### What changes were proposed in this pull request?
In the PR, I propose to change behavior of the `date_part()` function in handling `null` field, and make it the same as PostgreSQL has. If `field` parameter is `null`, the function should return `null` of the `double` type as PostgreSQL does:
```sql
# select date_part(null, date '2019-09-20');
date_part
-----------
(1 row)
# select pg_typeof(date_part(null, date '2019-09-20'));
pg_typeof
------------------
double precision
(1 row)
```
### Why are the changes needed?
The `date_part()` function was added to maintain feature parity with PostgreSQL but current behavior of the function is different in handling null as `field`.
### Does this PR introduce any user-facing change?
Yes.
Before:
```sql
spark-sql> select date_part(null, date'2019-09-20');
Error in query: null; line 1 pos 7
```
After:
```sql
spark-sql> select date_part(null, date'2019-09-20');
NULL
```
### How was this patch tested?
Add new tests to `DateFunctionsSuite for 2 cases:
- `field` = `null`, `source` = a date literal
- `field` = `null`, `source` = a date column
Closes#25865 from MaxGekk/date_part-null.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This pr is to propagate all the SQL configurations to executors in `SQLQueryTestSuite`. When the propagation enabled in the tests, a potential bug below becomes apparent;
```
CREATE TABLE num_data (id int, val decimal(38,10)) USING parquet;
....
select sum(udf(CAST(null AS Decimal(38,0)))) from range(1,4): QueryOutput(select sum(udf(CAST(null AS Decimal(38,0)))) from range(1,4),struct<>,java.lang.IllegalArgumentException
[info] requirement failed: MutableProjection cannot use UnsafeRow for output data types: decimal(38,0)) (SQLQueryTestSuite.scala:380)
```
The root culprit is that `InterpretedMutableProjection` has incorrect validation in the interpreter mode: `validExprs.forall { case (e, _) => UnsafeRow.isFixedLength(e.dataType) }`. This validation should be the same with the condition (`isMutable`) in `HashAggregate.supportsAggregate`: https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/aggregate/HashAggregateExec.scala#L1126
### Why are the changes needed?
Bug fixes.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Added tests in `AggregationQuerySuite`
Closes#25831 from maropu/SPARK-29122.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
## What changes were proposed in this pull request?
This adds a new write API as proposed in the [SPIP to standardize logical plans](https://issues.apache.org/jira/browse/SPARK-23521). This new API:
* Uses clear verbs to execute writes, like `append`, `overwrite`, `create`, and `replace` that correspond to the new logical plans.
* Only creates v2 logical plans so the behavior is always consistent.
* Does not allow table configuration options for operations that cannot change table configuration. For example, `partitionedBy` can only be called when the writer executes `create` or `replace`.
Here are a few example uses of the new API:
```scala
df.writeTo("catalog.db.table").append()
df.writeTo("catalog.db.table").overwrite($"date" === "2019-06-01")
df.writeTo("catalog.db.table").overwritePartitions()
df.writeTo("catalog.db.table").asParquet.create()
df.writeTo("catalog.db.table").partitionedBy(days($"ts")).createOrReplace()
df.writeTo("catalog.db.table").using("abc").replace()
```
## How was this patch tested?
Added `DataFrameWriterV2Suite` that tests the new write API. Existing tests for v2 plans.
Closes#25681 from rdblue/SPARK-28612-add-data-frame-writer-v2.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Burak Yavuz <brkyvz@gmail.com>
### What changes were proposed in this pull request?
This patch proposes to change the log level of logging generated code in case of compile error being occurred in UT. This would help to investigate compilation issue of generated code easier, as currently we got exception message of line number but there's no generated code being logged actually (as in most cases of UT the threshold of log level is at least WARN).
### Why are the changes needed?
This would help investigating issue on compilation error for generated code in UT.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#25835 from HeartSaVioR/MINOR-always-log-generated-code-on-fail-to-compile-in-unit-testing.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This addresses about 15 miscellaneous warnings that appear in the current build.
### Why are the changes needed?
No functional changes, it just slightly reduces the amount of extra warning output.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests, run manually.
Closes#25852 from srowen/BuildWarnings.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Currently, there are new configurations for compatibility with ANSI SQL:
* `spark.sql.parser.ansi.enabled`
* `spark.sql.decimalOperations.nullOnOverflow`
* `spark.sql.failOnIntegralTypeOverflow`
This PR is to add new configuration `spark.sql.ansi.enabled` and remove the 3 options above. When the configuration is true, Spark tries to conform to the ANSI SQL specification. It will be disabled by default.
### Why are the changes needed?
Make it simple and straightforward.
### Does this PR introduce any user-facing change?
The new features for ANSI compatibility will be set via one configuration `spark.sql.ansi.enabled`.
### How was this patch tested?
Existing unit tests.
Closes#25693 from gengliangwang/ansiEnabled.
Lead-authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR upgrade Scala to **2.12.10**.
Release notes:
- Fix regression in large string interpolations with non-String typed splices
- Revert "Generate shallower ASTs in pattern translation"
- Fix regression in classpath when JARs have 'a.b' entries beside 'a/b'
- Faster compiler: 5–10% faster since 2.12.8
- Improved compatibility with JDK 11, 12, and 13
- Experimental support for build pipelining and outline type checking
More details:
https://github.com/scala/scala/releases/tag/v2.12.10https://github.com/scala/scala/releases/tag/v2.12.9
## How was this patch tested?
Existing tests
Closes#25404 from wangyum/SPARK-28683.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Simplify the return type for `lookupV2Relation` which makes the 3 callers more straightforward.
## How was this patch tested?
Existing unit tests.
Closes#25735 from jzhuge/lookupv2relation.
Authored-by: John Zhuge <jzhuge@apache.org>
Signed-off-by: Burak Yavuz <brkyvz@gmail.com>
### What changes were proposed in this pull request?
#DataSet
fruit,color,price,quantity
apple,red,1,3
banana,yellow,2,4
orange,orange,3,5
xxx
This PR aims to fix the below
```
scala> spark.conf.set("spark.sql.csv.parser.columnPruning.enabled", false)
scala> spark.read.option("header", "true").option("mode", "DROPMALFORMED").csv("fruit.csv").count
res1: Long = 4
```
This is caused by the issue [SPARK-24645](https://issues.apache.org/jira/browse/SPARK-24645).
SPARK-24645 issue can also be solved by [SPARK-25387](https://issues.apache.org/jira/browse/SPARK-25387)
### Why are the changes needed?
SPARK-24645 caused this regression, so reverted the code as it can also be solved by SPARK-25387
### Does this PR introduce any user-facing change?
No,
### How was this patch tested?
Added UT, and also tested the bug SPARK-24645
**SPARK-24645 regression**

Closes#25820 from sandeep-katta/SPARK-29101.
Authored-by: sandeep katta <sandeep.katta2007@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Supported special string values for `TIMESTAMP` type. They are simply notational shorthands that will be converted to ordinary timestamp values when read. The following string values are supported:
- `epoch [zoneId]` - `1970-01-01 00:00:00+00 (Unix system time zero)`
- `today [zoneId]` - midnight today.
- `yesterday [zoneId]` -midnight yesterday
- `tomorrow [zoneId]` - midnight tomorrow
- `now` - current query start time.
For example:
```sql
spark-sql> SELECT timestamp 'tomorrow';
2019-09-07 00:00:00
```
### Why are the changes needed?
To maintain feature parity with PostgreSQL, see [8.5.1.4. Special Values](https://www.postgresql.org/docs/12/datatype-datetime.html)
### Does this PR introduce any user-facing change?
Previously, the parser fails on the special values with the error:
```sql
spark-sql> select timestamp 'today';
Error in query:
Cannot parse the TIMESTAMP value: today(line 1, pos 7)
```
After the changes, the special values are converted to appropriate dates:
```sql
spark-sql> select timestamp 'today';
2019-09-06 00:00:00
```
### How was this patch tested?
- Added tests to `TimestampFormatterSuite` to check parsing special values from regular strings.
- Tests in `DateTimeUtilsSuite` check parsing those values from `UTF8String`
- Uncommented tests in `timestamp.sql`
Closes#25716 from MaxGekk/timestamp-special-values.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. After https://github.com/apache/spark/pull/21599, if the option "spark.sql.failOnIntegralTypeOverflow" is enabled, all the Binary Arithmetic operator will used the exact version function.
However, only `Add`/`Substract`/`Multiply` has a corresponding exact function in java.lang.Math . When the option "spark.sql.failOnIntegralTypeOverflow" is enabled, a runtime exception "BinaryArithmetics must override either exactMathMethod or genCode" is thrown if the other Binary Arithmetic operators are used, such as "Divide", "Remainder".
The exact math method should be called only when there is a corresponding function in `java.lang.Math`
2. Revise the log output of casting to `Int`/`Short`
3. Enable `spark.sql.failOnIntegralTypeOverflow` for pgSQL tests in `SQLQueryTestSuite`.
### Why are the changes needed?
1. Fix the bugs of https://github.com/apache/spark/pull/21599
2. The test case of pgSQL intends to check the overflow of integer/long type. We should enable `spark.sql.failOnIntegralTypeOverflow`.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Unit test.
Closes#25804 from gengliangwang/enableIntegerOverflowInSQLTest.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
**What changes were proposed in this pull request?**
Issue 1 : modifications not required as these are different formats for the same info. In the case of a Spark DataFrame, null is correct.
Issue 2 mentioned in JIRA Spark SQL "desc formatted tablename" is not showing the header # col_name,data_type,comment , seems to be the header has been removed knowingly as part of SPARK-20954.
Issue 3:
Corrected the Last Access time, the value shall display 'UNKNOWN' as currently system wont support the last access time evaluation, since hive was setting Last access time as '0' in metastore even though spark CatalogTable last access time value set as -1. this will make the validation logic of LasAccessTime where spark sets 'UNKNOWN' value if last access time value set as -1 (means not evaluated).
**Does this PR introduce any user-facing change?**
No
**How was this patch tested?**
Locally and corrected a ut.
Attaching the test report below

Closes#25720 from sujith71955/master_describe_info.
Authored-by: s71955 <sujithchacko.2010@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This pr refines the code of DELETE, including, 1, make `whereClause` to be optional, in which case DELETE will delete all of the data of a table; 2, add more test cases; 3, some other refines.
This is a following-up of SPARK-28351.
### Why are the changes needed?
An optional where clause in DELETE respects the SQL standard.
### Does this PR introduce any user-facing change?
Yes. But since this is a non-released feature, this change does not have any end-user affects.
### How was this patch tested?
New case is added.
Closes#25652 from xianyinxin/SPARK-28950.
Authored-by: xy_xin <xianyin.xxy@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to create an instance of `TimestampFormatter` only once at the initialization, and reuse it inside of `nullSafeEval()` and `doGenCode()` in the case when the `fmt` parameter is foldable.
### Why are the changes needed?
The changes improve performance of the `date_format()` function.
Before:
```
format date: Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------
format date wholestage off 7180 / 7181 1.4 718.0 1.0X
format date wholestage on 7051 / 7194 1.4 705.1 1.0X
```
After:
```
format date: Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------
format date wholestage off 4787 / 4839 2.1 478.7 1.0X
format date wholestage on 4736 / 4802 2.1 473.6 1.0X
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
By existing test suites `DateExpressionsSuite` and `DateFunctionsSuite`.
Closes#25782 from MaxGekk/date_format-foldable.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
When InSet generates Java switch-based code, if the input set is empty, we don't generate switch condition, but a simple expression that is default case of original switch.
### Why are the changes needed?
SPARK-26205 adds an optimization to InSet that generates Java switch condition for certain cases. When the given set is empty, it is possibly that codegen causes compilation error:
```
[info] - SPARK-29100: InSet with empty input set *** FAILED *** (58 milliseconds)
[info] Code generation of input[0, int, true] INSET () failed:
[info] org.codehaus.janino.InternalCompilerException: failed to compile: org.codehaus.janino.InternalCompilerException: Compiling "GeneratedClass" in "generated.java": Compiling "apply(java.lang.Object _i)"; apply(java.lang.Object _i): Operand stack inconsistent at offset 45: Previous size 0, now 1
[info] org.codehaus.janino.InternalCompilerException: failed to compile: org.codehaus.janino.InternalCompilerException: Compiling "GeneratedClass" in "generated.java": Compiling "apply(java.lang.Object _i)"; apply(java.lang.Object _i): Operand stack inconsistent at offset 45: Previous size 0, now 1
[info] at org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator$.org$apache$spark$sql$catalyst$expressions$codegen$CodeGenerator$$doCompile(CodeGenerator.scala:1308)
[info] at org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator$$anon$1.load(CodeGenerator.scala:1386)
[info] at org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator$$anon$1.load(CodeGenerator.scala:1383)
```
### Does this PR introduce any user-facing change?
Yes. Previously, when users have InSet against an empty set, generated code causes compilation error. This patch fixed it.
### How was this patch tested?
Unit test added.
Closes#25806 from viirya/SPARK-29100.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This pr proposes to define an individual method for each common subexpression in HashAggregateExec. In the current master, the common subexpr elimination code in HashAggregateExec is expanded in a single method; 4664a082c2/sql/core/src/main/scala/org/apache/spark/sql/execution/aggregate/HashAggregateExec.scala (L397)
The method size can be too big for JIT compilation, so I believe splitting it is beneficial for performance. For example, in a query `SELECT SUM(a + b), AVG(a + b + c) FROM VALUES (1, 1, 1) t(a, b, c)`,
the current master generates;
```
/* 098 */ private void agg_doConsume_0(InternalRow localtablescan_row_0, int agg_expr_0_0, int agg_expr_1_0, int agg_expr_2_0) throws java.io.IOException {
/* 099 */ // do aggregate
/* 100 */ // common sub-expressions
/* 101 */ int agg_value_6 = -1;
/* 102 */
/* 103 */ agg_value_6 = agg_expr_0_0 + agg_expr_1_0;
/* 104 */
/* 105 */ int agg_value_5 = -1;
/* 106 */
/* 107 */ agg_value_5 = agg_value_6 + agg_expr_2_0;
/* 108 */ boolean agg_isNull_4 = false;
/* 109 */ long agg_value_4 = -1L;
/* 110 */ if (!false) {
/* 111 */ agg_value_4 = (long) agg_value_5;
/* 112 */ }
/* 113 */ int agg_value_10 = -1;
/* 114 */
/* 115 */ agg_value_10 = agg_expr_0_0 + agg_expr_1_0;
/* 116 */ // evaluate aggregate functions and update aggregation buffers
/* 117 */ agg_doAggregate_sum_0(agg_value_10);
/* 118 */ agg_doAggregate_avg_0(agg_value_4, agg_isNull_4);
/* 119 */
/* 120 */ }
```
On the other hand, this pr generates;
```
/* 121 */ private void agg_doConsume_0(InternalRow localtablescan_row_0, int agg_expr_0_0, int agg_expr_1_0, int agg_expr_2_0) throws java.io.IOException {
/* 122 */ // do aggregate
/* 123 */ // common sub-expressions
/* 124 */ long agg_subExprValue_0 = agg_subExpr_0(agg_expr_2_0, agg_expr_0_0, agg_expr_1_0);
/* 125 */ int agg_subExprValue_1 = agg_subExpr_1(agg_expr_0_0, agg_expr_1_0);
/* 126 */ // evaluate aggregate functions and update aggregation buffers
/* 127 */ agg_doAggregate_sum_0(agg_subExprValue_1);
/* 128 */ agg_doAggregate_avg_0(agg_subExprValue_0);
/* 129 */
/* 130 */ }
```
I run some micro benchmarks for this pr;
```
(base) maropu~:$system_profiler SPHardwareDataType
Hardware:
Hardware Overview:
Processor Name: Intel Core i5
Processor Speed: 2 GHz
Number of Processors: 1
Total Number of Cores: 2
L2 Cache (per Core): 256 KB
L3 Cache: 4 MB
Memory: 8 GB
(base) maropu~:$java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
(base) maropu~:$ /bin/spark-shell --master=local[1] --conf spark.driver.memory=8g --conf spark.sql.shurtitions=1 -v
val numCols = 40
val colExprs = "id AS key" +: (0 until numCols).map { i => s"id AS _c$i" }
spark.range(3000000).selectExpr(colExprs: _*).createOrReplaceTempView("t")
val aggExprs = (2 until numCols).map { i =>
(0 until i).map(d => s"_c$d")
.mkString("AVG(", " + ", ")")
}
// Drops the time of a first run then pick that of a second run
timer { sql(s"SELECT ${aggExprs.mkString(", ")} FROM t").write.format("noop").save() }
// the master
maxCodeGen: 12957
Elapsed time: 36.309858661s
// this pr
maxCodeGen=4184
Elapsed time: 2.399490285s
```
### Why are the changes needed?
To avoid the too-long-function issue in JVMs.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Added tests in `WholeStageCodegenSuite`
Closes#25710 from maropu/SplitSubexpr.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This pr proposes to print bytecode statistics (max class bytecode size, max method bytecode size, max constant pool size, and # of inner classes) for generated classes in debug prints, `debugCodegen`. Since these metrics are critical for codegen framework developments, I think its worth printing there. This pr intends to enable `debugCodegen` to print these metrics as following;
```
scala> sql("SELECT sum(v) FROM VALUES(1) t(v)").debugCodegen
Found 2 WholeStageCodegen subtrees.
== Subtree 1 / 2 (maxClassCodeSize:2693; maxMethodCodeSize:124; maxConstantPoolSize:130(0.20% used); numInnerClasses:0) ==
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
*(1) HashAggregate(keys=[], functions=[partial_sum(cast(v#0 as bigint))], output=[sum#5L])
+- *(1) LocalTableScan [v#0]
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage1(references);
/* 003 */ }
...
```
### Why are the changes needed?
For efficient developments
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manually tested
Closes#25766 from maropu/PrintBytecodeStats.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
It's more clear to only do table lookup in `ResolveTables` rule (for v2 tables) and `ResolveRelations` rule (for v1 tables). `ResolveInsertInto` should only resolve the `InsertIntoStatement` with resolved relations.
### Why are the changes needed?
to make the code simpler
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
existing tests
Closes#25774 from cloud-fan/simplify.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR add the `namespaces` keyword to `TableIdentifierParserSuite`.
### Why are the changes needed?
Improve the test.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#25758 from highmoutain/3.0bugfix.
Authored-by: changchun.wang <251922566@qq.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This patch fixes the bug regarding NPE in SQLConf.get, which is only possible when SparkContext._dagScheduler is null due to stopping SparkContext. The logic doesn't seem to consider active SparkContext could be in progress of stopping.
Note that it can't be encountered easily as SparkContext.stop() blocks the main thread, but there're many cases which SQLConf.get is accessed concurrently while SparkContext.stop() is executing - users run another threads, or listener is accessing SQLConf.get after dagScheduler is set to null (this is the case what I encountered.)
### Why are the changes needed?
The bug brings NPE.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Previous patch #25753 was tested with new UT, and due to disruption with other tests in concurrent test run, the test is excluded in this patch.
Closes#25790 from HeartSaVioR/SPARK-29046-v2.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose to fix comments of date-time expressions, and replace the `yyyy` pattern by `uuuu` when the implementation supposes the former one.
### Why are the changes needed?
To make comments consistent to implementations.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By running Scala Style checker.
Closes#25796 from MaxGekk/year-pattern-uuuu-followup.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
reorganize the packages of DS v2 interfaces/classes:
1. `org.spark.sql.connector.catalog`: put `TableCatalog`, `Table` and other related interfaces/classes
2. `org.spark.sql.connector.expression`: put `Expression`, `Transform` and other related interfaces/classes
3. `org.spark.sql.connector.read`: put `ScanBuilder`, `Scan` and other related interfaces/classes
4. `org.spark.sql.connector.write`: put `WriteBuilder`, `BatchWrite` and other related interfaces/classes
### Why are the changes needed?
Data Source V2 has evolved a lot. It's a bit weird that `Expression` is in `org.spark.sql.catalog.v2` and `Table` is in `org.spark.sql.sources.v2`.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
existing tests
Closes#25700 from cloud-fan/package.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
# What changes were proposed in this pull request?
This patch fixes the bug regarding NPE in SQLConf.get, which is only possible when SparkContext._dagScheduler is null due to stopping SparkContext. The logic doesn't seem to consider active SparkContext could be in progress of stopping.
Note that it can't be encountered easily as `SparkContext.stop()` blocks the main thread, but there're many cases which SQLConf.get is accessed concurrently while SparkContext.stop() is executing - users run another threads, or listener is accessing SQLConf.get after dagScheduler is set to null (this is the case what I encountered.)
### Why are the changes needed?
The bug brings NPE.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Added new UT to verify NPE doesn't occur. Without patch, the test fails with throwing NPE.
Closes#25753 from HeartSaVioR/SPARK-29046.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Remove `InsertIntoTable` and replace it's usage by `InsertIntoStatement`
### Why are the changes needed?
`InsertIntoTable` and `InsertIntoStatement` are almost identical (except some namings). It doesn't make sense to keep 2 identical plans. After the removal of `InsertIntoTable`, the analysis process becomes:
1. parser creates `InsertIntoStatement`
2. v2 rule `ResolveInsertInto` converts `InsertIntoStatement` to v2 commands.
3. v1 rules like `DataSourceAnalysis` and `HiveAnalysis` convert `InsertIntoStatement` to v1 commands.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
existing tests
Closes#25763 from cloud-fan/remove.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
- For trait without companion object constructor, currently the method to get constructor parameters `constructParams` in `ScalaReflection` will throw exception.
```
scala.ScalaReflectionException: <none> is not a term
at scala.reflect.api.Symbols$SymbolApi.asTerm(Symbols.scala:211)
at scala.reflect.api.Symbols$SymbolApi.asTerm$(Symbols.scala:211)
at scala.reflect.internal.Symbols$SymbolContextApiImpl.asTerm(Symbols.scala:106)
at org.apache.spark.sql.catalyst.ScalaReflection.getCompanionConstructor(ScalaReflection.scala:909)
at org.apache.spark.sql.catalyst.ScalaReflection.constructParams(ScalaReflection.scala:914)
at org.apache.spark.sql.catalyst.ScalaReflection.constructParams$(ScalaReflection.scala:912)
at org.apache.spark.sql.catalyst.ScalaReflection$.constructParams(ScalaReflection.scala:47)
at org.apache.spark.sql.catalyst.ScalaReflection.getConstructorParameters(ScalaReflection.scala:890)
at org.apache.spark.sql.catalyst.ScalaReflection.getConstructorParameters$(ScalaReflection.scala:886)
at org.apache.spark.sql.catalyst.ScalaReflection$.getConstructorParameters(ScalaReflection.scala:47)
```
- Instead this PR would throw exception:
```
Unable to find constructor for type [XXX]. This could happen if [XXX] is an interface or a trait without companion object constructor
UnsupportedOperationException:
```
In the normal usage of ExpressionEncoder, this can happen if the type is interface extending `scala.Product`. Also, since this is a protected method, this could have been other arbitrary types without constructor.
