### What changes were proposed in this pull request?
Rephrase the description for some operations to make it clearer.
### Why are the changes needed?
Add more detail in the document.
### Does this PR introduce _any_ user-facing change?
No, document only.
### How was this patch tested?
Document only.
Closes#29269 from xuanyuanking/SPARK-31792-follow.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
## What changes were proposed in this pull request?
This fixed SPARK-32672 a data corruption. Essentially the BooleanBitSet CompressionScheme would miss nulls at the end of a CompressedBatch. The values would then default to false.
### Why are the changes needed?
It fixes data corruption
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
I manually tested it against the original issue that was producing errors for me. I also added in a unit test.
Closes#29506 from revans2/SPARK-32672.
Authored-by: Robert (Bobby) Evans <bobby@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Fix typo for docs, log messages and comments
### Why are the changes needed?
typo fix to increase readability
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
manual test has been performed to test the updated
Closes#29443 from brandonJY/spell-fix-doc.
Authored-by: Brandon Jiang <Brandon.jiang.a@outlook.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR proposes to fix ORC predicate pushdown under case-insensitive analysis case. The field names in pushed down predicates don't need to match in exact letter case with physical field names in ORC files, if we enable case-insensitive analysis.
### Why are the changes needed?
Currently ORC predicate pushdown doesn't work with case-insensitive analysis. A predicate "a < 0" cannot pushdown to ORC file with field name "A" under case-insensitive analysis.
But Parquet predicate pushdown works with this case. We should make ORC predicate pushdown work with case-insensitive analysis too.
### Does this PR introduce _any_ user-facing change?
Yes, after this PR, under case-insensitive analysis, ORC predicate pushdown will work.
### How was this patch tested?
Unit tests.
Closes#29457 from viirya/fix-orc-pushdown.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Hive no serde mode when column less then output specified column, it will pad null value to it, spark should do this also.
```
hive> SELECT TRANSFORM(a, b)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '|'
> LINES TERMINATED BY '\n'
> NULL DEFINED AS 'NULL'
> USING 'cat' as (a string, b string, c string, d string)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '|'
> LINES TERMINATED BY '\n'
> NULL DEFINED AS 'NULL'
> FROM (
> select 1 as a, 2 as b
> ) tmp ;
OK
1 2 NULL NULL
Time taken: 24.626 seconds, Fetched: 1 row(s)
```
### Why are the changes needed?
Keep save behavior with hive data.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#29500 from AngersZhuuuu/SPARK-32667.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR reverts https://github.com/apache/spark/pull/27860 to downgrade Janino, as the new version has a bug.
### Why are the changes needed?
The symptom is about NaN comparison. For code below
```
if (double_value <= 0.0) {
...
} else {
...
}
```
If `double_value` is NaN, `NaN <= 0.0` is false and we should go to the else branch. However, current Spark goes to the if branch and causes correctness issues like SPARK-32640.
One way to fix it is:
```
boolean cond = double_value <= 0.0;
if (cond) {
...
} else {
...
}
```
I'm not familiar with Janino so I don't know what's going on there.
### Does this PR introduce _any_ user-facing change?
Yes, fix correctness bugs.
### How was this patch tested?
a new test
Closes#29495 from cloud-fan/revert.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/29469
Instead of passing the physical plan to the fallbacked v1 source directly and skipping analysis, optimization, planning altogether, this PR proposes to pass the optimized plan.
### Why are the changes needed?
It's a bit risky to pass the physical plan directly. When the fallbacked v1 source applies more operations to the input DataFrame, it will re-apply the post-planning physical rules like `CollapseCodegenStages`, `InsertAdaptiveSparkPlan`, etc., which is very tricky.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existing test suite with some new tests
Closes#29489 from cloud-fan/follow.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In case that a last `SQLQueryTestSuite` test run is killed, it will fail in a next run because of a following reason:
```
[info] org.apache.spark.sql.SQLQueryTestSuite *** ABORTED *** (17 seconds, 483 milliseconds)
[info] org.apache.spark.sql.AnalysisException: Can not create the managed table('`testdata`'). The associated location('file:/Users/maropu/Repositories/spark/spark-master/sql/core/spark-warehouse/org.apache.spark.sql.SQLQueryTestSuite/testdata') already exists.;
[info] at org.apache.spark.sql.catalyst.catalog.SessionCatalog.validateTableLocation(SessionCatalog.scala:355)
[info] at org.apache.spark.sql.execution.command.CreateDataSourceTableAsSelectCommand.run(createDataSourceTables.scala:170)
[info] at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:108)
```
This PR intends to add code to deletes orphan directories under a warehouse dir in `SQLQueryTestSuite` before creating test tables.
### Why are the changes needed?
To improve test convenience
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually checked
Closes#29488 from maropu/DeleteDirs.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Scrip Transform no-serde (`ROW FORMAT DELIMITED`) mode `LINE TERMINNATED BY `
only support `\n`.
Tested in hive :
Hive 1.1
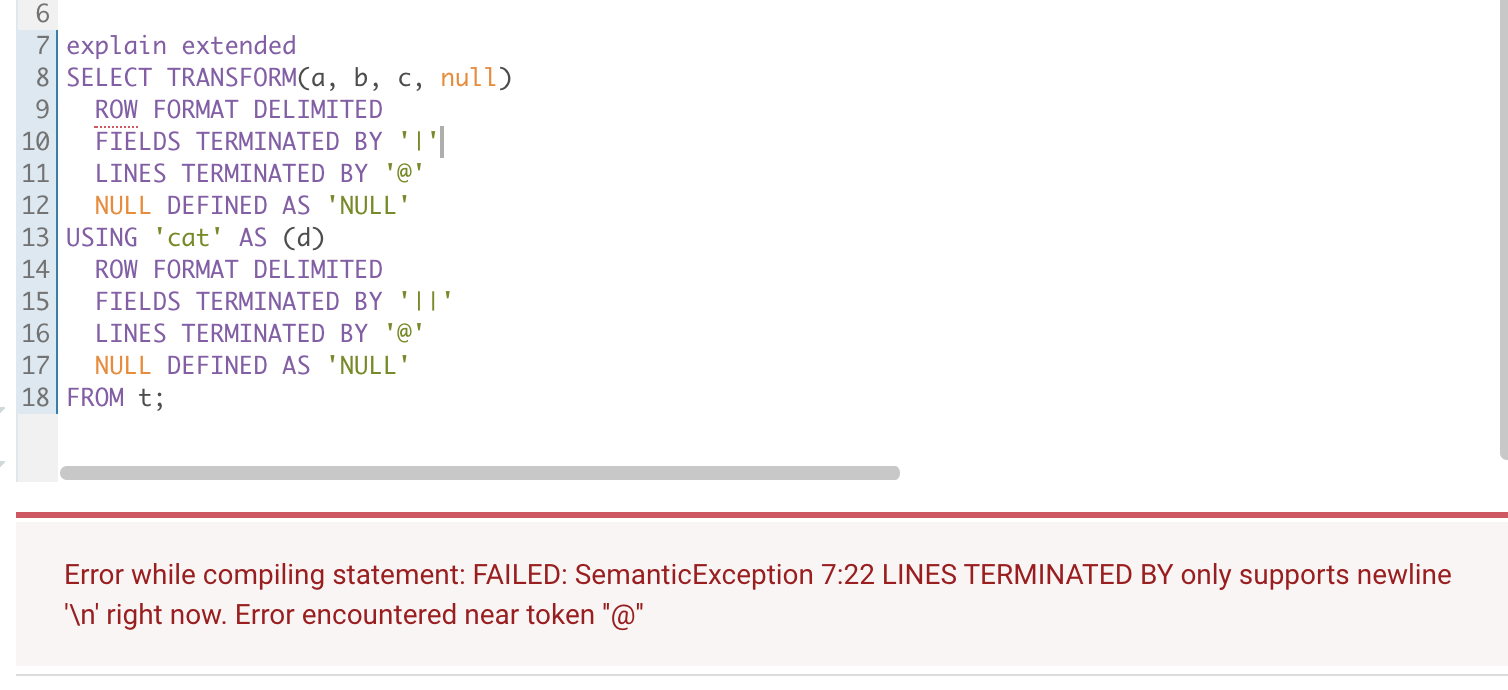
Hive 2.3.7
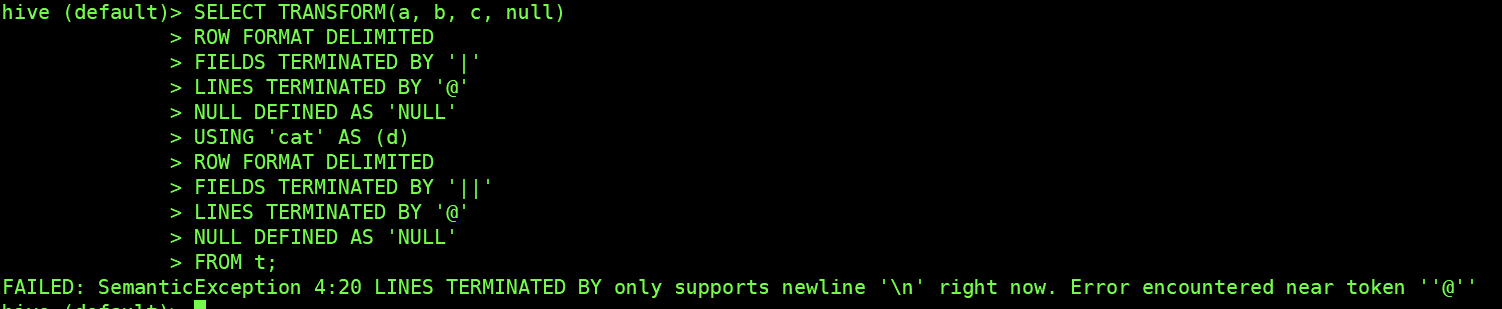
### Why are the changes needed?
Strictly limit the use method to ensure the accuracy of data
### Does this PR introduce _any_ user-facing change?
User use Scrip Transform no-serde (ROW FORMAT DELIMITED) mode with `LINE TERMINNATED BY `
not equal `'\n'`. will throw error
### How was this patch tested?
Added UT
Closes#29438 from AngersZhuuuu/SPARK-32607.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In many operations on CompactibleFileStreamLog reads a metadata log file and materializes all entries into memory. As the nature of the compact operation, CompactibleFileStreamLog may have a huge compact log file with bunch of entries included, and for now they're just monotonically increasing, which means the amount of memory to materialize also grows incrementally. This leads pressure on GC.
This patch proposes to streamline the logic on file stream source and sink whenever possible to avoid memory issue. To make this possible we have to break the existing behavior of excluding entries - now the `compactLogs` method is called with all entries, which forces us to materialize all entries into memory. This is hopefully no effect on end users, because only file stream sink has a condition to exclude entries, and the condition has been never true. (DELETE_ACTION has been never set.)
Based on the observation, this patch also changes the existing UT a bit which simulates the situation where "A" file is added, and another batch marks the "A" file as deleted. This situation simply doesn't work with the change, but as I mentioned earlier it hasn't been used. (I'm not sure the UT is from the actual run. I guess not.)
### Why are the changes needed?
The memory issue (OOME) is reported by both JIRA issue and user mailing list.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
* Existing UTs
* Manual test done
The manual test leverages the simple apps which continuously writes the file stream sink metadata log.
bea7680e4c
The test is configured to have a batch metadata log file at 1.9M (10,000 entries) whereas other Spark configuration is set to the default. (compact interval = 10) The app runs as driver, and the heap memory on driver is set to 3g.
> before the patch
<img width="1094" alt="Screen Shot 2020-06-23 at 3 37 44 PM" src="https://user-images.githubusercontent.com/1317309/85375841-d94f3480-b571-11ea-817b-c6b48b34888a.png">
It only ran for 40 mins, with the latest compact batch file size as 1.3G. The process struggled with GC, and after some struggling, it threw OOME.
> after the patch
<img width="1094" alt="Screen Shot 2020-06-23 at 3 53 29 PM" src="https://user-images.githubusercontent.com/1317309/85375901-eff58b80-b571-11ea-837e-30d107f677f9.png">
It sustained 2 hours run (manually stopped as it's expected to run more), with the latest compact batch file size as 2.2G. The actual memory usage didn't even go up to 1.2G, and be cleaned up soon without outstanding GC activity.
Closes#28904 from HeartSaVioR/SPARK-30462.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Address the [#comment](https://github.com/apache/spark/pull/28840#discussion_r471172006).
### Why are the changes needed?
Make code robust.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
ut.
Closes#29453 from ulysses-you/SPARK-31999-FOLLOWUP.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR introduces a LogicalNode AlreadyPlanned, and related physical plan and preparation rule.
With the DataSourceV2 write operations, we have a way to fallback to the V1 writer APIs using InsertableRelation. The gross part is that we're in physical land, but the InsertableRelation takes a logical plan, so we have to pass the logical plans to these physical nodes, and then potentially go through re-planning. This re-planning can cause issues for an already optimized plan.
A useful primitive could be specifying that a plan is ready for execution through a logical node AlreadyPlanned. This would wrap a physical plan, and then we can go straight to execution.
### Why are the changes needed?
To avoid having a physical plan that is disconnected from the physical plan that is being executed in V1WriteFallback execution. When a physical plan node executes a logical plan, the inner query is not connected to the running physical plan. The physical plan that actually runs is not visible through the Spark UI and its metrics are not exposed. In some cases, the EXPLAIN plan doesn't show it.
### Does this PR introduce _any_ user-facing change?
Nope
### How was this patch tested?
V1FallbackWriterSuite tests that writes still work
Closes#29469 from brkyvz/alreadyAnalyzed2.
Lead-authored-by: Burak Yavuz <brkyvz@gmail.com>
Co-authored-by: Burak Yavuz <burak@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When CSV/JSON datasources infer schema (e.g, `def inferSchema(files: Seq[FileStatus])`, they use the `files` along with the original options. `files` in `inferSchema` could have been deduced from the "path" option if the option was present, so this can cause issues (e.g., reading more data, listing the path again) since the "path" option is **added** to the `files`.
### Why are the changes needed?
The current behavior can cause the following issue:
```scala
class TestFileFilter extends PathFilter {
override def accept(path: Path): Boolean = path.getParent.getName != "p=2"
}
val path = "/tmp"
val df = spark.range(2)
df.write.json(path + "/p=1")
df.write.json(path + "/p=2")
val extraOptions = Map(
"mapred.input.pathFilter.class" -> classOf[TestFileFilter].getName,
"mapreduce.input.pathFilter.class" -> classOf[TestFileFilter].getName
)
// This works fine.
assert(spark.read.options(extraOptions).json(path).count == 2)
// The following with "path" option fails with the following:
// assertion failed: Conflicting directory structures detected. Suspicious paths
// file:/tmp
// file:/tmp/p=1
assert(spark.read.options(extraOptions).format("json").option("path", path).load.count() === 2)
```
### Does this PR introduce _any_ user-facing change?
Yes, the above failure doesn't happen and you get the consistent experience when you use `spark.read.csv(path)` or `spark.read.format("csv").option("path", path).load`.
### How was this patch tested?
Updated existing tests.
Closes#29437 from imback82/path_bug.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For SQL
```
SELECT TRANSFORM(a, b, c)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
NULL DEFINED AS 'null'
USING 'cat' AS (a, b, c)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
NULL DEFINED AS 'NULL'
FROM testData
```
The correct
TOK_TABLEROWFORMATFIELD should be `, `nut actually ` ','`
TOK_TABLEROWFORMATLINES should be `\n` but actually` '\n'`
### Why are the changes needed?
Fix string value format
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#29428 from AngersZhuuuu/SPARK-32608.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Update `ObjectSerializerPruning.alignNullTypeInIf`, to consider the isNull check generated in `RowEncoder`, which is `Invoke(inputObject, "isNullAt", BooleanType, Literal(index) :: Nil)`.
### Why are the changes needed?
Query fails if we don't fix this bug, due to type mismatch in `If`.
### Does this PR introduce _any_ user-facing change?
Yes, the failed query can run after this fix.
### How was this patch tested?
new tests
Closes#29467 from cloud-fan/bug.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
During working on SPARK-25557, we found that ORC predicate pushdown doesn't have case-sensitivity test. This PR proposes to add case-sensitivity test for ORC predicate pushdown.
### Why are the changes needed?
Increasing test coverage for ORC predicate pushdown.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass Jenkins tests.
Closes#29427 from viirya/SPARK-25557-followup3.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Found java.util.NoSuchElementException in UT log of AdaptiveQueryExecSuite. During AQE, when sub-plan changed, LiveExecutionData is using the new sub-plan SQLMetrics to override the old ones, But in the final aggregateMetrics, since the plan was updated, the old metrics will throw NoSuchElementException when it try to match with the new metricTypes. To sum up, we need to filter out those outdated metrics to avoid throwing java.util.NoSuchElementException, which cause SparkUI SQL Tab abnormally rendered.
### Why are the changes needed?
SQL Metrics is not correct for some AQE cases, and it break SparkUI SQL Tab when it comes to NAAJ rewritten to LocalRelation case.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
* Added case in SQLAppStatusListenerSuite.
* Run AdaptiveQueryExecSuite with no "java.util.NoSuchElementException".
* Validation on Spark Web UI
Closes#29431 from leanken/leanken-SPARK-32615.
Authored-by: xuewei.linxuewei <xuewei.linxuewei@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to detect possible regression inside `SparkPlan`. To achieve this goal, this PR added a base test suite called `PlanStabilitySuite`. The basic workflow of this test suite is similar to `SQLQueryTestSuite`. It also uses `SPARK_GENERATE_GOLDEN_FILES` to decide whether it should regenerate the golden files or compare to the golden result for each input query. The difference is, `PlanStabilitySuite` uses the serialized explain result(.txt format) of the `SparkPlan` as the output of a query, instead of the data result.
And since `SparkPlan` is non-deterministic for various reasons, e.g., expressions ids changes, expression order changes, we'd reduce the plan to a simplified version that only contains node names and references. And we only identify those important nodes, e.g., `Exchange`, `SubqueryExec`, in the simplified plan.
And we'd reuse TPC-DS queries(v1.4, v2.7, modified) to test plans' stability. Currently, one TPC-DS query can only have one corresponding simplified golden plan.
This PR also did a few refactor, which extracts `TPCDSBase` from `TPCDSQuerySuite`. So, `PlanStabilitySuite` can use the TPC-DS queries as well.
### Why are the changes needed?
Nowadays, Spark is getting more and more complex. Any changes might cause regression unintentionally. Spark already has some benchmark to catch the performance regression. But, yet, it doesn't have a way to detect the regression inside `SparkPlan`. It would be good if we could detect the possible regression early during the compile phase before the runtime phase.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added `PlanStabilitySuite` and it's subclasses.
Closes#29270 from Ngone51/plan-stable.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add support for full outer join inside shuffled hash join. Currently if the query is a full outer join, we only use sort merge join as the physical operator. However it can be CPU and IO intensive in case input table is large for sort merge join. Shuffled hash join on the other hand saves the sort CPU and IO compared to sort merge join, especially when table is large.
This PR implements the full outer join as followed:
* Process rows from stream side by looking up hash relation, and mark the matched rows from build side by:
* for joining with unique key, a `BitSet` is used to record matched rows from build side (`key index` to represent each row)
* for joining with non-unique key, a `HashSet[Long]` is used to record matched rows from build side (`key index` + `value index` to represent each row).
`key index` is defined as the index into key addressing array `longArray` in `BytesToBytesMap`.
`value index` is defined as the iterator index of values for same key.
* Process rows from build side by iterating hash relation, and filter out rows from build side being looked up already (done in `ShuffledHashJoinExec.fullOuterJoin`)
For context, this PR was originally implemented as followed (up to commit e3322766d4):
1. Construct hash relation from build side, with extra boolean value at the end of row to track look up information (done in `ShuffledHashJoinExec.buildHashedRelation` and `UnsafeHashedRelation.apply`).
2. Process rows from stream side by looking up hash relation, and mark the matched rows from build side be looked up (done in `ShuffledHashJoinExec.fullOuterJoin`).
3. Process rows from build side by iterating hash relation, and filter out rows from build side being looked up already (done in `ShuffledHashJoinExec.fullOuterJoin`).
See discussion of pros and cons between these two approaches [here](https://github.com/apache/spark/pull/29342#issuecomment-672275450), [here](https://github.com/apache/spark/pull/29342#issuecomment-672288194) and [here](https://github.com/apache/spark/pull/29342#issuecomment-672640531).
TODO: codegen for full outer shuffled hash join can be implemented in another followup PR.
### Why are the changes needed?
As implementation in this PR, full outer shuffled hash join will have overhead to iterate build side twice (once for building hash map, and another for outputting non-matching rows), and iterate stream side once. However, full outer sort merge join needs to iterate both sides twice, and sort the large table can be more CPU and IO intensive. So full outer shuffled hash join can be more efficient than sort merge join when stream side is much more larger than build side.
For example query below, full outer SHJ saved 30% wall clock time compared to full outer SMJ.
```
def shuffleHashJoin(): Unit = {
val N: Long = 4 << 22
withSQLConf(
SQLConf.SHUFFLE_PARTITIONS.key -> "2",
SQLConf.AUTO_BROADCASTJOIN_THRESHOLD.key -> "20000000") {
codegenBenchmark("shuffle hash join", N) {
val df1 = spark.range(N).selectExpr(s"cast(id as string) as k1")
val df2 = spark.range(N / 10).selectExpr(s"cast(id * 10 as string) as k2")
val df = df1.join(df2, col("k1") === col("k2"), "full_outer")
df.noop()
}
}
}
```
```
Running benchmark: shuffle hash join
Running case: shuffle hash join off
Stopped after 2 iterations, 16602 ms
Running case: shuffle hash join on
Stopped after 5 iterations, 31911 ms
Java HotSpot(TM) 64-Bit Server VM 1.8.0_181-b13 on Mac OS X 10.15.4
Intel(R) Core(TM) i9-9980HK CPU 2.40GHz
shuffle hash join: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
shuffle hash join off 7900 8301 567 2.1 470.9 1.0X
shuffle hash join on 6250 6382 95 2.7 372.5 1.3X
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit test in `JoinSuite.scala`, `AbstractBytesToBytesMapSuite.java` and `HashedRelationSuite.scala`.
Closes#29342 from c21/full-outer-shj.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
In the docs concerning the approx_count_distinct I have changed the description of the rsd parameter from **_maximum estimation error allowed_** to _**maximum relative standard deviation allowed**_
### Why are the changes needed?
Maximum estimation error allowed can be misleading. You can set the target relative standard deviation, which affects the estimation error, but on given runs the estimation error can still be above the rsd parameter.
### Does this PR introduce _any_ user-facing change?
This PR should make it easier for users reading the docs to understand that the rsd parameter in approx_count_distinct doesn't cap the estimation error, but just sets the target deviation instead,
### How was this patch tested?
No tests, as no code changes were made.
Closes#29424 from Comonut/fix-approx_count_distinct-rsd-param-description.
Authored-by: alexander-daskalov <alexander.daskalov@adevinta.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Remove `fullOutput` from `RowDataSourceScanExec`
### Why are the changes needed?
`RowDataSourceScanExec` requires the full output instead of the scan output after column pruning. However, in v2 code path, we don't have the full output anymore so we just pass the pruned output. `RowDataSourceScanExec.fullOutput` is actually meaningless so we should remove it.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existing tests
Closes#29415 from huaxingao/rm_full_output.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Discussion with [comment](https://github.com/apache/spark/pull/29244#issuecomment-671746329).
Add `HiveVoidType` class in `HiveClientImpl` then we can replace `NullType` to `HiveVoidType` before we call hive client.
### Why are the changes needed?
Better compatible with hive.
More details in [#29244](https://github.com/apache/spark/pull/29244).
### Does this PR introduce _any_ user-facing change?
Yes, user can create view with null type in Hive.
### How was this patch tested?
New test.
Closes#29423 from ulysses-you/add-HiveVoidType.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Added a new `dropFields` method to the `Column` class.
This method should allow users to drop a `StructField` in a `StructType` column (with similar semantics to the `drop` method on `Dataset`).
### Why are the changes needed?
Often Spark users have to work with deeply nested data e.g. to fix a data quality issue with an existing `StructField`. To do this with the existing Spark APIs, users have to rebuild the entire struct column.
For example, let's say you have the following deeply nested data structure which has a data quality issue (`5` is missing):
```
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
val data = spark.createDataFrame(sc.parallelize(
Seq(Row(Row(Row(1, 2, 3), Row(Row(4, null, 6), Row(7, 8, 9), Row(10, 11, 12)), Row(13, 14, 15))))),
StructType(Seq(
StructField("a", StructType(Seq(
StructField("a", StructType(Seq(
StructField("a", IntegerType),
StructField("b", IntegerType),
StructField("c", IntegerType)))),
StructField("b", StructType(Seq(
StructField("a", StructType(Seq(
StructField("a", IntegerType),
StructField("b", IntegerType),
StructField("c", IntegerType)))),
StructField("b", StructType(Seq(
StructField("a", IntegerType),
StructField("b", IntegerType),
StructField("c", IntegerType)))),
StructField("c", StructType(Seq(
StructField("a", IntegerType),
StructField("b", IntegerType),
StructField("c", IntegerType))))
))),
StructField("c", StructType(Seq(
StructField("a", IntegerType),
StructField("b", IntegerType),
StructField("c", IntegerType))))
)))))).cache
data.show(false)
+---------------------------------+
|a |
+---------------------------------+
|[[1, 2, 3], [[4,, 6], [7, 8, 9]]]|
+---------------------------------+
```
Currently, to drop the missing value users would have to do something like this:
```
val result = data.withColumn("a",
struct(
$"a.a",
struct(
struct(
$"a.b.a.a",
$"a.b.a.c"
).as("a"),
$"a.b.b",
$"a.b.c"
).as("b"),
$"a.c"
))
result.show(false)
+---------------------------------------------------------------+
|a |
+---------------------------------------------------------------+
|[[1, 2, 3], [[4, 6], [7, 8, 9], [10, 11, 12]], [13, 14, 15]]|
+---------------------------------------------------------------+
```
As you can see above, with the existing methods users must call the `struct` function and list all fields, including fields they don't want to change. This is not ideal as:
>this leads to complex, fragile code that cannot survive schema evolution.
[SPARK-16483](https://issues.apache.org/jira/browse/SPARK-16483)
In contrast, with the method added in this PR, a user could simply do something like this to get the same result:
```
val result = data.withColumn("a", 'a.dropFields("b.a.b"))
result.show(false)
+---------------------------------------------------------------+
|a |
+---------------------------------------------------------------+
|[[1, 2, 3], [[4, 6], [7, 8, 9], [10, 11, 12]], [13, 14, 15]]|
+---------------------------------------------------------------+
```
This is the second of maybe 3 methods that could be added to the `Column` class to make it easier to manipulate nested data.
Other methods under discussion in [SPARK-22231](https://issues.apache.org/jira/browse/SPARK-22231) include `withFieldRenamed`.
However, this should be added in a separate PR.
### Does this PR introduce _any_ user-facing change?
Only one minor change. If the user submits the following query:
```
df.withColumn("a", $"a".withField(null, null))
```
instead of throwing:
```
java.lang.IllegalArgumentException: requirement failed: fieldName cannot be null
```
it will now throw:
```
java.lang.IllegalArgumentException: requirement failed: col cannot be null
```
I don't believe its should be an issue to change this because:
- neither message is incorrect
- Spark 3.1.0 has yet to be released
but please feel free to correct me if I am wrong.
### How was this patch tested?
New unit tests were added. Jenkins must pass them.
### Related JIRAs:
More discussion on this topic can be found here:
- https://issues.apache.org/jira/browse/SPARK-22231
- https://issues.apache.org/jira/browse/SPARK-16483Closes#29322 from fqaiser94/SPARK-32511.
Lead-authored-by: fqaiser94@gmail.com <fqaiser94@gmail.com>
Co-authored-by: fqaiser94 <fqaiser94@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Update URL of the parquet project in code comment.
### Why are the changes needed?
The original url is not available.
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
No test needed.
Closes#29416 from izchen/Update-Parquet-URL.
Authored-by: Chen Zhang <izchen@126.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
We support partially push partition filters since SPARK-28169. We can also support partially push down data filters if it mixed in partition filters and data filters. For example:
```
spark.sql(
s"""
|CREATE TABLE t(i INT, p STRING)
|USING parquet
|PARTITIONED BY (p)""".stripMargin)
spark.range(0, 1000).selectExpr("id as col").createOrReplaceTempView("temp")
for (part <- Seq(1, 2, 3, 4)) {
sql(s"""
|INSERT OVERWRITE TABLE t PARTITION (p='$part')
|SELECT col FROM temp""".stripMargin)
}
spark.sql("SELECT * FROM t WHERE WHERE (p = '1' AND i = 1) OR (p = '2' and i = 2)").explain()
```
We can also push down ```i = 1 or i = 2 ```
### Why are the changes needed?
Extract more data filter to FileSourceScanExec
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
Added UT
Closes#29406 from AngersZhuuuu/SPARK-32352.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes the issue introduced during SPARK-26985.
SPARK-26985 changes the `putDoubles()` and `putFloats()` methods to respect the platform's endian-ness. However, that causes the RLE paths in VectorizedRleValuesReader.java to read the RLE entries in parquet as BIG_ENDIAN on big endian platforms (i.e., as is), even though parquet data is always in little endian format.
The comments in `WriteableColumnVector.java` say those methods are used for "ieee formatted doubles in platform native endian" (or floats), but since the data in parquet is always in little endian format, use of those methods appears to be inappropriate.
To demonstrate the problem with spark-shell:
```scala
import org.apache.spark._
import org.apache.spark.sql._
import org.apache.spark.sql.types._
var data = Seq(
(1.0, 0.1),
(2.0, 0.2),
(0.3, 3.0),
(4.0, 4.0),
(5.0, 5.0))
var df = spark.createDataFrame(data).write.mode(SaveMode.Overwrite).parquet("/tmp/data.parquet2")
var df2 = spark.read.parquet("/tmp/data.parquet2")
df2.show()
```
result:
```scala
+--------------------+--------------------+
| _1| _2|
+--------------------+--------------------+
| 3.16E-322|-1.54234871366845...|
| 2.0553E-320| 2.0553E-320|
| 2.561E-320| 2.561E-320|
|4.66726145843124E-62| 1.0435E-320|
| 3.03865E-319|-1.54234871366757...|
+--------------------+--------------------+
```
Also tests in ParquetIOSuite that involve float/double data would fail, e.g.,
- basic data types (without binary)
- read raw Parquet file
/examples/src/main/python/mllib/isotonic_regression_example.py would fail as well.
Purposed code change is to add `putDoublesLittleEndian()` and `putFloatsLittleEndian()` methods for parquet to invoke, just like the existing `putIntsLittleEndian()` and `putLongsLittleEndian()`. On little endian platforms they would call `putDoubles()` and `putFloats()`, on big endian they would read the entries as little endian like pre-SPARK-26985.
No new unit-test is introduced as the existing ones are actually sufficient.
### Why are the changes needed?
RLE float/double data in parquet files will not be read back correctly on big endian platforms.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
All unit tests (mvn test) were ran and OK.
Closes#29383 from tinhto-000/SPARK-31703.
Authored-by: Tin Hang To <tinto@us.ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Extract common test case (no serde) to BasicScriptTransformationExecSuite
2. Add more test case for no serde mode about supported data type and behavior in `BasicScriptTransformationExecSuite`
3. Add more test case for hive serde mode about supported type and behavior in `HiveScriptTransformationExecSuite`
### Why are the changes needed?
Improve test coverage of Script Transformation
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
Added UT
Closes#29401 from AngersZhuuuu/SPARK-32400.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Fix `DaysWritable` by overriding parent's method `def get(doesTimeMatter: Boolean): Date` from `DateWritable` instead of `Date get()` because the former one uses the first one. The bug occurs because `HiveOutputWriter.write()` call `def get(doesTimeMatter: Boolean): Date` transitively with default implementation from the parent class `DateWritable` which doesn't respect date rebases and uses not initialized `daysSinceEpoch` (0 which `1970-01-01`).
### Why are the changes needed?
The changes fix the bug:
```sql
spark-sql> CREATE TABLE table1 (d date);
spark-sql> INSERT INTO table1 VALUES (date '2020-08-11');
spark-sql> SELECT * FROM table1;
1970-01-01
```
The expected result of the last SQL statement must be **2020-08-11** but got **1970-01-01**.
### Does this PR introduce _any_ user-facing change?
Yes. After the fix, `INSERT` work correctly:
```sql
spark-sql> SELECT * FROM table1;
2020-08-11
```
### How was this patch tested?
Add new test to `HiveSerDeReadWriteSuite`
Closes#29409 from MaxGekk/insert-date-into-hive-table.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In [SPARK-32290](https://issues.apache.org/jira/browse/SPARK-32290), we introduced several new types of HashedRelation.
* EmptyHashedRelation
* EmptyHashedRelationWithAllNullKeys
They were all limited to used only in NAAJ scenario. These new HashedRelation could be applied to other scenario for performance improvements.
* EmptyHashedRelation could also be used in Normal AntiJoin for fast stop
* While AQE is on and buildSide is EmptyHashedRelationWithAllNullKeys, can convert NAAJ to a Empty LocalRelation to skip meaningless data iteration since in Single-Key NAAJ, if null key exists in BuildSide, will drop all records in streamedSide.
This Patch including two changes.
