### What changes were proposed in this pull request?
This PR aims to change run-test.py so that it does not fail when os.environ["APACHE_SPARK_REF"] is not defined.
### Why are the changes needed?
Currently, the run-test.py ends with an error.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the CIs.
Closes#33371 from williamhyun/SPARK-36164.
Authored-by: William Hyun <william@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
(cherry picked from commit c8a3c22628)
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Support TimestampNTZ type in file partitioning
* When there is no provided schema and the default Timestamp type is TimestampNTZ , Spark should infer and parse the timestamp value partitions as TimestampNTZ.
* When the provided Partition schema is TimestampNTZ, Spark should be able to parse the TimestampNTZ type partition column.
### Why are the changes needed?
File partitioning is an important feature and Spark should support TimestampNTZ type in it.
### Does this PR introduce _any_ user-facing change?
Yes, Spark supports TimestampNTZ type in file partitioning
### How was this patch tested?
Unit tests
Closes#33344 from gengliangwang/partition.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Gengliang Wang <gengliang@apache.org>
(cherry picked from commit 96c2919988)
Signed-off-by: Gengliang Wang <gengliang@apache.org>
### What changes were proposed in this pull request?
This pr fix Parquet filter pushdown `NOT` `IN` predicate if its values exceeds `spark.sql.parquet.pushdown.inFilterThreshold`. For example: `Not(In(a, Array(2, 3, 7))`. We can not push down `not(and(gteq(a, 2), lteq(a, 7)))`.
### Why are the changes needed?
Fix bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#33365 from wangyum/SPARK-32792-3.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
(cherry picked from commit 0062c03c15)
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR is a followup of https://github.com/apache/spark/pull/26330. There is the last place to fix in `dev/test-dependencies.sh`
### Why are the changes needed?
To stick to Python 3 instead of using Python 2 mistakenly.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Manually tested.
Closes#33368 from HyukjinKwon/change-python-3.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
(cherry picked from commit 6bd385f1e3)
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Added missing documentation of week and quarter as valid formats to pyspark sql/functions trunc
### Why are the changes needed?
Pyspark documentation and scala documentation didn't mentioned the same supported formats
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Only documentation change
Closes#33359 from dominikgehl/feature/SPARK-36154.
Authored-by: Dominik Gehl <dog@open.ch>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
(cherry picked from commit 802f632a28)
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Keep the output order is deterministic for `SHOW TBLPROPERTIES`
### Why are the changes needed?
[#33343](https://github.com/apache/spark/pull/33343#issue-689828187).
Keep the output order deterministic meaningful.
Since the properties are sorted and then compare result in the testcase for `SHOW TBLPROPERTIES`, it does not fail, but ideally, the output is ordered and deterministic.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existed ut test
Closes#33353 from Peng-Lei/order-ouput-properties.
Authored-by: PengLei <peng.8lei@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit e05441c223)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes a behavior of `SHOW CREATE TABLE` added in `SPARK-33898` (#32931) to output deterministic result.
A test `SPARK-33898: SHOW CREATE TABLE` in `DataSourceV2SQLSuite` compares two `CREATE TABLE` statements. One is generated by `SHOW CREATE TABLE` against a created table and the other is expected `CREATE TABLE` statement.
The created table has options `from` and `to`, and they are declared in this order.
```
CREATE TABLE $t (
a bigint NOT NULL,
b bigint,
c bigint,
`extra col` ARRAY<INT>,
`<another>` STRUCT<x: INT, y: ARRAY<BOOLEAN>>
)
USING foo
OPTIONS (
from = 0,
to = 1)
COMMENT 'This is a comment'
TBLPROPERTIES ('prop1' = '1')
PARTITIONED BY (a)
LOCATION '/tmp'
```
And the expected `CREATE TABLE` in the test code is like as follows.
```
"CREATE TABLE testcat.ns1.ns2.tbl (",
"`a` BIGINT NOT NULL,",
"`b` BIGINT,",
"`c` BIGINT,",
"`extra col` ARRAY<INT>,",
"`<another>` STRUCT<`x`: INT, `y`: ARRAY<BOOLEAN>>)",
"USING foo",
"OPTIONS(",
"'from' = '0',",
"'to' = '1')",
"PARTITIONED BY (a)",
"COMMENT 'This is a comment'",
"LOCATION '/tmp'",
"TBLPROPERTIES(",
"'prop1' = '1')"
```
As you can see, the order of `from` and `to` is expected.
But options are implemented as `Map` so the order of key cannot be kept.
In fact, this test fails with Scala 2.13.
```
[info] - SPARK-33898: SHOW CREATE TABLE *** FAILED *** (515 milliseconds)
[info] Array("CREATE TABLE testcat.ns1.ns2.tbl (", "`a` BIGINT NOT NULL,", "`b` BIGINT,", "`c` BIGINT,", "`extra col` ARRAY<INT>,", "`<another>` STRUCT<`x`: INT, `y`: ARRAY<BOOLEAN>>)", "USING foo", "OPTIONS(", "'to' = '1',", "'from' = '0')", "PARTITIONED BY (a)", "COMMENT 'This is a comment'", "LOCATION '/tmp'", "TBLPROPERTIES(", "'prop1' = '1')") did not equal Array("CREATE TABLE testcat.ns1.ns2.tbl (", "`a` BIGINT NOT NULL,", "`b` BIGINT,", "`c` BIGINT,", "`extra col` ARRAY<INT>,", "`<another>` STRUCT<`x`: INT, `y`: ARRAY<BOOLEAN>>)", "USING foo", "OPTIONS(", "'from' = '0',", "'to' = '1')", "PARTITIONED BY (a)", "COMMENT 'This is a comment'", "LOCATION '/tmp'", "TBLPROPERTIES(", "'prop1' = '1')") (DataSourceV2SQLSuite.scala:1997)
```
In the current master, the test doesn't fail with Scala 2.12 but it's still non-deterministic.
### Why are the changes needed?
Bug fix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
I confirmed that the modified test passed with both Scala 2.12 and Scala 2.13 with this change.