### Why are the changes needed?
- The error message `<none> is not a term` isn't helpful for users to understand the problem.
### Does this PR introduce any user-facing change?
- The exception would be thrown instead of runtime exception from the `scala.ScalaReflectionException`.
### How was this patch tested?
- Added a unit test to illustrate the `type` where expression encoder will fail and trigger the proposed error message.
Closes#25736 from mickjermsurawong-stripe/SPARK-29026.
Authored-by: Mick Jermsurawong <mickjermsurawong@stripe.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Implement the SHOW DATABASES logical and physical plans for data source v2 tables.
### Why are the changes needed?
To support `SHOW DATABASES` SQL commands for v2 tables.
### Does this PR introduce any user-facing change?
`spark.sql("SHOW DATABASES")` will return namespaces if the default catalog is set:
```
+---------------+
| namespace|
+---------------+
| ns1|
| ns1.ns1_1|
|ns1.ns1_1.ns1_2|
+---------------+
```
### How was this patch tested?
Added unit tests to `DataSourceV2SQLSuite`.
Closes#25601 from imback82/show_databases.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This is a ANSI SQL and feature id is `T312`
```
<binary overlay function> ::=
OVERLAY <left paren> <binary value expression> PLACING <binary value expression>
FROM <start position> [ FOR <string length> ] <right paren>
```
This PR related to https://github.com/apache/spark/pull/24918 and support treat byte array.
ref: https://www.postgresql.org/docs/11/functions-binarystring.html
## How was this patch tested?
new UT.
There are some show of the PR on my production environment.
```
spark-sql> select overlay(encode('Spark SQL', 'utf-8') PLACING encode('_', 'utf-8') FROM 6);
Spark_SQL
Time taken: 0.285 s
spark-sql> select overlay(encode('Spark SQL', 'utf-8') PLACING encode('CORE', 'utf-8') FROM 7);
Spark CORE
Time taken: 0.202 s
spark-sql> select overlay(encode('Spark SQL', 'utf-8') PLACING encode('ANSI ', 'utf-8') FROM 7 FOR 0);
Spark ANSI SQL
Time taken: 0.165 s
spark-sql> select overlay(encode('Spark SQL', 'utf-8') PLACING encode('tructured', 'utf-8') FROM 2 FOR 4);
Structured SQL
Time taken: 0.141 s
```
Closes#25172 from beliefer/ansi-overlay-byte-array.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
The PR proposes to create a custom `RDD` which enables to propagate `SQLConf` also in cases not tracked by SQL execution, as it happens when a `Dataset` is converted to and RDD either using `.rdd` or `.queryExecution.toRdd` and then the returned RDD is used to invoke actions on it.
In this way, SQL configs are effective also in these cases, while earlier they were ignored.
### Why are the changes needed?
Without this patch, all the times `.rdd` or `.queryExecution.toRdd` are used, all the SQL configs set are ignored. An example of a reproducer can be:
```
withSQLConf(SQLConf.SUBEXPRESSION_ELIMINATION_ENABLED.key, "false") {
val df = spark.range(2).selectExpr((0 to 5000).map(i => s"id as field_$i"): _*)
df.createOrReplaceTempView("spark64kb")
val data = spark.sql("select * from spark64kb limit 10")
// Subexpression elimination is used here, despite it should have been disabled
data.describe()
}
```
### Does this PR introduce any user-facing change?
When a user calls `.queryExecution.toRdd`, a `SQLExecutionRDD` is returned wrapping the `RDD` of the execute. When `.rdd` is used, an additional `SQLExecutionRDD` is present in the hierarchy.
### How was this patch tested?
added UT
Closes#25643 from mgaido91/SPARK-28939.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The `V2SessionCatalog` has 2 functionalities:
1. work as an adapter: provide v2 APIs and translate calls to the `SessionCatalog`.
2. allow users to extend it, so that they can add hooks to apply custom logic before calling methods of the builtin catalog (session catalog).
To leverage the second functionality, users must extend `V2SessionCatalog` which is an internal class. There is no doc to explain this usage.
This PR does 2 things:
1. refine the document of the config `spark.sql.catalog.session`.
2. add a public abstract class `CatalogExtension` for users to write implementations.
TODOs for followup PRs:
1. discuss if we should allow users to completely overwrite the v2 session catalog with a new one.
2. discuss to change the name of session catalog, so that it's less likely to conflict with existing namespace names.
## How was this patch tested?
existing tests
Closes#25104 from cloud-fan/session-catalog.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When we set spark.sql.decimalOperations.allowPrecisionLoss to false.
For the sql below, the result will overflow and return null.
Case a:
`select case when 1=2 then 1 else 1.000000000000000000000001 end * 1`
Similar with the division operation.
This sql below will lost precision.
Case b:
`select case when 1=2 then 1 else 1.000000000000000000000001 end / 1`
Let us check the code of TypeCoercion.scala.
a75467432e/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/TypeCoercion.scala (L864-L875).
For binaryOperator, if the two operands have differnt datatype, rule ImplicitTypeCasts will find a common type and cast both operands to common type.
So, for these cases menthioned, their left operand is Decimal(34, 24) and right operand is Literal.
Their common type is Decimal(34,24), and Literal(1) will be casted to Decimal(34,24).
Then both operands are decimal type and they will be processed by decimalAndDecimal method of DecimalPrecision class.
Let's check the relative code.
a75467432e/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/DecimalPrecision.scala (L123-L153)
When we don't allow precision loss, the result type of multiply operation in case a is Decimal(38, 38), and that of division operation in case b is Decimal(38, 20).
Then the multi operation in case a will overflow and division operation in case b will lost precision.
In this PR, we skip to handle the binaryOperator if DecimalType operands are involved and rule `DecimalPrecision` will handle it.
### Why are the changes needed?
Data will corrupt without this change.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#25701 from turboFei/SPARK-29000.
Authored-by: turbofei <fwang12@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The PR proposes to split the code for subexpression elimination before inlining the function calls all in the apply method for `Generate[Mutable|Unsafe]Projection`.
### Why are the changes needed?
Before this PR, code generation can fail due to the 64KB code size limit if a lot of subexpression elimination functions are generated. The added UT is a reproducer for the issue (thanks to the JIRA reporter and HyukjinKwon for it).
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
added UT
Closes#25642 from mgaido91/SPARK-28916.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to avoid AQE regressions by avoiding changing a sort merge join to a broadcast hash join when the expected build plan has a high ratio of empty partitions, in which case sort merge join can actually perform faster. This PR achieves this by adding an internal join hint in order to let the planner know which side has this high ratio of empty partitions and it should avoid planning it as a build plan of a BHJ. Still, it won't affect the other side if the other side qualifies for a build plan of a BHJ.
### Why are the changes needed?
It is a performance improvement for AQE.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Added UT.
Closes#25703 from maryannxue/aqe-demote-bhj.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In the PR, I propose new function `date_part()`. The function is modeled on the traditional Ingres equivalent to the SQL-standard function `extract`:
```
date_part('field', source)
```
and added for feature parity with PostgreSQL (https://www.postgresql.org/docs/11/functions-datetime.html#FUNCTIONS-DATETIME-EXTRACT).
The `source` can have `DATE` or `TIMESTAMP` type. Supported string values of `'field'` are:
- `millennium` - the current millennium for given date (or a timestamp implicitly casted to a date). For example, years in the 1900s are in the second millennium. The third millennium started _January 1, 2001_.
- `century` - the current millennium for given date (or timestamp). The first century starts at 0001-01-01 AD.
- `decade` - the current decade for given date (or timestamp). Actually, this is the year field divided by 10.
- isoyear` - the ISO 8601 week-numbering year that the date falls in. Each ISO 8601 week-numbering year begins with the Monday of the week containing the 4th of January.
- `year`, `month`, `day`, `hour`, `minute`, `second`
- `week` - the number of the ISO 8601 week-numbering week of the year. By definition, ISO weeks start on Mondays and the first week of a year contains January 4 of that year.
- `quarter` - the quarter of the year (1 - 4)
- `dayofweek` - the day of the week for date/timestamp (1 = Sunday, 2 = Monday, ..., 7 = Saturday)
- `dow` - the day of the week as Sunday (0) to Saturday (6)
- `isodow` - the day of the week as Monday (1) to Sunday (7)
- `doy` - the day of the year (1 - 365/366)
- `milliseconds` - the seconds field including fractional parts multiplied by 1,000.
- `microseconds` - the seconds field including fractional parts multiplied by 1,000,000.
- `epoch` - the number of seconds since 1970-01-01 00:00:00 local time in microsecond precision.
Here are examples:
```sql
spark-sql> select date_part('year', timestamp'2019-08-12 01:00:00.123456');
2019
spark-sql> select date_part('week', timestamp'2019-08-12 01:00:00.123456');
33
spark-sql> select date_part('doy', timestamp'2019-08-12 01:00:00.123456');
224
```
I changed implementation of `extract` to re-use `date_part()` internally.
## How was this patch tested?
Added `date_part.sql` and regenerated results of `extract.sql`.
Closes#25410 from MaxGekk/date_part.
Lead-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Support generator in aggregate expressions.
In this PR, I check the aggregate logical plan, if its aggregateExpressions include generator, then convert this agg plan into "normal agg plan + generator plan + projection plan". I.e:
```
aggregate(with generator)
|--child_plan
```
===>
```
project
|--generator(resolved)
|--aggregate
|--child_plan
```
### Why are the changes needed?
We should support sql like:
```
select explode(array(min(a), max(a))) from t
```
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Unit test added.
Closes#25512 from WeichenXu123/explode_bug.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Rename `UnresolvedTable` to `V1Table` because it is not unresolved.
### Why are the changes needed?
The class name is inaccurate. This should be fixed before it is in a release.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#25683 from rdblue/SPARK-28979-rename-unresolved-table.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch implements dynamic partition pruning by adding a dynamic-partition-pruning filter if there is a partitioned table and a filter on the dimension table. The filter is then planned using a heuristic approach:
1. As a broadcast relation if it is a broadcast hash join. The broadcast relation will then be transformed into a reused broadcast exchange by the `ReuseExchange` rule; or
2. As a subquery duplicate if the estimated benefit of partition table scan being saved is greater than the estimated cost of the extra scan of the duplicated subquery; otherwise
3. As a bypassed condition (`true`).
### Why are the changes needed?
This is an important performance feature.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Added UT
- Testing DPP by enabling / disabling the reuse broadcast results feature and / or the subquery duplication feature.
- Testing DPP with reused broadcast results.
- Testing the key iterators on different HashedRelation types.
- Testing the packing and unpacking of the broadcast keys in a LongType.
Closes#25600 from maryannxue/dpp.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Datasource table now supports partition tables long ago. This commit adds the ability to translate
the InsertIntoTable(HiveTableRelation) to datasource table insertion.
## How was this patch tested?
Existing tests with some modification
Closes#25306 from advancedxy/SPARK-28573.
Authored-by: Xianjin YE <advancedxy@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
drop the table after the test `query builtin functions don't call the external catalog` executed
This is required for [SPARK-25464](https://github.com/apache/spark/pull/22466)
## How was this patch tested?
existing UT
Closes#25427 from sandeep-katta/cleanuptable.
Authored-by: sandeep katta <sandeep.katta2007@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The Experimental and Evolving annotations are both (like Unstable) used to express that a an API may change. However there are many things in the code that have been marked that way since even Spark 1.x. Per the dev thread, anything introduced at or before Spark 2.3.0 is pretty much 'stable' in that it would not change without a deprecation cycle. Therefore I'd like to remove most of these annotations. And, remove the `:: Experimental ::` scaladoc tag too. And likewise for Python, R.
The changes below can be summarized as:
- Generally, anything introduced at or before Spark 2.3.0 has been unmarked as neither Evolving nor Experimental
- Obviously experimental items like DSv2, Barrier mode, ExperimentalMethods are untouched
- I _did_ unmark a few MLlib classes introduced in 2.4, as I am quite confident they're not going to change (e.g. KolmogorovSmirnovTest, PowerIterationClustering)
It's a big change to review, so I'd suggest scanning the list of _files_ changed to see if any area seems like it should remain partly experimental and examine those.
### Why are the changes needed?
Many of these annotations are incorrect; the APIs are de facto stable. Leaving them also makes legitimate usages of the annotations less meaningful.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#25558 from srowen/SPARK-28855.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This adds a new write API as proposed in the [SPIP to standardize logical plans](https://issues.apache.org/jira/browse/SPARK-23521). This new API:
* Uses clear verbs to execute writes, like `append`, `overwrite`, `create`, and `replace` that correspond to the new logical plans.
* Only creates v2 logical plans so the behavior is always consistent.
* Does not allow table configuration options for operations that cannot change table configuration. For example, `partitionedBy` can only be called when the writer executes `create` or `replace`.
Here are a few example uses of the new API:
```scala
df.writeTo("catalog.db.table").append()
df.writeTo("catalog.db.table").overwrite($"date" === "2019-06-01")
df.writeTo("catalog.db.table").overwritePartitions()
df.writeTo("catalog.db.table").asParquet.create()
df.writeTo("catalog.db.table").partitionedBy(days($"ts")).createOrReplace()
df.writeTo("catalog.db.table").using("abc").replace()
```
## How was this patch tested?
Added `DataFrameWriterV2Suite` that tests the new write API. Existing tests for v2 plans.
Closes#25354 from rdblue/SPARK-28612-add-data-frame-writer-v2.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Burak Yavuz <brkyvz@gmail.com>
## What changes were proposed in this pull request?
This PR aims to add "true", "yes", "1", "false", "no", "0", and unique prefixes as input for the boolean data type and ignore input whitespace. Please see the following what string representations are using for the boolean type in other databases.
https://www.postgresql.org/docs/devel/datatype-boolean.htmlhttps://docs.aws.amazon.com/redshift/latest/dg/r_Boolean_type.html
## How was this patch tested?
Added new tests to CastSuite.
Closes#25458 from younggyuchun/SPARK-27931.
Authored-by: younggyu chun <younggyuchun@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Adds support for the V2SessionCatalog for ALTER TABLE statements.
Implementation changes are ~50 loc. The rest is just test refactoring.
### Why are the changes needed?
To allow V2 DataSources to plug in through a configurable plugin interface without requiring the explicit use of catalog identifiers, and leverage ALTER TABLE statements.
### How was this patch tested?
By re-using existing tests in DataSourceV2SQLSuite.
Closes#25502 from brkyvz/alterV3.
Authored-by: Burak Yavuz <brkyvz@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
There are 2 in-memory `TableCatalog` and `Table` implementations for testing, in sql/catalyst and sql/core. This PR merges them.
After merging, there are 3 classes:
1. `InMemoryTable`
2. `InMemoryTableCatalog`
3. `StagingInMemoryTableCatalog`
For better maintainability, these 3 classes are put in 3 different files.
### Why are the changes needed?
reduce duplicated code
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
N/A
Closes#25610 from cloud-fan/dsv2-test.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Ryan Blue <blue@apache.org>
### What changes were proposed in this pull request?
Disallow conversions between `timestamp` type and `long` type in table insertion with ANSI store assignment policy.
### Why are the changes needed?
In the PR https://github.com/apache/spark/pull/25581, timestamp type is allowed to be converted to long type, since timestamp type is represented by long type internally, and both legacy mode and strict mode allows the conversion.
After reconsideration, I think we should disallow it. As per ANSI SQL section "4.4.2 Characteristics of numbers":
> A number is assignable only to sites of numeric type.
In PostgreSQL, the conversion between timestamp and long is also disallowed.
### Does this PR introduce any user-facing change?
Conversion between timestamp and long is disallowed in table insertion with ANSI store assignment policy.
### How was this patch tested?
Unit test
Closes#25615 from gengliangwang/disallowTimeStampToLong.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Revise the documentation of SQL option `spark.sql.storeAssignmentPolicy`.
### Why are the changes needed?
1. Need to point out the ANSI mode is mostly the same with PostgreSQL
2. Need to point out Legacy mode allows type coercion as long as it is valid casting
3. Better examples.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Uni test
Closes#25605 from gengliangwang/reviseDoc.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Introduce ANSI store assignment policy for table insertion.
With ANSI policy, Spark performs the type coercion of table insertion as per ANSI SQL.
### Why are the changes needed?
In Spark version 2.4 and earlier, when inserting into a table, Spark will cast the data type of input query to the data type of target table by coercion. This can be super confusing, e.g. users make a mistake and write string values to an int column.
In data source V2, by default, only upcasting is allowed when inserting data into a table. E.g. int -> long and int -> string are allowed, while decimal -> double or long -> int are not allowed. The rules of UpCast was originally created for Dataset type coercion. They are quite strict and different from the behavior of all existing popular DBMS. This is breaking change. It is possible that existing queries are broken after 3.0 releases.
Following ANSI SQL standard makes Spark consistent with the table insertion behaviors of popular DBMS like PostgreSQL/Oracle/Mysql.
### Does this PR introduce any user-facing change?
A new optional mode for table insertion.
### How was this patch tested?
Unit test
Closes#25581 from gengliangwang/ANSImode.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Make `spark.sql.crossJoin.enabled` default value true
### Why are the changes needed?
For implicit cross join, we can set up a watchdog to cancel it if running for a long time.
When "spark.sql.crossJoin.enabled" is false, because `CheckCartesianProducts` is implemented in logical plan stage, it may generate some mismatching error which may confuse end user:
* it's done in logical phase, so we may fail queries that can be executed via broadcast join, which is very fast.
* if we move the check to the physical phase, then a query may success at the beginning, and begin to fail when the table size gets larger (other people insert data to the table). This can be quite confusing.
* the CROSS JOIN syntax doesn't work well if join reorder happens.
* some non-equi-join will generate plan using cartesian product, but `CheckCartesianProducts` do not detect it and raise error.
So that in order to address this in simpler way, we can turn off showing this cross-join error by default.
For reference, I list some cases raising mismatching error here:
Providing:
```
spark.range(2).createOrReplaceTempView("sm1") // can be broadcast
spark.range(50000000).createOrReplaceTempView("bg1") // cannot be broadcast
spark.range(60000000).createOrReplaceTempView("bg2") // cannot be broadcast
```
1) Some join could be convert to broadcast nested loop join, but CheckCartesianProducts raise error. e.g.
```
select sm1.id, bg1.id from bg1 join sm1 where sm1.id < bg1.id
```
2) Some join will run by CartesianJoin but CheckCartesianProducts DO NOT raise error. e.g.
```
select bg1.id, bg2.id from bg1 join bg2 where bg1.id < bg2.id
```
### Does this PR introduce any user-facing change?
### How was this patch tested?
Closes#25520 from WeichenXu123/SPARK-28621.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Currently we have 2 configs to specify which v2 sources should fallback to v1 code path. One config for read path, and one config for write path.
However, I found it's awkward to work with these 2 configs:
1. for `CREATE TABLE USING format`, should this be read path or write path?
2. for `V2SessionCatalog.loadTable`, we need to return `UnresolvedTable` if it's a DS v1 or we need to fallback to v1 code path. However, at that time, we don't know if the returned table will be used for read or write.
We don't have any new features or perf improvement in file source v2. The fallback API is just a safeguard if we have bugs in v2 implementations. There are not many benefits to support falling back to v1 for read and write path separately.
This PR proposes to merge these 2 configs into one.
## How was this patch tested?
existing tests
Closes#25465 from cloud-fan/merge-conf.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR adds support for INSERT INTO through both the SQL and DataFrameWriter APIs through the V2SessionCatalog.
### Why are the changes needed?
This will allow V2 tables to be plugged in through the V2SessionCatalog, and be used seamlessly with existing APIs.
### Does this PR introduce any user-facing change?
No behavior changes.
### How was this patch tested?
Pulled out a lot of tests so that they can be shared across the DataFrameWriter and SQL code paths.
Closes#25507 from brkyvz/insertSesh.
Lead-authored-by: Burak Yavuz <brkyvz@gmail.com>
Co-authored-by: Burak Yavuz <burak@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR aims at improving the way physical plans are explained in spark.
Currently, the explain output for physical plan may look very cluttered and each operator's
string representation can be very wide and wraps around in the display making it little
hard to follow. This especially happens when explaining a query 1) Operating on wide tables
2) Has complex expressions etc.
This PR attempts to split the output into two sections. In the header section, we display
the basic operator tree with a number associated with each operator. In this section, we strictly
control what we output for each operator. In the footer section, each operator is verbosely
displayed. Based on the feedback from Maryann, the uncorrelated subqueries (SubqueryExecs) are not included in the main plan. They are printed separately after the main plan and can be
correlated by the originating expression id from its parent plan.
To illustrate, here is a simple plan displayed in old vs new way.
