### What changes were proposed in this pull request?
In the PR, I propose to update the SQL migration guide, in particular the section about the migration from Spark 2.4 to 3.0. New item informs users about the following issue:
**What**: Spark doesn't detect encoding (charset) in CSV files with BOM correctly. Such files can be read only in the multiLine mode when the CSV option encoding matches to the actual encoding of CSV files. For example, Spark cannot read UTF-16BE CSV files when encoding is set to UTF-8 which is the default mode. This is the case of the current ES ticket.
**Why**: In previous Spark versions, encoding wasn't propagated to the underlying library that means the lib tried to detect file encoding automatically. It could success for some encodings that require BOM presents at the beginning of files. Starting from the versions 3.0, users can specify file encoding via the CSV option encoding which has UTF-8 as the default value. Spark propagates such default to the underlying library (uniVocity), and as a consequence this turned off encoding auto-detection.
**When**: Since Spark 3.0. In particular, the commit 2df34db586 causes the issue.
**Workaround**: Enabling the encoding auto-detection mechanism in uniVocity by passing null as the value of CSV option encoding. A more recommended approach is to set the encoding option explicitly.
### Why are the changes needed?
To improve user experience with Spark SQL. This should help to users in their migration from Spark 2.4.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Should be checked by building docs in GA/jenkins.
Closes#33300 from MaxGekk/csv-encoding-migration-guide.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit e788a3fa88)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Update AQE is `disabled` to `enabled` in sql-performance-tuning docs
### Why are the changes needed?
Make docs correct.
### Does this PR introduce _any_ user-facing change?
yes, docs changed.
### How was this patch tested?
Not need.
Closes#33295 from ulysses-you/enable-AQE.
Lead-authored-by: ulysses-you <ulyssesyou18@gmail.com>
Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit 286c231c1e)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
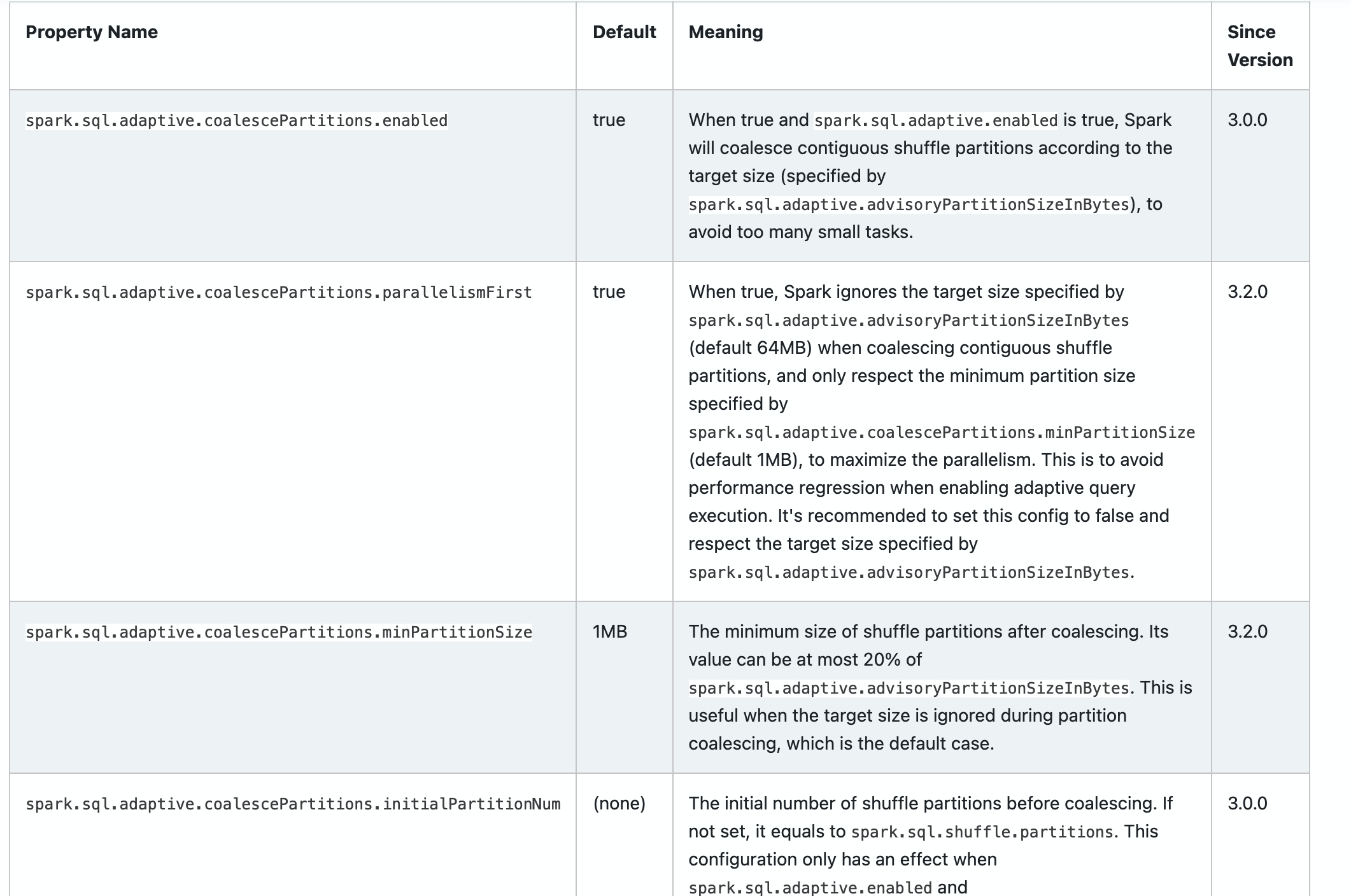
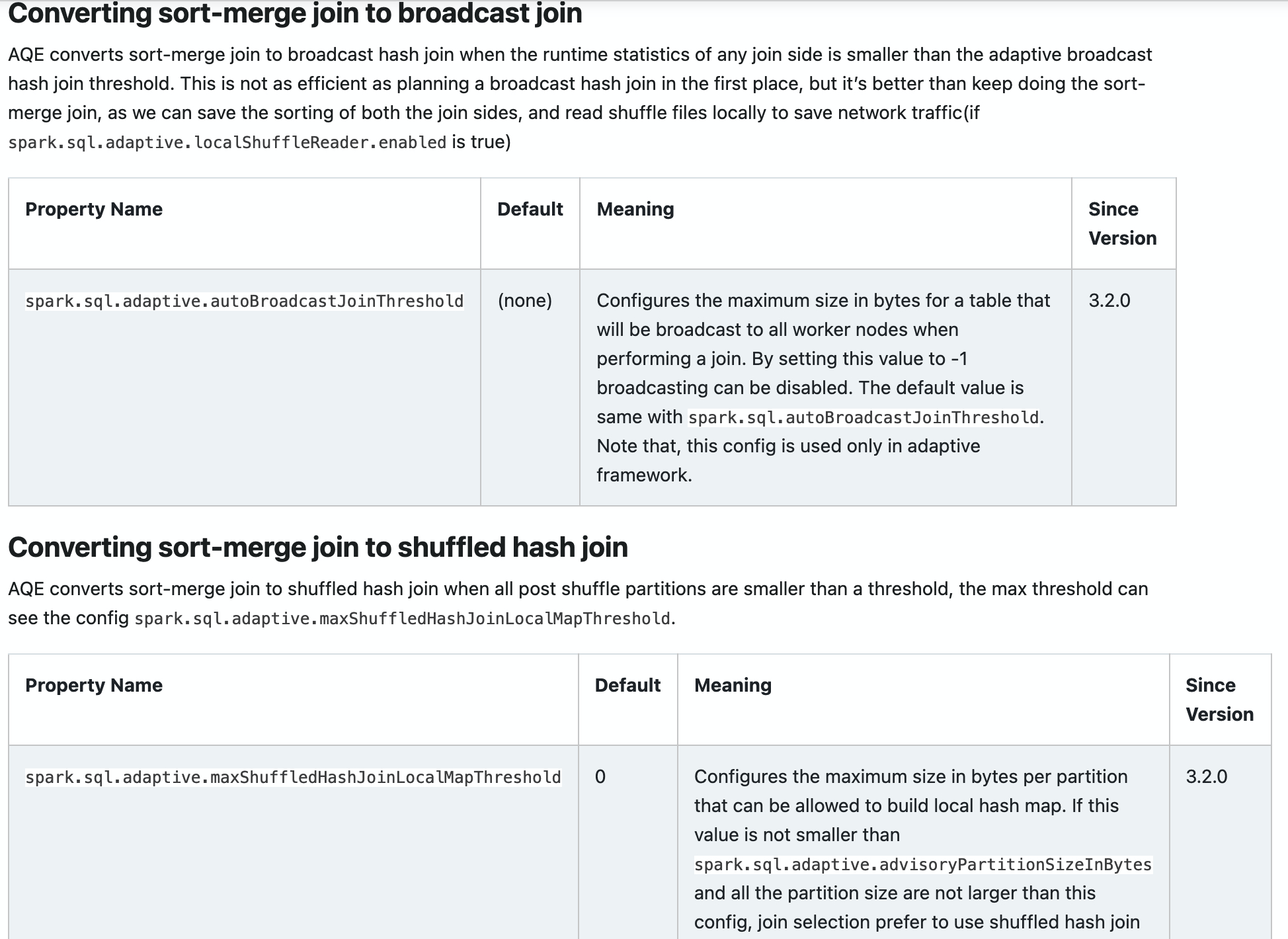
Add new configs in sql-performance-tuning docs.
* spark.sql.adaptive.coalescePartitions.parallelismFirst
* spark.sql.adaptive.coalescePartitions.minPartitionSize
* spark.sql.adaptive.autoBroadcastJoinThreshold
* spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold
### Why are the changes needed?
Help user to find them.
### Does this PR introduce _any_ user-facing change?
yes, docs changed.
### How was this patch tested?
Closes#32960 from ulysses-you/SPARK-35813.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit 0e9786c712)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to remove the automatic build guides of documentation in `docs/README.md`.
### Why are the changes needed?
This doesn't work very well:
1. It doesn't detect the changes in RST files. But PySpark internally generates RST files so we can't just simply include it in the detection. Otherwise, it goes to an infinite loop
2. During PySpark documentation generation, it launches some jobs to generate plot images now. This is broken with `entr` command, and the job fails. Seems like it's related to how `entr` creates the process internally.
3. Minor issue but the documentation build directory was changed (`_build` -> `build` in `python/docs`)
I don't think it's worthwhile testing and fixing the docs to show an working example because dev people are already able to do it manually.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Manually tested.
Closes#33266 from HyukjinKwon/SPARK-36051.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit a1ce64904f)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
As described in #32831, Spark has compatible issues when querying a view created by an
older version. The root cause is that Spark changed the auto-generated alias name. To avoid
this in the future, we could ask the user to specify explicit column names when creating
a view.
### Why are the changes needed?
Avoid compatible issue when querying a view
### Does this PR introduce _any_ user-facing change?
Yes. User will get error when running query below after this change
```
CREATE OR REPLACE VIEW v AS SELECT CAST(t.a AS INT), to_date(t.b, 'yyyyMMdd') FROM t
```
### How was this patch tested?
not yet
Closes#32832 from linhongliu-db/SPARK-35686-no-auto-alias.
