SPARK-22231](https://issues.apache.org/jira/browse/SPARK-22231) include `withFieldRenamed`.
However, this should be added in a separate PR.
### Does this PR introduce _any_ user-facing change?
Only one minor change. If the user submits the following query:
```
df.withColumn("a", $"a".withField(null, null))
```
instead of throwing:
```
java.lang.IllegalArgumentException: requirement failed: fieldName cannot be null
```
it will now throw:
```
java.lang.IllegalArgumentException: requirement failed: col cannot be null
```
I don't believe its should be an issue to change this because:
- neither message is incorrect
- Spark 3.1.0 has yet to be released
but please feel free to correct me if I am wrong.
### How was this patch tested?
New unit tests were added. Jenkins must pass them.
### Related JIRAs:
More discussion on this topic can be found here:
- https://issues.apache.org/jira/browse/SPARK-22231
- https://issues.apache.org/jira/browse/SPARK-16483Closes#29322 from fqaiser94/SPARK-32511.
Lead-authored-by: fqaiser94@gmail.com <fqaiser94@gmail.com>
Co-authored-by: fqaiser94 <fqaiser94@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Update URL of the parquet project in code comment.
### Why are the changes needed?
The original url is not available.
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
No test needed.
Closes#29416 from izchen/Update-Parquet-URL.
Authored-by: Chen Zhang <izchen@126.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
We support partially push partition filters since SPARK-28169. We can also support partially push down data filters if it mixed in partition filters and data filters. For example:
```
spark.sql(
s"""
|CREATE TABLE t(i INT, p STRING)
|USING parquet
|PARTITIONED BY (p)""".stripMargin)
spark.range(0, 1000).selectExpr("id as col").createOrReplaceTempView("temp")
for (part <- Seq(1, 2, 3, 4)) {
sql(s"""
|INSERT OVERWRITE TABLE t PARTITION (p='$part')
|SELECT col FROM temp""".stripMargin)
}
spark.sql("SELECT * FROM t WHERE WHERE (p = '1' AND i = 1) OR (p = '2' and i = 2)").explain()
```
We can also push down ```i = 1 or i = 2 ```
### Why are the changes needed?
Extract more data filter to FileSourceScanExec
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
Added UT
Closes#29406 from AngersZhuuuu/SPARK-32352.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes the issue introduced during SPARK-26985.
SPARK-26985 changes the `putDoubles()` and `putFloats()` methods to respect the platform's endian-ness. However, that causes the RLE paths in VectorizedRleValuesReader.java to read the RLE entries in parquet as BIG_ENDIAN on big endian platforms (i.e., as is), even though parquet data is always in little endian format.
The comments in `WriteableColumnVector.java` say those methods are used for "ieee formatted doubles in platform native endian" (or floats), but since the data in parquet is always in little endian format, use of those methods appears to be inappropriate.
To demonstrate the problem with spark-shell:
```scala
import org.apache.spark._
import org.apache.spark.sql._
import org.apache.spark.sql.types._
var data = Seq(
(1.0, 0.1),
(2.0, 0.2),
(0.3, 3.0),
(4.0, 4.0),
(5.0, 5.0))
var df = spark.createDataFrame(data).write.mode(SaveMode.Overwrite).parquet("/tmp/data.parquet2")
var df2 = spark.read.parquet("/tmp/data.parquet2")
df2.show()
```
result:
```scala
+--------------------+--------------------+
| _1| _2|
+--------------------+--------------------+
| 3.16E-322|-1.54234871366845...|
| 2.0553E-320| 2.0553E-320|
| 2.561E-320| 2.561E-320|
|4.66726145843124E-62| 1.0435E-320|
| 3.03865E-319|-1.54234871366757...|
+--------------------+--------------------+
```
Also tests in ParquetIOSuite that involve float/double data would fail, e.g.,
- basic data types (without binary)
- read raw Parquet file
/examples/src/main/python/mllib/isotonic_regression_example.py would fail as well.
Purposed code change is to add `putDoublesLittleEndian()` and `putFloatsLittleEndian()` methods for parquet to invoke, just like the existing `putIntsLittleEndian()` and `putLongsLittleEndian()`. On little endian platforms they would call `putDoubles()` and `putFloats()`, on big endian they would read the entries as little endian like pre-SPARK-26985.
No new unit-test is introduced as the existing ones are actually sufficient.