Example query1 :
```
EXPLAIN SELECT key, Max(val) FROM explain_temp1 WHERE key > 0 GROUP BY key HAVING max(val) > 0
```
Old :
```
*(2) Project [key#2, max(val)#15]
+- *(2) Filter (isnotnull(max(val#3)#18) AND (max(val#3)#18 > 0))
+- *(2) HashAggregate(keys=[key#2], functions=[max(val#3)], output=[key#2, max(val)#15, max(val#3)#18])
+- Exchange hashpartitioning(key#2, 200)
+- *(1) HashAggregate(keys=[key#2], functions=[partial_max(val#3)], output=[key#2, max#21])
+- *(1) Project [key#2, val#3]
+- *(1) Filter (isnotnull(key#2) AND (key#2 > 0))
+- *(1) FileScan parquet default.explain_temp1[key#2,val#3] Batched: true, DataFilters: [isnotnull(key#2), (key#2 > 0)], Format: Parquet, Location: InMemoryFileIndex[file:/user/hive/warehouse/explain_temp1], PartitionFilters: [], PushedFilters: [IsNotNull(key), GreaterThan(key,0)], ReadSchema: struct<key:int,val:int>
```
New :
```
Project (8)
+- Filter (7)
+- HashAggregate (6)
+- Exchange (5)
+- HashAggregate (4)
+- Project (3)
+- Filter (2)
+- Scan parquet default.explain_temp1 (1)
(1) Scan parquet default.explain_temp1 [codegen id : 1]
Output: [key#2, val#3]
(2) Filter [codegen id : 1]
Input : [key#2, val#3]
Condition : (isnotnull(key#2) AND (key#2 > 0))
(3) Project [codegen id : 1]
Output : [key#2, val#3]
Input : [key#2, val#3]
(4) HashAggregate [codegen id : 1]
Input: [key#2, val#3]
(5) Exchange
Input: [key#2, max#11]
(6) HashAggregate [codegen id : 2]
Input: [key#2, max#11]
(7) Filter [codegen id : 2]
Input : [key#2, max(val)#5, max(val#3)#8]
Condition : (isnotnull(max(val#3)#8) AND (max(val#3)#8 > 0))
(8) Project [codegen id : 2]
Output : [key#2, max(val)#5]
Input : [key#2, max(val)#5, max(val#3)#8]
```
Example Query2 (subquery):
```
SELECT * FROM explain_temp1 WHERE KEY = (SELECT Max(KEY) FROM explain_temp2 WHERE KEY = (SELECT Max(KEY) FROM explain_temp3 WHERE val > 0) AND val = 2) AND val > 3
```
Old:
```
*(1) Project [key#2, val#3]
+- *(1) Filter (((isnotnull(KEY#2) AND isnotnull(val#3)) AND (KEY#2 = Subquery scalar-subquery#39)) AND (val#3 > 3))
: +- Subquery scalar-subquery#39
: +- *(2) HashAggregate(keys=[], functions=[max(KEY#26)], output=[max(KEY)#45])
: +- Exchange SinglePartition
: +- *(1) HashAggregate(keys=[], functions=[partial_max(KEY#26)], output=[max#47])
: +- *(1) Project [key#26]
: +- *(1) Filter (((isnotnull(KEY#26) AND isnotnull(val#27)) AND (KEY#26 = Subquery scalar-subquery#38)) AND (val#27 = 2))
: : +- Subquery scalar-subquery#38
: : +- *(2) HashAggregate(keys=[], functions=[max(KEY#28)], output=[max(KEY)#43])
: : +- Exchange SinglePartition
: : +- *(1) HashAggregate(keys=[], functions=[partial_max(KEY#28)], output=[max#49])
: : +- *(1) Project [key#28]
: : +- *(1) Filter (isnotnull(val#29) AND (val#29 > 0))
: : +- *(1) FileScan parquet default.explain_temp3[key#28,val#29] Batched: true, DataFilters: [isnotnull(val#29), (val#29 > 0)], Format: Parquet, Location: InMemoryFileIndex[file:/user/hive/warehouse/explain_temp3], PartitionFilters: [], PushedFilters: [IsNotNull(val), GreaterThan(val,0)], ReadSchema: struct<key:int,val:int>
: +- *(1) FileScan parquet default.explain_temp2[key#26,val#27] Batched: true, DataFilters: [isnotnull(key#26), isnotnull(val#27), (val#27 = 2)], Format: Parquet, Location: InMemoryFileIndex[file:/user/hive/warehouse/explain_temp2], PartitionFilters: [], PushedFilters: [IsNotNull(key), IsNotNull(val), EqualTo(val,2)], ReadSchema: struct<key:int,val:int>
+- *(1) FileScan parquet default.explain_temp1[key#2,val#3] Batched: true, DataFilters: [isnotnull(key#2), isnotnull(val#3), (val#3 > 3)], Format: Parquet, Location: InMemoryFileIndex[file:/user/hive/warehouse/explain_temp1], PartitionFilters: [], PushedFilters: [IsNotNull(key), IsNotNull(val), GreaterThan(val,3)], ReadSchema: struct<key:int,val:int>
```
New:
```
Project (3)
+- Filter (2)
+- Scan parquet default.explain_temp1 (1)
(1) Scan parquet default.explain_temp1 [codegen id : 1]
Output: [key#2, val#3]
(2) Filter [codegen id : 1]
Input : [key#2, val#3]
Condition : (((isnotnull(KEY#2) AND isnotnull(val#3)) AND (KEY#2 = Subquery scalar-subquery#23)) AND (val#3 > 3))
(3) Project [codegen id : 1]
Output : [key#2, val#3]
Input : [key#2, val#3]
===== Subqueries =====
Subquery:1 Hosting operator id = 2 Hosting Expression = Subquery scalar-subquery#23
HashAggregate (9)
+- Exchange (8)
+- HashAggregate (7)
+- Project (6)
+- Filter (5)
+- Scan parquet default.explain_temp2 (4)
(4) Scan parquet default.explain_temp2 [codegen id : 1]
Output: [key#26, val#27]
(5) Filter [codegen id : 1]
Input : [key#26, val#27]
Condition : (((isnotnull(KEY#26) AND isnotnull(val#27)) AND (KEY#26 = Subquery scalar-subquery#22)) AND (val#27 = 2))
(6) Project [codegen id : 1]
Output : [key#26]
Input : [key#26, val#27]
(7) HashAggregate [codegen id : 1]
Input: [key#26]
(8) Exchange
Input: [max#35]
(9) HashAggregate [codegen id : 2]
Input: [max#35]
Subquery:2 Hosting operator id = 5 Hosting Expression = Subquery scalar-subquery#22
HashAggregate (15)
+- Exchange (14)
+- HashAggregate (13)
+- Project (12)
+- Filter (11)
+- Scan parquet default.explain_temp3 (10)
(10) Scan parquet default.explain_temp3 [codegen id : 1]
Output: [key#28, val#29]
(11) Filter [codegen id : 1]
Input : [key#28, val#29]
Condition : (isnotnull(val#29) AND (val#29 > 0))
(12) Project [codegen id : 1]
Output : [key#28]
Input : [key#28, val#29]
(13) HashAggregate [codegen id : 1]
Input: [key#28]
(14) Exchange
Input: [max#37]
(15) HashAggregate [codegen id : 2]
Input: [max#37]
```
Note:
I opened this PR as a WIP to start getting feedback. I will be on vacation starting tomorrow
would not be able to immediately incorporate the feedback. I will start to
work on them as soon as i can. Also, currently this PR provides a basic infrastructure
for explain enhancement. The details about individual operators will be implemented
in follow-up prs
## How was this patch tested?
Added a new test `explain.sql` that tests basic scenarios. Need to add more tests.
Closes#24759 from dilipbiswal/explain_feature.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Fix the physical plan (`DescribeTableExec`) to have the same output attributes as the corresponding logical plan.
2. Remove `output` in statements since they are unresolved plans.
### Why are the changes needed?
Correctness of how output attributes should work.
### Does this PR introduce any user-facing change?
NO
### How was this patch tested?
Existing tests
Closes#25568 from imback82/describe_table.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
To follow ANSI SQL, we should support a configurable mode that throws exceptions when casting to integers causes overflow.
The behavior is similar to https://issues.apache.org/jira/browse/SPARK-26218, which throws exceptions on arithmetical operation overflow.
To unify it, the configuration is renamed from "spark.sql.arithmeticOperations.failOnOverFlow" to "spark.sql.failOnIntegerOverFlow"
## How was this patch tested?
Unit test
Closes#25461 from gengliangwang/AnsiCastIntegral.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR removes the `canonicalize(attrs: AttributeSeq)` from `PlanExpression` and taking care of normalizing expressions in `QueryPlan`.
### Why are the changes needed?
`Expression` has already a `canonicalized` method and having the `canonicalize` method in `PlanExpression` is confusing.
### Does this PR introduce any user-facing change?
Removes the `canonicalize` plan from `PlanExpression`. Also renames the `normalizeExprId` to `normalizeExpressions` in query plan.
### How was this patch tested?
This PR is a refactoring and passes the existing tests
Closes#25534 from dbaliafroozeh/ImproveCanonicalizeAPI.
Authored-by: Ali Afroozeh <ali.afroozeh@databricks.com>
Signed-off-by: herman <herman@databricks.com>
## What changes were proposed in this pull request?
Implements the SHOW TABLES logical and physical plans for data source v2 tables.
## How was this patch tested?
Added unit tests to `DataSourceV2SQLSuite`.
Closes#25247 from imback82/dsv2_show_tables.
Lead-authored-by: terryk <yuminkim@gmail.com>
Co-authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
After all the discussions in the dev list: http://apache-spark-developers-list.1001551.n3.nabble.com/Discuss-Follow-ANSI-SQL-on-table-insertion-td27531.html#a27562.
Here I propose that we can make the store assignment rules in the analyzer configurable, and the behavior of V1 and V2 should be consistent.
When inserting a value into a column with a different data type, Spark will perform type coercion. After this PR, we support 2 policies for the type coercion rules:
legacy and strict.
1. With legacy policy, Spark allows casting any value to any data type. The legacy policy is the only behavior in Spark 2.x and it is compatible with Hive.
2. With strict policy, Spark doesn't allow any possible precision loss or data truncation in type coercion, e.g. `int` and `long`, `float` -> `double` are not allowed.
Eventually, the "legacy" mode will be removed, so it is disallowed in data source V2.
To ensure backward compatibility with existing queries, the default store assignment policy for data source V1 is "legacy".
## How was this patch tested?
Unit test
Closes#25453 from gengliangwang/tableInsertRule.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Fix minor typo in SQLConf.
`FILE_COMRESSION_FACTOR` -> `FILE_COMPRESSION_FACTOR`
### Why are the changes needed?
Make conf more understandable.
### Does this PR introduce any user-facing change?
No. (`spark.sql.sources.fileCompressionFactor` is unchanged.)
### How was this patch tested?
Pass the Jenkins with the existing tests.
Closes#25538 from triplesheep/TYPO-FIX.
Authored-by: triplesheep <triplesheep0419@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR adds a simple cost model and a mechanism to compare the costs of the before and after plans of each re-optimization in Adaptive Query Execution. Now the workflow of AQE re-optimization is changed to: If the cost of the plan after re-optimization is lower than or equal to that of the plan before re-optimization and the plan has been changed after re-optimization (if equal), the current physical plan will be updated to the plan after re-optimization, otherwise it will remain unchanged until the next re-optimization.
### Why are the changes needed?
This new mechanism is to prevent regressions in Adaptive Query Execution caused by change of the plan introducing extra cost, in this PR specifically, change of SMJ to BHJ leading to extra `ShuffleExchangeExec`s.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Added UT.
Closes#25456 from maryannxue/aqe-cost.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
<!--
Thanks for sending a pull request! Here are some tips for you:
1. If this is your first time, please read our contributor guidelines: https://spark.apache.org/contributing.html
2. Ensure you have added or run the appropriate tests for your PR: https://spark.apache.org/developer-tools.html
3. If the PR is unfinished, add '[WIP]' in your PR title, e.g., '[WIP][SPARK-XXXX] Your PR title ...'.
4. Be sure to keep the PR description updated to reflect all changes.
5. Please write your PR title to summarize what this PR proposes.
6. If possible, provide a concise example to reproduce the issue for a faster review.
-->
### What changes were proposed in this pull request?
<!--
Please clarify what changes you are proposing. The purpose of this section is to outline the changes and how this PR fixes the issue.
If possible, please consider writing useful notes for better and faster reviews in your PR. See the examples below.
1. If you refactor some codes with changing classes, showing the class hierarchy will help reviewers.
2. If you fix some SQL features, you can provide some references of other DBMSes.
3. If there is design documentation, please add the link.
4. If there is a discussion in the mailing list, please add the link.
-->
The current namespace/catalog should be set to None at the beginning, so that we can read the new configs when reporting currennt namespace/catalog later.
### Why are the changes needed?
<!--
Please clarify why the changes are needed. For instance,
1. If you propose a new API, clarify the use case for a new API.
2. If you fix a bug, you can clarify why it is a bug.
-->
Fix a bug in CatalogManager, to reflect the change of default catalog config when reporting current catalog.
### Does this PR introduce any user-facing change?
<!--
If yes, please clarify the previous behavior and the change this PR proposes - provide the console output, description and/or an example to show the behavior difference if possible.
If no, write 'No'.
-->
No. The current namespace/catalog stuff is still internal right now.
### How was this patch tested?
<!--
If tests were added, say they were added here. Please make sure to add some test cases that check the changes thoroughly including negative and positive cases if possible.
If it was tested in a way different from regular unit tests, please clarify how you tested step by step, ideally copy and paste-able, so that other reviewers can test and check, and descendants can verify in the future.
If tests were not added, please describe why they were not added and/or why it was difficult to add.
-->
a new test suite
Closes#25521 from cloud-fan/fix.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Burak Yavuz <brkyvz@gmail.com>
## What changes were proposed in this pull request?
Introduces the collectInPlanAndSubqueries and subqueriesAll methods in QueryPlan that consider all the plans in the query plan, including the ones in nested subqueries.
## How was this patch tested?
Unit test added
Closes#25433 from dbaliafroozeh/IntroduceCollectInPlanAndSubqueries.
Authored-by: Ali Afroozeh <ali.afroozeh@databricks.com>
Signed-off-by: herman <herman@databricks.com>
## What changes were proposed in this pull request?
This PR adds a V1 fallback interface for writing to V2 Tables using V1 Writer interfaces. The only supported SaveMode that will be called on the target table will be an Append. The target table must use V2 interfaces such as `SupportsOverwrite` or `SupportsTruncate` to support Overwrite operations. It is up to the target DataSource implementation if this operation can be atomic or not.
We do not support dynamicPartitionOverwrite, as we cannot call a `commit` method that actually cleans up the data in the partitions that were touched through this fallback.
## How was this patch tested?
Will add tests and example implementation after comments + feedback. This is a proposal at this point.
Closes#25348 from brkyvz/v1WriteFallback.
Lead-authored-by: Burak Yavuz <brkyvz@gmail.com>
Co-authored-by: Burak Yavuz <burak@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The expression `IntegralDivide`, which corresponds to the `div` operator, support only integral type. Postgres, though, allows it to work also with decimals.
The PR adds the support to decimal operands for this operation in order to have feature parity with postgres.
## How was this patch tested?
added UTs
Closes#25136 from mgaido91/SPARK-28322.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
## What changes were proposed in this pull request?
This is a pure refactor PR, which creates a new class `CatalogManager` to track the registered v2 catalogs, and provide the catalog up functionality.
`CatalogManager` also tracks the current catalog/namespace. We will implement corresponding commands in other PRs, like `USE CATALOG my_catalog`
## How was this patch tested?
existing tests
Closes#25368 from cloud-fan/refactor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Some newer JDKs use the tzdata2018i database, which changes how certain (obscure) historical dates and timezones are handled. As previously, we can pretty much safely ignore these in tests, as the value may vary by JDK.
### Why are the changes needed?
Test otherwise fails using, for example, JDK 1.8.0_222. https://bugs.openjdk.java.net/browse/JDK-8215982 has a full list of JDKs which has this.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests
Closes#25504 from srowen/SPARK-28775.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a follow-up of #24761 which added a higher-order function `ArrayForAll`.
The PR mistakenly removed the `prettyName` from `ArrayExists` and forgot to add it to `ArrayForAll`.
### Why are the changes needed?
This reverts the `prettyName` back to `ArrayExists` not to affect explained plans, and adds it to `ArrayForAll` to clarify the `prettyName` as the same as the expressions around.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#25501 from ueshin/issues/SPARK-27905/pretty_names.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR makes analysis error messages more meaningful when the function does not support the modifier DISTINCT:
```sql
postgres=# select upper(distinct a) from (values('a'), ('b')) v(a);
ERROR: DISTINCT specified, but upper is not an aggregate function
LINE 1: select upper(distinct a) from (values('a'), ('b')) v(a);
spark-sql> select upper(distinct a) from (values('a'), ('b')) v(a);
Error in query: upper does not support the modifier DISTINCT; line 1 pos 7
spark-sql>
```
After this pr:
```sql
spark-sql> select upper(distinct a) from (values('a'), ('b')) v(a);
Error in query: DISTINCT specified, but upper is not an aggregate function; line 1 pos 7
spark-sql>
```
## How was this patch tested?
Unit test
Closes#25486 from wangyum/DISTINCT.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
**Before Fix**
When a non existent permanent function is dropped, generic NoSuchFunctionException was thrown.- which printed "This function is neither a registered temporary function nor a permanent function registered in the database" .
This creates a ambiguity when a temp function in the same name exist.
**After Fix**
NoSuchPermanentFunctionException will be thrown, which will print
"NoSuchPermanentFunctionException:Function not found in database "
## How was this patch tested?
Unit test was run and corrected the UT.
Closes#25394 from PavithraRamachandran/funcIssue.
Lead-authored-by: pavithra <pavi.rams@gmail.com>
Co-authored-by: pavithraramachandran <pavi.rams@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
## What changes were proposed in this pull request?
We add support for the V2SessionCatalog for saveAsTable, such that V2 tables can plug in and leverage existing DataFrameWriter.saveAsTable APIs to write and create tables through the session catalog.
## How was this patch tested?
Unit tests. A lot of tests broke under hive when things were not working properly under `ResolveTables`, therefore I believe the current set of tests should be sufficient in testing the table resolution and read code paths.
Closes#25402 from brkyvz/saveAsV2.
Lead-authored-by: Burak Yavuz <brkyvz@gmail.com>
Co-authored-by: Burak Yavuz <burak@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In the PR, I propose new expressions `Epoch`, `IsoYear`, `Milliseconds` and `Microseconds`, and support additional parameters of `extract()` for feature parity with PostgreSQL (https://www.postgresql.org/docs/11/functions-datetime.html#FUNCTIONS-DATETIME-EXTRACT):
1. `epoch` - the number of seconds since 1970-01-01 00:00:00 local time in microsecond precision.
2. `isoyear` - the ISO 8601 week-numbering year that the date falls in. Each ISO 8601 week-numbering year begins with the Monday of the week containing the 4th of January.
3. `milliseconds` - the seconds field including fractional parts multiplied by 1,000.
4. `microseconds` - the seconds field including fractional parts multiplied by 1,000,000.
Here are examples:
```sql
spark-sql> SELECT EXTRACT(EPOCH FROM TIMESTAMP '2019-08-11 19:07:30.123456');
1565550450.123456
spark-sql> SELECT EXTRACT(ISOYEAR FROM DATE '2006-01-01');
2005
spark-sql> SELECT EXTRACT(MILLISECONDS FROM TIMESTAMP '2019-08-11 19:07:30.123456');
30123.456
spark-sql> SELECT EXTRACT(MICROSECONDS FROM TIMESTAMP '2019-08-11 19:07:30.123456');
30123456
```
## How was this patch tested?
Added new tests to `DateExpressionsSuite`, and uncommented existing tests in `extract.sql` and `pgSQL/date.sql`.
Closes#25408 from MaxGekk/extract-ext3.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr adds DELETE support for V2 datasources. As a first step, this pr only support delete by source filters:
```scala
void delete(Filter[] filters);
```
which could not deal with complicated cases like subqueries.
Since it's uncomfortable to embed the implementation of DELETE in the current V2 APIs, a new mix-in of datasource is added, which is called `SupportsMaintenance`, similar to `SupportsRead` and `SupportsWrite`. A datasource which can be maintained means we can perform DELETE/UPDATE/MERGE/OPTIMIZE on the datasource, as long as the datasource implements the necessary mix-ins.
## How was this patch tested?
new test case.
Please review https://spark.apache.org/contributing.html before opening a pull request.
Closes#25115 from xianyinxin/SPARK-28351.
Authored-by: xy_xin <xianyin.xxy@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Here is the problem description from the JIRA.
```
When the inputs contain the constant 'infinity', Spark SQL does not generate the expected results.
SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
FROM (VALUES ('1'), (CAST('infinity' AS DOUBLE))) v(x);
SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
FROM (VALUES ('infinity'), ('1')) v(x);
SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
FROM (VALUES ('infinity'), ('infinity')) v(x);
SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
FROM (VALUES ('-infinity'), ('infinity')) v(x);
The root cause: Spark SQL does not recognize the special constants in a case insensitive way. In PostgreSQL, they are recognized in a case insensitive way.
Link: https://www.postgresql.org/docs/9.3/datatype-numeric.html
```
In this PR, the casting code is enhanced to handle these `special` string literals in case insensitive manner.
## How was this patch tested?
Added tests in CastSuite and modified existing test suites.
Closes#25331 from dilipbiswal/double_infinity.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Changed type of `sec` argument in the `make_timestamp()` function from `DOUBLE` to `DECIMAL(8, 6)`. The scale is set to 6 to cover microsecond fractions, and the precision is 2 digits for seconds + 6 digits for microsecond fraction. New type prevents losing precision in some cases, for example:
Before:
```sql
spark-sql> select make_timestamp(2019, 8, 12, 0, 0, 58.000001);
2019-08-12 00:00:58
```
After:
```sql
spark-sql> select make_timestamp(2019, 8, 12, 0, 0, 58.000001);
2019-08-12 00:00:58.000001
```
Also switching to `DECIMAL` fixes rounding `sec` towards "nearest neighbor" unless both neighbors are equidistant, in which case round up. For example:
Before:
```sql
spark-sql> select make_timestamp(2019, 8, 12, 0, 0, 0.1234567);
2019-08-12 00:00:00.123456
```
After:
```sql
spark-sql> select make_timestamp(2019, 8, 12, 0, 0, 0.1234567);
2019-08-12 00:00:00.123457
```
## How was this patch tested?
This was tested by `DateExpressionsSuite` and `pgSQL/timestamp.sql`.
Closes#25421 from MaxGekk/make_timestamp-decimal.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
In the PR, I propose additional synonyms for the `field` argument of `extract` supported by PostgreSQL. The `extract.sql` is updated to check all supported values of the `field` argument. The list of synonyms was taken from https://github.com/postgres/postgres/blob/master/src/backend/utils/adt/datetime.c .
## How was this patch tested?
By running `extract.sql` via:
```
$ build/sbt "sql/test-only *SQLQueryTestSuite -- -z extract.sql"
```
Closes#25438 from MaxGekk/extract-field-synonyms.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
A GROUPED_AGG pandas python udf can't work, if without group by clause, like `select udf(id) from table`.
This doesn't match with aggregate function like sum, count..., and also dataset API like `df.agg(udf(df['id']))`.
When we parse a udf (or an aggregate function) like that from SQL syntax, it is known as a function in a project. `GlobalAggregates` rule in analysis makes such project as aggregate, by looking for aggregate expressions. At the moment, we should also look for GROUPED_AGG pandas python udf.
## How was this patch tested?
Added tests.
Closes#25352 from viirya/SPARK-28422.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
#25242 proposed to disallow upcasting complex data types to string type, however, upcasting from null type to any types should still be safe.
## How was this patch tested?
Add corresponding case in `CastSuite`.
Closes#25425 from jiangxb1987/nullToString.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR replaces `CatalogUtils.maskCredentials` with `SQLConf.get.redactOptions` to match other redacts.
