### What changes were proposed in this pull request?
As discussed in https://github.com/apache/spark/pull/26741#discussion_r357504518, `LookupCatalog.AsTemporaryViewIdentifier` is no longer used and can be removed.
### Why are the changes needed?
Code clean up
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Removed tests that were testing solely `AsTemporaryViewIdentifier` extractor.
Closes#26897 from imback82/30104-followup.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
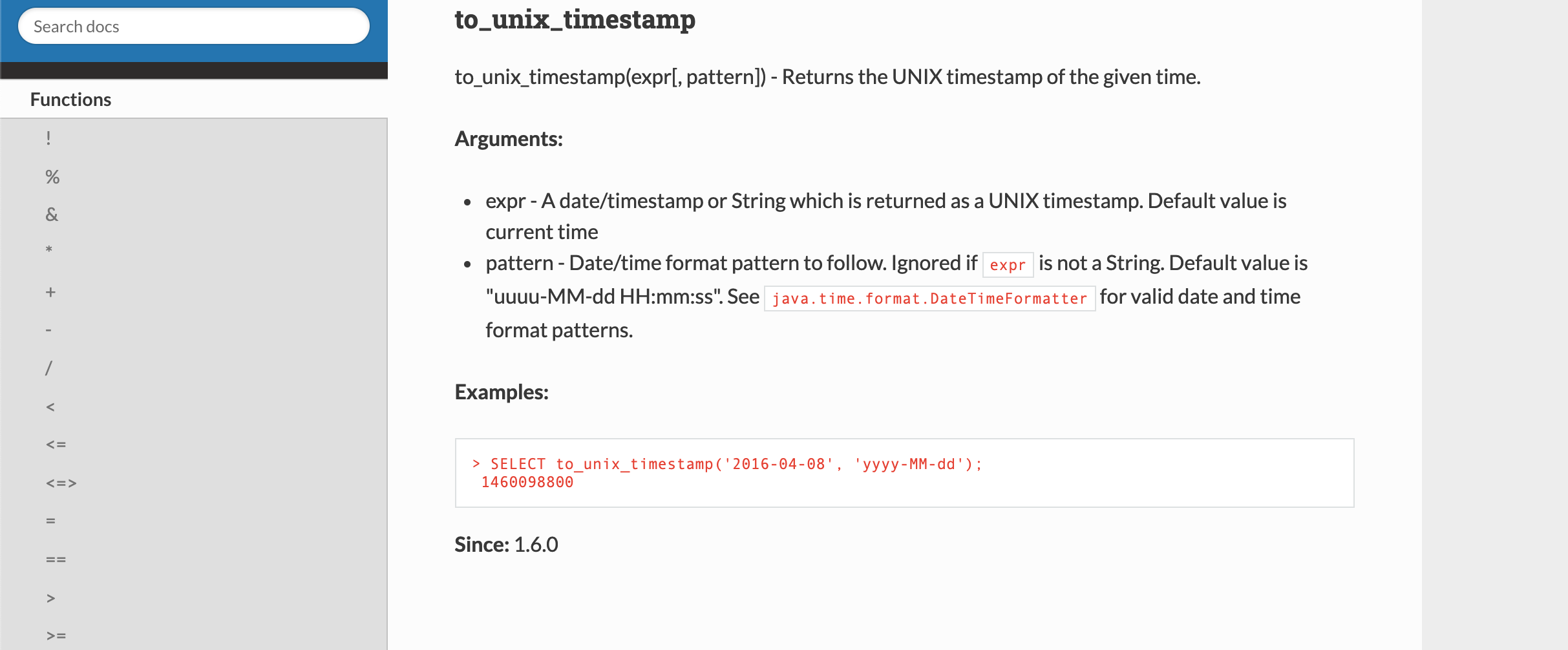
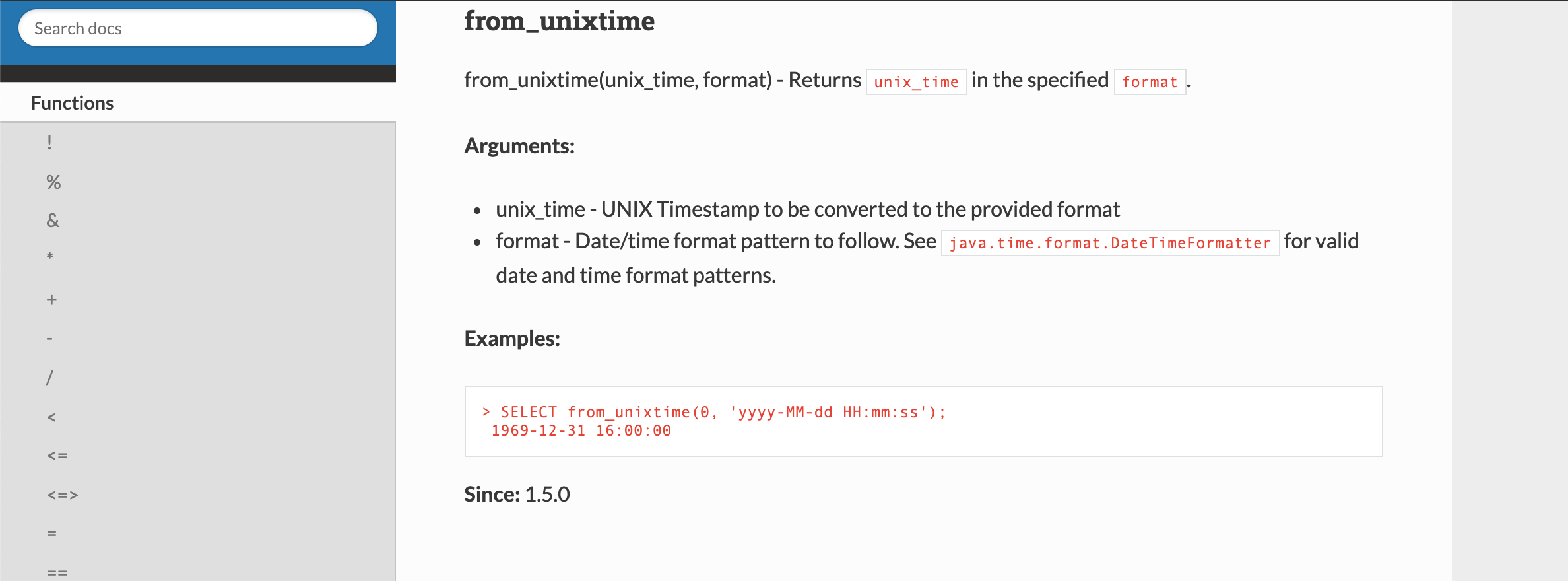
This PR proposes to fix documentation for slide function. Fixed the spacing issue and added some parameter related info.
