## What changes were proposed in this pull request?
File source V1 supports reading output of FileStreamSink as batch. https://github.com/apache/spark/pull/11897
We should support this in file source V2 as well. When reading with paths, we first check if there is metadata log of FileStreamSink. If yes, we use `MetadataLogFileIndex` for listing files; Otherwise, we use `InMemoryFileIndex`.
## How was this patch tested?
Unit test
Closes#24900 from gengliangwang/FileStreamV2.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Provide a way to recursively load data from datasource.
I add a "recursiveFileLookup" option.
When "recursiveFileLookup" option turn on, then partition inferring is turned off and all files from the directory will be loaded recursively.
If some datasource explicitly specify the partitionSpec, then if user turn on "recursive" option, then exception will be thrown.
## How was this patch tested?
Unit tests.
Please review https://spark.apache.org/contributing.html before opening a pull request.
Closes#24830 from WeichenXu123/recursive_ds.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR significantly improves the performance of `UTF8String.replace()` by performing direct replacement over UTF8 bytes instead of decoding those bytes into Java Strings.
In cases where the search string is not found (i.e. no replacements are performed, a case which I expect to be common) this new implementation performs no object allocation or memory copying.
My implementation is modeled after `commons-lang3`'s `StringUtils.replace()` method. As part of my implementation, I needed a StringBuilder / resizable buffer, so I moved `UTF8StringBuilder` from the `catalyst` package to `unsafe`.
## How was this patch tested?
Copied tests from `StringExpressionSuite` to `UTF8StringSuite` and added a couple of new cases.
To evaluate performance, I did some quick local benchmarking by running the following code in `spark-shell` (with Java 1.8.0_191):
```scala
import org.apache.spark.unsafe.types.UTF8String
def benchmark(text: String, search: String, replace: String) {
val utf8Text = UTF8String.fromString(text)
val utf8Search = UTF8String.fromString(search)
val utf8Replace = UTF8String.fromString(replace)
val start = System.currentTimeMillis
var i = 0
while (i < 1000 * 1000 * 100) {
utf8Text.replace(utf8Search, utf8Replace)
i += 1
}
val end = System.currentTimeMillis
println(end - start)
}
benchmark("ABCDEFGH", "DEF", "ZZZZ") // replacement occurs
benchmark("ABCDEFGH", "Z", "") // no replacement occurs
```
On my laptop this took ~54 / ~40 seconds seconds before this patch's changes and ~6.5 / ~3.8 seconds afterwards.
Closes#24707 from JoshRosen/faster-string-replace.
Authored-by: Josh Rosen <rosenville@gmail.com>
Signed-off-by: Josh Rosen <rosenville@gmail.com>
## What changes were proposed in this pull request?
[SPARK-28093](https://issues.apache.org/jira/browse/SPARK-28093) fixed `TRIM/LTRIM/RTRIM('str', 'trimStr')` returns an incorrect value, but that fix introduced a new bug, `TRIM(type trimStr FROM str)` returns an incorrect value. This pr fix this issue.
## How was this patch tested?
unit tests and manual tests:
Before this PR:
```sql
spark-sql> SELECT trim('yxTomxx', 'xyz'), trim(BOTH 'xyz' FROM 'yxTomxx');
Tom z
spark-sql> SELECT trim('xxxbarxxx', 'x'), trim(BOTH 'x' FROM 'xxxbarxxx');
bar
spark-sql> SELECT ltrim('zzzytest', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytest');
test xyz
spark-sql> SELECT ltrim('zzzytestxyz', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytestxyz');
testxyz
spark-sql> SELECT ltrim('xyxXxyLAST WORD', 'xy'), trim(LEADING 'xy' FROM 'xyxXxyLAST WORD');
XxyLAST WORD
spark-sql> SELECT rtrim('testxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'testxxzx');
test xy
spark-sql> SELECT rtrim('xyztestxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'xyztestxxzx');
xyztest
spark-sql> SELECT rtrim('TURNERyxXxy', 'xy'), trim(TRAILING 'xy' FROM 'TURNERyxXxy');
TURNERyxX
```
After this PR:
```sql
spark-sql> SELECT trim('yxTomxx', 'xyz'), trim(BOTH 'xyz' FROM 'yxTomxx');
Tom Tom
spark-sql> SELECT trim('xxxbarxxx', 'x'), trim(BOTH 'x' FROM 'xxxbarxxx');
bar bar
spark-sql> SELECT ltrim('zzzytest', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytest');
test test
spark-sql> SELECT ltrim('zzzytestxyz', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytestxyz');
testxyz testxyz
spark-sql> SELECT ltrim('xyxXxyLAST WORD', 'xy'), trim(LEADING 'xy' FROM 'xyxXxyLAST WORD');
XxyLAST WORD XxyLAST WORD
spark-sql> SELECT rtrim('testxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'testxxzx');
test test
spark-sql> SELECT rtrim('xyztestxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'xyztestxxzx');
xyztest xyztest
spark-sql> SELECT rtrim('TURNERyxXxy', 'xy'), trim(TRAILING 'xy' FROM 'TURNERyxXxy');
TURNERyxX TURNERyxX
```
And PostgreSQL:
```sql
postgres=# SELECT trim('yxTomxx', 'xyz'), trim(BOTH 'xyz' FROM 'yxTomxx');
btrim | btrim
-------+-------
Tom | Tom
(1 row)
postgres=# SELECT trim('xxxbarxxx', 'x'), trim(BOTH 'x' FROM 'xxxbarxxx');
btrim | btrim
-------+-------
bar | bar
(1 row)
postgres=# SELECT ltrim('zzzytest', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytest');
ltrim | ltrim
-------+-------
test | test
(1 row)
postgres=# SELECT ltrim('zzzytestxyz', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytestxyz');
ltrim | ltrim
---------+---------
testxyz | testxyz
(1 row)
postgres=# SELECT ltrim('xyxXxyLAST WORD', 'xy'), trim(LEADING 'xy' FROM 'xyxXxyLAST WORD');
ltrim | ltrim
--------------+--------------
XxyLAST WORD | XxyLAST WORD
(1 row)
postgres=# SELECT rtrim('testxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'testxxzx');
rtrim | rtrim
-------+-------
test | test
(1 row)
postgres=# SELECT rtrim('xyztestxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'xyztestxxzx');
rtrim | rtrim
---------+---------
xyztest | xyztest
(1 row)
postgres=# SELECT rtrim('TURNERyxXxy', 'xy'), trim(TRAILING 'xy' FROM 'TURNERyxXxy');
rtrim | rtrim
-----------+-----------
TURNERyxX | TURNERyxX
(1 row)
```
Closes#24911 from wangyum/SPARK-28109.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Current SQL parser's error message for hyphen-connected identifiers without surrounding backquotes(e.g. hyphen-table) is confusing for end users. A possible approach to tackle this is to explicitly capture these wrong usages in the SQL parser. In this way, the end users can fix these errors more quickly.