Authored-by: Linhong Liu <linhong.liu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In https://issues.apache.org/jira/browse/SPARK-34862, we added support for ORC nested column vectorized reader, and it is disabled by default for now. So we would like to add the user-facing documentation for it, and user can opt-in to use it if they want.
### Why are the changes needed?
To make user be aware of the feature, and let them know the instruction to use the feature.
### Does this PR introduce _any_ user-facing change?
Yes, the documentation itself.
### How was this patch tested?
Manually check generated documentation as below.
<img width="1153" alt="Screen Shot 2021-07-01 at 12 19 40 AM" src="https://user-images.githubusercontent.com/4629931/124083422-b0724280-da02-11eb-93aa-a25d118ba56e.png">
<img width="1147" alt="Screen Shot 2021-07-01 at 12 19 52 AM" src="https://user-images.githubusercontent.com/4629931/124083442-b5cf8d00-da02-11eb-899f-827d55b8558d.png">
Closes#33168 from c21/orc-doc.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR aims to deprecate old Java 8 versions prior to 8u201.
### Why are the changes needed?
This is a preparation of using G1GC during the migration among Java LTS versions (8/11/17).
8u162 has the following fix.
- JDK-8205376: JVM Crash during G1 GC
8u201 has the following fix.
- JDK-8208873: C1: G1 barriers don't preserve FP registers
### Does this PR introduce _any_ user-facing change?
No, Today's Java8 is usually 1.8.0_292 and this is just a deprecation in documentation.
### How was this patch tested?
N/A
Closes#33166 from dongjoon-hyun/SPARK-35962.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Deprecate Python 3.6 in Spark documentation
### Why are the changes needed?
According to https://endoflife.date/python, Python 3.6 will be EOL on 23 Dec, 2021.
We should prepare for the deprecation of Python 3.6 support in Spark in advance.
### Does this PR introduce _any_ user-facing change?
N/A.
### How was this patch tested?
Manual tests.
Closes#33141 from xinrong-databricks/deprecate3.6_doc.
Authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
There are two new Avro options `datetimeRebaseMode` and `positionalFieldMatching` after Spark 3.2.
We should document the since version so that users can know whether the option works in their Spark version.
### Why are the changes needed?
Better documentation.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manual preview on local setup.
<img width="828" alt="Screen Shot 2021-06-30 at 5 05 54 PM" src="https://user-images.githubusercontent.com/1097932/123934000-ba833b00-d947-11eb-9ca5-ce8ff8add74b.png">
<img width="711" alt="Screen Shot 2021-06-30 at 5 06 34 PM" src="https://user-images.githubusercontent.com/1097932/123934126-d4bd1900-d947-11eb-8d80-69df8f3d9900.png">
Closes#33153 from gengliangwang/version.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Gengliang Wang <gengliang@apache.org>
### What changes were proposed in this pull request?
Provide the (configurable) ability to perform Avro-to-Catalyst schema field matching using the position of the fields instead of their names. A new `option` is added for the Avro datasource, `positionalFieldMatching`, which instructs `AvroSerializer`/`AvroDeserializer` to perform positional field matching instead of matching by name.
### Why are the changes needed?
This by-name matching is somewhat recent; prior to PR #24635, at least on the write path, schemas were matched by positionally ("structural" comparison). While by-name is better behavior as a default, it will be better to make this configurable by a user. Even at the time that PR #24635 was handled, there was [interest in making this behavior configurable](https://github.com/apache/spark/pull/24635#issuecomment-494205251), but it appears it went unaddressed.
There is precedence for configurability of this behavior as seen in PR #29737, which added this support for ORC. Besides this precedence, the behavior of Hive is to perform matching positionally ([ref](https://cwiki.apache.org/confluence/display/Hive/AvroSerDe#AvroSerDe-WritingtablestoAvrofiles)), so this is behavior that Hadoop/Hive ecosystem users are familiar with.
### Does this PR introduce _any_ user-facing change?
Yes, a new option is provided for the Avro datasource, `positionalFieldMatching`, which provides compatibility with Hive and pre-3.0.0 Spark behavior.
### How was this patch tested?
New unit tests are added within `AvroSuite`, `AvroSchemaHelperSuite`, and `AvroSerdeSuite`; and most of the existing tests within `AvroSerdeSuite` are adapted to perform the same test using by-name and positional matching to ensure feature parity.
Closes#31490 from xkrogen/xkrogen-SPARK-34365-avro-positional-field-matching.
Authored-by: Erik Krogen <xkrogen@apache.org>
Signed-off-by: Gengliang Wang <gengliang@apache.org>
### What changes were proposed in this pull request?
This adds two new additional metrics to `ExternalBlockHandler`:
- `blockTransferRate` -- for indicating the rate of transferring blocks, vs. the data within them
- `blockTransferAvgSize_1min` -- a 1-minute trailing average of block sizes transferred by the ESS
Additionally, this enhances `YarnShuffleServiceMetrics` to expose the histogram/`Snapshot` information from `Timer` metrics within `ExternalBlockHandler`.
### Why are the changes needed?
Currently `ExternalBlockHandler` exposes some useful metrics, but is lacking around metrics for the rate of block transfers. We have `blockTransferRateBytes` to tell us the rate of _bytes_, but no metric to tell us the rate of _blocks_, which is especially relevant when running the ESS on HDDs that are sensitive to random reads. Many small block transfers can have a negative impact on performance, but won't show up as a spike in `blockTransferRateBytes` since the sizes are small. Thus the new metrics to show information around average block size and block transfer rate are very useful to monitor the health/performance of the ESS, especially when running on HDDs.
For the `YarnShuffleServiceMetrics`, currently the three `Timer` metrics exposed by `ExternalBlockHandler` are being underutilized in a YARN-based environment -- they are basically treated as a `Meter`, only exposing rate-based information, when the metrics themselves are collected detailed histograms of timing information. We should expose this information for better observability.
### Does this PR introduce _any_ user-facing change?
Yes, there are two entirely new metrics for the ESS, as documented in `monitoring.md`. Additionally in a YARN environment, `Timer` metrics exposed by the ESS will include more rich timing information.
### How was this patch tested?
New unit tests are added to verify that new metrics are showing up as expected.
We have been running this patch internally for approx. 1 year and have found it to be useful for monitoring the health of ESS and diagnosing performance issues.
Closes#32388 from xkrogen/xkrogen-SPARK-35258-ess-new-metrics.
Authored-by: Erik Krogen <xkrogen@apache.org>
Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com>
### What changes were proposed in this pull request?
The hyperlinks in Python code blocks in [Spark SQL Guide - Getting Started](https://spark.apache.org/docs/latest/sql-getting-started.html) currently point to invalid addresses and return 404. This pull request fixes that issue by pointing them to correct links in Python API docs.
### Why are the changes needed?
Error in documentation classifies as a bug and hence needs to be fixed.
### Does this PR introduce _any_ user-facing change?
Yes. This PR fixes documentation error in https://spark.apache.org/docs/latest/sql-getting-started.html
### How was this patch tested?
This patch was locally built after cloning the repo from scratch and then doing a clean build after fixing the required problems.
Closes#33107 from dhruvildave/sql-doc.
Authored-by: Dhruvil Dave <dhruvil.dave@outlook.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Update "Caching Data in Memory" section, add suggestion to call DataFrame `unpersist` method to make it consistent with previous suggestion of using `persist` method.
### Why are the changes needed?
Keep documentation consistent.
### Does this PR introduce _any_ user-facing change?
Yes, fixes the user-facing docs.
### How was this patch tested?
Manually.
Closes#33069 from Silverlight42/caching-data-doc.
Authored-by: Carlos Peña <Cdpm42@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR changes the unionByName with null filling logic to append new nested struct fields from the right side of the union to the schema versus sorting fields alphabetically. It removes the need to use UpdateField expressions, and just directly projects new nested structs from each side of the union with the correct schema. This changes the union'd schema from being alphabetically sorted previously to now "left dominant", where the fields from the left side of the union are included and then the missing ones from the right are added in the same order found originally.
### Why are the changes needed?
Certain nested structs would cause unionByName with null filling to error out due to part of the logic for rewriting the expression tree to sort the structs.
### Does this PR introduce _any_ user-facing change?
Yes, nested struct fields will be in a different order after unionByName with null filling than before, though shouldn't cause much effective difference.
### How was this patch tested?
Updated existing tests based on the new StructField ordering and added a new test for the case that was broken originally.
Closes#33040 from Kimahriman/union-by-name-struct-order.
Authored-by: Adam Binford <adamq43@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
* Add a new repartition operator `RebalanceRepartition`.
* Support a new hint `REBALANCE`
After this patch, user can run this query:
```sql
SELECT /*+ REBALANCE(c) */ * FROM t
```
### Why are the changes needed?
Add a new hint to distingush if we can optimize it safely.
This new hint can let AQE optimize with `CustomShuffleReaderExec` safely. Currently, AQE can only coalesce shuffle partitions but can not expand shuffle partitions due to the semantics of output partitioning.
Let's say we have a query:
```sql
SELECT /*+ REPARTITION(col) */ * FROM t
```
AQE can not expand the shuffle partitions even if `col` is skewed because expanding shuffle partitions will break the hashed output paritioning of `RepartitionByExpression`. But if the query is use`REPARTITION_BY_AQE`, AQE can optimize it without considering the semantics of output partitioning.
### Does this PR introduce _any_ user-facing change?
Yes, a new hint.
### How was this patch tested?
Add test.
Closes#32932 from ulysses-you/SPARK-35786.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This's a follow-up of https://github.com/apache/spark/pull/30710.
Rename the conf from `spark.speculation.min.threshold` to `spark.speculation.minTaskRuntime`.
### Why are the changes needed?
To follow the [config naming policy](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/internal/config/ConfigEntry.scala#L21).
### Does this PR introduce _any_ user-facing change?
No (since Spark 3.2 hasn't been released).
### How was this patch tested?
Pass existing tests.
Closes#33037 from Ngone51/spark-33741-followup.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to introduce the strategy on mismatched offset for start offset timestamp on Kafka data source.
Please read the section `Why are the changes needed?` to understand the rationalization of the functionality.
This would be pretty much helpful for the case where there's a skew between partitions and some partitions have older records.
* AS-IS: Spark simply fails the query and end users have to deal with workarounds requiring manual steps.
* TO-BE: Spark will assign the latest offset for these partitions, so that Spark can read newer records from these partitions in further micro-batches.
To retain the existing behavior and also give some help for the proposed "TO-BE" behavior, we'd like to introduce the strategy on mismatched offset for start offset timestamp to let end users choose from them.
The strategy will be added as source option, to ensure end users set the behavior explicitly (otherwise simply "known" default value).
* New source option to be added: startingOffsetsByTimestampStrategy
* Available values: `error` (fail the query as referred as AS-IS), `latest` (set the offset to the latest as referred as TO-BE)
Doc changes are following:


### Why are the changes needed?
We encountered a real-world case Spark fails the query if some of the partitions don't have matching offset by timestamp.