### Why are the changes needed?
Documentation improvement
### Does this PR introduce any user-facing change?
No (doc-only change).
### How was this patch tested?
Manually tested by documentation build.
Closes#26896 from bboutkov/pyspark_doc_fix.
Authored-by: Boris Boutkov <boris.boutkov@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR mainly targets:
1. Expose only explain(mode: String) in Scala side
2. Clean up related codes
- Hide `ExplainMode` under private `execution` package. No particular reason but just because `ExplainUtils` exists there
- Use `case object` + `trait` pattern in `ExplainMode` to look after `ParseMode`.
- Move `Dataset.toExplainString` to `QueryExecution.explainString` to look after `QueryExecution.simpleString`, and deduplicate the codes at `ExplainCommand`.
- Use `ExplainMode` in `ExplainCommand` too.
- Add `explainString` to `PythonSQLUtils` to avoid unexpected test failure of PySpark during refactoring Scala codes side.
### Why are the changes needed?
To minimised exposed APIs, deduplicate, and clean up.
### Does this PR introduce any user-facing change?
`Dataset.explain(mode: ExplainMode)` will be removed (which only exists in master).
### How was this patch tested?
Manually tested and existing tests should cover.
Closes#26898 from HyukjinKwon/SPARK-30200-followup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR add support do not add commits to master branch when releasing preview version.
### Why are the changes needed?
We need manual revert this change, example:

### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
manual test
Closes#26879 from wangyum/SPARK-30253.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
In the PR, I propose to replace `setJacksonOptions()` in `JSONOptions` by `buildJsonFactory()` which builds `JsonFactory` using `JsonFactoryBuilder`. This allows to avoid using **deprecated** feature configurations from `JsonParser.Feature`.
### Why are the changes needed?
- The changes eliminate the following compilation warnings in `sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JSONOptions.scala`:
```
Warning:Warning:line (137)Java enum ALLOW_NUMERIC_LEADING_ZEROS in Java enum Feature is deprecated: see corresponding Javadoc for more information.
factory.configure(JsonParser.Feature.ALLOW_NUMERIC_LEADING_ZEROS, allowNumericLeadingZeros)
Warning:Warning:line (138)Java enum ALLOW_NON_NUMERIC_NUMBERS in Java enum Feature is deprecated: see corresponding Javadoc for more information.
factory.configure(JsonParser.Feature.ALLOW_NON_NUMERIC_NUMBERS, allowNonNumericNumbers)
Warning:Warning:line (139)Java enum ALLOW_BACKSLASH_ESCAPING_ANY_CHARACTER in Java enum Feature is deprecated: see corresponding Javadoc for more information.
factory.configure(JsonParser.Feature.ALLOW_BACKSLASH_ESCAPING_ANY_CHARACTER,
Warning:Warning:line (141)Java enum ALLOW_UNQUOTED_CONTROL_CHARS in Java enum Feature is deprecated: see corresponding Javadoc for more information.
factory.configure(JsonParser.Feature.ALLOW_UNQUOTED_CONTROL_CHARS, allowUnquotedControlChars)
```
- This put together building JsonFactory and set options from JSONOptions. So, we will not forget to call `setJacksonOptions` in the future.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By `JsonSuite`, `JsonFunctionsSuite`, `JsonExpressionsSuite`.
Closes#26797 from MaxGekk/eliminate-warning.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR adds [a GitHub workflow to automatically close stale PRs](https://github.com/marketplace/actions/close-stale-issues).
### Why are the changes needed?
This will help cut down the number of open but stale PRs and keep the PR queue manageable.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
I'm not sure how to test this PR without impacting real PRs on the repo.
See: https://github.com/actions/stale/issues/32Closes#26877 from nchammas/SPARK-30173-stale-prs.
Authored-by: Nicholas Chammas <nicholas.chammas@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
The PR adds a new config option to configure an address for the
proxy server, and a new handler that intercepts redirects and replaces
the URL with one pointing at the proxy server. This is needed on top
of the "proxy base path" support because redirects use full URLs, not
just absolute paths from the server's root.