## How was this patch tested?
unit test and manual tests:
Before this PR:
```sql
spark-sql> DESC EXTENDED test_spark_28675;
id int NULL
# Detailed Table Information
Database default
Table test_spark_28675
Owner root
Created Time Fri Aug 09 08:23:17 GMT-07:00 2019
Last Access Wed Dec 31 17:00:00 GMT-07:00 1969
Created By Spark 3.0.0-SNAPSHOT
Type MANAGED
Provider org.apache.spark.sql.jdbc
Location file:/user/hive/warehouse/test_spark_28675
Serde Library org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat org.apache.hadoop.mapred.SequenceFileInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
Storage Properties [url=###, driver=com.mysql.jdbc.Driver, dbtable=test_spark_28675]
spark-sql> SHOW TABLE EXTENDED LIKE 'test_spark_28675';
default test_spark_28675 false Database: default
Table: test_spark_28675
Owner: root
Created Time: Fri Aug 09 08:23:17 GMT-07:00 2019
Last Access: Wed Dec 31 17:00:00 GMT-07:00 1969
Created By: Spark 3.0.0-SNAPSHOT
Type: MANAGED
Provider: org.apache.spark.sql.jdbc
Location: file:/user/hive/warehouse/test_spark_28675
Serde Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.SequenceFileInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
Storage Properties: [url=###, driver=com.mysql.jdbc.Driver, dbtable=test_spark_28675]
Schema: root
|-- id: integer (nullable = true)
```
After this PR:
```sql
spark-sql> DESC EXTENDED test_spark_28675;
id int NULL
# Detailed Table Information
Database default
Table test_spark_28675
Owner root
Created Time Fri Aug 09 08:19:49 GMT-07:00 2019
Last Access Wed Dec 31 17:00:00 GMT-07:00 1969
Created By Spark 3.0.0-SNAPSHOT
Type MANAGED
Provider org.apache.spark.sql.jdbc
Location file:/user/hive/warehouse/test_spark_28675
Serde Library org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat org.apache.hadoop.mapred.SequenceFileInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
Storage Properties [url=*********(redacted), driver=com.mysql.jdbc.Driver, dbtable=test_spark_28675]
spark-sql> SHOW TABLE EXTENDED LIKE 'test_spark_28675';
default test_spark_28675 false Database: default
Table: test_spark_28675
Owner: root
Created Time: Fri Aug 09 08:19:49 GMT-07:00 2019
Last Access: Wed Dec 31 17:00:00 GMT-07:00 1969
Created By: Spark 3.0.0-SNAPSHOT
Type: MANAGED
Provider: org.apache.spark.sql.jdbc
Location: file:/user/hive/warehouse/test_spark_28675
Serde Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.SequenceFileInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
Storage Properties: [url=*********(redacted), driver=com.mysql.jdbc.Driver, dbtable=test_spark_28675]
Schema: root
|-- id: integer (nullable = true)
```
Closes#25395 from wangyum/SPARK-28675.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
In the PR, I propose new expressions `Millennium`, `Century` and `Decade`, and support additional parameters of `extract()` for feature parity with PostgreSQL (https://www.postgresql.org/docs/11/functions-datetime.html#FUNCTIONS-DATETIME-EXTRACT):
1. `millennium` - the current millennium for given date (or a timestamp implicitly casted to a date). For example, years in the 1900s are in the second millennium. The third millennium started _January 1, 2001_.
2. `century` - the current millennium for given date (or timestamp). The first century starts at 0001-01-01 AD.
3. `decade` - the current decade for given date (or timestamp). Actually, this is the year field divided by 10.
Here are examples:
```sql
spark-sql> SELECT EXTRACT(MILLENNIUM FROM DATE '1981-01-19');
2
spark-sql> SELECT EXTRACT(CENTURY FROM DATE '1981-01-19');
20
spark-sql> SELECT EXTRACT(DECADE FROM DATE '1981-01-19');
198
```
## How was this patch tested?
Added new tests to `DateExpressionsSuite` and uncommented existing tests in `pgSQL/date.sql`.
Closes#25388 from MaxGekk/extract-ext2.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Right now, batch DataFrame always changes the schema to nullable automatically (See this line: 325bc8e9c6/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSource.scala (L399)). But streaming file source is missing this.
This PR updates the streaming file source schema to force it be nullable. I also added a flag `spark.sql.streaming.fileSource.schema.forceNullable` to disable this change since some users may rely on the old behavior.
## How was this patch tested?
The new unit test.
Closes#25382 from zsxwing/SPARK-28651.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
I propose new levels of truncations for the `date_trunc()` and `trunc()` functions:
1. `MICROSECOND` and `MILLISECOND` truncate values of the `TIMESTAMP` type to microsecond and millisecond precision.
2. `DECADE`, `CENTURY` and `MILLENNIUM` truncate dates/timestamps to lowest date of current decade/century/millennium.
Also the `WEEK` and `QUARTER` levels have been supported by the `trunc()` function.
The function is implemented similarly to `date_trunc` in PostgreSQL: https://www.postgresql.org/docs/11/functions-datetime.html#FUNCTIONS-DATETIME-TRUNC to maintain feature parity with it.
Here are examples of `TRUNC`:
```sql
spark-sql> SELECT TRUNC('2015-10-27', 'DECADE');
2010-01-01
spark-sql> set spark.sql.datetime.java8API.enabled=true;
spark.sql.datetime.java8API.enabled true
spark-sql> SELECT TRUNC('1999-10-27', 'millennium');
1001-01-01
```
Examples of `DATE_TRUNC`:
```sql
spark-sql> SELECT DATE_TRUNC('CENTURY', '2015-03-05T09:32:05.123456');
2001-01-01T00:00:00Z
```
## How was this patch tested?
Added new tests to `DateTimeUtilsSuite`, `DateExpressionsSuite` and `DateFunctionsSuite`, and uncommented existing tests in `pgSQL/date.sql`.
Closes#25336 from MaxGekk/date_truct-ext.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Adds checks around:
- The existence of transforms in the table schema (even in nested fields)
- Duplications of transforms
- Case sensitivity checks around column names
in the V2 table creation code paths.
## How was this patch tested?
Unit tests.
Closes#25305 from brkyvz/v2CreateTable.
Authored-by: Burak Yavuz <brkyvz@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR makes `spark.sql.function.preferIntegralDivision` to internal configuration because it is only used for PostgreSQL test cases.
More details:
https://github.com/apache/spark/pull/25158#discussion_r309764541
## How was this patch tested?
N/A
Closes#25376 from wangyum/SPARK-28395-2.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In `Catalogs.load`, the `pluginClassName` in the following code
```
String pluginClassName = conf.getConfString("spark.sql.catalog." + name, null);
```
is always null for built-in catalogs, e.g there is a SQLConf entry `spark.sql.catalog.session`.
This is because of https://github.com/apache/spark/pull/18852: SQLConf.conf.getConfString(key, null) always returns null.
## How was this patch tested?
Apply code changes of https://github.com/apache/spark/pull/24768 and tried loading session catalog.
Closes#25094 from gengliangwang/fixCatalogLoad.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Burak Yavuz <brkyvz@gmail.com>
## What changes were proposed in this pull request?
The flag `spark.sql.decimalOperations.nullOnOverflow` is not honored by the `Cast` operator. This means that a casting which causes an overflow currently returns `null`.
The PR makes `Cast` respecting that flag, ie. when it is turned to false and a decimal overflow occurs, an exception id thrown.
## How was this patch tested?
Added UT
Closes#25253 from mgaido91/SPARK-28470.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
## What changes were proposed in this pull request?
Sometimes when you explain a query, you will get stuck for a while. What's worse, you will get stuck again if you explain again.
This is caused by `FileSourceScanExec`:
1. In its `toString`, it needs to report the number of partitions it reads. This needs to query the hive metastore.
2. In its `outputOrdering`, it needs to get all the files. This needs to query the hive metastore.
This PR fixes by:
1. `toString` do not need to report the number of partitions it reads. We should report it via SQL metrics.
2. The `outputOrdering` is not very useful. We can only apply it if a) all the bucket columns are read. b) there is only one file in each bucket. This condition is really hard to meet, and even if we meet, sorting an already sorted file is pretty fast and avoiding the sort is not that useful. I think it's worth to give up this optimization so that explain don't need to get stuck.
## How was this patch tested?
existing tests
Closes#25328 from cloud-fan/ui.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Implements the `DESCRIBE TABLE` logical and physical plans for data source v2 tables.
## How was this patch tested?
Added unit tests to `DataSourceV2SQLSuite`.
Closes#25040 from mccheah/describe-table-v2.
Authored-by: mcheah <mcheah@palantir.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Add's the higher order function `forall`, which tests an array to see if a predicate holds for every element.
The function is implemented in `org.apache.spark.sql.catalyst.expressions.ArrayForAll`.
The function is added to the function registry under the pretty name `forall`.
## How was this patch tested?
I've added appropriate unit tests for the new ArrayForAll expression in
`sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/HigherOrderFunctionsSuite.scala`.
Also added tests for the function in `sql/core/src/test/scala/org/apache/spark/sql/DataFrameFunctionsSuite.scala`.
Not sure who is best to ask about this PR so:
HyukjinKwon rxin gatorsmile ueshin srowen hvanhovell gatorsmile
Closes#24761 from nvander1/feature/for_all.
Lead-authored-by: Nik Vanderhoof <nikolasrvanderhoof@gmail.com>
Co-authored-by: Nik <nikolasrvanderhoof@gmail.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
## What changes were proposed in this pull request?
In the PR, I propose to use existing expressions `DayOfYear`, `WeekDay` and `DayOfWeek`, and support additional parameters of `extract()` for feature parity with PostgreSQL (https://www.postgresql.org/docs/11/functions-datetime.html#FUNCTIONS-DATETIME-EXTRACT):
1. `dow` - the day of the week as Sunday (0) to Saturday (6)
2. `isodow` - the day of the week as Monday (1) to Sunday (7)
3. `doy` - the day of the year (1 - 365/366)
Here are examples:
```sql
spark-sql> SELECT EXTRACT(DOW FROM TIMESTAMP '2001-02-16 20:38:40');
5
spark-sql> SELECT EXTRACT(ISODOW FROM TIMESTAMP '2001-02-18 20:38:40');
7
spark-sql> SELECT EXTRACT(DOY FROM TIMESTAMP '2001-02-16 20:38:40');
47
```
## How was this patch tested?
Updated `extract.sql`.
Closes#25367 from MaxGekk/extract-ext.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR targets to rename `PullOutPythonUDFInJoinCondition` to `ExtractPythonUDFFromJoinCondition` and move to 'Extract Python UDFs' together with other Python UDF related rules.
Currently `PullOutPythonUDFInJoinCondition` rule is alone outside of other 'Extract Python UDFs' rules together.
and the name `ExtractPythonUDFFromJoinCondition` is matched to existing Python UDF extraction rules.
## How was this patch tested?
Existing tests should cover.
Closes#25358 from HyukjinKwon/move-python-join-rule.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This patch tries to keep consistency whenever UTF-8 charset is needed, as using `StandardCharsets.UTF_8` instead of using "UTF-8". If the String type is needed, `StandardCharsets.UTF_8.name()` is used.
This change also brings the benefit of getting rid of `UnsupportedEncodingException`, as we're providing `Charset` instead of `String` whenever possible.
This also changes some private Catalyst helper methods to operate on encodings as `Charset` objects rather than strings.
## How was this patch tested?
Existing unit tests.
Closes#25335 from HeartSaVioR/SPARK-28601.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This is an alternative solution of https://github.com/apache/spark/pull/24442 . It fails the query if ambiguous self join is detected, instead of trying to disambiguate it. The problem is that, it's hard to come up with a reasonable rule to disambiguate, the rule proposed by #24442 is mostly a heuristic.
### background of the self-join problem:
This is a long-standing bug and I've seen many people complaining about it in JIRA/dev list.
A typical example:
```
val df1 = …
val df2 = df1.filter(...)
df1.join(df2, df1("a") > df2("a")) // returns empty result
```
The root cause is, `Dataset.apply` is so powerful that users think it returns a column reference which can point to the column of the Dataset at anywhere. This is not true in many cases. `Dataset.apply` returns an `AttributeReference` . Different Datasets may share the same `AttributeReference`. In the example above, `df2` adds a Filter operator above the logical plan of `df1`, and the Filter operator reserves the output `AttributeReference` of its child. This means, `df1("a")` is exactly the same as `df2("a")`, and `df1("a") > df2("a")` always evaluates to false.
### The rule to detect ambiguous column reference caused by self join:
We can reuse the infra in #24442 :
1. each Dataset has a globally unique id.
2. the `AttributeReference` returned by `Dataset.apply` carries the ID and column position(e.g. 3rd column of the Dataset) via metadata.
3. the logical plan of a `Dataset` carries the ID via `TreeNodeTag`
When self-join happens, the analyzer asks the right side plan of join to re-generate output attributes with new exprIds. Based on it, a simple rule to detect ambiguous self join is:
1. find all column references (i.e. `AttributeReference`s with Dataset ID and col position) in the root node of a query plan.
2. for each column reference, traverse the query plan tree, find a sub-plan that carries Dataset ID and the ID is the same as the one in the column reference.
3. get the corresponding output attribute of the sub-plan by the col position in the column reference.
4. if the corresponding output attribute has a different exprID than the column reference, then it means this sub-plan is on the right side of a self-join and has regenerated its output attributes. This is an ambiguous self join because the column reference points to a table being self-joined.
## How was this patch tested?
existing tests and new test cases
Closes#25107 from cloud-fan/new-self-join.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This adds an interface for catalog plugins that exposes namespace operations:
* `listNamespaces`
* `namespaceExists`
* `loadNamespaceMetadata`
* `createNamespace`
* `alterNamespace`
* `dropNamespace`
## How was this patch tested?
API only. Existing tests for regressions.
Closes#24560 from rdblue/SPARK-27661-add-catalog-namespace-api.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Burak Yavuz <brkyvz@gmail.com>
## What changes were proposed in this pull request?
Explained why "Subquery" and "Join Reorder" optimization batches should be `FixedPoint(1)`, which was introduced in SPARK-28532 and SPARK-28530.
## How was this patch tested?
Existing UTs.
Closes#25320 from yeshengm/SPARK-28530-followup.
Lead-authored-by: Xiao Li <gatorsmile@gmail.com>
Co-authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
See discussion on the JIRA (and dev). At heart, we find that math.log and math.pow can actually return slightly different results across platforms because of hardware optimizations. For the actual SQL log and pow functions, I propose that we should use StrictMath instead to ensure the answers are already the same. (This should have the benefit of helping tests pass on aarch64.)
Further, the atanh function (which is not part of java.lang.Math) can be implemented in a slightly different and more accurate way.
## How was this patch tested?
Existing tests (which will need to be changed).
Some manual testing locally to understand the numeric issues.
Closes#25279 from srowen/SPARK-28519.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
When PythonUDF is used in group by, and it is also in aggregate expression, like
```
SELECT pyUDF(a + 1), COUNT(b) FROM testData GROUP BY pyUDF(a + 1)
```
It causes analysis exception in `CheckAnalysis`, like
```
org.apache.spark.sql.AnalysisException: expression 'testdata.`a`' is neither present in the group by, nor is it an aggregate function.
```
First, `CheckAnalysis` can't check semantic equality between PythonUDFs.
Second, even we make it possible, runtime exception will be thrown
```
org.apache.spark.sql.catalyst.errors.package$TreeNodeException: Binding attribute, tree: pythonUDF1#8615
...
Cause: java.lang.RuntimeException: Couldn't find pythonUDF1#8615 in [cast(pythonUDF0#8614 as int)#8617,count(b#8599)#8607L]
```
The cause is, `ExtractPythonUDFs` extracts both PythonUDFs in group by and aggregate expression. The PythonUDFs are two different aliases now in the logical aggregate. In runtime, we can't bind the resulting expression in aggregate to its grouping and aggregate attributes.
This patch proposes a rule `ExtractGroupingPythonUDFFromAggregate` to extract PythonUDFs in group by and evaluate them before aggregate. We replace the group by PythonUDF in aggregate expression with aliased result.
The query plan of query `SELECT pyUDF(a + 1), pyUDF(COUNT(b)) FROM testData GROUP BY pyUDF(a + 1)`, like
```
== Optimized Logical Plan ==
Project [CAST(pyUDF(cast((a + 1) as string)) AS INT)#8608, cast(pythonUDF0#8616 as bigint) AS CAST(pyUDF(cast(count(b) as string)) AS BIGINT)#8610L]
+- BatchEvalPython [pyUDF(cast(agg#8613L as string))], [pythonUDF0#8616]
+- Aggregate [cast(groupingPythonUDF#8614 as int)], [cast(groupingPythonUDF#8614 as int) AS CAST(pyUDF(cast((a + 1) as string)) AS INT)#8608, count(b#8599) AS agg#8613L]
+- Project [pythonUDF0#8615 AS groupingPythonUDF#8614, b#8599]
+- BatchEvalPython [pyUDF(cast((a#8598 + 1) as string))], [pythonUDF0#8615]
+- LocalRelation [a#8598, b#8599]
== Physical Plan ==
*(3) Project [CAST(pyUDF(cast((a + 1) as string)) AS INT)#8608, cast(pythonUDF0#8616 as bigint) AS CAST(pyUDF(cast(count(b) as string)) AS BIGINT)#8610L]
+- BatchEvalPython [pyUDF(cast(agg#8613L as string))], [pythonUDF0#8616]
+- *(2) HashAggregate(keys=[cast(groupingPythonUDF#8614 as int)#8617], functions=[count(b#8599)], output=[CAST(pyUDF(cast((a + 1) as string)) AS INT)#8608, agg#8613L])
+- Exchange hashpartitioning(cast(groupingPythonUDF#8614 as int)#8617, 5), true
+- *(1) HashAggregate(keys=[cast(groupingPythonUDF#8614 as int) AS cast(groupingPythonUDF#8614 as int)#8617], functions=[partial_count(b#8599)], output=[cast(groupingPythonUDF#8614 as int)#8617, count#8619L])
+- *(1) Project [pythonUDF0#8615 AS groupingPythonUDF#8614, b#8599]
+- BatchEvalPython [pyUDF(cast((a#8598 + 1) as string))], [pythonUDF0#8615]
+- LocalTableScan [a#8598, b#8599]
```
## How was this patch tested?
Added tests.
Closes#25215 from viirya/SPARK-28445.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
```sql
spark-sql> select cast(1);
19/07/26 00:54:17 ERROR SparkSQLDriver: Failed in [select cast(1)]
java.lang.UnsupportedOperationException: empty.init
at scala.collection.TraversableLike$class.init(TraversableLike.scala:451)
at scala.collection.mutable.ArrayOps$ofInt.scala$collection$IndexedSeqOptimized$$super$init(ArrayOps.scala:234)
at scala.collection.IndexedSeqOptimized$class.init(IndexedSeqOptimized.scala:135)
at scala.collection.mutable.ArrayOps$ofInt.init(ArrayOps.scala:234)
at org.apache.spark.sql.catalyst.analysis.FunctionRegistry$$anonfun$7$$anonfun$11.apply(FunctionRegistry.scala:565)
at org.apache.spark.sql.catalyst.analysis.FunctionRegistry$$anonfun$7$$anonfun$11.apply(FunctionRegistry.scala:558)
at scala.Option.getOrElse(Option.scala:121)
```
The reason is that we did not handle the case [`validParametersCount.length == 0`](2d74f14d74/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/FunctionRegistry.scala (L588)) because the [parameter types](2d74f14d74/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/FunctionRegistry.scala (L589)) can be `Expression`, `DataType` and `Option`. This PR makes it handle the case `validParametersCount.length == 0`.
## How was this patch tested?
unit tests
Closes#25261 from wangyum/SPARK-28521.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
When an overflow occurs performing an arithmetic operation, we are returning an incorrect value. Instead, we should throw an exception, as stated in the SQL standard.
## How was this patch tested?
added UT + existing UTs (improved)
Closes#21599 from mgaido91/SPARK-24598.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR moves `replaceFunctionName(usage: String, functionName: String)`
from `DescribeFunctionCommand` to `ExpressionInfo` in order to make `ExpressionInfo` returns actual name instead of placeholder. We can get `ExpressionInfo`s directly through `SessionCatalog.lookupFunctionInfo` API and get the real names.
## How was this patch tested?
unit tests
Closes#25314 from wangyum/SPARK-28581.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR aims to support ANSI SQL `Boolean-Predicate` syntax.
```sql
expression IS [NOT] TRUE
expression IS [NOT] FALSE
expression IS [NOT] UNKNOWN
```
There are some mainstream database support this syntax.
- **PostgreSQL:** https://www.postgresql.org/docs/9.1/functions-comparison.html
- **Hive:** https://issues.apache.org/jira/browse/HIVE-13583
- **Redshift:** https://docs.aws.amazon.com/redshift/latest/dg/r_Boolean_type.html
- **Vertica:** https://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/SQLReferenceManual/LanguageElements/Predicates/Boolean-predicate.htm
For example:
```sql
spark-sql> select null is true, null is not true;
false true
spark-sql> select false is true, false is not true;
false true
spark-sql> select true is true, true is not true;
true false
spark-sql> select null is false, null is not false;
false true
spark-sql> select false is false, false is not false;
true false
spark-sql> select true is false, true is not false;
false true
spark-sql> select null is unknown, null is not unknown;
true false
spark-sql> select false is unknown, false is not unknown;
false true
spark-sql> select true is unknown, true is not unknown;
false true
```
**Note**: A null input is treated as the logical value "unknown".
## How was this patch tested?
Pass the Jenkins with the newly added test cases.
Closes#25074 from beliefer/ansi-sql-boolean-test.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR makes the optimizer rule PullupCorrelatedPredicates idempotent.
## How was this patch tested?
A new test PullupCorrelatedPredicatesSuite
Closes#25268 from dilipbiswal/pr-25164.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
New function `make_timestamp()` takes 6 columns `year`, `month`, `day`, `hour`, `min`, `sec` + optionally `timezone`, and makes new column of the `TIMESTAMP` type. If values in the input columns are `null` or out of valid ranges, the function returns `null`. Valid ranges are:
- `year` - `[1, 9999]`
- `month` - `[1, 12]`
- `day` - `[1, 31]`
- `hour` - `[0, 23]`
- `min` - `[0, 59]`
- `sec` - `[0, 60]`. If the `sec` argument equals to 60, the seconds field is set to 0 and 1 minute is added to the final timestamp.
- `timezone` - an identifier of timezone. Actual database of timezones can be found there: https://www.iana.org/time-zones.
Also constructed timestamp must be valid otherwise `make_timestamp` returns `null`.