This is intended behavior to avoid bring unintended output for some cases like:
* timestamp 2 is presented as timestamp-offset, but the some of partitions don't have the record yet
* record with timestamp 1 comes "later" in the following micro-batch
which is possible since Kafka allows to specify the timestamp in record.
Here the unintended output we talked about was the risk of reading record with timestamp 1 in the next micro-batch despite the option specifying timestamp 2.
But for many cases end users just suppose timestamp is increasing monotonically with wall clocks are all in sync, and current behavior blocks these cases to make progress.
### Does this PR introduce _any_ user-facing change?
Yes, but not a breaking change. It's up to end users to choose the behavior which the default value is "error" (current behavior). And it's a source option (not config) so they need to explicitly set the behavior to let the functionality takes effect.
### How was this patch tested?
New UTs.
Closes#32747 from HeartSaVioR/SPARK-35611.
Authored-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
PySpark added pinned thread mode at https://github.com/apache/spark/pull/24898 to sync Python thread to JVM thread. Previously, one JVM thread could be reused which ends up with messed inheritance hierarchy such as thread local especially when multiple jobs run in parallel. To completely fix this, we should enable this mode by default.
### Why are the changes needed?
To correctly support parallel job submission and management.
### Does this PR introduce _any_ user-facing change?
Yes, now Python thread is mapped to JVM thread one to one.
### How was this patch tested?
Existing tests should cover it.
Closes#32429 from HyukjinKwon/SPARK-35303.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/32513
It's hard to keep the command execution name for `DataFrameWriter`, as the command logical plan is a bit messy (DS v1, file source and hive and different command logical plans) and sometimes it's hard to distinguish "insert" and "save".
However, `DataFrameWriterV2` only produce v2 commands which are pretty clean. It's easy to keep the command execution name for them.
### Why are the changes needed?
less breaking changes.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
N/A
Closes#32919 from cloud-fan/follow.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR updates the document about building Spark with Hadoop for Hadoop 3.x and Hadoop 3.2.
### Why are the changes needed?
The document says about how to build like as follows:
```
./build/mvn -Pyarn -Dhadoop.version=2.8.5 -DskipTests clean package
```
But this command fails because the default build settings are for Hadoop 3.x.
So, we need to modify the command example.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
I confirmed both of these commands successfully finished.
```
./build/mvn -Pyarn -Dhadoop.version=3.3.0 -DskipTests package
./build/mvn -Phadoop-2.7 -Pyarn -Dhadoop.version=2.8.5 -DskipTests package
```
I also built the document and confirmed the result.
This is before:

And this is after:

Closes#32917 from sarutak/fix-build-doc-with-hadoop.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR adda a feature which allow the parser parse any day-time interval types in SQL.
### Why are the changes needed?
To comply with ANSI standard, we additionally need to support the following types.
* INTERVAL DAY
* INTERVAL DAY TO HOUR
* INTERVAL DAY TO MINUTE
* INTERVAL HOUR
* INTERVAL HOUR TO MINUTE
* INTERVAL HOUR TO SECOND
* INTERVAL MINUTE
* INTERVAL MINUTE TO SECOND
* INTERVAL SECOND
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New tests.
Closes#32893 from sarutak/parse-any-day-time.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
The STRUCT type syntax is defined like this:
STRUCT(fieldNmae: fileType [NOT NULL][COMMENT stringLiteral][,.....])
So the field list is nearly the same as a column list
if we could make ':' optional it would be so much cleaner an less proprietary
### Why are the changes needed?
ease of use
### Does this PR introduce _any_ user-facing change?
Yes, you can use Struct type list is nearly the same as a column list
### How was this patch tested?
unit tests
Closes#32858 from jerqi/master.
Authored-by: RoryQi <1242949407@qq.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This pr upgrades built-in Hive to 2.3.9. Hive 2.3.9 changes:
- [HIVE-17155] - findConfFile() in HiveConf.java has some issues with the conf path
- [HIVE-24797] - Disable validate default values when parsing Avro schemas
- [HIVE-24608] - Switch back to get_table in HMS client for Hive 2.3.x
- [HIVE-21200] - Vectorization: date column throwing java.lang.UnsupportedOperationException for parquet
- [HIVE-21563] - Improve Table#getEmptyTable performance by disabling registerAllFunctionsOnce
- [HIVE-19228] - Remove commons-httpclient 3.x usage
### Why are the changes needed?
Fix regression caused by AVRO-2035.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#32750 from wangyum/SPARK-34512.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR updates documentation by removing reference to [hashicorp/nomad-spark](https://github.com/hashicorp/nomad-spark) which has been deprecated in April 2020, and will not be developed any longer.
### Why are the changes needed?
To keep the documentation updated and remove confusion for potential users being interested in running with Nomad.
### Does this PR introduce _any_ user-facing change?
Yes. A change to the documentation.
### How was this patch tested?
Generated to documentation, and checked everything is alright in the output.
Closes#32860 from pptaszynski/doc/remove-spark-nomad-project-reference.
Authored-by: Pawel Ptaszynski <pawel.ptaszynski@bolt.eu>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR adds support for lateral subqueries. A lateral subquery is a subquery preceded by the `LATERAL` keyword in the FROM clause of a query that can reference columns in the preceding FROM items. For example:
```sql
SELECT * FROM t1, LATERAL (SELECT * FROM t2 WHERE t1.a = t2.c)
```
A new subquery expression`LateralSubquery` is used to represent a lateral subquery. It is similar to `ScalarSubquery` but can return multiple rows and columns. A new logical unary node `LateralJoin` is used to represent a lateral join.
Here is the analyzed plan for the above query:
```scala
Project [a, b, c, d]
+- LateralJoin lateral-subquery [a], Inner
: +- Project [c, d]
: +- Filter (outer(a) = c)
: +- Relation [c, d]
+- Relation [a, b]
```
Similar to a correlated subquery, a lateral subquery can be viewed as a dependent (nested loop) join where the evaluation of the right subtree depends on the current value of the left subtree. The same technique to decorrelate a subquery is used to decorrelate a lateral join:
```scala
Project [a, b, c, d]
+- LateralJoin lateral-subquery [a && a = c], Inner // pull up correlated predicates as join conditions
: +- Project [c, d]
: +- Relation [c, d]
+- Relation [a, b]
```
Then the lateral join can be rewritten into a normal join:
```scala
Join Inner (a = c)
:- Relation [a, b]
+- Relation [c, d]
```
#### Follow-ups:
1. Similar to rewriting correlated scalar subqueries, rewriting lateral joins is also subject to the COUNT bug (See SPARK-15370 for more details). This is **not** handled in the current PR as it requires a sizeable amount of refactoring. It will be addressed in a subsequent PR (SPARK-35551).
2. Currently Spark does use outer query references to resolve star expressions in subqueries. This is not lateral subquery specific and can be handled in a separate PR (SPARK-35618)
### Why are the changes needed?
To support an ANSI SQL feature.
### Does this PR introduce _any_ user-facing change?
Yes. It allows users to use lateral subqueries in the FROM clause of a query.
### How was this patch tested?
- Parser test: `PlanParserSuite.scala`
- Analyzer test: `ResolveSubquerySuite.scala`
- Optimizer test: `PullupCorrelatedPredicatesSuite.scala`
- SQL test: `join-lateral.sql`, `postgreSQL/join.sql`
Closes#32303 from allisonwang-db/spark-34382-lateral.
Lead-authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR enhances `RepartitionByExpression` to make it coalesce partitions efficiently by AQE. Usually used to merge small files.
The basic logic is: Spark first tries to coalesce partitions, if it cannot be coalesced, then use the local shuffle reader to read data to avoid exchange the data over the network.
Usage:
```sql
SELECT /*+ REPARTITION */ * FROM t
```
```scala
df.repartition()
```
For example:
coalesce small output files | local shuffle reader
--- | ---
| 
### Why are the changes needed?
Coalesce partitions efficiently.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#32781 from wangyum/SPARK-35650.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, Spark eagerly executes commands on the caller side of `QueryExecution`, which is a bit hacky as `QueryExecution` is not aware of it and leads to confusion.
For example, if you run `sql("show tables").collect()`, you will see two queries with identical query plans in the web UI.



The first query is triggered at `Dataset.logicalPlan`, which eagerly executes the command.
The second query is triggered at `Dataset.collect`, which is the normal query execution.
From the web UI, it's hard to tell that these two queries are caused by eager command execution.
This PR proposes to move the eager command execution to `QueryExecution`, and turn the command plan to `CommandResult` to indicate that command has been executed already. Now `sql("show tables").collect()` still triggers two queries, but the quey plans are not identical. The second query becomes:

In addition to the UI improvements, this PR also has other benefits:
1. Simplifies code as caller side no need to worry about eager command execution. `QueryExecution` takes care of it.
2. It helps https://github.com/apache/spark/pull/32442 , where there can be more plan nodes above commands, and we need to replace commands with something like local relation that produces unsafe rows.
### Why are the changes needed?
Explained above.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existing tests
Closes#32513 from beliefer/SPARK-35378.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: beliefer <beliefer@163.com>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch introduces a new option to specify the minimum number of offsets to read per trigger i.e. minOffsetsPerTrigger and maxTriggerDelay to avoid the infinite wait for the trigger.
This new option will allow skipping trigger/batch when the number of records available in Kafka is low. This is a very useful feature in cases where we have a sudden burst of data at certain intervals in a day and data volume is low for the rest of the day.
'maxTriggerDelay' option will help to avoid cases of infinite delay in scheduling trigger and the trigger will happen irrespective of records available if the maxTriggerDelay time exceeds the last trigger. It would be an optional parameter with a default value of 15 mins. This option will be only applicable if minOffsetsPerTrigger is set.
minOffsetsPerTrigger option would be optional of course, but once specified it would take precedence over maxOffestsPerTrigger which will be honored only after minOffsetsPerTrigger is satisfied.
### Why are the changes needed?
There are many scenarios where there is a sudden burst of data at certain intervals in a day and data volume is low for the rest of the day. Tunning such jobs is difficult as decreasing trigger processing time increasing the number of batches and hence cluster resource usage and adds to small file issues. Increasing trigger processing time adds consumer lag. This patch tries to address this issue.
### How was this patch tested?
This patch was tested by adding test cases as well as manually on a cluster where the job was running for a full one day with a data burst happening once a day.
Here is the picture of databurst and hence consumer lag:
<img width="1198" alt="Screenshot 2021-04-29 at 11 39 35 PM" src="https://user-images.githubusercontent.com/1044003/116997587-9b2ab180-acfa-11eb-91fd-524802ce3316.png">
This is how the job behaved at burst time running every 4.5 mins (which is the specified trigger time):
<img width="1154" alt="Burst Time" src="https://user-images.githubusercontent.com/1044003/116997919-12f8dc00-acfb-11eb-9b0a-98387fc67560.png">
This is job behavior during the non-burst time where it is skipping 2 to 3 triggers and running once every 9 to 13.5 mins
<img width="1154" alt="Non Burst Time" src="https://user-images.githubusercontent.com/1044003/116998244-8b5f9d00-acfb-11eb-8340-33d47149ef81.png">
Here are some more stats from the two-run i.e. one normal run and the other with minOffsetsperTrigger set:
| Run | Data Size | Number of Batch Runs | Number of Files |
| ------------- | ------------- |------------- |------------- |
| Normal Run | 54.2 GB | 320 | 21968 |
| Run with minOffsetsperTrigger | 54.2 GB | 120 | 12104 |
Closes#32653 from satishgopalani/SPARK-35312.
