### What changes were proposed in this pull request?
1. Extend SQL syntax rules to support a sign before the interval strings of ANSI year-month and day-time intervals.
2. Recognize `-` in `AstBuilder` and negate parsed intervals.
### Why are the changes needed?
To conform to the SQL standard which allows a sign before the string interval, see `"5.3 <literal>"`:
```
<interval literal> ::=
INTERVAL [ <sign> ] <interval string> <interval qualifier>
<interval string> ::=
<quote> <unquoted interval string> <quote>
<unquoted interval string> ::=
[ <sign> ] { <year-month literal> | <day-time literal> }
<sign> ::=
<plus sign>
| <minus sign>
```
### Does this PR introduce _any_ user-facing change?
Should not because it just extends supported intervals syntax.
### How was this patch tested?
By running new tests in `interval.sql`:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#32134 from MaxGekk/negative-parsed-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
According to http://www.tpc.org/tpc_documents_current_versions/pdf/tpc-ds_v2.9.0.pdf
```
2.2.2 Datatype
2.2.2.1 Each column employs one of the following datatypes:
a) Identifier means that the column shall be able to hold any key value generated for that column.
b) Integer means that the column shall be able to exactly represent integer values (i.e., values in increments of
1) in the range of at least ( − 2n − 1) to (2n − 1 − 1), where n is 64.
c) Decimal(d, f) means that the column shall be able to represent decimal values up to and including d digits,
of which f shall occur to the right of the decimal place; the values can be either represented exactly or
interpreted to be in this range.
d) Char(N) means that the column shall be able to hold any string of characters of a fixed length of N.
Comment: If the string that a column of datatype char(N) holds is shorter than N characters, then trailing
spaces shall be stored in the database or the database shall automatically pad with spaces upon retrieval such
that a CHAR_LENGTH() function will return N.
e) Varchar(N) means that the column shall be able to hold any string of characters of a variable length with a
maximum length of N. Columns defined as "varchar(N)" may optionally be implemented as "char(N)".
f) Date means that the column shall be able to express any calendar day between January 1, 1900 and
December 31, 2199.
2.2.2.2 The datatypes do not correspond to any specific SQL-standard datatype. The definitions are provided to
highlight the properties that are required for a particular column. The benchmark implementer may employ any internal representation or SQL datatype that meets those requirements.
```
This PR proposes that we use int for identifiers instead of bigint to reach a compromise with TPC-DS Standard Specification.
After this PR, the field schemas are now consistent with those DDLs in the `tpcds.sql` from tpc-ds tool kit, see https://gist.github.com/yaooqinn/b9978a77bbf4f871a95d6a9103019907
### Why are the changes needed?
reach a compromise with TPC-DS Standard Specification
### Does this PR introduce _any_ user-facing change?
no test only
### How was this patch tested?
test only
Closes#32037 from yaooqinn/SPARK-34944.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
Disallow group by aliases under ANSI mode.
### Why are the changes needed?
As per the ANSI SQL standard secion 7.12 <group by clause>:
>Each `grouping column reference` shall unambiguously reference a column of the table resulting from the `from clause`. A column referenced in a `group by clause` is a grouping column.
By forbidding it, we can avoid ambiguous SQL queries like:
```
SELECT col + 1 as col FROM t GROUP BY col
```
### Does this PR introduce _any_ user-facing change?
Yes, group by aliases is not allowed under ANSI mode.
### How was this patch tested?
Unit tests
Closes#32129 from gengliangwang/disallowGroupByAlias.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
For Spark SQL, it can't support script transform SQL with aggregationClause/windowClause/LateralView.
This case we can't directly migration Hive SQL to Spark SQL.
In this PR, we treat all script transform statement's query part (exclude transform about part) as a separate query block and solve it as ScriptTransformation's child and pass a UnresolvedStart as ScriptTransform's input. Then in analyzer level, we pass child's output as ScriptTransform's input. Then we can support all kind of normal SELECT query combine with script transformation.
Such as transform with aggregation:
```
SELECT TRANSFORM ( d2, max(d1) as max_d1, sum(d3))
USING 'cat' AS (a,b,c)
FROM script_trans
WHERE d1 <= 100
GROUP BY d2
HAVING max_d1 > 0
```
When we build AST, we treat it as
```
SELECT TRANSFORM (*)
USING 'cat' AS (a,b,c)
FROM (
SELECT d2, max(d1) as max_d1, sum(d3)
FROM script_trans
WHERE d1 <= 100
GROUP BY d2
HAVING max_d1 > 0
) tmp
```
then in Analyzer's `ResolveReferences`, resolve `* (UnresolvedStar)`, then sql behavior like
```
SELECT TRANSFORM ( d2, max(d1) as max_d1, sum(d3))
USING 'cat' AS (a,b,c)
FROM script_trans
WHERE d1 <= 100
GROUP BY d2
HAVING max_d1 > 0
```
About UT, in this pr we add a lot of different SQL to check we can support all kind of such SQL and each kind of expressions can work well, such as alias, case when, binary compute etc...
### Why are the changes needed?
Support transform with aggregateClause/windowClause/LateralView etc , make sql migration more smoothly
### Does this PR introduce _any_ user-facing change?
User can write transform with aggregateClause/windowClause/LateralView.
### How was this patch tested?
Added UT
Closes#29087 from AngersZhuuuu/SPARK-28227-NEW.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/31708 . For full outer join, the final result RDD is created from
```
sparkContext.union(
matchedStreamRows,
sparkContext.makeRDD(notMatchedBroadcastRows)
)
```
It's incorrect to say that the final output partitioning is `UnknownPartitioning(left.outputPartitioning.numPartitions)`
### Why are the changes needed?
Fix a correctness bug
### Does this PR introduce _any_ user-facing change?
Yes, see the added test. Fortunately, this bug is not released yet.
### How was this patch tested?
new test
Closes#32132 from cloud-fan/bug.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
This pr add test and document for Parquet Bloom filter push down.
### Why are the changes needed?
Improve document.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Generating docs:

Closes#32123 from wangyum/SPARK-34562.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Remove `spark.sql.legacy.interval.enabled` settings from `SQLQueryTestSuite`/`ThriftServerQueryTestSuite` that enables new ANSI intervals by default.
### Why are the changes needed?
To use default settings for intervals, and test new ANSI intervals - year-month and day-time interval introduced by SPARK-27793.
### Does this PR introduce _any_ user-facing change?
Should not because this affects tests only.
### How was this patch tested?
By running the affected tests, for instance:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#32099 from MaxGekk/enable-ansi-intervals-sql-tests.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Support GROUP BY use Separate columns and CUBE/ROLLUP
In postgres sql, it support
```
select a, b, c, count(1) from t group by a, b, cube (a, b, c);
select a, b, c, count(1) from t group by a, b, rollup(a, b, c);
select a, b, c, count(1) from t group by cube(a, b), rollup (a, b, c);
select a, b, c, count(1) from t group by a, b, grouping sets((a, b), (a), ());
```
In this pr, we have done two things as below:
1. Support partial grouping analytics such as `group by a, cube(a, b)`
2. Support mixed grouping analytics such as `group by cube(a, b), rollup(b,c)`
*Partial Groupings*
Partial Groupings means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
in GROUP BY clause. For example:
`GROUP BY warehouse, CUBE(product, location)` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse, location), (warehouse))`.
`GROUP BY warehouse, ROLLUP(product, location)` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse))`.
`GROUP BY warehouse, GROUPING SETS((product, location), (producet), ())` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, location), (warehouse))`.
*Concatenated Groupings*
Concatenated groupings offer a concise way to generate useful combinations of groupings. Groupings specified
with concatenated groupings yield the cross-product of groupings from each grouping set. The cross-product
operation enables even a small number of concatenated groupings to generate a large number of final groups.
The concatenated groupings are specified simply by listing multiple `GROUPING SETS`, `CUBES`, and `ROLLUP`,
and separating them with commas. For example:
`GROUP BY GROUPING SETS((warehouse), (producet)), GROUPING SETS((location), (size))` is equivalent to
`GROUP BY GROUPING SETS((warehouse, location), (warehouse, size), (product, location), (product, size))`.
`GROUP BY CUBE((warehouse), (producet)), ROLLUP((location), (size))` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product), (warehouse), (producet), ()), GROUPING SETS((location, size), (location), ())`
`GROUP BY GROUPING SETS(
(warehouse, product, location, size), (warehouse, product, location), (warehouse, product),
(warehouse, location, size), (warehouse, location), (warehouse),
(product, location, size), (product, location), (product),
(location, size), (location), ())`.
`GROUP BY order, CUBE((warehouse), (producet)), ROLLUP((location), (size))` is equivalent to
`GROUP BY order, GROUPING SETS((warehouse, product), (warehouse), (producet), ()), GROUPING SETS((location, size), (location), ())`
`GROUP BY GROUPING SETS(
(order, warehouse, product, location, size), (order, warehouse, product, location), (order, warehouse, product),
(order, warehouse, location, size), (order, warehouse, location), (order, warehouse),
(order, product, location, size), (order, product, location), (order, product),
(order, location, size), (order, location), (order))`.
### Why are the changes needed?
Support more flexible grouping analytics
### Does this PR introduce _any_ user-facing change?
User can use sql like
```
select a, b, c, agg_expr() from table group by a, cube(b, c)
```
### How was this patch tested?
Added UT
Closes#30144 from AngersZhuuuu/SPARK-33229.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
before when we use aggregate ordinal in group by expression and index position is a aggregate function, it will show error as
```
– !query
select a, b, sum(b) from data group by 3
– !query schema
struct<>
– !query output
org.apache.spark.sql.AnalysisException
aggregate functions are not allowed in GROUP BY, but found sum(data.b)
```
It't not clear enough refactor this error message in this pr
### Why are the changes needed?
refactor error message
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existed UT
Closes#32089 from AngersZhuuuu/SPARK-34986.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. Extend `IntervalUtils` methods: `toYearMonthIntervalString` and `toDayTimeIntervalString` to support formatting of year-month/day-time intervals in Hive style. The methods get new parameter style which can have to values; `HIVE_STYLE` and `ANSI_STYLE`.
2. Invoke `toYearMonthIntervalString` and `toDayTimeIntervalString` from the `Cast` expression with the `style` parameter is set to `ANSI_STYLE`.
3. Invoke `toYearMonthIntervalString` and `toDayTimeIntervalString` from `HiveResult` with `style` is set to `HIVE_STYLE`.
### Why are the changes needed?
The `spark-sql` shell formats its output in Hive style by using `HiveResult.hiveResultString()`. The changes are needed to match Hive behavior. For instance,
Hive:
```sql
0: jdbc:hive2://localhost:10000/default> select timestamp'2021-01-01 01:02:03.000001' - date'2020-12-31';
+-----------------------+
| _c0 |
+-----------------------+
| 1 01:02:03.000001000 |
+-----------------------+
```
Spark before the changes:
```sql
spark-sql> select timestamp'2021-01-01 01:02:03.000001' - date'2020-12-31';
INTERVAL '1 01:02:03.000001' DAY TO SECOND
```
Also this should unblock #32099 which enables *.sql tests in `SQLQueryTestSuite`.
### Does this PR introduce _any_ user-facing change?
Yes. After the changes:
```sql
spark-sql> select timestamp'2021-01-01 01:02:03.000001' - date'2020-12-31';
1 01:02:03.000001000
```
### How was this patch tested?
1. Added new tests to `IntervalUtilsSuite`:
```
$ build/sbt "test:testOnly *IntervalUtilsSuite"
```
2. Modified existing tests in `HiveResultSuite`:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "testOnly *HiveResultSuite"
```
3. By running cast tests:
```
$ build/sbt "testOnly *CastSuite*"
```
Closes#32120 from MaxGekk/ansi-intervals-hive-thrift-server.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This patch proposes a fix of nested column pruning for extracting case-insensitive struct field from array of struct.
### Why are the changes needed?
Under case-insensitive mode, nested column pruning rule cannot correctly push down extractor of a struct field of an array of struct, e.g.,
```scala
val query = spark.table("contacts").select("friends.First", "friends.MiDDle")
```
Error stack:
```
[info] java.lang.IllegalArgumentException: Field "First" does not exist.
[info] Available fields:
[info] at org.apache.spark.sql.types.StructType$$anonfun$apply$1.apply(StructType.scala:274)
[info] at org.apache.spark.sql.types.StructType$$anonfun$apply$1.apply(StructType.scala:274)
[info] at scala.collection.MapLike$class.getOrElse(MapLike.scala:128)
[info] at scala.collection.AbstractMap.getOrElse(Map.scala:59)
[info] at org.apache.spark.sql.types.StructType.apply(StructType.scala:273)
[info] at org.apache.spark.sql.execution.ProjectionOverSchema$$anonfun$getProjection$3.apply(ProjectionOverSchema.scala:44)
[info] at org.apache.spark.sql.execution.ProjectionOverSchema$$anonfun$getProjection$3.apply(ProjectionOverSchema.scala:41)
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes#32059 from viirya/fix-array-nested-pruning.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
Implements `readShorts` in `VectorizedPlainValuesReader`, which decodes `total` shorts in the input buffer at one time, similar to other types.
### Why are the changes needed?
Currently `VectorizedRleValuesReader` reads short integer in the following way:
```java
for (int i = 0; i < n; i++) {
c.putShort(rowId + i, (short)data.readInteger());
}
```
For PLAIN encoding `data.readInteger` is done via:
```java
public final int readInteger() {
return getBuffer(4).getInt();
}
```
which means it needs to repeatedly call `slice` buffer for the batch size number of times. This is more expensive than calling it once in a big chunk and then reading the ints out.
Micro benchmark via `DataSourceReadBenchmark` showed ~35% perf improvement.
Before:
```
[info] OpenJDK 64-Bit Server VM 11.0.8+10-LTS on Mac OS X 10.16
[info] Intel(R) Core(TM) i9-9880H CPU 2.30GHz
[info] SQL Single SMALLINT Column Scan: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] SQL CSV 10249 10271 32 1.5 651.6 1.0X
[info] SQL Json 5963 5982 28 2.6 379.1 1.7X
[info] SQL Parquet Vectorized 141 151 15 111.9 8.9 72.9X
[info] SQL Parquet MR 1454 1491 52 10.8 92.4 7.0X
[info] SQL ORC Vectorized 160 164 3 98.3 10.2 64.1X
[info] SQL ORC MR 1133 1164 44 13.9 72.0 9.0X
```
After:
```
[info] OpenJDK 64-Bit Server VM 11.0.8+10-LTS on Mac OS X 10.16
[info] Intel(R) Core(TM) i9-9880H CPU 2.30GHz
[info] SQL Single SMALLINT Column Scan: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] SQL CSV 10489 10535 65 1.5 666.8 1.0X
[info] SQL Json 5864 5888 34 2.7 372.8 1.8X
[info] SQL Parquet Vectorized 104 111 8 151.0 6.6 100.7X
[info] SQL Parquet MR 1458 1472 20 10.8 92.7 7.2X
[info] SQL ORC Vectorized 157 166 7 100.0 10.0 66.7X
[info] SQL ORC MR 1121 1147 37 14.0 71.2 9.4X
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests
Closes#32104 from sunchao/smallint.
Authored-by: Chao Sun <sunchao@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
One of the main performance bottlenecks in query compilation is overly-generic tree transformation methods, namely `mapChildren` and `withNewChildren` (defined in `TreeNode`). These methods have an overly-generic implementation to iterate over the children and rely on reflection to create new instances. We have observed that, especially for queries with large query plans, a significant amount of CPU cycles are wasted in these methods. In this PR we make these methods more efficient, by delegating the iteration and instantiation to concrete node types. The benchmarks show that we can expect significant performance improvement in total query compilation time in queries with large query plans (from 30-80%) and about 20% on average.
#### Problem detail
The `mapChildren` method in `TreeNode` is overly generic and costly. To be more specific, this method:
- iterates over all the fields of a node using Scala’s product iterator. While the iteration is not reflection-based, thanks to the Scala compiler generating code for `Product`, we create many anonymous functions and visit many nested structures (recursive calls).
The anonymous functions (presumably compiled to Java anonymous inner classes) also show up quite high on the list in the object allocation profiles, so we are putting unnecessary pressure on GC here.
- does a lot of comparisons. Basically for each element returned from the product iterator, we check if it is a child (contained in the list of children) and then transform it. We can avoid that by just iterating over children, but in the current implementation, we need to gather all the fields (only transform the children) so that we can instantiate the object using the reflection.
- creates objects using reflection, by delegating to the `makeCopy` method, which is several orders of magnitude slower than using the constructor.
#### Solution
The proposed solution in this PR is rather straightforward: we rewrite the `mapChildren` method using the `children` and `withNewChildren` methods. The default `withNewChildren` method suffers from the same problems as `mapChildren` and we need to make it more efficient by specializing it in concrete classes. Similar to how each concrete query plan node already defines its children, it should also define how they can be constructed given a new list of children. Actually, the implementation is quite simple in most cases and is a one-liner thanks to the copy method present in Scala case classes. Note that we cannot abstract over the copy method, it’s generated by the compiler for case classes if no other type higher in the hierarchy defines it. For most concrete nodes, the implementation of `withNewChildren` looks like this:
```
override def withNewChildren(newChildren: Seq[LogicalPlan]): LogicalPlan = copy(children = newChildren)
```
The current `withNewChildren` method has two properties that we should preserve:
- It returns the same instance if the provided children are the same as its children, i.e., it preserves referential equality.
- It copies tags and maintains the origin links when a new copy is created.
These properties are hard to enforce in the concrete node type implementation. Therefore, we propose a template method `withNewChildrenInternal` that should be rewritten by the concrete classes and let the `withNewChildren` method take care of referential equality and copying:
```
override def withNewChildren(newChildren: Seq[LogicalPlan]): LogicalPlan = {
if (childrenFastEquals(children, newChildren)) {
this
} else {
CurrentOrigin.withOrigin(origin) {
val res = withNewChildrenInternal(newChildren)
res.copyTagsFrom(this)
res
}
}
}
```
With the refactoring done in a previous PR (https://github.com/apache/spark/pull/31932) most tree node types fall in one of the categories of `Leaf`, `Unary`, `Binary` or `Ternary`. These traits have a more efficient implementation for `mapChildren` and define a more specialized version of `withNewChildrenInternal` that avoids creating unnecessary lists. For example, the `mapChildren` method in `UnaryLike` is defined as follows:
```
override final def mapChildren(f: T => T): T = {
val newChild = f(child)
if (newChild fastEquals child) {
this.asInstanceOf[T]
} else {
CurrentOrigin.withOrigin(origin) {
val res = withNewChildInternal(newChild)
res.copyTagsFrom(this.asInstanceOf[T])
res
}
}
}
```
#### Results
With this PR, we have observed significant performance improvements in query compilation time, more specifically in the analysis and optimization phases. The table below shows the TPC-DS queries that had more than 25% speedup in compilation times. Biggest speedups are observed in queries with large query plans.
| Query | Speedup |
| ------------- | ------------- |
|q4 |29%|
|q9 |81%|
|q14a |31%|
|q14b |28%|
|q22 |33%|
|q33 |29%|
|q34 |25%|
|q39 |27%|
|q41 |27%|
|q44 |26%|
|q47 |28%|
|q48 |76%|
|q49 |46%|
|q56 |26%|
|q58 |43%|
|q59 |46%|
|q60 |50%|
|q65 |59%|
|q66 |46%|
|q67 |52%|
|q69 |31%|
|q70 |30%|
|q96 |26%|
|q98 |32%|
#### Binary incompatibility
Changing the `withNewChildren` in `TreeNode` breaks the binary compatibility of the code compiled against older versions of Spark because now it is expected that concrete `TreeNode` subclasses all implement the `withNewChildrenInternal` method. This is a problem, for example, when users write custom expressions. This change is the right choice, since it forces all newly added expressions to Catalyst implement it in an efficient manner and will prevent future regressions.
Please note that we have not completely removed the old implementation and renamed it to `legacyWithNewChildren`. This method will be removed in the future and for now helps the transition. There are expressions such as `UpdateFields` that have a complex way of defining children. Writing `withNewChildren` for them requires refactoring the expression. For now, these expressions use the old, slow method. In a future PR we address these expressions.
### Does this PR introduce _any_ user-facing change?
This PR does not introduce user facing changes but my break binary compatibility of the code compiled against older versions. See the binary compatibility section.
### How was this patch tested?
This PR is mainly a refactoring and passes existing tests.
Closes#32030 from dbaliafroozeh/ImprovedMapChildren.
Authored-by: Ali Afroozeh <ali.afroozeh@databricks.com>
Signed-off-by: herman <herman@databricks.com>
### What changes were proposed in this pull request?
Implement toString() and sql() methods for TRY_CAST
### Why are the changes needed?
The new expression should have a different name from `CAST` in SQL/String representation.
### Does this PR introduce _any_ user-facing change?
Yes, in the result of `explain()`, users can see try_cast if the new expression is used.
### How was this patch tested?
Unit tests.
Closes#32098 from gengliangwang/tryCastString.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
Remove some unused fields and methods in `SpecificParquetRecordReaderBase` and `VectorizedColumnReader`.
### Why are the changes needed?
Some fields and methods in these classes are no longer used since years ago. It's better to clean them up to make the code easier to maintain and read.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests
Closes#32071 from sunchao/cleanup-parquet.
Authored-by: Chao Sun <sunchao@apple.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
Extend `HiveResult.toHiveString()` to support new interval types `YearMonthIntervalType` and `DayTimeIntervalType`.
### Why are the changes needed?
To fix failures while formatting ANSI intervals as Hive strings. For example:
```sql
spark-sql> select timestamp'now' - date'2021-01-01';
21/04/08 09:42:49 ERROR SparkSQLDriver: Failed in [select timestamp'now' - date'2021-01-01']
scala.MatchError: (PT2337H42M46.649S,DayTimeIntervalType) (of class scala.Tuple2)
at org.apache.spark.sql.execution.HiveResult$.toHiveString(HiveResult.scala:97)
```
### Does this PR introduce _any_ user-facing change?
Yes. After the changes:
```sql
spark-sql> select timestamp'now' - date'2021-01-01';
INTERVAL '97 09:37:52.171' DAY TO SECOND
```
### How was this patch tested?
By running new tests:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "testOnly *HiveResultSuite"
```
Closes#32087 from MaxGekk/ansi-interval-hiveResultString.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Change UpdateAction and InsertAction of MergeIntoTable to explicitly represent star,
### Why are the changes needed?
Currently, UpdateAction and InsertAction in the MergeIntoTable implicitly represent `update set *` and `insert *` with empty assignments. That means there is no way to differentiate between the representations of "update all columns" and "update no columns". For SQL MERGE queries, this inability does not matter because the SQL MERGE grammar that generated the MergeIntoTable plan does not allow "update no columns". However, other ways of generating the MergeIntoTable plan may not have that limitation, and may want to allow specifying "update no columns". For example, in the Delta Lake project we provide a type-safe Scala API for Merge, where it is perfectly valid to produce a Merge query with an update clause but no update assignments. Currently, we cannot use MergeIntoTable to represent this plan, thus complicating the generation, and resolution of merge query from scala API.
Side note: fixed another bug where a merge plan with star and no other expressions with unresolved attributes (e.g. all non-optional predicates are `literal(true)`), then resolution will be skipped and star wont expanded. added test for that.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing unit tests
Closes#32067 from tdas/SPARK-34962-2.
Authored-by: Tathagata Das <tathagata.das1565@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, we can't support use ordinal in CUBE/ROLLUP/GROUPING SETS,
this pr make CUBE/ROLLUP/GROUPING SETS support GROUP BY ordinal
### Why are the changes needed?
Make CUBE/ROLLUP/GROUPING SETS support GROUP BY ordinal.
Postgres SQL and TeraData support this use case.
### Does this PR introduce _any_ user-facing change?
User can use ordinal in CUBE/ROLLUP/GROUPING SETS, such as
```
-- can use ordinal in CUBE
select a, b, count(1) from data group by cube(1, 2);
-- mixed cases: can use ordinal in CUBE
select a, b, count(1) from data group by cube(1, b);
-- can use ordinal with cube
select a, b, count(1) from data group by 1, 2 with cube;
-- can use ordinal in ROLLUP
select a, b, count(1) from data group by rollup(1, 2);
-- mixed cases: can use ordinal in ROLLUP
select a, b, count(1) from data group by rollup(1, b);
-- can use ordinal with rollup
select a, b, count(1) from data group by 1, 2 with rollup;
-- can use ordinal in GROUPING SETS
select a, b, count(1) from data group by grouping sets((1), (2), (1, 2));
-- mixed cases: can use ordinal in GROUPING SETS
select a, b, count(1) from data group by grouping sets((1), (b), (a, 2));
select a, b, count(1) from data group by a, 2 grouping sets((1), (b), (a, 2));
```
### How was this patch tested?
Added UT
Closes#30145 from AngersZhuuuu/SPARK-33233.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes an issue that `ADD JAR` command can't add jar files which contain whitespaces in the path though `ADD FILE` and `ADD ARCHIVE` work with such files.
If we have `/some/path/test file.jar` and execute the following command:
```
ADD JAR "/some/path/test file.jar";
```
The following exception is thrown.
```
21/04/05 10:40:38 ERROR SparkSQLDriver: Failed in [add jar "/some/path/test file.jar"]
java.lang.IllegalArgumentException: Illegal character in path at index 9: /some/path/test file.jar
at java.net.URI.create(URI.java:852)
at org.apache.spark.sql.hive.HiveSessionResourceLoader.addJar(HiveSessionStateBuilder.scala:129)
at org.apache.spark.sql.execution.command.AddJarCommand.run(resources.scala:34)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:79)
```
This is because `HiveSessionStateBuilder` and `SessionStateBuilder` don't check whether the form of the path is URI or plain path and it always regards the path as URI form.
Whitespces should be encoded to `%20` so `/some/path/test file.jar` is rejected.
We can resolve this part by checking whether the given path is URI form or not.
Unfortunatelly, if we fix this part, another problem occurs.
When we execute `ADD JAR` command, Hive's `ADD JAR` command is executed in `HiveClientImpl.addJar` and `AddResourceProcessor.run` is transitively invoked.
In `AddResourceProcessor.run`, the command line is just split by `
s+` and the path is also split into `/some/path/test` and `file.jar` and passed to `ss.add_resources`.
f1e8713703/ql/src/java/org/apache/hadoop/hive/ql/processors/AddResourceProcessor.java (L56-L75)
So, the command still fails.
Even if we convert the form of the path to URI like `file:/some/path/test%20file.jar` and execute the following command:
```
ADD JAR "file:/some/path/test%20file";
```
The following exception is thrown.
```
21/04/05 10:40:53 ERROR SessionState: file:/some/path/test%20file.jar does not exist
java.lang.IllegalArgumentException: file:/some/path/test%20file.jar does not exist
at org.apache.hadoop.hive.ql.session.SessionState.validateFiles(SessionState.java:1168)
at org.apache.hadoop.hive.ql.session.SessionState$ResourceType.preHook(SessionState.java:1289)
at org.apache.hadoop.hive.ql.session.SessionState$ResourceType$1.preHook(SessionState.java:1278)
at org.apache.hadoop.hive.ql.session.SessionState.add_resources(SessionState.java:1378)
at org.apache.hadoop.hive.ql.session.SessionState.add_resources(SessionState.java:1336)
at org.apache.hadoop.hive.ql.processors.AddResourceProcessor.run(AddResourceProcessor.java:74)
```
The reason is `Utilities.realFile` invoked in `SessionState.validateFiles` returns `null` as the result of `fs.exists(path)` is `false`.
f1e8713703/ql/src/java/org/apache/hadoop/hive/ql/exec/Utilities.java (L1052-L1064)
`fs.exists` checks the existence of the given path by comparing the string representation of Hadoop's `Path`.
The string representation of `Path` is similar to URI but it's actually different.
`Path` doesn't encode the given path.
For example, the URI form of `/some/path/jar file.jar` is `file:/some/path/jar%20file.jar` but the `Path` form of it is `file:/some/path/jar file.jar`. So `fs.exists` returns false.
So the solution I come up with is removing Hive's `ADD JAR` from `HiveClientimpl.addJar`.
I think Hive's `ADD JAR` was used to add jar files to the class loader for metadata and isolate the class loader from the one for execution.
https://github.com/apache/spark/pull/6758/files#diff-cdb07de713c84779a5308f65be47964af865e15f00eb9897ccf8a74908d581bbR94-R103
But, as of SPARK-10810 and SPARK-10902 (#8909) are resolved, the class loaders for metadata and execution seem to be isolated with different way.
https://github.com/apache/spark/pull/8909/files#diff-8ef7cabf145d3fe7081da799fa415189d9708892ed76d4d13dd20fa27021d149R635-R641
In the current implementation, such class loaders seem to be isolated by `SharedState.jarClassLoader` and `IsolatedClientLoader.classLoader`.
https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/internal/SessionState.scala#L173-L188https://github.com/apache/spark/blob/master/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala#L956-L967
So I wonder we can remove Hive's `ADD JAR` from `HiveClientImpl.addJar`.
### Why are the changes needed?
This is a bug.
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#32052 from sarutak/add-jar-whitespace.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
The `explain()` method prints the arguments of tree nodes in logical/physical plans. The arguments could contain a map-type option that contains sensitive data.
We should map-type options in the output of `explain()`. Otherwise, we will see sensitive data in explain output or Spark UI.
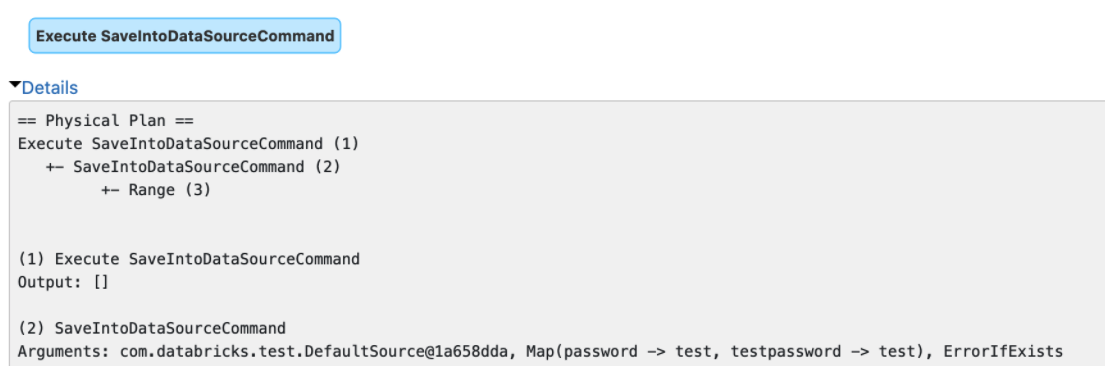
### Why are the changes needed?
Data security.
### Does this PR introduce _any_ user-facing change?
Yes, redact the map-type options in the output of `explain()`
### How was this patch tested?
Unit tests
Closes#32066 from gengliangwang/redactOptions.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
This is a followup for https://github.com/apache/spark/pull/31932.
In this PR we:
- Introduce the `QuaternaryLike` trait for node types with 4 children.
- Specialize more node types
- Fix a number of style errors that were introduced in the original PR.
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
This is a refactoring, passes existing tests.
Closes#32065 from dbaliafroozeh/FollowupSPARK-34906.
Authored-by: Ali Afroozeh <ali.afroozeh@databricks.com>
Signed-off-by: herman <herman@databricks.com>
### What changes were proposed in this pull request?
This PR extends the current function registry and catalog to support table-valued functions by adding a table function registry. It also refactors `range` to be a built-in function in the table function registry.
