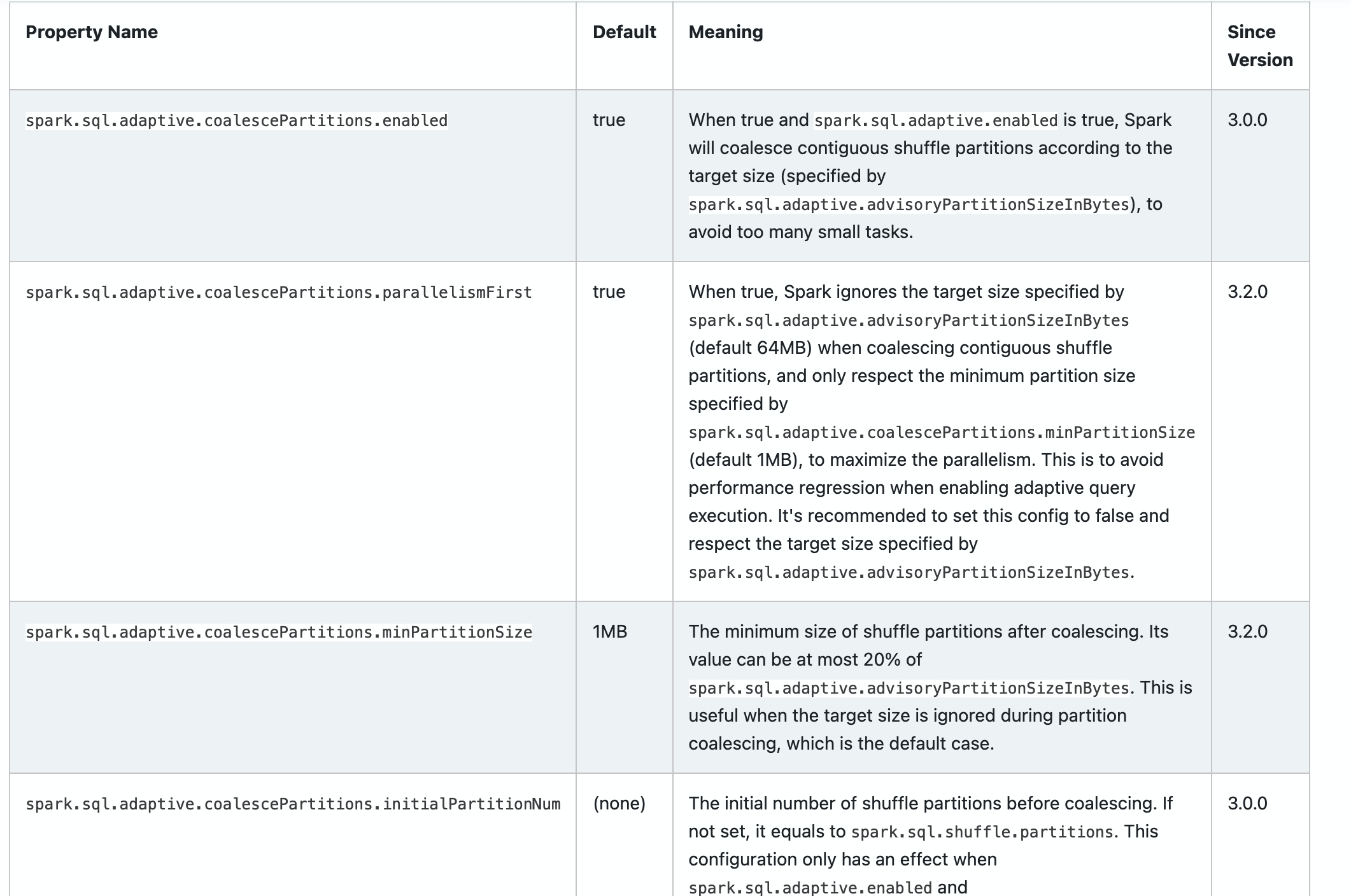
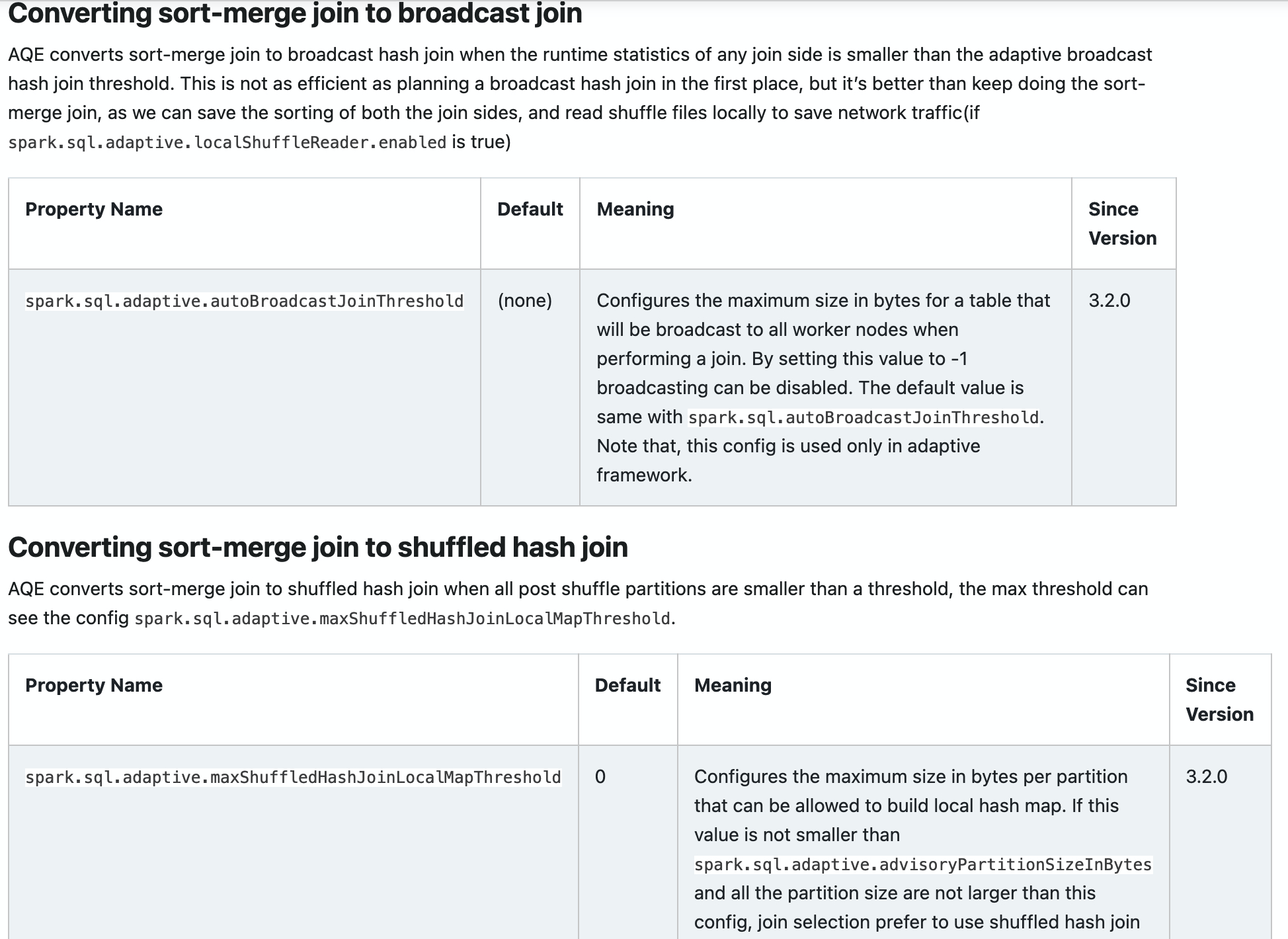
### What changes were proposed in this pull request?
Add new configs in sql-performance-tuning docs.
* spark.sql.adaptive.coalescePartitions.parallelismFirst
* spark.sql.adaptive.coalescePartitions.minPartitionSize
* spark.sql.adaptive.autoBroadcastJoinThreshold
* spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold
### Why are the changes needed?
Help user to find them.
### Does this PR introduce _any_ user-facing change?
yes, docs changed.
### How was this patch tested?
Closes#32960 from ulysses-you/SPARK-35813.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Properly set `InternalField` more in `DataTypeOps`.
### Why are the changes needed?
There are more places in `DataTypeOps` where we can manage `InternalField`.
We should manage `InternalField` for these cases.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#33275 from ueshin/issues/SPARK-36064/fields.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The SQL function MAKE_TIMESTAMP should return different results based on the default timestamp type:
* when "spark.sql.timestampType" is TIMESTAMP_NTZ, return TimestampNTZType literal
* when "spark.sql.timestampType" is TIMESTAMP_LTZ, return TimestampType literal
### Why are the changes needed?
As "spark.sql.timestampType" sets the default timestamp type, the make_timestamp function should behave consistently with it.
### Does this PR introduce _any_ user-facing change?
Yes, when the value of "spark.sql.timestampType" is TIMESTAMP_NTZ, the result type of `MAKE_TIMESTAMP` is of TIMESTAMP_NTZ type.
### How was this patch tested?
Unit test
Closes#33290 from gengliangwang/mkTS.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