Closes#33343 from sarutak/fix-show-create-table-test.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit f95ca31c0f)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Only use the zone ids that has no daylight saving for testing `localtimestamp`
### Why are the changes needed?
https://github.com/apache/spark/pull/33346#discussion_r670135296 MaxGekk suggests that we should avoid wrong results if possible.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes#33354 from gengliangwang/FIxDST.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
(cherry picked from commit 564d3de7c6)
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR aims to disable MiMa check for Scala 2.13 artifacts.
### Why are the changes needed?
Apache Spark doesn't have Scala 2.13 Maven artifacts yet.
SPARK-36151 will enable this after Apache Spark 3.2.0 release.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual. The following should succeed without real testing.
```
$ dev/mima -Pscala-2.13
```
Closes#33355 from dongjoon-hyun/SPARK-36150.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
(cherry picked from commit 5acfecbf97)
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
The threshold of the test case "datetime function localtimestamp" is small, which leads to flaky test results
https://github.com/gengliangwang/spark/runs/3067396143?check_suite_focus=true
This PR is to increase the threshold for checking two the different current local datetimes from 5ms to 1 second. (The test case of current_timestamp uses 5 seconds)
### Why are the changes needed?
Fix flaky test
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes#33346 from gengliangwang/fixFlaky.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Gengliang Wang <gengliang@apache.org>
(cherry picked from commit 0973397721)
Signed-off-by: Gengliang Wang <gengliang@apache.org>
### What changes were proposed in this pull request?
Adds error classes to some of the exceptions in QueryCompilationErrors.
### Why are the changes needed?
Improves auditing for developers and adds useful fields for users (error class and SQLSTATE).
### Does this PR introduce _any_ user-facing change?
Yes, fills in missing error class and SQLSTATE fields.
### How was this patch tested?
Existing tests and new unit tests.
Closes#33309 from karenfeng/group-compilation-errors-1.
Authored-by: Karen Feng <karen.feng@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit e92b8ea6f8)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Implement non-equality comparison operators between two Categoricals.
Non-goal: supporting Scalar input will be a follow-up task.
### Why are the changes needed?
pandas supports non-equality comparisons between two Categoricals. We should follow that.
### Does this PR introduce _any_ user-facing change?
Yes. No `NotImplementedError` for `<`, `<=`, `>`, `>=` operators between two Categoricals. An example is shown as below:
From:
```py
>>> import pyspark.pandas as ps
>>> from pandas.api.types import CategoricalDtype
>>> psser = ps.Series([1, 2, 3]).astype(CategoricalDtype([3, 2, 1], ordered=True))
>>> other_psser = ps.Series([2, 1, 3]).astype(CategoricalDtype([3, 2, 1], ordered=True))
>>> with ps.option_context("compute.ops_on_diff_frames", True):
... psser <= other_psser
...
Traceback (most recent call last):
...
NotImplementedError: <= can not be applied to categoricals.
```
To:
```py
>>> import pyspark.pandas as ps
>>> from pandas.api.types import CategoricalDtype
>>> psser = ps.Series([1, 2, 3]).astype(CategoricalDtype([3, 2, 1], ordered=True))
>>> other_psser = ps.Series([2, 1, 3]).astype(CategoricalDtype([3, 2, 1], ordered=True))
>>> with ps.option_context("compute.ops_on_diff_frames", True):
... psser <= other_psser
...
0 False
1 True
2 True
dtype: bool
```
### How was this patch tested?
Unit tests.
Closes#33331 from xinrong-databricks/categorical_compare.
Authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
(cherry picked from commit 0cb120f390)
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
### What changes were proposed in this pull request?
Add `CoalescedPartitionSpec(0, 0, _)` check if a `CoalescedPartitionSpec` is coalesced.
### Why are the changes needed?
Fix corner case.
### Does this PR introduce _any_ user-facing change?
yes, UI may be changed
### How was this patch tested?
Add test
Closes#33342 from ulysses-you/SPARK-35639-FOLLOW.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit 3819641201)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Fix the skipping values logic in Parquet vectorized reader when column index is effective, by considering nulls and only call `ParquetVectorUpdater.skipValues` when the values are non-null.
### Why are the changes needed?
Currently, the Parquet vectorized reader may not work correctly if column index filtering is effective, and the data page contains null values. For instance, let's say we have two columns `c1: BIGINT` and `c2: STRING`, and the following pages:
```
* c1 500 500 500 500
* |---------|---------|---------|---------|
* |-------|-----|-----|---|---|---|---|---|
* c2 400 300 300 200 200 200 200 200
```
and suppose we have a query like the following:
```sql
SELECT * FROM t WHERE c1 = 500
```
this will create a Parquet row range `[500, 1000)` which, when applied to `c2`, will require us to skip all the rows in `[400,500)`. However the current logic for skipping rows is via `updater.skipValues(n, valueReader)` which is incorrect since this skips the next `n` non-null values. In the case when nulls are present, this will not work correctly.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added a new test in `ParquetColumnIndexSuite`.
Closes#33330 from sunchao/SPARK-36123-skip-nulls.
Authored-by: Chao Sun <sunchao@apple.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit e980c7a840)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
DATE/TIMESTAMP literals support years 0000 to 9999. However, internally we support a range that is much larger.
We can add or subtract large intervals from a date/timestamp and the system will happily process and display large negative and positive dates.
Since we obviously cannot put this genie back into the bottle the only thing we can do is allow matching DATE/TIMESTAMP literals.
### Why are the changes needed?
make spark more usable and bug fix
### Does this PR introduce _any_ user-facing change?
Yes, after this PR, below SQL will have different results
```sql
select cast('-10000-1-2' as date) as date_col
-- before PR: NULL
-- after PR: -10000-1-2
```
```sql
select cast('2021-4294967297-11' as date) as date_col
-- before PR: 2021-01-11
-- after PR: NULL
```
### How was this patch tested?
newly added test cases
Closes#32959 from linhongliu-db/SPARK-35780-full-range-datetime.
Lead-authored-by: Linhong Liu <linhong.liu@databricks.com>
Co-authored-by: Linhong Liu <67896261+linhongliu-db@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit b86645776b)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
Introduction: this PR is a part of SPARK-10816 (EventTime based sessionization (session window)). Please refer #31937 to see the overall view of the code change. (Note that code diff could be diverged a bit.)
### What changes were proposed in this pull request?
This PR introduces MergingSortWithSessionWindowStateIterator, which does "merge sort" between input rows and sessions in state based on group key and session's start time.