### Why are the changes needed?
Currently, Spark resolves table-valued functions very differently from the other functions. This change is to make the behavior for table and non-table functions consistent. It also allows Spark to display information about built-in table-valued functions:
Before:
```scala
scala> sql("describe function range").show(false)
+--------------------------+
|function_desc |
+--------------------------+
|Function: range not found.|
+--------------------------+
```
After:
```scala
Function: range
Class: org.apache.spark.sql.catalyst.plans.logical.Range
Usage:
range(start: Long, end: Long, step: Long, numPartitions: Int)
range(start: Long, end: Long, step: Long)
range(start: Long, end: Long)
range(end: Long)
// Extended
Function: range
Class: org.apache.spark.sql.catalyst.plans.logical.Range
Usage:
range(start: Long, end: Long, step: Long, numPartitions: Int)
range(start: Long, end: Long, step: Long)
range(start: Long, end: Long)
range(end: Long)
Extended Usage:
Examples:
> SELECT * FROM range(1);
+---+
| id|
+---+
| 0|
+---+
> SELECT * FROM range(0, 2);
+---+
|id |
+---+
|0 |
|1 |
+---+
> SELECT range(0, 4, 2);
+---+
|id |
+---+
|0 |
|2 |
+---+
Since: 2.0.0
```
### Does this PR introduce _any_ user-facing change?
Yes. User will not be able to create a function with name `range` in the default database:
Before:
```scala
scala> sql("create function range as 'range'")
res3: org.apache.spark.sql.DataFrame = []
```
After:
```
scala> sql("create function range as 'range'")
org.apache.spark.sql.catalyst.analysis.FunctionAlreadyExistsException: Function 'default.range' already exists in database 'default'
```
### How was this patch tested?
Unit test
Closes#31791 from allisonwang-db/spark-34678-table-func-registry.
Authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Changed the cost comparison function of the CBO to use the ratios of row counts and sizes in bytes.
### Why are the changes needed?
In #30965 we changed to CBO cost comparison function so it would be "symetric": `A.betterThan(B)` now implies, that `!B.betterThan(A)`.
With that we caused a performance regressions in some queries - TPCDS q19 for example.
The original cost comparison function used the ratios `relativeRows = A.rowCount / B.rowCount` and `relativeSize = A.size / B.size`. The changed function compared "absolute" cost values `costA = w*A.rowCount + (1-w)*A.size` and `costB = w*B.rowCount + (1-w)*B.size`.
Given the input from wzhfy we decided to go back to the relative values, because otherwise one (size) may overwhelm the other (rowCount). But this time we avoid adding up the ratios.
Originally `A.betterThan(B) => w*relativeRows + (1-w)*relativeSize < 1` was used. Besides being "non-symteric", this also can exhibit one overwhelming other.
For `w=0.5` If `A` size (bytes) is at least 2x larger than `B`, then no matter how many times more rows does the `B` plan have, `B` will allways be considered to be better - `0.5*2 + 0.5*0.00000000000001 > 1`.
When working with ratios, then it would be better to multiply them.
The proposed cost comparison function is: `A.betterThan(B) => relativeRows^w * relativeSize^(1-w) < 1`.
### Does this PR introduce _any_ user-facing change?
Comparison of the changed TPCDS v1.4 query execution times at sf=10:
| absolute | multiplicative | | additive |
-- | -- | -- | -- | -- | --
q12 | 145 | 137 | -5.52% | 141 | -2.76%
q13 | 264 | 271 | 2.65% | 271 | 2.65%
q17 | 4521 | 4243 | -6.15% | 4348 | -3.83%
q18 | 758 | 466 | -38.52% | 480 | -36.68%
q19 | 38503 | 2167 | -94.37% | 2176 | -94.35%
q20 | 119 | 120 | 0.84% | 126 | 5.88%
q24a | 16429 | 16838 | 2.49% | 17103 | 4.10%
q24b | 16592 | 16999 | 2.45% | 17268 | 4.07%
q25 | 3558 | 3556 | -0.06% | 3675 | 3.29%
q33 | 362 | 361 | -0.28% | 380 | 4.97%
q52 | 1020 | 1032 | 1.18% | 1052 | 3.14%
q55 | 927 | 938 | 1.19% | 961 | 3.67%
q72 | 24169 | 13377 | -44.65% | 24306 | 0.57%
q81 | 1285 | 1185 | -7.78% | 1168 | -9.11%
q91 | 324 | 336 | 3.70% | 337 | 4.01%
q98 | 126 | 129 | 2.38% | 131 | 3.97%
All times are in ms, the change is compared to the situation in the master branch (absolute).
The proposed cost function (multiplicative) significantlly improves the performance on q18, q19 and q72. The original cost function (additive) has similar improvements at q18 and q19. All other chagnes are within the error bars and I would ignore them - perhaps q81 has also improved.
### How was this patch tested?
PlanStabilitySuite
Closes#32014 from tanelk/SPARK-34922_cbo_better_cost_function.
Lead-authored-by: Tanel Kiis <tanel.kiis@gmail.com>
Co-authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Changes the metadata propagation framework.
Previously, most `LogicalPlan`'s propagated their `children`'s `metadataOutput`. This did not make sense in cases where the `LogicalPlan` did not even propagate their `children`'s `output`.
I set the metadata output for plans that do not propagate their `children`'s `output` to be `Nil`. Notably, `Project` and `View` no longer have metadata output.
### Why are the changes needed?
Previously, `SELECT m from (SELECT a from tb)` would output `m` if it were metadata. This did not make sense.
### Does this PR introduce _any_ user-facing change?
Yes. Now, `SELECT m from (SELECT a from tb)` will encounter an `AnalysisException`.
### How was this patch tested?
Added unit tests. I did not cover all cases, as they are fairly extensive. However, the new tests cover major cases (and an existing test already covers Join).
Closes#32017 from karenfeng/spark-34923.
Authored-by: Karen Feng <karen.feng@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
CREATE TABLE LIKE should respect the reserved properties of tables and fail if specified, using `spark.sql.legacy.notReserveProperties` to restore.
### Why are the changes needed?
Make DDLs consistently treat reserved properties
### Does this PR introduce _any_ user-facing change?
YES, this is a breaking change as using `create table like` w/ reserved properties will fail.
### How was this patch tested?
new test
Closes#32025 from yaooqinn/SPARK-34935.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
https://github.com/apache/spark/pull/32015 added a way to run benchmarks much more easily in the same GitHub Actions build. This PR updates the benchmark results by using the way.
**NOTE** that looks like GitHub Actions use four types of CPU given my observations:
- Intel(R) Xeon(R) Platinum 8171M CPU 2.60GHz
- Intel(R) Xeon(R) CPU E5-2673 v4 2.30GHz
- Intel(R) Xeon(R) CPU E5-2673 v3 2.40GHz
- Intel(R) Xeon(R) Platinum 8272CL CPU 2.60GHz
Given my quick research, seems like they perform roughly similarly:

I couldn't find enough information about Intel(R) Xeon(R) Platinum 8272CL CPU 2.60GHz but the performance seems roughly similar given the numbers.
So shouldn't be a big deal especially given that this way is much easier, encourages contributors to run more and guarantee the same number of cores and same memory with the same softwares.
### Why are the changes needed?
To have a base line of the benchmarks accordingly.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
It was generated from:
- [Run benchmarks: * (JDK 11)](https://github.com/HyukjinKwon/spark/actions/runs/713575465)
- [Run benchmarks: * (JDK 8)](https://github.com/HyukjinKwon/spark/actions/runs/713154337)
Closes#32044 from HyukjinKwon/SPARK-34950.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR proposes to add a workflow that allows developers to run benchmarks and download the results files. After this PR, developers can run benchmarks in GitHub Actions in their fork.
### Why are the changes needed?
1. Very easy to use.
2. We can use the (almost) same environment to run the benchmarks. Given my few experiments and observation, the CPU, cores, and memory are same.
3. Does not burden ASF's resource at GitHub Actions.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Manually tested in https://github.com/HyukjinKwon/spark/pull/31.
Entire benchmarks are being run as below:
- [Run benchmarks: * (JDK 11)](https://github.com/HyukjinKwon/spark/actions/runs/713575465)
- [Run benchmarks: * (JDK 8)](https://github.com/HyukjinKwon/spark/actions/runs/713154337)
### How do developers use it in their fork?
1. **Go to Actions in your fork, and click "Run benchmarks"**

2. **Run the benchmarks with JDK 8 or 11 with benchmark classes to run. Glob pattern is supported just like `testOnly` in SBT**

3. **After finishing the jobs, the benchmark results are available on the top in the underlying workflow:**

4. **After downloading it, unzip and untar at Spark git root directory:**
```bash
cd .../spark
mv ~/Downloads/benchmark-results-8.zip .
unzip benchmark-results-8.zip
tar -xvf benchmark-results-8.tar
```
5. **Check the results:**
```bash
git status
```
```
...
modified: core/benchmarks/MapStatusesSerDeserBenchmark-results.txt
```
Closes#32015 from HyukjinKwon/SPARK-34821-pr.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
When we insert data into a partition table partition with empty DataFrame. We will call `PartitioningUtils.getPathFragment()`
then to update this partition's metadata too.
When we insert to a partition when partition value is `null`, it will throw exception like
```
[info] java.lang.NullPointerException:
[info] at scala.collection.immutable.StringOps$.length$extension(StringOps.scala:51)
[info] at scala.collection.immutable.StringOps.length(StringOps.scala:51)
[info] at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:35)
[info] at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
[info] at scala.collection.immutable.StringOps.foreach(StringOps.scala:33)
[info] at org.apache.spark.sql.catalyst.catalog.ExternalCatalogUtils$.escapePathName(ExternalCatalogUtils.scala:69)
[info] at org.apache.spark.sql.catalyst.catalog.ExternalCatalogUtils$.getPartitionValueString(ExternalCatalogUtils.scala:126)
[info] at org.apache.spark.sql.execution.datasources.PartitioningUtils$.$anonfun$getPathFragment$1(PartitioningUtils.scala:354)
[info] at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
[info] at scala.collection.Iterator.foreach(Iterator.scala:941)
[info] at scala.collection.Iterator.foreach$(Iterator.scala:941)
[info] at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
[info] at scala.collection.IterableLike.foreach(IterableLike.scala:74)
[info] at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
```
`PartitioningUtils.getPathFragment()` should support `null` value too
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#32018 from AngersZhuuuu/SPARK-34926.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
In the PR, I propose to disable ANSI intervals as the result of dates/timestamp subtraction in `ExtractBenchmark` and benchmark only legacy intervals because `EXTRACT( .. FROM ..)` doesn't support ANSI intervals so far.
### Why are the changes needed?
This fixes the benchmark failure:
```
[info] Running case: YEAR of interval
[error] Exception in thread "main" org.apache.spark.sql.AnalysisException: cannot resolve 'year((subtractdates(CAST(timestamp_seconds(id) AS DATE), DATE '0001-01-01') + subtracttimestamps(timestamp_seconds(id), TIMESTAMP '1000-01-01 01:02:03.123456')))' due to data type mismatch: argument 1 requires date type, however, '(subtractdates(CAST(timestamp_seconds(id) AS DATE), DATE '0001-01-01') + subtracttimestamps(timestamp_seconds(id), TIMESTAMP '1000-01-01 01:02:03.123456'))' is of day-time interval type.; line 1 pos 0;
[error] 'Project [extract(YEAR, (subtractdates(cast(timestamp_seconds(id#1456L) as date), 0001-01-01, false) + subtracttimestamps(timestamp_seconds(id#1456L), 1000-01-01 01:02:03.123456, false, Some(Europe/Moscow)))) AS YEAR#1458]
[error] +- Range (1262304000, 1272304000, step=1, splits=Some(1))
[error] at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:42)
[error] at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$$nestedInanonfun$checkAnalysis$1$2.applyOrElse(CheckAnalysis.scala:194)
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running the `ExtractBenchmark` benchmark via:
```
$ build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.ExtractBenchmark"
```
Closes#32035 from MaxGekk/fix-ExtractBenchmark.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR introduces a new analysis rule `DeduplicateRelations`, which deduplicates any duplicate relations in a plan first and then deduplicates conflicting attributes(which resued the `dedupRight` of `ResolveReferences`).
### Why are the changes needed?
`CostBasedJoinReorder` could fail when applying on self-join, e.g.,
```scala
// test in JoinReorderSuite
test("join reorder with self-join") {
val plan = t2.join(t1, Inner, Some(nameToAttr("t1.k-1-2") === nameToAttr("t2.k-1-5")))
.select(nameToAttr("t1.v-1-10"))
.join(t2, Inner, Some(nameToAttr("t1.v-1-10") === nameToAttr("t2.k-1-5")))
// this can fail
Optimize.execute(plan.analyze)
}
```
Besides, with the new rule `DeduplicateRelations`, we'd be able to enable some optimizations, e.g., LeftSemiAnti pushdown, redundant project removal, as reflects in updated unit tests.
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Added and updated unit tests.
Closes#32027 from Ngone51/join-reorder-3.
Lead-authored-by: yi.wu <yi.wu@databricks.com>
Co-authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR is to support nested column type in Spark ORC vectorized reader. Currently ORC vectorized reader [does not support nested column type (struct, array and map)](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcFileFormat.scala#L138). We implemented nested column vectorized reader for FB-ORC in our internal fork of Spark. We are seeing performance improvement compared to non-vectorized reader when reading nested columns. In addition, this can also help improve the non-nested column performance when reading non-nested and nested columns together in one query.
Before this PR:
* `OrcColumnVector` is the implementation class for Spark's `ColumnVector` to wrap Hive's/ORC's `ColumnVector` to read `AtomicType` data.
After this PR:
* `OrcColumnVector` is an abstract class to keep interface being shared between multiple implementation class of orc column vectors, namely `OrcAtomicColumnVector` (for `AtomicType`), `OrcArrayColumnVector` (for `ArrayType`), `OrcMapColumnVector` (for `MapType`), `OrcStructColumnVector` (for `StructType`). So the original logic to read `AtomicType` data is moved from `OrcColumnVector` to `OrcAtomicColumnVector`. The abstract class of `OrcColumnVector` is needed here because of supporting nested column (i.e. nested column vectors).
* A utility method `OrcColumnVectorUtils.toOrcColumnVector` is added to create Spark's `OrcColumnVector` from Hive's/ORC's `ColumnVector`.
* A new user-facing config `spark.sql.orc.enableNestedColumnVectorizedReader` is added to control enabling/disabling vectorized reader for nested columns. The default value is false (i.e. disabling by default). For certain tables having deep nested columns, vectorized reader might take too much memory for each sub-column vectors, compared to non-vectorized reader. So providing a config here to work around OOM for query reading wide and deep nested columns if any. We plan to enable it by default on 3.3. Leave it disable in 3.2 in case for any unknown bugs.
### Why are the changes needed?
Improve query performance when reading nested columns from ORC file format.
Tested with locally adding a small benchmark in `OrcReadBenchmark.scala`. Seeing more than 1x run time improvement.
```
Running benchmark: SQL Nested Column Scan
Running case: Native ORC MR
Stopped after 2 iterations, 37850 ms
Running case: Native ORC Vectorized (Enabled Nested Column)
Stopped after 2 iterations, 15892 ms
Running case: Native ORC Vectorized (Disabled Nested Column)
Stopped after 2 iterations, 37954 ms
Running case: Hive built-in ORC
Stopped after 2 iterations, 35118 ms
Java HotSpot(TM) 64-Bit Server VM 1.8.0_181-b13 on Mac OS X 10.15.7
Intel(R) Core(TM) i9-9980HK CPU 2.40GHz
SQL Nested Column Scan: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------------
Native ORC MR 18706 18925 310 0.1 17839.6 1.0X
Native ORC Vectorized (Enabled Nested Column) 7625 7946 455 0.1 7271.6 2.5X
Native ORC Vectorized (Disabled Nested Column) 18415 18977 796 0.1 17561.5 1.0X
Hive built-in ORC 17469 17559 127 0.1 16660.1 1.1X
```
Benchmark:
```
nestedColumnScanBenchmark(1024 * 1024)
def nestedColumnScanBenchmark(values: Int): Unit = {
val benchmark = new Benchmark(s"SQL Nested Column Scan", values, output = output)
withTempPath { dir =>
withTempTable("t1", "nativeOrcTable", "hiveOrcTable") {
import spark.implicits._
spark.range(values).map(_ => Random.nextLong).map { x =>
val arrayOfStructColumn = (0 until 5).map(i => (x + i, s"$x" * 5))
val mapOfStructColumn = Map(
s"$x" -> (x * 0.1, (x, s"$x" * 100)),
(s"$x" * 2) -> (x * 0.2, (x, s"$x" * 200)),
(s"$x" * 3) -> (x * 0.3, (x, s"$x" * 300)))
(arrayOfStructColumn, mapOfStructColumn)
}.toDF("col1", "col2")
.createOrReplaceTempView("t1")
prepareTable(dir, spark.sql(s"SELECT * FROM t1"))
benchmark.addCase("Native ORC MR") { _ =>
withSQLConf(SQLConf.ORC_VECTORIZED_READER_ENABLED.key -> "false") {
spark.sql("SELECT SUM(SIZE(col1)), SUM(SIZE(col2)) FROM nativeOrcTable").noop()
}
}
benchmark.addCase("Native ORC Vectorized (Enabled Nested Column)") { _ =>
spark.sql("SELECT SUM(SIZE(col1)), SUM(SIZE(col2)) FROM nativeOrcTable").noop()
}
benchmark.addCase("Native ORC Vectorized (Disabled Nested Column)") { _ =>
withSQLConf(SQLConf.ORC_VECTORIZED_READER_NESTED_COLUMN_ENABLED.key -> "false") {
spark.sql("SELECT SUM(SIZE(col1)), SUM(SIZE(col2)) FROM nativeOrcTable").noop()
}
}
benchmark.addCase("Hive built-in ORC") { _ =>
spark.sql("SELECT SUM(SIZE(col1)), SUM(SIZE(col2)) FROM hiveOrcTable").noop()
}
benchmark.run()
}
}
}
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added one simple test in `OrcSourceSuite.scala` to verify correctness.
Definitely need more unit tests and add benchmark here, but I want to first collect feedback before crafting more tests.
Closes#31958 from c21/orc-vector.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
Using char and varchar with the string functions and some other expressions might be confusing and ambiguous. In this PR we add test cases for char and varchar with these operations to reveal these behavior and see if we can come up with a general pattern for them.
### Why are the changes needed?
test coverage
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
new tests
Closes#32010 from yaooqinn/SPARK-34908.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Modify the `SubtractTimestamps` expression to return values of `DayTimeIntervalType` when `spark.sql.legacy.interval.enabled` is set to `false` (which is the default).
### Why are the changes needed?
To conform to the ANSI SQL standard which requires ANSI intervals as the result of timestamps subtraction, see
<img width="656" alt="Screenshot 2021-03-29 at 19 09 34" src="https://user-images.githubusercontent.com/1580697/112866455-7e2f0d00-90c2-11eb-96e6-3feb7eea7e09.png">
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateTimeUtilsSuite"
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
and some tests from `SQLQueryTestSuite`:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#32016 from MaxGekk/subtract-timestamps-to-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Change partitioning to `SinglePartition`.
### Why are the changes needed?
For node `Repartition` and `RepartitionByExpression`, if partition number is 1 we can use `SinglePartition` instead of other `Partitioning`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Add test
Closes#32012 from ulysses-you/SPARK-34919.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Replaced the `agg(if (('gid = 1)) 'cat1 else null)` pattern in `RewriteDistinctAggregates` with `agg('cat1) FILTER (WHERE 'gid = 1)`
### Why are the changes needed?
For aggregate functions, that do not ignore NULL values (`First`, `Last` or `UDAF`s) the current approach can return wrong results.
In the added UT there are no nulls in the input `testData`. The query returned `Row(0, 1, 0, 51, 100)` before this PR.
### Does this PR introduce _any_ user-facing change?
Bugfix
### How was this patch tested?
UT
Closes#31983 from tanelk/SPARK-34882_distinct_agg_filter.
Lead-authored-by: Tanel Kiis <tanel.kiis@gmail.com>
Co-authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Add a new SQL function `try_cast`.
`try_cast` is identical to `AnsiCast` (or `Cast` when `spark.sql.ansi.enabled` is true), except it returns NULL instead of raising an error.
This expression has one major difference from `cast` with `spark.sql.ansi.enabled` as true: when the source value can't be stored in the target integral(Byte/Short/Int/Long) type, `try_cast` returns null instead of returning the low order bytes of the source value.
Note that the result of `try_cast` is not affected by the configuration `spark.sql.ansi.enabled`.
This is learned from Google BigQuery and Snowflake:
https://docs.snowflake.com/en/sql-reference/functions/try_cast.htmlhttps://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators#safe_casting
### Why are the changes needed?
This is an useful for the following scenarios:
1. When ANSI mode is on, users can choose `try_cast` an alternative way to run SQL without errors for certain operations.
2. When ANSI mode is off, users can use `try_cast` to get a more reasonable result for casting a value to an integral type: when an overflow error happens, `try_cast` returns null while `cast` returns the low order bytes of the source value.
### Does this PR introduce _any_ user-facing change?
Yes, adding a new function `try_cast`
### How was this patch tested?
Unit tests.
Closes#31982 from gengliangwang/tryCast.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
This PR introduces a new analysis rule `DeduplicateRelations`, which deduplicates any duplicate relations in a plan first and then deduplicates conflicting attributes(which resued the `dedupRight` of `ResolveReferences`).
### Why are the changes needed?
`CostBasedJoinReorder` could fail when applying on self-join, e.g.,
```scala
// test in JoinReorderSuite
test("join reorder with self-join") {
val plan = t2.join(t1, Inner, Some(nameToAttr("t1.k-1-2") === nameToAttr("t2.k-1-5")))
.select(nameToAttr("t1.v-1-10"))
.join(t2, Inner, Some(nameToAttr("t1.v-1-10") === nameToAttr("t2.k-1-5")))
// this can fail
Optimize.execute(plan.analyze)
}
```
Besides, with the new rule `DeduplicateRelations`, we'd be able to enable some optimizations, e.g., LeftSemiAnti pushdown, redundant project removal, as reflects in updated unit tests.
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Added and updated unit tests.
Closes#31470 from Ngone51/join-reorder.
Lead-authored-by: yi.wu <yi.wu@databricks.com>
Co-authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When SparkContext is initialed, if we want to start SparkSession, when we call
`SparkSession.builder.enableHiveSupport().getOrCreate()`, the SparkSession we created won't have hive support since
we have't reset existed SC's conf's `spark.sql.catalogImplementation`.
In this PR we use sharedState.conf to decide whether we should enable Hive Support.
### Why are the changes needed?
We should respect `enableHiveSupport`
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#31680 from AngersZhuuuu/SPARK-34568.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Add the SQL config `spark.sql.legacy.interval.enabled` which will control when Spark SQL should use `CalendarIntervalType` instead of ANSI intervals.
2. Modify the `SubtractDates` expression to return values of `DayTimeIntervalType` when `spark.sql.legacy.interval.enabled` is set to `false` (which is the default).
### Why are the changes needed?
To conform to the ANSI SQL standard which requires ANSI intervals as the result of dates subtraction, see
<img width="656" alt="Screenshot 2021-03-29 at 19 09 34" src="https://user-images.githubusercontent.com/1580697/112866455-7e2f0d00-90c2-11eb-96e6-3feb7eea7e09.png">
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
and some tests from `SQLQueryTestSuite`:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#31996 from MaxGekk/subtract-dates-to-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR proposes to add a new job in GitHub Actions to check the output of TPC-DS queries.
NOTE: I've checked that the new job took 17m 35s in the GitHub Actions env.
### Why are the changes needed?
There are some cases where we noticed runtime-realted bugs after merging commits (e.g. .SPARK-33822). Therefore, I think it is worth adding a new job in GitHub Actions to check query output of TPC-DS (sf=1).
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
The new test added.
Closes#31886 from maropu/TPCDSQueryTestSuite.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Spark query plan node hierarchy has specialized traits (or abstract classes) for handling nodes with fixed number of children, for example `UnaryExpression`, `UnaryNode` and `UnaryExec` for representing an expression, a logical plan and a physical plan with only one child, respectively. This PR refactors the `TreeNode` hierarchy by extracting the children handling functionality into the following traits. `UnaryExpression` and other similar classes now extend the corresponding new trait:
```
trait LeafLike[T <: TreeNode[T]] { self: TreeNode[T] =>
override final def children: Seq[T] = Nil
}
trait UnaryLike[T <: TreeNode[T]] { self: TreeNode[T] =>
def child: T
transient override final lazy val children: Seq[T] = child :: Nil
}
trait BinaryLike[T <: TreeNode[T]] { self: TreeNode[T] =>
def left: T
def right: T
transient override final lazy val children: Seq[T] = left :: right :: Nil
}
trait TernaryLike[T <: TreeNode[T]] { self: TreeNode[T] =>
def first: T
def second: T
def third: T
transient override final lazy val children: Seq[T] = first :: second :: third :: Nil
}
```
This refactoring, which is part of a bigger effort to make tree transformations in Spark more efficient, has two benefits:
- It moves the children handling methods to a single place, instead of being spread in specific subclasses, which will help the future optimizations for tree traversals.
- It allows to mix in these traits with some concrete node types that could not extend the previous classes. For example, expressions with one child that extend `AggregateFunction` cannot extend `UnaryExpression` as `AggregateFunction` defines the `foldable` method final while `UnaryExpression` defines it as non final. With the new traits, we can directly extend the concrete class from `UnaryLike` in these cases. Classes with more specific child handling will make tree traversal methods faster.
In this PR we have also updated many concrete node types to extend these traits to benefit from more specific child handling.
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
This is a refactoring, passes existing tests.
Closes#31932 from dbaliafroozeh/FactorOutChildHandlnigIntoSeparateTraits.
Authored-by: Ali Afroozeh <ali.afroozeh@databricks.com>
Signed-off-by: herman <herman@databricks.com>
### What changes were proposed in this pull request?
Add check if `CoalesceShufflePartitions` really coalesce shuffle partition number.
### Why are the changes needed?
The `CoalesceShufflePartitions` can not coalesce such case if the total shuffle partitions size of mappers are big enough. Then it's confused to use `CustomShuffleReaderExec` which marked as `coalesced` but has no affect with partition number.
### Does this PR introduce _any_ user-facing change?
Probably yes, the plan changed.
### How was this patch tested?
Add test.
Closes#31994 from ulysses-you/SPARK-34899.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Improve dynamic partition pruning evaluation to make filtering side must can broadcast by size or broadcast by hint.
### Why are the changes needed?
1. Fast fail if filtering side can not broadcast by size or broadcast by hint.
2. We can safely disable `spark.sql.optimizer.dynamicPartitionPruning.reuseBroadcastOnly`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing unit test.
Closes#31984 from wangyum/SPARK-34884.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
As discussed in
https://github.com/apache/spark/pull/30145#discussion_r514728642https://github.com/apache/spark/pull/30145#discussion_r514734648
We need to rewrite current Grouping Analytics grammar to support as flexible as Postgres SQL to support subsequent development.
In postgres sql, it support
```
select a, b, c, count(1) from t group by cube (a, b, c);
select a, b, c, count(1) from t group by cube(a, b, c);
select a, b, c, count(1) from t group by cube (a, b, c, (a, b), (a, b, c));
select a, b, c, count(1) from t group by rollup(a, b, c);
select a, b, c, count(1) from t group by rollup (a, b, c);
select a, b, c, count(1) from t group by rollup (a, b, c, (a, b), (a, b, c));
```
In this pr, we have done three things as below, and we will split it to different pr:
- Refactor CUBE/ROLLUP (regarding them as ANTLR tokens in a parser)
- Refactor GROUPING SETS (the logical node -> a new expr)
- Support new syntax for CUBE/ROLLUP (e.g., GROUP BY CUBE ((a, b), (a, c)))
### Why are the changes needed?
Rewrite current Grouping Analytics grammar to support as flexible as Postgres SQL to support subsequent development.
### Does this PR introduce _any_ user-facing change?
User can write Grouping Analytics grammar as flexible as Postgres SQL to support subsequent development.
### How was this patch tested?
Added UT
Closes#30212 from AngersZhuuuu/refact-grouping-analytics.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Co-authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR is a followup change to address comments in https://github.com/apache/spark/pull/31413#discussion_r603280965 and https://github.com/apache/spark/pull/31413#discussion_r603296475 . Minor change in `FileSourceScanExec`. No actual logic change here.
### Why are the changes needed?
Better readability.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing unit tests.
Closes#32000 from c21/bucket-scan.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Some `spark-submit` commands used to run benchmarks in the user's guide is wrong, we can't use these commands to run benchmarks successful.
So the major changes of this pr is correct these wrong commands, for example, run a benchmark which inherits from `SqlBasedBenchmark`, we must specify `--jars <spark core test jar>,<spark catalyst test jar>` because `SqlBasedBenchmark` based benchmark extends `BenchmarkBase(defined in spark core test jar)` and `SQLHelper(defined in spark catalyst test jar)`.
Another change of this pr is removed the `scalatest Assertions` dependency of Benchmarks because `scalatest-*.jar` are not in the distribution package, it will be troublesome to use.
### Why are the changes needed?
Make sure benchmarks can run using spark-submit cmd described in the guide
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Use the corrected `spark-submit` commands to run benchmarks successfully.
Closes#31995 from LuciferYang/fix-benchmark-guide.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to extend the functionality of requirement for distribution and ordering on V2 write to specify the number of partitioning on repartition, so that data source is able to control the parallelism and determine the data distribution per partition in prior.
The partitioning with static number is optional, and by default disabled via default method, so only implementations required to restrict the number of partition statically need to override the method and provide the number.
Note that we don't support static number of partitions with unspecified distribution for this PR, as we haven't found the real use cases, and for hypothetical case the static number isn't good enough. Javadoc clearly describes the limitation.
### Why are the changes needed?
The use case comes from feature parity with DSv1.
I have state data source which enables the state in SS to be rewritten, which enables repartitioning, schema evolution, etc via batch query. The writer requires hash partitioning against group key, with the "desired number of partitions", which is same as what Spark does read and write against state.
This is now implemented as DSv1, and the requirement is simply done by calling repartition with the "desired number".
```
val fullPathsForKeyColumns = keySchema.map(key => new Column(s"key.${key.name}"))
data
.repartition(newPartitions, fullPathsForKeyColumns: _*)
.queryExecution
.toRdd
.foreachPartition(
writeFn(resolvedCpLocation, version, operatorId, storeName, keySchema, valueSchema,
storeConf, hadoopConfBroadcast, queryId))
```
Thanks to SPARK-34026, it's now possible to require the hash partitioning, but still not able to require the number of partitions. This PR will enable to let data source require the number of partitions.
### Does this PR introduce _any_ user-facing change?
Yes, but only for data source implementors. Even for them, this is no breaking change as default method is added.
### How was this patch tested?
Added UTs.
Closes#31355 from HeartSaVioR/SPARK-34255.
Lead-authored-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
Co-authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes an issue that `quoteIfNeeded` quotes a name only if it contains `.` or ``` ` ```.
This method should quote it if it contains non-word characters.
### Why are the changes needed?
It's a potential bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New test.
Closes#31964 from sarutak/fix-quoteIfNeeded.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Filled the `defaultResult` field on non-nullable aggregates
### Why are the changes needed?
The `defaultResult` defaults to `None` and in some situations (like correlated scalar subqueries) it is used for the value of the aggregation.