### Why are the changes needed?
Spark's web UI has support for generating links to paths with a
prefix, to support a proxy server, but those do not apply when
the UI is responding with redirects. In that case, Spark is sending
its own URL back to the client, and if it's behind a dumb proxy
server that doesn't do rewriting (like when using stunnel for HTTPS
support) then the client will see the wrong URL and may fail.
### Does this PR introduce any user-facing change?
Yes. It's a new UI option.
### How was this patch tested?
Tested with added unit test, with Spark behind stunnel, and in a
more complicated app using a different HTTPS proxy.
Closes#26873 from vanzin/SPARK-30240.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Fix the bug when invoking saveAsNewAPIHadoopDataset to store data, the job will fail because the class TaskCommitMessage hasn't be registered if serializer is KryoSerializer and spark.kryo.registrationRequired is true
## How was this patch tested?
UT
Closes#26714 from deshanxiao/SPARK-25100.
Authored-by: xiaodeshan <xiaodeshan@xiaomi.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Fix bug : CREATE TABLE throw error when session catalog specified explicitly.
### Why are the changes needed?
Currently, Spark throw error when the session catalog is specified explicitly in "CREATE TABLE" and "CREATE TABLE AS SELECT" command, eg.
> CREATE TABLE spark_catalog.tbl USING json AS SELECT 1 AS i;
the error message is like below:
> 19/12/14 10:56:08 INFO HiveMetaStore: 0: get_table : db=spark_catalog tbl=tbl
> 19/12/14 10:56:08 INFO audit: ugi=fuwhu ip=unknown-ip-addr cmd=get_table : db=spark_catalog tbl=tbl
> 19/12/14 10:56:08 INFO HiveMetaStore: 0: get_database: spark_catalog
> 19/12/14 10:56:08 INFO audit: ugi=fuwhu ip=unknown-ip-addr cmd=get_database: spark_catalog
> 19/12/14 10:56:08 WARN ObjectStore: Failed to get database spark_catalog, returning NoSuchObjectException
> Error in query: Database 'spark_catalog' not found;
### Does this PR introduce any user-facing change?
Yes, after this PR, "CREATE TALBE" and "CREATE TABLE AS SELECT" can complete successfully when session catalog "spark_catalog" specified explicitly.
### How was this patch tested?
New unit tests added.
Closes#26887 from fuwhu/SPARK-30259.
Authored-by: fuwhu <bestwwg@163.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This pr is a followup of #26861 to address minor comments from viirya.
### Why are the changes needed?
For better error messages.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Manually tested.
Closes#26886 from maropu/SPARK-30231-FOLLOWUP.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
The value of non-Spark config properties ignored in spark-submit is no longer logged.
### Why are the changes needed?
The value isn't really needed in the logs, and could contain potentially sensitive info. While we can redact the values selectively too, I figured it's more robust to just not log them at all here, as the values aren't important in this log statement.
### Does this PR introduce any user-facing change?
Other than the change to logging above, no.
### How was this patch tested?
Existing tests
Closes#26893 from srowen/SPARK-30263.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Columnar execution support for interval types
### Why are the changes needed?
support cache tables with interval columns
improve performance too
### Does this PR introduce any user-facing change?
Yes cache table with accept interval columns
### How was this patch tested?
add ut
Closes#26699 from yaooqinn/SPARK-30066.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add a timeout configuration for StreamingQuery.stop()
### Why are the changes needed?
The stop() method on a Streaming Query awaits the termination of the stream execution thread. However, the stream execution thread may block forever depending on the streaming source implementation (like in Kafka, which runs UninterruptibleThreads).
This causes control flow applications to hang indefinitely as well. We'd like to introduce a timeout to stop the execution thread, so that the control flow thread can decide to do an action if a timeout is hit.
### Does this PR introduce any user-facing change?
By default, no. If the timeout configuration is set, then a TimeoutException will be thrown if a stream cannot be stopped within the given timeout.
### How was this patch tested?
Unit tests
Closes#26771 from brkyvz/stopTimeout.
Lead-authored-by: Burak Yavuz <brkyvz@gmail.com>
Co-authored-by: Burak Yavuz <burak@databricks.com>
Signed-off-by: Burak Yavuz <brkyvz@gmail.com>
### What changes were proposed in this pull request?
In the current implementation of `SparkShellLoggingFilter`, if the log level of the root logger and the log level of a message are different, whether a message should logged is decided based on log4j's configuration but whether the message should be output to the REPL's console is not cared.
So, if the log level of the root logger is `DEBUG`, the log level of REPL's logger is `WARN` and the log level of a message is `INFO`, the message will output to the REPL's console even though `INFO < WARN`.
https://github.com/apache/spark/pull/26798/files#diff-bfd5810d8aa78ad90150e806d830bb78L237
The ideal behavior should be like as follows and implemented them in this change.
1. If the log level of a message is greater than or equal to the log level of the root logger, the message should be logged but whether the message is output to the REPL's console should be decided based on whether the log level of the message is greater than or equal to the log level of the REPL's logger.
2. If a log level or custom appenders are explicitly defined for a category, whether a log message via the logger corresponding to the category is logged and output to the REPL's console should be decided baed on the log level of the category.