There was a regression since Spark started storing large remote files on disk (https://issues.apache.org/jira/browse/SPARK-22062). In 2018 a refactoring introduced a hidden reference preventing the auto-deletion of the files (a97001d217 (diff-42a673b8fa5f2b999371dc97a5de7ebd2c2ec19447353d39efb7e8ebc012fe32L1677)). Since then all underlying files of DownloadFile instances are kept on disk for the duration of the Spark application which sometimes results in "no space left" errors.
`ReferenceWithCleanup` class uses `file` (the `DownloadFile`) in `cleanUp(): Unit` method so it has to keep a reference to it which prevents it from being garbage-collected.
```
def cleanUp(): Unit = {
logDebug(s"Clean up file $filePath")
if (!file.delete()) { <--- here
logDebug(s"Fail to delete file $filePath")
}
}
```
### Why are the changes needed?
Long-running Spark applications require freeing resources when they are not needed anymore, and iterative algorithms could use all the disk space quickly too.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added a test in BlockManagerSuite and tested manually.
Closes#33251 from dtarima/fix-download-file-cleanup.
Authored-by: Denis Tarima <dtarima@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
The main change of this is use the static `Integer.compare()` method and `Long.compare()` method instead of the handwriting compare method in Java code.
### Why are the changes needed?
Removing unnecessary handwriting compare methods
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass the Jenkins or GitHub Action
Closes#33260 from LuciferYang/static-compare.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
We have a job that has a stage that contains about 8k tasks. Most tasks take about 1~10min to finish but 3 of them tasks run extremely slow with similar data sizes. They take about 1 hour each to finish and also do their speculations.
The root cause is most likely the delay of the storage system. But it's not straightforward enough to find where the performance issue occurs, in the phase of shuffle read, task execution, output, commitment e.t.c..