The UT result before the fix:
```
-- !query
SELECT t1a,
(SELECT count(t2d) FROM t2 WHERE t2a = t1a) count_t2,
(SELECT count_if(t2d > 0) FROM t2 WHERE t2a = t1a) count_if_t2,
(SELECT approx_count_distinct(t2d) FROM t2 WHERE t2a = t1a) approx_count_distinct_t2,
(SELECT collect_list(t2d) FROM t2 WHERE t2a = t1a) collect_list_t2,
(SELECT collect_set(t2d) FROM t2 WHERE t2a = t1a) collect_set_t2,
(SELECT hex(count_min_sketch(t2d, 0.5d, 0.5d, 1)) FROM t2 WHERE t2a = t1a) collect_set_t2
FROM t1
-- !query schema
struct<t1a:string,count_t2:bigint,count_if_t2:bigint,approx_count_distinct_t2:bigint,collect_list_t2:array<bigint>,collect_set_t2:array<bigint>,collect_set_t2:string>
-- !query output
val1a 0 0 NULL NULL NULL NULL
val1a 0 0 NULL NULL NULL NULL
val1a 0 0 NULL NULL NULL NULL
val1a 0 0 NULL NULL NULL NULL
val1b 6 6 3 [19,119,319,19,19,19] [19,119,319] 0000000100000000000000060000000100000004000000005D8D6AB90000000000000000000000000000000400000000000000010000000000000001
val1c 2 2 2 [219,19] [219,19] 0000000100000000000000020000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000001
val1d 0 0 NULL NULL NULL NULL
val1d 0 0 NULL NULL NULL NULL
val1d 0 0 NULL NULL NULL NULL
val1e 1 1 1 [19] [19] 0000000100000000000000010000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000000
val1e 1 1 1 [19] [19] 0000000100000000000000010000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000000
val1e 1 1 1 [19] [19] 0000000100000000000000010000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000000
```
### Does this PR introduce _any_ user-facing change?
Bugfix
### How was this patch tested?
UT
Closes#31973 from tanelk/SPARK-34876_non_nullable_agg_subquery.
Authored-by: Tanel Kiis <tanel.kiis@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The changes being proposed are to increase the accuracy of JDBCRelation's stride calculation, as outlined in: https://issues.apache.org/jira/browse/SPARK-34843
In summary:
Currently, in JDBCRelation (line 123), the stride size is calculated as follows:
val stride: Long = upperBound / numPartitions - lowerBound / numPartitions
Due to truncation happening on both divisions, the stride size can fall short of what it should be. This can lead to a big difference between the provided upper bound and the actual start of the last partition.
I'm proposing a different formula that doesn't truncate to early, and also maintains accuracy using fixed-point decimals. This helps tremendously with the size of the last partition, which can be even more amplified if there is data skew in that direction. In a real-life test, I've seen a 27% increase in performance with this more proper stride alignment. The reason for fixed-point decimals instead of floating-point decimals is because inaccuracy due to limitation of what the float can represent. This may seem small, but could shift the midpoint a bit, and depending on how granular the data is, that could translate to quite a difference. It's also just inaccurate, and I'm striving to make the partitioning as accurate as possible, within reason.
Lastly, since the last partition's predicate is determined by how the strides align starting from the lower bound (plus one stride), there can be skew introduced creating a larger last partition compared to the first partition. Therefore, after calculating a more precise stride size, I've also introduced logic to move the first partition's predicate (which is an offset from the lower bound) to a position that closely matches the offset of the last partition's predicate (in relation to the upper bound). This makes the first and last partition more evenly distributed compared to each other, and helps with the last task being the largest (reducing its size).
### Why are the changes needed?
The current implementation is inaccurate and can lead to the last task/partition running much longer than previous tasks. Therefore, you can end up with a single node/core running for an extended period while other nodes/cores are sitting idle.
### Does this PR introduce _any_ user-facing change?
No. I would suspect some users will just get a good performance increase. As stated above, if we were to run our code on Spark that has this change implemented, we would have all of the sudden got a 27% increase in performance.
### How was this patch tested?
I've added two new unit tests. I did need to update one unit test, but when you look at the comparison of the before and after, you'll see better alignment of the partitioning with the new implementation. Given that the lower partition's predicate is exclusive and the upper's is inclusive, the offset of the lower was 3 days, and the offset of the upper was 6 days... that's potentially twice the amount of data in that upper partition (could be much more depending on how the user's data is distributed).
Other unit tests that utilize timestamps and two partitions have maintained their midpoint.
### Examples
I've added results with and without the realignment logic to better highlight both improvements this PR brings.
**Example 1:**
Given the following partition config:
"lowerBound" -> "1930-01-01"
"upperBound" -> "2020-12-31"
"numPartitions" -> 1000
_Old method (exactly what it would be BEFORE this PR):_
First partition: "PartitionColumn" < '1930-02-02' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2017-07-11'
_Old method, but with new realingment logic of first partition:_
First partition: "PartitionColumn" < '1931-10-14' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2019-03-22'
_New method:_
First partition: "PartitionColumn" < '1930-02-03' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2020-04-05'
_New with new realingment logic of first partition (exactly what it would be AFTER this PR):_
First partition: "PartitionColumn" < '1930-06-02' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2020-08-02'
**Example 2:**
Given the following partition config:
"lowerBound" -> "1927-04-05",
"upperBound" -> "2020-10-16"
"numPartitions" -> 2000
_Old method (exactly what it would be BEFORE this PR):_
First partition: "PartitionColumn" < '1927-04-21' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2014-10-29'
_Old method, but with new realingment logic of first partition::_
First partition: "PartitionColumn" < '1930-04-07' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2017-10-15'
_New method:_
First partition: "PartitionColumn" < '1927-04-22' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2020-04-19'
_New method with new realingment logic of first partition (exactly what it would be AFTER this PR):_
First partition: "PartitionColumn" < '1927-07-13' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2020-07-10'
Closes#31965 from hanover-fiste/SPARK-34843.
Authored-by: hanover-fiste <jyarbrough.git@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR fixes a correctness issue with higher order functions. The results of function expressions needs to be copied in some higher order functions as such an expression can return with internal buffers and higher order functions can call multiple times the expression.
The issue was discovered with typed `ScalaUDF`s after https://github.com/apache/spark/pull/28979.
### Why are the changes needed?
To fix a bug.
### Does this PR introduce _any_ user-facing change?
Yes, some queries return the right results again.
### How was this patch tested?
Added new UT.
Closes#31955 from peter-toth/SPARK-34829-fix-scalaudf-resultconversion.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Fix code format in `SQLConf` and comment in `PartitionPruning`.
### Why are the changes needed?
Make code more readable.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
N/A
Closes#31969 from wangyum/SPARK-32855-2.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Apache Parquet 1.12.0 switches its ZSTD compression from Hadoop codec to its own codec.
### Why are the changes needed?
**Apache Spark 3.1 (It requires libhadoop built with zstd)**
```scala
scala> spark.range(10).write.option("compression", "zstd").parquet("/tmp/a")
21/03/27 08:49:38 ERROR Executor: Exception in task 11.0 in stage 0.0 (TID 11)2]
java.lang.RuntimeException: native zStandard library not available:
this version of libhadoop was built without zstd support.
```
**Apache Spark 3.2 (No libhadoop requirement)**
```scala
scala> spark.range(10).write.option("compression", "zstd").parquet("/tmp/a")
```
### Does this PR introduce _any_ user-facing change?
Yes, this is an improvement.
### How was this patch tested?
Pass the CI with the newly added test coverage.
Closes#31981 from dongjoon-hyun/SPARK-34880.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Improve error message for casting cause overflow error. We should use DataType's catalogString.
### Why are the changes needed?
Improve error message
### Does this PR introduce _any_ user-facing change?
For example:
```
set spark.sql.ansi.enabled=true;
select tinyint(128) * tinyint(2);
```
Error message before this pr:
```
Casting 128 to scala.Byte$ causes overflow
```
After this pr:
```
Casting 128 to tinyint causes overflow
```
### How was this patch tested?
Added UT
Closes#31971 from AngersZhuuuu/SPARK-34744.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
1. Add new expression `DivideDTInterval` which multiplies a `DayTimeIntervalType` expression by a `NumericType` expression including ByteType, ShortType, IntegerType, LongType, FloatType, DoubleType, DecimalType.
2. Extend binary arithmetic rules to support `day-time interval / numeric`.
### Why are the changes needed?
To conform the ANSI SQL standard which requires such operation over day-time intervals:
<img width="656" alt="Screenshot 2021-03-25 at 18 44 58" src="https://user-images.githubusercontent.com/1580697/112501559-68f07080-8d9a-11eb-8781-66e6631bb7ef.png">
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *IntervalExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31972 from MaxGekk/div-dt-interval-by-num.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Add new expression `DivideYMInterval` which multiplies a `YearMonthIntervalType` expression by a `NumericType` expression including ByteType, ShortType, IntegerType, LongType, FloatType, DoubleType, DecimalType.
2. Extend binary arithmetic rules to support `year-month interval / numeric`.
### Why are the changes needed?
To conform the ANSI SQL standard which requires such operation over year-month intervals:
<img width="656" alt="Screenshot 2021-03-25 at 18 44 58" src="https://user-images.githubusercontent.com/1580697/112501559-68f07080-8d9a-11eb-8781-66e6631bb7ef.png">
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *IntervalExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31961 from MaxGekk/div-ym-interval-by-num.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This pr improve the cost model in `pruningHasBenefit` for filtering side can not build broadcast by join type:
1. The filtering side must be small enough to build broadcast by size.
2. The estimated size of the pruning side must be big enough: `estimatePruningSideSize * spark.sql.optimizer.dynamicPartitionPruning.pruningSideExtraFilterRatio > overhead`.
### Why are the changes needed?
Improve query performance for these cases.
This a real case from cluster. Left join and left size very small and right side can build DPP:
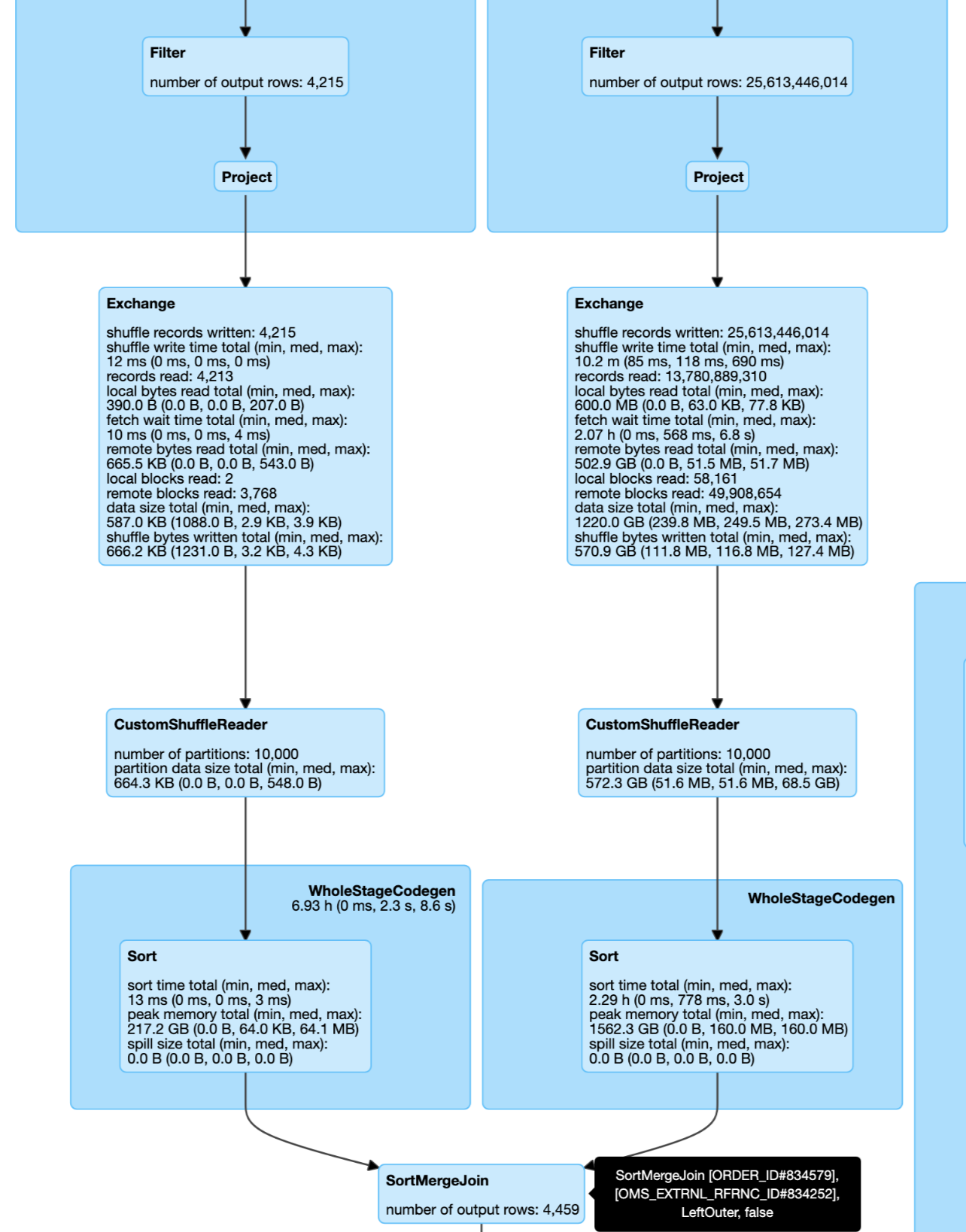
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#29726 from wangyum/SPARK-32855.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
A companion PR for SPARK-34817, when we handle the unsigned int(<=32) logical types. In this PR, we map the unsigned int64 to decimal(20, 0) for better compatibility.
### Why are the changes needed?
Spark won't have unsigned types, but spark should be able to read existing parquet files written by other systems that support unsigned types for better compatibility.
### Does this PR introduce _any_ user-facing change?
yes, we can read parquet uint64 now
### How was this patch tested?
new unit tests
Closes#31960 from yaooqinn/SPARK-34786-2.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
Move the checkpoint location resolving into the rule ResolveWriteToStream, which is added in SPARK-34748.
### Why are the changes needed?
After SPARK-34748, we have a rule ResolveWriteToStream for the analysis logic for the resolving logic of stream write plans. Based on it, we can further move the checkpoint location resolving work in the rule. Then, all the checkpoint resolving logic was done in the analyzer.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing UT.
Closes#31963 from xuanyuanking/SPARK-34871.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR groups exception messages in `execution/datasources/v2`.
### Why are the changes needed?
It will largely help with standardization of error messages and its maintenance.
### Does this PR introduce _any_ user-facing change?
No. Error messages remain unchanged.
### How was this patch tested?
No new tests - pass all original tests to make sure it doesn't break any existing behavior.
Closes#31619 from karenfeng/spark-33600.
Authored-by: Karen Feng <karen.feng@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Update the plan stability golden files even if only the `explain.txt` changes.
This is resubmition of #31927. The schema for one of the TPCDS tables was updated and that changed the `explain.txt` for the q17.
### Why are the changes needed?
Currently only `simplified.txt` change is checked. There are some PRs, that update the `explain.txt`, that do not change the `simplified.txt`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
The updated golden files.
Closes#31957 from tanelk/SPARK-34822_update_plan_stability.
Lead-authored-by: Tanel Kiis <tanel.kiis@gmail.com>
Co-authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Add new expression `MultiplyDTInterval` which multiplies a `DayTimeIntervalType` expression by a `NumericType` expression including ByteType, ShortType, IntegerType, LongType, FloatType, DoubleType, DecimalType.
2. Extend binary arithmetic rules to support `numeric * day-time interval` and `day-time interval * numeric`.
3. Invoke `DoubleMath.roundToInt` in `double/float * year-month interval`.
### Why are the changes needed?
To conform the ANSI SQL standard which requires such operation over day-time intervals:
<img width="667" alt="Screenshot 2021-03-22 at 16 33 16" src="https://user-images.githubusercontent.com/1580697/111997810-77d1eb80-8b2c-11eb-951d-e43911d9c5db.png">
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *IntervalExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31951 from MaxGekk/mul-day-time-interval.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Unsigned types may be used to produce smaller in-memory representations of the data. These types used by frameworks(e.g. hive, pig) using parquet. And parquet will map them to its base types.
see more https://github.com/apache/parquet-format/blob/master/LogicalTypes.mdhttps://github.com/apache/parquet-format/blob/master/src/main/thrift/parquet.thrift
```thrift
/**
* An unsigned integer value.
*
* The number describes the maximum number of meaningful data bits in
* the stored value. 8, 16 and 32 bit values are stored using the
* INT32 physical type. 64 bit values are stored using the INT64
* physical type.
*
*/
UINT_8 = 11;
UINT_16 = 12;
UINT_32 = 13;
UINT_64 = 14;
```
```
UInt8-[0:255]
UInt16-[0:65535]
UInt32-[0:4294967295]
UInt64-[0:18446744073709551615]
```
In this PR, we support read UINT_8 as ShortType, UINT_16 as IntegerType, UINT_32 as LongType to fit their range. Support for UINT_64 will be in another PR.
### Why are the changes needed?
better parquet support
### Does this PR introduce _any_ user-facing change?
yes, we can read unit[8/16/32] from parquet files
### How was this patch tested?
new tests
Closes#31921 from yaooqinn/SPARK-34817.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to remove re-analyzing the already analyzed plan for `CreateViewCommand` as discussed https://github.com/apache/spark/pull/31273/files#r581592786.
### Why are the changes needed?
No need to analyze the plan if it's already analyzed.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests should cover this.
Closes#31933 from imback82/remove_analyzed_from_create_temp_view.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR intends to fix the bug that does not apply right-padding for char types inside correlated subquries.
For example, a query below returns nothing in master, but a correct result is `c`.
```
scala> sql(s"CREATE TABLE t1(v VARCHAR(3), c CHAR(5)) USING parquet")
scala> sql(s"CREATE TABLE t2(v VARCHAR(5), c CHAR(7)) USING parquet")
scala> sql("INSERT INTO t1 VALUES ('c', 'b')")
scala> sql("INSERT INTO t2 VALUES ('a', 'b')")
scala> val df = sql("""
|SELECT v FROM t1
|WHERE 'a' IN (SELECT v FROM t2 WHERE t2.c = t1.c )""".stripMargin)
scala> df.show()
+---+
| v|
+---+
+---+
```
This is because `ApplyCharTypePadding` does not handle the case above to apply right-padding into `'abc'`. This PR modifies the code in `ApplyCharTypePadding` for handling it correctly.
```
// Before this PR:
scala> df.explain(true)
== Analyzed Logical Plan ==
v: string
Project [v#13]
+- Filter a IN (list#12 [c#14])
: +- Project [v#15]
: +- Filter (c#16 = outer(c#14))
: +- SubqueryAlias spark_catalog.default.t2
: +- Relation default.t2[v#15,c#16] parquet
+- SubqueryAlias spark_catalog.default.t1
+- Relation default.t1[v#13,c#14] parquet
scala> df.show()
+---+
| v|
+---+
+---+
// After this PR:
scala> df.explain(true)
== Analyzed Logical Plan ==
v: string
Project [v#43]
+- Filter a IN (list#42 [c#44])
: +- Project [v#45]
: +- Filter (c#46 = rpad(outer(c#44), 7, ))
: +- SubqueryAlias spark_catalog.default.t2
: +- Relation default.t2[v#45,c#46] parquet
+- SubqueryAlias spark_catalog.default.t1
+- Relation default.t1[v#43,c#44] parquet
scala> df.show()
+---+
| v|
+---+
| c|
+---+
```
This fix is lated to TPCDS q17; the query returns nothing because of this bug: https://github.com/apache/spark/pull/31886/files#r599333799
### Why are the changes needed?
Bugfix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit tests added.
Closes#31940 from maropu/FixCharPadding.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Currently, when implicit casting a data type to a `TypeCollection`, Spark returns the first convertible data type among `TypeCollection`.
In ANSI mode, we can make the behavior more reasonable by returning the closet convertible data type in `TypeCollection`.
In details, we first try to find the all the expected types we can implicitly cast:
1. if there is no convertible data types, return None;
2. if there is only one convertible data type, cast input as it;
3. otherwise if there are multiple convertible data types, find the closet data
type among them. If there is no such closet data type, return None.
Note that if the closet type is Float type and the convertible types contains Double type, simply return Double type as the closet type to avoid potential
precision loss on converting the Integral type as Float type.
### Why are the changes needed?
Make the type coercion rule for TypeCollection more reasonable and ANSI compatible.
E.g. returning Long instead of Double for`implicast(int, TypeCollect(Double, Long))`.
From ANSI SQL Spec section 4.33 "SQL-invoked routines"

Section 9.6 "Subject routine determination"

Section 10.4 "routine invocation"

### Does this PR introduce _any_ user-facing change?
Yes, in ANSI mode, implicit casting to a `TypeCollection` returns the narrowest convertible data type instead of the first convertible one.
### How was this patch tested?
Unit tests.
Closes#31859 from gengliangwang/implicitCastTypeCollection.
Lead-authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Co-authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Update the plan stability golden files even if only the `explain.txt` changes.
### Why are the changes needed?
Currently only `simplified.txt` change is checked. There are some PRs, that update the `explain.txt`, that do not change the `simplified.txt`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
The updated golden files.
Closes#31927 from tanelk/SPARK-34822_update_plan_stability.
Lead-authored-by: Tanel Kiis <tanel.kiis@gmail.com>
Co-authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Both local limit and global limit define the output partitioning and output ordering in the same way and this is duplicated (https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/limit.scala#L159-L175 ). We can move the output partitioning and ordering into their parent trait - `BaseLimitExec`. This is doable as `BaseLimitExec` has no more other child class. This is a minor code refactoring.
### Why are the changes needed?
Clean up the code a little bit. Better readability.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pure refactoring. Rely on existing unit tests.
Closes#31950 from c21/limit-cleanup.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
SPARK-32160 add a config(`EXECUTOR_ALLOW_SPARK_CONTEXT`) to switch allow/disallow to create `SparkContext` in executors and the default value of the config is `false`
`ExternalAppendOnlyUnsafeRowArrayBenchmark` will run fail when `EXECUTOR_ALLOW_SPARK_CONTEXT` use the default value because the `ExternalAppendOnlyUnsafeRowArrayBenchmark#withFakeTaskContext` method try to create a `SparkContext` manually in Executor Side.
So the main change of this pr is set `EXECUTOR_ALLOW_SPARK_CONTEXT` to `true` to ensure `ExternalAppendOnlyUnsafeRowArrayBenchmark` run successfully.
### Why are the changes needed?
Bug fix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual test:
```
bin/spark-submit --class org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark --jars spark-core_2.12-3.2.0-SNAPSHOT-tests.jar spark-sql_2.12-3.2.0-SNAPSHOT-tests.jar
```
**Before**
```
Exception in thread "main" java.lang.IllegalStateException: SparkContext should only be created and accessed on the driver.
at org.apache.spark.SparkContext$.org$apache$spark$SparkContext$$assertOnDriver(SparkContext.scala:2679)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:89)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:137)
at org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark$.withFakeTaskContext(ExternalAppendOnlyUnsafeRowArrayBenchmark.scala:52)
at org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark$.testAgainstRawArrayBuffer(ExternalAppendOnlyUnsafeRowArrayBenchmark.scala:119)
at org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark$.$anonfun$runBenchmarkSuite$1(ExternalAppendOnlyUnsafeRowArrayBenchmark.scala:189)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.benchmark.BenchmarkBase.runBenchmark(BenchmarkBase.scala:40)
at org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark$.runBenchmarkSuite(ExternalAppendOnlyUnsafeRowArrayBenchmark.scala:186)
at org.apache.spark.benchmark.BenchmarkBase.main(BenchmarkBase.scala:58)
at org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark.main(ExternalAppendOnlyUnsafeRowArrayBenchmark.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:951)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1030)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1039)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
```
**After**
`ExternalAppendOnlyUnsafeRowArrayBenchmark` run successfully.
Closes#31939 from LuciferYang/SPARK-34832.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR fixes an issue that `col()`, `$"<name>"` and `df("name")` don't handle quoted column names like ``` `a``b.c` ```properly.
For example, if we have a following DataFrame.
```
val df1 = spark.sql("SELECT 'col1' AS `a``b.c`")
```
For the DataFrame, this query is successfully executed.
```
scala> df1.selectExpr("`a``b.c`").show
+-----+
|a`b.c|
+-----+
| col1|
+-----+
```
But the following query will fail because ``` df1("`a``b.c`") ``` throws an exception.
```
scala> df1.select(df1("`a``b.c`")).show
org.apache.spark.sql.AnalysisException: syntax error in attribute name: `a``b.c`;
at org.apache.spark.sql.catalyst.analysis.UnresolvedAttribute$.e$1(unresolved.scala:152)
at org.apache.spark.sql.catalyst.analysis.UnresolvedAttribute$.parseAttributeName(unresolved.scala:162)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveQuoted(LogicalPlan.scala:121)
at org.apache.spark.sql.Dataset.resolve(Dataset.scala:221)
at org.apache.spark.sql.Dataset.col(Dataset.scala:1274)
at org.apache.spark.sql.Dataset.apply(Dataset.scala:1241)
... 49 elided
```
### Why are the changes needed?
It's a bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New tests.
Closes#31854 from sarutak/fix-parseAttributeName.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
SPARK-34842 (#31012) has a typo in the type of `date_dim.d_quarter_name` in the TPCDS schema (`TPCDSBase`). This PR replace `CHAR(1)` with `CHAR(6)`. This fix comes from p28 in [the TPCDS official doc](http://www.tpc.org/tpc_documents_current_versions/pdf/tpc-ds_v2.9.0.pdf).
### Why are the changes needed?
Bugfix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
N/A
Closes#31943 from maropu/SPARK-34083-FOLLOWUP.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
1. Add new expression `MultiplyYMInterval` which multiplies a `YearMonthIntervalType` expression by a `NumericType` expression including ByteType, ShortType, IntegerType, LongType, FloatType, DoubleType, DecimalType.
2. Extend binary arithmetic rules to support `numeric * year-month interval` and `year-month interval * numeric`.
### Why are the changes needed?
To conform the ANSI SQL standard which requires such operation over year-month intervals:
<img width="667" alt="Screenshot 2021-03-22 at 16 33 16" src="https://user-images.githubusercontent.com/1580697/111997810-77d1eb80-8b2c-11eb-951d-e43911d9c5db.png">
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *IntervalExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31929 from MaxGekk/interval-mul-div.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
forward-port https://github.com/apache/spark/pull/31811 to master
### What changes were proposed in this pull request?
For permanent views (and the new SQL temp view in Spark 3.1), we store the view SQL text and re-parse/analyze the view SQL text when reading the view. In the case of `SELECT * FROM ...`, we want to avoid view schema change (e.g. the referenced table changes its schema) and will record the view query output column names when creating the view, so that when reading the view we can add a `SELECT recorded_column_names FROM ...` to retain the original view query schema.
In Spark 3.1 and before, the final SELECT is added after the analysis phase: https://github.com/apache/spark/blob/branch-3.1/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/view.scala#L67
If the view query has duplicated output column names, we always pick the first column when reading a view. A simple repro:
```
scala> sql("create view c(x, y) as select 1 a, 2 a")
res0: org.apache.spark.sql.DataFrame = []
scala> sql("select * from c").show
+---+---+
| x| y|
+---+---+
| 1| 1|
+---+---+
```
In the master branch, we will fail at the view reading time due to b891862fb6 , which adds the final SELECT during analysis, so that the query fails with `Reference 'a' is ambiguous`
This PR proposes to resolve the view query output column names from the matching attributes by ordinal.
For example, `create view c(x, y) as select 1 a, 2 a`, the view query output column names are `[a, a]`. When we reading the view, there are 2 matching attributes (e.g.`[a#1, a#2]`) and we can simply match them by ordinal.
A negative example is
```
create table t(a int)
create view v as select *, 1 as col from t
replace table t(a int, col int)
```
When reading the view, the view query output column names are `[a, col]`, and there are two matching attributes of `col`, and we should fail the query. See the tests for details.
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
yes
### How was this patch tested?
new test
Closes#31930 from cloud-fan/view2.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This bug was introduced by SPARK-30428 at Apache Spark 3.0.0.
This PR fixes `FileScan.equals()`.
### Why are the changes needed?
- Without this fix `FileScan.equals` doesn't take `fileIndex` and `readSchema` into account.
- Partition filters and data filters added to `FileScan` (in #27112 and #27157) caused that canonicalized form of some `BatchScanExec` nodes don't match and this prevents some reuse possibilities.
### Does this PR introduce _any_ user-facing change?
Yes, before this fix incorrect reuse of `FileScan` and so `BatchScanExec` could have happed causing correctness issues.
### How was this patch tested?
Added new UTs.
Closes#31848 from peter-toth/SPARK-34756-fix-filescan-equality-check.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Move `ExecutionListenerBus` register (both `ListenerBus` and `ContextCleaner` register) into itself.
Also with a minor change that put `registerSparkListenerForCleanup` to a better place.
### Why are the changes needed?
improve code
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass existing tests.
Closes#31919 from Ngone51/SPARK-34087-followup.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch proposes to disable fetching shuffle blocks in batch when io encryption is enabled. Adaptive Query Execution fetch contiguous shuffle blocks for the same map task in batch to reduce IO and improve performance. However, we found that batch fetching is incompatible with io encryption.
### Why are the changes needed?
Before this patch, we set `spark.io.encryption.enabled` to true, then run some queries which coalesced partitions by AEQ, may got following error message:
```14:05:52.638 WARN org.apache.spark.scheduler.TaskSetManager: Lost task 1.0 in stage 2.0 (TID 3) (11.240.37.88 executor driver): FetchFailed(BlockManagerId(driver, 11.240.37.88, 63574, None), shuffleId=0, mapIndex=0, mapId=0, reduceId=2, message=
org.apache.spark.shuffle.FetchFailedException: Stream is corrupted
at org.apache.spark.storage.ShuffleBlockFetcherIterator.throwFetchFailedException(ShuffleBlockFetcherIterator.scala:772)
at org.apache.spark.storage.BufferReleasingInputStream.read(ShuffleBlockFetcherIterator.scala:845)
at java.io.BufferedInputStream.fill(BufferedInputStream.java:246)
at java.io.BufferedInputStream.read(BufferedInputStream.java:265)
at java.io.DataInputStream.readInt(DataInputStream.java:387)
at org.apache.spark.sql.execution.UnsafeRowSerializerInstance$$anon$2$$anon$3.readSize(UnsafeRowSerializer.scala:113)
at org.apache.spark.sql.execution.UnsafeRowSerializerInstance$$anon$2$$anon$3.next(UnsafeRowSerializer.scala:129)
at org.apache.spark.sql.execution.UnsafeRowSerializerInstance$$anon$2$$anon$3.next(UnsafeRowSerializer.scala:110)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:494)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:459)
at org.apache.spark.util.CompletionIterator.next(CompletionIterator.scala:29)
at org.apache.spark.InterruptibleIterator.next(InterruptibleIterator.scala:40)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:459)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:345)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:898)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:898)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:498)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1437)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:501)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.io.IOException: Stream is corrupted
at net.jpountz.lz4.LZ4BlockInputStream.refill(LZ4BlockInputStream.java:200)
at net.jpountz.lz4.LZ4BlockInputStream.refill(LZ4BlockInputStream.java:226)
at net.jpountz.lz4.LZ4BlockInputStream.read(LZ4BlockInputStream.java:157)
at org.apache.spark.storage.BufferReleasingInputStream.read(ShuffleBlockFetcherIterator.scala:841)
... 25 more
)
```
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
New tests.