For example, for a simple query such as `SELECT * FROM test-table`, the original error message is
```
Error in SQL statement: ParseException:
mismatched input '-' expecting <EOF>(line 1, pos 18)
```
which can be confusing in a large query.
After the fix, the error message is:
```
Error in query:
Possibly unquoted identifier test-table detected. Please consider quoting it with back-quotes as `test-table`(line 1, pos 14)
== SQL ==
SELECT * FROM test-table
--------------^^^
```
which is easier for end users to identify the issue and fix.
We safely augmented the current grammar rule to explicitly capture these error cases. The error handling logic is implemented in the SQL parsing listener `PostProcessor`.
However, note that for cases such as `a - my-func(b)`, the parser can't actually tell whether this should be ``a -`my-func`(b) `` or `a - my - func(b)`. Therefore for these cases, we leave the parser as is. Also, in this patch we only provide better error messages for character-only identifiers.
## How was this patch tested?
Adding new unit tests.
Closes#24749 from yeshengm/hyphen-ident.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The original `references` and `validConstraints` implementations in a few `QueryPlan` and `Expression` classes are methods, which means unnecessary re-computation can happen at times. This PR resolves this problem by making these method `lazy val`s.
As shown in the following chart, the planning time(without cost-based optimization) was dramatically reduced after this optimization.
- The average planning time of TPC-DS queries was reduced by 19.63%.
- The planning time of the most time-consuming TPC-DS query (q64) was reduced by 43.03%.
- The running time for rule-based reordering joins(not cost-based join reordering) optimization, which are common in real-world OLAP queries, was largely reduced.
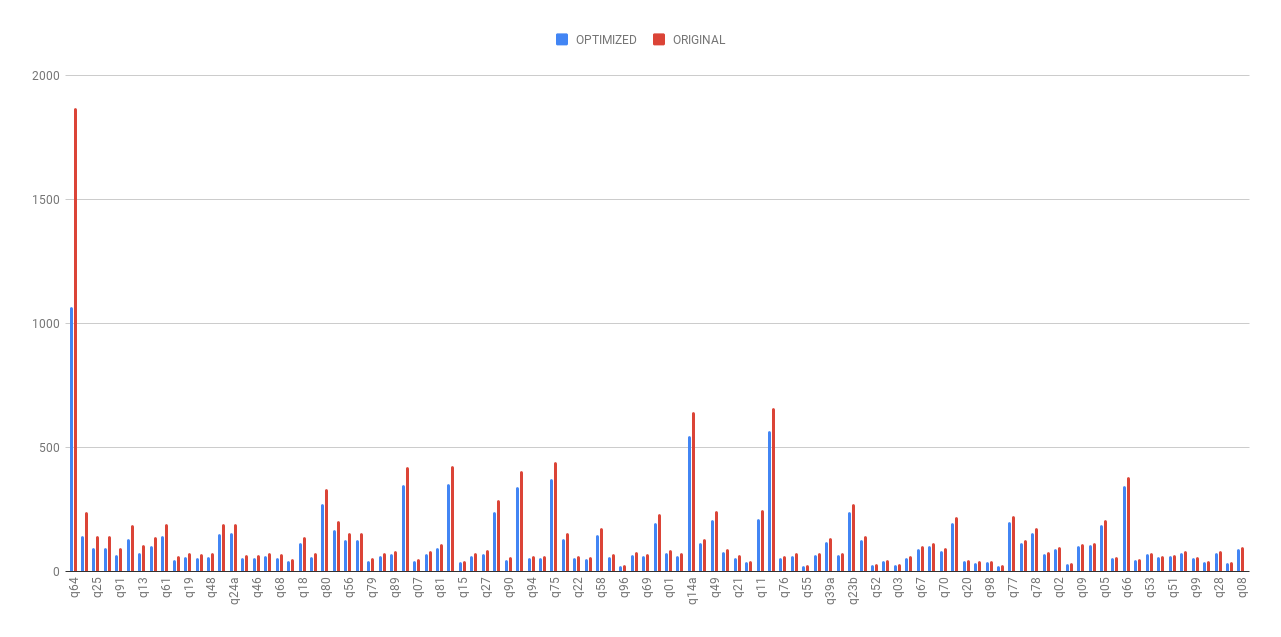
Detailed stats are listed in the following spreadsheet (we warmed up the queries 5 iterations and then took average of the next 5 iterations).
[Lazy val benchmark.xlsx](https://github.com/apache/spark/files/3303530/Lazy.val.benchmark.xlsx)
## How was this patch tested?
Existing UTs.
Closes#24866 from yeshengm/plannode-micro-opt.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
`OrcFilters.createBuilder` has exponential complexity in the height of the filter tree due to the way the check-and-build pattern is implemented. We've hit this in production by passing a `Column` filter to Spark directly, with a job taking multiple hours for a simple set of ~30 filters. This PR changes the checking logic so that the conversion has linear complexity in the size of the tree instead of exponential in its height.