```log
2021-07-09 03:05:17 CST SparkHadoopMapRedUtil INFO - attempt_20210709022249_0003_m_007050_37351: Committed
2021-07-09 03:05:17 CST Executor INFO - Finished task 7050.0 in stage 3.0 (TID 37351). 3311 bytes result sent to driver
2021-07-09 04:06:10 CST ShuffleBlockFetcherIterator INFO - Getting 9 non-empty blocks including 0 local blocks and 9 remote blocks
2021-07-09 04:06:10 CST TransportClientFactory INFO - Found inactive connection to
```
### Why are the changes needed?
On the spark side, we can record the time cost in logs for better bug hunting or performance tuning.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
passing GA
Closes#33279 from yaooqinn/SPARK-36070.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
This PR improve some implement for Spark.
### Why are the changes needed?
This PR improve some implement for Spark.
### Does this PR introduce _any_ user-facing change?
'No'.
### How was this patch tested?
Jenkins test.
Closes#33216 from beliefer/gather-code-format.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR fixes an issue that no tests in `hadoop-cloud` are compiled and run unless `hadoop-3.2` profile is activated explicitly.
The root cause seems similar to SPARK-36067 (#33276) so the solution is to activate `hadoop-3.2` profile in `hadoop-cloud/pom.xml` by default.
### Why are the changes needed?
`hadoop-3.2` profile should be activated by default so tests in `hadoop-cloud` also should be compiled and run without activating `hadoop-3.2` profile explicitly.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Confirmed tests in `hadoop-cloud` ran with both SBT and Maven.
```
build/sbt -Phadoop-cloud "hadoop-cloud/test"
...
[info] CommitterBindingSuite:
[info] - BindingParquetOutputCommitter binds to the inner committer (258 milliseconds)
[info] - committer protocol can be serialized and deserialized (11 milliseconds)
[info] - local filesystem instantiation (3 milliseconds)
[info] - reject dynamic partitioning (1 millisecond)
[info] Run completed in 1 second, 234 milliseconds.
[info] Total number of tests run: 4
[info] Suites: completed 1, aborted 0
[info] Tests: succeeded 4, failed 0, canceled 0, ignored 0, pending 0
[info] All tests passed.
build/mvn -Phadoop-cloud -pl hadoop-cloud test
...
CommitterBindingSuite:
- BindingParquetOutputCommitter binds to the inner committer
- committer protocol can be serialized and deserialized
- local filesystem instantiation
- reject dynamic partitioning
Run completed in 560 milliseconds.
Total number of tests run: 4
Suites: completed 2, aborted 0
Tests: succeeded 4, failed 0, canceled 0, ignored 0, pending 0
All tests passed.
```
Closes#33277 from sarutak/fix-hadoop-3.2-cloud.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Adjust `test_astype`, `test_neg` for old pandas versions.
### Why are the changes needed?
There are issues in old pandas versions that fail tests in pandas API on Spark. We ought to adjust `test_astype` and `test_neg` for old pandas versions.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit tests. Please refer to https://github.com/apache/spark/pull/33272 for test results with pandas 1.0.1.
Closes#33250 from xinrong-databricks/SPARK-36035.
Authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR fixes an issue that `YarnClusterSuite` fails due to `NoClassDefFoundError unless `hadoop-3.2` profile is activated explicitly regardless of building with SBT or Maven.
```
build/sbt -Pyarn "yarn/testOnly org.apache.spark.deploy.yarn.YarnClusterSuite"
...
[info] YarnClusterSuite:
[info] org.apache.spark.deploy.yarn.YarnClusterSuite *** ABORTED *** (598 milliseconds)
[info] java.lang.NoClassDefFoundError: org/bouncycastle/operator/OperatorCreationException
[info] at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager$RMActiveServices.serviceInit(ResourceManager.java:888)
[info] at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
[info] at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.createAndInitActiveServices(ResourceManager.java:1410)
[info] at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceInit(ResourceManager.java:344)
[info] at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster.initResourceManager(MiniYARNCluster.java:359)
```
The solution is modifying `yarn/pom.xml` to activate `hadoop-3.2` profiles by default.
### Why are the changes needed?
hadoop-3.2 profile should be enabled by default so `YarnClusterSuite` should also successfully finishes without `-Phadoop-3.2`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Run `YarnClusterSuite` with both SBT and Maven without `-Phadoop-3.2` and it successfully finished.
```
build/sbt -Pyarn "yarn/testOnly org.apache.spark.deploy.yarn.YarnClusterSuite"
...
[info] Run completed in 5 minutes, 38 seconds.
[info] Total number of tests run: 27
[info] Suites: completed 1, aborted 0
[info] Tests: succeeded 27, failed 0, canceled 0, ignored 0, pending 0
[info] All tests passed.
build/mvn -Pyarn -pl resource-managers/yarn test -Dtest=none -DwildcardSuites=org.apache.spark.deploy.yarn.YarnClusterSuite
...
Run completed in 5 minutes, 49 seconds.
Total number of tests run: 27
Suites: completed 2, aborted 0
Tests: succeeded 27, failed 0, canceled 0, ignored 0, pending 0
All tests passed.
```
Closes#33276 from sarutak/fix-bouncy-issue.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Change `currentPhysicalPlan.logicalLink.get` to `inputPlan.logicalLink.get` for initial logical link.
### Why are the changes needed?
At `initialPlan` we may remove some Spark Plan with `queryStagePreparationRules`, if removed Spark Plan is top level node, then we will lose the linked logical node.