Closes#31898 from hezuojiao/fetch_shuffle_in_batch.
Authored-by: hezuojiao <hezuojiao@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Marked `RowNumberLike` and `RankLike` as not-nullable.
### Why are the changes needed?
`RowNumberLike` and `RankLike` SQL expressions never return null value. Marking them as non-nullable can have some performance benefits, because some optimizer rules apply only to non-nullable expressions
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Did not find any existing tests on the nullability of aggregate functions.
Plan stability suite partially covers this.
Closes#31924 from tanelk/SPARK-34812_nullability.
Authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Now that all the temporary views are wrapped with `TemporaryViewRelation`(#31273, #31652, and #31825), this PR proposes to update `SessionCatalog`'s APIs for temporary views to take or return more concrete types.
APIs that will take `TemporaryViewRelation` instead of `LogicalPlan`:
```
createTempView, createGlobalTempView, alterTempViewDefinition
```
APIs that will return `TemporaryViewRelation` instead of `LogicalPlan`:
```
getRawTempView, getRawGlobalTempView
```
APIs that will return `View` instead of `LogicalPlan`:
```
getTempView, getGlobalTempView, lookupTempView
```
### Why are the changes needed?
Internal refactoring to work with more concrete types.
### Does this PR introduce _any_ user-facing change?
No, this is internal refactoring.
### How was this patch tested?
Updated existing tests affected by the refactoring.
Closes#31906 from imback82/use_temporary_view_relation.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes the `HybridRowQueue ` to respect the configured memory mode.
Besides, this PR also refactored the constructor of `MemoryConsumer` to accept the memory mode explicitly.
### Why are the changes needed?
`HybridRowQueue` supports both onHeap and offHeap manipulation. But it inherited the wrong `MemoryConsumer` constructor, which hard-coded the memory mode to `onHeap`.
### Does this PR introduce _any_ user-facing change?
No. (Maybe yes in some cases where users can't complete the job before could complete successfully after the fix because of `HybridRowQueue` is able to spill under offHeap mode now. )
### How was this patch tested?
Updated the existing test to make it test both offHeap and onHeap modes.
Closes#31152 from Ngone51/fix-MemoryConsumer-memorymode.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR updates CSVBenchmark especially we have a fix like https://github.com/apache/spark/pull/31858 that could potentially improve the performance.
### Why are the changes needed?
To have the updated benchmark results.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually ran the benchmark
Closes#31917 from HyukjinKwon/SPARK-34815.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR proposes to optimize WAL commit phase via following changes:
* cache offset log to avoid FS get operation per batch
* just directly delete instead of employing FS list operation on purge
### Why are the changes needed?
There're inefficiency on WAL commit phase which can be easily optimized via using a small driver memory.
1. To provide the offset metadata to source side (via `source.commit()`), we read offset metadata for previous batch from file system, which is probably written by this driver in previous batches. Caching it into driver memory would reduce the get operation.
2. Spark calls purge against offset log & commit log per batch, which calls list operation. If the previous batch succeeded to purge, the current batch just needs to check one batch which can be simply done via direct delete operation, instead of calling list operation.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually tested with additional debug log. (Verified that cache is used, cache keeps the size as 2, only one delete call is used instead of list call)
Did some experiment with simple rate to console query. (NOTE: wasn't done with master branch - tested against Spark 2.4.x, but WAL commit phase hasn't been changed AFAIK during these versions)
AWS S3 + S3 guard:
> before the patch
<img width="1075" alt="aws-before" src="https://user-images.githubusercontent.com/1317309/107108721-6cc54380-687d-11eb-8f10-b906b9d58397.png">
> after the patch
<img width="1071" alt="aws-after" src="https://user-images.githubusercontent.com/1317309/107108724-7189f780-687d-11eb-88da-26912ac15c85.png">
Azure:
> before the patch
<img width="1074" alt="azure-before" src="https://user-images.githubusercontent.com/1317309/107108726-75b61500-687d-11eb-8c06-9048fa10ff9a.png">
> after the patch
<img width="1069" alt="azure-after" src="https://user-images.githubusercontent.com/1317309/107108729-79e23280-687d-11eb-8d97-e7f3aeec51be.png">
Closes#31495 from HeartSaVioR/SPARK-34383.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
### What changes were proposed in this pull request?
- Create a new rule `ResolveStreamWrite` for all analysis logic for streaming write.
- Add corresponding logical plans `WriteToStreamStatement` and `WriteToStream`.
### Why are the changes needed?
Currently, the analysis logic for streaming write is mixed in StreamingQueryManager. If we create a specific analyzer rule and separated logical plans, it should be helpful for further extension.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#31842 from xuanyuanking/SPARK-34748.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Consistently correct the spelling of `PushedFilters`
### Why are the changes needed?
bersprockets noted that it's wrong
### Does this PR introduce _any_ user-facing change?
Technically, I think it does. Practically, neither Google nor GitHub show anyone using `pushedFilers` outside of forks (or the discussion about fixing it started at https://github.com/apache/spark/pull/30323#issuecomment-725568719)
### How was this patch tested?
None beyond CI in the previous PR
Closes#30678 from jsoref/spelling-filters.
Authored-by: Josh Soref <jsoref@users.noreply.github.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR is to fix the LIMIT code-gen bug in https://issues.apache.org/jira/browse/SPARK-34796, where the counter variable from `BaseLimitExec` is not initialized but used in code-gen. This is because the limit counter variable will be used in upstream operators (LIMIT's child plan, e.g. `ColumnarToRowExec` operator for early termination), but in the same stage, there can be some operators doing the shortcut and not calling `BaseLimitExec`'s `doConsume()`, e.g. [HashJoin.codegenInner](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/joins/HashJoin.scala#L402). So if we have query that `LocalLimit - BroadcastHashJoin - FileScan` in the same stage, the whole stage code-gen compilation will be failed.
Here is an example:
```
test("failed limit query") {
withTable("left_table", "empty_right_table", "output_table") {
spark.range(5).toDF("k").write.saveAsTable("left_table")
spark.range(0).toDF("k").write.saveAsTable("empty_right_table")
withSQLConf(SQLConf.ADAPTIVE_EXECUTION_ENABLED.key -> "false") {
spark.sql("CREATE TABLE output_table (k INT) USING parquet")
spark.sql(
s"""
|INSERT INTO TABLE output_table
|SELECT t1.k FROM left_table t1
|JOIN empty_right_table t2
|ON t1.k = t2.k
|LIMIT 3
|""".stripMargin)
}
}
}
```
Query plan:
```
Execute InsertIntoHadoopFsRelationCommand file:/Users/chengsu/spark/sql/core/spark-warehouse/org.apache.spark.sql.SQLQuerySuite/output_table, false, Parquet, Map(path -> file:/Users/chengsu/spark/sql/core/spark-warehouse/org.apache.spark.sql.SQLQuerySuite/output_table), Append, CatalogTable(
Database: default
Table: output_table
Created Time: Thu Mar 18 21:46:26 PDT 2021
Last Access: UNKNOWN
Created By: Spark 3.2.0-SNAPSHOT
Type: MANAGED
Provider: parquet
Location: file:/Users/chengsu/spark/sql/core/spark-warehouse/org.apache.spark.sql.SQLQuerySuite/output_table
Schema: root
|-- k: integer (nullable = true)
), org.apache.spark.sql.execution.datasources.InMemoryFileIndexb25d08b, [k]
+- *(3) Project [ansi_cast(k#228L as int) AS k#231]
+- *(3) GlobalLimit 3
+- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#179]
+- *(2) LocalLimit 3
+- *(2) Project [k#228L]
+- *(2) BroadcastHashJoin [k#228L], [k#229L], Inner, BuildRight, false
:- *(2) Filter isnotnull(k#228L)
: +- *(2) ColumnarToRow
: +- FileScan parquet default.left_table[k#228L] Batched: true, DataFilters: [isnotnull(k#228L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[file:/Users/chengsu/spark/sql/core/spark-warehouse/org.apache.spark.sq..., PartitionFilters: [], PushedFilters: [IsNotNull(k)], ReadSchema: struct<k:bigint>
+- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [id=#173]
+- *(1) Filter isnotnull(k#229L)
+- *(1) ColumnarToRow
+- FileScan parquet default.empty_right_table[k#229L] Batched: true, DataFilters: [isnotnull(k#229L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[file:/Users/chengsu/spark/sql/core/spark-warehouse/org.apache.spark.sq..., PartitionFilters: [], PushedFilters: [IsNotNull(k)], ReadSchema: struct<k:bigint>
```
Codegen failure - https://gist.github.com/c21/ea760c75b546d903247582be656d9d66 .
The uninitialized variable `_limit_counter_1` from `LocalLimitExec` is referenced in `ColumnarToRowExec`, but `BroadcastHashJoinExec` does not call `LocalLimitExec.doConsume()` to initialize the counter variable.
The fix is to move the counter variable initialization to `doProduce()`, as in whole stage code-gen framework, `doProduce()` will definitely be called if upstream operators `doProduce()`/`doConsume()` is called.
Note: this only happens in AQE disabled case, because we have an AQE optimization rule [EliminateUnnecessaryJoin](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/EliminateUnnecessaryJoin.scala#L69) to change the whole query to an empty `LocalRelation` if inner join broadcast side is empty with AQE enabled.
### Why are the changes needed?
Fix query failure.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit test in `SQLQuerySuite.scala`.
Closes#31892 from c21/limit-fix.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This patch proposes to fix a bug related to `NestedColumnAliasing`. The root cause is `Window` doesn't override `producedAttributes` so `NestedColumnAliasing` rule wrongly prune attributes produced by `Window`.
The master and branch-3.1 both have this issue.
### Why are the changes needed?
It is needed to fix a bug of nested column pruning.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test.
Closes#31897 from viirya/SPARK-34776.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
For all built-in datasources, prohibit saving of year-month and day-time intervals that were introduced by SPARK-27793. We plan to support saving of such types at the milestone 2, see SPARK-27790.
### Why are the changes needed?
To improve user experience with Spark SQL, and print nicer error message. Current error message might confuse users:
```
scala> Seq(java.time.Period.ofMonths(1)).toDF.write.mode("overwrite").json("/Users/maximgekk/tmp/123")
21/03/18 22:44:35 ERROR FileFormatWriter: Aborting job 8de402d7-ab69-4dc0-aa8e-14ef06bd2d6b.
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 1.0 failed 1 times, most recent failure: Lost task 0.0 in stage 1.0 (TID 1) (192.168.1.66 executor driver): org.apache.spark.SparkException: Task failed while writing rows.
at org.apache.spark.sql.errors.QueryExecutionErrors$.taskFailedWhileWritingRowsError(QueryExecutionErrors.scala:418)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeTask(FileFormatWriter.scala:298)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$write$15(FileFormatWriter.scala:211)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:498)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1437)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:501)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.RuntimeException: Failed to convert value 1 (class of class java.lang.Integer}) with the type of YearMonthIntervalType to JSON.
at scala.sys.package$.error(package.scala:30)
at org.apache.spark.sql.catalyst.json.JacksonGenerator.$anonfun$makeWriter$23(JacksonGenerator.scala:179)
at org.apache.spark.sql.catalyst.json.JacksonGenerator.$anonfun$makeWriter$23$adapted(JacksonGenerator.scala:176)
```
### Does this PR introduce _any_ user-facing change?
Yes. After the changes, the example above:
```
scala> Seq(java.time.Period.ofMonths(1)).toDF.write.mode("overwrite").json("/Users/maximgekk/tmp/123")
org.apache.spark.sql.AnalysisException: Cannot save interval data type into external storage.
```
### How was this patch tested?
1. Checked nested intervals:
```
scala> spark.range(1).selectExpr("""struct(timestamp'2021-01-02 00:01:02' - timestamp'2021-01-01 00:00:00')""").write.mode("overwrite").parquet("/Users/maximgekk/tmp/123")
org.apache.spark.sql.AnalysisException: Cannot save interval data type into external storage.
scala> Seq(Seq(java.time.Period.ofMonths(1))).toDF.write.mode("overwrite").json("/Users/maximgekk/tmp/123")
org.apache.spark.sql.AnalysisException: Cannot save interval data type into external storage.
```
2. By running existing test suites:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *DataSourceV2DataFrameSuite"
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *DataSourceV2SQLSuite"
```
Closes#31884 from MaxGekk/ban-save-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/31671https://github.com/apache/spark/pull/31671 has an unexpected behavior change that it uses a different Hadoop conf (`sparkContext.hadoopConfiguration`) to instantiate `FileSystem`, which is used to qualify the warehouse path. Before https://github.com/apache/spark/pull/31671 , the Hadoop conf to instantiate `FileSystem` is `session.sessionState.newHadoopConf()`.
More specifically, `session.sessionState.newHadoopConf()` has more conf entries:
1. it includes configs from `SharedState.initialConfigs`
2. in includes configs from `sparkContext.conf`
This PR updates `SharedState` to use the final Hadoop conf to instantiate `FileSystem`.
### Why are the changes needed?
fix behavior change
### Does this PR introduce _any_ user-facing change?
yes, the behavior will be the same before https://github.com/apache/spark/pull/31671
### How was this patch tested?
manually check the log of `FileSystem` and verify the passed in configs.
Closes#31868 from cloud-fan/followup.
Lead-authored-by: Wenchen Fan <wenchen@databricks.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Support `timestamp +/- day-time interval`. In the PR, I propose to extend the `TimeAdd` expression and support `DayTimeIntervalType` as the `interval` parameter. The expression invokes the new method `DateTimeUtils.timestampAddDayTime()` which splits the input day-time interval to `days` and `microsecond adjustment` of a day, and adds `days` (and the microseconds) to a local timestamp derived from the given timestamp at the given time zone. The resulted local timestamp is converted back to the offset in microseconds since the epoch.
Also I updated the rules that handle `CalendarIntervalType` and produce `TimeAdd` to take into account new type `DateTimeIntervalType` for the `interval` parameter of `TimeAdd`.
### Why are the changes needed?
To conform the ANSI SQL standard which requires to support such operation over timestamps and intervals:
<img width="811" alt="Screenshot 2021-03-12 at 11 36 14" src="https://user-images.githubusercontent.com/1580697/111081674-865d4900-8515-11eb-86c8-3538ecaf4804.png">
### Does this PR introduce _any_ user-facing change?
Should not since new intervals have not been released yet.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateTimeUtilsSuite"
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31855 from MaxGekk/timestamp-add-day-time-interval.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In `EliminateJoinToEmptyRelation.scala`, we can extend it to cover more cases for LEFT SEMI and LEFT ANI joins:
* Join is left semi join, join right side is non-empty and condition is empty. Eliminate join to its left side.
* Join is left anti join, join right side is empty. Eliminate join to its left side.
Given we eliminate join to its left side here, renaming the current optimization rule to `EliminateUnnecessaryJoin` instead.
In addition, also change to use `checkRowCount()` to check run time row count, instead of using `EmptyHashedRelation`. So this can cover `BroadcastNestedLoopJoin` as well. (`BroadcastNestedLoopJoin`'s broadcast side is `Array[InternalRow]`, not `HashedRelation`).
### Why are the changes needed?
Cover more join cases, and improve query performance for affected queries.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit tests in `AdaptiveQueryExecSuite.scala`.
Closes#31873 from c21/aqe-join.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Remove all SQLConf.get to conf if extends from SQLConfHelper
### Why are the changes needed?
Clean up code.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing unit tests.
Closes#31822 from leoluan2009/SPARK-34728.
Authored-by: Luan <luanxuedong2009@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes an alternative way to fix the memory leak of `ExecutionListenerBus`, which would automatically clean them up.
Basically, the idea is to add `registerSparkListenerForCleanup` to `ContextCleaner`, so we can remove the `ExecutionListenerBus` from `LiveListenerBus` when the `SparkSession` is GC'ed.
On the other hand, to make the `SparkSession` GC-able, we need to get rid of the reference of `SparkSession` in `ExecutionListenerBus`. Therefore, we introduced the `sessionUUID`, which is a unique identifier for SparkSession, to replace the `SparkSession` object.
Note that, the proposal wouldn't take effect when `spark.cleaner.referenceTracking=false` since it depends on `ContextCleaner`.
### Why are the changes needed?
Fix the memory leak caused by `ExecutionListenerBus` mentioned in SPARK-34087.
### Does this PR introduce _any_ user-facing change?
Yes, save memory for users.
### How was this patch tested?
Added unit test.
Closes#31839 from Ngone51/fix-mem-leak-of-ExecutionListenerBus.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR group exception messages in `/core/src/main/scala/org/apache/spark/sql/execution/datasources`.
### Why are the changes needed?
It will largely help with standardization of error messages and its maintenance.
### Does this PR introduce _any_ user-facing change?
No. Error messages remain unchanged.
### How was this patch tested?
No new tests - pass all original tests to make sure it doesn't break any existing behavior.
Closes#31757 from beliefer/SPARK-33602.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Skip capture maven repo config for views.
### Why are the changes needed?
Due to the bad network, we always use the thirdparty maven repo to run test. e.g.,
```
build/sbt "test:testOnly *SQLQueryTestSuite" -Dspark.sql.maven.additionalRemoteRepositories=xxxxx
```
It's failed with such error msg
```
[info] - show-tblproperties.sql *** FAILED *** (128 milliseconds)
[info] show-tblproperties.sql
[info] Expected "...rredTempViewNames [][]", but got "...rredTempViewNames [][
[info] view.sqlConfig.spark.sql.maven.additionalRemoteRepositories xxxxx]" Result did not match for query #6
[info] SHOW TBLPROPERTIES view (SQLQueryTestSuite.scala:464)
```
It's not necessary to capture the maven config to view since it's a session level config.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
manual test pass
```
build/sbt "test:testOnly *SQLQueryTestSuite" -Dspark.sql.maven.additionalRemoteRepositories=xxx
```
Closes#31856 from ulysses-you/skip-maven-config.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
This PR proposes to follow Univocity's input buffer.
### Why are the changes needed?
- Firstly, it's best to trust their judgement on the default values. Also 128 is too low.
- Default values arguably have more test coverage in Univocity.
- It will also fix https://github.com/uniVocity/univocity-parsers/issues/449
- ^ is a regression compared to Spark 2.4
### Does this PR introduce _any_ user-facing change?
No. In addition, It fixes a regression.
### How was this patch tested?
Manually tested, and added a unit test.
Closes#31858 from HyukjinKwon/SPARK-34768.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Push down limit through `Window` when the partitionSpec of all window functions is empty and the same order is used. This is a real case from production:

This pr support 2 cases:
1. All window functions have same orderSpec:
```sql
SELECT *, ROW_NUMBER() OVER(ORDER BY a) AS rn, RANK() OVER(ORDER BY a) AS rk FROM t1 LIMIT 5;
== Optimized Logical Plan ==
Window [row_number() windowspecdefinition(a#9L ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rn#4, rank(a#9L) windowspecdefinition(a#9L ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#5], [a#9L ASC NULLS FIRST]
+- GlobalLimit 5
+- LocalLimit 5
+- Sort [a#9L ASC NULLS FIRST], true
+- Relation default.t1[A#9L,B#10L,C#11L] parquet
```
2. There is a window function with a different orderSpec:
```sql
SELECT a, ROW_NUMBER() OVER(ORDER BY a) AS rn, RANK() OVER(ORDER BY b DESC) AS rk FROM t1 LIMIT 5;
== Optimized Logical Plan ==
Project [a#9L, rn#4, rk#5]
+- Window [rank(b#10L) windowspecdefinition(b#10L DESC NULLS LAST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#5], [b#10L DESC NULLS LAST]
+- GlobalLimit 5
+- LocalLimit 5
+- Sort [b#10L DESC NULLS LAST], true
+- Window [row_number() windowspecdefinition(a#9L ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rn#4], [a#9L ASC NULLS FIRST]
+- Project [a#9L, b#10L]
+- Relation default.t1[A#9L,B#10L,C#11L] parquet
```
### Why are the changes needed?
Improve query performance.
```scala
spark.range(500000000L).selectExpr("id AS a", "id AS b").write.saveAsTable("t1")
spark.sql("SELECT *, ROW_NUMBER() OVER(ORDER BY a) AS rowId FROM t1 LIMIT 5").show
```
Before this pr | After this pr
-- | --
 | 
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#31691 from wangyum/SPARK-34575.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes:
1. `CREATE OR REPLACE TEMP VIEW USING` should use `TemporaryViewRelation` to store temp views.
2. By doing #1, it fixes the issue where the temp view being replaced is not uncached.
### Why are the changes needed?
This is a part of an ongoing work to wrap all the temporary views with `TemporaryViewRelation`: [SPARK-34698](https://issues.apache.org/jira/browse/SPARK-34698).
This also fixes a bug where the temp view being replaced is not uncached.
### Does this PR introduce _any_ user-facing change?
Yes, the temp view being replaced with `CREATE OR REPLACE TEMP VIEW USING` is correctly uncached if the temp view is cached.
### How was this patch tested?
Added new tests.
Closes#31825 from imback82/create_temp_view_using.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For DDL commands like DROP VIEW, they don't really need to resolve the view (parse and analyze the view SQL text), they just need to get the view metadata.
This PR fixes the rule `ResolveTempViews` to only resolve the temp view for `UnresolvedRelation`. This also fixes a bug for DROP VIEW, as previously it tried to resolve the view and failed to drop invalid views.
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
new test
Closes#31853 from cloud-fan/view-resolve.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a followup minor change from https://github.com/apache/spark/pull/31821#discussion_r594110622 , where we change from using `execute()` to `executeTake()`. Performance-wise there's no difference. We are just using a different API to be aligned with code path of `Dataset`.
### Why are the changes needed?
To align with other code paths in SQL/Dataset.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing unit tests same as https://github.com/apache/spark/pull/31821 .
Closes#31845 from c21/join-followup.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Support `timestamp +/- year-month interval`. In the PR, I propose to introduce new binary expression `TimestampAddYMInterval` similarly to `DateAddYMInterval`. It invokes new method `timestampAddMonths` from `DateTimeUtils` by passing a timestamp as an offset in microseconds since the epoch, amount of months from the giveb year-month interval, and the time zone ID in which the operation is performed. The `timestampAddMonths()` method converts the input microseconds to a local timestamp, adds months to it, and converts the results back to an instant in microseconds at the given time zone.
### Why are the changes needed?
To conform the ANSI SQL standard which requires to support such operation over timestamps and intervals:
<img width="811" alt="Screenshot 2021-03-12 at 11 36 14" src="https://user-images.githubusercontent.com/1580697/111081674-865d4900-8515-11eb-86c8-3538ecaf4804.png">
### Does this PR introduce _any_ user-facing change?
Should not since new intervals have not been released yet.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateTimeUtilsSuite"
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31832 from MaxGekk/timestamp-add-year-month-interval.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
In `Analyzer.resolveExpression`, we have a parameter to decide if we should remove unnecessary `Alias` or not. This is over complicated and we can always remove unnecessary `Alias`.
This PR simplifies this part and removes the parameter.
### Why are the changes needed?
code cleanup
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing tests
Closes#31758 from cloud-fan/resolve.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For `BroadcastNestedLoopJoinExec` left semi and left anti join without condition. If we broadcast left side. Currently we check whether every row from broadcast side has a match or not by [iterating broadcast side a lot of time](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/joins/BroadcastNestedLoopJoinExec.scala#L256-L275). This is unnecessary and very inefficient when there's no condition, as we only need to check whether stream side is empty or not. Create this PR to add the optimization. This can boost the affected query execution performance a lot.
In addition, create a common method `getMatchedBroadcastRowsBitSet()` shared by several methods.
Refactor `defaultJoin()` to move
* left semi and left anti join related logic to `leftExistenceJoin`
* existence join related logic to `existenceJoin`.
After this, `defaultJoin()` holds logic only for outer join (left outer, right outer and full outer), which is much easier to read from my own opinion.
### Why are the changes needed?
Improve the affected query performance a lot.
Test with a simple query by modifying `JoinBenchmark.scala` locally:
```
val N = 20 << 20
val M = 1 << 4
val dim = broadcast(spark.range(M).selectExpr("id as k"))
val df = dim.join(spark.range(N), Seq.empty, "left_semi")
df.noop()
```
See >30x run time improvement. Note the stream side is only `spark.range(N)`. For complicated query with non-trivial stream side, the saving would be much more.
```
Running benchmark: broadcast nested loop left semi join
Running case: broadcast nested loop left semi join optimization off
Stopped after 2 iterations, 3163 ms
Running case: broadcast nested loop left semi join optimization on
Stopped after 5 iterations, 366 ms
Java HotSpot(TM) 64-Bit Server VM 1.8.0_181-b13 on Mac OS X 10.15.7
Intel(R) Core(TM) i9-9980HK CPU 2.40GHz
broadcast nested loop left semi join: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
-------------------------------------------------------------------------------------------------------------------------------------
broadcast nested loop left semi join optimization off 1568 1582 19 13.4 74.8 1.0X
broadcast nested loop left semi join optimization on 46 73 18 456.0 2.2 34.1X
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit test in `ExistenceJoinSuite.scala`.
Closes#31821 from c21/nested-join.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
The main change of this pr as follows:
- Use `org.junit.Assert.assertThrows(String, Class, ThrowingRunnable)` method instead of `ExpectedException.none()`
- Use `org.hamcrest.MatcherAssert.assertThat()` method instead of `org.junit.Assert.assertThat(T, org.hamcrest.Matcher<? super T>)`
### Why are the changes needed?
Clean up deprecated API usage
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the Jenkins or GitHub Action
Closes#31815 from LuciferYang/SPARK-34722.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Support `date +/- year-month interval`. In the PR, I propose to re-use existing code from the `AddMonths` expression, and extract it to the common base class `AddMonthsBase`. That base class is used in new expression `DateAddYMInterval` and in the existing one `AddMonths` (the `add_months` function).
### Why are the changes needed?
To conform the ANSI SQL standard which requires to support such operation over dates and intervals:
<img width="811" alt="Screenshot 2021-03-12 at 11 36 14" src="https://user-images.githubusercontent.com/1580697/110914390-5f412480-8327-11eb-9f8b-e92e73c0b9cd.png">
### Does this PR introduce _any_ user-facing change?
Should not since new intervals have not been released yet.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *ColumnExpressionSuite"
$ build/sbt "test:testOnly *DateExpressionsSuite"
```
Closes#31812 from MaxGekk/date-add-year-month-interval.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes an issue that `sql` method in the following classes which take qualified names don't quote the qualified names properly.
* UnresolvedAttribute
* AttributeReference
* Alias
One instance caused by this issue is reported in SPARK-34626.
```
UnresolvedAttribute("a" :: "b" :: Nil).sql
`a.b` // expected: `a`.`b`
```
And other instances are like as follows.
```
UnresolvedAttribute("a`b"::"c.d"::Nil).sql
a`b.`c.d` // expected: `a``b`.`c.d`
AttributeReference("a.b", IntegerType)(qualifier = "c.d"::Nil).sql
c.d.`a.b` // expected: `c.d`.`a.b`
Alias(AttributeReference("a", IntegerType)(), "b.c")(qualifier = "d.e"::Nil).sql
`a` AS d.e.`b.c` // expected: `a` AS `d.e`.`b.c`
```
### Why are the changes needed?
This is a bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New test.
Closes#31754 from sarutak/fix-qualified-names.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to override the `typeName()` method in `YearMonthIntervalType` and `DayTimeIntervalType`, and assign them names according to the ANSI SQL standard:
<img width="836" alt="Screenshot 2021-03-11 at 17 29 04" src="https://user-images.githubusercontent.com/1580697/110802854-a54aa980-828f-11eb-956d-dd4fbf14aa72.png">
but keep the type name as singular according existing naming convention for other types.
### Why are the changes needed?
To improve Spark SQL user experience, and have readable types in error messages.
### Does this PR introduce _any_ user-facing change?
Should not since the types has not been released yet.
### How was this patch tested?
By running the modified tests:
```
$ build/sbt "test:testOnly *ExpressionTypeCheckingSuite"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z windowFrameCoercion.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z literals.sql"
```
Closes#31810 from MaxGekk/interval-types-name.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a bug caused by https://issues.apache.org/jira/browse/SPARK-31670 . We remove the `Alias` when resolving column references in grouping expressions, which breaks `ResolveCreateNamedStruct`
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
new tests
Closes#31808 from cloud-fan/bug.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
As a followup from code review in https://github.com/apache/spark/pull/31736#discussion_r588134104 , for `JoinCodegenSupport.genBuildSideVars`, we only need to generate build side variables with default values for LEFT OUTER and RIGHT OUTER join, but not for other join types (i.e. LEFT SEMI and LEFT ANTI). Create this PR to clean up the code.
In addition, change `BroadcastNestedLoopJoinExec` unit test to cover both whole stage code-gen enabled and disabled. Harden the unit tests to exercise all code paths.
### Why are the changes needed?
Avoid unnecessary code generation.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing unit tests.
* BHJ and SHJ inner join is covered in `InnerJoinSuite.scala`
* BHJ and SHJ left outer and right outer join are covered in `OuterJoinSuite.scala`
* BHJ and SHJ left semi, left anti and existence join are covered in `ExistenceJoinSuite.scala`
Closes#31802 from c21/join-codegen-fix.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes the behavior of `SHOW FUNCTIONS` and `DESCRIBE FUNCTION` for the `||` operator.
The result of `SHOW FUNCTIONS` doesn't contains `||` and `DESCRIBE FUNCTION ||` says `Function: || not found.` even though `||` is supported.
### Why are the changes needed?
It's a bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Confirmed manually with the following commands.
```
spark-sql> DESCRIBE FUNCTION ||;
Function: ||
Usage: expr1 || expr2 - Returns the concatenation of `expr1` and `expr2`.
spark-sql> SHOW FUNCTIONS;
!
!=
%
...
|
||
~
```
Closes#31800 from sarutak/fix-describe-concat-pipe.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Extend the `Add`, `Subtract` and `UnaryMinus` expression to support `DayTimeIntervalType` and `YearMonthIntervalType` added by #31614.
Note: the expressions can throw the `overflow` exception independently from the SQL config `spark.sql.ansi.enabled`. In this way, the modified expressions always behave in the ANSI mode for the intervals.
### Why are the changes needed?
To conform to the ANSI SQL standard which defines `-/+` over intervals:
<img width="822" alt="Screenshot 2021-03-09 at 21 59 22" src="https://user-images.githubusercontent.com/1580697/110523128-bd50ea80-8122-11eb-9982-782da0088d27.png">
### Does this PR introduce _any_ user-facing change?
Should not since new types have not been released yet.
### How was this patch tested?
By running new tests in the test suites:
```
$ build/sbt "test:testOnly *ArithmeticExpressionSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31789 from MaxGekk/add-subtruct-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is just a minor fix. `HashJoin` already extends `JoinCodegenSupport`. So we don't need `CodegenSupport` here for `BroadcastHashJoinExec`. Submitted separately as a PR here per https://github.com/apache/spark/pull/31802#discussion_r592066686 .
### Why are the changes needed?
Clean up code.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing unit tests.
Closes#31805 from c21/bhj-minor.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Per comment in https://github.com/apache/spark/pull/31802#discussion_r592068440 , we would like to exercise whole stage code-gen enabled and disabled code paths in join unit test suites. This is for better test coverage of shuffled hash join.
### Why are the changes needed?
Better test coverage.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing and added unit tests here.
Closes#31806 from c21/test-minor.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR proposes the following:
* `AlterViewAs.query` is currently analyzed in the physical operator `AlterViewAsCommand`, but it should be analyzed during the analysis phase.