* using EmptyHashedRelation to do fast stop for common anti join as well
* In AQE, eliminate BroadcastHashJoin(NAAJ) if buildSide is a EmptyHashedRelationWithAllNullKeys
### Why are the changes needed?
LeftAntiJoin could apply `fast stop` when BuildSide is EmptyHashedRelation, While within AQE with EmptyHashedRelationWithAllNullKeys, we can eliminate the NAAJ. This should be a performance improvement in AntiJoin.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
* added case in AdaptiveQueryExecSuite.
* added case in HashedRelationSuite.
* Make sure SubquerySuite JoinSuite SQLQueryTestSuite passed.
Closes#29389 from leanken/leanken-SPARK-32573.
Authored-by: xuewei.linxuewei <xuewei.linxuewei@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR added a physical rule to remove redundant project nodes. A `ProjectExec` is redundant when
1. It has the same output attributes and order as its child's output when ordering of these attributes is required.
2. It has the same output attributes as its child's output when attribute output ordering is not required.
For example:
After Filter:
```
== Physical Plan ==
*(1) Project [a#14L, b#15L, c#16, key#17]
+- *(1) Filter (isnotnull(a#14L) AND (a#14L > 5))
+- *(1) ColumnarToRow
+- FileScan parquet [a#14L,b#15L,c#16,key#17]
```
The `Project a#14L, b#15L, c#16, key#17` is redundant because its output is exactly the same as filter's output.
Before Aggregate:
```
== Physical Plan ==
*(2) HashAggregate(keys=[key#17], functions=[sum(a#14L), last(b#15L, false)], output=[sum_a#39L, key#17, last_b#41L])
+- Exchange hashpartitioning(key#17, 5), true, [id=#77]
+- *(1) HashAggregate(keys=[key#17], functions=[partial_sum(a#14L), partial_last(b#15L, false)], output=[key#17, sum#49L, last#50L, valueSet#51])
+- *(1) Project [key#17, a#14L, b#15L]
+- *(1) Filter (isnotnull(a#14L) AND (a#14L > 100))
+- *(1) ColumnarToRow
+- FileScan parquet [a#14L,b#15L,key#17]
```
The `Project key#17, a#14L, b#15L` is redundant because hash aggregate doesn't require child plan's output to be in a specific order.
### Why are the changes needed?
It removes unnecessary query nodes and makes query plan cleaner.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests
Closes#29031 from allisonwang-db/remove-project.
Lead-authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Co-authored-by: allisonwang-db <allison.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR makes `ApplyColumnarRulesAndInsertTransitions` idempotent (assuming the custom columnar rules are also idempotent).
### Why are the changes needed?
It's good hygiene to keep rules idempotent
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
new suite
Closes#29273 from cloud-fan/rule.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
# What changes were proposed in this pull request?
This PR comes from the comment: #29085 (comment)
- Extract common Script IOSchema `ScriptTransformationIOSchema`
- avoid repeated judgement extract process output row method `createOutputIteratorWithoutSerde` && `createOutputIteratorWithSerde`
- add default no serde IO schemas `ScriptTransformationIOSchema.defaultIOSchema`
### Why are the changes needed?
Refactor code
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
NO
Closes#29199 from AngersZhuuuu/spark-32105-followup.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add a new test suite `CTEHintSuite`
### Why are the changes needed?
This ticket is to address the below comments to help us understand the test coverage of SQL HINT for CTE.
https://github.com/apache/spark/pull/29062#discussion_r463247491https://github.com/apache/spark/pull/29062#discussion_r463248167
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Add a test suite.
Closes#29359 from LantaoJin/SPARK-32537.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Check the Distinct nodes by assuming it as Aggregate in `UnsupportOperationChecker` for streaming.
### Why are the changes needed?
We want to fix 2 things here:
1. Give better error message for Distinct related operations in append mode that doesn't have a watermark
We use the union streams as the example, distinct in SQL has the same issue. Since the union clause in SQL has the requirement of deduplication, the parser will generate `Distinct(Union)` and the optimizer rule `ReplaceDistinctWithAggregate` will change it to `Aggregate(Union)`. This logic is of both batch and streaming queries. However, in the streaming, the aggregation will be wrapped by state store operations so we need extra checking logic in `UnsupportOperationChecker`.
Before this change, the SS union queries in Append mode will get the following confusing error when the watermark is lacking.
```
java.util.NoSuchElementException: None.get
at scala.None$.get(Option.scala:529)
at scala.None$.get(Option.scala:527)
at org.apache.spark.sql.execution.streaming.StateStoreSaveExec.$anonfun$doExecute$9(statefulOperators.scala:346)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.util.Utils$.timeTakenMs(Utils.scala:561)
at org.apache.spark.sql.execution.streaming.StateStoreWriter.timeTakenMs(statefulOperators.scala:112)
...
```
2. Make `Distinct` in complete mode runnable.
Before this fix, the distinct in complete mode will throw the exception:
```
Complete output mode not supported when there are no streaming aggregations on streaming DataFrames/Datasets;
```
### Does this PR introduce _any_ user-facing change?
Yes, return a better error message.
### How was this patch tested?
New UT added.
Closes#29256 from xuanyuanking/SPARK-32456.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR adds initial plan in `AdaptiveSparkPlanExec` and generates tree string for both current plan and initial plan. When the adaptive plan is not final, `Current Plan` will be used to indicate current physical plan, and `Final Plan` will be used when the adaptive plan is final. The difference between `Current Plan` and `Final Plan` here is that current plan indicates an intermediate state. The plan is subject to further transformations, while final plan represents an end state, which means the plan will no longer be changed.
Examples:
Before this change:
```
AdaptiveSparkPlan isFinalPlan=true
+- *(3) BroadcastHashJoin
:- BroadcastQueryStage 2
...
```
`EXPLAIN FORMATTED`
```
== Physical Plan ==
AdaptiveSparkPlan (9)
+- BroadcastHashJoin Inner BuildRight (8)
:- Project (3)
: +- Filter (2)
```
After this change
```
AdaptiveSparkPlan isFinalPlan=true
+- == Final Plan ==
*(3) BroadcastHashJoin
:- BroadcastQueryStage 2
: +- BroadcastExchange
...
+- == Initial Plan ==
SortMergeJoin
:- Sort
: +- Exchange
...
```
`EXPLAIN FORMATTED`
```
== Physical Plan ==
AdaptiveSparkPlan (9)
+- == Current Plan ==
BroadcastHashJoin Inner BuildRight (8)
:- Project (3)
: +- Filter (2)
+- == Initial Plan ==
BroadcastHashJoin Inner BuildRight (8)
:- Project (3)
: +- Filter (2)
```
### Why are the changes needed?
It provides better visibility into the plan change introduced by AQE.
### Does this PR introduce _any_ user-facing change?
Yes. It changed the AQE plan output string.
### How was this patch tested?
Unit test
Closes#29137 from allisonwang-db/aqe-plan.
Lead-authored-by: allisonwang-db <allison.wang@databricks.com>
Co-authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch caches the fetched list of files in FileStreamSource to avoid re-fetching whenever possible.
This improvement would be effective when the source options are being set to below:
* `maxFilesPerTrigger` is set
* `latestFirst` is set to `false` (default)
as
* if `maxFilesPerTrigger` is unset, Spark will process all the new files within a batch
* if `latestFirst` is set to `true`, it intends to process "latest" files which Spark has to refresh for every batch
Fetched list of files are filtered against SeenFilesMap before caching - unnecessary files are filtered in this phase. Once we cached the file, we don't check the file again for `isNewFile`, as Spark processes the files in timestamp order so cached files should have equal or later timestamp than latestTimestamp in SeenFilesMap.
Cache is only persisted in memory to simplify the logic - if we support restore cache when restarting query, we should deal with the changes of source options.
To avoid tiny set of inputs on the batch due to have tiny unread files (that could be possible when the list operation provides slightly more than the max files), this patch employs the "lower-bar" to determine whether it's helpful to retain unread files. Spark will discard unread files and do listing in the next batch if the number of unread files is lower than the specific (20% for now) ratio of max files.
This patch will have synergy with SPARK-20568 - while this patch helps to avoid redundant cost of listing, SPARK-20568 will get rid of the cost of listing for processed files. Once the query processes all files in initial load, the cost of listing for the files in initial load will be gone.
### Why are the changes needed?
Spark spends huge cost to fetch the list of files from input paths, but restricts the usage of list in a batch. If the streaming query starts from huge input data for various reasons (initial load, reprocessing, etc.) the cost to fetch the files will be applied to all batches as it is unusual to let first microbatch to process all of initial load.
SPARK-20568 will help to reduce the cost to fetch as processed files will be either deleted or moved outside of input paths, but it still won't help in early phase.
### Does this PR introduce any user-facing change?
Yes, the driver process would require more memory than before if maxFilesPerTrigger is set and latestFirst is set to "false" to cache fetched files. Previously Spark only takes some amount from left side of the list and discards remaining - so technically the peak memory would be same, but they can be freed sooner.
It may not hurt much, as peak memory is still be similar, and it would require similar amount of memory in any way when maxFilesPerTrigger is unset.
### How was this patch tested?
New unit tests. Manually tested under the test environment:
* input files
* 171,839 files distributed evenly into 24 directories
* each file contains 200 lines
* query: read from the "file stream source" and repartition to 50, and write to the "file stream sink"
* maxFilesPerTrigger is set to 100
> before applying the patch

> after applying the patch

The area of brown color represents "latestOffset" where listing operation is performed for FileStreamSource. After the patch the cost for listing is paid "only once", whereas before the patch
it was for "every batch".
Closes#27620 from HeartSaVioR/SPARK-30866.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR fixes the support for char(n)[], character(n)[] data types. Prior to this change, a user would get `Unsupported type ARRAY` exception when attempting to interact with the table with such types.
The description is a bit more detailed in the [JIRA](https://issues.apache.org/jira/browse/SPARK-32393) itself, but the crux of the issue is that postgres driver names char and character types as `bpchar`. The relevant driver code can be found [here](https://github.com/pgjdbc/pgjdbc/blob/master/pgjdbc/src/main/java/org/postgresql/jdbc/TypeInfoCache.java#L85-L87). `char` is very likely to be still needed, as it seems that pg makes a distinction between `char(1)` and `char(n > 1)` as per [this code](b7fd9f3cef/pgjdbc/src/main/java/org/postgresql/core/Oid.java (L64)).
### Why are the changes needed?
For completeness of the pg dialect support.
### Does this PR introduce _any_ user-facing change?
Yes, successful reads of tables with bpchar array instead of errors after this fix.
### How was this patch tested?
Unit tests
Closes#29192 from kujon/fix_postgres_bpchar_array_support.
Authored-by: kujon <jakub.korzeniowski@vortexa.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This is the follow-up PR of #29384 to address the cloud-fan comment: https://github.com/apache/spark/pull/29384#issuecomment-670595111
This PR re-enables `TPCDSQuerySuite` with empty tables for better test coverages.
### Why are the changes needed?
For better test coverage.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#29391 from maropu/SPARK-32564-FOLLOWUP.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR adds unique ID on QueryExecution, so that listeners can leverage the ID to deduplicate redundant calls.
### Why are the changes needed?
I've observed that Spark calls QueryExecutionListener multiple times on same QueryExecution instance (even same funcName for onSuccess). There's no unique ID on QueryExecution, hence it's a bit tricky if the listener would like to deal with same query execution only once.
Note that streaming query has both query ID and run ID which can be leveraged as unique ID.
### Does this PR introduce _any_ user-facing change?
Yes for who uses query execution listener - they'll see `id` field in QueryExecution and leverage it.
### How was this patch tested?
Manually tested. I think the change is obvious hence don't think it warrants a new UT. StreamingQueryListener has been using UUID as `queryId` and `runId` so it should work for the same.
Closes#29372 from HeartSaVioR/SPARK-32555.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
We added nested column predicate pushdown for Parquet in #27728. This patch extends the feature support to ORC.
### Why are the changes needed?
Extending the feature to ORC for feature parity. Better performance for handling nested predicate pushdown.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests.
Closes#28761 from viirya/SPARK-25557.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Disallow `FileSystem.get(Configuration conf)` in Scala style check by default and suggest developers use `FileSystem.get(URI uri, Configuration conf)` or `Path.getFileSystem()` instead.
### Why are the changes needed?
The method `FileSystem.get(Configuration conf)` will return a default FileSystem instance if the conf `fs.file.impl` is not set. This can cause file not found exception on reading a target path of non-default file system, e.g. S3. It is hard to discover such a mistake via unit tests.
If we disallow it in Scala style check by default and suggest developers use `FileSystem.get(URI uri, Configuration conf)` or `Path.getFileSystem(Configuration conf)`, we can reduce potential regression and PR review effort.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually run scala style check and test.
Closes#29357 from gengliangwang/newStyleRule.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
PR #26548 means that RecordBinaryComparator now uses big endian
byte order for long comparisons. However, this means that some of
the constants in the regression tests no longer map to the same
values in the comparison that they used to.
For example, one of the tests does a comparison between
Long.MIN_VALUE and 1 in order to trigger an overflow condition that
existed in the past (i.e. Long.MIN_VALUE - 1). These constants
correspond to the values 0x80..00 and 0x00..01. However on a
little-endian machine the bytes in these values are now swapped
before they are compared. This means that we will now be comparing
0x00..80 with 0x01..00. 0x00..80 - 0x01..00 does not overflow
therefore missing the original purpose of the test.
To fix this the constants are now explicitly written out in big
endian byte order to match the byte order used in the comparison.
This also fixes the tests on big endian machines (which would
otherwise get a different comparison result to the little-endian
machines).
### Why are the changes needed?
The regression tests no longer serve their initial purposes and also fail on big-endian systems.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Tests run on big-endian system (s390x).
Closes#29259 from mundaym/fix-endian.
Authored-by: Michael Munday <mike.munday@ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Implement ALTER TABLE in JDBC Table Catalog
The following ALTER TABLE are implemented:
```
ALTER TABLE table_name ADD COLUMNS ( column_name datatype [ , ... ] );
ALTER TABLE table_name RENAME COLUMN old_column_name TO new_column_name;
ALTER TABLE table_name DROP COLUMN column_name;
ALTER TABLE table_name ALTER COLUMN column_name TYPE new_type;
ALTER TABLE table_name ALTER COLUMN column_name SET NOT NULL;
```
I haven't checked ALTER TABLE syntax for all the databases yet. I will check. If there are different syntax, I will have a follow-up to override the dialect.
Seems most of the databases don't support updating comments and column position, so I didn't implement UpdateColumnComment and UpdateColumnPosition.
### Why are the changes needed?
Complete the JDBCTableCatalog implementation
### Does this PR introduce _any_ user-facing change?
Yes
`JDBCTableCatalog.alterTable`
### How was this patch tested?
add new tests
Closes#29324 from huaxingao/alter_table.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Change casting of map and struct values to strings by using the `{}` brackets instead of `[]`. The behavior is controlled by the SQL config `spark.sql.legacy.castComplexTypesToString.enabled`. When it is `true`, `CAST` wraps maps and structs by `[]` in casting to strings. Otherwise, if this is `false`, which is the default, maps and structs are wrapped by `{}`.
### Why are the changes needed?
- To distinguish structs/maps from arrays.
- To make `show`'s output consistent with Hive and conversions to Hive strings.
- To display dataframe content in the same form by `spark-sql` and `show`
- To be consistent with the `*.sql` tests
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
By existing test suite `CastSuite`.
Closes#29308 from MaxGekk/show-struct-map.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Make WithFields Expression not foldable.
### Why are the changes needed?
The following query currently fails on master brach:
```
sql("SELECT named_struct('a', 1, 'b', 2) a")
.select($"a".withField("c", lit(3)).as("a"))
.show(false)
// java.lang.UnsupportedOperationException: Cannot evaluate expression: with_fields(named_struct(a, 1, b, 2), c, 3)
```
This happens because the Catalyst optimizer sees that the WithFields Expression is foldable and tries to statically evaluate the WithFields Expression (via the ConstantFolding rule), however it cannot do so because WithFields Expression is Unevaluable.
### Does this PR introduce _any_ user-facing change?
Yes, queries like the one shared above will now succeed.
That said, this bug was introduced in Spark 3.1.0 which has yet to be released.
### How was this patch tested?
A new unit test was added.
Closes#29338 from fqaiser94/SPARK-32521.
Lead-authored-by: fqaiser94@gmail.com <fqaiser94@gmail.com>
Co-authored-by: fqaiser94 <fqaiser94@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to clean up `InMemoryRelation.ser` in `CachedBatchSerializerSuite`.
### Why are the changes needed?
SPARK-32274 makes SQL cache serialization pluggable.
```
[SPARK-32274][SQL] Make SQL cache serialization pluggable
```
This causes UT failures.
```
$ build/sbt "sql/testOnly *.CachedBatchSerializerSuite *.CachedTableSuite"
...
[info] Cause: java.lang.IllegalStateException: This does not work. This is only for testing
[info] at org.apache.spark.sql.execution.columnar.TestSingleIntColumnarCachedBatchSerializer.convertInternalRowToCachedBatch(CachedBatchSerializerSuite.scala:49)
...
[info] *** 30 TESTS FAILED ***
[error] Failed: Total 51, Failed 30, Errors 0, Passed 21
[error] Failed tests:
[error] org.apache.spark.sql.CachedTableSuite
[error] (sql/test:testOnly) sbt.TestsFailedException: Tests unsuccessful
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually.
```
$ build/sbt "sql/testOnly *.CachedBatchSerializerSuite *.CachedTableSuite"
[info] Tests: succeeded 51, failed 0, canceled 0, ignored 0, pending 0
[info] All tests passed.
[info] Passed: Total 51, Failed 0, Errors 0, Passed 51
```
Closes#29346 from dongjoon-hyun/SPARK-32524-3.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR is related to https://github.com/apache/spark/pull/26656.
https://github.com/apache/spark/pull/26656 only support use FILTER clause on aggregate expression without DISTINCT.
This PR will enhance this feature when one or more DISTINCT aggregate expressions which allows the use of the FILTER clause.
Such as:
```
select sum(distinct id) filter (where sex = 'man') from student;
select class_id, sum(distinct id) filter (where sex = 'man') from student group by class_id;
select count(id) filter (where class_id = 1), sum(distinct id) filter (where sex = 'man') from student;
select class_id, count(id) filter (where class_id = 1), sum(distinct id) filter (where sex = 'man') from student group by class_id;
select sum(distinct id), sum(distinct id) filter (where sex = 'man') from student;
select class_id, sum(distinct id), sum(distinct id) filter (where sex = 'man') from student group by class_id;
select class_id, count(id), count(id) filter (where class_id = 1), sum(distinct id), sum(distinct id) filter (where sex = 'man') from student group by class_id;
```
### Why are the changes needed?
Spark SQL only support use FILTER clause on aggregate expression without DISTINCT.
This PR support Filter expression allows simultaneous use of DISTINCT
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
Exists and new UT
Closes#29291 from beliefer/support-distinct-with-filter.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: beliefer <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a follow-up of #29278.
This PR changes the config name to switch allow/disallow `SparkContext` in executors as per the comment https://github.com/apache/spark/pull/29278#pullrequestreview-460256338.
### Why are the changes needed?
The config name `spark.executor.allowSparkContext` is more reasonable.
### Does this PR introduce _any_ user-facing change?
Yes, the config name is changed.
### How was this patch tested?
Updated tests.
Closes#29340 from ueshin/issues/SPARK-32160/change_config_name.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR modified the parser code to handle invalid usages of a SET/RESET command.
For example;
```
SET spark.sql.ansi.enabled true
```
The above SQL command does not change the configuration value and it just tries to display the value of the configuration
`spark.sql.ansi.enabled true`. This PR disallows using special characters including spaces in the configuration name and reports a user-friendly error instead. In the error message, it tells users a workaround to use quotes or a string literal if they still needs to specify a configuration with them.
Before this PR:
```
scala> sql("SET spark.sql.ansi.enabled true").show(1, -1)
+---------------------------+-----------+
|key |value |
+---------------------------+-----------+
|spark.sql.ansi.enabled true|<undefined>|
+---------------------------+-----------+
```
After this PR:
```
scala> sql("SET spark.sql.ansi.enabled true")
org.apache.spark.sql.catalyst.parser.ParseException:
Expected format is 'SET', 'SET key', or 'SET key=value'. If you want to include special characters in key, please use quotes, e.g., SET `ke y`=value.(line 1, pos 0)
== SQL ==
SET spark.sql.ansi.enabled true
^^^
```
### Why are the changes needed?
For better user-friendly errors.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added tests in `SparkSqlParserSuite`.
Closes#29146 from maropu/SPARK-32257.
Lead-authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Co-authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, the user home directory is used as the base path for the database and table locations when their locationa are specified with a relative paths, e.g.
```sql
> set spark.sql.warehouse.dir;
spark.sql.warehouse.dir file:/Users/kentyao/Downloads/spark/spark-3.1.0-SNAPSHOT-bin-20200512/spark-warehouse/
spark-sql> create database loctest location 'loctestdbdir';
spark-sql> desc database loctest;
Database Name loctest
Comment
Location file:/Users/kentyao/Downloads/spark/spark-3.1.0-SNAPSHOT-bin-20200512/loctestdbdir
Owner kentyao
spark-sql> create table loctest(id int) location 'loctestdbdir';
spark-sql> desc formatted loctest;
id int NULL
# Detailed Table Information
Database default
Table loctest
Owner kentyao
Created Time Thu May 14 16:29:05 CST 2020
Last Access UNKNOWN
Created By Spark 3.1.0-SNAPSHOT
Type EXTERNAL
Provider parquet
Location file:/Users/kentyao/Downloads/spark/spark-3.1.0-SNAPSHOT-bin-20200512/loctestdbdir
Serde Library org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
InputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
```
The user home is not always warehouse-related, unchangeable in runtime, and shared both by database and table as the parent directory. Meanwhile, we use the table path as the parent directory for relative partition locations.
The config `spark.sql.warehouse.dir` represents `the default location for managed databases and tables`.
For databases, the case above seems not to follow its semantics, because it should use ` `spark.sql.warehouse.dir` as the base path instead.
For tables, it seems to be right but here I suggest enriching the meaning that lets it also be the for external tables with relative paths for locations.
With changes in this PR,
The location of a database will be `warehouseDir/dbpath` when `dbpath` is relative.
The location of a table will be `dbpath/tblpath` when `tblpath` is relative.
### Why are the changes needed?
bugfix and improvement
Firstly, the databases with relative locations should be created under the default location specified by `spark.sql.warehouse.dir`.
Secondly, the external tables with relative paths may also follow this behavior for consistency.
At last, the behavior for database, tables and partitions with relative paths to choose base paths should be the same.
### Does this PR introduce _any_ user-facing change?
Yes, this PR changes the `createDatabase`, `alterDatabase`, `createTable` and `alterTable` APIs and related DDLs. If the LOCATION clause is followed by a relative path, the root path will be `spark.sql.warehouse.dir` for databases, and `spark.sql.warehouse.dir` / `dbPath` for tables.
e.g.
#### after
```sql
spark-sql> desc database loctest;
Database Name loctest
Comment
Location file:/Users/kentyao/Downloads/spark/spark-3.1.0-SNAPSHOT-bin-SPARK-31709/spark-warehouse/loctest
Owner kentyao
spark-sql> use loctest;
spark-sql> create table loctest(id int) location 'loctest';
20/05/14 18:18:02 WARN InMemoryFileIndex: The directory file:/Users/kentyao/Downloads/spark/spark-3.1.0-SNAPSHOT-bin-SPARK-31709/loctest was not found. Was it deleted very recently?
20/05/14 18:18:02 WARN SessionState: METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory.
20/05/14 18:18:03 WARN HiveConf: HiveConf of name hive.internal.ss.authz.settings.applied.marker does not exist
20/05/14 18:18:03 WARN HiveConf: HiveConf of name hive.stats.jdbc.timeout does not exist
20/05/14 18:18:03 WARN HiveConf: HiveConf of name hive.stats.retries.wait does not exist
spark-sql> desc formatted loctest;
id int NULL
# Detailed Table Information
Database loctest
Table loctest
Owner kentyao
Created Time Thu May 14 18:18:03 CST 2020
Last Access UNKNOWN
Created By Spark 3.1.0-SNAPSHOT
Type EXTERNAL
Provider parquet
Location file:/Users/kentyao/Downloads/spark/spark-3.1.0-SNAPSHOT-bin-SPARK-31709/spark-warehouse/loctest/loctest
Serde Library org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
InputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
spark-sql> alter table loctest set location 'loctest2'
> ;
spark-sql> desc formatted loctest;
id int NULL
# Detailed Table Information
Database loctest
Table loctest
Owner kentyao
Created Time Thu May 14 18:18:03 CST 2020
Last Access UNKNOWN
Created By Spark 3.1.0-SNAPSHOT
Type EXTERNAL
Provider parquet
Location file:/Users/kentyao/Downloads/spark/spark-3.1.0-SNAPSHOT-bin-SPARK-31709/spark-warehouse/loctest/loctest2
Serde Library org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
InputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
```
### How was this patch tested?
Add unit tests.
Closes#28527 from yaooqinn/SPARK-31709.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
`regexp_extract_all` is a very useful function expanded the capabilities of `regexp_extract`.
There are some description of this function.
```
SELECT regexp_extract('1a 2b 14m', '\d+', 0); -- 1
SELECT regexp_extract_all('1a 2b 14m', '\d+', 0); -- [1, 2, 14]
SELECT regexp_extract('1a 2b 14m', '(\d+)([a-z]+)', 2); -- 'a'
SELECT regexp_extract_all('1a 2b 14m', '(\d+)([a-z]+)', 2); -- ['a', 'b', 'm']
```
There are some mainstream database support the syntax.
**Presto:**
https://prestodb.io/docs/current/functions/regexp.html
**Pig:**
https://pig.apache.org/docs/latest/api/org/apache/pig/builtin/REGEX_EXTRACT_ALL.html
Note: This PR pick up the work of https://github.com/apache/spark/pull/21985
### Why are the changes needed?
`regexp_extract_all` is a very useful function and make work easier.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
New UT
Closes#27507 from beliefer/support-regexp_extract_all.
Lead-authored-by: beliefer <beliefer@163.com>
Co-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes issues relate to Canonicalization of FileSourceScanExec when it contains unused DPP Filter.
### Why are the changes needed?
As part of PlanDynamicPruningFilter rule, the unused DPP Filter are simply replaced by `DynamicPruningExpression(TrueLiteral)` so that they can be avoided. But these unnecessary`DynamicPruningExpression(TrueLiteral)` partition filter inside the FileSourceScanExec affects the canonicalization of the node and so in many cases, this can prevent ReuseExchange from happening.
This PR fixes this issue by ignoring the unused DPP filter in the `def doCanonicalize` method.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT.
Closes#29318 from prakharjain09/SPARK-32509_df_reuse.
Authored-by: Prakhar Jain <prakharjain09@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Check that there are not duplicate column names on the same level (top level or nested levels) in reading from JDBC datasource. If such duplicate columns exist, throw the exception:
```
org.apache.spark.sql.AnalysisException: Found duplicate column(s) in the customSchema option value:
```
The check takes into account the SQL config `spark.sql.caseSensitive` (`false` by default).
### Why are the changes needed?
To make handling of duplicate nested columns is similar to handling of duplicate top-level columns i. e. output the same error:
```Scala
org.apache.spark.sql.AnalysisException: Found duplicate column(s) in the customSchema option value: `camelcase`
```
Checking of top-level duplicates was introduced by https://github.com/apache/spark/pull/17758, and duplicates in nested structures by https://github.com/apache/spark/pull/29234.
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
Added new test suite `JdbcNestedDataSourceSuite`.
Closes#29317 from MaxGekk/jdbc-dup-nested-columns.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add a config to let users change how SQL/Dataframe data is compressed when cached.
This adds a few new classes/APIs for use with this config.
1. `CachedBatch` is a trait used to tag data that is intended to be cached. It has a few APIs that lets us keep the compression/serialization of the data separate from the metrics about it.
2. `CachedBatchSerializer` provides the APIs that must be implemented to cache data.
* `convertForCache` is an API that runs a cached spark plan and turns its result into an `RDD[CachedBatch]`. The actual caching is done outside of this API
* `buildFilter` is an API that takes a set of predicates and builds a filter function that can be used to filter the `RDD[CachedBatch]` returned by `convertForCache`
* `decompressColumnar` decompresses an `RDD[CachedBatch]` into an `RDD[ColumnarBatch]` This is only used for a limited set of data types. These data types may expand in the future. If they do we can add in a new API with a default value that says which data types this serializer supports.
* `decompressToRows` decompresses an `RDD[CachedBatch]` into an `RDD[InternalRow]` this API, like `decompressColumnar` decompresses the data in `CachedBatch` but turns it into `InternalRow`s, typically using code generation for performance reasons.
There is also an API that lets you reuse the current filtering based on min/max values. `SimpleMetricsCachedBatch` and `SimpleMetricsCachedBatchSerializer`.
### Why are the changes needed?
This lets users explore different types of compression and compression ratios.
### Does this PR introduce _any_ user-facing change?
This adds in a single config, and exposes some developer API classes described above.
### How was this patch tested?
I ran the unit tests around this and I also did some manual performance tests. I could find any performance difference between the old and new code, and if there is any it is within error.
Closes#29067 from revans2/pluggable_cache_serializer.
Authored-by: Robert (Bobby) Evans <bobby@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR updates the AQE framework to at least return one partition during coalescing.
This PR also updates `ShuffleExchangeExec.canChangeNumPartitions` to not coalesce for `SinglePartition`.
### Why are the changes needed?
It's a bit risky to return 0 partitions, as sometimes it's different from empty data. For example, global aggregate will return one result row even if the input table is empty. If there is 0 partition, no task will be run and no result will be returned. More specifically, the global aggregate requires `AllTuples` and we can't coalesce to 0 partitions.
This is not a real bug for now. The global aggregate will be planned as partial and final physical agg nodes. The partial agg will return at least one row, so that the shuffle still have data. But it's better to fix this issue to avoid potential bugs in the future.
According to https://github.com/apache/spark/pull/28916, this change also fix some perf problems.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
updated test.
Closes#29307 from cloud-fan/aqe.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This followup addresses comments from https://github.com/apache/spark/pull/29202#discussion_r462054784
1. make RESET static SQL configs/spark core configs fail as same as the SET command. Not that, for core ones, they have to be pre-registered, otherwise, they are still able to be SET/RESET
2. add test cases for configurations w/ optional default values
### Why are the changes needed?
behavior change with suggestions from PMCs
### Does this PR introduce _any_ user-facing change?
Yes, RESET will fail after this PR, before it just does nothing because the static ones are static.
### How was this patch tested?
add more tests.
Closes#29297 from yaooqinn/SPARK-32406-F.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a follow-up of #28986.
This PR adds a config to switch allow/disallow to create `SparkContext` in executors.
- `spark.driver.allowSparkContextInExecutors`
### Why are the changes needed?
Some users or libraries actually create `SparkContext` in executors.
We shouldn't break their workloads.
### Does this PR introduce _any_ user-facing change?
Yes, users will be able to create `SparkContext` in executors with the config enabled.
### How was this patch tested?
More tests are added.
Closes#29278 from ueshin/issues/SPARK-32160/add_configs.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to:
1. Fix the error message when the output schema is misbatched with R DataFrame from the given function. For example,
```R
df <- createDataFrame(list(list(a=1L, b="2")))
count(gapply(df, "a", function(key, group) { group }, structType("a int, b int")))
```
**Before:**
```
Error in handleErrors(returnStatus, conn) :
...
java.lang.UnsupportedOperationException
...
```
**After:**
```
Error in handleErrors(returnStatus, conn) :
...
java.lang.AssertionError: assertion failed: Invalid schema from gapply: expected IntegerType, IntegerType, got IntegerType, StringType
...
```
2. Update documentation about the schema matching for `gapply` and `dapply`.
### Why are the changes needed?
To show which schema is not matched, and let users know what's going on.
### Does this PR introduce _any_ user-facing change?
Yes, error message is updated as above, and documentation is updated.
### How was this patch tested?
Manually tested and unitttests were added.
Closes#29283 from HyukjinKwon/r-vectorized-error.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
When `spark.sql.caseSensitive` is `false` (by default), check that there are not duplicate column names on the same level (top level or nested levels) in reading from in-built datasources Parquet, ORC, Avro and JSON. If such duplicate columns exist, throw the exception:
```
org.apache.spark.sql.AnalysisException: Found duplicate column(s) in the data schema:
```
### Why are the changes needed?
To make handling of duplicate nested columns is similar to handling of duplicate top-level columns i. e. output the same error when `spark.sql.caseSensitive` is `false`:
```Scala
org.apache.spark.sql.AnalysisException: Found duplicate column(s) in the data schema: `camelcase`
```
Checking of top-level duplicates was introduced by https://github.com/apache/spark/pull/17758.
### Does this PR introduce _any_ user-facing change?
Yes. For the example from SPARK-32431:
ORC:
```scala
java.io.IOException: Error reading file: file:/private/var/folders/p3/dfs6mf655d7fnjrsjvldh0tc0000gn/T/spark-c02c2f9a-0cdc-4859-94fc-b9c809ca58b1/part-00001-63e8c3f0-7131-4ec9-be02-30b3fdd276f4-c000.snappy.orc
at org.apache.orc.impl.RecordReaderImpl.nextBatch(RecordReaderImpl.java:1329)
at org.apache.orc.mapreduce.OrcMapreduceRecordReader.ensureBatch(OrcMapreduceRecordReader.java:78)
...