We can confirm whether a log level or appenders are explicitly set to a logger for a category by `Logger#getLevel` and `Logger#getAllAppenders.hasMoreElements`.
### Why are the changes needed?
This is a bug breaking a compatibility.
#9816 enabled REPL's log4j configuration to override root logger but #23675 seems to have broken the feature.
You can see one example when you modifies the default log4j configuration like as follows.
```
# Change the log level for rootCategory to DEBUG
log4j.rootCategory=DEBUG, console
...
# The log level for repl.Main remains WARN
log4j.logger.org.apache.spark.repl.Main=WARN
```
If you launch REPL with the configuration, INFO level logs appear even though the log level for REPL is WARN.
```
・・・
19/12/08 23:31:38 INFO Utils: Successfully started service 'sparkDriver' on port 33083.
19/12/08 23:31:38 INFO SparkEnv: Registering MapOutputTracker
19/12/08 23:31:38 INFO SparkEnv: Registering BlockManagerMaster
19/12/08 23:31:38 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
19/12/08 23:31:38 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
19/12/08 23:31:38 INFO SparkEnv: Registering BlockManagerMasterHeartbeat
・・・
```
Before #23675 was applied, those INFO level logs are not shown with the same log4j.properties.
### Does this PR introduce any user-facing change?
Yes. The logging behavior for REPL is fixed.
### How was this patch tested?
Manual test and newly added unit test.
Closes#26798 from sarutak/fix-spark-shell-loglevel.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
Adding tooltip to Stages tab for better usability.
### Why are the changes needed?
There are a few common points of confusion in the UI that could be clarified with tooltips. We
should add tooltips to explain.
### Does this PR introduce any user-facing change?
Yes

### How was this patch tested?
Manual
Closes#26859 from sharangk/tooltip1.
Authored-by: sharan.gk <sharan.gk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
- Reverts commit 1f94bf4 and d6be46e
- Switches python to python3 in Docker release image.
### Why are the changes needed?
`dev/make-distribution.sh` and `python/setup.py` are use python3.
https://github.com/apache/spark/pull/26844/files#diff-ba2c046d92a1d2b5b417788bfb5cb5f8L236https://github.com/apache/spark/pull/26330/files#diff-8cf6167d58ce775a08acafcfe6f40966
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
manual test:
```
yumwangubuntu-3513086:~/spark$ dev/create-release/do-release-docker.sh -n -d /home/yumwang/spark-release
Output directory already exists. Overwrite and continue? [y/n] y
Branch [branch-2.4]: master
Current branch version is 3.0.0-SNAPSHOT.
Release [3.0.0]: 3.0.0-preview2
RC # [1]:
This is a dry run. Please confirm the ref that will be built for testing.
Ref [master]:
ASF user [yumwang]:
Full name [Yuming Wang]:
GPG key [yumwangapache.org]: DBD447010C1B4F7DAD3F7DFD6E1B4122F6A3A338
================
Release details:
BRANCH: master
VERSION: 3.0.0-preview2
TAG: v3.0.0-preview2-rc1
NEXT: 3.0.1-SNAPSHOT
ASF USER: yumwang
GPG KEY: DBD447010C1B4F7DAD3F7DFD6E1B4122F6A3A338
FULL NAME: Yuming Wang
E-MAIL: yumwangapache.org
================
Is this info correct [y/n]? y
GPG passphrase:
========================
= Building spark-rm image with tag latest...
Command: docker build -t spark-rm:latest --build-arg UID=110302528 /home/yumwang/spark/dev/create-release/spark-rm
Log file: docker-build.log
Building v3.0.0-preview2-rc1; output will be at /home/yumwang/spark-release/output
gpg: directory '/home/spark-rm/.gnupg' created
gpg: keybox '/home/spark-rm/.gnupg/pubring.kbx' created
gpg: /home/spark-rm/.gnupg/trustdb.gpg: trustdb created
gpg: key 6E1B4122F6A3A338: public key "Yuming Wang <yumwangapache.org>" imported
gpg: key 6E1B4122F6A3A338: secret key imported
gpg: Total number processed: 1
gpg: imported: 1
gpg: secret keys read: 1
gpg: secret keys imported: 1
========================
= Creating release tag v3.0.0-preview2-rc1...
Command: /opt/spark-rm/release-tag.sh
Log file: tag.log
It may take some time for the tag to be synchronized to github.
Press enter when you've verified that the new tag (v3.0.0-preview2-rc1) is available.
========================
= Building Spark...
Command: /opt/spark-rm/release-build.sh package
Log file: build.log
========================
= Building documentation...
Command: /opt/spark-rm/release-build.sh docs
Log file: docs.log
========================
= Publishing release
Command: /opt/spark-rm/release-build.sh publish-release
Log file: publish.log
```
Generated doc:

Closes#26848 from wangyum/SPARK-30216.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
This reverts commit cada5beef7.
Closes#26883 from gengliangwang/revert.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
If a table name is qualified with session catalog name `spark_catalog`, the `DROP TABLE` command fails.