* When `spark.sql.legacy.storeAnalyzedPlanForView` is set to true, store `TermporaryViewRelation` which wraps the analyzed plan, similar to #31273.
* Try to uncache the view you are altering.
### Why are the changes needed?
Analyzing a plan should be done in the analysis phase if possible.
Not uncaching the view (existing behavior) seems like a bug since the cache may not be used again.
### Does this PR introduce _any_ user-facing change?
Yes, now the view can be uncached if it's already cached.
### How was this patch tested?
Added new tests around uncaching.
The existing tests such as `SQLViewSuite` should cover the analysis changes.
Closes#31652 from imback82/alter_view_child.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### Why are the changes needed?
SPARK-34682 was merged prematurely. This PR implements feedback from the review. I wasn't sure whether I should create a new JIRA or not.
### Does this PR introduce _any_ user-facing change?
No. Just improves the test.
### How was this patch tested?
Updated test.
Closes#31798 from andygrove/SPARK-34682-follow-up.
Authored-by: Andy Grove <andygrove73@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
There is a regression in 3.1.1 compared to 3.0.2 when checking for a canonicalized plan when executing CustomShuffleReaderExec.
The regression was caused by the call to `sendDriverMetrics` which happens before the check and will always fail if the plan is canonicalized.
### Why are the changes needed?
This is a regression in a useful error check.
### Does this PR introduce _any_ user-facing change?
No. This is not an error that a user would typically see, as far as I know.
### How was this patch tested?
I tested this change locally by making a distribution from this PR branch. Before fixing the regression I saw:
```
java.util.NoSuchElementException: key not found: numPartitions
```
After fixing this regression I saw:
```
java.lang.IllegalStateException: operating on canonicalized plan
```
Closes#31793 from andygrove/SPARK-34682.
Lead-authored-by: Andy Grove <andygrove73@gmail.com>
Co-authored-by: Andy Grove <andygrove@nvidia.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
For full outer shuffled hash join with building hash map on left side, and having non-equal condition, the join can produce wrong result.
The root cause is `boundCondition` in `HashJoin.scala` always assumes the left side row is `streamedPlan` and right side row is `buildPlan` ([streamedPlan.output ++ buildPlan.output](https://github.com/apache/spark/blob/branch-3.1/sql/core/src/main/scala/org/apache/spark/sql/execution/joins/HashJoin.scala#L141)). This is valid assumption, except for full outer + build left case.
The fix is to correct `boundCondition` in `HashJoin.scala` to handle full outer + build left case properly. See reproduce in https://issues.apache.org/jira/browse/SPARK-32399?focusedCommentId=17298414&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-17298414 .
### Why are the changes needed?
Fix data correctness bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Changed the test in `OuterJoinSuite.scala` to cover full outer shuffled hash join.
Before this change, the unit test `basic full outer join using ShuffledHashJoin` in `OuterJoinSuite.scala` is failed.
Closes#31792 from c21/join-bugfix.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Fixes a mistake in `TableCapabilityCheckSuite`, which runs some tests repeatedly.
### Why are the changes needed?
code cleanup
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
N/A
Closes#31788 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR adds `ADD ARCHIVE` and `LIST ARCHIVES` commands to SQL and updates relevant documents.
SPARK-33530 added `addArchive` and `listArchives` to `SparkContext` but it's not supported yet to add/list archives with SQL.
### Why are the changes needed?
To complement features.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added new test and confirmed the generated HTML from the updated documents.
Closes#31721 from sarutak/sql-archive.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposed to fix a bug introduced in #31273 (https://github.com/apache/spark/pull/31273/files#r589494855).
### Why are the changes needed?
This fixes a bug where global temp view's database name was not passed correctly.
### Does this PR introduce _any_ user-facing change?
Yes, now the global temp view's database is correctly stored.
### How was this patch tested?
Added a new test that catches the bug.
Closes#31783 from imback82/SPARK-34152-bug-fix.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Use resolved attributes instead of data-frame fields for replacing values.
### Why are the changes needed?
dataframe.na.replace() does not work for column having a dot in the name
### Does this PR introduce _any_ user-facing change?
None
### How was this patch tested?
Added unit tests for the same
Closes#31769 from amandeep-sharma/master.
Authored-by: Amandeep Sharma <happyaman91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Added new tests to `UDFSuite` to check `java.time.Period`/`java.time.Duration` in UDF as input parameters as well as UDF results.
### Why are the changes needed?
To improve test coverage.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *UDFSuite"
```
Closes#31779 from MaxGekk/interval-udf.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to extend Spark SQL API to accept [`java.time.Period`](https://docs.oracle.com/javase/8/docs/api/java/time/Period.html) as an external type of recently added new Catalyst type - `YearMonthIntervalType` (see #31614). The Java class `java.time.Period` has similar semantic to ANSI SQL year-month interval type, and it is the most suitable to be an external type for `YearMonthIntervalType`. In more details:
1. Added `PeriodConverter` which converts `java.time.Period` instances to/from internal representation of the Catalyst type `YearMonthIntervalType` (to `Int` type). The `PeriodConverter` object uses new methods of `IntervalUtils`:
- `periodToMonths()` converts the input period to the total length in months. If this period is too large to fit `Int`, the method throws the exception `ArithmeticException`. **Note:** _the input period has "days" precision, the method just ignores the days unit._
- `monthToPeriod()` obtains a `java.time.Period` representing a number of months.
2. Support new type `YearMonthIntervalType` in `RowEncoder` via the methods `createDeserializerForPeriod()` and `createSerializerForJavaPeriod()`.
3. Extended the Literal API to construct literals from `java.time.Period` instances.
### Why are the changes needed?
1. To allow users parallelization of `java.time.Period` collections, and construct year-month interval columns. Also to collect such columns back to the driver side.
2. This will allow to write tests in other sub-tasks of SPARK-27790.
### Does this PR introduce _any_ user-facing change?
The PR extends existing functionality. So, users can parallelize instances of the `java.time.Duration` class and collect them back:
```scala
scala> val ds = Seq(java.time.Period.ofYears(10).withMonths(2)).toDS
ds: org.apache.spark.sql.Dataset[java.time.Period] = [value: yearmonthinterval]
scala> ds.collect
res0: Array[java.time.Period] = Array(P10Y2M)
```
### How was this patch tested?
- Added a few tests to `CatalystTypeConvertersSuite` to check conversion from/to `java.time.Period`.
- Checking row encoding by new tests in `RowEncoderSuite`.
- Making literals of `YearMonthIntervalType` are tested in `LiteralExpressionSuite`.
- Check collecting by `DatasetSuite` and `JavaDatasetSuite`.
- New tests in `IntervalUtilsSuites` to check conversions `java.time.Period` <-> months.
Closes#31765 from MaxGekk/java-time-period.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
`ParquetFileReader.readFooter` related methods has been identified as `Deprecated` and `Apache Parquet` suggests replace it with the combination of `ParquetFileReader.open() and getFooter()` methods.
This PR introduces the `ParquetFooterReader` utility class due to some repetitive code patterns when read parquet file footer.
### Why are the changes needed?
Cleanup deprecated API usage.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass the Jenkins or GitHub Action
Closes#31711 from LuciferYang/parquet-read-footer.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
pyrolite 4.21 introduced and enabled value comparison by default (`valueCompare=true`) during object memoization and serialization: https://github.com/irmen/Pyrolite/blob/pyrolite-4.21/java/src/main/java/net/razorvine/pickle/Pickler.java#L112-L122
This change has undesired effect when we serialize a row (actually `GenericRowWithSchema`) to be passed to python: https://github.com/apache/spark/blob/branch-3.0/sql/core/src/main/scala/org/apache/spark/sql/execution/python/EvaluatePython.scala#L60. A simple example is that
```
new GenericRowWithSchema(Array(1.0, 1.0), StructType(Seq(StructField("_1", DoubleType), StructField("_2", DoubleType))))
```
and
```
new GenericRowWithSchema(Array(1, 1), StructType(Seq(StructField("_1", IntegerType), StructField("_2", IntegerType))))
```
are currently equal and the second instance is replaced to the short code of the first one during serialization.
### Why are the changes needed?
The above can cause nasty issues like the one in https://issues.apache.org/jira/browse/SPARK-34545 description:
```
>>> from pyspark.sql.functions import udf
>>> from pyspark.sql.types import *
>>>
>>> def udf1(data_type):
def u1(e):
return e[0]
return udf(u1, data_type)
>>>
>>> df = spark.createDataFrame([((1.0, 1.0), (1, 1))], ['c1', 'c2'])
>>>
>>> df = df.withColumn("c3", udf1(DoubleType())("c1"))
>>> df = df.withColumn("c4", udf1(IntegerType())("c2"))
>>>
>>> df.select("c3").show()
+---+
| c3|
+---+
|1.0|
+---+
>>> df.select("c4").show()
+---+
| c4|
+---+
| 1|
+---+
>>> df.select("c3", "c4").show()
+---+----+
| c3| c4|
+---+----+
|1.0|null|
+---+----+
```
This is because during serialization from JVM to Python `GenericRowWithSchema(1.0, 1.0)` (`c1`) is memoized first and when `GenericRowWithSchema(1, 1)` (`c2`) comes next, it is replaced to some short code of the `c1` (instead of serializing `c2` out) as they are `equal()`. The python functions then runs but the return type of `c4` is expected to be `IntegerType` and if a different type (`DoubleType`) comes back from python then it is discarded: https://github.com/apache/spark/blob/branch-3.0/sql/core/src/main/scala/org/apache/spark/sql/execution/python/EvaluatePython.scala#L108-L113
After this PR:
```
>>> df.select("c3", "c4").show()
+---+---+
| c3| c4|
+---+---+
|1.0| 1|
+---+---+
```
### Does this PR introduce _any_ user-facing change?
Yes, fixes a correctness issue.
### How was this patch tested?
Added new UT + manual tests.
Closes#31682 from peter-toth/SPARK-34545-fix-row-comparison.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
When we do self join with transform in a CTE, spark will throw AnalysisException.
A simple way to reproduce is
```
create temporary view t as select * from values 0, 1, 2 as t(a);
WITH temp AS (
SELECT TRANSFORM(a) USING 'cat' AS (b string) FROM t
)
SELECT t1.b FROM temp t1 JOIN temp t2 ON t1.b = t2.b
```
before this patch, it throws
```
org.apache.spark.sql.AnalysisException: cannot resolve '`t1.b`' given input columns: [t1.b]; line 6 pos 41;
'Project ['t1.b]
+- 'Join Inner, ('t1.b = 't2.b)
:- SubqueryAlias t1
: +- SubqueryAlias temp
: +- ScriptTransformation [a#1], cat, [b#2], ScriptInputOutputSchema(List(),List(),Some(org.apache.hadoop.hive.serde2.DelimitedJSONSerDe),Some(org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe),List((field.delim, )),List((field.delim, )),Some(org.apache.hadoop.hive.ql.exec.TextRecordReader),Some(org.apache.hadoop.hive.ql.exec.TextRecordWriter),false)
: +- SubqueryAlias t
: +- Project [a#1]
: +- SubqueryAlias t
: +- LocalRelation [a#1]
+- SubqueryAlias t2
+- SubqueryAlias temp
+- ScriptTransformation [a#1], cat, [b#2], ScriptInputOutputSchema(List(),List(),Some(org.apache.hadoop.hive.serde2.DelimitedJSONSerDe),Some(org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe),List((field.delim, )),List((field.delim, )),Some(org.apache.hadoop.hive.ql.exec.TextRecordReader),Some(org.apache.hadoop.hive.ql.exec.TextRecordWriter),false)
+- SubqueryAlias t
+- Project [a#1]
+- SubqueryAlias t
+- LocalRelation [a#1]
```
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
Add a UT
Closes#31752 from WangGuangxin/selfjoin-with-transform.
Authored-by: wangguangxin.cn <wangguangxin.cn@bytedance.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This pr make DPP support RLIKE expression:
```sql
SELECT date_id, product_id FROM fact_sk f
JOIN dim_store s
ON f.store_id = s.store_id WHERE s.country RLIKE '[DE|US]'
```
### Why are the changes needed?
Improve query performance.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#31722 from chaojun-zhang/SPARK-34595.
Authored-by: helloman <zcj23085@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Unify output of ShowCreateTableAsSerdeCommand and ShowCreateTableCommand
### Why are the changes needed?
Unify output of ShowCreateTableAsSerdeCommand and ShowCreateTableCommand
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Closes#31737 from AngersZhuuuu/SPARK-34621.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Remove unused output of AddJarCommand, keep consistence and clean
### Why are the changes needed?
Keep consistence and clean
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#31725 from AngersZhuuuu/SPARK-34608.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add allow list to capture sql config for view.
### Why are the changes needed?
Spark use origin text sql to store view then capture and store sql config into view metadata.
Capture config will skip some config with some prefix, e.g. `spark.sql.optimizer.` but unfortunately `spark.sql.optimizer.disableHints` is start with `spark.sql.optimizer.`.
We need a allow list to help capture the config.
### Does this PR introduce _any_ user-facing change?
Yes bug fix.
### How was this patch tested?
Add test.
Closes#31732 from ulysses-you/SPARK-34613.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
We have equality in `SqlBase.g4` for `RLIKE: 'RLIKE' | 'REGEXP';`
We seemed to miss adding` REGEXP` as a SQL function just like` RLIKE`
### Why are the changes needed?
symmetry and beauty
This is also a builtin function in Hive, we can reduce the migration pain for those users
### Does this PR introduce _any_ user-facing change?
yes new regexp function as an alias as rlike
### How was this patch tested?
new tests
Closes#31488 from yaooqinn/SPARK-34376.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to extend Spark SQL API to accept [`java.time.Duration`](https://docs.oracle.com/javase/8/docs/api/java/time/Duration.html) as an external type of recently added new Catalyst type - `DayTimeIntervalType` (see #31614). The Java class `java.time.Duration` has similar semantic to ANSI SQL day-time interval type, and it is the most suitable to be an external type for `DayTimeIntervalType`. In more details:
1. Added `DurationConverter` which converts `java.time.Duration` instances to/from internal representation of the Catalyst type `DayTimeIntervalType` (to `Long` type). The `DurationConverter` object uses new methods of `IntervalUtils`:
- `durationToMicros()` converts the input duration to the total length in microseconds. If this duration is too large to fit `Long`, the method throws the exception `ArithmeticException`. **Note:** _the input duration has nanosecond precision, the method casts the nanos part to microseconds by dividing by 1000._
- `microsToDuration()` obtains a `java.time.Duration` representing a number of microseconds.
2. Support new type `DayTimeIntervalType` in `RowEncoder` via the methods `createDeserializerForDuration()` and `createSerializerForJavaDuration()`.
3. Extended the Literal API to construct literals from `java.time.Duration` instances.
### Why are the changes needed?
1. To allow users parallelization of `java.time.Duration` collections, and construct day-time interval columns. Also to collect such columns back to the driver side.
2. This will allow to write tests in other sub-tasks of SPARK-27790.
### Does this PR introduce _any_ user-facing change?
The PR extends existing functionality. So, users can parallelize instances of the `java.time.Duration` class and collect them back:
```Scala
scala> val ds = Seq(java.time.Duration.ofDays(10)).toDS
ds: org.apache.spark.sql.Dataset[java.time.Duration] = [value: daytimeinterval]
scala> ds.collect
res0: Array[java.time.Duration] = Array(PT240H)
```
### How was this patch tested?
- Added a few tests to `CatalystTypeConvertersSuite` to check conversion from/to `java.time.Duration`.
- Checking row encoding by new tests in `RowEncoderSuite`.
- Making literals of `DayTimeIntervalType` are tested in `LiteralExpressionSuite`
- Check collecting by `DatasetSuite` and `JavaDatasetSuite`.
Closes#31729 from MaxGekk/java-time-duration.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Set the active SparkSession to `sparkSessionForStream` and diable AQE & CBO before initializing the `StreamExecution.logicalPlan`.
### Why are the changes needed?
The active session should be `sparkSessionForStream`. Otherwise, settings like
6b34745cb9/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamExecution.scala (L332-L335)
wouldn't take effect if callers access them from the active SQLConf, e.g., the rule of `InsertAdaptiveSparkPlan`. Besides, unlike `InsertAdaptiveSparkPlan` (which skips streaming plan), `CostBasedJoinReorder` seems to have the chance to take effect theoretically.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Tested manually. Before the fix, `InsertAdaptiveSparkPlan` would try to apply AQE on the plan(wouldn't take effect though). After this fix, the rule returns directly.
Closes#31600 from Ngone51/active-session-for-stream.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In ANSI mode, casting String to Boolean should throw an exception on parse error, instead of returning null
### Why are the changes needed?
For better ANSI compliance
### Does this PR introduce _any_ user-facing change?
Yes, in ANSI mode there will be an exception on parse failure of casting String value to Boolean type.
### How was this patch tested?
Unit tests.
Closes#31734 from gengliangwang/ansiCastToBoolean.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
`ResolveInsertInto.staticDeleteExpression` should use `UnresolvedAttribute.quoted` to create the delete expression so that we will treat the entire `attr.name` as a column name.
### Why are the changes needed?
When users use `dot` in a partition column name, queries like ```INSERT OVERWRITE $t1 PARTITION (`a.b` = 'a') (`c.d`) VALUES('b')``` is not working.
### Does this PR introduce _any_ user-facing change?
Without this test, the above query will throw
```
[info] org.apache.spark.sql.AnalysisException: cannot resolve '`a.b`' given input columns: [a.b, c.d];
[info] 'OverwriteByExpression RelationV2[a.b#17, c.d#18] default.tbl, ('a.b <=> cast(a as string)), false
[info] +- Project [a.b#19, ansi_cast(col1#16 as string) AS c.d#20]
[info] +- Project [cast(a as string) AS a.b#19, col1#16]
[info] +- LocalRelation [col1#16]
```
With the fix, the query will run correctly.
### How was this patch tested?
The new added test.
Closes#31713 from zsxwing/SPARK-34599.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to generate "stable" output attributes per the logical node of the DESCRIBE NAMESPACE command.
### Why are the changes needed?
This fixes the issue demonstrated by the example:
```
sql(s"CREATE NAMESPACE ns")
val description = sql(s"DESCRIBE NAMESPACE ns")
description.drop("name")
```
```
[info] org.apache.spark.sql.AnalysisException: Resolved attribute(s) name#74 missing from name#25,value#26 in operator !Project [name#74]. Attribute(s) with the same name appear in the operation: name. Please check if the right attribute(s) are used.;
[info] !Project [name#74]
[info] +- LocalRelation [name#25, value#26]
```
### Does this PR introduce _any_ user-facing change?
After this change user `drop()/add()` works well.
### How was this patch tested?
Added UT
Closes#31705 from AngersZhuuuu/SPARK-34577.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/27597 and simply apply the fix in the v2 table insertion code path.
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
yes, now v2 table insertion with static partitions also follow StoreAssignmentPolicy.
### How was this patch tested?
moved the test from https://github.com/apache/spark/pull/27597 to the general test suite `SQLInsertTestSuite`, which covers DS v2, file source, and hive tables.
Closes#31726 from cloud-fan/insert.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add the `ResetSystemProperties` trait to `SQLQuerySuite` so that system property changes made by any of the tests will not affect other suites/tests. Specifically, the system property changes made by `SPARK-33084: Add jar support Ivy URI in SQL -- jar contains udf class` are targeted here (which sets and then clears `ivy.home`).
### Why are the changes needed?
PR #29966 added a new test case that adjusts the `ivy.home` system property to force Ivy to resolve an artifact from a custom location. At the end of the test, the value is cleared. Clearing the value meant that, if a custom value of `ivy.home` was configured externally, it would not apply for tests run after this test case.
### Does this PR introduce _any_ user-facing change?
No, this is only in tests.
### How was this patch tested?
Existing unit tests continue to pass, whether or not `spark.jars.ivySettings` is configured (which adjusts the behavior of Ivy w.r.t. handling of `ivy.home` and `ivy.default.ivy.user.dir` properties).
Closes#31694 from xkrogen/xkrogen-SPARK-33084-ivyhome-sysprop-followon.
Authored-by: Erik Krogen <xkrogen@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add metadataOutput as a fallback to resolution.
Builds off https://github.com/apache/spark/pull/31654.
### Why are the changes needed?
The metadata columns could not be resolved via `df.col("metadataColName")` from the DataFrame API.
### Does this PR introduce _any_ user-facing change?
Yes, the metadata columns can now be resolved as described above.
### How was this patch tested?
Scala unit test.
Closes#31668 from karenfeng/spark-34555.
Authored-by: Karen Feng <karen.feng@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Hive support type constructed value as partition spec value, spark should support too.
### Why are the changes needed?
Support TypeConstructed partition spec value keep same with hive
### Does this PR introduce _any_ user-facing change?
Yes, user can use TypeConstruct value as partition spec value such as
```
CREATE TABLE t1(name STRING) PARTITIONED BY (part DATE)
INSERT INTO t1 PARTITION(part = date'2019-01-02') VALUES('a')
CREATE TABLE t2(name STRING) PARTITIONED BY (part TIMESTAMP)
INSERT INTO t2 PARTITION(part = timestamp'2019-01-02 11:11:11') VALUES('a')
CREATE TABLE t4(name STRING) PARTITIONED BY (part BINARY)
INSERT INTO t4 PARTITION(part = X'537061726B2053514C') VALUES('a')
```
### How was this patch tested?
Added UT
Closes#30421 from AngersZhuuuu/SPARK-33474.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
spark.sql.adaptive.coalescePartitions.initialPartitionNum 200 -> (none)
spark.sql.adaptive.skewJoin.skewedPartitionFactor is 10 -> 5
### Why are the changes needed?
the wrong doc misguide people
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
passing doc
Closes#31717 from yaooqinn/minordoc0.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to generate "stable" output attributes per the logical node of the DESCRIBE COLUMN command.
### Why are the changes needed?
This fixes the issue demonstrated by the example:
```
val tbl = "testcat.ns1.ns2.tbl"
sql(s"CREATE TABLE $tbl (c0 INT) USING _")
val description = sql(s"DESCRIBE TABLE $tbl c0")
description.drop("info_name")
```
```
[info] org.apache.spark.sql.AnalysisException: Resolved attribute(s) info_name#74 missing from info_name#25,info_value#26 in operator !Project [info_name#74]. Attribute(s) with the same name appear in the operation: info_name. Please check if the right attribute(s) are used.;
[info] !Project [info_name#74]
[info] +- LocalRelation [info_name#25, info_value#26]
```
### Does this PR introduce _any_ user-facing change?
After this change user `drop()/add()` works well.
### How was this patch tested?
Added UT
Closes#31696 from AngersZhuuuu/SPARK-34576.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
`BroadcastNestedLoopJoinExec` does not preserve `outputPartitioning` and `outputOrdering` right now. But it can preserve the streamed side partitioning and ordering when possible. This can help avoid shuffle and sort in later stage, if there's join and aggregation in the query. See example queries in added unit test in `JoinSuite.scala`.
In addition, fix a bunch of minor places in `BroadcastNestedLoopJoinExec.scala` for better style and readability.
### Why are the changes needed?
Avoid shuffle and sort for certain complicated query shape. Better query performance can be achieved.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit test in `JoinSuite.scala`.
Closes#31708 from c21/nested-join.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch proposes to remove unnecessary children from Union under Distince and Deduplicate
### Why are the changes needed?
If there are any duplicate child of `Union` under `Distinct` and `Deduplicate`, it can be removed to simplify query plan.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes#31656 from viirya/SPARK-34548.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
Currently, the warehouse path gets fully qualified in the caller side for creating a database, table, partition, etc. An unqualified path is populated into Spark and Hadoop confs, which leads to inconsistent API behaviors. We should make it qualified ahead.
When the value is a relative path `spark.sql.warehouse.dir=lakehouse`, some behaviors become inconsistent, for example.
If the default database is absent at runtime, the app fails with
```java
Caused by: java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: file:./lakehouse
at org.apache.hadoop.fs.Path.initialize(Path.java:263)
at org.apache.hadoop.fs.Path.<init>(Path.java:254)
at org.apache.hadoop.hive.metastore.Warehouse.getDnsPath(Warehouse.java:133)
at org.apache.hadoop.hive.metastore.Warehouse.getDnsPath(Warehouse.java:137)
at org.apache.hadoop.hive.metastore.Warehouse.getWhRoot(Warehouse.java:150)
at org.apache.hadoop.hive.metastore.Warehouse.getDefaultDatabasePath(Warehouse.java:163)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.createDefaultDB_core(HiveMetaStore.java:636)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.createDefaultDB(HiveMetaStore.java:655)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.init(HiveMetaStore.java:431)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.invokeInternal(RetryingHMSHandler.java:148)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.invoke(RetryingHMSHandler.java:107)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.<init>(RetryingHMSHandler.java:79)
... 73 more
```
If the default database is present at runtime, the app can work with it, and if we create a database, it gets fully qualified, for example
```sql
spark-sql> create database test;
Time taken: 0.052 seconds
spark-sql> desc database test;
Database Name test
Comment
Location file:/Users/kentyao/Downloads/spark/spark-3.2.0-SNAPSHOT-bin-20210226/lakehouse/test.db
Owner kentyao
Time taken: 0.023 seconds, Fetched 4 row(s)
```
Another thing is that the log becomes nubilous, for example.
```logtalk
21/02/27 13:54:17 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('datalake').
21/02/27 13:54:17 INFO SharedState: Warehouse path is 'lakehouse'.
```
### Why are the changes needed?
fix bug and ambiguity
### Does this PR introduce _any_ user-facing change?
yes, the path now resolved with proper order - `warehouse->database->table->partition`
### How was this patch tested?
w/ ut added
Closes#31671 from yaooqinn/SPARK-34558.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a followup of #31560,
In #31560, we added `JavaSimpleWritableDataSource ` and left some little problems like unused interface `SessionConfigSupport` 、 inconsistent schema between `JavaSimpleWritableDataSource ` and `SimpleWritableDataSource`.
This PR fixes the remaining problems in #31560.
### Why are the changes needed?
1. `SessionConfigSupport` in `JavaSimpleWritableDataSource ` and `SimpleWritableDataSource` is never used, so we don't need to implement it.
2. change the schema of `SimpleWritableDataSource`, to match `TestingV2Source`
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
existing testsuites
Closes#31621 from kevincmchen/SPARK-34498.
Authored-by: kevincmchen <kevincmchen@tencent.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Today, child expressions may be resolved based on "real" or metadata output attributes. We should prefer the real attribute during resolution if one exists.
### Why are the changes needed?
Today, attempting to resolve an expression when there is a "real" output attribute and a metadata attribute with the same name results in resolution failure. This is likely unexpected, as the user may not know about the metadata attribute.
### Does this PR introduce _any_ user-facing change?
Yes. Previously, the user would see an error message when resolving a column with the same name as a "real" output attribute and a metadata attribute as below:
```
org.apache.spark.sql.AnalysisException: Reference 'index' is ambiguous, could be: testcat.ns1.ns2.tableTwo.index, testcat.ns1.ns2.tableOne.index.; line 1 pos 71
at org.apache.spark.sql.catalyst.expressions.package$AttributeSeq.resolve(package.scala:363)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveChildren(LogicalPlan.scala:107)
```
Now, resolution succeeds and provides the "real" output attribute.
### How was this patch tested?
Added a unit test.
Closes#31654 from karenfeng/fallback-resolve-metadata.
Authored-by: Karen Feng <karen.feng@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
**What changes were proposed in this pull request?**
This PR fixes dataframe.na.fillMap() for column having a dot in the name as mentioned in [SPARK-34417](https://issues.apache.org/jira/browse/SPARK-34417).
Use resolved attributes of a column for replacing null values.
**Why are the changes needed?**
dataframe.na.fillMap() does not work for column having a dot in the name
**Does this PR introduce any user-facing change?**
None
**How was this patch tested?**
Added unit test for the same
Closes#31545 from amandeep-sharma/master.
Lead-authored-by: Amandeep Sharma <happyaman91@gmail.com>
Co-authored-by: Amandeep Sharma <amandeep.sharma@oracle.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
As a follow-up to SPARK-34456, this PR removes `BatchWriteHelper` completely.
### Why are the changes needed?
These changes remove no longer used code.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#31699 from aokolnychyi/spark-34585.
Authored-by: Anton Okolnychyi <aokolnychyi@apple.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. This PR aims to ignore ORC encryption tests when ORC shim is loaded by old Hadoop library by some other tests. The test coverage is preserved by Jenkins SBT runs and GitHub Action jobs. This PR only aims to recover Maven Jenkins jobs.
2. In addition, this PR simplifies SBT testing by refactor the test config to `SparkBuild.scala/pom.xml` and remove `DedicatedJVMTest`. This will remove one GitHub Action job which was recently added for `DedicatedJVMTest` tag.
### Why are the changes needed?
Currently, Maven test fails when it runs in a batch mode because `HadoopShimsPre2_3$NullKeyProvider` is loaded.
**MVN COMMAND**
```
$ mvn test -pl sql/core --am -Dtest=none -DwildcardSuites=org.apache.spark.sql.execution.datasources.orc.OrcV1QuerySuite,org.apache.spark.sql.execution.datasources.orc.OrcEncryptionSuite
```
**BEFORE**
```
- Write and read an encrypted table *** FAILED ***
...
Cause: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 1.0 failed 1 times, most recent failure: Lost task 0.0 in stage 1.0 (TID 1) (localhost executor driver): java.lang.IllegalArgumentException: Unknown key pii
at org.apache.orc.impl.HadoopShimsPre2_3$NullKeyProvider.getCurrentKeyVersion(HadoopShimsPre2_3.java:71)
at org.apache.orc.impl.WriterImpl.getKey(WriterImpl.java:871)
```
**AFTER**
```
OrcV1QuerySuite
...
OrcEncryptionSuite:
- Write and read an encrypted file !!! CANCELED !!!
[] was empty org.apache.orc.impl.HadoopShimsPre2_3$NullKeyProvider1b705f65 doesn't has the test keys. ORC shim is created with old Hadoop libraries (OrcEncryptionSuite.scala:39)
- Write and read an encrypted table !!! CANCELED !!!
[] was empty org.apache.orc.impl.HadoopShimsPre2_3$NullKeyProvider22adeee1 doesn't has the test keys. ORC shim is created with old Hadoop libraries (OrcEncryptionSuite.scala:67)
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the Jenkins Maven tests.
For SBT command,
- the test suite required a dedicated JVM (Before)
- the test suite doesn't require a dedicated JVM (After)
```
$ build/sbt "sql/testOnly *.OrcV1QuerySuite *.OrcEncryptionSuite"
...
[info] OrcV1QuerySuite
...
[info] - SPARK-20728 Make ORCFileFormat configurable between sql/hive and sql/core (26 milliseconds)
[info] OrcEncryptionSuite:
[info] - Write and read an encrypted file (431 milliseconds)
[info] - Write and read an encrypted table (359 milliseconds)
[info] All tests passed.
[info] Passed: Total 35, Failed 0, Errors 0, Passed 35
```
Closes#31697 from dongjoon-hyun/SPARK-34578-TEST.
Lead-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Currently in `SpecificParquetRecordReaderBase` we use deprecated APIs in a few places from Parquet, such as `readFooter`, `ParquetInputSplit`, `new ParquetFileReader`, `filterRowGroups`, etc. This replaces these with the newer APIs. In specific this:
- Replaces `ParquetInputSplit` with `FileSplit`. We never use specific things in the former such as `rowGroupOffsets` so the swap is pretty simple.
- Removes `readFooter` calls by using `ParquetFileReader.open`
- Replace deprecated `ParquetFileReader` ctor with the newer API which takes `ParquetReadOptions`.