Caused by: java.io.EOFException: Read past end of RLE integer from compressed stream Stream for column 3 kind DATA position: 6 length: 6 range: 0 offset: 12 limit: 12 range 0 = 0 to 6 uncompressed: 3 to 3
at org.apache.orc.impl.RunLengthIntegerReaderV2.readValues(RunLengthIntegerReaderV2.java:61)
at org.apache.orc.impl.RunLengthIntegerReaderV2.next(RunLengthIntegerReaderV2.java:323)
```
JSON:
```scala
+------------+
|StructColumn|
+------------+
| [,,]|
+------------+
```
Parquet:
```scala
+------------+
|StructColumn|
+------------+
| [0,, 1]|
+------------+
```
Avro:
```scala
+------------+
|StructColumn|
+------------+
| [,,]|
+------------+
```
After the changes, Parquet, ORC, JSON and Avro output the same error:
```scala
Found duplicate column(s) in the data schema: `camelcase`;
org.apache.spark.sql.AnalysisException: Found duplicate column(s) in the data schema: `camelcase`;
at org.apache.spark.sql.util.SchemaUtils$.checkColumnNameDuplication(SchemaUtils.scala:112)
at org.apache.spark.sql.util.SchemaUtils$.checkSchemaColumnNameDuplication(SchemaUtils.scala:51)
at org.apache.spark.sql.util.SchemaUtils$.checkSchemaColumnNameDuplication(SchemaUtils.scala:67)
```
### How was this patch tested?
Run modified test suites:
```
$ build/sbt "sql/test:testOnly org.apache.spark.sql.FileBasedDataSourceSuite"
$ build/sbt "avro/test:testOnly org.apache.spark.sql.avro.*"
```
and added new UT to `SchemaUtilsSuite`.
Closes#29234 from MaxGekk/nested-case-insensitive-column.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR adds abstract classes for shuffle and broadcast, so that users can provide their columnar implementations.
This PR updates several places to use the abstract exchange classes, and also update `AdaptiveSparkPlanExec` so that the columnar rules can see exchange nodes.
This is an alternative of https://github.com/apache/spark/pull/29134 .
Close https://github.com/apache/spark/pull/29134
### Why are the changes needed?
To allow columnar exchanges.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
new tests
Closes#29262 from cloud-fan/columnar.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
`spark.kryo.registrator` in 3.0 has a regression problem. From [SPARK-12080](https://issues.apache.org/jira/browse/SPARK-12080), it supports multiple user registrators by
```scala
private val userRegistrators = conf.get("spark.kryo.registrator", "")
.split(',').map(_.trim)
.filter(!_.isEmpty)
```
But it donsn't work in 3.0. Fix it by `toSequence` in `Kryo.scala`
### Why are the changes needed?
In previous Spark version (2.x), it supported multiple user registrators by
```scala
private val userRegistrators = conf.get("spark.kryo.registrator", "")
.split(',').map(_.trim)
.filter(!_.isEmpty)
```
But it doesn't work in 3.0. It's should be a regression.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existed unit tests.
Closes#29123 from LantaoJin/SPARK-32283.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to migrate the following function related commands to use `UnresolvedFunc` to resolve function identifier:
- DROP FUNCTION
- DESCRIBE FUNCTION
- SHOW FUNCTIONS
`DropFunctionStatement`, `DescribeFunctionStatement` and `ShowFunctionsStatement` logical plans are replaced with `DropFunction`, `DescribeFunction` and `ShowFunctions` logical plans respectively, and each contains `UnresolvedFunc` as its child so that it can be resolved in `Analyzer`.
### Why are the changes needed?
Migrating to the new resolution framework, which resolves `UnresolvedFunc` in `Analyzer`.
### Does this PR introduce _any_ user-facing change?
The message of exception thrown when a catalog is resolved to v2 has been merged to:
`function is only supported in v1 catalog`
Previously, it printed out the command used. E.g.,:
`CREATE FUNCTION is only supported in v1 catalog`
### How was this patch tested?
Updated existing tests.
Closes#29198 from imback82/function_framework.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Describe the JSON option `allowNonNumericNumbers` which is used in read
2. Add new test cases for allowed JSON field values: NaN, +INF, +Infinity, Infinity, -INF and -Infinity
### Why are the changes needed?
To improve UX with Spark SQL and to provide users full info about the supported option.
### Does this PR introduce _any_ user-facing change?
Yes, in PySpark.
### How was this patch tested?
Added new test to `JsonParsingOptionsSuite`
Closes#29275 from MaxGekk/allowNonNumericNumbers-doc.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR supports `WrappedArray` as `customCollectionCls` in `MapObjects`.
### Why are the changes needed?
This helps fix the regression caused by SPARK-31826. For the following test, it can pass in branch-3.0 but fail in master branch:
```scala
test("WrappedArray") {
val myUdf = udf((a: WrappedArray[Int]) =>
WrappedArray.make[Int](Array(a.head + 99)))
checkAnswer(Seq(Array(1))
.toDF("col")
.select(myUdf(Column("col"))),
Row(ArrayBuffer(100)))
}
```
In SPARK-31826, we've changed the catalyst-to-scala converter from `CatalystTypeConverters` to `ExpressionEncoder.deserializer`. However, `CatalystTypeConverters` supports `WrappedArray` while `ExpressionEncoder.deserializer` doesn't.
### Does this PR introduce _any_ user-facing change?
No, SPARK-31826 is merged into master and branch-3.1, which haven't been released.
### How was this patch tested?
Added a new test for `WrappedArray` in `UDFSuite`; Also updated `ObjectExpressionsSuite` for `MapObjects`.
Closes#29261 from Ngone51/fix-wrappedarray.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Normally, a Null aware anti join will be planed into BroadcastNestedLoopJoin which is very time consuming, for instance, in TPCH Query 16.
```
select
p_brand,
p_type,
p_size,
count(distinct ps_suppkey) as supplier_cnt
from
partsupp,
part
where
p_partkey = ps_partkey
and p_brand <> 'Brand#45'
and p_type not like 'MEDIUM POLISHED%'
and p_size in (49, 14, 23, 45, 19, 3, 36, 9)
and ps_suppkey not in (
select
s_suppkey
from
supplier
where
s_comment like '%Customer%Complaints%'
)
group by
p_brand,
p_type,
p_size
order by
supplier_cnt desc,
p_brand,
p_type,
p_size
```
In above query, will planed into
LeftAnti
condition Or((ps_suppkey=s_suppkey), IsNull(ps_suppkey=s_suppkey))
Inside BroadcastNestedLoopJoinExec will perform O(M\*N), BUT if there is only single column in NAAJ, we can always change buildSide into a HashSet, and streamedSide just need to lookup in the HashSet, then the calculation will be optimized into O(M).
But this optimize is only targeting on null aware anti join with single column case, because multi-column support is much more complicated, we might be able to support multi-column in future.
After apply this patch, the TPCH Query 16 performance decrease from 41mins to 30s
The semantic of null-aware anti join is:

### Why are the changes needed?
TPCH is a common benchmark for distributed compute engine, all other 21 Query works fine on Spark, except for Query 16, apply this patch will make Spark more competitive among all these popular engine. BTW, this patch has restricted rules and only apply on NAAJ Single Column case, which is safe enough.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
1. SQLQueryTestSuite with NOT IN keyword SQL, add CONFIG_DIM with spark.sql.optimizeNullAwareAntiJoin on and off
2. added case in org.apache.spark.sql.JoinSuite.
3. added case in org.apache.spark.sql.SubquerySuite.
3. Compare performance before and after applying this patch against TPCH Query 16.
4. config combination against e2e test with following
```
Map(
"spark.sql.optimizeNullAwareAntiJoin" -> "true",
"spark.sql.adaptive.enabled" -> "false",
"spark.sql.codegen.wholeStage" -> "false"
),
Map(
"sspark.sql.optimizeNullAwareAntiJoin" -> "true",
"spark.sql.adaptive.enabled" -> "false",
"spark.sql.codegen.wholeStage" -> "true"
),
Map(
"spark.sql.optimizeNullAwareAntiJoin" -> "true",
"spark.sql.adaptive.enabled" -> "true",
"spark.sql.codegen.wholeStage" -> "false"
),
Map(
"spark.sql.optimizeNullAwareAntiJoin" -> "true",
"spark.sql.adaptive.enabled" -> "true",
"spark.sql.codegen.wholeStage" -> "true"
)
```
Closes#29104 from leanken/leanken-SPARK-32290.
Authored-by: xuewei.linxuewei <xuewei.linxuewei@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR is intended to solve schema pruning not working with window functions, as described in SPARK-32059. It also solved schema pruning not working with `Sort`. It also generalizes with `Project->Filter->[any node can be pruned]`.
### Why are the changes needed?
This is needed because of performance issues with nested structures with querying using window functions as well as sorting.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Introduced two tests: 1) optimizer planning level 2) end-to-end tests with SQL queries.
Closes#28898 from frankyin-factual/master.
Authored-by: Frank Yin <frank@factual.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
When using `Seconds.toMicros` API to convert epoch seconds to microseconds,
```scala
/**
* Equivalent to
* {link #convert(long, TimeUnit) MICROSECONDS.convert(duration, this)}.
* param duration the duration
* return the converted duration,
* or {code Long.MIN_VALUE} if conversion would negatively
* overflow, or {code Long.MAX_VALUE} if it would positively overflow.
*/
```
This PR change it to `Math.multiplyExact(epochSeconds, MICROS_PER_SECOND)`
### Why are the changes needed?
fix silent data change between 3.x and 2.x
```
~/Downloads/spark/spark-3.1.0-SNAPSHOT-bin-20200722 bin/spark-sql -S -e "select to_timestamp('300000', 'y');"
+294247-01-10 12:00:54.775807
```
```
kentyaohulk ~/Downloads/spark/spark-2.4.5-bin-hadoop2.7 bin/spark-sql -S -e "select to_timestamp('300000', 'y');"
284550-10-19 15:58:1010.448384
```
### Does this PR introduce _any_ user-facing change?
Yes, we will raise `ArithmeticException` instead of giving the wrong answer if overflow.
### How was this patch tested?
add unit test
Closes#29220 from yaooqinn/SPARK-32424.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
`HashRelation` has two separate code paths for unique key look up and non-unique key look up E.g. in its subclass [`UnsafeHashedRelation`](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/joins/HashedRelation.scala#L144-L177), unique key look up is more efficient as it does not have e.g. extra `Iterator[UnsafeRow].hasNext()/next()` overhead per row.
`BroadcastHashJoinExec` has handled unique key vs non-unique key separately in [code-gen path](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/joins/BroadcastHashJoinExec.scala#L289-L321). But the non-codegen path for broadcast hash join and shuffled hash join do not separate it yet, so adding the support here.
### Why are the changes needed?
Shuffled hash join and non-codegen broadcast hash join still rely on this code path for execution. So this PR will help save CPU for executing this two type of join. Adding codegen for shuffled hash join would be a different topic and I will add it in https://issues.apache.org/jira/browse/SPARK-32421 .
Ran the same query as [`JoinBenchmark`](https://github.com/apache/spark/blob/master/sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/JoinBenchmark.scala#L153-L167), with enabling and disabling this feature. Verified 20% wall clock time improvement (switch control and test group order as well to verify the improvement to not be the noise).
```
Running benchmark: shuffle hash join
Running case: shuffle hash join unique key SHJ off
Stopped after 5 iterations, 4039 ms
Running case: shuffle hash join unique key SHJ on
Stopped after 5 iterations, 2898 ms
Java HotSpot(TM) 64-Bit Server VM 1.8.0_181-b13 on Mac OS X 10.15.4
Intel(R) Core(TM) i9-9980HK CPU 2.40GHz
shuffle hash join: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
shuffle hash join unique key SHJ off 707 808 81 5.9 168.6 1.0X
shuffle hash join unique key SHJ on 547 580 50 7.7 130.4 1.3X
```
```
Running benchmark: shuffle hash join
Running case: shuffle hash join unique key SHJ on
Stopped after 5 iterations, 3333 ms
Running case: shuffle hash join unique key SHJ off
Stopped after 5 iterations, 4268 ms
Java HotSpot(TM) 64-Bit Server VM 1.8.0_181-b13 on Mac OS X 10.15.4
Intel(R) Core(TM) i9-9980HK CPU 2.40GHz
shuffle hash join: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
shuffle hash join unique key SHJ on 565 667 60 7.4 134.8 1.0X
shuffle hash join unique key SHJ off 774 854 85 5.4 184.4 0.7X
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
* Added test in `OuterJoinSuite` to cover left outer and right outer join.
* Added test in `ExistenceJoinSuite` to cover left semi join, and existence join.
* [Existing `joinSuite` already covered inner join.](https://github.com/apache/spark/blob/master/sql/core/src/test/scala/org/apache/spark/sql/JoinSuite.scala#L182)
* [Existing `ExistenceJoinSuite` already covered left anti join, and existence join.](https://github.com/apache/spark/blob/master/sql/core/src/test/scala/org/apache/spark/sql/execution/joins/ExistenceJoinSuite.scala#L228)
Closes#29216 from c21/unique-key.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
As the part of this PR https://github.com/apache/spark/pull/29045 added the helper method. This PR is the FOLLOWUP PR to update the description of helper method.
### Why are the changes needed?
For better readability and understanding of the code
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Since its only change of updating the description , So ran the Spark shell
Closes#29232 from SaurabhChawla100/SPARK-32234-Desc.
Authored-by: SaurabhChawla <s.saurabhtim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR uses `python3` instead of `python3.6` executable as a fallback in `IntegratedUDFTestUtils`.
### Why are the changes needed?
Currently, GitHub Actions skips pandas UDFs. Python 3.8 is installed explicitly but somehow `python3.6` looks available in GitHub Actions build environment by default.
```
[info] - udf/postgreSQL/udf-case.sql - Scalar Pandas UDF is skipped because pyspark,pandas and/or pyarrow were not available in [python3.6]. !!! IGNORED !!!
...
[info] - udf/postgreSQL/udf-select_having.sql - Scalar Pandas UDF is skipped because pyspark,pandas and/or pyarrow were not available in [python3.6]. !!! IGNORED !!!
...
```
It was chosen as `python3.6` for Jenkins to pick one Python explicitly; however, looks we're already using `python3` here and there.
It will also reduce the overhead to fix when we deprecate or drop Python versions.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
It should be tested in Jenkins and GitHub Actions environments here.
Closes#29217 from HyukjinKwon/SPARK-32422.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Provide a generic mechanism for plugins to inject rules into the AQE "query prep" stage that happens before query stage creation.
This goes along with https://issues.apache.org/jira/browse/SPARK-32332 where the current AQE implementation doesn't allow for users to properly extend it for columnar processing.
### Why are the changes needed?
The issue here is that we create new query stages but we do not have access to the parent plan of the new query stage so certain things can not be determined because you have to know what the parent did. With this change it would allow you to add TAGs to be able to figure out what is going on.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
A new unit test is included in the PR.
Closes#29224 from andygrove/insert-aqe-rule.
Authored-by: Andy Grove <andygrove@nvidia.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR extends the RESET command to support reset SQL configuration one by one.
### Why are the changes needed?
Currently, the reset command only supports restore all of the runtime configurations to their defaults. In most cases, users do not want this, but just want to restore one or a small group of settings.
The SET command can work as a workaround for this, but you have to keep the defaults in your mind or by temp variables, which turns out not very convenient to use.
Hive supports this:
https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients#HiveServer2Clients-BeelineExample
reset <key> | Resets the value of a particular configuration variable (key) to the default value.Note: If you misspell the variable name, Beeline will not show an error.
-- | --
PostgreSQL supports this too
https://www.postgresql.org/docs/9.1/sql-reset.html
### Does this PR introduce _any_ user-facing change?
yes, reset can restore one configuration now
### How was this patch tested?
add new unit tests.
Closes#29202 from yaooqinn/SPARK-32406.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR implements basic functionalities of the `TableCatalog` interface, so that end-users can use the JDBC as a catalog.
### Why are the changes needed?
To have at least one built implementation of Catalog Plugin API available to end users. JDBC is perfectly fit for this.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
By new test suite `JDBCTableCatalogSuite`.
Closes#29168 from MaxGekk/jdbc-v2.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently the by-name resolution logic of `unionByName` is put in API code. This patch moves the logic to analysis phase.
See https://github.com/apache/spark/pull/28996#discussion_r453460284.
### Why are the changes needed?
Logically we should do resolution in analysis phase. This refactoring cleans up API method and makes consistent resolution.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests.
Closes#29107 from viirya/move-union-by-name.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Enable two tests from `JsonParsingOptionsSuite`:
- `allowNonNumericNumbers off`
- `allowNonNumericNumbers on`
### Why are the changes needed?
To improve test coverage.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running the enabled tests.
Closes#29207 from MaxGekk/allowNonNumericNumbers-tests.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Updates to scalatest 3.2.0. Though it looks large, it is 99% changes to the new location of scalatest classes.
### Why are the changes needed?
3.2.0+ has a fix that is required for Scala 2.13.3+ compatibility.
### Does this PR introduce _any_ user-facing change?
No, only affects tests.
### How was this patch tested?
Existing tests.
Closes#29196 from srowen/SPARK-32398.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Currently, you can specify properties when creating a temporary view. However, the specified properties are not used and can be misleading.
This PR propose to disallow specifying properties when creating temporary views.
### Why are the changes needed?
To avoid confusion by disallowing specifying unused properties.
### Does this PR introduce _any_ user-facing change?
Yes, now if you create a temporary view with properties, the operation will fail:
```
scala> sql("CREATE TEMPORARY VIEW tv TBLPROPERTIES('p1'='v1') AS SELECT 1 AS c1")
org.apache.spark.sql.catalyst.parser.ParseException:
Operation not allowed: CREATE TEMPORARY VIEW ... TBLPROPERTIES (property_name = property_value, ...)(line 1, pos 0)
== SQL ==
CREATE TEMPORARY VIEW tv TBLPROPERTIES('p1'='v1') AS SELECT 1 AS c1
^^^
```
### How was this patch tested?
Added tests
Closes#29167 from imback82/disable_properties_temp_view.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR refactors `ResolveReferences.dedupRight` to make sure it only rewrite attributes for ancestor nodes of the conflict plan.
### Why are the changes needed?
This is a bug fix.
```scala
sql("SELECT name, avg(age) as avg_age FROM person GROUP BY name")
.createOrReplaceTempView("person_a")
sql("SELECT p1.name, p2.avg_age FROM person p1 JOIN person_a p2 ON p1.name = p2.name")
.createOrReplaceTempView("person_b")
sql("SELECT * FROM person_a UNION SELECT * FROM person_b")
.createOrReplaceTempView("person_c")
sql("SELECT p1.name, p2.avg_age FROM person_c p1 JOIN person_c p2 ON p1.name = p2.name").show()
```
When executing the above query, we'll hit the error:
```scala
[info] Failed to analyze query: org.apache.spark.sql.AnalysisException: Resolved attribute(s) avg_age#231 missing from name#223,avg_age#218,id#232,age#234,name#233 in operator !Project [name#233, avg_age#231]. Attribute(s) with the same name appear in the operation: avg_age. Please check if the right attribute(s) are used.;;
...
```
The plan below is the problematic plan which is the right plan of a `Join` operator. And, it has conflict plans comparing to the left plan. In this problematic plan, the first `Aggregate` operator (the one under the first child of `Union`) becomes a conflict plan compares to the left one and has a rewrite attribute pair as `avg_age#218` -> `avg_age#231`. With the current `dedupRight` logic, we'll first replace this `Aggregate` with a new one, and then rewrites the attribute `avg_age#218` from bottom to up. As you can see, projects with the attribute `avg_age#218` of the second child of the `Union` can also be replaced with `avg_age#231`(That means we also rewrite attributes for non-ancestor plans for the conflict plan). Ideally, the attribute `avg_age#218` in the second `Aggregate` operator (the one under the second child of `Union`) should also be replaced. But it didn't because it's an `Alias` while we only rewrite `Attribute` yet. Therefore, the project above the second `Aggregate` becomes unresolved.
```scala
:
:
+- SubqueryAlias p2
+- SubqueryAlias person_c
+- Distinct
+- Union
:- Project [name#233, avg_age#231]
: +- SubqueryAlias person_a
: +- Aggregate [name#233], [name#233, avg(cast(age#234 as bigint)) AS avg_age#231]
: +- SubqueryAlias person
: +- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$Person, true])).id AS id#232, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$Person, true])).name, true, false) AS name#233, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$Person, true])).age AS age#234]
: +- ExternalRDD [obj#165]
+- Project [name#233 AS name#227, avg_age#231 AS avg_age#228]
+- Project [name#233, avg_age#231]
+- SubqueryAlias person_b
+- !Project [name#233, avg_age#231]
+- Join Inner, (name#233 = name#223)
:- SubqueryAlias p1
: +- SubqueryAlias person
: +- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$Person, true])).id AS id#232, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$Person, true])).name, true, false) AS name#233, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$Person, true])).age AS age#234]
: +- ExternalRDD [obj#165]
+- SubqueryAlias p2
+- SubqueryAlias person_a
+- Aggregate [name#223], [name#223, avg(cast(age#224 as bigint)) AS avg_age#218]
+- SubqueryAlias person
+- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$Person, true])).id AS id#222, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$Person, true])).name, true, false) AS name#223, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$Person, true])).age AS age#224]
+- ExternalRDD [obj#165]
```
### Does this PR introduce _any_ user-facing change?
Yes, users would no longer hit the error after this fix.
### How was this patch tested?
Added test.
Closes#29166 from Ngone51/impr-dedup.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/29160. We already removed the indeterministicity. This PR aims the following for the existing code base.
1. Add an explicit document to `DataFrameReader/DataFrameWriter`.
2. Add `toMap` to `CaseInsensitiveMap` in order to return `originalMap: Map[String, T]` because it's more consistent with the existing `case-sensitive key names` behavior for the existing code pattern like `AppendData.byName(..., extraOptions.toMap)`. Previously, it was `HashMap.toMap`.
3. During (2), we need to change the following to keep the original logic using `CaseInsensitiveMap.++`.
```scala
- val params = extraOptions.toMap ++ connectionProperties.asScala.toMap
+ val params = extraOptions ++ connectionProperties.asScala
```
4. Additionally, use `.toMap` in the following because `dsOptions.asCaseSensitiveMap()` is used later.
```scala
- val options = sessionOptions ++ extraOptions
+ val options = sessionOptions.filterKeys(!extraOptions.contains(_)) ++ extraOptions.toMap
val dsOptions = new CaseInsensitiveStringMap(options.asJava)
```
### Why are the changes needed?
`extraOptions.toMap` is used in several places (e.g. `DataFrameReader`) to hand over `Map[String, T]`. In this case, `CaseInsensitiveMap[T] private (val originalMap: Map[String, T])` had better return `originalMap`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the Jenkins or GitHub Action with the existing tests and newly add test case at `JDBCSuite`.
Closes#29191 from dongjoon-hyun/SPARK-32364-3.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR is to move `Substitution` rule before `Hints` rule in `Analyzer` to avoid hint in CTE not working.
### Why are the changes needed?
Below SQL in Spark3.0 will throw AnalysisException, but it works in Spark2.x
```sql
WITH cte AS (SELECT /*+ REPARTITION(3) */ T.id, T.data FROM $t1 T)
SELECT cte.id, cte.data FROM cte
```
```
Failed to analyze query: org.apache.spark.sql.AnalysisException: cannot resolve '`cte.id`' given input columns: [cte.data, cte.id]; line 3 pos 7;
'Project ['cte.id, 'cte.data]
+- SubqueryAlias cte
+- Project [id#21L, data#22]
+- SubqueryAlias T
+- SubqueryAlias testcat.ns1.ns2.tbl
+- RelationV2[id#21L, data#22] testcat.ns1.ns2.tbl
'Project ['cte.id, 'cte.data]
+- SubqueryAlias cte
+- Project [id#21L, data#22]
+- SubqueryAlias T
+- SubqueryAlias testcat.ns1.ns2.tbl
+- RelationV2[id#21L, data#22] testcat.ns1.ns2.tbl
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Add a unit test
Closes#29062 from LantaoJin/SPARK-32237.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In Hive mode, permanent functions are shared with Hive metastore so that functions may be modified by other Hive client. With in long-lived spark scene, it's hard to update the change of function.
Here are 2 reasons:
* Spark cache the function in memory using `FunctionRegistry`.
* User may not know the location or classname of udf when using `replace function`.
Note that we use v2 command code path to add new command.
### Why are the changes needed?
Give a easy way to make spark function registry sync with Hive metastore.
Then we can call
```
refresh function functionName
```
### Does this PR introduce _any_ user-facing change?
Yes, new command.
### How was this patch tested?
New UT.
Closes#28840 from ulysses-you/SPARK-31999.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When a user have multiple options like `path`, `paTH`, and `PATH` for the same key `path`, `option/options` is non-deterministic because `extraOptions` is `HashMap`. This PR aims to use `CaseInsensitiveMap` instead of `HashMap` to fix this bug fundamentally.
### Why are the changes needed?
Like the following, DataFrame's `option/options` have been non-deterministic in terms of case-insensitivity because it stores the options at `extraOptions` which is using `HashMap` class.
```scala
spark.read
.option("paTh", "1")
.option("PATH", "2")
.option("Path", "3")
.option("patH", "4")
.load("5")
...
org.apache.spark.sql.AnalysisException:
Path does not exist: file:/.../1;
```
### Does this PR introduce _any_ user-facing change?
Yes. However, this is a bug fix for the indeterministic cases.
### How was this patch tested?
Pass the Jenkins or GitHub Action with newly added test cases.
Closes#29160 from dongjoon-hyun/SPARK-32364.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR is to define prettyName for `WidthBucket`.
This comes from the gatorsmile's suggestion: https://github.com/apache/spark/pull/28764#discussion_r457802957
### Why are the changes needed?
For a better name.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#29183 from maropu/SPARK-21117-FOLLOWUP.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
In PR, I propose to create input tables once before executing tests in `JDBCSuite` and `JdbcRDDSuite`. Currently, the table are created before every test in the test suites.
### Why are the changes needed?
This speed up the test suites up 30-40%.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Run the modified test suites
Closes#29176 from MaxGekk/jdbc-suite-before-all.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Based on a follow up comment in https://github.com/apache/spark/pull/28123, where we can coalesce buckets for shuffled hash join as well. The note here is we only coalesce the buckets from shuffled hash join stream side (i.e. the side not building hash map), so we don't need to worry about OOM when coalescing multiple buckets in one task for building hash map.
> If you refactor some codes with changing classes, showing the class hierarchy will help reviewers.
Refactor existing physical plan rule `CoalesceBucketsInSortMergeJoin` to `CoalesceBucketsInJoin`, for covering shuffled hash join as well.
Refactor existing unit test `CoalesceBucketsInSortMergeJoinSuite` to `CoalesceBucketsInJoinSuite`, for covering shuffled hash join as well.
### Why are the changes needed?
Avoid shuffle for joining different bucketed tables, is also useful for shuffled hash join. In production, we are seeing users to use shuffled hash join to join bucketed tables (set `spark.sql.join.preferSortMergeJoin`=false, to avoid sort), and this can help avoid shuffle if number of buckets are not same.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit tests in `CoalesceBucketsInJoinSuite` for verifying shuffled hash join physical plan.
### Performance number per request from maropu
I was looking at TPCDS per suggestion from maropu. But I found most of queries from TPCDS are doing aggregate, and only several ones are doing join. None of input tables are bucketed. So I took the approach to test a modified version of `TPCDS q93` as
```
SELECT ss_ticket_number, sr_ticket_number
FROM store_sales
JOIN store_returns
ON ss_ticket_number = sr_ticket_number
```
And make `store_sales` and `store_returns` to be bucketed tables.
Physical query plan without coalesce:
```
ShuffledHashJoin [ss_ticket_number#109L], [sr_ticket_number#120L], Inner, BuildLeft
:- Exchange hashpartitioning(ss_ticket_number#109L, 4), true, [id=#67]
: +- *(1) Project [ss_ticket_number#109L]
: +- *(1) Filter isnotnull(ss_ticket_number#109L)
: +- *(1) ColumnarToRow
: +- FileScan parquet default.store_sales[ss_ticket_number#109L] Batched: true, DataFilters: [isnotnull(ss_ticket_number#109L)], Format: Parquet, Location: InMemoryFileIndex[file:/Users/chengsu/spark/spark-warehouse/store_sales], PartitionFilters: [], PushedFilters: [IsNotNull(ss_ticket_number)], ReadSchema: struct<ss_ticket_number:bigint>, SelectedBucketsCount: 2 out of 2
+- *(2) Project [sr_returned_date_sk#111L, sr_return_time_sk#112L, sr_item_sk#113L, sr_customer_sk#114L, sr_cdemo_sk#115L, sr_hdemo_sk#116L, sr_addr_sk#117L, sr_store_sk#118L, sr_reason_sk#119L, sr_ticket_number#120L, sr_return_quantity#121L, sr_return_amt#122, sr_return_tax#123, sr_return_amt_inc_tax#124, sr_fee#125, sr_return_ship_cost#126, sr_refunded_cash#127, sr_reversed_charge#128, sr_store_credit#129, sr_net_loss#130]
+- *(2) Filter isnotnull(sr_ticket_number#120L)
+- *(2) ColumnarToRow
+- FileScan parquet default.store_returns[sr_returned_date_sk#111L,sr_return_time_sk#112L,sr_item_sk#113L,sr_customer_sk#114L,sr_cdemo_sk#115L,sr_hdemo_sk#116L,sr_addr_sk#117L,sr_store_sk#118L,sr_reason_sk#119L,sr_ticket_number#120L,sr_return_quantity#121L,sr_return_amt#122,sr_return_tax#123,sr_return_amt_inc_tax#124,sr_fee#125,sr_return_ship_cost#126,sr_refunded_cash#127,sr_reversed_charge#128,sr_store_credit#129,sr_net_loss#130] Batched: true, DataFilters: [isnotnull(sr_ticket_number#120L)], Format: Parquet, Location: InMemoryFileIndex[file:/Users/chengsu/spark/spark-warehouse/store_returns], PartitionFilters: [], PushedFilters: [IsNotNull(sr_ticket_number)], ReadSchema: struct<sr_returned_date_sk:bigint,sr_return_time_sk:bigint,sr_item_sk:bigint,sr_customer_sk:bigin..., SelectedBucketsCount: 4 out of 4
```
Physical query plan with coalesce:
```
ShuffledHashJoin [ss_ticket_number#109L], [sr_ticket_number#120L], Inner, BuildLeft
:- *(1) Project [ss_ticket_number#109L]
: +- *(1) Filter isnotnull(ss_ticket_number#109L)
: +- *(1) ColumnarToRow
: +- FileScan parquet default.store_sales[ss_ticket_number#109L] Batched: true, DataFilters: [isnotnull(ss_ticket_number#109L)], Format: Parquet, Location: InMemoryFileIndex[file:/Users/chengsu/spark/spark-warehouse/store_sales], PartitionFilters: [], PushedFilters: [IsNotNull(ss_ticket_number)], ReadSchema: struct<ss_ticket_number:bigint>, SelectedBucketsCount: 2 out of 2
+- *(2) Project [sr_returned_date_sk#111L, sr_return_time_sk#112L, sr_item_sk#113L, sr_customer_sk#114L, sr_cdemo_sk#115L, sr_hdemo_sk#116L, sr_addr_sk#117L, sr_store_sk#118L, sr_reason_sk#119L, sr_ticket_number#120L, sr_return_quantity#121L, sr_return_amt#122, sr_return_tax#123, sr_return_amt_inc_tax#124, sr_fee#125, sr_return_ship_cost#126, sr_refunded_cash#127, sr_reversed_charge#128, sr_store_credit#129, sr_net_loss#130]
+- *(2) Filter isnotnull(sr_ticket_number#120L)
+- *(2) ColumnarToRow
+- FileScan parquet default.store_returns[sr_returned_date_sk#111L,sr_return_time_sk#112L,sr_item_sk#113L,sr_customer_sk#114L,sr_cdemo_sk#115L,sr_hdemo_sk#116L,sr_addr_sk#117L,sr_store_sk#118L,sr_reason_sk#119L,sr_ticket_number#120L,sr_return_quantity#121L,sr_return_amt#122,sr_return_tax#123,sr_return_amt_inc_tax#124,sr_fee#125,sr_return_ship_cost#126,sr_refunded_cash#127,sr_reversed_charge#128,sr_store_credit#129,sr_net_loss#130] Batched: true, DataFilters: [isnotnull(sr_ticket_number#120L)], Format: Parquet, Location: InMemoryFileIndex[file:/Users/chengsu/spark/spark-warehouse/store_returns], PartitionFilters: [], PushedFilters: [IsNotNull(sr_ticket_number)], ReadSchema: struct<sr_returned_date_sk:bigint,sr_return_time_sk:bigint,sr_item_sk:bigint,sr_customer_sk:bigin..., SelectedBucketsCount: 4 out of 4 (Coalesced to 2)
```
Run time improvement as 50% of wall clock time:
```
Java HotSpot(TM) 64-Bit Server VM 1.8.0_181-b13 on Mac OS X 10.15.4
Intel(R) Core(TM) i9-9980HK CPU 2.40GHz
shuffle hash join: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
shuffle hash join coalesce bucket off 1541 1664 106 1.9 535.1 1.0X
shuffle hash join coalesce bucket on 1060 1169 81 2.7 368.1 1.5X
```
Closes#29079 from c21/split-bucket.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Verify results for `AdaptiveQueryExecSuite`
### Why are the changes needed?
`AdaptiveQueryExecSuite` misses verifying AE results
```scala
QueryTest.sameRows(result.toSeq, df.collect().toSeq)
```
Even the results are different, no fail.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Exists unit tests.