Note that the iterator does merge sort among input rows and sessions grouped by grouping key. The iterator doesn't provide sessions in state which keys don't exist in input rows. For input rows, the iterator will provide all rows regardless of the existence of matching sessions in state.
MergingSortWithSessionWindowStateIterator works on the precondition that given iterator is sorted by "group keys + start time of session window", and the iterator still retains the characteristic of the sort.
### Why are the changes needed?
This part is a one of required on implementing SPARK-10816.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New UT added.
Closes#33077 from HeartSaVioR/SPARK-34892-SPARK-10816-PR-31570-part-4.
Authored-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
(cherry picked from commit 12a576f175)
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
Fix [comment](https://github.com/apache/spark/pull/32488#issuecomment-879315179)
This PR fix rule `UnwrapCastInBinaryComparison` bug. Rule UnwrapCastInBinaryComparison should skip In expression when in.list contains an expression that is not literal.
- In
Before this pr, the following example will throw an exception.
```scala
withTable("tbl") {
sql("CREATE TABLE tbl (d decimal(33, 27)) USING PARQUET")
sql("SELECT d FROM tbl WHERE d NOT IN (d + 1)")
}
```
- InSet
As the analyzer guarantee that all the elements in the `inSet.hset` are literal, so this is not an issue for `InSet`.
fbf53dee37/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/expressions.scala (L264-L279)
### Does this PR introduce _any_ user-facing change?
No, only bug fix.
### How was this patch tested?
New test.
Closes#33335 from cfmcgrady/SPARK-36130.
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit 103d16e868)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Fix `CustomShuffleReaderExec.hasCoalescedPartition` so that it returns true only if some original partitions got combined
### Why are the changes needed?
W/o this change `CustomShuffleReaderExec` description can report `coalesced` even though partitions are unchanged
### Does this PR introduce _any_ user-facing change?
Yes, the `Arguments` in the node description is now accurate:
```
(16) CustomShuffleReader
Input [3]: [registration#4, sum#85, count#86L]
Arguments: coalesced
```
### How was this patch tested?
Existing tests
Closes#32872 from ekoifman/PRISM-77023-fix-hasCoalescedPartition.
Authored-by: Eugene Koifman <eugene.koifman@workday.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit 4033b2a3f4)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
`LOCALTIMESTAMP()` is a datetime value function from ANSI SQL.
The syntax show below:
```
<datetime value function> ::=
<current date value function>
| <current time value function>
| <current timestamp value function>
| <current local time value function>
| <current local timestamp value function>
<current date value function> ::=
CURRENT_DATE
<current time value function> ::=
CURRENT_TIME [ <left paren> <time precision> <right paren> ]
<current local time value function> ::=
LOCALTIME [ <left paren> <time precision> <right paren> ]
<current timestamp value function> ::=
CURRENT_TIMESTAMP [ <left paren> <timestamp precision> <right paren> ]
<current local timestamp value function> ::=
LOCALTIMESTAMP [ <left paren> <timestamp precision> <right paren> ]
```
`LOCALTIMESTAMP()` returns the current timestamp at the start of query evaluation as TIMESTAMP WITH OUT TIME ZONE. This is similar to `CURRENT_TIMESTAMP()`.
Note we need to update the optimization rule `ComputeCurrentTime` so that Spark returns the same result in a single query if the function is called multiple times.
### Why are the changes needed?
`CURRENT_TIMESTAMP()` returns the current timestamp at the start of query evaluation.
`LOCALTIMESTAMP()` returns the current timestamp without time zone at the start of query evaluation.
The `LOCALTIMESTAMP` function is an ANSI SQL.
The `LOCALTIMESTAMP` function is very useful.
### Does this PR introduce _any_ user-facing change?
'Yes'. Support new function `LOCALTIMESTAMP()`.
### How was this patch tested?
New tests.
Closes#33258 from beliefer/SPARK-36037.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit b4f7758944)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR upgrades `commons-compress` from `1.20` to `1.21` to deal with CVEs.
### Why are the changes needed?
Some CVEs which affect `commons-compress 1.20` are reported and fixed in `1.21`.
https://commons.apache.org/proper/commons-compress/security-reports.html
* CVE-2021-35515
* CVE-2021-35516
* CVE-2021-35517
* CVE-2021-36090
The severities are reported as low for all the CVEs but it would be better to deal with them just in case.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
CI.
Closes#33333 from sarutak/upgrade-commons-compress-1.21.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
(cherry picked from commit fd06cc211d)
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Refactor `ParquetColumnIndexSuite` and allow better code reuse.
### Why are the changes needed?
A few methods in the test suite can share the same utility method `checkUnalignedPages` so it's better to do that and remove code duplication.
Additionally, `parquet.enable.dictionary` is tested for both `true` and `false` combination.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests.
Closes#33334 from sunchao/SPARK-35743-test-refactoring.
Authored-by: Chao Sun <sunchao@apple.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
(cherry picked from commit 7a7b086534)
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Currently when the push-based shuffle tests are run in an ad-hoc manner through IDE, `spark.testing` is not set to true therefore `Utils#isPushBasedShuffleEnabled` returns false disabling push-based shuffle eventually causing the tests to fail. This doesn't happen when it is run on command line using maven as `spark.testing` is set to true.
Changes made - set `spark.testing` to true in `initPushBasedShuffleConfs`
### Why are the changes needed?
Fix to run DAGSchedulerSuite tests in ad-hoc manner
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
In my local IDE
Closes#33303 from venkata91/SPARK-32920-follow-up.
Authored-by: Venkata krishnan Sowrirajan <vsowrirajan@linkedin.com>
Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com>
(cherry picked from commit fbf53dee37)
Signed-off-by: Mridul Muralidharan <mridulatgmail.com>
Introduction: this PR is a part of SPARK-10816 (`EventTime based sessionization (session window)`). Please refer #31937 to see the overall view of the code change. (Note that code diff could be diverged a bit.)
### What changes were proposed in this pull request?
This PR introduces state store manager for session window in streaming query. Session window in batch query wouldn't need to leverage state store manager.
This PR ensures versioning on state format for state store manager, so that we can apply further optimization after releasing Spark version. StreamingSessionWindowStateManager is a trait defining the available methods in session window state store manager. Its subclasses are classes implementing the trait with versioning.