Authored-by: Satish Gopalani <satish.gopalani@pubmatic.com>
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
Override `getJDBCType` method in `MySQLDialect` so that `FloatType` is mapped to `FLOAT` instead of `REAL`
### Why are the changes needed?
MySQL treats `REAL` as a synonym to `DOUBLE` by default (see https://dev.mysql.com/doc/refman/8.0/en/numeric-types.html). Therefore, when creating a table with a column of `REAL` type, it will be created as `DOUBLE`. However, currently, `MySQLDialect` does not provide an implementation for `getJDBCType`, and will thus ultimately fall back to `JdbcUtils.getCommonJDBCType`, which maps `FloatType` to `REAL`. This change is needed so that we can properly map the `FloatType` to `FLOAT` for MySQL.
### Does this PR introduce _any_ user-facing change?
Prior to this PR, when writing a dataframe with a `FloatType` column to a MySQL table, it will create a `DOUBLE` column. After the PR, it will create a `FLOAT` column.
### How was this patch tested?
Added a test case in `JDBCSuite` that verifies the mapping.
Closes#32605 from mariosmeim-db/SPARK-35446.
Authored-by: Marios Meimaris <marios.meimaris@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes fix the default value in Data Source Option page based on the Scala documentation.
### Why are the changes needed?
Some of the existing default value in Data Source Option page follow the Python documentation, which has `None` as the default value for all options.
### Does this PR introduce _any_ user-facing change?
Yes, the default value in the Data Source Option page is fixed (from `None` to proper default value)
- Before
<img width="361" alt="Screen Shot 2021-06-02 at 6 31 12 PM" src="https://user-images.githubusercontent.com/44108233/120456594-b8719f00-c3d0-11eb-9778-071ab2ba9f45.png">
- After
<img width="562" alt="Screen Shot 2021-06-02 at 6 32 47 PM" src="https://user-images.githubusercontent.com/44108233/120456844-f1117880-c3d0-11eb-9c7c-9dcd66776444.png">
### How was this patch tested?
Manually built the docs and checked one by one.
Closes#32745 from itholic/SPARK-35523.
Lead-authored-by: itholic <haejoon.lee@databricks.com>
Co-authored-by: Haejoon Lee <44108233+itholic@users.noreply.github.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to port Koalas documentation to PySpark documentation as its initial step.
It ports almost as is except these differences:
- Renamed import from `databricks.koalas` to `pyspark.pandas`.
- Renamed `to_koalas` -> `to_pandas_on_spark`
- Renamed `(Series|DataFrame).koalas` -> `(Series|DataFrame).pandas_on_spark`
- Added a `ps_` prefix in the RST file names of Koalas documentation
Other then that,
- Excluded `python/docs/build/html` in linter
- Fixed GA dependency installataion
### Why are the changes needed?
To document pandas APIs on Spark.
### Does this PR introduce _any_ user-facing change?
Yes, it adds new documentations.
### How was this patch tested?
Manually built the docs and checked the output.
Closes#32726 from HyukjinKwon/SPARK-35587.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes adding more methods to set data source option to `Data Source Option` page for each data source.
For example, Data Source Option page for JSON as below:
- Before
<img width="322" alt="Screen Shot 2021-06-03 at 10 51 54 AM" src="https://user-images.githubusercontent.com/44108233/120574245-eb13aa00-c459-11eb-9f81-0b356023bcb5.png">
- After
<img width="470" alt="Screen Shot 2021-06-03 at 10 52 21 AM" src="https://user-images.githubusercontent.com/44108233/120574253-ed760400-c459-11eb-9008-1f075e0b9267.png">
### Why are the changes needed?
To provide users various options when they set options for data source.
### Does this PR introduce _any_ user-facing change?
Yes, now the document provides more methods for setting options than before, as in above screen capture.
### How was this patch tested?
Manually built the docs and check one by one.
Closes#32757 from itholic/SPARK-35528.
Authored-by: itholic <haejoon.lee@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to support special datetime values introduced by #25708 and by #25716 only in typed literals, and don't recognize them in parsing strings to dates/timestamps. The following string values are supported only in typed timestamp literals:
- `epoch [zoneId]` - `1970-01-01 00:00:00+00 (Unix system time zero)`
- `today [zoneId]` - midnight today.
- `yesterday [zoneId]` - midnight yesterday
- `tomorrow [zoneId]` - midnight tomorrow
- `now` - current query start time.
For example:
```sql
spark-sql> SELECT timestamp 'tomorrow';
2019-09-07 00:00:00
```
Similarly, the following special date values are supported only in typed date literals:
- `epoch [zoneId]` - `1970-01-01`
- `today [zoneId]` - the current date in the time zone specified by `spark.sql.session.timeZone`.
- `yesterday [zoneId]` - the current date -1
- `tomorrow [zoneId]` - the current date + 1
- `now` - the date of running the current query. It has the same notion as `today`.
For example:
```sql
spark-sql> SELECT date 'tomorrow' - date 'yesterday';
2
```
### Why are the changes needed?
In the current implementation, Spark supports the special date/timestamp value in any input strings casted to dates/timestamps that leads to the following problems:
- If executors have different system time, the result is inconsistent, and random. Column values depend on where the conversions were performed.
- The special values play the role of distributed non-deterministic functions though users might think of the values as constants.
### Does this PR introduce _any_ user-facing change?
Yes but the probability should be small.
### How was this patch tested?
By running existing test suites:
```
$ build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite -- -z interval.sql"
$ build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite -- -z date.sql"
$ build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite -- -z timestamp.sql"
$ build/sbt "test:testOnly *DateTimeUtilsSuite"
```
Closes#32714 from MaxGekk/remove-datetime-special-values.
Lead-authored-by: Max Gekk <max.gekk@gmail.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
Fixed some places in cluster-overview that are obsolete (i.e. not mentioning Kubernetes), and also fixed the Yarn spark-submit sample command in submitting-applications.
### What changes were proposed in this pull request?
This is to fix the docs in "Cluster Overview" and "Submitting Applications" for places where Kubernetes is missed (mostly due to obsolete docs that haven't got updated) and where Yarn sample spark-submit command is incorrectly written.
### Why are the changes needed?
To help the Spark users who uses Kubernetes as cluster manager to have a correct idea when reading the "Cluster Overview" doc page. Also to make the sample spark-submit command for Yarn actually runnable in the "Submitting Applications" doc page, by removing the invalid comment after line continuation char `\`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
No test, as this is doc fix.
Closes#32701 from huskysun/doc-fix.
Authored-by: Shiqi Sun <s.sun@salesforce.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This patch is a follow-up of SPARK-26848 (#23747). In SPARK-26848, we decided to open possibility to let end users set individual timestamp per partition. But in many cases, specifying timestamp represents the intention that we would want to go back to specific timestamp and reprocess records, which should be applied to all topics and partitions.
This patch proposes to provide a way to set a global timestamp across topic-partitions which the source is subscribing to, so that end users can set all offsets by specific timestamp easily. To provide the way to config the timestamp easier, the new options only receive "a" timestamp for start/end timestamp.
New options introduced in this PR:
* startingTimestamp
* endingTimestamp
All two options receive timestamp as string.
There're priorities for options regarding starting/ending offset as we will have three options for start offsets and another three options for end offsets. Priorities are following:
* starting offsets: startingTimestamp -> startingOffsetsByTimestamp -> startingOffsets
* ending offsets: startingTimestamp -> startingOffsetsByTimestamp -> startingOffsets
### Why are the changes needed?
Existing option to specify timestamp as offset is quite verbose if there're a lot of partitions across topics. Suppose there're 100s of partitions in a topic, the json should contain 100s of times of the same timestamp.
Also, the number of partitions can also change, which requires either:
* fixing the code if the json is statically created
* introducing the dependencies on Kafka client and deal with Kafka API on crafting json programmatically
Both approaches are even not "acceptable" if we're dealing with ad-hoc query; anyone doesn't want to write the code more complicated than the query itself. Flink [provides the option](https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/connectors/datastream/kafka/#kafka-consumers-start-position-configuration) to specify a timestamp for all topic-partitions like this PR, and even doesn't provide the option to specify the timestamp per topic-partition.
With this PR, end users are only required to provide a single timestamp value. No more complicated JSON format end users need to know about the structure.
### Does this PR introduce _any_ user-facing change?
Yes, this PR introduces two new options, described in above section.
Doc changes are following:




### How was this patch tested?
New UTs covering new functionalities. Also manually tested via simple batch & streaming queries.
Closes#32609 from HeartSaVioR/SPARK-29223-v2.
Authored-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This PR upgrades Dropwizard metrics to 4.2.0.
I also modified the corresponding links in `docs/monitoring.md`.
### Why are the changes needed?
The latest version was released last week and it contains some improvements.
https://github.com/dropwizard/metrics/releases/tag/v4.2.0
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Build succeeds and all the modified links are reachable.
Closes#32628 from sarutak/upgrade-dropwizard-4.2.0.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
CTAS with location clause acts as an insert overwrite. This can cause problems when there are subdirectories within a location directory.
This causes some users to accidentally wipe out directories with very important data. We should not allow CTAS with location to a non-empty directory.
### Why are the changes needed?
Hive already handled this scenario: HIVE-11319
Steps to reproduce:
```scala
sql("""create external table `demo_CTAS`( `comment` string) PARTITIONED BY (`col1` string, `col2` string) STORED AS parquet location '/tmp/u1/demo_CTAS'""")
sql("""INSERT OVERWRITE TABLE demo_CTAS partition (col1='1',col2='1') VALUES ('abc')""")
sql("select* from demo_CTAS").show
sql("""create table ctas1 location '/tmp/u2/ctas1' as select * from demo_CTAS""")
sql("select* from ctas1").show
sql("""create table ctas2 location '/tmp/u2' as select * from demo_CTAS""")
```
Before the fix: Both create table operations will succeed. But values in table ctas1 will be replaced by ctas2 accidentally.
After the fix: `create table ctas2...` will throw `AnalysisException`:
```
org.apache.spark.sql.AnalysisException: CREATE-TABLE-AS-SELECT cannot create table with location to a non-empty directory /tmp/u2 . To allow overwriting the existing non-empty directory, set 'spark.sql.legacy.allowNonEmptyLocationInCTAS' to true.
```
### Does this PR introduce _any_ user-facing change?
Yes, if the location directory is not empty, CTAS with location will throw AnalysisException
```
sql("""create table ctas2 location '/tmp/u2' as select * from demo_CTAS""")
```
```
org.apache.spark.sql.AnalysisException: CREATE-TABLE-AS-SELECT cannot create table with location to a non-empty directory /tmp/u2 . To allow overwriting the existing non-empty directory, set 'spark.sql.legacy.allowNonEmptyLocationInCTAS' to true.