Right now, due to the way ORC `SearchArgument` works, the code is forced to do two separate phases when converting a given Spark filter to an ORC filter:
1. Check if the filter is convertible.
2. Only if the check in 1. succeeds, perform the actual conversion into the resulting ORC filter.
However, there's one detail which is the culprit in the exponential complexity: phases 1. and 2. are both done using the exact same method. The resulting exponential complexity is easiest to see in the `NOT` case - consider the following code:
```
val f1 = col("id") === lit(5)
val f2 = !f1
val f3 = !f2
val f4 = !f3
val f5 = !f4
```
Now, when we run `createBuilder` on `f5`, we get the following behaviour:
1. call `createBuilder(f4)` to check if the child `f4` is convertible
2. call `createBuilder(f4)` to actually convert it
This seems fine when looking at a single level, but what actually ends up happening is:
- `createBuilder(f3)` will then recursively be called 4 times - 2 times in step 1., and two times in step 2.
- `createBuilder(f2)` will be called 8 times - 4 times in each top-level step, 2 times in each sub-step.
- `createBuilder(f1)` will be called 16 times.
As a result, having a tree of height > 30 leads to billions of calls to `createBuilder`, heap allocations, and so on and can take multiple hours.
The way this PR solves this problem is by separating the `check` and `convert` functionalities into separate functions. This way, the call to `createBuilder` on `f5` above would look like this:
1. call `isConvertible(f4)` to check if the child `f4` is convertible - amortized constant complexity
2. call `createBuilder(f4)` to actually convert it - linear complexity in the size of the subtree.
This way, we get an overall complexity that's linear in the size of the filter tree, allowing us to convert tree with 10s of thousands of nodes in milliseconds.
The reason this split (`check` and `build`) is possible is that the checking never actually depends on the actual building of the filter. The `check` part of `createBuilder` depends mainly on:
- `isSearchableType` for leaf nodes, and
- `check`-ing the child filters for composite nodes like NOT, AND and OR.
Situations like the `SearchArgumentBuilder` throwing an exception while building the resulting ORC filter are not handled right now - they just get thrown out of the class, and this change preserves this behaviour.
This PR extracts this part of the code to a separate class which allows the conversion to make very efficient checks to confirm that a given child is convertible before actually converting it.
Results:
Before:
- converting a skewed tree with a height of ~35 took about 6-7 hours.
- converting a skewed tree with hundreds or thousands of nodes would be completely impossible.
Now:
- filtering against a skewed tree with a height of 1500 in the benchmark suite finishes in less than 10 seconds.
## Steps to reproduce
```scala
val schema = StructType.fromDDL("col INT")
(20 to 30).foreach { width =>
val whereFilter = (1 to width).map(i => EqualTo("col", i)).reduceLeft(Or)
val start = System.currentTimeMillis()
OrcFilters.createFilter(schema, Seq(whereFilter))
println(s"With $width filters, conversion takes ${System.currentTimeMillis() - start} ms")
}
```
### Before this PR
```
With 20 filters, conversion takes 363 ms
With 21 filters, conversion takes 496 ms
With 22 filters, conversion takes 939 ms
With 23 filters, conversion takes 1871 ms
With 24 filters, conversion takes 3756 ms
With 25 filters, conversion takes 7452 ms
With 26 filters, conversion takes 14978 ms
With 27 filters, conversion takes 30519 ms
With 28 filters, conversion takes 60361 ms // 1 minute
With 29 filters, conversion takes 126575 ms // 2 minutes 6 seconds
With 30 filters, conversion takes 257369 ms // 4 minutes 17 seconds
```
### After this PR
```
With 20 filters, conversion takes 12 ms
With 21 filters, conversion takes 0 ms
With 22 filters, conversion takes 1 ms
With 23 filters, conversion takes 0 ms
With 24 filters, conversion takes 1 ms
With 25 filters, conversion takes 1 ms
With 26 filters, conversion takes 0 ms
With 27 filters, conversion takes 1 ms
With 28 filters, conversion takes 0 ms
With 29 filters, conversion takes 1 ms
With 30 filters, conversion takes 0 ms
```
## How was this patch tested?
There are no changes in behaviour, and the existing tests pass. Added new benchmarks that expose the problematic behaviour and they finish quickly with the changes applied.
Closes#24068 from IvanVergiliev/optimize-orc-filters.
Authored-by: Ivan Vergiliev <ivan.vergiliev@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Added an interface for handling hint errors, with a default implementation class that logs warnings in the callbacks.
## How was this patch tested?
Passed existing tests.
Closes#24653 from maryannxue/hint-handler.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
With JDK9+, the generate **bytecode** of `FromUnixTime` raise `java.lang.IncompatibleClassChangeError` due to [JDK-8145148](https://bugs.openjdk.java.net/browse/JDK-8145148) . This is a blocker in [Apache Spark JDK11 Jenkins job](https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7-jdk-11-ubuntu-testing/). Locally, this is reproducible by the following unit test suite with JDK9+.
```
$ build/sbt "catalyst/testOnly *.DateExpressionsSuite"
...
[info] org.apache.spark.sql.catalyst.expressions.DateExpressionsSuite *** ABORTED *** (23 seconds, 75 milliseconds)
[info] java.lang.IncompatibleClassChangeError: Method org.apache.spark.sql.catalyst.util.TimestampFormatter.apply(Ljava/lang/String;Ljava/time/ZoneId;Ljava/util/Locale;)Lorg/apache/spark/sql/catalyst/util/TimestampFormatter; must be InterfaceMeth
```
This bytecode issue is generated by `Janino` , so we replace `.apply` to `.MODULE$$.apply` and adds test coverage for similar codes.
## How was this patch tested?
Manually with the existing UTs by doing the following with JDK9+.