The format of version 1 leverages the new feature of "prefix match scan" to represent the session windows:
* full key : [ group keys, start time in session window ]
* prefix key [ group keys ]
### Why are the changes needed?
This part is a one of required on implementing SPARK-10816.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New test suite added
Closes#31989 from HeartSaVioR/SPARK-34891-SPARK-10816-PR-31570-part-3.
Authored-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
(cherry picked from commit 0fe2d809d6)
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
Support TimestampNTZ type column in SQL command Cache table
### Why are the changes needed?
Cache table should support the new timestamp type.
### Does this PR introduce _any_ user-facing change?
Yes, the TimemstampNTZ type column can used in `CACHE TABLE`
### How was this patch tested?
Unit test
Closes#33322 from gengliangwang/cacheTable.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
(cherry picked from commit 067432705f)
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Make sure all physical plans of TPCDS queries are valid (satisfy the partitioning requirement).
### Why are the changes needed?
improve test coverage
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
N/A
Closes#33248 from cloud-fan/aqe2.
Lead-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Co-authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit 583173b7cc)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR adds an INVALID_FIELD_NAME error class for the errors in `StructType.findNestedField`. It also cleans up the code there and adds UT for this method.
### Why are the changes needed?
follow the new error message framework
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing tests
Closes#33282 from cloud-fan/error.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR modifies comment for `UTF8String.trimAll` and`sql-migration-guide.mld`.
The comment for `UTF8String.trimAll` says like as follows.
```
Trims whitespaces ({literal <=} ASCII 32) from both ends of this string.
```
Similarly, `sql-migration-guide.md` mentions about the behavior of `cast` like as follows.
```
In Spark 3.0, when casting string value to integral types(tinyint, smallint, int and bigint),
datetime types(date, timestamp and interval) and boolean type,
the leading and trailing whitespaces (<= ASCII 32) will be trimmed before converted to these type values,
for example, `cast(' 1\t' as int)` results `1`, `cast(' 1\t' as boolean)` results `true`,
`cast('2019-10-10\t as date)` results the date value `2019-10-10`.
In Spark version 2.4 and below, when casting string to integrals and booleans,
it does not trim the whitespaces from both ends; the foregoing results is `null`,
while to datetimes, only the trailing spaces (= ASCII 32) are removed.
```
But SPARK-32559 (#29375) changed the behavior and only whitespace ASCII characters will be trimmed since Spark 3.0.1.
### Why are the changes needed?
To follow the previous change.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Confirmed the document built by the following command.
```
SKIP_API=1 bundle exec jekyll build
```
Closes#33287 from sarutak/fix-utf8string-trim-issue.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit 57a4f310df)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Remove the private method `checkIntervalStringDataType()` from `IntervalUtils` since it hasn't been used anymore after https://github.com/apache/spark/pull/33242.
### Why are the changes needed?
To improve code maintenance.
### Does this PR introduce _any_ user-facing change?
No. The method is private, and it existing in code base for short time.
### How was this patch tested?
By existing GAs/tests.
Closes#33321 from MaxGekk/SPARK-35735-remove-unused-method.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
(cherry picked from commit 1ba3982d16)
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR allow the parser to parse unit list interval literals like `'3' day '10' hours '3' seconds` or `'8' years '3' months` as `YearMonthIntervalType` or `DayTimeIntervalType`.
### Why are the changes needed?
For ANSI compliance.
### Does this PR introduce _any_ user-facing change?
Yes. I noted the following things in the `sql-migration-guide.md`.
* Unit list interval literals are parsed as `YearMonthIntervaType` or `DayTimeIntervalType` instead of `CalendarIntervalType`.
* `WEEK`, `MILLISECONS`, `MICROSECOND` and `NANOSECOND` are not valid units for unit list interval literals.
* Units of year-month and day-time cannot be mixed like `1 YEAR 2 MINUTES`.
### How was this patch tested?
New tests and modified tests.
Closes#32949 from sarutak/day-time-multi-units.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit 8e92ef825a)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add new SQL function `to_timestamp_ltz`
syntax:
```
to_timestamp_ltz(timestamp_str_column[, fmt])
to_timestamp_ltz(timestamp_column)
to_timestamp_ltz(date_column)
```
### Why are the changes needed?
As the result of to_timestamp become consistent with the SQL configuration spark.sql.timestmapType and there is already a SQL function to_timestmap_ntz, we need new function to_timestamp_ltz to construct timestamp with local time zone values.
### Does this PR introduce _any_ user-facing change?
Yes, a new function for constructing timestamp with local time zone values
### How was this patch tested?
Unit test
Closes#33318 from gengliangwang/to_timestamp_ltz.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Gengliang Wang <gengliang@apache.org>
(cherry picked from commit 01ddaf3918)
Signed-off-by: Gengliang Wang <gengliang@apache.org>
### What changes were proposed in this pull request?
This PR modifies `DecorrelateInnerQuery` to handle the COUNT bug for lateral subqueries. Similar to SPARK-15370, rewriting lateral subqueries as joins can change the semantics of the subquery and lead to incorrect answers.
However we can't reuse the existing code to handle the count bug for correlated scalar subqueries because it assumes the subquery to have a specific shape (either with Filter + Aggregate or Aggregate as the root node). Instead, this PR proposes a more generic way to handle the COUNT bug. If an Aggregate is subject to the COUNT bug, we insert a left outer domain join between the outer query and the aggregate with a `alwaysTrue` marker and rewrite the final result conditioning on the marker. For example:
```sql
-- t1: [(0, 1), (1, 2)]
-- t2: [(0, 2), (0, 3)]
select * from t1 left outer join lateral (select count(*) from t2 where t2.c1 = t1.c1)
```
Without count bug handling, the query plan is
```
Project [c1#44, c2#45, count(1)#53L]
+- Join LeftOuter, (c1#48 = c1#44)
:- LocalRelation [c1#44, c2#45]
+- Aggregate [c1#48], [count(1) AS count(1)#53L, c1#48]
+- LocalRelation [c1#48]
```
and the answer is wrong:
```
+---+---+--------+
|c1 |c2 |count(1)|
+---+---+--------+
|0 |1 |2 |
|1 |2 |null |
+---+---+--------+
```
With the count bug handling:
```
Project [c1#1, c2#2, count(1)#10L]
+- Join LeftOuter, (c1#34 <=> c1#1)
:- LocalRelation [c1#1, c2#2]
+- Project [if (isnull(alwaysTrue#32)) 0 else count(1)#33L AS count(1)#10L, c1#34]
+- Join LeftOuter, (c1#5 = c1#34)
:- Aggregate [c1#1], [c1#1 AS c1#34]
: +- LocalRelation [c1#1]
+- Aggregate [c1#5], [count(1) AS count(1)#33L, c1#5, true AS alwaysTrue#32]
+- LocalRelation [c1#5]
```
and we have the correct answer:
```
+---+---+--------+
|c1 |c2 |count(1)|
+---+---+--------+
|0 |1 |2 |
|1 |2 |0 |
+---+---+--------+
```
### Why are the changes needed?
Fix a correctness bug with lateral join rewrite.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added SQL query tests. The results are consistent with Postgres' results.