```
`CREATE TABLE AS SELECT` with non-empty `LOCATION` will throw `AnalysisException`. To restore the behavior before Spark 3.2, need to set `spark.sql.legacy.allowNonEmptyLocationInCTAS` to `true`. , default value is `false`.
Updated SQL migration guide.
### How was this patch tested?
Test case added in SQLQuerySuite.scala
Closes#32411 from vinodkc/br_fixCTAS_nonempty_dir.
Authored-by: Vinod KC <vinod.kc.in@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The following two things are done in this PR.
* Add note about Jinja2 as a required dependency for document build.
* Add Jinja2 dependency for the document build to `spark-rm/Dockerfile`
### Why are the changes needed?
SPARK-35375(#32509) confined the version of Jinja to <3.0.0.
So it's good to note about it in `docs/README.md` and add the dependency to `spark-rm/Dockerfile`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
I confimed that `make html` succeed under `python/docs` with the following command.
```
sudo pip install 'sphinx<3.1.0' mkdocs numpy pydata_sphinx_theme ipython nbsphinx numpydoc 'jinja2<3.0.0'
```
Closes#32573 from sarutak/required-module-for-python-doc.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
Fix incorrect statement that state is no longer needed in the event of executor failure and document that it is needed in the case of a flaky app causing occasional executor failure.
SO [discussion](https://stackoverflow.com/questions/67466878/can-spark-with-external-shuffle-service-use-saved-shuffle-files-in-the-event-of/67507439#67507439).
### Why are the changes needed?
To fix the documentation and guide users as to additional use case for the Shuffle Service.
### Does this PR introduce _any_ user-facing change?
Documentation only.
### How was this patch tested?
N/A.
Closes#32538 from chrisheaththomas/shuffle-service-and-executor-failure.
Authored-by: Chris Thomas <chrisheaththomas@hotmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Add toc tag on monitoring.md
### Why are the changes needed?
fix doc
### Does this PR introduce _any_ user-facing change?
yes, the table of content of the monitoring page will be shown on the official doc site.
### How was this patch tested?
pass GA doc build
Closes#32545 from yaooqinn/minor.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
Generally, we would expect that x = y => hash( x ) = hash( y ). However +-0 hash to different values for floating point types.
```
scala> spark.sql("select hash(cast('0.0' as double)), hash(cast('-0.0' as double))").show
+-------------------------+--------------------------+
|hash(CAST(0.0 AS DOUBLE))|hash(CAST(-0.0 AS DOUBLE))|
+-------------------------+--------------------------+
| -1670924195| -853646085|
+-------------------------+--------------------------+
scala> spark.sql("select cast('0.0' as double) == cast('-0.0' as double)").show
+--------------------------------------------+
|(CAST(0.0 AS DOUBLE) = CAST(-0.0 AS DOUBLE))|
+--------------------------------------------+
| true|
+--------------------------------------------+
```
Here is an extract from IEEE 754:
> The two zeros are distinguishable arithmetically only by either division-byzero ( producing appropriately signed infinities ) or else by the CopySign function recommended by IEEE 754 /854. Infinities, SNaNs, NaNs and Subnormal numbers necessitate four more special cases
From this, I deduce that the hash function must produce the same result for 0 and -0.
### Why are the changes needed?
It is a correctness issue
### Does this PR introduce _any_ user-facing change?
This changes only affect to the hash function applied to -0 value in float and double types
### How was this patch tested?
Unit testing and manual testing
Closes#32496 from planga82/feature/spark35207_hashnegativezero.
Authored-by: Pablo Langa <soypab@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In this PR I'm adding Structured Streaming Web UI state information documentation.
### Why are the changes needed?
Missing documentation.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
```
cd docs/
SKIP_API=1 bundle exec jekyll build
```
Manual webpage check.
Closes#32433 from gaborgsomogyi/SPARK-35311.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This proposes to document the available metrics for ExecutorAllocationManager in the Spark monitoring documentation.
### Why are the changes needed?
The ExecutorAllocationManager is instrumented with metrics using the Spark metrics system.
The relevant work is in SPARK-7007 and SPARK-33763
ExecutorAllocationManager metrics are currently undocumented.
### Does this PR introduce _any_ user-facing change?
This PR adds documentation only.
### How was this patch tested?
na
Closes#32500 from LucaCanali/followupMetricsDocSPARK33763.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR proposes to introduces three new configurations to limit the maximum number of jobs/stages/executors on the timeline view.
### Why are the changes needed?
If the number of items on the timeline view grows +1000, rendering can be significantly slow.
https://issues.apache.org/jira/browse/SPARK-35229
The maximum number of tasks on the timeline is already limited by `spark.ui.timeline.tasks.maximum` so l proposed to mitigate this issue with the same manner.
### Does this PR introduce _any_ user-facing change?
Yes. the maximum number of items shown on the timeline view is limited.
I proposed the default value 500 for jobs and stages, and 250 for executors.
A executor has at most 2 items (added and removed) 250 is chosen.
### How was this patch tested?
I manually confirm this change works with the following procedures.
```
# launch a cluster
$ bin/spark-shell --conf spark.ui.retainedDeadExecutors=300 --master "local-cluster[4, 1, 1024]"
// Confirm the maximum number of jobs
(1 to 1000).foreach { _ => sc.parallelize(List(1)).collect }
// Confirm the maximum number of stages
var df = sc.parallelize(1 to 2)
(1 to 1000).foreach { i => df = df.repartition(i % 5 + 1) }
df.collect
// Confirm the maximum number of executors
(1 to 300).foreach { _ => try sc.parallelize(List(1)).foreach { _ => System.exit(0) } catch { case e => }}
```
Screenshots here.



Closes#32381 from sarutak/mitigate-timeline-issue.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
1. Extend Spark SQL parser to support parsing of:
- `INTERVAL YEAR TO MONTH` to `YearMonthIntervalType`
- `INTERVAL DAY TO SECOND` to `DayTimeIntervalType`
2. Assign new names to the ANSI interval types according to the SQL standard to be able to parse the names back by Spark SQL parser. Override the `typeName()` name of `YearMonthIntervalType`/`DayTimeIntervalType`.
### Why are the changes needed?
To be able to use new ANSI interval types in SQL. The SQL standard requires the types to be defined according to the rules:
```
<interval type> ::= INTERVAL <interval qualifier>
<interval qualifier> ::= <start field> TO <end field> | <single datetime field>
<start field> ::= <non-second primary datetime field> [ <left paren> <interval leading field precision> <right paren> ]
<end field> ::= <non-second primary datetime field> | SECOND [ <left paren> <interval fractional seconds precision> <right paren> ]
<primary datetime field> ::= <non-second primary datetime field | SECOND
<non-second primary datetime field> ::= YEAR | MONTH | DAY | HOUR | MINUTE
<interval fractional seconds precision> ::= <unsigned integer>
<interval leading field precision> ::= <unsigned integer>
```
Currently, Spark SQL supports only `YEAR TO MONTH` and `DAY TO SECOND` as `<interval qualifier>`.
### Does this PR introduce _any_ user-facing change?
Should not since the types has not been released yet.
### How was this patch tested?
By running the affected tests such as:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "test:testOnly *ExpressionTypeCheckingSuite"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z windowFrameCoercion.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z literals.sql"
```
Closes#32409 from MaxGekk/parse-ansi-interval-types.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR extends `ADD FILE/JAR/ARCHIVE` commands to be able to take multiple path arguments like Hive.
### Why are the changes needed?
To make those commands more useful.
### Does this PR introduce _any_ user-facing change?
Yes. In the current implementation, those commands can take a path which contains whitespaces without enclose it by neither `'` nor `"` but after this change, users need to enclose such paths.
I've note this incompatibility in the migration guide.
### How was this patch tested?
New tests.
Closes#32205 from sarutak/add-multiple-files.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
This PR proposes to introduce a new JDBC option `refreshKrb5Config` which allows to reflect the change of `krb5.conf`.
### Why are the changes needed?
In the current master, JDBC datasources can't accept `refreshKrb5Config` which is defined in `Krb5LoginModule`.
So even if we change the `krb5.conf` after establishing a connection, the change will not be reflected.
The similar issue happens when we run multiple `*KrbIntegrationSuites` at the same time.
`MiniKDC` starts and stops every KerberosIntegrationSuite and different port number is recorded to `krb5.conf`.
Due to `SecureConnectionProvider.JDBCConfiguration` doesn't take `refreshKrb5Config`, KerberosIntegrationSuites except the first running one see the wrong port so those suites fail.
You can easily confirm with the following command.
```
build/sbt -Phive Phive-thriftserver -Pdocker-integration-tests "testOnly org.apache.spark.sql.jdbc.*KrbIntegrationSuite"
```
### Does this PR introduce _any_ user-facing change?
Yes. Users can set `refreshKrb5Config` to refresh krb5 relevant configuration.
### How was this patch tested?
New test.
Closes#32344 from sarutak/kerberos-refresh-issue.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
Add doc about `TRANSFORM` and related function.
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32257 from AngersZhuuuu/SPARK-33976-followup.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Add JindoFS SDK documents link in the cloud integration section of Spark's official document.
### Why are the changes needed?
If Spark users need to interact with Alibaba Cloud OSS, JindoFS SDK is the official solution provided by Alibaba Cloud.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
tested the url manually.
Closes#32360 from adrian-wang/jindodoc.
Authored-by: Daoyuan Wang <daoyuan.wdy@alibaba-inc.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Add note in migration guide about DayTimeIntervalType/YearMonthIntervalType show different between Hive SerDe and row format delimited
### Why are the changes needed?
Add note
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32343 from AngersZhuuuu/SPARK-35220-FOLLOWUP.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Extract common doc about hive format for `sql-ref-syntax-ddl-create-table-hiveformat.md` and `sql-ref-syntax-qry-select-transform.md` to refer.

### Why are the changes needed?
Improve doc
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32264 from AngersZhuuuu/SPARK-35159.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
PG and Oracle both support use CUBE/ROLLUP/GROUPING SETS in GROUPING SETS's grouping set as a sugar syntax.

In this PR, we support it in Spark SQL too
### Why are the changes needed?
Keep consistent with PG and oracle
### Does this PR introduce _any_ user-facing change?
User can write grouping analytics like
```
SELECT a, b, count(1) FROM testData GROUP BY a, GROUPING SETS(ROLLUP(a, b));
SELECT a, b, count(1) FROM testData GROUP BY a, GROUPING SETS((a, b), (a), ());
SELECT a, b, count(1) FROM testData GROUP BY a, GROUPING SETS(GROUPING SETS((a, b), (a), ()));
```
### How was this patch tested?
Added Test
Closes#32201 from AngersZhuuuu/SPARK-35026.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In YARN, ship the `spark.jars.ivySettings` file to the driver when using `cluster` deploy mode so that `addJar` is able to find it in order to resolve ivy paths.