```
build/sbt "catalyst/testOnly *.DateExpressionsSuite"
```
Actually, this is the last JDK11 error in `catalyst` module. So, we can verify with the following, too.
```
$ build/sbt "project catalyst" test
...
[info] Total number of tests run: 3552
[info] Suites: completed 210, aborted 0
[info] Tests: succeeded 3552, failed 0, canceled 0, ignored 2, pending 0
[info] All tests passed.
[info] Passed: Total 3583, Failed 0, Errors 0, Passed 3583, Ignored 2
[success] Total time: 294 s, completed Jun 16, 2019, 10:15:08 PM
```
Closes#24889 from dongjoon-hyun/SPARK-28072.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
When using `DROPMALFORMED` mode, corrupted records aren't dropped if malformed columns aren't read. This behavior is due to CSV parser column pruning. Current doc of `DROPMALFORMED` doesn't mention the effect of column pruning. Users will be confused by the fact that `DROPMALFORMED` mode doesn't work as expected.
Column pruning also affects other modes. This is a doc improvement to add a note to doc of `mode` to explain it.
## How was this patch tested?
N/A. This is just doc change.
Closes#24894 from viirya/SPARK-28058.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The `TRIM` function accept these patterns:
```sql
TRIM(str)
TRIM(trimStr, str)
TRIM(BOTH trimStr FROM str)
TRIM(LEADING trimStr FROM str)
TRIM(TRAILING trimStr FROM str)
```
This pr add support other three patterns:
```sql
TRIM(BOTH FROM str)
TRIM(LEADING FROM str)
TRIM(TRAILING FROM str)
```
PostgreSQL, Vertica, MySQL, Teradata, Oracle and DB2 support these patterns. Hive, Presto and SQL Server does not support this feature.
**PostgreSQL**:
```sql
postgres=# select substr(version(), 0, 16), trim(BOTH from ' SparkSQL '), trim(LEADING FROM ' SparkSQL '), trim(TRAILING FROM ' SparkSQL ');
substr | btrim | ltrim | rtrim
-----------------+----------+-------------+--------------
PostgreSQL 11.3 | SparkSQL | SparkSQL | SparkSQL
(1 row)
```
**Vertica**:
```
dbadmin=> select version(), trim(BOTH from ' SparkSQL '), trim(LEADING FROM ' SparkSQL '), trim(TRAILING FROM ' SparkSQL ');
version | btrim | ltrim | rtrim
------------------------------------+----------+-------------+--------------
Vertica Analytic Database v9.1.1-0 | SparkSQL | SparkSQL | SparkSQL
(1 row)
```
**MySQL**:
```
mysql> select version(), trim(BOTH from ' SparkSQL '), trim(LEADING FROM ' SparkSQL '), trim(TRAILING FROM ' SparkSQL ');
+-----------+-----------------------------------+--------------------------------------+---------------------------------------+
| version() | trim(BOTH from ' SparkSQL ') | trim(LEADING FROM ' SparkSQL ') | trim(TRAILING FROM ' SparkSQL ') |
+-----------+-----------------------------------+--------------------------------------+---------------------------------------+
| 5.7.26 | SparkSQL | SparkSQL | SparkSQL |
+-----------+-----------------------------------+--------------------------------------+---------------------------------------+
1 row in set (0.01 sec)
```
**Teradata**:

**Oracle**:

**DB2**:

## How was this patch tested?
unit tests
Closes#24891 from wangyum/SPARK-28075.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR aims to replace deprecated `.newInstance()` in DSv2 `Catalogs` and distinguish the plugin class errors more. According to the JDK11 build log, there is no other new instance.
- https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7-jdk-11-ubuntu-testing/978/consoleFull
SPARK-25984 removes all instances of the deprecated `.newInstance()` usages at Nov 10, 2018, but this was added at SPARK-24252 on March 8, 2019.
## How was this patch tested?
Pass the Jenkins with the updated test case.
Closes#24882 from dongjoon-hyun/SPARK-28063.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Currently `ArrayExists` always returns boolean values (if the arguments are not `null`), but it should follow the three-valued boolean logic:
- `true` if the predicate holds at least one `true`
- otherwise, `null` if the predicate holds `null`
- otherwise, `false`
This behavior change is made to match Postgres' equivalent function `ANY/SOME (array)`'s behavior: https://www.postgresql.org/docs/9.6/functions-comparisons.html#AEN21174
## How was this patch tested?
Modified tests and existing tests.
Closes#24873 from ueshin/issues/SPARK-28052/fix_exists.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Allow Pandas UDF to take an iterator of pd.Series or an iterator of tuple of pd.Series.
Note the UDF input args will be always one iterator:
* if the udf take only column as input, the iterator's element will be pd.Series (corresponding to the column values batch)
* if the udf take multiple columns as inputs, the iterator's element will be a tuple composed of multiple `pd.Series`s, each one corresponding to the multiple columns as inputs (keep the same order). For example:
```
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def the_udf(iterator):
for col1_batch, col2_batch in iterator:
yield col1_batch + col2_batch
df.select(the_udf("col1", "col2"))
```
The udf above will add col1 and col2.
I haven't add unit tests, but manually tests show it works fine. So it is ready for first pass review.