Closes#33070 from allisonwang-db/spark-35551-lateral-count-bug.
Authored-by: allisonwang-db <allison.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit 4f760f2b1f)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch proposes to check data after adding data to topic in `KafkaSourceStressSuite`.
### Why are the changes needed?
The test logic in `KafkaSourceStressSuite` is not stable. For example, https://github.com/apache/spark/runs/3049244904.
Once we add data to a topic and then delete the topic before checking data, the expected answer is different to retrieved data from the sink.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests.
Closes#33311 from viirya/stream-assert.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
(cherry picked from commit 201566cdd5)
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This is a followup PR for SPARK-36104 (#33307) and removes unused import `typing.cast`.
After that change, Python linter fails.
```
./dev/lint-python
shell: sh -e {0}
env:
LC_ALL: C.UTF-8
LANG: C.UTF-8
pythonLocation: /__t/Python/3.6.13/x64
LD_LIBRARY_PATH: /__t/Python/3.6.13/x64/lib
starting python compilation test...
python compilation succeeded.
starting black test...
black checks passed.
starting pycodestyle test...
pycodestyle checks passed.
starting flake8 test...
flake8 checks failed:
./python/pyspark/pandas/data_type_ops/num_ops.py:19:1: F401 'typing.cast' imported but unused
from typing import cast, Any, Union
^
1 F401 'typing.cast' imported but unused
```
### Why are the changes needed?
To recover CI.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
CI.
Closes#33315 from sarutak/followup-SPARK-36104.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit 47fd3173a5)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR reverts https://github.com/apache/spark/pull/32455 and its followup https://github.com/apache/spark/pull/32536 , because the new janino version has a bug that is not fixed yet: https://github.com/janino-compiler/janino/pull/148
### Why are the changes needed?
avoid regressions
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing tests
Closes#33302 from cloud-fan/revert.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit ae6199af44)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Manage InternalField for DataTypeOps.neg/abs.
### Why are the changes needed?
The spark data type and nullability must be the same as the original when DataTypeOps.neg/abs.
We should manage InternalField for this case.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit tests.
Closes#33307 from xinrong-databricks/internalField.
Authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit 5afc27f899)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Properly set `InternalField` for `DataTypeOps.invert`.
### Why are the changes needed?
The spark data type and nullability must be the same as the original when `DataTypeOps.invert`.
We should manage `InternalField` for this case.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#33306 from ueshin/issues/SPARK-36103/invert.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit e2021daafb)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Support new functions make_timestamp_ntz and make_timestamp_ltz
Syntax:
* `make_timestamp_ntz(year, month, day, hour, min, sec)`: Create local date-time from year, month, day, hour, min, sec fields
* `make_timestamp_ltz(year, month, day, hour, min, sec[, timezone])`: Create current timestamp with local time zone from year, month, day, hour, min, sec and timezone fields
### Why are the changes needed?
As the result of `make_timestamp` become consistent with the SQL configuration `spark.sql.timestmapType`, we need these two new functions to construct timestamp literals. They align to the functions [`make_timestamp` and `make_timestamptz`](https://www.postgresql.org/docs/9.4/functions-datetime.html) in PostgreSQL
### Does this PR introduce _any_ user-facing change?
Yes, two new datetime functions: make_timestamp_ntz and make_timestamp_ltz.
### How was this patch tested?
End-to-end tests.
Closes#33299 from gengliangwang/make_timestamp_ntz_ltz.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
(cherry picked from commit 92bf83ed0a)
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR group exception messages in sql/core/src/main/scala/org/apache/spark/sql/execution/command
### Why are the changes needed?
It will largely help with standardization of error messages and its maintenance.
### Does this PR introduce any user-facing change?
No. Error messages remain unchanged.
### How was this patch tested?
No new tests - pass all original tests to make sure it doesn't break any existing behavior.
Closes#32951 from dgd-contributor/SPARK-33603_grouping_execution/command.
Authored-by: dgd-contributor <dgd_contributor@viettel.com.vn>
Signed-off-by: Gengliang Wang <gengliang@apache.org>
(cherry picked from commit d03f71657e)
Signed-off-by: Gengliang Wang <gengliang@apache.org>
### What changes were proposed in this pull request?
This PR proposes to introduce a new feature "prefix match scan" on state store, which enables users of state store (mostly stateful operators) to group the keys into logical groups, and scan the keys in the same group efficiently.
For example, if the schema of the key of state store is `[ sessionId | session.start ]`, we can scan with prefix key which schema is `[ sessionId ]` (leftmost 1 column) and retrieve all key-value pairs in state store which keys are matched with given prefix key.
This PR will bring the API changes, though the changes are done in the developer API.
* Registering the prefix key
We propose to make an explicit change to the init() method of StateStoreProvider, as below:
```
def init(
stateStoreId: StateStoreId,
keySchema: StructType,
valueSchema: StructType,
numColsPrefixKey: Int,
storeConfs: StateStoreConf,
hadoopConf: Configuration): Unit
```
Please note that we remove an unused parameter “keyIndexOrdinal” as well. The parameter is coupled with getRange() which we will remove as well. See below for rationalization.
Here we provide the number of columns we take to project the prefix key from the full key. If the operator doesn’t leverage prefix match scan, the value can (and should) be 0, because the state store provider may optimize the underlying storage format which may bring extra overhead.