- Removes the unnecessary handling of case when `rowGroupOffsets` is not null. It seems this never happens.
### Why are the changes needed?
The aforementioned APIs were deprecated and is going to be removed at some point in future. This is to ensure better supportability.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
This is a cleanup and relies on existing tests on the relevant code paths.
Closes#31667 from sunchao/SPARK-32703.
Lead-authored-by: Chao Sun <sunchao@apache.org>
Co-authored-by: Chao Sun <sunchao@apple.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### Why is this change being proposed?
This patch adds support for a new "product" aggregation function in `sql.functions` which multiplies-together all values in an aggregation group.
This is likely to be useful in statistical applications which involve combining probabilities, or financial applications that involve combining cumulative interest rates, but is also a versatile mathematical operation of similar status to `sum` or `stddev`. Other users [have noted](https://stackoverflow.com/questions/52991640/cumulative-product-in-spark) the absence of such a function in current releases of Spark.
This function is both much more concise than an expression of the form `exp(sum(log(...)))`, and avoids awkward edge-cases associated with some values being zero or negative, as well as being less computationally costly.
### Does this PR introduce _any_ user-facing change?
No - only adds new function.
### How was this patch tested?
Built-in tests have been added for the new `catalyst.expressions.aggregate.Product` class and its invocation via the (scala) `sql.functions.product` function. The latter, and the PySpark wrapper have also been manually tested in spark-shell and pyspark sessions. The SparkR wrapper is currently untested, and may need separate validation (I'm not an "R" user myself).
An illustration of the new functionality, within PySpark is as follows:
```
import pyspark.sql.functions as pf, pyspark.sql.window as pw
df = sqlContext.range(1, 17).toDF("x")
win = pw.Window.partitionBy(pf.lit(1)).orderBy(pf.col("x"))
df.withColumn("factorial", pf.product("x").over(win)).show(20, False)
+---+---------------+
|x |factorial |
+---+---------------+
|1 |1.0 |
|2 |2.0 |
|3 |6.0 |
|4 |24.0 |
|5 |120.0 |
|6 |720.0 |
|7 |5040.0 |
|8 |40320.0 |
|9 |362880.0 |
|10 |3628800.0 |
|11 |3.99168E7 |
|12 |4.790016E8 |
|13 |6.2270208E9 |
|14 |8.71782912E10 |
|15 |1.307674368E12 |
|16 |2.0922789888E13|
+---+---------------+
```
Closes#30745 from rwpenney/feature/agg-product.
Lead-authored-by: Richard Penney <rwp@rwpenney.uk>
Co-authored-by: Richard Penney <rwpenney@users.noreply.github.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to generate unique attributes in the logical nodes of the `SHOW TABLES` command.
Also, this PR fixes similar issues in other logical nodes:
- ShowTableExtended
- ShowViews
- ShowTableProperties
- ShowFunctions
- ShowColumns
- ShowPartitions
- ShowNamespaces
### Why are the changes needed?
This fixes the issue which is demonstrated by the example below:
```scala
scala> val show1 = sql("SHOW TABLES IN ns1")
show1: org.apache.spark.sql.DataFrame = [namespace: string, tableName: string ... 1 more field]
scala> val show2 = sql("SHOW TABLES IN ns2")
show2: org.apache.spark.sql.DataFrame = [namespace: string, tableName: string ... 1 more field]
scala> show1.show
+---------+---------+-----------+
|namespace|tableName|isTemporary|
+---------+---------+-----------+
| ns1| tbl1| false|
+---------+---------+-----------+
scala> show2.show
+---------+---------+-----------+
|namespace|tableName|isTemporary|
+---------+---------+-----------+
| ns2| tbl2| false|
+---------+---------+-----------+
scala> show1.join(show2).where(show1("tableName") =!= show2("tableName")).show
org.apache.spark.sql.AnalysisException: Column tableName#17 are ambiguous. It's probably because you joined several Datasets together, and some of these Datasets are the same. This column points to one of the Datasets but Spark is unable to figure out which one. Please alias the Datasets with different names via `Dataset.as` before joining them, and specify the column using qualified name, e.g. `df.as("a").join(df.as("b"), $"a.id" > $"b.id")`. You can also set spark.sql.analyzer.failAmbiguousSelfJoin to false to disable this check.
at org.apache.spark.sql.execution.analysis.DetectAmbiguousSelfJoin$.apply(DetectAmbiguousSelfJoin.scala:157)
```
### Does this PR introduce _any_ user-facing change?
Yes. After the changes, the example above works as expected:
```scala
scala> show1.join(show2).where(show1("tableName") =!= show2("tableName")).show
+---------+---------+-----------+---------+---------+-----------+
|namespace|tableName|isTemporary|namespace|tableName|isTemporary|
+---------+---------+-----------+---------+---------+-----------+
| ns1| tbl1| false| ns2| tbl2| false|
+---------+---------+-----------+---------+---------+-----------+
```
### How was this patch tested?
By running the new test:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *ShowTablesSuite"
```
Closes#31675 from MaxGekk/fix-output-attrs.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to generate "stable" output attributes per the logical node of the `DESCRIBE TABLE` command.
### Why are the changes needed?
This fixes the issue demonstrated by the example:
```scala
val tbl = "testcat.ns1.ns2.tbl"
sql(s"CREATE TABLE $tbl (c0 INT) USING _")
val description = sql(s"DESCRIBE TABLE $tbl")
description.drop("comment")
```
The `drop()` method fails with the error:
```
org.apache.spark.sql.AnalysisException: Resolved attribute(s) col_name#102,data_type#103 missing from col_name#29,data_type#30,comment#31 in operator !Project [col_name#102, data_type#103]. Attribute(s) with the same name appear in the operation: col_name,data_type. Please check if the right attribute(s) are used.;
!Project [col_name#102, data_type#103]
+- LocalRelation [col_name#29, data_type#30, comment#31]
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.failAnalysis(CheckAnalysis.scala:51)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.failAnalysis$(CheckAnalysis.scala:50)
```
### Does this PR introduce _any_ user-facing change?
Yes. After the changes, `drop()`/`add()` works as expected:
```scala
description.drop("comment").show()
+---------------+---------+
| col_name|data_type|
+---------------+---------+
| c0| int|
| | |
| # Partitioning| |
|Not partitioned| |
+---------------+---------+
```
### How was this patch tested?
1. Run new test:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *DataSourceV2SQLSuite"
```
2. Run existing test suite:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *CatalogedDDLSuite"
```
Closes#31676 from MaxGekk/describe-table-drop-column.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR makes partition spec parsing respect case sensitive conf.
### Why are the changes needed?
When parsing the partition spec, Spark will call `org.apache.spark.sql.catalyst.parser.ParserUtils.checkDuplicateKeys` to check if there are duplicate partition column names in the list. But this method is always case sensitive and doesn't detect duplicate partition column names when using different cases.
### Does this PR introduce _any_ user-facing change?
Yep. This prevents users from writing incorrect queries such as `INSERT OVERWRITE t PARTITION (c='2', C='3') VALUES (1)` when they don't enable case sensitive conf.
### How was this patch tested?
The new added test will fail without this change.
Closes#31669 from zsxwing/SPARK-34556.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
the parameter - `options` is never used. The changes here was part of https://github.com/apache/spark/pull/30642, It got reverted for easier backporting #30642 as a hotfix by dad24543aa, this PR brings it back to master.
### Why are the changes needed?
remove unless dead code
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
Passing CI is enough.
Closes#31683 from yaooqinn/SPARK-34570.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
SPARK-33084 added the ability to use ivy coordinates with `SparkContext.addJar`. PR #29966 claims to mimic Hive behavior although I found a few cases where it doesn't
1) The default value of the transitive parameter is false, both in case of parameter not being specified in coordinate or parameter value being invalid. The Hive behavior is that transitive is [true if not specified](cb2ac3dcc6/ql/src/java/org/apache/hadoop/hive/ql/util/DependencyResolver.java (L169)) in the coordinate and [false for invalid values](cb2ac3dcc6/ql/src/java/org/apache/hadoop/hive/ql/util/DependencyResolver.java (L124)). Also, regardless of Hive, I think a default of true for the transitive parameter also matches [ivy's own defaults](https://ant.apache.org/ivy/history/2.5.0/ivyfile/dependency.html#_attributes).
2) The parameter value for transitive parameter is regarded as case-sensitive [based on the understanding](https://github.com/apache/spark/pull/29966#discussion_r547752259) that Hive behavior is case-sensitive. However, this is not correct, Hive [treats the parameter value case-insensitively](cb2ac3dcc6/ql/src/java/org/apache/hadoop/hive/ql/util/DependencyResolver.java (L122)).
I propose that we be compatible with Hive for these behaviors
### Why are the changes needed?
To make `ADD JAR` with ivy coordinates compatible with Hive's transitive behavior
### Does this PR introduce _any_ user-facing change?
The user-facing changes here are within master as the feature introduced in SPARK-33084 has not been released yet
1. Previously an ivy coordinate without `transitive` parameter specified did not resolve transitive dependency, now it does.
2. Previously an `transitive` parameter value was treated case-sensitively. e.g. `transitive=TRUE` would be treated as false as it did not match exactly `true`. Now it will be treated case-insensitively.
### How was this patch tested?
Modified existing unit tests to test new behavior
Add new unit test to cover usage of `exclude` with unspecified `transitive`
Closes#31623 from shardulm94/spark-34506.
Authored-by: Shardul Mahadik <smahadik@linkedin.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
if child rdd has only one partition or zero partition, skip the shuffle
### Why are the changes needed?
skip shuffle if possible
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existing testsuites
Closes#31468 from zhengruifeng/collect_limit_single_partition.
Authored-by: Ruifeng Zheng <ruifengz@foxmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
To support +8:00 in Spark3 when execute sql
`select to_utc_timestamp("2020-02-07 16:00:00", "GMT+8:00")`
### Why are the changes needed?
+8:00 this format is supported in PostgreSQL,hive, presto, but not supported in Spark3
https://issues.apache.org/jira/browse/SPARK-34392
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
unit test
Closes#31624 from Karl-WangSK/zone.
Lead-authored-by: ShiKai Wang <wskqing@gmail.com>
Co-authored-by: Karl-WangSK <shikai.wang@linkflowtech.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Implement `ColumnarMap.copy()` by using the `copy()` method of `ColumnarArray`.
### Why are the changes needed?
To eliminate `java.lang.UnsupportedOperationException` while using `ColumnarMap`.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
By running new tests in `ColumnarBatchSuite`.
Closes#31663 from MaxGekk/columnar-map-copy.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
I discovered from review discussion - https://github.com/apache/spark/pull/31630#discussion_r581774000 , that we can eliminate LEFT ANTI join (with no join condition) to empty relation, if the right side is known to be non-empty. So with AQE, this is doable similar to https://github.com/apache/spark/pull/29484 .
### Why are the changes needed?
This can help eliminate the join operator during logical plan optimization.
Before this PR, [left side physical plan `execute()` will be called](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/joins/BroadcastNestedLoopJoinExec.scala#L192), so if left side is complicated (e.g. contain broadcast exchange operator), then some computation would happen. However after this PR, the join operator will be removed during logical plan, and nothing will be computed from left side. Potentially it can save resource for these kinds of query.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit tests for positive and negative queries in `AdaptiveQueryExecSuite.scala`.
Closes#31641 from c21/left-anti-aqe.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR simplifies the resolution of v2 partition commands:
1. Add a common trait for v2 partition commands, so that we don't need to match them one by one in the rules.
2. Make partition spec an expression, so that it's easier to resolve them via tree node transformation.
3. Add `TruncatePartition` so that `TruncateTable` doesn't need to be a v2 partition command.
4. Simplify `CheckAnalysis` to only check if the table is partitioned. For partitioned tables, partition spec is always resolved, so we don't need to check it. The `SupportsAtomicPartitionManagement` check is also done in the runtime. Since Spark eagerly executes commands, exception in runtime will also be thrown at analysis time.
### Why are the changes needed?
code cleanup
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing tests
Closes#31637 from cloud-fan/simplify.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Preprocess the partition spec passed to the V1 `ALTER TABLE .. SET LOCATION` implementation `AlterTableSetLocationCommand`, and normalize the passed spec according to the partition columns w.r.t the case sensitivity flag **spark.sql.caseSensitive**.
### Why are the changes needed?
V1 `ALTER TABLE .. SET LOCATION` is case sensitive in fact, and doesn't respect the SQL config **spark.sql.caseSensitive** which is false by default, for instance:
```sql
spark-sql> CREATE TABLE tbl (id INT, part INT) PARTITIONED BY (part);
spark-sql> INSERT INTO tbl PARTITION (part=0) SELECT 0;
spark-sql> SHOW TABLE EXTENDED LIKE 'tbl' PARTITION (part=0);
Location: file:/Users/maximgekk/proj/set-location-case-sense/spark-warehouse/tbl/part=0
spark-sql> ALTER TABLE tbl ADD PARTITION (part=1);
spark-sql> SELECT * FROM tbl;
0 0
```
Create new partition folder in the file system:
```
$ cp -r /Users/maximgekk/proj/set-location-case-sense/spark-warehouse/tbl/part=0 /Users/maximgekk/proj/set-location-case-sense/spark-warehouse/tbl/aaa
```
Set new location for the partition part=1:
```sql
spark-sql> ALTER TABLE tbl PARTITION (part=1) SET LOCATION '/Users/maximgekk/proj/set-location-case-sense/spark-warehouse/tbl/aaa';
spark-sql> SELECT * FROM tbl;
0 0
0 1
spark-sql> ALTER TABLE tbl ADD PARTITION (PART=2);
spark-sql> SELECT * FROM tbl;
0 0
0 1
```
Set location for a partition in the upper case:
```
$ cp -r /Users/maximgekk/proj/set-location-case-sense/spark-warehouse/tbl/part=0 /Users/maximgekk/proj/set-location-case-sense/spark-warehouse/tbl/bbb
```
```sql
spark-sql> ALTER TABLE tbl PARTITION (PART=2) SET LOCATION '/Users/maximgekk/proj/set-location-case-sense/spark-warehouse/tbl/bbb';
Error in query: Partition spec is invalid. The spec (PART) must match the partition spec (part) defined in table '`default`.`tbl`'
```
### Does this PR introduce _any_ user-facing change?
Yes. After the changes, the command above works as expected:
```sql
spark-sql> ALTER TABLE tbl PARTITION (PART=2) SET LOCATION '/Users/maximgekk/proj/set-location-case-sense/spark-warehouse/tbl/bbb';
spark-sql> SELECT * FROM tbl;
0 0
0 1
0 2
```
### How was this patch tested?
By running the modified test suite:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *CatalogedDDLSuite"
```
Closes#31651 from MaxGekk/set-location-case-sense.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Cleanup unused symbol in Orc related code as follows:
- `OrcDeserializer` : parameter `dataSchema` in constructor
- `OrcFilters` : parameter `schema ` in method `convertibleFilters`.
- `OrcPartitionReaderFactory`: ignore return value of `OrcUtils.orcResultSchemaString` in method `buildReader(file: PartitionedFile)`
### Why are the changes needed?
Cleanup code.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass the Jenkins or GitHub Action
Closes#31644 from LuciferYang/cleanup-orc-unused-symbol.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR fixes a mistake in https://github.com/apache/spark/pull/31273. When CREATE OR REPLACE a temp view, we need to uncache the to-be-replaced existing temp view. However, we shouldn't uncache if there is no existing temp view.
This doesn't cause real issues because the uncache action is failure-safe. But it produces a lot of warning messages.
### Why are the changes needed?
Avoid unnecessary warning logs.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
manually run tests and check the warning messages.
Closes#31650 from cloud-fan/warnning.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This patch proposes to let optimizer to remove unnecessary `Union` under `Distinct`/`Deduplicate`.
### Why are the changes needed?
For an `Union` under `Distinct`/`Deduplicate`, if its children are all the same, we can just keep one among them and remove the `Union`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests.
Closes#31595 from viirya/remove-union.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
This pr make DPP support LIKE ANY/ALL expression:
```sql
SELECT date_id, product_id FROM fact_sk f
JOIN dim_store s
ON f.store_id = s.store_id WHERE s.country LIKE ANY ('%D%E%', '%A%B%')
```
### Why are the changes needed?
Improve query performance.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#31563 from wangyum/SPARK-34436.
Lead-authored-by: Yuming Wang <yumwang@apache.org>
Co-authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Rename the execution node `AlterTableRecoverPartitionsCommand` for the commands:
- `MSCK REPAIR TABLE table [{ADD|DROP|SYNC} PARTITIONS]`
- `ALTER TABLE table RECOVER PARTITIONS`
to `RepairTableCommand`.
### Why are the changes needed?
1. After the PR https://github.com/apache/spark/pull/31499, `ALTER TABLE table RECOVER PARTITIONS` is equal to `MSCK REPAIR TABLE table ADD PARTITIONS`. And mapping of the generic command `MSCK REPAIR TABLE` to the more specific execution node `AlterTableRecoverPartitionsCommand` can confuse devs in the future.
2. `ALTER TABLE table RECOVER PARTITIONS` does not support any options/extensions. So, additional parameters `enableAddPartitions` and `enableDropPartitions` in `AlterTableRecoverPartitionsCommand` confuse as well.
### Does this PR introduce _any_ user-facing change?
No because this is internal API.
### How was this patch tested?
By running the existing test suites:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableRecoverPartitionsSuite"
$ build/sbt "test:testOnly *AlterTableRecoverPartitionsParserSuite"
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *MsckRepairTableSuite"
$ build/sbt "test:testOnly *MsckRepairTableParserSuite"
```
Closes#31635 from MaxGekk/rename-recover-partitions.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Some of the built-in JDBC connection providers are changing the JVM security context to do the authentication which is fine. The problematic part is that executors can be reused by another query. The following situation leads to incorrect behaviour:
* Query1 opens JDBC connection and changes JVM security context in Executor1
* Query2 tries to open JDBC connection but it realizes there is already an entry for that DB type in Executor1
* Query2 is not changing JVM security context and uses Query1 keytab and principal
* Query2 fails with authentication error
In this PR I've changed to code such a way that JVM security context is changed all the time but only temporarily until the connection built-up and then rolled back. Since `getConnection` is synchronised with `SecurityConfigurationLock` it ends-up in correct behaviour without any race.
### Why are the changes needed?
Incorrect JVM security context handling.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing unit + integration tests.
Closes#31622 from gaborgsomogyi/SPARK-34497.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
I found out during code review of https://github.com/apache/spark/pull/31567#discussion_r577379572, where we can push down limit to the left side of LEFT SEMI and LEFT ANTI join, if the join condition is empty.
Why it's safe to push down limit:
The semantics of LEFT SEMI join without condition:
(1). if right side is non-empty, output all rows from left side.
(2). if right side is empty, output nothing.
The semantics of LEFT ANTI join without condition:
(1). if right side is non-empty, output nothing.
(2). if right side is empty, output all rows from left side.
With the semantics of output all rows from left side or nothing (all or nothing), it's safe to push down limit to left side.
NOTE: LEFT SEMI / LEFT ANTI join with non-empty condition is not safe for limit push down, because output can be a portion of left side rows.
Reference: physical operator implementation for LEFT SEMI / LEFT ANTI join without condition - https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/joins/BroadcastNestedLoopJoinExec.scala#L200-L204 .
### Why are the changes needed?
Better performance. Save CPU and IO for these joins, as limit being pushed down before join.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit test in `LimitPushdownSuite.scala` and `SQLQuerySuite.scala`.
Closes#31630 from c21/limit-pushdown.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR follows up https://github.com/apache/spark/pull/30717
Maybe some contributors don't know the job and added some exception by the old way.
### Why are the changes needed?
It will largely help with standardization of error messages and its maintenance.
### Does this PR introduce _any_ user-facing change?
No. Error messages remain unchanged.
### How was this patch tested?
No new tests - pass all original tests to make sure it doesn't break any existing behavior.
Closes#31316 from beliefer/SPARK-33599-followup.
Lead-authored-by: beliefer <beliefer@163.com>
Co-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to make `CreateViewStatement.child` to be `LogicalPlan`'s `children` so that it's resolved in the analyze phase.
### Why are the changes needed?
Currently, the `CreateViewStatement.child` is resolved when the create view command runs, which is inconsistent with other plan resolutions. For example, you may see the following in the physical plan:
```
== Physical Plan ==
Execute CreateViewCommand (1)
+- CreateViewCommand (2)
+- Project (4)
+- UnresolvedRelation (3)
```
### Does this PR introduce _any_ user-facing change?
Yes. For the example, you will now see the resolved plan:
```
== Physical Plan ==
Execute CreateViewCommand (1)
+- CreateViewCommand (2)
+- Project (5)
+- SubqueryAlias (4)
+- LogicalRelation (3)
```
### How was this patch tested?
Updated existing tests.
Closes#31273 from imback82/spark-34152.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In Spark ANSI mode, the type coercion rules are based on the type precedence lists of the input data types.
As per the section "Type precedence list determination" of "ISO/IEC 9075-2:2011
Information technology — Database languages - SQL — Part 2: Foundation (SQL/Foundation)", the type precedence lists of primitive data types are as following:
- Byte: Byte, Short, Int, Long, Decimal, Float, Double
- Short: Short, Int, Long, Decimal, Float, Double
- Int: Int, Long, Decimal, Float, Double
- Long: Long, Decimal, Float, Double
- Decimal: Any wider Numeric type
- Float: Float, Double
- Double: Double
- String: String
- Date: Date, Timestamp
- Timestamp: Timestamp
- Binary: Binary
- Boolean: Boolean
- Interval: Interval
As for complex data types, Spark will determine the precedent list recursively based on their sub-types.
With the definition of type precedent list, the general type coercion rules are as following:
- Data type S is allowed to be implicitly cast as type T iff T is in the precedence list of S
- Comparison is allowed iff the data type precedence list of both sides has at least one common element. When evaluating the comparison, Spark casts both sides as the tightest common data type of their precedent lists.
- There should be at least one common data type among all the children's precedence lists for the following operators. The data type of the operator is the tightest common precedent data type.
```
In, Except(odd), Intersect, Greatest, Least, Union, If, CaseWhen, CreateArray, Array Concat,Sequence, MapConcat, CreateMap
```
- For complex types (struct, array, map), Spark recursively looks into the element type and applies the rules above. If the element nullability is converted from true to false, add runtime null check to the elements.
Note: this new type coercion system will allow implicit converting String type literals as other primitive types, in case of breaking too many existing Spark SQL queries. This is a special rule and it is not from the ANSI SQL standard.
### Why are the changes needed?
The current type coercion rules are complex. Also, they are very hard to describe and understand. For details please refer the attached documentation "Default Type coercion rules of Spark"
[Default Type coercion rules of Spark.pdf](https://github.com/apache/spark/files/5874362/Default.Type.coercion.rules.of.Spark.pdf)
This PR is to create a new and strict type coercion system under ANSI mode. The rules are simple and clean, so that users can follow them easily
### Does this PR introduce _any_ user-facing change?
Yes, new implicit cast syntax rules in ANSI mode. All the details are in the first section of this description.
### How was this patch tested?
Unit tests
Closes#31349 from gengliangwang/ansiImplicitConversion.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
Implement the v2 execution node for the `TRUNCATE TABLE` command.
### Why are the changes needed?
To have feature parity with DS v1, and support truncation of v2 tables.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
By running the unified tests for v1 and v2 tables:
```
$ build/sbt -Phive -Phive-thriftserver "test:testOnly *TruncateTableSuite"
```
Closes#31605 from MaxGekk/truncate-table-v2.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to extend the `MSCK REPAIR TABLE` command, and support new options `{ADD|DROP|SYNC} PARTITIONS`. In particular:
1. Extend the logical node `RepairTable`, and add two new flags `enableAddPartitions` and `enableDropPartitions`.
2. Add similar flags to the v1 execution node `AlterTableRecoverPartitionsCommand`
3. Add new method `dropPartitions()` to `AlterTableRecoverPartitionsCommand` which drops partitions from the catalog if their locations in the file system don't exist.
4. Updated public docs about the `MSCK REPAIR TABLE` command:
<img width="1037" alt="Screenshot 2021-02-16 at 13 46 39" src="https://user-images.githubusercontent.com/1580697/108052607-7446d280-705d-11eb-8e25-7398254787a4.png">
Closes#31097
### Why are the changes needed?
- The changes allow to recover tables with removed partitions. The example below portraits the problem:
```sql
spark-sql> create table tbl2 (col int, part int) partitioned by (part);
spark-sql> insert into tbl2 partition (part=1) select 1;
spark-sql> insert into tbl2 partition (part=0) select 0;
spark-sql> show table extended like 'tbl2' partition (part = 0);
default tbl2 false Partition Values: [part=0]
Location: file:/Users/maximgekk/proj/apache-spark/spark-warehouse/tbl2/part=0
...
```
Remove the partition (part = 0) from the filesystem:
```
$ rm -rf /Users/maximgekk/proj/apache-spark/spark-warehouse/tbl2/part=0
```
Even after recovering, we cannot query the table:
```sql
spark-sql> msck repair table tbl2;
spark-sql> select * from tbl2;
21/01/08 22:49:13 ERROR SparkSQLDriver: Failed in [select * from tbl2]
org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: file:/Users/maximgekk/proj/apache-spark/spark-warehouse/tbl2/part=0
```
- To have feature parity with Hive: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-RecoverPartitions(MSCKREPAIRTABLE)
### Does this PR introduce _any_ user-facing change?
Yes. After the changes, we can query recovered table:
```sql
spark-sql> msck repair table tbl2 sync partitions;
spark-sql> select * from tbl2;
1 1
spark-sql> show partitions tbl2;
part=1
```
### How was this patch tested?
- By running the modified test suite:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *MsckRepairTableParserSuite"
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *PlanResolutionSuite"
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableRecoverPartitionsSuite"
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableRecoverPartitionsParallelSuite"
```
- Added unified v1 and v2 tests for `MSCK REPAIR TABLE`:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *MsckRepairTableSuite"
```
Closes#31499 from MaxGekk/repair-table-drop-partitions.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
A few minor improvements for `DynamicPartitionPruningSuiteBase`.
### Why are the changes needed?
code cleanup
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing tests
Closes#31625 from cloud-fan/followup.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Remove unused parameters in `CoalesceBucketsInJoin`, `UnsafeCartesianRDD` and `ShuffledHashJoinExec`.
### Why are the changes needed?
Clean up
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests
Closes#31617 from huaxingao/join-minor.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
In the PR, I propose to rename logical nodes of v2 commands in the form: `<verb> + <object>` like:
- AlterTableAddPartition -> AddPartition
- AlterTableSetLocation -> SetTableLocation
### Why are the changes needed?
1. For simplicity and readability of logical plans
2. For consistency with other logical nodes. For example, the logical node `RenameTable` for `ALTER TABLE .. RENAME TO` was added before `AlterTableRenamePartition`.
### Does this PR introduce _any_ user-facing change?
Should not since this is non-public APIs.
### How was this patch tested?
1. Check scala style: `./dev/scalastyle`
2. Affected test suites:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableRenamePartitionSuite"
```
Closes#31596 from MaxGekk/rename-alter-table-logic-nodes.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When resolving a view, we use the captured view name in `AnalysisContext` to
distinguish whether a relation name is a view or a table. But if the resolution failed,
other rules (e.g. `ResolveTables`) will try to resolve the relation again but without
`AnalysisContext`. So, in this case, the resolution may be incorrect. For example,
if the view refers to a dropped table while a view with the same name exists, the
dropped table will be resolved as a view rather than an unresolved exception.
### Why are the changes needed?
bugfix
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
newly added test cases
Closes#31606 from linhongliu-db/fix-temp-view-master.
Lead-authored-by: Linhong Liu <linhong.liu@databricks.com>
Co-authored-by: Linhong Liu <67896261+linhongliu-db@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR replaces all the occurrences of symbol literals (`'name`) with string interpolation (`$"name"`) in examples and documents.
### Why are the changes needed?
Symbol literals are used to represent columns in Spark SQL but the Scala community seems to remove `Symbol` completely.
As we discussed in #31569, first we should replacing symbol literals with `$"name"` in user facing examples and documents.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Build docs.
Closes#31615 from sarutak/replace-symbol-literals-in-doc-and-examples.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This fixes a regression in `DataFrameReader.schema(StructType)`, to avoid NPE if the given `StructType` is null. Note that, passing null to Spark public APIs leads to undefined behavior. There is no document mentioning the null behavior, and it's just an accident that `DataFrameReader.schema(StructType)` worked before. So I think this is not a 3.1 blocker.
### Why are the changes needed?
It fixes a 3.1 regression
### Does this PR introduce _any_ user-facing change?
yea, now `df.read.schema(null: StructType)` is a noop as before, while in the current branch-3.1 it throws NPE.
### How was this patch tested?
It's undefined behavior and is very obvious, so I didn't add a test. We should add tests when we clearly define and fix the null behavior for all public APIs.
Closes#31593 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/19269
In #19269 , there is only a scala implementation of simple writable data source in `DataSourceV2Suite`.
This PR adds a java implementation of it.
### Why are the changes needed?
To improve test coverage.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existing testsuites
Closes#31560 from kevincmchen/SPARK-34432.
Lead-authored-by: kevincmchen <kevincmchen@tencent.com>
Co-authored-by: Kevin Pis <68981916+kevincmchen@users.noreply.github.com>
Co-authored-by: Kevin Pis <kc4163568@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Move parser tests from `DDLParserSuite` to `AlterTableRenameParserSuite`.
2. Port DS v1 tests from `DDLSuite` and other test suites to `v1.AlterTableRenameBase` and to `v1.AlterTableRenameSuite`.
3. Add a test for DSv2 `ALTER TABLE .. RENAME` to `v2.AlterTableRenameSuite`.
### Why are the changes needed?
To improve test coverage.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running new test suites:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableRenameSuite"
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableRenameParserSuite"
```
Closes#31575 from MaxGekk/unify-rename-table-tests.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to add a test tag, `DedicatedJVMTest`, and replace `SecurityTest` with this.
### Why are the changes needed?
To have a reusable general test tag.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the CIs.
Closes#31607 from dongjoon-hyun/SPARK-34495.
Lead-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
If an IntDecimal type was written as a LongDecimal in a parquet file. Spark should read it as a long from `VectorizedValuesReader` but write it to the `WritableColumnVector` as an int by down-casting it and calling the appropriate method. `readLongs` has been modified to take in a boolean flag that tells it if the number would fit in a 32-bit Decimal and subsequently downsized.
### Why are the changes needed?
If a Parquet file writes an IntDecimal as LongDecimal, which is supported by the parquet spec, Spark will not be able to read it and will throw an exception. The reason this happens is because method `readLong` tries to write the long to a `WritableColumnVector` which has been initialized to accept only Ints which leads to a `NullPointerException`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
manually tested and added unit-test
Closes#31284 from razajafri/decimal_fix.
Authored-by: Raza Jafri <rjafri@nvidia.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
If new table name consists of single part (no namespaces), the v2 `ALTER TABLE .. RENAME TO` command renames the table while keeping it in the same namespace. For example:
```sql
ALTER TABLE catalog_name.ns1.ns2.ns3.ns4.ns5.tbl RENAME TO new_table
```
the command should rename the source table to `catalog_name.ns1.ns2.ns3.ns4.ns5.new_table`. Before the changes, the command moves the table to the "root" name space i.e. `catalog_name.new_table`.