### Why are the changes needed?
SPARK-33084 introduced support for Ivy paths in `sc.addJar` or Spark SQL `ADD JAR`. If we use a custom ivySettings file using `spark.jars.ivySettings`, it is loaded at b26e7b510b/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala (L1280). However, this file is only accessible on the client machine. In YARN cluster mode, this file is not available on the driver and so `addJar` fails to find it.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added unit tests to verify that the `ivySettings` file is localized by the YARN client and that a YARN cluster mode application is able to find to load the `ivySettings` file.
Closes#31591 from shardulm94/SPARK-34472.
Authored-by: Shardul Mahadik <smahadik@linkedin.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
Add doc about `TRANSFORM` and related function.

### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#31010 from AngersZhuuuu/SPARK-33976.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to support a new configuration, `spark.kubernetes.driver.service.deleteOnTermination`, to clean up `Driver Service` resource during app termination.
### Why are the changes needed?
The K8s service is one of the important resources and sometimes it's controlled by quota.
```
$ k describe quota
Name: service
Namespace: default
Resource Used Hard
-------- ---- ----
services 1 3
```
Apache Spark creates a service for driver whose lifecycle is the same with driver pod.
It means a new Spark job submission fails if the number of completed Spark jobs equals the number of service quota.
**BEFORE**
```
$ k get pod
NAME READY STATUS RESTARTS AGE
org-apache-spark-examples-sparkpi-a32c9278e7061b4d-driver 0/1 Completed 0 31m
org-apache-spark-examples-sparkpi-a9f1f578e721ef62-driver 0/1 Completed 0 78s
$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 80m
org-apache-spark-examples-sparkpi-a32c9278e7061b4d-driver-svc ClusterIP None <none> 7078/TCP,7079/TCP,4040/TCP 31m
org-apache-spark-examples-sparkpi-a9f1f578e721ef62-driver-svc ClusterIP None <none> 7078/TCP,7079/TCP,4040/TCP 80s
$ k describe quota
Name: service
Namespace: default
Resource Used Hard
-------- ---- ----
services 3 3
$ bin/spark-submit...
Exception in thread "main" io.fabric8.kubernetes.client.KubernetesClientException:
Failure executing: POST at: https://192.168.64.50:8443/api/v1/namespaces/default/services.
Message: Forbidden! User minikube doesn't have permission.
services "org-apache-spark-examples-sparkpi-843f6978e722819c-driver-svc" is forbidden:
exceeded quota: service, requested: services=1, used: services=3, limited: services=3.
```
**AFTER**
```
$ k get pod
NAME READY STATUS RESTARTS AGE
org-apache-spark-examples-sparkpi-23d5f278e77731a7-driver 0/1 Completed 0 26s
org-apache-spark-examples-sparkpi-d1292278e7768ed4-driver 0/1 Completed 0 67s
org-apache-spark-examples-sparkpi-e5bedf78e776ea9d-driver 0/1 Completed 0 44s
$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 172m
$ k describe quota
Name: service
Namespace: default
Resource Used Hard
-------- ---- ----
services 1 3
```
### Does this PR introduce _any_ user-facing change?
Yes, this PR adds a new configuration, `spark.kubernetes.driver.service.deleteOnTermination`, and enables it by default.
The change is documented at the migration guide.
### How was this patch tested?
Pass the CIs.
This is tested with K8s IT manually.
```
KubernetesSuite:
- Run SparkPi with no resources
- Run SparkPi with a very long application name.
- Use SparkLauncher.NO_RESOURCE
- Run SparkPi with a master URL without a scheme.
- Run SparkPi with an argument.
- Run SparkPi with custom labels, annotations, and environment variables.
- All pods have the same service account by default
- Run extraJVMOptions check on driver
- Run SparkRemoteFileTest using a remote data file
- Verify logging configuration is picked from the provided SPARK_CONF_DIR/log4j.properties
- Run SparkPi with env and mount secrets.
- Run PySpark on simple pi.py example
- Run PySpark to test a pyfiles example
- Run PySpark with memory customization
- Run in client mode.
- Start pod creation from template
- PVs with local storage
- Launcher client dependencies
- SPARK-33615: Launcher client archives
- SPARK-33748: Launcher python client respecting PYSPARK_PYTHON
- SPARK-33748: Launcher python client respecting spark.pyspark.python and spark.pyspark.driver.python
- Launcher python client dependencies using a zip file
- Test basic decommissioning
- Test basic decommissioning with shuffle cleanup
- Test decommissioning with dynamic allocation & shuffle cleanups
- Test decommissioning timeouts
- Run SparkR on simple dataframe.R example
Run completed in 19 minutes, 9 seconds.
Total number of tests run: 27
Suites: completed 2, aborted 0
Tests: succeeded 27, failed 0, canceled 0, ignored 0, pending 0
All tests passed.
```
Closes#32226 from dongjoon-hyun/SPARK-35131.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Parse the year-month interval literals like `INTERVAL '1-1' YEAR TO MONTH` to values of `YearMonthIntervalType`, and day-time interval literals to `DayTimeIntervalType` values. Currently, Spark SQL supports:
- DAY TO HOUR
- DAY TO MINUTE
- DAY TO SECOND
- HOUR TO MINUTE
- HOUR TO SECOND
- MINUTE TO SECOND
All such interval literals are converted to `DayTimeIntervalType`, and `YEAR TO MONTH` to `YearMonthIntervalType` while loosing info about `from` and `to` units.
**Note**: new behavior is under the SQL config `spark.sql.legacy.interval.enabled` which is `false` by default. When the config is set to `true`, the interval literals are parsed to `CaledarIntervalType` values.
Closes#32176
### Why are the changes needed?
To conform the ANSI SQL standard which assumes conversions of interval literals to year-month or day-time interval but not to mixed interval type like Catalyst's `CalendarIntervalType`.
### Does this PR introduce _any_ user-facing change?
Yes.
Before:
```sql
spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND;
1 days 1 hours 2 minutes 3.123 seconds
spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND);
interval
```
After:
```sql
spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND;
1 01:02:03.123000000
spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND);
day-time interval
```
### How was this patch tested?
1. By running the affected test suites:
```
$ ./build/sbt "test:testOnly *.ExpressionParserSuite"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z create_view.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql"
```
2. PostgresSQL tests are executed with `spark.sql.legacy.interval.enabled` is set to `true` to keep compatibility with PostgreSQL output:
```sql
> SELECT interval '999' second;
0 years 0 mons 0 days 0 hours 16 mins 39.00 secs
```
Closes#32209 from MaxGekk/parse-ansi-interval-literals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Support no-serde mode script transform use ArrayType/MapType/StructStpe data.
### Why are the changes needed?
Make user can process array/map/struct data
### Does this PR introduce _any_ user-facing change?
Yes, user can process array/map/struct data in script transform `no-serde` mode
### How was this patch tested?
Added UT
Closes#30957 from AngersZhuuuu/SPARK-31937.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Soften security warning and keep it in cluster management docs only, not in the main doc page, where it's not necessarily relevant.
### Why are the changes needed?
The statement is perhaps unnecessarily 'frightening' as the first section in the main docs page. It applies to clusters not local mode, anyhow.
### Does this PR introduce _any_ user-facing change?
Just a docs change.
### How was this patch tested?
N/A
Closes#32206 from srowen/SecurityStatement.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Use hadoop FileSystem instead of FileInputStream.
### Why are the changes needed?
Make `spark.scheduler.allocation.file` suport remote file. When using Spark as a server (e.g. SparkThriftServer), it's hard for user to specify a local path as the scheduler pool.
### Does this PR introduce _any_ user-facing change?
Yes, a minor feature.
### How was this patch tested?
Pass `core/src/test/scala/org/apache/spark/scheduler/PoolSuite.scala` and manul test
After add config `spark.scheduler.allocation.file=hdfs:///tmp/fairscheduler.xml`. We intrudoce the configed pool.

Closes#32184 from ulysses-you/SPARK-35083.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Normal function parameters should not support alias, hive not support too
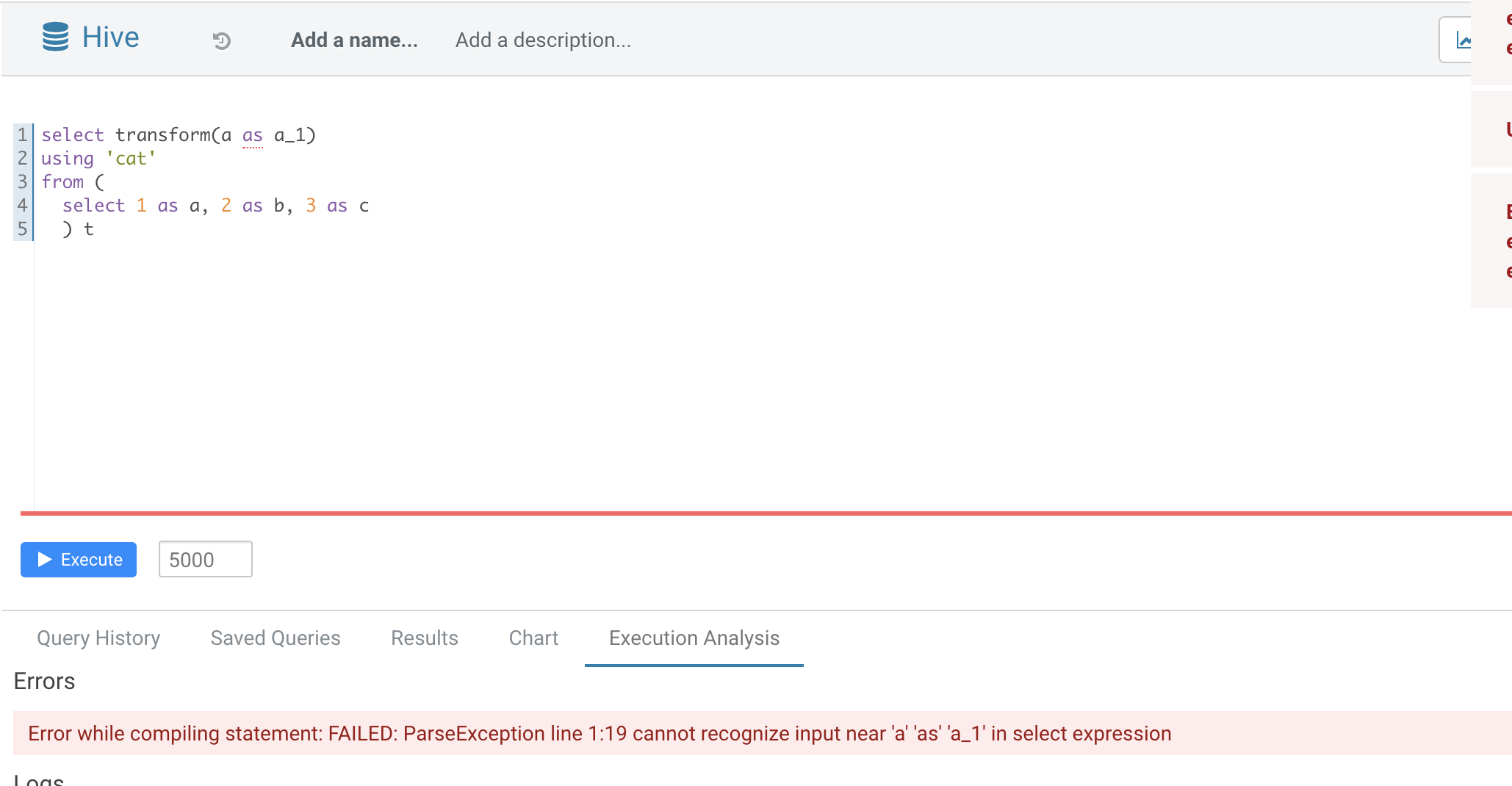
In this pr we forbid use alias in `TRANSFORM`'s inputs
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#32165 from AngersZhuuuu/SPARK-35070.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add change of `DESC NAMESPACE`'s schema to migration guide
### Why are the changes needed?
Update doc
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32155 from AngersZhuuuu/SPARK-34577-followup.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Deprecate Apache Mesos support for Spark 3.2.0 by adding documentation to this effect.