We would like to apply some restrictions on prefix key to simplify the functionality:
* Prefix key is a part of the full key. It can’t be the same as the full key.
* That said, the full key will be the (prefix key + remaining parts), and both prefix key and remaining parts should have at least one column.
* We always take the columns from the leftmost sequentially, like “seq.take(nums)”.
* We don’t allow reordering of the columns.
* We only guarantee “equality” comparison against prefix keys, and don’t support the prefix “range” scan.
* We only support scanning on the keys which match with the prefix key.
* E.g. We don’t support the range scan from user A to user B due to technical complexity. That’s the reason we can’t leverage the existing getRange API.
As we mentioned, we want to make an explicit change to the init() method of StateStoreProvider which would break backward compatibility, assuming that 3rd party state store providers need to update their code in any way to support prefix match scan. Given RocksDB state store provider is being donated to the OSS and plan to be available in Spark 3.2, the majority of the users would migrate to the built-in state store providers, which would remedy the concerns.
* Scanning key-value pairs matched to the prefix key
We propose to add a new method to the ReadStateStore (and StateStore by inheritance), as below:
```
def prefixScan(prefixKey: UnsafeRow): Iterator[UnsafeRowPair]
```
We require callers to pass the `prefixKey` which would have the same schema with the registered prefix key schema. In other words, the schema of the parameter `prefixKey` should match to the projection of the prefix key on the full key based on the number of columns for the prefix key.
The method contract is clear - the method will return the iterator which will give the key-value pairs whose prefix key is matched with the given prefix key. Callers should only rely on the contract and should not expect any other characteristics based on specific details on the state store provider.
In the caller’s point of view, the prefix key is only used for retrieving key-value pairs via prefix match scan. Callers should keep using the full key to do CRUD.
Note that this PR also proposes to make a breaking change, removal of getRange(), which is never be implemented properly and hence never be called properly.
### Why are the changes needed?
* Introducing prefix match scan feature
Currently, the API in state store is only based on key-value data structure. This lacks on advanced data structures like list-like one, which required us to implement the data structure on our own whenever we need it. We had one in stream-stream join, and we were about to have another one in native session window. The custom implementation of data structure based on the state store API tends to be complicated and has to deal with multiple state stores.
We decided to enhance the state store API a bit to remove the requirement for native session window to implement its own. From the operator of native session window, it will just need to do prefix scan on group key to retrieve all sessions belonging to the group key.
Thanks to adding the feature to the part of state store API, this would enable state store providers to optimize the implementation based on the characteristic. (e.g. We will implement this in RocksDB state store provider via leveraging the characteristic that RocksDB sorts the key by natural order of binary format.)
* Removal of getRange API
Before introducing this we sought the way to leverage getRange, but it's quite hard to implement efficiently, with respecting its method contract. Spark always calls the method with (None, None) parameter and all the state store providers (including built-in) implement it as just calling iterator(), which is not respecting the method contract. That said, we can replace all getRange() usages to iterator(), and remove the API to remove any confusions/concerns.
### Does this PR introduce _any_ user-facing change?
Yes for the end users & maintainers of 3rd party state store provider. They will need to upgrade their state store provider implementations to adopt this change.
### How was this patch tested?
Added UT, and also existing UTs to make sure it doesn't break anything.
Closes#33038 from HeartSaVioR/SPARK-35861.
Authored-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
(cherry picked from commit 094300fa60)
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
Combine `readBatch` and `readIntegers` in `VectorizedRleValuesReader` by having them share the same `readBatchInternal` method.
### Why are the changes needed?
`readBatch` and `readIntegers` share similar code path and this Jira aims to combine them into one method for easier maintenance.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests as this is just a refactoring.
Closes#33271 from sunchao/SPARK-35743-read-integers.
Authored-by: Chao Sun <sunchao@apple.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit 5edbbd1711)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to update the SQL migration guide, in particular the section about the migration from Spark 2.4 to 3.0. New item informs users about the following issue:
**What**: Spark doesn't detect encoding (charset) in CSV files with BOM correctly. Such files can be read only in the multiLine mode when the CSV option encoding matches to the actual encoding of CSV files. For example, Spark cannot read UTF-16BE CSV files when encoding is set to UTF-8 which is the default mode. This is the case of the current ES ticket.
**Why**: In previous Spark versions, encoding wasn't propagated to the underlying library that means the lib tried to detect file encoding automatically. It could success for some encodings that require BOM presents at the beginning of files. Starting from the versions 3.0, users can specify file encoding via the CSV option encoding which has UTF-8 as the default value. Spark propagates such default to the underlying library (uniVocity), and as a consequence this turned off encoding auto-detection.
**When**: Since Spark 3.0. In particular, the commit 2df34db586 causes the issue.
**Workaround**: Enabling the encoding auto-detection mechanism in uniVocity by passing null as the value of CSV option encoding. A more recommended approach is to set the encoding option explicitly.
### Why are the changes needed?
To improve user experience with Spark SQL. This should help to users in their migration from Spark 2.4.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Should be checked by building docs in GA/jenkins.
Closes#33300 from MaxGekk/csv-encoding-migration-guide.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit e788a3fa88)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Update AQE is `disabled` to `enabled` in sql-performance-tuning docs
### Why are the changes needed?
Make docs correct.
### Does this PR introduce _any_ user-facing change?
yes, docs changed.
### How was this patch tested?
Not need.
Closes#33295 from ulysses-you/enable-AQE.
Lead-authored-by: ulysses-you <ulyssesyou18@gmail.com>
Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit 286c231c1e)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The SQL function TO_TIMESTAMP should return different results based on the default timestamp type:
* when "spark.sql.timestampType" is TIMESTAMP_NTZ, return TimestampNTZType literal
* when "spark.sql.timestampType" is TIMESTAMP_LTZ, return TimestampType literal
This PR also refactor the class GetTimestamp and GetTimestampNTZ to reduce duplicated code.
### Why are the changes needed?
As "spark.sql.timestampType" sets the default timestamp type, the to_timestamp function should behave consistently with it.
### Does this PR introduce _any_ user-facing change?
Yes, when the value of "spark.sql.timestampType" is TIMESTAMP_NTZ, the result type of `TO_TIMESTAMP` is of TIMESTAMP_NTZ type.