We can test several typical cases:
```
from pyspark.sql import SparkSession
from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql.functions import udf
from pyspark.taskcontext import TaskContext
df = spark.createDataFrame([(1, 20), (3, 40)], ["a", "b"])
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi1(it):
pid = TaskContext.get().partitionId()
print("DBG: fi1: do init stuff, partitionId=" + str(pid))
for batch in it:
yield batch + 100
print("DBG: fi1: do close stuff, partitionId=" + str(pid))
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi2(it):
pid = TaskContext.get().partitionId()
print("DBG: fi2: do init stuff, partitionId=" + str(pid))
for batch in it:
yield batch + 10000
print("DBG: fi2: do close stuff, partitionId=" + str(pid))
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi3(it):
pid = TaskContext.get().partitionId()
print("DBG: fi3: do init stuff, partitionId=" + str(pid))
for x, y in it:
yield x + y * 10 + 100000
print("DBG: fi3: do close stuff, partitionId=" + str(pid))
pandas_udf("int", PandasUDFType.SCALAR)
def fp1(x):
return x + 1000
udf("int")
def fu1(x):
return x + 10
# test select "pandas iter udf/pandas udf/sql udf" expressions at the same time.
# Note this case the `fi1("a"), fi2("b"), fi3("a", "b")` will generate only one plan,
# and `fu1("a")`, `fp1("a")` will generate another two separate plans.
df.select(fi1("a"), fi2("b"), fi3("a", "b"), fu1("a"), fp1("a")).show()
# test chain two pandas iter udf together
# Note this case `fi2(fi1("a"))` will generate only one plan
# Also note the init stuff/close stuff call order will be like:
# (debug output following)
# DBG: fi2: do init stuff, partitionId=0
# DBG: fi1: do init stuff, partitionId=0
# DBG: fi1: do close stuff, partitionId=0
# DBG: fi2: do close stuff, partitionId=0
df.select(fi2(fi1("a"))).show()
# test more complex chain
# Note this case `fi1("a"), fi2("a")` will generate one plan,
# and `fi3(fi1_output, fi2_output)` will generate another plan
df.select(fi3(fi1("a"), fi2("a"))).show()
```
## How was this patch tested?
To be added.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24643 from WeichenXu123/pandas_udf_iter.
Lead-authored-by: WeichenXu <weichen.xu@databricks.com>
Co-authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
Migrate Parquet to File Data Source V2
## How was this patch tested?
Unit test
Closes#24327 from gengliangwang/parquetV2.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Implemented a new SparkPlan that executes the query adaptively. It splits the query plan into independent stages and executes them in order according to their dependencies. The query stage materializes its output at the end. When one stage completes, the data statistics of the materialized output will be used to optimize the remainder of the query.
The adaptive mode is off by default, when turned on, user can see "AdaptiveSparkPlan" as the top node of a query or sub-query. The inner plan of "AdaptiveSparkPlan" is subject to change during query execution but becomes final once the execution is complete. Whether the inner plan is final is included in the EXPLAIN string. Below is an example of the EXPLAIN plan before and after execution:
Query:
```
SELECT * FROM testData JOIN testData2 ON key = a WHERE value = '1'
```
Before execution:
```
== Physical Plan ==
AdaptiveSparkPlan(isFinalPlan=false)
+- SortMergeJoin [key#13], [a#23], Inner
:- Sort [key#13 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(key#13, 5)
: +- Filter (isnotnull(value#14) AND (value#14 = 1))
: +- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).key AS key#13, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).value, true, false) AS value#14]
: +- Scan[obj#12]
+- Sort [a#23 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(a#23, 5)
+- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).a AS a#23, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).b AS b#24]
+- Scan[obj#22]
```
After execution:
```
== Physical Plan ==
AdaptiveSparkPlan(isFinalPlan=true)
+- *(1) BroadcastHashJoin [key#13], [a#23], Inner, BuildLeft
:- BroadcastQueryStage 2
: +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint)))
: +- ShuffleQueryStage 0
: +- Exchange hashpartitioning(key#13, 5)
: +- *(1) Filter (isnotnull(value#14) AND (value#14 = 1))
: +- *(1) SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).key AS key#13, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).value, true, false) AS value#14]
: +- Scan[obj#12]
+- ShuffleQueryStage 1
+- Exchange hashpartitioning(a#23, 5)
+- *(1) SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).a AS a#23, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).b AS b#24]
+- Scan[obj#22]
```
Credit also goes to carsonwang and cloud-fan
## How was this patch tested?
Added new UT.
Closes#24706 from maryannxue/aqe.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: herman <herman@databricks.com>
## What changes were proposed in this pull request?
This PR adds support of column aliasing in a CTE so this query becomes valid:
```
WITH t(x) AS (SELECT 1)
SELECT * FROM t WHERE x = 1
```
## How was this patch tested?
Added new UTs.
Closes#24842 from peter-toth/SPARK-28002.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This patch proposes making `purge` in `CompactibleFileStreamLog` to throw `UnsupportedOperationException` to prevent purging necessary batch files, as well as adding javadoc to document its behavior. Actually it would only break when latest compaction batch is requested to be purged, but caller wouldn't be aware of this so safer to just prevent it.
## How was this patch tested?
Added UT.
Closes#23850 from HeartSaVioR/SPARK-26949.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Implemented the `clone` method for `TreeNode` based on `mapChildren`.
## How was this patch tested?
Added new UT.
Closes#24876 from maryannxue/treenode-clone.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: herman <herman@databricks.com>
## What changes were proposed in this pull request?
I suspect that the doc of `rowsBetween` methods in Scala and PySpark looks wrong.
Because:
```scala
scala> val df = Seq((1, "a"), (2, "a"), (3, "a"), (4, "a"), (5, "a"), (6, "a")).toDF("id", "category")
df: org.apache.spark.sql.DataFrame = [id: int, category: string]
scala> val byCategoryOrderedById = Window.partitionBy('category).orderBy('id).rowsBetween(-1, 2)
byCategoryOrderedById: org.apache.spark.sql.expressions.WindowSpec = org.apache.spark.sql.expressions.WindowSpec7f04de97
scala> df.withColumn("sum", sum('id) over byCategoryOrderedById).show()
+---+--------+---+
| id|category|sum|
+---+--------+---+
| 1| a| 6| # sum from index 0 to (0 + 2): 1 + 2 + 3 = 6
| 2| a| 10| # sum from index (1 - 1) to (1 + 2): 1 + 2 + 3 + 4 = 10
| 3| a| 14|
| 4| a| 18|
| 5| a| 15|
| 6| a| 11|
+---+--------+---+
```
So the frame (-1, 2) for row with index 5, as described in the doc, should range from index 4 to index 7.