The function is implemented similarly to `make_timestamp` in PostgreSQL: https://www.postgresql.org/docs/11/functions-datetime.html to maintain feature parity with it.
Here is an example:
```sql
select make_timestamp(2014, 12, 28, 6, 30, 45.887);
2014-12-28 06:30:45.887
select make_timestamp(2014, 12, 28, 6, 30, 45.887, 'CET');
2014-12-28 10:30:45.887
select make_timestamp(2019, 6, 30, 23, 59, 60)
2019-07-01 00:00:00
```
Returned value has Spark Catalyst type `TIMESTAMP` which is similar to Oracle's `TIMESTAMP WITH LOCAL TIME ZONE` (see https://docs.oracle.com/cd/B28359_01/server.111/b28298/ch4datetime.htm#i1006169) where data is stored in the session time zone, and the time zone offset is not stored as part of the column data. When users retrieve the data, Spark returns it in the session time zone specified by the SQL config `spark.sql.session.timeZone`.
## How was this patch tested?
Added new tests to `DateExpressionsSuite`, and uncommented a test for `make_timestamp` in `pgSQL/timestamp.sql`.
Closes#25220 from MaxGekk/make_timestamp.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
These are what I found during working on #22282.
- Remove unused value: `UnsafeArraySuite#defaultTz`
- Remove redundant new modifier to the case class, `KafkaSourceRDDPartition`
- Remove unused variables from `RDD.scala`
- Remove trailing space from `structured-streaming-kafka-integration.md`
- Remove redundant parameter from `ArrowConvertersSuite`: `nullable` is `true` by default.
- Remove leading empty line: `UnsafeRow`
- Remove trailing empty line: `KafkaTestUtils`
- Remove unthrown exception type: `UnsafeMapData`
- Replace unused declarations: `expressions`
- Remove duplicated default parameter: `AnalysisErrorSuite`
- `ObjectExpressionsSuite`: remove duplicated parameters, conversions and unused variable
Closes#25251 from dongjinleekr/cleanup/201907.
Authored-by: Lee Dongjin <dongjin@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR aims to add a SQL function alias `random` to the existing `rand` function.
Please note that this adds the alias to SQL layer only because this is for PostgreSQL feature parity.
- [PostgreSQL Random function](https://www.postgresql.org/docs/11/functions-math.html)
- [SPARK-23160 Port window.sql](https://github.com/apache/spark/pull/24881/files#diff-14489bae6b27814d4cde0456a7ae75c8R702)
- [SPARK-28406 Port union.sql](https://github.com/apache/spark/pull/25163/files#diff-23a3430e0e1ff88830cbb43701da1f2cR402)
## How was this patch tested?
Manual.
```sql
spark-sql> DESCRIBE FUNCTION random;
Function: random
Class: org.apache.spark.sql.catalyst.expressions.Rand
Usage: random([seed]) - Returns a random value with independent and identically distributed (i.i.d.) uniformly distributed values in [0, 1).
```
Closes#25282 from dongjoon-hyun/SPARK-28086.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In the PR, I propose to use `uuuu` for years instead of `yyyy` in date/timestamp patterns without the era pattern `G` (https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html). **Parsing/formatting of positive years (current era) will be the same.** The difference is in formatting negative years belong to previous era - BC (Before Christ).
I replaced the `yyyy` pattern by `uuuu` everywhere except:
1. Test, Suite & Benchmark. Existing tests must work as is.
2. `SimpleDateFormat` because it doesn't support the `uuuu` pattern.
3. Comments and examples (except comments related to already replaced patterns).
Before the changes, the year of common era `100` and the year of BC era `-99`, showed similarly as `100`. After the changes negative years will be formatted with the `-` sign.
Before:
```Scala
scala> Seq(java.time.LocalDate.of(-99, 1, 1)).toDF().show
+----------+
| value|
+----------+
|0100-01-01|
+----------+
```
After:
```Scala
scala> Seq(java.time.LocalDate.of(-99, 1, 1)).toDF().show
+-----------+
| value|
+-----------+
|-0099-01-01|
+-----------+
```
## How was this patch tested?
By existing test suites, and added tests for negative years to `DateFormatterSuite` and `TimestampFormatterSuite`.
Closes#25230 from MaxGekk/year-pattern-uuuu.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR add support typed `interval` expression:
```sql
spark-sql> select interval 'interval 3 year 1 hour';
interval 3 years 1 hours
spark-sql>
```
Please note that this pr did not add a cast alias for `interval` type like [other types](2d74f14d74/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/FunctionRegistry.scala (L529-L541)) because neither PostgreSQL nor Hive supports this syntax.
## How was this patch tested?
unit tests
Closes#25241 from wangyum/SPARK-28424.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Since for AQP the cost for joins can change between multiple runs, there is no reason that we have an idempotence enforcement on this optimizer batch. We thus make it `FixedPoint(1)` instead of `Once`.
## How was this patch tested?
Existing UTs.
Closes#25266 from yeshengm/SPARK-28530.
Lead-authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In the Catalyst optimizer, the batch subquery actually calls the optimizer recursively. Therefore it makes no sense to enforce idempotence on it and we change this batch to `FixedPoint(1)`.
## How was this patch tested?
Existing UTs.
Closes#25267 from yeshengm/SPARK-28532.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In SPARK-15370, We checked the expression at the root of the correlated subquery, in order to fix count bug. If a `PythonUDF` in in the checking path, evaluating it causes the failure as we can't statically evaluate `PythonUDF`. The Python UDF test added at SPARK-28277 shows this issue.
If we can statically evaluate the expression, we intercept NULL values coming from the outer join and replace them with the value that the subquery's expression like before, if it is not, we replace them with the `PythonUDF` expression, with statically evaluated parameters.
After this, the last query in `udf-except.sql` which throws `java.lang.UnsupportedOperationException` can be run:
```
SELECT t1.k
FROM t1
WHERE t1.v <= (SELECT udf(max(udf(t2.v)))
FROM t2
WHERE udf(t2.k) = udf(t1.k))
MINUS
SELECT t1.k
FROM t1
WHERE udf(t1.v) >= (SELECT min(udf(t2.v))
FROM t2
WHERE t2.k = t1.k)
-- !query 2 schema
struct<k:string>
-- !query 2 output
two
```
Note that this issue is also for other non-foldable expressions, like rand. As like PythonUDF, we can't call `eval` on this kind of expressions in optimization. The evaluation needs to defer to query runtime.
## How was this patch tested?
Added tests.
Closes#25204 from viirya/SPARK-28441.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In adaptive query processing (AQE), query plans are optimized on the fly during execution. However, a few `Once` rules can be problematic for such optimization since they can either generate wrong plan/unnecessary intermediate plan nodes.
This PR enforces idempotence for "Once" batches that are supposed to run once. This is a key enabler for AQE re-optimization and can improve robustness for existing optimizer rules.
Once batches that are currently not idempotent are marked in a blacklist. We will submit followup PRs to fix idempotence of these rules.
## How was this patch tested?
Existing UTs. Failing Once rules are temporarily blacklisted.
Closes#25249 from yeshengm/idempotence-checker.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Support multiple catalogs in the following InsertTable use cases:
- INSERT INTO [TABLE] catalog.db.tbl
- INSERT OVERWRITE TABLE catalog.db.tbl
Support matrix:
Overwrite|Partitioned Table|Partition Clause |Partition Overwrite Mode|Action
---------|-----------------|-----------------|------------------------|-----
false|*|*|*|AppendData
true|no|(empty)|*|OverwriteByExpression(true)
true|yes|p1,p2 or p1 or p2 or (empty)|STATIC|OverwriteByExpression(true)
true|yes|p2,p2 or p1 or p2 or (empty)|DYNAMIC|OverwritePartitionsDynamic
true|yes|p1=23,p2=3|*|OverwriteByExpression(p1=23 and p2=3)
true|yes|p1=23,p2 or p1=23|STATIC|OverwriteByExpression(p1=23)
true|yes|p1=23,p2 or p1=23|DYNAMIC|OverwritePartitionsDynamic
Notes:
- Assume the partitioned table has 2 partitions: p1 and p2.
- `STATIC` is the default Partition Overwrite Mode for data source tables.
- DSv2 tables currently do not support `IfPartitionNotExists`.
## How was this patch tested?
New tests.
All existing catalyst and sql/core tests.
Closes#24832 from jzhuge/SPARK-27845-pr.
Lead-authored-by: Ryan Blue <blue@apache.org>
Co-authored-by: John Zhuge <jzhuge@apache.org>
Signed-off-by: Burak Yavuz <brkyvz@gmail.com>
## What changes were proposed in this pull request?
In the current implementation. complex types like Array/Map/StructType are allowed to upcast as StringType.
This is not safe casting. We should disallow it.
## How was this patch tested?
Update the existing test case
Closes#25242 from gengliangwang/fixUpCastStringType.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/7355 add support casting between IntervalType and StringType for scala interface:
```scala
import org.apache.spark.sql.types._
import org.apache.spark.sql.catalyst.expressions._
Cast(Literal("interval 3 month 1 hours"), CalendarIntervalType).eval()
res0: Any = interval 3 months 1 hours
```
But SQL interface does not support it:
```sql
scala> spark.sql("SELECT CAST('interval 3 month 1 hour' AS interval)").show
org.apache.spark.sql.catalyst.parser.ParseException:
DataType interval is not supported.(line 1, pos 41)
== SQL ==
SELECT CAST('interval 3 month 1 hour' AS interval)
-----------------------------------------^^^
at org.apache.spark.sql.catalyst.parser.AstBuilder.$anonfun$visitPrimitiveDataType$1(AstBuilder.scala:1931)
at org.apache.spark.sql.catalyst.parser.ParserUtils$.withOrigin(ParserUtils.scala:108)
at org.apache.spark.sql.catalyst.parser.AstBuilder.visitPrimitiveDataType(AstBuilder.scala:1909)
at org.apache.spark.sql.catalyst.parser.AstBuilder.visitPrimitiveDataType(AstBuilder.scala:52)
...
```
This PR add supports accepting the `interval` keyword in the schema string. So that SQL interface can support this feature.
## How was this patch tested?
unit tests
Closes#25189 from wangyum/SPARK-28435.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
query plan was designed to be immutable, but sometimes we do allow it to carry mutable states, because of the complexity of the SQL system. One example is `TreeNodeTag`. It's a state of `TreeNode` and can be carried over during copy and transform. The adaptive execution framework relies on it to link the logical and physical plans.
This leads to a problem: when we get `QueryExecution#analyzed`, the plan can be changed unexpectedly because it's mutable. I hit a real issue in https://github.com/apache/spark/pull/25107 : I use `TreeNodeTag` to carry dataset id in logical plans. However, the analyzed plan ends up with many duplicated dataset id tags in different nodes. It turns out that, the optimizer transforms the logical plan and add the tag to more nodes.
For example, the logical plan is `SubqueryAlias(Filter(...))`, and I expect only the `SubqueryAlais` has the dataset id tag. However, the optimizer removes `SubqueryAlias` and carries over the dataset id tag to `Filter`. When I go back to the analyzed plan, both `SubqueryAlias` and `Filter` has the dataset id tag, which breaks my assumption.
Since now query plan is mutable, I think it's better to limit the life cycle of a query plan instance. We can clone the query plan between analyzer, optimizer and planner, so that the life cycle is limited in one stage.
## How was this patch tested?
new test
Closes#25111 from cloud-fan/clone.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR change `CalendarIntervalType`'s readable string representation from `calendarinterval` to `interval`.
## How was this patch tested?
Existing UT
Closes#25225 from wangyum/SPARK-28469.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Fix CSV datasource to throw `com.univocity.parsers.common.TextParsingException` with large size message, which will make log output consume large disk space.
This issue is troublesome when sometimes we need parse CSV with large size column.
This PR proposes to set CSV parser/writer settings by `setErrorContentLength(1000)` to limit the error message length.
## How was this patch tested?
Manually.
```
val s = "a" * 40 * 1000000
Seq(s).toDF.write.mode("overwrite").csv("/tmp/bogdan/es4196.csv")
spark.read .option("maxCharsPerColumn", 30000000) .csv("/tmp/bogdan/es4196.csv").count
```
**Before:**
The thrown message will include error content of about 30MB size (The column size exceed the max value 30MB, so the error content include the whole parsed content, so it is 30MB).
**After:**
The thrown message will include error content like "...aaa...aa" (the number of 'a' is 1024), i.e. limit the content size to be 1024.
Closes#25184 from WeichenXu123/limit_csv_exception_size.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
New function `make_date()` takes 3 columns `year`, `month` and `day`, and makes new column of the `DATE` type. If values in the input columns are `null` or out of valid ranges, the function returns `null`. Valid ranges are:
- `year` - `[1, 9999]`
- `month` - `[1, 12]`
- `day` - `[1, 31]`
Also constructed date must be valid otherwise `make_date` returns `null`.
The function is implemented similarly to `make_date` in PostgreSQL: https://www.postgresql.org/docs/11/functions-datetime.html to maintain feature parity with it.
Here is an example:
```sql
select make_date(2013, 7, 15);
2013-07-15
```
## How was this patch tested?
Added new tests to `DateExpressionsSuite`.
Closes#25210 from MaxGekk/make_date-timestamp.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Because `Encoder` is not thread safe, the user cannot reuse an `Encoder` in multiple `Dataset`s. However, creating an `Encoder` for a complicated class is slow due to Scala Reflection. To eliminate the cost of Scala Reflection, right now I usually use the private API `ExpressionEncoder.copy` as follows:
```scala
object FooEncoder {
private lazy val _encoder: ExpressionEncoder[Foo] = ExpressionEncoder[Foo]()
implicit def encoder: ExpressionEncoder[Foo] = _encoder.copy()
}
```
This PR proposes a new method `makeCopy` in `Encoder` so that the above codes can be rewritten using public APIs.
```scala
object FooEncoder {
private lazy val _encoder: Encoder[Foo] = Encoders.product[Foo]()
implicit def encoder: Encoder[Foo] = _encoder.makeCopy
}
```
The method name is consistent with `TreeNode.makeCopy`.
## How was this patch tested?
Jenkins
Closes#25209 from zsxwing/encoder-copy.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Implements the `REPLACE TABLE` and `REPLACE TABLE AS SELECT` logical plans. `REPLACE TABLE` is now a valid operation in spark-sql provided that the tables being modified are managed by V2 catalogs.
This also introduces an atomic mix-in that table catalogs can choose to implement. Table catalogs can now implement `TransactionalTableCatalog`. The semantics of this API are that table creation and replacement can be "staged" and then "committed".
On the execution of `REPLACE TABLE AS SELECT`, `REPLACE TABLE`, and `CREATE TABLE AS SELECT`, if the catalog implements transactional operations, the physical plan will use said functionality. Otherwise, these operations fall back on non-atomic variants. For `REPLACE TABLE` in particular, the usage of non-atomic operations can unfortunately lead to inconsistent state.
## How was this patch tested?
Unit tests - multiple additions to `DataSourceV2SQLSuite`.
Closes#24798 from mccheah/spark-27724.
Authored-by: mcheah <mcheah@palantir.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
When a `ScalaUDF` returns a value which overflows, currently it returns null regardless of the value of the config `spark.sql.decimalOperations.nullOnOverflow`.
The PR makes it respect the above-mentioned config and behave accordingly.
## How was this patch tested?
added UT
Closes#25144 from mgaido91/SPARK-28369.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This pr proposes to add a prefix '*' to non-nullable attribute names in PlanTestBase.comparePlans failures. In the current master, nullability mismatches might generate the same error message for left/right logical plans like this;
```
// This failure message was extracted from #24765
- constraints should be inferred from aliased literals *** FAILED ***
== FAIL: Plans do not match ===
!'Join Inner, (two#0 = a#0) 'Join Inner, (two#0 = a#0)
:- Filter (isnotnull(a#0) AND (2 <=> a#0)) :- Filter (isnotnull(a#0) AND (2 <=> a#0))
: +- LocalRelation <empty>, [a#0, b#0, c#0] : +- LocalRelation <empty>, [a#0, b#0, c#0]
+- Project [2 AS two#0] +- Project [2 AS two#0]
+- LocalRelation <empty>, [a#0, b#0, c#0] +- LocalRelation <empty>, [a#0, b#0, c#0] (PlanTest.scala:145)
```
With this pr, this error message is changed to one below;
```
- constraints should be inferred from aliased literals *** FAILED ***
== FAIL: Plans do not match ===
!'Join Inner, (*two#0 = a#0) 'Join Inner, (*two#0 = *a#0)
:- Filter (isnotnull(a#0) AND (2 <=> a#0)) :- Filter (isnotnull(a#0) AND (2 <=> a#0))
: +- LocalRelation <empty>, [a#0, b#0, c#0] : +- LocalRelation <empty>, [a#0, b#0, c#0]
+- Project [2 AS two#0] +- Project [2 AS two#0]
+- LocalRelation <empty>, [a#0, b#0, c#0] +- LocalRelation <empty>, [a#0, b#0, c#0] (PlanTest.scala:145)
```
## How was this patch tested?
N/A
Closes#25213 from maropu/MarkForNullability.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
The optimize rule `PushDownPredicate` has been combined into `PushDownPredicates`, update the comment that references the old rule.
## How was this patch tested?
N/A
Closes#25207 from jiangxb1987/comment.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Performance issue using explode was found when a complex field contains huge array is to get duplicated as the number of exploded array elements. Given example:
```scala
val df = spark.sparkContext.parallelize(Seq(("1",
Array.fill(M)({
val i = math.random
(i.toString, (i + 1).toString, (i + 2).toString, (i + 3).toString)
})))).toDF("col", "arr")
.selectExpr("col", "struct(col, arr) as st")
.selectExpr("col", "st.col as col1", "explode(st.arr) as arr_col")
```
The explode causes `st` to be duplicated as many as the exploded elements.
Benchmarks it:
```
[info] Java HotSpot(TM) 64-Bit Server VM 1.8.0_202-b08 on Mac OS X 10.14.4
[info] Intel(R) Core(TM) i7-8750H CPU 2.20GHz
[info] generate big nested struct array: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] generate big nested struct array wholestage off 52668 53162 699 0.0 877803.4 1.0X
[info] generate big nested struct array wholestage on 47261 49093 1125 0.0 787690.2 1.1X
[info]
```
The query plan:
```
== Physical Plan ==
Project [col#508, st#512.col AS col1#515, arr_col#519]
+- Generate explode(st#512.arr), [col#508, st#512], false, [arr_col#519]
+- Project [_1#503 AS col#508, named_struct(col, _1#503, arr, _2#504) AS st#512]
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, scala.Tuple2, true]))._1, true, false) AS _1#503, mapobjects(MapObjects_loopValue84, MapObjects_loopIsNull84, ObjectType(class scala.Tuple4), if (isnull(lambdavariable(MapObjects_loopValue84, MapObjects_loopIsNull84, ObjectType(class scala.Tuple4), true))) null else named_struct(_1, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue84, MapObjects_loopIsNull84, ObjectType(class scala.Tuple4), true))._1, true, false), _2, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue84, MapObjects_loopIsNull84, ObjectType(class scala.Tuple4), true))._2, true, false), _3, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue84, MapObjects_loopIsNull84, ObjectType(class scala.Tuple4), true))._3, true, false), _4, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue84, MapObjects_loopIsNull84, ObjectType(class scala.Tuple4), true))._4, true, false)), knownnotnull(assertnotnull(input[0, scala.Tuple2, true]))._2, None) AS _2#504]
+- Scan[obj#534]
```
This patch takes nested column pruning approach to prune unnecessary nested fields. It adds a projection of the needed nested fields as aliases on the child of `Generate`, and substitutes them by alias attributes on the projection on top of `Generate`.
Benchmarks it after the change:
```
[info] Java HotSpot(TM) 64-Bit Server VM 1.8.0_202-b08 on Mac OS X 10.14.4
[info] Intel(R) Core(TM) i7-8750H CPU 2.20GHz
[info] generate big nested struct array: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] generate big nested struct array wholestage off 311 331 28 0.2 5188.6 1.0X
[info] generate big nested struct array wholestage on 297 312 15 0.2 4947.3 1.0X
[info]
```
The query plan:
```
== Physical Plan ==
Project [col#592, _gen_alias_608#608 AS col1#599, arr_col#603]
+- Generate explode(st#596.arr), [col#592, _gen_alias_608#608], false, [arr_col#603]
+- Project [_1#587 AS col#592, named_struct(col, _1#587, arr, _2#588) AS st#596, _1#587 AS _gen_alias_608#608]
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(in
put[0, scala.Tuple2, true]))._1, true, false) AS _1#587, mapobjects(MapObjects_loopValue102, MapObjects_loopIsNull102, ObjectType(class scala.Tuple4),
if (isnull(lambdavariable(MapObjects_loopValue102, MapObjects_loopIsNull102, ObjectType(class scala.Tuple4), true))) null else named_struct(_1, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue102, MapObjects_loopIsNull102, ObjectType(class scala.Tuple4), true))._1, true, false), _2, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue102, MapObjects_loopIsNull102, ObjectType(class scala.Tuple4), true))._2, true, false), _3, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue102, MapObjects_loopIsNull102, ObjectType(class scala.Tuple4), true))._3, true, false), _4, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue102, MapObjects_loopIsNull102, ObjectType(class scala.Tuple4), true))._4, true, false)), knownnotnull(assertnotnull(input[0, scala.Tuple2, true]))._2, None) AS _2#588]
+- Scan[obj#586]
```
This behavior is controlled by a SQL config `spark.sql.optimizer.expression.nestedPruning.enabled`.
## How was this patch tested?
Added benchmark.
Closes#24637 from viirya/SPARK-27707.
Lead-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
The `DateTimeUtils.timestampAddInterval` method was rewritten by using Java 8 time API. To add months and microseconds, I used the `plusMonths()` and `plus()` methods of `ZonedDateTime`. Also the signature of `timestampAddInterval()` was changed to accept an `ZoneId` instance instead of `TimeZone`. Using `ZoneId` allows to avoid the conversion `TimeZone` -> `ZoneId` on every invoke of `timestampAddInterval()`.
## How was this patch tested?
By existing test suites `DateExpressionsSuite`, `TypeCoercionSuite` and `CollectionExpressionsSuite`.
Closes#25173 from MaxGekk/timestamp-add-interval.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
A `Filter` predicate using `PythonUDF` can't be push down into join condition, currently. A predicate like that should be able to push down to join condition. For `PythonUDF`s that can't be evaluated in join condition, `PullOutPythonUDFInJoinCondition` will pull them out later.