For example, the following
```
sql("CREATE TABLE tbl USING json AS SELECT 1 AS i")
sql("DROP TABLE spark_catalog.tbl")
```
fails with:
```
org.apache.spark.sql.catalyst.analysis.NoSuchDatabaseException: Database 'spark_catalog' not found;
at org.apache.spark.sql.catalyst.catalog.ExternalCatalog.requireDbExists(ExternalCatalog.scala:42)
at org.apache.spark.sql.catalyst.catalog.ExternalCatalog.requireDbExists$(ExternalCatalog.scala:40)
at org.apache.spark.sql.catalyst.catalog.InMemoryCatalog.requireDbExists(InMemoryCatalog.scala:45)
at org.apache.spark.sql.catalyst.catalog.InMemoryCatalog.tableExists(InMemoryCatalog.scala:336)
```
This PR correctly resolves `spark_catalog` as a catalog.
### Why are the changes needed?
It's fixing a bug.
### Does this PR introduce any user-facing change?
Yes, now, the `spark_catalog.tbl` in the above example is dropped as expected.
### How was this patch tested?
Added a test.
Closes#26878 from imback82/fix_drop_table.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This pr intends to support explain modes implemented in #26829 for PySpark.
### Why are the changes needed?
For better debugging info. in PySpark dataframes.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Added UTs.
Closes#26861 from maropu/ExplainModeInPython.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This patch adds close() method to the DataWriter interface, which will become the place to cleanup the resource.
### Why are the changes needed?
The lifecycle of DataWriter instance ends at either commit() or abort(). That makes datasource implementors to feel they can place resource cleanup in both sides, but abort() can be called when commit() fails; so they have to ensure they don't do double-cleanup if cleanup is not idempotent.
### Does this PR introduce any user-facing change?
Depends on the definition of user; if they're developers of custom DSv2 source, they have to add close() in their DataWriter implementations. It's OK to just add close() with empty content as they should have already dealt with resource cleanup in commit/abort, but they would love to migrate the resource cleanup logic to close() as it avoids double cleanup. If they're just end users using the provided DSv2 source (regardless of built-in/3rd party), no change.
### How was this patch tested?
Existing tests.
Closes#26855 from HeartSaVioR/SPARK-30227.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add DropFunctionStatement and make DROP FUNCTION go through the same catalog/table resolution framework of v2 commands.
### Why are the changes needed?
It's important to make all the commands have the same table resolution behavior, to avoid confusing
DROP FUNCTION namespace.function
### Does this PR introduce any user-facing change?
Yes. When running DROP FUNCTION namespace.function Spark fails the command if the current catalog is set to a v2 catalog.
### How was this patch tested?
Unit tests.
Closes#26854 from planga82/feature/SPARK-30040_DropFunctionV2Catalog.
Authored-by: Pablo Langa <soypab@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR exposes the existing logic for nested schema pruning to all sources, which is in line with the description of `SupportsPushDownRequiredColumns` .
Right now, `SchemaPruning` (rule, not helper utility) is applied in the optimizer directly on certain instances of `Table` ignoring `SupportsPushDownRequiredColumns` that is part of `ScanBuilder`. I think it would be cleaner to perform schema pruning and filter push-down in one place. Therefore, this PR moves all the logic into `V2ScanRelationPushDown`.
### Why are the changes needed?
This change allows all V2 data sources to benefit from nested column pruning (if they support it).
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
This PR mostly relies on existing tests. On top, it adds one test to verify that top-level schema pruning works as well as one test for predicates with subqueries.
Closes#26751 from aokolnychyi/nested-schema-pruning-ds-v2.
Authored-by: Anton Okolnychyi <aokolnychyi@apple.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
Check the partition column data type and only allow string and integral types in hive partition pruning.
### Why are the changes needed?
Currently we only support string and integral types in hive partition pruning, but the check is done for literals. If the predicate is `InSet`, then there is no literal and we may pass an unsupported partition predicate to Hive and cause problems.
### Does this PR introduce any user-facing change?
yes. fix a bug. A query fails before and can run now.
### How was this patch tested?
a new test
Closes#26871 from cloud-fan/bug.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Since [25001](https://github.com/apache/spark/pull/25001), spark support like escape syntax.
But '%' and '_' is the reserve char in `Like` expression. We can not use them as escape char.
### Why are the changes needed?
Avoid some unexpect problem when using like escape syntax.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Add UT.
Closes#26860 from ulysses-you/SPARK-30230.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to add `PushedFilters` into metadata to show the pushed filters in Parquet DSv2 implementation. In case of ORC, it is already added at https://github.com/apache/spark/pull/24719/files#diff-0fc82694b20da3cd2cbb07206920eef7R62-R64
### Why are the changes needed?
In order for users to be able to debug, and to match with ORC.
### Does this PR introduce any user-facing change?
```scala
spark.range(10).write.mode("overwrite").parquet("/tmp/foo")
spark.read.parquet("/tmp/foo").filter("5 > id").explain()
```
**Before:**
```
== Physical Plan ==
*(1) Project [id#20L]
+- *(1) Filter (isnotnull(id#20L) AND (5 > id#20L))
+- *(1) ColumnarToRow
+- BatchScan[id#20L] ParquetScan Location: InMemoryFileIndex[file:/tmp/foo], ReadSchema: struct<id:bigint>
```
**After:**
```
== Physical Plan ==
*(1) Project [id#13L]
+- *(1) Filter (isnotnull(id#13L) AND (5 > id#13L))
+- *(1) ColumnarToRow
+- BatchScan[id#13L] ParquetScan Location: InMemoryFileIndex[file:/tmp/foo], ReadSchema: struct<id:bigint>, PushedFilters: [IsNotNull(id), LessThan(id,5)]
```
### How was this patch tested?
Unittest were added and manually tested.