### Why are the changes needed?
RLE float/double data in parquet files will not be read back correctly on big endian platforms.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
All unit tests (mvn test) were ran and OK.
Closes#29383 from tinhto-000/SPARK-31703.
Authored-by: Tin Hang To <tinto@us.ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Extract common test case (no serde) to BasicScriptTransformationExecSuite
2. Add more test case for no serde mode about supported data type and behavior in `BasicScriptTransformationExecSuite`
3. Add more test case for hive serde mode about supported type and behavior in `HiveScriptTransformationExecSuite`
### Why are the changes needed?
Improve test coverage of Script Transformation
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
Added UT
Closes#29401 from AngersZhuuuu/SPARK-32400.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Fix `DaysWritable` by overriding parent's method `def get(doesTimeMatter: Boolean): Date` from `DateWritable` instead of `Date get()` because the former one uses the first one. The bug occurs because `HiveOutputWriter.write()` call `def get(doesTimeMatter: Boolean): Date` transitively with default implementation from the parent class `DateWritable` which doesn't respect date rebases and uses not initialized `daysSinceEpoch` (0 which `1970-01-01`).
### Why are the changes needed?
The changes fix the bug:
```sql
spark-sql> CREATE TABLE table1 (d date);
spark-sql> INSERT INTO table1 VALUES (date '2020-08-11');
spark-sql> SELECT * FROM table1;
1970-01-01
```
The expected result of the last SQL statement must be **2020-08-11** but got **1970-01-01**.
### Does this PR introduce _any_ user-facing change?
Yes. After the fix, `INSERT` work correctly:
```sql
spark-sql> SELECT * FROM table1;
2020-08-11
```
### How was this patch tested?
Add new test to `HiveSerDeReadWriteSuite`
Closes#29409 from MaxGekk/insert-date-into-hive-table.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In [SPARK-32290](https://issues.apache.org/jira/browse/SPARK-32290), we introduced several new types of HashedRelation.
* EmptyHashedRelation
* EmptyHashedRelationWithAllNullKeys
They were all limited to used only in NAAJ scenario. These new HashedRelation could be applied to other scenario for performance improvements.
* EmptyHashedRelation could also be used in Normal AntiJoin for fast stop
* While AQE is on and buildSide is EmptyHashedRelationWithAllNullKeys, can convert NAAJ to a Empty LocalRelation to skip meaningless data iteration since in Single-Key NAAJ, if null key exists in BuildSide, will drop all records in streamedSide.
This Patch including two changes.
* using EmptyHashedRelation to do fast stop for common anti join as well
* In AQE, eliminate BroadcastHashJoin(NAAJ) if buildSide is a EmptyHashedRelationWithAllNullKeys
### Why are the changes needed?
LeftAntiJoin could apply `fast stop` when BuildSide is EmptyHashedRelation, While within AQE with EmptyHashedRelationWithAllNullKeys, we can eliminate the NAAJ. This should be a performance improvement in AntiJoin.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
* added case in AdaptiveQueryExecSuite.
* added case in HashedRelationSuite.
* Make sure SubquerySuite JoinSuite SQLQueryTestSuite passed.
Closes#29389 from leanken/leanken-SPARK-32573.
Authored-by: xuewei.linxuewei <xuewei.linxuewei@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR added a physical rule to remove redundant project nodes. A `ProjectExec` is redundant when
1. It has the same output attributes and order as its child's output when ordering of these attributes is required.
2. It has the same output attributes as its child's output when attribute output ordering is not required.
For example:
After Filter:
```
== Physical Plan ==
*(1) Project [a#14L, b#15L, c#16, key#17]
+- *(1) Filter (isnotnull(a#14L) AND (a#14L > 5))
+- *(1) ColumnarToRow
+- FileScan parquet [a#14L,b#15L,c#16,key#17]
```
The `Project a#14L, b#15L, c#16, key#17` is redundant because its output is exactly the same as filter's output.
Before Aggregate:
```
== Physical Plan ==
*(2) HashAggregate(keys=[key#17], functions=[sum(a#14L), last(b#15L, false)], output=[sum_a#39L, key#17, last_b#41L])
+- Exchange hashpartitioning(key#17, 5), true, [id=#77]
+- *(1) HashAggregate(keys=[key#17], functions=[partial_sum(a#14L), partial_last(b#15L, false)], output=[key#17, sum#49L, last#50L, valueSet#51])
+- *(1) Project [key#17, a#14L, b#15L]
+- *(1) Filter (isnotnull(a#14L) AND (a#14L > 100))
+- *(1) ColumnarToRow
+- FileScan parquet [a#14L,b#15L,key#17]
```
The `Project key#17, a#14L, b#15L` is redundant because hash aggregate doesn't require child plan's output to be in a specific order.