## How was this patch tested?
N/A, just doc change.
Closes#24864 from viirya/window-spec-doc.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Currently, SparkSQL can support interval format like this.
```sql
SELECT INTERVAL '0 23:59:59.155' DAY TO SECOND
```
Like Presto/Teradata, this PR aims to support grammar like below.
```sql
SELECT INTERVAL '23:59:59.155' HOUR TO SECOND
```
Although we can add a new function for this pattern, we had better extend the existing code to handle a missing day case. So, the following is also supported.
```sql
SELECT INTERVAL '23:59:59.155' DAY TO SECOND
SELECT INTERVAL '1 23:59:59.155' HOUR TO SECOND
```
Currently Vertica/Teradata/Postgresql/SQL Server have fully support of below interval functions.
- interval ... year to month
- interval ... day to hour
- interval ... day to minute
- interval ... day to second
- interval ... hour to minute
- interval ... hour to second
- interval ... minute to second
https://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/SQLReferenceManual/LanguageElements/Literals/interval-qualifier.htmdf1a699e5b/src/test/regress/sql/interval.sql (L180-L203)https://docs.teradata.com/reader/S0Fw2AVH8ff3MDA0wDOHlQ/KdCtT3pYFo~_enc8~kGKVwhttps://docs.microsoft.com/en-us/sql/odbc/reference/appendixes/interval-literals?view=sql-server-2017
## How was this patch tested?
Pass the Jenkins with the updated test cases.
Closes#24472 from lipzhu/SPARK-27578.
Lead-authored-by: Zhu, Lipeng <lipzhu@ebay.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Lipeng Zhu <lipzhu@icloud.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Support multi-catalog in the following SELECT code paths:
- SELECT * FROM catalog.db.tbl
- TABLE catalog.db.tbl
- JOIN or UNION tables from different catalogs
- SparkSession.table("catalog.db.tbl")
- CTE relation
- View text
## How was this patch tested?
New unit tests.
All existing unit tests in catalyst and sql core.
Closes#24741 from jzhuge/SPARK-27322-pr.
Authored-by: John Zhuge <jzhuge@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Convert `PartitionedFile.filePath` to URI first in binary file data source. Otherwise Spark will throw a FileNotFound exception because we create `Path` with URL encoded string, instead of wrapping it with URI.
## How was this patch tested?
Unit test.
Closes#24855 from mengxr/SPARK-28030.
Authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
`NestedColumnAliasing` rule covers `GetStructField` only, currently. It means that some nested field extraction expressions aren't pruned. For example, if only accessing a nested field in an array of struct (`GetArrayStructFields`), this column isn't pruned.
This patch extends the rule to cover general nested field cases, including `GetArrayStructFields`.
## How was this patch tested?
Added tests.
Closes#24599 from viirya/nested-pruning-extract-value.
Lead-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
Current Spark SQL parser can have pretty confusing error messages when parsing an incorrect SELECT SQL statement. The proposed fix has the following effect.
BEFORE:
```
spark-sql> SELECT * FROM test WHERE x NOT NULL;
Error in query:
mismatched input 'FROM' expecting {<EOF>, 'CLUSTER', 'DISTRIBUTE', 'EXCEPT', 'GROUP', 'HAVING', 'INTERSECT', 'LATERAL', 'LIMIT', 'ORDER', 'MINUS', 'SORT', 'UNION', 'WHERE', 'WINDOW'}(line 1, pos 9)
== SQL ==
SELECT * FROM test WHERE x NOT NULL
---------^^^
```
where in fact the error message should be hinted to be near `NOT NULL`.
AFTER:
```
spark-sql> SELECT * FROM test WHERE x NOT NULL;
Error in query:
mismatched input 'NOT' expecting {<EOF>, 'AND', 'CLUSTER', 'DISTRIBUTE', 'EXCEPT', 'GROUP', 'HAVING', 'INTERSECT', 'LIMIT', 'OR', 'ORDER', 'MINUS', 'SORT', 'UNION', 'WINDOW'}(line 1, pos 27)
== SQL ==
SELECT * FROM test WHERE x NOT NULL
---------------------------^^^
```
In fact, this problem is brought by some problematic Spark SQL grammar. There are two kinds of SELECT statements that are supported by Hive (and thereby supported in SparkSQL):
* `FROM table SELECT blahblah SELECT blahblah`
* `SELECT blah FROM table`
*Reference* [HiveQL single-from stmt grammar](https://github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/parse/HiveParser.g)
It is fine when these two SELECT syntaxes are supported separately. However, since we are currently supporting these two kinds of syntaxes in a single ANTLR rule, this can be problematic and therefore leading to confusing parser errors. This is because when a SELECT clause was parsed, it can't tell whether the following FROM clause actually belongs to it or is just the beginning of a new `FROM table SELECT *` statement.
## What changes were proposed in this pull request?
1. Modify ANTLR grammar to fix the above-mentioned problem. This fix is important because the previous problematic grammar does affect a lot of real-world queries. Due to the previous problematic and messy grammar, we refactored the grammar related to `querySpecification`.
2. Modify `AstBuilder` to have separate visitors for `SELECT ... FROM ...` and `FROM ... SELECT ...` statements.
3. Drop the `FROM table` statement, which is supported by accident and is actually parsed in the wrong code path. Both Hive and Presto do not support this syntax.
## How was this patch tested?
Existing UTs and new UTs.
Closes#24809 from yeshengm/parser-refactor.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
## What changes were proposed in this pull request?
The new Spark ThriftServer SparkGetTablesOperation implemented in https://github.com/apache/spark/pull/22794 does a catalog.getTableMetadata request for every table. This can get very slow for large schemas (~50ms per table with an external Hive metastore).