### Why are the changes needed?
Apache Mesos is ceasing development (https://lists.apache.org/thread.html/rab2a820507f7c846e54a847398ab20f47698ec5bce0c8e182bfe51ba%40%3Cdev.mesos.apache.org%3E) ; at some point we'll want to drop support, so, deprecate it now.
This doesn't mean it'll go away in 3.3.0.
### Does this PR introduce _any_ user-facing change?
No, docs only.
### How was this patch tested?
N/A
Closes#32150 from srowen/SPARK-35050.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Disallow group by aliases under ANSI mode.
### Why are the changes needed?
As per the ANSI SQL standard secion 7.12 <group by clause>:
>Each `grouping column reference` shall unambiguously reference a column of the table resulting from the `from clause`. A column referenced in a `group by clause` is a grouping column.
By forbidding it, we can avoid ambiguous SQL queries like:
```
SELECT col + 1 as col FROM t GROUP BY col
```
### Does this PR introduce _any_ user-facing change?
Yes, group by aliases is not allowed under ANSI mode.
### How was this patch tested?
Unit tests
Closes#32129 from gengliangwang/disallowGroupByAlias.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
This pr add test and document for Parquet Bloom filter push down.
### Why are the changes needed?
Improve document.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Generating docs:

Closes#32123 from wangyum/SPARK-34562.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Support GROUP BY use Separate columns and CUBE/ROLLUP
In postgres sql, it support
```
select a, b, c, count(1) from t group by a, b, cube (a, b, c);
select a, b, c, count(1) from t group by a, b, rollup(a, b, c);
select a, b, c, count(1) from t group by cube(a, b), rollup (a, b, c);
select a, b, c, count(1) from t group by a, b, grouping sets((a, b), (a), ());
```
In this pr, we have done two things as below:
1. Support partial grouping analytics such as `group by a, cube(a, b)`
2. Support mixed grouping analytics such as `group by cube(a, b), rollup(b,c)`
*Partial Groupings*
Partial Groupings means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
in GROUP BY clause. For example:
`GROUP BY warehouse, CUBE(product, location)` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse, location), (warehouse))`.
`GROUP BY warehouse, ROLLUP(product, location)` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse))`.
`GROUP BY warehouse, GROUPING SETS((product, location), (producet), ())` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, location), (warehouse))`.
*Concatenated Groupings*
Concatenated groupings offer a concise way to generate useful combinations of groupings. Groupings specified
with concatenated groupings yield the cross-product of groupings from each grouping set. The cross-product
operation enables even a small number of concatenated groupings to generate a large number of final groups.
The concatenated groupings are specified simply by listing multiple `GROUPING SETS`, `CUBES`, and `ROLLUP`,
and separating them with commas. For example:
`GROUP BY GROUPING SETS((warehouse), (producet)), GROUPING SETS((location), (size))` is equivalent to
`GROUP BY GROUPING SETS((warehouse, location), (warehouse, size), (product, location), (product, size))`.
`GROUP BY CUBE((warehouse), (producet)), ROLLUP((location), (size))` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product), (warehouse), (producet), ()), GROUPING SETS((location, size), (location), ())`
`GROUP BY GROUPING SETS(
(warehouse, product, location, size), (warehouse, product, location), (warehouse, product),
(warehouse, location, size), (warehouse, location), (warehouse),
(product, location, size), (product, location), (product),
(location, size), (location), ())`.
`GROUP BY order, CUBE((warehouse), (producet)), ROLLUP((location), (size))` is equivalent to
`GROUP BY order, GROUPING SETS((warehouse, product), (warehouse), (producet), ()), GROUPING SETS((location, size), (location), ())`
`GROUP BY GROUPING SETS(
(order, warehouse, product, location, size), (order, warehouse, product, location), (order, warehouse, product),
(order, warehouse, location, size), (order, warehouse, location), (order, warehouse),
(order, product, location, size), (order, product, location), (order, product),
(order, location, size), (order, location), (order))`.
### Why are the changes needed?
Support more flexible grouping analytics
### Does this PR introduce _any_ user-facing change?
User can use sql like
```
select a, b, c, agg_expr() from table group by a, cube(b, c)
```
### How was this patch tested?
Added UT
Closes#30144 from AngersZhuuuu/SPARK-33229.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch fixes wrong Python code sample for doc.
### Why are the changes needed?
Sample code is wrong.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Doc only.
Closes#32119 from Hisssy/ss-doc-typo-1.
Authored-by: hissy <aozora@live.cn>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR aims to add a documentation on how to read and write TEXT files through various APIs such as Scala, Python and JAVA in Spark to [Data Source documents](https://spark.apache.org/docs/latest/sql-data-sources.html#data-sources).
### Why are the changes needed?
Documentation on how Spark handles TEXT files is missing. It should be added to the document for user convenience.
### Does this PR introduce _any_ user-facing change?
Yes, this PR adds a new page to Data Sources documents.
### How was this patch tested?
Manually build documents and check the page on local as below.

Closes#32053 from itholic/SPARK-34491-TEXT.
Authored-by: itholic <haejoon.lee@databricks.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
CREATE TABLE LIKE should respect the reserved properties of tables and fail if specified, using `spark.sql.legacy.notReserveProperties` to restore.
### Why are the changes needed?
Make DDLs consistently treat reserved properties
### Does this PR introduce _any_ user-facing change?
YES, this is a breaking change as using `create table like` w/ reserved properties will fail.
### How was this patch tested?
new test
Closes#32025 from yaooqinn/SPARK-34935.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
GROUP BY ... GROUPING SETS (...) is a weird SQL syntax we copied from Hive. It's not in the SQL standard or any other mainstream databases. This syntax requires users to repeat the expressions inside `GROUPING SETS (...)` after `GROUP BY`, and has a weird null semantic if `GROUP BY` contains extra expressions than `GROUPING SETS (...)`.
This PR deprecates this syntax:
1. Do not promote it in the document and only mention it as a Hive compatible sytax.
2. Simplify the code to only keep it for Hive compatibility.
### Why are the changes needed?
Deprecate a weird grammar.
### Does this PR introduce _any_ user-facing change?
No breaking change, but it removes a check to simplify the code: `GROUP BY a GROUPING SETS(a, b)` fails before and forces users to also put `b` after `GROUP BY`. Now this works just as `GROUP BY GROUPING SETS(a, b)`.
### How was this patch tested?
existing tests
Closes#32022 from cloud-fan/followup.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Fix [SPARK-34492], add Scala examples to read/write CSV files.
### Why are the changes needed?
Fix [SPARK-34492].
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Build the document with "SKIP_API=1 bundle exec jekyll build", and everything looks fine.
Closes#31827 from twoentartian/master.
Authored-by: twoentartian <twoentartian@hotmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR removes the description that `||` and `&&` can be used as logical operators from the migration guide.
### Why are the changes needed?
At the `Compatibility with Apache Hive` section in the migration guide, it describes that `||` and `&&` can be used as logical operators.
But, in fact, they cannot be used as described.
AFAIK, Hive also doesn't support `&&` and `||` as logical operators.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
I confirmed that `&&` and `||` cannot be used as logical operators with both Hive's interactive shell and `spark-sql`.
I also built the modified document and confirmed that the modified document doesn't break layout.
Closes#32023 from sarutak/modify-hive-compatibility-doc.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Add more flexable parameters for stage end point
endpoint /application/{app-id}/stages. It can be:
/application/{app-id}/stages?details=[true|false]&status=[ACTIVE|COMPLETE|FAILED|PENDING|SKIPPED]&withSummaries=[true|false]$quantiles=[comma separated quantiles string]&taskStatus=[RUNNING|SUCCESS|FAILED|PENDING]
where
```
query parameter details=true is to show the detailed task information within each stage. The default value is details=false;
query parameter status can select those stages with the specified status. When status parameter is not specified, a list of all stages are generated.
query parameter withSummaries=true is to show both task summary information in percentile distribution and executor summary information in percentile distribution. The default value is withSummaries=false.
query parameter quantiles support user defined quantiles, default quantiles is `0.0,0.25,0.5,0.75,1.0`
query parameter taskStatus is to show only those tasks with the specified status within their corresponding stages. This parameter will be set when details=true (i.e. this parameter will be ignored when details=false).
```
### Why are the changes needed?
More flexable restful API
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
UT
Closes#31204 from AngersZhuuuu/SPARK-26399-NEW.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Modify the `SubtractTimestamps` expression to return values of `DayTimeIntervalType` when `spark.sql.legacy.interval.enabled` is set to `false` (which is the default).
### Why are the changes needed?
To conform to the ANSI SQL standard which requires ANSI intervals as the result of timestamps subtraction, see
<img width="656" alt="Screenshot 2021-03-29 at 19 09 34" src="https://user-images.githubusercontent.com/1580697/112866455-7e2f0d00-90c2-11eb-96e6-3feb7eea7e09.png">
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateTimeUtilsSuite"
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
and some tests from `SQLQueryTestSuite`:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#32016 from MaxGekk/subtract-timestamps-to-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Add a new SQL function `try_cast`.
`try_cast` is identical to `AnsiCast` (or `Cast` when `spark.sql.ansi.enabled` is true), except it returns NULL instead of raising an error.
This expression has one major difference from `cast` with `spark.sql.ansi.enabled` as true: when the source value can't be stored in the target integral(Byte/Short/Int/Long) type, `try_cast` returns null instead of returning the low order bytes of the source value.
Note that the result of `try_cast` is not affected by the configuration `spark.sql.ansi.enabled`.
This is learned from Google BigQuery and Snowflake:
https://docs.snowflake.com/en/sql-reference/functions/try_cast.htmlhttps://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators#safe_casting
### Why are the changes needed?
This is an useful for the following scenarios:
1. When ANSI mode is on, users can choose `try_cast` an alternative way to run SQL without errors for certain operations.
2. When ANSI mode is off, users can use `try_cast` to get a more reasonable result for casting a value to an integral type: when an overflow error happens, `try_cast` returns null while `cast` returns the low order bytes of the source value.
### Does this PR introduce _any_ user-facing change?
Yes, adding a new function `try_cast`
### How was this patch tested?
Unit tests.