Since we support AQE side broadcast join config. It's more common that a join is SMJ at normal planner and changed to BHJ after AQE reOptimize. However, `RemoveRedundantSorts` is applied before reOptimize at `initialPlan`, then a local sort might be removed incorrectly if a join is SMJ at first but changed to BHJ during reOptimize.
### Does this PR introduce _any_ user-facing change?
yes, bug fix
### How was this patch tested?
add test
Closes#33244 from ulysses-you/SPARK-36032.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
Merge test_decimal_ops into test_num_ops
- merge test_isnull() into test_num_ops.test_isnull()
- remove test_datatype_ops(), which already covered in 11fcbc73cb/python/pyspark/pandas/tests/data_type_ops/test_base.py (L58-L59)
### Why are the changes needed?
Tests for data-type-based operations of decimal Series are in two places:
- python/pyspark/pandas/tests/data_type_ops/test_decimal_ops.py
- python/pyspark/pandas/tests/data_type_ops/test_num_ops.py
We'd better merge test_decimal_ops into test_num_ops.
See also [SPARK-36002](https://issues.apache.org/jira/browse/SPARK-36002) .
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
unittests passed
Closes#33206 from Yikun/SPARK-36002.
Authored-by: Yikun Jiang <yikunkero@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
For tests with operations on different Series, sort index of results before comparing them with pandas.
### Why are the changes needed?
We have many tests with operations on different Series in `spark/python/pyspark/pandas/tests/data_type_ops/` that assume the result's index to be sorted and then compare to the pandas' behavior.
The assumption on the result's index ordering is wrong since Spark DataFrame join is used internally and the order is not preserved if the data being in different partitions.
So we should assume the result to be disordered and sort the index of such results before comparing them with pandas.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit tests.
Closes#33274 from xinrong-databricks/datatypeops_testdiffframe.
Authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Try to capture the error message from the `faulthandler` when the Python worker crashes.
### Why are the changes needed?
Currently, we just see an error message saying `"exited unexpectedly (crashed)"` when the UDFs causes the Python worker to crash by like segmentation fault.
We should take advantage of [`faulthandler`](https://docs.python.org/3/library/faulthandler.html) and try to capture the error message from the `faulthandler`.
### Does this PR introduce _any_ user-facing change?
Yes, when a Spark config `spark.python.worker.faulthandler.enabled` is `true`, the stack trace will be seen in the error message when the Python worker crashes.
```py
>>> def f():
... import ctypes
... ctypes.string_at(0)
...
>>> sc.parallelize([1]).map(lambda x: f()).count()
```
```
org.apache.spark.SparkException: Python worker exited unexpectedly (crashed): Fatal Python error: Segmentation fault
Current thread 0x000000010965b5c0 (most recent call first):
File "/.../ctypes/__init__.py", line 525 in string_at
File "<stdin>", line 3 in f
File "<stdin>", line 1 in <lambda>
...
```
### How was this patch tested?
Added some tests, and manually.
Closes#33273 from ueshin/issues/SPARK-36062/faulthandler.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to remove the automatic build guides of documentation in `docs/README.md`.
### Why are the changes needed?
This doesn't work very well:
1. It doesn't detect the changes in RST files. But PySpark internally generates RST files so we can't just simply include it in the detection. Otherwise, it goes to an infinite loop
2. During PySpark documentation generation, it launches some jobs to generate plot images now. This is broken with `entr` command, and the job fails. Seems like it's related to how `entr` creates the process internally.
3. Minor issue but the documentation build directory was changed (`_build` -> `build` in `python/docs`)
I don't think it's worthwhile testing and fixing the docs to show an working example because dev people are already able to do it manually.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Manually tested.
Closes#33266 from HyukjinKwon/SPARK-36051.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Remove IntervalUnit
### Why are the changes needed?
Clean code
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#33265 from AngersZhuuuu/SPARK-36049.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Support group by TimestampNTZ type column
### Why are the changes needed?
It's a basic SQL operation.
### Does this PR introduce _any_ user-facing change?
No, the new timestmap type is not released yet.
### How was this patch tested?
Unit test
Closes#33268 from gengliangwang/agg.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
The PR is proposed to standardize TypeError messages for unsupported basic operations by:
- Capitalize the first letter
- Leverage TypeError messages defined in `pyspark/pandas/data_type_ops/base.py`
- Take advantage of the utility `is_valid_operand_for_numeric_arithmetic` to save duplicated TypeError messages
Related unit tests should be adjusted as well.
### Why are the changes needed?
Inconsistent TypeError messages are shown for unsupported data-type-based basic operations.
Take addition's TypeError messages for example:
- addition can not be applied to given types.
- string addition can only be applied to string series or literals.
Standardizing TypeError messages would improve user experience and reduce maintenance costs.
### Does this PR introduce _any_ user-facing change?
No user-facing behavior change. Only TypeError messages are modified.
### How was this patch tested?
Unit tests.
Closes#33237 from xinrong-databricks/datatypeops_err.
Authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
### What changes were proposed in this pull request?
Currently the TimestampNTZ literals shows only long value instead of timestamp string in its SQL string and toString result.
Before changes (with default timestamp type as TIMESTAMP_NTZ)
```
– !query
select timestamp '2019-01-01\t'
– !query schema
struct<1546300800000000:timestamp_ntz>
```
After changes:
```
– !query
select timestamp '2019-01-01\t'
– !query schema
struct<TIMESTAMP_NTZ '2019-01-01 00:00:00':timestamp_ntz>
```
### Why are the changes needed?
Make the schema of TimestampNTZ literals readable.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes#33269 from gengliangwang/ntzLiteralString.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
When exec the command `SHOW CREATE TABLE`, we should not lost the info null flag if the table column that
is specified `NOT NULL`
### Why are the changes needed?
[SPARK-36012](https://issues.apache.org/jira/browse/SPARK-36012)
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Add UT test for V1 and existed UT for V2
Closes#33219 from Peng-Lei/SPARK-36012.