### Why are the changes needed?
To have the same behavior as v1 implementation of `ALTER TABLE .. RENAME TO`, and other DBMSs.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
By running new test:
```
$ build/sbt "sql/test:testOnly *DataSourceV2SQLSuite"
```
Closes#31594 from MaxGekk/rename-table-single-part.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Update public docs of SQL commands about altering cached tables/views. For instance:
<img width="869" alt="Screenshot 2021-02-08 at 15 11 48" src="https://user-images.githubusercontent.com/1580697/107217940-fd3b8980-6a1f-11eb-98b9-9b2e3fe7f4ef.png">
### Why are the changes needed?
To inform users about commands behavior in altering cached tables or views.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running the command below and manually checking the docs:
```
$ SKIP_API=1 SKIP_SCALADOC=1 SKIP_PYTHONDOC=1 SKIP_RDOC=1 jekyll serve --watch
```
Closes#31524 from MaxGekk/doc-cmd-caching.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a retry of #31065 . Last time, the newly add test cases passed in Jenkins and individually, but it's reverted because they fail when `GitHub Action` runs with `SERIAL_SBT_TESTS=1`.
In this PR, `SecurityTest` tag is used to isolate `KeyProvider`.
This PR aims to add a basis for columnar encryption test framework by add `OrcEncryptionSuite` and `FakeKeyProvider`.
Please note that we will improve more in both Apache Spark and Apache ORC in Apache Spark 3.2.0 timeframe.
### Why are the changes needed?
Apache ORC 1.6 supports columnar encryption.
### Does this PR introduce _any_ user-facing change?
No. This is for a test case.
### How was this patch tested?
Pass the newly added test suite.
Closes#31603 from dongjoon-hyun/SPARK-34486-RETRY.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Extract optionsWithPath logic into their own function.
### Why are the changes needed?
Reduce the code duplication and improve modularity.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Just some refactoring. Existing tests.
Closes#31599 from yuchenhuo/SPARK-34481.
Authored-by: Yuchen Huo <yuchen.huo@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR fix an issue that `java.sql.RowId` is mapped to `LongType` and prefer `StringType`.
In the current implementation, JDBC RowID type is mapped to `LongType` except for `OracleDialect`, but there is no guarantee to be able to convert RowID to long.
`java.sql.RowId` declares `toString` and the specification of `java.sql.RowId` says
> _all methods on the RowId interface must be fully implemented if the JDBC driver supports the data type_
(https://docs.oracle.com/javase/8/docs/api/java/sql/RowId.html)
So, we should prefer StringType to LongType.
### Why are the changes needed?
This seems to be a potential bug.
### Does this PR introduce _any_ user-facing change?
Yes. RowID is mapped to StringType rather than LongType.
### How was this patch tested?
New test and the existing test case `SPARK-32992: map Oracle's ROWID type to StringType` in `OracleIntegrationSuite` passes.
Closes#31491 from sarutak/rowid-type.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
Handled 'Deduplicate(Keys, Union)' operation in rule 'CombineUnions' to combine adjacent 'Union' operators into a single 'Union' if necessary when using 'Dataset.union.distinct.union.distinct'.
Currently only handle distinct-like 'Deduplicate', where the keys == output, for example:
```
val df1 = Seq((1, 2, 3)).toDF("a", "b", "c")
val df2 = Seq((6, 2, 5)).toDF("a", "b", "c")
val df3 = Seq((2, 4, 3)).toDF("c", "a", "b")
val df4 = Seq((1, 4, 5)).toDF("b", "a", "c")
val unionDF1 = df1.unionByName(df2).dropDuplicates(Seq("b", "a", "c"))
.unionByName(df3).dropDuplicates().unionByName(df4)
.dropDuplicates("a")
```
In this case, **all Union operators will be combined**.
but,
```
val df1 = Seq((1, 2, 3)).toDF("a", "b", "c")
val df2 = Seq((6, 2, 5)).toDF("a", "b", "c")
val df3 = Seq((2, 4, 3)).toDF("c", "a", "b")
val df4 = Seq((1, 4, 5)).toDF("b", "a", "c")
val unionDF = df1.unionByName(df2).dropDuplicates(Seq("a"))
.unionByName(df3).dropDuplicates("c").unionByName(df4)
.dropDuplicates("b")
```
In this case, **all unions will not be combined, because the Deduplicate.keys doesn't equal to Union.output**.
### Why are the changes needed?
When using 'Dataset.union.distinct.union.distinct', the operator is 'Deduplicate(Keys, Union)', but AstBuilder transform sql-style 'Union' to operator 'Distinct(Union)', the rule 'CombineUnions' in Optimizer only handle 'Distinct(Union)' operator but not Deduplicate(Keys, Union).
Please see the detailed description in [SPARK-34283](https://issues.apache.org/jira/browse/SPARK-34283).
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests.
Closes#31404 from zzcclp/SPARK-34283.
Authored-by: Zhichao Zhang <441586683@qq.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR:
- Fixes a bug that prevents analysis of:
```
CREATE TEMPORARY VIEW temp_view AS WITH cte AS (SELECT temp_func(0)) SELECT * FROM cte;
SELECT * FROM temp_view
```
by throwing:
```
Undefined function: 'temp_func'. This function is neither a registered temporary function nor a permanent function registered in the database 'default'.
```
- and doesn't report analysis error when it should:
```
CREATE TEMPORARY VIEW temp_view AS SELECT 0;
CREATE VIEW view_on_temp_view AS WITH cte AS (SELECT * FROM temp_view) SELECT * FROM cte
```
by properly collecting temporary objects from VIEW definitions with CTEs.
- Minor refactor to make the affected code more readable.
### Why are the changes needed?
To fix a bug introduced with https://github.com/apache/spark/pull/30567
### Does this PR introduce _any_ user-facing change?
Yes, the query works again.
### How was this patch tested?
Added new UT + existing ones.
Closes#31550 from peter-toth/SPARK-34421-temp-functions-in-views-with-cte.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Infer the partitions schema by:
1. interring the common type over all partition part values, and
2. casting those values to the common type
Before the changes:
1. Spark creates a literal with most appropriate type for concrete partition value i.e. `part0=-0` -> `Literal(0, IntegerType)`, `part0=abc` -> `Literal(UTF8String.fromString("abc"), StringType)`.
2. Finds the common type for all literals of a partition column. For the example above, it is `StringType`.
3. Casts those literal to the desired type:
- `Cast(Literal(0, IntegerType), StringType)` -> `UTF8String.fromString("0")`
- `Cast(Literal(UTF8String.fromString("abc", StringType), StringType)` -> `UTF8String.fromString("abc")`
In the example, we get a partition part value "0" which is different from the original one "-0". Spark shouldn't modify partition part values of the string type because it can influence on query results.
Closes#31423
### Why are the changes needed?
The changes fix the bug demonstrated by the example:
1. There are partitioned parquet files (file format doesn't matter):
```
/private/var/folders/p3/dfs6mf655d7fnjrsjvldh0tc0000gn/T/spark-e09eae99-7ecf-4ab2-b99b-f63f8dea658d
├── _SUCCESS
├── part=-0
│ └── part-00001-02144398-2896-4d21-9628-a8743d098cb4.c000.snappy.parquet
└── part=AA
└── part-00000-02144398-2896-4d21-9628-a8743d098cb4.c000.snappy.parquet
```
placed to two partitions "AA" and **"-0"**.
2. When reading them w/o specified schema:
```
val df = spark.read.parquet(path)
df.printSchema()
root
|-- id: integer (nullable = true)
|-- part: string (nullable = true)
```
the inferred type of the partition column `part` is the **string** type.
3. The expected values in the column `part` are "AA" and "-0" but we get:
```
df.show(false)
+---+----+
|id |part|
+---+----+
|0 |AA |
|1 |0 |
+---+----+
```
So, Spark returns **"0"** instead of **"-0"**.
### Does this PR introduce _any_ user-facing change?
This PR can change query results.
### How was this patch tested?
By running new test and existing test suites:
```
$ build/sbt "test:testOnly *FileIndexSuite"
$ build/sbt "test:testOnly *ParquetV1PartitionDiscoverySuite"
$ build/sbt "test:testOnly *ParquetV2PartitionDiscoverySuite"
```
Closes#31549 from MaxGekk/fix-partition-file-index-2.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
`functions.scala` window function has an comment error in the field name. The column should be `time` per `timestamp:TimestampType`.
### Why are the changes needed?
To deliver the correct documentation and examples.
### Does this PR introduce _any_ user-facing change?
Yes, it fixes the user-facing docs.
### How was this patch tested?
CI builds in this PR should test the documentation build.
Closes#31582 from yzjg/yzjg-patch-1.
Authored-by: yzjg <785246661@qq.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Rename the following v2 exec nodes:
- AlterTableAddPartitionExec -> AddPartitionExec
- AlterTableRenamePartitionExec -> RenamePartitionExec
- AlterTableDropPartitionExec -> DropPartitionExec
### Why are the changes needed?
- To be consistent with v2 exec node added before: ALTER TABLE .. RENAME TO` -> RenameTableExec.
- For simplicity and readability of the execution plans.
### Does this PR introduce _any_ user-facing change?
Should not since this is internal API.
### How was this patch tested?
By running the existing test suites:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableAddPartitionSuite"
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableDropPartitionSuite"
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableRenamePartitionSuite"
```
Closes#31584 from MaxGekk/rename-alter-table-exec-nodes.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
1. Make the following SQL configs as internal:
- spark.sql.legacy.allowHashOnMapType
- spark.sql.legacy.sessionInitWithConfigDefaults
2. Add a test to check that all SQL configs from the `legacy` namespace are marked as internal configs.
### Why are the changes needed?
Assuming that legacy SQL configs shouldn't be set by users in common cases. The purpose of such configs is to allow switching to old behavior in corner cases. So, the configs should be marked as internals.
### Does this PR introduce _any_ user-facing change?
Should not.
### How was this patch tested?
By running new test:
```
$ build/sbt "test:testOnly *SQLConfSuite"
```
Closes#31577 from MaxGekk/mark-legacy-configs-as-internal.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Currently in `SpecificParquetRecordReaderBase` we use deprecated APIs in a few places from Parquet, such as `readFooter`, `ParquetInputSplit`, `new ParquetFileReader`, `filterRowGroups`, etc. This replaces these with the newer APIs. In specific this:
- Replaces `ParquetInputSplit` with `FileSplit`. We never use specific things in the former such as `rowGroupOffsets` so the swap is pretty simple.
- Removes `readFooter` calls by using `ParquetFileReader.open`
- Replace deprecated `ParquetFileReader` ctor with the newer API which takes `ParquetReadOptions`.
- Removes the unnecessary handling of case when `rowGroupOffsets` is not null. It seems this never happens.
### Why are the changes needed?
The aforementioned APIs were deprecated and is going to be removed at some point in future. This is to ensure better supportability.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
This is a cleanup and relies on existing tests on the relevant code paths.
Closes#29542 from sunchao/SPARK-32703.
Authored-by: Chao Sun <sunchao@apache.org>
Signed-off-by: Sean Owen <srowen@gmail.com>
BasicWriteStatsTracker to probe for a custom Xattr if the size of
the generated file is 0 bytes; if found and parseable use that as
the declared length of the output.
The matching Hadoop patch in HADOOP-17414:
* Returns all S3 object headers as XAttr attributes prefixed "header."
* Sets the custom header x-hadoop-s3a-magic-data-length to the length of
the data in the marker file.
As a result, spark job tracking will correctly report the amount of data uploaded
and yet to materialize.
### Why are the changes needed?
Now that S3 is consistent, it's a lot easier to use the S3A "magic" committer
which redirects a file written to `dest/__magic/job_0011/task_1245/__base/year=2020/output.avro`
to its final destination `dest/year=2020/output.avro` , adding a zero byte marker file at
the end and a json file `dest/__magic/job_0011/task_1245/__base/year=2020/output.avro.pending`
containing all the information for the job committer to complete the upload.
But: the write tracker statictics don't show progress as they measure the length of the
created file, find the marker file and report 0 bytes.
By probing for a specific HTTP header in the marker file and parsing that if
retrieved, the real progress can be reported.
There's a matching change in Hadoop [https://github.com/apache/hadoop/pull/2530](https://github.com/apache/hadoop/pull/2530)
which adds getXAttr API support to the S3A connector and returns the headers; the magic
committer adds the relevant attributes.
If the FS being probed doesn't support the XAttr API, the header is missing
or the value not a positive long then the size of 0 is returned.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
New tests in BasicWriteTaskStatsTrackerSuite which use a filter FS to
implement getXAttr on top of LocalFS; this is used to explore the set of
options:
* no XAttr API implementation (existing tests; what callers would see with
most filesystems)
* no attribute found (HDFS, ABFS without the attribute)
* invalid data of different forms
All of these return Some(0) as file length.
The Hadoop PR verifies XAttr implementation in S3A and that
the commit protocol attaches the header to the files.
External downstream testing has done the full hadoop+spark end
to end operation, with manual review of logs to verify that the
data was successfully collected from the attribute.
Closes#30714 from steveloughran/cdpd/SPARK-33739-magic-commit-tracking-master.
Authored-by: Steve Loughran <stevel@cloudera.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
The current implement of some DDL not unify the output and not pass the output properly to physical command.
Such as: The output attributes of `ShowFunctions` does't pass to `ShowFunctionsCommand` properly.
As the query plan, this PR pass the output attributes from `ShowFunctions` to `ShowFunctionsCommand`.
### Why are the changes needed?
This PR pass the output attributes could keep the expr ID unchanged, so that avoid bugs when we apply more operators above the command output dataframe.
### Does this PR introduce _any_ user-facing change?
'No'.
### How was this patch tested?
Jenkins test.
Closes#31519 from beliefer/SPARK-34394.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The current implement of some DDL not unify the output and not pass the output properly to physical command.
Such as: The output attributes of `ShowViews` does't pass to `ShowViewsCommand` properly.
As the query plan, this PR pass the output attributes from `ShowViews` to `ShowViewsCommand`.
### Why are the changes needed?
This PR pass the output attributes could keep the expr ID unchanged, so that avoid bugs when we apply more operators above the command output dataframe.
### Does this PR introduce _any_ user-facing change?
'No'.
### How was this patch tested?
Jenkins test.
Closes#31508 from beliefer/SPARK-34393.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR removes dead code from `BatchWriteHelper` after SPARK-33808.
### Why are the changes needed?
These changes simplify `BatchWriteHelper` by removing write options that are no longer needed as we build `Write` earlier.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#31581 from aokolnychyi/simplify-batch-write-helper.
Authored-by: Anton Okolnychyi <aokolnychyi@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Move the datetime rebase SQL configs from the `legacy` namespace by:
1. Renaming of the existing rebase configs like `spark.sql.legacy.parquet.datetimeRebaseModeInRead` -> `spark.sql.parquet.datetimeRebaseModeInRead`.
2. Add the legacy configs as alternatives
3. Deprecate the legacy rebase configs.
### Why are the changes needed?
The rebasing SQL configs like `spark.sql.legacy.parquet.datetimeRebaseModeInRead` can be used not only for migration from previous Spark versions but also to read/write datatime columns saved by other systems/frameworks/libs. So, the configs shouldn't be considered as legacy configs.
### Does this PR introduce _any_ user-facing change?
Should not. Users will see a warning if they still use one of the legacy configs.
### How was this patch tested?
1. Manually checking new configs:
```scala
scala> spark.conf.get("spark.sql.parquet.datetimeRebaseModeInRead")
res0: String = EXCEPTION
scala> spark.conf.set("spark.sql.legacy.parquet.datetimeRebaseModeInRead", "LEGACY")
21/02/17 14:57:10 WARN SQLConf: The SQL config 'spark.sql.legacy.parquet.datetimeRebaseModeInRead' has been deprecated in Spark v3.2 and may be removed in the future. Use 'spark.sql.parquet.datetimeRebaseModeInRead' instead.
scala> spark.conf.get("spark.sql.parquet.datetimeRebaseModeInRead")
res2: String = LEGACY
```
2. By running a datetime rebasing test suite:
```
$ build/sbt "test:testOnly *ParquetRebaseDatetimeV1Suite"
```
Closes#31576 from MaxGekk/rebase-confs-alternatives.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR changes the type mapping for `money` and `money[]` types for PostgreSQL.
Currently, those types are tried to convert to `DoubleType` and `ArrayType` of `double` respectively.
But the JDBC driver seems not to be able to handle those types properly.
https://github.com/pgjdbc/pgjdbc/issues/100https://github.com/pgjdbc/pgjdbc/issues/1405
Due to these issue, we can get the error like as follows.
money type.
```
[info] org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0) (192.168.1.204 executor driver): org.postgresql.util.PSQLException: Bad value for type double : 1,000.00
[info] at org.postgresql.jdbc.PgResultSet.toDouble(PgResultSet.java:3104)
[info] at org.postgresql.jdbc.PgResultSet.getDouble(PgResultSet.java:2432)
[info] at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.$anonfun$makeGetter$5(JdbcUtils.scala:418)
```
money[] type.
```
[info] org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0) (192.168.1.204 executor driver): org.postgresql.util.PSQLException: Bad value for type double : $2,000.00
[info] at org.postgresql.jdbc.PgResultSet.toDouble(PgResultSet.java:3104)
[info] at org.postgresql.jdbc.ArrayDecoding$5.parseValue(ArrayDecoding.java:235)
[info] at org.postgresql.jdbc.ArrayDecoding$AbstractObjectStringArrayDecoder.populateFromString(ArrayDecoding.java:122)
[info] at org.postgresql.jdbc.ArrayDecoding.readStringArray(ArrayDecoding.java:764)
[info] at org.postgresql.jdbc.PgArray.buildArray(PgArray.java:310)
[info] at org.postgresql.jdbc.PgArray.getArrayImpl(PgArray.java:171)
[info] at org.postgresql.jdbc.PgArray.getArray(PgArray.java:111)
```
For money type, a known workaround is to treat it as string so this PR do it.
For money[], however, there is no reasonable workaround so this PR remove the support.
### Why are the changes needed?
This is a bug.
### Does this PR introduce _any_ user-facing change?
Yes. As of this PR merged, money type is mapped to `StringType` rather than `DoubleType` and the support for money[] is stopped.
For money type, if the value is less than one thousand, `$100.00` for instance, it works without this change so I also updated the migration guide because it's a behavior change for such small values.
On the other hand, money[] seems not to work with any value but mentioned in the migration guide just in case.
### How was this patch tested?
New test.
Closes#31442 from sarutak/fix-for-money-type.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
Mention the DS options introduced by https://github.com/apache/spark/pull/31529 and by https://github.com/apache/spark/pull/31489 in `SparkUpgradeException`.
### Why are the changes needed?
To improve user experience with Spark SQL. Before the changes, the error message recommends to set SQL configs but the configs cannot help in the some situations (see the PRs for more details).
### Does this PR introduce _any_ user-facing change?
Yes. After the changes, the error message is:
_org.apache.spark.SparkUpgradeException: You may get a different result due to the upgrading of Spark 3.0: reading dates before 1582-10-15 or timestamps before 1900-01-01T00:00:00Z from Parquet files can be ambiguous, as the files may be written by Spark 2.x or legacy versions of Hive, which uses a legacy hybrid calendar that is different from Spark 3.0+'s Proleptic Gregorian calendar. See more details in SPARK-31404. You can set the SQL config 'spark.sql.legacy.parquet.datetimeRebaseModeInRead' or the datasource option 'datetimeRebaseMode' to 'LEGACY' to rebase the datetime values w.r.t. the calendar difference during reading. To read the datetime values as it is, set the SQL config 'spark.sql.legacy.parquet.datetimeRebaseModeInRead' or the datasource option 'datetimeRebaseMode' to 'CORRECTED'._
### How was this patch tested?
1. By checking coding style: `./dev/scalastyle`
2. By running the related test suite:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *ParquetRebaseDatetimeV1Suite"
```
Closes#31562 from MaxGekk/rebase-upgrade-exception.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR proposes to support `ifExists` flag for v2 `ALTER TABLE ... UNSET TBLPROPERTIES` command. Currently, the flag is not respected and the command behaves as `ifExists = true` where the command always succeeds when the properties do not exist.
### Why are the changes needed?
To support `ifExists` flag and align with v1 command behavior.
### Does this PR introduce _any_ user-facing change?
Yes, now if the property does not exist and `IF EXISTS` is not specified, the command will fail:
```
ALTER TABLE t UNSET TBLPROPERTIES ('unknown') // Fails with "Attempted to unset non-existent property 'unknown'"
ALTER TABLE t UNSET TBLPROPERTIES IF EXISTS ('unknown') // OK
```
### How was this patch tested?
Added new test
Closes#31494 from imback82/AlterTableUnsetPropertiesIfExists.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add a test and modify an existing one to check that partitions still exist after v1 `TRUNCATE TABLE`.
### Why are the changes needed?
To improve test coverage.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running new test:
```
$ build/sbt -Phive -Phive-thriftserver "test:testOnly *TruncateTableSuite"
```
Closes#31544 from MaxGekk/test-truncate-partitioned-table.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This patch proposes to throw exception if non-streaming `Deduplicate` is not replaced by aggregate in query planner.
### Why are the changes needed?
We replace some operations in the query optimizer. For them we throw some exceptions accordingly in query planner if these logical nodes are not replaced. But `Deduplicate` is missing and it opens a possible hole. For code consistency and to prevent possible unexpected query planning error, we should add similar exception case to query planner.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test.
Closes#31547 from viirya/minor-deduplicate.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
`TreeNodeException` causes the error msg not clear and it didn't work well.
Because the `TreeNodeException` looks redundancy, we could remove it.
There are show a case:
```
val df = Seq(("1", 1), ("1", 2), ("2", 3), ("2", 4)).toDF("x", "y")
val hashAggDF = df.groupBy("x").agg(c, sum("y"))
```
The above code will use `HashAggregateExec`. In order to ensure that an exception will be thrown when executing `HashAggregateExec`, I added `throw new RuntimeException("calculate error")` into 72b7f8abfb/sql/core/src/main/scala/org/apache/spark/sql/execution/aggregate/HashAggregateExec.scala (L85)
So, if the above code is executed, `RuntimeException("calculate error")` will be thrown.
Before this PR, the error is:
```
execute, tree:
ShuffleQueryStage 0
+- Exchange hashpartitioning(x#105, 5), ENSURE_REQUIREMENTS, [id=#168]
+- HashAggregate(keys=[x#105], functions=[partial_sum(y#106)], output=[x#105, sum#118L])
+- Project [_1#100 AS x#105, _2#101 AS y#106]
+- LocalTableScan [_1#100, _2#101]
org.apache.spark.sql.catalyst.errors.package$TreeNodeException: execute, tree:
ShuffleQueryStage 0
+- Exchange hashpartitioning(x#105, 5), ENSURE_REQUIREMENTS, [id=#168]
+- HashAggregate(keys=[x#105], functions=[partial_sum(y#106)], output=[x#105, sum#118L])
+- Project [_1#100 AS x#105, _2#101 AS y#106]
+- LocalTableScan [_1#100, _2#101]
at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:56)
at org.apache.spark.sql.execution.adaptive.ShuffleQueryStageExec.doMaterialize(QueryStageExec.scala:163)
at org.apache.spark.sql.execution.adaptive.QueryStageExec.$anonfun$materialize$1(QueryStageExec.scala:81)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)
at org.apache.spark.sql.execution.adaptive.QueryStageExec.materialize(QueryStageExec.scala:79)
at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.$anonfun$getFinalPhysicalPlan$5(AdaptiveSparkPlanExec.scala:207)
at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.$anonfun$getFinalPhysicalPlan$5$adapted(AdaptiveSparkPlanExec.scala:205)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.$anonfun$getFinalPhysicalPlan$1(AdaptiveSparkPlanExec.scala:205)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772)
at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.getFinalPhysicalPlan(AdaptiveSparkPlanExec.scala:179)
at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.executeCollect(AdaptiveSparkPlanExec.scala:289)
at org.apache.spark.sql.Dataset.collectFromPlan(Dataset.scala:3708)
at org.apache.spark.sql.Dataset.$anonfun$collect$1(Dataset.scala:2977)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3699)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3697)
at org.apache.spark.sql.Dataset.collect(Dataset.scala:2977)
at org.apache.spark.sql.DataFrameAggregateSuite.$anonfun$assertNoExceptions$3(DataFrameAggregateSuite.scala:665)
at org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf(SQLHelper.scala:54)
at org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf$(SQLHelper.scala:38)
at org.apache.spark.sql.DataFrameAggregateSuite.org$apache$spark$sql$test$SQLTestUtilsBase$$super$withSQLConf(DataFrameAggregateSuite.scala:37)
at org.apache.spark.sql.test.SQLTestUtilsBase.withSQLConf(SQLTestUtils.scala:246)
at org.apache.spark.sql.test.SQLTestUtilsBase.withSQLConf$(SQLTestUtils.scala:244)
at org.apache.spark.sql.DataFrameAggregateSuite.withSQLConf(DataFrameAggregateSuite.scala:37)
at org.apache.spark.sql.DataFrameAggregateSuite.$anonfun$assertNoExceptions$2(DataFrameAggregateSuite.scala:659)
at org.apache.spark.sql.DataFrameAggregateSuite.$anonfun$assertNoExceptions$2$adapted(DataFrameAggregateSuite.scala:655)
at scala.collection.TraversableLike$WithFilter.$anonfun$foreach$1(TraversableLike.scala:877)
at scala.collection.immutable.List.foreach(List.scala:392)
at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:876)
at org.apache.spark.sql.DataFrameAggregateSuite.assertNoExceptions(DataFrameAggregateSuite.scala:655)
at org.apache.spark.sql.DataFrameAggregateSuite.$anonfun$new$126(DataFrameAggregateSuite.scala:695)
at org.apache.spark.sql.DataFrameAggregateSuite.$anonfun$new$126$adapted(DataFrameAggregateSuite.scala:695)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.apache.spark.sql.DataFrameAggregateSuite.$anonfun$new$125(DataFrameAggregateSuite.scala:695)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85)
at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83)
at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104)
at org.scalatest.Transformer.apply(Transformer.scala:22)
at org.scalatest.Transformer.apply(Transformer.scala:20)
at org.scalatest.funsuite.AnyFunSuiteLike$$anon$1.apply(AnyFunSuiteLike.scala:190)
at org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:176)
at org.scalatest.funsuite.AnyFunSuiteLike.invokeWithFixture$1(AnyFunSuiteLike.scala:188)
at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTest$1(AnyFunSuiteLike.scala:200)
at org.scalatest.SuperEngine.runTestImpl(Engine.scala:306)
at org.scalatest.funsuite.AnyFunSuiteLike.runTest(AnyFunSuiteLike.scala:200)
at org.scalatest.funsuite.AnyFunSuiteLike.runTest$(AnyFunSuiteLike.scala:182)
at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterEach$$super$runTest(SparkFunSuite.scala:61)
at org.scalatest.BeforeAndAfterEach.runTest(BeforeAndAfterEach.scala:234)
at org.scalatest.BeforeAndAfterEach.runTest$(BeforeAndAfterEach.scala:227)
at org.apache.spark.SparkFunSuite.runTest(SparkFunSuite.scala:61)
at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTests$1(AnyFunSuiteLike.scala:233)
at org.scalatest.SuperEngine.$anonfun$runTestsInBranch$1(Engine.scala:413)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.scalatest.SuperEngine.traverseSubNodes$1(Engine.scala:401)
at org.scalatest.SuperEngine.runTestsInBranch(Engine.scala:396)
at org.scalatest.SuperEngine.runTestsImpl(Engine.scala:475)
at org.scalatest.funsuite.AnyFunSuiteLike.runTests(AnyFunSuiteLike.scala:233)
at org.scalatest.funsuite.AnyFunSuiteLike.runTests$(AnyFunSuiteLike.scala:232)
at org.scalatest.funsuite.AnyFunSuite.runTests(AnyFunSuite.scala:1563)
at org.scalatest.Suite.run(Suite.scala:1112)
at org.scalatest.Suite.run$(Suite.scala:1094)
at org.scalatest.funsuite.AnyFunSuite.org$scalatest$funsuite$AnyFunSuiteLike$$super$run(AnyFunSuite.scala:1563)
at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$run$1(AnyFunSuiteLike.scala:237)
at org.scalatest.SuperEngine.runImpl(Engine.scala:535)
at org.scalatest.funsuite.AnyFunSuiteLike.run(AnyFunSuiteLike.scala:237)
at org.scalatest.funsuite.AnyFunSuiteLike.run$(AnyFunSuiteLike.scala:236)
at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterAll$$super$run(SparkFunSuite.scala:61)
at org.scalatest.BeforeAndAfterAll.liftedTree1$1(BeforeAndAfterAll.scala:213)
at org.scalatest.BeforeAndAfterAll.run(BeforeAndAfterAll.scala:210)
at org.scalatest.BeforeAndAfterAll.run$(BeforeAndAfterAll.scala:208)
at org.apache.spark.SparkFunSuite.run(SparkFunSuite.scala:61)
at org.scalatest.tools.SuiteRunner.run(SuiteRunner.scala:45)
at org.scalatest.tools.Runner$.$anonfun$doRunRunRunDaDoRunRun$13(Runner.scala:1320)
at org.scalatest.tools.Runner$.$anonfun$doRunRunRunDaDoRunRun$13$adapted(Runner.scala:1314)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.scalatest.tools.Runner$.doRunRunRunDaDoRunRun(Runner.scala:1314)
at org.scalatest.tools.Runner$.$anonfun$runOptionallyWithPassFailReporter$24(Runner.scala:993)
at org.scalatest.tools.Runner$.$anonfun$runOptionallyWithPassFailReporter$24$adapted(Runner.scala:971)
at org.scalatest.tools.Runner$.withClassLoaderAndDispatchReporter(Runner.scala:1480)
at org.scalatest.tools.Runner$.runOptionallyWithPassFailReporter(Runner.scala:971)
at org.scalatest.tools.Runner$.run(Runner.scala:798)
at org.scalatest.tools.Runner.run(Runner.scala)
at org.jetbrains.plugins.scala.testingSupport.scalaTest.ScalaTestRunner.runScalaTest2(ScalaTestRunner.java:131)
at org.jetbrains.plugins.scala.testingSupport.scalaTest.ScalaTestRunner.main(ScalaTestRunner.java:28)
Caused by: org.apache.spark.sql.catalyst.errors.package$TreeNodeException: execute, tree:
HashAggregate(keys=[x#105], functions=[partial_sum(y#106)], output=[x#105, sum#118L])
+- Project [_1#100 AS x#105, _2#101 AS y#106]
+- LocalTableScan [_1#100, _2#101]
at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:56)
at org.apache.spark.sql.execution.aggregate.HashAggregateExec.doExecute(HashAggregateExec.scala:84)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:180)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:176)
at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.inputRDD$lzycompute(ShuffleExchangeExec.scala:118)
at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.inputRDD(ShuffleExchangeExec.scala:118)
at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.mapOutputStatisticsFuture$lzycompute(ShuffleExchangeExec.scala:122)
at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.mapOutputStatisticsFuture(ShuffleExchangeExec.scala:121)
at org.apache.spark.sql.execution.adaptive.ShuffleQueryStageExec.$anonfun$doMaterialize$1(QueryStageExec.scala:163)
at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:52)
... 91 more
Caused by: java.lang.RuntimeException: calculate error
at org.apache.spark.sql.execution.aggregate.HashAggregateExec.$anonfun$doExecute$1(HashAggregateExec.scala:85)
at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:52)
... 103 more
```
After this PR, the error is:
```
calculate error
java.lang.RuntimeException: calculate error
at org.apache.spark.sql.execution.aggregate.HashAggregateExec.doExecute(HashAggregateExec.scala:84)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:180)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:176)
at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.inputRDD$lzycompute(ShuffleExchangeExec.scala:117)
at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.inputRDD(ShuffleExchangeExec.scala:117)
at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.mapOutputStatisticsFuture$lzycompute(ShuffleExchangeExec.scala:121)
at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.mapOutputStatisticsFuture(ShuffleExchangeExec.scala:120)
at org.apache.spark.sql.execution.adaptive.ShuffleQueryStageExec.doMaterialize(QueryStageExec.scala:161)
at org.apache.spark.sql.execution.adaptive.QueryStageExec.$anonfun$materialize$1(QueryStageExec.scala:80)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)
at org.apache.spark.sql.execution.adaptive.QueryStageExec.materialize(QueryStageExec.scala:78)
at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.$anonfun$getFinalPhysicalPlan$5(AdaptiveSparkPlanExec.scala:207)
at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.$anonfun$getFinalPhysicalPlan$5$adapted(AdaptiveSparkPlanExec.scala:205)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.$anonfun$getFinalPhysicalPlan$1(AdaptiveSparkPlanExec.scala:205)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772)
at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.getFinalPhysicalPlan(AdaptiveSparkPlanExec.scala:179)
at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.executeCollect(AdaptiveSparkPlanExec.scala:289)
at org.apache.spark.sql.Dataset.collectFromPlan(Dataset.scala:3708)
at org.apache.spark.sql.Dataset.$anonfun$collect$1(Dataset.scala:2977)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3699)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3697)
at org.apache.spark.sql.Dataset.collect(Dataset.scala:2977)
at org.apache.spark.sql.DataFrameAggregateSuite.$anonfun$assertNoExceptions$3(DataFrameAggregateSuite.scala:665)
at org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf(SQLHelper.scala:54)
at org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf$(SQLHelper.scala:38)
at org.apache.spark.sql.DataFrameAggregateSuite.org$apache$spark$sql$test$SQLTestUtilsBase$$super$withSQLConf(DataFrameAggregateSuite.scala:37)
at org.apache.spark.sql.test.SQLTestUtilsBase.withSQLConf(SQLTestUtils.scala:246)
at org.apache.spark.sql.test.SQLTestUtilsBase.withSQLConf$(SQLTestUtils.scala:244)
at org.apache.spark.sql.DataFrameAggregateSuite.withSQLConf(DataFrameAggregateSuite.scala:37)
at org.apache.spark.sql.DataFrameAggregateSuite.$anonfun$assertNoExceptions$2(DataFrameAggregateSuite.scala:659)
at org.apache.spark.sql.DataFrameAggregateSuite.$anonfun$assertNoExceptions$2$adapted(DataFrameAggregateSuite.scala:655)
at scala.collection.TraversableLike$WithFilter.$anonfun$foreach$1(TraversableLike.scala:877)
at scala.collection.immutable.List.foreach(List.scala:392)
at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:876)
at org.apache.spark.sql.DataFrameAggregateSuite.assertNoExceptions(DataFrameAggregateSuite.scala:655)
at org.apache.spark.sql.DataFrameAggregateSuite.$anonfun$new$126(DataFrameAggregateSuite.scala:695)
at org.apache.spark.sql.DataFrameAggregateSuite.$anonfun$new$126$adapted(DataFrameAggregateSuite.scala:695)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.apache.spark.sql.DataFrameAggregateSuite.$anonfun$new$125(DataFrameAggregateSuite.scala:695)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85)
at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83)
at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104)
at org.scalatest.Transformer.apply(Transformer.scala:22)
at org.scalatest.Transformer.apply(Transformer.scala:20)
at org.scalatest.funsuite.AnyFunSuiteLike$$anon$1.apply(AnyFunSuiteLike.scala:190)
at org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:176)
at org.scalatest.funsuite.AnyFunSuiteLike.invokeWithFixture$1(AnyFunSuiteLike.scala:188)
at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTest$1(AnyFunSuiteLike.scala:200)
at org.scalatest.SuperEngine.runTestImpl(Engine.scala:306)
at org.scalatest.funsuite.AnyFunSuiteLike.runTest(AnyFunSuiteLike.scala:200)
at org.scalatest.funsuite.AnyFunSuiteLike.runTest$(AnyFunSuiteLike.scala:182)
at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterEach$$super$runTest(SparkFunSuite.scala:61)
at org.scalatest.BeforeAndAfterEach.runTest(BeforeAndAfterEach.scala:234)
at org.scalatest.BeforeAndAfterEach.runTest$(BeforeAndAfterEach.scala:227)
at org.apache.spark.SparkFunSuite.runTest(SparkFunSuite.scala:61)
at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTests$1(AnyFunSuiteLike.scala:233)
at org.scalatest.SuperEngine.$anonfun$runTestsInBranch$1(Engine.scala:413)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.scalatest.SuperEngine.traverseSubNodes$1(Engine.scala:401)
at org.scalatest.SuperEngine.runTestsInBranch(Engine.scala:396)
at org.scalatest.SuperEngine.runTestsImpl(Engine.scala:475)
at org.scalatest.funsuite.AnyFunSuiteLike.runTests(AnyFunSuiteLike.scala:233)
at org.scalatest.funsuite.AnyFunSuiteLike.runTests$(AnyFunSuiteLike.scala:232)
at org.scalatest.funsuite.AnyFunSuite.runTests(AnyFunSuite.scala:1563)
at org.scalatest.Suite.run(Suite.scala:1112)
at org.scalatest.Suite.run$(Suite.scala:1094)
at org.scalatest.funsuite.AnyFunSuite.org$scalatest$funsuite$AnyFunSuiteLike$$super$run(AnyFunSuite.scala:1563)
at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$run$1(AnyFunSuiteLike.scala:237)
at org.scalatest.SuperEngine.runImpl(Engine.scala:535)
at org.scalatest.funsuite.AnyFunSuiteLike.run(AnyFunSuiteLike.scala:237)
at org.scalatest.funsuite.AnyFunSuiteLike.run$(AnyFunSuiteLike.scala:236)
at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterAll$$super$run(SparkFunSuite.scala:61)
at org.scalatest.BeforeAndAfterAll.liftedTree1$1(BeforeAndAfterAll.scala:213)
at org.scalatest.BeforeAndAfterAll.run(BeforeAndAfterAll.scala:210)
at org.scalatest.BeforeAndAfterAll.run$(BeforeAndAfterAll.scala:208)
at org.apache.spark.SparkFunSuite.run(SparkFunSuite.scala:61)
at org.scalatest.tools.SuiteRunner.run(SuiteRunner.scala:45)
at org.scalatest.tools.Runner$.$anonfun$doRunRunRunDaDoRunRun$13(Runner.scala:1320)
at org.scalatest.tools.Runner$.$anonfun$doRunRunRunDaDoRunRun$13$adapted(Runner.scala:1314)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.scalatest.tools.Runner$.doRunRunRunDaDoRunRun(Runner.scala:1314)
at org.scalatest.tools.Runner$.$anonfun$runOptionallyWithPassFailReporter$24(Runner.scala:993)
at org.scalatest.tools.Runner$.$anonfun$runOptionallyWithPassFailReporter$24$adapted(Runner.scala:971)
at org.scalatest.tools.Runner$.withClassLoaderAndDispatchReporter(Runner.scala:1480)
at org.scalatest.tools.Runner$.runOptionallyWithPassFailReporter(Runner.scala:971)
at org.scalatest.tools.Runner$.run(Runner.scala:798)
at org.scalatest.tools.Runner.run(Runner.scala)
at org.jetbrains.plugins.scala.testingSupport.scalaTest.ScalaTestRunner.runScalaTest2(ScalaTestRunner.java:131)
at org.jetbrains.plugins.scala.testingSupport.scalaTest.ScalaTestRunner.main(ScalaTestRunner.java:28)