Closes#26857 from HyukjinKwon/SPARK-30162.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Fixed typo in exception message of HashedRelations
### Why are the changes needed?
Better exception messages
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
No tests needed
Closes#26822 from aaron-lau/master.
Authored-by: Aaron Lau <aaron.lau@datadoghq.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
- Replace `Seq[String]` by `Seq[_]` in `StopWordsRemoverSuite` because `String` type is unchecked due erasure.
- Throw an exception for default case in `MLTest.checkNominalOnDF` because we don't expect other attribute types currently.
- Explicitly cast float to double in `BigDecimal(y)`. This is what the `apply()` method does for `float`s.
- Replace deprecated `verifyZeroInteractions` by `verifyNoInteractions`.
- Equivalent replacement of `\0` by `\u0000` in `CSVExprUtilsSuite`
- Import `scala.language.implicitConversions` in `CollectionExpressionsSuite`, `HashExpressionsSuite` and in `ExpressionParserSuite`.
### Why are the changes needed?
The changes fix compiler warnings showed in the JIRA ticket https://issues.apache.org/jira/browse/SPARK-30170 . Eliminating the warning highlights other warnings which could take more attention to real problems.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By existing test suites `StopWordsRemoverSuite`, `AnalysisExternalCatalogSuite`, `CSVExprUtilsSuite`, `CollectionExpressionsSuite`, `HashExpressionsSuite`, `ExpressionParserSuite` and sub-tests of `MLTest`.
Closes#26799 from MaxGekk/eliminate-warning-2.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
sparkContext.addFile and sparkContext.addJar fails when file path contains spaces
### Why are the changes needed?
When uploading a file to the spark context via the addFile and addJar function, an exception is thrown when file path contains a space character. Escaping the space with %20 or
or + doesn't change the result.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Add test case.
Closes#26773 from 07ARB/SPARK-30126.
Authored-by: 07ARB <ankitrajboudh@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
An empty Spark DataFrame converted to a Pandas DataFrame wouldn't have the right column types. Several type mappings were missing.
### Why are the changes needed?
Empty Spark DataFrames can be used to write unit tests, and verified by converting them to Pandas first. But this can fail when the column types are wrong.
### Does this PR introduce any user-facing change?
Yes; the error reported in the JIRA issue should not happen anymore.
### How was this patch tested?
Through unit tests in `pyspark.sql.tests.test_dataframe.DataFrameTests#test_to_pandas_from_empty_dataframe`
Closes#26747 from dlindelof/SPARK-29188.
Authored-by: David <dlindelof@expediagroup.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
`add file "abc.txt"` and `add file 'abc.txt'` are not supported.
For these two spark sql gives `FileNotFoundException`.
Only `add file abc.txt` is supported currently.
After these changes path can be given as quoted text for ADD FILE, ADD JAR, LIST FILE, LIST JAR commands in spark-sql
### Why are the changes needed?
In many of the spark-sql commands (like create table ,etc )we write path in quoted format only. To maintain this consistency we should support quoted format with this command as well.
### Does this PR introduce any user-facing change?
Yes. Now users can write path with quotes.
### How was this patch tested?
Manually tested.
Closes#26779 from iRakson/SPARK-30150.
Authored-by: root1 <raksonrakesh@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a follow up to #26741 to address the following:
1. V2 catalog named `global_temp` should always be masked.
2. #26741 introduces `CatalogAndIdentifer` that supersedes `CatalogObjectIdentfier`. This PR removes `CatalogObjectIdentfier` and its usages and replace them with `CatalogAndIdentifer`.
3. `CatalogObjectIdentifier(catalog, ident) if !isSessionCatalog(catalog)` and `CatalogObjectIdentifier(catalog, ident) if isSessionCatalog(catalog)` are replaced with `NonSessionCatalogAndIdentifier` and `SessionCatalogAndIdentifier` respectively.
### Why are the changes needed?
To fix an existing with handling v2 catalog named `global_temp` and to simplify the code base.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Added new tests.
Closes#26853 from imback82/lookup_table.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to update zstd-jni library to 1.4.4-3.
### Why are the changes needed?
This will bring the latest bug fixes in zstd itself and some performance improvement.
- https://github.com/facebook/zstd/releases/tag/v1.4.4
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Pass the Jenkins.
Closes#26856 from dongjoon-hyun/SPARK-ZSTD-144.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Currently `ShuffleQueryStageExec `contain the mutable status, eg `mapOutputStatisticsFuture `variable. So It is not easy to pass when we copy `ShuffleQueryStageExec`. This PR will put the `mapOutputStatisticsFuture ` variable from `ShuffleQueryStageExec` to `ShuffleExchangeExec`. And then we can pass the value of `mapOutputStatisticsFuture ` when copying.
### Why are the changes needed?
In order to remove the mutable status in `ShuffleQueryStageExec`
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing uts
Closes#26846 from JkSelf/removeMutableVariable.
Authored-by: jiake <ke.a.jia@intel.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR aims to recover `spark.ui.port` and `spark.blockManager.port` from checkpoint like `spark.driver.port`.
### Why are the changes needed?
When the user configures these values, we can respect them.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Pass the Jenkins with the newly added test cases.
Closes#26827 from dongjoon-hyun/SPARK-30199.