Hive ThriftServer GetTablesOperation uses HiveMetastoreClient.getTableObjectsByName to get table information in bulk, but we don't expose that through our APIs that go through Hive -> HiveClientImpl (HiveClient) -> HiveExternalCatalog (ExternalCatalog) -> SessionCatalog.
If we added and exposed getTableObjectsByName through our catalog APIs, we could resolve that performance problem in SparkGetTablesOperation.
## How was this patch tested?
Add UT
Closes#24774 from LantaoJin/SPARK-27899.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Handle the case when ParsedStatement subclass has a Map field but not of type Map[String, String].
In ParsedStatement.productIterator, `case mapArg: Map[_, _]` can match any Map type due to type erasure, thus causing `asInstanceOf[Map[String, String]]` to throw ClassCastException.
The following test reproduces the issue:
```
case class TestStatement(p: Map[String, Int]) extends ParsedStatement {
override def output: Seq[Attribute] = Nil
override def children: Seq[LogicalPlan] = Nil
}
TestStatement(Map("abc" -> 1)).toString
```
Changing the code to `case mapArg: Map[String, String]` will not help due to type erasure. As a matter of fact, compiler gives this warning:
```
Warning:(41, 18) non-variable type argument String in type pattern
scala.collection.immutable.Map[String,String] (the underlying of Map[String,String])
is unchecked since it is eliminated by erasure
case mapArg: Map[String, String] =>
```
## How was this patch tested?
Add 2 unit tests.
Closes#24800 from jzhuge/SPARK-27947.
Authored-by: John Zhuge <jzhuge@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
For caseWhen Object canonicalized is not handled
for e.g let's consider below CaseWhen Object
val attrRef = AttributeReference("ACCESS_CHECK", StringType)()
val caseWhenObj1 = CaseWhen(Seq((attrRef, Literal("A"))))
caseWhenObj1.canonicalized **ouput** is as below
CASE WHEN ACCESS_CHECK#0 THEN A END (**Before Fix)**
**After Fix** : CASE WHEN none#0 THEN A END
So when there will be aliasref like below statements, semantic equals will fail. Sematic equals returns true if the canonicalized form of both the expressions are same.
val attrRef = AttributeReference("ACCESS_CHECK", StringType)()
val aliasAttrRef = attrRef.withName("access_check")
val caseWhenObj1 = CaseWhen(Seq((attrRef, Literal("A"))))
val caseWhenObj2 = CaseWhen(Seq((aliasAttrRef, Literal("A"))))
**assert(caseWhenObj2.semanticEquals(caseWhenObj1.semanticEquals) fails**
**caseWhenObj1.canonicalized**
Before Fix:CASE WHEN ACCESS_CHECK#0 THEN A END
After Fix: CASE WHEN none#0 THEN A END
**caseWhenObj2.canonicalized**
Before Fix:CASE WHEN access_check#0 THEN A END
After Fix: CASE WHEN none#0 THEN A END
## How was this patch tested?
Added UT
Closes#24766 from sandeep-katta/caseWhenIssue.
Authored-by: sandeep katta <sandeep.katta2007@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR is the same fix as https://github.com/apache/spark/pull/24816 but in vectorized `dapply` in SparkR.
## How was this patch tested?
Manually tested.
Closes#24818 from HyukjinKwon/SPARK-27971.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The newly added `Refresh` method in PR #24401 prevented the work of moving DataSourceV2Relation into catalyst. It calls `case table: FileTable => table.fileIndex.refresh()` while `FileTable` belongs to sql/core.
More importantly, Ryan Blue pointed out DataSourceV2Relation is immutable by design, it should not have refresh method.
## How was this patch tested?
Unit test
Closes#24815 from gengliangwang/removeRefreshTable.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
It seems that some users are using Hive 3.0.0. This pr makes it support Hive 3.0 metastore.
## How was this patch tested?
unit tests
Closes#24688 from wangyum/SPARK-26145.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Flush batch timely for pandas UDF.
This could improve performance when multiple pandas UDF plans are pipelined.
When batch being flushed in time, downstream pandas UDFs will get pipelined as soon as possible, and pipeline will help hide the donwstream UDFs computation time. For example:
When the first UDF start computing on batch-3, the second pipelined UDF can start computing on batch-2, and the third pipelined UDF can start computing on batch-1.
If we do not flush each batch in time, the donwstream UDF's pipeline will lag behind too much, which may increase the total processing time.
I add flush at two places:
* JVM process feed data into python worker. In jvm side, when write one batch, flush it
* VM process read data from python worker output, In python worker side, when write one batch, flush it
If no flush, the default buffer size for them are both 65536. Especially in the ML case, in order to make realtime prediction, we will make batch size very small. The buffer size is too large for the case, which cause downstream pandas UDF pipeline lag behind too much.
### Note
* This is only applied to pandas scalar UDF.
* Do not flush for each batch. The minimum interval between two flush is 0.1 second. This avoid too frequent flushing when batch size is small. It works like:
```
last_flush_time = time.time()
for batch in iterator:
writer.write_batch(batch)
flush_time = time.time()
if self.flush_timely and (flush_time - last_flush_time > 0.1):
stream.flush()
last_flush_time = flush_time
```
## How was this patch tested?
### Benchmark to make sure the flush do not cause performance regression
#### Test code:
```
numRows = ...
batchSize = ...