An example like:
```scala
val pythonTestUDF = TestPythonUDF(name = "udf")
val left = Seq((1, 2), (2, 3)).toDF("a", "b")
val right = Seq((1, 2), (3, 4)).toDF("c", "d")
val df = left.crossJoin(right).where(pythonTestUDF($"a") === pythonTestUDF($"c"))
```
Query plan before the PR:
```
== Physical Plan ==
*(3) Project [a#2121, b#2122, c#2132, d#2133]
+- *(3) Filter (pythonUDF0#2142 = pythonUDF1#2143)
+- BatchEvalPython [udf(a#2121), udf(c#2132)], [pythonUDF0#2142, pythonUDF1#2143]
+- BroadcastNestedLoopJoin BuildRight, Cross
:- *(1) Project [_1#2116 AS a#2121, _2#2117 AS b#2122]
: +- LocalTableScan [_1#2116, _2#2117]
+- BroadcastExchange IdentityBroadcastMode
+- *(2) Project [_1#2127 AS c#2132, _2#2128 AS d#2133]
+- LocalTableScan [_1#2127, _2#2128]
```
Query plan after the PR:
```
== Physical Plan ==
*(3) Project [a#2121, b#2122, c#2132, d#2133]
+- *(3) BroadcastHashJoin [pythonUDF0#2142], [pythonUDF0#2143], Cross, BuildRight
:- BatchEvalPython [udf(a#2121)], [pythonUDF0#2142]
: +- *(1) Project [_1#2116 AS a#2121, _2#2117 AS b#2122]
: +- LocalTableScan [_1#2116, _2#2117]
+- BroadcastExchange HashedRelationBroadcastMode(List(input[2, string, true]))
+- BatchEvalPython [udf(c#2132)], [pythonUDF0#2143]
+- *(2) Project [_1#2127 AS c#2132, _2#2128 AS d#2133]
+- LocalTableScan [_1#2127, _2#2128]
```
After this PR, the join can use `BroadcastHashJoin`, instead of `BroadcastNestedLoopJoin`.
## How was this patch tested?
Added tests.
Closes#25106 from viirya/pythonudf-join-condition.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Existing random generators in tests produce wide ranges of values that can be out of supported ranges for:
- `DateType`, the valid range is `[0001-01-01, 9999-12-31]`
- `TimestampType` supports values in `[0001-01-01T00:00:00.000000Z, 9999-12-31T23:59:59.999999Z]`
- `CalendarIntervalType` should define intervals for the ranges above.
Dates and timestamps produced by random literal generators are usually out of valid ranges for those types. And tests just check invalid values or values caused by arithmetic overflow.
In the PR, I propose to restrict tested pseudo-random values by valid ranges of `DateType`, `TimestampType` and `CalendarIntervalType`. This should allow to check valid values in test, and avoid wasting time on a priori invalid inputs.
## How was this patch tested?
The changes were checked by `DateExpressionsSuite` and modified `DateTimeUtils.dateAddMonths`:
```Scala
def dateAddMonths(days: SQLDate, months: Int): SQLDate = {
localDateToDays(LocalDate.ofEpochDay(days).plusMonths(months))
}
```
Closes#25166 from MaxGekk/datetime-lit-random-gen.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Idempotence of the `NormalizeFloatingNumbers` rule was broken due to the implementation of `ExtractEquiJoinKeys`. There is no reason that we don't remove `EqualNullSafe` join keys from an equi-join's `otherPredicates`.
## How was this patch tested?
A new UT.
Closes#25126 from yeshengm/spark-28306.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In the PR, I propose to use the `plusMonths()` method of `LocalDate` to add months to a date. This method adds the specified amount to the months field of `LocalDate` in three steps:
1. Add the input months to the month-of-year field
2. Check if the resulting date would be invalid
3. Adjust the day-of-month to the last valid day if necessary
The difference between current behavior and propose one is in handling the last day of month in the original date. For example, adding 1 month to `2019-02-28` will produce `2019-03-28` comparing to the current implementation where the result is `2019-03-31`.
The proposed behavior is implemented in MySQL and PostgreSQL.
## How was this patch tested?
By existing test suites `DateExpressionsSuite`, `DateFunctionsSuite` and `DateTimeUtilsSuite`.
Closes#25153 from MaxGekk/add-months.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Adding support to hyperbolic functions like asinh\acosh\atanh in spark SQL.
Feature parity: https://www.postgresql.org/docs/12/functions-math.html#FUNCTIONS-MATH-HYP-TABLE
The followings are the diffence from PostgreSQL.
```
spark-sql> SELECT acosh(0); (PostgreSQL returns `ERROR: input is out of range`)
NaN
spark-sql> SELECT atanh(2); (PostgreSQL returns `ERROR: input is out of range`)
NaN
```
Teradata has similar behavior as PostgreSQL with out of range input float values - It outputs **Invalid Input: numeric value within range only.**
These newly added asinh/acosh/atanh handles special input(NaN, +-Infinity) in the same way as existing cos/sin/tan/acos/asin/atan in spark. For which input value range is not (-∞, ∞)):
out of range float values: Spark returns NaN and PostgreSQL shows input is out of range
NaN: Spark returns NaN, PostgreSQL also returns NaN
Infinity: Spark return NaN, PostgreSQL shows input is out of range
## How was this patch tested?
```
spark.sql("select asinh(xx)")
spark.sql("select acosh(xx)")
spark.sql("select atanh(xx)")
./build/sbt "testOnly org.apache.spark.sql.MathFunctionsSuite"
./build/sbt "testOnly org.apache.spark.sql.catalyst.expressions.MathExpressionsSuite"
```
Closes#25041 from Tonix517/SPARK-28133.
Authored-by: Tony Zhang <tony.zhang@uber.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds compatibility of handling a `WITH` clause within another `WITH` cause. Before this PR these queries retuned `1` while after this PR they return `2` as PostgreSQL does:
```
WITH
t AS (SELECT 1),
t2 AS (
WITH t AS (SELECT 2)
SELECT * FROM t
)
SELECT * FROM t2
```
```
WITH t AS (SELECT 1)
SELECT (
WITH t AS (SELECT 2)
SELECT * FROM t
)
```
As this is an incompatible change, the PR introduces the `spark.sql.legacy.cte.substitution.enabled` flag as an option to restore old behaviour.
## How was this patch tested?
Added new UTs.
Closes#25029 from peter-toth/SPARK-28228.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
There are some hardcoded configs, using config entry to replace them.
## How was this patch tested?
Existing UT
Closes#25059 from WangGuangxin/ConfigEntry.
Authored-by: wangguangxin.cn <wangguangxin.cn@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Implement `ALTER TABLE` for v2 tables:
* Add `AlterTable` logical plan and `AlterTableExec` physical plan
* Convert `ALTER TABLE` parsed plans to `AlterTable` when a v2 catalog is responsible for an identifier
* Validate that columns to alter exist in analyzer checks
* Fix nested type handling in `CatalogV2Util`
## How was this patch tested?
* Add extensive tests in `DataSourceV2SQLSuite`
Closes#24937 from rdblue/SPARK-28139-add-v2-alter-table.
Lead-authored-by: Ryan Blue <blue@apache.org>
Co-authored-by: Ryan Blue <rdblue@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The optimizer rule `NormalizeFloatingNumbers` is not idempotent. It will generate multiple `NormalizeNaNAndZero` and `ArrayTransform` expression nodes for multiple runs. This patch fixed this non-idempotence by adding a marking tag above normalized expressions. It also adds missing UTs for `NormalizeFloatingNumbers`.
## How was this patch tested?
New UTs.
Closes#25080 from yeshengm/spark-28306.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The new adaptive execution framework introduced configuration `spark.sql.runtime.reoptimization.enabled`. We now rename it back to `spark.sql.adaptive.enabled` as the umbrella configuration for adaptive execution.
## How was this patch tested?
Existing tests.
Closes#25102 from carsonwang/renameAE.
Authored-by: Carson Wang <carson.wang@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Fix `stringToDate()` for the formats `yyyy` and `yyyy-[m]m` that assumes there are no additional chars after the last components `yyyy` and `[m]m`. In the PR, I propose to check that entire input was consumed for the formats.
After the fix, the input `1999 08 01` will be invalid because it matches to the pattern `yyyy` but the strings contains additional chars ` 08 01`.
Since Spark 1.6.3 ~ 2.4.3, the behavior is the same.
```
spark-sql> SELECT CAST('1999 08 01' AS DATE);
1999-01-01
```
This PR makes it return NULL like Hive.
```
spark-sql> SELECT CAST('1999 08 01' AS DATE);
NULL
```
## How was this patch tested?
Added new checks to `DateTimeUtilsSuite` for the `1999 08 01` and `1999 08` inputs.
Closes#25097 from MaxGekk/spark-28015-invalid-date-format.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This fixes a problem where it is possible to create a v2 table using the default catalog that cannot be loaded with the session catalog. A session catalog should be used when the v1 catalog is responsible for tables with no catalog in the table identifier.
* Adds a v2 catalog implementation that delegates to the analyzer's SessionCatalog
* Uses the v2 session catalog for CTAS and CreateTable when the provider is a v2 provider and no v2 catalog is in the table identifier
* Updates catalog lookup to always provide the default if it is set for consistent behavior
## How was this patch tested?
* Adds a new test suite for the v2 session catalog that validates the TableCatalog API
* Adds test cases in PlanResolutionSuite to validate the v2 session catalog is used
* Adds test suite for LookupCatalog with a default catalog
Closes#24768 from rdblue/SPARK-27919-add-v2-session-catalog.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The interval conversion behavior is same with the PostgreSQL.
https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/sql/interval.sql#L180-L203
## How was this patch tested?
UT.
Closes#25000 from lipzhu/SPARK-28107.
Lead-authored-by: Zhu, Lipeng <lipzhu@ebay.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Lipeng Zhu <lipzhu@icloud.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This is a followup of the discussion in https://github.com/apache/spark/pull/24675#discussion_r286786053
`QueryPlan#references` is an important property. The `ColumnPrunning` rule relies on it.
Some query plan nodes have `Seq[Attribute]` parameter, which is used as its output attributes. For example, leaf nodes, `Generate`, `MapPartitionsInPandas`, etc. These nodes override `producedAttributes` to make `missingInputs` correct.
However, these nodes also need to override `references` to make column pruning work. This PR proposes to exclude `producedAttributes` from the default implementation of `QueryPlan#references`, so that we don't need to override `references` in all these nodes.
Note that, technically we can remove `producedAttributes` and always ask query plan nodes to override `references`. But I do find the code can be simpler with `producedAttributes` in some places, where there is a base class for some specific query plan nodes.
## How was this patch tested?
existing tests
Closes#25052 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds some tests converted from `pgSQL/case.sql'` to test UDFs. Please see contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
This PR also contains two minor fixes:
1. Change name of Scala UDF from `UDF:name(...)` to `name(...)` to be consistent with Python'
2. Fix Scala UDF at `IntegratedUDFTestUtils.scala ` to handle `null` in strings.
<details><summary>Diff comparing to 'pgSQL/case.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/pgSQL/case.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-case.sql.out
index fa078d16d6d..55bef64338f 100644
--- a/sql/core/src/test/resources/sql-tests/results/pgSQL/case.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-case.sql.out
-115,7 +115,7 struct<>
-- !query 13
SELECT '3' AS `One`,
CASE
- WHEN 1 < 2 THEN 3
+ WHEN CAST(udf(1 < 2) AS boolean) THEN 3
END AS `Simple WHEN`
-- !query 13 schema
struct<One:string,Simple WHEN:int>
-126,10 +126,10 struct<One:string,Simple WHEN:int>
-- !query 14
SELECT '<NULL>' AS `One`,
CASE
- WHEN 1 > 2 THEN 3
+ WHEN 1 > 2 THEN udf(3)
END AS `Simple default`
-- !query 14 schema
-struct<One:string,Simple default:int>
+struct<One:string,Simple default:string>
-- !query 14 output
<NULL> NULL
-137,17 +137,17 struct<One:string,Simple default:int>
-- !query 15
SELECT '3' AS `One`,
CASE
- WHEN 1 < 2 THEN 3
- ELSE 4
+ WHEN udf(1) < 2 THEN udf(3)
+ ELSE udf(4)
END AS `Simple ELSE`
-- !query 15 schema
-struct<One:string,Simple ELSE:int>
+struct<One:string,Simple ELSE:string>
-- !query 15 output
3 3
-- !query 16
-SELECT '4' AS `One`,
+SELECT udf('4') AS `One`,
CASE
WHEN 1 > 2 THEN 3
ELSE 4
-159,10 +159,10 struct<One:string,ELSE default:int>
-- !query 17
-SELECT '6' AS `One`,
+SELECT udf('6') AS `One`,
CASE
- WHEN 1 > 2 THEN 3
- WHEN 4 < 5 THEN 6
+ WHEN CAST(udf(1 > 2) AS boolean) THEN 3
+ WHEN udf(4) < 5 THEN 6
ELSE 7
END AS `Two WHEN with default`
-- !query 17 schema
-173,7 +173,7 struct<One:string,Two WHEN with default:int>
-- !query 18
SELECT '7' AS `None`,
- CASE WHEN rand() < 0 THEN 1
+ CASE WHEN rand() < udf(0) THEN 1
END AS `NULL on no matches`
-- !query 18 schema
struct<None:string,NULL on no matches:int>
-182,36 +182,36 struct<None:string,NULL on no matches:int>
-- !query 19
-SELECT CASE WHEN 1=0 THEN 1/0 WHEN 1=1 THEN 1 ELSE 2/0 END
+SELECT CASE WHEN CAST(udf(1=0) AS boolean) THEN 1/0 WHEN 1=1 THEN 1 ELSE 2/0 END
-- !query 19 schema
-struct<CASE WHEN (1 = 0) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
+struct<CASE WHEN CAST(udf((1 = 0)) AS BOOLEAN) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
-- !query 19 output
1.0
-- !query 20
-SELECT CASE 1 WHEN 0 THEN 1/0 WHEN 1 THEN 1 ELSE 2/0 END
+SELECT CASE 1 WHEN 0 THEN 1/udf(0) WHEN 1 THEN 1 ELSE 2/0 END
-- !query 20 schema
-struct<CASE WHEN (1 = 0) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
+struct<CASE WHEN (1 = 0) THEN (CAST(1 AS DOUBLE) / CAST(CAST(udf(0) AS DOUBLE) AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
-- !query 20 output
1.0
-- !query 21
-SELECT CASE WHEN i > 100 THEN 1/0 ELSE 0 END FROM case_tbl
+SELECT CASE WHEN i > 100 THEN udf(1/0) ELSE udf(0) END FROM case_tbl
-- !query 21 schema
-struct<CASE WHEN (i > 100) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) ELSE CAST(0 AS DOUBLE) END:double>
+struct<CASE WHEN (i > 100) THEN udf((cast(1 as double) / cast(0 as double))) ELSE udf(0) END:string>
-- !query 21 output
-0.0
-0.0
-0.0
-0.0
+0
+0
+0
+0
-- !query 22
-SELECT CASE 'a' WHEN 'a' THEN 1 ELSE 2 END
+SELECT CASE 'a' WHEN 'a' THEN udf(1) ELSE udf(2) END
-- !query 22 schema
-struct<CASE WHEN (a = a) THEN 1 ELSE 2 END:int>
+struct<CASE WHEN (a = a) THEN udf(1) ELSE udf(2) END:string>
-- !query 22 output
1
-283,7 +283,7 big
-- !query 27
-SELECT * FROM CASE_TBL WHERE COALESCE(f,i) = 4
+SELECT * FROM CASE_TBL WHERE udf(COALESCE(f,i)) = 4
-- !query 27 schema
struct<i:int,f:double>
-- !query 27 output
-291,7 +291,7 struct<i:int,f:double>
-- !query 28
-SELECT * FROM CASE_TBL WHERE NULLIF(f,i) = 2
+SELECT * FROM CASE_TBL WHERE udf(NULLIF(f,i)) = 2
-- !query 28 schema
struct<i:int,f:double>
-- !query 28 output
-299,10 +299,10 struct<i:int,f:double>
-- !query 29
-SELECT COALESCE(a.f, b.i, b.j)
+SELECT udf(COALESCE(a.f, b.i, b.j))
FROM CASE_TBL a, CASE2_TBL b
-- !query 29 schema
-struct<coalesce(f, CAST(i AS DOUBLE), CAST(j AS DOUBLE)):double>
+struct<udf(coalesce(f, cast(i as double), cast(j as double))):string>
-- !query 29 output
-30.3
-30.3
-332,8 +332,8 struct<coalesce(f, CAST(i AS DOUBLE), CAST(j AS DOUBLE)):double>
-- !query 30
SELECT *
- FROM CASE_TBL a, CASE2_TBL b
- WHERE COALESCE(a.f, b.i, b.j) = 2
+ FROM CASE_TBL a, CASE2_TBL b
+ WHERE udf(COALESCE(a.f, b.i, b.j)) = 2
-- !query 30 schema
struct<i:int,f:double,i:int,j:int>
-- !query 30 output
-342,7 +342,7 struct<i:int,f:double,i:int,j:int>
-- !query 31
-SELECT '' AS Five, NULLIF(a.i,b.i) AS `NULLIF(a.i,b.i)`,
+SELECT udf('') AS Five, NULLIF(a.i,b.i) AS `NULLIF(a.i,b.i)`,
NULLIF(b.i, 4) AS `NULLIF(b.i,4)`
FROM CASE_TBL a, CASE2_TBL b
-- !query 31 schema
-377,7 +377,7 struct<Five:string,NULLIF(a.i,b.i):int,NULLIF(b.i,4):int>
-- !query 32
SELECT '' AS `Two`, *
FROM CASE_TBL a, CASE2_TBL b
- WHERE COALESCE(f,b.i) = 2
+ WHERE CAST(udf(COALESCE(f,b.i) = 2) AS boolean)
-- !query 32 schema
struct<Two:string,i:int,f:double,i:int,j:int>
-- !query 32 output
-388,15 +388,15 struct<Two:string,i:int,f:double,i:int,j:int>
-- !query 33
SELECT CASE
(CASE vol('bar')
- WHEN 'foo' THEN 'it was foo!'
- WHEN vol(null) THEN 'null input'
+ WHEN udf('foo') THEN 'it was foo!'
+ WHEN udf(vol(null)) THEN 'null input'
WHEN 'bar' THEN 'it was bar!' END
)
- WHEN 'it was foo!' THEN 'foo recognized'
- WHEN 'it was bar!' THEN 'bar recognized'
- ELSE 'unrecognized' END
+ WHEN udf('it was foo!') THEN 'foo recognized'
+ WHEN 'it was bar!' THEN udf('bar recognized')
+ ELSE 'unrecognized' END AS col
-- !query 33 schema
-struct<CASE WHEN (CASE WHEN (UDF:vol(bar) = foo) THEN it was foo! WHEN (UDF:vol(bar) = UDF:vol(null)) THEN null input WHEN (UDF:vol(bar) = bar) THEN it was bar! END = it was foo!) THEN foo recognized WHEN (CASE WHEN (UDF:vol(bar) = foo) THEN it was foo! WHEN (UDF:vol(bar) = UDF:vol(null)) THEN null input WHEN (UDF:vol(bar) = bar) THEN it was bar! END = it was bar!) THEN bar recognized ELSE unrecognized END:string>
+struct<col:string>
-- !query 33 output
bar recognized
```
</p>
</details>
https://github.com/apache/spark/pull/25069 contains the same minor fixes as it's required to write the tests.
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25070 from HyukjinKwon/SPARK-28273.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
We changed our non-standard syntax for `trim` function in #24902 from `TRIM(trimStr, str)` to `TRIM(str, trimStr)` to be compatible with other databases. This pr update the migration guide.
I checked various databases(PostgreSQL, Teradata, Vertica, Oracle, DB2, SQL Server 2019, MySQL, Hive, Presto) and it seems that only PostgreSQL and Presto support this non-standard syntax.
**PostgreSQL**:
```sql
postgres=# select substr(version(), 0, 16), trim('yxTomxx', 'x');
substr | btrim
-----------------+-------
PostgreSQL 11.3 | yxTom
(1 row)
```
**Presto**:
```sql
presto> select trim('yxTomxx', 'x');
_col0
-------
yxTom
(1 row)
```
## How was this patch tested?
manual tests
Closes#24948 from wangyum/SPARK-28093-FOLLOW-UP-DOCS.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds some more WITH test cases as a follow-up to https://github.com/apache/spark/pull/24842
## How was this patch tested?
Add new UTs.
Closes#24949 from peter-toth/SPARK-28002-follow-up.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
- Currently, `ExpressionEncoder` does not handle bigdecimal overflow. Round-tripping overflowing java/scala BigDecimal/BigInteger returns null.
- The serializer encode java/scala BigDecimal to to sql Decimal, which still has the underlying data to the former.
- When writing out to UnsafeRow, `changePrecision` will be false and row has null value.
24e1e41648/sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/codegen/UnsafeRowWriter.java (L202-L206)
- In [SPARK-23179](https://github.com/apache/spark/pull/20350), an option to throw exception on decimal overflow was introduced.
- This PR adds the option in `ExpressionEncoder` to throw when detecting overflowing BigDecimal/BigInteger before its corresponding Decimal gets written to Row. This gives a consistent behavior between decimal arithmetic on sql expression (DecimalPrecision), and getting decimal from dataframe (RowEncoder)
Thanks to mgaido91 for the very first PR `SPARK-23179` and follow-up discussion on this change.
Thanks to JoshRosen for working with me on this.
## How was this patch tested?
added unit tests
Closes#25016 from mickjermsurawong-stripe/SPARK-28200.
Authored-by: Mick Jermsurawong <mickjermsurawong@stripe.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR proposes to rename `mapPartitionsInPandas` to `mapInPandas` with a separate evaluation type .
Had an offline discussion with rxin, mengxr and cloud-fan
The reason is basically:
1. `SCALAR_ITER` doesn't make sense with `mapPartitionsInPandas`.
2. It cannot share the same Pandas UDF, for instance, at `select` and `mapPartitionsInPandas` unlike `GROUPED_AGG` because iterator's return type is different.
3. `mapPartitionsInPandas` -> `mapInPandas` - see https://github.com/apache/spark/pull/25044#issuecomment-508298552 and https://github.com/apache/spark/pull/25044#issuecomment-508299764
Renaming `SCALAR_ITER` as `MAP_ITER` is abandoned due to 2. reason.
For `XXX_ITER`, it might have to have a different interface in the future if we happen to add other versions of them. But this is an orthogonal topic with `mapPartitionsInPandas`.
## How was this patch tested?
Existing tests should cover.