Closes#29158 from LantaoJin/SPARK-32362.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The current implement of regexp_extract will throws a unprocessed exception show below:
SELECT regexp_extract('1a 2b 14m', 'd+' -1)
```
java.lang.IndexOutOfBoundsException: No group -1
java.util.regex.Matcher.group(Matcher.java:538)
org.apache.spark.sql.catalyst.expressions.RegExpExtract.nullSafeEval(regexpExpressions.scala:455)
org.apache.spark.sql.catalyst.expressions.TernaryExpression.eval(Expression.scala:704)
org.apache.spark.sql.catalyst.optimizer.ConstantFolding$$anonfun$apply$1$$anonfun$applyOrElse$1.applyOrElse(expressions.scala:52)
org.apache.spark.sql.catalyst.optimizer.ConstantFolding$$anonfun$apply$1$$anonfun$applyOrElse$1.applyOrElse(expressions.scala:45)
```
### Why are the changes needed?
Fix a bug `java.lang.IndexOutOfBoundsException: No group -1`
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
new UT
Closes#29161 from beliefer/regexp_extract-group-not-allow-less-than-zero.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Add an overload for the `slice` function that can accept Columns for the `start` and `length` parameters.
### Why are the changes needed?
This will allow users to take slices of arrays based on the length of the arrays, or via data in other columns.
```scala
df.select(slice(x, 4, size(x) - 4))
```
### Does this PR introduce _any_ user-facing change?
Yes, before the `slice` method would only accept Ints for the start and length parameters, now we can pass in Columns and/or Ints.
### How was this patch tested?
I've extended the existing tests for slice but using combinations of Column and Ints.
Closes#29138 from nvander1/SPARK-32338.
Authored-by: Nik Vanderhoof <nikolasrvanderhoof@gmail.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to make the datasource options at `PartitioningAwareFileIndex` respect case insensitivity consistently:
- `pathGlobFilter`
- `recursiveFileLookup `
- `basePath`
### Why are the changes needed?
To support consistent case insensitivity in datasource options.
### Does this PR introduce _any_ user-facing change?
Yes, now users can also use case insensitive options such as `PathglobFilter`.
### How was this patch tested?
Unittest were added. It reuses existing tests and adds extra clues to make it easier to track when the test is broken.
Closes#29165 from HyukjinKwon/SPARK-32368.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Currently `ShuffledHashJoin.outputPartitioning` inherits from `HashJoin.outputPartitioning`, which only preserves stream side partitioning (`HashJoin.scala`):
```
override def outputPartitioning: Partitioning = streamedPlan.outputPartitioning
```
This loses build side partitioning information, and causes extra shuffle if there's another join / group-by after this join.
Example:
```
withSQLConf(
SQLConf.AUTO_BROADCASTJOIN_THRESHOLD.key -> "50",
SQLConf.SHUFFLE_PARTITIONS.key -> "2",
SQLConf.PREFER_SORTMERGEJOIN.key -> "false") {
val df1 = spark.range(10).select($"id".as("k1"))
val df2 = spark.range(30).select($"id".as("k2"))
Seq("inner", "cross").foreach(joinType => {
val plan = df1.join(df2, $"k1" === $"k2", joinType).groupBy($"k1").count()
.queryExecution.executedPlan
assert(plan.collect { case _: ShuffledHashJoinExec => true }.size === 1)
// No extra shuffle before aggregate
assert(plan.collect { case _: ShuffleExchangeExec => true }.size === 2)
})
}
```
Current physical plan (having an extra shuffle on `k1` before aggregate)
```
*(4) HashAggregate(keys=[k1#220L], functions=[count(1)], output=[k1#220L, count#235L])
+- Exchange hashpartitioning(k1#220L, 2), true, [id=#117]
+- *(3) HashAggregate(keys=[k1#220L], functions=[partial_count(1)], output=[k1#220L, count#239L])
+- *(3) Project [k1#220L]
+- ShuffledHashJoin [k1#220L], [k2#224L], Inner, BuildLeft
:- Exchange hashpartitioning(k1#220L, 2), true, [id=#109]
: +- *(1) Project [id#218L AS k1#220L]
: +- *(1) Range (0, 10, step=1, splits=2)
+- Exchange hashpartitioning(k2#224L, 2), true, [id=#111]
+- *(2) Project [id#222L AS k2#224L]
+- *(2) Range (0, 30, step=1, splits=2)
```
Ideal physical plan (no shuffle on `k1` before aggregate)
```
*(3) HashAggregate(keys=[k1#220L], functions=[count(1)], output=[k1#220L, count#235L])
+- *(3) HashAggregate(keys=[k1#220L], functions=[partial_count(1)], output=[k1#220L, count#239L])
+- *(3) Project [k1#220L]
+- ShuffledHashJoin [k1#220L], [k2#224L], Inner, BuildLeft
:- Exchange hashpartitioning(k1#220L, 2), true, [id=#107]
: +- *(1) Project [id#218L AS k1#220L]
: +- *(1) Range (0, 10, step=1, splits=2)
+- Exchange hashpartitioning(k2#224L, 2), true, [id=#109]
+- *(2) Project [id#222L AS k2#224L]
+- *(2) Range (0, 30, step=1, splits=2)
```
This can be fixed by overriding `outputPartitioning` method in `ShuffledHashJoinExec`, similar to `SortMergeJoinExec`.
In addition, also fix one typo in `HashJoin`, as that code path is shared between broadcast hash join and shuffled hash join.
### Why are the changes needed?
To avoid shuffle (for queries having multiple joins or group-by), for saving CPU and IO.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit test in `JoinSuite`.
Closes#29130 from c21/shj.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, the `BroadcastHashJoinExec`'s `outputPartitioning` only uses the streamed side's `outputPartitioning`. However, if the join type of `BroadcastHashJoinExec` is an inner-like join, the build side's info (the join keys) can be added to `BroadcastHashJoinExec`'s `outputPartitioning`.
For example,
```Scala
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "500")
val t1 = (0 until 100).map(i => (i % 5, i % 13)).toDF("i1", "j1")
val t2 = (0 until 100).map(i => (i % 5, i % 13)).toDF("i2", "j2")
val t3 = (0 until 20).map(i => (i % 7, i % 11)).toDF("i3", "j3")
val t4 = (0 until 100).map(i => (i % 5, i % 13)).toDF("i4", "j4")
// join1 is a sort merge join.
val join1 = t1.join(t2, t1("i1") === t2("i2"))
// join2 is a broadcast join where t3 is broadcasted.
val join2 = join1.join(t3, join1("i1") === t3("i3"))
// Join on the column from the broadcasted side (i3).
val join3 = join2.join(t4, join2("i3") === t4("i4"))
join3.explain
```
You see that `Exchange hashpartitioning(i2#103, 200)` is introduced because there is no output partitioning info from the build side.
```
== Physical Plan ==
*(6) SortMergeJoin [i3#29], [i4#40], Inner
:- *(4) Sort [i3#29 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(i3#29, 200), true, [id=#55]
: +- *(3) BroadcastHashJoin [i1#7], [i3#29], Inner, BuildRight
: :- *(3) SortMergeJoin [i1#7], [i2#18], Inner
: : :- *(1) Sort [i1#7 ASC NULLS FIRST], false, 0
: : : +- Exchange hashpartitioning(i1#7, 200), true, [id=#28]
: : : +- LocalTableScan [i1#7, j1#8]
: : +- *(2) Sort [i2#18 ASC NULLS FIRST], false, 0
: : +- Exchange hashpartitioning(i2#18, 200), true, [id=#29]
: : +- LocalTableScan [i2#18, j2#19]
: +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint))), [id=#34]
: +- LocalTableScan [i3#29, j3#30]
+- *(5) Sort [i4#40 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(i4#40, 200), true, [id=#39]
+- LocalTableScan [i4#40, j4#41]
```
This PR proposes to introduce output partitioning for the build side for `BroadcastHashJoinExec` if the streamed side has a `HashPartitioning` or a collection of `HashPartitioning`s.
There is a new internal config `spark.sql.execution.broadcastHashJoin.outputPartitioningExpandLimit`, which can limit the number of partitioning a `HashPartitioning` can expand to. It can be set to "0" to disable this feature.
### Why are the changes needed?
To remove unnecessary shuffle.
### Does this PR introduce _any_ user-facing change?
Yes, now the shuffle in the above example can be eliminated:
```
== Physical Plan ==
*(5) SortMergeJoin [i3#108], [i4#119], Inner
:- *(3) Sort [i3#108 ASC NULLS FIRST], false, 0
: +- *(3) BroadcastHashJoin [i1#86], [i3#108], Inner, BuildRight
: :- *(3) SortMergeJoin [i1#86], [i2#97], Inner
: : :- *(1) Sort [i1#86 ASC NULLS FIRST], false, 0
: : : +- Exchange hashpartitioning(i1#86, 200), true, [id=#120]
: : : +- LocalTableScan [i1#86, j1#87]
: : +- *(2) Sort [i2#97 ASC NULLS FIRST], false, 0
: : +- Exchange hashpartitioning(i2#97, 200), true, [id=#121]
: : +- LocalTableScan [i2#97, j2#98]
: +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint))), [id=#126]
: +- LocalTableScan [i3#108, j3#109]
+- *(4) Sort [i4#119 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(i4#119, 200), true, [id=#130]
+- LocalTableScan [i4#119, j4#120]
```
### How was this patch tested?
Added new tests.
Closes#28676 from imback82/broadcast_join_output.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In https://github.com/apache/spark/pull/28733 and #28805, CNF conversion is used to push down disjunctive predicates through join and partitions pruning.
It's a good improvement, however, converting all the predicates in CNF can lead to a very long result, even with grouping functions over expressions. For example, for the following predicate
```
(p0 = '1' AND p1 = '1') OR (p0 = '2' AND p1 = '2') OR (p0 = '3' AND p1 = '3') OR (p0 = '4' AND p1 = '4') OR (p0 = '5' AND p1 = '5') OR (p0 = '6' AND p1 = '6') OR (p0 = '7' AND p1 = '7') OR (p0 = '8' AND p1 = '8') OR (p0 = '9' AND p1 = '9') OR (p0 = '10' AND p1 = '10') OR (p0 = '11' AND p1 = '11') OR (p0 = '12' AND p1 = '12') OR (p0 = '13' AND p1 = '13') OR (p0 = '14' AND p1 = '14') OR (p0 = '15' AND p1 = '15') OR (p0 = '16' AND p1 = '16') OR (p0 = '17' AND p1 = '17') OR (p0 = '18' AND p1 = '18') OR (p0 = '19' AND p1 = '19') OR (p0 = '20' AND p1 = '20')
```
will be converted into a long query(130K characters) in Hive metastore, and there will be error:
```
javax.jdo.JDOException: Exception thrown when executing query : SELECT DISTINCT 'org.apache.hadoop.hive.metastore.model.MPartition' AS NUCLEUS_TYPE,A0.CREATE_TIME,A0.LAST_ACCESS_TIME,A0.PART_NAME,A0.PART_ID,A0.PART_NAME AS NUCORDER0 FROM PARTITIONS A0 LEFT OUTER JOIN TBLS B0 ON A0.TBL_ID = B0.TBL_ID LEFT OUTER JOIN DBS C0 ON B0.DB_ID = C0.DB_ID WHERE B0.TBL_NAME = ? AND C0."NAME" = ? AND ((((((A0.PART_NAME LIKE '%/p1=1' ESCAPE '\' ) OR (A0.PART_NAME LIKE '%/p1=2' ESCAPE '\' )) OR (A0.PART_NAME LIKE '%/p1=3' ESCAPE '\' )) OR ((A0.PART_NAME LIKE '%/p1=4' ESCAPE '\' ) O ...
```
Essentially, we just need to traverse predicate and extract the convertible sub-predicates like what we did in https://github.com/apache/spark/pull/24598. There is no need to maintain the CNF result set.
### Why are the changes needed?
A better implementation for pushing down disjunctive and complex predicates. The pushed down predicates is always equal or shorter than the CNF result.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests
Closes#29101 from gengliangwang/pushJoin.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR intends to fix a bug of distinct FIRST/LAST aggregates in v2.4.6/v3.0.0/master;
```
scala> sql("SELECT FIRST(DISTINCT v) FROM VALUES 1, 2, 3 t(v)").show()
...
Caused by: java.lang.UnsupportedOperationException: Cannot evaluate expression: false#37
at org.apache.spark.sql.catalyst.expressions.Unevaluable$class.eval(Expression.scala:258)
at org.apache.spark.sql.catalyst.expressions.AttributeReference.eval(namedExpressions.scala:226)
at org.apache.spark.sql.catalyst.expressions.aggregate.First.ignoreNulls(First.scala:68)
at org.apache.spark.sql.catalyst.expressions.aggregate.First.updateExpressions$lzycompute(First.scala:82)
at org.apache.spark.sql.catalyst.expressions.aggregate.First.updateExpressions(First.scala:81)
at org.apache.spark.sql.execution.aggregate.HashAggregateExec$$anonfun$15.apply(HashAggregateExec.scala:268)
```
A root cause of this bug is that the `Aggregation` strategy replaces a foldable boolean `ignoreNullsExpr` expr with a `Unevaluable` expr (`AttributeReference`) for distinct FIRST/LAST aggregate functions. But, this operation cannot be allowed because the `Analyzer` has checked that it must be foldabe;
ffdbbae1d4/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/aggregate/First.scala (L74-L76)
So, this PR proposes to change a vriable for `IGNORE NULLS` from `Expression` to `Boolean` to avoid the case.
### Why are the changes needed?
Bugfix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added a test in `DataFrameAggregateSuite`.
Closes#29143 from maropu/SPARK-32344.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
New `spark.sql.metadataCacheTTLSeconds` option that adds time-to-live cache behaviour to the existing caches in `FileStatusCache` and `SessionCatalog`.
### Why are the changes needed?
Currently Spark [caches file listing for tables](https://spark.apache.org/docs/2.4.4/sql-data-sources-parquet.html#metadata-refreshing) and requires issuing `REFRESH TABLE` any time the file listing has changed outside of Spark. Unfortunately, simply submitting `REFRESH TABLE` commands could be very cumbersome. Assuming frequently added files, hundreds of tables and dozens of users querying the data (and expecting up-to-date results), manually refreshing metadata for each table is not a solution.
This is a pretty common use-case for streaming ingestion of data, which can be done outside of Spark (with tools like Kafka Connect, etc.).
A similar feature exists in Presto: `hive.file-status-cache-expire-time` can be found [here](https://prestosql.io/docs/current/connector/hive.html#hive-configuration-properties).
### Does this PR introduce _any_ user-facing change?
Yes, it's controlled with the new `spark.sql.metadataCacheTTLSeconds` option.
When it's set to `-1` (by default), the behaviour of caches doesn't change, so it stays _backwards-compatible_.
Otherwise, you can specify a value in seconds, for example `spark.sql.metadataCacheTTLSeconds: 60` means 1-minute cache TTL.
### How was this patch tested?
Added new tests in:
- FileIndexSuite
- SessionCatalogSuite
Closes#28852 from sap1ens/SPARK-30616-metadata-cache-ttl.
Authored-by: Yaroslav Tkachenko <sapiensy@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to support pushed down filters in JSON datasource. The reason of pushing a filter up to `JacksonParser` is to apply the filter as soon as all its attributes become available i.e. converted from JSON field values to desired values according to the schema. This allows to skip parsing of the rest of JSON record and conversions of other values if the filter returns `false`. This can improve performance when pushed filters are highly selective and conversion of JSON string fields to desired values are comparably expensive ( for example, the conversion to `TIMESTAMP` values).
The main idea behind of `JsonFilters` is to group pushdown filters by their references, convert the grouped filters to expressions, and then compile to predicates. The predicates are indexed by schema field positions. Each predicate has a state with reference counter to non-set row fields. As soon as the counter reaches `0`, it can be applied to the row because all its dependencies has been set. Before processing new row, predicate's reference counter is reset to total number of predicate references (dependencies in a row).
The common code shared between `CSVFilters` and `JsonFilters` is moved to the `StructFilters` class and its companion object.
### Why are the changes needed?
The changes improve performance on synthetic benchmarks up to **27 times** on JDK 8 and **25** times on JDK 11:
```
OpenJDK 64-Bit Server VM 1.8.0_242-8u242-b08-0ubuntu3~18.04-b08 on Linux 4.15.0-1044-aws
Intel(R) Xeon(R) CPU E5-2670 v2 2.50GHz
Filters pushdown: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
w/o filters 25230 25255 22 0.0 252299.6 1.0X
pushdown disabled 25248 25282 33 0.0 252475.6 1.0X
w/ filters 905 911 8 0.1 9047.9 27.9X
```
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
- Added new test suites `JsonFiltersSuite` and `JacksonParserSuite`.
- By new end-to-end and case sensitivity tests in `JsonSuite`.
- By `CSVFiltersSuite`, `UnivocityParserSuite` and `CSVSuite`.
- Re-running `CSVBenchmark` and `JsonBenchmark` using Amazon EC2:
| Item | Description |
| ---- | ----|
| Region | us-west-2 (Oregon) |
| Instance | r3.xlarge (spot instance) |
| AMI | ami-06f2f779464715dc5 (ubuntu/images/hvm-ssd/ubuntu-bionic-18.04-amd64-server-20190722.1) |
| Java | OpenJDK8/11 installed by`sudo add-apt-repository ppa:openjdk-r/ppa` & `sudo apt install openjdk-11-jdk`|
and `./dev/run-benchmarks`:
```python
#!/usr/bin/env python3
import os
from sparktestsupport.shellutils import run_cmd
benchmarks = [
['sql/test', 'org.apache.spark.sql.execution.datasources.csv.CSVBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.datasources.json.JsonBenchmark']
]
print('Set SPARK_GENERATE_BENCHMARK_FILES=1')
os.environ['SPARK_GENERATE_BENCHMARK_FILES'] = '1'
for b in benchmarks:
print("Run benchmark: %s" % b[1])
run_cmd(['build/sbt', '%s:runMain %s' % (b[0], b[1])])
```
Closes#27366 from MaxGekk/json-filters-pushdown.
Lead-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Spark sql commands are failing on selecting the orc tables
Steps to reproduce
Example 1 -
Prerequisite - This is the location(/Users/test/tpcds_scale5data/date_dim) for orc data which is generated by the hive.
```
val table = """CREATE TABLE `date_dim` (
`d_date_sk` INT,
`d_date_id` STRING,
`d_date` TIMESTAMP,
`d_month_seq` INT,
`d_week_seq` INT,
`d_quarter_seq` INT,
`d_year` INT,
`d_dow` INT,
`d_moy` INT,
`d_dom` INT,
`d_qoy` INT,
`d_fy_year` INT,
`d_fy_quarter_seq` INT,
`d_fy_week_seq` INT,
`d_day_name` STRING,
`d_quarter_name` STRING,
`d_holiday` STRING,
`d_weekend` STRING,
`d_following_holiday` STRING,
`d_first_dom` INT,
`d_last_dom` INT,
`d_same_day_ly` INT,
`d_same_day_lq` INT,
`d_current_day` STRING,
`d_current_week` STRING,
`d_current_month` STRING,
`d_current_quarter` STRING,
`d_current_year` STRING)
USING orc
LOCATION '/Users/test/tpcds_scale5data/date_dim'"""
spark.sql(table).collect
val u = """select date_dim.d_date_id from date_dim limit 5"""
spark.sql(u).collect
```
Example 2
```
val table = """CREATE TABLE `test_orc_data` (
`_col1` INT,
`_col2` STRING,
`_col3` INT)
USING orc"""
spark.sql(table).collect
spark.sql("insert into test_orc_data values(13, '155', 2020)").collect
val df = """select _col2 from test_orc_data limit 5"""
spark.sql(df).collect
```
Its Failing with below error
```
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 2.0 failed 1 times, most recent failure: Lost task 0.0 in stage 2.0 (TID 2, 192.168.0.103, executor driver): java.lang.ArrayIndexOutOfBoundsException: 1
at org.apache.spark.sql.execution.datasources.orc.OrcColumnarBatchReader.initBatch(OrcColumnarBatchReader.java:156)
at org.apache.spark.sql.execution.datasources.orc.OrcFileFormat.$anonfun$buildReaderWithPartitionValues$7(OrcFileFormat.scala:258)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.org$apache$spark$sql$execution$datasources$FileScanRDD$$anon$$readCurrentFile(FileScanRDD.scala:141)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.nextIterator(FileScanRDD.scala:203)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:116)
at org.apache.spark.sql.execution.FileSourceScanExec$$anon$1.hasNext(DataSourceScanExec.scala:620)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.columnartorow_nextBatch_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:729)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:343)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:895)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:895)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:372)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:336)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:133)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:445)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1489)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:448)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)`
```
The reason behind this initBatch is not getting the schema that is needed to find out the column value in OrcFileFormat.scala
```
batchReader.initBatch(
TypeDescription.fromString(resultSchemaString)
```
### Why are the changes needed?
Spark sql queries for orc tables are failing
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test is added for this .Also Tested through spark shell and spark submit the failing queries
Closes#29045 from SaurabhChawla100/SPARK-32234.
Lead-authored-by: SaurabhChawla <saurabhc@qubole.com>
Co-authored-by: SaurabhChawla <s.saurabhtim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR adds the SQL standard command - `SET TIME ZONE` to the current default time zone displacement for the current SQL-session, which is the same as the existing `set spark.sql.session.timeZone=xxx'.
All in all, this PR adds syntax as following,
```
SET TIME ZONE LOCAL;
SET TIME ZONE 'valid time zone'; -- zone offset or region
SET TIME ZONE INTERVAL XXXX; -- xxx must in [-18, + 18] hours, * this range is bigger than ansi [-14, + 14]
```
### Why are the changes needed?
ANSI compliance and supply pure SQL users a way to retrieve all supported TimeZones
### Does this PR introduce _any_ user-facing change?
yes, add new syntax.
### How was this patch tested?
add unit tests.
and locally verified reference doc

Closes#29064 from yaooqinn/SPARK-32272.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR will remove references to these "blacklist" and "whitelist" terms besides the blacklisting feature as a whole, which can be handled in a separate JIRA/PR.
This touches quite a few files, but the changes are straightforward (variable/method/etc. name changes) and most quite self-contained.
### Why are the changes needed?
As per discussion on the Spark dev list, it will be beneficial to remove references to problematic language that can alienate potential community members. One such reference is "blacklist" and "whitelist". While it seems to me that there is some valid debate as to whether these terms have racist origins, the cultural connotations are inescapable in today's world.
### Does this PR introduce _any_ user-facing change?
In the test file `HiveQueryFileTest`, a developer has the ability to specify the system property `spark.hive.whitelist` to specify a list of Hive query files that should be tested. This system property has been renamed to `spark.hive.includelist`. The old property has been kept for compatibility, but will log a warning if used. I am open to feedback from others on whether keeping a deprecated property here is unnecessary given that this is just for developers running tests.
### How was this patch tested?
Existing tests should be suitable since no behavior changes are expected as a result of this PR.
Closes#28874 from xkrogen/xkrogen-SPARK-32036-rename-blacklists.
Authored-by: Erik Krogen <ekrogen@linkedin.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
This removes the undocumented and incomplete feature of "stateful aggregation" in continuous mode, which would reduce 1100+ lines of code.
### Why are the changes needed?
The work for the feature had been stopped for over an year, and no one asked/requested for the availability of such feature in community. Current state for the feature is that it only works with `coalesce(1)` which force the query to read and process, and write in "a" task, which doesn't make sense in production.
The remaining code increases the work on DSv2 changes as well - that's why I don't simply propose reverting relevant commits - the code path has been changed due to DSv2 evolution.
### Does this PR introduce _any_ user-facing change?
Technically no, because it's never documented and can't be used in production in current shape.
### How was this patch tested?
Existing tests.
Closes#29077 from HeartSaVioR/SPARK-31985.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This PR proposes to port forward #29098 to `collectAsArrowToR`. `collectAsArrowToR` follows `collectAsArrowToPython` in branch-2.4 due to the limitation of ARROW-4512. SparkR vectorization currently cannot use streaming format.
### Why are the changes needed?
For simplicity and consistency.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
The same code is being tested in `collectAsArrowToPython` of branch-2.4.
Closes#29100 from HyukjinKwon/minor-parts.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Override `canonicalized` to empty the `inputEncoders` for the canonicalized `ScalaUDF`.
### Why are the changes needed?
The following fails on `branch-3.0` currently, not on Apache Spark 3.0.0 release.
```scala
spark.udf.register("key", udf((m: Map[String, String]) => m.keys.head.toInt))
Seq(Map("1" -> "one", "2" -> "two")).toDF("a").createOrReplaceTempView("t")
checkAnswer(sql("SELECT key(a) AS k FROM t GROUP BY key(a)"), Row(1) :: Nil)
[info] org.apache.spark.sql.AnalysisException: expression 't.`a`' is neither present in the group by, nor is it an aggregate function. Add to group by or wrap in first() (or first_value) if you don't care which value you get.;;
[info] Aggregate [UDF(a#6)], [UDF(a#6) AS k#8]
[info] +- SubqueryAlias t
[info] +- Project [value#3 AS a#6]
[info] +- LocalRelation [value#3]
[info] at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.failAnalysis(CheckAnalysis.scala:49)
[info] at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.failAnalysis$(CheckAnalysis.scala:48)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer.failAnalysis(Analyzer.scala:130)
[info] at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.checkValidAggregateExpression$1(CheckAnalysis.scala:257)
[info] at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.$anonfun$checkAnalysis$10(CheckAnalysis.scala:259)
[info] at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.$anonfun$checkAnalysis$10$adapted(CheckAnalysis.scala:259)
[info] at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
[info] at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
[info] at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
[info] at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.checkValidAggregateExpression$1(CheckAnalysis.scala:259)
[info] at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.$anonfun$checkAnalysis$10(CheckAnalysis.scala:259)
[info] at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.$anonfun$checkAnalysis$10$adapted(CheckAnalysis.scala:259)
[info] at scala.collection.immutable.List.foreach(List.scala:392)
[info] at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.checkValidAggregateExpression$1(CheckAnalysis.scala:259)
...
```
We use the rule`ResolveEncodersInUDF` to resolve `inputEncoders` and the original`ScalaUDF` instance will be updated to a new `ScalaUDF` instance with the resolved encoders at the end. Note, during encoder resolving, types like `map`, `array` will be resolved to new expression(e.g. `MapObjects`, `CatalystToExternalMap`).
However, `ExpressionEncoder` can't be canonicalized. Thus, the canonicalized `ScalaUDF`s become different even if their original `ScalaUDF`s are the same. Finally, it fails the `checkValidAggregateExpression` when this `ScalaUDF` is used as a group expression.
### Does this PR introduce _any_ user-facing change?
Yes, users will not hit the exception after this fix.
### How was this patch tested?
Added tests.
Closes#29106 from Ngone51/spark-32307.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Continuation of https://github.com/apache/spark/pull/28971 which lets streaming, catalyst and sql compile for 2.13. Same idea.
### Why are the changes needed?
Eventually, we need to support a Scala 2.13 build, perhaps in Spark 3.1.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests. (2.13 was not tested; this is about getting it to compile without breaking 2.12)
Closes#29078 from srowen/SPARK-29292.2.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
follow comment https://github.com/apache/spark/pull/29035#discussion_r453468999
Explain for pr
### Why are the changes needed?
add comment
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#29084 from AngersZhuuuu/follow-spark-32220.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
* Renamed hive transform scrip class `hive/execution/ScriptTransformationExec` to `hive/execution/HiveScriptTransformationExec` (don't rename file)
* Extract class `BaseScriptTransformationExec ` about common code used across `SparkScriptTransformationExec(next pr add this)` and `HiveScriptTransformationExec`
* Extract class `BaseScriptTransformationWriterThread` of writing data thread across `SparkScriptTransformationWriterThread(added next for support transform in sql/core )` and `HiveScriptTransformationWriterThread` ,
* `HiveScriptTransformationWriterThread` additionally supports Hive serde format
* Rename current `Script` strategies in hive module to `HiveScript`, in next pr will add `SparkScript` strategies for support transform in sql/core.
Todo List;
- Support transform in sql/core base on `BaseScriptTransformationExec`, which would run script operator in SQL mode (without Hive).
The output of script would be read as a string and column values are extracted by using a delimiter (default : tab character)
- For Hive, by default only serde's must be used, and without hive we can run without serde
- Cleanup past hacks that are observed (and people suggest / report), such as
- [Solve string value error about Date/Timestamp in ScriptTransform](https://issues.apache.org/jira/browse/SPARK-31947)
- [support use transform with aggregation](https://issues.apache.org/jira/browse/SPARK-28227)
- [support array/map as transform's input](https://issues.apache.org/jira/browse/SPARK-22435)
- Use code-gen projection to serialize rows to output stream()
### Why are the changes needed?
Support run transform in SQL mode without hive
### Does this PR introduce any user-facing change?
Yes
### How was this patch tested?
Added UT
Closes#27983 from AngersZhuuuu/follow_spark_15694.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to use text datasource in CSV's schema inference. This shares the same reasons of SPARK-18362, SPARK-19885 and SPARK-19918 - we're currently using Hadoop RDD when the encoding is different, which is unnecessary. This PR completes SPARK-18362, and address the comment at https://github.com/apache/spark/pull/15813#discussion_r90751405.
We should better keep the code paths consistent with existing CSV and JSON datasources as well, but this CSV schema inference with the encoding specified is different from UTF-8 alone.
There can be another story that this PR might lead to a bug fix: Spark session configurations, say Hadoop configurations, are not respected during CSV schema inference when the encoding is different (but it has to be set to Spark context for schema inference when the encoding is different).
### Why are the changes needed?
For consistency, potentially better performance, and fixing a potentially very corner case bug.
### Does this PR introduce _any_ user-facing change?
Virtually no.
### How was this patch tested?
Existing tests should cover.
Closes#29063 from HyukjinKwon/SPARK-32270.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR proposes to use `ExpressionEncoder` for the return type of ScalaUDF to convert to the catalyst type, instead of using `CatalystTypeConverters`.
Note, this change only takes effect for typed Scala UDF since its the only case where we know the type tag of the raw type.
### Why are the changes needed?
Users now could register a UDF with `Instant`/`LocalDate` as return types even with `spark.sql.datetime.java8API.enabled=false`. However, the UDF can not really be used.
For example, if we try:
```scala
scala> sql("set spark.sql.datetime.java8API.enabled=false")
scala> spark.udf.register("buildDate", udf{ d: String => java.time.LocalDate.parse(d) })
scala> Seq("2020-07-02").toDF("d").selectExpr("CAST(buildDate(d) AS STRING)").show
```
Then, we will hit the error:
```scala
java.lang.ClassCastException: java.time.LocalDate cannot be cast to java.sql.Date
at org.apache.spark.sql.catalyst.CatalystTypeConverters$DateConverter$.toCatalystImpl(CatalystTypeConverters.scala:304)
at org.apache.spark.sql.catalyst.CatalystTypeConverters$CatalystTypeConverter.toCatalyst(CatalystTypeConverters.scala:107)
at org.apache.spark.sql.catalyst.CatalystTypeConverters$.$anonfun$createToCatalystConverter$2(CatalystTypeConverters.scala:425)
at org.apache.spark.sql.catalyst.expressions.ScalaUDF.eval(ScalaUDF.scala:1169)
...
```
as it actually requires enabling `spark.sql.datetime.java8API.enabled` when using the UDF. And I think this could make users get confused.
This happens because when registering the UDF, Spark actually uses `ExpressionEncoder` to ser/deser types. However, when using UDF, Spark uses `CatalystTypeConverters`, which is under control of `spark.sql.datetime.java8API.enabled`, to ser/deser types. Therefore, Spark would fail to convert the Java8 date time types.
If we could also use `ExpressionEncoder` to ser/deser types for the return type, similar to what we do for the input parameter types, then, UDF could support Instant/LocalDate, event other combined complex types as well.
### Does this PR introduce _any_ user-facing change?
Yes. Before this PR, if users run the demo above, they would hit the error. After this PR, the demo will run successfully.
### How was this patch tested?
Updated 2 tests and added a new one for combined types of `Instant` and `LocalDate`.
Closes#28979 from Ngone51/udf-return-encoder.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This patch proposes to make `unionByName` optionally fill missing columns with nulls.
### Why are the changes needed?
Currently, `unionByName` throws exception if detecting different column names between two Datasets. It is strict requirement and sometimes users require more flexible usage that two Datasets with different subset of columns can be union by name resolution.
### Does this PR introduce _any_ user-facing change?
Yes. Adding overloading `Dataset.unionByName` with a boolean parameter that allows different set of column names between two Datasets. Missing columns at each side, will be filled with null values.
### How was this patch tested?
Unit test.
Closes#28996 from viirya/SPARK-29358.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
The purpose of this PR is to partly resolve SPARK-29292, and fully resolve SPARK-30010, which should allow Spark to compile vs Scala 2.13 in Spark Core and up through GraphX (not SQL, Streaming, etc).