Authored-by: PengLei <peng.8lei@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, AQE uses a very tricky way to trigger and wait for the subqueries:
1. submitting stage calls `QueryStageExec.materialize`
2. `QueryStageExec.materialize` calls `executeQuery`
3. `executeQuery` does some preparation works, which goes to `QueryStageExec.doPrepare`
4. `QueryStageExec.doPrepare` calls `prepare` of shuffle/broadcast, which triggers all the subqueries in this stage
5. `executeQuery` then calls `waitForSubqueries`, which does nothing because `QueryStageExec` itself has no subqueries
6. then we submit the shuffle/broadcast job, without waiting for subqueries
7. for `ShuffleExchangeExec.mapOutputStatisticsFuture`, it calls `child.execute`, which calls `executeQuery` and wait for subqueries in the query tree of `child`
8. The only missing case is: `ShuffleExchangeExec` itself may contain subqueries(repartition expression) and AQE doesn't wait for it.
A simple fix would be overwriting `waitForSubqueries` in `QueryStageExec`, and forward the request to shuffle/broadcast, but this PR proposes a different and probably cleaner way: we follow `execute`/`doExecute` in `SparkPlan`, and add similar APIs in the AQE version of "execute", which gets a future from shuffle/broadcast.
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
a query fails without the fix and can run now
### How was this patch tested?
new test
Closes#33058 from cloud-fan/aqe.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Refactors the base Throwable trait `SparkError.scala` (introduced in SPARK-34920) an interface `SparkThrowable.java`.
### Why are the changes needed?
- Renaming `SparkError` to `SparkThrowable` better reflect sthat this is the base interface for both `Exception` and `Error`
- Migrating to Java maximizes its extensibility
### Does this PR introduce _any_ user-facing change?
Yes; the base trait has been renamed and the accessor methods have changed (eg. `sqlState` -> `getSqlState()`).
### How was this patch tested?
Unit tests.
Closes#33164 from karenfeng/SPARK-35958.
Authored-by: Karen Feng <karen.feng@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add the implementation for the RocksDBStateStoreProvider. It's the subclass of StateStoreProvider that leverages all the functionalities implemented in the RocksDB instance.
### Why are the changes needed?
The interface for the end-user to use the RocksDB state store.
### Does this PR introduce _any_ user-facing change?
Yes. New RocksDBStateStore can be used in their applications.
### How was this patch tested?
New UT added.
Closes#33187 from xuanyuanking/SPARK-35988.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
Run end-to-end tests with default timestamp type as TIMESTAMP_NTZ to increase test coverage.
### Why are the changes needed?
Inrease test coverage.
Also, there will be more and more expressions have different behaviors when the default timestamp type is TIMESTAMP_NTZ, for example, `to_timestamp`, `from_json`, `from_csv`, and so on. Having this new test suite helps future developments.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
CI tests.
Closes#33259 from gengliangwang/ntzTest.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Gengliang Wang <gengliang@apache.org>
### What changes were proposed in this pull request?
With more thought, all DT/YM function use field byte to keep consistence is better
### Why are the changes needed?
Keep code consistence
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#33252 from AngersZhuuuu/SPARK-36021-FOLLOWUP.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR fixes an issue about `extract`.
`Extract` should process only existing fields of interval types. For example:
```
spark-sql> SELECT EXTRACT(MONTH FROM INTERVAL '2021-11' YEAR TO MONTH);
11
spark-sql> SELECT EXTRACT(MONTH FROM INTERVAL '2021' YEAR);
0
```
The last command should fail as the month field doesn't present in INTERVAL YEAR.
### Why are the changes needed?
Bug fix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New tests.
Closes#33247 from sarutak/fix-extract-interval.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This is the followup from https://github.com/apache/spark/pull/33236#issuecomment-875242730, where we are fixing the config value of shuffled hash join, for all other test queries. Found all configs by searching in https://github.com/apache/spark/search?q=spark.sql.join.preferSortMergeJoin .
### Why are the changes needed?
Fix test to have better test coverage.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#33249 from c21/join-test.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Make unary and comparison operators data-type-based. Refactored operators include:
- Unary operators: `__neg__`, `__abs__`, `__invert__`,
- Comparison operators: `>`, `>=`, `<`, `<=`, `==`, `!=`
Non-goal: Tasks below are inspired during the development of this PR.
[[SPARK-35997] Implement comparison operators for CategoricalDtype in pandas API on Spark](https://issues.apache.org/jira/browse/SPARK-35997)
[[SPARK-36000] Support creating a ps.Series/Index with `Decimal('NaN')` with Arrow disabled](https://issues.apache.org/jira/browse/SPARK-36000)
[[SPARK-36001] Assume result's index to be disordered in tests with operations on different Series](https://issues.apache.org/jira/browse/SPARK-36001)
[[SPARK-36002] Consolidate tests for data-type-based operations of decimal Series](https://issues.apache.org/jira/browse/SPARK-36002)
[[SPARK-36003] Implement unary operator `invert` of numeric ps.Series/Index](https://issues.apache.org/jira/browse/SPARK-36003)
### Why are the changes needed?
We have been refactoring basic operators to be data-type-based for readability, flexibility, and extensibility.
Unary and comparison operators are still not data-type-based yet. We should fill the gaps.
### Does this PR introduce _any_ user-facing change?
Yes.