Closes#31982 from gengliangwang/tryCast.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
Fix code not close issue in monitoring.md
### Why are the changes needed?
Fix doc issue
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32008 from AngersZhuuuu/SPARK-34911.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
1. Add the SQL config `spark.sql.legacy.interval.enabled` which will control when Spark SQL should use `CalendarIntervalType` instead of ANSI intervals.
2. Modify the `SubtractDates` expression to return values of `DayTimeIntervalType` when `spark.sql.legacy.interval.enabled` is set to `false` (which is the default).
### Why are the changes needed?
To conform to the ANSI SQL standard which requires ANSI intervals as the result of dates subtraction, see
<img width="656" alt="Screenshot 2021-03-29 at 19 09 34" src="https://user-images.githubusercontent.com/1580697/112866455-7e2f0d00-90c2-11eb-96e6-3feb7eea7e09.png">
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
and some tests from `SQLQueryTestSuite`:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#31996 from MaxGekk/subtract-dates-to-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Add a new config, `spark.shuffle.service.name`, which allows for Spark applications to look for a YARN shuffle service which is defined at a name other than the default `spark_shuffle`.
Add a new config, `spark.yarn.shuffle.service.metrics.namespace`, which allows for configuring the namespace used when emitting metrics from the shuffle service into the NodeManager's `metrics2` system.
Add a new mechanism by which to override shuffle service configurations independently of the configurations in the NodeManager. When a resource `spark-shuffle-site.xml` is present on the classpath of the shuffle service, the configs present within it will be used to override the configs coming from `yarn-site.xml` (via the NodeManager).
### Why are the changes needed?
There are two use cases which can benefit from these changes.
One use case is to run multiple instances of the shuffle service side-by-side in the same NodeManager. This can be helpful, for example, when running a YARN cluster with a mixed workload of applications running multiple Spark versions, since a given version of the shuffle service is not always compatible with other versions of Spark (e.g. see SPARK-27780). With this PR, it is possible to run two shuffle services like `spark_shuffle` and `spark_shuffle_3.2.0`, one of which is "legacy" and one of which is for new applications. This is possible because YARN versions since 2.9.0 support the ability to run shuffle services within an isolated classloader (see YARN-4577), meaning multiple Spark versions can coexist.
Besides this, the separation of shuffle service configs into `spark-shuffle-site.xml` can be useful for administrators who want to change and/or deploy Spark shuffle service configurations independently of the configurations for the NodeManager (e.g., perhaps they are owned by two different teams).
### Does this PR introduce _any_ user-facing change?
Yes. There are two new configurations related to the external shuffle service, and a new mechanism which can optionally be used to configure the shuffle service. `docs/running-on-yarn.md` has been updated to provide user instructions; please see this guide for more details.
### How was this patch tested?
In addition to the new unit tests added, I have deployed this to a live YARN cluster and successfully deployed two Spark shuffle services simultaneously, one running a modified version of Spark 2.3.0 (which supports some of the newer shuffle protocols) and one running Spark 3.1.1. Spark applications of both versions are able to communicate with their respective shuffle services without issue.
Closes#31936 from xkrogen/xkrogen-SPARK-34828-shufflecompat-config-from-classpath.
Authored-by: Erik Krogen <xkrogen@apache.org>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
As discussed in
https://github.com/apache/spark/pull/30145#discussion_r514728642https://github.com/apache/spark/pull/30145#discussion_r514734648
We need to rewrite current Grouping Analytics grammar to support as flexible as Postgres SQL to support subsequent development.
In postgres sql, it support
```
select a, b, c, count(1) from t group by cube (a, b, c);
select a, b, c, count(1) from t group by cube(a, b, c);
select a, b, c, count(1) from t group by cube (a, b, c, (a, b), (a, b, c));
select a, b, c, count(1) from t group by rollup(a, b, c);
select a, b, c, count(1) from t group by rollup (a, b, c);
select a, b, c, count(1) from t group by rollup (a, b, c, (a, b), (a, b, c));
```
In this pr, we have done three things as below, and we will split it to different pr:
- Refactor CUBE/ROLLUP (regarding them as ANTLR tokens in a parser)
- Refactor GROUPING SETS (the logical node -> a new expr)
- Support new syntax for CUBE/ROLLUP (e.g., GROUP BY CUBE ((a, b), (a, c)))
### Why are the changes needed?
Rewrite current Grouping Analytics grammar to support as flexible as Postgres SQL to support subsequent development.
### Does this PR introduce _any_ user-facing change?
User can write Grouping Analytics grammar as flexible as Postgres SQL to support subsequent development.
### How was this patch tested?
Added UT
Closes#30212 from AngersZhuuuu/refact-grouping-analytics.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Co-authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, when a connection for TransportClient is marked as idled and closed, we suggest users adjust `spark.network.timeout` for all transport modules. As a lot of timeout configs will fallback to the `spark.network.timeout`, this could be a piece of overkill advice, we should give a more targeted one with `spark.${moduleName}.io.connectionTimeout`
### Why are the changes needed?
better advise for overloaded network traffic cases
### Does this PR introduce _any_ user-facing change?
yes, when a connection is zombied and closed by spark internally, users can use a more targeted config to tune their jobs
### How was this patch tested?
Just log and doc. Passing Jenkins and GA
Closes#31990 from yaooqinn/SPARK-34894.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
When we want to get stage's detail info with task information, it will return all tasks, the content is huge and always we just want to know some failed tasks/running tasks with whole stage info to judge is a task has some problem. This pr support
user to use
```
/application/[appid]/stages/[stage-id]?details=true&taskStatus=xxx
/application/[appid]/stages/[stage-id]/[stage-attempted-id]?details=true&taskStatus=xxx
```
to filter task details by task status
### Why are the changes needed?
More flexiable Restful API
### Does this PR introduce _any_ user-facing change?
User can use
```
/application/[appid]/stages/[stage-id]?details=true&taskStatus=xxx
/application/[appid]/stages/[stage-id]/[stage-attempted-id]?details=true&taskStatus=xxx
```
to filter task details by task status
### How was this patch tested?
Added
Closes#31165 from AngersZhuuuu/SPARK-34092.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Deprecating `spark.launcher.childConectionTimeout` in favor of `spark.launcher.childConnectionTimeout`
### Why are the changes needed?
srowen suggested it https://github.com/apache/spark/pull/30323#discussion_r521449342
### How was this patch tested?
No testing. Not even compiled
Closes#30679 from jsoref/spelling-connection.
Authored-by: Josh Soref <jsoref@users.noreply.github.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Allow casting complex types as string type in ANSI mode.
### Why are the changes needed?
Currently, complex types are not allowed to cast as string type. This breaks the DataFrame.show() API. E.g
```
scala> sql(“select array(1, 2, 2)“).show(false)
org.apache.spark.sql.AnalysisException: cannot resolve ‘CAST(`array(1, 2, 2)` AS STRING)’ due to data type mismatch:
cannot cast array<int> to string with ANSI mode on.
```
We should allow the conversion as the extension of the ANSI SQL standard, so that the DataFrame.show() still work in ANSI mode.
### Does this PR introduce _any_ user-facing change?
Yes, casting complex types as string type is now allowed in ANSI mode.
### How was this patch tested?
Unit tests.
Closes#31954 from gengliangwang/fixExplicitCast.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
For a specific stage, it is useful to show the task metrics in percentile distribution. This information can help users know whether or not there is a skew/bottleneck among tasks in a given stage. We list an example in taskMetricsDistributions.json
Similarly, it is useful to show the executor metrics in percentile distribution for a specific stage. This information can show whether or not there is a skewed load on some executors. We list an example in executorMetricsDistributions.json
We define `withSummaries` and `quantiles` query parameter in the REST API for a specific stage as:
applications/<application_id>/<application_attempt/stages/<stage_id>/<stage_attempt>?withSummaries=[true|false]& quantiles=0.05,0.25,0.5,0.75,0.95
1. withSummaries: default is false, define whether to show current stage's taskMetricsDistribution and executorMetricsDistribution
2. quantiles: default is `0.0,0.25,0.5,0.75,1.0` only effect when `withSummaries=true`, it define the quantiles we use when calculating metrics distributions.
When withSummaries=true, both task metrics in percentile distribution and executor metrics in percentile distribution are included in the REST API output. The default value of withSummaries is false, i.e. no metrics percentile distribution will be included in the REST API output.
### Why are the changes needed?
For a specific stage, it is useful to show the task metrics in percentile distribution. This information can help users know whether or not there is a skew/bottleneck among tasks in a given stage. We list an example in taskMetricsDistributions.json
### Does this PR introduce _any_ user-facing change?
User can use below restful API to get task metrics distribution and executor metrics distribution for indivial stage
```
applications/<application_id>/<application_attempt/stages/<stage_id>/<stage_attempt>?withSummaries=[true|false]
```
### How was this patch tested?
Added UT
Closes#31611 from AngersZhuuuu/SPARK-34488.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This patch adds a config `spark.yarn.kerberos.renewal.excludeHadoopFileSystems` which lists the filesystems to be excluded from delegation token renewal at YARN.
### Why are the changes needed?
MapReduce jobs can instruct YARN to skip renewal of tokens obtained from certain hosts by specifying the hosts with configuration mapreduce.job.hdfs-servers.token-renewal.exclude=<host1>,<host2>,..,<hostN>.
But seems Spark lacks of similar option. So the job submission fails if YARN fails to renew DelegationToken for any of the remote HDFS cluster. The failure in DT renewal can happen due to many reason like Remote HDFS does not trust Kerberos identity of YARN etc. We have a customer facing such issue.
### Does this PR introduce _any_ user-facing change?
No, if the config is not set. Yes, as users can use this config to instruct YARN not to renew delegation token from certain filesystems.
### How was this patch tested?
It is hard to do unit test for this. We did verify it work from the customer using this fix in the production environment.
Closes#31761 from viirya/SPARK-34295.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
the given example uses a non-standard syntax for CREATE TABLE, by defining the partitioning column with the other columns, instead of in PARTITION BY.
This works is this case, because the partitioning column happens to be the last column defined, but it will break if instead 'name' would be used for partitioning.
I suggest therefore to change the example to use a standard syntax, like in
https://spark.apache.org/docs/3.1.1/sql-ref-syntax-ddl-create-table-hiveformat.html
### Why are the changes needed?
To show the better documentation.
### Does this PR introduce _any_ user-facing change?
Yes, this fixes the user-facing docs.
### How was this patch tested?
CI should test it out.
Closes#31900 from robert4os/patch-1.
Authored-by: robert4os <robert4os@users.noreply.github.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Current link for `Azure Blob Storage and Azure Datalake Gen 2` leads to AWS information. Replacing the link to point to the right page.
### Why are the changes needed?
For users to access to the correct link.
### Does this PR introduce _any_ user-facing change?
Yes, it fixes the link correctly.
### How was this patch tested?
N/A
Closes#31938 from lenadroid/patch-1.
Authored-by: Lena <alehall@microsoft.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Update the Avro version to 1.10.2
### Why are the changes needed?
To stay up to date with upstream and catch compatibility issues with zstd
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests
Closes#31866 from iemejia/SPARK-27733-upgrade-avro-1.10.2.
Authored-by: Ismaël Mejía <iemejia@gmail.com>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}