Note that we are not trying to determine here whether this makes Spark work on 2.13 yet, just compile, as a prerequisite for assessing test outcomes. However, of course, we need to ensure that the change does not break 2.12.
The changes are, in the main, adding .toSeq and .toMap calls where mutable collections / maps are returned as Seq / Map, which are immutable by default in Scala 2.13. The theory is that it should be a no-op for Scala 2.12 (these return themselves), and required for 2.13.
There are a few non-trivial changes highlighted below.
In particular, to get Core to compile, we need to resolve SPARK-30010 which removes a deprecated SparkConf method
### Why are the changes needed?
Eventually, we need to support a Scala 2.13 build, perhaps in Spark 3.1.
### Does this PR introduce _any_ user-facing change?
Yes, removal of the deprecated SparkConf.setAll overload, which isn't legal in Scala 2.13 anymore.
### How was this patch tested?
Existing tests. (2.13 was not _tested_; this is about getting it to compile without breaking 2.12)
Closes#28971 from srowen/SPARK-29292.1.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR proposes to use `Utils.getSimpleName(function)` instead of `function.getClass.getSimpleName` to get the class name.
### Why are the changes needed?
For some functions(see the demo below), using `function.getClass.getSimpleName` can hit "Malformed class name" error.
### Does this PR introduce _any_ user-facing change?
Yes. For the demo,
```scala
object MalformedClassObject extends Serializable {
class MalformedNonPrimitiveFunction extends (String => Int) with Serializable {
override def apply(v1: String): Int = v1.toInt / 0
}
}
OuterScopes.addOuterScope(MalformedClassObject)
val f = new MalformedClassObject.MalformedNonPrimitiveFunction()
Seq("20").toDF("col").select(udf(f).apply(Column("col"))).collect()
```
Before this PR, user can only see the error about "Malformed class name":
```scala
An exception or error caused a run to abort: Malformed class name
java.lang.InternalError: Malformed class name
at java.lang.Class.getSimpleName(Class.java:1330)
at org.apache.spark.sql.catalyst.expressions.ScalaUDF.udfErrorMessage$lzycompute(ScalaUDF.scala:1157)
at org.apache.spark.sql.catalyst.expressions.ScalaUDF.udfErrorMessage(ScalaUDF.scala:1155)
at org.apache.spark.sql.catalyst.expressions.ScalaUDF.doGenCode(ScalaUDF.scala:1077)
at org.apache.spark.sql.catalyst.expressions.Expression.$anonfun$genCode$3(Expression.scala:147)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.catalyst.expressions.Expression.genCode(Expression.scala:142)
at org.apache.spark.sql.catalyst.expressions.Alias.genCode(namedExpressions.scala:160)
at org.apache.spark.sql.execution.ProjectExec.$anonfun$doConsume$1(basicPhysicalOperators.scala:69)
...
```
After this PR, user can see the real root cause of the udf failure:
```scala
org.apache.spark.SparkException: Failed to execute user defined function(UDFSuite$MalformedClassObject$MalformedNonPrimitiveFunction: (string) => int)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:753)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:340)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:898)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:898)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:127)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:464)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:467)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.ArithmeticException: / by zero
at org.apache.spark.sql.UDFSuite$MalformedClassObject$MalformedNonPrimitiveFunction.apply(UDFSuite.scala:677)
at org.apache.spark.sql.UDFSuite$MalformedClassObject$MalformedNonPrimitiveFunction.apply(UDFSuite.scala:676)
... 17 more
```
### How was this patch tested?
Added a test.
Closes#29050 from Ngone51/fix-malformed-udf.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
In current Join Hint strategies, if we use SHUFFLE_REPLICATE_NL hint, it will directly convert join to Cartesian Product Join and loss join condition making result not correct.
For Example:
```
spark-sql> select * from test4 order by a asc;
1 2
Time taken: 1.063 seconds, Fetched 4 row(s)20/07/08 14:11:25 INFO SparkSQLCLIDriver: Time taken: 1.063 seconds, Fetched 4 row(s)
spark-sql>select * from test5 order by a asc
1 2
2 2
Time taken: 1.18 seconds, Fetched 24 row(s)20/07/08 14:13:59 INFO SparkSQLCLIDriver: Time taken: 1.18 seconds, Fetched 24 row(s)spar
spark-sql>select /*+ shuffle_replicate_nl(test4) */ * from test4 join test5 where test4.a = test5.a order by test4.a asc ;
1 2 1 2
1 2 2 2
Time taken: 0.351 seconds, Fetched 2 row(s)
20/07/08 14:18:16 INFO SparkSQLCLIDriver: Time taken: 0.351 seconds, Fetched 2 row(s)
```
### Why are the changes needed?
Fix wrong data result
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
Added UT
Closes#29035 from AngersZhuuuu/SPARK-32220.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
In this PR, I suppose we support 'f'-suffixed float literal, e.g. `select 1.1f`
### Why are the changes needed?
a very common feature across platforms, checked with pg, presto, hive, MySQL...
### Does this PR introduce _any_ user-facing change?
yes,
`select 1.1f` results float value 1.1 instead of throwing AnlaysisExceptiion`Can't extract value from 1: need struct type but got int;`
### How was this patch tested?
add unit tests
Closes#29022 from yaooqinn/SPARK-32207.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR proposes to partially reverts the simple string in `NullType` at https://github.com/apache/spark/pull/28833: `NullType.simpleString` back from `unknown` to `null`.
### Why are the changes needed?
- Technically speaking, it's orthogonal with the issue itself, SPARK-20680.
- It needs some more discussion, see https://github.com/apache/spark/pull/28833#issuecomment-655277714
### Does this PR introduce _any_ user-facing change?
It reverts back the user-facing changes at https://github.com/apache/spark/pull/28833.
The simple string of `NullType` is back to `null`.
### How was this patch tested?
I just logically reverted. Jenkins should test it out.
Closes#29041 from HyukjinKwon/SPARK-20680.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Introduce a new SQL config `spark.sql.optimizer.ignoreHints`. When this is set to true
application of hints are disabled. This is similar to Oracle's OPTIMIZER_IGNORE_HINTS.
This can be helpful to study the impact of performance difference when hints are applied vs when they are not.
### Why are the changes needed?
Can be helpful to study the impact of performance difference when hints are applied vs when they are not.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
New tests added in ResolveHintsSuite.
Closes#28683 from dilipbiswal/disable_hint.
Authored-by: Dilip Biswal <dkbiswal@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
Context: The fix for SPARK-27296 introduced by #25024 allows `Aggregator` objects to appear in queries. This works fine for aggregators with atomic input types, e.g. `Aggregator[Double, _, _]`.
However it can cause a null pointer exception if the input type is `Array[_]`. This was historically considered an ignorable case for serialization of `UnresolvedMapObjects`, but the new ScalaAggregator class causes these expressions to be serialized over to executors because the resolve-and-bind is being deferred.
### What changes were proposed in this pull request?
A new rule `ResolveEncodersInScalaAgg` that performs the resolution of the expressions contained in the encoders so that properly resolved expressions are serialized over to executors.
### Why are the changes needed?
Applying an aggregator of the form `Aggregator[Array[_], _, _]` using `functions.udaf()` currently causes a null pointer error in Catalyst.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
A unit test has been added that does aggregation with array types for input, buffer, and output. I have done additional testing with my own custom aggregators in the spark REPL.
Closes#28983 from erikerlandson/fix-spark-32159.
Authored-by: Erik Erlandson <eerlands@redhat.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch fixes the odd join result being occurred from stream-stream join for state store format V2.
There're some spots on V2 path which leverage UnsafeProjection. As the result row is reused, the row should be copied to avoid changing value during reading (or make sure the caller doesn't affect by such behavior) but `SymmetricHashJoinStateManager.removeByValueCondition` violates the case.
This patch makes `KeyWithIndexToValueRowConverterV2.convertValue` copy the row by itself so that callers don't need to take care about it. This patch doesn't change the behavior of `KeyWithIndexToValueRowConverterV2.convertToValueRow` to avoid double-copying, as the caller is expected to store the row which the implementation of state store will call `copy()`.
This patch adds such behavior into each method doc in `KeyWithIndexToValueRowConverter`, so that further contributors can read through and make sure the change / new addition doesn't break the contract.
### Why are the changes needed?
Stream-stream join with state store format V2 (newly added in Spark 3.0.0) has a serious correctness bug which brings indeterministic result.
### Does this PR introduce _any_ user-facing change?
Yes, some of Spark 3.0.0 users using stream-stream join from the new checkpoint (as the bug exists to only v2 format path) may encounter wrong join result. This patch will fix it.
### How was this patch tested?
Reported case is converted to the new UT, and confirmed UT passed. All UTs in StreamingInnerJoinSuite and StreamingOuterJoinSuite passed as well
Closes#28975 from HeartSaVioR/SPARK-32148.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/27627 to fix the remaining issues. There are 2 issues fixed in this PR:
1. `UnsafeRow.setDecimal` can set an overflowed decimal and causes an error when reading it. The expected behavior is to return null.
2. The update/merge expression for decimal type in `Sum` is wrong. We shouldn't turn the `sum` value back to 0 after it becomes null due to overflow. This issue was hidden because:
2.1 for hash aggregate, the buffer is unsafe row. Due to the first bug, we fail when overflow happens, so there is no chance to mistakenly turn null back to 0.
2.2 for sort-based aggregate, the buffer is generic row. The decimal can overflow (the Decimal class has unlimited precision) and we don't have the null problem.
If we only fix the first bug, then the second bug is exposed and test fails. If we only fix the second bug, there is no way to test it. This PR fixes these 2 bugs together.
### Why are the changes needed?
Fix issues during decimal sum when overflow happens
### Does this PR introduce _any_ user-facing change?
Yes. Now decimal sum can return null correctly for overflow under non-ansi mode.
### How was this patch tested?
new test and updated test
Closes#29026 from cloud-fan/decimal.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to disallow to create `SparkContext` in executors, e.g., in UDFs.
### Why are the changes needed?
Currently executors can create SparkContext, but shouldn't be able to create it.
```scala
sc.range(0, 1).foreach { _ =>
new SparkContext(new SparkConf().setAppName("test").setMaster("local"))
}
```
### Does this PR introduce _any_ user-facing change?
Yes, users won't be able to create `SparkContext` in executors.
### How was this patch tested?
Addes tests.
Closes#28986 from ueshin/issues/SPARK-32160/disallow_spark_context_in_executors.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
When converting an `INSERT OVERWRITE` query to a v2 overwrite plan, Spark attempts to detect when a dynamic overwrite and a static overwrite will produce the same result so it can use the static overwrite. Spark incorrectly detects when dynamic and static overwrites are equivalent when there are hidden partitions, such as `days(ts)`.
This updates the analyzer rule `ResolveInsertInto` to always use a dynamic overwrite when the mode is dynamic, and static when the mode is static. This avoids the problem by not trying to determine whether the two plans are equivalent and always using the one that corresponds to the partition overwrite mode.
### Why are the changes needed?
This is a correctness bug. If a table has hidden partitions, all of the values for those partitions are dropped instead of dynamically overwriting changed partitions.
This only affects SQL commands (not `DataFrameWriter`) writing to tables that have hidden partitions. It is also only a problem when the partition overwrite mode is dynamic.
### Does this PR introduce _any_ user-facing change?
Yes, it fixes the correctness bug detailed above.
### How was this patch tested?
* This updates the in-memory table to support a hidden partition transform, `days`, and adds a test case to `DataSourceV2SQLSuite` in which the table uses this hidden partition function. This test fails without the fix to `ResolveInsertInto`.
* This updates the test case `InsertInto: overwrite - multiple static partitions - dynamic mode` in `InsertIntoTests`. The result of the SQL command is unchanged, but the SQL command will now use a dynamic overwrite so the test now uses `dynamicOverwriteTest`.
Closes#28993 from rdblue/fix-insert-overwrite-v2-conversion.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR fixes an inconsistency in `EvaluatePython.makeFromJava`, which creates a type conversion function for some Java/Scala types.
`other` is a type but it should actually pass `obj`:
```scala
case other => (obj: Any) => nullSafeConvert(other)(PartialFunction.empty)
```
This does not change the output because it always returns `null` for unsupported datatypes.
### Why are the changes needed?
To make the codes coherent, and consistent.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
No behaviour change.
Closes#29029 from sarutak/fix-makeFromJava.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is the new PR which to address the close one #17953
1. support "void" primitive data type in the `AstBuilder`, point it to `NullType`
2. forbid creating tables with VOID/NULL column type
### Why are the changes needed?
1. Spark is incompatible with hive void type. When Hive table schema contains void type, DESC table will throw an exception in Spark.
>hive> create table bad as select 1 x, null z from dual;
>hive> describe bad;
OK
x int
z void
In Spark2.0.x, the behaviour to read this view is normal:
>spark-sql> describe bad;
x int NULL
z void NULL
Time taken: 4.431 seconds, Fetched 2 row(s)
But in lastest Spark version, it failed with SparkException: Cannot recognize hive type string: void
>spark-sql> describe bad;
17/05/09 03:12:08 ERROR thriftserver.SparkSQLDriver: Failed in [describe bad]
org.apache.spark.SparkException: Cannot recognize hive type string: void
Caused by: org.apache.spark.sql.catalyst.parser.ParseException:
DataType void() is not supported.(line 1, pos 0)
== SQL ==
void
^^^
... 61 more
org.apache.spark.SparkException: Cannot recognize hive type string: void
2. Hive CTAS statements throws error when select clause has NULL/VOID type column since HIVE-11217
In Spark, creating table with a VOID/NULL column should throw readable exception message, include
- create data source table (using parquet, json, ...)
- create hive table (with or without stored as)
- CTAS
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Add unit tests
Closes#28833 from LantaoJin/SPARK-20680_COPY.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This patch proposes to deal with cosmetic variations when processing nested column extractors in `NestedColumnAliasing`. Currently if cosmetic variations are in the nested column extractors, the query is not optimized.
### Why are the changes needed?
If the expressions extracting nested fields have cosmetic variations like qualifier difference, currently nested column pruning cannot work well.
For example, two attributes which are semantically the same, are referred in a query, but the nested column extractors of them are treated differently when we deal with nested column pruning.
### Does this PR introduce _any_ user-facing change?
Yes, fixing a bug in nested column pruning.
### How was this patch tested?
Unit test.
Closes#28988 from viirya/SPARK-32163.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Added a new `withField` method to the `Column` class. This method should allow users to add or replace a `StructField` in a `StructType` column (with very similar semantics to the `withColumn` method on `Dataset`).
### Why are the changes needed?
Often Spark users have to work with deeply nested data e.g. to fix a data quality issue with an existing `StructField`. To do this with the existing Spark APIs, users have to rebuild the entire struct column.
For example, let's say you have the following deeply nested data structure which has a data quality issue (`5` is missing):
```
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
val data = spark.createDataFrame(sc.parallelize(
Seq(Row(Row(Row(1, 2, 3), Row(Row(4, null, 6), Row(7, 8, 9), Row(10, 11, 12)), Row(13, 14, 15))))),
StructType(Seq(
StructField("a", StructType(Seq(
StructField("a", StructType(Seq(
StructField("a", IntegerType),
StructField("b", IntegerType),
StructField("c", IntegerType)))),
StructField("b", StructType(Seq(
StructField("a", StructType(Seq(
StructField("a", IntegerType),
StructField("b", IntegerType),
StructField("c", IntegerType)))),
StructField("b", StructType(Seq(
StructField("a", IntegerType),
StructField("b", IntegerType),
StructField("c", IntegerType)))),
StructField("c", StructType(Seq(
StructField("a", IntegerType),
StructField("b", IntegerType),
StructField("c", IntegerType))))
))),
StructField("c", StructType(Seq(
StructField("a", IntegerType),
StructField("b", IntegerType),
StructField("c", IntegerType))))
)))))).cache
data.show(false)
+---------------------------------+
|a |
+---------------------------------+
|[[1, 2, 3], [[4,, 6], [7, 8, 9]]]|
+---------------------------------+
```
Currently, to replace the missing value users would have to do something like this:
```
val result = data.withColumn("a",
struct(
$"a.a",
struct(
struct(
$"a.b.a.a",
lit(5).as("b"),
$"a.b.a.c"
).as("a"),
$"a.b.b",
$"a.b.c"
).as("b"),
$"a.c"
))
result.show(false)
+---------------------------------------------------------------+
|a |
+---------------------------------------------------------------+
|[[1, 2, 3], [[4, 5, 6], [7, 8, 9], [10, 11, 12]], [13, 14, 15]]|
+---------------------------------------------------------------+
```
As you can see above, with the existing methods users must call the `struct` function and list all fields, including fields they don't want to change. This is not ideal as:
>this leads to complex, fragile code that cannot survive schema evolution.
[SPARK-16483](https://issues.apache.org/jira/browse/SPARK-16483)
In contrast, with the method added in this PR, a user could simply do something like this:
```
val result = data.withColumn("a", 'a.withField("b.a.b", lit(5)))
result.show(false)
+---------------------------------------------------------------+
|a |
+---------------------------------------------------------------+
|[[1, 2, 3], [[4, 5, 6], [7, 8, 9], [10, 11, 12]], [13, 14, 15]]|
+---------------------------------------------------------------+
```
This is the first of maybe a few methods that could be added to the `Column` class to make it easier to manipulate nested data. Other methods under discussion in [SPARK-22231](https://issues.apache.org/jira/browse/SPARK-22231) include `drop` and `renameField`. However, these should be added in a separate PR.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
New unit tests were added. Jenkins must pass them.
### Related JIRAs:
- https://issues.apache.org/jira/browse/SPARK-22231
- https://issues.apache.org/jira/browse/SPARK-16483Closes#27066 from fqaiser94/SPARK-22231-withField.
Lead-authored-by: fqaiser94@gmail.com <fqaiser94@gmail.com>
Co-authored-by: fqaiser94 <fqaiser94@gmail.com>
Co-authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Fix nullability of `GetArrayStructFields`. It should consider both the original array's `containsNull` and the inner field's nullability.
### Why are the changes needed?
Fix a correctness issue.
### Does this PR introduce _any_ user-facing change?
Yes. See the added test.
### How was this patch tested?
a new UT and end-to-end test
Closes#28992 from cloud-fan/bug.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Set the JSON option `inferTimestamp` to `true` for the cases that measure perf of timestamp inference.
### Why are the changes needed?
The PR https://github.com/apache/spark/pull/28966 disabled timestamp inference by default. As a consequence, some benchmarks don't measure perf of timestamp inference from JSON fields. This PR explicitly enable such inference.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By re-generating results of `JsonBenchmark`.
Closes#28981 from MaxGekk/json-inferTimestamps-disable-by-default-followup.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Check the namespace existence while calling "use namespace", and throw NoSuchNamespaceException if namespace not exists.
### Why are the changes needed?
Users need to know that the namespace does not exist when they try to set a wrong namespace.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Run all suites and add a test for this
Closes#27900 from stczwd/SPARK-31100.
Authored-by: stczwd <qcsd2011@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For queries like `t1d in (SELECT t2d FROM t2 ORDER BY t2c LIMIT 2)`, the result can be non-deterministic as the result of the subquery may output different results (it's not sorted by `t2d` and it has shuffle).
This PR makes the test more robust by sorting the output column.
### Why are the changes needed?
avoid flaky test
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
N/A
Closes#28976 from cloud-fan/small.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This patch fixes wrong groupBy result if the grouping key is a null-value struct.
### Why are the changes needed?
`NormalizeFloatingNumbers` reconstructs a struct if input expression is StructType. If the input struct is null, it will reconstruct a struct with null-value fields, instead of null.
### Does this PR introduce _any_ user-facing change?
Yes, fixing incorrect groupBy result.
### How was this patch tested?
Unit test.
Closes#28962 from viirya/SPARK-32136.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
As the followup of #28900, this patch extends coalescing partitions to repartitioning using hints and SQL syntax without specifying number of partitions, when AQE is enabled.
### Why are the changes needed?
When repartitionning using hints and SQL syntax, we should follow the shuffling behavior of repartition by expression/range to coalesce partitions when AQE is enabled.
### Does this PR introduce _any_ user-facing change?
Yes. After this change, if users don't specify the number of partitions when repartitioning using `REPARTITION`/`REPARTITION_BY_RANGE` hint or `DISTRIBUTE BY`/`CLUSTER BY`, AQE will coalesce partitions.
### How was this patch tested?
Unit tests.
Closes#28952 from viirya/SPARK-32056-sql.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Set the JSON option `inferTimestamp` to `false` if an user don't pass it as datasource option.
### Why are the changes needed?
To prevent perf regression while inferring schemas from JSON with potential timestamps fields.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
- Modified existing tests in `JsonSuite` and `JsonInferSchemaSuite`.
- Regenerated results of `JsonBenchmark` in the environment:
| Item | Description |
| ---- | ----|
| Region | us-west-2 (Oregon) |
| Instance | r3.xlarge |
| AMI | ubuntu/images/hvm-ssd/ubuntu-bionic-18.04-amd64-server-20190722.1 (ami-06f2f779464715dc5) |
| Java | OpenJDK 64-Bit Server VM 1.8.0_252 and OpenJDK 64-Bit Server VM 11.0.7+10 |
Closes#28966 from MaxGekk/json-inferTimestamps-disable-by-default.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/28760 to fix the remaining issues:
1. should consider data source options when refreshing cache by path at the end of `InsertIntoHadoopFsRelationCommand`
2. should consider data source options when inferring schema for file source
3. should consider data source options when getting the qualified path in file source v2.
### Why are the changes needed?
We didn't catch these issues in https://github.com/apache/spark/pull/28760, because the test case is to check error when initializing the file system. If we initialize the file system multiple times during a simple read/write action, the test case actually only test the first time.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
rewrite the test to make sure the entire data source read/write action can succeed.
Closes#28948 from cloud-fan/fix.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/28534 , to make `TIMESTAMP_SECONDS` function support fractional input as well.
### Why are the changes needed?
Previously the cast function can cast fractional values to timestamp. Now we suggest users to ues these new functions, and we need to cover all the cast use cases.
### Does this PR introduce _any_ user-facing change?
Yes, now `TIMESTAMP_SECONDS` function accepts fractional input.
### How was this patch tested?
new tests
Closes#28956 from cloud-fan/follow.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Spark can't push down scan predicate condition of **Or**:
Such as if I have a table `default.test`, it's partition col is `dt`,
If we use query :
```
select * from default.test
where dt=20190625 or (dt = 20190626 and id in (1,2,3) )
```
In this case, Spark will resolve **Or** condition as one expression, and since this expr has reference of "id", then it can't been push down.
Base on pr https://github.com/apache/spark/pull/28733, In my PR , for SQL like
`select * from default.test`
`where dt = 20190626 or (dt = 20190627 and xxx="a") `
For this condition `dt = 20190626 or (dt = 20190627 and xxx="a" )`, it will been converted to CNF
```
(dt = 20190626 or dt = 20190627) and (dt = 20190626 or xxx = "a" )
```
then condition `dt = 20190626 or dt = 20190627` will be push down when partition pruning
### Why are the changes needed?
Optimize partition pruning
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
Added UT
Closes#28805 from AngersZhuuuu/cnf-for-partition-pruning.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to partially reverts back in the tests and some codes at https://github.com/apache/spark/pull/27728 without touching any behaivours.
Most of changes in tests are back before #27728 by combining `withNestedDataFrame` and `withParquetDataFrame`.
Basically, it addresses the comments https://github.com/apache/spark/pull/27728#discussion_r397655390, and my own comment in another PR at https://github.com/apache/spark/pull/28761#discussion_r446761037
### Why are the changes needed?
For maintenance purpose and to avoid a potential conflicts during backports. And also in case when other codes are matched with this.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Manually tested.
Closes#28955 from HyukjinKwon/SPARK-25556-followup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
JDBC connection providers implementation formatted in a wrong way. In this PR I've fixed the formatting.
### Why are the changes needed?
Wrong spacing in JDBC connection providers.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing unit tests.
Closes#28945 from gaborgsomogyi/provider_spacing.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
When loading DataFrames from JDBC datasource with Kerberos authentication, remote executors (yarn-client/cluster etc. modes) fail to establish a connection due to lack of Kerberos ticket or ability to generate it.
This is a real issue when trying to ingest data from kerberized data sources (SQL Server, Oracle) in enterprise environment where exposing simple authentication access is not an option due to IT policy issues.
In this PR I've added Oracle support.
What this PR contains:
* Added `OracleConnectionProvider`
* Added `OracleConnectionProviderSuite`
### Why are the changes needed?
Missing JDBC kerberos support.
### Does this PR introduce _any_ user-facing change?
Yes, now user is able to connect to Oracle using kerberos.
### How was this patch tested?
* Additional + existing unit tests
* Test on cluster manually
Closes#28863 from gaborgsomogyi/SPARK-31336.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This patch fixes the missed spot - the test initializes FileStreamSinkLog with its "output" directory instead of "metadata" directory, hence the verification against sink log was no-op.
### Why are the changes needed?
Without the fix, the verification against sink log was no-op.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Checked with debugger in test, and verified `allFiles()` returns non-zero entries. (It returned zero entry, as there's no metadata.)
Closes#28930 from HeartSaVioR/SPARK-29999-FOLLOWUP-fix-test.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR tries to unify the method `getReader` and `getReaderForRange` in `ShuffleManager`.
### Why are the changes needed?
Reduce the duplicate codes, simplify the implementation, and for better maintenance.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Covered by existing tests.
Closes#28895 from Ngone51/unify-getreader.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch proposes to coalesce partitions for repartition by expressions without specifying number of partitions, when AQE is enabled.
### Why are the changes needed?
When repartition by some partition expressions, users can specify number of partitions or not. If the number of partitions is specified, we should not coalesce partitions because it breaks user expectation. But if without specifying number of partitions, AQE should be able to coalesce partitions as other shuffling.
### Does this PR introduce _any_ user-facing change?
Yes. After this change, if users don't specify the number of partitions when repartitioning data by expressions, AQE will coalesce partitions.
### How was this patch tested?
Added unit test.
Closes#28900 from viirya/SPARK-32056.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/28876/files
This PR proposes to use the name of the original expression, as the alias name of the normalization expression.
### Why are the changes needed?
make the query plan looks pretty when EXPLAIN.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
manually explain the query
Closes#28919 from cloud-fan/follow.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR fix `UserDefinedType.equal()` by comparing the UDT class instead of checking `acceptsType()`.
### Why are the changes needed?
It's weird that equality comparison between two UDT types can have different result by switching the order:
```scala
// ExampleSubTypeUDT.userClass is a subclass of ExampleBaseTypeUDT.userClass
val udt1 = new ExampleBaseTypeUDT
val udt2 = new ExampleSubTypeUDT
println(udt1 == udt2) // true
println(udt2 == udt1) // false
```
### Does this PR introduce _any_ user-facing change?
Yes.
Before:
```scala
// ExampleSubTypeUDT.userClass is a subclass of ExampleBaseTypeUDT.userClass
val udt1 = new ExampleBaseTypeUDT
val udt2 = new ExampleSubTypeUDT
println(udt1 == udt2) // true
println(udt2 == udt1) // false
```
After:
```scala
// ExampleSubTypeUDT.userClass is a subclass of ExampleBaseTypeUDT.userClass
val udt1 = new ExampleBaseTypeUDT
val udt2 = new ExampleSubTypeUDT
println(udt1 == udt2) // false
println(udt2 == udt1) // false
```
### How was this patch tested?
Added a unit test.
Closes#28923 from Ngone51/fix-udt-equal.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
The `optimizedPlan` in IncrementalExecution should also be scoped in `withActive`.
### Why are the changes needed?
Follow-up of SPARK-30798 for the Streaming side.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing UT.
Closes#28936 from xuanyuanking/SPARK-30798-follow.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Add benchmarks for interval constructor `make_interval` and measure perf of 4 cases:
1. Constant (year, month)
2. Constant (week, day)
3. Constant (hour, minute, second, second fraction)
4. All fields are NOT constant.
The benchmark results are generated in the environment:
| Item | Description |
| ---- | ----|
| Region | us-west-2 (Oregon) |
| Instance | r3.xlarge |
| AMI | ubuntu/images/hvm-ssd/ubuntu-bionic-18.04-amd64-server-20190722.1 (ami-06f2f779464715dc5) |
| Java | OpenJDK 64-Bit Server VM 1.8.0_252 and OpenJDK 64-Bit Server VM 11.0.7+10 |
### Why are the changes needed?
To have a base line for future perf improvements of `make_interval`, and to prevent perf regressions in the future.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running `IntervalBenchmark` via:
```
$ SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.IntervalBenchmark"
```
Closes#28905 from MaxGekk/benchmark-make_interval.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Add American timezone during timestamp_seconds doctest
### Why are the changes needed?
`timestamp_seconds` doctest in `functions.py` used default timezone to get expected result
For example:
```python
>>> time_df = spark.createDataFrame([(1230219000,)], ['unix_time'])
>>> time_df.select(timestamp_seconds(time_df.unix_time).alias('ts')).collect()
[Row(ts=datetime.datetime(2008, 12, 25, 7, 30))]
```
But when we have a non-american timezone, the test case will get different test result.
For example, when we set current timezone as `Asia/Shanghai`, the test result will be
```
[Row(ts=datetime.datetime(2008, 12, 25, 23, 30))]
```
So no matter where we run the test case ,we will always get the expected permanent result if we set the timezone on one specific area.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes#28932 from GuoPhilipse/SPARK-32088-fix-timezone-issue.
Lead-authored-by: GuoPhilipse <46367746+GuoPhilipse@users.noreply.github.com>
Co-authored-by: GuoPhilipse <guofei_ok@126.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This pull request fixes a bug present in the csv type inference.
We have problems when we have different types in the same column.
**Previously:**
```
$ cat /example/f1.csv
col1
43200000
true
spark.read.csv(path="file:///example/*.csv", header=True, inferSchema=True).show()
+----+
|col1|
+----+
|null|
|true|
+----+
root
|-- col1: boolean (nullable = true)
```
**Now**
```
spark.read.csv(path="file:///example/*.csv", header=True, inferSchema=True).show()
+-------------+
|col1 |
+-------------+
|43200000 |
|true |
+-------------+
root
|-- col1: string (nullable = true)
```
Previously the hierarchy of type inference is the following:
> IntegerType
> > LongType
> > > DecimalType
> > > > DoubleType
> > > > > TimestampType
> > > > > > BooleanType
> > > > > > > StringType
So, when, for example, we have integers in one column, and the last element is a boolean, all the column is inferred as a boolean column incorrectly and all the number are shown as null when you see the data
We need the following hierarchy. When we have different numeric types in the column it will be resolved correctly. And when we have other different types it will be resolved as a String type column
> IntegerType
> > LongType
> > > DecimalType
> > > > DoubleType
> > > > > StringType
> TimestampType
> > StringType
> BooleanType
> > StringType
> StringType
### Why are the changes needed?
Fix the bug explained
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test and manual tests
Closes#28896 from planga82/feature/SPARK-32025_csv_inference.
Authored-by: Pablo Langa <soypab@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR tries to address the comment: https://github.com/apache/spark/pull/28645#discussion_r442183888
It changes `canUpCast/canCast` to allow cast from sub UDT to base UDT, in order to achieve the goal to allow UserDefinedType to use `ExpressionEncoder` to deserialize rows in ScalaUDF as well.
One thing that needs to mention is, even we allow cast from sub UDT to base UDT, it doesn't really do the cast in `Cast`. Because, yet, sub UDT and base UDT are considered as the same type(because of #16660), see:
5264164a67/sql/catalyst/src/main/scala/org/apache/spark/sql/types/UserDefinedType.scala (L81-L86)5264164a67/sql/catalyst/src/main/scala/org/apache/spark/sql/types/UserDefinedType.scala (L92-L95)
Therefore, the optimize rule `SimplifyCast` will eliminate the cast at the end.
### Why are the changes needed?
Reduce the special case caused by `UserDefinedType` in `ResolveEncodersInUDF` and `ScalaUDF`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
It should be covered by the test of `SPARK-19311`, which is also updated a little in this PR.
Closes#28920 from Ngone51/fix-udf-udt.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Reset listenerRegistered when application end.
### Why are the changes needed?
Within a jvm, stop and create `SparkContext` multi times will cause the bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Add UT.
Closes#28899 from ulysses-you/SPARK-32062.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Replace Decimal by Int op in the `MakeInterval` & `MakeTimestamp` expression. For instance, `(secs * Decimal(MICROS_PER_SECOND)).toLong` can be replaced by the unscaled long because the former one already contains microseconds.
### Why are the changes needed?
To improve performance.
Before:
```
make_timestamp(): Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
...
make_timestamp(2019, 1, 2, 3, 4, 50.123456) 94 99 4 10.7 93.8 38.8X
```
After:
```
make_timestamp(2019, 1, 2, 3, 4, 50.123456) 76 92 15 13.1 76.5 48.1X
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- By existing test suites `IntervalExpressionsSuite`, `DateExpressionsSuite` and etc.
- Re-generate results of `MakeDateTimeBenchmark` in the environment:
| Item | Description |
| ---- | ----|
| Region | us-west-2 (Oregon) |
| Instance | r3.xlarge |
| AMI | ubuntu/images/hvm-ssd/ubuntu-bionic-18.04-amd64-server-20190722.1 (ami-06f2f779464715dc5) |
| Java | OpenJDK 64-Bit Server VM 1.8.0_252 and OpenJDK 64-Bit Server VM 11.0.7+10 |
Closes#28886 from MaxGekk/make_interval-opt-decimal.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR changes the references of the `PartialMerge`/`Final` `AggregateExpression` from `aggBufferAttributes` to `inputAggBufferAttributes`.