- Better error messages. For example,
Before:
```py
>>> import pyspark.pandas as ps
>>> psser = ps.Series([b"2", b"3", b"4"])
>>> -psser
Traceback (most recent call last):
...
pyspark.sql.utils.AnalysisException: cannot resolve '(- `0`)' due to data type mismatch: ...
```
After:
```py
>>> import pyspark.pandas as ps
>>> psser = ps.Series([b"2", b"3", b"4"])
>>> -psser
Traceback (most recent call last):
...
TypeError: Unary - can not be applied to binaries.
>>>
```
- Support unary `-` of `bool` Series. For example,
Before:
```py
>>> psser = ps.Series([True, False, True])
>>> -psser
Traceback (most recent call last):
...
pyspark.sql.utils.AnalysisException: cannot resolve '(- `0`)' due to data type mismatch: ...
```
After:
```py
>>> psser = ps.Series([True, False, True])
>>> -psser
0 False
1 True
2 False
dtype: bool
```
### How was this patch tested?
Unit tests.
Closes#33162 from xinrong-databricks/datatypeops_refactor.
Authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
### What changes were proposed in this pull request?
For case
```
spark-sql> select interval '123456:12' minute to second;
Error in query:
requirement failed: Interval string must match day-time format of '^(?<sign>[+|-])?(?<minute>\d{1,2}):(?<second>(\d{1,2})(\.(\d{1,9}))?)$': 123456:12, set spark.sql.legacy.fromDayTimeString.enabled to true to restore the behavior before Spark 3.0.(line 1, pos 16)
== SQL ==
select interval '123456:12' minute to second
----------------^^^
```
we should support hour/minute/second when for more than 2 digits when parse interval literal string
### Why are the changes needed?
Keep consistence
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#33231 from AngersZhuuuu/SPARK-36021.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
The method `WindowSpecDefinition.isValidFrameType` doesn't consider `TimestampNTZType`. We should support it as for `TimestampType`.
### Why are the changes needed?
Support `TimestampNTZType` in the Window spec definition.
### Does this PR introduce _any_ user-facing change?
'Yes'. This PR allows users use `TimestampNTZType` as the sort spec in window spec definition.
### How was this patch tested?
New tests.
Closes#33246 from beliefer/SPARK-36015.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
The current `ApproxCountDistinctForInterval`s supports `TimestampType`, but not supports timestamp without time zone yet.
This PR will add the function.
### Why are the changes needed?
`ApproxCountDistinctForInterval` need supports `TimestampNTZType`.
### Does this PR introduce _any_ user-facing change?
'Yes'. `ApproxCountDistinctForInterval` accepts `TimestampNTZType`.
### How was this patch tested?
New tests.
Closes#33243 from beliefer/SPARK-36016.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
The code of method: createDirectory in class: org.apache.spark.util.Utils is modified.
### Why are the changes needed?
To solve the problem of ambiguous exception handling in traditional IO creating directories.
What's more, there shouldn't be an improper comment in Spark's source code.
### Does this PR introduce _any_ user-facing change?
Yes
The modified method would be called to create the working directory when Worker starts.
The modified method would be called to create local directories for storing block data when the class: DiskBlockManager instantiates.
The modified method would be called to create a temporary directory inside the given parent directory in several classes.
### How was this patch tested?
I have provided test cases as much as possible.
Authored-by: Shockang <shockangaliyun.com>
Closes#33101 from Shockang/SPARK-35907.
Authored-by: Shockang <shockang@163.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
The current `ApproximatePercentile` supports `TimestampType`, but not supports timestamp without time zone yet.
This PR will add the function.
### Why are the changes needed?
`ApproximatePercentile` need supports `TimestampNTZType`.
### Does this PR introduce _any_ user-facing change?
'Yes'. `ApproximatePercentile` accepts `TimestampNTZType`.
### How was this patch tested?
New tests.
Closes#33241 from beliefer/SPARK-36017.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
When cast `10:10` to interval minute to second, it can be catch by hour to minute regex, here to fix this.
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#33242 from AngersZhuuuu/SPARK-35735-FOLLOWUP.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
We found the `in-join.sql` does not test shuffled hash join properly in https://issues.apache.org/jira/browse/SPARK-32577, but didn't find a good way to fix it. Given we now have a test config to enforce shuffled hash join in https://github.com/apache/spark/pull/33182, we can fix the test here now as well.
### Why are the changes needed?
Fix test to have better test coverage.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Reran the test to compare the output, and verified the query plan manually to make sure shuffled hash join being used.
Closes#33236 from c21/join-test.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Currently, inferring nested structs is always using `MapType`.
This behavior causes an issue because it infers the schema with a value type of the first field of the struct as below:
```python
data = [{"inside_struct": {"payment": 100.5, "name": "Lee"}}]
df = spark.createDataFrame(data)
df.show(truncate=False)
+--------------------------------+
|inside_struct |
+--------------------------------+
|{name -> null, payment -> 100.5}|
+--------------------------------+
```
The "name" became `null`, but it should've been `"Lee"`.
In this case, we need to be able to infer the schema with a `StructType` instead of a `MapType`.
Therefore, this PR proposes adding an new configuration `spark.sql.pyspark.inferNestedDictAsStruct.enabled` to handle which type is used for inferring nested structs.
- When `spark.sql.pyspark.inferNestedDictAsStruct.enabled` is `false` (by default), inferring nested structs by `MapType`
- When `spark.sql.pyspark.inferNestedDictAsStruct.enabled` is `true`, inferring nested structs by `StructType`
### Why are the changes needed?
Because always inferring the nested structs by `MapType` doesn't work properly for some cases.