### Why are the changes needed?
It removes unnecessary query nodes and makes query plan cleaner.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests
Closes#29031 from allisonwang-db/remove-project.
Lead-authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Co-authored-by: allisonwang-db <allison.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR makes `ApplyColumnarRulesAndInsertTransitions` idempotent (assuming the custom columnar rules are also idempotent).
### Why are the changes needed?
It's good hygiene to keep rules idempotent
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
new suite
Closes#29273 from cloud-fan/rule.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
# What changes were proposed in this pull request?
This PR comes from the comment: #29085 (comment)
- Extract common Script IOSchema `ScriptTransformationIOSchema`
- avoid repeated judgement extract process output row method `createOutputIteratorWithoutSerde` && `createOutputIteratorWithSerde`
- add default no serde IO schemas `ScriptTransformationIOSchema.defaultIOSchema`
### Why are the changes needed?
Refactor code
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
NO
Closes#29199 from AngersZhuuuu/spark-32105-followup.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add a new test suite `CTEHintSuite`
### Why are the changes needed?
This ticket is to address the below comments to help us understand the test coverage of SQL HINT for CTE.
https://github.com/apache/spark/pull/29062#discussion_r463247491https://github.com/apache/spark/pull/29062#discussion_r463248167
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Add a test suite.
Closes#29359 from LantaoJin/SPARK-32537.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Check the Distinct nodes by assuming it as Aggregate in `UnsupportOperationChecker` for streaming.
### Why are the changes needed?
We want to fix 2 things here:
1. Give better error message for Distinct related operations in append mode that doesn't have a watermark
We use the union streams as the example, distinct in SQL has the same issue. Since the union clause in SQL has the requirement of deduplication, the parser will generate `Distinct(Union)` and the optimizer rule `ReplaceDistinctWithAggregate` will change it to `Aggregate(Union)`. This logic is of both batch and streaming queries. However, in the streaming, the aggregation will be wrapped by state store operations so we need extra checking logic in `UnsupportOperationChecker`.
Before this change, the SS union queries in Append mode will get the following confusing error when the watermark is lacking.
```
java.util.NoSuchElementException: None.get
at scala.None$.get(Option.scala:529)
at scala.None$.get(Option.scala:527)
at org.apache.spark.sql.execution.streaming.StateStoreSaveExec.$anonfun$doExecute$9(statefulOperators.scala:346)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.util.Utils$.timeTakenMs(Utils.scala:561)
at org.apache.spark.sql.execution.streaming.StateStoreWriter.timeTakenMs(statefulOperators.scala:112)
...
```
2. Make `Distinct` in complete mode runnable.
Before this fix, the distinct in complete mode will throw the exception:
```
Complete output mode not supported when there are no streaming aggregations on streaming DataFrames/Datasets;
```
### Does this PR introduce _any_ user-facing change?
Yes, return a better error message.
### How was this patch tested?
New UT added.
Closes#29256 from xuanyuanking/SPARK-32456.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR adds initial plan in `AdaptiveSparkPlanExec` and generates tree string for both current plan and initial plan. When the adaptive plan is not final, `Current Plan` will be used to indicate current physical plan, and `Final Plan` will be used when the adaptive plan is final. The difference between `Current Plan` and `Final Plan` here is that current plan indicates an intermediate state. The plan is subject to further transformations, while final plan represents an end state, which means the plan will no longer be changed.
Examples:
Before this change:
```
AdaptiveSparkPlan isFinalPlan=true
+- *(3) BroadcastHashJoin
:- BroadcastQueryStage 2
...
```
`EXPLAIN FORMATTED`
```
== Physical Plan ==
AdaptiveSparkPlan (9)
+- BroadcastHashJoin Inner BuildRight (8)
:- Project (3)
: +- Filter (2)
```
After this change
```
AdaptiveSparkPlan isFinalPlan=true
+- == Final Plan ==
*(3) BroadcastHashJoin
:- BroadcastQueryStage 2
: +- BroadcastExchange
...
+- == Initial Plan ==
SortMergeJoin
:- Sort
: +- Exchange
...