After this change, the tests of `SPARK-31620` can fail on the assertion of `QueryTest.assertEmptyMissingInput`. So, this PR also fixes it by overriding the `inputAggBufferAttributes` of the Aggregate operators.
### Why are the changes needed?
With my understanding of Aggregate framework, especially, according to the logic of `AggUtils.planAggXXX`, I think for the `PartialMerge`/`Final` `AggregateExpression` the right references should be `inputAggBufferAttributes`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Before this patch, for an Aggregate operator, its input attributes will always be equal to or more than(because it refers to its own attributes while it should refer to the attributes from the child) its reference attributes. Therefore, its missing inputs must always be empty and break nothing. Thus, it's impossible to add a UT for this patch.
However, after correcting the right references in this PR, the problem is then exposed by `QueryTest.assertEmptyMissingInput` in the UT of SPARK-31620, since missing inputs are no longer always empty. This PR can fix the problem.
Closes#28869 from Ngone51/fix-agg-reference.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch applies `NormalizeFloatingNumbers` to distinct aggregate to fix a regression of distinct aggregate on NaNs.
### Why are the changes needed?
We added `NormalizeFloatingNumbers` optimization rule in 3.0.0 to normalize special floating numbers (NaN and -0.0). But it is missing in distinct aggregate so causes a regression. We need to apply this rule on distinct aggregate to fix it.
### Does this PR introduce _any_ user-facing change?
Yes, fixing a regression of distinct aggregate on NaNs.
### How was this patch tested?
Added unit test.
Closes#28876 from viirya/SPARK-32038.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Add compatibility tests for streaming state store format.
### Why are the changes needed?
After SPARK-31894, we have a validation checking for the streaming state store. It's better to add integrated tests in the PR builder as soon as the breaking changes introduced.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Test only.
Closes#28725 from xuanyuanking/compatibility_check.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add a new config `spark.sql.files.minPartitionNum` to control file split partition in local session.
### Why are the changes needed?
Aims to control file split partitions in session level.
More details see discuss in [PR-28778](https://github.com/apache/spark/pull/28778).
### Does this PR introduce _any_ user-facing change?
Yes, new config.
### How was this patch tested?
Add UT.
Closes#28853 from ulysses-you/SPARK-32019.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Change precision of seconds and its fraction from 8 to 18 to be able to construct intervals of max allowed microseconds value (long).
### Why are the changes needed?
To improve UX of Spark SQL.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
- Add tests to IntervalExpressionsSuite
- Add an example to the `MakeInterval` expression
- Add tests to `interval.sql`
Closes#28873 from MaxGekk/make_interval-sec-precision.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
When two bucketed tables with different number of buckets are joined, it can introduce a full shuffle:
```
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "0")
val df1 = (0 until 20).map(i => (i % 5, i % 13, i.toString)).toDF("i", "j", "k")
val df2 = (0 until 20).map(i => (i % 7, i % 11, i.toString)).toDF("i", "j", "k")
df1.write.format("parquet").bucketBy(8, "i").saveAsTable("t1")
df2.write.format("parquet").bucketBy(4, "i").saveAsTable("t2")
val t1 = spark.table("t1")
val t2 = spark.table("t2")
val joined = t1.join(t2, t1("i") === t2("i"))
joined.explain
== Physical Plan ==
*(5) SortMergeJoin [i#44], [i#50], Inner
:- *(2) Sort [i#44 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(i#44, 200), true, [id=#105]
: +- *(1) Project [i#44, j#45, k#46]
: +- *(1) Filter isnotnull(i#44)
: +- *(1) ColumnarToRow
: +- FileScan parquet default.t1[i#44,j#45,k#46] Batched: true, DataFilters: [isnotnull(i#44)], Format: Parquet, Location: InMemoryFileIndex[...], PartitionFilters: [], PushedFilters: [IsNotNull(i)], ReadSchema: struct<i:int,j:int,k:string>, SelectedBucketsCount: 8 out of 8
+- *(4) Sort [i#50 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(i#50, 200), true, [id=#115]
+- *(3) Project [i#50, j#51, k#52]
+- *(3) Filter isnotnull(i#50)
+- *(3) ColumnarToRow
+- FileScan parquet default.t2[i#50,j#51,k#52] Batched: true, DataFilters: [isnotnull(i#50)], Format: Parquet, Location: InMemoryFileIndex[...], PartitionFilters: [], PushedFilters: [IsNotNull(i)], ReadSchema: struct<i:int,j:int,k:string>, SelectedBucketsCount: 4 out of 4
```
This PR proposes to introduce coalescing buckets when the following conditions are met to eliminate the full shuffle:
- Join is the sort merge one (which is created only for equi-join).
- Join keys match with output partition expressions on their respective sides.
- The larger bucket number is divisible by the smaller bucket number.
- `spark.sql.bucketing.coalesceBucketsInSortMergeJoin.enabled` is set to `true`.
- The ratio of the number of buckets should be less than the value set in `spark.sql.bucketing.coalesceBucketsInSortMergeJoin.maxBucketRatio`.
### Why are the changes needed?
Eliminating the full shuffle can benefit for scenarios where two large tables are joined. Especially when the tables are already bucketed but differ in the number of buckets, we could take advantage of it.
### Does this PR introduce any user-facing change?
If the bucket coalescing conditions explained above are met, a full shuffle can be eliminated (also note that you will see `SelectedBucketsCount: 8 out of 8 (Coalesced to 4)` in the physical plan):
```
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "0")
spark.conf.set("spark.sql.bucketing.coalesceBucketsInSortMergeJoin.enabled", "true")
val df1 = (0 until 20).map(i => (i % 5, i % 13, i.toString)).toDF("i", "j", "k")
val df2 = (0 until 20).map(i => (i % 7, i % 11, i.toString)).toDF("i", "j", "k")
df1.write.format("parquet").bucketBy(8, "i").saveAsTable("t1")
df2.write.format("parquet").bucketBy(4, "i").saveAsTable("t2")
val t1 = spark.table("t1")
val t2 = spark.table("t2")
val joined = t1.join(t2, t1("i") === t2("i"))
joined.explain
== Physical Plan ==
*(3) SortMergeJoin [i#44], [i#50], Inner
:- *(1) Sort [i#44 ASC NULLS FIRST], false, 0
: +- *(1) Project [i#44, j#45, k#46]
: +- *(1) Filter isnotnull(i#44)
: +- *(1) ColumnarToRow
: +- FileScan parquet default.t1[i#44,j#45,k#46] Batched: true, DataFilters: [isnotnull(i#44)], Format: Parquet, Location: InMemoryFileIndex[...], PartitionFilters: [], PushedFilters: [IsNotNull(i)], ReadSchema: struct<i:int,j:int,k:string>, SelectedBucketsCount: 8 out of 8 (Coalesced to 4)
+- *(2) Sort [i#50 ASC NULLS FIRST], false, 0
+- *(2) Project [i#50, j#51, k#52]
+- *(2) Filter isnotnull(i#50)
+- *(2) ColumnarToRow
+- FileScan parquet default.t2[i#50,j#51,k#52] Batched: true, DataFilters: [isnotnull(i#50)], Format: Parquet, Location: InMemoryFileIndex[...], PartitionFilters: [], PushedFilters: [IsNotNull(i)], ReadSchema: struct<i:int,j:int,k:string>, SelectedBucketsCount: 4 out of 4
```
### How was this patch tested?
Added unit tests
Closes#28123 from imback82/coalescing_bucket.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR adds support for typed Scala UDF to accept composed type of case class, e.g. Seq[T], Array[T], Map[Int, T] (assuming T is case class type), as input parameter type.
### Why are the changes needed?
After #27937, typed Scala UDF now has supported case class as its input parameter type. However, it can not accept the composed type of case class, such as Seq[T], Array[T], Map[Int, T] (assuming T is case class type), which causing confuse(e.g. https://github.com/apache/spark/pull/27937#discussion_r422699979) to the user.
### Does this PR introduce _any_ user-facing change?
Yes.
Run the query:
```
scala> case class Person(name: String, age: Int)
scala> Seq((1, Seq(Person("Jack", 5)))).toDF("id", "persons").withColumn("ages", udf{ s: Seq[Person] => s.head.age }.apply(col("persons"))).show
```
Before:
```
org.apache.spark.SparkException: Failed to execute user defined function($read$$Lambda$2861/628175152: (array<struct<name:string,age:int>>) => int)
at org.apache.spark.sql.catalyst.expressions.ScalaUDF.eval(ScalaUDF.scala:1129)
at org.apache.spark.sql.catalyst.expressions.Alias.eval(namedExpressions.scala:156)
at org.apache.spark.sql.catalyst.expressions.InterpretedMutableProjection.apply(InterpretedMutableProjection.scala:83)
at org.apache.spark.sql.catalyst.optimizer.ConvertToLocalRelation$$anonfun$apply$17.$anonfun$applyOrElse$69(Optimizer.scala:1492)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
....
Caused by: java.lang.ClassCastException: org.apache.spark.sql.catalyst.expressions.GenericRowWithSchema cannot be cast to Person
at $anonfun$res3$1(<console>:30)
at $anonfun$res3$1$adapted(<console>:30)
at org.apache.spark.sql.catalyst.expressions.ScalaUDF.$anonfun$f$2(ScalaUDF.scala:156)
at org.apache.spark.sql.catalyst.expressions.ScalaUDF.eval(ScalaUDF.scala:1126)
... 142 more
```
After:
```
+---+-----------+----+
| id| persons|ages|
+---+-----------+----+
| 1|[[Jack, 5]]| [5]|
+---+-----------+----+
```
### How was this patch tested?
Added tests.
Closes#28645 from Ngone51/impr-udf.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Introduce UnsafeRow format validation for streaming state store.
### Why are the changes needed?
Currently, Structured Streaming directly puts the UnsafeRow into StateStore without any schema validation. It's a dangerous behavior when users reusing the checkpoint file during migration. Any changes or bug fix related to the aggregate function may cause random exceptions, even the wrong answer, e.g SPARK-28067.
### Does this PR introduce _any_ user-facing change?
Yes. If the underlying changes are detected when the checkpoint is reused during migration, the InvalidUnsafeRowException will be thrown.
### How was this patch tested?
UT added. Will also add integrated tests for more scenario in another PR separately.
Closes#28707 from xuanyuanking/SPARK-31894.
Lead-authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Co-authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Move TimeZoneUTC and TimeZoneGMT to DateTimeTestUtils
2. Remove TimeZoneGMT
3. Use ZoneId.systemDefault() instead of defaultTimeZone().toZoneId
4. Alias SQLDate & SQLTimestamp to internal types of DateType and TimestampType
5. Avoid one `*` `DateTimeUtils`.`in fromJulianDay()`
6. Use toTotalMonths in `DateTimeUtils`.`subtractDates()`
7. Remove `julianCommonEraStart`, `timestampToString()`, `microsToEpochDays()`, `epochDaysToMicros()`, `instantToDays()` from `DateTimeUtils`.
8. Make splitDate() private.
9. Remove `def daysToMicros(days: Int): Long` and `def microsToDays(micros: Long): Int`.
### Why are the changes needed?
This simplifies the common code related to date-time operations, and should improve maintainability. In particular:
1. TimeZoneUTC and TimeZoneGMT are moved to DateTimeTestUtils because they are used only in tests
2. TimeZoneGMT can be removed because it is equal to TimeZoneUTC
3. After the PR #27494, Spark expressions and DateTimeUtils functions switched to ZoneId instead of TimeZone completely. `defaultTimeZone()` with `TimeZone` as return type is not needed anymore.
4. SQLDate and SQLTimestamp types can be explicitly aliased to internal types of DateType and and TimestampType instead of declaring this in a comment.
5. Avoid one `*` `DateTimeUtils`.`in fromJulianDay()`.
6. Use toTotalMonths in `DateTimeUtils`.`subtractDates()`.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By existing test suites
Closes#27617 from MaxGekk/move-time-zone-consts.
Lead-authored-by: Max Gekk <max.gekk@gmail.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Better error message when SPARK_HOME or spark,test.home is not set.
### Why are the changes needed?
Currently the error message is not easily consumable as it prints (see below) the real error after printing the current environment which is rather long.
**Old output**
`
time.name" -> "Java(TM) SE Runtime Environment", "sun.boot.library.path" -> "/Library/Java/JavaVirtualMachines/jdk1.8.0_221.jdk/Contents/Home/jre/lib",
"java.vm.version" -> "25.221-b11",
. . .
. . .
. . .
) did not contain key "SPARK_HOME" spark.test.home or SPARK_HOME is not set.
at org.scalatest.Assertions.newAssertionFailedExceptio
`
**New output**
An exception or error caused a run to abort: spark.test.home or SPARK_HOME is not set.
org.scalatest.exceptions.TestFailedException: spark.test.home or SPARK_HOME is not set
### Does this PR introduce any user-facing change?
`
No.
### How was this patch tested?
Ran the tests in intellej manually to see the new error.
Closes#28825 from dilipbiswal/minor-spark-31950-followup.
Authored-by: Dilip Biswal <dkbiswal@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. Add method `getTimeFormatters` to `HiveResult` which creates timestamp and date formatters.
2. Move creation of `dateFormatter` and `timestampFormatter` from the constructor of the `HiveResult` object to `HiveResult. hiveResultString()` via `getTimeFormatters`. This allows to resolve time zone ID from Spark's session time zone `spark.sql.session.timeZone` and create date/timestamp formatters only once before collecting `java.sql.Timestamp`/`java.sql.Date` values.
3. Create date/timestamp formatters once in SparkExecuteStatementOperation.
### Why are the changes needed?
To fix perf regression comparing to Spark 2.4
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- By existing test suite `HiveResultSuite` and etc.
- Re-generate benchmarks results of `DateTimeBenchmark` in the environment:
| Item | Description |
| ---- | ----|
| Region | us-west-2 (Oregon) |
| Instance | r3.xlarge |
| AMI | ubuntu/images/hvm-ssd/ubuntu-bionic-18.04-amd64-server-20190722.1 (ami-06f2f779464715dc5) |
| Java | OpenJDK 64-Bit Server VM 1.8.0_252 and OpenJDK 64-Bit Server VM 11.0.7+10 |
Closes#28842 from MaxGekk/opt-toHiveString-oss-master.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When loading DataFrames from JDBC datasource with Kerberos authentication, remote executors (yarn-client/cluster etc. modes) fail to establish a connection due to lack of Kerberos ticket or ability to generate it.
This is a real issue when trying to ingest data from kerberized data sources (SQL Server, Oracle) in enterprise environment where exposing simple authentication access is not an option due to IT policy issues.
In this PR I've added MS SQL support.
What this PR contains:
* Added `MSSQLConnectionProvider`
* Added `MSSQLConnectionProviderSuite`
* Changed MS SQL JDBC driver to use the latest (test scope only)
* Changed `MsSqlServerIntegrationSuite` docker image to use the latest
* Added a version comment to `MariaDBConnectionProvider` to increase trackability
### Why are the changes needed?
Missing JDBC kerberos support.
### Does this PR introduce _any_ user-facing change?
Yes, now user is able to connect to MS SQL using kerberos.
### How was this patch tested?
* Additional + existing unit tests
* Existing integration tests
* Test on cluster manually
Closes#28635 from gaborgsomogyi/SPARK-31337.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@apache.org>
### What changes were proposed in this pull request?
Replace `CAST(... AS TIMESTAMP` by `TIMESTAMP_SECONDS` in the following benchmarks:
- ExtractBenchmark
- DateTimeBenchmark
- FilterPushdownBenchmark
- InExpressionBenchmark
### Why are the changes needed?
The benchmarks fail w/o the changes:
```
[info] Running benchmark: datetime +/- interval
[info] Running case: date + interval(m)
[error] Exception in thread "main" org.apache.spark.sql.AnalysisException: cannot resolve 'CAST(`id` AS TIMESTAMP)' due to data type mismatch: cannot cast bigint to timestamp,you can enable the casting by setting spark.sql.legacy.allowCastNumericToTimestamp to true,but we strongly recommend using function TIMESTAMP_SECONDS/TIMESTAMP_MILLIS/TIMESTAMP_MICROS instead.; line 1 pos 5;
[error] 'Project [(cast(cast(id#0L as timestamp) as date) + 1 months) AS (CAST(CAST(id AS TIMESTAMP) AS DATE) + INTERVAL '1 months')#2]
[error] +- Range (0, 10000000, step=1, splits=Some(1))
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running the affected benchmarks.
Closes#28843 from MaxGekk/GuoPhilipse-31710-fix-compatibility-followup.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
we fail casting from numeric to timestamp by default.
## Why are the changes needed?
casting from numeric to timestamp is not a non-standard,meanwhile it may generate different result between spark and other systems,for example hive
## Does this PR introduce any user-facing change?
Yes,user cannot cast numeric to timestamp directly,user have to use the following function to achieve the same effect:TIMESTAMP_SECONDS/TIMESTAMP_MILLIS/TIMESTAMP_MICROS
## How was this patch tested?
unit test added
Closes#28593 from GuoPhilipse/31710-fix-compatibility.
Lead-authored-by: GuoPhilipse <guofei_ok@126.com>
Co-authored-by: GuoPhilipse <46367746+GuoPhilipse@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR renames the variable from "numLateInputs" to "numRowsDroppedByWatermark" so that it becomes self-explanation.
### Why are the changes needed?
This is originated from post-review, see https://github.com/apache/spark/pull/28607#discussion_r439853232
### Does this PR introduce _any_ user-facing change?
No, as SPARK-24634 is not introduced in any release yet.
### How was this patch tested?
Existing UTs.
Closes#28828 from HeartSaVioR/SPARK-24634-v3-followup.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR partially revert SPARK-31292 in order to provide a hot-fix for a bug in `Dataset.dropDuplicates`; we must preserve the input order of `colNames` for `groupCols` because the Streaming's state store depends on the `groupCols` order.
### Why are the changes needed?
Bug fix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added tests in `DataFrameSuite`.
Closes#28830 from maropu/SPARK-31990.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
- Modify `DateTimeRebaseBenchmark` to benchmark the default date-time rebasing mode - `EXCEPTION` for saving/loading dates/timestamps from/to parquet files. The mode is benchmarked for modern timestamps after 1900-01-01 00:00:00Z and dates after 1582-10-15.
- Regenerate benchmark results in the environment:
| Item | Description |
| ---- | ----|
| Region | us-west-2 (Oregon) |
| Instance | r3.xlarge |
| AMI | ubuntu/images/hvm-ssd/ubuntu-bionic-18.04-amd64-server-20190722.1 (ami-06f2f779464715dc5) |
| Java | OpenJDK 64-Bit Server VM 1.8.0_252 and OpenJDK 64-Bit Server VM 11.0.7+10 |
### Why are the changes needed?
The `EXCEPTION` rebasing mode is the default mode of the SQL configs `spark.sql.legacy.parquet.datetimeRebaseModeInRead` and `spark.sql.legacy.parquet.datetimeRebaseModeInWrite`. The changes are needed to improve benchmark coverage for default settings.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running the benchmark and check results manually.
Closes#28829 from MaxGekk/benchmark-exception-mode.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In #28485 pagination support for tables of Structured Streaming Tab was added.
It missed 2 things:
* For sorting duration column, `String` was used which sometimes gives wrong results(consider `"3 ms"` and `"12 ms"`). Now we first sort the duration column and then convert it to readable String
* Status column was not made sortable.
### Why are the changes needed?
To fix the wrong result for sorting and making Status column sortable.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
After changes:
<img width="1677" alt="Screenshot 2020-06-08 at 2 18 48 PM" src="https://user-images.githubusercontent.com/15366835/84010992-153fa280-a993-11ea-9846-bf176f2ec5d7.png">
Closes#28752 from iRakson/ssTests.
Authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Please refer https://issues.apache.org/jira/browse/SPARK-24634 to see rationalization of the issue.
This patch adds a new metric to count the number of inputs arrived later than watermark plus allowed delay. To make changes simpler, this patch doesn't count the exact number of input rows which are later than watermark plus allowed delay. Instead, this patch counts the inputs which are dropped in the logic of operator. The difference of twos are shown in streaming aggregation: to optimize the calculation, streaming aggregation "pre-aggregates" the input rows, and later checks the lateness against "pre-aggregated" inputs, hence the number might be reduced.
The new metric will be provided via two places:
1. On Spark UI: check the metrics in stateful operator nodes in query execution details page in SQL tab
2. On Streaming Query Listener: check "numLateInputs" in "stateOperators" in QueryProcessEvent.
### Why are the changes needed?
Dropping late inputs means that end users might not get expected outputs. Even end users may indicate the fact and tolerate the result (as that's what allowed lateness is for), but they should be able to observe whether the current value of allowed lateness drops inputs or not so that they can adjust the value.
Also, whatever the chance they have multiple of stateful operators in a single query, if Spark drops late inputs "between" these operators, it becomes "correctness" issue. Spark should disallow such possibility, but given we already provided the flexibility, at least we should provide the way to observe the correctness issue and decide whether they should make correction of their query or not.
### Does this PR introduce _any_ user-facing change?
Yes. End users will be able to retrieve the information of late inputs via two ways:
1. SQL tab in Spark UI
2. Streaming Query Listener
### How was this patch tested?
New UTs added & existing UTs are modified to reflect the change.
And ran manual test reproducing SPARK-28094.
I've picked the specific case on "B outer C outer D" which is enough to represent the "intermediate late row" issue due to global watermark.
https://gist.github.com/jammann/b58bfbe0f4374b89ecea63c1e32c8f17
Spark logs warning message on the query which means SPARK-28074 is working correctly,
```
20/05/30 17:52:47 WARN UnsupportedOperationChecker: Detected pattern of possible 'correctness' issue due to global watermark. The query contains stateful operation which can emit rows older than the current watermark plus allowed late record delay, which are "late rows" in downstream stateful operations and these rows can be discarded. Please refer the programming guide doc for more details.;
Join LeftOuter, ((D_FK#28 = D_ID#87) AND (B_LAST_MOD#26-T30000ms = D_LAST_MOD#88-T30000ms))
:- Join LeftOuter, ((C_FK#27 = C_ID#58) AND (B_LAST_MOD#26-T30000ms = C_LAST_MOD#59-T30000ms))
: :- EventTimeWatermark B_LAST_MOD#26: timestamp, 30 seconds
: : +- Project [v#23.B_ID AS B_ID#25, v#23.B_LAST_MOD AS B_LAST_MOD#26, v#23.C_FK AS C_FK#27, v#23.D_FK AS D_FK#28]
: : +- Project [from_json(StructField(B_ID,StringType,false), StructField(B_LAST_MOD,TimestampType,false), StructField(C_FK,StringType,true), StructField(D_FK,StringType,true), value#21, Some(UTC)) AS v#23]
: : +- Project [cast(value#8 as string) AS value#21]
: : +- StreamingRelationV2 org.apache.spark.sql.kafka010.KafkaSourceProvider3a7fd18c, kafka, org.apache.spark.sql.kafka010.KafkaSourceProvider$KafkaTable396d2958, org.apache.spark.sql.util.CaseInsensitiveStringMapa51ee61a, [key#7, value#8, topic#9, partition#10, offset#11L, timestamp#12, timestampType#13], StreamingRelation DataSource(org.apache.spark.sql.SparkSessiond221af8,kafka,List(),None,List(),None,Map(inferSchema -> true, startingOffsets -> earliest, subscribe -> B, kafka.bootstrap.servers -> localhost:9092),None), kafka, [key#0, value#1, topic#2, partition#3, offset#4L, timestamp#5, timestampType#6]
: +- EventTimeWatermark C_LAST_MOD#59: timestamp, 30 seconds
: +- Project [v#56.C_ID AS C_ID#58, v#56.C_LAST_MOD AS C_LAST_MOD#59]
: +- Project [from_json(StructField(C_ID,StringType,false), StructField(C_LAST_MOD,TimestampType,false), value#54, Some(UTC)) AS v#56]
: +- Project [cast(value#41 as string) AS value#54]
: +- StreamingRelationV2 org.apache.spark.sql.kafka010.KafkaSourceProvider3f507373, kafka, org.apache.spark.sql.kafka010.KafkaSourceProvider$KafkaTable7b6736a4, org.apache.spark.sql.util.CaseInsensitiveStringMapa51ee61b, [key#40, value#41, topic#42, partition#43, offset#44L, timestamp#45, timestampType#46], StreamingRelation DataSource(org.apache.spark.sql.SparkSessiond221af8,kafka,List(),None,List(),None,Map(inferSchema -> true, startingOffsets -> earliest, subscribe -> C, kafka.bootstrap.servers -> localhost:9092),None), kafka, [key#33, value#34, topic#35, partition#36, offset#37L, timestamp#38, timestampType#39]
+- EventTimeWatermark D_LAST_MOD#88: timestamp, 30 seconds
+- Project [v#85.D_ID AS D_ID#87, v#85.D_LAST_MOD AS D_LAST_MOD#88]
+- Project [from_json(StructField(D_ID,StringType,false), StructField(D_LAST_MOD,TimestampType,false), value#83, Some(UTC)) AS v#85]
+- Project [cast(value#70 as string) AS value#83]
+- StreamingRelationV2 org.apache.spark.sql.kafka010.KafkaSourceProvider2b90e779, kafka, org.apache.spark.sql.kafka010.KafkaSourceProvider$KafkaTable36f8cd29, org.apache.spark.sql.util.CaseInsensitiveStringMapa51ee620, [key#69, value#70, topic#71, partition#72, offset#73L, timestamp#74, timestampType#75], StreamingRelation DataSource(org.apache.spark.sql.SparkSessiond221af8,kafka,List(),None,List(),None,Map(inferSchema -> true, startingOffsets -> earliest, subscribe -> D, kafka.bootstrap.servers -> localhost:9092),None), kafka, [key#62, value#63, topic#64, partition#65, offset#66L, timestamp#67, timestampType#68]
```
and we can find the late inputs from the batch 4 as follows:

which represents intermediate inputs are being lost, ended up with correctness issue.
Closes#28607 from HeartSaVioR/SPARK-24634-v3.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
A unit test is added
Partition duplicate check added in `org.apache.spark.sql.execution.datasources.PartitioningUtils#validatePartitionColumn`
### Why are the changes needed?
When people write data with duplicate partition column, it will cause a `org.apache.spark.sql.AnalysisException: Found duplicate column ...` in loading data from the writted.
### Does this PR introduce _any_ user-facing change?
Yes.
It will prevent people from using duplicate partition columns to write data.
1. Before the PR:
It will look ok at `df.write.partitionBy("b", "b").csv("file:///tmp/output")`,
but get an exception when read:
`spark.read.csv("file:///tmp/output").show()`
org.apache.spark.sql.AnalysisException: Found duplicate column(s) in the partition schema: `b`;
2. After the PR:
`df.write.partitionBy("b", "b").csv("file:///tmp/output")` will trigger the exception:
org.apache.spark.sql.AnalysisException: Found duplicate column(s) b, b: `b`;
### How was this patch tested?
Unit test.
Closes#28814 from TJX2014/master-SPARK-31968.
Authored-by: TJX2014 <xiaoxingstack@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Currently we only push nested column pruning through a few operators such as LIMIT, SAMPLE, etc. This patch extends the feature to other operators including RepartitionByExpression, Join.
### Why are the changes needed?
Currently nested column pruning only applied on a few operators. It limits the benefit of nested column pruning. Extending nested column pruning coverage to make this feature more generally applied through different queries.
### Does this PR introduce _any_ user-facing change?
Yes. More SQL operators are covered by nested column pruning.
### How was this patch tested?
Added unit test, end-to-end tests.
Closes#28556 from viirya/others-column-pruning.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR upgrades HtmlUnit.
Selenium and Jetty also upgraded because of dependency.
### Why are the changes needed?
Recently, a security issue which affects HtmlUnit is reported.
https://nvd.nist.gov/vuln/detail/CVE-2020-5529
According to the report, arbitrary code can be run by malicious users.
HtmlUnit is used for test so the impact might not be large but it's better to upgrade it just in case.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing testcases.
Closes#28585 from sarutak/upgrade-htmlunit.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/23388 .
https://github.com/apache/spark/pull/23388 has an issue: it doesn't handle subquery expressions and assumes they will be turned into joins. However, this is not true for non-correlated subquery expressions.
This PR fixes this issue. It now doesn't skip `Subquery`, and subquery expressions will be handled by `OptimizeSubqueries`, which runs the optimizer with the subquery.
Note that, correlated subquery expressions will be handled twice: once in `OptimizeSubqueries`, once later when it becomes join. This is OK as `NormalizeFloatingNumbers` is idempotent now.
### Why are the changes needed?
fix a bug
### Does this PR introduce _any_ user-facing change?
yes, see the newly added test.
### How was this patch tested?
new test
Closes#28785 from cloud-fan/normalize.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to remove package private in classes/objects in sql.execution package, as per SPARK-16964.
### Why are the changes needed?
This is per post-hoc review comment, see https://github.com/apache/spark/pull/24996#discussion_r437126445
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
N/A
Closes#28790 from HeartSaVioR/SPARK-28199-FOLLOWUP-apply-SPARK-16964.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR updates the test case to accept Hadoop 2/3 error message correctly.
### Why are the changes needed?
SPARK-31935(#28760) breaks Hadoop 3.2 UT because Hadoop 2 and Hadoop 3 have different exception messages.
In https://github.com/apache/spark/pull/28791, there are two test suites missed the fix
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes#28796 from gengliangwang/SPARK-31926-followup.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This reverts commit b9737c3c22 while keeping following changes
* set default value of `spark.sql.adaptive.skewJoin.skewedPartitionFactor` to 5
* improve tests
* remove unused imports
### Why are the changes needed?
As discussed in https://github.com/apache/spark/pull/28669#issuecomment-641044531, revert SPARK-31864 for optimizing skew join to work for extremely clustered keys.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#28770 from manuzhang/spark-31942.
Authored-by: manuzhang <owenzhang1990@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
If a datetime pattern contains no year field, the day of year field should not be ignored if exists
e.g.
```
spark-sql> select to_timestamp('31', 'DD');
1970-01-01 00:00:00
spark-sql> select to_timestamp('31 30', 'DD dd');
1970-01-30 00:00:00
spark.sql.legacy.timeParserPolicy legacy
spark-sql> select to_timestamp('31', 'DD');
1970-01-31 00:00:00
spark-sql> select to_timestamp('31 30', 'DD dd');
NULL
```
This PR only fixes some corner cases that use 'D' pattern to parse datetimes and there is w/o 'y'.
### Why are the changes needed?
fix some corner cases
### Does this PR introduce _any_ user-facing change?
yes, the day of year field will not be ignored
### How was this patch tested?
add unit tests.
Closes#28766 from yaooqinn/SPARK-31939.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR updates the test case to accept Hadoop 2/3 error message correctly.
### Why are the changes needed?
SPARK-31935(https://github.com/apache/spark/pull/28760) breaks Hadoop 3.2 UT because Hadoop 2 and Hadoop 3 have different exception messages.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the Jenkins with both Hadoop 2/3 or do the following manually.
**Hadoop 2.7**
```
$ build/sbt "sql/testOnly *.FileBasedDataSourceSuite -- -z SPARK-31935"
...
[info] All tests passed.
```
**Hadoop 3.2**
```
$ build/sbt "sql/testOnly *.FileBasedDataSourceSuite -- -z SPARK-31935" -Phadoop-3.2
...
[info] All tests passed.
```
Closes#28791 from dongjoon-hyun/SPARK-31935.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This is another approach to fix the issue. See the previous try https://github.com/apache/spark/pull/28745. It was too invasive so I took more conservative approach.
This PR proposes to resolve grouping attributes separately first so it can be properly referred when `FlatMapGroupsInPandas` and `FlatMapCoGroupsInPandas` are resolved without ambiguity.
Previously,
```python
from pyspark.sql.functions import *
df = spark.createDataFrame([[1, 1]], ["column", "Score"])
pandas_udf("column integer, Score float", PandasUDFType.GROUPED_MAP)
def my_pandas_udf(pdf):
return pdf.assign(Score=0.5)
df.groupby('COLUMN').apply(my_pandas_udf).show()
```
was failed as below:
```
pyspark.sql.utils.AnalysisException: "Reference 'COLUMN' is ambiguous, could be: COLUMN, COLUMN.;"
```
because the unresolved `COLUMN` in `FlatMapGroupsInPandas` doesn't know which reference to take from the child projection.
After this fix, it resolves the child projection first with grouping keys and pass, to `FlatMapGroupsInPandas`, the attribute as a grouping key from the child projection that is positionally selected.
### Why are the changes needed?
To resolve grouping keys correctly.