### Does this PR introduce _any_ user-facing change?
New configuration `spark.sql.pyspark.inferNestedDictAsStruct.enabled` is added.
### How was this patch tested?
Added an unit test
Closes#33214 from itholic/SPARK-35929.
Lead-authored-by: itholic <haejoon.lee@databricks.com>
Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Make it recursive remove sort if the maximum number of rows less than or equal to 1. For example:
```sql
select a from (select a from values(0, 1) t(a, b) order by a) order by a
```
### Why are the changes needed?
Fix Once strategy's idempotence is broken for batch Eliminate Sorts.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#33240 from wangyum/SPARK-35906-2.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to bump up the mypy version to 0.910 which is the latest.
### Why are the changes needed?
To catch the type hint mistakes better in PySpark.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
GitHub Actions should test it out.
Closes#33223 from HyukjinKwon/SPARK-35684.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR allows the `Project` node to host outer references in scalar subqueries when `decorrelateInnerQuery` is enabled. It is already supported by the new decorrelation framework and the `RewriteCorrelatedScalarSubquery` rule.
Note currently by default all correlated subqueries will be decorrelated, which is not necessarily the most optimal approach. Consider `SELECT (SELECT c1) FROM t`. This should be optimized as `SELECT c1 FROM t` instead of rewriting it as a left outer join. This will be done in a separate PR to optimize correlated scalar/lateral subqueries with OneRowRelation.
### Why are the changes needed?
To allow more types of correlated scalar subqueries.
### Does this PR introduce _any_ user-facing change?
Yes. This PR allows outer query column references in the SELECT cluase of a correlated scalar subquery. For example:
```sql
SELECT (SELECT c1) FROM t;
```
Before this change:
```
org.apache.spark.sql.AnalysisException: Expressions referencing the outer query are not supported
outside of WHERE/HAVING clauses
```
After this change:
```
+------------------+
|scalarsubquery(c1)|
+------------------+
|0 |
|1 |
+------------------+
```
### How was this patch tested?
Added unit tests and SQL tests.
Closes#33235 from allisonwang-db/spark-36028-outer-in-project.
Authored-by: allisonwang-db <allison.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Upgrading the kubernetes-client to 5.5.0
### Why are the changes needed?
There are [several bugfixes](https://github.com/fabric8io/kubernetes-client/releases/tag/v5.5.0) but the main reason is version 5.5.0 contains [Support HTTP operation retry with exponential backoff (for status code >= 500)](https://github.com/fabric8io/kubernetes-client/issues/3087).
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
By running the integration tests including `persistentVolume` tests:
```
./resource-managers/kubernetes/integration-tests/dev/dev-run-integration-tests.sh \
--spark-tgz $TARBALL_TO_TEST --hadoop-profile $HADOOP_PROFILE --exclude-tags r --include-tags persistentVolume
...
[INFO] --- scalatest-maven-plugin:2.0.0:test (integration-test) spark-kubernetes-integration-tests_2.12 ---
Discovery starting.
Discovery completed in 413 milliseconds.
Run starting. Expected test count is: 26
KubernetesSuite:
- Run SparkPi with no resources
- Run SparkPi with a very long application name.
- Use SparkLauncher.NO_RESOURCE
- Run SparkPi with a master URL without a scheme.
- Run SparkPi with an argument.
- Run SparkPi with custom labels, annotations, and environment variables.
- All pods have the same service account by default
- Run extraJVMOptions check on driver
- Run SparkRemoteFileTest using a remote data file
- Verify logging configuration is picked from the provided SPARK_CONF_DIR/log4j.properties
- Run SparkPi with env and mount secrets.
- Run PySpark on simple pi.py example
- Run PySpark to test a pyfiles example
- Run PySpark with memory customization
- Run in client mode.
- Start pod creation from template
- PVs with local storage
- Launcher client dependencies
- SPARK-33615: Launcher client archives
- SPARK-33748: Launcher python client respecting PYSPARK_PYTHON
- SPARK-33748: Launcher python client respecting spark.pyspark.python and spark.pyspark.driver.python
- Launcher python client dependencies using a zip file
- Test basic decommissioning
- Test basic decommissioning with shuffle cleanup
- Test decommissioning with dynamic allocation & shuffle cleanups
- Test decommissioning timeouts
Run completed in 18 minutes, 34 seconds.
Total number of tests run: 26
Suites: completed 2, aborted 0
Tests: succeeded 26, failed 0, canceled 0, ignored 0, pending 0
All tests passed.
```
Checked the compatibility matrix and the same k8s versions are supported as were by version 5.4.1.
Closes#33233 from attilapiros/SPARK-36026.
Authored-by: attilapiros <piros.attila.zsolt@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add a config `spark.sql.join.forceApplyShuffledHashJoin` to force applying shuffled hash join
during the join selection.
### Why are the changes needed?
In the `SQLQueryTestSuite`, we want to cover 3 kinds of join (BHJ, SHJ, SMJ) in join.sql. But even
if the `spark.sql.join.preferSortMergeJoin` is set to `false`, shuffled hash join is still not guaranteed.
Thus, we need another config to force the selection.
### Does this PR introduce _any_ user-facing change?
No, only for testing
### How was this patch tested?
newly added tests
Verified all queries in join.sql will use `ShuffledHashJoin` when the config set to `true`
Closes#33182 from linhongliu-db/SPARK-35984-hash-join-config.