```
`EXPLAIN FORMATTED`
```
== Physical Plan ==
AdaptiveSparkPlan (9)
+- == Current Plan ==
BroadcastHashJoin Inner BuildRight (8)
:- Project (3)
: +- Filter (2)
+- == Initial Plan ==
BroadcastHashJoin Inner BuildRight (8)
:- Project (3)
: +- Filter (2)
```
### Why are the changes needed?
It provides better visibility into the plan change introduced by AQE.
### Does this PR introduce _any_ user-facing change?
Yes. It changed the AQE plan output string.
### How was this patch tested?
Unit test
Closes#29137 from allisonwang-db/aqe-plan.
Lead-authored-by: allisonwang-db <allison.wang@databricks.com>
Co-authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch caches the fetched list of files in FileStreamSource to avoid re-fetching whenever possible.
This improvement would be effective when the source options are being set to below:
* `maxFilesPerTrigger` is set
* `latestFirst` is set to `false` (default)
as
* if `maxFilesPerTrigger` is unset, Spark will process all the new files within a batch
* if `latestFirst` is set to `true`, it intends to process "latest" files which Spark has to refresh for every batch
Fetched list of files are filtered against SeenFilesMap before caching - unnecessary files are filtered in this phase. Once we cached the file, we don't check the file again for `isNewFile`, as Spark processes the files in timestamp order so cached files should have equal or later timestamp than latestTimestamp in SeenFilesMap.
Cache is only persisted in memory to simplify the logic - if we support restore cache when restarting query, we should deal with the changes of source options.
To avoid tiny set of inputs on the batch due to have tiny unread files (that could be possible when the list operation provides slightly more than the max files), this patch employs the "lower-bar" to determine whether it's helpful to retain unread files. Spark will discard unread files and do listing in the next batch if the number of unread files is lower than the specific (20% for now) ratio of max files.
This patch will have synergy with SPARK-20568 - while this patch helps to avoid redundant cost of listing, SPARK-20568 will get rid of the cost of listing for processed files. Once the query processes all files in initial load, the cost of listing for the files in initial load will be gone.
### Why are the changes needed?
Spark spends huge cost to fetch the list of files from input paths, but restricts the usage of list in a batch. If the streaming query starts from huge input data for various reasons (initial load, reprocessing, etc.) the cost to fetch the files will be applied to all batches as it is unusual to let first microbatch to process all of initial load.
SPARK-20568 will help to reduce the cost to fetch as processed files will be either deleted or moved outside of input paths, but it still won't help in early phase.
### Does this PR introduce any user-facing change?
Yes, the driver process would require more memory than before if maxFilesPerTrigger is set and latestFirst is set to "false" to cache fetched files. Previously Spark only takes some amount from left side of the list and discards remaining - so technically the peak memory would be same, but they can be freed sooner.
It may not hurt much, as peak memory is still be similar, and it would require similar amount of memory in any way when maxFilesPerTrigger is unset.
### How was this patch tested?
New unit tests. Manually tested under the test environment:
* input files
* 171,839 files distributed evenly into 24 directories
* each file contains 200 lines
* query: read from the "file stream source" and repartition to 50, and write to the "file stream sink"
* maxFilesPerTrigger is set to 100
> before applying the patch

> after applying the patch

The area of brown color represents "latestOffset" where listing operation is performed for FileStreamSource. After the patch the cost for listing is paid "only once", whereas before the patch
it was for "every batch".
Closes#27620 from HeartSaVioR/SPARK-30866.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR fixes the support for char(n)[], character(n)[] data types. Prior to this change, a user would get `Unsupported type ARRAY` exception when attempting to interact with the table with such types.
The description is a bit more detailed in the [JIRA](https://issues.apache.org/jira/browse/SPARK-32393) itself, but the crux of the issue is that postgres driver names char and character types as `bpchar`. The relevant driver code can be found [here](https://github.com/pgjdbc/pgjdbc/blob/master/pgjdbc/src/main/java/org/postgresql/jdbc/TypeInfoCache.java#L85-L87). `char` is very likely to be still needed, as it seems that pg makes a distinction between `char(1)` and `char(n > 1)` as per [this code](b7fd9f3cef/pgjdbc/src/main/java/org/postgresql/core/Oid.java (L64)).
### Why are the changes needed?
For completeness of the pg dialect support.
### Does this PR introduce _any_ user-facing change?
Yes, successful reads of tables with bpchar array instead of errors after this fix.