### Does this PR introduce _any_ user-facing change?
Yes,
```python
from pyspark.sql.functions import *
df = spark.createDataFrame([[1, 1]], ["column", "Score"])
pandas_udf("column integer, Score float", PandasUDFType.GROUPED_MAP)
def my_pandas_udf(pdf):
return pdf.assign(Score=0.5)
df.groupby('COLUMN').apply(my_pandas_udf).show()
```
```python
df1 = spark.createDataFrame([(1, 1)], ("column", "value"))
df2 = spark.createDataFrame([(1, 1)], ("column", "value"))
df1.groupby("COLUMN").cogroup(
df2.groupby("COLUMN")
).applyInPandas(lambda r, l: r + l, df1.schema).show()
```
Before:
```
pyspark.sql.utils.AnalysisException: Reference 'COLUMN' is ambiguous, could be: COLUMN, COLUMN.;
```
```
pyspark.sql.utils.AnalysisException: cannot resolve '`COLUMN`' given input columns: [COLUMN, COLUMN, value, value];;
'FlatMapCoGroupsInPandas ['COLUMN], ['COLUMN], <lambda>(column#9L, value#10L, column#13L, value#14L), [column#22L, value#23L]
:- Project [COLUMN#9L, column#9L, value#10L]
: +- LogicalRDD [column#9L, value#10L], false
+- Project [COLUMN#13L, column#13L, value#14L]
+- LogicalRDD [column#13L, value#14L], false
```
After:
```
+------+-----+
|column|Score|
+------+-----+
| 1| 0.5|
+------+-----+
```
```
+------+-----+
|column|value|
+------+-----+
| 2| 2|
+------+-----+
```
### How was this patch tested?
Unittests were added and manually tested.
Closes#28777 from HyukjinKwon/SPARK-31915-another.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/28695 , to fix the problem completely.
The root cause is that, `df("col").as("name")` is not a column reference anymore, and should not have the special column metadata. However, this was broken in ba7adc4949 (diff-ac415c903887e49486ba542a65eec980L1050-L1053)
This PR fixes the regression, by strip the special column metadata in `Column.name`, which is the behavior before https://github.com/apache/spark/pull/28326 .
### Why are the changes needed?
Fix a regression. We shouldn't fail if there is no ambiguous self-join.
### Does this PR introduce _any_ user-facing change?
Yes, the query in the test can run now.
### How was this patch tested?
updated test
Closes#28783 from cloud-fan/self-join.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Currently we only push nested column pruning from a Project through a few operators such as LIMIT, SAMPLE, etc. There are a few operators like Aggregate, Expand which can prune nested columns by themselves, without a Project on top.
This patch extends the feature to those operators.
### Why are the changes needed?
Currently nested column pruning only applied on a few cases. It limits the benefit of nested column pruning. Extending nested column pruning coverage to make this feature more generally applied through different queries.
### Does this PR introduce _any_ user-facing change?
Yes. More SQL operators are covered by nested column pruning.
### How was this patch tested?
Added unit test, end-to-end tests.
Closes#28560 from viirya/SPARK-27217-2.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to make `PythonFunction` holds `Seq[Byte]` instead of `Array[Byte]` to be able to compare if the byte array has the same values for the cache manager.
### Why are the changes needed?
Currently the cache manager doesn't use the cache for `udf` if the `udf` is created again even if the functions is the same.
```py
>>> func = lambda x: x
>>> df = spark.range(1)
>>> df.select(udf(func)("id")).cache()
```
```py
>>> df.select(udf(func)("id")).explain()
== Physical Plan ==
*(2) Project [pythonUDF0#14 AS <lambda>(id)#12]
+- BatchEvalPython [<lambda>(id#0L)], [pythonUDF0#14]
+- *(1) Range (0, 1, step=1, splits=12)
```
This is because `PythonFunction` holds `Array[Byte]`, and `equals` method of array equals only when the both array is the same instance.
### Does this PR introduce _any_ user-facing change?
Yes, if the user reuse the Python function for the UDF, the cache manager will detect the same function and use the cache for it.
### How was this patch tested?
I added a test case and manually.
```py
>>> df.select(udf(func)("id")).explain()
== Physical Plan ==
InMemoryTableScan [<lambda>(id)#12]
+- InMemoryRelation [<lambda>(id)#12], StorageLevel(disk, memory, deserialized, 1 replicas)
+- *(2) Project [pythonUDF0#5 AS <lambda>(id)#3]
+- BatchEvalPython [<lambda>(id#0L)], [pythonUDF0#5]
+- *(1) Range (0, 1, step=1, splits=12)
```
Closes#28774 from ueshin/issues/SPARK-31945/udf_cache.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Mkae Hadoop file system config effective in data source options.
From `org.apache.hadoop.fs.FileSystem.java`:
```
public static FileSystem get(URI uri, Configuration conf) throws IOException {
String scheme = uri.getScheme();
String authority = uri.getAuthority();
if (scheme == null && authority == null) { // use default FS
return get(conf);
}
if (scheme != null && authority == null) { // no authority
URI defaultUri = getDefaultUri(conf);
if (scheme.equals(defaultUri.getScheme()) // if scheme matches default
&& defaultUri.getAuthority() != null) { // & default has authority
return get(defaultUri, conf); // return default
}
}
String disableCacheName = String.format("fs.%s.impl.disable.cache", scheme);
if (conf.getBoolean(disableCacheName, false)) {
return createFileSystem(uri, conf);
}
return CACHE.get(uri, conf);
}
```
Before changes, the file system configurations in data source options are not propagated in `DataSource.scala`.
After changes, we can specify authority and URI schema related configurations for scanning file systems.
This problem only exists in data source V1. In V2, we already use `sparkSession.sessionState.newHadoopConfWithOptions(options)` in `FileTable`.
### Why are the changes needed?
Allow users to specify authority and URI schema related Hadoop configurations for file source reading.
### Does this PR introduce _any_ user-facing change?
Yes, the file system related Hadoop configuration in data source option will be effective on reading.
### How was this patch tested?
Unit test
Closes#28760 from gengliangwang/ds_conf.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
Currently, `date_format` and `from_unixtime`, `unix_timestamp`,`to_unix_timestamp`, `to_timestamp`, `to_date` have different exception handling behavior for formatting datetime values.
In this PR, we apply the exception handling behavior of `date_format` to `from_unixtime`, `unix_timestamp`,`to_unix_timestamp`, `to_timestamp` and `to_date`.
In the phase of creating the datetime formatted or formating, exceptions will be raised.
e.g.
```java
spark-sql> select date_format(make_timestamp(1, 1 ,1,1,1,1), 'yyyyyyyyyyy-MM-aaa');
20/05/28 15:25:38 ERROR SparkSQLDriver: Failed in [select date_format(make_timestamp(1, 1 ,1,1,1,1), 'yyyyyyyyyyy-MM-aaa')]
org.apache.spark.SparkUpgradeException: You may get a different result due to the upgrading of Spark 3.0: Fail to recognize 'yyyyyyyyyyy-MM-aaa' pattern in the DateTimeFormatter. 1) You can set spark.sql.legacy.timeParserPolicy to LEGACY to restore the behavior before Spark 3.0. 2) You can form a valid datetime pattern with the guide from https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html
```
```java
spark-sql> select date_format(make_timestamp(1, 1 ,1,1,1,1), 'yyyyyyyyyyy-MM-AAA');
20/05/28 15:26:10 ERROR SparkSQLDriver: Failed in [select date_format(make_timestamp(1, 1 ,1,1,1,1), 'yyyyyyyyyyy-MM-AAA')]
java.lang.IllegalArgumentException: Illegal pattern character: A
```
```java
spark-sql> select date_format(make_timestamp(1,1,1,1,1,1), 'yyyyyyyyyyy-MM-dd');
20/05/28 15:23:23 ERROR SparkSQLDriver: Failed in [select date_format(make_timestamp(1,1,1,1,1,1), 'yyyyyyyyyyy-MM-dd')]
java.lang.ArrayIndexOutOfBoundsException: 11
at java.time.format.DateTimeFormatterBuilder$NumberPrinterParser.format(DateTimeFormatterBuilder.java:2568)
```
In the phase of parsing, `DateTimeParseException | DateTimeException | ParseException` will be suppressed, but `SparkUpgradeException` will still be raised
e.g.
```java
spark-sql> set spark.sql.legacy.timeParserPolicy=exception;
spark.sql.legacy.timeParserPolicy exception
spark-sql> select to_timestamp("2020-01-27T20:06:11.847-0800", "yyyy-MM-dd'T'HH:mm:ss.SSSz");
20/05/28 15:31:15 ERROR SparkSQLDriver: Failed in [select to_timestamp("2020-01-27T20:06:11.847-0800", "yyyy-MM-dd'T'HH:mm:ss.SSSz")]
org.apache.spark.SparkUpgradeException: You may get a different result due to the upgrading of Spark 3.0: Fail to parse '2020-01-27T20:06:11.847-0800' in the new parser. You can set spark.sql.legacy.timeParserPolicy to LEGACY to restore the behavior before Spark 3.0, or set to CORRECTED and treat it as an invalid datetime string.
```
```java
spark-sql> set spark.sql.legacy.timeParserPolicy=corrected;
spark.sql.legacy.timeParserPolicy corrected
spark-sql> select to_timestamp("2020-01-27T20:06:11.847-0800", "yyyy-MM-dd'T'HH:mm:ss.SSSz");
NULL
spark-sql> set spark.sql.legacy.timeParserPolicy=legacy;
spark.sql.legacy.timeParserPolicy legacy
spark-sql> select to_timestamp("2020-01-27T20:06:11.847-0800", "yyyy-MM-dd'T'HH:mm:ss.SSSz");
2020-01-28 12:06:11.847
```
### Why are the changes needed?
Consistency
### Does this PR introduce _any_ user-facing change?
Yes, invalid datetime patterns will fail `from_unixtime`, `unix_timestamp`,`to_unix_timestamp`, `to_timestamp` and `to_date` instead of resulting `NULL`
### How was this patch tested?
add more tests
Closes#28650 from yaooqinn/SPARK-31830.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR makes `repartition`/`DISTRIBUTE BY` obeys [initialPartitionNum](af4248b2d6/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala (L446-L455)) when adaptive execution enabled.
### Why are the changes needed?
To make `DISTRIBUTE BY`/`GROUP BY` partitioned by same partition number.
How to reproduce:
```scala
spark.sql("CREATE TABLE spark_31220(id int)")
spark.sql("set spark.sql.adaptive.enabled=true")
spark.sql("set spark.sql.adaptive.coalescePartitions.initialPartitionNum=1000")
```
Before this PR:
```
scala> spark.sql("SELECT id from spark_31220 GROUP BY id").explain
== Physical Plan ==
AdaptiveSparkPlan(isFinalPlan=false)
+- HashAggregate(keys=[id#5], functions=[])
+- Exchange hashpartitioning(id#5, 1000), true, [id=#171]
+- HashAggregate(keys=[id#5], functions=[])
+- FileScan parquet default.spark_31220[id#5]
scala> spark.sql("SELECT id from spark_31220 DISTRIBUTE BY id").explain
== Physical Plan ==
AdaptiveSparkPlan(isFinalPlan=false)
+- Exchange hashpartitioning(id#5, 200), false, [id=#179]
+- FileScan parquet default.spark_31220[id#5]
```
After this PR:
```
scala> spark.sql("SELECT id from spark_31220 GROUP BY id").explain
== Physical Plan ==
AdaptiveSparkPlan(isFinalPlan=false)
+- HashAggregate(keys=[id#5], functions=[])
+- Exchange hashpartitioning(id#5, 1000), true, [id=#171]
+- HashAggregate(keys=[id#5], functions=[])
+- FileScan parquet default.spark_31220[id#5]
scala> spark.sql("SELECT id from spark_31220 DISTRIBUTE BY id").explain
== Physical Plan ==
AdaptiveSparkPlan(isFinalPlan=false)
+- Exchange hashpartitioning(id#5, 1000), false, [id=#179]
+- FileScan parquet default.spark_31220[id#5]
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#27986 from wangyum/SPARK-31220.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add benchmarks for `HiveResult.hiveResultString()/toHiveString()` to measure throughput of `toHiveString` for the date/timestamp types:
- java.sql.Date/Timestamp
- java.time.Instant
- java.time.LocalDate
Benchmark results were generated in the environment:
| Item | Description |
| ---- | ----|
| Region | us-west-2 (Oregon) |
| Instance | r3.xlarge |
| AMI | ubuntu/images/hvm-ssd/ubuntu-bionic-18.04-amd64-server-20190722.1 (ami-06f2f779464715dc5) |
| Java | OpenJDK 64-Bit Server VM 1.8.0_242 and OpenJDK 64-Bit Server VM 11.0.6+10 |
### Why are the changes needed?
To detect perf regressions of `toHiveString` in the future.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running `DateTimeBenchmark` and check dataset content.
Closes#28757 from MaxGekk/benchmark-toHiveString.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
# What changes were proposed in this pull request?
After all these attempts https://github.com/apache/spark/pull/28692 and https://github.com/apache/spark/pull/28719 an https://github.com/apache/spark/pull/28727.
they all have limitations as mentioned in their discussions.
Maybe the only way is to forbid them all
### Why are the changes needed?
These week-based fields need Locale to express their semantics, the first day of the week varies from country to country.
From the Java doc of WeekFields
```java
/**
* Gets the first day-of-week.
* <p>
* The first day-of-week varies by culture.
* For example, the US uses Sunday, while France and the ISO-8601 standard use Monday.
* This method returns the first day using the standard {code DayOfWeek} enum.
*
* return the first day-of-week, not null
*/
public DayOfWeek getFirstDayOfWeek() {
return firstDayOfWeek;
}
```
But for the SimpleDateFormat, the day-of-week is not localized
```
u Day number of week (1 = Monday, ..., 7 = Sunday) Number 1
```
Currently, the default locale we use is the US, so the result moved a day or a year or a week backward.
e.g.
For the date `2019-12-29(Sunday)`, in the Sunday Start system(e.g. en-US), it belongs to 2020 of week-based-year, in the Monday Start system(en-GB), it goes to 2019. the week-of-week-based-year(w) will be affected too
```sql
spark-sql> SELECT to_csv(named_struct('time', to_timestamp('2019-12-29', 'yyyy-MM-dd')), map('timestampFormat', 'YYYY', 'locale', 'en-US'));
2020
spark-sql> SELECT to_csv(named_struct('time', to_timestamp('2019-12-29', 'yyyy-MM-dd')), map('timestampFormat', 'YYYY', 'locale', 'en-GB'));
2019
spark-sql> SELECT to_csv(named_struct('time', to_timestamp('2019-12-29', 'yyyy-MM-dd')), map('timestampFormat', 'YYYY-ww-uu', 'locale', 'en-US'));
2020-01-01
spark-sql> SELECT to_csv(named_struct('time', to_timestamp('2019-12-29', 'yyyy-MM-dd')), map('timestampFormat', 'YYYY-ww-uu', 'locale', 'en-GB'));
2019-52-07
spark-sql> SELECT to_csv(named_struct('time', to_timestamp('2020-01-05', 'yyyy-MM-dd')), map('timestampFormat', 'YYYY-ww-uu', 'locale', 'en-US'));
2020-02-01
spark-sql> SELECT to_csv(named_struct('time', to_timestamp('2020-01-05', 'yyyy-MM-dd')), map('timestampFormat', 'YYYY-ww-uu', 'locale', 'en-GB'));
2020-01-07
```
For other countries, please refer to [First Day of the Week in Different Countries](http://chartsbin.com/view/41671)
### Does this PR introduce _any_ user-facing change?
With this change, user can not use 'YwuW', but 'e' for 'u' instead. This can at least turn this not to be a silent data change.
### How was this patch tested?
add unit tests
Closes#28728 from yaooqinn/SPARK-31879-NEW2.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In `Dataset.collectAsArrowToR` and `Dataset.collectAsArrowToPython`, since the code block for `serveToStream` is run in the separate thread, `withAction` finishes as soon as it starts the thread. As a result, it doesn't collect the metrics of the actual action and Query UI shows the plan graph without metrics.
We should call `serveToStream` first, then `withAction` in it.
### Why are the changes needed?
When calling toPandas, usually Query UI shows each plan node's metric and corresponding Stage ID and Task ID:
```py
>>> df = spark.createDataFrame([(1, 10, 'abc'), (2, 20, 'def')], schema=['x', 'y', 'z'])
>>> df.toPandas()
x y z
0 1 10 abc
1 2 20 def
```

but if Arrow execution is enabled, it shows only plan nodes and the duration is not correct:
```py
>>> spark.conf.set('spark.sql.execution.arrow.pyspark.enabled', True)
>>> df.toPandas()
x y z
0 1 10 abc
1 2 20 def
```

### Does this PR introduce _any_ user-facing change?
Yes, the Query UI will show the plan with the correct metrics.
### How was this patch tested?
I checked it manually in my local.

Closes#28730 from ueshin/issues/SPARK-31903/to_pandas_with_arrow_query_ui.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. Replace `def dateFormatter` to `val dateFormatter`.
2. Modify the `date formatting in hive result` test in `HiveResultSuite` to check modified code on various time zones.
### Why are the changes needed?
To avoid creation of `DateFormatter` per every incoming date in `HiveResult.toHiveString`. This should eliminate unnecessary creation of `SimpleDateFormat` instances and compilation of the default pattern `yyyy-MM-dd`. The changes can speed up processing of legacy date values of the `java.sql.Date` type which is collected by default.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Modified a test in `HiveResultSuite`.
Closes#28687 from MaxGekk/HiveResult-val-dateFormatter.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR disables week-based date filed for parsing
closes#28674
### Why are the changes needed?
1. It's an un-fixable behavior change to fill the gap between SimpleDateFormat and DateTimeFormater and backward-compatibility for different JDKs.A lot of effort has been made to prove it at https://github.com/apache/spark/pull/28674
2. The existing behavior itself in 2.4 is confusing, e.g.
```sql
spark-sql> select to_timestamp('1', 'w');
1969-12-28 00:00:00
spark-sql> select to_timestamp('1', 'u');
1970-01-05 00:00:00
```
The 'u' here seems not to go to the Monday of the first week in week-based form or the first day of the year in non-week-based form but go to the Monday of the second week in week-based form.
And, e.g.
```sql
spark-sql> select to_timestamp('2020 2020', 'YYYY yyyy');
2020-01-01 00:00:00
spark-sql> select to_timestamp('2020 2020', 'yyyy YYYY');
2019-12-29 00:00:00
spark-sql> select to_timestamp('2020 2020 1', 'YYYY yyyy w');
NULL
spark-sql> select to_timestamp('2020 2020 1', 'yyyy YYYY w');
2019-12-29 00:00:00
```
I think we don't need to introduce all the weird behavior from Java
3. The current test coverage for week-based date fields is almost 0%, which indicates that we've never imagined using it.
4. Avoiding JDK bugs
https://issues.apache.org/jira/browse/SPARK-31880
### Does this PR introduce _any_ user-facing change?
Yes, the 'Y/W/w/u/F/E' pattern cannot be used datetime parsing functions.
### How was this patch tested?
more tests added
Closes#28706 from yaooqinn/SPARK-31892.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
# What changes were proposed in this pull request?
This PR switches the default Locale from the `US` to `GB` to change the behavior of the first day of the week from Sunday-started to Monday-started as same as v2.4
### Why are the changes needed?
#### cases
```sql
spark-sql> select to_timestamp('2020-1-1', 'YYYY-w-u');
2019-12-29 00:00:00
spark-sql> set spark.sql.legacy.timeParserPolicy=legacy;
spark.sql.legacy.timeParserPolicy legacy
spark-sql> select to_timestamp('2020-1-1', 'YYYY-w-u');
2019-12-30 00:00:00
```
#### reasons
These week-based fields need Locale to express their semantics, the first day of the week varies from country to country.
From the Java doc of WeekFields
```java
/**
* Gets the first day-of-week.
* <p>
* The first day-of-week varies by culture.
* For example, the US uses Sunday, while France and the ISO-8601 standard use Monday.
* This method returns the first day using the standard {code DayOfWeek} enum.
*
* return the first day-of-week, not null
*/
public DayOfWeek getFirstDayOfWeek() {
return firstDayOfWeek;
}
```
But for the SimpleDateFormat, the day-of-week is not localized
```
u Day number of week (1 = Monday, ..., 7 = Sunday) Number 1
```
Currently, the default locale we use is the US, so the result moved a day backward.
For other countries, please refer to [First Day of the Week in Different Countries](http://chartsbin.com/view/41671)
With this change, it restores the first day of week calculating for functions when using the default locale.
### Does this PR introduce _any_ user-facing change?
Yes, but the behavior change is used to restore the old one of v2.4
### How was this patch tested?
add unit tests
Closes#28692 from yaooqinn/SPARK-31879.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
With this pull request I want to improve the Web UI / SQL tab visualization. The principal problem that I find is when you have a cache in your plan, the SQL visualization don’t show any information about the part of the plan that has been cached.
Before the change
After the change

### Why are the changes needed?
When we have a SQL plan with cached dataframes we lose the graphical information of this dataframe in the sql tab
### Does this PR introduce any user-facing change?
Yes, in the sql tab
### How was this patch tested?
Unit testing and manual tests throught spark shell
Closes#26082 from planga82/feature/SPARK-29431_SQL_Cache_webUI.
Lead-authored-by: Pablo Langa <soypab@gmail.com>
Co-authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Co-authored-by: Unknown <soypab@gmail.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
This PR upgrades HtmlUnit.
Selenium and Jetty also upgraded because of dependency.
### Why are the changes needed?
Recently, a security issue which affects HtmlUnit is reported.
https://nvd.nist.gov/vuln/detail/CVE-2020-5529
According to the report, arbitrary code can be run by malicious users.
HtmlUnit is used for test so the impact might not be large but it's better to upgrade it just in case.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing testcases.
Closes#28585 from sarutak/upgrade-htmlunit.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
We should use dataType.catalogString to unified the data type mismatch message.
Before:
```sql
spark-sql> create table SPARK_31834(a int) using parquet;
spark-sql> insert into SPARK_31834 select '1';
Error in query: Cannot write incompatible data to table '`default`.`spark_31834`':
- Cannot safely cast 'a': StringType to IntegerType;
```
After:
```sql
spark-sql> create table SPARK_31834(a int) using parquet;
spark-sql> insert into SPARK_31834 select '1';
Error in query: Cannot write incompatible data to table '`default`.`spark_31834`':
- Cannot safely cast 'a': string to int;
```
### How was this patch tested?
UT.
Closes#28654 from lipzhu/SPARK-31834.
Authored-by: lipzhu <lipzhu@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. Modified `ParquetFilters.valueCanMakeFilterOn()` to accept filters with `java.time.Instant` attributes.
2. Added `ParquetFilters.timestampToMicros()` to support both types `java.sql.Timestamp` and `java.time.Instant` in conversions to microseconds.
3. Re-used `timestampToMicros` in constructing of Parquet filters.
### Why are the changes needed?
To support pushed down filters with `java.time.Instant` attributes. Before the changes, date filters are not pushed down to Parquet datasource when `spark.sql.datetime.java8API.enabled` is `true`.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Modified tests to `ParquetFilterSuite` to check the case when Java 8 API is enabled.
Closes#28696 from MaxGekk/support-instant-parquet-filters.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
JIRA SPARK-28067: Wrong results are returned for aggregate sum with decimals with whole stage codegen enabled
**Repro:**
WholeStage enabled enabled -> Wrong results
WholeStage disabled -> Returns exception Decimal precision 39 exceeds max precision 38
**Issues:**
1. Wrong results are returned which is bad
2. Inconsistency between whole stage enabled and disabled.
**Cause:**
Sum does not take care of possibility of overflow for the intermediate steps. ie the updateExpressions and mergeExpressions.
This PR makes the following changes:
- Add changes to check if overflow occurs for decimal in aggregate Sum and if there is an overflow, it will return null for the Sum operation when spark.sql.ansi.enabled is false.
- When spark.sql.ansi.enabled is true, then the sum operation will return an exception if an overflow occurs for the decimal operation in Sum.
- This is keeping it consistent with the behavior defined in spark.sql.ansi.enabled property
**Before the fix: Scenario 1:** - WRONG RESULTS
```
scala> val df = Seq(
| (BigDecimal("10000000000000000000"), 1),
| (BigDecimal("10000000000000000000"), 1),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2)).toDF("decNum", "intNum")
df: org.apache.spark.sql.DataFrame = [decNum: decimal(38,18), intNum: int]
scala> val df2 = df.withColumnRenamed("decNum", "decNum2").join(df, "intNum").agg(sum("decNum"))
df2: org.apache.spark.sql.DataFrame = [sum(decNum): decimal(38,18)]
scala> df2.show(40,false)
+---------------------------------------+
|sum(decNum) |
+---------------------------------------+
|20000000000000000000.000000000000000000|
+---------------------------------------+
```
--
**Before fix: Scenario2: Setting spark.sql.ansi.enabled to true** - WRONG RESULTS
```
scala> spark.conf.set("spark.sql.ansi.enabled", "true")
scala> val df = Seq(
| (BigDecimal("10000000000000000000"), 1),
| (BigDecimal("10000000000000000000"), 1),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2)).toDF("decNum", "intNum")
df: org.apache.spark.sql.DataFrame = [decNum: decimal(38,18), intNum: int]
scala> val df2 = df.withColumnRenamed("decNum", "decNum2").join(df, "intNum").agg(sum("decNum"))
df2: org.apache.spark.sql.DataFrame = [sum(decNum): decimal(38,18)]
scala> df2.show(40,false)
+---------------------------------------+
|sum(decNum) |
+---------------------------------------+
|20000000000000000000.000000000000000000|
+---------------------------------------+
```
**After the fix: Scenario1:**
```
scala> val df = Seq(
| (BigDecimal("10000000000000000000"), 1),
| (BigDecimal("10000000000000000000"), 1),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2)).toDF("decNum", "intNum")
df: org.apache.spark.sql.DataFrame = [decNum: decimal(38,18), intNum: int]
scala> val df2 = df.withColumnRenamed("decNum", "decNum2").join(df, "intNum").agg(sum("decNum"))
df2: org.apache.spark.sql.DataFrame = [sum(decNum): decimal(38,18)]
scala> df2.show(40,false)
+-----------+
|sum(decNum)|
+-----------+
|null |
+-----------+
```
**After fix: Scenario2: Setting the spark.sql.ansi.enabled to true:**
```
scala> spark.conf.set("spark.sql.ansi.enabled", "true")
scala> val df = Seq(
| (BigDecimal("10000000000000000000"), 1),
| (BigDecimal("10000000000000000000"), 1),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2),
| (BigDecimal("10000000000000000000"), 2)).toDF("decNum", "intNum")
df: org.apache.spark.sql.DataFrame = [decNum: decimal(38,18), intNum: int]
scala> val df2 = df.withColumnRenamed("decNum", "decNum2").join(df, "intNum").agg(sum("decNum"))
df2: org.apache.spark.sql.DataFrame = [sum(decNum): decimal(38,18)]
scala> df2.show(40,false)
20/02/18 10:57:43 ERROR Executor: Exception in task 5.0 in stage 4.0 (TID 30)
java.lang.ArithmeticException: Decimal(expanded,100000000000000000000.000000000000000000,39,18}) cannot be represented as Decimal(38, 18).
```
### Why are the changes needed?
The changes are needed in order to fix the wrong results that are returned for decimal aggregate sum.
### Does this PR introduce any user-facing change?
User would see wrong results on aggregate sum that involved decimal overflow prior to this change, but now the user will see null. But if user enables the spark.sql.ansi.enabled flag to true, then the user will see an exception and not incorrect results.
### How was this patch tested?
New test has been added and existing tests for sql, catalyst and hive suites were run ok.
Closes#27627 from skambha/decaggfixwrongresults.
Lead-authored-by: Sunitha Kambhampati <skambha@us.ibm.com>
Co-authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Fix configurations and ensure there is skew join in the test "Do not optimize skew join if additional shuffle".
### Why are the changes needed?
The existing "Do not optimize skew join if additional shuffle" test has no skew join at all.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Fixed existing test.
Closes#28679 from manuzhang/spark-31870.
Authored-by: manuzhang <owenzhang1990@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to check `DetectAmbiguousSelfJoin` only if there is `Join` in the plan. Currently, the checking is too strict even to non-join queries.
For example, the codes below don't have join at all but it fails as the ambiguous self-join:
```scala
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions.sum
val df = Seq(1, 1, 2, 2).toDF("A")
val w = Window.partitionBy(df("A"))
df.select(df("A").alias("X"), sum(df("A")).over(w)).explain(true)
```
It is because `ExtractWindowExpressions` can create a `AttributeReference` with the same metadata but a different expression ID, see:
0fd98abd85/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala (L2679)71c73d58f6/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala (L63)5945d46c11/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/namedExpressions.scala (L180)
Before:
```
'Project [A#19 AS X#21, sum(A#19) windowspecdefinition(A#19, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS sum(A) OVER (PARTITION BY A unspecifiedframe$())#23L]
+- Relation[A#19] parquet
```
After:
```
Project [X#21, sum(A) OVER (PARTITION BY A unspecifiedframe$())#23L]
+- Project [X#21, A#19, sum(A) OVER (PARTITION BY A unspecifiedframe$())#23L, sum(A) OVER (PARTITION BY A unspecifiedframe$())#23L]
+- Window [sum(A#19) windowspecdefinition(A#19, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS sum(A) OVER (PARTITION BY A unspecifiedframe$())#23L], [A#19]
+- Project [A#19 AS X#21, A#19]
+- Relation[A#19] parquet
```
`X#21` holds the same metadata of DataFrame ID and column position with `A#19` but it has a different expression ID which ends up with the checking fails.
### Why are the changes needed?
To loose the checking and make users not surprised.
### Does this PR introduce _any_ user-facing change?
It's the changes in unreleased branches only.
### How was this patch tested?
Manually tested and unittest was added.
Closes#28695 from HyukjinKwon/SPARK-28344-followup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Fixed conversions of `java.sql.Timestamp` to milliseconds in `ParquetFilter` by using existing functions from `DateTimeUtils` `fromJavaTimestamp()` and `microsToMillis()`.
### Why are the changes needed?
The changes fix the bug:
```scala
scala> spark.conf.set("spark.sql.parquet.outputTimestampType", "TIMESTAMP_MILLIS")
scala> spark.conf.set("spark.sql.legacy.parquet.datetimeRebaseModeInWrite", "CORRECTED")
scala> Seq(java.sql.Timestamp.valueOf("1000-06-14 08:28:53.123")).toDF("ts").write.mode("overwrite").parquet("/Users/maximgekk/tmp/ts_millis_old_filter")
scala> spark.read.parquet("/Users/maximgekk/tmp/ts_millis_old_filter").filter($"ts" === "1000-06-14 08:28:53.123").show(false)
+---+
|ts |
+---+
+---+
```
### Does this PR introduce _any_ user-facing change?
Yes, after the changes (for the example above):
```scala
scala> spark.read.parquet("/Users/maximgekk/tmp/ts_millis_old_filter").filter($"ts" === "1000-06-14 08:28:53.123").show(false)
+-----------------------+
|ts |
+-----------------------+
|1000-06-14 08:28:53.123|
+-----------------------+
```
### How was this patch tested?
Modified tests in `ParquetFilterSuite` to check old timestamps.
Closes#28693 from MaxGekk/parquet-ts-millis-filter.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
As mentioned in https://github.com/apache/spark/pull/28673 and suggested via cloud-fan at https://github.com/apache/spark/pull/28673#discussion_r432817075
In this PR, we disable datetime pattern in the form of `y..y` and `Y..Y` whose lengths are greater than 10 to avoid sort of JDK bug as described below
he new datetime formatter introduces silent data change like,
```sql
spark-sql> select from_unixtime(1, 'yyyyyyyyyyy-MM-dd');
NULL
spark-sql> set spark.sql.legacy.timeParserPolicy=legacy;
spark.sql.legacy.timeParserPolicy legacy
spark-sql> select from_unixtime(1, 'yyyyyyyyyyy-MM-dd');
00000001970-01-01
spark-sql>
```
For patterns that support `SignStyle.EXCEEDS_PAD`, e.g. `y..y`(len >=4), when using the `NumberPrinterParser` to format it
```java
switch (signStyle) {
case EXCEEDS_PAD:
if (minWidth < 19 && value >= EXCEED_POINTS[minWidth]) {
buf.append(decimalStyle.getPositiveSign());
}
break;
....
```
the `minWidth` == `len(y..y)`
the `EXCEED_POINTS` is
```java
/**
* Array of 10 to the power of n.
*/
static final long[] EXCEED_POINTS = new long[] {
0L,
10L,
100L,
1000L,
10000L,
100000L,
1000000L,
10000000L,
100000000L,
1000000000L,
10000000000L,
};
```
So when the `len(y..y)` is greater than 10, ` ArrayIndexOutOfBoundsException` will be raised.
And at the caller side, for `from_unixtime`, the exception will be suppressed and silent data change occurs. for `date_format`, the `ArrayIndexOutOfBoundsException` will continue.
### Why are the changes needed?
fix silent data change
### Does this PR introduce _any_ user-facing change?
Yes, SparkUpgradeException will take place of `null` result when the pattern contains 10 or more continuous 'y' or 'Y'
### How was this patch tested?
new tests
Closes#28684 from yaooqinn/SPARK-31867-2.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR makes a minor change in deciding whether a partition is skewed by comparing the partition size to the median size of coalesced partitions instead of median size of raw partitions before coalescing.
### Why are the changes needed?
This change is line with target size criteria of splitting skew join partitions and can also cope with situations of extra empty partitions caused by over-partitioning. This PR has also improved skew join tests in AQE tests.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Updated UTs.
Closes#28669 from maryannxue/spark-31864.
Authored-by: Maryann Xue <maryann.xue@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR removes the excessive exception wrapping in AQE so that error messages are less verbose and mostly consistent with non-aqe execution. Exceptions from stage materialization are now only wrapped with `SparkException` if there are multiple stage failures. Also, stage cancelling errors will not be included as part the exception thrown, but rather just be error logged.