Authored-by: Aaruna <aaruna@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This patch changes the condition to check if BytesToBytesMap should grow up its internal array. Specifically, it changes to compare by the capacity of the array, instead of its size.
### Why are the changes needed?
One Spark job on our cluster hangs forever at BytesToBytesMap.safeLookup. After inspecting, the long array size is 536870912.
Currently in BytesToBytesMap.append, we only grow the internal array if the size of the array is less than its MAX_CAPACITY that is 536870912. So in above case, the array can not be grown up, and safeLookup can not find an empty slot forever.
But it is wrong because we use two array entries per key, so the array size is twice the capacity. We should compare the current capacity of the array, instead of its size.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
This issue only happens when loading big number of values into BytesToBytesMap, so it is hard to do unit test. This is tested manually with internal Spark job.
Closes#26828 from viirya/fix-bytemap.
Lead-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Co-authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add DescribeFunctionsStatement and make DESCRIBE FUNCTIONS go through the same catalog/table resolution framework of v2 commands.
### Why are the changes needed?
It's important to make all the commands have the same table resolution behavior, to avoid confusing
DESCRIBE FUNCTIONS namespace.function
### Does this PR introduce any user-facing change?
Yes. When running DESCRIBE FUNCTIONS namespace.function Spark fails the command if the current catalog is set to a v2 catalog.
### How was this patch tested?
Unit tests.
Closes#26840 from planga82/feature/SPARK-30038_DescribeFunction_V2Catalog.
Authored-by: Pablo Langa <soypab@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
See https://issues.apache.org/jira/browse/SPARK-30195 for the background; I won't repeat it here. This is sort of a grab-bag of related issues.
### Why are the changes needed?
To cross-compile with Scala 2.13 later.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests for 2.12. I've been manually checking that this actually resolves the compile problems in 2.13 separately.
Closes#26826 from srowen/SPARK-30195.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This patch fixes the availability of `minPartitions` option for Kafka source, as it is only supported by micro-batch for now. There's a WIP PR for batch (#25436) as well but there's no progress on the PR so far, so safer to fix the doc first, and let it be added later when we address it with batch case as well.
### Why are the changes needed?
The doc is wrong and misleading.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Just a doc change.
Closes#26849 from HeartSaVioR/MINOR-FIX-minPartition-availability-doc.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose new implementation of `fromDayTimeString` which strictly parses strings in day-time formats to intervals. New implementation accepts only strings that match to a pattern defined by the `from` and `to`. Here is the mapping of user's bounds and patterns:
- `[+|-]D+ H[H]:m[m]:s[s][.SSSSSSSSS]` for **DAY TO SECOND**
- `[+|-]D+ H[H]:m[m]` for **DAY TO MINUTE**
- `[+|-]D+ H[H]` for **DAY TO HOUR**
- `[+|-]H[H]:m[m]s[s][.SSSSSSSSS]` for **HOUR TO SECOND**
- `[+|-]H[H]:m[m]` for **HOUR TO MINUTE**
- `[+|-]m[m]:s[s][.SSSSSSSSS]` for **MINUTE TO SECOND**
Closes#26327Closes#26358
### Why are the changes needed?
- Improve user experience with Spark SQL, and respect to the bound specified by users.
- Behave the same as other broadly used DBMS - Oracle and MySQL.
### Does this PR introduce any user-facing change?
Yes, before:
```sql
spark-sql> SELECT INTERVAL '10 11:12:13.123' HOUR TO MINUTE;
interval 1 weeks 3 days 11 hours 12 minutes
```
After:
```sql
spark-sql> SELECT INTERVAL '10 11:12:13.123' HOUR TO MINUTE;
Error in query:
requirement failed: Interval string must match day-time format of '^(?<sign>[+|-])?(?<hour>\d{1,2}):(?<minute>\d{1,2})$': 10 11:12:13.123(line 1, pos 16)
== SQL ==
SELECT INTERVAL '10 11:12:13.123' HOUR TO MINUTE
----------------^^^
```
### How was this patch tested?
- Added tests to `IntervalUtilsSuite`
- By `ExpressionParserSuite`
- Updated `literals.sql`
Closes#26473 from MaxGekk/strict-from-daytime-string.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This pr is a follow-up of #26829 to fix typos in ExplainMode.
### Why are the changes needed?
For better docs.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#26851 from maropu/SPARK-30200-FOLLOWUP.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Adding tooltip for jobs tab column - Job Id (Job Group), Description ,Submitted, Duration, Stages, Tasks
Before:

After:

### Why are the changes needed?
Jobs tab do not have any tooltip for the columns, Some page provide tooltip , inorder to resolve the inconsistency and for better user experience.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manual
Closes#26384 from PavithraRamachandran/jobTab_tooltip.
Authored-by: Pavithra Ramachandran <pavi.rams@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Enhancement of the SQL NULL Semantics document: sql-ref-null-semantics.html.
### Why are the changes needed?
Clarify the behavior of `UNKNOWN` for both `EXIST` and `IN` operation.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Doc changes only.
Closes#26837 from xuanyuanking/SPARK-30207.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
Follow up of https://github.com/apache/spark/pull/24405
### What changes were proposed in this pull request?
The current implementation of _from_avro_ and _AvroDataToCatalyst_ doesn't allow doing schema evolution since it requires the deserialization of an Avro record with the exact same schema with which it was serialized.