### How was this patch tested?
Unit tests
Closes#29192 from kujon/fix_postgres_bpchar_array_support.
Authored-by: kujon <jakub.korzeniowski@vortexa.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This is the follow-up PR of #29384 to address the cloud-fan comment: https://github.com/apache/spark/pull/29384#issuecomment-670595111
This PR re-enables `TPCDSQuerySuite` with empty tables for better test coverages.
### Why are the changes needed?
For better test coverage.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#29391 from maropu/SPARK-32564-FOLLOWUP.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR adds unique ID on QueryExecution, so that listeners can leverage the ID to deduplicate redundant calls.
### Why are the changes needed?
I've observed that Spark calls QueryExecutionListener multiple times on same QueryExecution instance (even same funcName for onSuccess). There's no unique ID on QueryExecution, hence it's a bit tricky if the listener would like to deal with same query execution only once.
Note that streaming query has both query ID and run ID which can be leveraged as unique ID.
### Does this PR introduce _any_ user-facing change?
Yes for who uses query execution listener - they'll see `id` field in QueryExecution and leverage it.
### How was this patch tested?
Manually tested. I think the change is obvious hence don't think it warrants a new UT. StreamingQueryListener has been using UUID as `queryId` and `runId` so it should work for the same.
Closes#29372 from HeartSaVioR/SPARK-32555.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
We added nested column predicate pushdown for Parquet in #27728. This patch extends the feature support to ORC.
### Why are the changes needed?
Extending the feature to ORC for feature parity. Better performance for handling nested predicate pushdown.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests.
Closes#28761 from viirya/SPARK-25557.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Disallow `FileSystem.get(Configuration conf)` in Scala style check by default and suggest developers use `FileSystem.get(URI uri, Configuration conf)` or `Path.getFileSystem()` instead.
### Why are the changes needed?
The method `FileSystem.get(Configuration conf)` will return a default FileSystem instance if the conf `fs.file.impl` is not set. This can cause file not found exception on reading a target path of non-default file system, e.g. S3. It is hard to discover such a mistake via unit tests.
If we disallow it in Scala style check by default and suggest developers use `FileSystem.get(URI uri, Configuration conf)` or `Path.getFileSystem(Configuration conf)`, we can reduce potential regression and PR review effort.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually run scala style check and test.
Closes#29357 from gengliangwang/newStyleRule.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
PR #26548 means that RecordBinaryComparator now uses big endian
byte order for long comparisons. However, this means that some of
the constants in the regression tests no longer map to the same
values in the comparison that they used to.
For example, one of the tests does a comparison between
Long.MIN_VALUE and 1 in order to trigger an overflow condition that
existed in the past (i.e. Long.MIN_VALUE - 1). These constants
correspond to the values 0x80..00 and 0x00..01. However on a
little-endian machine the bytes in these values are now swapped
before they are compared. This means that we will now be comparing
0x00..80 with 0x01..00. 0x00..80 - 0x01..00 does not overflow
therefore missing the original purpose of the test.
To fix this the constants are now explicitly written out in big
endian byte order to match the byte order used in the comparison.
This also fixes the tests on big endian machines (which would
otherwise get a different comparison result to the little-endian
machines).
### Why are the changes needed?
The regression tests no longer serve their initial purposes and also fail on big-endian systems.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Tests run on big-endian system (s390x).
Closes#29259 from mundaym/fix-endian.
Authored-by: Michael Munday <mike.munday@ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Implement ALTER TABLE in JDBC Table Catalog
The following ALTER TABLE are implemented:
```
ALTER TABLE table_name ADD COLUMNS ( column_name datatype [ , ... ] );
ALTER TABLE table_name RENAME COLUMN old_column_name TO new_column_name;
ALTER TABLE table_name DROP COLUMN column_name;
ALTER TABLE table_name ALTER COLUMN column_name TYPE new_type;
ALTER TABLE table_name ALTER COLUMN column_name SET NOT NULL;
```
I haven't checked ALTER TABLE syntax for all the databases yet. I will check. If there are different syntax, I will have a follow-up to override the dialect.
Seems most of the databases don't support updating comments and column position, so I didn't implement UpdateColumnComment and UpdateColumnPosition.