Closes#25044 from HyukjinKwon/SPARK-28198.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Before this PR inserting into a non-existing table returned a weird error message:
```
sql("INSERT INTO test VALUES (1)").show
org.apache.spark.sql.AnalysisException: unresolved operator 'InsertIntoTable 'UnresolvedRelation [test], false, false;;
'InsertIntoTable 'UnresolvedRelation [test], false, false
+- LocalRelation [col1#4]
```
after this PR the error message becomes:
```
org.apache.spark.sql.AnalysisException: Table not found: test;;
'InsertIntoTable 'UnresolvedRelation [test], false, false
+- LocalRelation [col1#0]
```
## How was this patch tested?
Added a new UT.
Closes#25054 from peter-toth/SPARK-28251.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds support of `WITH` clause within a subquery so this query becomes valid:
```
SELECT max(c) FROM (
WITH t AS (SELECT 1 AS c)
SELECT * FROM t
)
```
## How was this patch tested?
Added new UTs.
Closes#24831 from peter-toth/SPARK-19799-2.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This is to implement a ReduceNumShufflePartitions rule in the new adaptive execution framework introduced in #24706. This rule is used to adjust the post shuffle partitions based on the map output statistics.
## How was this patch tested?
Added ReduceNumShufflePartitionsSuite
Closes#24978 from carsonwang/reduceNumShufflePartitions.
Authored-by: Carson Wang <carson.wang@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR makes the predicate pushdown logic in catalyst optimizer more efficient by unifying two existing rules `PushdownPredicates` and `PushPredicateThroughJoin`. Previously pushing down a predicate for queries such as `Filter(Join(Join(Join)))` requires n steps. This patch essentially reduces this to a single pass.
To make this actually work, we need to unify a few rules such as `CombineFilters`, `PushDownPredicate` and `PushDownPrdicateThroughJoin`. Otherwise cases such as `Filter(Join(Filter(Join)))` still requires several passes to fully push down predicates. This unification is done by composing several partial functions, which makes a minimal code change and can reuse existing UTs.
Results show that this optimization can improve the catalyst optimization time by 16.5%. For queries with more joins, the performance is even better. E.g., for TPC-DS q64, the performance boost is 49.2%.
## How was this patch tested?
Existing UTs + new a UT for the new rule.
Closes#24956 from yeshengm/fixed-point-opt.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This pr add `PLACING` to `ansiNonReserved` and add `overlay` and `placing` to `TableIdentifierParserSuite`.
## How was this patch tested?
N/A
Closes#25013 from wangyum/SPARK-28077.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Right now they fail only for inner joins, because we implemented the check when that was the only supported type.
## How was this patch tested?
new unit test
Closes#25023 from jose-torres/changevalidation.
Authored-by: Jose Torres <torres.joseph.f+github@gmail.com>
Signed-off-by: Jose Torres <torres.joseph.f+github@gmail.com>
## What changes were proposed in this pull request?
This PR proposes to add `mapPartitionsInPandas` API to DataFrame by using existing `SCALAR_ITER` as below:
1. Filtering via setting the column
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
df = spark.createDataFrame([(1, 21), (2, 30)], ("id", "age"))
pandas_udf(df.schema, PandasUDFType.SCALAR_ITER)
def filter_func(iterator):
for pdf in iterator:
yield pdf[pdf.id == 1]
df.mapPartitionsInPandas(filter_func).show()
```
```
+---+---+
| id|age|
+---+---+
| 1| 21|
+---+---+
```
2. `DataFrame.loc`
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
import pandas as pd
df = spark.createDataFrame([['aa'], ['bb'], ['cc'], ['aa'], ['aa'], ['aa']], ["value"])
pandas_udf(df.schema, PandasUDFType.SCALAR_ITER)
def filter_func(iterator):
for pdf in iterator:
yield pdf.loc[pdf.value.str.contains('^a'), :]
df.mapPartitionsInPandas(filter_func).show()
```
```
+-----+
|value|
+-----+
| aa|
| aa|
| aa|
| aa|
+-----+
```
3. `pandas.melt`
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
import pandas as pd
df = spark.createDataFrame(
pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},
'B': {0: 1, 1: 3, 2: 5},
'C': {0: 2, 1: 4, 2: 6}}))
pandas_udf("A string, variable string, value long", PandasUDFType.SCALAR_ITER)
def filter_func(iterator):
for pdf in iterator:
import pandas as pd
yield pd.melt(pdf, id_vars=['A'], value_vars=['B', 'C'])
df.mapPartitionsInPandas(filter_func).show()
```
```
+---+--------+-----+
| A|variable|value|
+---+--------+-----+
| a| B| 1|
| a| C| 2|
| b| B| 3|
| b| C| 4|
| c| B| 5|
| c| C| 6|
+---+--------+-----+
```
The current limitation of `SCALAR_ITER` is that it doesn't allow different length of result, which is pretty critical in practice - for instance, we cannot simply filter by using Pandas APIs but we merely just map N to N. This PR allows map N to M like flatMap.
This API mimics the way of `mapPartitions` but keeps API shape of `SCALAR_ITER` by allowing different results.
### How does this PR implement?
This PR adds mimics both `dapply` with Arrow optimization and Grouped Map Pandas UDF. At Python execution side, it reuses existing `SCALAR_ITER` code path.
Therefore, externally, we don't introduce any new type of Pandas UDF but internally we use another evaluation type code `205` (`SQL_MAP_PANDAS_ITER_UDF`).
This approach is similar with Pandas' Windows function implementation with Grouped Aggregation Pandas UDF functions - internally we have `203` (`SQL_WINDOW_AGG_PANDAS_UDF`) but externally we just share the same `GROUPED_AGG`.
## How was this patch tested?
Manually tested and unittests were added.
Closes#24997 from HyukjinKwon/scalar-udf-iter.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In SPARK-23179, it has been introduced a flag to control the behavior in case of overflow on decimals. The behavior is: returning `null` when `spark.sql.decimalOperations.nullOnOverflow` (default and traditional Spark behavior); throwing an `ArithmeticException` if that conf is false (according to SQL standards, other DBs behavior).
`MakeDecimal` so far had an ambiguous behavior. In case of codegen mode, it returned `null` as the other operators, but in interpreted mode, it was throwing an `IllegalArgumentException`.
The PR aligns `MakeDecimal`'s behavior with the one of other operators as defined in SPARK-23179. So now both modes return `null` or throw `ArithmeticException` according to `spark.sql.decimalOperations.nullOnOverflow`'s value.
Credits for this PR to mickjermsurawong-stripe who pointed out the wrong behavior in #20350.
## How was this patch tested?
improved UTs
Closes#25010 from mgaido91/SPARK-28201.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This pr add two API for [SessionCatalog](df4cb471c9/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala):
```scala
def listTables(db: String, pattern: String, includeLocalTempViews: Boolean): Seq[TableIdentifier]
def listLocalTempViews(pattern: String): Seq[TableIdentifier]
```
Because in some cases `listTables` does not need local temporary view and sometimes only need list local temporary view.
## How was this patch tested?
unit tests
Closes#24995 from wangyum/SPARK-28196.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Currently, ORC's `inferSchema` is implemented as randomly choosing one ORC file and reading its schema.
This PR follows the behavior of Parquet, it implements merge schemas logic by reading all ORC files in parallel through a spark job.
Users can enable merge schema by `spark.read.orc("xxx").option("mergeSchema", "true")` or by setting `spark.sql.orc.mergeSchema` to `true`, the prior one has higher priority.
## How was this patch tested?
tested by UT OrcUtilsSuite.scala
Closes#24043 from WangGuangxin/SPARK-11412.
Lead-authored-by: wangguangxin.cn <wangguangxin.cn@gmail.com>
Co-authored-by: wangguangxin.cn <wangguangxin.cn@bytedance.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This is the first part of [SPARK-27396](https://issues.apache.org/jira/browse/SPARK-27396). This is the minimum set of changes necessary to support a pluggable back end for columnar processing. Follow on JIRAs would cover removing some of the duplication between functionality in this patch and functionality currently covered by things like ColumnarBatchScan.
## How was this patch tested?
I added in a new unit test to cover new code not really covered in other places.
I also did manual testing by implementing two plugins/extensions that take advantage of the new APIs to allow for columnar processing for some simple queries. One version runs on the [CPU](https://gist.github.com/revans2/c3cad77075c4fa5d9d271308ee2f1b1d). The other version run on a GPU, but because it has unreleased dependencies I will not include a link to it yet.
The CPU version I would expect to add in as an example with other documentation in a follow on JIRA
This is contributed on behalf of NVIDIA Corporation.
Closes#24795 from revans2/columnar-basic.
Authored-by: Robert (Bobby) Evans <bobby@apache.org>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
The `OVERLAY` function is a `ANSI` `SQL`.
For example:
```
SELECT OVERLAY('abcdef' PLACING '45' FROM 4);
SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5);
SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5 FOR 0);
SELECT OVERLAY('babosa' PLACING 'ubb' FROM 2 FOR 4);
```
The results of the above four `SQL` are:
```
abc45f
yabadaba
yabadabadoo
bubba
```
Note: If the input string is null, then the result is null too.
There are some mainstream database support the syntax.
**PostgreSQL:**
https://www.postgresql.org/docs/11/functions-string.html
**Vertica:** https://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/SQLReferenceManual/Functions/String/OVERLAY.htm?zoom_highlight=overlay
**Oracle:**
https://docs.oracle.com/en/database/oracle/oracle-database/19/arpls/UTL_RAW.html#GUID-342E37E7-FE43-4CE1-A0E9-7DAABD000369
**DB2:**
https://www.ibm.com/support/knowledgecenter/SSGMCP_5.3.0/com.ibm.cics.rexx.doc/rexx/overlay.html
There are some show of the PR on my production environment.
```
spark-sql> SELECT OVERLAY('abcdef' PLACING '45' FROM 4);
abc45f
Time taken: 6.385 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5);
yabadaba
Time taken: 0.191 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5 FOR 0);
yabadabadoo
Time taken: 0.186 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY('babosa' PLACING 'ubb' FROM 2 FOR 4);
bubba
Time taken: 0.151 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING '45' FROM 4);
NULL
Time taken: 0.22 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING 'daba' FROM 5);
NULL
Time taken: 0.157 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING 'daba' FROM 5 FOR 0);
NULL
Time taken: 0.254 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING 'ubb' FROM 2 FOR 4);
NULL
Time taken: 0.159 seconds, Fetched 1 row(s)
```
## How was this patch tested?
Exists UT and new UT.
Closes#24918 from beliefer/ansi-sql-overlay.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
## What changes were proposed in this pull request?
Avoid hard-coded config: `spark.sql.globalTempDatabase`.
## How was this patch tested?
N/A
Closes#24979 from wangyum/SPARK-28179.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
For simplicity, all `LambdaVariable`s are globally unique, to avoid any potential conflicts. However, this causes a perf problem: we can never hit codegen cache for encoder expressions that deal with collections (which means they contain `LambdaVariable`).
To overcome this problem, `LambdaVariable` should have per-query unique IDs. This PR does 2 things:
1. refactor `LambdaVariable` to carry an ID, so that it's easier to change the ID.
2. add an optimizer rule to reassign `LambdaVariable` IDs, which are per-query unique.
## How was this patch tested?
new tests
Closes#24735 from cloud-fan/dataset.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
SQL ANSI 2011 states that in case of overflow during arithmetic operations, an exception should be thrown. This is what most of the SQL DBs do (eg. SQLServer, DB2). Hive currently returns NULL (as Spark does) but HIVE-18291 is open to be SQL compliant.
The PR introduce an option to decide which behavior Spark should follow, ie. returning NULL on overflow or throwing an exception.
## How was this patch tested?
added UTs
Closes#20350 from mgaido91/SPARK-23179.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
[PostgreSQL](7c850320d8/src/test/regress/sql/strings.sql (L624)) support another trim pattern: `TRIM(trimStr FROM str)`:
Function | Return Type | Description | Example | Result
--- | --- | --- | --- | ---
trim([leading \| trailing \| both] [characters] from string) | text | Remove the longest string containing only characters from characters (a space by default) from the start, end, or both ends (both is the default) of string | trim(both 'xyz' from 'yxTomxx') | Tom
This pr add support this trim pattern. After this pr. We can support all standard syntax except `TRIM(FROM str)` because it conflicts with our Literals:
```sql
Literals of type 'FROM' are currently not supported.(line 1, pos 12)
== SQL ==
SELECT TRIM(FROM ' SPARK SQL ')
```
PostgreSQL, Vertica and MySQL support this pattern. Teradata, Oracle, DB2, SQL Server, Hive and Presto
**PostgreSQL**:
```
postgres=# SELECT substr(version(), 0, 16), trim('xyz' FROM 'yxTomxx');
substr | btrim
-----------------+-------
PostgreSQL 11.3 | Tom
(1 row)
```
**Vertica**:
```
dbadmin=> SELECT version(), trim('xyz' FROM 'yxTomxx');
version | btrim
------------------------------------+-------
Vertica Analytic Database v9.1.1-0 | Tom
(1 row)
```
**MySQL**:
```
mysql> SELECT version(), trim('xyz' FROM 'yxTomxx');
+-----------+----------------------------+
| version() | trim('xyz' FROM 'yxTomxx') |
+-----------+----------------------------+
| 5.7.26 | yxTomxx |
+-----------+----------------------------+
1 row in set (0.00 sec)
```
More details:
https://www.postgresql.org/docs/11/functions-string.html
## How was this patch tested?
unit tests
Closes#24924 from wangyum/SPARK-28075-2.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The `mapChildren` method in the TreeNode class is commonly used across the whole Spark SQL codebase. In this method, there's a if statement that checks non-empty children. However, there's a cached lazy val `containsChild`, which can avoid unnecessary computation since `containsChild` is used in other methods and therefore constructed anyway.
Benchmark showed that this optimization can improve the whole TPC-DS planning time by 6.8%. There is no regression on any TPC-DS query.
## How was this patch tested?
Existing UTs.
Closes#24925 from yeshengm/treenode-children.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR significantly improves the performance of `UTF8String.replace()` by performing direct replacement over UTF8 bytes instead of decoding those bytes into Java Strings.
In cases where the search string is not found (i.e. no replacements are performed, a case which I expect to be common) this new implementation performs no object allocation or memory copying.
My implementation is modeled after `commons-lang3`'s `StringUtils.replace()` method. As part of my implementation, I needed a StringBuilder / resizable buffer, so I moved `UTF8StringBuilder` from the `catalyst` package to `unsafe`.
## How was this patch tested?
Copied tests from `StringExpressionSuite` to `UTF8StringSuite` and added a couple of new cases.
To evaluate performance, I did some quick local benchmarking by running the following code in `spark-shell` (with Java 1.8.0_191):
```scala
import org.apache.spark.unsafe.types.UTF8String
def benchmark(text: String, search: String, replace: String) {
val utf8Text = UTF8String.fromString(text)
val utf8Search = UTF8String.fromString(search)
val utf8Replace = UTF8String.fromString(replace)
val start = System.currentTimeMillis
var i = 0
while (i < 1000 * 1000 * 100) {
utf8Text.replace(utf8Search, utf8Replace)
i += 1
}
val end = System.currentTimeMillis
println(end - start)
}
benchmark("ABCDEFGH", "DEF", "ZZZZ") // replacement occurs
benchmark("ABCDEFGH", "Z", "") // no replacement occurs
```
On my laptop this took ~54 / ~40 seconds seconds before this patch's changes and ~6.5 / ~3.8 seconds afterwards.
Closes#24707 from JoshRosen/faster-string-replace.
Authored-by: Josh Rosen <rosenville@gmail.com>
Signed-off-by: Josh Rosen <rosenville@gmail.com>
## What changes were proposed in this pull request?
[SPARK-28093](https://issues.apache.org/jira/browse/SPARK-28093) fixed `TRIM/LTRIM/RTRIM('str', 'trimStr')` returns an incorrect value, but that fix introduced a new bug, `TRIM(type trimStr FROM str)` returns an incorrect value. This pr fix this issue.
## How was this patch tested?
unit tests and manual tests:
Before this PR:
```sql
spark-sql> SELECT trim('yxTomxx', 'xyz'), trim(BOTH 'xyz' FROM 'yxTomxx');
Tom z
spark-sql> SELECT trim('xxxbarxxx', 'x'), trim(BOTH 'x' FROM 'xxxbarxxx');
bar
spark-sql> SELECT ltrim('zzzytest', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytest');
test xyz
spark-sql> SELECT ltrim('zzzytestxyz', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytestxyz');
testxyz
spark-sql> SELECT ltrim('xyxXxyLAST WORD', 'xy'), trim(LEADING 'xy' FROM 'xyxXxyLAST WORD');
XxyLAST WORD
spark-sql> SELECT rtrim('testxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'testxxzx');
test xy
spark-sql> SELECT rtrim('xyztestxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'xyztestxxzx');
xyztest
spark-sql> SELECT rtrim('TURNERyxXxy', 'xy'), trim(TRAILING 'xy' FROM 'TURNERyxXxy');
TURNERyxX
```
After this PR:
```sql
spark-sql> SELECT trim('yxTomxx', 'xyz'), trim(BOTH 'xyz' FROM 'yxTomxx');
Tom Tom
spark-sql> SELECT trim('xxxbarxxx', 'x'), trim(BOTH 'x' FROM 'xxxbarxxx');
bar bar
spark-sql> SELECT ltrim('zzzytest', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytest');
test test
spark-sql> SELECT ltrim('zzzytestxyz', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytestxyz');
testxyz testxyz
spark-sql> SELECT ltrim('xyxXxyLAST WORD', 'xy'), trim(LEADING 'xy' FROM 'xyxXxyLAST WORD');
XxyLAST WORD XxyLAST WORD
spark-sql> SELECT rtrim('testxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'testxxzx');
test test
spark-sql> SELECT rtrim('xyztestxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'xyztestxxzx');
xyztest xyztest
spark-sql> SELECT rtrim('TURNERyxXxy', 'xy'), trim(TRAILING 'xy' FROM 'TURNERyxXxy');
TURNERyxX TURNERyxX
```
And PostgreSQL:
```sql
postgres=# SELECT trim('yxTomxx', 'xyz'), trim(BOTH 'xyz' FROM 'yxTomxx');
btrim | btrim
-------+-------
Tom | Tom
(1 row)
postgres=# SELECT trim('xxxbarxxx', 'x'), trim(BOTH 'x' FROM 'xxxbarxxx');
btrim | btrim
-------+-------
bar | bar
(1 row)
postgres=# SELECT ltrim('zzzytest', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytest');
ltrim | ltrim
-------+-------
test | test
(1 row)
postgres=# SELECT ltrim('zzzytestxyz', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytestxyz');
ltrim | ltrim
---------+---------
testxyz | testxyz
(1 row)
postgres=# SELECT ltrim('xyxXxyLAST WORD', 'xy'), trim(LEADING 'xy' FROM 'xyxXxyLAST WORD');
ltrim | ltrim
--------------+--------------
XxyLAST WORD | XxyLAST WORD
(1 row)
postgres=# SELECT rtrim('testxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'testxxzx');
rtrim | rtrim
-------+-------
test | test
(1 row)
postgres=# SELECT rtrim('xyztestxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'xyztestxxzx');
rtrim | rtrim
---------+---------
xyztest | xyztest
(1 row)
postgres=# SELECT rtrim('TURNERyxXxy', 'xy'), trim(TRAILING 'xy' FROM 'TURNERyxXxy');
rtrim | rtrim
-----------+-----------
TURNERyxX | TURNERyxX
(1 row)
```
Closes#24911 from wangyum/SPARK-28109.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Current SQL parser's error message for hyphen-connected identifiers without surrounding backquotes(e.g. hyphen-table) is confusing for end users. A possible approach to tackle this is to explicitly capture these wrong usages in the SQL parser. In this way, the end users can fix these errors more quickly.
For example, for a simple query such as `SELECT * FROM test-table`, the original error message is
```
Error in SQL statement: ParseException:
mismatched input '-' expecting <EOF>(line 1, pos 18)
```
which can be confusing in a large query.
After the fix, the error message is:
```
Error in query:
Possibly unquoted identifier test-table detected. Please consider quoting it with back-quotes as `test-table`(line 1, pos 14)
== SQL ==
SELECT * FROM test-table
--------------^^^
```
which is easier for end users to identify the issue and fix.
We safely augmented the current grammar rule to explicitly capture these error cases. The error handling logic is implemented in the SQL parsing listener `PostProcessor`.
However, note that for cases such as `a - my-func(b)`, the parser can't actually tell whether this should be ``a -`my-func`(b) `` or `a - my - func(b)`. Therefore for these cases, we leave the parser as is. Also, in this patch we only provide better error messages for character-only identifiers.
## How was this patch tested?
Adding new unit tests.
Closes#24749 from yeshengm/hyphen-ident.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The original `references` and `validConstraints` implementations in a few `QueryPlan` and `Expression` classes are methods, which means unnecessary re-computation can happen at times. This PR resolves this problem by making these method `lazy val`s.
As shown in the following chart, the planning time(without cost-based optimization) was dramatically reduced after this optimization.
- The average planning time of TPC-DS queries was reduced by 19.63%.
- The planning time of the most time-consuming TPC-DS query (q64) was reduced by 43.03%.
- The running time for rule-based reordering joins(not cost-based join reordering) optimization, which are common in real-world OLAP queries, was largely reduced.