### How was this patch tested?
Unit test
Closes#33280 from gengliangwang/to_timestamp.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
(cherry picked from commit 32720dd3e1)
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
The functions `unix_timestamp`/`to_unix_timestamp` should be able to accept input of `TimestampNTZType`.
### Why are the changes needed?
The functions `unix_timestamp`/`to_unix_timestamp` should be able to accept input of `TimestampNTZType`.
### Does this PR introduce _any_ user-facing change?
'Yes'.
### How was this patch tested?
New tests.
Closes#33278 from beliefer/SPARK-36044.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
(cherry picked from commit 8738682f6a)
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Implement unary operator `invert` of integral ps.Series/Index.
### Why are the changes needed?
Currently, unary operator `invert` of integral ps.Series/Index is not supported. We ought to implement that following pandas' behaviors.
### Does this PR introduce _any_ user-facing change?
Yes.
Before:
```py
>>> import pyspark.pandas as ps
>>> psser = ps.Series([1, 2, 3])
>>> ~psser
Traceback (most recent call last):
...
NotImplementedError: Unary ~ can not be applied to integrals.
```
After:
```py
>>> import pyspark.pandas as ps
>>> psser = ps.Series([1, 2, 3])
>>> ~psser
0 -2
1 -3
2 -4
dtype: int64
```
### How was this patch tested?
Unit tests.
Closes#33285 from xinrong-databricks/numeric_invert.
Authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit badb0393d4)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add new configs in sql-performance-tuning docs.
* spark.sql.adaptive.coalescePartitions.parallelismFirst
* spark.sql.adaptive.coalescePartitions.minPartitionSize
* spark.sql.adaptive.autoBroadcastJoinThreshold
* spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold
### Why are the changes needed?
Help user to find them.
### Does this PR introduce _any_ user-facing change?
yes, docs changed.
### How was this patch tested?
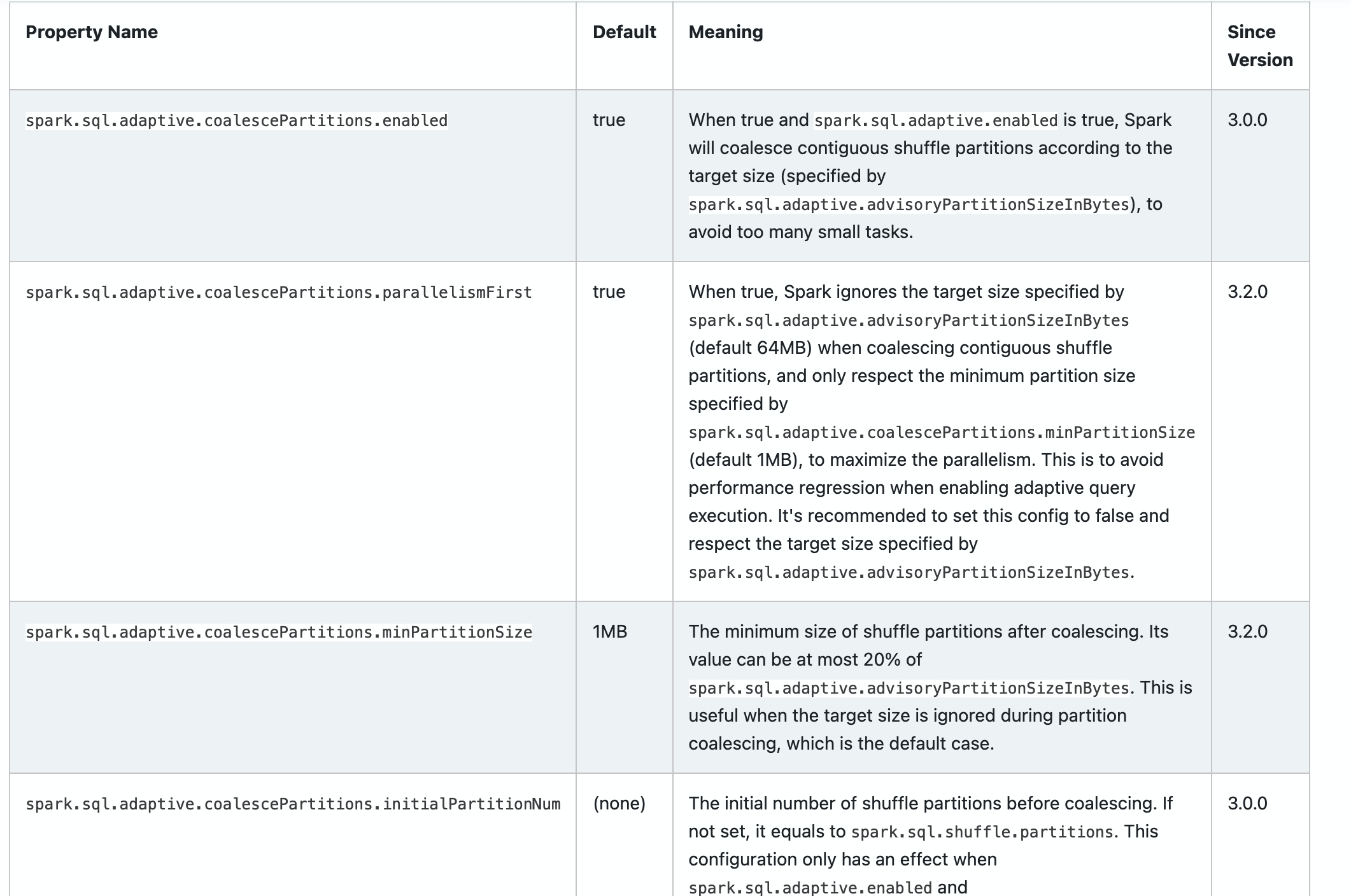
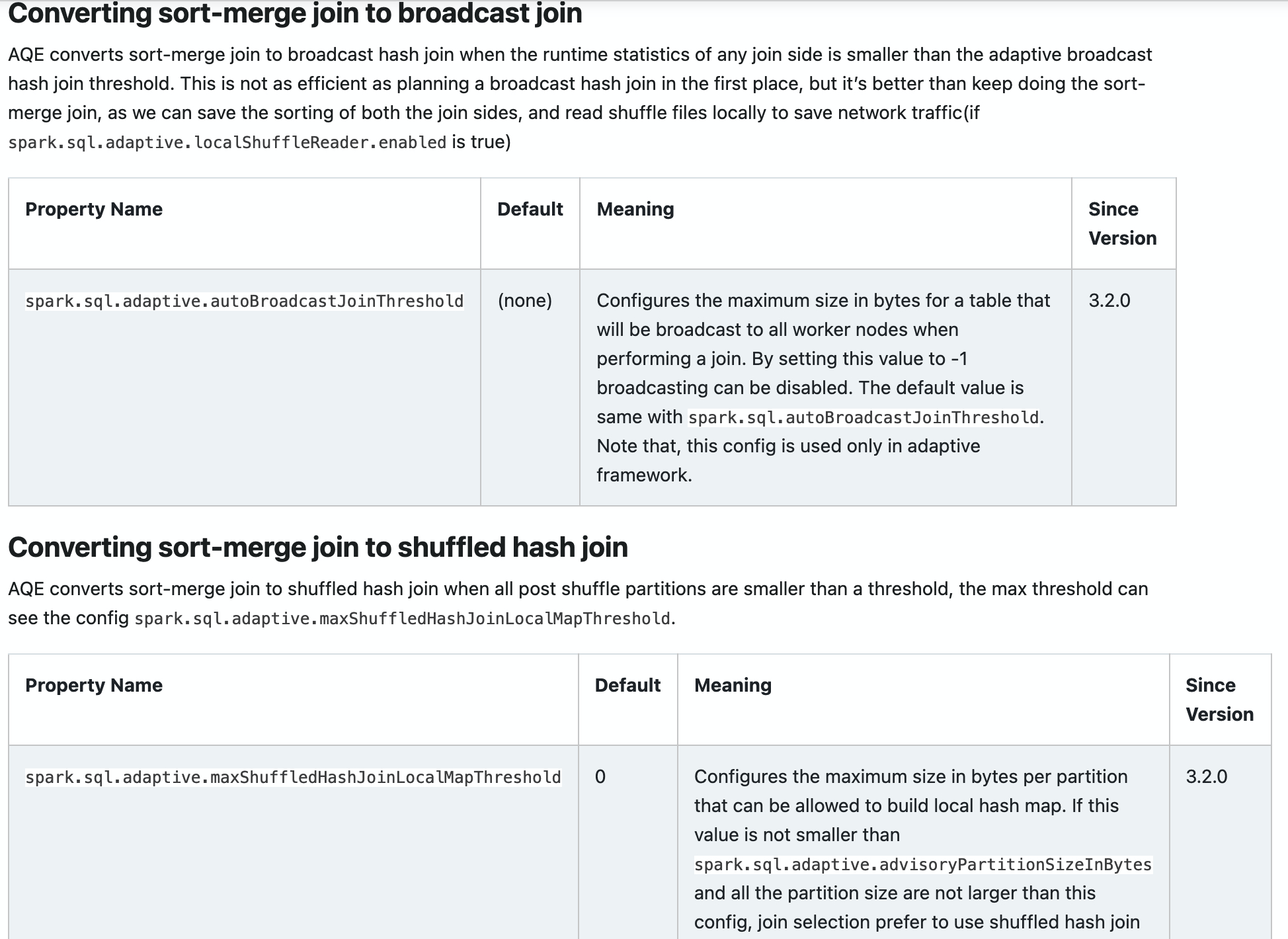
Closes#32960 from ulysses-you/SPARK-35813.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit 0e9786c712)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Properly set `InternalField` more in `DataTypeOps`.
### Why are the changes needed?
There are more places in `DataTypeOps` where we can manage `InternalField`.
We should manage `InternalField` for these cases.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#33275 from ueshin/issues/SPARK-36064/fields.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit 95e6c6e3e9)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The SQL function MAKE_TIMESTAMP should return different results based on the default timestamp type:
* when "spark.sql.timestampType" is TIMESTAMP_NTZ, return TimestampNTZType literal
* when "spark.sql.timestampType" is TIMESTAMP_LTZ, return TimestampType literal
### Why are the changes needed?
As "spark.sql.timestampType" sets the default timestamp type, the make_timestamp function should behave consistently with it.
### Does this PR introduce _any_ user-facing change?
Yes, when the value of "spark.sql.timestampType" is TIMESTAMP_NTZ, the result type of `MAKE_TIMESTAMP` is of TIMESTAMP_NTZ type.
### How was this patch tested?
Unit test
Closes#33290 from gengliangwang/mkTS.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
(cherry picked from commit 17ddcc9e82)
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR fixes an issue that no tests in `hadoop-cloud` are compiled and run unless `hadoop-3.2` profile is activated explicitly.
The root cause seems similar to SPARK-36067 (#33276) so the solution is to activate `hadoop-3.2` profile in `hadoop-cloud/pom.xml` by default.
### Why are the changes needed?
`hadoop-3.2` profile should be activated by default so tests in `hadoop-cloud` also should be compiled and run without activating `hadoop-3.2` profile explicitly.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Confirmed tests in `hadoop-cloud` ran with both SBT and Maven.
```
build/sbt -Phadoop-cloud "hadoop-cloud/test"
...
[info] CommitterBindingSuite:
[info] - BindingParquetOutputCommitter binds to the inner committer (258 milliseconds)
[info] - committer protocol can be serialized and deserialized (11 milliseconds)
[info] - local filesystem instantiation (3 milliseconds)
[info] - reject dynamic partitioning (1 millisecond)
[info] Run completed in 1 second, 234 milliseconds.
[info] Total number of tests run: 4
[info] Suites: completed 1, aborted 0
[info] Tests: succeeded 4, failed 0, canceled 0, ignored 0, pending 0
[info] All tests passed.
build/mvn -Phadoop-cloud -pl hadoop-cloud test
...
CommitterBindingSuite:
- BindingParquetOutputCommitter binds to the inner committer
- committer protocol can be serialized and deserialized
- local filesystem instantiation
- reject dynamic partitioning
Run completed in 560 milliseconds.
Total number of tests run: 4
Suites: completed 2, aborted 0
Tests: succeeded 4, failed 0, canceled 0, ignored 0, pending 0
All tests passed.
```
Closes#33277 from sarutak/fix-hadoop-3.2-cloud.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit c3c5af884e)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
{kind=link}
{kind=link}