### Why are the changes needed?
Complete the JDBCTableCatalog implementation
### Does this PR introduce _any_ user-facing change?
Yes
`JDBCTableCatalog.alterTable`
### How was this patch tested?
add new tests
Closes#29324 from huaxingao/alter_table.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Change casting of map and struct values to strings by using the `{}` brackets instead of `[]`. The behavior is controlled by the SQL config `spark.sql.legacy.castComplexTypesToString.enabled`. When it is `true`, `CAST` wraps maps and structs by `[]` in casting to strings. Otherwise, if this is `false`, which is the default, maps and structs are wrapped by `{}`.
### Why are the changes needed?
- To distinguish structs/maps from arrays.
- To make `show`'s output consistent with Hive and conversions to Hive strings.
- To display dataframe content in the same form by `spark-sql` and `show`
- To be consistent with the `*.sql` tests
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
By existing test suite `CastSuite`.
Closes#29308 from MaxGekk/show-struct-map.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Make WithFields Expression not foldable.
### Why are the changes needed?
The following query currently fails on master brach:
```
sql("SELECT named_struct('a', 1, 'b', 2) a")
.select($"a".withField("c", lit(3)).as("a"))
.show(false)
// java.lang.UnsupportedOperationException: Cannot evaluate expression: with_fields(named_struct(a, 1, b, 2), c, 3)
```
This happens because the Catalyst optimizer sees that the WithFields Expression is foldable and tries to statically evaluate the WithFields Expression (via the ConstantFolding rule), however it cannot do so because WithFields Expression is Unevaluable.
### Does this PR introduce _any_ user-facing change?
Yes, queries like the one shared above will now succeed.
That said, this bug was introduced in Spark 3.1.0 which has yet to be released.
### How was this patch tested?
A new unit test was added.
Closes#29338 from fqaiser94/SPARK-32521.
Lead-authored-by: fqaiser94@gmail.com <fqaiser94@gmail.com>
Co-authored-by: fqaiser94 <fqaiser94@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to clean up `InMemoryRelation.ser` in `CachedBatchSerializerSuite`.
### Why are the changes needed?
SPARK-32274 makes SQL cache serialization pluggable.
```
[SPARK-32274][SQL] Make SQL cache serialization pluggable
```
This causes UT failures.
```
$ build/sbt "sql/testOnly *.CachedBatchSerializerSuite *.CachedTableSuite"
...
[info] Cause: java.lang.IllegalStateException: This does not work. This is only for testing
[info] at org.apache.spark.sql.execution.columnar.TestSingleIntColumnarCachedBatchSerializer.convertInternalRowToCachedBatch(CachedBatchSerializerSuite.scala:49)
...
[info] *** 30 TESTS FAILED ***
[error] Failed: Total 51, Failed 30, Errors 0, Passed 21
[error] Failed tests:
[error] org.apache.spark.sql.CachedTableSuite
[error] (sql/test:testOnly) sbt.TestsFailedException: Tests unsuccessful
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually.
```
$ build/sbt "sql/testOnly *.CachedBatchSerializerSuite *.CachedTableSuite"
[info] Tests: succeeded 51, failed 0, canceled 0, ignored 0, pending 0
[info] All tests passed.
[info] Passed: Total 51, Failed 0, Errors 0, Passed 51
```
Closes#29346 from dongjoon-hyun/SPARK-32524-3.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR is related to https://github.com/apache/spark/pull/26656.
https://github.com/apache/spark/pull/26656 only support use FILTER clause on aggregate expression without DISTINCT.
This PR will enhance this feature when one or more DISTINCT aggregate expressions which allows the use of the FILTER clause.
Such as:
```
select sum(distinct id) filter (where sex = 'man') from student;
select class_id, sum(distinct id) filter (where sex = 'man') from student group by class_id;
select count(id) filter (where class_id = 1), sum(distinct id) filter (where sex = 'man') from student;
select class_id, count(id) filter (where class_id = 1), sum(distinct id) filter (where sex = 'man') from student group by class_id;
select sum(distinct id), sum(distinct id) filter (where sex = 'man') from student;
select class_id, sum(distinct id), sum(distinct id) filter (where sex = 'man') from student group by class_id;
select class_id, count(id), count(id) filter (where class_id = 1), sum(distinct id), sum(distinct id) filter (where sex = 'man') from student group by class_id;
```
### Why are the changes needed?
Spark SQL only support use FILTER clause on aggregate expression without DISTINCT.
This PR support Filter expression allows simultaneous use of DISTINCT
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
Exists and new UT
Closes#29291 from beliefer/support-distinct-with-filter.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: beliefer <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}