Authored-by: Linhong Liu <linhong.liu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The `RemoveRedundantProjects` feature can conflict with the AQE broadcast threshold ([PR](https://github.com/apache/spark/pull/32391)) sometimes. After removing the project, the physical plan to logical plan link can be changed and we may have a `Project` above `LogicalQueryStage`. This breaks AQE broadcast threshold, because the stats of `Project` does not have the `isRuntime = true` flag, and thus still use the normal broadcast threshold.
This PR updates `RemoveRedundantProjects` to not remove `ProjectExec` that has a different logical plan link than its child.
### Why are the changes needed?
Make AQE broadcast threshold work in more cases.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
new tests
Closes#33222 from cloud-fan/aqe2.
Lead-authored-by: Wenchen Fan <wenchen@databricks.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add `ShippableVertexPartition` and `RoutingTablePartition` to the classes registered with Kryo in `GraphXUtils.registerKryoClasses`.
### Why are the changes needed?
`VertexRDDImpl` uses an `RDD[ShippableVertexPartition[VD]]` however, `GraphXUtils.registerKryoClasses` does not register `ShippableVertexPartition`. This means when running with `spark.kryo.registrationRequired` set to `true`, we get a "Class is not registered" exception. This is an issue as it prevents other unregistered classes from being discovered using `spark.kryo.registrationRequired` as the first unregistered class found halts the whole job. It also potentially decreases the serialised size of the RDD when using Kryo.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Tested manually by running with `spark.kryo.registrationRequired` set to `true` and verifying no "Class is not registered" exception was thrown.
Closes#32973 from matthewrj/bug/register-graphx-classes.
Lead-authored-by: Matthew Jones <matthew@vitaler.com>
Co-authored-by: Matthew Jones <mlety2@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Some of the test cases in `DateExpressionsSuite` are quite slow:
- `Hour`: 24s
- `Minute`: 26s
- `Day / DayOfMonth`: 8s
- `Year`: 4s
Each test case has a large loop. We should improve them.
### Why are the changes needed?
Save test running time
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Verified the run times on local:
- `Hour`: 2s
- `Minute`: 3.2
- `Day / DayOfMonth`:0.5s
- `Year`: 2s
Total reduced time: 54.3s
Closes#33229 from gengliangwang/improveTest.
Authored-by: Gengliang Wang <gengliang@apache.org>
Signed-off-by: Gengliang Wang <gengliang@apache.org>
### What changes were proposed in this pull request?
This PR aims to update MiMa based on Apache Spark 3.1.1 (the first release on 3.1 line) for Apache Spark 3.2.0 release.
### Why are the changes needed?
Old MiMa rules hides the breaking changes in Apache Spark 3.2.0. We need to audit and document it correctly in MiMa exclusion file. This issue is discussed here originally.
- https://github.com/apache/spark/pull/33196#issuecomment-873249068
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass the CIs
Closes#33199 from dongjoon-hyun/SPARK-36004.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Refactor code about parse string to DT/YM intervals.
### Why are the changes needed?
Extracting the common code about parse string to DT/YM should improve code maintenance.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existed UT.
Closes#33217 from AngersZhuuuu/SPARK-35735-35768.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR fixes an issue that `from_csv/to_csv` doesn't handle day-time intervals properly.
`from_csv` throws exception if day-time interval types are given.
```
spark-sql> select from_csv("interval '1 2:3:4' day to second", "a interval day to second");
21/07/03 04:39:13 ERROR SparkSQLDriver: Failed in [select from_csv("interval '1 2:3:4' day to second", "a interval day to second")]
java.lang.Exception: Unsupported type: interval day to second
at org.apache.spark.sql.errors.QueryExecutionErrors$.unsupportedTypeError(QueryExecutionErrors.scala:775)
at org.apache.spark.sql.catalyst.csv.UnivocityParser.makeConverter(UnivocityParser.scala:224)
at org.apache.spark.sql.catalyst.csv.UnivocityParser.$anonfun$valueConverters$1(UnivocityParser.scala:134)
```
Also, `to_csv` doesn't handle day-time interval types properly though any exception is thrown.
The result of `to_csv` for day-time interval types is not ANSI interval compliant form.
```
spark-sql> select to_csv(named_struct("a", interval '1 2:3:4' day to second));
93784000000
```
The result above should be `INTERVAL '1 02:03:04' DAY TO SECOND`.
### Why are the changes needed?
Bug fix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New tests.
Closes#33226 from sarutak/csv-dtinterval.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes two issues. One is that `to_json` doesn't support `map` types where value types are `day-time` interval types like:
```
spark-sql> select to_json(map('a', interval '1 2:3:4' day to second));
21/07/06 14:53:58 ERROR SparkSQLDriver: Failed in [select to_json(map('a', interval '1 2:3:4' day to second))]
java.lang.RuntimeException: Failed to convert value 93784000000 (class of class java.lang.Long) with the type of DayTimeIntervalType(0,3) to JSON.
```
The other issue is that even if the issue of `to_json` is resolved, `from_json` doesn't support to convert `day-time` interval string to JSON. So the result of following query will be `null`.
```
spark-sql> select from_json(to_json(map('a', interval '1 2:3:4' day to second)), 'a interval day to second');
{"a":null}
```
### Why are the changes needed?
There should be no reason why day-time intervals cannot used as map value types.
`CalendarIntervalTypes` can do it.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New tests.
Closes#33225 from sarutak/json-dtinterval.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Ideally, in SQL query, nested columns should result to GetStructField with non-None name. But there are places that can create GetStructField with None name, such as UnresolvedStar.expand, Dataset encoder stuff, etc.
the current `nestedFieldToAlias` cannot catch it up and will cause job failed.
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT,
Closes#33183 from AngersZhuuuu/SPARK-35972.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
{kind=link}
{kind=link}