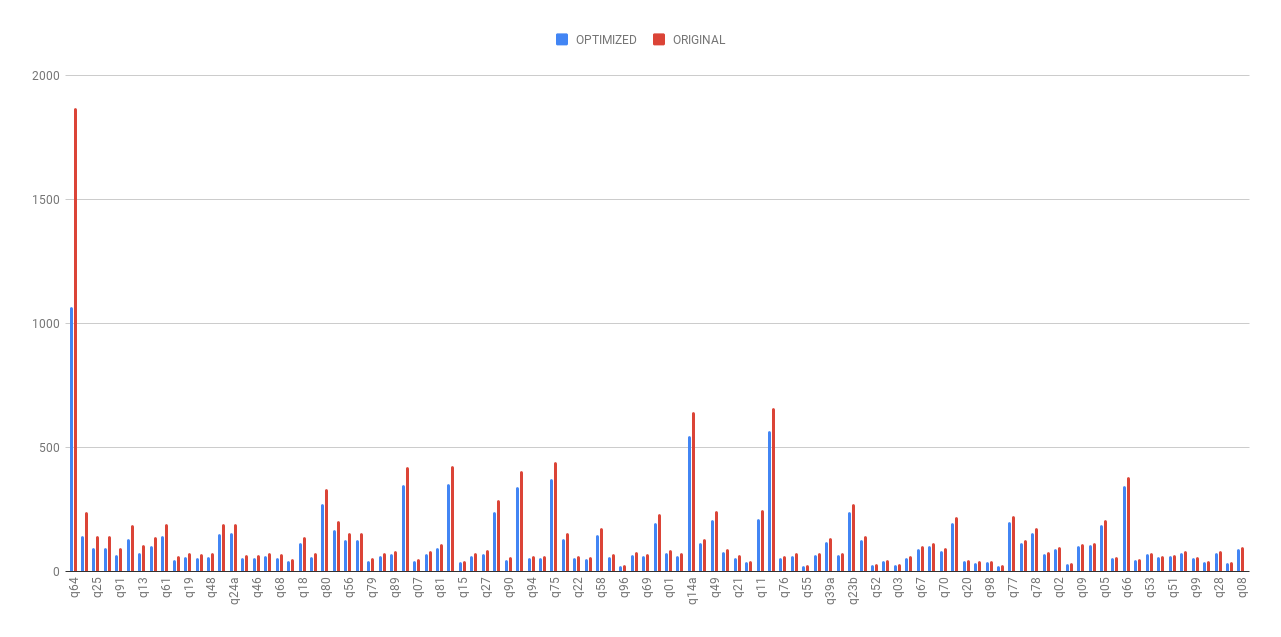
Detailed stats are listed in the following spreadsheet (we warmed up the queries 5 iterations and then took average of the next 5 iterations).
[Lazy val benchmark.xlsx](https://github.com/apache/spark/files/3303530/Lazy.val.benchmark.xlsx)
## How was this patch tested?
Existing UTs.
Closes#24866 from yeshengm/plannode-micro-opt.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Added an interface for handling hint errors, with a default implementation class that logs warnings in the callbacks.
## How was this patch tested?
Passed existing tests.
Closes#24653 from maryannxue/hint-handler.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
With JDK9+, the generate **bytecode** of `FromUnixTime` raise `java.lang.IncompatibleClassChangeError` due to [JDK-8145148](https://bugs.openjdk.java.net/browse/JDK-8145148) . This is a blocker in [Apache Spark JDK11 Jenkins job](https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7-jdk-11-ubuntu-testing/). Locally, this is reproducible by the following unit test suite with JDK9+.
```
$ build/sbt "catalyst/testOnly *.DateExpressionsSuite"
...
[info] org.apache.spark.sql.catalyst.expressions.DateExpressionsSuite *** ABORTED *** (23 seconds, 75 milliseconds)
[info] java.lang.IncompatibleClassChangeError: Method org.apache.spark.sql.catalyst.util.TimestampFormatter.apply(Ljava/lang/String;Ljava/time/ZoneId;Ljava/util/Locale;)Lorg/apache/spark/sql/catalyst/util/TimestampFormatter; must be InterfaceMeth
```
This bytecode issue is generated by `Janino` , so we replace `.apply` to `.MODULE$$.apply` and adds test coverage for similar codes.
## How was this patch tested?
Manually with the existing UTs by doing the following with JDK9+.
```
build/sbt "catalyst/testOnly *.DateExpressionsSuite"
```
Actually, this is the last JDK11 error in `catalyst` module. So, we can verify with the following, too.
```
$ build/sbt "project catalyst" test
...
[info] Total number of tests run: 3552
[info] Suites: completed 210, aborted 0
[info] Tests: succeeded 3552, failed 0, canceled 0, ignored 2, pending 0
[info] All tests passed.
[info] Passed: Total 3583, Failed 0, Errors 0, Passed 3583, Ignored 2
[success] Total time: 294 s, completed Jun 16, 2019, 10:15:08 PM
```
Closes#24889 from dongjoon-hyun/SPARK-28072.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
The `TRIM` function accept these patterns:
```sql
TRIM(str)
TRIM(trimStr, str)
TRIM(BOTH trimStr FROM str)
TRIM(LEADING trimStr FROM str)
TRIM(TRAILING trimStr FROM str)
```
This pr add support other three patterns:
```sql
TRIM(BOTH FROM str)
TRIM(LEADING FROM str)
TRIM(TRAILING FROM str)
```
PostgreSQL, Vertica, MySQL, Teradata, Oracle and DB2 support these patterns. Hive, Presto and SQL Server does not support this feature.
**PostgreSQL**:
```sql
postgres=# select substr(version(), 0, 16), trim(BOTH from ' SparkSQL '), trim(LEADING FROM ' SparkSQL '), trim(TRAILING FROM ' SparkSQL ');
substr | btrim | ltrim | rtrim
-----------------+----------+-------------+--------------
PostgreSQL 11.3 | SparkSQL | SparkSQL | SparkSQL
(1 row)
```
**Vertica**:
```
dbadmin=> select version(), trim(BOTH from ' SparkSQL '), trim(LEADING FROM ' SparkSQL '), trim(TRAILING FROM ' SparkSQL ');
version | btrim | ltrim | rtrim
------------------------------------+----------+-------------+--------------
Vertica Analytic Database v9.1.1-0 | SparkSQL | SparkSQL | SparkSQL
(1 row)
```
**MySQL**:
```
mysql> select version(), trim(BOTH from ' SparkSQL '), trim(LEADING FROM ' SparkSQL '), trim(TRAILING FROM ' SparkSQL ');
+-----------+-----------------------------------+--------------------------------------+---------------------------------------+
| version() | trim(BOTH from ' SparkSQL ') | trim(LEADING FROM ' SparkSQL ') | trim(TRAILING FROM ' SparkSQL ') |
+-----------+-----------------------------------+--------------------------------------+---------------------------------------+
| 5.7.26 | SparkSQL | SparkSQL | SparkSQL |
+-----------+-----------------------------------+--------------------------------------+---------------------------------------+
1 row in set (0.01 sec)
```
**Teradata**:

**Oracle**:

**DB2**:

## How was this patch tested?
unit tests
Closes#24891 from wangyum/SPARK-28075.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR aims to replace deprecated `.newInstance()` in DSv2 `Catalogs` and distinguish the plugin class errors more. According to the JDK11 build log, there is no other new instance.
- https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7-jdk-11-ubuntu-testing/978/consoleFull
SPARK-25984 removes all instances of the deprecated `.newInstance()` usages at Nov 10, 2018, but this was added at SPARK-24252 on March 8, 2019.
## How was this patch tested?
Pass the Jenkins with the updated test case.
Closes#24882 from dongjoon-hyun/SPARK-28063.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Currently `ArrayExists` always returns boolean values (if the arguments are not `null`), but it should follow the three-valued boolean logic:
- `true` if the predicate holds at least one `true`
- otherwise, `null` if the predicate holds `null`
- otherwise, `false`
This behavior change is made to match Postgres' equivalent function `ANY/SOME (array)`'s behavior: https://www.postgresql.org/docs/9.6/functions-comparisons.html#AEN21174
## How was this patch tested?
Modified tests and existing tests.
Closes#24873 from ueshin/issues/SPARK-28052/fix_exists.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Allow Pandas UDF to take an iterator of pd.Series or an iterator of tuple of pd.Series.
Note the UDF input args will be always one iterator:
* if the udf take only column as input, the iterator's element will be pd.Series (corresponding to the column values batch)
* if the udf take multiple columns as inputs, the iterator's element will be a tuple composed of multiple `pd.Series`s, each one corresponding to the multiple columns as inputs (keep the same order). For example:
```
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def the_udf(iterator):
for col1_batch, col2_batch in iterator:
yield col1_batch + col2_batch
df.select(the_udf("col1", "col2"))
```
The udf above will add col1 and col2.
I haven't add unit tests, but manually tests show it works fine. So it is ready for first pass review.
We can test several typical cases:
```
from pyspark.sql import SparkSession
from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql.functions import udf
from pyspark.taskcontext import TaskContext
df = spark.createDataFrame([(1, 20), (3, 40)], ["a", "b"])
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi1(it):
pid = TaskContext.get().partitionId()
print("DBG: fi1: do init stuff, partitionId=" + str(pid))
for batch in it:
yield batch + 100
print("DBG: fi1: do close stuff, partitionId=" + str(pid))
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi2(it):
pid = TaskContext.get().partitionId()
print("DBG: fi2: do init stuff, partitionId=" + str(pid))
for batch in it:
yield batch + 10000
print("DBG: fi2: do close stuff, partitionId=" + str(pid))
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi3(it):
pid = TaskContext.get().partitionId()
print("DBG: fi3: do init stuff, partitionId=" + str(pid))
for x, y in it:
yield x + y * 10 + 100000
print("DBG: fi3: do close stuff, partitionId=" + str(pid))
pandas_udf("int", PandasUDFType.SCALAR)
def fp1(x):
return x + 1000
udf("int")
def fu1(x):
return x + 10
# test select "pandas iter udf/pandas udf/sql udf" expressions at the same time.
# Note this case the `fi1("a"), fi2("b"), fi3("a", "b")` will generate only one plan,
# and `fu1("a")`, `fp1("a")` will generate another two separate plans.
df.select(fi1("a"), fi2("b"), fi3("a", "b"), fu1("a"), fp1("a")).show()
# test chain two pandas iter udf together
# Note this case `fi2(fi1("a"))` will generate only one plan
# Also note the init stuff/close stuff call order will be like:
# (debug output following)
# DBG: fi2: do init stuff, partitionId=0
# DBG: fi1: do init stuff, partitionId=0
# DBG: fi1: do close stuff, partitionId=0
# DBG: fi2: do close stuff, partitionId=0
df.select(fi2(fi1("a"))).show()
# test more complex chain
# Note this case `fi1("a"), fi2("a")` will generate one plan,
# and `fi3(fi1_output, fi2_output)` will generate another plan
df.select(fi3(fi1("a"), fi2("a"))).show()
```
## How was this patch tested?
To be added.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24643 from WeichenXu123/pandas_udf_iter.
Lead-authored-by: WeichenXu <weichen.xu@databricks.com>
Co-authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
Migrate Parquet to File Data Source V2
## How was this patch tested?
Unit test
Closes#24327 from gengliangwang/parquetV2.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Implemented a new SparkPlan that executes the query adaptively. It splits the query plan into independent stages and executes them in order according to their dependencies. The query stage materializes its output at the end. When one stage completes, the data statistics of the materialized output will be used to optimize the remainder of the query.
The adaptive mode is off by default, when turned on, user can see "AdaptiveSparkPlan" as the top node of a query or sub-query. The inner plan of "AdaptiveSparkPlan" is subject to change during query execution but becomes final once the execution is complete. Whether the inner plan is final is included in the EXPLAIN string. Below is an example of the EXPLAIN plan before and after execution:
Query:
```
SELECT * FROM testData JOIN testData2 ON key = a WHERE value = '1'
```
Before execution:
```
== Physical Plan ==
AdaptiveSparkPlan(isFinalPlan=false)
+- SortMergeJoin [key#13], [a#23], Inner
:- Sort [key#13 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(key#13, 5)
: +- Filter (isnotnull(value#14) AND (value#14 = 1))
: +- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).key AS key#13, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).value, true, false) AS value#14]
: +- Scan[obj#12]
+- Sort [a#23 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(a#23, 5)
+- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).a AS a#23, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).b AS b#24]
+- Scan[obj#22]
```
After execution:
```
== Physical Plan ==
AdaptiveSparkPlan(isFinalPlan=true)
+- *(1) BroadcastHashJoin [key#13], [a#23], Inner, BuildLeft
:- BroadcastQueryStage 2
: +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint)))
: +- ShuffleQueryStage 0
: +- Exchange hashpartitioning(key#13, 5)
: +- *(1) Filter (isnotnull(value#14) AND (value#14 = 1))
: +- *(1) SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).key AS key#13, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).value, true, false) AS value#14]
: +- Scan[obj#12]
+- ShuffleQueryStage 1
+- Exchange hashpartitioning(a#23, 5)
+- *(1) SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).a AS a#23, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).b AS b#24]
+- Scan[obj#22]
```
Credit also goes to carsonwang and cloud-fan
## How was this patch tested?
Added new UT.
Closes#24706 from maryannxue/aqe.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: herman <herman@databricks.com>
## What changes were proposed in this pull request?
This PR adds support of column aliasing in a CTE so this query becomes valid:
```
WITH t(x) AS (SELECT 1)
SELECT * FROM t WHERE x = 1
```
## How was this patch tested?
Added new UTs.
Closes#24842 from peter-toth/SPARK-28002.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Implemented the `clone` method for `TreeNode` based on `mapChildren`.
## How was this patch tested?
Added new UT.
Closes#24876 from maryannxue/treenode-clone.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: herman <herman@databricks.com>
## What changes were proposed in this pull request?
Currently, SparkSQL can support interval format like this.
```sql
SELECT INTERVAL '0 23:59:59.155' DAY TO SECOND
```
Like Presto/Teradata, this PR aims to support grammar like below.
```sql
SELECT INTERVAL '23:59:59.155' HOUR TO SECOND
```
Although we can add a new function for this pattern, we had better extend the existing code to handle a missing day case. So, the following is also supported.
```sql
SELECT INTERVAL '23:59:59.155' DAY TO SECOND
SELECT INTERVAL '1 23:59:59.155' HOUR TO SECOND
```
Currently Vertica/Teradata/Postgresql/SQL Server have fully support of below interval functions.
- interval ... year to month
- interval ... day to hour
- interval ... day to minute
- interval ... day to second
- interval ... hour to minute
- interval ... hour to second
- interval ... minute to second
https://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/SQLReferenceManual/LanguageElements/Literals/interval-qualifier.htmdf1a699e5b/src/test/regress/sql/interval.sql (L180-L203)https://docs.teradata.com/reader/S0Fw2AVH8ff3MDA0wDOHlQ/KdCtT3pYFo~_enc8~kGKVwhttps://docs.microsoft.com/en-us/sql/odbc/reference/appendixes/interval-literals?view=sql-server-2017
## How was this patch tested?
Pass the Jenkins with the updated test cases.
Closes#24472 from lipzhu/SPARK-27578.
Lead-authored-by: Zhu, Lipeng <lipzhu@ebay.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Lipeng Zhu <lipzhu@icloud.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Support multi-catalog in the following SELECT code paths:
- SELECT * FROM catalog.db.tbl
- TABLE catalog.db.tbl
- JOIN or UNION tables from different catalogs
- SparkSession.table("catalog.db.tbl")
- CTE relation
- View text
## How was this patch tested?
New unit tests.
All existing unit tests in catalyst and sql core.
Closes#24741 from jzhuge/SPARK-27322-pr.
Authored-by: John Zhuge <jzhuge@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
`NestedColumnAliasing` rule covers `GetStructField` only, currently. It means that some nested field extraction expressions aren't pruned. For example, if only accessing a nested field in an array of struct (`GetArrayStructFields`), this column isn't pruned.
This patch extends the rule to cover general nested field cases, including `GetArrayStructFields`.
## How was this patch tested?
Added tests.
Closes#24599 from viirya/nested-pruning-extract-value.
Lead-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
Current Spark SQL parser can have pretty confusing error messages when parsing an incorrect SELECT SQL statement. The proposed fix has the following effect.
BEFORE:
```
spark-sql> SELECT * FROM test WHERE x NOT NULL;
Error in query:
mismatched input 'FROM' expecting {<EOF>, 'CLUSTER', 'DISTRIBUTE', 'EXCEPT', 'GROUP', 'HAVING', 'INTERSECT', 'LATERAL', 'LIMIT', 'ORDER', 'MINUS', 'SORT', 'UNION', 'WHERE', 'WINDOW'}(line 1, pos 9)
== SQL ==
SELECT * FROM test WHERE x NOT NULL
---------^^^
```
where in fact the error message should be hinted to be near `NOT NULL`.
AFTER:
```
spark-sql> SELECT * FROM test WHERE x NOT NULL;
Error in query:
mismatched input 'NOT' expecting {<EOF>, 'AND', 'CLUSTER', 'DISTRIBUTE', 'EXCEPT', 'GROUP', 'HAVING', 'INTERSECT', 'LIMIT', 'OR', 'ORDER', 'MINUS', 'SORT', 'UNION', 'WINDOW'}(line 1, pos 27)
== SQL ==
SELECT * FROM test WHERE x NOT NULL
---------------------------^^^
```
In fact, this problem is brought by some problematic Spark SQL grammar. There are two kinds of SELECT statements that are supported by Hive (and thereby supported in SparkSQL):
* `FROM table SELECT blahblah SELECT blahblah`
* `SELECT blah FROM table`
*Reference* [HiveQL single-from stmt grammar](https://github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/parse/HiveParser.g)
It is fine when these two SELECT syntaxes are supported separately. However, since we are currently supporting these two kinds of syntaxes in a single ANTLR rule, this can be problematic and therefore leading to confusing parser errors. This is because when a SELECT clause was parsed, it can't tell whether the following FROM clause actually belongs to it or is just the beginning of a new `FROM table SELECT *` statement.
## What changes were proposed in this pull request?
1. Modify ANTLR grammar to fix the above-mentioned problem. This fix is important because the previous problematic grammar does affect a lot of real-world queries. Due to the previous problematic and messy grammar, we refactored the grammar related to `querySpecification`.
2. Modify `AstBuilder` to have separate visitors for `SELECT ... FROM ...` and `FROM ... SELECT ...` statements.
3. Drop the `FROM table` statement, which is supported by accident and is actually parsed in the wrong code path. Both Hive and Presto do not support this syntax.
## How was this patch tested?
Existing UTs and new UTs.
Closes#24809 from yeshengm/parser-refactor.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
## What changes were proposed in this pull request?
The new Spark ThriftServer SparkGetTablesOperation implemented in https://github.com/apache/spark/pull/22794 does a catalog.getTableMetadata request for every table. This can get very slow for large schemas (~50ms per table with an external Hive metastore).
Hive ThriftServer GetTablesOperation uses HiveMetastoreClient.getTableObjectsByName to get table information in bulk, but we don't expose that through our APIs that go through Hive -> HiveClientImpl (HiveClient) -> HiveExternalCatalog (ExternalCatalog) -> SessionCatalog.
If we added and exposed getTableObjectsByName through our catalog APIs, we could resolve that performance problem in SparkGetTablesOperation.
## How was this patch tested?
Add UT
Closes#24774 from LantaoJin/SPARK-27899.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Handle the case when ParsedStatement subclass has a Map field but not of type Map[String, String].
In ParsedStatement.productIterator, `case mapArg: Map[_, _]` can match any Map type due to type erasure, thus causing `asInstanceOf[Map[String, String]]` to throw ClassCastException.
The following test reproduces the issue:
```
case class TestStatement(p: Map[String, Int]) extends ParsedStatement {
override def output: Seq[Attribute] = Nil
override def children: Seq[LogicalPlan] = Nil
}
TestStatement(Map("abc" -> 1)).toString
```
Changing the code to `case mapArg: Map[String, String]` will not help due to type erasure. As a matter of fact, compiler gives this warning:
```
Warning:(41, 18) non-variable type argument String in type pattern
scala.collection.immutable.Map[String,String] (the underlying of Map[String,String])
is unchecked since it is eliminated by erasure
case mapArg: Map[String, String] =>
```
## How was this patch tested?
Add 2 unit tests.
Closes#24800 from jzhuge/SPARK-27947.
Authored-by: John Zhuge <jzhuge@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
For caseWhen Object canonicalized is not handled
for e.g let's consider below CaseWhen Object
val attrRef = AttributeReference("ACCESS_CHECK", StringType)()
val caseWhenObj1 = CaseWhen(Seq((attrRef, Literal("A"))))
caseWhenObj1.canonicalized **ouput** is as below
CASE WHEN ACCESS_CHECK#0 THEN A END (**Before Fix)**
**After Fix** : CASE WHEN none#0 THEN A END
So when there will be aliasref like below statements, semantic equals will fail. Sematic equals returns true if the canonicalized form of both the expressions are same.
val attrRef = AttributeReference("ACCESS_CHECK", StringType)()
val aliasAttrRef = attrRef.withName("access_check")
val caseWhenObj1 = CaseWhen(Seq((attrRef, Literal("A"))))
val caseWhenObj2 = CaseWhen(Seq((aliasAttrRef, Literal("A"))))
**assert(caseWhenObj2.semanticEquals(caseWhenObj1.semanticEquals) fails**
**caseWhenObj1.canonicalized**
Before Fix:CASE WHEN ACCESS_CHECK#0 THEN A END
After Fix: CASE WHEN none#0 THEN A END
**caseWhenObj2.canonicalized**
Before Fix:CASE WHEN access_check#0 THEN A END
After Fix: CASE WHEN none#0 THEN A END
## How was this patch tested?
Added UT
Closes#24766 from sandeep-katta/caseWhenIssue.
Authored-by: sandeep katta <sandeep.katta2007@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
When using `from_avro` to deserialize avro data to catalyst StructType format, if `ConvertToLocalRelation` is applied at the time, `from_avro` produces only the last value (overriding previous values).
The cause is `AvroDeserializer` reuses output row for StructType. Normally, it should be fine in Spark SQL. But `ConvertToLocalRelation` just uses `InterpretedProjection` to project local rows. `InterpretedProjection` creates new row for each output thro, it includes the same nested row object from `AvroDeserializer`. By the end, converted local relation has only last value.
I think there're two possible options:
1. Make `AvroDeserializer` output new row for StructType.
2. Use `InterpretedMutableProjection` in `ConvertToLocalRelation` and call `copy()` on output rows.
Option 2 is chose because previously `ConvertToLocalRelation` also creates new rows, this `InterpretedMutableProjection` + `copy()` shoudn't bring too much performance penalty. `ConvertToLocalRelation` should be arguably less critical, compared with `AvroDeserializer`.
## How was this patch tested?
Added test.
Closes#24805 from viirya/SPARK-27798.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Add extractors for v2 catalog transforms.
These extractors are used to match transforms that are equivalent to Spark's internal case classes. This makes it easier to work with v2 transforms.
## How was this patch tested?
Added test suite for the new extractors.
Closes#24812 from rdblue/SPARK-27965-add-transform-extractors.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In PR https://github.com/apache/spark/pull/24365, we pass in the partitionBy columns as options in `DataFrameWriter`. To make this change less intrusive for a patch release, we added a feature flag `LEGACY_PASS_PARTITION_BY_AS_OPTIONS` with the default to be false.
For 3.0, we should just do the correct behavior for DSV1, i.e., always passing partitionBy as options, and remove this legacy feature flag.
## How was this patch tested?
Existing tests.
Closes#24784 from liwensun/SPARK-27453-default.
Authored-by: liwensun <liwen.sun@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}