spark.conf.set('spark.sql.execution.arrow.maxRecordsPerBatch', str(batchSize))
df = spark.range(1, numRows + 1, numPartitions=1).select(col('id').alias('a'))
pandas_udf("int", PandasUDFType.SCALAR)
def fp1(x):
return x + 10
beg_time = time.time()
result = df.select(sum(fp1('a'))).head()
print("result: " + str(result[0]))
print("consume time: " + str(time.time() - beg_time))
```
#### Test Result:
params | Consume time (Before) | Consume time (After)
------------ | ----------------------- | ----------------------
numRows=100000000, batchSize=10000 | 23.43s | 24.64s
numRows=100000000, batchSize=1000 | 36.73s | 34.50s
numRows=10000000, batchSize=100 | 35.67s | 32.64s
numRows=1000000, batchSize=10 | 33.60s | 32.11s
numRows=100000, batchSize=1 | 33.36s | 31.82s
### Benchmark pipelined pandas UDF
#### Test code:
```
spark.conf.set('spark.sql.execution.arrow.maxRecordsPerBatch', '1')
df = spark.range(1, 31, numPartitions=1).select(col('id').alias('a'))
pandas_udf("int", PandasUDFType.SCALAR)
def fp1(x):
print("run fp1")
time.sleep(1)
return x + 100
pandas_udf("int", PandasUDFType.SCALAR)
def fp2(x, y):
print("run fp2")
time.sleep(1)
return x + y
beg_time = time.time()
result = df.select(sum(fp2(fp1('a'), col('a')))).head()
print("result: " + str(result[0]))
print("consume time: " + str(time.time() - beg_time))
```
#### Test Result:
**Before**: consume time: 63.57s
**After**: consume time: 32.43s
**So the PR improve performance by make downstream UDF get pipelined early.**
Please review https://spark.apache.org/contributing.html before opening a pull request.
Closes#24734 from WeichenXu123/improve_pandas_udf_pipeline.
Lead-authored-by: WeichenXu <weichen.xu@databricks.com>
Co-authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
When using `from_avro` to deserialize avro data to catalyst StructType format, if `ConvertToLocalRelation` is applied at the time, `from_avro` produces only the last value (overriding previous values).
The cause is `AvroDeserializer` reuses output row for StructType. Normally, it should be fine in Spark SQL. But `ConvertToLocalRelation` just uses `InterpretedProjection` to project local rows. `InterpretedProjection` creates new row for each output thro, it includes the same nested row object from `AvroDeserializer`. By the end, converted local relation has only last value.
I think there're two possible options:
1. Make `AvroDeserializer` output new row for StructType.
2. Use `InterpretedMutableProjection` in `ConvertToLocalRelation` and call `copy()` on output rows.
Option 2 is chose because previously `ConvertToLocalRelation` also creates new rows, this `InterpretedMutableProjection` + `copy()` shoudn't bring too much performance penalty. `ConvertToLocalRelation` should be arguably less critical, compared with `AvroDeserializer`.
## How was this patch tested?
Added test.
Closes#24805 from viirya/SPARK-27798.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Add extractors for v2 catalog transforms.
These extractors are used to match transforms that are equivalent to Spark's internal case classes. This makes it easier to work with v2 transforms.
## How was this patch tested?
Added test suite for the new extractors.
Closes#24812 from rdblue/SPARK-27965-add-transform-extractors.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In PR https://github.com/apache/spark/pull/24365, we pass in the partitionBy columns as options in `DataFrameWriter`. To make this change less intrusive for a patch release, we added a feature flag `LEGACY_PASS_PARTITION_BY_AS_OPTIONS` with the default to be false.
For 3.0, we should just do the correct behavior for DSV1, i.e., always passing partitionBy as options, and remove this legacy feature flag.
## How was this patch tested?
Existing tests.
Closes#24784 from liwensun/SPARK-27453-default.
Authored-by: liwensun <liwen.sun@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Issued fixed in https://github.com/apache/spark/pull/24734 but that PR might takes longer to merge.
## How was this patch tested?
It should pass existing unit tests.
Closes#24816 from mengxr/SPARK-27968.
Authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
Move methods that implement v2 catalog operations to CatalogV2Util so they can be used in #24768.
## How was this patch tested?
Behavior is validated by existing tests.
Closes#24813 from rdblue/SPARK-27964-add-catalog-v2-util.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
I believe the log message: `Committer $committerClass is not a ParquetOutputCommitter and cannot create job summaries. Set Parquet option ${ParquetOutputFormat.JOB_SUMMARY_LEVEL} to NONE.` is at odds with the `if` statement that logs the warning. Despite the instructions in the warning, users still encounter the warning if `JOB_SUMMARY_LEVEL` is already set to `NONE`.
This pull request introduces a change to skip logging the warning if `JOB_SUMMARY_LEVEL` is set to `NONE`.
## How was this patch tested?
I built to make sure everything still compiled and I ran the existing test suite. I didn't feel it was worth the overhead to add a test to make sure a log message does not get logged, but if reviewers feel differently, I can add one.
Closes#24808 from jmsanders/master.
Authored-by: Jordan Sanders <jmsanders@users.noreply.github.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This moves parsing logic for `ALTER TABLE` into Catalyst and adds parsed logical plans for alter table changes that use multi-part identifiers. This PR is similar to SPARK-27108, PR #24029, that created parsed logical plans for create and CTAS.
* Create parsed logical plans
* Move parsing logic into Catalyst's AstBuilder
* Convert to DataSource plans in DataSourceResolution
* Parse `ALTER TABLE ... SET LOCATION ...` separately from the partition variant
* Parse `ALTER TABLE ... ALTER COLUMN ... [TYPE dataType] [COMMENT comment]` [as discussed on the dev list](http://apache-spark-developers-list.1001551.n3.nabble.com/DISCUSS-Syntax-for-table-DDL-td25197.html#a25270)
* Parse `ALTER TABLE ... RENAME COLUMN ... TO ...`
* Parse `ALTER TABLE ... DROP COLUMNS ...`
## How was this patch tested?
* Added new tests in Catalyst's `DDLParserSuite`
* Moved converted plan tests from SQL `DDLParserSuite` to `PlanResolutionSuite`
* Existing tests for regressions
Closes#24723 from rdblue/SPARK-27857-add-alter-table-statements-in-catalyst.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
Extracting the common purge "behaviour" to the parent StreamExecution.
## How was this patch tested?
No added behaviour so relying on existing tests.
Closes#24781 from jaceklaskowski/StreamExecution-purge.
Authored-by: Jacek Laskowski <jacek@japila.pl>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}