### Why are the changes needed?
This will make the AQE error reporting more readable and debuggable.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Updated existing tests.
Closes#28668 from maryannxue/spark-31862.
Authored-by: Maryann Xue <maryann.xue@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes the issue of complex query stages that contain sub stages not being reused at times due to dynamic plan changes. This PR synchronizes the "finished" flag between all reused stages so that the runtime replanning would always produce the same sub plan for their potentially reusable parent stages.
### Why are the changes needed?
Without this change, complex query stages that contain sub stages will sometimes not be reused due to dynamic plan changes and the status of their child query stages not being synced.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually tested TPC-DS q47 and q57. Before this PR, the reuse of the biggest stage would happen with a 50/50 chance; and after this PR, it will happen 100% of the time.
Closes#28670 from maryannxue/fix-aqe-reuse.
Authored-by: Maryann Xue <maryann.xue@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR extracts the logic for selecting the planned join type out of the `JoinSelection` rule and moves it to `JoinSelectionHelper` in Catalyst.
### Why are the changes needed?
This change both cleans up the code in `JoinSelection` and allows the logic to be in one place and be used from other rules that need to make decision based on the join type before the planning time.
### Does this PR introduce _any_ user-facing change?
`BuildSide`, `BuildLeft`, and `BuildRight` are moved from `org.apache.spark.sql.execution` to Catalyst in `org.apache.spark.sql.catalyst.optimizer`.
### How was this patch tested?
This is a refactoring, passes existing tests.
Closes#28540 from dbaliafroozeh/RefactorJoinSelection.
Authored-by: Ali Afroozeh <ali.afroozeh@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Pagination code across pages needs to be cleaned.
I have tried to clear out these things :
* Unused methods
* Unused method arguments
* remove redundant `if` expressions
* fix indentation
### Why are the changes needed?
This fix will make code more readable and remove unnecessary methods and variables.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually
Closes#28448 from iRakson/refactorPagination.
Authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Some alias of expression can not display correctly in schema. This PR will fix them.
- `ln`
- `rint`
- `lcase`
- `position`
### Why are the changes needed?
Improve the implement of some expression.
### Does this PR introduce _any_ user-facing change?
'Yes'. This PR will let user see the correct alias in schema.
### How was this patch tested?
Jenkins test.
Closes#28551 from beliefer/show-correct-alias-in-schema.
Lead-authored-by: beliefer <beliefer@163.com>
Co-authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Modified formatting of expected timestamp strings in the test `JavaBeanDeserializationSuite`.`testSpark22000` to correctly format timestamps with **zero** seconds fraction. Current implementation outputs `.0` but must be empty string. From SPARK-31820 failure:
- should be `2020-05-25 12:39:17`
- but incorrect expected string is `2020-05-25 12:39:17.0`
### Why are the changes needed?
To make `JavaBeanDeserializationSuite` stable, and avoid test failures like https://github.com/apache/spark/pull/28630#issuecomment-633695723
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
I changed 7dff3b125d/sql/core/src/test/java/test/org/apache/spark/sql/JavaBeanDeserializationSuite.java (L207) to
```java
new java.sql.Timestamp((System.currentTimeMillis() / 1000) * 1000),
```
to force zero seconds fraction.
Closes#28639 from MaxGekk/fix-JavaBeanDeserializationSuite.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Add the following parquet files to the resource folder `sql/core/src/test/resources/test-data`:
- Files saved by Spark 2.4.5 (cee4ecbb16) without meta info `org.apache.spark.version`
- `before_1582_date_v2_4_5.snappy.parquet` with 2 date columns of the type **INT32 L:DATE** - `PLAIN` (8 date values of `1001-01-01`) and `PLAIN_DICTIONARY` (`1001-01-01`..`1001-01-08`).
- `before_1582_timestamp_micros_v2_4_5.snappy.parquet` with 2 timestamp columns of the type **INT64 L:TIMESTAMP(MICROS,true)** - `PLAIN` (8 date values of `1001-01-01 01:02:03.123456`) and `PLAIN_DICTIONARY` (`1001-01-01 01:02:03.123456`..`1001-01-08 01:02:03.123456`).
- `before_1582_timestamp_millis_v2_4_5.snappy.parquet` with 2 timestamp columns of the type **INT64 L:TIMESTAMP(MILLIS,true)** - `PLAIN` (8 date values of `1001-01-01 01:02:03.123`) and `PLAIN_DICTIONARY` (`1001-01-01 01:02:03.123`..`1001-01-08 01:02:03.123`).
- `before_1582_timestamp_int96_plain_v2_4_5.snappy.parquet` with 2 timestamp columns of the type **INT96** - `PLAIN` (8 date values of `1001-01-01 01:02:03.123456`) and `PLAIN` (`1001-01-01 01:02:03.123456`..`1001-01-08 01:02:03.123456`).
- `before_1582_timestamp_int96_dict_v2_4_5.snappy.parquet` with 2 timestamp columns of the type **INT96** - `PLAIN_DICTIONARY` (8 date values of `1001-01-01 01:02:03.123456`) and `PLAIN_DICTIONARY` (`1001-01-01 01:02:03.123456`..`1001-01-08 01:02:03.123456`).
- Files saved by Spark 2.4.6-rc3 (570848da7c) with the meta info `org.apache.spark.version = 2.4.6`:
- `before_1582_date_v2_4_6.snappy.parquet` replaces `before_1582_date_v2_4.snappy.parquet`. And it is similar to `before_1582_date_v2_4_5.snappy.parquet` except Spark version in parquet meta info.
- `before_1582_timestamp_micros_v2_4_6.snappy.parquet` replaces `before_1582_timestamp_micros_v2_4.snappy.parquet`. And it is similar to `before_1582_timestamp_micros_v2_4_5.snappy.parquet` except meta info.
- `before_1582_timestamp_millis_v2_4_6.snappy.parquet` replaces `before_1582_timestamp_millis_v2_4.snappy.parquet`. And it is similar to `before_1582_timestamp_millis_v2_4_5.snappy.parquet` except meta info.
- `before_1582_timestamp_int96_plain_v2_4_6.snappy.parquet` is similar to `before_1582_timestamp_int96_dict_v2_4_5.snappy.parquet` except meta info.
- `before_1582_timestamp_int96_dict_v2_4_6.snappy.parquet` replaces `before_1582_timestamp_int96_v2_4.snappy.parquet`. And it is similar to `before_1582_timestamp_int96_dict_v2_4_5.snappy.parquet` except meta info.
2. Add new test "generate test files for checking compatibility with Spark 2.4" to `ParquetIOSuite` (marked as ignored). The parquet files above were generated by this test.
3. Modified "SPARK-31159: compatibility with Spark 2.4 in reading dates/timestamps" in `ParquetIOSuite` to use new parquet files.
### Why are the changes needed?
To improve test coverage.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running `ParquetIOSuite`.
Closes#28630 from MaxGekk/parquet-files-update.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Use the correct API in AlterTableRecoverPartition tests to modify the `RDD_PARALLEL_LISTING_THRESHOLD` conf.
### Why are the changes needed?
The existing AlterTableRecoverPartitions test modify the RDD_PARALLEL_LISTING_THRESHOLD as a SQLConf using the withSQLConf API. But since, this is not a SQLConf, it is not overridden and so the test doesn't end up testing the required behaviour.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
This is UT Fix. UTs are still passing after the fix.
Closes#28634 from prakharjain09/SPARK-31810-fix-recover-partitions.
Authored-by: Prakhar Jain <prakharjain09@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to set the alias, and class name in its `ExpressionInfo` for `struct`.
- Class name in `ExpressionInfo`
- from: `org.apache.spark.sql.catalyst.expressions.NamedStruct`
- to:`org.apache.spark.sql.catalyst.expressions.CreateNamedStruct`
- Alias name: `named_struct(col1, v, ...)` -> `struct(v, ...)`
This PR takes over https://github.com/apache/spark/pull/28631
### Why are the changes needed?
To show the correct output name and class names to users.
### Does this PR introduce _any_ user-facing change?
Yes.
**Before:**
```scala
scala> sql("DESC FUNCTION struct").show(false)
+------------------------------------------------------------------------------------+
|function_desc |
+------------------------------------------------------------------------------------+
|Function: struct |
|Class: org.apache.spark.sql.catalyst.expressions.NamedStruct |
|Usage: struct(col1, col2, col3, ...) - Creates a struct with the given field values.|
+------------------------------------------------------------------------------------+
```
```scala
scala> sql("SELECT struct(1, 2)").show(false)
+------------------------------+
|named_struct(col1, 1, col2, 2)|
+------------------------------+
|[1, 2] |
+------------------------------+
```
**After:**
```scala
scala> sql("DESC FUNCTION struct").show(false)
+------------------------------------------------------------------------------------+
|function_desc |
+------------------------------------------------------------------------------------+
|Function: struct |
|Class: org.apache.spark.sql.catalyst.expressions.CreateNamedStruct |
|Usage: struct(col1, col2, col3, ...) - Creates a struct with the given field values.|
+------------------------------------------------------------------------------------+
```
```scala
scala> sql("SELECT struct(1, 2)").show(false)
+------------+
|struct(1, 2)|
+------------+
|[1, 2] |
+------------+
```
### How was this patch tested?
Manually tested, and Jenkins tests.
Closes#28633 from HyukjinKwon/SPARK-31808.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Convert `java.time.Instant` to `java.sql.Timestamp` in pushed down filters to ORC datasource when Java 8 time API enabled.
### Why are the changes needed?
The changes fix the exception raised while pushing date filters when `spark.sql.datetime.java8API.enabled` is set to `true`:
```
java.lang.IllegalArgumentException: Wrong value class java.time.Instant for TIMESTAMP.EQUALS leaf
at org.apache.hadoop.hive.ql.io.sarg.SearchArgumentImpl$PredicateLeafImpl.checkLiteralType(SearchArgumentImpl.java:192)
at org.apache.hadoop.hive.ql.io.sarg.SearchArgumentImpl$PredicateLeafImpl.<init>(SearchArgumentImpl.java:75)
```
### Does this PR introduce any user-facing change?
Yes
### How was this patch tested?
Added tests to `OrcFilterSuite`.
Closes#28636 from MaxGekk/orc-timestamp-filter-pushdown.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Five continuous pattern characters with 'G/M/L/E/u/Q/q' means Narrow-Text Style while we turn to use `java.time.DateTimeFormatterBuilder` since 3.0.0, which output the leading single letter of the value, e.g. `December` would be `D`. In Spark 2.4 they mean Full-Text Style.
In this PR, we explicitly disable Narrow-Text Style for these pattern characters.
### Why are the changes needed?
Without this change, there will be a silent data change.
### Does this PR introduce _any_ user-facing change?
Yes, queries with datetime operations using datetime patterns, e.g. `G/M/L/E/u` will fail if the pattern length is 5 and other patterns, e,g. 'k', 'm' also can accept a certain number of letters.
1. datetime patterns that are not supported by the new parser but the legacy will get SparkUpgradeException, e.g. "GGGGG", "MMMMM", "LLLLL", "EEEEE", "uuuuu", "aa", "aaa". 2 options are given to end-users, one is to use legacy mode, and the other is to follow the new online doc for correct datetime patterns
2, datetime patterns that are not supported by both the new parser and the legacy, e.g. "QQQQQ", "qqqqq", will get IllegalArgumentException which is captured by Spark internally and results NULL to end-users.
### How was this patch tested?
add unit tests
Closes#28592 from yaooqinn/SPARK-31771.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Re-generate results of:
- DateTimeBenchmark
- CSVBenchmark
- JsonBenchmark
in the environment:
| Item | Description |
| ---- | ----|
| Region | us-west-2 (Oregon) |
| Instance | r3.xlarge |
| AMI | ubuntu/images/hvm-ssd/ubuntu-bionic-18.04-amd64-server-20190722.1 (ami-06f2f779464715dc5) |
| Java | OpenJDK 64-Bit Server VM 1.8.0_242 and OpenJDK 64-Bit Server VM 11.0.6+10 |
### Why are the changes needed?
1. The PR https://github.com/apache/spark/pull/28576 changed date-time parser. The `DateTimeBenchmark` should confirm that the PR didn't slow down date/timestamp parsing.
2. CSV/JSON datasources are affected by the above PR too. This PR updates the benchmark results in the same environment as other benchmarks to have a base line for future optimizations.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running benchmarks via the script:
```python
#!/usr/bin/env python3
import os
from sparktestsupport.shellutils import run_cmd
benchmarks = [
['sql/test', 'org.apache.spark.sql.execution.benchmark.DateTimeBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.datasources.csv.CSVBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.datasources.json.JsonBenchmark']
]
print('Set SPARK_GENERATE_BENCHMARK_FILES=1')
os.environ['SPARK_GENERATE_BENCHMARK_FILES'] = '1'
for b in benchmarks:
print("Run benchmark: %s" % b[1])
run_cmd(['build/sbt', '%s:runMain %s' % (b[0], b[1])])
```
Closes#28613 from MaxGekk/missing-hour-year-benchmarks.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
As we support multiple catalogs with DataSourceV2, we may need the `CURRENT_CATALOG` value expression from the SQL standard.
`CURRENT_CATALOG` is a general value specification in the SQL Standard, described as:
> The value specified by CURRENT_CATALOG is the character string that represents the current default catalog name.
### Why are the changes needed?
improve catalog v2 with ANSI SQL standard.
### Does this PR introduce any user-facing change?
yes, add a new function `current_catalog()` to point the current active catalog
### How was this patch tested?
add ut
Closes#27006 from yaooqinn/SPARK-30352.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add unit tests to the 'number of output rows metric' for some join types in the SQLMetricSuite. A list of unit tests added are as follows.
- ShuffledHashJoin: leftOuter, RightOuter, LeftAnti, LeftSemi
- BroadcastNestedLoopJoin: RightOuter
- BroadcastHashJoin: LeftAnti
### Why are the changes needed?
For some combinations of JoinType and Join algorithm there is no test coverage for the 'number of output rows' metric.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
I added debug statements in the code to ensure the correct combination if JoinType and Join algorithms are triggered.
I further used Intellij debugger to test the same.
Closes#28330 from sririshindra/SPARK-31377.
Authored-by: rishi <spothireddi@cloudera.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Currently, the data source scan node stores all the paths in its metadata. The metadata is kept when a SparkPlan is converted into SparkPlanInfo. SparkPlanInfo can be used to construct the Spark plan graph in UI.
However, the paths can be very large (e.g. it can be many partitions after partition pruning), while UI pages only require up to 100 bytes for the location metadata. We can reduce the paths stored in metadata to reduce memory usage.
### Why are the changes needed?
Reduce unnecessary memory cost.
In the heap dump of a driver, the SparkPlanInfo instances are quite large and it should be avoided:

### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests
Closes#28610 from gengliangwang/improveLocationMetadata.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
Add Pagination Support for structured streaming page. Now both tables `Active Queries` and `Completed Queries` will have pagination.
To implement pagination, pagination framework from #7399 is used.
* Also tables will only be shown if there is at least one entry in the table.
### Why are the changes needed?
* This will help users in analysing their structured streaming queries in much better way.
* Other Web UI pages support pagination in their table. So this will make web UI more consistent across pages.
* This can prevent potential OOM errors.
### Does this PR introduce _any_ user-facing change?
Yes. Both tables will support pagination.
### How was this patch tested?
Manually. I will add snapshots soon.
Closes#28485 from iRakson/SPARK-31642.
Authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
This PR intends to add trivial tests to check https://github.com/apache/spark/pull/27024 has already been fixed in the master.
Closes#27024
### Why are the changes needed?
For test coverage.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added tests.
Closes#28604 from maropu/SPARK-29854.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This patch adds the new method `getLatestBatchId()` in CompactibleFileStreamLog in complement of getLatest() which doesn't read the content of the latest batch metadata log file, and apply to both FileStreamSource and FileStreamSink to avoid unnecessary latency on reading log file.
### Why are the changes needed?
Once compacted metadata log file becomes huge, writing outputs for the compact + 1 batch is also affected due to unnecessarily reading the compacted metadata log file. This unnecessary latency can be simply avoided.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
New UT. Also manually tested under query which has huge metadata log on file stream sink:
> before applying the patch

> after applying the patch

Peaks are compact batches - please compare the next batch after compact batches, especially the area of "light brown".
Closes#27664 from HeartSaVioR/SPARK-30915.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
### What changes were proposed in this pull request?
Add and register three new functions: `TIMESTAMP_SECONDS`, `TIMESTAMP_MILLIS` and `TIMESTAMP_MICROS`
A test is added.
Reference: [BigQuery](https://cloud.google.com/bigquery/docs/reference/standard-sql/timestamp_functions?hl=en#timestamp_seconds)
### Why are the changes needed?
People will have convenient way to get timestamps from seconds,milliseconds and microseconds.
### Does this PR introduce _any_ user-facing change?
Yes, people will have the following ways to get timestamp:
```scala
sql("select TIMESTAMP_SECONDS(t.a) as timestamp from values(1230219000),(-1230219000) as t(a)").show(false)
```
```
+-------------------------+
|timestamp |
+-------------------------+
|2008-12-25 23:30:00|
|1931-01-07 16:30:00|
+-------------------------+
```
```scala
sql("select TIMESTAMP_MILLIS(t.a) as timestamp from values(1230219000123),(-1230219000123) as t(a)").show(false)
```
```
+-------------------------------+
|timestamp |
+-------------------------------+
|2008-12-25 23:30:00.123|
|1931-01-07 16:29:59.877|
+-------------------------------+
```
```scala
sql("select TIMESTAMP_MICROS(t.a) as timestamp from values(1230219000123123),(-1230219000123123) as t(a)").show(false)
```
```
+------------------------------------+
|timestamp |
+------------------------------------+
|2008-12-25 23:30:00.123123|
|1931-01-07 16:29:59.876877|
+------------------------------------+
```
### How was this patch tested?
Unit test.
Closes#28534 from TJX2014/master-SPARK-31710.
Authored-by: TJX2014 <xiaoxingstack@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR allows missing hour fields when parsing date/timestamp string, with 0 as the default value.
If the year field is missing, this PR still fail the query by default, but provides a new legacy config to allow it and use 1970 as the default value. It's not a good default value, as it is not a leap year, which means that it would never parse Feb 29. We just pick it for backward compatibility.
### Why are the changes needed?
To keep backward compatibility with Spark 2.4.
### Does this PR introduce _any_ user-facing change?
Yes.
Spark 2.4:
```
scala> sql("select to_timestamp('16', 'dd')").show
+------------------------+
|to_timestamp('16', 'dd')|
+------------------------+
| 1970-01-16 00:00:00|
+------------------------+
scala> sql("select to_date('16', 'dd')").show
+-------------------+
|to_date('16', 'dd')|
+-------------------+
| 1970-01-16|
+-------------------+
scala> sql("select to_timestamp('2019 40', 'yyyy mm')").show
+----------------------------------+
|to_timestamp('2019 40', 'yyyy mm')|
+----------------------------------+
| 2019-01-01 00:40:00|
+----------------------------------+
scala> sql("select to_timestamp('2019 10:10:10', 'yyyy hh:mm:ss')").show
+----------------------------------------------+
|to_timestamp('2019 10:10:10', 'yyyy hh:mm:ss')|
+----------------------------------------------+
| 2019-01-01 10:10:10|
+----------------------------------------------+
```
in branch 3.0
```
scala> sql("select to_timestamp('16', 'dd')").show
+--------------------+
|to_timestamp(16, dd)|
+--------------------+
| null|
+--------------------+
scala> sql("select to_date('16', 'dd')").show
+---------------+
|to_date(16, dd)|
+---------------+
| null|
+---------------+
scala> sql("select to_timestamp('2019 40', 'yyyy mm')").show
+------------------------------+
|to_timestamp(2019 40, yyyy mm)|
+------------------------------+
| 2019-01-01 00:00:00|
+------------------------------+
scala> sql("select to_timestamp('2019 10:10:10', 'yyyy hh:mm:ss')").show
+------------------------------------------+
|to_timestamp(2019 10:10:10, yyyy hh:mm:ss)|
+------------------------------------------+
| 2019-01-01 00:00:00|
+------------------------------------------+
```
After this PR, the behavior becomes the same as 2.4, if the legacy config is enabled.
### How was this patch tested?
new tests
Closes#28576 from cloud-fan/bug.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add `withAllParquetReaders` to `ParquetTest`. The function allow to run a block of code for all available Parquet readers.
### Why are the changes needed?
1. It simplifies tests
2. Allow to test all parquet readers that could be available in projects based on Apache Spark.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running affected test suites.
Closes#28598 from MaxGekk/add-withAllParquetReaders.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
This reverts commit 92877c4ef2.
Closes#28602 from gengliangwang/revertSPARK-31765.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
This PR upgrades HtmlUnit.
Selenium and Jetty also upgraded because of dependency.
### Why are the changes needed?
Recently, a security issue which affects HtmlUnit is reported.
https://nvd.nist.gov/vuln/detail/CVE-2020-5529
According to the report, arbitrary code can be run by malicious users.
HtmlUnit is used for test so the impact might not be large but it's better to upgrade it just in case.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing testcases.
Closes#28585 from sarutak/upgrade-htmlunit.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
Currently while implementing pagination using the existing pagination framework, a lot of code is being copied as pointed out [here](https://github.com/apache/spark/pull/28485#pullrequestreview-408881656).
I introduced some changes in `PagedTable` which is the main trait for implementing the pagination.
* Added function for getting table parameters.
* Added a function for table header row. This will help in maintaining consistency across the tables. All the header rows across tables will be consistent now.
### Why are the changes needed?
* A lot of code is copied every time pagination is implemented for any table.
* Code readability is not great as lot of HTML is embedded.
* Paginating other tables will be a lot easier now.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually. This is mainly refactoring work, no new functionality introduced. Existing test cases should pass.
Closes#28512 from iRakson/refactorPaginationFramework.
Authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
## What changes were proposed in this pull request?
This change was made as a result of the conversation on https://issues.apache.org/jira/browse/SPARK-31354 and is intended to continue work from that ticket here.
This change fixes a memory leak where SparkSession listeners are never cleared off of the SparkContext listener bus.
Before running this PR, the following code:
```
SparkSession.builder().master("local").getOrCreate()
SparkSession.clearActiveSession()
SparkSession.clearDefaultSession()
SparkSession.builder().master("local").getOrCreate()
SparkSession.clearActiveSession()
SparkSession.clearDefaultSession()
```
would result in a SparkContext with the following listeners on the listener bus:
```
[org.apache.spark.status.AppStatusListener5f610071,
org.apache.spark.HeartbeatReceiverd400c17,
org.apache.spark.sql.SparkSession$$anon$125849aeb, <-First instance
org.apache.spark.sql.SparkSession$$anon$1fadb9a0] <- Second instance
```
After this PR, the execution of the same code above results in SparkContext with the following listeners on the listener bus:
```
[org.apache.spark.status.AppStatusListener5f610071,
org.apache.spark.HeartbeatReceiverd400c17,
org.apache.spark.sql.SparkSession$$anon$125849aeb] <-One instance
```
## How was this patch tested?
* Unit test included as a part of the PR
Closes#28128 from vinooganesh/vinooganesh/SPARK-27958.
Lead-authored-by: Vinoo Ganesh <vinoo.ganesh@gmail.com>
Co-authored-by: Vinoo Ganesh <vganesh@palantir.com>
Co-authored-by: Vinoo Ganesh <vinoo@safegraph.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Add new methods that accept date-time Java types to the DateFormatter and TimestampFormatter traits. The methods format input date-time instances to strings:
- TimestampFormatter:
- `def format(ts: Timestamp): String`
- `def format(instant: Instant): String`
- DateFormatter:
- `def format(date: Date): String`
- `def format(localDate: LocalDate): String`
2. Re-use the added methods from `HiveResult.toHiveString`
3. Borrow the code for formatting of `java.sql.Timestamp` from Spark 2.4 `DateTimeUtils.timestampToString` to `FractionTimestampFormatter` because legacy formatters don't support variable length patterns for seconds fractions.
### Why are the changes needed?
To avoid unnecessary overhead of converting Java date-time types to micros/days before formatting. Also formatters have to convert input micros/days back to Java types to pass instances to standard library API.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By existing tests for toHiveString and new tests in `TimestampFormatterSuite`.
Closes#28582 from MaxGekk/opt-format-old-types.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR adds a private `WriteBuilder` mixin trait: `SupportsStreamingUpdate`, so that the builtin v2 streaming sinks can still support the update mode.
Note: it's private because we don't have a proper design yet. I didn't take the proposal in https://github.com/apache/spark/pull/23702#discussion_r258593059 because we may want something more general, like updating by an expression `key1 = key2 + 10`.
### Why are the changes needed?
In Spark 2.4, all builtin v2 streaming sinks support all streaming output modes, and v2 sinks are enabled by default, see https://issues.apache.org/jira/browse/SPARK-22911
It's too risky for 3.0 to go back to v1 sinks, so I propose to add a private trait to fix builtin v2 sinks, to keep backward compatibility.
### Does this PR introduce _any_ user-facing change?
Yes, now all the builtin v2 streaming sinks support all streaming output modes, which is the same as 2.4
### How was this patch tested?
existing tests.
Closes#28523 from cloud-fan/update.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Eliminate the `UpCast` if it's child data type is already decimal type.
### Why are the changes needed?
While deserializing internal `Decimal` value to external `BigDecimal`(Java/Scala) value, Spark should also respect `Decimal`'s precision and scale, otherwise it will cause precision lost and look weird in some cases, e.g.:
```
sql("select cast(11111111111111111111111111111111111111 as decimal(38, 0)) as d")
.write.mode("overwrite")
.parquet(f.getAbsolutePath)
// can fail
spark.read.parquet(f.getAbsolutePath).as[BigDecimal]
```
```
[info] org.apache.spark.sql.AnalysisException: Cannot up cast `d` from decimal(38,0) to decimal(38,18).
[info] The type path of the target object is:
[info] - root class: "scala.math.BigDecimal"
[info] You can either add an explicit cast to the input data or choose a higher precision type of the field in the target object;
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveUpCast$.org$apache$spark$sql$catalyst$analysis$Analyzer$ResolveUpCast$$fail(Analyzer.scala:3060)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveUpCast$$anonfun$apply$33$$anonfun$applyOrElse$174.applyOrElse(Analyzer.scala:3087)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveUpCast$$anonfun$apply$33$$anonfun$applyOrElse$174.applyOrElse(Analyzer.scala:3071)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDown$1(TreeNode.scala:309)
[info] at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:72)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:309)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDown$3(TreeNode.scala:314)
```
### Does this PR introduce _any_ user-facing change?
Yes, for cases(cause precision lost) mentioned above will fail before this change but run successfully after this change.
### How was this patch tested?
Added tests.
Closes#28572 from Ngone51/fix_encoder.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The QueryPlanningTracker in QueryExeuction reports the planning time that also includes the optimization time. This happens because the optimizedPlan in QueryExecution is lazy and only will initialize when first called. When df.queryExecution.executedPlan is called, the the tracker starts recording the planning time, and then calls the optimized plan. This causes the planning time to start before optimization and also include the planning time.
This PR fixes this behavior by introducing a method assertOptimized, similar to assertAnalyzed that explicitly initializes the optimized plan. This method is called before measuring the time for sparkPlan and executedPlan. We call it before sparkPlan because that also counts as planning time.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests
Closes#28543 from dbaliafroozeh/AddAssertOptimized.
Authored-by: Ali Afroozeh <ali.afroozeh@databricks.com>
Signed-off-by: herman <herman@databricks.com>
### What changes were proposed in this pull request?
SQL Rest API exposes query execution metrics as Public API. This PR aims to apply following improvements on SQL Rest API by aligning Spark-UI.
**Proposed Improvements:**
1- Support Physical Operations and group metrics per physical operation by aligning Spark UI.
2- Support `wholeStageCodegenId` for Physical Operations
3- `nodeId` can be useful for grouping metrics and sorting physical operations (according to execution order) to differentiate same operators (if used multiple times during the same query execution) and their metrics.
4- Filter `empty` metrics by aligning with Spark UI - SQL Tab. Currently, Spark UI does not show empty metrics.
5- Remove line breakers(`\n`) from `metricValue`.
6- `planDescription` can be `optional` Http parameter to avoid network cost where there is specially complex jobs creating big-plans.
7- `metrics` attribute needs to be exposed at the bottom order as `nodes`. Specially, this can be useful for the user where `nodes` array size is high.
8- `edges` attribute is being exposed to show relationship between `nodes`.
9- Reverse order on `metricDetails` aims to match with Spark UI by supporting Physical Operators' execution order.
### Why are the changes needed?
Proposed improvements provides more useful (e.g: physical operations and metrics correlation, grouping) and clear (e.g: filtering blank metrics, removing line breakers) result for the end-user.
### Does this PR introduce any user-facing change?
Yes. Please find both current and improved versions of the results as attached for following SQL Rest Endpoint:
```
curl -X GET http://localhost:4040/api/v1/applications/$appId/sql/$executionId?details=true
```
**Current version:**
https://issues.apache.org/jira/secure/attachment/12999821/current_version.json
**Improved version:**
https://issues.apache.org/jira/secure/attachment/13000621/improved_version.json
### Backward Compatibility
SQL Rest API will be started to expose with `Spark 3.0` and `3.0.0-preview2` (released on 12/23/19) does not cover this API so if PR can catch 3.0 release, this will not have any backward compatibility issue.
### How was this patch tested?
1. New Unit tests are added.
2. Also, patch has been tested manually through both **Spark Core** and **History Server** Rest APIs.
Closes#28208 from erenavsarogullari/SPARK-31440.
Authored-by: Eren Avsarogullari <eren.avsarogullari@gmail.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
This patch effectively reverts SPARK-30098 via below changes:
* Removed the config
* Removed the changes done in parser rule
* Removed the usage of config in tests
* Removed tests which depend on the config
* Rolled back some tests to before SPARK-30098 which were affected by SPARK-30098
* Reflect the change into docs (migration doc, create table syntax)
### Why are the changes needed?
SPARK-30098 brought confusion and frustration on using create table DDL query, and we agreed about the bad effect on the change.
Please go through the [discussion thread](http://apache-spark-developers-list.1001551.n3.nabble.com/DISCUSS-Resolve-ambiguous-parser-rule-between-two-quot-create-table-quot-s-td29051i20.html) to see the details.
### Does this PR introduce _any_ user-facing change?
No, compared to Spark 2.4.x. End users tried to experiment with Spark 3.0.0 previews will see the change that the behavior is going back to Spark 2.4.x, but I believe we won't guarantee compatibility in preview releases.
### How was this patch tested?
Existing UTs.
Closes#28517 from HeartSaVioR/revert-SPARK-30098.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Set default time zone and locale in the default constructor of `SparkFunSuite`:
- Default time zone to `America/Los_Angeles`
- Default locale to `Locale.US`
### Why are the changes needed?
1. To deduplicate code by moving common time zone and locale settings to one place SparkFunSuite
2. To have the same default time zone and locale in all tests. This should prevent errors like https://github.com/apache/spark/pull/28538
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
by running all affected test suites
Closes#28548 from MaxGekk/timezone-settings-SparkFunSuite.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
- Resolve the havingcondition with expanding the GROUPING SETS/CUBE/ROLLUP expressions together in `ResolveGroupingAnalytics`:
- Change the operations resolving directions to top-down.
- Try resolving the condition of the filter as though it is in the aggregate clause by reusing the function in `ResolveAggregateFunctions`
- Push the aggregate expressions into the aggregate which contains the expanded operations.
- Use UnresolvedHaving for all having clause.
### Why are the changes needed?
Correctness bug fix. See the demo and analysis in SPARK-31663.
### Does this PR introduce _any_ user-facing change?
Yes, correctness bug fix for HAVING with GROUPING SETS.
### How was this patch tested?
New UTs added.
Closes#28501 from xuanyuanking/SPARK-31663.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Instead of using `child.output` directly, we should use `inputAggBufferAttributes` from the current agg expression for `Final` and `PartialMerge` aggregates to bind references for their `mergeExpression`.
### Why are the changes needed?
When planning aggregates, the partial aggregate uses agg fucs' `inputAggBufferAttributes` as its output, see https://github.com/apache/spark/blob/v3.0.0-rc1/sql/core/src/main/scala/org/apache/spark/sql/execution/aggregate/AggUtils.scala#L105
For final `HashAggregateExec`, we need to bind the `DeclarativeAggregate.mergeExpressions` with the output of the partial aggregate operator, see https://github.com/apache/spark/blob/v3.0.0-rc1/sql/core/src/main/scala/org/apache/spark/sql/execution/aggregate/HashAggregateExec.scala#L348
This is usually fine. However, if we copy the agg func somehow after agg planning, like `PlanSubqueries`, the `DeclarativeAggregate` will be replaced by a new instance with new `inputAggBufferAttributes` and `mergeExpressions`. Then we can't bind the `mergeExpressions` with the output of the partial aggregate operator, as it uses the `inputAggBufferAttributes` of the original `DeclarativeAggregate` before copy.
Note that, `ImperativeAggregate` doesn't have this problem, as we don't need to bind its `mergeExpressions`. It has a different mechanism to access buffer values, via `mutableAggBufferOffset` and `inputAggBufferOffset`.
### Does this PR introduce _any_ user-facing change?
Yes, user hit error previously but run query successfully after this change.
### How was this patch tested?
Added a regression test.
Closes#28496 from Ngone51/spark-31620.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}