The proposed change is to add a new option `actualSchema` to allow passing the schema used to serialize the records. This allows using a different compatible schema for reading by passing both schemas to _GenericDatumReader_. If no writer's schema is provided, nothing changes from before.
### Why are the changes needed?
Consider the following example.
```
// schema ID: 1
val schema1 = """
{
"type": "record",
"name": "MySchema",
"fields": [
{"name": "col1", "type": "int"},
{"name": "col2", "type": "string"}
]
}
"""
// schema ID: 2
val schema2 = """
{
"type": "record",
"name": "MySchema",
"fields": [
{"name": "col1", "type": "int"},
{"name": "col2", "type": "string"},
{"name": "col3", "type": "string", "default": ""}
]
}
"""
```
The two schemas are compatible - i.e. you can use `schema2` to deserialize events serialized with `schema1`, in which case there will be the field `col3` with the default value.
Now imagine that you have two dataframes (read from batch or streaming), one with Avro events from schema1 and the other with events from schema2. **We want to combine them into one dataframe** for storing or further processing.
With the current `from_avro` function we can only decode each of them with the corresponding schema:
```
scalaval df1 = ... // Avro events created with schema1
df1: org.apache.spark.sql.DataFrame = [eventBytes: binary]
scalaval decodedDf1 = df1.select(from_avro('eventBytes, schema1) as "decoded")
decodedDf1: org.apache.spark.sql.DataFrame = [decoded: struct<col1: int, col2: string>]
scalaval df2= ... // Avro events created with schema2
df2: org.apache.spark.sql.DataFrame = [eventBytes: binary]
scalaval decodedDf2 = df2.select(from_avro('eventBytes, schema2) as "decoded")
decodedDf2: org.apache.spark.sql.DataFrame = [decoded: struct<col1: int, col2: string, col3: string>]
```
but then `decodedDf1` and `decodedDf2` have different Spark schemas and we can't union them. Instead, with the proposed change we can decode `df1` in the following way:
```
scalaimport scala.collection.JavaConverters._
scalaval decodedDf1 = df1.select(from_avro(data = 'eventBytes, jsonFormatSchema = schema2, options = Map("actualSchema" -> schema1).asJava) as "decoded")
decodedDf1: org.apache.spark.sql.DataFrame = [decoded: struct<col1: int, col2: string, col3: string>]
```
so that both dataframes have the same schemas and can be merged.
### Does this PR introduce any user-facing change?
This PR allows users to pass a new configuration but it doesn't affect current code.
### How was this patch tested?
A new unit test was added.
Closes#26780 from Fokko/SPARK-27506.
Lead-authored-by: Fokko Driesprong <fokko@apache.org>
Co-authored-by: Gianluca Amori <gianluca.amori@gmail.com>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
`global_temp` is used as a database name to access global temp views. The current catalog lookup logic considers only the first element of multi-part name when it resolves a catalog. This results in using the session catalog even `global_temp` is used as a table name under v2 catalog. This PR addresses this by making sure multi-part name has two elements before using the session catalog.
### Why are the changes needed?
Currently, 'global_temp' can be used as a table name in certain commands (CREATE) but not in others (DESCRIBE):
```
// Assume "spark.sql.globalTempDatabase" is set to "global_temp".
sql(s"CREATE TABLE testcat.t (id bigint, data string) USING foo")
sql(s"CREATE TABLE testcat.global_temp (id bigint, data string) USING foo")
sql("USE testcat")
sql(s"DESCRIBE TABLE t").show
+---------------+---------+-------+
| col_name|data_type|comment|
+---------------+---------+-------+
| id| bigint| |
| data| string| |
| | | |
| # Partitioning| | |
|Not partitioned| | |
+---------------+---------+-------+
sql(s"DESCRIBE TABLE global_temp").show
org.apache.spark.sql.AnalysisException: Table not found: global_temp;;
'DescribeTable 'UnresolvedV2Relation [global_temp], org.apache.spark.sql.connector.InMemoryTableSessionCatalog2f1af64f, `global_temp`, false
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.failAnalysis(CheckAnalysis.scala:47)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.failAnalysis$(CheckAnalysis.scala:46)
at org.apache.spark.sql.catalyst.analysis.Analyzer.failAnalysis(Analyzer.scala:122)
```
### Does this PR introduce any user-facing change?
Yes, `sql(s"DESCRIBE TABLE global_temp").show` in the above example now displays:
```
+---------------+---------+-------+
| col_name|data_type|comment|
+---------------+---------+-------+
| id| bigint| |
| data| string| |
| | | |
| # Partitioning| | |
|Not partitioned| | |
+---------------+---------+-------+
```
instead of throwing an exception.
### How was this patch tested?
Added new tests.
Closes#26741 from imback82/global_temp.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR switches python to python3 in `make-distribution.sh`.
### Why are the changes needed?
SPARK-29672 changed this
- https://github.com/apache/spark/pull/26330/files#diff-8cf6167d58ce775a08acafcfe6f40966
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#26844 from wangyum/SPARK-30211.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Another continuation of https://github.com/apache/spark/pull/26748
### Why are the changes needed?
To cleanly cross compile with Scala 2.13.
### Does this PR introduce any user-facing change?
None.
### How was this patch tested?
Existing tests
Closes#26842 from srowen/SPARK-29392.4.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}