```
### Why are the changes needed?
`TreeNodeException` didn't work well.
### Does this PR introduce _any_ user-facing change?
'No'.
### How was this patch tested?
Jenkins test.
Closes#31337 from beliefer/SPARK-34234.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: beliefer <beliefer@163.com>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR includes the following changes:
1. in `CatalogImpl.uncacheTable`, invalidate caches in cascade when the target table is
a temp view, and `spark.sql.legacy.storeAnalyzedPlanForView` is false (default value).
2. make `SessionCatalog.lookupTempView` public and return processed temp view plan (i.e., with `View` op).
### Why are the changes needed?
Following [SPARK-34052](https://issues.apache.org/jira/browse/SPARK-34052) (#31107), we should invalidate in cascade for `CatalogImpl.uncacheTable` when the table is a temp view, so that the behavior is consistent.
### Does this PR introduce _any_ user-facing change?
Yes, now `SQLContext.uncacheTable` will drop temp view in cascade by default.
### How was this patch tested?
Added a UT
Closes#31462 from sunchao/SPARK-34347.
Authored-by: Chao Sun <sunchao@apple.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
JDBC connection provider API and embedded connection providers already added to the code but no in-depth description about the internals. In this PR I've added both user and developer documentation and additionally added an example custom JDBC connection provider.
### Why are the changes needed?
No documentation and example custom JDBC provider.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
```
cd docs/
SKIP_API=1 jekyll build
```
<img width="793" alt="Screenshot 2021-02-02 at 16 35 43" src="https://user-images.githubusercontent.com/18561820/106623428-e48d2880-6574-11eb-8d14-e5c2aa7c37f1.png">
Closes#31384 from gaborgsomogyi/SPARK-31816.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This pull request exposes the `make_interval` function, [as suggested here](https://github.com/apache/spark/pull/31000#pullrequestreview-560812433), and as agreed to [here](https://github.com/apache/spark/pull/31000#issuecomment-754856820) and [here](https://github.com/apache/spark/pull/31000#issuecomment-755040234).
This powerful little function allows for idiomatic datetime arithmetic via the Scala API:
```scala
// add two hours
df.withColumn("plus_2_hours", col("first_datetime") + make_interval(hours = lit(2)))
// subtract one week and 30 seconds
col("d") - make_interval(weeks = lit(1), secs = lit(30))
```
The `make_interval` [SQL function](https://github.com/apache/spark/pull/26446) already exists.
Here is [the JIRA ticket](https://issues.apache.org/jira/browse/SPARK-33995) for this PR.
### Why are the changes needed?
The Spark API makes it easy to perform datetime addition / subtraction with months (`add_months`) and days (`date_add`). Users need to write code like this to perform datetime addition with years, weeks, hours, minutes, or seconds:
```scala
df.withColumn("plus_2_hours", expr("first_datetime + INTERVAL 2 hours"))
```
We don't want to force users to manipulate SQL strings when they're using the Scala API.
### Does this PR introduce _any_ user-facing change?
Yes, this PR adds `make_interval` to the `org.apache.spark.sql.functions` API.
This single function will benefit a lot of users. It's a small increase in the surface of the API for a big gain.
### How was this patch tested?
This was tested via unit tests.
cc: MaxGekk
Closes#31073 from MrPowers/SPARK-33995.
Authored-by: MrPowers <matthewkevinpowers@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When explain SQL with cost, treeString about subquery won't show it's statistics:
How to reproduce:
```
spark.sql("create table t1 using parquet as select id as a, id as b from range(1000)")
spark.sql("create table t2 using parquet as select id as c, id as d from range(2000)")
spark.sql("ANALYZE TABLE t1 COMPUTE STATISTICS FOR ALL COLUMNS")
spark.sql("ANALYZE TABLE t2 COMPUTE STATISTICS FOR ALL COLUMNS")
spark.sql("set spark.sql.cbo.enabled=true")
spark.sql(
"""
|WITH max_store_sales AS
| (SELECT max(csales) tpcds_cmax
| FROM (SELECT
| sum(b) csales
| FROM t1 WHERE a < 100 ) x),
|best_ss_customer AS
| (SELECT
| c
| FROM t2
| WHERE d > (SELECT * FROM max_store_sales))
|
|SELECT c FROM best_ss_customer
|""".stripMargin).explain("cost")
```
Before this PR's output:
```
== Optimized Logical Plan ==
Project [c#4263L], Statistics(sizeInBytes=31.3 KiB, rowCount=2.00E+3)
+- Filter (isnotnull(d#4264L) AND (d#4264L > scalar-subquery#4262 [])), Statistics(sizeInBytes=46.9 KiB, rowCount=2.00E+3)
: +- Aggregate [max(csales#4260L) AS tpcds_cmax#4261L]
: +- Aggregate [sum(b#4266L) AS csales#4260L]
: +- Project [b#4266L]
: +- Filter ((a#4265L < 100) AND isnotnull(a#4265L))
: +- Relation default.t1[a#4265L,b#4266L] parquet, Statistics(sizeInBytes=23.4 KiB, rowCount=1.00E+3)
+- Relation default.t2[c#4263L,d#4264L] parquet, Statistics(sizeInBytes=46.9 KiB, rowCount=2.00E+3)
```
After this pr:
```
== Optimized Logical Plan ==
Project [c#4481L], Statistics(sizeInBytes=31.3 KiB, rowCount=2.00E+3)
+- Filter (isnotnull(d#4482L) AND (d#4482L > scalar-subquery#4480 [])), Statistics(sizeInBytes=46.9 KiB, rowCount=2.00E+3)
: +- Aggregate [max(csales#4478L) AS tpcds_cmax#4479L], Statistics(sizeInBytes=16.0 B, rowCount=1)
: +- Aggregate [sum(b#4484L) AS csales#4478L], Statistics(sizeInBytes=16.0 B, rowCount=1)
: +- Project [b#4484L], Statistics(sizeInBytes=1616.0 B, rowCount=101)
: +- Filter (isnotnull(a#4483L) AND (a#4483L < 100)), Statistics(sizeInBytes=2.4 KiB, rowCount=101)
: +- Relation[a#4483L,b#4484L] parquet, Statistics(sizeInBytes=23.4 KiB, rowCount=1.00E+3)
+- Relation[c#4481L,d#4482L] parquet, Statistics(sizeInBytes=46.9 KiB, rowCount=2.00E+3)
```
### Why are the changes needed?
Complete explain treeString's statistics
### Does this PR introduce _any_ user-facing change?
When user use explain with cost mode, user can see subquery's statistic too.
### How was this patch tested?
Added UT
Closes#31485 from AngersZhuuuu/SPARK-34137.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Passing around the output attributes should have more benefits like keeping the exprID unchanged to avoid bugs when we apply more operators above the command output DataFrame.
This PR did 2 things :
1. After this pr, a `SHOW TBLPROPERTIES` clause's output shows `key` and `value` columns whether you specify the table property `key`. Before this pr, a `SHOW TBLPROPERTIES` clause's output only show a `value` column when you specify the table property `key`..
2. Keep `SHOW TBLPROPERTIES` command's output attribute exprId unchanged.
### Why are the changes needed?
1. Keep `SHOW TBLPROPERTIES`'s output schema consistence
2. Keep `SHOW TBLPROPERTIES` command's output attribute exprId unchanged.
### Does this PR introduce _any_ user-facing change?
After this pr, a `SHOW TBLPROPERTIES` clause's output shows `key` and `value` columns whether you specify the table property `key`. Before this pr, a `SHOW TBLPROPERTIES` clause's output only show a `value` column when you specify the table property `key`.
Before this PR:
```
sql > SHOW TBLPROPERTIES tabe_name('key')
value
value_of_key
```
After this PR
```
sql > SHOW TBLPROPERTIES tabe_name('key')
key value
key value_of_key
```
### How was this patch tested?
Added UT
Closes#31378 from AngersZhuuuu/SPARK-34240.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes the issue that `PostgresDialect` can't treat arrays of some types.
Though PostgreSQL supports wide range of types (https://www.postgresql.org/docs/13/datatype.html), the current `PostgresDialect` can't treat arrays of the following types.
* xml
* tsvector
* tsquery
* macaddr
* macaddr8
* txid_snapshot
* pg_snapshot
* point
* line
* lseg
* box
* path
* polygon
* circle
* pg_lsn
* bit varying
* interval
NOTE: PostgreSQL doesn't implement arrays of serial types so this PR doesn't care about them.
### Why are the changes needed?
To provide better support with PostgreSQL.
### Does this PR introduce _any_ user-facing change?
Yes. PostgresDialect can handle arrays of types shown above.
### How was this patch tested?
New test.
Closes#31419 from sarutak/postgres-array-types.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Keep consistence with other `SHOW` command according to https://github.com/apache/spark/pull/31341#issuecomment-774613080
### Why are the changes needed?
Keep consistence
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#31516 from AngersZhuuuu/SPARK-34238-follow-up.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Delegate table name validation to the session catalog
### Why are the changes needed?
Queerying of tables with nested namespaces.
### Does this PR introduce _any_ user-facing change?
SQL queries of nested namespace queries
### How was this patch tested?
Unit tests updated.
Closes#31427 from holdenk/SPARK-34209-delegate-table-name-validation-to-the-catalog.
Authored-by: Holden Karau <hkarau@apple.com>
Signed-off-by: Holden Karau <hkarau@apple.com>
### What changes were proposed in this pull request?
When doing https://issues.apache.org/jira/browse/SPARK-34399 based on https://github.com/apache/spark/pull/31471
Found FileBatchWrite will use `FileFormatWrite.processStates()` too. We need log commit duration in other writer too.
In this pr:
1. Extract a commit job method in SparkHadoopWriter
2. address other commit writer
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
No
Closes#31520 from AngersZhuuuu/SPARK-34355-followup.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
The current implement of `SQLQueryTestSuite` cannot run on windows system.
Becasue the code below will fail on windows system:
`assume(TestUtils.testCommandAvailable("/bin/bash"))`
For operation system that cannot support `/bin/bash`, we just skip some tests.
### Why are the changes needed?
SQLQueryTestSuite has a bug on windows system.
### Does this PR introduce _any_ user-facing change?
'No'.
### How was this patch tested?
Jenkins test
Closes#31466 from beliefer/SPARK-34352.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Use standard methods to extract `keys` or `values` from a `Map`, it's semantically consistent and use the `DefaultKeySet` and `DefaultValuesIterable` instead of a manual loop.
**Before**
```
map.map(_._1)
map.map(_._2)
```
**After**
```
map.keys
map.values
```
### Why are the changes needed?
Code Simpilefications.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the Jenkins or GitHub Action
Closes#31484 from LuciferYang/keys-and-values.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR is to enable AQE and DPP when the join is broadcast hash join at the beginning, which can benefit the performance improvement from DPP and AQE at the same time. This PR will make use of the result of build side and then insert the DPP filter into the probe side.
### Why are the changes needed?
Improve performance
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
adding new ut
Closes#31258 from JkSelf/supportDPP1.
Authored-by: jiake <ke.a.jia@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to propagate the name used for registering UDFs to `ScalaUDF`, `ScalaUDAF` and `ScaalAggregator`.
Note that `PythonUDF` gets the name correctly: 466c045bfa/python/pyspark/sql/udf.py (L358-L359)
, and same for Hive UDFs:
466c045bfa/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveSessionCatalog.scala (L67)
### Why are the changes needed?
This PR can help in the following scenarios:
1) Better EXPLAIN output
2) By adding `def name: String` to `UserDefinedExpression`, we can match an expression by `UserDefinedExpression` and look up the catalog, an use case needed for #31273.
### Does this PR introduce _any_ user-facing change?
The EXPLAIN output involving udfs will be changed to use the name used for UDF registration.
For example, for the following:
```
sql("CREATE TEMPORARY FUNCTION test_udf AS 'org.apache.spark.examples.sql.Spark33084'")
sql("SELECT test_udf(col1) FROM VALUES (1), (2), (3)").explain(true)
```
The output of the optimized plan will change from:
```
Aggregate [spark33084(cast(col1#223 as bigint), org.apache.spark.examples.sql.Spark330846906be0f, 1, 1) AS spark33084(col1)#237]
+- LocalRelation [col1#223]
```
to
```
Aggregate [test_udf(cast(col1#223 as bigint), org.apache.spark.examples.sql.Spark330847a62d697, 1, 1, Some(test_udf)) AS test_udf(col1)#237]
+- LocalRelation [col1#223]
```
### How was this patch tested?
Added new tests.
Closes#31500 from imback82/udaf_name.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In Spark, `set -v` is defined as "Queries all properties that are defined in the SQLConf of the sparkSession".
But there are other external modules that also define properties and register them to SQLConf. In this case,
it can't be displayed by `set -v` until the conf object is initiated (i.e. calling the object at least once).
In this PR, I propose to eagerly initiate all the objects registered to SQLConf, so that `set -v` will always output
the completed properties.
### Why are the changes needed?
Improve the `set -v` command to produces completed and deterministic results
### Does this PR introduce _any_ user-facing change?
`set -v` command will dump more configs
### How was this patch tested?
existing tests
Closes#30363 from linhongliu-db/set-v.
Authored-by: Linhong Liu <linhong.liu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose new options for the Parquet datasource:
1. `datetimeRebaseMode`
2. `int96RebaseMode`
Both options influence on loading ancient dates and timestamps column values from parquet files. The `datetimeRebaseMode` option impacts on loading values of the `DATE`, `TIMESTAMP_MICROS` and `TIMESTAMP_MILLIS` types, `int96RebaseMode` impacts on loading of `INT96` timestamps.
The options support the same values as the SQL configs `spark.sql.legacy.parquet.datetimeRebaseModeInRead` and `spark.sql.legacy.parquet.int96RebaseModeInRead` namely;
- `"LEGACY"`, when an option is set to this value, Spark rebases dates/timestamps from the legacy hybrid calendar (Julian + Gregorian) to the Proleptic Gregorian calendar.
- `"CORRECTED"`, dates/timestamps are read AS IS from parquet files.
- `"EXCEPTION"`, when it is set as an option value, Spark will fail the reading if it sees ancient dates/timestamps that are ambiguous between the two calendars.
### Why are the changes needed?
1. New options will allow to load parquet files from at least two sources in different rebasing modes in the same query. For instance:
```scala
val df1 = spark.read.option("datetimeRebaseMode", "legacy").parquet(folder1)
val df2 = spark.read.option("datetimeRebaseMode", "corrected").parquet(folder2)
df1.join(df2, ...)
```
Before the changes, it is impossible because the SQL config `spark.sql.legacy.parquet.datetimeRebaseModeInRead` influences on both reads.
2. Mixing of Dataset/DataFrame and RDD APIs should become possible. Since SQL configs are not propagated through RDDs, the following code fails on ancient timestamps:
```scala
spark.conf.set("spark.sql.legacy.parquet.datetimeRebaseModeInRead", "legacy")
spark.read.parquet(folder).distinct.rdd.collect()
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
By running the modified test suites:
```
$ build/sbt "sql/test:testOnly *ParquetRebaseDatetimeV1Suite"
$ build/sbt "sql/test:testOnly *ParquetRebaseDatetimeV2Suite"
```
Closes#31489 from MaxGekk/parquet-rebase-options.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR is a followup of https://github.com/apache/spark/pull/31245:
```
[error] /home/runner/work/spark/spark/sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/ShowTablesSuite.scala:112:53: value deep is not a member of Array[String]
[error] assert(sql("show tables").schema.fieldNames.deep ==
[error] ^
[error] /home/runner/work/spark/spark/sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/ShowTablesSuite.scala:115:72: value deep is not a member of Array[String]
[error] assert(sql("show table extended like 'tbl'").schema.fieldNames.deep ==
[error] ^
[error] /home/runner/work/spark/spark/sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/ShowTablesSuite.scala:121:55: value deep is not a member of Array[String]
[error] assert(sql("show tables").schema.fieldNames.deep ==
[error] ^
[error] /home/runner/work/spark/spark/sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/ShowTablesSuite.scala:124:74: value deep is not a member of Array[String]
[error] assert(sql("show table extended like 'tbl'").schema.fieldNames.deep ==
[error] ^
```
It broke Scala 2.13 build. This PR works around by using ScalaTests' `===` that can compare `Array`s safely.
### Why are the changes needed?
To fix the build.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
CI in this PR should test it out.
Closes#31526 from HyukjinKwon/SPARK-34157.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Keep consistence with other `SHOW` command according to https://github.com/apache/spark/pull/31341#issuecomment-774613080
### Why are the changes needed?
Keep consistence
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#31518 from AngersZhuuuu/SPARK-34239-followup.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The current implement of some DDL not unify the output and not pass the output properly to physical command.
Such as: The `ShowTables` output attributes `namespace`, but `ShowTablesCommand` output attributes `database`.
As the query plan, this PR pass the output attributes from `ShowTables` to `ShowTablesCommand`, `ShowTableExtended ` to `ShowTablesCommand`.
Take `show tables` and `show table extended like 'tbl'` as example.
The output before this PR:
`show tables`
|database|tableName|isTemporary|
-- | -- | --
| default| tbl| false|
If catalog is v2 session catalog, the output before this PR:
|namespace|tableName|
-- | --
| default| tbl
`show table extended like 'tbl'`
|database|tableName|isTemporary| information|
-- | -- | -- | --
| default| tbl| false|Database: default...|
The output after this PR:
`show tables`
|namespace|tableName|isTemporary|
-- | -- | --
| default| tbl| false|
`show table extended like 'tbl'`
|namespace|tableName|isTemporary| information|
-- | -- | -- | --
| default| tbl| false|Database: default...|
### Why are the changes needed?
This PR have benefits as follows:
First, Unify schema for the output of SHOW TABLES.
Second, pass the output attributes could keep the expr ID unchanged, so that avoid bugs when we apply more operators above the command output dataframe.
### Does this PR introduce _any_ user-facing change?
Yes.
The output schema of `SHOW TABLES` replace `database` by `namespace`.
### How was this patch tested?
Jenkins test.
Closes#31245 from beliefer/SPARK-34157.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: beliefer <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add some info log around commit log.
### Why are the changes needed?
Th commit job is a heavy option and we have seen many times Spark block at this code place due to the slow rpc with namenode or other.
It's better to record the time that commit job cost.
### Does this PR introduce _any_ user-facing change?
Yes, more info log.
### How was this patch tested?
Not need.
Closes#31471 from ulysses-you/add-commit-log.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This pr format DateLiteral and TimestampLiteral toString. For example:
```sql
SELECT * FROM date_dim WHERE d_date BETWEEN (cast('2000-03-11' AS DATE) - INTERVAL 30 days) AND (cast('2000-03-11' AS DATE) + INTERVAL 30 days)
```
Before this pr:
```
Condition : (((isnotnull(d_date#18) AND (d_date#18 >= 10997)) AND (d_date#18 <= 11057))
```
After this pr:
```
Condition : (((isnotnull(d_date#14) AND (d_date#14 >= 2000-02-10)) AND (d_date#14 <= 2000-04-10))
```
### Why are the changes needed?
Make the plan more readable.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#31455 from wangyum/SPARK-34342.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Unwrap `SparkUpgradeException` from `ParquetDecodingException` in v2 `FilePartitionReader` in the same way as v1 implementation does: 3a299aa648/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileScanRDD.scala (L180-L183)
### Why are the changes needed?
1. To be compatible with v1 implementation of the Parquet datasource.
2. To improve UX with Spark SQL by making `SparkUpgradeException` more visible.
### Does this PR introduce _any_ user-facing change?
Yes, it can.
### How was this patch tested?
By running the affected test suites:
```
$ build/sbt "sql/test:testOnly *ParquetRebaseDatetimeV1Suite"
$ build/sbt "sql/test:testOnly *ParquetRebaseDatetimeV2Suite"
```
Closes#31497 from MaxGekk/parquet-spark-upgrade-exception.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
As a followup from discussion in https://github.com/apache/spark/pull/29804#discussion_r493100510 . Currently in data source v1 file scan `FileSourceScanExec`, [bucket filter pruning will only take effect with bucket table scan](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/DataSourceScanExec.scala#L542 ). However this is unnecessary, as bucket filter pruning can also happen if we disable bucketed table scan. Read files with bucket hash partitioning, and bucket filter pruning are two orthogonal features, and do not need to couple together.
### Why are the changes needed?
This help query leverage the benefit from bucket filter pruning to save CPU/IO to not read unnecessary bucket files, and do not bound by bucket table scan when the parallelism of tasks is a concern.
In addition, this also resolves the issue to reduce number of tasks launched for simple query with bucket column filter - SPARK-33207, because with bucket scan, we launch # of tasks to equal to # of buckets, and this is unnecessary.
### Does this PR introduce _any_ user-facing change?
Users will notice query to start pruning irrelevant files for reading bucketed table, when disabling bucketing. If the input data does not follow spark data source bucketing convention, by default exception will be thrown and query will be failed. The exception can be bypassed with setting config `spark.sql.files.ignoreCorruptFiles` to true.
### How was this patch tested?
Added unit test in `BucketedReadSuite.scala` to make all existing unit tests for bucket filter work with this PR.
Closes#31413 from c21/bucket-pruning.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/28027https://github.com/apache/spark/pull/28027 added a DS v2 API that allows data sources to produce metadata/hidden columns that can only be seen when it's explicitly selected. The way we integrate this API into Spark is:
1. The v2 relation gets normal output and metadata output from the data source, and the metadata output is excluded from the plan output by default.
2. column resolution can resolve `UnresolvedAttribute` with metadata columns, even if the child plan doesn't output metadata columns.
3. An analyzer rule searches the query plan, trying to find a node that has missing inputs. If such node is found, transform the sub-plan of this node, and update the v2 relation to include the metadata output.
The analyzer rule in step 3 brings a perf regression, for queries that do not read v2 tables at all. This rule will calculate `QueryPlan.inputSet` (which builds an `AttributeSet` from outputs of all children) and `QueryPlan.missingInput` (which does a set exclusion and creates a new `AttributeSet`) for every plan node in the query plan. In our benchmark, the TPCDS query compilation time gets increased by more than 10%
This PR proposes a simple way to improve it: we add a special metadata entry to the metadata attribute, which allows us to quickly check if a plan needs to add metadata columns: we just check all the references of this plan, and see if the attribute contains the special metadata entry, instead of calculating `QueryPlan.missingInput`.
This PR also fixes one bug: we should not change the final output schema of the plan, if we only use metadata columns in operators like filter, sort, etc.
### Why are the changes needed?
Fix perf regression in SQL query compilation, and fix a bug.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Run `org.apache.spark.sql.TPCDSQuerySuite`, before this PR, `AddMetadataColumns` is the top 4 rule ranked by running time
```
=== Metrics of Analyzer/Optimizer Rules ===
Total number of runs: 407641
Total time: 47.257239779 seconds
Rule Effective Time / Total Time Effective Runs / Total Runs
OptimizeSubqueries 4157690003 / 8485444626 49 / 2778
Analyzer$ResolveAggregateFunctions 1238968711 / 3369351761 49 / 2141
ColumnPruning 660038236 / 2924755292 338 / 6391
Analyzer$AddMetadataColumns 0 / 2918352992 0 / 2151
```
after this PR:
```
Analyzer$AddMetadataColumns 0 / 122885629 0 / 2151
```
This rule is 20 times faster and is negligible to the total compilation time.
This PR also add new tests to verify the bug fix.
Closes#31440 from cloud-fan/metadata-col.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Extract the date/timestamps rebasing tests from `ParquetIOSuite` to `ParquetRebaseDatetimeSuite` to run them for both DSv1 and DSv2 implementations of Parquet datasource.
### Why are the changes needed?
To improve test coverage.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running new test suites:
```
$ build/sbt "sql/test:testOnly *ParquetRebaseDatetimeV2Suite"
$ build/sbt "sql/test:testOnly *ParquetRebaseDatetimeV1Suite"
$ build/sbt "sql/test:testOnly *ParquetIOSuite"
```
Closes#31478 from MaxGekk/rebase-tests-dsv1-and-dsv2.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}